5. Introduzione a Spring Data JPA
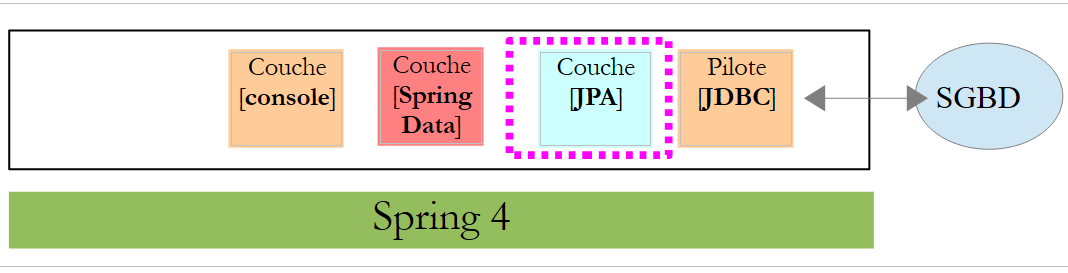
In questo capitolo analizzeremo la seguente architettura:
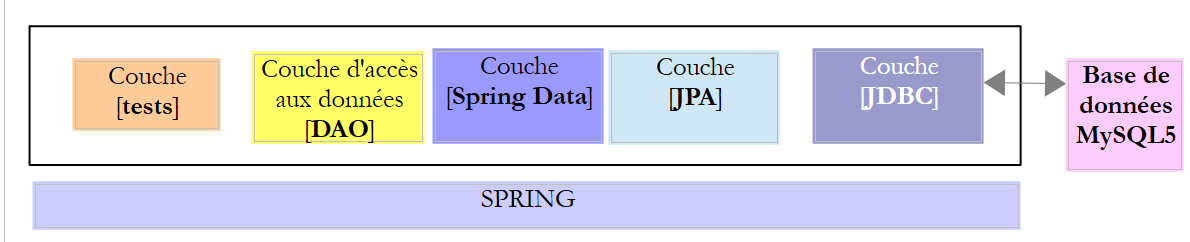 |
Si inserisce un livello [JPA] (Java Persistence API) tra il livello [DAO] e il driver JDBC del SGBD. Ora è il livello JPA a emettere i comandi SQL destinati al SGBD. Il livello [DAO] non gestisce più comandi SQL, ma solo oggetti denominati entità JPA, che sono immagini delle diverse tabelle del database utilizzato. I campi di queste entità sono associati in modo univoco alle colonne delle tabelle tramite annotazioni Java. È questo che permette al livello JPA di tradurre in SQL le operazioni del livello [DAO] effettuate sulle entità JPA.
Spring Data è un ramo di Spring che si occupa dell’accesso ai dati, indipendentemente dal fatto che questi siano memorizzati in un database relazionale SGBDR, in un database NOSQL o in altri tipi di archivi. In questa sede ci interessano solo i SGBDR e il loro accesso tramite JPA. In seguito, a volte scriveremo [Spring JPA] per indicare in realtà [Spring Data JPA]. Nell’architettura sopra descritta, il livello [Spring Data] fornisce funzionalità al livello [DAO] per la gestione delle entità JPA.
JPA è in realtà una specifica. Testeremo tre delle sue implementazioni:
- Hibernate (http://hibernate.org/);
- EclipseLink (http://www.eclipse.org/eclipselink/);
- OpenJpa (http://openjpa.apache.org/);
5.1. Exemple-01
Sul sito di Spring sono disponibili numerosi tutorial per iniziare a utilizzare Spring [http://spring.io/guides]. Ne useremo uno per introdurre Spring Data. A tal fine utilizzeremo Spring Tool Suite (STS).
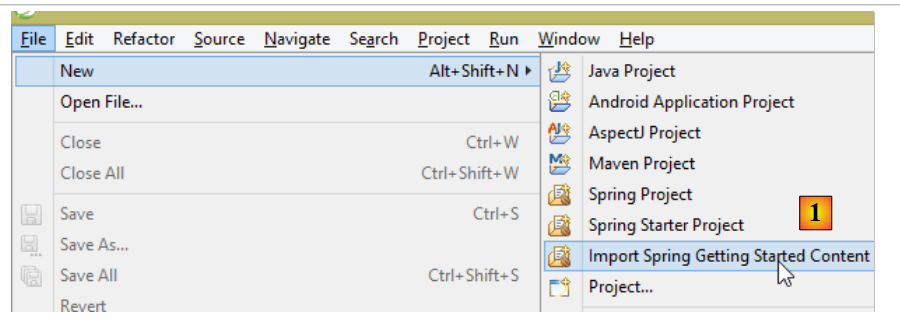 |
- in [1], importiamo uno dei tutorial da [spring.io/guides];
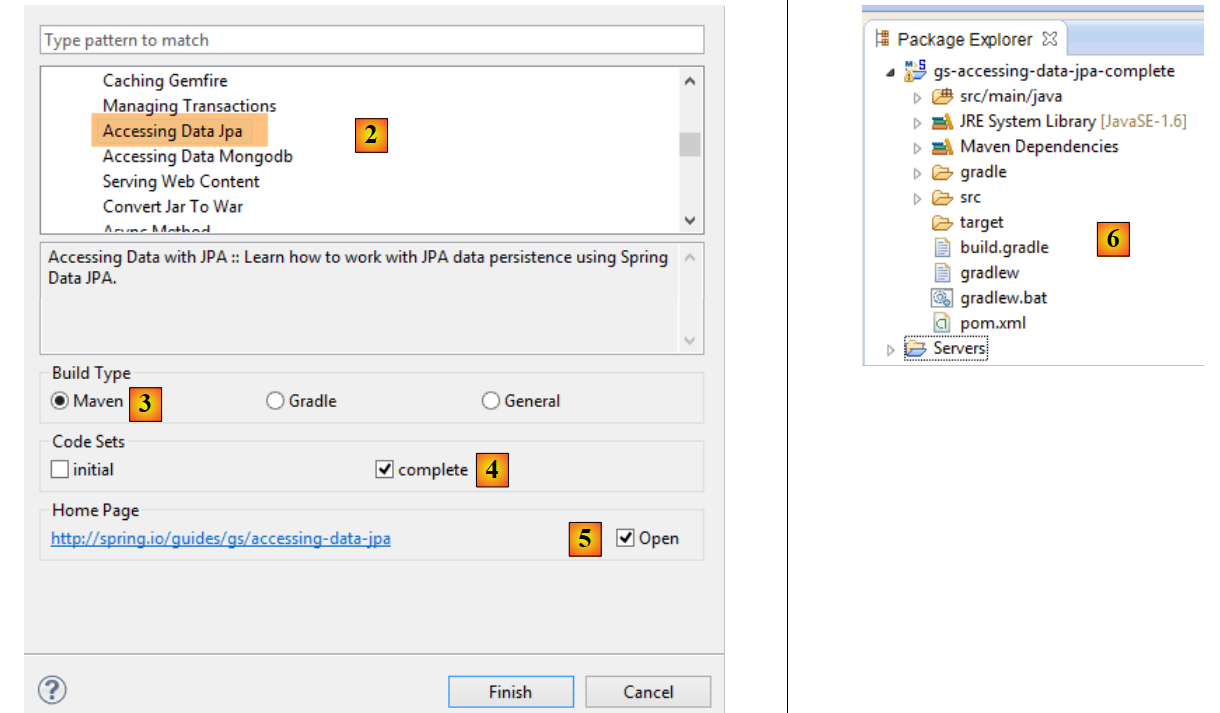 |
- in [2], si sceglie il tutorial [Accessing Data Jpa] che mostra come accedere a un database con Spring Data;
- in [3], si sceglie un progetto configurato da Maven;
- in [4], il tutorial può essere fornito in due forme: [initial], che è una versione vuota da compilare seguendo il tutorial, oppure [complete], che è la versione finale del tutorial. Scegliamo quest'ultima;
- in [5], è possibile scegliere di visualizzare il tutorial in un browser;
- in [6], il progetto finale.
5.1.1. La configurazione Maven del progetto
Le dipendenze Maven del progetto sono configurate nel file [pom.xml]:
<groupId>org.springframework</groupId>
<artifactId>gs-accessing-data-jpa</artifactId>
<version>0.1.0</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
</parent>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
</dependencies>
