2. Layered Architecture of a Java Application
A Java application is often divided into layers, each with a well-defined role. Let’s consider a common architecture, the three-layer architecture:
 |
- the [1] layer, referred to here as [ui] (User Interface), is the layer that interacts with the user via a Swing GUI, a console interface, or a web interface. Its role is to provide data from the user to the [2] layer or to present data provided by the [2] layer to the user.
- The [2] layer, referred to here as [metier], is the layer that applies the so-called business rules, c.a.d. the application-specific logic, without concerning itself with where the data it is given comes from, or where the results it produces go.
- The [3] layer, referred to here as [DAO] (Data Access Object), is the layer that provides the [2] layer with pre-stored data (files, databases, ...) and which saves some of the results provided by the [2] layer.
There are various ways to implement the [DAO] layer. Let’s examine a few of them:
 |
The [JDBC] layer above is the standard layer used in Java to access databases. It isolates the [DAO] layer from the SGBD layer, which manages the database. In theory, you can change the SGBD layer without modifying the code in the [DAO] layer. Despite this advantage, the API and JDBC layers have certain drawbacks:
- all operations on SGBD are likely to trigger the controlled exception (checked) SQLException. This forces the calling code (the [DAO] layer here) to wrap them in try/catch blocks, making the code quite verbose.
- The [DAO] layer is not completely independent of SGBD. For example, these have proprietary methods for the automatic generation of primary key values that the [DAO] layer cannot ignore. Thus, when inserting a record:
- with Oracle, the [DAO] layer must first obtain a value for the record’s primary key and then insert the record.
- With SQL Server, the [DAO] layer inserts the record, which is automatically assigned a primary key value by SGBD; this value is then passed to the [DAO] layer.
These differences can be eliminated by using stored procedures. In the previous example, the [DAO] layer will call a stored procedure in Oracle or SQL Server that will account for the specific characteristics of the SGBD layer. These will be hidden from the [DAO] layer. However, while changing SGBD will not require rewriting the [DAO] layer, it will still require rewriting the stored procedures. This may not be considered a deal-breaker.
Significant efforts have been made to isolate the [DAO] layer from the proprietary aspects of SGBD. One solution that has been highly successful in this area in recent years is Hibernate’s:
 |
The [Hibernate] layer sits between the [DAO] layer written by the developer and the [JDBC] layer. Hibernate is an ORM (Object-Relational Mapper), a tool that bridges the gap between the relational world of databases and the world of objects manipulated by Java. The developer of the [DAO] layer no longer sees the [JDBC] layer or the database tables whose content they wish to utilize. They see only the object representation of the database, provided by the [Hibernate] layer. The bridge between the database tables and the objects manipulated by the [DAO] layer is established primarily in two ways:
- via XML configuration files
- via Java annotations in the code, a technique available only since JDK 1.5
The [Hibernate] layer is an abstraction layer designed to be as transparent as possible. The ideal scenario is for the [DAO] layer developer to be completely unaware that they are working with a database. This is feasible if they are not the one writing the configuration that bridges the relational and object-oriented worlds. Configuring this bridge is quite delicate and requires some experience.
The [4] object layer, a mirror of BD, is called the "persistence context." A [DAO] layer based on Hibernate performs persistence operations (CRUD: create, read, update, delete) on the objects in the persistence context, actions translated by Hibernate into SQL commands executed by the JDBC layer. For database query operations (the SQL Select), Hibernate provides the developer with a HQL language (Hibernate Query Language) to query the [4] persistence context rather than the BD itself.
Hibernate is popular but complex to master. The learning curve, often described as easy, is actually quite steep. As soon as you have a database with tables featuring one-to-many or many-to-many relationships, configuring the relational-to-object bridge is not something just any beginner can handle. Configuration errors can lead to poor application performance.
