19. استخدام SQLAlchemy ORM
أظهر الفصل السابق أنه في بعض الحالات، يمكننا كتابة كود مستقل عن نظام إدارة قواعد البيانات المستخدم باستخدام البنية التالية:
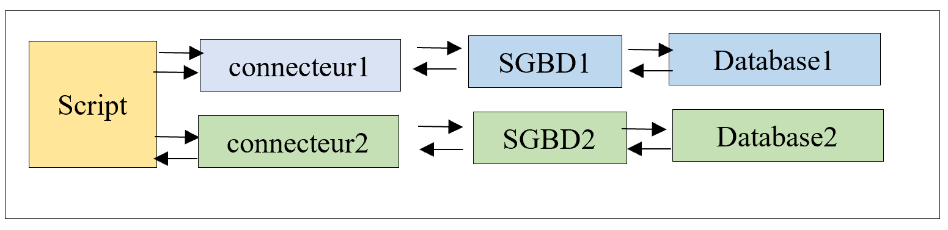
في هذا الفصل، سنستخدم ORM (Object Relational Mapper) [SQLAlchemy] للوصول إلى أنظمة إدارة قواعد البيانات (DBMS) بشكل موحد، بغض النظر عن نظام إدارة قواعد البيانات المستخدم. يتيح ORM أمرين:
- يسمح للبرنامج النصي بالتفاعل مع نظام إدارة قواعد البيانات دون إصدار أوامر SQL؛
- يخفي تفاصيل كل نظام إدارة قواعد البيانات عن البرنامج النصي؛
تصبح البنية كما يلي:
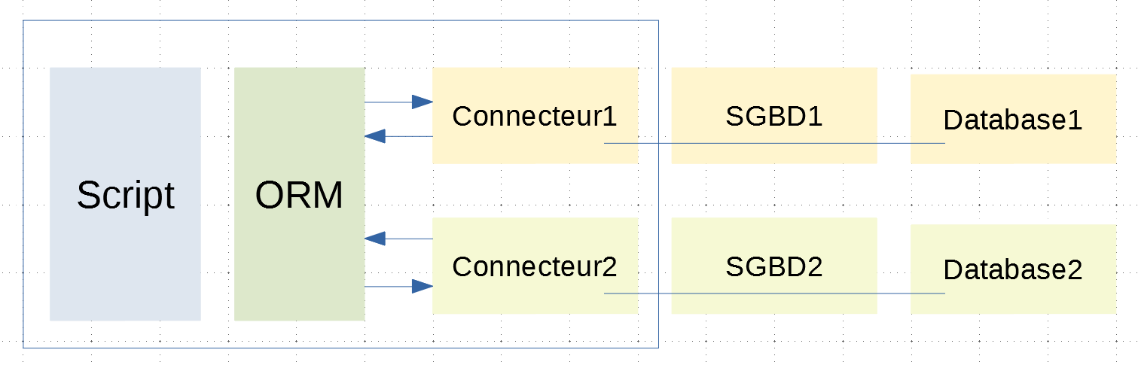
أصبح البرنامج النصي الآن منفصلاً عن الموصلات بواسطة ORM. ويتواصل مع ORM باستخدام الفئات والأساليب. ولا يقوم بتنفيذ كود SQL. يقوم ORM بذلك باستخدام الموصلات التي يتصل بها. ويخفي تفاصيل هذه الموصلات عن البرنامج النصي. وبالتالي، لا يتأثر كود البرنامج النصي بأي تغيير في الموصل (وبالتالي في نظام إدارة قواعد البيانات)؛
ستكون بنية الدليل للبرامج النصية قيد النظر على النحو التالي:
19.1. تثبيت ORM [SQLAlchemy]
يأتي ORM [SQLAlchemy] كحزمة Python يجب تثبيتها في محطة Python:
(venv) C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\databases\sqlalchemy>pip install sqlalchemy
Collecting sqlalchemy
Downloading SQLAlchemy-1.3.18-cp38-cp38-win_amd64.whl (1.2 MB)
|| 1.2 MB 3.3 MB/s
Installing collected packages: sqlalchemy
Successfully installed sqlalchemy-1.3.18
19.2. البرامج النصية 01: الأساسيات

- في [1]، البرامج النصية التي سيتم دراستها. ستستخدم هذه البرامج النصية الفئات من [2]: BaseEntity، MyException، Person، Utils؛
19.2.1. التكوين
يقوم ملف [config] بتكوين التطبيق على النحو التالي:
تعليقات
- السطر 8: أضف المجلد الذي يحتوي على الفئات [BaseEntity، MyException، Person، Utils] إلى مسار Python؛
- السطران 12-13: نحدد مسار Python للتطبيق؛
- السطران 16-17: قد تتذكر أن فئة |BaseEntity| تحتوي على سمة فئة تسمى [excluded_keys]. هذه السمة عبارة عن قائمة نضع فيها خصائص الفئة التي لا نريدها أن تظهر في قاموس الفئة (وظيفة asdict). هنا نستبعد الخاصية [_sa_instance_state] من حالة فئة [Person]. سنرى السبب قريبًا؛
19.2.2. نص [demo]
يُظهر البرنامج النصي [demo] الاستخدام الأولي لـ ORM [sqlalchemy]:
تعليقات
- الأسطر 1-4: نقوم بتكوين التطبيق؛
- الأسطر 6-10: نستورد الوحدات النمطية اللازمة للنص البرمجي؛
- السطر 13: [MetaData] هي فئة في [sqlalchemy]؛
- الأسطر 15-22: [Table] هي فئة في [sqlalchemy]. تُستخدم لوصف جدول قاعدة بيانات. هنا، سنصف جدول [people] في قاعدة بيانات MySQL [dbpeople] التي تمت تغطيتها في فصل |MySQL|؛
- السطر 16: المعلمة الأولى [people] هي اسم الجدول الذي يتم وصفه؛
- السطر 16: المعلمة الثانية [metadata] هي مثيل [MetaData] الذي تم إنشاؤه في السطر 13؛
- الأسطر 17–22: تصف كل معلمة من المعلمات التالية عمودًا من أعمدة الجدول باستخدام صيغة خاصة بـ [SQLAlchemy] ولكنها مشابهة لصيغة SQL؛
- يتم وصف كل عمود باستخدام مثيل لفئة [Column] من [sqlalchemy]؛
- المعلمة الأولى هي اسم العمود؛
- المعلمة الثانية هي نوعه؛
- المعلمات التالية هي معلمات مسماة:
- السطر 17: [primary_key=True] للإشارة إلى أن عمود [id] هو المفتاح الأساسي لجدول [people]؛
- السطر 18: [nullable=False] للإشارة إلى أن العمود يجب أن يحتوي على قيمة عند إدراج صف في الجدول؛
- السطر 21: أخيرًا، تسمح لك فئة [UniqueConstraint] بتعريف قيد التفرد. هنا، نحدد أن الأعمدة (last_name، first_name) يجب أن تكون فريدة داخل الجدول. تسمح لك الخاصية المسماة [name] بإعطاء اسم لهذا القيد. هنا، هناك حالتان يجب أخذهما في الاعتبار:
- نحن نصف جدولًا موجودًا. في هذه الحالة، يجب أن نبحث عن اسم القيد في خصائص الجدول (phpMyAdmin أو pgAdmin)؛
- نحن نصف جدولًا نحن على وشك إنشائه. في هذه الحالة، ندخل الاسم الذي نريده؛
- الأسطر 23–25: نقوم بإنشاء شخص [person1] وعرض قاموسه [__dict__]. هنا سيكون لدينا:
personne1={'_BaseEntity__id': 67, '_Personne__prénom': 'x', '_Personne__nom': 'y', '_Personne__âge': 10}
- الأسطر 27–33: نقوم بعملية تعيين، أي ننشئ توافقًا بين الفئة [Person] والجدول [people]. وهذا في الأساس تعيين [خصائص الفئة أعمدة الجدول]. تأخذ الدالة [mapper] هنا ثلاثة معلمات:
- السطر 28: المعلمة الأولى هي اسم الفئة التي يتم إجراء التعيين لها؛
- السطر 28: المعلمة الثانية هي الجدول الذي سيتم ربطه بها. هذا هو كائن [Table] الذي تم إنشاؤه في السطر 16؛
- السطر 28: المعلمة الثالثة هنا هي معلمة تُسمى [properties]. وهي عبارة عن قاموس تكون مفاتيحه هي خصائص الفئة المُعَدَّلة، وقيمه هي أعمدة الجدول المُعَدَّل. للإشارة إلى العمود X في جدول [personnes_table]، نكتب [personnes_table.c.X]؛
- السطران 35-36: نعرض الشخص [person1] مرة أخرى بمجرد اكتمال التعيين. نرى أنه لم يتغير:
personne1={'_BaseEntity__id': 67, '_Personne__prénom': 'x', '_Personne__nom': 'y', '_Personne__âge': 10}
- السطور 37-39: نقوم بإنشاء شخص جديد [person2] وعرضه. ثم نرى النتيجة التالية:
personne2={'_sa_instance_state': <sqlalchemy.orm.state.InstanceState object at 0x00000259A6747FA0>, 'id': 68, 'prénom': 'x1', 'nom': 'y1', 'âge': 11}
يمكننا أن نرى أن القاموس [__dict__] قد تم تعديله بشكل كبير:
- (تابع)
- ظهرت خاصية جديدة [_sa_instance_state]. يمكننا أن نرى أنها كائن ORM [sqlalchemy]؛
- تمت إزالة البادئات من الخصائص الأخرى، والتي كانت تشير سابقًا إلى الفئة التي تنتمي إليها؛
وبالتالي يمكننا أن نستنتج أن عملية التعيين في الأسطر 27–33 قد عدلت فئة [Person].
عندما نرغب في عرض حالة كائن [Person]، فإننا لا نرغب عمومًا في الخاصية [_sa_instance_state]. فهي موجودة فقط من أجل العمليات الداخلية لـ [SQLAlchemy] ولا تهمنا عمومًا. ولهذا السبب كتبنا في البرنامج النصي [config]:
19.2.3. البرنامج النصي [main]
سيقوم البرنامج النصي [main] بمعالجة الجدول [people] في قاعدة بيانات MySQL [dbpeople] من خلال التفاعل مع [sqlalchemy]. لفهم ما يلي، نحتاج إلى تذكر البنية المستخدمة هنا:
إذا كانت [Database1] هي قاعدة البيانات [dbpersonnes]، فيمكننا أن نرى أن الاتصال بين البرنامج النصي وقاعدة البيانات هذه يتضمن مكونين:
- موصل Python بنظام إدارة قواعد البيانات MySQL؛
- نظام إدارة قواعد البيانات MySQL؛
سيتواصل البرنامج النصي [main] مع ORM، الذي سيتواصل بدوره مع موصل Python. يتواصل ORM مع هذا الموصل باستخدام الأدوات الموضحة في أقسام |MySQL| و|PostgreSQL|، ولا سيما عن طريق إصدار أوامر SQL. لن يستخدم البرنامج النصي [main] أوامر SQL. سيعتمد على واجهة برمجة التطبيقات (API) الخاصة بـ ORM، والتي تتكون من فئات وواجهات.
النص البرمجي [main] هو كما يلي:
تعليقات
- الأسطر 1–4: يتم تكوين التطبيق؛
- الأسطر 7–9: نستورد سلسلة كاملة من الفئات والواجهات من مكتبة [sqlalchemy]؛
- السطر 11: يتم استيراد فئة [Person]؛
- السطر 14: سلسلة اتصال قاعدة البيانات. وهي تحدد:
- نظام إدارة قواعد البيانات المستخدم (mysql)؛
- موصل Python المستخدم (mysql.connector بدون النقطة)؛
- المستخدم الذي يقوم بتسجيل الدخول (admpersonnes)؛
- كلمة المرور الخاصة به (nobody)؛
- الجهاز الذي يوجد عليه نظام إدارة قواعد البيانات (localhost = الجهاز الذي يعمل عليه البرنامج النصي)؛
- اسم قاعدة البيانات (dbpersonnes)؛
باستخدام هذه المعلومات، يمكن لـ [sqlalchemy] الاتصال بقاعدة البيانات. لاحظ أن موصل Python المستخدم يجب أن يكون مثبتًا بالفعل. [sqlalchemy] لا يقوم بتثبيته.
- الأسطر 19–26: وصف جدول [people]؛
- الأسطر 28–34: التعيين بين فئة [Person] وجدول [people]؛
- الأسطر 36–38: تُنفَّذ معظم عمليات [sqlalchemy] ضمن جلسة عمل. ويشبه مفهوم جلسة عمل [sqlalchemy] مفهوم معاملة SQL. يتم إنشاء جلسات العمل من فئة [Session] التي تُرجعها الدالة [sessionmaker] في السطر 37؛
- السطر 38: ترتبط فئة [Session] بقاعدة البيانات [dbpeople] عبر سلسلة الاتصال في السطر 14؛
- السطر 43: يتم إنشاء جلسة عمل. كما ذكرنا، يمكن تشبيه جلسة العمل بمعاملة؛
- السطران 45-46: تسمح طريقة [Session.execute] بتنفيذ عبارة SQL. هذه ليست ممارسة شائعة، حيث ذكرنا أن ORM يسمح بتجنب استخدام SQL؛
- السطران 48-49: تقوم طريقة [metadata.create_all] بإنشاء جميع الجداول باستخدام مثيل [MetaData] من السطر 17. لدينا جدول واحد فقط: جدول [people] المحدد في الأسطر 20-26. سيستخدم [SQLAlchemy] المعلومات الواردة في هذه الأسطر لإنشاء الجدول. هنا نرى فائدة رئيسية لـ ORM: إنه يخفي تفاصيل نظام إدارة قواعد البيانات (DBMS). في الواقع، يمكن أن تختلف عبارة SQL [create] بشكل كبير من نظام إدارة قواعد البيانات (DBMS) إلى آخر بسبب أنواع البيانات المخصصة للأعمدة. لم تكن هناك توحيد لأنواع البيانات في SQL. وبالتالي، تختلف عبارة [create] من نظام إدارة قواعد البيانات (DBMS) إلى آخر. هنا، بفضل [SQLAlchemy]:
- نصف الجدول الذي نريده بطريقة واحدة ومتسقة؛
- يتمكن [SQLAlchemy] من إنشاء جملة [create] المناسبة لنظام إدارة قواعد البيانات الذي يعمل معه؛
- السطر 52: نضيف كائن [Person] إلى الجلسة. هذا لا يضيفه تلقائيًا إلى قاعدة البيانات. في الواقع، يتبع ORM قواعده الخاصة للتزامن مع قاعدة البيانات. سيسعى دائمًا إلى تحسين عدد الاستعلامات التي يقوم بها. لنأخذ مثالاً. يضيف البرنامج النصي (add) شخصين (person1، person2) إلى الجلسة ثم يقوم باستعلام: يريد رؤية جميع الأشخاص في الجدول. يمكن لـ [SQLAlchemy] المضي قدماً على النحو التالي:
- يمكن إضافة [person1] في الذاكرة. لا داعي لإدراجه في قاعدة البيانات في الوقت الحالي؛
- وينطبق الأمر نفسه على [person2]؛
- يأتي بعد ذلك استعلام [select]. يجب علينا بعد ذلك استرداد جميع الصفوف من جدول [people]. سيقوم [SQLAlchemy] بعد ذلك بإدراج [person1، person2] في قاعدة البيانات وتنفيذ الاستعلام؛
وبالتالي، سيقوم [SQLAlchemy] بإجراء تحسينات تكون شفافة للمطور.