<properties>
<!-- utilizza UTF-8 per tutto -->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<start-class>hello.Application</start-class>
</properties>
- righe 5-9: definiscono un progetto Maven padre. È questo che definisce la maggior parte delle dipendenze del progetto. Possono essere sufficienti, nel qual caso non se ne aggiungono altre, oppure no, nel qual caso si aggiungono le dipendenze mancanti;
- righe 12-15: definiscono una dipendenza da [spring-boot-starter-data-jpa]. Questo artefatto contiene le classi di Spring Data;
- righe 16-19: definiscono una dipendenza da SGBD e H2, che consentono di creare e gestire database in memoria.
Diamo un'occhiata alle classi fornite da queste dipendenze:
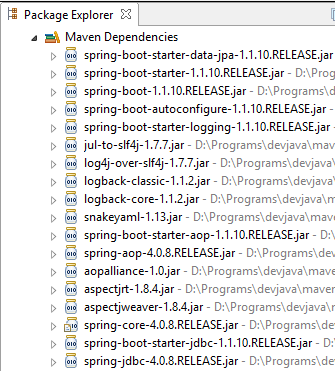 |  |  |
Sono davvero numerose:
- alcune appartengono all'ecosistema Spring (quelle che iniziano con spring);
- altre appartengono all'ecosistema Hibernate (hibernate, jboss), di cui qui si utilizza l'implementazione JPA;
- altre sono librerie di test (junit, hamcrest);
- altre sono librerie di log (log4j, logback, slf4j);
Le manterremo tutte. Per un'applicazione in produzione, bisognerebbe mantenere solo quelle necessarie.
Alla riga 26 del file [pom.xml] si trova la riga:
<start-class>hello.Application</start-class>
Questa riga è collegata alle righe seguenti:
<build>
<plugins>
<plugin>
<artifactId>maven-compiler-plugin</artifactId>
</plugin>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
Righe 6-9: il plugin [spring-boot-maven-plugin] consente di generare il file jar eseguibile dell'applicazione. La riga 26 del file [pom.xml] indica quindi la classe eseguibile di questo file jar.
5.1.2. Il livello [JPA]
L’accesso al database avviene tramite un livello [JPA], Java Persistence API:
 |
 |
L'applicazione è di base e gestisce i clienti [Customer]. La classe [Customer] fa parte del livello [JPA] ed è la seguente:
package hello;
import javax.persistence.Entity;
import javax.persistence.GeneratedValue;
import javax.persistence.GenerationType;
import javax.persistence.Id;
@Entity
public class Customer {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
private String firstName;
private String lastName;
protected Customer() {
}
public Customer(String firstName, String lastName) {
this.firstName = firstName;
this.lastName = lastName;
}
@Override
public String toString() {
return String.format("Customer[id=%d, firstName='%s', lastName='%s']", id, firstName, lastName);
}
}
Un cliente ha un identificativo [id], un nome [firstName] e un cognome [lastName]. Ogni istanza [Customer] rappresenta una riga di una tabella del database.
