13. SQL Server 2014
Passamos agora à migração para o SQL Server 2014 do que foi feito com o MySQL.
 |
13.1. Configuração do ambiente de trabalho
13.1.1. Ambiente Eclipse
Iremos trabalhar com o seguinte ambiente Eclipse:
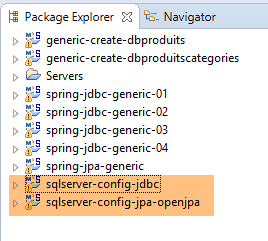 |
Os projetos SQL Server acima referidos encontram-se na pasta [<exemples>/spring-database-config\sqlserver\eclipse].
Nota: execute o comando [Alt-F5] para regenerar todos os projetos Maven.
13.1.2. Geração das bases de dados
Tal como foi feito com o Oracle e o DB2, teremos de instalar o controlador JDBC do SQL Server no repositório Maven local.
O ficheiro [install.bat] contém o seguinte código:
"%M2_HOME%\bin\mvn.bat" install:install-file -Dfile=sqljdbc4-3.0.jar -Dpackaging=jar -DgroupId=com.microsoft.sqlserver -DartifactId=sqljdbc4 -Dversion=4.0
onde [%M2-HOME%] é a pasta de instalação do Maven (ver parágrafo 23.2, página 466). Após esta instalação, o controlador JDBC do SQL Server pode ser referenciado nos ficheiros [pom.xml] através da seguinte dependência:
<dependency>
<groupId>com.microsoft.sqlserver</groupId>
<artifactId>sqljdbc4</artifactId>
<version>4.0</version>
</dependency>
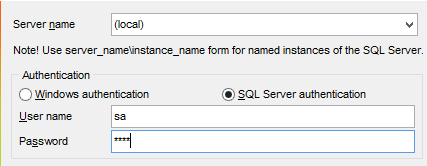
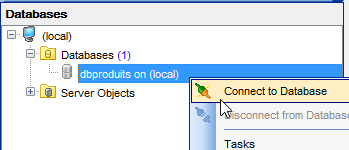
A partir daqui, a ligação às bases de dados SQL e SERVER é efetuada com as credenciais [sa / msde]. Inicie o servidor SQL e o seu cliente [MsManager] (ver parágrafo 23.9).
 |  |
 |  |
 |  |
 |  |
 |  |
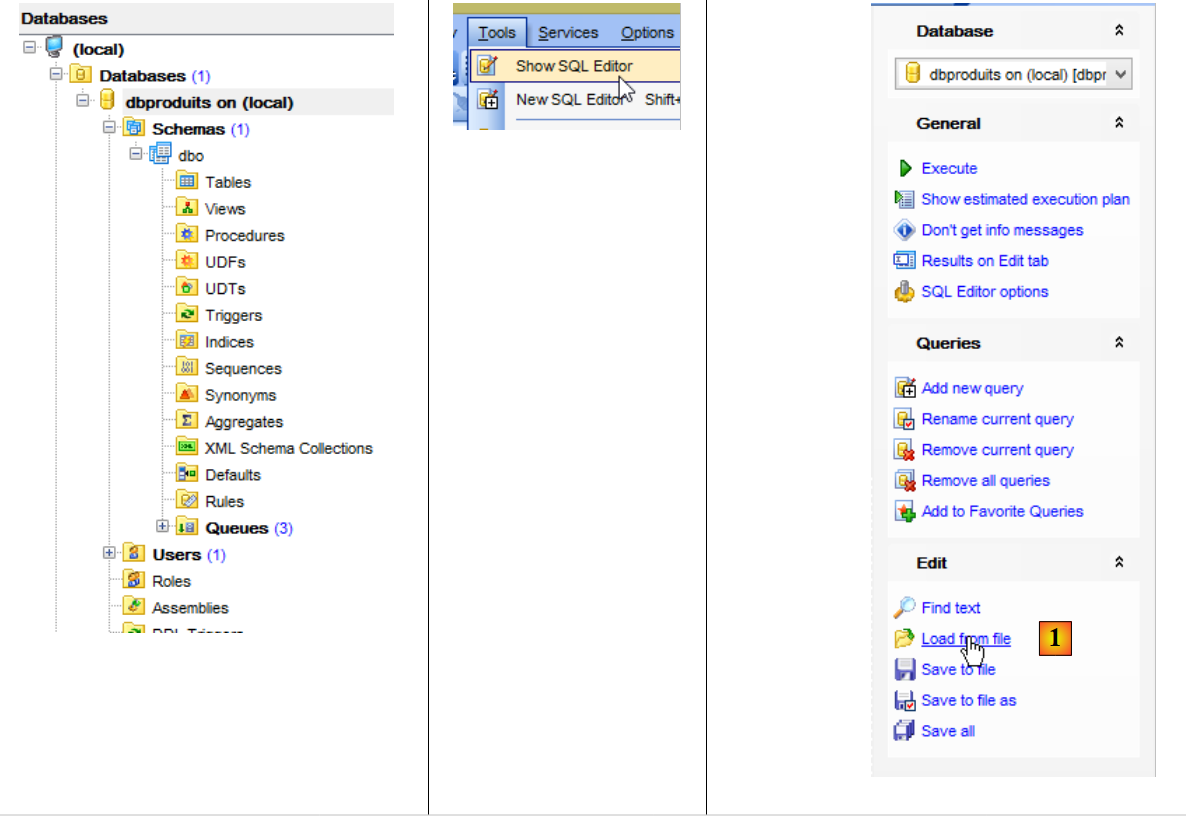 |
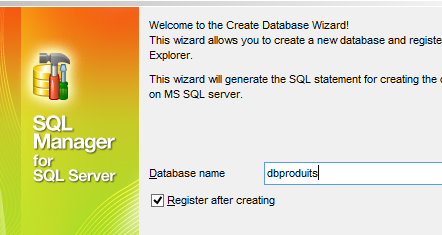
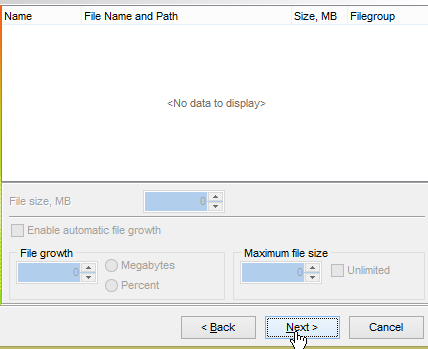
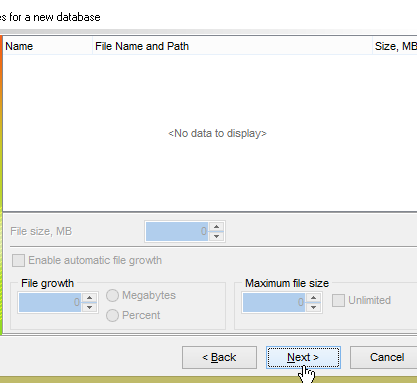
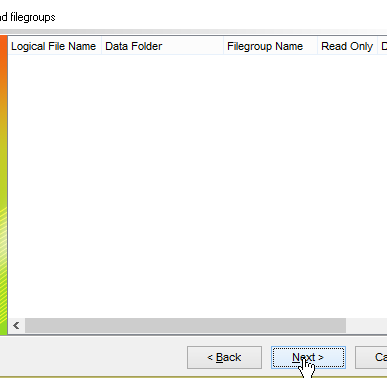
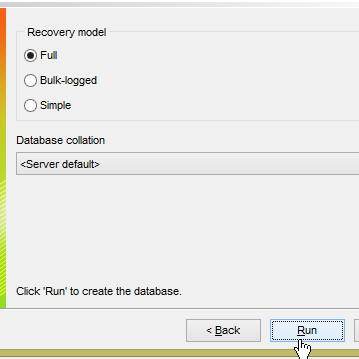
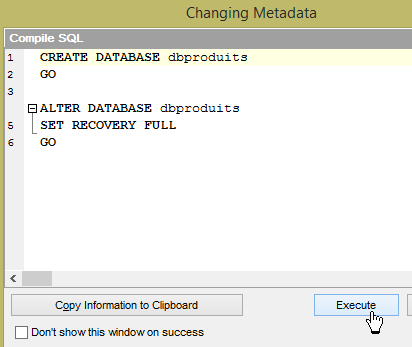
