19. Utilizzo dell'ORM SQLAlchemy
Il capitolo precedente ha mostrato che in alcuni casi è possibile scrivere codice indipendente dal DBMS utilizzato con la seguente architettura:
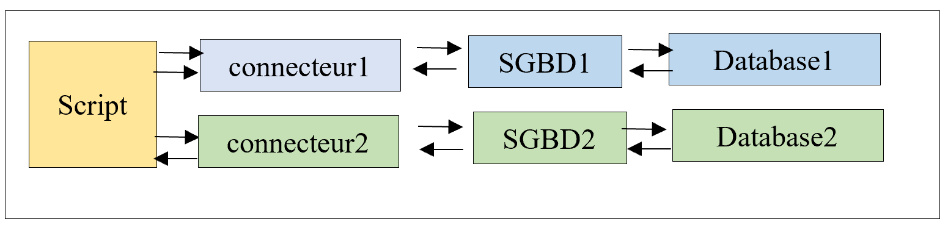
In questo capitolo, useremo l'ORM (Object Relational Mapper) [SQLAlchemy] per accedere ai DBMS in modo uniforme, indipendentemente dal DBMS utilizzato. Un ORM consente due cose:
- permette a uno script di interagire con il DBMS senza emettere comandi SQL;
- nasconde allo script le specificità di ciascun DBMS;
L'architettura diventa la seguente:
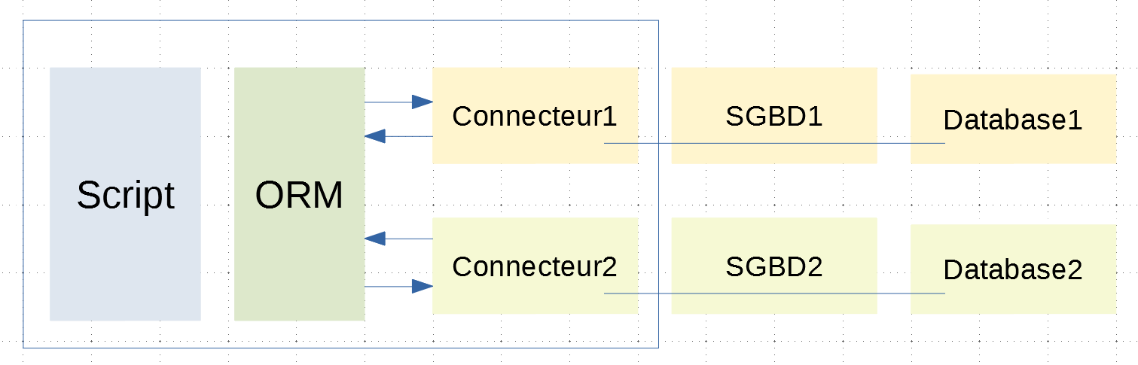
Lo script è ora separato dai connettori dall'ORM. Comunica con l'ORM utilizzando classi e metodi. Non esegue codice SQL. L'ORM lo fa utilizzando i connettori a cui è collegato. Nasconde le specificità di questi connettori allo script. Pertanto, il codice dello script non è influenzato da un cambiamento nel connettore (e quindi nel DBMS);
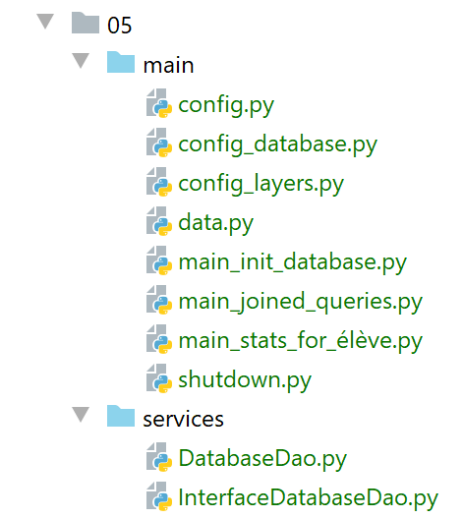
La struttura delle directory degli script in questione sarà la seguente:
19.1. Installazione dell'ORM [SQLAlchemy]
L'ORM [SQLAlchemy] è disponibile come pacchetto Python che deve essere installato in un terminale Python:
(venv) C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\databases\sqlalchemy>pip install sqlalchemy
Collecting sqlalchemy
Downloading SQLAlchemy-1.3.18-cp38-cp38-win_amd64.whl (1.2 MB)
|| 1.2 MB 3.3 MB/s
Installing collected packages: sqlalchemy
Successfully installed sqlalchemy-1.3.18
19.2. Script 01: Nozioni di base

- in [1], gli script che verranno studiati. Questi script utilizzeranno le classi di [2]: BaseEntity, MyException, Person, Utils;
19.2.1. Configurazione
Il file [config] configura l'applicazione come segue:
Commenti
- riga 8: aggiungi la cartella contenente le classi [BaseEntity, MyException, Person, Utils] al Python Path;
- righe 12-13: impostiamo il Python Path dell'applicazione;
- righe 16-17: ricorderete che la classe |BaseEntity| ha un attributo di classe denominato [excluded_keys]. Questo attributo è una lista in cui inseriamo le proprietà della classe che non vogliamo compaiano nel dizionario della classe (funzione asdict). Qui escludiamo la proprietà [_sa_instance_state] dallo stato della classe [Person]. Vedremo tra poco il perché;
19.2.2. Script [demo]
Lo script [demo] mostra un primo utilizzo dell'ORM [sqlalchemy]:
Commenti
- righe 1-4: configuriamo l'applicazione;
- righe 6-10: importiamo i moduli necessari per lo script;
- riga 13: [MetaData] è una classe in [sqlalchemy];
- righe 15-22: [Table] è una classe in [sqlalchemy]. Viene utilizzata per descrivere una tabella del database. Qui descriveremo la tabella [people] nel database MySQL [dbpeople] trattato nel capitolo |MySQL|;
- riga 16: il primo parametro [people] è il nome della tabella che viene descritta;
- riga 16: il secondo parametro [metadata] è l'istanza [MetaData] creata alla riga 13;
- righe 17–22: ciascuno dei seguenti parametri descrive una colonna della tabella utilizzando una sintassi specifica di [SQLAlchemy] ma simile alla sintassi SQL;
- ogni colonna è descritta utilizzando un'istanza della classe [Column] di [sqlalchemy];
- il primo parametro è il nome della colonna;
- il secondo parametro è il suo tipo;
- i parametri seguenti sono parametri denominati:
- Riga 17: [primary_key=True] per indicare che la colonna [id] è la chiave primaria della tabella [people];
- riga 18: [nullable=False] per indicare che una colonna deve avere un valore quando viene inserita una riga nella tabella;
- riga 21: infine, la classe [UniqueConstraint] consente di definire un vincolo di unicità. Qui, specifichiamo che le colonne (last_name, first_name) devono essere uniche all'interno della tabella. La proprietà denominata [name] consente di assegnare un nome a questo vincolo. Qui, ci sono due casi da considerare:
- stiamo descrivendo una tabella esistente. In tal caso, dobbiamo cercare il nome del vincolo nelle proprietà della tabella (phpMyAdmin o pgAdmin);
- stiamo descrivendo una tabella che stiamo per creare. In tal caso, inseriamo il nome che desideriamo;
- righe 23–25: creiamo una persona [person1] e visualizziamo il suo dizionario [__dict__]. Qui avremo:
personne1={'_BaseEntity__id': 67, '_Personne__prénom': 'x', '_Personne__nom': 'y', '_Personne__âge': 10}
- righe 27–33: eseguiamo una mappatura, ovvero creiamo una corrispondenza tra la classe [Person] e la tabella [people]. Si tratta essenzialmente di una mappatura [proprietà della classe colonne della tabella]. La funzione [mapper] accetta qui tre parametri:
- riga 28: il primo parametro è il nome della classe per la quale viene eseguita la mappatura;
- riga 28: il secondo parametro è la tabella a cui verrà associata. Si tratta dell'oggetto [Table] creato alla riga 16;
- riga 28: il terzo parametro qui è un parametro denominato [properties]. Si tratta di un dizionario in cui le chiavi sono le proprietà della classe mappata e i valori sono le colonne della tabella mappata. Per fare riferimento alla colonna X della tabella [personnes_table], scriviamo [personnes_table.c.X];
- righe 35–36: visualizziamo nuovamente la persona [person1] una volta completata la mappatura. Vediamo che non è cambiata:
personne1={'_BaseEntity__id': 67, '_Personne__prénom': 'x', '_Personne__nom': 'y', '_Personne__âge': 10}
- righe 37-39: creiamo una nuova persona [person2] e la visualizziamo. Vediamo quindi il seguente output:
personne2={'_sa_instance_state': <sqlalchemy.orm.state.InstanceState object at 0x00000259A6747FA0>, 'id': 68, 'prénom': 'x1', 'nom': 'y1', 'âge': 11}
Possiamo notare che il dizionario [__dict__] è stato modificato in modo significativo:
- (continua)
- appare una nuova proprietà [_sa_instance_state]. Possiamo notare che si tratta di un oggetto ORM [sqlalchemy];
- alle altre proprietà sono stati rimossi i prefissi, che in precedenza indicavano a quale classe appartenessero;
Possiamo quindi concludere che l'operazione di mappatura nelle righe 27–33 ha modificato la classe [Person].
Quando vogliamo visualizzare lo stato di un oggetto [Person], in genere non vogliamo la proprietà [_sa_instance_state]. È presente esclusivamente per il funzionamento interno di [SQLAlchemy] e in genere non ci interessa. Ecco perché abbiamo scritto nello script [config]:
19.2.3. Lo script [main]
Lo script [main] manipolerà la tabella [people] nel database MySQL [dbpeople] interfacciandosi con [sqlalchemy]. Per comprendere quanto segue, è necessario ricordare l'architettura qui utilizzata:
Se [Database1] è il database [dbpersonnes], possiamo vedere che la connessione tra lo script e questo database coinvolge due componenti:
- il connettore Python al DBMS MySQL;
- il DBMS MySQL;
Lo script [main] comunicherà con l'ORM, che a sua volta comunicherà con il connettore Python. L'ORM comunica con questo connettore utilizzando gli strumenti descritti nelle sezioni |MySQL| e |PostgreSQL|, in particolare emettendo comandi SQL. Lo script [main] non utilizzerà comandi SQL. Si baserà sull'API (Application Programming Interface) dell'ORM, costituita da classi e interfacce.
Lo script [main] è il seguente:
Commenti
- righe 1–4: l'applicazione viene configurata;
- righe 7–9: importiamo un'intera serie di classi e interfacce dalla libreria [sqlalchemy];
- Riga 11: viene importata la classe [Person];
- Riga 14: la stringa di connessione al database. Essa specifica:
- il DBMS utilizzato (mysql);
- il connettore Python utilizzato (mysql.connector senza il punto);
- l'utente che effettua l'accesso (admpersonnes);
- la sua password (nobody);
- la macchina su cui si trova il DBMS (localhost = la macchina su cui è in esecuzione lo script);
- il nome del database (dbpersonnes);
Con queste informazioni, [sqlalchemy] può connettersi al database. Si noti che il connettore Python utilizzato deve essere già installato. [sqlalchemy] non lo installa.
- righe 19–26: descrizione della tabella [people];
- righe 28–34: mappatura tra la classe [Person] e la tabella [people];
- righe 36–38: la maggior parte delle operazioni [sqlalchemy] viene eseguita all'interno di una sessione. Il concetto di sessione [sqlalchemy] è simile a quello di transazione SQL. Le sessioni vengono create a partire dalla classe [Session] restituita dalla funzione [sessionmaker] alla riga 37;
- riga 38: la classe [Session] è associata al database [dbpeople] tramite la stringa di connessione alla riga 14;
- riga 43: viene creata una sessione. Come accennato, una sessione può essere paragonata a una transazione;
- righe 45–46: il metodo [Session.execute] consente l'esecuzione di un'istruzione SQL. Non si tratta di una pratica comune, poiché abbiamo menzionato che l'ORM permette di evitare l'uso di SQL;
- righe 48–49: il metodo [metadata.create_all] crea tutte le tabelle utilizzando l'istanza [MetaData] della riga 17. Ne abbiamo solo una: la tabella [people] definita nelle righe 20–26. [SQLAlchemy] utilizzerà le informazioni di queste righe per creare la tabella. Qui vediamo un vantaggio chiave dell'ORM: nasconde le specificità del DBMS. Infatti, l'istruzione SQL [create] può variare in modo significativo da un DBMS all'altro a causa dei tipi di dati assegnati alle colonne. Non c'è stata alcuna standardizzazione dei tipi di dati in SQL. Pertanto, l'istruzione [create] varia da un DBMS all'altro. Qui, grazie a [SQLAlchemy]:
- descriviamo la tabella che vogliamo in un unico modo coerente;
- [SQLAlchemy] riesce a generare l'istruzione [create] appropriata per il DBMS con cui sta lavorando;
- riga 52: aggiungiamo un oggetto [Person] alla sessione. Questo non lo aggiunge automaticamente al database. Infatti, un ORM segue le proprie regole per sincronizzarsi con il database. Cercherà sempre di ottimizzare il numero di query che effettua. Facciamo un esempio. Lo script aggiunge (add) due persone (person1, person2) alla sessione e poi esegue una query: vuole vedere tutte le persone nella tabella. [SQLAlchemy] può procedere come segue:
- l'aggiunta di [person1] può essere effettuata in memoria. Non c'è bisogno di inserirla nel database per ora;
- lo stesso vale per [person2];
- Segue la query [select]. Dobbiamo quindi recuperare tutte le righe dalla tabella [people]. [SQLAlchemy] inserirà quindi [person1, person2] nel database ed eseguirà la query;
[SQLAlchemy] eseguirà quindi ottimizzazioni trasparenti per lo sviluppatore.
