4. JPA :概述
我们将通过几个示例来介绍 JPA(Java Persistence API)。本课程涵盖了 JPA 的相关内容:
- 《Java 5 持久化实战》:[http://tahe.developpez.com/java/jpa] - 提供使用 JPA 构建数据访问层的工具
4.1. 分层架构中JPA的作用
建议读者回顾本文开头(第 2 段),其中解释了 JPA 层在分层架构中的作用。JPA 层是数据访问层的一部分:
 |
[DAO]层与JPA规范进行交互。无论由何种产品实现,JPA层向[DAO]层展示的接口始终保持一致。下面,我们将介绍[ref1]中的一些示例,这些示例将有助于我们构建自己的JPA层。
4.2. JPA - 示例
4.2.1. 示例 1 - 单张表的对象表示
4.2.1.1. [person] 表
假设有一个数据库,其中包含一个名为 [person] 的表,其作用是存储有关个人的某些信息:
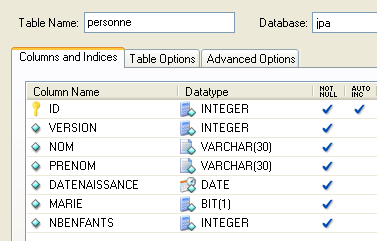 |
该表的主键 | |
表中该行的版本号。每次修改该人时,其版本号都会递增。 | |
该人的姓氏 | |
名字 | |
出生日期 | |
整数 0(未婚)或 1(已婚) | |
子女数 |
4.2.1.2. [Person] 实体
我们处于以下运行时环境中:
 |
JPA 层 [5] 必须在数据库 [7] 的关系型世界与 Java 程序 [3] 操作的对象世界 [4] 之间架起桥梁。这种连接是通过配置建立的,主要有两种实现方式:
- 使用 XML 文件。在 JDK 1.5 问世之前,这几乎是唯一的方法
- 自 JDK 1.5 起,使用 Java 注解
在本文档中,我们将仅使用第二种方法。
代表前面介绍的 [person] 表的 [Person] 对象可以如下所示:
...
@SuppressWarnings("unused")
@Entity
@Table(name="Personne")
public class Personne implements Serializable{
@Id
@Column(name = "ID", nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Column(name = "VERSION", nullable = false)
@Version
private int version;
@Column(name = "NOM", length = 30, nullable = false, unique = true)
private String nom;
@Column(name = "PRENOM", length = 30, nullable = false)
private String prenom;
@Column(name = "DATENAISSANCE", nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(name = "MARIE", nullable = false)
private boolean marie;
@Column(name = "NBENFANTS", nullable = false)
private int nbenfants;
// manufacturers
public Personne() {
}
public Personne(String nom, String prenom, Date datenaissance, boolean marie,
int nbenfants) {
setNom(nom);
setPrenom(prenom);
setDatenaissance(datenaissance);
setMarie(marie);
setNbenfants(nbenfants);
}
// toString
public String toString() {
...
}
// getters and setters
...
}
配置通过 Java 注解(@Annotation)实现。Java 注解要么由编译器处理,要么由运行时的专用工具处理。除了第 3 行用于编译器的注解外,此处的所有注解都是针对所使用的 JPA 实现(Hibernate 或 Toplink)而设计的。因此,它们将在运行时被处理。 如果没有能够解释这些注解的工具,这些注解将被忽略。因此,上面的 [Person] 类可以在非 JPA 环境中使用。
在与表 T 关联的类 C 中使用 JPA 注解有两种截然不同的情况:
- 表 T 已存在:此时 JPA 注解必须复制现有结构(列名和定义、完整性约束、外键、主键等)
- 表 T 不存在,并将根据类 C 中发现的注解进行创建。
情况 2 最容易处理。通过使用 JPA 注解,我们可以指定所需表 T 的结构。 情况 1 通常更为复杂。表 T 可能早在很久以前就在任何 JPA 上下文之外被创建,因此其结构可能与 JPA 的关系-对象桥接机制不匹配。为简化讨论,我们将重点关注情况 2,即与类 C 关联的表 T 将基于类 C 中的 JPA 注解进行创建。
让我们来查看 [Person] 类的 JPA 注解:
- 第 4 行:@Entity 注解是第一个必不可少的注解。它位于声明该类的行之前,表明该类必须由 JPA 持久化层进行管理。如果没有此注解,所有其他 JPA 注解都将被忽略。
- 第 5 行:@Table 注解用于指定该类所代表的数据库表。其主要参数是 name,用于指定表名。若省略该参数,表名将默认采用类名,本例中即为 [Person]。因此,在本例中 @Table 注解是多余的。
- 第 8 行:@Id 注解用于指定类中对应于表主键的字段。该注解是必需的。此处表明第 11 行的 id 字段对应于表的主键。
- 第 9 行:@Column 注解用于将类字段与该字段所代表的表列建立关联。name 属性指定表中列的名称。如果省略该属性,则列将与字段同名。因此,在本例中,name 参数是可选的。nullable=false 参数指定与该字段关联的列不能为 NULL 值,因此该字段必须有值。
- 第 10 行:@GeneratedValue 注解指定了当主键由数据库管理系统(DBMS)自动生成时,其生成方式。在我们的所有示例中均采用此方式。该注解并非强制要求。因此,我们的 Person 类可以拥有一个作为主键的学生 ID,该 ID 并非由 DBMS 生成,而是由应用程序设置。在这种情况下,应省略 @GeneratedValue 注解。 strategy 参数指定了当主键由 DBMS 生成时,其生成方式。并非所有 DBMS 都采用相同的技术来生成主键值。例如:
在每次插入前调用一个值生成器 | |
主键字段被定义为 Identity 类型。其结果与 Firebird 的值生成器类似,不同之处在于,在行插入完成之前无法得知键值。 | |
使用名为 SEQUENCE 的对象,该对象同样充当值生成器 |
JPA 层必须根据不同的数据库管理系统(DBMS)生成不同的 SQL 语句来创建值生成器。它通过配置来指定需要处理的 DBMS 类型。因此,它可以确定针对该 DBMS 生成主键值的标准策略。参数 strategy = GenerationType.*****AUTO* 指示 JPA 层使用此标准策略。在本文档中,该技术在所使用的七种 DBMS 的所有示例中均能正常工作。
- 第 14 行:@Version 注解用于指定管理对表中同一行并发访问的字段。
为理解 [person] 表中同一行数据并发访问的问题,假设某个 Web 应用程序允许更新人员信息,并考虑以下场景:
在时间点 T1,用户 U1 开始编辑某人 P。此时,子女数为 0。他将该数值改为 1,但在提交更改之前,用户 U2 开始编辑同一人 P。由于 U1 尚未提交更改,U2 在屏幕上看到的子女数仍是 0。U2 将人 P 的名字改为大写。 随后,U1和U2按此顺序保存了各自的修改。U2的修改将具有优先权:在数据库中,姓名将显示为大写,且子女数量仍保持为零,尽管U1认为自己已将其修改为1。
“人员版本”的概念有助于我们解决这个问题。让我们重新审视这个用例:
在时间点 T1,用户 U1 开始编辑人员 P。此时,子女数为 0,版本号为 V1。他将子女数改为 1,但在提交更改之前,用户 U2 开始编辑同一个人 P。由于 U1 尚未提交更改,U2 看到的子女数为 0,版本号为 V1。 U2 将人物 P 的名字改为大写。随后 U1 和 U2 按此顺序提交了各自的修改。在提交修改前,我们会验证修改人物 P 的用户所持有的版本是否与当前已保存的人物 P 版本一致。对于用户 U1 而言,情况确实如此。因此其修改被接受,随后我们将被修改人物的版本号从 V1 更改为 V2,以表明该人物已发生变更。 在验证 U2 的修改时,我们会发现 U2 持有的 P 用户版本为 V1,而当前版本是 V2。此时我们可以告知用户 U2,有人已先于其进行操作,因此必须基于 P 用户的新版本开始操作。用户 U2 将照此操作,获取现在已有一个孩子的 P 用户版本 V2,将姓名首字母大写,并进行验证。如果注册的 P 用户仍为版本 V2,则其修改将被接受。 最终,U1和U2所做的修改都将被采纳;而在没有版本控制的用例中,其中一项修改本会丢失。
客户端应用程序的 [DAO] 层可以自行管理 [Person] 类的版本。每次对象 P 被修改时,该对象在表中的版本号将增加 1。@Version 注解允许将此管理职责转移至 JPA 层。相关字段无需像示例中那样命名为“version”,可以使用任意名称。
对应 @Id 和 @Version 注解的字段是为了持久化目的而存在的。如果 [Person] 类不需要被持久化,这些字段就不再需要。因此,我们可以看到,一个对象的表示方式会因其是否需要被持久化而有所不同。
- 第 17 行:同样,@Column 注解提供了关于 [person] 表中与 Person 类的 name 字段关联的列的信息。这里出现了两个新参数:
- unique=true 表示人员的姓名必须唯一。这将在数据库的 [person] 表中 NAME 列上添加一个唯一性约束。
- length=30 将 NAME 列的字符数设置为 30。这意味着该列的类型将为 VARCHAR(30)。
