7. File di testo
7.1. Script [fic_01]: Lettura/scrittura di un file di testo
Lo script seguente illustra un esempio di utilizzo dei file di testo:
Note:
- riga 28: apre il file in scrittura (w=write). Se il file esiste già, verrà sovrascritto;
- Righe 30–34: generano 100 righe nel file di testo;
- riga 34: per scrivere una riga nel file di testo. Il metodo [write] non aggiunge un carattere di nuova riga. Pertanto, è necessario includerlo nel testo scritto;
- righe 35–37: gestiscono eventuali eccezioni;
- riga 37: interrompe l'esecuzione dello script (tuttavia, dopo che il blocco finally è stato eseguito);
- righe 38–41: in tutti i casi, indipendentemente dal verificarsi o meno di un errore, chiudere il file se è aperto;
- riga 47: aprire il file in lettura (r=read);
- riga 49: definizione di un dizionario vuoto;
- riga 52: il metodo [readline] legge una riga di testo, compreso il carattere di fine riga. Il metodo [strip] rimuove gli "spazi" dall'inizio e dalla fine della stringa. Per "spazio" si intendono i caratteri di spaziatura, le interruzioni di riga, le interruzioni di pagina, i tabulatori e alcuni altri. Quindi, in questo caso, [line] non conterrà i caratteri di interruzione di riga [\r\n] (Windows) o [\n] (Unix);
- riga 54: il file viene elaborato fino a quando non si incontra una riga vuota;
- righe 54–64: il file di testo viene trasferito al dizionario [dico]. La chiave è il campo [login] e il valore è costituito dai campi [uid:gid:infos:dir:shell];
- righe 65–67: gestiscono eventuali eccezioni;
- righe 68–71: chiudere il file in ogni caso, indipendentemente dal verificarsi o meno di un errore;
- righe 74-75: interrogare il dizionario [dico];
Il file [data/infos.txt]:
Output dello schermo:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/fichiers/fic_01.py
login10 : ['uid10', 'gid10', 'infos10', 'dir10', 'shell10']
la clé [X] n'existe pas
Process finished with exit code 0
7.2. Script [fic_02]: Gestione dei file di testo codificati in UTF-8
Nel resto di questo documento, lavoreremo esclusivamente con file di testo codificati in UTF-8. Per prima cosa, configureremo PyCharm:
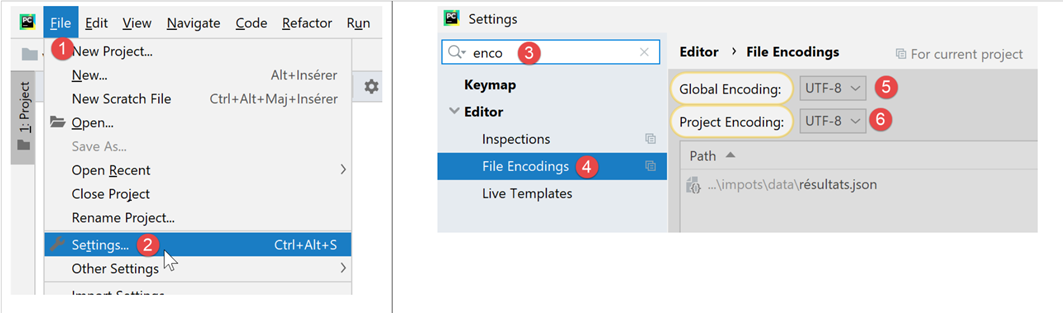
- in [5-6]: selezionare la codifica UTF-8 per i file di progetto;
Per creare un file codificato in UTF-8, procedere come segue (fic-02):
Note
- riga 2: per gestire la codifica del file, importiamo il modulo [codecs];
- riga 6: il metodo [codecs.open] viene utilizzato come la funzione standard [open]. Tuttavia, è possibile specificare la codifica desiderata (durante la creazione) o quella esistente (durante la lettura). Dopo l'apertura, l'oggetto [file] ottenuto alla riga 6 viene utilizzato come un file standard;
- riga 7: sono stati utilizzati caratteri accentati, che solitamente hanno rappresentazioni diverse a seconda della codifica dei caratteri utilizzata;
Risultati
All'apertura del file [data/utf8.txt] ottenuto (vedi riga 6), si ottiene il seguente risultato:

7.3. Script [fic_03]: gestione di file di testo codificati in ISO-8859-1
Lo script [fic_03] fa la stessa cosa dello script [fic_02], ma codifica il file di testo in ISO-8859-1. Vogliamo mostrare la differenza tra i file risultanti:
Quando apriamo il file [data/iso-8859-1] creato alla riga 6, otteniamo il seguente risultato:

Poiché abbiamo configurato il progetto per lavorare con file UTF-8, PyCharm ha tentato di aprire il file [iso-8859-1.txt] in UTF-8. Come si può vedere [1], il file non è in UTF-8. Suggerisce quindi [2] di ricaricare il file con una codifica diversa:

- in [3-5]: il file viene ricaricato utilizzando la codifica ISO-8859-1;

- in [6], lo stesso file ma visualizzato con una codifica diversa;
Se torniamo alle impostazioni del progetto:
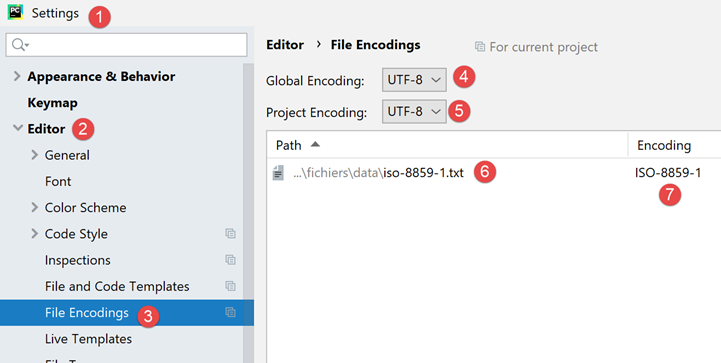
- vediamo che in [6-7], PyCharm ha indicato che il file [iso-8859-1.txt] dovrebbe essere aperto con la codifica ISO-8859-1. Si tratta quindi di un'eccezione alla regola [5];
7.4. Script [json_01]: Lavorare con un file JSON
JSON sta per JavaScript Object Notation. Come suggerisce il nome, si tratta di una rappresentazione testuale degli oggetti JavaScript. In questo caso, lo useremo con oggetti Python.
Il file JSON gestito [data/in.json] avrà questo aspetto:
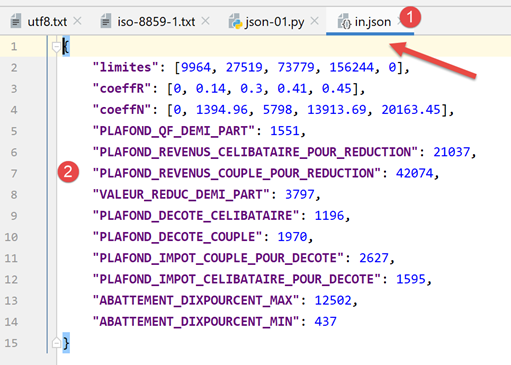
- In [2], possiamo vedere che il contenuto testuale del file [in.json] potrebbe rappresentare un dizionario Python. PyCharm ha formattato (Ctrl-Alt-L) questo testo, ma anche se fosse su una singola riga, non farebbe alcuna differenza. Il formato del testo è irrilevante purché rappresenti sintatticamente un oggetto Python;
Lo script [json-01] mostra come utilizzare questo file:
Note
- Riga 3: per lavorare con JSON, importiamo il modulo [json];
- riga 11: lavoreremo con file JSON codificati in UTF-8. Qui, apriamo il file [data/in.json] utilizzando il modulo [codecs];
- riga 13: il metodo [json.load] legge il contenuto del file JSON e lo memorizza nella variabile [data]. Il tipo di questa variabile sarà un dizionario;
- righe 15–18: per verificare di aver effettivamente ottenuto un dizionario Python, visualizziamo alcuni dei suoi elementi;
- righe 20–21: eseguiamo l'operazione inversa: il dizionario [data] viene scritto in un file codificato in UTF-8 utilizzando il metodo [json.dump];
- righe 22–25: gestione delle eventuali eccezioni;
- righe 26-31: in ogni caso, indipendentemente dal verificarsi o meno di un errore, chiudiamo tutti i file che potrebbero essere stati aperti;
Risultati
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/fichiers/json_01.py
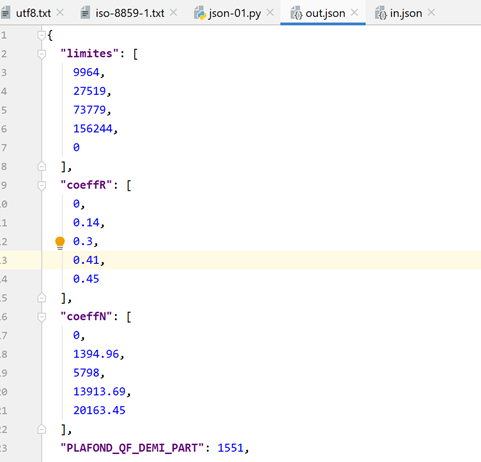
data={'limites': [9964, 27519, 73779, 156244, 0], 'coeffR': [0, 0.14, 0.3, 0.41, 0.45], 'coeffN': [0, 1394.96, 5798, 13913.69, 20163.45], 'PLAFOND_QF_DEMI_PART': 1551, 'PLAFOND_REVENUS_CELIBATAIRE_POUR_REDUCTION': 21037, 'PLAFOND_REVENUS_COUPLE_POUR_REDUCTION': 42074, 'VALEUR_REDUC_DEMI_PART': 3797, 'PLAFOND_DECOTE_CELIBATAIRE': 1196, 'PLAFOND_DECOTE_COUPLE': 1970, 'PLAFOND_IMPOT_COUPLE_POUR_DECOTE': 2627, 'PLAFOND_IMPOT_CELIBATAIRE_POUR_DECOTE': 1595, 'ABATTEMENT_DIXPOURCENT_MAX': 12502, 'ABATTEMENT_DIXPOURCENT_MIN': 437}, type(data)=<class 'dict'>
limites=[9964, 27519, 73779, 156244, 0], type(limites)=<class 'list'>
limites[1]=27519, type(limites[1])=<class 'int'>
Process finished with exit code 0
- Le righe 2–4 mostrano che abbiamo recuperato con successo il dizionario dal file JSON;
Ora, diamo un'occhiata al contenuto del file [data/out.json]:

Il testo nel file è su una singola riga. Tuttavia, PyCharm riconosce i file JSON e possiamo formattarli — proprio come i file Python e altri — utilizzando Ctrl-Alt-L. Questo ci dà il seguente risultato:
7.5. Script [json_02]: Gestione dei file JSON codificati in UTF-8
Un file JSON codificato in UTF-8 può assumere due forme:
- In questo script, il dizionario [data] (riga 7) viene scritto in due file JSON (righe 14, 17);
- righe 14, 17: in entrambi i casi, viene creato un file di testo UTF-8;
- riga 15: durante la scrittura del dizionario, utilizziamo il parametro denominato [ensure_ascii=True];
- riga 18: durante la scrittura del dizionario, utilizziamo il parametro denominato [ensure_ascii=False];
Ecco i due file risultanti:

- Nel file [out1.json], i caratteri accentati sono stati sostituiti da una sequenza di caratteri che ne rappresenta il codice UTF-8. Questo processo viene talvolta definito "escaping". Tecnicamente, nel formato binario di [out1.json], il carattere é in [marié] è rappresentato dai codici binari UTF-8 dei 6 caratteri [\u00e9] in successione;
- Nel file [out2.json], i caratteri accentati sono stati lasciati così come sono. Ciò significa che nei dati binari di [out2.json], questi caratteri sono rappresentati dal loro codice binario UTF-8 (un solo codice UTF-8, anziché 6 come in [out1]). Per il carattere é in [marié], troviamo quindi il codice binario a 4 byte [00e9];
- è il valore del parametro [ensure_ascii] del metodo [json.dump] che determina il formato utilizzato;
Alcune applicazioni utilizzano l'UTF-8 "escaped" per i propri file JSON. In tal caso, deve essere utilizzato il valore [ensure_ascii=True]. Questo valore è in realtà quello predefinito. Pertanto, se il parametro [ensure_ascii] non viene utilizzato, lavoreremo con file JSON UTF-8 escaped.
Lo script prosegue come segue:
Note
- righe 11–34: leggere i due file [out1.json, out2.json] e visualizzare il dizionario letto in ciascun caso;
Risultati
Sorprendentemente, vediamo che non è stato necessario specificare il tipo di codifica (con o senza escape) della stringa JSON da leggere alla funzione [json.load] (righe 17, 22). In entrambi i casi, otteniamo il dizionario corretto.