4. : resumo
Propomos apresentar o JPA (Java Persistence API) com alguns exemplos. O JPA é abordado no curso:
- Persistência Java 5 na prática: [http://tahe.developpez.com/java/jpa] — fornece as ferramentas para construir a camada de acesso aos dados com JPA
4.1. O papel do JPA numa arquitetura em camadas
Convida-se o leitor a reler o início deste documento (parágrafo 2), que explica o papel da camada JPA numa arquitetura em camadas. A camada JPA insere-se nas camadas de acesso aos dados:
 |
A camada [DAO] interage com a especificação JPA. Independentemente do produto que a implemente, a interface da camada JPA apresentada à camada [DAO] permanece a mesma. Apresentamos a seguir alguns exemplos retirados de [ref1] que nos permitirão construir a nossa própria camada JPA.
4.2. JPA - exemplos
4.2.1. Exemplo 1 - Representação de um único objeto de tabela
4.2.1.1. A tabela [personne]
Consideremos uma base de dados com uma única tabela [personne], cuja função é armazenar algumas informações sobre indivíduos:
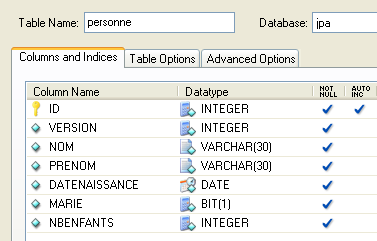 |
chave primária da tabela | |
versão do registo na tabela. Sempre que a pessoa é alterada, o seu número de versão é incrementado. | |
nome da pessoa | |
o seu nome próprio | |
data de nascimento | |
número inteiro 0 (solteiro) ou 1 (casado) | |
número de filhos da pessoa |
4.2.1.2. A entidade [Personne]
Encontramo-nos no seguinte ambiente de execução:
 |
A camada JPA [5] deve servir de ponte entre o mundo relacional da base de dados [7] e o mundo de objetos [4] manipulado pelos programas Java [3]. Esta ligação é estabelecida através da configuração e há duas formas de o fazer:
- com ficheiros XML. Esta era praticamente a única forma de o fazer até ao advento do JDK 1.5
- com anotações Java a partir do JDK 1.5
Neste documento, utilizaremos exclusivamente o segundo método.
O objeto [Personne] correspondente à tabela [personne] apresentada anteriormente poderia ser o seguinte:
...
@SuppressWarnings("unused")
@Entity
@Table(name="Personne")
public class Personne implements Serializable{
@Id
@Column(name = "ID", nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Column(name = "VERSION", nullable = false)
@Version
private int version;
@Column(name = "NOM", length = 30, nullable = false, unique = true)
private String nom;
@Column(name = "PRENOM", length = 30, nullable = false)
private String prenom;
@Column(name = "DATENAISSANCE", nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(name = "MARIE", nullable = false)
private boolean marie;
@Column(name = "NBENFANTS", nullable = false)
private int nbenfants;
// construtores
public Personne() {
}
public Personne(String nom, String prenom, Date datenaissance, boolean marie,
int nbenfants) {
setNom(nom);
setPrenom(prenom);
setDatenaissance(datenaissance);
setMarie(marie);
setNbenfants(nbenfants);
}
// toString
public String toString() {
...
}
// getters e setters
...
}
A configuração é feita através das anotações Java @Annotation. As anotações Java são interpretadas pelo compilador ou por ferramentas especializadas no momento da execução. Com exceção da anotação da linha 3, destinada ao compilador, todas as anotações aqui referidas destinam-se à implementação JPA utilizada, seja o Hibernate ou o Toplink. Serão, portanto, interpretadas durante a execução. Na ausência de ferramentas capazes de as interpretar, estas anotações são ignoradas. Assim, a classe [Personne] acima referida poderia ser utilizada num contexto fora do JPA.
É necessário distinguir dois casos de utilização das anotações JPA numa classe C associada a uma tabela T:
- a tabela T já existe: as anotações JPA devem, nesse caso, reproduzir o que já existe (nome e definição das colunas, restrições de integridade, chaves estrangeiras, chaves primárias, etc.)
- a tabela T não existe e vai ser criada com base nas anotações encontradas na classe C.
O caso 2 é o mais fácil de gerir. Com a ajuda das anotações JPA, indicamos a estrutura da tabela T que pretendemos. O caso 1 é frequentemente mais complexo. A tabela T pode ter sido criada, há muito tempo, fora de qualquer contexto JPA. A sua estrutura pode, então, estar mal adaptada à ponte relacional/objeto de JPA. Para simplificar, consideramos o caso 2, em que a tabela T associada à classe C será criada com base nas anotações JPA da classe C.
Vamos comentar as anotações JPA da classe [Personne]:
- linha 4: a anotação @Entity é a primeira anotação indispensável. É colocada antes da linha que declara a classe e indica que a classe em questão deve ser gerida pela camada de persistência JPA. Na ausência desta anotação, todas as outras anotações JPA seriam ignoradas.
- linha 5: a anotação @Table designa a tabela da base de dados que a classe representa. O seu principal argumento é name, que indica o nome da tabela. Na ausência deste argumento, a tabela terá o nome da classe, neste caso [Personne]. No nosso exemplo, a anotação @Table é, portanto, supérflua.
- linha 8: a anotação @Id serve para indicar o campo na classe que corresponde à chave primária da tabela. Esta anotação é obrigatória. Indica aqui que o campo id da linha 11 corresponde à chave primária da tabela.
- linha 9: a anotação @Column serve para estabelecer a ligação entre um campo da classe e a coluna da tabela que esse campo representa. O atributo name indica o nome da coluna na tabela. Na ausência deste atributo, a coluna tem o mesmo nome que o campo. No nosso exemplo, o argumento name não era, portanto, obrigatório. O argumento nullable=false indica que a coluna associada ao campo não pode ter o valor NULL e que, por conseguinte, o campo deve ter necessariamente um valor.
- linha 10: a anotação @GeneratedValue indica como é gerada a chave primária quando esta é gerada automaticamente pelo SGBD. Será este o caso em todos os nossos exemplos. Isto não é obrigatório. Assim, a nossa pessoa poderia ter um número de estudante que serviria de chave primária e que não seria gerado pelo SGBD, mas sim definido pela aplicação. Neste caso, a anotação @GeneratedValue estaria ausente. O argumento strategy indica como é gerada a chave primária quando esta é gerada pelo SGBD. Nem todos os SGBD utilizam a mesma técnica de geração de valores de chave primária. Por exemplo:
utiliza um gerador de valores chamado antes de cada inserção | |
o campo da chave primária é definido como tendo o tipo Identity. Obtém-se um resultado semelhante ao gerador de valores do Firebird, com a diferença de que o valor da chave só é conhecido após a inserção da linha. | |
utiliza um objeto denominado SEQUENCE que, mais uma vez, desempenha o papel de um gerador de valores |
A camada JPA deve gerar ordens SQL diferentes, dependendo dos SGBD, para criar o gerador de valores. Através da configuração, é-lhe indicado o tipo de SGBD que deve gerir. Assim, pode saber qual é a estratégia habitual de geração de valores de chave primária desse SGBD. O argumento strategy = GenerationType.AUTO indica à camada JPA que deve utilizar essa estratégia habitual. Esta técnica funcionou em todos os exemplos deste documento para os sete SGBD utilizados.
- linha 14: a anotação @Version identifica o campo utilizado para gerir os acessos simultâneos a uma mesma linha da tabela.
Para compreender este problema de acesso simultâneo a uma mesma linha da tabela [personne], suponhamos que uma aplicação web permita a atualização de um utilizador e analisemos o seguinte caso:
No momento T1, um utilizador U1 acede à edição de uma pessoa P. Nesse momento, o número de filhos é 0. Altera esse número para 1, mas antes de validar a sua alteração, um utilizador U2 acede à edição da mesma pessoa P. Uma vez que U1 ainda não validou a sua alteração, U2 vê no seu ecrã que o número de filhos é 0. U2 altera o nome da pessoa P para maiúsculas. Em seguida, U1 e U2 validam as suas alterações por esta ordem. É a alteração de U2 que vai prevalecer: na base de dados, o nome passará a estar em maiúsculas e o número de filhos permanecerá em zero, mesmo que U1 pense ter-o alterado para 1.
O conceito de versão de pessoa ajuda-nos a resolver este problema. Retomemos o mesmo caso de utilização:
No momento em que T1 está ativo, um utilizador U1 acede à edição de uma pessoa P. Nesse momento, o número de filhos é 0 e a versão é V1. Ele altera o número de filhos para 1, mas antes de validar a sua alteração, um utilizador U2 acede à edição da mesma pessoa P. Uma vez que U1 ainda não validou a sua alteração, U2 vê o número de filhos como 0 e a versão como V1. U2 altera o nome da pessoa P para maiúsculas. Em seguida, U1 e U2 validam as suas alterações por esta ordem. Antes de validar uma alteração, verifica-se se quem altera uma pessoa P possui a mesma versão que a pessoa P atualmente registada. Este será o caso do utilizador U1. A sua alteração é, portanto, aceite e a versão da pessoa alterada passa de V1 para V2, para indicar que a pessoa sofreu uma alteração. Ao validar a alteração de U2, ver-se-á que U2 possui uma versão V1 da pessoa P, quando, na realidade, a versão atual desta é V2. Será então possível informar ao utilizador U2 que alguém o antecedeu e que deve recomeçar a partir da nova versão da pessoa P. Ele fará isso, recuperará uma pessoa P da versão V2, que agora tem um filho, colocará o nome em maiúsculas e validará. A sua alteração será aceite se a pessoa P registada ainda tiver a versão V2. No final, as alterações feitas por U1 e U2 serão tidas em conta, enquanto que, no caso de utilização sem versão, uma das alterações teria sido perdida.
A camada [DAO] da aplicação cliente pode gerir por si própria a versão da classe [Personne]. Sempre que houver uma alteração num objeto P, a versão desse objeto será incrementada em 1 na tabela. A anotação @Version permite transferir esta gestão para a camada JPA. O campo em questão não precisa, de forma alguma, chamar-se version, como no exemplo. Pode ter qualquer nome.