- 第 24 行:@Temporal 注解用于指定日期/时间列或字段的 SQL 类型。类型 TemporalType.DATE 表示不包含时间的日期。其他可能的类型包括用于编码时间的 TemporalType.TIME,以及用于编码日期和时间的 TemporalType.TIMESTAMP。
现在让我们对 [Person] 类中的其余代码进行说明:
- 第 6 行:该类实现了 Serializable 接口。对象的序列化是指将其转换为一串二进制数据。反序列化则是相反的操作。序列化/反序列化特别适用于客户端/服务器应用程序,其中对象通过网络进行交换。 客户端或服务器应用程序无需知晓这一操作,该操作由 JVM 透明地执行。但要实现这一点,交换对象的类必须使用 Serializable 关键字进行“标记”。
- 第 37 行:该类的构造函数。请注意,id 和 version 字段未包含在参数中。这是因为这两个字段由 JPA 层管理,而非由应用程序管理。
- 第 51 行及之后:该类各字段的 get 和 set 方法。请注意,JPA 注解可以放置在字段的 get 方法上,而非字段本身。注解的位置决定了 JPA 访问字段时应采用的模式:
- 如果注解位于字段级别,JPA 将直接访问字段进行读写
- 如果注解位于 get 方法级别,JPA 将通过 get/set 方法访问字段以进行读写
@Id 注解的位置决定了类中其他 JPA 注解的放置方式。当置于字段级别时,表示直接访问字段;当置于 get 方法级别时,表示通过 get 和 set 方法访问字段。其他注解必须按照与 @Id 注解相同的方式进行放置。
4.2.2. 配置 JPA 层
可以使用以下架构对 JPA 层进行测试:
 |
- 在 [7] 中:该数据库将根据 [Person] 实体的注解以及在名为 [persistence.xml] 的文件中进行的额外配置生成
- 在 [5, 6] 中:由 Hibernate 实现的 JPA 层
- 在 [4] 中:[Person] 实体
- 在 [3] 中:一个基于控制台的测试程序
JPA 层通过 [META-INF/persistence.xml] 文件进行配置:
 |
运行时,系统会在应用程序的类路径中搜索 [META-INF/persistence.xml] 文件。
让我们来查看项目中 [persistence.xml] 文件中的 JPA 层配置:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Persistent classes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- logs SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
<property name="hibernate.connection.url" value="jdbc:mysql://localhost:3306/jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- automatic schematic creation -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
<!-- properties DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
要理解此配置,我们需要重新审视应用程序的数据访问架构:
 |
- [persistence.xml] 文件配置了第 [4、5、6] 层
- [4]:Hibernate 对 JPA 的实现
- [5]: Hibernate 通过连接池访问数据库。连接池是一组与 DBMS 建立的开放连接。虽然多个用户可以访问 DBMS,但出于性能考虑,同时打开的连接数量不能超过上限 N。 良好的代码会将与 DBMS 的连接保持在最短时间内:执行 SQL 命令后立即关闭连接。每次需要操作数据库时,都会重复这一过程。打开和关闭连接的开销不容忽视,这正是连接池发挥作用的地方。应用程序启动时,连接池会向 DBMS 建立 N1 个连接。应用程序每次需要连接时,都会从池中请求一个已打开的连接。 一旦应用程序不再需要该连接,应尽快将其归还给连接池。该连接不会被关闭,而是保持可用状态以供下一个用户使用。因此,连接池是一种共享已建立连接的系统。
- [6]:所用数据库管理系统(DBMS)的 JDBC 驱动程序
现在让我们看看 [persistence.xml] 文件是如何配置上述 [4、5、6] 层的:
- 第 2 行:XML 文件的根标签是 <persistence>。
- 第 3 行:<persistence-unit> 用于定义持久化单元。可以存在多个持久化单元。每个单元都有一个名称(name 属性)和一个事务类型(transaction-type 属性)。应用程序将通过其名称访问持久化单元,本例中为 jpa。事务类型 RESOURCE_LOCAL 表示应用程序自行管理与数据库管理系统的事务。本例中即采用此方式。 当应用程序在 EJB3 容器中运行时,可以使用容器的事务服务。在这种情况下,我们将设置 transaction-type=JTA(Java 事务 API)。如果省略 transaction-type 属性,JTA 是其默认值。
- 第 5 行:<provider> 标签用于定义一个实现 [javax.persistence.spi.PersistenceProvider] 接口的类,该接口允许应用程序初始化持久化层。由于我们使用的是 JPA/Hibernate 实现,因此此处使用的类是 Hibernate 类。
- 第 6 行:<properties> 标签用于声明所选提供程序特有的属性。因此,根据您选择的是 Hibernate、TopLink、Kodo 等,属性会有所不同。以下内容专用于 Hibernate。
- 第 8 行:指示 Hibernate 扫描项目的类路径,查找带有 @Entity 注解的类以便进行管理。@Entity 类也可以使用 <class>class_name</class> 标签在 <persistence-unit> 标签的直接下方进行声明。这就是我们将对 JPA/TopLink 提供程序所做的事情。
- 第 10–12 行(此处已注释掉)用于配置 Hibernate 的控制台日志:
- 第 10 行:用于启用或禁用显示 Hibernate 向 DBMS 发出的 SQL 语句。这在学习阶段非常有用。由于关系型/对象桥梁的存在,应用程序对持久化对象进行操作(如 [persist、merge、remove])。了解这些操作实际生成的 SQL 语句非常有帮助。 通过研究这些语句,您将逐渐学会预判 Hibernate 在对持久化对象执行此类操作时会生成哪些 SQL 语句,从而在脑海中逐渐形成对关系/对象桥接机制的清晰认知。
- 第 11 行:控制台上显示的 SQL 语句可以进行格式化,使其更易于阅读
- 第 12 行:显示的 SQL 语句还将添加注释
- 第 15–19 行定义了 JDBC 层(架构中的第 [6] 层):
- 第 15 行:DBMS 的 JDBC 驱动程序类,此处为 MySQL5
- 第 16 行:所用数据库的 URL
- 第 17、18 行:连接用户名和密码
- 第 22 行:Hibernate 需要知道它正在与哪个 DBMS 配合工作。这是因为所有 DBMS 都有专有的 SQL 扩展——例如它们自己自动生成主键值的方法——这意味着 Hibernate 必须识别具体的 DBMS,以便发送它能够理解的 SQL 语句。[MySQL5InnoDBDialect] 指的是使用支持事务的 InnoDB 表的 MySQL5 DBMS。
- 第 24–28 行配置 c3p0 连接池(架构中的第 [5] 层):
- 第 24、25 行:连接池中的最小(默认 3)和最大连接数(默认 15)。初始连接数的默认值为 3。
- 第 26 行:客户端连接请求的最大等待时间(单位为毫秒)。超时后,c3p0 将抛出异常。
- 第 27 行:为了访问数据库,Hibernate 使用预编译 SQL 语句(PreparedStatement),而 c3p0 可以对这些语句进行缓存。这意味着,如果应用程序第二次请求一个已经存在于缓存中的预编译 SQL 语句,则无需再次进行预编译(预编译 SQL 语句会产生开销),而是直接使用缓存中的那个。 在此,我们指定了缓存中可容纳的预编译 SQL 语句的最大数量,该数量适用于所有连接(一个预编译 SQL 语句属于单个连接)。
- 第 28 行:检查连接有效性的频率(单位为毫秒)。连接池中的连接可能因各种原因失效(例如 JDBC 驱动程序因连接保持打开状态过久而将其失效,或 JDBC 驱动程序存在“漏洞”等)。
- 第 20 行:此处指定在初始化持久层时,应生成 @Entity 对象的数据库模式。Hibernate 现已具备生成创建数据库表所需 SQL 语句的所有工具:
- @Entity 对象的配置使其能够确定需要生成哪些表
- 第 15–18 行和第 24–28 行使其能够与 DBMS 建立连接
- 第 22 行指定了生成表时应使用的 SQL 方言
因此,此处使用的 [persistence.xml] 文件会在每次运行应用程序时重建一个新的数据库。如果表已存在,则会在删除(drop table)后重新创建(create table)。请注意,这显然不适用于生产环境数据库……
4.2.3. 示例 2:一对多关系
4.2.3.1. 数据库模式文件 [
1 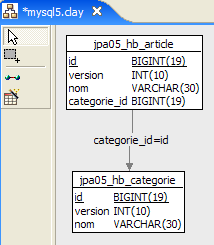 | 2 |
- 在 [1] 中,数据库;在 [2] 中,其 DDL(MySQL5)
一篇文章 A(id, version, name) 仅属于一个类别 C(id, version, name)。 一个类别 C 可以包含 0、1 或多个文章。我们有一个一对多关系(类别 -> 文章)和一个反向的多对一关系(文章 -> 类别)。这种关系由 [article] 表对 [category] 表的外键表示(DDL 的第 24–28 行)。
4.2.3.2. 表示数据库的 @Entity 对象
一篇文章由以下 @Entity [Article] 表示:
package entites;
...
