19. Utilização do ORM SQLALCHEMY
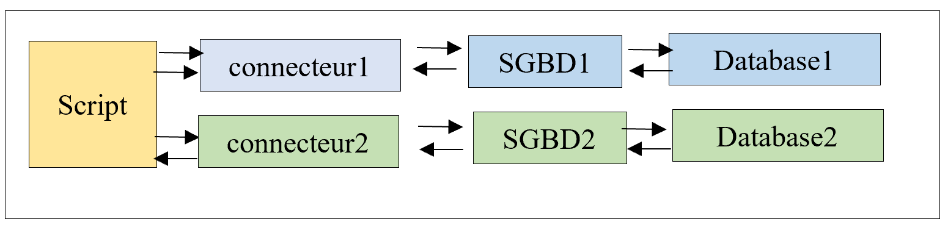
O capítulo anterior demonstrou que, em certos casos, é possível escrever código independente do SGBD, utilizado com a seguinte arquitetura:
Neste capítulo, vamos utilizar o ORM (Mapeador Objeto-Relacional) [sqlalchemy] para aceder aos SGBD de forma uniforme, independentemente do SGBD utilizado. Um ORM permite duas coisas:
- permite que um script comunique com o SGBD sem emitir comandos SQL;
- oculta ao script as particularidades de cada SGBD;
A arquitetura passa a ser a seguinte:
O script está agora separado dos conectores pelo ORM. Interage com o ORM através de classes e métodos. Não executa código SQL. É o ORM que o faz com os conectores aos quais está ligado. Este oculta ao script as particularidades desses conectores. Assim, o código do script é insensível a uma mudança de conector (ou seja, do SGBD);
A estrutura hierárquica dos scripts analisados será a seguinte:
19.1. Instalação do ORM [sqlalchemy]
O ORM [sqlalchemy] vem na forma de um pacote Python que deve ser instalado num terminal Python:
(venv) C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\databases\sqlalchemy>pip install sqlalchemy
Collecting sqlalchemy
Downloading SQLAlchemy-1.3.18-cp38-cp38-win_amd64.whl (1.2 MB)
|| 1.2 MB 3.3 MB/s
Installing collected packages: sqlalchemy
Successfully installed sqlalchemy-1.3.18
19.2. Scripts 01: o básico

- em [1], os scripts que serão analisados. Estes scripts irão utilizar as classes de [2]: BaseEntity, MyException, Pessoa, Utilitários;
19.2.1. Configuração
O ficheiro [config] configura a aplicação da seguinte forma:
def configure():
# root_dir
# caminho absoluto de referência dos caminhos relativos da configuração
root_dir = "C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020"
# caminhos absolutos das dependências
absolute_dependencies = [
# BaseEntity, MyException, Pessoa, Utilitários
f"{root_dir}/classes/02/entities",
]
# define-se o syspath
from myutils import set_syspath
set_syspath(absolute_dependencies)
# configuração das classes
from Personne import Personne
Personne.excluded_keys = ['_sa_instance_state']
# aplicamos a configuração
return {}
Comentários
- linha 8: adiciona-se ao Python Path a pasta que contém as classes [BaseEntity, MyException, Personne, Utils];
- linhas 12-13: define-se o Python Path da aplicação;
- linhas 16-17: talvez se lembre que a classe |BaseEntity| tem um atributo de classe denominado [excluded_keys]. Este atributo é uma lista na qual se colocam as propriedades da classe que não se quer que apareçam no dicionário da mesma (função asdict). Aqui, exclui-se a propriedade [_sa_instance_state] do estado da classe [Personne]. Veremos em breve porquê;
19.2.2. Script [démo]
O script [démo] mostra uma primeira utilização do ORM [sqlalchemy]:
# recupera-se a configuração da aplicação
import config
config = config.configure()
# importações
from sqlalchemy import Table, Column, Integer, String, MetaData, UniqueConstraint
from sqlalchemy.orm import mapper
from Personne import Personne
# metadados
metadata = MetaData()
# a tabela
personnes_table = Table("personnes", metadata,
Column('id', Integer, primary_key=True),
Column('prenom', String(30), nullable=False),
Column("nom", String(30), nullable=False),
Column("age", Integer, nullable=False),
UniqueConstraint('nom', 'prenom', name='uix_1')
)
# a classe Pessoa antes do mapeamento
personne1 = Personne().fromdict({"id": 67, "prénom": "x", "nom": "y", "âge": 10})
print(f"personne1={personne1.__dict__}")
# o mapeamento
mapper(Personne, personnes_table, properties={
'id': personnes_table.c.id,
'nome próprio: personnes_table.c.prenom,
'apelido: personnes_table.c.nom,
'idade': personnes_table.c.age
})
# a pessoa 1 não foi alterada
print(f"personne1={personne1.__dict__}")
# a classe Pessoa foi alterada — foi «enriquecida»
personne2 = Personne().fromdict({"id": 68, "prénom": "x1", "nom": "y1", "âge": 11})
print(f"personne2={personne2.__dict__}")
Comentários
- linhas 1-4: configura-se a aplicação;
- linhas 6-10: importam-se os módulos necessários para o script;
- linha 13: [MetaData] é uma classe de [sqlalchemy];
- linhas 15-22: [Table] é uma subclasse de [sqlalchemy]. Permite descrever uma tabela de uma base de dados. Aqui, vamos descrever a tabela [personnes] da base de dados MySQL [dbpersonnes] analisada no capítulo |MySQL|;
- linha 16: o primeiro parâmetro [personnes] é o nome da tabela descrita;
- linha 16: o segundo parâmetro [metadata] é a instância [MetaData] criada na linha 13;
- linhas 17-22: cada um dos parâmetros seguintes descreve uma coluna da tabela com uma sintaxe própria de [sqlalchemy], mas mais próxima da sintaxe de SQL;
- cada coluna é descrita por uma instância da classe [Column] de [sqlalchemy];
- o primeiro parâmetro é o nome da coluna;
- o segundo parâmetro é o seu tipo;
- os parâmetros seguintes são parâmetros nomeados:
- linha 17: [primary_key=True] para indicar que a coluna [id] é a chave primária da tabela [personnes];
- linha 18: [nullable=False] para indicar que uma coluna deve obrigatoriamente ter um valor quando uma linha é inserida na tabela;
- linha 21: por fim, a classe [UniqueConstraint] permite descrever uma restrição de unicidade. Aqui, indica-se que as colunas (apelido, nome próprio) devem ser únicas na tabela. A propriedade denominada [name] permite atribuir um nome a esta restrição. Neste caso, é necessário distinguir dois casos:
- estamos a descrever uma tabela existente. Nesse caso, é necessário procurar o nome da restrição nas propriedades da tabela (phpMyAdmin ou pgAdmin);
- estamos a descrever uma tabela que vamos criar. Nesse caso, introduzimos o nome que quisermos;
- linhas 23-25: criamos uma pessoa [personne1] e apresentamos o seu dicionário [__dict__]. Aqui teremos:
personne1={'_BaseEntity__id': 67, '_Personne__prénom': 'x', '_Personne__nom': 'y', '_Personne__âge': 10}
- linhas 27-33: faz-se um mapeamento, ou seja, cria-se uma correspondência entre a classe [Personne] e a tabela [personnes]. Trata-se essencialmente de uma correspondência [propriétés de la classe colonnes de la table]. A função [mapper] aceita aqui três parâmetros:
- linha 28: o primeiro parâmetro é o nome da classe para a qual se efetua o mapeamento;
- linha 28: o segundo parâmetro é a tabela à qual será associada. Trata-se do objeto [Table] criado na linha 16;
- linha 28: o terceiro parâmetro é, neste caso, um parâmetro denominado [properties]. Trata-se de um dicionário em que as chaves são as propriedades da classe mapeada e os valores são as colunas da tabela mapeada. Para designar a coluna X da tabela [personnes_table], escreve-se [personnes_table.c.X];
- linhas 35-36: volta a apresentar a pessoa [personne1] após a realização do mapeamento. Verifica-se que não sofreu alterações:
personne1={'_BaseEntity__id': 67, '_Personne__prénom': 'x', '_Personne__nom': 'y', '_Personne__âge': 10}
- linhas 37-39: cria-se uma nova pessoa [personne2] e exibe-se a mesma. Obtém-se então a seguinte exibição:
personne2={'_sa_instance_state': <sqlalchemy.orm.state.InstanceState object at 0x00000259A6747FA0>, 'id': 68, 'prénom': 'x1', 'nom': 'y1', 'âge': 11}
Verifica-se que o dicionário [__dict__] sofreu alterações profundas:
- (continuação)
- aparece uma nova propriedade [_sa_instance_state]. Vê-se que se trata de um objeto do ORM [sqlalchemy];
- as restantes propriedades foram despojadas do seu prefixo, que indicava a que classe pertenciam;
Pode-se, portanto, concluir que a operação de mapeamento das linhas 27-33 alterou a classe [Personne].
Quando se pretender visualizar o estado de um objeto [Personne], normalmente não se pretende a propriedade [_sa_instance_state]. Na verdade, esta existe apenas para o funcionamento interno de [sqlalchemy] e, em geral, não nos interessa. É por isso que escrevemos no script [config]:
# configuração das classes
from Personne import Personne
Personne.excluded_keys = ['_sa_instance_state']
19.2.3. O script [main]
O script [main] irá manipular a tabela [personnes] da base de dados MySQL [dbpersonnes], interagindo com a tabela [sqlalchemy]. Para compreender o que se segue, é necessário recordar a arquitetura aqui utilizada:
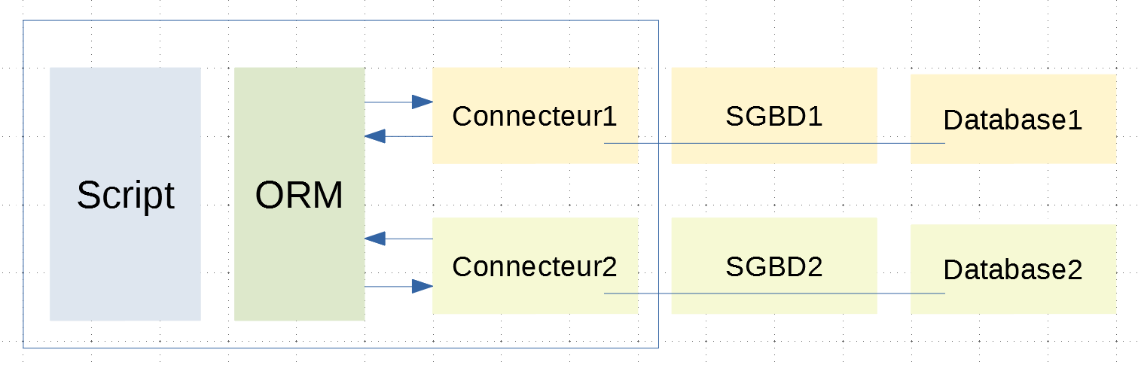
Se [Database1] for a base [dbpersonnes], verifica-se que a ligação entre o script e esta base passa por duas entidades:
- o conector Python para o SGBD MySQL;
- o SGBD MySQL;
O script [main] irá interagir com o ORM, que, por sua vez, irá interagir com o conector Python. O ORM comunica com este conector através das ferramentas descritas nos parágrafos |MySQL| e |PostgreSQL|, nomeadamente emitindo comandos SQL. O script [main] não irá utilizar comandos SQL. Vai basear-se na API (Interface de Programação de Aplicações) da ORM, composta por classes e interfaces.
O script [main] é o seguinte:
# configuramos a aplicação
import config
config = config.configure()
# importações
from sqlalchemy import create_engine, Table, Column, Integer, String, MetaData, UniqueConstraint
from sqlalchemy.exc import IntegrityError, InterfaceError
from sqlalchemy.orm import mapper, sessionmaker
from Personne import Personne
# cadeia de ligação a uma base de dados MySQL
engine = create_engine("mysql+mysqlconnector://admpersonnes:nobody@localhost/dbpersonnes")
# metadados
metadata = MetaData()
# a tabela
personnes_table = Table("personnes", metadata,
Column('id', Integer, primary_key=True),
Column('prenom', String(30), nullable=False),
Column("nom", String(30), nullable=False),
Column("age", Integer, nullable=False),
UniqueConstraint('nom', 'prenom', name='uix_1')
)
# o mapeamento
mapper(Personne, personnes_table, properties={
'id': personnes_table.c.id,
'nome próprio: personnes_table.c.prenom,
'apelido: personnes_table.c.nom,
'idade': personnes_table.c.age
})
# a fábrica de sessões
Session = sessionmaker()
Session.configure(bind=engine)
session = None
try:
# uma sessão
session = Session()
# eliminação da tabela [personnes]
session.execute("drop table if exists personnes")
# recriação da tabela a partir do mapeamento
metadata.create_all(engine)
# uma inserção
session.add(Personne().fromdict({"id": 67, "prénom": "x", "nom": "y", "âge": 10}))
# session.commit()
# uma consulta
personnes = session.query(Personne).all()
# exibição
print("Liste des personnes ---------")
for personne in personnes:
print(personne)
# duas outras inserções, das quais a segunda falha devido à regra de unicidade (nome, apelido)
session.add(Personne().fromdict({"id": 68, "prénom": "x1", "nom": "y1", "âge": 10}))
session.add(Personne().fromdict({"id": 69, "prénom": "x1", "nom": "y1", "âge": 10}))
# uma consulta
personnes = session.query(Personne).all()
# visualização
print("Liste des personnes ---------")
for personne in personnes:
print(personne)
# validação da sessão
session.commit()
except (InterfaceError, IntegrityError) as erreur:
# exibição
print(f"L'erreur suivante s'est produite : {erreur}")
# cancelamento da última sessão
if session:
print("rollback...")
session.rollback()
finally:
# libertação dos recursos da sessão
if session:
session.close()
Comentários
- linhas 1-4: a aplicação é configurada;
- linhas 7-9: importa-se toda uma série de classes e interfaces da biblioteca [sqlalchemy];
- linha 11: a classe [Personne] é importada;
- linha 14: a cadeia de ligação à base de dados. Esta especifica:
- o SGBD utilizado (mysql);
- o conector Python utilizado (mysql.connector sem o ponto);
- o utilizador que se liga (admpersonnes);
- a sua palavra-passe (nobody);
- a máquina onde se encontra o SGBD (localhost = máquina onde se encontra o script que está a ser executado);
- o nome da base de dados (dbpersonnes);
Com estas informações, o [sqlalchemy] pode ligar-se à base de dados. Note-se que o conector Python utilizado já deve estar instalado. O [sqlalchemy] não o faz.
- linhas 19-26: descrição da tabela [personnes];
- linhas 28-34: mapeamento entre a classe [Personne] e a tabela [personnes];
- linhas 36-38: a maioria das operações [sqlalchemy] é realizada numa sessão. O conceito de sessão [sqlalchemy] é semelhante ao de transação SQL. As sessões são criadas a partir da classe [Session], devolvida pela função [sessionmaker] da linha 37;
- linha 38: a classe [Session] é associada à base [dbpersonnes] através da cadeia de ligação da linha 14;
- linha 43: é criada uma sessão. Como já foi referido, uma sessão pode ser comparada a uma transação;
- linhas 45-46: o método [Session.execute] permite executar uma ordem SQL. Isto não é algo comum, uma vez que já foi referido que o ORM permitia evitar a linguagem SQL;
- linhas 48-49: o método [metadata.create_all] permite criar todas as tabelas utilizando a instância [MetaData] da linha 17. Temos apenas uma: a tabela [personnes] definida nas linhas 20-26. O [sqlalchemy] irá utilizar a informação destas linhas para criar a tabela. Aqui reside uma das principais vantagens do ORM: oculta as especificidades das ordens SGBD. Com efeito, a ordem SQL [create] pode ser muito diferente de uma SGBD para outra, devido aos tipos atribuídos às colunas. Não houve uma padronização dos tipos de dados. Assim, a ordem varia de um para outro. Aqui, graças a isto:
- descrevemos de forma única a tabela que pretendemos;
- o [sqlalchemy] consegue gerar o [create] adequado para o SGBD que tem à sua frente;
- linha 52: adicionamos um objeto [Personne] à sessão. Isto não o adiciona automaticamente à base de dados. Com efeito, um ORM segue as suas próprias regras para se sincronizar com a base de dados. Procura sempre otimizar o número de consultas que efetua. Vejamos um exemplo. O script adiciona (add) duas pessoas (pessoa1, pessoa2) à sessão e, em seguida, faz uma consulta: pretende ver todas as pessoas presentes na tabela. O [sqlalchemy] pode proceder da seguinte forma:
- a adição de [personne1] pode ser feita na memória. Não há necessidade, por enquanto, de a inserir na base de dados;
- o mesmo se aplica a [personne2];
- segue-se a consulta do tipo [select]. É então necessário recuperar todas as linhas da tabela [personnes]. O [sqlalchemy] irá então inserir o [personne1, personne2] na base de dados e, em seguida, efetuar a consulta;
[sqlalchemy] irá, assim, realizar otimizações transparentes para o programador.
