1. Introduzione
Il codice PDF di questo documento è disponibile |QUI||.
Gli esempi di questo documento sono disponibili |QUI|.
1.1. Contenu
In questo documento ci proponiamo di esaminare diverse configurazioni di gestione di un database. Consideriamo la seguente architettura a livelli:
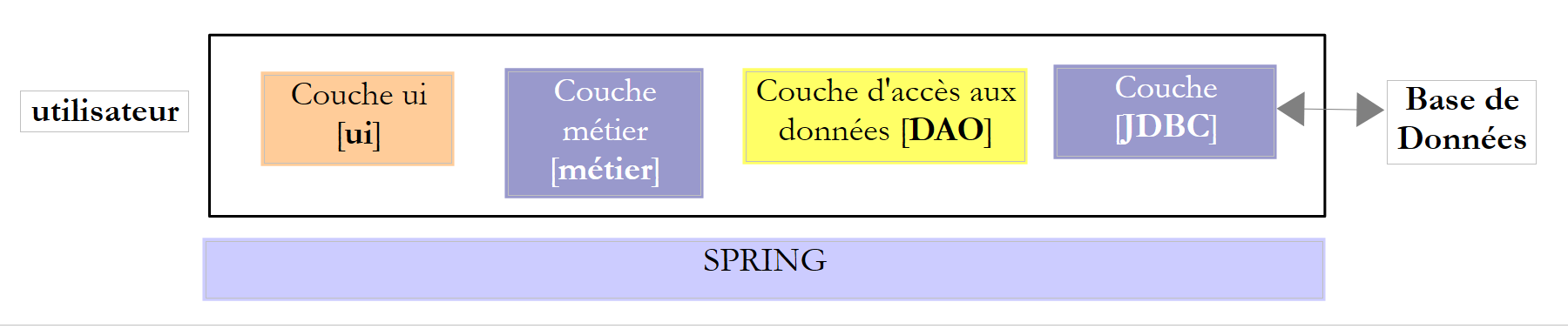 |
Il flusso di esecuzione va da sinistra a destra:
- è una delle classi del livello [ui] (Use Interface) a essere eseguita per prima. Essa istanzierà i livelli [metier] e [dao]. Se il livello [ui] è un'interfaccia grafica, attende quindi le azioni dell'utente. Un'azione da parte di quest'ultimo può provocare l'esecuzione di metodi in tutti i livelli dell'architettura fino al database. Il risultato di queste esecuzioni viene restituito all'utente in una forma o nell'altra;
Il ruolo dei diversi livelli potrebbe essere il seguente:
- il livello [JDBC] (Java DataBase Connectivity) è un’interfaccia di accesso universale ai database. Presenta sempre la stessa interfaccia al livello [DAO]. Se si cambia il SGBD, è sufficiente cambiare il driver JDBC. Il livello [DAO] non cambia se si è avuto cura di rispettare una serie di regole. È tuttavia difficile garantire una portabilità al 100% tra le versioni SGBD, poiché queste contengono spesso una parte significativa di codice proprietario SQL che è difficile ignorare, dato che spesso comporta miglioramenti delle prestazioni. Non appena si utilizza il codice proprietario, la portabilità tra i vari SGBD non è più possibile. Inoltre, i SGBD presentano spesso politiche diverse per la generazione automatica delle chiavi primarie, nonché parole riservate che non sono le stesse da un codice all’altro. In questo documento, siamo comunque riusciti a trasferire l’architettura JDBC studiata su sei diversi SGBD, accettando che vi fosse un progetto di configurazione per ciascuno di essi;
- il livello [DAO] espone un'interfaccia di accesso ai dati del database specifico utilizzato (da distinguere dall'interfaccia JDBC che espone metodi validi per qualsiasi SGBD);
- il livello [métier] implementa le regole di gestione o le regole di business dell’applicazione.
