4. Stringhe
4.1. Script [str_01]: notazione stringa
Lo script [str_01] è il seguente:
Commenti
- riga 3: una stringa delimitata da virgolette doppie ";
- riga 4: una stringa delimitata da virgolette singole ';
- Riga 5: una stringa racchiusa tra virgolette triple """. In questo caso, la stringa può estendersi su più righe;
I risultati sono i seguenti:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/strings/str_01.py
chaine1=[un], chaine2=[deux], chaine3=[hélène va au
marché acheter des légumes]
Process finished with exit code 0
4.2. Script [str_02]: Metodi della classe <str>
Lo script [str_02] presenta alcuni dei metodi della classe <str>, ovvero la classe delle stringhe:
I commenti, insieme ai risultati ottenuti, sono sufficienti per comprendere lo script. I risultati sono i seguenti:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/strings/str_02.py
'ABCD'.lower()=abcd
'abcd'.upper()=ABCD
'cheval[2]=e
'caractères accentués'[5:7]=tè
'caractères accentués'[4:]=ctères accentués
'caractères accentués'[:5]=carac
len('123')=3
' abcd '.strip()=[abcd]
' abcd '.rstrip()=[ abcd]
' abcd '.lstrip()=[abcd ]
str.strip()=[abcd]
'abcd'.replace('a','x')=xbcd
'abcd'.replace('ab','xy')=xycd
'abcd'.find('bc')=1
'abcd'.find('bc')=-1
'abcd'.startswith('ab')=True
'abcd'.startswith('x')=False
'abcd'.endswith('cd')=True
'abcd'.endswith('x')=False
'[X]'.join(['abcd', '123', 'èéà'])=abcd[X]123[X]èéà
''.join(['abcd', '123', 'èéà'])=abcd123èéà
'abcd 123 cdXY'.split('cd')=['ab', ' 123 ', 'XY']
'abcd 123 cdXY'.split(None)=['abcd', '123', 'cdXY']
Process finished with exit code 0
4.3. Script [str_03]: Codifica delle stringhe (1)
Lo script [str_03] introduce concetti relativi alla codifica delle stringhe:
La codifica di una stringa di tipo <str> produce una stringa binaria in cui ogni carattere della stringa è rappresentato da uno o più byte. Esistono diversi tipi di codifica. Lo script sopra riportato mostra i due più comuni in Occidente: "utf-8" e "iso-8859-1", noto anche come "latin1".
Il principio di codifica/decodifica è illustrato di seguito (rif. |https://realpython.com/python-encodings-guide/ |):
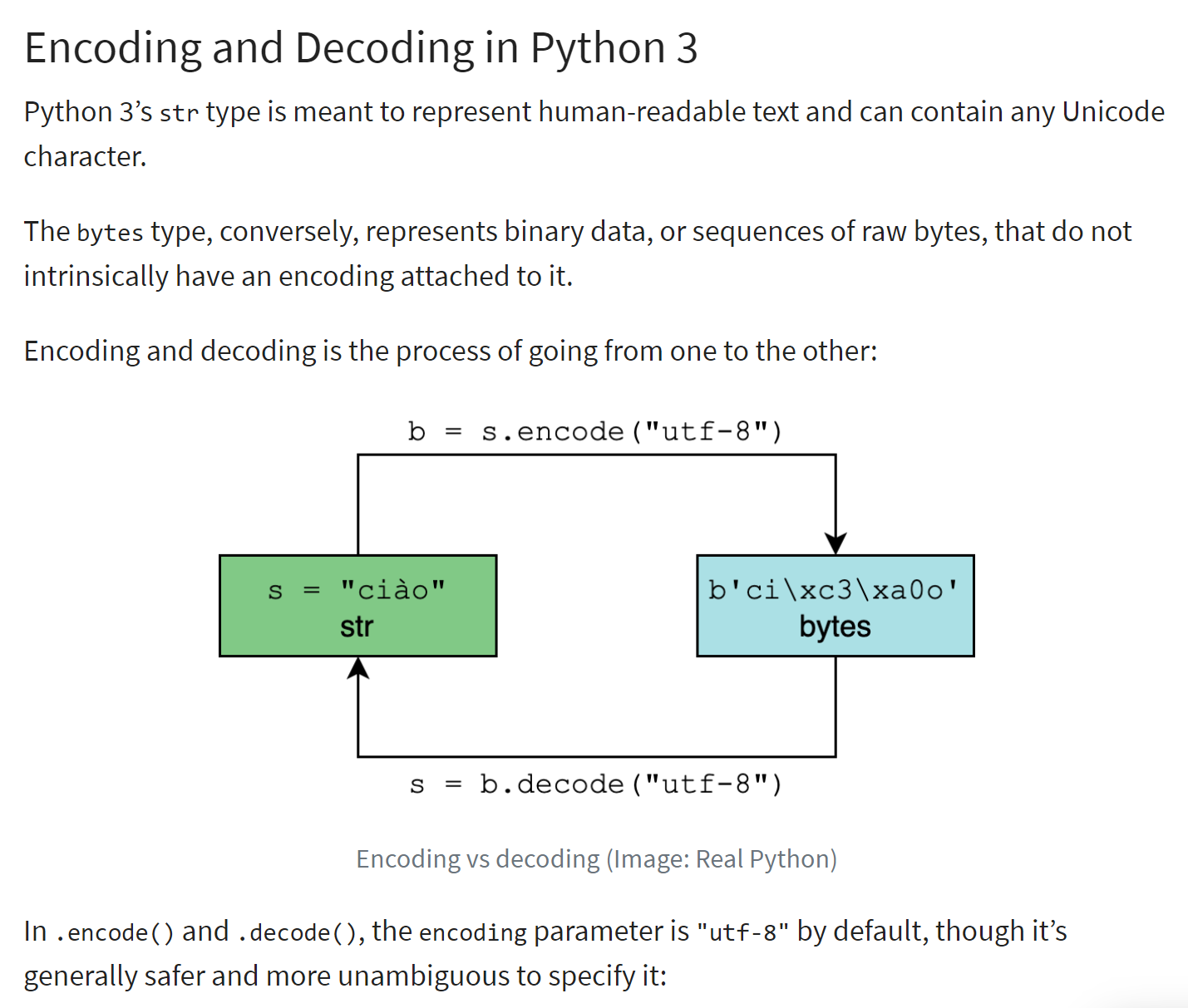
