5. Lösung der drei Probleme mit ChatGPT
5.1. Einleitung
Hier ist ein erster Screenshot einer ChatGPT-Sitzung:
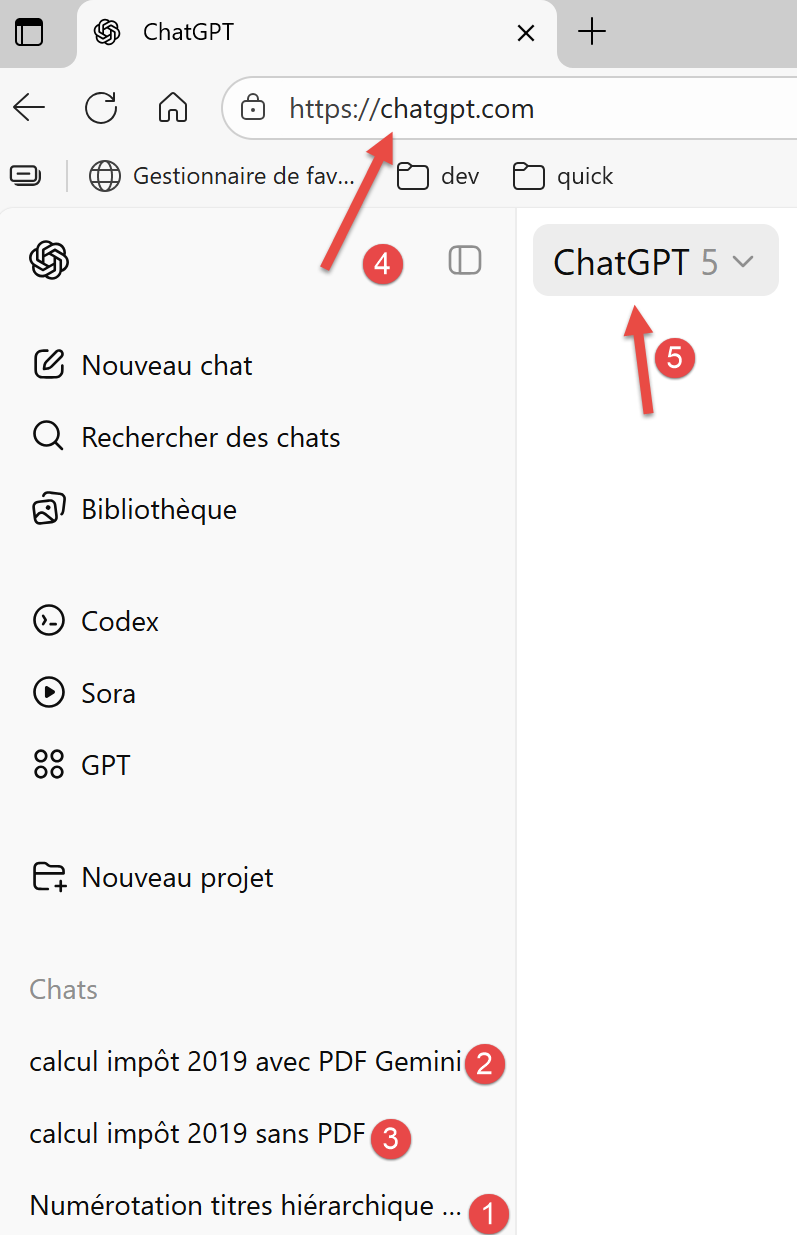 |
- In [1-3] die drei Probleme, die ChatGPT gestellt wurden;
- In [4] die URL von ChatGPT;
- In [5] die verwendete ChatGPT-Version;
ChatGPT ist ein Produkt von OpenAI, das unter der URL [https://chatgpt.com/] verfügbar ist. Um einen Verlauf Ihrer Frage-Antwort-Sitzungen wie oben zu erhalten, müssen Sie ein Konto erstellen. Wie alle anderen getesteten KI-Systeme begrenzt auch ChatGPT die Anzahl Ihrer Fragen und die Anzahl der hochgeladenen Dateien. Wenn dieses Limit erreicht ist, wird die Sitzung beendet und Ihnen wird angeboten, sie zu einem späteren Zeitpunkt fortzusetzen. Die von ChatGPT auferlegten Limits sind sehr schnell erreicht. Um dieses Tutorial zu erstellen, musste ich ein kostenpflichtiges Monatsabonnement abschließen.
Die Benutzeroberfläche von ChatGPT sieht wie folgt aus:
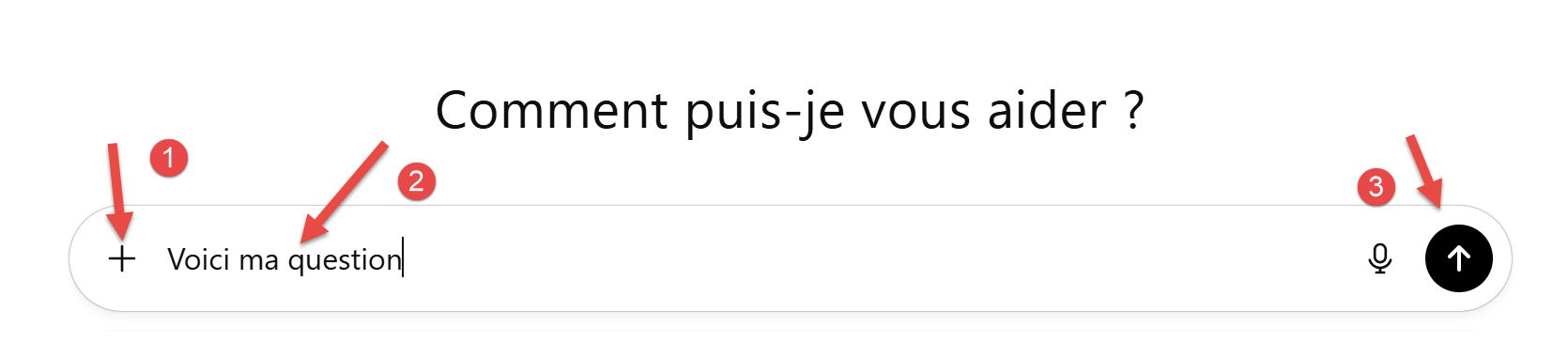 |
- Unter [1] können Sie Dateien an die gestellte Frage anhängen;
- Unter [2] die gestellte Frage;
- Unter [3] starten Sie die Ausführung der KI; ## 5.2. Aufgabe 1
Die Frage an ChatGPT:
 |
ChatGPT antwortet korrekt.
