7. Ficheiros de texto
7.1. Script [fic_01]: Ler/escrever um ficheiro de texto
O script seguinte ilustra um exemplo de trabalho com ficheiros de texto:
Notas:
- linha 28: abre o ficheiro para gravação (w=write). Se o ficheiro já existir, será sobrescrito;
- Linhas 30–34: Geram 100 linhas no ficheiro de texto;
- linha 34: para escrever uma linha no ficheiro de texto. O método [write] não adiciona um caractere de nova linha. Por isso, deve incluir este no texto escrito;
- linhas 35–37: trata de quaisquer exceções;
- linha 37: Aborta a execução do script (no entanto, após a execução do bloco finally);
- linhas 38–41: em todos os casos, ocorra ou não um erro, fechar o ficheiro se estiver aberto;
- linha 47: abrir o ficheiro para leitura (r=read);
- linha 49: definição de um dicionário vazio;
- linha 52: o método [readline] lê uma linha de texto, incluindo o caractere de fim de linha. O método [strip] remove os «espaços» do início e do fim da cadeia. Por «espaço», entendemos caracteres de espaço em branco, quebras de linha, quebras de página, tabulações e alguns outros. Assim, aqui, [line] não conterá os caracteres de quebra de linha [\r\n] (Windows) ou [\n] (Unix);
- linha 54: o ficheiro é processado até ser encontrada uma linha vazia;
- linhas 54–64: o ficheiro de texto é transferido para o dicionário [dico]. A chave é o campo [login] e o valor é composto pelos campos [uid:gid:infos:dir:shell];
- linhas 65–67: tratam quaisquer exceções;
- linhas 68–71: fechar o ficheiro em todos os casos, ocorra ou não um erro;
- linhas 74-75: consultar o dicionário [dico];
O ficheiro [data/infos.txt]:
Saída no ecrã:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/fichiers/fic_01.py
login10 : ['uid10', 'gid10', 'infos10', 'dir10', 'shell10']
la clé [X] n'existe pas
Process finished with exit code 0
7.2. Script [fic_02]: Tratamento de ficheiros de texto codificados em UTF-8
No restante deste documento, trabalharemos exclusivamente com ficheiros de texto codificados em UTF-8. Primeiro, vamos configurar o PyCharm:
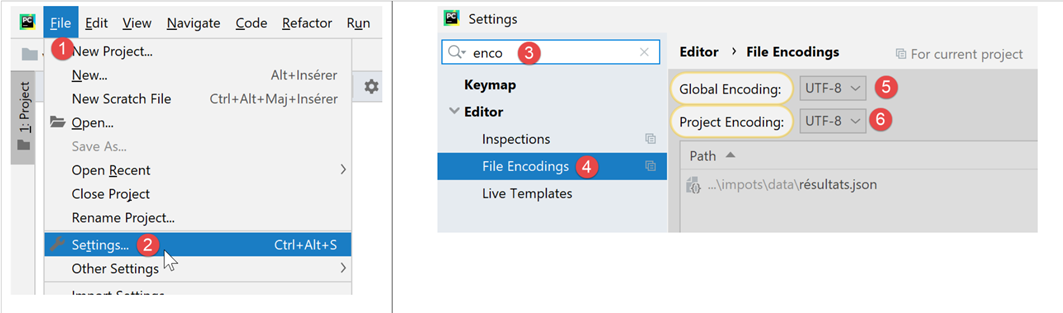
- em [5-6]: selecione a codificação UTF-8 para os ficheiros do projeto;
Para criar um ficheiro codificado em UTF-8, proceda da seguinte forma (fic-02):
Notas
- linha 2: para lidar com a codificação do ficheiro, importamos o módulo [codecs];
- linha 6: o método [codecs.open] é utilizado tal como a função padrão [open]. No entanto, é possível especificar a codificação desejada (ao criar) ou a codificação existente (ao ler). Após a abertura, o objeto [file] obtido na linha 6 é utilizado como um ficheiro padrão;
- linha 7: foram utilizados caracteres acentuados, que normalmente têm representações diferentes dependendo da codificação de caracteres utilizada;
Resultados
Ao abrir o ficheiro [data/utf8.txt] obtido (ver linha 6), obtém-se o seguinte resultado:

7.3. Script [fic_03]: tratamento de ficheiros de texto codificados em ISO-8859-1
O script [fic_03] faz o mesmo que o script [fic_02], mas codifica o ficheiro de texto em ISO-8859-1. Queremos mostrar a diferença entre os ficheiros resultantes:
Quando abrimos o ficheiro [data/iso-8859-1] criado na linha 6, obtemos o seguinte resultado:

Como configurámos o projeto para trabalhar com ficheiros UTF-8, o PyCharm tentou abrir o ficheiro [iso-8859-1.txt] em UTF-8. Ele consegue ver [1] que o ficheiro não está em UTF-8. Em seguida, sugere [2] recarregar o ficheiro com uma codificação diferente:

- em [3-5]: o ficheiro é recarregado utilizando a codificação ISO-8859-1;

- em [6], o mesmo ficheiro, mas apresentado com uma codificação diferente;
Se voltarmos às definições do projeto:
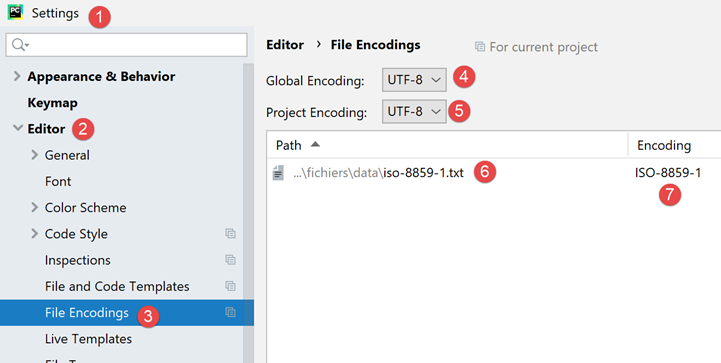
- vemos que em [6-7], o PyCharm indicou que o ficheiro [iso-8859-1.txt] deve ser aberto com a codificação ISO-8859-1. Trata-se, portanto, de uma exceção à regra [5];
7.4. Script [json_01]: Trabalhar com um ficheiro JSON
JSON significa JavaScript Object Notation. Como o nome sugere, trata-se de uma representação baseada em texto de objetos JavaScript. Aqui, iremos utilizá-lo com objetos Python.
O ficheiro JSON em questão [data/in.json] terá o seguinte aspeto:
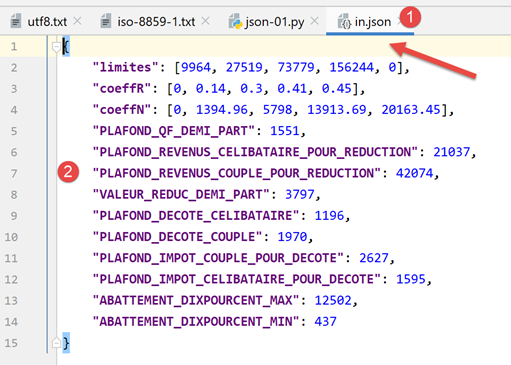
- Em [2], podemos ver que o conteúdo de texto do ficheiro [in.json] poderia representar um dicionário Python. O PyCharm formatou (Ctrl-Alt-L) este texto, mas mesmo que estivesse numa única linha, não faria qualquer diferença. O formato do texto é irrelevante, desde que represente sintaticamente um objeto Python;
O script [json-01] mostra como utilizar este ficheiro:
Notas
- Linha 3: Para trabalhar com JSON, importamos o módulo [json];
- linha 11: iremos trabalhar com ficheiros JSON codificados em UTF-8. Aqui, abrimos o ficheiro [data/in.json] utilizando o módulo [codecs];
- linha 13: o método [json.load] lê o conteúdo do ficheiro JSON e armazena-o na variável [data]. O tipo desta variável será um dicionário;
- linhas 15–18: para verificar se obtivemos efetivamente um dicionário Python, exibimos alguns dos seus elementos;
- linhas 20–21: realizamos a operação inversa: o dicionário [data] é gravado num ficheiro codificado em UTF-8 utilizando o método [json.dump];
- linhas 22–25: tratamento de eventuais exceções;
- linhas 26-31: em qualquer caso, quer ocorra um erro ou não, fechamos quaisquer ficheiros que possam ter sido abertos;
Resultados
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/fichiers/json_01.py
data={'limites': [9964, 27519, 73779, 156244, 0], 'coeffR': [0, 0.14, 0.3, 0.41, 0.45], 'coeffN': [0, 1394.96, 5798, 13913.69, 20163.45], 'PLAFOND_QF_DEMI_PART': 1551, 'PLAFOND_REVENUS_CELIBATAIRE_POUR_REDUCTION': 21037, 'PLAFOND_REVENUS_COUPLE_POUR_REDUCTION': 42074, 'VALEUR_REDUC_DEMI_PART': 3797, 'PLAFOND_DECOTE_CELIBATAIRE': 1196, 'PLAFOND_DECOTE_COUPLE': 1970, 'PLAFOND_IMPOT_COUPLE_POUR_DECOTE': 2627, 'PLAFOND_IMPOT_CELIBATAIRE_POUR_DECOTE': 1595, 'ABATTEMENT_DIXPOURCENT_MAX': 12502, 'ABATTEMENT_DIXPOURCENT_MIN': 437}, type(data)=<class 'dict'>
limites=[9964, 27519, 73779, 156244, 0], type(limites)=<class 'list'>
limites[1]=27519, type(limites[1])=<class 'int'>
Process finished with exit code 0
- As linhas 2–4 mostram que recuperámos com sucesso o dicionário do ficheiro JSON;
Agora, vamos ver o conteúdo do ficheiro [data/out.json]:

O texto no ficheiro está numa única linha. No entanto, o PyCharm reconhece ficheiros JSON e podemos formatá-los — tal como ficheiros Python e outros — utilizando Ctrl-Alt-L. Isto dá-nos o seguinte:
7.5. Script [json_02]: Tratamento de ficheiros JSON codificados em UTF-8
Um ficheiro JSON codificado em UTF-8 pode assumir duas formas:
- Neste script, o dicionário [data] (linha 7) é gravado em dois ficheiros JSON (linhas 14, 17);
- linhas 14, 17: em ambos os casos, é criado um ficheiro de texto UTF-8;
- linha 15: ao gravar o dicionário, usamos o parâmetro chamado [ensure_ascii=True];
- linhas 18: ao gravar o dicionário, utilizamos o parâmetro denominado [ensure_ascii=False];
Aqui estão os dois ficheiros resultantes:

- No ficheiro [out1.json], os caracteres acentuados foram substituídos por uma sequência de caracteres que representam o seu código UTF-8. Este processo é por vezes designado por «escaping». Tecnicamente, no ficheiro binário [out1.json], o caractere é em [marié] é representado pelos códigos binários UTF-8 dos 6 caracteres [\u00e9] em sucessão;
- No ficheiro [out2.json], os caracteres acentuados foram mantidos tal como estão. Isto significa que, nos dados binários de [out2.json], estes caracteres são representados pelo seu código binário UTF-8 (apenas um único código UTF-8, em vez de 6 como em [out1]). Para o caractere é em [marié], encontramos assim o código binário de 4 bytes [00e9];
- é o valor do parâmetro [ensure_ascii] do método [json.dump] que determina o formato utilizado;
Algumas aplicações utilizam UTF-8 «escapado» para os seus ficheiros JSON. Nesse caso, deve ser utilizado o valor [ensure_ascii=True]. Este valor é, na verdade, o padrão. Portanto, se o parâmetro [ensure_ascii] não for utilizado, estaremos a trabalhar com ficheiros JSON em UTF-8 escapado.
O script continua da seguinte forma:
Notas
- linhas 11–34: lê os dois ficheiros [out1.json, out2.json] e apresenta o dicionário lido em cada caso;
Resultados
Surpreendentemente, verificamos que não foi necessário especificar o tipo de codificação (escapada ou não) da cadeia JSON a ser lida pela função [json.load] (linhas 17, 22). Em ambos os casos, obtemos o dicionário correto.