5. Introdução ao Spring Data JPA
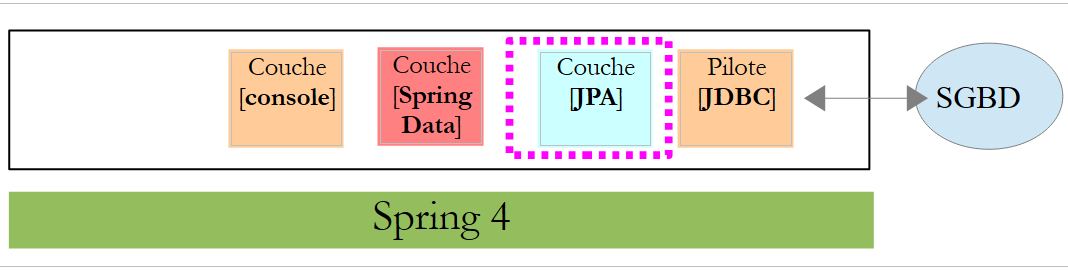
Neste capítulo, vamos estudar a seguinte arquitetura:
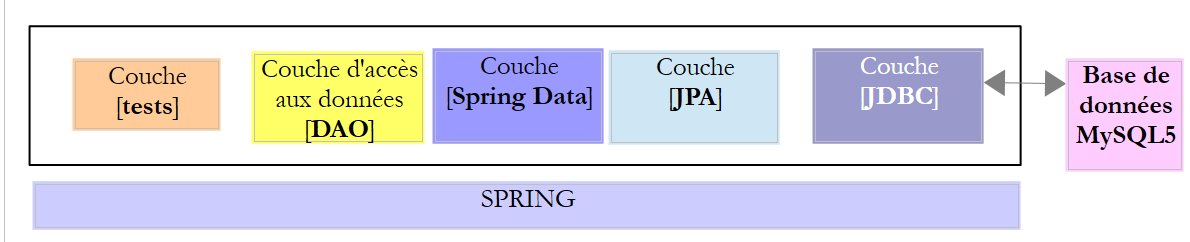 |
Inserimos uma camada [JPA] (Java Persistence API) entre a camada [DAO] e o controlador JDBC do SGBD. Agora, é a camada JPA que emite as ordens SQL destinadas ao SGBD. A camada [DAO] já não processa ordens SQL, mas apenas objetos denominados entidades JPA, que são representações das diferentes tabelas da base de dados utilizada. Os campos destas entidades estão associados de forma única às colunas das tabelas através de anotações Java. É isso que permite à camada JPA traduzir para SQL as operações da camada [DAO] realizadas nas entidades JPA.
O Spring Data é um ramo do Spring dedicado ao acesso a dados, quer estes se encontrem numa base de dados relacional SGBDR, numa base NOSQL ou noutros tipos de repositórios. Aqui, estamos interessados apenas nos SGBDR e no seu acesso através do JPA. Posteriormente, por vezes escreveremos [Spring JPA] para nos referirmos, na verdade, ao [Spring Data JPA]. Na arquitetura acima, a camada [Spring Data] fornece funcionalidades à camada [DAO] para gerir as entidades JPA.
JPA é, na verdade, uma especificação. Iremos testar três das suas implementações:
- Hibernate (http://hibernate.org/);
- EclipseLink (http://www.eclipse.org/eclipselink/);
- OpenJpa (http://openjpa.apache.org/);
5.1. Exemple-01
No site do Spring existem vários tutoriais para dar os primeiros passos com o Spring [http://spring.io/guides]. Vamos utilizar um deles para apresentar o Spring Data. Para tal, utilizamos o Spring Tool Suite (STS).
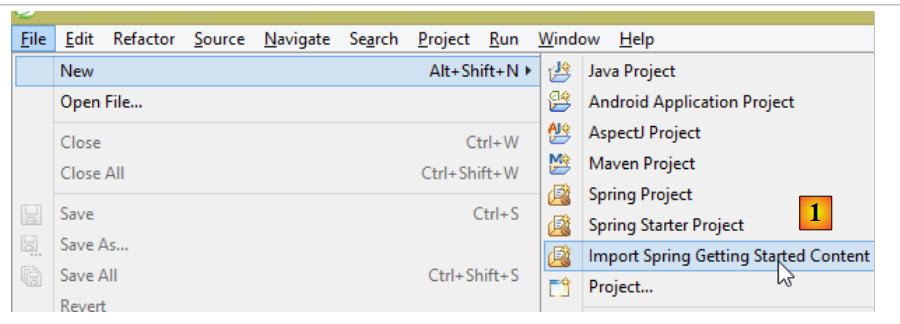 |
- em [1], importamos um dos tutoriais de [spring.io/guides];
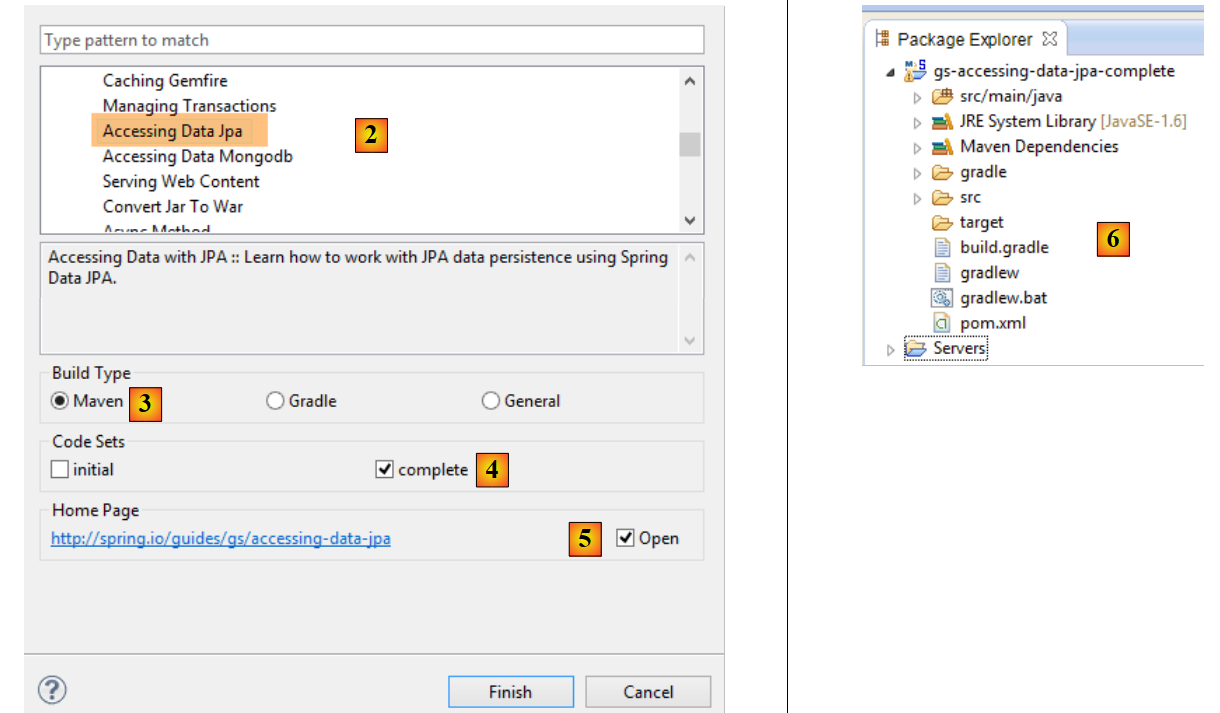 |
- em [2], selecionamos o tutorial [Accessing Data Jpa], que mostra como aceder a uma base de dados com o Spring Data;
- em [3], escolhe-se um projeto configurado pelo Maven;
- em [4], o tutorial pode ser apresentado de duas formas: [initial], que é uma versão em branco que se preenche seguindo o tutorial, ou [complete], que é a versão final do tutorial. Escolhemos esta última;
- em [5], é possível optar por visualizar o tutorial num navegador;
- em [6], o projeto final.
5.1.1. A configuração Maven do projeto
As dependências Maven do projeto estão configuradas no ficheiro [pom.xml]:
<groupId>org.springframework</groupId>
<artifactId>gs-accessing-data-jpa</artifactId>
<version>0.1.0</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
