4. [TD]:分层架构
关键词:多层架构、Spring、依赖注入。
4.1. Introduction
回顾一下之前的工作:
- 在练习 ELECTIONS 的第 1 部分中,未使用任何类。我们构建了一个解决方案,就像用 C 语言编写的一样。
- 在练习的第2部分中,引入了两个类:
- [ListeElectorale] 类,用于表示候选人名单的属性(id、姓名、票数、席位、淘汰)
- [ElectionsException] 是一个未受控异常类。当选举应用程序中发生致命错误时,会触发此类异常。由于它是未受控的(c.a.d),开发者无需使用 try-catch 进行处理。
迄今为止,选举结果的计算一直由[MainElections]类中的[main]方法负责
之前的解决方案包含三个经典阶段:
- 数据采集(第17-18行)
- 计算结果,第19-20行
- 结果的显示和/或持久化,第21-22行
只有第2阶段是真正固定的。第1阶段可能有所不同:数据可以来自键盘(如所研究的示例中那样),也可以来自文本文件、图形用户界面、数据库、网络等。 同样,在第3阶段呈现结果的方式也多种多样:如所研究的示例中那样在屏幕上显示,保存到文件中,存储在数据库中,发送至网络等……
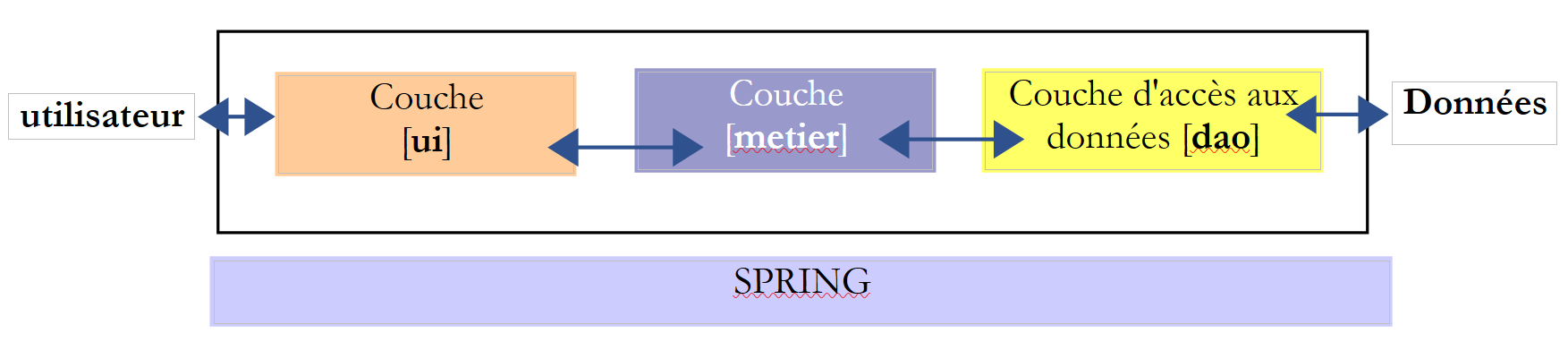
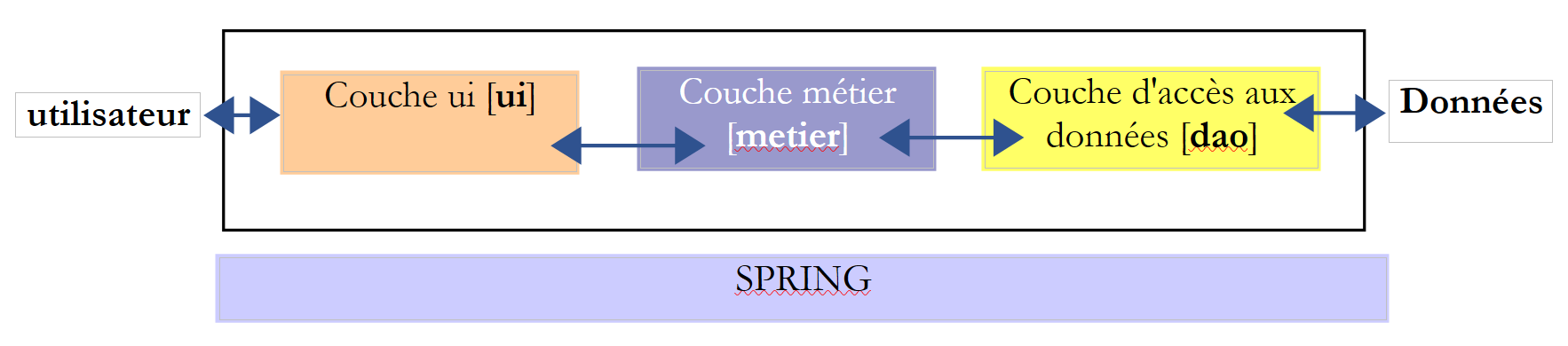
更普遍地说,应用程序通常可以建模为三个层,每个层都有明确的职责:
 |
这种架构也被称为“三层架构”,即英语“three-tier architecture”的译名。通常,“三层”一词指每层位于不同机器上的架构。当三层位于同一台机器上时,该架构便成为“三层架构”。
- [metier]层包含应用程序的业务规则。对于我们的选举应用程序而言,这些规则用于在已知各候选名单得票数的基础上,计算其获得的席位数。该层需要数据才能运行。例如在选举应用程序中:
- 各候选名单及其名称和得票数
- 待填补的席位数
- 选举门槛,低于该门槛的候选名单将被淘汰
在上图中,数据可能来自两个来源:
- 数据访问层或 [dao](DAO = 数据访问对象),用于已存储在文件或数据库中的数据。此处可能包括候选名单名称、待选席位数以及选举门槛。 事实上,这些信息在选举开始前就已经确定。
- 用户界面层或 [ui](UI = 用户界面),用于用户输入或向用户显示的数据。 在此情况下,各候选名单的得票数(通常直到最后一刻才公布)以及选举结果的显示可能属于此类。
- 一般而言,[dao] 层负责访问持久数据(文件、数据库)或非持久数据(网络、传感器等)。
- [ui] 层则负责与用户(如有)的交互。
- 通过使用 Java 接口,这三层被设计为相互独立。
- 要将这些层整合到应用程序中,有多种方法。我们将使用一个名为“Spring”的工具。在架构图中,它横跨其他各层。
我们将基于之前开发的 [Elections] 应用程序,为其构建三层架构。 为此,我们将依次研究 [ui, metier, dao] 的各层,首先从负责持久化数据的 [dao] 层开始。
在此之前,我们需要定义 [Elections] 应用程序各层的接口。
4.2. [Elections] 应用程序的接口
需要提醒的是,接口定义了一组方法签名。实现该接口的类为这些方法提供了具体实现。
让我们回到应用程序的三层架构:
