4. Cadeias de caracteres
4.1. Script [str_01]: notação de cadeias
O script [str_01] é o seguinte:
Comentários
- linha 3: uma string delimitada por aspas duplas ";
- linha 4: uma cadeia de caracteres delimitada por aspas simples ';
- Linha 5: uma cadeia de caracteres entre aspas triplas """. Neste caso, a cadeia de caracteres pode ocupar várias linhas;
Os resultados são os seguintes:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/strings/str_01.py
chaine1=[un], chaine2=[deux], chaine3=[hélène va au
marché acheter des légumes]
Process finished with exit code 0
4.2. Script [str_02]: Métodos da classe <str>
O script [str_02] apresenta alguns dos métodos da classe <str>, que é a classe de cadeias de caracteres:
Os comentários, combinados com os resultados obtidos, são suficientes para compreender o script. Os resultados são os seguintes:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/strings/str_02.py
'ABCD'.lower()=abcd
'abcd'.upper()=ABCD
'cheval[2]=e
'caractères accentués'[5:7]=tè
'caractères accentués'[4:]=ctères accentués
'caractères accentués'[:5]=carac
len('123')=3
' abcd '.strip()=[abcd]
' abcd '.rstrip()=[ abcd]
' abcd '.lstrip()=[abcd ]
str.strip()=[abcd]
'abcd'.replace('a','x')=xbcd
'abcd'.replace('ab','xy')=xycd
'abcd'.find('bc')=1
'abcd'.find('bc')=-1
'abcd'.startswith('ab')=True
'abcd'.startswith('x')=False
'abcd'.endswith('cd')=True
'abcd'.endswith('x')=False
'[X]'.join(['abcd', '123', 'èéà'])=abcd[X]123[X]èéà
''.join(['abcd', '123', 'èéà'])=abcd123èéà
'abcd 123 cdXY'.split('cd')=['ab', ' 123 ', 'XY']
'abcd 123 cdXY'.split(None)=['abcd', '123', 'cdXY']
Process finished with exit code 0
4.3. Script [str_03]: Codificação de cadeias de caracteres (1)
O script [str_03] apresenta conceitos relacionados com a codificação de cadeias de caracteres:
A codificação de uma cadeia de caracteres do tipo <str> produz uma cadeia binária em que cada caractere da cadeia é representado por um ou mais bytes. Existem diferentes tipos de codificação. O script acima mostra os dois mais comuns no Ocidente: "utf-8" e "iso-8859-1", também conhecido como "latin1".
O princípio da codificação/decodificação é ilustrado abaixo (ref. |https://realpython.com/python-encodings-guide/ |):
