7. Spring Data JPA EclipseLink
7.1. Introduction
Riprendiamo l'architettura precedente, che ora implementiamo con un livello JPA / EclipseLink.
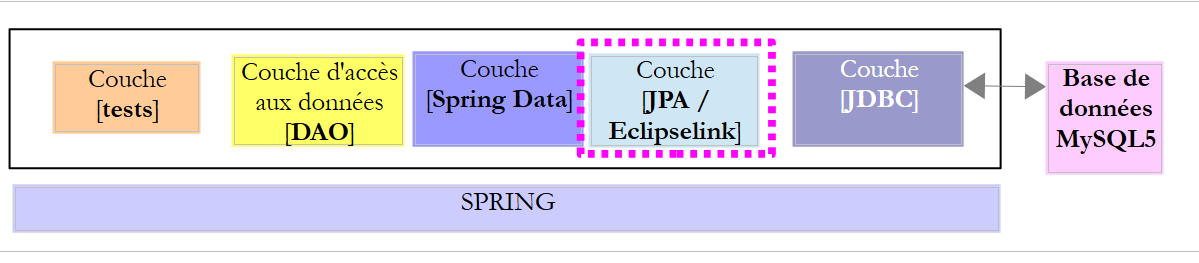 |
7.2. Configurazione dell’ambiente di lavoro
Con STS, scaricare il progetto [myql-config-jpa-hibernate] [1-4]:
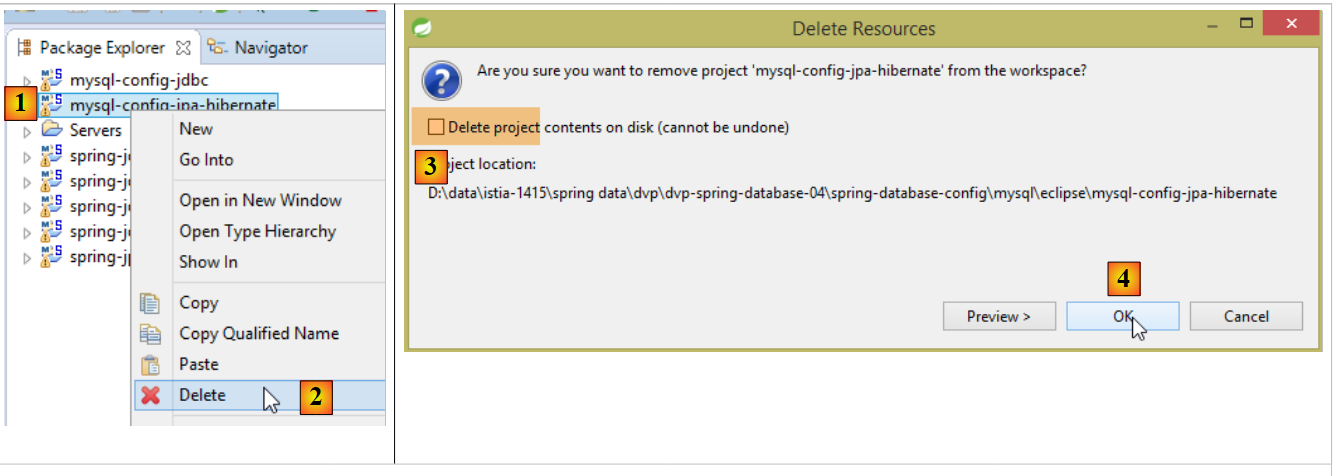 |
quindi importare il progetto [mysl-config-jpa-eclipselink] [5] che si trova nella cartella [<exemples>/spring-database-config/mysql/eclipse] [6]:
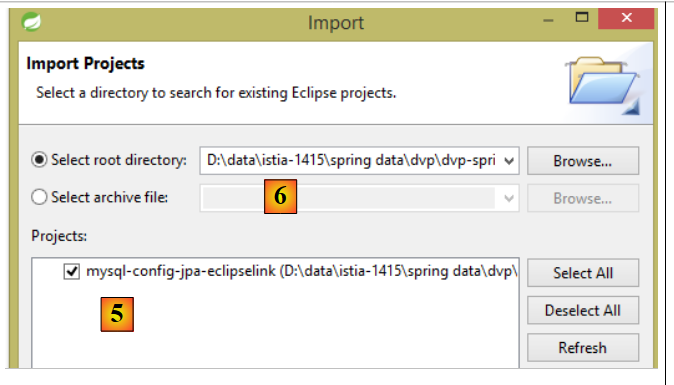 |
Fatto ciò, reinizializzate l’ambiente Maven (Alt-F5) di tutti i progetti presenti in [Package Explorer]:
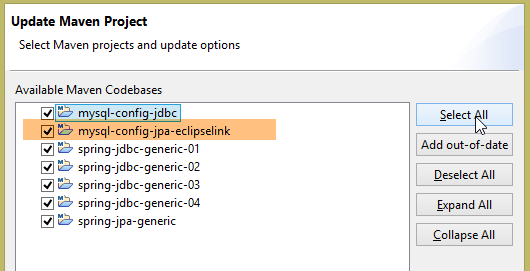 |
Quindi, per verificare l'ambiente di lavoro, eseguire la configurazione di esecuzione denominata [spring-jpa-generic-JUnitTestDao-hibernate-eclipselink]:
 |
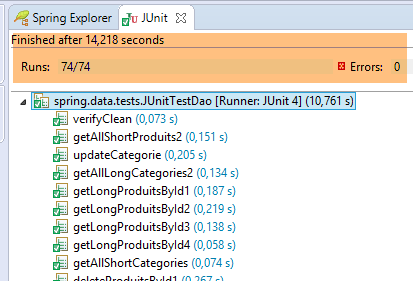
Questa configurazione esegue il test [JUnitTestDao]. Il test deve avere esito positivo:
 |
7.3. Il progetto di configurazione del livello JPA
 |
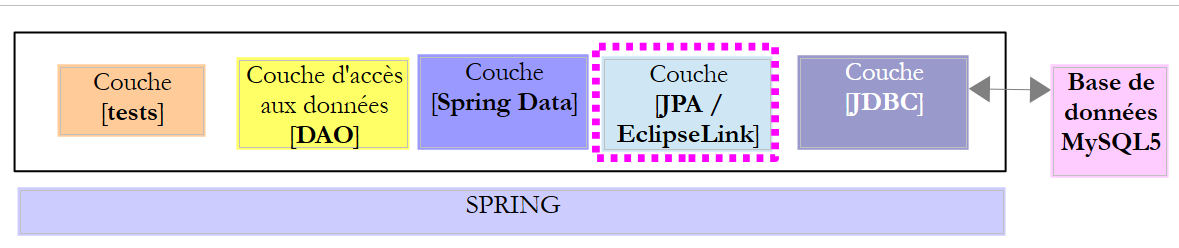
Questo progetto ha lo scopo di configurare il livello JPA dell'architettura riportata di seguito:
 |
7.3.1. Configurazione Maven
Il progetto è un progetto Maven configurato dal seguente file [pom.xml]:
<project xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd"
xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<modelVersion>4.0.0</modelVersion>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-config-jpa</artifactId>
<version>0.0.1-SNAPSHOT</version>
<name>configuration mysql openjpa</name>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
</parent>
<dependencies>
<!-- dipendenze variabili ********************************************** -->
<!-- JPA provider -->
<dependency>
<groupId>org.eclipse.persistence</groupId>
<artifactId>eclipselink</artifactId>
<version>2.6.0</version>
</dependency>
<!-- dipendenze costanti ********************************************** -->
<!-- Spring Data -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
</dependency>
<!-- configurazione ereditata JDBC -->
