1. Introdução
1.1. Objectifs
O PDF do documento está disponível |AQUI|.
Os exemplos do documento estão disponíveis |AQUI|.
O objetivo aqui é explorar os conceitos principais da persistência de dados com a API JPA (Java Persistence API). Após ler este documento e testar os exemplos, o leitor deverá ter adquirido as bases necessárias para, posteriormente, seguir o seu próprio caminho.
A API JPA é recente. Só ficou disponível a partir da versão 1.5 da JDK. A camada JPA tem o seu lugar numa arquitetura multicamadas. Consideremos uma arquitetura bastante comum, a de três camadas:
 |
- a camada [1], aqui designada por [ui] (Interface do Utilizador), é a camada que interage com o utilizador, através de uma interface gráfica Swing, de uma interface de consola ou de uma interface web. A sua função é fornecer dados provenientes do utilizador à camada [2] ou apresentar ao utilizador os dados fornecidos pela camada [2].
- A camada [2], aqui designada por [metier], é a camada que aplica as regras ditas de negócio, c.a.d. a lógica específica da aplicação, sem se preocupar com a origem dos dados que lhe são fornecidos, nem com o destino dos resultados que produz.
- A camada [3], aqui designada por [dao] (Data Access Object), é a camada que fornece à camada [2] dados pré-registados (ficheiros, bases de dados, ...) e que grava alguns dos resultados fornecidos pela camada [2].
- A camada [JDBC] é a camada padrão utilizada em Java para aceder a bases de dados. É o que se designa habitualmente por «driver JDBC» do SGBD.
Foram envidados vários esforços para facilitar a escrita destas diferentes camadas pelos programadores. Entre estes, o JPA visa facilitar a criação da camada [dao], que gere os dados ditos persistentes, daí o nome da API (Java Persistence API). Uma solução que se tem destacado nos últimos anos neste domínio é a do Hibernate:
 |
A camada [Hibernate] situa-se entre a camada [dao], escrita pelo programador, e a camada [Jdbc]. O Hibernate é um ORM (Mapeamento Objeto-Relacional), uma ferramenta que faz a ponte entre o mundo relacional das bases de dados e o dos objetos manipulados pelo Java. O programador da camada [dao] já não vê a camada [Jdbc] nem as tabelas da base de dados cujo conteúdo pretende explorar. Vê apenas a representação objeto da base de dados, representação essa fornecida pela camada [Hibernate]. A ligação entre as tabelas da base de dados e os objetos manipulados pela camada [dao] é estabelecida principalmente de duas formas:
- através de ficheiros de configuração do tipo XML
- através de anotações Java no código, técnica disponível apenas a partir da versão 1.5 da camada JDK
A camada [Hibernate] é uma camada de abstração que se pretende ser o mais transparente possível. O ideal é que o programador da camada [dao] possa ignorar completamente que está a trabalhar com uma base de dados. Isto é possível se não for ele a escrever a configuração que faz a ponte entre o mundo relacional e o mundo dos objetos. A configuração desta ponte é bastante delicada e requer alguma prática.
A camada [4] dos objetos, espelho da BD, é designada por «contexto de persistência». Uma camada [dao] baseada no Hibernate realiza ações de persistência (CRUD: criar - ler - atualizar - eliminar) nos objetos do contexto de persistência, ações traduzidas pelo Hibernate em ordens SQL. Para as ações de consulta à base de dados (o SQL Select), o Hibernate fornece ao programador uma linguagem HQL (Hibernate Query Language) para consultar o contexto de persistência [4] e não a própria BD.
O Hibernate é popular, mas complexo de dominar. A curva de aprendizagem, frequentemente apresentada como fácil, é, na verdade, bastante íngreme. Assim que se tem uma base de dados com tabelas que apresentam relações um-para-muitos ou muitos-para-muitos, a configuração da ponte relacional/objetos não está ao alcance de um principiante qualquer. Erros de configuração podem, então, conduzir a aplicações com baixo desempenho.
