4. Introduzione a Spring JDBC
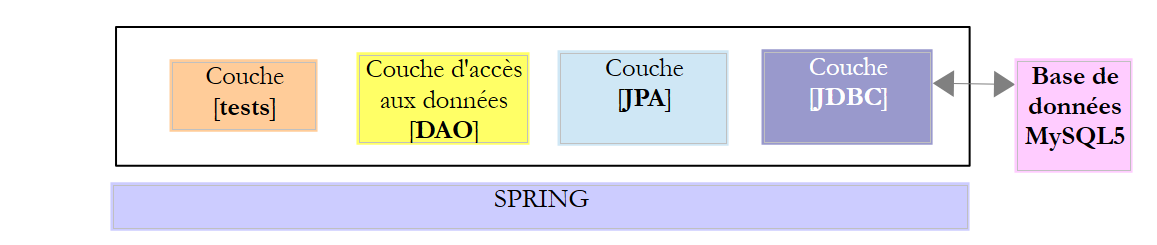
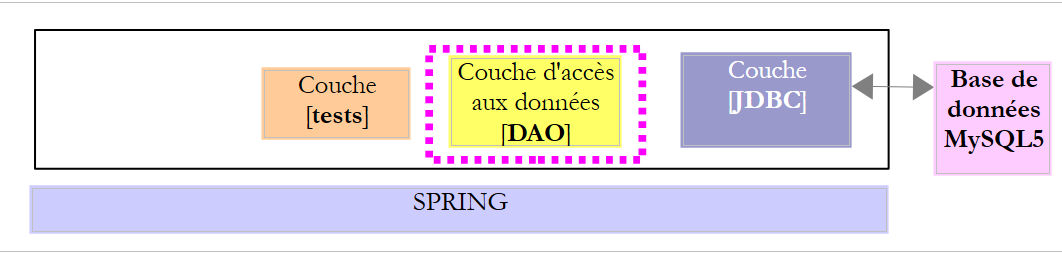
In questo capitolo analizzeremo la seguente architettura:
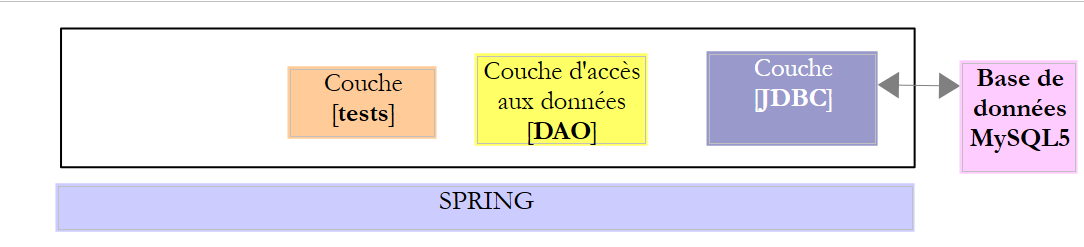 |
Si tratta quindi della stessa architettura di prima. Introdurremo due modifiche:
- il database avrà due tabelle collegate da una relazione di chiave esterna;
- il livello [DAO] sarà implementato con la libreria [Spring JDBC], che semplifica la gestione di API e JDBC;
4.1. Configurazione dell’ambiente di lavoro
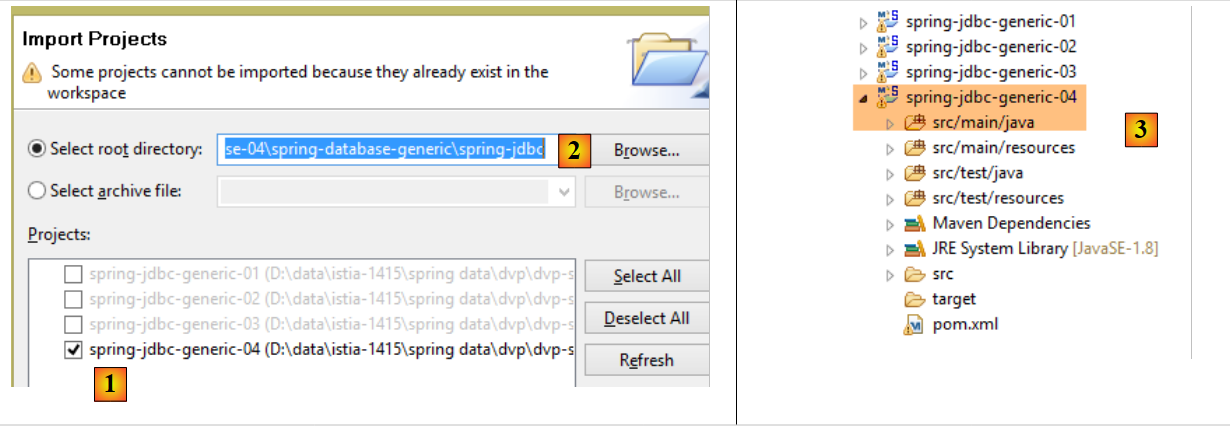
Con STS, importare il progetto [spring-jdbc-04] che si trova nella cartella [<exemples>/spring-database-generic/spring-jdbc]
 |
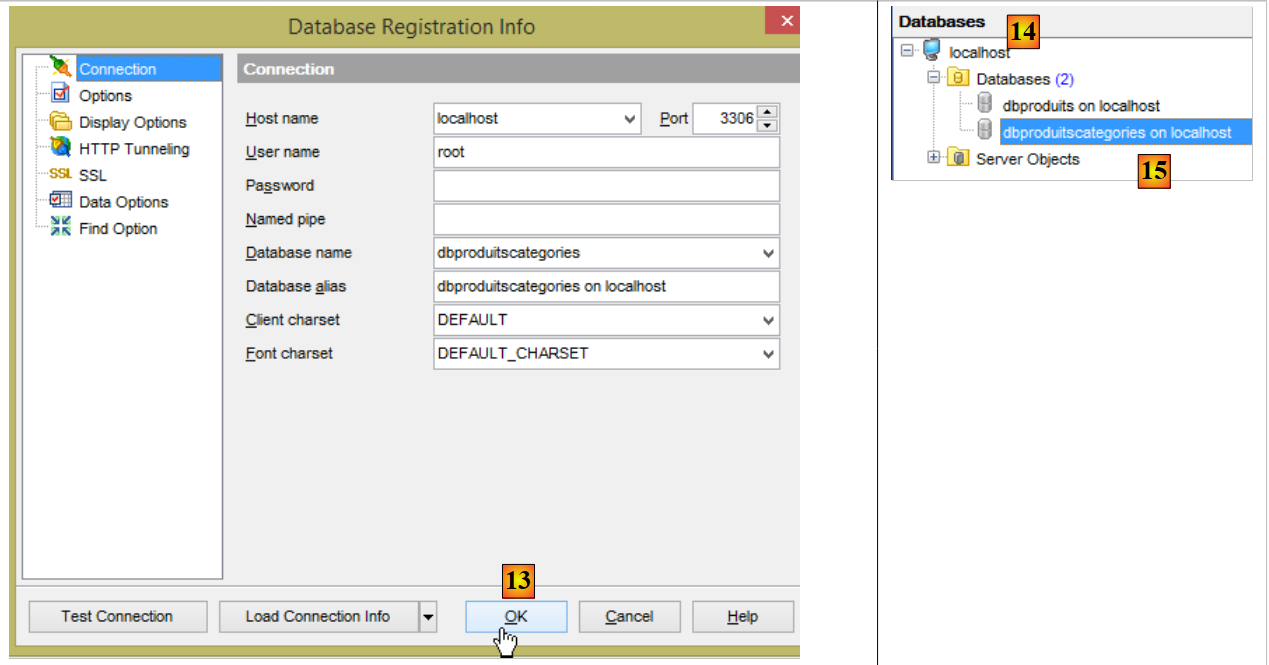
Inoltre, è necessario creare un nuovo database MySQL con il client [MyManager] (cfr. paragrafo 3.1):
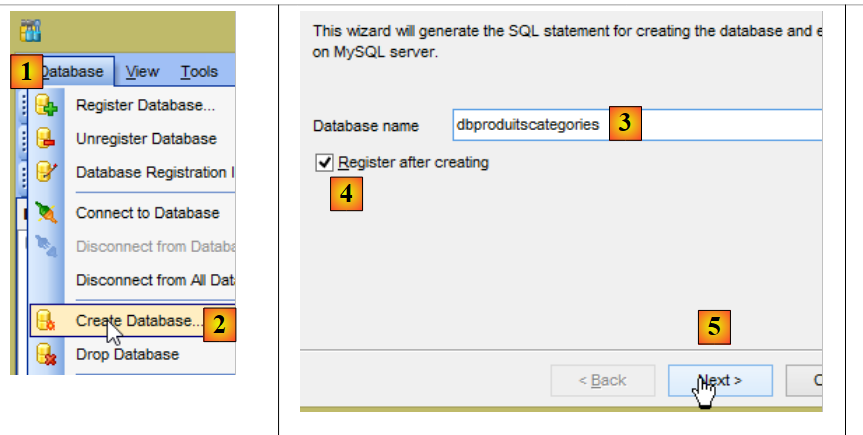 |
- in [3]; gli esempi che seguono si basano su un database MySQL denominato [dbproduitscategories];
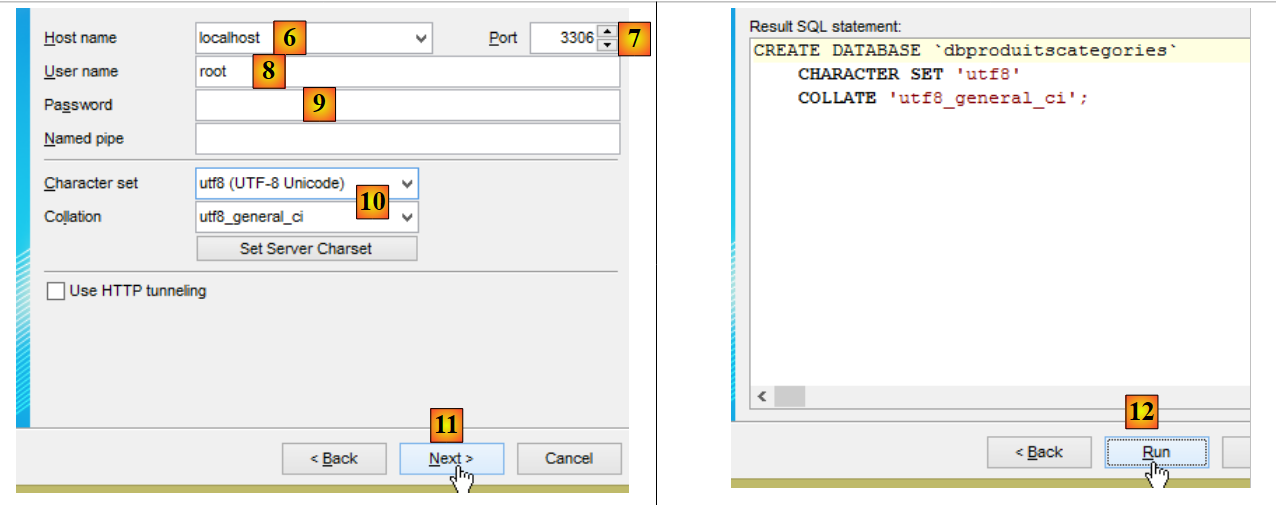 |
- in [9] inserire la password dell’utente root (in questo documento la password è root);
 |
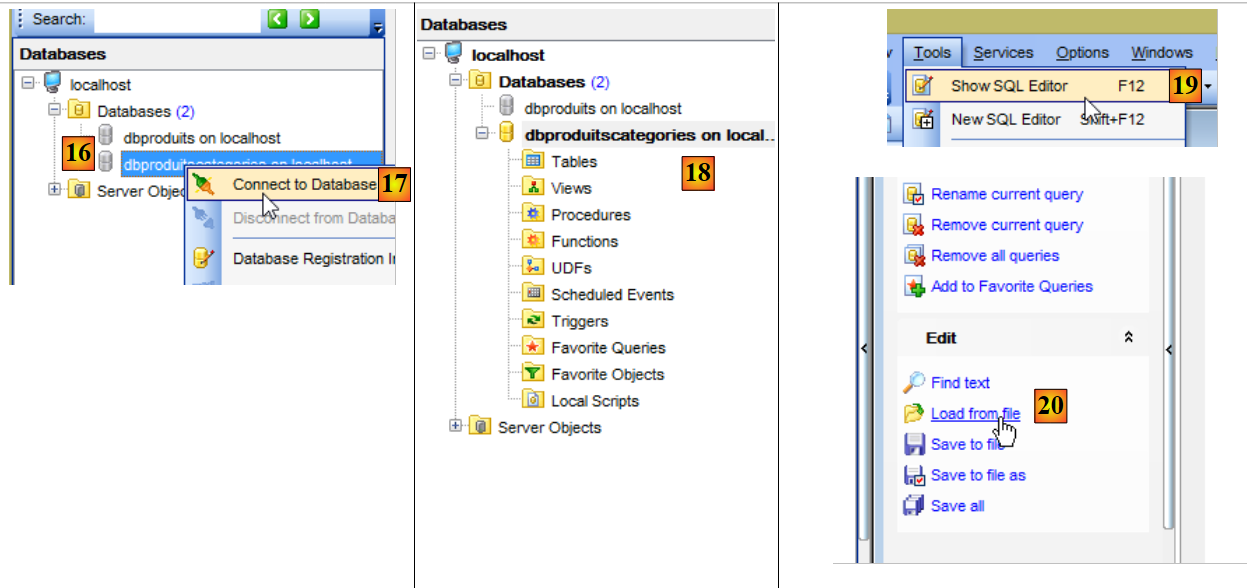 |
- in [18], il database [dbproduitscategories] è stato creato vuoto. Si creano le tabelle e lo si popola con uno script SQL [19-20];
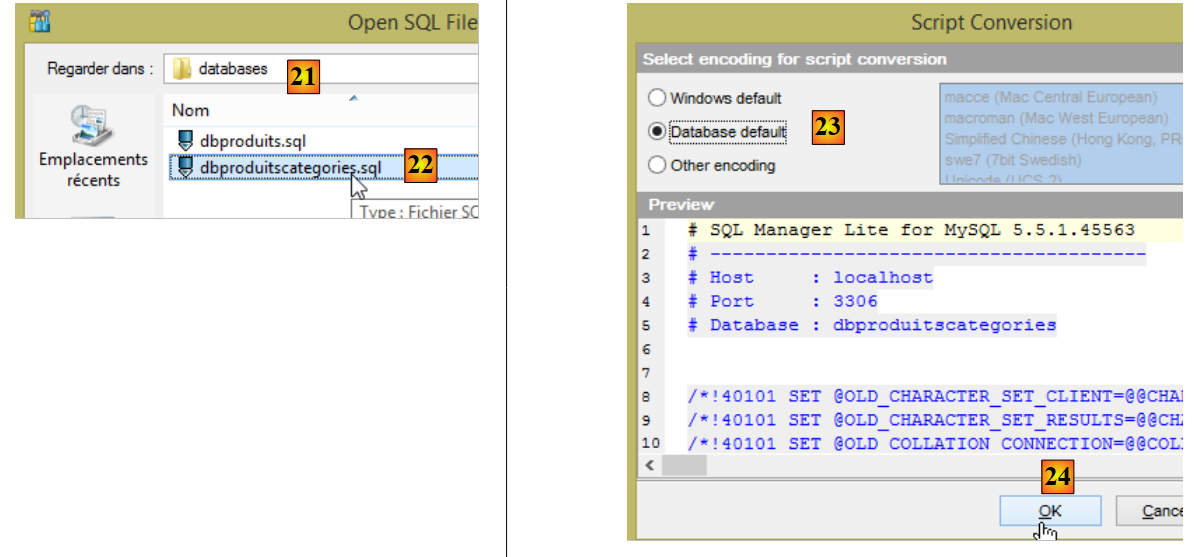 |
- in [21], selezionate la cartella [<exemples>/spring-database-config/mysql/databases];
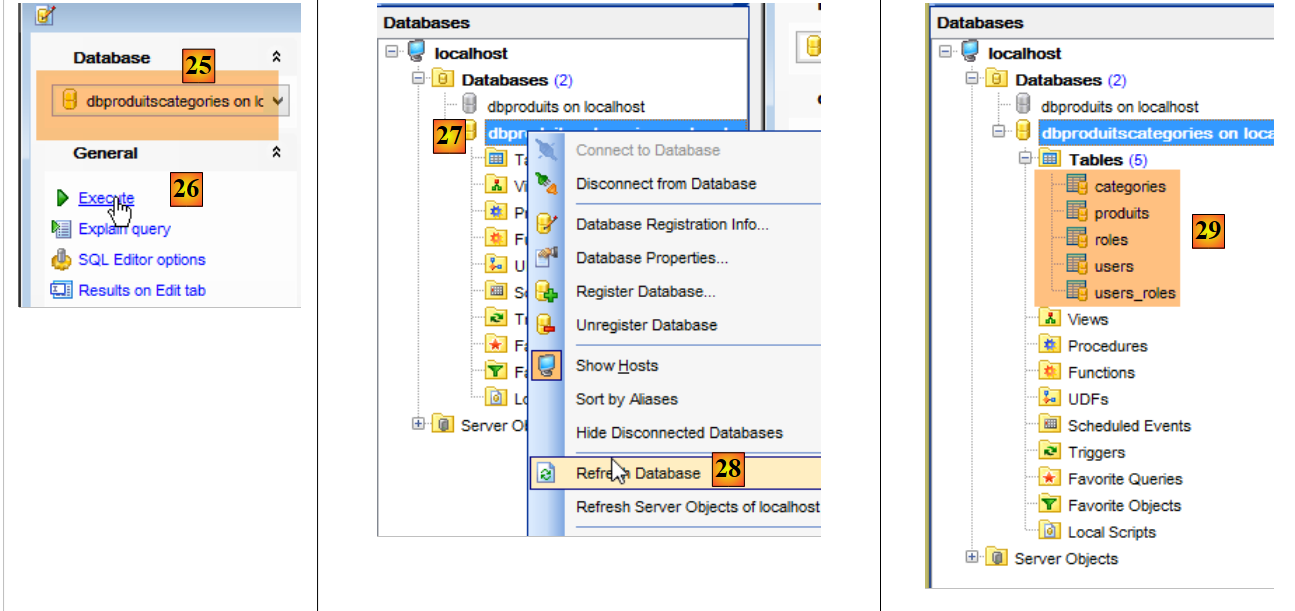 |
- in [25], assicurarsi di trovarsi sul database [dbproduitscategories] e non sul database [dbproduits];
- in [29], lo script SQL ha creato cinque tabelle. Le tabelle [ROLES, USERS, USERS_ROLES] saranno utilizzate solo quando si affronterà la questione della sicurezza del servizio web creato per rendere accessibile sul web il database [dbproduitscategories];
4.2. Il database [dbproduitscategories]
Il database [dbproduitscategories] è un'estensione del database [dbproduits] esaminato in precedenza. Mentre nella tabella [PRODUITS] il prodotto aveva una categoria identificata da un numero privo di significato particolare, qui tale numero costituirà una chiave esterna nella tabella [CATEGORIES].