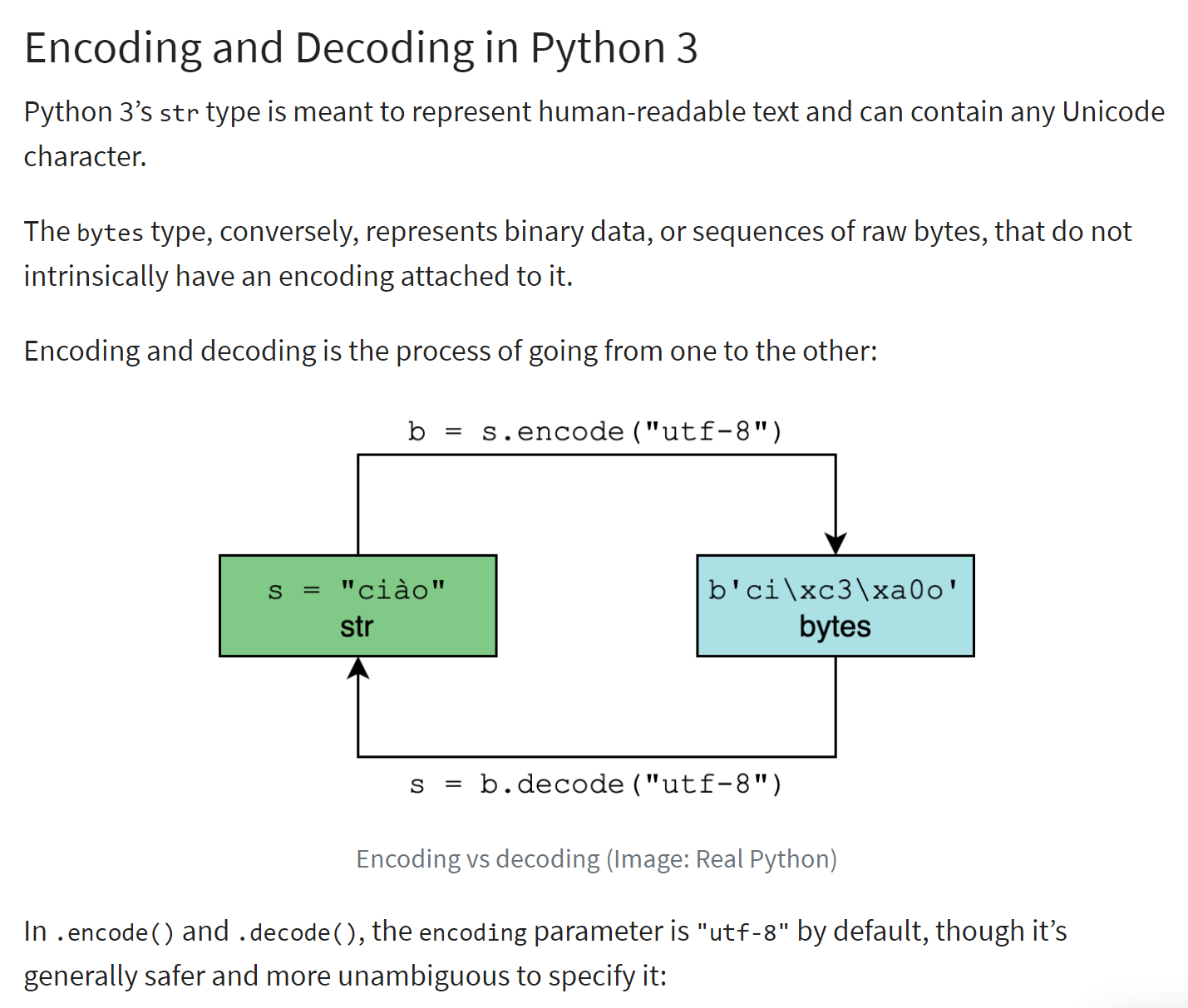
Comentários
- linhas 4-5: a cadeia de caracteres inicial a ser codificada. As instâncias do tipo <str> são cadeias Unicode |https://docs.python.org/3/howto/unicode.html|, |https://realpython.com/python-encodings-guide/ |;
- linhas 6-11: duas formas de codificar uma cadeia em UTF-8:
- linha 8: str.encode('utf-8');
- linha 10: bytes(str, 'utf-8');
- linhas 12-17: fazemos o mesmo com a codificação 'iso-8859-1';
- linhas 18-23: «latin1» é outro nome para a codificação «iso-8859-1»;
Os resultados são os seguintes:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/strings/str_03.py
str=[hélène va au marché acheter des légumes, type=<class 'str'>
--- utf-8
bytes1=b'h\xc3\xa9l\xc3\xa8ne va au march\xc3\xa9 acheter des l\xc3\xa9gumes', type=<class 'bytes'>
bytes2=b'h\xc3\xa9l\xc3\xa8ne va au march\xc3\xa9 acheter des l\xc3\xa9gumes', type=<class 'bytes'>
--- iso-8859-1
bytes1=b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes', type=<class 'bytes'>
bytes2=b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes', type=<class 'bytes'>
--- latin1
bytes1=b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes', type=<class 'bytes'>
bytes2=b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes', type=<class 'bytes'>
Process finished with exit code 0
Comentários
- linha 4: vemos que os caracteres acentuados foram codificados utilizando dois bytes:
- é: [\xc3\xa9], que é a sequência binária 11000011 10101001;
- è: [\xc3\xa8], que é a sequência binária 11000011 10101000;
- Linha 7: Com a codificação ISO-8859-1, estes dois caracteres acentuados são codificados de forma diferente:
- é: [\xe9], que é a sequência binária 11101001;
- è: [\xe8], que é a sequência binária 11101000;
4.4. Script [str_04]: Codificação de cadeias de caracteres (2)
O Script [str_04] apresenta dois outros tipos de codificação: «base64» e «quoted-printable». Estas duas codificações não codificam cadeias de caracteres Unicode, mas sim objetos binários. Por exemplo, quando anexa um documento do Word a um e-mail, este será submetido a uma destas duas codificações, dependendo do cliente de e-mail utilizado. Este será o caso da maioria dos ficheiros anexados.
