5. Versão 1: Arquitetura Spring / JPA
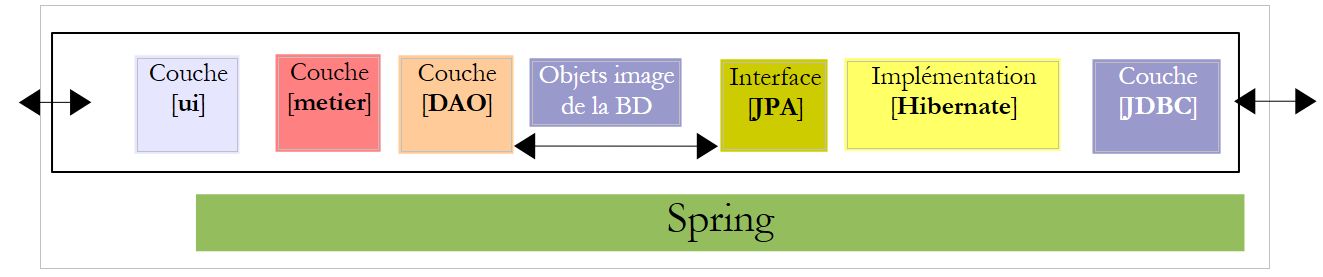
Propõe-se a criação de uma aplicação de consola e de uma aplicação gráfica que permitam elaborar a folha de pagamento das amas empregadas pela «Maison de la petite enfance» de um município. Esta aplicação terá a seguinte arquitetura:
 |
5.1. BD A base de dados
Os dados estáticos necessários para elaborar a folha de pagamento serão armazenados numa base de dados a que, doravante, nos referiremos como dbpam. Esta base de dados poderá conter as seguintes tabelas:
Estrutura:
chave primária | |
n.º de versão – aumenta a cada alteração da linha | |
número de segurança social do colaborador – único | |
nome do funcionário | |
o seu nome próprio | |
a sua morada | |
a sua cidade | |
o seu código postal | |
chave estrangeira no campo [ID] da tabela [INDEMNITES] |
O seu conteúdo poderia ser o seguinte:

Estrutura:
chave primária | |
n.º de versão – aumenta a cada alteração da linha | |
percentagem: contribuição social generalizada + contribuição para o reembolso da dívida social | |
percentagem: contribuição social generalizada dedutível | |
percentagem: segurança social, pensão de viuvez, velhice | |
percentagem: pensão complementar + seguro de desemprego |
O seu conteúdo poderia ser o seguinte:
![]()
As taxas das contribuições sociais são independentes do trabalhador. A tabela anterior tem apenas uma linha.
chave primária | ||
n.º de versão – aumenta a cada alteração da linha | ||
índice de processamento – único | ||
preço líquido em euros por hora de serviço de guarda | ||
Subsídio de manutenição em euros por dia de guarda | ||
Subsídio de refeição em euros por dia de serviço | ||
Subsídio de férias pagas. Trata-se de uma percentagem a aplicar ao salário base. | ||
O seu conteúdo poderá ser o seguinte:

Note-se que os subsídios podem variar de uma ama a outra. Estão, de facto, associados a uma ama específica através do seu índice salarial. Assim, a Sra. Marie Jouveinal, que tem um índice salarial de 2 (tabela EMPLOYES), tem um salário por hora de 2,1 euros (tabela INDEMNITES).
5.2. Método de cálculo do salário de uma ama
Apresentamos agora o método de cálculo do salário mensal de uma assistente maternal. Este não pretende ser o método utilizado na realidade. Tomamos como exemplo o salário da Sra. Marie Jouveinal, que trabalhou 150 horas ao longo de 20 dias durante o mês a pagar.
São tidos em conta os seguintes elementos: | | |
O salário base da ama é calculado através da seguinte fórmula: | ||
Uma determinada quantia de contribuições sociais devem ser deduzidas deste salário de base: | | |
Total das contribuições sociais: | ||
Além disso, a ama tem direito, por cada dia trabalhado, a um subsídio de subsistência e a um subsídio de refeição. A este título, recebe os seguintes subsídios: | | |
Em suma, o salário líquido a pagar à ama é o seguinte: |
5.3. Funcionamento da aplicação de consola
Eis um exemplo de execução da aplicação de consola numa janela do DOS:
Vamos escrever um programa que irá receber as seguintes informações:
- número de segurança social da ama (254104940426058 no exemplo — linha 1)
- número total de horas trabalhadas (150 no exemplo — linha 1)
- número total de dias trabalhados (20 no exemplo — linha 1)
Verifica-se que:
- linhas 9-14: apresentam as informações relativas ao trabalhador cujo número de segurança social foi indicado
- linhas 17-20: apresentam as taxas das diferentes contribuições
- linhas 23-26: apresentam os subsídios associados ao índice salarial do empregado (neste caso, o índice 2)
- linhas 29-33: apresentam os elementos que compõem o salário a pagar
A aplicação sinaliza eventuais erros:
Chamada sem parâmetros:
dos>java -jar pam-spring-ui-metier-dao-jpa-eclipselink.jar
Syntaxe : pg num_securite_sociale nb_heures_travaillées nb_jours_travaillés
Chamada com dados errados:
dos>java -jar pam-spring-ui-metier-dao-jpa-eclipselink.jar 254104940426058 150x 20x
Le nombre d'heures travaillées [150x] est erroné
Le nombre de jours travaillés [20x] est erroné
Chamada com um número de segurança social incorreto:
dos>java -jar pam-spring-ui-metier-dao-jpa-eclipselink.jar xx 150 20
L'erreur suivante s'est produite : L'employé de n°[xx] est introuvable
5.4. Funcionamento da aplicação gráfica
A aplicação gráfica permite o cálculo dos salários das amas através de um formulário Swing:
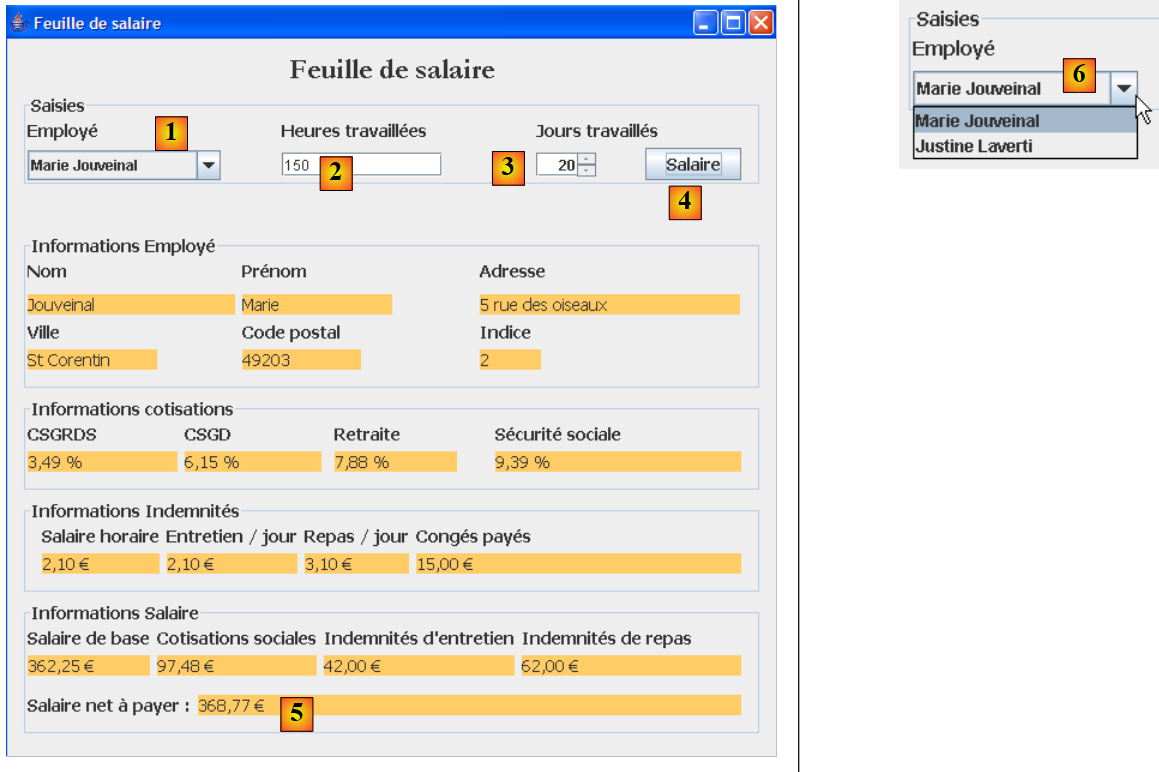 |
- as informações que eram passadas como parâmetros para o programa de consola são agora introduzidas através dos campos de introdução de dados [1, 2, 3].
- O botão [4] inicia o cálculo do salário
- O formulário apresenta os diferentes elementos do salário até ao salário líquido a pagar [5]
A lista suspensa [1, 6] não apresenta os números SS dos funcionários, mas sim os seus nomes e apelidos. Parte-se aqui do princípio de que não existem dois funcionários com o mesmo nome e apelido.
5.5. Criação da base de dados
Executamos o WampServer e utilizamos a ferramenta PhpMyAdmin [1]:
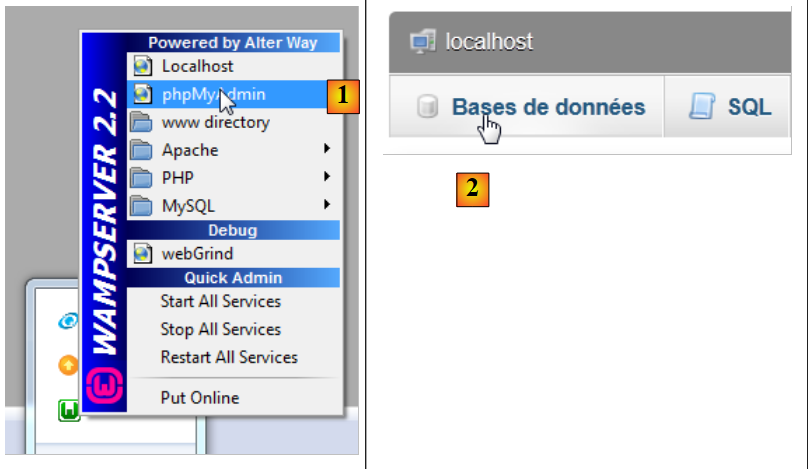 |
- no [2], selecionamos a opção [Bases de données],
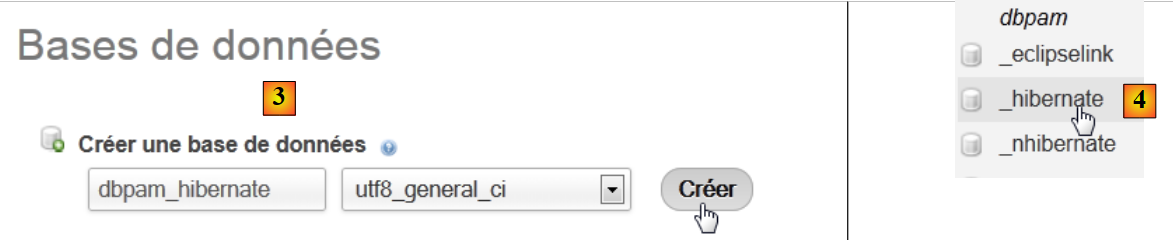 |
- em [3], cria-se uma base de dados [dbpam_hibernate],
- em [4], a base de dados criada. Selecionamo-la,
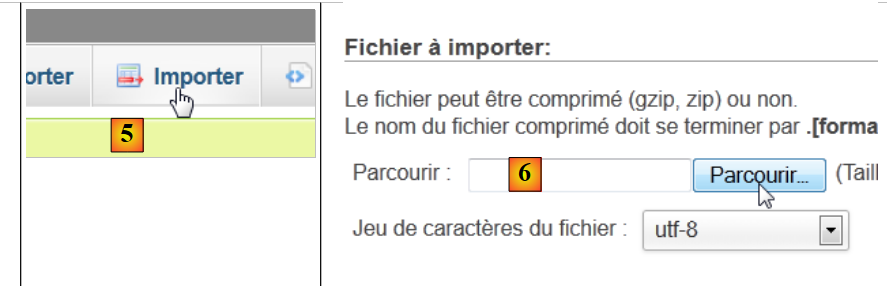 |
- em [5], pretende-se importar um script SQL,
- em [6], utiliza-se o botão [Parcourir] para indicar o ficheiro,
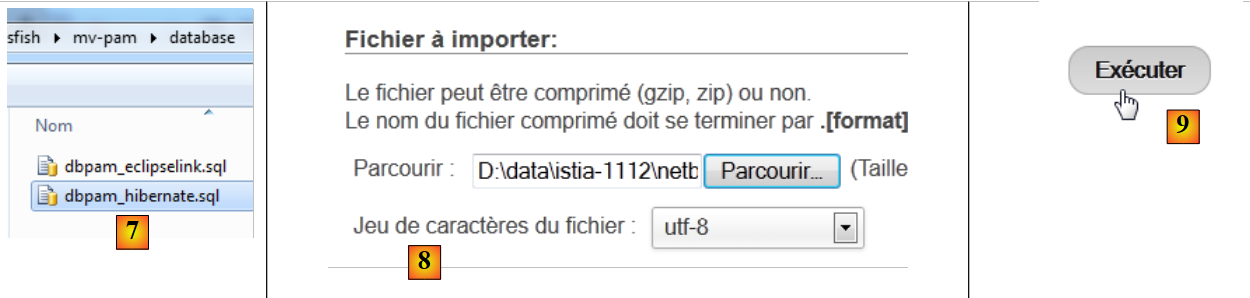 |
- em [7,8], seleciona-se o script SQL,
- em [9], executa-se o mesmo,
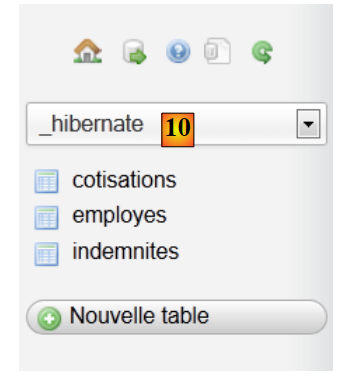 |
- em [10], as tabelas foram criadas. O seu conteúdo é o seguinte:
tabela EMPLOYES

tabela INDEMNITES

tabela COTISATIONS
![]()
5.6. Implementação JPA
5.6.1. Camada JPA / Hibernate
Vamos configurar a camada JPA no seguinte ambiente:
 |
Um programa de consola irá trabalhar com a base de dados. Para tal, é necessário:
- ter uma base de dados,
- ter o controlador JDBC do SGBD, neste caso o MySQL,
- implementar a camada JPA com o Hibernate,
- escrever o programa de consola.
Criamos o projeto Maven [mv-pam-jpa-hibernate] [1]:
 |
Na arquitetura da nossa aplicação, precisamos dos seguintes elementos:
- a base de dados,
- o controlador JDBC do SGBD MySQL,
- a camada JPA / Hibernate (entidades e configuração),
- o programa de consola de teste.
5.6.1.1. A base de dados
Vamos, em primeiro lugar, criar a base de dados vazia. Iniciamos o WampServer e utilizamos a ferramenta PhpMyAdmin [1]:
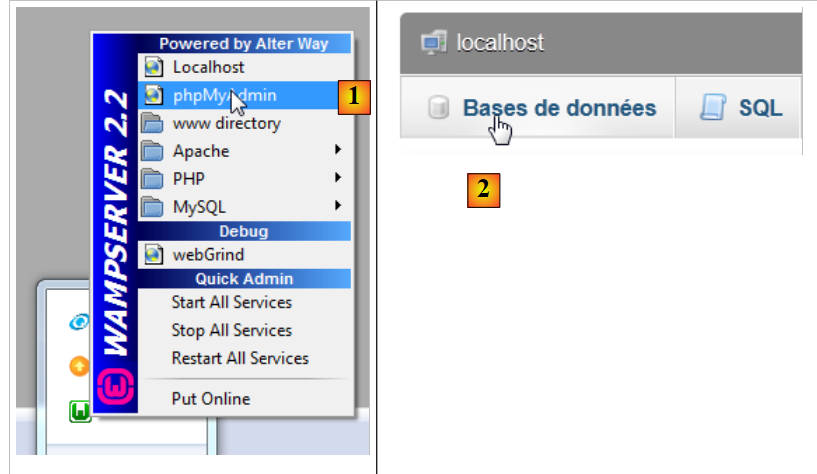 |
- no [2], selecionamos a opção [Bases de données],
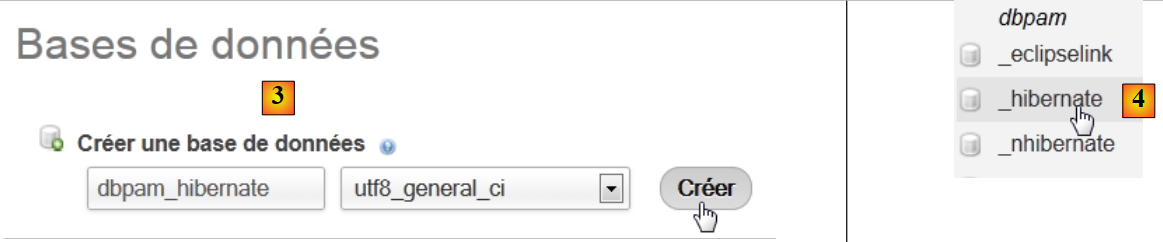 |
- em [3], cria-se uma base de dados [dbpam_hibernate],
- em [4], a base de dados criada.