- linha 56: para efetuar uma consulta do tipo [select] (quero ver…), utiliza-se o método [Session.query]. O parâmetro do método [query] é a classe mapeada com a tabela consultada. Este método devolve um tipo [Query]. O método [Query.all] solicita todos os objetos [Personne] da sessão. São-lhe devolvidas todas as linhas da tabela [personnes], cada uma na forma de um objeto [Personne]. Para o fazer, o [sqlalchemy] utiliza o mapeamento que foi definido entre a classe [Personne] e a tabela [personnes]. O resultado da linha 56 é uma lista de objetos [Personne];
- linhas 58-61: são apresentados os elementos da lista [personnes]. Como a classe [Personne] deriva da classe [BaseEntity], o método [Personne.__str__] utilizado aqui implicitamente na linha 61 é, na verdade, o método [BaseEntity.__str__], que devolve a cadeia jSON do objeto chamador. Esta cadeia é a cadeia jSON do dicionário [Personne.asdict] (ver |BaseEntity|). Já referimos que, após o mapeamento, iríamos encontrar a propriedade [_sa_instance_state] em cada objeto [Personne]. No entanto, o valor desta propriedade não é do tipo [BaseEntity]. É, portanto, necessário excluí-la do dicionário da classe [Personne]; caso contrário, a visualização «trava». Foi isso que foi feito no script [config];
- linhas 63-65: adicionam-se mais duas pessoas com o mesmo nome e apelido. No entanto, existe uma restrição de unicidade na união destas duas colunas. Por conseguinte, deveria ocorrer um erro. É isso que se pretende verificar;
- linhas 67-68: solicitamos novamente a lista de todas as pessoas da base de dados;
- linhas 70-73: e exibimo-las;
- linhas 75-76: a sessão é validada («committed»). Como o próprio nome indica, a transação subjacente vai ser validada;
- veremos, durante a execução, que as linhas 67-76 não serão executadas devido à exceção gerada pela linha 65. Passaremos então para as linhas 78-84 para tratar da exceção;
- linha 78: a exceção [InterfaceError] ocorre se [sqlalchemy] não conseguir ligar-se à base de dados [dbpersonnes]. A exceção [IntegrityError] ocorre na linha 65;
- linha 80: é exibido o erro;
- linhas 82-84: se a sessão existir, é cancelada. Isto equivale a cancelar a transação subjacente;
- linhas 85-88: em todos os casos, haja ou não erro, a sessão é encerrada para libertar recursos;
Os resultados da execução são os seguintes:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/databases/sqlalchemy/01/main.py
Liste des personnes ---------
{"nom": "y", "prénom": "x", "id": 67, "âge": 10}
L'erreur suivante s'est produite : (raised as a result of Query-invoked autoflush; consider using a session.no_autoflush block if this flush is occurring prematurely)
(mysql.connector.errors.IntegrityError) 1062 (23000): Duplicate entry 'y1-x1' for key 'uix_1'
[SQL: INSERT INTO personnes (id, prenom, nom, age) VALUES (%(id)s, %(prenom)s, %(nom)s, %(age)s)]
[parameters: ({'id': 68, 'prenom': 'x1', 'nom': 'y1', 'age': 10}, {'id': 69, 'prenom': 'x1', 'nom': 'y1', 'age': 10})]
(Background on this error at: http://sqlalche.me/e/13/gkpj)
rollback...
Process finished with exit code 0
- linhas 2-3: a lista de pessoas após a primeira inserção;
- linha 5: a exceção [IntegrityError] que ocorreu quando foram adicionadas duas pessoas com o mesmo nome e apelido;
- linhas 6-7: note-se a ordem SQL que falhou. Trata-se de uma ordem INSERT configurada: a ordem [sqlalchemy] inseriu as duas pessoas com uma única ordem INSERT. Vemos aqui que tentou otimizar as ordens SQL emitidas;
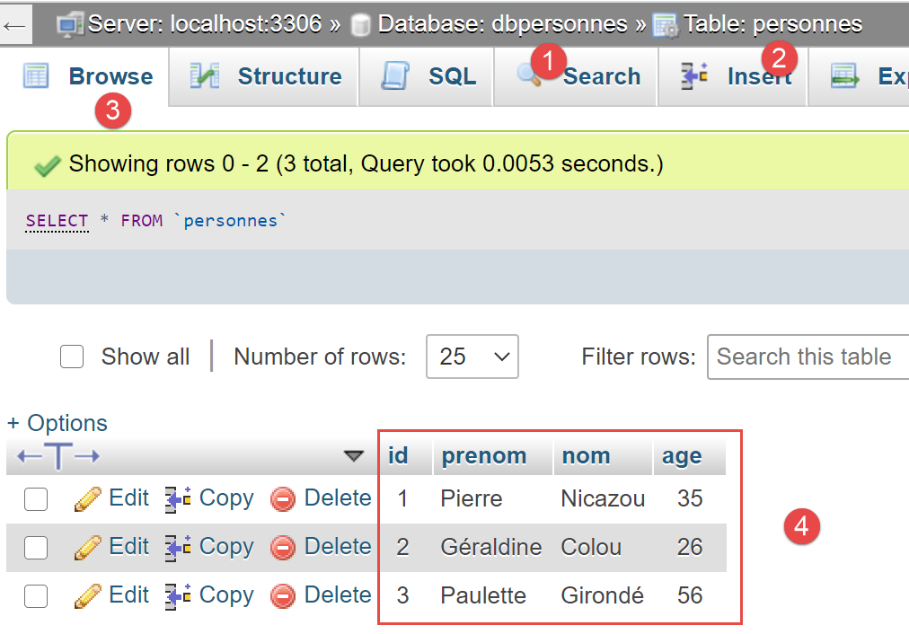
Agora vamos ver, com o phpMyAdmin, o conteúdo da tabela [personnes]:
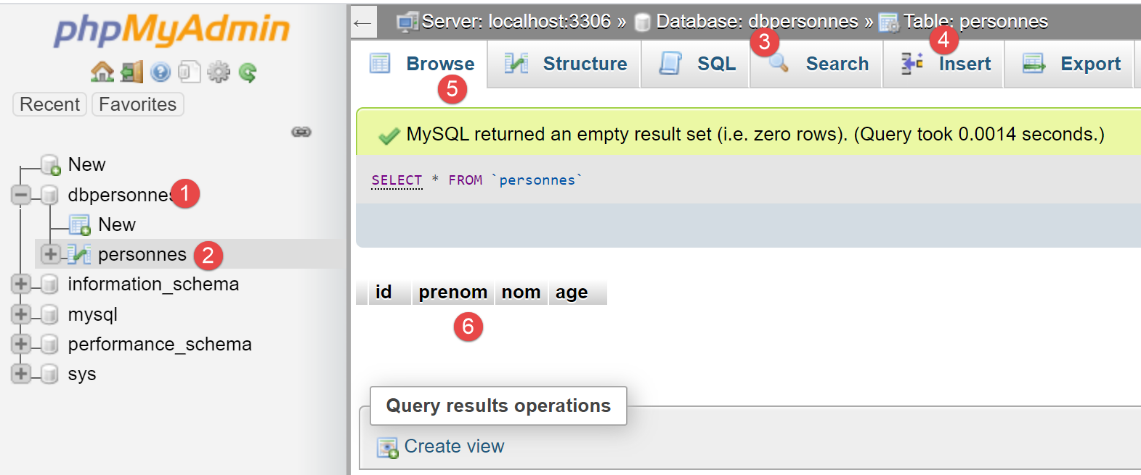
Vemos em [6] que a tabela está vazia. Nem sequer consta a primeira pessoa que o script tinha inserido na sessão. Isto porque a sessão decorria numa transação e esta foi revertida na cláusula [except] do script [main].
Vamos agora proceder à seguinte alteração no [main]:
# uma inserção
session.add(Personne().fromdict({"id": 67, "prénom": "x", "nom": "y", "âge": 10}))
# session.commit()
Depois de adicionar uma pessoa na linha 2, removemos o comentário da linha 3. A operação [session.commit] irá validar a transação subjacente e uma nova transação será iniciada. Após a execução, o conteúdo da tabela [personnes] é o seguinte:
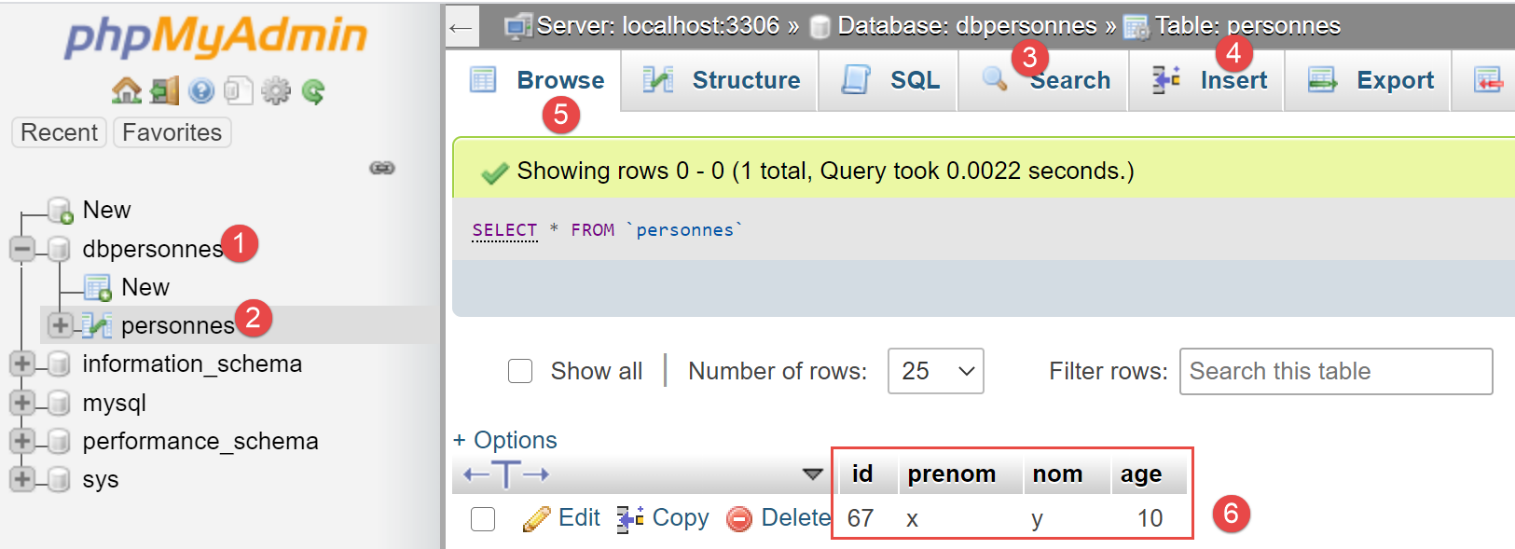
Vemos em [6] que a primeira inserção foi mantida. Isto deve-se ao facto de ter sido efetuada no âmbito de uma transação 1 e de o erro que se seguiu ter ocorrido no âmbito de uma transação 2.
19.3. Scripts 02: os mapeamentos de [sqlalchemy]

Os scripts 02 são uma variante dos scripts 01. Procuramos efetuar o máximo de configurações no [config.py]. Configuramos agora o ambiente [sqlalchemy] da aplicação:
def configure():
# caminho absoluto de referência dos caminhos relativos da configuração
root_dir = "C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020"
# caminhos absolutos das dependências
absolute_dependencies = [
# BaseEntity, MyException, Pessoa, Utilitários
f"{root_dir}/classes/02/entities",
]
# define-se o syspath
from myutils import set_syspath
set_syspath(absolute_dependencies)
# importações
from sqlalchemy import create_engine, Table, Column, Integer, String, MetaData, UniqueConstraint
from sqlalchemy.orm import mapper, sessionmaker
# ligação a uma base de dados MySQL
engine = create_engine("mysql+mysqlconnector://admpersonnes:nobody@localhost/dbpersonnes")
# metadados
metadata = MetaData()
# a tabela
personnes_table = Table("personnes", metadata,
Column('id', Integer, primary_key=True),
Column('prenom', String(30), nullable=False),
Column("nom", String(30), nullable=False),
Column("age", Integer, nullable=False),
UniqueConstraint('nom', 'prenom', name='uix_1')
)
# o mapeamento
from Personne import Personne
mapper(Personne, personnes_table, properties={
'id': personnes_table.c.id,
'nome próprio: personnes_table.c.prenom,
'apelido: personnes_table.c.nom,
'idade': personnes_table.c.age
})
# a fábrica de sessões
Session = sessionmaker()
Session.configure(bind=engine)
# estas informações são inseridas na configuração
config = {}
config["Session"] = Session
config["metadata"] = metadata
config["engine"] = engine
config["personnes_table"] = personnes_table
# configuração das classes
from Personne import Personne
Personne.excluded_keys = ['_sa_instance_state']
# carregamos a configuração
return config
Comentários
- linhas 2-12: configuração do Python Path;
- linhas 14-45: configuração do ambiente [sqlalchemy];
- linhas 47-52: o ambiente [sqlalchemy] é adicionado ao dicionário de configuração;
- linhas 54-56: configuração da classe [Personne];
Com esta configuração, o script [main] passa a ter o seguinte aspeto:
# configuramos a aplicação
import config
config = config.configure()
# o syspath está configurado — faz-se as importações
from sqlalchemy.exc import IntegrityError, DatabaseError, InterfaceError
from sqlalchemy.orm.exc import FlushError
from Personne import Personne
session = None
try:
# uma sessão
session = config["Session"]()
# eliminação da tabela [personnes]
session.execute("drop table if exists personnes")
# recriação da tabela a partir do mapeamento
config["metadata"].create_all(config["engine"])
# duas inserções
session.add(Personne().fromdict({"prénom": "x", "nom": "y", "âge": 10}))
personne = Personne().fromdict({"prénom": "x1", "nom": "y1", "âge": 7})
session.add(personne)
# validação das duas inserções
session.commit()
# uma consulta
personnes = session.query(Personne).all()
# exibição
print("Liste des personnes-----------")
for personne in personnes:
print(personne)
# duas outras inserções, das quais a segunda falha
session.add(Personne().fromdict({"prénom": "x2", "nom": "y2", "âge": 10}))
session.add(Personne().fromdict({"prénom": "x2", "nom": "y2", "âge": 10}))
# uma consulta
personnes = session.query(Personne).all()
# exibição
print("Liste des personnes-----------")
for personne in personnes:
print(personne)
# validação da sessão
session.commit()
except (FlushError, DatabaseError, InterfaceError, IntegrityError) as erreur:
# exibição
print(f"L'erreur suivante s'est produite : {erreur}")
# cancelamento da última sessão
if session:
print("rollback...")
session.rollback()
finally:
# exibição
print("Travail terminé...")
# libertação dos recursos da sessão
if session:
session.close()
Os resultados da execução são os seguintes:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/databases/sqlalchemy/02/main.py
Liste des personnes-----------
{"âge": 10, "nom": "y", "prénom": "x", "id": 1}
{"âge": 7, "nom": "y1", "prénom": "x1", "id": 2}
L'erreur suivante s'est produite : (raised as a result of Query-invoked autoflush; consider using a session.no_autoflush block if this flush is occurring prematurely)
(mysql.connector.errors.IntegrityError) 1062 (23000): Duplicate entry 'y2-x2' for key 'uix_1'
[SQL: INSERT INTO personnes (prenom, nom, age) VALUES (%(prenom)s, %(nom)s, %(age)s)]
[parameters: {'prenom': 'x2', 'nom': 'y2', 'age': 10}]
(Background on this error at: http://sqlalche.me/e/13/gkpj)
rollback...
Travail terminé...