No mundo comercial, existia um produto equivalente ao Hibernate chamado Toplink:
 |
Perante o sucesso dos produtos ORM, a Sun, criadora do Java, decidiu padronizar uma camada ORM através de uma especificação denominada JPA, lançada em simultâneo com o Java 5. A especificação JPA foi implementada pelos dois produtos Toplink e Hibernate. O Toplink, que era um produto comercial, tornou-se entretanto um produto de código aberto. Com o JPA, a arquitetura anterior passa a ser a seguinte:
 |
A camada [dao] interage agora com a especificação JPA, um conjunto de interfaces. O programador beneficiou com isso em termos de normalização. Anteriormente, se alterasse a sua camada ORM, teria também de alterar a sua camada [dao], que tinha sido escrita para interagir com um ORM específico. Agora, irá escrever uma camada [dao] que irá interagir com uma camada JPA. Independentemente do produto que a implemente, a interface da camada JPA apresentada à camada [dao] permanece a mesma.
Este documento irá apresentar exemplos JPA em diversas áreas:
- em primeiro lugar, iremos analisar a ponte relacional/objeto que a camada ORM constrói. Esta será criada com a ajuda de anotações Java 5 para bases de dados nas quais existem relações entre tabelas do tipo:
- um a um
- um para vários
- muitos para muitos
Para ilustrar esta área, iremos criar as seguintes arquiteturas de teste:
 |
Os nossos programas de teste serão aplicações de consola que irão interagir diretamente com a camada JPA. Nesta ocasião, iremos descobrir os principais métodos da camada JPA. Estaremos num ambiente denominado «Java SE» (Standard Edition). O JPA funciona tanto num ambiente Java SE como num ambiente Java EE5 (Enterprise Edition).
- Quando dominarmos tanto a configuração da ponte relacional/objeto como a utilização dos métodos da camada JPA, regressaremos a uma arquitetura multicamadas mais clássica:
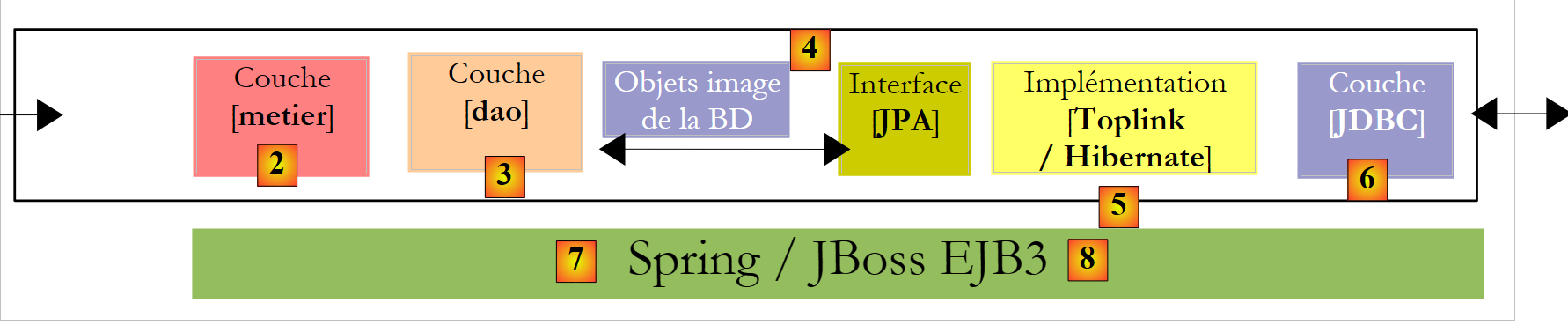 |
A camada [JPA] será acedida através de uma arquitetura de duas camadas [metier] e [dao]. O framework Spring [7] e, posteriormente, o contentor EJB3 de JBoss serão utilizados para ligar estas camadas entre si.
Como referimos anteriormente, o JPA está disponível nos ambientes SE e EE5. O ambiente Java EE5 fornece vários serviços na área do acesso a dados persistentes, nomeadamente pools de ligação, gestores de transações, etc. Pode ser interessante para um programador tirar partido destes serviços. O ambiente Java EE5 ainda não está muito difundido (maio de 2007). Encontra-se atualmente no servidor de aplicações Sun Application Server 9.x (Glassfish). Um servidor de aplicações é, essencialmente, um servidor de aplicações web. Se se criar uma aplicação gráfica autónoma do tipo Swing, não é possível dispor do ambiente EE nem dos serviços que este oferece. Isto constitui um problema. Começam a surgir ambientes «stand-alone» EE e c.a.d. que podem ser utilizados fora de um servidor de aplicações. É o caso do JBos e do EJB3, que iremos utilizar neste documento.
