5. Anexos
Descrevemos aqui a instalação e a utilização básica das ferramentas utilizadas no documento «Persistência Java 5 na prática». As informações fornecidas abaixo são as disponíveis em maio de 2007. Estas tornar-se-ão rapidamente obsoletas. Quando tal acontecer, o leitor será convidado a seguir procedimentos análogos, mas que não serão idênticos. As instalações foram realizadas numa máquina Windows XP Professional.
5.1. Java
Iremos utilizar a versão mais recente do Java disponível na Sun [http://www.sun.com]. Os downloads estão acessíveis através do URL [http://java.sun.com/javase/downloads/index.jsp]:


Inicie a instalação do JDK a partir do ficheiro descarregado. Por predefinição, o Java é instalado em [C:\Program Files\Java]:
5.2. Eclipse
5.2.1. Instalação básica
O Eclipse é um IDE disponível no endereço [http://www.eclipse.org/] e pode ser descarregado no endereço [http://www.eclipse.org/downloads/]. A seguir, descarregamos o Eclipse 3.2.2:
![]()
Depois de descarregar o ficheiro zip, descompactamo-lo numa pasta no disco:
A partir de agora, chamaremos de <eclipse> a pasta de instalação do Eclipse, acima indicada como [C:\devjava\eclipse 3.2.2\eclipse]. [eclipse.exe] é o executável e [eclipse.ini] é o ficheiro de configuração do mesmo. Vejamos o conteúdo deste último:
Estes argumentos são utilizados ao iniciar o Eclipse da seguinte forma:
Chegamos ao mesmo resultado que o obtido com o ficheiro .ini, criando um atalho que inicie o Eclipse com estes mesmos argumentos. Vamos explicar-lhes o significado:
- -vmargs: indica que os argumentos que se seguem se destinam à máquina virtual Java que irá executar o Eclipse. O Eclipse é uma aplicação Java.
- -Xms40m: ?
- -Xmx256m: define o tamanho da memória, em MB, atribuída à máquina virtual Java (JVM) que executa o Eclipse. Por predefinição, este tamanho é de 256 MB, como se pode ver aqui. Se a máquina o permitir, é preferível 512 MB.
Estes argumentos são passados para a JVM, que irá executar o Eclipse. A JVM é representada por um ficheiro [java.exe] ou [javaw.exe]. Como é que este é localizado? Na verdade, é procurado de várias formas:
- no ficheiro PATH do OS
- na pasta <JAVA_HOME>/jre/bin, em que JAVA_HOME é uma variável de sistema que define a pasta raiz de um JDK.
- num local passado como argumento ao Eclipse na forma -vm <caminho>\javaw.exe
Esta última solução é preferível, uma vez que as outras duas estão sujeitas a imprevistos decorrentes de instalações posteriores de aplicações que podem alterar o PATH do OS ou alterar a variável JAVA_HOME.
Por isso, criamos o seguinte atalho:
<eclipse>\eclipse.exe" -vm "C:\Program Files\Java\jre1.6.0_01\bin\javaw.exe" -vmargs -Xms40m -Xmx512m | |
pasta <eclipse> de instalação do Eclipse |
Feito isto, inicie o Eclipse através deste atalho. Aparece uma primeira caixa de diálogo:
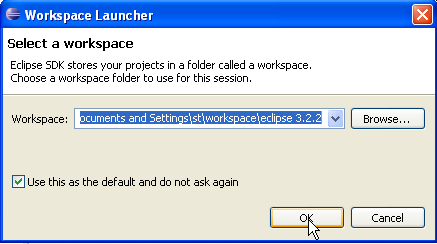
Um [workspace] é um espaço de trabalho. Aceitemos os valores predefinidos propostos. Por predefinição, os projetos Eclipse criados serão guardados na pasta <workspace> especificada nesta caixa de diálogo. É possível contornar este comportamento. É isso que faremos sistematicamente. Por isso, a resposta dada a esta caixa de diálogo não é importante.
Após esta etapa, é apresentado o ambiente de desenvolvimento Eclipse:
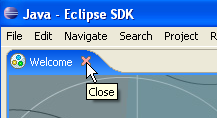
Fechamos a vista [Welcome], tal como sugerido acima:
Antes de criar um projeto Java, vamos configurar o Eclipse para indicar o JDK a utilizar para compilar os projetos Java. Para tal, selecionamos a opção [Window / Preferences / Java / Installed JREs ]:
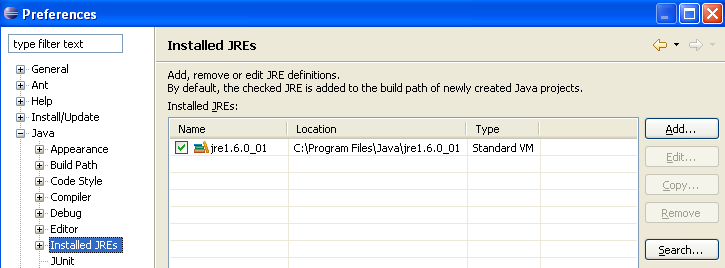
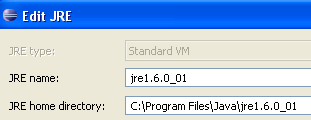
Normalmente, o JRE (Java Runtime Environment) que foi utilizado para iniciar o próprio Eclipse deve estar presente na lista de JRE. Normalmente, este será o único. É possível adicionar JRE através do botão [Add]. Nesse caso, é necessário indicar a raiz do JRE. O botão [Search], por sua vez, irá iniciar uma pesquisa pelo JREs no disco. Esta é uma boa forma de saber em que ponto se está em relação aos JREs que se instalam e depois se esquece de desinstalar quando se passa para uma versão mais recente. Acima, o JRE assinalado é aquele que será utilizado para compilar e executar os projetos Java. É o que foi instalado no parágrafo 5.1 e que também serviu para iniciar o Eclipse. Um duplo clique nele dá acesso às suas propriedades:
Agora, vamos criar um projeto Java [File / New / Project]:
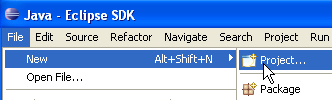 |  |
Selecione [Java Project] e, em seguida, [Next] ->
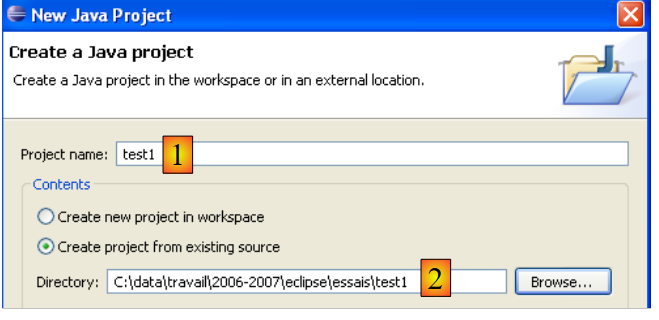
Em [2], indicamos uma pasta vazia na qual será instalado o projeto Java. Em [1], atribuímos um nome ao projeto. Não é necessário que o nome do projeto seja o mesmo que o da pasta, como o exemplo acima poderia sugerir. Feito isto, utilizamos o botão [Next] para avançar para a página seguinte do assistente de criação:
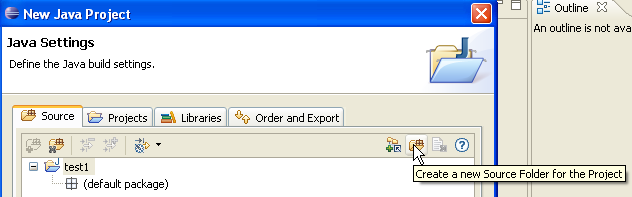
Acima, criamos uma pasta especial no projeto para armazenar os ficheiros de código-fonte (.java):
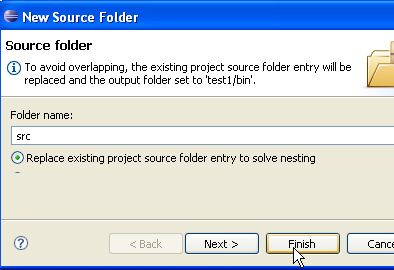
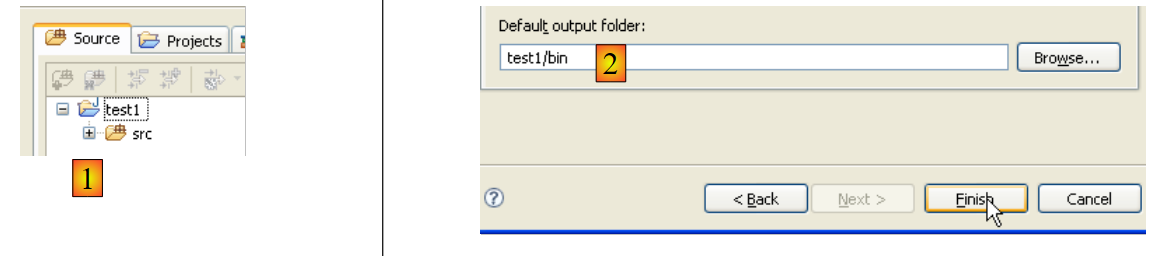 |
- em [1], vemos a pasta [src], na qual serão guardados os ficheiros fonte .java
- em [2], vemos a pasta [bin], na qual serão guardados os ficheiros compilados .class
Concluímos o assistente com [Finish]. Temos, assim, uma estrutura básica de projeto Java:
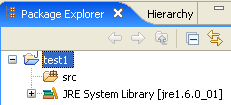
Clicamos com o botão direito do rato no projeto [test1] para criar uma classe Java:
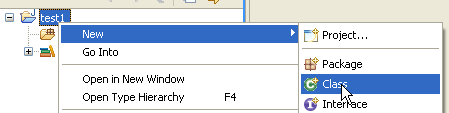
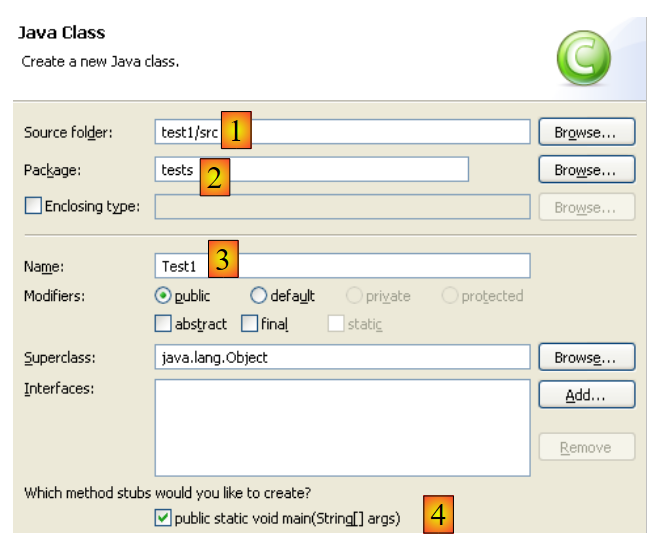 |
- em [1], a pasta onde a classe será criada. Por predefinição, o Eclipse sugere a pasta do projeto atual.
- em [2], o pacote no qual a classe será colocada
- em [3], o nome da classe
- em [4], solicitamos que o método estático [main] seja gerado
Confirmamos o assistente através de [Finish]. O projeto é então enriquecido com uma classe:
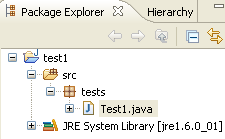
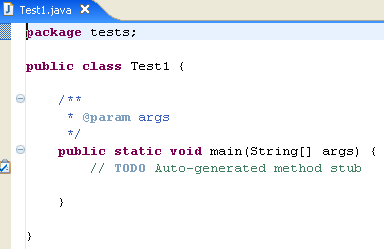
O Eclipse gerou o esqueleto da classe. Este pode ser acedido clicando duas vezes em [Test1.java], acima:
Alteramos o código acima da seguinte forma:
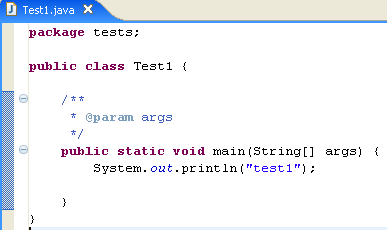
Executamos o programa [Test1.java]: [clic droit sur Test1.java -> Run As -> Java Application]
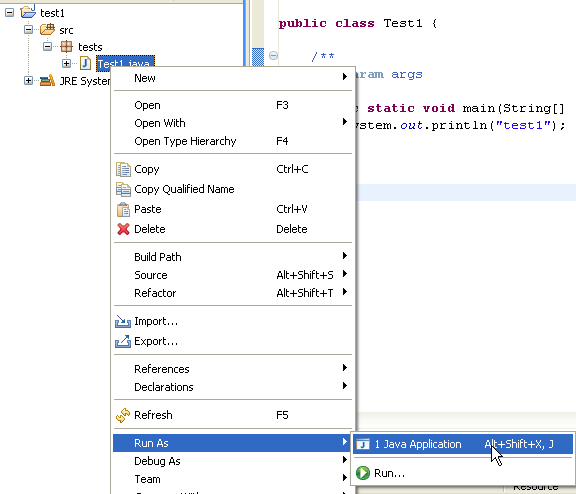
O resultado da execução é apresentado na janela [Console]:
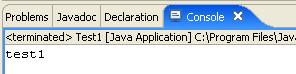
A janela [Console] deve aparecer por predefinição. Caso contrário, é possível solicitar a sua exibição através do [Window/Show View/Console]:
5.2.2. Escolha do compilador
O Eclipse permite gerar código compatível com Java 1.4, Java 1.5 e Java 1.6. Por predefinição, está configurado para gerar código compatível com Java 1.4. O API JPA requer código Java 1.5. Alteramos o tipo de código gerado pelo [Window / Preferences / Java / Compiler]:
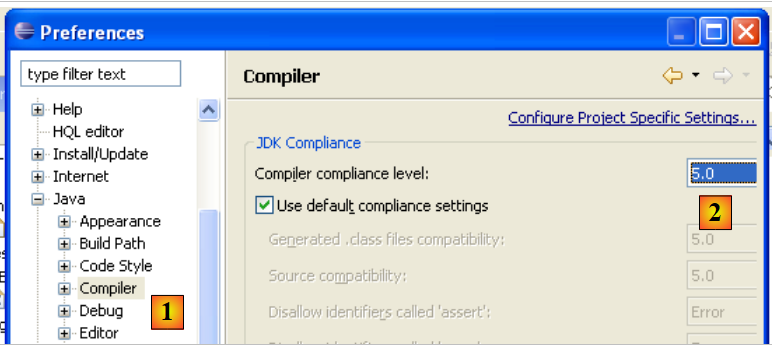 |
- para [1]: escolha da opção [Java / Compiler]
- para [2]: escolha da compatibilidade com Java 5.0
5.2.3. Instalação dos plug-ins Callisto do
A versão básica instalada acima permite criar aplicações Java de consola, mas não aplicações Java do tipo web ou Swing; caso contrário, é necessário fazer tudo manualmente. Vamos instalar vários plug-ins:
Procedamos da seguinte forma [Help/Software Udates/Find and Install]:
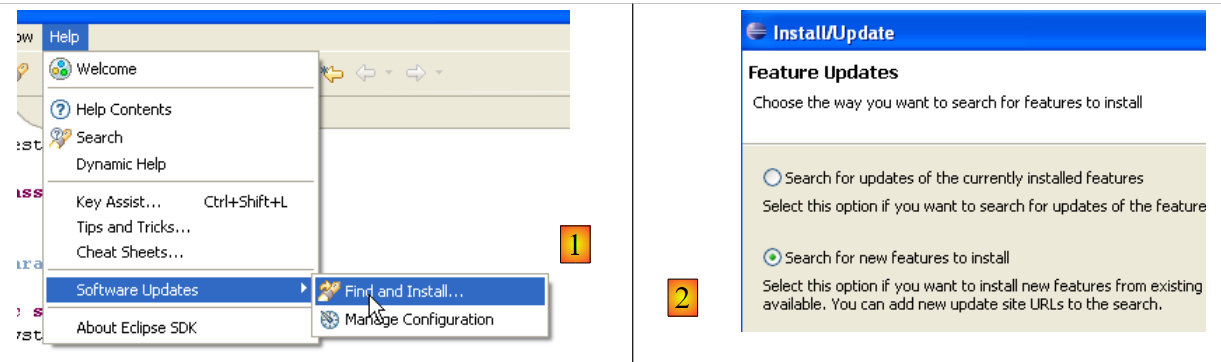 |
- no [2], indicamos que queremos instalar novos plug-ins
 |
- em [3], indicamos os sites a explorar para encontrar os plugins
- em [4], assinala-se os plugins desejados
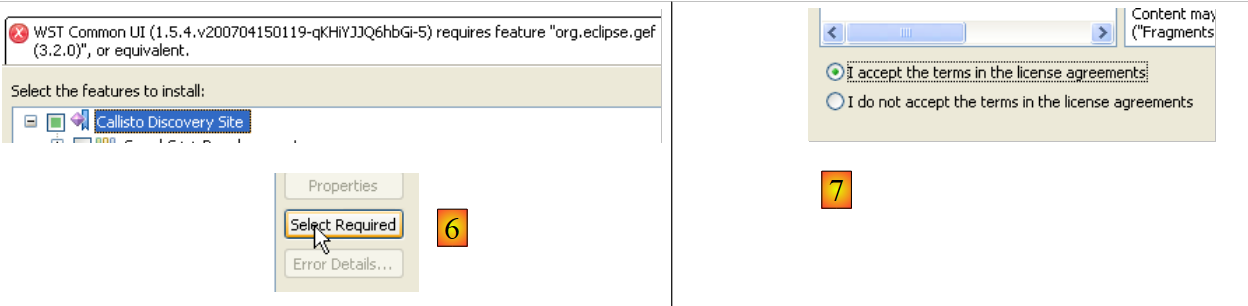 |
- em [5], o Eclipse avisa que foi escolhido um plugin que depende de outros plugins que não foram selecionados
- em [6], utiliza-se o botão [Select Required] para selecionar automaticamente os plugins em falta
- em [7], aceitam-se os termos das licenças destes vários plugins
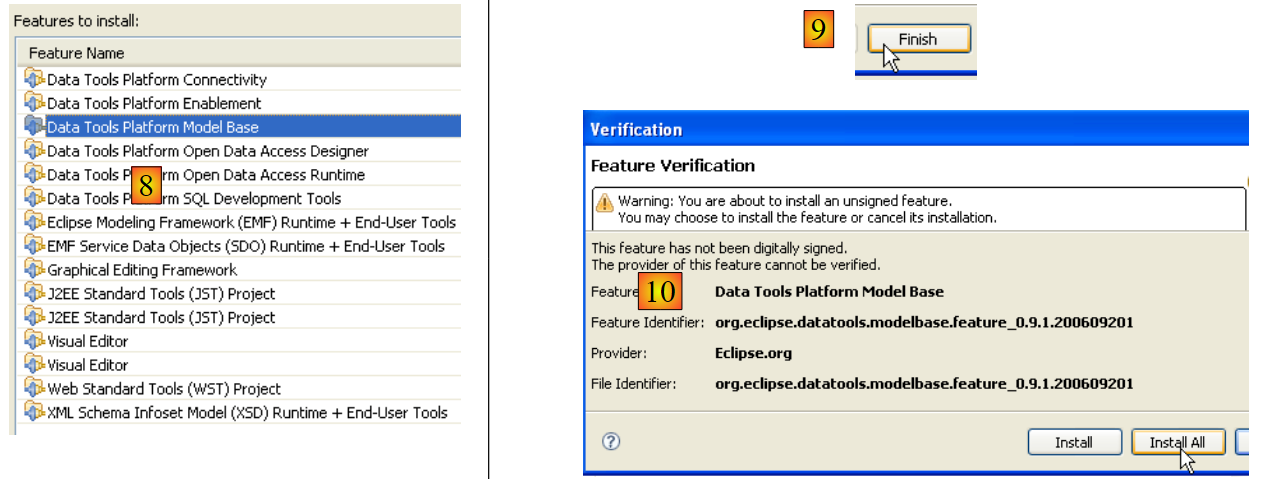 |
- em [8], é apresentada a lista de todos os plugins que vão ser instalados
- em [9], inicia-se o download desses plugins
- em [10], assim que estiverem descarregados, instalam-se todos sem verificar a sua assinatura
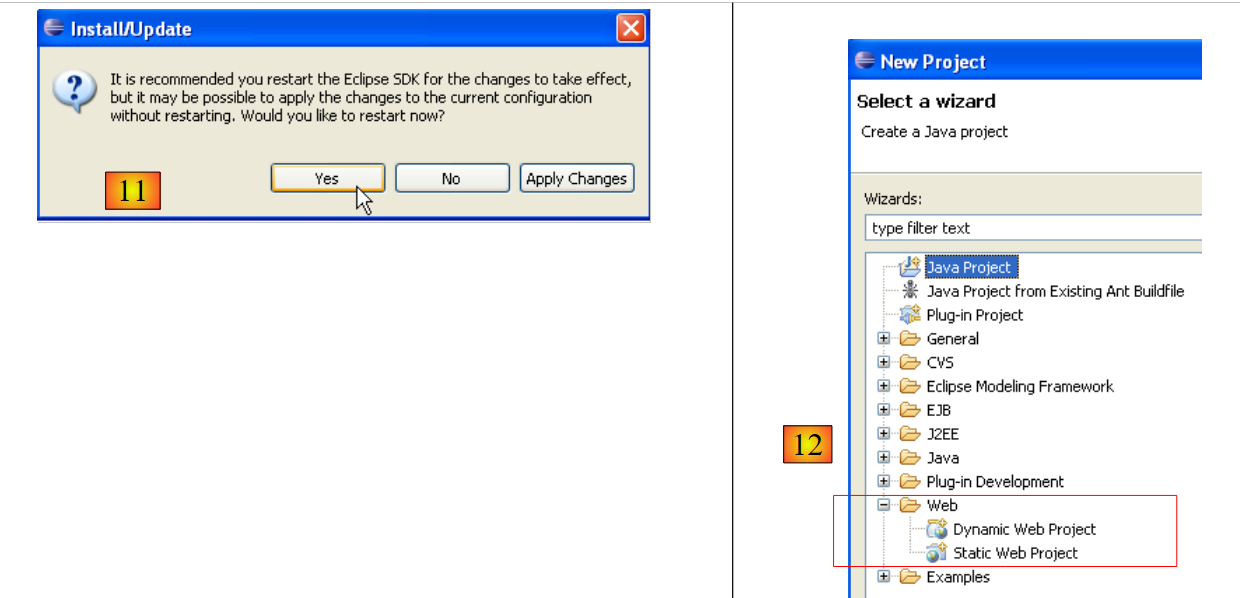 |
- em [11], no final da instalação dos plugins, deixa-se o Eclipse reiniciar
- em [12], se executarmos o [File/New/Project], descobrimos que agora é possível criar aplicações web, o que inicialmente não era possível.
5.2.4. Instalação do plugin [TestNG]
O TestNG (Test Next Generation) é uma ferramenta de testes unitários semelhante, na sua essência, ao JUnit. No entanto, apresenta melhorias que nos levam a preferi-lo aqui ao JUnit. Procedemos como anteriormente: [Help/Software Udates/Find and Install]:
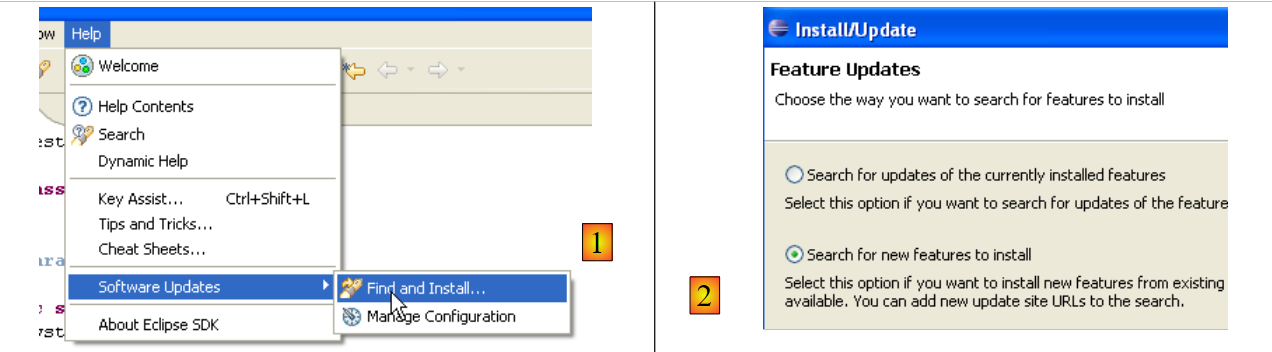 |
- no [2], indicamos que pretendemos instalar novos plugins
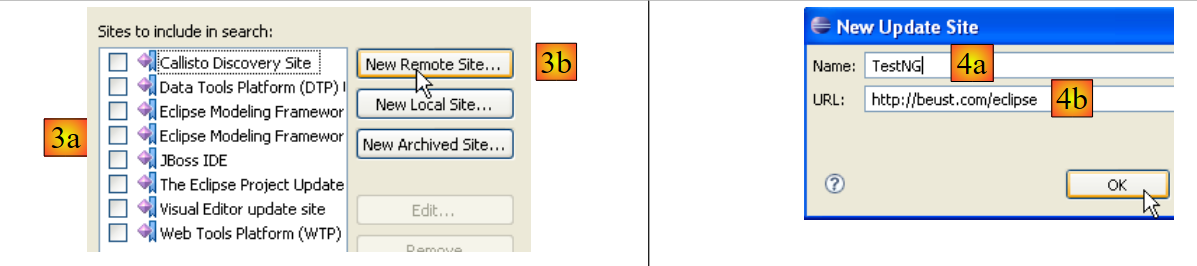 |
- em [3a], o site de download de [TestNG] não está presente. Adicionamo-lo com [3b]
- em [4b]: o site do plugin é [http://beust.com/eclipse]. Em [4a], colocamos o que quisermos.
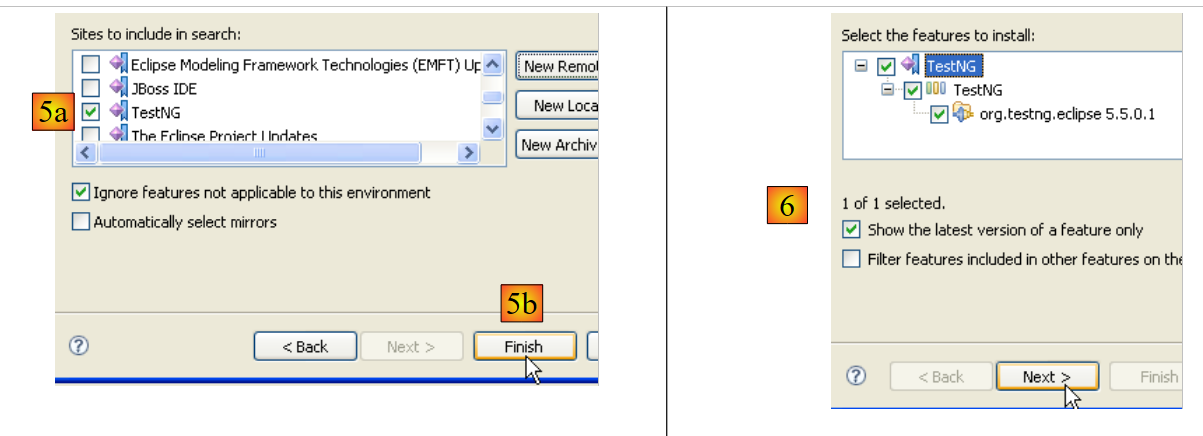 |
- em [5a], o plugin [TestNG] é selecionado para a atualização. Em [5b], inicia-se a atualização.
- em [6], a ligação ao site do plugin foi estabelecida. São-nos apresentados todos os plugins disponíveis no site. Aqui, selecionamos apenas um antes de avançarmos para a etapa seguinte.
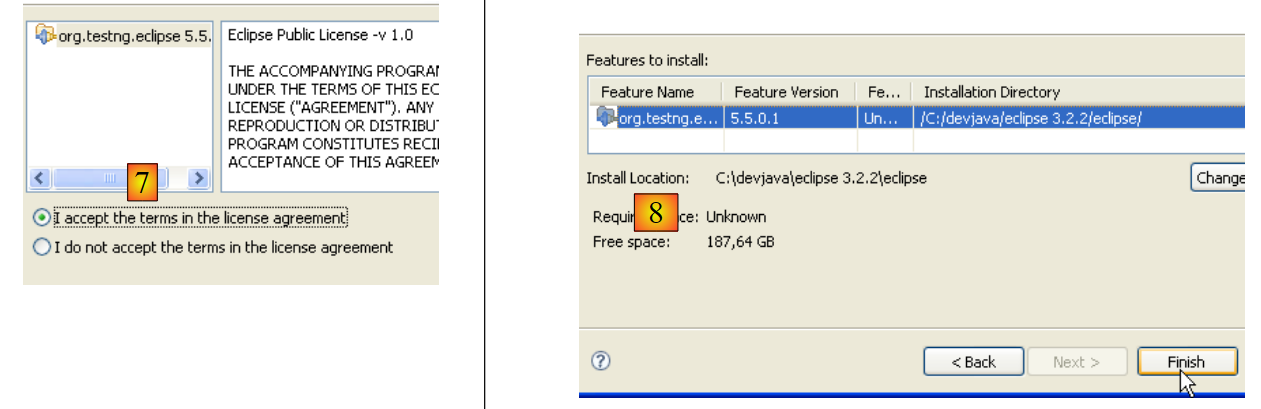 |
- em [7], aceitamos os termos das licenças do plugin
- em [8], é apresentada a lista de todos os plug-ins que serão instalados, um deles aqui. Iniciamos o download. Em seguida, tudo decorre conforme descrito acima, para os plug-ins Callisto.
Depois de reiniciar o Eclipse, é possível verificar a presença do novo plugin, por exemplo, ao solicitar a visualização das vistas disponíveis [Window / show View / Other]:
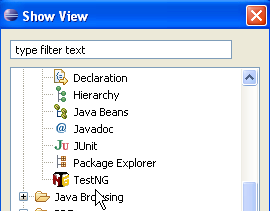 |
Vemos acima a existência de uma vista [TestNG] que não existia anteriormente.
5.2.5. Instalação do plugin [Hibernate Tools]
O Hibernate é um fornecedor JPA e o plugin [Hibernate Tools] para o Eclipse é útil na criação de aplicações JPA. Em maio de 2007, apenas a sua versão mais recente (3.2.0beta9) permite trabalhar com o Hibernate/JPA e esta não está disponível através do mecanismo que acabámos de descrever. Apenas as versões mais antigas estão disponíveis. Por isso, vamos proceder de forma diferente.
O plugin está disponível no site da Hibernate Tools: http://tools.hibernate.org/.
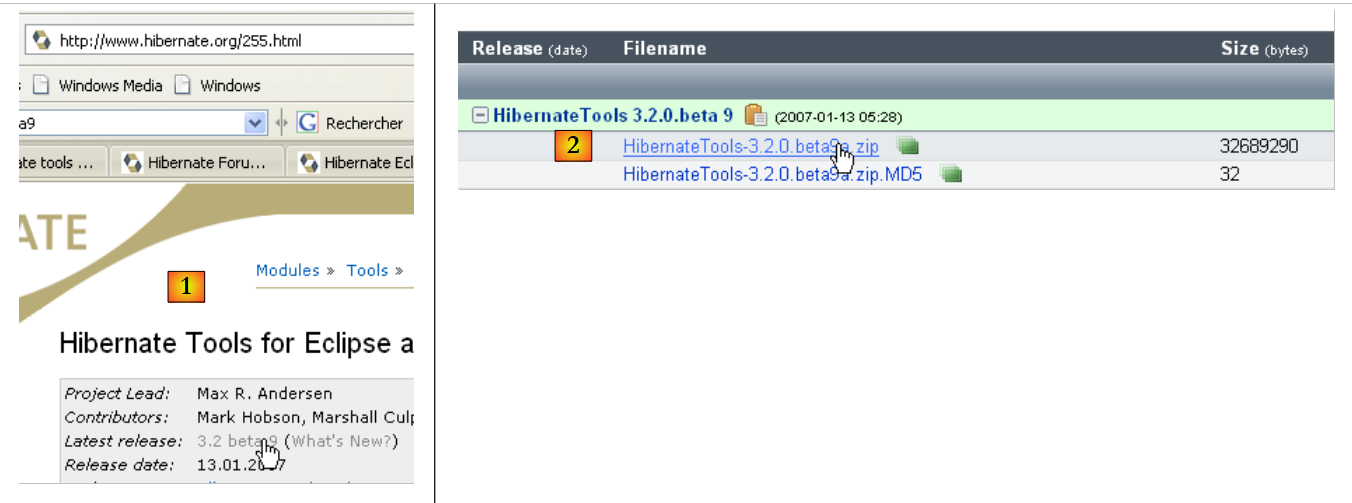 |
- em [1], seleciona-se a versão mais recente do Hibernate Tools
- em [2], faz-se o download
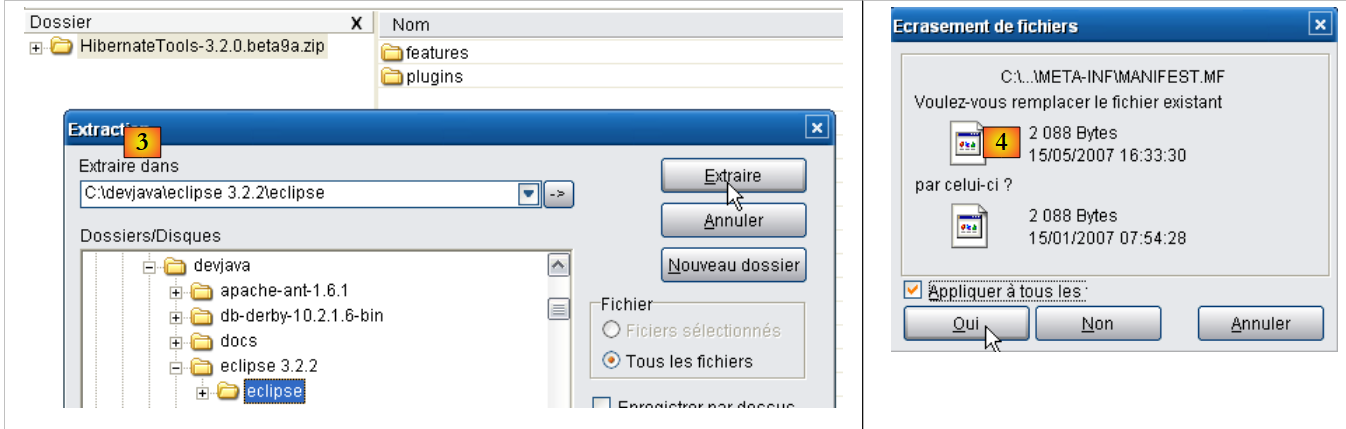 |
- em [3], com um programa de descompressão, descompacta-se na pasta <eclipse> o ficheiro zip descarregado (é preferível que o Eclipse não esteja ativo)
- em [4], aceita-se que alguns ficheiros sejam substituídos durante a operação
Reinicie o Eclipse:
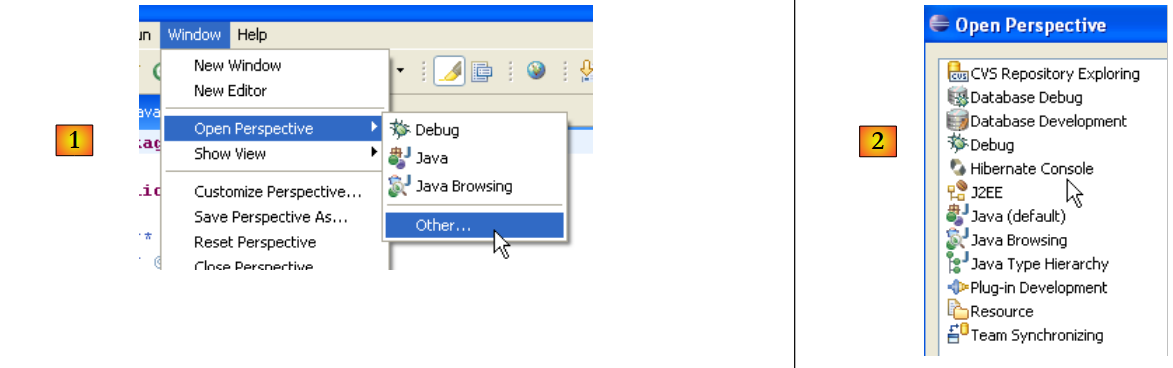 |
- em [1]: abre-se uma perspetiva
- em [2]: existe agora uma perspetiva [Hibernate Console]
Não iremos mais longe com o plugin [Hibernate Tools] (Cancel em [2]). A sua forma de utilização é explicada nos exemplos do tutorial.
Por vezes, o Eclipse não deteta a presença de novos plugins. É possível forçá-lo a voltar a analisar todos os seus plugins com a opção -clean. Assim, o executável do atalho do Eclipse seria alterado da seguinte forma:
"<eclipse>\eclipse.exe" -clean -vm "C:\Program Files\Java\jre1.6.0_01\bin\javaw.exe" -vmargs -Xms40m -Xmx512m
Assim que os novos plugins forem detetados pelo Eclipse, deverá remover a opção -clean acima referida.
5.2.6. Instalação do plugin [SQL Explorer]
Vamos agora instalar um plugin que nos permitirá explorar o conteúdo de uma base de dados diretamente a partir do Eclipse. Os plugins disponíveis para o Eclipse podem ser encontrados no site [http://eclipse-plugins.2y.net/eclipse/plugins.jsp]:
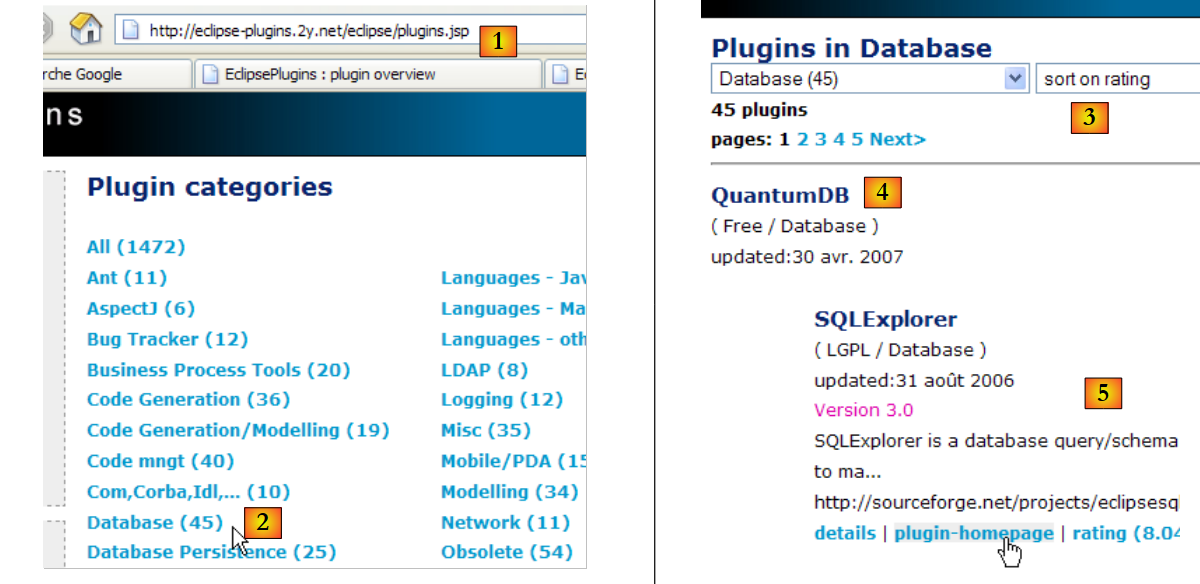 |
- em [1]: o site dos plugins do Eclipse
- em [2]: selecione a categoria [Database]
- em [3]: na categoria [Database], selecionar a visualização por classificação (pouco fiável, dado o reduzido número de pessoas que votam)
- em [4]: o QuantumDB aparece em 1.º lugar
- em [5]: escolhemos o SQLExplorer, mais antigo, com uma classificação inferior (3.º), mas mesmo assim muito bom. Acedemos ao site do plugin [plugin-homepage]
 |
- em [6] e [7]: procedemos ao download do plugin.
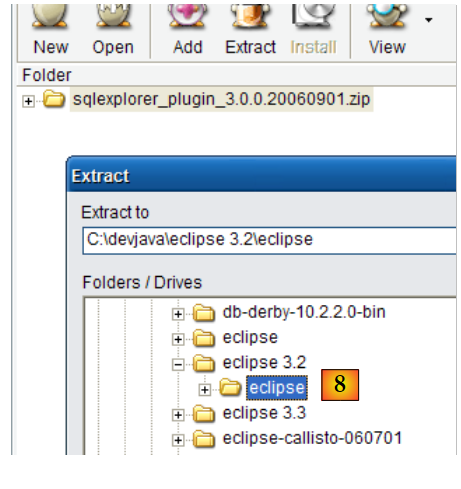 |
- em [8]: descompactamos o ficheiro zip do plugin na pasta do Eclipse.
Para verificar, reinicie o Eclipse, eventualmente com a opção -clean:
 |
- em [1]: abra uma nova perspetiva
- em [2]: verifica-se que está disponível uma perspetiva [SQL Explorer]. Voltaremos a este assunto mais tarde.
5.3. O contentor de servlets Tomcat 5.5
5.3.1. Instalação
Para executar servlets, precisamos de um contentor de servlets. Apresentamos aqui um deles, o Tomcat 5.5, disponível no endereço http://tomcat.apache.org/. Indicamos aqui o procedimento (maio de 2007) para a sua instalação. Se já estiver instalada uma versão anterior do Tomcat, é preferível removê-la primeiro.

