5. 版本 1:Spring / JPA 架构
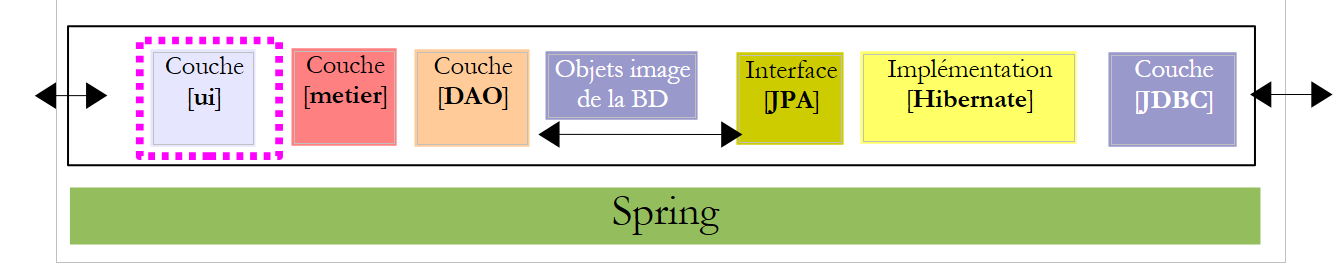
我们建议编写一个控制台应用程序和一个图形化应用程序,用于为某市“Maison de la petite enfance”雇佣的托儿服务人员生成工资单。该应用程序将采用以下架构:
 |
5.1. DB 数据库
生成工资单所需的静态数据将存储在一个数据库中,我们将该数据库称为 dbpam。该数据库可能包含以下表:
结构:
主键 | |
版本号 – 每当行被修改时递增 | |
员工的社会保障号码 – 唯一 | |
员工姓氏 | |
名字 | |
收件地址 | |
他的/她的城市 | |
他们的邮政编码 | |
[INDEMNITES] 表中 [ID] 字段的外键 |
其内容可能如下所示:

结构:
主键 | |
版本号 – 每当行被修改时递增 | |
百分比:一般社会贡献 + 偿还社会债务的贡献 | |
百分比:可扣除的一般社会贡献 | |
百分比:社会保障、遗属、养老 | |
百分比:补充养老金 + 失业保险 |
其内容可如下所示:
![]()
社会保障缴费率与员工无关。前表仅有一行。
主键 | |||
版本号 – 每当行数据发生修改时递增 | |||
处理索引 – 唯一 | |||
每小时待命服务的净价(欧元) | |||
每日护理津贴(欧元) | |||
护理期间每日餐费(欧元) | |||
带薪休假津贴。这是按基本工资的一定比例计算的。 | |||
其内容可能如下:

请注意,不同托儿服务提供者的津贴可能有所不同。这些津贴通过其薪级与特定的托儿服务提供者相关联。因此,薪级为2(见“员工”表)的玛丽·朱维纳尔女士,其时薪为2.1欧元(见“津贴”表)。
5.2. 保育员薪资的计算方法
下面我们将介绍计算保育员月薪的方法。此方法并非实际工作中采用的标准方法。作为示例,我们将以玛丽·朱维纳尔女士的薪资为例,她在该薪资周期内工作了20天,共计150小时。
计算时考虑以下因素: | | |
保育员的基本工资 由以下公式计算得出: | ||
需从该基本工资中扣除一定数额的社会保险费 必须从该基本工资中扣除 : | | |
社会保障缴费总额: | ||
此外,该保育员有权获得每日生活津贴和每日餐费津贴。因此,她可获得以下津贴: | ||
最终,支付给保育员的净薪资如下: |
5.3. 控制台应用程序的工作原理
以下是在 DOS 窗口中运行控制台应用程序的示例:
我们将编写一个程序,该程序将接收以下信息:
- 保育员的社会保险号(示例中为 254104940426058 - 第 1 行)
- 总工作小时数(示例中为 150 小时——第 1 行)
- 总工作日数(示例中为 20 天——第 1 行)
我们可以看到:
- 第 9–14 行:显示提供社会保障号码的雇员的相关信息
- 第17–20行:显示各项缴费的费率
- 第23–26行:显示与该员工薪级(此处为2级)相关的津贴
- 第29–33行:显示待支付薪资的构成部分
该应用程序会标记任何错误:
无参数调用:
dos>java -jar pam-spring-ui-metier-dao-jpa-eclipselink.jar
Syntaxe : pg num_securite_sociale nb_heures_travaillées nb_jours_travaillés
调用时数据错误:
dos>java -jar pam-spring-ui-metier-dao-jpa-eclipselink.jar 254104940426058 150x 20x
Le nombre d'heures travaillées [150x] est erroné
Le nombre de jours travaillés [20x] est erroné
使用错误的社会保险号拨打:
dos>java -jar pam-spring-ui-metier-dao-jpa-eclipselink.jar xx 150 20
L'erreur suivante s'est produite : L'employé de n°[xx] est introuvable
5.4. 图形化应用程序的工作原理
该图形化应用程序使用一个 Swing 表单来计算保育员的工资:
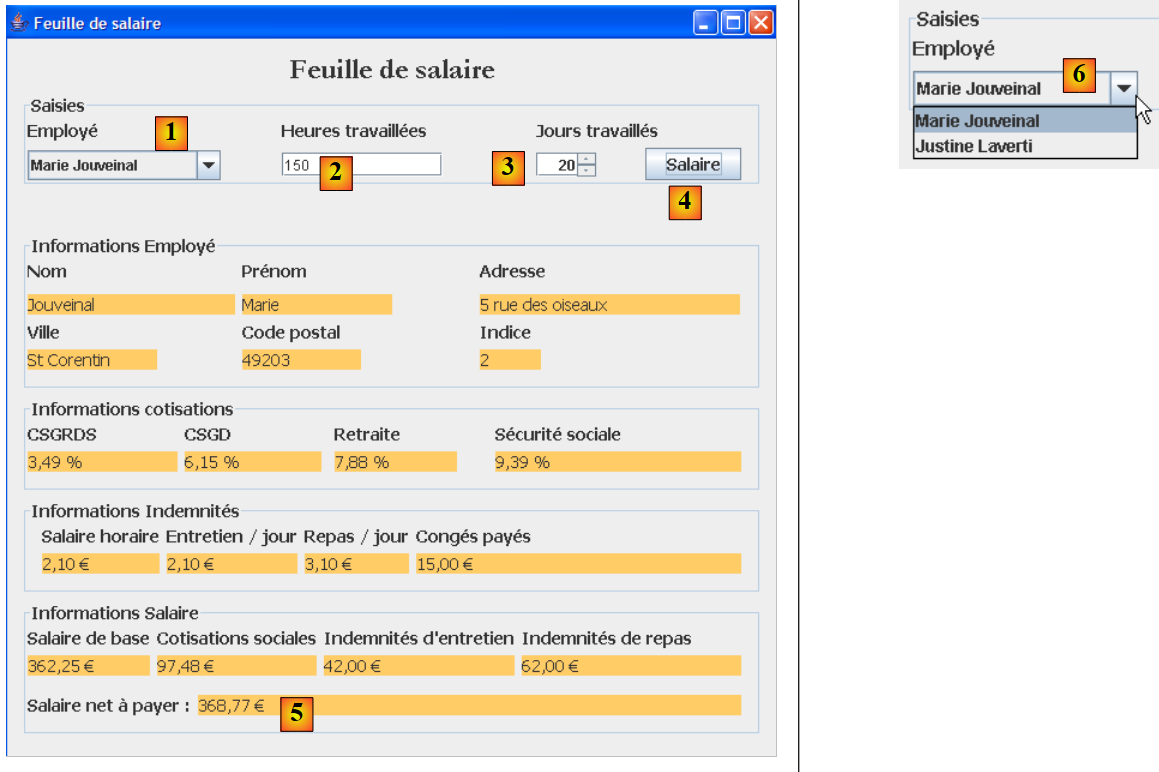 |
- 现在,作为参数传递给控制台程序的信息可通过输入字段 [1, 2, 3] 输入。
- 按钮 [4] 用于启动薪资计算
- 表单会显示各项工资组成部分,直至最终应支付的净工资 [5]
下拉列表 [1, 6] 不显示员工的社会保险号,而是显示其姓名。此处假设没有两名员工拥有相同的姓名。
5.5. 创建数据库
我们启动 WampServer,并使用 PhpMyAdmin 工具 [1]:
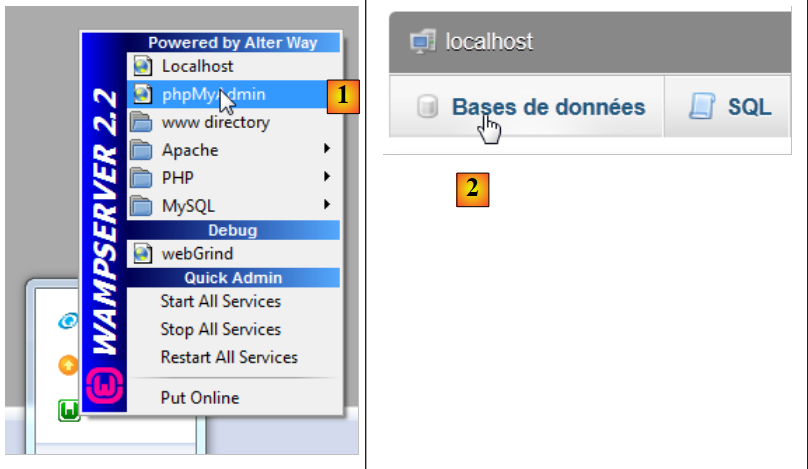 |
- 在 [2] 中,选择 [数据库] 选项,
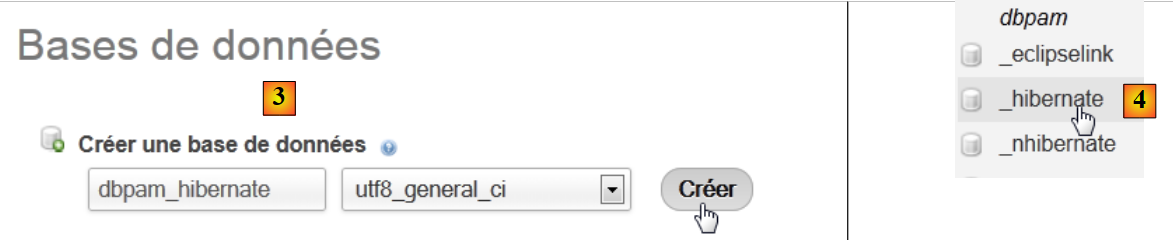 |
- 在 [3] 中,创建一个名为 [dbpam_hibernate] 的数据库,
- 在 [4] 中,数据库已创建。选择它,
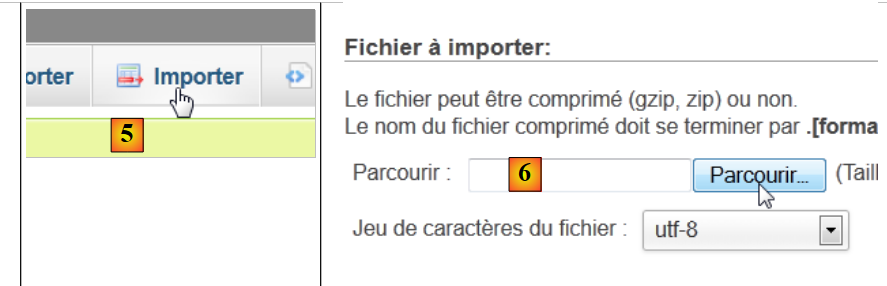 |
- 在 [5] 中,我们需要导入一个 SQL 脚本,
- 在 [6] 处,使用 [浏览] 按钮选择文件,
 |
- 在 [7,8] 中,选择 SQL 脚本,
- 在 [9] 中,我们执行它,
 |
- 在[10]中,已创建了这些表。其内容如下:
EMPLOYEES 表

表 INDEMNITIES

表 缴费
![]()
5.6. JPA 实现
5.6.1. JPA / Hibernate 层
我们将在以下环境中配置 JPA 层:
 |
一个控制台程序将与数据库进行交互。为此,您需要:
- 拥有一个数据库,
- 拥有该数据库管理系统(DBMS)的 JDBC 驱动程序,本例中为 MySQL,
- 使用 Hibernate 实现 JPA 层,
- 编写控制台程序。
我们创建 Maven 项目 [mv-pam-jpa-hibernate] [1]:
 |
在我们的应用程序架构中,我们需要以下组件:
- 数据库、
- MySQL 数据库管理系统(DBMS)的 JDBC 驱动程序,
- JPA/Hibernate 层(实体和配置),
- 测试控制台程序。
5.6.1.1. 数据库
首先,让我们创建一个空数据库。我们启动 WampServer 并使用 PhpMyAdmin 工具 [1]:
 |
- 在[2]中,选择[数据库]选项,
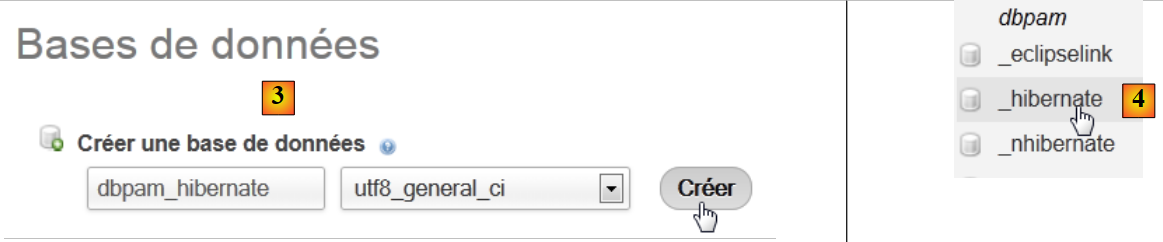 |
- 在 [3] 中,创建一个名为 [dbpam_hibernate] 的数据库,
- 在 [4] 中,数据库已创建。
5.6.1.2. 配置 JPA 层
JDBC 层与数据库之间的连接在 [persistence.xml] 文件中进行配置,该文件用于配置 JPA 层。此文件可通过 NetBeans 创建:
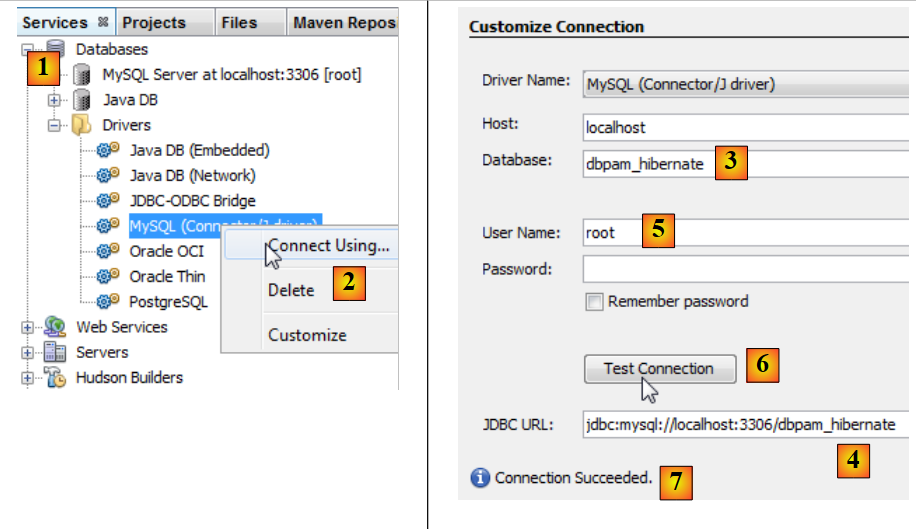 |
- 在 [Services] 选项卡 [1] 中,使用 MySQL JDBC 驱动程序 [2] 连接到数据库,
- 在 [3] 中,输入要连接的数据库名称。
- 在 [4] 中,输入数据库的 JDBC URL,
- 在 [5] 中,以 root 用户身份登录(无需密码),
- 在 [6] 中,您可以测试连接,
- 在 [7] 处,连接成功。
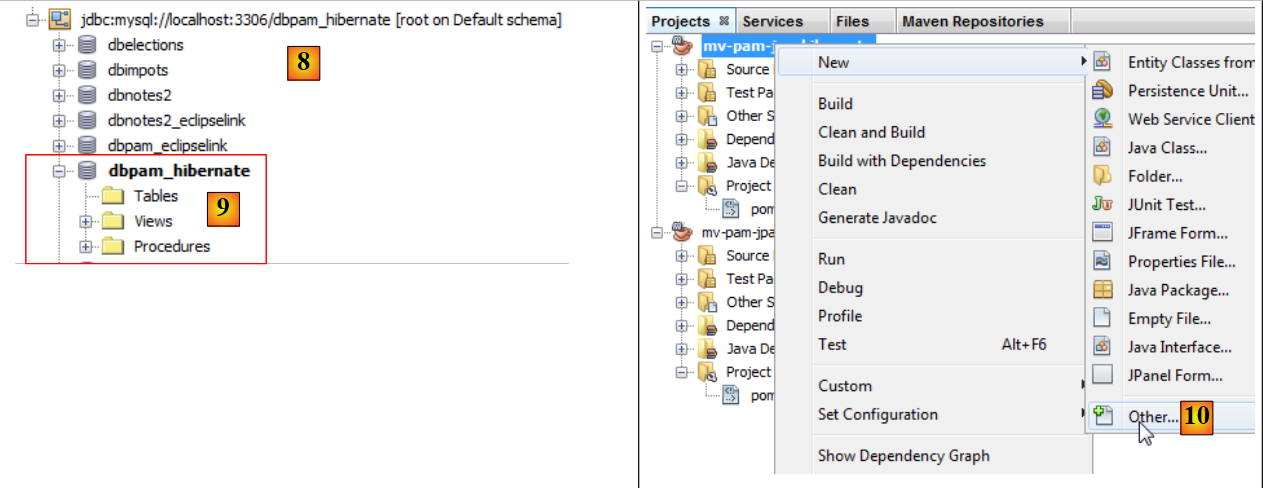 |
- 该关联见于[8]和[9],
- 在[10]中,向项目中添加一个新元素,
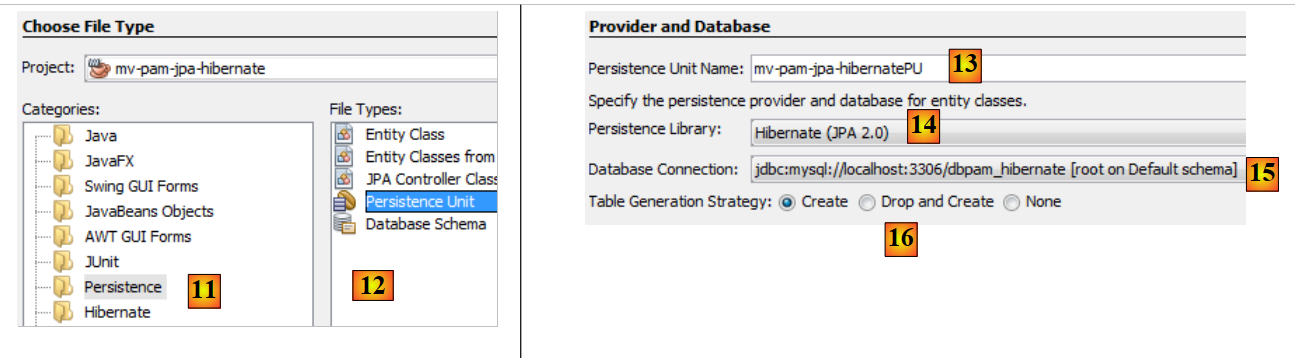 |
- 在[11]中选择[持久化]类别,并在[12]中选择[持久化单元]元素,
- 在 [13] 中,为该持久化单元命名,
- 在 [14] 中,选择一个 Hibernate 实现,
- 在 [15] 中,指定我们刚刚创建的连接到 MySQL 数据库的连接,
- 在 [16] 中,指定当 JPA 层被实例化时,必须创建与项目中 JPA 实体对应的表。
向导结束时会生成 [persistence.xml] 文件:
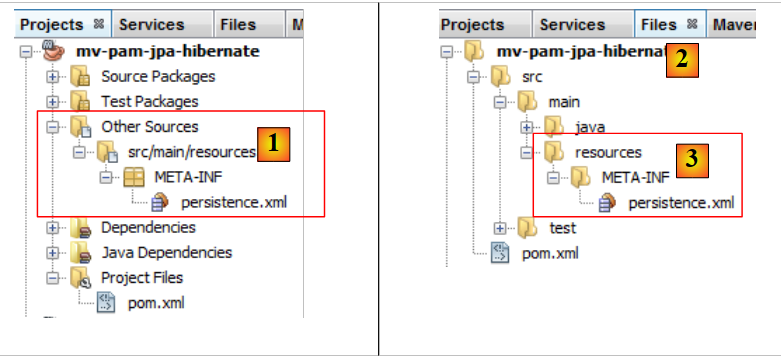 |
- 该文件位于项目的一个新分支中,处于 [META-INF] 文件夹内 [1],
- 该文件夹对应于项目的 [src/main/resources] 文件夹 [2,3]。
其内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="mv-pam-jpa-hibernatePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbpam_hibernate"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="hibernate.cache.provider_class" value="org.hibernate.cache.NoCacheProvider"/>
<property name="hibernate.hbm2ddl.auto" value="create-drop"/>
</properties>
</persistence-unit>
</persistence>
- 第 3 行:持久化单元的名称和事务类型。RESOURCE_LOCAL 表示项目自行管理事务。在这种情况下,控制台程序将负责处理事务,
- 第 4 行:使用的 JPA 实现是 Hibernate,
- 第 6–9 行:数据库连接的 JDBC 属性,
- 第 11 行:请求创建与 JPA 实体对应的表。实际上,NetBeans 在此处生成的配置有误。正确的配置应如下所示:
<property name="hibernate.hbm2ddl.auto" value="create"/>
使用 create 选项时,Hibernate 在实例化 JPA 层时会先删除再创建与 JPA 实体对应的表。create-drop 选项的作用相同,但在 JPA 层生命周期结束时,它会删除所有表。还有另一个选项:
<property name="hibernate.hbm2ddl.auto" value="update"/>
如果表不存在,此选项会创建它们;但如果表已存在,则不会删除它们。
我们将在 Hibernate 配置中再添加三个属性:
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
这些设置指示 Hibernate 显示其发送给数据库的 SQL 语句。因此,完整的文件如下:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="mv-pam-jpa-hibernatePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<class>jpa.Cotisation</class>
<class>jpa.Employe</class>
<class>jpa.Indemnite</class>
<properties>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbpam_hibernate"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="hibernate.cache.provider_class" value="org.hibernate.cache.NoCacheProvider"/>