|
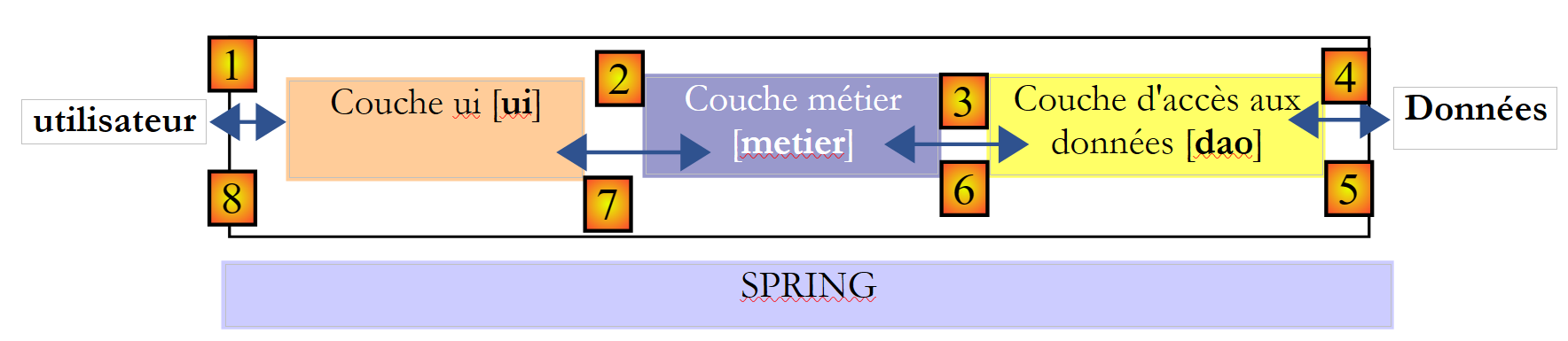
在此类架构中,通常由用户发起操作。用户在 [1] 中发起请求,并在 [8] 中收到响应。这被称为请求-响应循环。以选举当晚计算席位数为例,该过程需要多个步骤:
- [ui]层需要向用户询问各候选名单所获票数。为此,它必须向用户展示所有参选名单的名称。用户只需在每个名单旁填写票数,然后请求计算席位。
- [ui]层不包含候选名单的名称。这些名称存储在架构右侧的数据源中。该层将通过路径[2, 3, 4, 5, 6, 7]获取这些信息。 操作 [2] 用于请求候选名单,操作 [7] 用于响应该请求。完成上述步骤后,可通过 [8] 向用户展示名单。
- 用户将向 [ui] 层提交各候选名单所获的票数。这即为上述的 [1] 操作。 在此步骤中,用户仅与 [ui] 层进行交互。该层将主要负责验证所输入数据的有效性。完成验证后,用户将请求获取各候选名单所获得的席位列表。
- [ui]层将请求业务层进行席位计算。为此,它将向业务层传输从用户处接收到的数据。这就是操作[2]。
- [metier]层需要某些信息才能完成其工作。它已通过操作(b)获得了候选名单。此外,它还需要待分配的席位数以及选举门槛值。 它将通过路径 [3, 4, 5, 6] 向 [dao] 层请求这些信息。[3] 是初始请求,而 [6] 是对此请求的响应。
- 在获取所需全部数据后,[metier]层计算出各候选名单所获席位。
- [metier]层现在可以响应[ui]层在(d)中发出的请求。这就是路径[7]。
- [ui] 层将对这些结果进行格式化,以便以适当的形式呈现给用户,然后进行展示。这就是路径 [8]。
- 可以设想,这些结果需要存储在文件或数据库中。这可以自动完成。在这种情况下,在操作 (f) 之后,[metier] 层将请求 [dao] 层保存结果。 此时将采用路径 [3, 4, 5, 6]。该操作也可仅在用户请求时执行,此时请求-响应循环将使用路径 [1-8]。
从上述描述中可以看出,一个层会使用其右侧层的资源,但绝不会使用其左侧层的资源。考虑两个相邻的层:
 |
[A]层向[B]层发起请求。 在最简单的情况下,一个层由一个类实现。应用程序会随着时间推移而演变。因此,层 [B] 可能有不同的实现类 [B1, B2, ...]。 如果 [B] 层是 [dao] 层,那么该层可能有一个初始实现 [B1],它从文件中读取数据。几年后,我们可能希望将数据存入数据库。 此时,我们将构建第二个实现类 [B2]。 如果在最初的应用程序中,[A]层直接与[B1]类进行交互,那么我们就不得不部分重写[A]层的代码。 例如,假设我们在 [A] 层中编写了如下内容:
- 第 1 行:创建 [B1] 类的实例
- 第 3 行:向该实例请求数据
如果假设新的实现类 [B2] 使用的方法签名与类 [B1] 相同,则需要将所有 [B1] 改为 [B2]。 这属于非常理想的情况,但若未注意这些方法签名,这种情况发生的概率相当低。 实际上,[B1] 和 [B2] 这两个类通常不具备相同的方法签名,因此 [A] 层的大部分内容往往需要完全重写。
若在 [A] 层与 [B] 层之间添加一个接口,即可改善这一情况。 这意味着将 [B] 层向 [A] 层提供的方法签名固定在接口中。因此,之前的架构图变为如下所示:
