7. Textdateien
7.1. Skript [fic_01]: Lesen/Schreiben einer Textdatei
Das folgende Skript veranschaulicht ein Beispiel für die Arbeit mit Textdateien:
Hinweise:
- Zeile 28: Öffnet die Datei zum Schreiben (w=write). Wenn die Datei bereits existiert, wird sie überschrieben;
- Zeilen 30–34: Erzeugt 100 Zeilen in der Textdatei;
- Zeile 34: schreibt eine Zeile in die Textdatei. Die Methode [write] fügt kein Zeilenumbruchzeichen hinzu. Daher müssen Sie dieses in den geschriebenen Text einfügen;
- Zeilen 35–37: Behandeln Sie etwaige Ausnahmen;
- Zeile 37: Beendet die Ausführung des Skripts (jedoch erst nach Ausführung des finally-Blocks);
- Zeilen 38–41: In jedem Fall, unabhängig davon, ob ein Fehler auftritt oder nicht, die Datei schließen, falls sie geöffnet ist;
- Zeile 47: Öffne die Datei zum Lesen (r=read);
- Zeile 49: Definition eines leeren Wörterbuchs;
- Zeile 52: Die Methode [readline] liest eine Textzeile, einschließlich des Zeilenendezeichens. Die Methode [strip] entfernt „Leerzeichen“ am Anfang und am Ende der Zeichenkette. Unter „Leerzeichen“ verstehen wir Leerzeichen, Zeilenumbrüche, Seitenumbrüche, Tabulatoren und einige andere Zeichen. Daher enthält [line] hier keine Zeilenumbruchzeichen [\r\n] (Windows) oder [\n] (Unix);
- Zeile 54: Die Datei wird verarbeitet, bis eine Leerzeile auftritt;
- Zeilen 54–64: Die Textdatei wird in das Wörterbuch [dico] übertragen. Der Schlüssel ist das Feld [login], und der Wert besteht aus den Feldern [uid:gid:infos:dir:shell];
- Zeilen 65–67: Behandlung etwaiger Ausnahmen;
- Zeilen 68–71: Schließen der Datei in jedem Fall, unabhängig davon, ob ein Fehler auftritt oder nicht;
- Zeilen 74–75: Abfrage des Wörterbuchs [dico];
Die Datei [data/infos.txt]:
Bildschirmausgabe:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/fichiers/fic_01.py
login10 : ['uid10', 'gid10', 'infos10', 'dir10', 'shell10']
la clé [X] n'existe pas
Process finished with exit code 0
7.2. Skript [fic_02]: Umgang mit UTF-8-kodierten Textdateien
Im weiteren Verlauf dieses Dokuments werden wir ausschließlich mit UTF-8-kodierten Textdateien arbeiten. Zunächst konfigurieren wir PyCharm:
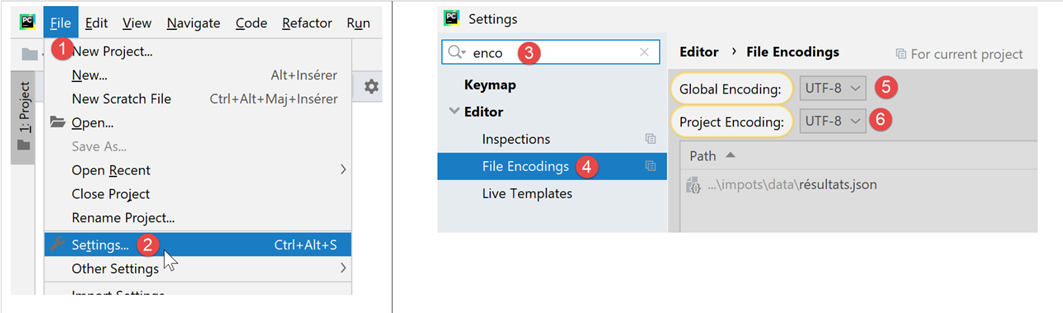
- in [5-6]: Wählen Sie die UTF-8-Kodierung für Projektdateien aus;
Um eine UTF-8-kodierte Datei zu erstellen, gehen Sie wie folgt vor (fic-02):
Anmerkungen
- Zeile 2: Um die Dateikodierung zu handhaben, importieren wir das Modul [codecs];
- Zeile 6: Die Methode [codecs.open] wird wie die Standardfunktion [open] verwendet. Sie können jedoch die gewünschte Kodierung (beim Erstellen) oder die vorhandene Kodierung (beim Lesen) angeben. Nach dem Öffnen wird das in Zeile 6 erhaltene [file]-Objekt wie eine Standarddatei verwendet;
- Zeile 7: Es wurden Zeichen mit Akzenten verwendet, die je nach verwendeter Zeichenkodierung meist unterschiedlich dargestellt werden;
Ergebnisse
Beim Öffnen der erhaltenen Datei [data/utf8.txt] (siehe Zeile 6) ergibt sich folgendes Ergebnis:

7.3. Skript [fic_03]: Verarbeitung von Textdateien, die in ISO-8859-1 kodiert sind
Das Skript [fic_03] führt dieselben Schritte aus wie das Skript [fic_02], kodiert die Textdatei jedoch in ISO-8859-1. Wir möchten den Unterschied zwischen den resultierenden Dateien aufzeigen:
Wenn wir die in Zeile 6 erstellte Datei [data/iso-8859-1] öffnen, erhalten wir folgendes Ergebnis:

Da wir das Projekt für die Arbeit mit UTF-8-Dateien konfiguriert haben, hat PyCharm versucht, die Datei [iso-8859-1.txt] im UTF-8-Format zu öffnen. Es erkennt [1], dass die Datei nicht im UTF-8-Format vorliegt. Daraufhin schlägt es vor [2], die Datei in einer anderen Kodierung neu zu laden:

- in [3-5]: Die Datei wird mit der ISO-8859-1-Kodierung neu geladen;

- in [6] wird dieselbe Datei mit einer anderen Kodierung angezeigt;
Wenn wir zurück zu den Projekteinstellungen gehen:
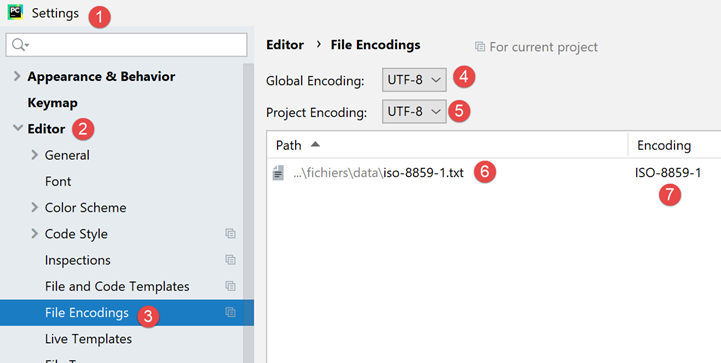
- sehen wir, dass PyCharm in [6-7] vermerkt hat, dass die Datei [iso-8859-1.txt] mit der Kodierung ISO-8859-1 geöffnet werden sollte. Dies ist daher eine Ausnahme von der Regel [5];
7.4. Skript [json_01]: Arbeiten mit einer JSON-Datei
JSON steht für JavaScript Object Notation. Wie der Name schon sagt, handelt es sich um eine textbasierte Darstellung von JavaScript-Objekten. Hier werden wir es mit Python-Objekten verwenden.
Die zu bearbeitende JSON-Datei [data/in.json] sieht wie folgt aus:
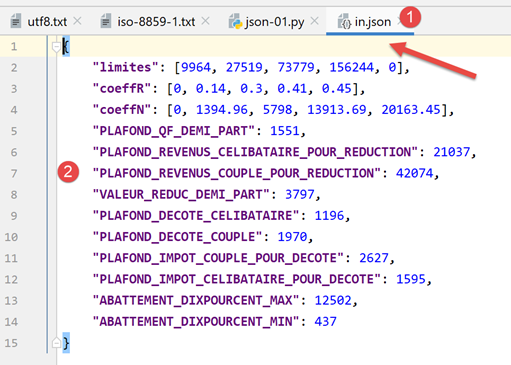
- In [2] sehen wir, dass der Textinhalt der Datei [in.json] ein Python-Dictionary darstellen könnte. PyCharm hat diesen Text formatiert (Strg-Alt-L), aber selbst wenn er in einer einzigen Zeile stünde, würde das keinen Unterschied machen. Das Format des Textes ist irrelevant, solange er syntaktisch ein Python-Objekt darstellt;
Das Skript [json-01] zeigt, wie diese Datei verwendet wird:
Anmerkungen
- Zeile 3: Um mit JSON zu arbeiten, importieren wir das [json]-Modul;
- Zeile 11: Wir arbeiten mit JSON-Dateien, die in UTF-8 kodiert sind. Hier öffnen wir die Datei [data/in.json] mithilfe des Moduls [codecs];
- Zeile 13: Die Methode [json.load] liest den Inhalt der JSON-Datei und speichert ihn in der Variablen [data]. Der Typ dieser Variablen ist ein Wörterbuch;
- Zeilen 15–18: Um zu überprüfen, ob wir tatsächlich ein Python-Wörterbuch erhalten haben, zeigen wir einige seiner Elemente an;
- Zeilen 20–21: Wir führen den umgekehrten Vorgang durch: Das Wörterbuch [data] wird mithilfe der Methode [json.dump] in eine UTF-8-kodierte Datei geschrieben;
- Zeilen 22–25: Behandlung etwaiger Ausnahmen;
- Zeilen 26–31: Unabhängig davon, ob ein Fehler auftritt oder nicht, schließen wir alle Dateien, die möglicherweise geöffnet wurden;
Ergebnisse
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/fichiers/json_01.py
data={'limites': [9964, 27519, 73779, 156244, 0], 'coeffR': [0, 0.14, 0.3, 0.41, 0.45], 'coeffN': [0, 1394.96, 5798, 13913.69, 20163.45], 'PLAFOND_QF_DEMI_PART': 1551, 'PLAFOND_REVENUS_CELIBATAIRE_POUR_REDUCTION': 21037, 'PLAFOND_REVENUS_COUPLE_POUR_REDUCTION': 42074, 'VALEUR_REDUC_DEMI_PART': 3797, 'PLAFOND_DECOTE_CELIBATAIRE': 1196, 'PLAFOND_DECOTE_COUPLE': 1970, 'PLAFOND_IMPOT_COUPLE_POUR_DECOTE': 2627, 'PLAFOND_IMPOT_CELIBATAIRE_POUR_DECOTE': 1595, 'ABATTEMENT_DIXPOURCENT_MAX': 12502, 'ABATTEMENT_DIXPOURCENT_MIN': 437}, type(data)=<class 'dict'>
limites=[9964, 27519, 73779, 156244, 0], type(limites)=<class 'list'>
limites[1]=27519, type(limites[1])=<class 'int'>
Process finished with exit code 0
- Die Zeilen 2–4 zeigen, dass wir das Wörterbuch erfolgreich aus der JSON-Datei abgerufen haben;
Sehen wir uns nun den Inhalt der Datei [data/out.json] an:

Der Text in der Datei steht in einer einzigen Zeile. PyCharm erkennt jedoch JSON-Dateien, und wir können sie – genau wie Python-Dateien und andere – mit Strg-Alt-L formatieren. Das ergibt folgendes Ergebnis:
7.5. Skript [json_02]: Umgang mit in UTF-8 kodierten JSON-Dateien
Eine in UTF-8 kodierte JSON-Datei kann zwei Formen annehmen:
- In diesem Skript wird das [data]-Wörterbuch (Zeile 7) in zwei JSON-Dateien geschrieben (Zeilen 14, 17);
- Zeilen 14, 17: In beiden Fällen wird eine UTF-8-Textdatei erstellt;
- Zeile 15: Beim Schreiben des Wörterbuchs verwenden wir den Parameter [ensure_ascii=True];
- Zeile 18: Beim Schreiben des Wörterbuchs verwenden wir den Parameter [ensure_ascii=False];
Hier sind die beiden resultierenden Dateien:

- In der Datei [out1.json] wurden Zeichen mit Akzenten durch eine Zeichenfolge ersetzt, die ihren UTF-8-Code darstellt. Dies wird manchmal als „Escaping“ bezeichnet. Technisch gesehen wird in der Binärdatei [out1.json] das Zeichen é in [marié] durch die aufeinanderfolgenden UTF-8-Binärcodes der 6 Zeichen [\u00e9] dargestellt;
- In der Datei [out2.json] wurden Zeichen mit Akzenten unverändert belassen. Das bedeutet, dass diese Zeichen in den Binärdaten von [out2.json] durch ihren UTF-8-Binärcode dargestellt werden (nur ein einziger UTF-8-Code statt 6 wie bei [out1]). Für das Zeichen é in [marié] finden wir somit den 4-Byte-Binärcode [00e9];
- es ist der Wert des Parameters [ensure_ascii] der Methode [json.dump], der das verwendete Format bestimmt;
Einige Anwendungen verwenden „escaped“ UTF-8 für ihre JSON-Dateien. In diesem Fall muss der Wert [ensure_ascii=True] verwendet werden. Dieser Wert ist eigentlich der Standardwert. Wenn der Parameter [ensure_ascii] also nicht verwendet wird, arbeiten wir mit escaped UTF-8-JSON-Dateien.
Das Skript setzt sich wie folgt fort:
Anmerkungen
- Zeilen 11–34: Lesen Sie die beiden Dateien [out1.json, out2.json] ein und zeigen Sie das jeweils eingelesene Wörterbuch an;
Ergebnisse
Überraschenderweise sehen wir, dass wir den Kodierungstyp (escaped oder nicht) der zu lesenden JSON-Zeichenkette nicht in der Funktion [json.load] angeben mussten (Zeilen 17, 22). In beiden Fällen erhalten wir das richtige Wörterbuch.