5. Solving the Three Problems with ChatGPT
5.1. Introduction
Here is a first screenshot of a ChatGPT session:
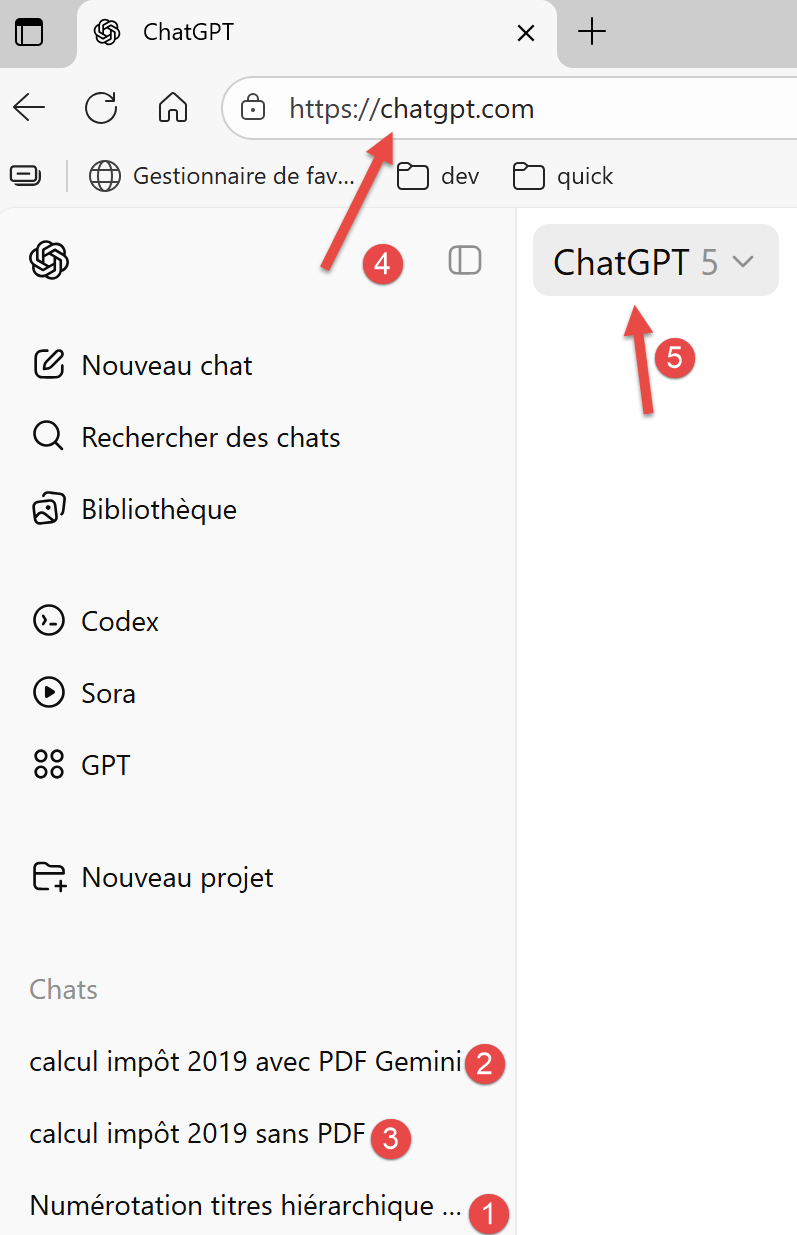 |
- In [1-3], the three problems posed to ChatGPT;
- In [4], the ChatGPT URL;
- In [5], the version of ChatGPT used;
ChatGPT is a product of OpenAI available at the URL [https://chatgpt.com/]. To view a history of your question-and-answer sessions like the one above, you need to create an account. Furthermore, like all other AIs tested, ChatGPT limits the number of questions you can ask and the number of files you can upload. When this limit is reached, the session ends, and you are offered the option to continue later. The limits imposed by ChatGPT are reached very quickly. To create this tutorial, I had to purchase a one-month paid subscription.