- Riga 56: Per eseguire una query [select] (voglio vedere…), usiamo il metodo [Session.query]. Il parametro del metodo [query] è la classe mappata alla tabella oggetto della query. Questo metodo restituisce un oggetto [Query]. Il metodo [Query.all] recupera tutti gli oggetti [Person] dalla sessione. Restituisce tutte le righe della tabella [people], ciascuna sotto forma di oggetto [Person]. Per farlo, [SQLAlchemy] utilizza la mappatura stabilita tra la classe [Person] e la tabella [people]. Il risultato della riga 56 è un elenco di oggetti [Person];
- righe 58–61: visualizziamo gli elementi dell'elenco [people]. Poiché la classe [Person] deriva dalla classe [BaseEntity], il metodo [Person.__str__] utilizzato implicitamente qui alla riga 61 è in realtà il metodo [BaseEntity.__str__], che restituisce la stringa JSON dell'oggetto chiamante. Questa stringa è la stringa JSON del dizionario [Person.asdict] (vedi |BaseEntity|). Abbiamo accennato al fatto che, dopo la mappatura, avremmo trovato la proprietà [_sa_instance_state] in ogni oggetto [Person]. Tuttavia, il valore di questa proprietà non è di tipo [BaseEntity]. Deve quindi essere escluso dal dizionario della classe [Person]; altrimenti, la visualizzazione andrà in crash. Questo è ciò che è stato fatto nello script [config];
- righe 63–65: aggiungiamo altre due persone che hanno lo stesso nome e cognome. Tuttavia, esiste un vincolo di unicità sull'unione di queste due colonne. Dovrebbe quindi verificarsi un errore. Questo è ciò che stiamo cercando di verificare;
- righe 67–68: richiediamo nuovamente l'elenco di tutte le persone presenti nel database;
- righe 70–73: e le visualizziamo;
- righe 75-76: la sessione viene confermata. Come suggerisce il nome, la transazione sottostante verrà confermata;
- durante l'esecuzione vedremo che le righe 67–76 non verranno eseguite a causa dell'eccezione generata dalla riga 65. Passeremo quindi alle righe 78–84 per gestire l'eccezione;
- Riga 78: l'eccezione [InterfaceError] si verifica se [SQLAlchemy] non riesce a connettersi al database [dbpersonnes]. L'eccezione [IntegrityError] si verifica alla riga 65;
- riga 80: viene visualizzato l'errore;
- righe 82–84: se la sessione esiste, la annulliamo. Ciò equivale ad annullare la transazione sottostante;
- righe 85–88: in tutti i casi, indipendentemente dal verificarsi o meno di un errore, la sessione viene chiusa per liberare risorse;
I risultati dell'esecuzione sono i seguenti:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/databases/sqlalchemy/01/main.py
Liste des personnes ---------
{"nom": "y", "prénom": "x", "id": 67, "âge": 10}
L'erreur suivante s'est produite : (raised as a result of Query-invoked autoflush; consider using a session.no_autoflush block if this flush is occurring prematurely)
(mysql.connector.errors.IntegrityError) 1062 (23000): Duplicate entry 'y1-x1' for key 'uix_1'
[SQL: INSERT INTO personnes (id, prenom, nom, age) VALUES (%(id)s, %(prenom)s, %(nom)s, %(age)s)]
[parameters: ({'id': 68, 'prenom': 'x1', 'nom': 'y1', 'age': 10}, {'id': 69, 'prenom': 'x1', 'nom': 'y1', 'age': 10})]
(Background on this error at: http://sqlalche.me/e/13/gkpj)
rollback...
Process finished with exit code 0
- righe 2-3: l'elenco delle persone dopo il primo inserimento;
- riga 5: l'eccezione [IntegrityError] verificatasi quando sono state aggiunte due persone con lo stesso nome e cognome;
- righe 6-7: nota l'istruzione SQL che ha dato errore. Si tratta di un'istruzione INSERT parametrizzata: [SQLAlchemy] ha inserito entrambe le persone con un unico INSERT. Qui possiamo vedere che ha tentato di ottimizzare le istruzioni SQL emesse;
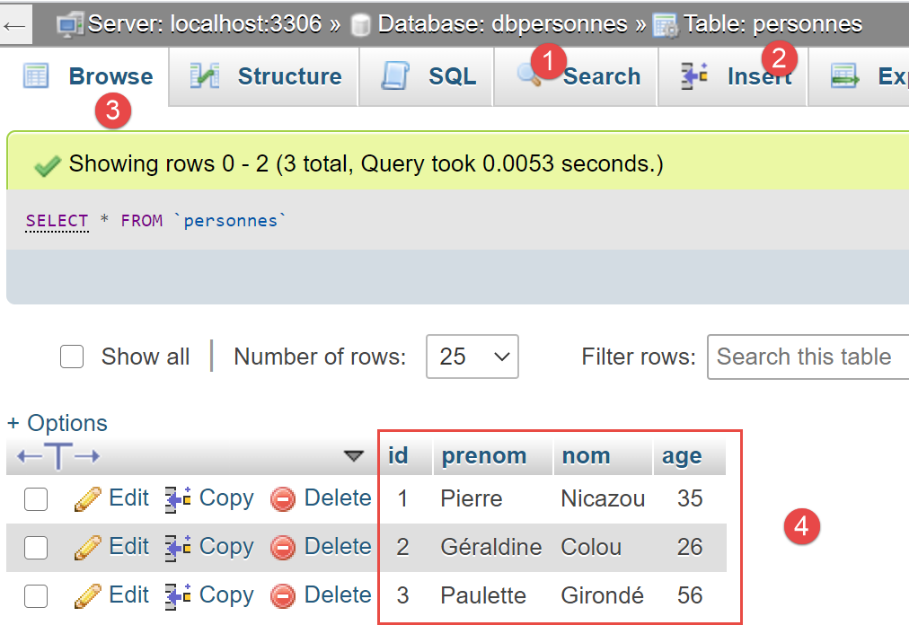
Ora utilizziamo phpMyAdmin per visualizzare il contenuto della tabella [people]:
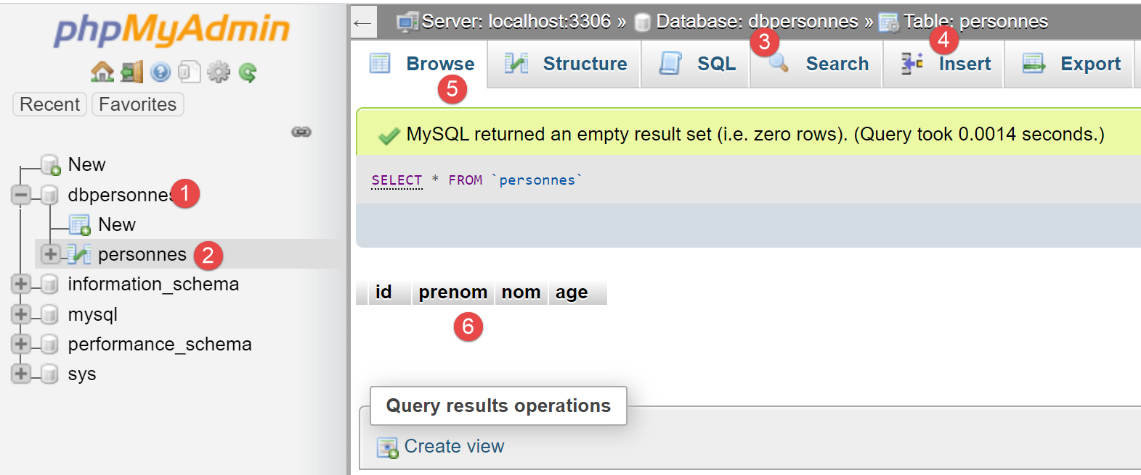
Possiamo vedere in [6] che la tabella è vuota. Non c'è nemmeno la prima persona che lo script ha aggiunto alla sessione. Questo perché la sessione faceva parte di una transazione e tale transazione è stata annullata nella clausola [except] dello script [main].
Apportiamo ora la seguente modifica in [main]:
Dopo aver aggiunto una persona alla riga 2, rimuoviamo il commento dalla riga 3. L'operazione [session.commit] confermerà la transazione sottostante e ne inizierà una nuova. Dopo l'esecuzione, il contenuto della tabella [people] è il seguente:
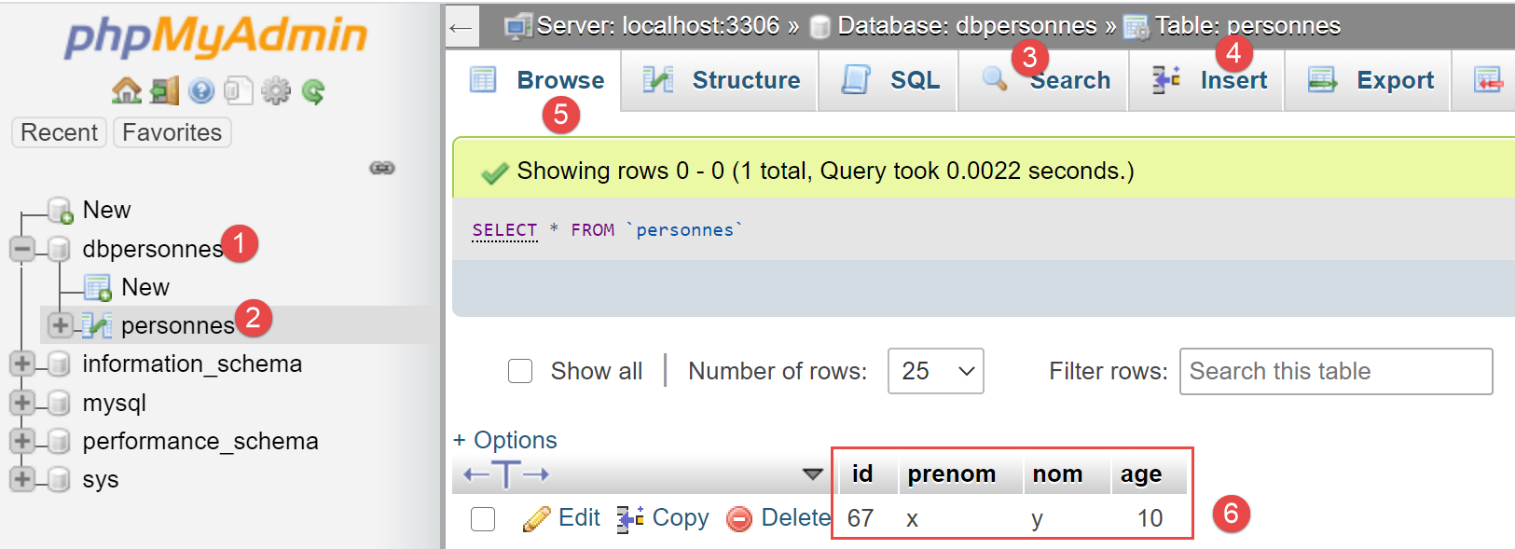
Come si può vedere in [6], il primo inserimento è stato mantenuto. Ciò è dovuto al fatto che è stato eseguito all'interno della transazione 1, mentre l'errore successivo si è verificato all'interno della transazione 2.
19.3. Script 02: mappature [sqlalchemy]

Gli script 02 sono una variante degli script 01. Cerchiamo di configurare il più possibile in [config.py]. Ora configuriamo lì l'ambiente [sqlalchemy] dell'applicazione:
Commenti
- righe 2–12: configurazione del percorso Python;
- righe 14–45: configurazione dell'ambiente [sqlalchemy];
- righe 47–52: l'ambiente [sqlalchemy] viene aggiunto al dizionario di configurazione;
- righe 54–56: configurazione della classe [Person];
Con questa configurazione, lo script [main] diventa il seguente:
I risultati dell'esecuzione sono i seguenti:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/databases/sqlalchemy/02/main.py
Liste des personnes-----------
{"âge": 10, "nom": "y", "prénom": "x", "id": 1}
{"âge": 7, "nom": "y1", "prénom": "x1", "id": 2}
L'erreur suivante s'est produite : (raised as a result of Query-invoked autoflush; consider using a session.no_autoflush block if this flush is occurring prematurely)
(mysql.connector.errors.IntegrityError) 1062 (23000): Duplicate entry 'y2-x2' for key 'uix_1'
[SQL: INSERT INTO personnes (prenom, nom, age) VALUES (%(prenom)s, %(nom)s, %(age)s)]
[parameters: {'prenom': 'x2', 'nom': 'y2', 'age': 10}]
(Background on this error at: http://sqlalche.me/e/13/gkpj)
rollback...