Os campos correspondentes às anotações @Id e @Version existem devido à persistência. Não seriam necessários se a classe [Personne] não precisasse de ser persistida. Vemos, portanto, que um objeto não tem a mesma representação consoante precise ou não de ser persistido.
- linha 17: mais uma vez, a anotação @Column para fornecer informações sobre a coluna da tabela [personne] associada ao campo nom da classe Personne. Encontramos aqui dois novos argumentos:
- unique=true indica que o nome de uma pessoa deve ser único. Isto traduzir-se-á na base de dados pela adição de uma restrição de unicidade na coluna NOM da tabela [personne].
- length=30 define em 30 o número de caracteres da coluna NOM. Isto significa que o tipo desta coluna será VARCHAR(30).
- linha 24: a anotação @Temporal serve para indicar que tipo SQL deve ser atribuído a uma coluna/campo do tipo data/hora. O tipo TemporalType.DATE designa apenas uma data, sem hora associada. Os outros tipos possíveis são TemporalType.TIME para codificar uma hora e TemporalType.TIMESTAMP para codificar uma data com hora.
Vamos agora comentar o resto do código da classe [Personne]:
- linha 6: a classe implementa a interface Serializable. A sérialisation de um objeto consiste em transformá-lo numa sequência de bits. A désérialisation é a operação inversa. A serialização/deserialização é utilizada, nomeadamente, em aplicações cliente/servidor, nas quais os objetos são trocados através da rede. As aplicações cliente ou servidor não têm conhecimento desta operação, que é realizada de forma transparente pelos JVM. Para que tal seja possível, é necessário, no entanto, que as classes dos objetos trocados sejam «marcadas» com a palavra-chave Serializable.
- linha 37: um construtor da classe. Note-se que os campos id e version não fazem parte dos parâmetros. Com efeito, estes dois campos são geridos pela camada JPA e não pela aplicação.
- linhas 51 e seguintes: os métodos get e set de cada um dos campos da classe. É de salientar que as anotações JPA podem ser colocadas nos métodos get dos campos, em vez de serem colocadas nos próprios campos. A localização das anotações indica o modo que o JPA deve utilizar para aceder aos campos:
- se as anotações forem colocadas ao nível do campo, o JPA acederá diretamente aos campos para os ler ou gravar
- se as anotações forem colocadas ao nível dos métodos get, o JPA acederá aos campos através dos métodos get/set para os ler ou gravar
É a posição da anotação @Id que determina a posição das anotações JPA numa classe. Quando colocada ao nível do campo, indica um acesso direto aos campos; quando colocada ao nível de get, indica um acesso aos campos através dos métodos get e set. As restantes anotações devem, então, ser colocadas da mesma forma que a anotação @Id.
4.2.2. Configuração da camada JPA
Os testes da camada JPA podem ser realizados com a seguinte arquitetura:
 |
- em [7]: a base de dados que será gerada a partir das anotações da entidade [Personne], bem como de configurações complementares efetuadas num ficheiro denominado [persistence.xml]
- em [5, 6]: uma camada JPA implementada pelo Hibernate
- em [4]: a entidade [Personne]
- em [3]: um programa de teste do tipo consola
A configuração da camada JPA é assegurada pelo ficheiro [META-INF/persistence.xml]:
 |
Durante a execução, o ficheiro [META-INF/persistence.xml] é procurado no ficheiro Classpath da aplicação.
Vamos analisar a configuração da camada JPA definida no ficheiro [persistence.xml] do nosso projeto:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provedor -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Classes persistentes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- registos SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- ligação JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
<property name="hibernate.connection.url" value="jdbc:mysql://localhost:3306/jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- criação automática do esquema -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialeto -->
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
<!-- propriedades DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
Para compreender esta configuração, temos de rever a arquitetura de acesso aos dados da nossa aplicação:
 |
- o ficheiro [persistence.xml] irá configurar as camadas [4, 5, 6]
- [4]: implementação do Hibernate de JPA
- [5]: o Hibernate acede à base de dados através de um conjunto de ligações. Um conjunto de ligações é uma reserva de ligações abertas com o SGBD. Um SGBD é acedido por vários utilizadores, embora, por razões de desempenho, não possa exceder um número limite N de ligações abertas em simultâneo. Um código bem escrito abre uma ligação ao SGBD durante o mínimo de tempo possível: envia comandos SQL e encerra a ligação. Irá repetir este processo sempre que precisar de trabalhar com a base de dados. O custo de abrir e fechar uma ligação não é insignificante e é aqui que entra o conjunto de ligações. Este, no arranque da aplicação, abre N1 ligações com o SGBD. É a este pool que a aplicação solicitará uma ligação aberta quando precisar. Esta será devolvida ao pool assim que a aplicação deixar de precisar dela, de preferência o mais rapidamente possível. A ligação não é encerrada e permanece disponível para o utilizador seguinte. Um pool de ligações é, portanto, um sistema de partilha de ligações abertas.
- [6]: o controlador JDBC do SGBD utilizado
Agora, vamos ver como o ficheiro [persistence.xml] configura as camadas [4, 5, 6] acima referidas:
- linha 2: a baliza raiz do ficheiro XML é <persistence>.
- linha 3: <persistence-unit> serve para definir uma unidade de persistência. Podem existir várias unidades de persistência. Cada uma delas tem um nome (atributo name) e um tipo de transação (atributo transaction-type). A aplicação terá acesso à unidade de persistência através do seu nome, neste caso jpa. O tipo de transação RESOURCE_LOCAL indica que a aplicação gere ela própria as transações com o SGBD. Será esse o caso aqui. Quando a aplicação é executada num contentor EJB3, pode utilizar o serviço de transações deste. Neste caso, definirá-se transaction-type=JTA (Transação Java API). JTA é o valor por predefinição quando o atributo transaction-type está ausente.
- linha 5: a baliza <provider> serve para definir uma classe que implementa a interface [javax.persistence.spi.PersistenceProvider], interface que permite à aplicação inicializar a camada de persistência. Como estamos a utilizar uma implementação JPA / Hibernate, a classe aqui utilizada é uma classe do Hibernate.
- linha 6: a baliza <properties> introduz propriedades específicas do provider em particular que foi escolhido. Assim, dependendo de se ter escolhido o Hibernate, o Toplink, o Kodo, etc., teremos propriedades diferentes. As que se seguem são específicas do Hibernate.
- linha 8: solicita ao Hibernate que explore o classpath do projeto para encontrar as classes com a anotação @Entity, a fim de as gerir. As classes @Entity também podem ser declaradas através das tags <class>nom_de_la_classe</class>, diretamente abaixo da tag <persistence-unit>. É isso que faremos com o provider JPA / Toplink.
- As linhas 10-12, aqui colocadas em comentários, configuram os registos da consola do Hibernate:
- linha 10: para decidir se se devem ou não exibir os comandos SQL emitidos pelo Hibernate no SGBD. Isto é muito útil durante a fase de aprendizagem. Devido à ponte relacional/objeto, a aplicação trabalha com objetos persistentes aos quais aplica operações do tipo [persist, merge, remove]. É muito interessante saber quais são os comandos SQL efetivamente emitidos nessas operações. Ao analisá-las, aos poucos, começa-se a adivinhar os comandos SQL que o Hibernate irá gerar quando se realiza determinada operação nos objetos persistentes, e a ponte relacional/objeto começa a ganhar consistência na mente.
- linha 11: as ordens SQL apresentadas na consola podem ser formatadas de forma elegante para facilitar a sua leitura
- linha 12: os comandos SQL apresentados serão, além disso, comentados
- as linhas 15-19 definem a camada JDBC (camada [6] na arquitetura):
- linha 15: a classe do controlador JDBC do SGBD, neste caso MySQL5
- linha 16: o URL da base de dados utilizada
- linhas 17 e 18: o utilizador da ligação e a sua palavra-passe
- linha 22: o Hibernate precisa de saber qual é o SGBD com que está a lidar. Com efeito, todos os SGBD têm extensões SQL próprias, uma forma específica de gerir a geração automática dos valores de uma chave primária, ... o que faz com que o Hibernate precise de conhecer o SGBD com quem está a trabalhar, para lhe enviar os comandos SQL que este compreenderá. [MySQL5InnoDBDialect] designa o SGBD MySQL5 com tabelas do tipo InnoDB que suportam transações.
- as linhas 24-28 configuram o conjunto de ligações c3p0 (camada [5] na arquitetura):
- linhas 24 e 25: o número mínimo (padrão 3) e máximo de ligações (padrão 15) no conjunto. O número inicial de ligações por predefinição é 3.
- linha 26: tempo máximo, em milissegundos, de espera por um pedido de ligação por parte do cliente. Passado esse tempo, o c3p0 devolverá uma exceção.
- linha 27: para aceder à BD, o Hibernate utiliza ordens SQL preparadas (PreparedStatement) que o c3p0 pode armazenar em cache. Isto significa que, se a aplicação solicitar pela segunda vez uma ordem SQL já preparada e em cache, esta não precisará de ser preparada (a preparação de uma ordem SQL tem um custo) e será utilizada a que se encontra em cache. Aqui, indica-se o número máximo de ordens SQL preparadas que a cache pode conter, considerando todas as ligações (uma ordem SQL preparada pertence a uma ligação).
- linha 28: frequência de verificação, em milissegundos, da validade das ligações. Uma ligação do pool pode tornar-se inválida por várias razões (o controlador JDBC invalida a ligação por esta estar a demorar demasiado tempo, o controlador JDBC apresenta «bugs», etc.).