La tabella [PRODUITS] è la seguente:
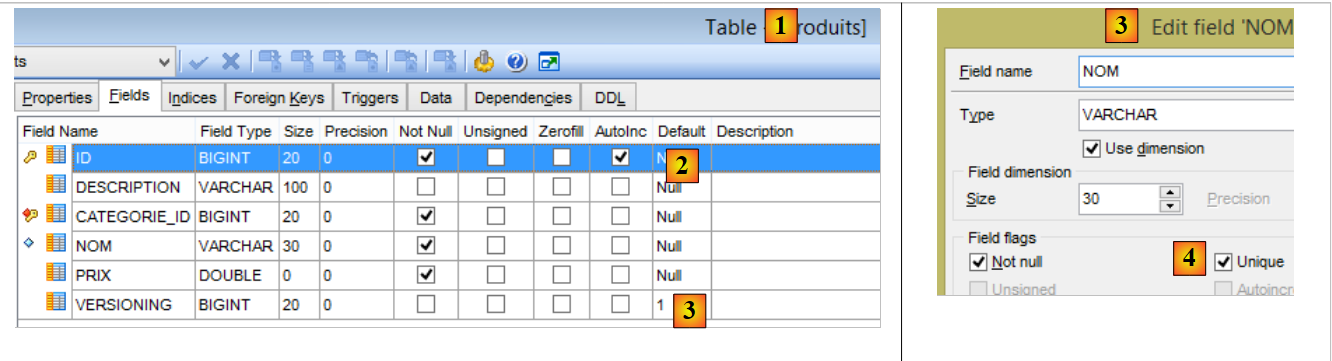 |
- [ID]: la chiave primaria autoincrementale della tabella [2];
- [NOM]: il nome univoco del prodotto [4];
- [PRIX]: il prezzo del prodotto;
- [DESCRIPTION]: la descrizione del prodotto;
- [VERSIONING] è il numero di versione del prodotto. La sua versione iniziale è 1 [3]. Ogni volta che il prodotto verrà modificato, il suo numero di versione verrà incrementato dal codice che gestisce la tabella;
- [CATEGORIE_ID]: la chiave esterna nella tabella [CATEGORIES] per indicare la categoria a cui appartiene il prodotto;
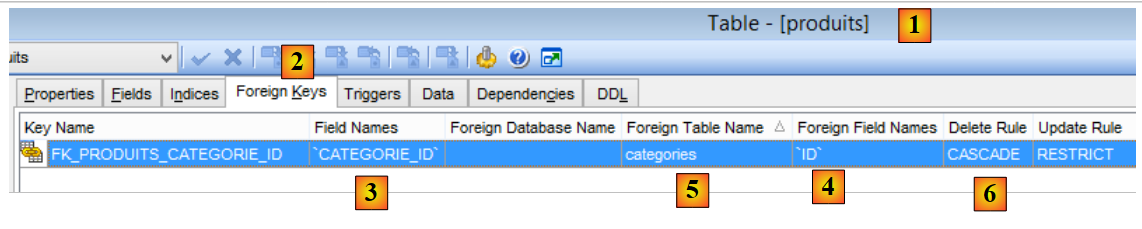 |
- in [1-3], la chiave esterna [CATEGORIE_ID] della tabella [PRODUITS]. Si riferisce alla colonna [ID] della tabella [CATEGORIES] [4-5];
- quando una categoria viene eliminata, vengono eliminati anche tutti i prodotti ad essa collegati [6]. È importante sottolineare questo punto poiché viene utilizzato nella costruzione del livello [DAO] che sfrutta la base [dbproduitscategories];
La tabella delle categorie [CATEGORIES] è la seguente:
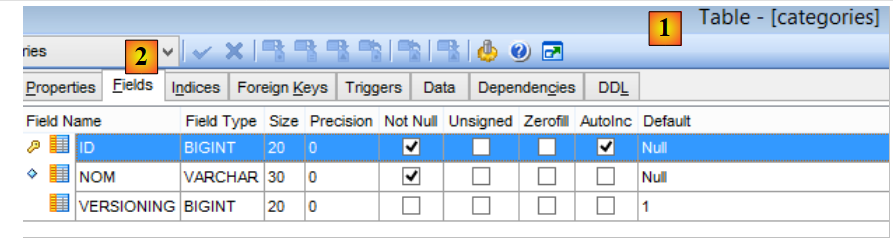 |
- [ID]: chiave primaria autoincrementale;
- [VERSIONING]: numero di versione della categoria;
- [NOM]: nome univoco della categoria;
4.3. Il progetto Eclipse
 |
Il progetto [spring-jdbc-04] implementa la seguente architettura:
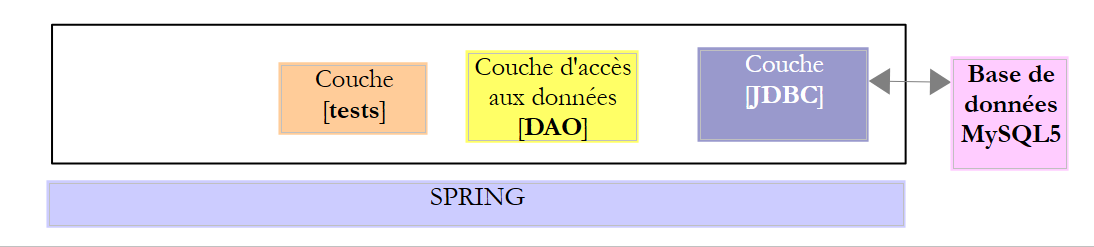 |
Il progetto [spring-jdbc-04] è un progetto Maven configurato dal seguente file [pom.xml]:
 |
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>dvp.spring.database</groupId>
<artifactId>spring-jdbc-generic-04</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>spring-jdbc-generic-04</name>
<description>Demo project for Spring JdbcTemplate</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
<relativePath /> <!-- ricerca genitore dal repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<!-- configurazione JDBC del SGBD -->
<dependency>
<groupId>dvp.spring.database</groupId>
<artifactId>generic-config-jdbc</artifactId>
<version>0.0.1-SNAPSHOT</version>
</dependency>
<!-- Spring JdbcTemplate -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-jdbc</artifactId>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-surefire-plugin</artifactId>
<version>2.18.1</version>
</plugin>
</plugins>
</build>
</project>
- righe 28-32: il progetto si basa sul progetto [mysql-config-jdbc] che configura il livello JDBC;
- righe 34-37: l'artefatto [spring-boot-starter-jdbc] include le librerie Spring JDBC;
In definitiva, le dipendenze sono le seguenti:
 |
4.4. Configurazione Spring
 |
La classe [AppConfig] che configura il progetto Spring è la seguente:
package spring.jdbc.config;
import generic.jdbc.config.ConfigJdbc;
import org.apache.tomcat.jdbc.pool.DataSource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.ComponentScan;
import org.springframework.context.annotation.Configuration;
import org.springframework.context.annotation.Import;
import org.springframework.jdbc.core.namedparam.NamedParameterJdbcTemplate;
import org.springframework.jdbc.core.simple.SimpleJdbcInsert;
import org.springframework.jdbc.datasource.DataSourceTransactionManager;
import org.springframework.transaction.PlatformTransactionManager;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@Configuration
@ComponentScan(basePackages = { "spring.jdbc.dao" })
@EnableTransactionManagement
@Import({ generic.jdbc.config.ConfigJdbc.class })
public class AppConfig {
// fonte dati
@Bean
public DataSource dataSource() {
// fonte dati TomcatJdbc
DataSource dataSource = new DataSource();
// configurazione dell'accesso JDBC
dataSource.setDriverClassName(ConfigJdbc.DRIVER_CLASSNAME);
dataSource.setUsername(ConfigJdbc.USER_DBPRODUITSCATEGORIES);
dataSource.setPassword(ConfigJdbc.PASSWD_DBPRODUITSCATEGORIES);
dataSource.setUrl(ConfigJdbc.URL_DBPRODUITSCATEGORIES);
// connessioni inizialmente aperte
dataSource.setInitialSize(5);
// risultato
return dataSource;
}
// Gestore delle transazioni
@Bean
public PlatformTransactionManager transactionManager(DataSource dataSource) {
return new DataSourceTransactionManager(dataSource);
}
// JdbcTemplate
@Bean
public NamedParameterJdbcTemplate namedParameterJdbcTemplate(DataSource dataSource) {
return new NamedParameterJdbcTemplate(dataSource);
}
// inserimento prodotto
@Bean
public SimpleJdbcInsert simpleJdbcInsertProduit(DataSource dataSource) {
return new SimpleJdbcInsert(dataSource).withTableName(ConfigJdbc.TAB_PRODUITS).usingGeneratedKeyColumns(
ConfigJdbc.TAB_PRODUITS_ID);
}
// inserimento categoria
@Bean
public SimpleJdbcInsert simpleJdbcInsertCategorie(DataSource dataSource) {
return new SimpleJdbcInsert(dataSource).withTableName(ConfigJdbc.TAB_CATEGORIES).usingGeneratedKeyColumns(
ConfigJdbc.TAB_CATEGORIES_ID);
}
}
- riga 16: la classe è una classe di configurazione Spring;
- riga 17: il pacchetto [spring.jdbc.dao] verrà analizzato alla ricerca di componenti Spring diversi da quelli presenti nella classe [AppConfig]. In esso si troverà il componente che implementa il livello [DAO];
- riga 18: non gestiremo le transazioni autonomamente, ma lasceremo che se ne occupi Spring JDBC. L’unica cosa da fare sarà annotare i metodi che devono essere eseguiti all’interno di una transazione con l’annotazione Spring [@Transactional]. La riga 18 garantisce che questa annotazione venga gestita e non ignorata. La gestione delle transazioni è assicurata da una delle dipendenze del progetto Spring JDBC importato dal file [pom.xml];
- riga 19: si importano i bean già definiti nella classe [generic.jdbc.config.ConfigJdbc] del progetto [mysql-config-jdbc];
- righe 23-36: la fonte dati [tomcat-jdbc] introdotta nell'esempio [spring-jdbc-02];
- righe 40-42: il gestore delle transazioni associato alla fonte dati definita in precedenza. Il bean deve chiamarsi obbligatoriamente [transactionManager] poiché è questo il nome utilizzato dall’annotazione [@EnableTransactionManagement]. Il gestore [DataSourceTransactionManager] viene fornito dalla libreria Spring JDBC (riga 12);
- righe 45-48: il bean [namedParameterJdbcTemplate] su cui si baserà l’implementazione del livello [DAO]. Questo bean è fornito dalla libreria Spring JDBC (riga 10). Anche questo bean è collegato alla fonte di dati definita in precedenza (riga 47);
- righe 51-55: il bean [simpleJdbcInsertProduit] (nome libero) verrà utilizzato per inserire un prodotto nella tabella [PRODUITS] e recuperare la chiave primaria generata. I vari parametri utilizzati sono i seguenti:
- [dataSource]: la fonte dati [tomcat-jdbc] delle righe 24-36;
- [ConfigJdbc.TAB_PRODUITS]: la tabella [PRODUITS];
- [ConfigJdbc.TAB_CATEGORIES_ID]: la colonna chiave primaria della tabella [PRODUITS]. Si ricorda che per PostgreSQL il nome di questa colonna dovrà essere in minuscolo;
- righe 58-62: il bean [simpleJdbcInsertCategorie] verrà utilizzato per inserire una categoria nella tabella [CATEGORIES] e recuperare la chiave primaria generata;
4.5. Le eccezioni del progetto
 |
Abbiamo già visto le classi [UncheckedException, DaoException, ShortException] nel progetto [spring-jdbc-03]. Ne aggiungiamo una nuova:
package spring.jdbc.infrastructure;
public class MyIllegalArgumentException extends UncheckedException {
private static final long serialVersionUID = 1L;
// produttori
public MyIllegalArgumentException() {
super();
}
public MyIllegalArgumentException(int code, Throwable e, String className) {
super(code, e, className);
}
}
- la classe [MyIllegalArgumentException] deriva dalla classe [UncheckedException] ed è quindi una classe non controllata. Verrà utilizzata per segnalare una chiamata con argomenti errati a un metodo del livello [DAO]. Non è stata denominata [IllegalArgumentException] perché questa eccezione esiste già nella classe JDK e ciò talvolta induceva il compilatore a generare una classe [import] errata;
4.6. Le entità del progetto
 |
Le classi del pacchetto [spring.jdbc.entities] rappresentano le immagini delle righe delle tabelle del database [dbproduitscategories]. Per il momento tralasceremo le immagini delle tabelle [USERS, ROLES, USERS_ROLE].
Tutte le entità estendono la classe padre [AbstractCoreEntity]:
package spring.jdbc.entities;
public abstract class AbstractCoreEntity {
// caratteristiche
protected Long id;
protected Long version;
// costruttori
public AbstractCoreEntity() {
}
public AbstractCoreEntity(Long id, Long version) {
this.id = id;
this.version = version;
}
public AbstractCoreEntity(AbstractCoreEntity entity) {
this.id = entity.id;
this.version = entity.version;
}
public void setAbstractCoreEntity(AbstractCoreEntity entity) {
this.id = entity.id;
this.version = entity.version;
}
// ------------------------------------------------------------
// ridefinizione di [equals] e [hashcode]
@Override
public int hashCode() {
return (id != null ? id.hashCode() : 0);
}
@Override
public boolean equals(Object entity) {
if (!(entity instanceof AbstractCoreEntity)) {
return false;
}
String class1 = this.getClass().getName();
String class2 = entity.getClass().getName();
if (!class2.equals(class1)) {
return false;
}
AbstractCoreEntity other = (AbstractCoreEntity) entity;
return id != null && other.id != null && id.equals(other.id);
}
// getter e setter
...
}
- riga 5: il campo [id] sarà associato alla colonna [ID], chiave primaria delle tabelle;
- riga 6: il campo [version] sarà associato alla colonna [VERSIONING] delle tabelle;
- righe 8-26: diversi costruttori e metodi per creare o inizializzare un oggetto [AbstractCoreEntity];
- righe 35-47: il metodo [equals] stabilisce che due oggetti [AbstractCoreEntity] sono uguali se hanno lo stesso campo [id]. Va ricordato che gli oggetti [AbstractCoreEntity] saranno rappresentazioni di righe di tabelle in cui [id] è la chiave primaria e in cui, pertanto, non possono esistere due righe con lo stesso [id];
- righe 30-33: una proposta di [hashCode];
La classe [Produit] sarà l'immagine di una riga della tabella [PRODUITS]:
package spring.jdbc.entities;
import com.fasterxml.jackson.annotation.JsonFilter;
@JsonFilter("jsonFilterProduit")
public class Produit extends AbstractCoreEntity {
// proprietà
private String nom;
private Long idCategorie;
private double prix;
private String description;
private Categorie categorie;
// costruttori
public Produit() {
}
public Produit(Long id, Long version, String nom, Long idCategorie, double prix, String description,
Categorie categorie) {
super(id, version);
this.nom = nom;
this.idCategorie = idCategorie;
this.prix = prix;
this.description = description;
this.categorie = categorie;
}
// firma
public String toString() {
return String.format("[id=%s, version=%s, nom=%s, prix=10.2f, desc=%s, idCategorie=%s]", id, version, nom, prix,
description, idCategorie);
}
// getter e setter
...
}
- riga 6: la classe [Produit] estende la classe [AbstractCoreEntity];
- righe 8-12: i campi [id, version, nom, idCategorie, prix, description] sono le immagini delle colonne [ID, VERSIONING, NOM, CATEGORIE_ID, PRIX, DESCRIPTION] della tabella [PRODUITS];
- riga 12: l’oggetto di tipo [Categorie] con chiave primaria [idCategorie]. Questo campo potrà essere compilato o meno a seconda dei casi. Quando è compilato, si parlerà di prodotto in versione lunga [LongProduit], altrimenti di prodotto in versione breve [ShortProduit];
- riga 5: un filtro jSON. Si ricorda che il progetto [mysql-config-jdbc] include una libreria jSON. La necessità del filtro deriva dal fatto che il campo [categorie] può essere compilato o meno. In questo caso, la rappresentazione jSON del prodotto risulta diversa. Per gestire questi due casi, si configurerà il filtro [jsonFilterProduit] alla riga 5. Un filtro jSON consente di specificare, in modo dinamico, i campi da escludere dalla rappresentazione jSON. Quando si rileva che il campo [categorie] non è stato compilato, lo si escluderà dalla rappresentazione jSON del prodotto;
La classe [Categorie] rappresenta una riga della tabella [CATEGORIES]:
package spring.jdbc.entities;
import java.util.ArrayList;
import java.util.List;
import com.fasterxml.jackson.annotation.JsonFilter;
@JsonFilter("jsonFilterCategorie")
public class Categorie extends AbstractCoreEntity {
// proprietà
private String nom;
public List<Produit> produits;
// costruttori
public Categorie() {
}
public Categorie(Long id, Long version, String nom, List<Produit> produits) {
super(id, version);
this.nom = nom;
this.produits = produits;
}
// firma
public String toString() {
return String.format("[id=%s, version=%s, nom=%s]", id, version, nom);
}
// metodi
public void addProduit(Produit produit) {
// aggiunta di un prodotto
if (produits == null) {
produits = new ArrayList<Produit>();
}
if (produit != null) {
// si aggiunge il prodotto
produits.add(produit);
// si imposta la categoria
produit.setCategorie(this);
produit.setIdCategorie(this.id);
}
}
// getter e setter
...