Process finished with exit code 0
Em phpMyAdmin, a tabela [personnes] passou a ter o seguinte aspeto:
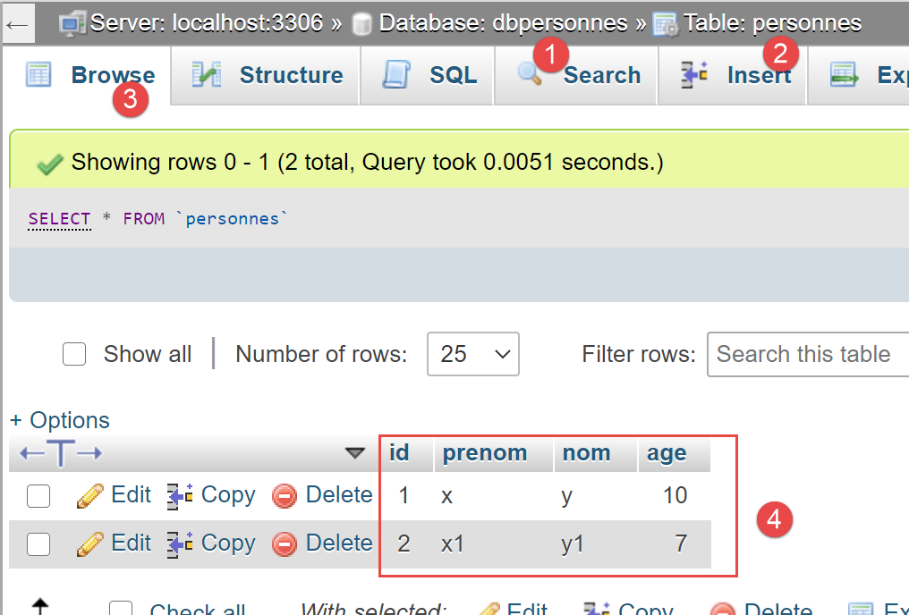
Agora, vejamos a tabela [personnes] gerada por [sqlalchemy]:
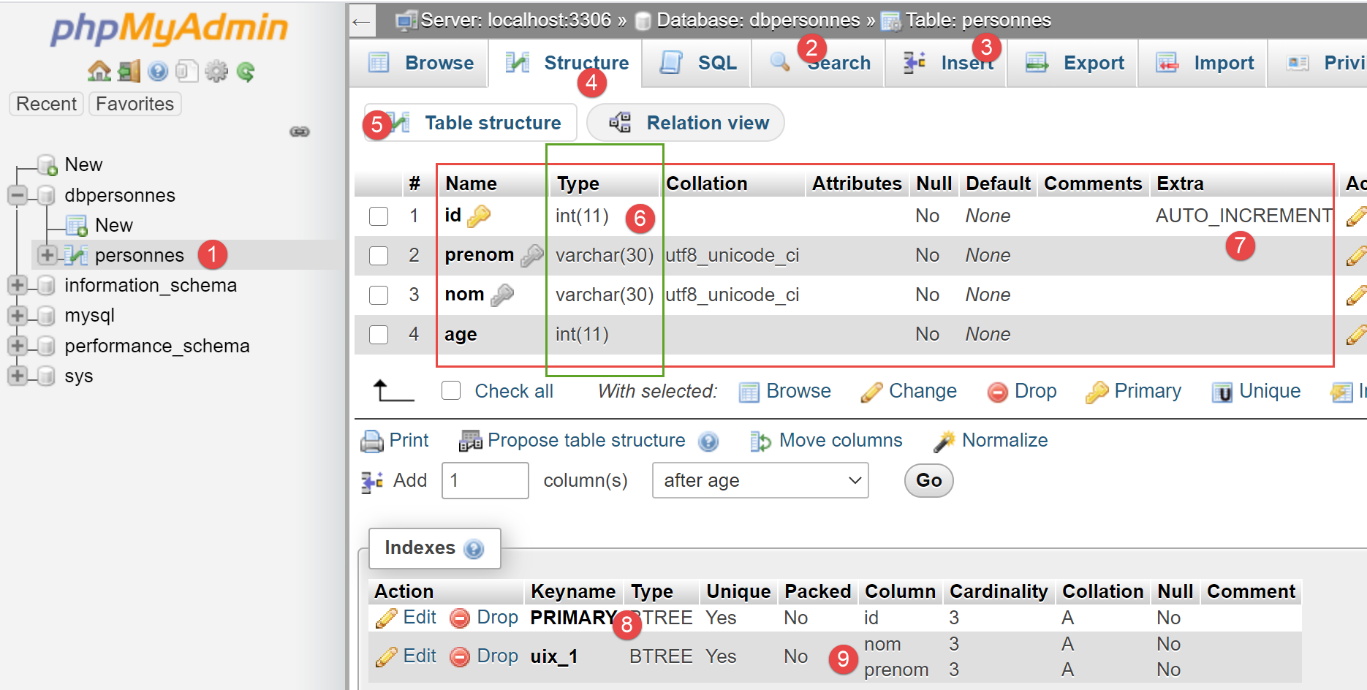
- em [6], os tipos utilizados para as diferentes colunas;
- em [7], vemos que a coluna [id] tem o atributo [AUTO_INCREMENT]. Isto significa que, ao inserir uma linha na tabela, se essa linha não tiver um valor para a coluna [id], este será gerado por MySQL de forma incremental: 1, 2, 3, … Esta propriedade evita que tenhamos de nos preocupar com o valor da chave primária quando efetuamos uma inserção na tabela: deixamos que a MySQL a gere;
- em [8], vemos que a coluna [id] é a chave primária;
- em [9], encontramos a restrição de unicidade nos campos [nom, prenom];
19.4. Scripts 03: manipulação das entidades da sessão [sqlalchemy]
O ficheiro de configuração [config] é o mesmo que no exemplo anterior. No script [main], realizam-se as operações clássicas [INSERT, UPDATE, DELETE, SELECT] na tabela [personnes] utilizando os métodos de [sqlalchemy]:
# configuração da aplicação
import config
config = config.configure()
# importações
from sqlalchemy import func
from sqlalchemy.exc import IntegrityError, DatabaseError, InterfaceError
from sqlalchemy.orm.session import Session
from Personne import Personne
# exibe o conteúdo da tabela [personnes]
def affiche_table(session: Session):
print("----------------")
# uma consulta
personnes = session.query(Personne).all()
# visualização
affiche_personnes(personnes)
# exibe uma lista de pessoas
def affiche_personnes(personnes: list):
print("----------------")
# visualização
for personne in personnes:
print(personne)
# principal ---------------------------
session = None
try:
# uma sessão
session = config["Session"]()
# eliminação da tabela [personnes]
# checkfirst=True: verifica primeiro se a tabela existe
config["personnes_table"].drop(config["engine"], checkfirst=True)
# recriação da tabela a partir do mapeamento
config["metadata"].create_all(config["engine"])
# inserções
session.add(Personne().fromdict({"prénom": "Pierre", "nom": "Nicazou", "âge": 35}))
session.add(Personne().fromdict({"prénom": "Géraldine", "nom": "Colou", "âge": 26}))
session.add(Personne().fromdict({"prénom": "Paulette", "nom": "Girondé", "âge": 56}))
# exibe-se o conteúdo da sessão
affiche_table(session)
# lista de pessoas por ordem alfabética dos apelidos e, em caso de igualdade de apelidos, por ordem alfabética dos nomes próprios
personnes = session.query(Personne).order_by(Personne.nom.desc(), Personne.prénom.desc())
# exibição
affiche_personnes(personnes)
# lista de pessoas com idade no intervalo [20,40], por ordem decrescente de idade
# e, em caso de idades iguais, por ordem alfabética dos apelidos e, em caso de apelidos iguais, por ordem alfabética dos nomes próprios
personnes = session.query(Personne). \
filter(Personne.âge >= 20, Personne.âge <= 40). \
order_by(Personne.âge.desc(), Personne.nom.asc(), Personne.prénom.asc())
# exibição
affiche_personnes(personnes)
# inserção da Sra. Bruneau
bruneau = Personne().fromdict({"prénom": "Josette", "nom": "Bruneau", "âge": 46})
session.add(bruneau)
# alteração da sua idade
bruneau.âge = 47
# lista de pessoas com o apelido Bruneau
personne = session.query(Personne).filter(func.lower(Personne.nom) == "bruneau").first()
# visualização
affiche_personnes([personne])
# eliminação da Sra. Bruneau
session.delete(personne)
# lista de pessoas com o apelido Bruneau
personnes = session.query(Personne).filter(func.lower(Personne.nom) == "bruneau")
# visualização
affiche_personnes(personnes)
# validação da sessão
session.commit()
except (DatabaseError, InterfaceError, IntegrityError) as erreur:
# visualização
print(f"L'erreur suivante s'est produite : {erreur}")
# anulação da última sessão
if session:
session.rollback()
finally:
# visualização
print("Travail terminé...")
# libertação dos recursos da sessão
if session:
session.close()
Comentários
- linhas 20-25: a função [affiche_personnes] apresenta os elementos de uma lista de pessoas;
- linhas 12-18: a função [affiche_table] apresenta o conteúdo da tabela [personnes];
- linhas 34-36: elimina-se a tabela [personnes]. Ao contrário das versões anteriores, não se utiliza uma ordem SQL, mas sim um método de [sqlalchemy]:
- config["personnes_table"] é o objeto [Table] que descreve a tabela [personnes];
- config["engine"] é a cadeia de ligação à base de dados [dbpersonnes];
- o parâmetro denominado [checkfirst=True] determina que a operação só seja executada se a tabela [personnes] existir;
- linhas 38-39: a tabela [personnes] é recriada;
- linhas 41-44: são adicionadas três pessoas à sessão. Recorde-se que estas não são necessariamente inseridas de imediato na tabela [personnes]. Isso depende da estratégia da [sqlalchemy], que visa o desempenho;
- linhas 46-47: o conteúdo da tabela [personnes] é apresentado. Se as inserções das três pessoas ainda não tivessem sido efetuadas, são agora inseridas devido a este pedido;
- linhas 49-50: um exemplo de utilização do método [order_by], que permite apresentar os resultados de uma consulta numa determinada ordem. A sintaxe [order_by(critère1, critère2)] apresenta os resultados primeiro de acordo com o critério [critère1] e, quando as linhas apresentam o mesmo valor de [critère1], são então ordenadas de acordo com o critério [critère2]. É possível definir vários critérios desta forma;
- linhas 55-59: introduzem o conceito de filtro com o método [filter]. A notação [filter(critère1, critère2)] estabelece uma relação lógica (ET) entre os critérios utilizados;
- linhas 64-67: é iniciada uma nova sessão;
- linhas 70-71: outro exemplo de consulta filtrada. A função [func.lower(param)] converte [param] em minúsculas. Existem, assim, outras funções disponíveis, designadas por [func.xx]. Na expressão da linha 71:
- [session.query.filter] devolve uma lista de objetos [Personne];
- [session.query.filter.first] devolve o primeiro elemento dessa lista;
- linha 77: remove-se um elemento da sessão;
- linha 86: a sessão é validada;
Os resultados da execução são os seguintes:
- linhas 4-6: o conteúdo da sessão;
- linhas 8-10: o conteúdo da sessão por ordem decrescente dos nomes;
- linhas 12-13: o conteúdo da sessão para as pessoas cuja idade se situa no intervalo [20, 40];
- linha 15: a pessoa com o nome «bruneau»;
Em phpMyAdmin, o conteúdo da tabela [personnes] no final da execução é o seguinte:
19.5. Scripts 04: utilização de uma base de dados [PostgreSQL]
A pasta [04] é uma cópia da pasta [03]. Altera-se apenas um elemento: a cadeia de ligação no ficheiro [config]:
# ligação a uma base de dados PostgreSQL
engine = create_engine("postgresql+psycopg2://admpersonnes:nobody@localhost/dbpersonnes")
Agora, esta cadeia de ligação aponta para a base de dados [dbpersonnes] de um SGBD [PostgreSQL]. Deve-se notar a utilização do conector [psycopg2]. Este tem de estar instalado.
A execução do script [main] produz os seguintes resultados:
Com a ferramenta [pgAdmin] (ver parágrafo |pgAdmin|), a tabela [personnes] apresenta o seguinte estado:
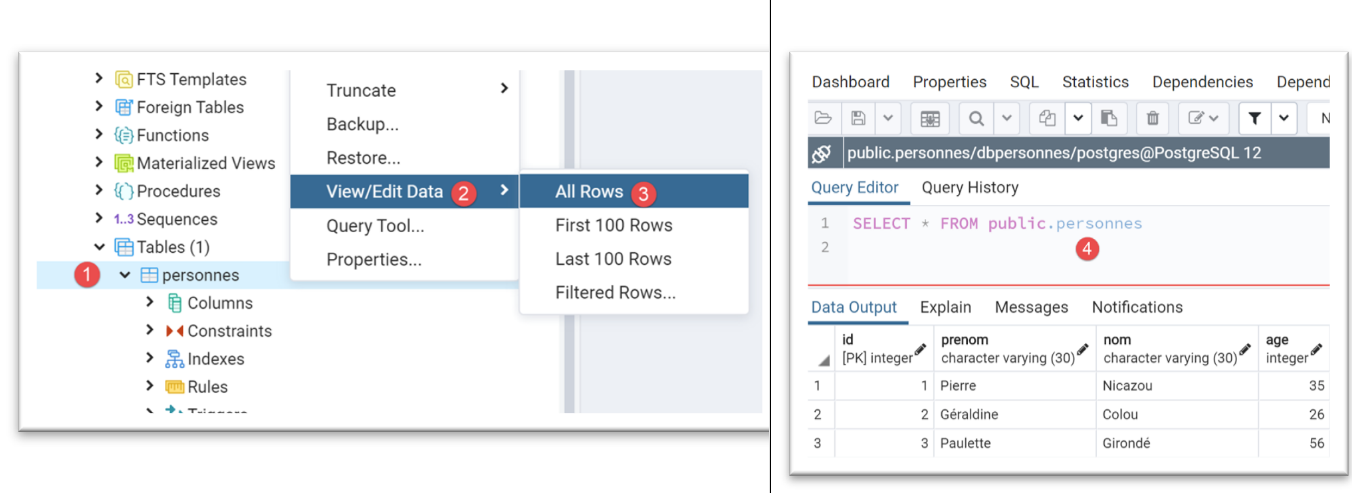
A tabela [personnes] foi gerada com o código SQL seguinte:
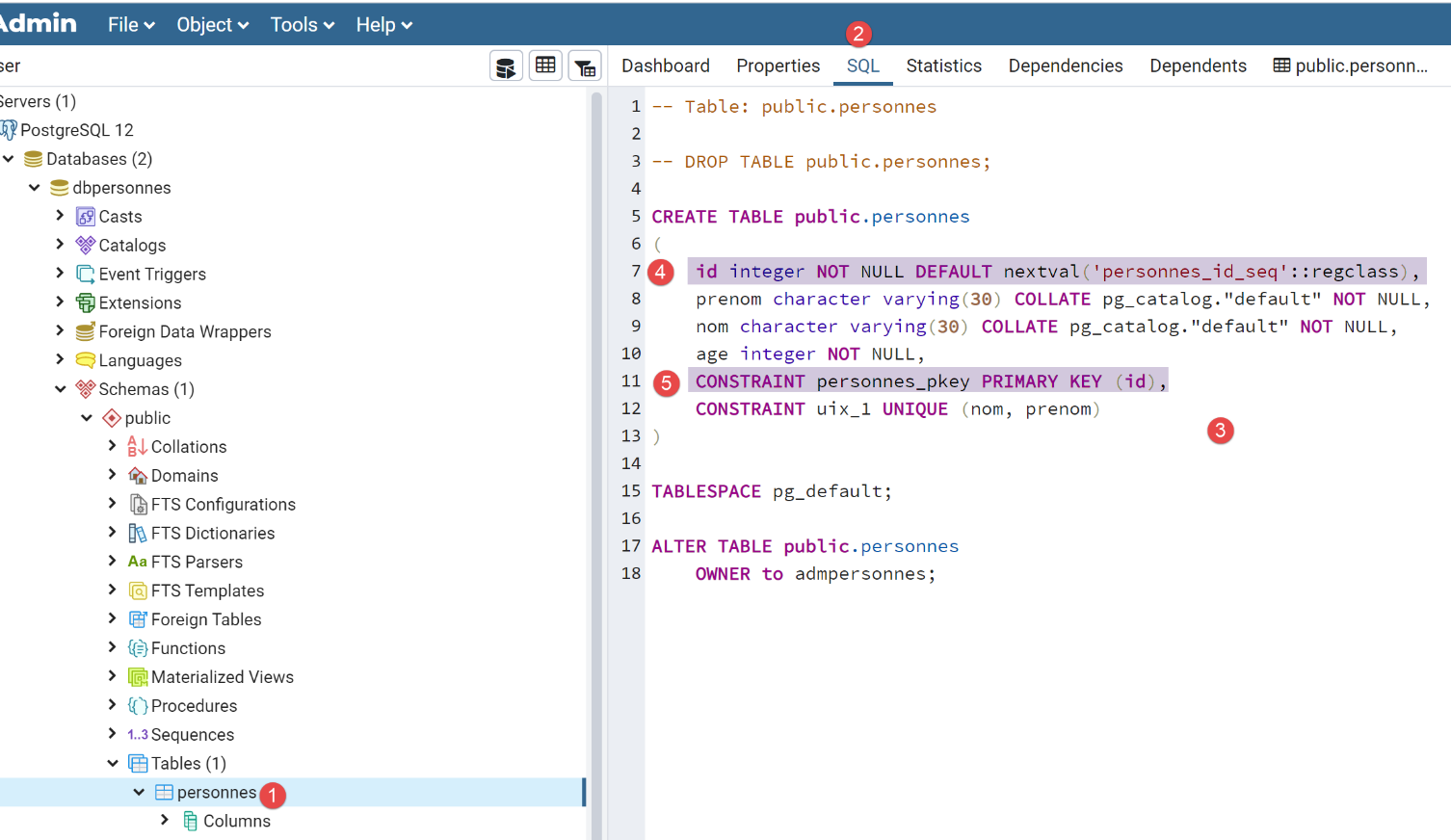
- em [4-5], verifica-se que a coluna [id] é a chave primária. Vê-se também que tem um valor por defeito [mot clé DEFAULT], o que faz com que, se se inserir uma linha sem chave primária, esta seja gerada pelo SGBD. Trata-se de um procedimento comum: deixa-se que o SGBD gere as chaves primárias;
Esta versão 05 dos scripts [sqlalchemy] ilustra bem a facilidade de passar de um SGBD para outro: bastou alterar a cadeia de ligação num script de configuração. Nada mais mudou. Se compararmos os tipos das colunas do [id, nom, prenom, age] acima com os da tabela MySQL do exemplo |02|, verificamos que são diferentes. O [sqlalchemy] adapta-as ao SGBD utilizado. Esta facilidade de adaptação a um novo SGBD é motivo suficiente para adotar o [sqlalchemy] ou outro ORM.
