9. Geração de bases de dados a partir das entidades JPA
É possível criar as tabelas de uma base de dados a partir das entidades JPA. É isso que vamos mostrar agora. O objetivo é verificar se a base de dados gerada a partir das entidades JPA é, de facto, aquela que pretendemos.
9.1. Configuração do ambiente de trabalho
Vamos trabalhar, em primeiro lugar, com uma implementação JPA, EclipseLink e [1].
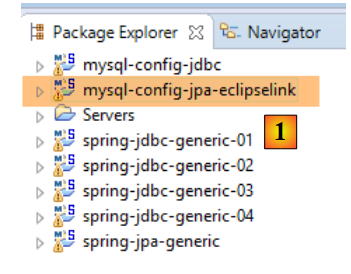 |
Em seguida, eliminamos as tabelas da base de dados MySQL e [dbproduitscategories] com o cliente [MyManager] (ver parágrafo 23.5). Começamos por eliminar as tabelas que contêm as chaves estrangeiras [1-3]:
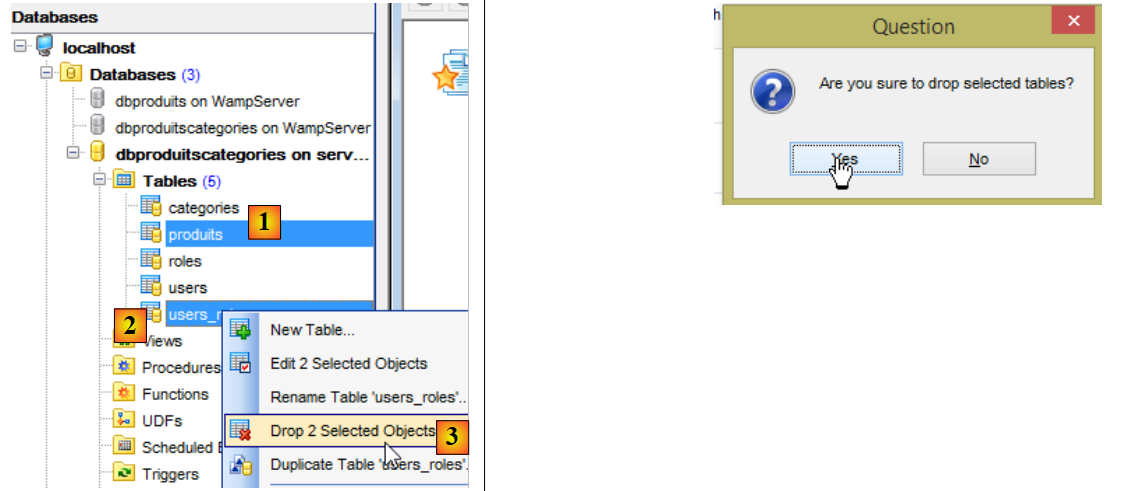 |
Em seguida, recomeçamos com as três tabelas restantes [4-6]:
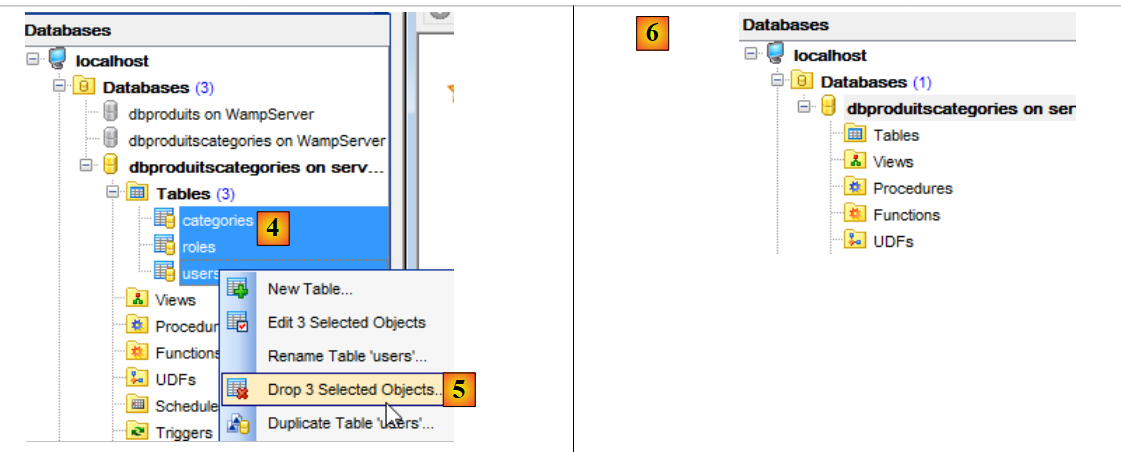 |
Fazemos o mesmo com a tabela [dbproduits] utilizada pelos projetos [spring-jdbc-01 à 03]:
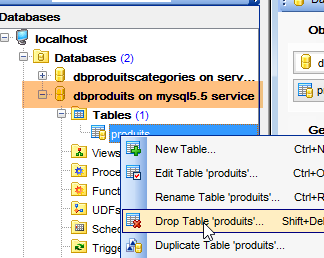 |  |
Além disso, é necessário importar os dois projetos de geração das duas bases de dados:
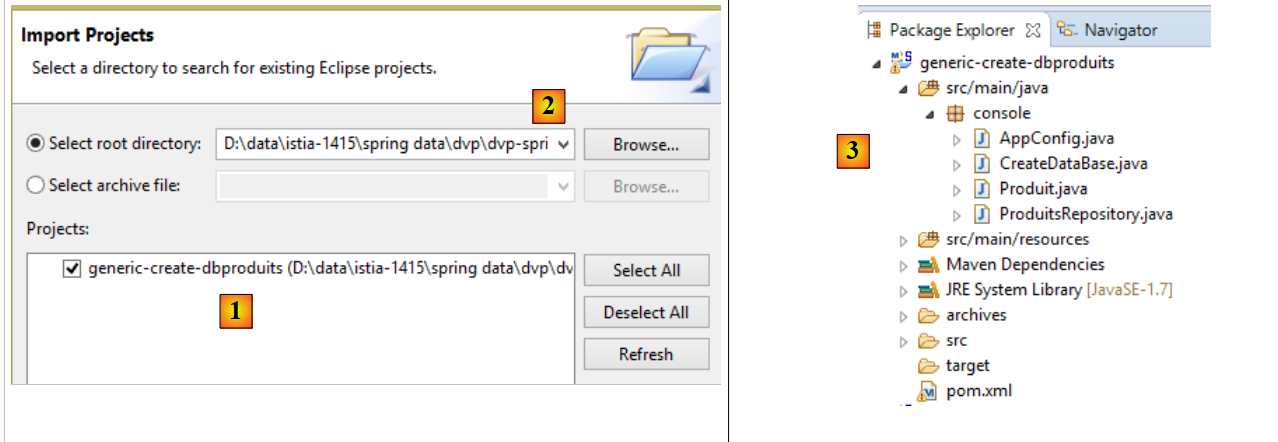 |
- no [1], importa-se o projeto [generic-create-dbproduits], que se encontra no [<exemples>/spring-database-generic/spring-jpa] [2];
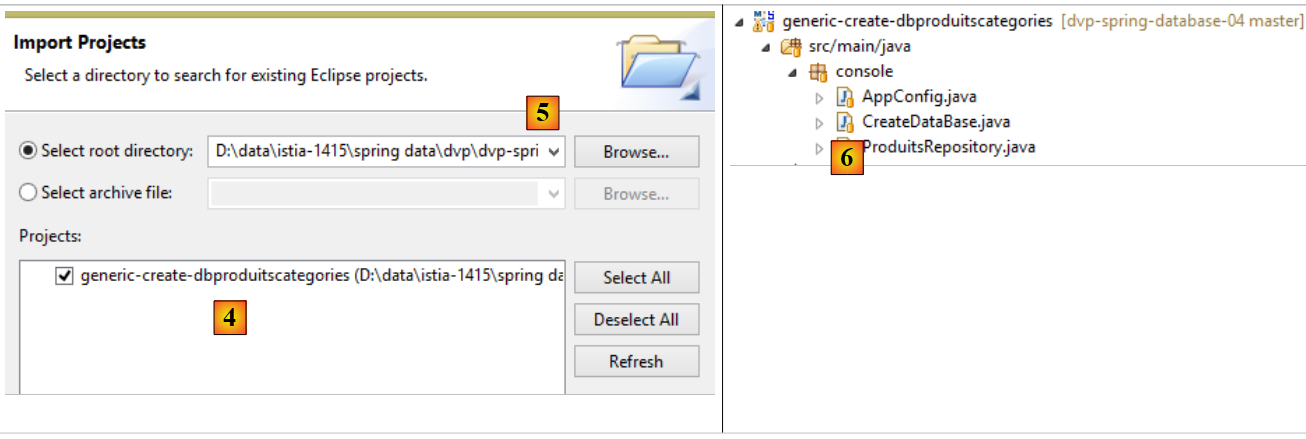 |
- no [4], importa-se o projeto [generic-create-dbproduitscategories], que se encontra em [<exemples>/spring-database-generic/spring-jpa] e [5];
Nota: premir Alt-F5 e regenerar todos os projetos Maven;
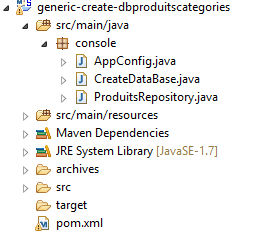
9.2. Geração da base de dados [dbproduitscategories]
 |
9.2.1. Configuração do Maven
O ficheiro [pom.xml] do projeto é o seguinte:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-create-dbproduitscategories</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>generic-create-dbproduitscategories</name>
<description>création de la bases de données [dbproduitscategories] à l'aide des annotations JPA</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
</parent>
<dependencies>
<!-- spring-jpa-generic -->
<dependency>
<groupId>dvp.spring.database</groupId>
<artifactId>spring-jpa-generic</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
<!-- Weaver Spring -->
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-instrument</artifactId>