5.6.1.2. Configuração da camada JPA
A ligação entre a camada JDBC e a base de dados é feita no ficheiro [persistence.xml], que configura a camada JPA. Este ficheiro pode ser criado com o NetBeans:
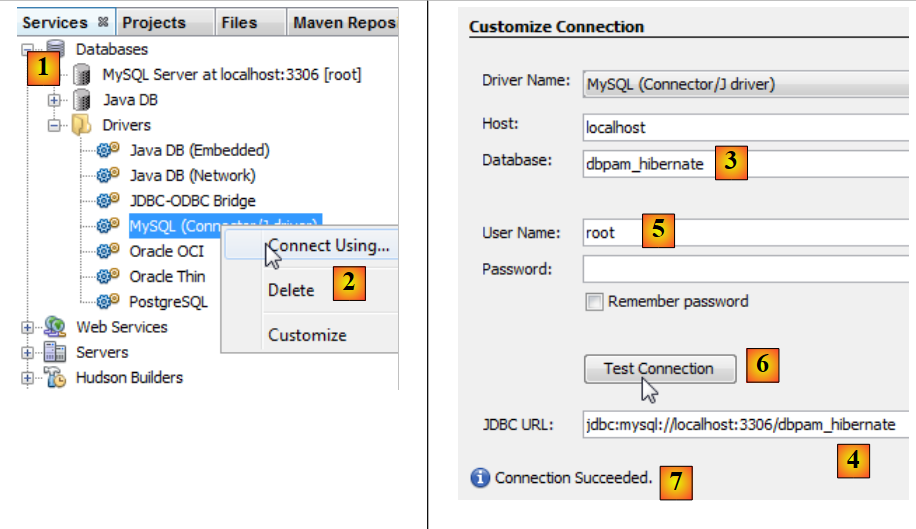 |
- no separador [services] [1], estabelece-se a ligação à base de dados com o controlador JDBC de MySQL [2],
- em [3], o nome da base de dados à qual se pretende ligar.
- em [4], o nome da base de dados,
- em [5], liga-se como root sem palavra-passe,
- no [6], é possível testar a ligação,
- em [7], a ligação foi bem-sucedida.
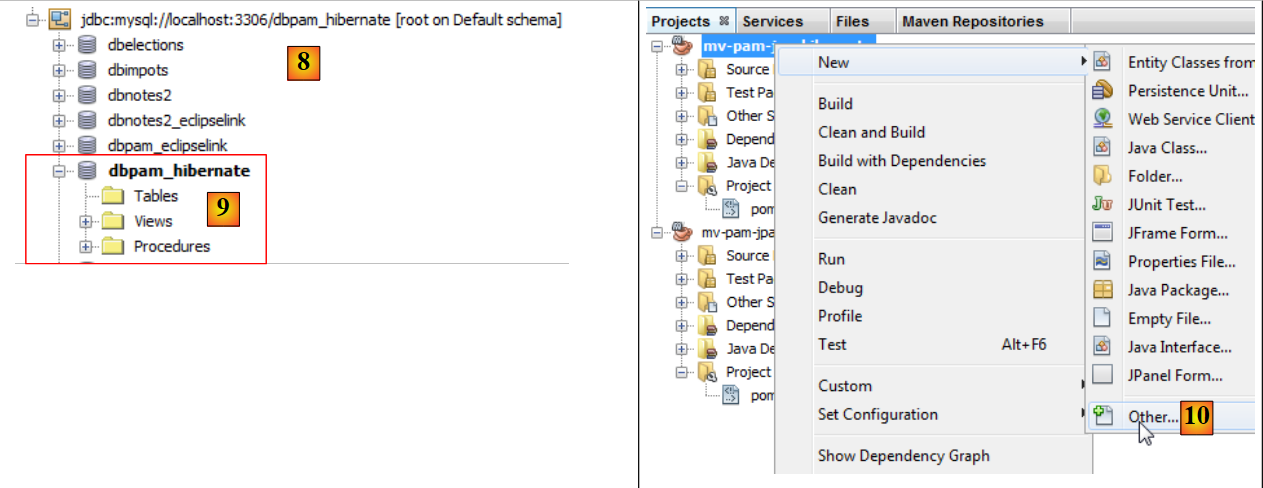 |
- a ligação aparece em [8] e em [9],
- em [10], adiciona-se um novo elemento ao projeto,
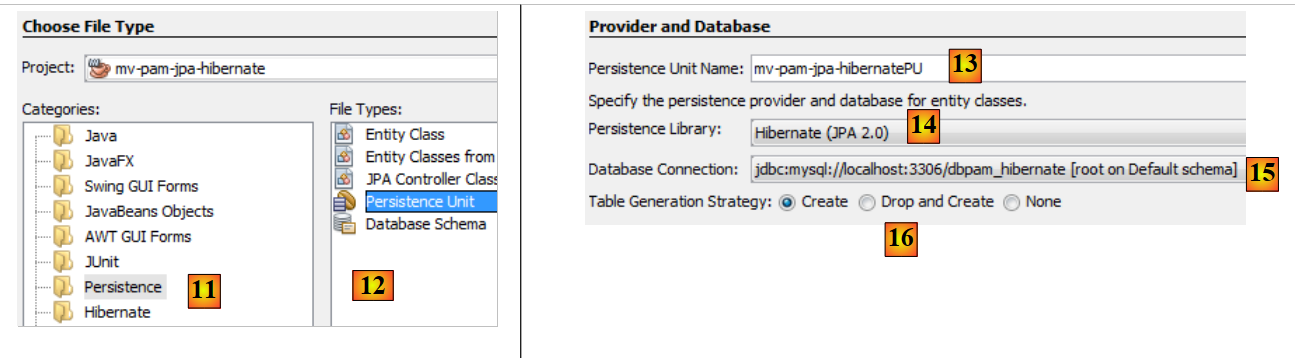 |
- em [11], seleciona-se a categoria [Persistence] e, em [12], o elemento [Persistence Unit],
- em [13], atribui-se um nome a esta unidade de persistência,
- em [14], seleciona-se uma implementação do Hibernate,
- em [15], designa-se a ligação que acabámos de criar à base de dados MySQL,
- em [16], indica-se que, aquando da instanciação da camada JPA, esta deve criar as tabelas correspondentes às entidades JPA do projeto.
No final do assistente, é gerado o ficheiro [persistence.xml]:
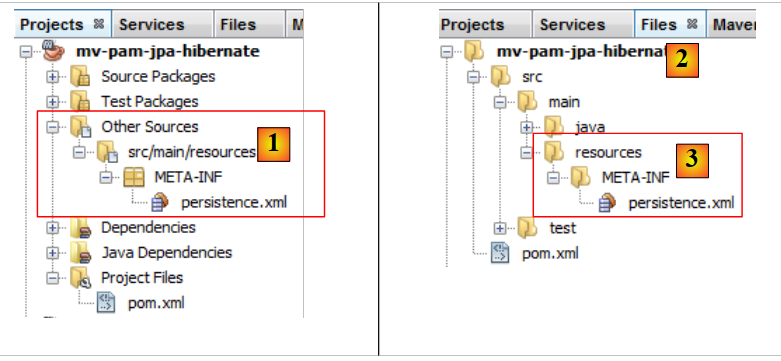 |
- o ficheiro aparece num novo ramo do projeto, numa pasta [META-INF] [1],
- que corresponde à pasta [src/main/resources] do projeto [2,3].
O seu conteúdo é o seguinte:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="mv-pam-jpa-hibernatePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbpam_hibernate"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="hibernate.cache.provider_class" value="org.hibernate.cache.NoCacheProvider"/>
<property name="hibernate.hbm2ddl.auto" value="create-drop"/>
</properties>
</persistence-unit>
</persistence>
- linha 3: o nome da unidade de persistência e o tipo de transações. RESOURCE_LOCAL indica que o próprio projeto gere as transações. Neste caso, será o programa de consola que terá de o fazer,
- linha 4: a implementação JPA utilizada é o Hibernate,
- linhas 6-9: as características JDBC da ligação à base de dados,
- linha 11: solicita a criação das tabelas correspondentes às entidades JPA. Na verdade, o NetBeans gera aqui uma configuração errada. A configuração deve ser a seguinte:
<property name="hibernate.hbm2ddl.auto" value="create"/>
Com a opção «create», o Hibernate, ao instanciar a camada JPA, elimina e, em seguida, cria as tabelas correspondentes às entidades JPA. A opção «create-drop» faz o mesmo, mas, no final do ciclo de vida da camada JPA, elimina todas as tabelas. Existe outra opção:
<property name="hibernate.hbm2ddl.auto" value="update"/>
Esta opção cria as tabelas se estas não existirem, mas não as elimina se já existirem.
Iremos adicionar mais três propriedades à configuração do Hibernate:
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
Estas propriedades solicitam ao Hibernate que exiba os comandos SQL que este envia à base de dados. O ficheiro completo é, portanto, o seguinte:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="mv-pam-jpa-hibernatePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<class>jpa.Cotisation</class>
<class>jpa.Employe</class>
<class>jpa.Indemnite</class>
<properties>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbpam_hibernate"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="hibernate.cache.provider_class" value="org.hibernate.cache.NoCacheProvider"/>
<property name="hibernate.hbm2ddl.auto" value="create"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
</properties>
</persistence-unit>
</persistence>
5.6.1.3. As dependências
Voltemos à arquitetura do projeto:
 |
Configurámos a camada JPA através do ficheiro [persistence.xml]. A implementação escolhida foi o Hibernate. Isto introduziu dependências no projeto:
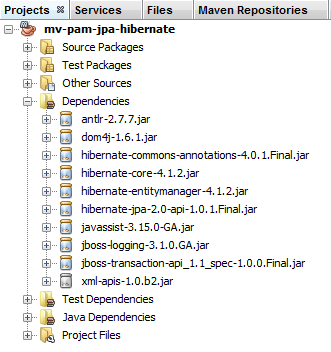 |
Estas dependências devem-se à inclusão do Hibernate no projeto. Temos de adicionar outra dependência, a do controlador JDBC do MySQL, que implementa a camada JDBC da arquitetura. Alteramos o ficheiro [pom.xml] da seguinte forma:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>4.1.2</version>
</dependency>
...
<dependency>
<groupId>org.hibernate.common</groupId>
<artifactId>hibernate-commons-annotations</artifactId>
<version>4.0.1.Final</version>
</dependency>
</dependencies>
As linhas 8-12 adicionam a dependência do controlador JDBC do MySQL.
5.6.1.4. As entidades JPA
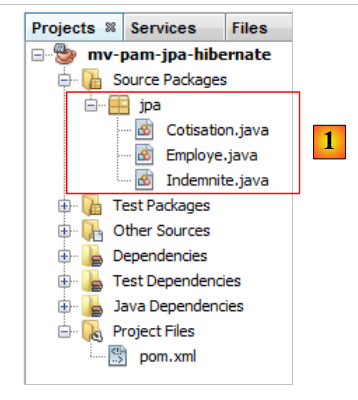 |
Pergunta: Seguindo o procedimento do exemplo do parágrafo 4.4, gere as entidades [Cotisation, Indemnite, Employe].
Notas:
- as entidades farão parte de um pacote denominado [jpa],
- cada entidade terá um número de versão,
- se duas entidades estiverem ligadas por uma relação, apenas a relação principal @ManyToOne será criada. A relação inversa @OneToMany não será criada.
5.6.1.5. O código da classe principal
Incluímos no projeto as entidades JPA e [1], desenvolvidas anteriormente:
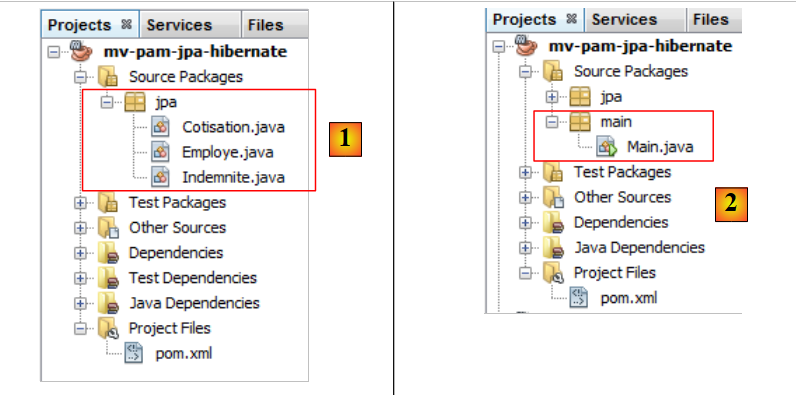 |
e, em seguida, adicionamos a [2], a seguinte classe [main.Main]:
package main;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public class Main {
public static void main(String[] args) {
// basta criar o Entity Manager para construir a camada JPA
EntityManagerFactory emf = Persistence.createEntityManagerFactory("mv-pam-jpa-hibernatePU");
EntityManager em=emf.createEntityManager();
// libertação de recursos
em.close();
emf.close();
}
}
- linha 10: criamos a EntityManagerFactory a partir da unidade de persistência denominada [mv-pam-jpa-hibernatePU]. Este nome provém do ficheiro [persistence.xml]:
<persistence-unit name="mv-pam-jpa-hibernatePU" transaction-type="RESOURCE_LOCAL">
...
</persistence-unit>
- linha 12: cria-se o EntityManager. Esta criação gera a camada JPA. O ficheiro [persistence.xml] será processado e, consequentemente, as tabelas da base de dados serão criadas,
- linhas 14-15: libertam-se os recursos.
5.6.1.6. Tests
Voltemos à arquitetura do nosso projeto:
 |
Todas as camadas foram implementadas. Executamos o projeto [2].
 |
Os resultados na consola são os seguintes:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 | |
Na consola, encontram-se apenas registos do Hibernate, uma vez que o programa executado não faz nada além de instanciar a camada JPA. Destacam-se os seguintes pontos:
- linha 43: o Hibernate tenta eliminar a chave estrangeira da tabela [EMPLOYES],
- linhas 51-55: eliminação das três tabelas,
- linha 57: criação da tabela [COTISATIONS],
- linha 67: criação da tabela [EMPLOYES],
- linha 80: criação da tabela [INDEMNITES],
- linha 91: criação da chave estrangeira da tabela [EMPLOYES].
No NetBeans, é possível ver as tabelas na ligação que foi criada anteriormente:
 |
As tabelas criadas dependem tanto da implementação da camada JPA utilizada como da implementação da camada SGBD utilizada. Assim, uma implementação JPA / EclipseLink com a mesma base de dados pode gerar tabelas diferentes. É isso que vamos ver agora.
5.6.2. Camada JPA / EclipseLink
Vamos criar um novo projeto Maven no seguinte ambiente:
 |
Seguiremos o procedimento descrito no parágrafo anterior:
- criar uma base de dados MySQL [dbpam_eclipselink]. Utilizaremos o script [dbpam_eclipselink.sql] para a gerar,
- criar o ficheiro [persistence.xml] do projeto. Utilizar a implementação JPA 2.0 EclipseLink,
- adicionar às dependências geradas a dependência do controlador JDBC do MySQL,
- adicionar as entidades JPA e o programa de consola,
- e realizar os testes.
O ficheiro [persistence.xml] terá o seguinte conteúdo:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="pam-jpa-eclipselinkPU" transaction-type="RESOURCE_LOCAL">
<provider>org.eclipse.persistence.jpa.PersistenceProvider</provider>
<class>jpa.Cotisation</class>
<class>jpa.Employe</class>
<class>jpa.Indemnite</class>
<properties>
<property name="eclipselink.target-database" value="MySQL"/>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbpam_eclipselink"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="eclipselink.logging.level" value="FINE"/>
<property name="eclipselink.ddl-generation" value="drop-and-create-tables"/>
</properties>
</persistence-unit>
</persistence>
- as propriedades 9-13 foram geradas pelo assistente do NetBeans,
- linha 14: esta propriedade permite-nos definir o nível de registo do EclipseLink. O nível FINE permite-nos conhecer as ordens SQL que EclipseLink irá emitir na base de dados,
- linha 15: aquando da instanciação da camada JPA / EclipseLink, as tabelas das entidades JPA serão eliminadas e, em seguida, criadas.
Os resultados obtidos na consola são os seguintes:
- linhas 26-30: ligação à base de dados MySQL,
- linhas 31-34: confirmação de que a ligação foi bem-sucedida,
- linha 36: eliminação da chave estrangeira da tabela [EMPLOYES],
- linha 37: eliminação da tabela [COTISATIONS],
- linha 38: criação da tabela [COTISATIONS]. É interessante notar que a chave primária ID não possui o atributo MySQL auto_increment. Isto significa que não é a MySQL que gera os valores da chave primária,
- linha 39: eliminação da tabela [EMPLOYES],
- linha 40: criação da tabela [EMPLOYES]. A sua chave primária ID não possui o atributo MySQL auto_increment,
- linha 41: eliminação da tabela [INDEMNITES],
- linha 42: criação da tabela [INDEMNITES]. A sua chave primária ID não possui o atributo MySQL auto_increment,
- linha 43: criação da chave estrangeira da tabela [EMPLOYES] para a tabela [INDEMNITES],
- linha 44: criação de uma tabela [SEQUENCE]. Esta será utilizada para gerar as chaves primárias das três tabelas anteriores,
- linha 47: ocorre uma exceção porque esta tabela já existia,
- linhas 51-53: inicialização da tabela [SEQUENCE].