- linha 20: aqui solicita-se que, aquando da inicialização da unidade de persistência, seja gerada a base de dados de imagem dos objetos @Entity. O Hibernate dispõe agora de todas as ferramentas para emitir os comandos SQL de geração das tabelas da base de dados:
- a configuração dos objetos @Entity permite-lhe identificar as tabelas a gerar
- as linhas 15-18 e 24-28 permitem-lhe estabelecer uma ligação com o SGBD
- a linha 22 permite-lhe saber qual o dialeto SQL a utilizar para gerar as tabelas
Assim, o ficheiro [persistence.xml] aqui utilizado recria uma nova base de dados a cada nova execução da aplicação. As tabelas são recriadas (create table) após terem sido eliminadas (drop table), caso já existissem. Note-se que isto não deve, obviamente, ser feito numa base de dados em produção...
4.2.3. Exemplo 2: relação um-para-muitos
4.2.3.1. O esquema « » da base de dados
1 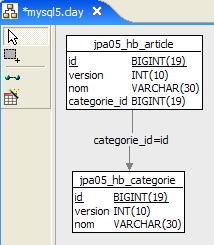 | 2 |
- em [1], a base de dados, e em [2], a sua DDL (MySQL5)
Um artigo A(id, versão, nome) pertence exatamente a uma categoria C(id, versão, nome). Uma categoria C pode conter 0, 1 ou vários artigos. Existe uma relação um-para-muitos (Categoria -> Artigo) e a relação inversa muitos-para-um (Artigo -> Categoria). Esta relação é concretizada pela chave estrangeira que a tabela [article] possui na tabela [categorie] (linhas 24-28 da DDL).
4.2.3.2. Os objetos @Entity que representam a base de dados
Um artigo é representado pela seguinte @Entity [Article]:
package entites;
...
@Entity
@Table(name="jpa05_hb_article")
public class Article implements Serializable {
// campos
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// relação principal Artigo (muitos) -> Categoria (um)
// implementada por uma chave estrangeira (categorie_id) na tabela Artigo
// 1 Artigo tem necessariamente 1 Categoria (nullable=false)
@ManyToOne(fetch=FetchType.LAZY)
@JoinColumn(name = "categorie_id", nullable = false)
private Categorie categorie;
// construtores
public Article() {
}
// getters e setters
...
// toString
public String toString() {
return String.format("Article[%d,%d,%s,%d]", id, version, nom, categorie.getId());
}
}
- linhas 9-11: chave primária da @Entity
- linhas 13-15: o seu n.º de versão
- linhas 17-18: nome do artigo
- linhas 20-25: relação muitos-para-um que liga a @Entity Article à @Entity Categorie:
- linha 23: a anotação ManyToOne. O «Many» refere-se à @Entity Article, na qual nos encontramos, e o «One» à @Entity Categorie (linha 25). Uma categoria (One) pode ter vários artigos (Many).
- linha 24: a anotação ManyToOne define a coluna-chave estrangeira na tabela [article]. Esta coluna será denominada (name) categorie_id e cada linha deverá ter um valor nesta coluna (nullable=false).
- linha 25: a categoria à qual o artigo pertence. Quando um artigo for colocado no contexto de persistência, solicita-se que a sua categoria não seja inserida imediatamente (fetch=FetchType.LAZY, linha 23). Não se sabe se esta solicitação faz sentido. Veremos.
Uma categoria é representada pela seguinte @Entity [Categorie]:
package entites;
...
@Entity
@Table(name="jpa05_hb_categorie")
public class Categorie implements Serializable {
// campos
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// relação inversa Categoria (um) -> Artigo (muitos) da relação Artigo (muitos) -> Categoria (um)
// inserção em cascata de Categoria -> inserção de Artigos
// atualização em cascata de Categoria -> atualização de Artigos
// eliminação em cascata de Categoria -> eliminação de Artigos
@OneToMany(mappedBy = "categorie", cascade = { CascadeType.ALL })
private Set<Article> articles = new HashSet<Article>();
// construtores
public Categorie() {
}
// getters e setters
...
// toString
public String toString() {
return String.format("Categorie[%d,%d,%s]", id, version, nom);
}
// associação bidirecional Categoria <--> Artigo
public void addArticle(Article article) {
// o artigo é adicionado à coleção de artigos da categoria
articles.add(article);
// o artigo muda de categoria
article.setCategorie(this);
}
}
- linhas 8-11: a chave primária da @Entity
- linhas 12-14: a sua versão
- linhas 16-17: o nome da categoria
- linhas 19-24: o conjunto (set) de artigos da categoria
- linha 23: a anotação @OneToMany indica uma relação um-para-muitos. O «One» refere-se à @Entity [Categorie] em que nos encontramos, e o «Many» ao tipo [Article] da linha 24: uma (One) categoria tem vários (Many) artigos.
- linha 23: a anotação é o inverso (mappedBy) da anotação ManyToOne colocada no campo categorie da @Entity Article: mappedBy=categoria. A relação ManyToOne definida no campo categorie da @Entity Article é a relação principal. É indispensável. Ela concretiza a relação de chave estrangeira que liga a @Entity Article à @Entity Categorie. A relação OneToMany definida no campo articles da @Entity Categorie é a relação inversa. Não é indispensável. Trata-se de uma funcionalidade para obter os artigos de uma categoria. Sem esta funcionalidade, esses artigos seriam obtidos através de uma consulta JPQL.
- linha 23: cascadeType.ALL especifica que as operações (persist, merge, remove) realizadas numa @Entity Categorie sejam aplicadas em cadeia aos seus artigos.
- linha 24: os artigos de uma categoria serão colocados num objeto do tipo Set<Article>. O tipo Set não aceita duplicados. Assim, não é possível colocar duas vezes o mesmo artigo no objeto Set<Article>. O que significa «o mesmo artigo»? Para indicar que o artigo a é o mesmo que o artigo b, o Java utiliza a expressão a.equals(b). Na classe Object, classe-pai de todas as classes, a.equals(b) é verdadeira se a==b, c.a.d. se os objetos a e b tiverem a mesma localização na memória. Poderíamos querer dizer que os artigos a e b são os mesmos se tiverem o mesmo nome. Neste caso, o programador deve redefinir dois métodos na classe [Article]:
- equals: que deve devolver «verdadeiro» se os dois artigos tiverem o mesmo nome
- hashCode: deve devolver um valor inteiro idêntico para dois objetos [Article] que o método equals considere iguais. Neste caso, o valor será, portanto, construído a partir do nome do artigo. O valor devolvido por hashCode pode ser qualquer número inteiro. É utilizado em diferentes contentores de objetos, nomeadamente nos dicionários (Hashtable).
A relação OneToMany pode utilizar outros tipos além do Set para armazenar o Many, por exemplo, objetos do tipo List. Não abordaremos estes casos neste documento. O leitor poderá encontrá-los em [ref1].
- linha 38: o método [addArticle] permite-nos adicionar um artigo a uma categoria. O método encarrega-se de atualizar ambas as extremidades da relação OneToMany que liga [Categorie] a [Article].
4.3. O API da camada JPA
Vamos explicar o ambiente de execução de um cliente JPA:
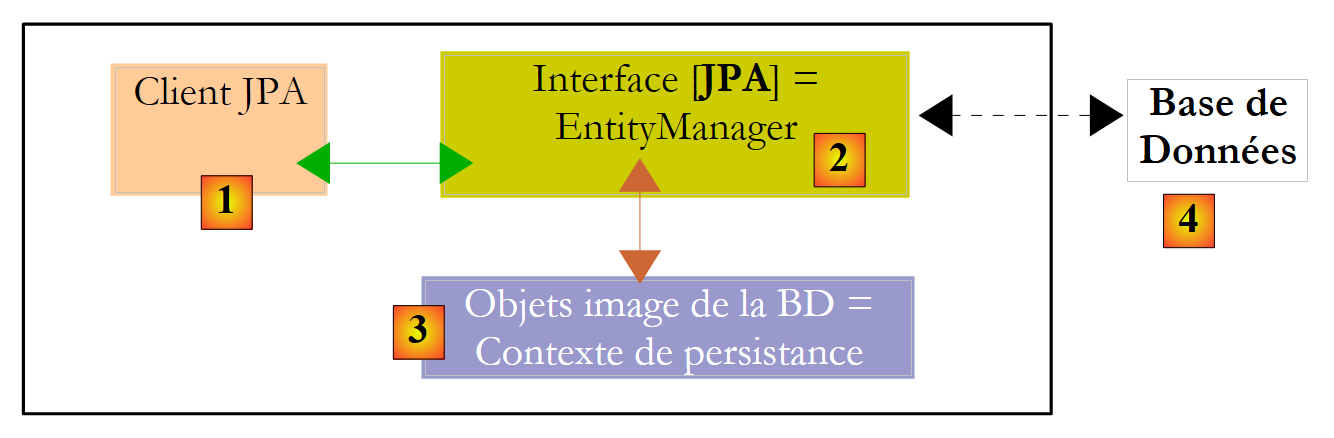 |
Sabemos que a camada JPA [2] cria uma ponte objeto [3] / relacional [4]. Denomina-se «contexto de persistência» o conjunto de objetos geridos pela camada JPA no âmbito desta ponte objeto/relacional. Para aceder aos dados do contexto de persistência, um cliente JPA [1] deve passar pela camada JPA [2]:
- pode criar um objeto e solicitar à camada JPA que o torne persistente. O objeto passa então a fazer parte do contexto de persistência.
- pode solicitar à camada [JPA] uma referência a um objeto persistente existente.
- pode modificar um objeto persistente obtido da camada JPA.
- pode solicitar à camada JPA que elimine um objeto do contexto de persistência.