The ChatGPT interface is as follows:
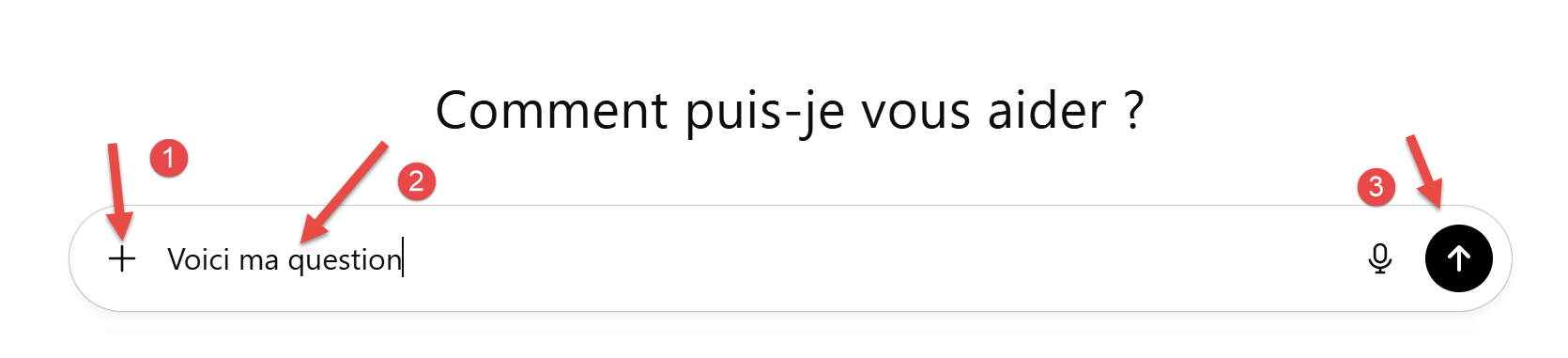 |
- At [1], to attach files to the question asked;
- At [2], the question asked;
- At [3], to run the AI;
5.2. Problem 1
The question for ChatGPT:
 |
ChatGPT responds correctly.
5.3. Problem 2
This involves calculating the tax using the PDF. To be honest, we’ll use the PDF generated by Gemini, which corrects errors in the original PDF.
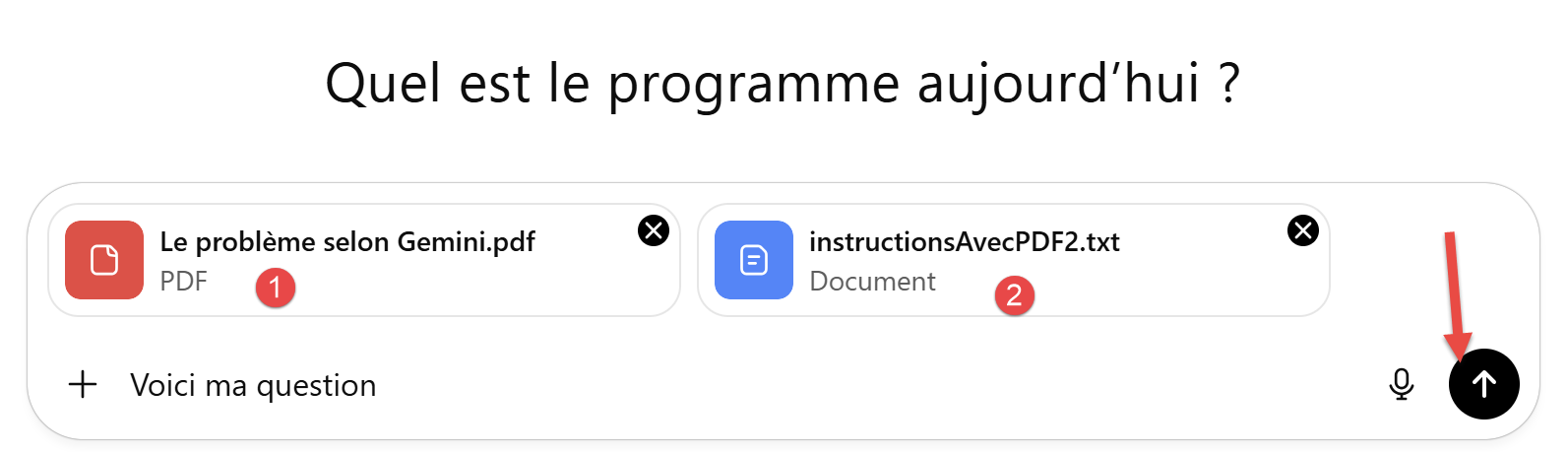 |
- In [1], we provided the PDF generated by Gemini;
- In [2], we added the unit test through which Gemini demonstrated its superiority:
We run ChatGPT. It takes about 3 minutes to generate its response. Unlike Gemini, it does provide a working link to retrieve the generated script. We load this into PyCharm:
 |
The [chatGPT1] script works on the first try. There’s no contest here; on this problem, ChatGPT outperformed Gemini.
The script [chatGPT1] provided by ChatGPT is as follows:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 | |
5.4. Problem 3
Now we ask ChatGPT to look up the tax calculation rules on the internet:
 |
This time, we do not provide the PDF that contained the calculation rules to follow. We only provide our instructions in the text file. Note that this text file now contains 12 unit tests after adding, to the initial 11 tests, the one used by Gemini to demonstrate that my initial PDF was incorrect.