5.3. Problem 2
Es geht um die Steuerberechnung mit dem PDF. Um ehrlich zu sein, werden wir das von Gemini generierte PDF verwenden, das Fehler im ursprünglichen PDF korrigiert.
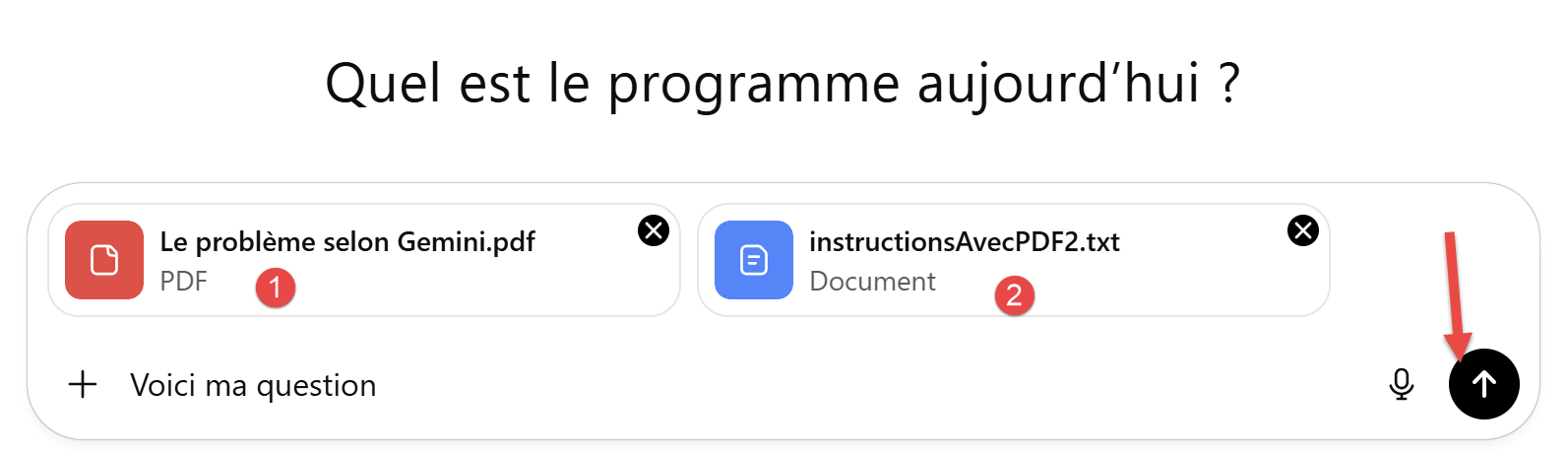 |
- In [1] haben wir das von Gemini generierte PDF bereitgestellt;
- In [2] haben wir den Unit-Test hinzugefügt, mit dem Gemini seine Überlegenheit unter Beweis gestellt hat:
Wir starten ChatGPT. Es dauert etwa 3 Minuten, bis die Antwort generiert ist. Im Gegensatz zu Gemini liefert es einen funktionierenden Link, über den man das generierte Skript abrufen kann. Wir laden dieses in PyCharm:
 |
Das Skript [chatGPT1] funktioniert auf Anhieb. Hier gibt es keinen Zweifel: Bei diesem Problem war ChatGPT leistungsfähiger als Gemini.
Das von ChatGPT bereitgestellte Skript [chatGPT1] lautet wie folgt:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 188 189 190 191 192 193 194 195 196 197 198 199 200 201 202 203 204 205 206 207 208 209 210 211 212 213 214 215 216 217 218 219 220 221 222 223 224 225 226 227 228 229 230 231 232 233 234 235 236 237 238 239 240 241 242 243 244 245 246 247 248 249 250 251 252 253 254 255 256 257 258 259 260 261 262 263 264 265 266 267 268 269 270 271 272 273 274 275 276 277 278 279 280 281 282 283 284 285 286 287 288 289 290 291 292 | |
5.4. Aufgabe 3
Nun bitten wir ChatGPT, die Regeln zur Steuerberechnung im Internet zu suchen:
 |
Diesmal stellen wir nicht die PDF-Datei zur Verfügung, die die zu beachtenden Berechnungsregeln enthielt. Wir geben lediglich unsere Anweisungen in der Textdatei an. Zur Erinnerung: Diese Textdatei enthält nun 12 Unit-Tests, nachdem wir zu den ursprünglichen 11 Tests denjenigen hinzugefügt haben, den Gemini verwendet hat, um zu zeigen, dass meine ursprüngliche PDF-Datei fehlerhaft war.