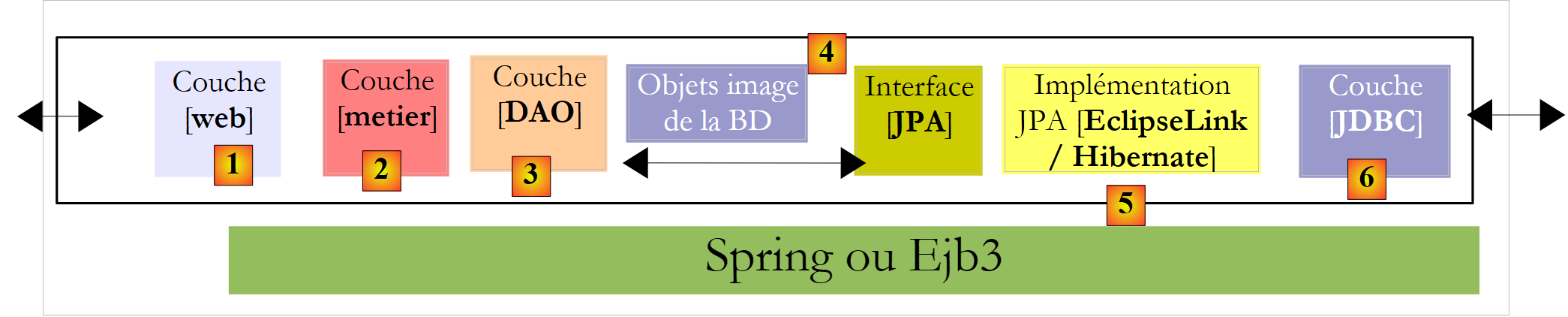
Given the success of the ORM products, Sun, the creator of Java, decided to standardize a ORM layer via a specification called JPA (Java Persistence API), which appeared alongside Java 5. The JPA specification has been implemented by various products: Hibernate, Toplink, EclipseLink, OpenJpa, .... With JPA, the previous architecture becomes the following:
 |
The [DAO] layer now communicates with the JPA specification, a set of interfaces. The developer has gained in terms of standardization. Previously, if he changed his ORM layer, he also had to change his [DAO] layer, which had been written to interface with a specific ORM. Now, they will write a [DAO] layer that will interact with a JPA layer. Regardless of the product that implements it, the interface of the JPA layer presented to the [DAO] layer remains the same.
In this document, we will use a [DAO] layer based on a JPA/Hibernate or JPA/EclipseLink layer. In addition, we will use the Spring 2.8 framework to link these layers together.
 |
The main advantage of Spring is that it allows the layers to be linked via configuration rather than in the code. Thus, if the JPA / Hibernate needs to be replaced by a Hibernate implementation without JPA—for example, because the application is running in a JDK 1.4 environment that does not support JPA— this change in the [DAO] layer implementation has no impact on the [métier] layer code. Only the Spring configuration file that links the layers together needs to be modified.
With Java EE 5, another solution exists: implement the [metier] and [DAO] layers using EJB3 (Enterprise Java Bean 3):
 |
We will see that this solution is not very different from the one using Spring. The Java environment EE5 is available within so-called application servers such as Sun Application Server 9.x (Glassfish), JBoss Application Server, Oracle Container for Java (OC4J), ... An application server is essentially a web application server. There are also so-called "stand-alone" environments, EE 5, c.a.d. that can be used outside of an application server. This is the case for JBoss, EJB3, or OpenEJB.
In a EE5 environment, the layers are implemented by objects called EJB (Enterprise Java Beans). In previous versions of EE, EJB (EJB 2.x) were considered difficult to implement, test, and sometimes underperformed. We distinguish between EJB2.x "entity" and EJB2.x "session". In short, a EJB2.x "entity" represents a database table row, and a EJB2.x "session" is an object used to implement the [metier], [DAO] layers of a multi-layer architecture. One of the main criticisms of layers implemented with EJB is that they can only be used within EJB containers, a service provided by the EE environment. This environment, which is more complex to set up than a SE (Standard Edition) environment, may discourage developers from testing frequently. Nevertheless, there are Java development environments that simplify the use of an application server by automating the deployment of EJB to the server: Eclipse, Netbeans, JDeveloper, IntelliJ, IDEA. Here we will use Netbeans 6.8 and the Glassfish v3 application server.
The Spring framework was created in response to the complexity of EJB2. Spring provides, within a SE environment, a significant number of the services typically provided by EE environments. Thus, in the "Data Persistence" section, Spring provides the connection pools and transaction managers that applications require. The emergence of Spring has fostered a culture of unit testing, which has become easier to implement in the SE context than in the EE context. Spring enables the implementation of application layers using standard Java objects (POJO, Plain Old/Ordinary Java Object), allowing for their reuse in a different context. Finally, it integrates numerous third-party tools fairly transparently, notably persistence tools such as Hibernate, EclipseLink, iBatis, ...
Java EE5 was designed to address the shortcomings of the EJB2 specification. EJB 2.x has become EJB3. These are POJOs instances tagged with annotations that make them special objects when they are inside a EJB3 container. Within this container, the EJB3 will be able to benefit from the container’s services (connection pool, transaction manager, etc.). Outside the EJB3 container, the EJB3 becomes a normal Java object. Its EJB annotations are ignored.
Above, we have depicted Spring and a EJB3 container as a possible infrastructure (framework) for our multi-layer architecture. It is this infrastructure that will provide the services we need: a connection pool and a transaction manager.
- With Spring, the layers will be implemented using POJOs. These will have access to Spring’s services (connection pool, transaction manager) through dependency injection into these POJOs: when constructing them, Spring injects references to the services they will need.
- With the EJB3 container, the layers will be implemented using EJB. A layered architecture implemented with EJB3 is not very different from those implemented with POJO instantiated by Spring. We will find many similarities.
- Finally, we will present an example of a multi-layered web application:
 |