@Entity
@Table(name="jpa05_hb_article")
public class Article implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// main relationship Article (many) -> Category (one)
// implemented by a foreign key (categorie_id) in Article
// 1 Article must have 1 Category (nullable=false)
@ManyToOne(fetch=FetchType.LAZY)
@JoinColumn(name = "categorie_id", nullable = false)
private Categorie categorie;
// manufacturers
public Article() {
}
// getters and setters
...
// toString
public String toString() {
return String.format("Article[%d,%d,%s,%d]", id, version, nom, categorie.getId());
}
}
- 第 9-11 行:@Entity 的主键
- 第 13-15 行:其版本号
- 第 17-18 行:文章的名称
- 第 20-25 行:将 @Entity Article 与 @Entity Category 关联的多对一关系:
- 第 23 行:ManyToOne 注解。Many 指代当前所在的 @Entity Article,One 指代 @Entity Category(第 25 行)。一个类别(One)可以关联多个文章(Many)。
- 第 24 行:ManyToOne 注解定义了 [article] 表中的外键列。该列将被命名为 (name) categorie_id,且每行必须在此列中具有一个值(nullable=false)。
- 第 25 行:文章所属的类别。当文章被添加到持久化上下文中时,我们要求其类别不要立即被加载(fetch=FetchType.LAZY,第 23 行)。我们尚不确定此请求是否合理。稍后再看。
类别由以下 @Entity [Category] 表示:
package entites;
...
@Entity
@Table(name="jpa05_hb_categorie")
public class Categorie implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// inverse relationship Category (one) -> Article (many) from relationship Article (many) -> Category (one)
// cascade insertion Category -> insertion Articles
// cascade maj Category -> maj Articles
// cascade delete Category -> delete Articles
@OneToMany(mappedBy = "categorie", cascade = { CascadeType.ALL })
private Set<Article> articles = new HashSet<Article>();
// manufacturers
public Categorie() {
}
// getters and setters
...
// toString
public String toString() {
return String.format("Categorie[%d,%d,%s]", id, version, nom);
}
// bidirectional association Category <--> Article
public void addArticle(Article article) {
// the item is added to the collection of items in the category
articles.add(article);
// article changes category
article.setCategorie(this);
}
}
- 第 8-11 行:@Entity 的主键
- 第 12-14 行:其版本号
- 第 16-17 行:类别名称
- 第 19-24 行:该分类下的文章集合
- 第 23 行:@OneToMany 注解表示一对多关系。其中的“One”指代当前所在的 @Entity [Category],而“Many”指代第 24 行的 [Article] 类型:一个(One)类别包含多个(Many)文章。
- 第 23 行:该注解是 @Entity Article 的 category 字段上所置 ManyToOne 注解的反向(mappedBy)关系:mappedBy=category。@Entity Article 的 category 字段上所置的 ManyToOne 关系是主关系。它是必不可少的。它实现了将 @Entity Article 与 @Entity Category 关联的外键关系。 位于 @Entity Category 的 articles 字段上的 OneToMany 关系是反向关系。它并非必需的。它是为了方便检索某个类别的文章而提供的。如果没有这种便利,这些文章将需要通过 JPQL 查询来检索。
- 第 23 行:cascadeType.ALL 确保对 @Entity Category 执行的操作(persist、merge、remove)会级联到其所属的文章上。
- 第 24 行:类别中的文章将被放入一个类型为 `Set<Article>` 的对象中。`Set` 类型不允许重复项。因此,同一篇文章不能被两次添加到 `Set<Article>` 对象中。“同一篇文章”是什么意思?为了表示文章 `a` 与文章 `b` 相同,Java 使用表达式 `a.equals(b)`。 在所有类的父类 Object 类中,如果 a==b,即对象 a 和 b 具有相同的内存位置,则 a.equals(b) 为 true。有人可能希望定义:如果项目 a 和 b 具有相同的名称,则它们是相同的。在这种情况下,开发者必须在 [Item] 类中重新定义两个方法:
- equals:当两个项名称相同时,该方法必须返回 true
- hashCode:对于 equals 方法认为相等的两个 [Article] 对象,必须返回相同的整数值。因此,该值将根据文章的名称生成。hashCode 返回的值可以是任意整数。它被用于各种对象容器中,特别是字典(Hashtable)。
OneToMany 关系可以使用 Set 以外的类型来存储“多”方,例如 List 对象。本文档中将不涉及这些情况。读者可在 [ref1] 中查阅相关内容。
- 第 38 行:[addArticle] 方法允许我们将一篇文章添加到某个类别中。该方法确保连接 [Category] 与 [Article] 的 OneToMany 关系两端均被更新。
4.3. JPA 层 API
