19. Verwendung des SQLAlchemy-ORM
Das vorangegangene Kapitel hat gezeigt, dass wir in einigen Fällen mit der folgenden Architektur DBMS-unabhängigen Code schreiben können:
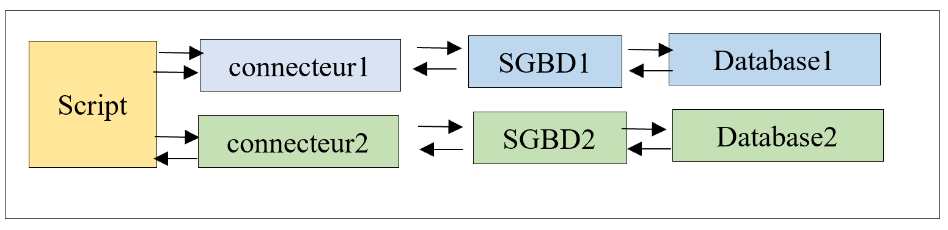
In diesem Kapitel werden wir das ORM (Object Relational Mapper) [SQLAlchemy] verwenden, um unabhängig vom verwendeten DBMS einheitlich auf DBMS zuzugreifen. Ein ORM ermöglicht zwei Dinge:
- Es ermöglicht einem Skript, mit dem DBMS zu interagieren, ohne SQL-Befehle auszuführen;
- es verbirgt die Besonderheiten der einzelnen DBMS vor dem Skript;
Die Architektur sieht wie folgt aus:
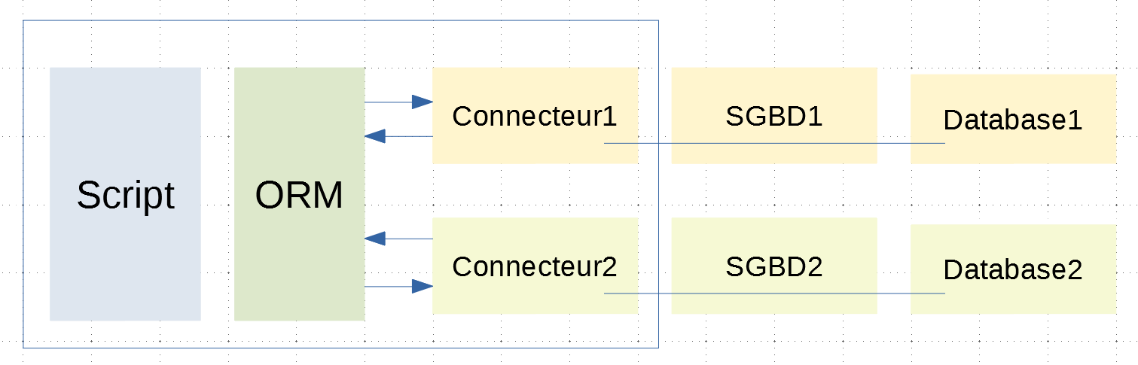
Das Skript ist nun durch das ORM von den Konnektoren getrennt. Es kommuniziert mit dem ORM über Klassen und Methoden. Es führt keinen SQL-Code aus. Das ORM übernimmt dies mithilfe der Konnektoren, mit denen es verbunden ist. Es verbirgt die Besonderheiten dieser Konnektoren vor dem Skript. Daher bleibt der Code des Skripts von einer Änderung des Konnektors (und damit des DBMS) unberührt;
Die Verzeichnisstruktur der betreffenden Skripte sieht wie folgt aus:
19.1. Installation des ORM [SQLAlchemy]
Das ORM [SQLAlchemy] wird als Python-Paket bereitgestellt, das in einem Python-Terminal installiert werden muss:
(venv) C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\databases\sqlalchemy>pip install sqlalchemy
Collecting sqlalchemy
Downloading SQLAlchemy-1.3.18-cp38-cp38-win_amd64.whl (1.2 MB)
|| 1.2 MB 3.3 MB/s
Installing collected packages: sqlalchemy
Successfully installed sqlalchemy-1.3.18
19.2. Skripte 01: Die Grundlagen

- in [1], die Skripte, die behandelt werden. Diese Skripte verwenden die Klassen aus [2]: BaseEntity, MyException, Person, Utils;
19.2.1. Konfiguration
Die [config]-Datei konfiguriert die Anwendung wie folgt:
Kommentare
- Zeile 8: Fügen Sie den Ordner, der die Klassen [BaseEntity, MyException, Person, Utils] enthält, zum Python-Pfad hinzu;
- Zeilen 12–13: Wir legen den Python-Pfad der Anwendung fest;
- Zeilen 16–17: Sie erinnern sich vielleicht, dass die Klasse |BaseEntity| ein Klassenattribut namens [excluded_keys] hat. Dieses Attribut ist eine Liste, in die wir die Klasseneigenschaften aufnehmen, die nicht im Klassendictionary (asdict-Funktion) erscheinen sollen. Hier schließen wir die Eigenschaft [_sa_instance_state] aus dem Zustand der Klasse [Person] aus. Wir werden gleich sehen, warum;
19.2.2. [demo]-Skript
Das Skript [demo] zeigt eine erste Verwendung des ORM [sqlalchemy]:
Kommentare
- Zeilen 1–4: Wir konfigurieren die Anwendung;
- Zeilen 6–10: Wir importieren die für das Skript benötigten Module;
- Zeile 13: [MetaData] ist eine Klasse in [sqlalchemy];
- Zeilen 15–22: [Table] ist eine Klasse in [sqlalchemy]. Sie wird verwendet, um eine Datenbanktabelle zu beschreiben. Hier beschreiben wir die Tabelle [people] in der MySQL-Datenbank [dbpeople], die im Kapitel |MySQL| behandelt wurde;
- Zeile 16: Der erste Parameter [people] ist der Name der zu beschreibenden Tabelle;
- Zeile 16: Der zweite Parameter [metadata] ist die in Zeile 13 erstellte [MetaData]-Instanz;
- Zeilen 17–22: Jeder der folgenden Parameter beschreibt eine Spalte der Tabelle unter Verwendung einer für [SQLAlchemy] spezifischen, aber der SQL-Syntax ähnlichen Syntax;
- jede Spalte wird mithilfe einer Instanz der Klasse [Column] aus [sqlalchemy] beschrieben;
- der erste Parameter ist der Spaltenname;
- der zweite Parameter ist ihr Typ;
- die folgenden Parameter sind benannte Parameter:
- Zeile 17: [primary_key=True], um anzugeben, dass die Spalte [id] der Primärschlüssel der Tabelle [people] ist;
- Zeile 18: [nullable=False], um anzugeben, dass eine Spalte einen Wert haben muss, wenn eine Zeile in die Tabelle eingefügt wird;
- Zeile 21: Schließlich ermöglicht die Klasse [UniqueConstraint] die Definition einer Eindeutigkeitsbeschränkung. Hier legen wir fest, dass die Spalten (last_name, first_name) innerhalb der Tabelle eindeutig sein müssen. Die Eigenschaft [name] ermöglicht es, dieser Beschränkung einen Namen zu geben. Hier sind zwei Fälle zu berücksichtigen:
- Wir beschreiben eine bereits vorhandene Tabelle. In diesem Fall müssen wir den Namen der Einschränkung in den Eigenschaften der Tabelle (phpMyAdmin oder pgAdmin) nachschlagen;
- Wir beschreiben eine Tabelle, die wir gerade erstellen wollen. In diesem Fall geben wir den gewünschten Namen ein;
- Zeilen 23–25: Wir erstellen eine Person [person1] und zeigen ihr Wörterbuch [__dict__] an. Hier haben wir:
personne1={'_BaseEntity__id': 67, '_Personne__prénom': 'x', '_Personne__nom': 'y', '_Personne__âge': 10}
- Zeilen 27–33: Wir führen ein Mapping durch, d. h. wir erstellen eine Zuordnung zwischen der Klasse [Person] und der Tabelle [people]. Dabei handelt es sich im Wesentlichen um ein Mapping [Klassenattribute Tabellenspalten]. Die Funktion [mapper] nimmt hier drei Parameter entgegen:
- Zeile 28: Der erste Parameter ist der Name der Klasse, für die das Mapping durchgeführt wird;
- Zeile 28: Der zweite Parameter ist die Tabelle, mit der sie verknüpft wird. Dies ist das in Zeile 16 erstellte [Table]-Objekt;
- Zeile 28: Der dritte Parameter hier ist ein Parameter namens [properties]. Es handelt sich um ein Wörterbuch, in dem die Schlüssel die Eigenschaften der abgebildeten Klasse und die Werte die Spalten der abgebildeten Tabelle sind. Um auf die Spalte X der Tabelle [personnes_table] zu verweisen, schreiben wir [personnes_table.c.X];
- Zeilen 35–36: Wir zeigen die Person [person1] erneut an, sobald die Zuordnung abgeschlossen ist. Wir sehen, dass sie sich nicht verändert hat:
personne1={'_BaseEntity__id': 67, '_Personne__prénom': 'x', '_Personne__nom': 'y', '_Personne__âge': 10}
- Zeilen 37–39: Wir erstellen eine neue Person [person2] und zeigen sie an. Wir sehen dann die folgende Ausgabe:
personne2={'_sa_instance_state': <sqlalchemy.orm.state.InstanceState object at 0x00000259A6747FA0>, 'id': 68, 'prénom': 'x1', 'nom': 'y1', 'âge': 11}
Wir sehen, dass das Wörterbuch [__dict__] erheblich verändert wurde:
- (Fortsetzung)
- es erscheint eine neue Eigenschaft [_sa_instance_state]. Wir sehen, dass es sich um ein ORM-Objekt [sqlalchemy] handelt;
- bei den anderen Eigenschaften wurden die Präfixe entfernt, die zuvor angaben, zu welcher Klasse sie gehörten;
Wir können daher schlussfolgern, dass die Zuordnungsoperation in den Zeilen 27–33 die Klasse [Person] verändert hat.
Wenn wir den Zustand eines [Person]-Objekts anzeigen wollen, möchten wir in der Regel nicht die Eigenschaft [_sa_instance_state] sehen. Sie dient ausschließlich den internen Abläufen von [SQLAlchemy] und ist für uns im Allgemeinen nicht von Interesse. Deshalb haben wir im [config]-Skript geschrieben:
19.2.3. Das [main]-Skript
Das [main]-Skript bearbeitet die Tabelle [people] in der MySQL-Datenbank [dbpeople] über eine Schnittstelle zu [sqlalchemy]. Um das Folgende zu verstehen, müssen wir uns die hier verwendete Architektur in Erinnerung rufen:
Wenn [Database1] die Datenbank [dbpersonnes] ist, sehen wir, dass die Verbindung zwischen dem Skript und dieser Datenbank zwei Komponenten umfasst:
- den Python-Konnektor zum MySQL-DBMS;
- das MySQL-DBMS;
Das Skript [main] kommuniziert mit dem ORM, das wiederum mit dem Python-Konnektor kommuniziert. Das ORM kommuniziert mit diesem Konnektor unter Verwendung der in den Abschnitten |MySQL| und |PostgreSQL| beschriebenen Werkzeuge, insbesondere durch die Ausgabe von SQL-Befehlen. Das Skript [main] verwendet keine SQL-Befehle. Es stützt sich auf die API (Application Programming Interface) des ORM, die aus Klassen und Schnittstellen besteht.
Das [main]-Skript lautet wie folgt:
Kommentare
- Zeilen 1–4: Die Anwendung wird konfiguriert;
- Zeilen 7–9: Wir importieren eine ganze Reihe von Klassen und Schnittstellen aus der [sqlalchemy]-Bibliothek;
- Zeile 11: Die Klasse [Person] wird importiert;
- Zeile 14: Die Datenbankverbindungszeichenfolge. Sie gibt Folgendes an:
- das verwendete DBMS (mysql);
- den verwendeten Python-Connector (mysql.connector ohne den Punkt);
- den anmeldenden Benutzer (admpersonnes);
- dessen Passwort (nobody);
- den Rechner, auf dem sich das DBMS befindet (localhost = der Rechner, auf dem das Skript läuft);
- den Namen der Datenbank (dbpersonnes);
Mit diesen Informationen kann [sqlalchemy] eine Verbindung zur Datenbank herstellen. Beachten Sie, dass der verwendete Python-Connector bereits installiert sein muss. [sqlalchemy] installiert ihn nicht.
- Zeilen 19–26: Beschreibung der Tabelle [people];
- Zeilen 28–34: Zuordnung zwischen der Klasse [Person] und der Tabelle [people];
- Zeilen 36–38: Die meisten [sqlalchemy]-Operationen werden innerhalb einer Sitzung ausgeführt. Das Konzept einer [sqlalchemy]-Sitzung ähnelt dem einer SQL-Transaktion. Sitzungen werden aus der [Session]-Klasse erstellt, die von der [sessionmaker]-Funktion in Zeile 37 zurückgegeben wird;
- Zeile 38: Die [Session]-Klasse wird über die Verbindungszeichenfolge in Zeile 14 mit der [dbpeople]-Datenbank verknüpft;
- Zeile 43: Eine Sitzung wird erstellt. Wie bereits erwähnt, lässt sich eine Sitzung mit einer Transaktion vergleichen;
- Zeilen 45–46: Die Methode [Session.execute] ermöglicht die Ausführung einer SQL-Anweisung. Dies ist jedoch nicht gängige Praxis, da wir bereits erwähnt haben, dass das ORM es ermöglicht, die Verwendung von SQL zu vermeiden;
- Zeilen 48–49: Die Methode [metadata.create_all] erstellt alle Tabellen unter Verwendung der [MetaData]-Instanz aus Zeile 17. Wir haben nur eine: die in den Zeilen 20–26 definierte Tabelle [people]. [SQLAlchemy] verwendet die Informationen aus diesen Zeilen, um die Tabelle zu erstellen. Hier sehen wir einen wesentlichen Vorteil des ORM: Es verbirgt die Besonderheiten des DBMS. Tatsächlich kann sich die SQL-Anweisung [create] aufgrund der den Spalten zugewiesenen Datentypen von einem DBMS zum anderen erheblich unterscheiden. Es gibt keine Standardisierung der Datentypen in SQL. Daher variiert die [create]-Anweisung von einem DBMS zum anderen. Hier beschreiben wir dank [SQLAlchemy]:
- beschreiben wir die gewünschte Tabelle auf einheitliche Weise;
- [SQLAlchemy] generiert die passende [create]-Anweisung für das DBMS, mit dem es arbeitet;
- Zeile 52: Wir fügen der Sitzung ein [Person]-Objekt hinzu. Dadurch wird es nicht automatisch zur Datenbank hinzugefügt. Tatsächlich folgt ein ORM seinen eigenen Regeln, um sich mit der Datenbank zu synchronisieren. Es wird stets versuchen, die Anzahl der von ihm durchgeführten Abfragen zu optimieren. Nehmen wir ein Beispiel. Das Skript fügt zwei Personen (person1, person2) zur Sitzung hinzu und führt dann eine Abfrage durch: Es möchte alle Personen in der Tabelle anzeigen. [SQLAlchemy] kann wie folgt vorgehen:
- Das Hinzufügen von [person1] kann im Arbeitsspeicher erfolgen. Es ist vorerst nicht notwendig, es in die Datenbank zu schreiben;
- das Gleiche gilt für [person2];
- Als Nächstes folgt die [select]-Abfrage. Wir müssen dann alle Zeilen aus der Tabelle [people] abrufen. [SQLAlchemy] fügt daraufhin [person1, person2] in die Datenbank ein und führt die Abfrage aus;
[SQLAlchemy] führt somit Optimierungen durch, die für den Entwickler transparent sind.