Travail terminé...
Process finished with exit code 0
In phpMyAdmin, la tabella [people] ora appare così:
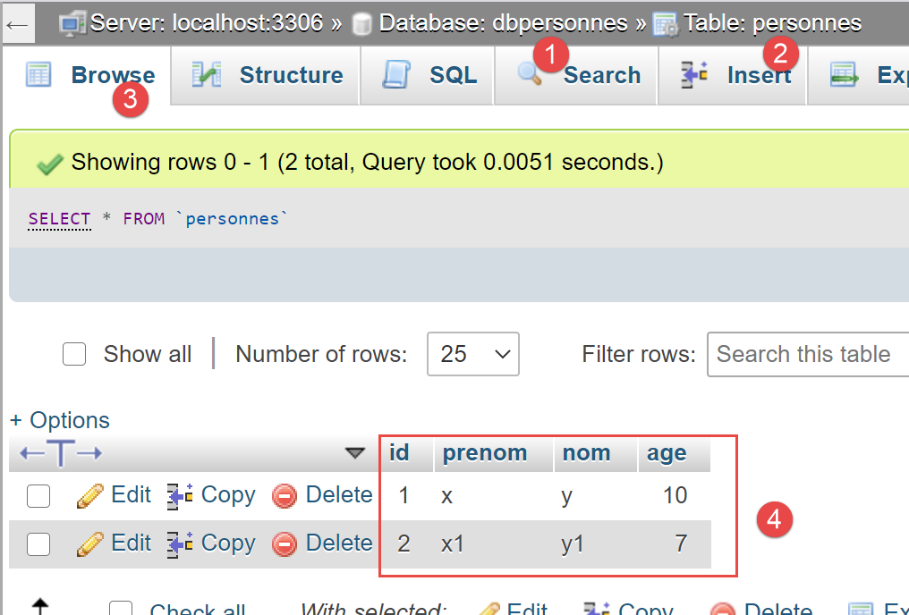
Ora, diamo un'occhiata alla tabella [people] generata da [SQLAlchemy]:
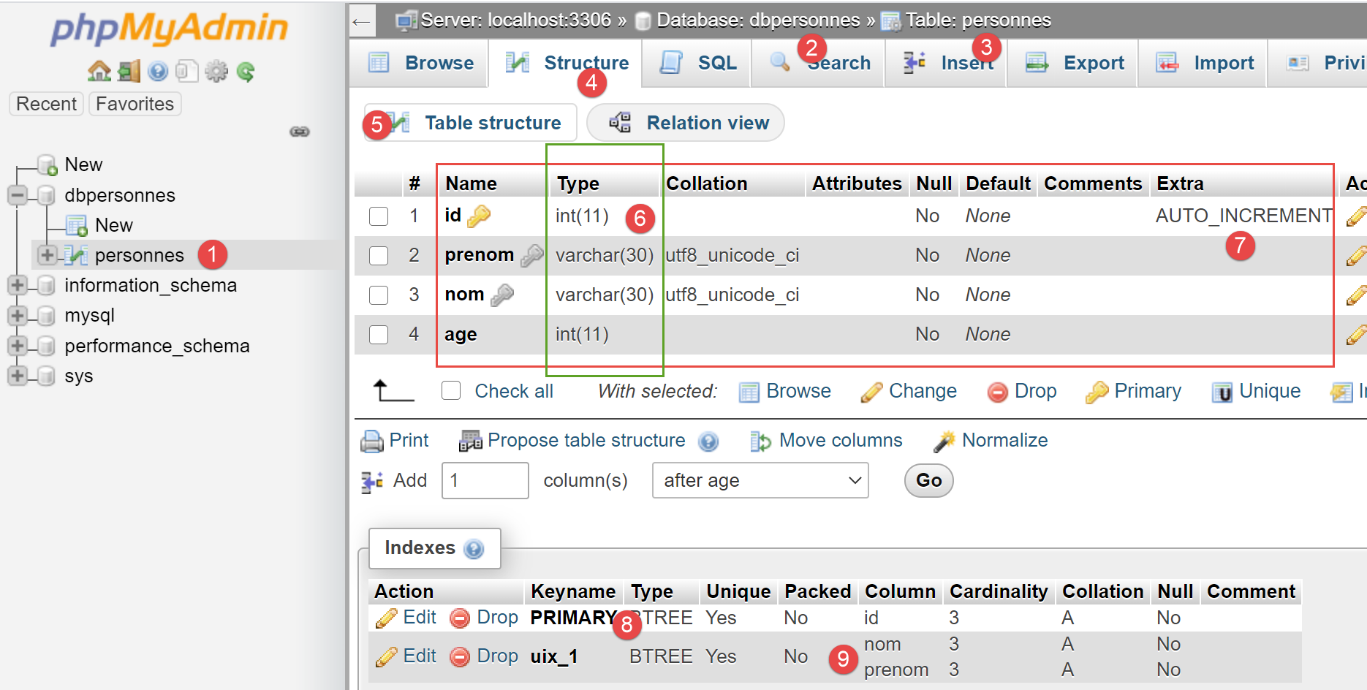
- In [6], i tipi utilizzati per le diverse colonne;
- in [7], vediamo che la colonna [id] presenta l'attributo [AUTO_INCREMENT]. Ciò significa che, quando si inserisce una riga nella tabella, se tale riga non ha un valore per la colonna [id], MySQL lo genererà in modo incrementale: 1, 2, 3, … Questa proprietà ci evita di doverci preoccupare del valore della chiave primaria durante l'inserimento nella tabella: lasciamo che sia MySQL a generarlo;
- in [8], vediamo che la colonna [id] è la chiave primaria;
- In [9], vediamo il vincolo di unicità sui campi [last_name, first_name];
19.4. Script 03: manipolazione delle entità di sessione [sqlalchemy]
Il file di configurazione [config] è lo stesso dell'esempio precedente. Nello script [main], eseguiamo operazioni standard [INSERT, UPDATE, DELETE, SELECT] sulla tabella [people] utilizzando i metodi [SQLAlchemy]:
Commenti
- righe 20–25: la funzione [display_people] visualizza gli elementi di un elenco di persone;
- righe 12–18: la funzione [display_people] visualizza il contenuto della tabella [people];
- Righe 34–36: eliminiamo la tabella [people]. A differenza delle versioni precedenti, non utilizziamo una query SQL ma un metodo [SQLAlchemy]:
- config["people_table"] è l'oggetto [Table] che descrive la tabella [people];
- config["engine"] è la stringa di connessione al database [dbpersonnes];
- il parametro denominato [checkfirst=True] garantisce che l'operazione venga eseguita solo se la tabella [people] esiste;
- righe 38–39: la tabella [people] viene ricreata;
- righe 41–44: tre persone vengono aggiunte alla sessione. Si noti che non vengono necessariamente inserite immediatamente nella tabella [people]. Ciò dipende dalla strategia orientata alle prestazioni di [SQLAlchemy];
- righe 46–47: viene visualizzato il contenuto della tabella [people]. Se le tre persone non erano ancora state inserite, vengono inserite ora a seguito di questa richiesta;
- Righe 49-50: un esempio di utilizzo del metodo [order_by], che consente di visualizzare i risultati della query in un ordine specifico. La sintassi [order_by(criterio1, criterio2)] visualizza i risultati prima in base al criterio [criterio1] e, quando le righe hanno lo stesso valore per [criterio1], vengono ordinate in base al criterio [criterio2]. In questo modo è possibile specificare più criteri;
- righe 55–59: introducono il concetto di filtraggio utilizzando il metodo [filter]. La notazione [filter(criterio1, criterio2)] esegue un'operazione logica AND tra i criteri utilizzati;
- righe 64–67: un nuovo utente effettua l'accesso;
- righe 70–71: un altro esempio di query filtrata. La funzione [func.lower(param)] converte [param] in minuscolo. Sono disponibili altre funzioni indicate con la forma [func.xx]. Nell'espressione alla riga 71:
- [session.query.filter] restituisce un elenco di oggetti [Person];
- [session.query.filter.first] restituisce il primo elemento di questo elenco;
- riga 77: un elemento viene rimosso dalla sessione;
- riga 86: la sessione viene convalidata;
I risultati dell'esecuzione sono i seguenti:
- righe 4-6: il contenuto della sessione;
- righe 8-10: il contenuto della sessione in ordine decrescente di nomi;
- righe 12–13: il contenuto della sessione per le persone la cui età è compresa nell'intervallo [20, 40];
- riga 15: la persona di nome “bruneau”;
In phpMyAdmin, il contenuto della tabella [people] al termine dell'esecuzione è il seguente:
19.5. Script 04: Utilizzo di un database [PostgreSQL]
La cartella [04] è una copia della cartella [03]. Modifichiamo solo una cosa: la stringa di connessione nel file [config]:
# lien vers une base de données PostgreSQL
engine = create_engine("postgresql+psycopg2://admpersonnes:nobody@localhost/dbpersonnes")
Questa stringa di connessione fa ora riferimento al database [dbpersonnes] in un DBMS [PostgreSQL]. Si noti l'uso del connettore [psycopg2]. Questo deve essere installato.
L'esecuzione dello script [main] produce i seguenti risultati:
Utilizzando lo strumento [pgAdmin] (vedere la sezione |pgAdmin|), la tabella [people] si presenta come segue:
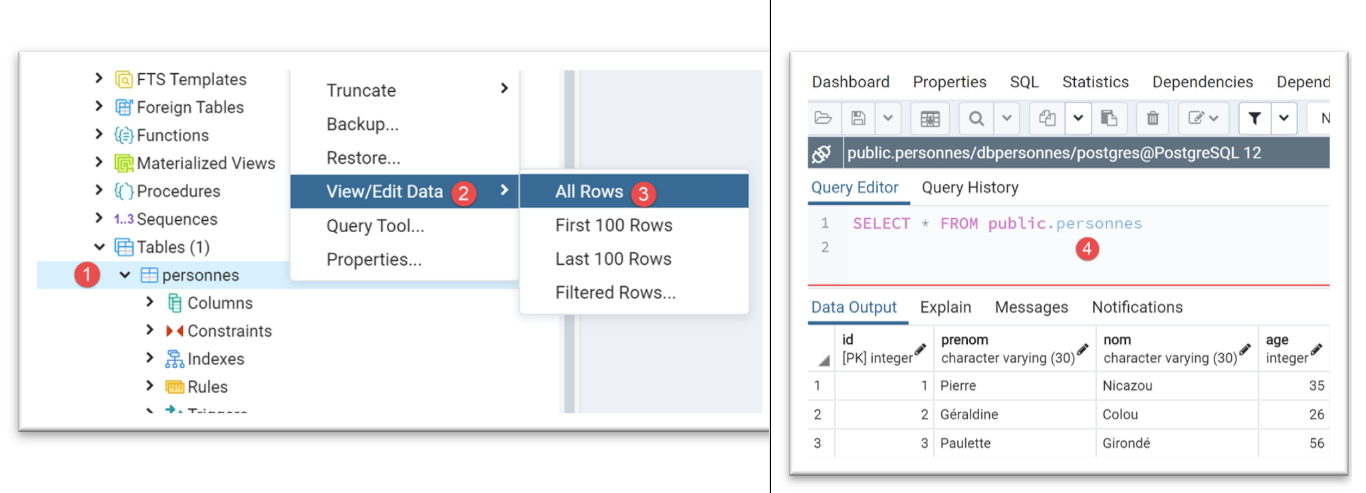
La tabella [people] è stata generata con il seguente codice SQL:
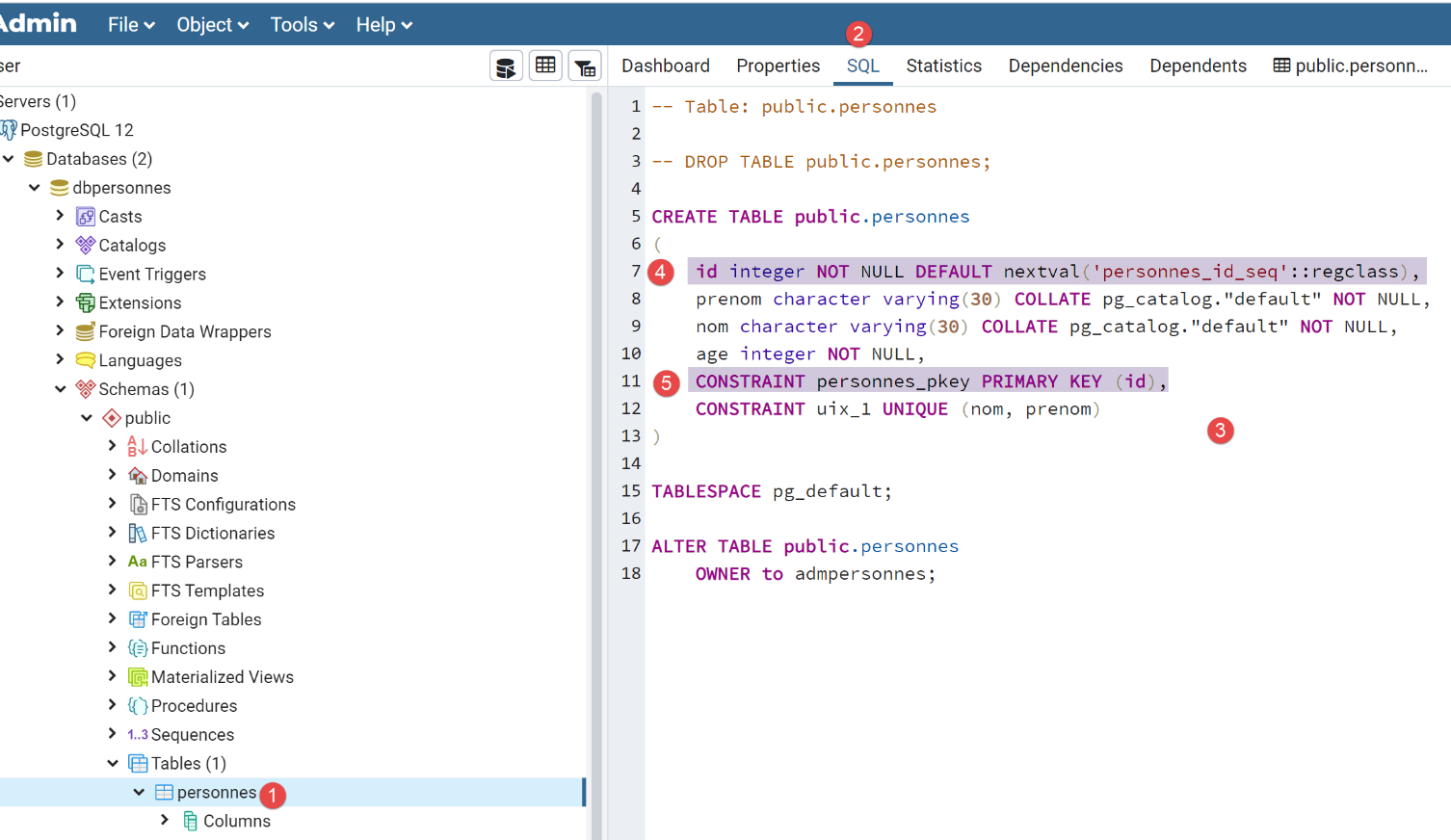
- In [4-5], vediamo che la colonna [id] è la chiave primaria. Vediamo anche che ha un valore predefinito [parola chiave DEFAULT], il che significa che se viene inserita una riga senza una chiave primaria, il DBMS ne genererà una. Questa è una pratica comune: lasciamo che sia il DBMS a generare le chiavi primarie;
Questa versione 05 degli script [sqlalchemy] dimostra chiaramente quanto sia facile passare da un DBMS a un altro: è bastato modificare la stringa di connessione in uno script di configurazione. Nient'altro è cambiato. Se confrontiamo i tipi di colonna [id, last_name, first_name, age] sopra riportati con quelli della tabella MySQL dell'esempio |02|, vediamo che sono diversi. [sqlalchemy] li adatta al DBMS in uso. Questa capacità di adattarsi a un nuovo DBMS è una ragione sufficiente per adottare [sqlalchemy] o un altro ORM.