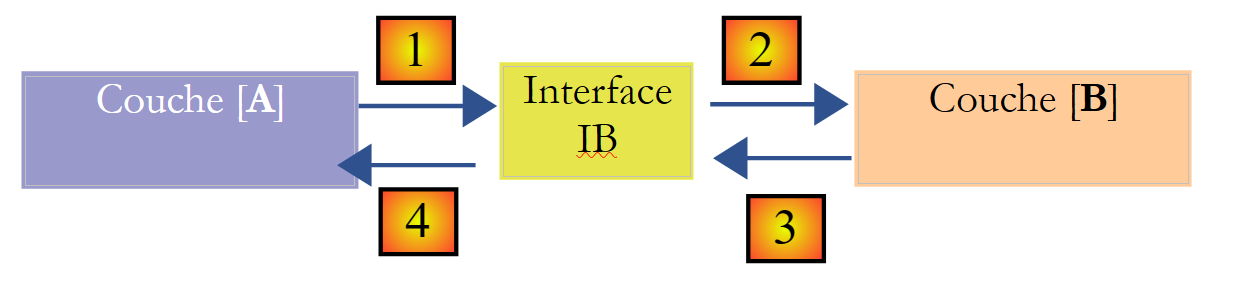 |
[A]层现在不再直接与[B]层通信,而是通过其接口[IB]进行通信。因此,在[A]层的代码中, [B] 层的实现类 [Bi] 仅在实现 [IB] 接口时出现一次。 这样一来,代码中使用的是接口 [IB] 而非其实现类。上述代码变为如下形式:
- 第 1 行:通过实例化 [B1] 类,创建了一个实现 [IB] 接口的 [ib] 实例
- 第 3 行:向 [ib] 实例请求数据
现在,如果将 [B] 层的 [B1] 实现替换为 [B2] 实现,且这两个实现都遵循相同的 [IB] 接口, 那么只需修改 [A] 层的第 1 行,其他行均无需修改。这本身就是一大优势,足以证明在两个层之间系统地使用接口是合理的。
我们还可以更进一步,使 [A] 层完全独立于 [B] 层。在上面的代码中,第 1 行存在问题,因为它硬编码引用了 [B1] 类。 理想情况下,[A]层应能使用[IB]接口的实现,而无需指定具体类名。这将与我们上文的架构图保持一致。 我们可以看到,[A]层面向[IB]接口,且无法理解它为何需要知道实现该接口的类名。这一细节对[A]层而言毫无用处。
Spring框架(http://www.springframework.org)可实现这一效果。上述架构演变如下:
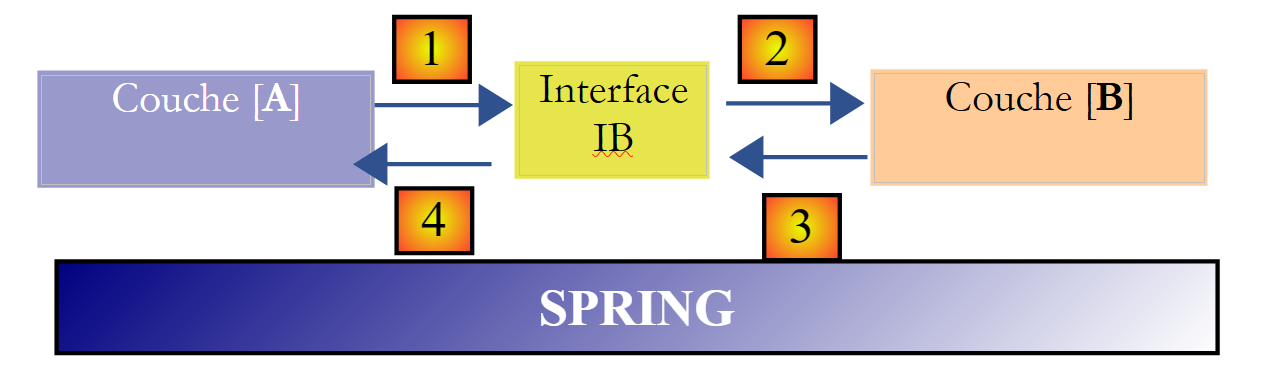 |
横向层 [Spring] 将允许一个层通过配置获取其右侧层的引用,而无需知道该层的实现类名称。该名称将保存在配置文件中,而非 Java 代码中。 [A] 层的 Java 代码形式如下:
- 第 1 行:一个 [ib] 实例,该实例实现了 [B] 层中的 [IB] 接口。该实例由 Spring 根据配置文件中的信息创建。Spring 将负责创建:
- 实现 [B] 层的 [b] 实例
- 实现 [A] 层的 [a] 实例。该实例将被初始化。 上文中的 [ib] 字段将获得 [b] 的引用值,该引用指向实现 [B] 层的对象
- 第 3 行:向 [ib] 实例请求数据
现在可以看到,B层的实现类[B1]在[A]层的代码中完全未出现。 当实现类 [B1] 被新的实现类 [B2] 替换时,类 [A] 的代码将保持不变。 我们只需修改 Spring 的配置文件,将实例化对象从 [B1] 更改为 [B2]。
Spring与Java接口的结合通过实现各层之间的隔离,为应用程序的维护带来了决定性的改进。我们将采用这一方案来构建[Elections]应用程序。
让我们回到应用程序的三层架构:
 |
在简单情况下,我们可以从 [metier] 层开始,以此探索应用程序的接口。该层运行时需要数据:
- 这些数据可能已存在于文件、数据库中,或通过网络获取。它们由 [dao] 层提供。
- 尚未可用。此时由 [ui] 层提供,该层从应用程序用户处获取数据。
[dao]层应向[metier]层提供哪些接口?这两个层之间可能存在哪些交互?[dao]层必须向[metier]层提供以下数据:
- 待填补的席位数
- 导致候选名单被淘汰的选举门槛值
- 候选名单名称
这些信息在选举前已知,因此可以预先存储。 在 [metier] -> [dao] 方向上,[metier] 层可要求 [dao] 层记录选举结果,特别是各候选名单所获得的席位。
基于这些信息,我们可以尝试初步定义 [dao] 层的接口:
public interface IElectionsDao {
public double getSeuilElectoral();
public int getNbSiegesAPourvoir();
public ListeElectorale[] getListesElectorales();
public void setListesElectorales(ListeElectorale[] listesElectorales);
}
- 第 1 行:该接口名为 [IElectionsDao]。它定义了四种方法:
- 三个用于从数据源读取数据的方法:[getSeuilElectoral, getNbSiegesAPourvoir, getListesElectorales]。这三个方法将使 [metier] 层能够获取当前选举的相关数据。
- 一个用于向数据源写入数据的方法:[setListesElectorales]。该方法将使 [metier] 层能够请求记录其计算出的结果。
让我们回到应用程序的三层架构:
|
[metier]层应向[ui]层提供何种接口?让我们来探讨这两层之间可能的交互。
- [ui]层将负责向用户征集对各参选名单的投票。 为此,它必须知道候选名单的数量。它可向 [metier] 层查询此信息,该层进而可向 [dao] 层请求竞争名单表。 如果 [metier] 层拥有该数组,不妨将其传递给 [ui] 层。这样,该层将掌握各候选名单的名称,并能通过询问“候选名单 A 的得票数”等方式,进一步优化向用户发送的消息。
- 当 [ui] 层获取了所有候选名单的得票数后,它将向 [metier] 层请求计算席位。该层可进行计算并将结果返回给 [ui] 层。
- 随后,[ui]层将向用户展示这些结果。用户还可以要求保存这些结果。
- 此外,[ui]层可能希望向用户展示补充信息,例如选举门槛或待填补席位数。
基于这些信息,我们可以尝试初步定义 [metier] 层 的接口:
public interface IElectionsMetier {
public ListeElectorale[] getListesElectorales();
public int getNbSiegesAPourvoir();
public double getSeuilElectoral();
public void recordResultats(ListeElectorale[] listesElectorales);
public ListeElectorale[] calculerSieges(ListeElectorale[] listesElectorales);
}
- 第 1 行:该接口名为 [IElectionsMetier]。它定义了以下方法:
- 第3行:方法[getListesElectorales],该方法将使[ui]层能够获取竞争名单数组;
- 第5行:方法[getNbSiegesAPourvoir]用于获取待填补的席位数;
- 第 7 行:方法 [getSeuilElectoral] 用于获取选举门槛;
- 第11行:方法[calculerSieges](第36行)将使[ui]层能够在各候选名单的得票数确定后,请求进行席位计算。 参数为参选名单数组,其中不包含席位信息,且未包含“被淘汰”布尔值。返回结果为该数组,但此次已初始化了 [sièges, elimine] 字段;