Num ambiente EE5, as camadas são implementadas por objetos denominados EJB (Enterprise Java Bean). Nas versões anteriores do EE, os EJB (EJB, 2.x) eram considerados difíceis de implementar, testar e, por vezes, pouco eficientes. Distinguem-se os EJB2.x «entity» e os EJB2.x «session». Resumindo, um EJB2.x «entity» corresponde a uma linha de uma tabela de base de dados e um EJB2.x «session» é um objeto utilizado para implementar as camadas [metier], [dao] de uma arquitetura multicamadas. Uma das principais críticas feitas às camadas implementadas com EJB é que estas só podem ser utilizadas no interior de contentores EJB, um serviço fornecido pelo ambiente EE. Isto torna os testes unitários problemáticos. Assim, no esquema acima, os testes unitários das camadas [metier] e [dao], construídas com EJB, exigiriam a implementação de um servidor de aplicações, uma operação bastante pesada que não incentiva realmente o programador a realizar testes com frequência.
O framework Spring surgiu em resposta à complexidade dos EJB2. O Spring fornece, num ambiente SE, um número significativo dos serviços normalmente fornecidos pelos ambientes EE. Assim, na parte «Persistência de dados» que nos interessa aqui, o Spring fornece os pools de ligação e os gestores de transações de que as aplicações necessitam. O surgimento do Spring promoveu a cultura dos testes unitários, que se tornaram, de repente, muito mais fáceis de implementar. O Spring permite a implementação das camadas de uma aplicação através de objetos Java clássicos (POJO, Plain Old/Ordinary Java Object), permitindo a reutilização destes noutro contexto. Por fim, integra numerosas ferramentas de terceiros de forma bastante transparente, nomeadamente ferramentas de persistência como o Hibernate, o Ibatis, ...
O Java EE5 foi concebido para corrigir as lacunas da especificação anterior, EE. Os EJB e 2.x passaram a ser os EJB3. Estes são POJOs marcados por anotações que os tornam objetos específicos quando se encontram dentro de um contentor EJB3. Nesse contentor, o EJB3 poderá beneficiar dos serviços do contentor (pool de ligações, gestor de transações, etc.). Fora do contentor EJB3, o EJB3 torna-se um objeto Java normal. As suas anotações EJB são ignoradas.
Acima, representámos o Spring e o JBoss EJB3 como uma possível infraestrutura (framework) da nossa arquitetura multicamadas. É esta infraestrutura que fornecerá os serviços de que necessitamos: um pool de ligações e um gestor de transações.
- Com o Spring, as camadas serão implementadas com POJOs. Estes terão acesso aos serviços do Spring (pool de ligações, gestor de transações) através da injeção de dependências nestes POJOs: durante a sua construção, o Spring injeta-lhes referências aos serviços de que irão necessitar.
-
O JBoss EJB3 é um contentor EJB capaz de funcionar fora de um servidor de aplicações. O seu princípio de funcionamento (para o programador) é análogo ao descrito para o Spring. Encontraremos poucas diferenças.
-
Concluiremos o documento com um exemplo de aplicação web de três camadas, básico mas, ainda assim, representativo:
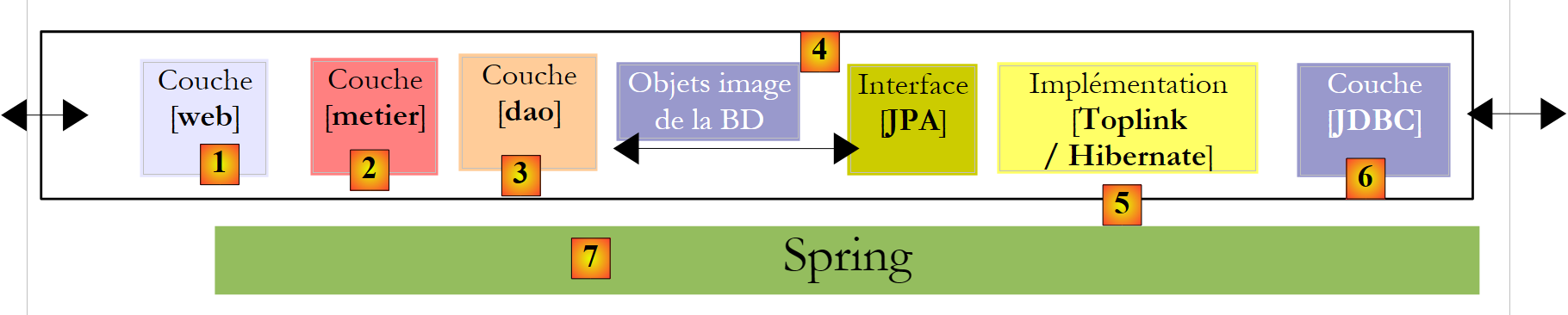 |
1.2. Références
[ref1]: Java Persistence with Hibernate, de Christian Bauer e Gavin King, editado pela Manning.