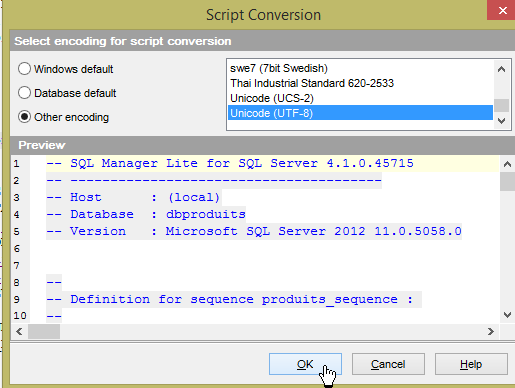
- em [1], carregue o script SQL [<exemples>\spring-database-config\sqlserver\databases\dbproduits.sql];
 |  |
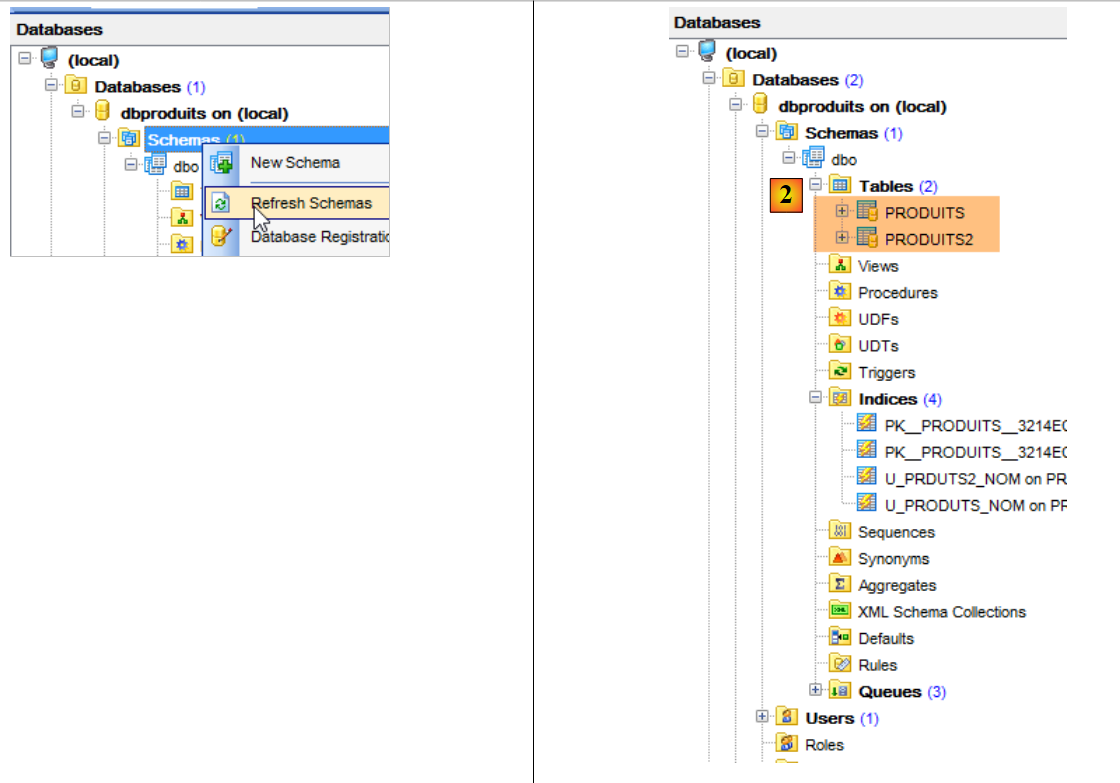 |
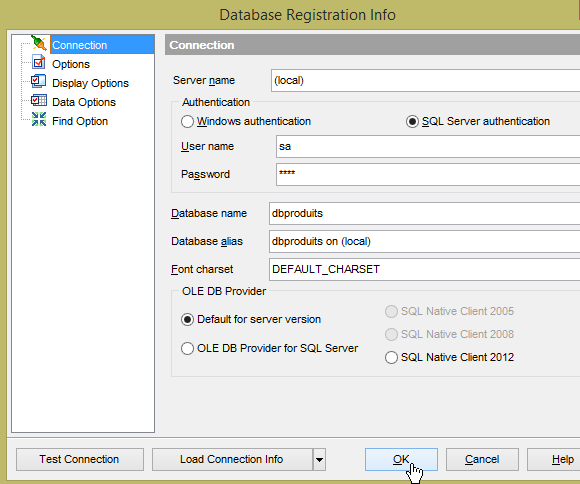
- no [2], não foi possível utilizar a mesma tabela [PRODUITS] para os projetos [spring-jdbc-01 à 03]. A razão para tal é que:
- os projetos [spring-jdbc-01 et 02] inserem linhas com as suas chaves primárias;
- o projeto [spring-jdbc-03] insere linhas sem chaves primárias e espera que o SGBD as gere. Para tal, é necessário que a chave primária [ID] seja do tipo [Identity]. No entanto, este tipo no SQL Server suporta apenas a geração automática de chaves primárias e não permite a inserção de uma linha com uma chave primária definida pelo utilizador. É então sinalizado um erro e não consegui contorná-lo. Os projetos [spring-jdbc-01 et 