7. Spring Data JPA EclipseLink
7.1. Introduction
Retomamos a arquitetura anterior, que agora implementamos com uma camada JPA / EclipseLink.
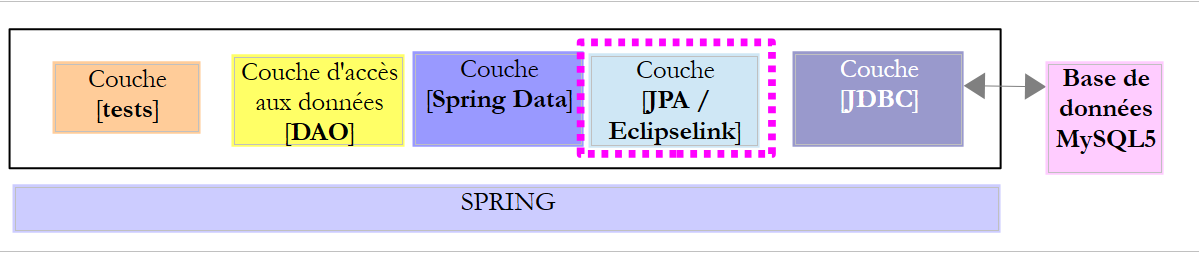 |
7.2. Configuração do ambiente de trabalho
Com o STS, descarregue o projeto [myql-config-jpa-hibernate] [1-4]:
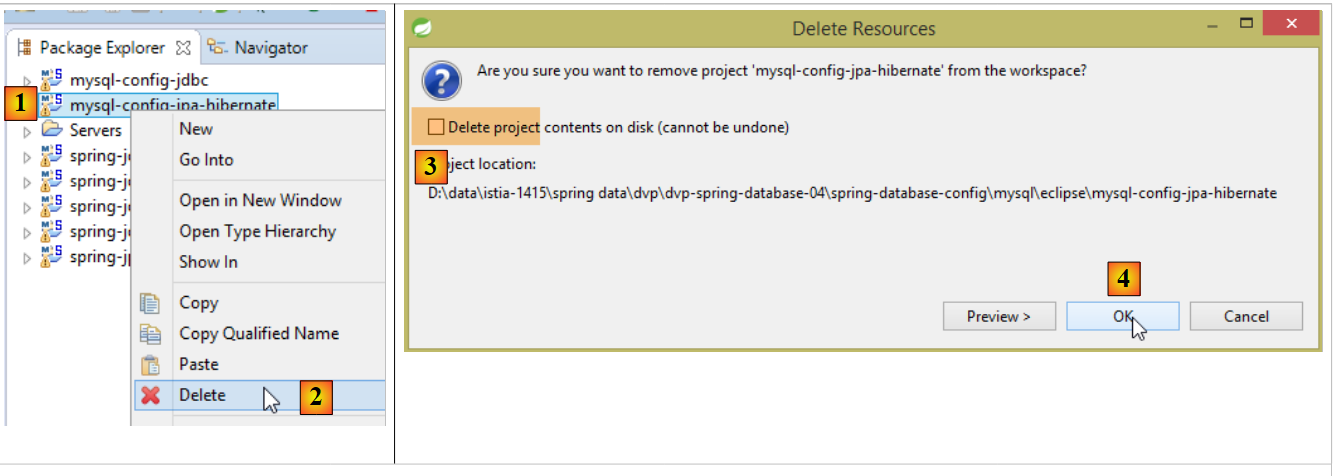 |
e, em seguida, importe o projeto [mysl-config-jpa-eclipselink] [5], que se encontra na pasta [<exemples>/spring-database-config/mysql/eclipse] [6]:
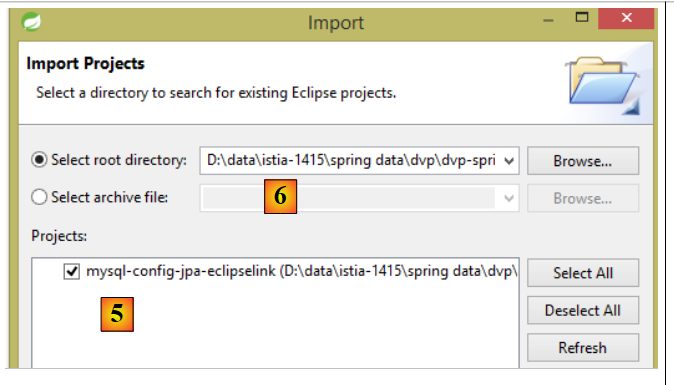 |
Feito isto, reinicie o ambiente Maven (Alt-F5) de todos os projetos presentes em [Package Explorer]:
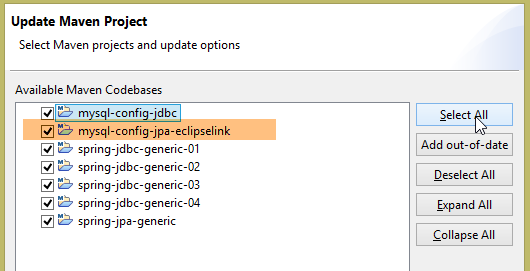 |
Em seguida, para verificar o ambiente de trabalho, execute a configuração de execução denominada [spring-jpa-generic-JUnitTestDao-hibernate-eclipselink]:
 |
Esta configuração executa o teste [JUnitTestDao]. Este teste deve ser bem-sucedido:
 |
7.3. O projeto de configuração da camada JPA
 |
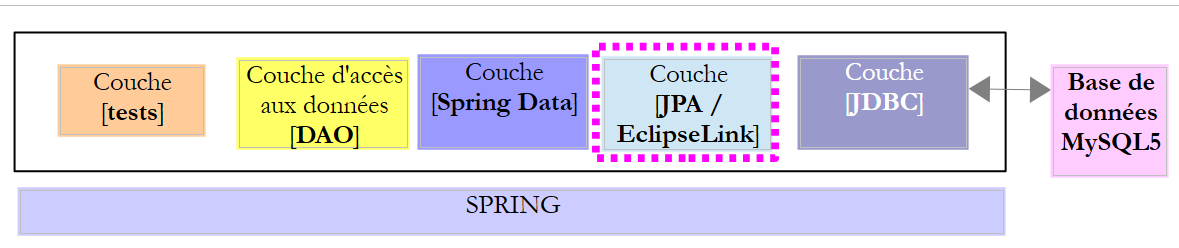
Este projeto tem como função configurar a camada JPA da arquitetura abaixo:
 |
7.3.1. Configuração do Maven
O projeto é um projeto Maven e está configurado pelo seguinte ficheiro [pom.xml]:
<project xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"
xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<modelVersion>4.0.0</modelVersion>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-config-jpa</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>configuration mysql openjpa</name>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
</parent>
<dependencies>
<!-- dependências variáveis ********************************************** -->
<!-- JPA provedor -->
<dependency>
<groupId>org.eclipse.persistence</groupId>
<artifactId>eclipselink</artifactId>
<version>2.6.0</version>
</dependency>
<!-- dependências constantes ********************************************** -->
<!-- Spring Data -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
</dependency>
<!-- configuração herdada JDBC -->
<dependency>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-config-jdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.7</java.version>
</properties>
<build>
<plugins>
<!-- [https://flexguse.wordpress.com/2013/08/10/maven-spring-data-jpa-eclipselink-and-static-weaving/] -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
</plugin>
<!-- Este plugin garante a integração estática do EclipseLink -->
<plugin>
<artifactId>staticweave-maven-plugin</artifactId>
<groupId>de.empulse.eclipselink</groupId>
<version>1.0.0</version>
<executions>
<execution>
<goals>
<goal>weave</goal>
</goals>
<phase>process-classes</phase>
<configuration>
<logLevel>ALL</logLevel>
<!-- <includeProjectClasspath>true</includeProjectClasspath> -->
</configuration>
</execution>
</executions>
<dependencies>
<dependency>
<groupId>org.eclipse.persistence</groupId>
<artifactId>eclipselink</artifactId>
<version>2.6.0</version>
</dependency>
</dependencies>
</plugin>
</plugins>
<pluginManagement>
