4. o JPA: Uma visão geral
O nosso objetivo é apresentar a JPA (Java Persistence API) com alguns exemplos. A JPA é abordada no curso:
- Persistência Java 5 na Prática: [http://tahe.developpez.com/java/jpa] - fornece as ferramentas para construir a camada de acesso aos dados com JPA
4.1. O papel da JPA numa arquitetura em camadas
Recomenda-se aos leitores que consultem o início deste documento (parágrafo 2), que explica o papel da camada JPA numa arquitetura em camadas. A camada JPA faz parte das camadas de acesso aos dados:
 |
A camada [DAO] interage com a especificação JPA. Independentemente do produto que a implementa, a interface da camada JPA apresentada à camada [DAO] permanece a mesma. A seguir, apresentamos alguns exemplos retirados de [ref1] que nos ajudarão a construir a nossa própria camada JPA.
4.2. JPA - Exemplos
4.2.1. Exemplo 1 - Representação de objeto de uma única tabela
4.2.1.1. A tabela [person]
Considere uma base de dados com uma única tabela [person], cuja função é armazenar algumas informações sobre indivíduos:
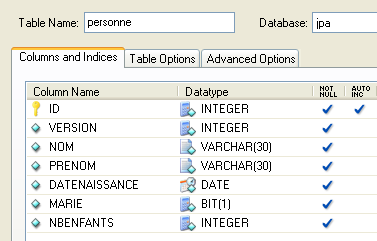 |
chave primária da tabela | |
versão da linha na tabela. Cada vez que a pessoa é modificada, o seu número de versão é incrementado. | |
apelido da pessoa | |
nome próprio | |
data de nascimento | |
número inteiro 0 (solteiro) ou 1 (casado) | |
número de filhos |
4.2.1.2. A entidade [Pessoa]
Estamos no seguinte ambiente de execução:
 |
A camada JPA [5] deve fazer a ponte entre o mundo relacional da base de dados [7] e o mundo dos objetos [4] manipulados pelos programas Java [3]. Esta ponte é estabelecida através da configuração, e há duas formas de o fazer:
- utilizando ficheiros XML. Esta era praticamente a única forma de o fazer até ao advento do JDK 1.5
- utilizando anotações Java desde o JDK 1.5
Neste documento, utilizaremos exclusivamente o segundo método.
O objeto [Person] que representa a tabela [person] apresentada anteriormente poderia ser o seguinte:
...
@SuppressWarnings("unused")
@Entity
@Table(name="Personne")
public class Personne implements Serializable{
@Id
@Column(name = "ID", nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Column(name = "VERSION", nullable = false)
@Version
private int version;
@Column(name = "NOM", length = 30, nullable = false, unique = true)
private String nom;
@Column(name = "PRENOM", length = 30, nullable = false)
private String prenom;
@Column(name = "DATENAISSANCE", nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(name = "MARIE", nullable = false)
private boolean marie;
@Column(name = "NBENFANTS", nullable = false)
private int nbenfants;
// manufacturers
public Personne() {
}
public Personne(String nom, String prenom, Date datenaissance, boolean marie,
int nbenfants) {
setNom(nom);
setPrenom(prenom);
setDatenaissance(datenaissance);
setMarie(marie);
setNbenfants(nbenfants);
}
// toString
public String toString() {
...
}
// getters and setters
...
}
A configuração é realizada utilizando anotações Java (@Annotation). As anotações Java são processadas pelo compilador ou por ferramentas especializadas em tempo de execução. Além da anotação na linha 3 destinada ao compilador, todas as anotações aqui se destinam à implementação JPA utilizada, seja Hibernate ou Toplink. Serão, portanto, processadas em tempo de execução. Na ausência de ferramentas capazes de as interpretar, estas anotações são ignoradas. Assim, a classe [Person] acima poderia ser utilizada num contexto não-JPA.
Existem dois casos distintos para a utilização de anotações JPA numa classe C associada a uma tabela T:
- a tabela T já existe: as anotações JPA devem então replicar a estrutura existente (nomes e definições de colunas, restrições de integridade, chaves estrangeiras, chaves primárias, etc.)
- A tabela T não existe e será criada com base nas anotações encontradas na classe C.
O caso 2 é o mais fácil de lidar. Utilizando anotações JPA, especificamos a estrutura da tabela T que pretendemos. O caso 1 é frequentemente mais complexo. A tabela T pode ter sido criada há muito tempo fora de qualquer contexto JPA. A sua estrutura pode, portanto, ser inadequada para a ponte relacional-objeto do JPA. Para simplificar as coisas, vamos concentrar-nos no caso 2, em que a tabela T associada à classe C será criada com base nas anotações JPA na classe C.
Vamos examinar as anotações JPA da classe [Person]:
- linha 4: a anotação @Entity é a primeira anotação essencial. É colocada antes da linha que declara a classe e indica que a classe em questão deve ser gerida pela camada de persistência do JPA. Sem esta anotação, todas as outras anotações JPA seriam ignoradas.
- linha 5: a anotação @Table designa a tabela da base de dados que a classe representa. O seu principal argumento é name, que especifica o nome da tabela. Sem este argumento, a tabela receberá o nome da classe, neste caso [Person]. No nosso exemplo, a anotação @Table é, portanto, desnecessária.
- Linha 8: A anotação @Id é utilizada para designar o campo na classe que corresponde à chave primária da tabela. Esta anotação é obrigatória. Aqui, indica que o campo id na linha 11 corresponde à chave primária da tabela.
- Linha 9: A anotação @Column é utilizada para associar um campo da classe à coluna da tabela que o campo representa. O atributo name especifica o nome da coluna na tabela. Se este atributo for omitido, a coluna recebe o mesmo nome que o campo. No nosso exemplo, o argumento name era, portanto, opcional. O argumento nullable=false especifica que a coluna associada ao campo não pode ter um valor NULL e que o campo deve, portanto, ter um valor.
- Linha 10: A anotação @GeneratedValue especifica como a chave primária é gerada quando é criada automaticamente pelo SGBD. Este será o caso em todos os nossos exemplos. Não é obrigatória. Assim, a nossa entidade Person poderia ter um número de identificação de aluno que funcionasse como chave primária e que não fosse gerado pelo SGBD, mas sim definido pela aplicação. Neste caso, a anotação @GeneratedValue seria omitida. O argumento strategy especifica como a chave primária é gerada quando gerada pelo SGBD. Nem todos os SGBDs utilizam a mesma técnica para gerar valores de chave primária. Por exemplo:
utiliza um gerador de valores chamado antes de cada inserção | |
o campo da chave primária é definido como tendo o tipo Identity. O resultado é semelhante ao gerador de valores do Firebird, exceto que o valor da chave só é conhecido após a inserção da linha. | |
utiliza um objeto chamado SEQUENCE, que, mais uma vez, atua como um gerador de valores |
A camada JPA deve gerar instruções SQL diferentes, dependendo do SGBD, para criar o gerador de valores. Está configurada para especificar o tipo de SGBD que deve suportar. Como resultado, pode determinar a estratégia padrão para gerar valores de chave primária para esse SGBD. O argumento strategy = GenerationType.*****AUTO* instrui a camada JPA a utilizar esta estratégia padrão. Esta técnica funcionou em todos os exemplos deste documento para os sete SGBDs utilizados.
- Linha 14: A anotação @Version designa o campo utilizado para gerir o acesso simultâneo à mesma linha na tabela.
Para compreender esta questão do acesso simultâneo à mesma linha na tabela [person], vamos supor que uma aplicação web permite que as informações de uma pessoa sejam atualizadas e considerar o seguinte cenário:
No momento T1, o utilizador U1 começa a editar uma pessoa P. Neste momento, o número de filhos é 0. Ele altera este número para 1, mas antes de enviar as suas alterações, o utilizador U2 começa a editar a mesma pessoa P. Como U1 ainda não enviou as suas alterações, U2 vê o número de filhos como 0 no seu ecrã. U2 altera o nome da pessoa P para maiúsculas. Em seguida, U1 e U2 guardam as suas alterações nessa ordem. A alteração de U2 terá precedência: na base de dados, o nome estará em maiúsculas e o número de filhos permanecerá em zero, mesmo que U1 acredite que o tenha alterado para 1.
O conceito de versão de uma pessoa ajuda-nos a resolver este problema. Vamos revisitar o mesmo caso de uso:
No momento T1, um utilizador U1 começa a editar uma pessoa P. Nesta altura, o número de filhos é 0 e a versão é V1. Ele altera o número de filhos para 1, mas antes de confirmar a alteração, um utilizador U2 começa a editar a mesma pessoa P. Como U1 ainda não confirmou a alteração, U2 vê o número de filhos como 0 e a versão como V1. U2 altera o nome da pessoa P para maiúsculas. Em seguida, U1 e U2 confirmam as suas alterações nessa ordem. Antes de confirmar uma alteração, verificamos se o utilizador que está a modificar a pessoa P possui a mesma versão que a versão atualmente guardada da pessoa P. Este será o caso do utilizador U1. A sua alteração é, portanto, aceite e, em seguida, alteramos a versão da pessoa modificada de V1 para V2 para indicar que a pessoa sofreu uma alteração. Ao validar a modificação de U2, verificaremos que U2 tem a versão V1 da pessoa P, enquanto a versão atual é V2. Podemos então informar o utilizador U2 de que outra pessoa agiu antes dele e que deve começar com a nova versão da pessoa P. Ele fará isso, recuperará a versão V2 da pessoa P, que agora tem um filho, colocará o nome em maiúsculas e validará. A sua modificação será aceite se a pessoa P registada ainda estiver na versão V2. Em última análise, as modificações feitas por U1 e U2 serão tidas em conta, enquanto que no caso de utilização sem versões, uma das modificações teria sido perdida.
A camada [DAO] da aplicação cliente pode gerir a versão da própria classe [Person]. Sempre que um objeto P for modificado, a versão desse objeto será incrementada em 1 na tabela. A anotação @Version permite que esta gestão seja transferida para a camada JPA. O campo em questão não precisa de se chamar «version», como no exemplo. Pode ter qualquer nome.