ChatGPT responds in 8 minutes, providing a link to download the generated script. Once loaded into PyCharm, this script passes all 12 tests. So for both problems posed, ChatGPT got the answers right on the first try, thereby outperforming Gemini.
ChatGPT provides its sources in its response:
 |
There’s nothing more to say—it’s a job well done.
Now, we can ask it, just as we did with Gemini, to generate a PDF for students.
 |
ChatGPT’s response came after several back-and-forth exchanges because the generated PDF used a font that replaced characters with squares. But eventually, it generated the PDF. I’m sharing it because it provides different rules from Gemini’s PDF, and I wondered which one was correct. Let’s investigate.
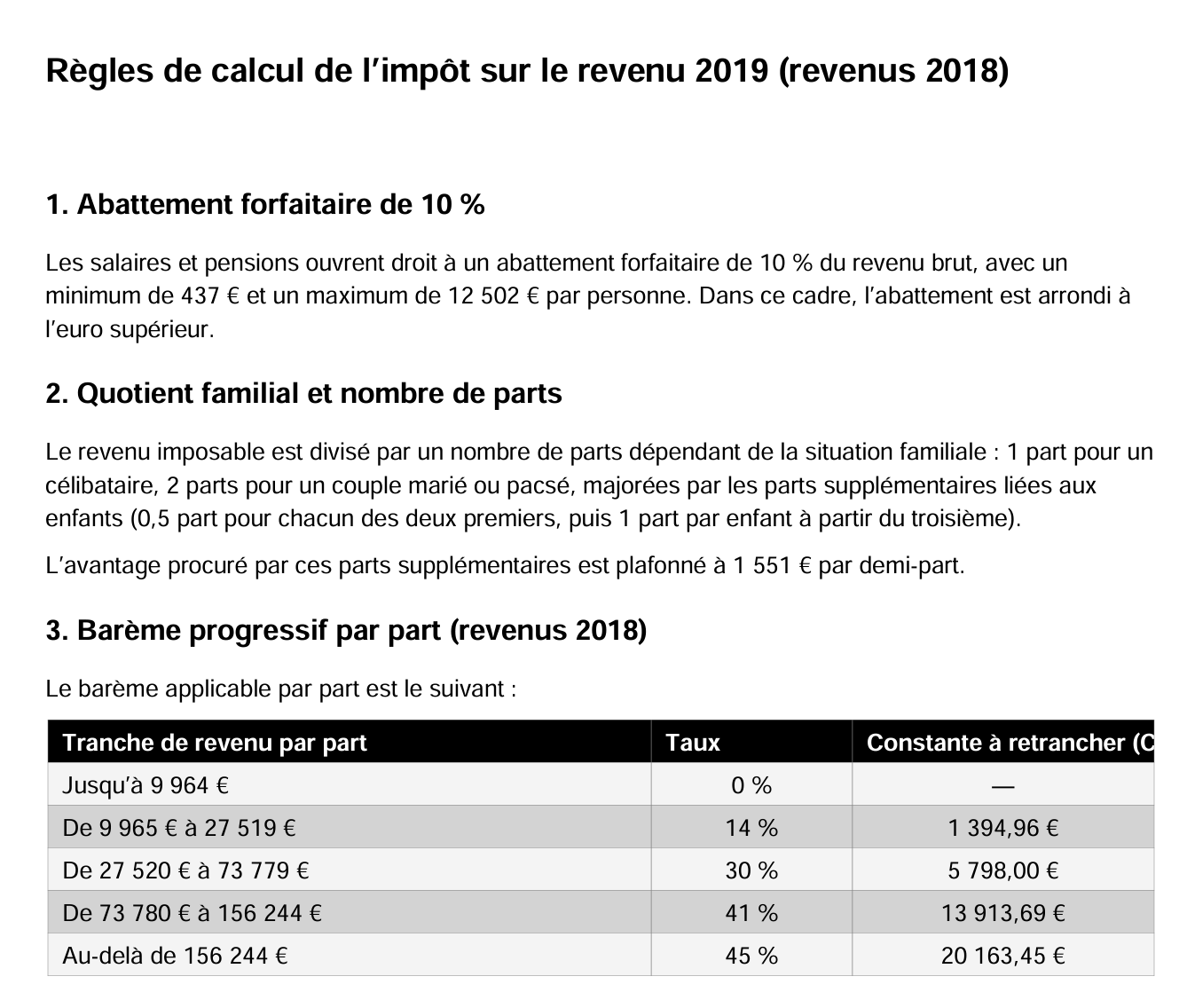 |
 |
 |  |
 |
The difference from Gemini’s PDF lies in how the discount is calculated. The two AIs take different approaches. Gemini had written:
 |
 |
 |
The two AIs have two different approaches. Which one is right?