<plugins>
<!--A configuração deste plugin é utilizada apenas para armazenar as definições do Eclipse m2e. Não tem qualquer influência na própria compilação do Maven. -->
<plugin>
<groupId>org.eclipse.m2e</groupId>
<artifactId>lifecycle-mapping</artifactId>
<version>1.0.0</version>
<configuration>
<lifecycleMappingMetadata>
<pluginExecutions>
<pluginExecution>
<pluginExecutionFilter>
<groupId>
de.empulse.eclipselink
</groupId>
<artifactId>
staticweave-maven-plugin
</artifactId>
<versionRange>
[1.0.0,)
</versionRange>
<goals>
<goal>weave</goal>
</goals>
</pluginExecutionFilter>
<action>
<execute>
<runOnIncremental>true</runOnIncremental>
</execute>
</action>
</pluginExecution>
</pluginExecutions>
</lifecycleMappingMetadata>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
- linhas 5-7: o artefacto Maven gerado por este projeto. É o mesmo que o do projeto [mysql-config-jpa-hibernate]. Isto significa que apenas um destes projetos pode estar ativo de cada vez;
- linhas 10-14: o projeto Maven pai que define a versão da maioria das dependências necessárias ao projeto;
- linhas 19-22: a biblioteca EclipseLink;
- linhas 26-29: a biblioteca Spring Data;
- linhas 32-34: o projeto de configuração da camada JPA baseia-se no projeto de configuração da camada JDBC, que define, entre outras coisas, o controlador JDBC do SGBD utilizado e as coordenadas da base de dados a utilizar;
- linhas 35-40: o projeto de configuração da camada JDBC inclui a biblioteca [Spring JDBC], que aqui é substituída pela biblioteca [Spring Data JPA]. Por isso, recomenda-se que não seja incluída nas dependências do projeto. No entanto, se permanecer, isso não causará erros;
- o plugin das linhas 58-81 implementa o «weaving» das entidades JPA. O que os anglo-saxónicos designam por «weaving» é a transformação (o enriquecimento) das entidades «JPA» para que suportem o Lazy Loading. Não foi necessário configurar o Hibernate para que este weaving ocorresse. Para o EclipseLink, é necessário um plugin do Maven. Procurei durante muito tempo uma forma de forçar o EclipseLink a respeitar o atributo [fetch = FetchType.LAZY] da anotação [@ManyToOne] abaixo:
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = ConfigJdbc.TAB_PRODUITS_CATEGORIE_ID)
private Categorie categorie;
A especificação JPA indica que o atributo [fetch = FetchType.LAZY] da anotação [@ManyToOne] é uma «sugestão» (sugestão) que a implementação JPA não é obrigada a respeitar. E, de facto, a EclipseLink não a respeita por predefinição. É necessária uma configuração especial para que a respeite. Após muitas pesquisas infrutíferas, encontrei a solução para o URL mencionado na linha 51. Quando se incluem as linhas 58-81 no ficheiro [pom.xml], o Eclipse apresenta um erro relativo ao ficheiro. Trata-se de um problema de configuração do plugin [m2e], que assegura a gestão dos projetos Maven no Eclipse. É necessário adicionar as linhas 83 a 119 para resolver o erro.
No final, as dependências são as seguintes:
 |
7.3.2. Configuração do Spring