- Zeile 56: Um eine [select]-Abfrage auszuführen (ich möchte sehen…), verwenden wir die Methode [Session.query]. Der Parameter für die [query]-Methode ist die Klasse, die der abzufragenden Tabelle zugeordnet ist. Diese Methode gibt ein [Query]-Objekt zurück. Die Methode [Query.all] ruft alle [Person]-Objekte aus der Session ab. Sie gibt alle Zeilen aus der Tabelle [people] zurück, jeweils in Form eines [Person]-Objekts. Dazu nutzt [SQLAlchemy] die Zuordnung, die zwischen der Klasse [Person] und der Tabelle [people] hergestellt wurde. Das Ergebnis von Zeile 56 ist eine Liste von [Person]-Objekten;
- Zeilen 58–61: Wir geben die Elemente der Liste [people] aus. Da die Klasse [Person] von der Klasse [BaseEntity] abgeleitet ist, ist die hier in Zeile 61 implizit verwendete Methode [Person.__str__] tatsächlich die Methode [BaseEntity.__str__], die die JSON-Zeichenkette des aufrufenden Objekts zurückgibt. Diese Zeichenkette ist die JSON-Zeichenkette des Wörterbuchs [Person.asdict] (siehe |BaseEntity|). Wir haben erwähnt, dass wir nach dem Mapping die Eigenschaft [_sa_instance_state] in jedem [Person]-Objekt finden würden. Der Wert dieser Eigenschaft ist jedoch nicht vom Typ [BaseEntity]. Er muss daher aus dem Wörterbuch der Klasse [Person] ausgeschlossen werden; andernfalls stürzt die Anzeige ab. Genau das wurde im Skript [config] getan;
- Zeilen 63–65: Wir fügen zwei weitere Personen hinzu, die denselben Vor- und Nachnamen haben. Es gibt jedoch eine Eindeutigkeitsbeschränkung für die Vereinigung dieser beiden Spalten. Daher sollte ein Fehler auftreten. Dies versuchen wir zu überprüfen;
- Zeilen 67–68: Wir fordern erneut die Liste aller Personen in der Datenbank an;
- Zeilen 70–73: und wir zeigen sie an;
- Zeilen 75–76: Die Sitzung wird festgeschrieben. Wie der Name schon sagt, wird die zugrunde liegende Transaktion festgeschrieben;
- wir werden während der Ausführung sehen, dass die Zeilen 67–76 aufgrund der in Zeile 65 ausgelösten Ausnahme nicht ausgeführt werden. Wir fahren dann mit den Zeilen 78–84 fort, um die Ausnahme zu behandeln;
- Zeile 78: Die Ausnahme [InterfaceError] tritt auf, wenn [SQLAlchemy] keine Verbindung zur Datenbank [dbpersonnes] herstellen kann. Die Ausnahme [IntegrityError] tritt in Zeile 65 auf;
- Zeile 80: Der Fehler wird angezeigt;
- Zeilen 82–84: Wenn die Sitzung existiert, führen wir ein Rollback durch. Dies entspricht einem Rollback der zugrunde liegenden Transaktion;
- Zeilen 85–88: In jedem Fall, unabhängig davon, ob ein Fehler auftritt oder nicht, wird die Sitzung geschlossen, um Ressourcen freizugeben;
Die Ergebnisse der Ausführung lauten wie folgt:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/databases/sqlalchemy/01/main.py
Liste des personnes ---------
{"nom": "y", "prénom": "x", "id": 67, "âge": 10}
L'erreur suivante s'est produite : (raised as a result of Query-invoked autoflush; consider using a session.no_autoflush block if this flush is occurring prematurely)
(mysql.connector.errors.IntegrityError) 1062 (23000): Duplicate entry 'y1-x1' for key 'uix_1'
[SQL: INSERT INTO personnes (id, prenom, nom, age) VALUES (%(id)s, %(prenom)s, %(nom)s, %(age)s)]
[parameters: ({'id': 68, 'prenom': 'x1', 'nom': 'y1', 'age': 10}, {'id': 69, 'prenom': 'x1', 'nom': 'y1', 'age': 10})]
(Background on this error at: http://sqlalche.me/e/13/gkpj)
rollback...
Process finished with exit code 0
- Zeilen 2–3: die Liste der Personen nach dem ersten Einfügen;
- Zeile 5: die [IntegrityError]-Ausnahme, die auftrat, als zwei Personen mit demselben Vor- und Nachnamen hinzugefügt wurden;
- Zeilen 6–7: Beachten Sie die fehlgeschlagene SQL-Anweisung. Es handelt sich um eine parametrisierte INSERT-Anweisung: [SQLAlchemy] hat beide Personen mit einem einzigen INSERT eingefügt. Hier sehen wir, dass versucht wurde, die ausgegebenen SQL-Anweisungen zu optimieren;
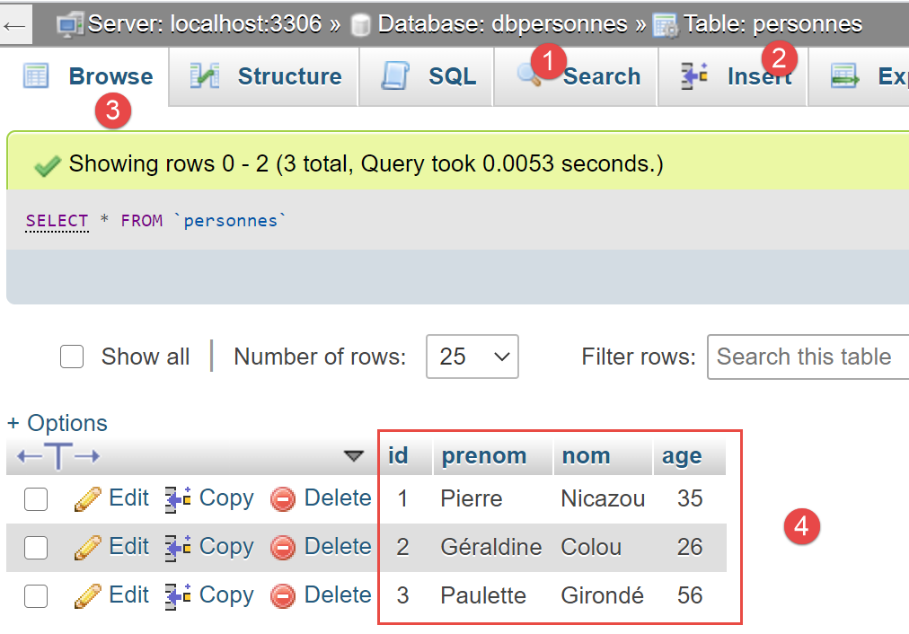
Sehen wir uns nun mit phpMyAdmin den Inhalt der Tabelle [people] an:
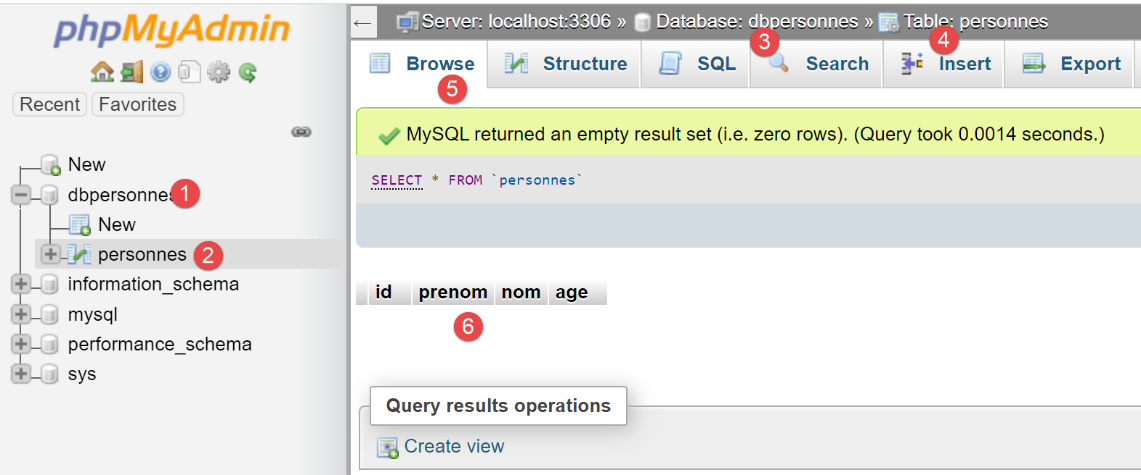
Wir sehen in [6], dass die Tabelle leer ist. Nicht einmal die erste Person, die das Skript zur Sitzung hinzugefügt hat, ist dort zu finden. Das liegt daran, dass die Sitzung Teil einer Transaktion war und diese Transaktion in der [except]-Klausel des [main]-Skripts zurückgesetzt wurde.
Nehmen wir nun die folgende Änderung in [main] vor:
Nachdem wir in Zeile 2 eine Person hinzugefügt haben, entfernen wir das Kommentarzeichen in Zeile 3. Der Befehl [session.commit] schließt die zugrunde liegende Transaktion ab, und eine neue Transaktion beginnt. Nach der Ausführung sieht der Inhalt der Tabelle [people] wie folgt aus:
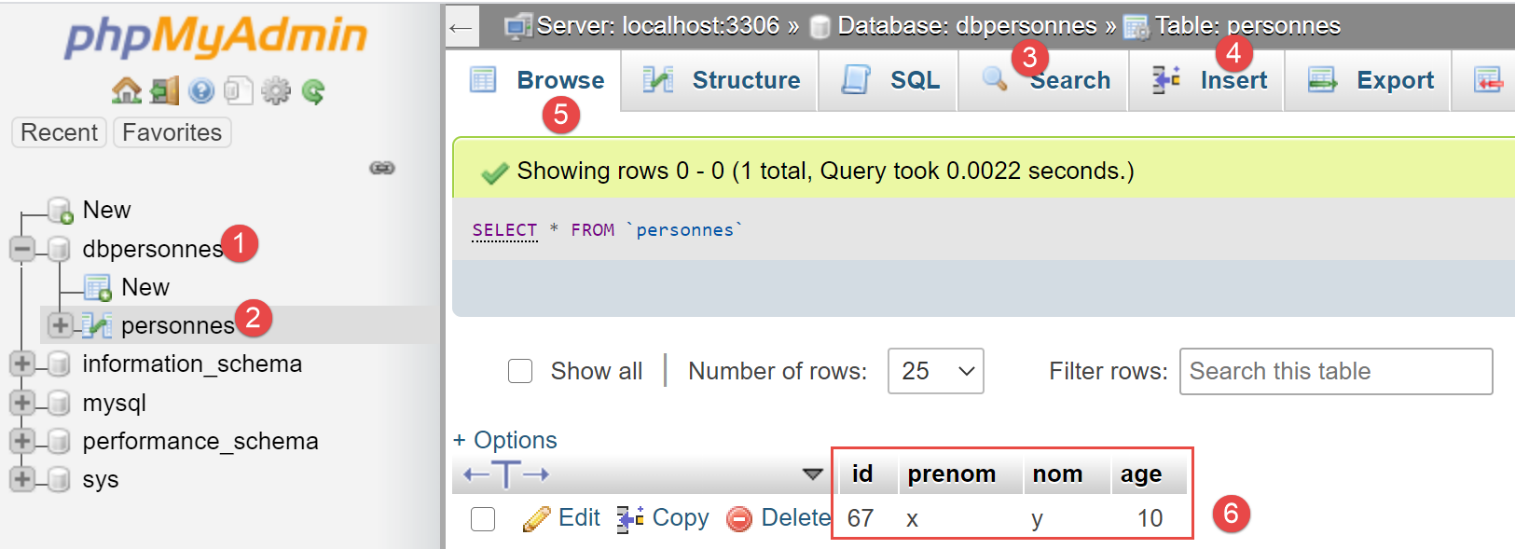
In [6] ist zu sehen, dass der erste Eintrag beibehalten wurde. Das liegt daran, dass er innerhalb von Transaktion 1 durchgeführt wurde, während der nachfolgende Fehler innerhalb von Transaktion 2 auftrat.
19.3. Skripte 02: [sqlalchemy]-Zuordnungen

Skripte 02 sind eine Variante von Skripten 01. Wir versuchen, so viel wie möglich in [config.py] zu konfigurieren. Dort konfigurieren wir nun die [sqlalchemy]-Umgebung der Anwendung:
Kommentare
- Zeilen 2–12: Konfiguration des Python-Pfads;
- Zeilen 14–45: Konfiguration der [sqlalchemy]-Umgebung;
- Zeilen 47–52: Die [sqlalchemy]-Umgebung wird dem Konfigurationswörterbuch hinzugefügt;
- Zeilen 54–56: Konfiguration der [Person]-Klasse;
Mit dieser Konfiguration sieht das [main]-Skript wie folgt aus:
Die Ergebnisse der Ausführung lauten wie folgt:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/databases/sqlalchemy/02/main.py
Liste des personnes-----------
{"âge": 10, "nom": "y", "prénom": "x", "id": 1}
{"âge": 7, "nom": "y1", "prénom": "x1", "id": 2}
L'erreur suivante s'est produite : (raised as a result of Query-invoked autoflush; consider using a session.no_autoflush block if this flush is occurring prematurely)
(mysql.connector.errors.IntegrityError) 1062 (23000): Duplicate entry 'y2-x2' for key 'uix_1'
[SQL: INSERT INTO personnes (prenom, nom, age) VALUES (%(prenom)s, %(nom)s, %(age)s)]
[parameters: {'prenom': 'x2', 'nom': 'y2', 'age': 10}]
(Background on this error at: http://sqlalche.me/e/13/gkpj)
rollback...