}
- riga 9: la classe [Categorie] estende la classe [AbstractCoreEntity];
- riga 12: i campi [id, version, nom] sono le immagini delle colonne [ID, VERSIONING, NOM] della tabella [CATEGORIES];
- riga 13: il campo [produits] rappresenta l'elenco dei prodotti della categoria. Questo campo non è sempre compilato. Quando non lo è, si parlerà di categoria in versione breve [ShortCategorie], altrimenti di categoria in versione lunga [LongCategorie];
- righe 32-44: il metodo [addProduit] consente di aggiungere un prodotto alla categoria (riga 39) e di impostare, nel prodotto aggiunto, le caratteristiche della sua categoria (idCategorie e categoria);
- riga 8: un filtro jSON. Quando la libreria jSON dovrà serializzare/deserializzare un oggetto [Categorie], sarà necessario indicarle come gestire il filtro denominato [jsonFilterCategorie];
4.7. L'interfaccia Idao<T>
 |
 |
L'interfaccia [IDao] del livello [DAO] ha la seguente firma:
package spring.jdbc.dao;
import java.util.List;
import spring.jdbc.entities.AbstractCoreEntity;
public interface IDao<T extends AbstractCoreEntity> {
// elenco di tutte le entità T
public List<T> getAllShortEntities();
public List<T> getAllLongEntities();
// di entità specifiche - versione breve
public List<T> getShortEntitiesById(Iterable<Long> ids);
public List<T> getShortEntitiesById(Long... ids);
public List<T> getShortEntitiesByName(Iterable<String> names);
public List<T> getShortEntitiesByName(String... names);
// di entità specifiche - versione estesa
public List<T> getLongEntitiesById(Iterable<Long> ids);
public List<T> getLongEntitiesById(Long... ids);
public List<T> getLongEntitiesByName(Iterable<String> names);
public List<T> getLongEntitiesByName(String... names);
// aggiornamento di più entità
public List<T> saveEntities(Iterable<T> entities);
public List<T> saveEntities(@SuppressWarnings("unchecked") T... entities);
// eliminazione di tutte le entità
public void deleteAllEntities();
// eliminazione di più entità
public void deleteEntitiesById(Iterable<Long> ids);
public void deleteEntitiesById(Long... ids);
public void deleteEntitiesByName(Iterable<String> names);
public void deleteEntitiesByName(String... names);
public void deleteEntitiesByEntity(Iterable<T> entities);
public void deleteEntitiesByEntity(@SuppressWarnings("unchecked") T... entities);
}
- riga 7: qui abbiamo un'interfaccia [IDao] parametrizzata da un tipo T con una condizione: tale tipo deve estendere la classe [AbstractCoreEntity] o implementare l'interfaccia [AbstractCoreEntity]. La parola chiave [extends] si utilizza in entrambi i casi. In questo caso, T verrà istanziato dal tipo [Produit] oppure dal tipo [Categorie]. Infatti, ci si accorge abbastanza rapidamente che si eseguono le stesse operazioni (inserimento, modifica, cancellazione, selezione) sui tipi [Produit] e [Categorie]. Sembra quindi logico raggruppare questi metodi in un’interfaccia generica;
- a seconda dei casi, i termini [LongEntity] e [ShortEntity] indicano situazioni diverse:
- quando T è il tipo [Produit]:
- [ShortEntity] è il prodotto senza il campo [Categorie categorie] compilato;
- [LongEntity] è il prodotto con il campo [Categorie categorie] compilato;
- quando T è il tipo [Categorie]:
- [ShortEntity] è la categoria senza il campo [List<Produit> produits] compilato;
- [LongEntity] è il prodotto con il campo [List<Produit> produits] compilato;
- quando T è il tipo [Produit]:
Abbiamo quindi un'interfaccia che comprende 19 metodi. La maggior parte dei metodi è presente in duplicato. Prendiamo ad esempio il metodo [getShortEntitiesById]:
public List<T> getShortEntitiesById(Iterable<Long> ids);
public List<T> getShortEntitiesById(Long... ids);
- righe 1 e 3: il parametro è l’elenco delle chiavi primarie delle entità di cui si desidera la versione abbreviata. Questo elenco è presentato in due forme diverse:
- riga 1: un elenco che implementa l’interfaccia [Iterable<Long>]. Il tipo [List<Long>] implementa questa interfaccia, ma ce ne sono molti altri. Se avessimo specificato [List<Long> ids], sarebbe stato sufficiente per i nostri esempi, ma avremmo costretto l’utente dei nostri esempi a effettuare delle conversioni se il suo parametro non fosse stato del tipo esatto previsto;
- riga 3: purtroppo il tipo Long[] non implementa l’interfaccia [Iterable<Long>]. In questo caso, useremo la versione della riga 3. Il parametro formale [Long... ids] (3 punti) può ricevere il valore sia di un array che di una sequenza di ID: getShortEntitiesById(id1, id2, ...);
È proprio questa stessa interfaccia IDao<T> che verrà implementata dalla seguente architettura:
 |
dove un livello [JPA] (Java Persistence API) si interporrà tra il livello [DAO] e il driver JDBC del SGBD. Ciò ci consentirà di disporre di un livello di test comune alle due architetture. In entrambi i casi, il livello [DAO] presenterà due interfacce:
- IDao<Prodotto> per accedere alla tabella [PRODUITS];
- IDao<Categoria> per accedere alla tabella [CATEGORIES];
4.8. Implementazione dell'interfaccia IDao<T>
|
- l'interfaccia IDao<Prodotto> è implementata dalla classe [DaoProduit] ;
- l'interfaccia IDao<Categoria> è implementata dalla classe [DaoCategorie];
Le classi [DaoProduit] e [DaoCategorie] estendono entrambe la classe astratta [AbstractDao] e seguente:
package spring.jdbc.dao;
import java.util.ArrayList;
import java.util.List;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.beans.factory.annotation.Qualifier;
import org.springframework.transaction.annotation.Transactional;
import spring.jdbc.entities.AbstractCoreEntity;
import spring.jdbc.infrastructure.MyIllegalArgumentException;
import com.google.common.collect.Lists;
public abstract class AbstractDao<T extends AbstractCoreEntity> implements IDao<T> {
// inserimenti
@Autowired
@Qualifier("maxPreparedStatementParameters")
protected int maxPreparedStatementParameters;
// locale
protected String simpleClassName = getClass().getSimpleName();
@Override
@Transactional(readOnly = true)
public List<T> getShortEntitiesById(Iterable<Long> ids) {
// validità dell'argomento
List<T> entities = checkNullOrEmptyArgument(true, ids);
if (entities != null) {
return entities;
}
// recupero a tranche
entities = new ArrayList<T>();
int taille = maxPreparedStatementParameters;
List<Long> listIds = Lists.newArrayList(ids);
int nbIds = listIds.size();
for (int i = 0; i < nbIds; i += taille) {
int limit = Math.min(nbIds, i + taille);
entities.addAll(getShortEntitiesById(listIds.subList(i, limit)));
}
// risultato
return entities;
}
@Override
@Transactional(readOnly = true)
public List<T> getShortEntitiesById(Long... ids) {
// validità dell'argomento
List<T> entities = checkNullOrEmptyArgument(true, ids);
if (entities != null) {
return entities;
}
// risultato
return getShortEntitiesById((Iterable<Long>) Lists.newArrayList(ids));
}
@Override
@Transactional(readOnly = true)
public List<T> getShortEntitiesByName(Iterable<String> names) {
...
}
@Override
@Transactional(readOnly = true)
public List<T> getShortEntitiesByName(String... names) {
...
}
@Override
@Transactional(readOnly = true)
public List<T> getLongEntitiesById(Iterable<Long> ids) {
...
}
@Override
@Transactional(readOnly = true)
public List<T> getLongEntitiesById(Long... ids) {
...
}
@Override
@Transactional(readOnly = true)
public List<T> getLongEntitiesByName(Iterable<String> names) {
...
}
@Override
@Transactional(readOnly = true)
public List<T> getLongEntitiesByName(String... names) {
...
}
@Override
@Transactional
public List<T> saveEntities(Iterable<T> entities) {
...
}
@Override
@Transactional
public List<T> saveEntities(@SuppressWarnings("unchecked") T... entities) {
...
}
@Override
public void deleteEntitiesById(Iterable<Long> ids) {
...
}
@Override
public void deleteEntitiesById(Long... ids) {
...
}
@Override
public void deleteEntitiesByName(Iterable<String> names) {
...
}
@Override
public void deleteEntitiesByName(String... names) {
...
}
@Override
public void deleteEntitiesByEntity(Iterable<T> entities) {
...
}
@Override
public void deleteEntitiesByEntity(@SuppressWarnings("unchecked") T... entities) {
...
}
protected void deleteEntitiesByEntity(List<T> entities) {
...
}
@Override
@Transactional(readOnly = true)
public abstract List<T> getAllShortEntities();
@Override
@Transactional(readOnly = true)
public abstract List<T> getAllLongEntities();
@Override
public abstract void deleteAllEntities();
// metodi privati ----------------------------------------------
private <T2> List<T> checkNullOrEmptyArgument(boolean checkEmpty, Iterable<T2> elements) {
...
}
@SuppressWarnings("unchecked")
private <T2> List<T> checkNullOrEmptyArgument(boolean checkEmpty, T2... elements) {
...
}
// metodi protetti ----------------------------------------------
abstract protected List<T> getShortEntitiesById(List<Long> ids);
abstract protected List<T> getShortEntitiesByName(List<String> names);
abstract protected List<T> getLongEntitiesById(List<Long> ids);
abstract protected List<T> getLongEntitiesByName(List<String> names);
abstract protected List<T> saveEntities(List<T> entities);
abstract protected void deleteEntitiesById(List<Long> ids);
abstract protected void deleteEntitiesByName(List<String> names);
}
- riga 15: la classe [AbstractDao] è astratta (parola chiave abstract). In quanto tale, non può essere istanziata, ma solo derivata. Questa classe ha diversi ruoli:
- definire la natura della transazione in cui si svolge ciascun metodo;
- rendere il più possibile comuni gli elementi alle due implementazioni delle interfacce [IDao<Produit>] e [IDao<Categorie>]. Si tratta principalmente di verificare la validità degli argomenti. Non saranno accettati né l’argomento null, né liste vuote;
- uniformare il tipo dei parametri T... params e Iterable<T> params in un unico tipo: List<T> params;
- delegare il lavoro alle classi figlie non appena questo diventa specifico per una delle due interfacce;
Grazie all’uniformazione dei parametri dei diversi metodi operata dalla classe [AbstractDao], le classi figlie [DaoProduit] e [DaoCategorie] avranno solo 10 metodi da implementare invece di 19:
// metodi implementati dalle classi figlie ----------------------------------------------
abstract protected List<T> getShortEntitiesById(List<Long> ids);
abstract protected List<T> getShortEntitiesByName(List<String> names);
abstract protected List<T> getLongEntitiesById(List<Long> ids);
abstract protected List<T> getLongEntitiesByName(List<String> names);
abstract protected List<T> saveEntities(List<T> entities);
abstract protected void deleteEntitiesById(List<Long> ids);
abstract protected void deleteEntitiesByName(List<String> names);
@Override
@Transactional(readOnly = true)
public abstract List<T> getAllShortEntities();
@Override
@Transactional(readOnly = true)
public abstract List<T> getAllLongEntities();
@Override
public abstract void deleteAllEntities();
Vediamo alcuni metodi della classe [AbstractDao].
Metodo [getShortEntitiesById]
Questo metodo serve a ottenere la versione abbreviata delle entità di cui vengono fornite le chiavi primarie.
// iniezioni
@Autowired
@Qualifier("maxPreparedStatementParameters")
protected int maxPreparedStatementParameters;
// locale
protected String simpleClassName = getClass().getSimpleName();
@Override
@Transactional(readOnly = true)
public List<T> getShortEntitiesById(Iterable<Long> ids) {
...
}
- righe 2-4: si inietta il bean [maxPreparedStatementParameters] definito nel file di configurazione [ConfigJdbc] che configura il livello JDBC di un particolare SGBD:
// numero massimo di parametri di un [PreparedStatement]
public final static int MAX_PREPAREDSTATEMENT_PARAMETERS = 10000;
@Bean(name = "maxPreparedStatementParameters")
public int maxPreparedStatementParameters() {
return MAX_PREPAREDSTATEMENT_PARAMETERS;
}
- righe 1-7: definiscono il bean [maxPreparedStatementParameters] che stabilirà il numero massimo di parametri che potranno essere assegnati a un tipo [PreparedStatement]. Questa esigenza non si è presentata con il SGBD MySQL, che ha accettato 10.000 parametri per un tipo [PreparedStatement]. Durante i test con il server SGBD e SQL, quest’ultimo ha generato un’eccezione indicando che il numero massimo di parametri per un tipo [PreparedStatement] era pari a 2100. Pertanto, tale numero è diventato un parametro di configurazione dei vari SGBD. Deve quindi essere inserito nel progetto di configurazione [sgbd-config-jdbc] di ciascun SGBD;
Torniamo al codice del metodo [getShortEntitiesById]:
// iniezioni
@Autowired
@Qualifier("maxPreparedStatementParameters")
protected int maxPreparedStatementParameters;
// locale
protected String simpleClassName = getClass().getSimpleName();
@Override
@Transactional(readOnly = true)
public List<T> getShortEntitiesById(Iterable<Long> ids) {
...
}
- riga 7: il nome della classe. Viene utilizzato come parametro di uno dei costruttori della classe di eccezione [DaoException];
- riga 10: l'annotazione [@Transactional(readOnly = true)] indica che il metodo deve essere eseguito in una transazione in sola lettura. Ci si potrebbe chiedere quale sia l’utilità di una transazione di questo tipo, dato che il metodo esegue solo operazioni di lettura e quindi, in caso di errore, non c’è nulla da annullare. È l’autore della libreria [Spring Data] a consigliarlo e a spiegarne il motivo. Ho seguito il suo consiglio;
Il corpo del metodo è il seguente:
@Override
@Transactional(readOnly = true)
public List<T> getShortEntitiesById(Iterable<Long> ids) {
// validità dell'argomento
List<T> entities = checkNullOrEmptyArgument(true, ids);
if (entities != null) {
return entities;
}
...
}
- riga 5: la validità del parametro [ids] viene verificata dal seguente metodo:
private <T2> List<T> checkNullOrEmptyArgument(boolean checkEmpty, Iterable<T2> elements) {
// elementi nulli?
if (elements == null) {
throw new MyIllegalArgumentException(222, new NullPointerException("L'argument ne peut être null"), simpleClassName);
}
// elementi vuoti?
if (!elements.iterator().hasNext()) {
if (checkEmpty) {
throw new MyIllegalArgumentException(223, new RuntimeException("l'argument ne peut être une liste vide"),
simpleClassName);
} else {
return new ArrayList<T>();
}
}
// risultato predefinito
return null;
}
- riga 1: il metodo [checkNullOrEmptyArgument] è un metodo generico parametrizzato dal tipo <T2>. T2 è il tipo degli elementi passati come secondo parametro del metodo. Può trattarsi di [Long, String, AbstractCoreEntity];
- riga 1: il metodo [checkNullOrEmptyArgument] accetta due parametri:
- [Iterable<T2> elements]: il parametro da testare;
- [checkEmpty]: impostato a vero se si deve verificare che il parametro precedente sia un elenco non vuoto;
- righe 4-6: si verifica che il parametro [elements] non sia null. In caso contrario, viene generata un'eccezione di tipo [MyIllegalArgumentException];
- righe 8-15: se la lista è vuota e si doveva verificare che non fosse vuota, viene generata un'eccezione di tipo [MyIllegalArgumentException];
- riga 13: se la lista è vuota e non si dovesse verificare che non fosse vuota, allora si restituisce una lista vuota di elementi di tipo T. L'interfaccia [Iterable<T2>] dispone di un metodo [iterator()] che consente di iterare sugli elementi della lista che implementa l'interfaccia. Due metodi di questo iteratore sono utili:
- [itérateur].hasNext(): restituisce vero se la lista contiene ancora un elemento da elaborare, falso in caso contrario;
- [iterateur].next(): restituisce l’elemento corrente della lista e avanza di un elemento;
- infine,
- se l’argomento [T2... elements] è null o vuoto, viene generata un’eccezione di tipo [MyIllegalArgumentException];
- se l'argomento [T2... elements] è una lista vuota e ciò era consentito, allora viene restituita una lista vuota di elementi di tipo T;
Esiste un metodo analogo quando l'argomento da verificare è di tipo [T2... elements]:
@SuppressWarnings("unchecked")
private <T2> List<T> checkNullOrEmptyArgument(boolean checkEmpty, T2... elements) {
...
}
Torniamo al codice del metodo [getShortEntitiesById]:
@Override
@Transactional(readOnly = true)
public List<T> getShortEntitiesById(Iterable<Long> ids) {
// validità dell'argomento
List<T> entities = checkNullOrEmptyArgument(true, ids);
// ottenimento per tranche
entities = new ArrayList<T>();
int taille = maxPreparedStatementParameters;
List<Long> listIds = Lists.newArrayList(ids);
int nbIds = listIds.size();
for (int i = 0; i < nbIds; i += taille) {
int limit = Math.min(nbIds, i + taille);
entities.addAll(getShortEntitiesById(listIds.subList(i, limit)));
}
// risultato
return entities;
}
- riga 7: se si arriva a questo punto, significa che l’argomento [Iterable<Long> ids] è valido;
- righe 7-14: vedremo in seguito che il metodo [getShortEntitiesById] verrà implementato da un tipo [PreparedStatement] che avrà come parametri l'elenco delle chiavi primarie da cercare. Ad esempio:
public final static String SELECT_SHORTCATEGORIE_BYID = "SELECT c.ID as c_ID, c.VERSIONING as c_VERSIONING, c.NOM as c_NOM FROM CATEGORIES c WHERE c.ID in (:ids)";
: ids è un parametro il cui valore effettivo sarà un tipo List<Long>. Ogni elemento di questa lista sarà oggetto di un parametro ? in un tipo [PreparedStatement]. Abbiamo però detto che questo tipo accetta un numero massimo di parametri, numero fissato dal campo [maxPreparedStatementParameters] della classe;
- riga 7: l’elenco delle entità T che verrà restituito dal metodo [getShortEntitiesById]. Questo elenco verrà costruito in blocchi di [maxPreparedStatementParameters] elementi;
- riga 9: a partire dall’argomento [Iterable<Long> ids], viene creato un tipo [List<Long> listIds]. La classe [Lists] è una classe della libreria Google Guava che offre numerosi metodi statici per la gestione di collezioni di oggetti. La libreria Google Guava è stata importata (pom.xml) dal progetto Maven [mysql-config-jdbc]:
<!-- Google Guava -->
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>16.0.1</version>
</dependency>
- riga 10: il numero di entità T da cercare nel database;
- righe 11-13: vengono ricercati in gruppi di [taille = maxPreparedStatementParameters] elementi;
- riga 12: un calcolo per evitare di superare la fine dell’elenco [listIds];
- riga 13: le entità T vengono ottenute tramite la chiamata [getShortEntitiesById(listIds.subList(i, limit))]. Questo metodo è definito nella classe da:
abstract protected List<T> getShortEntitiesById(List<Long> ids);
È quindi la classe figlia che andrà a recuperare le entità T dal database:
- [DaoProduit] se T è del tipo [Produit];
- [DaoCategorie] se T è del tipo [Categorie];
L'utilità di questo lavoro della classe padre è duplice:
- la firma del metodo [getShortEntitiesById] nella classe figlia è univoca: il suo argomento è di tipo [List<Long> ids];
- la classe figlia non deve occuparsi del problema dei parametri [maxPreparedStatementParameters] di un [PreparedStatement]. La sua classe madre se ne è occupata per lei;
- riga 13: le entità restituite dalla classe figlia vengono aggiunte all'elenco delle entità che verrà restituito dalla classe madre (riga 16);
Ora vediamo l'implementazione dell'altro metodo [getShortEntitiesById] della classe:
@Override
@Transactional(readOnly = true)
public List<T> getShortEntitiesById(Long... ids) {
// validità dell'argomento
List<T> entities = checkNullOrEmptyArgument(true, ids);
// risultato
return getShortEntitiesById((Iterable<Long>) Lists.newArrayList(ids));
}
- riga 3: la natura dell'argomento è cambiata: Long... ids;
- riga 5: viene verificata la validità di questo argomento;
- riga 7: viene chiamato il metodo [getShortEntitiesById] che abbiamo appena descritto. Anche in questo caso, ci si avvale della classe [Lists] della libreria [Google Guava]. Si noti che è necessario effettuare un cast esplicito al tipo [Iterable<Long>] per aiutare il compilatore a scegliere il metodo corretto, poiché il metodo [getShortEntitiesById] ha tre firme nella classe:
- List<T> getShortEntitiesById(Long... ids);
- List<T> getShortEntitiesById(Iterable<Long> ids);
- List<T> getShortEntitiesById(List<Long> ids), che è astratta e implementata dalla classe figlia;
Non ci soffermeremo ulteriormente sulla classe astratta [AbstractDao], classe padre delle classi [DaoProduit] e [DaoCategorie]. Ricorderemo semplicemente che a volte è interessante fattorizzare comportamenti comuni a più classi in una classe padre, astratta o meno. Dopo questo lavoro, alle classi figlie resta solo da implementare i seguenti metodi:
// metodi implementati dalle classi figlie ----------------------------------------------
abstract protected List<T> getShortEntitiesById(List<Long> ids);
abstract protected List<T> getShortEntitiesByName(List<String> names);
abstract protected List<T> getLongEntitiesById(List<Long> ids);
abstract protected List<T> getLongEntitiesByName(List<String> names);
abstract protected List<T> saveEntities(List<T> entities);
abstract protected void deleteEntitiesById(List<Long> ids);
abstract protected void deleteEntitiesByName(List<String> names);
@Override
@Transactional(readOnly = true)
public abstract List<T> getAllShortEntities();
@Override
@Transactional(readOnly = true)
public abstract List<T> getAllLongEntities();
@Override
public abstract void deleteAllEntities();
Il codice del paragrafo 4.8 mostra i diversi tipi di transazione utilizzati per ciascun metodo. Si notino alcuni punti:
- i metodi che leggono il database sono contrassegnati con [@Transactional(readOnly = true)];
- i metodi che modificano il database sono contrassegnati con [@Transactional];
- i metodi [delete] non sono annotati e quindi non vengono eseguiti all'interno di una transazione. L'idea è che, se un'operazione di cancellazione fallisce, l'utente probabilmente non desidera annullare tutte quelle che sono state eseguite con successo in precedenza;
4.9. La classe [DaoCategorie]
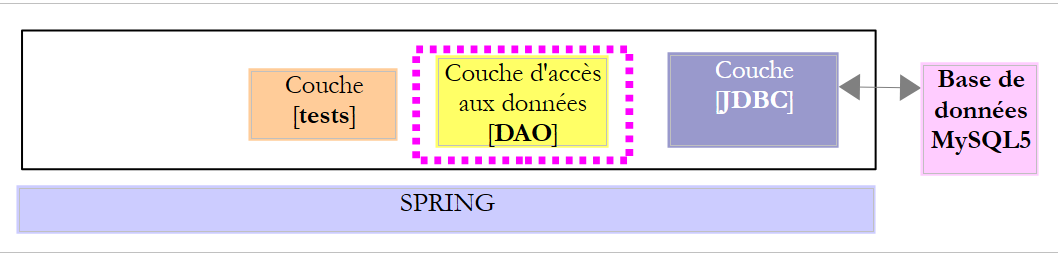
 |
|
La classe [DaoCategorie] implementa l'interfaccia [IDao<Categorie>] che garantisce l'accesso ai dati della tabella [CATEGORIES] del database MySQL [dbproduitscategories]. Il suo scheletro è il seguente:
package spring.jdbc.dao;
import generic.jdbc.config.ConfigJdbc;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.RowMapper;
import org.springframework.jdbc.core.namedparam.MapSqlParameterSource;
import org.springframework.jdbc.core.namedparam.NamedParameterJdbcTemplate;
import org.springframework.jdbc.core.namedparam.SqlParameterSource;
import org.springframework.jdbc.core.namedparam.SqlParameterSourceUtils;
import org.springframework.jdbc.core.simple.SimpleJdbcInsert;
import org.springframework.stereotype.Component;
import spring.jdbc.entities.Categorie;
import spring.jdbc.entities.Produit;
import spring.jdbc.infrastructure.DaoException;
import com.google.common.collect.Lists;
@Component
public class DaoCategorie extends AbstractDao<Categorie> {
// costanti
// iniezioni
@Autowired
private NamedParameterJdbcTemplate namedParameterJdbcTemplate;
@Autowired
private SimpleJdbcInsert simpleJdbcInsertCategorie;
@Autowired
private IDao<Produit> daoProduit;
@Override
public List<Categorie> getAllShortEntities() {
...