Commenti
- righe 4-5: la stringa di caratteri iniziale da codificare. Le istanze di tipo <str> sono stringhe Unicode |https://docs.python.org/3/howto/unicode.html|, |https://realpython.com/python-encodings-guide/ |;
- righe 6-11: due modi per codificare una stringa in UTF-8:
- riga 8: str.encode('utf-8');
- riga 10: bytes(str, 'utf-8');
- righe 12-17: facciamo la stessa cosa con la codifica 'iso-8859-1';
- righe 18-23: 'latin1' è un altro nome per la codifica 'iso-8859-1';
I risultati sono i seguenti:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/strings/str_03.py
str=[hélène va au marché acheter des légumes, type=<class 'str'>
--- utf-8
bytes1=b'h\xc3\xa9l\xc3\xa8ne va au march\xc3\xa9 acheter des l\xc3\xa9gumes', type=<class 'bytes'>
bytes2=b'h\xc3\xa9l\xc3\xa8ne va au march\xc3\xa9 acheter des l\xc3\xa9gumes', type=<class 'bytes'>
--- iso-8859-1
bytes1=b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes', type=<class 'bytes'>
bytes2=b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes', type=<class 'bytes'>
--- latin1
bytes1=b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes', type=<class 'bytes'>
bytes2=b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes', type=<class 'bytes'>
Process finished with exit code 0
Commenti
- riga 4: vediamo che i caratteri accentati sono stati codificati utilizzando due byte:
- é: [\xc3\xa9], che è la sequenza binaria 11000011 10101001;
- è: [\xc3\xa8], che è la sequenza binaria 11000011 10101000;
- Riga 7: Con la codifica ISO-8859-1, questi due caratteri accentati sono codificati in modo diverso:
- é: [\xe9], che è la sequenza binaria 11101001;
- è: [\xe8], che è la sequenza binaria 11101000;
4.4. Script [str_04]: Codifica delle stringhe di caratteri (2)
Lo script [str_04] introduce altri due tipi di codifica: "base64" e "quoted-printable". Queste due codifiche non codificano stringhe di caratteri Unicode, ma piuttosto oggetti binari. Ad esempio, quando si allega un documento Word a un'e-mail, questo verrà sottoposto a una di queste due codifiche a seconda del client di posta elettronica utilizzato. Questo vale per la maggior parte dei file allegati.