A camada JPA apresenta ao cliente uma interface denominada [EntityManager] que, tal como o próprio nome indica, permite gerir os objetos @Entity do contexto de persistência. Apresentamos abaixo os principais métodos desta interface:
coloca entity no contexto de persistência | |
retira entity do contexto de persistência | |
funde um objeto entity do cliente, não gerido pelo contexto de persistência, com o objeto entity do contexto de persistência que possui a mesma chave primária. O resultado obtido é o objeto entity do contexto de persistência. | |
insere no contexto de persistência um objeto pesquisado na base de dados através da sua chave primária. O tipo T do objeto permite à camada JPA saber qual a tabela a consultar. O objeto persistente assim criado é devolvido ao cliente. | |
cria um objeto Query a partir de uma consulta JPQL (Java Persistence Query Language). Uma consulta JPQL é análoga a uma consulta SQL se , exceto pelo facto de consultar objetos em vez de tabelas. | |
método semelhante ao anterior, com a diferença de que queryText é um ordem SQL e não JPQL. | |
Método idêntico ao de createQuery, com a diferença de que a ordem JPQL queryText foi foi externalizado para um ficheiro de configuração e associado a um nome. É esse nome que constitui o parâmetro do método. |
Um objeto EntityManager tem um ciclo de vida que não é necessariamente o da aplicação. Tem um início e um fim. Assim, um cliente JPA pode trabalhar sucessivamente com diferentes objetos EntityManager. O contexto de persistência associado a um EntityManager tem o mesmo ciclo de vida que este. São indissociáveis um do outro. Quando um objeto EntityManager é encerrado, o seu contexto de persistência é, se necessário, sincronizado com a base de dados e, em seguida, deixa de existir. É necessário criar um novo EntityManager para voltar a ter um contexto de persistência.
O cliente JPA pode criar um EntityManager e, consequentemente, um contexto de persistência com a seguinte instrução:
EntityManagerFactory emf = Persistence.createEntityManagerFactory("nom d'une unité de persistance");
- javax.persistence.Persistence é uma classe estática que permite obter uma fábrica (factory) de objetos EntityManager. Esta fábrica está associada a uma unidade de persistência específica. Recorde-se que o ficheiro de configuração [META-INF/persistence.xml] permite definir unidades de persistência e que estas têm um nome:
<persistence-unit name="elections-dao-jpa-mysql-01PU" transaction-type="RESOURCE_LOCAL">
No exemplo acima, a unidade de persistência chama-se elections-dao-jpa-mysql-01PU. Juntamente com ela, vem toda uma configuração que lhe é própria, nomeadamente o SGBD com o qual ela funciona. A instrução [Persistence.createEntityManagerFactory("elections-dao-jpa-mysql-01PU")] cria uma fábrica de objetos do tipo EntityManagerFactory capaz de fornecer objetos EntityManager destinados a gerir contextos de persistência associados à unidade de persistência denominada elections-dao-jpa-mysql-01PU. A obtenção de um objeto EntityManager e, consequentemente, de um contexto de persistência, é feita a partir do objeto EntityManagerFactory da seguinte forma:
Os seguintes métodos da interface [EntityManager] permitem gerir o ciclo de vida do contexto de persistência:
o contexto de persistência é encerrado. Força a sincronização do contexto de persistência com a base de dados:
| |
O contexto de persistência é esvaziado de todos os seus objetos, mas não é encerrado. | |
o contexto de persistência é sincronizado com a base de dados da forma descrita para close() |
O cliente JPA pode forçar a sincronização do contexto de persistência com a base de dados através do método [EntityManager].flush anterior. A sincronização pode ser explícita ou implícita. No primeiro caso, cabe ao cliente executar as operações flush quando pretender efetuar sincronizações; caso contrário, estas são realizadas em determinados momentos que iremos especificar. O modo de sincronização é gerido pelos seguintes métodos da interface [EntityManager]:
Existem dois valores possíveis para flushmode: FlushModeType.AUTO (padrão): a sincronização ocorre antes de cada consulta SELECT efetuada na base de dados. FlushModeType.COMMIT: a sincronização só ocorre no final das transações na base de dados. | |
indica o modo atual de sincronização |
Resumindo. No modo FlushModeType.AUTO, que é o modo predefinido, o contexto de persistência será sincronizado com a base de dados nos seguintes momentos:
- antes de cada operação SELECT na base de dados
- no final de uma transação na base de dados
- após uma operação flush ou close no contexto de persistência
No modo FlushModeType.COMMIT, o procedimento é idêntico, exceto no que diz respeito à operação 1, que não ocorre. O modo normal de interação com a camada JPA é um modo transacional. O cliente realiza várias operações no contexto de persistência, no âmbito de uma transação. Neste caso, os momentos de sincronização do contexto de persistência com a base de dados correspondem aos casos 1 e 2 acima referidos no modo AUTO, e apenas ao caso 2 no modo COMMIT.
Concluímos com o API da interface Query, interface que permite emitir ordens JPQL no contexto de persistência ou ordens SQL diretamente na base de dados para recuperar dados. A interface Query é a seguinte:
 |
- 1 - o método getResultList executa um SELECT que devolve vários objetos. Estes serão obtidos num objeto List. Este objeto é uma interface. Esta oferece um objeto Iterator que permite percorrer os elementos da lista L da seguinte forma:
Iterator iterator = L.iterator();
while (iterator.hasNext()) {
// utilizar o objeto iterator.next() que representa o elemento atual da lista
...
}
A lista L também pode ser explorada com um for:
for (Object o : L) {
// utilizar o objeto o
}
- 2 - o método getSingleResult executa uma ordem JPQL / SQL SELECT que devolve um único objeto.
- 3 - O método executeUpdate executa uma ordem SQL de atualização ou eliminação e devolve o número de linhas afetadas pela operação.
- 4 - O método setParameter(String, Object) permite atribuir um valor a um parâmetro nomeado de uma ordem JPQL configurada
- 5 - O método setParameter(int, Object) tem o parâmetro designado não pelo seu nome, mas pela sua posição na ordem JPQL.
4.4. As consultas JPQL
JPQL (Java Persistence Query Language) é a linguagem de consultas da camada JPA. A linguagem JPQL está relacionada com a linguagem SQL das bases de dados. Enquanto o SQL trabalha com tabelas, o JPQL trabalha com os objetos de imagem dessas tabelas. Vamos analisar um exemplo no âmbito da seguinte arquitetura:
 |
A base de dados a que chamaremos [dbrdvmedecins2] é uma base de dados MySQL5 com quatro tabelas:
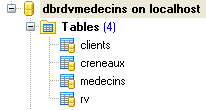 |
Reúne informações que permitem gerir as consultas de um grupo de médicos.
4.4.1. A tabela [MEDECINS]
Contém informações sobre os médicos.
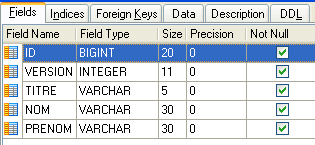 | 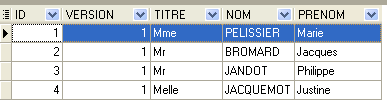 |
- ID: número que identifica o médico — chave primária da tabela
- VERSION: número que identifica a versão da linha na tabela. Este número é incrementado em 1 sempre que é feita uma alteração na linha.
- NOM: o nome do médico
- PRENOM: o seu nome próprio
- TITRE: o seu título (Menina, Sra., Sr.)
4.4.2. A tabela [CLIENTS]
Os clientes dos diferentes médicos estão registados na tabela [CLIENTS]:
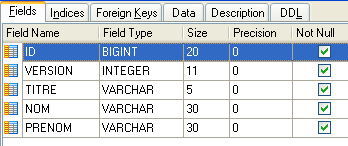 | 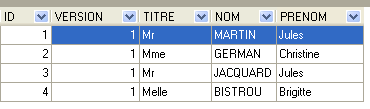 |
- ID: número de identificação do cliente — chave primária da tabela
- VERSION: número que identifica a versão da linha na tabela. Este número é incrementado em 1 sempre que é feita uma alteração na linha.
- NOM: o nome do cliente
- PRENOM: o seu nome próprio
- TITRE: o seu título (Menina, Sra., Sr.)
4.4.3. A tabela [CRENEAUX]
Esta tabela lista os intervalos horários em que os RV são possíveis:
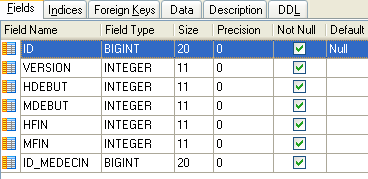 |
 |
- ID: número que identifica o intervalo horário — chave primária da tabela (linha 8)
- VERSION: número que identifica a versão da linha na tabela. Este número é incrementado em 1 sempre que é feita uma alteração na linha.
- ID_MEDECIN: número que identifica o médico a quem pertence este intervalo horário – chave estrangeira na coluna MEDECINS (ID).
- HDEBUT: hora de início do intervalo
- MDEBUT: minutos de início do intervalo
- HFIN: hora de fim do intervalo
- MFIN: minutos de fim do intervalo
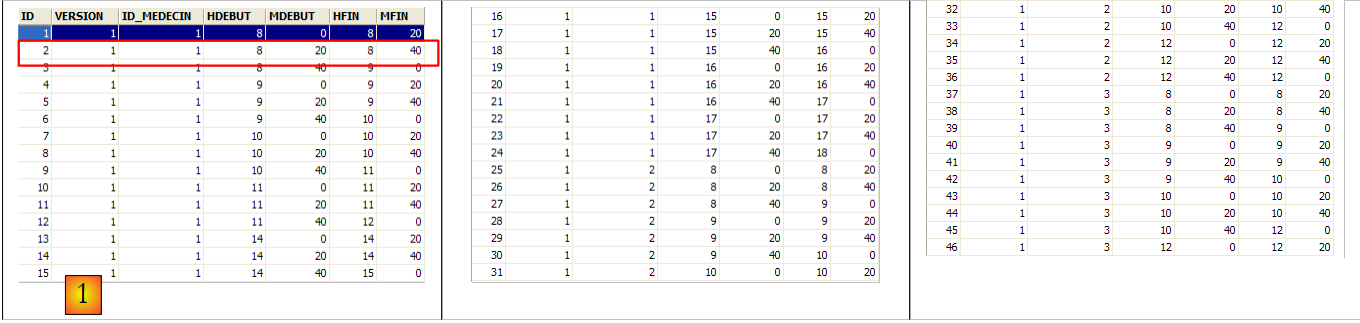
A segunda linha da tabela [CRENEAUX] (ver [1] acima) indica, por exemplo, que o intervalo n.º 2 começa às 8h20 e termina às 8h40 e pertence à médica n.º 1 (Sra. Marie PELISSIER).
