4. Zeichenfolgen
4.1. Skript [str_01]: Zeichenfolgen-Notation
Das Skript [str_01] lautet wie folgt:
Kommentare
- Zeile 3: eine durch doppelte Anführungszeichen " begrenzte Zeichenkette;
- Zeile 4: eine Zeichenkette, die durch einfache Anführungszeichen ' begrenzt ist;
- Zeile 5: eine Zeichenkette, die in dreifache Anführungszeichen """ eingeschlossen ist. In diesem Fall kann die Zeichenkette mehrere Zeilen umfassen;
Die Ergebnisse lauten wie folgt:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/strings/str_01.py
chaine1=[un], chaine2=[deux], chaine3=[hélène va au
marché acheter des légumes]
Process finished with exit code 0
4.2. Skript [str_02]: Methoden der Klasse <str>
Das Skript [str_02] stellt einige der Methoden der Klasse <str> vor, bei der es sich um die Zeichenfolgenklasse handelt:
Die Kommentare in Verbindung mit den erhaltenen Ergebnissen reichen aus, um das Skript zu verstehen. Die Ergebnisse lauten wie folgt:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/strings/str_02.py
'ABCD'.lower()=abcd
'abcd'.upper()=ABCD
'cheval[2]=e
'caractères accentués'[5:7]=tè
'caractères accentués'[4:]=ctères accentués
'caractères accentués'[:5]=carac
len('123')=3
' abcd '.strip()=[abcd]
' abcd '.rstrip()=[ abcd]
' abcd '.lstrip()=[abcd ]
str.strip()=[abcd]
'abcd'.replace('a','x')=xbcd
'abcd'.replace('ab','xy')=xycd
'abcd'.find('bc')=1
'abcd'.find('bc')=-1
'abcd'.startswith('ab')=True
'abcd'.startswith('x')=False
'abcd'.endswith('cd')=True
'abcd'.endswith('x')=False
'[X]'.join(['abcd', '123', 'èéà'])=abcd[X]123[X]èéà
''.join(['abcd', '123', 'èéà'])=abcd123èéà
'abcd 123 cdXY'.split('cd')=['ab', ' 123 ', 'XY']
'abcd 123 cdXY'.split(None)=['abcd', '123', 'cdXY']
Process finished with exit code 0
4.3. Skript [str_03]: Zeichenfolgenkodierung (1)
Das Skript [str_03] führt in Konzepte der Zeichenfolgenkodierung ein:
Die Kodierung einer Zeichenkette vom Typ <str> erzeugt eine binäre Zeichenkette, in der jedes Zeichen der Zeichenkette durch ein oder mehrere Bytes dargestellt wird. Es gibt verschiedene Arten der Kodierung. Das obige Skript zeigt die beiden im westlichen Raum gängigsten: „utf-8“ und „iso-8859-1“, auch bekannt als „latin1“.
Das Prinzip der Kodierung/Dekodierung wird im Folgenden veranschaulicht (Ref. |https://realpython.com/python-encodings-guide/ |):