</dependencies>
<properties>
<!-- utilizar UTF-8 para tudo -->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<start-class>hello.Application</start-class>
</properties>
- linhas 5-9: definem um projeto pai do Maven. É este que define a maior parte das dependências do projeto. Estas podem ser suficientes, caso em que não se adicionam mais, ou não, caso em que se adicionam as dependências em falta;
- linhas 12-15: definem uma dependência do [spring-boot-starter-data-jpa]. Este artefacto contém as classes do Spring Data;
- linhas 16-19: definem uma dependência do SGBD e do H2, que permitem criar e gerir bases de dados em memória.
Vejamos as classes fornecidas por estas dependências:
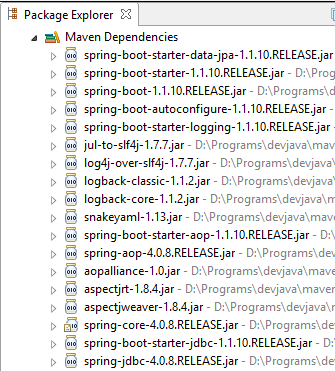 | 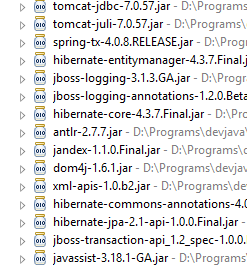 | 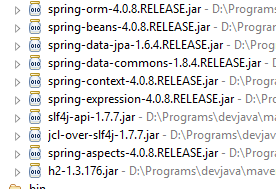 |
São em grande número:
- algumas pertencem ao ecossistema Spring (as que começam por «spring»);
- outras pertencem ao ecossistema Hibernate (hibernate, jboss), cuja implementação JPA é aqui utilizada;
- outras são bibliotecas de testes (junit, hamcrest);
- outras são bibliotecas de registos (log4j, logback, slf4j);
Vamos mantê-las todas. Para uma aplicação em produção, seria necessário manter apenas as que são necessárias.
Na linha 26 do ficheiro [pom.xml], encontra-se a linha:
<start-class>hello.Application</start-class>
Esta linha está relacionada com as seguintes linhas:
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
Nas linhas 6 a 9, o plugin [spring-boot-maven-plugin] permite gerar o ficheiro JAR executável da aplicação. A linha 26 do ficheiro [pom.xml] indica, então, a classe executável desse ficheiro JAR.
5.1.2. A camada [JPA]
O acesso à base de dados é feito através de uma camada [JPA], Java Persistence API:
 |
 |
A aplicação é básica e gere clientes [Customer]. A classe [Customer] faz parte da camada [JPA] e é a seguinte:
package hello;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class Customer {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
private String firstName;
private String lastName;
protected Customer() {
}
public Customer(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
@Override
public String toString() {
return String.format("Customer[id=%d, firstName='%s', lastName='%s']", id, firstName, lastName);
}
}
Um cliente tem um identificador [id], um nome próprio [firstName] e um apelido [lastName]. Cada instância [Customer] representa uma linha de uma tabela da base de dados.