4.4.4. A tabela [RV]
Esta tabela lista os RV atribuídos a cada médico:
 |
- ID: número que identifica o RV de forma única – chave primária
- JOUR: dia do RV
- ID_CRENEAU: intervalo horário do RV – chave estrangeira no campo [ID] da tabela [CRENEAUX] – define simultaneamente o intervalo horário e o médico em questão.
- ID_CLIENT: número do cliente para quem é feita a reserva – chave estrangeira no campo [ID] da tabela [CLIENTS]
Esta tabela possui uma restrição de unicidade na sobre os valores das colunas associadas (JOUR, ID_CRENEAU):
Se uma linha da tabela [RV] tiver o valor (JOUR1, ID_CRENEAU1) para as colunas (JOUR, ID_CRENEAU), esse valor não pode aparecer em mais nenhum outro local. Caso contrário, isso significaria que dois RV foram registados ao mesmo tempo para o mesmo médico. Do ponto de vista da programação Java, o controlador JDBC da base de dados lança um SQLException quando esta situação ocorre.
A linha de id igual a 3 (ver [1] acima) significa que um RV foi marcado para o horário n.º 20 e o cliente n.º 4 em 23/08/2006. A tabela [CRENEAUX] indica-nos que o horário n.º 20 corresponde ao intervalo horário das 16h20 às 16h40 e pertence à médica n.º 1 (Sra. Marie PELISSIER). A tabela [CLIENTS] indica-nos que o cliente n.º 4 é a Srta. Brigitte BISTROU.
4.4.5. Criação da base de dados
Para criar as tabelas e preenchê-las, pode utilizar-se o script [dbrdvmedecins2.sql]. Com o [WampServer], pode proceder-se da seguinte forma:
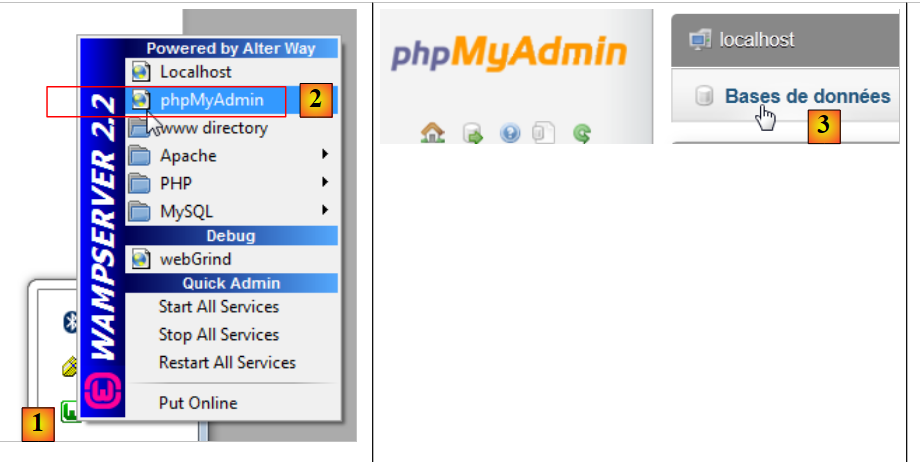 |
- em [1], clica-se no ícone de [WampServer] e seleciona-se a opção [PhpMyAdmin] [2],
- em [3], na janela que se abriu, selecione o link [Bases de données],
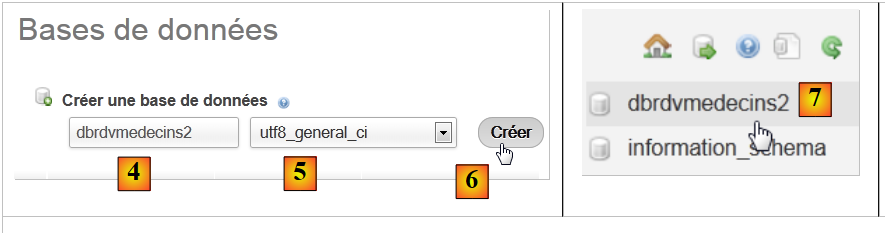 |
- em [2], cria-se uma base de dados à qual se atribuiu o nome [4] e a codificação [5],
- em [7], a base de dados foi criada. Clica-se no respetivo link,
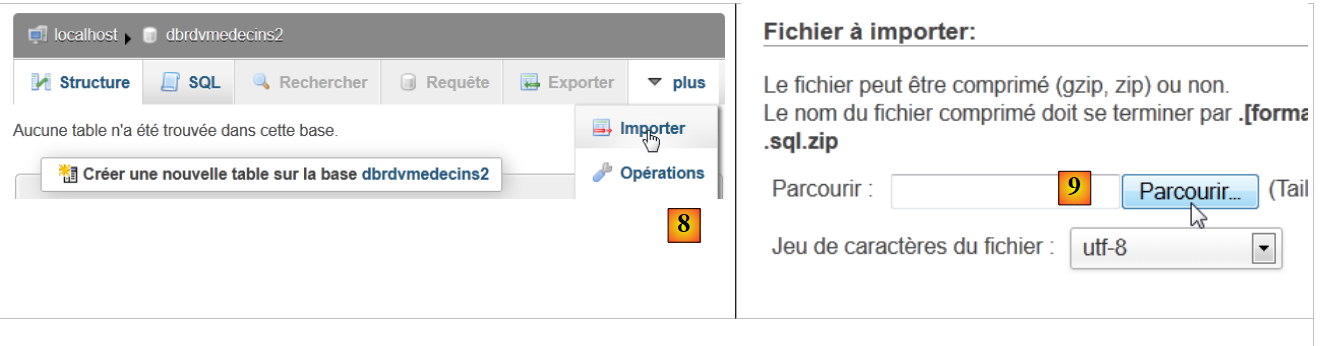 |
- em [8], importa-se um ficheiro SQL,
- que se seleciona no sistema de ficheiros com o botão [9],
 |
- em [11], seleciona-se o script SQL e, em [12], executa-se o mesmo,
- em [13], as quatro tabelas da base de dados foram criadas. Seguimos uma das ligações,
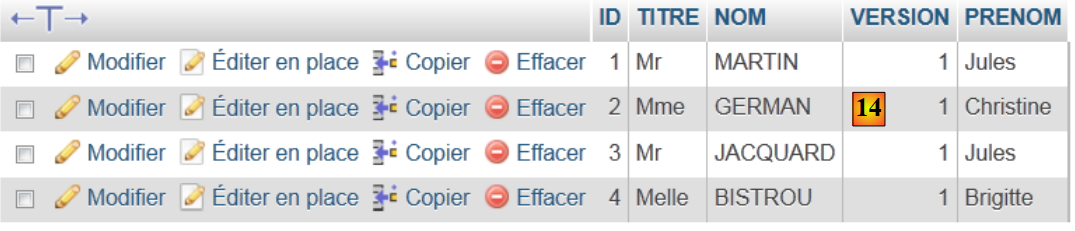 |
- em [14], o conteúdo da tabela.
A partir daqui, não voltaremos a abordar esta base de dados. No entanto, convidamos o leitor a acompanhar a sua evolução ao longo dos programas, sobretudo quando algo não funcionar.
4.4.6. A camada [JPA]
Voltemos à arquitetura do exemplo:
 |
Vamos agora construir o projeto Maven da camada [JPA].
4.4.7. O projeto NetBeans
É o seguinte:
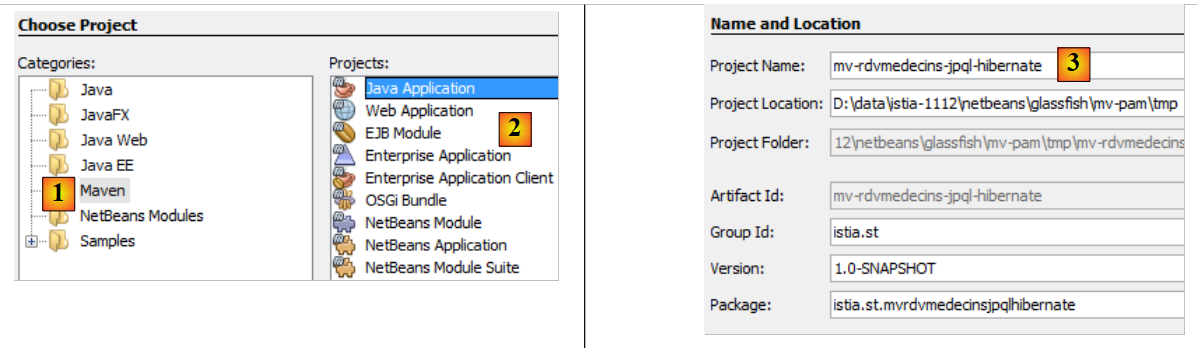 |
- em [1], criamos um projeto Maven do tipo [Java Application] [2],
- em [3], atribui-se um nome ao projeto,
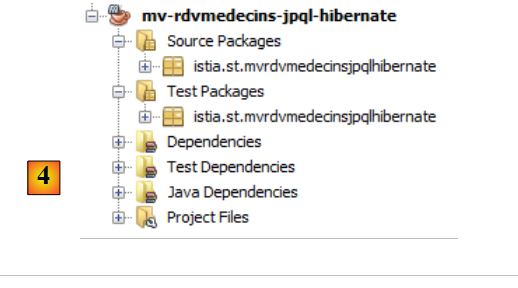 |
- em [4], o projeto gerado.
4.4.8. Geração da camada [JPA]
Voltemos à arquitetura que temos de construir:
 |
Com o NetBeans, é possível gerar automaticamente a camada [JPA]. É interessante conhecer estes métodos de geração automática, pois o código gerado fornece indicações valiosas sobre como escrever entidades JPA.