02] utilizam a tabela [PRODUITS] sem geração automática de chaves primárias. O projeto [spring-jdbc-03] utiliza a tabela [PRODUITS2] com geração automática de chaves primárias.
Agora, execute as configurações:
- [spring-jdbc-generic-01.IntroJdbc01];
- [spring-jdbc-generic-01.IntroJdbc02];
- [spring-jdbc-generic-03.JUnitTestDao1];
- [spring-jdbc-generic-03.JUnitTestDao2];
Todas elas devem ser bem-sucedidas.
Vamos agora gerar a base [dbproduitscategories]. Repita para [dbproduitscategories] o procedimento seguido para criar [dbproduits]. O script SQL a carregar encontra-se na localização [<exemples>\spring-database-config\sqlserver\databases\ dbproduitscategories.sql];
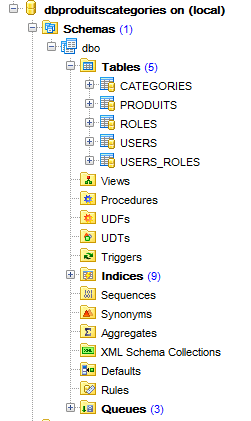 |
Agora, execute as configurações:
- [spring-jdbc-generic-04.JUnitTestDao];
- [spring-jpa-generic-JUnitTestDao-openjpa];
Ambas devem ser bem-sucedidas.
