4. سلاسل
4.1. البرنامج النصي [str_01]: تدوين السلاسل
النص [str_01] هو كما يلي:
تعليقات
- السطر 3: سلسلة محددة بعلامات اقتباس مزدوجة ";
- السطر 4: سلسلة محددة بعلامات اقتباس مفردة '؛
- السطر 5: سلسلة محاطة بعلامات اقتباس ثلاثية """. في هذه الحالة، يمكن أن تمتد السلسلة على عدة أسطر؛
والنتائج هي كما يلي:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/strings/str_01.py
chaine1=[un], chaine2=[deux], chaine3=[hélène va au
marché acheter des légumes]
Process finished with exit code 0
4.2. البرنامج النصي [str_02]: طرق فئة <str>
يقدم البرنامج النصي [str_02] بعض أساليب فئة <str>، وهي فئة السلسلة:
التعليقات مقترنة بالنتائج التي تم الحصول عليها كافية لفهم البرنامج النصي. النتائج هي كما يلي:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/strings/str_02.py
'ABCD'.lower()=abcd
'abcd'.upper()=ABCD
'cheval[2]=e
'caractères accentués'[5:7]=tè
'caractères accentués'[4:]=ctères accentués
'caractères accentués'[:5]=carac
len('123')=3
' abcd '.strip()=[abcd]
' abcd '.rstrip()=[ abcd]
' abcd '.lstrip()=[abcd ]
str.strip()=[abcd]
'abcd'.replace('a','x')=xbcd
'abcd'.replace('ab','xy')=xycd
'abcd'.find('bc')=1
'abcd'.find('bc')=-1
'abcd'.startswith('ab')=True
'abcd'.startswith('x')=False
'abcd'.endswith('cd')=True
'abcd'.endswith('x')=False
'[X]'.join(['abcd', '123', 'èéà'])=abcd[X]123[X]èéà
''.join(['abcd', '123', 'èéà'])=abcd123èéà
'abcd 123 cdXY'.split('cd')=['ab', ' 123 ', 'XY']
'abcd 123 cdXY'.split(None)=['abcd', '123', 'cdXY']
Process finished with exit code 0
4.3. البرنامج النصي [str_03]: ترميز السلاسل (1)
يقدم البرنامج النصي [str_03] مفاهيم متعلقة بترميز السلاسل:
يؤدي ترميز سلسلة من النوع <str> إلى إنتاج سلسلة ثنائية حيث يتم تمثيل كل حرف في السلسلة بواسطة بايت واحد أو أكثر. هناك أنواع مختلفة من الترميز. يوضح البرنامج النصي أعلاه النوعين الأكثر شيوعًا في الغرب: "utf-8" و"iso-8859-1"، المعروف أيضًا باسم "latin1".
يتم توضيح مبدأ الترميز/فك الترميز أدناه (المرجع |https://realpython.com/python-encodings-guide/ |):
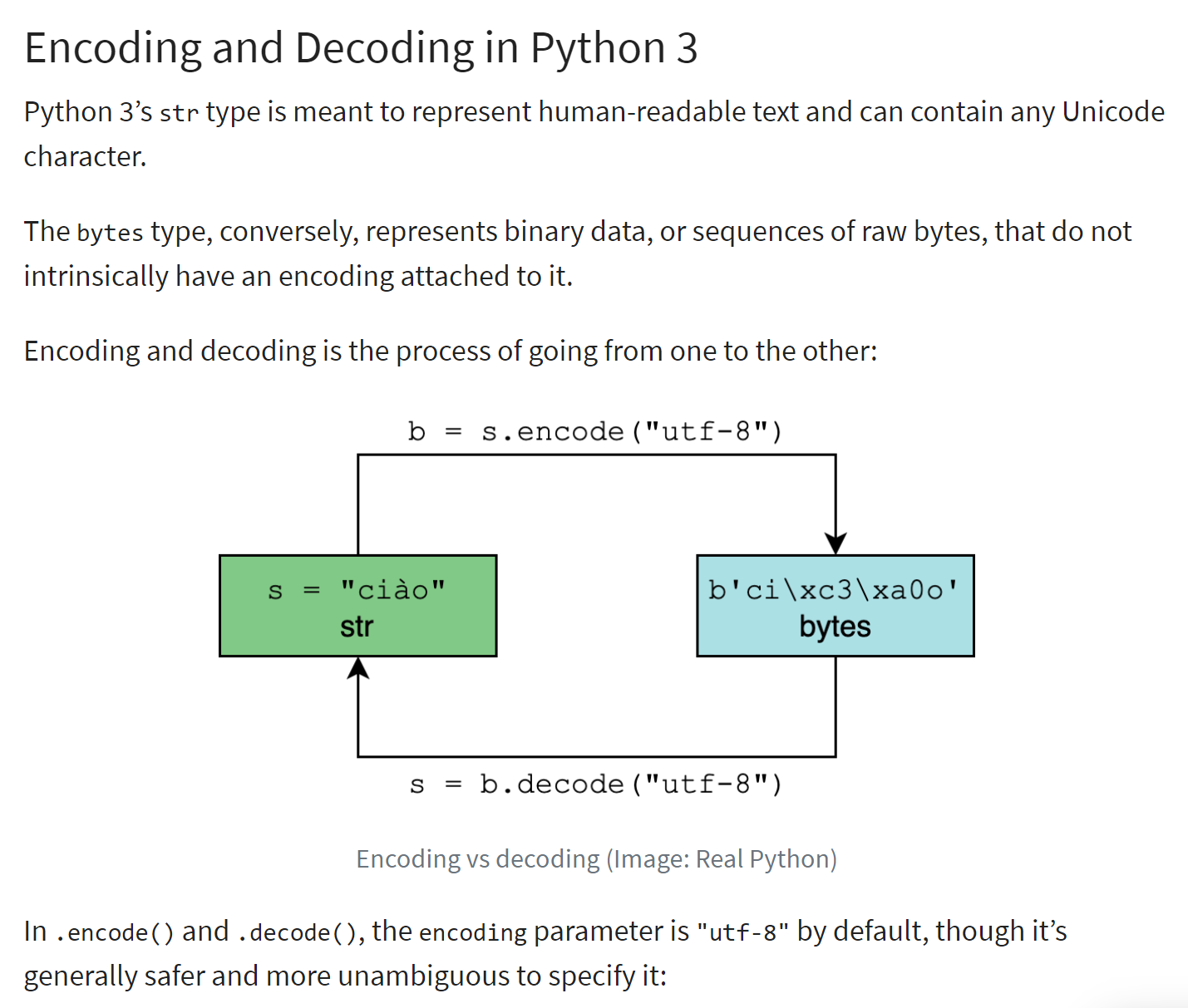
التعليقات
- السطران 4-5: سلسلة الأحرف الأولية المراد ترميزها. مثيلات النوع <str> هي سلاسل أحرف Unicode |https://docs.python.org/3/howto/unicode.html|، |https://realpython.com/python-encodings-guide/ |؛
- الأسطر 6-11: طريقتان لترميز سلسلة في UTF-8:
- السطر 8: str.encode('utf-8');
- السطر 10: bytes(str, 'utf-8');
- الأسطر 12-17: نقوم بنفس الشيء مع ترميز 'iso-8859-1'؛
- الأسطر 18-23: 'latin1' هو اسم آخر لترميز 'iso-8859-1'؛
النتائج هي كما يلي:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/strings/str_03.py
str=[hélène va au marché acheter des légumes, type=<class 'str'>
--- utf-8
bytes1=b'h\xc3\xa9l\xc3\xa8ne va au march\xc3\xa9 acheter des l\xc3\xa9gumes', type=<class 'bytes'>
bytes2=b'h\xc3\xa9l\xc3\xa8ne va au march\xc3\xa9 acheter des l\xc3\xa9gumes', type=<class 'bytes'>
--- iso-8859-1
bytes1=b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes', type=<class 'bytes'>
bytes2=b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes', type=<class 'bytes'>
--- latin1
bytes1=b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes', type=<class 'bytes'>
bytes2=b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes', type=<class 'bytes'>
Process finished with exit code 0
تعليقات
- السطر 4: نرى أن الأحرف المُشَدَّدة قد تم ترميزها باستخدام بايتين:
- é: [\xc3\xa9]، وهو التسلسل الثنائي 11000011 10101001؛
- è: [\xc3\xa8]، وهو التسلسل الثنائي 11000011 10101000؛
- السطر 7: باستخدام ترميز ISO-8859-1، يتم ترميز هذين الحرفين المُشَدَّدين بشكل مختلف:
- é: [\xe9]، وهو التسلسل الثنائي 11101001؛
- è: [\xe8]، وهو التسلسل الثنائي 11101000؛
4.4. النص البرمجي [str_04]: ترميز سلاسل الأحرف (2)
يقدم النص [str_04] نوعين آخرين من الترميز: 'base64' و 'quoted-printable'. لا يقوم هذان النوعان من الترميز بترميز سلاسل أحرف Unicode بل كائنات ثنائية. على سبيل المثال، عند إرفاق مستند Word برسالة بريد إلكتروني، سيخضع لإحدى هاتين الطريقتين من الترميز اعتمادًا على عميل البريد الإلكتروني المستخدم. وينطبق هذا على معظم الملفات المرفقة.
النص البرمجي هو كما يلي:
تعليقات
- السطر 2: تسمح وحدة [codecs] بترميزات 'base64' و'quoted-printable'. ويمكنها التعامل مع العديد من الترميزات الأخرى؛
- الأسطر 4–7: سلسلة Unicode التي ستخضع لترميزات مختلفة؛
- الأسطر 9-12: ترميز UTF-8. ينتج عن ذلك سلسلة ثنائية؛
- الأسطر 14-18: فك تشفير UTF-8 للعودة إلى سلسلة Unicode الأصلية؛
- الأسطر 20–29: نكرر نفس العملية باستخدام ترميز 'iso-8859-1'؛
- الأسطر 31–34: يظهر خطأ في فك الترميز:
- السطر 33: bytes1 هي سلسلة ثنائية مشفرة بـ 'utf-8'. نقوم بفك تشفيرها إلى 'iso-8859-1'؛
- الأسطر 36-39: طريقة أخرى لترميز سلسلة في UTF-8 باستخدام وحدة [codecs]؛
- الأسطر 41-44: يتم ترميز سلسلة ثنائية 'utf-8' بـ 'base64'؛
- الأسطر 46–49: توضح كيفية تحويل السلسلة الثنائية 'base64' مرة أخرى إلى سلسلة Unicode الأصلية؛
- الأسطر 51–59: نكرر هذه العملية باستخدام ترميز 'quoted-printable' بدلاً من 'base64'؛
النتائج هي كما يلي:
C:\Data\st-2020\dev\python\cours-2020\python3-flask-2020\venv\Scripts\python.exe C:/Data/st-2020/dev/python/cours-2020/python3-flask-2020/strings/str_04.py
---- chaîne unicode
str1=[hélène va au marché acheter des légumes], type(str1)=<class 'str'>
---- chaîne unicode -> binaire utf-8
bytes1=[b'h\xc3\xa9l\xc3\xa8ne va au march\xc3\xa9 acheter des l\xc3\xa9gumes'], type(bytes1)=<class 'bytes'>
---- binaire utf-8 -> chaîne unicode
str2=[hélène va au marché acheter des légumes], type(str2)=<class 'str'>
str2==str1=True
---- chaîne unicode -> binaire iso-8859-1
bytes2=[b'h\xe9l\xe8ne va au march\xe9 acheter des l\xe9gumes'], type(bytes2)=<class 'bytes'>
---- binaire iso-8859-1 -> chaîne unicode
str3=[hélène va au marché acheter des légumes], type(str3)=<class 'str'>
str3==str1=True
--- binaire utf-8 (décodage iso-8859-1) --> chaîne unicode
str4=[hélène va au marché acheter des légumes], type(str4)=<class 'str'>
---- chaîne unicode -> binaire utf-8
bytes3=[b'h\xc3\xa9l\xc3\xa8ne va au march\xc3\xa9 acheter des l\xc3\xa9gumes'], type(bytes3)=<class 'bytes'>
---- binaire utf-8 -> binaire base64
bytes4=[b'aMOpbMOobmUgdmEgYXUgbWFyY2jDqSBhY2hldGVyIGRlcyBsw6lndW1lcw==\n'], type(bytes4)=<class 'bytes'>
---- binaire base64 -> binaire utf-8 -> chaîne unicode
str6=[hélène va au marché acheter des légumes], type(str6)=<class 'str'>
---- binaire utf-8 -> binaire quoted-printable
str7=[b'h=C3=A9l=C3=A8ne=20va=20au=20march=C3=A9=20acheter=20des=20l=C3=A9gumes'], type(str7)=<class 'bytes'>
---- binaire quoted-printable -> binaire utf-8 -> chaîne unicode
str8=[hélène va au marché acheter des légumes], type(str8)=<class 'str'>
Process finished with exit code 0
- السطران 14-15: يتم فك تشفير ملف ثنائي بتنسيق UTF-8 إلى سلسلة Unicode باستخدام أداة فك التشفير الخاطئة 'iso-8859-1'. ونتيجة لذلك، تكون بعض أحرف Unicode التي تم إنشاؤها غير صحيحة، وفي هذه الحالة الأحرف التي تحتوي على علامات التشكيل؛
- السطران 18-19: يتضمن ترميز «base64» استخدام 64 حرفًا من أحرف ASCII (المشفرة بـ 7 بتات) لترميز أي بيانات ثنائية. وكما نرى، يؤدي ذلك إلى زيادة حجم البيانات الثنائية للسلسلة؛
- السطران 22-23: يستخدم ترميز "quoted-printable" أيضًا أحرف ASCII (مشفرة بـ 7 بتات) لترميز أي بيانات ثنائية؛
من المهم أن تتذكر أنه عند تلقي بيانات ثنائية — من الإنترنت، على سبيل المثال — تمثل نصًا، يجب أن تعرف الترميزات التي خضعت لها من أجل استعادة النص الأصلي.