4.4.9. Criação de uma ligação do NetBeans à base de dados
- Execute o SGBD MySQL 5 para que o BD fique disponível,
- criar uma ligação do NetBeans à base de dados [dbrdvmedecins2],
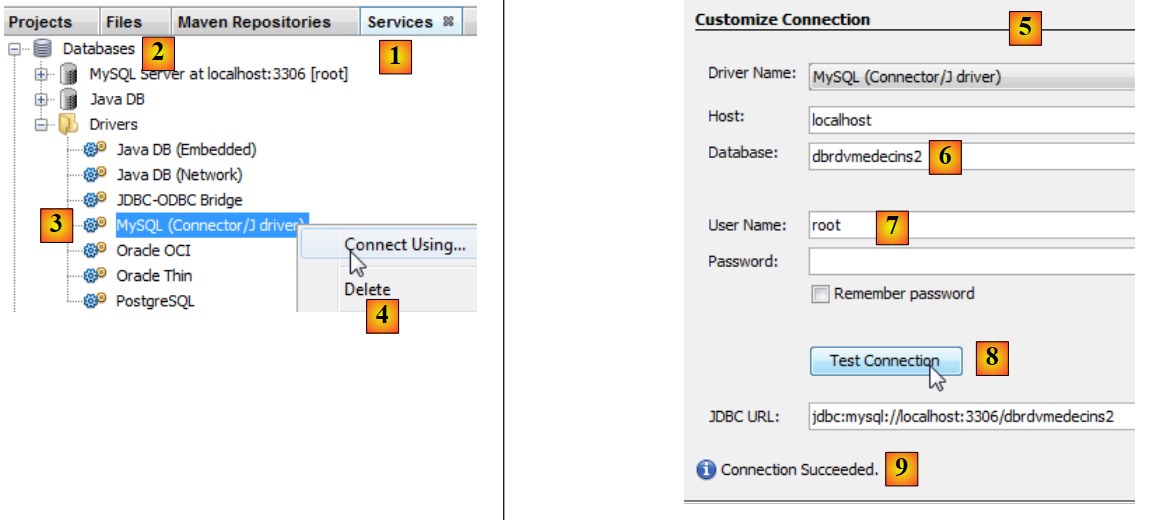 |
- no separador [Services] [1], no ramo [Databases] [2], selecione o controlador JDBC MySQL [3],
- depois selecione a opção [4] «Connect Using», que permite criar uma ligação a uma base de dados MySQL,
- em [5], introduza as informações solicitadas. Em [6], o nome da base de dados; em [7], o utilizador da base de dados e a sua palavra-passe;
- em [8], é possível testar as informações fornecidas,
- em [9], a mensagem esperada quando estas estão corretas,
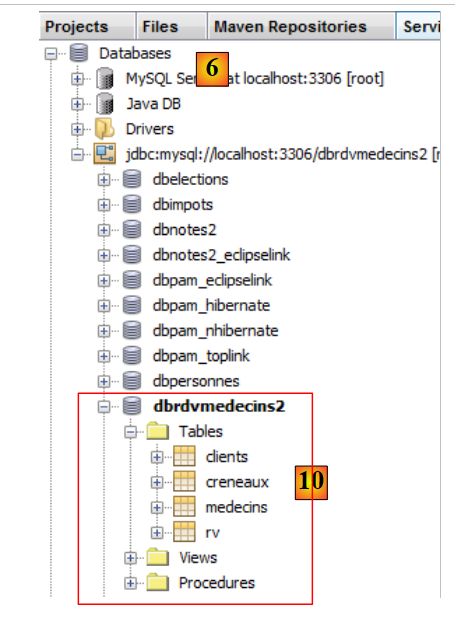 |
- em [10], a ligação é estabelecida. Aqui podem ver-se as quatro tabelas da base de dados à qual se ligou.
4.4.10. Criação de uma unidade de persistência
Voltemos à arquitetura em fase de construção:
 |
Estamos a construir a camada [JPA]. A sua configuração é feita num ficheiro [persistence.xml], no qual se definem as unidades de persistência. Cada uma delas necessita das seguintes informações:
- as características JDBC de acesso à base de dados (URL, utilizador, palavra-passe),
- as classes que servirão de representação das tabelas da base de dados,
- a implementação JPA utilizada. Com efeito, JPA é uma especificação implementada por vários produtos. Neste caso, utilizaremos o Hibernate.
O NetBeans pode gerar este ficheiro de persistência através de um assistente.
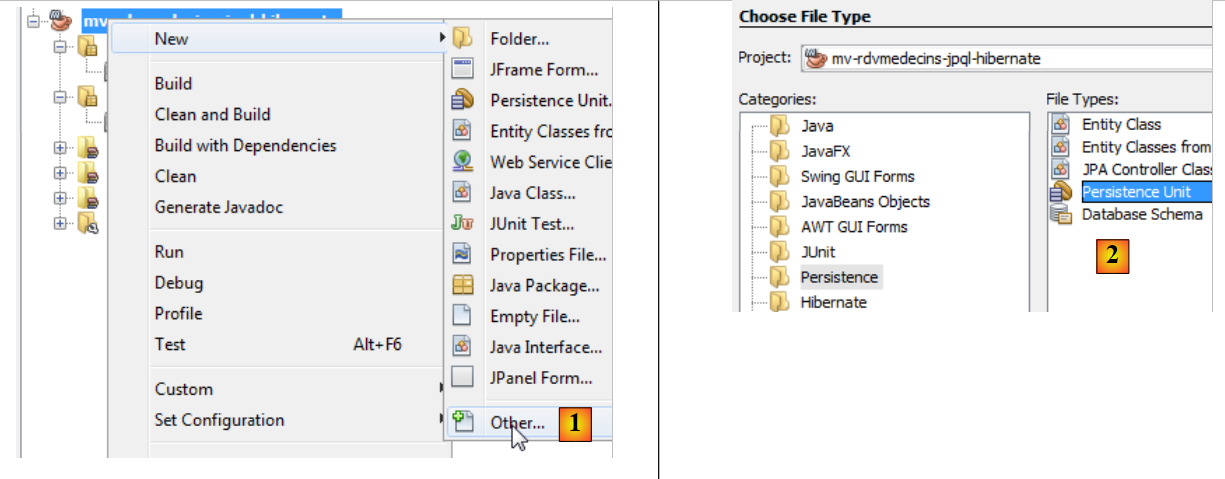 |
- clique com o botão direito do rato no projeto e selecione a criação de uma unidade de persistência [1],
- em [2], criar uma unidade de persistência,
|
- em [3], atribuir um nome à unidade de persistência que está a ser criada,
- em [4], selecionar a implementação JPA Hibernate (JPA 2.0),
- em [5], indicar que as tabelas de BD já estão criadas e que, por isso, não as criamos. Confirmamos o assistente,
- no [6], o novo projeto,
- no [7], o ficheiro [persistence.xml] foi gerado na pasta [META-INF],
- em [8], foram adicionadas novas dependências ao projeto Maven.
O ficheiro [META-INF/persistence.xml] gerado é o seguinte:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="mv-rdvmedecins-jpql-hibernatePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbrdvmedecins2"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="hibernate.cache.provider_class" value="org.hibernate.cache.NoCacheProvider"/>
</properties>
</persistence-unit>
</persistence>
Este ficheiro retoma as informações fornecidas no assistente:
- linha 3: o nome da unidade de persistência,
- linha 3: o tipo de transações com a base de dados. Aqui, RESOURCE_LOCAL indica que a aplicação irá gerir as suas próprias transações,
- linhas 6-9: as propriedades JDBC da fonte de dados.
No separador [Design], é possível obter uma visão geral do ficheiro [persistence.xml]:
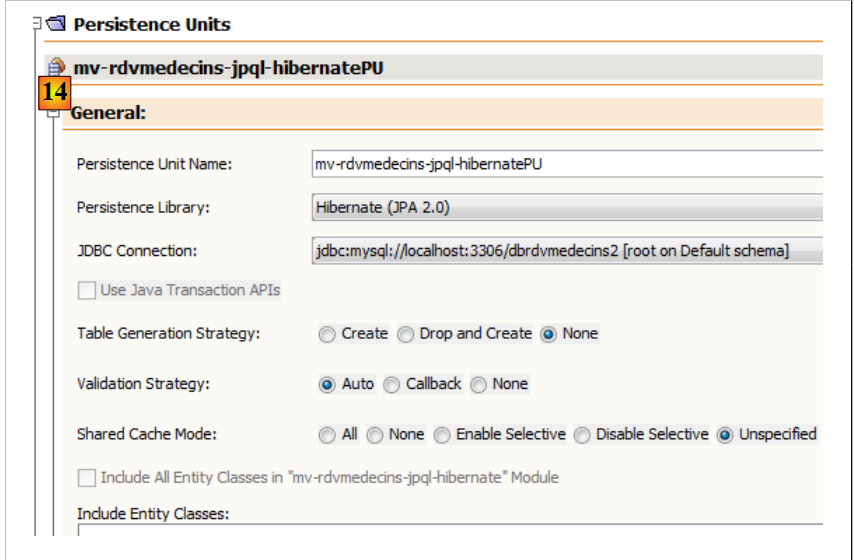 |
Para obter os registos do Hibernate, completamos o ficheiro [persistence.xml] da seguinte forma:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="mv-rdvmedecins-jpql-hibernatePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbrdvmedecins2"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="hibernate.cache.provider_class" value="org.hibernate.cache.NoCacheProvider"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
</properties>
</persistence-unit>
</persistence>
- linha 11: solicita-se a visualização dos comandos SQL emitidos pelo Hibernate,
- linha 12: esta propriedade permite obter uma visualização formatada das mesmas.