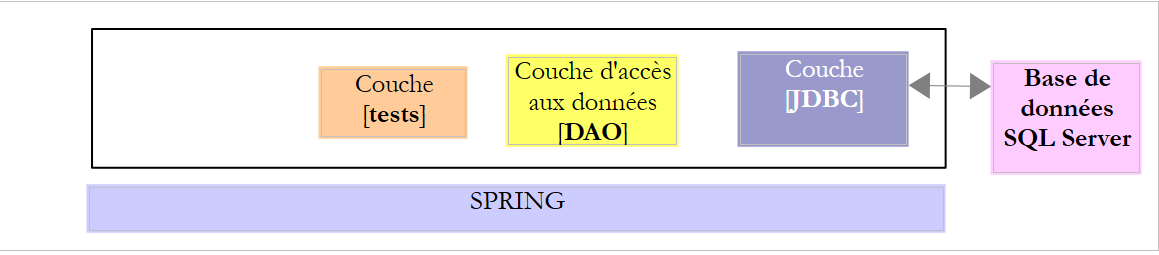
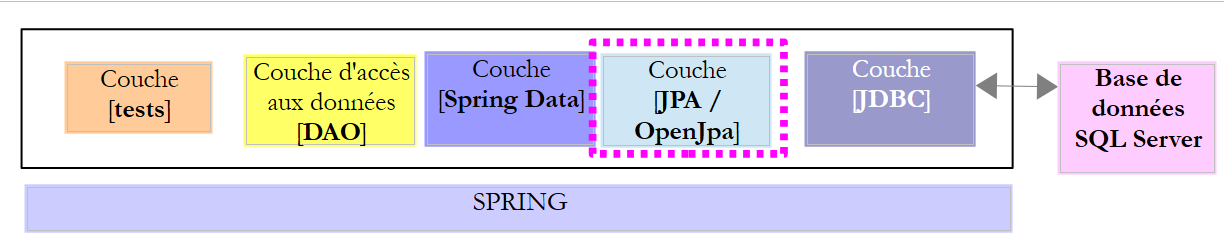
13.2. Configuração da camada JDBC
 | 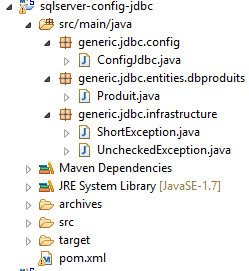 |
O projeto [sqlserver-config-jdbc] configura a camada [JDBC] da seguinte arquitetura de testes:
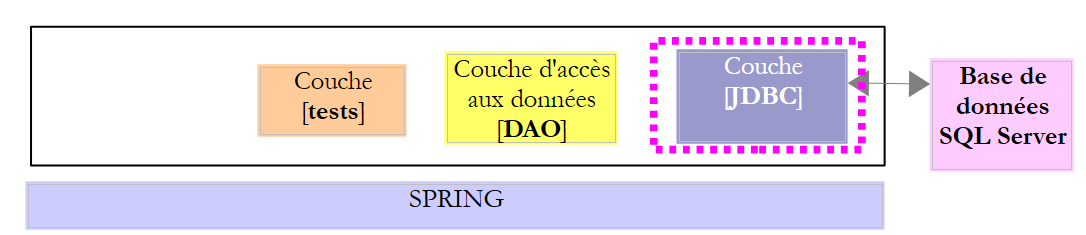 |
O projeto é análogo ao projeto de configuração [mysql-config-jdbc] da camada JDBC do SGBD MySQL (ver parágrafo 3.3). Apresentamos apenas as alterações:
O ficheiro [pom.xml] importa o controlador JDBC do servidor SQL:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-config-jdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>configuration generic jdbc</name>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
</parent>
<dependencies>
<!-- dependências variáveis ********************************************** -->
<!-- controlador JDBC do SGBD -->
<dependency>
<groupId>com.microsoft.sqlserver</groupId>
<artifactId>sqljdbc4</artifactId>
<version>4.0</version>
</dependency>
<!-- dependências constantes ********************************************** -->
...
</dependencies>
...