- come dati di input utilizza quelli provenienti dal database tramite il livello [dao] e/o quelli dell’utente che le vengono trasmessi dal livello [ui];
- produce dati che può salvare nel database tramite il livello [dao] e/o restituire al livello [ui] che lo ha interrogato, per la visualizzazione da parte dell’utente;
- il livello [ui] è il livello che esegue le azioni dell’utente e gli restituisce i risultati delle stesse;
Nell’esempio sopra riportato, il livello [DAO] invia richieste SQL al livello [JDBC] affinché vengano eseguite nel livello SGBD. Da alcuni anni (2006) questa architettura può evolversi nel modo seguente:
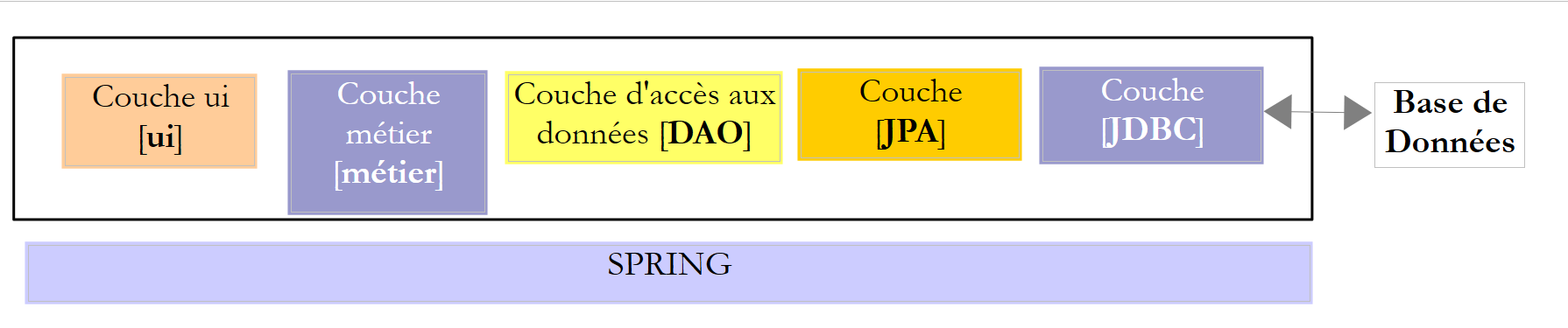 |
Ora è il livello JPA (Java Persistence API) a inviare le richieste SQL al livello JDBC e a riceverne i risultati. Il livello [JPA] presenta al livello [DAO] operazioni per la persistenza, la modifica, l’eliminazione e il recupero di oggetti. Il livello [DAO] non invia più comandi SQL. Questo approccio è più portabile poiché le implementazioni JPA gestiscono le differenze rispetto a SGBD, ma è più lento rispetto alla tecnologia JDBC. Effettueremo dei test di prestazione per dimostrarlo. La tecnologia JPA formalizza il lavoro svolto dal framework Hibernate [http://hibernate.org/] anni fa.
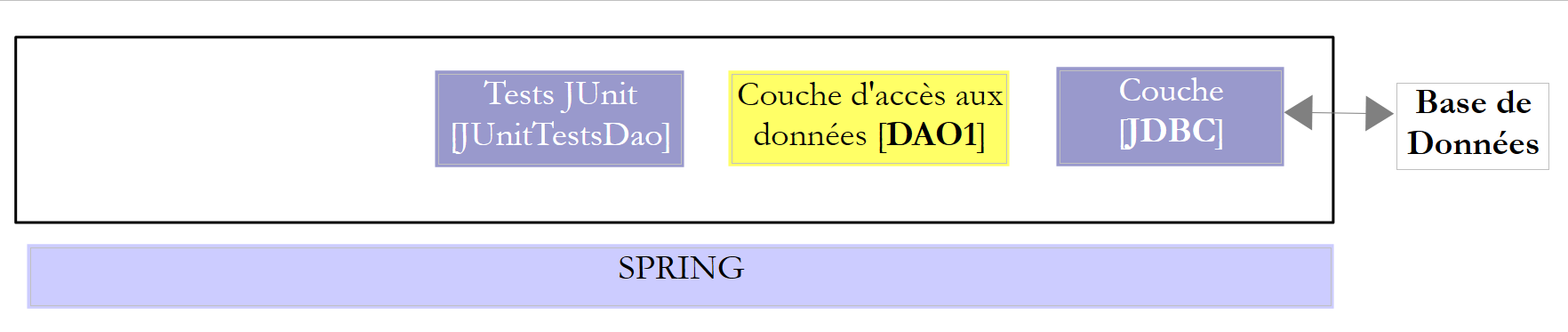
Esamineremo due livelli [DAO] con una delle due architetture seguenti:
 |
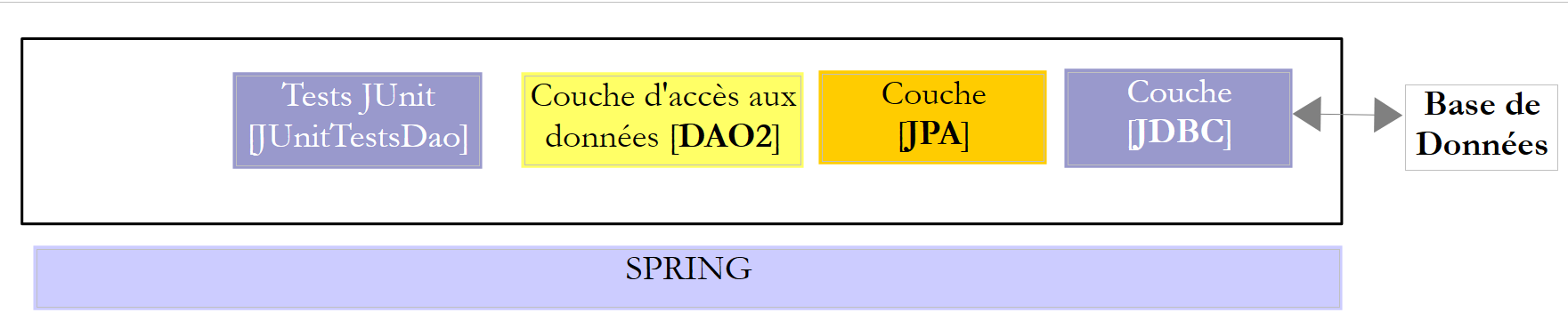 |
Ai livelli [DAO1] e [DAO2] verrà richiesto di implementare la stessa interfaccia [IDAO]. Pertanto, il test [JUnitTestsDao] sarà identico per entrambe le configurazioni e ci consentirà di confrontare le prestazioni. Il livello [DAO1] verrà implementato con Spring JDBC e il livello [DAO2] con Spring JPA;
Fatto ciò, esporremo l’interfaccia [IDAO] sul web nel modo seguente:
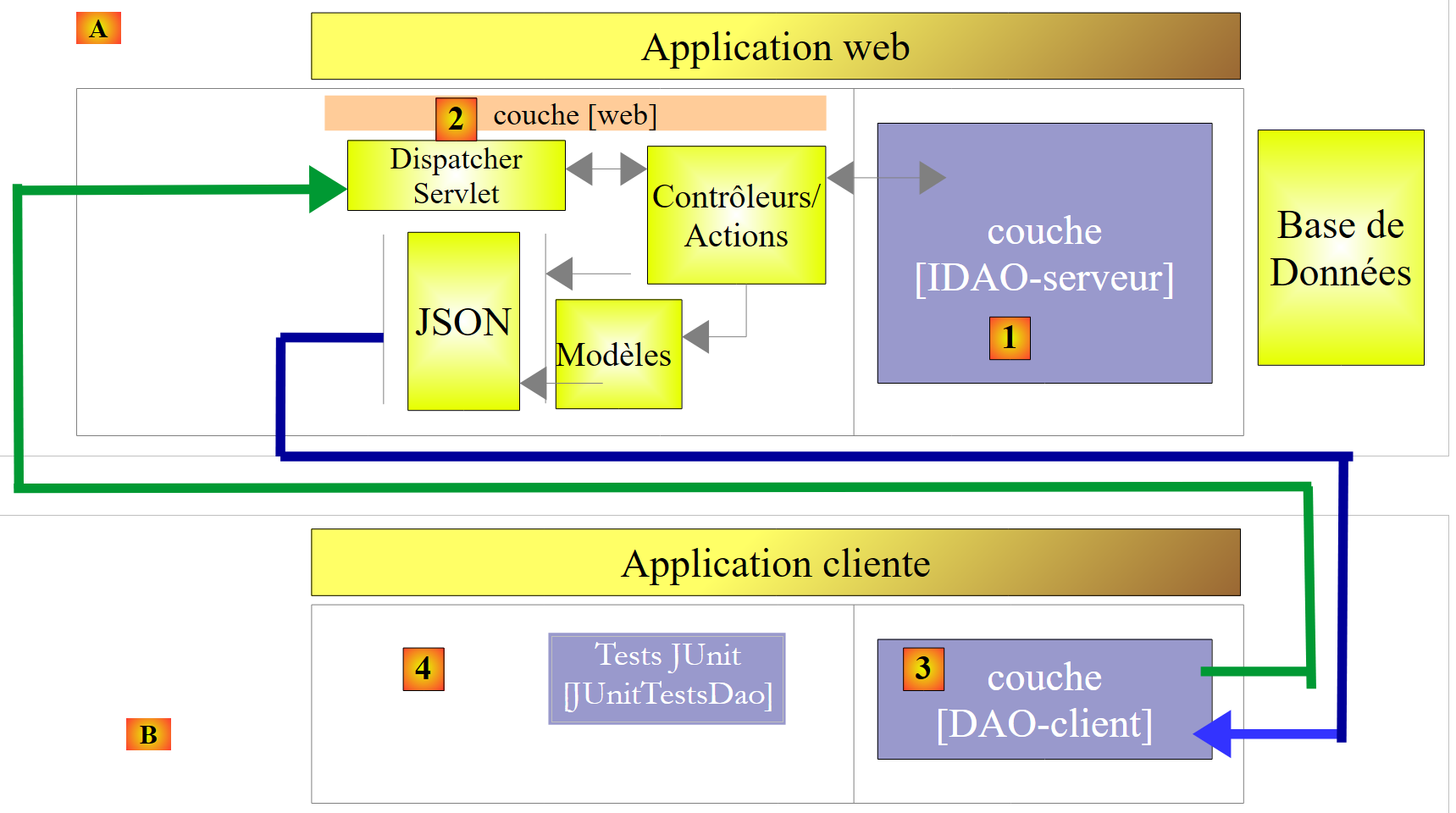 |
- in [1], il livello [IDAO] viene esposto sul web tramite un livello web [2] implementato da Spring MVC. È proprio l’interfaccia [IDAO] ad essere esposta e realizzeremo due versioni del servizio web a seconda che tale interfaccia sia implementata con un’architettura [DAO-JDBC] o [DAO-JPA-JDBC];
- In [B], un client remoto utilizza le URL esposte dal servizio web, che consentono l'accesso ai metodi del livello [IDAO-serveur]. Faremo in modo che il livello [DAO-Client] [3] implementi l'interfaccia [IDAO-serveur] [1]. Ciò ci consentirà di utilizzare lo stesso test [JUnitTestsDao] già utilizzato due volte ([4]);
- in [3], il livello [DAO-client] verrà implementato con Spring RestTemplate;
Fatto ciò, renderemo sicuro l’accesso al servizio web:
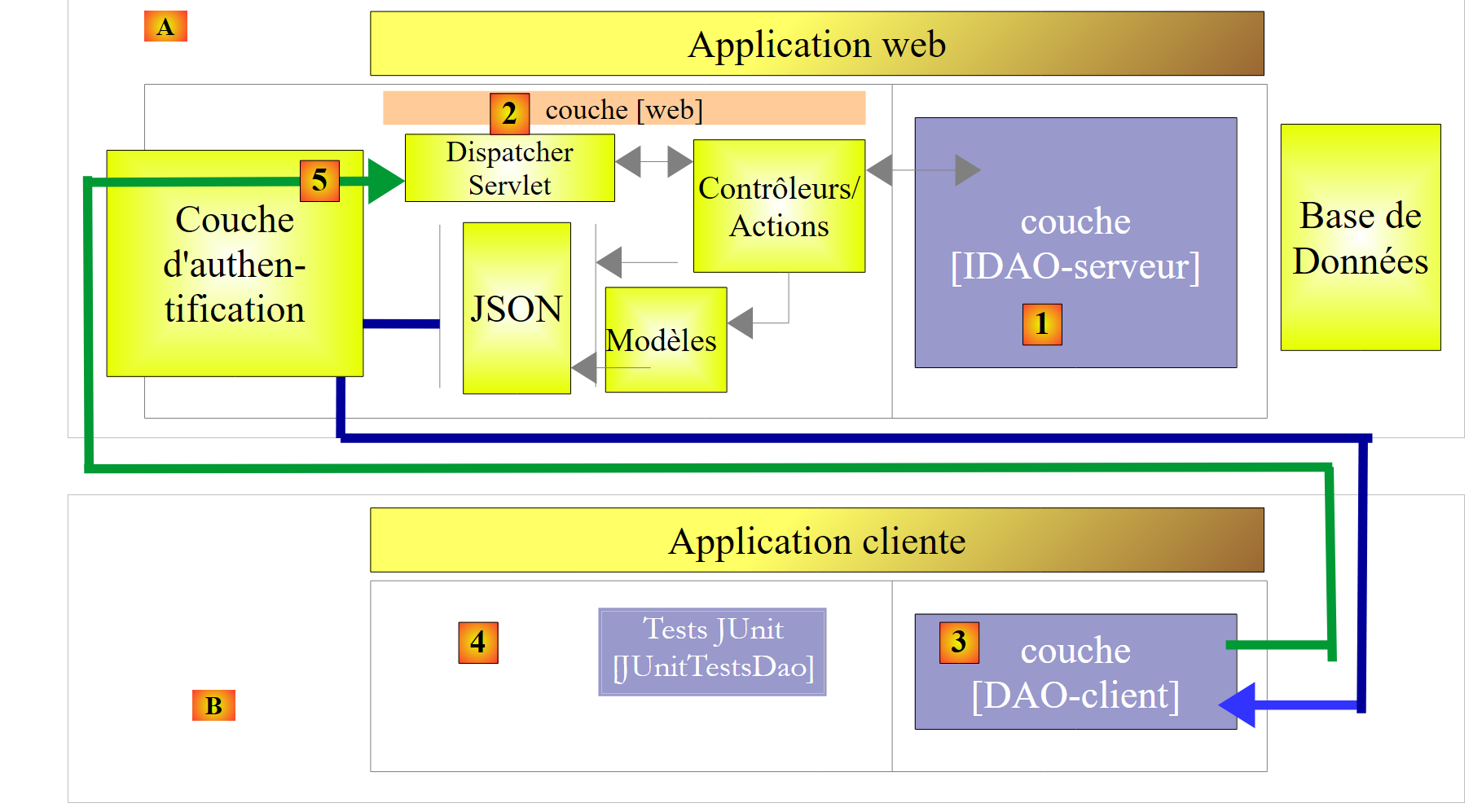 |
- in [5], la richiesta HTTP del client passa attraverso un livello di autenticazione implementato con Spring Security;
Fatto ciò, evolveremo l’architettura precedente verso la seguente:
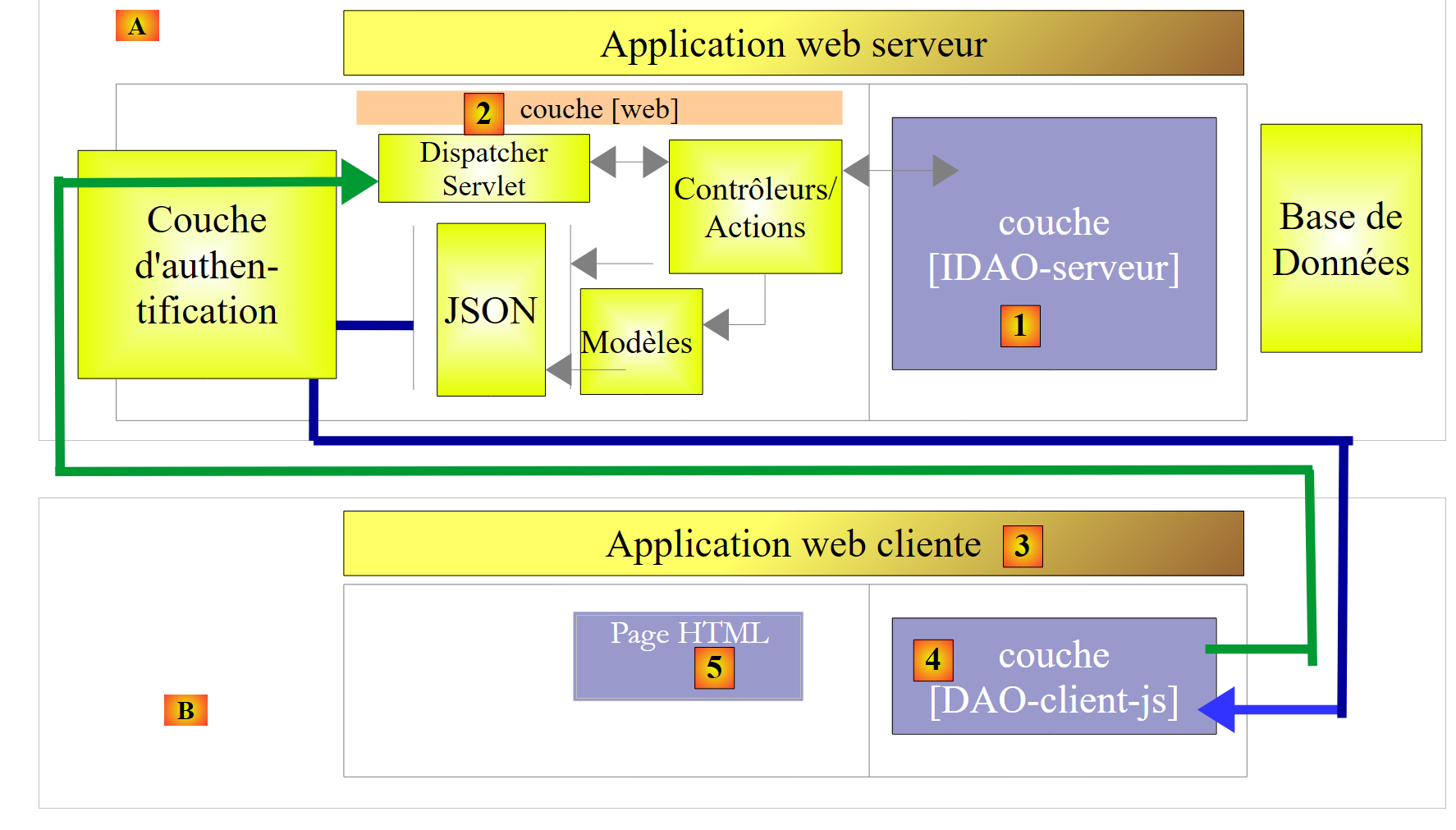 |
- in [3], l'applicazione client è essa stessa un'applicazione web. Questa presenterà un modulo [5] che consentirà di interrogare i URL del servizio web protetto. Gli accessi HTTP al servizio web protetto avverranno tramite un livello [DAO-client-js] implementato in JavaScript. Questa architettura utilizza le cosiddette richieste interdominio:
- il servizio web [2] presenta URL della forma [http://machine1:port1/];
- l’applicazione web client [3] viene scaricata da una URL [http://machine2:port2/]. Se [http://machine2:port2/] non è identico a [http://machine1:port1/] (stessa macchina, stessa porta), il browser client bloccherà le chiamate HTTP provenienti dal livello [DAO-client-js]. Per risolvere questo problema, il servizio web deve autorizzare le richieste interdominio. Vedremo come;