- 第9行:一个名为[recordResultats]的方法,该方法将使[ui]层能够请求记录结果。
注:基于其位置,[métier]层继承了[DAO]层的部分方法,以便将其提供给[UI]层。 由于这种冗余,人们可能会试图将业务逻辑和数据访问全部整合到一个单一层中。 这一单一层有时被称为模型,即 MVC 缩写中的 M(模型 - 视图 - 控制器)。MVC 是 Web 应用程序中广泛采用的一种设计模式。
让我们来分析一下方法 [calculerSieges] 的签名:
public ListeElectorale[] calculerSieges(ListeElectorale[] listesElectorales);
前文曾提到:“参数是竞争列表的数组,不包含其席位,也不包含已被淘汰的布尔值。返回值是该数组,但此次包含 [sièges, elimine] 字段。”该方法的签名也可以写成如下形式:
public void calculerSieges(ListeElectorale[] listesElectorales);
参数 [listesElectorales] 是一个对象引用,此处为数组。每个元素又是一个对象引用,此处为类型 [ListeElectorale]。 方法 [calculerSieges] 将修改这些对象中每个对象的 [sieges, elimine] 字段。调用该方法的方法持有指针 [listesElectorales],该指针:
- 在调用之前,是对象数组 [ListeElectorale] 的引用,该数组的字段 [sieges, elimine] 尚未初始化;
- 调用后,是对象数组 [ListeElectorale] 的引用(与调用前相同),该数组的字段 [sieges, elimine] 已初始化;
那么为什么使用以下签名:
public ListeElectorale[] calculerSieges(ListeElectorale[] listesElectorales);
编写接口时,应记住它可能在两个不同的上下文中使用: local 和 distant。 在 local 上下文中,调用方法和被调用方法都在同一个 JVM(Java 虚拟机)中执行:
|
如果 [ui] 层调用 [DAO] 层中的 calculerSieges 方法,那么它确实持有参数 [ListeElectorale[] listesElectorales] 参数上,并将其传递给该方法。
在 distant 上下文中,调用方法和被调用方法在不同的 JVM 中执行:
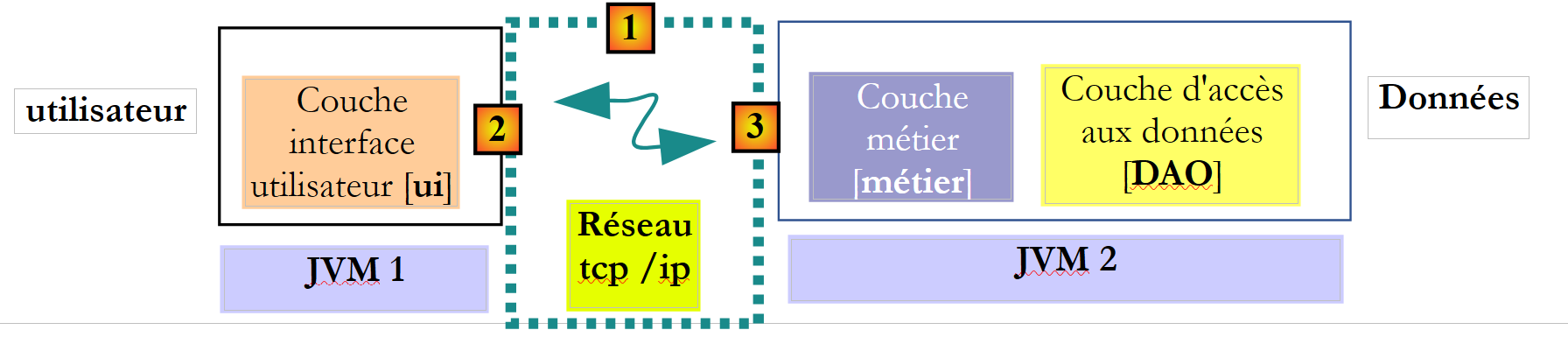 |
在上文中,[ui] 层在 JVM 1 上运行,而 [métier] 层在 JVM 2 上运行,它们位于两台不同的机器上。 这两个层之间并不直接通信。它们之间插入了一个层,我们称之为通信层 [1]。该层由发送层 [2] 和接收层 [3] 组成。 通常情况下,开发人员无需编写这些通信层。它们由软件工具自动生成。 [metier]层的设计方式,使其仿佛与[DAO]层在同一个JVM中运行。因此无需修改代码。
[ui]层与[métier]层之间的通信机制如下:
- [ui]层调用[métier]层的calculerSieges方法,并向其传递参数 [ListeElectorale[] listesElectorales1];
- 该参数实际上被传递给了发送层 [2]。该层将通过网络传输参数 listesElectorales1 的值,而非其引用。该值的具体形式取决于所使用的通信协议;
- 接收层 [3] 将获取该值,并据此重建一个 [ListeElectorale[] listesElectorales2] 对象,该对象是 [metier] 层发送的初始参数的镜像。 现在,我们在两个不同的 JVM 中拥有两个(就内容而言)相同的对象:listesElectorales1 和 listesElectorales2。
- 接收层将把对象 listesElectorales2 传递给 [métier] 层的 calculerSieges 方法;该方法将把该对象持久化到数据库中。 此操作完成后,引用 listesElectorales2 指向一个 [ListeElectorale] 对象数组,该数组中各对象的 [sieges, elimine] 字段已初始化。 而 [ui] 层引用的 listesElectorales1 对象则并非如此。 如果希望 [ui] 层引用 listesElectorales2 对象,则必须将其发送给该层。因此,对于 [calculerSieges] 方法,需要使用以下签名:
public ListeElectorale[] calculerSieges(ListeElectorale[] listesElectorales);
- 使用此签名,方法 calculerSieges 将返回引用 listesElectorales2。该结果将返回给调用 [métier] 层的接收层 [3]。 该层将 listesElectorales2 的值(而非引用)返回给发送层 [2];
- 发送层 [2] 将获取该值,并据此重建一个 [ListeElectorale[] listesElectorales3] 对象,该对象是 [métier] 层中 calculerSieges 方法渲染结果的映射。
- 对象 [ListeElectorale[] listesElectorales3] 被传递给 [ui] 层的方法,而正是该层对 [DAO] 层中 calculerSieges 方法的调用,启动了整个机制;
在此过程中,[ListeElectorale]类型的对象将在[2]层与[3]层之间传递:
- 当 [2] 层将 [ListeElectorale] 对象的值传递给 [3] 层时,该对象被称为被序列化。这种序列化的具体形式取决于所使用的通信协议;
- 当 [3] 层从 [ListeElectorale] 对象中获取值以重新创建 [ListeElectorale] 对象时,该对象被称为反序列化;
为了使对象能够进行序列化/反序列化,某些协议要求该对象实现 [Serializable] 接口。该接口仅作为标记,无需实现任何方法。 因此,类 [ListeElectorale] 今后将按以下方式声明:
public abstract class ListeElectorale implements Serializable {
private static final long serialVersionUID = 1L;
- 第2行的字段是强制要求的。可以保留其原样,并将其用于所有类型为[Serializable]的类。