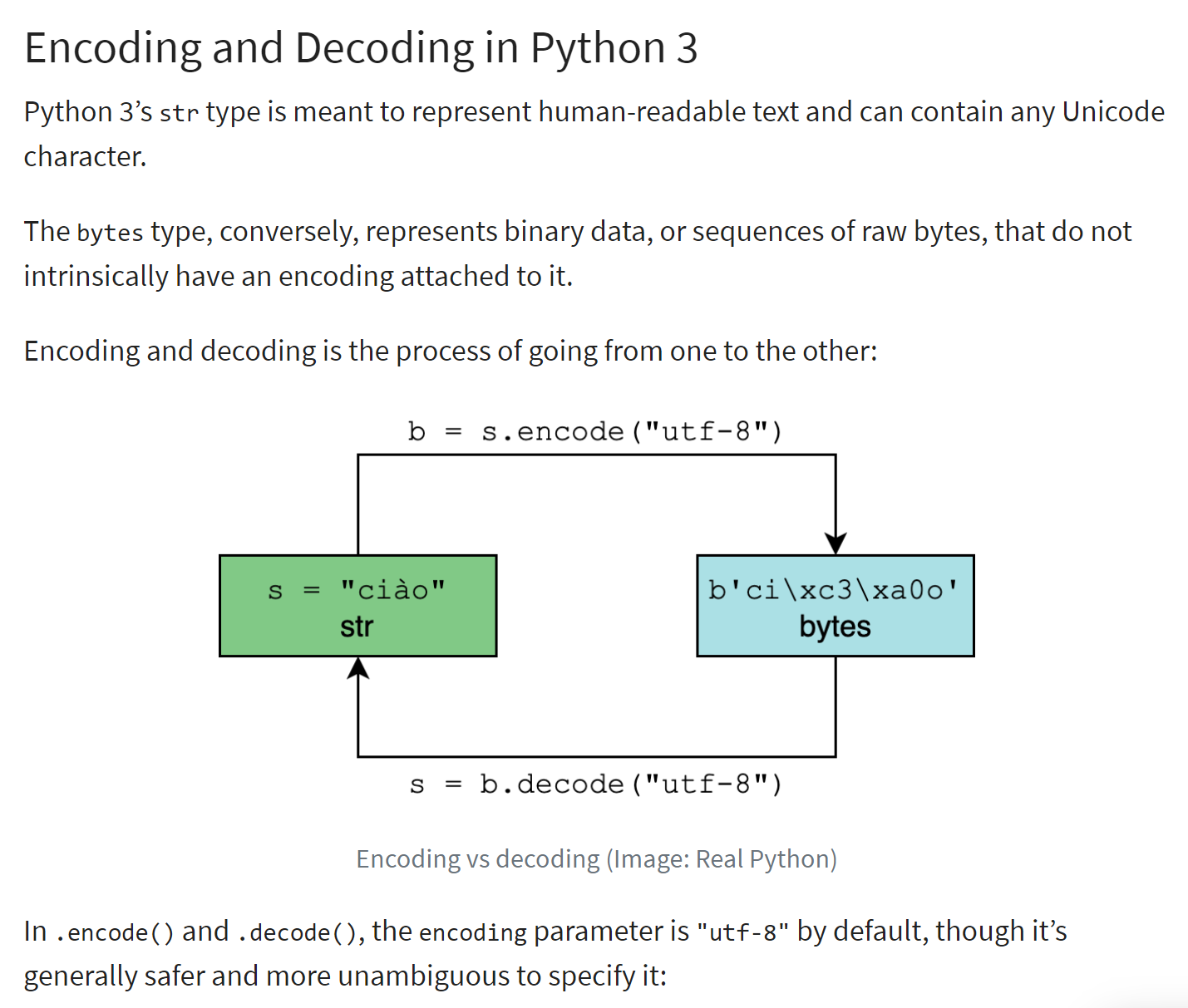
Kommentare
- Zeilen 4–5: Die zu kodierende Ausgangszeichenkette. Instanzen vom Typ <str> sind Unicode-Zeichenketten |https://docs.python.org/3/howto/unicode.html|, |https://realpython.com/python-encodings-guide/ |;
- Zeilen 6–11: Zwei Möglichkeiten, eine Zeichenkette in UTF-8 zu kodieren:
- Zeile 8: str.encode('utf-8');
- Zeile 10: bytes(str, 'utf-8');
- Zeilen 12–17: Wir machen dasselbe mit der Kodierung „iso-8859-1“;
- Zeilen 18–23: „latin1“ ist ein anderer Name für die „iso-8859-1“-Kodierung;
Die Ergebnisse lauten wie folgt:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/strings/str_03.py
str=[hélène va au marché acheter des légumes, type=<class 'str'>
--- utf-8
bytes1=b'h\xc3\xa9l\xc3\xa8ne va au march\xc3\xa9 acheter des l\xc3\xa9gumes', type=<class 'bytes'>
bytes2=b'h\xc3\xa9l\xc3\xa8ne va au march\xc3\xa9 acheter des l\xc3\xa9gumes', type=<class 'bytes'>
--- iso-8859-1
bytes1=b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes', type=<class 'bytes'>
bytes2=b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes', type=<class 'bytes'>
--- latin1
bytes1=b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes', type=<class 'bytes'>
bytes2=b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes', type=<class 'bytes'>
Process finished with exit code 0
Kommentare
- Zeile 4: Wir sehen, dass die Zeichen mit Akzent mit zwei Bytes kodiert wurden:
- é: [\xc3\xa9], was der Binärsequenz 11000011 10101001 entspricht;
- è: [\xc3\xa8], was der Binärsequenz 11000011 10101000 entspricht;
- Zeile 7: Bei der ISO-8859-1-Kodierung werden diese beiden Zeichen mit Akzent anders kodiert:
- é: [\xe9], was der Binärsequenz 11101001 entspricht;
- è: [\xe8], was der Binärsequenz 11101000 entspricht;
4.4. Skript [str_04]: Zeichenfolgenkodierung (2)
Skript [str_04] führt zwei weitere Kodierungsarten ein: „base64“ und „quoted-printable“. Diese beiden Kodierungen kodieren keine Unicode-Zeichenfolgen, sondern binäre Objekte. Wenn Sie beispielsweise ein Word-Dokument an eine E-Mail anhängen, wird es je nach verwendetem E-Mail-Client einer dieser beiden Kodierungen unterzogen. Dies ist bei den meisten angehängten Dateien der Fall.