- riga 8: annotazione JPA che fa sì che la persistenza delle istanze [Customer] (Create, Read, Update, Delete) venga gestita da un'implementazione JPA. In base alle dipendenze Maven, si vede che viene utilizzata l’implementazione JPA / Hibernate;
- righe 11-12: annotazioni JPA che associano il campo [id] alla chiave primaria della tabella [Customer]. La riga 12 indica che l'implementazione JPA utilizzerà il metodo di generazione della chiave primaria specifico del SGBD utilizzato, in questo caso H2;
Non sono presenti altre annotazioni relative a JPA. Verranno quindi utilizzati i valori predefiniti:
- la tabella di [Customer] porterà il nome della classe, ovvero [Customer];
- le colonne di questa tabella porteranno il nome dei campi della classe: [id, firstName, lastName], tenendo presente che nel nome di una colonna della tabella non viene fatta distinzione tra maiuscole e minuscole;
Si noti che in nessun momento viene menzionata l’implementazione JPA utilizzata.
5.1.3. Il livello [Spring Data]
La classe [CustomerRepository] implementa il livello di accesso alla tabella [Customer]. Il suo codice è il seguente:
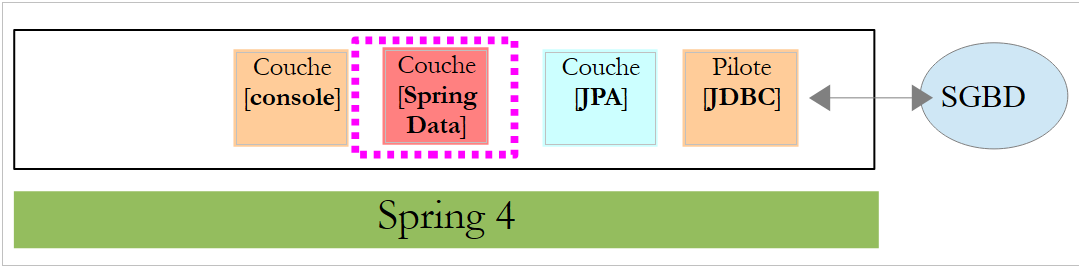 |
 |
package hello;
import java.util.List;
import org.springframework.data.repository.CrudRepository;
public interface CustomerRepository extends CrudRepository<Customer, Long> {
List<Customer> findByLastName(String lastName);
}
Si tratta quindi di un'interfaccia e non di una classe (riga 7). Essa estende l'interfaccia [CrudRepository], un'interfaccia di Spring Data (riga 5). Questa interfaccia è parametrizzata da due tipi: il primo è il tipo degli elementi gestiti, in questo caso il tipo [Customer]; il secondo è il tipo della chiave primaria degli elementi gestiti, in questo caso un tipo [Long]. L’interfaccia [CrudRepository] è la seguente:
package org.springframework.data.repository;
import java.io.Serializable;
@NoRepositoryBean
public interface CrudRepository<T, ID extends Serializable> extends Repository<T, ID> {
<S extends T> S save(S entity);
<S extends T> Iterable<S> save(Iterable<S> entities);
T findOne(ID id);
boolean exists(ID id);
Iterable<T> findAll();
Iterable<T> findAll(Iterable<ID> ids);
long count();
void delete(ID id);
void delete(T entity);
void delete(Iterable<? extends T> entities);
void deleteAll();
}
Questa interfaccia definisce le operazioni CRUD (Create – Read – Update – Delete) che è possibile eseguire su un tipo JPA T:
- riga 8: il metodo save consente di salvare un'entità T nel database. L'entità viene salvata con la chiave primaria assegnatale da SGBD. Consente inoltre di aggiornare un'entità T identificata dalla sua chiave primaria id. La scelta tra l'una o l'altra azione dipende dal valore della chiave primaria id: se questa è null, viene eseguita l'operazione di salvataggio, altrimenti viene eseguita l'operazione di aggiornamento;
- riga 10: lo stesso, ma per un elenco di entità;
- riga 12: il metodo findOne consente di recuperare un'entità T identificata dalla sua chiave primaria id;
- riga 22: il metodo delete consente di eliminare un'entità T identificata dalla sua chiave primaria id;
- righe 24-28: varianti del metodo [delete];
- riga 16: il metodo [findAll] consente di recuperare tutte le entità T persistenti;
- riga 18: idem, ma limitato alle entità di cui è stato fornito l’elenco degli identificatori;
Torniamo all'interfaccia [CustomerRepository]:
package hello;
import java.util.List;
import org.springframework.data.repository.CrudRepository;
public interface CustomerRepository extends CrudRepository<Customer, Long> {
List<Customer> findByLastName(String lastName);
}
- la riga 9 consente di recuperare un [Customer] tramite il suo nome [lastName];
E questo è tutto per il livello [DAO]. Non esiste una classe di implementazione dell’interfaccia precedente. Questa viene generata in fase di esecuzione da [Spring Data]. I metodi dell’interfaccia [CrudRepository] vengono implementati automaticamente. Per i metodi aggiunti nell’interfaccia [CustomerRepository], dipende. Torniamo alla definizione di [Customer]:
private long id;
private String firstName;
private String lastName;
Il metodo alla riga 9 viene implementato automaticamente da [Spring Data] poiché fa riferimento al campo [lastName] (riga 3) di [Customer]. Quando incontra un metodo [findBySomething] nell’interfaccia da implementare, Spring Data lo implementa tramite la seguente query JPQL (Java Persistence Query Language):
È quindi necessario che il tipo T abbia un campo denominato [something]. Pertanto, il metodo
verrà implementato con un codice simile al seguente:
return [em].createQuery("select c from Customer c where c.lastName=:value").setParameter("value",lastName).getResultList()
dove [em] indica il contesto di persistenza JPA. Ciò è possibile solo se la classe [Customer] dispone di un campo denominato [lastName], come effettivamente avviene.
In conclusione, nei casi semplici, Spring Data ci permette di implementare il livello [DAO] con una semplice interfaccia.