}
@Override
public List<Categorie> getAllLongEntities() {
...
}
@Override
public void deleteAllEntities() {
...
}
@Override
protected List<Categorie> getShortEntitiesById(List<Long> ids) {
...
}
@Override
protected List<Categorie> getShortEntitiesByName(List<String> names) {
...
}
@Override
protected List<Categorie> getLongEntitiesById(List<Long> ids) {
...
}
@Override
protected List<Categorie> getLongEntitiesByName(List<String> names) {
...
}
@Override
protected List<Categorie> saveEntities(List<Categorie> entities) {
...
}
@Override
protected void deleteEntitiesById(List<Long> ids) {
...
}
@Override
protected void deleteEntitiesByName(List<String> names) {
...
}
...
}
// --------------------- mappatori
class ShortCategorieMapper implements RowMapper<Categorie> {
....
}
class LongCategorieMapper implements RowMapper<Categorie> {
....
}
- riga 28: la classe [DaoCategorie] è un componente Spring e, in quanto tale, potrà essere iniettato in altri componenti Spring;
- riga 29: la classe [DaoCategorie] estende la classe astratta [AbstractDao<Categorie>], il che la rende un’implementazione dell’interfaccia [IDao<Categorie>];
- righe 34-37: iniezione di bean definiti nella classe [AppConfig] descritta al paragrafo 4.4;
- righe 38-39: iniezione di un riferimento alla classe [DaoProduit] che implementa l'interfaccia [IDao<Produit>], la quale gestisce l'accesso ai dati della tabella [PRODUITS];
- righe 41-89: implementazione dell'interfaccia [IDao<Categorie>];
- righe 95-101: due classi interne che implementano l'interfaccia [RowMapper<T>];
Esaminiamo i metodi uno dopo l’altro.
4.9.1. Il metodo [getAllShortEntities]
Il metodo [getAllShortEntities] restituisce tutte le categorie della tabella [CATEGORIES] nella loro versione abbreviata:
@Override
public List<Categorie> getAllShortEntities() {
try {
return namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_ALLSHORTCATEGORIES, new ShortCategorieMapper());
} catch (Exception e) {
throw new DaoException(202, e, simpleClassName);
}
}
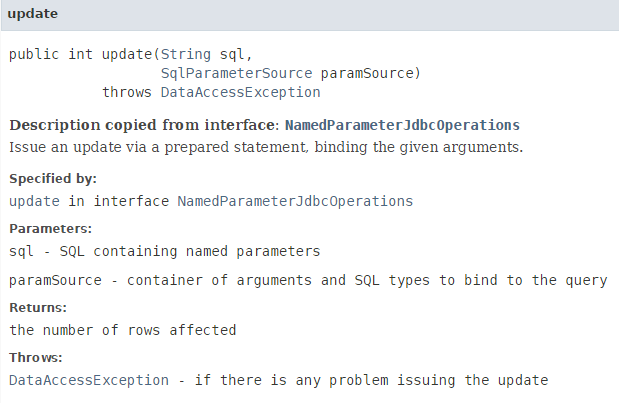
Tutti i metodi si basano sull’oggetto [namedParameterJdbcTemplate] definito nel file di configurazione Spring e fornito dalla libreria Spring JDBC. I suoi metodi sono numerosi. Quello utilizzato sopra è il seguente:
![]()
- [sql] è il comando SQL da eseguire;
- [rowMapper] è un'istanza della seguente interfaccia [RowMapper<T>]:

L'idea è la seguente:
- il metodo [namedParameterJdbcTemplate].query(String sql, RowMapper<T> rowMapper) esegue il comando SQL di tipo [Select]. Gestisce le eventuali eccezioni, nonché l’apertura e la chiusura della connessione verso il SGBD. L’unica cosa che non può fare èincapsulare gli elementi del [ResultSet] degli oggetti che ottiene in un tipo [Categorie], poiché non conosce il collegamento esistente tra i campi del tipo [Categorie] e le colonne del [Resultset]. Vedremo in seguito che tale collegamento viene creato tramite la tecnologia JPA, il che renderà automatico l’incapsulamento degli elementi di un [ResultSet] in istanze di tipo T. Per il momento, il secondo parametro del metodo [query] è un'istanza dell'interfaccia [RowMapper<T>] in grado di eseguire tale incapsulamento;
Torniamo al codice:
@Override
public List<Categorie> getAllShortEntities() {
try {
return namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_ALLSHORTCATEGORIES, new ShortCategorieMapper());
} catch (Exception e) {
throw new DaoException(202, e, simpleClassName);
}
}
L'ordine SQL [ConfigJdbc.SELECT_ALLSHORTCATEGORIES] è il seguente:
public final static String SELECT_ALLSHORTCATEGORIES = "SELECT c.ID as c_ID, c.VERSIONING as c_VERSIONING, c.NOM as c_NOM FROM CATEGORIES c";
La query richiede le colonne [ID, VERSIONING, NOM] degli elementi della tabella [CATEGORIES]. Utilizzeremo sistematicamente la sintassi:
SELECT t1.COL1 as t1_COL1, t1.COL2 as t1_COL2 FROM TABLE1 t1, TABLE2 t2 WHERE ...
Ciò che è importante è la denominazione delle colonne ottenute tramite SELECT con l’attributo [as nom_colonne]. Questo è l’unico modo per garantire la portabilità tra i SGBD, poiché questi hanno tutti un metodo proprietario per denominare le colonne ottenute da un SELECT, in cui colonne di tabelle diverse hanno lo stesso nome (ad esempio ID, NOM o VERSIONING nel nostro caso). Si risolve quindi questa ambiguità specificando noi stessi il nome che queste colonne devono avere.
La classe interna [ShortCategorieMapper] è la seguente:
class ShortCategorieMapper implements RowMapper<Categorie> {
@Override
public Categorie mapRow(ResultSet rs, int rowNum) throws SQLException {
return new Categorie(rs.getLong("c_ID"), rs.getLong("c_VERSIONING"), rs.getString("c_NOM"), null);
}
}
- riga 1: la classe [ShortCategorieMapper] implementa l’interfaccia [RowMapper<Categorie>] e, in quanto tale, deve implementare il metodo [mapRow] delle righe 4-5, il cui ruolo è quello di incapsulare una riga del [ResultSet rs] generata dall'ordine [SELECT] in un tipo [Categorie];
- riga 5: tale incapsulamento è stato effettuato. Si noti che il nome utilizzato dai metodi [rs.getType(nom)] è lo stesso utilizzato negli attributi [as nom] delle colonne del SELECT;
Abbiamo quindi ottenuto l’elenco delle categorie nella loro versione abbreviata senza dover gestire eccezioni né connessioni. È questo il vantaggio della libreria Spring JDBC, che gestisce tutto ciò che può essere standardizzato nella gestione degli elementi di una tabella e lascia allo sviluppatore ciò che non può esserlo.
4.9.2. Il metodo [getAllLongEntities]
Il metodo [getAllLongEntities] restituisce tutte le categorie della tabella [CATEGORIES] nella loro versione estesa:
@Override
public List<Categorie> getAllLongEntities() {
try {
return filterCategories(namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_ALLLONGCATEGORIES,
new LongCategorieMapper()));
} catch (Exception e) {
throw new DaoException(223, e, simpleClassName);
}
}
L'ordine SQL [ConfigJdbc.SELECT_ALLLONGCATEGORIES] è il seguente:
public final static String SELECT_ALLLONGCATEGORIES = "SELECT p.ID as p_ID, p.VERSIONING as p_VERSION, p.NOM as p_NOM, p.PRIX as p_PRIX, p.DESCRIPTION as p_DESCRIPTION, p.CATEGORIE_ID AS p_CATEGORIE_ID, c.ID as c_ID, c.NOM as c_NOM, c.VERSIONING as c_VERSION FROM PRODUITS p RIGHT JOIN CATEGORIES c ON p.CATEGORIE_ID=c.ID";
Si tratta di ricollegare le categorie ai relativi prodotti. Ciò si ottiene effettuando un join tra la tabella [CATEGORIES] e la tabella [PRODUITS] tramite la chiave esterna [CATEGORIE_ID] checollega la tabella [PRODUITS] alla tabella [CATEGORIES]. La sintassi [FROM PRODUITS p RIGHT JOIN CATEGORIES c ON p.CATEGORIE_ID=c.ID] consente di recuperare anche le categorie che non hanno prodotti associati. In questo caso, la query SELECT restituisce una categoria e un prodotto con tutte le colonne presenti in NULL.
La classe [LongCategorieMapper] è la seguente:
class LongCategorieMapper implements RowMapper<Categorie> {
@Override
public Categorie mapRow(ResultSet rs, int rowNum) throws SQLException {
Categorie categorie = new Categorie(rs.getLong("c_ID"), rs.getLong("c_VERSION"), rs.getString("c_NOM"), null);
List<Produit> produits = new ArrayList<Produit>();
long idProduit = rs.getLong("p_ID");
// caso della categoria senza prodotti
if (!rs.wasNull()) {
produits.add(new Produit(idProduit, rs.getLong("p_VERSION"), rs.getString("p_NOM"), rs.getLong("p_CATEGORIE_ID"),
rs.getDouble("p_PRIX"), rs.getString("p_DESCRIPTION"), categorie));
}
categorie.setProduits(produits);
return categorie;
}
}
- riga 4: il metodo [mapRow] deve restituire un oggetto [Categorie] con il campo [produits] compilato, partendo da una riga del [ResultSet] derivante dal precedente ordine SELECT;
In definitiva, l'operazione:
[namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_ALLLONGCATEGORIES,new LongCategorieMapper())]
restituirà un elenco del tipo:
in cui ogni categoria [ci] avrà un campo [produits] che sarà un elenco di prodotti contenente un unico elemento [produitsij]. Tuttavia, ci serve il seguente elenco:
dove ogni categoria [ci] avrà un campo [produits] che conterrà l'elenco dei prodotti [produiti1, produiti2, ...]. Ciò si ottiene passando l'elenco delle categorie ottenuto a un metodo privato [filterCategories]:
@Override
public List<Categorie> getAllLongEntities() {
try {
return filterCategories(namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_ALLLONGCATEGORIES,
new LongCategorieMapper()));
} catch (Exception e) {
throw new DaoException(223, e, simpleClassName);
}
}
Il metodo [filterCategories] è il seguente:
private List<Categorie> filterCategories(List<Categorie> categories) {
if (categories.size() == 0) {
return categories;
}
// categorie da restituire
List<Categorie> cats = new ArrayList<Categorie>();
// si scorre l'elenco delle categorie ottenute
for (Categorie categorie : categories) {
boolean trouve = false;
for (Categorie cat : cats) {
if (categorie.equals(cat)) {
cat.addProduit(categorie.getProduits().get(0));
trouve = true;
break;
}
}
// Trovato?
if (!trouve) {
cats.add(categorie);
}
}
// risultato
return cats;
}
- riga 1: [List<Categorie> categories] è l'elenco delle categorie da filtrare (o raggruppare);
- riga 6: l'elenco delle categorie da restituire al chiamante;
- righe 8-21: si elabora ogni categoria dell’elenco da filtrare;
- righe 10-16: si verifica se la categoria corrente [categorie] è già presente nell’elenco delle categorie [cats] da costruire (si ricorda che due categorie sono considerate uguali se hanno la stessa chiave primaria, cfr. paragrafo 4.6);
- righe 11-14: se è già presente, il prodotto contenuto in [categorie] viene aggiunto all’elenco dei prodotti di [cat];
- righe 18-20: se la categoria corrente [categorie] non è già presente nell’elenco delle categorie [cats] da costruire, allora viene aggiunta con il suo elenco di prodotti che contiene un unico elemento;
Esaminiamo il caso in cui l’ordine SQL Select restituisca categorie senza prodotti associati. Quale entità restituisce la classe [LongCategorieMapper]?
class LongCategorieMapper implements RowMapper<Categorie> {
@Override
public Categorie mapRow(ResultSet rs, int rowNum) throws SQLException {
Categorie categorie = new Categorie(rs.getLong("c_ID"), rs.getLong("c_VERSION"), rs.getString("c_NOM"), null);
List<Produit> produits = new ArrayList<Produit>();
long idProduit = rs.getLong("p_ID");
// caso della categoria senza prodotti
if (!rs.wasNull()) {
produits.add(new Produit(idProduit, rs.getLong("p_VERSION"), rs.getString("p_NOM"), rs.getLong("p_CATEGORIE_ID"),
rs.getDouble("p_PRIX"), rs.getString("p_DESCRIPTION"), categorie));
}
categorie.setProduits(produits);
return categorie;
}
}
Nel caso in cui l’ordine SQL Select abbia restituito una categoria senza prodotti, le colonne del prodotto restituito insieme alla categoria contengono tutte il valore SQL NULL. Questo caso viene trattato nelle righe 7-9:
- riga 7: si recupera la chiave primaria del prodotto come numero intero lungo;
- riga 9: si verifica se il valore letto era SQL NULL (rs.wasNull). Se non è così, si aggiunge il prodotto all’elenco della riga 6; altrimenti non viene aggiunto nulla e l’elenco dei prodotti rimane vuoto.
Si noti che in ogni caso viene restituita una categoria con un campo [produits] che non è null.
4.9.3. Il metodo [getShortEntitiesById]
Il metodo [getShortEntitiesById] è analogo al metodo [getAllShortEntities], tranne per il fatto che restituisce solo le entità le cui chiavi primarie sono specificate in un elenco:
@Override
protected List<Categorie> getShortEntitiesById(List<Long> ids) {
try {
return namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_SHORTCATEGORIE_BYID,
Collections.singletonMap("ids", ids), new ShortCategorieMapper());
} catch (Exception e) {
throw new DaoException(203, e, simpleClassName);
}
}
- alla riga 4, la firma del metodo [query] utilizzato è la seguente:

Il primo parametro è un comando SQL [Select] configurato. Il secondo è un dizionario che associa a ciascun parametro un valore. Il terzo è l’istanza della classe che incapsula una riga del [ResultSet], risultato del [Select], in un oggetto di tipo T;
- riga 4: l'ordine SQL [Select] con i parametri impostati è il seguente:
public final static String SELECT_SHORTCATEGORIE_BYID = "SELECT c.ID as c_ID, c.VERSIONING as c_VERSIONING, c.NOM as c_NOM FROM CATEGORIES c WHERE c.ID in (:ids)";
Questo comando estrae dalla tabella [CATEGORIES] le categorie le cui chiavi primarie sono presenti nell'elenco: ids.
- riga 5: il secondo parametro del metodo [query] è qui un dizionario che associa la chiave 'ids' (1° parametro) all'elenco [ids] passato alla riga 1 come parametro al metodo [getShortEntitiesById]. La classe [Collections] appartiene alla libreria [Google Guava] di cui abbiamo già parlato. [Collections.singleMap] restituisce un dizionario composto da un elemento;
- riga 5: la classe incaricata di incapsulare una riga del [ResultSet], risultato del [Select], in un oggetto di tipo [Categorie] è la classe [ShortCategorieMapper] già esaminata;
È proprio qui che entra in gioco il bean [maxPreparedStatementParameters]. Infatti, il parametro [:ids] dell’ordine SQL, che rappresenta un elenco di chiavi primarie, può contenere da 1 a diverse migliaia di parametri. Esiste un limite a tale numero che dipende da ciascun SGBD. Per MySQL, siamo riusciti a superare i 10.000 parametri senza errori e non abbiamo effettuato test oltre tale soglia. Per il server SQL il limite ufficiale è 2100. Per Firebird, 1000 era già troppo. Siamo scesi a 100. In generale, non abbiamo testato il limite massimo di questo numero per i diversi SGBD.