让我们明确 JPA 客户端的运行时环境:
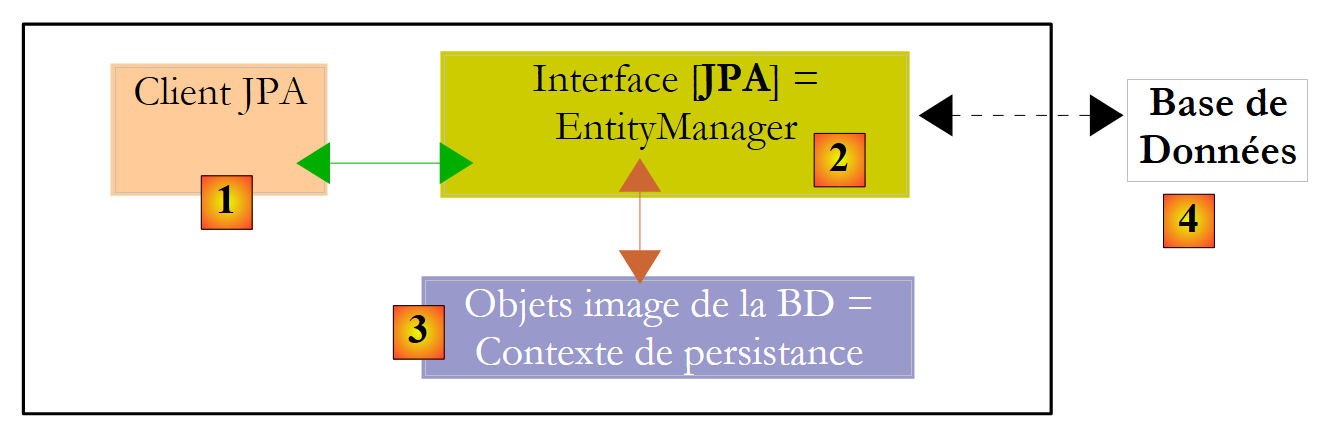 |
我们知道,JPA 层 [2] 在对象 [3] 域与关系 [4] 域之间搭建了一座桥梁。在这个对象/关系桥梁中,由 JPA 层管理的对象集合被称为“持久化上下文”。要访问持久化上下文中的数据,JPA 客户端 [1] 必须通过 JPA 层 [2]:
- 它可以创建一个对象,并请求 JPA 层使其持久化。该对象随后便成为持久化上下文的一部分。
- 它可向 [JPA] 层请求现有持久化对象的引用。
- 它可以修改从 JPA 层获取的持久化对象。
- 它可请求 JPA 层将对象从持久化上下文中移除。
JPA 层为客户端提供了一个名为 [EntityManager] 的接口,顾名思义,该接口用于管理持久化上下文中的 @Entity 对象。以下是该接口的主要方法:
将实体添加到持久化上下文中 | |
从持久化上下文中移除实体 | |
将客户端提供的、未被持久化上下文管理的实体对象 与持久化上下文中具有相同主键的实体对象进行合并。 返回的结果是持久化上下文中的实体对象。 | |
将从数据库检索到的对象通过其主键放入持久化上下文 。该对象的类型 T 使 JPA 层 确定应查询哪张表。由此创建的持久化对象将返回给客户端。 | |
根据 JPQL(Java 持久化 查询语言) 创建一个 Query 对象。JPQL 查询类似于 SQL 查询, 不同之处在于它查询的是对象而非表。 | |
一个与前一个方法类似的方法,区别在于 queryText 是 SQL 查询而非 JPQL 查询。 | |
该方法与 createQuery 完全相同,唯一的区别在于 JPQL 查询 queryText 已被 已外部化到配置文件中,并关联了一个名称。 该名称即为该方法的参数。 |
EntityManager 对象的生命周期不一定与应用程序的生命周期相同。它有开始和结束。因此,JPA 客户端可以依次与不同的 EntityManager 对象进行交互。 与 EntityManager 关联的持久化上下文具有与 EntityManager 本身相同的生命周期。它们彼此密不可分。当 EntityManager 对象被关闭时,其持久化上下文会在必要时与数据库同步,然后停止存在。必须创建一个新的 EntityManager 才能获得新的持久化上下文。
JPA 客户端可通过以下语句创建 EntityManager 并由此建立持久化上下文:
EntityManagerFactory emf = Persistence.createEntityManagerFactory("nom d'une unité de persistance");
- javax.persistence.Persistence 是一个静态类,用于获取 EntityManager 对象的工厂。该工厂与特定的持久化单元相关联。请注意,配置文件 [META-INF/persistence.xml] 用于定义持久化单元,且这些单元都有一个名称:
<persistence-unit name="elections-dao-jpa-mysql-01PU" transaction-type="RESOURCE_LOCAL">
上文中的持久化单元名为 elections-dao-jpa-mysql-01PU。它带有自己的特定配置,包括其所使用的数据库管理系统(DBMS)。 语句 [Persistence.createEntityManagerFactory("elections-dao-jpa-mysql-01PU")] 创建了一个 EntityManagerFactory,该工厂能够提供用于管理与名为 elections-dao-jpa-mysql-01PU 的持久化单元相关联的持久化上下文的 EntityManager 对象。可以如下方式从 EntityManagerFactory 对象中获取 EntityManager 对象(从而获得持久化上下文):
[EntityManager] 接口的以下方法允许您管理持久化上下文的生命周期:
关闭持久化上下文。强制持久化上下文与数据库进行同步:
| |
持久化上下文中的所有对象将被清除,但不会关闭。 | |
持久化上下文将与数据库进行同步,具体操作如 close() 所述 |
JPA 客户端可以通过 [EntityManager].flush 方法强制将持久化上下文与数据库进行同步。同步可以是显式的,也可以是隐式的。在第一种情况下,由客户端决定何时执行刷新操作以进行同步;否则,同步将在我们指定的特定时间发生。同步模式由 [EntityManager] 接口的以下方法管理:
flushMode 可能有两个取值: FlushModeType.AUTO(默认):在 每次对数据库执行 SELECT 查询之前。 FlushModeType.COMMIT:仅在 事务结束时才进行同步。 | |
返回当前的同步模式 |
总结:在 FlushModeType.AUTO 模式下(即默认模式),持久化上下文将在以下时间点与数据库进行同步:
- 每次对数据库执行 SELECT 操作之前
- 数据库事务结束时
- 在持久化上下文执行 flush 或 close 操作之后
在 FlushModeType.COMMIT 模式下,情况相同,但第 1 项操作不会发生。与 JPA 层交互的常规模式是事务模式。客户端在事务内对持久化上下文执行各种操作。在此情况下,持久化上下文与数据库之间的同步点在 AUTO 模式下为上述第 1 和第 2 项,而在 COMMIT 模式下仅为第 2 项。
最后,让我们来探讨 Query 接口 API,它允许您在持久化上下文中执行 JPQL 命令,或直接在数据库上执行 SQL 命令以检索数据。Query 接口如下所示:
 |
- 1 - getResultList 方法执行一个 SELECT 查询,该查询返回多个对象。这些对象被封装在一个 List 对象中。该对象是一个接口。它提供了一个 Iterator 对象,允许您按以下方式遍历列表 L 中的元素:
Iterator iterator = L.iterator();
while (iterator.hasNext()) {
// exploiter l'objet iterator.next() qui représente l'élément courant de la liste
...
}
列表 L 也可以使用 for 循环进行遍历:
for (Object o : L) {
// exploiter objet o
}
- 2 - getSingleResult 方法执行一个 JPQL/SQL SELECT 语句,该语句返回单个对象。
- 3 - executeUpdate 方法执行 SQL UPDATE 或 DELETE 语句,并返回受该操作影响的行数。
- 4 - setParameter(String, Object) 方法允许您为带参数的 JPQL 查询中的命名参数赋值
- 5 - setParameter(int, Object) 方法用于设置参数,但该参数并非通过名称来识别,而是通过其在 JPQL 查询中的位置来识别。
4.4. s (JPQL)
JPQL(Java 持久化查询语言)是 JPA 层的查询语言。JPQL 语言与数据库中使用的 SQL 语言类似。SQL 操作的是表,而 JPQL 操作的是代表这些表的对象。我们将通过以下架构中的一个示例进行说明:
 |
我们将该数据库命名为 [ dbrdvmedecins2],这是一个包含四个表的 MySQL5 数据库:
 |
该表用于收集管理一组医生预约所需的信息。
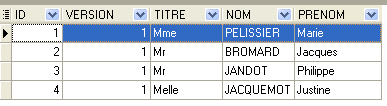
4.4.1. [MEDECINS] 表
该表包含有关医生的信息。
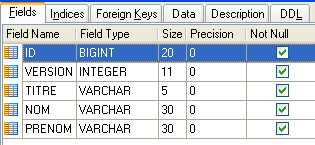 |  |
- ID:医生的ID号——该表的主键
- VERSION:一个标识表中该行版本的数字。每次对该行进行修改时,该数字都会增加 1。
- LAST_NAME:医生的姓
- FIRST NAME:医生的名字
- TITLE:称谓(Ms.、Mrs.、Mr.)
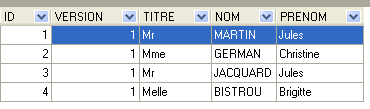
4.4.2. [CLIENTS] 表
各医生的患者信息存储在 [CLIENTS] 表中:
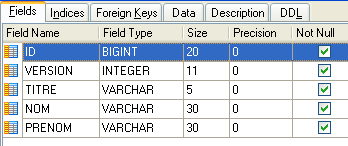 |  |
- ID:用于标识客户的ID号——该表的主键
- VERSION:标识该表中该行版本的编号。每次对该行进行修改时,该编号会递增1。
- LAST NAME:客户的姓
- 名字:客户的名字
- 称谓:称谓(Ms.、Mrs.、Mr.)
4.4.3. [SLOTS] 表
该表格列出了可预约的时间段:
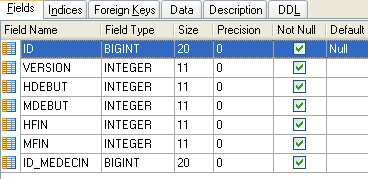 |
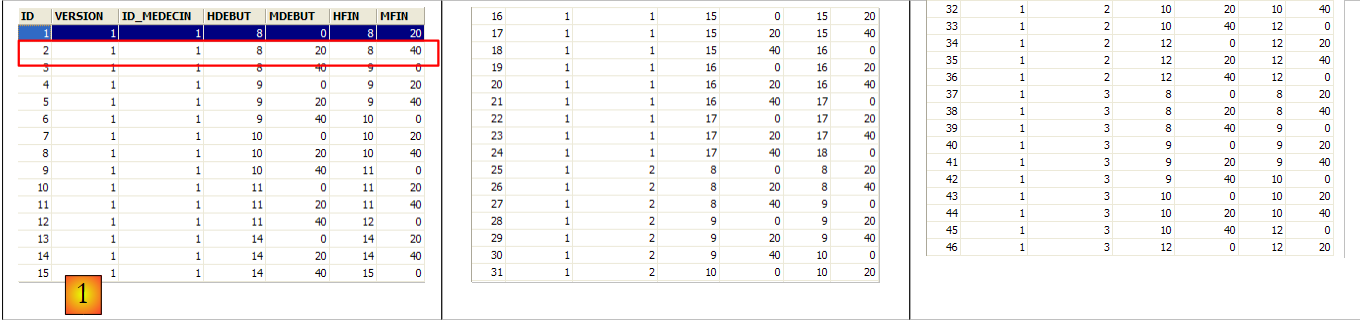 |
- ID:时间段的ID号——该表的主键(第8行)
- VERSION:标识表中该行版本的编号。每次对该行进行修改时,该编号会递增1。
- DOCTOR_ID:标识该时段所属医生的ID号——作为DOCTORS表中ID列的外键。
- START_TIME:时间段的开始时间
- MSTART:时间段的起始分钟
- HFIN:时段结束时间
- MFIN:该时段的结束分钟
例如,[SLOTS] 表(参见上文 [1])的第二行表明,第 2 号时段于上午 8:20 开始,上午 8:40 结束,属于第 1 号医生(Marie PELISSIER 女士)。
4.4.4. [RV] 表
该表列出了每位医生的预约情况:
 |
- ID:预约的唯一标识符——主键
- DAY:预约日期
- SLOT_ID:预约时段——作为外键关联至 [SLOTS] 表的 [ID] 字段——同时确定时段及负责医生。
- CLIENT_ID:预约对象的客户ID——作为[CLIENTS]表中[ID]字段的外键
该表对关联列(DAY、SLOT_ID)的值设置了唯一性约束:
如果 [RV] 表中某行 (DAY, SLOT_ID) 列的值为 (DAY1, SLOT_ID1),则该值不能出现在其他任何地方。否则,这意味着同一医生在同一时间被预约了两次。从 Java 编程的角度来看,当这种情况发生时,数据库的 JDBC 驱动程序会抛出一个 SQLException。
ID 为 3 的行(参见上文 [1])表示,2006 年 8 月 23 日为第 20 个时段和第 4 号客户预订了一次预约。[SLOTS] 表告诉我们,第 20 个时段对应于下午 4:20 至 4:40,并属于第 1 号医生(Marie PELISSIER 女士)。 [CLIENTS] 表显示,客户编号 4 是 Brigitte BISTROU 女士。
4.4.5. 生成数据库
要创建这些表并填充数据,您可以使用脚本 [dbrdvmedecins2.sql]。使用 [WampServer] 时,操作步骤如下:
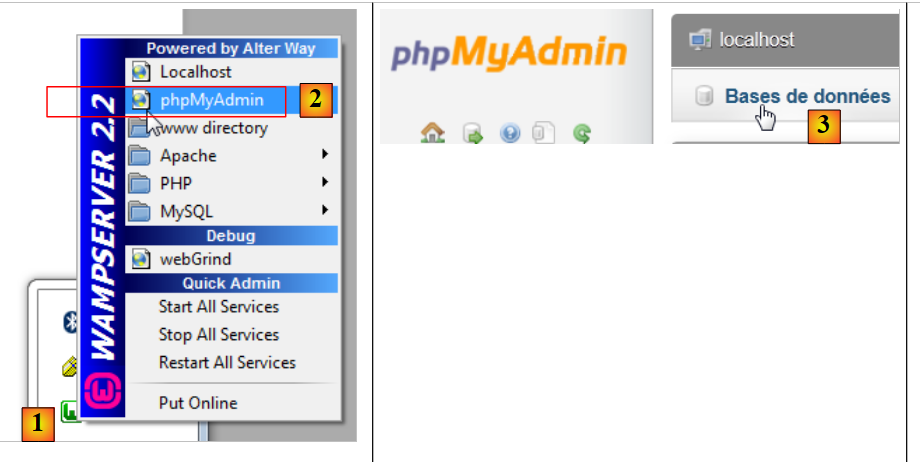 |
- 在 [1] 中,点击 [WampServer] 图标并选择 [PhpMyAdmin] 选项 [2],
- 在 [3] 处,在弹出的窗口中,选择 [数据库] 链接,
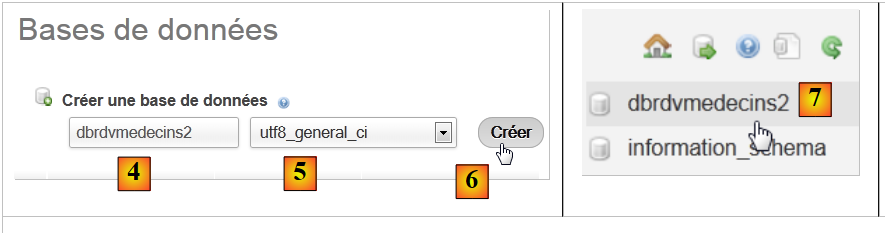 |
- 在 [2] 中,创建一个名称为 [4]、编码为 [5] 的数据库,
- 在 [7] 中,数据库已创建。点击其链接,
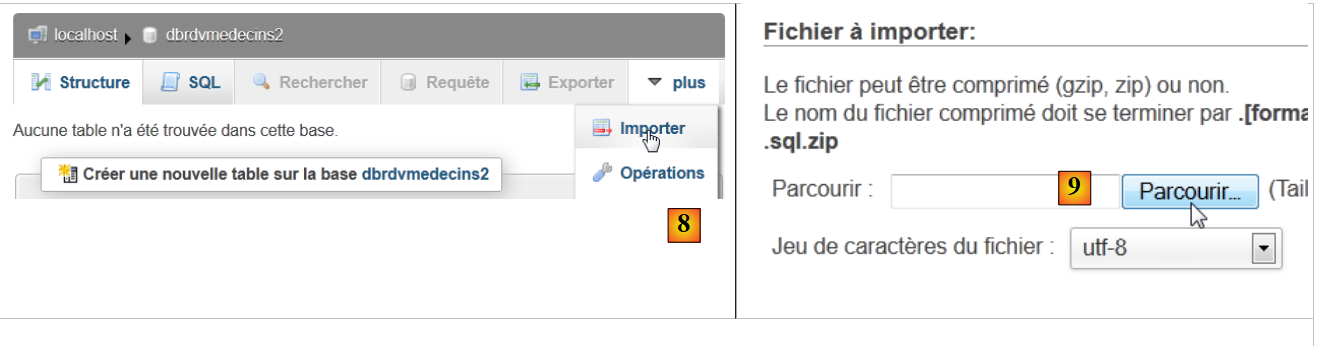 |
- 在 [8] 中,导入一个 SQL 文件,
- 该文件可通过 [9] 按钮从文件系统中选择,
 |
- 在 [11] 中选择 SQL 脚本,并在 [12] 中执行它,
- 在[13]处,数据库中的四个表已创建完成。请点击其中一个链接,
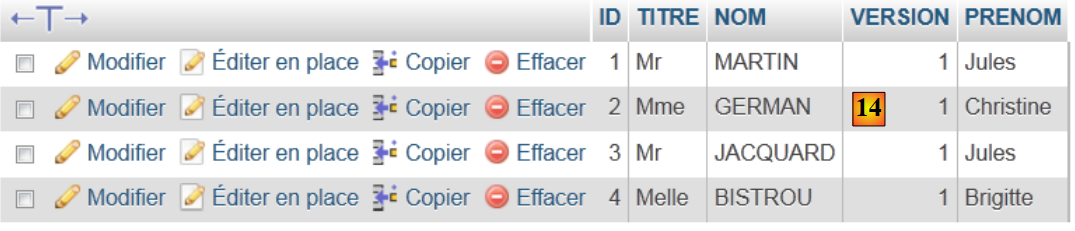 |
- 在 [14] 中,显示该表的内容。
我们不会再回到这个数据库。不过,欢迎读者在阅读程序时关注其演变过程,特别是在出现问题时。
4.4.6. [JPA] 层
让我们回到示例的架构:
 |
我们现在正在构建 [JPA] 层的 Maven 项目。
4.4.7. NetBeans 项目
以下是其外观:
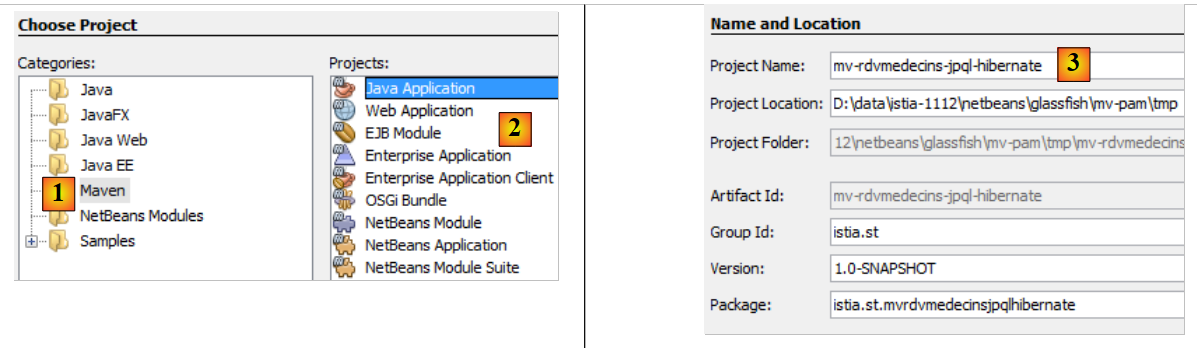 |
- 在 [1] 中,我们创建了一个类型为 [Java 应用程序] 的 Maven 项目 [2],
- 在 [3] 中,我们为项目命名,
 |
- 在 [4] 中,生成的项目。
4.4.8. 生成 [JPA] 层
让我们回到需要构建的架构:
 |
使用 NetBeans,可以自动生成 [JPA] 层。熟悉这些自动生成方法非常有用,因为生成的代码能为如何编写 JPA 实体提供宝贵的参考。
4.4.9. 在 NetBeans 中建立与数据库的连接
- 启动 MySQL 5 数据库管理系统,以便数据库可用,
- 创建一个连接到 [dbrdvmedecins2] 数据库的 NetBeans 连接,
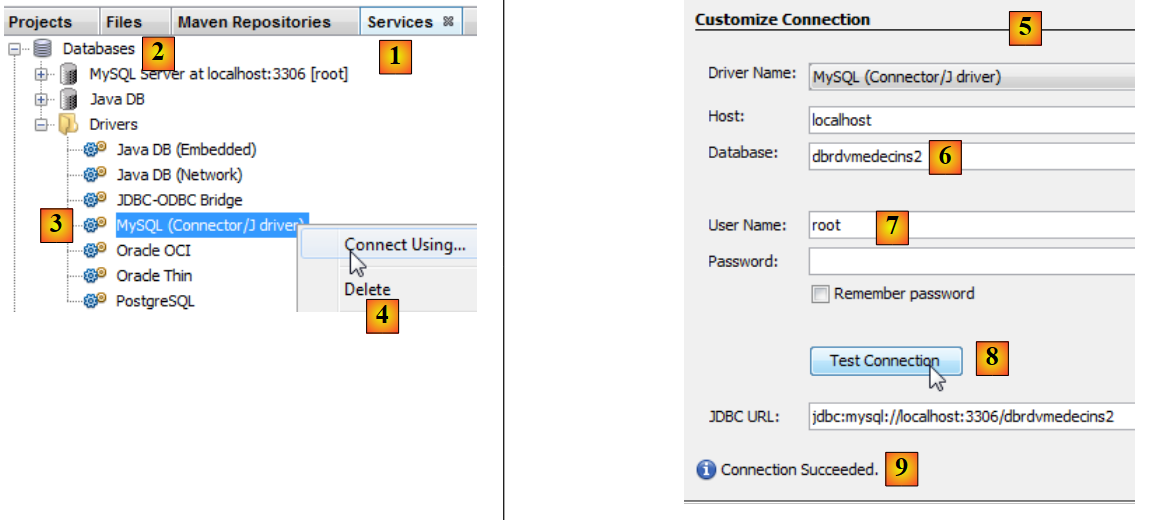 |
- 在 [服务] 选项卡 [1] 的 [数据库] 部分 [2] 下,选择 MySQL JDBC 驱动程序 [3],
- 然后选择 [4] “使用” 选项以建立与 MySQL 数据库的连接,
- 在 [5] 中,输入所需信息。在 [6] 中输入数据库名称;在 [7] 中输入数据库用户名和密码;
- 在 [8] 中,您可以测试所提供的信息,
- 在 [9] 中,若信息正确,将显示预期消息,
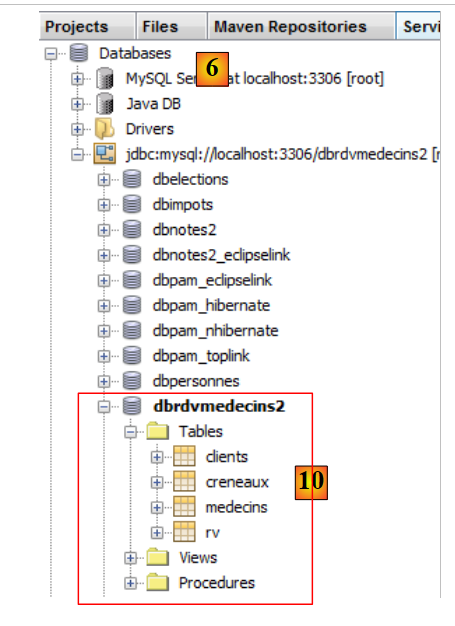 |
- 在 [10] 中,连接已建立。您可以在已连接的数据库中看到这四个表。
4.4.10. 创建持久化单元
让我们回到正在构建的架构:
 |
我们目前正在构建 [JPA] 层。其配置在 [persistence.xml] 文件中完成,该文件中定义了持久化单元。每个持久化单元都需要以下信息:
- JDBC 连接详细信息(URL、用户名、密码),
- 将代表数据库表的类,
- 所使用的 JPA 实现。实际上,JPA 是一项由多种产品实现的规范。在此,我们将使用 Hibernate。
NetBeans 可以通过向导生成此持久化文件。
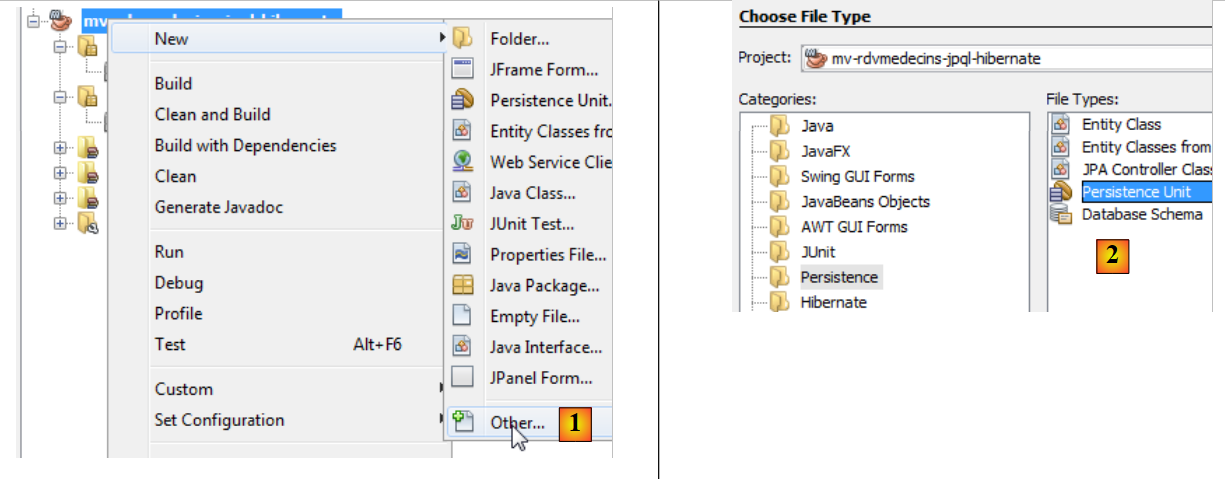 |
- 右键单击项目并选择“创建持久化单元” [1],
- 在 [2] 中,创建一个持久化单元,
|
- 在 [3] 中,为正在创建的持久化单元命名,