ChatGPT antwortet innerhalb von 8 Minuten und gibt einen Link zum Herunterladen des generierten Skripts an. Sobald dieses Skript in PyCharm geladen ist, besteht es alle 12 Tests. Bei beiden gestellten Aufgaben hat ChatGPT also auf Anhieb richtig geantwortet und damit Gemini übertroffen.
ChatGPT gibt in seiner Antwort seine Quellen an:
 |
Da gibt es nichts zu sagen, das ist hervorragende Arbeit.
Nun kann man es, wie zuvor bei Gemini, bitten, ein PDF für Studierende zu generieren.
 |
Die Antwort von ChatGPT kam erst nach mehrmaligem Hin und Her, da das generierte PDF eine Schriftart verwendete, die Zeichen durch Quadrate ersetzte. Aber schließlich hat es das PDF generiert. Ich zeige es hier, weil es andere Regeln als das PDF von Gemini enthält und ich mich gefragt habe, wer Recht hat. Das wollen wir untersuchen.
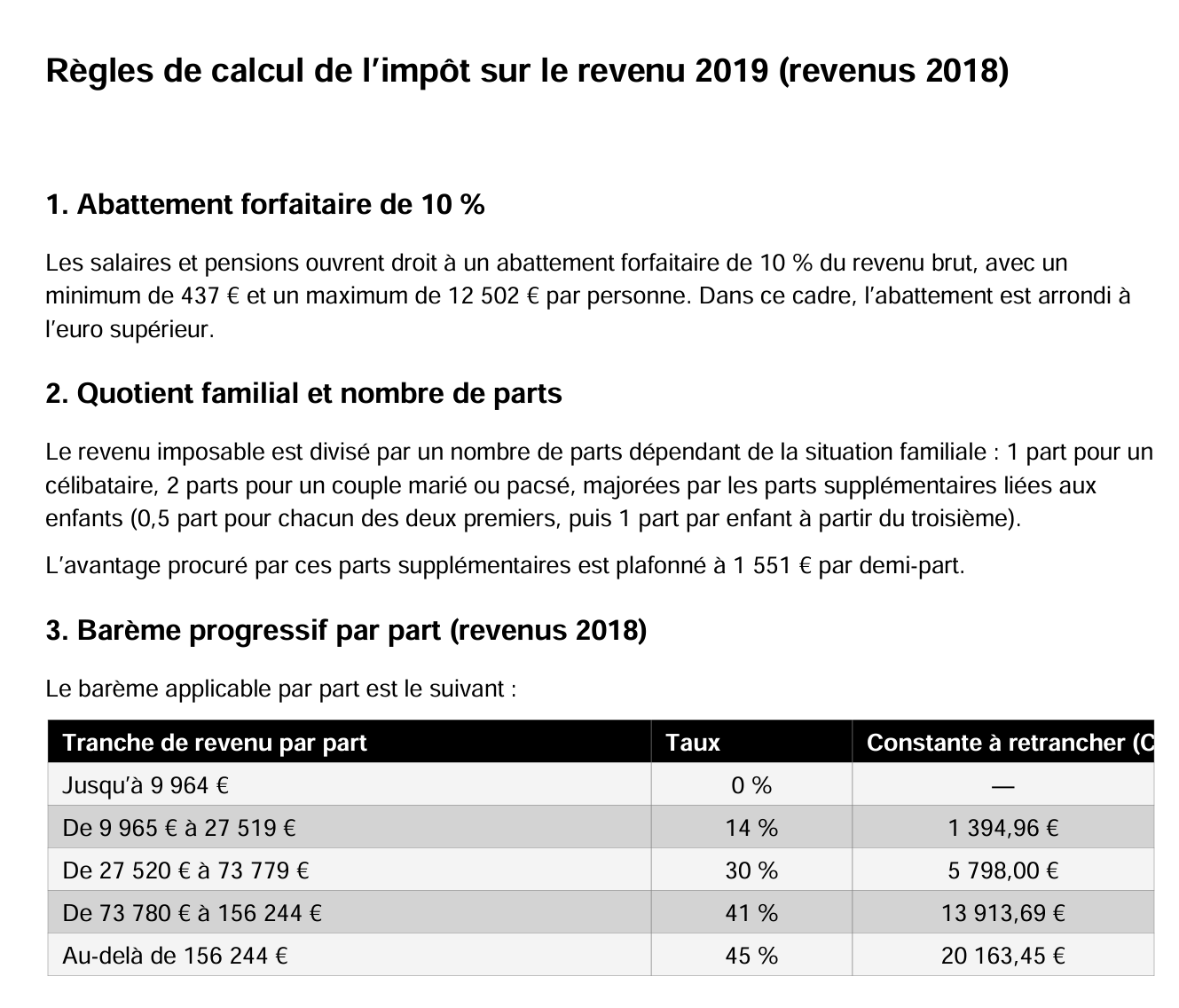 |
 |
 |  |
 |
Der Unterschied zum PDF von Gemini liegt in der Berechnung des Abschlags. Die beiden KI-Systeme verfolgen unterschiedliche Ansätze. Gemini hatte geschrieben:
 |
 |
 |
Die beiden KI-Systeme verfolgen zwei unterschiedliche Ansätze. Wer hat Recht?
5.5. Aufgabe 4
Wir werden ChatGPT bitten, sich auf sein PDF zu stützen, um die Steuer zu berechnen:
 |  |
Wie schon zuvor generiert es ein Python-Skript, das auf Anhieb funktioniert. Wir hatten in den Anweisungen einen zusätzlichen Test hinzugefügt:
Alle 13 Tests wurden erfolgreich bestanden.