<property name="hibernate.hbm2ddl.auto" value="create"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
</properties>
</persistence-unit>
</persistence>
5.6.1.3. 依赖项
让我们回到项目架构:
 |
我们通过 [persistence.xml] 文件配置了 JPA 层。选定的实现是 Hibernate。这为项目引入了依赖项:
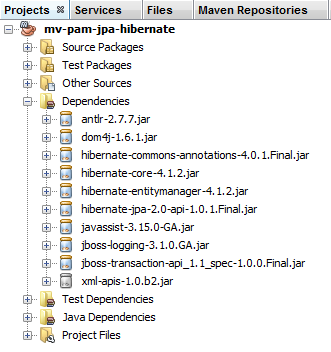 |
这些依赖关系源于项目中引入了 Hibernate。我们需要添加另一个依赖:MySQL JDBC 驱动程序,它实现了架构中的 JDBC 层。我们将 [pom.xml] 文件更新如下:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>4.1.2</version>
</dependency>
...
<dependency>
<groupId>org.hibernate.common</groupId>
<artifactId>hibernate-commons-annotations</artifactId>
<version>4.0.1.Final</version>
</dependency>
</dependencies>
第 8–12 行添加了 MySQL JDBC 驱动程序的依赖项。
5.6.1.4. JPA 实体
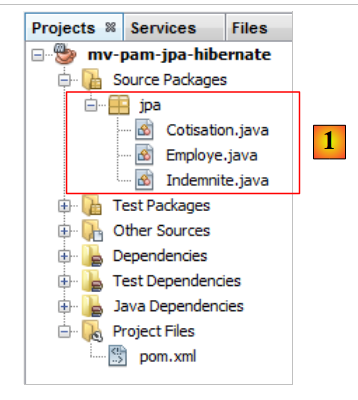 |
问题:按照第 4.4 节示例中的方法,生成实体 [Cotisation、Indemnite、Employe]。
注:
- 这些实体将属于名为 [jpa] 的包,
- 每个实体都将有一个版本号,
- 如果两个实体通过关系关联,则仅创建主 @ManyToOne 关系。反向的 @OneToMany 关系将不会被创建。
5.6.1.5. 主类的代码
我们将之前开发的 JPA 实体 [1] 引入项目:
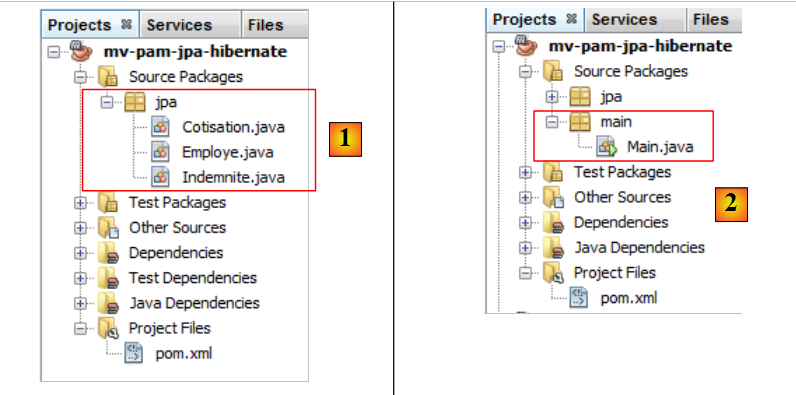 |
然后,我们添加 [2],即以下 [main.Main] 类:
package main;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public class Main {
public static void main(String[] args) {
// creating the Entity Manager is enough to build the JPA layer
EntityManagerFactory emf = Persistence.createEntityManagerFactory("mv-pam-jpa-hibernatePU");
EntityManager em=emf.createEntityManager();
// resource release
em.close();
emf.close();
}
}
- 第 10 行:我们为名为 [mv-pam-jpa-hibernatePU] 的持久化单元创建 EntityManagerFactory。该名称来自 [persistence.xml] 文件:
<persistence-unit name="mv-pam-jpa-hibernatePU" transaction-type="RESOURCE_LOCAL">
...
</persistence-unit>
- 第 12 行:创建 EntityManager。这将建立 JPA 层。系统将使用 [persistence.xml] 文件,从而创建数据库表。
- 第 14–15 行:释放资源。
5.6.1.6. 测试
让我们回到项目的架构:
 |
所有层都已实现。我们运行该项目 [2]。
 |
控制台输出如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 | |
控制台仅包含Hibernate日志,因为执行的程序除了实例化JPA层外没有执行其他操作。请注意以下几点:
- 第 43 行:Hibernate 尝试从 [EMPLOYEES] 表中删除外键,
- 第 51–55 行:删除三个表,
- 第 57 行:创建 [COTISATIONS] 表,
- 第 67 行:创建 [EMPLOYEES] 表,
- 第 80 行:创建 [INDEMNITIES] 表,
- 第 91 行:为 [EMPLOYEES] 表创建外键。
在 NetBeans 中,您可以查看先前创建的连接中的表:
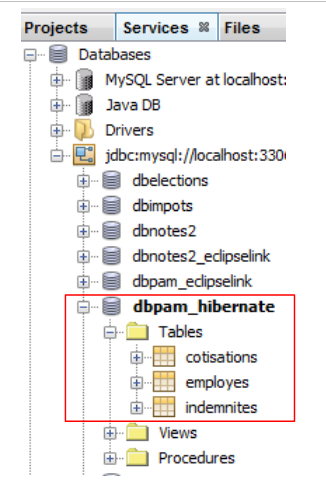 |
生成的表既取决于所使用的 JPA 层实现,也取决于所使用的 DBMS。因此,即使使用相同的数据库,不同的 JPA/EclipseLink 实现生成的表也可能不同。这就是我们接下来要探讨的内容。
5.6.2. JPA / EclipseLink 层
我们将在以下环境中创建一个新的 Maven 项目:
 |
我们将按照上一节中的步骤进行:
- 创建一个名为 [dbpam_eclipselink] 的 MySQL 数据库。我们将使用脚本 [dbpam_eclipselink.sql] 来生成它,
- 创建项目的 [persistence.xml] 文件。使用 EclipseLink JPA 2.0 实现,
- 将 MySQL JDBC 驱动程序依赖项添加到生成的依赖项中,
- 添加 JPA 实体和控制台程序,
- 运行测试。
[persistence.xml] 文件内容如下:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="pam-jpa-eclipselinkPU" transaction-type="RESOURCE_LOCAL">
<provider>org.eclipse.persistence.jpa.PersistenceProvider</provider>
<class>jpa.Cotisation</class>
<class>jpa.Employe</class>
<class>jpa.Indemnite</class>
<properties>
<property name="eclipselink.target-database" value="MySQL"/>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbpam_eclipselink"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="eclipselink.logging.level" value="FINE"/>
<property name="eclipselink.ddl-generation" value="drop-and-create-tables"/>
</properties>
</persistence-unit>
</persistence>
- 属性 9–13 由 NetBeans 向导生成,
- 第 14 行:此属性允许我们设置 EclipseLink 的日志级别。FINE 级别可让我们查看 EclipseLink 将在数据库上执行的 SQL 语句,
- 第 15 行:当 JPA/EclipseLink 层被实例化时,JPA 实体表将被删除,然后重新创建。
控制台输出如下:
- 第26-30行:连接到MySQL数据库,
- 第31-34行:确认连接成功,
- 第 36 行:从 [EMPLOYEES] 表中删除外键,
- 第 37 行:删除 [COTISATIONS] 表,
- 第 38 行:创建 [CONTRIBUTIONS] 表。值得注意的是,主键 ID 没有 MySQL 的 auto_increment 属性。这意味着 MySQL 不会自动生成主键值,
- 第 39 行:删除 [EMPLOYEES] 表,
- 第 40 行:创建 [EMPLOYEES] 表。其主键 ID 未设置 MySQL 的 auto_increment 属性,
- 第 41 行:删除 [INDEMNITIES] 表,
- 第 42 行:创建 [INDEMNITIES] 表。其主键 ID 未设置 MySQL 的 auto_increment 属性,
- 第 43 行:创建从 [EMPLOYEES] 表到 [BENEFITS] 表的外键,
- 第 44 行:创建表 [SEQUENCE]。它将用于为前三个表生成主键,
- 第 47 行:因该表已存在而引发异常,
- 第 51–53 行:初始化 [SEQUENCE] 表。
可在 NetBeans [1] 中验证生成的表是否存在:
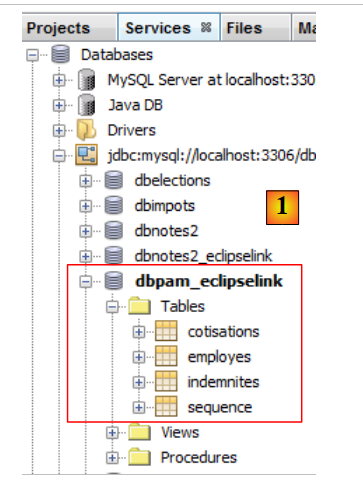 |
因此,基于相同的 JPA 实体,Hibernate 和 EclipseLink 的 JPA 实现生成的表并不相同。在本文档的剩余部分中,当使用的 JPA 实现为:
- Hibernate,我们将使用 [dbpam_hibernate] 数据库,
- EclipseLink,我们将使用 [dbpam_eclipselink] 数据库。
5.6.3. 待完成的工作
按照之前的相同步骤,
- 创建并测试一个项目 [mv-pam-jpa-hibernate-oracle],使用 Hibernate JPA 实现和 Oracle 数据库管理系统,
- 创建并测试一个项目 [mv-pam-jpa-hibernate-mssql],使用 Hibernate JPA 实现和 SQL Server 数据库管理系统,
- 创建并测试一个项目 [mv-pam-jpa-eclipselink-oracle],使用 EclipseLink JPA 实现和 Oracle 数据库管理系统,
- 创建并测试一个项目 [mv-pam-jpa-eclipselink-mssql],使用 EclipseLink JPA 实现和 SQL Server 数据库管理系统,
5.6.4. 延迟加载还是立即加载?
让我们回到 [Employee] 实体的可能定义:
package jpa;
...
@Entity
@Table(name="EMPLOYES")
public class Employe implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Version
@Column(name="VERSION",nullable=false)
private int version;
@Column(name="SS", nullable=false, unique=true, length=15)
private String SS;
@Column(name="NOM", nullable=false, length=30)
private String nom;
@Column(name="PRENOM", nullable=false, length=20)
private String prenom;
@Column(name="ADRESSE", nullable=false, length=50)
private String adresse;
@Column(name="VILLE", nullable=false, length=30)
private String ville;
@Column(name="CP", nullable=false, length=5)
private String codePostal;
@ManyToOne(fetch= FetchType.LAZY)
@JoinColumn(name="INDEMNITE_ID",nullable=false)
private Indemnite indemnite;
...
