9. Verwendung des Konverters DOCX → HTML
Die befehl für die Konvertierung eines Word-Dokuments DOCX ist sehr analog zum Befehl für die Konvertierung eines Dokuments LibreOffice ODT. Wir werden die Formatvorlage für den Titel des Dokuments in [config.py] ändern:
STYLES = {
"style_names": [
"Titel"
]
}
- zeile 3: Setzen Sie 'Titel' ein. Dies ist der Stil des Dokuments DOCX, das Sie konvertieren werden. Wir werden ihn in den Zeilen zur Fehlerbeseitigung des Konverters sehen.
Geben Sie ebenfalls im Terminal PyCharm den folgenden Befehl ein:
PS C:\Data\st-2025\GitHub Pages\word-odt-vers-html\v2> python .\convert_docx_v18.py .\word-odt-vers-html-janv-2026.docx .\config.py
C:\Data\st-2025\GitHub Pages\word-odt-vers-html\v2\convert_docx_v18.py:976: SyntaxWarning: invalid escape sequence '\h'
- REF Bookmark \h
--- DOCX to MkDocs Converter V16 ---
Copié : google5179c0eaff293e02.html
Copié : robots.txt
Copié : word-odt-vers-html-janv-2026.pdf
Copié : word-odt-vers-html-janv-2026.zip
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=StandardWW heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=StandardWW heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Titre heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='<span>Convertir un document Word ou ODT vers un site statique HTML compatible Mk...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='<b>Serge Tahé</b><span>, janvier 2026</span>...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=StandardWW heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=StandardWW heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=StandardWW heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=StandardWW heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='<b>Ce site a été créé avec le convertisseur [Word ou ODT - > HTML] cr...'
[DEBUG PRE-H1] style=Titre1 heading=1 rebase=0 numId=1 ilvl=0 list=numPr:1/ordered txt='<span>Introduction</span>...'
Terminé. (audit.json, audit.txt, report.txt générés)
- zeile 1: Der Befehl lautet: [ python .\convert_docx_v18.py .\word-odt-vers-html-janv-2026.docx .\config.py ] (Passen Sie die Versionsnummer (ici 18) an die Version an, die Sie heruntergeladen haben) :
- der erste Parameter [.\convert_docx_v18.py] ist der Konverter DOCX → HTML
- der zweite Parameter [.\word-odt-vers-html-janv-2026.docx] ist der Name des zu konvertierenden Dokuments DOCX ;
- der dritte Parameter [.\config.py] ist die Konfigurationsdatei ;
- zeile 33: Der Konverter meldet, dass drei Dateien erzeugt wurden:
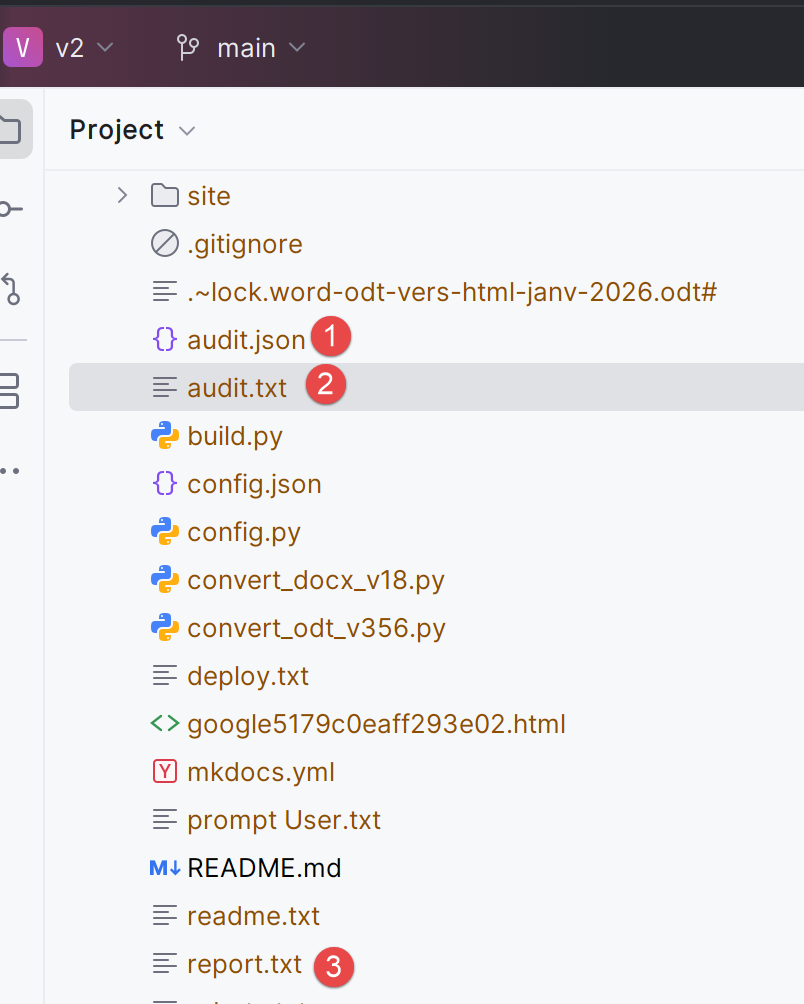 |
Die Datei [audit.txt] ist wie folgt:
Version: V16
Paragraphs: 2029
Tables: 97
Images (blips): 2
Headings detected (raw): 53
Min heading level detected (raw): 1
Rebase offset applied: 0
Top paragraph styles:
- SourceCodenumrot: 1054
- StandardWW: 594
- Standard: 146
- Paragraphedeliste: 113
- SourceCodenumrotrsultats: 33
- codenouveau: 28
- Titre2: 25
- Titre1: 14
- Titre3: 14
- StandardWWWW: 6
- Textebrut: 1
- Titre: 1
List paragraphs:
- with numPr: 1329
- by style fallback: 49
- not recognized: 0
- zeile 2: die Anzahl der Absätze im Word-Dokument ;
- zeile 3: Anzahl der Tische ;
- zeilen 9-21: Die im Dokument gefundenen Stile ;
- zeilen 10, 14, 15: der Stil der Codeblöcke. Ein einziger Stil hätte wahrscheinlich ausgereicht ;
- zeilen 11-12, 19: Der Stil der Standardabsätze. Ein einziger Stil hätte wahrscheinlich ausgereicht ;
- zeilen 16-18, 21: die Stile der Überschriften im Dokument. Zeile 21: Wir sehen, dass nur ein Absatz den Stil 'Überschrift' hat. Das ist der Titel des Dokuments, der vor dem ersten 'Titel1' steht;
Diese Prüfung des Word-Dokuments ist ein gutes Mittel, um die Qualität des Dokuments zu beurteilen. Hier sehe ich, dass ich in meinem Word-Dokument zu viele verschiedene Formatvorlagen für ein und dieselbe Sache verwendet habe.
Die Datei [audit.json] ist identisch mit der Datei [audit.txt], aber in einer Form jSON :
{
"version": "V16",
"file": "word-odt-vers-html-janv-2026.docx",
"counts": {
"paragraphs": 2029,
"tables": 97,
"image_blips": 2,
"headings_raw": 53
},
"lists": {
"with_numpr": 1329,
"by_style": 49,
"unrecognized": 0
},
"heading": {
"min_level_raw": 1,
"rebase_offset": 0
},
"top_styles": [
[
"SourceCodenumrot",
1054
],
[
"StandardWW",
594
],
[
"Standard",
146
],
[
"Paragraphedeliste",
113
],
[
"SourceCodenumrotrsultats",
33
],
[
"codenouveau",
28
],
[
"Titre2",
25
],
[
"Titre1",
14
],
[
"Titre3",
14
],
[
"StandardWWWW",
6
],
[
"Textebrut",
1
],
[
"Titre",
1
]
]
}
Die Datei [report.txt] ist diese :
[SUMMARY] Listes détectées via fallback "par style" (agrégé)
- Paragraphedeliste -> level=1 type=unordered: 49
[SUMMARY] Blocs Word ignorés (agrégé)
- <w:sectPr>: 1
Ich habe es nicht verstanden..
Es ist möglich, nur die Prüfung des Word-Dokuments anzufordern, um seine Qualität zu beurteilen, mit dem Parameter [--audit] :
python .\convert_docx_v18.py .\word-odt-vers-html-janv-2026.docx .\config.py --audit
In diesem Fall wird nur die Prüfung des Dokuments durchgeführt. Die Seite MkDocs wird nicht generiert.