I progetti presentati sono stati testati con i seguenti sei SGBD:
- MySQL 5 Community Edition;
- SQL Server 2014 Express;
- PostgreSQL 9.4;
- Oracle Express 11g release 2;
- IBM DB2 Express-C 10.5;
- Firebird 2.5.4;
Per ciascuno di questi SGBD, sono stati sviluppati quattro diversi livelli [DAO]:
- un livello implementato con Spring JDBC;
- un livello implementato con Spring JPA e il provider JPA Hibernate;
- un livello implementato con Spring JPA e il provider JPA EclipseLink;
- un livello implementato con Spring JPA e il provider JPA OpenJPA;
Si tratta quindi di un insieme di ventiquattro configurazioni diverse presentate qui. È stato compiuto un grande sforzo di fattorizzazione:
- la maggior parte del codice è stata scritta una sola volta. Si basa su due progetti Maven di configurazione:
- uno configura il livello JDBC;
- l’altro configura il livello JPA;
 |
 |
Il progetto di configurazione Maven del livello JDBC [1] di un particolare SGBD consiste in due punti:
- importare l’archivio del driver JDBC;
- definire le credenziali di accesso al database utilizzato e i vari comandi SQL che il livello [DAO1] invierà al driver JDBC. Sebbene SQL sia standardizzato, si sono verificati problemi di portabilità dovuti essenzialmente alla presenza nelle query di nomi di tabelle/colonne che si sono rivelati essere parole chiave non consentite in alcuni SGBD (tabella ROLES per DB2, colonna PASSWORD per Firebird). Inoltre, sebbene un nome di colonna sia normalmente insensibile alle maiuscole e alle minuscole, si è verificato un problema con PostgreSQL relativo alla colonna ID della chiave primaria delle tabelle. Il sistema ha richiesto che fosse denominata id in minuscolo. Si tratta di tipici problemi di portabilità inaspettati;