[ref1] é o documento que serviu de base para o que se segue. Trata-se de um livro exaustivo com mais de 800 páginas sobre a utilização do ORM Hibernate em dois contextos diferentes: com ou sem JPA. A utilização do Hibernate sem o JPA continua, de facto, a ser relevante para os programadores que utilizam o JDK 1.4 ou versões anteriores, uma vez que o JPA só surgiu com o JDK 1.5.
Depois de ter lido mais de três quartos do livro e de ter dado uma vista de olhos pelo resto, pareceu-me que tudo era útil neste documento. O utilizador experiente do Hibernate deverá conhecer a quase totalidade das informações apresentadas nas 800 páginas. Christian Bauer e Gavin King foram exaustivos, mas raramente descreveram situações com as quais nunca nos depararemos. Vale a pena ler tudo. O livro está escrito de forma pedagógica: há uma vontade genuína de não deixar nada na obscuridade. O facto de ter sido escrito para a utilização do Hibernate tanto com como sem o JPA constitui uma dificuldade para quem está interessado apenas numa ou noutra destas tecnologias. Por exemplo, os autores descrevem, com base em numerosos exemplos, a ponte relacional/objeto em ambos os contextos. Os conceitos utilizados são muito semelhantes, uma vez que o JPA se inspirou fortemente no Hibernate. No entanto, apresentam algumas diferenças. A tal ponto que algo que é válido para o Hibernate pode já não o ser para o JPA, o que acaba por criar confusão no leitor.
Os autores apresentam exemplos de aplicações de três camadas no contexto de um contentor EJB3. Não fazem referência ao Spring. Veremos, através de um exemplo, que o Spring é, no entanto, mais simples de utilizar e tem um âmbito mais abrangente do que o contentor JBoss EJB3 utilizado no [ref1]. No entanto, «Java Persistence with Hibernate» é um excelente livro que recomendo por todos os conceitos fundamentais que nele se aprendem sobre os ORM.
Utilizar um ORM é complexo para um principiante.
- Há conceitos que é preciso compreender para configurar a ponte relacional/objeto.
- Existe a noção de contexto de persistência, com os seus conceitos de objetos num estado «persistente», «desligado» ou «novo»
- Há a mecânica em torno da persistência (transações, conjuntos de ligações), geralmente serviços fornecidos por um contentor
- Há ajustes a fazer para otimizar o desempenho (cache de segundo nível)
- ...
Iremos apresentar estes conceitos através de exemplos. Não nos deteremos muito em desenvolvimentos teóricos em torno deles. O nosso objetivo é simplesmente, em cada caso, permitir que o leitor compreenda o exemplo e o assimile, até ser capaz de lhe introduzir alterações por si próprio ou de o reproduzir noutro contexto.
1.3. Ferramentas utilizadas
Os exemplos deste documento utilizam as seguintes ferramentas. Algumas delas são descritas nos anexos (transferência, instalação, configuração, utilização). Nesses casos, indicam-se o número do parágrafo e a página.
