2. Arquitetura de uma aplicação Java em camadas
Uma aplicação Java é frequentemente dividida em camadas, cada uma com uma função bem definida. Consideremos uma arquitetura comum, a de três camadas:
 |
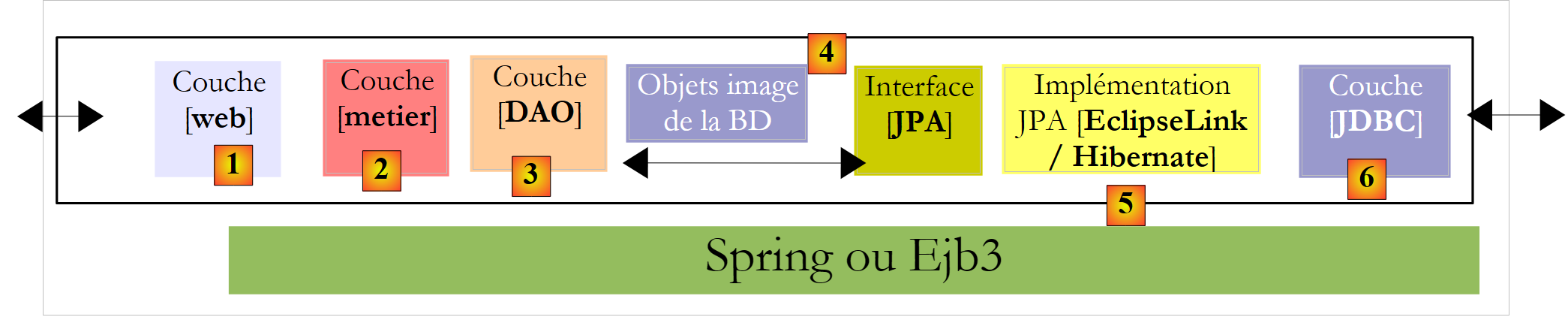
- A camada [1], aqui designada por [ui] (Interface do Utilizador), é a camada que interage com o utilizador, através de uma interface gráfica Swing, de uma interface de consola ou de uma interface web. A sua função é fornecer dados provenientes do utilizador à camada [2] ou apresentar ao utilizador os dados fornecidos pela camada [2].
- A camada [2], aqui designada por [metier], é a camada que aplica as regras ditas de negócio, c.a.d. a lógica específica da aplicação, sem se preocupar com a origem dos dados que lhe são fornecidos, nem com o destino dos resultados que produz.
- A camada [3], aqui designada por [DAO] (Data Access Object), é a camada que fornece à camada [2] dados pré-registados (ficheiros, bases de dados, ...) e que grava alguns dos resultados fornecidos pela camada [2].
Existem várias possibilidades para implementar a camada [DAO]. Vejamos algumas delas:
 |
A camada [JDBC] acima referida é a camada padrão utilizada em Java para aceder a bases de dados. Ela isola a camada [DAO] da camada SGBD, que gere a base de dados. Teoricamente, é possível alterar a camada SGBD sem alterar o código da camada [DAO]. Apesar desta vantagem, a camada API JDBC apresenta algumas desvantagens:
- todas as operações na camada SGBD são suscetíveis de lançar a exceção controlada (checked) SQLException. Isto obriga o código chamador (a camada [DAO], neste caso) a envolver essas operações em blocos try/catch, tornando assim o código bastante pesado.
- a camada [DAO] não é totalmente independente da SGBD. Estas possuem, por exemplo, métodos próprios relativos à geração automática de valores de chaves primárias que a camada [DAO] não pode ignorar. Assim, ao inserir um registo:
- com o Oracle, a camada [DAO] tem de obter primeiro um valor para a chave primária do registo e, em seguida, inseri-lo.
- com o SQL Server, a camada [DAO] insere o registo, ao qual é atribuído automaticamente um valor de chave primária pela camada SGBD, valor esse que é devolvido à camada [DAO].