Foram adicionadas dependências ao projeto. O ficheiro [pom.xml] é o seguinte:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>istia.st</groupId>
<artifactId>mv-rdvmedecins-jpql-hibernate</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>mv-rdvmedecins-jpql-hibernate</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>org.jboss.logging</groupId>
<artifactId>jboss-logging</artifactId>
<version>3.1.0.GA</version>
</dependency>
<dependency>
<groupId>org.jboss.spec.javax.transaction</groupId>
<artifactId>jboss-transaction-api_1.1_spec</artifactId>
<version>1.0.0.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>antlr</groupId>
<artifactId>antlr</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.hibernate.javax.persistence</groupId>
<artifactId>hibernate-jpa-2.0-api</artifactId>
<version>1.0.1.Final</version>
</dependency>
<dependency>
<groupId>org.javassist</groupId>
<artifactId>javassist</artifactId>
<version>3.15.0-GA</version>
</dependency>
<dependency>
<groupId>org.hibernate.common</groupId>
<artifactId>hibernate-commons-annotations</artifactId>
<version>4.0.1.Final</version>
</dependency>
</dependencies>
</project>
As dependências adicionadas dizem todas respeito ao Hibernate ORM. Iremos adicionar a dependência do controlador JDBC do MySQL:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
4.4.11. Geração das entidades JPA
As entidades JPA podem ser geradas por um assistente do NetBeans:
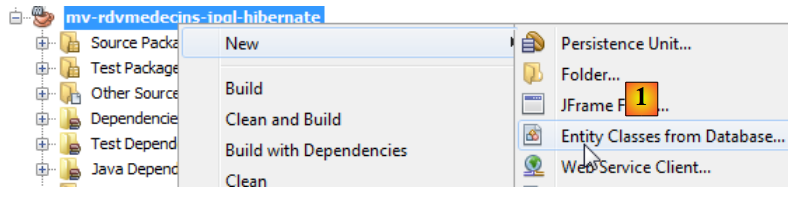 |
- em [1], criam-se entidades JPA a partir de uma base de dados,
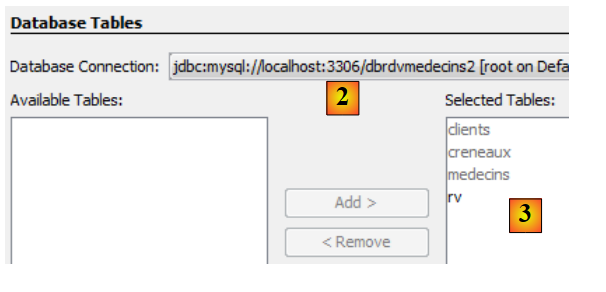 |
- em [2], seleciona-se a ligação [dbrdvmedecins2] criada anteriormente,
- em [3], selecionam-se todas as tabelas da base de dados associada,
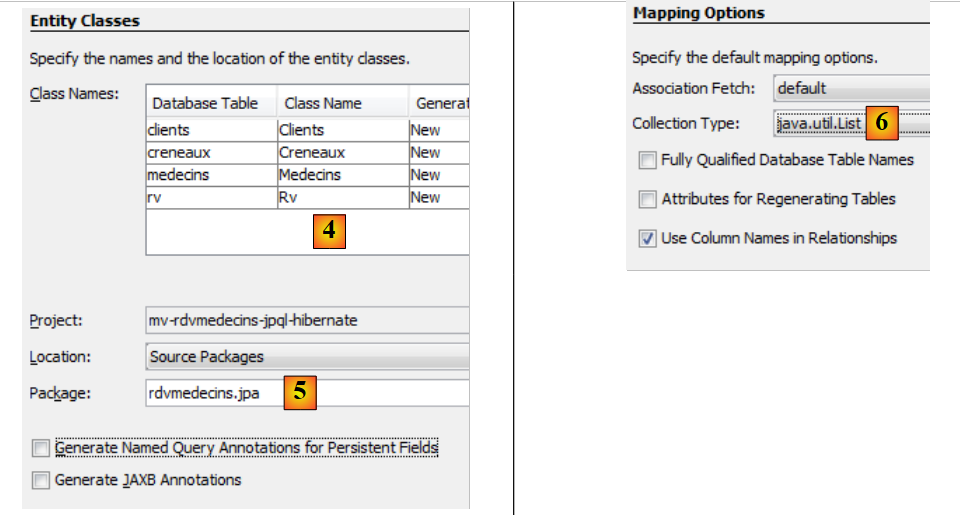 |
- em [4], atribui-se um nome às classes Java associadas às quatro tabelas,
- bem como um nome de pacote [5],
- em [6], o JPA reúne linhas das tabelas do BD em coleções. Escolhemos a lista como coleção,
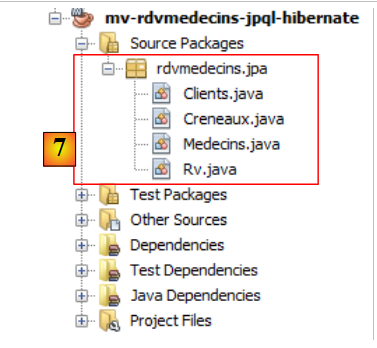 |
- em [7], as classes Java criadas pelo assistente.
4.4.12. As entidades JPA geradas
A entidade [Medecin] é a representação da tabela [medecins]. A classe Java está repleta de anotações que tornam o código pouco legível à primeira vista. Se mantivermos apenas o que é essencial para compreender a função da entidade, obtemos o seguinte código:
package rdvmedecins.jpa;
...
@Entity
@Table(name = "medecins")
public class Medecin implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "TITRE")
private String titre;
@Column(name = "NOM")
private String nom;
@Column(name = "VERSION")
private int version;
@Column(name = "PRENOM")
private String prenom;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "idMedecin")
private List<Creneau> creneauList;
// construtores
....
// getters e setters
....
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
...
}
}
- na linha 4, a anotação @Entity transforma a classe [Medecin] numa entidade JPA, c.a.d. uma classe ligada a uma tabela de BD através de API e JPA,
- na linha 5, o nome da tabela BD associada à entidade JPA. Cada campo da tabela corresponde a um campo na classe Java,
- linha 6, a classe implementa a interface Serializable. Isto é necessário em aplicações cliente/servidor, onde as entidades são serializadas entre o cliente e o servidor.
- linhas 10-11: o campo id da classe [Medecin] corresponde ao campo [ID] (linha 10) da tabela [medecins],
- linhas 13-14: o campo «título» da classe [Medecin] corresponde ao campo [TITRE] (linha 13) da tabela [medecins],
- linhas 16-17: o campo «nome» da classe [Medecin] corresponde ao campo [NOM] (linha 16) da tabela [medecins],
- linhas 19-20: o campo «versão» da classe [Medecin] corresponde ao campo [VERSION] (linha 19) da tabela [medecins]. Aqui, o assistente não reconhece que a coluna é, na verdade, uma coluna de versão que deve ser incrementada sempre que a linha a que pertence for alterada. Para lhe atribuir essa função, é necessário adicionar a anotação @Version. Faremos isso numa etapa seguinte,
- linhas 22-23: o campo prenom da classe [Medecin] corresponde ao campo [PRENOM] da tabela [medecins],
- linhas 10-11: o campo id corresponde à chave primária [ID] da tabela. As anotações das linhas 8-9 esclarecem este ponto,
- linha 8: a anotação @Id indica que o campo anotado está associado à chave primária da tabela,
- linha 9: a camada [JPA] irá gerar a chave primária das linhas que irá inserir na tabela [Medecins]. Existem várias estratégias possíveis. Aqui, a estratégia GenerationType.IDENTITY indica que a camada JPA irá utilizar o modo auto_increment da tabela MySQL,
- linhas 25-26: a tabela [creneaux] possui uma chave estrangeira na tabela [medecins]. Um horário pertence a um médico. Por outro lado, um médico tem vários horários que lhe estão associados. Temos, portanto, uma relação de um (médico) para vários (intervalos), uma relação qualificada pela anotação @OneToMany por JPA (linha 25). O campo da linha 26 conterá todos os horários do médico. Isto sem qualquer programação. Para compreender totalmente a linha 25, é necessário apresentar a classe [Creneau].
Esta é a seguinte:
package rdvmedecins.jpa;
import java.io.Serializable;
import java.util.List;
import javax.persistence.*;
import javax.validation.constraints.NotNull;
@Entity
@Table(name = "creneaux")
public class Creneau implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "MDEBUT")
private int mdebut;
@Column(name = "HFIN")
private int hfin;
@Column(name = "HDEBUT")
private int hdebut;
@Column(name = "MFIN")
private int mfin;
@Column(name = "VERSION")
private int version;
@JoinColumn(name = "ID_MEDECIN", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Medecin idMedecin;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "idCreneau")
private List<Rv> rvList;
// construtores
...
// getters e setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
...
}
}
Apenas comentamos as novas anotações:
- já referimos que a tabela [creneaux] possui uma chave estrangeira para a tabela [medecins]: um horário está associado a um médico. Podem estar associados vários horários ao mesmo médico. Existe uma relação da tabela [creneaux] para a tabela [medecins], que é qualificada como «muitos (intervalos) para um (médico)». É a anotação @ManyToOne da linha 32 que serve para definir a chave estrangeira,
- A linha 31, com a anotação @JoinColumn, especifica a relação de chave estrangeira: a coluna [ID_MEDECIN] da tabela [creneaux] é uma chave estrangeira na coluna [ID] da tabela [medecins],
- linha 33: uma referência ao médico titular do horário. Mais uma vez, obtém-se esta informação sem necessidade de programação.
A ligação de chave estrangeira entre a entidade [Creneau] e a entidade [Medecin] é, portanto, concretizada por duas anotações:
- na entidade [Creneau]:
@JoinColumn(name = "ID_MEDECIN", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Medecin idMedecin;
- na entidade [Medecin]:
@OneToMany(cascade = CascadeType.ALL, mappedBy = "idMedecin")
private List<Creneau> creneauList;
Ambas as anotações refletem a mesma relação: a da chave estrangeira da tabela [creneaux] para a tabela [medecins]. Diz-se que são inversas uma da outra. Apenas a relação @ManyToOne é indispensável. Esta qualifica, sem ambiguidade, a relação de chave estrangeira. A relação @OneToMany é opcional. Se estiver presente, limita-se a referenciar a relação @ManyToOne à qual está associada. É este o significado do atributo mappedBy da linha 1 da entidade [Medecin]. O valor deste atributo é o nome do campo da entidade [Creneau] que possui a anotação @ManyToOne, a qual especifica a chave estrangeira. Ainda nesta mesma linha 1 da entidade [Medecin], o atributo cascade=CascadeType.ALL define o comportamento da entidade [Medecin] em relação à entidade [Creneau]:
- se for inserida uma nova entidade [Medecin] na base de dados, então as entidades [Creneau] do campo da linha 2 também devem ser inseridas,
- se se alterar uma entidade [Medecin] na base de dados, então as entidades [Creneau] do campo da linha 2 também devem ser alteradas,
- se se eliminar uma entidade [Medecin] da base de dados, então as entidades [Creneau] do campo da linha 2 também devem ser eliminadas.