<scope>runtime</scope>
</dependency>
</dependencies>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<start-class>spring.data.console.Main</start-class>
<java.version>1.7</java.version>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
</plugin>
</plugins>
</build>
</project>
- linhas 22-26: a dependência do projeto [spring-jpa-generic] analisado no parágrafo 6.4;
- linhas 28-32: a dependência de um «weaver» que será utilizado para enriquecer as entidades JPA das implementações EclipseLink e OpenJpa. A sua dependência não é necessária no ficheiro [pom.xml], mas o seu JAR será o agente Java utilizado. Colocar a dependência no ficheiro [pom.xml] garante-nos que o JAR estará efetivamente disponível;
No final, as dependências são as seguintes:
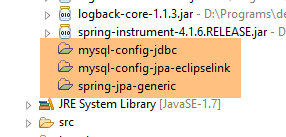 |
9.2.2. Configuração do Spring
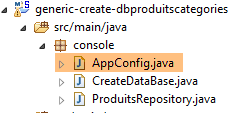 |
A classe [AppConfig] configura o projeto Spring:
package console;
import generic.jpa.config.ConfigJpa;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
@Configuration
@Import({ ConfigJpa.class })
@EnableJpaRepositories(basePackages = { "console" })
public class AppConfig {
}
- linha 10: a classe recupera os beans da classe [ConfigJpa]. Recorde-se que esta classe trabalha com as entidades JPA da base de dados [dbproduitscategories] (ver parágrafo 6.3);
- linha 11: declara-se que o pacote [console] deve ser analisado para encontrar instâncias de [CrudRepository];
Na classe [ConfigJpa], encontra-se o seguinte bean (varia consoante a implementação JPA utilizada):
// o provedor JPA
@Bean
public JpaVendorAdapter jpaVendorAdapter() {
// Nota: as entidades JPA e a configuração do EclipseLink encontram-se no ficheiro META-INF/persistence.xml
EclipseLinkJpaVendorAdapter eclipseLinkJpaVendorAdapter = new EclipseLinkJpaVendorAdapter();
eclipseLinkJpaVendorAdapter.setShowSql(false);
eclipseLinkJpaVendorAdapter.setDatabase(Database.MYSQL);
eclipseLinkJpaVendorAdapter.setGenerateDdl(true);
return eclipseLinkJpaVendorAdapter;
}
A linha 8 é importante neste contexto. Está presente em todas as implementações JPA utilizadas. Indica que, se as tabelas associadas às entidades JPA não existirem, devem ser criadas. Vamos basear-nos nesta propriedade para gerar as tabelas.