</project>
- linhas 18-22: o controlador JDBC do servidor SQL;
A segunda alteração encontra-se na classe [ConfigJdbc], que define os identificadores de acesso às bases de dados:
// parâmetros de ligação
public final static String DRIVER_CLASSNAME = "com.microsoft.sqlserver.jdbc.SQLServerDriver";
public final static String URL_DBPRODUITS = "jdbc:sqlserver://localhost\\SQLEXPRESS:1433;databaseName=dbproduits";
public final static String USER_DBPRODUITS = "sa";
public final static String PASSWD_DBPRODUITS = "msde";
public final static String URL_DBPRODUITSCATEGORIES = "jdbc:sqlserver://localhost\\SQLEXPRESS:1433;databaseName=dbproduitscategories";
public final static String USER_DBPRODUITSCATEGORIES = "sa";
public final static String PASSWD_DBPRODUITSCATEGORIES = "msde";
A terceira alteração que pode ser efetuada diz respeito ao número máximo de parâmetros que um [PreparedStatement] pode suportar:
// número máximo de parâmetros de um [PreparedStatement]
public final static int MAX_PREPAREDSTATEMENT_PARAMETERS = 2000;
O teste [JUnitTestPushTheLimits] gera ordens SQL para 5000 produtos, que, por sua vez, irão gerar [PreparedStatement] com 5000 parâmetros. O MySQL suportava este valor. O servidor SQL emitiu um erro indicando que esse limite era de 2100.
A quarta alteração diz respeito à tabela utilizada pelo projeto [spring-jdbc-03]. Já não é o [PRODUITS], mas sim o [PRODUITS2]:
// ordens SQL [jdbc-03]
public final static String V2_INSERT_PRODUITS = "INSERT INTO PRODUITS2(NOM, CATEGORIE, PRIX, DESCRIPTION) VALUES (?, ?, ?, ?)";
public final static String V2_DELETE_ALLPRODUITS = "DELETE FROM PRODUITS2";
public final static String V2_DELETE_PRODUITS = "DELETE FROM PRODUITS2 WHERE ID=?";
public final static String V2_SELECT_ALLPRODUITS = "SELECT ID, NOM, CATEGORIE, PRIX, DESCRIPTION FROM PRODUITS2";
public final static String V2_SELECT_PRODUIT_BYID = "SELECT NOM, CATEGORIE, PRIX, DESCRIPTION FROM PRODUITS2 WHERE ID=?";
public final static String V2_SELECT_PRODUIT_BYNAME = "SELECT ID, CATEGORIE, PRIX, DESCRIPTION FROM PRODUITS2 WHERE NOM=?";
public final static String V2_UPDATE_PRODUITS = "UPDATE PRODUITS2 SET NOM=?, PRIX=?, CATEGORIE=?, DESCRIPTION=? WHERE ID=?";
13.3. Configuração da camada JPA OpenJpa
 | 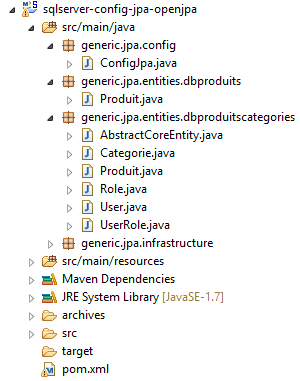 |
O projeto [sqlserver-config-jpa-openjpa] configura a camada [JPA] da arquitetura de testes:
 |
O projeto é análogo ao projeto de configuração [mysql-config-jpa-openjpa] da camada JPA OpenJpa do SGBD MySQL (ver parágrafo 8.3). Com efeito, ambos os SGBD utilizam a anotação [@GeneratedValue(strategy = GenerationType.IDENTITY)] para gerar as chaves primárias. Há duas alterações a efetuar. Encontram-se na definição do bean [jpaVendorAdapter] da classe [ConfigJpa]:
// o provedor JPA
@Bean
public JpaVendorAdapter jpaVendorAdapter() {
OpenJpaVendorAdapter openJpaVendorAdapter = new OpenJpaVendorAdapter();
openJpaVendorAdapter.setShowSql(false);
openJpaVendorAdapter.setDatabase(Database.SQL_SERVER);
openJpaVendorAdapter.setGenerateDdl(true);
return openJpaVendorAdapter;
}
- linha 6: indica-se à implementação JPA que irá trabalhar com uma base de dados SQL Server. A implementação JPA irá então adotar tanto os tipos de dados proprietários como o SQL proprietário deste SGBD.