Os campos correspondentes às anotações @Id e @Version estão presentes para fins de persistência. Não seriam necessários se a classe [Person] não precisasse de ser persistida. Podemos ver, portanto, que um objeto é representado de forma diferente dependendo de precisar ou não de ser persistido.
- Linha 17: Mais uma vez, a anotação @Column fornece informações sobre a coluna na tabela [person] associada ao campo name da classe Person. Aqui encontramos dois novos argumentos:
- unique=true indica que o nome de uma pessoa deve ser único. Isto resultará na adição de uma restrição de unicidade na coluna NAME da tabela [person] na base de dados.
- length=30 define o número de caracteres na coluna NAME para 30. Isto significa que o tipo desta coluna será VARCHAR(30).
- Linha 24: A anotação @Temporal é utilizada para especificar o tipo SQL para uma coluna ou campo de data/hora. O tipo TemporalType.DATE denota uma data sem hora associada. Os outros tipos possíveis são TemporalType.TIME para codificar uma hora e TemporalType.TIMESTAMP para codificar uma data e hora.
Vamos agora comentar o resto do código na classe [Person]:
- Linha 6: A classe implementa a interface Serializable. A serialização de um objeto envolve a sua conversão numa sequência de bits. A deserialização é a operação inversa. A serialização/deserialização é particularmente utilizada em aplicações cliente/servidor, onde os objetos são trocados através da rede. As aplicações cliente ou servidor não têm conhecimento desta operação, que é realizada de forma transparente pelas JVMs. Para que isto seja possível, no entanto, as classes dos objetos trocados devem ser «marcadas» com a palavra-chave Serializable.
- Linha 37: um construtor para a classe. Note-se que os campos id e version não estão incluídos entre os parâmetros. Isto deve-se ao facto de estes dois campos serem geridos pela camada JPA e não pela aplicação.
- Linhas 51 e seguintes: os métodos get e set para cada um dos campos da classe. Note que as anotações JPA podem ser colocadas nos métodos get dos campos, em vez de nos próprios campos. A localização das anotações indica o modo que o JPA deve utilizar para aceder aos campos:
- se as anotações forem colocadas ao nível do campo, o JPA acederá diretamente aos campos para os ler ou gravar
- se as anotações forem colocadas no nível get, o JPA acederá aos campos através dos métodos get/set para os ler ou gravar
A posição da anotação @Id determina a colocação das anotações JPA numa classe. Quando colocada ao nível do campo, indica acesso direto aos campos; quando colocada ao nível do get, indica acesso aos campos através dos métodos get e set. As outras anotações devem então ser colocadas da mesma forma que a anotação @Id.
4.2.2. Configurar a camada JPA
Os testes da camada JPA podem ser realizados utilizando a seguinte arquitetura:
 |
- em [7]: a base de dados que será gerada a partir das anotações da entidade [Person], bem como de configurações adicionais feitas num ficheiro chamado [persistence.xml]
- em [5, 6]: uma camada JPA implementada pelo Hibernate
- em [4]: a entidade [Person]
- em [3]: um programa de teste baseado em consola
A camada JPA é configurada através do ficheiro [META-INF/persistence.xml]:
 |
Em tempo de execução, o ficheiro [META-INF/persistence.xml] é procurado no classpath da aplicação.
Vamos examinar a configuração da camada JPA no ficheiro [persistence.xml] do nosso projeto:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Persistent classes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- logs SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
<property name="hibernate.connection.url" value="jdbc:mysql://localhost:3306/jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- automatic schematic creation -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
<!-- properties DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
Para compreender esta configuração, precisamos de rever a arquitetura de acesso aos dados da nossa aplicação:
 |
- o ficheiro [persistence.xml] configura as camadas [4, 5, 6]
- [4]: Implementação do JPA pelo Hibernate
- [5]: O Hibernate acede à base de dados através de um conjunto de ligações. Um conjunto de ligações é um conjunto de ligações abertas ao SGBD. Um SGBD é acedido por vários utilizadores, mas, por razões de desempenho, não pode exceder um limite N de ligações abertas simultaneamente. Um código bem escrito abre uma ligação ao SGBD pelo tempo mínimo necessário: executa comandos SQL e fecha a ligação. Faz isso repetidamente, sempre que precisa de trabalhar com a base de dados. O custo de abrir e fechar uma ligação não é insignificante, e é aqui que entra o conjunto de ligações. Quando a aplicação arranca, o conjunto de ligações abre N1 ligações ao SGBD. A aplicação solicita uma ligação aberta ao conjunto sempre que precisa de uma. A ligação é devolvida ao conjunto assim que a aplicação deixa de precisar dela, de preferência o mais rapidamente possível. A ligação não é encerrada e permanece disponível para o próximo utilizador. Um conjunto de ligações é, portanto, um sistema para partilhar ligações abertas.
- [6]: o controlador JDBC para o SGBD que está a ser utilizado
Agora vamos ver como o ficheiro [persistence.xml] configura as camadas [4, 5, 6] acima:
- linha 2: a tag raiz do ficheiro XML é <persistence>.
- linha 3: <persistence-unit> é utilizado para definir uma unidade de persistência. Podem existir várias unidades de persistência. Cada uma tem um nome (atributo name) e um tipo de transação (atributo transaction-type). A aplicação acederá à unidade de persistência através do seu nome, neste caso jpa. O tipo de transação RESOURCE_LOCAL indica que a aplicação gere as transações com o próprio SGBD. Este será o caso aqui. Quando a aplicação é executada num contentor EJB3, pode utilizar o serviço de transações do contentor. Neste caso, definiremos transaction-type=JTA (Java Transaction API). JTA é o valor predefinido quando o atributo transaction-type é omitido.
- Linha 5: A tag <provider> é utilizada para definir uma classe que implementa a interface [javax.persistence.spi.PersistenceProvider], o que permite à aplicação inicializar a camada de persistência. Como estamos a utilizar uma implementação JPA/Hibernate, a classe utilizada aqui é uma classe Hibernate.
- Linha 6: A tag <properties> introduz propriedades específicas do fornecedor escolhido. Assim, dependendo de ter escolhido Hibernate, TopLink, Kodo, etc., terá propriedades diferentes. As seguintes são específicas do Hibernate.
- Linha 8: Instrui o Hibernate a analisar o classpath do projeto para encontrar classes anotadas com @Entity, para que possam ser geridas. As classes @Entity também podem ser declaradas utilizando as tags <class>class_name</class>, diretamente sob a tag <persistence-unit>. É isto que faremos com o fornecedor JPA/Toplink.
- As linhas 10–12, que estão comentadas aqui, configuram os registos da consola do Hibernate:
- Linha 10: para ativar ou desativar a exibição das instruções SQL emitidas pelo Hibernate para o SGBD. Isto é muito útil durante a fase de aprendizagem. Devido à ponte relacional/objeto, a aplicação trabalha com objetos persistentes aos quais aplica operações como [persist, merge, remove]. É muito útil saber quais as instruções SQL que são efetivamente emitidas para estas operações. Ao estudá-las, aprende-se gradualmente a antecipar as instruções SQL que o Hibernate irá gerar ao realizar tais operações em objetos persistentes, e a ponte relacional/objeto começa a tomar forma na sua mente.
- Linha 11: As instruções SQL exibidas na consola podem ser formatadas de forma organizada para facilitar a sua leitura
- Linha 12: As instruções SQL exibidas também serão anotadas
- As linhas 15–19 definem a camada JDBC (camada [6] na arquitetura):
- linha 15: a classe do controlador JDBC para o SGBD, neste caso o MySQL5
- linha 16: o URL da base de dados que está a ser utilizada
- Linhas 17 e 18: o nome de utilizador e a palavra-passe de ligação
- linha 22: O Hibernate precisa de saber com que SGBD está a trabalhar. Isto deve-se ao facto de todos os SGBDs terem extensões SQL proprietárias — tais como os seus próprios métodos para gerar automaticamente valores de chave primária — o que significa que o Hibernate deve identificar o SGBD específico para enviar instruções SQL que este consiga compreender. [MySQL5InnoDBDialect] refere-se ao SGBD MySQL5 com tabelas InnoDB que suportam transações.
- As linhas 24–28 configuram o conjunto de ligações do c3p0 (camada [5] na arquitetura):
- Linhas 24, 25: o número mínimo (padrão 3) e máximo de ligações (padrão 15) no conjunto. O número inicial padrão de ligações é 3.
- Linha 26: tempo máximo de espera, em milissegundos, para um pedido de ligação do cliente. Após este tempo limite, o c3p0 devolverá uma exceção.
- Linha 27: Para aceder à base de dados, o Hibernate utiliza instruções SQL preparadas (PreparedStatement) que o c3p0 pode armazenar em cache. Isto significa que, se a aplicação solicitar uma instrução SQL preparada que já se encontre no cache pela segunda vez, não será necessário prepará-la (a preparação de uma instrução SQL implica um custo), sendo utilizada a que se encontra no cache. Aqui, especificamos o número máximo de instruções SQL preparadas que o cache pode conter, em todas as ligações (uma instrução SQL preparada pertence a uma única ligação).
- Linha 28: Frequência, em milissegundos, para verificar a validade das ligações. Uma ligação no conjunto pode tornar-se inválida por várias razões (o controlador JDBC invalida a ligação porque esta esteve aberta durante demasiado tempo, o controlador JDBC tem «bugs», etc.).