19.6. Script 05: Esempio completo
L'esempio che stiamo esaminando è una rielaborazione di quello trattato nella sezione |troiscouches-v01|. Quell'esempio presentava un'architettura a tre livelli [UI, logica di business, DAO] che manipolava entità [Class, Student, Subject, Grade]. Le entità erano hard-coded in un livello [DAO]. Ora le stiamo inserendo in un database. Useremo due DBMS: MySQL e PostgreSQL.
19.6.1. L'architettura dell'applicazione
L'architettura dell'applicazione sarà la seguente:
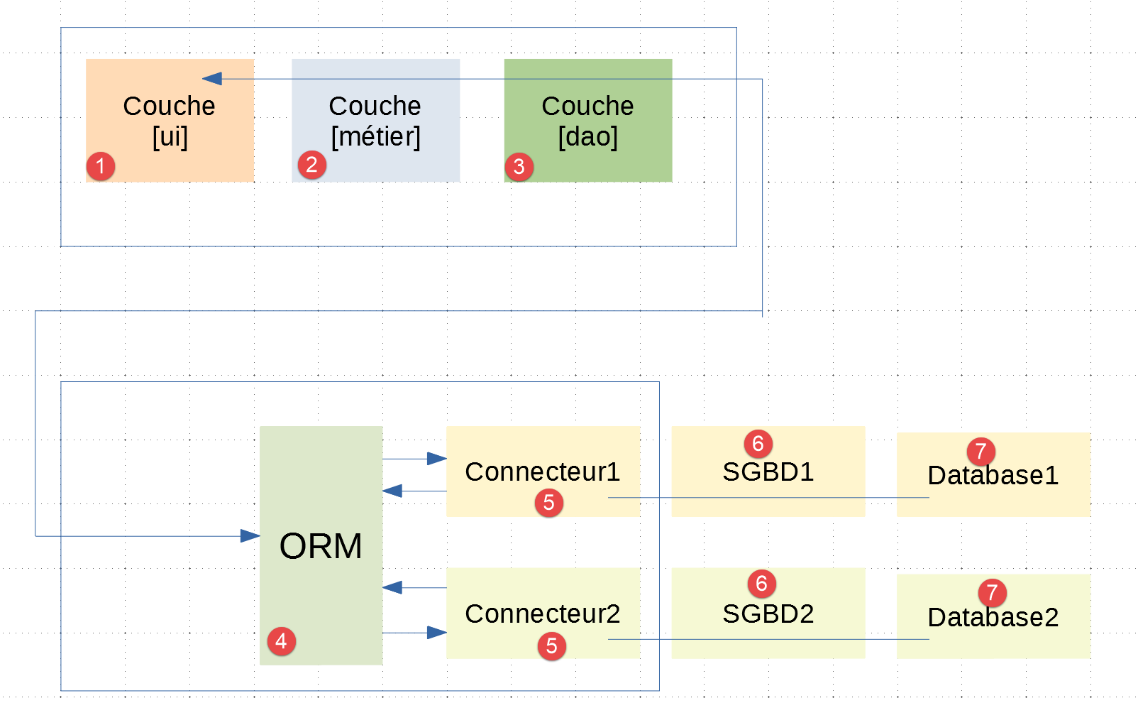
- In [1-3], troviamo i livelli [UI, Business, DAO] già presenti nell'esempio |troiscouches-v01|. Il livello [DAO] ora comunica con il livello [ORM];
- i livelli [1-5] sono implementati utilizzando codice Python;
19.6.2. I database
Stiamo creando un database MySQL denominato [dbecole] di proprietà dell'utente [admecole] con la password [mdpecole]. Per farlo, seguiamo la procedura descritta nella sezione |Creazione di un database|:
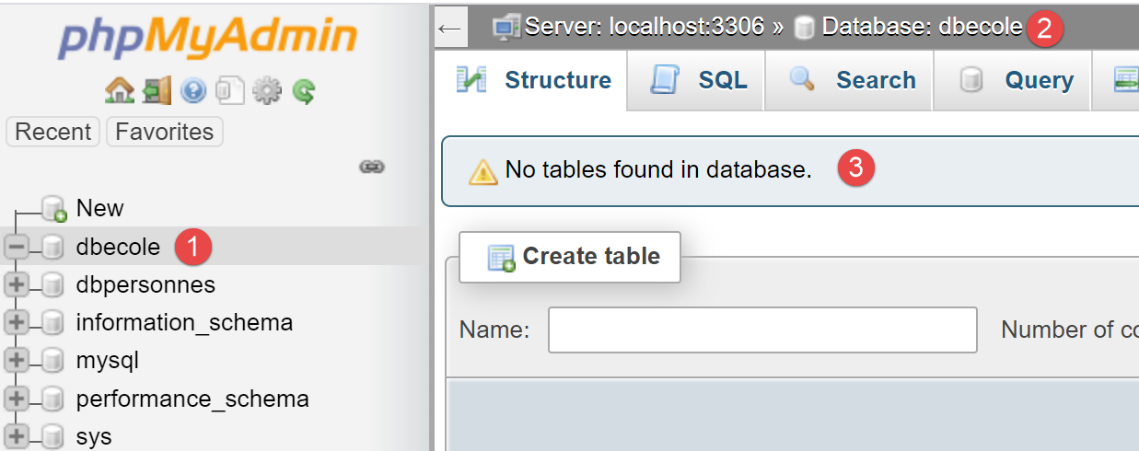
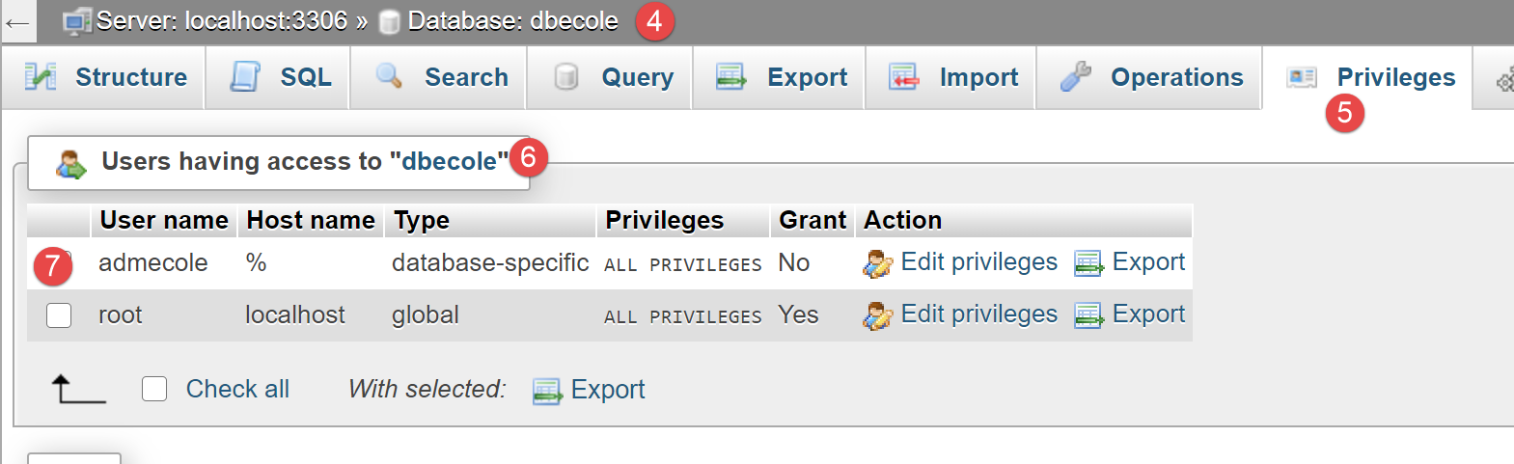
- in [1], il database [dbecole] non contiene tabelle [3];
- in [7], l'utente [admecole] ha privilegi completi su questo database;
Procediamo allo stesso modo con il DBMS PostgreSQL. Creiamo un database denominato [dbecole] di proprietà dell'utente [admecole] con la password [mdpecole]. A tal fine, seguiamo la procedura descritta nella sezione |creazione di un database|:
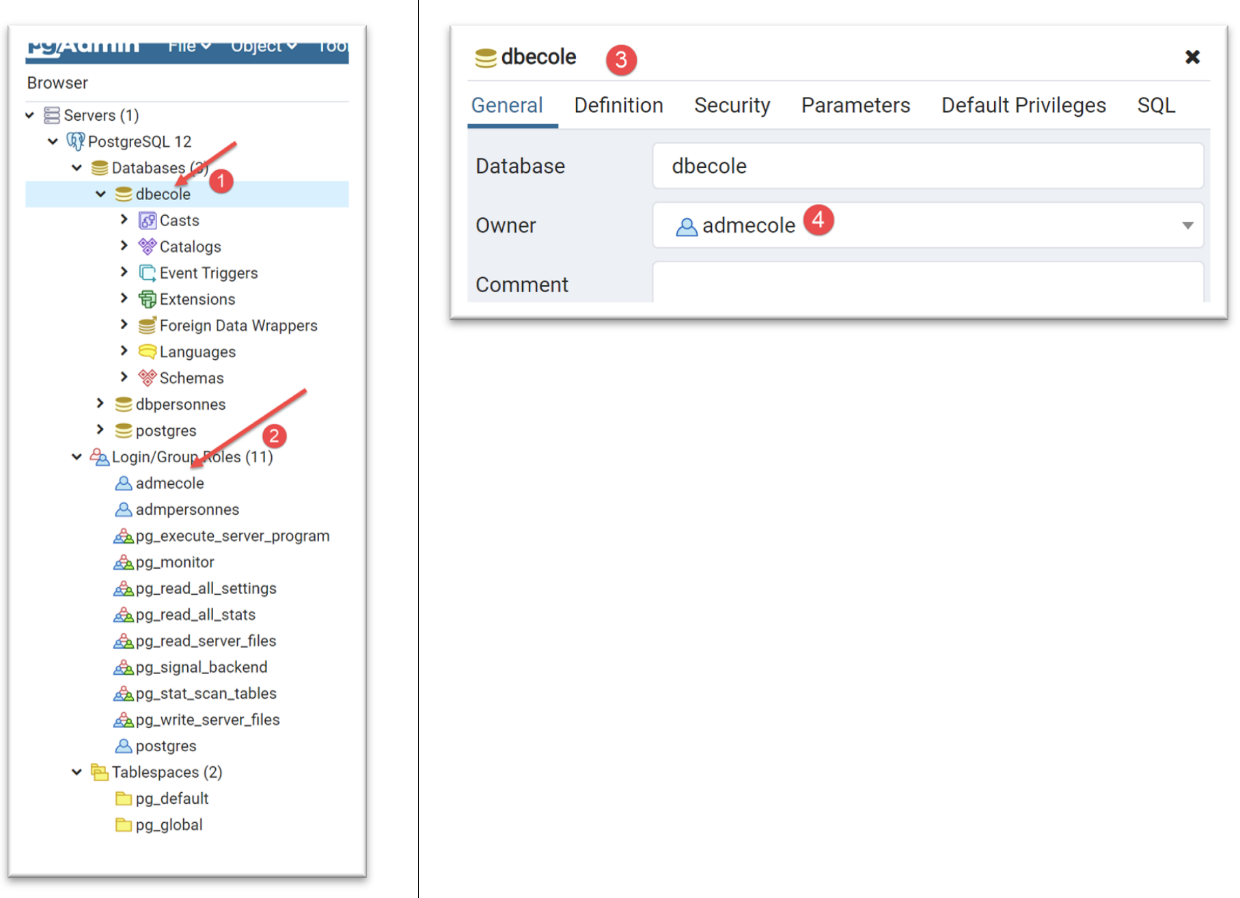
- in [1], il database [dbecole];
- in [2], l'utente [admecole];
- in [3-4], il database [dbecole] è di proprietà dell'utente [admecole];
19.6.3. Entità gestite dall'applicazione
Nell'applicazione |troiscouches v01|, le entità gestite erano le seguenti (vedi |entities|). Queste sono le entità che saranno memorizzate nei database precedenti. Non duplicheremo queste entità nella nuova applicazione. Le recupereremo da dove sono già definite.