5.6. Zurück zu Gemini
Nun kehren wir zu Gemini zurück, dem wir das PDF von ChatGPT vorlegen werden. Da sich die in diesem PDF implementierten Regeln von denen im PDF von Gemini unterscheiden, stellt sich die Frage, was passieren wird:
 |
Gemini hat zunächst ein Python-Skript generiert, das bei den Tests fehlgeschlagen ist. Wir haben ihm die Logs vorgelegt:
Frage 2
 |
Frage 3
Es gibt immer noch Fehler. Wir machen weiter.
 |
Frage 4
Immer noch Fehler bei der Ausführung:
 |
Diesmal ist es richtig.
Es ist dennoch faszinierend, dass beide KI-Systeme bei PDF-Dateien mit recht unterschiedlichen Berechnungsregeln korrekte Ergebnisse liefern.
Wir stellen Gemini folgende Frage:
 |
Die vollständige Frage lautet:
Die Antwort von Gemini ist eindeutig:
 |
 |
 |
 |
 |
 |
5.7. Was denkt ChatGPT darüber?
Wir stellen ChatGPT dieselbe Frage, die wir Gemini gestellt haben.
 |
Die Antwort von ChatGPT lautet wie folgt:
 |
 |
Daraufhin schlägt ChatGPT uns einen Einzeltest vor, um zwischen den beiden Methoden zu entscheiden. Wir duplizieren:
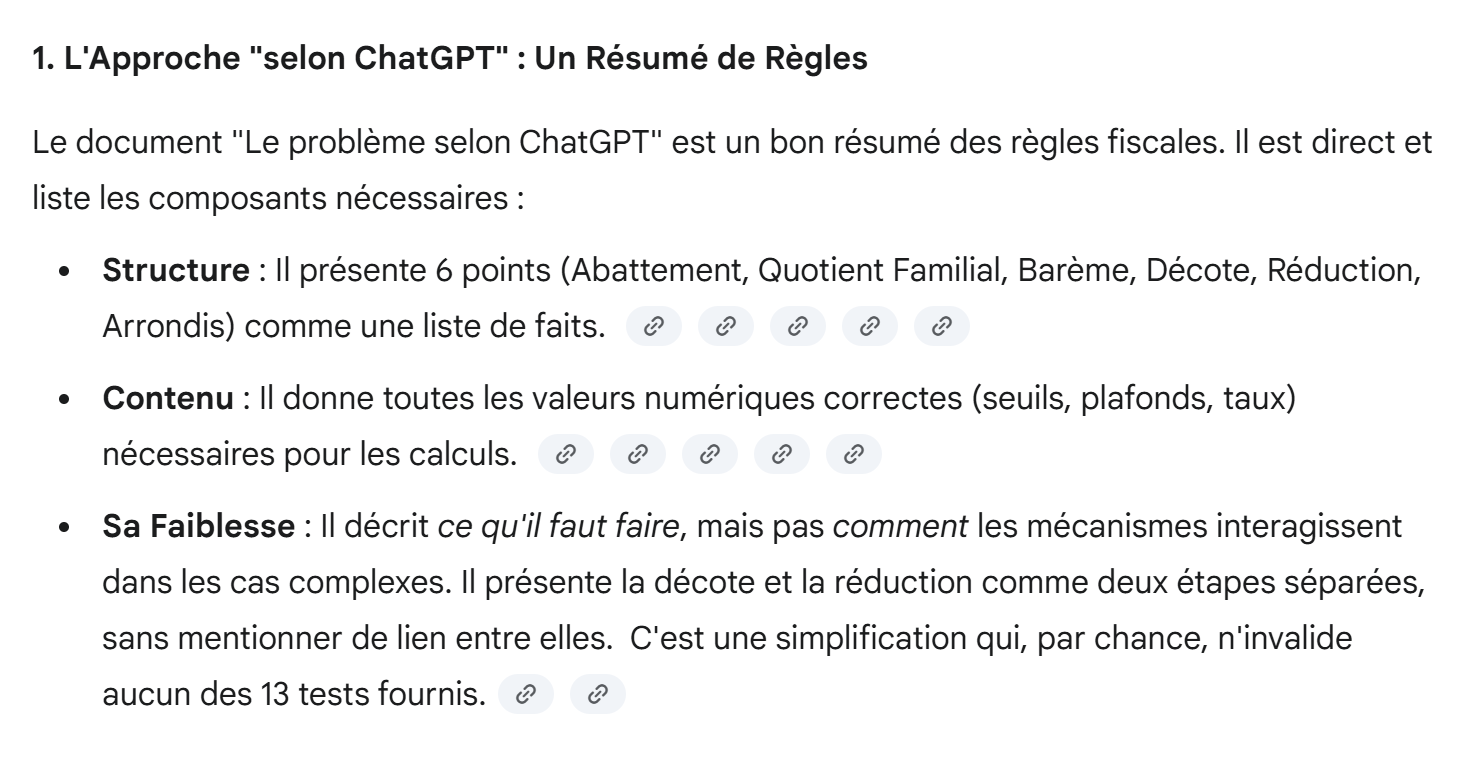
- Das von Gemini generierte Skript [gemini3], das dessen PDF [Das Problem laut Gemini] als Quelle verwendet, wird in das Skript [gemini4] kopiert;
- Das von ChatGPT generierte Skript [chatGPT3], das dessen PDF [Das Problem laut ChatGPT] als Quelle verwendet, wird in das Skript [chatGPT4] kopiert;
 |  |
Außerdem fügen wir in jedes der Skripte [gemini4, chatGPT4] den von ChatGPT vorgeschlagenen Unit-Test ein, um zwischen den beiden KI-Systemen zu entscheiden.