<dependency>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-config-jdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
<exclusions>
<exclusion>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</exclusion>
</exclusions>
</dependency>
</dependencies>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.7</java.version>
</properties>
<build>
<plugins>
<!-- [https://flexguse.wordpress.com/2013/08/10/maven-spring-data-jpa-eclipselink-and-static-weaving/] -->
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
</plugin>
<!-- Questo plugin garantisce l'intricamento statico EclipseLink -->
<plugin>
<artifactId>staticweave-maven-plugin</artifactId>
<groupId>de.empulse.eclipselink</groupId>
<version>1.0.0</version>
<executions>
<execution>
<goals>
<goal>weave</goal>
</goals>
<phase>process-classes</phase>
<configuration>
<logLevel>ALL</logLevel>
<!-- <includeProjectClasspath>true</includeProjectClasspath> -->
</configuration>
</execution>
</executions>
<dependencies>
<dependency>
<groupId>org.eclipse.persistence</groupId>
<artifactId>eclipselink</artifactId>
<version>2.6.0</version>
</dependency>
</dependencies>
</plugin>
</plugins>
<pluginManagement>
<plugins>
<!--La configurazione di questo plugin viene utilizzata esclusivamente per memorizzare le impostazioni m2e di Eclipse. Non ha alcuna influenza sulla compilazione Maven stessa. -->
<plugin>
<groupId>org.eclipse.m2e</groupId>
<artifactId>lifecycle-mapping</artifactId>
<version>1.0.0</version>
<configuration>
<lifecycleMappingMetadata>
<pluginExecutions>
<pluginExecution>
<pluginExecutionFilter>
<groupId>
de.empulse.eclipselink
</groupId>
<artifactId>
staticweave-maven-plugin
</artifactId>
<versionRange>
[1.0.0,)
</versionRange>
<goals>
<goal>weave</goal>
</goals>
</pluginExecutionFilter>
<action>
<execute>
<runOnIncremental>true</runOnIncremental>
</execute>
</action>
</pluginExecution>
</pluginExecutions>
</lifecycleMappingMetadata>
</configuration>
</plugin>
</plugins>
</pluginManagement>
</build>
</project>
- righe 5-7: l’artefatto Maven generato da questo progetto. È lo stesso di quello del progetto [mysql-config-jpa-hibernate]. Ciò significa che solo uno di questi progetti può essere attivo in un dato momento;