Estas diferenças podem ser eliminadas através da utilização de procedimentos armazenados. No exemplo anterior, a camada [DAO] chamará um procedimento armazenado no Oracle ou no SQL Server, que terá em conta as particularidades do SGBD. Estas particularidades ficarão ocultas na camada [DAO]. No entanto, embora a alteração do SGBD não implique reescrever a camada [DAO], implica, ainda assim, reescrever os procedimentos armazenados. Isto pode não ser considerado um obstáculo insuperável.
Foram envidados múltiplos esforços para isolar a camada [DAO] dos aspetos proprietários da SGBD. Uma solução que tem tido um verdadeiro sucesso nesta área nos últimos anos é a do Hibernate:
 |
A camada [Hibernate] situa-se entre a camada [DAO], escrita pelo programador, e a camada [JDBC]. O Hibernate é um ORM (Object Relational Mapper), uma ferramenta que faz a ponte entre o mundo relacional das bases de dados e o dos objetos manipulados pelo Java. O programador da camada [DAO] já não vê a camada [JDBC] nem as tabelas da base de dados cujo conteúdo pretende explorar. Vê apenas a representação objeto da base de dados, representação essa fornecida pela camada [Hibernate]. A ligação entre as tabelas da base de dados e os objetos manipulados pela camada [DAO] é estabelecida principalmente de duas formas:
- através de ficheiros de configuração do tipo XML
- através de anotações Java no código, técnica disponível apenas a partir da versão 1.5 da camada JDK
A camada [Hibernate] é uma camada de abstração que se pretende ser o mais transparente possível. O ideal é que o programador da camada [DAO] possa ignorar completamente que está a trabalhar com uma base de dados. Isto é possível se não for ele a escrever a configuração que faz a ponte entre o mundo relacional e o mundo dos objetos. A configuração desta ponte é bastante delicada e requer alguma prática.
A camada [4] dos objetos, espelho da BD, é designada por «contexto de persistência». Uma camada [DAO] baseada no Hibernate realiza ações de persistência (CRUD: criar, ler, atualizar, eliminar) nos objetos do contexto de persistência, ações traduzidas pelo Hibernate em ordens SQL executadas pela camada JDBC. No que diz respeito às ações de consulta à base de dados (o SQL Select), o Hibernate fornece ao programador uma linguagem HQL (Hibernate Query Language) para consultar o contexto de persistência [4] e não a própria BD.
O Hibernate é popular, mas complexo de dominar. A curva de aprendizagem, muitas vezes apresentada como fácil, é, na verdade, bastante íngreme. Assim que se tem uma base de dados com tabelas que apresentam relações um-para-muitos ou muitos-para-muitos, a configuração da ponte relacional/objetos não está ao alcance de um principiante qualquer. Erros de configuração podem levar a aplicações com baixo desempenho.
Perante o sucesso dos produtos ORM, a Sun, criadora do Java, decidiu padronizar uma camada ORM através de uma especificação denominada JPA (Java Persistence API), lançada em simultâneo com o Java 5. A especificação JPA foi implementada por vários produtos: Hibernate, Toplink, EclipseLink, OpenJpa, ... Com o JPA, a arquitetura anterior passa a ser a seguinte:
 |
A camada [DAO] interage agora com a especificação JPA, um conjunto de interfaces. O programador beneficiou com uma maior padronização. Anteriormente, se alterasse a sua camada ORM, teria também de alterar a sua camada [DAO], que tinha sido escrita para interagir com um ORM específico. Agora, irá escrever uma camada [DAO] que irá interagir com uma camada JPA. Independentemente do produto que a implemente, a interface da camada JPA apresentada à camada [DAO] permanece a mesma.
Neste documento, utilizaremos uma camada [DAO] que se baseia numa camada JPA/Hibernate ou JPA/EclipseLink. Além disso, utilizaremos o framework Spring 2.8 para ligar estas camadas entre si.
 |
A grande vantagem do Spring é que permite ligar as camadas através da configuração e não no código. Assim, se a implementação JPA / Hibernate tiver de ser substituída por uma implementação do Hibernate sem JPA, porque, por exemplo, a aplicação é executada num ambiente JDK 1.4 que não suporta JPA, esta alteração na implementação da camada [DAO] não tem impacto no código da camada [métier]. Apenas o ficheiro de configuração do Spring que liga as camadas entre si deve ser alterado.