Das Skript lautet wie folgt:
Kommentare
- Zeile 2: Das Modul [codecs] unterstützt die Kodierungen „base64“ und „quoted-printable“. Es kann viele weitere verarbeiten;
- Zeilen 4–7: Die Unicode-Zeichenkette, die verschiedenen Kodierungen unterzogen wird;
- Zeilen 9–12: UTF-8-Kodierung. Dies erzeugt eine binäre Zeichenkette;
- Zeilen 14–18: UTF-8-Dekodierung, um zur ursprünglichen Unicode-Zeichenkette zurückzukehren;
- Zeilen 20–29: Wir wiederholen denselben Vorgang mit der „iso-8859-1“-Kodierung;
- Zeilen 31–34: Es wird ein Dekodierungsfehler angezeigt:
- Zeile 33: bytes1 ist eine in „utf-8“ kodierte Binärzeichenfolge. Wir dekodieren sie in „iso-8859-1“;
- Zeilen 36–39: Eine weitere Möglichkeit, eine Zeichenkette mit dem Modul [codecs] in UTF-8 zu kodieren;
- Zeilen 41–44: Eine „utf-8“-Binärzeichenfolge wird in „base64“ kodiert;
- Zeilen 46–49: zeigen, wie die „base64“-Binärzeichenfolge wieder in die ursprüngliche Unicode-Zeichenfolge konvertiert wird;
- Zeilen 51–59: Wir wiederholen diesen Vorgang mit der „quoted-printable“-Kodierung anstelle von „base64“;
Die Ergebnisse lauten wie folgt:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/strings/str_04.py
---- chaîne unicode
str1=[hélène va au marché acheter des légumes], type(str1)=<class 'str'>
---- chaîne unicode -> binaire utf-8
bytes1=[b'h\xc3\xa9l\xc3\xa8ne va au march\xc3\xa9 acheter des l\xc3\xa9gumes'], type(bytes1)=<class 'bytes'>
---- binaire utf-8 -> chaîne unicode
str2=[hélène va au marché acheter des légumes], type(str2)=<class 'str'>
str2==str1=True
---- chaîne unicode -> binaire iso-8859-1
bytes2=[b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes'], type(bytes2)=<class 'bytes'>
---- binaire iso-8859-1 -> chaîne unicode
str3=[hélène va au marché acheter des légumes], type(str3)=<class 'str'>
str3==str1=True
--- binaire utf-8 (décodage iso-8859-1) --> chaîne unicode
str4=[hélène va au marché acheter des légumes], type(str4)=<class 'str'>
---- chaîne unicode -> binaire utf-8
bytes3=[b'h\xc3\xa9l\xc3\xa8ne va au march\xc3\xa9 acheter des l\xc3\xa9gumes'], type(bytes3)=<class 'bytes'>
---- binaire utf-8 -> binaire base64
bytes4=[b'aMOpbMOobmUgdmEgYXUgbWFyY2jDqSBhY2hldGVyIGRlcyBsw6lndW1lcw==\n'], type(bytes4)=<class 'bytes'>
---- binaire base64 -> binaire utf-8 -> chaîne unicode
str6=[hélène va au marché acheter des légumes], type(str6)=<class 'str'>
---- binaire utf-8 -> binaire quoted-printable
str7=[b'h=C3=A9l=C3=A8ne=20va=20au=20march=C3=A9=20acheter=20des=20l=C3=A9gumes'], type(str7)=<class 'bytes'>
---- binaire quoted-printable -> binaire utf-8 -> chaîne unicode
str8=[hélène va au marché acheter des légumes], type(str8)=<class 'str'>
Process finished with exit code 0
- Zeilen 14–15: Eine UTF-8-Binärdatei wird mit dem falschen Decoder „iso-8859-1“ in eine Unicode-Zeichenkette dekodiert. Infolgedessen sind einige der generierten Unicode-Zeichen fehlerhaft, in diesem Fall die Zeichen mit Akzenten;
- Zeilen 18–19: Bei der „Base64“-Kodierung werden beliebige Binärdaten mithilfe von 64 ASCII-Zeichen (kodiert auf 7 Bit) kodiert. Wie wir sehen können, erhöht dies die Größe der Binärdaten der Zeichenkette;
- Zeilen 22–23: Auch die „quoted-printable“-Kodierung verwendet ASCII-Zeichen (kodiert auf 7 Bit), um beliebige Binärdaten zu kodieren;
Es ist wichtig zu beachten, dass man beim Empfang von Binärdaten – beispielsweise aus dem Internet –, die Text darstellen, die verwendeten Kodierungen kennen muss, um den Originaltext wiederherzustellen.