- linha 8: anotação JPA que faz com que a persistência das instâncias [Customer] (Create, Read, Update, Delete) venha a ser gerida por uma implementação JPA. De acordo com as dependências do Maven, verifica-se que é utilizada a implementação JPA / Hibernate;
- linhas 11-12: anotações JPA que associam o campo [id] à chave primária da tabela [Customer]. A linha 12 indica que a implementação JPA utilizará o método de geração da chave primária específico do SGBD utilizado, neste caso o H2;
Não existem outras anotações para JPA. Serão, então, utilizados valores por predefinição:
- a tabela [Customer] terá o nome da classe, ou seja, [Customer];
- as colunas desta tabela terão o nome dos campos da classe: [id, firstName, lastName], tendo em conta que as maiúsculas e minúsculas não são distinguidas no nome de uma coluna da tabela;
Note-se que, em nenhum momento, a implementação JPA utilizada é referida pelo nome.
5.1.3. A camada [Spring Data]
A classe [CustomerRepository] implementa a camada de acesso à tabela [Customer]. O seu código é o seguinte:
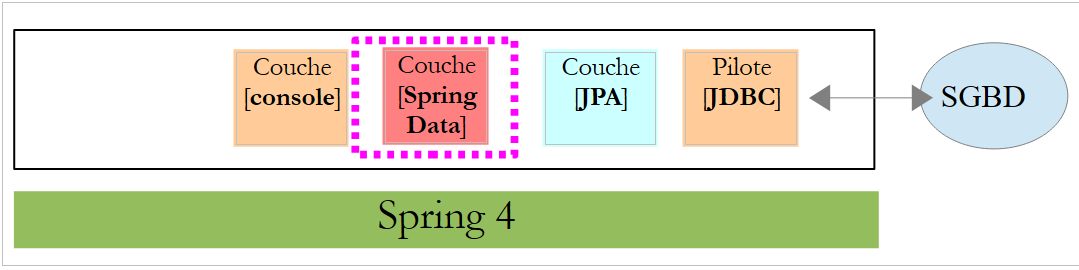 |
 |
package hello;
import java.util.List;
import org.springframework.data.repository.CrudRepository;
public interface CustomerRepository extends CrudRepository<Customer, Long> {
List<Customer> findByLastName(String lastName);
}
Trata-se, portanto, de uma interface e não de uma classe (linha 7). Ela estende a interface [CrudRepository], uma interface do Spring Data (linha 5). Esta interface é definida por dois tipos: o primeiro é o tipo dos elementos geridos, neste caso o tipo [Customer]; o segundo é o tipo da chave primária dos elementos geridos, neste caso um tipo [Long]. A interface [CrudRepository] é a seguinte:
package org.springframework.data.repository;
import java.io.Serializable;
@NoRepositoryBean
public interface CrudRepository<T, ID extends Serializable> extends Repository<T, ID> {
<S extends T> S save(S entity);
<S extends T> Iterable<S> save(Iterable<S> entities);
T findOne(ID id);
boolean exists(ID id);
Iterable<T> findAll();
Iterable<T> findAll(Iterable<ID> ids);
long count();
void delete(ID id);
void delete(T entity);
void delete(Iterable<? extends T> entities);
void deleteAll();
}
Esta interface define as operações CRUD (Criar – Ler – Atualizar – Eliminar) que podem ser realizadas num tipo JPA T:
- linha 8: o método save permite persistir uma entidade T na base de dados. Este método persiste a entidade com a chave primária que lhe foi atribuída pelo SGBD. Permite também atualizar uma entidade T identificada pela sua chave primária id. A escolha de uma ou outra ação depende do valor da chave primária id: se este for nulo, é realizada a operação de persistência; caso contrário, é realizada a operação de atualização;
- linha 10: o mesmo, mas para uma lista de entidades;
- linha 12: o método findOne permite recuperar uma entidade T identificada pela sua chave primária id;
- linha 22: o método delete permite eliminar uma entidade T identificada pela sua chave primária id;
- linhas 24-28: variantes do método [delete];
- linha 16: o método [findAll] permite recuperar todas as entidades T persistentes;
- linha 18: o mesmo, mas limitado às entidades cuja lista de identificadores foi passada;
Voltemos à interface [CustomerRepository]:
package hello;
import java.util.List;
import org.springframework.data.repository.CrudRepository;
public interface CustomerRepository extends CrudRepository<Customer, Long> {
List<Customer> findByLastName(String lastName);
}
- a linha 9 permite recuperar um [Customer] pelo seu nome [lastName];
E é tudo no que diz respeito à camada [DAO]. Não existe uma classe de implementação da interface anterior. Esta é gerada em tempo de execução pelo [Spring Data]. Os métodos da interface [CrudRepository] são implementados automaticamente. Quanto aos métodos adicionados à interface [CustomerRepository], isso depende. Voltemos à definição de [Customer]:
private long id;
private String firstName;
private String lastName;
O método da linha 9 é implementado automaticamente por [Spring Data] porque faz referência ao campo [lastName] (linha 3) de [Customer]. Quando encontra um método [findBySomething] na interface a implementar, o Spring Data implementa-o através da seguinte consulta JPQL (Java Persistence Query Language):
É, portanto, necessário que o tipo T tenha um campo denominado [something]. Assim, o método
será implementado por um código semelhante ao seguinte:
return [em].createQuery("select c from Customer c where c.lastName=:value").setParameter("value",lastName).getResultList()
onde [em] designa o contexto de persistência JPA. Isto só é possível se a classe [Customer] tiver um campo denominado [lastName], o que é o caso.