4.9.4. Il metodo [getLongEntitiesById]
Il metodo [getLongEntitiesById] è analogo al metodo [getShortEntitiesById], tranne per il fatto che restituisce le versioni estese delle categorie:
@Override
protected List<Categorie> getLongEntitiesById(List<Long> ids) {
try {
return filterCategories(namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_LONGCATEGORIE_BYID,
Collections.singletonMap("ids", ids), new LongCategorieMapper()));
} catch (Exception e) {
throw new DaoException(205, e, simpleClassName);
}
}
Riga 4, la query SQL [ConfigJdbc.SELECT_LONGCATEGORIE_BYID] è la seguente:
public final static String SELECT_LONGCATEGORIE_BYID = "SELECT p.ID as p_ID, p.VERSIONING as p_VERSION, p.NOM as p_NOM, p.PRIX as p_PRIX, p.DESCRIPTION as p_DESCRIPTION, p.CATEGORIE_ID AS p_CATEGORIE_ID, c.ID as c_ID, c.NOM as c_NOM, c.VERSIONING as c_VERSION FROM PRODUITS p RIGHT JOIN CATEGORIES c ON c.ID=p.CATEGORIE_ID WHERE c.ID in (:ids)";
4.9.5. Il metodo [getShortEntitiesByName]
Il metodo [getShortEntitiesByName] è analogo al metodo [getShortEntitiesById], tranne per il fatto che le categorie vengono ricercate tramite i loro nomi anziché tramite le loro chiavi primarie:
@Override
protected List<Categorie> getShortEntitiesByName(List<String> names) {
try {
return namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_SHORTCATEGORIE_BYNAME,
Collections.singletonMap("noms", names), new ShortCategorieMapper());
} catch (Exception e) {
throw new DaoException(204, e, simpleClassName);
}
}
Riga 4, l'ordine SQL [ConfigJdbc.SELECT_SHORTCATEGORIE_BYNAME] è il seguente:
public final static String SELECT_SHORTCATEGORIE_BYNAME = "SELECT c.ID as c_ID, c.VERSIONING as c_VERSIONING, c.NOM as c_NOM FROM CATEGORIES c WHERE c.NOM in (:noms)";
4.9.6. Il metodo [getLongEntitiesByName]
Il metodo [getLongEntitiesByName] è analogo al metodo [getShortEntitiesByName], tranne per il fatto che le categorie vengono cercate nelle loro versioni estese:
@Override
protected List<Categorie> getLongEntitiesByName(List<String> names) {
try {
return filterCategories(namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_LONGCATEGORIE_BYNAME,
Collections.singletonMap("noms", names), new LongCategorieMapper()));
} catch (Exception e) {
throw new DaoException(215, e, simpleClassName);
}
}
Riga 4, l'ordine SQL [ConfigJdbc.SELECT_LONGCATEGORIE_BYNAME] è il seguente:
public final static String SELECT_LONGCATEGORIE_BYNAME = "SELECT p.ID as p_ID, p.VERSIONING as p_VERSION, p.NOM as p_NOM, p.PRIX as p_PRIX, p.DESCRIPTION as p_DESCRIPTION, p.CATEGORIE_ID AS p_CATEGORIE_ID, c.ID as c_ID, c.NOM as c_NOM, c.VERSIONING as c_VERSION FROM PRODUITS p RIGHT JOIN CATEGORIES c ON c.ID=p.CATEGORIE_ID WHERE c.NOM in(:noms)";
4.9.7. Il metodo [deleteAllEntities]
Il metodo [deleteAllEntities] elimina tutte le categorie dalla tabella [CATEGORIES]:
@Override
public void deleteAllEntities() {
try {
// si eliminano tutte le categorie e, di conseguenza, tutti i prodotti
namedParameterJdbcTemplate.update(ConfigJdbc.DELETE_ALLCATEGORIES, (Map<String, Object>) null);
} catch (Exception e) {
throw new DaoException(208, e, simpleClassName);
}
}
- riga 4: il metodo [namedParameterJdbcTemplate.update] utilizzato ha la seguente firma:
![]()
Il primo parametro è un ordine SQL configurato per l'aggiornamento (INSERT, UPDATE, DELETE). Il secondo parametro è il dizionario che associa i valori ai diversi parametri dell'ordine SQL. Il metodo restituisce il numero di righe aggiornate dall'ordine SQL.
- riga 4: l'ordine SQL [ConfigJdbc.DELETE_ALLCATEGORIES] è il seguente:
public final static String DELETE_ALLCATEGORIES = "DELETE FROM CATEGORIES";
Non si tratta quindi di un ordine con parametri. Per questo motivo, il secondo parametro del metodo [update] ha il valore null.
4.9.8. Il metodo [deleteAllEntitiesById]
Il metodo [deleteAllEntitiesById] elimina le categorie dalla tabella [CATEGORIES] di cui vengono passati i chiavi primarie:
@Override
protected void deleteEntitiesById(List<Long> ids) {
try {
namedParameterJdbcTemplate.update(ConfigJdbc.DELETE_CATEGORIESBYID, Collections.singletonMap("ids", ids));
} catch (Exception e) {
throw new DaoException(209, e, simpleClassName);
}
}
Riga 4, l'ordine SQL [ConfigJdbc.DELETE_CATEGORIESBYID] è il seguente:
public final static String DELETE_CATEGORIESBYID = "DELETE FROM CATEGORIES WHERE ID in (:ids)";
4.9.9. Il metodo [deleteAllEntitiesByName]
Il metodo [deleteAllEntitiesByName] elimina le categorie dalla tabella [CATEGORIES] di cui si passano i nomi:
@Override
protected void deleteEntitiesByName(List<String> names) {
try {
namedParameterJdbcTemplate.update(ConfigJdbc.DELETE_CATEGORIESBYNAME, Collections.singletonMap("noms", names));
} catch (Exception e) {
throw new DaoException(225, e, simpleClassName);
}
}
Riga 4, l'ordine SQL [ConfigJdbc.DELETE_CATEGORIESBYNAME] è il seguente:
public final static String DELETE_CATEGORIESBYNAME = "DELETE FROM CATEGORIES WHERE NOM in (:noms)";
4.9.10. Il metodo [saveEntities]
4.9.10.1. Il codice
La firma di questo metodo è la seguente:
@Override
protected List<Categorie> saveEntities(List<Categorie> entities) {
Il metodo riceve come parametro un elenco di categorie. Su di esse esegue le seguenti operazioni:
- se la categoria ha una chiave primaria null, viene eseguita un'operazione SQL INSERT; in caso contrario, viene eseguita un'operazione SQL UPDATE;
- questa operazione viene ripetuta per ciascuno dei prodotti della categoria;
Il metodo restituisce l'elenco delle categorie salvate o aggiornate. L'elenco restituito è l'immagine esatta delle categorie e dei prodotti presenti nelle tabelle, salvo le versioni: queste ultime, infatti, non vengono modificate nelle entità aggiornate, pur essendo state incrementate nel database.
Si tratta di gran lunga del metodo più complesso. Il suo codice è il seguente:
@Override
protected List<Categorie> saveEntities(List<Categorie> entities) {
try {
// --------------------------------------------- categorie
List<Categorie> insertCategories = new ArrayList<Categorie>();
List<Categorie> updateCategories = new ArrayList<Categorie>();
// si eseguono la scansione delle categorie
for (Categorie categorie : entities) {
// inserire o aggiornare?
if (categorie.getId() == null) {
insertCategories.add(categorie);
} else {
updateCategories.add(categorie);
}
}
// Inserimento categorie
if (insertCategories.size() > 0) {
insertCategories(insertCategories);
}
// aggiornamenti delle categorie
if (updateCategories.size() > 0) {
updateCategories(updateCategories);
}
// --------------------------------------------- prodotti
// si aggiornano i prodotti delle categorie
List<Produit> allProduits = new ArrayList<Produit>();
for (Categorie categorie : entities) {
List<Produit> produits = categorie.getProduits();
Long idCategorie = categorie.getId();
if (produits != null) {
// si aggiunge all'elenco di tutti i prodotti
allProduits.addAll(produits);
// si scansionano i prodotti uno per uno per associarli alla loro categoria
for (Produit produit : produits) {
// si associa il prodotto alla sua categoria
produit.setIdCategorie(idCategorie);
produit.setCategorie(categorie);
}
}
}
// inserimento/aggiornamento dei prodotti
daoProduit.saveEntities(allProduits);
// risultato
return entities;
} catch (DaoException e) {
throw e;
} catch (Exception e) {
throw new DaoException(207, e, simpleClassName);
}
}
- righe 5-23: inserimento o aggiornamento delle categorie;
- righe 26-43: inserimento o aggiornamento dei prodotti;
- righe 35-39: questo codice associa ogni prodotto alla sua categoria. Nella fase precedente di inserimento delle categorie, a queste è stata assegnata una chiave primaria che deve essere inserita nel campo [idCategorie] del prodotto (riga 37). Inoltre, le righe 37-38 consentono di correggere i casi in cui l’utente non abbia collegato correttamente ciascun prodotto alla propria categoria. Affinché questa relazione sia corretta, è necessario utilizzare il metodo [Categorie] .add(Prodotto p), ma nulla impedisce a un utente di aggiungere un prodotto direttamente all’elenco dei prodotti della categoria senza passare attraverso questo metodo, con il rischio che i campi [idCategorie, categorie] del prodotto p siano compilati in modo errato;
- riga 43: si delega all’istanza dell’interfaccia [IDao<Produit>] il compito di salvare / aggiornare i prodotti. Si ricorda che questa istanza è stata iniettata nella classe [DaoCategorie]:
@Autowired
private IDao<Produit> daoProduit;
4.9.10.2. Inserimento delle categorie
Le categorie vengono inserite nella tabella [CATEGORIES] tramite il seguente metodo privato [insertCategories]:
private List<Categorie> insertCategories(List<Categorie> categories) {
Map<Long, Categorie> mapCategories=new HashMap<Long,Categorie>();
try {
// categorie da aggiungere
for (Categorie categorie : categories) {
Number newId = simpleJdbcInsertCategorie.executeAndReturnKey(getMapForCategorie(categorie));
// si memorizza la chiave primaria
mapCategories.put(newId.longValue(), categorie);
}
} catch (Exception e) {
throw new DaoException(201, e, simpleClassName);
}
// tutto è OK - si assegnano le chiavi primarie alle categorie salvate
for(Long id : mapCategories.keySet()){
Categorie categorie=mapCategories.get(id);
categorie.setId(id);
}
// risultato
return categories;
}
- riga 6: si utilizza il bean [simpleJdbcInsertCategorie] iniettato nella classe dalle seguenti righe:
@Autowired
private SimpleJdbcInsert simpleJdbcInsertCategorie;
Questo bean è definito nella classe [AppConfig] del progetto nel modo seguente:
import org.springframework.jdbc.core.simple.SimpleJdbcInsert;
@Bean
public SimpleJdbcInsert simpleJdbcInsertCategorie(DataSource dataSource) {
return new SimpleJdbcInsert(dataSource).withTableName(ConfigJdbc.TAB_CATEGORIES)
.usingGeneratedKeyColumns(ConfigJdbc.TAB_CATEGORIES_ID)
.usingColumns(ConfigJdbc.TAB_CATEGORIES_NOM);
}
- alla riga 5, la classe [SimpleJdbcInsert] è una classe della libreria Spring JDBC (riga 1):
- il parametro del costruttore [SimpleJdbcInsert] è la fonte di dati su cui si opera;
- la clausola [withTableName] consente di specificare la tabella in cui si desidera inserire un elemento, in questo caso la tabella [CATEGORIES];
- la clausola [usingGeneratedKeyColumns] consente di specificare la colonna della chiave primaria generata automaticamente, in questo caso la colonna [ID];
- la clausola [usingColumns] consente di limitare l'inserimento a determinate colonne. In questo caso si esclude la colonna [ID], generata automaticamente dalla colonna SGBD, e la colonna [VERSIONING], il cui valore predefinito è 1;
Torniamo al codice del metodo [insertCategories]:
private List<Categorie> insertCategories(List<Categorie> categories) {
Map<Long, Categorie> mapCategories=new HashMap<Long,Categorie>();
try {
// categorie da aggiungere
for (Categorie categorie : categories) {
Number newId = simpleJdbcInsertCategorie.executeAndReturnKey(getMapForCategorie(categorie));
// si memorizza la chiave primaria
mapCategories.put(newId.longValue(), categorie);
}
} catch (Exception e) {
throw new DaoException(201, e, simpleClassName);
}
// tutto è OK - si assegnano le chiavi primarie alle categorie persistenti
for(Long id : mapCategories.keySet()){
Categorie categorie=mapCategories.get(id);
categorie.setId(id);
}
// risultato
return categories;
}
- riga 6: viene utilizzato il metodo [simpleJdbcInsertCategorie.executeAndReturnKey]:
![]()
Il metodo richiede come parametro un dizionario che stabilisce le corrispondenze tra le colonne della tabella e i valori da inserire in esse. Restituisce come risultato la chiave primaria sotto forma di un tipo [Number]. Il metodo [Number.longValue()] consente di ottenere la chiave primaria sotto forma di un tipo [Long].
Il metodo [getMapForCategorie] è il seguente metodo privato:
private Map<String, ?> getMapForCategorie(Categorie categorie) {
Map<String, Object> map = new HashMap<String, Object>();
map.put(ConfigJdbc.TAB_CATEGORIES_NOM, categorie.getNom());
return map;
}
Le chiavi del dizionario sono i nomi delle colonne da compilare [NOM], mentre i valori del dizionario sono i valori da inserire in tali colonne.
- riga 8 [insertCategories]: la chiave primaria recuperata viene memorizzata in un dizionario. Aspetteremo di essere sicuri che tutte le entità siano state inserite prima di assegnare loro le chiavi primarie. Infatti, in caso di eccezione, tutti gli inserimenti verranno annullati e vogliamo che anche le entità [categories] della riga 1 rimangano invariate;
- righe 14-17: ora che siamo certi che tutto sia andato a buon fine, assegniamo le chiavi primarie generate alle categorie;
- riga 19: restituiamo l’elenco delle categorie con le relative chiavi primarie;
4.9.10.3. Aggiornamento delle categorie
Le categorie vengono aggiornate con il seguente metodo privato [updateCategories]:
private void updateCategories(List<Categorie> categories) {
try {
for (Categorie categorie : categories) {
// aggiornamento della categoria nel database
int nbLignes = namedParameterJdbcTemplate.update(ConfigJdbc.UPDATE_CATEGORIES,
new BeanPropertySqlParameterSource(categorie));
// è andata a buon fine?
Long idCategorie = null;
if (nbLignes == 0) {
// Non è andata a buon fine - si cerca di capire il motivo
// si sta cercando la categoria nel database
idCategorie = categorie.getId();
List<Categorie> categoriesInBd = getShortEntitiesById(idCategorie);
if (categoriesInBd.size() == 0) {
// la categoria non esiste
throw new RuntimeException(String.format("Erreur de mise à jour. La catégorie de clé [%s] n'existe pas",
idCategorie));
} else {
// la versione non era corretta
throw new RuntimeException(String.format(
"Erreur de mise à jour. La catégorie de clé [%s] n'a pas la bonne version", idCategorie));
}
}
}
} catch (DaoException e) {
throw e;
} catch (Exception e) {
throw new DaoException(206, e, simpleClassName);
}
}
L'aggiornamento di una categoria C1 nel database con una categoria C2 in memoria è consentito solo se le categorie C1 e C2 hanno la stessa versione. Questo numero di versione serve a impedire l'aggiornamento simultaneo dell'entità da parte di due utenti diversi: due utenti, U1 e U2, leggono l'entità E con un numero di versione pari a V1. U1 modifica E e salva tale modifica nel database: il numero di versione passa quindi a V1+1. U2 a sua volta modifica E e salva questa modifica nel database: riceverà un'eccezione poiché possiede una versione (V1) diversa da quella presente nel database (V1+1).
- righe 2-29: il blocco `try` ha due blocchi `catch`:
- il primo, alla riga 25, serve a far passare l'eventuale eccezione di tipo [DaoException] generata dal codice della riga 13;
- il secondo, alla riga 27, serve a gestire gli altri tipi di eccezione;
- riga 3: si eseguono le operazioni di scansione su tutte le categorie da aggiornare;
- riga 4: si aggiorna la categoria corrente con il metodo [namedParameterJdbcTemplate.update]:
- Analizziamo l’istruzione:
int nbLignes = namedParameterJdbcTemplate.update(ConfigJdbc.UPDATE_CATEGORIES, new BeanPropertySqlParameterSource(categorie));
La sequenza SQL [ConfigJdbc.UPDATE_CATEGORIES] è la seguente:
public final static String UPDATE_CATEGORIES = "UPDATE CATEGORIES SET VERSIONING=VERSIONING+1, NOM=:nom WHERE ID=:id AND VERSIONING=:version";
L'ordine ha tre parametri (:id, :version, :nom) i cui valori si trovano nei campi con lo stesso nome dell'oggetto [categorie] modificato. Si sfrutta questa particolarità passando come secondo parametro [new BeanPropertySqlParameterSource(categorie)], che indica che «i valori dei parametri si trovano nei campi con lo stesso nome di questo Java bean»;
Il risultato restituito da questa operazione, quando si svolge normalmente, è il numero di righe modificate, quindi 0 o 1.
Torniamo al codice esaminato:
private void updateCategories(List<Categorie> categories) {
try {
for (Categorie categorie : categories) {
// aggiornamento della categoria nel database
int nbLignes = namedParameterJdbcTemplate.update(ConfigJdbc.UPDATE_CATEGORIES,
new BeanPropertySqlParameterSource(categorie));
// L'operazione è andata a buon fine?