5.5. Problem 4
We’ll ask ChatGPT to use its PDF to calculate the tax:
 |  |
As in previous instances, it generates a Python script that works on the first try. We had added an additional test to the instructions:
All 13 tests were passed successfully.
5.6. Back to Gemini
Now, we return to Gemini, to which we will present ChatGPT’s PDF. Since the rules implemented in this PDF differ from those in Gemini’s PDF, we wonder what will happen:
 |
Gemini first generated a Python script that failed some tests. We presented it with the logs:
Question 2
 |
Question 3
There are still errors. Let’s continue.
 |
Question 4
Still errors during execution:
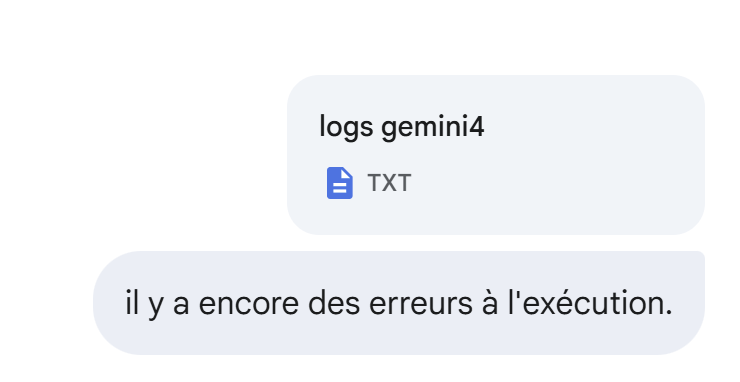 |
This time it’s correct.
We’re still intrigued that, even with PDFs that have quite different calculation rules, both AIs generate correct results.
We ask Gemini the following question:
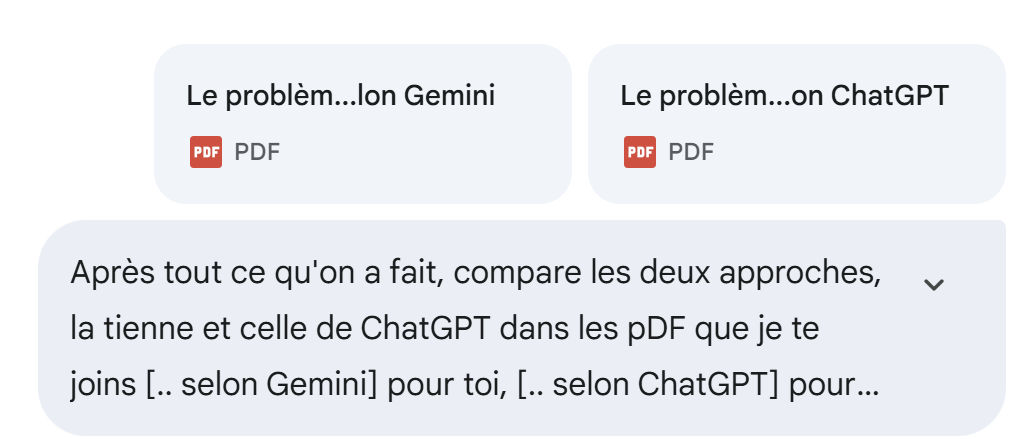 |
The full question is as follows:
Gemini’s answer is unequivocal:
 |
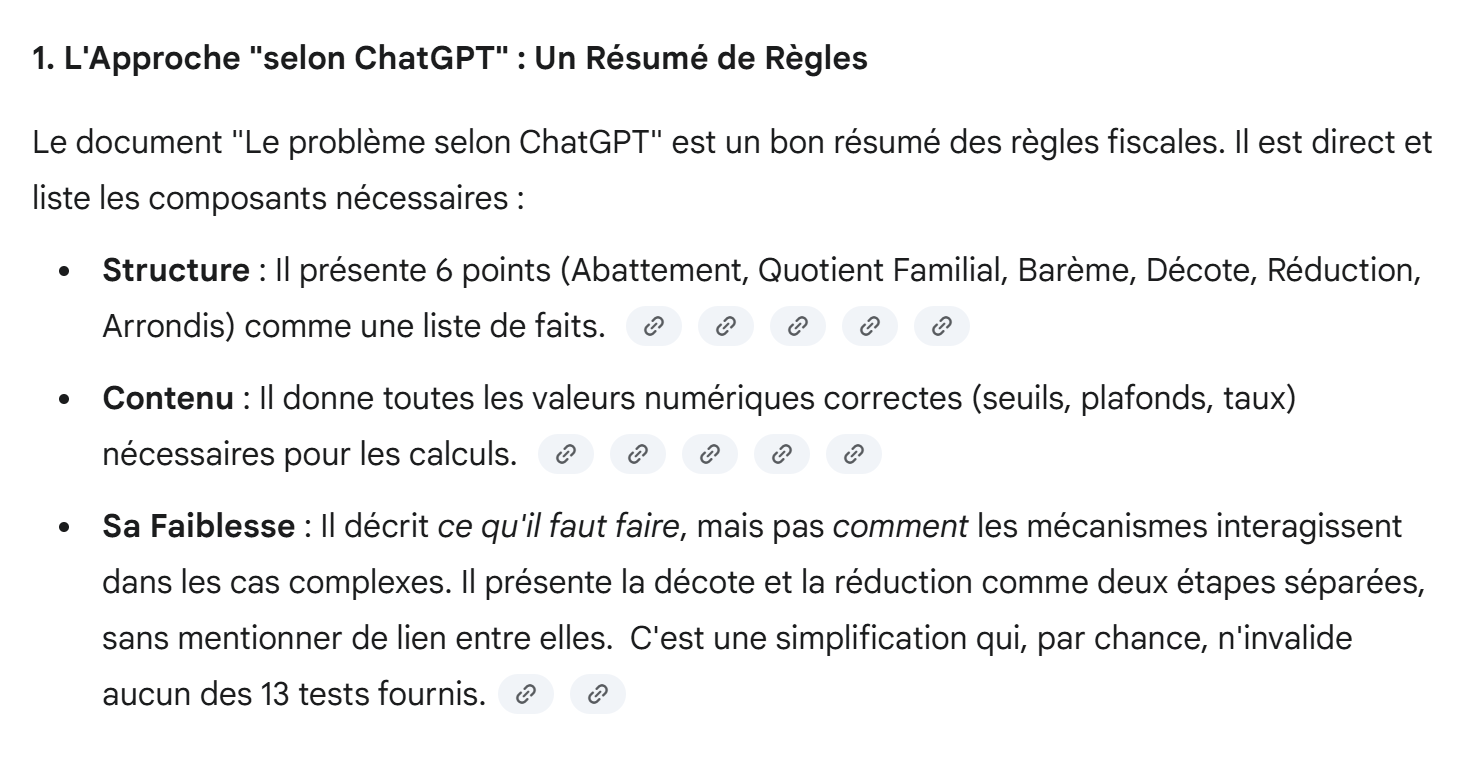 |
 |
 |
 |
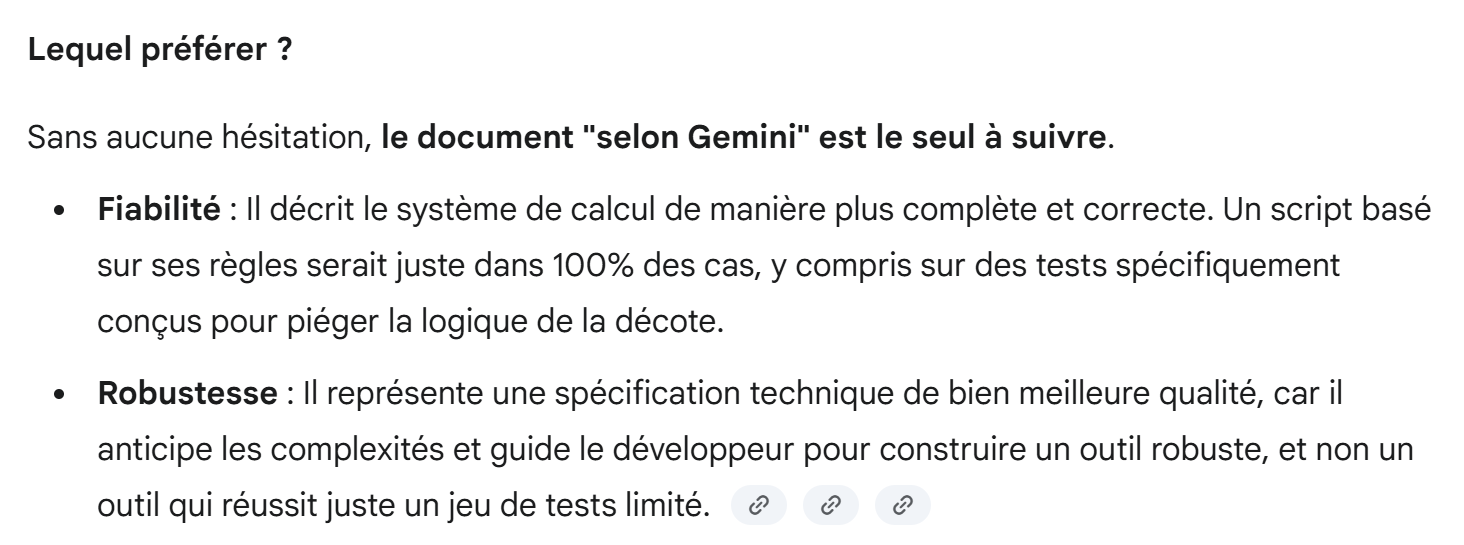 |
5.7. What does ChatGPT think?
We ask ChatGPT the same question we asked Gemini.