9.2.3. Os repositórios
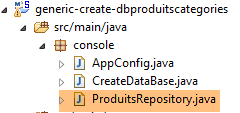 |
A interface [ProduitsRepository] é a seguinte:
package console;
import generic.jpa.entities.dbproduitscategories.Produit;
import org.springframework.data.repository.CrudRepository;
public interface ProduitsRepository extends CrudRepository<Produit, Long> {
}
É a sua instanciação que irá provocar a instanciação da camada JPA. Com efeito, na linha 7, a interface faz referência à entidade JPA [Produit], o que forçará a instanciação da camada JPA. Poderíamos ter colocado qualquer interface [CrudRepository] que fizesse referência a uma das entidades JPA. Verifica-se, de facto, que, embora o [repository] apenas faça referência à entidade JPA [Produit], são geradas todas as tabelas de todas as entidades JPA.
9.2.4. A classe executável
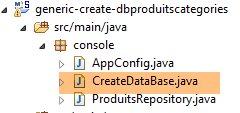 |
A classe [CreateDatabase] é a seguinte:
package console;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
public class CreateDataBase {
public static void main(String[] args) {
// basta instanciar o contexto Spring para criar as tabelas da base de dados [dbproduitscategories]
// é também necessário, pelo menos, um Spring Data Repository; caso contrário, nada acontece
System.out.println("Travail en cours...");
new AnnotationConfigApplicationContext(AppConfig.class).close();
System.out.println("Travail terminé...");
}
}
- linha 11: instanciamos o contexto Spring para o encerrar imediatamente. Neste contexto, existe o bean [ProduitsRepository] que faz referência às entidades JPA e [Produit]. Isto é suficiente para instanciar a camada JPA e, consequentemente, gerar as tabelas da base de dados [dbproduitscategories].
9.2.5. Geração das tabelas com EclipseLink
Estamos na seguinte configuração:
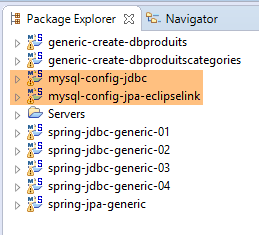 |
- a camada [JDBC] está configurada para a base de dados [dbproduitscategories] de MySQL;
- a camada [JPA] está implementada com EclipseLink;
- a base de dados [dbproduitscategories] não tem tabelas;
Nota: prima Alt-F5 e regenera todos os projetos Maven;
Utiliza-se a seguinte configuração de execução:
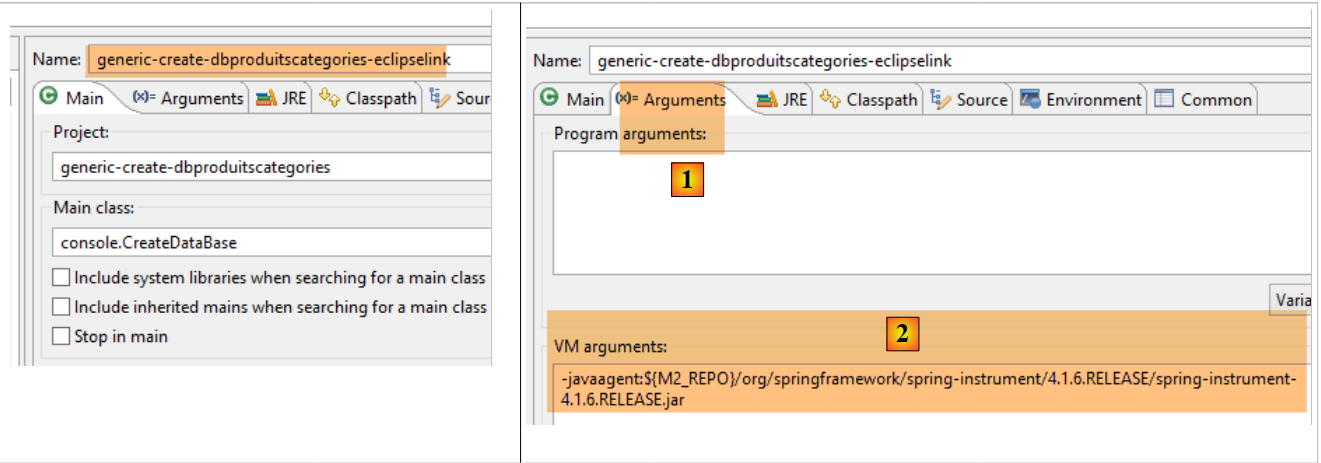 |
- no [1-2], esta configuração de execução requer um agente Java para que o teste seja bem-sucedido. Dependendo do caso, o EclipseLink nem sempre necessita deste agente, mas, neste caso, a execução falha se ele não estiver presente. Este agente não é um agente EclipseLink, mas sim um agente Spring. É fornecido pela dependência:
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-instrument</artifactId>
<scope>runtime</scope>
</dependency>
registada no ficheiro [pom.xml] do projeto. O agente encontra-se em [<m2-repo>/org/springframework/spring-instrument/4.1.6.RELEASE/spring-instrument-4.1.6.RELEASE.jar], onde <m2-repo> é o repositório local do Maven;
A execução produz o seguinte resultado:
 |
No ficheiro [3], verifica-se que as tabelas foram geradas. Agora, vamos verificar o ficheiro DDL (Domain Definition Language) da base de dados:
 | 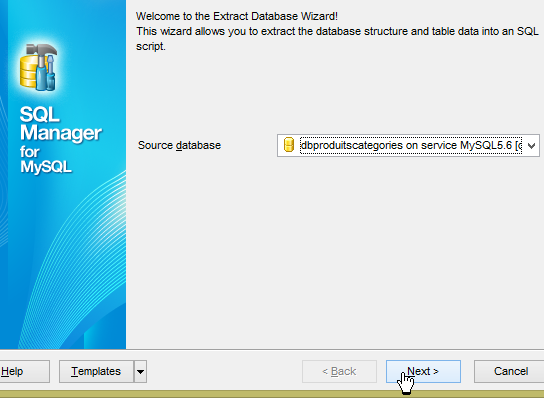 |
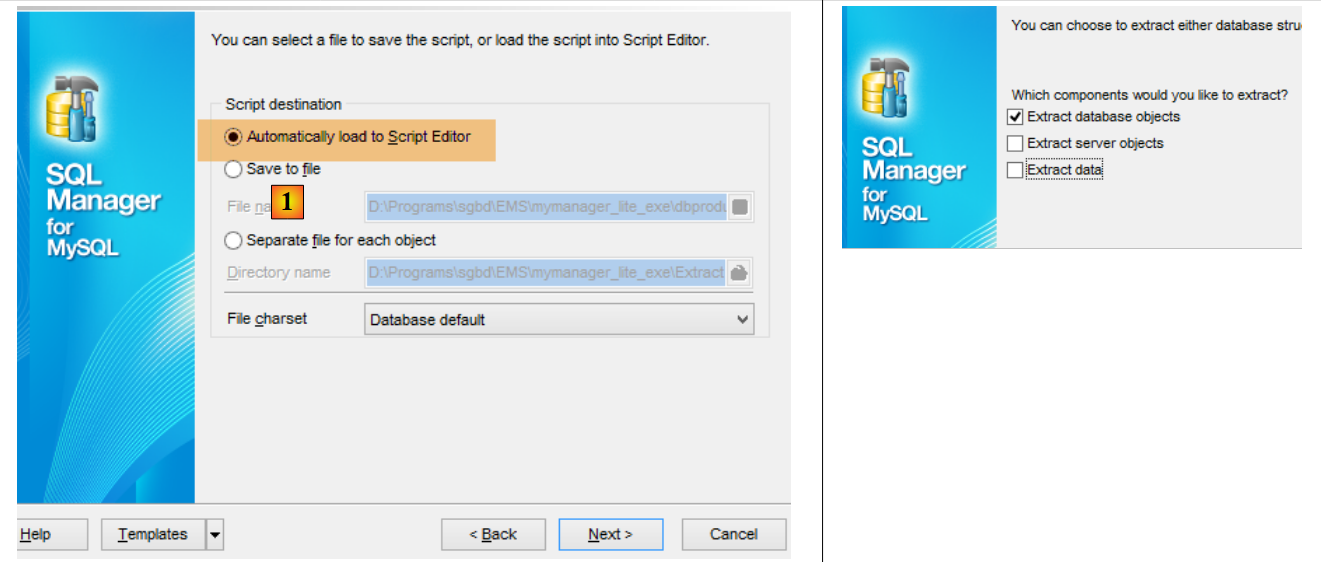 |
O script SQL de geração das tabelas também pode ser guardado num ficheiro [1].