Lo script è il seguente:
Commenti
- riga 2: il modulo [codecs] supporta le codifiche 'base64' e 'quoted-printable'. Ne supporta molte altre;
- righe 4–7: la stringa Unicode che verrà sottoposta a varie codifiche;
- righe 9-12: codifica UTF-8. Questo produce una stringa binaria;
- righe 14-18: decodifica UTF-8 per tornare alla stringa Unicode originale;
- righe 20–29: ripetiamo lo stesso processo con la codifica 'iso-8859-1';
- righe 31–34: viene visualizzato un errore di decodifica:
- riga 33: bytes1 è una stringa binaria codificata in 'utf-8'. La decodifichiamo in 'iso-8859-1';
- righe 36–39: un altro modo per codificare una stringa in UTF-8 utilizzando il modulo [codecs];
- righe 41-44: una stringa binaria 'utf-8' viene codificata in 'base64';
- righe 46–49: mostrano come convertire la stringa binaria 'base64' nella stringa Unicode originale;
- righe 51–59: ripetiamo questo processo utilizzando la codifica 'quoted-printable' invece di 'base64';
I risultati sono i seguenti:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/strings/str_04.py
---- chaîne unicode
str1=[hélène va au marché acheter des légumes], type(str1)=<class 'str'>
---- chaîne unicode -> binaire utf-8
bytes1=[b'h\xc3\xa9l\xc3\xa8ne va au march\xc3\xa9 acheter des l\xc3\xa9gumes'], type(bytes1)=<class 'bytes'>
---- binaire utf-8 -> chaîne unicode
str2=[hélène va au marché acheter des légumes], type(str2)=<class 'str'>
str2==str1=True
---- chaîne unicode -> binaire iso-8859-1
bytes2=[b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes'], type(bytes2)=<class 'bytes'>
---- binaire iso-8859-1 -> chaîne unicode
str3=[hélène va au marché acheter des légumes], type(str3)=<class 'str'>
str3==str1=True
--- binaire utf-8 (décodage iso-8859-1) --> chaîne unicode
str4=[hélène va au marché acheter des légumes], type(str4)=<class 'str'>
---- chaîne unicode -> binaire utf-8
bytes3=[b'h\xc3\xa9l\xc3\xa8ne va au march\xc3\xa9 acheter des l\xc3\xa9gumes'], type(bytes3)=<class 'bytes'>
---- binaire utf-8 -> binaire base64
bytes4=[b'aMOpbMOobmUgdmEgYXUgbWFyY2jDqSBhY2hldGVyIGRlcyBsw6lndW1lcw==\n'], type(bytes4)=<class 'bytes'>
---- binaire base64 -> binaire utf-8 -> chaîne unicode
str6=[hélène va au marché acheter des légumes], type(str6)=<class 'str'>
---- binaire utf-8 -> binaire quoted-printable
str7=[b'h=C3=A9l=C3=A8ne=20va=20au=20march=C3=A9=20acheter=20des=20l=C3=A9gumes'], type(str7)=<class 'bytes'>
---- binaire quoted-printable -> binaire utf-8 -> chaîne unicode
str8=[hélène va au marché acheter des légumes], type(str8)=<class 'str'>
Process finished with exit code 0
- righe 14-15: un file binario UTF-8 viene decodificato in una stringa Unicode utilizzando il decodificatore errato 'iso-8859-1'. Di conseguenza, alcuni caratteri Unicode generati sono errati, in questo caso i caratteri accentati;
- righe 18-19: la codifica «base64» prevede l'uso di 64 caratteri ASCII (codificati su 7 bit) per codificare qualsiasi dato binario. Come si può notare, ciò aumenta la dimensione dei dati binari della stringa;
- righe 22–23: anche la codifica "quoted-printable" utilizza caratteri ASCII (codificati su 7 bit) per codificare qualsiasi dato binario;
È importante ricordare che quando si ricevono dati binari — da Internet, ad esempio — che rappresentano del testo, è necessario conoscere le codifiche a cui sono stati sottoposti per poter recuperare il testo originale.