2. Arquitetura em camadas de uma aplicação Java
Uma aplicação Java é frequentemente dividida em camadas, cada uma com uma função bem definida. Vamos considerar uma arquitetura comum, a arquitetura de três camadas:
 |
- A camada [1], aqui referida como [ui] (Interface do Utilizador), é a camada que interage com o utilizador através de uma GUI Swing, uma interface de consola ou uma interface web. A sua função é fornecer dados do utilizador à camada [2] ou apresentar ao utilizador os dados fornecidos pela camada [2].
- A camada [2], aqui designada por [business], é a camada que aplica as chamadas regras de negócio — ou seja, a lógica específica da aplicação — sem se preocupar com a origem dos dados que recebe ou com o destino dos resultados que produz.
- A camada [3], aqui referida como [DAO] (Data Access Object), é a camada que fornece à camada [2] dados pré-armazenados (ficheiros, bases de dados, etc.) e armazena alguns dos resultados fornecidos pela camada [2].
Existem várias formas de implementar a camada [DAO]. Vamos examinar algumas delas:
 |
A camada [JDBC] acima é a camada padrão utilizada em Java para aceder a bases de dados. Ela isola a camada [DAO] do SGBD que gere a base de dados. Teoricamente, é possível mudar de SGBD sem alterar o código da camada [DAO]. Apesar desta vantagem, a API JDBC apresenta certas desvantagens:
- É provável que todas as operações no SGBD lancem a exceção SQLException verificada. Isto obriga o código de chamada (a camada [DAO], neste caso) a envolvê-las em blocos try/catch, tornando assim o código bastante prolixo.
- A camada [DAO] não é completamente independente do SGBD. Por exemplo, os SGBDs têm métodos proprietários para gerar automaticamente valores de chave primária que a camada [DAO] não pode ignorar. Assim, ao inserir um registo:
- Com o Oracle, a camada [DAO] deve primeiro obter um valor para a chave primária do registo e, em seguida, inserir o registo.
- Com o SQL Server, a camada [DAO] insere o registo, ao qual o SGBD atribui automaticamente um valor de chave primária, valor esse que é devolvido à camada [DAO].
Estas diferenças podem ser eliminadas através da utilização de procedimentos armazenados. No exemplo anterior, a camada [DAO] chamará um procedimento armazenado no Oracle ou no SQL Server que tenha em conta as características específicas do SGBD. Estas ficarão ocultas da camada [DAO]. No entanto, embora a mudança de SGBD não exija a reescrita da camada [DAO], continuará a exigir a reescrita dos procedimentos armazenados. Isto pode não ser considerado um impedimento.
Foram envidados inúmeros esforços para isolar a camada [DAO] dos aspetos proprietários dos SGBDs. Uma solução que tem tido grande sucesso nesta área nos últimos anos é o Hibernate:
 |
A camada [Hibernate] situa-se entre a camada [DAO] escrita pelo programador e a camada [JDBC]. O Hibernate é um ORM (Mapeador Objeto-Relacional), uma ferramenta que faz a ponte entre o mundo relacional das bases de dados e o mundo dos objetos manipulados pelo Java. O programador da camada [DAO] já não vê a camada [JDBC] nem as tabelas da base de dados cujo conteúdo pretende utilizar. Vê apenas a representação objeto da base de dados, fornecida pela camada [Hibernate]. A ponte entre as tabelas da base de dados e os objetos manipulados pela camada [DAO] é estabelecida principalmente de duas formas:
- através de ficheiros de configuração em estilo XML
- através de anotações Java no código, uma técnica disponível apenas a partir do JDK 1.5
A camada [Hibernate] é uma camada de abstração concebida para ser o mais transparente possível. O cenário ideal é que o programador da camada [DAO] não tenha qualquer consciência de que está a trabalhar com uma base de dados. Isto é viável se não for ele a escrever a configuração que faz a ponte entre os mundos relacional e orientado a objetos. Configurar esta ponte é bastante delicado e requer alguma experiência.