 |
A classe [ConfigJpa] configura o projeto Spring:
package generic.jpa.config;
import generic.jdbc.config.ConfigJdbc;
import javax.persistence.EntityManagerFactory;
import org.apache.tomcat.jdbc.pool.DataSource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.orm.jpa.JpaTransactionManager;
import org.springframework.orm.jpa.JpaVendorAdapter;
import org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean;
import org.springframework.orm.jpa.vendor.Database;
import org.springframework.orm.jpa.vendor.EclipseLinkJpaVendorAdapter;
import org.springframework.transaction.PlatformTransactionManager;
@Configuration
@Import({ ConfigJdbc.class })
public class ConfigJpa {
// o provedor JPA
@Bean
public JpaVendorAdapter jpaVendorAdapter() {
// Nota: as entidades JPA e a configuração do EclipseLink encontram-se no ficheiro META-INF/persistence.xml
EclipseLinkJpaVendorAdapter eclipseLinkJpaVendorAdapter = new EclipseLinkJpaVendorAdapter();
eclipseLinkJpaVendorAdapter.setShowSql(false);
eclipseLinkJpaVendorAdapter.setDatabase(Database.MYSQL);
eclipseLinkJpaVendorAdapter.setGenerateDdl(true);
return eclipseLinkJpaVendorAdapter;
}
// fonte de dados
@Bean
public DataSource dataSource() {
// fonte de dados TomcatJdbc
DataSource dataSource = new DataSource();
// configuração de acesso JDBC
dataSource.setDriverClassName(ConfigJdbc.DRIVER_CLASSNAME);
dataSource.setUsername(ConfigJdbc.USER_DBPRODUITSCATEGORIES);
dataSource.setPassword(ConfigJdbc.PASSWD_DBPRODUITSCATEGORIES);
dataSource.setUrl(ConfigJdbc.URL_DBPRODUITSCATEGORIES);
// ligações abertas inicialmente
dataSource.setInitialSize(5);
// resultado
return dataSource;
}
// EntityManagerFactory
@Bean
public EntityManagerFactory entityManagerFactory(JpaVendorAdapter jpaVendorAdapter, DataSource dataSource) {
LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();
factory.setJpaVendorAdapter(jpaVendorAdapter);
factory.setDataSource(dataSource);
factory.afterPropertiesSet();
EntityManagerFactory entityManagerFactory = factory.getObject();
return entityManagerFactory;
}
// Gestor de transações
@Bean
public PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) {
JpaTransactionManager txManager = new JpaTransactionManager();
txManager.setEntityManagerFactory(entityManagerFactory);
return txManager;
}
}
Esta configuração é semelhante à descrita no parágrafo 6.3.2, para a implementação JPA do Hibernate. Apresentamos apenas as diferenças:
- linhas 23-31: o bean [jpaVendorAdapter] está agora implementado com EclipseLink;
- linhas 50-58: na versão JPA do Hibernate, estava escrito:
que servia para indicar onde deviam ser procuradas as entidades JPA. Aqui, recorre-se ao ficheiro [persistence.xml] (comentário na linha 25) (ver parágrafo 6.3.4) para, simultaneamente:
- definir as entidades JPA;
- configurar EclipseLink para o weaving destas entidades;
7.4. O ficheiro [persistence.xml]
 |
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd">
<persistence-unit name="generic-jpa-entities-dbproduitscategories" transaction-type="RESOURCE_LOCAL">