Travail terminé...
Process finished with exit code 0
In phpMyAdmin sieht die Tabelle [people] nun wie folgt aus:
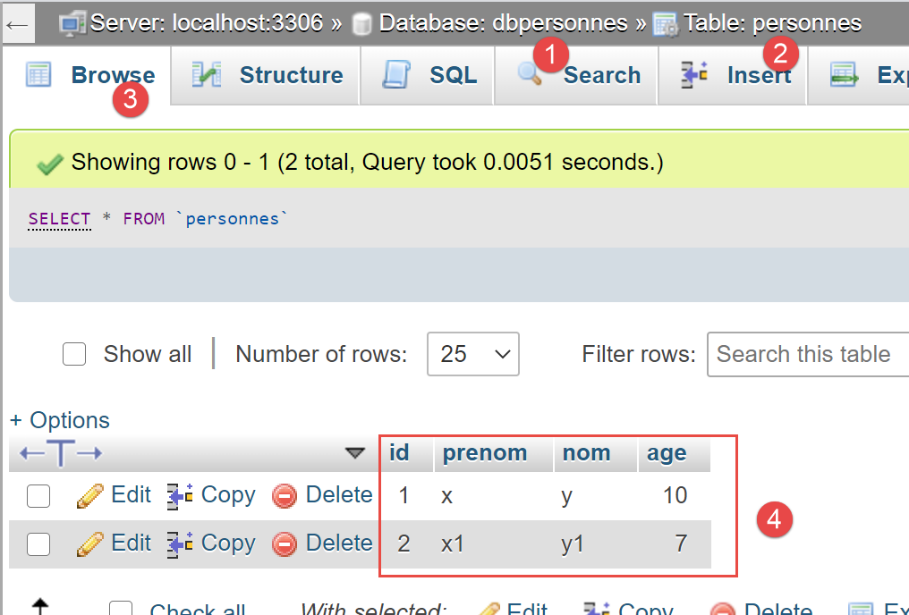
Sehen wir uns nun die von [SQLAlchemy] generierte Tabelle [people] an:
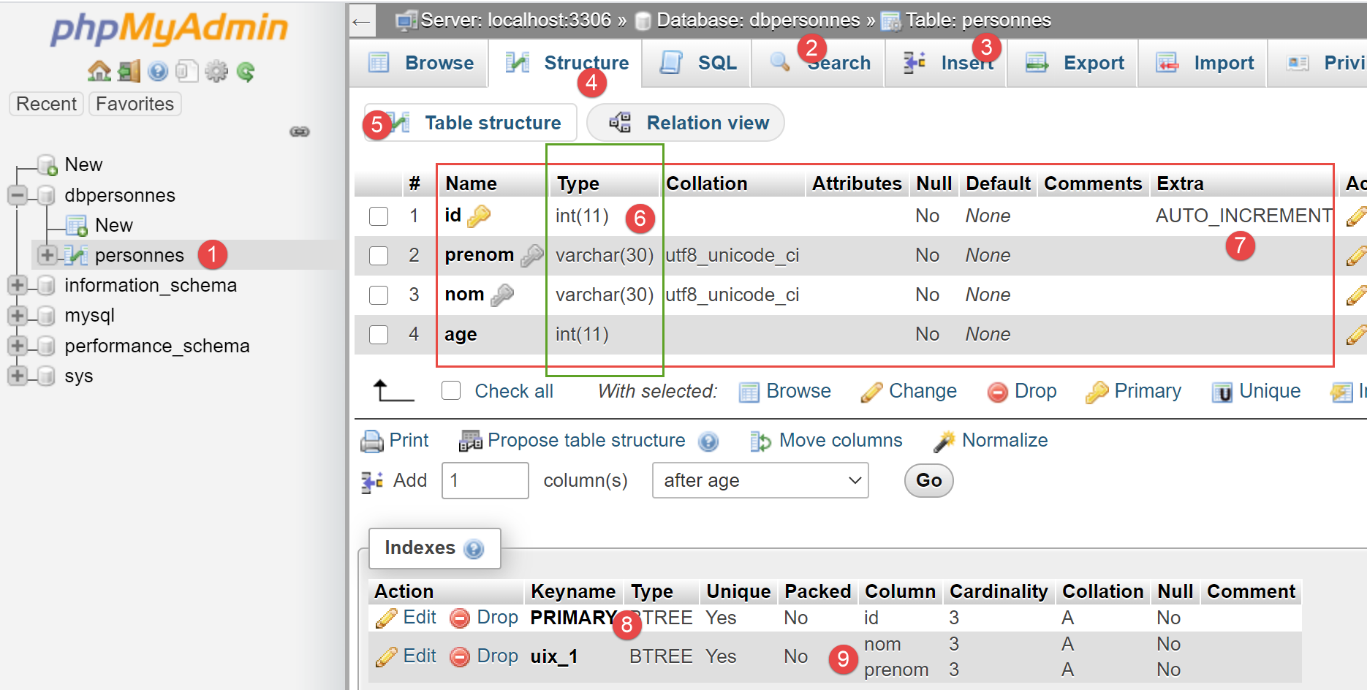
- In [6] die für die verschiedenen Spalten verwendeten Typen;
- In [7] sehen wir, dass die Spalte [id] das Attribut [AUTO_INCREMENT] aufweist. Das bedeutet: Wenn beim Einfügen einer Zeile in die Tabelle für die Spalte [id] kein Wert vorhanden ist, generiert MySQL diesen in aufsteigender Reihenfolge: 1, 2, 3, … Dank dieser Eigenschaft müssen wir uns beim Einfügen in die Tabelle keine Gedanken über den Wert des Primärschlüssels machen: Wir überlassen die Generierung MySQL;
- In [8] sehen wir, dass die Spalte [id] der Primärschlüssel ist;
- In [9] sehen wir die Eindeutigkeitsbeschränkung für die Felder [last_name, first_name];
19.4. Skripte 03: Bearbeiten von Session-Entitäten [SQLAlchemy]
Die Konfigurationsdatei [config] ist dieselbe wie im vorherigen Beispiel. Im Skript [main] führen wir Standardoperationen [INSERT, UPDATE, DELETE, SELECT] an der Tabelle [people] mithilfe von [SQLAlchemy]-Methoden durch:
Kommentare
- Zeilen 20–25: Die Funktion [display_people] zeigt die Elemente einer Liste von Personen an;
- Zeilen 12–18: Die Funktion [display_people] zeigt den Inhalt der Tabelle [people] an;
- Zeilen 34–36: Wir löschen die Tabelle [people]. Anders als in früheren Versionen verwenden wir keine SQL-Abfrage, sondern eine [SQLAlchemy]-Methode:
- config["people_table"] ist das [Table]-Objekt, das die Tabelle [people] beschreibt;
- config["engine"] ist die Verbindungszeichenfolge zur Datenbank [dbpersonnes];
- Der Parameter [checkfirst=True] stellt sicher, dass der Vorgang nur ausgeführt wird, wenn die Tabelle [people] existiert;
- Zeilen 38–39: Die Tabelle [people] wird neu erstellt;
- Zeilen 41–44: Drei Personen werden zur Sitzung hinzugefügt. Beachten Sie, dass sie nicht unbedingt sofort in die [people]-Tabelle eingefügt werden. Dies hängt von der leistungsorientierten Strategie von [SQLAlchemy] ab;
- Zeilen 46–47: Der Inhalt der Tabelle [people] wird angezeigt. Falls die drei Personen noch nicht eingefügt wurden, werden sie aufgrund dieser Abfrage nun eingefügt;
- Zeilen 49–50: Ein Beispiel für die Verwendung der Methode [order_by], mit der Abfrageergebnisse in einer bestimmten Reihenfolge angezeigt werden können. Die Syntax [order_by(Kriterium1, Kriterium2)] zeigt die Ergebnisse zunächst nach dem Kriterium [Kriterium1] an, und wenn Zeilen denselben Wert für [Kriterium1] haben, werden sie anschließend nach dem Kriterium [Kriterium2] sortiert. Auf diese Weise können mehrere Kriterien angegeben werden;
- Zeilen 55–59: Einführung in das Konzept der Filterung mit der Methode [filter]. Die Notation [filter(Kriterium1, Kriterium2)] führt eine logische UND-Verknüpfung zwischen den verwendeten Kriterien durch;
- Zeilen 64–67: Ein neuer Benutzer wird angemeldet;
- Zeilen 70–71: ein weiteres Beispiel für eine gefilterte Abfrage. Die Funktion [func.lower(param)] wandelt [param] in Kleinbuchstaben um. Es stehen weitere Funktionen zur Verfügung, die als [func.xx] bezeichnet werden. Im Ausdruck in Zeile 71:
- gibt [session.query.filter] eine Liste von [Person]-Objekten zurück;
- [session.query.filter.first] gibt das erste Element dieser Liste zurück;
- Zeile 77: Ein Element wird aus der Sitzung entfernt;
- Zeile 86: Die Sitzung wird validiert;
Die Ergebnisse der Ausführung lauten wie folgt:
- Zeilen 4–6: der Inhalt der Sitzung;
- Zeilen 8–10: der Sitzungsinhalt in absteigender Reihenfolge der Namen;
- Zeilen 12–13: der Sitzungsinhalt für Personen, deren Alter im Bereich [20, 40] liegt;
- Zeile 15: die Person namens „bruneau“;
In phpMyAdmin sieht der Inhalt der Tabelle [people] am Ende der Ausführung wie folgt aus:
19.5. Skripte 04: Verwendung einer [PostgreSQL]-Datenbank
Der Ordner [04] ist eine Kopie des Ordners [03]. Wir ändern nur eine Sache: die Verbindungszeichenfolge in der Datei [config]:
# lien vers une base de données PostgreSQL
engine = create_engine("postgresql+psycopg2://admpersonnes:nobody@localhost/dbpersonnes")
Diese Verbindungszeichenfolge verweist nun auf die Datenbank [dbpersonnes] in einem [PostgreSQL]-DBMS. Beachten Sie die Verwendung des [psycopg2]-Konnektors. Dieser muss installiert sein.
Die Ausführung des Skripts [main] liefert folgende Ergebnisse:
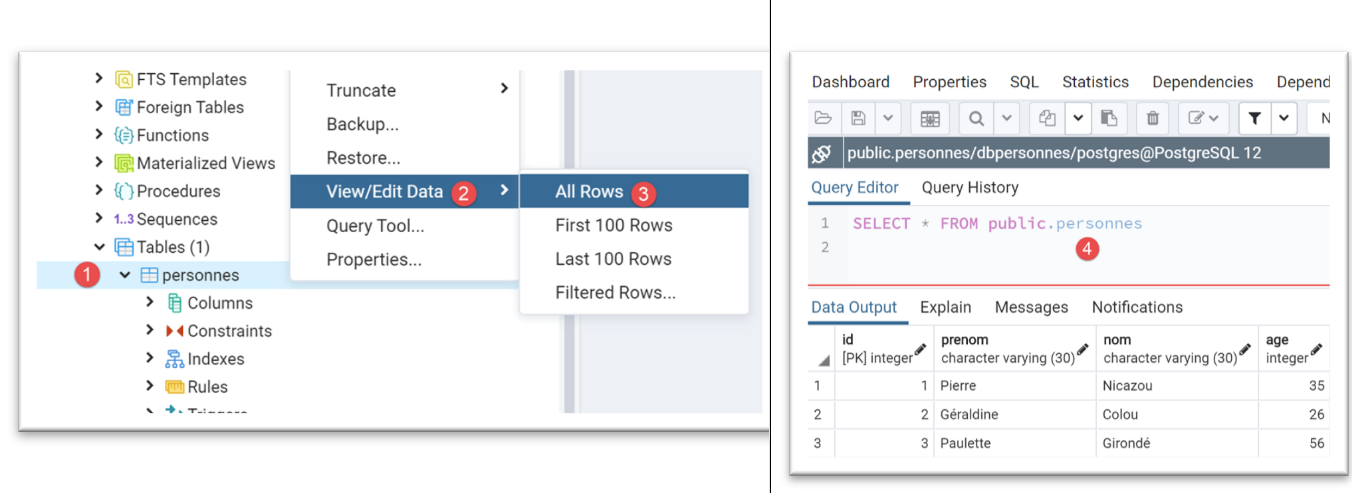
Bei Verwendung des Tools [pgAdmin] (siehe Abschnitt |pgAdmin|) befindet sich die Tabelle [people] im folgenden Zustand:
Die Tabelle [people] wurde mit dem folgenden SQL-Code generiert:
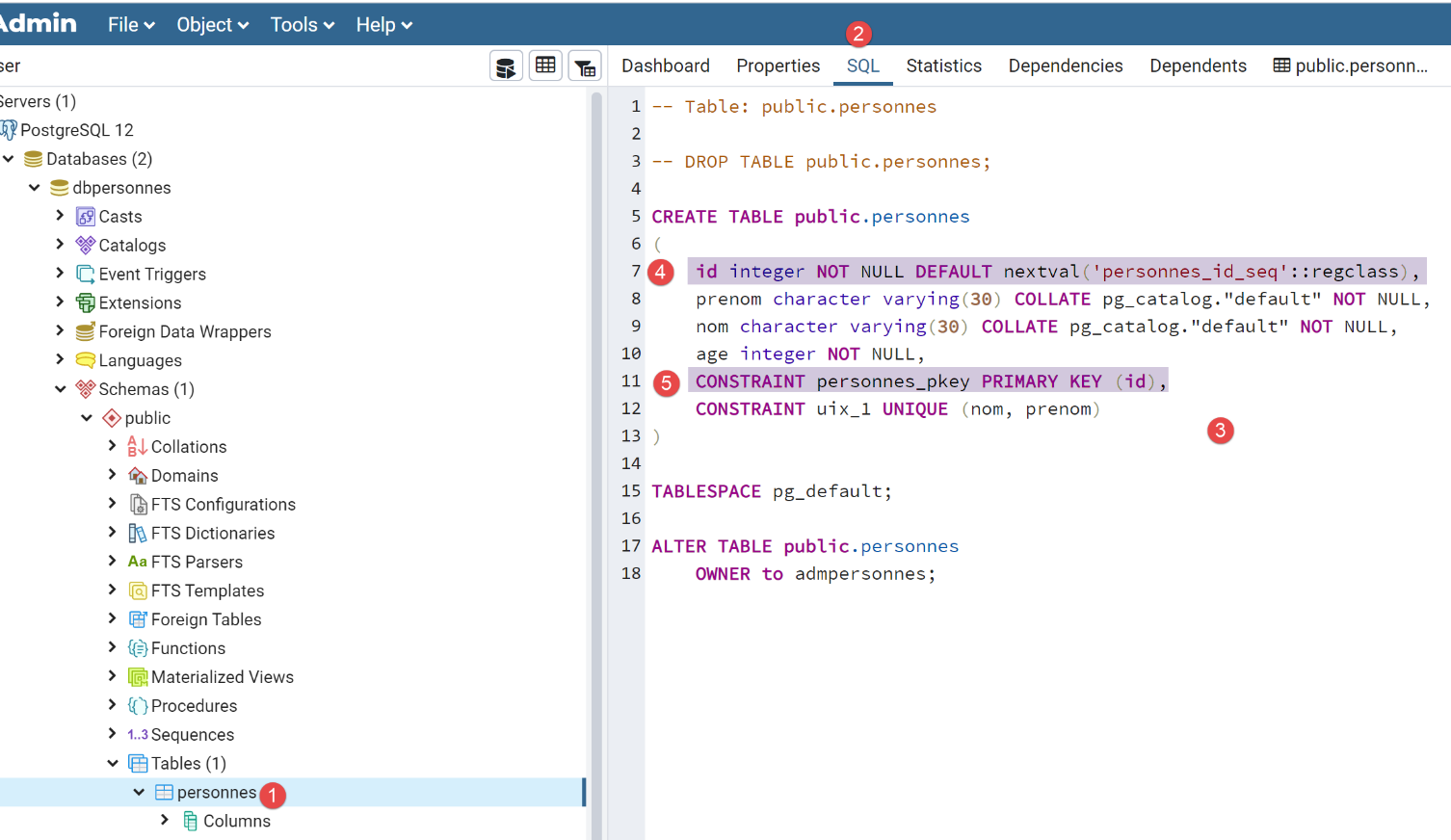
- In [4-5] sehen wir, dass die Spalte [id] der Primärschlüssel ist. Wir sehen auch, dass sie einen Standardwert [DEFAULT-Schlüsselwort] hat, was bedeutet, dass das DBMS einen Primärschlüssel generiert, wenn eine Zeile ohne Primärschlüssel eingefügt wird. Dies ist gängige Praxis: Wir lassen das DBMS die Primärschlüssel generieren;
Diese Version 05 der [sqlalchemy]-Skripte zeigt deutlich, wie einfach es ist, von einem DBMS zu einem anderen zu wechseln: Es musste lediglich die Verbindungszeichenfolge in einem Konfigurationsskript geändert werden. Sonst hat sich nichts geändert. Wenn wir die Spaltentypen [id, last_name, first_name, age] oben mit denen in der MySQL-Tabelle aus Beispiel |02| vergleichen, sehen wir, dass sie unterschiedlich sind. [sqlalchemy] passt sie an das verwendete DBMS an. Diese Fähigkeit, sich an ein neues DBMS anzupassen, ist Grund genug, [sqlalchemy] oder ein anderes ORM einzusetzen.