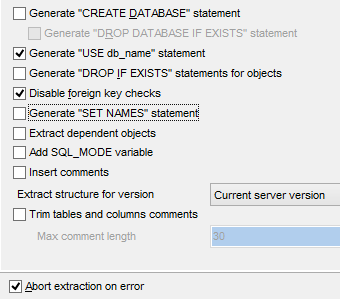 |  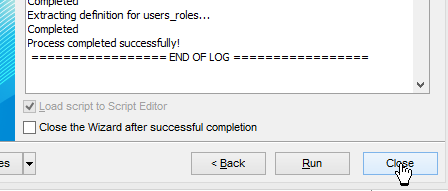 |
O script SQL gerado é o seguinte:
SET FOREIGN_KEY_CHECKS=0;
USE `dbproduitscategories`;
CREATE TABLE `categories` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `NOM` (`NOM`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `produits` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`DESCRIPTION` VARCHAR(100) COLLATE utf8_general_ci DEFAULT NULL,
`CATEGORIE_ID` BIGINT(20) NOT NULL,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PRIX` DOUBLE NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
`CATEGORIE` INTEGER(11) NOT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `NOM` (`NOM`) USING BTREE,
KEY `FK_PRODUITS_CATEGORIE_ID` (`CATEGORIE_ID`) USING BTREE,
CONSTRAINT `FK_PRODUITS_CATEGORIE_ID` FOREIGN KEY (`CATEGORIE_ID`) REFERENCES `categories` (`ID`) ON DELETE CASCADE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `roles` (
...
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `users` (
...
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `users_roles` (
...
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
Vejamos, por exemplo, o script SQL, que gera a tabela [PRODUITS] (linhas 15-29):
- linha 16: [ID] é a chave primária (linha 23) com o atributo [AUTO_INCREMENT] (linha 5). Isto corresponde às anotações [@Id, @GeneratedValue(strategy = GenerationType.IDENTITY), @Column(name = ConfigJdbc.TAB_JPA_ID)] do campo [id] da entidade JPA;
- linha 17: a definição da coluna [DESCRIPTION] corresponde à anotação [@Column(name = ConfigJdbc.TAB_PRODUITS_DESCRIPTION, length = 100)] do campo [description] da entidade JPA;
- linha 18: a coluna [CATEGORIE_ID] é uma chave estrangeira da tabela [PRODUITS] na coluna [CATEGORIES.ID] (linha 26). Além disso, esta chave estrangeira possui o atributo [ON DELETE CASCADE]. Isto corresponde às anotações [@ManyToOne(fetch = FetchType.LAZY), @JoinColumn(name = ConfigJdbc.TAB_PRODUITS_CATEGORIE_ID)] do campo [Produit.categorie] e à anotação [@OneToMany(fetch = FetchType.LAZY, mappedBy = "categorie", cascade = { CascadeType.ALL }), @CascadeOnDelete] do campo [Categorie.produits];
- linha 19: a definição da coluna [NOM] corresponde à anotação [@Column(name = ConfigJdbc.TAB_PRODUITS_NOM, unique = true, length = 30, nullable = false)] do campo [Produit.nom];
- linha 20: a definição da coluna [PRIX] corresponde à anotação [@Column(name = ConfigJdbc.TAB_PRODUITS_PRIX, nullable = false)] do campo [Produit.prix];
- linhas 24-25: o script cria três índices para cada uma das colunas únicas da tabela;
As tabelas geradas não têm um valor por defeito para o campo VERSIONING das tabelas, enquanto o código Java espera que exista um. Se este valor por defeito não estiver presente, alguns testes não são aprovados. Adiciona-se este atributo da seguinte forma:
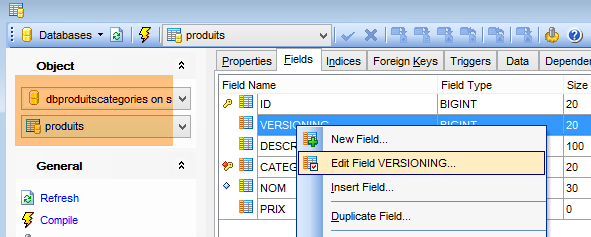 |
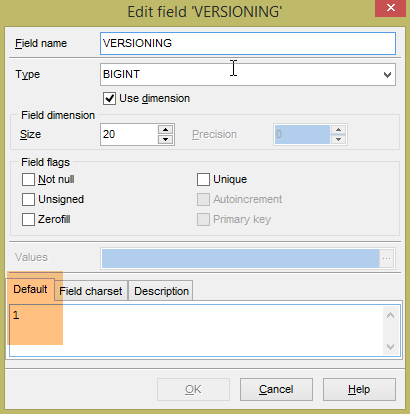 |
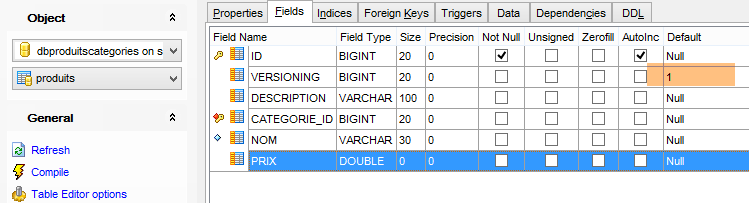 |
Faz-se isto para as cinco tabelas que têm a coluna [VERSIONING]. O valor por defeito não tem importância. Basta que exista. Em seguida, é incrementado em 1 a cada alteração da linha a que pertence.