A existência das tabelas geradas pode ser verificada no NetBeans [1]:
 |
Assim, a partir das mesmas entidades JPA, as implementações JPA, Hibernate e EclipseLink não geram as mesmas tabelas. No restante do documento, quando a implementação JPA utilizada for:
- Hibernate, será utilizada a base de dados [dbpam_hibernate],
- EclipseLink, será utilizada a base de dados [dbpam_eclipselink].
5.6.3. Tarefa a realizar
Seguindo o mesmo procedimento que anteriormente,
- crie e teste um projeto [mv-pam-jpa-hibernate-oracle] utilizando uma implementação JPA do Hibernate e uma implementação SGBD do Oracle,
- criar e testar um projeto [mv-pam-jpa-hibernate-mssql] utilizando uma implementação JPA do Hibernate e um servidor SGBD SQL,
- criar e testar um projeto [mv-pam-jpa-eclipselink-oracle] utilizando uma implementação JPA EclipseLink e um servidor Oracle SGBD,
- criar e testar um projeto [mv-pam-jpa-eclipselink-mssql] utilizando uma implementação JPA EclipseLink e um servidor SGBD SQL,
5.6.4. Lazy ou Eager?
Voltemos a uma possível definição da entidade [Employe]:
package jpa;
...
@Entity
@Table(name="EMPLOYES")
public class Employe implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Version
@Column(name="VERSION",nullable=false)
private int version;
@Column(name="SS", nullable=false, unique=true, length=15)
private String SS;
@Column(name="NOM", nullable=false, length=30)
private String nom;
@Column(name="PRENOM", nullable=false, length=20)
private String prenom;
@Column(name="ADRESSE", nullable=false, length=50)
private String adresse;
@Column(name="VILLE", nullable=false, length=30)
private String ville;
@Column(name="CP", nullable=false, length=5)
private String codePostal;
@ManyToOne(fetch= FetchType.LAZY)
@JoinColumn(name="INDEMNITE_ID",nullable=false)
private Indemnite indemnite;
...
}
As linhas 27-29 definem a chave estrangeira da tabela [EMPLOYES] para a tabela [INDEMNITES]. O atributo «fetch» da linha 27 define a estratégia de pesquisa do campo indemnite da linha 29. Existem dois modos:
- FetchType.LAZY: quando se procura um funcionário, a indemnização que lhe corresponde não é apresentada. Será apresentada quando o campo [Employe].indemnite for referenciado pela primeira vez.
- FetchType.EAGER: quando se procura um colaborador, a indemnização que lhe corresponde é apresentada. Este é o modo predefinido quando não é especificado nenhum modo.
Para compreender a utilidade da opção FetchType.LAZY, podemos considerar o seguinte exemplo. Uma lista de funcionários sem as indemnizações é apresentada numa página web com um link [Details]. Ao clicar nesse link, são então apresentadas as indemnizações do funcionário selecionado. Verifica-se que:
- para apresentar a primeira página, não é necessário incluir os funcionários com as respetivas indemnizações. O modo FetchType.LAZY é, portanto, adequado;
- para apresentar a segunda página com os detalhes, é necessário efetuar uma consulta adicional à base de dados para obter os subsídios do funcionário selecionado.
O modo FetchType.LAZY evita a recuperação de dados em excesso de que a aplicação não necessita de imediato. Vejamos um exemplo.
O projeto [mv-pam-jpa-hibernate] é duplicado:
 |
- em [1], copia-se o projeto,
- em [2], indica-se a pasta da cópia e, em [3], o seu nome,
- em [4], o novo projeto tem o mesmo nome que o antigo. Alteramos isso:
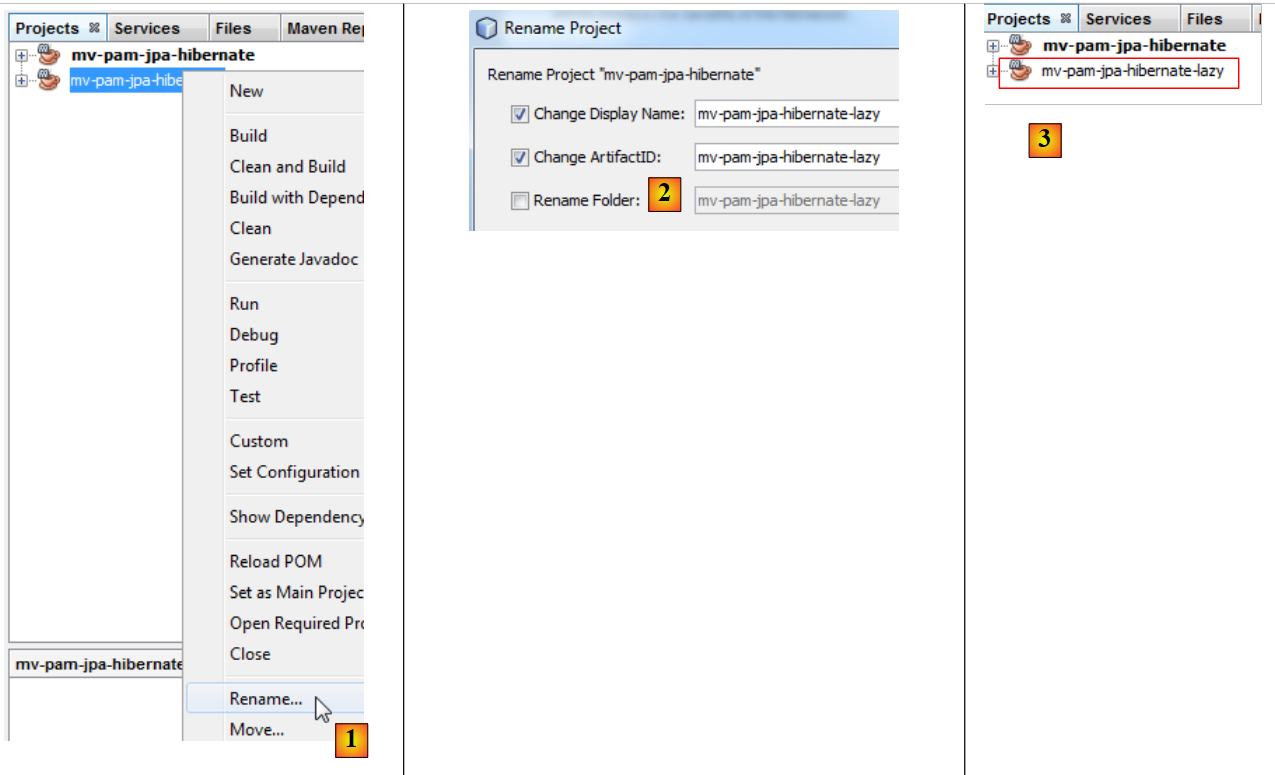 |
- em [1], renomeamos o projeto,
- em [2], renomeamos o projeto e o seu artifactId,
- para [3], o novo projeto.
Alteramos o programa [Main.java] da seguinte forma:
package main;
import java.util.List;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
import jpa.Employe;
public class Main {
// a consulta JPQL abaixo apresenta um funcionário
// a chave estrangeira [Employe].indemnite está em FetchType.LAZY
public static void main(String[] args) {
// basta criar o Entity Manager para construir a camada JPA
EntityManagerFactory emf = Persistence.createEntityManagerFactory("pam-jpa-hibernatePU");
// primeira tentativa
EntityManager em = emf.createEntityManager();
Employe employe = (Employe) em.createQuery("select e from Employe e where e.nom=:nom").setParameter("nom", "Jouveinal").getSingleResult();
em.close();
// exibe-se o funcionário
try {
System.out.println(employe);
} catch (Exception ex) {
System.out.println(ex);
}
// segunda tentativa
em = emf.createEntityManager();
employe = (Employe) em.createQuery("select e from Employe e left join fetch e.indemnite where e.nom=:nom").setParameter("nom", "Jouveinal").getSingleResult();
// liberar os recursos
em.close();
// exibir o colaborador
try {
System.out.println(employe);
} catch (Exception ex) {
System.out.println(ex);
}
// libertação de recursos
emf.close();
}
}
- linha 15: criamos o EntityManagerFactory a partir da camada JPA,
- linha 17: obtém-se o EntityManager, que nos permite interagir com a camada JPA,
- linha 18: solicita-se o funcionário com o nome Jouveinal,
- linha 19: encerra-se o EntityManager. Isto tem como efeito encerrar o contexto de persistência.
- linha 22: exibimos o funcionário recebido.
A classe [Employe] é a seguinte:
package jpa;
...
@Entity
@Table(name="EMPLOYES")
public class Employe implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Version
@Column(name="VERSION",nullable=false)
private int version;
@Column(name="SS", nullable=false, unique=true, length=15)
private String SS;
@Column(name="NOM", nullable=false, length=30)
private String nom;
@Column(name="PRENOM", nullable=false, length=20)
private String prenom;
@Column(name="ADRESSE", nullable=false, length=50)
private String adresse;
@Column(name="VILLE", nullable=false, length=30)
private String ville;
@Column(name="CP", nullable=false, length=5)
private String codePostal;
@ManyToOne(fetch= FetchType.LAZY)
@JoinColumn(name="INDEMNITE_ID",nullable=false)
private Indemnite indemnite;
/**
* Returns a string representation of the object. This implementation constructs
* that representation based on the id fields.
* @return a string representation of the object.
*/
@Override
public String toString() {
return "jpa.Employe[id=" + getId()
+ ",version="+getVersion()
+",SS="+getSS()
+ ",nom="+getNom()
+ ",prenom="+getPrenom()
+ ",adresse="+getAdresse()
+",ville="+getVille()
+",code postal="+getCodePostal()
+",indice="+getIndemnite().getIndice()
+"]";
}
...
}
- linha 27: o campo indemnite é reposto no modo LAZY,
- linha 47: utiliza o campo indemnite. Se o método toString for chamado enquanto o campo indemnite ainda não tiver sido revertido, este será revertido nesse momento. Exceto se o contexto de persistência tiver sido encerrado, como no exemplo.
Voltemos ao código do [Main]:
- linhas 21-25: deveria ocorrer uma exceção. Com efeito, o método toString vai ser chamado. Este irá utilizar o campo indemnite. Este campo será procurado. Como o contexto de persistência foi encerrado, a entidade [Employe] recuperada já não existe, daí a exceção.
- linha 27: cria-se um novo EntityManager,
- linha 28: solicita-se o funcionário Jouveinal, indicando explicitamente na consulta JPQL o subsídio associado. Esta solicitação explícita é necessária porque o modo de pesquisa deste subsídio é LAZY,
- linha 30: encerra-se o EntityManager,
- linhas 32-36: volta a apresentar o funcionário. Não deverá haver nenhuma exceção.
Para executar o projeto, é necessária uma base de dados preenchida. Iremos criá-la seguindo os passos descritos no parágrafo 5.5. Além disso, o ficheiro [persistence.xml] deve ser alterado:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="mv-pam-jpa-hibernatePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<class>jpa.Cotisation</class>
<class>jpa.Employe</class>
<class>jpa.Indemnite</class>
<properties>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbpam_hibernate"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="hibernate.cache.provider_class" value="org.hibernate.cache.NoCacheProvider"/>
</properties>
</persistence-unit>
</persistence>
- foi removida a opção que criava as tabelas. A base de dados já existe e está preenchida,
- eliminámos as opções que faziam com que o Hibernate registasse os comandos SQL que emitia para a base de dados.
A execução do projeto apresenta as duas seguintes mensagens na consola:
- linha 1: a exceção que ocorreu quando foi necessário procurar a indemnização em falta, uma vez que a sessão estava encerrada. Vê-se que a indemnização não tinha sido recuperada devido ao modo LAZY,
- linha 2: o funcionário com o seu subsídio obtido através de uma consulta que contornou o modo LAZY.
5.6.5. Tarefa a realizar
Seguindo um procedimento semelhante ao que acabou de ser seguido, crie um projeto [mv-pam-pa-eclipselink-lazy] que mostre o comportamento do EclipseLink em comparação com o modo LAZY.
Obtêm-se os seguintes resultados:
No modo LAZY, ambas as consultas apresentaram a indemnização associada ao colaborador. Ao pesquisar na Internet sobre esta anomalia, descobre-se que a anotação [FetchType.LAZY] (linha 1):
@ManyToOne(fetch= FetchType.LAZY)
@JoinColumn(name="INDEMNITE_ID",nullable=false)
private Indemnite indemnite;
não é uma ordem, mas sim uma sugestão. O implementador JPA não é obrigado a segui-la. Vê-se, portanto, que o código torna-se, por vezes, dependente da implementação JPA utilizada. É possível definir, através da configuração, o comportamento esperado para o modo LAZY no EclipseLink.
5.6.6. Para a continuação
A arquitetura da aplicação a construir é a seguinte:
 |
Para o resto do documento, iremos duplicar o projeto Maven [mv-pam-jpa-hibernate] no projeto [mv-pam-spring-hibernate] [1, 2, 3]:
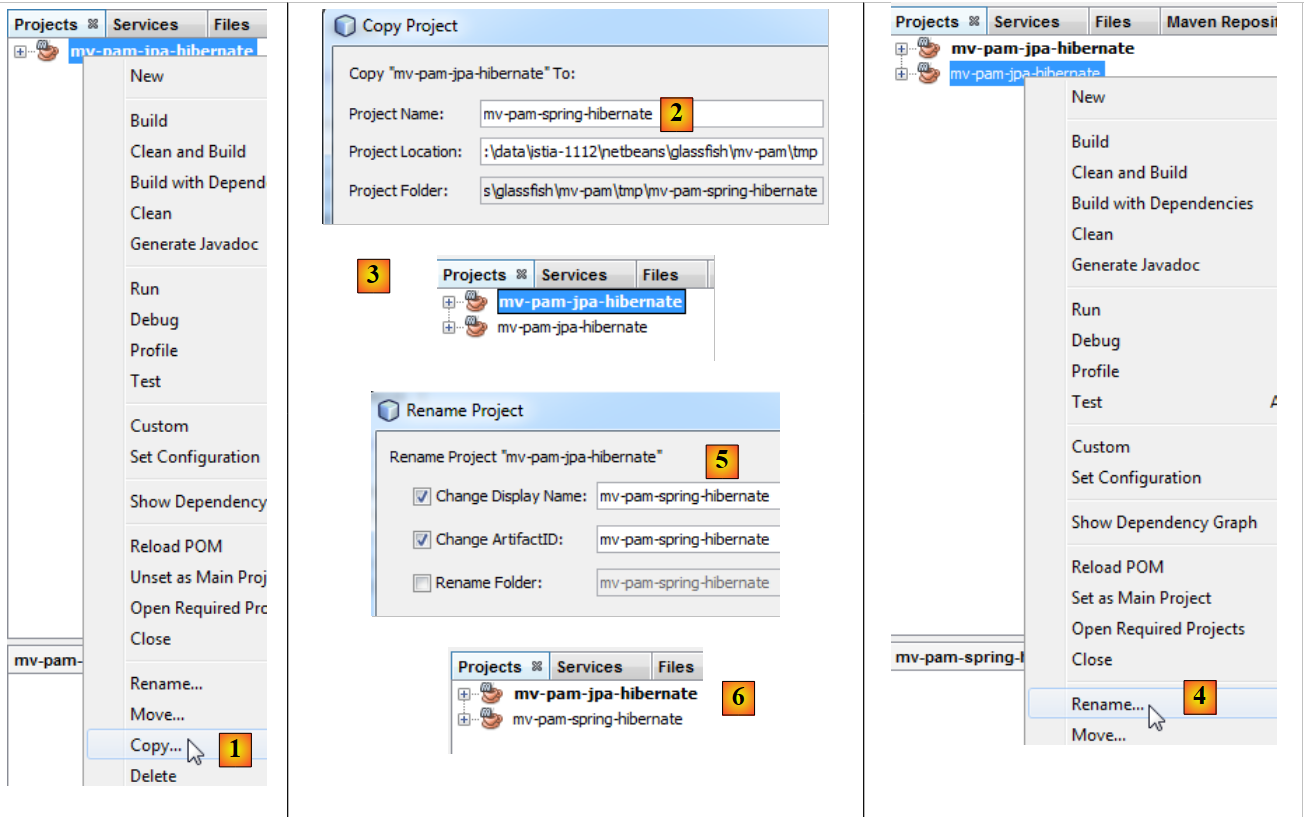 |
- e, em seguida, renomearemos o novo projeto para [4, 5, 6].
Alteraremos as dependências do novo projeto. O ficheiro [pom.xml] passa a ter o seguinte conteúdo:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>istia.st</groupId>
<artifactId>mv-pam-spring-hibernate</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>mv-pam-spring-hibernate</name>
<url>http://maven.apache.org</url>
<repositories>
<repository>
<url>http://repo1.maven.org/maven2/</url>
<id>swing-layout</id>
<layout>default</layout>
<name>Repository for library Library[swing-layout]</name>
</repository>
</repositories>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
<type>jar</type>
</dependency>
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.2.2</version>
</dependency>
<dependency>
<groupId>commons-pool</groupId>
<artifactId>commons-pool</artifactId>
<version>1.6</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>4.1.2</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>org.swinglabs</groupId>
<artifactId>swing-layout</artifactId>
<version>1.0.3</version>
</dependency>
</dependencies>
</project>
- linhas 25-31: a dependência para os testes JUnit,
- linhas 32-41: as dependências para o pool de ligações do Apache DBCP,
- linhas 42-65: as dependências para o framework Spring,
- linhas 67-71: as dependências para a implementação JPA / Hibernate,
- linhas 72-76: a dependência do controlador JDBC do MySQL,
- linhas 77-81: a dependência da interface Swing. Esta é adicionada automaticamente pelo NetBeans quando se adiciona uma interface Swing ao projeto.