19.6. Skripte 05: Vollständiges Beispiel
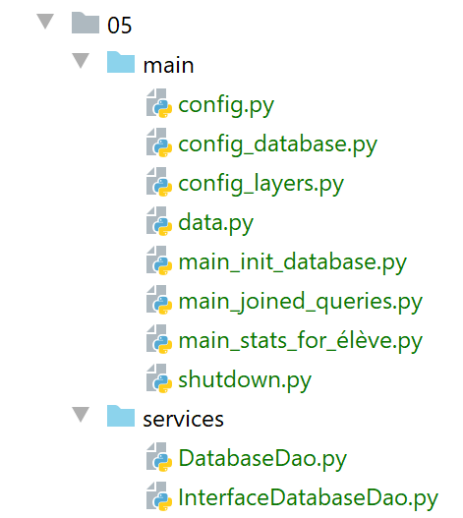
Das Beispiel, das wir uns hier ansehen, ist eine Überarbeitung des in Abschnitt |troiscouches-v01| behandelten Beispiels. Dieses Beispiel enthielt eine dreischichtige Architektur [UI, Geschäftslogik, DAO], die Entitäten [Class, Student, Subject, Grade] manipulierte. Die Entitäten waren in einer [DAO]-Schicht fest codiert. Wir legen sie nun in einer Datenbank ab. Wir werden zwei DBMS verwenden: MySQL und PostgreSQL.
19.6.1. Die Anwendungsarchitektur
Die Anwendungsarchitektur sieht wie folgt aus:
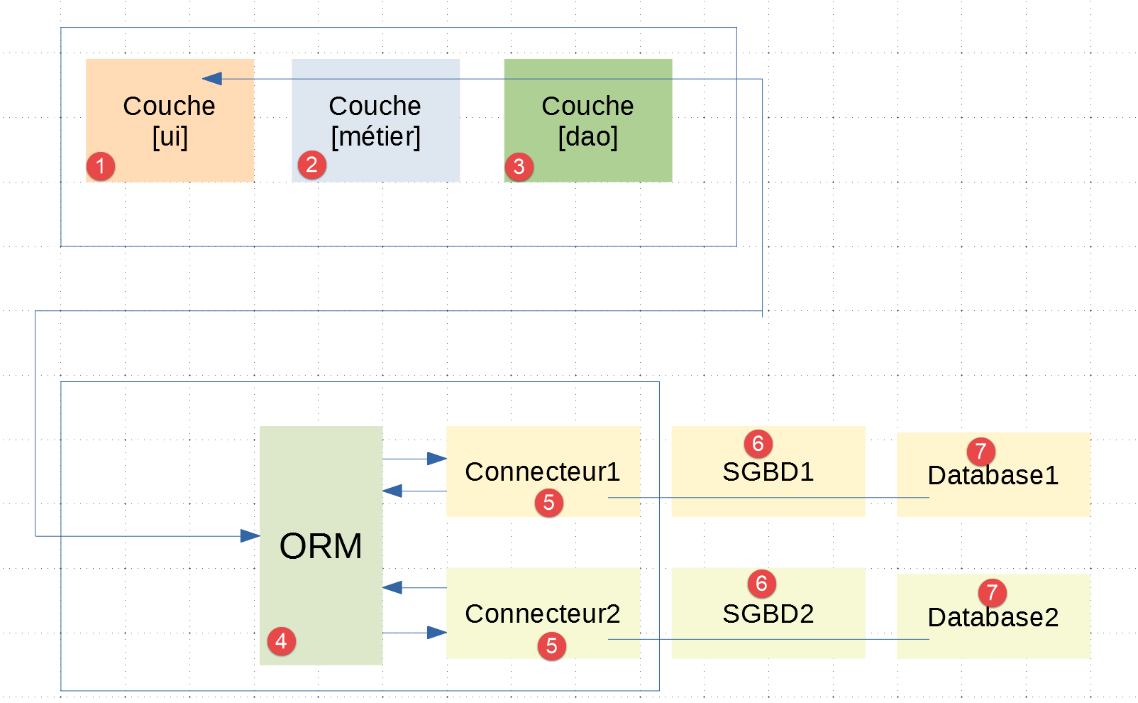
- In [1-3] finden wir die Schichten [UI, Business, DAO], die bereits im Beispiel |troiscouches-v01| vorhanden waren. Die [DAO]-Schicht kommuniziert nun mit der [ORM]-Schicht;
- die Schichten [1-5] werden mit Python-Code implementiert;
19.6.2. Die Datenbanken
Wir erstellen eine MySQL-Datenbank namens [dbecole], die dem Benutzer [admecole] gehört und das Passwort [mdpecole] hat. Dazu folgen wir der im Abschnitt |Erstellen einer Datenbank| beschriebenen Vorgehensweise:
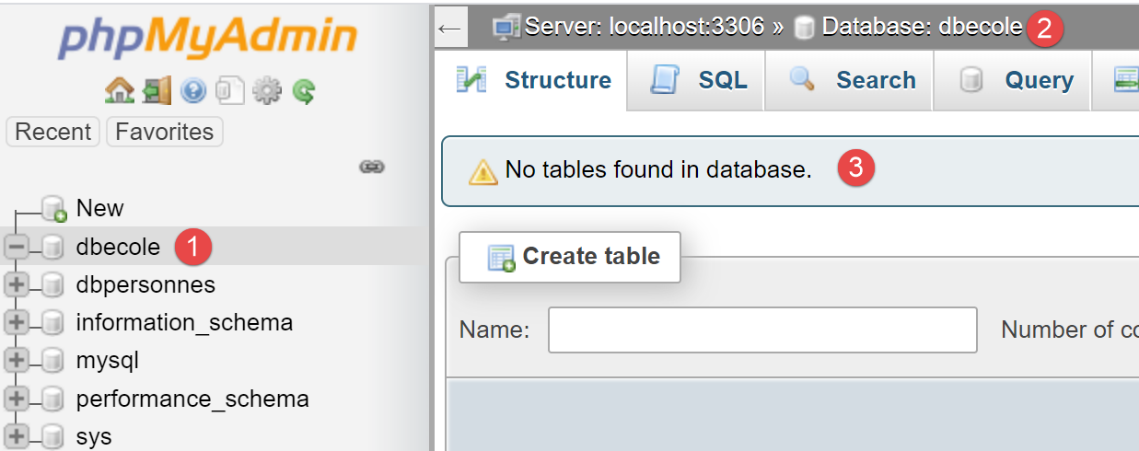
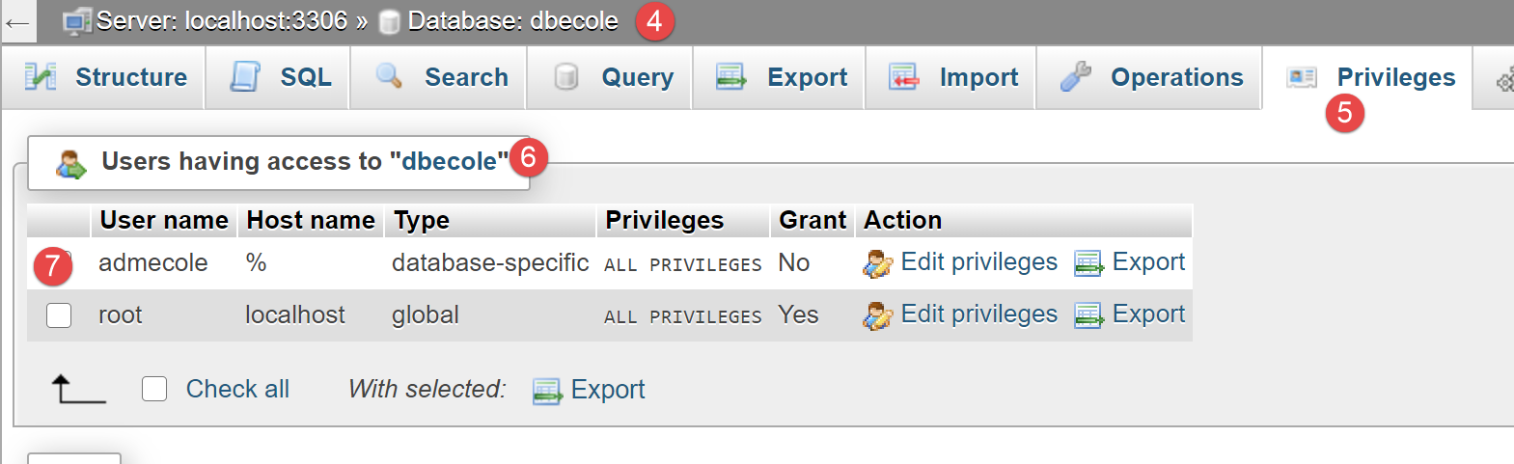
- In [1] enthält die Datenbank [dbecole] keine Tabellen [3];
- in [7] hat der Benutzer [admecole] volle Berechtigungen für diese Datenbank;
Wir verfahren ebenso mit dem PostgreSQL-DBMS. Wir erstellen eine Datenbank namens [dbecole], die dem Benutzer [admecole] gehört und das Passwort [mdpecole] hat. Dazu befolgen wir die im Abschnitt |Erstellen einer Datenbank| beschriebene Vorgehensweise:
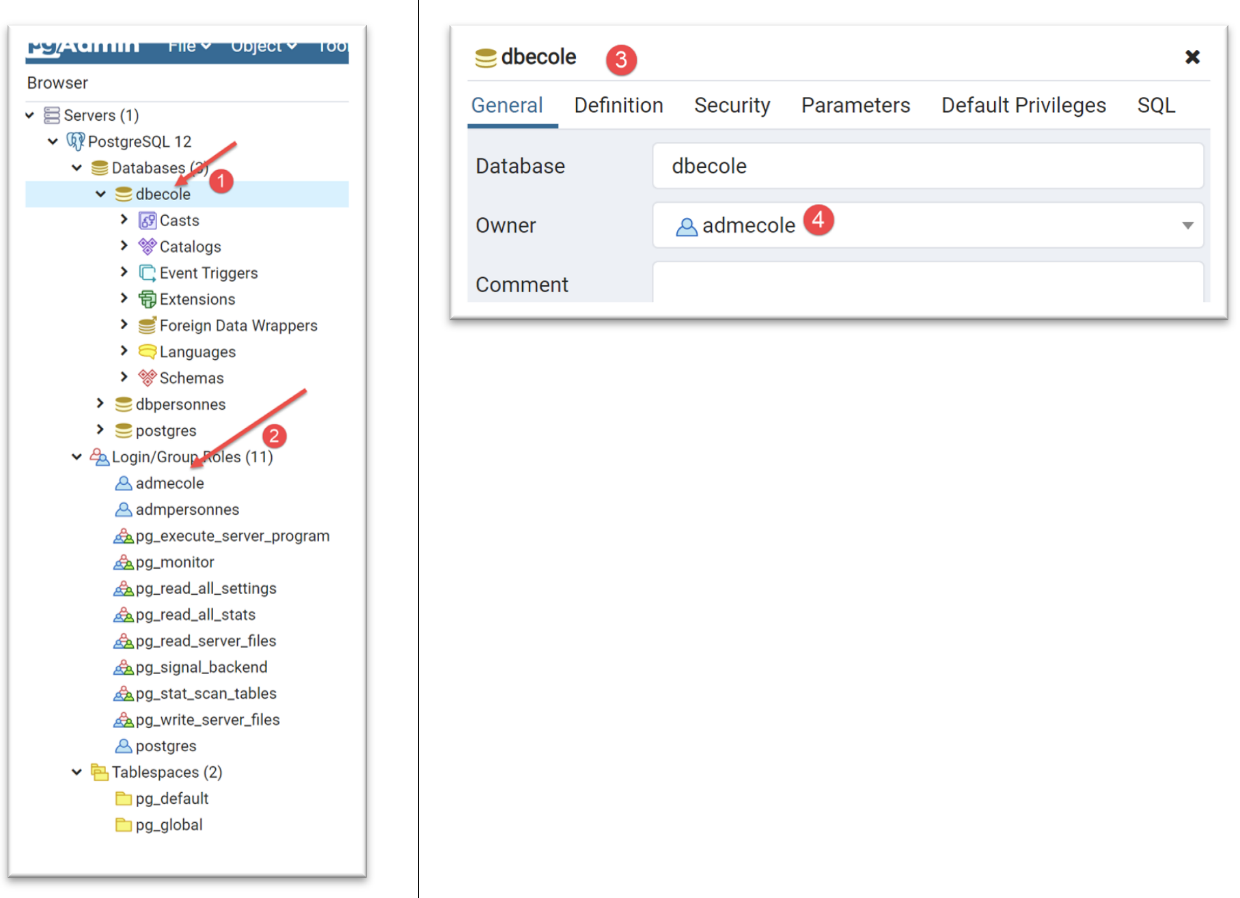
- in [1] die Datenbank [dbecole];
- in [2], der Benutzer [admecole];
- In [3-4] gehört die Datenbank [dbecole] dem Benutzer [admecole];
19.6.3. Von der Anwendung verarbeitete Entitäten
In der Anwendung |troiscouches v01| wurden folgende Entitäten verarbeitet (siehe |entities|). Dies sind die Entitäten, die in den bisherigen Datenbanken gespeichert werden. Wir werden diese Entitäten in der neuen Anwendung nicht duplizieren. Wir werden sie von dort abrufen, wo sie bereits definiert sind.