Em conclusão, em casos simples, o Spring Data permite-nos implementar a camada [DAO] com uma interface simples.
5.1.4. A camada [console]
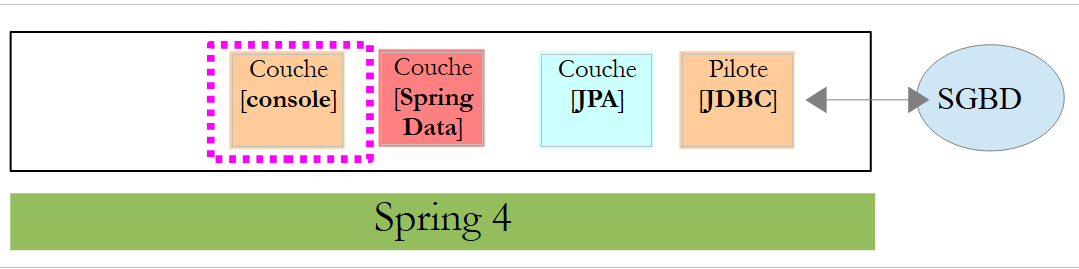 |
 |
A classe [Application] é a seguinte:
package hello;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class Application implements CommandLineRunner {
@Autowired
CustomerRepository repository;
public static void main(String[] args) {
SpringApplication.run(Application.class);
}
@Override
public void run(String... strings) throws Exception {
// guardar alguns clientes
repository.save(new Customer("Jack", "Bauer"));
repository.save(new Customer("Chloe", "O'Brian"));
repository.save(new Customer("Kim", "Bauer"));
repository.save(new Customer("David", "Palmer"));
repository.save(new Customer("Michelle", "Dessler"));
// recuperar todos os clientes
System.out.println("Customers found with findAll():");
System.out.println("-------------------------------");
for (Customer customer : repository.findAll()) {
System.out.println(customer);
}
System.out.println();
// recuperar um cliente específico por ID
Customer customer = repository.findOne(1L);
System.out.println("Customer found with findOne(1L):");
System.out.println("--------------------------------");
System.out.println(customer);
System.out.println();
// recuperar clientes pelo apelido
System.out.println("Customer found with findByLastName('Bauer'):");
System.out.println("--------------------------------------------");
for (Customer bauer : repository.findByLastName("Bauer")) {
System.out.println(bauer);
}
}
}
- linha 9: a classe implementa a interface [CommandLineRunner], que é uma interface [Spring Boot] (linha 4). Esta interface tem apenas um método, o da linha 19;
- linha 8: @SpringBootApplication é uma anotação que agrupa várias anotações [Spring Boot]:
- @Configuration: indica que a classe é uma classe de configuração;
- @EnableAutoConfiguration: solicita ao [Spring Boot] que crie ele próprio um determinado número de beans com base em várias propriedades, nomeadamente o conteúdo do Classpath do projeto. Como as bibliotecas do Hibernate se encontram no Classpath, o bean [entityManagerFactory] será implementado com o Hibernate. Como a biblioteca do SGBD H2 se encontra no Classpath, o bean [dataSource] será implementado com o H2. No bean [dataSource], é necessário definir também o utilizador e a sua palavra-passe. Aqui, o Spring Boot utilizará o administrador predefinido do H2, que não tem palavra-passe. Como a biblioteca [spring-tx] se encontra no Classpath, será utilizado o gestor de transações do Spring;
- @EnableWebMvc: se a biblioteca [spring-mvc] estiver no Classpath. Neste caso, é efetuada uma configuração automática para a aplicação web;
- @ComponentScan: que indica ao Spring onde procurar os outros beans, configurações e serviços. Aqui, estes são procurados por predefinição no pacote que contém a classe marcada, ou seja, o pacote [hello]. Assim, as classes [Customer] e [CustomerRepository] serão encontradas. Como a primeira tem a anotação [@Entity], será catalogada como uma entidade a ser gerida pelo Hibernate. Como a segunda estende a interface [CrudRepository], será registada como um bean do Spring;
- linhas 11-12: o bean [CustomerRepository] é injetado no código da classe principal;
- linha 15: o método estático [run] da classe [SpringApplication] do projeto Spring Boot é executado. O seu parâmetro é a classe que possui uma anotação [Configuration] ou [EnableAutoConfiguration]. Tudo o que foi explicado anteriormente irá então ocorrer. O resultado é um contexto de aplicação Spring, ou seja, um conjunto de beans geridos pelo Spring;
- linhas 19-48: as operações que se seguem limitam-se a utilizar os métodos do bean que implementa a interface [CustomerRepository];
Os resultados na consola são os seguintes:
- linhas 1-8: o logótipo do projeto Spring Boot;
- linha 9: a classe [hello.Application] é executada;
- linha 10: [AnnotationConfigApplicationContext] é uma classe que implementa a interface [ApplicationContext] do Spring. Trata-se de um contentor de beans;
- linha 11: o bean [entityManagerFactory] é implementado pela classe [LocalContainerEntityManagerFactory], uma classe do Spring. Este bean gere a camada [JPA];
- linha 12: surge o [Hibernate]. Foi esta implementação, JPA, que foi escolhida;
- linha 19: um dialeto do Hibernate é a variante SQL a utilizar com o SGBD. Aqui, o dialeto [H2Dialect] indica que o Hibernate irá trabalhar com o SGBD e o H2;
- linhas 21-22: a base de dados é criada. A tabela [CUSTOMER] é criada. Isto significa que o Hibernate foi configurado para gerar as tabelas a partir das definições JPA; neste caso, a definição JPA da classe [Customer];
- linhas 26-30: resultado do método [findAll] da interface;
- linha 34: resultado do método [findOne] da interface;
- linhas 38-39: resultados do método [findByLastName];
- linhas 41 e seguintes: registos do encerramento do contexto Spring.