- 在 [4] 中,选择 Hibernate JPA 实现(JPA 2.0),
- 在 [5] 中,指定数据库表已存在,因此无需创建。确认向导,
- 在 [6] 中,新项目,
- 在 [7] 中,[persistence.xml] 文件已生成在 [META-INF] 文件夹中,
- 在 [8] 中,Maven 项目已添加了新的依赖项。
生成的 [META-INF/persistence.xml] 文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="mv-rdvmedecins-jpql-hibernatePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbrdvmedecins2"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="hibernate.cache.provider_class" value="org.hibernate.cache.NoCacheProvider"/>
</properties>
</persistence-unit>
</persistence>
它包含向导中提供的信息:
- 第 3 行:持久化单元的名称,
- 第 3 行:数据库事务的类型。此处的 RESOURCE_LOCAL 表示应用程序将自行管理事务,
- 第 6–9 行:数据源的 JDBC 属性。
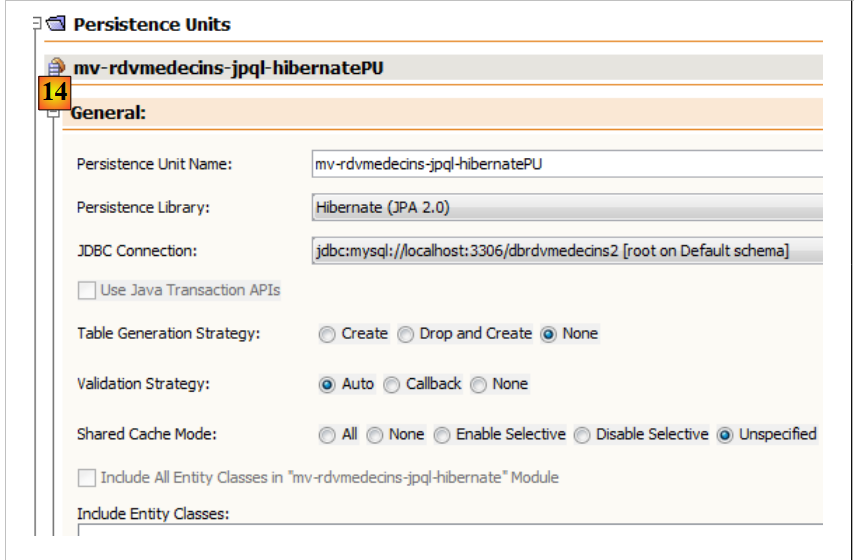
在 [设计] 选项卡中,您可以查看 [persistence.xml] 文件的概览:
 |
要启用 Hibernate 日志记录,请按以下方式完善 [persistence.xml] 文件:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="mv-rdvmedecins-jpql-hibernatePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbrdvmedecins2"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="hibernate.cache.provider_class" value="org.hibernate.cache.NoCacheProvider"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
</properties>
</persistence-unit>
</persistence>
- 第 11 行:我们请求查看 Hibernate 生成的 SQL 语句,
- 第 12 行:此属性可实现对这些语句的格式化显示。
已向项目中添加了依赖项。[pom.xml] 文件内容如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>istia.st</groupId>
<artifactId>mv-rdvmedecins-jpql-hibernate</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>mv-rdvmedecins-jpql-hibernate</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>org.jboss.logging</groupId>
<artifactId>jboss-logging</artifactId>
<version>3.1.0.GA</version>
</dependency>
<dependency>
<groupId>org.jboss.spec.javax.transaction</groupId>
<artifactId>jboss-transaction-api_1.1_spec</artifactId>
<version>1.0.0.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>antlr</groupId>
<artifactId>antlr</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.hibernate.javax.persistence</groupId>
<artifactId>hibernate-jpa-2.0-api</artifactId>
<version>1.0.1.Final</version>
</dependency>
<dependency>
<groupId>org.javassist</groupId>
<artifactId>javassist</artifactId>
<version>3.15.0-GA</version>
</dependency>
<dependency>
<groupId>org.hibernate.common</groupId>
<artifactId>hibernate-commons-annotations</artifactId>
<version>4.0.1.Final</version>
</dependency>
</dependencies>
</project>
添加的依赖项均与 Hibernate ORM 相关。我们将添加 MySQL JDBC 驱动程序的依赖项:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
4.4.11. 生成 JPA 实体
可以使用 NetBeans 向导生成 JPA 实体:
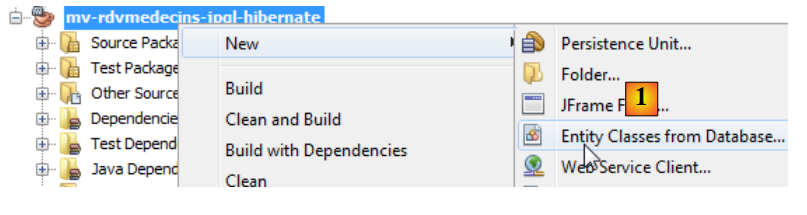 |
- 在 [1] 中,从数据库创建 JPA 实体,
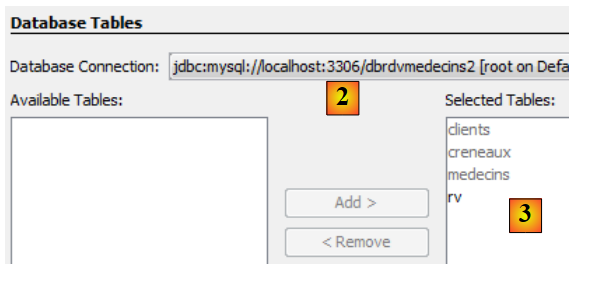 |
- 在[2]中,选择之前创建的连接[dbrdvmedecins2],
- 在 [3] 中,选择关联数据库中的所有表,
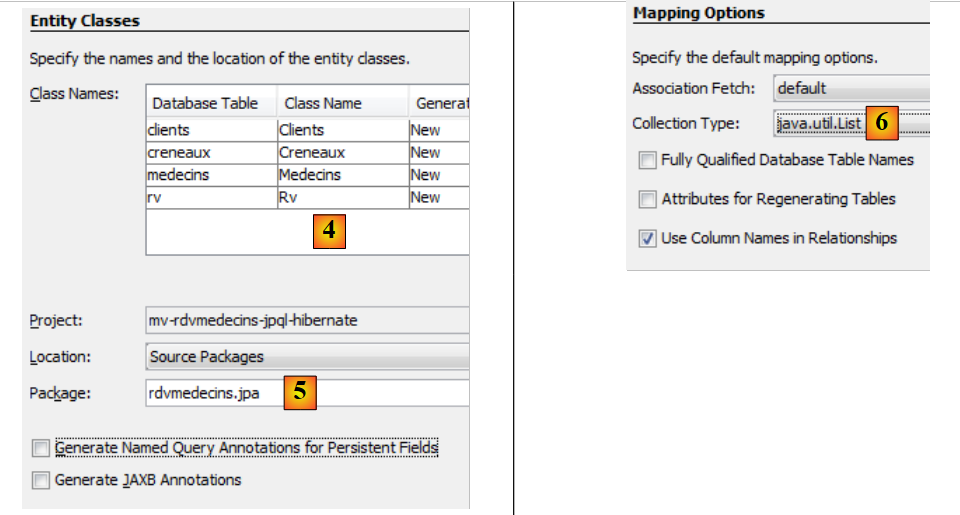 |
- 在 [4] 中,为与这四个表关联的 Java 类命名,
- 以及包名 [5],
- 在 [6] 中,JPA 将数据库表中的行分组为集合。我们选择列表作为集合,
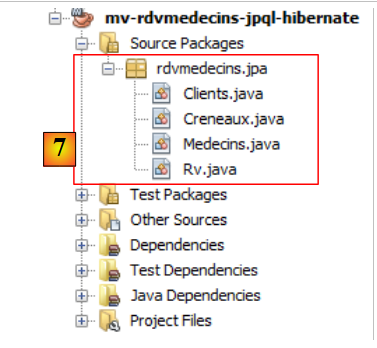 |
- 在 [7] 中,向导生成的 Java 类。
4.4.12. 生成的 JPA 实体
[Medecin] 实体映射了 [medecins] 表。该 Java 类布满了注解,乍看之下使得代码难以阅读。如果我们只保留理解该实体作用所必需的内容,则得到以下代码:
package rdvmedecins.jpa;
...
@Entity
@Table(name = "medecins")
public class Medecin implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "TITRE")
private String titre;
@Column(name = "NOM")
private String nom;
@Column(name = "VERSION")