- um JDK 1.6 (parágrafo 5.1)
- o IDE para desenvolvimento Java no Eclipse 3.2.2 (parágrafo 5.2)
- plug-in Eclipse WTP (Web Tools Package) (parágrafo 5.2.3)
- plug-in do Eclipse SQL Explorer (parágrafo 5.2.6)
- plug-in Eclipse Hibernate Tools (parágrafo 5.2.5)
- plugin Eclipse TestNG (parágrafo 5.2.4)
- contêiner de servlets Tomcat 5.5.23 (parágrafo 5.3)
- SGBD Firebird 2.1 (parágrafo 5.4)
- SGBD MySQL5 (parágrafo 5.5)
- SGBD PosgreSQL (parágrafo 5.6)
- SGBD Oracle 10g Express (parágrafo 5.7)
- SGBD SQL Server 2005 Express (parágrafo 5.8)
- SGBD HSQLDB (parágrafo 5.9)
- SGBD Apache Derby (ponto 5.10)
- Spring 2.1 (parágrafo 5.11)
- contentor EJB3 de JBoss (parágrafo 5.12)
1.4. Download dos exemplos de
No site deste documento, os exemplos analisados podem ser descarregados sob a forma de um ficheiro zip que, uma vez descompactado, cria a seguinte pasta:
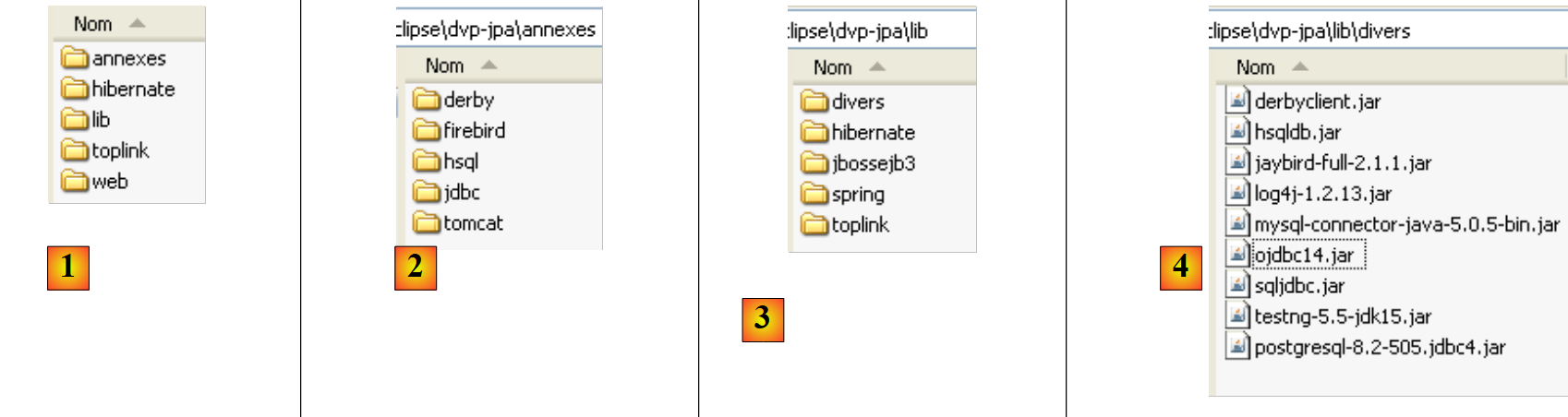 |
- em [1]: a estrutura dos exemplos