I tre progetti Maven di configurazione del livello JPA [2] di un particolare SGBD consistono anch’essi in due punti:
- importare l’archivio dell’implementazione JPA;
- configurare l’implementazione JPA utilizzata per il SGBD specifico collegato. Infatti, è il livello JPA che invia i comandi SQL al livello JDBC. Per funzionare correttamente, deve conoscere il SGBD per potergli inviare i comandi SQL che esso riconoscerà. Tali comandi potranno utilizzare il SQL proprietario di questo SGBD, nonché le caratteristiche specifiche di quest’ultimo (tipi di dati, sequenze, trigger, procedure, generazione automatica di chiavi primarie, ...);
Si hanno così ventiquattro progetti (4 configurazioni x 6 SGBD) di configurazione Maven su cui si baseranno tutti gli altri progetti di gestione del database. Negli schemi sopra riportati, poiché i livelli [DAO1] e [DAO2] offrono la stessa interfaccia, le 24 configurazioni delle due architetture sopra indicate saranno testate con un'unica classe di test [JUnitTestsDao]. Una volta verificate queste architetture, non ci sono più difficoltà:
- il progetto Maven per la pubblicazione del database sul web si basa su queste due architetture. Anche in questo caso vi sono quindi 24 configurazioni possibili;
- il progetto Maven per la protezione dell’accesso al servizio web si basa sul progetto precedente e presenta anch’esso 24 configurazioni possibili;
- infine, il progetto Maven che consente le richieste interdominio al servizio web protetto si basa sul progetto precedente e presenta anch’esso 24 configurazioni possibili;
Lo studio è stato condotto con SGBD, MySQL5 e l’implementazione Hibernate JPA. Si procede quindi al porting verso le implementazioni JPA Eclipselink e OpenJPA. Successivamente si procede al porting verso gli altri database (PostgresQL, Oracle, SQL Server, DB2, Firebird).