5.1.5. Configuração manual do projeto Spring Data
Duplicamos o projeto anterior no projeto [gs-accessing-data-jpa-02]:
 |
Neste novo projeto, não vamos basear-nos na configuração automática feita pelo Spring Boot. Vamos fazê-la manualmente. Isto pode ser útil se as configurações predefinidas não nos servirem.
Em primeiro lugar, vamos especificar as dependências necessárias no ficheiro [pom.xml]:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<modelVersion>4.0.0</modelVersion>
<groupId>org.springframework</groupId>
<artifactId>gs-accessing-data-jpa-02</artifactId>
<version>0.1.0</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
</parent>
<dependencies>
<!-- Spring Data -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
</dependency>
<!-- Hibernate -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
</dependency>
<!-- Base de dados H2 -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
<!-- Tomcat JDBC -->
<dependency>
<groupId>org.apache.tomcat</groupId>
<artifactId>tomcat-jdbc</artifactId>
</dependency>
</dependencies>
<properties>
<!-- utilize UTF-8 para tudo -->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-releases</id>
<name>Spring Releases</name>
<url>https://repo.spring.io/libs-release</url>
</repository>
<repository>
<id>org.jboss.repository.releases</id>
<name>JBoss Maven Release Repository</name>
<url>https://repository.jboss.org/nexus/content/repositories/releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>spring-releases</id>
<name>Spring Releases</name>
<url>https://repo.spring.io/libs-release</url>
</pluginRepository>
</pluginRepositories>
</project>
- linhas 10-14: o projeto Maven pai, cujas bibliotecas iremos utilizar;
- linhas 18-21: o Spring Data utilizado para aceder à base de dados;
- linhas 23-26: a implementação Hibernate da especificação JPA;
- linhas 28-31: o SGBD H2;
- linhas 33-36: as bases de dados são frequentemente utilizadas com conjuntos de ligações abertas, o que evita a abertura e o encerramento repetidos de ligações. Aqui, a implementação utilizada é a de [tomcat-jdbc];
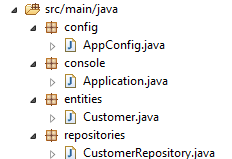
No novo projeto, a entidade [Customer] e a interface [CustomerRepository] não sofrem alterações. Vamos alterar a classe [Application], que será dividida em duas classes:
- [Config], que será a classe de configuração:
- [Main], que será a classe executável;
 |
A classe executável [Application] é agora a seguinte:
package console;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
import repositories.CustomerRepository;
import config.AppConfig;
import entities.Customer;
public class Application {
public static void main(String[] args) {
// instanciação do contexto Spring
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
CustomerRepository repository = context.getBean(CustomerRepository.class);
// guardar alguns clientes
repository.save(new Customer("Jack", "Bauer"));
repository.save(new Customer("Chloe", "O'Brian"));
repository.save(new Customer("Kim", "Bauer"));
repository.save(new Customer("David", "Palmer"));
repository.save(new Customer("Michelle", "Dessler"));
