2. The three problems studied and the results
We will ask the IA to study three problems, from the simplest to the most complicated. Let’s look at a screenshot of Google Gemini:
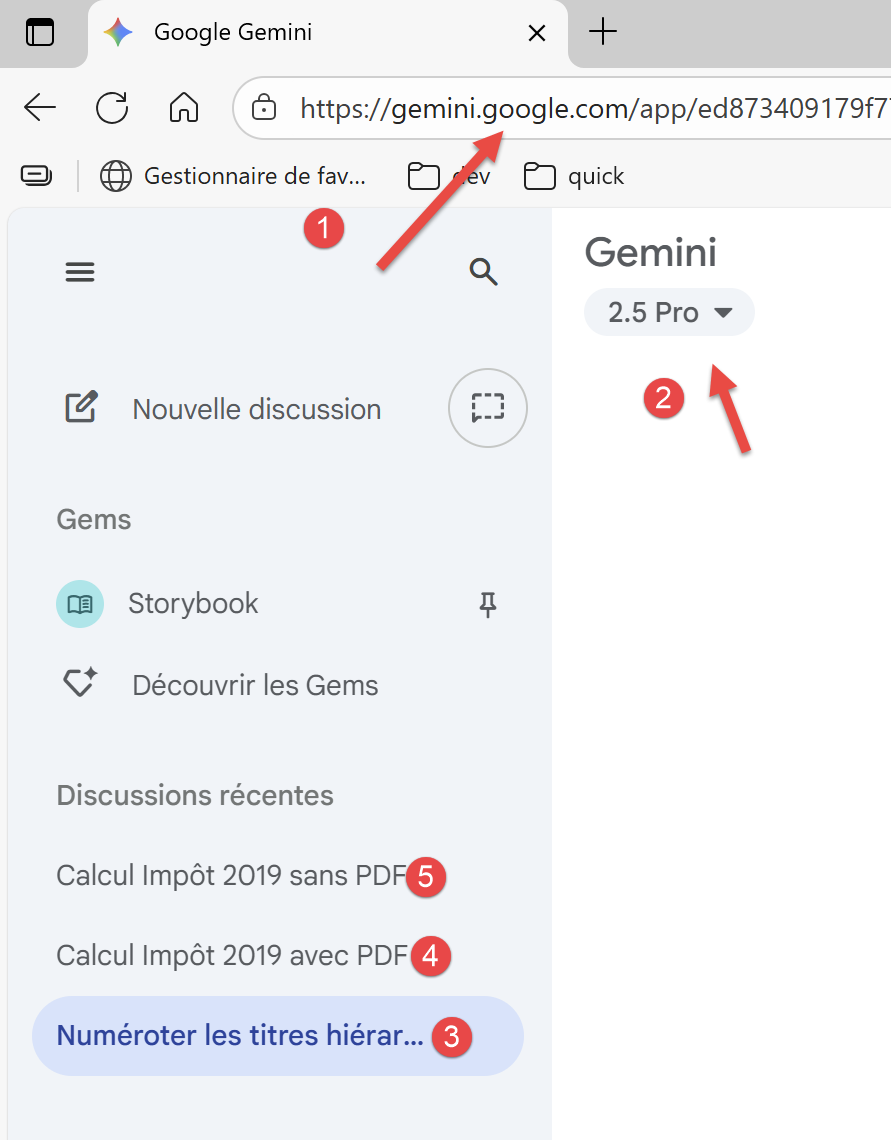 |
- In [1], Gemini’s URL;
- In [2], the version used by Gemini;
- In [3-5], the three problems posed to Gemini;
2.1. Problem 1
Problem 1 is a simple question:
 |
All IAs will answer this question correctly.
2.2. Problem 2
Problem 2 is as follows (screenshot from Gemini):
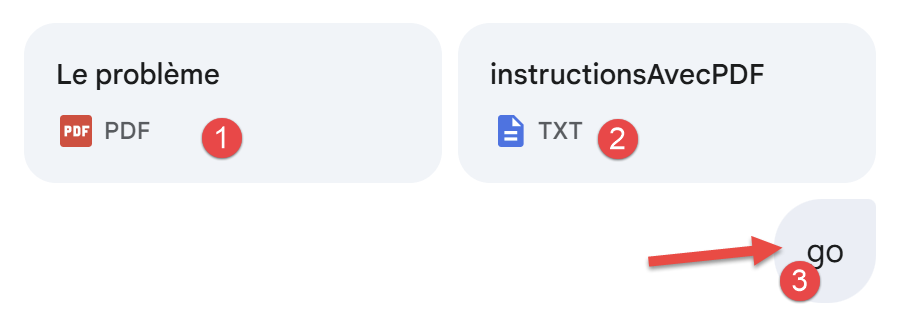 |
- In [1], the principle of calculating the 2019 tax on 2018 income is explained in a PDF. We’ll come back to that;
- In [2], we give Gemini precise instructions on what we want: a clean Python script that solves the problem and validates the proposed solution with 11 unit tests;
- In [3], to run Gemini, we have to write something;
This is exactly the same situation as that of a TD given at the university.
The tested IAs will solve the problem with the exception of MistralAI and Perplexity.
2.3. Problem 3
Still using a screenshot from Google Gemini, Problem 3 is as follows:
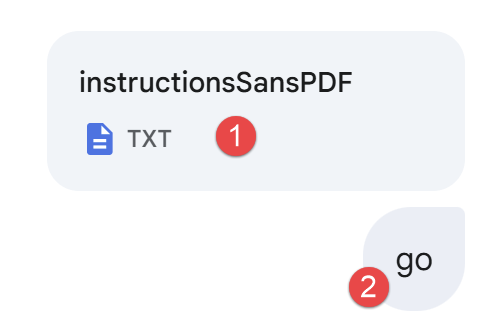 |
- In [1], we provide our instructions, the same as before. But since we do not provide the PDF that gave the exact calculation rules, IA will have to search for these rules on the internet;
- In [3], we launch the execution of IA;
Only three IAs passed this test, in order of excellence (strictly personal opinion, of course):
- ChatGPT by OpenAI;
- Grok from xAI;
- Goggle Gemini;
IA ClaudeAI failed on problem 3. IA and MistralAI failed on problems 2 and 3, as did IA Perplexity. IA and DeepSeek failed on problem 3.