11. Examen du site HTML généré
Nous allons examiner maintenant le rendu HTML de ce Document ODT / DOCX. On a déjà vu que le convertisseur respectait la table des matières.
11.1. La barre supérieure du site
Regardons la barre supérieure du site :
 |
- En [1], le nom du site défini dans [config.py] ;
- En [2], l’icône qui permet de passer au mode sombre ou clair ;
- En [3], l’icône qui est un lien sur le dépôt GitHub où sera exporté le site HTML. Aussi défini dans [config.py] ;
- En [4], l’icône qui permet de cacher / montrer la table des matières ;
11.2. Le bas de page du site
Regardons maintenant le bas de page :
 |
C’est le bas de page défini dans le fichier [config.py].
11.3. La page d’accueil
La page de titre du Document ODT / DOCX était la suivante :
 |
Cette page de titre du Document ODT / DOCX devient la page d’accueil du site HTML :
 |
Le convertisseur Gemini 3 / ChatGPT met dans la page Accueil tout ce qui précède, dans le Document ODT / DOCX, le premier titre de niveau 1, de style ‘Titre 1’ donc. Si vous y mettez des images comme ci-dessus, il va les afficher. Vous pouvez donc imaginer donner une couverture à votre site comme avec un livre réel. En [1], c’est le titre principal du document. Son rendu est contrôlé par le lignes suivantes du fichier de configuration [config.py] :
# -------------------------------------------------------------------------
# Détection du Titre du Document
# -------------------------------------------------------------------------
"document_title": {
# Styles ODT à considérer comme le titre principal du document (H1 global)
"style_names": [
"P1"
],
# CSS appliqué à ce titre dans le Markdown généré
"css": "font-size: 28px; font-weight: bold; margin-bottom: 1em; line-height: 1.2; color: #2c3e50;"
},
- lignes [6-8] : la liste des styles possibles pour le titre de votre document. Quand je regarde ce document, le style LibreOffice de mon titre est ‘Titre principal’. Or le convertisseur Gemini ne le trouvait pas. Il a fait des logs des styles qu’il rencontrait et cela a affiché [P1]. C’est un gros souci avec LibreOffice : les noms affichés des styles ne correspondent pas aux noms internes utilisés par le logiciel. Ils ne sont là que pour s’adapter à la langue de l’utilisateur ;
- ligne 10 : une fois que le titre principal a été détecté, vous pouvez paramétrer son rendu. Moi je voulais une police de taille 28 (font-size: 28px;) et du gras (font-weight: bold) ;
Avec les images et le style du titre, vous pouvez faire une page d’accueil attirante.
Le titre principal de votre document n’aura peut-être pas un des styles définis aux lignes [6-8]. Pour trouver le style de votre titre principal, utilisez la ligne suivante du fichier [config.py]
Avec la valeur [true], le style des paragraphes qui précèdent le premier titre de niveau 1, donc les paragraphes de la page d’accueil, va être affiché lors de l’exécution du convertisseur Gemini / ChatGPT. Ainsi pour un autre document que celui-ci, j’ai obtenu les logs suivants :
[DEBUG PRE-H1] Style='Standard (WW)' (Clean='standard (ww)') | Texte='...'
[DEBUG PRE-H1] Style='P1' (Clean='p1') | Texte='...'
[DEBUG PRE-H1] Style='P1' (Clean='p1') | Texte='...'
[DEBUG PRE-H1] Style='P1' (Clean='p1') | Texte='...'
[DEBUG PRE-H1] Style='P3' (Clean='p3') | Texte='...'
[DEBUG PRE-H1] Style='P1' (Clean='p1') | Texte='...'
[DEBUG PRE-H1] Style='P1' (Clean='p1') | Texte='...'
[DEBUG PRE-H1] Style='P1' (Clean='p1') | Texte='...'
[DEBUG PRE-H1] Style='P1' (Clean='p1') | Texte='...'
[DEBUG PRE-H1] Style='P4' (Clean='p4') | Texte='Introduction au langage PHP7 par l’exemp...'
>>> TITRE DOCUMENT DETECTÉ : Introduction au langage PHP7 par l’exemple
[DEBUG PRE-H1] Style='Standard (WW)' (Clean='standard (ww)') | Texte='...'
[DEBUG PRE-H1] Style='Standard (WW)' (Clean='standard (ww)') | Texte='...'
[DEBUG PRE-H1] Style='Standard (WW)' (Clean='standard (ww)') | Texte='...'
[DEBUG PRE-H1] Style='Standard (WW)' (Clean='standard (ww)') | Texte='...'
[DEBUG PRE-H1] Style='Standard (WW)' (Clean='standard (ww)') | Texte='...'
[DEBUG PRE-H1] Style='Standard (WW)' (Clean='standard (ww)') | Texte='...'
[DEBUG PRE-H1] Style='P5' (Clean='p5') | Texte='Serge Tahé, juillet 2019...'
[DEBUG PRE-H1] Style='P5' (Clean='p5') | Texte='...'
[DEBUG PRE-H1] Style='P6' (Clean='p6') | Texte='...'
[DEBUG PRE-H1] Style='Heading 1' (Clean='heading 1') | Texte='Introduction au langage PHP 7...'
- ligne 10, le titre du document a le style ‘P4’ ;
Dans le fichier [config.py], j’ai alors mis les lignes suivantes :
"document_title": {
"style_names": [
"P4"
],
"css": "font-size: 28px; font-weight: bold; margin-bottom: 1em; line-height: 1.2; color: #2c3e50;"
},
- ligne 3, le style que je cherchais ;
C’est pour cette raison que le débogueur affiche les lignes :
[DEBUG PRE-H1] Style='P4' (Clean='p4') | Texte='Introduction au langage PHP7 par l’exemp...'
>>> TITRE DOCUMENT DETECTÉ : Introduction au langage PHP7 par l’exemple
Il a rencontré le style ‘P4’ et affiche alors que le titre du document a été trouvé. Lorsque celui-ci a été trouvé, vous pouvez mettre la clé [debug] à [false] dans [config.py] :
Regardons maintenant la conversion du chapitre [Exemples] qui regroupe les exemples que le convertisseur Gemini / ChatGPT sait gérer :
11.4. Les listes à puces
Document ODT / DOCX :
 |
Cidessus, le texte [Listes à puces] est surligné parce que c’est une référence associée à un renvoi.
Document HTML :
 |
On remarque si le Document ODT / DOCX utilise différentes puces, le document HTML n’utilise qu’une sorte de puce.
11.5. Les listes numérotées
Document ODT / DOCX :
 |
Document HTML :
 |
11.5.1. Listes mixtes 1
Document ODT / DOCX
 |
Document HTML
 |
Là également, il y a parfois des différences entre les types de puces utilisés.
11.5.2. Listes mixtes 2
Document ODT / DOCX
 |
Document HTML
 |
11.6. Les blocs de code enrichis
Les blocs de code enrichi sont rendus à l’identique dans le HTML (en-dehors de la couleur de fond). Voici trois exemples :
11.6.1. Exemple 1
Document ODT / DOCX
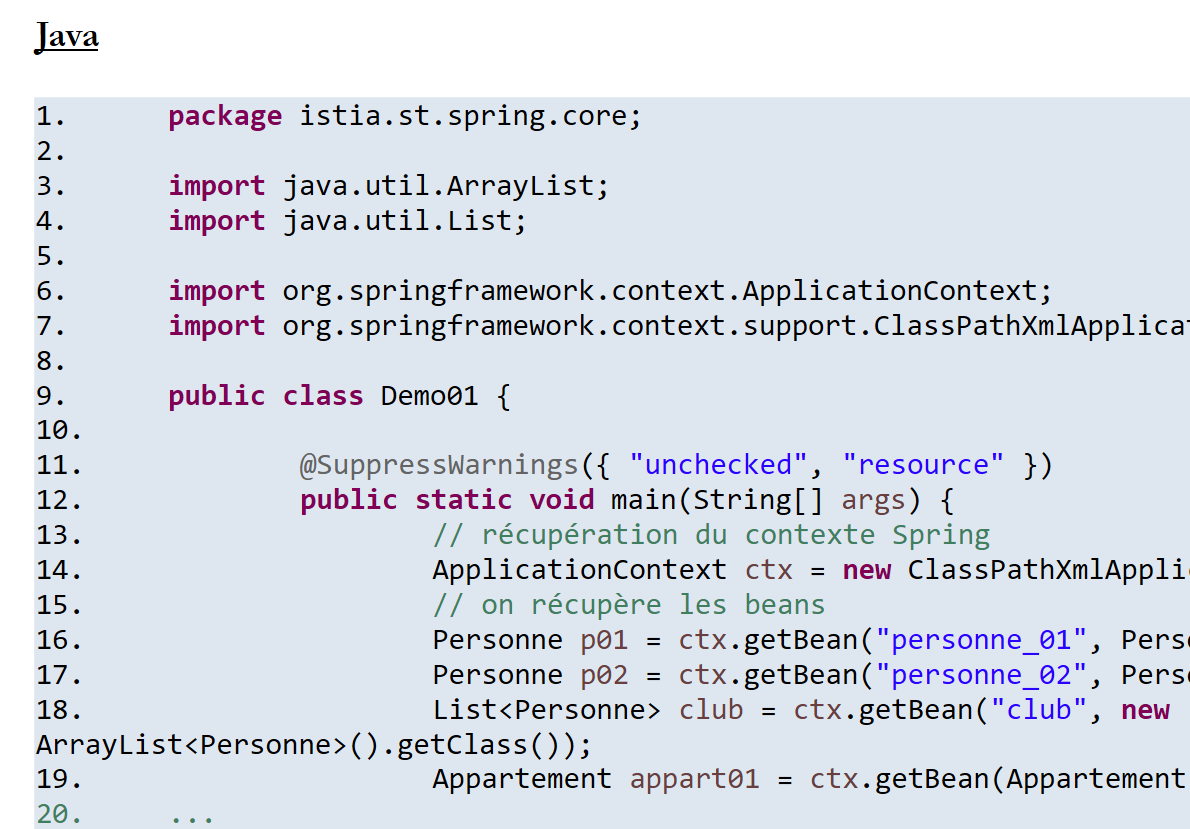 |
Rendu HTML
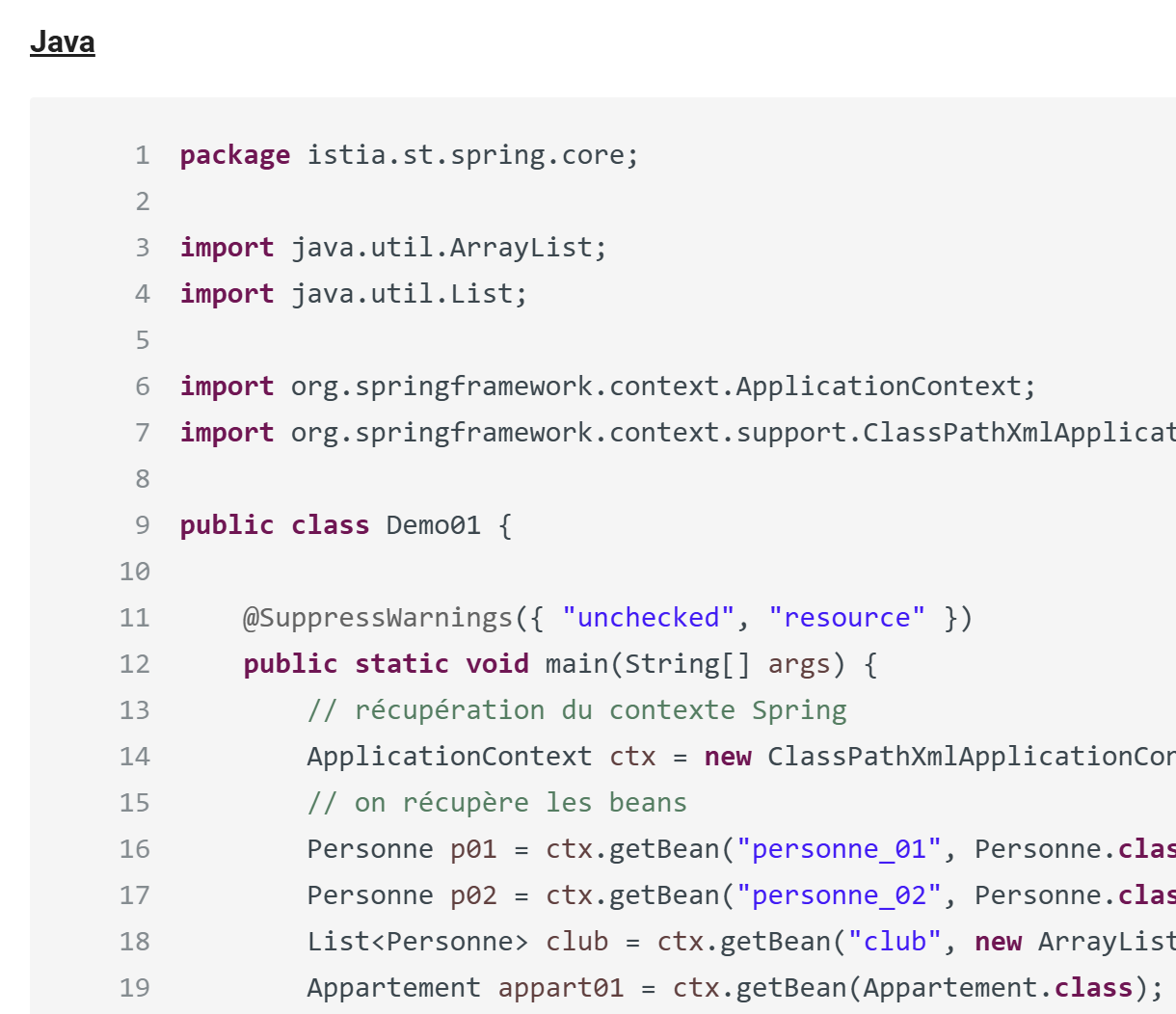 |
11.6.2. Exemple 2
Document ODT / DOCX :
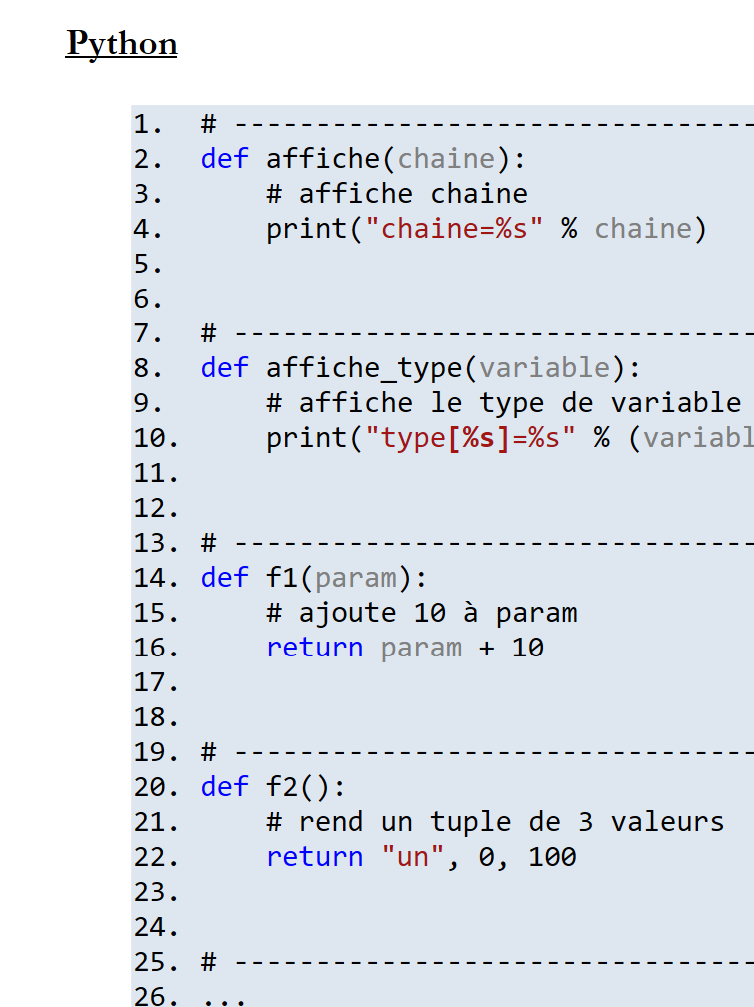 |
Rendu HTML
 |
11.6.3. Exemple 3
Document ODT / DOCX
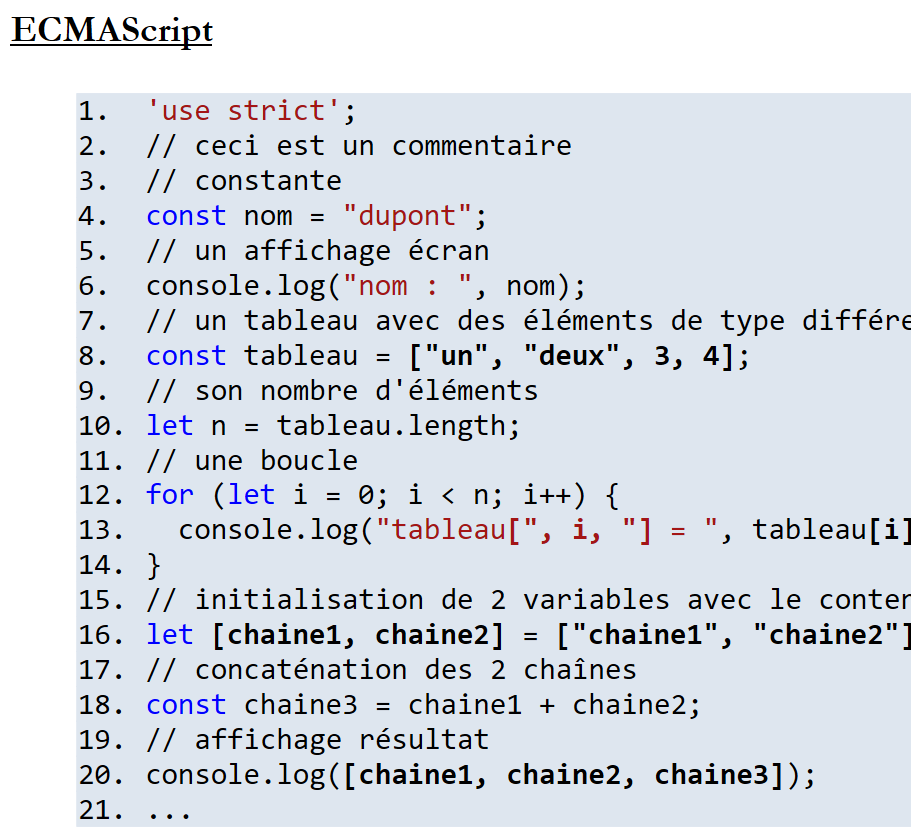 |
Rendu HTML
 |
11.7. Les blocs de code brut (plain text)
Les blocs de code brut trouvés dans le Document ODT / DOCX sont colorés syntaxiquement par MkDocs selon le langage trouvé dans le bloc de code. Pour aider le convertisseur à trouver le bon langage, on a mis des « chaînes clés » dans le fichier [config.py] pour chaque langage. Le convertisseur compte les « chaînes clés » trouvées. Il associe alors le bloc de code au langage ayant le plus de « chaînes clés » trouvées.
Voyons quelques exemples.
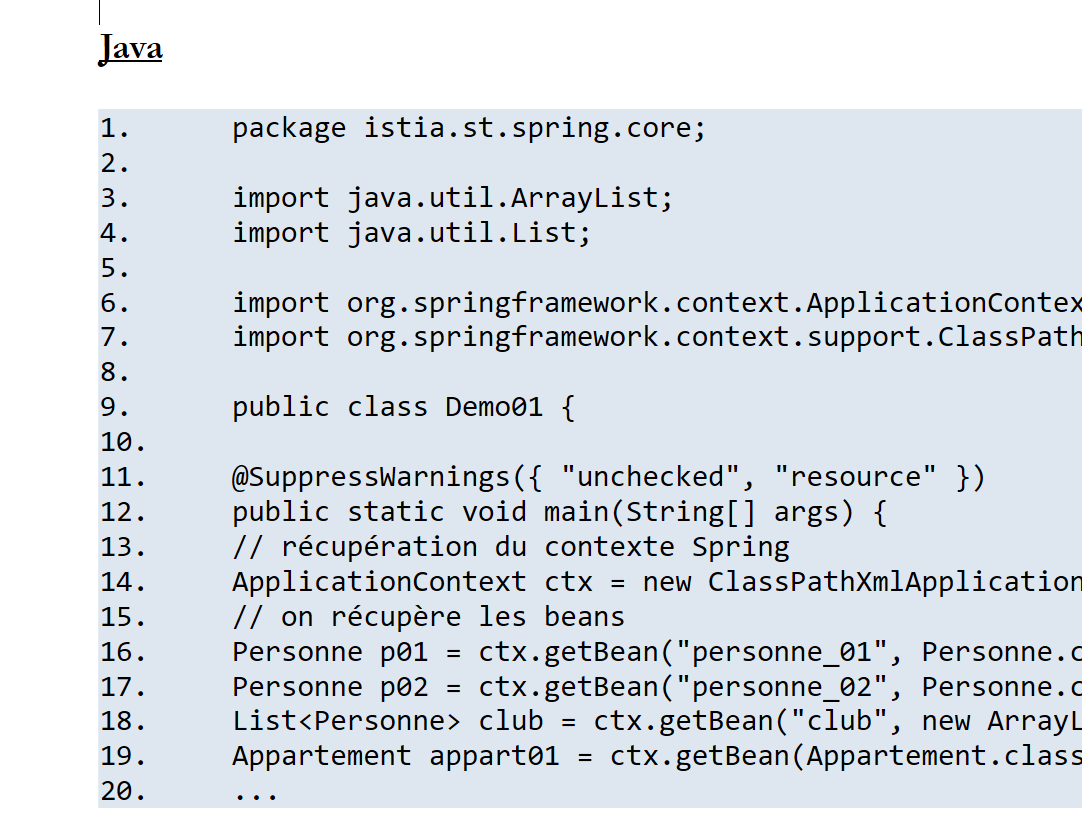
11.7.1. Exemple 1
Document ODT / DOCX (Java)
 |
Rendu HTML
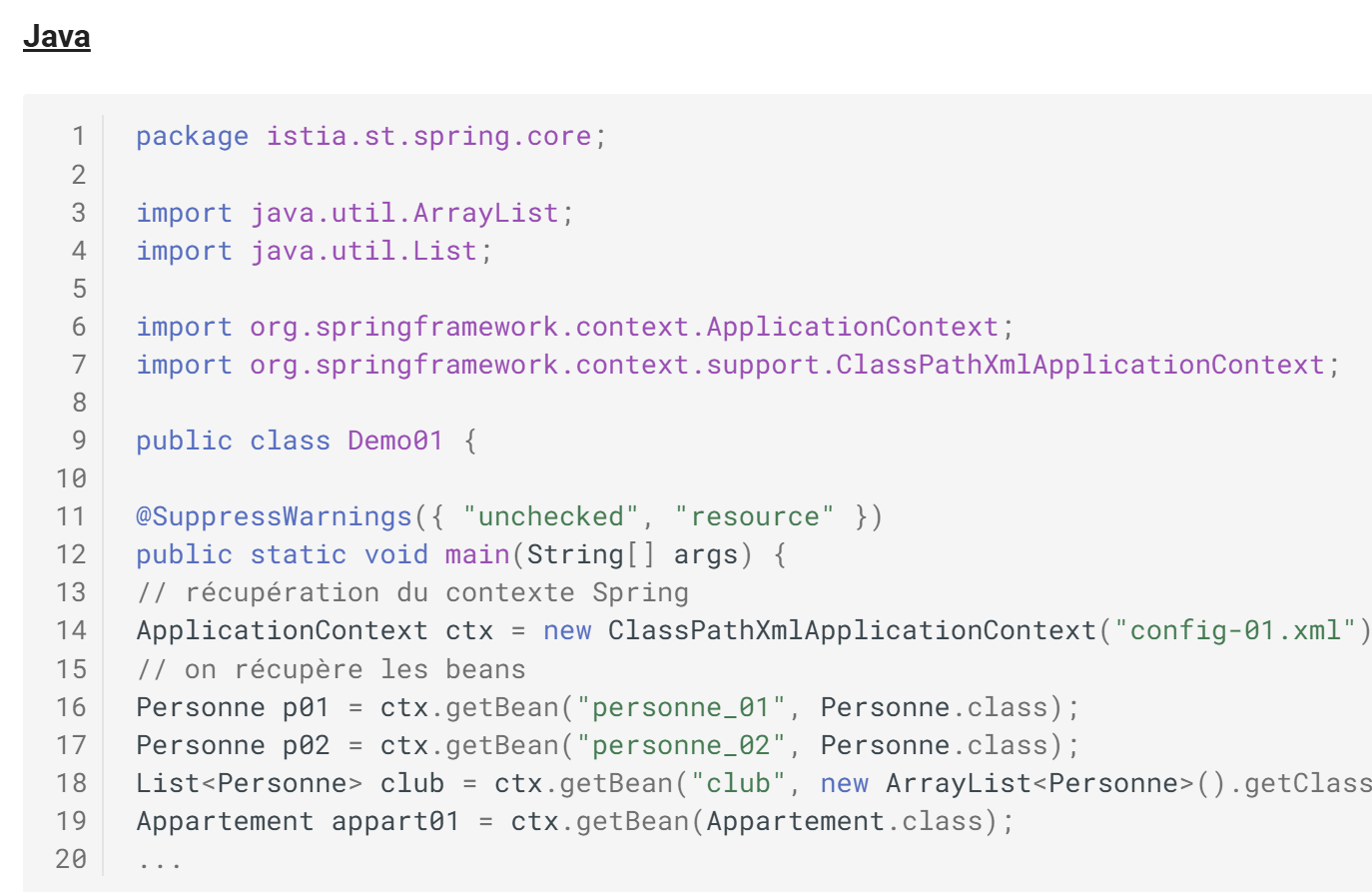 |
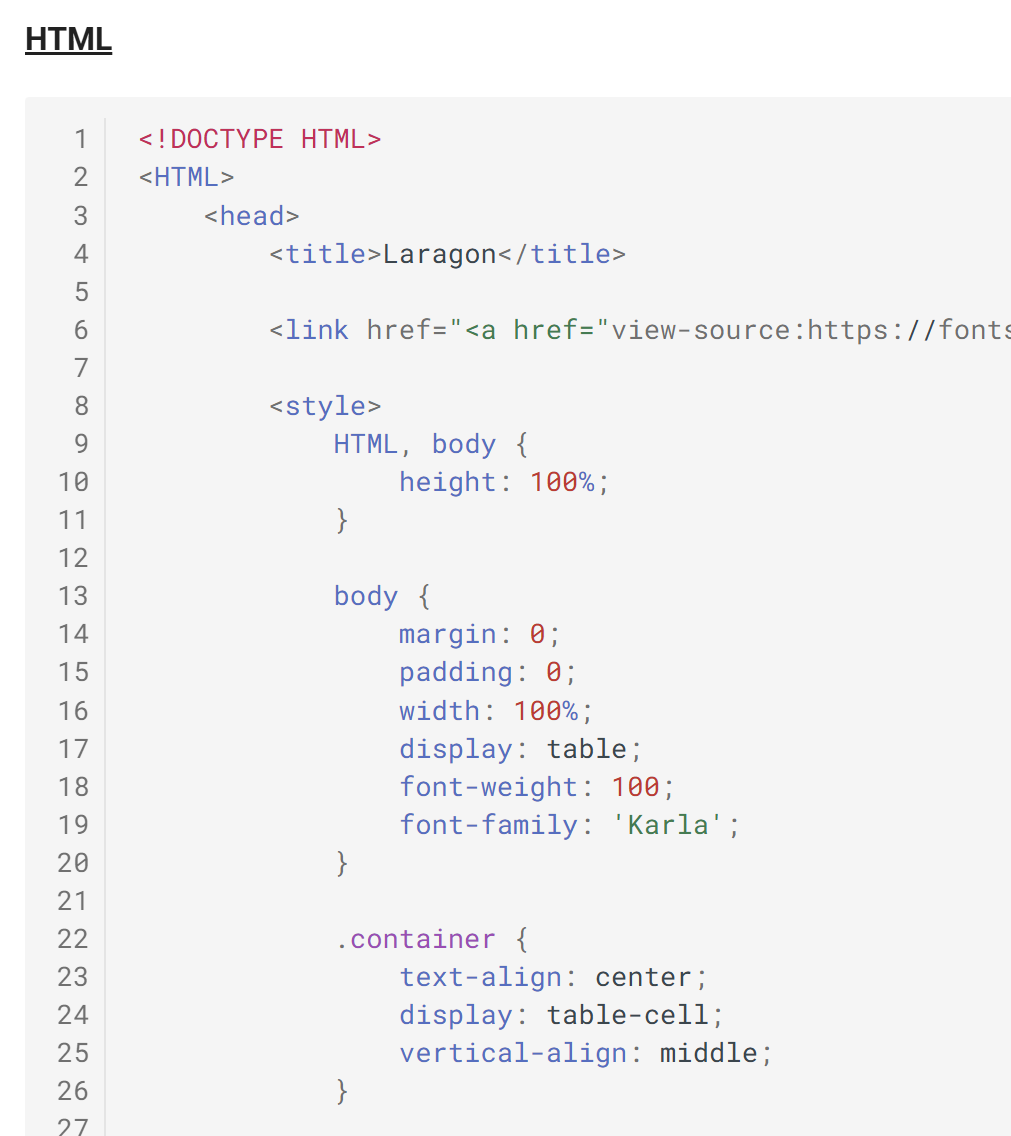
Dans le document HTML on voit que le code Java a été coloré syntaxiquement.
11.7.2. Exemple 2
Document ODT / DOCX (XML)
 |
Rendu HTML
 |
11.7.3. Exemple 3
Document ODT / DOCX (HTML)
 |
Rendu HTML
 |
11.8. Autres blocs de code
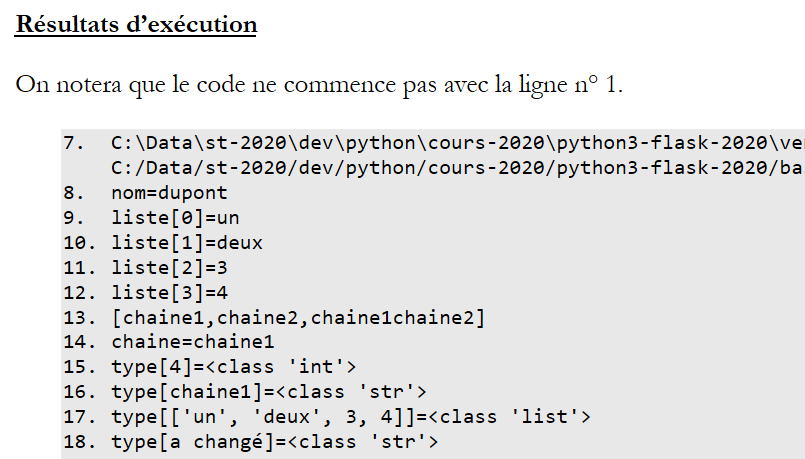
Document ODT / DOCX
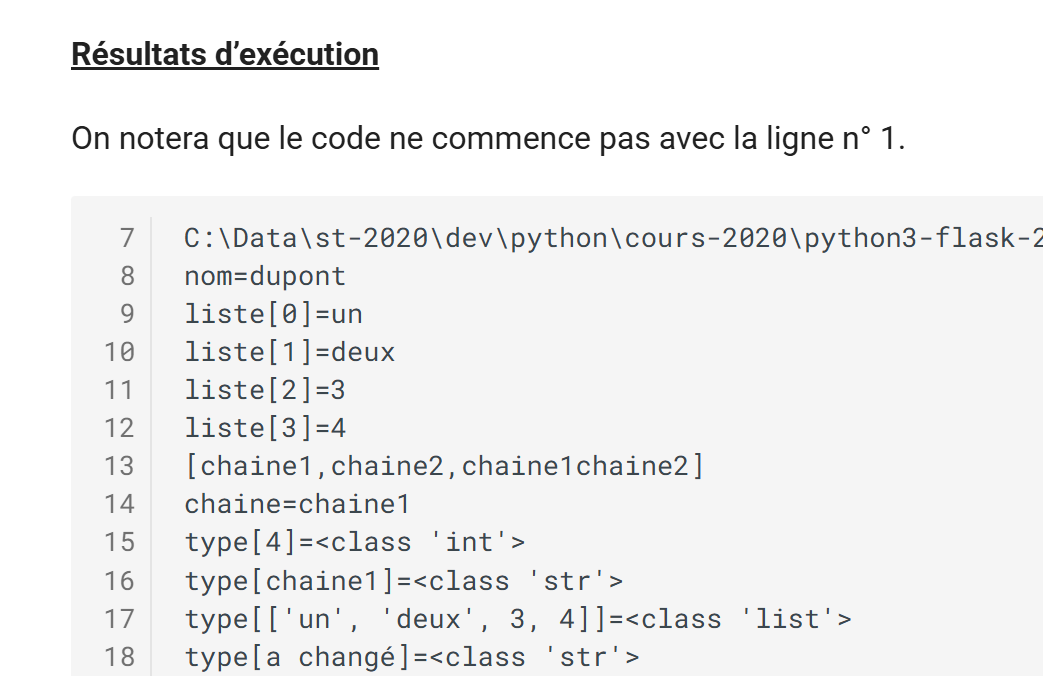
Un résultat d’exécution avec une première ligne qui ne commence pas à 1 :
 |
Rendu HTML
 |
Un bloc de code non numéroté dans ODT le reste dans le HTML :
Document ODT / DOCX
 |
Rendu HTML
 |
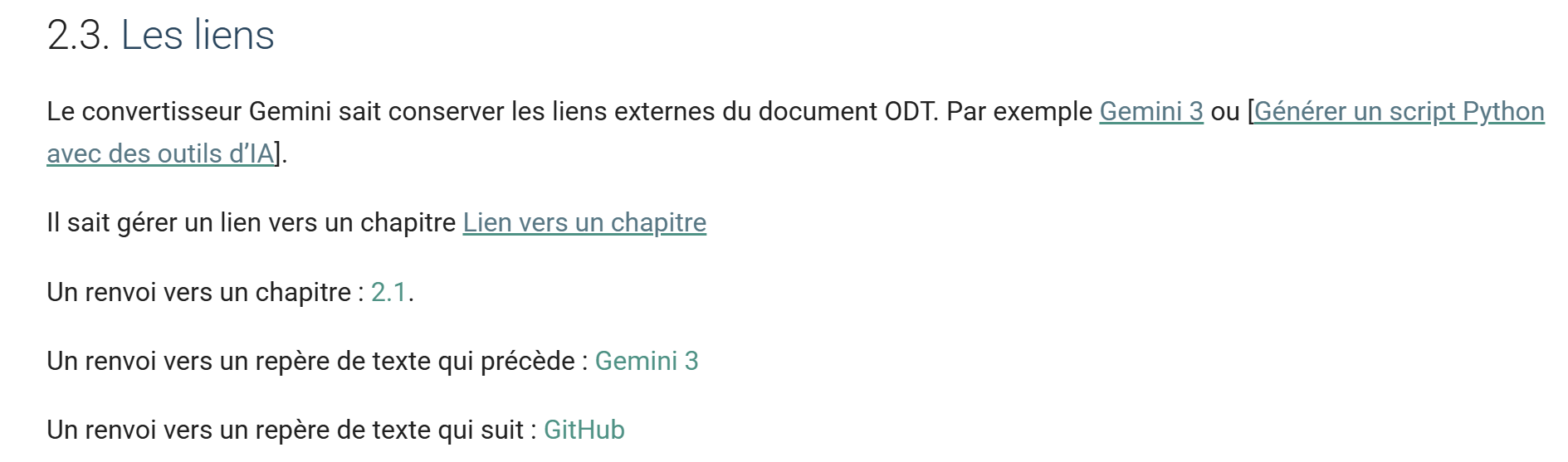
11.9. Les liens
Document ODT / DOCX
 |
Rendu HTML
 |
11.10. L’enrichissement de texte
Document ODT / DOCX
  |
Rendu HTML
 |
11.11. Les images
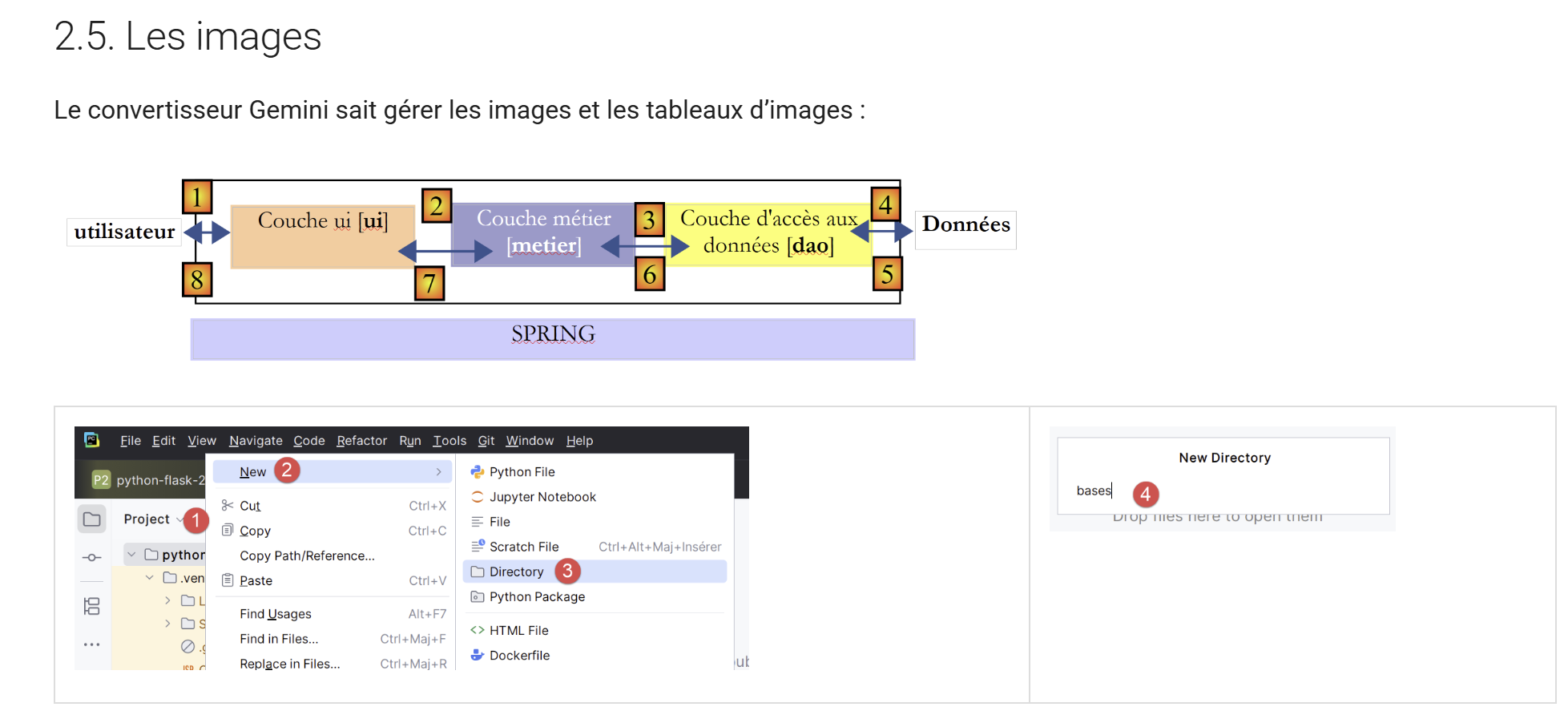 |
Il faut noter que le convertisseur Gemini / ChatGPT respecte les redimensionnements des images, faits dans le Document ODT / DOCX.
11.12. Les caractères protégés
Document ODT / DOCX
 |
Rendu HTML
 |
Document ODT / DOCX (MarkDown)
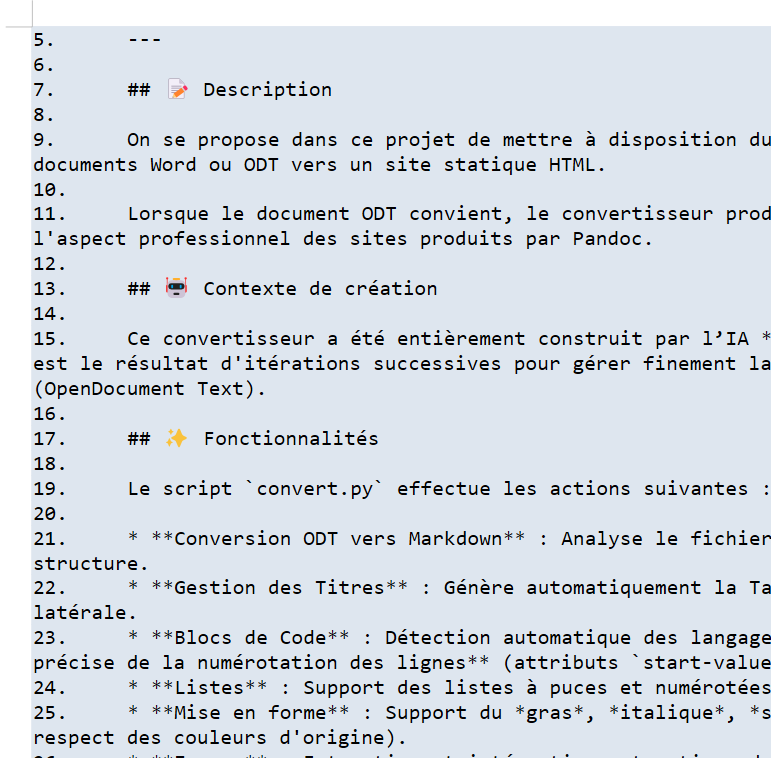 |
Rendu HTML
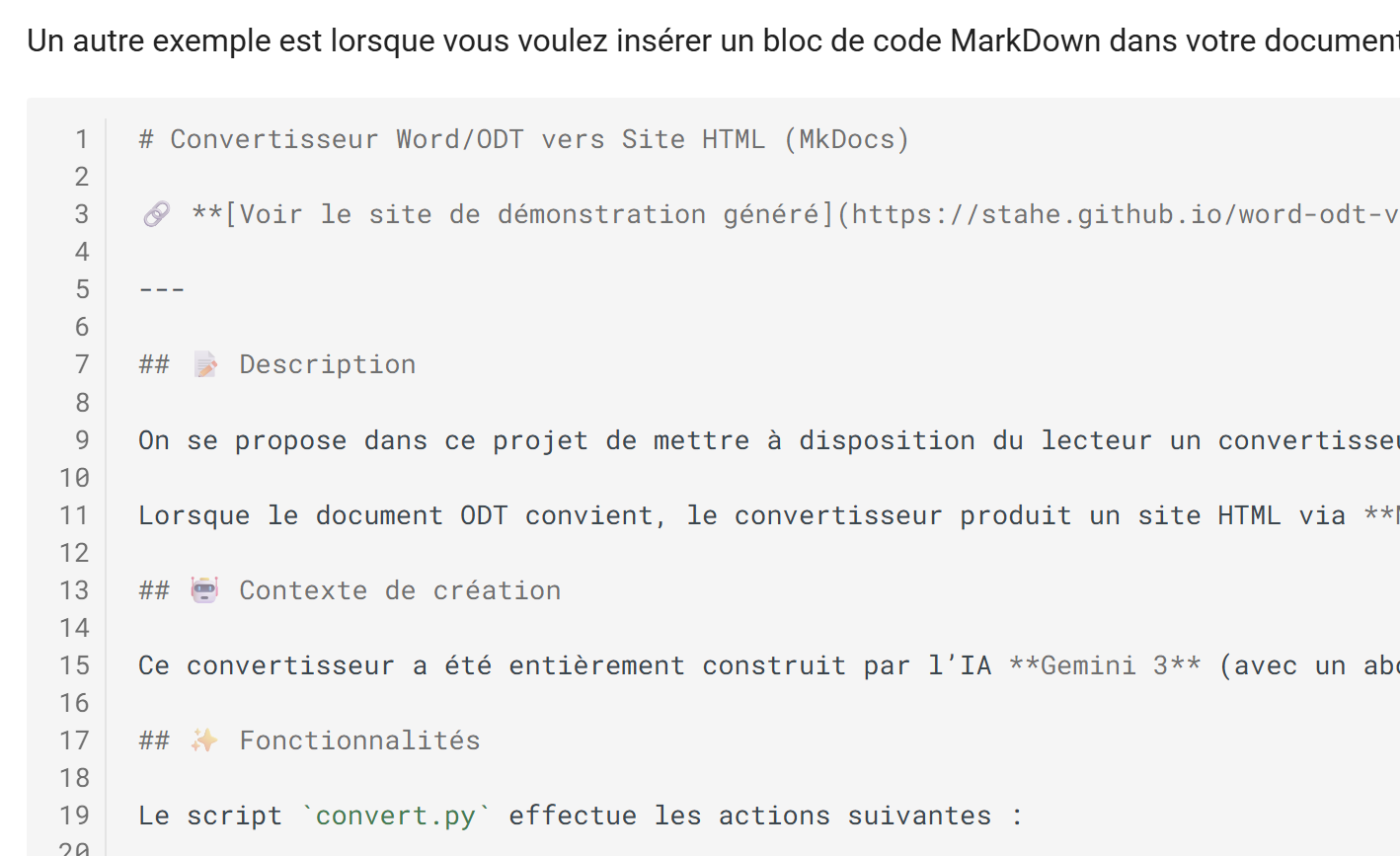 |
- le code MarkDown a été préservé ;
11.13. Les tableaux
Document ODT / DOCX
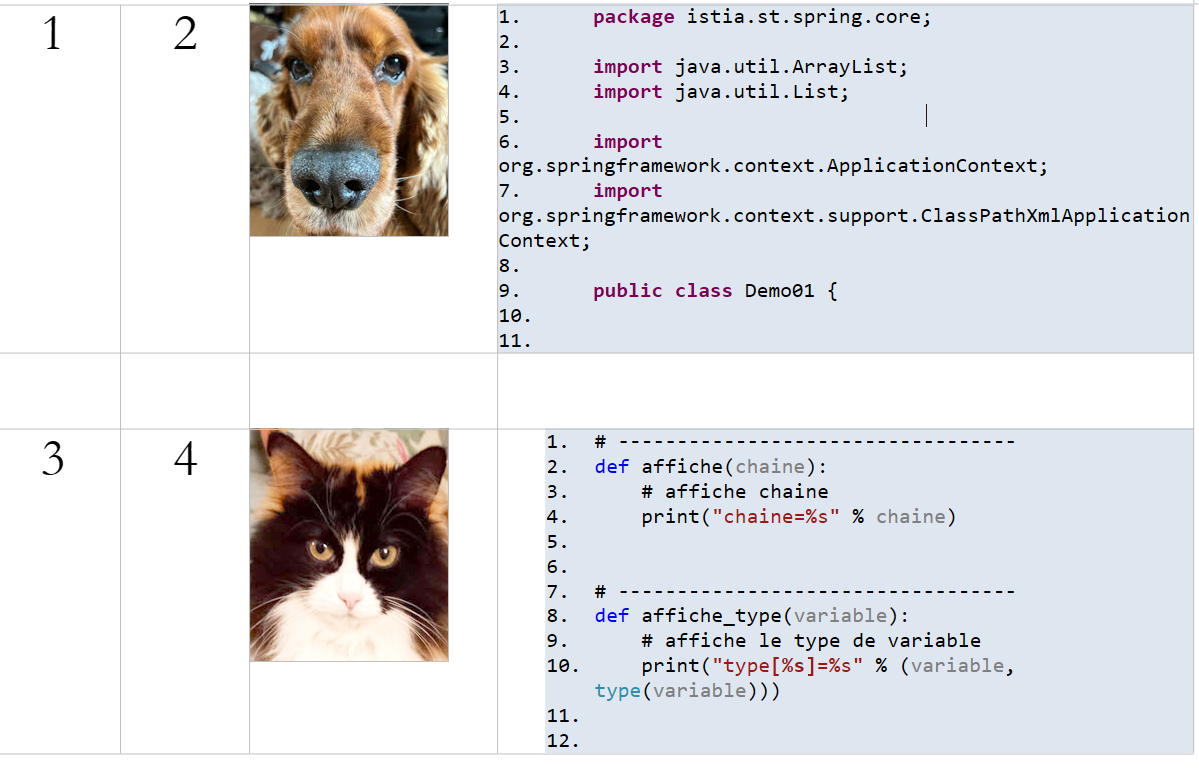 |
Rendu HTML
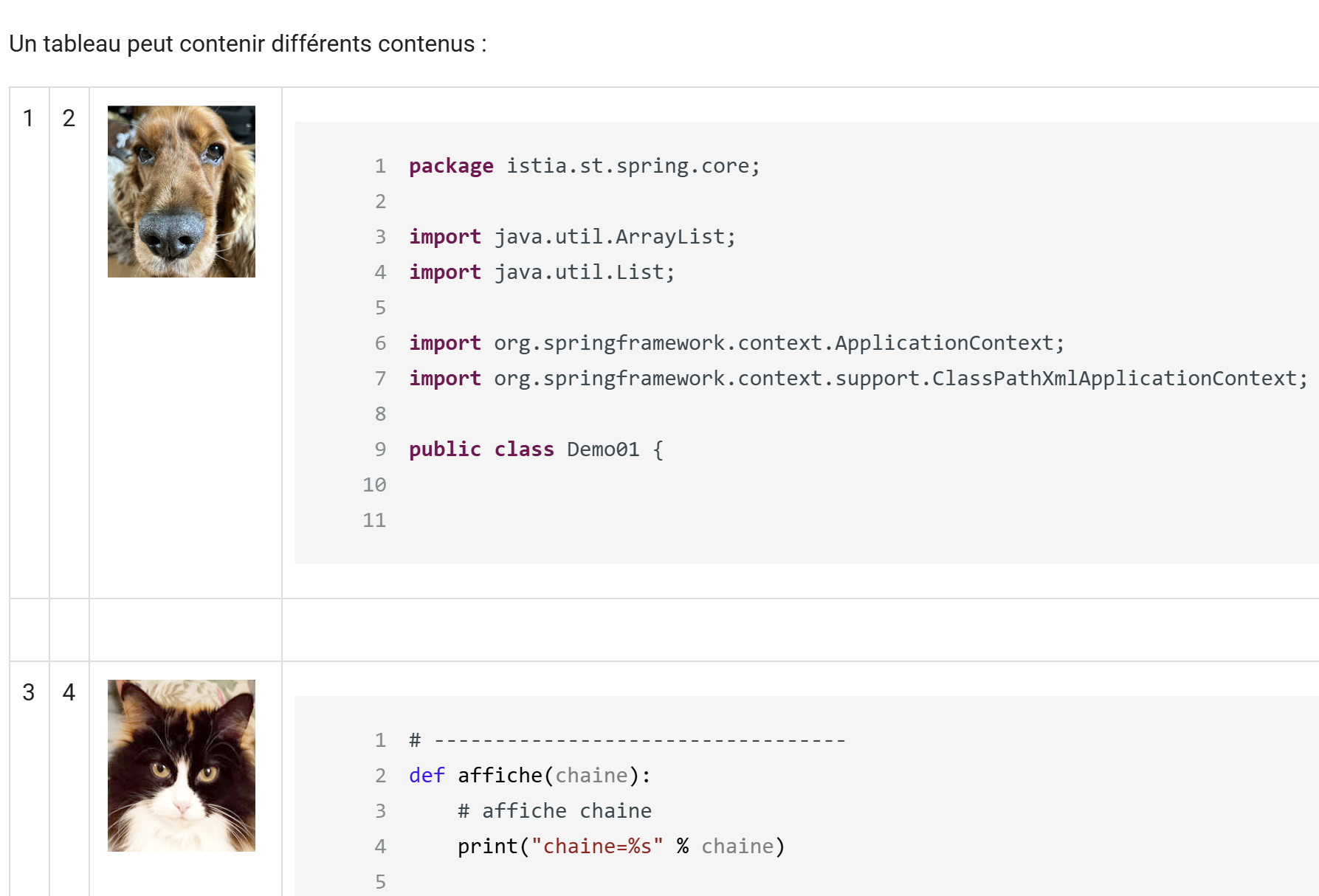 |
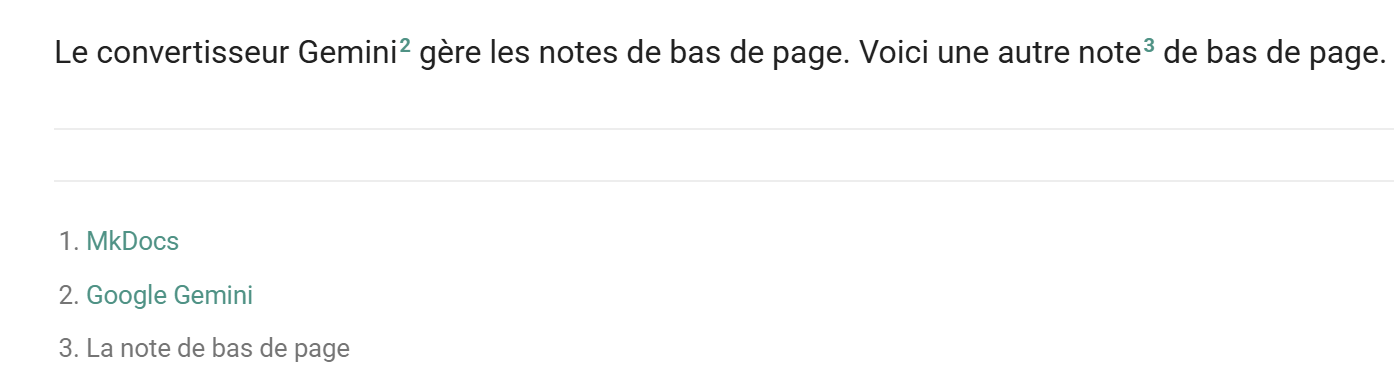
11.14. Notes de bas de page
 |
11.15. Anomalies connues
Certaines anomalies ont été repérées mais elles peuvent être corrigées en modifiant l’ODT / DOCX :
- les blocs de code doivent être suivis d’une ligne vide sinon le bloc de code peut être mal rendu. Le cas repéré est un code suivi immédiatement d’un titre sans être séparé de celui-ci par une ligne vide ;
- les listes à puces ne peuvent pas voir de bordure inférieure. Pour avoir celle-ci, il faut ajouter une ligne vide derrière le dernier élément de la liste ;
- les listes à puces doivent être hiérarchisées. Ainsi une liste de niveau 2 doit être toujours incluse dans une liste de niveau 1, sinon la liste de niveau 2 est rendue comme étant du code ;
Au fil des versions du convertisseur, certaines de ces anomalies sont appelées à disparaître. Les trois précédentes sont évitables en corrigeant le document source.
11.16. Autres cas
Si votre document utilise d’autres particularités que celles évoquées précédemment, il est hautement probable que celles-ci ne seront pas prises en compte par le convertisseur Gemini / ChatGPT . Que faire alors ? Vous pouvez faire part de votre nouvelle demande à l’une des IA en lui donnant le convertisseur actuel :
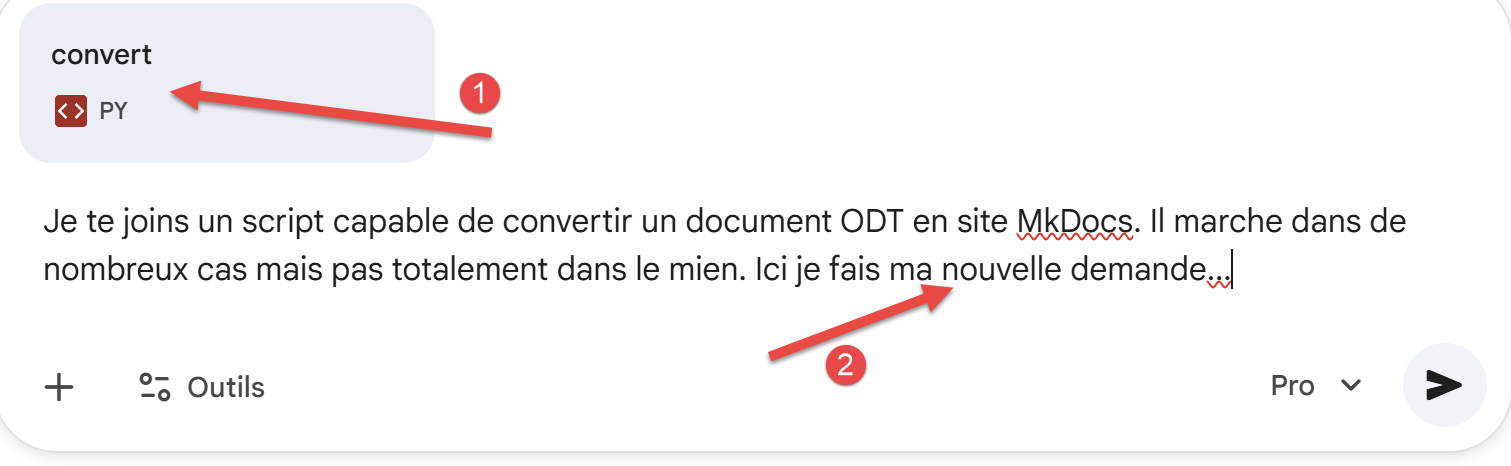 |
- En [1], je joins le convertisseur de ce document ;
- En [2], je fais ma nouvelle demande ;
Vous allez partir probablement pour de nombreuses itérations. Lorsqu’une version est stable, notez son numéro pour pouvoir le redonner à l’IA en cas de régression. Il est conseillé également de faire une copie de chaque version stable. Un inconvénient majeur des deux IA est qu’elles régressent assez facilement. Il suffit de lui demander une nouvelle fonctionnalité pour que l’IA casse le code qui marchait auparavant. D’où l’importance de noter le numéro de version des versions stables afin de pouvoir y revenir. En janvier 2026, il m’a semblé que ChatGPT 5.2 avait moins tendance à régresser que Gemini 3.