O script é o seguinte:
Comentários
- linha 2: o módulo [codecs] permite as codificações 'base64' e 'quoted-printable'. Pode lidar com muitas outras;
- linhas 4–7: a cadeia Unicode que será submetida a várias codificações;
- linhas 9-12: codificação UTF-8. Isto produz uma cadeia binária;
- linhas 14–18: descodificação UTF-8 para regressar à cadeia Unicode original;
- linhas 20–29: repetimos o mesmo processo com a codificação «iso-8859-1»;
- linhas 31–34: é apresentado um erro de descodificação:
- linha 33: bytes1 é uma cadeia binária codificada em 'utf-8'. Decodificamo-la para 'iso-8859-1';
- linhas 36–39: outra forma de codificar uma cadeia em UTF-8 utilizando o módulo [codecs];
- linhas 41–44: uma cadeia binária «utf-8» é codificada em «base64»;
- linhas 46–49: mostram como converter a cadeia binária «base64» de volta para a cadeia Unicode original;
- linhas 51–59: repetimos este processo utilizando a codificação «quoted-printable» em vez de «base64»;
Os resultados são os seguintes:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/strings/str_04.py
---- chaîne unicode
str1=[hélène va au marché acheter des légumes], type(str1)=<class 'str'>
---- chaîne unicode -> binaire utf-8
bytes1=[b'h\xc3\xa9l\xc3\xa8ne va au march\xc3\xa9 acheter des l\xc3\xa9gumes'], type(bytes1)=<class 'bytes'>
---- binaire utf-8 -> chaîne unicode
str2=[hélène va au marché acheter des légumes], type(str2)=<class 'str'>
str2==str1=True
---- chaîne unicode -> binaire iso-8859-1
bytes2=[b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes'], type(bytes2)=<class 'bytes'>
---- binaire iso-8859-1 -> chaîne unicode
str3=[hélène va au marché acheter des légumes], type(str3)=<class 'str'>
str3==str1=True
--- binaire utf-8 (décodage iso-8859-1) --> chaîne unicode
str4=[hélène va au marché acheter des légumes], type(str4)=<class 'str'>
---- chaîne unicode -> binaire utf-8
bytes3=[b'h\xc3\xa9l\xc3\xa8ne va au march\xc3\xa9 acheter des l\xc3\xa9gumes'], type(bytes3)=<class 'bytes'>
---- binaire utf-8 -> binaire base64
bytes4=[b'aMOpbMOobmUgdmEgYXUgbWFyY2jDqSBhY2hldGVyIGRlcyBsw6lndW1lcw==\n'], type(bytes4)=<class 'bytes'>
---- binaire base64 -> binaire utf-8 -> chaîne unicode
str6=[hélène va au marché acheter des légumes], type(str6)=<class 'str'>
---- binaire utf-8 -> binaire quoted-printable
str7=[b'h=C3=A9l=C3=A8ne=20va=20au=20march=C3=A9=20acheter=20des=20l=C3=A9gumes'], type(str7)=<class 'bytes'>
---- binaire quoted-printable -> binaire utf-8 -> chaîne unicode
str8=[hélène va au marché acheter des légumes], type(str8)=<class 'str'>
Process finished with exit code 0
- linhas 14-15: um binário UTF-8 é descodificado para uma cadeia Unicode utilizando o descodificador errado 'iso-8859-1'. Como resultado, alguns caracteres Unicode gerados estão incorretos, neste caso os caracteres acentuados;
- linhas 18-19: a codificação «base64» envolve a utilização de 64 caracteres ASCII (codificados em 7 bits) para codificar quaisquer dados binários. Como podemos ver, isto aumenta o tamanho dos dados binários da cadeia de caracteres;
- linhas 22–23: a codificação «quoted-printable» também utiliza caracteres ASCII (codificados em 7 bits) para codificar quaisquer dados binários;
É importante lembrar que, ao receber dados binários — da Internet, por exemplo — que representam texto, é necessário conhecer as codificações a que foram submetidos para recuperar o texto original.