- righe 10-14: il progetto Maven padre che definisce la versione della maggior parte delle dipendenze necessarie al progetto;
- righe 19-22: la libreria EclipseLink;
- righe 26-29: la libreria Spring Data;
- righe 32-34: il progetto di configurazione del livello JPA si basa su quello del livello JDBC, che definisce, tra le altre cose, il driver JDBC del SGBD utilizzato e le coordinate del database da utilizzare;
- righe 35-40: il progetto di configurazione del livello JDBC include la libreria [Spring JDBC], che in questo caso viene sostituita dalla libreria [Spring Data JPA]. Si raccomanda quindi di non includerla nelle dipendenze del progetto. Se rimane, tuttavia, ciò non causa errori;
- il plugin delle righe 58-81 implementa il 'weaving' delle entità JPA. Ciò che gli anglosassoni chiamano weaving è la trasformazione (l'arricchimento) delle entità JPA affinché supportino il Lazy Loading. Non è stato necessario configurare Hibernate affinché questo weaving avvenisse. Per EclipseLink è necessario un plugin Maven. Ho cercato a lungo un modo per forzare EclipseLink a rispettare l’attributo [fetch = FetchType.LAZY] dell’annotazione [@ManyToOne] riportata di seguito:
@ManyToOne(fetch = FetchType.LAZY)
@JoinColumn(name = ConfigJdbc.TAB_PRODUITS_CATEGORIE_ID)
private Categorie categorie;
La specifica JPA indica che l’attributo [fetch = FetchType.LAZY] dell’annotazione [@ManyToOne] è un «suggerimento» (suggerimento) che l’implementazione JPA non è tenuta a rispettare. E infatti EclipseLink non lo rispetta per impostazione predefinita. È necessaria una configurazione speciale affinché lo rispetti. Dopo molte ricerche infruttuose, ho trovato la soluzione al problema relativo a URL citato alla riga 51. Quando si includono le righe 58-81 nel file [pom.xml], Eclipse segnala un errore relativo al file. Si tratta di un problema di configurazione del plugin [m2e], che gestisce i progetti Maven all’interno di Eclipse. Per risolvere l’errore è necessario aggiungere le righe da 83 a 119.