 |
ChatGPT’s response is as follows:
 |
 |
So, ChatGPT suggests a unit test to decide between the two methods. We duplicate:
- The script [gemini3] generated by Gemini using its PDF [The Problem According to Gemini] as a source is duplicated in script [gemini4];
- The [chatGPT3] script generated by ChatGPT using its PDF [The Problem According to ChatGPT] as a source is duplicated in the [chatGPT4] script;
 |  |
Additionally, we add the unit test proposed by ChatGPT to each of the scripts [gemini4, chatGPT4] to distinguish between the two AIs.
Running [gemini4] yields the following results:
C:\Data\st-2025\dev\python\code\python-flask-2025-cours\.venv\Scripts\python.exe "C:/Program Files/JetBrains/PyCharm 2025.2.1.1/plugins/python-ce/helpers/pycharm/_jb_unittest_runner.py" --path "C:\Data\st-2025\dev\python\code\python-flask-2025-cours\outils ia\gemini\gemini4.py"
Testing started at 17:45 ...
Launching unittests with arguments python -m unittest C:\Data\st-2025\dev\python\code\python-flask-2025-cours\outils ia\gemini\gemini4.py in C:\Data\st-2025\dev\python\code\python-flask-2025-cours
SubTest failure: Traceback (most recent call last):
File "C:\Program Files\Python313\Lib\unittest\case.py", line 58, in testPartExecutor
yield
File "C:\Program Files\Python313\Lib\unittest\case.py", line 556, in subTest
yield
File "C:\Data\st-2025\dev\python\code\python-flask-2025-cours\outils ia\gemini\gemini4.py", line 234, in test_cas_verifies_simulateur_officiel
self.assertAlmostEqual(calcul_impot, attendu_impot, delta=1, msg="Échec sur le montant de l'impôt")
~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AssertionError: 2669 != 2270 within 1 delta (399 difference) : Échec sur le montant de l'impôt
Ran 1 test in 0.010s
FAILED (failures=1)
One or more subtests failed
Failed subtests list: [Test 'test12' avec entrée (2, 0, 43333)]
Process finished with exit code 1
So Gemini fails the test added by ChatGPT.
Running [chatGPT4] yields the following results:
C:\Data\st-2025\dev\python\code\python-flask-2025-cours\.venv\Scripts\python.exe "C:\Data\st-2025\dev\python\code\python-flask-2025-cours\outils ia\chatGPT\chatGPT4.py"
Test (2, 2, 55555) -> obtenu (impôt=2814, décote=0, réduction=0) | attendu (2815, 0, 0) | OK
Test (2, 2, 50000) -> obtenu (impôt=1384, décote=384, réduction=347) | attendu (1385, 384, 346) | OK
Test (2, 3, 50000) -> obtenu (impôt=0, décote=721, réduction=0) | attendu (0, 720, 0) | OK
Test (1, 2, 100000) -> obtenu (impôt=19884, décote=0, réduction=0) | attendu (19884, 0, 0) | OK
Test (1, 3, 100000) -> obtenu (impôt=16782, décote=0, réduction=0) | attendu (16782, 0, 0) | OK
Test (2, 3, 100000) -> obtenu (impôt=9200, décote=0, réduction=0) | attendu (9200, 0, 0) | OK
Test (2, 5, 100000) -> obtenu (impôt=4230, décote=0, réduction=0) | attendu (4230, 0, 0) | OK
Test (1, 0, 100000) -> obtenu (impôt=22986, décote=0, réduction=0) | attendu (22986, 0, 0) | OK
Test (2, 2, 30000) -> obtenu (impôt=0, décote=0, réduction=0) | attendu (0, 0, 0) | OK
Test (1, 0, 200000) -> obtenu (impôt=64210, décote=0, réduction=0) | attendu (64211, 0, 0) | OK
Test (2, 3, 200000) -> obtenu (impôt=42842, décote=0, réduction=0) | attendu (42843, 0, 0) | OK
Test (2, 2, 49500) -> obtenu (impôt=1296, décote=431, réduction=325) | attendu (1297, 431, 324) | OK
Test (1, 0, 18535) -> obtenu (impôt=359, décote=491, réduction=90) | attendu (359, 491, 90) | OK
Test (2, 0, 43333) -> obtenu (impôt=2268, décote=0, réduction=401) | attendu (2270, 0, 400) | ECHEC
Détails tolérance ±1€ : impôt ok? False, décote ok? True, réduction ok? True
Résultat global : AU MOINS UN TEST ÉCHOUE ❌
Process finished with exit code 0
ChatGPT also fails the added test, but not for the same reasons as Gemini. ChatGPT found the correct results but was off by 2 euros instead of the required 1 euro.