La classe [Class]:
La classe [Student]:
La classe [Subject]:
La classe [Grade]:
19.6.4. Configurazione
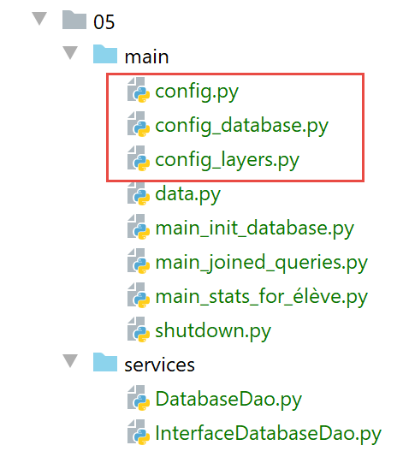
La configurazione è stata suddivisa in diversi file:
- configurazione generale in [config.py]: imposta il Python Path dell'applicazione e istanzia i livelli dell'architettura;
- configurazione [SQLAlchemy] in [config_database]: gestisce le mappature Classe/Tabella;
- I livelli dell'applicazione sono configurati in [config_layers];
Il file [config] è il seguente:
- righe 4–27: creazione del Python Path dell'applicazione;
- righe 29–32: configurazione [SQLAlchemy];
- righe 34–37: configurazione dei livelli dell'applicazione;
Il file [config_database] è il seguente:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 | |
Commenti
- righe 1-4: la funzione [configure] riceve un dizionario come parametro. Viene utilizzata solo la chiave [db]. È impostata su [mysql] se il database è un database MySQL, su [pgres] se il database è un database PostgreSQL;
- righe 6-9: importazioni di elementi da [sqlalchemy]. Lo script [config_database] esegue le mappature tra le tabelle nel database [dbecole] e le entità [Classes, Student, Subject, Grade]. Nella tabella, i dati dell'entità sono incapsulati in una riga. Nel codice Python, sono incapsulati in un oggetto. Da qui il nome ORM (Object Relational Mapper): l'ORM stabilisce una mappatura (un collegamento) tra le righe di un database relazionale e gli oggetti. In questa applicazione, abbiamo quattro entità [Class, Student, Subject, Grade] che saranno collegate a quattro tabelle [classes, students, subjects, grades]. Si noti che i nomi delle tabelle possono contenere caratteri accentati;
- righe 11–17: la stringa di connessione al database in uso. Questa dipende da config['db'].
- righe 24–28: le entità dell'applicazione che saranno mappate [SQLAlchemy]. Quando queste righe vengono eseguite, il Python Path sarà già stato stabilito dallo script [config];
- righe 30–40: la mappatura tra l'entità [Class] e la tabella [classes];
- righe 30–35: la tabella [classes] viene definita utilizzando la classe [Table] di [sqlalchemy]. Specifichiamo che questa tabella ha due colonne:
- la colonna [id], che è la chiave primaria e rappresenta il numero della classe, riga 33;
- la colonna [nome], che contiene il nome della classe, riga 34;
- righe 31–32: si noti che la sintassi x=y=z è valida in Python: il valore di z viene assegnato a y, poi il valore di y a x;
- righe 37–40: sono elencate le mappature tra le colonne della tabella [classes] e le proprietà dell'entità [Class];
- righe 42–57: la mappatura tra l'entità [Student] e la tabella [students];
- righe 51–57: la tabella [students] viene definita utilizzando la classe [Table] di [SQLAlchemy]. Specifichiamo che questa tabella ha quattro colonne:
- la colonna [id], che è la chiave primaria e rappresenta l'ID dello studente, riga 45;
- la colonna [name], che contiene il cognome dello studente, riga 46;
- la colonna [first_name], che contiene il nome dello studente, riga 47. Si noti che il nome di una colonna può contenere caratteri accentati;
- riga 49, la colonna [class_id], che conterrà l'ID della classe a cui appartiene lo studente. Questa è chiamata chiave esterna. [students.class_id] è una chiave esterna (ForeignKey) sulla colonna [classes.id]. Ciò significa che il valore di [students.class_id] deve esistere nella colonna [classes.id];
- Righe 51–57: Elenchiamo le mappature tra le colonne della tabella [students] e le proprietà dell'entità [Student]:
- Le righe 53–55 sono facili da comprendere;
- la riga 56 è più complessa: definisce il valore della proprietà [Student.class] come calcolato dalla relazione di chiave esterna che collega le tabelle [students] e [classes]. I parametri della funzione [relationship] sono i seguenti:
- [Class]: è il nome dell'entità con cui l'entità [Student] ha una relazione di chiave esterna. Ciò deve riflettersi nella tabella [students] con la presenza di una chiave esterna che fa riferimento alla tabella [classes]. Sappiamo che questa esiste;
- [backref="students"]: il nome di una proprietà che verrà aggiunta all'entità [Class]. [Class.students] sarà l'elenco di tutti gli studenti della classe. Questa proprietà non deve già esister . Se esiste già, basta scegliere qui un nome diverso per [backref]. Lo sviluppatore non ha bisogno di gestire questa proprietà. [SQLAlchemy] se ne occuperà. Lo sviluppatore deve semplicemente sapere che esiste, che è stata aggiunta da [SQLAlchemy] e che può usarla nel proprio codice;
- [lazy='select']: ciò significa che l'ORM non deve tentare di assegnare immediatamente un valore alla proprietà [Student.class]. Deve recuperare il suo valore solo quando il codice lo richiede esplicitamente. Pertanto:
- se il codice richiede un elenco di tutti gli studenti, questi verranno restituiti ma la loro proprietà [class] non verrà calcolata;
- poco dopo, il codice si concentra su uno studente specifico [e] e fa riferimento alla sua classe [e.class]. Questo riferimento costringerà quindi [SQLAlchemy] a eseguire una query sul database per recuperare la classe dello studente, il tutto in modo trasparente per lo sviluppatore;
- l'impostazione [lazy='select'] ha anche lo scopo di evitare query al database non necessarie;
- Riga 56: Quando l'ORM recupera una riga dalla tabella [students], recupera i campi [id, last_name, first_name, class_id]. Da lì, deve costruire un oggetto Student (id, last_name, first_name, class). Per le proprietà [id, last_name, first_name], ciò non pone alcuna difficoltà. Per la proprietà [class], è più complicato. Il suo valore è un riferimento a un oggetto di tipo [Class]. Tuttavia, l'ORM dispone solo di un'informazione: [students.class_id]. Poiché [students.class_id] è una chiave esterna sulla colonna [classes.id], qui gli indichiamo di utilizzare questa relazione per recuperare la riga con id=[students.class_id] dalla tabella [classes] (deve esistere) e di creare l'oggetto [Class] previsto dalla proprietà [Student.class] a partire da quella riga;
- righe 59–71: la mappatura tra l'entità [Subject] e la tabella [subjects];
- righe 59–65: definizione della tabella [SQLAlchemy] denominata [subjects];
- righe 66–71: elenchiamo le mappature tra le colonne della tabella [subjects] e le proprietà dell'entità [Subject]. Qui non ci sono difficoltà;
- righe 73–90: la mappatura tra l'entità [Note] e la tabella [notes];
- righe 73-82: definizione della tabella [sqlalchemy] denominata [notes]. Ha due chiavi esterne:
- riga 79, la colonna [notes.student_id] prende i suoi valori dalla colonna [students.id]. Questa chiave esterna riflette il fatto che una nota appartiene a uno studente specifico;
- riga 81: la colonna [notes.subject_id] prende i suoi valori dalla colonna [subjects.id]. Questa chiave esterna rappresenta il fatto che un voto è un voto in una materia specifica;
- Righe 84–90: la mappatura tra l'entità [Note] e la tabella [notes]:
- riga 88: la proprietà [Note.student] deve avere come valore un'istanza di tipo [Student]. L'ORM ha solo la colonna [notes.student_id] nella riga della tabella [notes], che fa riferimento alla colonna [students.id]. Qui specifichiamo di utilizzare questa relazione di chiave esterna per recuperare l'istanza [Student] per la quale abbiamo il voto. Inoltre, [relationship(Student, backref="grades", …)] creerà la nuova proprietà [Student.grades], che sarà l'elenco dei voti dello studente. Questa proprietà non deve già esistere nella classe [Student];
- Riga 89: La proprietà [Grade.subject] deve avere come valore un'istanza di tipo [Subject]. L'ORM dispone solo della colonna [notes.subject_id] nella riga della tabella [grades], che fa riferimento alla colonna [subjects.id]. Qui, stiamo specificando di utilizzare questa relazione di chiave esterna per recuperare l'istanza [Subject] per la quale disponiamo del voto. Inoltre, [relationship(Subject, backref="grades", …)] creerà la nuova proprietà [Subject.grades], che sarà l'elenco dei voti per la materia. Questa proprietà non deve già esistere nella classe [Subject];
- Righe 92–96: Per ogni entità derivata da [BaseEntity], definiamo l'elenco delle proprietà da escludere dal dizionario delle proprietà dell'entità (BaseEntity.asdict). Abbiamo visto che [sqlalchemy] aggiunge la proprietà [_sa_instance_state] a tutte le entità mappate. Non vogliamo che questa sia presente nel dizionario delle proprietà. Inoltre, abbiamo visto che le mappature precedenti aggiungevano nuove proprietà alle entità:
- [Student.grades]: tutti i voti dello studente;
- [Class.students]: tutti gli studenti della classe;
- [Subject.grades]: tutti i voti per la materia;
In generale, non vogliamo che queste proprietà vengano aggiunte allo stato dell'entità. Infatti, il calcolo del loro valore comporta un costo SQL e spesso questo valore non è necessario. Quindi, se recuperiamo lo studente di nome "X":
- (continua)
- l'ORM restituirà un'entità [Student(id, last_name, first_name, class, grades)]. A causa di [lazy='select'], le proprietà [class, grades] collegate alle chiavi esterne nel database non saranno state calcolate;
- ora, se visualizzo la stringa JSON per questo studente, sappiamo che sarà la stringa JSON proveniente dal dizionario [asdict] dell'entità. Se le proprietà [class] e [grades] sono incluse, [SQLAlchemy] sarà costretto a eseguire query SQL per calcolarne i valori. Questo è costoso. Se possiamo evitare queste query, è preferibile;
- qui abbiamo escluso tutte le proprietà collegate a una chiave esterna;
- righe 98–100: istanziazione e configurazione di una [Session factory] (factory = factory di produzione). L'oggetto [Session] viene utilizzato per creare sessioni [SQLAlchemy] supportate da transazioni;
- righe 102–103: creazione di una sessione [SQLAlchemy];
- riga 106: alcuni elementi della configurazione [SQLAlchemy] vengono inseriti nel dizionario di configurazione globale dell'applicazione;
- riga 109: questo dizionario viene restituito;
Il file [config_layers] configura i livelli dell'applicazione:
- Riga 1: la funzione [configure] riceve il dizionario contenente la configurazione globale dell'applicazione;
- righe 2–12: vengono istanziati i livelli dell'applicazione;
- righe 15–17: i riferimenti ai livelli vengono aggiunti alla configurazione globale;
- riga 20: viene restituita la nuova configurazione;
19.6.5. Il livello [dao] - 1
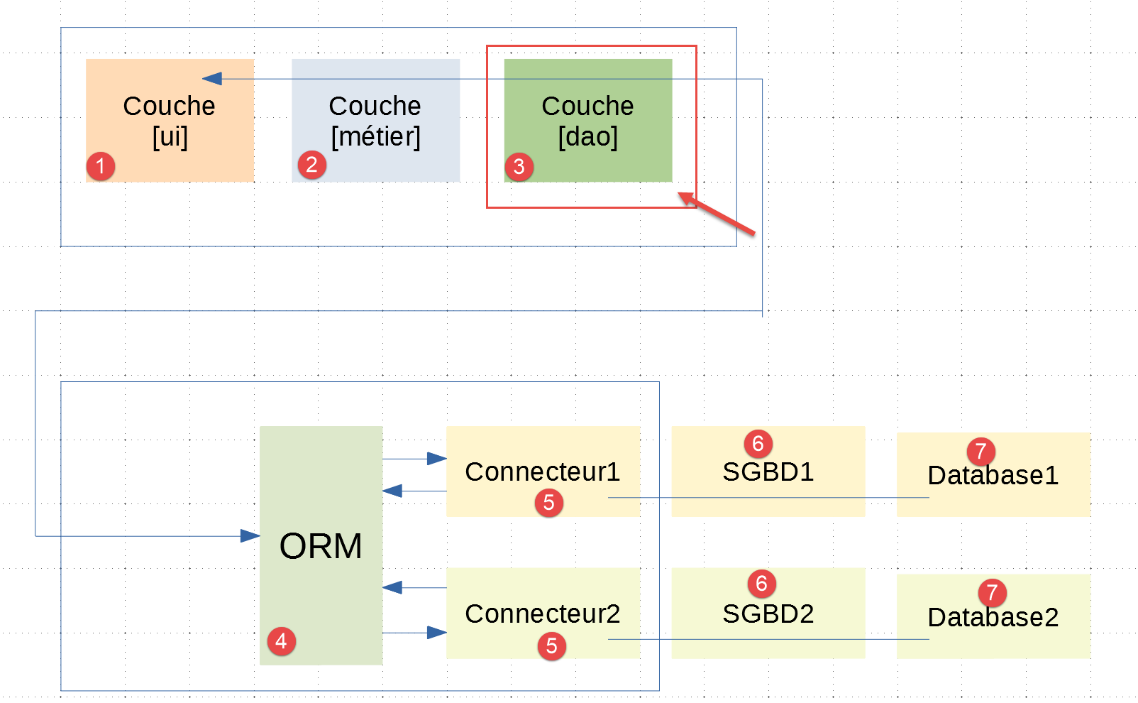
È importante comprendere che il livello [dao] [3] comunica con l'ORM [sqlalchemy] [4] configurato come descritto nel paragrafo precedente. Dei tre livelli [ui, business, dao] dell'applicazione |troiscouches v01|, solo il livello [dao] deve essere riscritto. I livelli [ui, business] vengono mantenuti.