...
// encerramento do contexto
context.close();
}
}
- linha 9: a classe [Application] já não tem anotações de configuração;
- linhas 3-7: note-se que já não existem importações de pacotes [Spring Boot];
- linha 12: instanciamos os beans Spring. Obtemos o contexto do Spring que contém a referência aos beans assim criados;
- linha 13: solicita-se uma referência ao bean do tipo [CustomerRepository];
A classe [Config] que configura o projeto é a seguinte:
package config;
import javax.persistence.EntityManagerFactory;
import org.apache.tomcat.jdbc.pool.DataSource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
import org.springframework.orm.jpa.JpaTransactionManager;
import org.springframework.orm.jpa.JpaVendorAdapter;
import org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean;
import org.springframework.orm.jpa.vendor.Database;
import org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter;
import org.springframework.transaction.PlatformTransactionManager;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@EnableTransactionManagement
@EnableJpaRepositories(basePackages = { "repositories" })
@Configuration
// @ComponentScan(basePackages={"package1","package2"})
public class AppConfig {
// a base de dados H2
@Bean
public DataSource dataSource() {
// fonte de dados TomcatJdbc
DataSource dataSource = new DataSource();
// configuração de acesso JDBC
dataSource.setDriverClassName("org.h2.Driver");
dataSource.setUrl("jdbc:h2:./demo");
dataSource.setUsername("sa");
dataSource.setPassword("");
// uma ligação inicialmente aberta
dataSource.setInitialSize(1);
// resultado
return dataSource;
}
// o provedor JPA
@Bean
public JpaVendorAdapter jpaVendorAdapter() {
HibernateJpaVendorAdapter hibernateJpaVendorAdapter = new HibernateJpaVendorAdapter();
hibernateJpaVendorAdapter.setShowSql(false);
hibernateJpaVendorAdapter.setGenerateDdl(true);
hibernateJpaVendorAdapter.setDatabase(Database.H2);
return hibernateJpaVendorAdapter;
}
// EntityManagerFactory
@Bean
public EntityManagerFactory entityManagerFactory(JpaVendorAdapter jpaVendorAdapter, DataSource dataSource) {
LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();
factory.setJpaVendorAdapter(jpaVendorAdapter);
factory.setPackagesToScan("entities");
factory.setDataSource(dataSource);
factory.afterPropertiesSet();
return factory.getObject();
}
// Gestor de transações
@Bean
public PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) {
JpaTransactionManager txManager = new JpaTransactionManager();
txManager.setEntityManagerFactory(entityManagerFactory);
return txManager;
}
}
- linha 17: a anotação [@EnableTransactionManagement] indica que as anotações [@Transactional] devem ser interpretadas. Os métodos das interfaces [CrudRepository] possuem essas anotações. São, portanto, executados no âmbito de uma transação;
- linha 18: a anotação [@EnableJpaRepositories] permite indicar as pastas onde se encontram as interfaces Spring Data [CrudRepository]. Estas interfaces tornar-se-ão componentes Spring e estarão disponíveis no seu contexto;
