2. Die drei untersuchten Probleme und die Ergebnisse
Wir werden die IA bitten, drei Probleme vom einfachsten bis zum kompliziertesten zu untersuchen. Sehen wir uns einen Screenshot von Google Gemini :
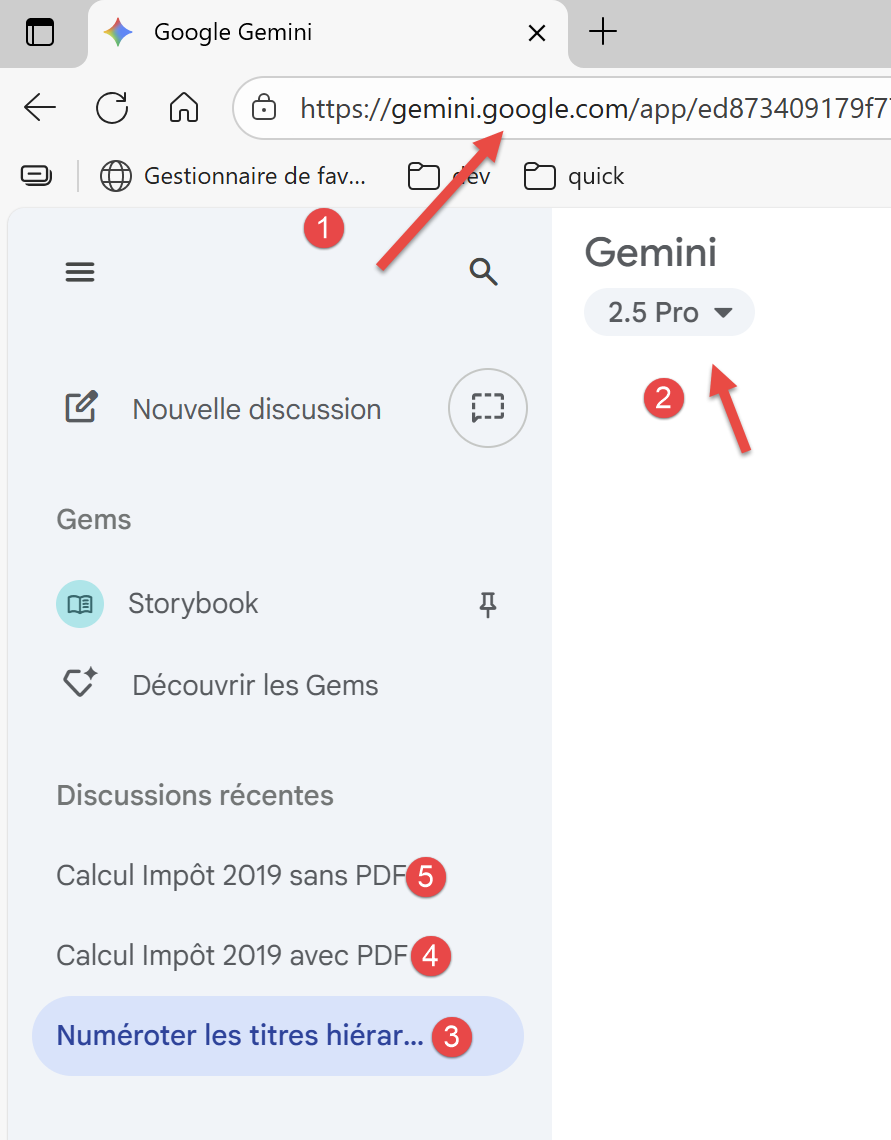 |
- In [1] wurde der URL von Gemini ;
- In [2] wurde die verwendete Version von Gemini ;
- In [3-5] werden die drei Probleme, die Gemini gestellt wurden ;
2.1. Aufgabe 1
Problem 1 ist eine einfache Frage:
 |
Alle IA werden diese Frage richtig beantworten.
2.2. Aufgabe 2
Problem 2 lautet wie folgt (Screenshot aus Gemini):
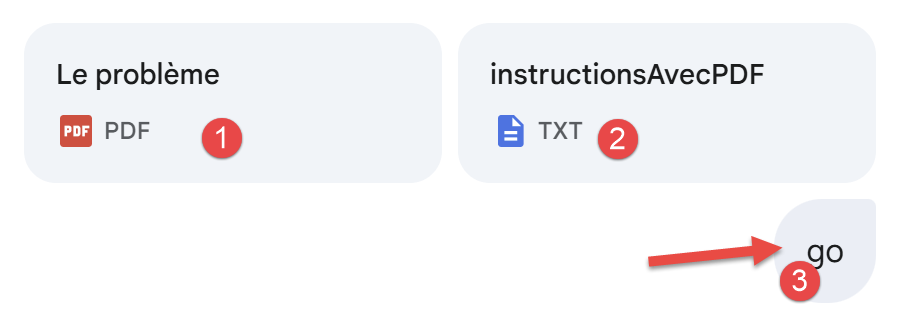 |
- In [1] wird das Prinzip der Berechnung der Steuer 2019 auf das Einkommen 2018 in einem PDF erläutert. Wir kommen darauf zurück ;
- In [2] geben wir Gemini genaue Anweisungen, was wir wollen, einen sauberen script Python, der das gestellte Problem löst und die vorgeschlagene Lösung mit 11 Unit-Tests validiert ;
- In [3] muss man, um Gemini zu starten, etwas schreiben;
Hier liegt genau derselbe Fall vor wie bei einem TD, der an der Universität gegeben wird.
Die getesteten IA werden das Problem lösen, mit Ausnahme von MistralAI und Perplexity.
2.3. Aufgabe 3
Immer noch mit einem Screenshot von Google Gemini, ist Problem 3 folgendes:
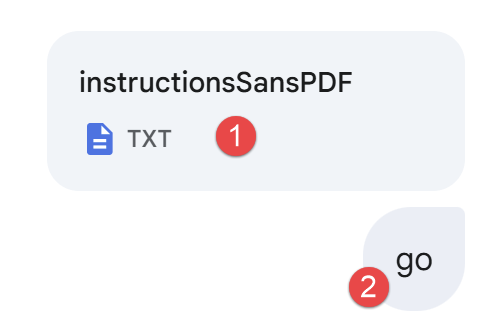 |
- In [1] geben wir unsere Anweisungen, die gleichen wie zuvor. Da wir aber nicht den PDF angeben, der die genauen Rechenregeln enthielt. Der IA wird diese Regeln im Internet suchen müssen;
- In [3] wird die Ausführung von IA gestartet;
Nur drei IA haben diesen Test bestanden, in der Reihenfolge ihrer Exzellenz (streng persönliche Meinung, das versteht sich von selbst) :
- ChatGPT von OpenAI ;
- Grok von xAI ;
- Goggle Gemini ;
Die IA ClaudeAI scheiterte an Problem 3. Der IA MistralAI schlug bei den Problemen 2 und 3 fehl, ebenso wie der IA Perplexity. Die IA DeepSeek schlug bei Problem 3 fehl.