- em [2]: a pasta <annexes> contém os elementos apresentados na secção ANNEXES, parágrafo 5. Em particular, a pasta <jdbc> contém os controladores JDBC do SGBD utilizados nos exemplos do tutorial.
- em [3]: a pasta <lib> agrupa, em 5 pastas, os diferentes ficheiros .jar utilizados pelo tutorial
- no [4]: a pasta <lib/divers> agrupa os ficheiros: - dos controladores JDBC do SGBD - da ferramenta de testes unitários [testNG] - da ferramenta de registos [log4j]
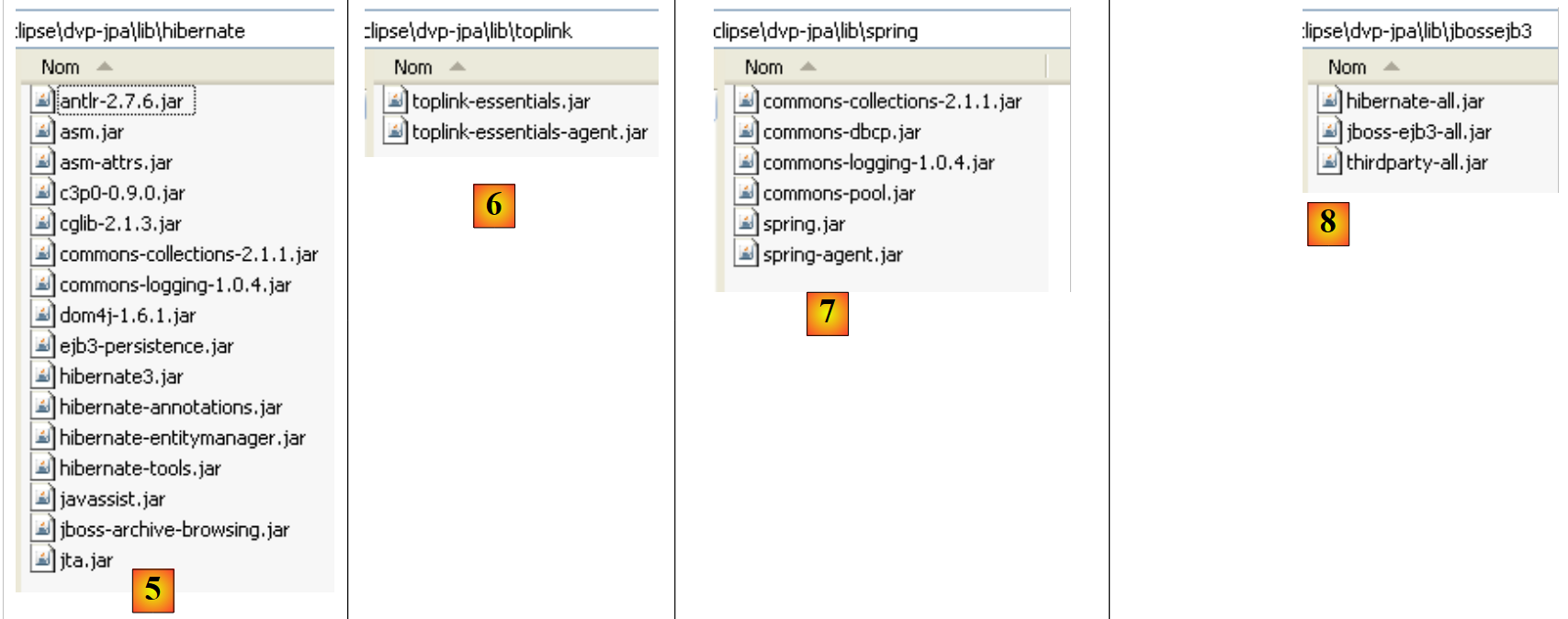 |
- em [5]: os arquivos da implementação JPA/Hibernate e das ferramentas de terceiros necessárias para o Hibernate
- em [6]: os arquivos da implementação JPA/Toplink
- em [7]: os arquivos do Spring 2.x e das ferramentas de terceiros necessárias para o Spring
- em [8]: os arquivos do contentor EJB3 de JBoss
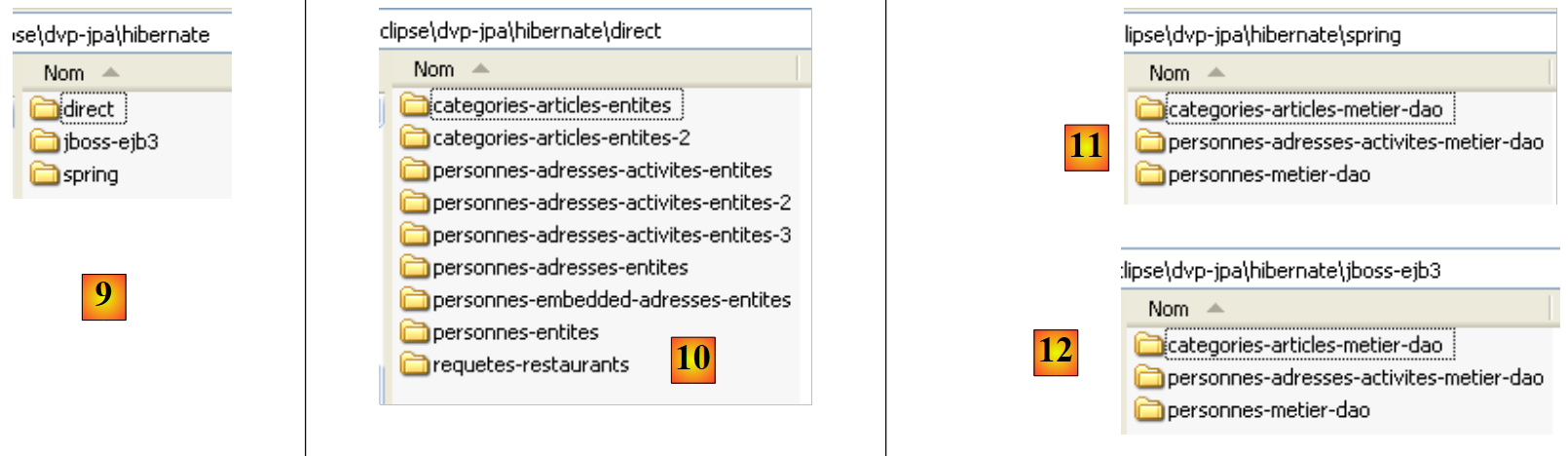 |
- em [9]: a pasta <hibernate> reúne os exemplos tratados com a camada de persistência JPA/Hibernate
- em [10]: a pasta <hibernate/direct> reúne os exemplos em que a camada JPA é utilizada diretamente com um programa do tipo [Main].