Questo corso è rivolto ai principianti. La maggior parte dei concetti utilizzati viene spiegata. Non è necessario conoscere né la programmazione dei database né la programmazione web. È invece necessaria una solida conoscenza del linguaggio SQL, poiché le query SQL utilizzate non vengono spiegate.
Per comprendere gli esempi è necessaria una conoscenza di base del linguaggio Java, che si può acquisire in qualsiasi corso introduttivo a tale linguaggio. I primi due capitoli del documento [Introduzione al linguaggio Java (1998)] sono sufficienti. Si tratta di un documento datato (1998, rivisto nel 2002), ma le nozioni di base ci sono tutte. Per un corso completo, si può consultare l’imponente libro di Jean-Marie Doudoux [http://www.jmdoudoux.fr/java].
Questo documento non è affatto esaustivo. Ha il solo scopo di fornire una metodologia e dei codici che è possibile riutilizzare in contesti simili. Il documento è stato scritto in modo tale da poter essere letto senza avere un computer a portata di mano. Per questo motivo sono presenti numerose schermate.
Sebbene non copra tutte le funzionalità del linguaggio Java né tutti i suoi ambiti di applicazione, questo documento può essere utilizzato come guida all’apprendimento del linguaggio. Seguendo questo documento, anche se non nella sua interezza, il lettore principiante raggiungerà un livello «Java avanzato» sia nell’uso del linguaggio che in quello del framework Spring. Potrà quindi proseguire la sua formazione su Java con le seguenti opere:
- [Introduzione a Spring MVC e Thymeleaf attraverso esempi (2015)], che approfondisce l’apprendimento dell’ecosistema Spring presentando il suo ramo «programmazione web MVC»;
- [Un esempio client/server - AngularJS 1.x / Spring 4 (2014)], che presenta un’architettura web client/server, in cui il client è implementato con il framework [AngularJS] e il server con [Spring MVC];
- [Introduzione a Java EE con l'IDE NetBeans e il server applicativo GlassFish (2012)], che abbandona l’ecosistema Spring a favore di un’architettura web basata su JSF (Java Server Faces) e EJB (Enterprise Java Bean);
- [Introduzione alla programmazione per tablet Android con Android Studio (2016)] che descrive un'architettura client/server, in cui il client è un tablet Android e il server un servizio web implementato con Spring MVC;
1.2. Sources
Questo documento ha due fonti principali:
- [ref1] : da [Introduzione a Spring MVC e Thymeleaf attraverso esempi (2015)]. Il presente documento riprende, utilizzando un altro database, il lavoro svolto e presentato in [ref1]. Semplicemente, lo estrapola dal contesto della programmazione web con Spring MVC. Ho deciso di redigere un documento a sé stante proprio perché ho ritenuto che i codici e la metodologia utilizzati in [ref1] per pubblicare un database sul web fossero riutilizzabili;
- [ref2] : da [Persistenza in Java 5 attraverso la pratica (2007)];
Per approfondire Spring, è possibile consultare i seguenti riferimenti:
- il documento di riferimento del framework Spring [http://docs.spring.io/spring/docs/current/spring-framework-reference/pdf/spring-framework-reference.pdf];
- numerosi tutorial su Spring sono disponibili all'indirizzo URL [http://spring.io/guides];
- il sito di [developpez.com] dedicato a Spring [http://spring.developpez.com/];
- il tutorial [http://www.tutorialspoint.com/spring/spring_tutorial.pdf];
Il lettore con conoscenze SQL insufficienti potrà acquisire le nozioni di base con l’opera [Introduction au langage SQL avec le SGBD Firebird] all’indirizzo URL [Introduzione al linguaggio SQL con il DBMS Firebird (2006)].