5.1.4. Il livello [console]
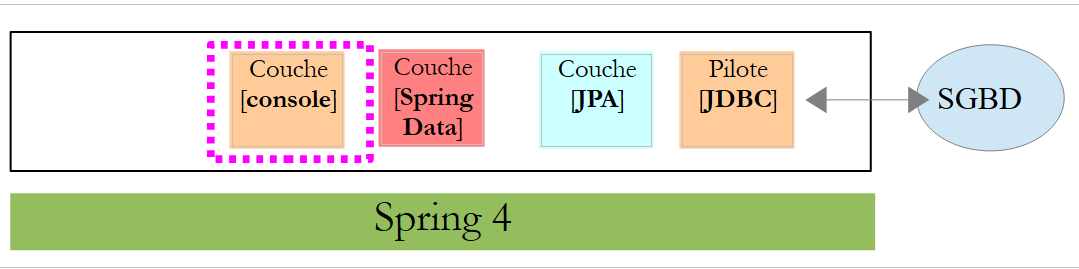 |
 |
La classe [Application] è la seguente:
package hello;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.CommandLineRunner;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class Application implements CommandLineRunner {
@Autowired
CustomerRepository repository;
public static void main(String[] args) {
SpringApplication.run(Application.class);
}
@Override
public void run(String... strings) throws Exception {
// salva un paio di clienti
repository.save(new Customer("Jack", "Bauer"));
repository.save(new Customer("Chloe", "O'Brian"));
repository.save(new Customer("Kim", "Bauer"));
repository.save(new Customer("David", "Palmer"));
repository.save(new Customer("Michelle", "Dessler"));
// recupera tutti i clienti
System.out.println("Customers found with findAll():");
System.out.println("-------------------------------");
for (Customer customer : repository.findAll()) {
System.out.println(customer);
}
System.out.println();
// recupera un singolo cliente tramite ID
Customer customer = repository.findOne(1L);
System.out.println("Customer found with findOne(1L):");
System.out.println("--------------------------------");
System.out.println(customer);
System.out.println();
// recupera i clienti in base al cognome
System.out.println("Customer found with findByLastName('Bauer'):");
System.out.println("--------------------------------------------");
for (Customer bauer : repository.findByLastName("Bauer")) {
System.out.println(bauer);
}
}
}
- riga 9: la classe implementa l'interfaccia [CommandLineRunner], che a sua volta è un'interfaccia di [Spring Boot] (riga 4). Questa interfaccia ha un solo metodo, quello alla riga 19;
- riga 8: @SpringBootApplication è un'annotazione che raggruppa diverse annotazioni [Spring Boot]:
- @Configuration: indica che la classe è una classe di configurazione;
- @EnableAutoConfiguration: richiede a [Spring Boot] di creare autonomamente un certo numero di bean in base a diverse proprietà, in particolare al contenuto del Classpath del progetto. Poiché le librerie Hibernate si trovano nel Classpath, il bean [entityManagerFactory] verrà implementato con Hibernate. Poiché la libreria di SGBD H2 si trova nel Classpath, il bean [dataSource] verrà implementato con H2. Nel bean [dataSource], è necessario definire anche l'utente e la relativa password. In questo caso Spring Boot utilizzerà l’amministratore predefinito di H2, che non ha password. Poiché la libreria [spring-tx] si trova nel Classpath, verrà utilizzato il gestore delle transazioni di Spring;
- @EnableWebMvc: se nel Classpath è presente la libreria [spring-mvc]. In questo caso, viene eseguita una configurazione automatica per l’applicazione web;
- @ComponentScan: indica a Spring dove cercare gli altri bean, le configurazioni e i servizi. Qui vengono cercati per impostazione predefinita nel pacchetto contenente la classe annotata, ovvero il pacchetto [hello]. In questo modo verranno individuate le classi [Customer] e [CustomerRepository]. Poiché la prima presenta l’annotazione [@Entity], verrà catalogata come entità da gestire da Hibernate. Poiché la seconda estende l’interfaccia [CrudRepository], verrà registrata come bean Spring;
- righe 11-12: il bean [CustomerRepository] viene iniettato nel codice della classe principale;
- riga 15: viene eseguito il metodo statico [run] della classe [SpringApplication] del progetto Spring Boot. Il suo parametro è la classe che presenta un'annotazione [Configuration] o [EnableAutoConfiguration]. A questo punto si verificherà tutto ciò che è stato spiegato in precedenza. Il risultato è un contesto applicativo Spring, ovvero un insieme di bean gestiti da Spring;
- righe 19-48: le operazioni che seguono si limitano a utilizzare i metodi del bean che implementa l’interfaccia [CustomerRepository];
I risultati in console sono i seguenti:
- righe 1-8: il logo del progetto Spring Boot;
- riga 9: viene eseguita la classe [hello.Application];
- riga 10: [AnnotationConfigApplicationContext] è una classe che implementa l’interfaccia [ApplicationContext] di Spring. Si tratta di un contenitore di bean;
- riga 11: il bean [entityManagerFactory] è implementato dalla classe [LocalContainerEntityManagerFactory], una classe di Spring. Gestisce il livello [JPA];
- riga 12: compare [Hibernate]. È stata scelta proprio questa implementazione JPA;
- riga 19: un dialetto Hibernate è la variante SQL da utilizzare con SGBD. Qui il dialetto [H2Dialect] indica che Hibernate opererà con SGBD e H2;
- righe 21-22: viene creato il database. Viene creata la tabella [CUSTOMER]. Ciò significa che Hibernate è stato configurato per generare le tabelle a partire dalle definizioni JPA; in questo caso, la definizione JPA della classe [Customer];
- righe 26-30: risultato del metodo [findAll] dell'interfaccia;
- riga 34: risultato del metodo [findOne] dell'interfaccia;
- righe 38-39: risultati del metodo [findByLastName];
- righe 41 e seguenti: log relativi alla chiusura del contesto Spring.