}
第 27–29 行定义了从 [EMPLOYEES] 表到 [INDEMNITIES] 表的外键。第 27 行的 fetch 属性定义了第 29 行 indemnity 字段的检索策略。共有两种模式:
- FetchType.LAZY:查询员工时,不会检索相应的津贴。当首次引用 [Employee].indemnity 字段时,才会检索该字段。
- FetchType.EAGER:搜索员工时,会立即检索对应的津贴。若未指定模式,此为默认模式。
要理解 FetchType.LAZY 选项的优势,请考虑以下示例。网页上显示了一份不包含薪酬信息的员工列表,其中包含一个 [Details] 链接。点击该链接后,将显示所选员工的薪酬。我们可以看到:
- 要显示第一页,我们不需要同时获取员工及其福利信息。因此,FetchType.LAZY 模式是合适的;
- 要显示包含详细信息的第二页,必须向数据库发出额外查询以检索所选员工的福利信息。
FetchType.LAZY 模式可避免获取应用程序当前不需要的大量数据。让我们来看一个示例。
复制 [mv-pam-jpa-hibernate] 项目:
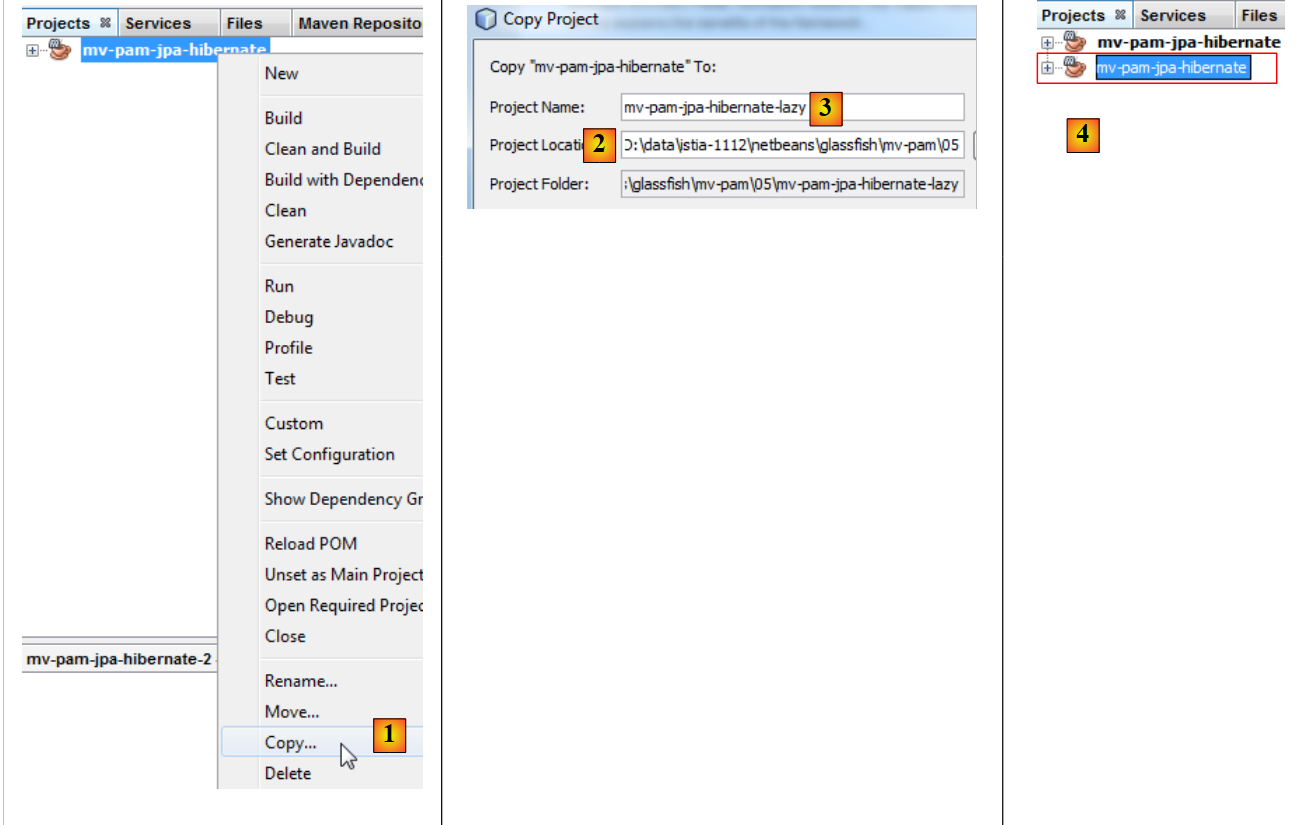 |
- 在 [1] 中,该项目被复制,
- 在 [2] 中,我们指定了复制的目标文件夹,而在 [3] 中指定了其名称,
- 在 [4] 中,新项目与旧项目名称相同。我们将此处修改为:
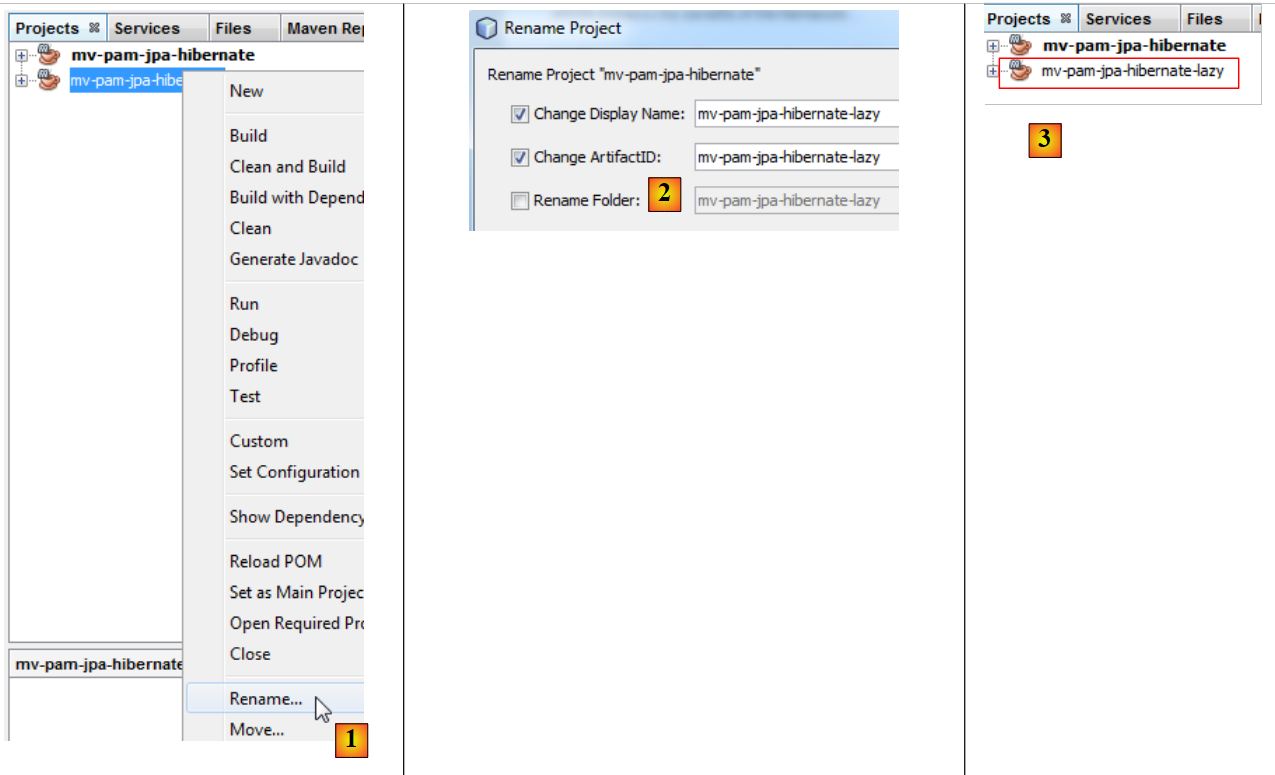 |
- 在 [1] 中,我们重命名项目,
- 在 [2] 中,重命名项目及其 artifactId,
- 在 [3] 中,新建项目。
我们将 [Main.java] 程序修改如下:
package main;
import java.util.List;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
import jpa.Employe;
public class Main {
// the JPQL query below brings back an employee
// the foreign key [Employe].indemnite is in FetchType.LAZY
public static void main(String[] args) {
// creating the Entity Manager is enough to build the JPA layer
EntityManagerFactory emf = Persistence.createEntityManagerFactory("pam-jpa-hibernatePU");
// first attempt
EntityManager em = emf.createEntityManager();
Employe employe = (Employe) em.createQuery("select e from Employe e where e.nom=:nom").setParameter("nom", "Jouveinal").getSingleResult();
em.close();
// we display the employee
try {
System.out.println(employe);
} catch (Exception ex) {
System.out.println(ex);
}
// second test
em = emf.createEntityManager();
employe = (Employe) em.createQuery("select e from Employe e left join fetch e.indemnite where e.nom=:nom").setParameter("nom", "Jouveinal").getSingleResult();
// free up resources
em.close();
// we display the employee
try {
System.out.println(employe);
} catch (Exception ex) {
System.out.println(ex);
}
// resource release
emf.close();
}
}
- 第 15 行:我们为 JPA 层创建 EntityManagerFactory,
- 第 17 行:获取 EntityManager,它允许我们与 JPA 层进行交互,
- 第 18 行:我们检索名为 Jouveinal 的员工,
- 第 19 行:我们关闭 EntityManager。这将关闭持久化上下文。
- 第 22 行:我们显示检索到的员工。
[Employee] 类定义如下:
package jpa;
...
@Entity
@Table(name="EMPLOYES")
public class Employe implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Version
@Column(name="VERSION",nullable=false)
private int version;
@Column(name="SS", nullable=false, unique=true, length=15)
private String SS;
@Column(name="NOM", nullable=false, length=30)
private String nom;
@Column(name="PRENOM", nullable=false, length=20)
private String prenom;
@Column(name="ADRESSE", nullable=false, length=50)
private String adresse;
@Column(name="VILLE", nullable=false, length=30)
private String ville;
@Column(name="CP", nullable=false, length=5)
private String codePostal;
@ManyToOne(fetch= FetchType.LAZY)
@JoinColumn(name="INDEMNITE_ID",nullable=false)
private Indemnite indemnite;
/**
* Returns a string representation of the object. This implementation constructs
* that representation based on the id fields.
* @return a string representation of the object.
*/
@Override
public String toString() {
return "jpa.Employe[id=" + getId()
+ ",version="+getVersion()
+",SS="+getSS()
+ ",nom="+getNom()
+ ",prenom="+getPrenom()
+ ",adresse="+getAdresse()
+",ville="+getVille()
+",code postal="+getCodePostal()
+",indice="+getIndemnite().getIndice()
+"]";
}
...
}
- 第 27 行:indemnite 字段以 LAZY 模式加载,
- 第 47 行:使用了 indemnite 字段。如果在 indemnite 字段尚未被获取时调用了 toString 方法,系统将在此时获取该字段。除非持久化上下文已被关闭,如示例中所示。
让我们回到 [Main] 代码:
- 第 21–25 行:此时应抛出异常。这是因为将调用 toString 方法,该方法会使用 indemnite 字段。系统将尝试查找该字段。由于持久化上下文已被关闭,检索到的 [Employee] 实体已不存在,因此抛出异常。
- 第 27 行:我们创建了一个新的 EntityManager,
- 第 28 行:我们通过在 JPQL 查询中显式请求关联的津贴来检索员工 Jouveinal。这种显式请求是必要的,因为该津贴的检索模式为 LAZY,
- 第 30 行:我们关闭 EntityManager,
- 第 32–36 行:再次显示该员工。此时不应抛出异常。
要运行该项目,您需要一个已导入数据的数据库。请按照第 5.5 节中的步骤创建该数据库。此外,还必须修改 [persistence.xml] 文件:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="mv-pam-jpa-hibernatePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<class>jpa.Cotisation</class>
<class>jpa.Employe</class>
<class>jpa.Indemnite</class>
<properties>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbpam_hibernate"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="hibernate.cache.provider_class" value="org.hibernate.cache.NoCacheProvider"/>
</properties>
</persistence-unit>
</persistence>
- 我们移除了用于创建表的选项。此处的数据库已存在且已填充数据,
- 我们已移除了导致 Hibernate 记录其发送给数据库的 SQL 语句的选项。
运行该项目时,控制台会输出以下两条消息:
- 第 1 行:在会话已关闭时尝试检索缺失的薪酬所引发的异常。我们可以看到,由于 LAZY 模式,薪酬未被检索,
- 第2行:通过绕过LAZY模式的查询获取了该员工的津贴。
5.6.5. 待完成的工作
按照与上述类似的步骤,创建一个名为 [mv-pam-pa-eclipselink-lazy] 的项目,用于演示 EclipseLink 在 LAZY 模式下的行为。
得到以下结果:
在 LAZY 模式下,这两个查询都返回了薪酬信息以及员工信息。在网上研究这一异常现象时,我们发现注释 [FetchType.LAZY](第 1 行):
@ManyToOne(fetch= FetchType.LAZY)