private int version;
@Column(name = "PRENOM")
private String prenom;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "idMedecin")
private List<Creneau> creneauList;
// manufacturers
....
// getters and setters
....
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
...
}
}
- 第 4 行:@Entity 注解将 [Medecin] 类定义为 JPA 实体,即通过 JPA API 与数据库表关联的类。
- 第 5 行:与 JPA 实体关联的数据库表名。表中的每个字段都对应 Java 类中的一个字段,
- 第 6 行:该类实现了 Serializable 接口。在客户端/服务器应用程序中,实体需要在客户端和服务器之间进行序列化,因此此接口是必需的。
- 第 10–11 行:[Doctor] 类的 id 字段对应于 [doctors] 表中的 [ID] 字段(第 10 行),
- 第 13–14 行:[Doctor] 类的 title 字段对应于 [doctors] 表中的 [TITLE] 字段(第 13 行),
- 第 16–17 行:[Medecin] 类的 `nom` 字段对应于 [medecins] 表的 `[NOM]` 字段(第 16 行),
- 第 19-20 行:[Medecin] 类的 version 字段对应于 [doctors] 表的 [VERSION] 字段(第 19 行)。在此处,向导未能识别出该列实际上是一个版本列,每次修改其所属的行时,该列都必须递增。要为其赋予此角色,必须添加 @Version 注解。 我们将在后续步骤中进行此操作,
- 第 22–23 行:[Doctor] 类的 first_name 字段对应于 [doctors] 表的 [FIRST_NAME] 字段,
- 第 10–11 行:id 字段对应于该表的主键 [ID]。第 8–9 行的注解阐明了这一点,
- 第 8 行:@Id 注解表明被注解的字段与表的主键相关联,
- 第 9 行:[JPA] 层将为插入到 [Doctors] 表中的行生成主键。有几种可能的策略。此处,GenerationType.IDENTITY 策略表示 JPA 层将使用 MySQL 表的 auto_increment 模式,
- 第25–26行:[slots]表拥有指向[doctors]表的外键。一个槽位属于一位医生。反之,一位医生则关联着多个槽位。 因此,我们建立了一对多关系(一位医生对应多个插槽),该关系通过 JPA 中的 @OneToMany 注解进行定义(第 25 行)。第 26 行的字段将包含该医生所有的插槽。这一功能无需任何编程即可实现。要完全理解第 25 行,我们需要介绍 [Creneau] 类。
其定义如下:
package rdvmedecins.jpa;
import java.io.Serializable;
import java.util.List;
import javax.persistence.*;
import javax.validation.constraints.NotNull;
@Entity
@Table(name = "creneaux")
public class Creneau implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "MDEBUT")
private int mdebut;
@Column(name = "HFIN")
private int hfin;
@Column(name = "HDEBUT")
private int hdebut;
@Column(name = "MFIN")
private int mfin;
@Column(name = "VERSION")
private int version;
@JoinColumn(name = "ID_MEDECIN", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Medecin idMedecin;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "idCreneau")
private List<Rv> rvList;
// manufacturers
...
// getters and setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
...
}
}
我们仅对新的注解进行说明:
- 我们已指定 [slots] 表与 [doctors] 表之间存在外键关系:一个时段(slot)与一位医生相关联。多位医生可以关联多个时段。我们定义了从 [slots] 表到 [doctors] 表的多对一关系(时段到医生)。第 32 行上的 @ManyToOne 注解用于定义外键,
- 第 31 行通过 @JoinColumn 注解指定了外键关系:[slots] 表中的 [ID_MEDECIN] 列是 [doctors] 表中 [ID] 列的外键,
- 第 33 行:引用拥有该时段的医生。此处同样无需任何编码即可实现。
因此,[Creneau] 实体与 [Medecin] 实体之间的外键关系通过两个注解实现:
- 在 [Creneau] 实体中:
@JoinColumn(name = "ID_MEDECIN", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Medecin idMedecin;
- 在 [Doctor] 实体中:
@OneToMany(cascade = CascadeType.ALL, mappedBy = "idMedecin")
private List<Creneau> creneauList;
这两个注解反映了相同的关系:即从 [appointments] 表到 [doctors] 表的外键关系。它们被称为彼此的逆关系。只有 @ManyToOne 关系是必需的。它明确地定义了外键关系。 @OneToMany 关系是可选的。如果存在,它仅引用与其关联的 @ManyToOne 关系。这就是 [Medecin] 实体第 1 行中 mappedBy 属性的含义。 该属性的值是 [Creneau] 实体中带有 @ManyToOne 注解(用于指定外键)的字段名称。同样在 [Medecin] 实体的第 1 行,cascade=CascadeType.ALL 属性定义了 [Medecin] 实体相对于 [Creneau] 实体的行为:
- 如果向数据库插入新的 [Doctor] 实体,则第 2 行字段中的 [TimeSlot] 实体也必须被插入,
- 如果数据库中修改了 [Doctor] 实体,则第 2 行字段中的 [Slot] 实体也必须被修改,
- 如果从数据库中删除了一个 [Doctor] 实体,则第 2 行字段中的 [Slot] 实体也必须被删除。
我们提供了另外两个实体的代码,但未附具体注释,因为它们未引入任何新语法。
[Client] 实体
package rdvmedecins.jpa;
...