5.1.5. Configurazione manuale del progetto Spring Data
Duplichiamo il progetto precedente nel progetto [gs-accessing-data-jpa-02]:
 |
In questo nuovo progetto non ci affideremo alla configurazione automatica effettuata da Spring Boot. La eseguiremo manualmente. Ciò può essere utile se le configurazioni predefinite non ci soddisfano.
Per prima cosa, specificheremo le dipendenze necessarie nel file [pom.xml]:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/maven-v4_0_0.xsd"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance">
<modelVersion>4.0.0</modelVersion>
<groupId>org.springframework</groupId>
<artifactId>gs-accessing-data-jpa-02</artifactId>
<version>0.1.0</version>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
</parent>
<dependencies>
<!-- Spring Data -->
<dependency>
<groupId>org.springframework.data</groupId>
<artifactId>spring-data-jpa</artifactId>
</dependency>
<!-- Hibernate -->
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
</dependency>
<!-- Database H2 -->
<dependency>
<groupId>com.h2database</groupId>
<artifactId>h2</artifactId>
</dependency>
<!-- Tomcat JDBC -->
<dependency>
<groupId>org.apache.tomcat</groupId>
<artifactId>tomcat-jdbc</artifactId>
</dependency>
</dependencies>
<properties>
<!-- utilizza UTF-8 per tutto -->
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
</properties>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
<repositories>
<repository>
<id>spring-releases</id>
<name>Spring Releases</name>
<url>https://repo.spring.io/libs-release</url>
</repository>
<repository>
<id>org.jboss.repository.releases</id>
<name>JBoss Maven Release Repository</name>
<url>https://repository.jboss.org/nexus/content/repositories/releases</url>
</repository>
</repositories>
<pluginRepositories>
<pluginRepository>
<id>spring-releases</id>
<name>Spring Releases</name>
<url>https://repo.spring.io/libs-release</url>
</pluginRepository>
</pluginRepositories>
</project>
- righe 10-14: il progetto Maven padre di cui utilizzeremo le librerie che definisce;
- righe 18-21: Spring Data utilizzato per accedere al database;
- righe 23-26: l’implementazione Hibernate della specifica JPA;
- righe 28-31: il SGBD H2;
- righe 33-36: i database vengono spesso utilizzati con pool di connessioni aperte che evitano ripetute operazioni di apertura e chiusura delle connessioni. In questo caso, l'implementazione utilizzata è quella di [tomcat-jdbc];
Nel nuovo progetto, l'entità [Customer] e l'interfaccia [CustomerRepository] rimangono invariate. Modificheremo la classe [Application], che verrà suddivisa in due classi:
- [Config], che sarà la classe di configurazione:
- [Main], che sarà la classe eseguibile;
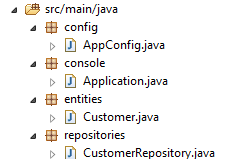 |
La classe eseguibile [Application] è ora la seguente:
package console;
import org.springframework.context.annotation.AnnotationConfigApplicationContext;
import repositories.CustomerRepository;
import config.AppConfig;
import entities.Customer;
public class Application {
public static void main(String[] args) {
// istanziazione del contesto Spring
AnnotationConfigApplicationContext context = new AnnotationConfigApplicationContext(AppConfig.class);
CustomerRepository repository = context.getBean(CustomerRepository.class);
// salvataggio di un paio di clienti
repository.save(new Customer("Jack", "Bauer"));
repository.save(new Customer("Chloe", "O'Brian"));