Para descarregar o produto, siga a ligação [Tomcat 5.x] acima:

Pode-se escolher o ficheiro .exe destinado à plataforma Windows. Depois de o ter descarregado, inicie a instalação do Tomcat clicando duas vezes no ficheiro:
Aceite os termos da licença ->
Execute [next] ->
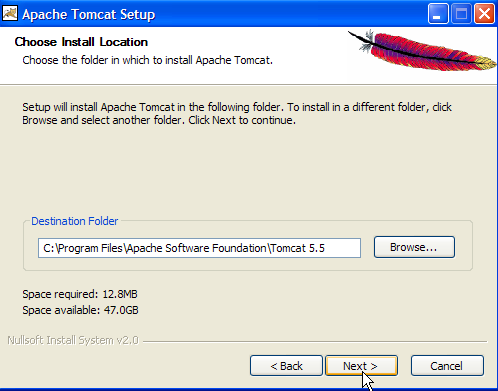
Aceitar a pasta de instalação sugerida ou alterá-la com [Browse] ->
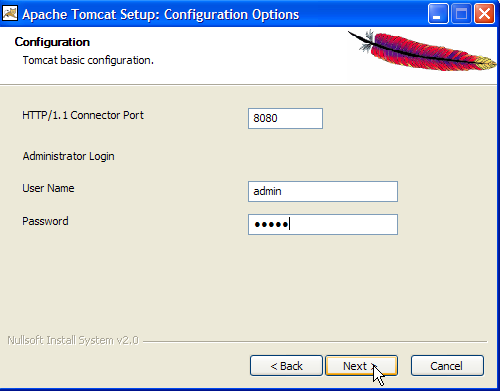
Definir o nome de utilizador e a palavra-passe do administrador do servidor Tomcat. Aqui, definimos [admin / admin] ->
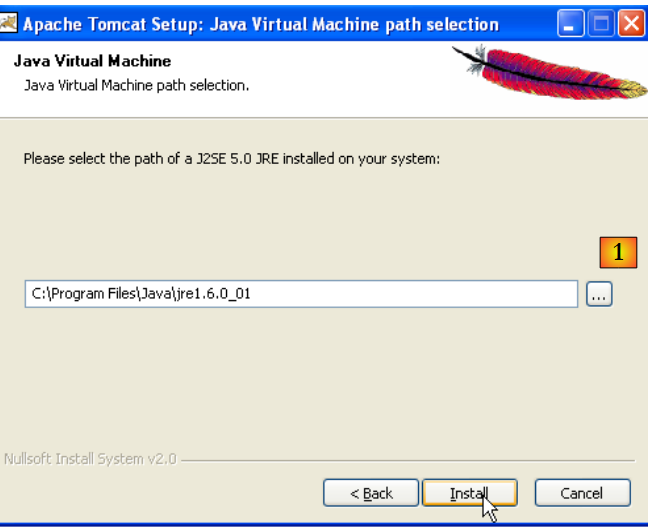 |
O Tomcat 5.x necessita do JRE 1.5. Normalmente, deve encontrar a versão instalada no seu computador. Acima, o caminho indicado é o do JRE 1.6 descarregado no parágrafo 5.1. Se não for encontrado nenhum JRE, indique a sua pasta raiz utilizando o botão [1]. Feito isto, utilize o botão [Install] para instalar o Tomcat 5.x ->
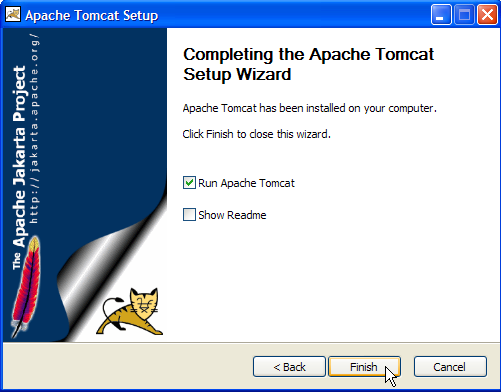
O botão [Finish] conclui a instalação. A presença do Tomcat é indicada por um ícone à direita na barra de tarefas do Windows:
Um clique com o botão direito do rato neste ícone dá acesso aos comandos Iniciar – Parar do servidor:
Utilizamos a opção [Stop service] para parar agora o servidor web:
Repare na mudança de estado do ícone. Este pode ser removido da barra de tarefas:
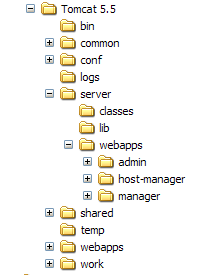
A instalação do Tomcat foi efetuada na pasta escolhida pelo utilizador, à qual passaremos a chamar <tomcat>. A estrutura de pastas desta pasta para a versão Tomcat 5.5.23 descarregada é a seguinte:
A instalação do Tomcat criou vários atalhos no menu [Démarrer]. Utilizamos o link [Monitor] abaixo para iniciar a ferramenta de paragem/arranque do Tomcat:
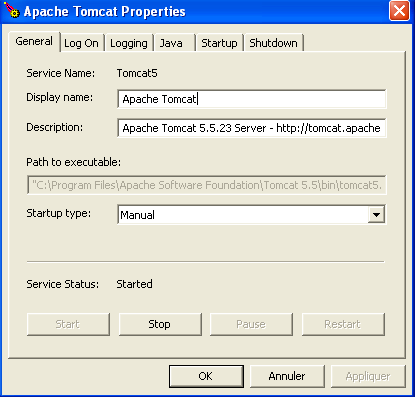
Encontramos então o ícone apresentado anteriormente:
O monitor do Tomcat pode ser ativado clicando duas vezes neste ícone:
Os botões [Start - Stop - Pause] - Restart permitem-nos iniciar, parar e reiniciar o servidor. Iniciamos o servidor através de [Start] e, em seguida, num navegador, acedemos ao endereço http://localhost:8080. Devemos obter uma página semelhante à seguinte:
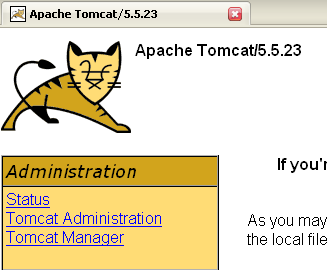
Poderemos seguir as ligações abaixo para verificar se o Tomcat foi instalado corretamente:

Todos os links da página [http://localhost:8080] são interessantes e o leitor é convidado a explorá-los. Teremos oportunidade de voltar aos links que permitem gerir as aplicações web implementadas no servidor:

5.3.2. Implantação de uma aplicação web no servidor Tomcat
5.3.3. Implantação
Uma aplicação web deve seguir determinadas regras para ser implementada num contentor de servlets. Seja <webapp> a pasta de uma aplicação web. Uma aplicação web é composta por:
na pasta <webapp>\WEB-INF\classes | |
na pasta <webapp>\WEB-INF\lib | |
na pasta <webapp> ou nas subpastas |
A aplicação web é configurada por um ficheiro XML: <webapp>\WEB-INF\web.xml. Este ficheiro não é necessário em casos simples, nomeadamente quando a aplicação web contém apenas ficheiros estáticos. Vamos criar o seguinte ficheiro HTML:
<html>
<head>
<title>Application exemple</title>
</head>
<body>
Application exemple active ....
</body>
</html>
e guardemo-lo numa pasta:
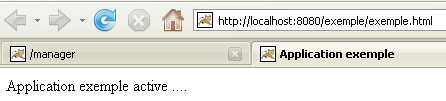
Se carregarmos este ficheiro num navegador, obtemos a seguinte página:

O código URL apresentado pelo navegador mostra que a página não foi servida por um servidor web, mas carregada diretamente pelo navegador. Queremos agora que ela esteja disponível através do servidor web Tomcat.
Voltemos à estrutura de diretórios do <tomcat>:
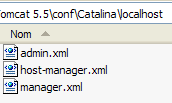
A configuração das aplicações web implementadas no servidor Tomcat é feita através de ficheiros XML localizados na pasta [<tomcat>\conf\Catalina\localhost]:
 |  |
Estes ficheiros XML podem ser criados manualmente, uma vez que a sua estrutura é simples. Em vez de seguir este procedimento, vamos utilizar as ferramentas web que o Tomcat nos disponibiliza.
5.3.4. Administração do Tomcat
Na sua página inicial http://localhost:8080, o servidor disponibiliza-nos ligações para a sua administração:

O link [Tomcat Administration] permite-nos configurar os recursos que o Tomcat disponibiliza às aplicações web implementadas no seu ambiente, por exemplo, um conjunto de ligações a uma base de dados. Sigamos o link:

A página apresentada indica-nos que a administração do Tomcat 5.x requer um pacote específico denominado «admin». Voltemos ao site do Tomcat [http://tomcat.apache.org/download-55.cgi]:
Vamos descarregar o ficheiro zip com a designação [Administration Web Application] e, em seguida, descompactá-lo. O seu conteúdo é o seguinte:
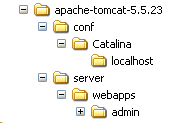
A pasta [admin] deve ser copiada para [<tomcat>\server\webapps], onde <tomcat> é a pasta onde foi instalado o Tomcat 5.x:
A pasta [localhost] contém um ficheiro [admin.xml] que deve ser copiado para [<tomcat>\conf\Catalina\localhost]:
Vamos parar e, em seguida, reiniciar o Tomcat, caso este estivesse ativo. Depois, utilizando um navegador, acedamos novamente à página inicial do servidor web:

Sigamos a ligação [Tomcat Administration]. Obtemos uma página de identificação (para a obter, pode ser necessário fazer um «reload/refresh» da página):
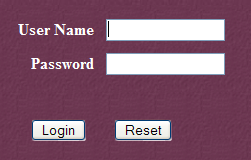 | 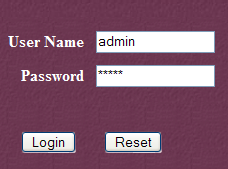 |
Aqui, é necessário introduzir novamente as informações que fornecemos durante a instalação do Tomcat. No nosso caso, introduzimos o par admin / admin. O botão [Login] leva-nos à página seguinte:
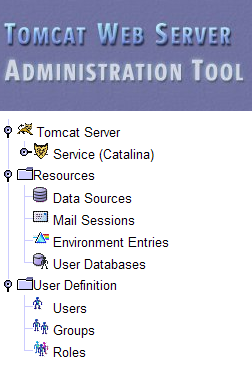
Esta página permite ao administrador do Tomcat definir
- fontes de dados (Data Sources),
- as informações necessárias para o envio de e-mail (Mail Sessions),
- dados de ambiente acessíveis a todas as aplicações (Entries de Ambiente),
- gerir os utilizadores/administradores do Tomcat (Users),
- gerir grupos de utilizadores (Groups),
- definir funções (= o que um utilizador pode ou não fazer),
- definir as características das aplicações web implementadas pelo servidor (Service Catalina)
Vamos seguir o link [Roles] acima:
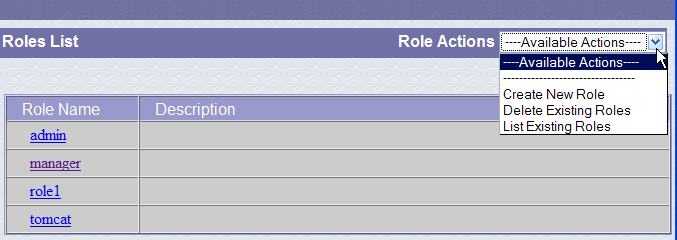
Uma função permite definir o que um utilizador ou um grupo de utilizadores pode ou não fazer. A uma função são associados determinados direitos. Cada utilizador está associado a uma ou mais funções e dispõe dos direitos a elas associados. A função [manager] abaixo concede o direito de gerir as aplicações web implementadas no Tomcat (implementação, arranque, paragem, descarregamento). Vamos criar um utilizador [manager] que associaremos à função [manager], para lhe permitir gerir as aplicações do Tomcat. Para tal, seguimos o link [Users] na página de administração:
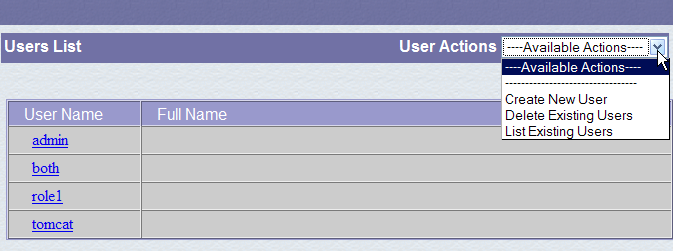
Verificamos que já existe um certo número de utilizadores. Utilizamos a opção [Create New User] para criar um novo utilizador:
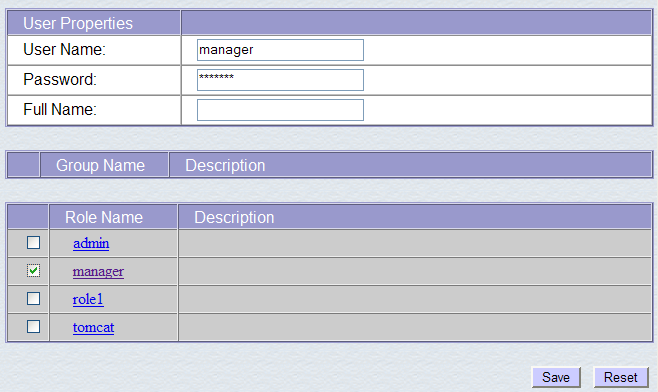
Atribuímos ao utilizador «manager» a palavra-passe «manager» e atribuímos-lhe a função «manager». Utilizamos o botão [Save] para confirmar esta adição. O novo utilizador aparece na lista de utilizadores:
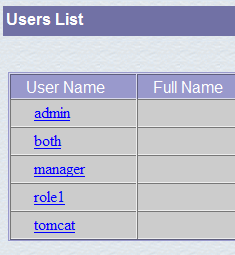
Este novo utilizador será adicionado ao ficheiro [<tomcat>\conf\tomcat-users.xml]:
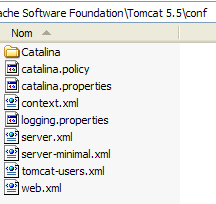
cujo conteúdo é o seguinte:
<?xml version='1.0' encoding='utf-8'?>
<tomcat-users>
<role rolename="tomcat"/>
<role rolename="role1"/>
<role rolename="manager"/>
<role rolename="admin"/>
<user username="tomcat" password="tomcat" roles="tomcat"/>
<user username="role1" password="tomcat" roles="role1"/>
<user username="both" password="tomcat" roles="tomcat,role1"/>
<user username="manager" password="manager" fullName="" roles="manager"/>
<user username="admin" password="admin" roles="admin,manager"/>
</tomcat-users>
- linha 10: o utilizador [manager] que foi criado
Outra forma de adicionar utilizadores é editar diretamente este ficheiro. É assim que se deve proceder, nomeadamente, caso se tenha esquecido a palavra-passe do administrador «admin» ou do gestor.
5.3.5. Gestão das aplicações web implementadas
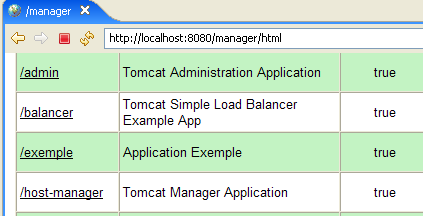
Voltemos agora à página inicial [http://localhost:8080] e sigamos a ligação [Tomcat Manager]:

Surge então uma página de autenticação. Identificamo-nos como «manager / manager», c.a.d, o utilizador com a função [manager] que acabámos de criar. Com efeito, apenas um utilizador com esta função pode utilizar este link. Na linha 11 de [tomcat-users.xml], verificamos que o utilizador [admin] também possui a função [manager]. Assim, poderíamos também utilizar a autenticação [admin / admin].
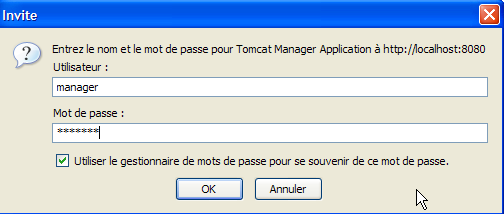
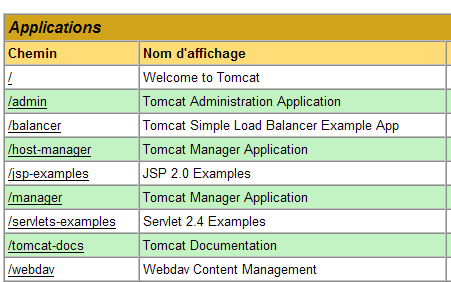
Obtenemos uma página que lista as aplicações atualmente implementadas no Tomcat:
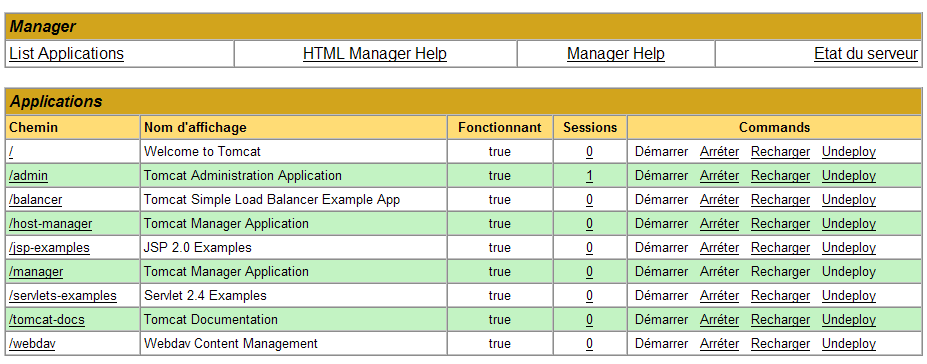
Podemos adicionar uma nova aplicação através dos formulários localizados na parte inferior da página:
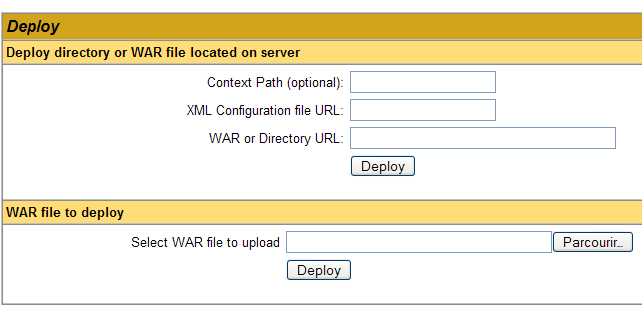
Neste caso, pretendemos implementar no Tomcat a aplicação de exemplo que criámos anteriormente. Fazemo-lo da seguinte forma:
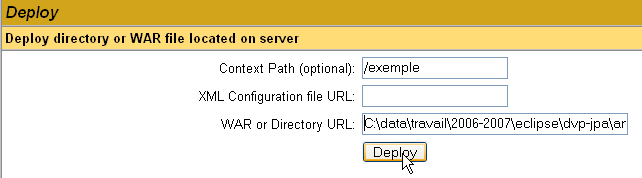
/exemplo | o nome utilizado para designar a aplicação web a ser implementada | |
C:\data\trabalho\2006-2007\eclipse\dvp-jpa\anexos\tomcat\exemplo | a pasta da aplicação web |
Para obter o ficheiro [C:\data\travail\2006-2007\eclipse\dvp-jpa\annexes\tomcat\exemple\exemple.html], solicitaremos ao Tomcat o URL e o [http://localhost:8080/exemple/exemple.html]. O contexto serve para atribuir um nome à raiz da árvore de diretórios da aplicação web implementada. Utilizamos o botão [Deploy] para efetuar a implementação da aplicação. Se tudo correr bem, obtemos a seguinte página de resposta:

e a nova aplicação aparece na lista de aplicações implementadas:
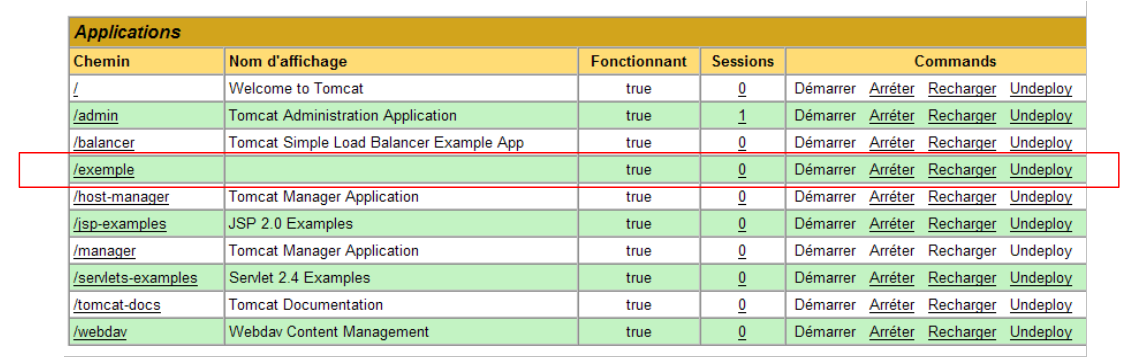 |
Vamos comentar a linha do contexto /exemplo acima:
ligação para http://localhost:8080/exemple | |
permite iniciar a aplicação | |
permite encerrar a aplicação | |
permite recarregar a aplicação. Isto é necessário, por exemplo, quando se adicionaram, alterado ou eliminado determinadas classes da aplicação. | |
eliminação do contexto [/exemple]. A aplicação desaparece da lista de aplicações disponíveis. |
Agora que a nossa aplicação /exemplo está implementada, podemos realizar alguns testes. Acedemos à página [exemple.html] através do URL [http://localhost:8080/exemple/vues/exemple.html]:
Outra forma de implementar uma aplicação web no servidor Tomcat consiste em introduzir as informações que fornecemos através da interface web num ficheiro [contexte].xml, colocado na pasta [<tomcat>\conf\Catalina\localhost], onde [contexte] é o nome da aplicação web.
Voltemos à interface de administração do Tomcat:

Vamos eliminar a aplicação [/exemple] juntamente com o seu link [Undeploy]:
A aplicação [/exemple] já não faz parte da lista de aplicações ativas. Agora, vamos definir o seguinte ficheiro [exemple.xml]:
O ficheiro XML é constituído por uma única baliza <Context>, cujo atributo docBase define a pasta que contém a aplicação web a implementar. Coloquemos este ficheiro em <tomcat>\conf\Catalina\localhost:
Se necessário, paremos e reiniciemos o Tomcat e, em seguida, visualizemos a lista de aplicações ativas com o gestor do Tomcat:
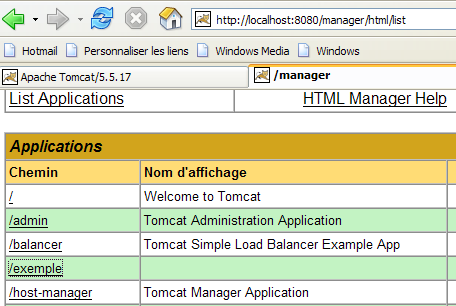
A aplicação [/exemple] está efetivamente presente. Acedamos, através de um navegador, à URL:
[http://localhost:8080/exemple/exemple.html]:
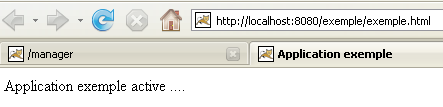
Uma aplicação web assim implementada pode ser removida da lista de aplicações implementadas, da mesma forma que anteriormente, através do link [Undeploy]:
Neste caso, o ficheiro [exemple.xml] é automaticamente removido da pasta [<tomcat>\conf\Catalina\localhost].
Por fim, para implementar uma aplicação web no Tomcat, também é possível definir o seu contexto no ficheiro [<tomcat>\conf\server.xml]. Não iremos aprofundar este ponto aqui.
5.3.6. Aplicação web com página inicial
Quando acedemos à URL [http://localhost:8080/exemple/], obtemos a seguinte resposta:
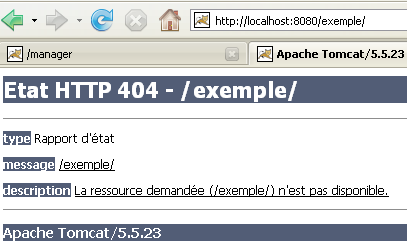
Com algumas versões anteriores do Tomcat, teríamos obtido o conteúdo da pasta física da aplicação [/exemple].
É possível fazer com que, quando o contexto for solicitado, seja apresentada uma página denominada «página inicial». Para tal, criamos um ficheiro [web.xml] que colocamos na pasta <exemplo>\WEB-INF, onde <exemplo> é a pasta física da aplicação web [/exemple]. Este ficheiro é o seguinte:
- linhas 2-5: a baliza raiz <web-app> com atributos obtidos através de copiar/colar do ficheiro [web.xml] da aplicação [/admin] do Tomcat (<tomcat>/server/webapps/admin/WEB-INF/web.xml).
- linha 7: o nome de exibição da aplicação web. Trata-se de um nome livre, com menos restrições do que o nome de contexto da aplicação. É possível incluir espaços, por exemplo, o que não é possível com o nome de contexto. Este nome é exibido, por exemplo, pelo administrador do Tomcat:

- linha 8: descrição da aplicação web. Este texto pode posteriormente ser obtido por programação.
- linhas 9-11: a lista de ficheiros de boas-vindas. A baliza <welcome-file-list> serve para definir a lista de vistas a apresentar quando um cliente solicita o contexto da aplicação. Podem existir várias vistas. A primeira encontrada é apresentada ao cliente. Aqui, temos apenas uma: [/exemple.html]. Assim, quando um cliente solicitar a URL [/exemple], será, na verdade, a URL [/exemple/exemple.html] que lhe será fornecida.
Vamos guardar este ficheiro [web.xml] em <exemplo>\WEB-INF:
Se o Tomcat ainda estiver ativo, é possível forçá-lo a recarregar a aplicação web [/exemple] através do link [Recharger]:

Durante esta operação de «recarregamento», o Tomcat volta a ler o ficheiro [web.xml] contido em [<exemple>\WEB-INF], caso este exista. Será esse o caso aqui. Se o Tomcat estiver parado, reinicie-o.
Com um navegador, vamos aceder ao URL e ao [http://localhost:8080/exemple/]:
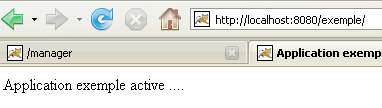
O mecanismo dos ficheiros de acolhimento funcionou.
5.3.7. Integração do Tomcat no Eclipse
Vamos agora integrar o Tomcat no Eclipse. Esta integração permite:
- iniciar/parar o Tomcat a partir do Eclipse
- desenvolver aplicações web em Java e executá-las no Tomcat. A integração Eclipse/Tomcat permite depurar a execução da aplicação, incluindo a execução das classes Java (servlets) executadas pelo Tomcat.
Vamos iniciar o Eclipse e, em seguida, aceder à vista [Servers]:
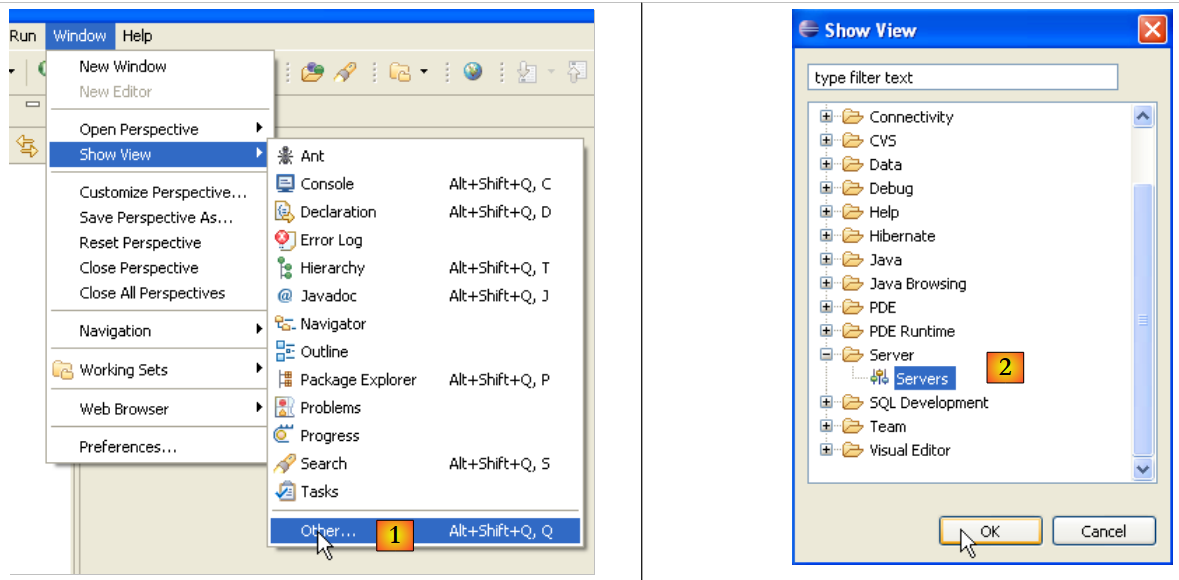 |
- em [1]: Window/Show View/Other
- em [2]: selecione a vista [Servers] e execute [OK]
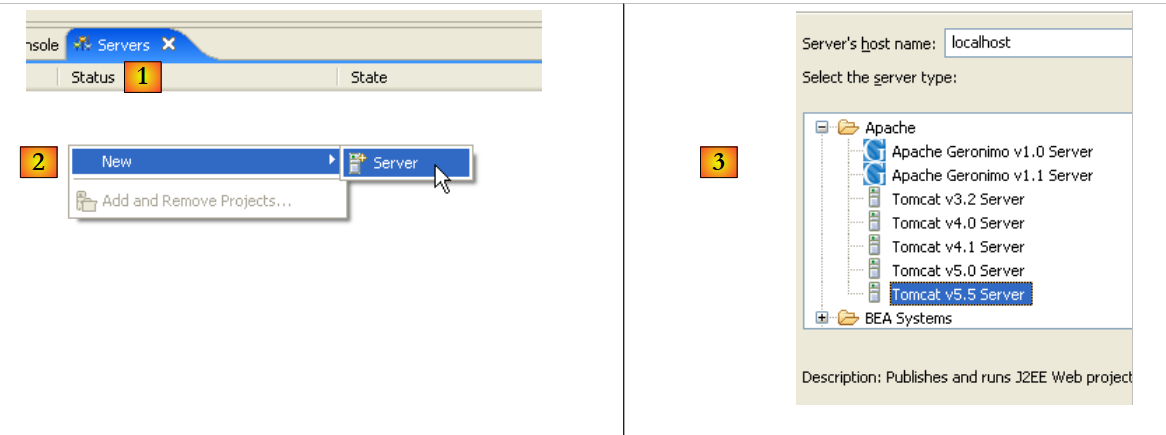 |
- em [1], temos uma nova vista [Servers]
- em [2], clica-se com o botão direito do rato na vista e solicita-se a criação de um novo servidor [New/Server]
- em [3], seleciona-se o servidor [Tomcat 5.5] e, em seguida, passa-se para [Next]
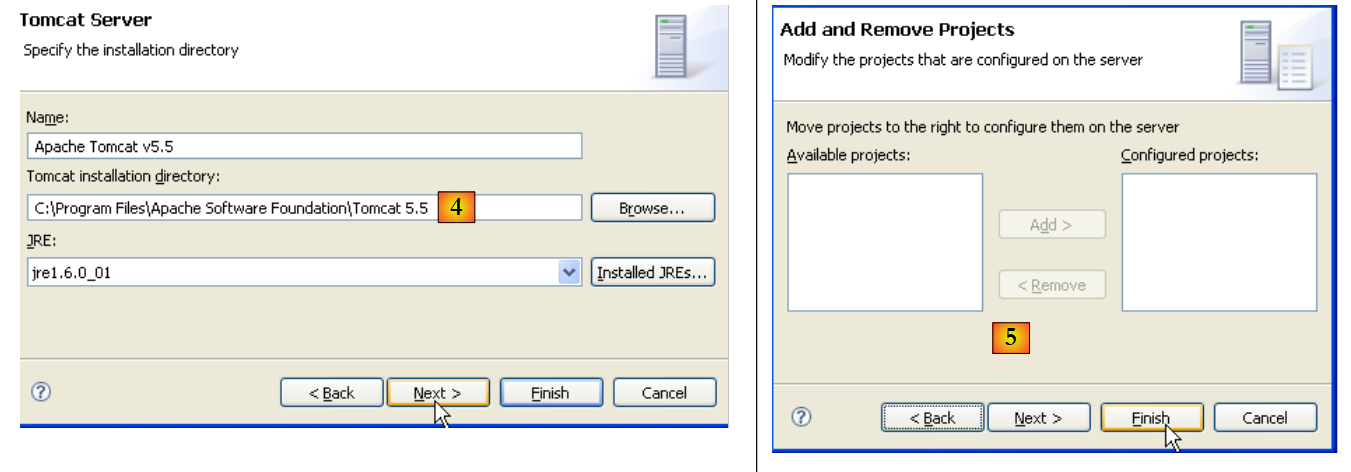 |
- em [4], indicamos a pasta de instalação do Tomcat 5.5
- em [5], indica-se que não existem projetos Eclipse/Tomcat neste momento. Executa-se [Finish]
A adição do servidor concretiza-se com a inclusão de uma pasta no explorador de projetos do Eclipse [6] e com o aparecimento de um servidor na vista [servers] [7]:
 |
Na vista [Servers] aparecem todos os servidores declarados; neste caso, apenas o servidor Tomcat 5.5 que acabámos de registar. Um clique com o botão direito do rato sobre o mesmo dá acesso aos comandos que permitem iniciar, parar e reiniciar o servidor:
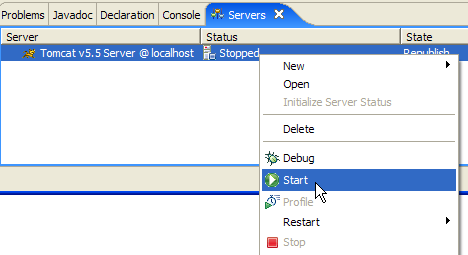
Acima, iniciamos o servidor. Durante o seu arranque, são registados vários registos na vista [Console]:
A compreensão destes registos requer alguma prática. Não nos deteremos neste assunto por enquanto. No entanto, é importante verificar se não indicam erros no carregamento dos contextos. Com efeito, quando é iniciado, o servidor Tomcat/Eclipse procura carregar o contexto das aplicações que gere. Carregar o contexto de uma aplicação implica utilizar o seu ficheiro [web.xml] e carregar uma ou mais classes que o inicializam. Podem então ocorrer vários tipos de erros:
- o ficheiro [web.xml] apresenta erros de sintaxe. Este é o erro mais frequente. Recomenda-se a utilização de uma ferramenta capaz de verificar a validade de um documento XML durante a sua criação.
- algumas das classes a carregar não foram encontradas. Estas são procuradas nos ficheiros [WEB-INF/classes] e [WEB-INF/lib]. Em geral, é necessário verificar a presença das classes necessárias e a ortografia das classes declaradas no ficheiro [web.xml].
O servidor iniciado a partir do Eclipse não tem a mesma configuração que o instalado no parágrafo 5.3. Para nos certificarmos disso, acedamos ao URL [http://localhost:8080] com um navegador:
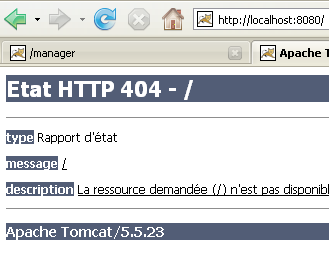
Esta resposta não indica que o servidor não esteja a funcionar, mas sim que o recurso / solicitado não está disponível. Com o servidor Tomcat integrado no Eclipse, estes recursos serão projetos web. Veremos isso mais adiante. Por enquanto, vamos parar o Tomcat:
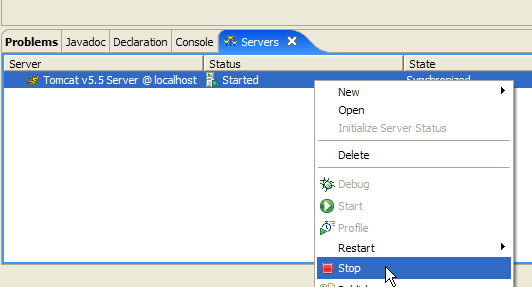
O modo de funcionamento anterior pode ser alterado. Voltemos à vista [Servers] e façamos duplo-clique no servidor Tomcat para aceder às suas propriedades:
 | 1 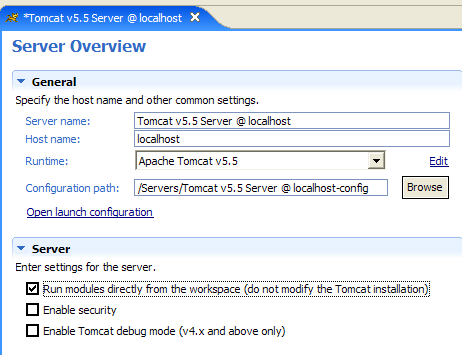 |
A caixa de seleção [1] é responsável pelo modo de funcionamento anterior. Quando está marcada, as aplicações web desenvolvidas no Eclipse não são declaradas nos ficheiros de configuração do servidor Tomcat associado, mas sim em ficheiros de configuração separados. Ao fazê-lo, deixamos de dispor das aplicações definidas por predefinição no servidor Tomcat: [admin] e [manager], que são duas aplicações úteis. Por isso, vamos desmarcar a caixa de seleção [1] e reiniciar o Tomcat:
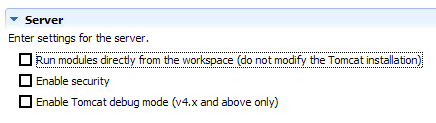 |  |
Feito isto, vamos aceder à URL [http://localhost:8080] num navegador:
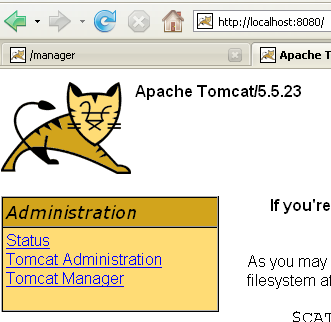
Encontramos aqui o funcionamento descrito no parágrafo 5.3.4.
Nos nossos exemplos anteriores, utilizámos um navegador externo ao Eclipse. Também é possível utilizar um navegador interno ao Eclipse:
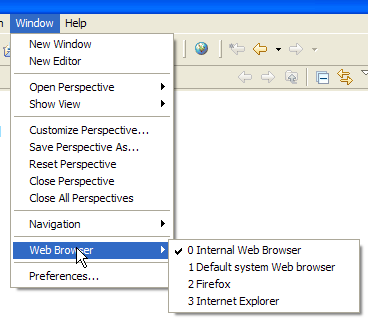
Selecionamos acima o navegador interno. Para o iniciar a partir do Eclipse, pode-se utilizar o seguinte ícone:
O navegador efetivamente iniciado será aquele selecionado pela opção [Window -> Web Browser]. Neste caso, obtemos o navegador interno:
1