Feito isto, verifique se as seguintes configurações de execução são bem-sucedidas:
- [spring-jdbc-generic-04.JUnitTestDao], que testa a implementação JDBC;
- [spring-jpa-generic-JUnitTestDao-hibernate-eclipselink], que testa as implementações JPA Hibernate ou Eclipselink (neste caso, será EclipseLink)
Ambas as execuções têm de ser bem-sucedidas.
9.2.6. Geração das tabelas com o Hibernate
Criamos as tabelas do Hibernate com o seguinte ambiente Eclipse:
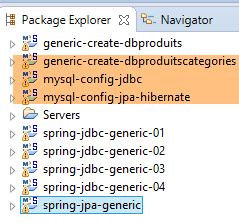 |
A geração das tabelas é efetuada pela configuração de execução denominada [generic-create-dbproduitscategories-hibernate], sem agente Java;
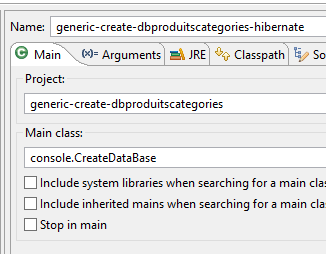 |  |
O script SQL da base de dados gerada pelo Hibernate é o seguinte:
SET FOREIGN_KEY_CHECKS=0;
USE `dbproduitscategories`;
CREATE TABLE `categories` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `UK_7ajcg7japnxw846ru01damg8s` (`NOM`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `produits` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`DESCRIPTION` VARCHAR(100) COLLATE utf8_general_ci DEFAULT NULL,
`CATEGORIE_ID` BIGINT(20) NOT NULL,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PRIX` DOUBLE NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `UK_hfvjn9lp7qoo5x79uu0ump3rf` (`NOM`) USING BTREE,
KEY `FK_p3foj9yrqnmi7856n9s8mbpue` (`CATEGORIE_ID`) USING BTREE,
CONSTRAINT `FK_p3foj9yrqnmi7856n9s8mbpue` FOREIGN KEY (`CATEGORIE_ID`) REFERENCES `categories` (`ID`)
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `roles` (
...
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `users` (
...
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `users_roles` (
...
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
As tabelas geradas são as mesmas, uma vez que o Hibernate também utilizou as anotações JPA. No caso do Hibernate, não encontrei o equivalente à anotação EclipseLink [@OnCascadeDelete] que gerou oatributo SQL [ON DELTE CASCADE] na chave estrangeira [PRODUITS.CATEGORIE_ID] (linha 25). Por isso, é necessário gerar este atributo manualmente, uma vez que é necessário para os testes:
 |
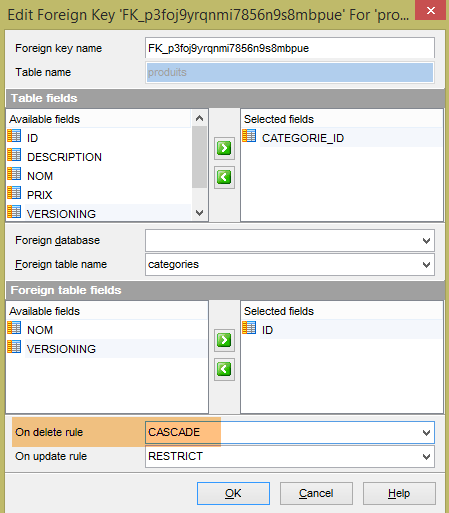 |
 |
É necessário fazer o mesmo com as duas chaves estrangeiras da tabela [USERS_ROLES]:
 |
Por fim, tal como foi feito com a implementação EclipseLink, as colunas [VERSIONING] das cinco tabelas devem ter um valor por defeito:
|
Feito isto, verifique se as seguintes configurações de execução são bem-sucedidas:
- [spring-jdbc-generic-04.JUnitTestDao], que testa a implementação JDBC;
- [spring-jpa-generic-JUnitTestDao-hibernate-eclipselink], que testa as implementações JPA do Hibernate ou do Eclipselink (neste caso, será o Hibernate)
Ambas as execuções devem ser bem-sucedidas.
9.2.7. Geração das tabelas com o OpenJpa
Repetimos o procedimento anterior com uma implementação JPA OpenJpa:
 |
Nota: premir Alt-F5 e regenerar todos os projetos Maven;
Alteramos a classe [ConfigJpa], que configura o projeto [mysql-config-jpa-openjpa], da seguinte forma:
package generic.jpa.config;
import generic.jdbc.config.ConfigJdbc;
import java.util.Map;
import javax.persistence.EntityManagerFactory;
import org.apache.tomcat.jdbc.pool.DataSource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.orm.jpa.JpaTransactionManager;
import org.springframework.orm.jpa.JpaVendorAdapter;
import org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean;
import org.springframework.orm.jpa.vendor.Database;
import org.springframework.orm.jpa.vendor.OpenJpaVendorAdapter;
import org.springframework.transaction.PlatformTransactionManager;
@Configuration
@Import({ ConfigJdbc.class })
public class ConfigJpa {
// o provedor JPA
@Bean
public JpaVendorAdapter jpaVendorAdapter() {
OpenJpaVendorAdapter openJpaVendorAdapter = new OpenJpaVendorAdapter();
openJpaVendorAdapter.setShowSql(false);
openJpaVendorAdapter.setDatabase(Database.MYSQL);
openJpaVendorAdapter.setGenerateDdl(true);
return openJpaVendorAdapter;
}
..