- السطر 56: لتنفيذ استعلام [select] (أريد أن أرى...)، نستخدم طريقة [Session.query]. المعلمة لطريقة [query] هي الفئة المرتبطة بالجدول الذي يتم الاستعلام عنه. ترجع هذه الطريقة كائن [Query]. تسترد طريقة [Query.all] جميع كائنات [Person] من الجلسة. وهي تُرجع جميع الصفوف من جدول [people]، كل منها في شكل كائن [Person]. للقيام بذلك، يستخدم [SQLAlchemy] التعيين الذي تم إنشاؤه بين فئة [Person] وجدول [people]. نتيجة السطر 56 هي قائمة بكائنات [Person]؛
- الأسطر 58–61: نعرض عناصر قائمة [people]. ونظرًا لأن فئة [Person] مشتقة من فئة [BaseEntity]، فإن الدالة [Person.__str__] المستخدمة هنا ضمناً في السطر 61 هي في الواقع الدالة [BaseEntity.__str__]، والتي تُرجع سلسلة JSON للكائن المستدعي. هذه السلسلة هي سلسلة JSON الخاصة بقاموس [Person.asdict] (انظر |BaseEntity|). ذكرنا أنه بعد التعيين، سنجد الخاصية [_sa_instance_state] في كل كائن [Person]. ومع ذلك، فإن قيمة هذه الخاصية ليست من النوع [BaseEntity]. لذلك يجب استبعادها من قاموس فئة [Person]؛ وإلا، فسوف يتعطل العرض. وهذا ما تم في البرنامج النصي [config]؛
- الأسطر 63-65: نضيف شخصين آخرين لهما نفس الاسم الأول واسم العائلة. ومع ذلك، هناك قيد تفرد على اتحاد هذين العمودين. لذلك، من المفترض أن يحدث خطأ. وهذا ما نحاول التحقق منه؛
- الأسطر 67-68: نطلب قائمة بجميع الأشخاص في قاعدة البيانات مرة أخرى؛
- الأسطر 70-73: ونعرضهم؛
- السطور 75-76: يتم تثبيت الجلسة. كما يوحي الاسم، سيتم تثبيت المعاملة الأساسية؛
- سنرى أثناء التنفيذ أن الأسطر 67-76 لن يتم تنفيذها بسبب الاستثناء الذي أثاره السطر 65. سننتقل بعد ذلك إلى الأسطر 78-84 لمعالجة الاستثناء؛
- السطر 78: يحدث استثناء [InterfaceError] إذا تعذر على [SQLAlchemy] الاتصال بقاعدة البيانات [dbpersonnes]. يحدث استثناء [IntegrityError] في السطر 65؛
- السطر 80: يتم عرض الخطأ؛
- الأسطر 82-84: إذا كانت الجلسة موجودة، نقوم بإرجاعها. وهذا يعادل إرجاع المعاملة الأساسية؛
- الأسطر 85–88: في جميع الحالات، سواء حدث خطأ أم لا، يتم إغلاق الجلسة لتحرير الموارد؛
نتائج التنفيذ هي كما يلي:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/databases/sqlalchemy/01/main.py
Liste des personnes ---------
{"nom": "y", "prénom": "x", "id": 67, "âge": 10}
L'erreur suivante s'est produite : (raised as a result of Query-invoked autoflush; consider using a session.no_autoflush block if this flush is occurring prematurely)
(mysql.connector.errors.IntegrityError) 1062 (23000): Duplicate entry 'y1-x1' for key 'uix_1'
[SQL: INSERT INTO personnes (id, prenom, nom, age) VALUES (%(id)s, %(prenom)s, %(nom)s, %(age)s)]
[parameters: ({'id': 68, 'prenom': 'x1', 'nom': 'y1', 'age': 10}, {'id': 69, 'prenom': 'x1', 'nom': 'y1', 'age': 10})]
(Background on this error at: http://sqlalche.me/e/13/gkpj)
rollback...
Process finished with exit code 0
- السطران 2-3: قائمة الأشخاص بعد الإدراج الأول؛
- السطر 5: استثناء [IntegrityError] الذي حدث عند إضافة شخصين يحملان نفس الاسم الأول واسم العائلة؛
- السطران 6-7: لاحظ عبارة SQL التي فشلت. إنها عبارة INSERT معلمة: [SQLAlchemy] أدخلت كلا الشخصين بعبارة INSERT واحدة. هنا يمكننا أن نرى أنها حاولت تحسين عبارات SQL الصادرة؛
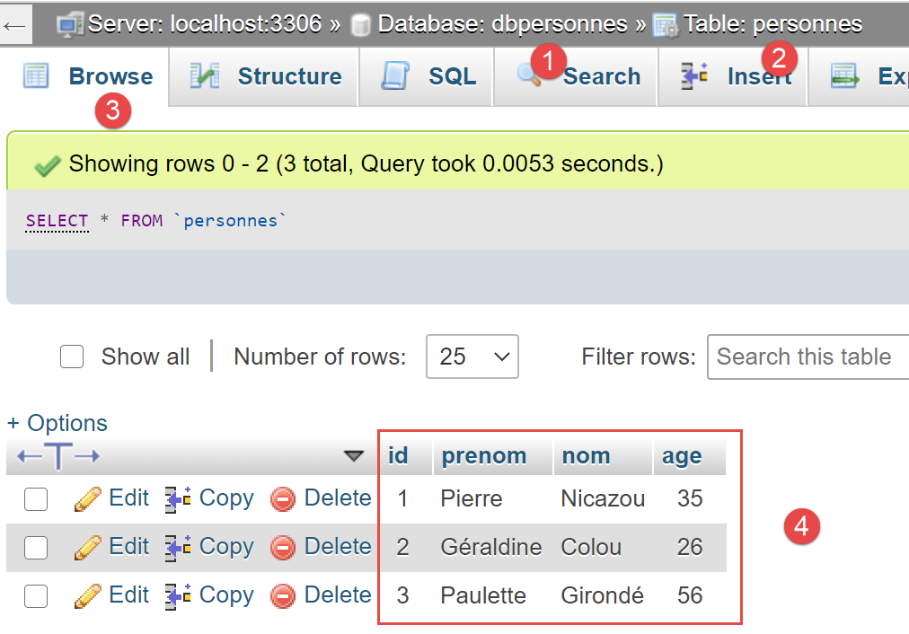
الآن دعونا نستخدم phpMyAdmin لعرض محتويات جدول [people]:
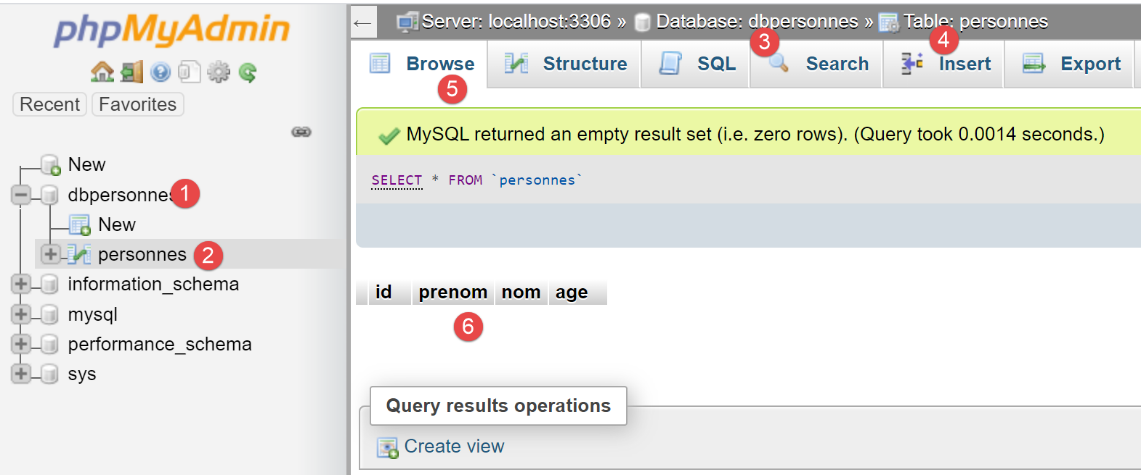
يمكننا أن نرى في [6] أن الجدول فارغ. حتى الشخص الأول الذي أضافه البرنامج النصي إلى الجلسة غير موجود. ويرجع ذلك إلى أن الجلسة كانت جزءًا من معاملة، وتم التراجع عن تلك المعاملة في جملة [except] في البرنامج النصي [main].
دعونا الآن نجري التغيير التالي في [main]:
بعد إضافة شخص في السطر 2، نقوم بإلغاء تعليق السطر 3. ستقوم عملية [session.commit] بتثبيت المعاملة الأساسية، وستبدأ معاملة جديدة. بعد التنفيذ، يكون محتوى جدول [people] كما يلي:
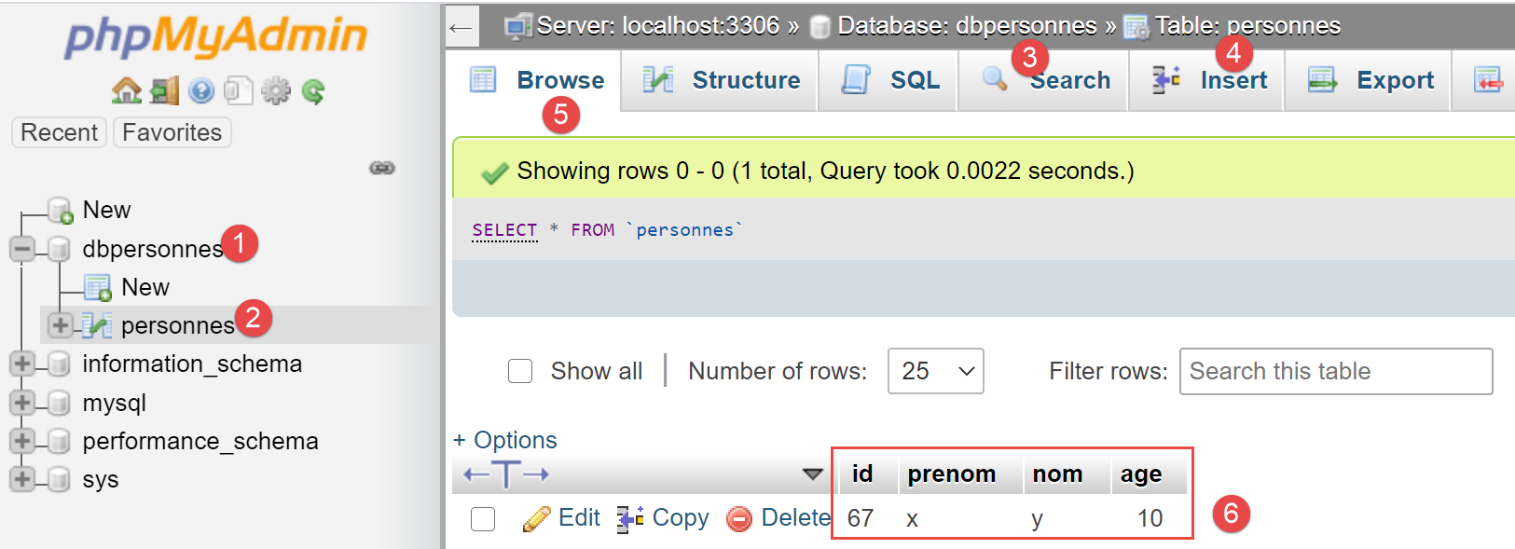
يمكننا أن نلاحظ في [6] أن عملية الإدراج الأولى قد تم الاحتفاظ بها. ويرجع ذلك إلى أنها تمت ضمن المعاملة 1، بينما وقع الخطأ اللاحق ضمن المعاملة 2.
19.3. البرامج النصية 02: تعيينات [sqlalchemy]

النصوص البرمجية 02 هي نسخة معدلة من النصوص البرمجية 01. نحاول التهيئة قدر الإمكان في [config.py]. نقوم الآن بتهيئة بيئة [sqlalchemy] للتطبيق هناك:
تعليقات
- الأسطر 2–12: تكوين مسار Python؛
- الأسطر 14–45: تكوين بيئة [sqlalchemy]؛
- الأسطر 47–52: تتم إضافة بيئة [sqlalchemy] إلى قاموس التكوين؛
- الأسطر 54–56: تكوين فئة [Person]؛
مع هذا التكوين، يصبح البرنامج النصي [main] كما يلي:
نتائج التنفيذ هي كما يلي:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/databases/sqlalchemy/02/main.py
Liste des personnes-----------
{"âge": 10, "nom": "y", "prénom": "x", "id": 1}
{"âge": 7, "nom": "y1", "prénom": "x1", "id": 2}
L'erreur suivante s'est produite : (raised as a result of Query-invoked autoflush; consider using a session.no_autoflush block if this flush is occurring prematurely)
(mysql.connector.errors.IntegrityError) 1062 (23000): Duplicate entry 'y2-x2' for key 'uix_1'
[SQL: INSERT INTO personnes (prenom, nom, age) VALUES (%(prenom)s, %(nom)s, %(age)s)]
[parameters: {'prenom': 'x2', 'nom': 'y2', 'age': 10}]
(Background on this error at: http://sqlalche.me/e/13/gkpj)
rollback...