@JoinColumn(name="INDEMNITE_ID",nullable=false)
private Indemnite indemnite;
这并非强制要求,而仅为建议。JPA 实现者没有义务遵循此规范。因此,我们可以看到,代码有时会依赖于所使用的 JPA 实现。可以通过配置使 EclipseLink 在 LAZY 模式下按预期工作。
5.6.6. 后续进展
即将构建的应用程序架构如下:
 |
在本文档的剩余部分,我们将把 Maven 项目 [mv-pam-jpa-hibernate] 复制到项目 [mv-pam-spring-hibernate] 中 [1, 2, 3]:
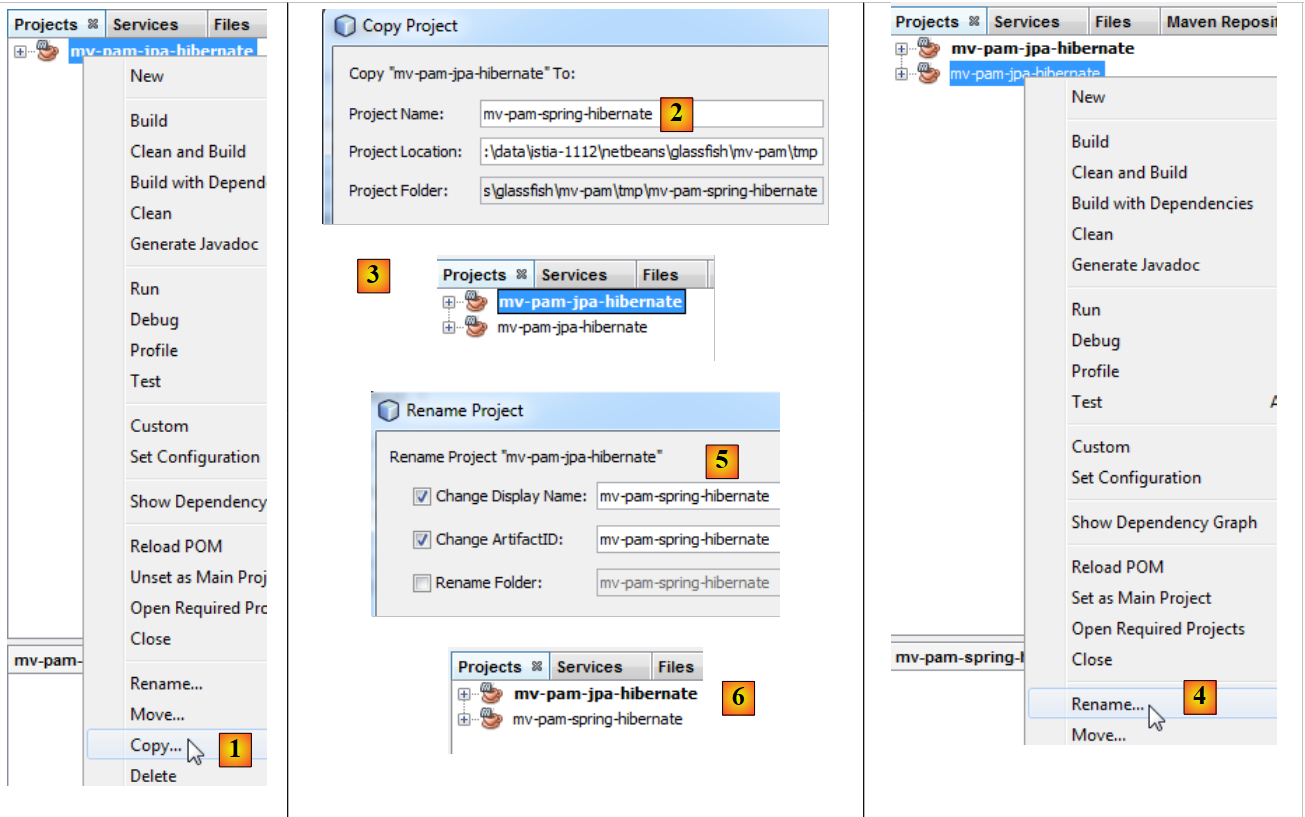 |
- 然后我们将重命名新项目 [4, 5, 6]。
我们将修改新项目的依赖项。[pom.xml] 文件内容如下:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>istia.st</groupId>
<artifactId>mv-pam-spring-hibernate</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>mv-pam-spring-hibernate</name>
<url>http://maven.apache.org</url>
<repositories>
<repository>
<url>http://repo1.maven.org/maven2/</url>
<id>swing-layout</id>
<layout>default</layout>
<name>Repository for library Library[swing-layout]</name>
</repository>
</repositories>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
<type>jar</type>
</dependency>
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.2.2</version>
</dependency>
<dependency>
<groupId>commons-pool</groupId>
<artifactId>commons-pool</artifactId>
<version>1.6</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>4.1.2</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>org.swinglabs</groupId>
<artifactId>swing-layout</artifactId>
<version>1.0.3</version>
</dependency>
</dependencies>
</project>
- 第 25–31 行:JUnit 测试的依赖项,
- 第 32–41 行:Apache DBCP 连接池的依赖项,
- 第 42–65 行:Spring 框架的依赖项,
- 第 67–71 行:JPA/Hibernate 实现的依赖项,
- 第 72–76 行:MySQL JDBC 驱动程序的依赖项,
- 第 77–81 行:Swing 界面的依赖项。当向项目中添加 Swing 界面时,NetBeans 会自动添加此项。
此外,我们将生成两个 MySQL 数据库:
- [dbpam_hibernate] 来自 [dbpam_hibernate.sql] 脚本,
- [dbpam_eclipselink] 来自脚本 [dbpam_eclipselink.sql],
5.7. 中的接口用于[业务]层和[DAO]层
让我们回到应用程序架构:
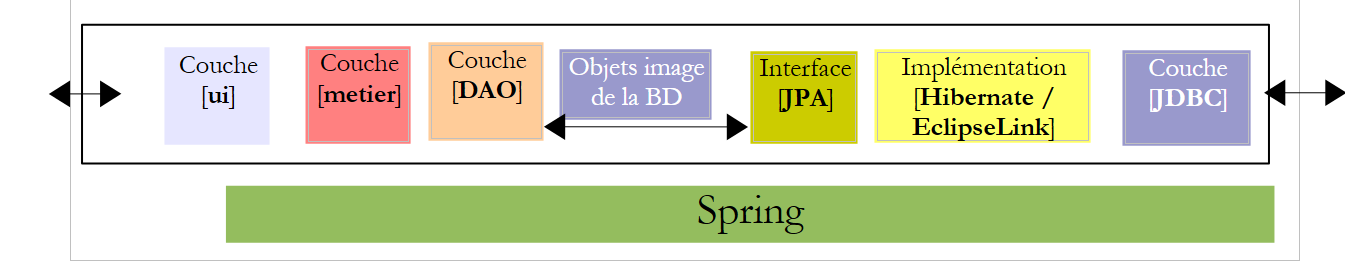 |
在上述架构中,[DAO]层应向[业务]层提供哪些接口,而[业务]层又应向[UI]层提供哪些接口?定义各层接口的一种初步方法是分析应用程序的各种用例。根据所选的用户界面(控制台或图形界面),这里有两种情况。
让我们来分析一下控制台应用程序的使用方式:
该应用程序从用户处获取三项信息(参见上文第1行)
- 保育人员的社保号
- 当月工作小时数
- 当月工作天数
基于这些信息以及配置文件中存储的其他数据,应用程序将显示以下信息:
- 第4–6行:输入的数值
- 第8–10行:与提供社会保障号码的员工相关的信息
- 第 12–14 行:各项社会保障缴费的费率
- 第16–17行:支付给托儿服务提供者的各项津贴
- 第19–24行:托儿服务提供者的工资单明细
[业务]层必须向[UI]层提供一定数量的信息:
- 与保育员相关的信息,该信息通过其社会保障号码进行标识。该信息存储在[EMPLOYEES]表中。这使得第6–8行能够显示。
- 从毛薪中扣除的各项社会保障缴费率金额。该信息位于[COTISATIONS]表中。这使得第10–12行得以显示。
- 与保育员角色相关的各项津贴金额。该信息存储在 [INDEMNITES] 表中。这使得第 14–15 行得以显示。
- 显示在第18至22行的工资构成部分。
据此,我们可以确定由 [metier] 层向 [ui] 层提供的 [IMetier] 接口的初始实现方案:
- 第 1 行:[business] 层的元素被放置在 [business] 包中
- 第 5 行:[calculatePaystub] 方法接收由 [ui] 层获取的三项信息作为参数,并返回一个 [Paystub] 类型的对象,其中包含 [ui] 层将在控制台上显示的信息。[ Paystub] 类可能如下所示:
- 第 9 行:工资单所涵盖的员工——由 [ui] 层显示的信息 #1
- 第10行:各项缴费率——由[ui]层显示的信息#2
- 第 11 行:与员工指数挂钩的各项津贴——由 [ui] 层显示的信息 #3
- 第 12 行:薪资构成——由 [ui] 层显示的信息 #4
[business] 层的第二个用例出现在图形界面中:
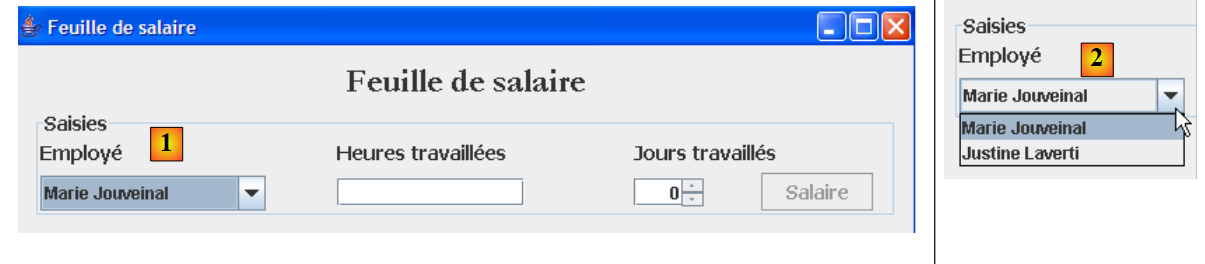 |
如上所示,下拉列表 [1, 2] 显示了所有员工。该列表必须从 [业务] 层获取。该层的接口 随后演变为如下形式:
- 第 10 行:该方法将允许 [UI] 层向 [业务] 层请求所有员工的列表。
[业务]层只能通过查询[DAO]层来初始化上文所述[Payroll]对象的[Employee、Contribution、Allowance]字段,因为这些信息存储在数据库表中。检索所有员工的列表时也是如此。 我们可以创建一个单一的 [DAO] 接口来管理对 [Employee、Contribution、Allowance] 这三个实体的访问。不过,我们在此决定为每个实体创建一个 [DAO] 接口。
用于访问 [CONTRIBUTIONS] 表中 [Contribution] 实体的 [DAO] 接口如下所示:
- 第 6 行:[ICotisationDao] 接口负责管理对 [Cotisation] 实体的访问,从而管理对数据库中 [COTISATIONS] 表的访问。 我们的应用程序仅需第 16 行中的 [findAll] 方法,该方法用于检索 [COTISATIONS] 表中的所有内容。在此,我们希望处理一种更通用的情况,即对该实体执行所有 CRUD 操作(创建、读取、更新、删除)。
- 第 8 行:[create] 方法创建一个新的 [Cotisation] 实体
- 第 10 行:[edit] 方法修改现有的 [Cotisation] 实体
- 第 12 行:[destroy] 方法删除一个现有的 [Cotisation] 实体
- 第 14 行:[find] 方法通过 ID 检索现有的 [Cotisation] 实体
- 第 16 行:[findAll] 方法返回所有现有 [Membership] 实体的列表
让我们仔细看看 [create] 方法的签名:
create 方法有一个类型为 Cotisation 的 cotisation 参数。该 cotisation 参数必须被持久化,即存储在 [COTISATIONS] 表中。在持久化之前,cotisation 参数的 id 标识符没有值。持久化后,id 字段的值即为添加到 [COTISATIONS] 表中的记录的主键。因此,cotisation 参数是 create 方法的输入/输出参数。 create 方法似乎没有必要额外将 cotisation 参数作为结果返回。由于调用方法持有对 [Cotisation cotisation] 对象的引用,如果该对象被修改,调用方法可以通过该引用访问修改后的对象。因此,它可以知道 create 方法为 [Cotisation cotisation] 对象的 id 字段赋予的值。因此,方法签名可以简化为:
编写接口时,必须记住它可在两种不同的上下文中使用:本地和远程 。在本地上下文中,调用方法和被调用方法在同一台 JVM 中执行:
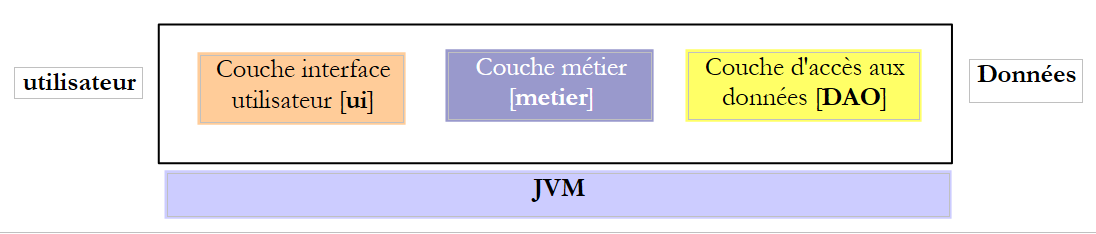 |
如果[业务]层调用了[DAO]层的create方法,那么它确实持有传递给该方法的[Membership membership]参数的引用。
在远程调用场景中,调用方法和被调用方法是在不同的 JVM 中执行的:
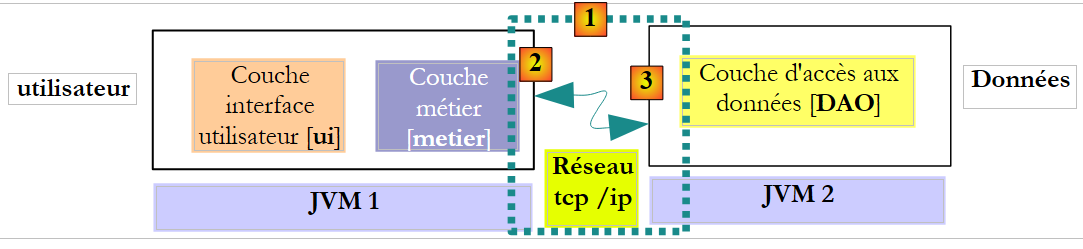 |
在上例中,[业务]层运行在JVM 1上,[DAO]层运行在JVM 2上,且位于两台不同的机器上。这两个层之间不直接通信。它们之间存在一个我们称之为通信层[1]的层。该层由传输层[2]和接收层[3]组成。开发人员通常无需编写这些通信层,它们由软件工具自动生成。 [业务]层的编写方式,就如同它与[DAO]层运行在同一个JVM中一样。因此,无需修改任何代码。
[业务]层与[DAO]层之间的通信机制如下:
- [业务]层调用[DAO]层的create方法,并向其传递参数[Contribution contribution1]
- 该参数实际上会被传递给传输层 [2]。该层将通过网络传输 cotisation1 参数的值,而非其引用。该值的具体形式取决于所使用的通信协议。
- 接收层 [3] 获取该值,并利用它重建一个 [Cotisation cotisation2] 对象,该对象与 [业务] 层发送的初始参数完全一致。现在,我们在两个不同的 JVM 中拥有了两个内容完全相同的对象:cotisation1 和 cotisation2。