// EntityManagerFactory
@Bean
public EntityManagerFactory entityManagerFactory(JpaVendorAdapter jpaVendorAdapter, DataSource dataSource) {
LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();
factory.setJpaVendorAdapter(jpaVendorAdapter);
factory.setPackagesToScan(ENTITIES_PACKAGES);
Map<String, Object> mapJpaProperties = factory.getJpaPropertyMap();
mapJpaProperties.put("openjpa.jdbc.MappingDefaults",
"ForeignKeyDeleteAction=cascade,JoinForeignKeyDeleteAction=restrict");
factory.setDataSource(dataSource);
factory.afterPropertiesSet();
return factory.getObject();
}
}
- linhas 40-41: criamos uma propriedade para OpenJPA que indica a forma de gerar as chaves estrangeiras durante a geração das tabelas. Sem esta propriedade, as chaves estrangeiras não são geradas. O atributo [ForeignKeyDeleteAction=cascade] permite gerar o atributo [ON DELETE CASCADE] nessas chaves estrangeiras;
A geração das tabelas é efetuada pela configuração de execução denominada [generic-create-dbproduitscategories-openjpa], que possui dois agentes Java;
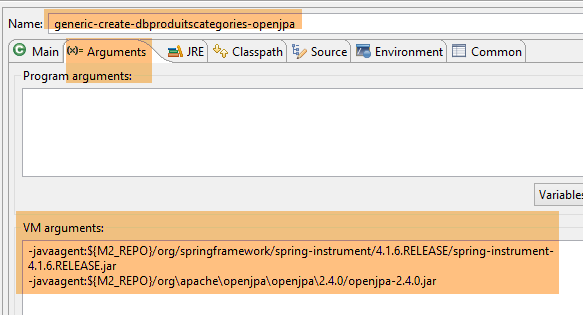
- o primeiro agente Java é o agente Spring já utilizado com o EclipseLink;
- o segundo agente Java é fornecido por OpenJpa;
O script SQL da base gerada é, então, o seguinte:
SET FOREIGN_KEY_CHECKS=0;
USE `dbproduitscategories`;
CREATE TABLE `categories` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `U_CTGORIS_NOM` (`NOM`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `produits` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`DESCRIPTION` VARCHAR(100) COLLATE utf8_general_ci DEFAULT NULL,
`CATEGORIE_ID` BIGINT(20) DEFAULT NULL,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PRIX` DOUBLE NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `U_PRODUTS_NOM` (`NOM`) USING BTREE,
KEY `CATEGORIE_ID` (`CATEGORIE_ID`) USING BTREE,
CONSTRAINT `produits_ibfk_1` FOREIGN KEY (`CATEGORIE_ID`) REFERENCES `categories` (`ID`) ON DELETE CASCADE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `roles` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`NAME` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `U_ROLES_NAME` (`NAME`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `users` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`LOGIN` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`NAME` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PASSWORD` VARCHAR(60) COLLATE utf8_general_ci NOT NULL,
`VERSIONING` BIGINT(20) DEFAULT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `U_USERS_LOGIN` (`LOGIN`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
CREATE TABLE `users_roles` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`VERSIONING` BIGINT(20) DEFAULT NULL,
`ROLE_ID` BIGINT(20) NOT NULL,
`USER_ID` BIGINT(20) NOT NULL,
PRIMARY KEY (`ID`) USING BTREE,
KEY `ROLE_ID` (`ROLE_ID`) USING BTREE,
KEY `USER_ID` (`USER_ID`) USING BTREE,
CONSTRAINT `users_roles_ibfk_2` FOREIGN KEY (`USER_ID`) REFERENCES `users` (`ID`) ON DELETE CASCADE,
CONSTRAINT `users_roles_ibfk_1` FOREIGN KEY (`ROLE_ID`) REFERENCES `roles` (`ID`) ON DELETE CASCADE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
É o mesmo que com o EclipseLink. Por isso, serão efetuadas as mesmas correções nas tabelas. Depois de fazer isso, verifique se as seguintes configurações de execução são bem-sucedidas:
- [spring-jdbc-generic-04.JUnitTestDao], que testa a implementação JDBC;
- [spring-jpa-generic-JUnitTestDao-openjpa], que testa uma implementação de JPA e OpenJpa;
Ambas as execuções devem ser bem-sucedidas.
9.3. Geração da base de dados [dbproduits]
A base [dbproduits] é utilizada pelos projetos [spring-jdbc-01 à 03]. Também é possível gerá-la a partir de uma entidade JPA.
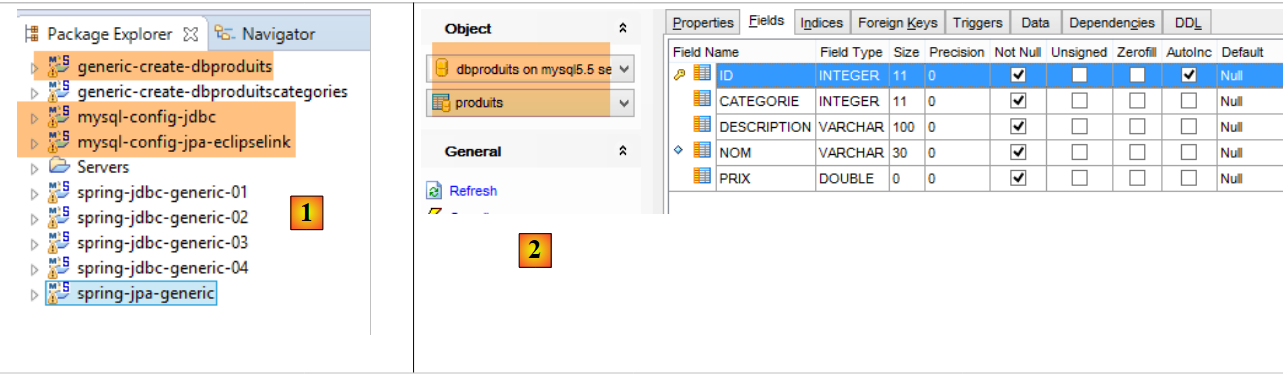 |
- em [1], os projetos Eclipse. Estaremos numa configuração MySQL / EclipseLink. O projeto de geração da base de dados [dbproduits] é o [generic-create-dbproduits];
- no [2], a tabela [PRODUITS] a gerar;
Nota: premir Alt-F5 e regenerar todos os projetos Maven;
9.3.1. Configuração do Maven
A configuração Maven do projeto [generic-create-dbproduits] é a seguinte:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-create-dbproduits</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>generic-create-dbproduits</name>
<description>création de la bases de données [dbproduits] à l'aide des annotations JPA</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
</parent>
<dependencies>
<!-- configuração JPA do SGBD -->
<dependency>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-config-jpa</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
</dependencies>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<start-class>spring.data.console.Main</start-class>
<java.version>1.7</java.version>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
</plugin>
</plugins>
</build>
</project>
Existe apenas uma dependência, nas linhas 22-26, no projeto que configura a camada JPA. No final, as dependências são as seguintes:
 |
9.3.2. A configuração do Spring
 |
A classe de configuração do Spring é a seguinte:
package console;
import generic.jdbc.config.ConfigJdbc;
import generic.jpa.config.ConfigJpa;
import javax.persistence.EntityManagerFactory;
import org.apache.tomcat.jdbc.pool.DataSource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
import org.springframework.orm.jpa.JpaVendorAdapter;
import org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean;
@EnableJpaRepositories(basePackages = { "console" })
@Configuration
@Import({ ConfigJpa.class })
public class AppConfig {
// fonte de dados
@Bean
public DataSource dataSource() {
// fonte de dados TomcatJdbc
DataSource dataSource = new DataSource();
// configuração de acesso JDBC
dataSource.setDriverClassName(ConfigJdbc.DRIVER_CLASSNAME);
dataSource.setUsername(ConfigJdbc.USER_DBPRODUITS);
dataSource.setPassword(ConfigJdbc.PASSWD_DBPRODUITS);
dataSource.setUrl(ConfigJdbc.URL_DBPRODUITS);
// ligações inicialmente abertas
dataSource.setInitialSize(5);
// resultado
return dataSource;
}
// EntityManagerFactory
@Bean
public EntityManagerFactory entityManagerFactory(JpaVendorAdapter jpaVendorAdapter, DataSource dataSource) {
LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();
factory.setJpaVendorAdapter(jpaVendorAdapter);
factory.setPersistenceUnitName("generic-jpa-entities-dbproduits");
factory.setDataSource(dataSource);
factory.afterPropertiesSet();
return factory.getObject();
}
}
- linha 18: importam-se os beans da classe [ConfigJpa] (parágrafo 7.3);
- linhas 22-35: redefine-se a fonte de dados [dataSource]. Na classe [ConfigJpa], a fonte de dados é a base de dados [dbproduitscategories]. Aqui, será a base de dados [dbproduits];
- linhas 38-46: redefine-se o bean [entityManagerFactory] da classe [ConfigJpa]. Nesta classe, as entidades JPA eram [Produit, Categorie]. Aqui, é apenas [Produit] e não tem a mesma definição que no projeto que configura a camada JPA;
- linha 42: para definir esta nova entidade JPA, faz-se referência às entidades JPA definidas no ficheiro [META-INF/persistence.xml]:
 |
O ficheiro [persistence.xml] é o seguinte:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd">
<persistence-unit name="generic-jpa-entities-dbproduits" transaction-type="RESOURCE_LOCAL">
<!-- entidades JPA -->
<class>generic.jpa.entities.dbproduits.Produit</class>
<exclude-unlisted-classes>true</exclude-unlisted-classes>
</persistence-unit>
</persistence>
- linha 6: a única entidade JPA;
- linha 4: o nome da unidade de persistência [generic-jpa-entities-dbproduits], que é referenciada no bean [entityManagerFactory];
9.3.3. A entidade JPA [Produit]
 |
A entidade JPA está definida no projeto [mysql-config-jpa-eclipselink] da seguinte forma:
package generic.jpa.entities.dbproduits;
import generic.jdbc.config.ConfigJdbc;
import javax.persistence.Column;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
import javax.persistence.Table;
@Entity(name="Produit1")
@Table(name = ConfigJdbc.TAB_PRODUITS)
public class Produit {
// campos
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = ConfigJdbc.TAB_PRODUITS_ID)
private int id;
@Column(name = ConfigJdbc.TAB_PRODUITS_NOM, unique = true, length = 30, nullable = false)
private String nom;
@Column(name = ConfigJdbc.TAB_PRODUITS_CATEGORIE, nullable = false)
private int categorie;
@Column(name = ConfigJdbc.TAB_PRODUITS_PRIX, nullable = false)
private double prix;
@Column(name = ConfigJdbc.TAB_PRODUITS_DESCRIPTION, length = 100, nullable = false)
private String description;
// construtores
public Produit() {
}
public Produit(int id, String nom, int categorie, double prix, String description) {
this.id = id;
this.nom = nom;
this.categorie = categorie;
this.prix = prix;
this.description = description;
}
// getters e setters
...
}
Trata-se de uma definição JPA que já se tornou clássica. Basta referir os seguintes pontos:
- linha 12: foi atribuído o nome [Produit1] à entidade. Por predefinição, o nome de uma entidade é o nome da classe, neste caso [Produit]. No entanto, como existe outra entidade JPA [Produit] no mesmo projeto, foi sinalizado um erro antes mesmo de qualquer execução. Resolvemos o problema desta forma;
- linha 24: a categoria é, neste caso, um simples número;
- não existem relações entre entidades. Temos, portanto, uma situação muito simples;
9.3.4. A classe executável
 |
A classe [CreateDatabase] é a seguinte:
package console;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
public class CreateDataBase {
public static void main(String[] args) {
// basta instanciar o contexto Spring para criar as tabelas da base de dados [dbproduits]
// é também necessário, pelo menos, um Spring Data Repository; caso contrário, nada acontece
System.out.println("Travail en cours...");
new AnnotationConfigApplicationContext(AppConfig.class).close();
System.out.println("Travail terminé...");
}
}
Este é um código com o qual já nos deparámos.