Travail terminé...
Process finished with exit code 0
في phpMyAdmin، يبدو جدول [people] الآن كما يلي:
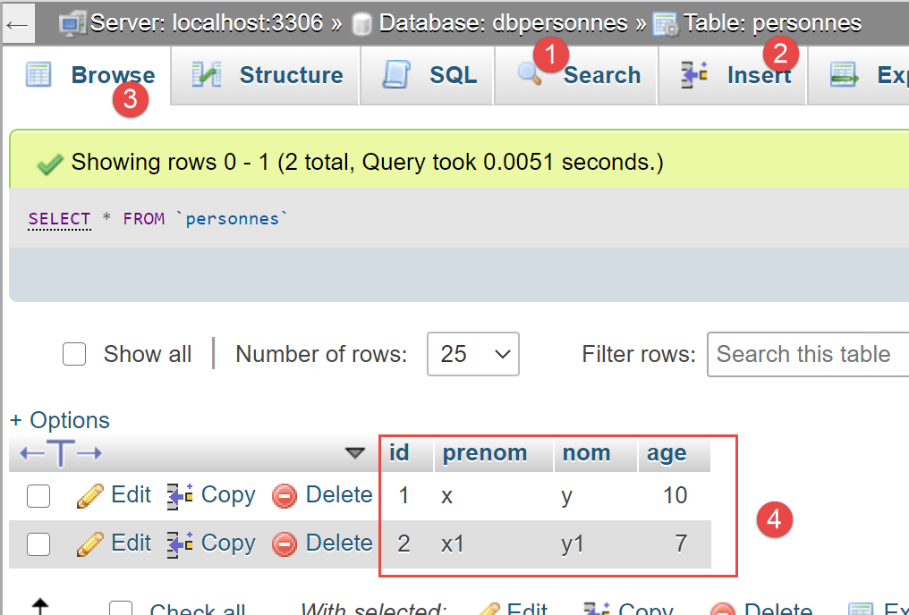
الآن، دعونا نلقي نظرة على جدول [people] الذي تم إنشاؤه بواسطة [SQLAlchemy]:
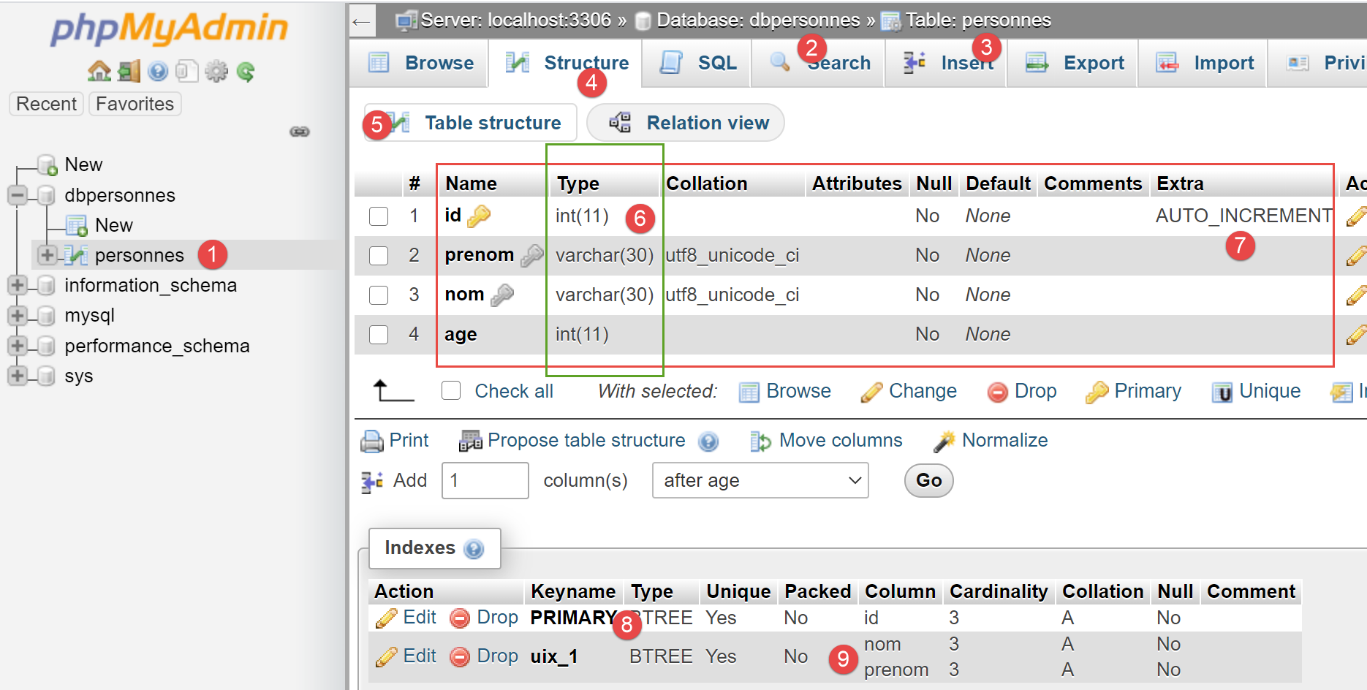
- في [6]، الأنواع المستخدمة للأعمدة المختلفة؛
- في [7]، نلاحظ أن العمود [id] يحمل السمة [AUTO_INCREMENT]. وهذا يعني أنه عند إدراج صف في الجدول، إذا لم يكن لهذا الصف قيمة في عمود [id]، فسوف يقوم MySQL بإنشائها بشكل متزايد: 1، 2، 3، … هذه الخاصية توفر علينا عناء القلق بشأن قيمة المفتاح الأساسي عند الإدراج في الجدول: فنحن نترك MySQL يتولى إنشائها؛
- في [8]، نرى أن العمود [id] هو المفتاح الأساسي؛
- في [9]، نرى قيد التفرد على الحقول [last_name, first_name]؛
19.4. البرامج النصية 03: معالجة كيانات الجلسة [sqlalchemy]
ملف التكوين [config] هو نفسه كما في المثال السابق. في البرنامج النصي [main]، نقوم بإجراء عمليات قياسية [INSERT، UPDATE، DELETE، SELECT] على الجدول [people] باستخدام أساليب [SQLAlchemy]:
تعليقات
- الأسطر 20–25: تعرض الدالة [display_people] العناصر الموجودة في قائمة الأشخاص؛
- الأسطر 12–18: تعرض الدالة [display_people] محتويات جدول [people]؛
- الأسطر 34–36: نقوم بإسقاط الجدول [people]. على عكس الإصدارات السابقة، لا نستخدم استعلام SQL بل طريقة [SQLAlchemy]:
- config["people_table"] هو كائن [Table] الذي يصف جدول [people]؛
- config["engine"] هو سلسلة الاتصال بقاعدة البيانات [dbpersonnes]؛
- يضمن المعامل المسمى [checkfirst=True] أن العملية لا تُنفذ إلا إذا كان الجدول [people] موجودًا؛
- السطور 38–39: يتم إعادة إنشاء جدول [people]؛
- الأسطر 41–44: تتم إضافة ثلاثة أشخاص إلى الجلسة. لاحظ أنهم لا يتم إدراجهم بالضرورة على الفور في جدول [people]. يعتمد هذا على استراتيجية [SQLAlchemy] الموجهة نحو الأداء؛
- السطران 46-47: يتم عرض محتويات جدول [people]. إذا لم يتم إدراج الأشخاص الثلاثة بعد، فسيتم إدراجهم الآن بسبب هذا الطلب؛
- السطور 49-50: مثال على استخدام طريقة [order_by]، التي تسمح بعرض نتائج الاستعلام بترتيب معين. تعرض صيغة [order_by(criterion1, criterion2)] النتائج أولاً وفقًا للمعيار [criterion1]، وعندما تحتوي الصفوف على نفس القيمة لـ [criterion1]، يتم فرزها وفقًا للمعيار [criterion2]. يمكن تحديد معايير متعددة بهذه الطريقة؛
- الأسطر 55-59: تقدم مفهوم التصفية باستخدام طريقة [filter]. تقوم الصيغة [filter(criterion1, criterion2)] بإجراء عملية منطقية AND بين المعايير المستخدمة؛
- الأسطر 64–67: يتم تسجيل دخول مستخدم جديد؛
- السطران 70-71: مثال آخر على استعلام مُصفى. تقوم الدالة [func.lower(param)] بتحويل [param] إلى أحرف صغيرة. وهناك دوال أخرى متاحة يُشار إليها بـ [func.xx]. في التعبير الموجود في السطر 71:
- [session.query.filter] تُرجع قائمة من كائنات [Person]؛
- [session.query.filter.first] تُرجع العنصر الأول من هذه القائمة؛
- السطر 77: يتم إزالة عنصر من الجلسة؛
- السطر 86: يتم التحقق من صحة الجلسة؛
نتائج التنفيذ هي كما يلي:
- الأسطر 4-6: محتوى الجلسة؛
- الأسطر 8-10: محتوى الجلسة مرتبة حسب الأسماء من الأكبر إلى الأصغر؛
- السطور 12–13: محتوى الجلسة للأشخاص الذين تتراوح أعمارهم بين [20، 40]؛
- السطر 15: الشخص المسمى "bruneau"؛
في phpMyAdmin، يكون محتوى جدول [people] في نهاية التنفيذ كما يلي:
19.5. البرامج النصية 04: استخدام قاعدة بيانات [PostgreSQL]
المجلد [04] هو نسخة من المجلد [03]. نغير شيئًا واحدًا فقط: سلسلة الاتصال في ملف [config]:
# lien vers une base de données PostgreSQL
engine = create_engine("postgresql+psycopg2://admpersonnes:nobody@localhost/dbpersonnes")
تشير سلسلة الاتصال هذه الآن إلى قاعدة البيانات [dbpersonnes] في نظام إدارة قواعد البيانات [PostgreSQL]. لاحظ استخدام موصل [psycopg2]. يجب تثبيت هذا الموصل.
يؤدي تشغيل البرنامج النصي [main] إلى النتائج التالية:
باستخدام أداة [pgAdmin] (انظر قسم |pgAdmin|)، تكون حالة الجدول [people] كما يلي:
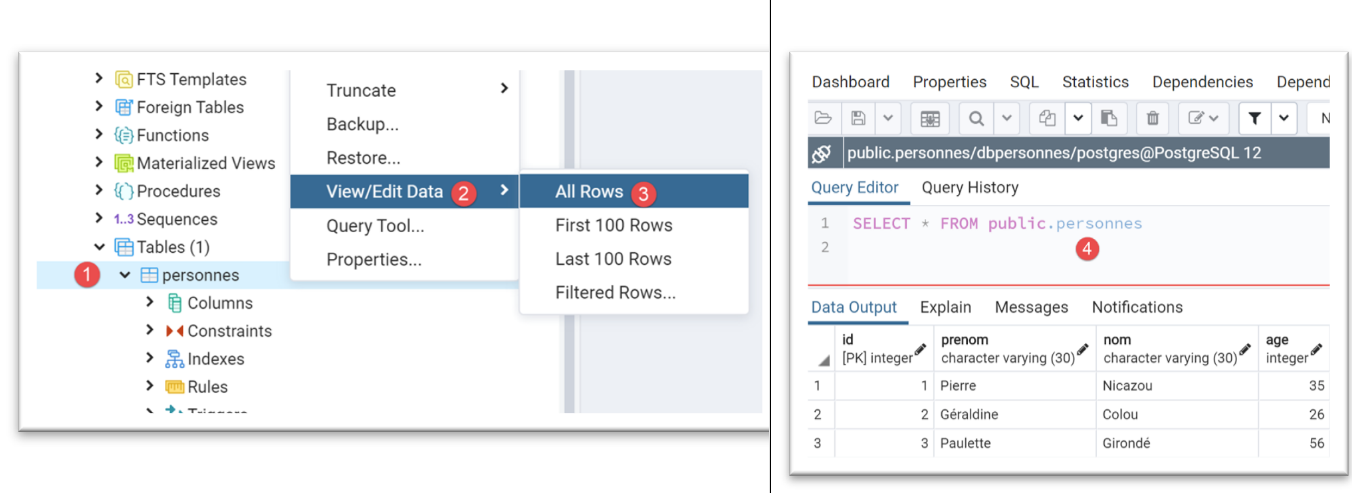
تم إنشاء الجدول [people] باستخدام كود SQL التالي:
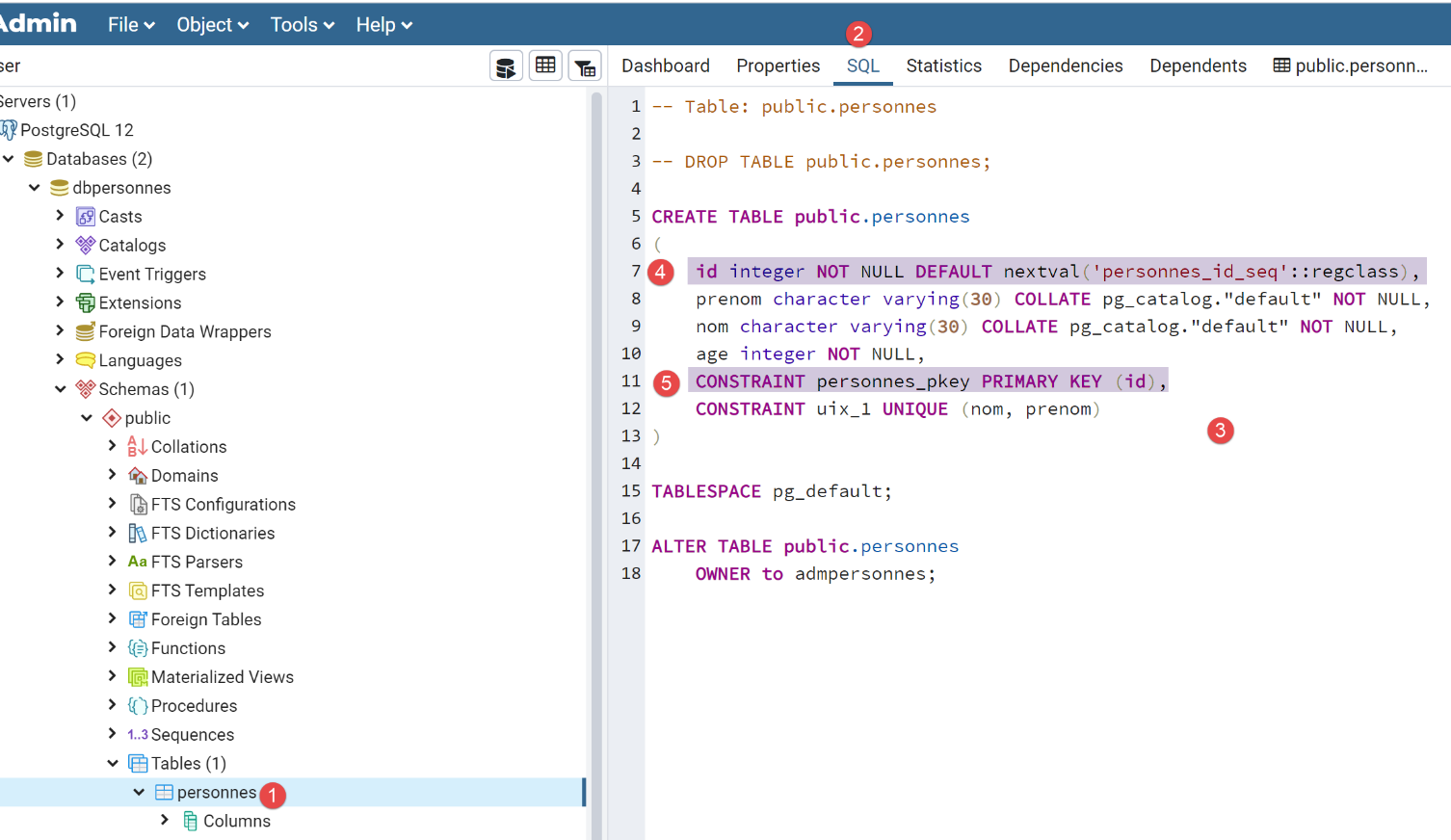
- في [4-5]، نرى أن العمود [id] هو المفتاح الأساسي. ونرى أيضًا أنه يحتوي على قيمة افتراضية [كلمة DEFAULT]، مما يعني أنه إذا تم إدراج صف بدون مفتاح أساسي، فسيقوم نظام إدارة قواعد البيانات (DBMS) بإنشاء واحد. هذه ممارسة شائعة: نترك نظام إدارة قواعد البيانات (DBMS) يقوم بإنشاء المفاتيح الأساسية؛
توضح هذه النسخة 05 من نصوص [sqlalchemy] بوضوح مدى سهولة التبديل من نظام إدارة قواعد البيانات (DBMS) إلى آخر: كل ما كان مطلوبًا هو تغيير سلسلة الاتصال في نص التكوين. لم يتغير أي شيء آخر. إذا قارنا أنواع الأعمدة [id, last_name, first_name, age] أعلاه بتلك الموجودة في جدول MySQL من المثال |02|، نرى أنها مختلفة. يقوم [sqlalchemy] بتكييفها مع نظام إدارة قواعد البيانات المستخدم. هذه القدرة على التكيف مع نظام إدارة قواعد بيانات جديد هي سبب كافٍ لاعتماد [sqlalchemy] أو أي ORM آخر.