Die Klasse [Class]:
Die Klasse [Student]:
Die Klasse [Subject]:
Die Klasse [Grade]:
19.6.4. Konfiguration
Die Konfiguration wurde auf mehrere Dateien aufgeteilt:
- Allgemeine Konfiguration in [config.py]: Hier werden der Python-Pfad der Anwendung festgelegt und die Architekturschichten instanziiert;
- [SQLAlchemy]-Konfiguration in [config_database]: Sie verwaltet die Zuordnungen zwischen Klassen und Tabellen;
- Die Anwendungsschichten werden in [config_layers] konfiguriert;
Die [config]-Datei sieht wie folgt aus:
- Zeilen 4–27: Erstellen des Python-Pfads der Anwendung;
- Zeilen 29–32: [SQLAlchemy]-Konfiguration;
- Zeilen 34–37: Konfiguration der Anwendungsschichten;
Die Datei [config_database] sieht wie folgt aus:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 | |
Kommentare
- Zeilen 1–4: Die Funktion [configure] erhält ein Wörterbuch als Parameter. Es wird nur der Schlüssel [db] verwendet. Er wird auf [mysql] gesetzt, wenn es sich um eine MySQL-Datenbank handelt, und auf [pgres], wenn es sich um eine PostgreSQL-Datenbank handelt;
- Zeilen 6–9: Import von Elementen aus [sqlalchemy]. Das Skript [config_database] führt die Zuordnungen zwischen den Tabellen in der Datenbank [dbecole] und den Entitäten [Classes, Student, Subject, Grade] durch. In der Tabelle sind die Entitätsdaten in einer Zeile gekapselt. Im Python-Code sind sie in einem Objekt gekapselt. Daher der Name ORM (Object Relational Mapper): Der ORM stellt eine Zuordnung (eine Verbindung) zwischen den Zeilen einer relationalen Datenbank und Objekten her. In dieser Anwendung haben wir vier Entitäten [Class, Student, Subject, Grade], die mit vier Tabellen [classes, students, subjects, grades] verknüpft werden. Beachten Sie, dass Tabellennamen Zeichen mit Akzenten enthalten können;
- Zeilen 11–17: die Verbindungszeichenfolge zur verwendeten Datenbank. Diese hängt von config['db'] ab.
- Zeilen 24–28: Die Anwendungsentitäten, die zugeordnet werden [SQLAlchemy]. Wenn diese Zeilen ausgeführt werden, ist der Python-Pfad bereits durch das Skript [config] festgelegt worden;
- Zeilen 30–40: die Zuordnung zwischen der [Class]-Entität und der [classes]-Tabelle;
- Zeilen 30–35: Die [classes]-Tabelle wird mithilfe der [Table]-Klasse aus [sqlalchemy] definiert. Wir legen fest, dass diese Tabelle zwei Spalten hat:
- die Spalte [id], die den Primärschlüssel darstellt und die Klassennummer angibt, Zeile 33;
- die Spalte [name], die den Klassennamen enthält, Zeile 34;
- Zeilen 31–32: Beachten Sie, dass die Syntax x=y=z in Python gültig ist: Der Wert von z wird y zugewiesen, anschließend der Wert von y an x;
- Zeilen 37–40: Die Zuordnungen zwischen den Spalten der Tabelle [classes] und den Eigenschaften der Entität [Class] sind aufgeführt;
- Zeilen 42–57: die Zuordnung zwischen der Entität [Student] und der Tabelle [students];
- Zeilen 51–57: Die Tabelle [students] wird mithilfe der Klasse [Table] aus [SQLAlchemy] definiert. Wir legen fest, dass diese Tabelle vier Spalten hat:
- die Spalte [id], die den Primärschlüssel darstellt und die ID des Schülers enthält, Zeile 45;
- die Spalte [name], die den Nachnamen des Schülers enthält, Zeile 46;
- die Spalte [first_name], die den Vornamen des Schülers enthält, Zeile 47. Beachten Sie, dass ein Spaltenname Zeichen mit Akzenten enthalten kann;
- Zeile 49, die Spalte [class_id], die die ID der Klasse enthält, zu der der Schüler gehört. Dies wird als Fremdschlüssel bezeichnet. [students.class_id] ist ein Fremdschlüssel (ForeignKey) auf die Spalte [classes.id]. Das bedeutet, dass der Wert von [students.class_id] in der Spalte [classes.id] vorhanden sein muss;
- Zeilen 51–57: Wir listen die Zuordnungen zwischen den Spalten der Tabelle [students] und den Eigenschaften der Entität [Student] auf:
- Die Zeilen 53–55 sind leicht zu verstehen;
- Zeile 56 ist schwieriger: Sie definiert den Wert der Eigenschaft [Student.class] als Ergebnis der Fremdschlüsselbeziehung, die die Tabellen [students] und [classes] miteinander verknüpft. Die Parameter der Funktion [relationship] lauten wie folgt:
- [Class]: Dies ist der Name der Entität, mit der die Entität [Student] eine Fremdschlüsselbeziehung unterhält. Dies muss sich in der Tabelle [students] durch das Vorhandensein eines Fremdschlüssels widerspiegeln, der auf die Tabelle [classes] verweist. Wir wissen, dass dieser existiert;
- [backref="students"]: Der Name einer Eigenschaft, die der Entität [Class] hinzugefügt wird. [Class.students] ist die Liste aller Schüler in der Klasse. Diese Eigenschaft darf noch nicht vorhanden sein . Falls sie bereits existiert, wählen Sie hier einfach einen anderen Namen für [backref]. Der Entwickler muss diese Eigenschaft nicht verwalten. [SQLAlchemy] kümmert sich darum. Der Entwickler muss lediglich wissen, dass sie existiert, von [SQLAlchemy] hinzugefügt wurde und dass er sie in seinem Code verwenden kann;
- [lazy='select']: Dies bedeutet, dass das ORM nicht versuchen sollte, der Eigenschaft [Student.class] sofort einen Wert zuzuweisen. Es sollte ihren Wert nur abrufen, wenn der Code dies explizit anfordert. Somit:
- Wenn der Code eine Liste aller Schüler anfordert, werden diese zurückgegeben, aber ihre [class]-Eigenschaft wird nicht berechnet;
- etwas später konzentriert sich der Code auf einen bestimmten Studenten [e] und verweist auf dessen Klasse [e.class]. Dieser Verweis zwingt [SQLAlchemy] dann dazu, eine Datenbankabfrage durchzuführen, um die Klasse des Studenten abzurufen – alles für den Entwickler transparent;
- Die Einstellung [lazy='select'] soll ebenfalls unnötige Datenbankabfragen vermeiden;
- Zeile 56: Wenn das ORM eine Zeile aus der Tabelle [students] abruft, ruft es die Felder [id, last_name, first_name, class_id] ab. Daraus muss es ein Student-Objekt (id, last_name, first_name, class) erstellen. Für die Eigenschaften [id, last_name, first_name] stellt dies keine Schwierigkeit dar. Bei der Eigenschaft [class] ist es komplizierter. Ihr Wert ist eine Objektreferenz vom Typ [Class]. Das ORM verfügt jedoch nur über eine einzige Information: [students.class_id]. Da [students.class_id] ein Fremdschlüssel auf der Spalte [classes.id] ist, weisen wir das ORM hier an, diese Beziehung zu nutzen, um die Zeile mit id=[students.class_id] aus der Tabelle [classes] abzurufen (sie muss vorhanden sein) und aus dieser Zeile das von der Eigenschaft [Student.class] erwartete [Class]-Objekt zu erstellen;
- Zeilen 59–71: die Zuordnung zwischen der Entität [Subject] und der Tabelle [subjects];
- Zeilen 59–65: Definition der [SQLAlchemy]-Tabelle mit dem Namen [subjects];
- Zeilen 66–71: Wir listen die Zuordnungen zwischen den Spalten der Tabelle [subjects] und den Eigenschaften der Entität [Subject] auf. Hier gibt es keine Schwierigkeiten;
- Zeilen 73–90: die Zuordnung zwischen der Entität [Note] und der Tabelle [notes];
- Zeilen 73–82: Definition der [SQLAlchemy]-Tabelle mit dem Namen [notes]. Sie hat zwei Fremdschlüssel:
- Zeile 79: Die Spalte [notes.student_id] bezieht ihre Werte aus der Spalte [students.id]. Dieser Fremdschlüssel spiegelt die Tatsache wider, dass eine Notiz zu einem bestimmten Schüler gehört;
- Zeile 81: Die Spalte [notes.subject_id] bezieht ihre Werte aus der Spalte [subjects.id]. Dieser Fremdschlüssel steht dafür, dass eine Note eine Note in einem bestimmten Fach ist;
- Zeilen 84–90: die Zuordnung zwischen der Entität [Note] und der Tabelle [notes]:
- Zeile 88: Die Eigenschaft [Note.student] muss den Wert einer Instanz vom Typ [Student] haben. Das ORM verfügt in der Zeile der Tabelle [notes] nur über die Spalte [notes.student_id], die auf die Spalte [students.id] verweist. Hier legen wir fest, dass diese Fremdschlüsselbeziehung verwendet werden soll, um die [Student]-Instanz abzurufen, für die wir die Note haben. Darüber hinaus erstellt [relationship(Student, backref="grades", …)] die neue Eigenschaft [Student.grades], die die Liste der Noten des Schülers enthält. Diese Eigenschaft darf in der Klasse [Student] noch nicht vorhanden sein;
- Zeile 89: Die Eigenschaft [Grade.subject] muss den Wert einer Instanz vom Typ [Subject] haben. Das ORM verfügt nur über die Spalte [notes.subject_id] in der Zeile der Tabelle [grades], die auf die Spalte [subjects.id] verweist. Hier legen wir fest, diese Fremdschlüsselbeziehung zu verwenden, um die [Subject]-Instanz abzurufen, für die wir die Note haben. Zusätzlich erstellt [relationship(Subject, backref="grades", …)] die neue Eigenschaft [Subject.grades], die die Liste der Noten für das Fach enthält. Diese Eigenschaft darf in der Klasse [Subject] noch nicht vorhanden sein;
- Zeilen 92–96: Für jede von [BaseEntity] abgeleitete Entität definieren wir die Liste der Eigenschaften, die aus dem Eigenschaftswörterbuch der Entität (BaseEntity.asdict) ausgeschlossen werden sollen. Wir haben gesehen, dass [sqlalchemy] allen zugeordneten Entitäten die Eigenschaft [_sa_instance_state] hinzufügt. Diese soll nicht im Eigenschaftswörterbuch enthalten sein. Außerdem haben wir gesehen, dass die vorherigen Zuordnungen den Entitäten neue Eigenschaften hinzugefügt haben:
- [Student.grades]: alle Noten des Studenten;
- [Class.students]: alle Schüler in der Klasse;
- [Subject.grades]: alle Noten für das Fach;
Im Allgemeinen möchten wir nicht, dass diese Eigenschaften zum Zustand der Entität hinzugefügt werden. Tatsächlich verursacht die Berechnung ihres Werts einen SQL-Aufwand, und dieser Wert ist oft unnötig. Wenn wir also den Studenten namens „X“ abrufen:
- (Fortsetzung)
- gibt das ORM eine Entität [Student(id, last_name, first_name, class, grades)] zurück. Aufgrund von [lazy='select'] wurden die Eigenschaften [class, grades], die mit Fremdschlüsseln in der Datenbank verknüpft sind, nicht berechnet;
- wenn ich nun die JSON-Zeichenkette für diesen Studenten anzeige, wissen wir, dass es sich um die JSON-Zeichenkette aus dem [asdict]-Wörterbuch der Entität handelt. Wenn die Eigenschaften [class] und [grades] enthalten sind, wird [SQLAlchemy] gezwungen sein, SQL-Abfragen auszuführen, um ihre Werte zu berechnen. Dies ist aufwendig. Wenn wir diese Abfragen vermeiden können, ist das vorzuziehen;
- Hier haben wir alle Eigenschaften ausgeschlossen, die mit einem Fremdschlüssel verknüpft sind;
- Zeilen 98–100: Instanziierung und Konfiguration einer [Session-Factory] (Factory = Produktions-Factory). Das [Session]-Objekt wird verwendet, um [SQLAlchemy]-Sitzungen zu erstellen, die durch Transaktionen abgesichert sind;
- Zeilen 102–103: Erstellung einer [SQLAlchemy]-Sitzung;
- Zeile 106: Bestimmte Elemente der [SQLAlchemy]-Konfiguration werden in das globale Konfigurationswörterbuch der Anwendung aufgenommen;
- Zeile 109: Dieses Wörterbuch wird zurückgegeben;
Die Datei [config_layers] konfiguriert die Anwendungsschichten:
- Zeile 1: Die Funktion [configure] erhält das Wörterbuch, das die globale Konfiguration der Anwendung enthält;
- Zeilen 2–12: Die Anwendungsschichten werden instanziiert;
- Zeilen 15–17: Die Layer-Referenzen werden der globalen Konfiguration hinzugefügt;
- Zeile 20: Die neue Konfiguration wird zurückgegeben;
19.6.5. Die [dao]-Schicht – 1
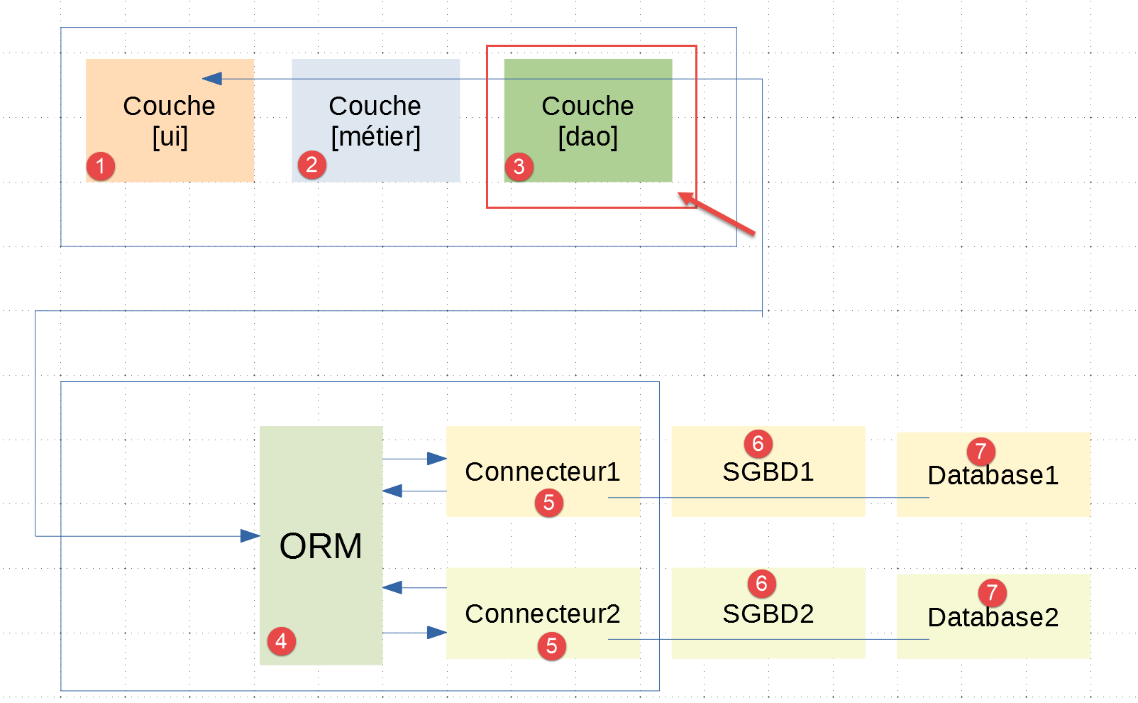
Es ist wichtig zu verstehen, dass die [dao]-Schicht [3] mit dem [sqlalchemy]-ORM [4] kommuniziert, das wie im vorigen Absatz beschrieben konfiguriert wurde. Von den drei Schichten [ui, business, dao] der Anwendung |troiscouches v01| muss nur die [dao]-Schicht neu geschrieben werden. Die Schichten [ui, business] bleiben erhalten.