- Linha 20: Aqui, especificamos que, quando a camada de persistência for inicializada, o esquema da base de dados para objetos @Entity deve ser gerado. O Hibernate dispõe agora de todas as ferramentas para gerar as instruções SQL para a criação das tabelas da base de dados:
- a configuração dos objetos @Entity permite-lhe determinar quais as tabelas a gerar
- As linhas 15–18 e 24–28 permitem-lhe estabelecer uma ligação com o SGBD
- a linha 22 indica-lhe qual o dialeto SQL a utilizar para gerar as tabelas
Assim, o ficheiro [persistence.xml] utilizado aqui recria uma nova base de dados sempre que a aplicação é executada. As tabelas são recriadas (create table) após serem eliminadas (drop table), caso existissem. Note-se que isto não é, obviamente, algo a fazer com uma base de dados de produção...
4.2.3. Exemplo 2: Relação um-para-muitos
4.2.3.1. O ficheiro de esquema da base de dados [
1 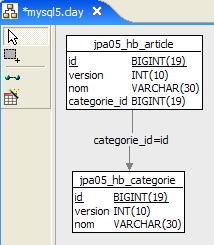 | 2 |
- em [1], a base de dados, e em [2], o seu DDL (MySQL5)
Um artigo A(id, versão, nome) pertence a exatamente uma categoria C(id, versão, nome). Uma categoria C pode conter 0, 1 ou mais artigos. Temos uma relação um-para-muitos (Categoria -> Artigo) e a relação inversa muitos-para-um (Artigo -> Categoria). Esta relação é representada pela chave estrangeira que a tabela [artigo] possui na tabela [categoria] (linhas 24–28 do DDL).
4.2.3.2. Os objetos @Entity que representam a base de dados
Um artigo é representado pela seguinte @Entity [Artigo]:
package entites;
...
@Entity
@Table(name="jpa05_hb_article")
public class Article implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// main relationship Article (many) -> Category (one)
// implemented by a foreign key (categorie_id) in Article
// 1 Article must have 1 Category (nullable=false)
@ManyToOne(fetch=FetchType.LAZY)
@JoinColumn(name = "categorie_id", nullable = false)
private Categorie categorie;
// manufacturers
public Article() {
}
// getters and setters
...
// toString
public String toString() {
return String.format("Article[%d,%d,%s,%d]", id, version, nom, categorie.getId());
}
}
- linhas 9-11: chave primária da @Entity
- linhas 13-15: o seu número de versão
- linhas 17-18: nome do artigo
- linhas 20-25: relação muitos-para-um que liga a @Entity Article à @Entity Category:
- linha 23: a anotação ManyToOne. O Many refere-se à @Entity Article na qual nos encontramos, e o One refere-se à @Entity Category (linha 25). Uma categoria (One) pode ter vários artigos (Many).
- linha 24: a anotação ManyToOne define a coluna de chave estrangeira na tabela [article]. Ela será denominada (name) categorie_id, e cada linha deve ter um valor nesta coluna (nullable=false).
- Linha 25: A categoria à qual o artigo pertence. Quando um artigo é adicionado ao contexto de persistência, solicitamos que a sua categoria não seja adicionada imediatamente (fetch=FetchType.LAZY, linha 23). Não sabemos se este pedido faz sentido. Veremos.
Uma categoria é representada pela seguinte @Entity [Category]:
package entites;
...
@Entity
@Table(name="jpa05_hb_categorie")
public class Categorie implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// inverse relationship Category (one) -> Article (many) from relationship Article (many) -> Category (one)
// cascade insertion Category -> insertion Articles
// cascade maj Category -> maj Articles
// cascade delete Category -> delete Articles
@OneToMany(mappedBy = "categorie", cascade = { CascadeType.ALL })
private Set<Article> articles = new HashSet<Article>();
// manufacturers
public Categorie() {
}
// getters and setters
...
// toString
public String toString() {
return String.format("Categorie[%d,%d,%s]", id, version, nom);
}
// bidirectional association Category <--> Article
public void addArticle(Article article) {
// the item is added to the collection of items in the category
articles.add(article);
// article changes category
article.setCategorie(this);
}
}
- linhas 8-11: a chave primária da @Entity
- linhas 12-14: a sua versão
- linhas 16-17: o nome da categoria
- linhas 19-24: o conjunto de artigos na categoria
- linha 23: a anotação @OneToMany denota uma relação um-para-muitos. O «One» refere-se à @Entity [Category] em que nos encontramos, e o «Many» refere-se ao tipo [Article] na linha 24: uma (One) categoria tem muitos (Many) artigos.
- linha 23: a anotação é o inverso (mappedBy) da anotação ManyToOne colocada no campo category da @Entity Article: mappedBy=category. A relação ManyToOne colocada no campo category da @Entity Article é a relação primária. É essencial. Implementa a relação de chave estrangeira que liga a @Entity Article à @Entity Category. A relação OneToMany colocada no campo articles da @Entity Category é a relação inversa. Não é essencial. É uma facilidade para recuperar os artigos de uma categoria. Sem esta facilidade, estes artigos seriam recuperados através de uma consulta JPQL.
- Linha 23: cascadeType.ALL garante que as operações (persist, merge, remove) realizadas numa @Entity Category sejam propagadas aos seus artigos.
- Linha 24: Os artigos de uma categoria serão colocados num objeto do tipo `Set<Article>`. O tipo `Set` não permite duplicados. Assim, o mesmo artigo não pode ser adicionado duas vezes ao objeto `Set<Article>`. O que significa «o mesmo artigo»? Para indicar que o artigo `a` é igual ao artigo `b`, o Java utiliza a expressão `a.equals(b)`. Na classe Object, a classe pai de todas as classes, a.equals(b) é verdadeiro se a==b, ou seja, se os objetos a e b tiverem a mesma localização na memória. Pode-se querer dizer que os itens a e b são iguais se tiverem o mesmo nome. Neste caso, o programador deve redefinir dois métodos na classe [Item]:
- equals: que deve devolver true se os dois itens tiverem o mesmo nome
- hashCode: deve devolver o mesmo valor inteiro para dois objetos [Article] que o método equals considere iguais. Aqui, o valor será, portanto, construído a partir do nome do artigo. O valor devolvido por hashCode pode ser qualquer inteiro. É utilizado em vários contentores de objetos, particularmente dicionários (Hashtable).
A relação OneToMany pode utilizar tipos diferentes de Set para armazenar o Many, tais como objetos List. Não abordaremos estes casos neste documento. O leitor pode encontrá-los em [ref1].
- Linha 38: O método [addArticle] permite-nos adicionar um artigo a uma categoria. O método garante que ambas as extremidades da relação OneToMany que liga [Category] a [Article] sejam atualizadas.
4.3. A API da Camada JPA
Vamos esclarecer o ambiente de execução de um cliente JPA:
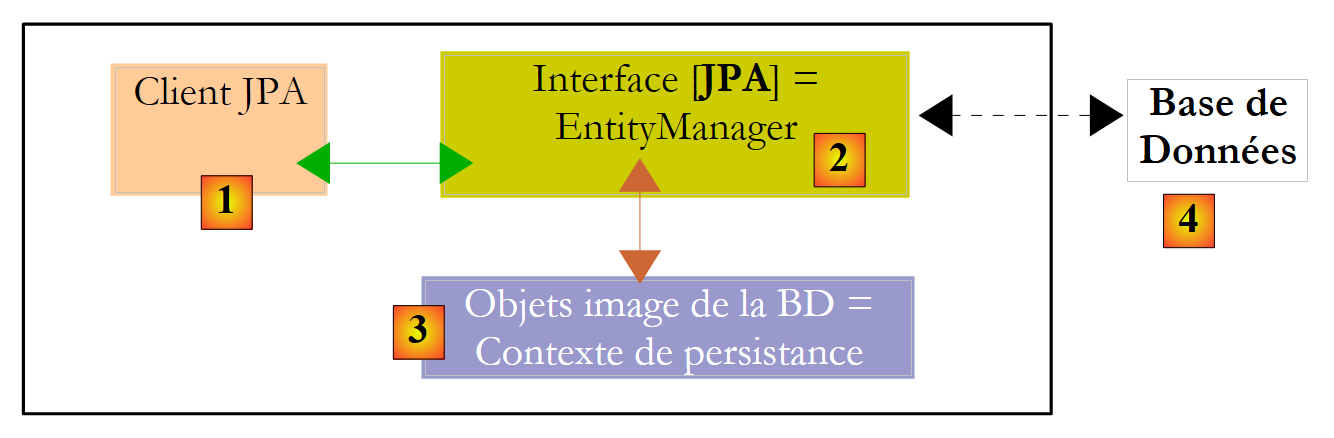 |
Sabemos que a camada JPA [2] cria uma ponte entre os domínios do objeto [3] e do relacional [4]. O conjunto de objetos geridos pela camada JPA dentro desta ponte objeto/relacional é chamado de «contexto de persistência». Para aceder aos dados no contexto de persistência, um cliente JPA [1] deve passar pela camada JPA [2]:
- pode criar um objeto e pedir à camada JPA para o tornar persistente. O objeto passa então a fazer parte do contexto de persistência.
- pode solicitar uma referência a um objeto persistente existente à camada [JPA].
- pode modificar um objeto persistente obtido da camada JPA.
- pode solicitar à camada JPA que remova um objeto do contexto de persistência.
A camada JPA fornece ao cliente uma interface chamada [EntityManager] que, como o próprio nome sugere, permite a gestão de objetos @Entity no contexto de persistência. Seguem-se os principais métodos desta interface:
Adiciona a entidade ao contexto de persistência | |
Remove a entidade do contexto de persistência | |
mescla um objeto de entidade proveniente do cliente que não é gerido pelo contexto de persistência com o objeto de entidade no contexto de persistência que possui a mesma chave primária. O resultado devolvido é o objeto de entidade do contexto de persistência. | |
coloca um objeto recuperado da base de dados no contexto de persistência através da sua chave primária. O tipo T do objeto permite que a camada JPA saber qual a tabela a consultar. O objeto persistente assim criado é devolvido ao cliente. | |
cria um objeto Query a partir de uma JPQL (Java Persistence Query Language). Uma consulta JPQL é análoga a uma consulta SQL, exceto que consulta objetos em vez de tabelas. | |
Um método semelhante ao anterior, exceto que queryText é um Consulta SQL em vez de uma consulta JPQL. | |
Um método idêntico ao createQuery, exceto que a consulta JPQL queryText foi foi externalizada para um ficheiro de configuração e associada a um nome. Este nome é o parâmetro do método. |
Um objeto EntityManager tem um ciclo de vida que não é necessariamente o mesmo que o da aplicação. Tem um início e um fim. Assim, um cliente JPA pode trabalhar sucessivamente com diferentes objetos EntityManager. O contexto de persistência associado a um EntityManager tem o mesmo ciclo de vida que o próprio EntityManager. São inseparáveis um do outro. Quando um objeto EntityManager é fechado, o seu contexto de persistência é, se necessário, sincronizado com a base de dados e, em seguida, deixa de existir. Deve ser criado um novo EntityManager para obter um novo contexto de persistência.