4.3. 例外类
让我们回到 [DAO] 层的接口:
 |
public interface IElectionsDao {
public double getSeuilElectoral();
public int getNbSiegesAPourvoir();
public ListeElectorale[] getListesElectorales();
public void setListesElectorales(ListeElectorale[] listesElectorales);
}
这些方法涉及数据库操作,可能会遇到各种错误,例如 SGBD 不可用。编写方法时,必须始终预先处理错误情况。通常,这些错误会通过异常来报告。 我们在第 3.3 节中已经遇到过 [ElectionsException] 类。我们将继续使用它,但会按以下方式对其进行扩展:
package ...;
import java.io.Serializable;
import java.util.ArrayList;
import java.util.List;
// Elections 应用程序的异常类
// 该异常为非受控异常
public class ElectionsException extends RuntimeException implements Serializable {
// 序列化ID
private static final long serialVersionUID = 1L;
// 本地字段
private int code;
private List<String> erreurs;
// 构造函数
public ElectionsException() {
super();
}
public ElectionsException(int code, Throwable e) {
// 父类
super(e);
// 本地
this.code = code;
this.erreurs = getErreursForException(e);
}
public ElectionsException(int code, String message, Throwable e) {
// 父级
super(message,e);
// 本地
this.code = code;
this.erreurs = getErreursForException(e);
}
public ElectionsException(int code, String message) {
// 父级
super(message);
// 本地
this.code = code;
List<String> erreurs = new ArrayList<>();
erreurs.add(message);
this.erreurs = erreurs;
}
public ElectionsException(int code, List<String> erreurs) {
// 父级
super();
// 本地
this.code = code;
this.erreurs = erreurs;
}
// 异常的错误消息列表
private List<String> getErreursForException(Throwable th) {