Além disso, serão geradas as duas bases MySQL:
- [dbpam_hibernate] a partir do script [dbpam_hibernate.sql],
- [dbpam_eclipselink] a partir do script [dbpam_eclipselink.sql],
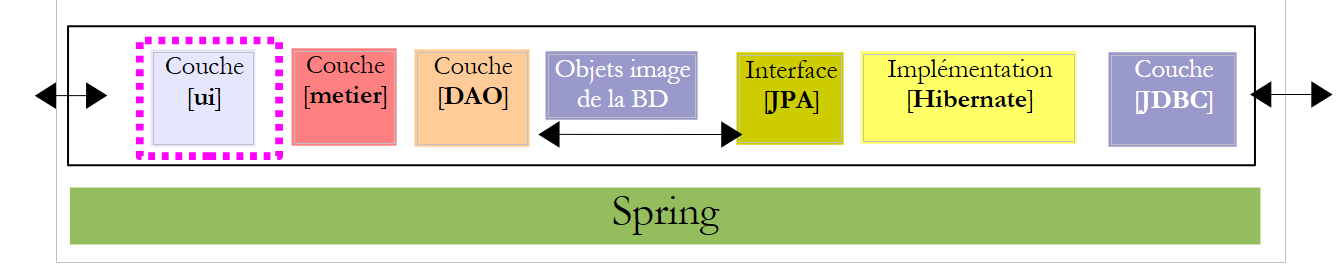
5.7. As interfaces das camadas [metier] e [DAO]
Voltemos à arquitetura da aplicação:
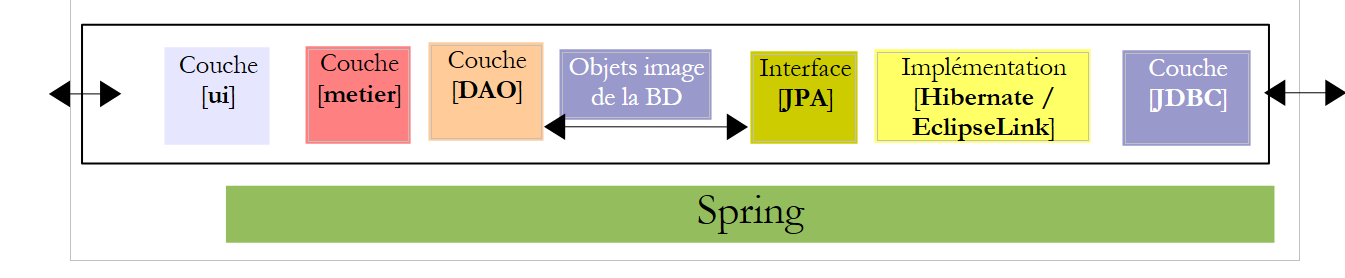 |
Na arquitetura acima, que interface deve a camada [DAO] disponibilizar à camada [metier] e que interface deve a camada [metier] disponibilizar à camada [ui]? Uma primeira abordagem para definir as interfaces das diferentes camadas consiste em analisar os diferentes casos de utilização (use cases) da aplicação. Neste caso, temos dois, dependendo da interface de utilizador escolhida: consola ou formulário gráfico.
Analisemos o modo de utilização da aplicação de consola:
A aplicação recebe três informações do utilizador (ver linha 1 acima)
- o número de segurança social da ama
- o número de horas trabalhadas no mês
- o número de dias trabalhados no mês
A partir destas informações e de outras registadas em ficheiros de configuração, a aplicação apresenta as seguintes informações:
- linhas 4-6: os valores introduzidos
- linhas 8-10: as informações relativas ao trabalhador cujo número de segurança social foi indicado
- linhas 12-14: as taxas das diferentes contribuições sociais
- linhas 16-17: os diferentes subsídios pagos à ama
- linhas 19-24: os elementos da folha de vencimento da ama
A camada [metier] deve fornecer uma série de informações à camada [ui]:
- as informações relativas a uma ama identificada pelo seu número de segurança social. Estas informações encontram-se na tabela [EMPLOYES]. Isto permite apresentar as linhas 6-8.
- os montantes das diversas taxas de contribuições sociais a deduzir do salário bruto. Estas informações encontram-se na tabela [COTISATIONS]. Isto permite apresentar as linhas 10 a 12.
- os montantes das diversas indemnizações relacionadas com a função de ama. Estas informações encontram-se na tabela [INDEMNITES]. Isto permite apresentar as linhas 14-15.
- os elementos constitutivos do salário apresentados nas linhas 18 a 22.
A partir daí, poder-se-ia decidir um primeiro registo da interface [IMetier], apresentada pela camada [metier] à camada [ui]:
- linha 1: os elementos da camada [metier] são colocados no pacote [metier]
- linha 5: o método [ calculerFeuilleSalaire ] recebe como parâmetros as três informações obtidas pela camada [ui] e devolve um objeto do tipo [FeuilleSalaire] contendo as informações que a camada [ui] irá apresentar na consola. A classe [FeuilleSalaire] poderia ser a seguinte:
- linha 9: o trabalhador a quem se refere a folha de pagamento — informação n.º 1 apresentada pela camada [ui]
- linha 10: as diferentes taxas de contribuição — informação n.º 2 apresentada pela camada [ui]
- linha 11: os diferentes subsídios relacionados com o índice do funcionário — informação n.º 3 apresentada pela camada [ui]
- linha 12: os elementos constitutivos do seu salário - informação n.º 4 apresentada pela camada [ui]
Surge um segundo caso de utilização da camada [métier] com a interface gráfica:
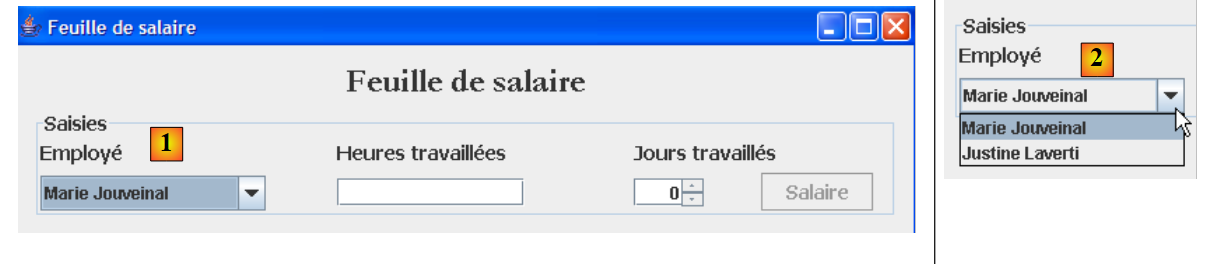 |
Como se pode ver acima, a lista suspensa [1, 2] apresenta todos os funcionários. Esta lista deve ser solicitada à camada [métier]. A interface ace desta camada evolui então da seguinte forma:
- linha [10]: o método que permitirá à camada [ui] solicitar a lista de todos os funcionários à camada [métier].
A camada [metier] só pode inicializar os campos [Employe, Cotisation, Indemnite] do objeto [FeuilleSalaire] acima referenciado consultando a camada [DAO], uma vez que essas informações se encontram nas tabelas da base de dados. O mesmo se aplica à obtenção da lista de todos os funcionários. É possível criar uma única interface [DAO] que gere o acesso às três entidades [Employe, Cotisation, Indemnite]. No entanto, decidimos aqui criar uma interface [DAO] por entidade.
A interface [DAO] para o acesso às entidades [Cotisation] da tabela [COTISATIONS] será a seguinte:
- na linha 6, a interface [ICotisationDao] gere o acesso à entidade [Cotisation] e, consequentemente, à tabela [COTISATIONS] da base de dados. A nossa aplicação necessita apenas do método [findAll] da linha 16, que permite recuperar todo o conteúdo da tabela [COTISATIONS]. Pretendemos aqui abordar um caso mais geral, em que todas as operações CRUD (Create, Read, Update, Delete) são realizadas na entidade.
- linha 8: o método [create] cria uma nova entidade [Cotisation]
- linha 10: o método [edit] altera uma entidade [Cotisation] existente
- linha 12: o método [destroy] elimina uma entidade [Cotisation] existente
- linha 14: o método [find] permite recuperar uma entidade [Cotisation] existente através do seu identificador id
- linha 16: o método [findAll] devolve, numa lista, todas as entidades [Cotisation] existentes
Vamos analisar a assinatura do método [create]:
O método create tem um parâmetro cotisation do tipo Cotisation. O parâmetro cotisation deve ser persistido, c.a.d. aqui inserido na tabela [COTISATIONS]. Antes desta persistência, o parâmetro cotisation tem um identificador id sem valor. Após a persistência, o campo id tem um valor que corresponde à chave primária do registo adicionado à tabela [COTISATIONS]. O parâmetro cotisation é, portanto, um parâmetro de entrada/saída do método create. Não parece ser necessário que o método create devolva também o parâmetro cotisation como resultado. Como o método chamador possui uma referência ao objeto [Cotisation cotisation], caso este seja alterado, o método chamador tem acesso ao objeto alterado, uma vez que possui uma referência ao mesmo. Pode, portanto, conhecer o valor que o método create atribuiu ao campo id do objeto [Cotisation cotisation]. A assinatura do método poderia, assim, ser mais simples:
Ao escrever uma interface, é importante lembrar que esta pode ser utilizada em dois contextos diferentes: local e distant. No contexto local, o método chamador e o método chamado são executados no mesmo JVM:
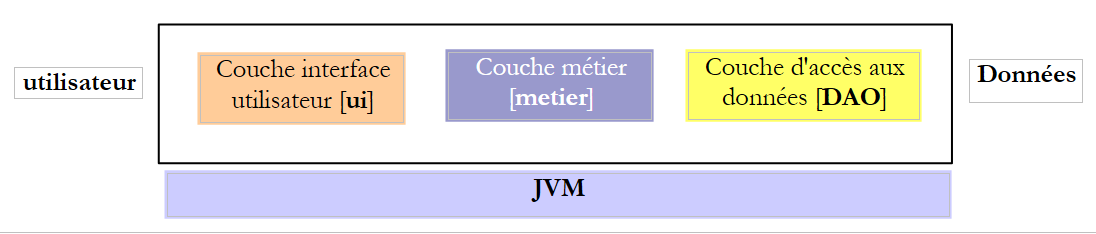 |
Se a camada [metier] chamar o método create da camada [DAO], ela tem, de facto, uma referência no parâmetro [Cotisation cotisation] que passa para o método.
No contexto distant, o método chamador e o método chamado são executados em JVM diferentes:
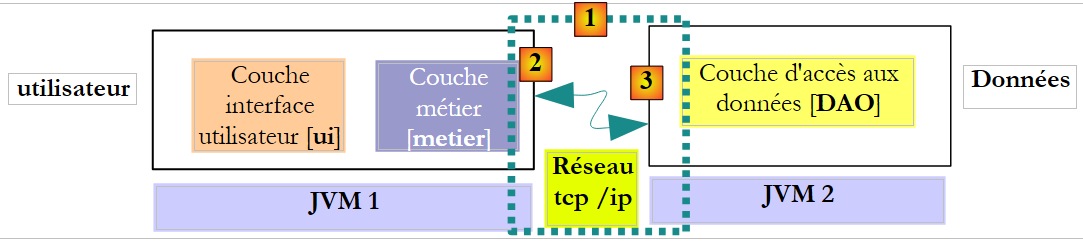 |
No exemplo acima, a camada [metier] é executada na JVM 1 e a camada [DAO] na JVM 2, em duas máquinas diferentes. As duas camadas não comunicam diretamente entre si. Entre elas intercala-se uma camada a que chamaremos camada de comunicação [1]. Esta é composta por uma camada de emissão [2] e por uma camada de receção [3]. Normalmente, o programador não precisa de escrever estas camadas de comunicação. São geradas automaticamente por ferramentas de software. A camada [metier] é escrita como se fosse executada na mesma JVM que a camada [DAO]. Não há, portanto, qualquer alteração no código.
O mecanismo de comunicação entre a camada [metier] e a camada [DAO] é o seguinte:
- a camada [metier] invoca o método create da camada [DAO], passando-lhe o parâmetro [Cotisation cotisation1]
- este parâmetro é, na verdade, passado para a camada de emissão [2]. Esta irá transmitir na rede o valor do parâmetro cotisation1 e não a sua referência. A forma exata deste valor depende do protocolo de comunicação utilizado.
- A camada de receção [3] irá recuperar esse valor e, a partir dele, reconstruir um objeto [Cotisation cotisation2] que é uma réplica do parâmetro inicial enviado pela camada [metier]. Temos agora dois objetos idênticos (em termos de conteúdo) em duas camadas JVM diferentes: cotisation1 e cotisation2.
- A camada de receção irá passar o objeto cotisation2 para o método create da camada [DAO], que irá armazená-lo na base de dados. Após esta operação, o campo id do objeto cotisation2 foi inicializado com a chave primária do registo adicionado à tabela [COTISATIONS]. Não é o caso do objeto cotisation1, ao qual a camada [metier] faz referência. Se se pretender que a camada [metier] tenha uma referência ao objeto cotisation2, é necessário enviá-la para ela. Por isso, é necessário alterar a assinatura do método create da camada [DAO]:
- Com esta nova assinatura, o método create irá devolver como resultado o objeto persistido cotisation2. Este resultado é devolvido à camada de receção [3], que tinha chamado a camada [DAO]. Esta, por sua vez, irá devolver o valor (e não a referência) de cotisation2 à camada de emissão [2].
- A camada de emissão [2] irá recuperar esse valor e, a partir dele, reconstruir um objeto [Cotisation cotisation3], que é uma representação do resultado devolvido pelo método create da camada [DAO].
- O objeto [Cotisation cotisation3] é devolvido ao método da camada [metier], cuja chamada ao método create da camada [DAO] tinha iniciado todo este mecanismo. A camada [metier] pode, portanto, conhecer o valor da chave primária atribuído ao objeto [Cotisation cotisation1], cuja persistência tinha solicitado: trata-se do valor do campo id de cotisation3.
A arquitetura anterior não é a mais comum. É mais frequente encontrar as camadas [metier] e [DAO] na mesma JVM:
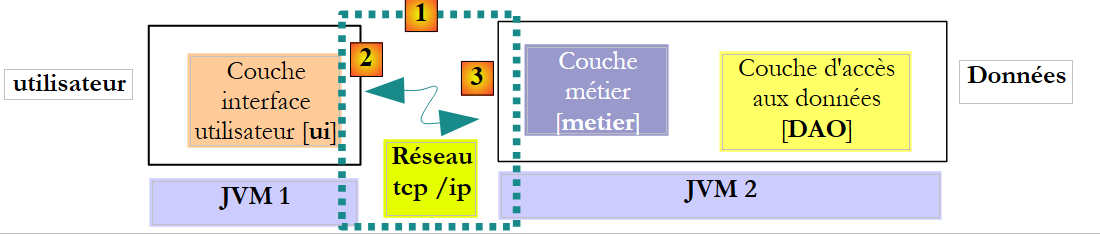 |
Nesta arquitetura, são os métodos da camada [metier] que devem devolver resultados e não os da camada [DAO]. No entanto, a seguinte assinatura do método create da camada [DAO]:
permite-nos não fazer suposições sobre a arquitetura efetivamente implementada. Utilizar assinaturas que funcionem independentemente da arquitetura escolhida, local ou remota, implica que, no caso de um método chamado alterar alguns dos seus parâmetros:
- estes devem também fazer parte do resultado do método chamado
- o método chamador deve utilizar o resultado do método chamado e não as referências dos parâmetros alterados que transmitiu ao método chamado.
Assim, mantemos a possibilidade de passar de uma camada de uma arquitetura locale para uma arquitetura distante sem alterar o código. Reexaminemos, à luz disto, a interface [ICotisationDao]:
- linha 8: o caso do método create foi tratado
- linha 10: o método edit utiliza o seu parâmetro [Cotisation cotisation1] para atualizar o registo da tabela [COTISATIONS] com a mesma chave primária que o objeto cotisation. O resultado é o objeto cotisation2, que representa o registo alterado. O parâmetro cotisation1, por sua vez, não é alterado. O método deve devolver cotisation2 como resultado, quer se esteja no âmbito de uma arquitetura distante ou locale.
- linha 12: o método destroy elimina o registo da tabela [COTISATIONS] com a mesma chave primária que o objeto cotisation passado como parâmetro. Este não é alterado. Por conseguinte, não tem de ser devolvido.
- linha 14: o parâmetro id do método find não é alterado pelo método. Não precisa de fazer parte do resultado.
- linha 16: o método findAll não tem parâmetros. Por conseguinte, não é necessário analisá-lo.
Em suma, apenas a assinatura do método create deve ser adaptada para poder ser utilizada no âmbito de uma arquitetura distante. Os raciocínios anteriores serão válidos para as outras interfaces [DAO]. Não as repetiremos e utilizaremos diretamente assinaturas que podem ser utilizadas tanto no âmbito de uma arquitetura distante como de uma locale.