O cliente JPA pode criar um EntityManager e, consequentemente, um contexto de persistência com a seguinte instrução:
EntityManagerFactory emf = Persistence.createEntityManagerFactory("nom d'une unité de persistance");
- javax.persistence.Persistence é uma classe estática utilizada para obter uma fábrica de objetos EntityManager. Esta fábrica está associada a uma unidade de persistência específica. Recorde-se que o ficheiro de configuração [META-INF/persistence.xml] é utilizado para definir unidades de persistência e que estas unidades têm um nome:
<persistence-unit name="elections-dao-jpa-mysql-01PU" transaction-type="RESOURCE_LOCAL">
Acima, a unidade de persistência é denominada elections-dao-jpa-mysql-01PU. Ela vem com a sua própria configuração específica, incluindo o SGBD com o qual trabalha. A instrução [Persistence.createEntityManagerFactory("elections-dao-jpa-mysql-01PU")] cria uma EntityManagerFactory capaz de fornecer objetos EntityManager destinados a gerir contextos de persistência associados à unidade de persistência denominada elections-dao-jpa-mysql-01PU. Um objeto EntityManager — e, portanto, um contexto de persistência — é obtido a partir do objeto EntityManagerFactory da seguinte forma:
Os seguintes métodos da interface [EntityManager] permitem-lhe gerir o ciclo de vida do contexto de persistência:
O contexto de persistência é fechado. Força a sincronização do contexto de persistência com a base de dados:
| |
O contexto de persistência é limpo de todos os seus objetos, mas não é fechado. | |
O contexto de persistência é sincronizado com a base de dados, tal como descrito para close() |
O cliente JPA pode forçar a sincronização do contexto de persistência com a base de dados utilizando o método [EntityManager].flush. A sincronização pode ser explícita ou implícita. No primeiro caso, cabe ao cliente realizar operações de flush quando quiser sincronizar; caso contrário, a sincronização ocorre em momentos específicos que iremos especificar. O modo de sincronização é gerido pelos seguintes métodos da interface [EntityManager]:
Existem dois valores possíveis para flushMode: FlushModeType.AUTO (padrão): a sincronização ocorre antes de cada consulta SELECT efetuada na base de dados. FlushModeType.COMMIT: a sincronização ocorre apenas no no final das transações na base de dados. | |
retorna o modo de sincronização atual |
Resumindo: No modo FlushModeType.AUTO, que é o padrão, o contexto de persistência será sincronizado com a base de dados nos seguintes momentos:
- antes de cada operação SELECT no banco de dados
- no final de uma transação na base de dados
- após uma operação de flush ou de fecho no contexto de persistência
No modo FlushModeType.COMMIT, o mesmo se aplica, exceto para a operação 1, que não ocorre. O modo normal de interação com a camada JPA é o modo transacional. O cliente realiza várias operações no contexto de persistência dentro de uma transação. Neste caso, os pontos de sincronização entre o contexto de persistência e a base de dados são os casos 1 e 2 acima no modo AUTO, e apenas o caso 2 no modo COMMIT.
Concluamos com a API da interface Query, que permite emitir comandos JPQL no contexto de persistência ou comandos SQL diretamente na base de dados para recuperar dados. A interface Query é a seguinte:
 |
- 1 - O método getResultList executa uma consulta SELECT que devolve vários objetos. Estes são devolvidos num objeto List. Este objeto é uma interface. Fornece um objeto Iterator que permite percorrer os elementos da lista L da seguinte forma:
Iterator iterator = L.iterator();
while (iterator.hasNext()) {
// exploiter l'objet iterator.next() qui représente l'élément courant de la liste
...
}
A lista L também pode ser percorrida utilizando um ciclo for:
for (Object o : L) {
// exploiter objet o
}
- 2 - O método getSingleResult executa uma instrução JPQL/SQL SELECT que devolve um único objeto.
- 3 - O método executeUpdate executa uma instrução SQL UPDATE ou DELETE e devolve o número de linhas afetadas pela operação.
- 4 - O método setParameter(String, Object) permite atribuir um valor a um parâmetro nomeado de uma consulta JPQL parametrizada
- 5 - O método setParameter(int, Object) define o parâmetro, mas este é identificado não pelo seu nome, mas pela sua posição na consulta JPQL.
4.4. s (JPQL)
JPQL (Java Persistence Query Language) é a linguagem de consulta da camada JPA. A linguagem JPQL é semelhante à linguagem SQL utilizada em bases de dados. Enquanto o SQL trabalha com tabelas, o JPQL trabalha com os objetos que representam essas tabelas. Iremos examinar um exemplo dentro da seguinte arquitetura:
 |
A base de dados, a que chamaremos [ dbrdvmedecins2], é uma base de dados MySQL5 com quatro tabelas:
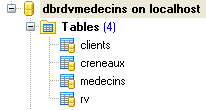 |
Esta tabela contém informações utilizadas para gerir as consultas de um grupo de médicos.
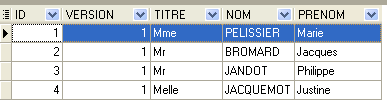
4.4.1. A tabela [MEDECINS]
Contém informações sobre os médicos.
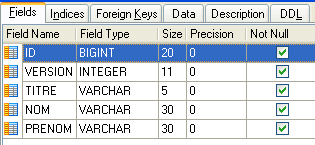 |  |
- ID: o número de identificação do médico — a chave primária da tabela
- VERSION: um número que identifica a versão da linha na tabela. Este número é incrementado em 1 cada vez que é feita uma alteração na linha.
- LAST_NAME: o apelido do médico
- FIRST NAME: o nome próprio do médico
- TITLE: o seu título (Sra., Sra., Sr.)
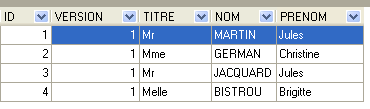
4.4.2. A tabela [CLIENTS]
Os clientes dos vários médicos estão armazenados na tabela [CLIENTS]:
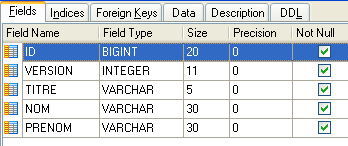 |  |
- ID: número de identificação do cliente - chave primária da tabela
- VERSION: número que identifica a versão da linha na tabela. Este número é incrementado em 1 cada vez que é feita uma alteração na linha.
- APELIDO: o apelido do cliente
- NOME: o nome do cliente
- TÍTULO: o seu título (Sra., Sra., Sr.)
4.4.3. A tabela [SLOTS]
Apresenta os horários disponíveis para marcação de consultas:
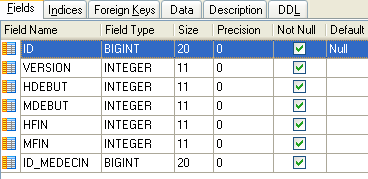 |
 |
- ID: Número de identificação do intervalo de tempo - chave primária da tabela (linha 8)
- VERSION: número que identifica a versão da linha na tabela. Este número é incrementado em 1 cada vez que é feita uma alteração na linha.
- DOCTOR_ID: número de identificação do médico a quem este intervalo de tempo pertence – chave estrangeira na coluna DOCTORS(ID).
- START_TIME: hora de início do intervalo de tempo
- MSTART: Minutos de início do intervalo de tempo
- HFIN: hora de fim do intervalo
- MFIN: minutos de fim do intervalo
A segunda linha da tabela [SLOTS] (ver [1] acima) indica, por exemplo, que o intervalo n.º 2 começa às 8h20 e termina às 8h40 e pertence à médica n.º 1 (Sra. Marie PELISSIER).
4.4.4. A tabela [RV]
Apresenta a lista de consultas marcadas para cada médico:
 |
- ID: identificador único da consulta – chave primária
- DAY: dia da consulta
- SLOT_ID: intervalo horário da consulta – chave estrangeira no campo [ID] da tabela [SLOTS] – determina tanto o intervalo horário como o médico envolvido.
- CLIENT_ID: ID do cliente para quem a reserva é feita – chave estrangeira no campo [ID] da tabela [CLIENTS]
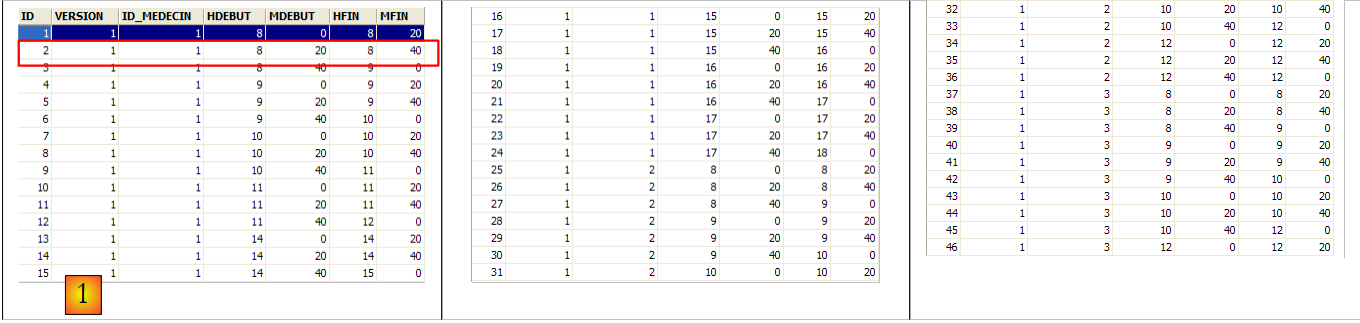
Esta tabela possui uma restrição de exclusividade nos valores das colunas associadas (DAY, SLOT_ID):
Se uma linha na tabela [RV] tiver o valor (DAY1, SLOT_ID1) para as colunas (DAY, SLOT_ID), este valor não pode aparecer em mais nenhum outro local. Caso contrário, isso significaria que foram marcadas duas consultas ao mesmo tempo para o mesmo médico. Do ponto de vista da programação Java, o controlador JDBC da base de dados lança uma SQLException quando isto ocorre.