Com o Java EE 5, existe outra solução: implementar as camadas [metier] e [DAO] com EJB3 (Enterprise Java Bean versão 3):
 |
Veremos que esta solução não é muito diferente daquela que utiliza o Spring. O ambiente Java EE5 está disponível em servidores denominados «servidores de aplicações», tais como o Sun Application Server 9.x (Glassfish), Jboss Application Server, Oracle Container for Java (OC4J), ... Um servidor de aplicações é, essencialmente, um servidor de aplicações web. Existem também ambientes EE 5 denominados «stand-alone», c.a.d. que podem ser utilizados fora de um servidor de aplicações. É o caso do JBoss, EJB3 ou OpenEJB.
Num ambiente EE5, as camadas são implementadas por objetos denominados EJB (Enterprise Java Bean). Nas versões anteriores do EE, os EJB (EJB e 2.x) eram considerados difíceis de implementar, testar e, por vezes, de baixo desempenho. Distinguem-se os EJB2.x «entity» e os EJB2.x «session». Resumindo, um EJB2.x «entity» é a representação de uma linha de uma tabela de base de dados e um EJB2.x «session» é um objeto utilizado para implementar as camadas [metier], [DAO] de uma arquitetura multicamadas. Uma das principais críticas feitas às camadas implementadas com EJB é que só podem ser utilizadas no interior de contentores EJB, um serviço fornecido pelo ambiente EE. Este ambiente, mais complexo de implementar do que um ambiente SE (Standard Edition), pode desmotivar o programador a realizar testes com frequência. No entanto, existem ambientes de desenvolvimento Java que facilitam a utilização de um servidor de aplicações, automatizando a implementação dos EJB no servidor: Eclipse, NetBeans, JDeveloper, IntelliJ e IDEA. Aqui, utilizaremos o NetBeans 6.8 e o servidor de aplicações GlassFish v3.
O framework Spring surgiu em resposta à complexidade dos EJB2. O Spring fornece, num ambiente SE, um número significativo dos serviços normalmente fornecidos pelos ambientes EE. Assim, na secção «Persistência de dados», o Spring fornece os pools de ligação e os gestores de transações de que as aplicações necessitam. O surgimento do Spring promoveu a cultura dos testes unitários, que se tornaram mais fáceis de implementar no contexto SE do que no contexto EE. O Spring permite a implementação das camadas de uma aplicação através de objetos Java clássicos (POJO, Plain Old/Ordinary Java Object), permitindo a reutilização destes noutro contexto. Por fim, integra numerosas ferramentas de terceiros de forma bastante transparente, nomeadamente ferramentas de persistência como o Hibernate, EclipseLink, Ibatis, ...
O Java EE5 foi concebido para corrigir as lacunas da especificação EJB2. Os EJB 2.x passaram a ser os EJB3. Estes são POJOs marcados por anotações que os tornam objetos específicos quando se encontram dentro de um contentor EJB3. Nesse contentor, o EJB3 poderá beneficiar dos serviços do contentor (pool de ligações, gestor de transações, etc.). Fora do contentor EJB3, o EJB3 torna-se um objeto Java normal. As suas anotações EJB são ignoradas.
Acima, representámos o Spring e um contentor EJB3 como uma possível infraestrutura (framework) da nossa arquitetura multicamadas. É esta infraestrutura que fornecerá os serviços de que necessitamos: um pool de ligações e um gestor de transações.
- Com o Spring, as camadas serão implementadas com POJOs. Estes terão acesso aos serviços do Spring (pool de ligações, gestor de transações) através da injeção de dependências nestes POJOs: durante a sua construção, o Spring injeta-lhes referências aos serviços de que irão necessitar.
- Com o contentor EJB3, as camadas serão implementadas com EJB. Uma arquitetura em camadas implementada com EJB3 difere pouco daquelas implementadas com POJO instanciados pelo Spring. Encontraremos muitas semelhanças.
- Para concluir, apresentaremos um exemplo de aplicação web multicamadas:
 |