<!-- entidades JPA -->
<class>generic.jpa.entities.dbproduitscategories.Categorie</class>
<class>generic.jpa.entities.dbproduitscategories.Produit</class>
<class>generic.jpa.entities.dbproduitscategories.User</class>
<class>generic.jpa.entities.dbproduitscategories.Role</class>
<class>generic.jpa.entities.dbproduitscategories.UserRole</class>
<exclude-unlisted-classes>true</exclude-unlisted-classes>
<!-- propriedades necessárias para que o [@ManyToOne] possa ser pesquisado no modo LAZY -->
<properties>
<property name="eclipselink.weaving" value="static" />
<property name="eclipselink.weaving.lazy" value="true" />
<property name="eclipselink.weaving.internal" value="true" />
</properties>
</persistence-unit>
</persistence>
- linha 4: a unidade de persistência. Pode ter qualquer nome (atributo name);
- linhas 6-10: as cinco entidades JPA a gerir;
- a linha 11 é importante. Por vezes, um projeto define entidades utilizadas em contextos diferentes. A linha 11 garante que não haverá outras entidades além das definidas nas linhas 5-10. Isto é importante quando estas são utilizadas para gerar as tabelas da fonte de dados. Ter entidades a mais geraria tabelas a mais;
- linhas 13-17: configuração de EclipseLink para um weaving estático. Existem dois tipos de weaving:
- [statique]: as entidades JPA são enriquecidas (woven) assim que a camada JPA é instanciada;
- [dynamique]: as entidades JPA são enriquecidas (woven) na primeira vez que chegam à camada JPA;
7.5. As entidades JPA
 |
As entidades JPA são as descritas no parágrafo 6.3.3 para a implementação do Hibernate, com duas diferenças:
- todas as entidades JPA têm a anotação [@Cache(alwaysRefresh = true)], que desativa o cache de EclipseLink. Neste documento, não são utilizados os caches das implementações JPA utilizadas. O de EclipseLink parece estar ativo por predefinição e provocava erros nos testes.
@Entity
@Table(name = ConfigJdbc.TAB_CATEGORIES)
@JsonFilter("jsonFilterCategorie")
@Cache(alwaysRefresh = true)
public class Categorie implements AbstractCoreEntity {
- todas as anotações [@OneToMany] são acompanhadas pela anotação [@CascadeOnDelete]:
@OneToMany(fetch = FetchType.LAZY, mappedBy = "categorie", cascade = { CascadeType.ALL })
@CascadeOnDelete
private List<Produit> produits;
Esta anotação desempenha um papel na geração das tabelas a partir das entidades JPA. Adiciona às chaves estrangeiras (neste caso, PRODUITS[CATEGORIE_ID] ---> CATEGORIES[ID]) o atributo SQL [ON DELETE CASCADE], o que faz com que, sempre que se elimina uma categoria na tabela [CATEGORIES], os produtos correspondentes na tabela [PRODUITS] também sejam eliminados;
Nota: é importante referir que esta anotação é utilizada tanto na criação da tabela, como acabámos de ver, como na sua utilização. A tabela EclipseLink pressupõe que o atributo SQL [ON DELETE CASCADE] está efetivamente presente e utiliza-o sempre que lhe é solicitado que elimine uma categoria. A sua ausência provocaria erros.