19.6. البرامج النصية 05: مثال كامل
المثال الذي ننظر إليه هو إعادة صياغة للمثال الذي تمت تغطيته في القسم |troiscouches-v01|. تضمن ذلك المثال بنية ثلاثية المستويات [UI، منطق الأعمال، DAO] التي تعاملت مع الكيانات [Class، Student، Subject، Grade]. تم ترميز الكيانات بشكل ثابت في طبقة [DAO]. نحن الآن نضعها في قاعدة بيانات. سنستخدم نظامي إدارة قواعد البيانات: MySQL و PostgreSQL.
19.6.1. بنية التطبيق
ستكون بنية التطبيق كما يلي:
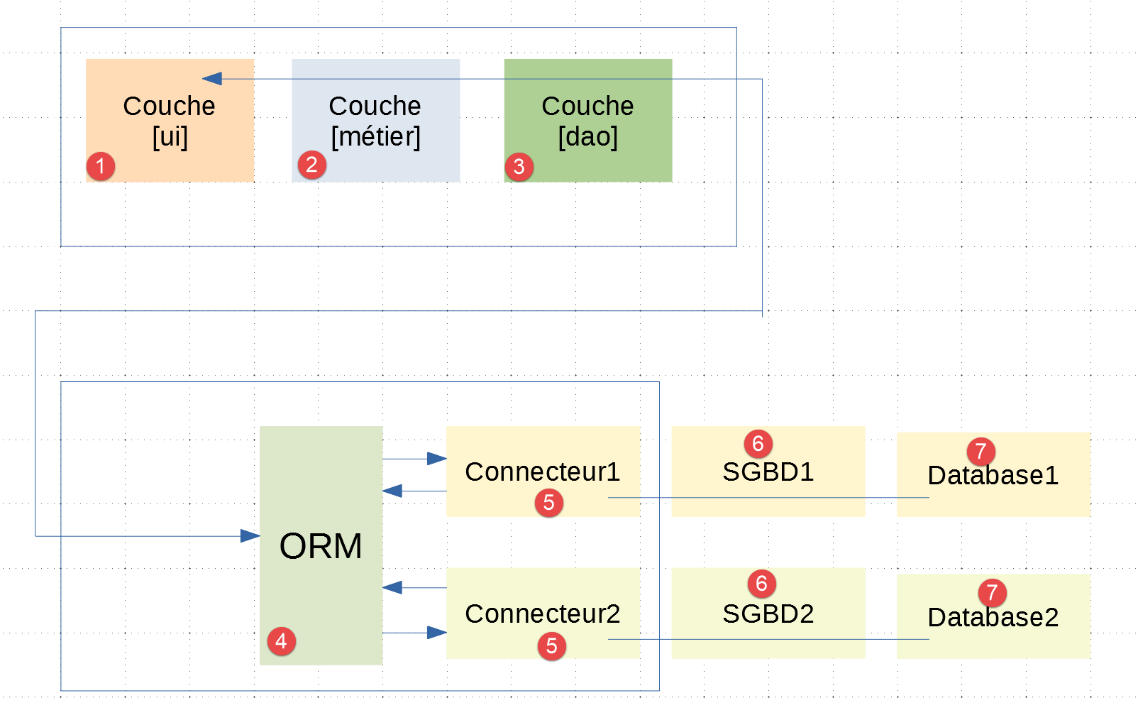
- في [1-3]، نجد الطبقات [UI، Business، DAO] الموجودة بالفعل في المثال |troiscouches-v01|. تتواصل طبقة [DAO] الآن مع طبقة [ORM]؛
- يتم تنفيذ الطبقات [1-5] باستخدام كود Python؛
19.6.2. قواعد البيانات
نقوم بإنشاء قاعدة بيانات MySQL باسم [dbecole] مملوكة للمستخدم [admecole] بكلمة مرور [mdpecole]. للقيام بذلك، نتبع الإجراء الموضح في قسم |إنشاء قاعدة بيانات|:
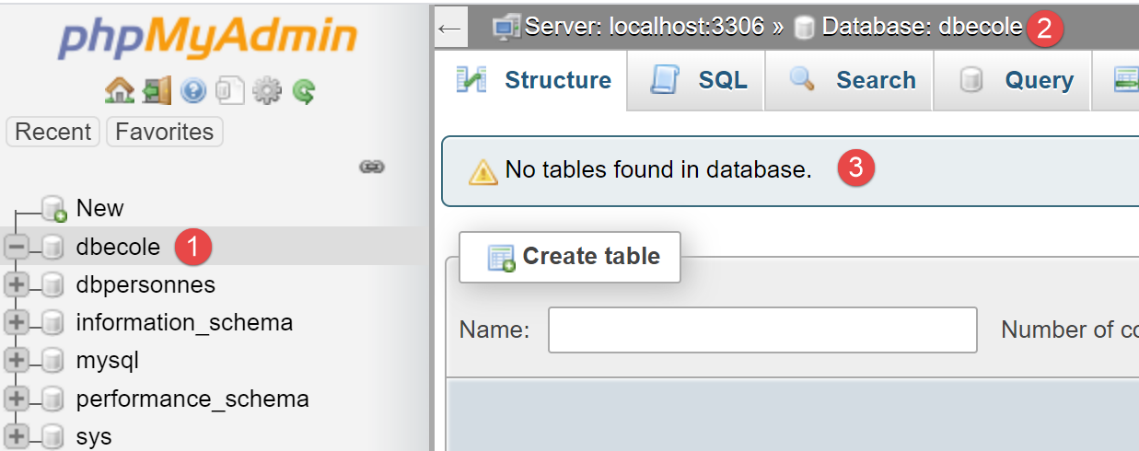
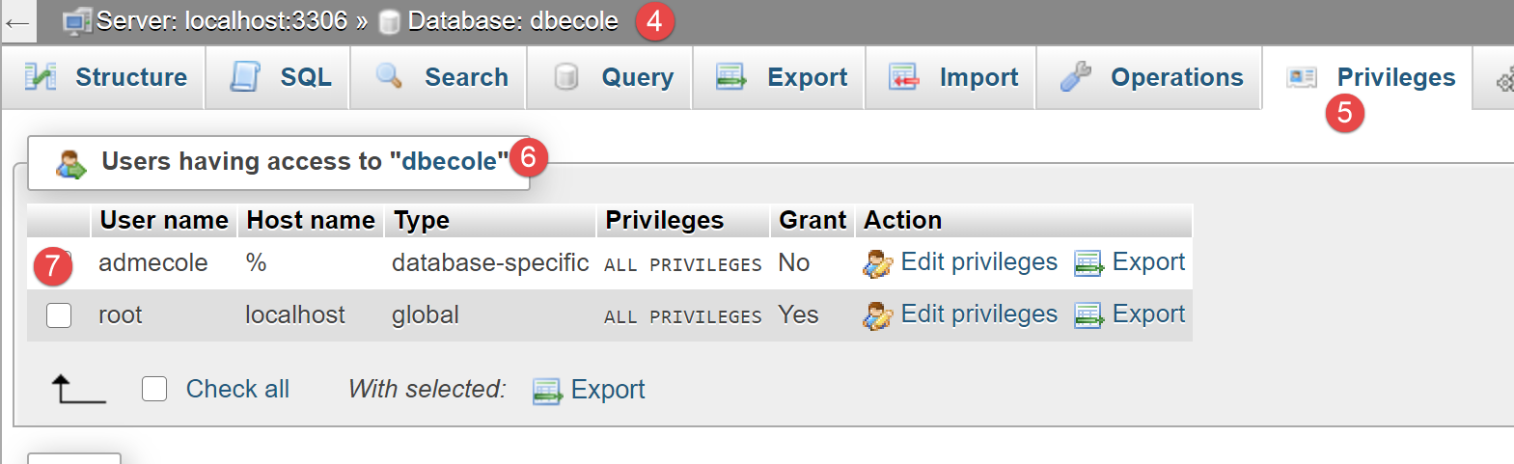
- في [1]، لا تحتوي قاعدة البيانات [dbecole] على أي جداول [3]؛
- في [7]، يتمتع المستخدم [admecole] بامتيازات كاملة على قاعدة البيانات هذه؛
نقوم بنفس الشيء مع نظام إدارة قواعد البيانات PostgreSQL. ننشئ قاعدة بيانات باسم [dbecole] يملكها المستخدم [admecole] بكلمة مرور [mdpecole]. للقيام بذلك، نتبع الإجراء الموصوف في قسم |إنشاء قاعدة بيانات|:
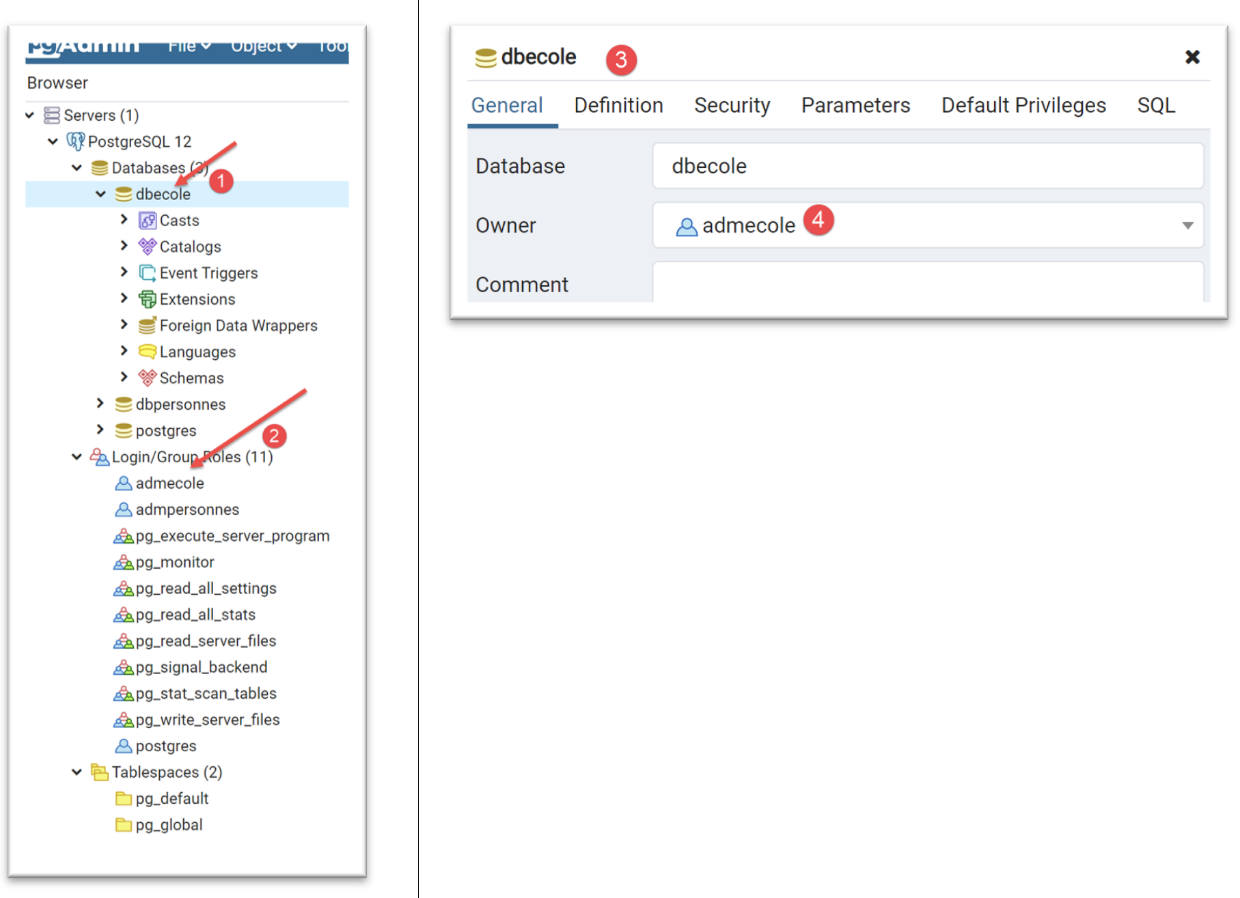
- في [1]، قاعدة البيانات [dbecole]؛
- في [2]، المستخدم [admecole]؛
- في [3-4]، قاعدة البيانات [dbecole] مملوكة للمستخدم [admecole]؛
19.6.3. الكيانات التي يتعامل معها التطبيق
في تطبيق |troiscouches v01|، كانت الكيانات التي تم التعامل معها كما يلي (انظر |entities|). هذه هي الكيانات التي سيتم تخزينها في قواعد البيانات السابقة. لن نقوم بتكرار هذه الكيانات في التطبيق الجديد. سنقوم باستردادها من المكان الذي تم تعريفها فيه بالفعل.