repository.save(new Customer("Kim", "Bauer"));
repository.save(new Customer("David", "Palmer"));
repository.save(new Customer("Michelle", "Dessler"));
...
// chiusura del contesto
context.close();
}
}
- riga 9: la classe [Application] non presenta più annotazioni di configurazione;
- righe 3-7: si noti che non ci sono più importazioni di pacchetti [Spring Boot];
- riga 12: si istanziano i bean Spring. Si ottiene il contesto Spring che contiene il riferimento ai bean così creati;
- riga 13: si richiede un riferimento al bean di tipo [CustomerRepository];
La classe [Config] che configura il progetto è la seguente:
package config;
import javax.persistence.EntityManagerFactory;
import org.apache.tomcat.jdbc.pool.DataSource;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.jpa.repository.config.EnableJpaRepositories;
import org.springframework.orm.jpa.JpaTransactionManager;
import org.springframework.orm.jpa.JpaVendorAdapter;
import org.springframework.orm.jpa.LocalContainerEntityManagerFactoryBean;
import org.springframework.orm.jpa.vendor.Database;
import org.springframework.orm.jpa.vendor.HibernateJpaVendorAdapter;
import org.springframework.transaction.PlatformTransactionManager;
import org.springframework.transaction.annotation.EnableTransactionManagement;
@EnableTransactionManagement
@EnableJpaRepositories(basePackages = { "repositories" })
@Configuration
// @ComponentScan(basePackages={"package1","package2"})
public class AppConfig {
// il database H2
@Bean
public DataSource dataSource() {
// fonte dati TomcatJdbc
DataSource dataSource = new DataSource();
// configurazione di accesso JDBC
dataSource.setDriverClassName("org.h2.Driver");
dataSource.setUrl("jdbc:h2:./demo");
dataSource.setUsername("sa");
dataSource.setPassword("");
// una connessione inizialmente aperta
dataSource.setInitialSize(1);
// risultato
return dataSource;
}
// il provider JPA
@Bean
public JpaVendorAdapter jpaVendorAdapter() {
HibernateJpaVendorAdapter hibernateJpaVendorAdapter = new HibernateJpaVendorAdapter();
hibernateJpaVendorAdapter.setShowSql(false);
hibernateJpaVendorAdapter.setGenerateDdl(true);
hibernateJpaVendorAdapter.setDatabase(Database.H2);
return hibernateJpaVendorAdapter;
}
// EntityManagerFactory
@Bean
public EntityManagerFactory entityManagerFactory(JpaVendorAdapter jpaVendorAdapter, DataSource dataSource) {
LocalContainerEntityManagerFactoryBean factory = new LocalContainerEntityManagerFactoryBean();
factory.setJpaVendorAdapter(jpaVendorAdapter);
factory.setPackagesToScan("entities");
factory.setDataSource(dataSource);
factory.afterPropertiesSet();
return factory.getObject();
}
// Gestore delle transazioni
@Bean
public PlatformTransactionManager transactionManager(EntityManagerFactory entityManagerFactory) {
JpaTransactionManager txManager = new JpaTransactionManager();
txManager.setEntityManagerFactory(entityManagerFactory);
return txManager;
}
}
- riga 17: l'annotazione [@EnableTransactionManagement] indica che devono essere interpretate le annotazioni [@Transactional]. I metodi delle interfacce [CrudRepository] presentano queste annotazioni. Essi vengono quindi eseguiti all'interno di una transazione;
- riga 18: l’annotazione [@EnableJpaRepositories] consente di indicare le cartelle in cui si trovano le interfacce Spring Data [CrudRepository]. Queste interfacce diventeranno componenti Spring e saranno disponibili nel relativo contesto;