A segunda alteração diz respeito às entidades JPA associadas às tabelas [PRODUITS] e [PRODUITS2]:
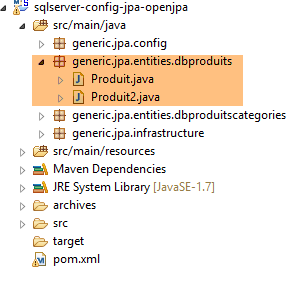 |
A entidade [Produit] está associada à tabela [PRODUITS] sem geração automática de chaves primárias (ausência da notação [@GeneratedValue]):
@Entity(name = "Produit1")
@Table(name = ConfigJdbc.TAB_PRODUITS)
public class Produit {
// campos
@Id
@Column(name = ConfigJdbc.TAB_PRODUITS_ID)
private Long id;
A entidade [Produit2] está associada à tabela [PRODUITS2] com geração automática de chaves primárias:
@Entity(name = "Produit2")
@Table(name = ConfigJdbc.TAB_PRODUITS2)
public class Produit2 {
// campos
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = ConfigJdbc.TAB_PRODUITS_ID)
private Long id;
Além disso, o projeto que gera a base de dados [dbproduits] deve ser alterado para indicar que existem agora duas entidades JPA na base de dados:
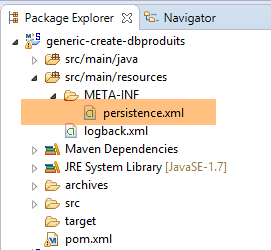 |
O ficheiro [persistence.xml] sofre as seguintes alterações:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd">
<persistence-unit name="generic-jpa-entities-dbproduits" transaction-type="RESOURCE_LOCAL">
<!-- entidades JPA -->
<class>generic.jpa.entities.dbproduits.Produit</class>
<class>generic.jpa.entities.dbproduits.Produit2</class>
<exclude-unlisted-classes>true</exclude-unlisted-classes>
</persistence-unit>
</persistence>
O projeto [generic-create-dbproduits] é comum a todos os SGBD. A camada JPA dos projetos analisados anteriormente não continha a entidade [Produit2]. Pode-se então questionar se o facto de referenciar uma entidade JPA inexistente não irá causar uma falha no projeto para esses SGBD. Os testes demonstram que não.
Após estas alterações, a execução da configuração [spring-jpa-generic-JUnitTestDao-openjpa] deverá ser bem-sucedida.
 |  |
13.4. Configuração da camada JPA do Hibernate
 |  |
Nota: execute o comando [Alt-F5] para regenerar todos os projetos Maven.
O projeto [sqlserver-config-jpa-hibernate] é análogo ao projeto [mysql-config-jpa-hibernate] (parágrafo 6.3), com as mesmas alterações que estiveram na base da migração do [mysql-config-jpa-openjpa] para o projeto [sqlserver-config-jpa-openjpa] (parágrafo 8.3).
Após estas alterações, a execução da configuração [spring-jpa-generic-JUnitTestDao-hibernate-eclipselink] deverá ser bem-sucedida.
13.5. Configuração da camada JPA EclipseLink
 |  |
Nota: execute o [Alt-F5] para regenerar todos os projetos Maven.
O projeto [sqlserver-config-jpa-eclipselink] é análogo ao projeto [mysql-config-jpa-eclipselink] (parágrafo 7.3) com as mesmas alterações que estiveram na base da migração do [mysql-config-jpa-openjpa] para o projeto [sqlserver-config-jpa-openjpa] (parágrafo 8.3).
Após estas alterações, a execução da configuração [spring-jpa-generic-JUnitTestDao-hibernate-eclipselink] deverá ser bem-sucedida.