Long idCategorie = null;
if (nbLignes == 0) {
// Non ci siamo riusciti - stiamo cercando di capire perché
// si sta cercando la categoria nel database
idCategorie = categorie.getId();
List<Categorie> categoriesInBd = getShortEntitiesById(idCategorie);
if (categoriesInBd.size() == 0) {
// la categoria non esiste
throw new RuntimeException(String.format("Erreur de mise à jour. La catégorie de clé [%s] n'existe pas",
idCategorie));
} else {
// la versione non era corretta
throw new RuntimeException(String.format(
"Erreur de mise à jour. La catégorie de clé [%s] n'a pas la bonne version", idCategorie));
}
}
}
} catch (DaoException e) {
throw e;
} catch (Exception e) {
throw new DaoException(206, e, simpleClassName);
}
}
- riga 9: si verifica se la modifica è andata a buon fine;
- riga 10: la modifica non è andata a buon fine. Poiché la clausola [WHERE] coinvolge le colonne [ID] e [VERSIONING], si individua la colonna che ha causato il fallimento di [WHERE];
- righe 12-18: si verifica che la chiave [id] della categoria sia presente nel database. In caso contrario, si avvia una [RuntimeException] con un messaggio di errore appropriato;
- righe 19-22: gestiscono il caso in cui fosse la versione a non essere corretta;
4.10. La classe [DaoProduit]
 |
|
La classe [DaoProduit] implementa l'interfaccia [IDao<Produit>] che garantisce l'accesso ai dati della tabella [PRODUITS] del database MySQL [dbproduitscategories]. Il suo scheletro è il seguente:
package spring.jdbc.dao;
import generic.jdbc.config.ConfigJdbc;
import java.sql.ResultSet;
import java.sql.SQLException;
import java.util.ArrayList;
import java.util.Collections;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.jdbc.core.RowMapper;
import org.springframework.jdbc.core.namedparam.NamedParameterJdbcTemplate;
import org.springframework.jdbc.core.namedparam.SqlParameterSource;
import org.springframework.jdbc.core.simple.SimpleJdbcInsert;
import org.springframework.stereotype.Component;
import spring.jdbc.entities.Categorie;
import spring.jdbc.entities.Produit;
import spring.jdbc.infrastructure.DaoException;
import com.google.common.collect.Lists;
@Component
public class DaoProduit extends AbstractDao<Produit> {
// inserimenti
@Autowired
private NamedParameterJdbcTemplate namedParameterJdbcTemplate;
@Autowired
private SimpleJdbcInsert simpleJdbcInsertProduit;
@Override
public List<Produit> getAllShortEntities() {
...
}
@Override
public List<Produit> getAllLongEntities() {
....
}
@Override
public void deleteAllEntities() {
...
}
@Override
protected List<Produit> getShortEntitiesById(List<Long> ids) {
...
}
@Override
protected List<Produit> getShortEntitiesByName(List<String> names) {
....
}
@Override
protected List<Produit> getLongEntitiesById(List<Long> ids) {
...
}
@Override
protected List<Produit> getLongEntitiesByName(List<String> names) {
try {
return namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_LONGPRODUIT_BYNAME,
Collections.singletonMap("noms", names), new LongProduitMapper());
} catch (Exception e) {
throw new DaoException(112, e, simpleClassName);
}
}
@Override
protected List<Produit> saveEntities(List<Produit> entities) {
...
}
@Override
protected void deleteEntitiesById(List<Long> ids) {
....
}
@Override
protected void deleteEntitiesByName(List<String> names) {
...
}
}
// --------------------- mappatori
class ShortProduitMapper implements RowMapper<Produit> {
...
}
class LongProduitMapper implements RowMapper<Produit> {
...
}
Il codice è molto simile a quello della classe [DaoCategorie]. Esamineremo solo alcuni metodi.
4.10.1. Il metodo [getShortEntitiesById]
Il metodo [getShortEntitiesById] restituisce la versione abbreviata dei prodotti di cui vengono passati i chiavi primarie:
@Override
protected List<Produit> getShortEntitiesById(List<Long> ids) {
try {
return namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_SHORTPRODUIT_BYID,
Collections.singletonMap("ids", ids), new ShortProduitMapper());
} catch (Exception e) {
throw new DaoException(109, e, simpleClassName);
}
}
- riga 4: l’ordine SQL Select [ConfigJdbc.SELECT_SHORTPRODUIT_BYID] è il seguente:
public final static String SELECT_SHORTPRODUIT_BYID = "SELECT p.ID as p_ID, p.VERSIONING as p_VERSIONING, p.NOM as p_NOM, p.CATEGORIE_ID as p_CATEGORIE_ID, p.PRIX as p_PRIX, p.DESCRIPTION as p_DESCRIPTION FROM PRODUITS p WHERE p.ID in (:ids)";
- riga 4: la classe [ShortProduitMapper] incaricata di incapsulare [ResultSet] in un elenco di prodotti è la seguente:
class ShortProduitMapper implements RowMapper<Produit> {
@Override
public Produit mapRow(ResultSet rs, int rowNum) throws SQLException {
return new Produit(rs.getLong("p_ID"), rs.getLong("p_VERSIONING"), rs.getString("p_NOM"),
rs.getLong("p_CATEGORIE_ID"), rs.getDouble("p_PRIX"), rs.getString("p_DESCRIPTION"), null);
}
}
4.10.2. Il metodo [getLongEntitiesByName]
Il metodo [getShortEntitiesById] restituisce la versione estesa dei prodotti di cui vengono passati i nomi:
@Override
protected List<Produit> getLongEntitiesByName(List<String> names) {
try {
return namedParameterJdbcTemplate.query(ConfigJdbc.SELECT_LONGPRODUIT_BYNAME,
Collections.singletonMap("noms", names), new LongProduitMapper());
} catch (Exception e) {
throw new DaoException(112, e, simpleClassName);
}
}
- riga 4: l'ordine SQL Select [ConfigJdbc.SELECT_LONGPRODUIT_BYNAME] è il seguente:
public final static String SELECT_LONGPRODUIT_BYID = "SELECT p.ID as p_ID, p.VERSIONING as p_VERSION, p.NOM as p_NOM, p.PRIX as p_PRIX, p.DESCRIPTION as p_DESCRIPTION, p.CATEGORIE_ID AS p_CATEGORIE_ID, c.ID as c_ID, c.NOM as c_NOM, c.VERSIONING as c_VERSION FROM PRODUITS p, CATEGORIES c WHERE p.ID in (:ids) AND p.CATEGORIE_ID=c.ID";
- riga 4: la classe [LongProduitMapper] incaricata di incapsulare gli elementi di [ResultSet] in prodotti, versione estesa, è la seguente:
class LongProduitMapper implements RowMapper<Produit> {
@Override
public Produit mapRow(ResultSet rs, int rowNum) throws SQLException {
return new Produit(rs.getLong("p_ID"), rs.getLong("p_VERSION"), rs.getString("p_NOM"),
rs.getLong("p_CATEGORIE_ID"), rs.getDouble("p_PRIX"), rs.getString("p_DESCRIPTION"), new Categorie(rs.getLong("c_ID"), rs.getLong("c_VERSION"), rs.getString("c_NOM"), null));
}
}
4.10.3. Il metodo [saveEntities]
Il metodo [saveEntities] viene utilizzato indifferentemente per inserire nuovi prodotti (id==null) o aggiornare prodotti esistenti (id!=null):
@Override
protected List<Produit> saveEntities(List<Produit> entities) {
try {
// prodotti da inserire
List<Produit> insertProduits = new ArrayList<Produit>();
// prodotti da aggiornare
List<Produit> updateproduits = new ArrayList<Produit>();
// si esegue la scansione dell'elenco delle entità ricevute
for (Produit produit : entities) {
Long id = produit.getId();
if (id == null) {
insertProduits.add(produit);
} else {
updateproduits.add(produit);
}
}
// aggiunte
insertProduits(insertProduits);
// modifiche
updateProduits(updateproduits);
// risultato
return entities;
} catch (DaoException e) {
throw e;
} catch (Exception e) {
throw new DaoException(103, e, simpleClassName);
}
}
Riga 18: i prodotti da inserire vengono inseriti tramite il seguente metodo privato [insertProduits]:
private List<Produit> insertProduits(List<Produit> produits) {
Map<Long, Produit> mapProduits = new HashMap<Long, Produit>();
try {
// prodotti da aggiungere
for (Produit produit : produits) {
Number newId = simpleJdbcInsertProduit.executeAndReturnKey(getMapForProduit(produit));
// si annota la chiave primaria
mapProduits.put(newId.longValue(), produit);
}
} catch (Exception e) {
throw new DaoException(201, e, simpleClassName);
}
// tutto è OK - si assegnano le chiavi primarie ai prodotti salvati
for (Long id : mapProduits.keySet()) {
Produit produit = mapProduits.get(id);
produit.setId(id);
}
// risultato
return produits;
}
private Map<String, ?> getMapForProduit(Produit produit) {
Map<String, Object> map = new HashMap<String, Object>();
map.put(ConfigJdbc.TAB_PRODUITS_NOM, produit.getNom());
map.put(ConfigJdbc.TAB_PRODUITS_CATEGORIE_ID, produit.getIdCategorie());
map.put(ConfigJdbc.TAB_PRODUITS_PRIX, produit.getPrix());
map.put(ConfigJdbc.TAB_PRODUITS_DESCRIPTION, produit.getDescription());
return map;
}
Questo metodo è analogo al metodo [insertCategories] illustrato nel paragrafo 4.9.10.3.
- riga 4: si utilizza il bean [simpleJdbcInsertProduit] che è stato iniettato nella classe:
@Autowired
private SimpleJdbcInsert simpleJdbcInsertProduit;
Questo bean è stato definito nella classe [AppConfig] che configura il progetto:
@Bean
public SimpleJdbcInsert simpleJdbcInsertProduit(DataSource dataSource) {
return new SimpleJdbcInsert(dataSource)
.withTableName(ConfigJdbc.TAB_PRODUITS)
.usingGeneratedKeyColumns(ConfigJdbc.TAB_PRODUITS_ID)
.usingColumns(ConfigJdbc.TAB_PRODUITS_NOM, ConfigJdbc.TAB_PRODUITS_PRIX, ConfigJdbc.TAB_PRODUITS_DESCRIPTION,ConfigJdbc.TAB_PRODUITS_CATEGORIE_ID);
}
- righe 3-6: il bean [simpleJdbcInsertProduit]
- è collegato alla fonte dati del database [dbproduitscategories] (riga 3) e alla tabella [ConfigJdbc.TAB_PRODUITS] di tale fonte (riga 4);
- la chiave primaria di questa tabella viene generata nella colonna [ConfigJdbc.TAB_PRODUITS_ID] (riga 5);
- vengono assegnati valori solo alle colonne [ConfigJdbc.TAB_PRODUITS_NOM, ConfigJdbc.TAB_PRODUITS_PRIX, ConfigJdbc.TAB_PRODUITS_DESCRIPTION, ConfigJdbc.TAB_PRODUITS_CATEGORIE_ID] (riga 6);
Il metodo [updateProduits] che aggiorna i prodotti (riga 20 di [saveEntities]) è il seguente:
private void updateProduits(List<Produit> updateProduits) {
try {
// si esegue la scansione dei prodotti
for (Produit produit : updateProduits) {
// aggiornamento del prodotto nel database
int nbLignes = namedParameterJdbcTemplate.update(ConfigJdbc.UPDATE_PRODUITS,
new BeanPropertySqlParameterSource(produit));
// L'operazione è andata a buon fine?
Long idProduit = null;
if (nbLignes == 0) {
// Non è andata a buon fine - si cerca di capire il motivo
// si sta cercando il prodotto nel database
idProduit = produit.getId();
List<Produit> produitsInBd = getShortEntitiesById(idProduit);
if (produitsInBd.size() == 0) {
// il prodotto non esiste
throw new RuntimeException(String.format("Erreur de mise à jour. Le produit de clé [%s] n'existe pas",
idProduit));
} else {
// la versione non era corretta
throw new RuntimeException(String.format(
"Erreur de mise à jour. Le produit de clé [%s] n'a pas la bonne version", idProduit));
}
}
}
} catch (DaoException e) {
throw e;
} catch (Exception e) {
throw new DaoException(106, e, simpleClassName);
}
}
È analoga a quella che aggiorna le categorie (cfr. paragrafo 4.9.10.3). Alla riga 23, il comando SQL [ConfigJdbc.UPDATE_PRODUITS] eseguito per aggiornare i prodotti è il seguente:
public final static String UPDATE_PRODUITS = "UPDATE PRODUITS SET VERSIONING=VERSIONING+1, NOM=:nom, PRIX=:prix, CATEGORIE_ID=:idCategorie, DESCRIPTION=:description WHERE ID=:id AND VERSIONING=:version";
I nomi dei parametri [:id,:version,:nom,:prix,:idCategorie,:description] corrispondono anche ai nomi dei campi della classe [Produit], il che consente di utilizzare l’istruzione delle righe 6-7 per aggiornare il prodotto corrente.
4.11. Il livello di test
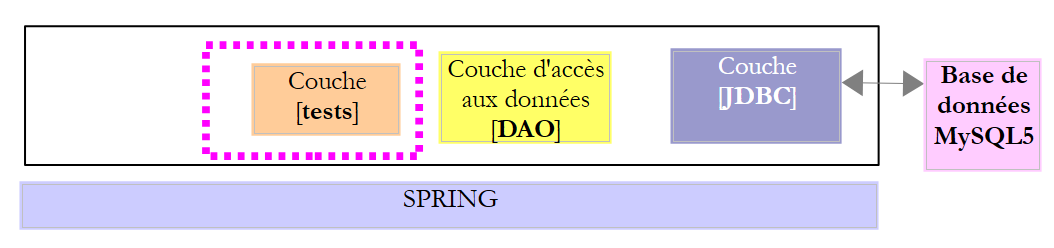 |
 |
Il livello di test è composto da tre classi di test:
- [JUnitTestCheckArguments]: i test di questa classe richiamano i diversi metodi del livello [DAO] con argomenti non validi e verificano che reagiscano correttamente;
- [JUnitTestDao]: i test di questa classe chiamano i vari metodi del livello [DAO] e verificano che facciano ciò che ci si aspetta;
- [JUnitTestPushTheLimits] non ha lo scopo di testare il livello [DAO], ma di misurarne le prestazioni;
Questo livello di test riveste un ruolo importante in questo documento. È infatti comune a tutte le implementazioni dell’interfaccia [IDao<T>]. Ce ne sono sei per SGBD (1 implementazione JDBC, 3 implementazioni JPA, 1 implementazione Spring MVC, 1 implementazione Spring MVC protetta), per un totale di 36 per i sei SGBD testati. Il livello di test ci permette di verificare che tutte le implementazioni reagiscano allo stesso modo.
4.11.1. Il test [JUnitTestCheckArguments]
La classe di test [JUnitTestCheckArguments] contiene 48 metodi che verificano il comportamento dei metodi del livello [DAO] quando vengono chiamati con argomenti errati. La sua struttura è la seguente:
package spring.jdbc.tests;
import org.junit.Assert;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.SpringApplicationConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import spring.jdbc.config.AppConfig;
import spring.jdbc.dao.IDao;
import spring.jdbc.entities.Categorie;
import spring.jdbc.entities.Produit;
import spring.jdbc.infrastructure.MyIllegalArgumentException;
import com.google.common.collect.Lists;
@SpringApplicationConfiguration(classes = AppConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class JUnitTestCheckArguments {
// livello [DAO]
@Autowired
private IDao<Produit> daoProduit;
@Autowired
private IDao<Categorie> daoCategorie;
// dati locali
private Iterable<String> names1 = null;
private Iterable<String> names2 = Lists.newArrayList(new String[0]);
private String[] names3 = null;
private String[] names4 = new String[0];
private Iterable<Long> ids1 = null;
private Iterable<Long> ids2 = Lists.newArrayList(new Long[0]);
private Long[] ids3 = null;
private Long[] ids4 = new Long[0];
private Iterable<Categorie> categories1 = null;
private Iterable<Categorie> categories2 = Lists.newArrayList(new Categorie[0]);
private Categorie[] categories3 = null;
private Categorie[] categories4 = new Categorie[0];
private Iterable<Produit> produits1 = null;
private Iterable<Produit> produits2 = Lists.newArrayList(new Produit[0]);
private Produit[] produits3 = null;
private Produit[] produits4 = new Produit[0];
...
}
- riga 19: il test JUnit verrà eseguito in integrazione con il framework Spring;
- riga 18: prima dei test, verranno istanziati i bean definiti nella classe [AppConfig] del progetto;
- righe 23-26: iniezione di un'istanza di ciascuna delle due interfacce del livello [DAO];
- righe 29-44: i parametri di chiamata dei metodi del livello [DAO] sono errati;
- riga 29: un puntatore null di tipo [Iterable<String>] come lista di nomi;
- riga 30: un elenco vuoto di tipo [Iterable<String>] come elenco di nomi;
- riga 29: un puntatore null di tipo String[] come array di nomi;
- riga 30: un array vuoto di tipo String[] come array di nomi;
- ...
Con il campo [names1], si esegue ad esempio il seguente test:
@Test(expected = MyIllegalArgumentException.class)
public void getShortProduitsByName1() {
daoProduit.getShortEntitiesByName(names1);
}
- riga 1: si specifica che il test [getShortProduitsByName1] deve generare l'eccezione di tipo [MyIllegalArgumentException]
Con il campo [names2], si esegue ad esempio il seguente test:
@Test(expected = MyIllegalArgumentException.class)
public void getLongCategoriesByName2() {
daoCategorie.getLongEntitiesByName(names2);
}
Con il campo [names3], si esegue ad esempio il seguente test:
@Test(expected = MyIllegalArgumentException.class)
public void getLongCategoriesByName3() {
daoCategorie.getLongEntitiesByName(names3);
}
Con il campo [names4], si esegue ad esempio il seguente test:
@Test(expected = MyIllegalArgumentException.class)
public void getShortProduitsByName4() {
daoProduit.getShortEntitiesByName(names4);
}
Si eseguono così 48 test per verificare tutti i casi possibili. Si esegue la configurazione di esecuzione denominata [spring-jdbc-generic-04-JUnitTestCheckArguments] [1]. Il risultato ottenuto è il seguente [2]:
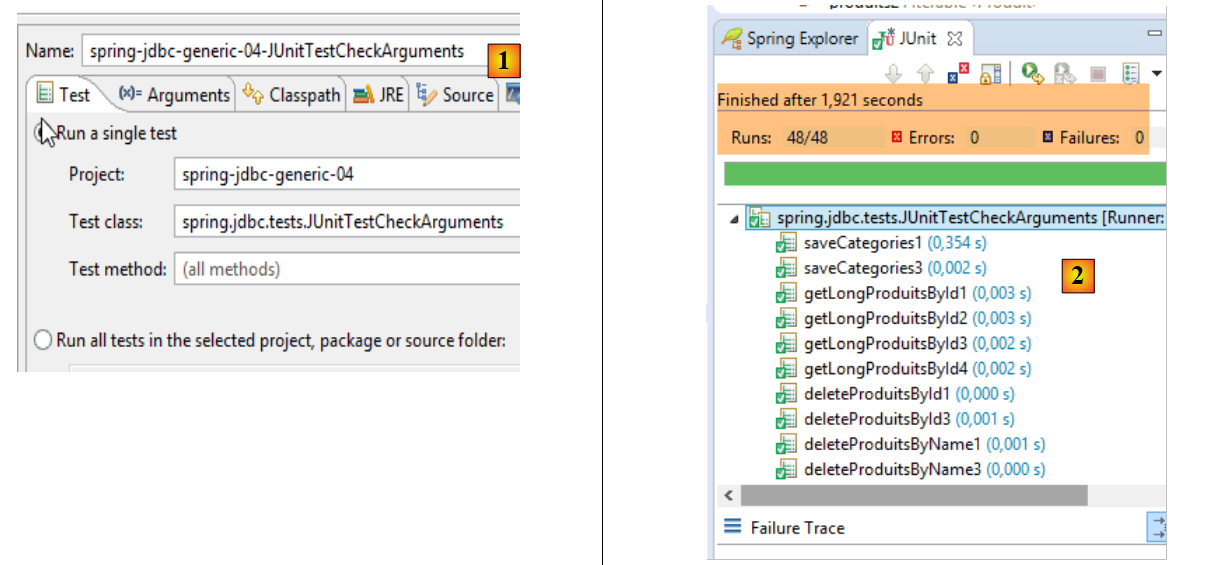 |
4.11.2. Il test [JUnitTestDao]
Il test [JUnitTestDao] richiama i metodi del livello [DAO] con argomenti validi e verifica che i metodi funzionino come previsto. Ci sono in totale 74 test che verificano le operazioni di inserimento, selezione, aggiornamento ed eliminazione di entità, categorie o prodotti. In totale, ci sono più di 1000 righe di codice. Esamineremo solo alcuni di questi metodi.