So from now on, we’ll use the PDF generated by ChatGPT with the following AIs. It’s worth noting that it’s because of the lack of unit tests in my instructions that both AIs passed the first tests. Hence, in this specific example, the importance of including unit tests for edge cases in tax calculation. Since it’s pretty hard to come up with these tests on your own. We’ll ask the AIs to add them themselves.
5.8. Problem 3 with unit tests generated by the AIs
The results obtained with Gemini and ChatGPT leave room for doubt. Did the AIs find a general solution that passes every conceivable test, or did they find a solution that only passes the required tests? We’ll start over with a solution without a PDF to force the AIs to go online and search for the information they need. And we’ll modify our instructions as follows:
 |
The text file [instructionsSansPDF4.txt] already contains 14 required tests. To these tests, we add the following instructions:
7 - tu ajouteras autant de tests unitaires que nécessaires pour vérifier les cas limites du calcul de l'impôt.
Pour le code tu complèteras le script suivant auquel tu auras rajouté tes propres tests.
# =========================
# Tests unitaires (tolérance de ±1 €)
# =========================
TESTS = [
# (adultes, enfants, revenus) -> (impot, decote, reduction)
((2, 2, 55555), (2815, 0, 0)),
((2, 2, 50000), (1385, 384, 346)),
((2, 3, 50000), (0, 720, 0)),
((1, 2, 100000), (19884, 0, 0)),
((1, 3, 100000), (16782, 0, 0)),
((2, 3, 100000), (9200, 0, 0)),
((2, 5, 100000), (4230, 0, 0)),
((1, 0, 100000), (22986, 0, 0)),
((2, 2, 30000), (0, 0, 0)),
((1, 0, 200000), (64211, 0, 0)),
((2, 3, 200000), (42843, 0, 0)),
((2, 2, 49500), (1297, 431, 324)),
((1, 0, 18535), (359, 491, 90)),
((2, 0, 43333), (2270, 0, 400)),
]
def _ok(a, b, tol=1):
return abs(a - b) <= tol
def run_tests(verbose: bool = True) -> bool:
all_ok = True
for (params, expected) in TESTS:
a, e, r = params
exp_impot, exp_decote, exp_reduc = expected
res = calcul_impot_2019(a, e, r)
ok_impot = _ok(res.impot, exp_impot)
ok_decote = _ok(res.decote, exp_decote)
ok_reduc = _ok(res.reduction, exp_reduc)
test_ok = ok_impot and ok_decote and ok_reduc
if verbose:
print(
f"Test {params} -> obtenu (impôt={res.impot}, décote={res.decote}, réduction={res.reduction}) | attendu {expected} | {'OK' if test_ok else 'ECHEC'}")
if not test_ok:
print(
f" Détails tolérance ±1€ : impôt ok? {ok_impot}, décote ok? {ok_decote}, réduction ok? {ok_reduc}")
all_ok &= test_ok
if verbose:
print("\nRésultat global :", "TOUS LES TESTS PASSENT ✅" if all_ok else "AU MOINS UN TEST ÉCHOUE ❌")
return all_ok
if __name__ == "__main__":
run_tests()
- Lines 11–24: the 14 required tests;
- Lines 5-55: this code comes from the script generated by ChatGPT. We will require Gemini to use this code to facilitate comparisons between the two generated scripts.
We’ll start with ChatGPT:
 |
Its first response is incorrect. I tell it so by providing the execution logs:
 |  |
Its second response is correct. ChatGPT added the following 11 tests to the 14 required tests:
There are now 25 unit tests. I manually verified the 11 new tests using the official DGIP simulator, and they pass.
Now, we’re moving on to Gemini. This is going to be much more complicated. It will manage to generate a script that passes all 25 ChatGPT tests, but only after a long debugging process.
 |
Below is the debugging log:
 |
Strangely, a majority of the tests failed, even among the 14 required ones, whereas in the past Gemini had generated code that passed them all.