- linha 19: a anotação [@Configuration] transforma a classe [Config] numa classe de configuração do Spring;
- linha 20: a anotação [@ComponentScan] permite listar as pastas onde os componentes Spring devem ser procurados. Os componentes Spring são classes marcadas com anotações Spring, tais como @Service, @Component, @Controller, ... Aqui, não existem outros além dos que estão definidos na classe [AppConfig], pelo que a anotação foi colocada em comentário;
- linhas 24-37: definem a fonte de dados, a base de dados H2. É a anotação @Bean na linha 25 que torna o objeto criado por este método um componente gerido pelo Spring. O nome do método pode ser qualquer um. No entanto, deve chamar-se [dataSource] se o EntityManagerFactory da linha 51 estiver ausente e for definido por autoconfiguração;
- linha 30: a base de dados chamar-se-á [demo] e será gerada na pasta do projeto;
- linhas 40-47: definem a implementação JPA utilizada, neste caso uma implementação do Hibernate. O nome do método pode ser qualquer um;
- linha 43: sem registos SQL;
- linha 44: a base de dados será criada caso não exista;
- linhas 50-58: definem o EntityManagerFactory que irá gerir a persistência do JPA. O método deve chamar-se obrigatoriamente [entityManagerFactory];
- linha 51: o método recebe dois parâmetros com o tipo dos dois beans definidos anteriormente. Estes serão então criados e, em seguida, injetados pelo Spring como parâmetros do método;
- linha 53: define a implementação JPA utilizada;
- linha 54: define as pastas onde se encontram as entidades JPA;
- linha 55: define a fonte de dados a gerir;
- linhas 61-66: o gestor de transações. O método deve chamar-se obrigatoriamente [transactionManager]. Recebe como parâmetro o bean das linhas 51-58;
- linha 64: o gestor de transações é associado ao EntityManagerFactory;
Os métodos anteriores podem ser definidos em qualquer ordem.
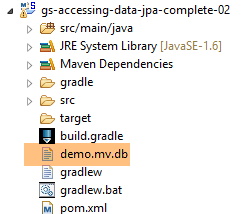
A execução do projeto produz os mesmos resultados. Surge um novo ficheiro na pasta do projeto, o da base de dados H2:
 |
5.1.6. Criação de um arquivo executável
Para criar um arquivo executável do projeto, pode-se proceder da seguinte forma:
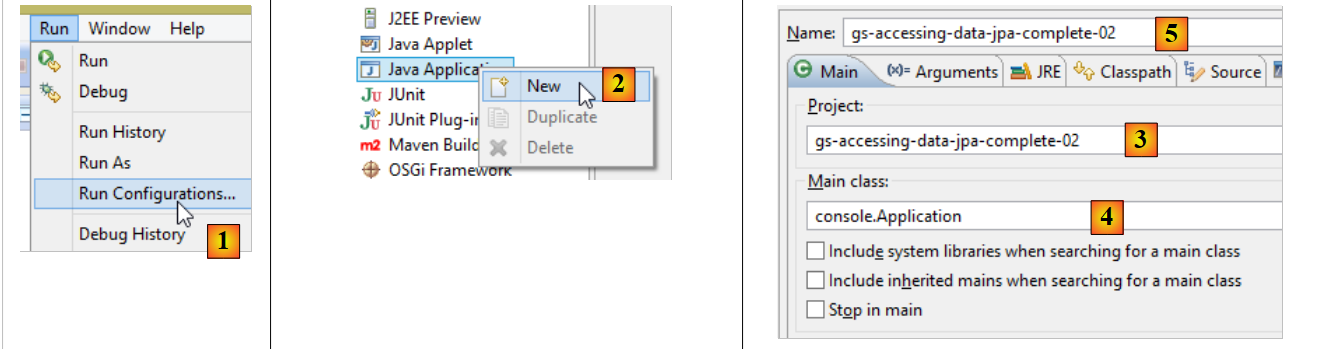 |
- em [1]: cria-se uma configuração de execução;
- em [2]: do tipo [Java Application]
- em [3]: indica o projeto a executar (utilize o botão Browse);
- em [4]: indica a classe a executar;
- em [5]: o nome da configuração de execução – pode ser qualquer um;
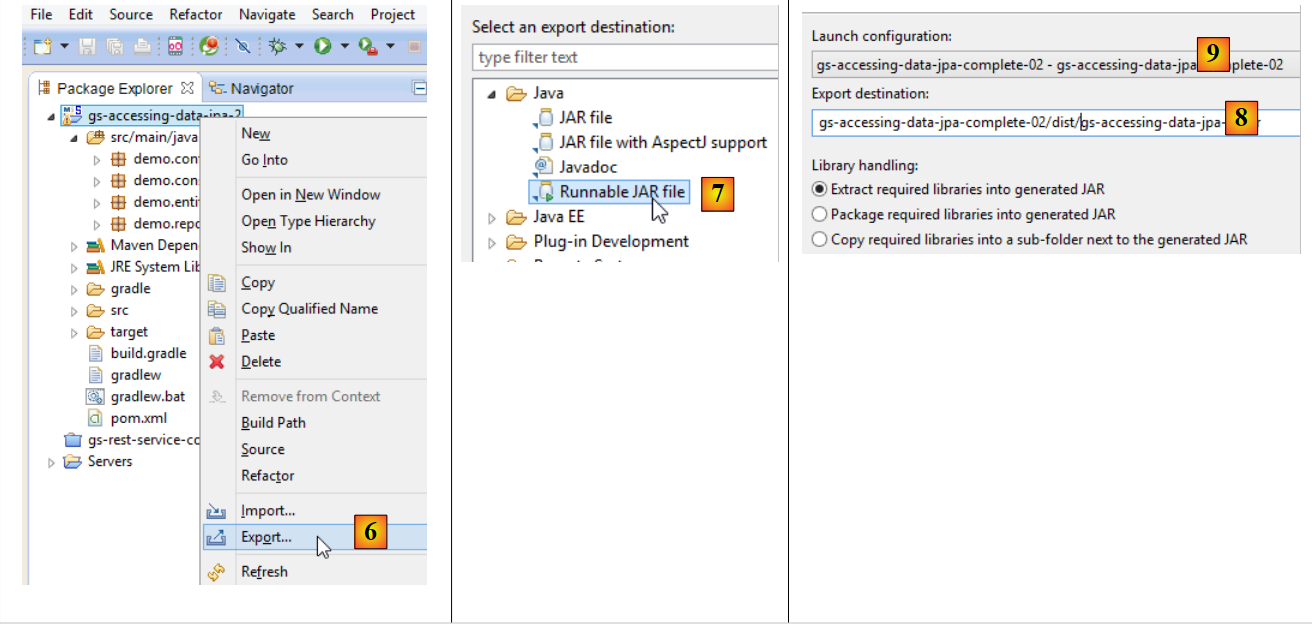 |
- em [6]: exporta-se o projeto;
- em [7]: sob a forma de um arquivo executável JAR;
- em [8]: indica o caminho e o nome do ficheiro executável a criar;
- em [9]: o nome da configuração de execução criada em [5];
10 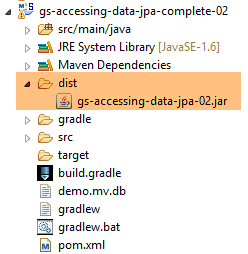 |
- em [10], o arquivo criado;
Feito isto, abre-se um terminal na pasta que contém o arquivo executável:
O ficheiro executável é executado da seguinte forma:
.....\dist>java -jar gs-accessing-data-jpa-02.jar
Os resultados obtidos no terminal são os seguintes:
5.1.7. Criação de um projeto [Spring Data]