A interface [DAO] para o acesso às entidades [Indemnite] da tabela [INDEMNITES] será a seguinte:
- Na linha 6, a interface [IIndemniteDao] gere os acessos à entidade [Indemnite] e, consequentemente, à tabela [INDEMNITES] da base de dados. A nossa aplicação necessita apenas do método [findAll] da linha 16, que permite recuperar todo o conteúdo da tabela [INDEMNITES]. Pretendemos aqui abordar um caso mais geral, em que todas as operações CRUD (Create, Read, Update, Delete) são realizadas na entidade.
- linha 8: o método [create] cria uma nova entidade [Indemnite]
- linha 10: o método [edit] altera uma entidade [Indemnite] existente
- linha 12: o método [destroy] elimina uma entidade [Indemnite] existente
- linha 14: o método [find] permite recuperar uma entidade [Indemnite] existente através do seu identificador id
- linha 16: o método [findAll] devolve, numa lista, todas as entidades [Indemnite] existentes
A interface [DAO] para o acesso às entidades [Employe] da tabela [EMPLOYES] será a seguinte:
- na linha 6, a interface [IEmployeDao] gere o acesso à entidade [Employe] e, consequentemente, à tabela [EMPLOYES] da base de dados. A nossa aplicação necessita apenas do método [findAll] da linha 16, que permite recuperar todo o conteúdo da tabela [EMPLOYES]. Pretendemos aqui abordar um caso mais geral, em que todas as operações CRUD (Create, Read, Update, Delete) são realizadas na entidade.
- linha 8: o método [create] cria uma nova entidade [Employe]
- linha 10: o método [edit] altera uma entidade [Employe] existente
- linha 12: o método [destroy] elimina uma entidade [Employe] existente
- linha 14: o método [find] permite localizar uma entidade [Employe] existente através do seu identificador id
- linha 16: o método [find(String SS)] permite recuperar uma entidade [Employe] existente através do seu n.º SS. Vimos que este método era necessário para a aplicação de consola.
- linha 18: o método [findAll] devolve, numa lista, todas as entidades [Employe] existentes. Vimos que este método era necessário para a aplicação gráfica.
5.8. A classe [PamException]
A camada [DAO] irá trabalhar com a classe API e JDBC em Java. Esta API lança exceções controladas do tipo [SQLException], que apresentam duas desvantagens:
- sobrecarregam o código, que tem de gerir obrigatoriamente essas exceções com try/catch.
- têm de ser declaradas na assinatura dos métodos da interface [IDao] através de um «throws SQLException». Isto tem como consequência impedir a implementação desta interface por classes que lançariam uma exceção controlada de um tipo diferente de [SQLException].
Para resolver este problema, a camada [DAO] apenas «encaminhará» exceções não controladas do tipo [PamException].
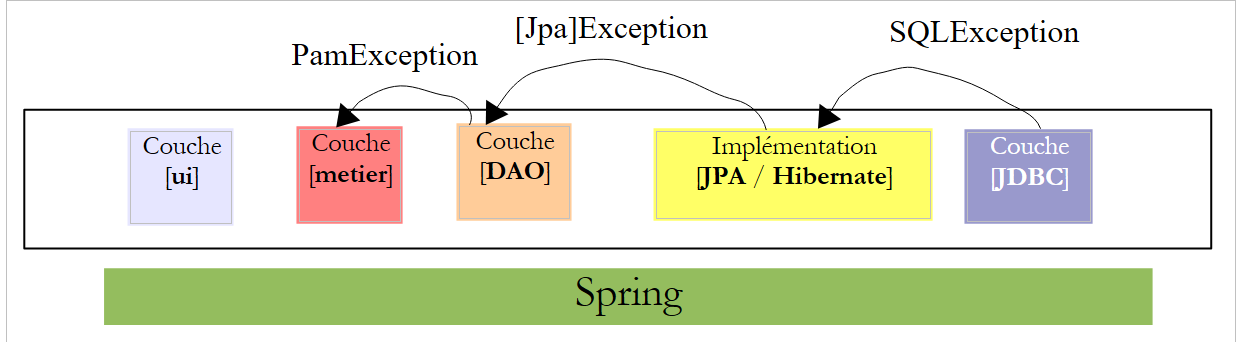 |
- a camada [JDBC] lança exceções do tipo [SQLException]
- a camada [JPA] lança exceções específicas da implementação JPA utilizada
- a camada [DAO] lança exceções do tipo [PamException] não controladas
Isto tem duas consequências:
- a camada [metier] não terá a obrigação de gerir as exceções da camada [DAO] com try/catch. Poderá simplesmente deixá-las subir até à camada [ui].
- os métodos da interface [IDao] não têm de incluir na sua assinatura a natureza da exceção [PamException], o que permite implementar esta interface com classes que lançariam outro tipo de exceção não controlada.
A classe [PamException] será colocada no pacote [exception] do projeto NetBeans:
 |
O seu código é o seguinte:
- linha 4: [PamException] deriva de [RuntimeException]. Trata-se, portanto, de um tipo de exceção que o compilador não nos obriga a gerir através de um try/catch nem a incluir na assinatura dos métodos. É por esta razão que [PamException] não consta da assinatura dos métodos da interface [IDao]. Isto permite que esta interface seja implementada por uma classe que lance outro tipo de exceções, desde que esta também derive de [RuntimeException].
- Para diferenciar os erros que podem ocorrer, utiliza-se o código de erro da linha 7. Os três construtores das linhas 14, 19 e 24 são os da classe pai [RuntimeException], aos quais foi adicionado um parâmetro: o do código de erro que se pretende atribuir à exceção.
O funcionamento da aplicação, do ponto de vista das exceções, será o seguinte:
- a camada [DAO] encapsulará qualquer exceção encontrada numa exceção do tipo [PamException] e re-lançará esta última para a camada [métier].
- A camada [métier] permitirá que as exceções lançadas pela camada [DAO] sejam encaminhadas para cima. Esta encapsulará qualquer exceção que ocorra na camada [métier] numa exceção do tipo [PamException] e reenviará esta última para a camada [ui].
- A camada [ui] intercepta todas as exceções que são reenviadas pelas camadas [métier] e [DAO]. Limitar-se-á a apresentar a exceção na consola ou na interface gráfica.
Vamos agora analisar sucessivamente a implementação das camadas [DAO] e [metier].
5.9. A camada [DAO] da aplicação [PAM]
Enquadramo-nos na seguinte arquitetura:
 |
5.9.1. Implementação
Leituras recomendadas: parágrafo 3.1.3 de [ref1]
Questão: Utilizando a integração Spring / JPA, escreva as classes [CotisationDao, IndemniteDao, EmployeDao] para implementar as interfaces [ICotisationDao, IIndemniteDao, IEmployeDao]. Cada método de classe irá interceptar uma eventual exceção e encapsulá-la numa exceção do tipo [PamException] com um código de erro específico da exceção interceptada.
As classes de implementação farão parte do pacote [dao]:
 |
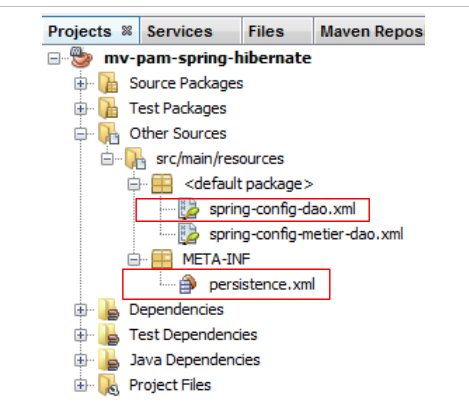
5.9.2. Configuração
Leituras recomendadas: parágrafo 3.1.5 de [ref1]
A integração DAO / JPA é configurada pelo ficheiro Spring [spring-config-dao.xml] e pelos ficheiros JPA e [persistence.xml]:
 |
Pergunta: escreva o conteúdo destes dois ficheiros. Suponha-se que a base de dados utilizada é a base MySQL5 [dbpam_hibernate] gerada pelo script SQL [dbpam_hibernate.sql]. O ficheiro Spring definirá os três beans seguintes: employeDao do tipo EmployeDao, indemniteDao do tipo IndemniteDao, cotisationDao do tipo CotisationDao. Além disso, a implementação JPA utilizada será Hibernate.
5.9.3. Testes
Leituras recomendadas: parágrafos 3.1.6 e 3.1.7 de [ref1]
Agora que a camada [DAO] está escrita e configurada, podemos testá-la. A arquitetura dos testes será a seguinte:
 |
5.9.4. InitDB
Vamos criar dois programas de teste para a camada [DAO]. Estes serão colocados no pacote [dao] [2] do ramo [Test Packages] [1] do projeto NetBeans. Este ramo não está incluído no projeto gerado pela opção [Build project], o que nos garante que os programas de teste que lá colocarmos não serão incluídos no ficheiro .jar final do projeto.
 |
As classes colocadas no ramo [Test Packages] têm acesso às classes presentes no ramo [Source Packages], bem como às bibliotecas de classes do projeto. Se os testes necessitarem de bibliotecas diferentes das do projeto, estas devem ser declaradas no ramo [Test Libraries] [2].
As classes de teste utilizam a ferramenta de testes unitários JUnit:
- A [JUnitInitDB] não realiza nenhum teste. Preenche a base de dados com alguns registos e, em seguida, apresenta-os na consola.
- A [JUnitDao] realiza uma série de testes e verifica os resultados.
A estrutura da classe [JUnitInitDB] é a seguinte:
- O método [init] é executado antes do início da série de testes (anotação @BeforeClass). Este instancia a camada [DAO].
- O método [clean] é executado antes de cada teste (anotação @Before). Esvazia a base de dados.
- O método [initDB] é um teste (anotação @Test). É o único. Um teste deve conter instruções de verificação Assert.assertCondition. Neste caso, não haverá nenhuma. O método é, portanto, um falso teste. A sua função é preencher a base de dados com algumas linhas e, em seguida, apresentar o conteúdo da base de dados na consola. São utilizados aqui os métodos create e findAll das camadas [DAO].
Questão: completar o código da classe [JUnitInitDB]. Utilizar-se-á o exemplo do parágrafo 3.1.6 de [ref1]. O código irá gerar o conteúdo apresentado no parágrafo 5.1.
5.9.5. Implementaçã e dos testes
Estamos agora prontos para executar o [InitDB]. Descrevemos o procedimento com o SGBD e o MySQL5:
 |
- as classes [1], os ficheiros de configuração [2] e as classes de teste da camada [DAO] e [3] estão implementadas,
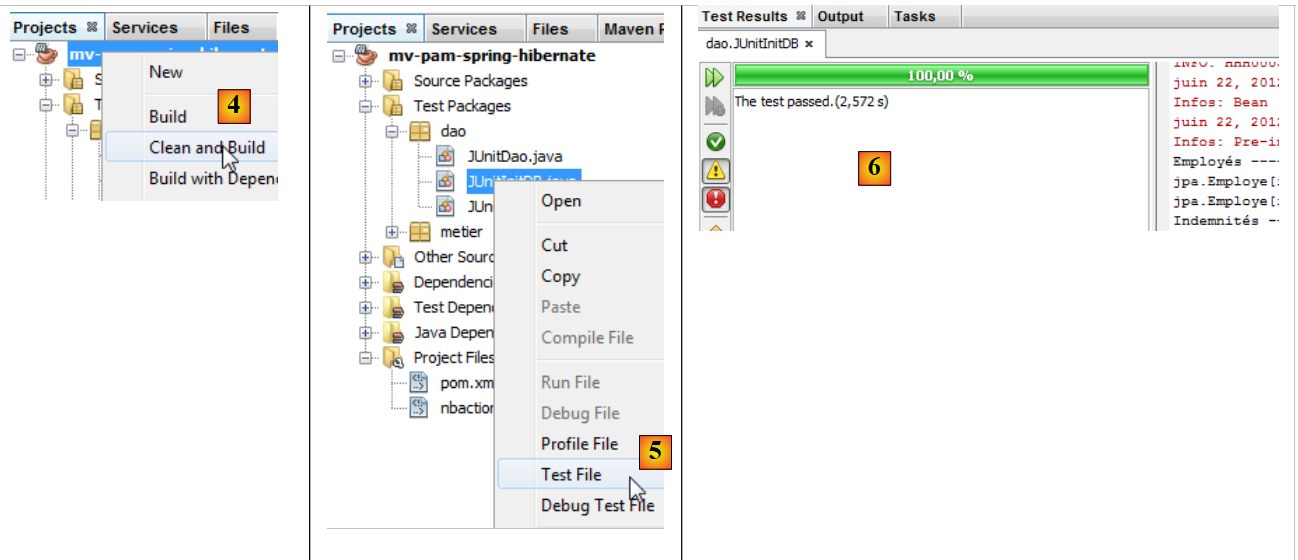 |
- o projeto é compilado [4]
- a classe [JUnitInitDB] é executada [5]. O SGBD MySQL5 é iniciado com uma base de dados [dbpam_hibernate] existente,
- a janela [Test Results] [6] indica que os testes foram bem-sucedidos. Esta mensagem não é relevante neste contexto, uma vez que o programa [JUnitInitDB] não contém nenhuma instrução de asserção Assert.assertCondition que pudesse provocar a falha do teste. No entanto, isto demonstra que não ocorreu nenhuma exceção durante a execução do teste.
A janela [Output] contém os registos da execução, os do Spring e os do próprio teste. As saídas geradas pela classe [JUnitInitDB] são as seguintes:
As tabelas [EMPLOYES, INDEMNITES, COTISATIONS] foram preenchidas. É possível verificar isso através de uma ligação do NetBeans à base de dados [dbpam_hibernate].
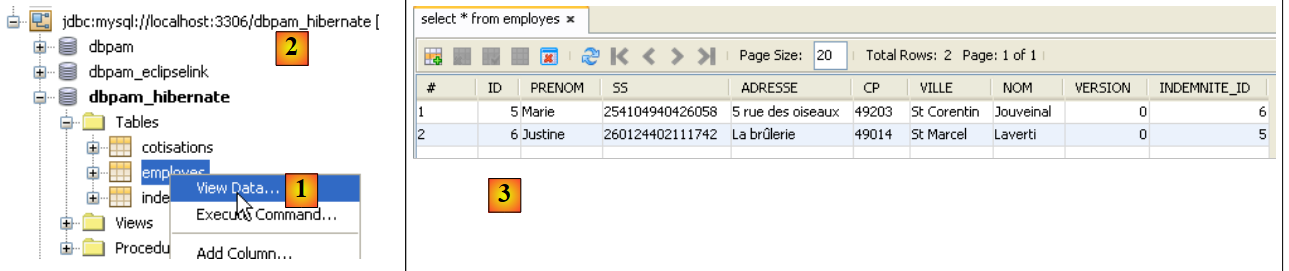 |
- em [1], no separador [services], visualizam-se os dados da tabela [employes] da ligação [dbpam_hibernate] [2],
- em [3], o resultado.
5.9.6. JUnitDao
Passamos agora a analisar uma segunda classe de testes, [JUnitDao]:
 |
A estrutura da classe será a seguinte:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 | |
Na classe de testes anterior, a base de dados é esvaziada antes de cada teste.
Questão: escreva os seguintes métodos:
1 - test02: inspire-se no test01
2 - test03: um funcionário tem um campo do tipo Indemnite. Por isso, é necessário criar uma entidade Indemnite e uma entidade Employe
3 - test04.
Seguindo o mesmo procedimento utilizado para a classe de testes [JUnitInitDB], obtêm-se os seguintes resultados:
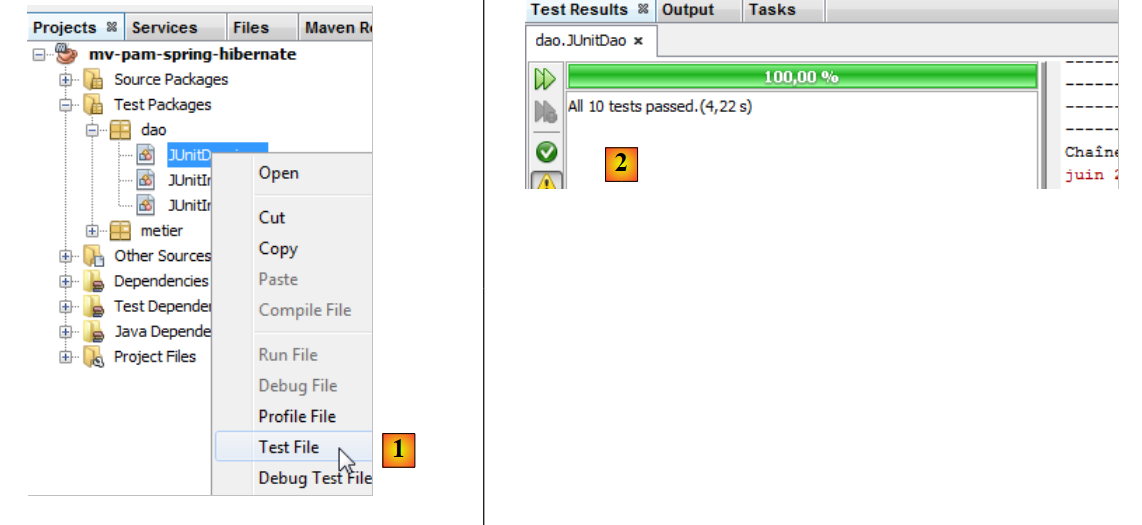 |
- em [1], executa-se a classe de testes
- em [2], os resultados dos testes na janela [Test Results]
Vamos provocar um erro para ver como é assinalado na página de resultados:
Na linha 13, a asserção irá provocar um erro, uma vez que o valor de Csgrds é 3,49 (linha 8). A execução da classe de testes apresenta os seguintes resultados:
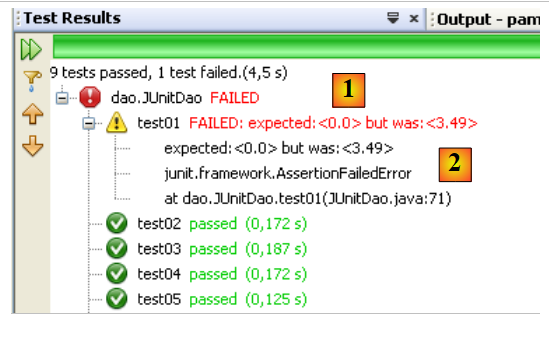 |
- A página de resultados [1] mostra agora que houve testes que não foram bem-sucedidos.