4.11.2.1. La struttura del test
La classe [JUnitTestDao] presenta la seguente struttura:
package spring.jdbc.tests;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.junit.Assert;
import org.junit.Before;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.BeansException;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.SpringApplicationConfiguration;
import org.springframework.context.ApplicationContext;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import spring.jdbc.config.AppConfig;
import spring.jdbc.dao.IDao;
import spring.jdbc.entities.Categorie;
import spring.jdbc.entities.Produit;
import com.fasterxml.jackson.core.JsonProcessingException;
import com.fasterxml.jackson.databind.ObjectMapper;
import com.google.common.collect.Lists;
@SpringApplicationConfiguration(classes = AppConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class JUnitTestDao {
// contesto Spring
@Autowired
private ApplicationContext context;
// livello [DAO]
@Autowired
private IDao<Produit> daoProduit;
@Autowired
private IDao<Categorie> daoCategorie;
// costanti
private final int NB_PRODUITS = 5;
private final int NB_CATEGORIES = 2;
// locale
// locale
private Map<Long, Categorie> mapCategories = new HashMap<Long, Categorie>();
private Map<Long, Produit> mapProduits = new HashMap<Long, Produit>();
@Before
public void clean() {
// si pulisce il database prima di ogni test
log("Vidage de la base de données", 1);
// si svuota la tabella [CATEGORIES] e, di conseguenza, la tabella [PRODUITS]
daoCategorie.deleteAllEntities();
// si svuotano i dizionari
for (Long id : mapCategories.keySet()) {
mapCategories.remove(id);
}
for (Long id : mapProduits.keySet()) {
mapProduits.remove(id);
}
}
...
}
- righe 27-28: come per il test [JUnitTestCheckArguments], si tratta di un test integrato con Spring e configurato dalla classe [AppConfig] del progetto;
- righe 32-33: iniezione del contesto Spring che consente l’accesso a tutti i suoi bean;
- righe 35-36: iniezione dell'istanza dell'interfaccia [IDao<Produit>] testata dalla classe;
- righe 37-38: iniezione dell’istanza dell’interfaccia [IDao<Categorie>] testata dalla classe;
- righe 41-42: quando un test richiederà dati dal database, verrà generato un database di [NB_CATEGORIES] categorie, ciascuna con [NB_PRODUITS] prodotti. Si avranno così le categorie [NB_CATEGORIES] nella tabella [CATEGORIES] e i prodotti [NB_CATEGORIES] * [NB_PRODUITS] nella tabella [PRODUITS];
- righe 46-47: due dizionari in cui verranno memorizzati i prodotti e le categorie;
- righe 49-62: il metodo [clean] viene eseguito prima di ogni test (riga 49). Alla riga 54, si svuota la tabella [CATEGORIES]. È importante ricordare che la tabella [PRODUITS] ha una chiave primaria [CATEGORIE_ID] sulla colonna ID della tabella [CATEGORIES] e che quest’ultima è definita come segue;
 |
- (continua)
- in [1-3], la chiave esterna [CATEGORIE_ID] della tabella [PRODUITS]. Essa punta alla colonna [ID] della tabella [CATEGORIES] [4-5];
- quando una categoria viene eliminata, vengono eliminati anche tutti i prodotti ad essa collegati [6]. È importante sottolineare questo punto poiché viene utilizzato nella costruzione del livello [DAO] che sfrutta il database [dbproduitscategories];
Pertanto, quando si elimina il contenuto della tabella [CATEGORIES], verrà eliminato anche quello della tabella [PRODUITS].
- righe 56-58: si svuota il dizionario delle categorie;
- righe 59-61: si procede allo stesso modo con quello dei prodotti;
Si noti che prima di ogni test si parte da tabelle vuote nel database e da dizionari vuoti in memoria.
4.11.2.2. Il metodo [verifyClean]
Il metodo [verifyClean] verifica che, dopo l’esecuzione del metodo [clean], le tabelle siano vuote:
@Test
public void verifyClean() {
log("verifyClean", 1);
List<Categorie> categories = daoCategorie.getAllShortEntities();
Assert.assertEquals(0, categories.size());
List<Produit> produits = daoProduit.getAllShortEntities();
Assert.assertEquals(0, produits.size());
}
4.11.2.3. Il metodo [fillDataBase]
Questo metodo verifica che il database sia stato correttamente popolato con dati di test:
@Test
public void fillDataBase() throws BeansException, JsonProcessingException {
// riempimento del database e dei dizionari
registerCategories(fill(NB_CATEGORIES, NB_PRODUITS));
// visualizzazione
Object[] data = showDataBase();
List<Categorie> categories = (List<Categorie>) data[0];
List<Produit> produits = (List<Produit>) data[1];
// alcune verifiche
Assert.assertEquals(NB_CATEGORIES, categories.size());
Assert.assertEquals(NB_PRODUITS * NB_CATEGORIES, produits.size());
for (Categorie categorie : categories) {
checkShortCategorie(categorie);
}
for (Produit produit : produits) {
checkShortProduit(produit);
}
// i dizionari devono essere stati svuotati
Assert.assertEquals(0, mapCategories.size());
Assert.assertEquals(0, mapProduits.size());
}
Questo test utilizza diversi metodi privati:
- [fill], riga 4, che popola il database con dati di test;
- [registerCategories], riga 4, che popola i dizionari con i dati restituiti dal metodo [fill]. Questi due dizionari rappresentano le entità persistenti;
- [showDataBase], riga 6, che legge le due tabelle [CATEGORIES] e [PRODUITS] e restituisce ciò che ha letto;
- [checkShortCategorie], riga 13, verifica la categoria letta da [showDataBase]. Verifica che la versione abbreviata di tale categoria corrisponda a quanto registrato nel dizionario delle categorie;
- [checkShortProduit], riga 16, esegue la stessa operazione per i prodotti;
- quando un'entità viene trovata in un dizionario, viene rimossa dal dizionario. Le righe 19-20 verificano che entrambi i dizionari siano vuoti. Se entrambe queste asserzioni sono valide, significa che:
- tutti i valori letti da [showDataBase] sono stati effettivamente trovati nei dizionari;
- che questi non contengono entità diverse da quelle che sono state lette;
Il metodo privato [fill] è il seguente:
private List<Categorie> fill(int nbCategories, int nbProduits) {
// si compilano le tabelle
List<Categorie> categories = new ArrayList<Categorie>();
for (int i = 0; i < nbCategories; i++) {
Categorie categorie = new Categorie(null, null, String.format("categorie[%d]", i), null);
for (int j = 0; j < nbProduits; j++) {
Produit produit = new Produit(null, null, String.format("produit[%d,%d]", i, j), null,
100 * (1 + (double) (i * 10 + j) / 100), String.format("desc[%d,%d]", i, j), null);
categorie.addProduit(produit);
}
categories.add(categorie);
}
// aggiunta della categoria - a cascata anche i prodotti verranno
// inseriti
categories = daoCategorie.saveEntities(categories);
// risultato
return categories;
}
- righe 3-12: si costruisce un elenco di [nbCategories] categorie, ciascuna delle quali contiene [nbProduits] prodotti;
- riga 15: questo elenco di categorie viene salvato. Abbiamo visto che il metodo [daoCategorie.saveEntities] salvava anche i prodotti delle categorie quando queste ne contenevano;
- riga 17: viene restituito l'elenco delle categorie salvate. Le entità salvate (categorie e prodotti) hanno ora una chiave primaria nel campo [id];
Il metodo privato [registerCategories] inserirà queste entità in entrambi i dizionari:
private void registerCategories(List<Categorie> categories) {
// dizionari
for (Categorie categorie : categories) {
mapCategories.put(categorie.getId(), categorie);
for (Produit produit : categorie.getProduits()) {
mapProduits.put(produit.getId(), produit);
}
}
}
Ogni dizionario ha come chiave di accesso la chiave primaria delle entità.
Fatto ciò, il database precedentemente compilato verrà letto e visualizzato dal seguente metodo privato [showDataBase]:
private Object[] showDataBase() throws BeansException, JsonProcessingException {
// elenco delle categorie
log("Liste des catégories", 2);
List<Categorie> categories = daoCategorie.getAllShortEntities();
affiche(categories, context.getBean("jsonMapperShortCategorie", ObjectMapper.class));
// elenco dei prodotti
log("Liste des produits", 2);
List<Produit> produits = daoProduit.getAllShortEntities();
affiche(produits, context.getBean("jsonMapperShortProduit", ObjectMapper.class));
// risultato
return new Object[] { categories, produits };
}
- righe 4 e 8: si recuperano le versioni abbreviate delle categorie e dei prodotti;
- riga 11: viene restituito un array contenente i due elenchi di entità recuperati;
- righe 5 e 9: gli elenchi di entità vengono visualizzati con il seguente metodo privato [affiche]:
// visualizzazione di un elenco di elementi di tipo T
private <T> void affiche(List<T> elements, ObjectMapper mapper) throws JsonProcessingException {
for (T element : elements) {
affiche(element, mapper);
}
}
// visualizzazione di un elemento di tipo T
private <T> void affiche(T element, ObjectMapper mapper) throws JsonProcessingException {
System.out.println(mapper.writeValueAsString(element));
}
Le entità vengono visualizzate tramite un mappatore jSON (riga 10). Questo mappatore è il secondo parametro del metodo [affiche], riga 2. Il contesto Spring definisce quattro mappatori jSON nel file [ConfigJdbc] della dipendenza Maven [mysql-config-jdbc]:
// filtri jSON -------------------------------------
@Bean
public ObjectMapper jsonMapper() {
return new ObjectMapper();
}
@Bean
@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)
ObjectMapper jsonMapperShortCategorie() {
ObjectMapper jsonMapper = jsonMapper();
jsonMapper.setFilters(new SimpleFilterProvider().addFilter("jsonFilterCategorie",
SimpleBeanPropertyFilter.serializeAllExcept("produits")));
return jsonMapper;
}
@Bean
@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)
ObjectMapper jsonMapperLongCategorie() {
ObjectMapper jsonMapper = jsonMapper();
jsonMapper.setFilters(new SimpleFilterProvider().addFilter("jsonFilterCategorie",
SimpleBeanPropertyFilter.serializeAllExcept()).addFilter("jsonFilterProduit",
SimpleBeanPropertyFilter.serializeAllExcept("categorie")));
return jsonMapper;
}
@Bean
@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)
ObjectMapper jsonMapperShortProduit() {
ObjectMapper jsonMapper = jsonMapper();
jsonMapper.setFilters(new SimpleFilterProvider().addFilter("jsonFilterProduit",
SimpleBeanPropertyFilter.serializeAllExcept("categorie")));
return jsonMapper;
}
@Bean
@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)
ObjectMapper jsonMapperLongProduit() {
ObjectMapper jsonMapper = jsonMapper();
jsonMapper.setFilters(new SimpleFilterProvider().addFilter("jsonFilterProduit",
SimpleBeanPropertyFilter.serializeAllExcept()).addFilter("jsonFilterCategorie",
SimpleBeanPropertyFilter.serializeAllExcept("produits")));
return jsonMapper;
}
- questi mappatori jSON (righe 7-9, 16-18, 26-28, 35-37) hanno un attributo
[@Scope(value = ConfigurableBeanFactory.SCOPE_PROTOTYPE)]
che li rende dei bean istanziati ad ogni richiesta effettuata al contesto Spring. Si tratta di una novità. Tutti i bean Spring visti finora erano singleton: ne veniva creato un unico esemplare ed era proprio quello che veniva restituito ogni volta che se ne richiedeva un riferimento al contesto Spring. Perché questo cambiamento? In realtà, i quattro bean [jsonMapperShortCategorie, jsonMapperLongCategorie, jsonMapperShortProduit , jsonMapperLongProduit] configurano l’unico mappatore jSON (che in questo caso è effettivamente un singleton) definito alle righe 2-5. Quest’ultimo deve essere riconfigurato ad ogni chiamata di uno dei quattro bean precedenti e non una sola volta all’inizializzazione del contesto. Se avessimo deciso di avere quattro mappatori jSON diversi, uno per ciascuno dei quattro bean, allora questi avrebbero potuto essere singleton. Era del tutto possibile. Avremmo quindi scritto alle righe 10, 19, 29, 38:
ObjectMapper jsonMapper = new ObjectMapper();
- i quattro mappatori json servono a configurare i filtri jSON delle entità [Produit] e [Categorie]. Abbiamo infatti scritto (cfr. paragrafi 4.6 e 4.6) quanto segue:
@JsonFilter("jsonFilterCategorie")
public class Categorie extends AbstractCoreEntity {
e
@JsonFilter("jsonFilterProduit")
public class Produit extends AbstractCoreEntity {
La rappresentazione jSON dell’entità [Categorie] è controllata dal filtro jSON [jsonFilterCategorie] e quella dell’entità [produit] dal filtro jSON [jsonFilterProduit]. I quattro mappatori jSON del contesto Spring configurano questi due filtri nel modo seguente:
- il mappatore [jsonMapperShortCategorie] configura il filtro jSON [jsonFilterCategorie] per una versione abbreviata della categoria: il campo [produits] non sarà incluso nella rappresentazione jSON della categoria;
- il mappatore [jsonMapperLongCategorie] configura il filtro jSON [jsonFilterCategorie] per una versione estesa della categoria: il campo [produits] sarà incluso nella rappresentazione jSON della categoria;
- il mappatore [jsonMapperShortProduit] configura il filtro jSON [jsonFilterProduit] per una versione breve del prodotto: il campo [categorie] non sarà incluso nella rappresentazione jSON del prodotto;
- il mappatore [jsonMapperLongProduit] configura il filtro jSON [jsonFilterProduit] per una versione estesa del prodotto: il campo [categorie] sarà incluso nella rappresentazione jSON del prodotto;
Abbiamo terminato con il metodo privato [showDataBase]. Torniamo al codice di test [fillDataBase]:
@Test
public void fillDataBase() throws BeansException, JsonProcessingException {
// compilazione della base dati e dei dizionari
registerCategories(fill(NB_CATEGORIES, NB_PRODUITS));
// visualizzazione
Object[] data = showDataBase();
List<Categorie> categories = (List<Categorie>) data[0];
List<Produit> produits = (List<Produit>) data[1];
// alcune verifiche
Assert.assertEquals(NB_CATEGORIES, categories.size());
Assert.assertEquals(NB_PRODUITS * NB_CATEGORIES, produits.size());
for (Categorie categorie : categories) {
checkShortCategorie(categorie);
}
for (Produit produit : produits) {
checkShortProduit(produit);
}
// i dizionari devono essere stati esauriti
Assert.assertEquals(0, mapCategories.size());
Assert.assertEquals(0, mapProduits.size());
}
- righe 6-8: recuperiamo le versioni abbreviate dei prodotti e delle categorie letti dal database;
- righe 10-11: prime verifiche;
- righe 12-14: ogni categoria restituita dal metodo [showDataBase] viene controllata dal seguente metodo privato [checkShortCategorie]:
private void checkShortCategorie(Categorie actual) {
Long id = actual.getId();
Categorie expected = mapCategories.get(actual.getId());
mapCategories.remove(id);
Assert.assertEquals(expected.getNom(), actual.getNom());
// non è possibile testare il campo [produits] in modo portabile con le implementazioni jPA
}
- riga 1: [Categorie actual] è la categoria letta dal database e deve essere identica alla categoria presente nel dizionario [mapCategories];
- riga 2: si recupera la chiave primaria della categoria letta;
- riga 3: si recupera la categoria registrata con questa chiave primaria nel dizionario delle categorie;
- riga 4: la chiave viene rimossa dal dizionario per assicurarsi che nessun'altra categoria letta utilizzi la stessa chiave;
- riga 5: si verifica che le due categorie abbiano lo stesso nome;
La versione abbreviata dei prodotti generata dal metodo [showDataBase] viene verificata dal seguente metodo privato [checkShortProduit]:
private void checkShortProduit(Produit actual) {
Long id = actual.getId();
Produit expected = mapProduits.get(id);
mapProduits.remove(id);
Assert.assertEquals(expected.getNom(), actual.getNom());
Assert.assertEquals(expected.getDescription(), actual.getDescription());
Assert.assertEquals(expected.getPrix(), actual.getPrix(), 1e-6);
Assert.assertEquals(actual.getIdCategorie(), expected.getIdCategorie());
// non è possibile testare il campo [categorie] in modo portabile con le implementazioni jPA
}
- riga 1: [Produit actual] è il prodotto abbreviato letto dal database;
- righe 2-3: dal dizionario dei prodotti persistenti viene recuperato il prodotto con la stessa chiave primaria;
- riga 4: si elimina la voce trovata nel dizionario;
- righe 5-8: si verifica che i due prodotti abbiano gli stessi valori dei campi;
4.11.2.4. Il metodo [getLongCategoriesByName3]
Questo test è il seguente:
@Test
public void getLongCategoriesByName3() {
// compilazione di base
List<Categorie> categories = fill(NB_CATEGORIES, NB_PRODUITS);
// test
log("getLongCategoriesByName3", 1);
List<Categorie> categories2 = daoCategorie.getLongEntitiesByName("categorie[0]", "categorie[1]");
Assert.assertEquals(2, categories2.size());
registerCategories(Lists.newArrayList(categories.get(0), categories.get(1)));
for (Categorie categorie : categories) {
checkLongCategorie(categorie);
}
Assert.assertEquals(0, mapCategories.size());
}
- riga 4: si popola il database e si recupera l'elenco delle categorie e dei prodotti salvati;
- riga 7: si testa il metodo [daoCategorie.getLongEntitiesByName(Iterable<String> names)] del livello [DAO]. Si richiede un elenco di due prodotti indicati con i loro nomi nella versione completa;
- riga 8: si verifica che l'elenco restituito da [daoCategorie.getLongEntitiesByName(Iterable<String> names)] contenga effettivamente due elementi;
- riga 9: i due elementi salvati alla riga 4 vengono inseriti nel dizionario delle categorie;
- righe 10-12: si verifica che i due elementi letti siano effettivamente quelli che sono stati salvati;
- riga 13: si verifica che il dizionario delle categorie sia vuoto, il che significa sia che tutte le categorie lette sono state trovate nel dizionario, sia che quest’ultimo non contenga valori che non siano stati letti;
Riga 11: il metodo [checkLongCategorie] verifica la versione estesa di una categoria:
private void checkLongCategorie(Categorie actual) {
Long id = actual.getId();
Categorie expected = mapCategories.get(actual.getId());
mapCategories.remove(id);
Assert.assertEquals(expected.getNom(), actual.getNom());
Assert.assertNotNull(actual.getProduits());
}
- la riga 6 verifica che il campo [produits] della categoria non sia null. Infatti, la lettura di una categoria in formato esteso restituisce sempre quest’ultima con un campo [produits] diverso da null. Se la categoria non contiene prodotti, allora il campo [produits] è un elenco vuoto ma esistente;
4.11.2.5. Il metodo [updateDataBase1]
@Test
public void updateDataBase1() {
// compilazione
fill(NB_CATEGORIES, NB_PRODUITS);
// test
log("Mise à jour du prix des produits de [categorie1]", 1);
Categorie categorie1 = daoCategorie.getLongEntitiesByName("categorie[1]").get(0);
List<Produit> produits = categorie1.getProduits();
Map<Produit, Long> versions = new HashMap<Produit, Long>();
for (Produit produit : produits) {
produit.setPrix(1.1 * produit.getPrix());
versions.put(produit, produit.getVersion());
}
daoProduit.saveEntities(produits);
// revisione
List<Produit> produitsInBd = daoCategorie.getLongEntitiesByName("categorie[1]").get(0)
.getProduits();
Assert.assertEquals(produits.size(), produitsInBd.size());
// verifiche
for (Produit produit2 : produitsInBd) {
Produit produit = findProduitByName(produit2.getNom(), produits);
Assert.assertEquals(produit2.getPrix(), produit.getPrix(), 1e-6);
Assert.assertEquals(produit2.getVersion().longValue(), versions.get(produit) + 1);
}
}
private Produit findProduitByName(String nom, List<Produit> produits) {
for (Produit produit : produits) {
if (produit.getNom().equals(nom)) {
return produit;
}
}
return null;
}
Il metodo [updateDataBase1] aumenta il prezzo dei prodotti della categoria denominata categorie[1] del 10% e verifica due cose:
- che il prezzo di base sia effettivamente cambiato;
- che la versione del prodotto aggiornato sia stata incrementata di 1;
Il codice esegue le seguenti operazioni:
- riga 4: popolamento del database;
- riga 7: si recupera dal database la categoria denominata 'categorie[1]';
- righe 8-13: si aumenta del 10% il prezzo di tutti i prodotti (riga 11). Inoltre, si crea un dizionario che associa un prodotto alla sua versione (righe 9 e 12);
- riga 14: viene chiamato il metodo [daoProduit.saveEntities], che provvederà all’aggiornamento dei prodotti;
- riga 16: si recuperano dal database i prodotti della categoria denominata «categorie[1]»;
- righe 20-24: per tutti i prodotti di questa categoria, si verifica che il prezzo sia stato effettivamente modificato (riga 22) e che la versione sia stata incrementata di 1 (riga 23);
4.11.2.6. Il metodo [deleteProduitsByProduit1]
Il metodo [deleteProduitsByProduit1] elimina i prodotti dalla tabella [PRODUITS]:
@Test
public void deleteProduitsByProduit1() {
// compilazione
fill(NB_CATEGORIES, NB_PRODUITS);
// eliminazione
daoProduit.deleteEntitiesByEntity(daoProduit.getShortEntitiesByName("produit[0,0]", "produit[1,1]"));
// verifica
List<Produit> produits = daoProduit.getShortEntitiesByName("produit[0,0]", "produit[1,1]");
Assert.assertEquals(0, produits.size());
}
- riga 6: si eliminano due prodotti;
- righe 8-9: si verifica che non siano più presenti nel database;
4.11.2.7. Il metodo [getLongProduitsById3]
@Test
public void getLongProduitsById3() {
// compilazione
List<Categorie> categories = fill(NB_CATEGORIES, NB_PRODUITS);
// test
log("getLongProduitsById3", 1);
List<Produit> produits = daoProduit.getLongEntitiesByName("produit[0,3]", "produit[1,4]");
Assert.assertEquals(2, produits.size());
registerProduits(Lists.newArrayList(categories.get(0).getProduits().get(3), categories.get(1).getProduits().get(4)));
produits = daoProduit.getLongEntitiesById(produits.get(0).getId(), produits.get(1).getId());
for (Produit produit : produits) {
checkLongProduit(produit);
}
Assert.assertEquals(0, mapProduits.size());
}
- riga 4: si popola il database e si recupera l'elenco delle categorie salvate;
- riga 7: si recuperano dal database le descrizioni complete di due prodotti identificati dai loro nomi;
- riga 9: i prodotti [produit[0,3], produit[1,4]] presenti nell'elenco delle categorie della riga 4 vengono inseriti nel dizionario dei prodotti;
- riga 10: questi stessi due prodotti vengono cercati nel database tramite le loro chiavi primarie;
- righe 11-14: si verifica che i dati letti siano identici a quelli registrati nel dizionario;
Il metodo privato [checkLongProduit] è il seguente:
private void checkLongProduit(Produit actual) {
Long id = actual.getId();
Produit expected = mapProduits.get(id);
mapProduits.remove(id);
Assert.assertEquals(expected.getNom(), actual.getNom());
Assert.assertEquals(expected.getDescription(), actual.getDescription());
Assert.assertEquals(expected.getPrix(), actual.getPrix(), 1e-6);
Assert.assertNotNull(actual.getCategorie());
}
4.11.2.8. Conclusion
Ci fermiamo qui. Al momento ci sono 74 test e se ne potrebbero aggiungere altri, poiché probabilmente ho tralasciato alcuni casi da testare. Pur non essendo esaustivi, questi test hanno permesso di individuare numerosi errori, in genere casi limite che non erano stati previsti durante la scrittura iniziale del livello [DAO]. Una fase di test esaustivi è indispensabile per qualsiasi progetto.