19.6. Scripts 05: exemplo completo
O exemplo analisado é uma repetição do exemplo estudado no parágrafo |troiscouches-v01|. Esse exemplo apresentava uma arquitetura de três camadas [ui, métier, dao] que manipulava entidades [Classe, Elève, Matière, Note]. As entidades estavam codificadas de forma estática numa camada [dao]. Agora, vamos colocá-las numa base de dados. Utilizaremos duas camadas SGBD: MySQL e PostgreSQL.
19.6.1. A arquitetura da aplicação
A arquitetura da aplicação será a seguinte:
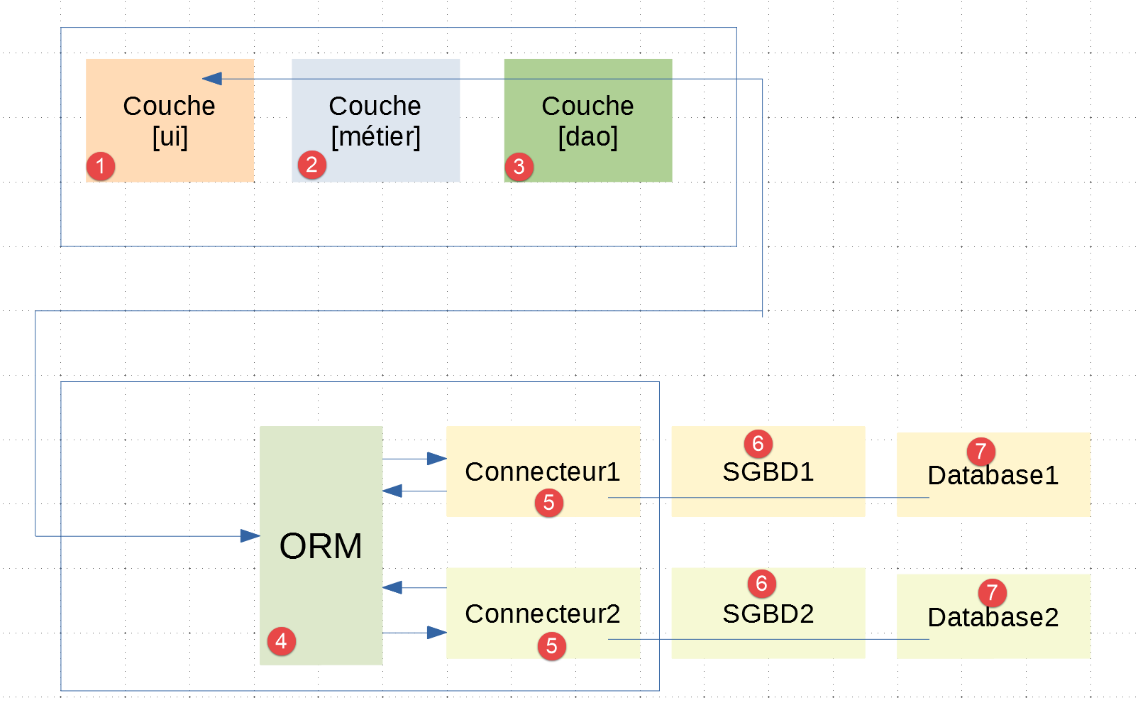
- No [1-3], encontram-se as camadas [ui, métier, dao] já presentes no exemplo |troiscouches-v01|. A camada [dao] comunica agora com a camada [ORM];
- as camadas [1-5] são implementadas por código Python;
19.6.2. As bases de dados
Criamos uma base de dados MySQL denominada [dbecole], propriedade do utilizador [admecole], com a palavra-passe [mdpecole]. Para tal, seguimos o procedimento descrito no parágrafo |criação de uma base de dados|:
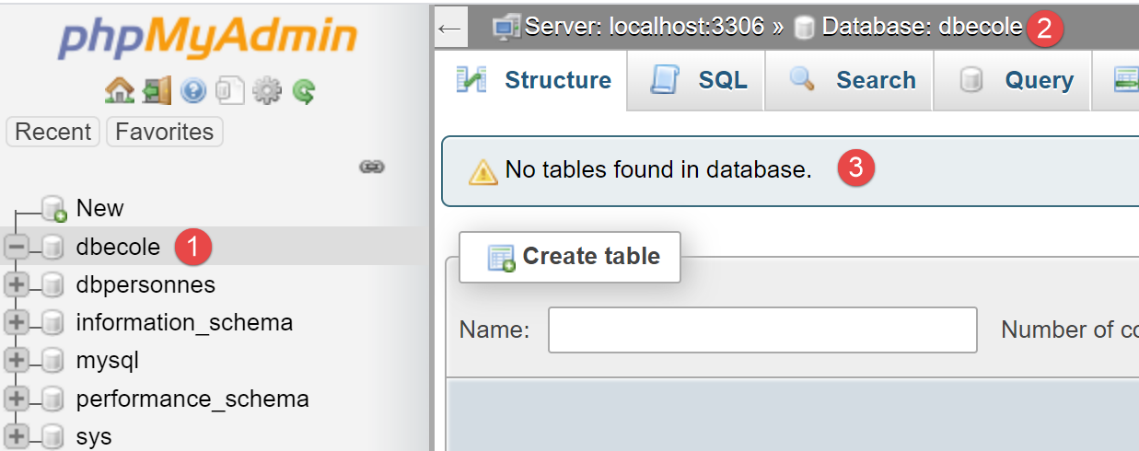
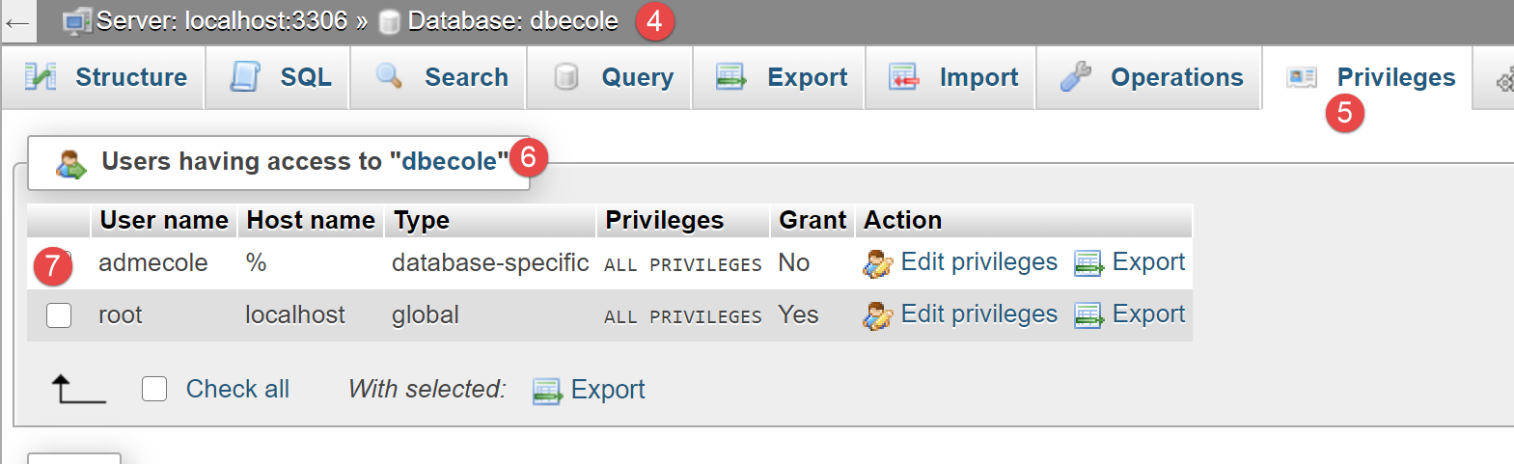
- em [1], a base de dados [dbecole] sem as tabelas [3];
- na base de dados [7], o utilizador [admecole] tem todos os privilégios sobre esta base de dados;
Fazemos o mesmo com a base SGBD e a PostgreSQL. Criamos uma base de dados denominada [dbecole], propriedade do utilizador [admecole], com a palavra-passe [mdpecole]. Para tal, seguimos o procedimento descrito no parágrafo |criação de uma base de dados|:
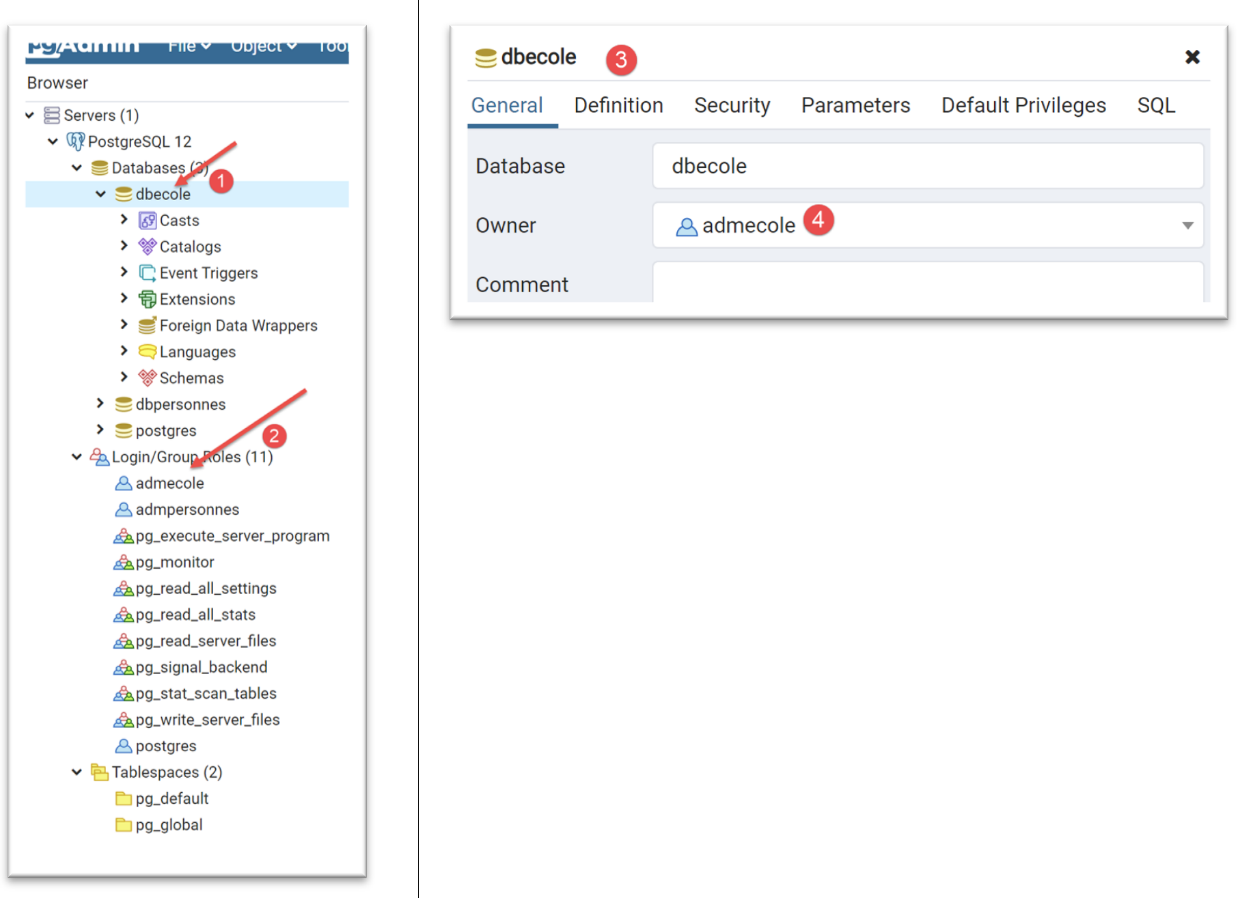
- em [1], a base de dados [dbecole];
- em [2], o utilizador [admecole];
- em [3-4], a base de dados [dbecole] é propriedade do utilizador [admecole];
19.6.3. As entidades manipuladas pela aplicação
Na aplicação |troiscouches v01|, as entidades manipuladas eram as seguintes (ver |entidades|). São estas entidades que serão armazenadas nas bases de dados anteriores. Não iremos duplicar estas entidades na nova aplicação. Iremos buscá-las onde já estão definidas.
A classe [Classe]:
# importações
from BaseEntity import BaseEntity
from MyException import MyException
from Utils import Utils
class Classe(BaseEntity):
# atributos excluídos do estado da classe
excluded_keys = []
# propriedades da classe
@staticmethod
def get_allowed_keys() -> list:
# id: identificador da classe
# nome: nome da classe
return BaseEntity.get_allowed_keys() + ["nom"]
# getter
@property
def nom(self: object) -> str:
return self.__nom
# setters
@nom.setter
def nom(self: object, nom: str):
# o nome deve ser uma cadeia de caracteres não vazia
if Utils.is_string_ok(nom):
self.__nom = nom
else:
raise MyException(11, f"Le nom de la classe {self.id} doit être une chaîne de caractères non vide")
A classe [Elève]:
# importações
from BaseEntity import BaseEntity
from Classe import Classe
from MyException import MyException
from Utils import Utils
class Elève(BaseEntity):
# atributos excluídos do estado da classe
excluded_keys = []
# propriedades da classe
@staticmethod
def get_allowed_keys() -> list:
# id: identificador do aluno
# apelido: apelido do aluno
# nome próprio: nome próprio do aluno
# turma: turma do aluno
return BaseEntity.get_allowed_keys() + ["nom", "prénom", "classe"]
# getters
@property
def nom(self: object) -> str:
return self.__nom
@property
def prénom(self: object) -> str:
return self.__prénom
@property
def classe(self: object) -> Classe:
return self.__classe
# setters
@nom.setter
def nom(self: object, nom: str) -> str:
# o apelido deve ser uma cadeia de caracteres não vazia
if Utils.is_string_ok(nom):
self.__nom = nom
else:
raise MyException(41, f"Le nom de l'élève {self.id} doit être une chaîne de caractères non vide")
@prénom.setter
def prénom(self: object, prénom: str) -> str:
# o nome próprio deve ser uma cadeia de caracteres não vazia
if Utils.is_string_ok(prénom):
self.__prénom = prénom
else:
raise MyException(42, f"Le prénom de l'élève {self.id} doit être une chaîne de caractères non vide")
@classe.setter
def classe(self: object, value):
try:
# é esperado um tipo Classe
if isinstance(value, Classe):
self.__classe = value
# ou um tipo «dict»
elif isinstance(value,dict):
self.__classe=Classe().fromdict(value)
# ou um tipo json
elif isinstance(value,str):
self.__classe = Classe().fromjson(value)
except BaseException as erreur:
raise MyException(43, f"L'attribut [{value}] de l'élève {self.id} doit être de type Classe ou dict ou json. Erreur : {erreur}")
A classe [Matière]:
# importações
from BaseEntity import BaseEntity
from MyException import MyException
from Utils import Utils
class Matière(BaseEntity):
# atributos excluídos do estado da classe
excluded_keys = []
# propriedades da classe
@staticmethod
def get_allowed_keys() -> list:
# id: identificador da disciplina
# nome: nome da disciplina
# coeficiente: coeficiente da disciplina
return BaseEntity.get_allowed_keys() + ["nom", "coefficient"]
# getter
@property
def nom(self: object) -> str:
return self.__nom
@property
def coefficient(self: object) -> float:
return self.__coefficient
# setters
@nom.setter
def nom(self: object, nom: str):
# o nome deve ser uma cadeia de caracteres não vazia
if Utils.is_string_ok(nom):
self.__nom = nom
else:
raise MyException(21, f"Le nom de la matière {self.id} doit être une chaîne de caractères non vide")
@coefficient.setter
def coefficient(self, coefficient: float):
# o coeficiente deve ser um número real >=0
erreur = False
if isinstance(coefficient, (int, float)):
if coefficient >= 0:
self.__coefficient = coefficient
else:
erreur = True
else:
erreur = True
# erro?
if erreur:
raise MyException(22, f"Le coefficient de la matière {self.nom} doit être un réel >=0")
A classe [Note]:
# importações
from BaseEntity import BaseEntity
from Elève import Elève
from Matière import Matière
from MyException import MyException
class Note(BaseEntity):
# atributos excluídos do estado da classe
excluded_keys = []
# propriedades da classe
@staticmethod
def get_allowed_keys() -> list:
# id: identificador da nota
# valor: a própria nota
# aluno: aluno (do tipo Aluno) a quem a nota diz respeito
# disciplina: disciplina (do tipo Disciplina) a que a nota se refere
# o objeto «Nota» corresponde, portanto, à nota de um aluno numa disciplina
return BaseEntity.get_allowed_keys() + ["valeur", "élève", "matière"]
# getters
@property
def valeur(self: object) -> float:
return self.__valeur
@property
def élève(self: object) -> Elève:
return self.__élève
@property
def matière(self: object) -> Matière:
return self.__matière
# getters
@valeur.setter
def valeur(self: object, valeur: float):
# a nota deve ser um número real entre 0 e 20
if isinstance(valeur, (int, float)) and 0 <= valeur <= 20:
self.__valeur = valeur
else:
raise MyException(31,
f"L'attribut {valeur} de la note {self.id} doit être un nombre dans l'intervalle [0,20]")
@élève.setter
def élève(self: object, value):
try:
# espera-se um tipo «Aluno»
if isinstance(value, Elève):
self.__élève = value
# ou um tipo «dict»
elif isinstance(value, dict):
self.__élève = Elève().fromdict(value)
# ou um tipo json
elif isinstance(value, str):
self.__élève = Elève().fromjson(value)
except BaseException as erreur:
raise MyException(32,
f"L'attribut [{value}] de la note {self.id} doit être de type Elève ou dict ou json. Erreur : {erreur}")
@matière.setter
def matière(self: object, value):
try:
# é esperado um tipo «Matière»
if isinstance(value, Matière):
self.__matière = value
# ou um tipo «dict»
elif isinstance(value, dict):
self.__matière = Matière().fromdict(value)
# ou um tipo json
elif isinstance(value, str):
self.__matière = Matière().fromjson(value)
except BaseException as erreur:
raise MyException(33,
f"L'attribut [{value}] de la note {self.id} doit être de type Matière ou dict ou json. Erreur : {erreur}")
19.6.4. Configuração
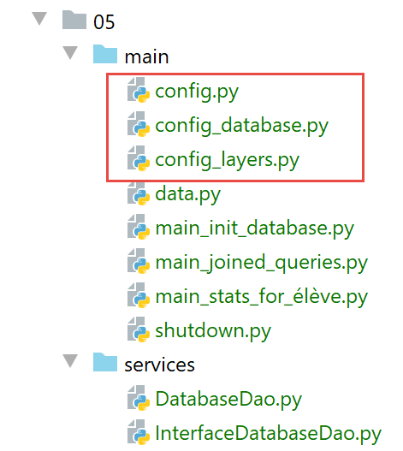
A configuração foi dividida em vários ficheiros:
- a configuração geral no ficheiro [config.py]: define o Python Path da aplicação e instancia as camadas da arquitetura;
- a configuração de [sqlalchemy] em [config_database]: realiza os mapeamentos entre classes e tabelas;
- as camadas da aplicação estão configuradas no ficheiro [config_layers];
O ficheiro [config] é o seguinte:
def configure(config: dict) -> dict:
import os
# passo 1 ---
# define-se o Python Path da aplicação
# caminho absoluto da pasta deste script
script_dir = os.path.dirname(os.path.abspath(__file__))
# caminho absoluto de referência para os caminhos relativos da configuração
root_dir = "C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020"
# caminhos absolutos das dependências
absolute_dependencies = [
# BaseEntity, MyException
f"{root_dir}/classes/02/entities",
# projeto de três camadas v01
f"{root_dir}/troiscouches/v01/interfaces",
f"{root_dir}/troiscouches/v01/services",
f"{root_dir}/troiscouches/v01/entities",
# documentação do presente projeto
script_dir,
f"{script_dir}/../services",
]
# atualização do syspath
from myutils import set_syspath
set_syspath(absolute_dependencies)
# etapa 2 ------
# configuração da base de dados
import config_database
config = config_database.configure(config)
# etapa 3 ------
# instanciação das camadas da aplicação
import config_layers
config = config_layers.configure(config)
# aplicamos a configuração
return config
- linhas 4-27: construção do Python Path da aplicação;
- linhas 29-32: configuração do [sqlalchemy];
- linhas 34-37: configuração das camadas da aplicação;
O ficheiro [config_database] é o seguinte:
def configure(config: dict) -> dict:
# config['sgbd'] é o nome do SGBD utilizado
# MySQL: MySQL
# pgres: PostgreSQL
# configuração do SQLAlchemy
from sqlalchemy import Table, Column, Integer, MetaData, String, Float, ForeignKey, create_engine
from sqlalchemy.orm import mapper, relationship, sessionmaker
# cadeias de ligação às bases de dados utilizadas
engines = {
'mysql': "mysql+mysqlconnector://admecole:mdpecole@localhost/dbecole",
'pgres': "postgresql+psycopg2://admecole:mdpecole@localhost/dbecole"
}
# cadeia de ligação à base de dados utilizada
engine = create_engine(engines[config['sgbd']])
# metadados
metadata = MetaData()
# as tabelas da base de dados
tables = {}
# as classes mapeadas
from Classe import Classe
from Elève import Elève
from Note import Note
from Matière import Matière
# a tabela de classes
tables['classes'] = classes_table = \
Table("classes", metadata,
Column('id', Integer, primary_key=True),
Column('nom', String(30), nullable=False),
)
mapper(Classe, tables['classes'], properties={
'id': classes_table.c.id,
'nome: classes_table.c.nom
})
# a tabela dos alunos
tables['élèves'] = élèves_table = \
Table("élèves", metadata,
Column('id', Integer, primary_key=True),
Column('nom', String(30), nullable=False),
Column('prénom', String(30), nullable=False),
# um aluno pertence a uma turma
Column('classe_id', Integer, ForeignKey('classes.id')),
)
# mapeamento
mapper(Elève, tables['élèves'], properties={
'id': élèves_table.c.id,
'apelido: élèves_table.c.nom,
'nome próprio': élèves_table.c.prénom,
'turma: relationship(Turma, backref="alunos", lazy="select")
})
# o índice
tables['matières'] = matières_table = \
Table("matières", metadata,
Column('id', Integer, primary_key=True),
Column('nom', String(30), nullable=False),
Column('coefficient', Float, nullable=False)
)
# mapeamento
mapper(Matière, tables['matières'], properties={
'id': matières_table.c.id,
'nome': matières_table.c.nom,
"coefficient": matières_table.c.coefficient
})
# a tabela de notas
tables['notes'] = notes_table = \
Table("notes", metadata,
Column('id', Integer, primary_key=True),
Column('valeur', Float, nullable=False),
# uma nota é a de um aluno
Column('élève_id', Integer, ForeignKey('élèves.id')),
# uma nota é a de uma disciplina
Column('matière_id', Integer, ForeignKey('matières.id')),
)
# mapeamento
mapper(Note, tables['notes'], properties={
'id': notes_table.c.id,
'valor': notes_table.c.valeur,
'aluno': relação(Aluno, backref="notas", lazy="select"),
'disciplina': relationship(Disciplina, backref="notas", lazy="select")
})
# configuração das entidades [BaseEntity]
Elève.excluded_keys = ['_sa_instance_state', 'notes', 'classe']
Classe.excluded_keys = ['_sa_instance_state', 'élèves']
Matière.excluded_keys = ['_sa_instance_state', 'notes']
Note.excluded_keys = ['_sa_instance_state', 'matière', 'élève']
# a fábrica de sessões
Session = sessionmaker()
Session.configure(bind=engine)
# uma sessão
session = Session()
# registam-se determinadas informações no dicionário de configuração
config['database'] = {"engine": engine, "metadata": metadata, "tables": tables, "session": session}
# a configuração é carregada
return config
Comentários
- linhas 1-4: a função [configure] recebe um dicionário como parâmetro. Apenas a chave [sgbd] é utilizada. O seu valor é [mysql] se a base for uma base MySQL, e [pgres] se a base for uma base PostgreSQL;
- linhas 6-9: importações de elementos da base [sqlalchemy]. O script [config_database] realiza os mapeamentos entre as tabelas da base de dados [dbecole] e as entidades [Classes, Elève, Matière, Note]. Na tabela, os dados da entidade estão encapsulados numa linha. No código Python, esses dados estão encapsulados num objeto. Daí o nome ORM (Object Relational Mapper): o ORM estabelece um mapeamento (uma ligação) entre as linhas de uma base de dados relacional e os objetos. Nesta aplicação, temos quatro entidades [Classe, Elève, Matière, Note] que serão ligadas a quatro tabelas [classes, élèves, matières, notes]. Note-se que os nomes das tabelas podem conter caracteres acentuados;
- linhas 11-17: a cadeia de ligação à base de dados utilizada. Esta depende do elemento config[‘sgbd’];
- linhas 24-28: as entidades da aplicação que serão objeto de um mapeamento [sqlalchemy]. Quando estas linhas forem executadas, o Python Path já terá sido estabelecido pelo script [config];
- linhas 30-40: o mapeamento entre a entidade [Classe] e a tabela [classes];
- linhas 30-35: a tabela [classes] é definida com a classe [Table] de [sqlalchemy]. Indicamos que esta tabela tem duas colunas:
- a coluna [id], que é a chave primária e corresponde ao número da classe, linha 33;
- a coluna [nom], que contém o nome da classe, linha 34;
- linhas 31-32: repare que a sintaxe x=y=z é válida em Python: o valor de z é atribuído a y e, em seguida, o valor de y é atribuído a x;
- linhas 37-40: enumeram-se as correspondências entre as colunas da tabela [classes] e as propriedades da entidade [Classe];
- linhas 42-57: o mapeamento entre a entidade [Elève] e a tabela [élèves];
- linhas 51-57: a tabela [élèves] é definida com a classe [Table] de [sqlalchemy]. Indicamos que esta tabela tem quatro colunas:
- a coluna [id], que é a chave primária e corresponde ao número do aluno, linha 45;
- a coluna [nom], que contém o apelido do aluno, linha 46;
- a coluna [prénom], que contém o nome próprio do aluno, linha 47. Note-se que o nome de uma coluna pode conter caracteres acentuados;
- linha 49, a coluna [classe_id], que conterá o número da turma a que o aluno pertence. A isto chama-se chave estrangeira. [élèves.classe_id] é uma chave estrangeira (ForeignKey) na coluna [classes.id]. Isto significa que o valor de [élèves.classe_id] deve existir na coluna [classes.id];
- linhas 51-57: são listadas as correspondências entre as colunas da tabela [élèves] e as propriedades da entidade [Elève]:
- as linhas 53-55 são fáceis de compreender;
- a linha 56 é mais complexa: define o valor da propriedade [Elève.classe] como sendo calculado pela relação de chave estrangeira que liga as tabelas [élèves] e [classes]. Os parâmetros da função [relationship] são os seguintes:
- [Classe]: é o nome da entidade com a qual a entidade [Elève] mantém uma relação de chave estrangeira. Esta relação deve concretizar-se na tabela [élèves] através da presença de uma chave estrangeira na tabela [classes]. Sabemos que esta existe;
- [backref="élèves"]: o nome de uma propriedade que será adicionada à entidade [Classe]. [Classe.élèves] será a lista de todos os alunos da turma. Esta propriedade não deve já existir. Se já existir, basta escolher aqui outro nome para [backref]. O programador não precisa de gerir esta propriedade. Será a [sqlalchemy] que o fará. Basta que saiba que ela existe, adicionada pela [sqlalchemy], e que pode utilizá-la no seu código;
- [lazy=’select’]: isto significa que o ORM não deve procurar atribuir imediatamente um valor à propriedade [Elève.classe]. Só deve procurar o seu valor quando o código o solicitar explicitamente. Assim:
- se o código solicitar a lista de todos os alunos, estes serão apresentados, mas a sua propriedade [classe] não será calculada;
- um pouco mais tarde, o código interessa-se por um aluno específico, [e], e faz referência à sua turma, [e.classe]. Esta referência irá, então, obrigar o [sqlalchemy] a efetuar uma consulta à base de dados para recuperar a turma do aluno, de forma transparente para o programador;
- da mesma forma, a inclusão de [lazy=’select’] visa evitar consultas desnecessárias à base de dados;
- linha 56: quando o ORM recupera uma linha da tabela [élèves], recupera as informações [id, nom, prénom, classe_id]. A partir daí, deve construir um objeto Aluno(id, apelido, nome próprio, turma). No que diz respeito às propriedades [id, nom, prénom], isso não apresenta dificuldades. Quanto à propriedade [classe], a situação é mais complicada. O seu valor é uma referência a um objeto do tipo [Classe]. No entanto, o ORM dispõe apenas de uma informação [élèves.classe_id]. Como [élèves.classe_id] é uma chave estrangeira na coluna [classes.id], indica-se aqui que utilize essa relação para recuperar, na tabela [classes], a linha com o ID=[élèves.classe_id] (que existe necessariamente) e de criar, a partir dessa linha, o objeto [Classe] esperado pela propriedade [Elève.classe];
- linhas 59-71: o mapeamento entre a entidade [Matière] e a tabela [matières];
- linhas 59-65: definição da tabela [sqlalchemy], denominada [matières];
- linhas 66-71: enumeram-se as correspondências entre as colunas da tabela [matières] e as propriedades da entidade [Matière]. Não há dificuldades aqui;
- linhas 73-90: o mapeamento entre a entidade [Note] e a tabela [notes];
- linhas 73-82: definição da tabela [sqlalchemy], denominada [notes]. Possui duas chaves estrangeiras:
- linha 79, a coluna [notes.élève_id] obtém os seus valores da coluna [élèves.id]]. Esta chave estrangeira reflete o facto de uma nota ser a nota de um aluno específico;
- linha 81, a coluna [notes.matière_id] obtém os seus valores da coluna [matières.id]. Esta chave estrangeira representa o facto de uma nota ser uma nota numa disciplina específica;
- linhas 84-90: o mapeamento entre a entidade [Note] e a tabela [notes]:
- linha 88: a propriedade [Note.élève] deve ter como valor uma instância do tipo [Elève]. O ORM apenas contém, na linha da tabela [notes], a coluna [notes.élève_id], que faz referência à coluna [élèves.id]. Aqui, indica-se que se utilize esta relação de chave estrangeira para recuperar a instância [Elève] cuja nota se conhece. Além disso, [relationship(Elève, backref="notes", …)] irá criar a nova propriedade [Elève.notes], que será a lista de notas do aluno. Esta propriedade não deve já existir na classe [Elève];
- linha 89: a propriedade [Note.matière] deve ter como valor uma instância do tipo [Matière]. A ORM contém, na linha da tabela [notes], apenas a coluna [notes.matière_id], que faz referência à coluna [matières.id]. Aqui, indica-se que se utilize esta relação de chave estrangeira para recuperar a instância [Matière], cuja nota já se conhece. Além disso, [relationship(Matière, backref="notes", …)] irá criar a nova propriedade [Matière.notes], que será a lista de notas na disciplina. Esta propriedade não deve já existir na classe [Matière];
- linhas 92-96: define-se, para cada entidade derivada de [BaseEntity], a lista de propriedades a excluir do dicionário de propriedades da entidade (BaseEntity.asdict). Vimos que [sqlalchemy] adicionava a propriedade [_sa_instance_state] a todas as entidades mapeadas. Não a queremos no dicionário de propriedades. Além disso, vimos que os mapeamentos anteriores tinham adicionado novas propriedades às entidades:
- [Elève.notes]: todas as notas do aluno;
- [Classe.élèves]: todos os alunos da turma;
- [Matière.notes]: todas as notas da disciplina;
Em geral, não queremos que estas propriedades sejam adicionadas ao estado da entidade. Com efeito, calcular o seu valor tem um custo SQL e esse valor é frequentemente desnecessário. Assim, se recuperarmos o aluno com o nome «X»:
- (continuação)
- o ORM irá devolver uma entidade [Elève(id, nom, prénom, classe, notes)]. Devido ao [lazy=’select’], as propriedades [classe, notes] associadas a chaves estrangeiras da base de dados não terão sido calculadas;
- agora, se eu exibir a cadeia jSON deste aluno, sabemos que será a cadeia jSON do dicionário [asdict] da entidade. Se as propriedades [classe] e [notes] estiverem presentes, a [sqlalchemy] será obrigada a efetuar consultas à SQL para calcular os seus valores. Isto é dispendioso. Se for possível evitar essas consultas, é preferível;
- aqui, excluímos todas as propriedades ligadas a uma chave estrangeira;
- linhas 98-100: instanciação e configuração de um [Session factory] (factory = fábrica de produção). O objeto [Session] serve para criar sessões [sqlalchemy] associadas a transações;
- linhas 102-103: criação de uma sessão sqlalchemy];
- linha 106: alguns elementos da configuração [sqlalchemy] são inseridos no dicionário global da configuração da aplicação;
- linha 109: este dicionário é devolvido;
O ficheiro [config_layers] configura as camadas da aplicação:
def configure(config: dict) -> dict:
# instanciação da camada [dao]
from DatabaseDao import DatabaseDao
dao = DatabaseDao(config)
# instanciação da camada [métier]
from Métier import Métier
métier = Métier(dao)
# instanciação da camada [ui]
from Console import Console
ui = Console(métier)
# colocamos as camadas na configuração
config['dao'] = dao
config['métier'] = métier
config['ui'] = ui
# carregamos a configuração
return config
- linha 1: a função [configure] recebe o dicionário da configuração global da aplicação;
- linhas 2-12: as camadas da aplicação são instanciadas;
- linhas 15-17: as referências das camadas são inseridas na configuração global;
- linha 20: a nova configuração é devolvida;
19.6.5. A camada [dao] - 1
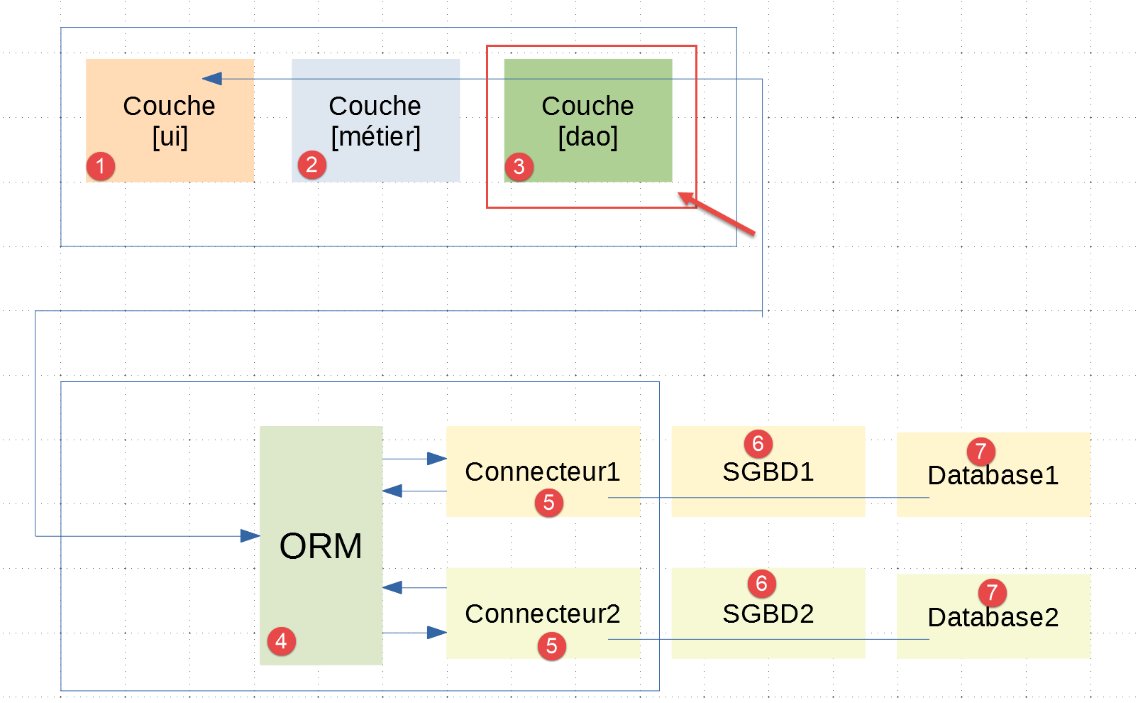
É importante compreender que a camada [dao] [3] comunica com aORM [sqlalchemy] [4], configurada conforme descrito no parágrafo anterior. Das três camadas [ui, métier, dao] da aplicação |troiscouches v01|, apenas a camada [dao] deve ser reescrita. As camadas [ui, métier] são mantidas.