Alla fine, le dipendenze sono le seguenti:
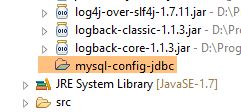 |
7.3.2. Configurazione Spring
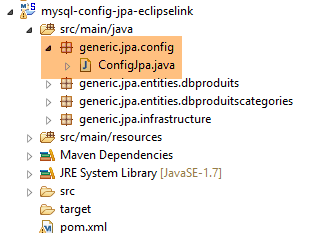 |
La classe [ConfigJpa] configura il progetto Spring:
package generic.jpa.config;
import generic.jdbc.config.ConfigJdbc;
import javax.persistence.EntityManagerFactory;
import org.apache.tomcat.jdbc.pool.DataSource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.orm.jpa.JpaTransactionManager;
import org.springframework.orm.jpa.JpaVendorAdapter;
import org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean;
import org.springframework.orm.jpa.vendor.Database;
import org.springframework.orm.jpa.vendor.EclipseLinkJpaVendorAdapter;
import org.springframework.transaction.PlatformTransactionManager;
@Configuration
@Import({ ConfigJdbc.class })
public class ConfigJpa {
// il provider JPA
@Bean
public JpaVendorAdapter jpaVendorAdapter() {
// Nota: le entità JPA e la configurazione di EclipseLink si trovano nel file META-INF/persistence.xml
EclipseLinkJpaVendorAdapter eclipseLinkJpaVendorAdapter = new EclipseLinkJpaVendorAdapter();
eclipseLinkJpaVendorAdapter.setShowSql(false);
eclipseLinkJpaVendorAdapter.setDatabase(Database.MYSQL);
eclipseLinkJpaVendorAdapter.setGenerateDdl(true);
return eclipseLinkJpaVendorAdapter;
}
// fonte dati
@Bean
public DataSource dataSource() {
// fonte dati TomcatJdbc
DataSource dataSource = new DataSource();
// configurazione di accesso JDBC
dataSource.setDriverClassName(ConfigJdbc.DRIVER_CLASSNAME);
dataSource.setUsername(ConfigJdbc.USER_DBPRODUITSCATEGORIES);
dataSource.setPassword(ConfigJdbc.PASSWD_DBPRODUITSCATEGORIES);
dataSource.setUrl(ConfigJdbc.URL_DBPRODUITSCATEGORIES);
// connessioni inizialmente aperte
dataSource.setInitialSize(5);
// risultato
return dataSource;
}
// EntityManagerFactory
@Bean
public EntityManagerFactory entityManagerFactory(JpaVendorAdapter jpaVendorAdapter, DataSource dataSource) {
LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();
factory.setJpaVendorAdapter(jpaVendorAdapter);
factory.setDataSource(dataSource);
factory.afterPropertiesSet();
EntityManagerFactory entityManagerFactory = factory.getObject();
return entityManagerFactory;
}
// Gestore delle transazioni
@Bean
public PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) {
JpaTransactionManager txManager = new JpaTransactionManager();
txManager.setEntityManagerFactory(entityManagerFactory);
return txManager;
}
}
Questa configurazione è analoga a quella descritta in dettaglio nel paragrafo 6.3.2, per l'implementazione JPA di Hibernate. Descriviamo solo le differenze:
- righe 23-31: il bean [jpaVendorAdapter] è ora implementato con EclipseLink;
- righe 50-58: nella versione JPA di Hibernate era scritto:
che serviva a indicare dove dovevano essere ricercate le entità JPA. In questo caso, ci si rimette al file [persistence.xml] (commento alla riga 25) (cfr. paragrafo 6.3.4) per:
- definire le entità JPA;
- configurare EclipseLink per il weaving di tali entità;
7.4. Il file [persistence.xml]
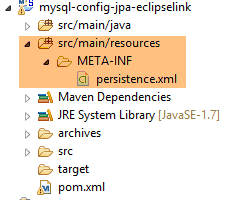 |
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_1_0.xsd">
<persistence-unit name="generic-jpa-entities-dbproduitscategories" transaction-type="RESOURCE_LOCAL">