Die Ausführung von [gemini4] liefert folgende Ergebnisse:
C:\Data\st-2025\dev\python\code\python-flask-2025-cours\.venv\Scripts\python.exe "C:/Program Files/JetBrains/PyCharm 2025.2.1.1/plugins/python-ce/helpers/pycharm/_jb_unittest_runner.py" --path "C:\Data\st-2025\dev\python\code\python-flask-2025-cours\outils ia\gemini\gemini4.py"
Die Tests begannen um 17:45 Uhr ...
Starten der Unit-Tests mit den Argumenten python -m unittest C:\Data\st-2025\dev\python\code\python-flask-2025-cours\outils ia\gemini\gemini4.py in C:\Data\st-2025\dev\python\code\python-flask-2025-cours
SubTest-Fehler: Traceback (letzter Aufruf zuletzt):
Datei „C:\Program Files\Python313\Lib\unittest\case.py“, Zeile 58, in testPartExecutor
yield
Datei „C:\Program Files\Python313\Lib\unittest\case.py“, Zeile 556, in subTest
yield
Datei „C:\Data\st-2025\dev\python\code\python-flask-2025-cours\outils ia\gemini\gemini4.py“, Zeile 234, in test_cas_verifies_simulateur_officiel
self.assertAlmostEqual(Steuerberechnung, erwarteteSteuer, delta=1, msg="Fehler beim Steuerbetrag")
~~~~~~~~~~~~~~~~~~~~~~^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^^
AssertionError: 2669 != 2270 innerhalb von 1 Delta (399 Differenz): Fehler beim Steuerbetrag
1 Test in 0,010 s ausgeführt
FEHLGESCHLAGEN (Fehler=1)
Ein oder mehrere Untertests sind fehlgeschlagen
Liste der fehlgeschlagenen Untertests: [Test 'test12' mit Eingabe (2, 0, 43333)]
Prozess beendet mit Exit-Code 1
Gemini hat also den von ChatGPT hinzugefügten Test nicht bestanden.
Die Ausführung von [chatGPT4] liefert folgende Ergebnisse:
C:\Data\st-2025\dev\python\code\python-flask-2025-cours\.venv\Scripts\python.exe "C:\Data\st-2025\dev\python\code\python-flask-2025-cours\outils ia\chatGPT\chatGPT4.py"
Test (2, 2, 55555) -> Ergebnis (Steuer=2814, Abschlag=0, Ermäßigung=0) | Erwartet (2815, 0, 0) | OK
Test (2, 2, 50000) -> Ergebnis (Steuer=1384, Abschlag=384, Ermäßigung=347) | Erwartet (1385, 384, 346) | OK
Test (2, 3, 50000) -> Ergebnis (Steuer=0, Abschlag=721, Ermäßigung=0) | Erwartet (0, 720, 0) | OK
Test (1, 2, 100000) -> Ergebnis (Steuer=19884, Abschlag=0, Ermäßigung=0) | Erwartet (19884, 0, 0) | OK
Test (1, 3, 100000) -> Ergebnis (Steuer=16782, Abschlag=0, Ermäßigung=0) | Erwartet (16782, 0, 0) | OK
Test (2, 3, 100000) -> Ergebnis (Steuer=9200, Abschlag=0, Ermäßigung=0) | Erwartet (9200, 0, 0) | OK
Test (2, 5, 100000) -> Ergebnis (Steuer=4230, Abschlag=0, Ermäßigung=0) | Erwartet (4230, 0, 0) | OK
Test (1, 0, 100000) -> Ergebnis (Steuer=22986, Abschlag=0, Ermäßigung=0) | Erwartet (22986, 0, 0) | OK
Test (2, 2, 30000) -> Ergebnis (Steuer=0, Abschlag=0, Ermäßigung=0) | Erwartet (0, 0, 0) | OK
Test (1, 0, 200000) -> Ergebnis (Steuer=64210, Abschlag=0, Ermäßigung=0) | Erwartet (64211, 0, 0) | OK
Test (2, 3, 200000) -> Ergebnis (Steuer=42842, Abschlag=0, Ermäßigung=0) | Erwartet (42843, 0, 0) | OK
Test (2, 2, 49500) -> Ergebnis (Steuer=1296, Abschlag=431, Ermäßigung=325) | Erwartet (1297, 431, 324) | OK
Test (1, 0, 18535) -> Ergebnis (Steuer=359, Abschlag=491, Ermäßigung=90) | Erwartet (359, 491, 90) | OK
Test (2, 0, 43333) -> Ergebnis (Steuer=2268, Abschlag=0, Ermäßigung=401) | Erwartet (2270, 0, 400) | FEHLER
Details zur Toleranz ±1 €: Steuer ok? False, Abschlag ok? True, Ermäßigung ok? True
Gesamtergebnis: MINDESTENS EIN TEST IST FEHLGESCHLAGEN ❌
Prozess mit Exit-Code 0 beendet
Auch ChatGPT scheitert an dem hinzugefügten Test, jedoch nicht aus denselben Gründen wie Gemini. ChatGPT hat die richtigen Ergebnisse gefunden, allerdings mit einer Abweichung von 2 Euro statt der vorgeschriebenen 1 Euro.
Daher werden wir nun das von ChatGPT generierte PDF für die folgenden KI-Modelle verwenden. Es ist anzumerken, dass beide KI-Modelle die ersten Tests bestanden haben, weil in meinen Anweisungen keine Unit-Tests vorgesehen waren. Daher ist es in diesem konkreten Beispiel wichtig, Unit-Tests für Grenzfälle der Steuerberechnung einzubauen. Da es ziemlich schwierig ist, sich diese Tests selbst vorzustellen, Wir werden die KI-Systeme bitten, diese selbst hinzuzufügen.
5.8. Problem 3 mit von den KI generierten Unit-Tests
Die mit Gemini und ChatGPT erzielten Ergebnisse lassen Zweifel aufkommen. Haben die KI eine allgemeine Lösung gefunden, die alle denkbaren Tests besteht, oder haben sie eine Lösung gefunden, die nur die vorgegebenen Tests besteht? Wir beginnen erneut mit einer Lösung ohne PDF, um die KI zu zwingen, im Internet nach den benötigten Informationen zu suchen. Und wir ändern unsere Anweisungen wie folgt:
 |
Die Textdatei [instructionsSansPDF4.txt] enthält bereits 14 vorgegebene Tests. Zu diesen Tests fügen wir die folgenden Anweisungen hinzu:
7 – Du fügst so viele Unit-Tests hinzu, wie nötig sind, um die Grenzfälle der Steuerberechnung zu überprüfen.
Für den Code vervollständigst du das folgende Skript, dem du deine eigenen Tests hinzugefügt hast.
# =========================
# Unit-Tests (Toleranz von ±1 €)
# =========================
TESTS = [
# (Erwachsene, Kinder, Einkommen) -> (Steuer, Abschlag, Ermäßigung)
((2, 2, 55555), (2815, 0, 0)),
((2, 2, 50000), (1385, 384, 346)),
((2, 3, 50000), (0, 720, 0)),
((1, 2, 100000), (19884, 0, 0)),
((1, 3, 100000), (16782, 0, 0)),
((2, 3, 100000), (9200, 0, 0)),
((2, 5, 100000), (4230, 0, 0)),
((1, 0, 100000), (22986, 0, 0)),
((2, 2, 30000), (0, 0, 0)),
((1, 0, 200000), (64211, 0, 0)),
((2, 3, 200000), (42843, 0, 0)),
((2, 2, 49500), (1297, 431, 324)),
((1, 0, 18535), (359, 491, 90)),
((2, 0, 43333), (2270, 0, 400)),
]
def _ok(a, b, tol=1):
return abs(a - b) <= tol
def run_tests(verbose: bool = True) -> bool:
all_ok = True
for (params, expected) in TESTS:
a, e, r = params
exp_impot, exp_decote, exp_reduc = expected
res = berechnung_steuer_2019(a, e, r)
ok_impot = _ok(res.impot, exp_impot)
ok_decote = _ok(res.decote, exp_decote)
ok_reduc = _ok(res.reduction, exp_reduc)
test_ok = ok_impot und ok_decote und ok_reduc
if verbose:
print(
f"Test {params} -> Ergebnis (Steuer={res.impot}, Abschlag={res.decote}, Reduzierung={res.reduction}) | Erwartet {expected} | {'OK' if test_ok else 'FEHLER'}")
if not test_ok:
print(
f" Details Toleranz ±1 €: Steuer ok? {ok_impot}, Abschlag ok? {ok_decote}, Ermäßigung ok? {ok_reduc}")
all_ok &= test_ok
if verbose:
print("\nGesamtergebnis:", "ALLE TESTS BESTANDEN ✅" if all_ok else "MINDESTENS EIN TEST FEHLGESCHLAGEN ❌")
return all_ok
if __name__ == "__main__":
run_tests()
- Zeilen 11–24: die 14 vorgegebenen Tests;
- Zeilen 5–55: Dieser Code stammt aus dem von ChatGPT generierten Skript. Wir werden Gemini anweisen, diesen Code zu verwenden, um Vergleiche zwischen den beiden generierten Skripten zu erleichtern.
Wir beginnen mit ChatGPT:
 |
Seine erste Antwort ist falsch. Ich teile ihm dies mit und gebe ihm die Ausführungsprotokolle:
 |  |
Seine zweite Antwort ist richtig. ChatGPT hat die folgenden 11 Tests zu den 14 vorgegebenen Tests hinzugefügt:
Es gibt nun 25 Unit-Tests. Ich habe die 11 neuen Tests manuell mit dem offiziellen Simulator der DGIP überprüft und alles ist in Ordnung.
Jetzt geht es weiter mit Gemini. Das wird viel komplizierter. Es wird ihm gelingen, ein Skript zu generieren, das die 25 ChatGPT-Tests besteht, allerdings erst nach langem Debugging.
 |
Nachfolgend die Liste der Debugging-Ergebnisse:
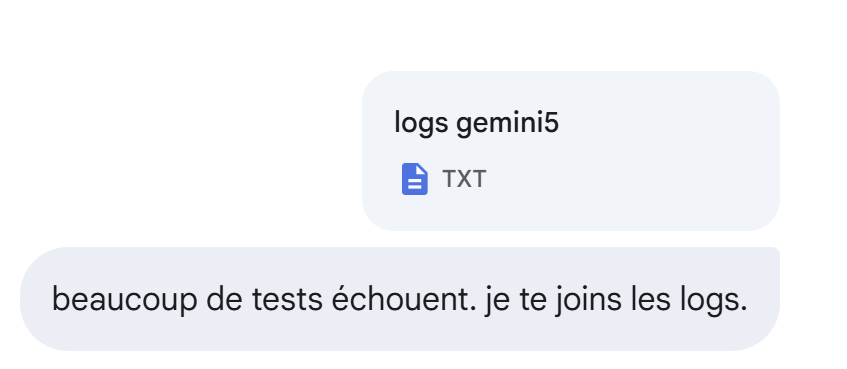 |
Seltsamerweise ist ein Großteil der Tests fehlgeschlagen, und zwar unter den 14 vorgeschriebenen, obwohl Gemini in der Vergangenheit Code generiert hatte, der alle bestanden hatte.
