4. Las cadenas de caracteres
4.1. Script [str_01]: notación de las cadenas de caracteres
El script [str_01] es el siguiente:
# cadenas de caracteres
# tres notaciones posibles
chaine1 = "un"
chaine2 = 'deux'
chaine3 = """hélène va au
marché acheter des légumes"""
# visualización
print(f"chaine1=[{chaine1}], chaine2=[{chaine2}], chaine3=[{chaine3}]")
Comentarios
- línea 3: una cadena delimitada por comillas ";
- línea 4: una cadena delimitada por apóstrofos ';
- línea 5: una cadena delimitada por comillas triples """. En este caso, la cadena puede extenderse a lo largo de varias líneas;
Los resultados son los siguientes:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/strings/str_01.py
chaine1=[un], chaine2=[deux], chaine3=[hélène va au
marché acheter des légumes]
Process finished with exit code 0
4.2. Script [str_02]: los métodos de la clase <str>
El script [str_02] presenta algunos de los métodos de la clase <str>, que es la clase de las cadenas de caracteres:
# funciones sobre cadenas de caracteres
# cadena en minúsculas
print(f"'ABCD'.lower()={'ABCD'.lower()}")
# cadena en mayúsculas
print(f"'abcd'.upper()={'abcd'.upper()}")
# carácter n.º 2
print(f"'cheval[2]={'cheval'[2]}")
# subcadena con los caracteres 5 y 6
print(f"'caractères accentués'[5:7]={'caractères accentués'[5:7]}")
# subcadena a partir del carácter 4 incluido
print(f"'caractères accentués'[4:]={'caractères accentués'[4:]}")
# subcadena hasta el carácter 6, excluido
print(f"'caractères accentués'[:5]={'caractères accentués'[:5]}")
# longitud de la cadena
print(f"len('123')={len('123')}")
# eliminación de los espacios que preceden y siguen a la cadena
print(f"' abcd '.strip()=[{' abcd '.strip()}]")
# eliminación de los espacios que siguen a la cadena
print(f"' abcd '.rstrip()=[{' abcd '.rstrip()}]")
# eliminación de los espacios que preceden a la cadena
print(f"' abcd '.lstrip()=[{' abcd '.lstrip()}]")
# el término «espacio» abarca, de hecho, diferentes caracteres
str = ' \r\nabcd \t\f'
print(f"str.strip()=[{str.strip()}]")
# sustitución de una subcadena por otra
print(f"'abcd'.replace('a','x')={'abcd'.replace('a', 'x')}")
print(f"'abcd'.replace('ab','xy')={'abcd'.replace('ab', 'xy')}")
# búsqueda de una subcadena: devuelve la posición o -1 si no se encuentra la subcadena
print(f"'abcd'.find('bc')={'abcd'.find('bc')}")
print(f"'abcd'.find('bc')={'abcd'.find('Bc')}")
# Inicio de una cadena
print(f"'abcd'.startswith('ab')={'abcd'.startswith('ab')}")
print(f"'abcd'.startswith('x')={'abcd'.startswith('x')}")
# fin de una cadena
print(f"'abcd'.endswith('cd')={'abcd'.endswith('cd')}")
print(f"'abcd'.endswith('x')={'abcd'.endswith('x')}")
# conversión de una lista de cadenas en una cadena
print(f"'[X]'.join(['abcd', '123', 'èéà'])={'[X]'.join(['abcd', '123', 'èéà'])}")
print(f"''.join(['abcd', '123', 'èéà'])={''.join(['abcd', '123', 'èéà'])}")
# paso de una cadena a una lista de cadenas
print(f"'abcd 123 cdXY'.split('cd')={'abcd 123 cdXY'.split('cd')}")
# extraer las palabras de una cadena
print(f"'abcd 123 cdXY'.split(None)={'abcd 123 cdXY'.split(None)}")
Los comentarios junto con los resultados obtenidos bastan para comprender el script. Los resultados son los siguientes:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/strings/str_02.py
'ABCD'.lower()=abcd
'abcd'.upper()=ABCD
'cheval[2]=e
'caractères accentués'[5:7]=tè
'caractères accentués'[4:]=ctères accentués
'caractères accentués'[:5]=carac
len('123')=3
' abcd '.strip()=[abcd]
' abcd '.rstrip()=[ abcd]
' abcd '.lstrip()=[abcd ]
str.strip()=[abcd]
'abcd'.replace('a','x')=xbcd
'abcd'.replace('ab','xy')=xycd
'abcd'.find('bc')=1
'abcd'.find('bc')=-1
'abcd'.startswith('ab')=True
'abcd'.startswith('x')=False
'abcd'.endswith('cd')=True
'abcd'.endswith('x')=False
'[X]'.join(['abcd', '123', 'èéà'])=abcd[X]123[X]èéà
''.join(['abcd', '123', 'èéà'])=abcd123èéà
'abcd 123 cdXY'.split('cd')=['ab', ' 123 ', 'XY']
'abcd 123 cdXY'.split(None)=['abcd', '123', 'cdXY']
Process finished with exit code 0
4.3. Script [str_03]: codificación de cadenas de caracteres (1)
El script [str_03] presenta conceptos sobre la codificación de cadenas de caracteres:
# codificación de caracteres
# cadena de tipo str
str = "hélène va au marché acheter des légumes"
print(f"str=[{str}, type={type(str)}]")
# codificación utf-8
print("--- utf-8")
bytes1 = str.encode('utf-8')
print(f"bytes1={bytes1}, type={type(bytes1)}")
bytes2 = bytes(str, 'utf-8')
print(f"bytes2={bytes2}, type={type(bytes2)}")
# codificación iso-8859-1
print("--- iso-8859-1")
bytes1 = str.encode('iso-8859-1')
print(f"bytes1={bytes1}, type={type(bytes1)}")
bytes2 = bytes(str, 'iso-8859-1')
print(f"bytes2={bytes2}, type={type(bytes2)}")
# codificación latin1=iso-8859-1
print("--- latin1")
bytes1 = str.encode('latin1')
print(f"bytes1={bytes1}, type={type(bytes1)}")
bytes2 = bytes(str, 'latin1')
print(f"bytes2={bytes2}, type={type(bytes2)}")
La codificación de una cadena de caracteres de tipo <str> produce una cadena binaria en la que cada carácter de la cadena se ha representado mediante uno o varios bytes. Existen diferentes tipos de codificación. El script anterior presenta los dos más habituales en Occidente: «utf-8» e «iso-8859-1», también conocido como «latin1».
El principio de la codificación/decodificación se ilustra a continuación (ref. |https://realpython.com/python-encodings-guide/ |):
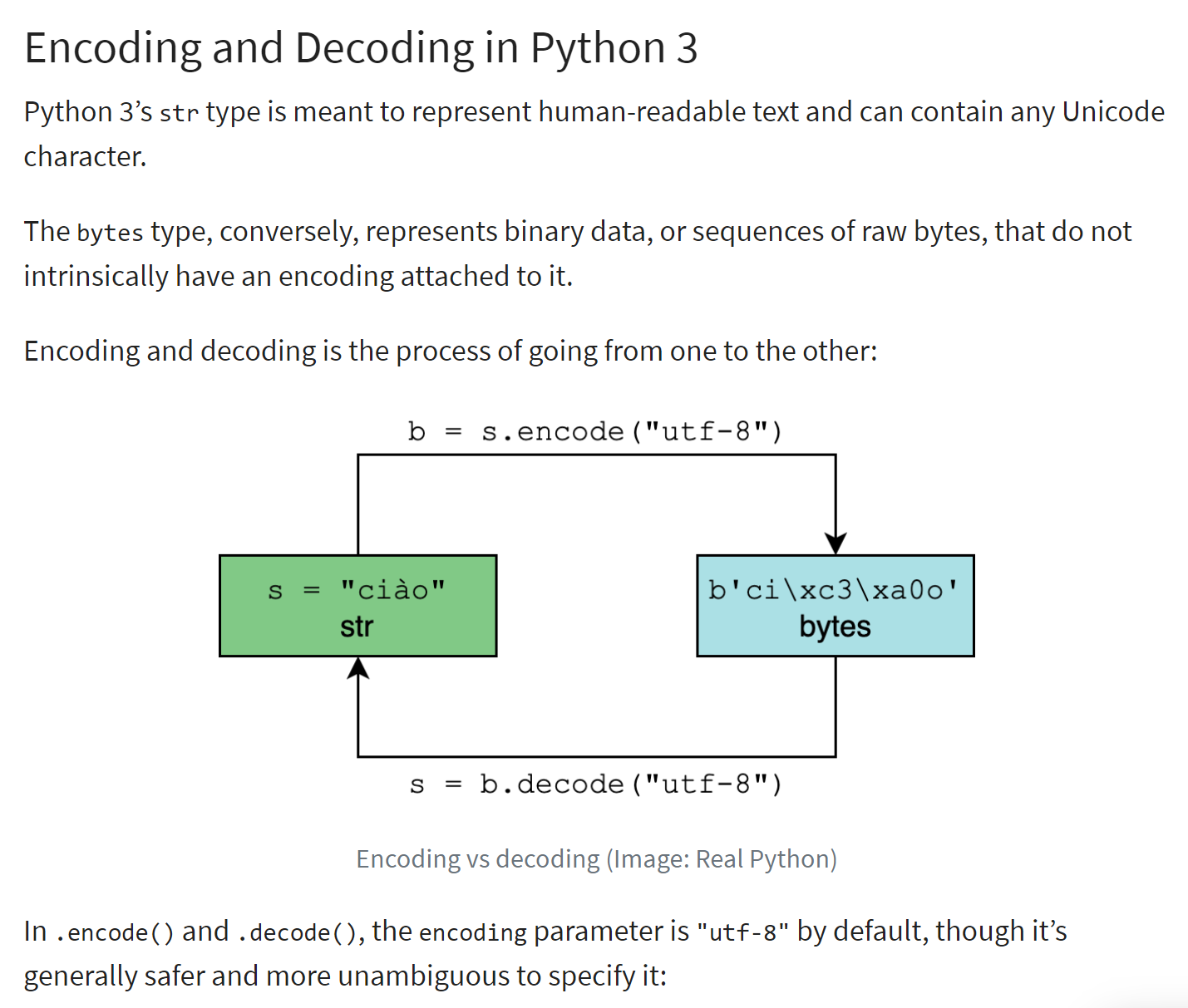
Comentarios
- líneas 4-5: la cadena de caracteres inicial que se va a codificar. Las instancias del tipo <str> son cadenas Unicode |https://docs.python.org/3/howto/unicode.html|, |https://realpython.com/python-encodings-guide/ |;
- líneas 6-11: dos formas de codificar una cadena de caracteres en UTF68:
- línea 8: str.encode('utf-8) ;
- línea 10: bytes(str, 'utf-8');
- líneas 12-17: se repite lo mismo con la codificación «iso-8859-1»;
- líneas 18-23: «latin1» es otro nombre de la codificación «iso-8859-1»;
Los resultados son los siguientes:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/strings/str_03.py
str=[hélène va au marché acheter des légumes, type=<class 'str'>
--- utf-8
bytes1=b'h\xc3\xa9l\xc3\xa8ne va au march\xc3\xa9 acheter des l\xc3\xa9gumes', type=<class 'bytes'>
bytes2=b'h\xc3\xa9l\xc3\xa8ne va au march\xc3\xa9 acheter des l\xc3\xa9gumes', type=<class 'bytes'>
--- iso-8859-1
bytes1=b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes', type=<class 'bytes'>
bytes2=b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes', type=<class 'bytes'>
--- latin1
bytes1=b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes', type=<class 'bytes'>
bytes2=b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes', type=<class 'bytes'>
Process finished with exit code 0
Comentarios
- línea 4: vemos que los caracteres acentuados se han codificado en dos bytes:
- é: [\xc3\xa9], que es la secuencia binaria 11000011 10101001;
- è: [\xc3\xa8], que es la secuencia binaria 11000011 10101000;
- líneas 7: con la codificación iso-8859-1, estos dos caracteres acentuados se codifican de forma diferente:
- é: [\xe9], que es la secuencia binaria 11101001;
- è: [\xe8], que es la secuencia binaria 11101000;
4.4. Script [str_04]: codificación de cadenas de caracteres (2)
El script [str_04] presenta otros dos tipos de codificación: «base64» y «quoted-printable». Estas dos codificaciones no codifican cadenas de caracteres Unicode, sino objetos binarios. Por ejemplo, cuando se adjunta un documento de Word a un correo electrónico, este se someterá a una de las dos codificaciones según el gestor de correo utilizado. Este será el caso de la mayoría de los archivos adjuntos.
El script es el siguiente:
# codificación/decodificación
import codecs
# cadena
print("---- chaîne unicode")
str1 = "hélène va au marché acheter des légumes"
print(f"str1=[{str1}], type(str1)={type(str1)}")
# codificación utf-8
print("---- chaîne unicode -> binaire utf-8")
bytes1 = bytes(str1, "utf-8")
print(f"bytes1=[{bytes1}], type(bytes1)={type(bytes1)}")
# decodificación utf-8
print("---- binaire utf-8 -> chaîne unicode")
str2 = bytes1.decode("utf-8")
print(f"str2=[{str2}], type(str2)={type(str2)}")
print(f"str2==str1={str2 == str1}")
# codificación iso-8859-1
print("---- chaîne unicode -> binaire iso-8859-1")
bytes2 = bytes(str1, "iso-8859-1")
print(f"bytes2=[{bytes2}], type(bytes2)={type(bytes2)}")
# decodificación iso-8859-1
print("---- binaire iso-8859-1 -> chaîne unicode")
str3 = bytes2.decode("iso-8859-1")
print(f"str3=[{str3}], type(str3)={type(str3)}")
print(f"str3==str1={str3 == str1}")
# error de decodificación: bytes1 está en utf-8, se decodifica en iso-8859-1
print("--- binaire utf-8 (décodage iso-8859-1) --> chaîne unicode")
str4 = bytes1.decode("iso-8859-1")
print(f"str4=[{str4}], type(str4)={type(str4)}")
# codificación utf-8 de una cadena Unicode
print("---- chaîne unicode -> binaire utf-8")
bytes3 = codecs.encode(str1, "utf-8")
print(f"bytes3=[{bytes3}], type(bytes3)={type(bytes3)}")
# codificación de una cadena binaria UTF-8 en base64
print("---- binaire utf-8 -> binaire base64")
bytes4 = codecs.encode(bytes1, "base64")
print(f"bytes4=[{bytes4}], type(bytes4)={type(bytes4)}")
# vuelta a la cadena Unicode original
print("---- binaire base64 -> binaire utf-8 -> chaîne unicode")
str6 = codecs.decode(bytes4, "base64").decode("utf-8")
print(f"str6=[{str6}], type(str6)={type(str6)}")
# codificación de una cadena binaria en quoted-printable
print("---- binaire utf-8 -> binaire quoted-printable")
str7 = codecs.encode(bytes1, "quoted-printable")
print(f"str7=[{str7}], type(str7)={type(str7)}")
# reversión a la cadena Unicode original
print("---- binaire quoted-printable -> binaire utf-8 -> chaîne unicode")
str8 = codecs.decode(str7, "quoted-printable").decode("utf-8")
print(f"str8=[{str8}], type(str8)={type(str8)}")
Comentarios
- línea 2: el módulo [codecs] permite realizar las codificaciones «base64» y «quoted-printable». Puede realizar muchas otras;
- líneas 4-7: la cadena Unicode que va a ser sometida a diversas codificaciones;
- líneas 9-12: codificación utf-8. Se obtiene un binario;
- líneas 14-18: decodificación utf-8 para volver a la cadena Unicode original;
- líneas 20-29: se repite el mismo proceso con la codificación «iso-8859-1»;
- líneas 31-34: se muestra un error de decodificación:
- línea 33: bytes1 es una cadena binaria codificada en «utf-8». Se decodifica en «iso-8859-1»;