- riga 19: l’annotazione [@Configuration] rende la classe [Config] una classe di configurazione Spring;
- riga 20: l'annotazione [@ComponentScan] consente di elencare le cartelle in cui devono essere cercati i componenti Spring. I componenti Spring sono classi contrassegnate con annotazioni Spring quali @Service, @Component, @Controller, ... In questo caso non ce ne sono altri oltre a quelli definiti all’interno della classe [AppConfig], pertanto l’annotazione è stata messa tra commenti;
- righe 24-37: definiscono la fonte dei dati, il database H2. È l'annotazione @Bean alla riga 25 che rende l'oggetto creato da questo metodo un componente gestito da Spring. Il nome del metodo può essere qualsiasi. Tuttavia, deve essere denominato [dataSource] se il metodo EntityManagerFactory della riga 51 è assente e viene definito tramite autoconfigurazione;
- riga 30: il database si chiamerà [demo] e verrà generato nella cartella del progetto;
- righe 40-47: definiscono l’implementazione JPA utilizzata, in questo caso un’implementazione Hibernate. Il nome del metodo può essere qualsiasi;
- riga 43: nessun log SQL;
- riga 44: il database verrà creato se non esiste;
- righe 50-58: definiscono il metodo EntityManagerFactory che gestirà la persistenza di JPA. Il metodo deve chiamarsi obbligatoriamente [entityManagerFactory];
- riga 51: il metodo riceve due parametri del tipo dei due bean definiti in precedenza. Questi verranno quindi creati e poi iniettati da Spring come parametri del metodo;
- riga 53: specifica l’implementazione JPA utilizzata;
- riga 54: specifica le cartelle in cui si trovano le entità JPA;
- riga 55: specifica la fonte dati da gestire;
- righe 61-66: il gestore delle transazioni. Il metodo deve chiamarsi obbligatoriamente [transactionManager]. Riceve come parametro il bean delle righe 51-58;
- riga 64: il gestore delle transazioni è associato a EntityManagerFactory;
I metodi precedenti possono essere definiti in qualsiasi ordine.
L'esecuzione del progetto produce gli stessi risultati. Nella cartella del progetto compare un nuovo file, quello del database H2:
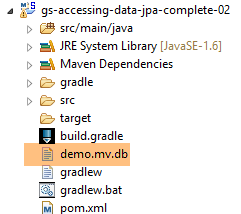 |
5.1.6. Creazione di un archivio eseguibile
Per creare un archivio eseguibile del progetto, è possibile procedere come segue:
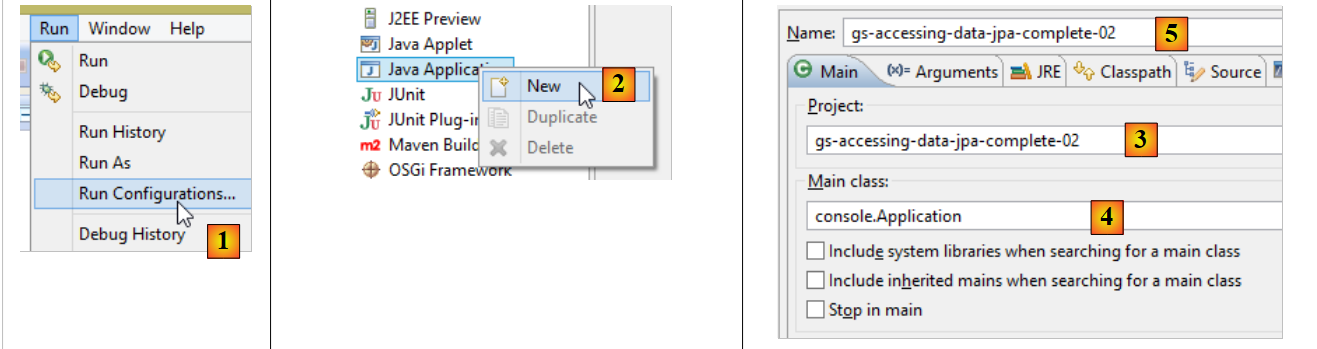 |
- in [1]: si crea una configurazione di esecuzione;
- in [2]: di tipo [Java Application]
- in [3]: si indica il progetto da eseguire (utilizzare il pulsante Browse);
- in [4]: indica la classe da eseguire;
- in [5]: il nome della configurazione di esecuzione – può essere qualsiasi;
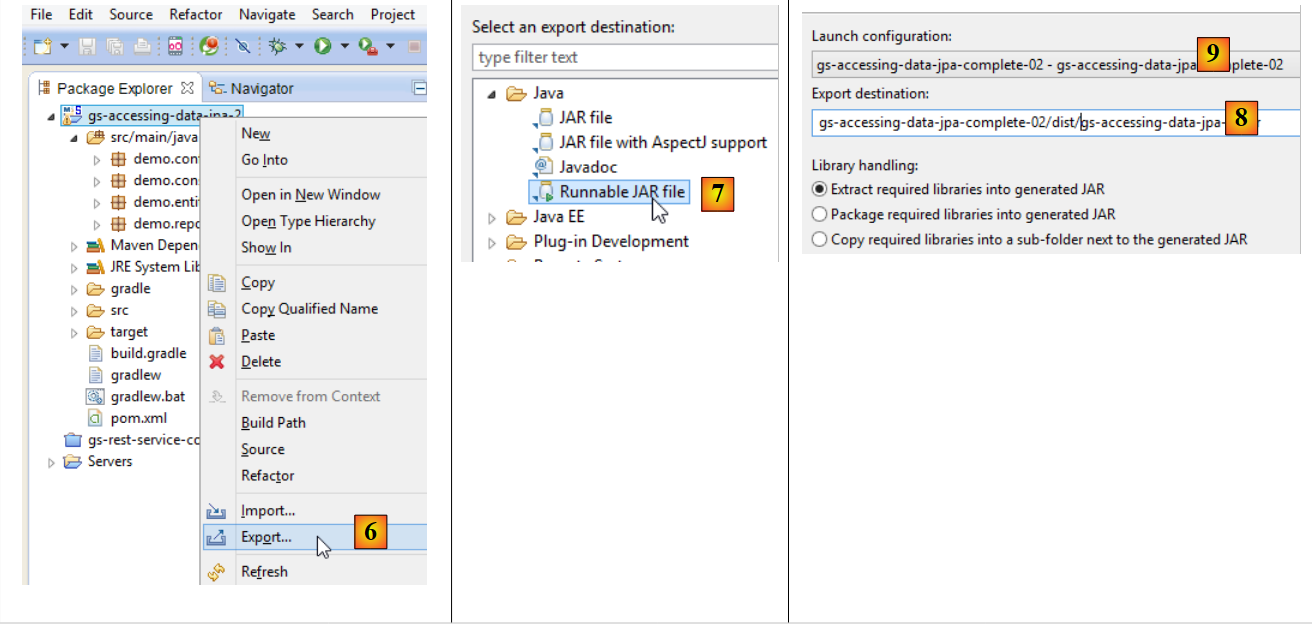 |
- in [6]: si esporta il progetto;
- in [7]: sotto forma di archivio eseguibile JAR;
- in [8]: indica il percorso e il nome del file eseguibile da creare;
- in [9]: il nome della configurazione di esecuzione creata in [5];
10 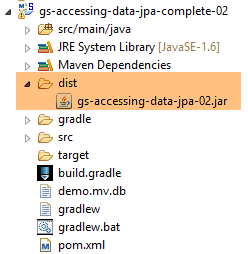 |
- in [10], l'archivio creato;
Fatto ciò, si apre una console nella cartella contenente l'archivio eseguibile:
L'archivio viene eseguito nel modo seguente:
.....\dist>java -jar gs-accessing-data-jpa-02.jar
I risultati ottenuti nella console sono i seguenti:
5.1.7. Creazione di un progetto [Spring Data]
Per creare uno scheletro di progetto Spring Data, è possibile procedere come segue:
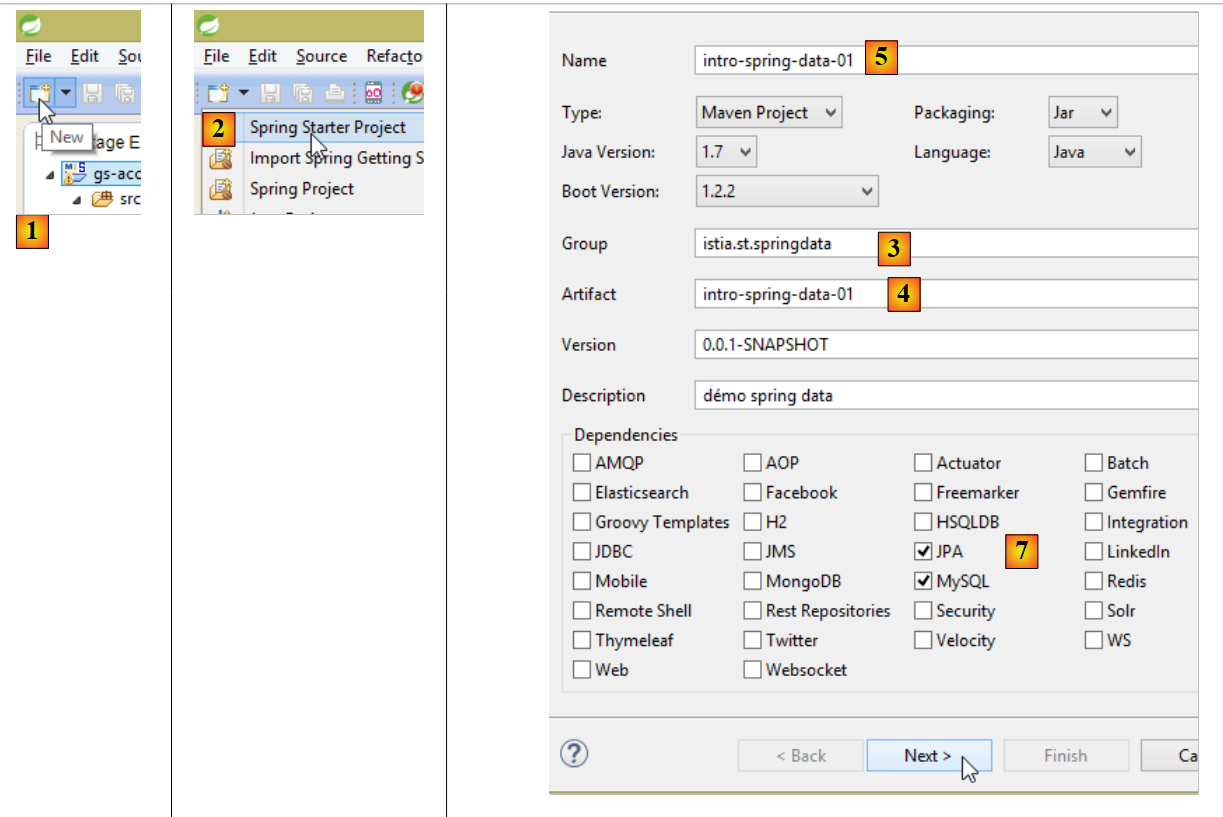 |