Die Implementierung der [dao]-Schicht wurde im Ordner [services] abgelegt:

[InterfaceDatabaseDao] ist die Schnittstelle für die [DAO]-Schicht:
- Zeile 6: Die Schnittstelle [InterfaceDatabaseDao] leitet sich sowohl von der Klasse [ABC] ab, um eine abstrakte Klasse zu sein, als auch von der Schnittstelle [InterfaceDao] des Projekts |troiscouches v01|;
- Zeilen 8–11: Wir fügen die Methode [init_database] zu den von [InterfaceDao] geerbten Methoden hinzu. Ihre Aufgabe besteht darin, die Datenbank mit den Daten aus dem Wörterbuch [data] zu initialisieren, das ihr in Zeile 10 als Parameter übergeben wird;
Zur Erinnerung: Die Schnittstelle [InterfaceDao] sah wie folgt aus:
Die Implementierung der [DAO]-Schicht sieht wie folgt aus:
- Zeile 11: Die Klasse [DatabaseDao] implementiert die Schnittstelle [InterfaceDatabaseDao];
- Zeilen 13–16: der Klassenkonstruktor. Er nimmt das Konfigurationswörterbuch der Anwendung als Parameter entgegen;
- Zeile 15: Die [sqlalchemy]-Konfiguration wird gespeichert;
- Zeile 16: Die [sqlalchemy]-Sitzung, über die die Datenbank bearbeitet wird, wird gespeichert;
- Zeile 18: Die Methode [init_database] initialisiert die Datenbank mit dem Wörterbuch [data];
Das [data]-Wörterbuch wird durch das folgende Skript [data.py] implementiert:
- Zeile 34: Das Wörterbuch, das an die Methode [init_database] übergeben wird. Dieses Wörterbuch besteht aus den folgenden Schlüsseln (Zeile 32):
- [students]: die Liste der Studenten;
- [classes]: die Liste der Klassen;
- [subjects]: die Liste der Fächer;
- [grades]: die Liste der Noten für alle Schüler in allen Fächern;
Kehren wir zur Methode [init_database] zurück:
- Zeilen 3–6: Abrufen von Informationen aus der Datenbankkonfiguration;
- Zeilen 9–14: Wir haben gesehen, dass die [sqlalchemy]-Konfiguration vier Entitäten vier Tabellen zugeordnet hat [students, subjects, classes, grades]. Wir beginnen damit, diese Tabellen zu löschen, falls sie vorhanden sind;
- Zeilen 16–17: Wir erstellen die vier soeben gelöschten Tabellen neu;
- Zeilen 22–25: Wir fügen alle Klassen zur Sitzung hinzu;
- Zeilen 27–30: Wir fügen alle Fächer zur Sitzung hinzu;
- Zeilen 32–35: Wir fügen alle Schüler zur Sitzung hinzu;
- Zeilen 37–40: Wir fügen alle Noten zur Sitzung hinzu;
- Um diese Hinzufügungen vorzunehmen, haben wir eine bestimmte Reihenfolge befolgt. Wir haben mit Entitäten begonnen, die keine Beziehungen zu anderen Entitäten haben, und mit denen geendet, die solche Beziehungen haben. Wenn wir also die Schüler zur Sitzung hinzufügen, befinden sich die Klassen, auf die sie verweisen, bereits in der Sitzung;
- Zeile 43: Die [sqlalchemy]-Sitzung wird festgeschrieben. Nach diesem Vorgang können wir sicher sein, dass alle Daten in der Sitzung mit der Datenbank synchronisiert wurden. Kurz gesagt: Die Daten wurden in die Tabellen eingefügt. Dies wurde durch die in der [sqlalchemy]-Konfiguration definierten Zuordnungen ermöglicht. [sqlalchemy] weiß, wie jede Entität in den Tabellen gespeichert werden soll. [sqlalchemy] hat außerdem alle Fremdschlüssel generiert, die die Tabellen möglicherweise enthalten;
- Zeilen 44–49: Wenn ein Problem auftritt, wird die [sqlalchemy]-Sitzung zurückgesetzt, und in Zeile 49 wird eine Ausnahme ausgelöst;
19.6.6. Initialisierung der Datenbank
Das Skript [main_init_database] initialisiert die Datenbank mit dem Inhalt des Skripts [data.py]. Sein Code lautet wie folgt:
- Zeilen 1–11: Das Skript erwartet einen Parameter [mysql] oder [pgres], je nachdem, ob Sie eine MySQL- oder eine PostgreSQL-Datenbank initialisieren möchten;
- Zeilen 13–15: Die Anwendung wird für das als Parameter übergebene DBMS konfiguriert;
- Zeilen 20–22: Die in die Datenbank einzufügenden Daten werden abgerufen;
- Zeile 25: Die [dao]-Schicht wurde bereits instanziiert und ist in der Anwendungskonfiguration verfügbar;
- Zeile 30: Die Datenbank wird initialisiert;
- Zeilen 34–37: Unabhängig davon, ob ein Fehler aufgetreten ist, werden die Ressourcen der Anwendung mithilfe des Moduls [shutdown] freigegeben;
Das Modul [shutdown.py] sieht wie folgt aus:
Die Funktion [shutdown.execute] schließt die [sqlalchemy]-Sitzung, die zur Initialisierung der Datenbank verwendet wurde.
Wir erstellen eine anfängliche Ausführungskonfiguration (siehe |Ausführungskonfiguration|), um [main_init_database] mit dem Datenbankmanagementsystem MySQL auszuführen:
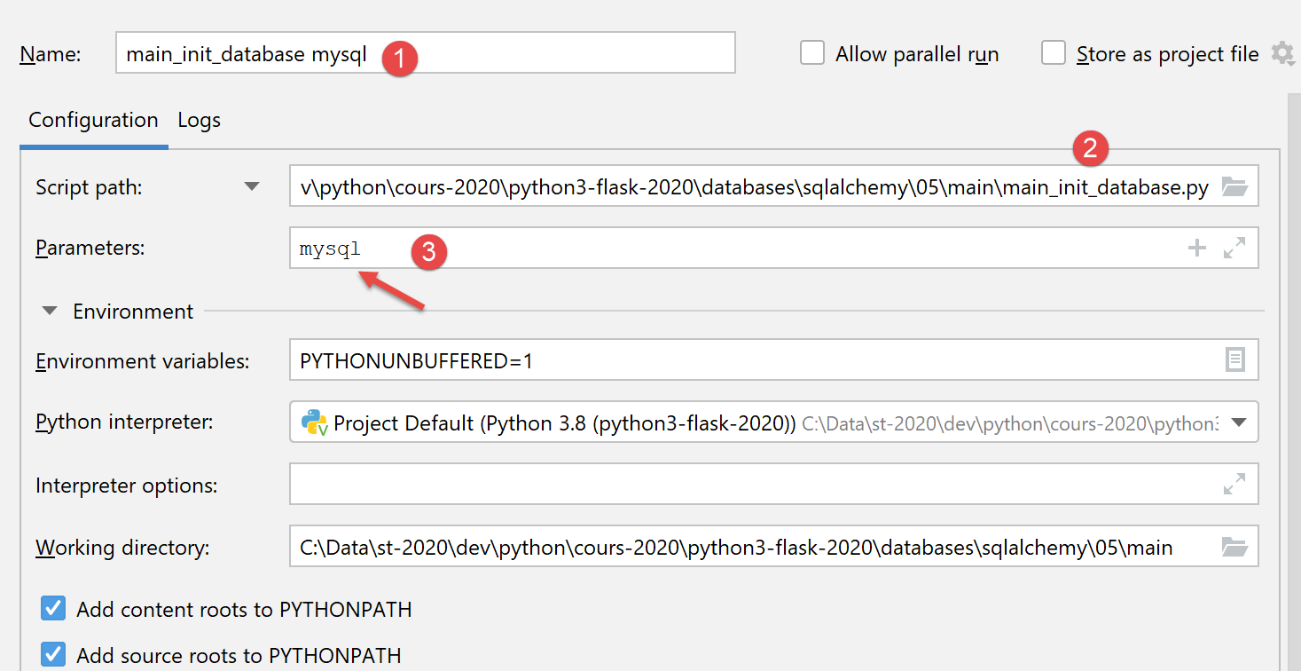
Die Ergebnisse der Ausführung dieser Konfiguration sehen in phpMyAdmin wie folgt aus:
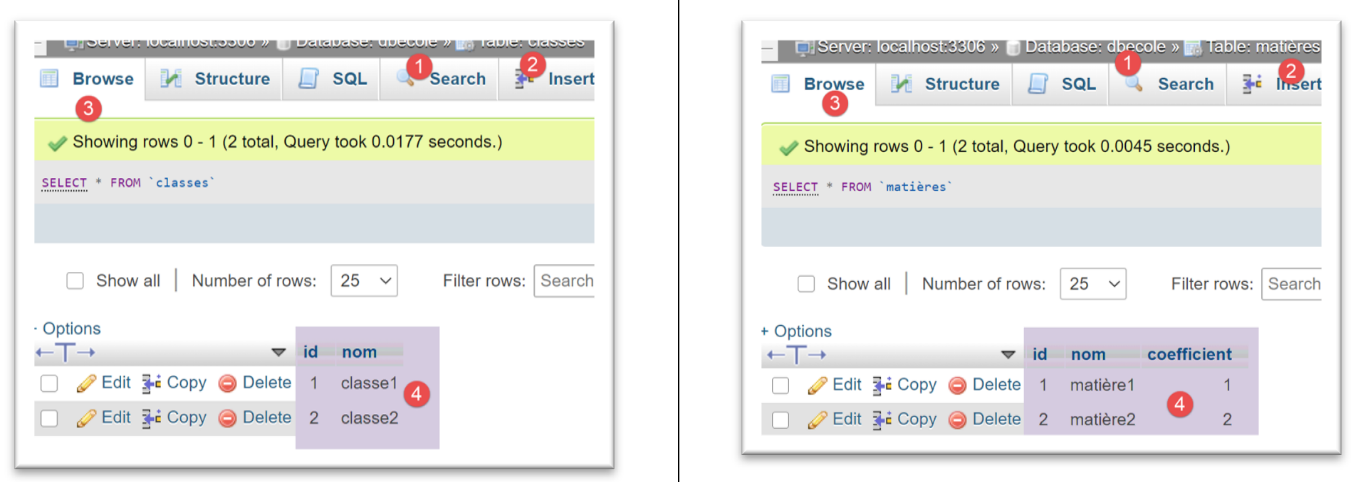
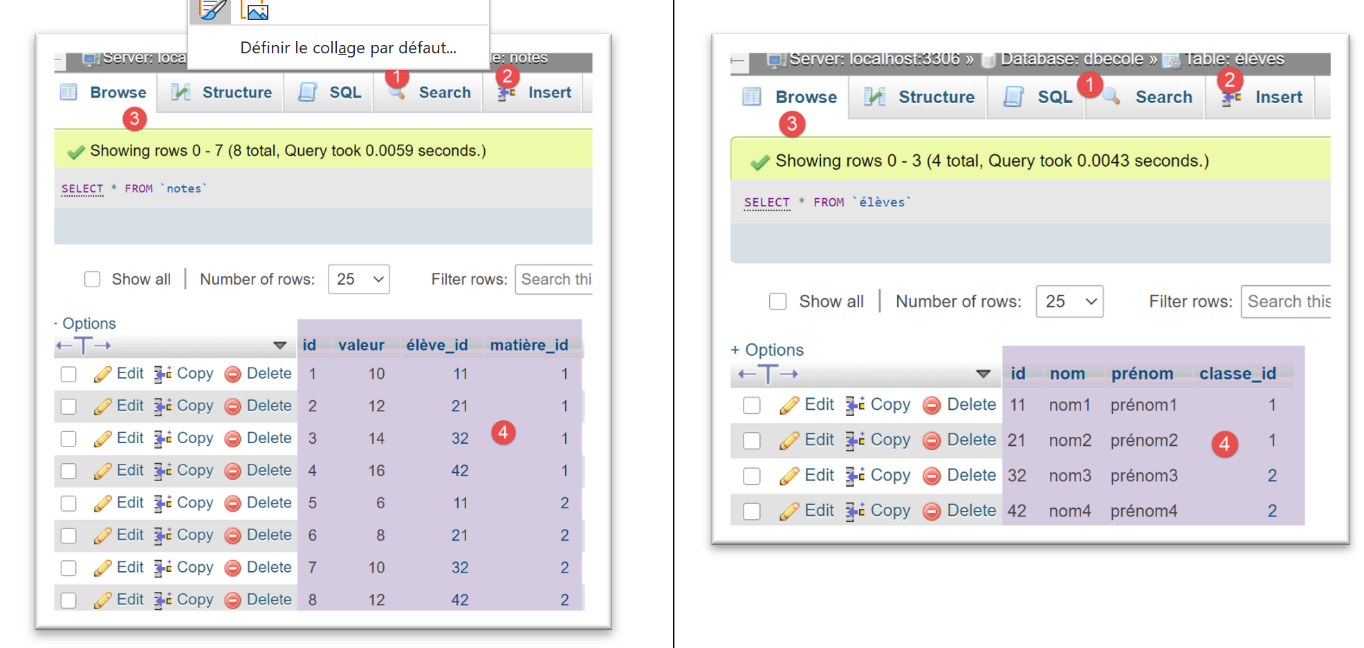
Für das [PostgreSQL]-DBMS verwenden wir die folgende Ausführungskonfiguration:
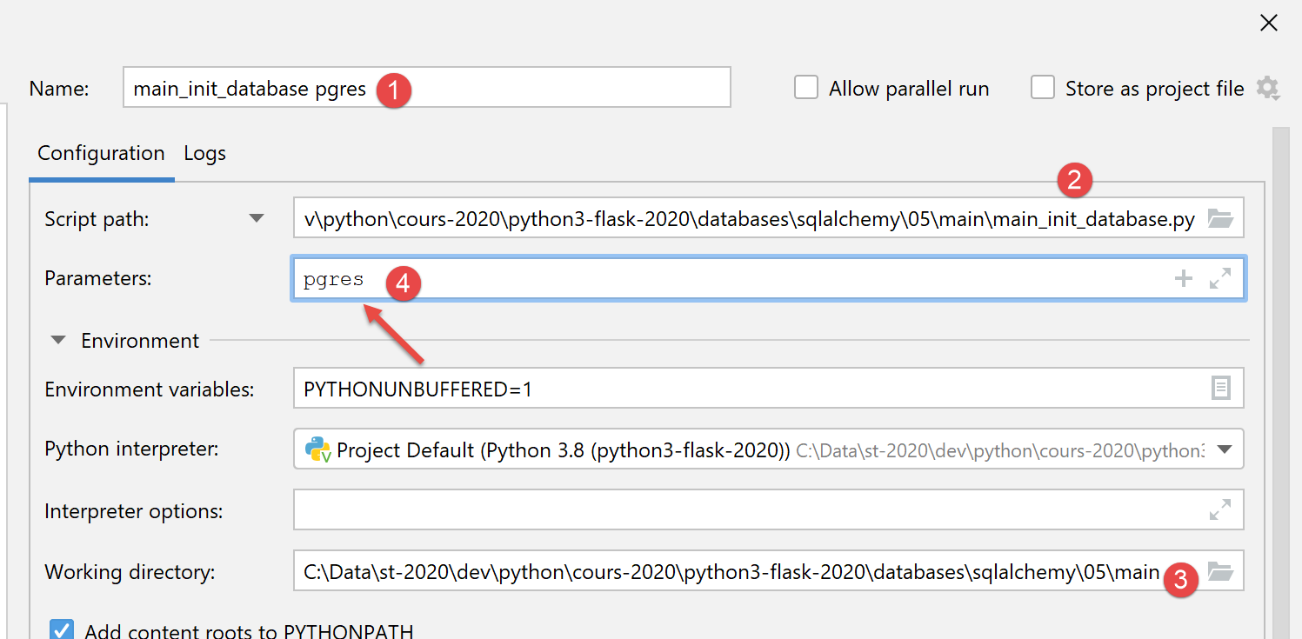
Nach der Ausführung sehen die Ergebnisse in [pgAdmin] wie folgt aus:

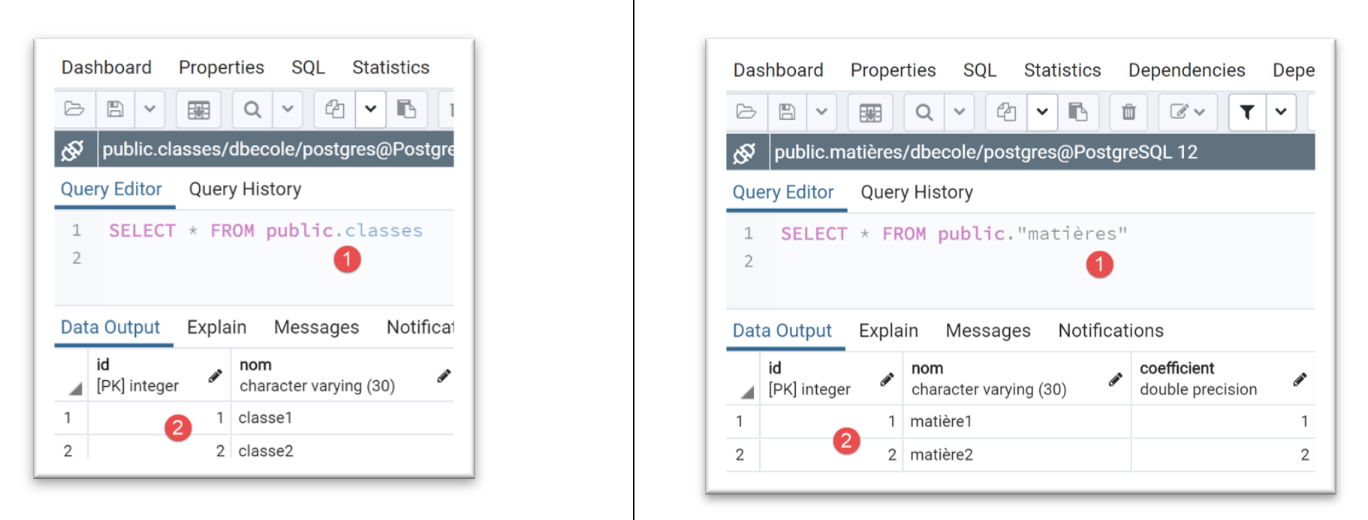
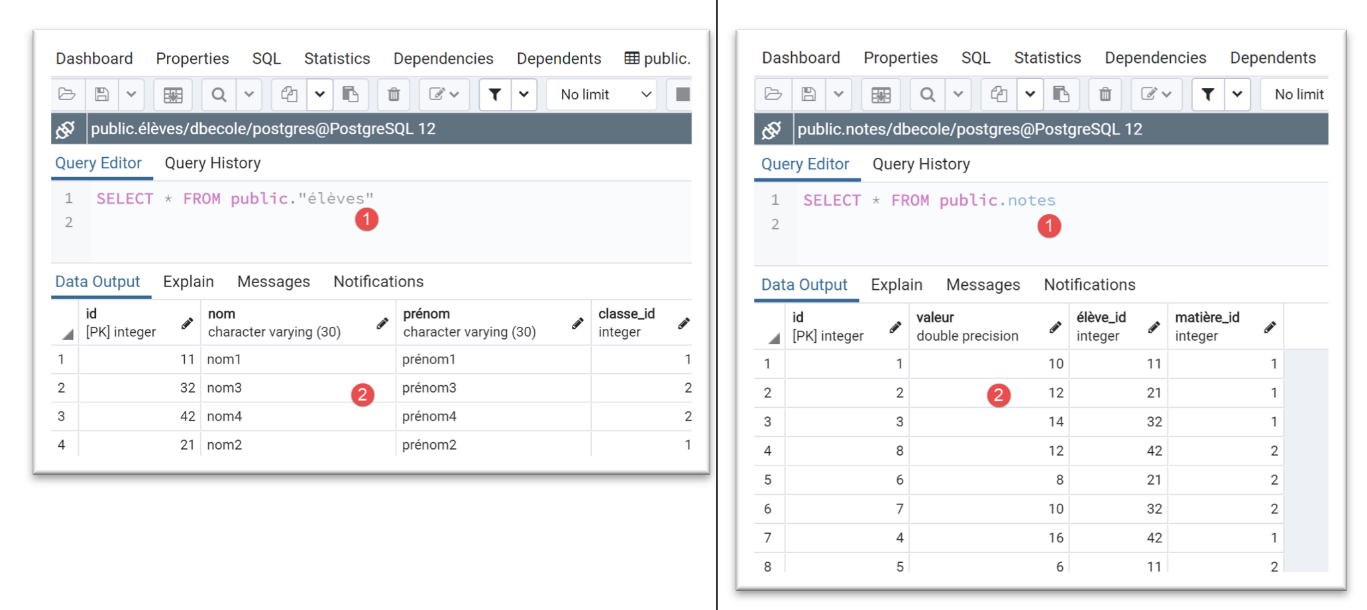
Beachten Sie, wie einfach wir das DBMS wechseln konnten.
19.6.7. Die [dao]-Schicht – 2
Wir kehren zur Klasse [DatabaseDao] zurück, die die [DAO]-Schicht implementiert. Bisher haben wir nur die Implementierung der Methode [init_database] gezeigt. Wir werden nun die Implementierung der anderen Methoden zeigen:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 | |
- Zeilen 21–24: Die Methode [get_classes] muss die Liste der Klassen an der Schule zurückgeben. In Zeile 20 verwenden wir eine Abfrage, die wir bereits kennen;
- Zeilen 26–39: drei weitere ähnliche Methoden zum Abrufen der Listen mit Schülern, Fächern und Noten;
- Zeilen 51–59: Die Methode [get_student_by_id] muss einen Schüler zurückgeben, der anhand seiner ID identifiziert wird. Es wird eine Ausnahme ausgelöst, wenn der Schüler nicht existiert;
- Zeile 54: Wir verwenden eine gefilterte Abfrage. Wir erhalten eine leere Liste oder eine Liste mit einem Element;
- Zeile 57: Wenn die abgerufene Liste nicht leer ist, geben wir das erste Element der Liste zurück;
- ansonsten, Zeile 59, wird eine Ausnahme ausgelöst;
- Zeilen 41–49: Die Methode [get_notes_for_student_by_id] muss die Noten eines durch seine ID identifizierten Schülers zurückgeben:
- Zeile 45: Wir verwenden die Methode [get_student_by_id], um die Student-Entität für den Studenten abzurufen;
- Zeile 47: Wir verwenden die Eigenschaft [Student.grades], die durch die Zuordnung zwischen der Entität [Grade] und der Tabelle [grades] erstellt wurde (siehe Abschnitt |SQLAlchemy-Konfiguration|) und die die Noten des Studenten darstellt;
- Zeile 49: Wir geben ein Wörterbuch zurück;
- Zeilen 61–109: eine Reihe ähnlicher Methoden, die es uns ermöglichen:
- einen Studenten nach Namen zu suchen, Zeilen 61–69;
- eine Klasse zu finden, Zeilen 71–89;
- ein Fach abrufen, Zeilen 91–109;
19.6.8. Das Skript [main_joined_queries]
Das Skript [main_joined_queries] trägt diesen Namen, weil es die Abfragen hervorheben soll, die [sqlalchemy] implizit ausführt, um Informationen aus mehreren Tabellen abzurufen. Diese für den Programmierer verborgenen Abfragen werden immer dann ausgeführt, wenn eine Eigenschaft einer Entität mit der Funktion [relationship] im Mapping der Entität verknüpft wurde. Zum Beispiel:
# mapping
mapper(Note, tables['notes'], properties={
'id': notes_table.c.id,
'valeur': notes_table.c.valeur,
'élève': relationship(Elève, backref="notes", lazy="select"),
'matière': relationship(Matière, backref="notes", lazy="select")
})
Oben ist die Zuordnung zwischen der Entität [Note] und der Tabelle [notes] dargestellt:
- Zeile 5: Wenn die Eigenschaft [student] einer [Grade]-Entität zum ersten Mal angefordert wird, wird sie über eine SQL-Abfrage aus der Tabelle [students] abgerufen. Solange diese Eigenschaft nicht angefordert wird, bleibt sie undefiniert (Lazy Loading). Sobald sie abgerufen wurde, verbleibt ihr Wert im Speicher des ORM. Bei einer zweiten Referenzierung gibt das ORM ihren Wert sofort zurück, ohne eine neue SQL-Abfrage auszuführen. All dies ist für den Entwickler transparent;
- das Gleiche gilt für die inverse Eigenschaft [Student.grades] (Backref), Zeile 5;
- das Gleiche gilt für die Eigenschaft [Grade.subject] und ihre inverse Eigenschaft [Subject.grades] (Backref), Zeile 6;
Das Skript [main_joined_queries] lautet wie folgt:
Die Kommentare reichen aus, um den Code zu verstehen.