A implementação da camada [dao] foi colocada na pasta [services]:

[InterfaceDatabaseDao] é a interface da camada [dao]:
from abc import ABC, abstractmethod
from InterfaceDao import InterfaceDao
class InterfaceDatabaseDao(InterfaceDao, ABC):
# inicialização da base de dados
@abstractmethod
def init_database(self, data: dict):
pass
- linha 6: a interface [InterfaceDatabaseDao] deriva tanto da classe [ABC], para ser uma classe abstrata, como da interface [InterfaceDao] do projeto |troiscouches v01|;
- linhas 8-11: adiciona-se o método [init_database] aos métodos herdados de [InterfaceDao]. A sua função será inicializar a base de dados com os dados do dicionário [data] que lhe são passados como parâmetro na linha 10;
Recorde-se que a interface [InterfaceDao] era a seguinte:
# importações
from abc import ABC, abstractmethod
# interface DAO
from Elève import Elève
class InterfaceDao(ABC):
# lista de turmas
@abstractmethod
def get_classes(self: object) -> list:
pass
# lista de alunos
@abstractmethod
def get_élèves(self: object) -> list:
pass
# lista de disciplinas
@abstractmethod
def get_matières(self: object) -> list:
pass
# lista de notas
@abstractmethod
def get_notes(self: object) -> list:
pass
# lista de notas de um aluno
@abstractmethod
def get_notes_for_élève_by_id(self: object, élève_id: int) -> list:
pass
# procurar um aluno pelo seu ID
@abstractmethod
def get_élève_by_id(self: object, élève_id: int) -> Elève:
pass
A implementação da camada [dao] é a seguinte:
from sqlalchemy.exc import DatabaseError, IntegrityError, InterfaceError
from Classe import Classe
from Elève import Elève
from InterfaceDatabaseDao import InterfaceDatabaseDao
from Matière import Matière
from MyException import MyException
from Note import Note
class DatabaseDao(InterfaceDatabaseDao):
def __init__(self, config: dict):
# base de dados = {"engine": engine, "metadata": metadata, "tables": tables, "session": session}
self.database = config['database']
self.session = self.database['session']
def init_database(self, data: dict):
…
…
- linha 11: a classe [DatabaseDao] implementa a interface [InterfaceDatabaseDao];
- linhas 13-16: o construtor da classe. Recebe como parâmetro o dicionário da configuração da aplicação;
- linha 15: guarda-se a configuração [sqlalchemy];
- linha 16: armazena-se a sessão [sqlalchemy] através da qual se irá manipular a base de dados;
- linha 18: o método [init_database] inicializa a base de dados com o dicionário [data];
O dicionário [data] é implementado pelo seguinte script [data.py]:
def configure():
from Classe import Classe
from Elève import Elève
from Matière import Matière
from Note import Note
# instanciamos as classes
classe1 = Classe().fromdict({"id": 1, "nom": "classe1"})
classe2 = Classe().fromdict({"id": 2, "nom": "classe2"})
classes = [classe1, classe2]
# as disciplinas
matière1 = Matière().fromdict({"id": 1, "nom": "matière1", "coefficient": 1})
matière2 = Matière().fromdict({"id": 2, "nom": "matière2", "coefficient": 2})
matières = [matière1, matière2]
# os alunos
élève11 = Elève().fromdict({"id": 11, "nom": "nom1", "prénom": "prénom1", "classe": classe1})
élève21 = Elève().fromdict({"id": 21, "nom": "nom2", "prénom": "prénom2", "classe": classe1})
élève32 = Elève().fromdict({"id": 32, "nom": "nom3", "prénom": "prénom3", "classe": classe2})
élève42 = Elève().fromdict({"id": 42, "nom": "nom4", "prénom": "prénom4", "classe": classe2})
élèves = [élève11, élève21, élève32, élève42]
# as notas dos alunos nas diferentes disciplinas
note1 = Note().fromdict({"id": 1, "valeur": 10, "élève": élève11, "matière": matière1})
note2 = Note().fromdict({"id": 2, "valeur": 12, "élève": élève21, "matière": matière1})
note3 = Note().fromdict({"id": 3, "valeur": 14, "élève": élève32, "matière": matière1})
note4 = Note().fromdict({"id": 4, "valeur": 16, "élève": élève42, "matière": matière1})
note5 = Note().fromdict({"id": 5, "valeur": 6, "élève": élève11, "matière": matière2})
note6 = Note().fromdict({"id": 6, "valeur": 8, "élève": élève21, "matière": matière2})
note7 = Note().fromdict({"id": 7, "valeur": 10, "élève": élève32, "matière": matière2})
note8 = Note().fromdict({"id": 8, "valeur": 12, "élève": élève42, "matière": matière2})
notes = [note1, note2, note3, note4, note5, note6, note7, note8]
# agrupa-se o conjunto
data = {"élèves": élèves, "classes": classes, "matières": matières, "notes": notes}
# os dados são apresentados
return data
- linha 34: o dicionário que será passado para o método [init_database]. Este dicionário é composto pelas seguintes chaves (linha 32):
- [élèves]: a lista de alunos;
- [classes]: a lista de turmas;
- [matières]: a lista das disciplinas;
- [notes]: a lista das notas de todos os alunos em todas as disciplinas;
Voltemos ao método [init_database]:
def init_database(self, data: dict):
# configuração da base de dados
database = self.database
engine = database['engine']
metadata = database['metadata']
tables = database['tables']
try:
# eliminação das tabelas existentes
# checkfirst=True: verifica primeiro se a tabela existe
tables["notes"].drop(engine, checkfirst=True)
tables["matières"].drop(engine, checkfirst=True)
tables["élèves"].drop(engine, checkfirst=True)
tables["classes"].drop(engine, checkfirst=True)
# recriação das tabelas a partir do mapeamento
metadata.create_all(engine)
# preenchimento das tabelas
session = self.session
# classes
classes = data["classes"]
for classe in classes:
session.add(classe)
# disciplinas
matières = data["matières"]
for matière in matières:
session.add(matière)
# alunos
élèves = data["élèves"]
for élève in élèves:
session.add(élève)
# notas
notes = data["notes"]
for note in notes:
session.add(note)
# confirmação
session.commit()
except (DatabaseError, InterfaceError, IntegrityError) as erreur:
# anulação da sessão
if session:
session.rollback()
# a exceção é reenviada
raise MyException(23, f"{erreur}")
- linhas 3-6: recuperam-se informações da configuração da base de dados;
- linhas 9-14: vimos que a configuração [sqlalchemy] tinha mapeado quatro entidades para quatro tabelas [élèves, matières, classes, notes]. Começamos por eliminar essas tabelas, caso existam;
- linhas 16-17: recriamos as quatro tabelas que acabámos de eliminar;
- linhas 22-25: colocamos todas as classes na sessão;
- linhas 27-30: colocam-se todas as disciplinas na sessão;
- linhas 32-35: colocamos todos os alunos na sessão;
- linhas 37-40: inserimos todas as notas na sessão;
- para efetuar estas adições, seguimos uma ordem. Começámos pelas entidades que não tinham relações com outras entidades e terminámos pelas que tinham. Assim, quando adicionamos os alunos à sessão, as turmas a que estes se referem já se encontram na sessão;
- linha 43: a sessão [sqlalchemy] foi validada. Após esta operação, temos a certeza de que todos os dados da sessão foram sincronizados com a base de dados. Em outras palavras, foram introduzidos nas tabelas. Isto foi possível graças aos mapeamentos definidos na configuração do [sqlalchemy]. O [sqlalchemy] sabe como cada entidade deve ser armazenada nas tabelas. O [sqlalchemy] também gerou as chaves estrangeiras que as tabelas podem possuir;
- linhas 44-49: se ocorrer um problema, a sessão [sqlalchemy] é cancelada e, na linha 49, é lançada uma exceção;
19.6.6. Inicialização da base de dados
O script [main_init_database] inicializa a base de dados com o conteúdo do script [data.py]. O seu código é o seguinte:
# à espera de um parâmetro mysql ou pgres
import sys
syntaxe = f"{sys.argv[0]} mysql / pgres"
erreur = len(sys.argv) != 2
if not erreur:
sgbd = sys.argv[1].lower()
erreur = sgbd != "mysql" and sgbd != "pgres"
if erreur:
print(f"syntaxe : {syntaxe}")
sys.exit()
# configurar a aplicação
import config
config = config.configure({'sgbd': sgbd})
# o syspath está configurado — é possível efetuar as importações
from MyException import MyException
# recuperam-se os dados a introduzir na base de dados
import data
data = data.configure()
# recuperar a camada [dao]
dao = config["dao"]
# ----------- principal
try:
# criação e inicialização das tabelas da base de dados
dao.init_database(data)
except MyException as ex:
# exibe-se o erro
print(f"L'erreur suivante s'est produite : {ex}")
finally:
# libertação dos recursos utilizados pela aplicação
import shutdown
shutdown.execute(config)
# fim
print("Travail terminé...")
- linhas 1-11: o script espera um parâmetro [mysql] ou [pgres], consoante se pretenda inicializar uma base de dados MySQL ou PostgreSQL;
- linhas 13-15: a aplicação está configurada para o SGBD passado como parâmetro;
- linhas 20-22: recuperam-se os dados a introduzir na base de dados;
- linha 25: a camada [dao] já foi instanciada e está acessível na configuração da aplicação;
- linha 30: a base de dados é inicializada;
- linhas 34-37: quer ocorra um erro ou não, libertam-se os recursos da aplicação utilizando o módulo [shutdown];
O módulo [shutdown.py] é o seguinte:
def execute(config: dict):
# libertação dos recursos utilizados pela aplicação
sqlalchemy_session = config['database']['session']
if sqlalchemy_session:
sqlalchemy_session.close()
A função [shutdown.execute] encerra a sessão [sqlalchemy] utilizada para inicializar a base de dados.