L'implementazione del livello [dao] è stata inserita nella cartella [services]:

[InterfaceDatabaseDao] è l'interfaccia per il livello [DAO]:
- riga 6: l'interfaccia [InterfaceDatabaseDao] deriva sia dalla classe [ABC] per essere una classe astratta, sia dall'interfaccia [InterfaceDao] del progetto |troiscouches v01|;
- righe 8–11: aggiungiamo il metodo [init_database] ai metodi ereditati da [InterfaceDao]. Il suo ruolo sarà quello di inizializzare il database con i dati del dizionario [data] che gli vengono passati come parametro alla riga 10;
Ricordiamo che l'interfaccia [InterfaceDao] era la seguente:
L'implementazione del livello [DAO] è la seguente:
- riga 11: la classe [DatabaseDao] implementa l'interfaccia [InterfaceDatabaseDao];
- righe 13–16: il costruttore della classe. Accetta come parametro il dizionario di configurazione dell'applicazione;
- riga 15: viene memorizzata la configurazione [sqlalchemy];
- riga 16: viene memorizzata la sessione [sqlalchemy] attraverso la quale verrà gestito il database;
- riga 18: il metodo [init_database] inizializza il database con il dizionario [data];
Il dizionario [data] è implementato dal seguente script [data.py]:
- riga 34: il dizionario che verrà passato al metodo [init_database]. Questo dizionario è composto dalle seguenti chiavi (riga 32):
- [students]: l'elenco degli studenti;
- [classes]: l'elenco delle classi;
- [materie]: l'elenco delle materie;
- [voti]: l'elenco dei voti di tutti gli studenti in tutte le materie;
Torniamo al metodo [init_database]:
- righe 3–6: recupero delle informazioni dalla configurazione del database;
- righe 9-14: abbiamo visto che la configurazione [sqlalchemy] aveva mappato quattro entità su quattro tabelle [studenti, materie, classi, voti]. Iniziamo eliminando queste tabelle se esistono;
- righe 16-17: ricreiamo le quattro tabelle appena eliminate;
- righe 22–25: aggiungiamo tutte le classi alla sessione;
- righe 27–30: aggiungiamo tutte le materie alla sessione;
- righe 32–35: aggiungiamo tutti gli studenti alla sessione;
- righe 37–40: aggiungiamo tutti i voti alla sessione;
- Per effettuare queste aggiunte, abbiamo seguito un ordine specifico. Abbiamo iniziato con le entità che non hanno relazioni con altre entità e abbiamo terminato con quelle che ne hanno. Pertanto, quando aggiungiamo gli studenti alla sessione, le classi a cui fanno riferimento sono già presenti nella sessione;
- riga 43: la sessione [sqlalchemy] viene confermata. Dopo questa operazione, possiamo essere certi che tutti i dati nella sessione siano stati sincronizzati con il database. In breve, i dati sono stati inseriti nelle tabelle. Ciò è stato reso possibile dalle mappature definite nella configurazione [sqlalchemy]. [sqlalchemy] sa come ogni entità debba essere memorizzata nelle tabelle. [sqlalchemy] ha anche generato eventuali chiavi esterne che le tabelle potrebbero avere;
- righe 44–49: se si verifica un problema, la sessione [sqlalchemy] viene annullata e, alla riga 49, viene generata un'eccezione;
19.6.6. Inizializzazione del database
Lo script [main_init_database] inizializza il database con il contenuto dello script [data.py]. Il suo codice è il seguente:
- righe 1-11: lo script si aspetta un parametro [mysql] o [pgres] a seconda che si voglia inizializzare un database MySQL o PostgreSQL;
- righe 13-15: l'applicazione viene configurata per il DBMS passato come parametro;
- righe 20-22: vengono recuperati i dati da inserire nel database;
- riga 25: il livello [dao] è già stato istanziato ed è accessibile nella configurazione dell'applicazione;
- riga 30: il database viene inizializzato;
- righe 34–37: indipendentemente dal fatto che si sia verificato un errore, le risorse dell'applicazione vengono rilasciate utilizzando il modulo [shutdown];
Il modulo [shutdown.py] è il seguente:
La funzione [shutdown.execute] chiude la sessione [sqlalchemy] utilizzata per inizializzare il database.
Creiamo una configurazione di esecuzione iniziale (vedi |configurazione di esecuzione|) per eseguire [main_init_database] con il sistema di gestione del database MySQL:
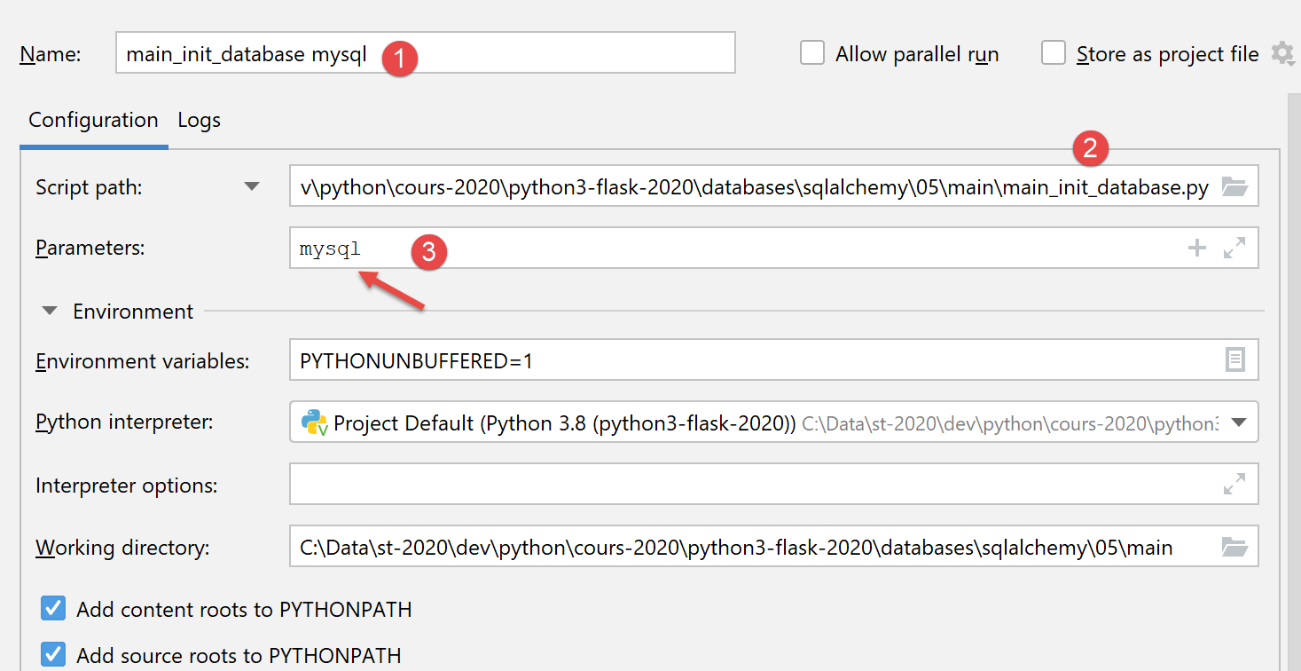
I risultati dell'esecuzione di questa configurazione in phpMyAdmin sono i seguenti:
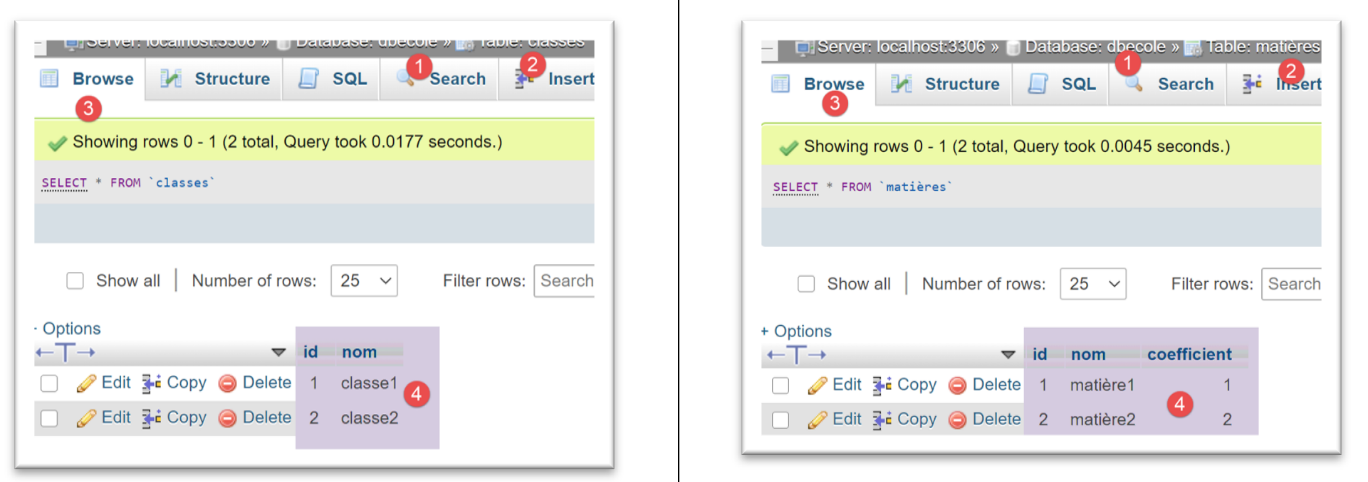
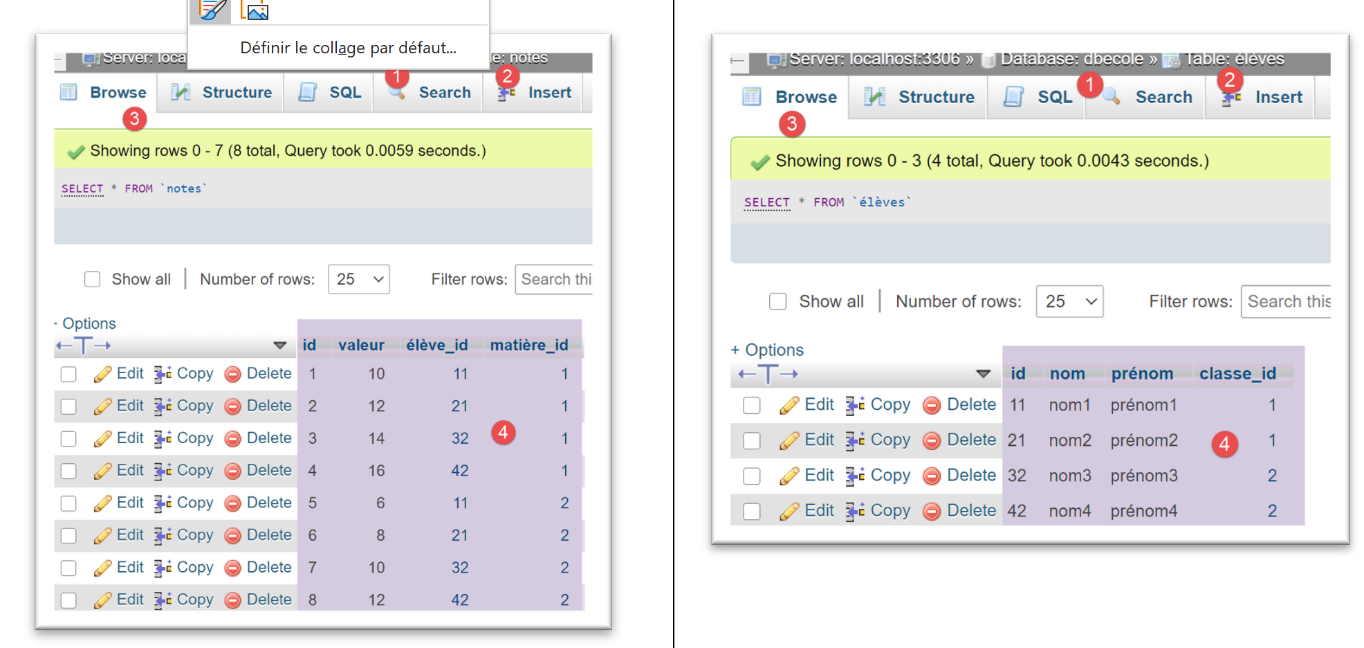
Per il DBMS [PostgreSQL], utilizziamo la seguente configurazione di esecuzione:
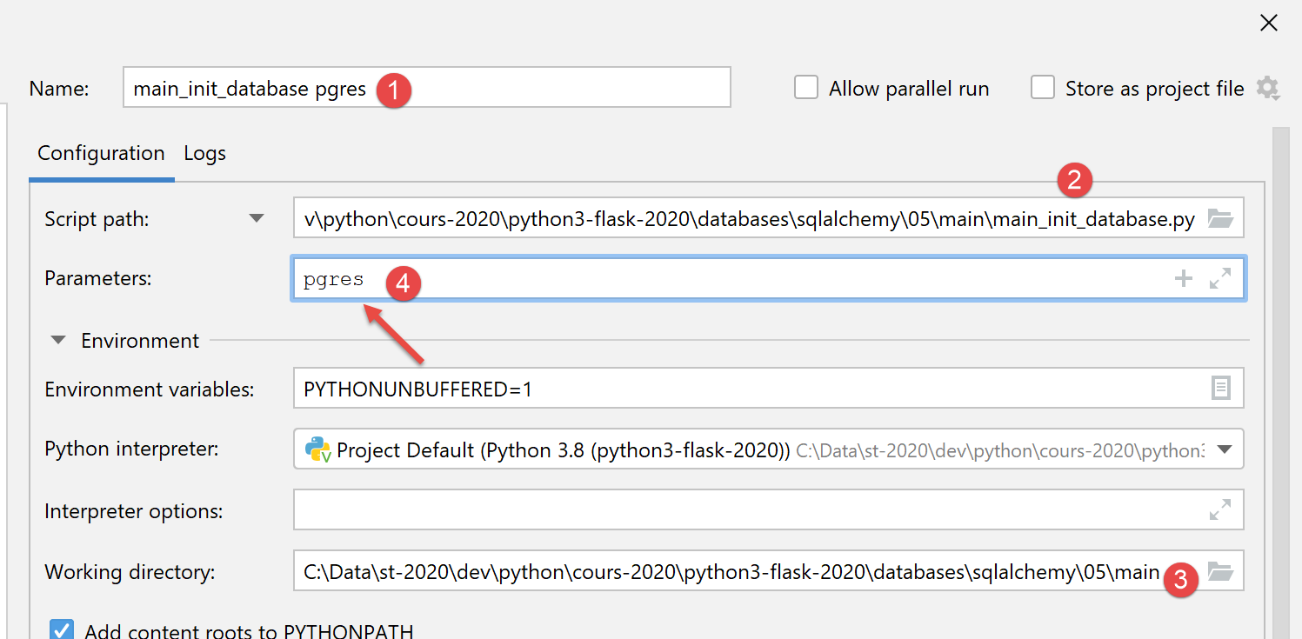
Una volta eseguita, i risultati in [pgAdmin] sono i seguenti:

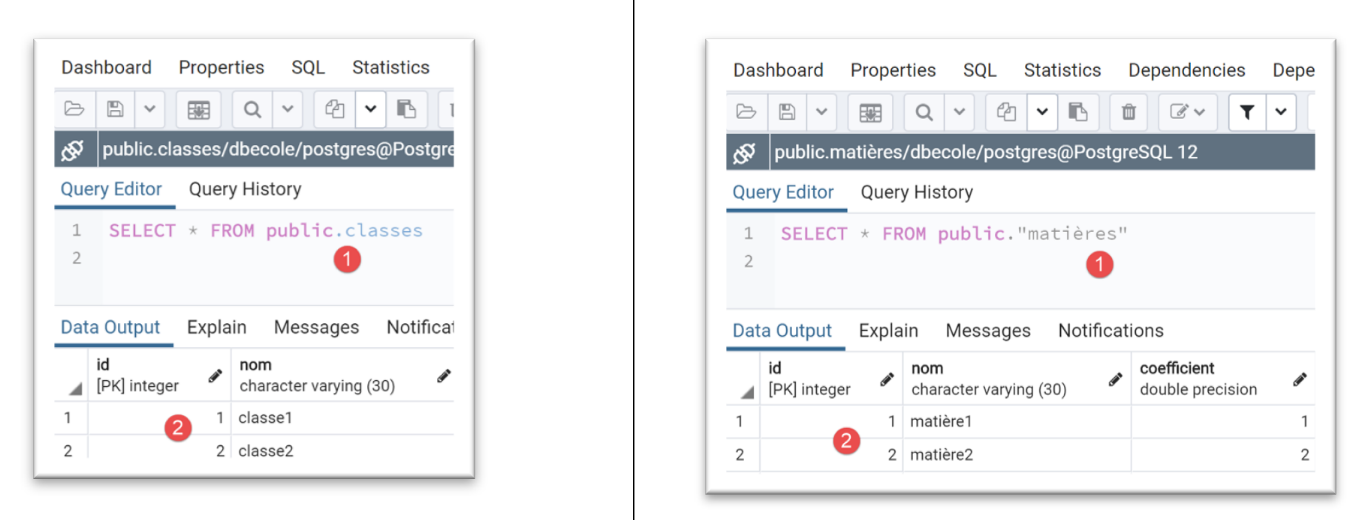
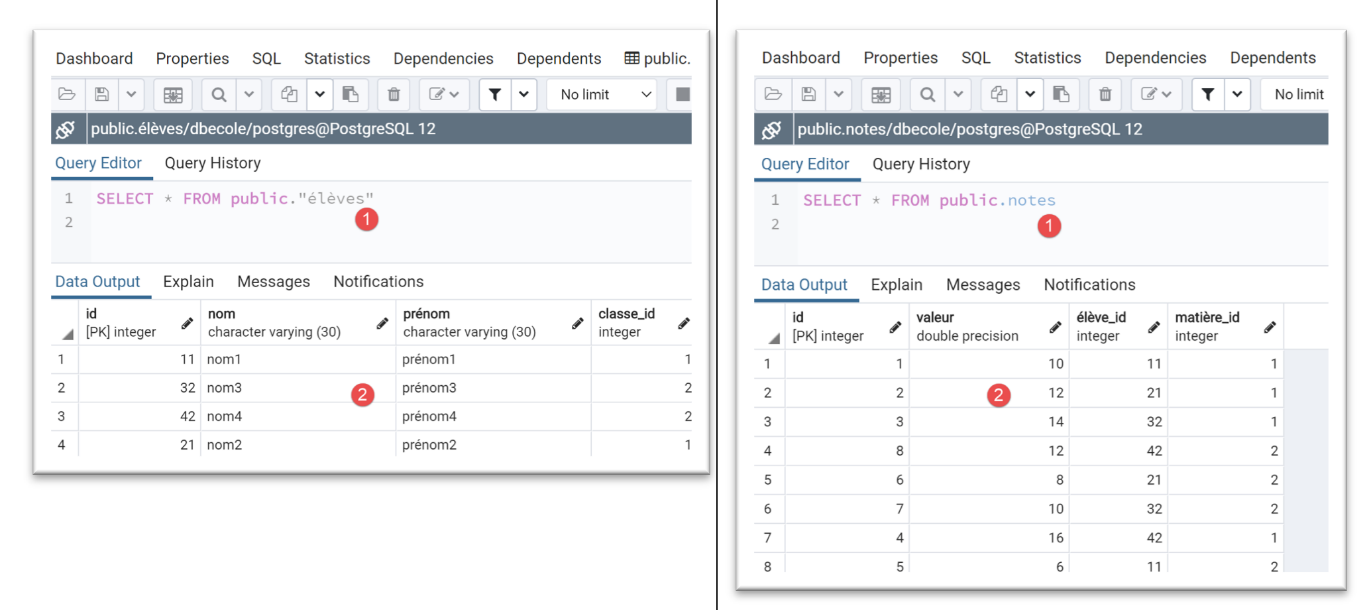
Si noti con quanta facilità siamo riusciti a cambiare DBMS.
19.6.7. Il livello [dao] – 2
Torniamo alla classe [DatabaseDao], che implementa il livello [DAO]. Finora abbiamo mostrato solo l'implementazione del metodo [init_database]. Ora mostreremo l'implementazione degli altri metodi:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 | |
- righe 21–24: il metodo [get_classes] deve restituire l'elenco delle classi della scuola. Alla riga 20 utilizziamo una query che abbiamo già visto in precedenza;
- righe 26–39: altri tre metodi simili per recuperare gli elenchi di studenti, materie e voti;
- righe 51–59: il metodo [get_student_by_id] deve restituire uno studente identificato dal proprio ID. Genera un'eccezione se lo studente non esiste;
- riga 54: usiamo una query filtrata. Otteniamo un elenco vuoto o un elenco con un solo elemento;
- riga 57: se l'elenco recuperato non è vuoto, restituisce il primo elemento dell'elenco;
- altrimenti, riga 59, viene generata un'eccezione;
- righe 41–49: il metodo [get_notes_for_student_by_id] deve restituire i voti di uno studente identificato dal proprio ID:
- riga 45: usiamo il metodo [get_student_by_id] per recuperare l'entità Student per lo studente;
- riga 47: usiamo la proprietà [Student.grades] creata dalla mappatura tra l'entità [Grade] e la tabella [grades] (vedi la sezione |Configurazione di SQLAlchemy|), che rappresenta i voti dello studente;
- riga 49: restituiamo un dizionario;
- Righe 61–109: una serie di metodi simili che ci consentono di:
- trovare uno studente per nome, righe 61–69;
- trovare una classe, righe 71–89;
- recuperare una materia, righe 91–109;
19.6.8. Lo script [main_joined_queries]
Lo script [main_joined_queries] si chiama così perché mira a evidenziare le query implicitamente eseguite da [sqlalchemy] per recuperare informazioni da più tabelle. Queste query, nascoste al programmatore, vengono eseguite ogni volta che una proprietà di un'entità è stata associata alla funzione [relationship] nella mappatura dell'entità. Ad esempio:
# mapping
mapper(Note, tables['notes'], properties={
'id': notes_table.c.id,
'valeur': notes_table.c.valeur,
'élève': relationship(Elève, backref="notes", lazy="select"),
'matière': relationship(Matière, backref="notes", lazy="select")
})
Quella sopra è la mappatura tra l'entità [Note] e la tabella [notes]:
- Riga 5: Quando la proprietà [student] di un'entità [Grade] viene richiesta per la prima volta, verrà recuperata dalla tabella [students] tramite una query SQL. Finché questa proprietà non viene richiesta, rimane indefinita (caricamento differito). Una volta recuperato, il suo valore rimane nella memoria dell’ORM. Quando viene richiamato una seconda volta, l’ORM restituirà immediatamente il suo valore senza eseguire una nuova query SQL. Tutto questo è trasparente per lo sviluppatore;
- lo stesso vale per la proprietà inversa [Student.grades] (backref), riga 5;
- lo stesso vale per la proprietà [Grade.subject] e la sua proprietà inversa [Subject.grades] (backref), riga 6;
Lo script [main_joined_queries] è il seguente:
I commenti sono sufficienti per comprendere il codice.