A camada de objetos [4], que espelha a base de dados, é chamada de «contexto de persistência». Uma camada [DAO] baseada no Hibernate executa operações de persistência (CRUD: criar, ler, atualizar, eliminar) nos objetos do contexto de persistência; estas operações são traduzidas pelo Hibernate em instruções SQL executadas pela camada JDBC. Para operações de consulta à base de dados (SQL SELECT), o Hibernate fornece aos programadores uma HQL (Hibernate Query Language) para consultar o contexto de persistência [4] em vez da própria base de dados.
O Hibernate é popular, mas complexo de dominar. A curva de aprendizagem, frequentemente apresentada como fácil, é, na verdade, bastante íngreme. Assim que se tem uma base de dados com tabelas que apresentam relações um-para-muitos ou muitos-para-muitos, a configuração da ponte relacional/objeto está fora do alcance do principiante médio. Erros de configuração podem levar a aplicações com baixo desempenho.
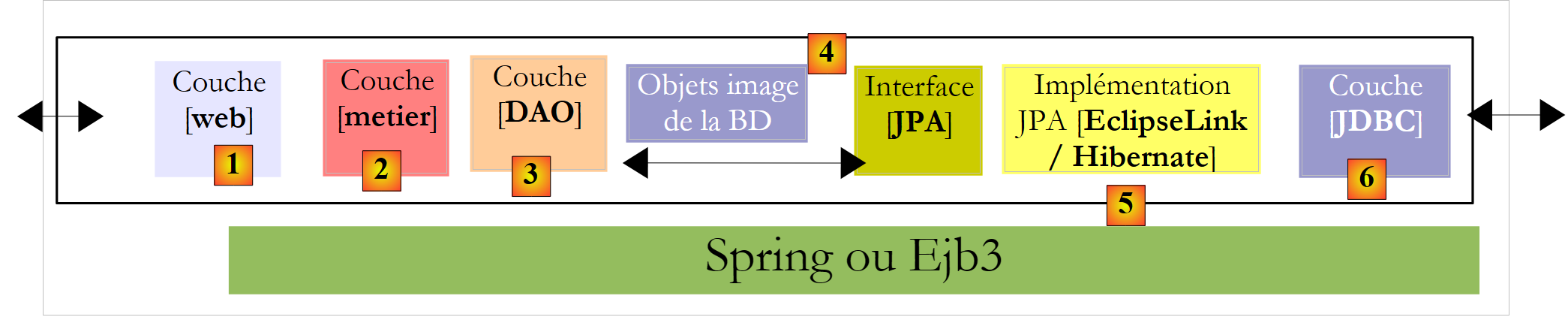
À luz do sucesso dos produtos ORM, a Sun, criadora do Java, decidiu padronizar uma camada ORM através de uma especificação chamada JPA (Java Persistence API), que foi lançada juntamente com o Java 5. A especificação JPA foi implementada por vários produtos: Hibernate, TopLink, EclipseLink, OpenJPA, etc. Com o JPA, a arquitetura anterior passa a ser a seguinte:
 |
A camada [DAO] interage agora com a especificação JPA, um conjunto de interfaces. Os programadores ganharam em termos de padronização. Anteriormente, se um programador alterasse a sua camada ORM, também teria de alterar a sua camada [DAO], que tinha sido escrita para interagir com um ORM específico. Agora, escreverão uma camada [DAO] que interage com uma camada JPA. Independentemente do produto que implemente a camada JPA, a interface apresentada à camada [DAO] permanece a mesma.
Neste documento, utilizaremos uma camada [DAO] construída sobre uma camada JPA/Hibernate ou JPA/EclipseLink. Utilizaremos também o framework Spring 2.8 para ligar estas camadas entre si.
 |
A principal vantagem do Spring é que permite ligar camadas através da configuração, em vez de no código. Assim, se a implementação JPA/Hibernate precisar de ser substituída por uma implementação Hibernate sem JPA — por exemplo, porque a aplicação está a ser executada num ambiente JDK 1.4 que não suporta JPA — esta alteração na implementação da camada [DAO] não tem impacto no código da camada [de negócio]. Apenas o ficheiro de configuração do Spring que liga as camadas entre si precisa de ser modificado.