- 表示层将把 `contribution2` 对象传递给 [DAO] 层的 `create` 方法,该方法会将其持久化到数据库中。此操作完成后,`contribution2` 对象的 `id` 字段已被初始化为添加到 [COTISATIONS] 表中的记录的主键。 但对于 [business] 层引用的 `contribution1` 对象,情况则不同。如果希望 [business] 层能够引用 `contribution2` 对象,就必须将其传递给该层。因此,我们需要修改 [DAO] 层中 `create` 方法的签名:
- 采用此新签名后,create 方法将返回持久化对象 contribution2。该结果将返回给调用 [DAO] 层的接收层 [3]。[DAO] 层将 contribution2 的值(而非引用)返回给发送层 [2]。
- 发送层 [2] 将获取该值,并利用它重建一个 [Membership membership3] 对象,该对象反映了 [DAO] 层 create 方法返回的结果。
- [Contribution contribution3] 对象将返回给 [business] 层中的方法——正是该方法对 [DAO] 层 create 方法的调用触发了整个机制。因此,[business] 层可以确定其请求持久化的 [Contribution contribution1] 对象所分配的主键值:即 contribution3 中 id 字段的值。
上述架构并非最常见。更常见的情况是,[业务]层和[DAO]层位于同一个JVM中:
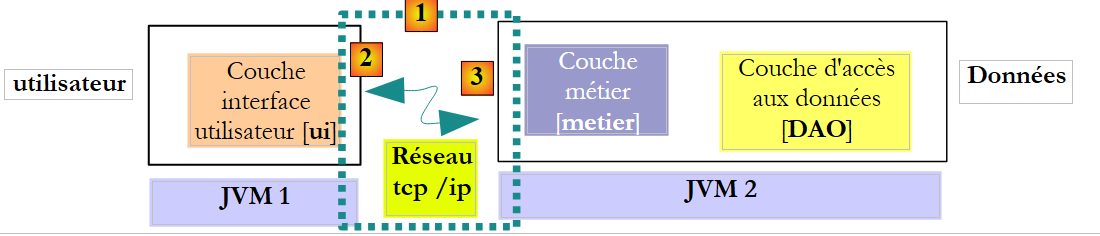 |
在此架构中,必须返回结果的是[业务]层的方法,而非[DAO]层的方法。尽管如此,[DAO]层 create 方法的以下签名:
这使我们无需对实际的架构做出任何假设。使用无论采用何种架构(无论是本地还是远程)都能正常工作的签名,意味着如果被调用方法修改了其部分参数:
- 这些也必须是被调用方法返回结果的一部分
- 调用方法必须使用被调用方法的返回值,而非其传递给被调用方法的、已被修改的参数的引用。
这使我们能够在不修改代码的情况下,从本地架构过渡到远程架构。让我们基于这一思路重新审视 [ICotisationDao] 接口:
- 第 8 行:已处理 create 方法的情况
- 第 10 行:edit 方法使用其参数 [Cotisation cotisation1] 来更新 [COTISATIONS] 表中与 cotisation 对象主键相同的记录。它返回 cotisation2 对象,该对象代表已修改的记录。contribution1 参数本身不会被修改。无论在远程还是本地架构中,该方法都必须返回 contribution2 作为结果。
- 第 12 行:destroy 方法从 [COTISATIONS] 表中删除与作为参数传递的 contribution 对象具有相同主键的记录。contribution 对象未被修改。因此,无需将其返回。
- 第 14 行:find 方法不会修改其 id 参数。因此无需将其包含在结果中。
- 第 16 行:findAll 方法没有参数。因此,我们无需对其进行分析。
最终,仅需调整 create 方法的签名,使其可在远程架构中使用。上述推理同样适用于其他 [DAO] 接口。此处不再赘述,我们将直接采用既适用于远程架构又适用于本地架构的签名。
用于访问 [INDEMNITES] 表中 [Indemnite] 实体的 [DAO] 接口如下:
- 第 6 行:[IIndemniteDao] 接口负责管理对 [Indemnite] 实体的访问,从而管理对数据库中 [INDEMNITES] 表的访问。 我们的应用程序仅需第 16 行中的 [findAll] 方法,该方法用于检索 [INDEMNITES] 表的全部内容。在此,我们希望处理一种更通用的情况,即对该实体执行所有 CRUD 操作(创建、读取、更新、删除)。
- 第 8 行:[create] 方法创建一个新的 [Indemnite] 实体
- 第 10 行:[edit] 方法修改现有的 [Indemnite] 实体
- 第 12 行:[destroy] 方法删除一个现有的 [Indemnite] 实体
- 第 14 行:[find] 方法通过 ID 检索现有的 [Indemnite] 实体
- 第 16 行:[findAll] 方法返回所有现有 [Indemnite] 实体的列表
用于访问 [EMPLOYES] 表中 [Employe] 实体的 [DAO] 接口如下:
- 第 6 行:[IEmployeDao] 接口管理对 [Employee] 实体的访问,从而管理对数据库中 [EMPLOYEES] 表的访问。 我们的应用程序仅需第 16 行中的 [findAll] 方法,该方法用于检索 [EMPLOYEES] 表中的所有内容。在此,我们希望处理一种更通用的情况,即对该实体执行所有 CRUD 操作(创建、读取、更新、删除)。
- 第 8 行:[create] 方法创建一个新的 [Employee] 实体
- 第 10 行:[edit] 方法修改现有的 [Employee] 实体
- 第 12 行:[destroy] 方法删除一个现有的 [Employee] 实体
- 第 14 行:[find] 方法通过 ID 检索现有的 [Employee] 实体
- 第 16 行:[find(String SS)] 方法使用 SS 号检索现有的 [Employee] 实体。我们看到,此方法对于控制台应用程序是必要的。
- 第 18 行:[findAll] 方法返回所有现有 [Employee] 实体的列表。我们看到,此方法对于图形化应用程序是必要的。
5.8. [PamException] 类
[DAO] 层将与 Java 的 JDBC API 配合使用。该 API 会抛出受控的 [SQLException] 异常,这有两个缺点:
- 它们会使代码臃肿,因为必须使用 try/catch 代码块来处理这些异常。
- 必须在 [IDao] 接口的方法签名中使用 "throws SQLException" 进行声明。这会阻止那些会抛出 [SQLException] 以外类型受控异常的类来实现该接口。
为解决此问题,[DAO] 层将仅“传播”类型为 [PamException] 的未检查异常。
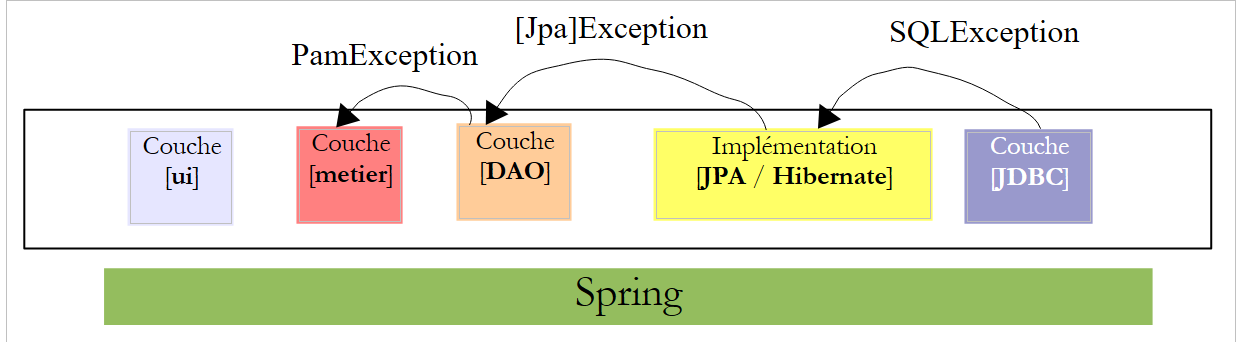 |
- [JDBC] 层抛出 [SQLException] 类型的异常
- [JPA] 层会抛出与所用 JPA 实现相关的特定异常
- [DAO] 层抛出了类型为 [PamException] 的未捕获异常
这会带来两个后果:
- [业务]层无需使用try/catch代码块来处理来自[DAO]层的异常,只需让它们向上传播至[UI]层即可。
- [IDao] 接口的方法在签名中无需指定 [PamException] 的具体类型,这使得通过抛出其他类型未捕获异常的类来实现该接口成为可能。
[PamException] 类将被放置在 NetBeans 项目的 [exception] 包中:
 |
其代码如下:
- 第 4 行:[PamException] 继承自 [RuntimeException]。因此,它属于编译器不要求我们使用 try/catch 代码块进行处理,也不要求在方法签名中包含的异常类型。 正因如此,[PamException] 未包含在 [IDao] 接口的方法签名中。这使得该接口可由抛出其他类型异常的类来实现,前提是该类也继承自 [RuntimeException]。
- 为了区分可能发生的错误,我们在第 7 行使用了错误代码。第 14、19 和 24 行中的三个构造函数是父类 [RuntimeException] 的构造函数,我们向其中添加了一个参数:即我们要分配给该异常的错误代码。
从异常的角度来看,应用程序的行为将如下所示:
- [DAO]层将把遇到的任何异常封装在[PamException]中,并将其重新抛出至[business]层。
- [business] 层将允许 [DAO] 层抛出的异常向上传播。它会将 [business] 层中发生的任何异常封装到 [PamException] 中,并将其重新抛出至 [UI] 层。
- [UI] 层将拦截从 [business] 和 [DAO] 层传播过来的所有异常。它将直接在控制台或图形用户界面上显示该异常。
现在,让我们依次考察 [DAO] 层和 [业务] 层的实现。
5.9. [PAM] 应用程序的 [DAO] 层
我们采用以下架构:
 |
5.9.1. 实现
推荐阅读:[ref1] 的第 3.1.3 节
问题:使用 Spring/JPA 集成,编写类 [CotisationDao、IndemniteDao、EmployeDao] 来实现接口 [ICotisationDao、IIndemniteDao、IEmployeDao]。每个类的方法都将捕获任何异常,并将其包装为 [PamException],同时为该异常指定一个特定的错误代码。
这些实现类将位于 [dao] 包中:
 |
5.9.2. 配置
推荐阅读:[ref1] 的第 3.1.5 节
DAO/JPA 的集成通过 Spring 配置文件 [spring-config-dao.xml] 和 JPA 配置文件 [persistence.xml] 进行配置:
 |
问题:请写出这两个文件的内容。 我们假设所使用的数据库是由 SQL 脚本 [dbpam_hibernate.sql] 生成的 MySQL5 数据库 [dbpam_hibernate]。Spring 文件将定义以下三个 Bean:类型为 EmployeDao 的 employeDao、类型为 IndemniteDao 的 indemniteDao,以及类型为 CotisationDao 的 cotisationDao。此外,所使用的 JPA 实现将是 Hibernate。
5.9.3. 测试
推荐阅读:[ref1] 的 3.1.6 和 3.1.7 节
既然 [DAO] 层已经编写并配置完毕,我们就可以对其进行测试了。测试架构如下:
 |
5.9.4. InitDB
我们将为 [DAO] 层创建两个测试程序。这些程序将放置在 NetBeans 项目 [Test Packages] 分支 [1] 下的 [dao] 包 [2] 中。该分支未包含在通过 [Build project] 选项生成的项目中,这可确保我们放置在此处的测试程序不会被包含在项目的最终 .jar 文件中。
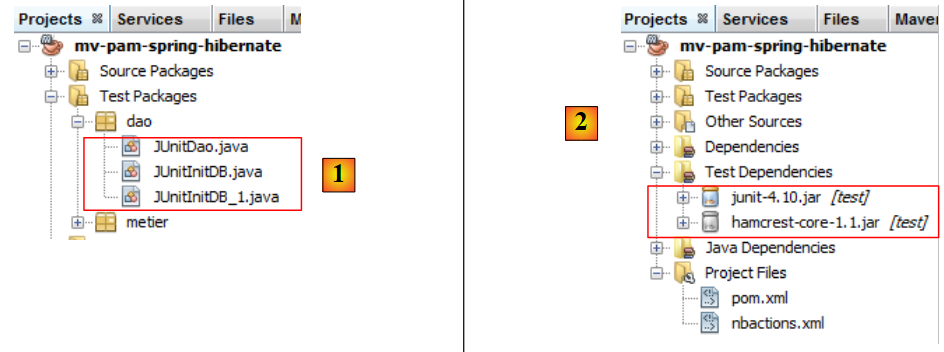 |
放置在 [Test Packages] 分支中的类可以访问 [Source Packages] 分支中的类以及项目的类库。如果测试需要项目中未包含的库,则必须在 [Test Libraries] 分支 [2] 中声明这些库。
测试类使用 JUnit 单元测试工具:
- [JUnitInitDB] 不会执行任何测试。它会向数据库中插入若干记录,然后在控制台上显示这些记录。
- [JUnitDao] 执行一系列测试并验证其结果。