- Em [2], encontra-se um resumo da exceção que fez com que o teste falhasse. Aí consta o número da linha do código Java onde ocorreu a exceção.
5.10. A camada [metier] da aplicação [PAM]
Agora que a camada [DAO] foi escrita, passamos à análise da camada de negócio [2]:
 |
5.10.1. A interface Java [IMetier]
Esta foi descrita no parágrafo 5.7. Recordamo-la abaixo:
A implementação da camada [metier] será feita num pacote [metier]:
 |
O pacote [metier] incluirá, para além da interface [IMetier] e da sua implementação [Metier], duas outras classes: [FeuilleSalaire] e [ElementsSalaire]. A classe [FeuilleSalaire] foi brevemente apresentada no parágrafo 5.7. Voltamos agora a abordá-la.
5.10.2. A classe [FeuilleSalaire]
O método [calculerFeuilleSalaire] da interface [IMetier] devolve um objeto do tipo [FeuilleSalaire] que representa os diferentes elementos de uma folha de vencimento. A sua definição é a seguinte:
- linha 7: a classe implementa a interface Serializable porque as suas instâncias podem ser trocadas na rede.
- linha 9: o funcionário a quem se refere a folha de vencimento
- linha 10: as diferentes taxas de contribuição
- linha 11: os diferentes subsídios associados ao índice do funcionário
- linha 12: os elementos que compõem o seu salário
- linhas 14-22: os dois construtores da classe
- linhas 25-27: método [toString] que identifica um objeto [FeuilleSalaire] específico
- linhas 29 e seguintes: os acessores públicos aos campos privados da classe
A classe [ElementsSalaire], referenciada na linha 11 da classe [FeuilleSalaire] acima, reúne os elementos que constituem uma folha de pagamento. A sua definição é a seguinte:
- linha 3: a classe implementa a interface Serializable porque é um componente da classe FeuilleSalaire, que deve ser serializável.
- linha 6: o salário base
- linha 7: as contribuições sociais pagas sobre este salário base
- linha 8: os subsídios diários para a manutenção da criança
- linha 9: os subsídios diários para refeições da criança
- linha 10: o salário líquido a pagar à ama
- linhas 12-24: os construtores da classe
- linhas 27-31: método [toString] que identifica um objeto [ElementsSalaire] específico
- linhas 34 e seguintes: os acessores públicos aos campos privados da classe
5.10.3. A classe de implementação [Metier] da camada [metier]
A classe de implementação [Metier] da camada [metier] poderia ser a seguinte:
- linha 5: a anotação Spring @Transactional faz com que cada método da classe seja executado no âmbito de uma transação.
- linhas 9-10: as referências às camadas [DAO] das entidades [Cotisation, Employe, Indemnite]
- linhas 14-17: o método [calculerFeuilleSalaire]
- linhas 20-22: o método [findAllEmployes]
- linha 24 e seguintes: os acessores públicos dos campos privados da classe
Questão: escreva o código do método [findAllEmployes].
Questão: escreva o código do método [calculerFeuilleSalaire].
Deve-se ter em conta os seguintes pontos:
- o modo de cálculo do salário foi explicado no parágrafo 5.2.
- Se o parâmetro [SS] não corresponder a nenhum colaborador (a camada [DAO] devolveu um ponteiro null), o método lançará uma exceção do tipo [PamException] com um código de erro adequado.
5.10.4. Testes da camada [metier]
Criamos dois programas de teste:
 |
As classes de teste [3] são criadas num pacote [metier] [2] do ramo [Test Packages] [1] do projeto.
A classe [JUnitMetier_1] poderia ser a seguinte:
Não existe nenhuma asserção Assert.assertCondition na classe. Pretende-se apenas calcular alguns salários para, posteriormente, os verificar manualmente. A saída de ecrã obtida pela execução da classe anterior é a seguinte:
- linha 4: a folha de vencimento de Justine Laverti
- linha 5: a folha de salário de Marie Jouveinal
- linha 6: a exceção devida ao facto de o funcionário com o n.º SS «xx» não existir.
Pergunta: a linha 17 de [JUnitMetier_1] utiliza o bean Spring denominado metier. Indique a definição deste bean no ficheiro [spring-config-metier-dao.xml].
A classe [JUnitMetier_2] poderia ser a seguinte:
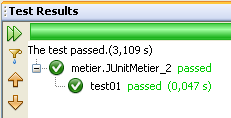
A classe [JUnitMetier_2] é uma cópia da classe [JUnitMetier_1], mas, desta vez, foram inseridas asserções no método test01.
Tarefa: escreva o método test01.
Ao executar a classe [JUnitMetier_2], obtêm-se os seguintes resultados, se tudo correr bem:
5.11. A camada [ui] da aplicação [PAM] – versão console
Agora que a camada [metier] foi escrita, resta-nos escrever a camada [ui] [1]:
 |
Iremos criar duas implementações diferentes da camada [ui]: uma versão console e uma versão gráfica swing:
 |
5.11.1. A classe [ui.console.Main]
Em primeiro lugar, vamos centrar-nos na aplicação de consola implementada pela classe [ui.console.Main] acima referida. O seu funcionamento foi descrito no parágrafo 5.3. A estrutura da classe [Main] poderia ser a seguinte:
Questão: complete o código acima.
5.11.2. Execução
Para executar a classe [ui.console.Main], deve-se proceder da seguinte forma:
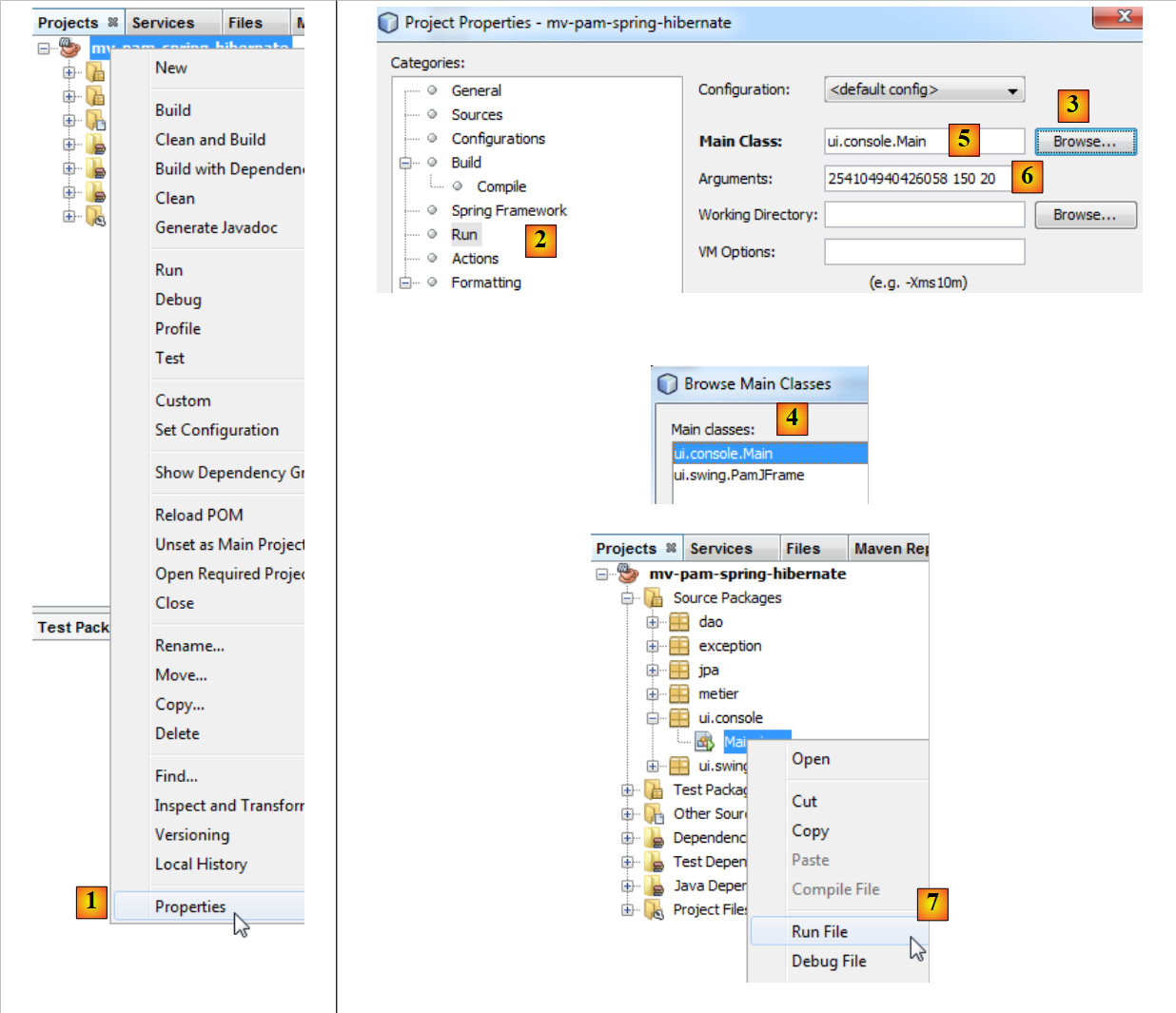 |
- em [1], selecione as propriedades do projeto,
- em [2], selecione a propriedade [Run] do projeto,
- utilize o botão [3] para indicar a classe (denominada classe principal) a executar,
- selecione a classe [4],
- a classe aparece em [5]. Esta necessita de três argumentos para ser executada (n.º SS, número de horas trabalhadas, número de dias trabalhados). Estes argumentos são colocados em [6],
- feito isto, é possível executar o projeto [7]. A configuração anterior faz com que seja a classe [ui.console.Main] a ser executada.
Os resultados da execução são apresentados na janela [output]:
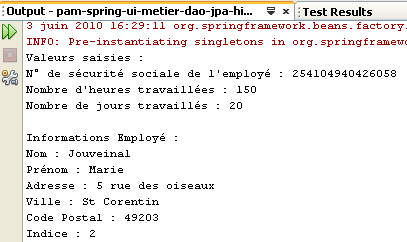 | 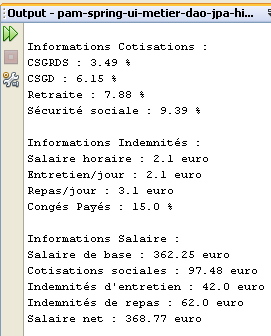 |
5.12. A camada [ui] da aplicação [PAM] – versão gráfica
Implementamos agora a camada [ui] com uma interface gráfica:
 |
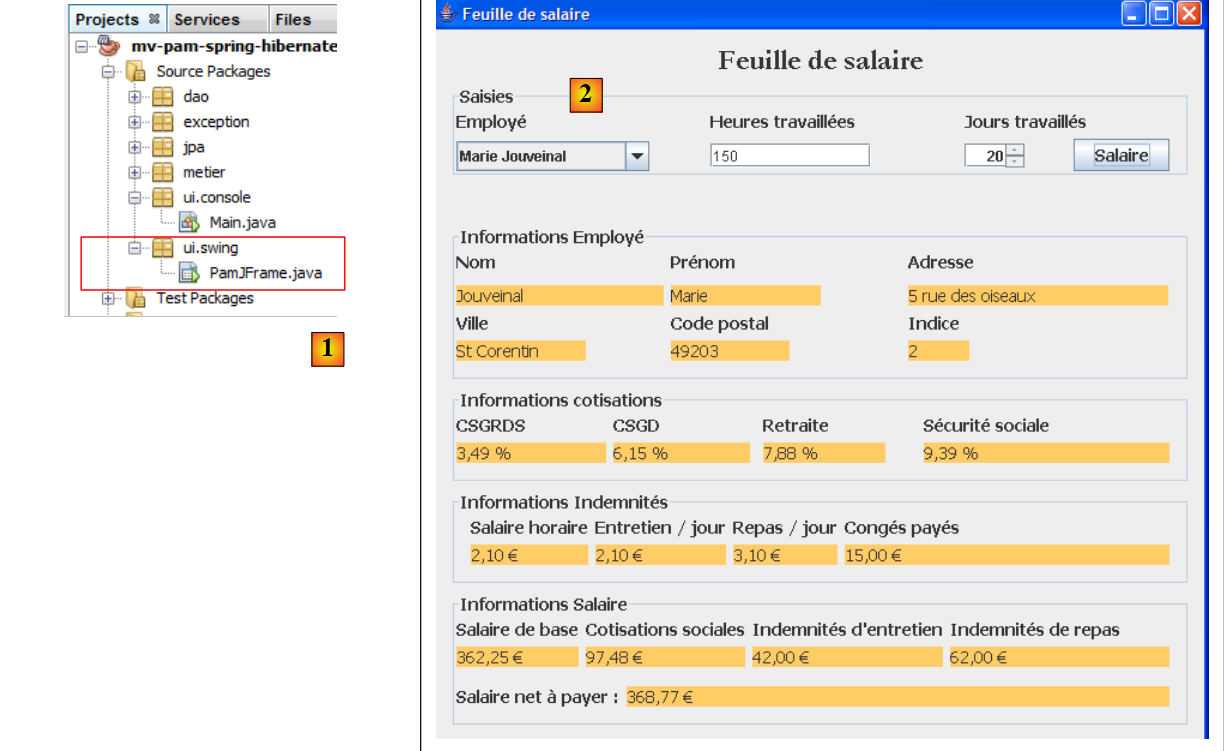 |
- em [1], a classe [PamJFrame] da interface gráfica
- em [2]: a interface gráfica
5.12.1. Um tutorial rápido
Para criar a interface gráfica, pode-se proceder da seguinte forma:
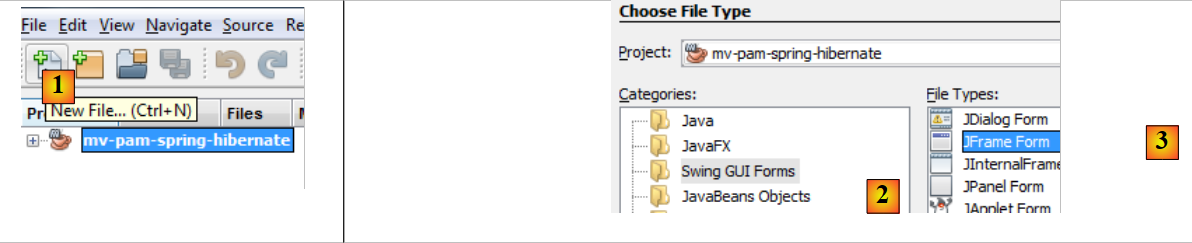 |
- [1]: cria-se um novo ficheiro com o botão [1] [New File...]
- [2]: seleciona-se a categoria do ficheiro [Swing GUI Forms], c.a.d. formulários gráficos
- [3]: seleciona-se o tipo [JFrame Form], um tipo de formulário vazio
 |
- [5]: atribui-se um nome ao formulário, que será também uma classe
- [6]: coloca-se o formulário num pacote
- [8]: o formulário é adicionado à árvore do projeto
- [9]: o formulário está acessível através de duas perspetivas: [Design] e [9], que permitem desenhar os diferentes componentes do formulário, e [Source] e [10 ci-dessous], que dão acesso ao código Java do formulário. Em suma, um formulário é uma classe Java como qualquer outra. A perspetiva [Design] facilita o desenho do formulário. Sempre que se adiciona um componente no modo [Design], é adicionado código Java na perspetiva [Source] para o integrar.
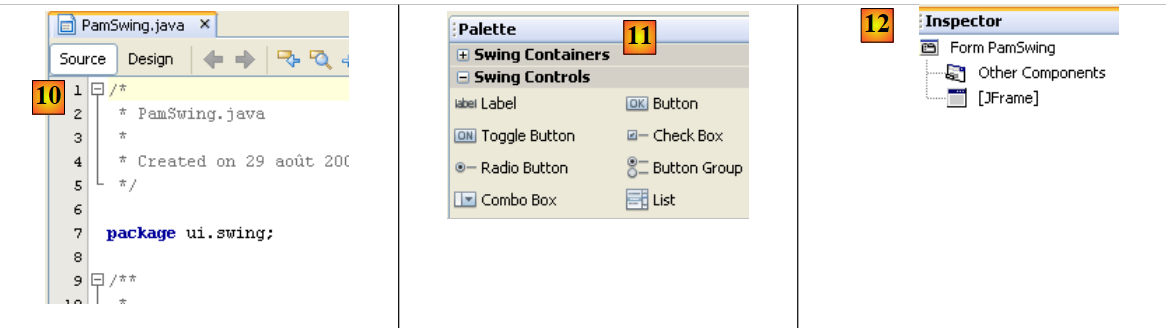 |
- [11]: a lista de componentes Swing disponíveis para um formulário encontra-se na janela [Palette].