Criamos uma primeira configuração de execução (ver |configuração de execução|) para executar o [main_init_database] com o SGBD e o MySQL:
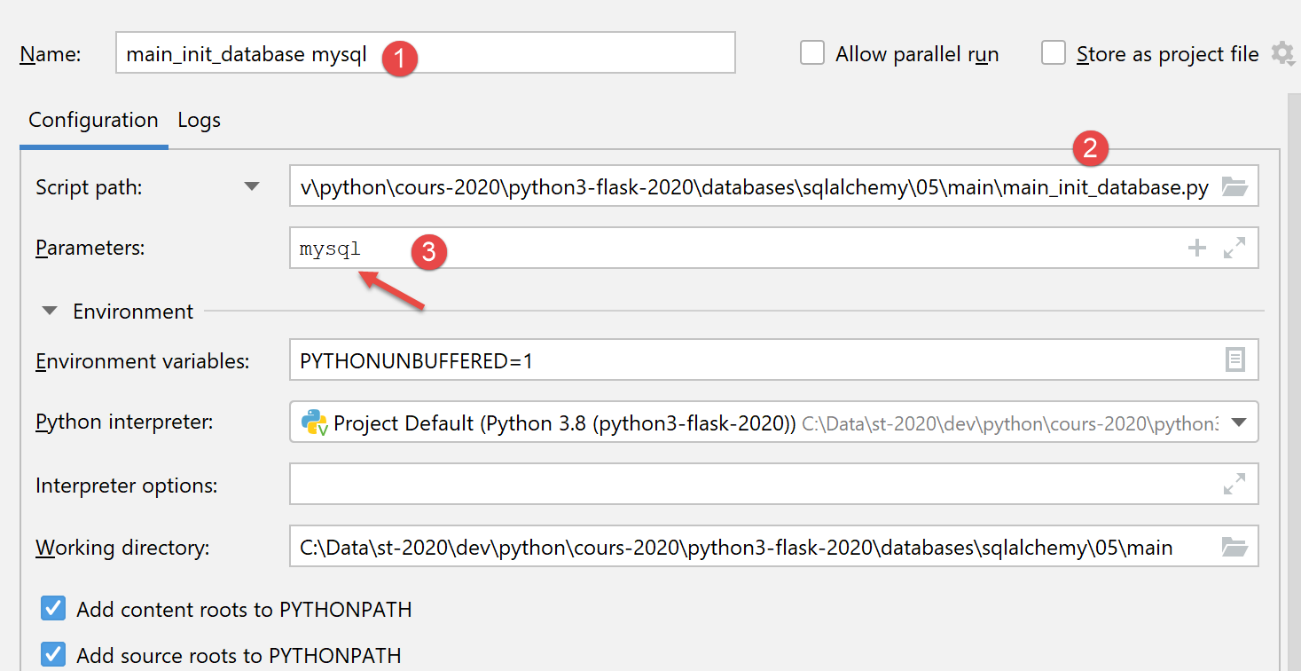
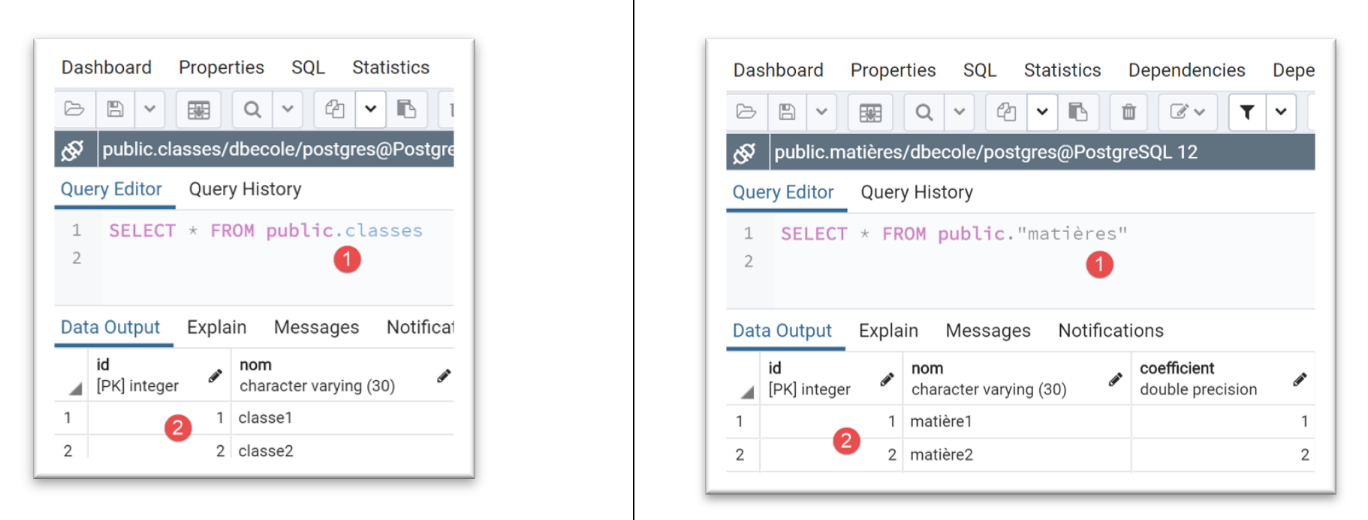
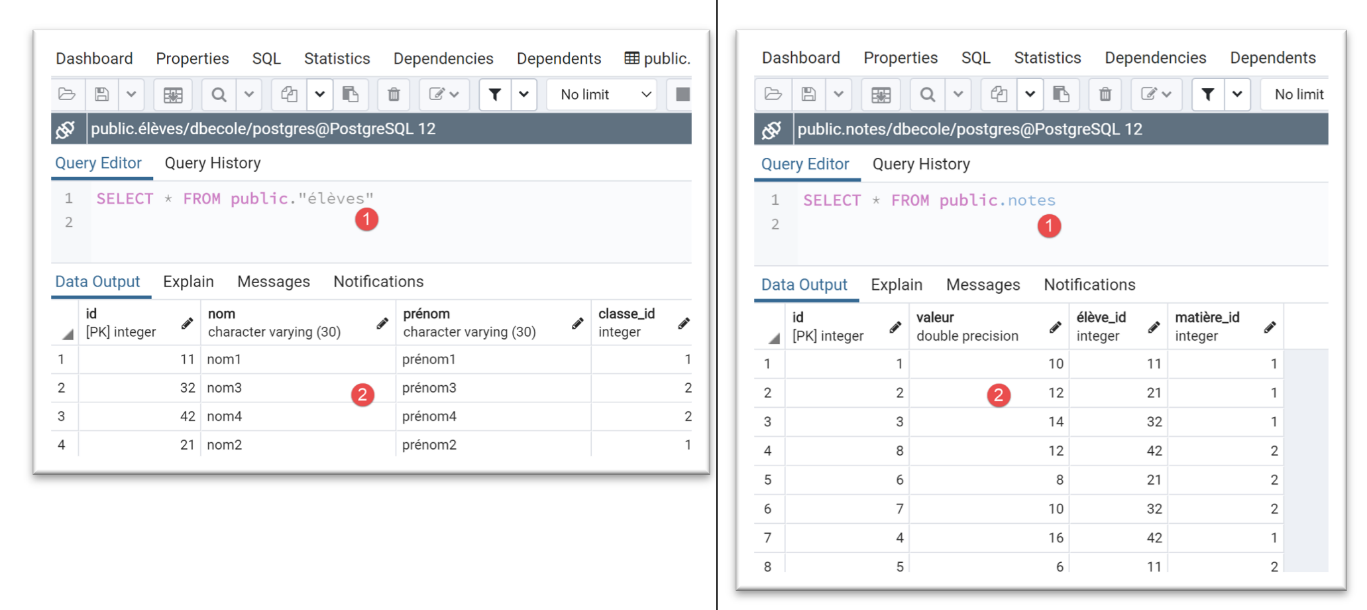
Os resultados da execução desta configuração são os seguintes no phpMyAdmin:
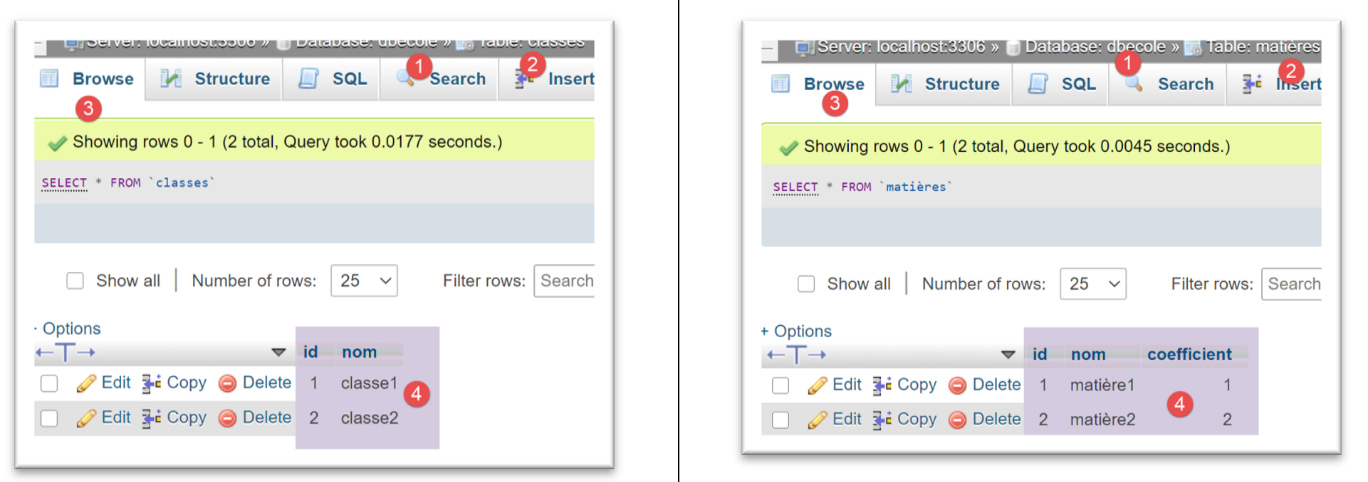
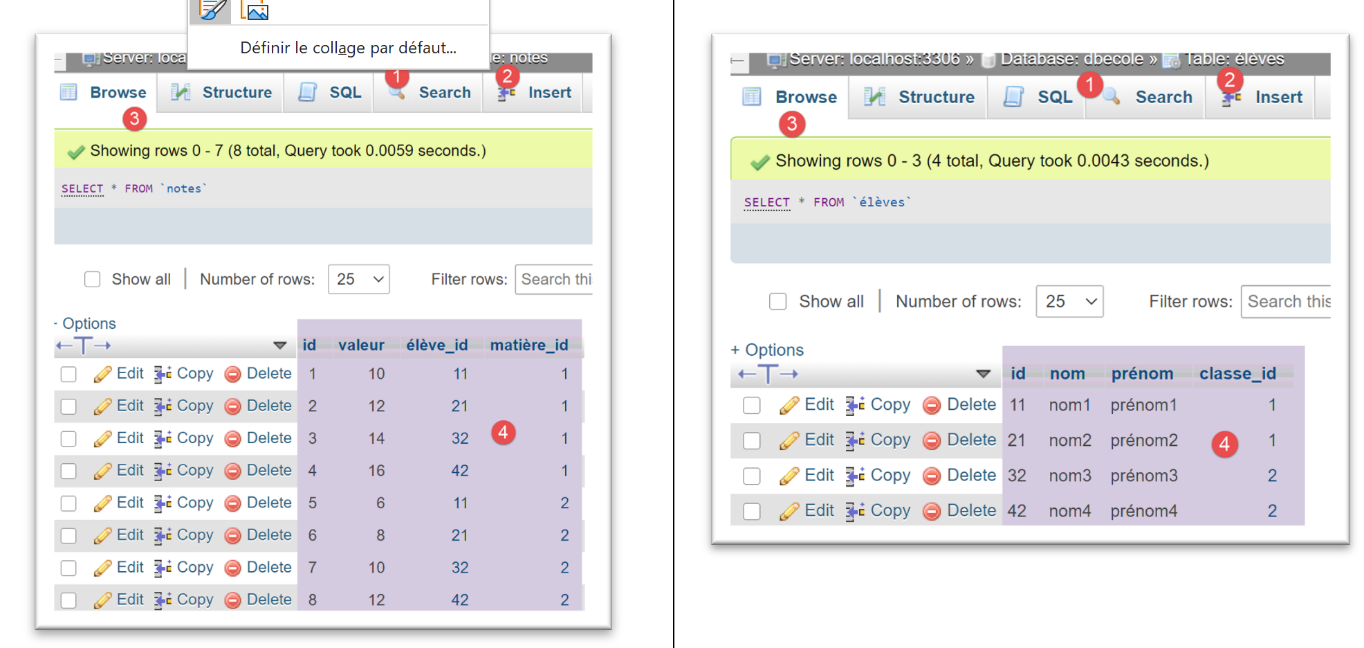
Para o SGBD e o [PostgreSQL], utilizamos a seguinte configuração de execução:
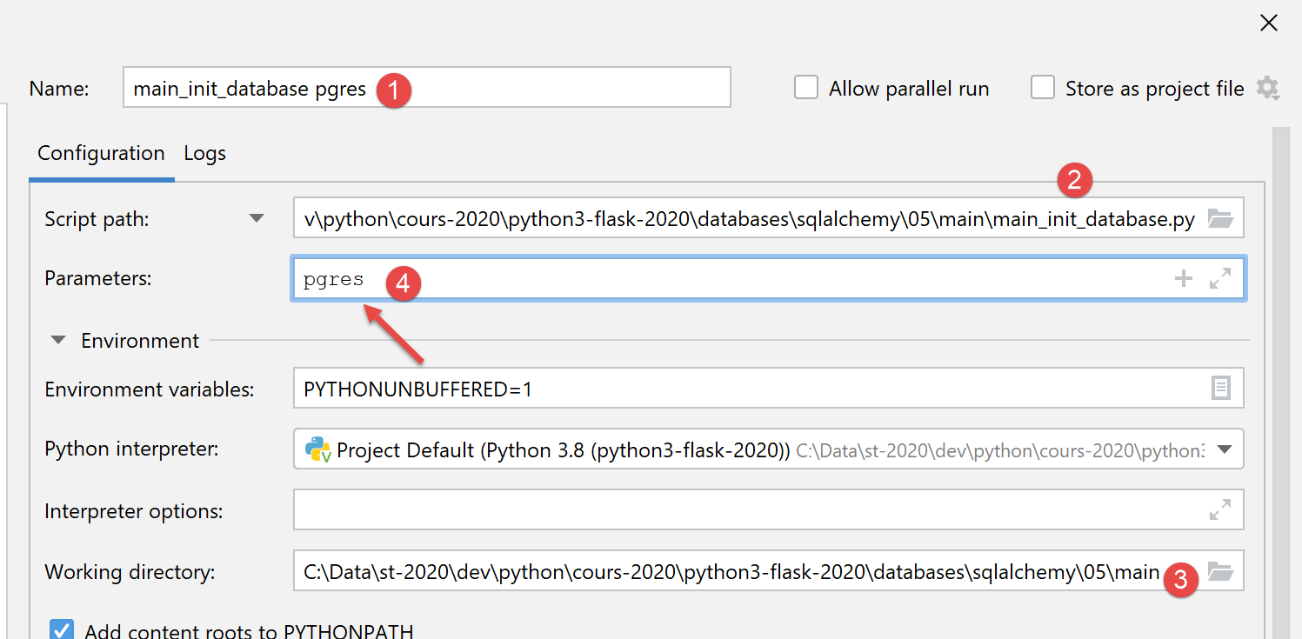
Após a execução, os resultados no [pgAdmin] são os seguintes:

É de salientar a facilidade com que foi possível alterar o SGBD.
19.6.7. A camada [dao] – 2
Voltamos à classe [DatabaseDao], que implementa a camada [dao]. Até agora, apenas mostrámos a implementação do método [init_database]. Passamos agora a mostrar a implementação dos restantes métodos:
from sqlalchemy.exc import DatabaseError, IntegrityError, InterfaceError
from Classe import Classe
from Elève import Elève
from InterfaceDatabaseDao import InterfaceDatabaseDao
from Matière import Matière
from MyException import MyException
from Note import Note
class DatabaseDao(InterfaceDatabaseDao):
def __init__(self, config: dict):
# base de dados = {"engine": engine, "metadata": metadata, "tables": tables, "session": session}
self.database = config['database']
self.session = self.database['session']
def init_database(self, data: dict):
…
# lista de todas as classes
def get_classes(self: object) -> list:
# consulta
return self.session.query(Classe).all()
# lista de todos os alunos
def get_élèves(self: object) -> list:
# consulta
return self.session.query(Elève).all()
# lista de todas as disciplinas
def get_matières(self: object) -> list:
# consulta
return self.session.query(Matière).all()
# lista das notas de todos os alunos
def get_notes(self: object) -> list:
# consulta
return self.session.query(Note).all()
# lista das notas de um aluno específico
def get_notes_for_élève_by_id(self: object, élève_id: int) -> list:
# procura-se o aluno — é lançada uma exceção se este não existir
# permite-se que a consulta seja executada
élève = self.get_élève_by_id(élève_id)
# recuperam-se as notas (carregamento diferido)
notes = élève.notes
# retorna-se um dicionário
return {"élève": élève, "notes": notes}
# um aluno identificado pelo seu n.º
def get_élève_by_id(self, élève_id: int) -> Elève:
# procura-se o aluno
élèves = self.session.query(Elève).filter(Elève.id == élève_id).all()
# Encontrou-se?
if élèves:
return élèves[0]
else:
raise MyException(11, f"L'élève d'identifiant {élève_id} n'existe pas")
# um aluno identificado pelo seu nome
def get_élève_by_name(self, élève_name: str) -> Elève:
# à procura do aluno
élèves = self.session.query(Elève).filter(Elève.nom == élève_name).all()
# já o encontrámos?
if élèves:
return élèves[0]
else:
raise MyException(12, f"L'élève de nom {élève_name} n'existe pas")
# uma turma identificada pelo seu n.º
def get_classe_by_id(self, classe_id: int) -> Classe:
# à procura da turma
classes = self.session.query(Classe).filter(Classe.id == classe_id).all()
# já a encontrámos?
if classes:
return classes[0]
else:
raise MyException(13, f"La classe d'identifiant {classe_id} n'existe pas")
# uma turma identificada pelo seu nome
def get_classe_by_name(self, classe_name: str) -> Classe:
# Estamos à procura da turma
classes = self.session.query(Classe).filter(Classe.nom == classe_name).all()
# já a encontrámos?
if classes:
return classes[0]
else:
raise MyException(14, f"La classe de nom {classe_name} n'existe pas")
# uma disciplina identificada pelo seu n.º
def get_matière_by_id(self, matière_id: int) -> Matière:
# procura-se a disciplina
matières = self.session.query(Matière).filter(Matière.id == matière_id).all()
# já foi encontrada?
if matières:
return matières[0]
else:
raise MyException(11, f"La matière d'identifiant {matière_id} n'existe pas")
# um material identificado pelo seu nome
def get_matière_by_name(self, matière_name: str) -> Matière:
# Estamos à procura da matéria
matières = self.session.query(Matière).filter(Matière.nom == matière_name).all()