Creiamo una configurazione di esecuzione per MySQL:
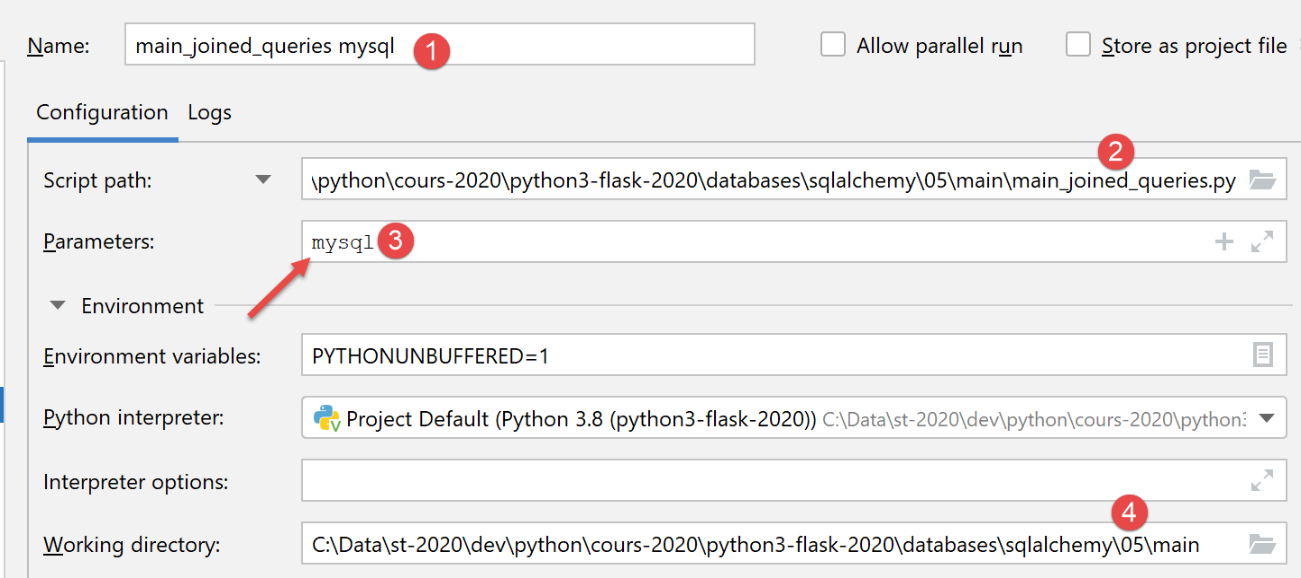
I risultati dell'esecuzione sono i seguenti:
Per comprendere questi risultati, ricorda che alcune proprietà sono state escluse dal dizionario delle entità (vedi |configurazione|):
# configuration des entités [BaseEntity]
Elève.excluded_keys = ['_sa_instance_state', 'notes', 'classe']
Classe.excluded_keys = ['_sa_instance_state', 'élèves']
Matière.excluded_keys = ['_sa_instance_state', 'notes']
Note.excluded_keys = ['_sa_instance_state', 'matière', 'élève']
Quindi, quando scriviamo [print(f"student={student}")] alla riga 26 del codice, la riga 1 sopra ci dice che le proprietà ['_sa_instance_state', 'grades', 'class'] non verranno visualizzate. Questo è ciò che vediamo alla riga 3 dei risultati. Tutte le altre proprietà vengono visualizzate. Pertanto, sempre alla riga 3, scopriamo una nuova proprietà [class_id] che inizialmente non esisteva nell'entità [Student]. Questa proprietà corrisponde direttamente alla colonna [class_id] nella tabella [students]. Pertanto, [SQLAlchemy] ha aggiunto le seguenti proprietà all'entità [Student]: [class_id, _sa_instance_state, grades]. È importante esserne consapevoli, in particolare perché queste proprietà non devono già esistere nell'entità mappata.
Le proprietà escluse dal dizionario dell'entità sono importanti. Ad esempio, se non si escludono le proprietà [grades, student] dall'entità [Student], l'operazione [print(f"student={student}")] le visualizzerà e, come appena spiegato, attiverà query SQL implicite (caricamento differito) per recuperare i valori di tali proprietà. Se, come in questo caso, viene visualizzato un elenco di studenti, le operazioni SQL implicite vengono eseguite per ogni studente. Ciò può essere sia superfluo che certamente dispendioso in termini di tempo di esecuzione.
Per eseguire lo script con un database PostgreSQL, creare la seguente configurazione di esecuzione:
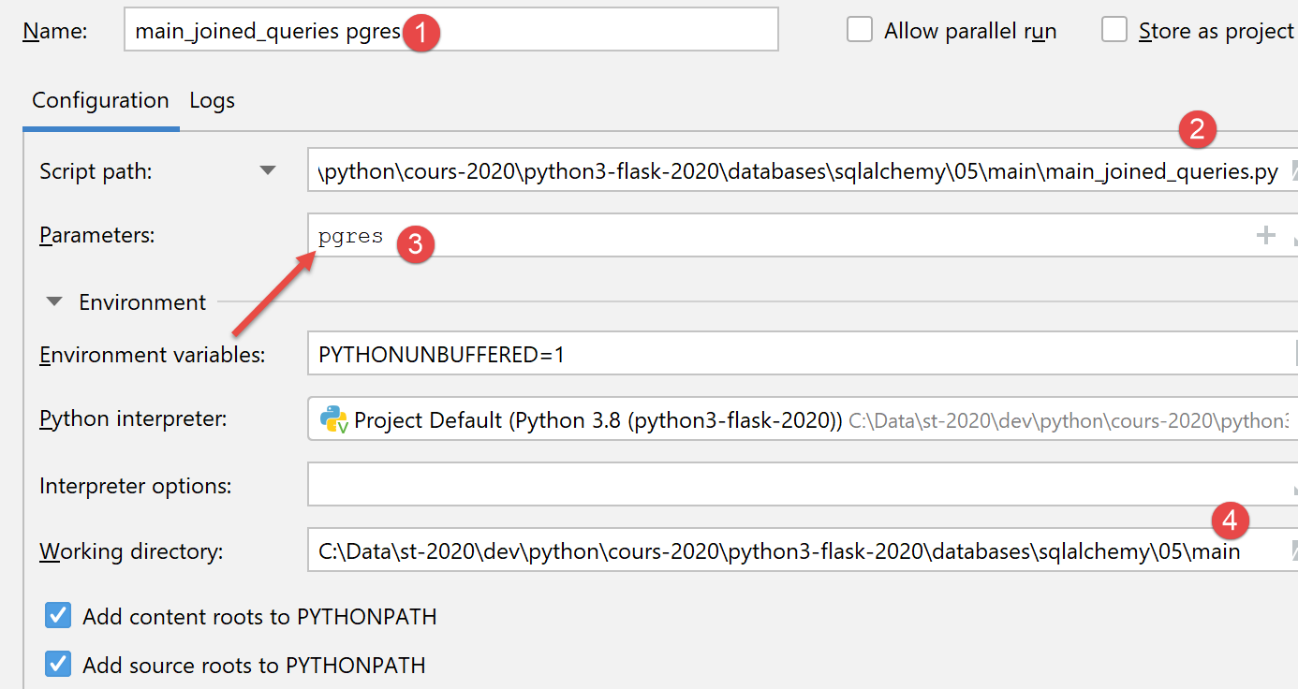
L'esecuzione produce gli stessi risultati di MySQL.
19.6.9. Lo script [main_stats_for_student]
Lo script [main_stats_for_student] è quello già utilizzato nell'applicazione |troiscouches v01|. In precedenza era denominato [main]. Si tratta di un'applicazione console che recupera alcune metriche relative ai voti di uno studente: [media ponderata, min, max, elenco]. Si inserisce nella seguente architettura:
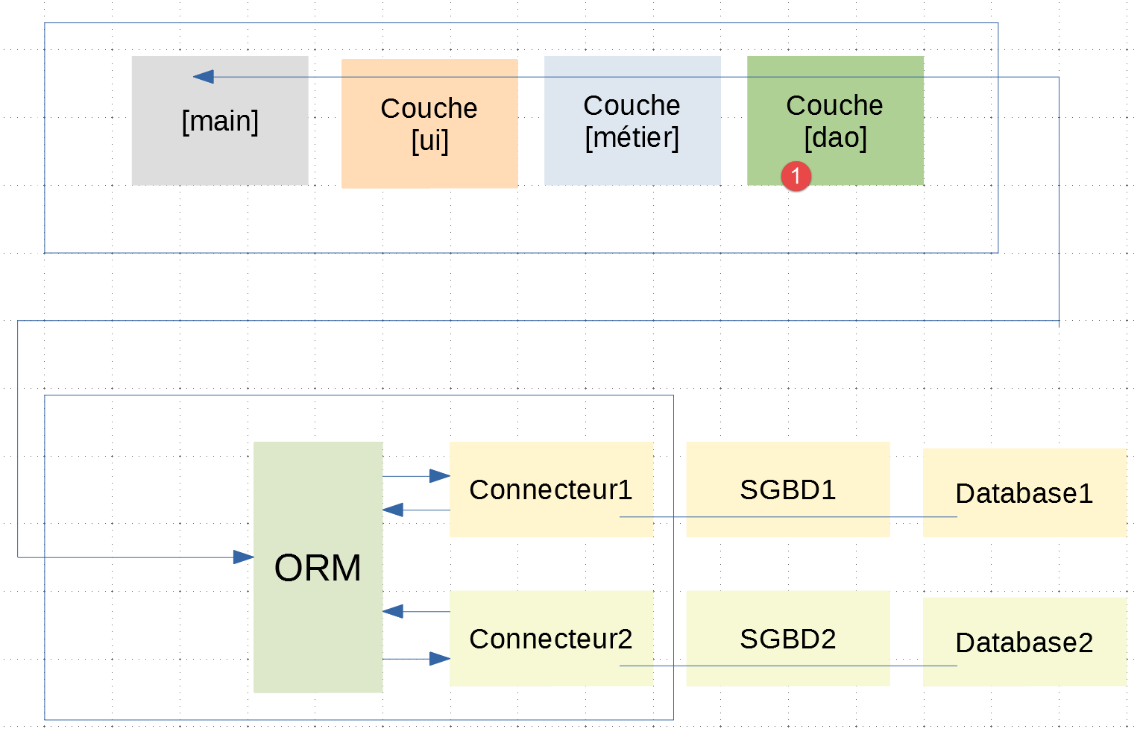
In questa architettura a livelli, solo il livello [dao] è stato modificato tra l'applicazione |troiscouches v01| e questa. Poiché il nuovo livello [dao] aderisce all'interfaccia [InterfaceDao] del vecchio livello [dao], i livelli [ui, business] non devono essere modificati. Possiamo quindi continuare a utilizzare quelli definiti nell'applicazione |troiscouches v01|.
Lo script [main_stats_for_élève] implementa il livello [main] del diagramma sopra riportato come segue:
- riga 20: recupera un riferimento al livello [ui] dalla configurazione dell'applicazione;
- riga 24: avviamo la finestra di dialogo utente utilizzando il metodo single del livello [ui];
Una configurazione di esecuzione per PostgreSQL sarebbe simile a questa:
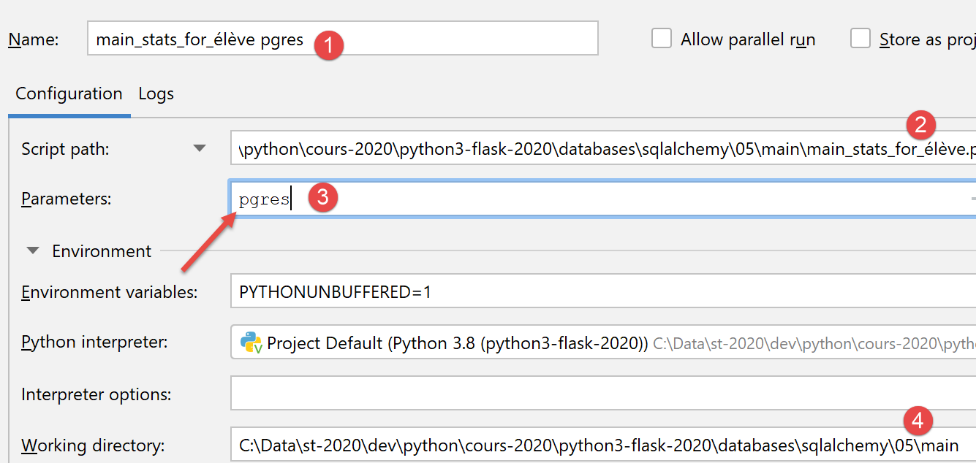
Ecco un esempio di esecuzione con questa configurazione:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/databases/sqlalchemy/05/main/main_stats_for_élève.py pgres
Numéro de l'élève (>=1 et * pour arrêter) : 11
Elève={"prénom": "prénom1", "id": 11, "classe_id": 1, "nom": "nom1"}, notes=[10.0 6.0], max=10.0, min=6.0, moyenne pondérée=7.33
Numéro de l'élève (>=1 et * pour arrêter) : 1
L'erreur suivante s'est produite : MyException[11, L'élève d'identifiant 1 n'existe pas]
Numéro de l'élève (>=1 et * pour arrêter) : *
Process finished with exit code 0