Com o Java EE 5, existe outra solução: implementar as camadas [negócio] e [DAO] utilizando o EJB3 (Enterprise JavaBeans versão 3):
 |
Veremos que esta solução não é muito diferente daquela que utiliza o Spring. O ambiente Java EE 5 está disponível nos chamados servidores de aplicações, tais como o Sun Application Server 9.x (Glassfish), o JBoss Application Server, o Oracle Container for Java (OC4J), ... Um servidor de aplicações é, essencialmente, um servidor de aplicações web. Existem também os chamados ambientes EE 5 «autónomos», ou seja, aqueles que podem ser utilizados fora de um servidor de aplicações. É o caso do JBoss EJB3 ou do OpenEJB.
Num ambiente EE5, as camadas são implementadas por objetos chamados EJBs (Enterprise Java Beans). Nas versões anteriores do EE, os EJBs (EJB 2.x) eram conhecidos por serem difíceis de implementar e testar, e por vezes apresentavam um desempenho inferior ao esperado. É feita uma distinção entre os beans «entidade» EJB 2.x e os beans «sessão» EJB 2.x. Em resumo, um EJB 2.x «entidade» corresponde a uma linha de uma tabela de base de dados, e um EJB 2.x «sessão» é um objeto utilizado para implementar as camadas [lógica de negócio] e [DAO] de uma arquitetura multicamadas. Uma das principais críticas às camadas implementadas com EJBs é que estas só podem ser utilizadas dentro de contentores EJB, um serviço fornecido pelo ambiente EE (Enterprise Edition). Este ambiente, que é mais complexo de configurar do que um ambiente SE (Standard Edition), pode desencorajar os programadores de realizar testes com frequência. No entanto, existem ambientes de desenvolvimento Java que facilitam a utilização de um servidor de aplicações, automatizando a implementação de EJBs no servidor: Eclipse, NetBeans, JDeveloper, IntelliJ IDEA. Aqui, utilizaremos o NetBeans 6.8 e o servidor de aplicações GlassFish v3.
O framework Spring foi criado em resposta à complexidade do EJB2. Num ambiente SE, o Spring fornece um número significativo dos serviços normalmente oferecidos pelos ambientes EE. Por exemplo, na secção «Persistência de Dados», o Spring fornece os pools de ligação e os gestores de transações de que as aplicações necessitam. O surgimento do Spring fomentou uma cultura de testes unitários, que se tornou mais fácil de implementar no contexto SE do que no contexto EE. O Spring permite a implementação de camadas de aplicação utilizando objetos Java padrão (POJO, Plain Old/Ordinary Java Object), possibilitando a sua reutilização noutros contextos. Por fim, integra inúmeras ferramentas de terceiros de forma bastante transparente, nomeadamente ferramentas de persistência como o Hibernate, o EclipseLink, o iBatis, ...
O Java EE 5 foi concebido para resolver as lacunas da especificação EJB 2. O EJB 2.x evoluiu para o EJB 3. Trata-se de POJOs anotados com tags que os tornam objetos especiais quando se encontram dentro de um contentor EJB 3. Dentro do contentor, o EJB 3 pode tirar partido dos serviços do contentor (pool de ligações, gestor de transações, etc.). Fora do contentor EJB 3, o EJB 3 torna-se um objeto Java padrão. As suas anotações EJB são ignoradas.
Acima, representámos o Spring e um contentor EJB 3 como uma possível infraestrutura (framework) para a nossa arquitetura multicamadas. É esta infraestrutura que fornecerá os serviços de que precisamos: um pool de ligações e um gestor de transações.
- Com o Spring, as camadas serão implementadas utilizando POJOs. Estes terão acesso aos serviços do Spring (pool de conexões, gerenciador de transações) por meio da injeção de dependências nesses POJOs: ao construí-los, o Spring injeta referências aos serviços de que eles precisarão.
- Com o contentor EJB3, as camadas serão implementadas utilizando EJBs. Uma arquitetura em camadas implementada com EJB3s não é muito diferente de uma implementada com POJOs instanciados pelo Spring. Encontraremos muitas semelhanças.
- Por fim, apresentaremos um exemplo de uma aplicação web multicamadas:
 |