# já foi encontrada?
if matières:
return matières[0]
else:
raise MyException(15, f"La matière de nom {matière_name} n'existe pas")
- linhas 21-24: o método [get_classes] deve devolver a lista das turmas da escola. Na linha 20, utilizamos uma consulta já apresentada;
- linhas 26-39: três outros métodos semelhantes para obter as listas de alunos, disciplinas e notas;
- linhas 51-59: o método [get_élève_by_id] deve apresentar um aluno identificado pelo seu n.º. Lança uma exceção se este não existir;
- linha 54: utiliza-se uma consulta filtrada. Obtém-se uma lista vazia ou com um elemento;
- linha 57: se a lista recuperada não estiver vazia, devolve-se o primeiro elemento da lista;
- caso contrário, na linha 59, é lançada uma exceção;
- linhas 41-49: o método [get_notes_for_élève_by_id] deve devolver as notas de um aluno identificado pelo seu n.º:
- linha 45: utiliza-se o método [get_élève_by_id] para obter a entidade «Aluno» do aluno;
- na linha 47, utiliza-se a propriedade [Elève.notes] criada pelo mapeamento entre a entidade [Note] e a tabela [notes] (ver parágrafo |configuração do SQLAlchemy|) e que representa as notas do aluno;
- linha 49: devolve-se um dicionário;
- linhas 61-109: uma série de métodos semelhantes que permitem:
- encontrar um aluno pelo nome, linhas 61-69;
- encontrar uma turma, linhas 71-89;
- localizar uma disciplina, linhas 91-109;
19.6.8. O script [main_joined_queries]
O script [main_joined_queries] tem este nome porque se destina a destacar as consultas feitas implicitamente pelo [sqlalchemy] para recuperar informações pertencentes a várias tabelas. Estas consultas, ocultas ao programador, são efetuadas sempre que uma propriedade de uma entidade é associada à função [relationship] no mapeamento da entidade. Por exemplo:
# mapeamento
mapper(Note, tables['notes'], properties={
'id': notes_table.c.id,
'valor: notes_table.c.valeur,
'aluno': relação(Aluno, backref="notas", lazy="select"),
'disciplina': relationship(Disciplina, backref="notas", lazy="select")
})
Acima, o mapeamento entre a entidade [Note] e a tabela [notes]:
- na linha 5, quando a propriedade [élève] de uma entidade [Note] for solicitada pela primeira vez, será procurada na tabela [élèves] através de uma consulta SQL. Enquanto esta propriedade não for solicitada, permanece indefinida (carregamento diferido). Depois de obtida, o seu valor permanece na memória da ORM. Quando for referenciada uma segunda vez, a ORM fornecerá imediatamente o seu valor sem passar por uma nova consulta SQL. Tudo isto é transparente para o programador;
- o mesmo se aplica à propriedade inversa [Elève.notes] (backref), linha 5;
- o mesmo se aplica à propriedade [Note.matière] e à sua propriedade inversa [Matière.notes] (backref), linha 6;
O script [main_joined_queries] é o seguinte:
# é esperado um parâmetro mysql ou pgres
import sys
syntaxe = f"{sys.argv[0]} mysql / pgres"
erreur = len(sys.argv) != 2
if not erreur:
sgbd = sys.argv[1].lower()
erreur = sgbd != "mysql" and sgbd != "pgres"
if erreur:
print(f"syntaxe : {syntaxe}")
sys.exit()
# configurar a aplicação
import config
config = config.configure({"sgbd": sgbd})
# o syspath está configurado — já se podem fazer as importações
from MyException import MyException
# a camada [dao]
dao = config["dao"]
try:
# aluno por ID
print("élève id=11 -----------")
élève = dao.get_élève_by_id(11)
print(f"élève={élève}")
# a turma do aluno (carregamento diferido)
classe = élève.classe
print(f"classe de l'élève : {classe}")
# os alunos da mesma turma (carregamento diferido)
print("élèves dans la même classe :")
for élève in classe.élèves:
print(f"élève={élève}")
# um aluno pelo nome
print("élève nom='nom2' -----------")
print(f"élève={dao.get_élève_by_name('nom2')}")
# a sua turma (carregamento diferido)
print(f"classe de l'élève : {élève.classe}")
# notas de um aluno
print("notes de l'élève id=11 -----------")
# primeiro o aluno
élève = dao.get_élève_by_id(11)
# depois as suas notas (carregamento diferido)
for note in élève.notes:
# a nota
print(f"note={note}, "
# a disciplina da nota (carregamento diferido)
f"matière={note.matière}")
# os alunos de uma turma
print("élèves de la classe nom='classe1' -----------")
# primeiro a turma
classe = dao.get_classe_by_name('classe1')
# depois os alunos (carregamento diferido)
for élève in classe.élèves:
print(élève)
# o mesmo se aplica a [classe2]
print("élèves de la classe de nom 'classe2' -----------")
classe = dao.get_classe_by_name('classe2')
for élève in classe.élèves:
print(élève)
# as notas numa disciplina
print("matière de nom='matière1' -----------")
# primeiro a disciplina
matière = dao.get_matière_by_name('matière1')
print(f"matière={matière}")
# depois as notas nessa disciplina (carregamento diferido)
print("Notes dans la matière : ")
for note in matière.notes:
print(note)
# o mesmo para a disciplina 2
print("matière de nom='matière2' -----------")
matière = dao.get_matière_by_name('matière2')
print(f"matière={matière}")
print("Notes dans la matière : ")
for note in matière.notes:
print(f"note={note}")
except MyException as ex1:
# é apresentado o erro
print(f"L'erreur 1 suivante s'est produite : {ex1}")
except BaseException as ex2:
# exibe-se o erro
print(f"L'erreur 2 suivante s'est produite : {ex2}")
finally:
# liberam-se os recursos
import shutdown
shutdown.execute(config)
Os comentários são suficientes para compreender o código.
Cria-se uma configuração de execução para MySQL:
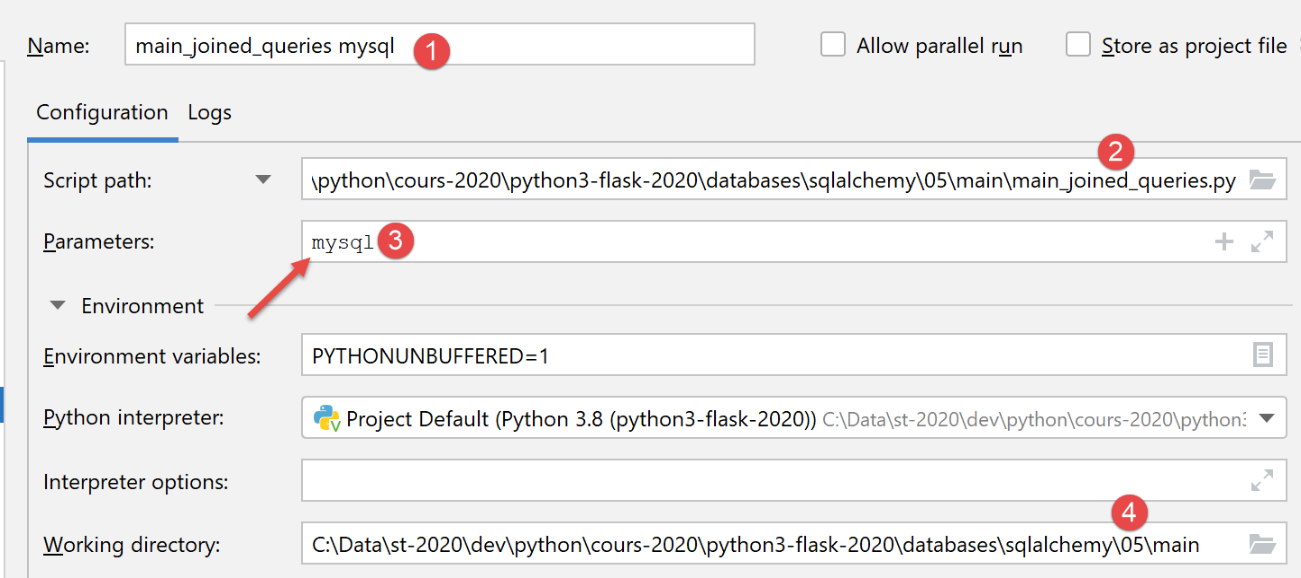
Os resultados da execução são os seguintes:
Para compreender estes resultados, é necessário ter em conta que foram excluídas algumas propriedades do dicionário de entidades (ver |configuração|):
# configuração das entidades [BaseEntity]
Elève.excluded_keys = ['_sa_instance_state', 'notes', 'classe']
Classe.excluded_keys = ['_sa_instance_state', 'élèves']
Matière.excluded_keys = ['_sa_instance_state', 'notes']
Note.excluded_keys = ['_sa_instance_state', 'matière', 'élève']
Assim, quando escrevemos [print(f"élève={élève}")] na linha 26 do código, a linha 1 acima indica-nos que as propriedades ['_sa_instance_state', 'notes', 'classe'] não serão apresentadas. É isso que se observa na linha 3 dos resultados. Todas as outras propriedades são apresentadas. Assim, ainda na linha 3, descobrimos uma nova propriedade [classe_id] que inicialmente não existia na entidade [Elève]. Esta propriedade corresponde diretamente à coluna [classe_id] da tabela [élèves]. Assim, [sqlalchemy] adicionou as seguintes propriedades à entidade [Elève]: [classe_id, _sa_instance_state, notes]. É importante ter isto em conta, sobretudo porque estas propriedades não devem já existir na entidade mapeada.
As propriedades excluídas do dicionário de entidades são importantes. Se, por exemplo, não se excluírem as propriedades [notes, élève] da entidade [Elève], então a operação [print(f"élève={élève}")] irá exibi-las e, consequentemente, tal como acabou de ser explicado, provocar consultas SQL implícitas (carregamento diferido) para recuperar os valores dessas propriedades. Se, como neste caso, for apresentada uma lista de alunos, as operações implícitas SQL são realizadas para cada aluno. Isto pode ser, por um lado, desnecessário e, por outro, certamente dispendioso em termos de tempo de execução.
Para executar o script com uma base PostgreSQL, cria-se a seguinte configuração de execução:
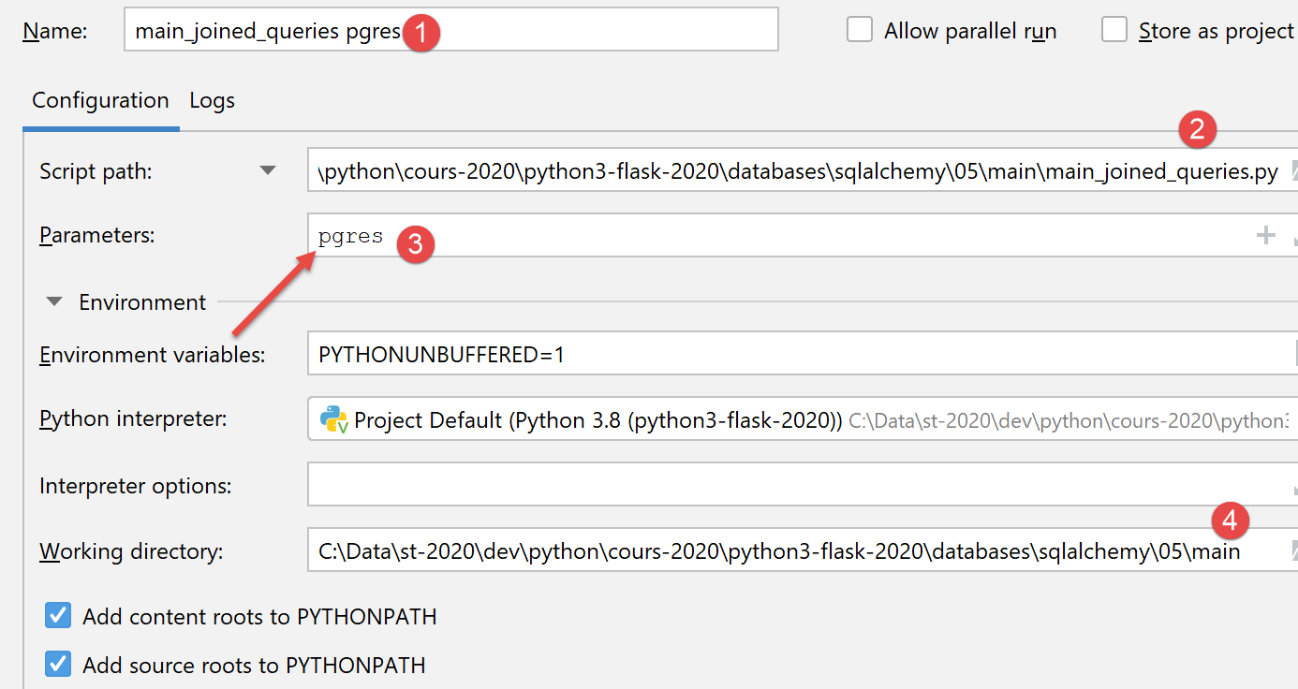
A execução produz os mesmos resultados que com MySQL.
19.6.9. O script [main_stats_for_élève]
O script [main_stats_for_élève] é o que já foi utilizado na aplicação |troiscouches v01]. Na altura, chamava-se [main]. Trata-se de uma aplicação de consola que permite obter determinados indicadores sobre as notas de um aluno: [moyenne pondérée, min, max, liste]. Inser-se na seguinte arquitetura:
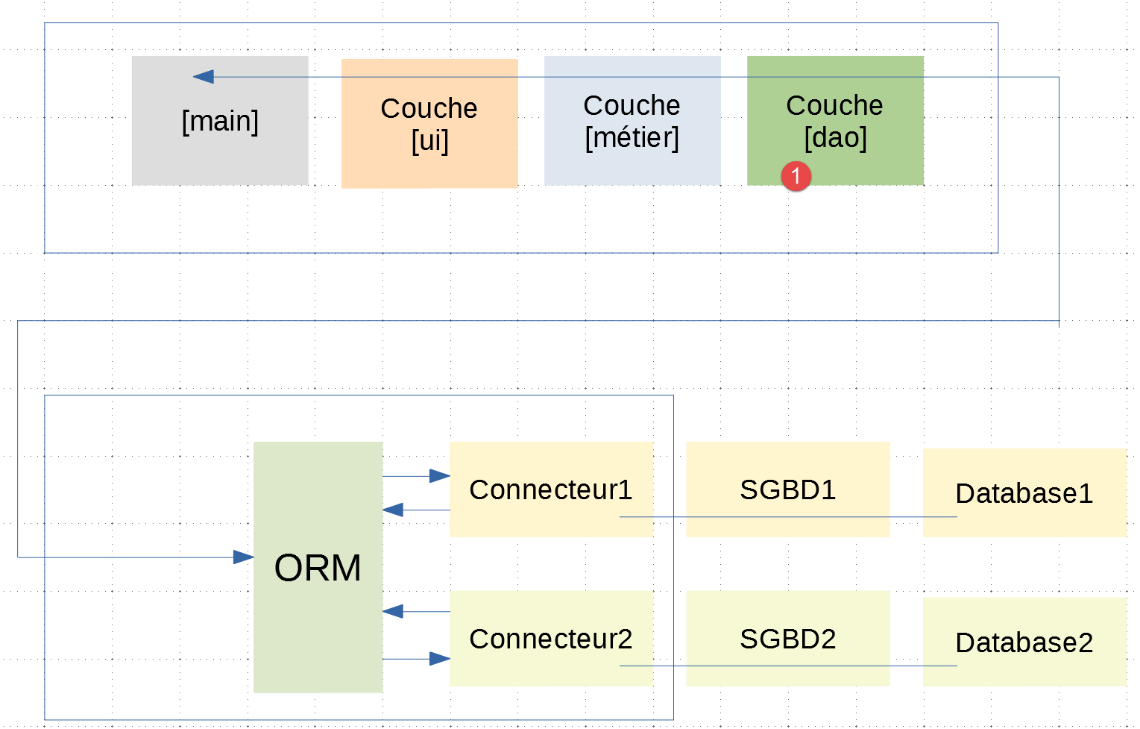
Nesta arquitetura em camadas, apenas a camada [dao] foi alterada entre a aplicação |troiscouches v01| e esta. Como a nova camada [dao] respeita a interface [InterfaceDao] da antiga camada [dao], as camadas [ui, métier] não precisam de ser alteradas. Por isso, é possível continuar a utilizar as camadas definidas na aplicação |troiscouches v01|.
O script [main_stats_for_élève] implementa a camada [main] do esquema acima da seguinte forma:
# aguarda-se um parâmetro mysql ou pgres
import sys
syntaxe = f"{sys.argv[0]} mysql / pgres"
erreur = len(sys.argv) != 2
if not erreur:
sgbd = sys.argv[1].lower()
erreur = sgbd != "mysql" and sgbd != "pgres"
if erreur:
print(f"syntaxe : {syntaxe}")
sys.exit()
# a aplicação está a ser configurada
import config
config = config.configure({'sgbd': sgbd})
# o syspath está configurado — já é possível efetuar as importações
from MyException import MyException
# a camada [ui]
ui = config["ui"]
try:
# Execução da camada [ui]
ui.run()
except MyException as ex1:
# é apresentado o erro
print(f"L'erreur 1 suivante s'est produite : {ex1}")
except BaseException as ex2:
# é exibido o erro
print(f"L'erreur 2 suivante s'est produite : {ex2}")
finally:
# os recursos são libertados
import shutdown
shutdown.execute(config)
- linha 20: obtém-se uma referência à camada [ui] na configuração da aplicação;
- linha 24: inicia-se o diálogo com o utilizador utilizando o único método da camada [ui];
Uma configuração de execução para PostgreSQL seria a seguinte:
Eis um exemplo de execução com esta configuração:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/databases/sqlalchemy/05/main/main_stats_for_élève.py pgres
Numéro de l'élève (>=1 et * pour arrêter) : 11
Elève={"prénom": "prénom1", "id": 11, "classe_id": 1, "nom": "nom1"}, notes=[10.0 6.0], max=10.0, min=6.0, moyenne pondérée=7.33
Numéro de l'élève (>=1 et * pour arrêter) : 1
L'erreur suivante s'est produite : MyException[11, L'élève d'identifiant 1 n'existe pas]
Numéro de l'élève (>=1 et * pour arrêter) : *
Process finished with exit code 0