[JUnitInitDB] 类的骨架如下:
- [init] 方法在测试套件开始之前执行(注解 @BeforeClass)。它会实例化 [DAO] 层。
- [clean] 方法在每次测试之前执行(注解 @Before)。它会清空数据库。
- [initDB] 方法是一个测试(注解 @Test)。它是唯一的测试。测试必须包含 Assert.assertCondition 断言语句。在此处,将不包含任何此类语句。因此,该方法是一个虚拟测试。其目的是向数据库中插入几行数据,然后在控制台上显示数据库内容。此处使用了 [DAO] 层的 create 和 findAll 方法。
问题:请完成 [JUnitInitDB] 类的代码。参考 [ref1] 第 3.1.6 节中的示例作为指导。该代码将生成第 5.1 节中所示的输出结果。
5.9.5. 实现测试
现在我们可以运行 [InitDB] 了。下面将介绍使用 MySQL5 数据库管理系统(DBMS)的操作流程:
 |
- 已设置好类 [1]、配置文件 [2] 以及 [DAO] 层的测试类 [3],
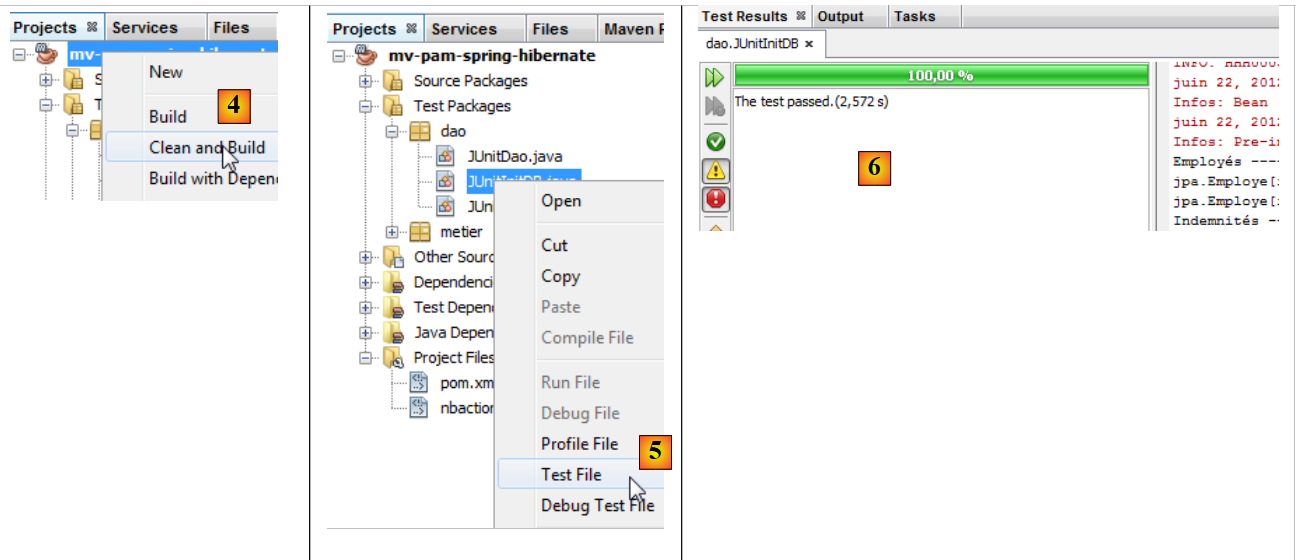 |
- 项目被构建 [4]
- 执行了 [JUnitInitDB] 类 [5]。MySQL5 数据库管理系统已启动,并加载了现有的 [dbpam_hibernate] 数据库,
- [测试结果]窗口[6]显示测试成功。此消息在此处并不重要,因为[JUnitInitDB]程序中不包含任何可能导致测试失败的Assert.assertCondition断言语句。尽管如此,它表明测试执行过程中未发生异常。
[输出] 窗口包含执行日志,包括来自 Spring 和测试本身的日志。[JUnitInitDB] 类生成的输出如下:
表 [EMPLOYEES、ALLOWANCES、CONTRIBUTIONS] 已填充数据。可通过将 NetBeans 连接到 [dbpam_hibernate] 数据库进行验证。
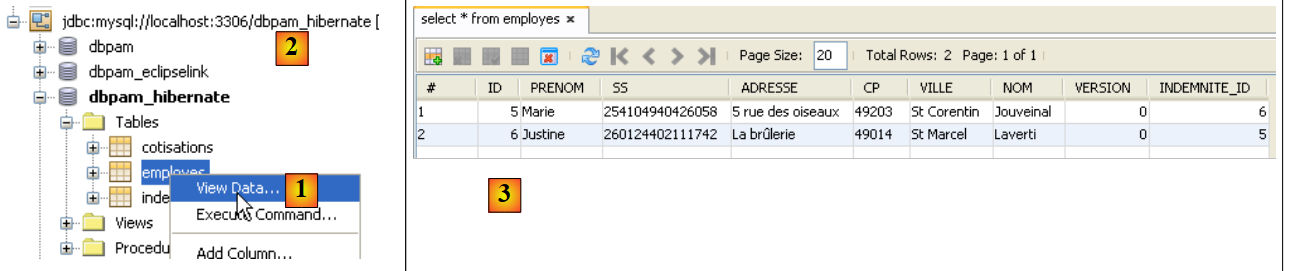 |
- 在 [1] 的 [services] 选项卡中,您可以查看 [dbpam_hibernate] 连接 [2] 中 [employees] 表的数据,
- 在 [3] 中显示结果。
5.9.6. JUnitD ao
接下来我们将查看第二个测试类 [JUnitDao]:
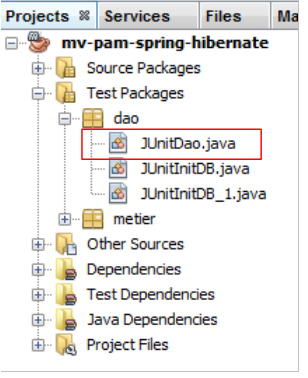 |
该类的骨架如下:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 | |
在之前的测试类中,每次测试前都会清空数据库。
问题:编写以下方法:
1 - test02:基于 test01
2 - test03:员工实体有一个类型为 Indemnity 的字段。因此,请创建 Indemnity 实体和 Employee 实体
3 - test04。
按照与 [JUnitInitDB] 测试类相同的方式进行操作,我们得到以下结果:
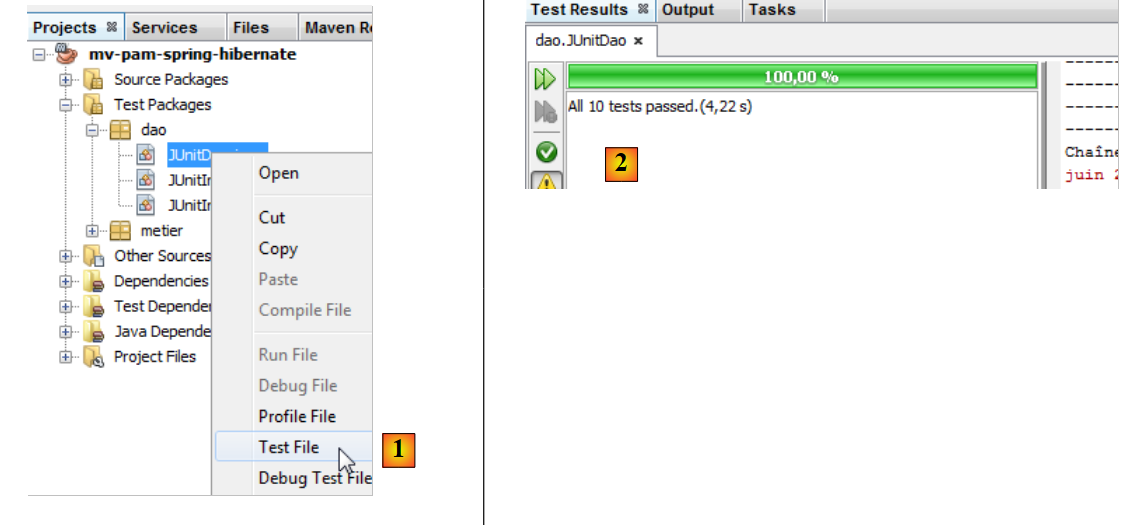 |
- 在[1]中,我们运行了
- 在 [2] 中,测试结果显示在 [Test Results] 窗口中
让我们触发一个错误,看看结果页面上会如何报告:
第 13 行:由于 Csgrds 的值为 3.49(第 8 行),该断言将引发错误。运行测试类后得到以下结果:
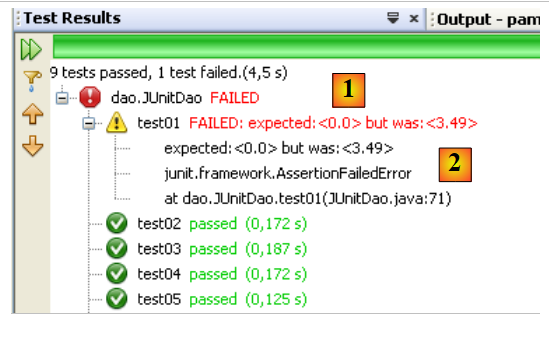 |
- 结果页面 [1] 现在显示部分测试失败。
- 在 [2] 中,显示了导致测试失败的异常摘要。其中包含 Java 代码中发生异常的行号。
5.10. [PAM] 应用程序的 [业务] 层
既然 [DAO] 层已经编写完成,接下来我们将研究业务层 [2]:
 |
5.10.1. Java接口 [IMetier]
这已在第 5.7 节中进行了描述。现将其内容重述如下:
[业务]层的实现将在[业务]包中完成:
 |
[Business] 包除了包含 [IMetier] 接口及其实现类 [Metier] 之外,还将包含另外两个类:[Payroll] 和 [PayrollItems]。[Payroll] 类在第 5.7 节中曾简要介绍过。现在我们将重新探讨它。
5.10.2. [Payroll] 类
[IMetier] 接口的 [calculatePayStub] 方法返回一个 [PayStub] 类型的对象,该对象表示工资单上的各项内容。其定义如下:
- 第 7 行:该类实现了 Serializable 接口,因为其实例可能会通过网络进行交换。
- 第 9 行:工资单所涉及的员工
- 第10行:各项缴费率
- 第 11 行:与员工指数挂钩的各项津贴
- 第12行:其薪资的组成部分
- 第 14–22 行:该类的两个构造函数
- 第 25–27 行:用于标识特定 [PayStub] 对象的 [toString] 方法
- 第 29 行及之后:该类私有字段的公共访问器
上文 [FeuilleSalaire] 类第 11 行引用的 [ElementsSalaire] 类包含构成工资单的各项要素。其定义如下:
- 第 3 行:该类实现了 Serializable 接口,因为它是 PayrollClass 的一个组件,而 PayrollClass 必须可序列化。
- 第 6 行:基本工资
- 第 7 行:基于此基本工资缴纳的社会保险费
- 第 8 行:每日子女抚养费
- 第 9 行:每日子女伙食津贴
- 第 10 行:支付给保育员的净工资
- 第12–24行:类构造函数
- 第 27–31 行:[toString] 方法,用于标识特定的 [ElementsSalaire] 对象
- 第 34 行及之后:类私有字段的公共访问器
5.10.3. [业务]层的[Metier]实现类
[业务]层的实现类 [Metier] 可以如下所示:
- 第 5 行:Spring 的 @Transactional 注解确保该类中的每个方法都在事务内运行。
- 第 9-10 行:引用了 [Cotisation、Employe、Indemnite] 实体的 [DAO] 层
- 第 14–17 行:[calculatePayroll] 方法
- 第 20–22 行:[findAllEmployees] 方法
- 第 24 行及之后:该类私有字段的公共访问器
问题:编写 [findAllEmployees] 方法的代码。
问题:编写 [calculatePayroll] 方法的代码。
请注意以下几点:
- 计算薪资的方法已在第 5.2 节中进行说明。
- 如果 [SS] 参数不对应任何员工([DAO] 层返回了空指针),该方法将抛出一个带有相应错误代码的 [PamException]。
5.10.4. 测试 [business] 层
我们编写两个测试程序:
 |
测试类 [3] 位于项目 [Test Packages] 分支 [1] 下的 [metier] 包 [2] 中。
[JUnitMetier_1] 类可能如下所示:
该类中没有 Assert.assertCondition 断言。我们只是试图计算几个薪资,以便随后手动验证它们。运行前一个类后得到的屏幕输出如下:
- 第4行:Justine Laverti的工资单
- 第 5 行:玛丽·朱维纳尔的工资单
- 第6行:由于社会安全号码为“xx”的员工不存在,因此引发异常。
问题:[JUnitMetier_1] 的第 17 行使用了名为 metier 的 Spring Bean。请在文件 [spring-config-metier-dao.xml] 中提供该 Bean 的定义。
类 [JUnitMetier_2] 可能如下所示:
[JUnitMetier_2] 类是 [JUnitMetier_1] 类的副本,不同之处在于,这次将断言放置在了 test01 方法中。
问题:编写 test01 方法。
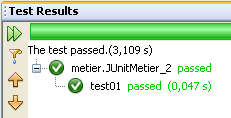
执行 [JUnitMetier_2] 类时,如果一切正常,将得到以下结果:
5.11. [PAM] 应用程序的 [ui] 层 – 版本 控制台
既然 [business] 层已经编写完成,我们还需要编写 [ui] 层 [1]:
 |
我们将为[ui]层创建两个不同的实现:一个是控制台版本,另一个是Swing图形界面版本:
 |
5.11.1. [ ui.console.Main] 类
我们将首先关注上文由 [ui.console.Main] 类实现的控制台应用程序。其工作原理已在第 5.3 节中描述。 [Main] 类的骨架代码如下:
问题:请补全上面的代码。
5.11.2. 执行
要运行 [ui.console.Main] 类,请按以下步骤操作:
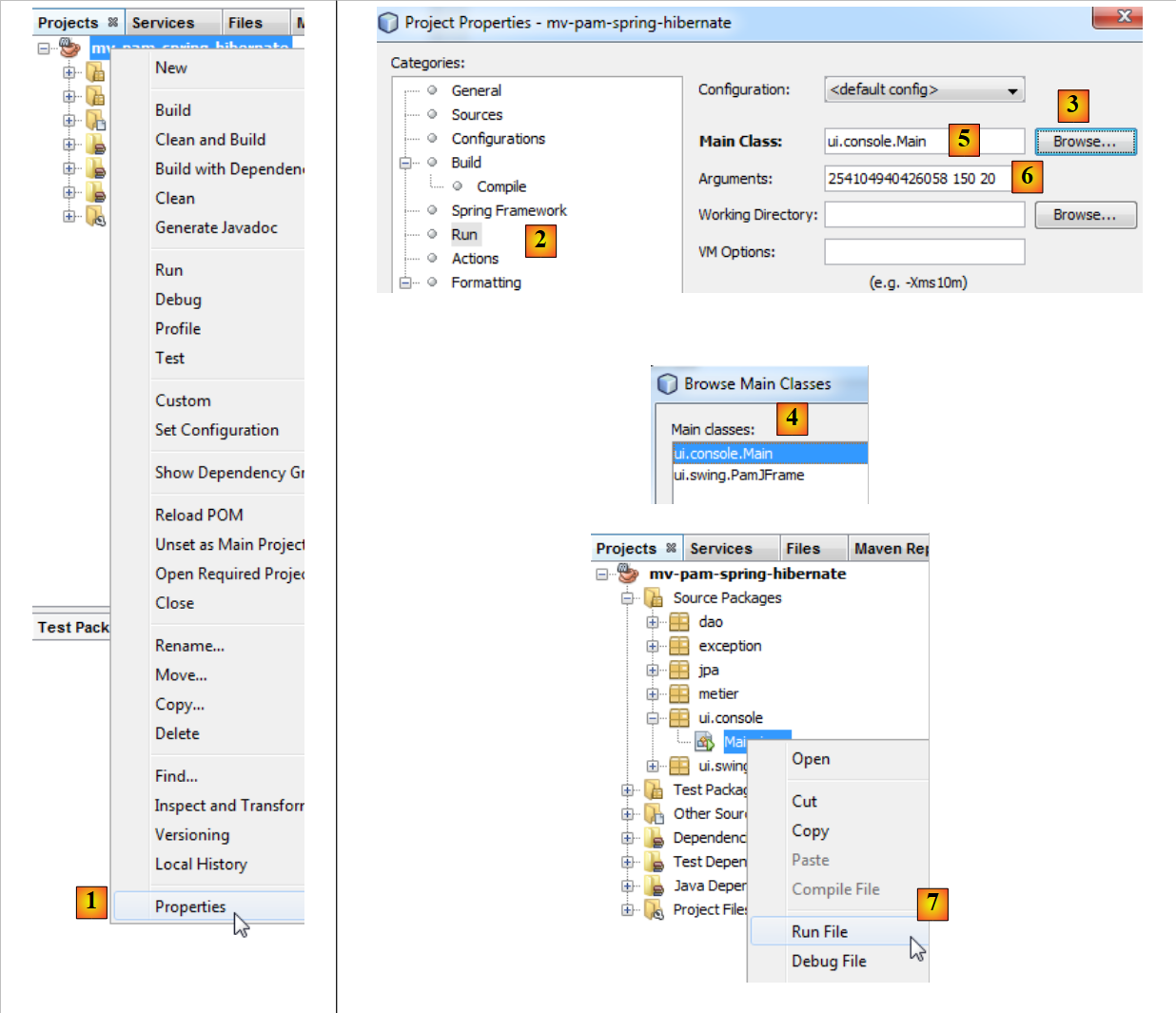 |
- 在 [1] 中,选择项目属性,
- 在 [2] 中,选择项目的 [运行] 属性,
- 使用 [3] 按钮指定要运行的类(即主类),
- 选择类 [4],
- 该类出现在[5]中。该类运行时需要三个参数(社会保险号、工作小时数、工作日数)。这些参数在[6]中输入,
- 输入完成后,即可执行该项目[7]。上述配置意味着将执行[ui.console.Main]类。
执行结果将显示在[输出]窗口中:
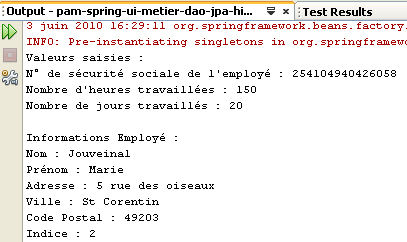 | 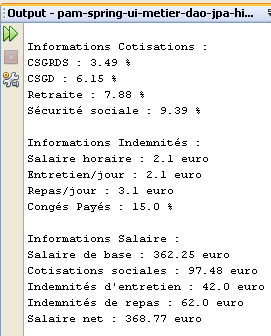 |
5.12. [PAM] 应用程序的 [ui] 层 – 图形版
接下来,我们将通过图形用户界面实现 [ui] 层:
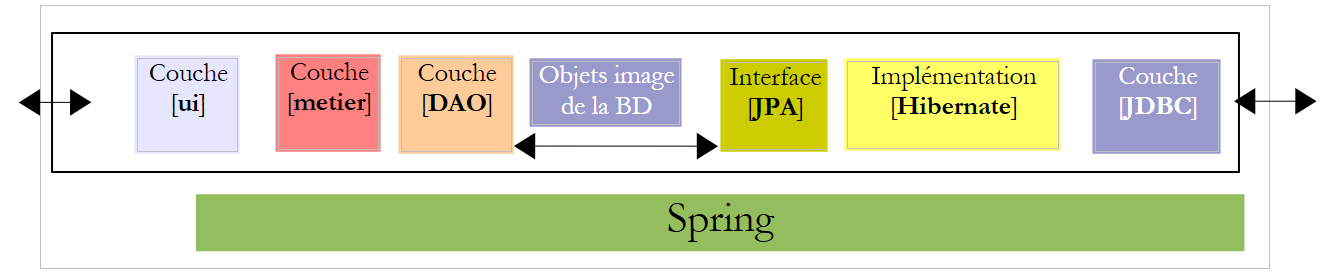 |
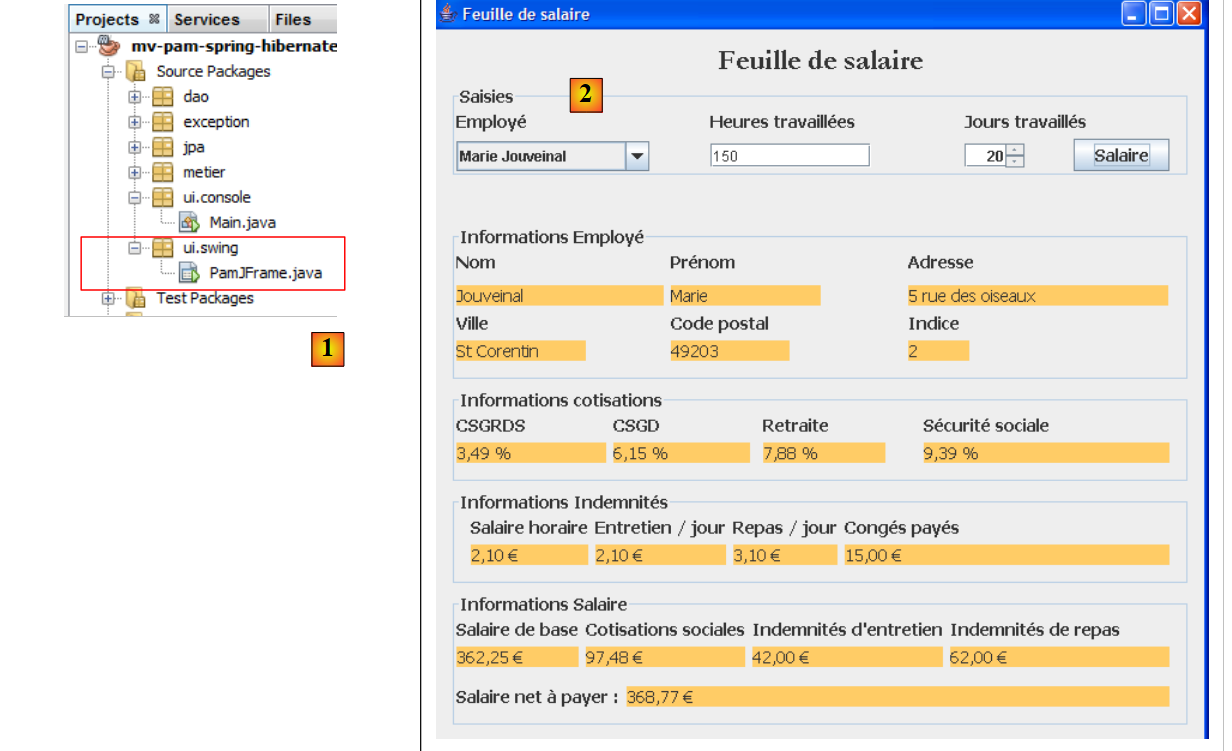 |
- 在[1]中,图形界面的[PamJFrame]类
- 在[2]中:图形用户界面
5.12.1. 快速入门指南
要创建图形用户界面,请按以下步骤操作:
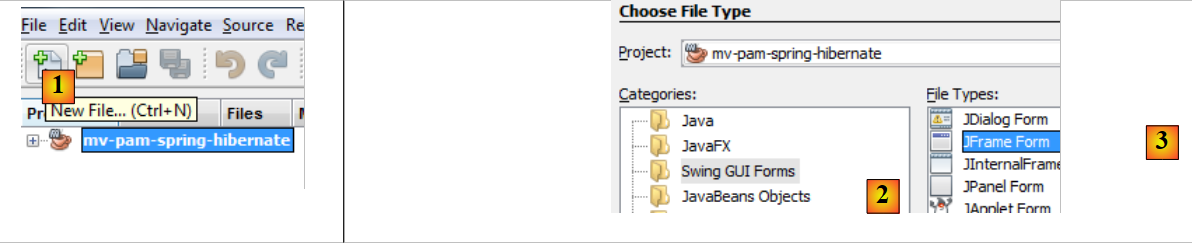 |
- [1]:使用 [1] [新建文件...] 按钮创建一个新文件
- [2]:选择文件类别 [Swing GUI 表单],即图形化表单
- [3]:选择类型 [JFrame 表单],即空表单类型
 |
- [5]:为表单命名;这也将是类名
- [6]: 将表单放置在某个包中
- [8]: 表单已添加到项目树中
- [9]: 可以通过两个视图访问该表单:[设计] [9],用于设计表单的各种组件;以及[源代码] [10],用于查看表单的 Java 代码。归根结底,表单与其他 Java 类并无二致。 [设计]视图是用于设计表单的工具。每次在[设计]模式下添加组件时,[源代码]视图中都会相应地生成相应的Java代码。