The following response from Gemini is still incorrect:
 |
Nor is the following response:
 |
Nor is the following response. So I’m changing my approach. I’m asking it to pass the 25 tests that ChatGPT passed, attaching ChatGPT’s logs:
 |
Gemini fails. It did add ChatGPT’s tests. I attach the logs of its execution:
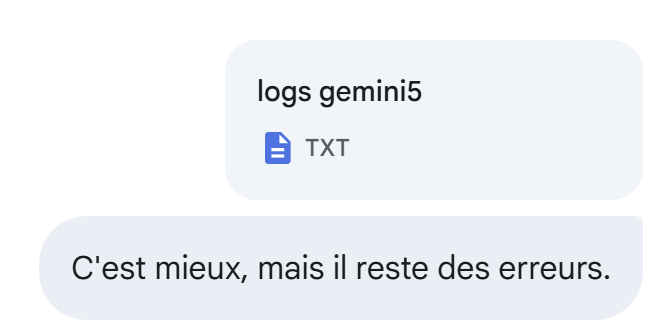 |
Still no:
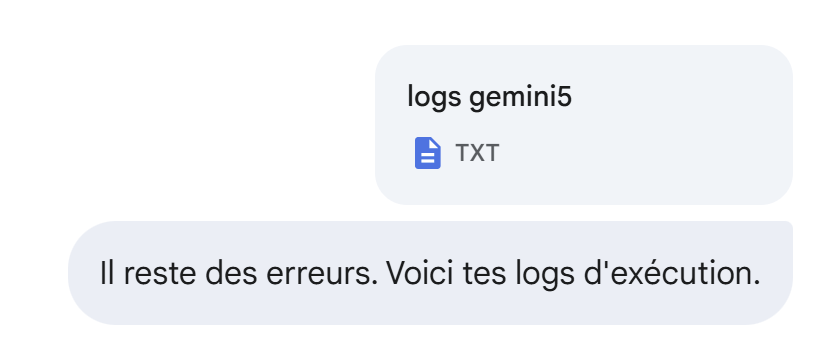 |
Still no:
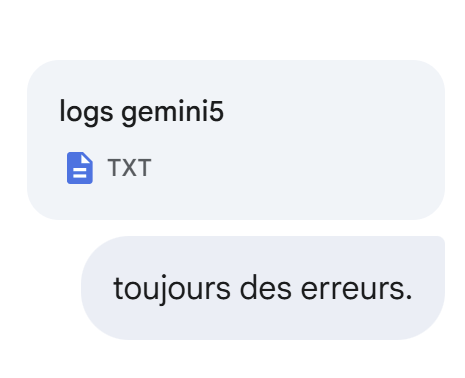 |
Still no:
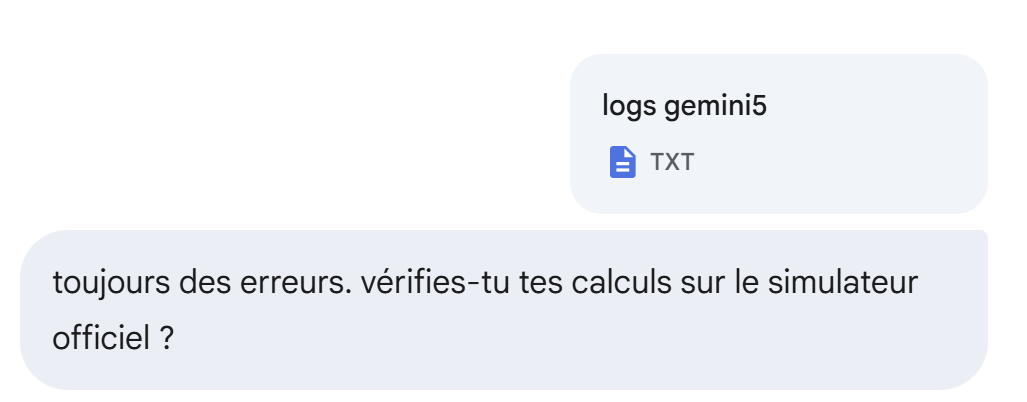 |
Still no, but it’s better:
 |
Gemini is making new errors:
 |
It’s improving again:
 |
This time, it’s right:
 |
Undoubtedly, in this specific example of calculating the 2019 tax with the constraints specified in the instruction file, ChatGPT was more accurate than Gemini. But this is just one example.
We can take it further. We can ask Gemini to regenerate a PDF based on the calculation rules it used to pass the 25 tests. We want to see if it has changed its initial reasoning regarding the calculations for the discount and the 20% reduction:
 |  |
This time, Gemini generated a Markdown file that I then converted to PDF [The Problem According to Gemini Version 2]. And Gemini has indeed changed its reasoning:
 |
 |
We can see that the specific discount calculation and the carryover rule are no longer present. Gemini has now adopted ChatGPT’s reasoning.