- em [11] e [12]: exemplos em que a camada JPA é utilizada através das camadas [metier] e [dao] numa arquitetura multicamadas, o que corresponde ao caso normal de utilização. Os serviços (pool de ligações, gestor de transações) utilizados pelas camadas [metier] e [dao] são fornecidos quer pelo Spring [11], quer pelo JBoss, EJB3 e [12].
 |
- em [13]: a pasta <toplink> retoma os exemplos da pasta <hibernate> [9], mas, desta vez, com uma camada de persistência JPA/Toplink em vez de JPA/Hibernate. Nãoexiste na pasta [13] nenhuma pasta <jbossejb3>, uma vez que não foi possível fazer funcionar um exemplo em que a camada de persistência fosse assegurada pelo Toplink e os serviços fossem assegurados pelo contentor EJB3 de JBoss.
- Em [14]: uma pasta <web> reúne três exemplos de aplicações web com uma camada de persistência JPA:
- [15]: um exemplo com Spring / JPA / Hibernate
- [16]: o mesmo exemplo com Spring / JPA / Toplink
- [17]: o mesmo exemplo com JBoss, EJB3 e JPA / Hibernate. Este exemplo não funciona, provavelmente devido a um problema de configuração ainda não esclarecido. No entanto, foi mantido para que o leitor possa analisá-lo e, eventualmente, encontrar uma solução para este problema.