- [12]: a janela [Inspector] apresenta a árvore de componentes do formulário. Os componentes com representação visual encontram-se no ramo [JFrame], os restantes no ramo [Other Components].
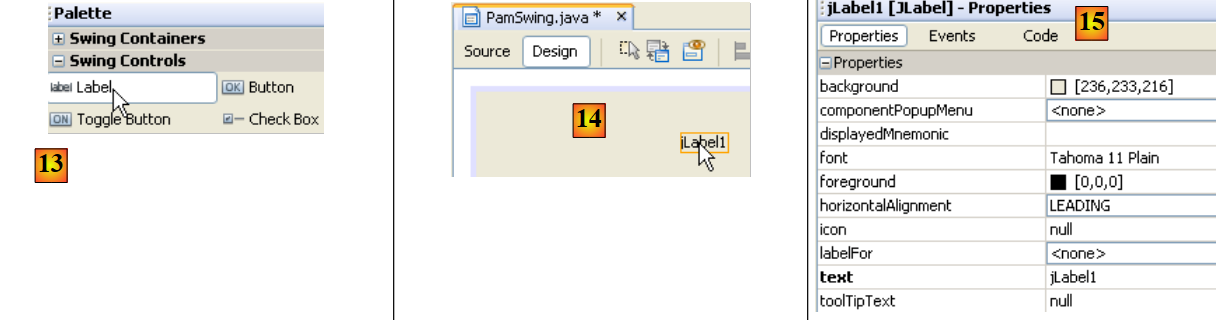 |
- em [13], selecionamos um componente [JLabel] com um simples clique
- em [14], colocamo-lo no formulário no modo [Design]
- em [15], definimos as propriedades do JLabel (texto, tipo de letra).
 |
- em [16], o resultado obtido.
- em [17], solicitamos a pré-visualização do formulário
- em [18], o resultado
- em [19], o rótulo [JLabel1] foi adicionado à árvore de componentes na janela [Inspector]
 |
- em [20] e [21]: na perspetiva [Source] do formulário, foi adicionado código Java para gerir o JLabel adicionado.
Está disponível um tutorial sobre a criação de formulários com o NetBeans na URL [http://www.netbeans.org/kb/trails/matisse.html].
5.12.2. A interface gráfica [PamJFrame]
Iremos criar a seguinte interface gráfica:
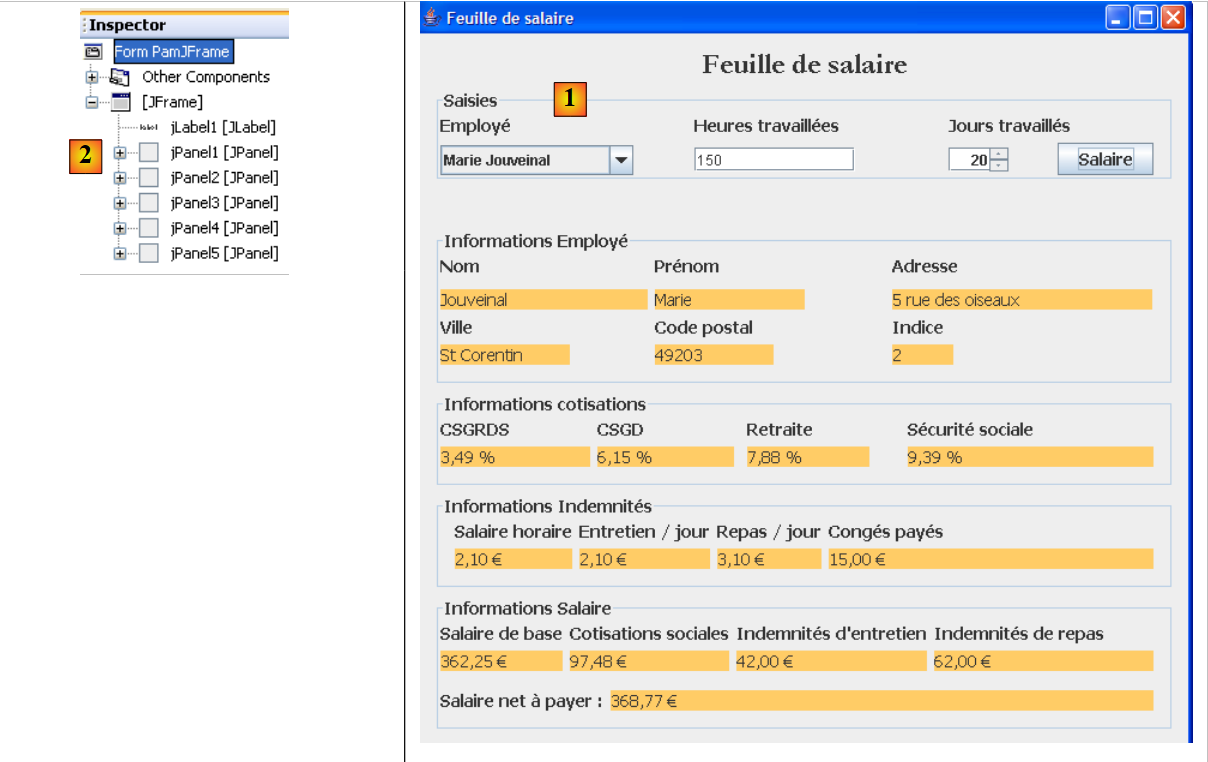 |
- em [1], a interface gráfica
- em [2], a árvore de componentes: um JLabel e seis contentores JPanel
JLabel1
 |
JPanel1
 |  |
JPanel2
 |  |
JPanel3
 |  |
JPanel4
 |  |
JPanel5
 |  |
Trabalho prático: construir a interface gráfica anterior com a ajuda do tutorial [http://www.netbeans.org/kb/trails/matisse.html].
5.12.3. Os eventos da interface gráfica
Leituras recomendadas: capítulo [Interfaces graphiques] de [ref2].
Vamos tratar o clique no botão [jButtonSalaire]. Para criar o método de tratamento deste evento, podemos proceder da seguinte forma:
 |
O gestor do clique no botão [JButtonSalaire] é gerado:
O código Java que associa o método anterior ao clique no botão [JButtonSalaire] também é gerado:
São as linhas 2 a 5 que indicam que o clique (eventualmente do tipo ActionPerformed) no botão [jButtonSalaire] (linha 2) deve ser tratado pelo método [jButtonSalaireActionPerformed] (linha 4).
Iremos também tratar o evento [caretUpdate] (deslocamento do cursor de introdução) no campo de introdução [jTextFieldHT]. Para criar o gestor deste evento, procedemos como anteriormente:
 |
O gestor do evento [caretUpdate] no campo de introdução de dados [jTextFieldHT] é gerado:
O código Java que associa o método anterior ao evento [caretUpdate] no campo de entrada [jTextFieldHT] também é gerado:
As linhas 1-4 indicam que o evento [caretUpdate] (linha 2) no botão [jTextFieldHT] (linha 1) deve ser tratado pelo método [ jTextFieldHTCaretUpdate] (linha 3).
5.12.4. Inicialização da interface gráfica
Voltemos à arquitetura da nossa aplicação:
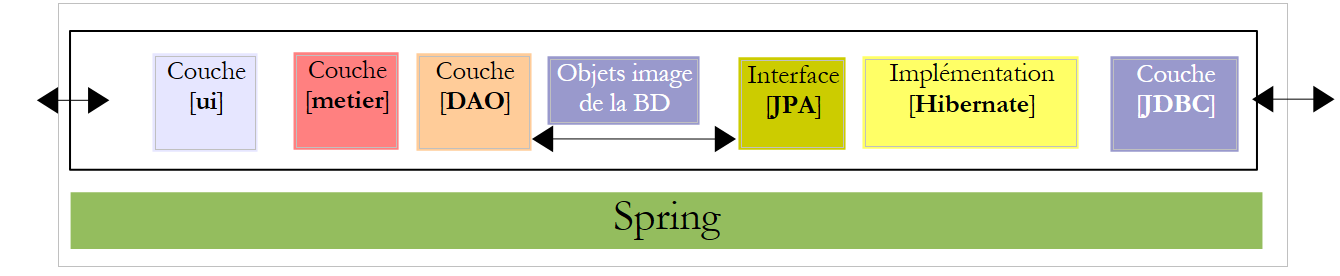 |
A camada [ui] necessita de uma referência à camada [metier]. Recorde-se como essa referência foi obtida na aplicação console:
O método é o mesmo na aplicação gráfica. É necessário que, quando esta for inicializada, a referência [IMetier metier] da linha 3 acima seja também inicializada. O código gerado para a interface gráfica é, por enquanto, o seguinte:
- linhas 29-35: o método estático [main] que inicia a aplicação
- linha 32: é criada e tornada visível uma instância da interface gráfica [PamJFrame].
- linhas 7-9: o construtor da interface gráfica.
- linha 8: chamada ao método [initComponents] definido na linha 17. Este método é gerado automaticamente a partir do trabalho realizado no modo [Design]. Não deve ser alterado.
- linha 21: o método que irá gerir o deslocamento do cursor de introdução de dados no campo [jTextFieldHT]
- linha 25: o método que irá gerir o clique no botão [jButtonSalaire]
Para adicionar ao código anterior as nossas próprias inicializações, podemos proceder da seguinte forma:
- linha 4: chamamos um método proprietário para efetuar as nossas próprias inicializações. Estas são definidas pelo código das linhas 10 a 42
Pergunta: com a ajuda dos comentários, complete o código da procedimento [doMyInit].
5.12.5. Gestores de eventos
Questão: escreva o método [jTextFieldHTCaretUpdate]. Este método deve garantir que, se o valor presente no campo [jTextFieldHT] não for um número real >=0, o botão [jButtonSalaire] fique inativo.
Questão: escreva o método [jButtonSalaireActionPerformed], que deve apresentar a folha de salário do funcionário selecionado em [jComboBoxEmployes].
5.12.6. Execução da interface gráfica
Para executar a interface gráfica, alteraremos a configuração [Run] do projeto:
 |
- para [1], definindo a classe da interface gráfica
O projeto deve estar completo com os seus ficheiros de configuração (persistence.xml, spring-config-metier-dao.xml) e a classe da interface gráfica. Deve-se iniciar o alvo SGBD antes de executar o projeto.
5.13. Implementação da camada JPA com EclipseLink
Estamos interessados na seguinte arquitetura, em que a camada JPA é agora implementada por EclipseLink:
 |
5.13.1. O projeto NetBeans
O novo projeto NetBeans é obtido através da cópia do projeto anterior:
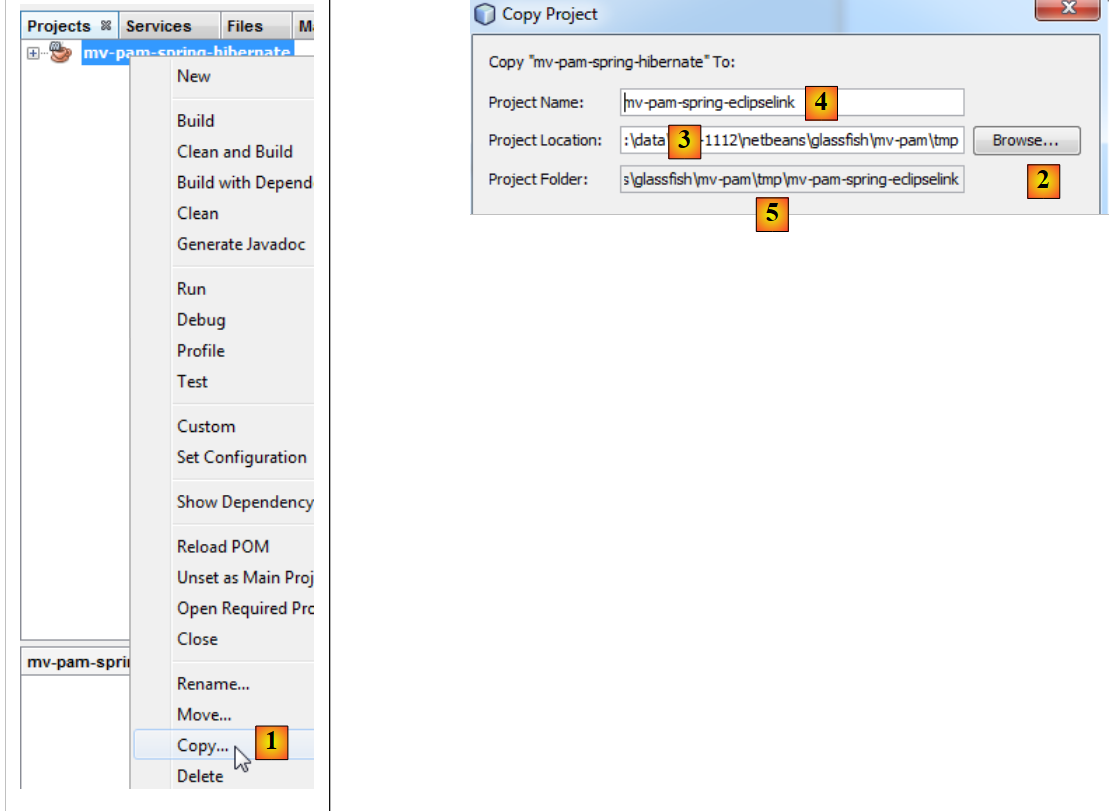 |
- em [1]: após clicar com o botão direito do rato no projeto Hibernate, selecione Copy
- e, utilizando o botão [2], selecione a pasta pai do novo projeto. O nome da pasta aparece em [3].
- em [4], atribua um nome ao novo projeto
- em [5], o nome da pasta do projeto
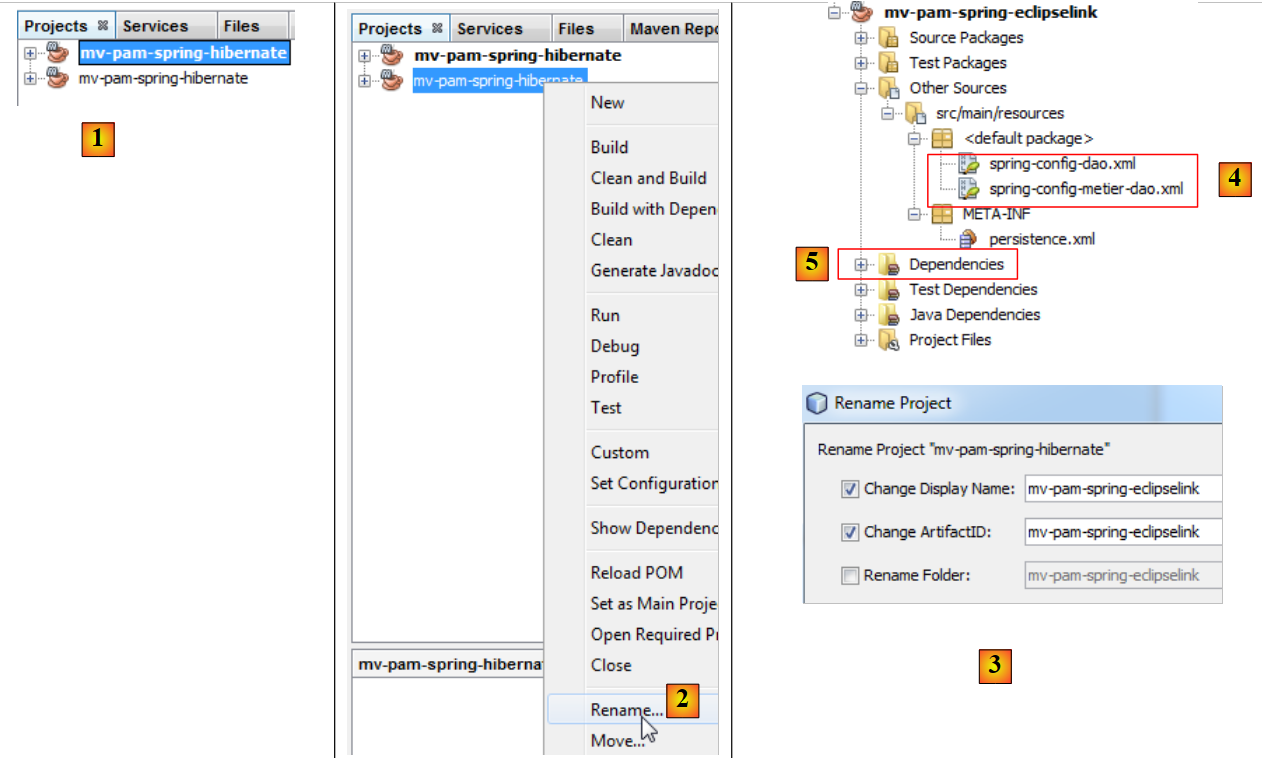 |
- em [1], o novo projeto foi criado. Tem o mesmo nome que o original,
- em [2] e [3], renomeia-se-o para [mv-pam-spring-eclipselink].
O projeto deve ser alterado em dois pontos para se adaptar à nova camada JPA / EclipseLink:
- no [4], os ficheiros de configuração do Spring têm de ser alterados. Neles encontra-se, de facto, a configuração da camada JPA.