A linha com ID igual a 3 (ver [1] acima) significa que foi marcada uma consulta para o horário n.º 20 e o cliente n.º 4 em 23/08/2006. A tabela [SLOTS] indica-nos que o horário n.º 20 corresponde ao intervalo horário das 16h20 às 16h40 e pertence à médica n.º 1 (Sra. Marie PELISSIER). A tabela [CLIENTS] indica-nos que o cliente n.º 4 é a Sra. Brigitte BISTROU.
4.4.5. Gerar a base de dados
Para criar as tabelas e preenchê-las, pode utilizar o script [dbrdvmedecins2.sql]. Com o [WampServer], pode proceder da seguinte forma:
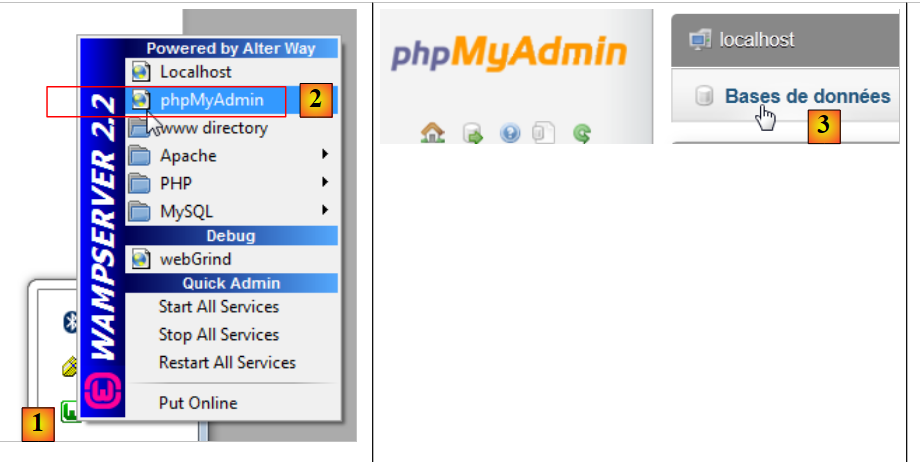 |
- Em [1], clique no ícone [WampServer] e selecione a opção [PhpMyAdmin] [2],
- Em [3], na janela que se abre, selecione o link [Bases de dados],
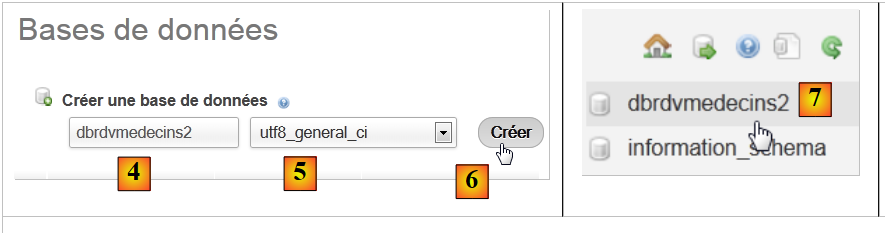 |
- Em [2], crie uma base de dados com o nome [4] e a codificação [5],
- Em [7], a base de dados foi criada. Clique no seu link,
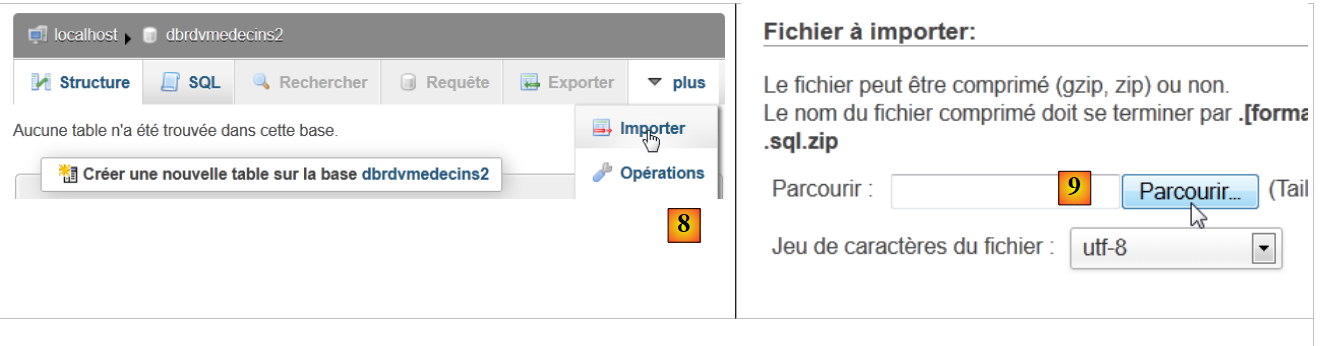 |
- em [8], importe um ficheiro SQL,
- que seleciona a partir do sistema de ficheiros utilizando o botão [9],
 |
- em [11], selecione o script SQL e, em [12], execute-o,
- em [13], as quatro tabelas na base de dados foram criadas. Siga uma das ligações,
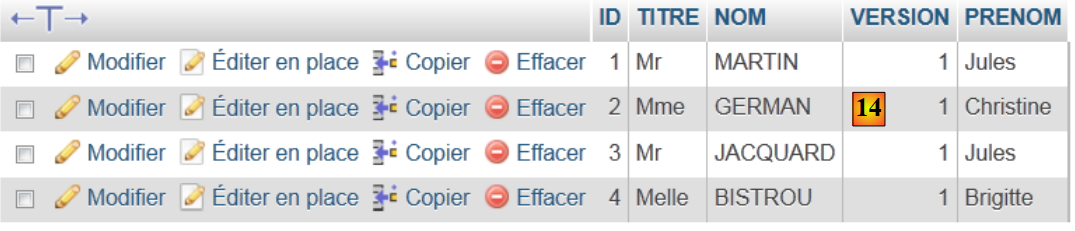 |
- em [14], o conteúdo da tabela.
Não voltaremos a esta base de dados. No entanto, convidamos o leitor a acompanhar a sua evolução ao longo dos programas, especialmente quando as coisas não funcionam.
4.4.6. A camada [JPA]
Voltemos à arquitetura do exemplo:
 |
Estamos agora a compilar o projeto Maven para a camada [JPA].
4.4.7. O projeto NetBeans
Eis como fica:
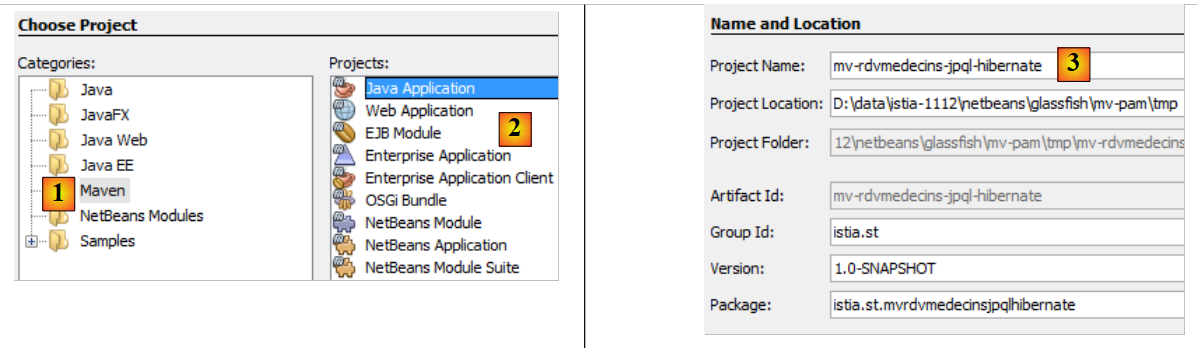 |
- Em [1], criamos um projeto Maven do tipo [Aplicação Java] [2],
- em [3], nomeamos o projeto,
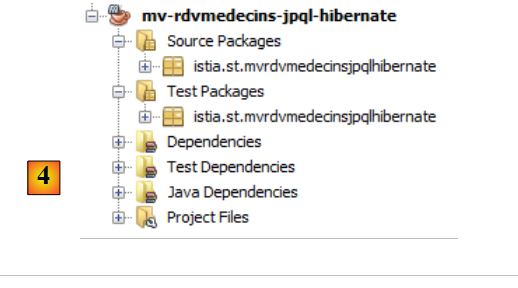 |
- em [4], o projeto gerado.
4.4.8. Gerar a camada [JPA]
Voltemos à arquitetura que precisamos de construir:
 |
Com o NetBeans, é possível gerar automaticamente a camada [JPA]. É útil familiarizar-se com estes métodos de geração automática, pois o código gerado fornece informações valiosas sobre como escrever entidades JPA.