فئة [Class]:
فئة [Student]:
فئة [Subject]:
فئة [Grade]:
19.6.4. التكوين
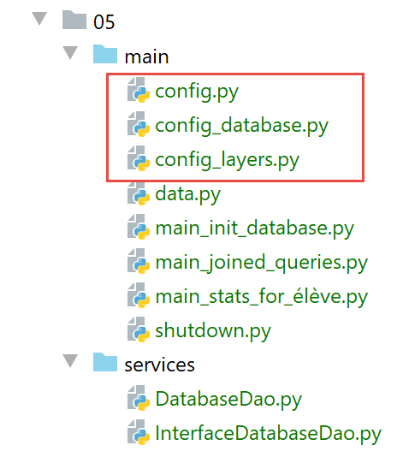
تم تقسيم التكوين على عدة ملفات:
- التكوين العام في [config.py]: يحدد مسار Python للتطبيق ويقوم بإنشاء مثيلات لطبقات البنية؛
- تكوين [SQLAlchemy] في [config_database]: يتولى معالجة تعيينات الفئات/الجداول؛
- يتم تكوين طبقات التطبيق في [config_layers]؛
ملف [config] كما يلي:
- الأسطر 4–27: إنشاء مسار Python للتطبيق؛
- الأسطر 29–32: تكوين [SQLAlchemy]؛
- الأسطر 34–37: تكوين طبقات التطبيق؛
ملف [config_database] كما يلي:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 | |
تعليقات
- الأسطر 1-4: تستقبل الدالة [configure] قاموسًا كمعلمة. يتم استخدام المفتاح [db] فقط. يتم تعيينه إلى [mysql] إذا كانت قاعدة البيانات هي قاعدة بيانات MySQL، وإلى [pgres] إذا كانت قاعدة البيانات هي قاعدة بيانات PostgreSQL؛
- الأسطر 6-9: استيراد عناصر من [sqlalchemy]. يقوم البرنامج النصي [config_database] بإجراء التعيينات بين الجداول في قاعدة البيانات [dbecole] والكيانات [Classes، Student، Subject، Grade]. في الجدول، يتم تغليف بيانات الكيان في صف. في كود Python، يتم تغليفها في كائن. ومن هنا جاء اسم ORM (Object Relational Mapper): يقوم ORM بإنشاء تعيين (رابط) بين صفوف قاعدة البيانات العلائقية والكائنات. في هذا التطبيق، لدينا أربعة كيانات [Class، Student، Subject، Grade] سيتم ربطها بأربعة جداول [classes، students، subjects، grades]. لاحظ أن أسماء الجداول قد تحتوي على أحرف مشددة؛
- الأسطر 11–17: سلسلة الاتصال بقاعدة البيانات المستخدمة. يعتمد هذا على config['db'].
- الأسطر 24-28: كيانات التطبيق التي سيتم تعيينها [SQLAlchemy]. عند تنفيذ هذه الأسطر، سيكون مسار Python قد تم إنشاؤه بالفعل بواسطة البرنامج النصي [config]؛
- الأسطر 30–40: التعيين بين كيان [Class] وجدول [classes]؛
- الأسطر 30–35: يتم تعريف جدول [classes] باستخدام فئة [Table] من [sqlalchemy]. نحدد أن هذا الجدول يحتوي على عمودين:
- عمود [id]، وهو المفتاح الأساسي ويمثل رقم الفئة، السطر 33؛
- العمود [name]، الذي يحتوي على اسم الفئة، السطر 34؛
- السطران 31-32: لاحظ أن صيغة x=y=z صحيحة في لغة Python: يتم تعيين قيمة z إلى y، ثم قيمة y إلى x؛
- الأسطر 37-40: يتم سرد التعيينات بين أعمدة جدول [classes] وخصائص كيان [Class]؛
- الأسطر 42–57: التعيين بين كيان [Student] وجدول [students]؛
- الأسطر 51–57: يتم تعريف جدول [students] باستخدام فئة [Table] من [SQLAlchemy]. نحدد أن هذا الجدول يحتوي على أربعة أعمدة:
- عمود [id]، وهو المفتاح الأساسي ويمثل معرف الطالب، السطر 45؛
- العمود [name]، الذي يحتوي على لقب الطالب، السطر 46؛
- العمود [first_name]، الذي يحتوي على الاسم الأول للطالب، السطر 47. لاحظ أن اسم العمود يمكن أن يحتوي على أحرف مشطوبة؛
- السطر 49، العمود [class_id]، الذي سيحتوي على معرّف الفصل الذي ينتمي إليه الطالب. وهذا ما يُسمى بالمفتاح الخارجي. [students.class_id] هو مفتاح خارجي (ForeignKey) في العمود [classes.id]. وهذا يعني أن قيمة [students.class_id] يجب أن تكون موجودة في العمود [classes.id]؛
- الأسطر 51–57: نسرد التعيينات بين أعمدة جدول [students] وخصائص كيان [Student]:
- السطور 53-55 سهلة الفهم؛
- السطر 56 أكثر صعوبة: فهو يحدد قيمة خاصية [Student.class] على أنها محسوبة بواسطة علاقة المفتاح الأجنبي التي تربط بين الجدولين [students] و [classes]. معلمات دالة [relationship] هي كما يلي:
- [Class]: هذا هو اسم الكيان الذي تربطه علاقة مفتاح خارجي بكيان [Student]. يجب أن ينعكس هذا في جدول [students] من خلال وجود مفتاح خارجي يشير إلى جدول [classes]. ونحن نعلم أن هذا موجود؛
- [backref="students"]: اسم الخاصية التي ستُضاف إلى كيان [Class]. [Class.students] ستكون قائمة بجميع الطلاب في الفصل. يجب ألا تكون هذه الخاصية موجودة بالفعل . إذا كانت موجودة بالفعل، فما عليك سوى اختيار اسم مختلف هنا لـ [backref]. لا يحتاج المطور إلى إدارة هذه الخاصية. سيتولى [SQLAlchemy] التعامل معها. يحتاج المطور فقط إلى معرفة أنها موجودة، وأن [SQLAlchemy] أضافها، وأنه يمكنه استخدامها في كوده؛
- [lazy='select']: هذا يعني أن ORM يجب ألا يحاول تعيين قيمة على الفور لخاصية [Student.class]. يجب أن يسترد قيمتها فقط عندما يطلبها الكود صراحةً. وبالتالي:
- إذا طلب الكود قائمة بجميع الطلاب، فسيتم إرجاعهم ولكن لن يتم حساب خاصية [class] الخاصة بهم؛
- بعد ذلك بقليل، يركز الكود على طالب معين [e] ويشير إلى فصله [e.class]. ستجبر هذه الإشارة [SQLAlchemy] على إجراء استعلام قاعدة بيانات لاسترداد فصل الطالب، كل ذلك بشكل شفاف للمطور؛
- يهدف تعيين [lazy='select'] أيضًا إلى تجنب استعلامات قاعدة البيانات غير الضرورية؛
- السطر 56: عندما يسترد ORM صفًا من جدول [students]، فإنه يسترد الحقول [id، last_name، first_name، class_id]. ومن هناك، يجب عليه إنشاء كائن Student (id، last_name، first_name، class). بالنسبة للخصائص [id، last_name، first_name]، لا يمثل هذا أي صعوبة. أما بالنسبة للخاصية [class]، فالأمر أكثر تعقيدًا. فقيمتها هي مرجع كائن من النوع [Class]. ومع ذلك، لا يمتلك ORM سوى معلومة واحدة: [students.class_id]. نظرًا لأن [students.class_id] هو مفتاح خارجي في عمود [classes.id]، فإننا نوجهه هنا لاستخدام هذه العلاقة لاسترداد الصف الذي يحتوي على id=[students.class_id] من جدول [classes] (يجب أن يكون موجودًا) وإنشاء كائن [Class] المتوقع بواسطة خاصية [Student.class] من هذا الصف؛
- الأسطر 59–71: التعيين بين كيان [Subject] وجدول [subjects]؛
- الأسطر 59–65: تعريف جدول [SQLAlchemy] المسمى [subjects]؛
- الأسطر 66–71: نسرد التعيينات بين أعمدة جدول [subjects] وخصائص كيان [Subject]. لا توجد صعوبات هنا؛
- الأسطر 73–90: التعيين بين كيان [Note] وجدول [notes]؛
- الأسطر 73-82: تعريف جدول [sqlalchemy] المسمى [notes]. يحتوي على مفتاحين خارجيين:
- السطر 79، العمود [notes.student_id] يأخذ قيمه من العمود [students.id]. يعكس هذا المفتاح الأجنبي حقيقة أن الملاحظة تخص طالبًا معينًا؛
- السطر 81: العمود [notes.subject_id] يأخذ قيمه من العمود [subjects.id]. يمثل هذا المفتاح الأجنبي حقيقة أن الدرجة هي درجة في مادة معينة؛
- الأسطر 84-90: التعيين بين كيان [Note] وجدول [notes]:
- السطر 88: يجب أن تكون قيمة الخاصية [Note.student] مثيلًا من النوع [Student]. لا يحتوي ORM إلا على عمود [notes.student_id] في صف جدول [notes]، والذي يشير إلى عمود [students.id]. هنا، نحدد استخدام علاقة المفتاح الخارجي هذه لاسترداد مثيل [Student] الذي لدينا درجته. علاوة على ذلك، سيؤدي [relationship(Student, backref="grades", …)] إلى إنشاء الخاصية الجديدة [Student.grades]، والتي ستكون قائمة بدرجات الطالب. يجب ألا تكون هذه الخاصية موجودة بالفعل في فئة [Student]؛
- السطر 89: يجب أن يكون لقيمة الخاصية [Grade.subject] قيمة مثيل من النوع [Subject]. لا يحتوي ORM إلا على عمود [notes.subject_id] في صف جدول [grades]، والذي يشير إلى عمود [subjects.id]. هنا، نحدد استخدام علاقة المفتاح الخارجي هذه لاسترداد مثيل [Subject] الذي لدينا درجته. بالإضافة إلى ذلك، سيؤدي [relationship(Subject, backref="grades", …)] إلى إنشاء الخاصية الجديدة [Subject.grades]، والتي ستكون قائمة الدرجات للموضوع. يجب ألا تكون هذه الخاصية موجودة بالفعل في فئة [Subject]؛
- الأسطر 92–96: بالنسبة لكل كيان مشتق من [BaseEntity]، نحدد قائمة الخصائص التي يجب استبعادها من قاموس خصائص الكيان (BaseEntity.asdict). لقد رأينا أن [sqlalchemy] تضيف خاصية [_sa_instance_state] إلى جميع الكيانات المخططة. لا نريد وجود هذه الخاصية في قاموس الخصائص. علاوة على ذلك، رأينا أن التخطيطات السابقة أضافت خصائص جديدة إلى الكيانات:
- [Student.grades]: جميع درجات الطالب؛
- [Class.students]: جميع الطلاب في الفصل؛
- [Subject.grades]: جميع الدرجات للمادة؛
بشكل عام، لا نريد إضافة هذه الخصائص إلى حالة الكيان. في الواقع، يتطلب حساب قيمتها تكلفة SQL، وغالبًا ما تكون هذه القيمة غير ضرورية. لذا، إذا استرجعنا الطالب المسمى "X":
- (تابع)
- فإن ORM سيعرض كيان [Student(id, last_name, first_name, class, grades)]. وبسبب [lazy='select'], لن يتم حساب الخصائص [class, grades] المرتبطة بالمفاتيح الخارجية في قاعدة البيانات؛
- الآن، إذا قمت بعرض سلسلة JSON لهذا الطالب، فإننا نعلم أنها ستكون سلسلة JSON من قاموس [asdict] الخاص بالكيان. إذا تم تضمين الخصائص [class] و [grades]، فسيضطر [SQLAlchemy] إلى تنفيذ استعلامات SQL لحساب قيمها. وهذا مكلف. إذا كان بإمكاننا تجنب هذه الاستعلامات، فهذا هو الأفضل؛
- هنا، قمنا باستبعاد جميع الخصائص المرتبطة بمفتاح خارجي؛
- الأسطر 98-100: إنشاء وتكوين [Session factory] (المصنع = مصنع الإنتاج). يُستخدم كائن [Session] لإنشاء جلسات [SQLAlchemy] مدعومة بالمعاملات؛
- الأسطر 102–103: إنشاء جلسة [SQLAlchemy]؛
- السطر 106: يتم وضع عناصر معينة من تكوين [SQLAlchemy] في قاموس التكوين العام للتطبيق؛
- السطر 109: يتم إرجاع هذا القاموس؛
يقوم ملف [config_layers] بتكوين طبقات التطبيق:
- السطر 1: تستقبل الدالة [configure] القاموس الذي يحتوي على التكوين العام للتطبيق؛
- الأسطر 2–12: يتم إنشاء مثيلات لطبقات التطبيق؛
- الأسطر 15-17: تتم إضافة مراجع الطبقات إلى التكوين العام؛
- السطر 20: يتم إرجاع التكوين الجديد؛
19.6.5. طبقة [dao] - 1
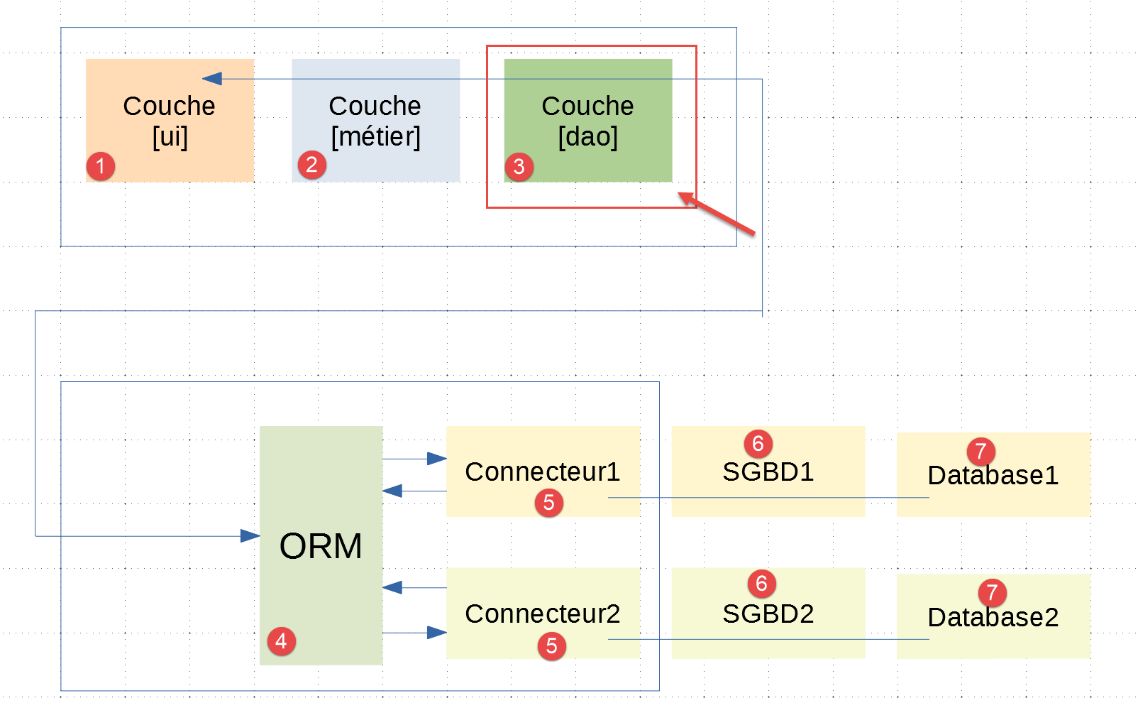
من المهم أن نفهم هنا أن طبقة [dao] [3] تتواصل مع ORM [sqlalchemy] [4] الذي تم تكوينه كما هو موضح في الفقرة السابقة. من بين الطبقات الثلاث [ui، business، dao] لتطبيق |troiscouches v01|، لا تحتاج سوى طبقة [dao] إلى إعادة كتابة. يتم الاحتفاظ بطبقتي [ui، business].
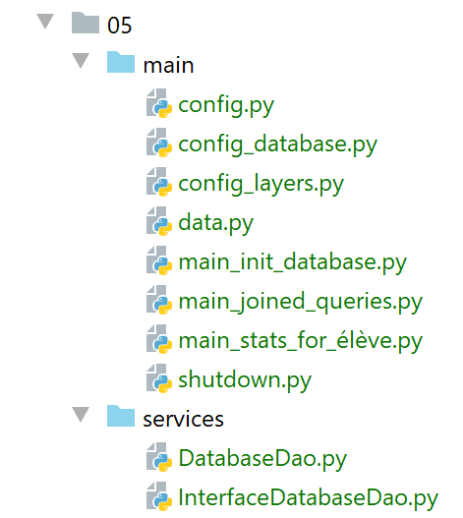
تم وضع تنفيذ طبقة [dao] في مجلد [services]:

[InterfaceDatabaseDao] هي واجهة طبقة [DAO]:
- السطر 6: واجهة [InterfaceDatabaseDao] مشتقة من فئة [ABC] لتكون فئة مجردة ومن واجهة [InterfaceDao] لمشروع |troiscouches v01|؛
- الأسطر 8–11: نضيف الطريقة [init_database] إلى الطرق الموروثة من [InterfaceDao]. وسيكون دورها تهيئة قاعدة البيانات بالبيانات الموجودة في القاموس [data] الذي تم تمريره إليها كمعلمة في السطر 10؛
تذكر أن واجهة [InterfaceDao] كانت كما يلي:
تنفيذ طبقة [DAO] هو كما يلي:
- السطر 11: تنفذ فئة [DatabaseDao] واجهة [InterfaceDatabaseDao]؛
- الأسطر 13–16: منشئ الفئة. يأخذ قاموس تكوين التطبيق كمعلمة؛
- السطر 15: يتم تخزين تكوين [sqlalchemy]؛
- السطر 16: يتم تخزين جلسة [sqlalchemy] التي سيتم من خلالها التعامل مع قاعدة البيانات؛
- السطر 18: تقوم طريقة [init_database] بتهيئة قاعدة البيانات باستخدام قاموس [data]؛
يتم تنفيذ قاموس [data] بواسطة البرنامج النصي [data.py] التالي:
- السطر 34: القاموس الذي سيتم تمريره إلى طريقة [init_database]. يتكون هذا القاموس من المفاتيح التالية (السطر 32):
- [students]: قائمة الطلاب؛
- [classes]: قائمة الفصول؛
- [subjects]: قائمة المواد الدراسية؛
- [grades]: قائمة الدرجات لجميع الطلاب في جميع المواد؛
لنعد إلى طريقة [init_database]:
- الأسطر 3–6: استرداد المعلومات من تكوين قاعدة البيانات؛
- الأسطر 9-14: رأينا أن تكوين [sqlalchemy] قد ربط أربعة كيانات بأربعة جداول [students, subjects, classes, grades]. نبدأ بحذف هذه الجداول إن وجدت؛
- السطور 16-17: نعيد إنشاء الجداول الأربعة التي حذفناها للتو؛
- الأسطر 22–25: نضيف جميع الفصول الدراسية إلى الجلسة؛
- الأسطر 27–30: نضيف جميع المواد الدراسية إلى الجلسة؛
- الأسطر 32–35: نضيف جميع الطلاب إلى الجلسة؛
- الأسطر 37-40: نضيف جميع الدرجات إلى الجلسة؛
- لإجراء هذه الإضافات، اتبعنا ترتيبًا محددًا. بدأنا بالكيانات التي لا توجد لها علاقات مع كيانات أخرى وانتهينا بتلك التي لها علاقات. وبالتالي، عندما نضيف الطلاب إلى الجلسة، تكون الفصول الدراسية التي يشيرون إليها موجودة بالفعل في الجلسة؛
- السطر 43: يتم تثبيت جلسة [sqlalchemy]. بعد هذه العملية، يمكننا التأكد من أن جميع البيانات في الجلسة قد تمت مزامنتها مع قاعدة البيانات. باختصار، تم إدراج البيانات في الجداول. وقد أصبح ذلك ممكنًا بفضل التعيينات المحددة في تكوين [sqlalchemy]. يعرف [sqlalchemy] كيف يجب تخزين كل كيان في الجداول. كما أنشأ [sqlalchemy] أي مفاتيح خارجية قد تحتوي عليها الجداول؛
- الأسطر 44–49: في حالة مواجهة مشكلة، يتم التراجع عن جلسة [sqlalchemy]، وفي السطر 49، يتم إثارة استثناء؛
19.6.6. تهيئة قاعدة البيانات
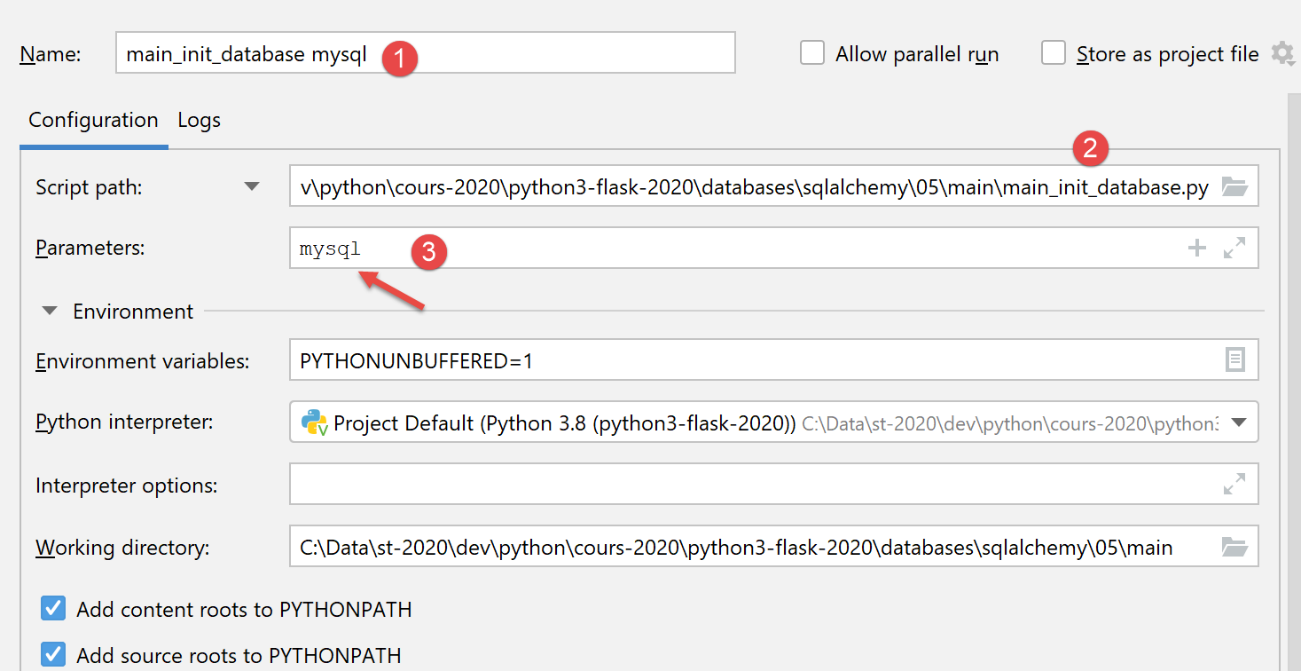
يقوم البرنامج النصي [main_init_database] بتهيئة قاعدة البيانات بمحتويات البرنامج النصي [data.py]. وفيما يلي كود البرنامج النصي:
- الأسطر 1-11: يتوقع البرنامج النصي معلمة [mysql] أو [pgres] اعتمادًا على ما إذا كنت تريد تهيئة قاعدة بيانات MySQL أو PostgreSQL؛
- الأسطر 13-15: يتم تكوين التطبيق لنظام إدارة قواعد البيانات (DBMS) الذي تم تمريره كمعلمة؛
- الأسطر 20-22: يتم استرداد البيانات المراد إدراجها في قاعدة البيانات؛
- السطر 25: تم بالفعل إنشاء مثيل لطبقة [dao] ويمكن الوصول إليها في تكوين التطبيق؛
- السطر 30: يتم تهيئة قاعدة البيانات؛
- الأسطر 34–37: بغض النظر عما إذا حدث خطأ أم لا، يتم تحرير موارد التطبيق باستخدام وحدة [shutdown]؛
وحدة [shutdown.py] هي كما يلي:
تقوم الدالة [shutdown.execute] بإغلاق جلسة [sqlalchemy] المستخدمة لتهيئة قاعدة البيانات.
نقوم بإنشاء تكوين تنفيذ أولي (انظر |تكوين التنفيذ|) لتشغيل [main_init_database] مع نظام إدارة قواعد البيانات MySQL:
فيما يلي نتائج تشغيل هذا التكوين في phpMyAdmin:
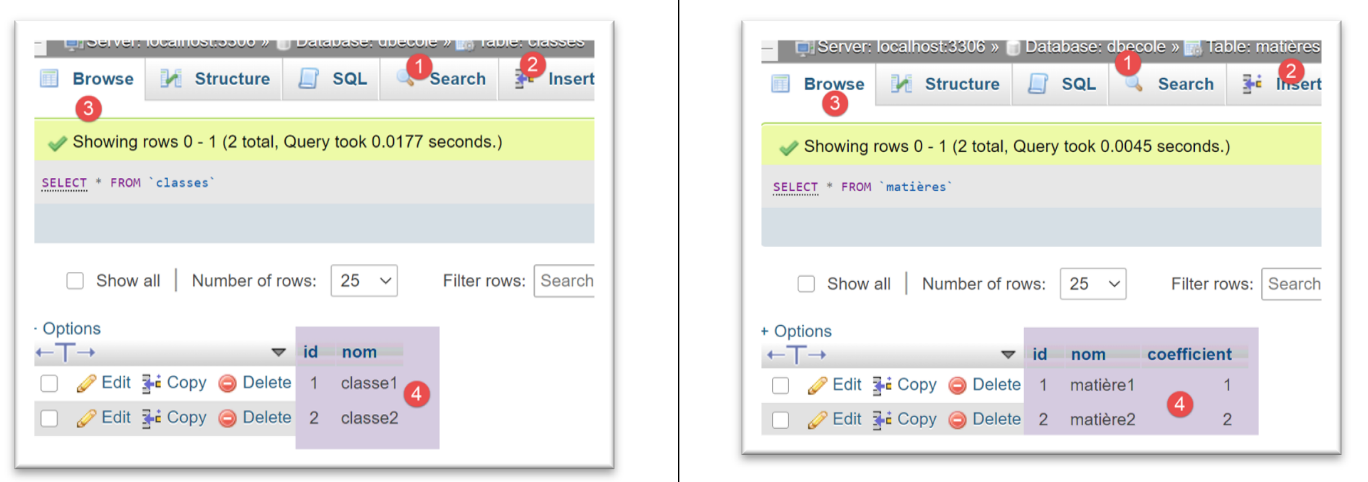
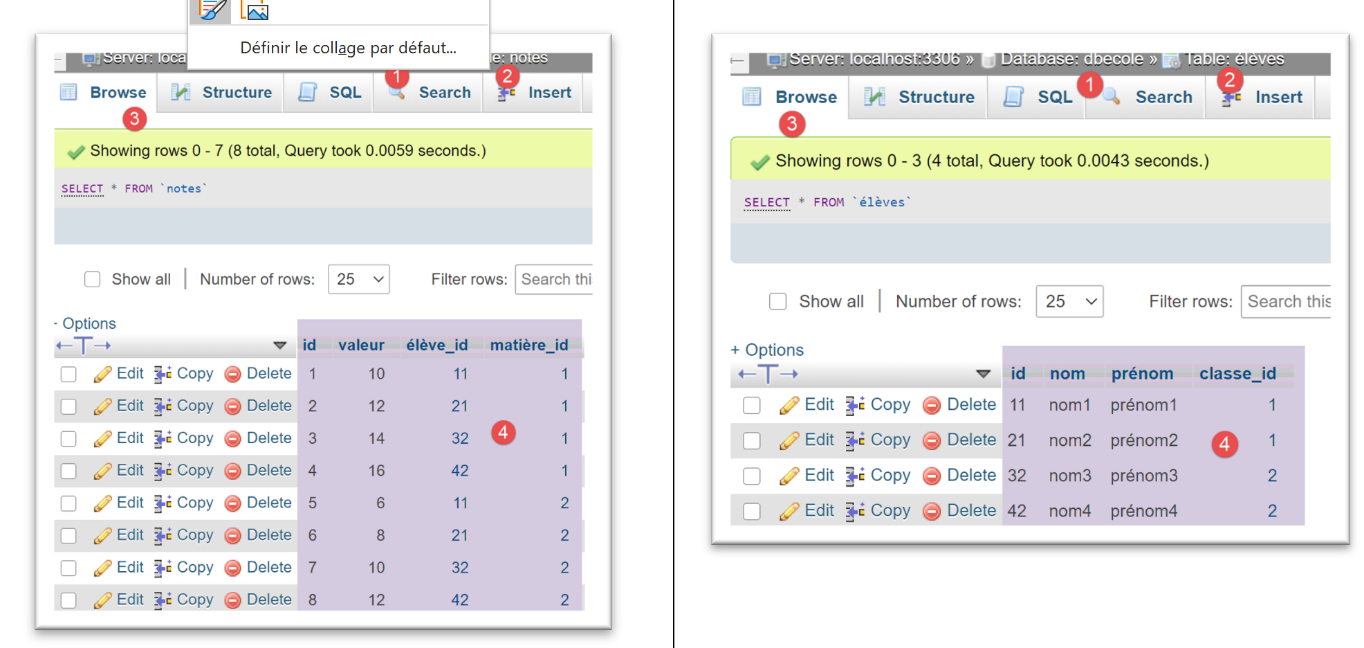
بالنسبة لنظام إدارة قواعد البيانات [PostgreSQL]، نستخدم تكوين التنفيذ التالي:
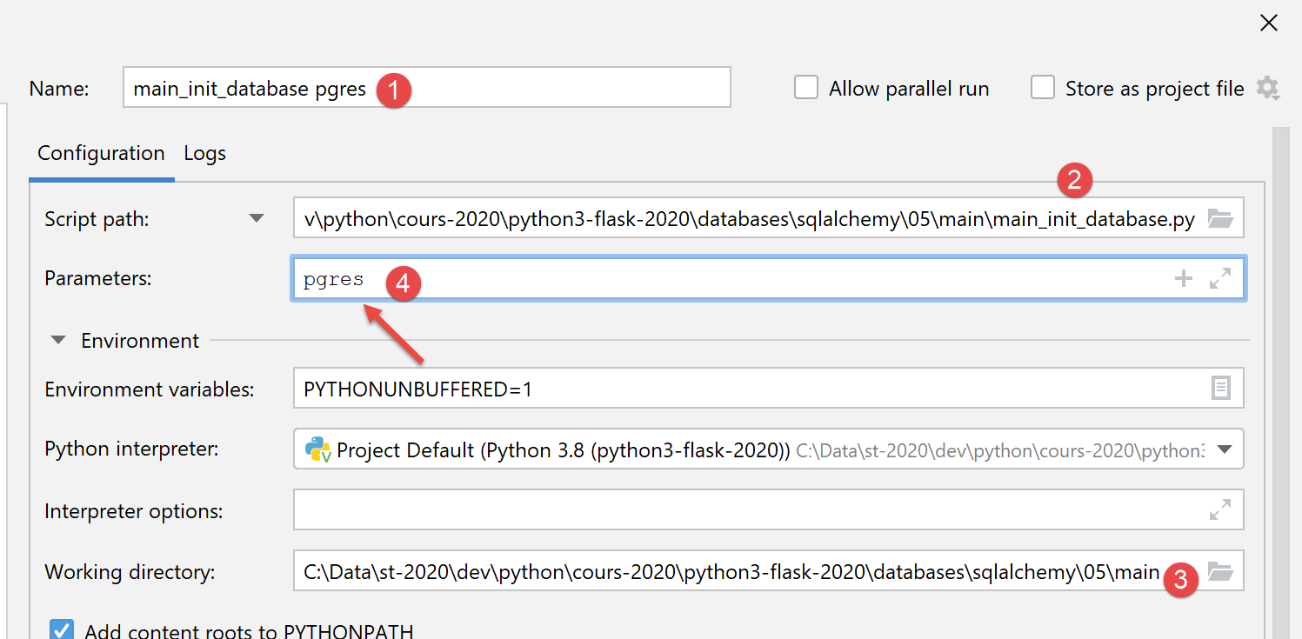
عند التنفيذ، تكون النتائج في [pgAdmin] كما يلي:

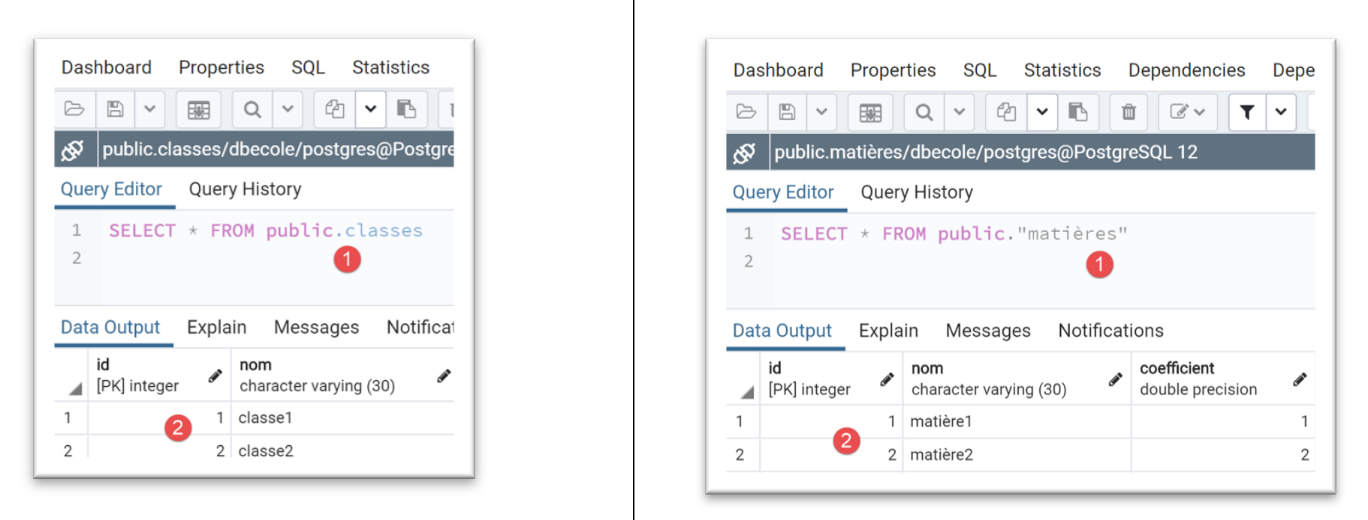
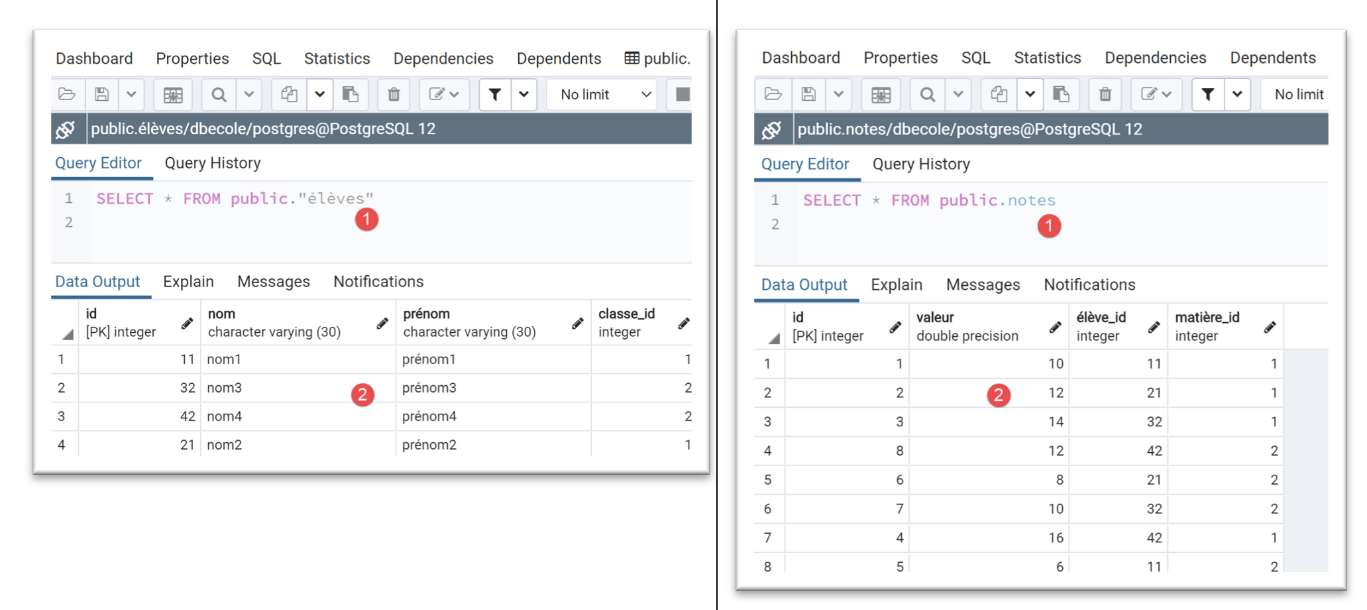
لاحظ مدى سهولة التبديل بين أنظمة إدارة قواعد البيانات.
19.6.7. طبقة [dao] – 2
نعود إلى فئة [DatabaseDao]، التي تنفذ طبقة [DAO]. حتى الآن، لم نعرض سوى تنفيذ طريقة [init_database]. سنعرض الآن تنفيذ الطرق الأخرى:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 | |
- الأسطر 21–24: يجب أن تُرجع الدالة [get_classes] قائمة الفصول الدراسية في المدرسة. في السطر 20، نستخدم استعلامًا سبق أن رأيناه من قبل؛
- الأسطر 26–39: ثلاث طرق أخرى مشابهة لاسترداد قوائم الطلاب والمواد الدراسية والدرجات؛
- الأسطر 51–59: يجب أن تُرجع الدالة [get_student_by_id] طالبًا محددًا برقمه التعريفي. وتُثير استثناءً إذا كان الطالب غير موجود؛
- السطر 54: نستخدم استعلامًا مفلترًا. نحصل على قائمة فارغة أو قائمة تحتوي على عنصر واحد؛
- السطر 57: إذا لم تكن القائمة المسترجعة فارغة، فقم بإرجاع العنصر الأول من القائمة؛
- وإلا، في السطر 59، يتم إثارة استثناء؛
- الأسطر 41–49: يجب أن تُرجع الطريقة [get_notes_for_student_by_id] درجات الطالب المحدد برقمه التعريفي:
- السطر 45: نستخدم الطريقة [get_student_by_id] لاسترداد كيان Student الخاص بالطالب؛
- السطر 47: نستخدم الخاصية [Student.grades] التي تم إنشاؤها عن طريق التعيين بين كيان [Grade] وجدول [grades] (انظر قسم |تكوين SQLAlchemy|)، والتي تمثل درجات الطالب؛
- السطر 49: نُرجع قاموسًا؛
- الأسطر 61–109: سلسلة من الطرق المماثلة التي تسمح لنا بما يلي:
- البحث عن طالب بالاسم، الأسطر 61–69؛
- البحث عن فصل دراسي، الأسطر 71–89؛
- استرداد مادة دراسية، الأسطر 91–109؛
19.6.8. نص [main_joined_queries]
سمي البرنامج النصي [main_joined_queries] بهذا الاسم لأنه يهدف إلى إبراز الاستعلامات التي يقوم بها [sqlalchemy] ضمناً لاسترداد المعلومات من جداول متعددة. يتم إجراء هذه الاستعلامات، المخفية عن المبرمج، كلما تم ربط خاصية كيان ما بوظيفة [relationship] في تعيين الكيان. على سبيل المثال:
# mapping
mapper(Note, tables['notes'], properties={
'id': notes_table.c.id,
'valeur': notes_table.c.valeur,
'élève': relationship(Elève, backref="notes", lazy="select"),
'matière': relationship(Matière, backref="notes", lazy="select")
})
أعلاه هو التعيين بين كيان [Note] وجدول [notes]:
- السطر 5: عندما يُطلب خاصية [student] لكيان [Grade] لأول مرة، سيتم استردادها من جدول [students] عبر استعلام SQL. وحتى يتم طلب هذه الخاصية، تظل غير محددة (تحميل متأخر). بمجرد استرجاعها، تظل قيمتها في ذاكرة ORM. وعند الإشارة إليها للمرة الثانية، سيعرض ORM قيمتها على الفور دون إصدار استعلام SQL جديد. كل هذا شفاف بالنسبة للمطور؛
- وينطبق الأمر نفسه على الخاصية العكسية [Student.grades] (backref)، السطر 5؛
- وينطبق الأمر نفسه على الخاصية [Grade.subject] وخاصيتها العكسية [Subject.grades] (backref)، السطر 6؛
النص البرمجي [main_joined_queries] هو كما يلي:
التعليقات كافية لفهم الكود.
نقوم بإنشاء تكوين تنفيذ لـ MySQL:
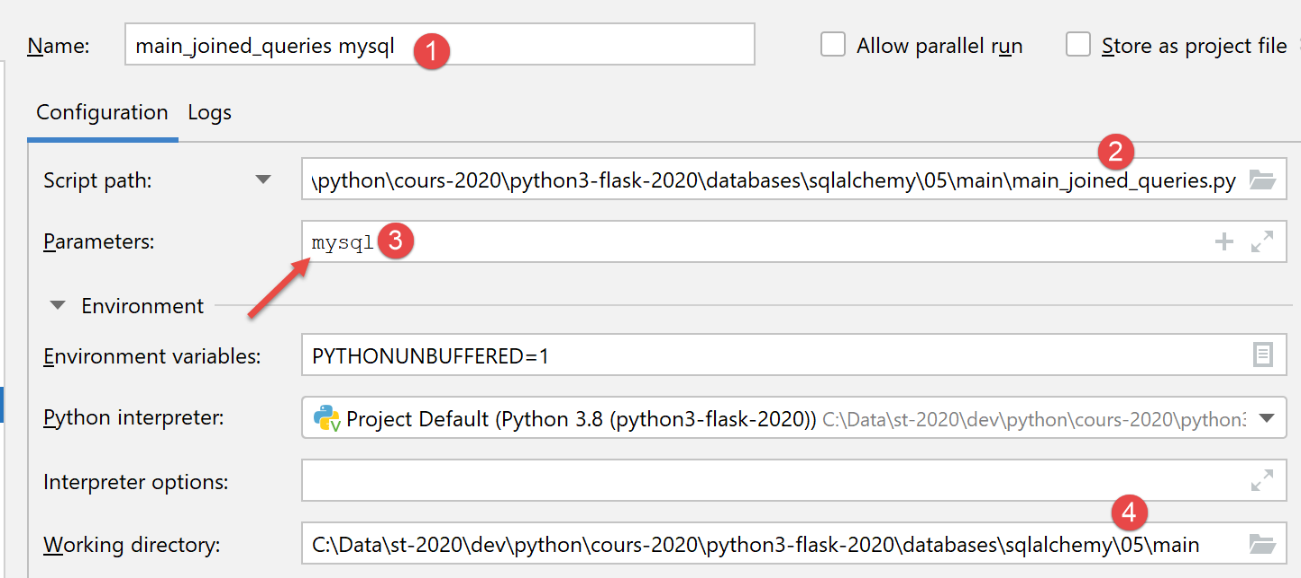
نتائج التنفيذ هي كما يلي:
لفهم هذه النتائج، تذكر أن بعض الخصائص تم استبعادها من قاموس الكيانات (انظر |التكوين|):
# configuration des entités [BaseEntity]
Elève.excluded_keys = ['_sa_instance_state', 'notes', 'classe']
Classe.excluded_keys = ['_sa_instance_state', 'élèves']
Matière.excluded_keys = ['_sa_instance_state', 'notes']
Note.excluded_keys = ['_sa_instance_state', 'matière', 'élève']
لذلك، عندما نكتب [print(f"student={student}")] في السطر 26 من الكود، يخبرنا السطر 1 أعلاه أن الخصائص ['_sa_instance_state', 'grades', 'class'] لن يتم عرضها. وهذا ما نراه في السطر 3 من النتائج. يتم عرض جميع الخصائص الأخرى. وبالتالي، في السطر 3 أيضًا، نكتشف خاصية جديدة [class_id] لم تكن موجودة في البداية في كيان [Student]. تتوافق هذه الخاصية مباشرة مع عمود [class_id] في جدول [students]. وبالتالي، أضاف [SQLAlchemy] الخصائص التالية إلى كيان [Student]: [class_id, _sa_instance_state, grades]. من المهم أن ندرك ذلك، خاصةً لأن هذه الخصائص يجب ألا تكون موجودة بالفعل في الكيان المعين.
تعد الخصائص المستبعدة من قاموس الكيانات أمرًا مهمًا. على سبيل المثال، إذا لم نستبعد الخصائص [grades, student] من كيان [Student]، فإن العملية [print(f"student={student}")] ستعرضها، وبالتالي ستؤدي، كما أوضحنا للتو، إلى تشغيل استعلامات SQL ضمنية (التحميل المؤجل) لاسترداد قيم هذه الخصائص. إذا تم عرض قائمة بالطلاب، كما في هذه الحالة، يتم تنفيذ عمليات SQL ضمنية لكل طالب. قد يكون هذا غير ضروري وبالتأكيد مكلفًا من حيث وقت التنفيذ.
لتشغيل البرنامج النصي باستخدام قاعدة بيانات PostgreSQL، قم بإنشاء تكوين التنفيذ التالي:
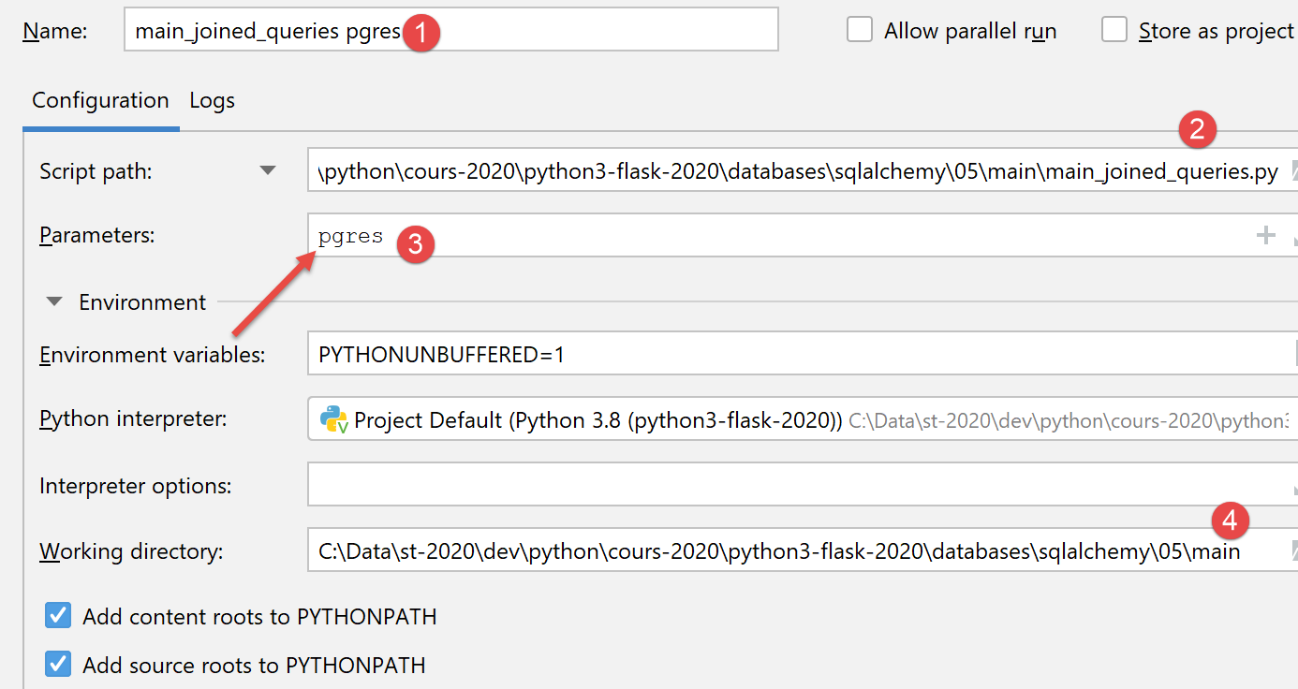
يؤدي التنفيذ إلى نفس النتائج كما هو الحال مع MySQL.
19.6.9. البرنامج النصي [main_stats_for_student]
البرنامج النصي [main_stats_for_student] هو البرنامج المستخدم بالفعل في تطبيق |troiscouches v01|. كان يُسمى سابقًا [main]. وهو تطبيق وحدة تحكم يسترد بعض المقاييس المتعلقة بدرجات الطالب: [المتوسط المرجح، الحد الأدنى، الحد الأقصى، القائمة]. وهو يتناسب مع البنية التالية:
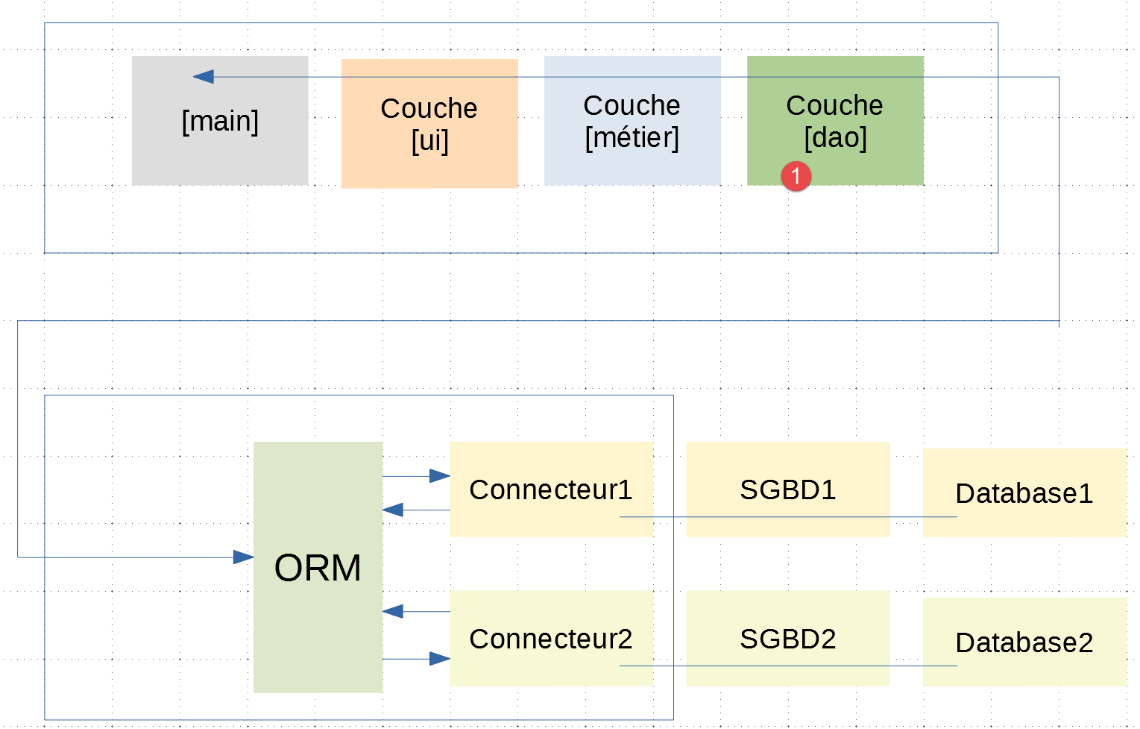
في هذه البنية الطبقية، لم تتغير سوى طبقة [dao] بين تطبيق |troiscouches v01| وهذا التطبيق. وبما أن طبقة [dao] الجديدة تتوافق مع واجهة [InterfaceDao] لطبقة [dao] القديمة، فلا داعي لتغيير طبقتي [ui, business]. وبالتالي، يمكننا الاستمرار في استخدام الطبقات المحددة في تطبيق |troiscouches v01|.
ينفذ البرنامج النصي [main_stats_for_élève] الطبقة [main] في الرسم البياني أعلاه على النحو التالي:
- السطر 20: استرداد مرجع إلى طبقة [ui] من تكوين التطبيق؛
- السطر 24: نبدأ حوار المستخدم باستخدام الطريقة الوحيدة لطبقة [ui]؛
سيبدو تكوين التنفيذ لـ PostgreSQL كما يلي:
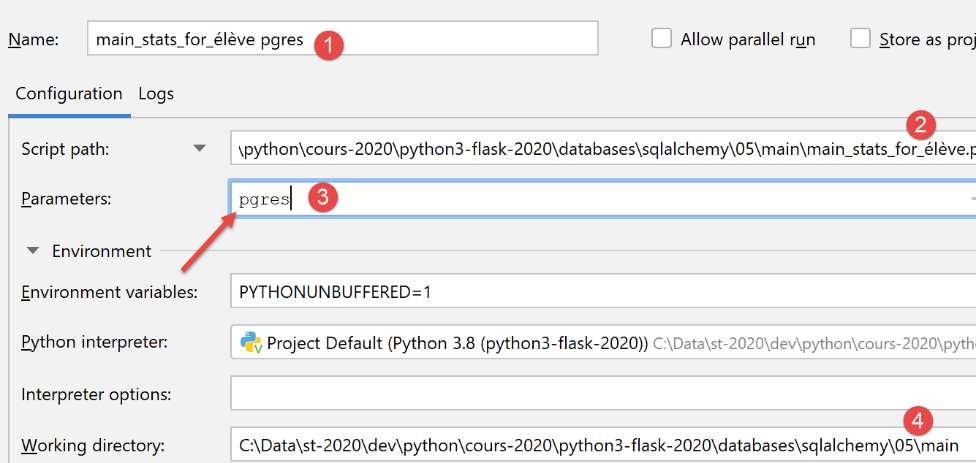
فيما يلي مثال على التنفيذ باستخدام هذا التكوين:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/databases/sqlalchemy/05/main/main_stats_for_élève.py pgres
Numéro de l'élève (>=1 et * pour arrêter) : 11
Elève={"prénom": "prénom1", "id": 11, "classe_id": 1, "nom": "nom1"}, notes=[10.0 6.0], max=10.0, min=6.0, moyenne pondérée=7.33
Numéro de l'élève (>=1 et * pour arrêter) : 1
L'erreur suivante s'est produite : MyException[11, L'élève d'identifiant 1 n'existe pas]
Numéro de l'élève (>=1 et * pour arrêter) : *
Process finished with exit code 0