<!-- entità JPA -->
<class>generic.jpa.entities.dbproduitscategories.Categorie</class>
<class>generic.jpa.entities.dbproduitscategories.Produit</class>
<class>generic.jpa.entities.dbproduitscategories.User</class>
<class>generic.jpa.entities.dbproduitscategories.Role</class>
<class>generic.jpa.entities.dbproduitscategories.UserRole</class>
<exclude-unlisted-classes>true</exclude-unlisted-classes>
<!-- Proprietà necessarie affinché [@ManyToOne] possa essere ricercato in modalità LAZY -->
<properties>
<property name="eclipselink.weaving" value="static" />
<property name="eclipselink.weaving.lazy" value="true" />
<property name="eclipselink.weaving.internal" value="true" />
</properties>
</persistence-unit>
</persistence>
- riga 4: l'unità di persistenza. Può avere un nome qualsiasi (attributo name);
- righe 6-10: le cinque entità JPA da gestire;
- la riga 11 è importante. A volte capita che un progetto definisca entità utilizzate in contesti diversi. La riga 11 garantisce che non vi siano altre entità oltre a quelle definite nelle righe 5-10. Ciò è importante quando queste ultime vengono utilizzate per generare le tabelle della fonte dati. La presenza di entità in eccesso genererebbe tabelle in eccesso;
- righe 13-17: configurazione di EclipseLink per un weaving statico. Esistono due tipi di weaving:
- [statique]: le entità JPA vengono arricchite (woven) non appena viene istanziato il livello JPA;
- [dynamique]: le entità JPA vengono arricchite (woven) la prima volta che entrano nel livello JPA;
7.5. Le entità JPA
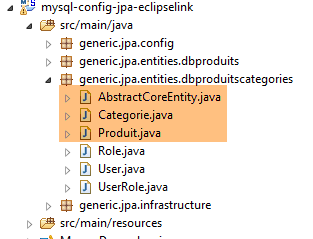 |
Le entità JPA sono quelle descritte al paragrafo 6.3.3 per l'implementazione Hibernate con due differenze:
- tutte le entità JPA presentano l’annotazione [@Cache(alwaysRefresh = true)] che disattiva la cache di EclipseLink. In questo documento non viene fatto uso delle cache delle implementazioni JPA utilizzate. Quella di EclipseLink sembra essere attiva per impostazione predefinita e causava errori nei test.
@Entity
@Table(name = ConfigJdbc.TAB_CATEGORIES)
@JsonFilter("jsonFilterCategorie")
@Cache(alwaysRefresh = true)
public class Categorie implements AbstractCoreEntity {
- tutte le annotazioni [@OneToMany] sono accompagnate dall’annotazione [@CascadeOnDelete]:
@OneToMany(fetch = FetchType.LAZY, mappedBy = "categorie", cascade = { CascadeType.ALL })
@CascadeOnDelete
private List<Produit> produits;
Questa annotazione svolge un ruolo nella generazione delle tabelle a partire dalle entità JPA. Aggiunge alle chiavi esterne (in questo caso PRODUITS[CATEGORIE_ID] ---> CATEGORIES[ID]) l'attributo SQL [ON DELETE CASCADE], che fa sì che ogni volta che si elimina una categoria dalla tabella [CATEGORIES], vengano eliminati anche i prodotti corrispondenti nella tabella [PRODUITS];
Nota: è importante sottolineare che questa annotazione viene utilizzata sia durante la creazione della tabella, come appena visto, sia durante il suo utilizzo. EclipseLink presuppone che l’attributo SQL [ON DELETE CASCADE] sia effettivamente presente e lo utilizza ogni volta che gli viene richiesto di eliminare una categoria. La sua assenza causerebbe degli errori.