4.4.9. Criar uma ligação do NetBeans à base de dados
- Inicie o SGBD MySQL 5 para que a base de dados fique disponível,
- crie uma ligação do NetBeans à base de dados [dbrdvmedecins2],
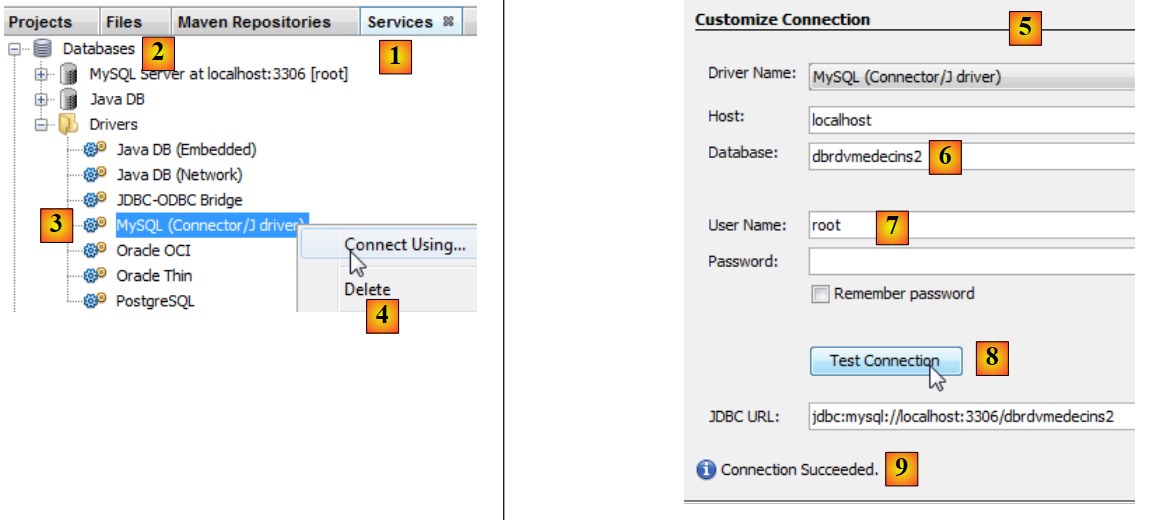 |
- no separador [Serviços] [1], na secção [Bases de dados] [2], selecione o controlador JDBC do MySQL [3],
- depois selecione a opção [4] «Ligar utilizando» para criar uma ligação a uma base de dados MySQL,
- em [5], introduza as informações solicitadas. Em [6], o nome da base de dados; em [7], o utilizador e a palavra-passe da base de dados;
- em [8], pode testar as informações que forneceu,
- em [9], a mensagem esperada se as informações estiverem corretas,
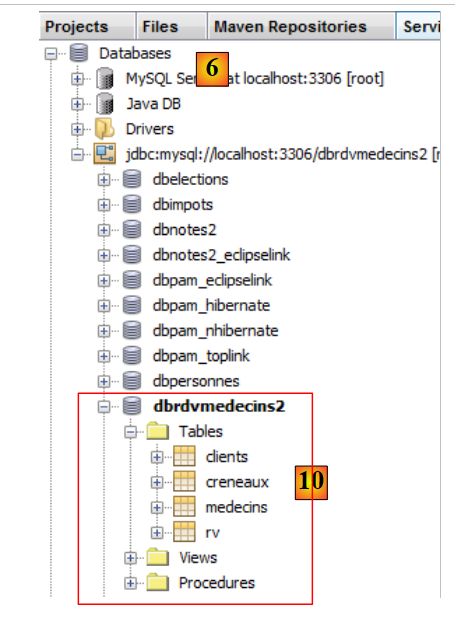 |
- em [10], a ligação é estabelecida. Pode ver as quatro tabelas na base de dados ligada.
4.4.10. Criação de uma unidade de persistência
Voltemos à arquitetura que estamos a construir:
 |
Estamos atualmente a construir a camada [JPA]. A sua configuração é feita num ficheiro [persistence.xml], onde são definidas as unidades de persistência. Cada uma delas requer as seguintes informações:
- os detalhes da ligação JDBC (URL, nome de utilizador, palavra-passe),
- as classes que representarão as tabelas da base de dados,
- a implementação JPA utilizada. De facto, o JPA é uma especificação implementada por vários produtos. Aqui, iremos utilizar o Hibernate.
O NetBeans pode gerar este ficheiro de persistência utilizando um assistente.
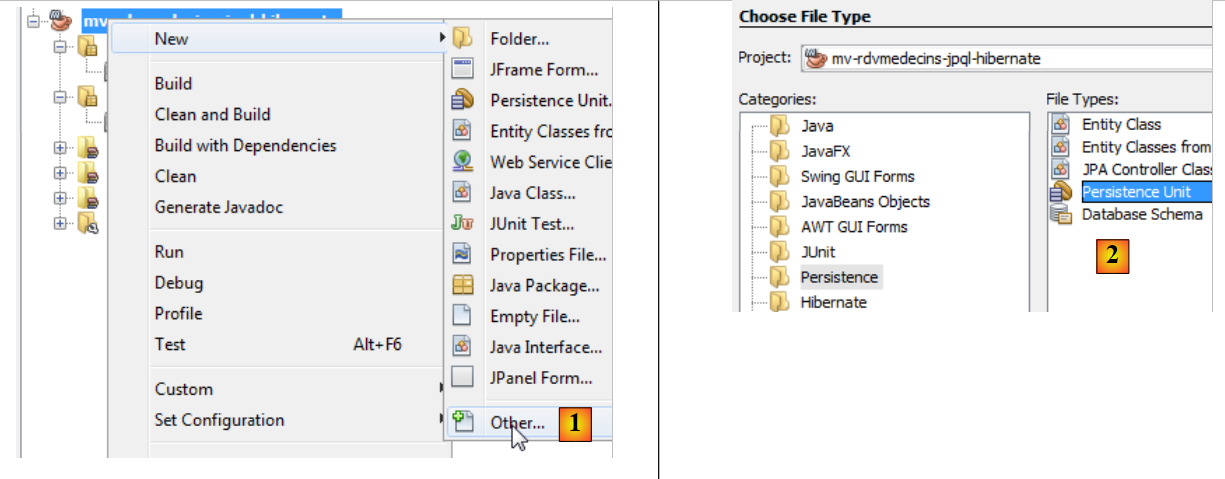 |
- Clique com o botão direito do rato no projeto e selecione «Criar Unidade de Persistência» [1],
- em [2], crie uma unidade de persistência,
|
- em [3], atribua um nome à unidade de persistência que está a criar,
- em [4], selecione a implementação do Hibernate JPA (JPA 2.0),
- em [5], indique que as tabelas da base de dados já existem e, por isso, não precisam de ser criadas. Confirme o assistente,
- em [6], o novo projeto,
- em [7], o ficheiro [persistence.xml] foi gerado na pasta [META-INF],
- em [8], foram adicionadas novas dependências ao projeto Maven.
O ficheiro [META-INF/persistence.xml] gerado é o seguinte:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="mv-rdvmedecins-jpql-hibernatePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbrdvmedecins2"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="hibernate.cache.provider_class" value="org.hibernate.cache.NoCacheProvider"/>
</properties>
</persistence-unit>
</persistence>
Inclui as informações fornecidas no assistente:
- linha 3: o nome da unidade de persistência,
- linha 3: o tipo de transações da base de dados. Aqui, RESOURCE_LOCAL indica que a aplicação irá gerir as suas próprias transações,
- linhas 6–9: as propriedades JDBC da fonte de dados.
No separador [Design], pode ver uma visão geral do ficheiro [persistence.xml]:
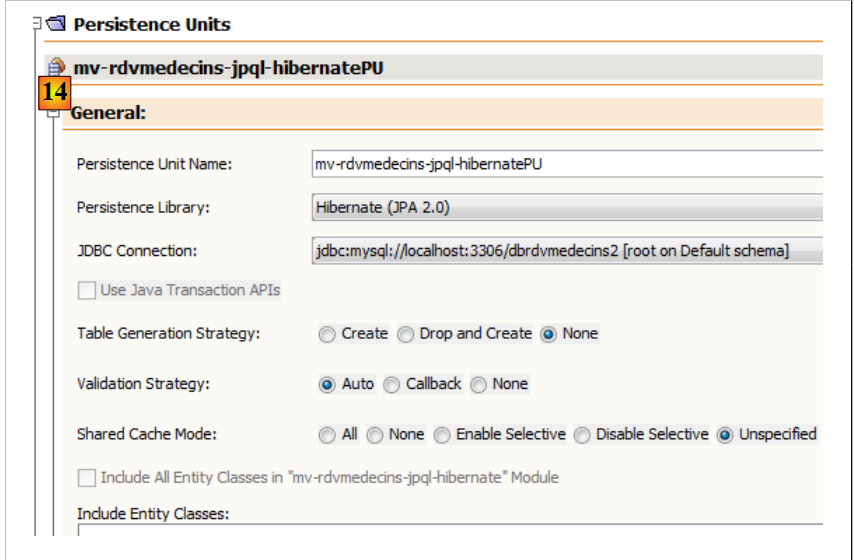 |
Para ativar o registo do Hibernate, completamos o ficheiro [persistence.xml] da seguinte forma:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="mv-rdvmedecins-jpql-hibernatePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbrdvmedecins2"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="hibernate.cache.provider_class" value="org.hibernate.cache.NoCacheProvider"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
</properties>
</persistence-unit>
</persistence>
- Linha 11: Solicitamos a visualização das instruções SQL emitidas pelo Hibernate,
- linha 12: esta propriedade permite uma exibição formatada dessas instruções.