Apresentamos o código das outras duas entidades sem comentários específicos, uma vez que não introduzem novas notações.
A entidade [Client]
package rdvmedecins.jpa;
...
@Entity
@Table(name = "clients")
public class Client implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "TITRE")
private String titre;
@Column(name = "NOM")
private String nom;
@Column(name = "VERSION")
private int version;
@Column(name = "PRENOM")
private String prenom;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "idClient")
private List<Rv> rvList;
// construtores
...
// getters e setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
...
}
}
- as linhas 24-25 refletem a relação de chave estrangeira entre a tabela [rv] e a tabela [clients].
A entidade [Rv]:
package rdvmedecins.jpa;
...
@Entity
@Table(name = "rv")
public class Rv implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "JOUR")
@Temporal(TemporalType.DATE)
private Date jour;
@JoinColumn(name = "ID_CRENEAU", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Creneau idCreneau;
@JoinColumn(name = "ID_CLIENT", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Client idClient;
// construtores
...
// getters e setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
...
}
}
- a linha 13 define o campo «dia» de tipo Java Date. Indica-se que, na tabela [rv], a coluna [JOUR] (linha 12) é do tipo data (sem hora),
- linhas 16-18: definem a relação de chave estrangeira da tabela [rv] com a tabela [creneaux],
- linhas 20-22: definem a relação de chave estrangeira da tabela [rv] com a tabela [clients].
A geração automática das entidades JPA permite-nos obter uma base de trabalho. Por vezes é suficiente, outras vezes não. É o caso aqui:
- é necessário adicionar a anotação @Version aos diferentes campos de versão das entidades,
- é necessário escrever métodos toString mais explícitos do que os gerados,
- as entidades [Medecin] e [Client] são análogas. Vamos fazê-las derivar de uma classe [Personne],
- vamos eliminar as relações @OneToMany inversas às relações @ManyToOne. Estas não são indispensáveis e causam complicações na programação,
- eliminamos a validação @NotNull nas chaves primárias. Quando se persiste uma entidade JPA com MySQL, a entidade inicial tem uma chave primária null. Só após a persistência na base de dados é que a chave primária do elemento persistido passa a ter um valor.
Com estas especificações, as diferentes classes passam a ser as seguintes:
A classe Pessoa é utilizada para representar médicos e clientes:
package rdvmedecins.jpa;
import java.io.Serializable;
import javax.persistence.*;
@MappedSuperclass
public class Personne implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Basic(optional = false)
@Column(name = "TITRE")
private String titre;
@Basic(optional = false)
@Column(name = "NOM")
private String nom;
@Basic(optional = false)
@Column(name = "VERSION")
@Version
private int version;
@Basic(optional = false)
@Column(name = "PRENOM")
private String prenom;
// construtores
...
// getters e setters
...
@Override
public String toString() {
return String.format("[%s,%s,%s,%s,%s]", id, version, titre, prenom, nom);
}
}
- linha 6: note-se que a classe [Personne] não é, ela própria, uma entidade (@Entity). Será a classe-pai das entidades. A anotação @MappedSuperClass designa esta situação.
A entidade [Client] encapsula os registos da tabela [clients]. Deriva da classe anterior [Personne]:
package rdvmedecins.jpa;
import java.io.Serializable;
import javax.persistence.*;
@Entity
@Table(name = "clients")
public class Client extends Personne implements Serializable {
private static final long serialVersionUID = 1L;
// construtores
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
return String.format("Client[%s,%s,%s,%s]", getId(), getTitre(), getPrenom(), getNom());
}
}
- linha 6: a classe [Client] é uma entidade JPA,
- linha 7: está associada à tabela [clients],
- linha 8: deriva da classe [Personne].
A entidade [Medecin], que encapsula as linhas da tabela [medecins], segue o mesmo modelo:
package rdvmedecins.jpa;
import java.io.Serializable;
import javax.persistence.*;
@Entity
@Table(name = "medecins")
public class Medecin extends Personne implements Serializable {
private static final long serialVersionUID = 1L;
// construtores
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
return String.format("Médecin[%s,%s,%s,%s]", getId(), getTitre(), getPrenom(), getNom());
}
}
A entidade [Creneau] encapsula as linhas da tabela [creneaux]:
package rdvmedecins.jpa;
import java.io.Serializable;
import java.util.List;
import javax.persistence.*;
@Entity
@Table(name = "creneaux")
public class Creneau implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Basic(optional = false)
@Column(name = "ID")
private Long id;
@Basic(optional = false)
@Column(name = "MDEBUT")
private int mdebut;
@Basic(optional = false)
@Column(name = "HFIN")
private int hfin;
@Basic(optional = false)
@NotNull
@Column(name = "HDEBUT")
private int hdebut;
@Basic(optional = false)
@Column(name = "MFIN")
private int mfin;
@Basic(optional = false)
@Column(name = "VERSION")
@Version
private int version;
@JoinColumn(name = "ID_MEDECIN", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Medecin medecin;
// construtores
...
// getters e setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
// TODO: Aviso - este método não funcionará caso os campos de ID não estejam definidos
...
}
@Override
public String toString() {
return String.format("Creneau [%s, %s, %s:%s, %s:%s,%s]", id, version, hdebut, mdebut, hfin, mfin, medecin);
}
}
- as linhas 40-42 modelam a relação «muitos para um» que existe entre a tabela [creneaux] e a tabela [medecins] da base de dados: um médico tem vários horários, um horário pertence a um único médico.
A entidade [Rv] encapsula as linhas da tabela [rv]:
package rdvmedecins.jpa;
import java.io.Serializable;
import java.util.Date;
import javax.persistence.*;
@Entity
@Table(name = "rv")
public class Rv implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Basic(optional = false)
@Column(name = "ID")
private Long id;
@Basic(optional = false)
@Column(name = "JOUR")
@Temporal(TemporalType.DATE)
private Date jour;
@JoinColumn(name = "ID_CRENEAU", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Creneau creneau;
@JoinColumn(name = "ID_CLIENT", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Client client;
// construtores
...
// getters e setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
return String.format("Rv[%s, %s, %s]", id, creneau, client);
}
}
- as linhas 27-29 modelam a relação «muitos para um» que existe entre a tabela [rv] e a tabela [clients] (um cliente pode aparecer em vários Rv) da base de dados e as linhas 23-25 a relação «muitos para um» que existe entre a tabela [rv] e a tabela [creneaux] (um intervalo de tempo pode aparecer em vários Rv).
4.4.13. O código de acesso aos dados
Vamos agora adicionar ao projeto o código de acesso aos dados através da camada JPA:
 |
 |
A classe [MainJpql] é a seguinte:
package rdvmedecins.console;
import java.util.Scanner;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public class MainJpql {
public static void main(String[] args) {
// EntityManagerFactory
EntityManagerFactory emf = Persistence.createEntityManagerFactory("mv-rdvmedecins-jpql-hibernatePU");
// entityManager
EntityManager em = emf.createEntityManager();
// leitor de teclado
Scanner clavier = new Scanner(System.in);
// ciclo de introdução de consultas JPQL
System.out.println("Requete JPQL sur la base dbrdvmedecins2 (* pour arrêter) :");
String requete = clavier.nextLine();
while (!requete.trim().equals("*")) {
try {
// exibição do resultado da consulta
for (Object o : em.createQuery(requete).getResultList()) {
System.out.println(o);
}
} catch (Exception e) {
System.out.println("L'exception suivante s'est produite : " + e);
}
// limpar o contexto de persistência
em.clear();
// nova consulta
System.out.println("---------------------------------------------");
System.out.println("Requete JPQL sur la base dbrdvmedecins2 (* pour arrêter) :");
requete = clavier.nextLine();
}
// encerramento dos recursos
em.close();
emf.close();
}
}
- linha 12: criação do EntityManagerFactory associado à unidade de persistência que criámos anteriormente. O parâmetro do método createEntityManagerFactory é o nome dessa unidade de persistência:
<persistence-unit name="mv-rdvmedecins-jpql-hibernatePU" transaction-type="RESOURCE_LOCAL">
...
</persistence-unit>
- linha 14: criação do EntityManager, que gere a camada de persistência,
- linha 19: introdução de uma consulta JPQL select,
- linhas 23-28: exibição do resultado da consulta,
- linha 20: a introdução de dados é interrompida quando o utilizador digita *.
Pergunta: indique as consultas JPQL que permitem obter as seguintes informações:
- lista de médicos por ordem decrescente dos seus nomes
- lista dos médicos cujo título é «Mr»
- lista dos horários da Sra. Pelissier
- lista das consultas marcadas por ordem crescente de dias
- lista de clientes (nome) que marcaram uma consulta com a Sra. PELISSIER no dia 24/08/2006
- número de clientes da Sra. PELISSIER em 24/08/2006
- os clientes que não marcaram consulta
- os médicos que não têm marcação
Inspirar-se-á no exemplo do parágrafo 2.7 de [ref1]. Eis um exemplo de execução:
- linha 2: a consulta JPQL,
- linhas 3-11: a consulta SQL correspondente,
- linhas 12-15: o resultado da consulta JPQL.
4.5. Relações entre o contexto de persistência e SGBD
4.5.1. A classe Pessoa
4.5.2. O programa de teste
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 | |
4.5.3. A configuração do Hibernate
4.5.4. A configuração do log4j.properties
4.5.5. Os resultados
Pergunta: estabeleça a ligação entre o código Java e os resultados apresentados.