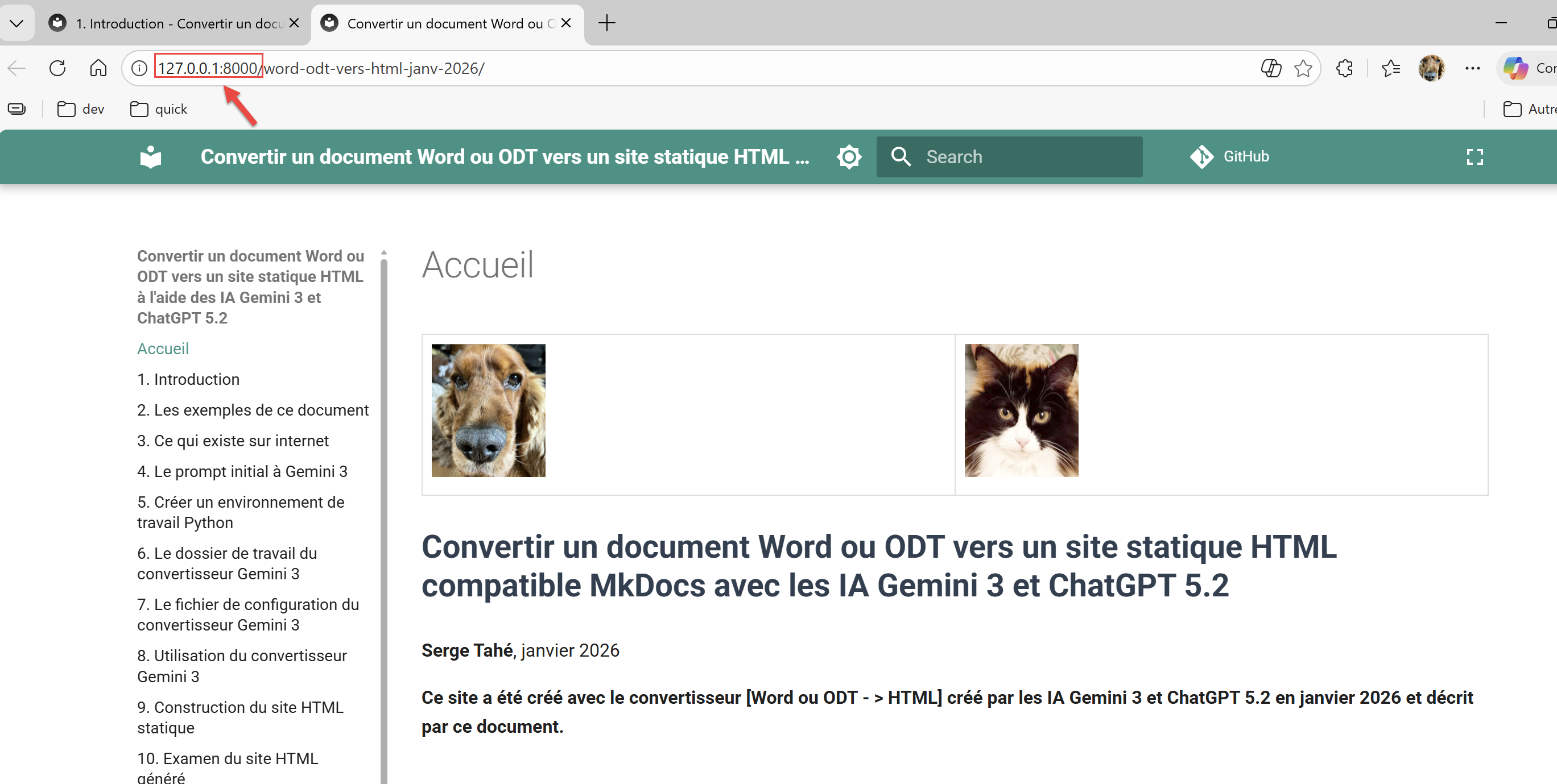
Wie bereits gezeigt wurde, können Sie visudie vom Konverter erzeugte Seite MkDocs alisieren:
PS C:\Data\st-2025\GitHub Pages\word-odt-vers-html\v2> python -m mkdocs serve
INFO - Building documentation...
INFO - Cleaning site directory
INFO - Documentation built in 0.59 seconds
INFO - [06:05:48] Serving on http://127.0.0.1:8000/word-odt-vers-html-janv-2026/
Ctrl-Klick auf den URL in Zeile 5 :
 |