Foram adicionadas dependências ao projeto. O ficheiro [pom.xml] é o seguinte:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>istia.st</groupId>
<artifactId>mv-rdvmedecins-jpql-hibernate</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>mv-rdvmedecins-jpql-hibernate</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>org.jboss.logging</groupId>
<artifactId>jboss-logging</artifactId>
<version>3.1.0.GA</version>
</dependency>
<dependency>
<groupId>org.jboss.spec.javax.transaction</groupId>
<artifactId>jboss-transaction-api_1.1_spec</artifactId>
<version>1.0.0.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>antlr</groupId>
<artifactId>antlr</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.hibernate.javax.persistence</groupId>
<artifactId>hibernate-jpa-2.0-api</artifactId>
<version>1.0.1.Final</version>
</dependency>
<dependency>
<groupId>org.javassist</groupId>
<artifactId>javassist</artifactId>
<version>3.15.0-GA</version>
</dependency>
<dependency>
<groupId>org.hibernate.common</groupId>
<artifactId>hibernate-commons-annotations</artifactId>
<version>4.0.1.Final</version>
</dependency>
</dependencies>
</project>
Todas as dependências adicionadas estão relacionadas com o ORM Hibernate. Vamos adicionar a dependência do controlador JDBC do MySQL:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
4.4.11. Gerar entidades JPA
As entidades JPA podem ser geradas utilizando um assistente do NetBeans:
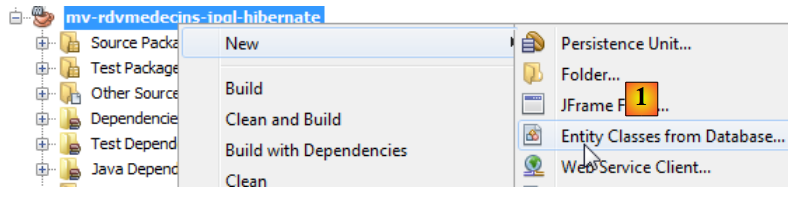 |
- Em [1], crie entidades JPA a partir de uma base de dados,
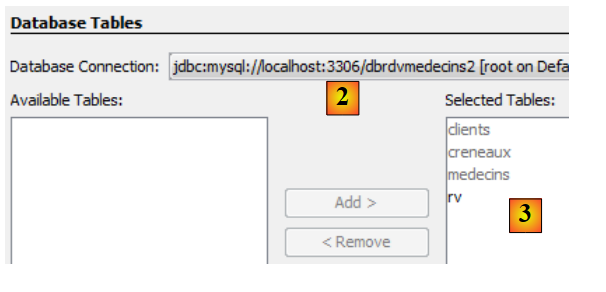 |
- em [2], selecione a ligação criada anteriormente [dbrdvmedecins2],
- em [3], selecione todas as tabelas da base de dados associada,
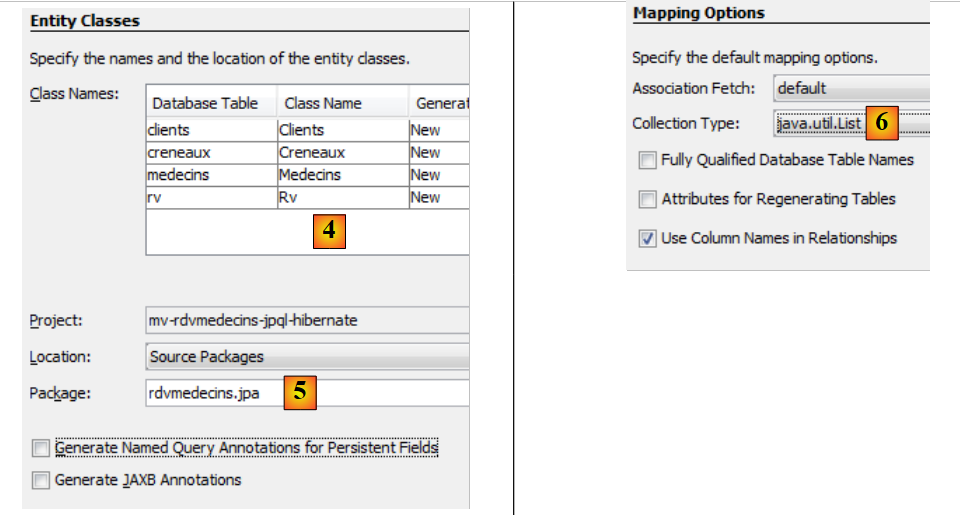 |
- em [4], nomeie as classes Java associadas às quatro tabelas,
- bem como um nome de pacote [5],
- em [6], o JPA agrupa linhas das tabelas da base de dados em coleções. Escolhemos uma lista como coleção,
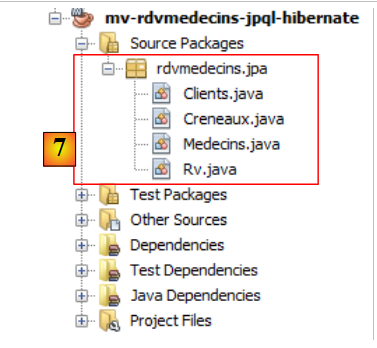 |
- em [7], as classes Java criadas pelo assistente.
4.4.12. As entidades JPA geradas
A entidade [Medecin] espelha a tabela [medecins]. A classe Java está repleta de anotações que tornam o código difícil de ler à primeira vista. Se mantivermos apenas o que é essencial para compreender o papel da entidade, obtemos o seguinte código:
package rdvmedecins.jpa;
...
@Entity
@Table(name = "medecins")
public class Medecin implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "TITRE")
private String titre;
@Column(name = "NOM")
private String nom;
@Column(name = "VERSION")
private int version;
@Column(name = "PRENOM")
private String prenom;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "idMedecin")
private List<Creneau> creneauList;
// manufacturers
....
// getters and setters
....
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
...
}
}
- Linha 4: A anotação @Entity torna a classe [Medecin] uma entidade JPA, ou seja, uma classe ligada a uma tabela de base de dados através da API JPA.
- linha 5: o nome da tabela de base de dados associada à entidade JPA. Cada campo da tabela corresponde a um campo na classe Java,
- linha 6: a classe implementa a interface Serializable. Isto é necessário em aplicações cliente/servidor, onde as entidades são serializadas entre o cliente e o servidor.
- linhas 10–11: o campo id da classe [Doctor] corresponde ao campo [ID] (linha 10) da tabela [doctors],
- linhas 13–14: o campo title da classe [Doctor] corresponde ao campo [TITLE] (linha 13) da tabela [doctors],
- linhas 16–17: o campo `nom` da classe [Medecin] corresponde ao campo `[NOM]` (linha 16) da tabela [medecins],
- linhas 19-20: o campo «version» da classe [Medecin] corresponde ao campo [VERSION] (linha 19) da tabela [doctors]. Aqui, o assistente não reconhece que a coluna é, na verdade, uma coluna de versão que deve ser incrementada sempre que a linha a que pertence for modificada. Para lhe atribuir essa função, é necessário adicionar a anotação @Version. Faremos isso numa etapa posterior,
- linhas 22–23: o campo first_name da classe [Doctor] corresponde ao campo [FIRST_NAME] da tabela [doctors],
- linhas 10–11: o campo id corresponde à chave primária [ID] da tabela. As anotações nas linhas 8–9 esclarecem este ponto,
- linha 8: a anotação @Id indica que o campo anotado está associado à chave primária da tabela,
- linha 9: a camada [JPA] irá gerar a chave primária para as linhas que inserir na tabela [Doctors]. Existem várias estratégias possíveis. Aqui, a estratégia GenerationType.IDENTITY indica que a camada JPA utilizará o modo auto_increment da tabela MySQL,
- linhas 25–26: a tabela [slots] tem uma chave estrangeira na tabela [doctors]. Um slot pertence a um médico. Por outro lado, um médico tem vários slots associados a si. Temos, portanto, uma relação um-para-muitos (um médico para muitos slots), uma relação qualificada pela anotação @OneToMany no JPA (linha 25). O campo na linha 26 conterá todos os slots do médico. Isto é conseguido sem qualquer programação. Para compreender totalmente a linha 25, precisamos de introduzir a classe [Creneau].
É a seguinte:
package rdvmedecins.jpa;
import java.io.Serializable;
import java.util.List;
import javax.persistence.*;
import javax.validation.constraints.NotNull;
@Entity
@Table(name = "creneaux")
public class Creneau implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "MDEBUT")
private int mdebut;
@Column(name = "HFIN")
private int hfin;
@Column(name = "HDEBUT")
private int hdebut;
@Column(name = "MFIN")
private int mfin;
@Column(name = "VERSION")
private int version;
@JoinColumn(name = "ID_MEDECIN", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Medecin idMedecin;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "idCreneau")
private List<Rv> rvList;
// manufacturers
...
// getters and setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
...
}
}
Comentamos apenas as novas anotações:
- especificámos que a tabela [slots] tem uma chave estrangeira para a tabela [doctors]: um slot está associado a um médico. Vários slots podem estar associados ao mesmo médico. Temos uma relação da tabela [slots] para a tabela [doctors] que é definida como muitos-para-um (slots para médico). A anotação @ManyToOne na linha 32 é utilizada para definir a chave estrangeira,
- a linha 31, com a anotação @JoinColumn, especifica a relação de chave estrangeira: a coluna [ID_MEDECIN] na tabela [slots] é uma chave estrangeira na coluna [ID] da tabela [doctors],
- Linha 33: uma referência ao médico proprietário do horário. Isto é conseguido aqui também sem qualquer codificação.
A relação de chave estrangeira entre a entidade [Creneau] e a entidade [Medecin] é, portanto, implementada por duas anotações:
- na entidade [Creneau]:
@JoinColumn(name = "ID_MEDECIN", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Medecin idMedecin;
- na entidade [Doctor]:
@OneToMany(cascade = CascadeType.ALL, mappedBy = "idMedecin")
private List<Creneau> creneauList;
Ambas as anotações refletem a mesma relação: a da chave estrangeira da tabela [appointments] para a tabela [doctors]. Diz-se que são inversas uma da outra. Apenas a relação @ManyToOne é essencial. Ela define de forma inequívoca a relação de chave estrangeira. A relação @OneToMany é opcional. Se estiver presente, ela simplesmente faz referência à relação @ManyToOne à qual está associada. Este é o significado do atributo mappedBy na linha 1 da entidade [Medecin]. O valor deste atributo é o nome do campo na entidade [Creneau] que possui a anotação @ManyToOne especificando a chave estrangeira. Também na linha 1 da entidade [Medecin], o atributo cascade=CascadeType.ALL define o comportamento da entidade [Medecin] em relação à entidade [Creneau]:
- se uma nova entidade [Doctor] for inserida na base de dados, então as entidades [TimeSlot] no campo da linha 2 também devem ser inseridas,
- se uma entidade [Doctor] for modificada na base de dados, então as entidades [Slot] no campo da linha 2 também devem ser modificadas,
- se uma entidade [Doctor] for eliminada da base de dados, então as entidades [Slot] no campo da linha 2 também devem ser eliminadas.