O tutorial faz frequentemente referência a esta estrutura de diretórios, nomeadamente durante os testes dos exemplos analisados. O leitor é convidado a descarregar estes exemplos e a instalá-los. Daqui em diante, designaremos por <exemplos> a estrutura de diretórios dos exemplos descrita acima.
1.5. Configuração dos projetos « » do Eclipse dos exemplos
Os exemplos utilizam bibliotecas «de utilizador». Trata-se de arquivos .jar agrupados sob um mesmo nome. Quando se inclui uma biblioteca deste tipo no classpath de um projeto Java, todos os arquivos que ela contém são incluídos nesse classpath. Vejamos como proceder no Eclipse:
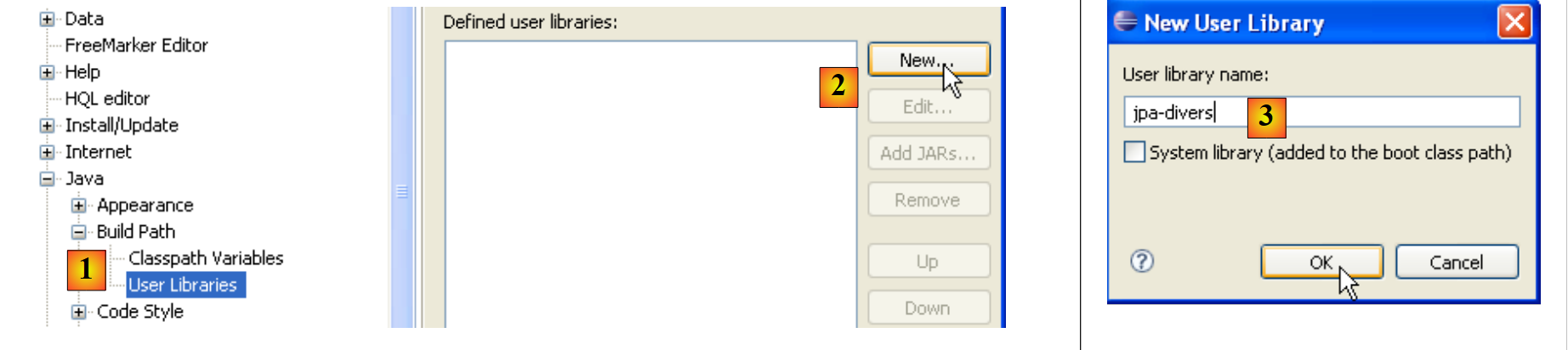 |
- no [1]: [Window / Preferences / Java / Buld Path / User Libraries]
- no [2]: cria-se uma nova biblioteca
- em [3]: atribuímos-lhe um nome e confirmamos
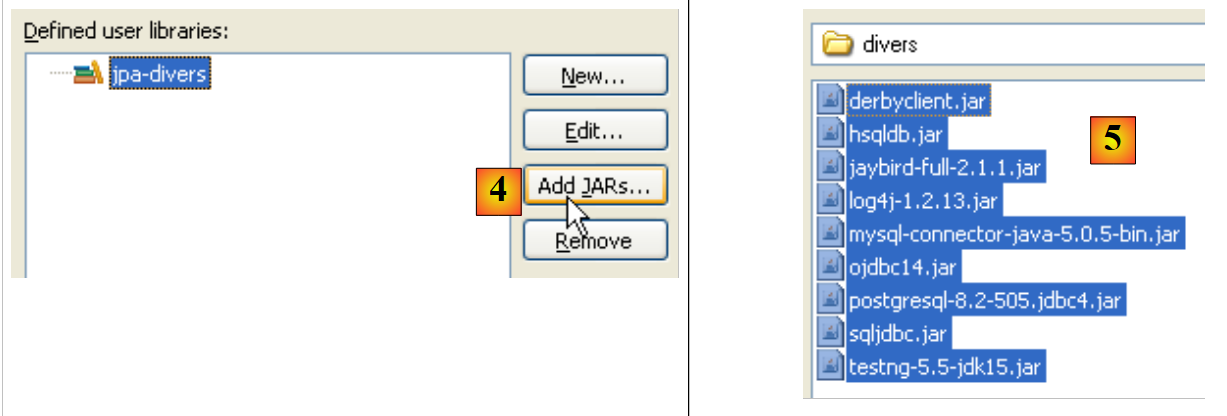 |
- em [4]: selecionamos os ficheiros JAR que farão parte da biblioteca [jpa-divers]
- em [5]: selecionamos todos os ficheiros JAR da pasta <exemplos>/lib/divers
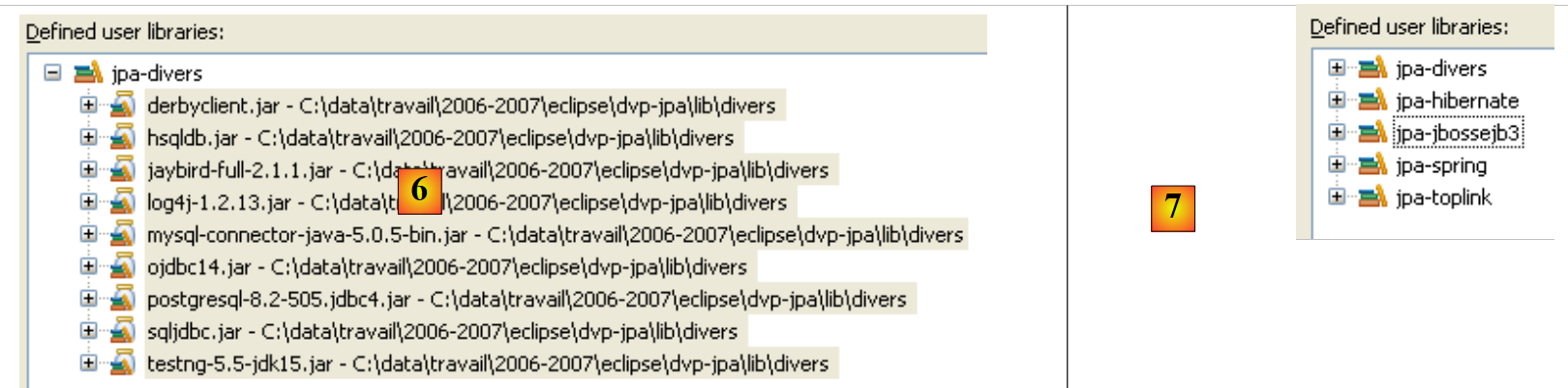 |
- em [6]: a biblioteca de utilizador [jpa-divers] foi definida
- em [7]: repete-se o mesmo procedimento para criar mais 4 bibliotecas:
Biblioteca | Pasta dos ficheiros JAR da biblioteca |
<exemplos>/lib/hibernate | |
<exemplos>/lib/toplink | |
<exemplos>/lib/spring | |
<exemplos>/lib/jbossejb3 |