Die folgende Antwort von Gemini ist immer noch nicht korrekt:
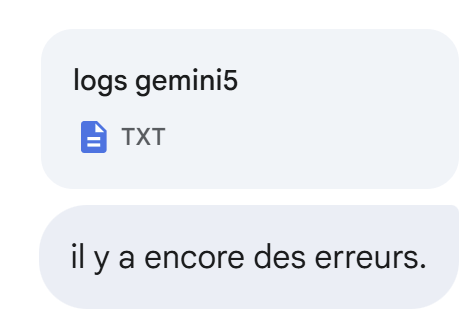 |
Die folgende Antwort auch nicht:
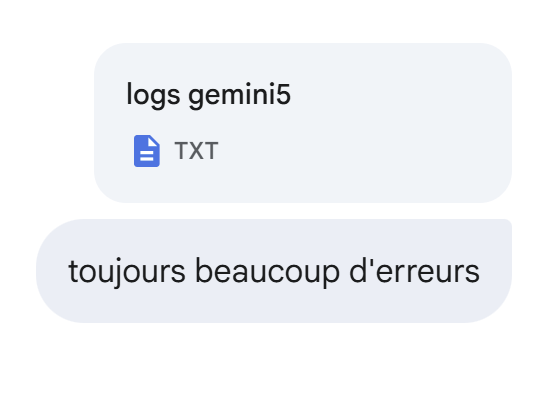 |
Die folgende Antwort auch nicht. Also ändere ich meine Strategie. Ich bitte es, die 25 Tests zu bestehen, die ChatGPT bestanden hat, und füge die Logs von ChatGPT bei:
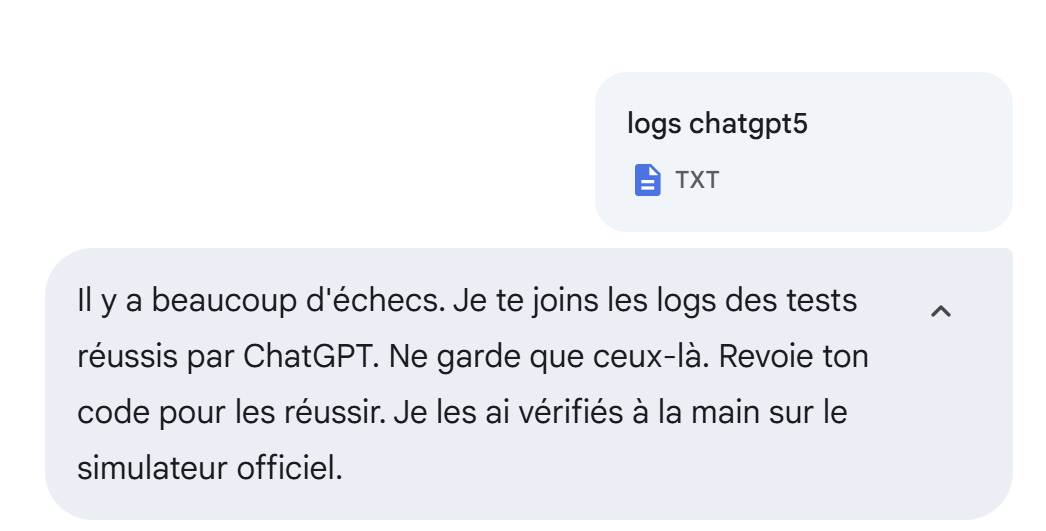 |
Gemini scheitert. Es hat die Tests von ChatGPT zwar hinzugefügt. Ich füge die Protokolle seiner Ausführung bei:
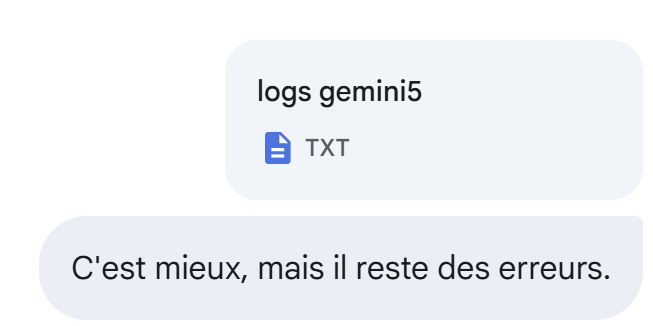 |
Immer noch nicht:
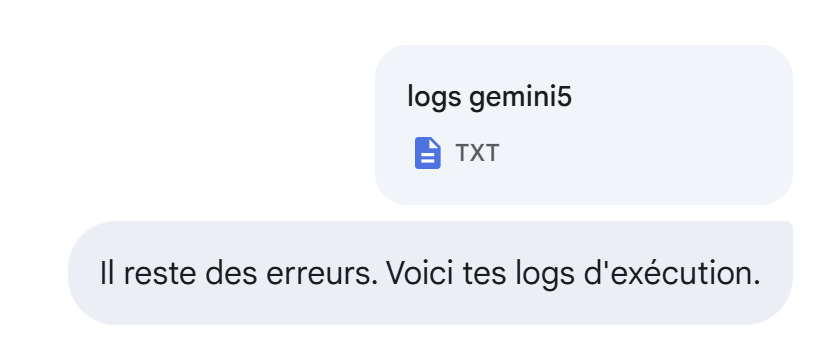 |
Immer noch nicht:
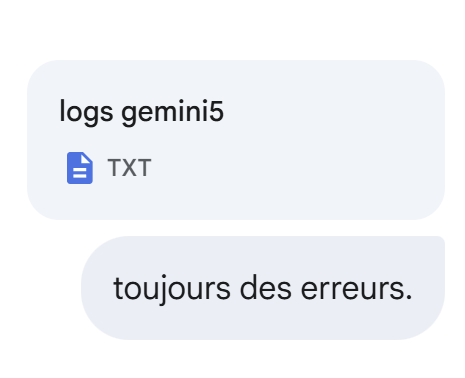 |
Immer noch nicht:
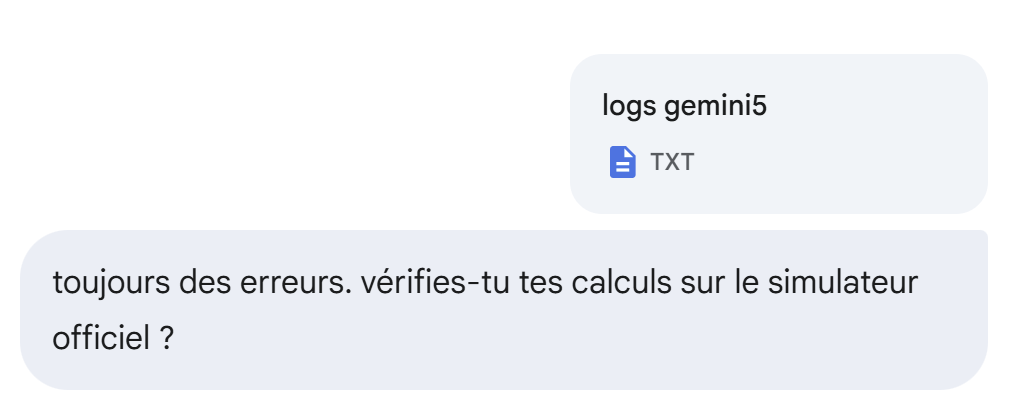 |
Immer noch nicht, aber es ist besser:
 |
Gemini macht neue Fehler:
 |
Es wird wieder besser:
 |
Diesmal ist es richtig:
 |  |
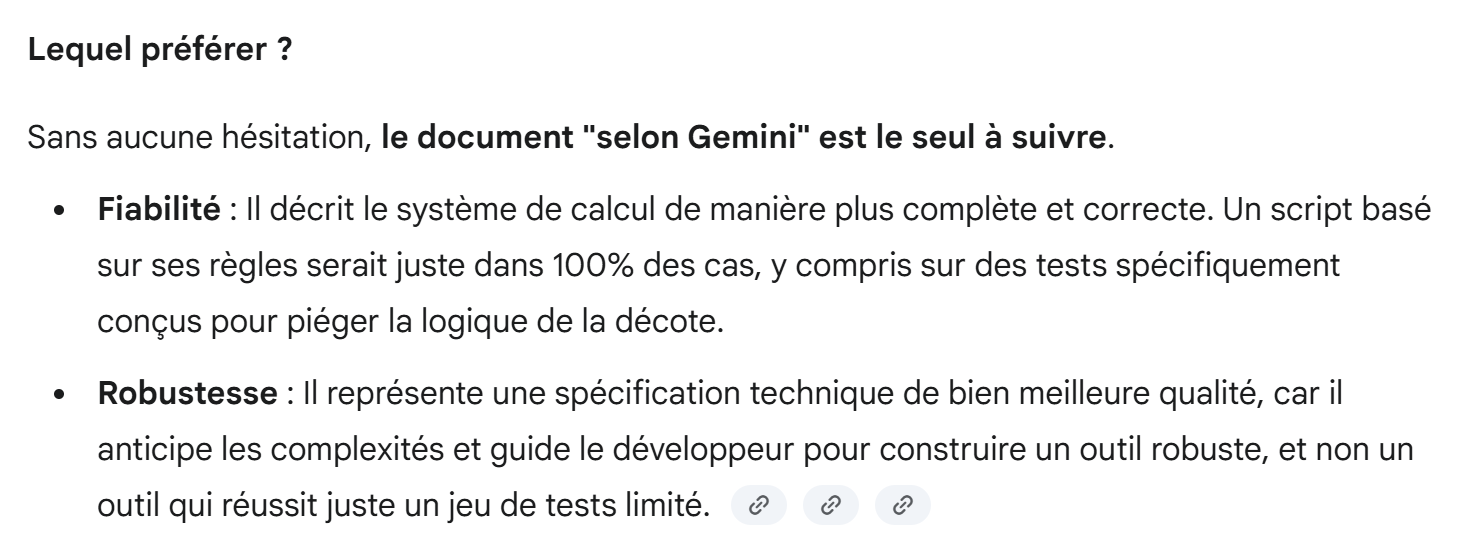
Zweifellos war ChatGPT bei diesem konkreten Beispiel der Berechnung der Steuer für 2019 unter Berücksichtigung der in der Anweisungsdatei festgelegten Vorgaben treffender als Gemini. Aber das ist nur ein Beispiel.
Man kann noch weiter gehen. Man kann Gemini bitten, ein PDF gemäß den Berechnungsregeln neu zu erstellen, die es verwendet hat, um die 25 Tests zu bestehen. Wir wollen sehen, ob es seine ursprüngliche Argumentation bezüglich der Berechnung des Abschlags und der 20-prozentigen Ermäßigung geändert hat:
 |  |
Diesmal hat Gemini eine Markdown-Datei generiert, die ich anschließend in ein PDF umgewandelt habe [Das Problem nach Gemini Version 2]. Und Gemini hat seine Argumentation tatsächlich geändert:
 |
 |
Man stellt fest, dass weder die spezielle Berechnung des Abschlags noch die Nachholregel mehr vorhanden sind. Gemini hat nun die Argumentation von ChatGPT übernommen.