1.3. Gli strumenti utilizzati
Gli esempi che seguono sono stati testati nel seguente ambiente:
- computer con Windows 8.1 Pro a 64 bit;
- JDK 1.8 (paragrafo 23.1);
- IDE Spring Tool Suite 3.6.3 (paragrafo 1);
- browser Chrome (non sono stati utilizzati altri browser);
- estensione Chrome [Advanced Rest Client] (paragrafo 1);
- SGBD MySQL 5.6 Community Edition (paragrafo 23.4);
- SGBD SQL Server 2014 Express (paragrafo 23.9);
- SGBD PostgreSQL 9.4 (paragrafo 23.7);
- SGBD Oracle Express 11g release 2 (paragrafo 23.6);
- SGBD IBM DB2 Express-C 10.5 (paragrafo 23.8);
- SGBD Firebird 2.5.4 (paragrafo 23.10);
- i client EMS Manager dei suoi sei SGBD (paragrafo 23.5);
Attenzione a JDK 1.8. Un metodo del caso di studio utilizza un metodo del pacchetto [java.lang] di Java 8.
La maggior parte degli esempi sono progetti Maven che possono essere aperti indifferentemente con IDE Eclipse, IntellijIDEA e NetBeans. Di seguito, le schermate provengono da IDE Spring Tool Suite, una variante di Eclipse.
1.4. Gli esempi
Gli esempi sono disponibili all'indirizzo URL [http://tahe.developpez.com/java/spring-database] sotto forma di un file zip da scaricare.
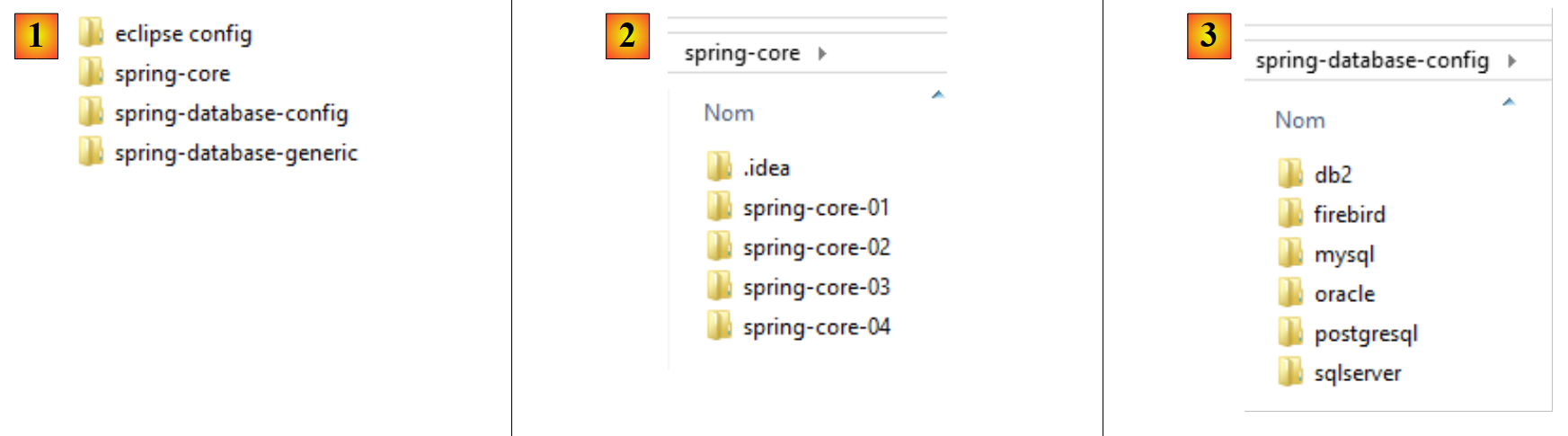 |
- in [1], le cartelle degli esempi;
- in [2], la cartella [spring-core] contiene i progetti di apprendimento su Spring;
- in [3], la cartella [spring-database-config] contiene i progetti di configurazione JDBC e JPA dei sei database;
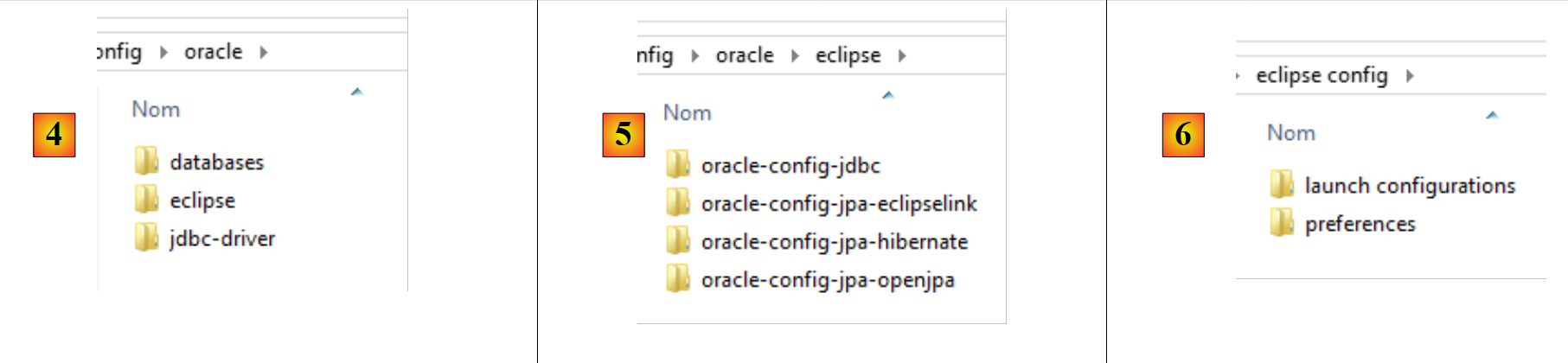 |
- in [4], la configurazione di SGBD Oracle. Al suo interno si trovano tre cartelle:
- [databases] contiene gli script SQL per la generazione dei due database utilizzati dal documento;
- [jdbc-driver] contiene il driver JDBC di Oracle e uno script per la sua installazione nel repository Maven locale;
- [eclipse] contiene [5] i quattro progetti di configurazione di Oracle:
- [oracle-config-jdbc] configura il livello di accesso JDBC a SGBD;
- [oracle-config-jpa-hibernate] configura il livello di accesso JPA a SGBD con il provider Hibernate JPA;
- [oracle-config-jpa-eclipselink] configura il livello di accesso JPA a SGBD con il provider JPA Eclipselink;
- [oracle-config-jpa-openjpa] configura il livello di accesso JPA a SGBD con il provider JPA OpenJPA;