Per eseguire il test, è possibile utilizzare la configurazione di esecuzione importata denominata [spring-jdbc-generic-04.JUnitTestDao].
 |  |
4.11.3. Il test [JUnitTestPushTheLimits]
Il test [JUnitTestPushTheLimits] è un test delle prestazioni. Si sfrutta il fatto che i test JUnit visualizzino il proprio tempo di esecuzione per misurare le prestazioni del livello [DAO]. Queste saranno poi confrontate con quelle delle implementazioni JPA del livello [DAO].
4.11.3.1. Squelette
Lo scheletro della classe [JUnitTestPushTheLimits] è il seguente:
package spring.jdbc.tests;
import java.util.ArrayList;
import java.util.HashMap;
import java.util.List;
import java.util.Map;
import org.junit.Assert;
import org.junit.Before;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.SpringApplicationConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
import spring.jdbc.config.AppConfig;
import spring.jdbc.dao.IDao;
import spring.jdbc.entities.Categorie;
import spring.jdbc.entities.Produit;
@SpringApplicationConfiguration(classes = AppConfig.class)
@RunWith(SpringJUnit4ClassRunner.class)
public class JUnitTestPushTheLimits {
// livello [DAO]
@Autowired
private IDao<Produit> daoProduit;
@Autowired
private IDao<Categorie> daoCategorie;
// costanti
private final int NB_CATEGORIES = 2500;
private final int NB_PRODUITS = 2;
// locale
private Map<Long, Categorie> hCategories;
private Map<Long, Produit> hProduits;
@Before
public void clean() {
// svuotamento della tabella [CATEGORIES]
daoCategorie.deleteAllEntities();
// dizionari
hCategories = new HashMap<Long, Categorie>();
hProduits = new HashMap<Long, Produit>();
}
private List<Categorie> fill(int nbCategories, int nbProduits) {
// si compilano le tabelle
List<Categorie> categories = new ArrayList<Categorie>();
for (int i = 0; i < nbCategories; i++) {
Categorie categorie = new Categorie(null, 0L, String.format("categorie[%d]", i), null);
for (int j = 0; j < nbProduits; j++) {
Produit produit = new Produit(null, 0L, String.format("produit[%d,%d]", i, j), 0L,
100 * (1 + (double) (i * 10 + j) / 100), String.format("desc[%d,%d]", i, j), null);
categorie.addProduit(produit);
}
categories.add(categorie);
}
// aggiunta della categoria - a cascata verranno inseriti anche i prodotti
categories = daoCategorie.saveEntities(categories);
// dizionari
for (Categorie categorie : categories) {
hCategories.put(categorie.getId(), categorie);
for (Produit produit : categorie.getProduits()) {
hProduits.put(produit.getId(), produit);
}
}
// risultato
return categories;
}
....
// -------------------- metodi privati
private void checkLongProduit(Produit actual) {
Long id = actual.getId();
Produit expected = hProduits.get(id);
hProduits.remove(id);
Assert.assertEquals(expected.getNom(), actual.getNom());
Assert.assertEquals(expected.getDescription(), actual.getDescription());
Assert.assertEquals(expected.getPrix(), actual.getPrix(), 1e-6);
Assert.assertEquals(expected.getIdCategorie(), actual.getIdCategorie());
Assert.assertNotNull(actual.getCategorie());
}
private void checkShortProduit(Produit actual) {
Long id = actual.getId();
Produit expected = hProduits.get(id);
hProduits.remove(id);
Assert.assertEquals(expected.getNom(), actual.getNom());
Assert.assertEquals(expected.getDescription(), actual.getDescription());
Assert.assertEquals(expected.getPrix(), actual.getPrix(), 1e-6);
Assert.assertEquals(expected.getIdCategorie(), actual.getIdCategorie());
boolean erreur = false;
try {
actual.getCategorie().getNom();
} catch (Exception e) {
erreur = true;
}
Assert.assertTrue(erreur);
}
private void checkShortCategorie(Categorie actual) {
Long id = actual.getId();
Categorie expected = hCategories.get(actual.getId());
hCategories.remove(id);
Assert.assertEquals(expected.getNom(), actual.getNom());
boolean erreur = false;
try {
actual.getProduits().size();
} catch (Exception e) {
erreur = true;
}
Assert.assertTrue(erreur);
}
private void checkLongCategorie(Categorie actual) {
Long id = actual.getId();
Categorie expected = hCategories.get(actual.getId());
hCategories.remove(id);
Assert.assertEquals(expected.getNom(), actual.getNom());
Assert.assertNotNull(actual.getProduits());
}
}
Qui ritroviamo lo scheletro della classe [JUnitTestDao]. Abbiamo già incontrato tutti questi metodi. Il test opera con un database di 2500 categorie, ciascuna delle quali contiene 2 prodotti (righe 32-33). La tabella [CATEGORIES] avrà quindi 2500 righe e la tabella [PRODUITS] 5000 righe. Si sarebbero potute inserire più righe, ma il test dura già quasi un minuto. Abbiamo quindi scelto valori accettabili per l’utente che attende la fine del test.
I test sono 18 in totale. Vengono eseguiti con la configurazione di esecuzione [1]. I tempi di esecuzione sono riportati in [2]:
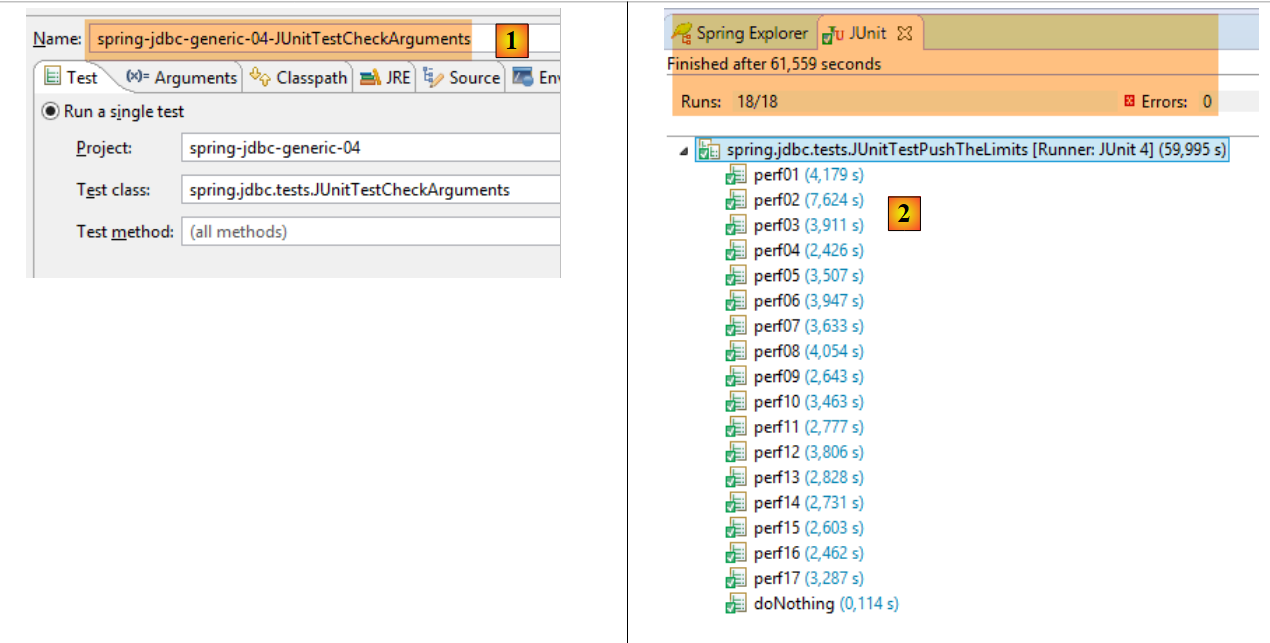 |
4.11.3.2. doNothing [0,114]
Il metodo [doNothing] non esegue alcuna operazione. Consente di misurare la durata del metodo [clean], eseguito prima di ogni test e che svuota il database. Come si può vedere sopra, la durata di questa operazione è trascurabile rispetto alle altre.
@Test
public void doNothing() {
// clean
}
4.11.3.3. perf01 [4,179]
Il test [perf01] serve a misurare il tempo necessario per riempire il database:
@Test
public void perf01() {
// insert
fill(NB_CATEGORIES, NB_PRODUITS);
}
4.11.3.4. perf02 [7,624]
Il metodo [perf02]:
- riempie il database;
- modifica quindi il nome di tutte le categorie e il prezzo di tutti i prodotti.
@Test
public void perf02() {
// aggiornamento
List<Categorie> categories = fill(NB_CATEGORIES, NB_PRODUITS);
for (Categorie categorie : categories) {
categorie.setNom(categorie.getNom() + "*");
for (Produit produit : categorie.getProduits()) {
produit.setPrix(produit.getPrix() * 1.1);
}
}
// aggiornamento
daoCategorie.saveEntities(categories);
}
4.11.3.5. perf03[3,911]
Il metodo [perf03]:
- compila il database
- poi elimina tutte le categorie una per una. Anche i prodotti vengono eliminati a causa della dipendenza a cascata esistente tra la tabella [CATEGORIES] e la tabella [PRODUITS].
Può sorprendere il fatto che questa operazione richieda meno tempo ([3,911 s]) rispetto all’operazione [perf01] [4,179 s], che esegue meno operazioni.
@Test
public void perf03() {
// elimina categorie e, di conseguenza, i prodotti
daoCategorie.deleteEntitiesByEntity(fill(NB_CATEGORIES, NB_PRODUITS));
}
Se si osserva il codice del metodo [daoCategorie.deleteEntitiesByEntity], si nota che verrà eseguito un [PreparedStatement] con 2500 parametri (il numero di categorie). È qui che interviene il bean [maxPreparedStatementParameters], che suddividerà l’ordine SQL in diversi [PreparedStatement] con un numero di parametri gestibile dal particolare SGBD utilizzato.
4.11.3.6. perf04[2,426]
Il metodo [perf04]:
- compila il database;
- richiede quindi la versione estesa di tutte le categorie;
@Test
public void perf04() {
// seleziona
List<Categorie> categories = fill(NB_CATEGORIES, NB_PRODUITS);
List<Long> ids = new ArrayList<Long>();
for (Categorie categorie : categories) {
ids.add(categorie.getId());
}
daoCategorie.getLongEntitiesById(ids);
}
4.11.3.7. perf05 [3,507]
Il metodo [perf05]:
- piena il database;
- quindi elimina i 5000 prodotti tramite le loro chiavi primarie (si ha quindi potenzialmente un [PreparedStatement] con 5000 parametri);
- verifica che la tabella dei prodotti sia quindi vuota;
@Test
public void perf05() {
// elimina prodotti
List<Categorie> categories = fill(NB_CATEGORIES, NB_PRODUITS);
List<Long> ids = new ArrayList<Long>();
for (Categorie categorie : categories) {
for (Produit p : categorie.getProduits()) {
ids.add(p.getId());
}
}
daoProduit.deleteEntitiesById(ids);
// verifica
List<Produit> produits = daoProduit.getAllShortEntities();
Assert.assertEquals(0, produits.size());
}
4.11.3.8. Résultats
Non continueremo a presentare i vari test. Ci limiteremo a indicare cosa fanno e la loro durata. Questi tempi sono significativi solo se confrontati tra loro. I loro valori dipendono infatti dall’ambiente di test utilizzato (hardware e configurazione software). Tuttavia, se ottenuti nello stesso ambiente, possono essere confrontati.
Durata totale del test: 59,995 secondi
ruolo | ||
piena la banca dati con 2500 categorie e 5000 prodotti | ||
piena e poi modifica il database | ||
compila il database, quindi elimina tutte le categorie e i relativi prodotti | ||
piena il database e richiede la versione estesa di tutte le categorie | ||
piena il database ed elimina i 5000 prodotti uno per uno tramite le loro chiavi primarie | ||
piena il database ed elimina i 5000 prodotti uno per uno in base ai loro nomi | ||
piena il database ed elimina i 5000 prodotti uno per uno in base ai loro codici | ||
piena il database e richiede la versione breve di tutti i prodotti tramite i loro nomi | ||
compila il database e richiede la versione estesa di tutti i prodotti in base ai loro nomi | ||
piena il database e richiede la versione breve di tutti i prodotti tramite le loro chiavi primarie | ||
piena il database e richiede la versione estesa di tutti i prodotti tramite le loro chiavi primarie | ||
piena il database e poi elimina tutte le categorie (e quindi i prodotti associati) una per una tramite i loro nomi | ||
piena il database e poi elimina tutte le categorie (e quindi i prodotti associati) una per una in base ai loro codici | ||
piena il database e richiede la versione breve di tutte le categorie tramite i loro nomi | ||
piena la banca dati e richiede la versione estesa di tutte le categorie in base ai loro nomi | ||
piena il database e richiede la versione breve di tutte le categorie tramite le loro chiavi primarie | ||
piena il database e richiede la versione estesa di tutte le categorie tramite le loro chiavi primarie |
Questi risultati sono talvolta sorprendenti:
- è stato più veloce ottenere la versione estesa dei prodotti (perf09) rispetto alla loro versione abbreviata (perf08), nonostante la versione estesa richieda un join tra due tabelle;
- la durata del primo popolamento (perf01) supera nettamente quella di tutti gli altri popolamenti che seguiranno;
- richiedere la versione breve dei prodotti tramite i loro nomi (perf08) richiede più tempo rispetto a richiederla tramite le chiavi primarie (perf10). Ciò sembra abbastanza logico. Ma per le versioni lunghe è il contrario (perf09, perf11);
Non ci soffermeremo quindi su questi risultati. Ci saranno tuttavia utili per confrontare questa soluzione [Spring JDBC] con le soluzioni:
- [Spring JDBC] delle altre cinque SGBD;
- [Spring JPA] che seguiranno;