- líneas 36-39: otra forma de codificar una cadena de caracteres en utf-8 con el módulo [codecs];
- líneas 41-44: una cadena binaria «utf-8» se codifica en «base64»;
- líneas 46-49: muestran cómo pasar de la cadena binaria «base64» a la cadena Unicode original;
- líneas 51-59: se repite este proceso con una codificación «quoted-printable» en lugar de «base64»;
Los resultados son los siguientes:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/strings/str_04.py
---- chaîne unicode
str1=[hélène va au marché acheter des légumes], type(str1)=<class 'str'>
---- chaîne unicode -> binaire utf-8
bytes1=[b'h\xc3\xa9l\xc3\xa8ne va au march\xc3\xa9 acheter des l\xc3\xa9gumes'], type(bytes1)=<class 'bytes'>
---- binaire utf-8 -> chaîne unicode
str2=[hélène va au marché acheter des légumes], type(str2)=<class 'str'>
str2==str1=True
---- chaîne unicode -> binaire iso-8859-1
bytes2=[b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes'], type(bytes2)=<class 'bytes'>
---- binaire iso-8859-1 -> chaîne unicode
str3=[hélène va au marché acheter des légumes], type(str3)=<class 'str'>
str3==str1=True
--- binaire utf-8 (décodage iso-8859-1) --> chaîne unicode
str4=[hélène va au marché acheter des légumes], type(str4)=<class 'str'>
---- chaîne unicode -> binaire utf-8
bytes3=[b'h\xc3\xa9l\xc3\xa8ne va au march\xc3\xa9 acheter des l\xc3\xa9gumes'], type(bytes3)=<class 'bytes'>
---- binaire utf-8 -> binaire base64
bytes4=[b'aMOpbMOobmUgdmEgYXUgbWFyY2jDqSBhY2hldGVyIGRlcyBsw6lndW1lcw==\n'], type(bytes4)=<class 'bytes'>
---- binaire base64 -> binaire utf-8 -> chaîne unicode
str6=[hélène va au marché acheter des légumes], type(str6)=<class 'str'>
---- binaire utf-8 -> binaire quoted-printable
str7=[b'h=C3=A9l=C3=A8ne=20va=20au=20march=C3=A9=20acheter=20des=20l=C3=A9gumes'], type(str7)=<class 'bytes'>
---- binaire quoted-printable -> binaire utf-8 -> chaîne unicode
str8=[hélène va au marché acheter des légumes], type(str8)=<class 'str'>
Process finished with exit code 0
- líneas 14-15: un binario utf-8 se decodifica en una cadena Unicode con el decodificador incorrecto «iso-8859-1». Por lo tanto, algunos caracteres Unicode generados son incorrectos, en este caso los caracteres acentuados;
- líneas 18-19: la codificación «base64» consiste en utilizar 64 caracteres ASCII (codificados en 7 bits) para codificar cualquier binario. Esto aumenta, como se ve, el tamaño del binario de la cadena;
- líneas 22-23: la codificación «quoted-printable» consiste también en utilizar los caracteres ASCII (codificados en 7 bits) para codificar cualquier binario;
Recordemos que cuando se recibe un binario, por ejemplo de Internet, que representa un texto, para recuperarlo es necesario conocer las codificaciones a las que ha sido sometido.