9.3.5. Geração de EclipseLink
A tabela [PRODUITS] é criada com a seguinte configuração de execução:
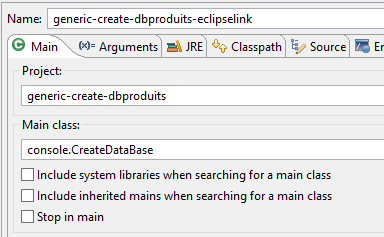 | 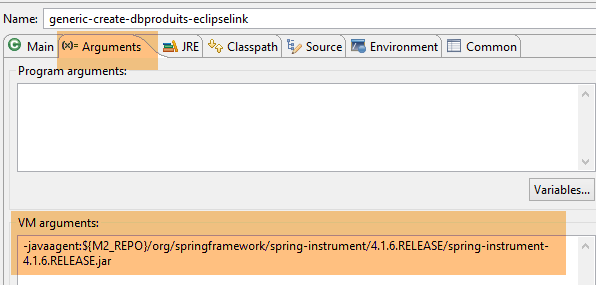 |
Os registos da consola são os seguintes:
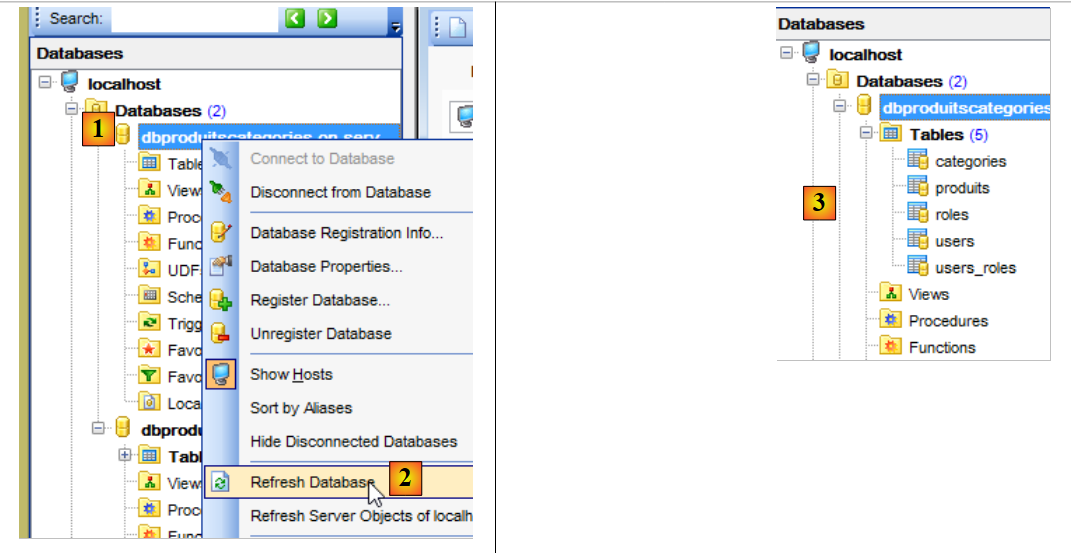
Agora, voltemos ao cliente [MyManager] e atualizemos a visualização [1-2]:
 |
Em [3], vemos que foi gerada uma tabela. Agora, vamos verificar a DDL (Domain Definition Language) da base de dados:
SET FOREIGN_KEY_CHECKS=0;
USE `dbproduits`;
CREATE TABLE `produits` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`CATEGORIE` INTEGER(11) NOT NULL,
`DESCRIPTION` VARCHAR(100) COLLATE utf8_general_ci NOT NULL,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PRIX` DOUBLE NOT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `NOM` (`NOM`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
Obtenemos, de facto, a tabela esperada. Para verificar isso, executaremos a seguinte configuração:
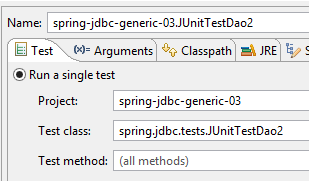 | 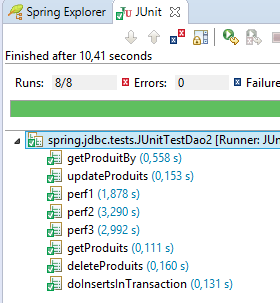 |
A execução deve ser bem-sucedida.
9.3.6. Geração do Hibernate
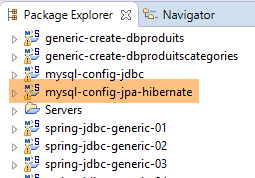 | 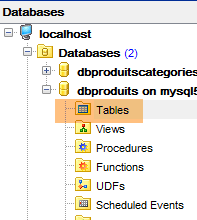 |
Nota: prima Alt-F5 e regenera todos os projetos Maven;
A configuração de execução é a seguinte:
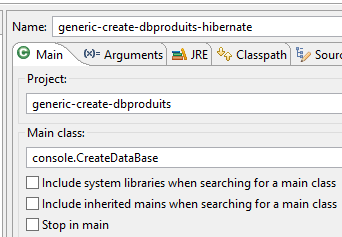 |  |
O script SQL gerado pelo Hibernate é o seguinte:
USE `dbproduits`;
CREATE TABLE `produits` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`CATEGORIE` INTEGER(11) NOT NULL,
`DESCRIPTION` VARCHAR(100) COLLATE utf8_general_ci NOT NULL,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PRIX` DOUBLE NOT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `UK_hfvjn9lp7qoo5x79uu0ump3rf` (`NOM`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;
9.3.7. Geração de OpenJpa
 | |
Nota: prima Alt-F5 e gere novamente todos os projetos Maven;
A configuração de execução é a seguinte:
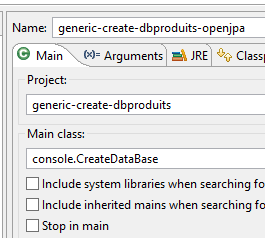 | 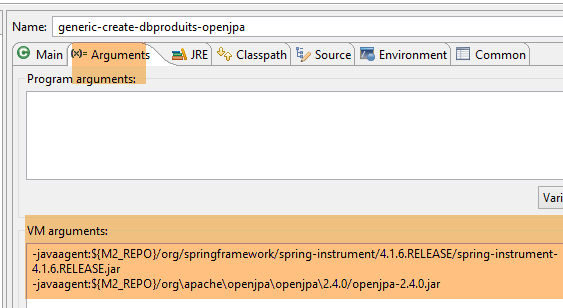 |
O script SQL gerado pelo OpenJpa é o seguinte:
USE `dbproduits`;
CREATE TABLE `produits` (
`ID` BIGINT(20) NOT NULL AUTO_INCREMENT,
`CATEGORIE` INTEGER(11) NOT NULL,
`DESCRIPTION` VARCHAR(100) COLLATE utf8_general_ci NOT NULL,
`NOM` VARCHAR(30) COLLATE utf8_general_ci NOT NULL,
`PRIX` DOUBLE NOT NULL,
PRIMARY KEY (`ID`) USING BTREE,
UNIQUE KEY `U_PRODUTS_NOM` (`NOM`) USING BTREE
) ENGINE=InnoDB
AUTO_INCREMENT=1 CHARACTER SET 'utf8' COLLATE 'utf8_general_ci'
;