7.6. A camada de testes
 |
 |
Os testes acima são idênticos aos das implementações Spring JDBC e Spring JPA Hibernate. Consulte as páginas seguintes, se necessário:
- [JUnitTestCheckArguments]: parágrafo 4.11.1;
- [JUnitTestDao]: parágrafo 4.11.2;
- [JUnitTestPushTheLimits]: parágrafo 4.11.3;
- [JUnitTestProxies]: parágrafo 6.4.5;
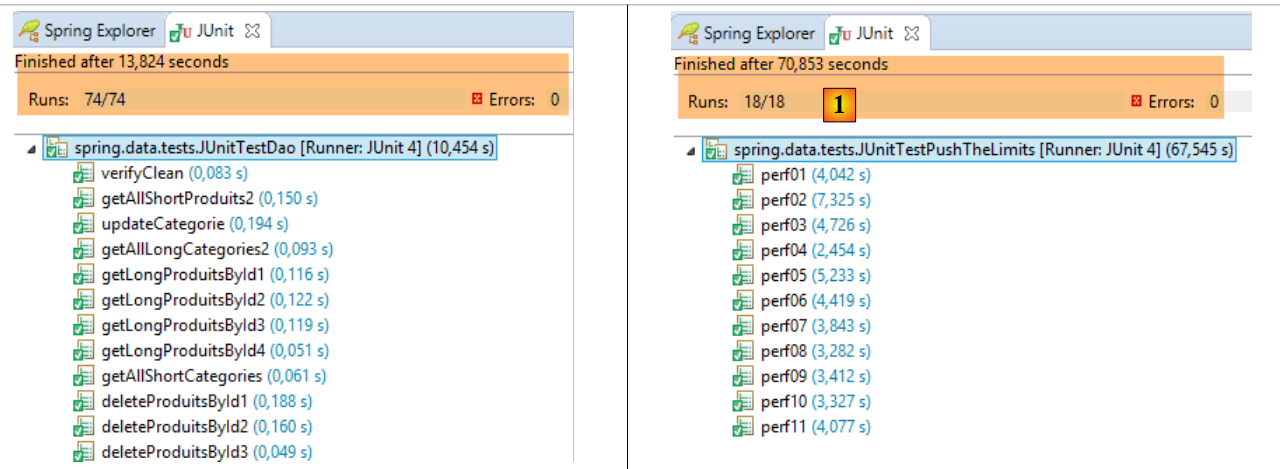
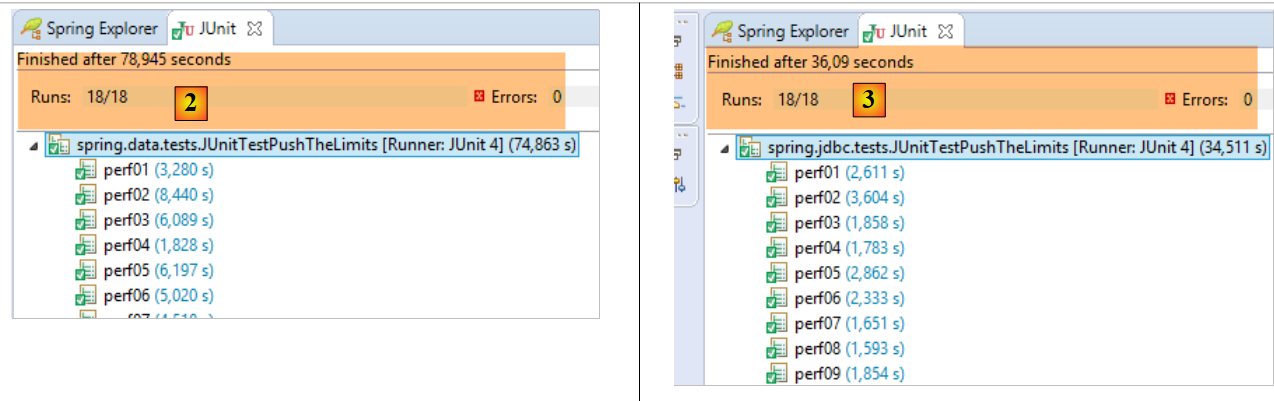
Os resultados obtidos são os seguintes:
 |
 |
- em [1], [JUnitTestPushTheLimits-EclipseLink]: 70,583 s
- em [2], [JUnitTestPushTheLimits-Hibernate]: 78,945 s
- em [3], [JUnitTestPushTheLimits-JDBC]: 36,09 s
O teste [JUnitTestProxies] apresenta os seguintes resultados na consola:
Vê-se aqui que, ao aceder ao campo [Categorie.produits] de uma categoria do tipo PROXY e ao campo [Produit.categorie] de um produto do tipo PROXY, consegue-se obter a informação em ambos os casos (linhas 7 e 17). Entre as três implementações JPA, esta é a única que permite isso nas entidades PROXY.