- in [6], la cartella [eclipse config / launch configurations] contiene le configurazioni di esecuzione che l'utente potrà importare in Eclipse per poi adattarle al proprio ambiente;
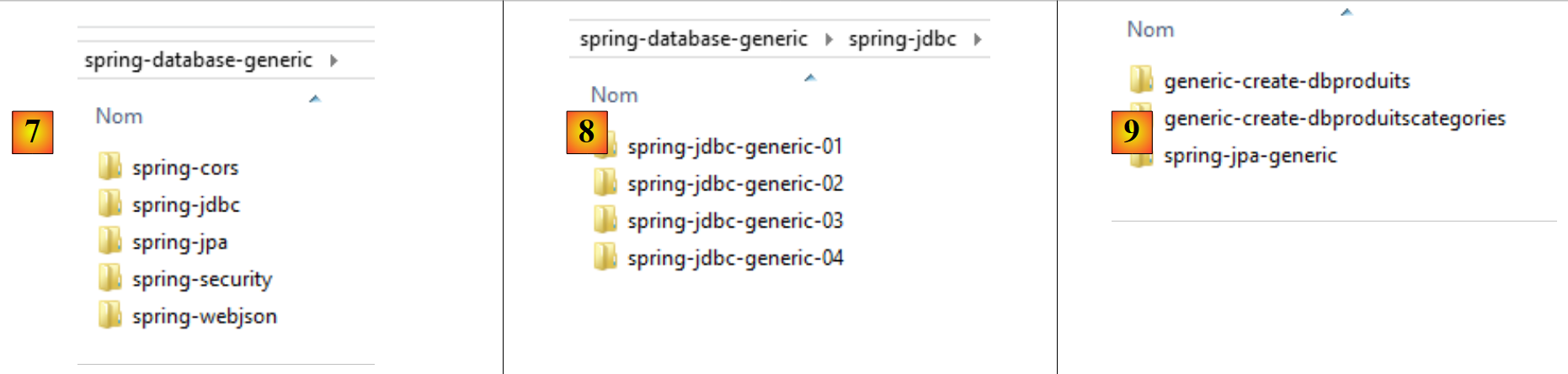 |
- in [7], la cartella [spring-database-generic] contiene tutto il codice di accesso a SGBD comune ai sei SGBD e ai tre fornitori JPA;
- in [8], [spring-jdbc] contiene quattro progetti che presentano API, JDBC e Spring JDBC;
- in [9], [spring-jpa / spring-jpa-generic] è il progetto che utilizza un livello JPA per accedere a un database. I progetti [generic-create-db*] sono progetti JPA che consentono di creare i database utilizzati dal livello JPA;
 |
-
in [10], la cartella [spring-webjson] contiene i progetti che espongono il database sul web;
- [spring-webjson-server-jdbc-generic] è il servizio web che espone il database a cui si accede tramite Spring JDBC;
- [spring-webjson-server-jpa-generic] è il servizio web che espone il database a cui si accede tramite Spring JPA;
- [spring-webjson-client-generic] è l’unico client che consente di accedere ai due servizi web precedenti;
-
in [11], la cartella [spring-security] contiene i progetti che espongono il database sul web con accesso protetto;
- [spring-security-server-jdbc-generic] è il servizio web protetto che espone il database a cui si accede tramite Spring JDBC;
- [spring-security-server-jpa-generic] è il servizio web protetto che espone il database a cui si accede tramite Spring JPA;
- [spring-security-client-generic] è l'unico client che consente di accedere ai due servizi web protetti precedenti;
-
in [12], la cartella [spring-cors] contiene i progetti che espongono il database sul web con un accesso protetto che consente accessi tra domini, come quelli provenienti dal codice JavaScript di un browser;
- [spring-cors-server-jdbc-generic] è il servizio web protetto che consente accessi tra domini e che espone il database a cui si accede tramite Spring JDBC;
- [spring-cors-server-jpa-generic] è il servizio web protetto che consente accessi tra domini e che espone il database a cui si accede tramite Spring JPA;
- [spring-cors-client-generic] è un'applicazione web che consente di interrogare i due servizi web precedenti;