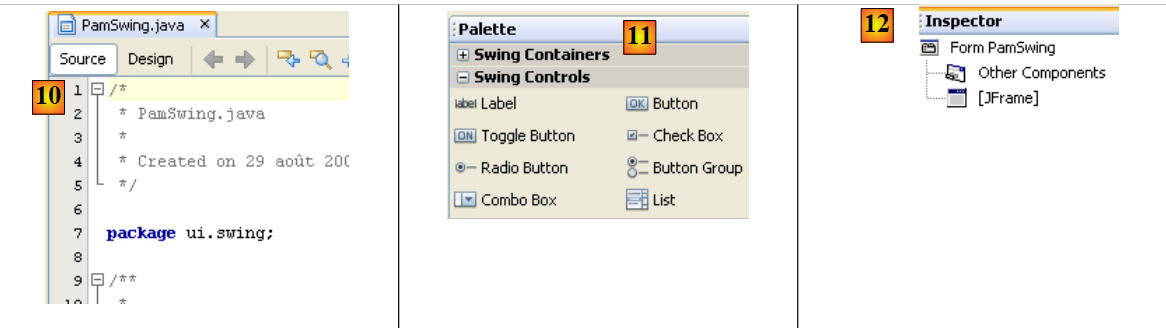 |
- [11]:表单可用的 Swing 组件列表可在 [调色板] 窗口中找到。
- [12]: [检查器] 窗口显示了表单组件的树形结构。具有视觉表现形式的组件位于 [JFrame] 分支中;其余组件位于 [其他组件] 分支中。
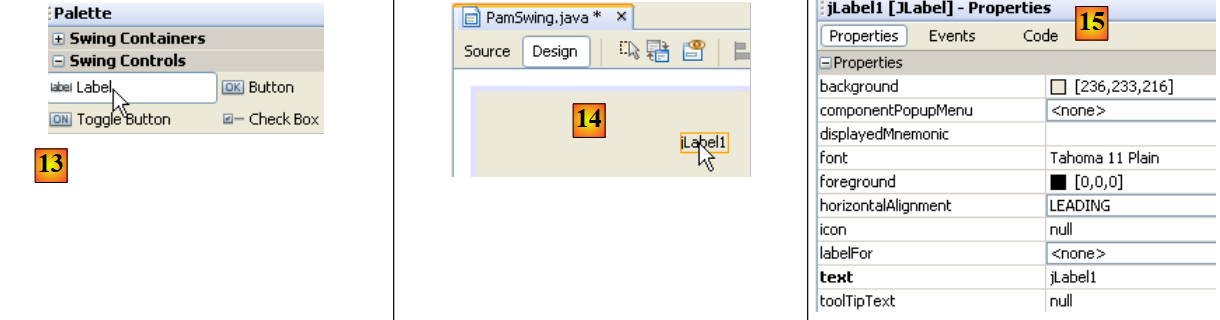 |
- 在 [13] 中,我们单击一次选中 [JLabel] 组件
- 在[14]中,我们在[设计]模式下将其拖放到表单上
- 在[15]中,我们定义了JLabel的属性(文本、字体)。
 |
- 在[16]中,结果。
- 在[17]中,我们请求预览该表单
- 在 [18] 中,结果
- 在 [19] 中,[JLabel1] 标签已添加到 [Inspector] 窗口的组件树中
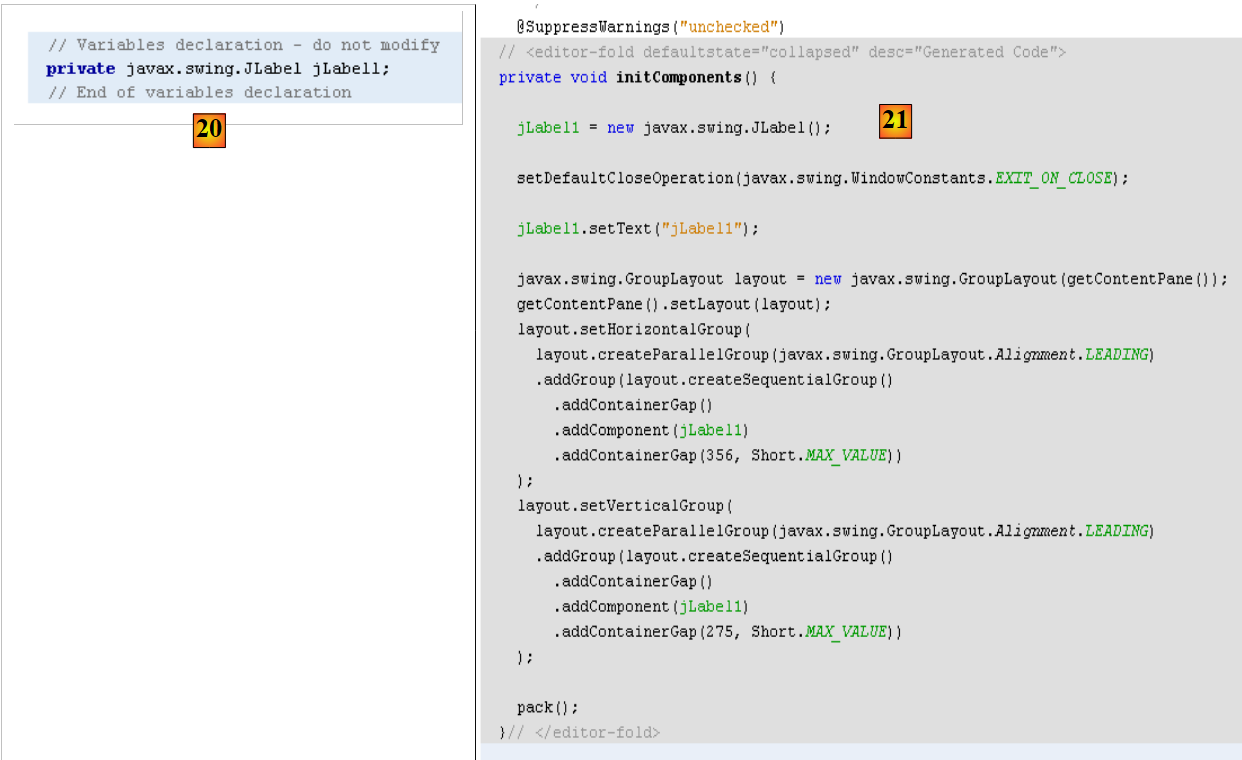 |
- 在 [20] 和 [21] 中:在表单的 [源代码] 视图中,已添加 Java 代码来处理新增的 JLabel。
有关使用 NetBeans 构建表单的教程,请访问网址 [http://www.netbeans.org/kb/trails/matisse.html]。
5.12.2. [PamJFrame] 图形用户界面
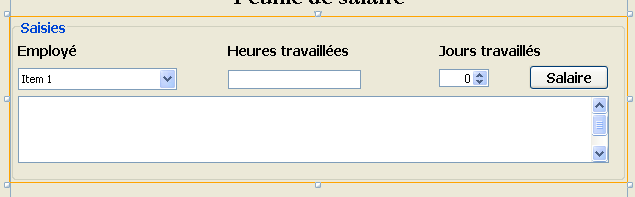
我们将构建以下图形用户界面:
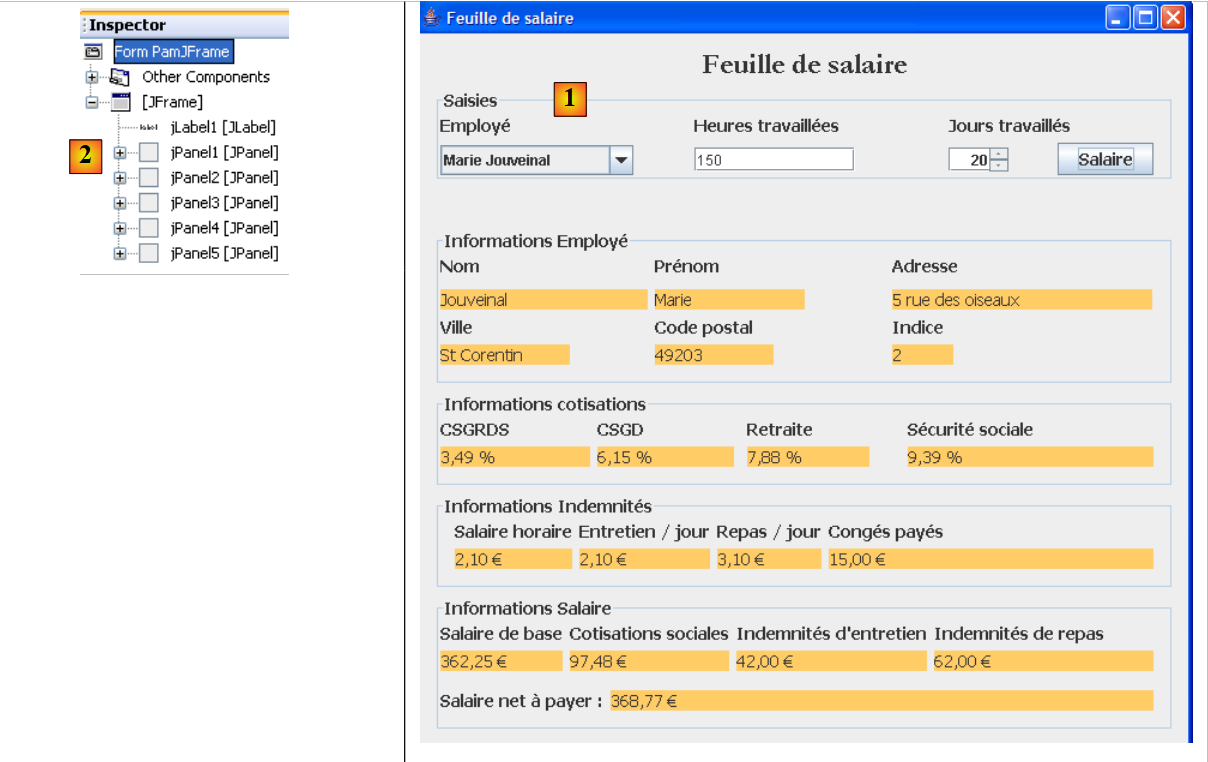 |
- 在[1]中,图形用户界面
- 在[2]中,其组件的树形结构:一个JLabel和六个JPanel容器
JLabel1
 |
JPanel1
 |  |
JPanel2
 |  |
JPanel3
 |  |
JPanel4
 |  |
JPanel5
 |  |
实践练习:使用教程 [http://www.netbeans.org/kb/trails/matisse.html] 构建前面的图形界面。
5.12.3. 图形用户界面事件
推荐阅读:[ref2]中的[图形用户界面]一章。
我们将处理 [jButtonSalaire] 按钮的点击事件。要创建处理此事件的方法,我们可以按以下步骤进行:
 |
[JButtonSalaire] 按钮的点击处理程序已生成:
与上述方法关联、用于处理 [JButtonSalaire] 按钮点击事件的 Java 代码也会被生成:
第 2–5 行指定,对 [jButtonSalaire] 按钮(第 2 行)的点击(类型为 ActionPerformed 的 evt)必须由 [jButtonSalaireActionPerformed] 方法(第 4 行)处理。
我们还将处理 [jTextFieldHT] 输入字段上的 [caretUpdate] 事件(光标移动)。要创建此事件的处理程序,我们按照之前的步骤进行:
 |
[jTextFieldHT] 输入字段的 [caretUpdate] 事件处理程序已生成:
还将生成将上述方法绑定到 [jTextFieldHT] 文本框的 [caretUpdate] 事件的 Java 代码:
第 1–4 行表示 [jTextFieldHT] 控件(第 1 行)上的 [caretUpdate] 事件(第 2 行)应由 [jTextFieldHTCaretUpdate] 方法(第 3 行)进行处理。
5.12.4. 初始化图形用户界面
让我们回到我们应用程序的架构:
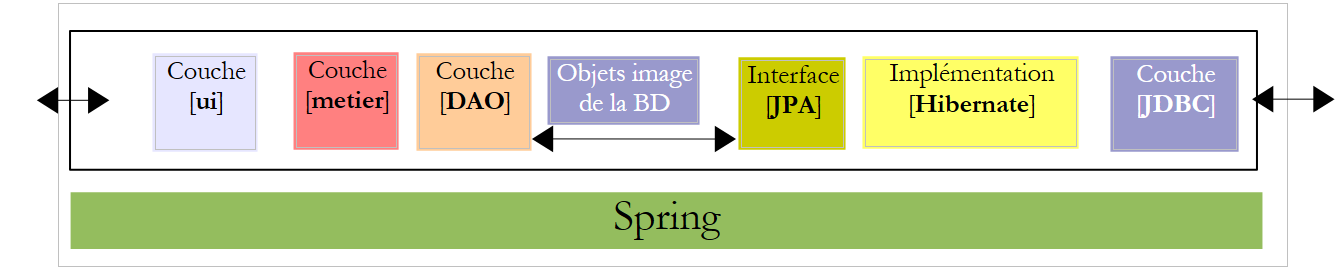 |
[ui] 层需要引用 [business] 层。让我们回顾一下在控制台应用程序中是如何获取这个引用的:
在 GUI 应用程序中,该方法也是相同的。当 GUI 应用程序初始化时,上述第 3 行中的 [IMetier metier] 引用也必须被初始化。目前为 GUI 生成的代码如下:
- 第 29–35 行:启动应用程序的静态方法 [main]
- 第 32 行:创建 GUI [PamJFrame] 的实例并使其可见。
- 第 7–9 行:GUI 的构造函数。
- 第 8 行:调用第 17 行定义的 [initComponents] 方法。该方法是根据 [设计] 模式中的操作自动生成的。请勿修改它。
- 第 21 行:用于处理 [jTextFieldHT] 字段中输入光标移动的方法
- 第 25 行:处理 [jButtonSalaire] 按钮点击事件的方法
若要在上述代码中添加自定义初始化内容,可按以下步骤操作:
- 第 4 行:我们调用一个自定义方法来执行自己的初始化操作。这些初始化操作由第 10–42 行的代码定义
问题:请参考注释,完成 [doMyInit] 过程的代码。
5.12.5. 事件处理程序
问题:编写方法 [jTextFieldHTCaretUpdate]。该方法必须确保:如果 [jTextFieldHT] 字段中的数据不是大于等于 0 的实数,则必须禁用 [jButtonSalaire] 按钮。
问题:编写 [jButtonSalaireActionPerformed] 方法,该方法必须显示 [jComboBoxEmployes] 中所选员工的工资单。
5.12.6. 运行图形用户界面
要运行图形用户界面,请修改项目的 [Run] 配置:
 |
- 在 [1] 中,输入 GUI 类
该项目必须包含完整的配置文件(persistence.xml、spring-config-metier-dao.xml)以及 GUI 类。在运行项目之前,请先启动目标数据库管理系统。
5.13. 使用 EclipseLink 实现 JPA 层
我们关注以下架构,其中 JPA 层现由 EclipseLink 实现:
 |
5.13.1. NetBeans 项目
新 NetBeans 项目是通过复制旧项目创建的:
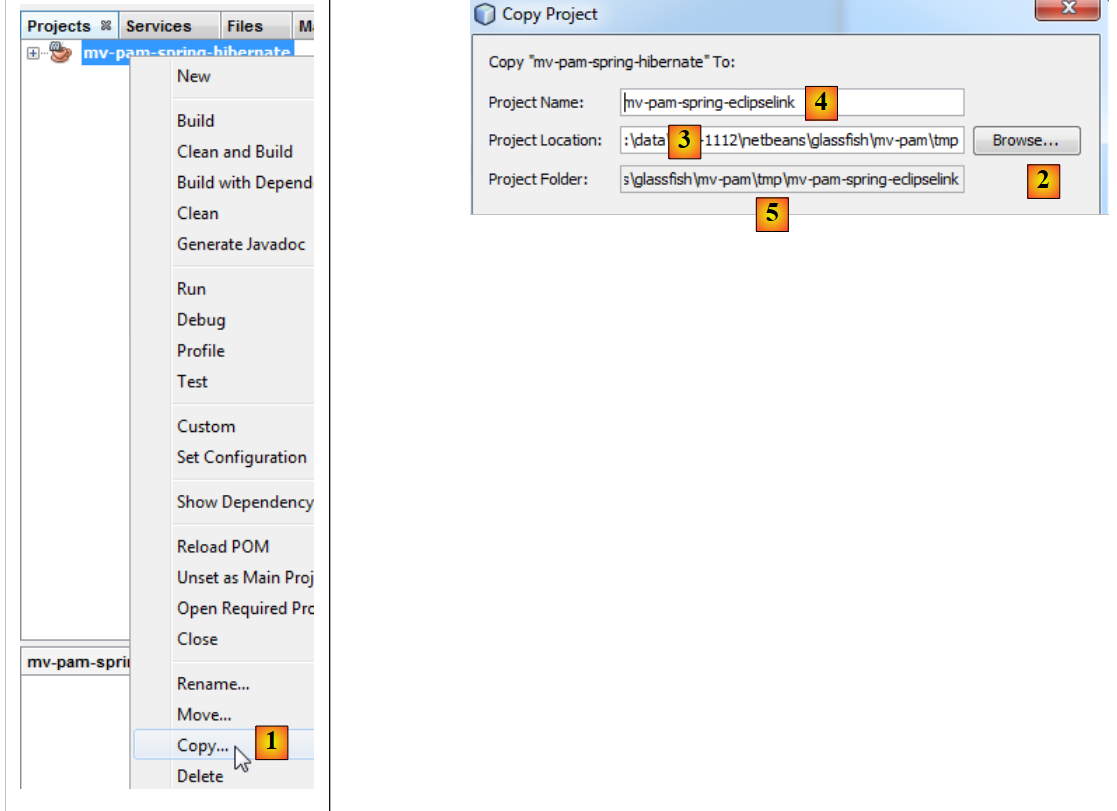 |
- 在 [1] 中:右键单击 Hibernate 项目,选择“复制”
- 使用 [2] 按钮,选择新项目的父文件夹。文件夹名称将显示在 [3] 中。
- 在 [4] 中,为新项目命名
- 在 [5] 中,输入项目文件夹名称
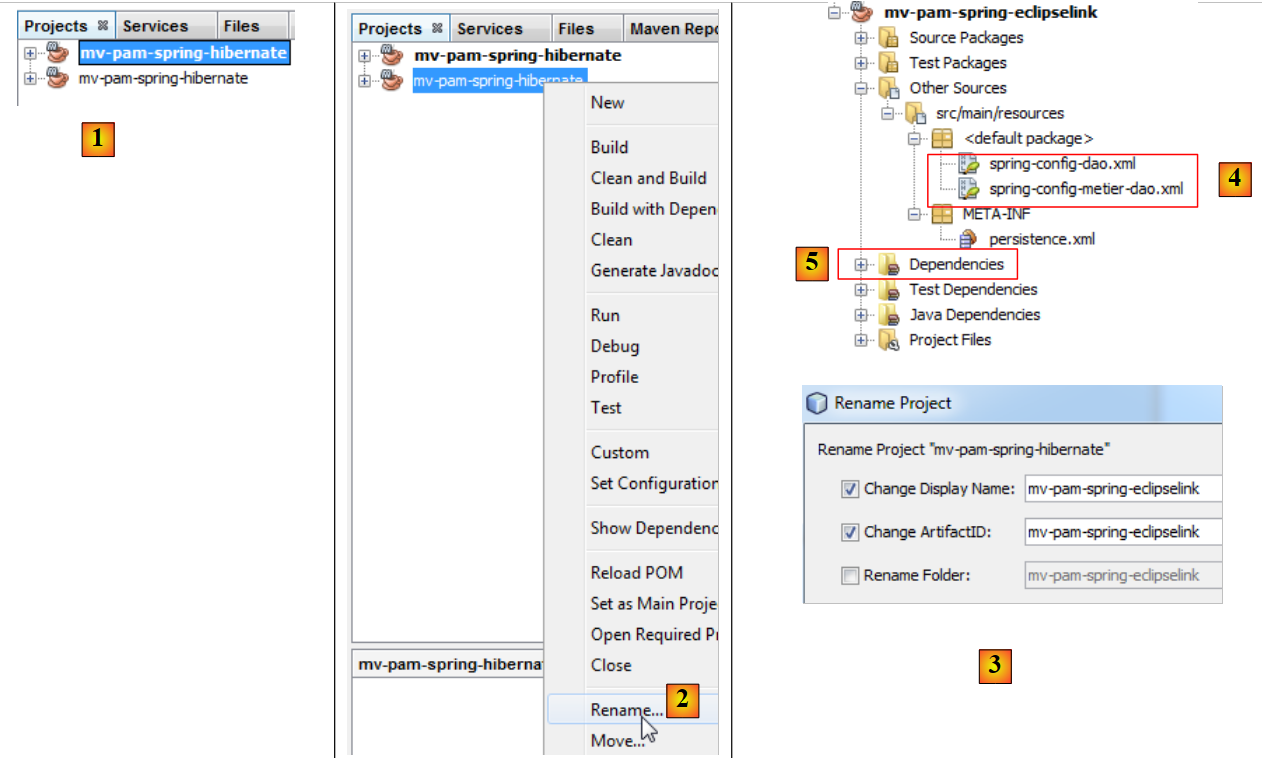 |
- 在 [1] 中,新项目已创建。其名称与原始项目相同,
- 在 [2] 和 [3] 中,将其重命名为 [mv-pam-spring-eclipselink]。
为了使其适应新的 JPA / EclipseLink 层,必须在两个地方修改该项目:
- 在 [4] 中,必须修改 Spring 配置文件。JPA 层的配置位于此处。
- 在 [5] 中,需修改项目库:将 Hibernate 库替换为 EclipseLink 的库。
让我们先从后者开始。新项目的 [pom.xml] 文件如下所示:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>istia.st</groupId>
<artifactId>mv-pam-spring-eclipselink</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>mv-pam-spring-eclipselink</name>
<url>http://maven.apache.org</url>
<repositories>
<repository>
<url>http://repo1.maven.org/maven2/</url>
<id>swing-layout</id>
<layout>default</layout>
<name>Repository for library Library[swing-layout]</name>
</repository>
<repository>
<url>http://download.eclipse.org/rt/eclipselink/maven.repo/</url>
<id>eclipselink</id>
<layout>default</layout>
<name>Repository for library Library[eclipselink]</name>
</repository>
</repositories>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
<type>jar</type>
</dependency>
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.2.2</version>
</dependency>
<dependency>
<groupId>commons-pool</groupId>
<artifactId>commons-pool</artifactId>
<version>1.6</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.eclipse.persistence</groupId>
<artifactId>eclipselink</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>org.eclipse.persistence</groupId>
<artifactId>javax.persistence</artifactId>
<version>2.0.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>org.swinglabs</groupId>
<artifactId>swing-layout</artifactId>
<version>1.0.3</version>
</dependency>
</dependencies>
</project>
- 第 73–82 行:EclipseLink JPA 实现的依赖项,
- 第 19–24 行:EclipseLink 的 Maven 仓库。
必须修改 Spring 配置文件,以表明 JPA 实现已发生变更。在这两个文件中,仅配置 JPA 层的段落会发生变化。例如,在 [spring-config-metier-dao.xml] 中,我们有:
第 19–36 行配置了 JPA 层。使用的 JPA 实现是 Hibernate(第 22 行)。此外,目标数据库是 [dbpam_hibernate](第 41 行)。
若要切换至 JPA/EclipseLink 实现,请将上述第 19–35 行替换为以下内容:
- 第 5 行:使用的 JPA 实现是 EclipseLink
- 第 9 行:databasePlatform 属性用于设置目标数据库管理系统(DBMS),此处为 MySQL