Fornecemos o código para as outras duas entidades sem comentários específicos, uma vez que não introduzem qualquer nova notação.
A entidade [Cliente]
package rdvmedecins.jpa;
...
@Entity
@Table(name = "clients")
public class Client implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "TITRE")
private String titre;
@Column(name = "NOM")
private String nom;
@Column(name = "VERSION")
private int version;
@Column(name = "PRENOM")
private String prenom;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "idClient")
private List<Rv> rvList;
// manufacturers
...
// getters and setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
...
}
}
- As linhas 24–25 refletem a relação de chave estrangeira entre a tabela [rv] e a tabela [clients].
A entidade [Rv]:
package rdvmedecins.jpa;
...
@Entity
@Table(name = "rv")
public class Rv implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "JOUR")
@Temporal(TemporalType.DATE)
private Date jour;
@JoinColumn(name = "ID_CRENEAU", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Creneau idCreneau;
@JoinColumn(name = "ID_CLIENT", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Client idClient;
// manufacturers
...
// getters and setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
...
}
}
- A linha 13 define o campo `jour` como um tipo Java Date. Especifica que, na tabela [rv], a coluna [JOUR] (linha 12) é do tipo data (sem hora),
- Linhas 16–18: definem a relação de chave estrangeira da tabela [rv] para a tabela [slots],
- Linhas 20–22: definem a relação de chave estrangeira da tabela [rv] para a tabela [clients].
A geração automática de entidades JPA fornece-nos uma base funcional. Por vezes, isto é suficiente; outras vezes, não. É o caso aqui:
- precisamos de adicionar a anotação @Version aos vários campos de versão das entidades,
- precisamos de escrever métodos toString que sejam mais explícitos do que os gerados,
- as entidades [Medecin] e [Client] são análogas. Vamos fazê-las derivar de uma classe [Person],
- vamos remover as relações inversas @OneToMany das relações @ManyToOne. Estas não são essenciais e introduzem complicações de programação,
- removemos a validação @NotNull nas chaves primárias. Ao persistir uma entidade JPA com MySQL, a entidade tem inicialmente uma chave primária nula. Só após a persistência na base de dados é que a chave primária da entidade persistida tem um valor.
Com estas especificações, as várias classes ficam da seguinte forma:
A classe Person é utilizada para representar médicos e clientes:
package rdvmedecins.jpa;
import java.io.Serializable;
import javax.persistence.*;
@MappedSuperclass
public class Personne implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Basic(optional = false)
@Column(name = "TITRE")
private String titre;
@Basic(optional = false)
@Column(name = "NOM")
private String nom;
@Basic(optional = false)
@Column(name = "VERSION")
@Version
private int version;
@Basic(optional = false)
@Column(name = "PRENOM")
private String prenom;
// manufacturers
...
// getters and setters
...
@Override
public String toString() {
return String.format("[%s,%s,%s,%s,%s]", id, version, titre, prenom, nom);
}
}
- Linha 6: Note que a classe [Person] não é, por si só, uma entidade (@Entity). Servirá como classe pai para as entidades. A anotação @MappedSuperClass indica isso.
A entidade [Client] encapsula as linhas da tabela [clients]. Ela deriva da classe [Person] anterior:
package rdvmedecins.jpa;
import java.io.Serializable;
import javax.persistence.*;
@Entity
@Table(name = "clients")
public class Client extends Personne implements Serializable {
private static final long serialVersionUID = 1L;
// manufacturers
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
return String.format("Client[%s,%s,%s,%s]", getId(), getTitre(), getPrenom(), getNom());
}
}
- Linha 6: A classe [Client] é uma entidade JPA,
- linha 7: está associada à tabela [clients],
- linha 8: deriva da classe [Person].
A entidade [Doctor], que encapsula as linhas da tabela [doctors], segue o mesmo padrão:
package rdvmedecins.jpa;
import java.io.Serializable;
import javax.persistence.*;
@Entity
@Table(name = "medecins")
public class Medecin extends Personne implements Serializable {
private static final long serialVersionUID = 1L;
// manufacturers
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
return String.format("Médecin[%s,%s,%s,%s]", getId(), getTitre(), getPrenom(), getNom());
}
}
A entidade [Creneau] encapsula as linhas da tabela [creneaux]:
package rdvmedecins.jpa;
import java.io.Serializable;
import java.util.List;
import javax.persistence.*;
@Entity
@Table(name = "creneaux")
public class Creneau implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Basic(optional = false)
@Column(name = "ID")
private Long id;
@Basic(optional = false)
@Column(name = "MDEBUT")
private int mdebut;
@Basic(optional = false)
@Column(name = "HFIN")
private int hfin;
@Basic(optional = false)
@NotNull
@Column(name = "HDEBUT")
private int hdebut;
@Basic(optional = false)
@Column(name = "MFIN")
private int mfin;
@Basic(optional = false)
@Column(name = "VERSION")
@Version
private int version;
@JoinColumn(name = "ID_MEDECIN", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Medecin medecin;
// manufacturers
...
// getters and setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
// TODO: Warning - this method won't work in the case the id fields are not set
...
}
@Override
public String toString() {
return String.format("Creneau [%s, %s, %s:%s, %s:%s,%s]", id, version, hdebut, mdebut, hfin, mfin, medecin);
}
}
- As linhas 40–42 modelam a relação «muitos-para-um» entre a tabela [slots] e a tabela [doctors] na base de dados: um médico tem vários horários, e um horário pertence a um único médico.
A entidade [Rv] encapsula as linhas da tabela [rv]:
package rdvmedecins.jpa;
import java.io.Serializable;
import java.util.Date;
import javax.persistence.*;
@Entity
@Table(name = "rv")
public class Rv implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Basic(optional = false)
@Column(name = "ID")
private Long id;
@Basic(optional = false)
@Column(name = "JOUR")
@Temporal(TemporalType.DATE)
private Date jour;
@JoinColumn(name = "ID_CRENEAU", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Creneau creneau;
@JoinColumn(name = "ID_CLIENT", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Client client;
// manufacturers
...
// getters and setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
return String.format("Rv[%s, %s, %s]", id, creneau, client);
}
}
- As linhas 27–29 modelam a relação «muitos-para-um» entre a tabela [rv] e a tabela [clients] (um cliente pode aparecer em várias entradas Rv) na base de dados, e as linhas 23–25 modelam a relação «muitos-para-um» entre a tabela [rv] e a tabela [slots] (um slot pode aparecer em várias entradas Rv).
4.4.13. O código de acesso aos dados
Vamos agora adicionar ao projeto o código para aceder aos dados através da camada JPA:
 |
 |
A classe [MainJpql] é a seguinte:
package rdvmedecins.console;
import java.util.Scanner;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public class MainJpql {
public static void main(String[] args) {
// EntityManagerFactory
EntityManagerFactory emf = Persistence.createEntityManagerFactory("mv-rdvmedecins-jpql-hibernatePU");
// entityManager
EntityManager em = emf.createEntityManager();
// keyboard scanner
Scanner clavier = new Scanner(System.in);
// query entry loop JPQL
System.out.println("Requete JPQL sur la base dbrdvmedecins2 (* pour arrêter) :");
String requete = clavier.nextLine();
while (!requete.trim().equals("*")) {
try {
// display query result
for (Object o : em.createQuery(requete).getResultList()) {
System.out.println(o);
}
} catch (Exception e) {
System.out.println("L'exception suivante s'est produite : " + e);
}
// clear the persistence context
em.clear();
// new request
System.out.println("---------------------------------------------");
System.out.println("Requete JPQL sur la base dbrdvmedecins2 (* pour arrêter) :");
requete = clavier.nextLine();
}
// resource closure
em.close();
emf.close();
}
}
- Linha 12: Criação do EntityManagerFactory associado à unidade de persistência que criámos anteriormente. O parâmetro do método `createEntityManagerFactory` é o nome desta unidade de persistência:
<persistence-unit name="mv-rdvmedecins-jpql-hibernatePU" transaction-type="RESOURCE_LOCAL">
...
</persistence-unit>
- linha 14: criação do EntityManager que gere a camada de persistência,
- Linha 19: introduza uma consulta JPQL SELECT,
- linhas 23–28: exibição do resultado da consulta,
- linha 20: a introdução de dados termina quando o utilizador digita *.
Pergunta: Indique as consultas JPQL para recuperar as seguintes informações:
- lista de médicos por ordem descendente de apelido
- lista de médicos cujo título é 'Sr.'
- lista dos horários de consulta da Sra. Pelissier
- lista de consultas por ordem crescente de data
- lista de clientes (apelido) que marcaram consultas com a Sra. Pelissier em 24/08/2006
- Número de clientes da Sra. Pelissier em 24/08/2006
- clientes que não marcaram consulta
- Médicos que não têm consultas
Vamos inspirar-nos no exemplo da secção 2.7 de [ref1]. Aqui está um exemplo de execução:
- linha 2: a consulta JPQL,
- linhas 3–11: a consulta SQL correspondente,
- linhas 12–15: o resultado da consulta JPQL.
4.5. Ligações entre o contexto de persistência e o SGBD
4.5.1. A classe Person
4.5.2. O programa de teste
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 | |
4.5.3. Configuração do Hibernate
4.5.4. A configuração do log4j.properties
4.5.5. Resultados
Pergunta: Explique a relação entre o código Java e os resultados apresentados.