// 获取异常的错误消息列表
Throwable cause = th;
List<String> erreurs = new ArrayList<>();
while (cause != null) {
// 仅当消息不为空且不为空字符串时才获取消息
String message = cause.getMessage();
if (message != null) {
message = message.trim();
if (message.length() != 0) {
erreurs.add(message);
}
}
// 下一个原因
cause = cause.getCause();
}
return erreurs;
}
// getter 和 setter
...
}
- 第 16-17 行:[ElectionsException] 类型封装了:
- 一个错误代码,第16行;
- 一组错误消息,第 17 行;
该类支持五个构造函数:
- 第 20 行:ElectionsException()
- 第 24 行:ElectionsException(int code, Throwable e):第二个参数是类型 [Throwable],它是类 [Exception] 的父类。 该构造函数允许将异常 e 与错误代码封装在一起。类型 [Throwable](以及类型 Exception)允许封装一个或多个异常。其设计思想是:
- 捕获(catch)发生的异常;
- 通过将其封装到一个新异常中,为其添加一条消息;
- 重新抛出该新异常;
封装操作在第34行通过指令[super(message,e)]进行。该封装过程可以重复执行,并将初始异常补充为包含不同消息的异常。此时,我们称之为异常堆栈。 通过方法 [private List<String> getErreursForException(Throwable th)],可以获取与封装的异常相关的各种消息:
- (待续)
- (续)
- 封装后的异常可通过 Throwable 类的方法 [Throwable].getCause() 获取;
- 获取异常相关消息的方法是 String 类中的 [Throwable].getMessage();
- (续)
- 第 28-29 行:构建字段 [code, erreurs];
- 第 32 行:public ElectionsException(int code, String message, Throwable e):该构造函数与前一个类似,只是它为即将封装的异常添加了代码和消息;
- 第 40 行:public ElectionsException(int code, String message):不封装异常的构造函数;
- 第 50 行:public ElectionsException(int code, List<String> errors):不封装异常,也不包含消息的构造函数;
[ElectionsException] 类可按以下方式使用:
其中消息可能存在也可能不存在。一旦创建,[ElectionsException] 异常并不旨在封装新的异常。 如上所述,它封装了异常 e1 以及 e1 所封装的异常。此后,不再有新的封装。
[ElectionsException] 类也可按以下方式使用: