2. As entidades JPA
2.1. Exemplo 1 - Representação orientada a objetos de uma única tabela
2.1.1. A tabela [personne]
Consideremos uma base de dados com uma única tabela [personne], cuja função é armazenar algumas informações sobre indivíduos:
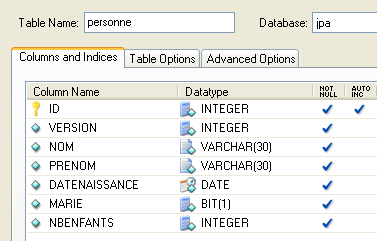 |
chave primária da tabela | |
versão do registo na tabela. Sempre que a pessoa for alterada, o seu número de versão é incrementado. | |
nome da pessoa | |
o seu nome próprio | |
data de nascimento | |
número inteiro 0 (solteiro) ou 1 (casado) | |
número de filhos da pessoa |
2.1.2. A entidade [Personne]
Encontramo-nos no seguinte ambiente de execução:
 |
A camada JPA [5] deve servir de ponte entre o mundo relacional da base de dados [7] e o mundo de objetos [4] manipulado pelos programas Java [3]. Esta ligação é estabelecida através da configuração e há duas formas de o fazer:
- com ficheiros XML. Esta era praticamente a única forma de o fazer até ao advento do JDK 1.5
- com anotações Java a partir da versão 1.5 do JDK
Neste documento, utilizaremos quase exclusivamente o segundo método.
O objeto [Personne] correspondente à tabela [personne] apresentada anteriormente poderia ser o seguinte:
...
@SuppressWarnings("unused")
@Entity
@Table(name="Personne")
public class Personne implements Serializable{
@Id
@Column(name = "ID", nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Column(name = "VERSION", nullable = false)
@Version
private int version;
@Column(name = "NOM", length = 30, nullable = false, unique = true)
private String nom;
@Column(name = "PRENOM", length = 30, nullable = false)
private String prenom;
@Column(name = "DATENAISSANCE", nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(name = "MARIE", nullable = false)
private boolean marie;
@Column(name = "NBENFANTS", nullable = false)
private int nbenfants;
// construtores
public Personne() {
}
public Personne(String nom, String prenom, Date datenaissance, boolean marie,
int nbenfants) {
setNom(nom);
setPrenom(prenom);
setDatenaissance(datenaissance);
setMarie(marie);
setNbenfants(nbenfants);
}
// toString
public String toString() {
...
}
// getters e setters
...
}
A configuração é feita através de anotações Java @Annotation. As anotações Java são interpretadas pelo compilador ou por ferramentas especializadas no momento da execução. Com exceção da anotação da linha 3, destinada ao compilador, todas as anotações aqui se destinam à implementação JPA utilizada, seja o Hibernate ou o Toplink. Serão, portanto, interpretadas durante a execução. Na ausência de ferramentas capazes de as interpretar, estas anotações são ignoradas. Assim, a classe [Personne] acima referida poderia ser utilizada num contexto fora do JPA.
É necessário distinguir dois casos de utilização das anotações JPA numa classe C associada a uma tabela T:
- a tabela T já existe: as anotações JPA devem, nesse caso, reproduzir o que já existe (nome e definição das colunas, restrições de integridade, chaves estrangeiras, chaves primárias, etc.)
- a tabela T não existe e vai ser criada com base nas anotações encontradas na classe C.
O caso 2 é o mais fácil de gerir. Com a ajuda das anotações JPA, indicamos a estrutura da tabela T que pretendemos. O caso 1 é frequentemente mais complexo. A tabela T pode ter sido criada, há muito tempo, fora de qualquer contexto JPA. A sua estrutura pode, então, estar mal adaptada à ponte relacional/objeto de JPA. Para simplificar, consideramos o caso 2, em que a tabela T associada à classe C será criada com base nas anotações JPA da classe C.
Vamos comentar as anotações JPA da classe [Personne]:
- linha 4: a anotação @Entity é a primeira anotação indispensável. É colocada antes da linha que declara a classe e indica que a classe em questão deve ser gerida pela camada de persistência JPA. Na ausência desta anotação, todas as outras anotações JPA seriam ignoradas.
- linha 5: a anotação @Table designa a tabela da base de dados que a classe representa. O seu principal argumento é name, que designa o nome da tabela. Na ausência deste argumento, a tabela terá o nome da classe, neste caso [Personne]. No nosso exemplo, a anotação @Table é, portanto, supérflua.
- linha 8: a anotação @Id serve para indicar o campo na classe que corresponde à chave primária da tabela. Esta anotação é obrigatória. Indica, neste caso, que o campo id da linha 11 corresponde à chave primária da tabela.
- linha 9: a anotação @Column serve para estabelecer a ligação entre um campo da classe e a coluna da tabela que esse campo representa. O atributo name indica o nome da coluna na tabela. Na ausência deste atributo, a coluna tem o mesmo nome que o campo. No nosso exemplo, o argumento name não era, portanto, obrigatório. O argumento nullable=false indica que a coluna associada ao campo não pode ter o valor NULL e que, por conseguinte, o campo deve ter necessariamente um valor.
- linha 10: a anotação @GeneratedValue indica como é gerada a chave primária quando esta é gerada automaticamente pelo SGBD. Será este o caso em todos os nossos exemplos. Isto não é obrigatório. Assim, a nossa pessoa poderia ter um número de estudante que serviria de chave primária e que não seria gerado pelo SGBD, mas sim definido pela aplicação. Neste caso, a anotação @GeneratedValue estaria ausente. O argumento strategy indica como é gerada a chave primária quando esta é gerada pelo SGBD. Nem todos os SGBD utilizam a mesma técnica de geração dos valores da chave primária. Por exemplo:
utiliza um gerador de valores chamado antes de cada inserção | |
o campo da chave primária é definido como tendo o tipo Identity. Obtém-se um resultado semelhante ao gerador de valores do Firebird, com a diferença de que o valor da chave só é conhecido após a inserção da linha. | |
utiliza um objeto denominado SEQUENCE que, mais uma vez, desempenha o papel de um gerador de valores |
A camada JPA deve gerar ordens SQL diferentes, dependendo dos SGBD, para criar o gerador de valores. Através da configuração, é-lhe indicado o tipo de SGBD que deve gerir. Assim, pode saber qual é a estratégia habitual de geração de valores de chave primária desse SGBD. O argumento strategy = GenerationType.AUTO indica à camada JPA que deve utilizar essa estratégia habitual. Esta técnica funcionou em todos os exemplos deste documento para os sete SGBD utilizados.
- linha 14: a anotação @Version identifica o campo utilizado para gerir os acessos simultâneos a uma mesma linha da tabela.
Para compreender este problema de acesso simultâneo a uma mesma linha da tabela [personne], suponhamos que uma aplicação web permita a atualização de um utilizador e analisemos o seguinte caso:
No momento T1, um utilizador U1 acede à edição de uma pessoa P. Nesse momento, o número de filhos é 0. Ele altera esse número para 1, mas antes de validar a sua alteração, um utilizador U2 acede à edição da mesma pessoa P. Uma vez que U1 ainda não validou a sua alteração, U2 vê no seu ecrã que o número de filhos é 0. U2 altera o nome da pessoa P para maiúsculas. Em seguida, U1 e U2 validam as suas alterações por esta ordem. É a alteração de U2 que vai prevalecer: na base de dados, o nome passará a estar em maiúsculas e o número de filhos permanecerá em zero, mesmo que U1 pense ter-o alterado para 1.
O conceito de versão de pessoa ajuda-nos a resolver este problema. Retomemos o mesmo caso de utilização:
No momento T1, um utilizador U1 inicia a edição de uma pessoa P. Nesse momento, o número de filhos é 0 e a versão é V1. Ele altera o número de filhos para 1, mas antes de validar a sua alteração, um utilizador U2 acede à edição da mesma pessoa P. Uma vez que U1 ainda não validou a sua alteração, U2 vê o número de filhos como 0 e a versão como V1. U2 altera o nome da pessoa P para maiúsculas. Em seguida, U1 e U2 validam as suas alterações por esta ordem. Antes de validar uma alteração, verifica-se se quem altera uma pessoa P possui a mesma versão que a pessoa P atualmente registada. Este será o caso do utilizador U1. A sua alteração é, portanto, aceite e a versão da pessoa alterada passa de V1 para V2, para indicar que a pessoa sofreu uma alteração. Ao validar a alteração de U2, ver-se-á que U2 possui uma versão V1 da pessoa P, quando, na realidade, a versão atual desta é V2. Será então possível informar ao utilizador U2 que alguém o antecedeu e que deve recomeçar a partir da nova versão da pessoa P. Ele fará isso, recuperará uma pessoa P da versão V2, que agora tem um filho, colocará o nome em maiúsculas e validará. A sua alteração será aceite se a pessoa P registada ainda tiver a versão V2. No final, as alterações feitas por U1 e U2 serão tidas em conta, enquanto que, no caso de utilização sem versão, uma das alterações teria sido perdida.
A camada [dao] da aplicação cliente pode gerir por si própria a versão da classe [Personne]. Sempre que houver uma alteração num objeto P, a versão desse objeto será incrementada em 1 na tabela. A anotação @Version permite transferir esta gestão para a camada JPA. O campo em questão não precisa, de forma alguma, chamar-se version, como no exemplo. Pode ter qualquer nome.
Os campos correspondentes às anotações @Id e @Version existem devido à persistência. Não seriam necessários se a classe [Personne] não precisasse de ser persistida. Vemos, portanto, que um objeto não tem a mesma representação consoante precise ou não de ser persistido.
- linha 17: mais uma vez, a anotação @Column para fornecer informações sobre a coluna da tabela [personne] associada ao campo nom da classe Personne. Encontramos aqui dois novos argumentos:
- unique=true indica que o nome de uma pessoa deve ser único. Isto traduz-se na base de dados pela adição de uma restrição de unicidade na coluna NOM da tabela [personne].
- length=30 define o número de caracteres da coluna NOM para 30. Isto significa que o tipo desta coluna será VARCHAR(30).
- linha 24: a anotação @Temporal serve para indicar que tipo SQL deve ser atribuído a uma coluna/campo do tipo data/hora. O tipo TemporalType.DATE designa apenas uma data, sem hora associada. Os outros tipos possíveis são TemporalType.TIME para codificar uma hora e TemporalType.TIMESTAMP para codificar uma data com hora.
Vamos agora comentar o resto do código da classe [Personne]:
- linha 6: a classe implementa a interface Serializable. A sérialisation de um objeto consiste em transformá-lo numa sequência de bits. A désérialisation é a operação inversa. A serialização/deserialização é utilizada, nomeadamente, em aplicações cliente/servidor, nas quais os objetos são trocados através da rede. As aplicações cliente ou servidor não têm conhecimento desta operação, que é realizada de forma transparente pelos JVM. Para que tal seja possível, é necessário, no entanto, que as classes dos objetos trocados sejam «marcadas» com a palavra-chave Serializable.
- linha 37: um construtor da classe. Note-se que os campos id e version não fazem parte dos parâmetros. Com efeito, estes dois campos são geridos pela camada JPA e não pela aplicação.
- linhas 51 e seguintes: os métodos get e set de cada um dos campos da classe. É de salientar que as anotações JPA podem ser colocadas nos métodos get dos campos, em vez de serem colocadas nos próprios campos. A localização das anotações indica o modo que o JPA deve utilizar para aceder aos campos:
- se as anotações forem colocadas ao nível do campo, o JPA acederá diretamente aos campos para os ler ou gravar
- se as anotações forem colocadas ao nível dos métodos get, o JPA acederá aos campos através dos métodos get/set para os ler ou gravar
É a posição da anotação @Id que determina a posição das anotações JPA numa classe. Colocada ao nível do campo, indica um acesso direto aos campos; colocada ao nível de get, indica um acesso aos campos através dos métodos get e set. As restantes anotações devem, então, ser colocadas da mesma forma que a anotação @Id.
2.1.3. O projeto Eclipse dos testes
Vamos realizar as nossas primeiras experiências com a entidade [Personne] acima referida. Realizá-las-emos com a seguinte arquitetura:
 |
- em [7]: a base de dados que será gerada a partir das anotações da entidade [Personne], bem como de configurações adicionais efetuadas num ficheiro denominado [persistence.xml]
- em [5, 6]: uma camada JPA implementada pelo Hibernate
- em [4]: a entidade [Personne]
- em [3]: um programa de teste do tipo consola
Iremos realizar várias experiências:
- gerar o esquema da BD a partir de um script Ant e da ferramenta Hibernate Tools
- gerar a BD e inicializá-la com alguns dados
- utilizar a tabela BD e realizar as quatro operações básicas na tabela [personne] (inserção, atualização, eliminação, consulta)
As ferramentas necessárias são as seguintes:
- Eclipse e os seus plugins descritos no parágrafo 5.2.
- o projeto [hibernate-personnes-entites], que se encontra na pasta <exemplos>/hibernate/direct/pessoas-entidades
- os vários SGBD descritos nos anexos (parágrafo 5 e seguintes).
O projeto Eclipse é o seguinte:
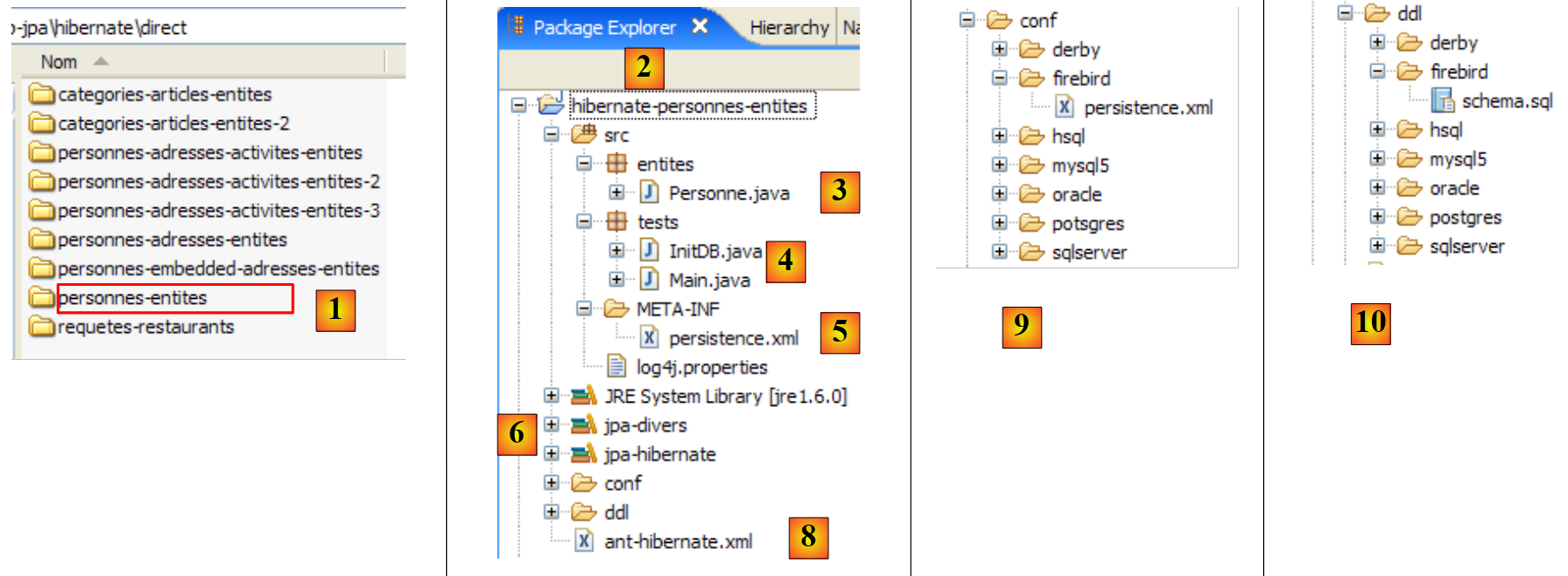 |
- em [1]: a pasta do projeto Eclipse
- em [2]: o projeto importado para o Eclipse (Ficheiro / Importar)
- em [3]: a entidade [Personne] objeto dos testes
- em [4]: os programas de teste
- em [5]: [persistence.xml] é o ficheiro de configuração da camada JPA
- em [6]: as bibliotecas utilizadas. Estas foram descritas no parágrafo 1.5.
- em [8]: um script ant que será utilizado para gerar a tabela associada à entidade [Personne]
- em [9]: os ficheiros [persistence.xml] para cada um dos SGBD utilizados
- em [10]: os esquemas da base de dados gerada para cada um dos SGBD utilizados
Vamos descrever estes elementos um a um.
2.1.4. A entidade [Personne] (2)
Introduzimos uma ligeira alteração à descrição anteriormente apresentada da entidade [Personne], bem como uma informação adicional:
package entites;
...
@SuppressWarnings({ "unused", "serial" })
@Entity
@Table(name="jpa01_personne")
public class Personne implements Serializable{
@Id
@Column(name = "ID", nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Column(name = "VERSION", nullable = false)
@Version
private int version;
@Column(name = "NOM", length = 30, nullable = false, unique = true)
private String nom;
@Column(name = "PRENOM", length = 30, nullable = false)
private String prenom;
@Column(name = "DATENAISSANCE", nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(name = "MARIE", nullable = false)
private boolean marie;
@Column(name = "NBENFANTS", nullable = false)
private int nbenfants;
// construtores
public Personne() {
}
public Personne(String nom, String prenom, Date datenaissance, boolean marie,
int nbenfants) {
....
}
// toString
public String toString() {
return String.format("[%d,%d,%s,%s,%s,%s,%d]", getId(), getVersion(),
getNom(), getPrenom(), new SimpleDateFormat("dd/MM/yyyy")
.format(getDatenaissance()), isMarie(), getNbenfants());
}
// getters e setters
...
}
- linha 7: atribuímos o nome [jpa01_personne] à tabela associada à entidade [Personne]. No documento, serão criadas várias tabelas num esquema sempre denominado jpa. No final deste tutorial, o esquema jpa conterá numerosas tabelas. Para que o leitor se oriente, as tabelas interligadas terão o mesmo prefixo jpaxx_.
- linha 45: um método [toString] para apresentar um objeto [Personne] na consola.
2.1.5. Configuração da camada de acesso aos dados
No projeto Eclipse acima, a configuração da camada JPA é assegurada pelo ficheiro [META-INF/persistence.xml]:
 |
Durante a execução, o ficheiro [META-INF/persistence.xml] é procurado no classpath da aplicação. No nosso projeto Eclipse, todo o conteúdo das pastas [/src] e [1] é copiado para as pastas [/bin] e [2]. Esta pasta faz parte do classpath do projeto. É por esta razão que o [META-INF/persistence.xml] será encontrado quando a camada JPA for configurada.
Por predefinição, o Eclipse não coloca os códigos-fonte na pasta [/src] do projeto, mas diretamente na própria pasta. Todos os nossos projetos Eclipse serão, por sua vez, configurados para que os códigos-fonte fiquem em [/src] e as classes compiladas em [/bin], tal como é mostrado no parágrafo 5.2.1.
Analisemos a configuração da camada JPA definida no ficheiro [persistence.xml] do nosso projeto:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provedor -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- classes persistentes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- registos SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- ligação JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
<property name="hibernate.connection.url" value="jdbc:mysql://localhost:3306/jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- criação automática do esquema -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialeto -->
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
<!-- propriedades DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
Para compreender esta configuração, temos de rever a arquitetura de acesso aos dados da nossa aplicação:
 |
- o ficheiro [persistence.xml] irá configurar as camadas [4, 5, 6]
- [4]: implementação do Hibernate de JPA
- [5]: o Hibernate acede à base de dados através de um conjunto de ligações. Um conjunto de ligações é uma reserva de ligações abertas com o SGBD. Um SGBD é acedido por vários utilizadores, embora, por razões de desempenho, não possa exceder um número limite N de ligações abertas em simultâneo. Um código bem escrito abre uma ligação ao SGBD durante o menor tempo possível: envia comandos ao SQL e encerra a ligação. Irá repetir este processo sempre que precisar de trabalhar com a base de dados. O custo de abrir e fechar uma ligação não é insignificante e é aqui que entra o conjunto de ligações. Este, no arranque da aplicação, abre N1 ligações com o SGBD. É a este pool que a aplicação solicitará uma ligação aberta quando precisar. Esta será devolvida ao pool assim que a aplicação deixar de precisar dela, de preferência o mais rapidamente possível. A ligação não é encerrada e permanece disponível para o utilizador seguinte. Um pool de ligações é, portanto, um sistema de partilha de ligações abertas.
- [6]: o controlador JDBC do SGBD utilizado
Agora, vamos ver como o ficheiro [persistence.xml] configura as camadas [4, 5, 6] acima referidas:
- linha 2: a baliza raiz do ficheiro XML é <persistence>.
- linha 3: <persistence-unit> serve para definir uma unidade de persistência. Podem existir várias unidades de persistência. Cada uma delas tem um nome (atributo name) e um tipo de transação (atributo transaction-type). A aplicação terá acesso à unidade de persistência através do seu nome, neste caso jpa. O tipo de transação RESOURCE_LOCAL indica que a aplicação gere ela própria as transações com o SGBD. Será esse o caso aqui. Quando a aplicação é executada num contentor EJB3, pode utilizar o serviço de transações deste. Neste caso, definirá-se transaction-type=JTA (Java Transaction API). JTA é o valor por predefinição quando o atributo transaction-type está ausente.
- linha 5: a baliza <provider> serve para definir uma classe que implementa a interface [javax.persistence.spi.PersistenceProvider], interface que permite à aplicação inicializar a camada de persistência. Como se utiliza uma implementação JPA / Hibernate, a classe aqui utilizada é uma classe do Hibernate.
- linha 6: a baliza <properties> introduz propriedades específicas do provider em particular que foi escolhido. Assim, dependendo de se ter escolhido o Hibernate, o Toplink, o Kodo, etc., teremos propriedades diferentes. As que se seguem são específicas do Hibernate.
- linha 8: solicita ao Hibernate que explore o classpath do projeto para encontrar as classes com a anotação @Entity, a fim de as gerir. As classes @Entity também podem ser declaradas através das tags <class>nom_de_la_classe</class>, diretamente abaixo da tag <persistence-unit>. É isso que faremos com o provider JPA / Toplink.
- As linhas 10-12, aqui colocadas em comentários, configuram os registos da consola do Hibernate:
- linha 10: para decidir se se devem ou não exibir os comandos SQL emitidos pelo Hibernate no SGBD. Isto é muito útil durante a fase de aprendizagem. Devido à ponte relacional/objeto, a aplicação trabalha com objetos persistentes aos quais aplica operações do tipo [persist, merge, remove]. É muito interessante saber quais são os comandos SQL efetivamente emitidos nessas operações. Ao analisá-las, aos poucos começa-se a adivinhar os comandos SQL que o Hibernate irá gerar quando se realiza determinada operação nos objetos persistentes, e a ponte relacional/objeto começa a ganhar consistência na mente.
- linha 11: as ordens SQL apresentadas na consola podem ser formatadas de forma elegante para facilitar a sua leitura
- linha 12: os comandos SQL apresentados serão, além disso, comentados
- as linhas 15-19 definem a camada JDBC (camada [6] na arquitetura):
- linha 15: a classe do controlador JDBC do SGBD, neste caso MySQL5
- linha 16: o URL da base de dados utilizada
- linhas 17 e 18: o utilizador da ligação e a sua palavra-passe
- Utilizamos aqui elementos explicados nos anexos, no parágrafo 5.5. O leitor é convidado a ler esta secção sobre o MySQL5.
- linha 22: O Hibernate precisa de saber qual é o SGBD com que está a trabalhar. Com efeito, todos os SGBD têm extensões SQL próprias, uma forma específica de gerir a geração automática dos valores de uma chave primária, ... o que faz com que o Hibernate precise de conhecer o SGBD com o qual está a trabalhar, para lhe enviar as ordens SQL que este compreenderá. O [MySQL5InnoDBDialect] designa o SGBD MySQL5 com tabelas do tipo InnoDB que suportam transações.
- as linhas 24-28 configuram o conjunto de ligações c3p0 (camada [5] na arquitetura):
- linhas 24 e 25: o número mínimo (padrão 3) e máximo de ligações (padrão 15) no conjunto. O número inicial de ligações por predefinição é 3.
- linha 26: tempo máximo, em milissegundos, de espera por um pedido de ligação por parte do cliente. Passado este prazo, o c3p0 devolverá uma exceção.
- linha 27: para aceder à BD, o Hibernate utiliza ordens SQL preparadas (PreparedStatement) que o c3p0 pode armazenar em cache. Isto significa que, se a aplicação solicitar pela segunda vez uma ordem SQL já preparada e em cache, esta não precisará de ser preparada (a preparação de uma ordem SQL tem um custo) e será utilizada a que se encontra em cache. Aqui, indica-se o número máximo de ordens SQL preparadas que a cache pode conter, considerando todas as ligações (uma ordem SQL preparada pertence a uma ligação).
- linha 28: frequência de verificação, em milissegundos, da validade das ligações. Uma ligação do pool pode tornar-se inválida por várias razões (o controlador JDBC invalida a ligação por esta estar a demorar demasiado tempo, o controlador JDBC apresenta «bugs», etc.).
- linha 20: aqui solicita-se que, aquando da inicialização da unidade de persistência, seja gerada a base de dados de imagem dos objetos @Entity. O Hibernate dispõe agora de todas as ferramentas para emitir os comandos SQL de geração das tabelas da base de dados:
- a configuração dos objetos @Entity permite-lhe identificar as tabelas a gerar
- as linhas 15-18 e 24-28 permitem-lhe estabelecer uma ligação com o SGBD
- a linha 22 permite-lhe saber qual o dialeto SQL a utilizar para gerar as tabelas
Assim, o ficheiro [persistence.xml] aqui utilizado recria uma nova base de dados a cada nova execução da aplicação. As tabelas são recriadas (create table) após terem sido eliminadas (drop table), caso já existissem. Note-se que isto não deve, obviamente, ser feito numa base de dados em produção...
Os testes demonstraram que a fase de eliminação/criação das tabelas podia falhar. Foi nomeadamente o caso quando, para um mesmo teste, se passava de uma camada JPA/Hibernate para uma camada JPA/Toplink ou vice-versa. A partir dos mesmos objetos @Entity, as duas implementações não geram exatamente as mesmas tabelas, geradores, sequências, etc., e, por vezes, a fase de eliminação/criação falhava, obrigando-nos a eliminar as tabelas manualmente. A secção «Anexos», parágrafo 5 e seguintes, descreve as aplicações que podem ser utilizadas para realizar este trabalho manualmente. Note-se que a implementação JPA/Hibernate revelou-se a mais eficaz nesta fase de criação inicial do conteúdo da base de dados: foram raras as falhas do sistema.
As ferramentas utilizadas pela camada JPA / Hibernate encontram-se na biblioteca [jpa-hibernate], apresentada no parágrafo 1.5, página 8. Os controladores JDBC necessários para aceder aos SGBD encontram-se na biblioteca [jpa-divers]. Estas duas bibliotecas foram incluídas no classpath do projeto aqui analisado. Recordamos abaixo o seu conteúdo:
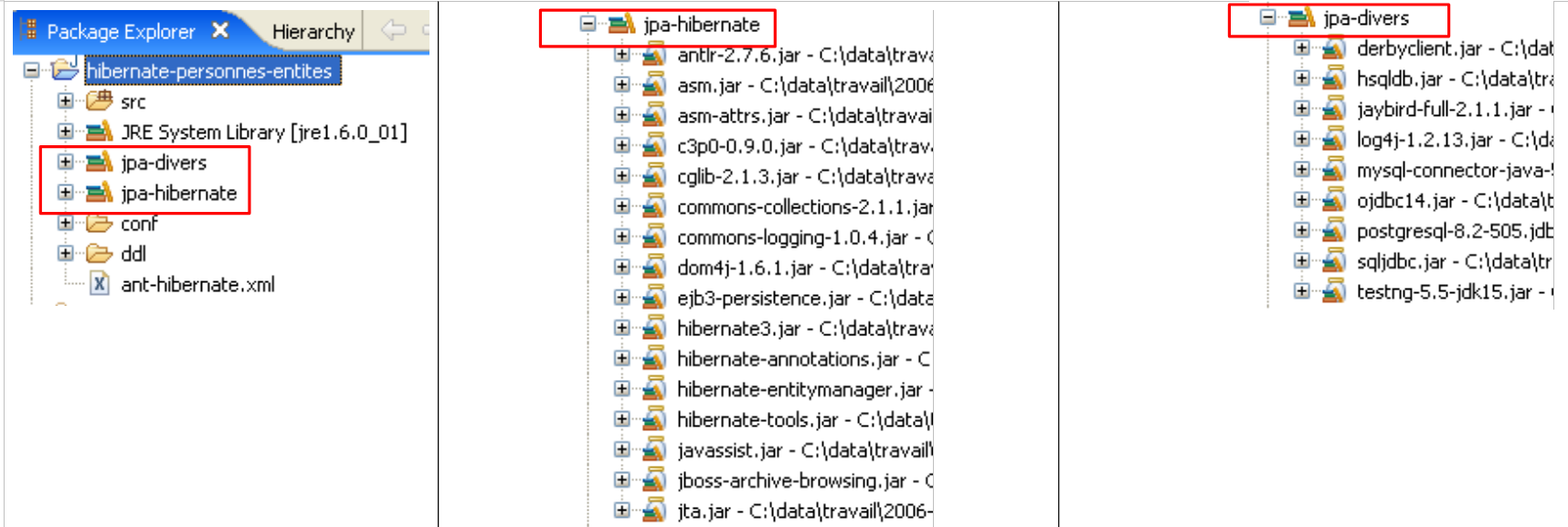 |
2.1.6. Geração da base de dados com um script Ant
Como acabámos de ver, o Hibernate fornece ferramentas para gerar a base de dados de imagem dos objetos @Entity da aplicação. O Hibernate pode:
- gerar o ficheiro de texto com as ordens SQL que criam a base de dados. Nesse caso, é utilizado apenas o dialeto definido em [persistence.xml].
- criar as tabelas correspondentes aos objetos @Entity na base de dados de destino definida no ficheiro [persistence.xml]. Neste caso, é utilizado o ficheiro [persistence.xml] na íntegra.
Vamos apresentar um script Ant capaz de gerar o esquema da base de dados, com as tabelas dos objetos @Entity. Este script não é da minha autoria: retoma um script análogo do [ref1]. O Ant (Another Neat Tool) é uma ferramenta de execução em lote de tarefas Java. Os scripts Ant não são fáceis de compreender para um principiante. Utilizaremos apenas um, aquele que vamos comentar agora:
 |
- em [1]: a estrutura de diretórios dos exemplos deste tutorial.
- em [2]: a pasta [personnes-entites] do projeto Eclipse atualmente em análise
- em [3]: a pasta <lib> que contém as cinco bibliotecas JAR definidas no parágrafo 1.5.
- em [4]: o arquivo [hibernate-tools.jar] necessário para uma das tarefas do script [ant-hibernate.xml] que vamos analisar.
 |
- em [5]: o projeto Eclipse e o script [ant-hibernate.xml]
- em [6]: a pasta [src] do projeto
O script [ant-hibernate.xml] [5] irá utilizar os ficheiros JAR da pasta <lib> [3], nomeadamente o arquivo [hibernate-tools.jar] [4] da pasta [lib/hibernate]. Reproduzimos a estrutura de pastas para que o leitor perceba que, para encontrar a pasta [lib] a partir da pasta [personnes-entites] [2] do script [ant-hibernate.xml], é necessário seguir o caminho: ../../../lib.
Analisemos o script [ant-hibernate.xml]:
<project name="jpa-hibernate" default="compile" basedir=".">
<!-- nome do projeto e versão -->
<property name="proj.name" value="jpa-hibernate" />
<property name="proj.shortname" value="jpa-hibernate" />
<property name="version" value="1.0" />
<!-- Propriedades globais -->
<property name="src.java.dir" value="src" />
<property name="lib.dir" value="../../../lib" />
<property name="build.dir" value="bin" />
<!-- o Classpath do projeto -->
<path id="project.classpath">
<fileset dir="${lib.dir}">
<include name="**/*.jar" />
</fileset>
</path>
<!-- os ficheiros de configuração que devem estar no classpath-->
<patternset id="conf">
<include name="**/*.xml" />
<include name="**/*.properties" />
</patternset>
<!-- Limpeza do projeto -->
<target name="clean" description="Nettoyer le projet">
<delete dir="${build.dir}" />
<mkdir dir="${build.dir}" />
</target>
<!-- Compilação do projeto -->
<target name="compile" depends="clean">
<javac srcdir="${src.java.dir}" destdir="${build.dir}" classpathref="project.classpath" />
</target>
<!-- Copiar os ficheiros de configuração para o classpath -->
<target name="copyconf">
<mkdir dir="${build.dir}" />
<copy todir="${build.dir}">
<fileset dir="${src.java.dir}">
<patternset refid="conf" />
</fileset>
</copy>
</target>
<!-- Ferramentas do Hibernate -->
<taskdef name="hibernatetool" classname="org.hibernate.tool.ant.HibernateToolTask" classpathref="project.classpath" />
<!-- Gerar o DDL da base de dados -->
<target name="DDL" depends="compile, copyconf" description="Génération DDL base">
<hibernatetool destdir="${basedir}">
<classpath path="${build.dir}" />
<!-- Utilizar META-INF/persistence.xml -->
<jpaconfiguration />
<!-- exportar -->
<hbm2ddl drop="true" create="true" export="false" outputfilename="ddl/schema.sql" delimiter=";" format="true" />
</hibernatetool>
</target>
<!-- Gerar a base -->
<target name="BD" depends="compile, copyconf" description="Génération BD">
<hibernatetool destdir="${basedir}">
<classpath path="${build.dir}" />
<!-- Utilizar META-INF/persistence.xml -->
<jpaconfiguration />
<!-- exportar -->
<hbm2ddl drop="true" create="true" export="true" outputfilename="ddl/schema.sql" delimiter=";" format="true" />
</hibernatetool>
</target>
</project>
- linha 1: o projeto [ant] chama-se «jpa-hibernate». Reúne um conjunto de tarefas, uma das quais é a tarefa predefinida: neste caso, a tarefa denominada «compile». É chamado um script ant para executar uma tarefa T. Se esta não for especificada, é executada a tarefa predefinida. basedir="." indica que, para todos os caminhos relativos encontrados no script, o ponto de partida é a pasta onde se encontra o script ant, neste caso a pasta <exemplos>/hibernate/direct/pessoas-entidades.
- linhas 3-11: definem variáveis de script com a baliza <property name="nomVariable" value="valeurVariable"/>. A variável pode depois ser utilizada no script com a notação ${nomVariable}. Os nomes podem ser quaisquer. Vamos analisar as variáveis definidas nas linhas 9-11:
- linha 9: define uma variável chamada «src.java.dir» (o nome é livre) que, no resto do script, irá designar a pasta que contém os códigos-fonte Java. O seu valor é «src», um caminho relativo à pasta designada pelo atributo basedir (linha 1). Trata-se, portanto, do caminho «./src», em que «.» designa aqui a pasta <exemplos>/hibernate/direct/pessoas-entidades. É precisamente na pasta <pessoas-entidades>/src que se encontram os códigos-fonte Java (ver [6] acima).
- linha 10: define uma variável denominada «lib.dir» que, no decorrer do script, irá designar a pasta que contém os ficheiros JAR necessários às tarefas Java do script. O seu valor ../../../lib refere-se à pasta <exemplos>/lib (ver [3] acima).
- linha 11: define uma variável chamada "build.dir" que, no resto do script, irá indicar a pasta onde devem ser gerados os ficheiros .class resultantes da compilação dos ficheiros .java. O seu valor "bin" indica a pasta <pessoas-entidades>/bin. Já explicámos que, no projeto Eclipse analisado, a pasta <bin> era aquela onde eram gerados os ficheiros .class. O Ant fará o mesmo.
- linhas 14-18: a baliza <path> serve para definir elementos do classpath que as tarefas ant deverão utilizar. Aqui, o caminho «project.classpath» (o nome é livre) reúne todos os ficheiros .jar da árvore de pastas <exemples>/lib.
- linhas 21-24: a baliza <patternset> serve para designar um conjunto de ficheiros através de padrões de nomes. Aqui, o patternset denominado «conf» designa todos os ficheiros com a extensão .xml ou .properties. Este patternset servirá para designar os ficheiros .xml e .properties da pasta <src> (persistence.xml, log4j.properties) (ver [6]), que são ficheiros de configuração da aplicação. No momento da execução de determinadas tarefas, estes ficheiros devem ser copiados para a pasta <bin> para que fiquem no classpath do projeto. Utilizar-se-á então o patternset conf para os designar.
- linhas 27-30: a baliza <target> designa uma tarefa do script. É a primeira que encontramos. Tudo o que precedeu diz respeito à configuração do ambiente de execução do script ant. A tarefa chama-se «clean». É executada em duas etapas: a pasta <bin> é eliminada (linha 28) para, em seguida, ser recriada (linha 29).
- linhas 33-35: a tarefa «compile», que é a tarefa por predefinição do script (linha 1). Depende (atributo «depends») da tarefa «clean». Isto significa que, antes de executar a tarefa «compile», o ant tem de executar a tarefa «clean», o c.a.d, para limpar a pasta <bin>. O objetivo da tarefa «compile» é, neste caso, compilar os códigos-fonte Java da pasta <src>.
- linha 34: chamada do compilador Java com três parâmetros:
- srcdir: a pasta que contém os códigos-fonte Java, neste caso a pasta <src>
- destdir: a pasta onde devem ser guardados os ficheiros .class gerados, neste caso a pasta <bin>
- classpathref: o classpath a utilizar para a compilação, neste caso todos os ficheiros jar da árvore de pastas <lib>
- (continuação)
- linhas 38-45: a tarefa «copyconf», cujo objetivo é copiar para a pasta <bin> todos os ficheiros .xml e .properties da pasta <src>.
- linha 48: definição de uma tarefa utilizando a baliza <taskdef>. Esta tarefa destina-se a ser reutilizada noutras partes do script. Trata-se de uma facilidade de codificação. Como a tarefa é utilizada em vários pontos do script, define-se uma única vez com a baliza <taskdef> e, posteriormente, reutiliza-se através do seu nome, sempre que necessário.
- A tarefa chama-se hibernatetool (atributo name).
- A sua classe é definida pelo atributo classname. Neste caso, a classe indicada será encontrada no arquivo [hibernate-tools.jar], de que já falámos.
- O atributo classpathref indica ao ant onde procurar a classe anterior
- (continuação)
- as linhas 51-60 dizem respeito à tarefa que nos interessa aqui, a da geração do esquema da base de dados de imagem dos objetos @Entity do nosso projeto Eclipse.
- linha 51: a tarefa chama-se DDL (como Data Definition Language, o SQL associado à criação de objetos de uma base de dados). Depende das tarefas «compile» e «copyconf», por esta ordem. A tarefa DDL irá, portanto, provocar, por ordem, a execução das tarefas «clean», «compile» e «copyconf». Quando a tarefa DDL é iniciada, a pasta <bin> contém os ficheiros .class das fontes .java, nomeadamente dos objetos @Entity, bem como o ficheiro [META-INF/persistence.xml] que configura a camada JPA / Hibernate.
- linhas 53-59: a tarefa [hibernatetool] definida na linha 48 é chamada. São-lhe passados vários parâmetros, para além dos já definidos na linha 48:
- linha 53: a pasta de saída dos resultados produzidos pela tarefa será a pasta atual.
- linha 54: o diretório <bin> será utilizado pela tarefa classpath
- linha 56: indica à tarefa [hibernatetool] como pode identificar o seu ambiente de execução: a baliza <jpaconfiguration/> indica-lhe que se encontra num ambiente JPA e que, por conseguinte, deve utilizar o ficheiro [META-INF/persistence.xml] que encontrará aqui no seu classpath.
- a linha 58 define as condições de geração da base de dados: drop=true indica que devem ser emitidos comandos SQL drop table antes da criação das tabelas; create=true indica que o ficheiro de texto com os comandos SQL para a criação da base de dados deve ser criado; outputfilename indica o nome desse ficheiro SQL — neste caso, schema.sql — na pasta <ddl> do projeto Eclipse; export=false indica que os comandos SQL gerados não devem ser executados numa ligação ao SGBD. Este ponto é importante: implica que, para executar a tarefa, o SGBD de destino não precisa de ser iniciado. delimiter define o caractere que separa duas ordens SQL no esquema gerado; format=true solicita que seja aplicada uma formatação básica ao texto gerado.
- as linhas 51-60 dizem respeito à tarefa que nos interessa aqui, a da geração do esquema da base de dados de imagem dos objetos @Entity do nosso projeto Eclipse.
- (continuação)
- as linhas 63-72 definem a tarefa denominada BD. É idêntica à tarefa anterior DDL, com a diferença de que, desta vez, gera a base de dados (export="true" na linha 70). A tarefa estabelece uma ligação à tarefa SGBD com as informações encontradas na tarefa [persistence.xml], para nela executar o esquema SQL e gerar a base de dados. Para executar a tarefa BD, é necessário, portanto, que a tarefa SGBD tenha sido iniciada.
2.1.7. Execução da tarefa antes da tarefa DDL
Para executar o script [ant-hibernate.xml], é necessário, em primeiro lugar, efetuar algumas configurações no Eclipse.
 |
- em [1]: selecionar [External Tools]
- em [2]: criar uma nova configuração ant
 |
- em [3]: atribuir um nome à configuração ant
- em [5]: selecionar o script ant utilizando o botão [4]
- em [6]: aplicar as alterações
- em [7]: foi criada a configuração ant DDL
 |
 |
- em [8]: no separador JRE, define-se o JRE a utilizar. O campo [10] é normalmente preenchido automaticamente com o JRE utilizado pelo Eclipse. Por isso, normalmente não é necessário fazer nada neste painel. No entanto, deparei-me com um caso em que o script ant não conseguia localizar o compilador <javac>. Este não se encontra num JRE (Java Runtime Environment), mas sim num JDK (Java Development Kit). A ferramenta ant do Eclipse localiza este compilador através da variável de ambiente JAVA_HOME (Iniciar / Painel de Configuração / Desempenho e Manutenção / Sistema / separador Avançado / botão Variáveis de ambiente) [A]. Se esta variável não tiver sido definida, é possível permitir que o ant localize o compilador <javac> definindo no [10], não um JRE, mas sim um JDK. Este está disponível na mesma pasta que o JRE e o [B]. Utilizaremos o botão [9] para declarar o JDK entre os JRE disponíveis e o [C], para que possamos, posteriormente, selecioná-lo no [10].
- em [12]: no separador [Targets], seleciona-se a tarefa DDL. Assim, a configuração ant, a que chamámos DDL [7], corresponderá à execução da tarefa denominada DDL [12], que, como sabemos, gera o esquema DDL da base de dados de imagens dos objetos @Entity da aplicação.
 |
- em [13]: valida-se a configuração
- em [14]: executa-se
Na vista [console], obtêm-se os registos da execução da tarefa ant DDL:
Buildfile: C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\ant-hibernate.xml
clean:
[delete] Deleting directory C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
[mkdir] Created dir: C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
compile:
[javac] Compiling 3 source files to C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
copyconf:
[copy] Copying 2 files to C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
DDL:
[hibernatetool] Executing Hibernate Tool with a JPA Configuration
[hibernatetool] 1. task: hbm2ddl (Generates database schema)
[hibernatetool] drop table if exists jpa01_personne;
[hibernatetool] create table jpa01_personne (
[hibernatetool] ID integer not null auto_increment,
[hibernatetool] VERSION integer not null,
[hibernatetool] NOM varchar(30) not null unique,
[hibernatetool] PRENOM varchar(30) not null,
[hibernatetool] DATENAISSANCE date not null,
[hibernatetool] MARIE bit not null,
[hibernatetool] NBENFANTS integer not null,
[hibernatetool] primary key (ID)
[hibernatetool] ) ENGINE=InnoDB;
BUILD SUCCESSFUL
Total time: 5 seconds
- lembramo-nos de que a tarefa DDL tem o nome [hibernatetool] (linha 10) e que depende das tarefas clean (linha 2), compile (linha 5) e copyconf (linha 7).
- linha 10: a tarefa [hibernatetool] utiliza o ficheiro [persistence.xml] de uma configuração JPA
- linha 11: a tarefa [hbm2ddl] irá gerar o esquema DDL da base de dados
- linhas 12-22: o esquema DDL da base de dados
Recordemos que solicitámos à tarefa [hbm2ddl] que gerasse o esquema DDL num local específico:
<hbm2ddl drop="true" create="true" export="true" outputfilename="ddl/schema.sql" delimiter=";" format="true" />
- linha 74: o esquema deve ser gerado no ficheiro ddl/schema.sql. Vamos verificar:
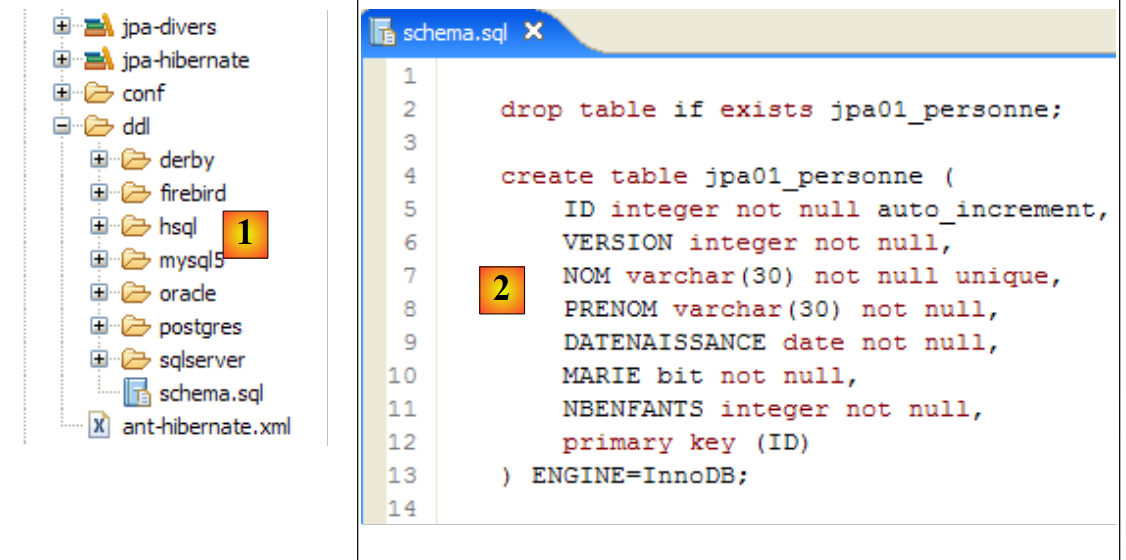 |
- em [1]: o ficheiro ddl/schema.sql está efetivamente presente (execute F5 para atualizar a árvore de diretórios)
- em [2]: o seu conteúdo. Trata-se do esquema de uma base de dados MySQL5. O ficheiro [persistence.xml] de configuração da camada JPA especificava, de facto, um SGBD MySQL5 (linha 8 abaixo):
<!-- ligação JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
...
<!-- criação automática do esquema -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialeto -->
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
<!-- propriedades DataSource c3p0 -->
...
Analisemos a ponte objeto/relacional que foi estabelecida aqui, examinando a configuração do objeto @Entity Pessoa e o esquema DDL gerado:
 |
 |
É importante destacar alguns pontos:
- A1-B1: o nome da tabela especificado em A1 é, de facto, o mesmo utilizado em B1. Deve-se notar que o drop precede o create em B1.
- A2-B2: mostra o modo de geração da chave primária. O modo AUTO especificado em A2 resultou no atributo autoincrement específico de MySQL5. O modo de geração da chave primária é, na maioria das vezes, específico do SGBD.
- A3-B3: apresenta o tipo SQL, um bit específico de MySQL5, para representar um tipo boolean em Java.
Vamos repetir este teste com outro SGBD:
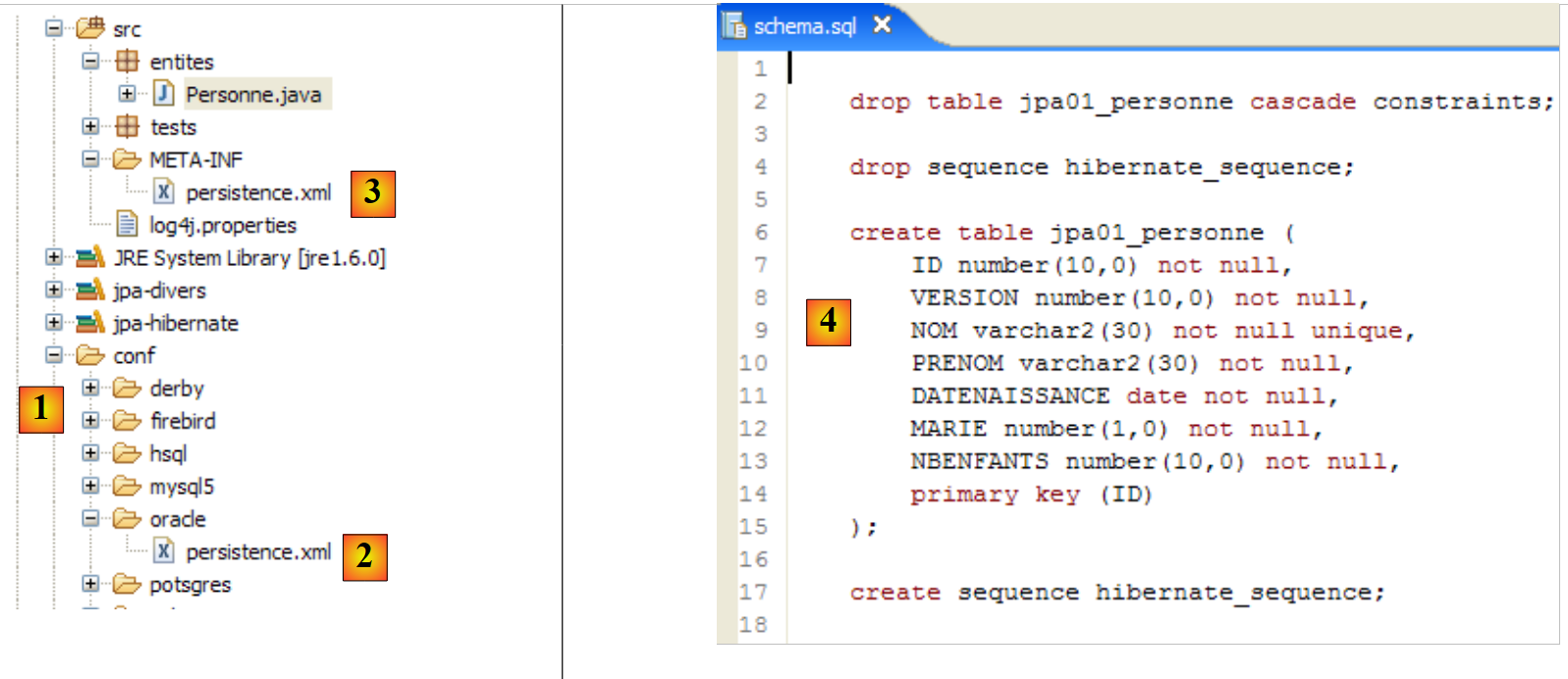 |
- A pasta [conf] [1] contém os ficheiros [persistence.xml] para vários SGBD. Tomemos como exemplo o ficheiro da Oracle [2] e coloquemo-lo na pasta [META-INF] [3], substituindo o anterior. O seu conteúdo é o seguinte:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provedor -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Classes persistentes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- registos SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- ligação JDBC -->
<property name="hibernate.connection.driver_class" value="oracle.jdbc.OracleDriver" />
<property name="hibernate.connection.url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- criação automática do esquema -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialeto -->
<property name="hibernate.dialect" value="org.hibernate.dialect.OracleDialect" />
<!-- propriedades DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
Recomenda-se ao leitor que consulte, nos anexos, a secção sobre a Oracle (parágrafo 5.7), nomeadamente para compreender a configuração JDBC.
Apenas a linha 25 é realmente importante aqui: indica-se ao Hibernate que, a partir de agora, o SGBD é um SGBD Oracle. A execução da tarefa ant DDL produz o resultado [4] acima. Note-se que o esquema Oracle é diferente do esquema MySQL5. Este é um ponto forte do JPA: o programador não precisa de se preocupar com estes detalhes, o que aumenta consideravelmente a portabilidade dos seus desenvolvimentos.
2.1.8. Execução da tarefa ant BD
Talvez nos lembremos que a tarefa ant, denominada BD, faz o mesmo que a tarefa ant DDL, mas gera adicionalmente a base de dados. Por isso, é necessário que a tarefa SGBD seja executada. Vamos considerar o caso das tarefas SGBD e MySQL5 e convidamos o leitor a copiar o ficheiro [conf/mysql5/persistence.xml] para a pasta [src/META-INF]. Para verificar o funcionamento da tarefa, vamos utilizar o plugin SQL Explorer (ver parágrafo 5.2.6) para verificar o estado do ficheiro jpa BD antes e depois da execução da tarefa ant BD.
Em primeiro lugar, temos de criar uma nova configuração ant para executar a tarefa BD. Sugere-se ao leitor que siga o procedimento descrito para a configuração anterior DDL no parágrafo 2.1.7. A nova configuração ant passará a chamar-se BD:
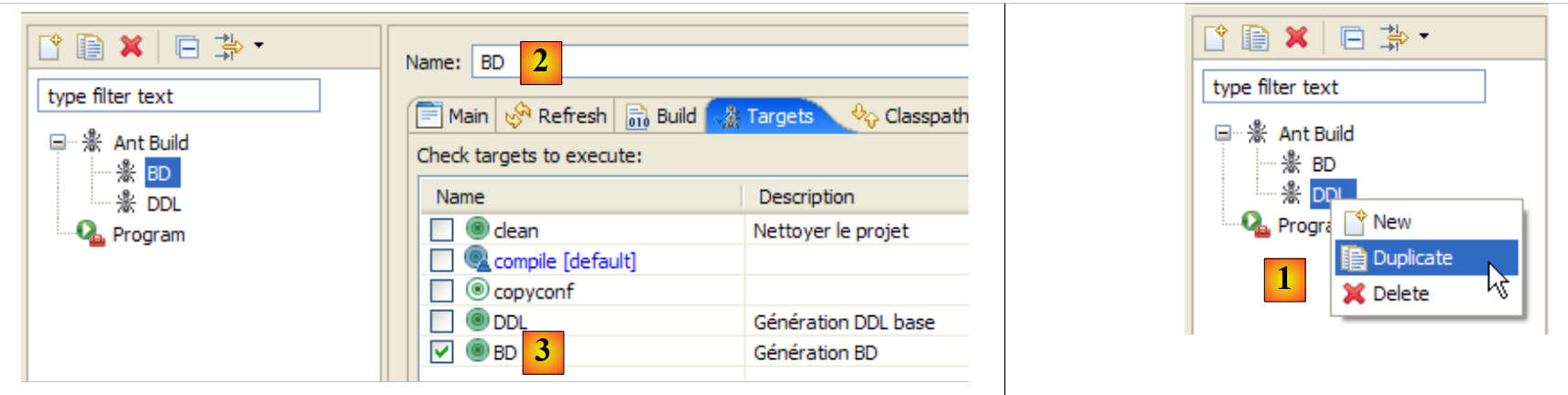 |
- em [1]: duplica-se a configuração anterior denominada DDL
- para [2]: a nova configuração passa a chamar-se BD. Esta executa a tarefa ant BD [3], que gera fisicamente a base de dados.
- Feito isto, execute o SGBD e o MySQL5 (parágrafo 5.5).
Utilizamos agora o plugin SQL Explorer para explorar as bases de dados geridas pelo SGBD. O leitor deve, previamente, familiarizar-se com este plugin, se necessário (ver parágrafo 5.2.6).
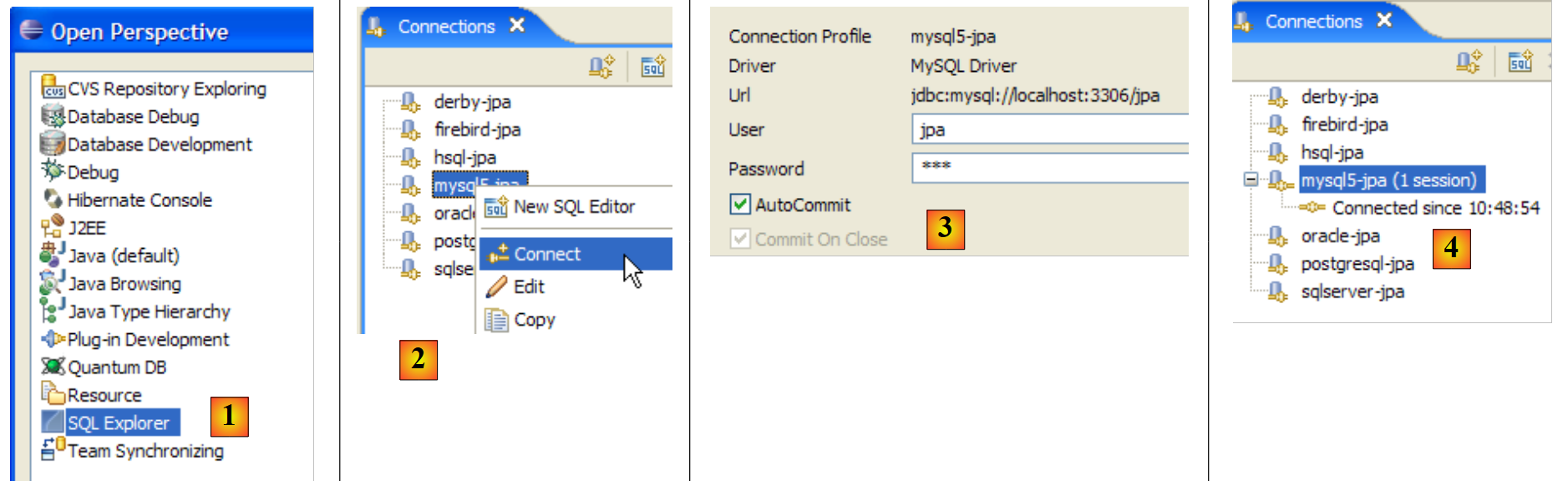 |
- [1]: abre-se a perspetiva SQL Explorer [Window / Open Perspective / Other]
- [2]: cria-se, se necessário, uma ligação [mysql5-jpa] (ver parágrafo 5.5.5, página 252) e abre-se a mesma
- [3]: efetua-se o login com jpa / jpa
- [4]: está-se ligado a MySQL5.
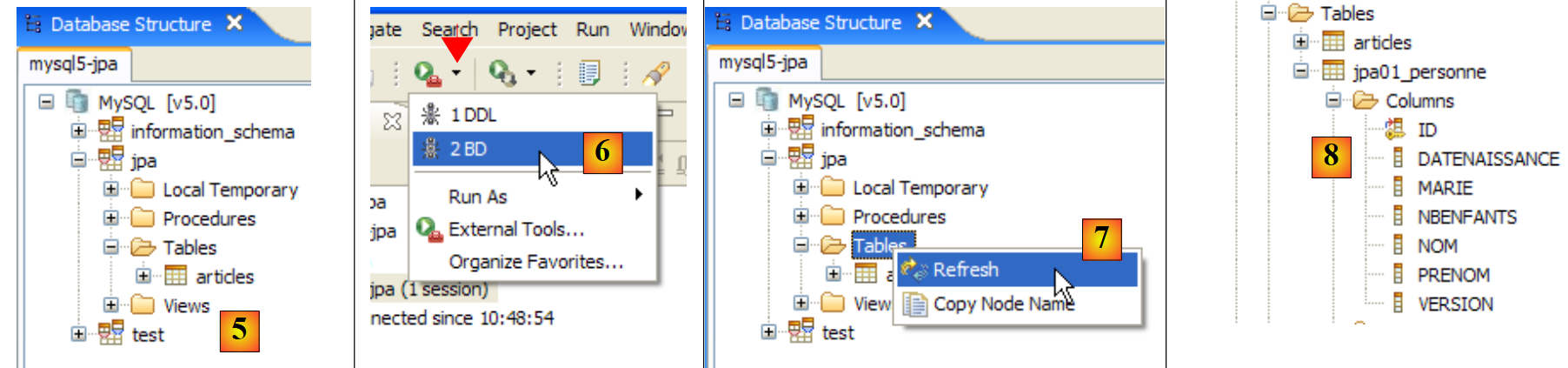 |
- em [5]: o BD jpa tem apenas uma tabela: [articles]
- em [6]: iniciamos a execução da tarefa ant BD. Como estamos na perspetiva [SQL Explorer], não vemos a vista [Console], que nos mostra os registos da tarefa. É possível exibir esta vista [Window / Show View / ...] ou regressar à perspetiva Java [Window / Open Perspective / ...].
- em [7]: assim que a tarefa ant BD estiver concluída, regresse, se necessário, à perspetiva [SQL Explorer] e atualize a árvore da BD jpa.
- em [8]: é possível ver a tabela [jpa01_personne] que foi criada.
O leitor é convidado a repetir esta geração de BD com outros SGBD. O procedimento a seguir é o seguinte:
- copiar o ficheiro [conf/<sgbd>/persistence.xml] para a pasta [src/META-INF], em que <sgbd> é o SGBD testado
- executar <sgbd> seguindo as instruções constantes dos anexos relativas a este
- na perspetiva SQL Explorer, criar uma ligação a <sgbd>. Isto também é explicado nos anexos para cada um dos SGBD
- repita os testes anteriores
Chegados a este ponto, temos alguns conhecimentos adquiridos:
- compreendemos melhor o conceito de ponte objeto-relacional. Neste caso, foi implementada pelo Hibernate. Mais tarde, utilizaremos o Toplink.
- sabemos que esta ponte objeto/relacional é configurada em dois locais:
- nos objetos @Entity, onde se indicam as ligações entre os campos dos objetos e as colunas das tabelas do BD
- no [META-INF/persistence.xml], onde fornecemos à implementação JPA informações sobre os dois elementos da ponte objeto/relacional: os objetos @Entity (objeto) e a base de dados (relacional).
- Criámos duas tarefas Ant, denominadas DDL e BD, que nos permitem criar a base de dados a partir da configuração anterior, antes mesmo de escrever qualquer código Java.
Agora que a camada JPA da nossa aplicação está corretamente configurada, podemos começar a explorar o API e o JPA com código Java.
2.1.9. O contexto de persistência de uma aplicação
Vamos explicar um pouco o ambiente de execução de um cliente JPA:
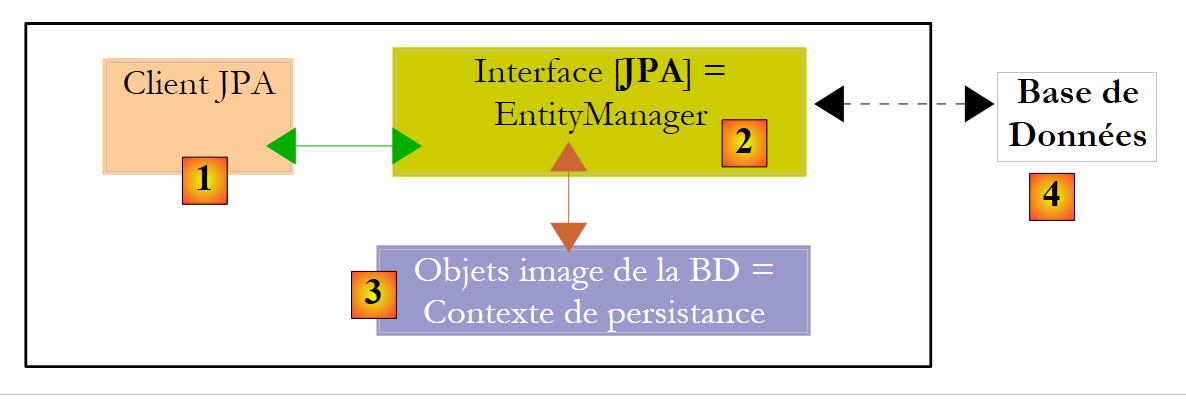 |
Sabemos que a camada JPA [2] cria uma ponte objeto [3] / relacional [4]. Denomina-se «contexto de persistência» o conjunto de objetos geridos pela camada JPA no âmbito desta ponte objeto/relacional. Para aceder aos dados do contexto de persistência, um cliente JPA [1] deve passar pela camada JPA [2]:
- pode criar um objeto e solicitar à camada JPA que o torne persistente. O objeto passa então a fazer parte do contexto de persistência.
- pode solicitar à camada [JPA] uma referência a um objeto persistente existente.
- pode modificar um objeto persistente obtido da camada JPA.
- pode solicitar à camada JPA que elimine um objeto do contexto de persistência.
A camada JPA apresenta ao cliente uma interface denominada [EntityManager] que, tal como o próprio nome indica, permite gerir os objetos @Entity do contexto de persistência. Apresentamos abaixo os principais métodos desta interface:
coloca entity no contexto de persistência | |
retira entity do contexto de persistência | |
funde um objeto entity do cliente, não gerido pelo contexto de persistência, com o objeto entity do contexto de persistência que possui a mesma chave primária. O resultado obtido é o objeto entity do contexto de persistência. | |
insere, no contexto de persistência, um objeto pesquisado na base de através da sua chave primária. O tipo T do objeto permite que a camada JPA saiba qual a tabela a consultar. O objeto persistente assim criado é devolvido ao cliente. | |
cria um objeto Query a partir de uma consulta JPQL (Java Persistence Query Language). Uma consulta JPQL é análoga a uma consulta SQL, com a diferença de que se consultam objetos em vez de tabelas. | |
método semelhante ao anterior, com a diferença de que queryText é, uma ordem SQL e não JPQL. | |
método idêntico ao de createQuery, com a diferença de que a ordem JPQL queryText foi foi externalizada para um ficheiro de configuração e associada a um nome. É esse nome que constitui o parâmetro do método. |
Um objeto EntityManager tem um ciclo de vida que não é necessariamente o da aplicação. Tem um início e um fim. Assim, um cliente JPA pode trabalhar sucessivamente com diferentes objetos EntityManager. O contexto de persistência associado a um EntityManager tem o mesmo ciclo de vida que este. São indissociáveis um do outro. Quando um objeto EntityManager é encerrado, o seu contexto de persistência é, se necessário, sincronizado com a base de dados e, em seguida, deixa de existir. É necessário criar um novo EntityManager para voltar a ter um contexto de persistência.
O cliente JPA pode criar um EntityManager e, consequentemente, um contexto de persistência com a seguinte instrução:
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
- O javax.persistence.Persistence é uma classe estática que permite obter uma fábrica (factory) de objetos EntityManager. Esta fábrica está associada a uma unidade de persistência específica. Recorde-se que o ficheiro de configuração [META-INF/persistence.xml] permite definir unidades de persistência e que estas têm um nome:
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
No exemplo acima, a unidade de persistência chama-se jpa. Juntamente com ela, vem toda uma configuração que lhe é própria, nomeadamente o SGBD com o qual trabalha. A instrução [Persistence.createEntityManagerFactory("jpa")] cria uma fábrica de objetos do tipo EntityManagerFactory capaz de fornecer objetos EntityManager destinados a gerir contextos de persistência associados à unidade de persistência denominada jpa. A obtenção de um objeto EntityManager e, consequentemente, de um contexto de persistência, é feita a partir do objeto EntityManagerFactory da seguinte forma:
Os seguintes métodos da interface [EntityManager] permitem gerir o ciclo de vida do contexto de persistência:
o contexto de persistência é encerrado. Força a sincronização do contexto de persistência com a base de dados:
| |
O contexto de persistência é esvaziado de todos os seus objetos, mas não é encerrado. | |
o contexto de persistência é sincronizado com a base de dados da forma descrita para close() |
O cliente JPA pode forçar a sincronização do contexto de persistência com a base de dados através do método [EntityManager].flush anterior. A sincronização pode ser explícita ou implícita. No primeiro caso, cabe ao cliente executar as operações flush quando pretender efetuar sincronizações; caso contrário, estas são realizadas em determinados momentos que iremos especificar. O modo de sincronização é gerido pelos seguintes métodos da interface [EntityManager]:
Existem dois valores possíveis para flushmode: FlushModeType.AUTO (padrão): a sincronização ocorre antes de cada consulta SELECT efetuada na base de dados. FlushModeType.COMMIT: a sincronização só ocorre no final das transações na base de dados. | |
define o modo atual de sincronização |
Resumindo. No modo FlushModeType.AUTO, que é o modo por predefinição, o contexto de persistência será sincronizado com a base de dados nos seguintes momentos:
- antes de cada operação SELECT, com base
- no final de uma transação na base
- na sequência de uma operação flush ou close no contexto de persistência
No modo FlushModeType.COMMIT, o procedimento é idêntico, exceto no que diz respeito à operação 1, que não ocorre. O modo normal de interação com a camada JPA é um modo transacional. O cliente realiza várias operações no contexto de persistência, no âmbito de uma transação. Neste caso, os momentos de sincronização do contexto de persistência com a base de dados correspondem aos casos 1 e 2 acima referidos no modo AUTO, e apenas ao caso 2 no modo COMMIT.
Concluímos com o API da interface Query, interface que permite emitir ordens JPQL no contexto de persistência ou ordens SQL diretamente na base de dados para recuperar dados. A interface Query é a seguinte:
 |
Iremos utilizar os métodos 1 a 4 acima referidos:
- 1 - o método getResultList executa um SELECT que devolve vários objetos. Estes serão obtidos num objeto List. Este objeto é uma interface. Esta interface disponibiliza um objeto Iterator que permite percorrer os elementos da lista L da seguinte forma:
Iterator iterator = L.iterator();
while (iterator.hasNext()) {
// processar o objeto iterator.next() que representa o elemento atual da lista
...
}
A lista L também pode ser explorada com um for:
for (Object o : L) {
// utilizar o objeto o
}
- 2 - o método getSingleResult executa um comando JPQL / SQL SELECT que devolve um único objeto.
- 3 - O método executeUpdate executa uma ordem SQL de atualização ou eliminação e devolve o número de linhas afetadas pela operação.
- 4 - O método setParameter(String, Object) permite atribuir um valor a um parâmetro nomeado de uma ordem JPQL configurada
- 5 - o método setParameter(int, Object), mas o parâmetro não é designado pelo seu nome, mas sim pela sua posição na ordem JPQL.
2.1.10. Um primeiro cliente JPA
Voltemos a uma perspetiva Java do projeto:
 |
Já sabemos praticamente tudo sobre este projeto, exceto o conteúdo da pasta [src/tests], que vamos agora examinar. A pasta contém dois programas de teste da camada JPA:
- O [InitDB.java] é um programa que insere algumas linhas na tabela [jpa01_personne] da base de dados. O seu código irá fornecer-nos os primeiros elementos da camada JPA.
- O [Main.java] é um programa que executa as operações CRUD na tabela [jpa01_personne]. A análise do seu código permitir-nos-á abordar os conceitos fundamentais do contexto de persistência e do ciclo de vida dos objetos desse contexto.
2.1.10.1. O código
O código do programa [InitDB.java] é o seguinte:
package tests;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
import javax.persistence.Persistence;
import entites.Personne;
public class InitDB {
// constantes
private final static String TABLE_NAME = "jpa01_personne";
public static void main(String[] args) throws ParseException {
// Unidade de persistência
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
// recuperar um EntityManagerFactory a partir da unidade de persistência
EntityManager em = emf.createEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// eliminar os elementos da tabela de pessoas
em.createNativeQuery("delete from " + TABLE_NAME).executeUpdate();
// criar duas pessoas
Personne p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// persistência das pessoas
em.persist(p1);
em.persist(p2);
// visualização de pessoas
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// fim da transação
tx.commit();
// fim de EntityManager
em.close();
// fim de EntityManagerFactory
emf.close();
// registo
System.out.println("terminé ...");
}
}
Este código deve ser lido à luz do que foi explicado no parágrafo 2.1.9.
- linha 19: solicita-se um objeto EntityManagerFactory emf para a unidade de persistência jpa (definida em persistence.xml). Esta operação é normalmente realizada apenas uma vez durante o ciclo de vida de uma aplicação.
- linha 21: solicita-se um objeto EntityManager do tipo «em» para gerir um contexto de persistência.
- linha 23: solicita-se um objeto Transaction para gerir uma transação. Recorde-se aqui que as operações no contexto de persistência são realizadas no interior de uma transação. Veremos que isto não é obrigatório, mas que, nesse caso, podem surgir problemas. Se a aplicação for executada num contentor EJB3, então as operações no contexto de persistência são sempre realizadas no interior de uma transação.
- linha 24: a transação começa
- linha 26: executa um comando «delete» SQL na tabela «jpa01_personne» (nativeQuery). Faz-se isto para esvaziar a tabela de todo o conteúdo e, assim, ver melhor o resultado da execução da aplicação [InitDB]
- linhas 28-29: são criados dois objetos Personne, p1 e p2. Trata-se de objetos normais e, por enquanto, não têm qualquer relação com o contexto de persistência. No que diz respeito ao contexto de persistência, o Hibernate afirma que estes objetos se encontram num estado transitório (transient), em oposição aos objetos persistentes (persistent), que são geridos pelo contexto de persistência. Preferimos falar de objetos não persistentes (expressão não francesa) para indicar que ainda não são geridos pelo contexto de persistência e de objetos persistentes para aqueles que são geridos por este. Encontraremos uma terceira categoria de objetos, os objetos desligados (detached), que são objetos anteriormente persistentes, mas cujo contexto de persistência foi encerrado. O cliente pode deter referências a esses objetos, o que explica que estes não sejam necessariamente destruídos ao fechar o contexto de persistência. Diz-se então que se encontram num estado «desvinculado». A operação [EntityManager].merge permite voltar a vinculá-los a um contexto de persistência recém-criado.
- linhas 31-32: as pessoas p1 e p2 são integradas no contexto de persistência através da operação [EntityManager].persist. Passam assim a ser objetos persistentes.
- linhas 35-37: é executada uma ordem JPQL «select p from Pessoa p order by p.nom asc». Personne não é a tabela (esta chama-se jpa01_personne), mas sim o objeto @Entity associado à tabela. Trata-se aqui de uma consulta JPQL (Java Persistence Query Language) no contexto de persistência e não de uma ordem SQL na base de dados. Dito isto, com exceção do objeto Personne, que substituiu a tabela jpa01_personne, as sintaxes são idênticas. Um ciclo for percorre a lista (de pessoas) resultante do select para apresentar cada elemento na consola. Pretende-se verificar aqui se os elementos inseridos no contexto de persistência nas linhas 31-32 se encontram efetivamente na tabela. De forma transparente, irá ocorrer uma sincronização do contexto de persistência com a base de dados. Com efeito, será emitida uma consulta select e já foi referido que este era um dos casos em que se realizava uma sincronização. É, portanto, neste momento que, em segundo plano, o JPA / Hibernate emitirá as duas ordens SQL e insert, que irão inserir as duas pessoas na tabela jpa01_personne. A operação persist não o tinha feito. Esta operação integra objetos no contexto de persistência sem que isso tenha qualquer consequência na base de dados. As ações efetivas ocorrem durante as sincronizações, neste caso, imediatamente antes da operação select na base de dados.
- linha 39: encerra-se a transação iniciada na linha 24. Vai ocorrer novamente uma sincronização. Nada acontecerá aqui, uma vez que o contexto de persistência não se alterou desde a última sincronização.
- linha 41: encerra-se o contexto de persistência.
- linha 43: encerra-se a fábrica de EntityManager.
2.1.10.2. A execução do código
- iniciar o SGBD MySQL5
- colocar conf/mysql5/persistence.xml em META-INF/persistence.xml, se necessário
- executar a aplicação [InitDB]
Obtêm-se os seguintes resultados:
 |
- em [1]: a visualização da consola na perspetiva Java. Obtém-se o resultado esperado.
- em [2]: verifica-se o conteúdo da tabela [jpa01_personne] com a perspetiva SQL Explorer, tal como explicado no parágrafo 2.1.8. É possível observar dois aspetos:
- a chave primária ID foi gerada automaticamente
- o mesmo se aplica ao número de versão. Verifica-se que a primeira versão tem o número 0..
Temos aqui os primeiros elementos da cultura JPA. Conseguimos inserir dados numa tabela. Vamos partir destes conhecimentos para escrever o segundo teste, mas antes disso vamos falar sobre registos.
2.1.11. Implementar os registos do Hibernate
É possível conhecer os comandos SQL emitidos na base de dados pela camada JPA / Hibernate. É interessante conhecê-los para verificar se a camada JPA é tão eficiente quanto um programador que tivesse escrito ele próprio as ordens SQL.
Com o JPA / Hibernate, os registos SQL podem ser verificados no ficheiro [persistence.xml]:
<!-- Classes persistentes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- registos SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- ligação JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
- linhas 4-6: os registos SQL não estavam, por enquanto, ativados. Ativam-se agora removendo a baliza de comentário das linhas 3 e 7.
Executa-se novamente a aplicação [InitDB]. As mensagens na consola passam então a ser as seguintes:
- linhas 2-4: a ordem SQL delete resultante da instrução:
// eliminar elementos da tabela de pessoas
em.createNativeQuery("delete from " + TABLE_NAME).executeUpdate();
- linhas 5-18: as ordens SQL insert resultantes das instruções:
// persistência de pessoas
em.persist(p1);
em.persist(p2);
- linhas 21-32: o comando «select» SQL proveniente da instrução:
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList())
Se fizermos exibições intermédias na consola, veremos que a gravação dos registos SQL de uma instrução I do código Java ocorre quando a instrução I é executada. Isso não significa que a ordem SQL exibida seja executada na base de dados nesse momento. Na verdade, é armazenada em cache para ser executada na próxima sincronização do contexto de persistência com a base de dados.
É possível obter outros registos através do ficheiro [src/log4j.properties]:
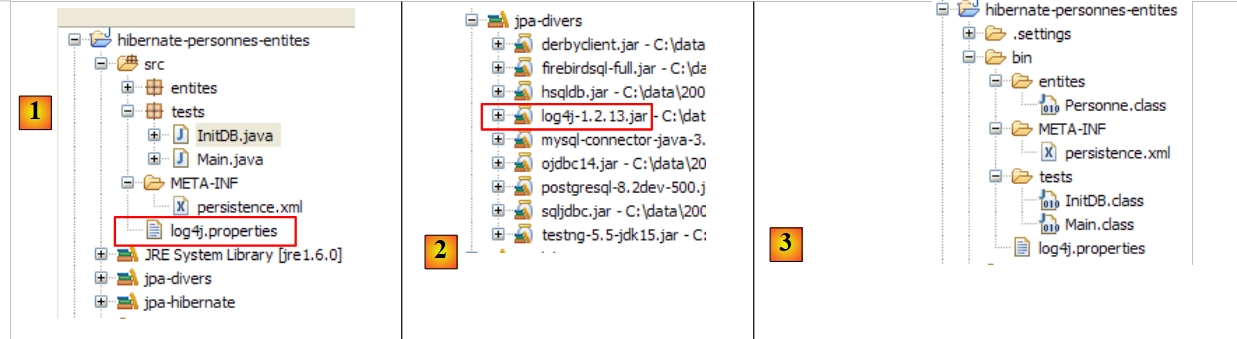 |
- no [1], o ficheiro [log4j.properties] é processado pelo arquivo [log4j-1.2.13.jar] [2] da ferramenta denominada LOG4j (Logs for Java), disponível no URL [http://logging.apache.org/log4j/docs/index.html]. Localizado na pasta [src] do projeto Eclipse, sabemos que o [log4j.properties] será copiado automaticamente para a pasta [bin] do projeto [3]. Feito isto, o ficheiro encontra-se agora na pasta classpath do projeto e é aí que o arquivo [2] irá buscá-lo.
O ficheiro [log4j.properties] permite-nos controlar determinados registos do Hibernate. Nas execuções anteriores, o seu conteúdo era o seguinte:
# Enviar mensagens de registo diretamente para a saída padrão
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n
# Opção de registo de root
log4j.rootLogger=ERROR, stdout
# Opções de registo do Hibernate (INFO mostra apenas mensagens de arranque)
#log4j.logger.org.hibernate=INFO
# Registar argumentos de tempo de execução dos parâmetros de ligação do JDBC
#log4j.logger.org.hibernate.type=DEBUG
Não vou comentar muito esta configuração, uma vez que nunca dediquei tempo a informar-me a sério sobre o LOG4j.
- As linhas 1 a 8 encontram-se em todos os ficheiros log4j.properties com os quais me deparei
- as linhas 10-14 estão presentes nos ficheiros log4j.properties dos exemplos do Hibernate.
- Linha 11: controla os registos gerais do Hibernate. Como a linha está comentada, esses registos estão aqui desativados. É possível ter vários níveis de registos: INFO (informações gerais sobre o que o Hibernate está a fazer), WARN (o Hibernate avisa-nos de um possível problema), DEBUG (registos detalhados). O nível INFO é o menos detalhado, enquanto o modo DEBUG é o mais detalhado. Ativar a linha 11 permite saber o que o Hibernate está a fazer, nomeadamente no arranque da aplicação. Isto é frequentemente interessante.
- A linha 12, se estiver ativa, permite saber quais são os argumentos efetivamente utilizados durante a execução das consultas SQL configuradas.
Comecemos por descomentar a linha 14
# Registo dos argumentos de tempo de execução dos parâmetros de ligação do JDBC
log4j.logger.org.hibernate.type=DEBUG
e voltemos a executar o [InitDB]. Os novos registos resultantes desta alteração são os seguintes (visão parcial):
- as linhas 8-10 são novos registos resultantes da ativação da linha 14 do [log4j.properties]. Indicam os 5 valores atribuídos aos parâmetros formais ? da consulta parametrizada das linhas 2-7. Assim, verifica-se que a coluna VERSION irá receber o valor 0 (linha 8).
Agora, vamos ativar a linha 11 de [log4j.properties]:
# Opções de registo do Hibernate (INFO mostra apenas mensagens de arranque)
log4j.logger.org.hibernate=INFO
e voltemos a executar o [InitDB]:
A análise destes registos fornece muita informação interessante:
- linha 7: o Hibernate indica o nome de uma classe @Entity que encontrou
- linha 8: indica que a classe [Personne] vai ser associada à tabela [jpa01_personne]
- linha 9: indica o pool de ligações C3P0 que vai ser utilizado, o nome do controlador JDBC e o URL da base de dados a gerir
- linha 10: fornece outras características da ligação JDBC: proprietário, tipo de commit, ...
- linha 14: o dialeto utilizado para comunicar com o SGBD
- linha 15: o tipo de transação utilizado. JDBCTransactionFactory indica que a aplicação gere ela própria as suas transações. Não é executada num contentor EJB3 que forneceria o seu próprio serviço de transações.
- As linhas seguintes referem-se a opções de configuração do Hibernate com as quais ainda não nos deparámos. O leitor interessado é convidado a consultar a documentação do Hibernate.
- linha 37: os comandos SQL serão apresentados na consola. Isto foi solicitado em [persistence.xml]:
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.format_sql" value="true" />
<property name="use_sql_comments" value="true" />
- linhas 43-45: o esquema da base de dados é exportado para os ficheiros SGBD e c.a.d. A base de dados é esvaziada e, em seguida, recriada. Este mecanismo resulta da configuração definida no [persistence.xml] (linha 4 abaixo):
...
<property name="hibernate.connection.password" value="jpa" />
<!-- Criação automática do esquema -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialeto -->
...
Quando uma aplicação «trava» com uma exceção do Hibernate que não se compreende, deve-se começar por ativar os registos do Hibernate no modo DEBUG no [log4j.properties] para obter uma visão mais clara:
# Opção do registador raiz
log4j.rootLogger=ERROR, stdout
# Opções de registo do Hibernate (o INFO mostra apenas mensagens de arranque)
log4j.logger.org.hibernate=DEBUG
No restante deste documento, os registos estão desativados por predefinição, para que a visualização na consola seja mais legível.
2.1.12. Descobrir a linguagem JPQL / HQL com a consola do Hibernate
Nota: Esta secção requer o plugin Hibernate Tools (parágrafo 5.2.5).
No código da aplicação [InitDB], utilizámos uma consulta JPQL. JPQL (Java Persistence Query Language) é uma linguagem para efetuar consultas ao contexto de persistência. A consulta encontrada era a seguinte:
Esta selecionava todos os elementos da tabela associada à @Entity [Personne] e apresentava-os por ordem crescente do nome. Na consulta acima, p.nom é o campo «nome» de uma instância p da classe [Personne]. Uma consulta JPQL opera, portanto, sobre os objetos @Entity do contexto de persistência e não diretamente sobre as tabelas da base de dados. A camada JPA irá, por sua vez, traduzir esta consulta JPQL numa consulta SQL adequada ao SGBD com o qual está a trabalhar. Assim, no caso de uma implementação JPA / Hibernate ligada a um SGBD MySQL5, a consulta JPQL anterior é convertida na consulta SQL seguinte:
select
personne0_.ID as ID0_,
personne0_.VERSION as VERSION0_,
personne0_.NOM as NOM0_,
personne0_.PRENOM as PRENOM0_,
personne0_.DATENAISSANCE as DATENAIS5_0_,
personne0_.MARIE as MARIE0_,
personne0_.NBENFANTS as NBENFANTS0_
from
jpa01_personne personne0_
order by
personne0_.NOM asc
A camada JPA utilizou a configuração do objeto @Entity [Personne] para gerar a ordem SQL correta. Foi aqui implementada a ponte objeto/relacional.
O plugin [Hibernate Tools] (parágrafo 5.2.5) disponibiliza uma ferramenta denominada «Console Hibernate» que permite
- emitir ordens JPQL ou do superconjunto HQL (Hibernate Query Language) no contexto de persistência
- obter os resultados
- de saber qual o equivalente SQL que foi executado na base de dados
A consola do Hibernate é uma ferramenta de grande valor para aprender a linguagem JPQL e familiarizar-se com a ponte JPQL / SQL. Sabe-se que o JPA se inspirou fortemente em ferramentas ORM como o Hibernate ou o Toplink. O JPQL é muito semelhante à linguagem HQL do Hibernate, mas não inclui todas as suas funcionalidades. Na consola do Hibernate, é possível emitir comandos HQL que serão executados normalmente na consola, mas que não fazem parte da linguagem JPQL e que, por isso, não poderiam ser utilizados num cliente JPA. Sempre que tal acontecer, iremos assinalá-lo.
Vamos criar uma consola Hibernate para o nosso projeto Eclipse atual:
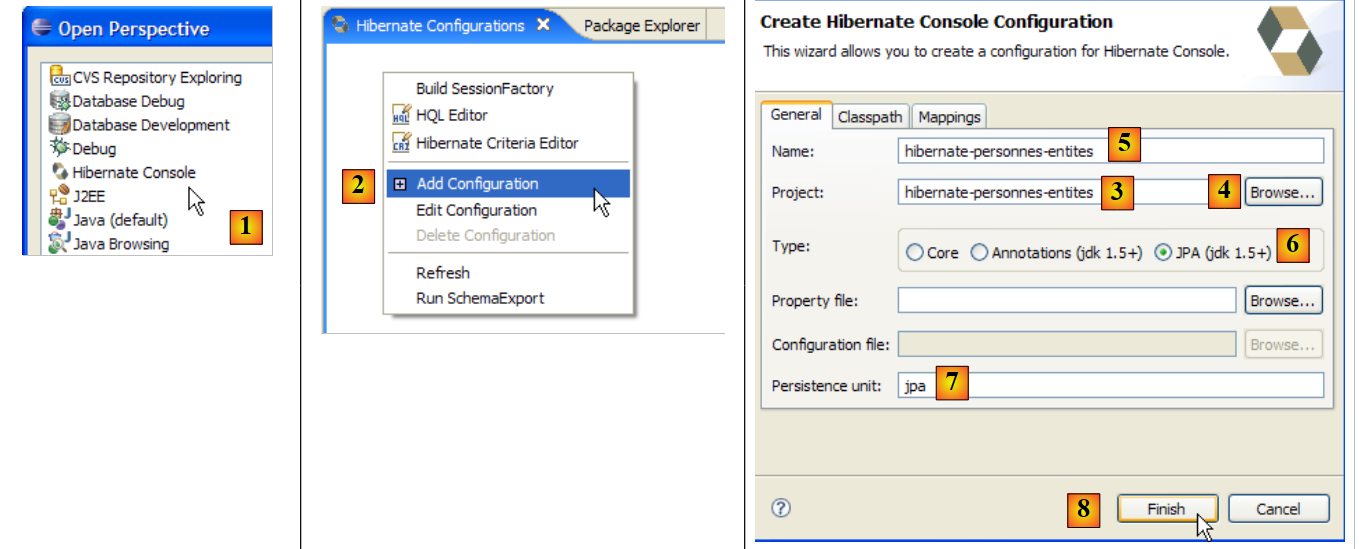 |
- [1]: mudamos para uma perspetiva [Hibernate Console] (Window / Open Perspective / Other)
- [2]: criamos uma nova configuração na janela [Hibernate Configuration]
- através do botão [4], selecionamos o projeto Java para o qual é criada a configuração do Hibernate. O seu nome é apresentado em [3].
- Em [5], atribuímos o nome que pretendemos a esta configuração. Aqui, utilizámos [3].
- No [6], indicamos que estamos a utilizar uma configuração JPA para que a ferramenta saiba que deve utilizar o ficheiro [META-INF/persistence.xml]
- em [7]: indicamos que, neste ficheiro [META-INF/persistence.xml], deve ser utilizada a unidade de persistência denominada jpa.
- No ficheiro [8], validamos a configuração.
A seguir, é necessário que o SGBD seja executado. Neste caso, trata-se do MySQL5.
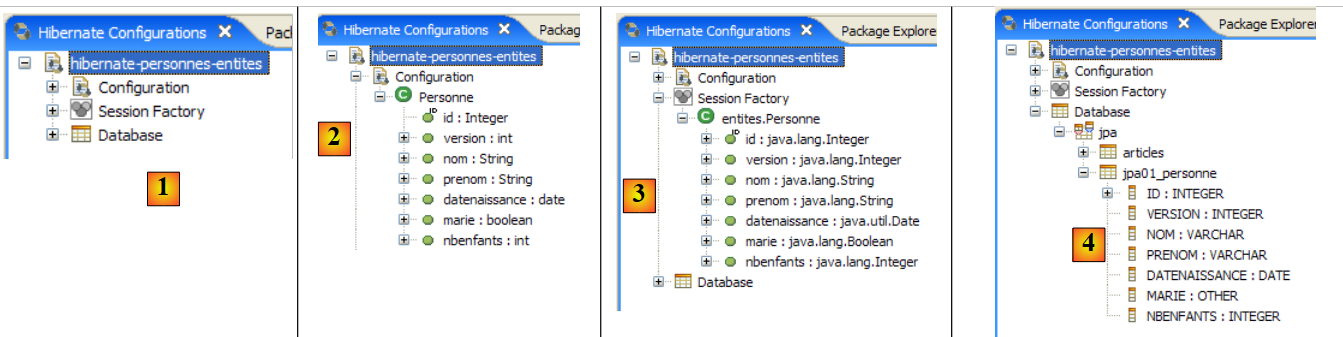 |
- no [1]: a configuração criada apresenta uma árvore com três ramos
- em [2]: o ramo [Configuration] lista os objetos que a consola utilizou para se configurar: neste caso, a @Entity Personne.
- em [3]: a Session Factory é um conceito do Hibernate semelhante ao EntityManager de JPA. Ela estabelece a ponte entre objetos e relações graças aos objetos do ramo [Configuration]. Em [3] são apresentados os objetos do contexto de persistência, neste caso, mais uma vez, o @Entity Personne.
- Em [4]: a base de dados acedida através da configuração encontrada em [persistence.xml]. Aqui encontra-se a tabela [jpa01_personne].
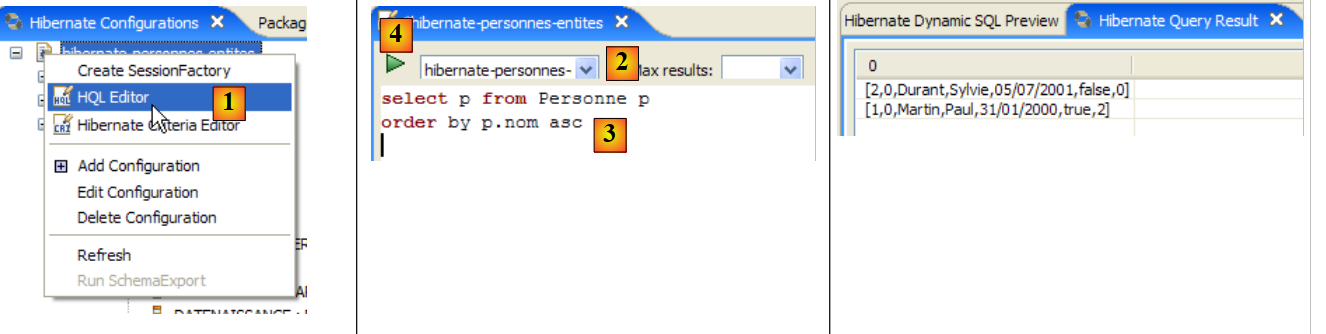 |
- em [1], cria-se um editor HQL
- no editor HQL,
- no [2], seleciona-se a configuração do Hibernate a utilizar, caso existam várias
- no [3], digita-se o comando JPQL que se pretende executar
- em [4], executa-se o comando
- em [5], obtêm-se os resultados da consulta na janela [Hibernate Query Result]. Podem surgir duas dificuldades aqui:
- não se obtém nada (nenhuma linha). A consola do Hibernate utilizou o conteúdo de [persistence.xml] para criar uma ligação com o SGBD. No entanto, esta configuração tem uma propriedade que indica que a base de dados deve ser esvaziada:
<property name="hibernate.hbm2ddl.auto" value="create" />
É, portanto, necessário executar novamente a aplicação [InitDB] antes de voltar a executar o comando JPQL acima.
- (continuação)
- Não aparece a janela [Hibernate Query Result]. Solicita-se a sua abertura através do comando [Window / Show View / ...]
A janela [Hibernate Dynamic SQL preview] ([1] abaixo) permite visualizar a consulta SQL que será executada para processar o comando JPQL que estamos a escrever. Assim que a sintaxe do comando JPQL estiver correta, o comando SQL correspondente aparece nesta janela:
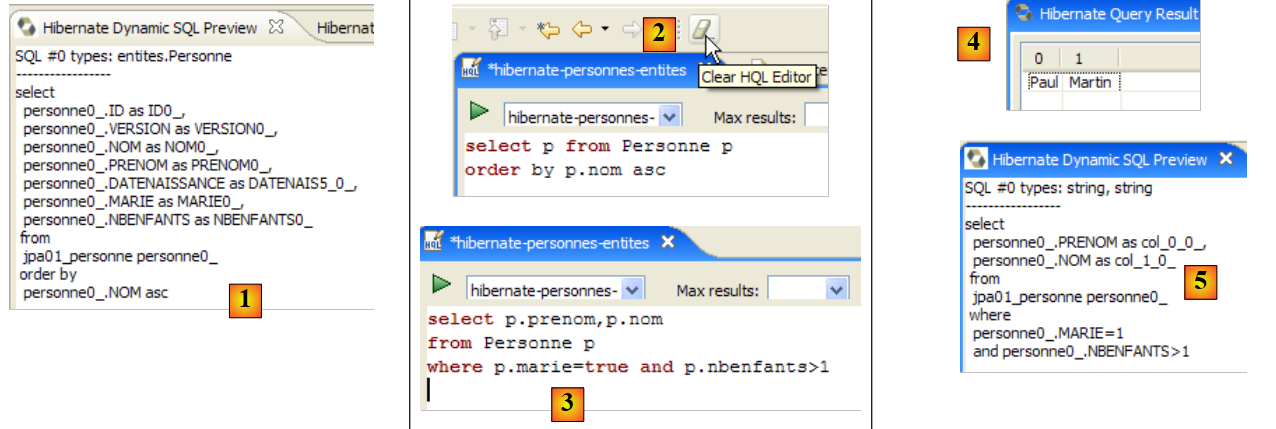 |
- em [2], apaga-se o comando anterior HQL
- em [3], executa-se um novo comando
- em [4], o resultado
- em [5], o comando SQL que foi executado com base
O editor HQL oferece ajuda na escrita dos comandos HQL:
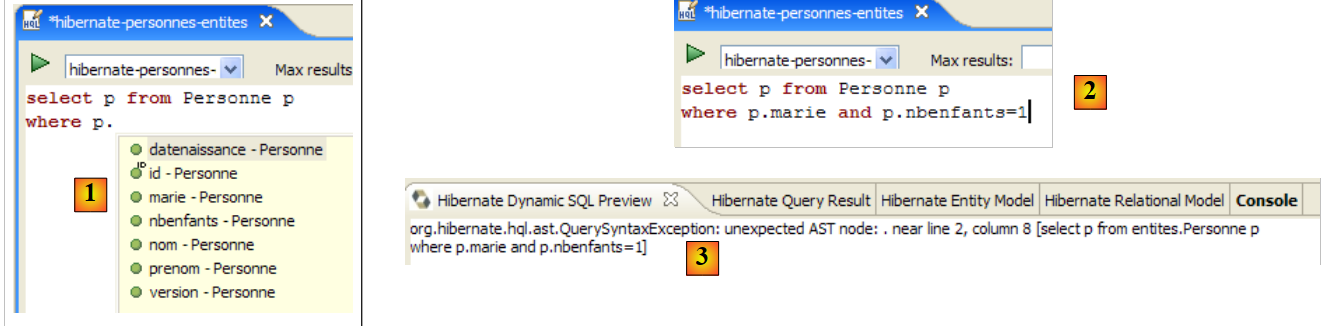 |
- em [1]: assim que o editor reconhece que p é um objeto Personne, pode sugerir-nos os campos de p à medida que escrevemos.
- em [2]: um comando HQL incorreto. Deve escrever-se where p.marie=true.
- em [3]: o erro é sinalizado na janela [SQL Preview]
Convidamos o leitor a executar outros comandos HQL / JPQL na base.
2.1.13. Um segundo cliente JPA
Voltemos a uma perspetiva Java do projeto:
|
- O [InitDB.java] é um programa que inseria algumas linhas na tabela [jpa01_personne] da base de dados. A análise do seu código permitiu-nos obter os primeiros elementos do API e do JPA.
- O [Main.java] é um programa que realiza as operações CRUD na tabela [jpa01_personne]. A análise do seu código permitir-nos-á rever os conceitos fundamentais do contexto de persistência e do ciclo de vida dos objetos desse contexto.
2.1.13.1. A estrutura do código
O [Main.java] irá encadear uma série de testes, cada um dos quais com o objetivo de demonstrar uma faceta específica do JPA:
 |
O método [main]
- chama sucessivamente os métodos test1 a test11. Apresentaremos separadamente o código de cada um destes métodos.
- Além disso, utiliza métodos utilitários privados: clean, dump, log, getEntityManager, getNewEntityManager.
Apresentamos o método main e os métodos denominados utilitários:
package tests;
...
import entites.Personne;
@SuppressWarnings("unchecked")
public class Main {
// constantes
private final static String TABLE_NAME = "jpa01_personne";
// Contexto de persistência
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
private static EntityManager em = null;
// Objetos partilhados
private static Personne p1, p2, newp1;
public static void main(String[] args) throws Exception {
// Limpeza da base de dados
log("clean");clean();
// dump da tabela
dump();
// teste1
log("test1");test1();
...
// teste11
log("test11");test11();
// fim do contexto de persistência
if (em.isOpen())
em.close();
// encerramento de EntityManagerFactory
emf.close();
}
// recuperar o EntityManager atual
private static EntityManager getEntityManager() {
if (em == null || !em.isOpen()) {
em = emf.createEntityManager();
}
return em;
}
// obter um novo EntityManager
private static EntityManager getNewEntityManager() {
if (em != null && em.isOpen()) {
em.close();
}
em = emf.createEntityManager();
return em;
}
// exibir o conteúdo da tabela
private static void dump() {
// contexto de persistência atual
EntityManager em = getEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// exibição de pessoas
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// fim da transação
tx.commit();
}
// limpar BD
private static void clean() {
// contexto de persistência
EntityManager em = getEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// eliminar os elementos da tabela PERSONNES
em.createNativeQuery("delete from " + TABLE_NAME).executeUpdate();
// fim da transação
tx.commit();
}
// registos
private static void log(String message) {
System.out.println("main : ----------- " + message);
}
// criação de objetos
public static void test1() throws ParseException {
...
}
// alterar um objeto do contexto
public static void test2() {
...
}
// solicitar objetos
public static void test3() {
...
}
// eliminar um objeto pertencente ao contexto de persistência
public static void test4() {
....
}
// desvincular, vincular novamente e modificar
public static void test5() {
...
}
// eliminar um objeto que não pertença ao contexto de persistência
public static void test6() {
...
}
// alterar um objeto que não pertença ao contexto de persistência
public static void test7() {
...
}
// reanexar um objeto ao contexto de persistência
public static void test8() {
...
}
// uma consulta SELECT provoca uma sincronização
// da base de dados com o contexto de persistência
public static void test9() {
....
}
// controlo de versão (bloqueio otimista)
public static void test10() {
...
}
// reversão de uma transação
public static void test11() throws ParseException {
...
}
}
- linha 13: o objeto EntityManagerFactory emf construído a partir da unidade de persistência jpa definida em [persistence.xml]. Este objeto permitir-nos-á criar, ao longo da aplicação, vários contextos de persistência.
- linha 14: um contexto de persistência EntityManager ainda não inicializado
- linha 17: três objetos [Personne] partilhados pelos testes
- linha 21: a tabela jpa01_personne é esvaziada e, em seguida, apresentada na linha 24 para garantir que se parte de uma tabela vazia.
- linhas 27-31: sequência de testes
- linhas 34-35: encerramento do contexto de persistência, caso este estivesse aberto.
- linha 38: encerramento do objeto EntityManagerFactory emf.
- linhas 42-47: o método [getEntityManager] torna o EntityManager (ou contexto de persistência) atual ou cria um novo, caso não exista (linhas 43-44).
- linhas 50-56: o método [getNewEntityManager] cria um novo contexto de persistência. Se já existisse um anteriormente, este é encerrado (linhas 51-52)
- linhas 59-72: o método [dump] apresenta o conteúdo da tabela [jpa01_personne]. Este código já foi encontrado em [InitDB].
- linhas 75-85: o método [clean] esvazia a tabela [jpa01_personne]. Este código já foi encontrado em [InitDB].
- linhas 88-90: o método [log] exibe na consola a mensagem que lhe é passada como parâmetro, para que seja notada.
Podemos agora passar à análise dos testes.
2.1.13.2. Teste 1
O código do teste 1 é o seguinte:
// criação de objetos
public static void test1() throws ParseException {
// contexto de persistência
EntityManager em = getEntityManager();
// criação de pessoas
p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// início de transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistência de pessoas
em.persist(p1);
em.persist(p2);
// fim da transação
tx.commit();
// exibição da tabela
dump();
}
Este código já foi encontrado em [InitDB]: cria duas pessoas e coloca-as no contexto de persistência.
- linha 4: solicita-se o contexto de persistência atual
- linhas 6-7: criam-se as duas pessoas
- linhas 9-15: as duas pessoas são colocadas no contexto de persistência no âmbito de uma transação.
- linha 15: devido ao commit da transação, ocorre a sincronização do contexto de persistência com a base de dados. As duas pessoas serão adicionadas à tabela [jpa01_personne].
- linha 17: exibe-se a tabela
A saída na consola deste primeiro teste é a seguinte:
main : ----------- test1
[personnes]
[2,0,Durant,Sylvie,05/07/2001,false,0]
[1,0,Martin,Paul,31/01/2000,true,2]
2.1.13.3. Teste 2
O código do teste 2 é o seguinte:
// alterar um objeto do contexto
public static void test2() {
// contexto de persistência
EntityManager em = getEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// incrementar o número de filhos de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// altera-se o seu estado civil
p1.setMarie(false);
// o objeto p1 é automaticamente guardado (verificação de alterações)
// na próxima sincronização (commit ou select)
// fim da transação
tx.commit();
// é apresentada a nova tabela
dump();
}
- O objetivo do teste 2 é alterar um objeto do contexto de persistência e, em seguida, apresentar o conteúdo da tabela para verificar se a alteração ocorreu
- linha 4: recupera-se o contexto de persistência atual
- linhas 6-7: as operações serão realizadas numa transação
- linhas 9 e 11: o número de filhos da pessoa p1 é alterado, assim como o seu estado civil
- linha 15: fim da transação, ou seja, sincronização do contexto de persistência com a base de dados
- linha 17: exibição da tabela
A saída na consola do teste 2 é a seguinte:
- linha 4: a pessoa p1 antes da alteração
- linha 8: a pessoa p1 após a modificação. Note-se que o seu número de versão passou para 1. Este é incrementado em 1 a cada atualização da linha.
2.1.13.4. Teste 3
O código do teste 3 é o seguinte:
// solicitar objetos
public static void test3() {
// contexto de persistência
EntityManager em = getEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// solicita-se a pessoa p1
Personne p1b = em.find(Personne.class, p1.getId());
// como p1 já se encontra no contexto de persistência, não houve acesso à base de dados
// p1b e p1 são as mesmas referências
System.out.format("p1==p1b ? %s%n", p1 == p1b);
// solicitar um objeto que não existe torna 1 ponteiro nulo
Personne px = em.find(Personne.class, -4);
System.out.format("px==null ? %s%n", px == null);
// fim da transação
tx.commit();
}
- O teste 3 centra-se no método [EntityManager.find], que permite recuperar um objeto da base de dados para o colocar no contexto de persistência. A partir de agora, já não explicaremos a transação que ocorre em todos os testes, exceto quando esta for utilizada de forma invulgar.
- linha 9: solicita-se ao contexto de persistência a pessoa que tem a mesma chave primária que a pessoa p1. Existem dois casos:
- p1 já se encontra no contexto de persistência. É o que acontece neste caso. Por isso, não é efetuado qualquer acesso à base de dados. O método find limita-se a devolver uma referência ao objeto persistido.
- p1 não se encontra no contexto de persistência. Nesse caso, é efetuado um acesso à base de dados, através da chave primária que foi fornecida. A linha recuperada é colocada no contexto de persistência e find devolve a referência a este novo objeto persistido.
- linha 12: verifica-se se find já devolveu a referência ao objeto p1 no contexto
- linha 14: solicita-se um objeto que não existe nem no contexto de persistência, nem na base de dados. O método find devolve então o ponteiro null. Este ponto é verificado na linha 15.
A saída na consola do teste 3 é a seguinte:
2.1.13.5. Teste 4
O código do teste 4 é o seguinte:
// eliminar um objeto pertencente ao contexto de persistência
public static void test4() {
// contexto de persistência
EntityManager em = getEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// elimina-se o objeto persistido p2
em.remove(p2);
// fim da transação
tx.commit();
// exibe-se a nova tabela
dump();
}
- O teste 4 centra-se no método [EntityManager.remove], que permite eliminar um elemento do contexto de persistência e, consequentemente, da base de dados.
- linha 9: a pessoa p2 é removida do contexto de persistência
- linha 11: sincronização do contexto com a base de dados
- linha 13: exibição da tabela. Normalmente, a pessoa p2 já não deve constar da tabela.
A saída na consola do teste 4 é a seguinte:
- linha 3: a pessoa p2 em test1
- linhas 12-14: já não existe após a execução de test4.
2.1.13.6. Teste 5
O código do teste 5 é o seguinte:
// desvincular, vincular novamente e modificar
public static void test5() {
// novo contexto de persistência
EntityManager em = getNewEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// p1 desligado
Personne oldp1=p1;
// reanexar p1 ao novo contexto
p1 = em.find(Personne.class, p1.getId());
// verificação
System.out.format("p1==oldp1 ? %s%n", p1 == oldp1);
// fim da transação
tx.commit();
// incrementa-se o número de filhos de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// exibe-se a nova tabela
dump();
}
- O teste 5 analisa o ciclo de vida dos objetos persistentes ao longo de vários contextos de persistência sucessivos. Até agora, tínhamos sempre utilizado o mesmo contexto de persistência nos diferentes testes.
- linha 4: é solicitado um novo contexto de persistência. O método [getNewEntityManager] encerra o anterior e abre um novo. Isto faz com que os objetos p1 e p2 detidos pela aplicação deixem de se encontrar num estado persistente. Pertenciam a um contexto que foi encerrado. Diz-se que se encontram num estado desligado. Não pertencem ao novo contexto de persistência.
- linhas 6-7: início da transação. Aqui, ela será utilizada de forma invulgar.
- linha 9: regista-se o endereço do objeto p1, agora desligado.
- linha 11: solicita-se ao contexto de persistência a pessoa p1 (com a chave primária de p1). Como o contexto é novo, a pessoa p1 não se encontra nele. Por conseguinte, será efetuado um acesso à base de dados. O objeto recuperado será colocado no novo contexto.
- linha 13: verifica-se se o objeto persistente p1 do contexto é diferente do objeto oldp1, que era o antigo objeto p1 desanexado.
- linha 15: a transação está concluída
- linha 17: altera-se, fora da transação, o novo objeto persistido p1. O que acontece neste caso? Queremos saber.
- linha 19: solicita-se a exibição da tabela. Recorde-se que, devido ao select emitido pelo método dump, é efetuada automaticamente uma sincronização do contexto de persistência com a base de dados.
A saída na consola do teste 5 é a seguinte:
- linha 5: o método find efetuou efetivamente um acesso à base de dados; caso contrário, os dois ponteiros seriam iguais
- linhas 7 e 3: o número de filhos de p1 aumentou efetivamente em 1. A alteração, efetuada fora da transação, foi, portanto, tida em conta. Na verdade, isto depende do SGBD utilizado. Num SGBD, uma ordem SQL é sempre executada no âmbito de uma transação. Se o cliente JPA não iniciar ele próprio uma transação explícita, o SGBD irá então iniciar uma transação implícita. Existem dois casos comuns:
- 1 - cada ordem SQL individual é objeto de uma transação, aberta antes da ordem e encerrada depois. Diz-se que se está no modo autocommit. Tudo decorre, portanto, como se o cliente JPA realizasse transações para cada ordem SQL.
- 2 - o SGBD não está no modo autocommit e inicia uma transação implícita na primeira ordem SQL que o cliente JPA emite fora de uma transação, deixando que seja o próprio cliente a encerrá-la. Todas as ordens SQL emitidas pelo cliente JPA passam então a fazer parte da transação implícita. Esta pode terminar em função de diferentes eventos: o cliente encerra a ligação, inicia uma nova transação, ...
Estamos numa situação que depende da configuração do SGBD. Temos, portanto, código não portátil. Mais adiante, apresentaremos um código sem transações e veremos que nem todos os SGBD têm o mesmo comportamento em relação a esse código. Consideraremos, portanto, que trabalhar fora de transações é um erro de programação.
- linha 7: note-se que o número da versão passou para 2.
2.1.13.7. Teste 6
O código do teste 6 é o seguinte:
// eliminar um objeto que não pertença ao contexto de persistência
public static void test6() {
// novo contexto de persistência
EntityManager em = getNewEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// elimina-se p1, que não pertence ao novo contexto
try {
em.remove(p1);
// fim da transação
tx.commit();
} catch (RuntimeException e1) {
System.out.format("Erreur à la suppression de p1 : [%s,%s]%n", e1.getClass().getName(), e1.getMessage());
// é efetuado um rollback da transação
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s,%s]%n", e2.getClass().getName(), e2.getMessage());
}
}
// exibe-se a nova tabela
dump();
}
- O teste 6 procura eliminar um objeto que não pertence ao contexto de persistência.
- linha 4: é solicitado um novo contexto de persistência. O anterior é, portanto, encerrado e os objetos que continha ficam desassociados. É o caso do objeto p1 do teste 5 anterior.
- linhas 6-7: início da transação.
- linha 10: elimina-se o objeto desanexado p1. Sabemos que isto irá provocar uma exceção, pelo que envolvemos a operação num try/catch.
- linha 12: o commit não será efetuado.
- linhas 16-21: uma transação deve terminar com um commit (todas as operações da transação são validadas) ou um rollback (todas as operações da transação são anuladas). Ocorreu uma exceção, pelo que executamos um rollback na transação. Não há nada a reverter, uma vez que a única operação da transação falhou, mas o rollback encerra a transação. É a primeira vez que utilizamos a operação [EntityTransaction].rollback. Devíamos tê-lo feito desde os primeiros exemplos. Foi para manter o código simples que não o fizemos. O leitor deve, no entanto, ter em mente que o caso do rollback da transação deve estar sempre previsto no código.
- linha 24: exibimos a tabela. Normalmente, esta não deve ter sofrido alterações.
A saída na consola do teste 6 é a seguinte:
- linha 6: a eliminação de p1 falhou. A mensagem de exceção explica que se tentou eliminar um objeto destacado, que, portanto, não faz parte do contexto. Isso não é possível.
- linha 8: a pessoa p1 continua presente.
2.1.13.8. Teste 7
O código do teste 7 é o seguinte:
// alterar um objeto que não pertence ao contexto de persistência
public static void test7() {
// novo contexto de persistência
EntityManager em = getNewEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// incrementa-se o número de filhos de p1 que não pertencem ao novo contexto
p1.setNbenfants(p1.getNbenfants() + 1);
// fim da transação
tx.commit();
// exibe-se a nova tabela — esta não deve ter sofrido alterações
dump();
}
- O teste 7 procura alterar um objeto que não pertence ao contexto de persistência e verificar o impacto que isso tem na base de dados. É de supor que não tenha qualquer impacto. É isso que os resultados do teste demonstram.
- linha 4: é solicitado um novo contexto de persistência. Temos, portanto, um contexto novo sem objetos persistentes no seu interior.
- linhas 6-7: início da transação.
- linha 9: altera-se o objeto desanexado p1. Trata-se de uma operação que não envolve o contexto de persistência em. Não se deve, portanto, esperar uma exceção ou algo do género. É uma operação básica num POJO.
- linha 11: o commit provoca a sincronização do contexto com a base de dados. Este contexto está vazio. A base de dados não é, portanto, alterada.
- linha 24: exibe-se a tabela. Normalmente, esta não deve ter sofrido alterações.
A saída da consola do teste 7 é a seguinte:
- linha 7: a pessoa p1 não sofreu alterações na base de dados. Para o teste seguinte, devemos, no entanto, ter em conta que, na memória, o número de filhos desta pessoa é agora 5.
2.1.13.9. Teste 8
O código do teste 8 é o seguinte:
// reassociar um objeto ao contexto de persistência
public static void test8() {
// novo contexto de persistência
EntityManager em = getNewEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// reassocia-se o objeto p1, que estava desassociado, ao novo contexto
newp1 = em.merge(p1);
// é o newp1 que agora faz parte do contexto, e não o p1
// fim da transação
tx.commit();
// é apresentada a nova tabela — o número de filhos de p1 deve ter mudado
dump();
}
- O teste 8 volta a associar ao contexto de persistência um objeto que tinha sido desassociado.
- linha 4: é solicitado um novo contexto de persistência. Temos, portanto, um contexto novo sem objetos persistentes no seu interior.
- linhas 6-7: início da transação.
- linha 9: o objeto desanexado p1 é reanexado ao contexto de persistência. A operação «merge» pode envolver várias operações:
- caso 1: existe no contexto de persistência um objeto persistente ps1 com a mesma chave primária que o objeto desligado p1. O conteúdo de p1 é copiado para ps1 e merge passa a referir-se a ps1.
- Caso 2: não existe no contexto de persistência um objeto persistente ps1 com a mesma chave primária que o objeto destacado p1. A base de dados é então consultada para verificar se o objeto procurado existe na base de dados. Se sim, esse objeto é trazido para o contexto de persistência, torna-se o objeto persistente ps1 e volta-se ao caso 1 anterior.
- Caso 3: não existe, nem no contexto de persistência nem na base de dados, um objeto com a mesma chave primária que o objeto desanexado p1. É então criado um novo objeto [Personne] (new), que é posteriormente colocado no contexto de persistência. Em seguida, volta-se ao caso 1.
- Conclusão: o objeto desligado p1 permanece desligado. A operação merge devolve uma referência (neste caso, newp1) ao objeto persistente ps1, derivado do merge. A aplicação cliente deve agora trabalhar com o objeto persistente ps1 e não com o objeto desanexado p1.
- Note-se uma diferença entre os casos 1 e 3 no que diz respeito à ordem SQL programada para o merge: nos casos 1 e 2, trata-se da ordem UPDATE, enquanto no caso 3 é uma ordem INSERT.
- linha 12: o commit provoca a sincronização do contexto com a base de dados. Este contexto já não está vazio. Contém o objeto newp1. Este será guardado na base de dados.
- linha 24: exibimos a tabela para verificar.
A saída na consola do teste 8 é a seguinte:
- O número de filhos de p1 era 4 no teste 6 (linha 4), tendo depois passado para 5 no teste 7, mas não foi guardado na base de dados (linha 7). Após o merge, o newp1 foi guardado na base de dados: na linha 10, verificam-se efetivamente 5 filhos.
- linha 10: o número de versão de newp1 passou para 3.
2.1.13.10. Teste 9
O código do teste 9 é o seguinte:
// uma consulta SELECT provoca uma sincronização
// da base de dados com o contexto de persistência
public static void test9() {
// contexto de persistência
EntityManager em = getEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// incrementa-se o número de filhos de newp1
newp1.setNbenfants(newp1.getNbenfants() + 1);
// exibição de pessoas — o número de filhos de newp1 deve ter mudado
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// fim da transação
tx.commit();
}
- O teste 9 pretende demonstrar o mecanismo de sincronização do contexto que ocorre automaticamente antes de um select.
- linha 5: não se altera o contexto de persistência. O newp1 está, portanto, incluído.
- linhas 7-8: início da transação.
- linha 10: o número de filhos do objeto persistente newp1 é aumentado em 1 (5 -> 6).
- linhas 12-15: a tabela é apresentada através de uma instrução SELECT. O contexto será sincronizado com a base de dados antes da execução do select.
- linha 17: fim da transação
Para ver a sincronização, ativamos a exibição dos registos do Hibernate no modo DEBUG (log4j.properties):
# Opção do registador raiz
log4j.rootLogger=ERROR, stdout
# Opções de registo do Hibernate (INFO mostra apenas mensagens de arranque)
log4j.logger.org.hibernate=DEBUG
A exibição na consola do teste 9 é a seguinte:
- linha 1: o teste 9 inicia
- linhas 2-6: a transação JDBC inicia. O modo autocommit do SGBD está desativado (linha 5)
- linha 7: saída provocada pela linha 12 do código Java. As linhas seguintes do código Java irão provocar um select e, consequentemente, uma sincronização do contexto de persistência com a base de dados.
- linha 8: a ordem JPQL que se pretende emitir já foi emitida. O Hibernate encontra-a no seu cache de «consultas preparadas».
- linha 9: o Hibernate anuncia que vai proceder a um flush do contexto de persistência
- linhas 11-12: o Hibernate (Hb) deteta que a entidade Pessoa#1 (com chave primária 1) foi alterada (dirty).
- linhas 12-13: O Hb anuncia que atualiza este elemento e altera o seu número de versão de 3 para 4.
- linha 15: a sincronização do contexto irá provocar 0 inserções, 1 atualização (update) e 0 eliminações (delete)
- linhas 17-34: sincronização do contexto (flush). A notar: o incremento da versão (linha 19), a ordem SQL update preparada (linha 21), os valores dos parâmetros da ordem update (linhas 24-31).
- linha 35: o select tem início
- linha 38: a ordem SQL que vai ser executada
- linha 40: o select devolve apenas uma linha
- linha 42: o Hb descobre que já tem no seu contexto de persistência a entidade Personne#1 que a instrução SELECT recuperou da base de dados. Por isso, não copia a linha obtida da base de dados para o contexto, operação a que chama «hidratação».
- linha 43: verifica se os objetos recuperados pelo select têm dependências (geralmente chaves estrangeiras) que também teriam de ser carregadas (coleções não preguiçosas). Neste caso, não há nenhuma.
- linha 44: exibição provocada pelo código Java
- linha 45: fim da transação JDBC solicitada pelo código Java
- linha 46: inicia-se a sincronização automática do contexto, que ocorre durante o commit.
- linha 48: o Hb deteta que o contexto não se alterou desde a sincronização anterior.
- linha 50: fim do commit.
Mais uma vez, os registos do Hibernate no modo DEBUG revelam-se muito úteis para saber exatamente o que o Hibernate está a fazer.
2.1.13.11. Teste 10
O código do teste 10 é o seguinte:
// controlo de versão (bloqueio otimista)
public static void test10() {
// Contexto de persistência
EntityManager em = getEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// incrementar a versão de newp1 diretamente na base de dados (consulta nativa)
em.createNativeQuery(String.format("update %s set VERSION=VERSION+1 WHERE ID=%d", TABLE_NAME, newp1.getId())).executeUpdate();
// fim da transação
tx.commit();
// início de uma nova transação
tx = em.getTransaction();
tx.begin();
// incrementa-se o número de filhos de newp1
newp1.setNbenfants(newp1.getNbenfants() + 1);
// fim da transação — deve falhar, pois o newp1 já não tem a versão correta
try {
tx.commit();
} catch (RuntimeException e1) {
System.out.format("Erreur lors de la mise à jour de newp1 [%s,%s,%s,%s]%n", e1.getClass().getName(), e1.getMessage(), e1.getCause().getClass().getName(), e1.getCause().getMessage());
// é efetuado um rollback da transação
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s,%s]%n", e2.getClass().getName(), e2.getMessage());
}
}
// fecha-se o contexto, que já não está atualizado
em.close();
// dump da tabela — a versão de p1 deve ter mudado
dump();
}
- O teste 10 pretende demonstrar o mecanismo introduzido pelo campo version da @Entity Pessoa, que possui o atributo JPA @Version. Já explicámos que esta anotação fazia com que, na base de dados, o valor da coluna associada à anotação @Version fosse incrementado a cada update efetuado na linha a que pertence. Este mecanismo, também denominado bloqueio otimista (optimistic locking), exige que o cliente que pretenda modificar um objeto O na base de dados disponha da versão mais recente do mesmo. Se não a tiver, significa que o objeto foi modificado desde que o obteve, pelo que deve ser avisado.
- linha 4: não se altera o contexto de persistência. newp1 encontra-se, portanto, nesse contexto.
- linhas 6-7: início de uma transação.
- linha 9: a versão do objeto newp1 é incrementada em 1 (4 → 5) diretamente na base de dados. As consultas do tipo nativeQuery contornam o contexto de persistência e acedem diretamente à base de dados. O resultado é que o objeto persistente newp1 e a sua imagem na base de dados já não têm a mesma versão.
- linha 10: fim da primeira transação
- linhas 13-14: início de uma segunda transação
- linha 16: o número de filhos do objeto persistente newp1 é aumentado em 1 (6 -> 7).
- linha 19: fim da transação. Ocorre, portanto, uma sincronização. Esta irá provocar a atualização do número de filhos de newp1 na base de dados. Esta atualização irá falhar porque o objeto persistente newp1 tem a versão 4, enquanto que na base de dados o objeto a atualizar tem a versão 5. Será lançada uma exceção, o que justifica o bloco try/catch do código.
- linha 21: exibe-se a exceção e a sua causa.
- linha 25: reversão da transação
- linha 33: exibição da tabela: deverá verificar-se que a versão de newp1 é 5 na base de dados.
A saída da consola do teste 10 é a seguinte:
- linha 5: o commit lança efetivamente uma exceção. É do tipo [javax.persistence.RollbackException]. A mensagem associada é vaga. Se analisarmos a causa desta exceção (Exception.getCause), verificamos que se trata de uma exceção do Hibernate, devida ao facto de se estar a tentar alterar uma linha da base de dados sem ter a versão correta.
- linha 7: verifica-se que a versão de newp1 na base de dados foi efetivamente alterada para 5 pela nativeQuery.
2.1.13.12. Teste 11
O código do teste 11 é o seguinte:
// reversão de uma transação
public static void test11() throws ParseException {
// contexto de persistência
EntityManager em = getEntityManager();
// início da transação
EntityTransaction tx = null;
try {
tx = em.getTransaction();
tx.begin();
// reassocia-se p1 ao contexto, indo buscá-lo à base de dados
p1 = em.find(Personne.class, p1.getId());
// incrementa-se o número de filhos de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// exibição de pessoas — o número de filhos de p1 deve ter mudado
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// criação de duas pessoas com o mesmo nome, o que é proibido pela DDL
Personne p3 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p4 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
// persistência das pessoas
em.persist(p3);
em.persist(p4);
// fim da transação
tx.commit();
} catch (RuntimeException e1) {
// ocorreu um problema
System.out.format("Erreur dans transaction [%s,%s,%s,%s,%s,%s]%n", e1.getClass().getName(), e1.getMessage(),
e1.getCause().getClass().getName(), e1.getCause().getMessage(), e1.getCause().getCause().getClass().getName(), e1.getCause().getCause()
.getMessage());
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s]%n", e2.getMessage());
}
// abandonamos o contexto atual
em.clear();
}
// dump - a tabela não deve ter sido alterada devido ao rollback
dump();
}
- O teste 11 centra-se no mecanismo da transação rollback. Uma transação funciona segundo o princípio «tudo ou nada»: as operações SQL que contém são ou todas executadas com sucesso (commit), ou todas anuladas em caso de falha de uma delas (rollback).
- linha 4: continua-se com o mesmo contexto de persistência. O leitor talvez se lembre de que o contexto foi encerrado na sequência da falha do teste anterior. Neste caso, o [getEntityManager] fornece um contexto totalmente novo e, portanto, vazio.
- linhas 7-27: um único try/catch para gerir os problemas que iremos encontrar
- linhas 8-9: início de uma transação que irá conter várias operações SQL
- linha 11: procura-se p1 na base de dados e insere-se no contexto
- linha 13: aumenta-se o número de filhos de p1 (6 → 7)
- linhas 15-18: exibe-se o conteúdo da base de dados, o que forçará uma sincronização do contexto. Na base de dados, o número de filhos de p1 passará para 7, o que deverá ser confirmado pela exibição na consola.
- linhas 20-21: criação de duas pessoas, p3 e p4, com o mesmo nome. No entanto, o campo «nome» da @Entity «Pessoa» tem o atributo «unique=true», o que resultou na criação de uma restrição de unicidade na coluna «NOM» da tabela «[jpa01_personne]».
- linhas 23-24: as pessoas p3 e p4 são inseridas no contexto de persistência.
- linha 26: a transação é confirmada. Segue-se uma segunda sincronização do contexto, tendo a primeira ocorrido aquando do select. JPA irá emitir duas ordens SQL e insert para as pessoas p3 e p4. O p3 será inserido. No caso do p4, o SGBD irá lançar uma exceção, uma vez que o p4 tem o mesmo nome que o p3. O p4 não é, portanto, inserido e o controlador JDBC devolve uma exceção ao cliente.
- linha 27: trata-se da exceção
- linhas 29-31: exibimos a exceção e as suas duas causas anteriores na cadeia de exceções que nos conduziram até aqui.
- linha 34: efetua-se um rollback da transação atualmente ativa. Esta teve início na linha 9 do código Java. Desde então, foi realizada uma operação update para alterar o número de filhos de p1 e, em seguida, uma operação insert para a pessoa p3. Tudo isto será anulado pelo rollback.
- linha 39: o contexto de persistência é esvaziado
- linha 42: a tabela [jpa01_personne] é apresentada. É necessário verificar se p1 continua a ter 6 filhos e se nem p3 nem p4 constam da tabela.
A saída na consola do teste 11 é a seguinte:
main : ----------- test11
[personnes]
[1,6,Martin,Paul,31/01/2000,false,7]
14:50:30,312 ERROR JDBCExceptionReporter:72 - Duplicate entry 'X' for key 2
Erreur dans transaction [javax.persistence.EntityExistsException,org.hibernate.exception.ConstraintViolationException: could not insert: [entites.Personne],org.hibernate.exception.ConstraintViolationException,could not insert: [entites.Personne],java.sql.SQLException,Duplicate entry 'X' for key 2]
[personnes]
[1,5,Martin,Paul,31/01/2000,false,6]
- linha 3: o número de filhos de p1 passou de 6 para 7 na base de dados; a versão de p1 passou para 6.
- linha 4: a exceção detetada durante o commit da transação. Se lermos com atenção, vemos que a causa é uma chave duplicada X (o nome). É a inserção de p4 que provoca este erro, uma vez que p3, já inserido, também tem o nome X.
- linha 7: a tabela após o rollback. p1 voltou à sua versão 5 e ao seu número de filhos 6; p3 e p4 não foram inseridos.
2.1.13.13. Teste 12
O código do teste 12 é o seguinte:
// repetimos o mesmo procedimento, mas sem as transações
// obtém-se o mesmo resultado que anteriormente com os SGBD: FIREBIRD, ORACLE XE, POSTGRES, MYSQL5
// com SQLSERVER, a tabela fica vazia. A ligação fica num estado que impede a reexecução
// do programa. É então necessário reiniciar o servidor.
// o mesmo acontece com o SGBD Derby
// O HSQL insere a primeira pessoa — não há rollback
public static void test12() throws ParseException {
// volta a associar p1
p1 = em.find(Personne.class, p1.getId());
// incrementa-se o número de filhos de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// exibição de pessoas — o número de filhos de p1 deve ter mudado
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// criação de 2 pessoas com o mesmo nome, o que é proibido pela DDL
Personne p3 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p4 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
// persistência das pessoas
em.persist(p3);
em.persist(p4);
// dump que irá provocar a sincronização do contexto em com o BD
try {
dump();
} catch (RuntimeException e3) {
System.out.format("Erreur dans dump [%s,%s,%s,%s]%n", e3.getClass().getName(), e3.getMessage(), e3.getCause().getClass().getName(), e3
.getCause().getMessage());
}
// fecha-se o contexto atual
em.close();
// dump
dump();
}
- O teste 12 repete o mesmo procedimento do teste 11, mas fora da transação. Pretendemos verificar o que acontece neste caso.
- linhas 1-6: apresentam os resultados dos testes com vários SGBD:
- com um determinado número de SGBD (Firebird, Oracle, MySQL5, Postgres), obtém-se o mesmo resultado que no teste 11. O que leva a pensar que estes SGBD iniciaram por si próprios uma transação que abrange todas as ordens SQL recebidas até àquela que provocou o erro e que eles próprios iniciaram um rollback.
- Com outros SGBD (SQL Server, Apache Derby), verifica-se uma falha da aplicação e/ou do SGBD.
- Com o SGBD e o HSQLDB, parece que a transação aberta pelo SGBD está no modo autocommit: a alteração do número de filhos do p1 e a inserção do p3 tornam-se permanentes. Apenas a inserção do p4 falha.
Temos, portanto, um resultado que depende do SGBD, o que torna a aplicação não portátil. É importante ter em conta que as operações no contexto de persistência devem ser sempre realizadas no âmbito de uma transação.
2.1.14. Alterar para SGBD
Voltemos à arquitetura de teste do nosso projeto atual:
 |
A aplicação cliente [3] apenas vê a interface JPA [5]. Não vê nem a implementação real desta, nem o SGBD de destino. Por isso, deve ser possível alterar estes dois elementos da cadeia sem alterações no cliente [3]. É isso que estamos a tentar verificar agora, começando por alterar o SGBD. Até agora, tínhamos utilizado o MySQL5. Apresentamos aqui mais seis, descritos nos anexos (parágrafo 5), na esperança de que, entre eles, se encontre o SGBD preferido do leitor.
Em qualquer caso, a alteração a efetuar no projeto Eclipse é simples (ver abaixo): substituir o ficheiro de configuração da camada JPA por um dos ficheiros da pasta conf [2] do projeto. Os controladores JDBC e SGBD já se encontram na biblioteca [jpa-divers], [3] e [4].
 |
2.1.14.1. Oracle 10g Express
O Oracle 10g Express é apresentado nos Anexos, no parágrafo 5.7. O ficheiro persistence.xml da Oracle é o seguinte:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provedor -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Classes persistentes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- registos SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- ligação JDBC -->
<property name="hibernate.connection.driver_class" value="oracle.jdbc.OracleDriver" />
<property name="hibernate.connection.url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- criação automática do esquema -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialeto -->
<property name="hibernate.dialect" value="org.hibernate.dialect.OracleDialect" />
<!-- propriedades DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
Esta configuração é idêntica à realizada para o SGBD e o MySQL5, com as seguintes diferenças:
- linhas 15-18, que configuram a ligação JDBC com a base de dados
- linha 22: que define o dialeto SQL a utilizar
Nos exemplos que se seguem, apenas especificaremos as linhas que se alteram. Para uma explicação da configuração, consulte-se o anexo dedicado ao SGBD utilizado. Nele é apresentado, em cada caso, um exemplo de utilização da ligação JDBC, no contexto do plugin [SQL Explorer]. Com as informações do anexo, o leitor poderá repetir a operação de verificação do resultado da aplicação do [InitDB] realizada no parágrafo 2.1.10.2.
Procedemos conforme indicado no parágrafo acima referido:
- executar o SGBD Oracle
- colocar conf/oracle/persistence.xml em META-INF/persistence.xml
- executar a aplicação [InitDB]
Obtêm-se os seguintes resultados na consola:
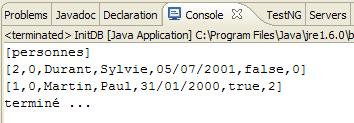 |
Daqui em diante, não voltaremos a apresentar esta captura de ecrã, que é sempre a mesma. Mais interessante é a perspetiva do SQL Explorer sobre a ligação entre o JDBC e o SGBD. Seguiremos o procedimento explicado no parágrafo 2.1.8.
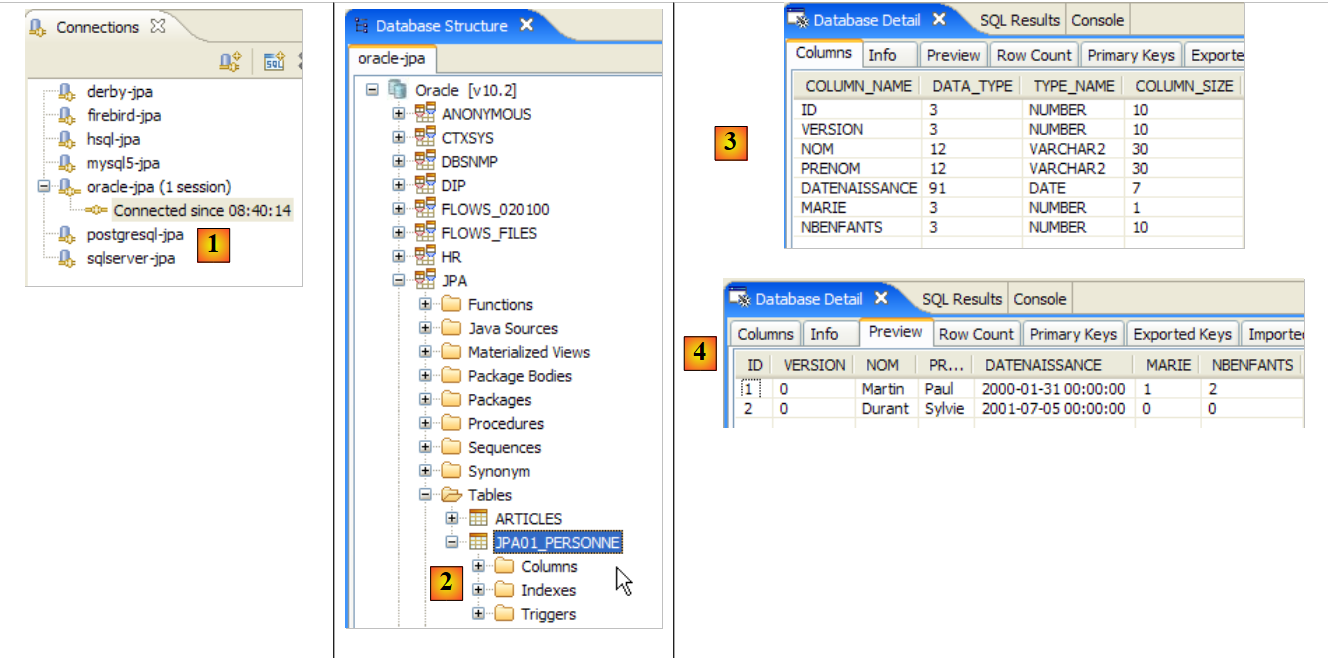 |
- em [1]: a ligação com o Oracle
- em [2]: a árvore de ligação após a execução de [InitDB]
- em [3]: a estrutura da tabela [jpa01_personne]
- em [4]: o seu conteúdo.
Feito isto, o leitor é convidado a executar a aplicação [Main] e, em seguida, a encerrar o SGBD.
2.1.14.2. PostgreSQL 8.2
O PostgreSQL 8.2 é apresentado nos Anexos, no parágrafo 5.6. O seu ficheiro persistence.xml é o seguinte:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- ligação JDBC -->
<property name="hibernate.connection.driver_class" value="org.postgresql.Driver" />
<property name="hibernate.connection.url" value="jdbc:postgresql:jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
...
<!-- Dialeto -->
<property name="hibernate.dialect" value="org.hibernate.dialect.PostgreSQLDialect" />
...
</persistence-unit>
</persistence>
Para executar o [InitDB]:
- executar o SGBD PostgreSQL
- colocar conf/postgres/persistence.xml em META-INF/persistence.xml
- executar a aplicação [InitDB]
A perspetiva do Explorer da ligação JDBC com o SGBD é a seguinte:
 |
- em [1]: a ligação com PostgreSQL
- em [2]: a árvore de ligações após a execução de [InitDB]
- em [3]: a estrutura da tabela [jpa01_personne]
- em [4]: o seu conteúdo.
Feito isto, o leitor é convidado a executar a aplicação [Main] e, em seguida, a encerrar o SGBD
2.1.14.3. SQL Server Express 2005
O SQL Server Express 2005 é apresentado nos Anexos, no parágrafo 5.8, página 270. O seu ficheiro persistence.xml é o seguinte:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- ligação JDBC -->
<property name="hibernate.connection.driver_class" value="com.microsoft.sqlserver.jdbc.SQLServerDriver" />
<property name="hibernate.connection.url" value="jdbc:sqlserver://localhost\\SQLEXPRESS:1433;databaseName=jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
...
<!-- Dialeto -->
<property name="hibernate.dialect" value="org.hibernate.dialect.SQLServerDialect" />
...
</persistence-unit>
</persistence>
Para executar o [InitDB]:
- execute o SGBD SQL Server
- colocar o ficheiro conf/sqlserver/persistence.xml no META-INF/persistence.xml
- executar a aplicação [InitDB]
A perspetiva do SQL Explorer da ligação entre o JDBC e o SGBD é a seguinte:
 |
- em [1]: a ligação com o servidor SQL
- em [2]: a árvore de ligações após a execução de [InitDB]
- em [3]: a estrutura da tabela [jpa01_personne]
- em [4]: o seu conteúdo.
Feito isto, o leitor é convidado a executar a aplicação [Main] e, em seguida, a encerrar o SGBD
2.1.14.4. Firebird 2.0
O Firebird 2.0 é apresentado nos Anexos, no parágrafo 5.4. O seu ficheiro persistence.xml é o seguinte:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- ligação JDBC -->
<property name="hibernate.connection.driver_class" value="org.firebirdsql.jdbc.FBDriver" />
<property name="hibernate.connection.url" value="jdbc:firebirdsql:localhost/3050:C:\data\2006-2007\eclipse\dvp-jpa\annexes\firebird\jpa.fdb" />
<property name="hibernate.connection.username" value="sysdba" />
<property name="hibernate.connection.password" value="masterkey" />
...
<!-- Dialeto -->
<property name="hibernate.dialect" value="org.hibernate.dialect.FirebirdDialect" />
...
</persistence-unit>
</persistence>
Para executar o [InitDB]:
- execute o SGBD Firebird
- colocar o ficheiro conf/firebird/persistence.xml no diretório META-INF/persistence.xml
- executar a aplicação [InitDB]
A perspetiva do SQL Explorer sobre a ligação entre o JDBC e o SGBD é a seguinte:
 |
- em [1]: a ligação com o Firebird
- em [2]: a árvore de ligações após a execução de [InitDB]
- em [3]: a estrutura da tabela [jpa01_personne]
- em [4]: o seu conteúdo.
Feito isto, o leitor é convidado a executar a aplicação [Main] e, em seguida, a encerrar o SGBD.
2.1.14.5. Apache Derby
O Apache Derby é apresentado nos Anexos, no parágrafo 5.10. O seu ficheiro persistence.xml é o seguinte:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- ligação JDBC -->
<property name="hibernate.connection.driver_class" value="org.apache.derby.jdbc.ClientDriver" />
<property name="hibernate.connection.url" value="jdbc:derby://localhost:1527//data/2006-2007/eclipse/dvp-jpa/annexes/derby/jpa;create=true" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
...
<!-- Dialeto -->
...
</persistence-unit>
</persistence>
Para executar o [InitDB]:
- execute o SGBD do Apache Derby
- colocar o ficheiro conf/derby/persistence.xml no diretório META-INF/persistence.xml
- executar a aplicação [InitDB]
A perspetiva do SQL Explorer sobre a ligação entre o JDBC e o SGBD é a seguinte:
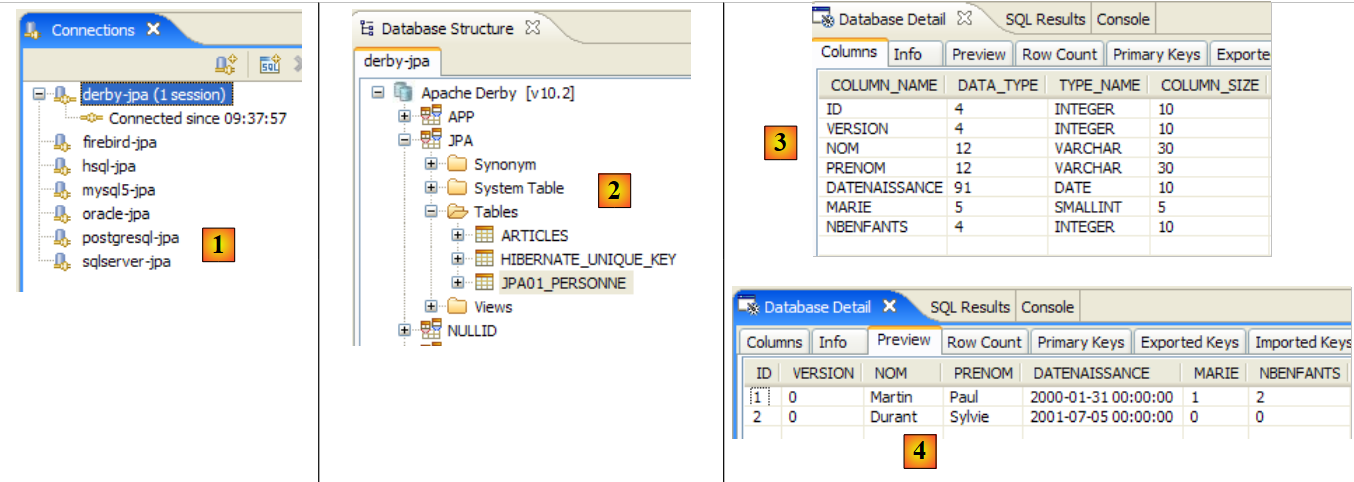 |
- em [1]: a ligação com o Apache Derby
- em [2]: a árvore de ligações após a execução de [InitDB]. Note-se a tabela [HIBERNATE_UNIQUE_KEY] criada pelo JPA / Hibernate para gerar automaticamente os valores sucessivos da chave primária ID. Já referimos que este mecanismo era frequentemente proprietário. Isso é claramente visível aqui. Graças ao JPA, o programador não precisa de se preocupar com estes detalhes do SGBD.
- em [3]: a estrutura da tabela [jpa01_personne]
- em [4]: o seu conteúdo.
Feito isto, o leitor é convidado a executar a aplicação [Main] e, em seguida, a encerrar o SGBD.
2.1.14.6. HSQLDB
O HSQLDB é apresentado nos Anexos, no parágrafo 5.9. O seu ficheiro persistence.xml é o seguinte:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- ligação JDBC -->
<property name="hibernate.connection.driver_class" value="org.hsqldb.jdbcDriver" />
<property name="hibernate.connection.url" value="jdbc:hsqldb:hsql://localhost" />
<property name="hibernate.connection.username" value="sa" />
<!--
<property name="hibernate.connection.password" value="" />
-->
...
<!-- Dialeto -->
<property name="hibernate.dialect" value="org.hibernate.dialect.HSQLDialect" />
...
</properties>
</persistence-unit>
</persistence>
Para executar o [InitDB]:
- execute o SGBD HSQL
- colocar o ficheiro conf/hsql/persistence.xml no META-INF/persistence.xml
- executar a aplicação [InitDB]
A perspetiva do Explorer da ligação JDBC com o SGBD é a seguinte:
 |
- em [1]: a ligação com HSQL
- em [2]: a árvore de ligações após a execução de [InitDB].
- em [3]: a estrutura da tabela [jpa01_personne]
- em [4]: o seu conteúdo.
Feito isto, o leitor é convidado a executar a aplicação [Main] e, em seguida, a encerrar a aplicação SGBD.
2.1.15. Alterar a implementação JPA
Voltemos à arquitetura de teste do nosso projeto atual:
 |
O estudo anterior demonstrou que conseguimos substituir o SGBD pelo [7] sem alterar o código do cliente [3]. Agora, alteramos a implementação JPA [6] e demonstramos, mais uma vez, que isso é feito de forma transparente para o código cliente [3]. Consideramos uma implementação TopLink e [http://www.oracle.com/technology/products/ias/toplink/jpa/index.html]:
 |
2.1.15.1. O projeto Eclipse
Por ocasião da mudança de implementação para o JPA, criamos um novo projeto Eclipse para não sobrecarregar o projeto existente. Com efeito, o novo projeto utiliza bibliotecas de persistência que podem entrar em conflito com as do Hibernate:
 |
- em [1]: a pasta [<exemples>/toplink/direct/personnes-entites] contém o projeto Eclipse. Importe-o.
- em [2]: o projeto [toplink-personnes-entites] importado. É idêntico (foi obtido por cópia) ao projeto [hibernate-personne-entites], com exceção de dois detalhes:
- o ficheiro [META-INF/persistence.xml] [3] configura agora uma camada JPA / Toplink
- a biblioteca [jpa-hibernate] foi substituída pelas bibliotecas [jpa-toplink], [4] e [5] (ver parágrafo 1.5).
- em [6]: a pasta [conf] contém uma versão do ficheiro [persistence.xml] para cada SGBD.
- em [7]: a pasta [ddl], que irá conter os scripts SQL para a geração do esquema da base de dados.
2.1.15.2. A configuração da camada JPA / Toplink
Sabemos que a camada JPA é configurada pelo ficheiro [META-INF/persistence.xml]. Este configura agora uma implementação JPA / Toplink. O seu conteúdo para uma camada JPA interligada com o SGBD e o MySQL5 é o seguinte:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provedor -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- classes persistentes -->
<class>entites.Personne</class>
<!-- propriedades da unidade de persistência -->
<properties>
<!-- ligação JDBC -->
<property name="toplink.jdbc.driver" value="com.mysql.jdbc.Driver" />
<property name="toplink.jdbc.url" value="jdbc:mysql://localhost:3306/jpa" />
<property name="toplink.jdbc.user" value="jpa" />
<property name="toplink.jdbc.password" value="jpa" />
<property name="toplink.jdbc.read-connections.max" value="3" />
<property name="toplink.jdbc.read-connections.min" value="1" />
<property name="toplink.jdbc.write-connections.max" value="5" />
<property name="toplink.jdbc.write-connections.min" value="2" />
<!-- SGBD -->
<property name="toplink.target-database" value="MySQL4" />
<!-- servidor de aplicações -->
<property name="toplink.target-server" value="None" />
<!-- geração de esquema -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
<property name="toplink.application-location" value="ddl/mysql5" />
<property name="toplink.create-ddl-jdbc-file-name" value="create.sql" />
<property name="toplink.drop-ddl-jdbc-file-name" value="drop.sql" />
<property name="toplink.ddl-generation.output-mode" value="both" />
<!-- registos -->
<property name="toplink.logging.level" value="OFF" />
</properties>
</persistence-unit>
</persistence>
- linha 3: não sofreu alterações
- linha 5: o fornecedor é agora a Toplink. A classe aqui referida pode ser encontrada na biblioteca [jpa-toplink] ([1] abaixo):
 |
- linha 7: a baliza <class> serve para nomear todas as classes @Entity do projeto; neste caso, apenas a classe Personne. O Hibernate tinha uma opção de configuração que nos poupava de ter de nomear estas classes. Ele explorava o ficheiro classpath do projeto para encontrar as classes @Entity.
- linha 9: a baliza <properties> que introduz propriedades específicas da implementação JPA utilizada, neste caso o Toplink.
- linhas 11-14: configuração da ligação JDBC com o SGBD MySQL5
- linhas 15-18: configuração do conjunto de ligações JDBC gerido nativamente pelo Toplink:
- linhas 15 e 16: número máximo e mínimo de ligações no conjunto de ligações de leitura. Valor predefinido (2,2)
- linhas 17 e 18: número máximo e mínimo de ligações no conjunto de ligações de escrita. Valor por defeito (10,2)
- linha 20: o SGBD de destino. A lista de SGBD utilizáveis está disponível no pacote [oracle.toplink.essentials.platform.database] (ver [2] acima). O SGBD MySQL5 não está presente na lista [2], pelo que se optou pelo MySQL4. O Toplink suporta um pouco menos de SGBD do que o Hibernate. Assim, dos sete SGBD utilizados nos nossos exemplos, o Firebird não é suportado. Também não se encontra o Oracle na lista. Na verdade, encontra-se noutro pacote ([3] acima). Se, nestes dois pacotes, o SGBD de destino for designado pela classe <Sgbd>Platform.class, a baliza será escrita da seguinte forma:
<property name="toplink.target-database" value="<Sgbd>" />
- linha 22: define o servidor de aplicações, caso a aplicação seja executada num servidor desse tipo. Valores possíveis atuais (None, OC4J_10_1_3, SunAS9). Valor predefinido (None).
- linhas 24-28: quando a camada JPA for inicializada, é-lhe solicitado que efetue uma limpeza da base de dados definida pela ligação JDBC das linhas 11-14. Assim, partire-se-á de uma base de dados vazia.
- linha 24: solicita-se ao Toplink que execute um drop seguido de um create nas tabelas do esquema da base de dados
- linha 25: vamos solicitar ao Toplink que gere os scripts SQL das operações drop e create. O application-location define a pasta na qual esses scripts serão gerados. Por predefinição: (pasta atual).
- linha 26: nome do script SQL das operações create.. Padrão: createDDL.jdbc.
- linha 27: nome do script SQL das operações drop.. Padrão: dropDDL.jdbc.
- linha 28: modo de geração do esquema (Padrão: both):
- both: scripts e base de dados
- database: apenas base de dados
- sql-script: apenas scripts
- linha 30: desativam-se (OFF) os registos do Toplink. Os diferentes níveis de início de sessão disponíveis são os seguintes: OFF, SEVERE, WARNING, INFO, CONFIG, FINE, FINER, FINEST. Por predefinição: INFO.
Consulte o URL [http://www.oracle.com/technology/products/ias/toplink/JPA/essentials/toplink-jpa-extensions.html] para obter uma definição exaustiva das balizas <property> que podem ser utilizadas com o Toplink.
2.1.15.3. Teste [InitDB]
Não há mais nada a fazer. Estamos prontos para executar o primeiro teste [InitDB]:
- executar o SGBD, neste caso o MySQL5
- executar o [InitDB]
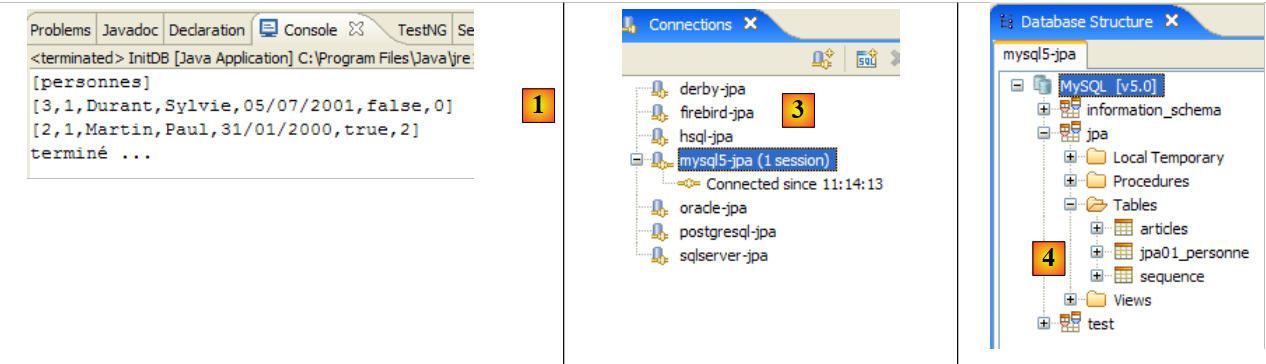 |
- no [1]: a saída da consola. Encontramos aqui os resultados já obtidos com o JPA / Hibernate.
- em [3]: abre-se a perspetiva [SQL Explorer] e, em seguida, abre-se a ligação [mysql5-jpa]
- em [4]: a árvore da base de dados jpa. Verifica-se que a execução de [InitDB] criou duas tabelas: [jpa01_personne], que era esperada, e a tabela [sequence], que era menos esperada.
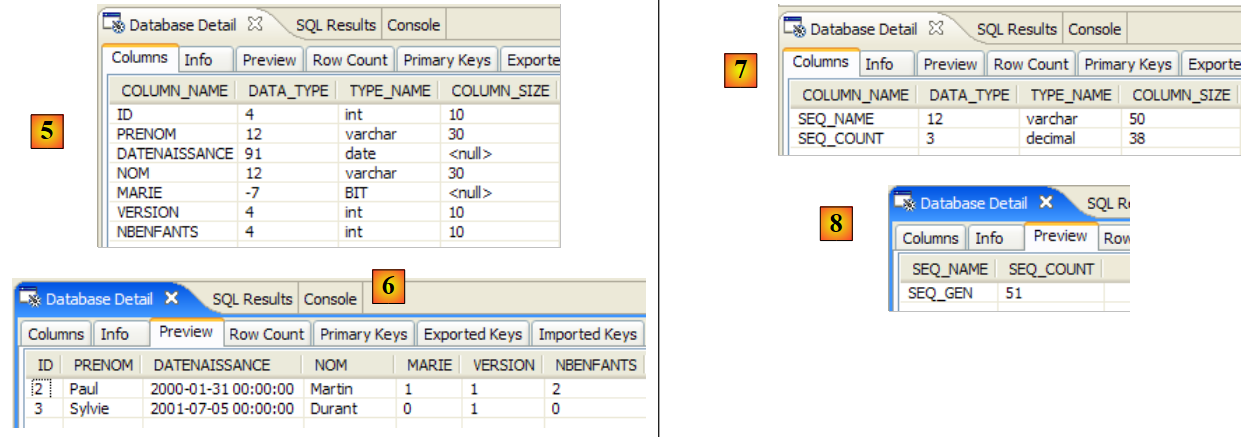 |
- em [5]: a estrutura da tabela [jpa01_personne] e, em [6], o seu conteúdo
- em [7]: a estrutura da tabela [sequence] e, em [8], o seu conteúdo.
O ficheiro de configuração [persistence.xml] solicitava a geração dos scripts da DDL:
<!-- geração de esquema -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
<property name="toplink.application-location" value="ddl/mysql5" />
<property name="toplink.create-ddl-jdbc-file-name" value="create.sql" />
<property name="toplink.drop-ddl-jdbc-file-name" value="drop.sql" />
<property name="toplink.ddl-generation.output-mode" value="both" />
Vamos ver o que foi gerado na pasta [ddl/mysql5]:
 |
create.sql
CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, VERSION INTEGER NOT NULL, NBENFANTS INTEGER NOT NULL, PRIMARY KEY (ID))
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
- linha 1: o DDL da tabela [jpa01_personne]. Verifica-se que o Toplink não utilizou o atributo autoincrement para a chave primária ID. O que faz com que não haja um incremento automático desta chave durante as inserções de linhas.
- linha 2: a DDL da tabela [sequence]. O seu nome parece indicar que a Toplink utiliza esta tabela para gerar os valores da chave primária ID.
- linha 3: inserção de uma única linha na tabela [SEQUENCE]
drop.sql
DROP TABLE jpa01_personne
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
- linha 1: eliminação da tabela [jpa01_personne]
- linha 2: eliminação de uma linha específica da tabela [SEQUENCE]. A tabela em si não é eliminada, nem as outras linhas que possa conter.
Para saber mais sobre a função da tabela [SEQUENCE], ativa-se, na tabela [persistence.xml], os registos do Toplink ao nível FINE, um nível que regista as ordens SQL emitidas pelo Toplink:
<!-- registos -->
<property name="toplink.logging.level" value="FINE" />
Executa-se novamente o InitDB. Abaixo, conservou-se apenas uma visão parcial do ecrã da consola:
...
[TopLink Config]: 2007.05.28 12:07:52.796--ServerSession(12910198)--Conexão(30708295)--Thread(Thread[main,5,main])--Ligado: jdbc:mysql://localhost:3306/jpa
User: jpa@localhost
Database: MySQL Version: 5.0.37-community-nt
Driver: MySQL-AB JDBC Driver Version: mysql-connector-java-3.1.9 ( $Date: 2005/05/19 15:52:23 $, $Revision: 1.1.2.2 $ )
...
[TopLink Fine]: 2007.05.28 12:07:53.093--ServerSession(12910198)--Conexão(19255406)--Thread(Thread[main,5,main])--DROP TABLE jpa01_personne
[TopLink Fine]: 2007.05.28 12:07:53.265--ServerSession(12910198)--Ligação(30708295)--Thread(Thread[main,5,main])--CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, MARIE TINYINT(1) padrão 0 NOT NULL, VERSION INTEGER NOT NULL, NBENFANTS INTEGER NOT NULL, PRIMARY KEY (ID))
[TopLink Fine]: 2007.05.28 12:07:53.468--ServerSession(12910198)--Conexão(19255406)--Tópico(Thread[main,5,main])--CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
[TopLink Warning]: 2007.05.28 12:07:53.468--ServerSession(12910198)--Tópico(Thread[main,5,main])--Exceção [TOPLINK-4002] (Oracle TopLink Essentials - 2.0 (Build b41-beta2 (30/03/2007))): oracle.toplink.essentials.exceptions.DatabaseException
Internal Exception: java.sql.SQLException: Table 'sequence' already exists
Error Code: 1050
Call: CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
Query: DataModifyQuery()
[TopLink Fine]: 2007.05.28 12:07:53.468--ServerSession(12910198)--Conexão(30708295)--Thread(Thread[main,5,main])--DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
[TopLink Fine]: 2007.05.28 12:07:53.609--ServerSession(12910198)--Conexão(19255406)--Thread(Thread[main,5,main])--SELECT * FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
[TopLink Fine]: 2007.05.28 12:07:53.609--ServerSession(12910198)--Conexão(30708295)--Thread(Thread[main,5,main])--INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) valores ('SEQ_GEN', 1)
[TopLink Fine]: 2007.05.28 12:07:53.734--ClientSession(15308417)--Conexão(14069849)--Thread(Thread[main,5,main])--eliminar de jpa01_personne
[TopLink Fine]: 2007.05.28 12:07:53.750--ClientSession(15308417)--Conexão(14069849)--Thread(Thread[main,5,main])--UPDATE SEQUENCE SET SEQ_COUNT = SEQ_COUNT + ? WHERE SEQ_NAME = ?
bind => [50, SEQ_GEN]
[TopLink Fine]: 2007.05.28 12:07:53.750--ClientSession(15308417)--Conexão(14069849)--Thread(Thread[main,5,main])--SELECT SEQ_COUNT FROM SEQUENCE WHERE SEQ_NAME = ?
bind => [SEQ_GEN]
[personnes]
[TopLink Fine]: 2007.05.28 12:07:53.906--ClientSession(15308417)--Ligação(14069849)--Thread(Thread[main,5,main])--INSERT INTO jpa01_personne (ID, PRENOM, DATENAISSANCE, NOM, MARIE, VERSION, NBENFANTS) VALUES (?, ?, ?, ?, ?, ?, ?)
bind => [3, Sylvie, 2001-07-05, Durant, false, 1, 0]
[TopLink Fine]: 2007.05.28 12:07:53.921--ClientSession(15308417)--Conexão(14069849)--Thread(Thread[main,5,main])--INSERT INTO jpa01_personne (ID, PRENOM, DATENAISSANCE, NOM, MARIE, VERSION, NBENFANTS) VALUES (?, ?, ?, ?, ?, ?, ?)
bind => [2, Paul, 2000-01-31, Martin, true, 1, 2]
[TopLink Fine]: 2007.05.28 12:07:53.937--ClientSession(15308417)--Ligação(14069849)--Thread(Thread[main,5,main])--SELECT ID, PRENOM, DATENAISSANCE, NOM, MARIE, VERSION, NBENFANTS FROM jpa01_personne ORDER BY NOM ASC
[3,1,Durant,Sylvie,05/07/2001,false,0]
[2,1,Martin,Paul,31/01/2000,true,2]
[TopLink Config]: 2007.05.28 12:07:54.062--ServerSession(12910198)--Conexão(30708295)--Thread(Thread[main,5,main])--desconexão
[TopLink Info]: 2007.05.28 12:07:54.062--ServerSession(12910198)--Thread(Thread[main,5,main])--file:/C:/data/2006-2007/eclipse/dvp-jpa/toplink/direct/personnes-entites/bin/-jpa logout bem-sucedido
...
terminé ...
- linhas 2-5: uma ligação ao SGBD com os respetivos parâmetros. Na verdade, os registos mostram que, na realidade, o Toplink cria 3 ligações com o SGBD. Seria necessário verificar se este número está relacionado com algum dos valores de configuração utilizados para o conjunto de ligações JDBC:
<property name="toplink.jdbc.read-connections.max" value="3" />
<property name="toplink.jdbc.read-connections.min" value="1" />
<property name="toplink.jdbc.write-connections.max" value="5" />
<property name="toplink.jdbc.write-connections.min" value="2" />
- linha 7: eliminação da tabela [jpa01_personne]. É normal, uma vez que o ficheiro [persistence.xml] solicita a limpeza da base de dados JPA.
- linha 8: criação da tabela [jpa01_personne]. Verifica-se que a chave primária ID não possui o atributo autoincrement.
- linha 9: criação da tabela [SEQUENCE], que já existe, tendo sido criada na execução anterior.
- linhas 10-13: o Toplink sinaliza o erro na criação da tabela [SEQUENCE].
- linhas 15-18: o Toplink limpa a tabela [SEQUENCE]. Após esta limpeza, a tabela [SEQUENCE] tem uma linha (SEQ_NAME, SEQ_COUNT) com os valores («SEQ_GEN», 1).
- linha 18: a tabela [jpa01_personne] é esvaziada.
- linhas 19-20: o Toplink transfere a única linha em que SEQ_NAME='SEQ_GEN' da tabela [SEQUENCE], do valor ('SEQ_GEN', 1) para o valor ('SEQ_GEN', 51)
- linha 21: o Toplink recupera o valor 51 da linha ('SEQ_GEN', 51) da tabela [SEQUENCE].
- linhas 24-27: o Toplink insere na tabela [jpa01_personne] as duas pessoas «Martin» e «Durant». Há aqui um mistério: as chaves primárias destas duas linhas recebem os valores 2 e 3, sem que se saiba como esses valores foram obtidos. Não se sabe se o valor SEQ_COUNT (51) obtido na linha 21 serviu para alguma coisa. Note-se que o valor da versão das linhas é 1, enquanto o Hibernate começava em 0.
- linha 28: o Toplink gera o SELECT para obter todas as linhas da tabela [jpa01_personne]
- linhas 29-30: linhas apresentadas pelo cliente Java
- linhas 31-32: o Toplink encerra uma ligação. Irá repetir a operação para cada uma das ligações inicialmente abertas.
No final, não se sabe exatamente qual é a função da tabela [SEQUENCE], mas parece, ainda assim, que ela desempenha um papel na geração dos valores da chave primária ID. Ao selecionar o nível de registos mais detalhado, FINEST, ficamos a saber um pouco mais sobre a função da tabela [SEQUENCE].
<!-- registos -->
<property name="toplink.logging.level" value="FINEST" />
Abaixo, mantivemos apenas os registos relativos à inserção das duas pessoas na tabela. É aqui que se observa o mecanismo de geração dos valores da chave primária:
- linha 4: verifica-se que o número 51 recuperado da tabela [SEQUENCE] na linha 2 serve para delimitar um intervalo de valores para a chave primária: [2,51]
- linha 5: a primeira pessoa recebe o valor 2 como chave primária
- linha 8: a segunda pessoa recebe o valor 3 como chave primária
- linha 12: mostra a gestão de versões da primeira pessoa
- linha 17: o mesmo se aplica à segunda pessoa
O nível de registos [FINEST] também mostra os limites das transações emitidas pelo Toplink. A análise destes registos revela o que o Toplink faz e constitui uma excelente forma de compreender a ponte entre o modelo orientada a objetos e o modelo relacional.
Do exposto, fica a retê-se o seguinte:
- que diferentes implementações do JPA irão gerar esquemas de bases de dados diferentes. Neste exemplo, o Hibernate e o Toplink não geraram os mesmos esquemas.
- que os níveis de registo FINE, FINER e FINEST do Toplink devem ser utilizados sempre que se pretenda obter esclarecimentos sobre o que o Toplink está exatamente a fazer.
2.1.15.4. Teste [Main]
Vamos agora executar o teste [Main]:
 |
- no [1]: todos os testes são bem-sucedidos, exceto o teste 11, [2]
- no [3]: linha 376, a linha de código onde ocorreu a exceção
O código que gera a exceção é o seguinte:
} catch (RuntimeException e1) {
// tivemos um problema
System.out.format("Erreur dans transaction [%s,%s,%s,%s,%s,%s]%n", e1.getClass().getName(), e1.getMessage(),
e1.getCause().getClass().getName(), e1.getCause().getMessage(), e1.getCause().getCause().getClass().getName(), e1.getCause().getCause()
.getMessage());
try {
...
- linha [3]: a linha da exceção. Temos um NullPointerException, o que sugere que um dos métodos getCause das linhas 4 e 5 devolveu um ponteiro null. Uma expressão como [e1.getCause().getCause()] pressupõe que a cadeia de exceções tem 3 elementos [e1.getCause().getCause(), e1.getCause(), e1]. Se tiver apenas dois, a primeira expressão provocará uma exceção.
Alteramos o código anterior para que apresente apenas as duas últimas exceções da cadeia de exceções:
} catch (RuntimeException e1) {
// tivemos um problema
System.out.format("Erreur dans transaction [%s,%s,%s,%s,]%n", e1.getClass().getName(), e1.getMessage(),
e1.getCause().getClass().getName(), e1.getCause().getMessage());
try {
...
Ao executar, obtemos então o seguinte resultado:
...
[personnes]
[2,5,Martin,Paul,31/01/2000,false,6]
main : ----------- teste11
[personnes]
Erreur dans transaction [javax.persistence.OptimisticLockException,Exception [TOPLINK-5006] (Oracle TopLink Essentials - 2.0 (Build b41-beta2 (03/30/2007))): oracle.toplink.essentials.exceptions.OptimisticLockException
Exception Description: The object [[2,6,Martin,Paul,31/01/2000,false,7]] cannot be updated because it has changed or been deleted since it was last read.
Class> entites.Personne Primary Key> [2],oracle.toplink.essentials.exceptions.OptimisticLockException,
Exception Description: The object [[2,6,Martin,Paul,31/01/2000,false,7]] cannot be updated because it has changed or been deleted since it was last read.
Class> entites.Personne Primary Key> [2],]
[personnes]
[2,5,Martin,Paul,31/01/2000,false,6]
Desta vez, o teste 11 é bem-sucedido. As mensagens relativas à exceção (linhas 6-10) foram solicitadas pelo código Java (linha 3 do código acima). Recorde-se que o teste 11 encadeava, numa mesma transação, várias operações SQL, uma das quais falhava e devia provocar um rollback da transação. Os estados da tabela [jpa01_personne] antes (linha 3) e depois do teste (linha 12) são idênticos, o que demonstra que o rollback ocorreu.
É importante referir aqui um ponto importante: as implementações JPA / Hibernate e JPA / Toplink não são 100% intercambiáveis. Neste exemplo, temos de alterar o código do cliente JPA para evitar um NullPointerException. Voltaremos a deparar-nos com este problema mais tarde, novamente no contexto de uma exceção.
2.1.16. Alterar de SGBD para JPA na implementação / Toplink
Voltemos à arquitetura de teste do nosso projeto atual:
 |
Anteriormente, o SGBD utilizado no [7] era o MySQL5. Mostramos, com a Oracle, como mudar para o SGBD. Em qualquer caso, a alteração a efetuar no projeto Eclipse é simples (ver abaixo): substituir o ficheiro de configuração da camada JPA, persistence.xml [1], por um dos ficheiros da pasta conf ([2] e [3]) do projeto.
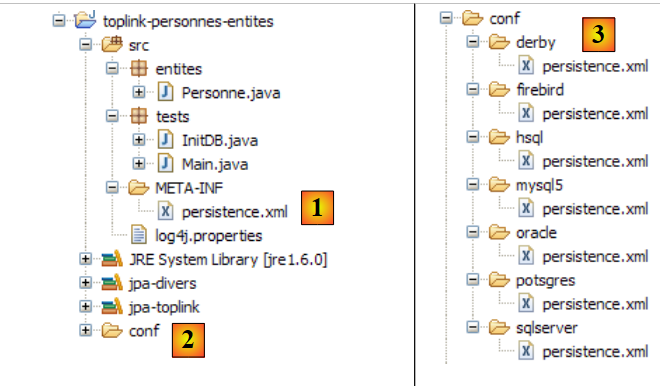 |
2.1.16.1. Oracle 10g Express
O Oracle 10g Express é apresentado nos Anexos, no parágrafo 5.7. O ficheiro persistence.xml da Oracle para o Toplink é o seguinte:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provedor -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- classes persistentes -->
<class>entites.Personne</class>
<!-- propriedades da unidade de persistência -->
<properties>
<!-- ligação JDBC -->
<property name="toplink.jdbc.driver" value="oracle.jdbc.OracleDriver" />
<property name="toplink.jdbc.url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="toplink.jdbc.user" value="jpa" />
<property name="toplink.jdbc.password" value="jpa" />
<property name="toplink.jdbc.read-connections.max" value="3" />
<property name="toplink.jdbc.read-connections.min" value="1" />
<property name="toplink.jdbc.write-connections.max" value="5" />
<property name="toplink.jdbc.write-connections.min" value="2" />
<!-- SGBD -->
<property name="toplink.target-database" value="Oracle" />
<!-- servidor de aplicações -->
<property name="toplink.target-server" value="None" />
<!-- geração de esquema -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
<property name="toplink.application-location" value="ddl/oracle" />
<property name="toplink.create-ddl-jdbc-file-name" value="create.sql" />
<property name="toplink.drop-ddl-jdbc-file-name" value="drop.sql" />
<property name="toplink.ddl-generation.output-mode" value="both" />
<!-- registos -->
<property name="toplink.logging.level" value="OFF" />
</properties>
</persistence-unit>
</persistence>
Esta configuração é idêntica à realizada para o SGBD e o MySQL5, com as seguintes diferenças:
- linhas 11-14, que configuram a ligação JDBC com a base de dados
- linha 20: que define o SGBD de destino
- linha 25: que define a pasta de geração dos scripts SQL do DDL
Para executar o teste [InitDB]:
- execute o SGBD Oracle
- colocar conf/oracle/persistence.xml em META-INF/persistence.xml
- executar a aplicação [InitDB]
Obteve-se os seguintes resultados na consola e na perspetiva [SQL Explorer]:
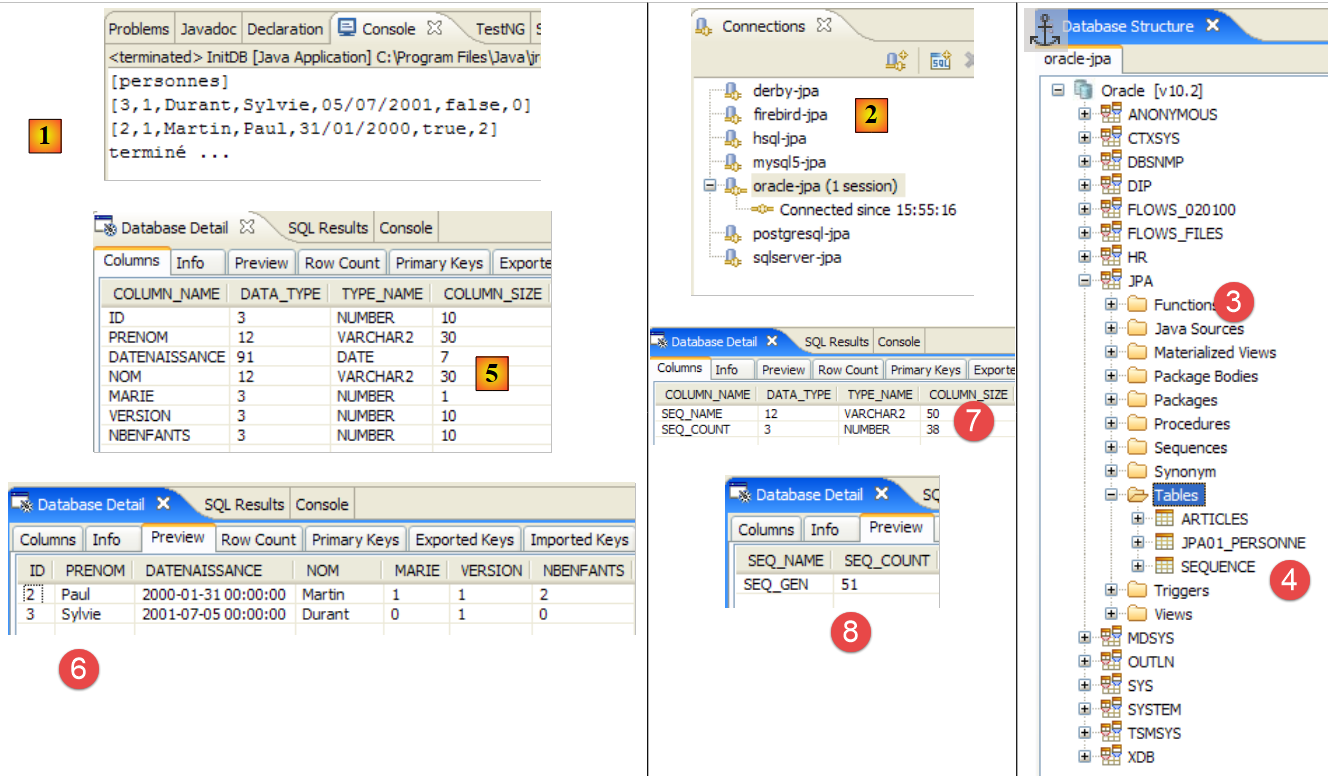 |
- [1]: a exibição da consola
- [2]: a ligação [oracle-jpa] no SQL Explorer
- [3]: a base de dados jpa
- [4]: o InitDB criou duas tabelas: JPA01_PERSONNE e SEQUENCE, tal como no MySQL5. Por vezes, no [4], surgem tabelas [BIN*]. Estas correspondem a tabelas eliminadas. Para observar este fenómeno, basta reexecutar o [InitDB]. A fase de inicialização da camada JPA inclui uma limpeza da base de dados jpa, durante a qual a tabela [JPA01_PERSONNE] é eliminada:
 |
Em [A], surge uma tabela [BIN]. O Oracle não elimina definitivamente uma tabela que tenha sido submetida a um drop, mas coloca-a numa lixeira [Recycle Bin]. Esta lixeira é visível ([B]) com a ferramenta SQL Developer descrita no parágrafo 5.7.4. No [B], é possível eliminar a tabela [JPA01_PERSONNE] que se encontra na lixeira. Isto esvazia a lixeira [C]. Se, no SQL Explorer, atualizarmos (clique com o botão direito do rato / Refresh) as tabelas, verificamos que a tabela BIN já não se encontra presente ([D]).
- [5, 6]: a estrutura e o conteúdo da tabela [JPA01_PERSONNE]
- [7, 8]: a estrutura e o conteúdo da tabela [SEQUENCE]
Pronto! O leitor é agora convidado a executar a aplicação [Main] no Oracle.
2.1.16.2. Os restantes SGBD
Não nos deteremos muito nos outros SGBD. Basta repetir o procedimento seguido para o Oracle. É importante notar os seguintes pontos:
- independentemente do SGBD, o Toplink utiliza sempre a mesma técnica para gerar os valores da chave primária ID da tabela [JPA01_PERSONNE]: utiliza a tabela [SEQUENCE] descrita anteriormente.
- O Toplink não reconhece o SGBD do Firebird. Existe uma base de dados genérica para estes casos:
Com esta base de dados genérica denominada [Auto], os testes com o Firebird falham devido a erros de sintaxe SQL. O Toplink utiliza, para a chave primária ID, um tipo SQL Number(10) que o Firebird não reconhece. É, portanto, necessário escolher um SGBD com os mesmos tipos SQL que o Firebird (para este exemplo). É o caso do Apache Derby:
<!-- ligação JDBC -->
<property name="toplink.jdbc.driver" value="org.firebirdsql.jdbc.FBDriver" />
...
<!-- SGBD -->
<!--
TopLink ne reconnaît pas Firebird pour l'instant (05/07). Derby convient pour remplacer.
-->
<property name="toplink.target-database" value="Derby" />
...
- O Toplink não consegue gerar o esquema original da base de dados para o SGBD HSQLDB. Ou seja, a diretiva:
<!-- geração de esquema -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
falha para o HSQLDB. A causa é um erro de sintaxe na criação da tabela [jpa01_personne]:
[TopLink Fine]: 2007.05.29 09:44:18.515--ServerSession(12910198)--Ligação(29775659)--Thread(Thread[main,5,main])--DROP TABLE jpa01_personne
[TopLink Fine]: 2007.05.29 09:44:18.531--ServerSession(12910198)--Conexão(29775659)--Thread(Thread[main,5,main])--CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, MARIE TINYINT NOT NULL, VERSION INTEGER NOT NULL, NBENFANTS INTEGER NOT NULL, PRIMARY KEY (ID))
[TopLink Warning]: 2007.05.29 09:44:18.531--ServerSession(12910198)--Tópico(Thread[main,5,main])--Exceção [TOPLINK-4002] (Oracle TopLink Essentials - 2.0 (Build b41-beta2 (30/03/2007))): oracle.toplink.essentials.exceptions.DatabaseException
Internal Exception: java.sql.SQLException: Unexpected token: UNIQUE in statement [CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE]
Linha 4, a sintaxe NOM VARCHAR(30) UNIQUE NOT NULL não é aceite pelo HSQL. O Hibernate tinha utilizado a sintaxe: NOM VARCHAR(30) NOT NULL, UNIQUE(NOM).
De um modo geral, o Hibernate revelou-se mais eficaz do que o Toplink na identificação dos SGBD utilizados nos testes deste documento.
2.1.17. Conclusão
O estudo da @Entity [Personne] termina aqui. Do ponto de vista conceptual, pouco foi feito: estudámos a ponte objeto/relacional no caso mais simples: um objeto @Entity <--> uma tabela. No entanto, este estudo permitiu-nos apresentar as ferramentas que iremos utilizar ao longo de todo o documento. Isto permitirá-nos avançar um pouco mais rapidamente daqui em diante no estudo dos outros casos da ponte objeto/relacional que iremos analisar:
- à @Entity [Personne] anterior, vamos adicionar um campo adresse modelado por uma classe [Adresse]. No que diz respeito à base de dados, veremos duas implementações possíveis. Os objetos [Personne] e [Adresse] dão origem a
- uma única tabela [personne] que inclui o endereço
- duas tabelas [personne] e [adresse] ligadas por uma relação de chave estrangeira do tipo um-para-um.
- um exemplo de relação um-para-muitos, em que uma tabela [article] está ligada a uma tabela [categorie] por uma chave estrangeira
- Um exemplo de relação «muitos-para-muitos», em que duas tabelas, [personne] e [activite], estão ligadas por uma tabela de junção [personne_activite].
2.2. Exemplo 2: relação um-para-um através de uma inclusão
2.2.1. O esquema da base de dados
1  | 2 |
- em [1]: a base de dados (plug-in Azurri Clay)
- em [2]: a tabela DDL gerada pelo Hibernate para a tabela MySQL5
A tabela [jpa02_personne] é a tabela [jpa01_personne] analisada anteriormente, à qual foi adicionado um endereço (linhas 12-18 da DDL).
2.2.2. Os objetos @Entity que representam a base de dados
A morada de uma pessoa será representada pela seguinte classe [Adresse]:
package entites;
...
@SuppressWarnings("serial")
@Embeddable
public class Adresse implements Serializable {
// campos
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
// construtores
public Adresse() {
}
public Adresse(String adr1, String adr2, String adr3, String codePostal, String ville, String cedex, String pays) {
...
}
// getters e setters
...
// toString
public String toString() {
return String.format("A[%s,%s,%s,%s,%s,%s,%s]", getAdr1(), getAdr2(), getAdr3(), getCodePostal(), getVille(), getCedex(), getPays());
}
}
- A principal inovação reside na anotação @Embeddable na linha 5. A classe [Adresse] não se destina a dar origem a uma tabela, pelo que não possui a anotação @Entity. A anotação @Embeddable indica que a classe se destina a ser integrada num objeto @Entity e, portanto, na tabela a ele associada. É por isso que, no esquema da base de dados, a classe [Adresse] não aparece como uma tabela separada, mas sim como parte da tabela associada à @Entity [Personne].
A @Entity [Personne] sofreu poucas alterações em relação à sua versão anterior: foi-lhe simplesmente adicionado um campo adresse:
package entites;
...
@Entity
@Table(name = "jpa02_hb_personne")
public class Personne implements Serializable{
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
@Embedded
private Adresse adresse;
// construtores
public Personne() {
}
...
}
- a alteração ocorre nas linhas 33-34. O objeto [Personne] tem agora um campo adresse do tipo Adresse. Isto aplica-se ao POJO. A anotação @Embedded destina-se à ponte objeto/relacional. Indica que o campo [Adresse adresse] deverá ser encapsulado na mesma tabela que o objeto [Personne].
2.2.3. O ambiente de testes
Vamos realizar testes muito semelhantes aos analisados anteriormente. Serão realizados no seguinte contexto:
 |
A implementação utilizada é JPA / Hibernate [6]. O projeto Eclipse dos testes é o seguinte:
 |
O projeto Eclipse [1] difere do anterior apenas nos seus códigos Java [2]. O ambiente (bibliotecas – persistence.xml – SGBD – pastas de configuração, DDL – script Ant) é o já analisado anteriormente, nomeadamente no parágrafo 2.1.5. Este será sempre o caso para os futuros projetos Hibernate e, salvo exceções, não voltaremos a abordar este ambiente. Em particular, os ficheiros persistence.xml que configuram a camada JPA/Hibernate para diferentes SGBD são os já analisados e que se encontram na pasta <conf>.
Caso tenha alguma dúvida sobre os procedimentos a seguir, o leitor é convidado a consultar os procedimentos seguidos no estudo anterior.
O projeto Eclipse encontra-se em [3] na pasta de exemplos [4]. Iremos importá-lo.
2.2.4. Geração do DDL da base de dados
Seguindo as instruções do parágrafo 2.1.7, o ficheiro DDL obtido para o SGBD MySQL5 é o seguinte:
drop table if exists jpa02_hb_personne;
create table jpa02_hb_personne (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
prenom varchar(30) not null,
datenaissance date not null,
marie bit not null,
nbenfants integer not null,
adr1 varchar(30) not null,
adr2 varchar(30),
adr3 varchar(30),
codePostal varchar(5) not null,
ville varchar(20) not null,
cedex varchar(3),
pays varchar(20) not null,
primary key (id)
) ENGINE=InnoDB;
O Hibernate reconheceu corretamente que a morada da pessoa devia ser incluída na tabela associada à @Entity Personne (linhas 11-17).
2.2.5. InitDB
O código de [InitDB] é o seguinte:
package tests;
...
public class InitDB {
// constantes
private final static String TABLE_NAME = "jpa02_hb_personne";
public static void main(String[] args) throws ParseException {
// Contexto de persistência
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// recupera-se um EntityManager a partir do EntityManagerFactory anterior
em = emf.createEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// pedido
Query sql1;
// eliminar os elementos da tabela PERSONNE
sql1 = em.createNativeQuery("delete from " + TABLE_NAME);
sql1.executeUpdate();
// criação de pessoas
Personne p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// criação de endereços
Adresse a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
Adresse a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
// associações pessoa <--> endereço
p1.setAdresse(a1);
p2.setAdresse(a2);
// persistência de pessoas
em.persist(p1);
em.persist(p2);
// visualização de pessoas
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// fim da transação
tx.commit();
// fim de EntityManager
em.close();
// fim de EntityManagerFactory
emf.close();
// registo
System.out.println("terminé...");
}
}
Não há nada de novo neste código. Já se encontrou tudo isto anteriormente. A execução de [InitDB] juntamente com MySQL5 produz os seguintes resultados:
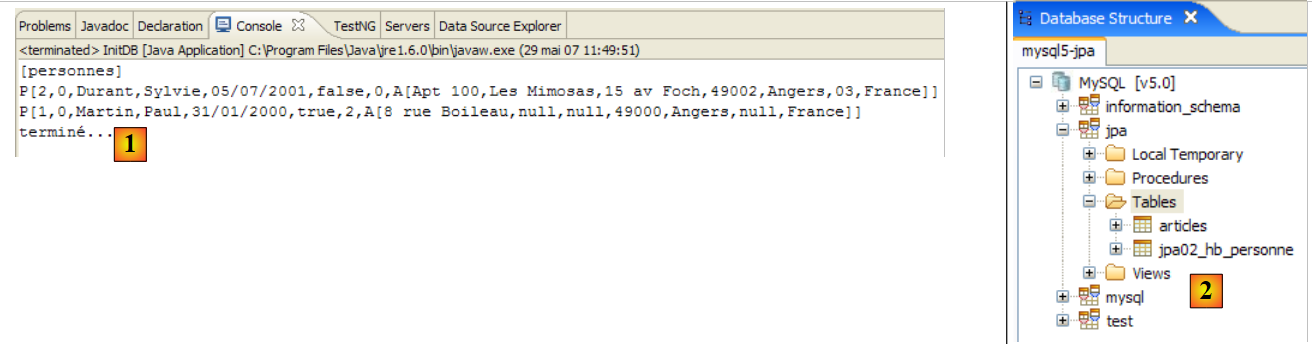 |
 |
- [1]: a saída da consola
- [2]: a tabela [jpa02_hb_personne] na perspetiva do SQL Explorer
- [3] e [4]: a sua estrutura e conteúdo.
2.2.6. Página inicial
A classe [Main] é a seguinte:
package tests;
...
import entites.Adresse;
import entites.Personne;
@SuppressWarnings( { "unused", "unchecked" })
public class Main {
// constantes
private final static String TABLE_NAME = "jpa02_hb_personne";
// Contexto de persistência
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
private static EntityManager em = null;
// objetos partilhados
private static Personne p1, p2, newp1;
private static Adresse a1, a2, a3, a4, newa1, newa4;
public static void main(String[] args) throws Exception {
// recupera-se um EntityManager a partir do EntityManagerFactory
em = emf.createEntityManager();
// limpeza da base de dados
log("clean");clean();
// descarregar tabela
dumpPersonne();
// teste1
log("test1"); test1();
// teste2
log("test2"); test2();
// teste3
log("test3"); test3();
// teste4
log("test4"); test4();
// teste5
log("test5");test5();
// fim do contexto de persistência
if (em != null && em.isOpen())
em.close();
// encerramento de EntityManagerFactory
emf.close();
}
// recuperar o EntityManager atual
private static EntityManager getEntityManager() {
...
}
// obter um novo EntityManager
private static EntityManager getNewEntityManager() {
...
}
// exibir o conteúdo da tabela Pessoa
private static void dumpPersonne() {
...
}
// limpar BD
private static void clean() {
...
}
// registos
private static void log(String message) {
...
}
// criação de objetos
public static void test1() throws ParseException {
// contexto de persistência
EntityManager em = getEntityManager();
// criação de pessoas
p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// criação de endereços
a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
// associações pessoa <--> endereço
p1.setAdresse(a1);
p2.setAdresse(a2);
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistência de pessoas
em.persist(p1);
em.persist(p2);
// fim da transação
tx.commit();
// dump
dumpPersonne();
}
// alterar um objeto do contexto
public static void test2() {
// contexto de persistência
EntityManager em = getEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// incrementar o número de filhos de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// altera-se o seu estado civil
p1.setMarie(false);
// o objeto p1 é automaticamente guardado (verificação de alterações)
// na próxima sincronização (commit ou select)
// fim da transação
tx.commit();
// é apresentada a nova tabela
dumpPersonne();
}
// eliminar um objeto pertencente ao contexto de persistência
public static void test4() {
// contexto de persistência
EntityManager em = getEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// elimina-se o objeto anexado p2
em.remove(p2);
// fim da transação
tx.commit();
// exibe-se a nova tabela
dumpPersonne();
}
// desanexar, reanexar e modificar
public static void test5() {
// novo contexto de persistência
EntityManager em = getNewEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// reanexar p1 ao novo contexto
p1 = em.find(Personne.class, p1.getId());
// fim da transação
tx.commit();
// altera-se o endereço de p1
p1.getAdresse().setVille("Paris");
// exibe-se a nova tabela
dumpPersonne();
}
}
Mais uma vez, nada que já não tenhamos visto. A saída da consola é a seguinte:
O leitor é convidado a estabelecer a ligação entre os resultados e o código.
2.2.7. Implementação JPA / Toplink
Utilizamos agora uma implementação JPA / Toplink:
 |
O novo projeto Eclipse dos testes é o seguinte:
 |
Os códigos Java são idênticos aos do projeto Hibernate anterior. O ambiente (bibliotecas – persistence.xml – SGBD – pastas conf, ddl – script Ant) é o já analisado no parágrafo 2.1.15.2. Será sempre assim para os futuros projetos Toplink e, salvo exceção, não voltaremos a abordar este ambiente. Em particular, os ficheiros persistence.xml que configuram a camada JPA/Toplink para diferentes SGBD são os já analisados e que se encontram na pasta <conf>.
Caso tenha alguma dúvida sobre os procedimentos a seguir, convidamos o leitor a consultar os procedimentos seguidos no estudo anterior.
O projeto Eclipse encontra-se em [3] na pasta de exemplos [4]. Iremos importá-lo.
A execução de [InitDB] com SGBD e MySQL5 produz os seguintes resultados:
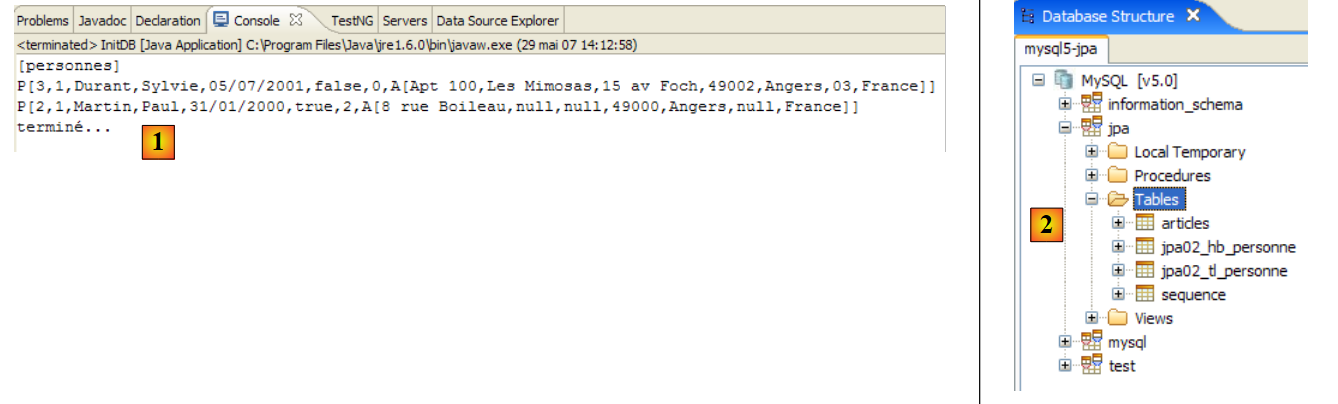 |
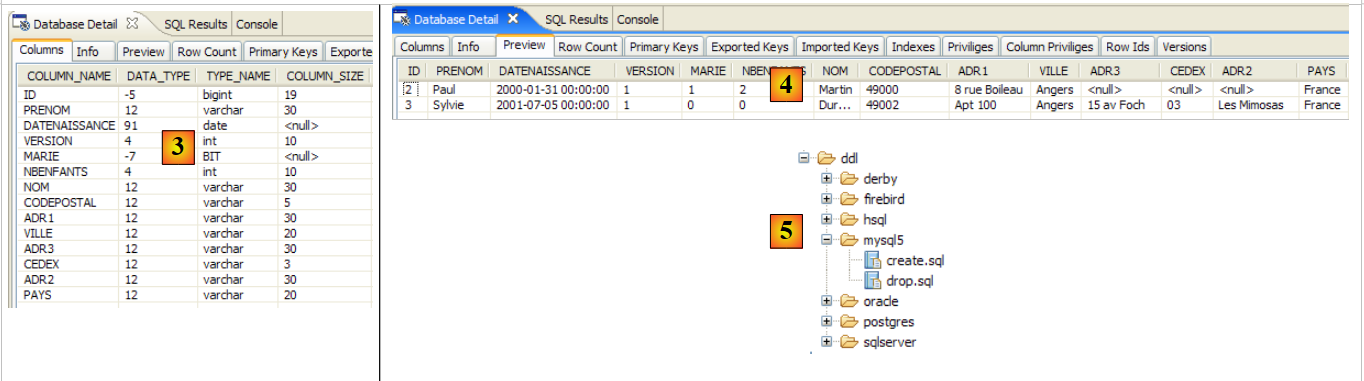 |
- [1]: a saída da consola
- [2]: as tabelas [jpa02_tl_personne] e [SEQENCE] na perspetiva do SQL Explorer
- [3] e [4]: a estrutura e o conteúdo de [jpa02_tl_personne].
Os scripts SQL gerados em ddl/mysql5 [5] são os seguintes:
create.sql
CREATE TABLE jpa02_tl_personne (ID BIGINT NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, VERSION INTEGER NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NBENFANTS INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, CODEPOSTAL VARCHAR(5) NOT NULL, ADR1 VARCHAR(30) NOT NULL, VILLE VARCHAR(20) NOT NULL, ADR3 VARCHAR(30), CEDEX VARCHAR(3), ADR2 VARCHAR(30), PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
drop.sql
DROP TABLE jpa02_tl_personne
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
2.3. Exemplo 3: relação um-para-um através de uma chave estrangeira
2.3.1. O esquema « » da base de dados
1  | 2 |
- para [1]: a base de dados. Desta vez, a morada da pessoa é colocada numa tabela própria, [adresse]. A tabela [personne] está ligada a esta tabela através de uma chave estrangeira.
- em [2]: a tabela DDL gerada pelo Hibernate para a tabela MySQL5:
- linhas 9-20: a tabela [adresse] que será associada à classe [Adresse], que se tornou um objeto @Entity.
- linha 10: a chave primária da tabela [adresse]
- linha 30: em vez de um endereço completo, encontra-se agora na tabela [personne] o identificador [adresse_id] desse endereço.
- linhas 34-38: «pessoa» (adresse_id) é uma chave estrangeira em «morada» (id).
2.3.2. Os objetos @Entity que representam a base de dados
Uma pessoa com morada é agora representada pela seguinte classe [Personne]:
package entites;
...
@Entity
@Table(name = "jpa03_hb_personne")
public class Personne implements Serializable{
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
@OneToOne(cascade = CascadeType.ALL, fetch=FetchType.LAZY)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
...
}
- linhas 32-34: o endereço da pessoa
- linha 32: a anotação @OneToOne indica uma relação um-para-um: uma pessoa tem, no mínimo, e no máximo, um endereço. O atributo cascade = CascadeType.ALL significa que qualquer operação (persist, merge, remove) na @Entity [Personne] deve ser propagada para a @Entity [Adresse]. Do ponto de vista do contexto de persistência, isto significa o seguinte. Se p for uma pessoa e tiver a sua morada:
- uma operação explícita em.persist(p) implicará uma operação implícita em.persist(a)
- uma operação explícita em.merge(p) implicará uma operação implícita em.merge(a)
- Uma operação explícita em.remove(p) dará origem a uma operação implícita em.remove(a)
- linha 32: a anotação @OneToOne indica uma relação um-para-um: uma pessoa tem, no mínimo, e no máximo, um endereço. O atributo cascade = CascadeType.ALL significa que qualquer operação (persist, merge, remove) na @Entity [Personne] deve ser propagada para a @Entity [Adresse]. Do ponto de vista do contexto de persistência, isto significa o seguinte. Se p for uma pessoa e tiver a sua morada:
A experiência mostra que estas cascatas implícitas não são a panaceia. O programador acaba por esquecer o que elas fazem. Pode ser preferível utilizar operações explícitas no código. Existem diferentes tipos de cascata. A anotação @OneToOne poderia ter sido escrita da seguinte forma:
//@OneToOne(cascade = CascadeType.ALL, fetch=FetchType.LAZY)
@OneToOne(cascade = {CascadeType.MERGE, CascadeType.PERSIST, CascadeType.REFRESH, CascadeType.REMOVE}, fetch=FetchType.LAZY)
O atributo cascade aceita aqui como valor um array de constantes que especificam os tipos de cascatas desejadas.
O atributo fetch=FetchType.LAZY solicita ao Hibernate que carregue a dependência no último momento. Quando se insere uma lista de pessoas no contexto de persistência, não se pretende necessariamente incluir os seus endereços. Por exemplo, pode-se querer essa morada apenas para uma pessoa específica escolhida por um utilizador através de uma interface web. O atributo fetch=FetchType.EAGER, por sua vez, solicita o carregamento imediato das dependências.
- (continuação)
- linha 33: a anotação @JoinColumn define a chave estrangeira que a tabela da @Entity [Personne] possui na tabela da @Entity [Adresse]. O atributo name define o nome da coluna que serve de chave estrangeira. O atributo unique=true impõe a relação um-para-um: não é possível ter duas vezes o mesmo valor na coluna [adresse_id]. O atributo nullable=false obriga uma pessoa a ter uma morada.
A morada de uma pessoa é agora representada pela seguinte @Entity [Adresse]:
package entites;
...
@Entity
@Table(name = "jpa03_hb_adresse")
public class Adresse implements Serializable {
// campos
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
@OneToOne(mappedBy = "adresse", fetch=FetchType.LAZY)
private Personne personne;
// construtores
public Adresse() {
}
...
}
- linha 4: a classe [Adresse] torna-se um objeto @Entity. Por conseguinte, será o objeto de uma tabela na base de dados.
- linhas 9-12: tal como qualquer objeto @Entity, [Adresse] tem uma chave primária. Esta foi denominada Id e apresenta as mesmas anotações (padrão) da chave primária Id da @Entity [Personne].
- linhas 39-40: a relação um-para-um com a @Entity [Personne]. Há aqui várias subtilezas:
- em primeiro lugar, o campo personne não é obrigatório. Permite-nos, a partir de uma morada, identificar a única pessoa com essa morada. Se não quiséssemos esta funcionalidade, o campo personne não existiria e tudo funcionaria na mesma.
- A relação um-para-um que liga as duas entidades [Personne] e [Adresse] já foi configurada na @Entity [Personne]:
@OneToOne(cascade = CascadeType.ALL, fetch=FetchType.LAZY)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
Para que as duas configurações «um-para-um» não entrem em conflito entre si, uma é considerada como principale e a outra como inverse. É a relação denominada principale que é gerida pela ponte objeto/relacional. A outra relação, denominada inverse, não é gerida diretamente: é gerida indiretamente pela relação principale. Na @Entity [Adresse]:
@OneToOne(mappedBy = "adresse", fetch=FetchType.LAZY)
private Personne personne;
é o atributo mappedBy que define a relação um-para-um acima, a relação inverse da relação principale, de um-para-um, definida pelo campo adresse da @Entity [Personne].
2.3.3. O projeto Eclipse / Hibernate 1
A implementação JPA aqui utilizada é a do Hibernate. O projeto Eclipse dos testes é o seguinte:
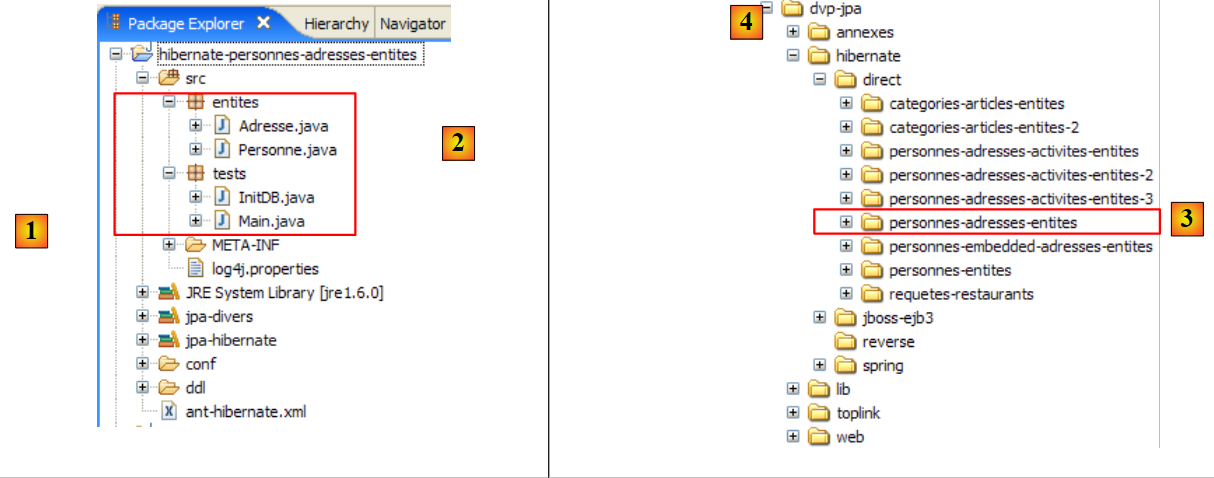 |
O projeto [3] encontra-se na pasta de exemplos [4]. Vamos importá-lo.
2.3.4. Geração do ficheiro DDL da base de dados
Seguindo as instruções do parágrafo 2.1.7, o ficheiro DDL obtido para o SGBD MySQL5 é o que se encontra no início deste parágrafo.
2.3.5. InitDB
O código de [InitDB] é o seguinte:
package tests;
...
import entites.Adresse;
import entites.Personne;
public class InitDB {
// constantes
private final static String TABLE_PERSONNE = "jpa03_hb_personne";
private final static String TABLE_ADRESSE = "jpa03_hb_adresse";
public static void main(String[] args) throws ParseException {
// Contexto de persistência
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// recupera-se um EntityManager a partir do EntityManagerFactory anterior
em = emf.createEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// pedido
Query sql1;
// eliminar os elementos da tabela PERSONNE
sql1 = em.createNativeQuery("delete from " + TABLE_PERSONNE);
sql1.executeUpdate();
// eliminar os elementos da tabela ADRESSE
sql1 = em.createNativeQuery("delete from " + TABLE_ADRESSE);
sql1.executeUpdate();
// criação de pessoas
Personne p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// criação de endereços
Adresse a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
Adresse a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
Adresse a3 = new Adresse("x", "x", "x", "x", "x", "x", "x");
Adresse a4 = new Adresse("y", "y", "y", "y", "y", "y", "y");
// associações pessoa <--> endereço
p1.setAdresse(a1);
a1.setPersonne(p1);
p2.setAdresse(a2);
a2.setPersonne(p2);
// persistência de pessoas e, em cadeia, das respetivas moradas
em.persist(p1);
em.persist(p2);
// e dos endereços a3 e a4 não associados a pessoas
em.persist(a3);
em.persist(a4);
// exibição de pessoas
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// visualização de endereços
System.out.println("[adresses]");
for (Object a : em.createQuery("select a from Adresse a").getResultList()) {
System.out.println(a);
}
// fim da transação
tx.commit();
// fim EntityManager
em.close();
// fim de EntityManagerFactory
emf.close();
// registo
System.out.println("terminé...");
}
}
Apenas comentamos o que apresenta um interesse novo em relação ao que já foi estudado:
- linhas 31-32: criam-se duas pessoas
- linhas 34-37: criam-se quatro endereços
- linhas 39-42: associam-se as pessoas (p1, p2) aos endereços (a1, a2). Os endereços (a3, a4) ficam órfãos. Nenhuma pessoa os referencia. O DDL permite isso. Se uma pessoa tem necessariamente um endereço, o inverso não é verdadeiro.
- linhas 44-45: mantêm-se as pessoas (p1, p2). Como atribuímos um atributo cascade = CascadeType.ALL à relação um-para-um que liga uma pessoa à sua morada, as moradas (a1, a2) destas duas pessoas também deveriam ser submetidas a um persist. É isso que queremos verificar. No caso dos endereços órfãos (a3, a4), somos obrigados a proceder de forma explícita (linhas 47-48).
- linhas 51-53: exibição da tabela de pessoas
- linhas 56-57: exibição da tabela de endereços
A execução do [InitDB] juntamente com o MySQL5 produz os seguintes resultados:
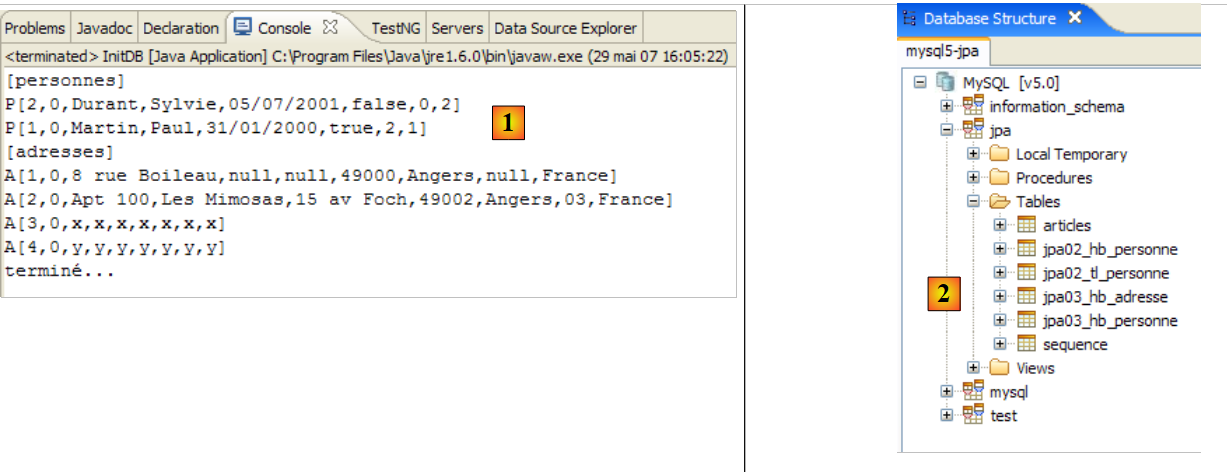 |
 |
- [1]: a exibição na consola
- [2]: as tabelas [jpa03_hb_*] na perspetiva do SQL Explorer
- [3]: a tabela de pessoas
- [4]: a tabela de endereços. Estão todas lá. Deve-se também notar a ligação entre a coluna [adresse_id] em [3] e a coluna [id] em [4] (chave estrangeira).
2.3.6. Página inicial
A classe [Main] encadeia seis testes que vamos analisar.
2.3.6.1. Teste 1
Este teste é o seguinte:
// criação de objetos
public static void test1() throws ParseException {
// contexto de persistência
EntityManager em = getEntityManager();
// criação de pessoas
p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// criação de endereços
a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
a3 = new Adresse("x", "x", "x", "x", "x", "x", "x");
a4 = new Adresse("y", "y", "y", "y", "y", "y", "y");
// associações pessoa <--> endereço
p1.setAdresse(a1);
a1.setPersonne(p1);
p2.setAdresse(a2);
a2.setPersonne(p2);
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistência de pessoas
em.persist(p1);
em.persist(p2);
// e dos endereços a3 e a4 não associados a pessoas
em.persist(a3);
em.persist(a4);
// fim da transação
tx.commit();
// exibição das tabelas
dumpPersonne();
dumpAdresse();
}
Este código foi retirado de [InitDB]. O seu resultado é o seguinte:
As duas tabelas foram preenchidas.
2.3.6.2. Teste 2
Este teste é o seguinte:
// alterar um objeto do contexto
public static void test2() {
// contexto de persistência
EntityManager em = getEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// incrementar o número de filhos de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// altera-se o seu estado civil
p1.setMarie(false);
// o objeto p1 é automaticamente guardado (verificação de alterações)
// na próxima sincronização (commit ou select)
// fim da transação
tx.commit();
// é apresentada a nova tabela
dumpPersonne();
}
O resultado é o seguinte:
- linha 4: a pessoa p1 viu o seu número de filhos aumentar em 1 e a sua versão passar de 0 para 1
2.3.6.3. Teste 4
Este teste é o seguinte:
// eliminar um objeto pertencente ao contexto de persistência
public static void test4() {
// contexto de persistência
EntityManager em = getEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// elimina-se o objeto associado p2
em.remove(p2);
// fim da transação
tx.commit();
// são apresentadas as novas tabelas
dumpPersonne();
dumpAdresse();
}
- linha 9: elimina-se a pessoa p2. Esta tem uma relação em cascata com a morada a2. Por isso, a morada a2 também deve ser eliminada.
O resultado do teste 4 é o seguinte:
- a pessoa p2, presente na linha 3 do teste 1, já não está presente no teste 4
- O mesmo se aplica ao seu endereço a2, que aparece na linha 7 do teste 1 e está ausente do teste 4.
2.3.6.4. Teste 5
Este teste é o seguinte:
// desanexar, reanexar e modificar
public static void test5() {
// novo contexto de persistência
EntityManager em = getNewEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// reanexar p1 ao novo contexto
p1 = em.find(Personne.class, p1.getId());
// alterar o endereço de p1
p1.getAdresse().setVille("Paris");
// fim da transação
tx.commit();
// exibem-se as novas tabelas
dumpPersonne();
dumpAdresse();
}
- linha 4: temos um contexto de persistência novo, portanto vazio.
- linha 9: insere-se a pessoa p1 nesse contexto. p1 é procurado na base de dados porque não se encontra no contexto. Os elementos dependentes de p1 (o seu endereço), por sua vez, não são recuperados da base de dados porque escrevemos:
@OneToOne(..., fetch=FetchType.LAZY)
Este é o conceito de «lazy loading» ou «carregamento na hora certa»: as dependências de um objeto persistente só são carregadas na memória quando são necessárias.
- linha 11: altera-se o campo «cidade» do endereço de p1. Devido ao getAdresse e caso o endereço de p1 ainda não estivesse no contexto de persistência, este será carregado através de uma leitura da base de dados.
- linha 13: valida-se a transação, o que levará à sincronização do contexto de persistência com a base de dados. Este irá constatar que a morada da pessoa p1 foi alterada e irá guardá-la.
A execução de test5 produz os seguintes resultados:
- a cidade da pessoa p1 (linha 3 do teste 4, linha 10 do teste 5) mudou efetivamente de Angers (linha 5 do teste 4) para Paris (linha 12 do teste 5).
2.3.6.5. Teste 6
Este teste é o seguinte:
// eliminar um objeto «Endereço»
public static void test6() {
EntityTransaction tx = null;
// novo contexto de persistência
EntityManager em = getNewEntityManager();
// início da transação
tx = em.getTransaction();
tx.begin();
// a endereço a3 é novamente associado ao novo contexto
a3 = em.find(Adresse.class, a3.getId());
System.out.println(a3);
// eliminá-la
em.remove(a3);
// fim da transação
tx.commit();
// dump da tabela «Endereço»
dumpAdresse();
}
- linha 5: estamos num contexto de persistência novo, portanto vazio.
- linha 10: insere-se o endereço a3 no contexto de persistência
- linha 13: eliminamo-la. Era um endereço órfão (não associado a uma pessoa). A eliminação é, portanto, possível.
O resultado da execução é o seguinte:
- o endereço a3 do teste 5 (linha 6) desapareceu dos endereços do teste 6 (linhas 11-12)
2.3.6.6. Teste 7
Este teste é o seguinte:
// revertida
public static void test7() {
EntityTransaction tx = null;
try {
// novo contexto de persistência
EntityManager em = getNewEntityManager();
// início da transação
tx = em.getTransaction();
tx.begin();
// reassocia o endereço a1 ao novo contexto
newa1 = em.find(Adresse.class, a1.getId());
// a morada a4 é novamente associada ao novo contexto
newa4 = em.find(Adresse.class, a4.getId());
// tenta-se eliminá-las — deverá ser lançada uma exceção, pois não é possível eliminar um endereço associado a uma pessoa, o que é o caso de newa1
em.remove(newa4);
em.remove(newa1);
// fim da transação
tx.commit();
} catch (RuntimeException e1) {
// ocorreu um problema
System.out.format("Erreur dans transaction [%s%n%s%n%s%n%s]%n", e1.getClass().getName(), e1.getMessage(), e1.getCause(), e1.getCause()
.getCause());
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s]%n", e2.getMessage());
}
// estamos a abandonar o contexto atual
em.clear();
}
// dump — a tabela «Endereço» não deve ter sido alterada devido ao rollback
dumpAdresse();
}
- test7: testa-se um rollback de uma transação
- linha 6: estamos num contexto de persistência novo, portanto vazio.
- linha 11: insere-se o endereço a1 no contexto de persistência, sob a referência newa1
- linha 13: insere-se o endereço a4 no contexto de persistência, sob a referência newa4
- linhas 15-16: eliminam-se os dois endereços newa1 e newa4. newa1 é o endereço da pessoa p1 e, por isso, na base de dados, p1 faz referência a newa1 através de uma chave estrangeira. A eliminação de newa1 irá, portanto, falhar e lançar uma exceção durante a sincronização do contexto de persistência no commit da transação (linha 18). Esta irá sofrer um rollback (linha 25) e, por conseguinte, as duas operações da transação serão anuladas. Dever-se-á, portanto, constatar que a morada newa4, que poderia ter sido legalmente eliminada, não o foi.
A execução produz o seguinte resultado:
main : ----------- test6
A[3,0,x,x,x,x,x,x,x]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
main : ----------- test7
Erreur dans transaction [javax.persistence.RollbackException
Error while commiting the transaction
org.hibernate.ObjectDeletedException: deleted entity passed to persist: [entites.Adresse#<null>]
null]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
- a tabela de endereços do teste 7 (linhas 12-13) é idêntica à do teste 6 (linhas 4-5). O rollback parece ter ocorrido. Dito isto, a mensagem de erro da linha 9 é um enigma e merece ser investigada. Parece que a exceção que ocorreu não é a esperada. É necessário passar os registos do Hibernate no log4j.properties para o modo DEBUG para obter uma visão mais clara:
# Opção do registador de enraizamento
log4j.rootLogger=ERROR, stdout
# Opções de registo do Hibernate (o INFO mostra apenas mensagens de arranque)
log4j.logger.org.hibernate=DEBUG
Verifica-se então que, quando o endereço a1 foi colocado no contexto de persistência, o Hibernate colocou aí também a entidade p1, provavelmente devido à relação um-para-um da @Entity [Adresse]:
@OneToOne(mappedBy = "adresse", fetch=FetchType.LAZY)
private Personne personne;
Embora tenha sido solicitado o «LazyLoading» aqui, a dependência [Personne] é, no entanto, carregada imediatamente. Isto significa provavelmente que o atributo fetch=FetchType.LAZY não faz sentido neste contexto. Verifica-se, em seguida, que, ao confirmar a transação, o Hibernate preparou a eliminação dos endereços a1 e a4, mas também o armazenamento da pessoa p1. E é aí que ocorre a exceção: como a pessoa p1 tem uma cascata na sua morada, o Hibernate pretende também persistir a morada a1, apesar de esta ter acabado de ser eliminada. É o Hibernate que lança a exceção e não o controlador JDBC. Daí a mensagem da linha 9 acima. Além disso, verifica-se que o rollback da linha 25 nunca é executado, uma vez que a transação se tornou inativa. O teste da linha 24 impede, portanto, o rollback.
Não se atingiu, portanto, o objetivo pretendido: demonstrar um rollback. Na verdade, não foi emitida nenhuma ordem SQL na base de dados. Retemos alguns pontos:
- a importância de ativar registos detalhados para compreender o que faz o ORM
- embora um ORM possa facilitar a vida do programador, também pode complicá-la ao ocultar comportamentos que o programador precisaria de conhecer. Neste caso, o modo de carregamento das dependências de uma @Entity.
2.3.7. Projeto Eclipse / Hibernate 2
Copiamos e colamos o projeto Eclipse / Hibernate para alterar ligeiramente a configuração dos objetos @Entity:
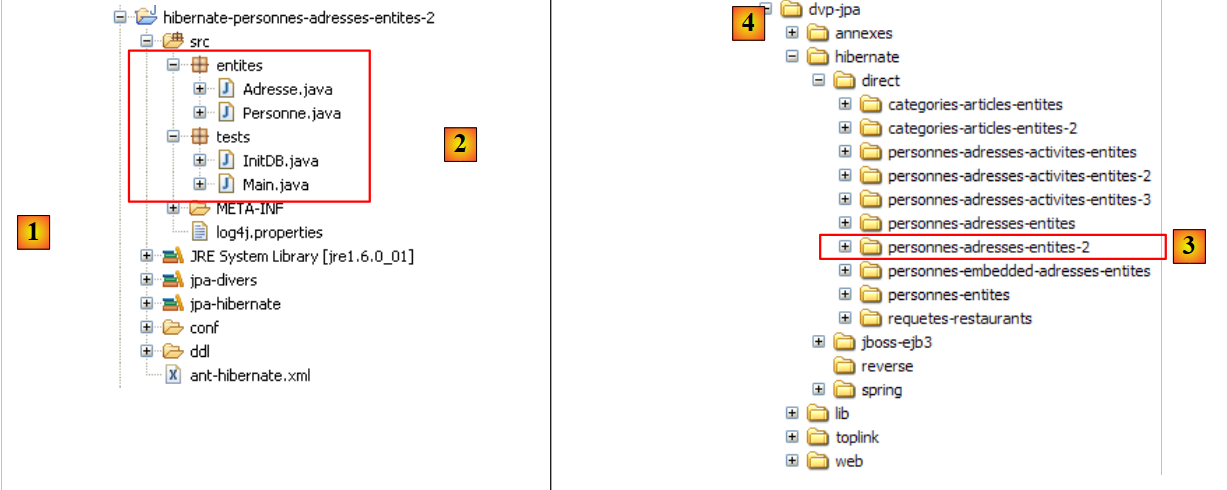 |
O projeto encontra-se em [3] na pasta de exemplos [4]. Vamos importá-lo.
Alteramos apenas a @Entity [Adresse] para que deixe de ter uma relação inversa um-para-um com a @Entity [Personne]:
package entites;
...
@Entity
@Table(name = "jpa04_hb_adresse")
public class Adresse implements Serializable {
// campos
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
...
@Column(length = 20, nullable = false)
private String pays;
// @OneToOne(mappedBy = «endereço», fetch=FetchType.LAZY)
// private Pessoa pessoa;
// construtores
public Adresse() {
}
- linhas 25-26: a relação inversa @OneToOne é eliminada. É importante compreender que uma relação inversa nunca é indispensável. Apenas a relação principal o é. A relação inversa pode ser utilizada por conveniência. Neste caso, permitia obter, de forma simples, o proprietário de um endereço. Uma relação inversa pode sempre ser substituída por uma consulta JPQL. É isso que vamos demonstrar no exemplo que se segue.
Os programas de teste são reproduzidos na íntegra. O que nos interessa é apenas o teste 7, aquele em que vimos a relação inversa um-para-um em ação. Acrescentamos ainda um teste 8 para mostrar como, sem a relação inversa Endereço -> Pessoa, é possível, mesmo assim, recuperar a pessoa com determinado endereço.
O teste 7 não sofre alterações. A sua execução apresenta agora os seguintes resultados (registos desativados):
main : ----------- teste6
A[3,0,x,x,x,x,x,x,x]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
main : ----------- teste7
Erreur dans transaction [javax.persistence.RollbackException
Error while commiting the transaction
org.hibernate.exception.ConstraintViolationException: could not delete: [entites.Adresse#1]
java.sql.SQLException: Cannot delete or update a parent row: a foreign key constraint fails (`jpa/jpa04_hb_personne`, CONSTRAINT `FKEA3F04515FE379D0` FOREIGN KEY (`adresse_id`) REFERENCES `jpa04_hb_adresse` (`id`))]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
- Desta vez, temos efetivamente a exceção esperada: aquela lançada pelo controlador JDBC porque tentámos eliminar, na tabela [adresse], uma linha referenciada por uma chave estrangeira de uma linha da tabela [personne]. A linha [10] é explícita quanto à causa do erro.
- O rollback ocorreu corretamente: no final do teste 7, a tabela [adresse] (linhas 12-13) é a mesma que tínhamos no final do teste 6 (linhas 4-5).
Qual é a diferença em relação ao teste 7 do projeto Eclipse anterior? Por que razão temos aqui uma exceção Jdbc que não se verificou no teste anterior? Porque a @Entity [Adresse] já não tem uma relação inversa um-para-um com a @Entity [Personne], sendo gerida de forma isolada pelo Hibernate. Quando a morada newa1 foi introduzida no contexto de persistência, o Hibernate não incluiu também nesse contexto a pessoa p1, à qual essa morada pertence. A eliminação dos endereços newa1 e newa4 foi, portanto, efetuada sem que a entidade Personne estivesse presente no contexto.
Agora, a partir do endereço newa1, como é que se poderia chegar à pessoa p1 que tem esse endereço? É uma questão legítima. O teste 8 que se segue responde a essa questão:
// relação inversa um-para-um
// realizada por uma consulta JPQL
public static void test8() {
EntityTransaction tx = null;
// novo contexto de persistência
EntityManager em = getNewEntityManager();
// início da transação
tx = em.getTransaction();
tx.begin();
// a morada a1 é novamente associada ao novo contexto
newa1 = em.find(Adresse.class, a1.getId());
// recupera-se a pessoa proprietária deste endereço
Personne p1 = (Personne) em.createQuery("select p from Personne p join p.adresse a where a.id=:adresseId").setParameter("adresseId", newa1.getId())
.getSingleResult();
// exibindo-os
System.out.println("adresse=" + newa1);
System.out.println("personne=" + p1);
// fim da transação
tx.commit();
}
- linha 6: novo contexto de persistência vazio
- linhas 8-9: início da transação
- linha 11: o endereço a1 é introduzido no contexto de persistência e referenciado por newa1.
- linha 13: recupera-se a pessoa p1 com a morada newa1 através de uma consulta JPQL. Sabe-se que [Personne] e [Adresse] estão ligadas por uma relação de chave estrangeira. Na classe [Personne], é o campo [adresse], que possui a anotação @OneToOne, que concretiza esta relação. A instrução JPQL «select p from Personne p join p.adresse a» realiza uma junção entre as tabelas [personne] e [adresse]. O equivalente SQL gerado numa consola Hibernate (ver exemplos do parágrafo 2.1.12) é o seguinte:
É possível ver claramente a junção das duas tabelas. Cada pessoa está agora associada ao seu endereço. Resta especificar que estamos interessados apenas no endereço newa1. A consulta passa a ser «select p from Pessoa p join p.adresse a where a.id=:adresseId». Note-se a utilização dos aliases p e a. As consultas JPQL utilizam os aliases de forma intensiva. Assim, a expressão «from Pessoa p join p.adresse a» faz com que uma pessoa seja representada pelo alias p e a sua morada (p.adresse) pelo alias a. A operação de restrição «where a.id=:adresseId» restringe as linhas solicitadas apenas às pessoas p que tenham o valor:adresseId como identificador da sua morada a. :adresseId é designado por parâmetro, e a ordem JPQL por ordem JPQL parametrizada. Na execução, este parâmetro deve receber um valor. Trata-se do método
que permite atribuir um valor a um parâmetro identificado pelo seu nome. Note-se que setParameter devolve um objeto Query, tal como o método createQuery. Assim, é possível encadear chamadas aos métodos [em.createQuery(...).setParameter(...).getSingleResult(...)], uma vez que os métodos [setParameter, getSingleResult] fazem parte da interface Query. O método [getSingleResult] é utilizado para as consultas Select que devolvem apenas um único resultado. É o caso aqui.
- linhas 16-17: exibe-se a morada newa1 e a pessoa p1 associada a essa morada, para verificação.
O resultado obtido é o seguinte:
Está correto. Retemos deste exemplo que a relação inversa um-para-um da @entity [Adresse] para a @entity [Personne] não era indispensável. A experiência demonstrou aqui que a sua remoção conduziu a um comportamento mais previsível do código. É frequentemente o caso.
2.3.8. Console do Hibernate
O teste 8 anterior utilizou um comando JPQL para efetuar uma junção entre as entidades Personne e Adresse. Embora sejam análogas à linguagem SQL, as linguagens JPQL, JPA ou HQL do Hibernate requerem uma fase de aprendizagem, e a consola do Hibernate é excelente para esse efeito. Já a utilizámos no parágrafo 2.1.12, para explorar uma única tabela. Vamos repeti-lo aqui para explorar duas tabelas ligadas por uma relação de chave estrangeira.
Vamos criar uma consola do Hibernate para o nosso projeto atual no Eclipse:
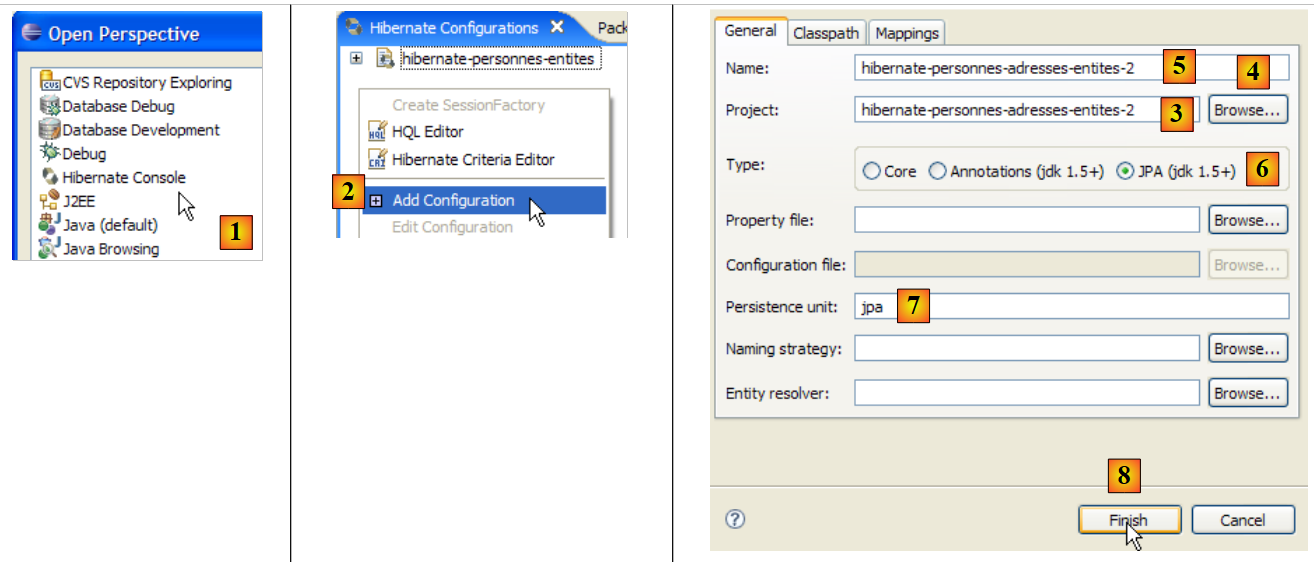 |
- [1]: mudamos para uma perspetiva [Hibernate Console] (Window / Open Perspective / Other)
- [2]: criamos uma nova configuração
- através do botão [4], selecionamos o projeto Java para o qual a configuração do Hibernate está a ser criada. O seu nome é exibido em [3].
- Em [5], atribuímos o nome que pretendemos a esta configuração. Neste caso, utilizámos o nome do projeto Java.
- No ficheiro [6], indicamos que estamos a utilizar uma configuração JPA, para que a ferramenta saiba que deve processar o ficheiro [META-INF/persistence.xml]
- no [7]: neste ficheiro [META-INF/persistence.xml], indicamos que é necessário utilizar a unidade de persistência denominada jpa.
- No ficheiro [8], validamos a configuração.
A seguir, é necessário que o SGBD seja executado. Neste caso, trata-se do MySQL5.
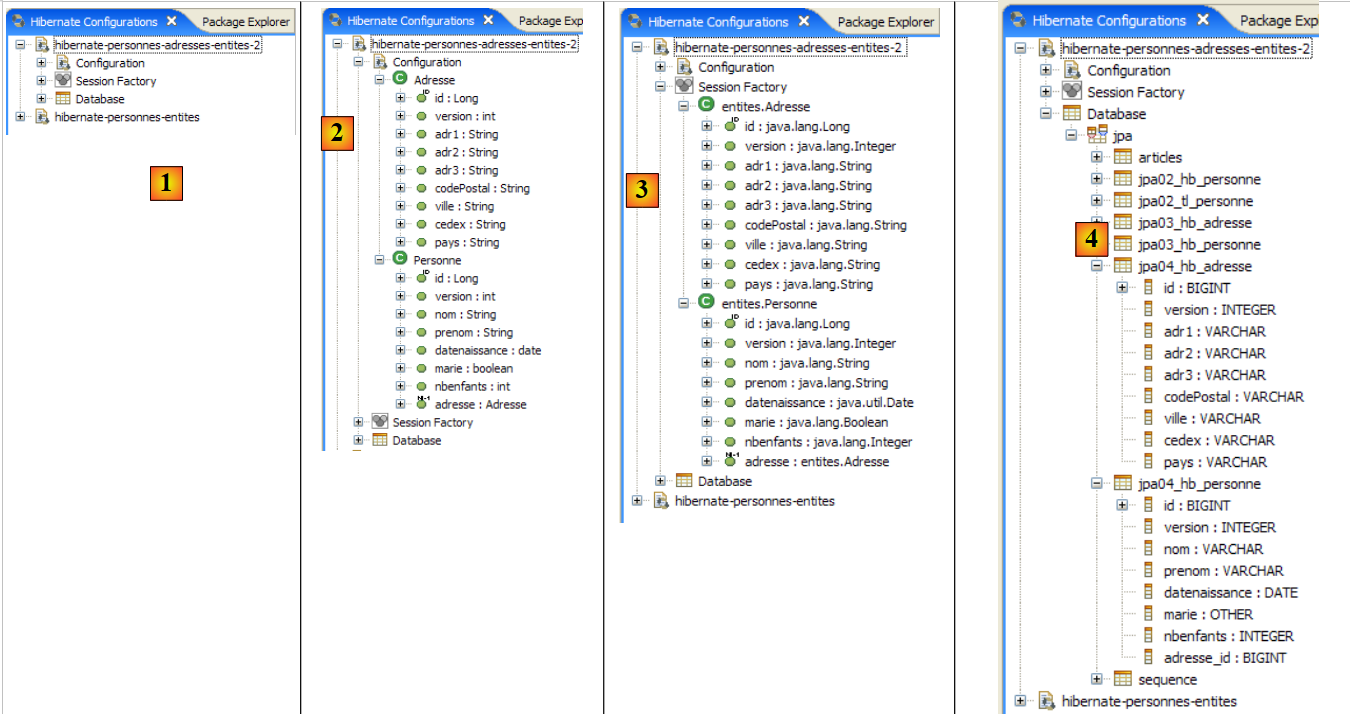 |
- no [1]: a configuração criada apresenta uma árvore com três ramos
- em [2]: o ramo [Configuration] lista os objetos que a consola utilizou para se configurar: neste caso, as @Entity Personne e Adresse.
- em [3]: a Session Factory é um conceito do Hibernate semelhante ao EntityManager de JPA. Ela estabelece a ponte entre objetos e relações através dos objetos do ramo [Configuration]. Em [3] são apresentados os objetos do contexto de persistência, neste caso, mais uma vez, os @Entity Personne e Adresse.
- Em [4]: a base de dados acedida através da configuração encontrada em [persistence.xml]. Aqui encontram-se as tabelas [jpa04_hb_*] geradas pelo nosso projeto Eclipse atual.
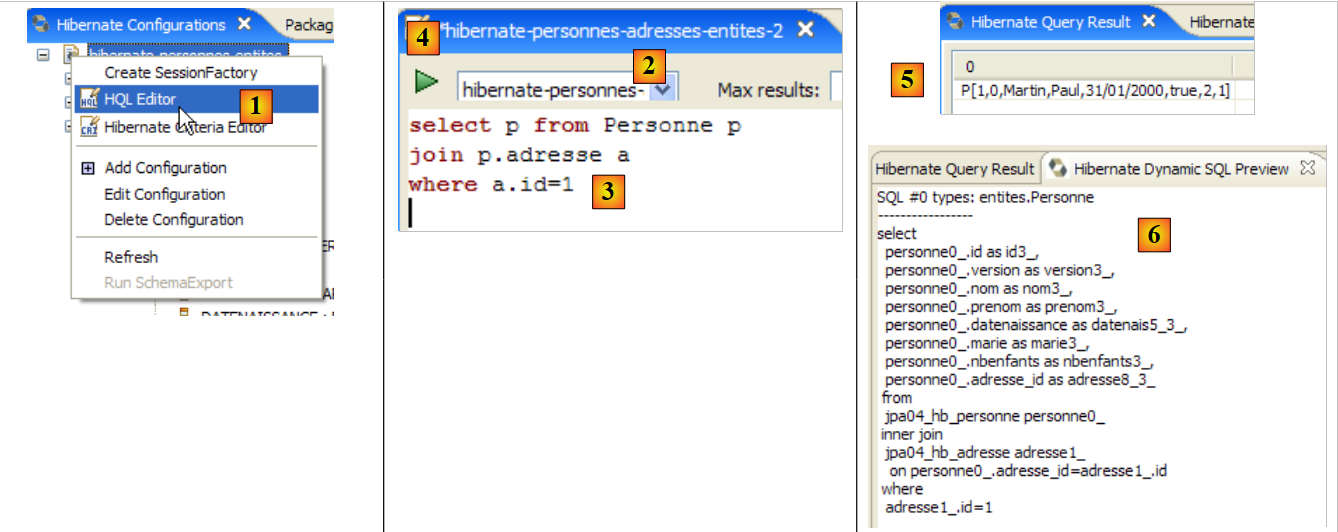 |
- em [1], cria-se um editor HQL
- no editor HQL,
- no [2], escolhe-se a configuração do Hibernate a utilizar, caso existam várias (o que é o caso aqui)
- no [3], introduz-se o comando JPQL que se pretende executar; neste caso, o comando JPQL do teste 8
- em [4], executa-se o comando
- em [5], obtêm-se os resultados da consulta na janela [Hibernate Query Result].
- em [6], a janela [Hibernate Dynamic SQL preview] permite ver a consulta SQL que foi executada.
Outra forma de obter o mesmo resultado:
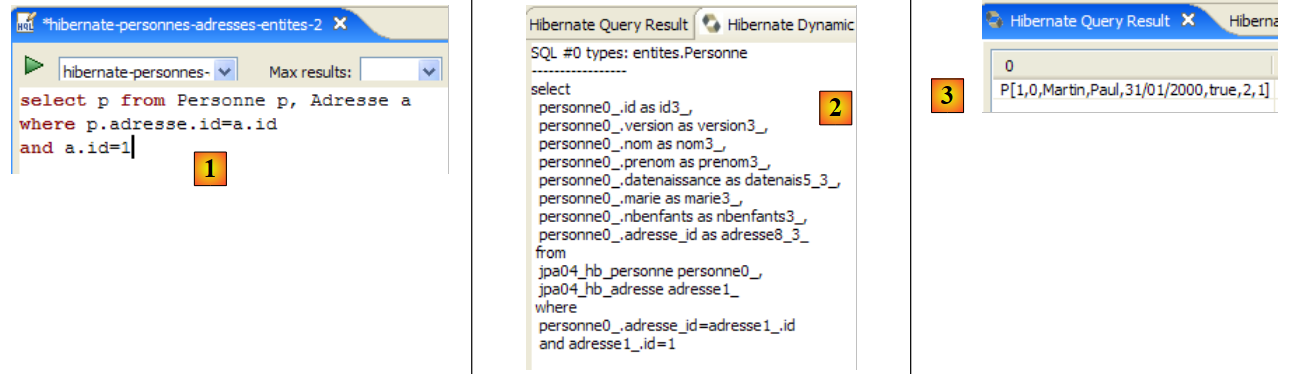 |
- em [1]: o comando JPQL que efetua a junção das entidades Personne e Adresse. [ref1] denomina esta forma «junção theta».
- em [2]: o equivalente SQL
- em [3]: o resultado
Uma terceira forma aceite apenas pelo Hibernate (HQL):
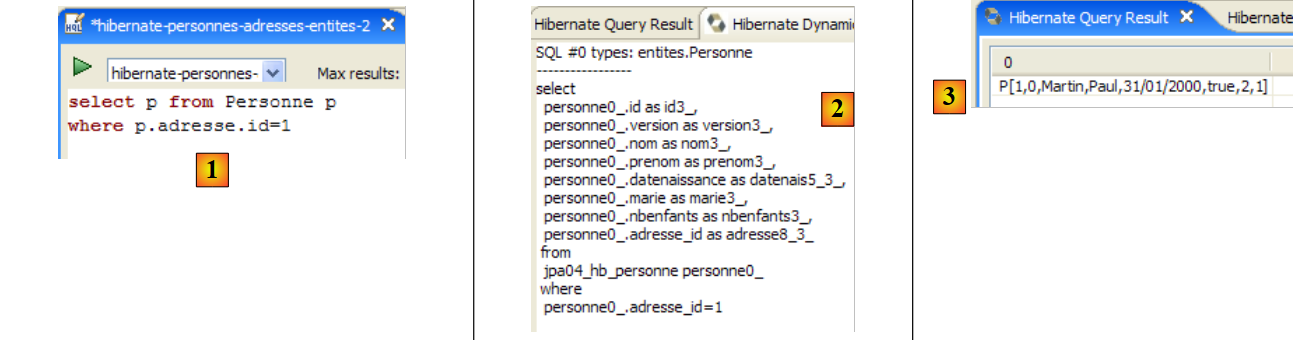 |
- em [1]: o comando HQL. O JPQL não aceita a notação p.adresse.id. Apenas aceita um nível de indireção.
- em [2]: o equivalente SQL. Vê-se que evita a junção entre tabelas.
- em [3]: o resultado
Eis outros exemplos:
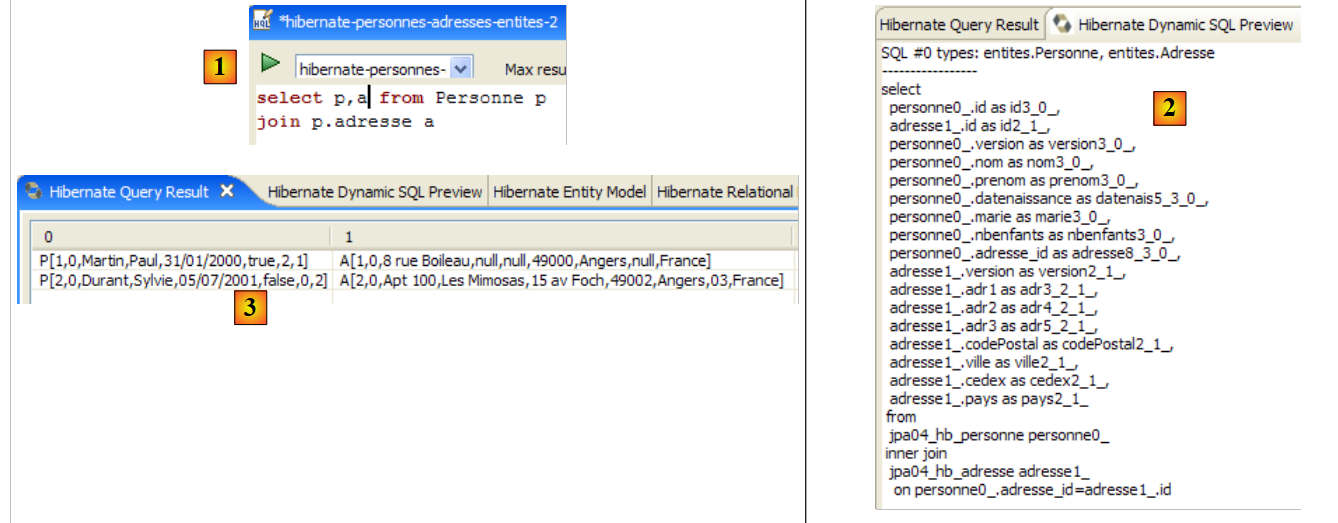 |
- em [1]: a lista de pessoas com os respetivos endereços
- em [2]: o equivalente SQL.
- em [3]: o resultado
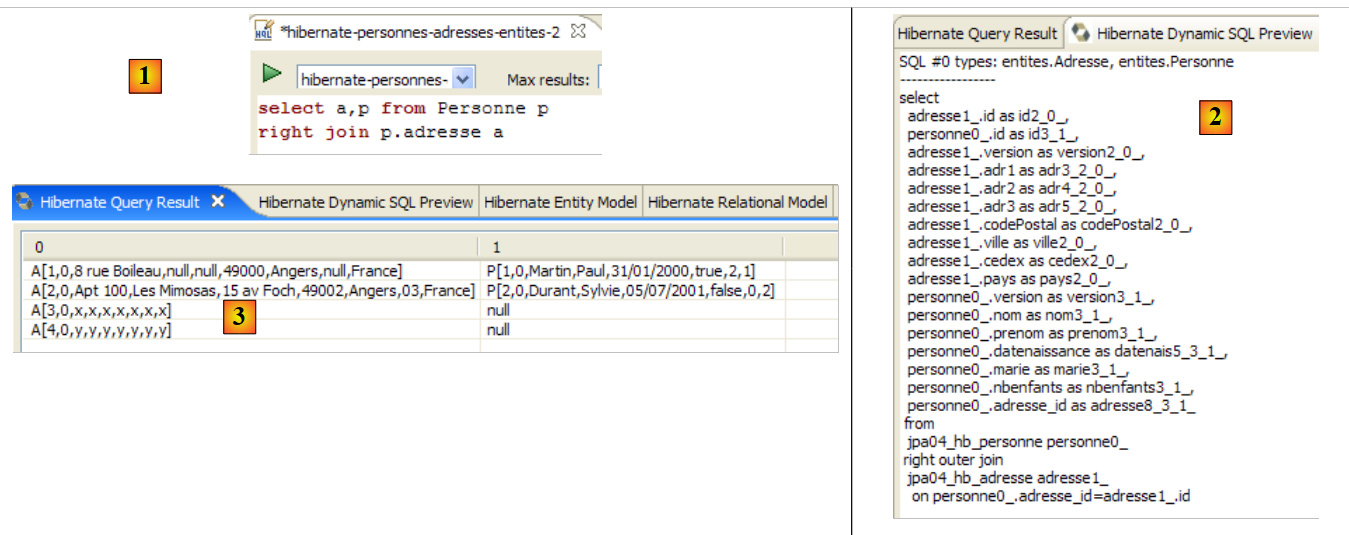 |
- em [1]: a lista de endereços com o respetivo proprietário, caso exista, ou nenhum, caso contrário (junção externa direita: a entidade Adresse, que fornecerá as linhas sem relação com Personne, encontra-se à direita da palavra-chave join).
- em [2]: o equivalente a SQL.
- em [3]: o resultado
Note-se que apenas a entidade Personne mantém uma relação com a entidade Adresse. O inverso já não é verdadeiro desde que se eliminou a relação inversa um-para-um denominada personne na entidade Adresse. Se essa relação inversa existisse, ter-se-ia podido escrever:
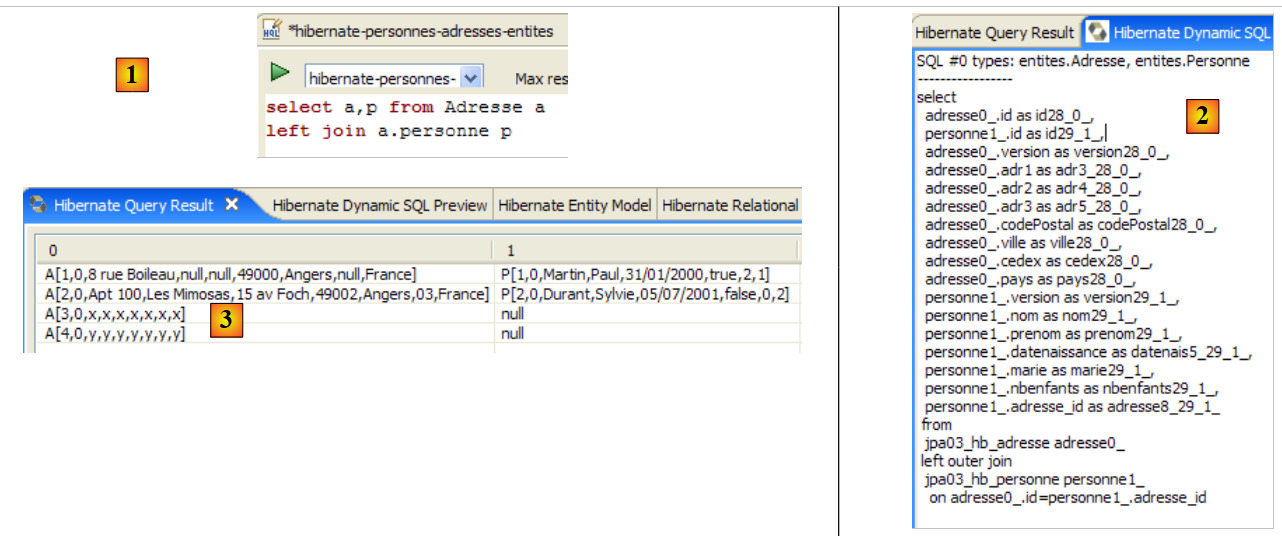 |
- em [1]: a lista de endereços com o respetivo proprietário, caso exista, ou nenhum, caso contrário (junção externa à esquerda: a entidade Adresse, que fornecerá as linhas sem relação com Personne, encontra-se à esquerda da palavra-chave join).
- em [2]: o equivalente a SQL.
- em [3]: o resultado
Convidamos vivamente o leitor a praticar a linguagem JPQL com a consola Hibernate.
2.3.9. Implementação JPA / Toplink
Estamos agora a utilizar uma implementação JPA / Toplink:
 |
O novo projeto Eclipse para os testes é o seguinte:
 |
Os códigos Java são idênticos aos do projeto Hibernate anterior. O ambiente (bibliotecas – persistence.xml – SGBD – pastas conf, ddl – script ant) é o analisado no parágrafo 2.1.15.2. O projeto Eclipse [3] encontra-se na pasta de exemplos [4]. Vamos importá-lo.
O ficheiro <persistence.xml> é alterado num ponto, o das entidades declaradas:
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- fornecedor -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- classes persistentes -->
<class>entites.Personne</class>
<class>entites.Adresse</class>
<!-- propriedades da unidade de persistência -->
...
- linhas 5 e 6: as duas entidades geridas
A execução do [InitDB] juntamente com o SGBD e o MySQL5 produz os seguintes resultados:
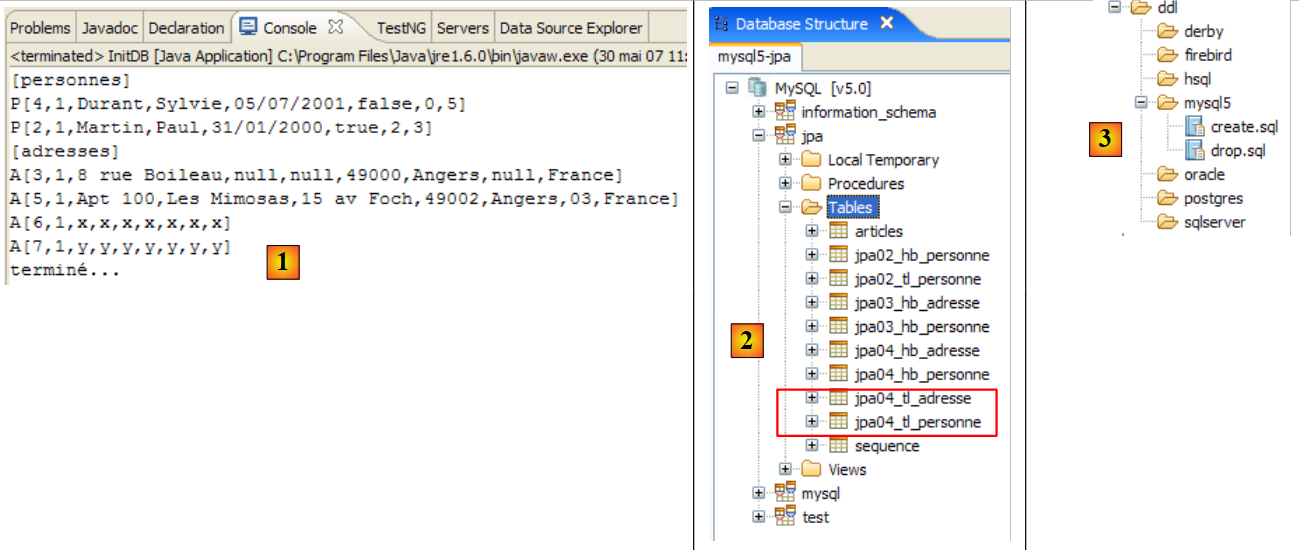 |
No [1], a saída da consola; no [2], as duas tabelas [jpa04_tl] geradas; no [3], os scripts SQL gerados. O seu conteúdo é o seguinte:
create.sql
CREATE TABLE jpa04_tl_personne (ID BIGINT NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, VERSION INTEGER NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NBENFANTS INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, adresse_id BIGINT UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa04_tl_adresse (ID BIGINT NOT NULL, ADR3 VARCHAR(30), CODEPOSTAL VARCHAR(5) NOT NULL, ADR1 VARCHAR(30) NOT NULL, VILLE VARCHAR(20) NOT NULL, VERSION INTEGER NOT NULL, CEDEX VARCHAR(3), ADR2 VARCHAR(30), PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa04_tl_personne ADD CONSTRAINT FK_jpa04_tl_personne_adresse_id FOREIGN KEY (adresse_id) REFERENCES jpa04_tl_adresse (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
drop.sql
ALTER TABLE jpa04_tl_personne DROP FOREIGN KEY FK_jpa04_tl_personne_adresse_id
DROP TABLE jpa04_tl_personne
DROP TABLE jpa04_tl_adresse
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
2.4. Exemplo 4: relação um-para-muitos
2.4.1. O esquema « » da base de dados
1  | 2 |
- em [1], a base de dados, e em [2], a sua DDL (MySQL5)
Um artigo A(id, versão, nome) pertence exatamente a uma categoria C(id, versão, nome). Uma categoria C pode conter 0, 1 ou vários artigos. Existe uma relação um-para-muitos (Categoria -> Artigo) e a relação inversa muitos-para-um (Artigo -> Categoria). Esta relação é concretizada pela chave estrangeira que a tabela [article] possui na tabela [categorie] (linhas 24-28 da DDL).
2.4.2. Os objetos @Entity que representam a base de dados
Um artigo é representado pela seguinte @Entity [Article]:
package entites;
...
@Entity
@Table(name="jpa05_hb_article")
public class Article implements Serializable {
// campos
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// relação principal Artigo (muitos) -> Categoria (um)
// implementada por uma chave estrangeira (categorie_id) na tabela Artigo
// 1 Artigo tem necessariamente 1 Categoria (nullable=false)
@ManyToOne(fetch=FetchType.LAZY)
@JoinColumn(name = "categorie_id", nullable = false)
private Categorie categorie;
// construtores
public Article() {
}
// getters e setters
...
// toString
public String toString() {
return String.format("Article[%d,%d,%s,%d]", id, version, nom, categorie.getId());
}
}
- linhas 9-11: chave primária da @Entity
- linhas 13-15: o seu número de versão
- linhas 17-18: nome do artigo
- linhas 20-25: relação muitos-para-um que liga a @Entity Article à @Entity Categorie:
- linha 23: a anotação ManyToOne. O «Many» refere-se à @Entity Article em que nos encontramos e o «One» à @Entity Categorie (linha 25). Uma categoria (One) pode ter vários artigos (Many).
- linha 24: a anotação ManyToOne define a coluna-chave estrangeira na tabela [article]. Esta coluna será denominada (name) categorie_id e cada linha deverá ter um valor nesta coluna (nullable=false).
- linha 25: a categoria a que o artigo pertence. Quando um artigo for colocado no contexto de persistência, solicita-se que a sua categoria não seja inserida imediatamente (fetch=FetchType.LAZY, linha 23). Não se sabe se esta solicitação faz sentido. Veremos.
Uma categoria é representada pela seguinte @Entity [Categorie]:
package entites;
...
@Entity
@Table(name="jpa05_hb_categorie")
public class Categorie implements Serializable {
// campos
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// relação inversa Categoria (um) -> Artigo (muitos) da relação Artigo (muitos) -> Categoria (um)
// inserção em cascata de Categoria -> inserção de Artigos
// cascata de atualização de Categoria -> atualização de Artigos
// eliminação em cascata de Categoria -> eliminação de Artigos
@OneToMany(mappedBy = "categorie", cascade = { CascadeType.ALL })
private Set<Article> articles = new HashSet<Article>();
// construtores
public Categorie() {
}
// getters e setters
...
// toString
public String toString() {
return String.format("Categorie[%d,%d,%s]", id, version, nom);
}
// associação bidirecional Categoria <--> Artigo
public void addArticle(Article article) {
// o artigo é adicionado à coleção de artigos da categoria
articles.add(article);
// o artigo muda de categoria
article.setCategorie(this);
}
}
- linhas 8-11: a chave primária da @Entity
- linhas 12-14: a sua versão
- linhas 16-17: o nome da categoria
- linhas 19-24: o conjunto (set) de artigos da categoria
- linha 23: a anotação @OneToMany indica uma relação um-para-muitos. O «One» refere-se à @Entity [Categorie] em que nos encontramos, e o «Many» ao tipo [Article] da linha 24: uma (One) categoria tem vários (Many) artigos.
- linha 23: a anotação é o inverso (mappedBy) da anotação ManyToOne colocada no campo categorie da @Entity Article: mappedBy=categoria. A relação ManyToOne definida no campo categorie da @Entity Article é a relação principal. É indispensável. Ela concretiza a relação de chave estrangeira que liga a @Entity Article à @Entity Categorie. A relação OneToMany definida no campo articles da @Entity Categorie é a relação inversa. Não é indispensável. Trata-se de uma funcionalidade para obter os artigos de uma categoria. Sem esta funcionalidade, esses artigos seriam obtidos através de uma consulta JPQL.
- linha 23: cascadeType.ALL especifica que as operações (persist, merge, remove) realizadas numa @Entity Categorie sejam aplicadas em cadeia aos seus artigos.
- linha 24: os artigos de uma categoria serão colocados num objeto do tipo Set<Article>. O tipo Set não aceita duplicados. Assim, não é possível colocar duas vezes o mesmo artigo no objeto Set<Article>. O que significa «o mesmo artigo»? Para indicar que o artigo a é o mesmo que o artigo b, o Java utiliza a expressão a.equals(b). Na classe Object, classe-pai de todas as classes, a.equals(b) é verdadeira se a==b, c.a.d. se os objetos a e b tiverem a mesma localização na memória. Poder-se-ia querer dizer que os artigos a e b são os mesmos se tiverem o mesmo nome. Neste caso, o programador deve redefinir dois métodos na classe [Article]:
- equals: que deve devolver «verdadeiro» se os dois artigos tiverem o mesmo nome
- hashCode: deve devolver um valor inteiro idêntico para dois objetos [Article] que o método equals considere iguais. Neste caso, o valor será, portanto, construído a partir do nome do artigo. O valor devolvido por hashCode pode ser qualquer número inteiro. É utilizado em diferentes contentores de objetos, nomeadamente nos dicionários (Hashtable).
A relação OneToMany pode utilizar outros tipos além do Set para armazenar o Many, por exemplo, objetos do tipo List. Não abordaremos estes casos neste documento. O leitor poderá encontrá-los em [ref1].
- linha 38: o método [addArticle] permite-nos adicionar um artigo a uma categoria. O método encarrega-se de atualizar ambas as extremidades da relação OneToMany que liga [Categorie] a [Article].
2.4.3. O projeto Eclipse / Hibernate 1
A implementação JPA aqui utilizada é a do Hibernate. O projeto Eclipse dos testes é o seguinte:
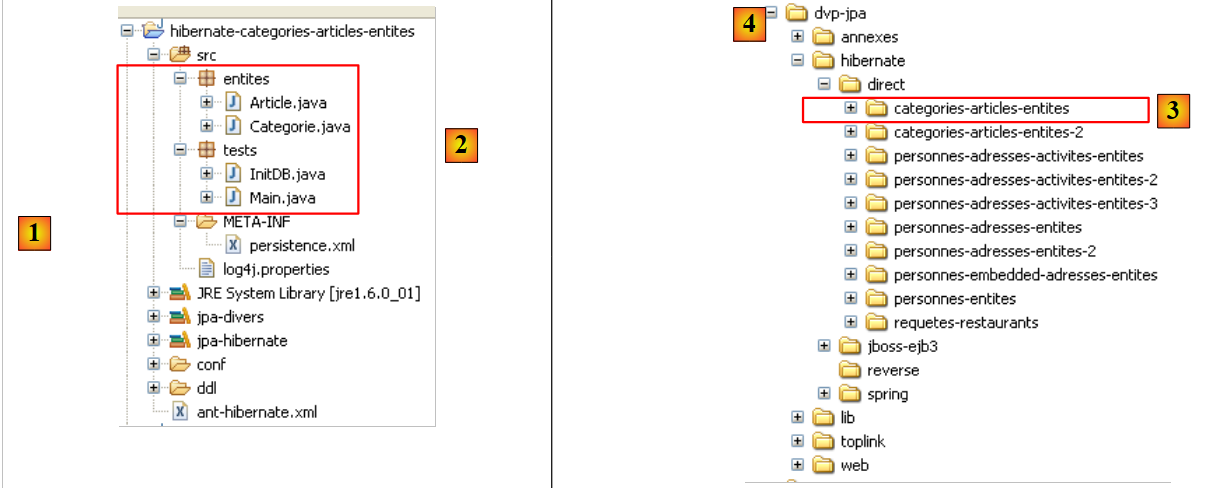 |
O projeto [3] encontra-se na pasta de exemplos [4]. Vamos importá-lo.
2.4.4. Geração do ficheiro DDL da base de dados
Seguindo as instruções do parágrafo 2.1.7, o ficheiro DDL obtido para o SGBD MySQL5 é o que é apresentado no início deste exemplo, no parágrafo 2.4.1.
2.4.5. InitDB
O código de [InitDB] é o seguinte:
package tests;
...
public class InitDB {
// constantes
private final static String TABLE_ARTICLE = "jpa05_hb_article";
private final static String TABLE_CATEGORIE = "jpa05_hb_categorie";
public static void main(String[] args) {
// Contexto de persistência
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// recupera-se um EntityManager a partir do EntityManagerFactory anterior
em = emf.createEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// pedido
Query sql1;
// eliminar os elementos da tabela ARTICLE
sql1 = em.createNativeQuery("delete from " + TABLE_ARTICLE);
sql1.executeUpdate();
// eliminar os elementos da tabela CATEGORIE
sql1 = em.createNativeQuery("delete from " + TABLE_CATEGORIE);
sql1.executeUpdate();
// criar três categorias
Categorie categorieA = new Categorie();
categorieA.setNom("A");
Categorie categorieB = new Categorie();
categorieB.setNom("B");
Categorie categorieC = new Categorie();
categorieC.setNom("C");
// criar 3 artigos
Article articleA1 = new Article();
articleA1.setNom("A1");
Article articleA2 = new Article();
articleA2.setNom("A2");
Article articleB1 = new Article();
articleB1.setNom("B1");
// associá-los à respetiva categoria
categorieA.addArticle(articleA1);
categorieA.addArticle(articleA2);
categorieB.addArticle(articleB1);
// guardar as categorias e, em cadeia (inserção), os artigos
em.persist(categorieA);
em.persist(categorieB);
em.persist(categorieC);
// exibição das categorias
System.out.println("[categories]");
for (Object p : em.createQuery("select c from Categorie c order by c.nom asc").getResultList()) {
System.out.println(p);
}
// exibição de artigos
System.out.println("[articles]");
for (Object p : em.createQuery("select a from Article a order by a.nom asc").getResultList()) {
System.out.println(p);
}
// fim da transação
tx.commit();
// fim de EntityManager
em.close();
// fim de EntityMangerFactory
emf.close();
// registo
System.out.println("terminé...");
}
}
- linhas 22-27: as tabelas [article] e [categorie] são esvaziadas. Note-se que é obrigatório começar pela tabela que contém a chave estrangeira. Se começássemos pela tabela [categorie], eliminaríamos categorias referenciadas por linhas da tabela [article], o que seria rejeitado pela tabela SGBD.
- linhas 29-34: criam-se três categorias A, B, C
- linhas 36-41: criam-se três artigos A1, A2, B1 (a letra indica a categoria)
- linhas 43-45: os 3 artigos são colocados nas respetivas categorias
- linhas 47-49: as três categorias são colocadas no contexto de persistência. Devido à cascata Categoria -> Artigo, os respetivos artigos serão também colocados nesse contexto. Assim, todos os objetos criados encontram-se agora no contexto de persistência.
- linhas 50-59: o contexto de persistência é solicitado para obter a lista de categorias e artigos. Sabe-se que isto irá provocar uma sincronização do contexto com a base de dados. É neste momento que as categorias e os artigos serão registados nas respetivas tabelas.
A execução de [InitDB] juntamente com MySQL5 produz os seguintes resultados:
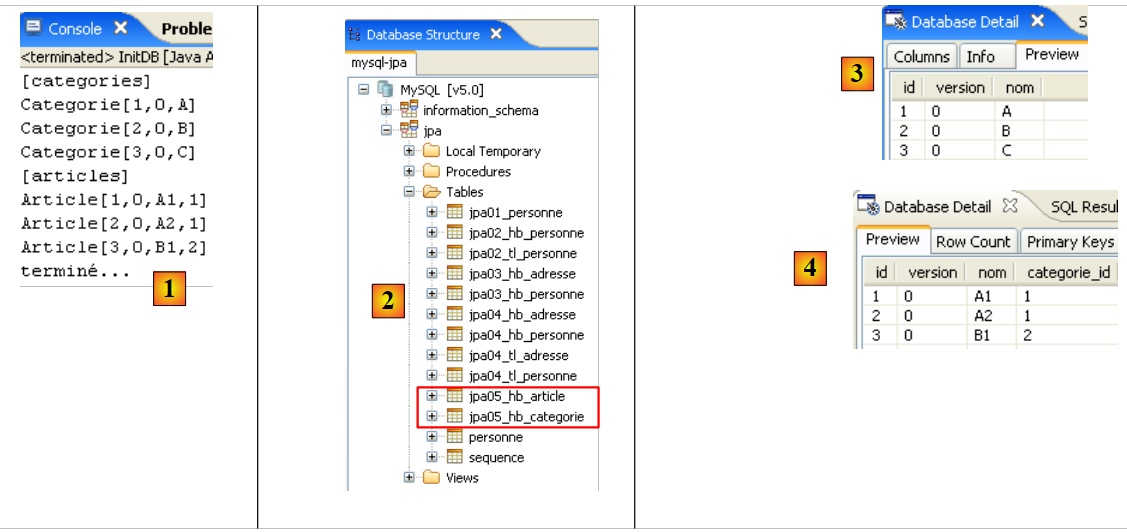 |
- [1]: a exibição na consola
- [2]: as tabelas [jpa05_hb_*] na perspetiva do SQL Explorer
- [3]: a tabela de categorias
- [4]: a tabela de artigos. De notar a ligação de [categorie_id] em [4] com [id] em [3] (chave estrangeira).
2.4.6. Página inicial
A classe [Main] encadeia testes que iremos analisar, com exceção dos testes 1 e 2, que reutilizam o código de [InitDB] para inicializar a base de dados.
2.4.6.1. Teste 3
Este teste é o seguinte:
// procurar um elemento específico
public static void test3() {
// novo contexto de persistência
EntityManager em = getNewEntityManager();
// transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// carregamento da categoria
Categorie categorie = em.find(Categorie.class, categorieA.getId());
// exibição da categoria e dos seus artigos associados
System.out.format("Articles de la catégorie %s :%n", categorie);
for (Article a : categorie.getArticles()) {
System.out.println(a);
}
// fim da transação
tx.commit();
}
- linha 4: temos um contexto de persistência novo, portanto vazio
- linhas 6-7: início da transação
- linha 9: a categoria A é transferida da base de dados para o contexto de persistência
- linha 11: exibe-se a categoria A
- linhas 12-14: exibimos os artigos da categoria A. Aqui fica patente a utilidade da relação inversa OneToMany, que remete para os artigos da @Entity Categorie. A sua existência evita-nos ter de efetuar uma consulta JPQL para solicitar os artigos da categoria A. Para os obter, utiliza-se o método get do campo articles.
Os resultados são os seguintes:
- linha 20: a categoria A
- linhas 21-22: os dois artigos da categoria A
2.4.6.2. Teste4
Este teste é o seguinte:
// eliminar um artigo
@SuppressWarnings("unchecked")
public static void test4() {
// novo contexto de persistência
EntityManager em = getNewEntityManager();
// transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// carregamento do artigo A1
Article newarticle1 = em.find(Article.class, articleA1.getId());
// eliminação do artigo A1 (nenhuma categoria está atualmente carregada)
em.remove(newarticle1);
// toplink: o artigo deve ser removido da sua categoria, caso contrário o teste6 falha
// hibernate: não é necessário
newarticle1.getCategorie().getArticles().remove(newarticle1);
// fim da transação
tx.commit();
// dump dos artigos
dumpArticles();
}
- O teste 4 elimina o artigo A1
- linha 5: parte-se de um contexto novo e vazio
- linha 10: o artigo A1 é introduzido no contexto de persistência. Aí será referenciado por newarticle1.
- linha 12: é eliminado do contexto
- linha 15: as categorias A, B e C e os artigos A1, A2 e B1, embora já não sejam persistentes, continuam na memória. Estão simplesmente separados do contexto de persistência. O artigo A1, que faz parte dos artigos da categoria A, é removido desta. Isto permitirá, posteriormente, voltar a associar a categoria A ao contexto de persistência. Se tal não for feito, a categoria A será associada a um conjunto de artigos, um dos quais foi eliminado. Isto não parece causar problemas ao Hibernate, mas faz com que o Toplink entre em falha.
- linha 19: exibimos todos os artigos para verificar se o A1 desapareceu.
Os resultados são os seguintes:
O artigo A1 desapareceu efetivamente.
2.4.6.3. Teste 5
Este teste consiste no seguinte:
// alteração de 1 artigo
public static void test5() {
// novo contexto de persistência
EntityManager em = getNewEntityManager();
// transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// alteração de articleA2
articleA2.setNom(articleA2.getNom() + "-");
// articleA2 é reposto no contexto de persistência
em.merge(articleA2);
// fim da transação
tx.commit();
// exportação dos artigos
dumpArticles();
}
- o teste 5 altera o nome do artigo A2
- linha 4: parte-se de um contexto novo e vazio
- linha 9: altera-se o nome do artigo destacado A2, que passará a ser «A2-».
- linha 11: o artigo separado A2 é novamente associado ao contexto de persistência. Note-se que A2 continua a ser um objeto separado. É o objeto em.merge (articleA2) que passa a fazer parte do contexto de persistência. Este objeto não foi aqui armazenado numa variável, como é habitual. Por conseguinte, é inacessível.
- linha 13: sincronização do contexto de persistência com a base de dados. O artigo A2 vai ser alterado na base de dados e o seu número de versão passará de N para N+1. A versão em memória isolada articleA2 já não é válida. O mesmo se aplica ao objeto separado que representa a categoria A, uma vez que este contém o artigo articleA2 entre os seus artigos.
- linha 15: são apresentados todos os artigos para verificar a alteração do nome do artigo A2
Os resultados são os seguintes:
O artigo A2 mudou efetivamente de nome.
2.4.6.4. Teste 6
Este teste é o seguinte:
// alteração de 1 categoria e dos seus artigos
public static void test6() {
// novo contexto de persistência
EntityManager em = getNewEntityManager();
// transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// carregamento da categoria
categorieA = em.find(Categorie.class, categorieA.getId());
// lista de artigos da categoria A
for (Article a : categorieA.getArticles()) {
a.setNom(a.getNom() + "-");
}
// alteração do nome da categoria
categorieA.setNom(categorieA.getNom() + "-");
// fim da transação
tx.commit();
// exportação das categorias e dos artigos
dumpCategories();
dumpArticles();
}
- o teste 6 altera o nome da categoria A e de todos os seus artigos
- linha 4: parte-se de um contexto novo e vazio
- linha 9: procura-se a categoria A na base de dados. Não se executa um merge a partir do objeto destacado categorieA, pois sabe-se que este tem uma referência ao artigo A2, que se tornou obsoleto. Por isso, recomeça-se do zero.
- linhas 11-12: alteramos o nome de todos os artigos da categoria A. Mais uma vez, utilizamos a relação inversa OneToMany através do método getArticles.
- linha 15: o nome da categoria também é alterado
- linha 17: fim da transação. É efetuada uma sincronização do contexto com a base de dados. Todos os objetos do contexto que foram alterados serão atualizados na base de dados.
- linhas 21-22: exibem-se os artigos e as categorias para verificação
Os resultados são os seguintes:
O artigo A2 mudou de nome mais uma vez, assim como a categoria A.
2.4.6.5. Teste7
Este teste é o seguinte:
// eliminação de uma categoria
public static void test7() {
// novo contexto de persistência
EntityManager em = getNewEntityManager();
// transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistência catégorieB e eliminação em cascata (merge) dos artigos associados
Categorie mergedcategorieB = em.merge(categorieB);
// eliminação da categoria e, em cadeia (delete), dos artigos associados
em.remove(mergedcategorieB);
// fim da transação
tx.commit();
// exportação das categorias e dos artigos
dumpCategories();
dumpArticles();
}
- o teste 7 elimina a categoria B e, consequentemente, os seus artigos
- linha 4: parte-se de um contexto novo e vazio
- linha 9: a categoria B existe na memória como um objeto separado do contexto de persistência. Reintegramo-la (merge) no contexto de persistência. Em cadeia, os seus artigos (o artigo B1) serão submetidos a um merge e, assim, reintegrados no contexto de persistência.
- linha 11: agora que a categoria B está no contexto, é possível eliminá-la (remove). Por efeito em cadeia, os seus artigos também serão submetidos a um remove. Esta operação só é possível porque a operação merge da linha 9 os reintegrou no contexto de persistência.
- linha 13: fim da transação. O contexto vai ser sincronizado. Os objetos do contexto que foram submetidos a uma operação remove vão ser eliminados da base de dados.
- linhas 15-16: exibem-se os artigos e as categorias para verificação
Os resultados são os seguintes:
A categoria B e o artigo B1 desapareceram efetivamente.
2.4.6.6. Teste 8
Este teste é o seguinte:
// consultas
@SuppressWarnings("unchecked")
public static void test8() {
// novo contexto de persistência
EntityManager em = getNewEntityManager();
// transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// lista de artigos da categoria A
List articles = em
.createQuery(
"select a from Categorie c join c.articles a where c.nom like 'A%' order by a.nom asc")
.getResultList();
// visualizações de artigos
System.out.println("Articles de la catégorie A");
for (Object a : articles) {
System.out.println(a);
}
// fim da transação
tx.commit();
}
- O teste 7 mostra como recuperar os artigos de uma categoria sem recorrer à relação inversa. Isto demonstra que esta não é, portanto, indispensável.
- linha 4: parte-se de um contexto novo e vazio
- linha 10: uma consulta JPQL que solicita todos os artigos de uma categoria cujo nome comece por A
- linhas 15-17: exibição do resultado da consulta.
Os resultados são os seguintes:
2.4.7. Projeto Eclipse / Hibernate 2
Copiamos e colamos o projeto Eclipse / Hibernate para esclarecer um ponto sobre o conceito de relação principal / relação inversa que criámos em torno da anotação @ManyToOne (principal) da @Entity [Article] e a relação inversa @OneToMany (inversa) da @Entity [Categorie]. Queremos demonstrar que, se esta última relação não for declarada como inversa da outra, o esquema gerado para a base de dados será completamente diferente do gerado anteriormente.
 |
Em [1], o novo projeto Eclipse. Em [2], os códigos Java; em [3], o script ant que irá gerar o esquema SQL da base de dados. O projeto encontra-se em [4] na pasta de exemplos [5]. Vamos importá-lo.
Alteramos apenas a @Entity [Categorie] para que a sua relação @OneToMany com a @Entity [Article] deixe de ser declarada como inversa da relação @ManyToOne que a @Entity [Article] mantém com a @Entity [Categorie]:
...
@Entity
@Table(name="jpa05_hb_categorie")
public class Categorie implements Serializable {
// campos
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// relação OneToMany não inversa (ausência de mappedby) Categoria (um) -> Artigo (muitos)
// implementada por uma tabela de junção Categorie_Article para que, a partir de uma categoria
// se possa aceder aos artigos dessa categoria
@OneToMany(cascade=CascadeType.ALL, fetch=FetchType.LAZY)
private Set<Article> articles = new HashSet<Article>();
// fabricantes
...
- linhas 18-22: pretende-se manter a possibilidade de encontrar os artigos de uma determinada categoria através da relação @OneToMany da linha 21. Mas queremos conhecer a influência do atributo mappedBy, que transforma uma relação no inverso de uma relação principal definida noutro local, noutra @Entity. Aqui, o mappedBy foi removido.
Executamos a tarefa ant-DLL (ver parágrafo 2.1.7) com o SGBD e o MySQL5. O esquema obtido é o seguinte:
 |
Deve-se ter em conta os seguintes pontos:
- foi criada uma nova tabela [categorie_article] [1]. Esta não existia anteriormente.
- trata-se de uma tabela de junção entre as tabelas [categorie] [2] e [article] [3]. Se os objetos Artigo a1 e a2 pertencerem à categoria c1, encontrar-se-ão na tabela de junção as seguintes linhas:
onde c1, a1 e a2 são as chaves primárias dos objetos correspondentes.
- A tabela de junção [categorie_article] [1] foi criada pelo Hibernate para que, a partir de um objeto Categoria c, seja possível recuperar os objetos Artigo a pertencentes a c. Foi a relação @OneToMany que forçou a criação desta tabela. Como não a declarámos como inversa da relação principal @ManyToOne da @Entity Article, o Hibernate não sabia que podia utilizar esta relação principal para recuperar os artigos de uma categoria c. Por isso, encontrou outra forma de o fazer.
- Com este exemplo, compreende-se melhor os conceitos das relações principale e inverse. Uma (a inversa) utiliza as propriedades da outra (a principal).
O esquema SQL desta base de dados para MySQL5 é o seguinte:
alter table jpa05_hb_categorie_jpa06_hb_article
drop
foreign key FK79D4BA1D26D17756;
alter table jpa05_hb_categorie_jpa06_hb_article
drop
foreign key FK79D4BA1D424C61C9;
alter table jpa06_hb_article
drop
foreign key FK4547168FECCE8750;
drop table if exists jpa05_hb_categorie;
drop table if exists jpa05_hb_categorie_jpa06_hb_article;
drop table if exists jpa06_hb_article;
create table jpa05_hb_categorie (
id bigint not null auto_increment,
version integer not null,
nom varchar(30),
primary key (id)
) ENGINE=InnoDB;
create table jpa05_hb_categorie_jpa06_hb_article (
jpa05_hb_categorie_id bigint not null,
articles_id bigint not null,
primary key (jpa05_hb_categorie_id, articles_id),
unique (articles_id)
) ENGINE=InnoDB;
create table jpa06_hb_article (
id bigint not null auto_increment,
version integer not null,
nom varchar(30),
categorie_id bigint not null,
primary key (id)
) ENGINE=InnoDB;
alter table jpa05_hb_categorie_jpa06_hb_article
add index FK79D4BA1D26D17756 (jpa05_hb_categorie_id),
add constraint FK79D4BA1D26D17756
foreign key (jpa05_hb_categorie_id)
references jpa05_hb_categorie (id);
alter table jpa05_hb_categorie_jpa06_hb_article
add index FK79D4BA1D424C61C9 (articles_id),
add constraint FK79D4BA1D424C61C9
foreign key (articles_id)
references jpa06_hb_article (id);
alter table jpa06_hb_article
add index FK4547168FECCE8750 (categorie_id),
add constraint FK4547168FECCE8750
foreign key (categorie_id)
references jpa05_hb_categorie (id);
- linhas 19-24, criação da tabela [categorie] e linhas 33-39, criação da tabela [article]. Note-se que são idênticas às do exemplo anterior.
- linhas 26-31: criação da tabela de junção [categorie_article] devido à presença da relação não inversa @OneToMany da @Entity Categorie. As linhas desta tabela são do tipo [c,a], em que c é a chave primária de uma categoria c e a é a chave primária deum artigo a pertencente à categoria c. A chave primária desta tabela de junção é constituída pelas duas chaves primárias [c,a] concatenadas (linha 29).
- linhas 41-45: a restrição de chave estrangeira da tabela [categorie_article] para a tabela [categorie]
- linhas 47-51: a restrição de chave estrangeira da tabela [categorie_article] para a tabela [article]
- linhas 53-57: a restrição de chave estrangeira da tabela [article] para a tabela [categorie]
Convida-se o leitor a executar os testes [InitDB] e [Main]. Estes apresentam os mesmos resultados que anteriormente. No entanto, o esquema da base de dados é redundante e o desempenho será inferior ao da versão anterior. Seria, sem dúvida, necessário aprofundar esta questão das relações inversas/principais para verificar se a nova configuração não acarreta, além disso, conflitos decorrentes do facto de existirem duas relações independentes para representar a mesma coisa: a relação muitos-para-um que a tabela [article] tem com a tabela [categorie].
2.4.8. Implementação JPA / Toplink - 1
Utilizamos agora uma implementação JPA / Toplink:
 |
O projeto Eclipse com Toplink é uma cópia do projeto Eclipse com Hibernate, versão 1:
 |
Os códigos Java são idênticos aos do projeto Hibernate — versão 1 — anterior. O ambiente (bibliotecas – persistence.xml – SGBD – pastas conf, ddl – script ant) é o analisado no parágrafo 2.1.15.2. O projeto Eclipse encontra-se em [3], na pasta de exemplos [4]. Iremos importá-lo.
O ficheiro <persistence.xml> [2] é alterado num ponto, o das entidades declaradas:
...
<!-- classes persistentes -->
<class>entites.Categorie</class>
<class>entites.Article</class>
...
- linhas 3 e 4: as duas entidades geridas
A execução do [InitDB] com o SGBD MySQL5 produz os seguintes resultados:
 |
No [1], a saída da consola; no [2], as duas tabelas [jpa05_tl] geradas; no [3], os scripts SQL gerados. O seu conteúdo é o seguinte:
create.sql
CREATE TABLE jpa05_tl_article (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), categorie_id BIGINT NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa05_tl_categorie (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), PRIMARY KEY (ID))
ALTER TABLE jpa05_tl_article ADD CONSTRAINT FK_jpa05_tl_article_categorie_id FOREIGN KEY (categorie_id) REFERENCES jpa05_tl_categorie (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
drop.sql
ALTER TABLE jpa05_tl_article DROP FOREIGN KEY FK_jpa05_tl_article_categorie_id
DROP TABLE jpa05_tl_article
DROP TABLE jpa05_tl_categorie
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
A execução do [Main] decorre sem erros.
2.4.9. Implementação JPA / Toplink - 2
Este projeto Eclipse foi criado a partir do anterior por cópia. Como foi feito com o Hibernate, remove-se o atributo mappedBy da relação @OneToMany da @Entity Categorie.
@Entity
@Table(name = "jpa06_tl_categorie")
public class Categorie implements Serializable {
// campos
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Version
private int version;
@Column(length = 30)
private String nom;
// relação OneToMany não inversa (ausência de mappedby) Categoria (one) ->
// Artigo (muitos)
// implementada por uma tabela de junção Categorie_Article para que, a partir
// uma categoria
// seja possível aceder a vários artigos
@OneToMany(cascade = CascadeType.ALL, fetch = FetchType.LAZY)
private Set<Article> articles = new HashSet<Article>();
O esquema SQL gerado para MySQL5 é, então, o seguinte:
create.sql
CREATE TABLE jpa06_tl_categorie (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), PRIMARY KEY (ID))
CREATE TABLE jpa06_tl_categorie_jpa06_tl_article (Categorie_ID BIGINT NOT NULL, articles_ID BIGINT NOT NULL, PRIMARY KEY (Categorie_ID, articles_ID))
CREATE TABLE jpa06_tl_article (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), categorie_id BIGINT NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa06_tl_categorie_jpa06_tl_article ADD CONSTRAINT FK_jpa06_tl_categorie_jpa06_tl_article_articles_ID FOREIGN KEY (articles_ID) REFERENCES jpa06_tl_article (ID)
ALTER TABLE jpa06_tl_categorie_jpa06_tl_article ADD CONSTRAINT jpa06_tl_categorie_jpa06_tl_article_Categorie_ID FOREIGN KEY (Categorie_ID) REFERENCES jpa06_tl_categorie (ID)
ALTER TABLE jpa06_tl_article ADD CONSTRAINT FK_jpa06_tl_article_categorie_id FOREIGN KEY (categorie_id) REFERENCES jpa06_tl_categorie (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
- linha 2: a tabela de junção que concretiza a relação @OneToMany não inversa anterior.
A execução de [InitDB] decorre sem erros, mas a de [Main] falha no teste 7, com os registos (FINEST) seguintes:
- linha 3: o merge na categoria B
- linha 4: o artigo dependente B1 é colocado no contexto
- linha 5: o mesmo se aplica à própria categoria B
- linha 6: o remove na categoria B
- linha 7: o remove no artigo B1 (por cascata)
- linha 8: o commit da transação é solicitado pelo código Java
- linha 9: inicia-se uma transação — aparentemente, esta ainda não tinha começado.
- linha 10: o artigo B1 vai ser eliminado por uma operação DELETE na tabela [article]. É aí que reside o problema. A tabela de junção [categorie_article] tem uma referência à linha B1 da tabela [article]. A eliminação de B1 em [article] irá violar uma restrição de chave estrangeira.
- linhas 13 e seguintes: ocorre a exceção
Que conclusão se pode tirar?
- Mais uma vez, temos um problema de portabilidade entre o Hibernate e o Toplink: o Hibernate tinha passado neste teste
- O Toplink não lida bem com a situação em que, quando duas relações são, na verdade, inversas uma da outra, uma delas não seja declarada como principal e a outra como inversa. Podemos aceitar isso, pois este caso representa, na verdade, um erro de configuração. No nosso exemplo, a tabela [article] não tem qualquer relação com a tabela de junção [categorie_article]. Parece, portanto, natural que, durante uma operação na tabela [article], o Toplink não tente trabalhar com a tabela [categorie_article].
2.5. Exemplo 5: relação muitos-para-muitos com uma tabela de junção explícita
2.5.1. O esquema da base de dados
|
- em [1], a base de dados MySQL5
Já conhecemos as tabelas [personne], [2] e [adresse], [3]. Estas foram analisadas no parágrafo 2.3.1. Consideramos a versão em que a morada da pessoa é objeto de uma tabela própria: [adresse] e [3]. Na tabela [personne], a relação que liga uma pessoa à sua morada é materializada por uma restrição de chave estrangeira.
Uma pessoa exerce atividades. Estas encontram-se na tabela [activite] [4]. Uma pessoa pode exercer várias atividades e uma atividade pode ser exercida por várias pessoas. Existe, portanto, uma relação muitos-a-muitos entre as tabelas [personne] e [activite]. Esta relação é concretizada pela tabela de junção [personne_activite] [5].
2.5.2. Os objetos @Entity que representam a base de dados
As tabelas anteriores serão representadas pelas seguintes @Entity:
- a @Entity Personne representará a tabela [personne]
- o @Entity Adresse representará a tabela [adresse]
- a @Entity Activite representará a tabela [activite]
- a @Entity PersonneActivite representará a tabela [personne_activite]
As relações entre estas entidades são as seguintes:
- uma relação um-para-um liga a entidade Personne à entidade Adresse: uma pessoa p tem uma morada a. A entidade Personne, que detém a chave estrangeira, terá a relação principal, enquanto a entidade Adresse terá a relação inversa.
- Uma relação muitos-a-muitos liga as entidades Personne e Activite: uma pessoa tem várias atividades e uma atividade é praticada por várias pessoas. Esta relação poderia ser implementada diretamente através de uma anotação @ManyToMany em cada uma das duas entidades, sendo uma delas declarada como inversa da outra. Esta solução será explorada posteriormente. Aqui, implementamos a relação muitos-para-muitos por meio de duas relações um-para-muitos:
- uma relação «um-para-muitos» que liga a entidade Personne à entidade PersonneActivite: uma linha (One) da tabela [personne] é referenciada por várias (Many) linhas da tabela [personne_activite]. A tabela [personne_activite], que contém a chave estrangeira, terá a relação principal @ManyToOne, e a entidade Personne terá a relação inversa @OneToMany.
- uma relação um-para-muitos que liga a entidade Activite à entidade PersonneActivite: uma linha (One) da tabela [activite] é referenciada por várias (Many) linhas da tabela [personne_activite]. A tabela [personne_activite], que contém a chave estrangeira, terá a relação principal @ManyToOne, e a entidade Activite terá a relação inversa @OneToMany.
A @Entity Personne é a seguinte:
@Entity
@Table(name = "jpa07_hb_personne")
public class Personne implements Serializable {
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
// relação principal Pessoa (one) -> Morada (one)
// implementada pela chave estrangeira Pessoa (adresse_id) -> Endereço
// inserção em cascata Pessoa -> inserção de Endereço
// cascata de atualização Pessoa -> atualização Endereço
// eliminação em cascata de Pessoa -> eliminação de Endereço
// uma Pessoa deve ter 1 Endereço (nullable=false)
// 1 Endereço pertence apenas a 1 Pessoa (único=true)
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
// relação Pessoa (one) -> PersonneActivite (many)
// inverso da relação existente PersonneActivite (muitos) -> Pessoa (um)
// eliminação em cascata Pessoa -> eliminação PersonneActivite
@OneToMany(mappedBy = "personne", cascade = { CascadeType.REMOVE })
private Set<PersonneActivite> activites = new HashSet<PersonneActivite>();
// construtores
Esta @Entity é conhecida. Apenas comentamos as relações que ela tem com as outras entidades:
- linhas 30-39: uma relação um-para-um @OneToOne com a @Entity Adresse, materializada por uma chave estrangeira [adresse_id] (linha 38) que a tabela [personne] terá na tabela [adresse].
- linhas 41-45: uma relação um-para-muitos @OneToMany com a @Entity PersonneActivite. Uma pessoa (One) é referenciada por várias (Many) linhas da tabela de junção [personne_activite], representada pela @Entity PersonneActivite. Estes objetos PersonneActivite serão colocados num tipo Set<PersonneActivite>, em que PersonneActivite é um tipo que iremos definir em breve.
- linha 44: a relação «um-para-muitos» aqui definida é a relação inversa de uma relação principal definida no campo personne da @Entity PersonneActivite (palavra-chave mappedBy). Temos uma cascata Pessoa -> Atividade nas eliminações: a eliminação de uma pessoa p implicará a eliminação dos elementos persistentes do tipo PersonneActivite encontrados no conjunto p.activites.
A @Entity Adresse é a seguinte:
@Entity
@Table(name = "jpa07_hb_adresse")
public class Adresse implements Serializable {
// campos
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
@OneToOne(mappedBy = "adresse")
private Personne personne;
- linhas 28-29: a relação @OneToOne, inversa da relação @OneToOne, remete para a @Entity Personne (linhas 37-38 de Personne).
A @Entity Activite é a seguinte
@Entity
@Table(name = "jpa07_hb_activite")
public class Activite implements Serializable {
// campos
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
// relação Atividade (um) -> PersonneActivite (muitos)
// inverso da relação existente PersonneActivite (muitos) -> Atividade (um)
// eliminação em cascata de Atividade -> eliminação de PersonneActivite
@OneToMany(mappedBy = "activite", cascade = { CascadeType.REMOVE })
private Set<PersonneActivite> personnes = new HashSet<PersonneActivite>();
- linhas 6-9: a chave primária da atividade
- linhas 11-13: o número de versão da atividade
- linhas 15-16: o nome da atividade
- linhas 18-22: a relação «um-para-muitos» que liga a @Entity Activite à @Entity PersonneActivite: uma atividade (One) é referenciada por várias (Many) linhas da tabela de junção [personne_activite], representada pela @Entity PersonneActivite. Estes objetos PersonneActivite serão colocados num tipo Set<PersonneActivite>.
- linha 22: a relação «um-para-muitos» aqui definida é a relação inversa de uma relação principal definida no campo activite na @Entity PersonneActivite (palavra-chave mappedBy). Existe uma cascata «Atividade» → «PersonneActivite» nas eliminações: a eliminação da tabela «[activite]» dauma atividade a implicará a eliminação da tabela de junção [personne_activite] dos elementos persistentes do tipo PersonneActivite encontrados no conjunto a.personnes.
A @Entity PersonneActivite é a seguinte:
@Entity
// tabela de junção
@Table(name = "jpa07_hb_personne_activite")
public class PersonneActivite {
@Embeddable
public static class Id implements Serializable {
// componentes da chave composta
// aponta para uma Pessoa
@Column(name = "PERSONNE_ID")
private Long personneId;
// aponta para uma Atividade
@Column(name = "ACTIVITE_ID")
private Long activiteId;
// construtores
...
// getters e setters
...
// toString
public String toString() {
return String.format("[%d,%d]", getPersonneId(), getActiviteId());
}
}
// campos da classe Personne_Activite
// chave composta
@EmbeddedId
private Id id = new Id();
// relação principal PersonneActivite (muitos) -> Pessoa (um)
// implementada pela chave estrangeira: personneId (PersonneActivite (muitos) -> Pessoa (um)
// personneId é, simultaneamente, um elemento da chave primária composta
// JPA não deve gerir esta chave estrangeira (insertable = false, updatable = false), pois isso é feito pela própria aplicação no seu construtor
@ManyToOne
@JoinColumn(name = "PERSONNE_ID", insertable = false, updatable = false)
private Personne personne;
// relação principal PersonneActivite -> Atividade
// implementada pela chave estrangeira: activiteId (PersonneActivite (muitos) -> Atividade (uma)
// activiteId é, ao mesmo tempo, um elemento da chave primária composta
// JPA não deve gerir esta chave estrangeira (insertable = false, updatable = false), pois isso é feito pela própria aplicação no seu construtor
@ManyToOne()
@JoinColumn(name = "ACTIVITE_ID", insertable = false, updatable = false)
private Activite activite;
// construtores
public PersonneActivite() {
}
public PersonneActivite(Personne p, Activite a) {
// as chaves estrangeiras são definidas pela aplicação
getId().setPersonneId(p.getId());
getId().setActiviteId(a.getId());
// associações bidirecionais
this.setPersonne(p);
this.setActivite(a);
p.getActivites().add(this);
a.getPersonnes().add(this);
}
// getters e setters
...
// toString
public String toString() {
return String.format("[%s,%s,%s]", getId(), getPersonne().getNom(), getActivite().getNom());
}
}
Esta classe é mais complexa do que as anteriores.
- A tabela [personne_activite] contém registos com o formato [p,a], em que p é a chave primária de uma pessoa e a é a chave primária de uma atividade. Qualquer tabela deve ter uma chave primária e [personne_activite] não foge à regra. Até agora, tínhamos definido chaves primárias geradas dinamicamente pelo SGBD. Poderíamos fazer o mesmo aqui. Vamos utilizar outra técnica, aquela em que a própria aplicação define os valores da chave primária de uma tabela. Aqui, uma linha [p1,a1] indica que uma pessoa p1 pratica a atividade a1. Não é possível encontrar essa mesma linha uma segunda vez na tabela. Assim, o par (p, a) é um bom candidato a chave primária. A isto chama-se chave primária composta.
- linhas 30-31: a chave primária composta. A anotação @EmbeddedId (normalmente era @Id) é análoga à notação @Embedded aplicada ao campo Adresse de uma pessoa. Neste último caso, isso significava que o campo Adresse era objeto de uma classe externa, mas devia ser inserido na mesma tabela que a pessoa. Aqui, o significado é o mesmo; apenas para indicar que se trata da chave primária, a notação passa a ser @EmbeddedId.
- linha 31: um objeto vazio que representa a chave primária id é criado assim que o objeto [PersonneActivite] é criado. A classe que representa a chave primária é definida nas linhas 7-26, como uma classe pública, estática e interna à classe [PersonneActivite]. O facto de ser pública e estática é imposto pelo Hibernate. Se substituirmos «public static» por «private,», ocorre uma exceção e vemos na mensagem de erro associada que o Hibernate tentou executar a instrução «new PersonneActivite$Id». Por isso, a classe Id tem de ser simultaneamente estática e pública.
- linha 6: a classe Id da chave primária é declarada como @Embeddable. Recorde-se que a chave primária id da linha 31 foi declarada como @EmbeddedId. A classe correspondente deve, portanto, ter a anotação @Embeddable.
- Já referimos que a chave primária da tabela [personne_activite] era composta pelo par (p,a), em que p é a chave primária de uma pessoa e a a chave primária de uma atividade. Encontramos os dois elementos (p,a) da chave composta, na linha 11 (personneId) e na linha 15 (activiteId). As colunas associadas a estes dois campos são denominadas: PERSONNE_ID para a pessoa e ACTIVITE_ID para a atividade.
- linha 31: a chave primária foi definida com as suas duas colunas (PERSONNE_ID, ACTIVITE_ID). Não existem outras colunas na tabela [personne_activite]. Resta apenas definir as relações existentes entre a @Entity PersonneActivite que estamos a descrever neste momento e as outras @Entity do esquema relacional. Estas relações traduzem as restrições de chaves estrangeiras que a tabela [personne_activite] tem com as outras tabelas.
- linhas 33-39: definem a chave estrangeira que a tabela [personne_activite] possui na tabela [personne]
- linha 37: a relação é do tipo @ManyToOne: uma linha (One) da tabela [personne] é referenciada por várias (Many) linhas da tabela [personne_activite].
- linha 38: nomeia-se a coluna-chave estrangeira. Utiliza-se o mesmo nome que foi atribuído ao componente «pessoa» da chave estrangeira (linha 10). Os atributos insertable=false, updatable=false servem para impedir que o Hibernate gere a chave estrangeira. Esta é, de facto, o componente de uma chave primária calculada pela aplicação e o Hibernate não deve intervir.
- linhas 41-47: definem a chave estrangeira que a tabela [personne_activite] possui sobre a tabela [activite]. As explicações são as mesmas que as apresentadas anteriormente.
- linhas 54-63: construtor de um objeto PersonneActivite a partir de uma pessoa p e de uma atividade a. Recorde-se que, aquando da criação de um objeto PersonneActivite, a chave primária id da linha 31 apontava para um objeto Id vazio. As linhas 56-57 atribuem um valor a cada um dos campos (personneId, activiteId) do objeto Id. Estes valores são, respetivamente, as chaves primárias da pessoa p e da atividade a, passadas como parâmetros ao construtor. A chave primária id (linha 31) tem, portanto, agora um valor.
- linha 59: o campo personne da linha 39 recebe o valor p
- linha 60: o campo activite da linha 47 recebe o valor a
- Foi criado e inicializado um objeto [PersonneActivite]. Atualizam-se as relações inversas que as @Entity Personne (linha 61) e Activite (linha 62) têm com a @Entity PersonneActivite que acabou de ser criada.
Concluímos a descrição das entidades da base de dados. Encontramo-nos numa situação complexa, mas infelizmente frequente. Veremos que existe outra configuração possível da camada JPA que oculta parte dessa complexidade: a tabela de junção torna-se implícita, construída e gerida pela camada JPA. Escolhemos aqui a solução mais complexa, mas que permite que o esquema relacional evolua. Assim, permite adicionar colunas à tabela de junção, o que não é possível na configuração em que a tabela de junção não é uma @Entity explícita. A [ref1] recomenda a solução que estamos a estudar. Foi no [ref1] que foram encontradas as informações que permitiram a elaboração desta solução.
2.5.3. O projeto Eclipse / Hibernate
A implementação JPA aqui utilizada é a do Hibernate. O projeto Eclipse dos testes é o seguinte:
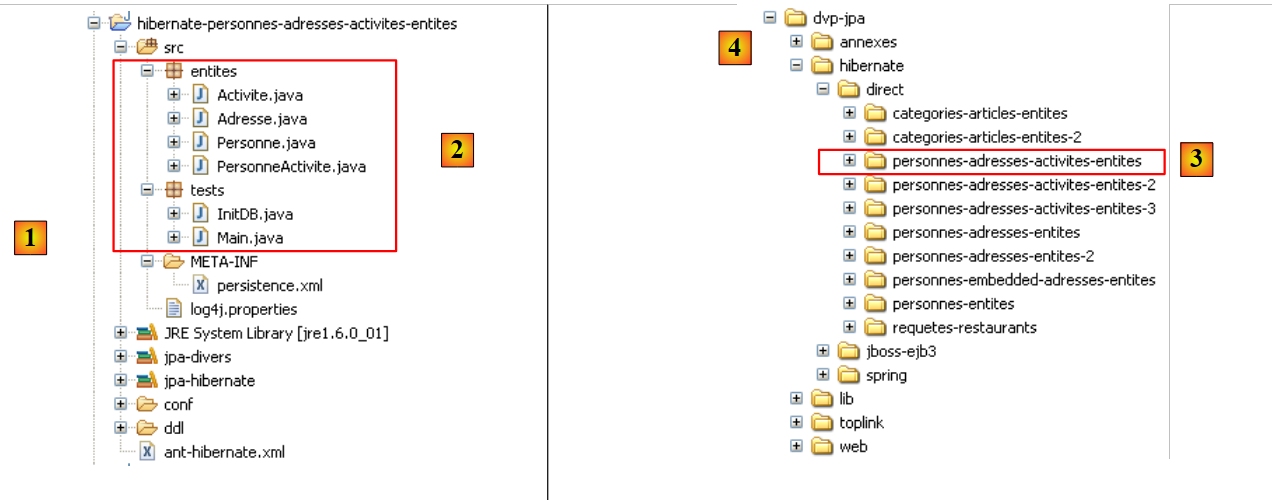
Em [1], encontra-se o projeto Eclipse; em [2], os códigos Java. O projeto está presente em [3], na pasta de exemplos [4]. Iremos importá-lo.
2.5.4. Geração do ficheiro DDL da base de dados
Seguindo as instruções do parágrafo 2.1.7, o DDL obtido para o SGBD MySQL5 é o seguinte:
alter table jpa07_hb_personne
drop
foreign key FKB5C817D45FE379D0;
alter table jpa07_hb_personne_activite
drop
foreign key FKD3E49B06CD852024;
alter table jpa07_hb_personne_activite
drop
foreign key FKD3E49B0668C7A284;
drop table if exists jpa07_hb_activite;
drop table if exists jpa07_hb_adresse;
drop table if exists jpa07_hb_personne;
drop table if exists jpa07_hb_personne_activite;
create table jpa07_hb_activite (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa07_hb_adresse (
id bigint not null auto_increment,
version integer not null,
adr1 varchar(30) not null,
adr2 varchar(30),
adr3 varchar(30),
codePostal varchar(5) not null,
ville varchar(20) not null,
cedex varchar(3),
pays varchar(20) not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa07_hb_personne (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
prenom varchar(30) not null,
datenaissance date not null,
marie bit not null,
nbenfants integer not null,
adresse_id bigint not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa07_hb_personne_activite (
PERSONNE_ID bigint not null,
ACTIVITE_ID bigint not null,
primary key (PERSONNE_ID, ACTIVITE_ID)
) ENGINE=InnoDB;
alter table jpa07_hb_personne
add index FKB5C817D45FE379D0 (adresse_id),
add constraint FKB5C817D45FE379D0
foreign key (adresse_id)
references jpa07_hb_adresse (id);
alter table jpa07_hb_personne_activite
add index FKD3E49B06CD852024 (ACTIVITE_ID),
add constraint FKD3E49B06CD852024
foreign key (ACTIVITE_ID)
references jpa07_hb_activite (id);
alter table jpa07_hb_personne_activite
add index FKD3E49B0668C7A284 (PERSONNE_ID),
add constraint FKD3E49B0668C7A284
foreign key (PERSONNE_ID)
references jpa07_hb_personne (id);
- linhas 21-26: a tabela [activite]
- linhas 28-39: a tabela [adresse]
- linhas 41-51: a tabela [personne]
- linhas 53-57: a tabela de junção [personne_activite]. De notar a chave composta (linha 56)
- linhas 59-63: a chave estrangeira da tabela [personne] para a tabela [adresse]
- linhas 65-69: a chave estrangeira da tabela [personne_activite] para a tabela [activite]
- linhas 71-75: a chave estrangeira da tabela [personne_activite] para a tabela [personne]
2.5.5. InitDB
O código de [InitDB] é o seguinte:
package tests;
...
public class InitDB {
// constantes
private final static String TABLE_PERSONNE_ACTIVITE = "jpa07_hb_personne_activite";
private final static String TABLE_PERSONNE = "jpa07_hb_personne";
private final static String TABLE_ACTIVITE = "jpa07_hb_activite";
private final static String TABLE_ADRESSE = "jpa07_hb_adresse";
public static void main(String[] args) throws ParseException {
// Contexto de persistência
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// recupera-se um EntityManager a partir do EntityManagerFactory
// anterior
em = emf.createEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// pedido
Query sql1;
// eliminar os elementos da tabela PERSONNE_ACTIVITE
sql1 = em.createNativeQuery("delete from " + TABLE_PERSONNE_ACTIVITE);
sql1.executeUpdate();
// eliminar os elementos da tabela PERSONNE
sql1 = em.createNativeQuery("delete from " + TABLE_PERSONNE);
sql1.executeUpdate();
// eliminar os elementos da tabela ACTIVITE
sql1 = em.createNativeQuery("delete from " + TABLE_ACTIVITE);
sql1.executeUpdate();
// eliminar os elementos da tabela ADRESSE
sql1 = em.createNativeQuery("delete from " + TABLE_ADRESSE);
sql1.executeUpdate();
// criação de atividades
Activite act1 = new Activite();
act1.setNom("act1");
Activite act2 = new Activite();
act2.setNom("act2");
Activite act3 = new Activite();
act3.setNom("act3");
// persistência de atividades
em.persist(act1);
em.persist(act2);
em.persist(act3);
// criação de pessoas
Personne p1 = new Personne("p1", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("p2", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
Personne p3 = new Personne("p3", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// criação de endereços
Adresse adr1 = new Adresse("adr1", null, null, "49000", "Angers", null, "France");
Adresse adr2 = new Adresse("adr2", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
Adresse adr3 = new Adresse("adr3", "x", "x", "x", "x", "x", "x");
Adresse adr4 = new Adresse("adr4", "y", "y", "y", "y", "y", "y");
// associações entre pessoas e endereços
p1.setAdresse(adr1);
adr1.setPersonne(p1);
p2.setAdresse(adr2);
adr2.setPersonne(p2);
p3.setAdresse(adr3);
adr3.setPersonne(p3);
// persistência de pessoas e, consequentemente, dos endereços associados
em.persist(p1);
em.persist(p2);
em.persist(p3);
// persistência do endereço a4 não associado a uma pessoa
em.persist(adr4);
// exibição de pessoas
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// visualização de endereços
System.out.println("[adresses]");
for (Object a : em.createQuery("select a from Adresse a").getResultList()) {
System.out.println(a);
}
System.out.println("[activites]");
for (Object a : em.createQuery("select a from Activite a").getResultList()) {
System.out.println(a);
}
// associações pessoa <--> atividade
PersonneActivite p1act1 = new PersonneActivite(p1, act1);
PersonneActivite p1act2 = new PersonneActivite(p1, act2);
PersonneActivite p2act1 = new PersonneActivite(p2, act1);
PersonneActivite p2act3 = new PersonneActivite(p2, act3);
// persistência das associações pessoa <--> atividade
em.persist(p1act1);
em.persist(p1act2);
em.persist(p2act1);
em.persist(p2act3);
// visualização de pessoas
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// visualização de endereços
System.out.println("[adresses]");
for (Object a : em.createQuery("select a from Adresse a").getResultList()) {
System.out.println(a);
}
System.out.println("[activites]");
for (Object a : em.createQuery("select a from Activite a").getResultList()) {
System.out.println(a);
}
System.out.println("[personnes/activites]");
for (Object pa : em.createQuery("select pa from PersonneActivite pa").getResultList()) {
System.out.println(pa);
}
// fim da transação
tx.commit();
// fim de EntityManager
em.close();
// fim de EntityManagerFactory
emf.close();
// registo
System.out.println("terminé...");
}
}
- linhas 27-38: as tabelas [personne_activite], [personne], [adresse] e [activite] são esvaziadas. Note-se que é obrigatório começar pelas tabelas que possuem chaves estrangeiras.
- linhas 40-45: criam-se três atividades act1, act2 e act3
- linhas 47-49: são colocadas no contexto de persistência.
- linhas 51-53: criam-se três pessoas: p1, p2 e p3.
- linhas 55-58: criam-se quatro endereços, de adr1 a adr4.
- linhas 60-65: os endereços adri são associados às pessoas pi. Em cada caso, há duas operações a realizar, uma vez que a relação Pessoa <-> Endereço é bidirecional.
- linhas 67-69: as pessoas p1 a p3 são colocadas no contexto de persistência. Devido à cascata Pessoa -> Endereço, o mesmo acontecerá com os endereços de adr1 a adr3.
- linha 71: o quarto endereço adr4, que não está associado a uma pessoa, é colocado explicitamente no contexto de persistência.
- linhas 73-85: o contexto de persistência é consultado para obter as listas das entidades do tipo [Personne], [Adresse] e [Activite]. Sabe-se que estas consultas irão provocar a sincronização do contexto com a base de dados: as entidades criadas serão inseridas na base de dados e receberão a sua chave primária. É importante compreender isto para o que se segue.
- linhas 87-90: criam-se 4 associações Pessoa <-> Atividade. O nome de cada uma indica qual a pessoa associada a cada atividade. Talvez nos lembremos que a chave primária de uma entidade PersonneActivite é uma chave composta formada pela chave primária de uma pessoa e pela de uma atividade. É, portanto, porque as entidades Personne e Activite obtiveram as suas chaves primárias durante uma sincronização anterior que esta operação é possível.
- linhas 92-95: estas 4 associações são colocadas no contexto de persistência.
- linhas 87-86: o contexto de persistência é consultado para obter a lista das entidades do tipo [Personne], [Adresse], [Activite] e [PersonneActivite]. Sabe-se que estas consultas irão provocar a sincronização do contexto com a base de dados: as entidades PersonneActivite criadas serão inseridas na base de dados.
A execução de [InitDB] juntamente com MySQL5 resulta na seguinte saída na consola:
Pode ser surpreendente verificar que, nas linhas 15-16, as pessoas p1 e p2 têm o seu número de versão igual a 1 e que o mesmo se verifica, nas linhas 24-26, para as três atividades. Vamos tentar compreender.
Nas linhas 2 a 4, os números de versão das pessoas estão a 0 e, nas linhas 11 a 13, os números de versão das atividades estão a 0. As exibições anteriores ocorrem antes da criação das relações Pessoa <-> Atividade. Nas linhas 87-90 do código Java, são criadas relações entre as pessoas p1 e p2 e as atividades act1, act2, act3. Estas relações são criadas através do construtor da @Entity PersonneActivite (ver parágrafo 2.5.2). A análise do código deste construtor mostra que, quando uma pessoa p está ligada a uma atividade a:
- a atividade a é adicionada ao conjunto p.activites
- a pessoa p é adicionada ao conjunto a.personnes
Assim, quando se escreve new PersonneActivite(p,a), a pessoa p e a atividade a sofrem uma alteração na memória. Quando nas linhas 97-113 de [InitDB], o contexto de persistência é sincronizado com a base de dados, JPA / o Hibernate deteta que os elementos persistentes p1, p2, act1, act2 e act3 foram alterados. Estas alterações devem ser efetuadas na base de dados. Na verdade, estas estão registadas na tabela de junção [personne_activite], mas o JPA / Hibernate aumenta, mesmo assim, o número de versão de cada um dos elementos persistentes alterados.
Na perspetiva do SQL Explorer, os resultados são os seguintes:
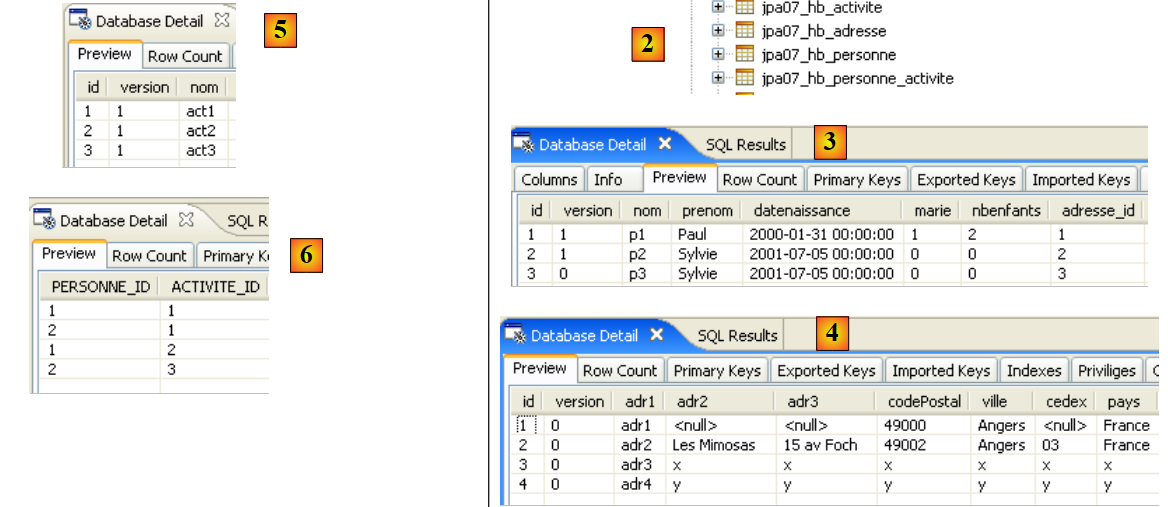 |
- [2]: as tabelas [jpa07_hb_*]
- [3]: a tabela de pessoas
- [4]: a tabela de endereços.
- [5]: a tabela de atividades
- [6]: a tabela de junção pessoa <-> atividade
2.5.6. Página inicial
A classe [Main] encadeia testes que iremos analisar, com exceção do teste 1, que reutiliza o código de [InitDB] para inicializar a base de dados.
2.5.6.1. Teste 2
Este teste é o seguinte:
// eliminação Pessoa p1
public static void test2() {
// contexto de persistência
EntityManager em = getEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// remoção de dependências em p1: não é necessário para o Hibernate, mas
// indispensável para o TopLink
act1.getPersonnes().remove(p1act1);
act2.getPersonnes().remove(p1act2);
// eliminação da pessoa p1
em.remove(p1);
// fim da transação
tx.commit();
// são apresentadas as novas tabelas
dumpPersonne();
dumpActivite();
dumpAdresse();
dumpPersonne_Activite();
}
- linha 4: utiliza-se o contexto de persistência de test1, onde a pessoa p1 é um objeto do contexto.
- linha 13: eliminação da pessoa p1. Devido ao atributo:
- cascadeType.ALL sobre Adresse, o endereço da pessoa p1 será eliminado
- cascadeType.REMOVE sobre PersonneActivite, as atividades da pessoa p1 serão eliminadas.
- linhas 10-11: eliminam-se as dependências que as outras entidades têm em relação à pessoa p1, que será eliminada na linha 13. As atividades act1 e act2 são exercidas pela pessoa p1. As ligações foram criadas pelo criador da entidade PersonneActivite, cujo código é o seguinte:
public PersonneActivite(Personne p, Activite a) {
// as chaves estrangeiras são definidas pela aplicação
getId().setPersonneId(p.getId());
getId().setActiviteId(a.getId());
// associações bidirecionais
setPersonne(p);
setActivite(a);
p.getActivites().add(this);
a.getPersonnes().add(this);
}
na linha 9, a atividade a recebe um elemento adicional do tipo PersonneActivite no seu conjunto personnes. Este elemento é do tipo (p,a) para indicar que a pessoa p exerce a atividade a. Em test1 de [Main], foram assim criadas duas ligações (p1,act1) e (p1,act2). As linhas 10 e 11 de test2 eliminam essas dependências. É importante referir que o Hibernate funciona sem a eliminação dessas dependências na entidade p1, mas o Toplink não.
- linhas 17-20: exibem-se todas as tabelas
Os resultados são os seguintes:
- A pessoa p1, presente em test1 (linha 3), já não se encontra presente no final de test2 (linhas 22-23)
- o endereço adr1 da pessoa p1, presente em test1 (linha 11) deixa de o ser após a execução de test2 (linhas 29-31)
- as atividades (p1,act1) (linha 16) e (p1,act2) (linha 18) da pessoa p1, presentes em test1, deixam de o ser após a execução de test2 (linhas 33-34)
2.5.6.2. Teste 3
Este teste é o seguinte:
// eliminação da atividade act1
public static void test3() {
// contexto de persistência
EntityManager em = getEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// eliminação de dependências na act1: não é necessário para o Hibernate, mas
// indispensável para o TopLink
p2.getActivites().remove(p2act1);
// eliminação da atividade act1
em.remove(act1);
// fim da transação
tx.commit();
// são apresentadas as novas tabelas
dumpPersonne();
dumpActivite();
dumpAdresse();
dumpPersonne_Activite();
}
- linha 4: utiliza-se o contexto de persistência de test2
- linha 12: eliminação da atividade act1. Devido ao atributo:
- cascadeType.REMOVE em PersonneActivite, as linhas (p, act1) da tabela [personne_activite] serão eliminadas.
- linha 10: antes de retirar act1 do contexto de persistência, eliminam-se as dependências que outras entidades possam ter em relação a este objeto persistente. Após a eliminação da pessoa p1 no teste anterior, apenas a pessoa p2 exerce a atividade act1.
- linhas 13-16: são apresentadas todas as tabelas
Os resultados são os seguintes:
- em test2, a atividade act1 existe (linha 6). No teste 3, já não existe (linhas 21-22)
- em test2, a ligação (p2,act1)) existe (linha 14). Em test3, já não existe (linha 28)
2.5.6.3. Test4
Este teste é o seguinte:
// recuperação das atividades de uma pessoa
public static void test4() {
// contexto de persistência
EntityManager em = getNewEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// recuperação da pessoa p2
p2 = em.find(Personne.class, p2.getId());
System.out.format("1 - Activités de la personne p2 (JPQL) :%n");
// analisam-se as suas atividades
for (Object pa : em.createQuery("select a.nom from Activite a join a.personnes pa where pa.personne.nom='p2'").getResultList()) {
System.out.println(pa);
}
// passa-se pela relação inversa de p2
p2 = em.find(Personne.class, p2.getId());
System.out.format("2 - Activités de la personne p2 (relation inverse) :%n");
// analisam-se as suas atividades
for (PersonneActivite pa : p2.getActivites()) {
System.out.println(pa.getActivite().getNom());
}
// fim da transação
tx.commit();
}
- o teste 4 apresenta as atividades da pessoa p2.
- linha 4: parte-se de um contexto novo e vazio
- linhas 12-14: exibem-se os nomes das atividades realizadas pela pessoa p2 através de uma consulta JPQL.
- É efetuada uma junção Activite (a) / PersonneActivite (pa) (join a.personnes)
- nas linhas desta junção (a,pa), é apresentado o nome da atividade (a.nom) para a pessoa p2 (pa.personne.nom='p2').
- linhas 16-21: faz-se o mesmo que anteriormente, mas com a ajuda da relação OneToMany p2.activites da pessoa p2. A consulta JPQL será gerada por JPA. Aqui fica patente a utilidade da relação inversa OneToMany: evita uma consulta JPQL.
Os resultados são os seguintes:
2.5.6.4. Teste5
Este teste é o seguinte:
// recuperação de pessoas que realizam uma determinada atividade
public static void test5() {
// contexto de persistência
EntityManager em = getNewEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
System.out.format("1 - Personnes pratiquant l'activité act3 (JPQL) :%n");
// solicita-se as atividades de p2
for (Object pa : em.createQuery("select p.nom from Personne p join p.activites pa where pa.activite.nom='act3'").getResultList()) {
System.out.println(pa);
}
// passa-se pela relação inversa de act3
System.out.format("2 - Personnes pratiquant l'activité act3 (relation inverse) :%n");
act3 = em.find(Activite.class, act3.getId());
for (PersonneActivite pa : act3.getPersonnes()) {
System.out.println(pa.getPersonne().getNom());
}
// fim da transação
tx.commit();
}
- O teste 6 apresenta as pessoas que realizam a atividade act3. O procedimento é semelhante ao do teste 6. Deixamos ao leitor a tarefa de estabelecer a ligação entre os dois códigos.
Os resultados são os seguintes:
Os testes 4 e 5 tinham como objetivo demonstrar, mais uma vez, que uma relação inversa nunca é indispensável e pode sempre ser substituída por uma consulta JPQL.
2.5.7. Implementação JPA / Toplink
Estamos agora a utilizar uma implementação JPA / Toplink:
 |
O projeto Eclipse com o Toplink é uma cópia do projeto Eclipse com o Hibernate:
 |
Os códigos Java são idênticos aos do projeto Hibernate anterior, com algumas pequenas diferenças que iremos abordar. O ambiente (bibliotecas – persistence.xml – SGBD – pastas conf, ddl – script ant) é o mesmo que foi analisado no parágrafo 2.1.15.2. O projeto Eclipse encontra-se em [3], na pasta de exemplos [4]. Vamos importá-lo.
O ficheiro <persistence.xml> [2] é alterado num ponto, o das entidades declaradas:
<!-- classes persistentes -->
<class>entites.Activite</class>
<class>entites.Adresse</class>
<class>entites.Personne</class>
<class>entites.PersonneActivite</class>
- linhas 2-5: as quatro entidades geridas
A execução do [InitDB] com o SGBD MySQL5 produz os seguintes resultados:
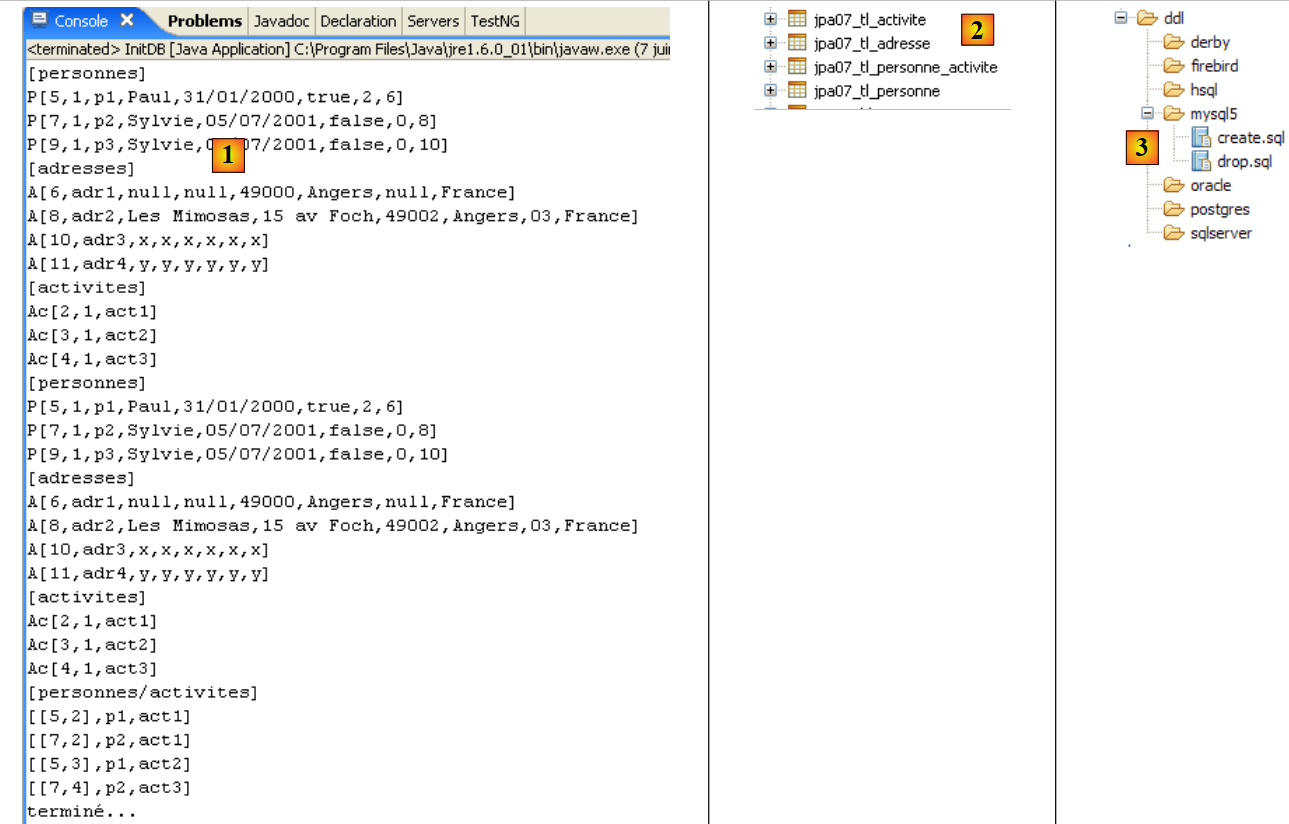 |
No [1], a saída da consola; no [2], as tabelas [jpa07_tl] geradas; no [3], os scripts SQL gerados. O seu conteúdo é o seguinte:
create.sql
CREATE TABLE jpa07_tl_activite (ID BIGINT NOT NULL, VERSION INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa07_tl_adresse (ID BIGINT NOT NULL, ADR3 VARCHAR(30), CODEPOSTAL VARCHAR(5) NOT NULL, VERSION INTEGER NOT NULL, VILLE VARCHAR(20) NOT NULL, ADR2 VARCHAR(30), CEDEX VARCHAR(3), ADR1 VARCHAR(30) NOT NULL, PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa07_tl_personne_activite (PERSONNE_ID BIGINT NOT NULL, ACTIVITE_ID BIGINT NOT NULL, PRIMARY KEY (PERSONNE_ID, ACTIVITE_ID))
CREATE TABLE jpa07_tl_personne (ID BIGINT NOT NULL, DATENAISSANCE DATE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, NBENFANTS INTEGER NOT NULL, VERSION INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, adresse_id BIGINT UNIQUE NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa07_tl_personne_activite ADD CONSTRAINT FK_jpa07_tl_personne_activite_ACTIVITE_ID FOREIGN KEY (ACTIVITE_ID) REFERENCES jpa07_tl_activite (ID)
ALTER TABLE jpa07_tl_personne_activite ADD CONSTRAINT FK_jpa07_tl_personne_activite_PERSONNE_ID FOREIGN KEY (PERSONNE_ID) REFERENCES jpa07_tl_personne (ID)
ALTER TABLE jpa07_tl_personne ADD CONSTRAINT FK_jpa07_tl_personne_adresse_id FOREIGN KEY (adresse_id) REFERENCES jpa07_tl_adresse (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
A execução de [InitDB] e de [Main] decorre sem erros.
2.6. Exemplo 6: relação muitos-para-muitos com uma tabela de junção implícita
Retomamos o exemplo 4, mas agora tratamo-lo com uma tabela de junção implícita gerada pela própria camada JPA.
2.6.1. O esquema da base de dados
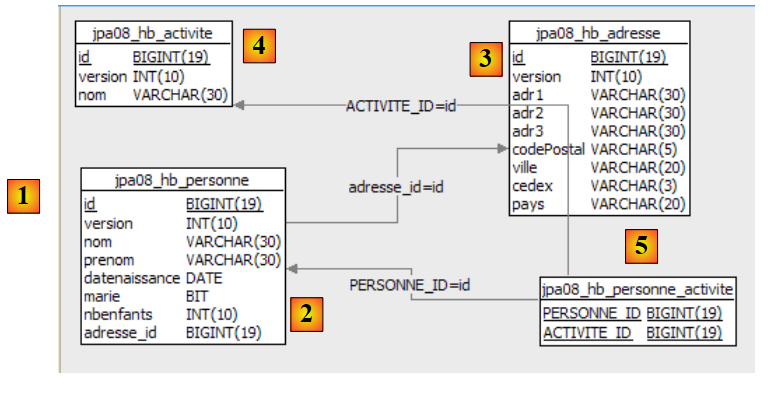 |
- em [1], a base de dados MySQL5 – em [2]: a tabela [personne] – para [3]: a tabela [adresse] associada – para [4]: a tabela [activite] das atividades – em [5]: a tabela de junção [personne_activite] que estabelece a ligação entre pessoas e atividades.
2.6.2. Os objetos @Entity que representam a base de dados
As tabelas anteriores serão representadas pelas seguintes @Entity:
- a @Entity Personne representará a tabela [personne]
- o @Entity Adresse representará a tabela [adresse]
- a @Entity Activite representará a tabela [activite]
- a tabela [personne_activite] já não é representada por uma @Entity
As relações entre estas entidades são as seguintes:
- uma relação um-para-um liga a entidade Personne à entidade Adresse: uma pessoa p tem uma morada a. A entidade Personne, que detém a chave estrangeira, terá a relação principal, enquanto a entidade Adresse terá a relação inversa.
- Uma relação muitos-a-muitos liga as entidades Personne e Activite: uma pessoa tem várias atividades e uma atividade é praticada por várias pessoas. Esta relação será concretizada por uma anotação @ManyToMany em cada uma das duas entidades, sendo uma delas declarada como inversa da outra.
A @Entity Personne é a seguinte:
@Entity
@Table(name = "jpa08_hb_personne")
public class Personne implements Serializable {
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
// toplink sqlserver: @GeneratedValue (strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
// relação principal Pessoa (one) -> Morada (one)
// implementada pela chave estrangeira Pessoa (adresse_id) -> Endereço
// cascata de inserção Pessoa -> inserção de Endereço
// cascata de atualização Pessoa -> atualização de Endereço
// eliminação em cascata de Pessoa -> eliminação de Endereço
// uma Pessoa deve ter 1 Endereço (nullable=false)
// 1 Endereço pertence apenas a 1 Pessoa (único=true)
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
// relação Pessoa (muitas) -> Atividade (muitas) através de uma tabela de junção personne_activite
// personne_activite(PERSONNE_ID) é uma chave estrangeira na tabela Pessoa (id)
// personne_activite(ACTIVITE_ID) é uma chave estrangeira na tabela «Atividade» (id)
// cascade=CascadeType.PERSIST: a persistência de uma pessoa implica a persistência das suas atividades
@ManyToMany(cascade={CascadeType.PERSIST})
@JoinTable(name="jpa08_hb_personne_activite",joinColumns = @JoinColumn(name = "PERSONNE_ID"), inverseJoinColumns = @JoinColumn(name = "ACTIVITE_ID"))
private Set<Activite> activites = new HashSet<Activite>();
// construtores
public Personne() {
}
Comentamos apenas a relação @ManyToMany das linhas 46-48, que liga a @Entity Personne à @Entity Activite:
- linha 48: uma pessoa tem atividades. O campo «activites» representará essas atividades. Na versão anterior, o tipo dos elementos do conjunto activites era PersonneActivite. Aqui, é Activite. Assim, acede-se diretamente às atividades de uma pessoa, enquanto que na versão anterior era necessário passar pela entidade intermédia PersonneActivite.
- linha 46: a relação que liga a @Entity Personne que estamos a analisar à @Entity Activite do conjunto activites da linha 48 é do tipo muitos-para-muitos (ManyToMany):
- uma pessoa (One) tem várias atividades (Many)
- uma atividade (One) é praticada por várias pessoas (Many)
- No final, as @Entity Personne e Activite estão ligadas por uma relação ManyToMany. Tal como na relação OneToOne, existe simetria entre as entidades nesta relação. É possível escolher livremente a @Entity que irá deter a relação principal e aquela que terá a relação inversa. Neste caso, decidimos que a @Entity Personne terá a relação principal.
- Tal como vimos no exemplo anterior, a relação @ManyToMany requer uma tabela de junção. Enquanto anteriormente a tínhamos definido utilizando uma @Entity, a tabela de junção aqui é definida através da anotação @JoinTable na linha 47.
- O atributo «name» atribui um nome à tabela.
- A tabela de junção é constituída pelas chaves estrangeiras das tabelas que ela une. Aqui, existem duas chaves estrangeiras: uma na tabela [personne] e outra na tabela [activite]. Estas colunas de chave estrangeira são definidas pelos atributos joinColumns e inverseJoinColumns.
- A anotação @JoinColumn do atributo joinColumns define a chave estrangeira na tabela da @Entity que detém a relação principal @ManyToMany, neste caso a tabela [personne]. Esta coluna de chave estrangeira será denominada PERSONNE_ID.
- A anotação @JoinColumn do atributo inverseJoinColumns define a chave estrangeira na tabela da @Entity que mantém a relação inversa @ManyToMany, neste caso a tabela [activite]. Esta coluna de chave estrangeira será denominada ACTIVITE_ID.
A @Entity Adresse é a seguinte:
@Entity
@Table(name = "jpa07_hb_adresse")
public class Adresse implements Serializable {
// campos
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
@OneToOne(mappedBy = "adresse")
private Personne personne;
- linhas 28-29: a relação @OneToOne, inversa da relação @OneToOne, que aponta para a @Entity Personne (linhas 37-38 de Personne).
A @Entity Activite é a seguinte
@Entity
@Table(name = "jpa08_hb_activite")
public class Activite implements Serializable {
// campos
@Id()
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
// toplink sqlserver: @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
// relação inversa Atividade -> Pessoa
@ManyToMany(mappedBy = "activites")
private Set<Personne> personnes = new HashSet<Personne>();
...
- linhas 20-21: a relação muitos-para-muitos que liga a @Entity Activite à @Entity Personne. Esta relação já foi definida na @Entity Personne. Basta, portanto, indicar aqui que a relação é inversa (mappedBy) à relação @ManyToMany existente no campo «activites» (mappedBy = «activites») da @Entidade Personne.
- Recorde-se que uma relação inversa é sempre opcional. Aqui, utilizamos-a para obter as pessoas que praticam a atividade atual. É o conjunto Set<Pessoa> pessoas que permitirá obter essas pessoas. O modo de carregamento das dependências Personne da @Entity Activite não está especificado. Também não o tínhamos especificado no exemplo anterior. Por predefinição, este modo é fetch=FetchType.LAZY.
Concluímos a descrição das entidades da base de dados. Foi mais simples do que no caso em que a tabela de junção [personne_activite] é uma tabela explícita. Esta solução mais simples pode apresentar desvantagens ao longo do tempo: não permite adicionar colunas à tabela de junção. No entanto, isso pode revelar-se necessário para satisfazer novas necessidades, por exemplo, adicionar à tabela [personne_activite] uma coluna que indique a data de inscrição da pessoa na atividade.
2.6.3. O projeto Eclipse / Hibernate
A implementação JPA aqui utilizada é a do Hibernate. O projeto Eclipse dos testes é o seguinte:
 |
Em [1], o projeto Eclipse; em [2], os códigos Java. O projeto encontra-se em [3], na pasta de exemplos [4]. Iremos importá-lo.
2.6.4. Geração do ficheiro DDL da base de dados
Seguindo as instruções do parágrafo 2.1.7, o DDL obtido para o SGBD MySQL5 é o seguinte:
alter table jpa08_hb_personne
drop
foreign key FKA44B1E555FE379D0;
alter table jpa08_hb_personne_activite
drop
foreign key FK5A6A55A5CD852024;
alter table jpa08_hb_personne_activite
drop
foreign key FK5A6A55A568C7A284;
drop table if exists jpa08_hb_activite;
drop table if exists jpa08_hb_adresse;
drop table if exists jpa08_hb_personne;
drop table if exists jpa08_hb_personne_activite;
create table jpa08_hb_activite (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa08_hb_adresse (
id bigint not null auto_increment,
version integer not null,
adr1 varchar(30) not null,
adr2 varchar(30),
adr3 varchar(30),
codePostal varchar(5) not null,
ville varchar(20) not null,
cedex varchar(3),
pays varchar(20) not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa08_hb_personne (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
prenom varchar(30) not null,
datenaissance date not null,
marie bit not null,
nbenfants integer not null,
adresse_id bigint not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa08_hb_personne_activite (
PERSONNE_ID bigint not null,
ACTIVITE_ID bigint not null,
primary key (PERSONNE_ID, ACTIVITE_ID)
) ENGINE=InnoDB;
alter table jpa08_hb_personne
add index FKA44B1E555FE379D0 (adresse_id),
add constraint FKA44B1E555FE379D0
foreign key (adresse_id)
references jpa08_hb_adresse (id);
alter table jpa08_hb_personne_activite
add index FK5A6A55A5CD852024 (ACTIVITE_ID),
add constraint FK5A6A55A5CD852024
foreign key (ACTIVITE_ID)
references jpa08_hb_activite (id);
alter table jpa08_hb_personne_activite
add index FK5A6A55A568C7A284 (PERSONNE_ID),
add constraint FK5A6A55A568C7A284
foreign key (PERSONNE_ID)
references jpa08_hb_personne (id);
Este DDL é análogo ao obtido com a tabela de junção explícita e corresponde ao esquema já apresentado:
 |
2.6.5. InitDB
Não nos deteremos muito na classe [InitDB], que é idêntica à sua versão anterior e produz os mesmos resultados. Limitar-nos-emos a analisar o código seguinte, que apresenta a junção Personne <-> Activite:
// visualização de pessoas/atividades
System.out.println("[personnes/activites]");
Iterator iterator = em.createQuery("select p.id,a.id from Personne p join p.activites a").getResultList().iterator();
while (iterator.hasNext()) {
Object[] row = (Object[]) iterator.next();
System.out.format("[%d,%d]%n", (Long) row[0], (Long) row[1]);
}
- linha 3: a ordem JPQL que efetua a junção. O resultado do select apresenta os identificadores das entidades Personne e Activite, ligadas entre si pela tabela de junção. A lista devolvida pelo select é composta por linhas que contêm dois objetos do tipo Long. Para percorrer esta lista, a linha 3 solicita um objeto Iterator da lista.
- linhas 4-7: com a ajuda do objeto do tipo Iterator anterior, percorre-se a lista.
- linha 5: cada elemento da lista é um tabuleiro que contém uma linha resultante do select
- linha 6: recuperam-se os elementos da linha atual resultante do select, efetuando as alterações de tipo adequadas.
O resultado do [InitDB] é o seguinte:
2.6.6. Main
A classe [Main] encadeia uma série de testes, alguns dos quais iremos analisar.
2.6.6.1. Teste 3
Este teste é o seguinte:
// eliminação da atividade act1
public static void test3() {
// contexto de persistência
EntityManager em = getEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// eliminação da atividade act1 de p2
p2.getActivites().remove(act1);
// retirar a atividade act1 do contexto de persistência
em.remove(act1);
// fim das transações
tx.commit();
// exibição das novas tabelas
dumpPersonne();
dumpActivite();
dumpAdresse();
dumpPersonne_Activite();
}
- linha 11: a atividade act1 é removida do contexto de persistência
- linha 9: a atividade act1 faz parte das atividades da única pessoa que permanece no contexto, a pessoa p2. A linha 9 retira a atividade act1 das atividades da pessoa p2. Fazemos isto para manter a coerência do contexto de persistência, uma vez que o conservamos para as etapas seguintes.
Os resultados são os seguintes:
- a atividade act1, que aparecia na linha 26 de test2, desapareceu das atividades de test3 (linhas 40-41)
- A pessoa p2 tinha, em test2, a atividade act1 (linha 33). No final de test3, já não a tem (linha 47)
2.6.6.2. Teste 6
Este teste é o seguinte:
// alteração das atividades de uma pessoa
public static void test6() {
// contexto de persistência
EntityManager em = getNewEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// recuperação da pessoa p2
p2 = em.find(Personne.class, p2.getId());
// recupera-se a atividade act2
act2 = em.find(Activite.class, act2.getId());
// p2 já só exerce a atividade act2
p2.getActivites().clear();
p2.getActivites().add(act2);
// fim da transação
tx.commit();
// são apresentadas as novas tabelas
dumpPersonne();
dumpActivite();
dumpPersonne_Activite();
}
- linha 4: utiliza-se um contexto de persistência novo e vazio
- linha 9: a pessoa p2 é transferida da base de dados para o contexto de persistência
- linha 11: a atividade act2 é transferida da base de dados para o contexto de persistência
- linha 13: as atividades da pessoa p2 (act3) são transferidas da base de dados para o contexto (fetchType.LAZY). É a chamada [getActivites] que provoca este carregamento. Eliminam-se as atividades de p2. Não se trata de uma eliminação efetiva das atividades (remove), mas sim de uma alteração do estado da pessoa p2. Esta já não exerce quaisquer atividades.
- linha 14: adiciona-se à pessoa p2 a atividade act2. No final, o conjunto de novas atividades da pessoa p2 é o conjunto {act2}.
- linha 16: fim da transação. A sincronização irá analisar os objetos do contexto (p2, act2, act3) e irá detetar que o estado de p2 mudou. As ordens SQL, que refletem esta alteração na base de dados, serão executadas.
- linhas 18-20: são apresentadas todas as tabelas
Os resultados são os seguintes:
- No final do teste 4, a pessoa p2 exercia a atividade act3 (linha 3).
- No final do teste 6 (linha 19), a pessoa p2 já não exerce a atividade act3 (linha 3) e exerce a atividade act2.
2.6.7. Implementação JPA / Toplink
Utilizamos agora uma implementação JPA / Toplink:
 |
O projeto Eclipse com Toplink é uma cópia do projeto Eclipse com Hibernate:
 |
O ficheiro <persistence.xml> [2] foi alterado num ponto, nomeadamente nas entidades declaradas:
<!-- provedor -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- classes persistentes -->
<class>entites.Activite</class>
<class>entites.Adresse</class>
<class>entites.Personne</class>
...
- linhas 4-6: as entidades geridas
A execução de [InitDB] com o SGBD MySQL5 produz os seguintes resultados:
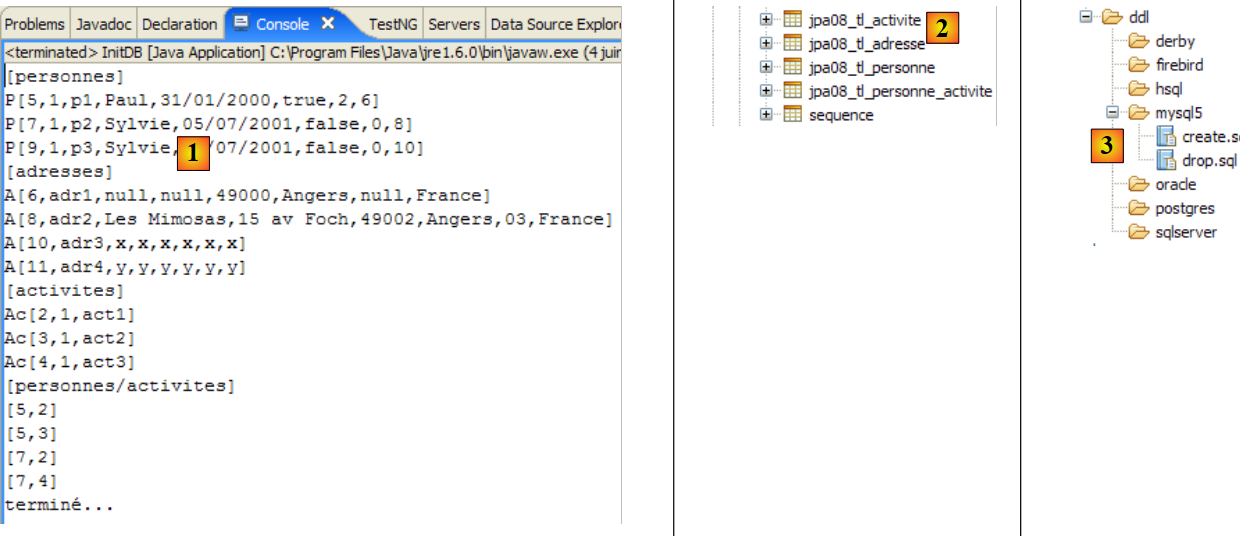 |
No [1], a saída da consola; no [2], as tabelas geradas [jpa07_tl]; no [3], os scripts gerados SQL. O seu conteúdo é o seguinte:
create.sql
CREATE TABLE jpa08_tl_personne_activite (PERSONNE_ID BIGINT NOT NULL, ACTIVITE_ID BIGINT NOT NULL, PRIMARY KEY (PERSONNE_ID, ACTIVITE_ID))
CREATE TABLE jpa08_tl_activite (ID BIGINT NOT NULL, VERSION INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa08_tl_personne (ID BIGINT NOT NULL, DATENAISSANCE DATE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, NBENFANTS INTEGER NOT NULL, VERSION INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, adresse_id BIGINT UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa08_tl_adresse (ID BIGINT NOT NULL, ADR3 VARCHAR(30), CODEPOSTAL VARCHAR(5) NOT NULL, VERSION INTEGER NOT NULL, VILLE VARCHAR(20) NOT NULL, ADR2 VARCHAR(30), CEDEX VARCHAR(3), ADR1 VARCHAR(30) NOT NULL, PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa08_tl_personne_activite ADD CONSTRAINT FK_jpa08_tl_personne_activite_ACTIVITE_ID FOREIGN KEY (ACTIVITE_ID) REFERENCES jpa08_tl_activite (ID)
ALTER TABLE jpa08_tl_personne_activite ADD CONSTRAINT FK_jpa08_tl_personne_activite_PERSONNE_ID FOREIGN KEY (PERSONNE_ID) REFERENCES jpa08_tl_personne (ID)
ALTER TABLE jpa08_tl_personne ADD CONSTRAINT FK_jpa08_tl_personne_adresse_id FOREIGN KEY (adresse_id) REFERENCES jpa08_tl_adresse (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
A execução de [InitDB] e de [Main] decorre sem erros.
2.6.8. O projeto Eclipse / Hibernate 2
Criamos um projeto Eclipse a partir do anterior, por cópia:
 |
Em [1], o projeto Eclipse; em [2], os códigos Java. O projeto encontra-se em [3] na pasta de exemplos [4]. Vamos importá-lo.
Alteramos a relação que liga o Personne ao Activité da seguinte forma:
Pessoa
// relação Pessoa (muitas) -> Atividade (muitas) através de uma tabela de junção personne_activite
// personne_activite(PERSONNE_ID) é uma chave estrangeira na tabela Pessoa (id)
// personne_activite(ACTIVITE_ID) é uma chave estrangeira na tabela «Atividade» (id)
// mais cascata nas atividades
// @ManyToMany(cascata={CascadeType.PERSIST})
@ManyToMany()
@JoinTable(name = "jpa09_hb_personne_activite", joinColumns = @JoinColumn(name = "PERSONNE_ID"), inverseJoinColumns = @JoinColumn(name = "ACTIVITE_ID"))
private Set<Activite> activites = new HashSet<Activite>();
- linha 6: a relação principal @ManyToMany já não tem a cascata de persistência Pessoa -> Atividade (ver versão anterior, linha 5)
Atividade
// sem relação inversa com Pessoa
// @ManyToMany(mappedBy = "atividades")
// private Set<Pessoa> pessoas = new HashSet<Pessoa>();
- linhas 2-3: a relação inversa @ManyToMany Atividade -> Pessoa foi eliminada
Pretendemos demonstrar que os atributos eliminados (cascata e relação inversa) não são indispensáveis. A primeira alteração introduzida por esta nova configuração encontra-se em [InitDB]:
// associações pessoas <--> atividades
p1.getActivites().add(act1);
p1.getActivites().add(act2);
p2.getActivites().add(act1);
p2.getActivites().add(act3);
// persistência das atividades
em.persist(act1);
em.persist(act2);
em.persist(act3);
// persistência das pessoas
em.persist(p1);
em.persist(p2);
em.persist(p3);
// e do endereço a4 não associado a uma pessoa
em.persist(adr4);
- linhas 7-9: somos obrigados a colocar explicitamente as atividades act1 a act3 no contexto de persistência. Quando a cascata de persistência Pessoa -> Atividade existia, as linhas 11-13 mantinham tanto as pessoas p1 a p3 como as atividades dessas pessoas act1 a act3.
É visível uma segunda alteração em [Main]:
// recuperação de pessoas que realizam uma determinada atividade
public static void test5() {
// contexto de persistência
EntityManager em = getNewEntityManager();
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
System.out.format("1 - Personnes pratiquant l'activité act3 (JPQL) :%n");
// solicitação das atividades de p2
for (Object pa : em.createQuery("select p.nom from Personne p join p.activites a where a.nom='act3'").getResultList()) {
System.out.println(pa);
}
// fim da transação
tx.commit();
}
- linhas 9-12: a consulta JPQL que obtém as pessoas que praticam a atividade act3
- na versão anterior, o mesmo resultado tinha sido obtido também através da relação inversa Atividade -> Pessoa, agora eliminada:
// passa-se pela relação inversa de act3
System.out.format("2 - Personnes pratiquant l'activité act3 (relation inverse) :%n");
act3 = em.find(Activite.class, act3.getId());
for (Personne p : act3.getPersonnes()) {
System.out.println(p.getNom());
}
2.6.9. O projeto Eclipse / Toplink 2
Estamos a criar um projeto Eclipse a partir do projeto Eclipse / Toplink anterior, por cópia:
 |
Em [1], o projeto Eclipse; em [2], os códigos Java. O projeto encontra-se em [3] na pasta de exemplos [4]. Vamos importá-lo.
Os códigos Java são idênticos aos da versão Hibernate.
2.7. Exemplo 7: utilizar consultas nomeadas
Concluímos esta longa apresentação das entidades JPA, iniciada no parágrafo 2, com um último exemplo que mostra a utilização de consultas JPQL externalizadas num ficheiro de configuração. Este exemplo tem origem na seguinte fonte:
[ref2]: «Getting started With JPA in Spring 2.0», de Mark Fisher, disponível na URL
[http://blog.springframework.com/markf/archives/2006/05/30/getting-started-with-jpa-in-spring-20/].
2.7.1. A base de dados de exemplo
A base de dados é a seguinte:
 |
- em [1]: uma lista de restaurantes com os respetivos nomes e moradas
- em [2]: a tabela dos endereços dos restaurantes, limitada ao n.º da rua e ao nome da rua. Existe uma relação um-para-um entre as tabelas restaurant e adresse: um restaurante tem um endereço e apenas um.
- em [3]: uma tabela de pratos com os respetivos nomes e um indicador verdadeiro/falso para indicar se o prato é vegetariano ou não
- em [4]: a tabela de junção restaurantes/pratos: um restaurante serve vários pratos e um mesmo prato pode ser servido por vários restaurantes. Existe uma relação muitos-para-muitos entre as tabelas restaurant e plat.
2.7.2. Os objetos @Entity que representam a base de dados
As tabelas anteriores serão representadas pelas seguintes @Entity:
- a @Entity Restaurant representará a tabela [restaurant]
- o @Entity Adresse representará a tabela [adresse]
- a @Entity Plat representará a tabela [plat]
As relações entre estas entidades são as seguintes:
- uma relação um-para-um liga a entidade Restaurant à entidade Adresse: um restaurante r tem uma morada a. A entidade Restaurant, que detém a chave estrangeira, terá a relação principal. A entidade Adresse não terá uma relação inversa.
- Uma relação muitos-para-muitos liga as entidades Restaurant e Plat: um restaurante serve vários pratos e um mesmo prato pode ser servido por vários restaurantes. Esta relação será representada por uma anotação @ManyToMany na entidade Restaurant. A entidade Plat não terá uma relação inversa.
A @Entity Restaurant é a seguinte:
package entites;
...
@Entity
@Table(name = "jpa10_hb_restaurant")
public class Restaurant implements java.io.Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(unique = true, length = 30, nullable = false)
private String nom;
@OneToOne(cascade = CascadeType.ALL)
private Adresse adresse;
@ManyToMany(cascade = { CascadeType.PERSIST, CascadeType.MERGE })
@JoinTable(name = "jpa10_hb_restaurant_plat", inverseJoinColumns = @JoinColumn(name = "plat_id"))
private Set<Plat> plats = new HashSet<Plat>();
// construtores
public Restaurant() {
}
public Restaurant(String name, Adresse address, Set<Plat> entrees) {
...
}
// getters e setters
...
// toString
public String toString() {
String signature = "R[" + getNom() + "," + getAdresse();
for (Plat e : getPlats()) {
signature += "," + e;
}
return signature + "]";
}
}
- linha 17: a relação um-para-um que a entidade Restaurant tem com a entidade Adresse. Todas as operações de persistência num restaurante são propagadas para a sua morada.
- linha 20: a relação que liga a @Entity Restaurant à @Entity Plat do conjunto plats da linha 22 é do tipo muitos-para-muitos (ManyToMany):
- um restaurante (One) tem vários pratos (Many)
- um prato (One) pode ser servido por vários restaurantes (Many)
- no final, as @Entity Restaurant e Plat estão ligadas por uma relação ManyToMany. Decidimos que a @Entity Restaurant terá a relação principal e que a @Entity Plat não terá uma relação inversa.
- A relação @ManyToMany requer uma tabela de junção. Esta é definida através da anotação @JoinTable na linha 47.
- O atributo «name» atribui um nome à tabela.
- A tabela de junção é constituída pelas chaves estrangeiras das tabelas que une. Neste caso, existem duas chaves estrangeiras: uma na tabela [restaurant] e outra na tabela [plat]. Estas colunas de chave estrangeira são definidas pelos atributos joinColumns e inverseJoinColumns.
- O atributo joinColumns define a chave estrangeira na tabela da @Entity que detém a relação principal @ManyToMany, neste caso a tabela [restaurant]. O atributo joinColumns está aqui ausente. O JPA tem um valor por defeito neste caso: [table]_[clé_primaire_de_table], neste caso, [jpa10_hb_restaurant_id].
- A anotação @JoinColumn do atributo inverseJoinColumns define a chave estrangeira na tabela da @Entity que mantém a relação inversa @ManyToMany, neste caso a tabela [plat]. Esta coluna de chave estrangeira terá o nome plat_id.
A @Entity Adresse é a seguinte:
package entites;
...
@Entity
@Table(name="jpa10_hb_adresse")
public class Adresse implements java.io.Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(name = "NUMERO_RUE")
private int numeroRue;
@Column(name = "NOM_RUE", length=30, nullable=false)
private String nomRue;
// getters e setters
...
// construtores
public Adresse(int streetNumber, String streetName){
...
}
public Adresse(){
}
// toString
public String toString(){
return "A["+getNumeroRue()+","+getNomRue()+"]";
}
}
- A @Entity «Endereço» é uma entidade sem relação direta com as outras entidades. Só pode ser persistida através de uma entidade Restaurant.
- Um endereço é definido por um nome de rua (linha 16) e um número na rua (linha 13).
A @Entity Plat é a seguinte
package entites;
...
@Entity
@Table(name="jpa10_hb_plat")
public class Plat implements java.io.Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(unique=true, length=50, nullable=false)
private String nom;
private boolean vegetarien;
// construtores
public Plat() {
}
public Plat(String name, boolean vegetarian) {
...
}
// getters e setters
...
// toString
public String toString() {
return "E[" + getNom() + "," + isVegetarien() + "]";
}
}
- A @Entity Plat é uma entidade sem relação direta com as outras entidades. Só pode ser persistida através de uma entidade Restaurant.
- Um prato é definido por um nome (linha 12) e pelo tipo (vegetariano ou não) (linha 14).
2.7.3. O projeto Eclipse / Hibernate
A implementação JPA aqui utilizada é a do Hibernate. O projeto Eclipse dos testes é o seguinte:
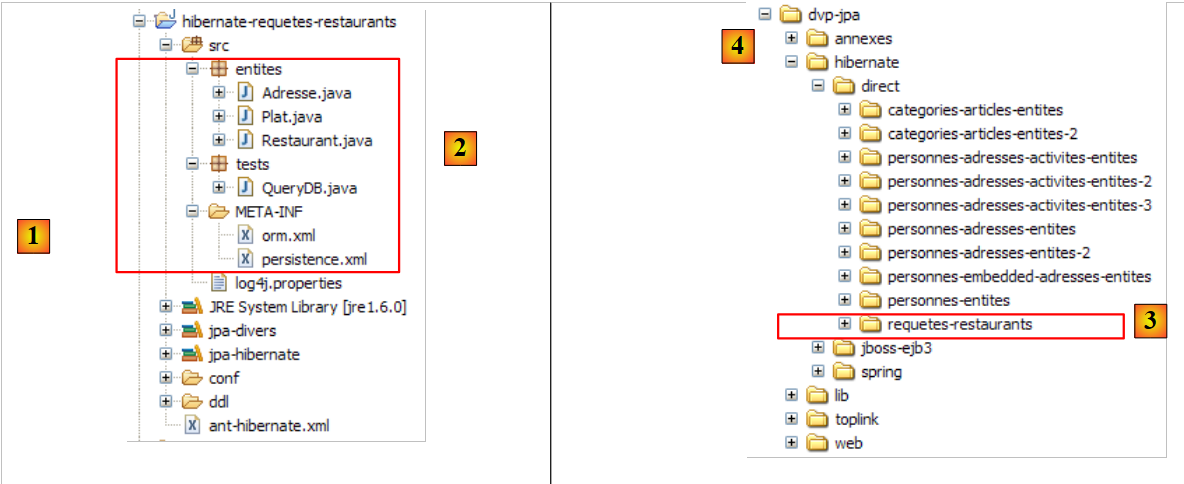 |
Em [1], o projeto Eclipse; em [2], os códigos Java; e em JPA, a configuração da camada. Note-se a presença de um ficheiro [orm.xml] que ainda não foi encontrado. O projeto encontra-se em [3], na pasta de exemplos [4]. Vamos importá-lo.
2.7.4. Geração do ficheiro DDL a partir da base de dados
Seguindo as instruções do parágrafo 2.1.7, o ficheiro DDL obtido para os ficheiros SGBD e MySQL5 é o seguinte:
alter table jpa10_hb_restaurant
drop
foreign key FK3E8E4F5D5FE379D0;
alter table jpa10_hb_restaurant_plat
drop
foreign key FK1D2D06D11F0F78A4;
alter table jpa10_hb_restaurant_plat
drop
foreign key FK1D2D06D1AFAC3E44;
drop table if exists jpa10_hb_adresse;
drop table if exists jpa10_hb_plat;
drop table if exists jpa10_hb_restaurant;
drop table if exists jpa10_hb_restaurant_plat;
create table jpa10_hb_adresse (
id bigint not null auto_increment,
NUMERO_RUE integer,
NOM_RUE varchar(30) not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa10_hb_plat (
id bigint not null auto_increment,
nom varchar(50) not null unique,
vegetarien bit not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa10_hb_restaurant (
id bigint not null auto_increment,
nom varchar(30) not null unique,
adresse_id bigint,
primary key (id)
) ENGINE=InnoDB;
create table jpa10_hb_restaurant_plat (
jpa10_hb_restaurant_id bigint not null,
plat_id bigint not null,
primary key (jpa10_hb_restaurant_id, plat_id)
) ENGINE=InnoDB;
alter table jpa10_hb_restaurant
add index FK3E8E4F5D5FE379D0 (adresse_id),
add constraint FK3E8E4F5D5FE379D0
foreign key (adresse_id)
references jpa10_hb_adresse (id);
alter table jpa10_hb_restaurant_plat
add index FK1D2D06D11F0F78A4 (plat_id),
add constraint FK1D2D06D11F0F78A4
foreign key (plat_id)
references jpa10_hb_plat (id);
alter table jpa10_hb_restaurant_plat
add index FK1D2D06D1AFAC3E44 (jpa10_hb_restaurant_id),
add constraint FK1D2D06D1AFAC3E44
foreign key (jpa10_hb_restaurant_id)
references jpa10_hb_restaurant (id);
- linhas 21-26: a tabela [adresse]
- linhas 28-33: a tabela [plat]
- linhas 35-40: a tabela [restaurant]
- linhas 42-46: a tabela de junção [restaurant_plat]. De notar a chave composta (linha 45)
- linhas 48-52: a chave estrangeira da tabela [restaurant] para a tabela [adresse]
- linhas 54-58: a chave estrangeira da tabela [restaurant_plat] para a tabela [plat]
- linhas 60-64: a chave estrangeira da tabela [restaurant_plat] para a tabela [restaurant]
Esta tabela DDL corresponde ao esquema já apresentado:
 |
Na perspetiva SQL Explorer, a base de dados apresenta-se da seguinte forma:
 |
- em [1]: as 4 tabelas da base de dados
- em [2]: os endereços
- em [3]: os pratos
- em [4]: os restaurantes. [adresse_id] faz referência aos endereços de [2].
- em [5]: a tabela de junção [restaurant,plat]. [jpa10_hb_restaurant_id] remete para os restaurantes de [4] e [plat_id] para os pratos de [3]. Assim, [1,1] significa que o restaurante «Burger Barn» serve o prato «CheeseBurger».
Para obter os dados acima, foi executado o programa [QueryDB] do projeto Eclipse.
2.7.5. Consultas JPQL com uma consola Hibernate
Criamos uma consola Hibernate associada ao projeto Eclipse anterior. Seguiremos o procedimento já exposto por duas vezes, nomeadamente no parágrafo 2.1.12.
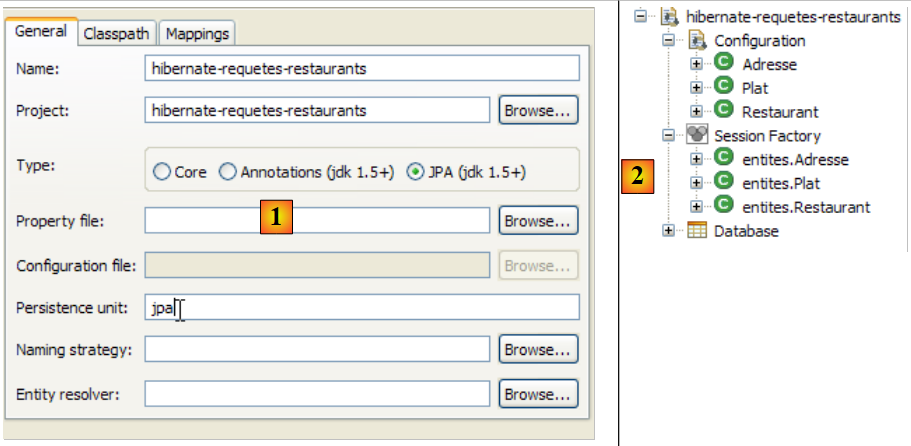 |
- em [1] e [2]: a configuração da consola Hibernate
 |
- em [3]: uma consulta JPQL e em [4] o resultado.
- em [5]: a ordem equivalente SQL
Apresentamos agora uma série de consultas JPQL. O leitor é convidado a executá-las e a descobrir a ordem SQL gerada pelo Hibernate para as executar.
Obter todos os restaurantes com os respetivos pratos:
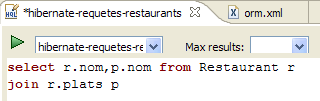 | 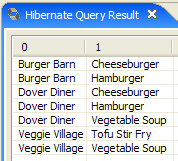 |
Obter os restaurantes que servem pelo menos um prato vegetariano:
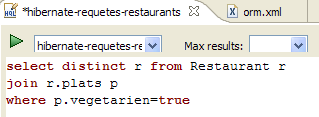 |  |
Obter os nomes dos restaurantes que servem apenas pratos vegetarianos:
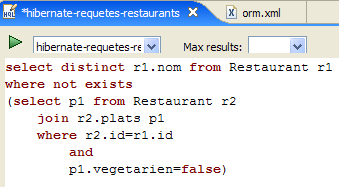 | 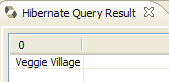 |
Obter os restaurantes que servem hambúrgueres:
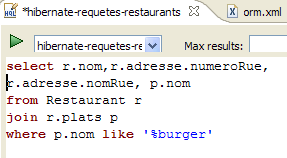 | 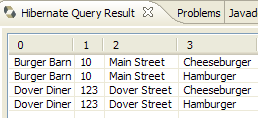 |
2.7.6. QueryDB
Vamos agora analisar o programa [QueryDB] do projeto Eclipse, que:
- preenche a base de dados
- e envia para ela um certo número de pedidos JPQL. Estes são registados no ficheiro [META-INF/orm.xml] do projeto Eclipse:
 |
O ficheiro [orm.xml] pode ser utilizado para configurar a camada JPA em vez das anotações Java. Isto proporciona flexibilidade na configuração da camada JPA. É possível alterá-la sem recompilar os códigos Java. É possível utilizar os dois métodos em simultâneo: anotações Java e ficheiro [orm.xml]. A configuração JPA é feita primeiro com as anotações Java e, em seguida, com o ficheiro [orm.xml]. Portanto, se se pretender alterar uma configuração feita por uma anotação Java sem recompilar, basta colocar essa configuração no ficheiro [orm.xml]. Será esta configuração que prevalecerá.
No nosso exemplo, o ficheiro [orm.xml] é utilizado para registar textos de consultas do JPQL. O seu conteúdo é o seguinte:
<?xml version="1.0" encoding="UTF-8" ?>
<entity-mappings xmlns="http://java.sun.com/xml/ns/persistence/orm" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence/orm http://java.sun.com/xml/ns/persistence/orm_1_0.xsd" version="1.0">
<description>Restaurants</description>
<named-query name="supprimer le contenu de la table restaurant">
<query>delete from Restaurant</query>
</named-query>
<named-query name="supprimer le contenu de la table plat">
<query>delete from Plat</query>
</named-query>
<named-query name="obtenir tous les restaurants">
<query>select r from Restaurant r order by r.nom asc</query>
</named-query>
<named-query name="obtenir toutes les adresses">
<query>select a from Adresse a order by a.nomRue asc</query>
</named-query>
<named-query name="obtenir tous les plats">
<query>select p from Plat p order by p.nom asc</query>
</named-query>
<named-query name="obtenir tous les restaurants avec leurs plats">
<query>select r.nom,p.nom from Restaurant r join r.plats p</query>
</named-query>
<named-query name="obtenir les restaurants ayant au moins un plat vegetarien">
<query>select distinct r from Restaurant r join r.plats p where p.vegetarien=true</query>
</named-query>
<named-query name="obtenir les restaurants avec uniquement des plats vegetariens">
<query>
select distinct r1.nom from Restaurant r1 where not exists (select p1 from Restaurant r2 join r2.plats p1 where r2.id=r1.id and
p1.vegetarien=false)
</query>
</named-query>
<named-query name="obtenir les restaurants d'une certaine rue">
<query>select r from Restaurant r where r.adresse.nomRue=:nomRue</query>
</named-query>
<named-query name="obtenir les restaurants qui servent des burgers">
<query>select r.nom,r.adresse.numeroRue, r.adresse.nomRue, p.nom from Restaurant r join r.plats p where p.nom like '%burger'</query>
</named-query>
<named-query name="obtenir les plats du restaurant untel">
<query>select p.nom from Restaurant r join r.plats p where r.nom=:nomRestaurant</query>
</named-query>
</entity-mappings>
- A raiz do ficheiro [orm.xml] é <entity-mappings> (linha 2).
- linhas 5-7: as consultas JPQL nomeadas são objeto das balizas <named-query name= "... ">texto</namedquery>.
- O atributo name da baliza é o nome da consulta.
- O conteúdo texte da baliza é o texto da consulta.
QueryDB irá executar as consultas anteriores. O seu código é o seguinte:
package tests;
...
public class QueryDB {
// Contexto de persistência
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
private static EntityManager em = emf.createEntityManager();
public static void main(String[] args) {
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// eliminar os elementos da tabela [restaurant]
em.createNamedQuery("supprimer le contenu de la table restaurant").executeUpdate();
// eliminar os elementos da tabela [plat]
em.createNamedQuery("supprimer le contenu de la table plat").executeUpdate();
// criação de objetos Address
Adresse adr1 = new Adresse(10, "Main Street");
Adresse adr2 = new Adresse(20, "Main Street");
Adresse adr3 = new Adresse(123, "Dover Street");
// Criação de objetos «Entrada»
Plat ent1 = new Plat("Hamburger", false);
Plat ent2 = new Plat("Cheeseburger", false);
Plat ent3 = new Plat("Tofu Stir Fry", true);
Plat ent4 = new Plat("Vegetable Soup", true);
// criação de objetos «Restaurant»
Restaurant restaurant1 = new Restaurant();
restaurant1.setNom("Burger Barn");
restaurant1.setAdresse(adr1);
restaurant1.getPlats().add(ent1);
restaurant1.getPlats().add(ent2);
Restaurant restaurant2 = new Restaurant();
restaurant2.setNom("Veggie Village");
restaurant2.setAdresse(adr2);
restaurant2.getPlats().add(ent3);
restaurant2.getPlats().add(ent4);
Restaurant restaurant3 = new Restaurant();
restaurant3.setNom("Dover Diner");
restaurant3.setAdresse(adr3);
restaurant3.getPlats().add(ent1);
restaurant3.getPlats().add(ent2);
restaurant3.getPlats().add(ent4);
// persistência dos objetos «Restaurant» (e dos outros objetos em cascata)
em.persist(restaurant1);
em.persist(restaurant2);
em.persist(restaurant3);
// fim da transação
tx.commit();
// dump da base de dados
dumpDataBase();
// fim EntityManager
em.close();
// fim de EntityManagerFactory
emf.close();
}
// visualização do conteúdo da base de dados
@SuppressWarnings("unchecked")
private static void dumpDataBase() {
// teste2
log("données de la base");
// início da transação
EntityTransaction tx = em.getTransaction();
tx.begin();
// visualizações de restaurantes
log("[restaurants]");
for (Object restaurant : em.createNamedQuery("obtenir tous les restaurants").getResultList()) {
System.out.println(restaurant);
}
// visualizações de endereços
log("[adresses]");
for (Object adresse : em.createNamedQuery("obtenir toutes les adresses").getResultList()) {
System.out.println(adresse);
}
// visualizações de pratos
log("[plats]");
for (Object plat : em.createNamedQuery("obtenir tous les plats").getResultList()) {
System.out.println(plat);
}
// visualizações de ligações entre restaurantes <--> pratos
log("[restaurants/plats]");
Iterator record = em.createNamedQuery("obtenir tous les restaurants avec leurs plats").getResultList().iterator();
while (record.hasNext()) {
Object[] currentRecord = (Object[]) record.next();
System.out.format("[%s,%s]%n", currentRecord[0], currentRecord[1]);
}
log("[Liste des restaurants avec au moins un plat végétarien]");
for (Object r : em.createNamedQuery("obtenir les restaurants ayant au moins un plat vegetarien").getResultList()) {
System.out.println(r);
}
// consulta
log("[Liste des restaurants avec seulement des plats végétariens]");
for (Object r : em.createNamedQuery("obtenir les restaurants avec uniquement des plats vegetariens").getResultList()) {
System.out.println(r);
}
// consulta
log("[Liste des restaurants dans Dover Street]");
for (Object r : em.createNamedQuery("obtenir les restaurants d'une certaine rue").setParameter("nomRue", "Dover Street").getResultList()) {
System.out.println(r);
}
// consulta
log("[Liste des restaurants ayant un plat de type burger]");
record = em.createNamedQuery("obtenir les restaurants qui servent des burgers").getResultList().iterator();
while (record.hasNext()) {
Object[] currentRecord = (Object[]) record.next();
System.out.format("[%s,%d,%s,%s]%n", currentRecord[0], currentRecord[1], currentRecord[2], currentRecord[3]);
}
// consulta
log("[Plats de Veggie Village]");
for (Object r : em.createNamedQuery("obtenir les plats du restaurant untel").setParameter("nomRestaurant", "Veggie Village").getResultList()) {
System.out.println(r);
}
// fim da transação
tx.commit();
}
// registos
private static void log(String message) {
System.out.println(" -----------" + message);
}
}
O resultado da execução de [QueryDB] é o seguinte:
Deixamos ao leitor a tarefa de estabelecer a ligação entre o código e os resultados. Para tal, aconselhamos que execute as consultas JPQL na consola do Hibernate e examine o código SQL que lhes está associado.
2.7.7. O projeto Eclipse / Toplink
O leitor interessado encontrará nos exemplos que podem ser descarregados com este tutorial o projeto anterior implementado com o Toplink:
 |
O projeto Eclipse com Toplink é uma cópia do projeto Eclipse com Hibernate:
 |
O ficheiro <persistence.xml> [2] declara as entidades geridas:
<!-- provedor -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- classes persistentes -->
<class>entites.Restaurant</class>
<class>entites.Adresse</class>
<class>entites.Plat</class>
...
- linhas 4-6: as entidades geridas
As consultas JPQL registadas em [orm.xml] são executadas corretamente pelo Toplink. Para tal, no projeto anterior, teve-se o cuidado de não utilizar consultas HQL (Hibernate Query Language), que é, de facto, um superconjunto de JPQL e cujas sintaxes não são aceites pelo JPQL.
2.8. Conclusion
Terminamos aqui o nosso estudo das entidades JPA. Foi um processo demorado e, no entanto, alguns aspetos importantes (para o programador avançado) não foram abordados. Mais uma vez, recomenda-se a leitura de um livro de referência como aquele que foi utilizado para este tutorial:
[ref1]: Java Persistence with Hibernate, de Christian Bauer e Gavin King, publicado pela Manning.