- 第 11 行:用于在 JPA 层实例化时生成数据库表。此处该属性已被注释掉。
- 第 7 行:用于在控制台上显示 JPA 层发出的 SQL 语句。此处该属性已被注释掉。
此外,目标数据库变为 [dbpam_eclipselink](见下文第 4 行):
5.13.2. 运行测试
在测试整个应用程序之前,最好先验证 JUnit 测试能否通过新的 JPA 实现。 在运行测试之前,我们将首先从数据库中删除这些表。为此,请在 NetBeans 的 [运行时] 选项卡中,如有必要,创建与 dbpam_eclipselink / MySQL5 数据库的连接。连接到 dbpam_eclipselink / MySQL5 数据库后,即可按照下图所示删除这些表:
- [1]:删除前
- [2]: 删除后
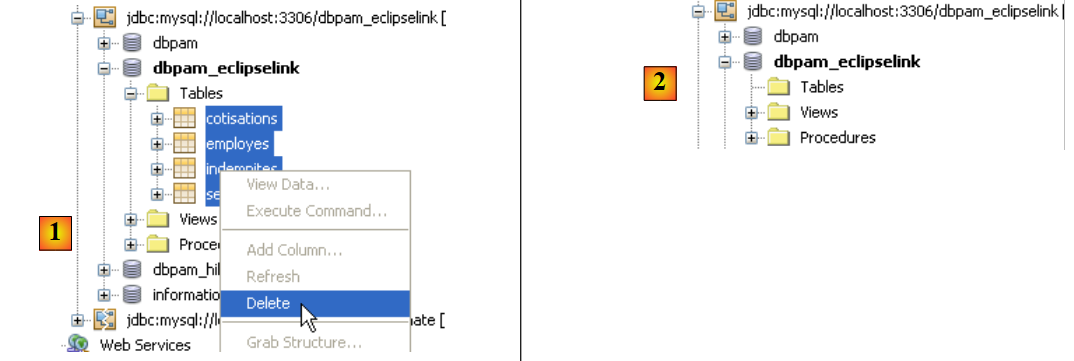 |
完成上述操作后,您可以在 [DAO] 层运行第一个测试:InitDB,该测试用于初始化数据库。为确保应用程序能重新创建之前已删除的表,请确认在 Spring JPA / EclipseLink 配置中,以下这行代码:
存在且未被注释掉。
我们构建项目,然后运行 [JUnit InitDB] 测试:
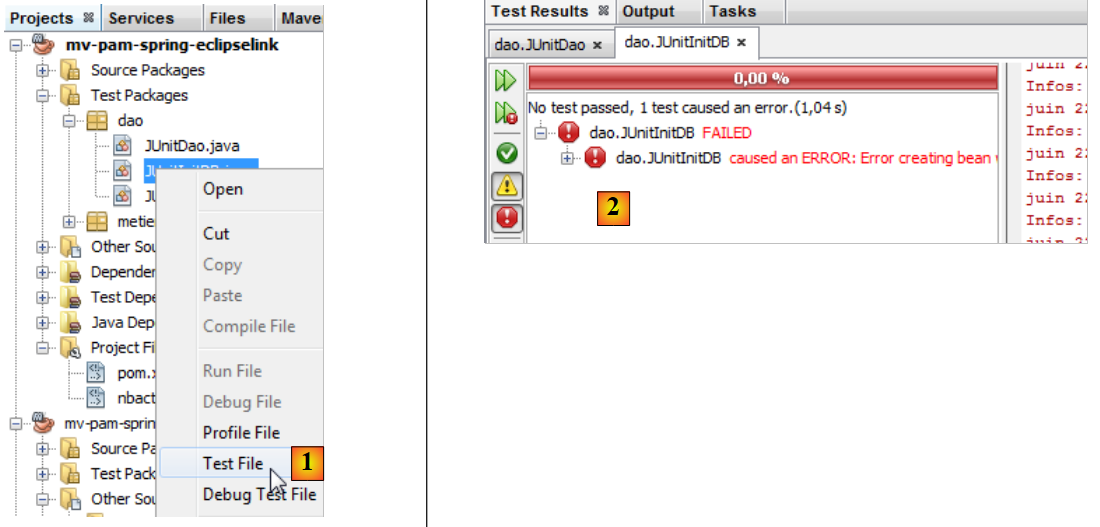 |
- 在[1]中,InitDB测试运行成功。
- 在[2]中,测试失败。该异常是由Spring抛出的,而非由失败的测试抛出。
原因:org.springframework.beans.factory.BeanCreationException:在类路径资源 [spring-config-DAO.xml] 中定义的名称为 'entityManagerFactory' 的 Bean 创建失败:调用 init 方法失败;嵌套异常为 java.lang.IllegalStateException:必须先启动 Java 代理才能使用 InstrumentationLoadTimeWeaver。请参阅 Spring 文档。
Spring 指出存在配置问题。该消息表述不清。异常的原因已在 [ref1] 的 3.1.9 节中解释。要使 Spring/EclipseLink 配置生效,运行应用程序的 JVM 必须通过一个特定参数(即 Java 代理)启动。该参数的格式如下:
[spring-agent.jar] 是 JVM 管理 Spring/EclipseLink 配置所需的 Java 代理。
在运行项目时,可以向 JVM 传递参数:
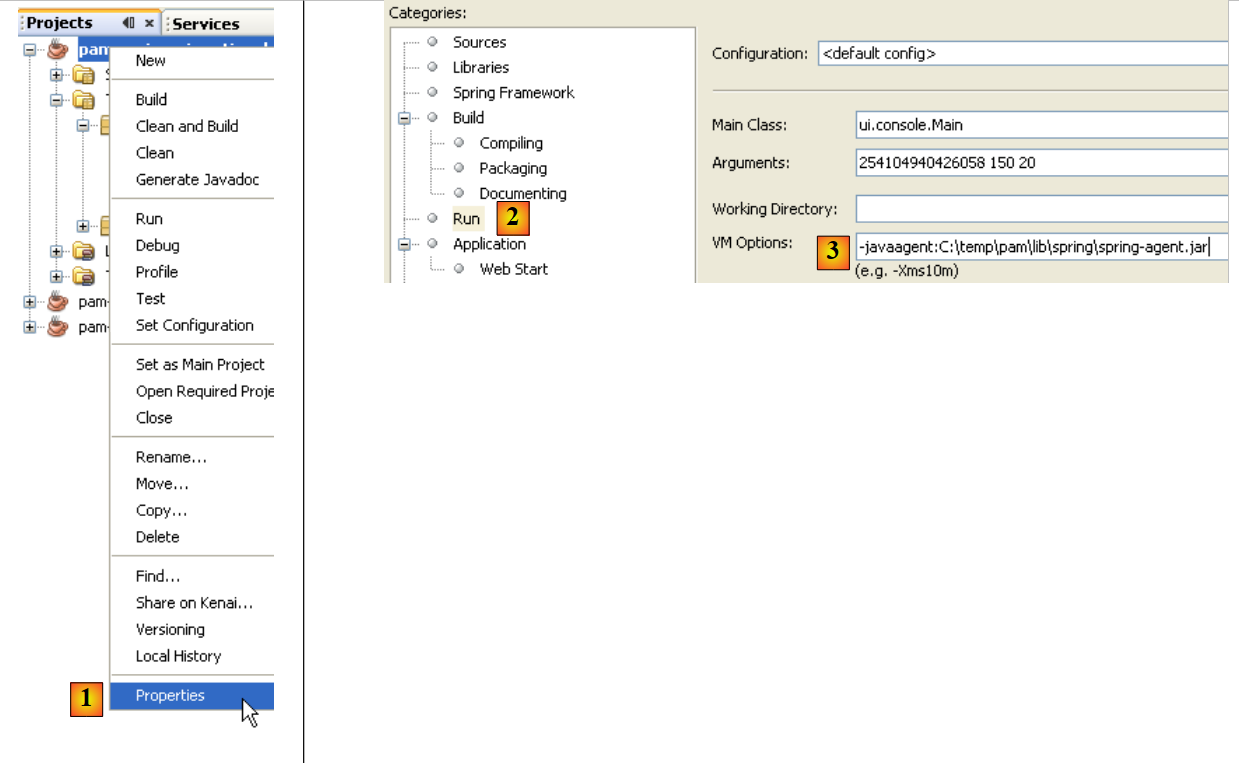 |
- 在 [1] 中,您可以访问项目属性
- 在 [2] 中,运行属性
- 在 [3] 中,向 JVM 传递 -javaagent 参数
5.13.3. InitDB
现在我们可以再次测试 [InitDB] 了。这次的结果如下:
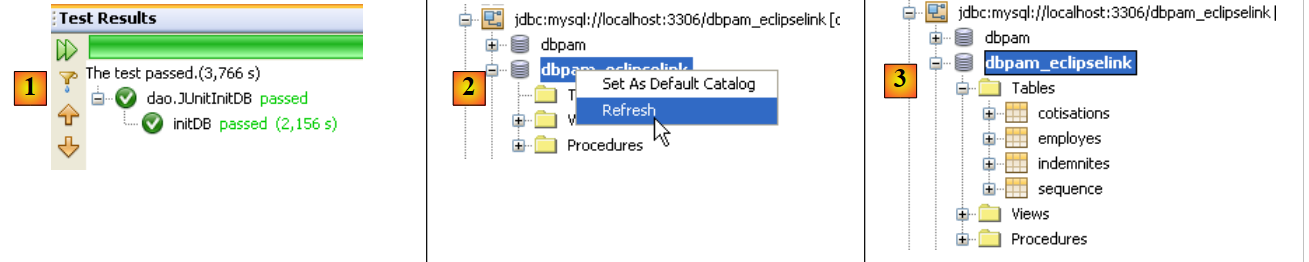 |
- 在 [1] 中,测试成功
- 在 [2] 中,位于 [Services] 选项卡下,我们刷新了 NetBeans 与 [dbpam_eclipselink] 数据库的连接
- 在 [3] 中,创建了四个表
 |
- 在 [5] 中,我们查看 [employees] 表的内容
- 在[6]中,显示结果。
5.13.4. JUnitDao
即使在 JPA/Hibernate 实现中测试通过,[JUnitDao] 测试类的执行仍可能失败。为了解原因,让我们分析一个示例。
待测试的方法是 IndemniteDao.create 方法:
- 第15–22行:正在测试的方法
测试方法如下:
package dao;
...
public class JUnitDao {
// layers DAO
static private IEmployeDao employeDao;
static private IIndemniteDao indemniteDao;
static private ICotisationDao cotisationDao;
@BeforeClass
public static void init() {
// log
log("init");
// application configuration
ApplicationContext ctx = new ClassPathXmlApplicationContext("spring-config-DAO.xml");
// layers DAO
employeDao = (IEmployeDao) ctx.getBean("employeDao");
indemniteDao = (IIndemniteDao) ctx.getBean("indemniteDao");
cotisationDao = (ICotisationDao) ctx.getBean("cotisationDao");
}
@Before()
public void clean() {
// empty the base
for (Employe employe : employeDao.findAll()) {
employeDao.destroy(employe);
}
for (Cotisation cotisation : cotisationDao.findAll()) {
cotisationDao.destroy(cotisation);
}
for (Indemnite indemnite : indemniteDao.findAll()) {
indemniteDao.destroy(indemnite);
}
}
// logs
private static void log(String message) {
System.out.println("----------- " + message);
}
// tests
….
@Test
public void test05() {
log("test05");
// we create two allowances with the same index
// violates index uniqueness constraint
boolean erreur = true;
Indemnite indemnite1 = null;
Indemnite indemnite2 = null;
Throwable th = null;
try {
indemnite1 = indemniteDao.create(new Indemnite(1, 1.93, 2, 3, 12));
indemnite2 = indemniteDao.create(new Indemnite(1, 1.93, 2, 3, 12));
erreur = false;
} catch (PamException ex) {
th = ex;
// checks
Assert.assertEquals(31, ex.getCode());
} catch (Throwable th1) {
th = th1;
}
// checks
Assert.assertTrue(erreur);
// exception chain
System.out.println("Chaîne des exceptions --------------------------------------");
System.out.println(th.getClass().getName());
while (th.getCause() != null) {
th = th.getCause();
System.out.println(th.getClass().getName());
}
// the 1st allowance had to be continued
Indemnite indemnite = indemniteDao.find(indemnite1.getId());
// check
Assert.assertNotNull(indemnite);
Assert.assertEquals(1, indemnite.getIndice());
Assert.assertEquals(1.93, indemnite.getBaseHeure(), 1e-6);
Assert.assertEquals(2, indemnite.getEntretienJour(), 1e-6);
Assert.assertEquals(3, indemnite.getRepasJour(), 1e-6);
Assert.assertEquals(12, indemnite.getIndemnitesCP(), 1e-6);
// the second indemnity should not have persisted
List<Indemnite> indemnites = indemniteDao.findAll();
int nbIndemnites = indemnites.size();
Assert.assertEquals(nbIndemnites, 1);
}
...
}
问题:请说明 test05 测试的功能,并指出预期结果。
使用 JPA/Hibernate 层获得的结果如下:
测试通过,这意味着断言已验证,且测试方法未抛出任何异常。
问题:请说明发生了什么。
使用 JPA/EclipseLink 层获得的结果如下:
与之前的 Hibernate 一样,测试通过,这意味着断言已得到验证,且测试方法未抛出任何异常。
问题:请解释发生了什么。
问题:从这两个例子中,我们可以得出关于 JPA 实现互换性的什么结论?这里是否完全互换?
5.13.5. 其他测试
一旦 [DAO] 层经过测试并确认无误,我们就可以继续测试 [业务] 层,以及项目本身的控制台或图形化版本。 更改 JPA 实现对 [业务] 和 [UI] 层没有任何影响;因此,如果这些层在 Hibernate 上运行正常,那么在 EclipseLink 上也同样能正常运行,但有少数例外:前面的示例表明,[DAO] 层抛出的异常可能有所不同。 因此,在测试中,Spring / JPA / Hibernate 会抛出 [PamException],这是 [pam] 应用程序特有的异常,而 Spring / JPA / EclipseLink 会抛出 [TransactionSystemException],这是 Spring 框架中的异常。 如果在测试用例中,[ui] 层因为是使用 Hibernate 构建的,所以预期会收到 [PamException],那么在切换到 EclipseLink 时,它将不再起作用。
5.13.6. 待完成的工作
实践任务:使用不同的数据库管理系统(DBMS)——MySQL5、Oracle XE、SQL Server——重新测试控制台和Swing应用程序。