- in [1], si crea un nuovo progetto;
- in [2]: di tipo [Spring Starter Project];
- il progetto generato sarà un progetto Maven. In [3], si indica il nome del gruppo del progetto;
- in [4]: si indica il nome dell’artefatto (in questo caso un jar) che verrà creato durante la compilazione del progetto;
- in [5]: il nome Eclipse del progetto – può essere qualsiasi nome (non deve necessariamente coincidere con [4]);
- in [7]: si specifica che verrà creato un progetto con un livello [JPA] contenente SGBD e MySQL. Le dipendenze necessarie per tale progetto saranno quindi incluse nel file [pom.xml];
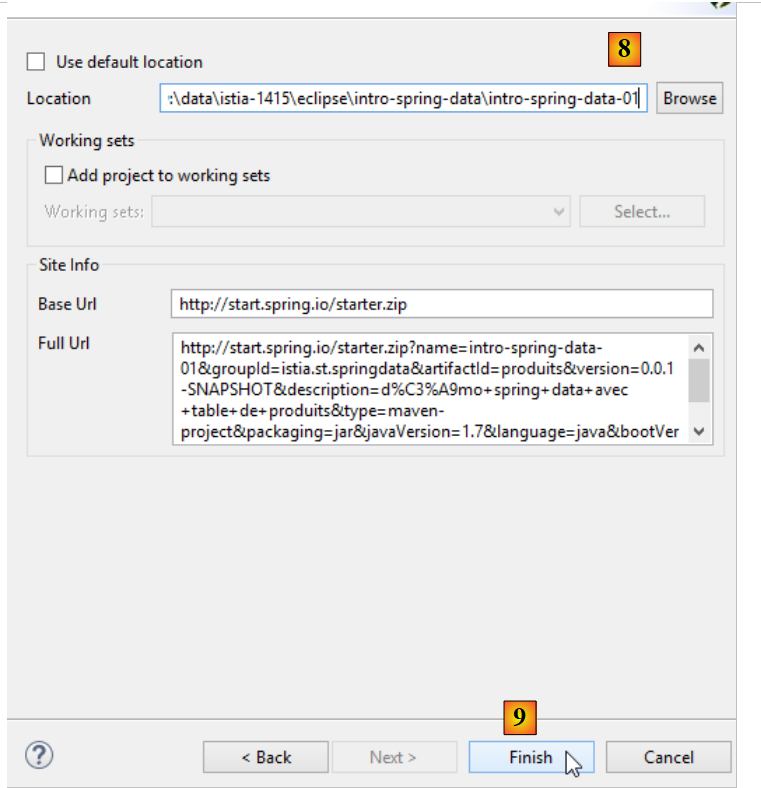 |
- in [8], specificare il nome della cartella del progetto;
- in [9], completare la procedura guidata;
 |
- in [10]: il progetto creato;
Il file [pom.xml] integra le dipendenze necessarie per un progetto JPA:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>istia.st.springdata</groupId>
<artifactId>intro-spring-data-01</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>intro-spring-data-01</name>
<description>démo spring data avec table de produits</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>1.2.3.RELEASE</version>
<relativePath/> <!-- ricerca del genitore dal repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<start-class>demo.IntroSpringData01Application</start-class>
<java.version>1.7</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-jpa</artifactId>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<scope>runtime</scope>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
- righe 14-19: il progetto Maven padre;
- righe 28-31: la dipendenza necessaria per JPA – includerà [Spring Data];
- righe 32-36: la dipendenza dal driver JDBC di MySQL;
- righe 37-41: le dipendenze necessarie per i test JUnit integrati con Spring;
La classe eseguibile [Application] non esegue alcuna operazione, ma è preconfigurata:
package demo;
import org.springframework.boot.SpringApplication;
import org.springframework.boot.autoconfigure.SpringBootApplication;
@SpringBootApplication
public class IntroSpringData01Application {
public static void main(String[] args) {
SpringApplication.run(IntroSpringData01Application.class, args);
}
}
- l'annotazione [@SpringBootApplication] rende la classe una classe di autoconfigurazione del progetto;
La classe di test [ApplicationTests] non esegue alcuna operazione, ma è preconfigurata:
package demo;
import org.junit.Test;
import org.junit.runner.RunWith;
import org.springframework.boot.test.SpringApplicationConfiguration;
import org.springframework.test.context.junit4.SpringJUnit4ClassRunner;
@RunWith(SpringJUnit4ClassRunner.class)
@SpringApplicationConfiguration(classes = IntroSpringData01Application.class)
public class IntroSpringData01ApplicationTests {
@Test
public void contextLoads() {
}
}
- riga 9: l'annotazione [@SpringApplicationConfiguration] consente di utilizzare il file di configurazione [IntroSpringData01Application]. La classe di test beneficerà così di tutti i bean definiti da questo file;
- riga 8: l'annotazione [@RunWith] consente l'integrazione di Spring con JUnit: la classe potrà essere eseguita come un test JUnit. [@RunWith] è un'annotazione JUnit (riga 4), mentre la classe [SpringJUnit4ClassRunner] è una classe Spring (riga 6);
Ora che disponiamo di uno scheletro dell’applicazione JPA, possiamo completarlo.