- no [5], as bibliotecas do projeto têm de ser alteradas: as do Hibernate têm de ser substituídas pelas do EclipseLink.
Comecemos por este último ponto. O ficheiro [pom.xml] para o novo projeto será este:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>istia.st</groupId>
<artifactId>mv-pam-spring-eclipselink</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>mv-pam-spring-eclipselink</name>
<url>http://maven.apache.org</url>
<repositories>
<repository>
<url>http://repo1.maven.org/maven2/</url>
<id>swing-layout</id>
<layout>default</layout>
<name>Repository for library Library[swing-layout]</name>
</repository>
<repository>
<url>http://download.eclipse.org/rt/eclipselink/maven.repo/</url>
<id>eclipselink</id>
<layout>default</layout>
<name>Repository for library Library[eclipselink]</name>
</repository>
</repositories>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
<type>jar</type>
</dependency>
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.2.2</version>
</dependency>
<dependency>
<groupId>commons-pool</groupId>
<artifactId>commons-pool</artifactId>
<version>1.6</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.eclipse.persistence</groupId>
<artifactId>eclipselink</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>org.eclipse.persistence</groupId>
<artifactId>javax.persistence</artifactId>
<version>2.0.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>org.swinglabs</groupId>
<artifactId>swing-layout</artifactId>
<version>1.0.3</version>
</dependency>
</dependencies>
</project>
- linhas 73-82: as dependências para a implementação JPA EclipseLink,
- linhas 19-24: o repositório Maven para EclipseLink.
Os ficheiros de configuração do Spring devem ser alterados para indicar que a implementação JPA foi alterada. Em ambos os ficheiros, apenas a secção que configura a camada JPA é alterada. Por exemplo, em [spring-config-metier-dao.xml] temos:
As linhas 19-36 configuram a camada JPA. A implementação JPA utilizada é o Hibernate (linha 22). Além disso, a base de dados de destino é [dbpam_hibernate] (linha 41).
Para mudar para uma implementação JPA / EclipseLink, as linhas 19-35 acima são substituídas pelas linhas abaixo:
- linha 5: a implementação JPA utilizada é a EclipseLink
- linha 9: a propriedade databasePlatform define o SGBD de destino, neste caso MySQL
- linha 11: para gerar as tabelas da base de dados quando a camada JPA é instanciada. Aqui, a propriedade está comentada.
- linha 7: para visualizar na consola os comandos SQL emitidos pela camada JPA. Aqui, a propriedade está comentada.
Além disso, a base de dados de destino passa a ser [dbpam_eclipselink] (linha 4 abaixo):
5.13.2. Execução dos testes
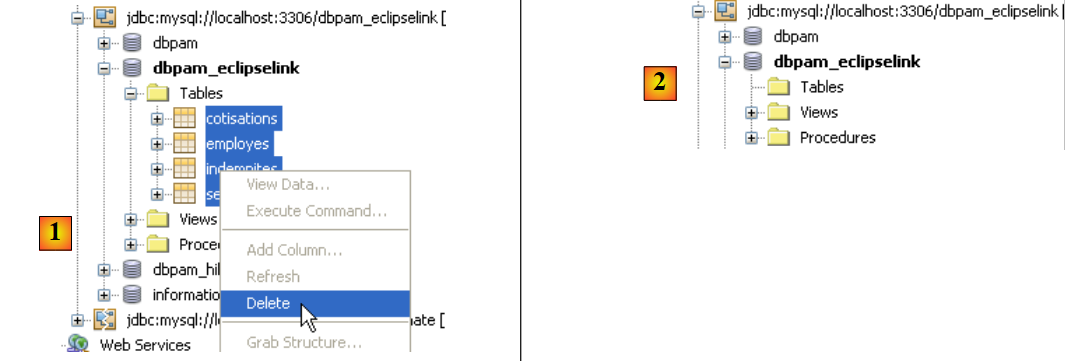
Antes de testar a aplicação na íntegra, é aconselhável verificar se os testes JUnit são bem-sucedidos com a nova implementação JPA. Antes de os executar, começaremos por eliminar as tabelas da base de dados. Para tal, no separador [Runtime] do NetBeans, se necessário, criaremos uma ligação à base de dados dbpam_eclipselink / MySQL5. Depois de nos ligarmos à base de dados dbpam_eclipselink / MySQL5, poderemos proceder à eliminação das tabelas, conforme ilustrado abaixo:
- [1]: antes da eliminação
- [2]: após a eliminação
 |
Feito isto, pode-se executar o primeiro teste na camada [DAO]: InitDB, que preenche a base de dados. Para que as tabelas eliminadas anteriormente sejam recriadas pela aplicação, é necessário garantir que, na configuração JPA / EclipseLink do Spring, a linha:
exista e não esteja comentada.
Compilamos o projeto (Build) e, em seguida, executamos o teste [JUnitInitDB] :
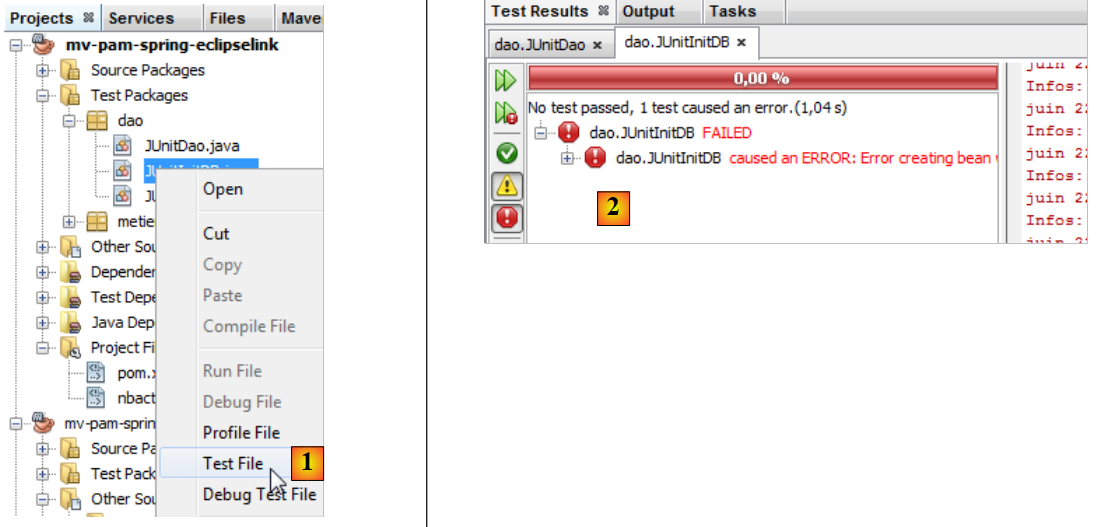 |
- em [1], o teste InitDB é executado.
- No [2], o teste falha. A exceção é lançada pelo Spring e não por um teste que tenha falhado.
Causado por: org.springframework.beans.factory.BeanCreationException: Erro ao criar o bean com o nome «entityManagerFactory» definido no recurso do caminho de classe [spring-config-DAO.xml]: Falha na invocação do método init; a exceção aninhada é java.lang.IllegalStateException: É necessário iniciar o agente Java para utilizar InstrumentationLoadTimeWeaver. Consulte a documentação do Spring.
O Spring indica que existe um problema de configuração. A mensagem não é clara. A razão da exceção foi explicada no parágrafo 3.1.9 de [ref1]. Para que a configuração do Spring / EclipseLink funcione, o JVM que executa a aplicação deve ser iniciado com um parâmetro específico, um agente Java. O formato deste parâmetro é o seguinte:
O [spring-agent.jar] é o agente Java de que o JVM necessita para gerir a configuração Spring / EclipseLink.
Ao executar um projeto, é possível passar argumentos para o JVM:
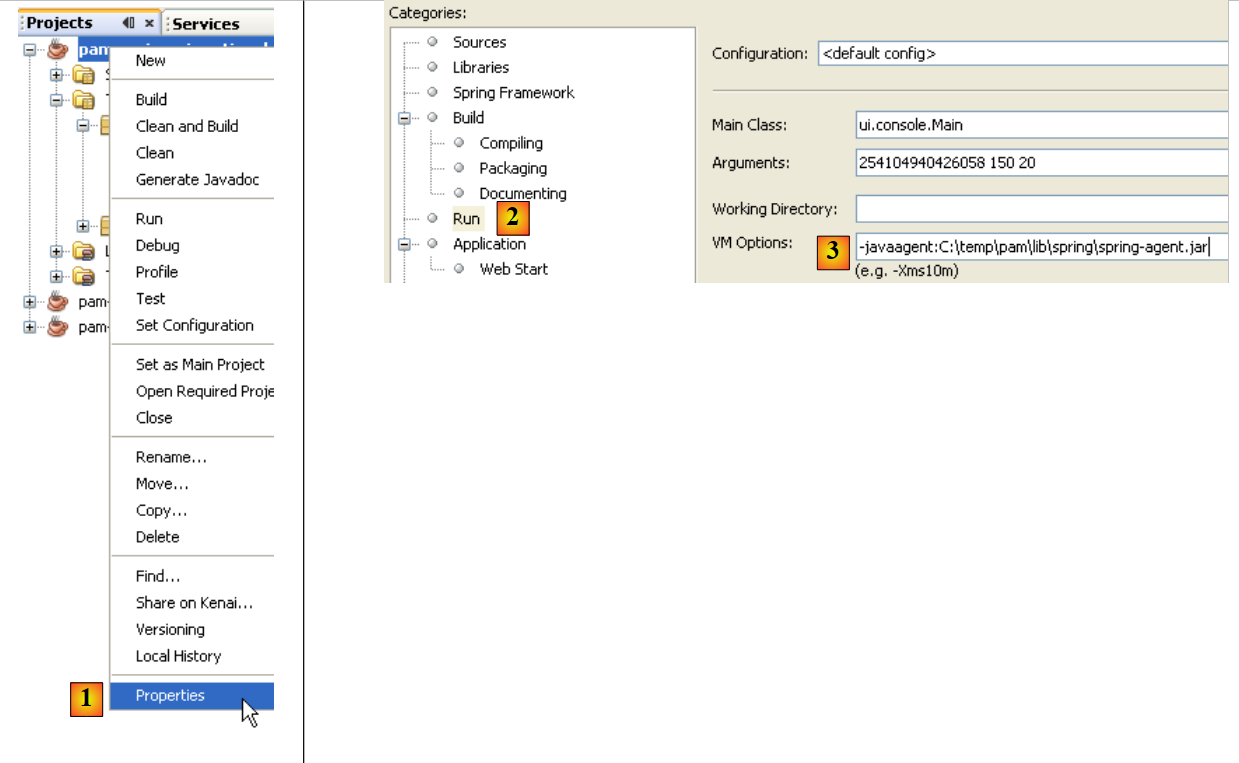 |
- no [1], acede-se às propriedades do projeto
- em [2], acede-se às propriedades do Run
- em [3], passa-se o parâmetro -javaagent para o JVM
5.13.3. InitDB
Agora, estamos prontos para testar novamente o [InitDB]. Desta vez, os resultados obtidos são os seguintes:
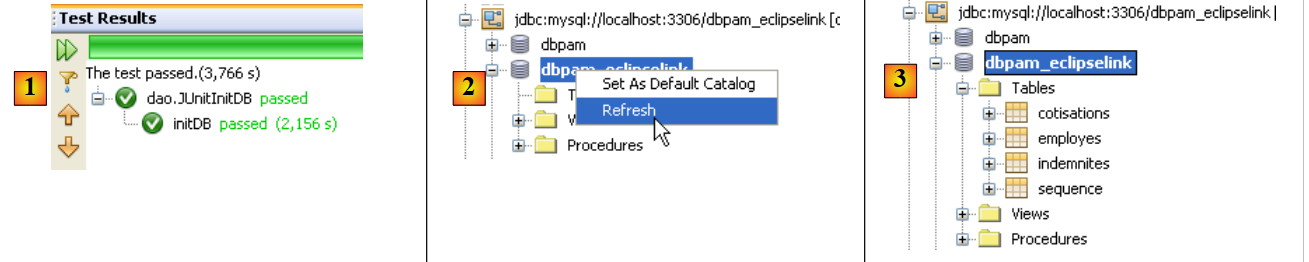 |
- em [1], o teste foi bem-sucedido
- em [2], no separador [Services], atualizamos a ligação do NetBeans à base de dados [dbpam_eclipselink]
- em [3], foram criadas quatro tabelas
 |
- em [5], visualiza-se o conteúdo da tabela [employes]
- em [6], o resultado.
5.13.4. JUnitDao
A execução da classe de testes [JUnitDao] pode falhar, mesmo que, com a implementação JPA / Hibernate, tenha sido bem-sucedida. Para compreender o motivo, analisemos um exemplo.
O método testado é o seguinte método IndemniteDao.create:
- linhas 15-22: o método testado
O método de teste é o seguinte:
package dao;
...
public class JUnitDao {
// camadas DAO
static private IEmployeDao employeDao;
static private IIndemniteDao indemniteDao;
static private ICotisationDao cotisationDao;
@BeforeClass
public static void init() {
// registo
log("init");
// configuração da aplicação
ApplicationContext ctx = new ClassPathXmlApplicationContext("spring-config-DAO.xml");
// camadas DAO
employeDao = (IEmployeDao) ctx.getBean("employeDao");
indemniteDao = (IIndemniteDao) ctx.getBean("indemniteDao");
cotisationDao = (ICotisationDao) ctx.getBean("cotisationDao");
}
@Before()
public void clean() {
// esvaziar a base de dados
for (Employe employe : employeDao.findAll()) {
employeDao.destroy(employe);
}
for (Cotisation cotisation : cotisationDao.findAll()) {
cotisationDao.destroy(cotisation);
}
for (Indemnite indemnite : indemniteDao.findAll()) {
indemniteDao.destroy(indemnite);
}
}
// registos
private static void log(String message) {
System.out.println("----------- " + message);
}
// testes
….
@Test
public void test05() {
log("test05");
// criam-se duas indemnizações com o mesmo índice
// viola a restrição de unicidade do índice
boolean erreur = true;
Indemnite indemnite1 = null;
Indemnite indemnite2 = null;
Throwable th = null;
try {
indemnite1 = indemniteDao.create(new Indemnite(1, 1.93, 2, 3, 12));
indemnite2 = indemniteDao.create(new Indemnite(1, 1.93, 2, 3, 12));
erreur = false;
} catch (PamException ex) {
th = ex;
// verificações
Assert.assertEquals(31, ex.getCode());
} catch (Throwable th1) {
th = th1;
}
// verificações
Assert.assertTrue(erreur);
// cadeia de exceções
System.out.println("Chaîne des exceptions --------------------------------------");
System.out.println(th.getClass().getName());
while (th.getCause() != null) {
th = th.getCause();
System.out.println(th.getClass().getName());
}
// a primeira indemnização teve de ser mantida
Indemnite indemnite = indemniteDao.find(indemnite1.getId());
// verificação
Assert.assertNotNull(indemnite);
Assert.assertEquals(1, indemnite.getIndice());
Assert.assertEquals(1.93, indemnite.getBaseHeure(), 1e-6);
Assert.assertEquals(2, indemnite.getEntretienJour(), 1e-6);
Assert.assertEquals(3, indemnite.getRepasJour(), 1e-6);
Assert.assertEquals(12, indemnite.getIndemnitesCP(), 1e-6);
// a segunda indemnização não teve de ser mantida
List<Indemnite> indemnites = indemniteDao.findAll();
int nbIndemnites = indemnites.size();
Assert.assertEquals(nbIndemnites, 1);
}
...
}
Pergunta: explique o que faz o teste test05 e indique os resultados esperados.
Os resultados obtidos com uma camada JPA / Hibernate são os seguintes:
O teste é bem-sucedido, c.a.d. As asserções são verificadas e não há nenhuma exceção a sair do método de teste.
Pergunta: explique o que aconteceu.
Os resultados obtidos com uma camada JPA / EclipseLink são os seguintes:
Tal como anteriormente com o Hibernate, o teste é bem-sucedido, c.a.d. As asserções são verificadas e não há nenhuma exceção a sair do método de teste.
Pergunta: explique o que aconteceu.
Pergunta: a partir destes dois exemplos, o que se pode concluir sobre a intercambiabilidade das implementações JPA? É total neste caso?
5.13.5. Os outros testes
Assim que a camada [DAO] for testada e considerada correta, poderemos passar aos testes da camada [metier] e aos do próprio projeto, na sua versão de consola ou gráfica. A alteração na implementação JPA não afeta de forma alguma as camadas [metier] e [ui] e, portanto, se estas camadas funcionavam com o Hibernate, funcionarão com o EclipseLink, com algumas exceções: o exemplo anterior mostra, de facto, que as exceções lançadas pelas camadas [DAO] podem diferir. Assim, no caso da utilização do teste, o Spring / JPA / Hibernate lança uma exceção do tipo [PamException], uma exceção específica da aplicação [pam], enquanto o Spring / JPA / EclipseLink, por sua vez, lança uma exceção do tipo [TransactionSystemException], uma exceção do framework Spring. Se, no caso de utilização do teste, a camada [ui] esperar uma exceção do tipo [PamException] porque foi construída com o Hibernate, deixará de funcionar quando se passar para EclipseLink.
5.13.6. Tarefa a realizar
Trabalho prático: refazer os testes das aplicações console e swing com diferentes SGBD: MySQL5, Oracle XE, SQL Server.