Wir erstellen eine Ausführungskonfiguration für MySQL:
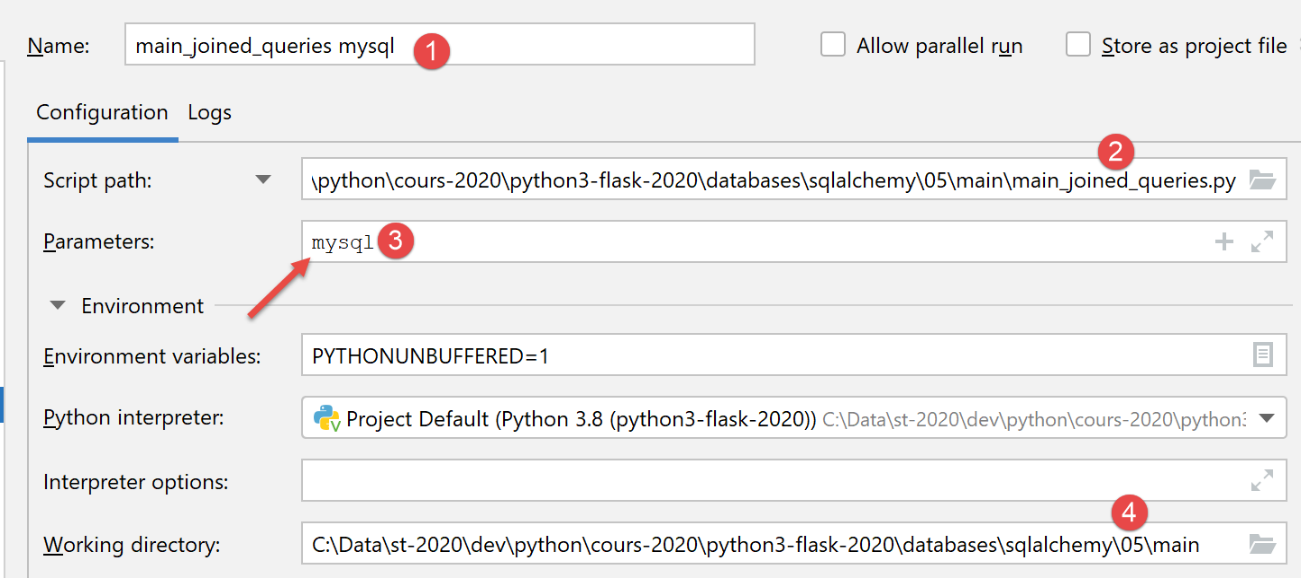
Die Ausführungsergebnisse lauten wie folgt:
Um diese Ergebnisse zu verstehen, beachten Sie bitte, dass bestimmte Eigenschaften aus dem Entitätswörterbuch ausgeschlossen wurden (siehe |Konfiguration|):
# configuration des entités [BaseEntity]
Elève.excluded_keys = ['_sa_instance_state', 'notes', 'classe']
Classe.excluded_keys = ['_sa_instance_state', 'élèves']
Matière.excluded_keys = ['_sa_instance_state', 'notes']
Note.excluded_keys = ['_sa_instance_state', 'matière', 'élève']
Wenn wir also in Zeile 26 des Codes [print(f"student={student}")] schreiben, sagt uns Zeile 1 oben, dass die Eigenschaften ['_sa_instance_state', 'grades', 'class'] nicht angezeigt werden. Das sehen wir in Zeile 3 der Ergebnisse. Alle anderen Eigenschaften werden angezeigt. So entdecken wir, ebenfalls in Zeile 3, eine neue Eigenschaft [class_id], die ursprünglich in der Entität [Student] nicht vorhanden war. Diese Eigenschaft entspricht direkt der Spalte [class_id] in der Tabelle [students]. Somit hat [SQLAlchemy] der Entität [Student] die folgenden Eigenschaften hinzugefügt: [class_id, _sa_instance_state, grades]. Es ist wichtig, sich dessen bewusst zu sein, insbesondere da diese Eigenschaften nicht bereits in der zugeordneten Entität vorhanden sein dürfen.
Die aus dem Entitätswörterbuch ausgeschlossenen Eigenschaften sind wichtig. Wenn wir beispielsweise die Eigenschaften [grades, student] nicht aus der Entität [Student] ausschließen, werden sie bei der Operation [print(f"student={student}")] angezeigt und lösen daher, wie gerade erläutert, implizite SQL-Abfragen (Lazy Loading) aus, um die Werte dieser Eigenschaften abzurufen. Wenn, wie in diesem Fall, eine Liste von Schülern angezeigt wird, werden für jeden Schüler implizite SQL-Operationen durchgeführt. Dies kann sowohl unnötig als auch hinsichtlich der Ausführungszeit sicherlich aufwendig sein.
Um das Skript mit einer PostgreSQL-Datenbank auszuführen, erstellen Sie die folgende Ausführungskonfiguration:
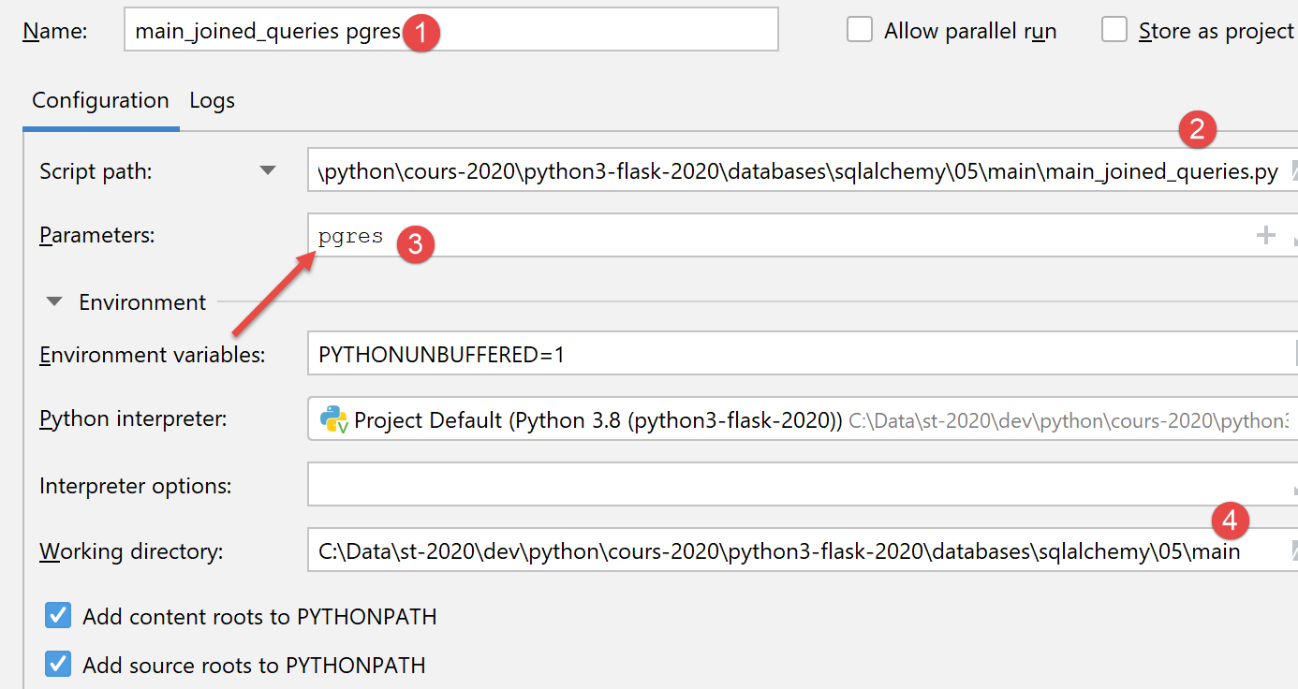
Die Ausführung liefert die gleichen Ergebnisse wie bei MySQL.
19.6.9. Das Skript [main_stats_for_student]
Das Skript [main_stats_for_student] ist dasjenige, das bereits in der Anwendung |troiscouches v01| verwendet wurde. Es hieß zuvor [main]. Es handelt sich um eine Konsolenanwendung, die bestimmte Kennzahlen zu den Noten eines Schülers abruft: [gewichteter Durchschnitt, Min, Max, Liste]. Es fügt sich in die folgende Architektur ein:
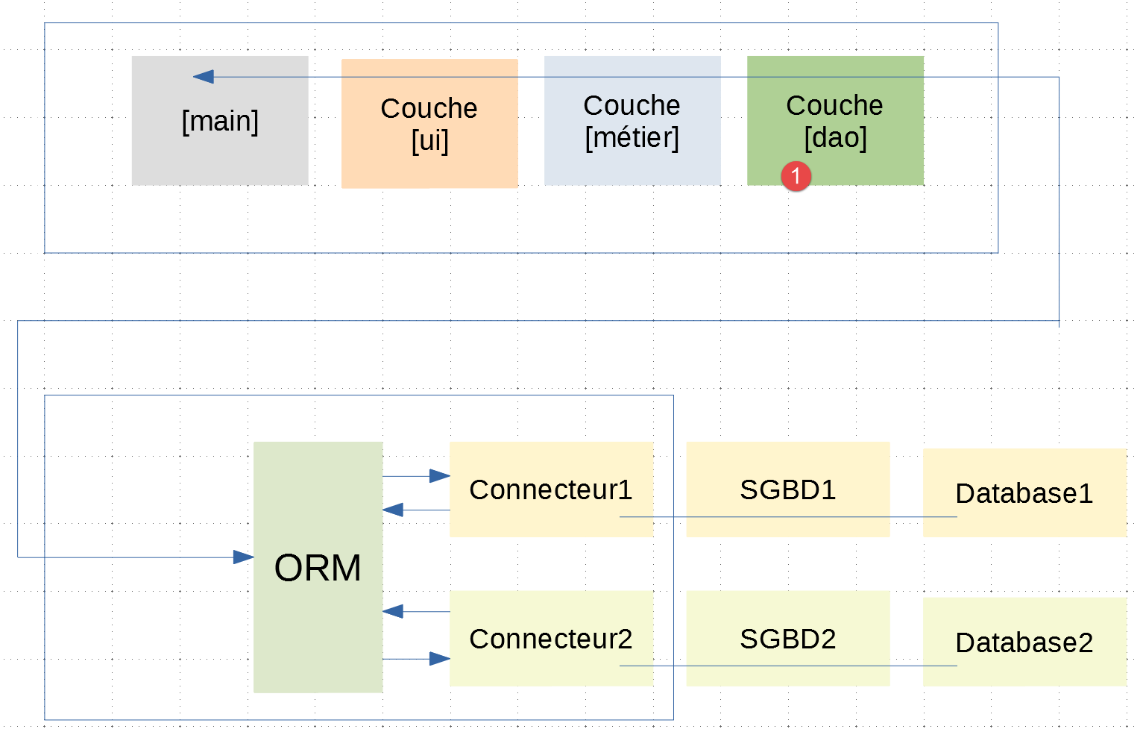
In dieser Schichtenarchitektur wurde zwischen der Anwendung |troiscouches v01| und dieser nur die [dao]-Schicht geändert. Da die neue [dao]-Schicht der [InterfaceDao]-Schnittstelle der alten [dao]-Schicht entspricht, müssen die [ui, business]-Schichten nicht geändert werden. Wir können daher weiterhin die in der Anwendung |troiscouches v01| definierten verwenden.
Das Skript [main_stats_for_élève] implementiert die [main]-Schicht des obigen Diagramms wie folgt:
- Zeile 20: Abrufen einer Referenz auf die [ui]-Ebene aus der Anwendungskonfiguration;
- Zeile 24: Wir initiieren den Benutzerdialog mithilfe der einzigen Methode der [ui]-Ebene;
Eine Ausführungskonfiguration für PostgreSQL würde wie folgt aussehen:
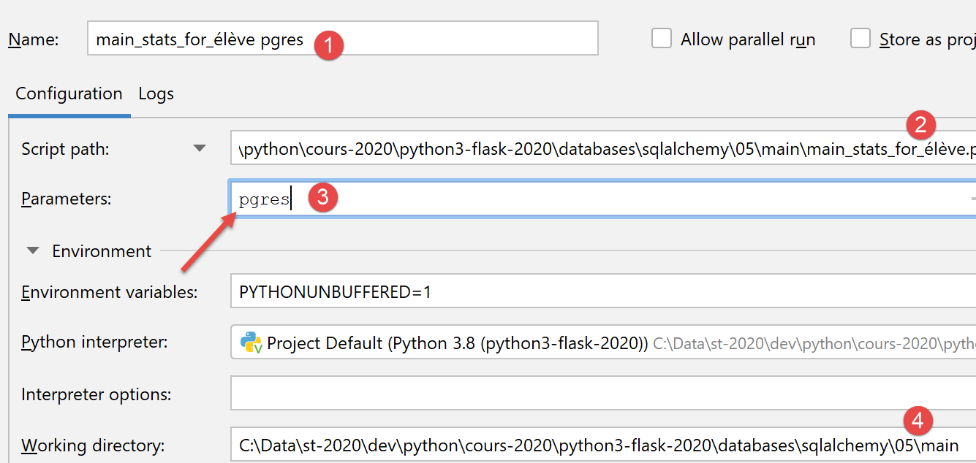
Hier ist ein Beispiel für die Ausführung mit dieser Konfiguration:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/databases/sqlalchemy/05/main/main_stats_for_élève.py pgres
Numéro de l'élève (>=1 et * pour arrêter) : 11
Elève={"prénom": "prénom1", "id": 11, "classe_id": 1, "nom": "nom1"}, notes=[10.0 6.0], max=10.0, min=6.0, moyenne pondérée=7.33
Numéro de l'élève (>=1 et * pour arrêter) : 1
L'erreur suivante s'est produite : MyException[11, L'élève d'identifiant 1 n'existe pas]
Numéro de l'élève (>=1 et * pour arrêter) : *
Process finished with exit code 0