Para criar um esqueleto de projeto Spring Data, pode-se proceder da seguinte forma:
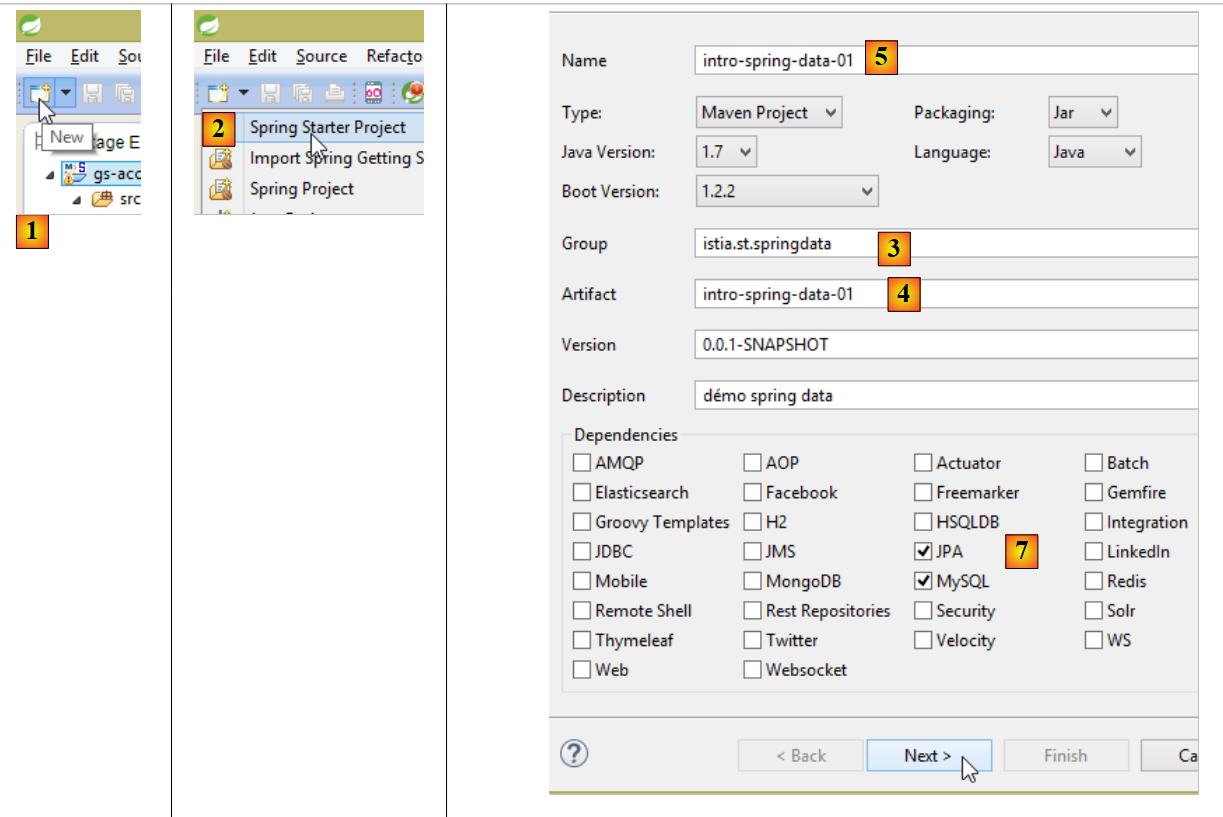 |
- em [1], cria-se um novo projeto;
- em [2]: do tipo [Spring Starter Project];
- o projeto gerado será um projeto Maven. Em [3], indica-se o nome do grupo do projeto;
- no [4]: indica-se o nome do artefacto (um jar, neste caso) que será criado durante a compilação do projeto;
- em [5]: o nome do projeto no Eclipse – pode ser qualquer um (não tem de ser idêntico a [4]);
- em [7]: indica-se que se vai criar um projeto com uma camada [JPA] com o SGBD MySQL. As dependências necessárias para esse projeto serão então incluídas no ficheiro [pom.xml];
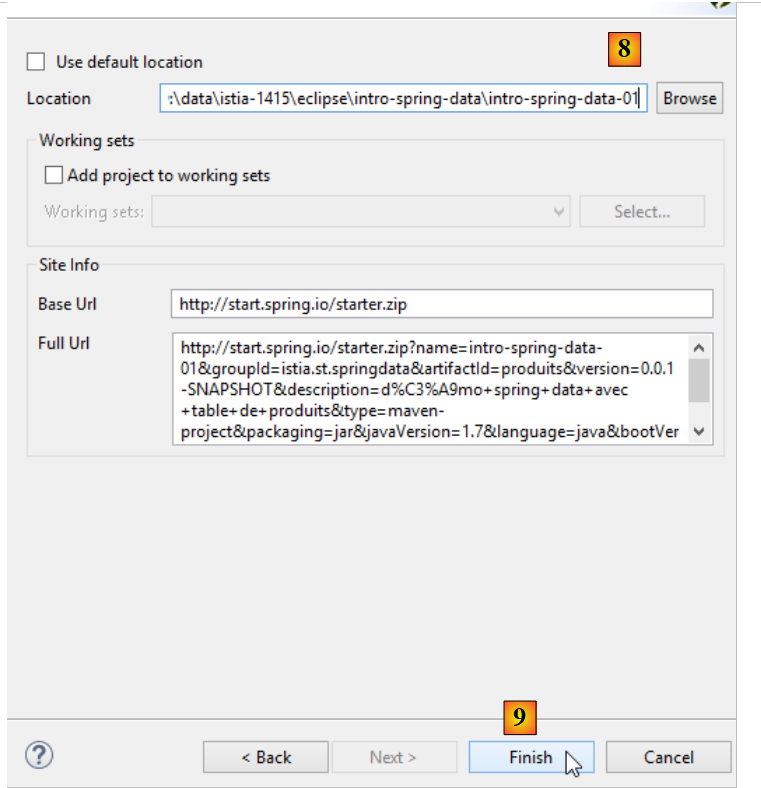 |
- no [8], indique o nome da pasta do projeto;
- no ficheiro [9], concluir o assistente;
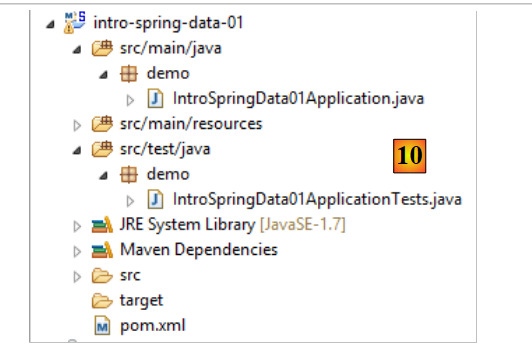 |
- em [10]: o projeto criado;
O ficheiro [pom.xml] inclui as dependências necessárias para um projeto JPA:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>istia.st.springdata</groupId>
<artifactId>intro-spring-data-01</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>intro-spring-data-01</name>
<description>démo spring data avec table de produits</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
<relativePath/> <!-- pesquisar pai no repositório -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<start-class>demo.IntroSpringData01Application</start-class>
<java.version>1.7</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
- linhas 14-19: o projeto Maven pai;
- linhas 28-31: a dependência necessária para o JPA – irá incluir o [Spring Data];
- linhas 32-36: a dependência do controlador JDBC do MySQL;
- linhas 37-41: as dependências necessárias para os testes JUnit integrados com o Spring;
A classe executável [Application] não faz nada, mas está pré-configurada:
package demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class IntroSpringData01Application {
public static void main(String[] args) {
SpringApplication.run(IntroSpringData01Application.class, args);
}
}
- a anotação [@SpringBootApplication] torna a classe uma classe de autoconfiguração do projeto;
A classe de testes [ApplicationTests] não executa nenhuma ação, mas está pré-configurada:
package demo;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.test.SpringApplicationConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
@RunWith(SpringJUnit4ClassRunner.class)
@SpringApplicationConfiguration(classes = IntroSpringData01Application.class)
public class IntroSpringData01ApplicationTests {
@Test
public void contextLoads() {
}
}
- linha 9: a anotação [@SpringApplicationConfiguration] permite utilizar o ficheiro de configuração [IntroSpringData01Application]. A classe de teste beneficiará assim de todos os beans definidos por este ficheiro;
- linha 8: a anotação [@RunWith] permite a integração do Spring com JUnit: a classe poderá ser executada como um teste JUnit. [@RunWith] é uma anotação JUnit (linha 4), enquanto a classe [SpringJUnit4ClassRunner] é uma classe Spring (linha 6);
Agora que temos um esqueleto de aplicação JPA, podemos completá-lo.