@Entity
@Table(name = "clients")
public class Client implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "TITRE")
private String titre;
@Column(name = "NOM")
private String nom;
@Column(name = "VERSION")
private int version;
@Column(name = "PRENOM")
private String prenom;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "idClient")
private List<Rv> rvList;
// manufacturers
...
// getters and setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
...
}
}
- 第 24–25 行反映了 [rv] 表与 [clients] 表之间的外键关系。
[Rv] 实体:
package rdvmedecins.jpa;
...
@Entity
@Table(name = "rv")
public class Rv implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "JOUR")
@Temporal(TemporalType.DATE)
private Date jour;
@JoinColumn(name = "ID_CRENEAU", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Creneau idCreneau;
@JoinColumn(name = "ID_CLIENT", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Client idClient;
// manufacturers
...
// getters and setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
...
}
}
- 第 13 行将 `jour` 字段定义为 Java Date 类型。它指定在 [rv] 表中,[JOUR] 列(第 12 行)的类型为日期(不含时间),
- 第 16–18 行:定义了从 [rv] 表到 [slots] 表的外键关系,
- 第 20–22 行:定义从 [rv] 表到 [clients] 表的外键关系。
JPA 实体的自动生成为我们提供了一个可用的基础。有时这已足够,有时则不然。本例即属于后者:
- 我们需要在实体的各个版本字段上添加 @Version 注解,
- 我们需要编写比生成的方法更明确的 toString 方法,
- [Medecin] 和 [Client] 实体具有相似性。我们将让它们继承自 [Person] 类,
- 我们将把 @OneToMany 关系中的反向 @OneToMany 关系移除。这些关系并非必需,且会增加编程复杂度,
- 我们将移除主键上的 @NotNull 验证。当使用 MySQL 持久化 JPA 实体时,该实体初始的主键为空。只有在数据中持久化之后,已持久化实体的主键才会获得值。
根据这些规范,各类将变为如下形式:
Person 类用于表示医生和客户:
package rdvmedecins.jpa;
import java.io.Serializable;
import javax.persistence.*;
@MappedSuperclass
public class Personne implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Basic(optional = false)
@Column(name = "TITRE")
private String titre;
@Basic(optional = false)
@Column(name = "NOM")
private String nom;
@Basic(optional = false)
@Column(name = "VERSION")
@Version
private int version;
@Basic(optional = false)
@Column(name = "PRENOM")
private String prenom;
// manufacturers
...
// getters and setters
...
@Override
public String toString() {
return String.format("[%s,%s,%s,%s,%s]", id, version, titre, prenom, nom);
}
}
- 第 6 行:请注意,[Person] 类本身并非实体(@Entity)。它将作为实体的父类。@MappedSuperClass 注解表明了这一点。
[Client] 实体封装了 [clients] 表中的行。它继承自前面的 [Person] 类:
package rdvmedecins.jpa;
import java.io.Serializable;
import javax.persistence.*;
@Entity
@Table(name = "clients")
public class Client extends Personne implements Serializable {
private static final long serialVersionUID = 1L;
// manufacturers
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
return String.format("Client[%s,%s,%s,%s]", getId(), getTitre(), getPrenom(), getNom());
}
}
- 第 6 行:[Client] 类是一个 JPA 实体,
- 第 7 行:它与 [clients] 表相关联,
- 第 8 行:它继承自 [Person] 类。
封装 [doctors] 表中各行的 [Doctor] 实体遵循相同的模式:
package rdvmedecins.jpa;
import java.io.Serializable;
import javax.persistence.*;
@Entity
@Table(name = "medecins")
public class Medecin extends Personne implements Serializable {
private static final long serialVersionUID = 1L;
// manufacturers
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
return String.format("Médecin[%s,%s,%s,%s]", getId(), getTitre(), getPrenom(), getNom());
}
}
[Creneau] 实体封装了 [creneaux] 表中的行:
package rdvmedecins.jpa;
import java.io.Serializable;
import java.util.List;
import javax.persistence.*;
@Entity
@Table(name = "creneaux")
public class Creneau implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Basic(optional = false)
@Column(name = "ID")
private Long id;
@Basic(optional = false)
@Column(name = "MDEBUT")
private int mdebut;
@Basic(optional = false)
@Column(name = "HFIN")
private int hfin;
@Basic(optional = false)
@NotNull
@Column(name = "HDEBUT")
private int hdebut;
@Basic(optional = false)
@Column(name = "MFIN")
private int mfin;
@Basic(optional = false)
@Column(name = "VERSION")
@Version
private int version;
@JoinColumn(name = "ID_MEDECIN", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Medecin medecin;
// manufacturers
...
// getters and setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
// TODO: Warning - this method won't work in the case the id fields are not set
...
}
@Override
public String toString() {
return String.format("Creneau [%s, %s, %s:%s, %s:%s,%s]", id, version, hdebut, mdebut, hfin, mfin, medecin);
}
}
- 第 40–42 行定义了数据库中 [slots] 表与 [doctors] 表之间的“多对一”关系:一名医生拥有多个时段,而一个时段仅属于一名医生。
[Rv] 实体封装了 [rv] 表中的行:
package rdvmedecins.jpa;
import java.io.Serializable;
import java.util.Date;
import javax.persistence.*;
@Entity
@Table(name = "rv")
public class Rv implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Basic(optional = false)
@Column(name = "ID")
private Long id;
@Basic(optional = false)
@Column(name = "JOUR")
@Temporal(TemporalType.DATE)
private Date jour;
@JoinColumn(name = "ID_CRENEAU", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Creneau creneau;
@JoinColumn(name = "ID_CLIENT", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Client client;
// manufacturers
...
// getters and setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
return String.format("Rv[%s, %s, %s]", id, creneau, client);
}
}
- 第 27–29 行描述了数据库中 [rv] 表与 [clients] 表之间的“多对一”关系(一个客户可能出现在多个 Rv 条目中),而第 23–25 行描述了 [rv] 表与 [slots] 表之间的“多对一”关系(一个插槽可能出现在多个 Rv 条目中)。
4.4.13. 数据访问代码
现在,我们将向项目中添加通过 JPA 层访问数据的代码:
 |
 |
[MainJpql] 类的定义如下:
package rdvmedecins.console;
import java.util.Scanner;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public class MainJpql {
public static void main(String[] args) {
// EntityManagerFactory
EntityManagerFactory emf = Persistence.createEntityManagerFactory("mv-rdvmedecins-jpql-hibernatePU");
// entityManager
EntityManager em = emf.createEntityManager();
// keyboard scanner
Scanner clavier = new Scanner(System.in);
// query entry loop JPQL
System.out.println("Requete JPQL sur la base dbrdvmedecins2 (* pour arrêter) :");
String requete = clavier.nextLine();
while (!requete.trim().equals("*")) {
try {
// display query result
for (Object o : em.createQuery(requete).getResultList()) {
System.out.println(o);
}
} catch (Exception e) {
System.out.println("L'exception suivante s'est produite : " + e);
}
// clear the persistence context
em.clear();
// new request
System.out.println("---------------------------------------------");
System.out.println("Requete JPQL sur la base dbrdvmedecins2 (* pour arrêter) :");
requete = clavier.nextLine();
}
// resource closure
em.close();
emf.close();
}
}
- 第 12 行:创建与我们之前创建的持久化单元关联的 EntityManagerFactory。`createEntityManagerFactory` 方法的参数是该持久化单元的名称:
<persistence-unit name="mv-rdvmedecins-jpql-hibernatePU" transaction-type="RESOURCE_LOCAL">
...
</persistence-unit>
- 第 14 行:创建管理持久化层的 EntityManager,
- 第 19 行:输入一个 JPQL SELECT 查询,
- 第 23–28 行:显示查询结果,
- 第 20 行:当用户输入 * 时停止输入。
问题:请提供用于检索以下信息的 JPQL 查询:
- 按姓氏降序排列的医生列表
- 按头衔为“Mr”排序的医生列表
- 佩利西耶女士的预约时段列表
- 按日期升序排列的预约列表
- 2006年8月24日预约了佩利西耶女士的客户(按姓氏排序)
- 2006年8月24日佩利西耶女士的客户数量
- 尚未预约的客户
- 没有预约的医生
我们将借鉴[ref1]第2.7节中的示例。以下是一个执行示例:
- 第 2 行:JPQL 查询,
- 第 3–11 行:对应的 SQL 查询,
- 第12–15行:JPQL查询的结果。
4.5. 持久化上下文与数据库管理系统之间的关联
4.5.1. Person 类
4.5.2. 测试程序
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 | |
4.5.3. Hibernate 配置
4.5.4. log4j.properties 配置
4.5.5. 结果
问题:解释 Java 代码与显示结果之间的关系。