7.6. Il livello di test
 |
 |
I test sopra riportati sono identici a quelli delle implementazioni Spring JDBC e Spring JPA Hibernate. Se necessario, si rimanda alle seguenti pagine:
- [JUnitTestCheckArguments]: paragrafo 4.11.1;
- [JUnitTestDao]: paragrafo 4.11.2;
- [JUnitTestPushTheLimits]: paragrafo 4.11.3;
- [JUnitTestProxies]: paragrafo 6.4.5;
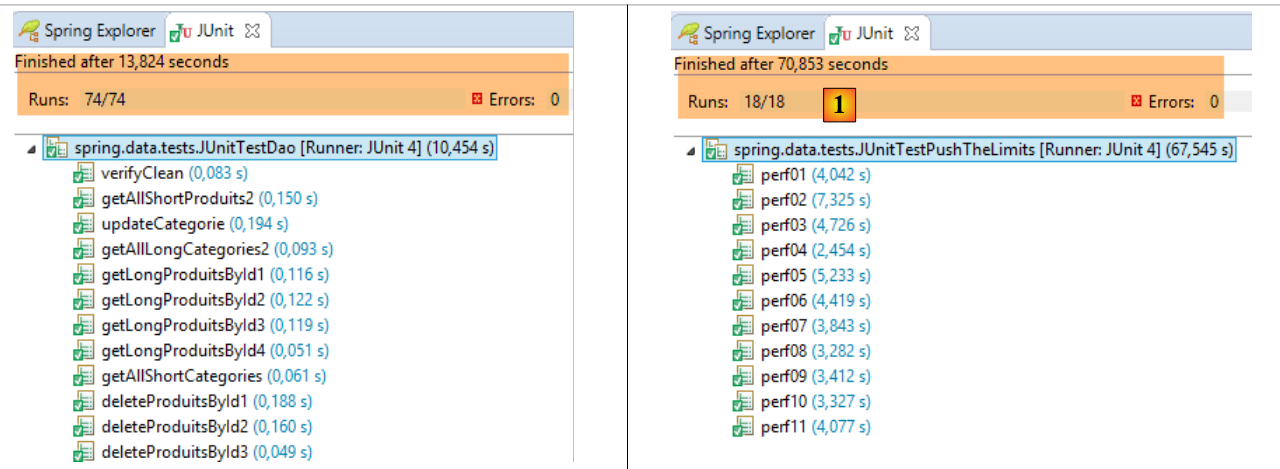
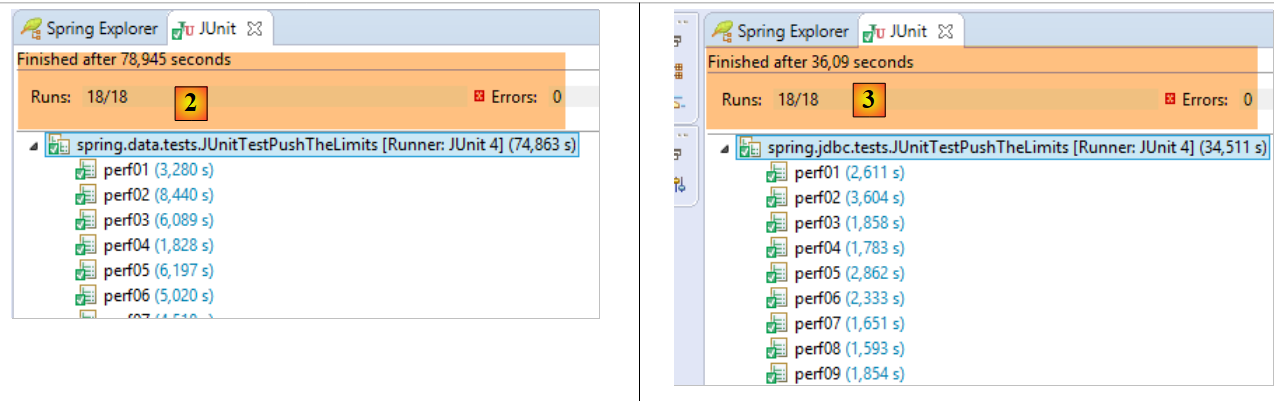
I risultati ottenuti sono i seguenti:
 |
 |
- in [1], [JUnitTestPushTheLimits-EclipseLink]: 70,583 s
- in [2], [JUnitTestPushTheLimits-Hibernate]: 78,945 s
- in [3], [JUnitTestPushTheLimits-JDBC]: 36,09 s
Il test [JUnitTestProxies] fornisce i seguenti risultati da console:
Si nota qui che, quando si accede al campo [Categorie.produits] di una categoria di tipo PROXY e al campo [Produit.categorie] di un prodotto di tipo PROXY, si riesce a ottenere le informazioni in entrambi i casi (righe 7 e 17). Tra le tre implementazioni JPA, questa è l’unica che lo consente sulle entità PROXY.