Se necessário, inicie o Tomcat a partir do Eclipse e, na opção [1], introduza o URL [http://localhost:8080]:
Sigamos a ligação [Tomcat Manager]:
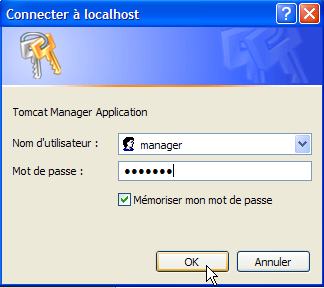
É solicitado o par [login / mot de passe] necessário para aceder à aplicação [manager]. De acordo com a configuração do Tomcat que efetuámos anteriormente, podemos introduzir [admin / admin] ou [manager / manager]. Obter-se-á então a lista das aplicações implementadas:
5.4. O SGBD a o Firebird
5.4.1. SGBD Firebird
O SGBD Firebird está disponível no URL [http://www.firebirdsql.org/]:
 |
- em [1]: utiliza-se a opção [Download.Firebird Relational Database]
- em [2]: especifica-se a versão pretendida do Firebird
- em [3]: descarrega-se o ficheiro binário de instalação
Depois de descarregar o ficheiro [3], clica-se duas vezes nele para instalar o Firebird SGBD. O SGBD é instalado numa pasta cujo conteúdo é semelhante ao seguinte:
Os ficheiros binários encontram-se na pasta [bin]:
permite iniciar/parar o SGBD | |
cliente de linha que permite gerir bases de dados |
Note-se que, por predefinição, o administrador do SGBD chama-se [SYSDBA] e a sua palavra-passe é [masterkey]. Foram instalados menus no [Démarrer]:
A opção [Firebird Guardian] permite iniciar/encerrar o SGBD. Após o arranque, o ícone do SGBD permanece na barra de tarefas do Windows:
 |
Para criar e utilizar bases de dados Firebird com o cliente de linha de comandos [isql.exe], é necessário consultar a documentação fornecida com o produto, acessível através dos atalhos do Firebird no [Démarrer/Programmes/Firebird 2.0].
Uma forma rápida de trabalhar com o Firebird e de aprender a linguagem SQL é utilizar um cliente gráfico. Um exemplo desse tipo de cliente é o IB-Expert, descrito no parágrafo seguinte.
5.4.2. Trabalhar com o SGBD Firebird com o IB- Expert
O site principal do IB-Expert é [http://www.ibexpert.com/].
 |
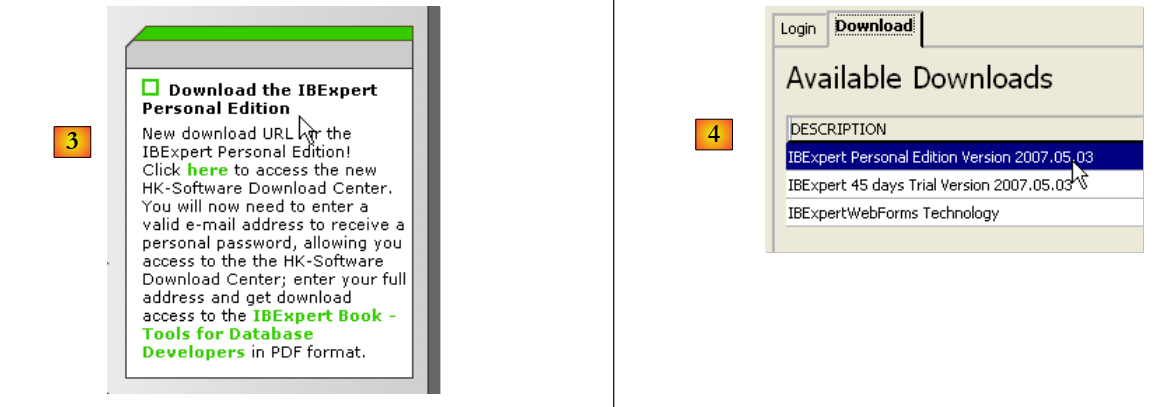 |
- em [1], seleciona-se IBExpert
- em [2], seleciona-se o download após, se necessário, escolher o idioma pretendido
- em [3], seleciona-se a versão denominada «pessoal», uma vez que é gratuita. No entanto, é necessário registar-se no site.
- no [4], descarrega-se o IBExpert
O IBExpert é instalado numa pasta semelhante à seguinte:
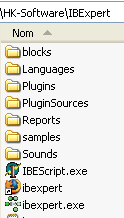
O executável é o [ibexpert.exe]. Normalmente, existe um atalho disponível no menu [Démarrer]:

Uma vez iniciado, o IBExpert apresenta a seguinte janela:
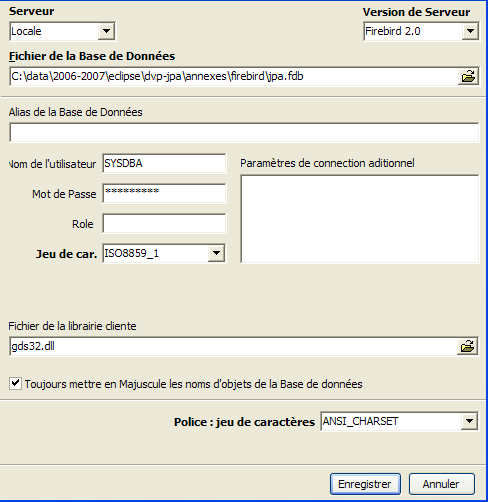
Vamos utilizar a opção [Database/Create Database] « » para criar uma base de dados:
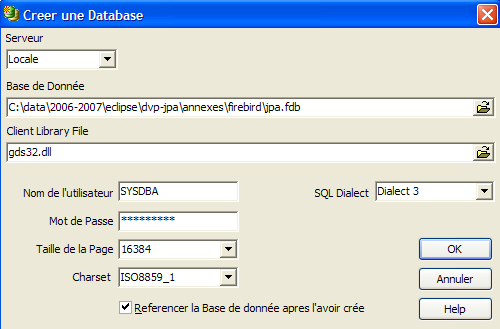
pode ser [local] ou [remote]. Neste caso, o nosso servidor está na mesma máquina que o [IBExpert]. Escolhemos , portanto, o [local] | |
utilizar o botão do tipo [dossier] do menu suspenso para indicar o ficheiro da base de dados. O Firebird coloca toda a base num único ficheiro. Esta é uma das suas vantagens. A base de dados é transferida de um computador para outro através de uma simples cópia do ficheiro. O sufixo [.fdb] é adicionado automaticamente. | |
SYSDBA é o administrador predefinido nas distribuições atuais do Firebird | |
masterkey é a palavra-passe do administrador SYSDBA das distribuições atuais do Firebird | |
o dialeto SQL a utilizar | |
se a caixa estiver marcada, o IBExpert apresentará um link para a base de dados criada após a sua criação |
Se, ao clicar no botão de criação [OK], receber o seguinte aviso:
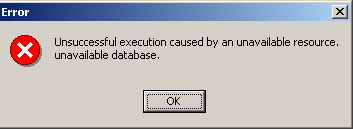
significa que não iniciou o Firebird. Inicie-o. Aparece uma nova janela:
Família de caracteres a utilizar. Recomenda-se selecionar na lista suspensa a família [ISO-8859-1], que permite utilizar caracteres latinos acentuados. |
[IBExpert] é capaz de gerir diferentes SGBD derivados do Interbase. Selecione a versão do Firebird que tem instalada. |
Assim que esta nova janela for validada pelo [Register], obtém-se o resultado [1] na janela [Database Explorer]. Esta janela pode ser fechada acidentalmente. Para a recuperar, execute o [2]:
 |
Para aceder à base de dados criada, basta clicar duas vezes no respetivo link. O IBExpert apresenta então uma árvore de navegação que dá acesso às propriedades da base de dados:
5.4.3. Criação de uma tabela de dados
Vamos criar uma tabela. Clica-se com o botão direito do rato em [Tables] (ver janela acima) e seleciona-se a opção [New Table]. É apresentada a janela de definição das propriedades da tabela:
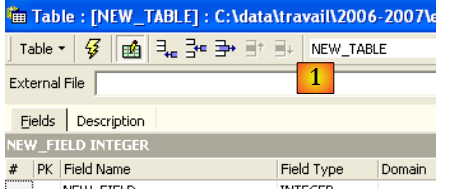 |
Comecemos por atribuir o nome [ARTICLES] à tabela, utilizando o campo de introdução [1]:
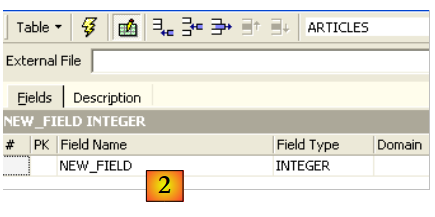
Utilizemos o campo de introdução [2] para definir uma chave primária [ID]:
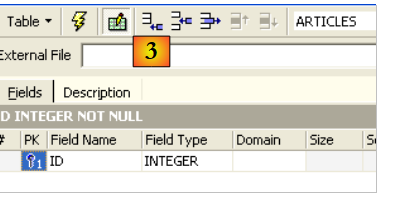
Um campo é definido como chave primária clicando duas vezes na zona [PK] (Primary Key) do campo. Vamos adicionar campos com o botão situado acima de [3]:
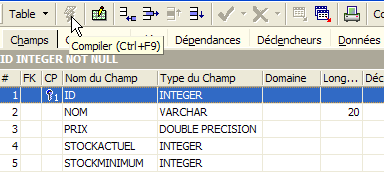
Enquanto não tivermos «compilado» a nossa definição, a tabela não é criada. Utilizemos o botão [Compile] acima para concluir a definição da tabela. O IBExpert prepara as consultas SQL para a geração da tabela e solicita confirmação:
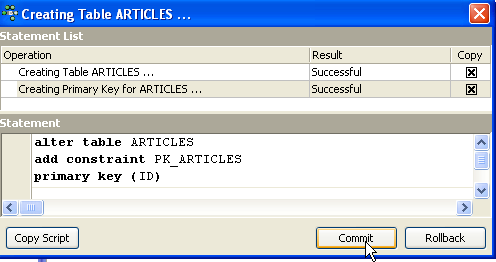
Curiosamente, o IBExpert apresenta as consultas SQL que executou. Isto permite a aprendizagem tanto da linguagem SQL como do dialeto SQL, que poderá ser proprietário. O botão [Commit] permite validar a transação em curso, enquanto o botão [Rollback] permite anulá-la. Aqui, aceitamo-la através de [Commit]. Feito isto, IBExpert adiciona a tabela criada à estrutura da nossa base de dados:
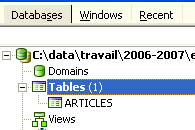
Ao clicar duas vezes na tabela, tem-se acesso às suas propriedades:
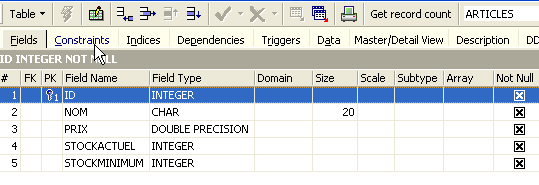
O painel [Constraints] permite-nos adicionar novas restrições de integridade à tabela. Vamos abri-lo:
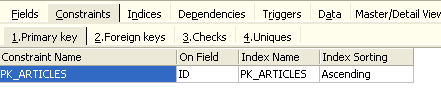
Encontramos aqui a restrição de chave primária que criámos. Podemos adicionar outras restrições:
- chaves estrangeiras [Foreign Keys]
- restrições de integridade de campos [Checks]
- restrições de unicidade de campos [Uniques]
Note-se que:
- os campos [ID, PRIX, STOCKACTUEL, STOKMINIMUM] devem ser >0
- o campo [NOM] deve ser diferente de vazio e único
Abramos o painel [Checks] e cliquemos com o botão direito do rato na sua área de definição de restrições para adicionar uma nova restrição:
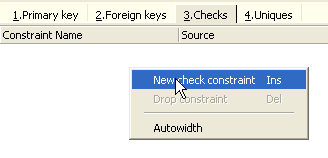
Definamos as restrições pretendidas:
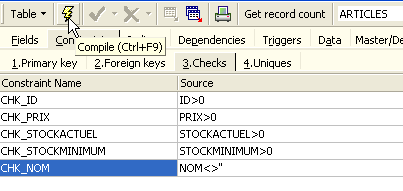
Note-se acima que a restrição [NOM<>''] utiliza dois apóstrofos e não aspas. Compilemos estas restrições com o botão [Compile] acima:
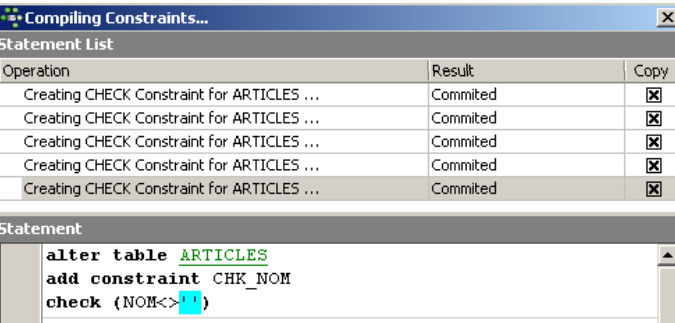
Mais uma vez, a restrição IBExpert demonstra ser didática ao indicar as consultas SQL que executou. Passemos agora ao painel [Constraints/Uniques] para indicar que o nome deve ser único. Isto significa que não é possível ter duas vezes o mesmo nome na tabela.
Vamos definir a restrição:
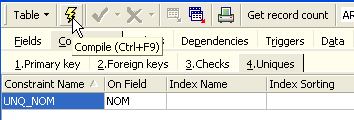
Em seguida, compilemo-la. Feito isto, abramos o painel [DDL] (Data Definition Language) da tabela [ARTICLES]:

Este painel fornece o código SQL para a geração da tabela com todas as suas restrições. É possível guardar este código num script para o executar posteriormente:
SET SQL DIALECT 3;
SET NAMES ISO8859_1;
CREATE TABLE ARTICLES (
ID INTEGER NOT NULL,
NOM VARCHAR(20) NOT NULL,
PRIX DOUBLE PRECISION NOT NULL,
STOCKACTUEL INTEGER NOT NULL,
STOCKMINIMUM INTEGER NOT NULL
);
ALTER TABLE ARTICLES ADD CONSTRAINT CHK_ID check (ID>0);
ALTER TABLE ARTICLES ADD CONSTRAINT CHK_PRIX check (PRIX>0);
ALTER TABLE ARTICLES ADD CONSTRAINT CHK_STOCKACTUEL check (STOCKACTUEL>0);
ALTER TABLE ARTICLES ADD CONSTRAINT CHK_STOCKMINIMUM check (STOCKMINIMUM>0);
ALTER TABLE ARTICLES ADD CONSTRAINT CHK_NOM check (NOM<>'');
ALTER TABLE ARTICLES ADD CONSTRAINT UNQ_NOM UNIQUE (NOM);
ALTER TABLE ARTICLES ADD CONSTRAINT PK_ARTICLES PRIMARY KEY (ID);
5.4.4. Inserção de dados numa tabela
Chegou a altura de inserir dados na tabela [ARTICLES]. Para tal, vamos utilizar o seu painel [Data]:
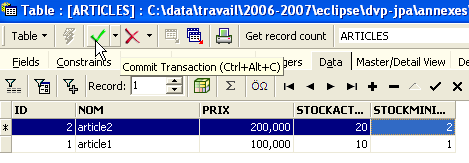
Os dados são introduzidos clicando duas vezes nos campos de introdução de cada linha da tabela. Adiciona-se uma nova linha com o botão [+] e elimina-se uma linha com o botão [-]. Estas operações são realizadas numa transação que é validada através do botão [Commit Transaction] (ver acima). Sem esta validação, os dados serão perdidos.
5.4.5. O editor SQL de [IB-Expert]
A linguagem SQL (Structured Query Language) permite ao utilizador:
- criar tabelas, especificando o tipo de dados que estas irão armazenar e as restrições que esses dados devem cumprir
- inserir dados nessas tabelas
- alterar alguns dados
- eliminar outros
- explorar o seu conteúdo para obter informações
- ...
O IBExpert permite que um utilizador realize as operações 1 a 4 de forma gráfica. Acabámos de ver isso. Quando a base de dados contém muitas tabelas, cada uma com centenas de linhas, são necessárias informações difíceis de obter visualmente. Suponhamos, por exemplo, que uma loja virtual na Internet tenha milhares de compradores por mês. Todas as compras são registadas numa base de dados. Ao fim de seis meses, descobre-se que um produto «X» apresenta defeitos. Pretende-se contactar todas as pessoas que o compraram para que devolvam o produto para uma troca gratuita. Como encontrar as moradas desses compradores?
- É possível consultar visualmente todas as tabelas e procurar esses compradores. Isso demorará algumas horas.
- Pode-se emitir uma ordem SQL que fornecerá a lista dessas pessoas em poucos segundos
A linguagem SQL é útil sempre que
- a quantidade de dados nas tabelas for significativa
- quando há muitas tabelas interligadas
- quando a informação a obter está distribuída por várias tabelas
- ...
Apresentamos agora o editor SQL do IBExpert. Este está acessível através da opção [Tools/SQL Editor] ou [F12]:
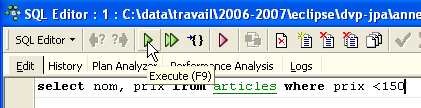
Temos então acesso a um editor de consultas SQL avançado, com o qual podemos experimentar consultas. Digitemos uma consulta:
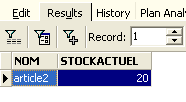
Executamos a consulta SQL com o botão [Execute] acima. Obtemos o seguinte resultado:
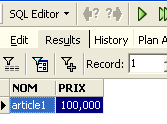
Acima, o separador [Results] apresenta a tabela de resultados da ordem SQL [Select]. Para emitir um novo comando SQL, basta regressar ao separador [Edit]. Encontramos então a ordem SQL que foi executada.

Vários botões da barra de ferramentas são úteis:
- o botão [New Query] permite passar para uma nova consulta SQL:

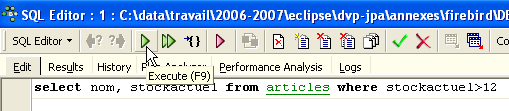
Obtém-se então uma página de edição em branco:
É então possível introduzir uma nova ordem SQL:
e executá-la:
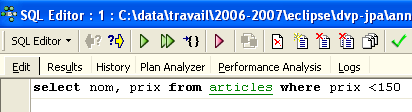
Voltemos ao separador [Edit]. As diferentes ordens SQL emitidas são guardadas por [IBExpert]. O botão [Previous Query] permite voltar a uma ordem SQL emitida anteriormente:

Voltamos então à consulta anterior:
O botão [Next Query] permite, por sua vez, avançar para a ordem seguinte, SQL:
Encontramos então a ordem SQL, que se segue na lista de ordens SQL memorizadas:
O botão [Delete Query] permite eliminar uma ordem SQL da lista de ordens guardadas:
O botão [Clear Current Query] permite apagar o conteúdo do editor para a ordem SQL apresentada:

O botão [Commit] permite validar definitivamente as alterações efetuadas na base de dados:

O botão [RollBack] permite anular as alterações efetuadas na base de dados desde o último [Commit]. Se não tiver sido executado nenhum [Commit] desde a ligação à base de dados, serão anuladas as alterações efetuadas a partir dessa ligação.
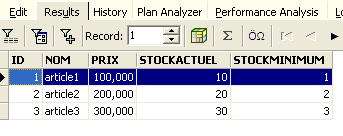
Vejamos um exemplo. Inserimos uma nova linha na tabela:

O comando SQL é executado, mas não é apresentado qualquer resultado. Não se sabe se a inserção ocorreu. Para o verificar, executemos o comando SQL a seguir ao [New Query]:
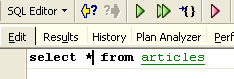
O resultado obtido com o [Execute] é o seguinte:
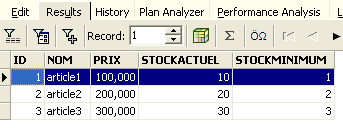
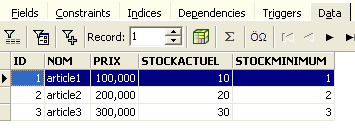
A linha foi, portanto, inserida com sucesso. Vamos agora examinar o conteúdo da tabela de outra forma. Cliquemos duas vezes na tabela [ARTICLES] no explorador de bases de dados:
Obtemos a seguinte tabela:
O botão com seta acima permite atualizar a tabela. Após a atualização, a tabela acima não se altera. Fica-se com a impressão de que a nova linha não foi inserida. Voltemos ao editor SQL (F12) e, em seguida, validemos a ordem SQL emitida com o botão [Commit]:
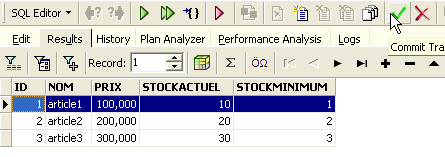
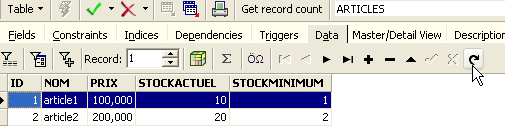
Feito isto, voltemos à tabela [ARTICLES]. Podemos constatar que nada mudou, mesmo utilizando o botão [Refresh]:
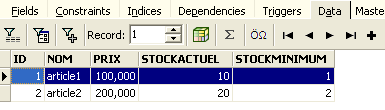
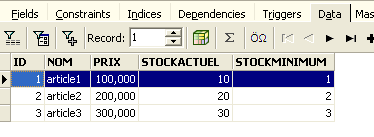
Acima, abramos o separador [Fields] e, em seguida, voltemos ao separador [Data]. Desta vez, a linha inserida aparece corretamente:
Quando começa a emissão das diferentes ordens SQL, o editor abre o que se denomina uma transação na base de dados. As alterações efetuadas por estas ordens SQL do editor SQL só serão visíveis enquanto permanecermos no mesmo editor SQL (é possível abrir vários). É como se o editor SQL não estivesse a trabalhar na base de dados real, mas sim numa cópia própria. Na realidade, não é exatamente assim que as coisas acontecem, mas esta imagem pode ajudar-nos a compreender o conceito de transação. Todas as alterações efetuadas na cópia durante uma transação só serão visíveis na base de dados real quando tiverem sido validadas por um [Commit Transaction]. A transação atual é então concluída e inicia-se uma nova transação.
As alterações efetuadas durante uma transação podem ser anuladas através de uma operação denominada [Rollback]. Vamos fazer a seguinte experiência. Iniciemos uma nova transação (basta executar o comando [Commit] na transação atual) com o comando SQL seguinte:
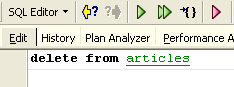
Executemos esta ordem, que elimina todas as linhas da tabela [ARTICLES], e, em seguida, executemos [New Query], a nova ordem SQL, da seguinte forma:
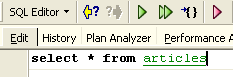
Obtemos o seguinte resultado:
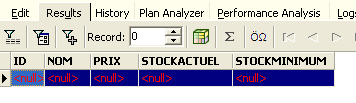
Todas as linhas foram eliminadas. Recorde-se que isto foi feito numa cópia da tabela [ARTICLES]. Para verificar, clique duas vezes na tabela [ARTICLES] abaixo:
e visualizemos o separador [Data]:
Mesmo utilizando o botão [Refresh] ou passando para o separador [Fields] para depois regressar ao separador [Data], o conteúdo acima não se altera. Isto já foi explicado. Estamos numa outra transação que trabalha com a sua própria cópia. Agora, voltemos ao editor SQL (F12) e utilizemos o botão [RollBack] para anular as eliminações de linhas que foram efetuadas:

É-nos solicitada uma confirmação:
Confirmemos. O editor SQL confirma que as alterações foram anuladas:
Vamos repetir a consulta SQL acima para verificar. Encontramos as linhas que tinham sido eliminadas:
A operação [Rollback] restaurou a cópia em que o editor SQL está a trabalhar, para o estado em que se encontrava no início da transação.
5.4.6. Exportação de uma base de dados Firebird para um script SQL
Quando se trabalha com vários SGBD, como é o caso no tutorial «Persistência Java 5 na prática», é interessante poder exportar uma base de dados a partir de um SGBD 1 para um script SQL, para posteriormente importar este último para um SGBD 2. Isto evita uma série de operações manuais. No entanto, isso nem sempre é possível, uma vez que os ficheiros SGBD têm frequentemente extensões SQL proprietárias.
Vamos mostrar como exportar a base de dados [dbarticles] anterior para um script SQL:
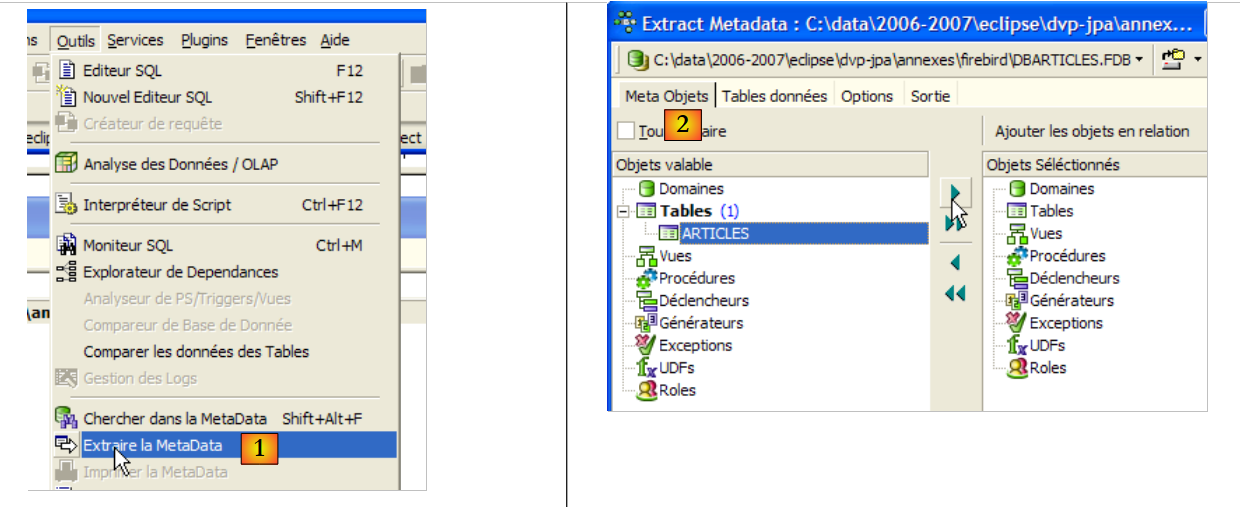 |
- para [1]: Ferramentas / Extrair o MetaData, para extrair os metadados
- para [2]: separador Meta Objetos
- em [3]: selecionar a tabela [Articles] da qual se pretende extrair a estrutura (metadados)
- em [4]: para transferir para a direita o objeto selecionado à esquerda
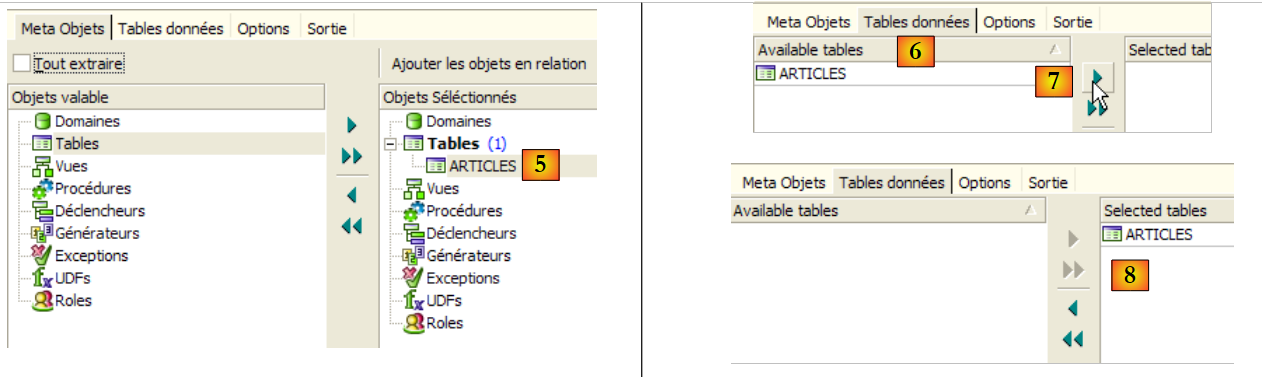 |
- em [5]: a tabela [ARTICLES] fará parte dos metadados extraídos
- em [6]: o separador [Table de données] serve para selecionar as tabelas cujo conteúdo se pretende extrair (na etapa anterior, era a estrutura da tabela que era exportada)
- em [7]: para deslocar para a direita o objeto selecionado à esquerda
- em [8]: o resultado obtido
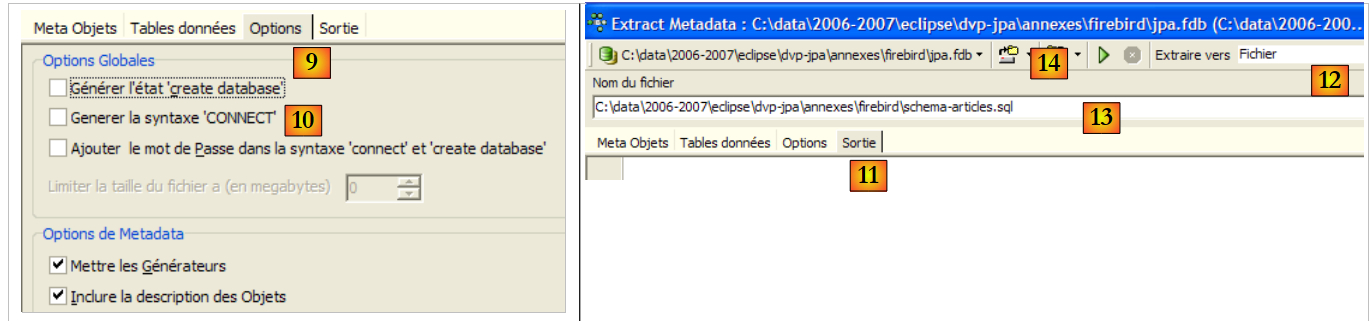 |
- em [9]: o separador [Options] permite configurar determinados parâmetros da extração
- em [10]: desmarca-se as opções relacionadas com a geração das ordens SQL que permitem ligar-se à base de dados. São específicas do Firebird e, por isso, não nos interessam.
- em [11]: o separador [Sortie] permite especificar onde será gerado o script SQL
- em [12]: especifica-se que o script deve ser gerado num ficheiro
- em [13]: especifica-se a localização desse ficheiro
- em [14]: inicia-se a geração do script SQL
O script gerado, sem os comentários, é o seguinte:
Nota: as linhas 1-2 são específicas do Firebird. Devem ser removidas do script gerado para se obter um SQL genérico.
5.4.7. Driver JDBC do Firebird para o « »
Um programa Java acede aos dados de uma base de dados através de um controlador JDBC específico do SGBD utilizado:
 |
Numa arquitetura multicamadas como a acima referida, o controlador JDBC [1] é utilizado pela camada [dao] (Data Access Object) para aceder aos dados de uma base de dados.
O controlador JDBC do Firebird está disponível no endereço URL onde o Firebird foi descarregado:
 |
 |
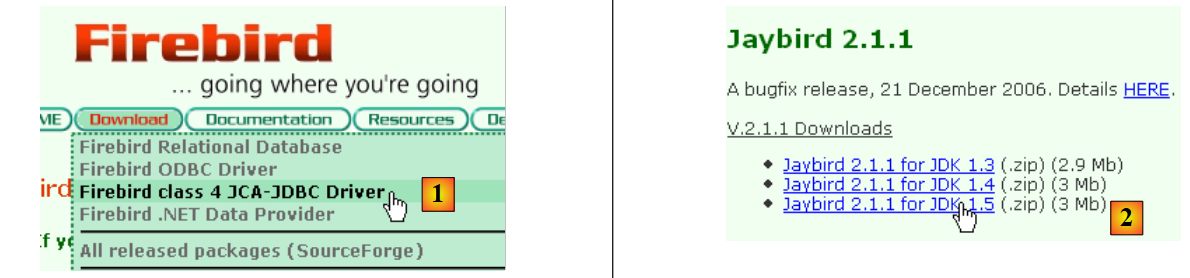
- em [1]: opta-se por descarregar o controlador JDBC
- em [2]: escolhe-se um controlador JDBC compatível com o JDK 1.5
- em [3]: o arquivo que contém o driver JDBC é o [jaybird-full-2.1.1.jar]. Vamos extrair este ficheiro. Será utilizado para todos os exemplos JPA com o Firebird.
Colocamo-lo numa pasta a que, doravante, chamaremos <jdbc>:
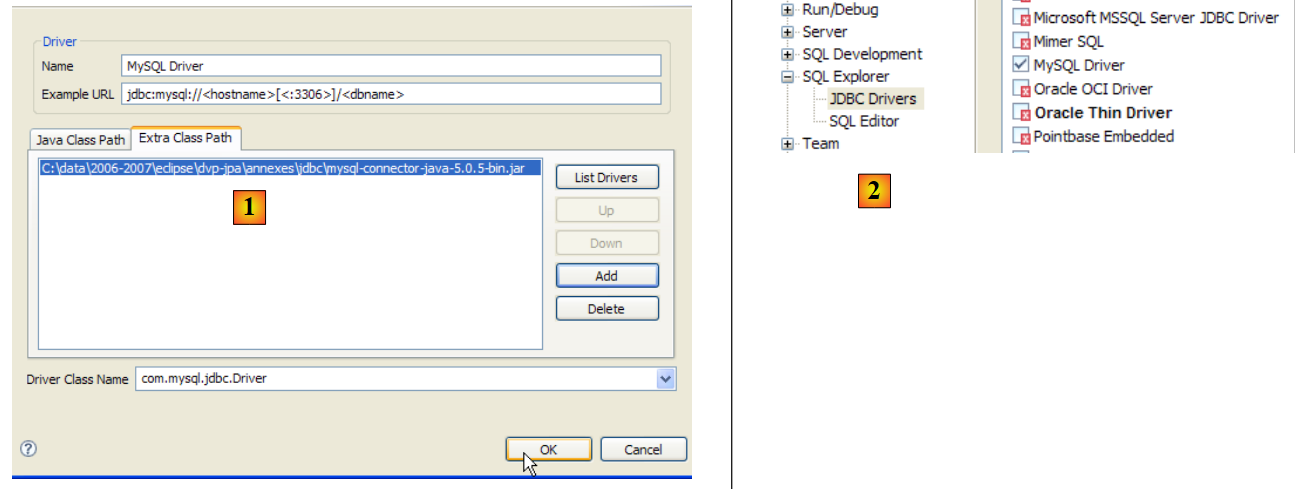
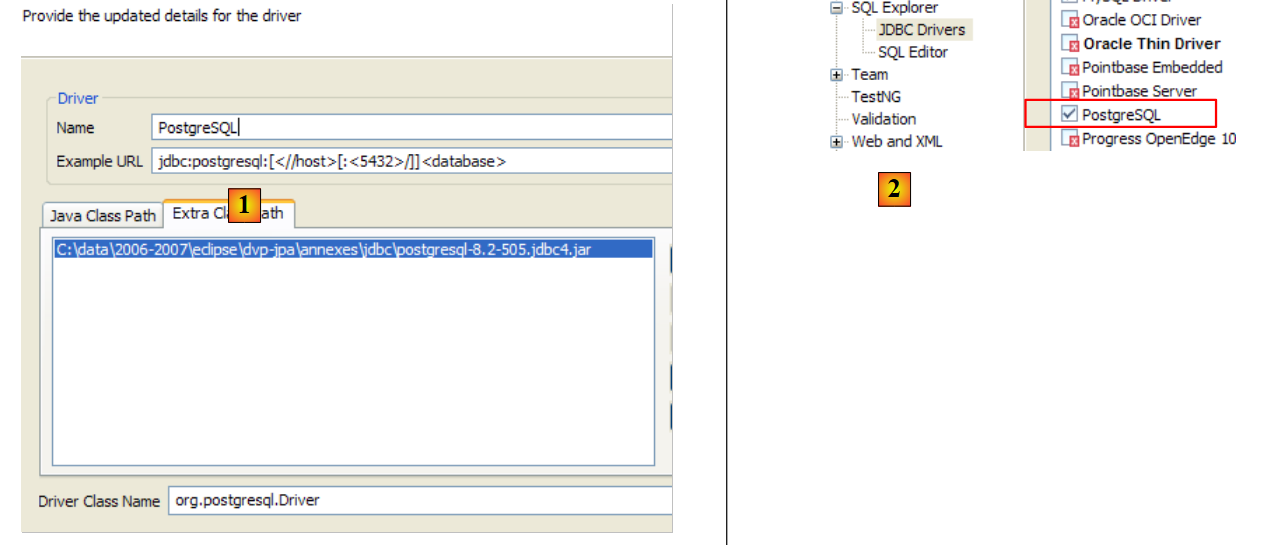
Para verificar este controlador JDBC, vamos utilizar o Eclipse e o plugin SQL Explorer (parágrafo 5.2.6). Começamos por declarar o controlador JDBC do Firebird:
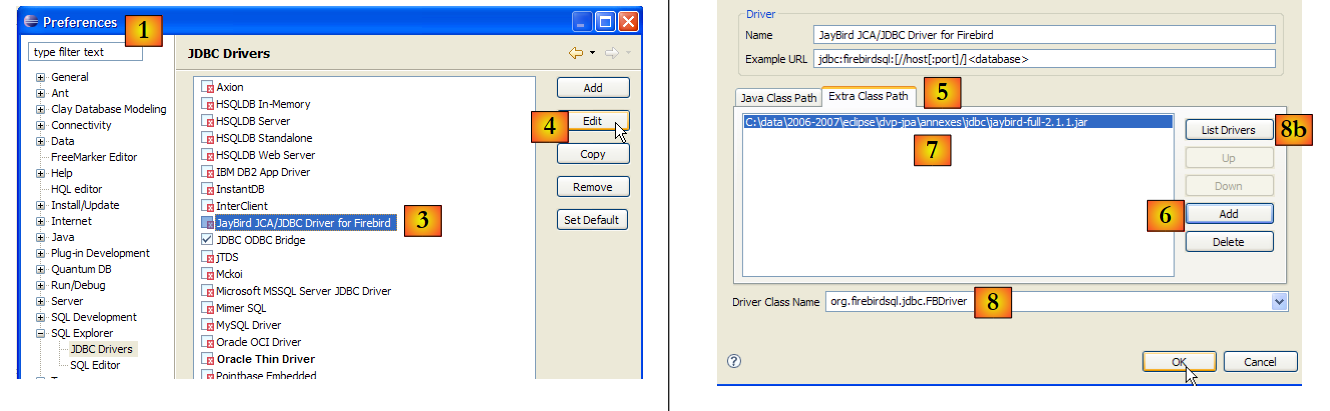 |
- no [1]: selecione «Window» / «Preferences»
- em [2]: selecione a opção SQL Explorer / JDBC Drivers
- em [3]: selecione o controlador JDBC para o Firebird
- em [4]: passar para a fase de configuração
- em [5]: aceder ao separador [Extra Class Path]
- com [6], indicar o ficheiro do controlador JDBC. Feito isto, este aparece em [7]. Aqui, selecionar-se-á o controlador previamente colocado na pasta <jdbc>
- em [8]: o nome da classe Java do controlador JDBC. Este pode ser obtido através do botão [8b].
- Executamos o [OK] para validar a configuração
 |
- em [9]: o controlador JDBC do Firebird está agora configurado. Já é possível começar a utilizá-lo.
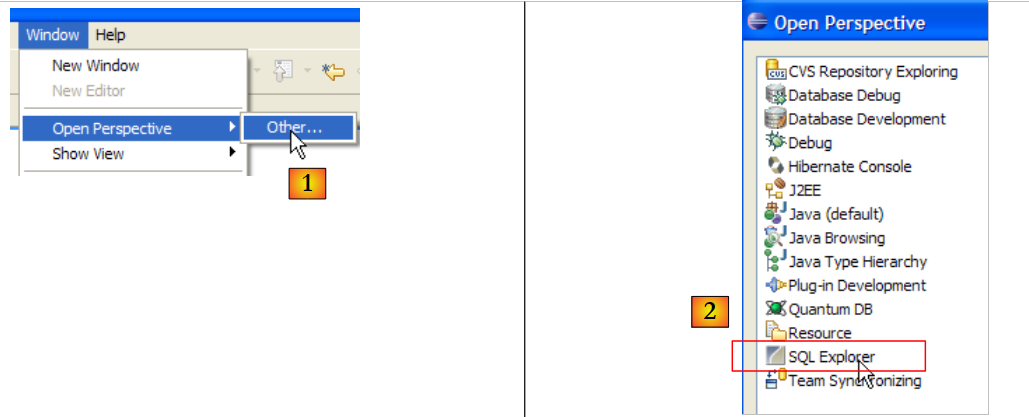 |
- para [1]: abrir uma nova perspetiva
- em [2]: selecionar a perspetiva [SQL Explorer]
 |
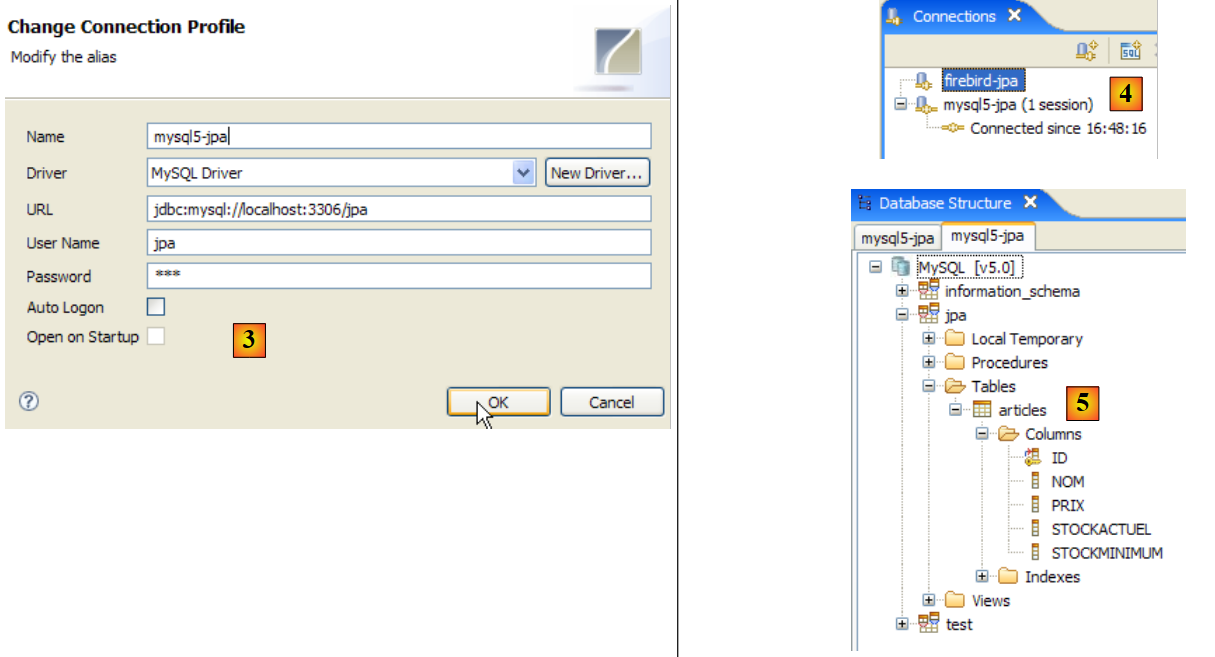
- em [3]: criar uma nova ligação
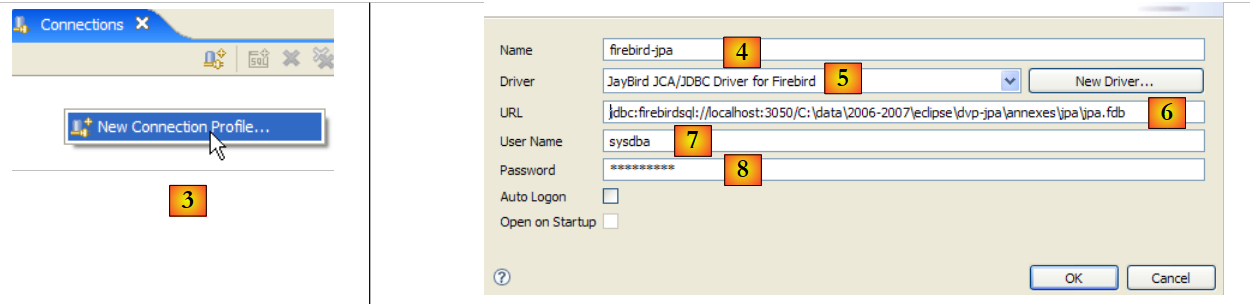
- em [4]: atribuir-lhe um nome
- em [5]: selecionar na lista suspensa o controlador JDBC do Firebird
- em [6]: indicar o URL da base de dados à qual se pretende ligar, neste caso: [jdbc:firebirdsql:localhost/3050:C:\data\2006-2007\eclipse\dvp-jpa\annexes\jpa\jpa.fdb]. [jpa.fdb] é a base de dados criada anteriormente com IBExpert.
- em [7]: o nome de utilizador da ligação, neste caso [sysdba], o administrador do Firebird
- em [8]: a sua palavra-passe [masterkey]
- Validamos a configuração da ligação através de [OK]
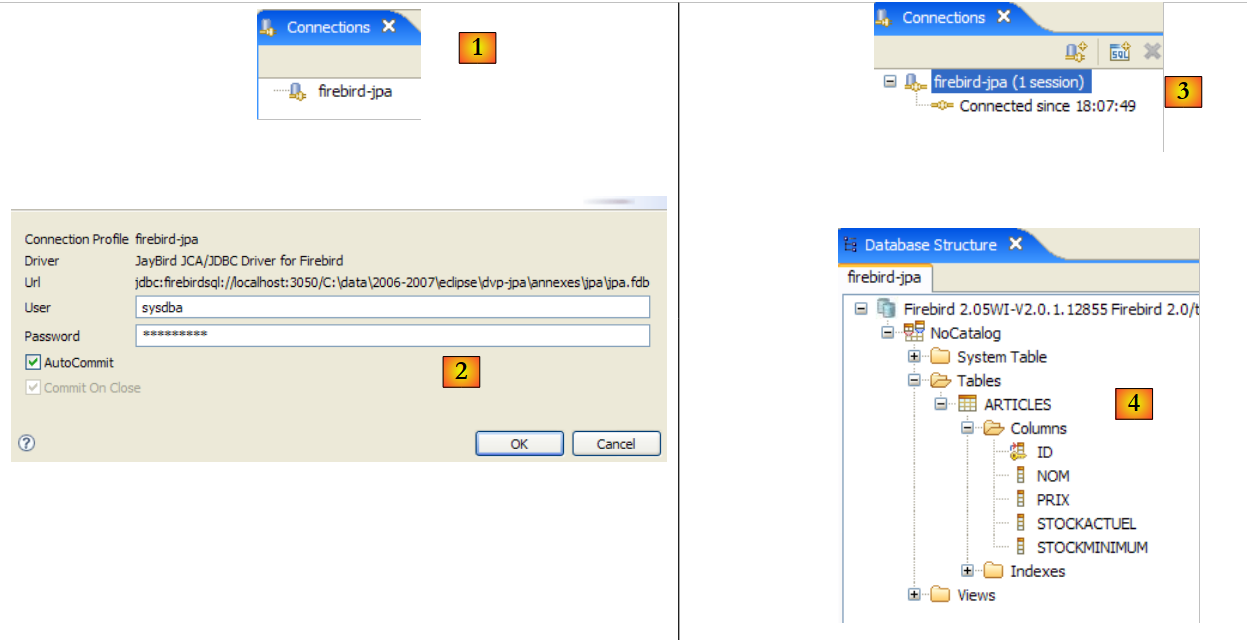 |
- em [1]: clica-se duas vezes no nome da ligação que se pretende abrir
- em [2]: faz-se o login (sysdba, masterkey)
- em [3]: a ligação está aberta
- em [4]: obtém-se a estrutura da base de dados. É possível ver a tabela [ARTICLES]. Seleciona-se essa tabela.
 |
- em [5]: na janela [Database Detail], apresentam-se os detalhes do objeto selecionado em [4], neste caso a tabela [ARTICLES]
- em [6]: o separador [Columns] apresenta a estrutura da tabela
- em [7]: o separador [Preview] apresenta a estrutura da tabela
É possível executar consultas SQL na janela [SQL Editor]:
 |
- em [1]: selecionar uma ligação aberta
- no [2]: introduzir o comando SQL a executar
- em [3]: executá-la
- em [4]: resumo do comando executado
- em [5]: o seu resultado
5.5. O SGBD e o MySQL5
5.5.1. Instalação
O SGBD MySQL5 está disponível no URL [http://dev.mysql.com/downloads/]:
 |
- em [1]: selecione a versão pretendida
- em [2]: selecione uma versão para Windows
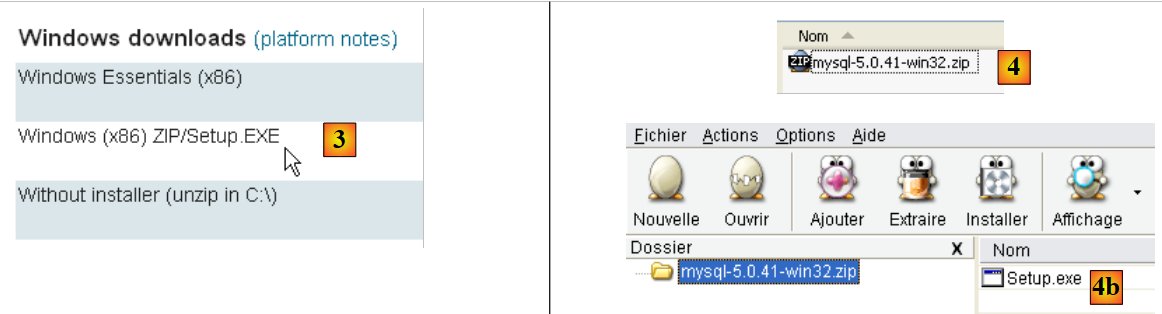 |
- em [3]: selecione a versão do Windows pretendida
- em [4]: o ficheiro ZIP descarregado contém um executável [Setup.exe] [4b] que deve ser extraído e executado para instalar o MySQL5
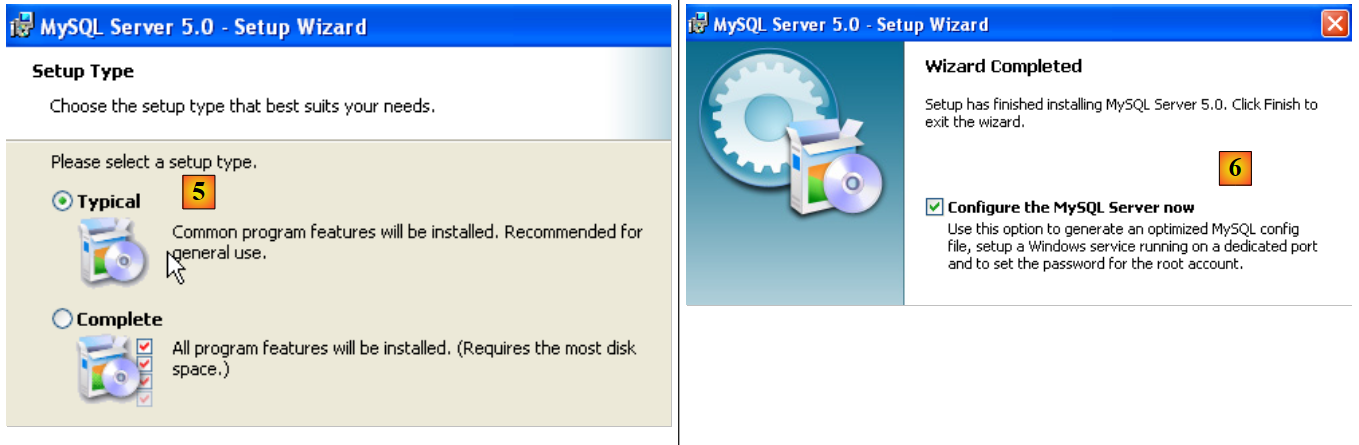 |
- em [5]: selecione uma instalação típica
- em [6]: assim que a instalação estiver concluída, é possível configurar o servidor MySQL5
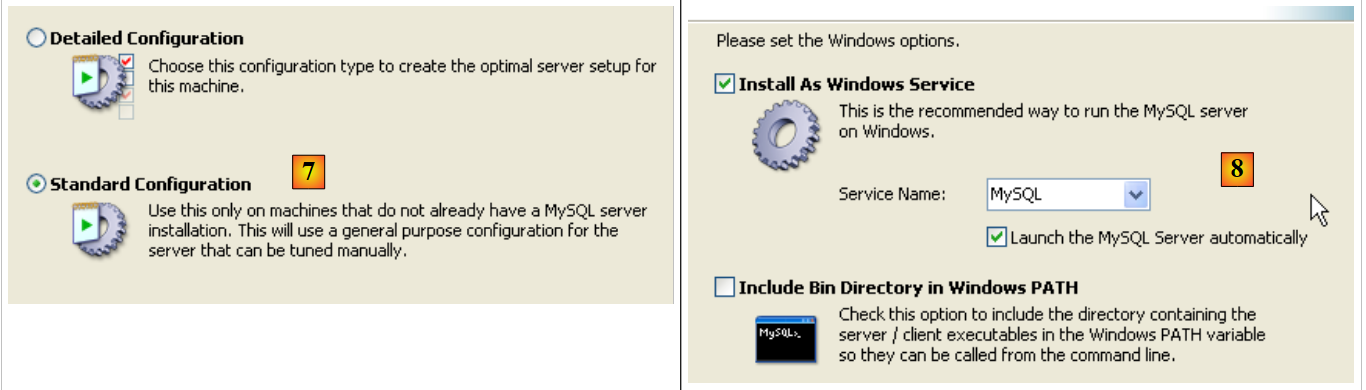 |
- em [7]: escolher uma configuração padrão, aquela que apresenta menos perguntas
- em [8]: o servidor MySQL5 será um serviço do Windows
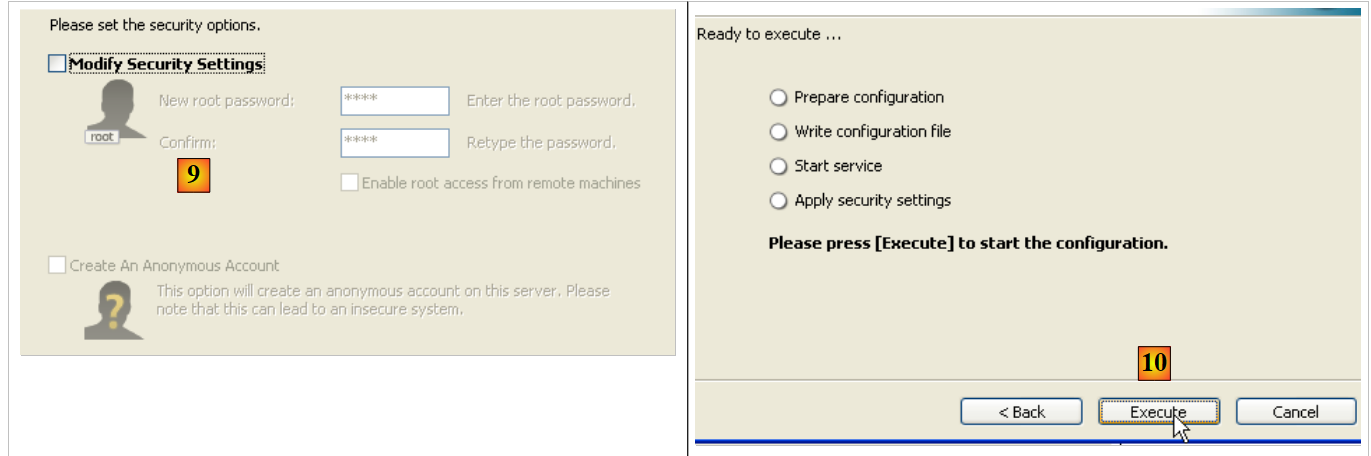 |
- em [9]: por predefinição, o administrador do servidor é o «root» sem palavra-passe. É possível manter esta configuração ou atribuir uma nova palavra-passe ao «root». Se a instalação do MySQL5 ocorrer após a desinstalação de uma versão anterior, esta operação poderá falhar. Há poucas formas de reverter a situação.
- em [10]: é solicitada a configuração do servidor
A instalação do MySQL5 cria uma pasta no [Démarrer / Programmes ]:

É possível utilizar o [MySQL Server Instance Config Wizard] para reconfigurar o servidor:
 |
 |
 |
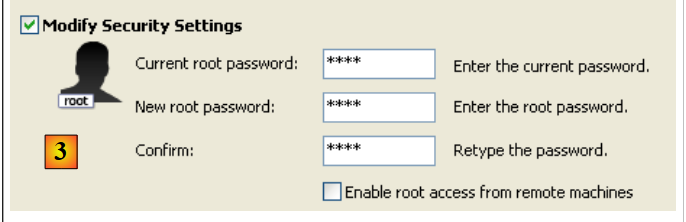
- para [3]: alteramos a palavra-passe do utilizador root (neste caso, root/root)
5.5.2. Iniciar/Parar o MySQL5
O servidor MySQL5 foi instalado como um serviço do Windows com arranque automático, sendo que o c.a.d é iniciado logo ao arrancar o Windows. Este modo de funcionamento é pouco prático. Vamos alterá-lo:
[Démarrer / Panneau de configuration / Performances et maintenance / Outils d'administration / Services ]:
 |
- para [1]: clicamos duas vezes em [Services]
- em [2]: vemos que existe um serviço chamado [MySQL], que está a ser executado ([3]) e que o seu arranque é automático ([4]).
Para alterar este comportamento, clicamos duas vezes no serviço [MySQL]:
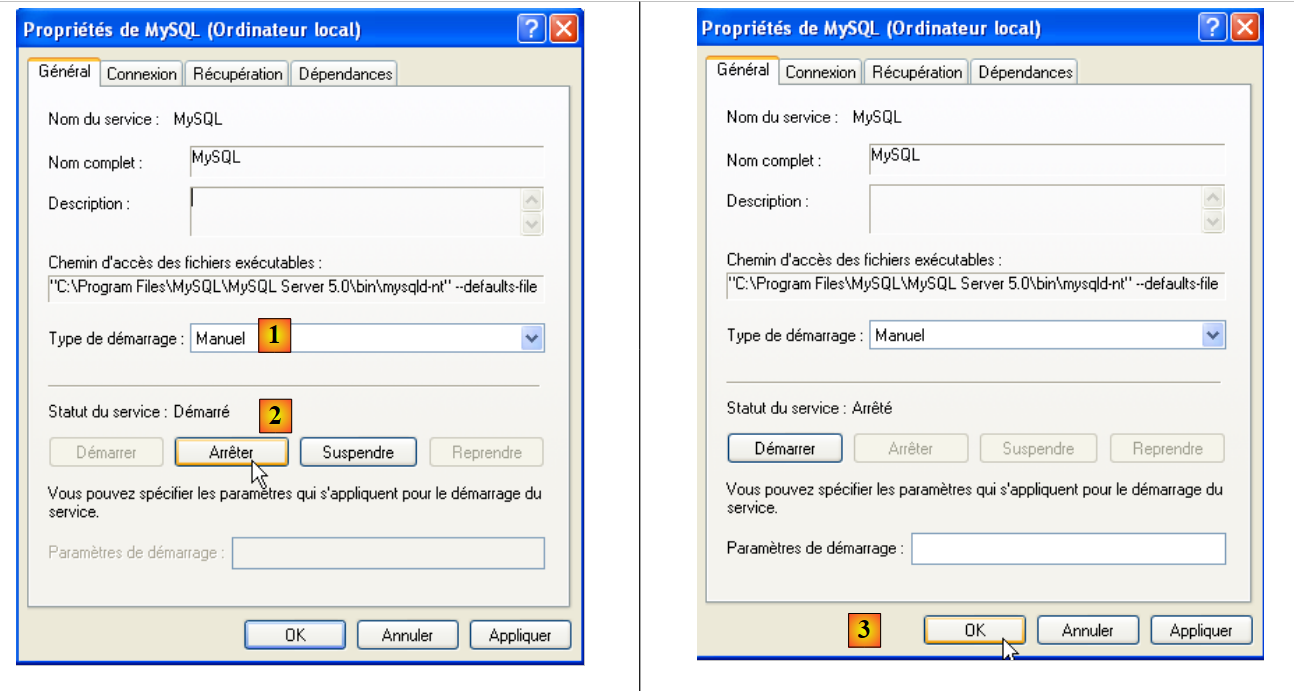 |
- em [1]: definimos o serviço para arranque manual
- em [2]: paramos o serviço
- no [3]: confirmamos a nova configuração do serviço
Para iniciar e parar manualmente o serviço MySQL, é possível criar dois atalhos:
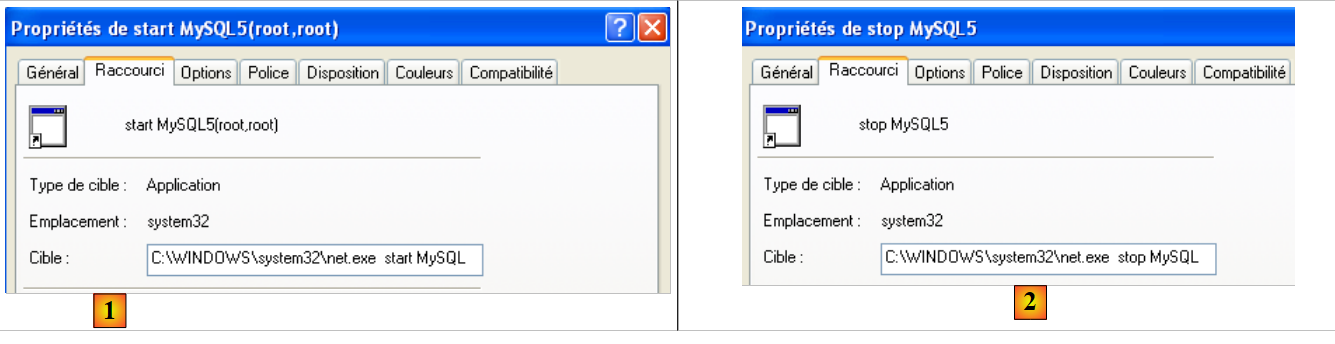 |
- em [1]: o atalho para iniciar o MySQL5
- e [2]: o atalho para o parar
5.5.3. Clientes de administração do MySQL
No site do MySQL, é possível encontrar clientes de administração do SGBD:
 |
- em [1]: escolher [MySQL GUI Tools], que inclui vários clientes gráficos que permitem tanto administrar o SGBD como utilizá-lo
- em [2]: selecione a versão para Windows adequada
 |
- em [3]: descarregue um ficheiro .msi para executar
- em [4]: assim que a instalação estiver concluída, surgem novos atalhos na pasta [Menu Démarrer / Programmes / mySQL].
Executemos o MySQL (através dos atalhos que criou) e, em seguida, executemos o [MySQL Administrator] através do menu acima:
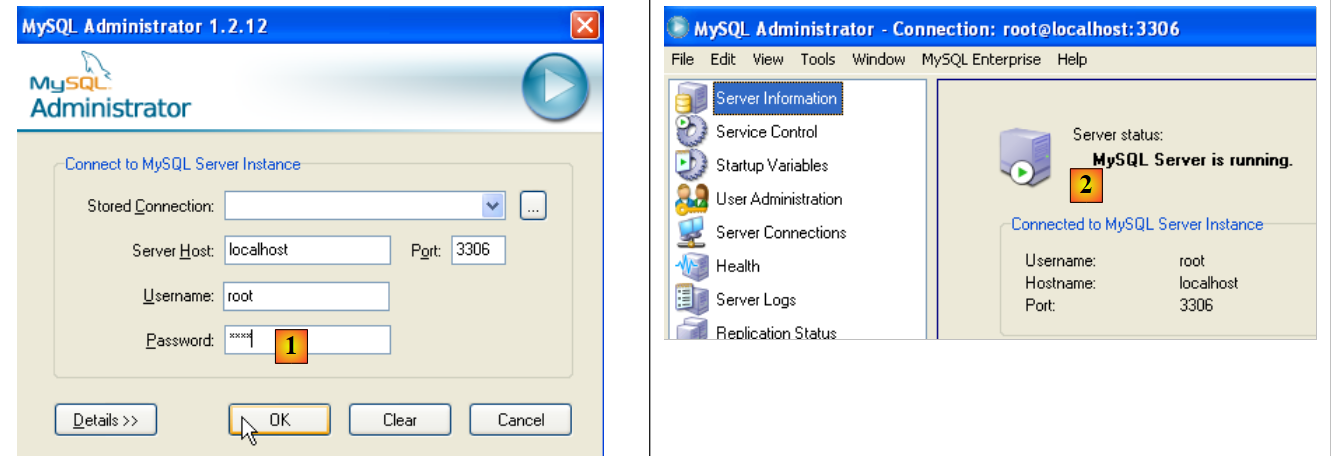 |
- em [1]: introduza a palavra-passe do utilizador root (root, neste caso)
- em [2]: já estamos ligados e vemos que o MySQL está ativo
5.5.4. Criação de um utilizador jpa e de uma base de dados jpa
O tutorial utiliza o MySQL5 com uma base de dados chamada jpa e um utilizador com o mesmo nome. Vamos criá-los agora. Primeiro, o utilizador:
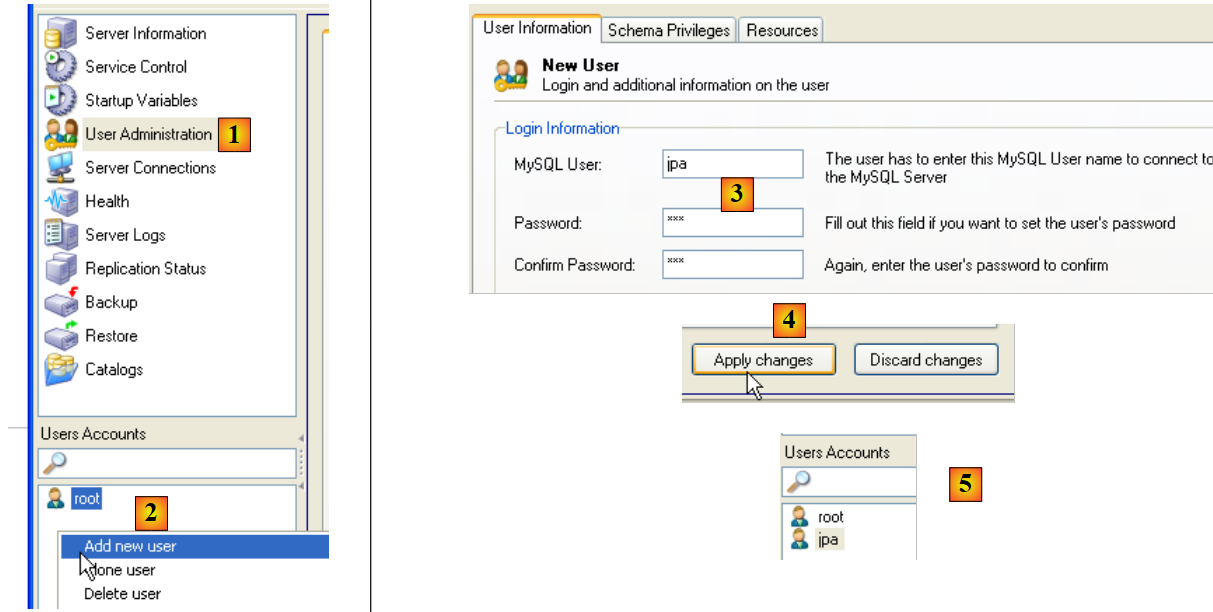 |
- no [1]: selecionamos o [User Administration]
- em [2]: clicamos com o botão direito na secção [User accounts] para criar um novo utilizador
- em [3]: o utilizador chama-se jpa e a sua palavra-passe é jpa
- em [4]: confirme a criação
- em [5]: o utilizador [jpa] aparece na janela [User Accounts]
Agora, a base de dados:
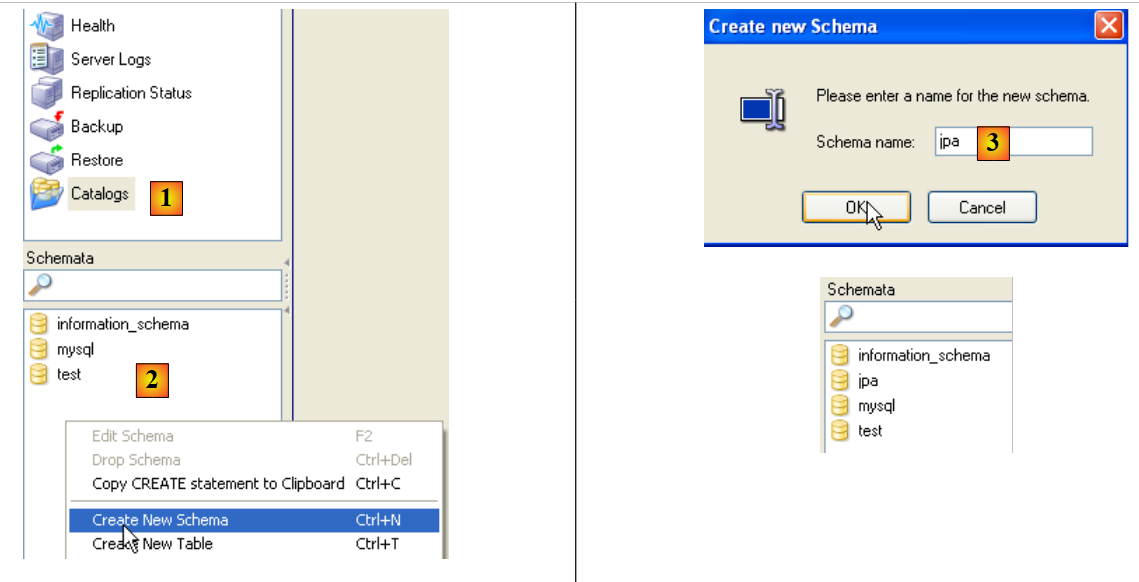 |
- em [1]: seleção da opção [Catalogs]
- em [2]: clique com o botão direito do rato na janela [Schemata] para criar um novo esquema (que designa uma base de dados)
- em [3]: nomeia-se o novo esquema
- em [4]: aparece na janela [Schemata]
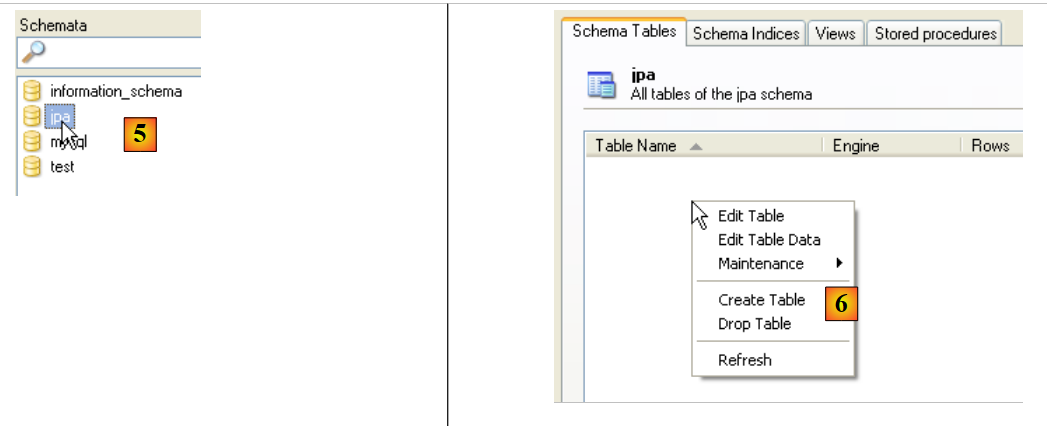 |
- em [5]: seleciona-se o esquema [jpa]
- em [6]: aparecem os objetos do esquema [jpa], nomeadamente as tabelas. Ainda não existem. Um clique com o botão direito do rato permitiria criá-las. Deixamos que seja o leitor a fazê-lo.
Voltemos ao utilizador [jpa] para lhe conceder todos os direitos sobre o esquema [jpa]:
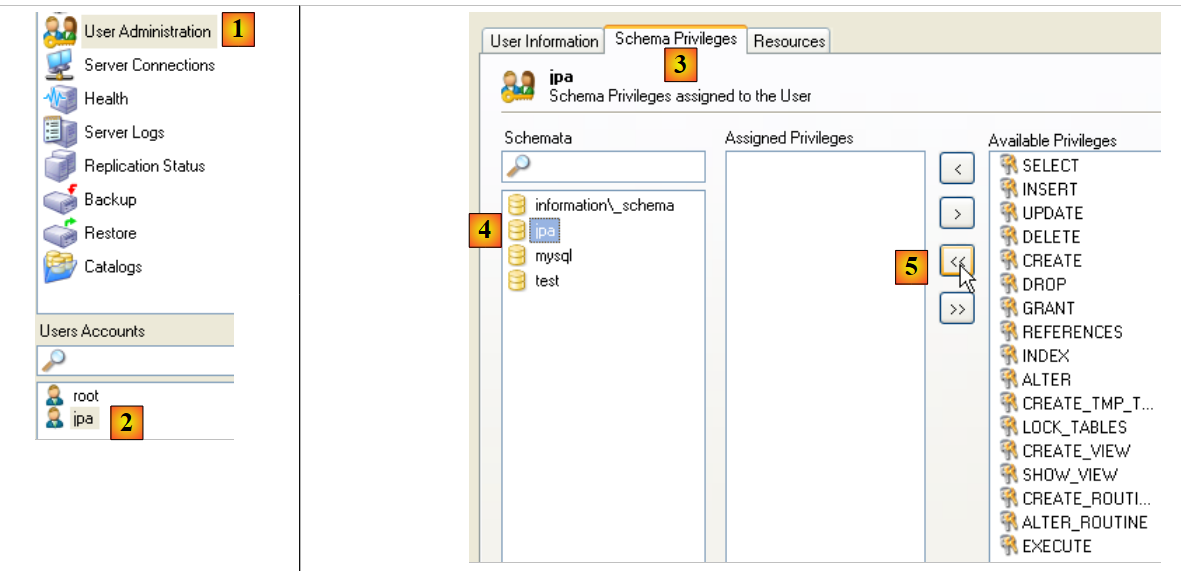 |
- em [1] e, em seguida, em [2]: seleciona-se o utilizador [jpa]
- em [3]: seleciona-se o separador [Schema Privileges]
- em [4]: seleciona-se o esquema [jpa]
- em [5]: vamos atribuir ao utilizador [jpa] todos os privilégios sobre o esquema [jpa]
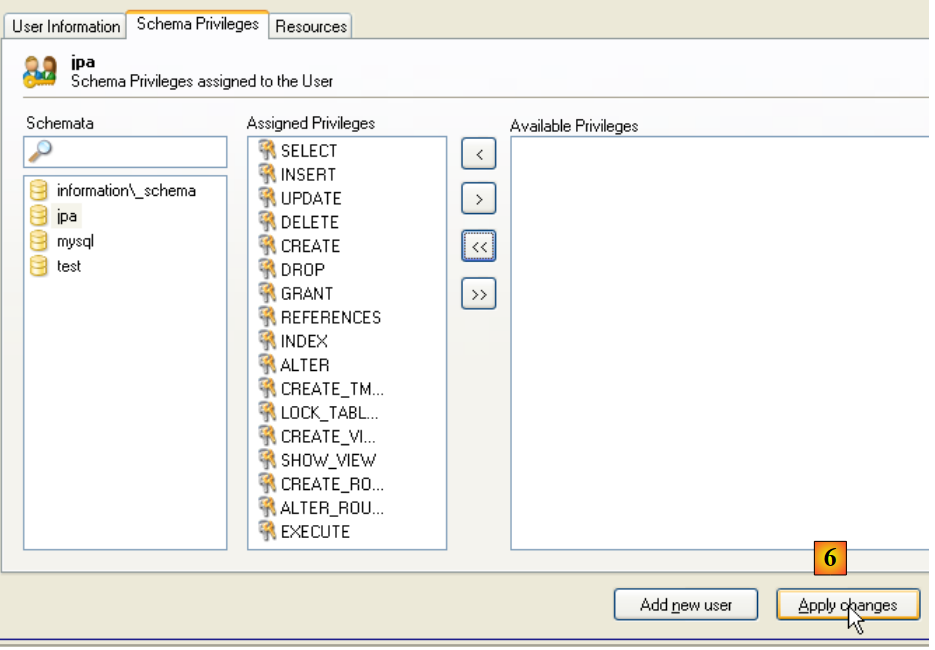 |
- em [6]: validamos as alterações efetuadas
Para verificar se o utilizador [jpa] pode trabalhar com o esquema [jpa], encerramos o administrador MySQL. Reiniciamo-lo e, desta vez, iniciamos sessão com o nome [jpa/jpa]:
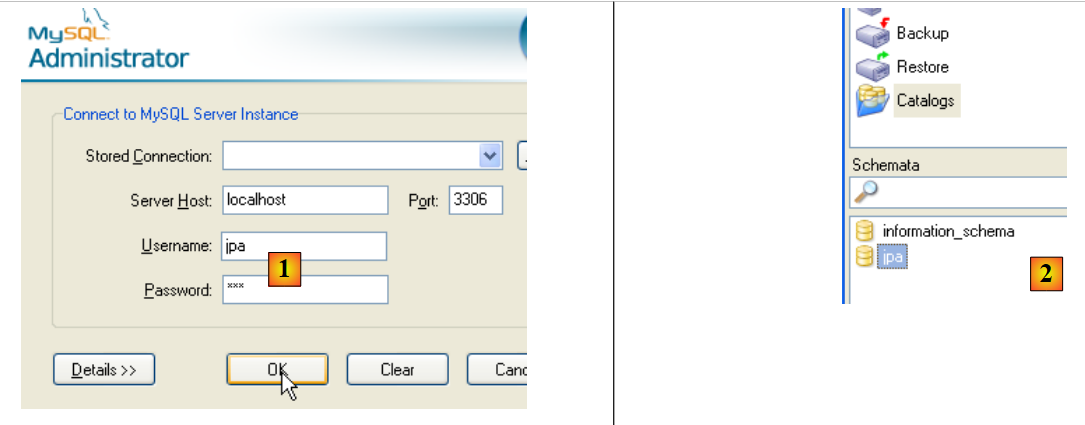 |
- em [1]: identificamo-nos (jpa/jpa)
- em [2]: a ligação foi bem-sucedida e, em [Schemata], vemos os esquemas sobre os quais temos direitos. Vemos o esquema [jpa].
Vamos agora criar a mesma tabela [ARTICLES] que criámos com o Firebird SGBD, utilizando o script SQL [schema-articles.sql] gerado no parágrafo 5.4.6.
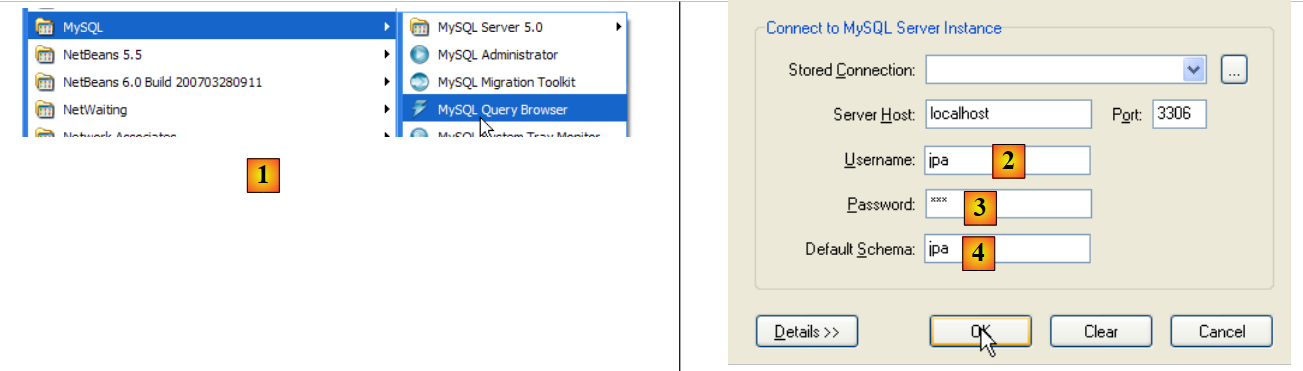 |
- em [1]: utilizar a aplicação [MySQL Query Browser]
- em [2], [3], [4]: autenticar-se (jpa / jpa / jpa)
 |
- em [5]: abrir um script SQL para o executar
- em [6]: indicar o script [schema-articles.sql] criado no parágrafo 5.4.6.
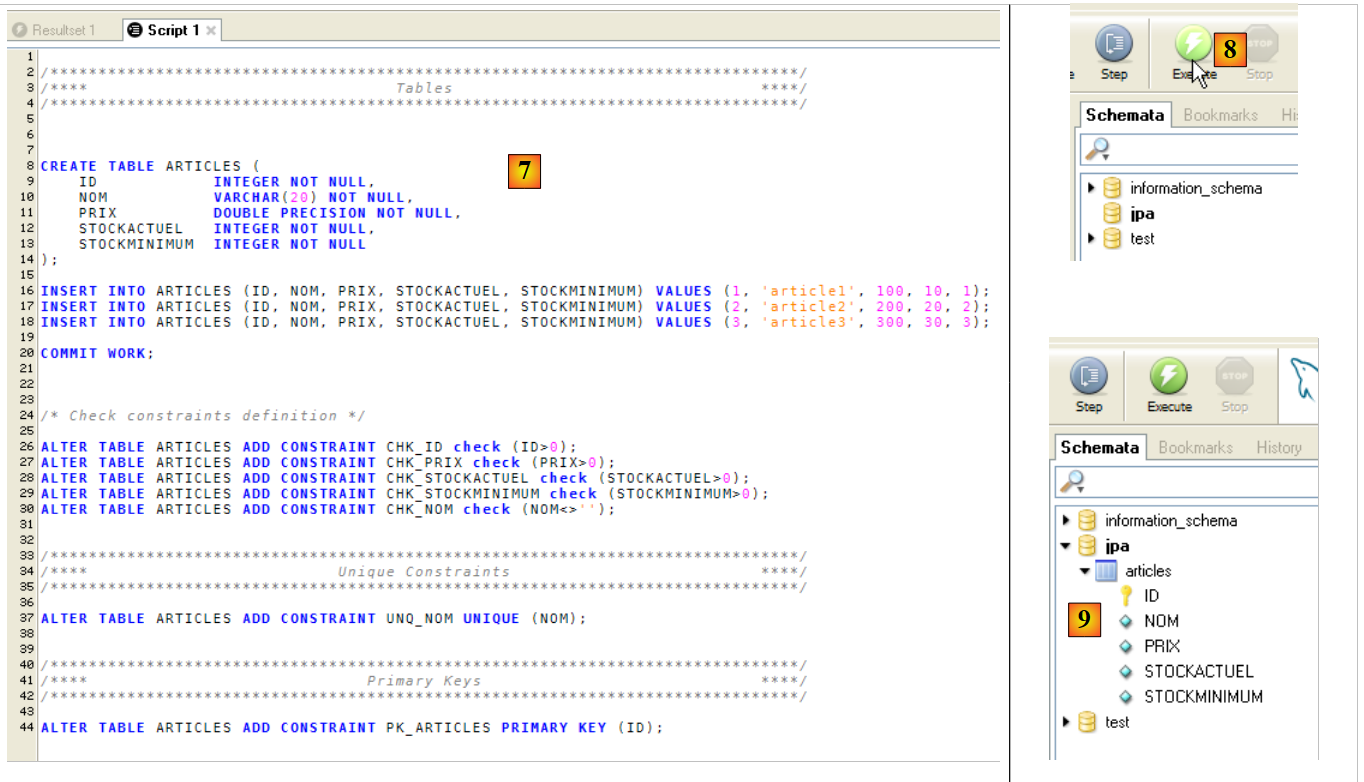 |
- em [7]: o script carregado
- em [8]: é executado
- em [9]: a tabela [ARTICLES] foi criada
5.5.5. Driver JDBC de MySQL5
O driver JDBC, a partir de MySQL, pode ser descarregado no mesmo local que o SGBD:
 |
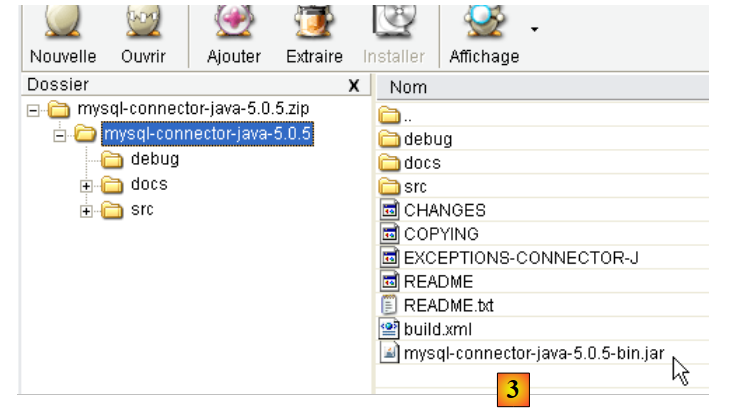 |
- no [1]: escolha o controlador JDBC adequado
- no [2]: selecione a versão para Windows adequada
- em [3]: no ficheiro zip obtido, o arquivo Java que contém o controlador JDBC é o [mysql-connector-java-5.0.5-bin.jar]. Iremos extraí-lo para o utilizar nos exemplos do tutorial JPA.
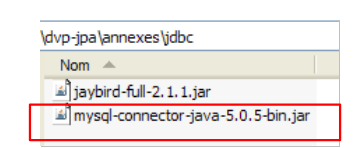
Colocamo-lo tal como o anterior (parágrafo 5.4.7) na pasta <jdbc>:
 |
Para testar este controlador JDBC, vamos utilizar o Eclipse e o plugin SQL Explorer. O leitor é convidado a seguir os passos explicados no parágrafo 5.4.7. Apresentamos algumas capturas de ecrã significativas:
 |
- em [1]: o arquivo do controlador JDBC foi renomeado de MySQL5
- em [2]: o controlador JDBC, proveniente de MySQL5, está disponível
 |
- para [3]: definição da ligação (utilizador, palavra-passe)=(jpa, jpa)
- em [4]: a ligação está ativa
- em [5]: a base conectada
5.6. O SGBD e o PostgreSQL
5.6.1. Instalação
O SGBD PostgreSQL está disponível no URL [http://www.postgresql.org/download/]:
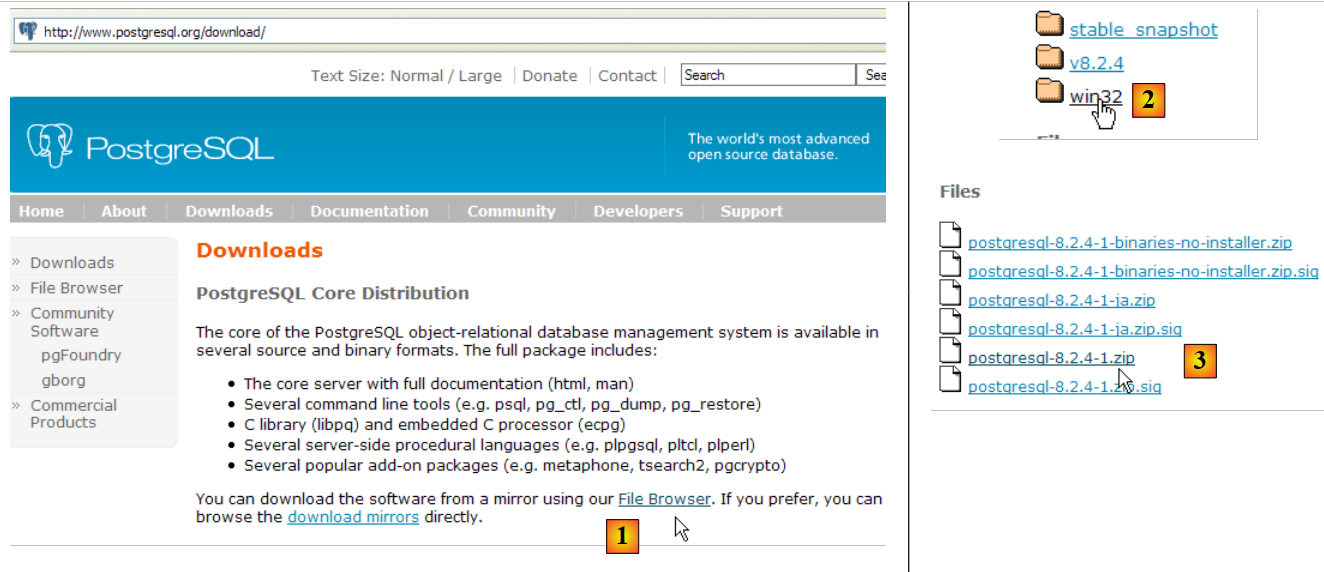 |
- em [1]: os sites de download do PostgreSQL
- em [2]: escolher uma versão para Windows
- em [3]: escolher uma versão com instalador
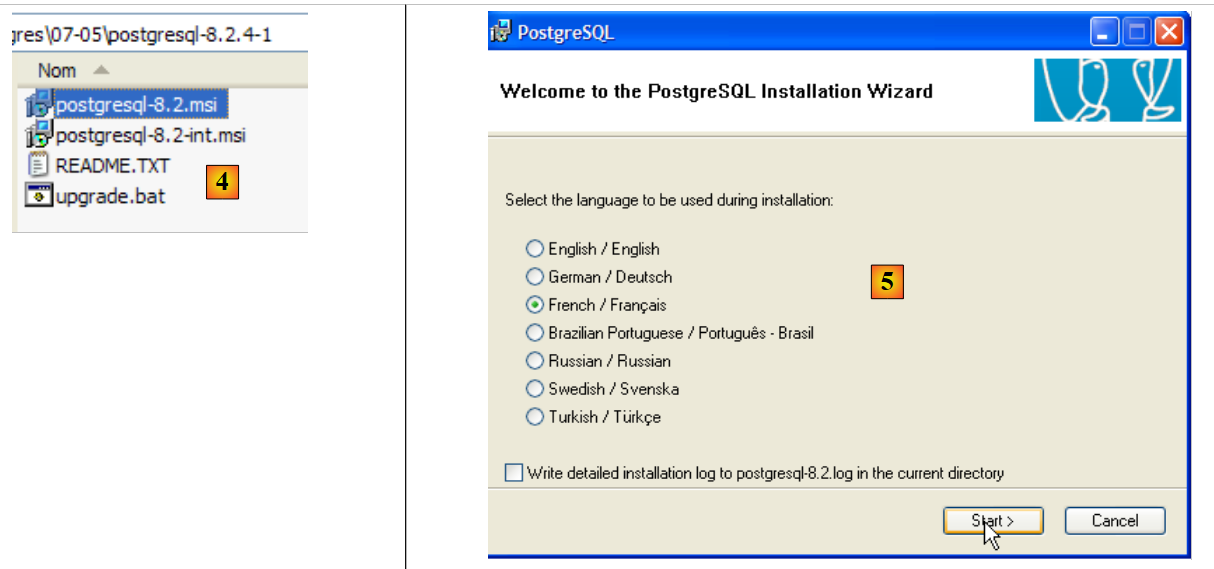 |
- em [4]: o conteúdo do ficheiro zip descarregado. Clique duas vezes no ficheiro [postgresql-8.2.msi]
- em [5]: a primeira página do assistente de instalação
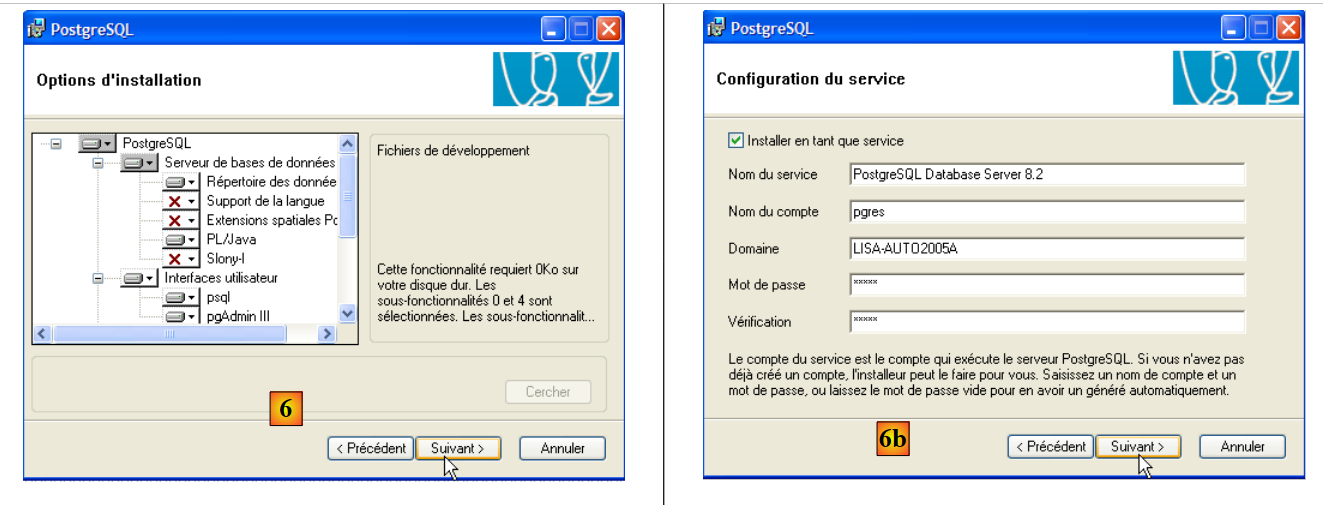 |
- em [6]: selecionar uma instalação típica, aceitando os valores predefinidos
- em [6b]: criação da conta do Windows que irá iniciar o serviço PostgreSQL; neste caso, a conta «pgres» com a palavra-passe «pgres».
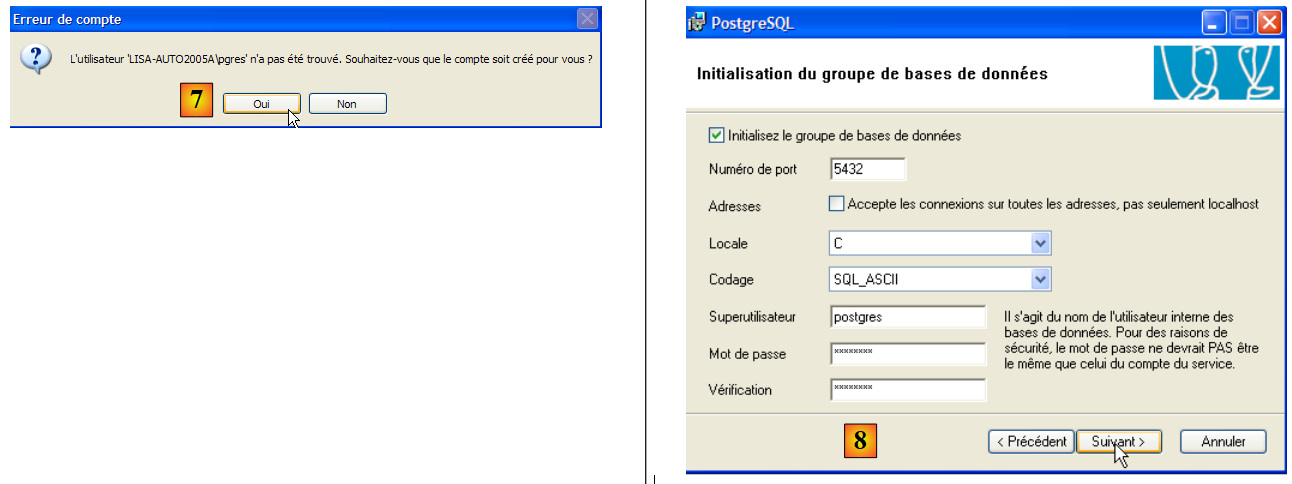 |
- em [7]: deixar que o PostgreSQL crie a conta [pgres], caso esta ainda não exista
- em [8]: definir a conta de administrador do SGBD, neste caso «postgres» com a palavra-passe «postgres»
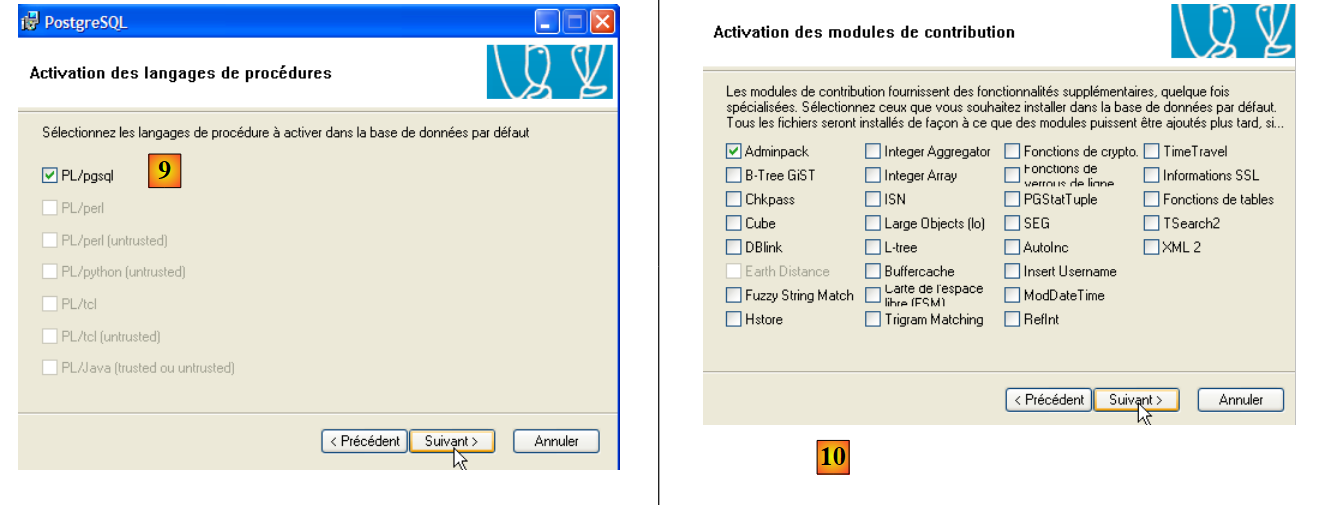 |
- em [9] e [10]: aceite os valores predefinidos até ao final do assistente. O PostgreSQL vai ser instalado.
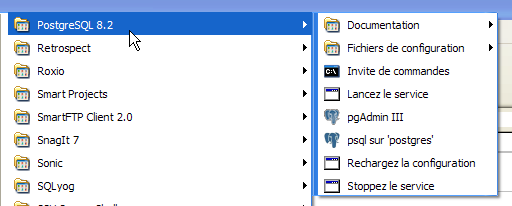
A instalação do PostgreSQL cria uma pasta no [Démarrer / Programmes ]:
5.6.2. Iniciar/Parar o PostgreSQL
O servidor PostgreSQL foi instalado como um serviço do Windows com arranque automático, sendo que o c.a.d é iniciado logo ao arrancar o Windows. Este modo de funcionamento é pouco prático. Vamos alterá-lo:
[Démarrer / Panneau de configuration / Performances et maintenance / Outils d'administration / Services ]:
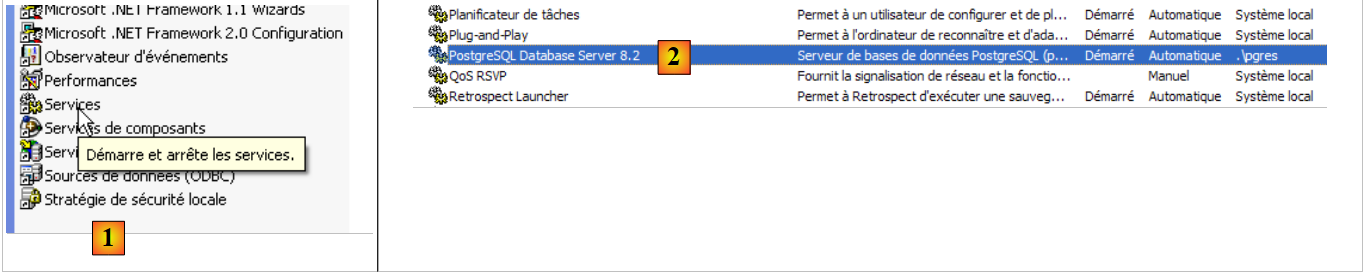 |
- para [1]: clicamos duas vezes em [Services]
- em [2]: vemos que existe um serviço chamado [PostgreSQL], que está a ser executado ([3]) e que o seu arranque é automático ([4]).
Para alterar este comportamento, clicamos duas vezes no serviço [PostgreSQL]:
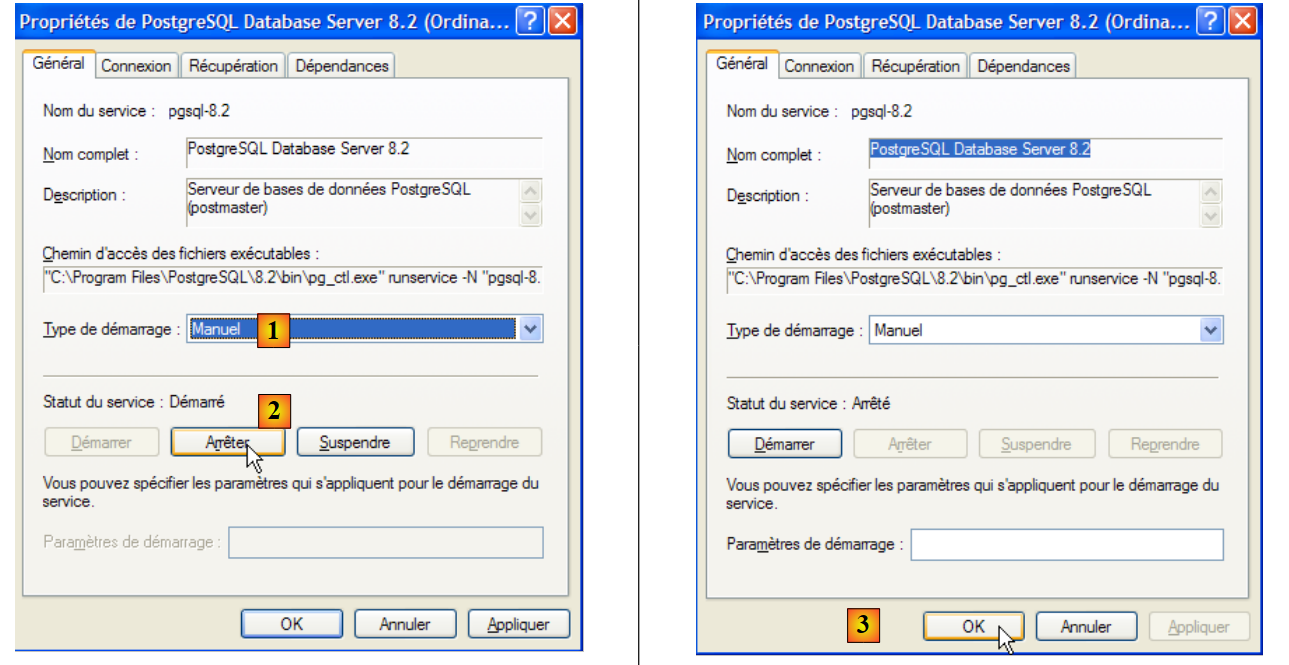 |
- em [1]: definimos o serviço para arranque manual
- em [2]: paramos o serviço
- no [3]: confirmamos a nova configuração do serviço
Para iniciar e parar manualmente o serviço PostgreSQL, pode-se utilizar os atalhos da pasta [PostgreSQL]:
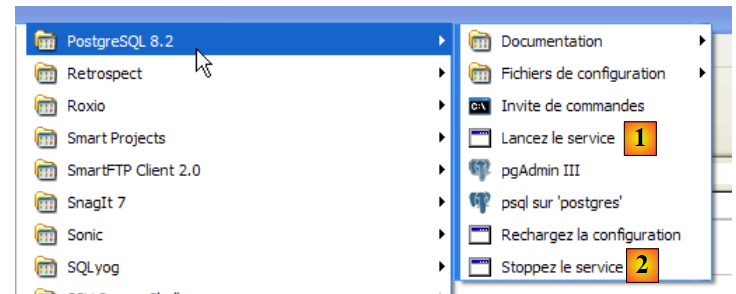 |
- em [1]: o atalho para iniciar o PostgreSQL
- em [2]: o atalho para o encerrar
5.6.3. Gerir o PostgreSQL
Na captura de ecrã acima, a aplicação [pgAdmin III] (3) permite administrar o SGBD e o PostgreSQL. Vamos iniciar o SGBD e, em seguida, o [pgAdmin III] através do menu acima:
 |
- no [1]: clicar duas vezes no servidor PostgreSQL para se ligar a ele
- para [2,3]: identifique-se como administrador do SGBD, neste caso (postgres / postgres)
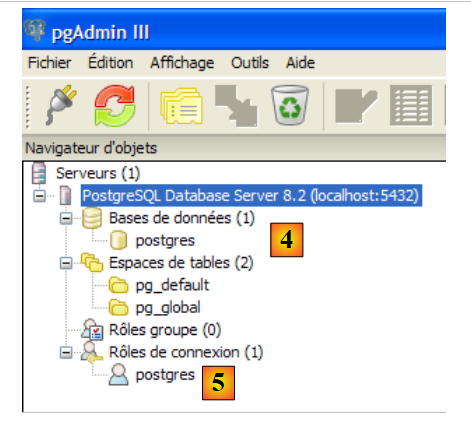 |
- no [4]: a única base de dados existente
- em [5]: o único utilizador existente
5.6.4. Criação de um utilizador jpa e de uma base de dados jpa
O tutorial utiliza o PostgreSQL com uma base de dados chamada jpa e um utilizador com o mesmo nome. Vamos criá-los agora. Primeiro, o utilizador:
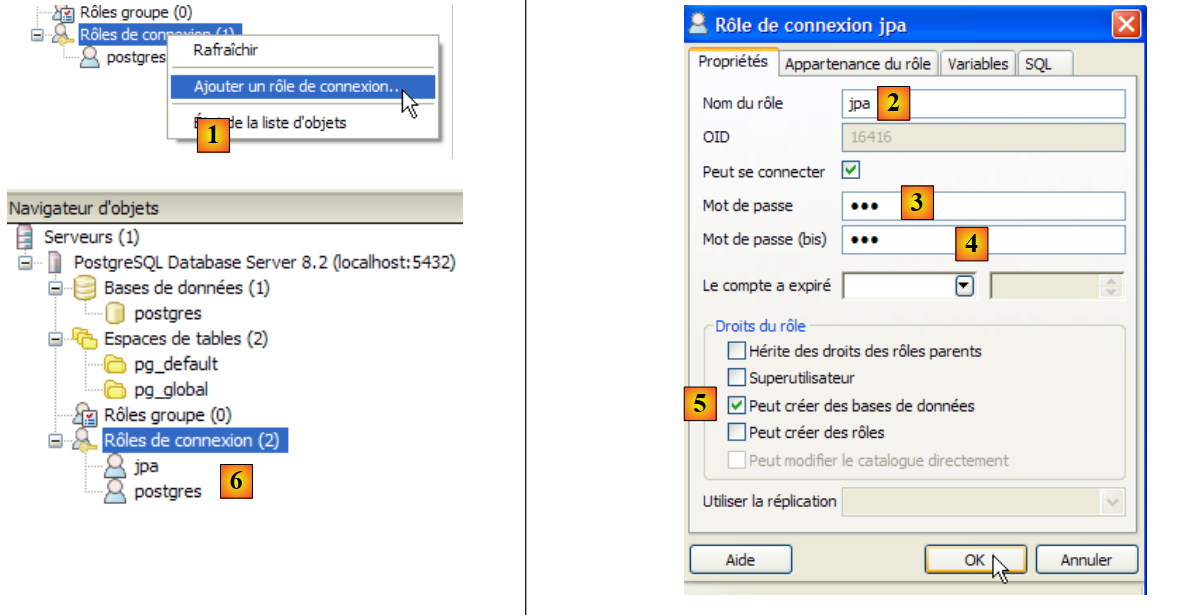 |
- em [1]: criamos uma nova função (~utilizador)
- em [2]: criação do utilizador jpa
- em [3]: a sua palavra-passe é jpa
- em [4]: repete-se a palavra-passe
- em [5]: autoriza-se o utilizador a criar bases de dados
- em [6]: o utilizador [jpa] aparece entre as funções de ligação
Agora, a base de dados:
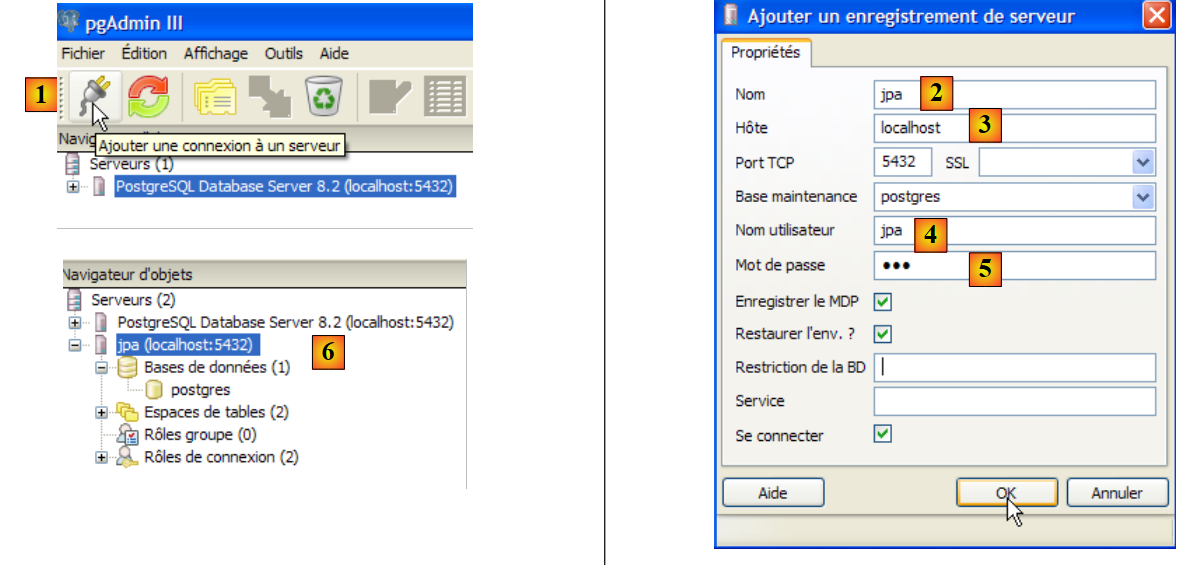 |
- em [1]: cria-se uma nova ligação ao servidor
- em [2]: a ligação terá o nome «jpa»
- em [3]: máquina à qual se pretende ligar
- em [4]: o utilizador que se liga
- em [5]: a sua palavra-passe. Valida-se a configuração da ligação através de [OK]
- em [6]: a nova ligação foi criada. Pertence ao utilizador jpa. Este vai agora criar uma nova base de dados:
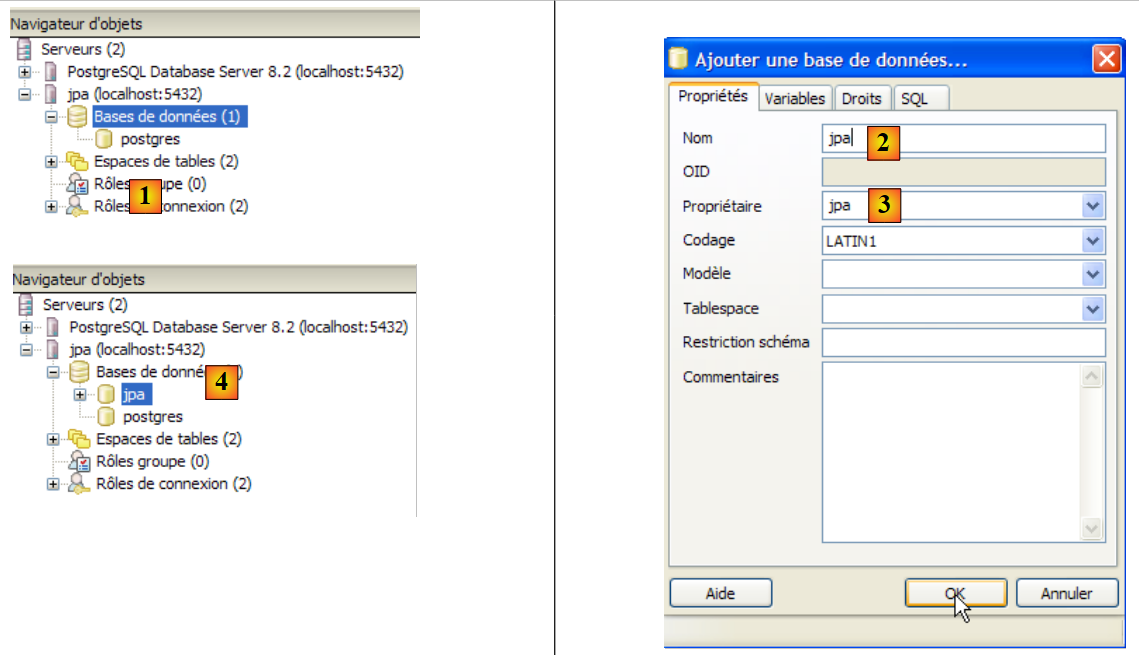 |
- n [1]: adiciona-se uma nova base de dados
- em [2]: o seu nome é jpa
- em [3]: o seu proprietário é o utilizador jpa criado anteriormente. Confirmamos através de [OK]
- em [4]: a base de dados jpa foi criada. Basta clicar nela para nos ligarmos à mesma e descobrirmos a sua estrutura:
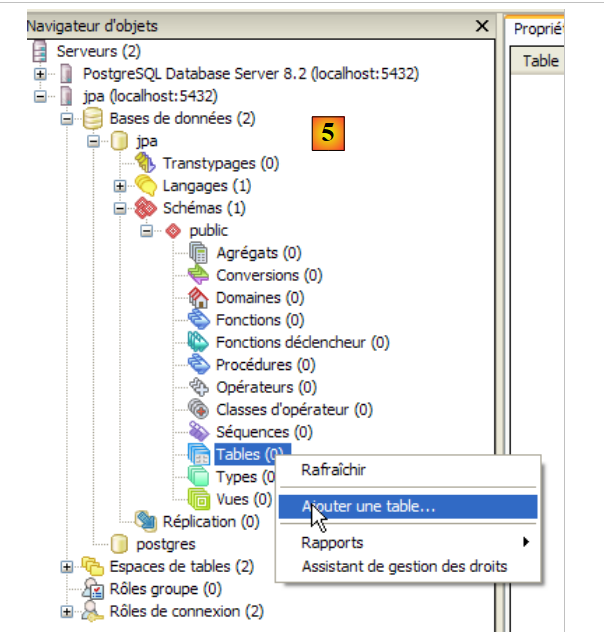 |
- em [5]: aparecem os objetos do esquema [jpa], nomeadamente as tabelas. Ainda não existem. Um clique com o botão direito do rato permitiria criá-las. Deixamos que seja o leitor a fazê-lo.
Vamos agora criar a mesma tabela [ARTICLES] que criámos com as SGBD anteriores, utilizando o script SQL [schema-articles.sql] gerado no parágrafo 5.4.6.
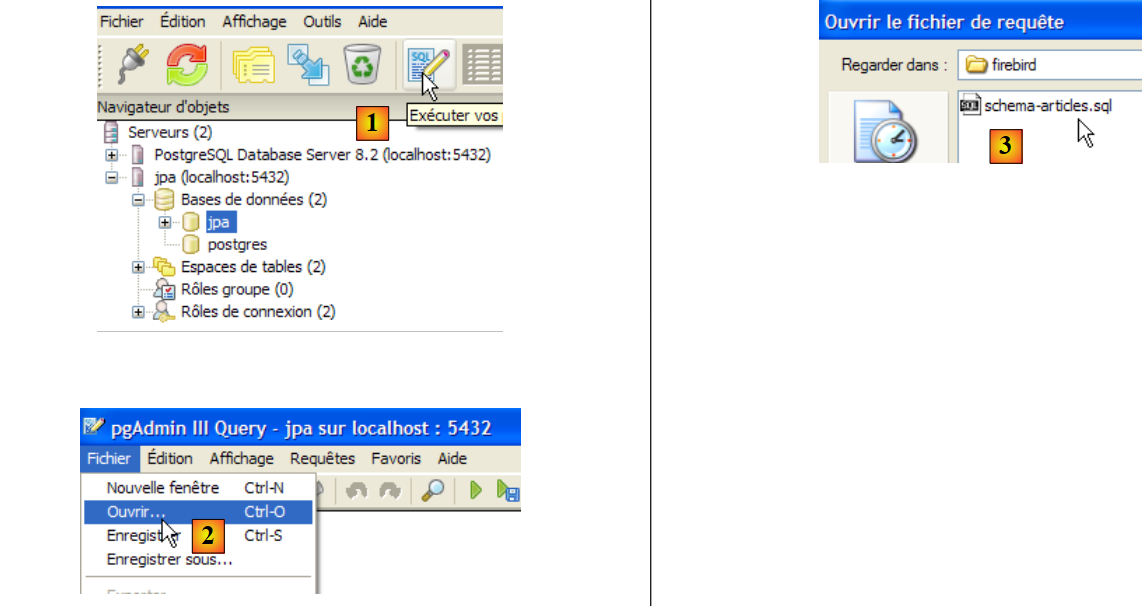 |
- em [1]: abrir o editor SQL
- em [2]: abrir um script SQL
- em [3]: indicar o script [schema-articles.sql] criado no parágrafo 5.4.6.
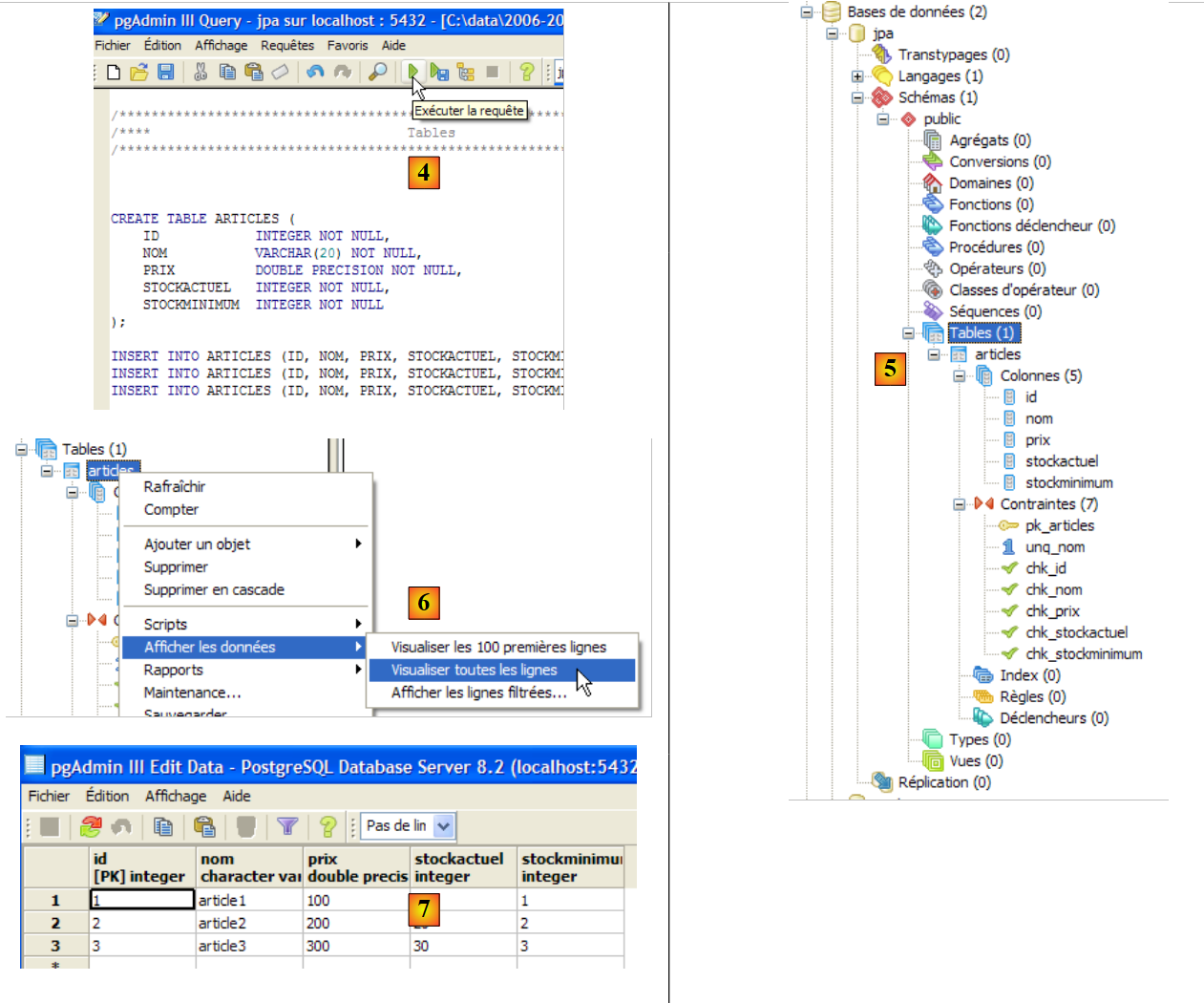 |
- em [4]: o script foi carregado. Executa-se o mesmo.
- em [5]: a tabela [ARTICLES] foi criada.
- em [6, 7]: o seu conteúdo
5.6.5. Driver JDBC de PostgreSQL
O driver JDBC do PostgreSQL está disponível na pasta [jdbc] da pasta de instalação do PostgreSQL:
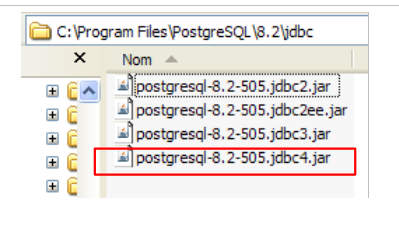 |
Colocamos o arquivo Jdbc, tal como nos casos anteriores (parágrafo 5.4.7), na pasta <jdbc>:
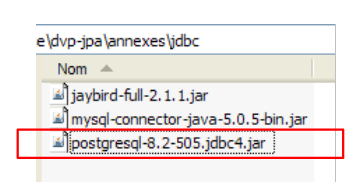 |
Para testar este controlador JDBC, vamos utilizar o Eclipse e o plugin SQL Explorer. O leitor é convidado a seguir os passos explicados no parágrafo 5.4.7. Apresentamos algumas capturas de ecrã significativas:
 |
- no [1]: foi especificado o arquivo do controlador JDBC de PostgreSQL
- em [2]: o controlador JDBC de PostgreSQL está disponível
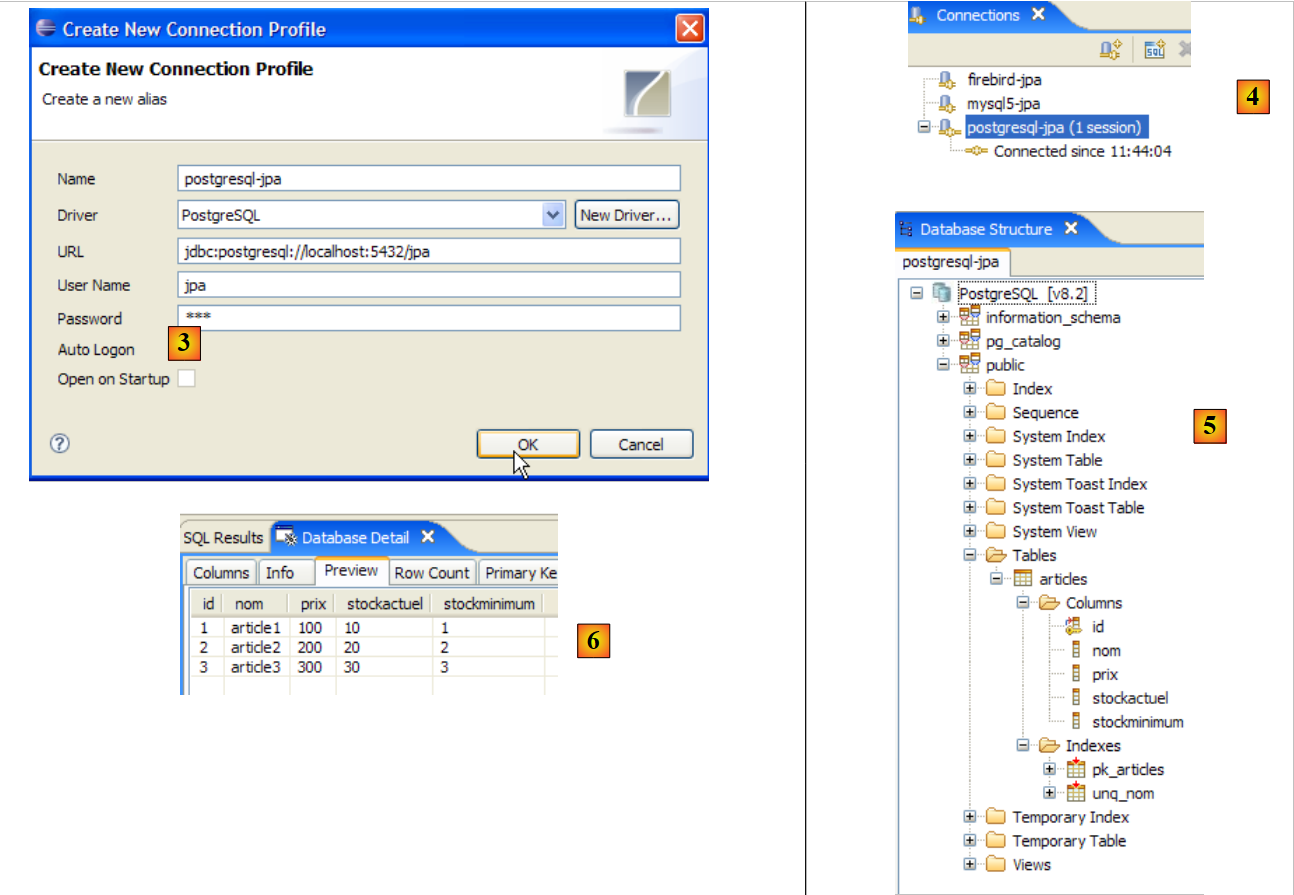 |
- para [3]: definição da ligação (utilizador, palavra-passe)=(jpa, jpa)
- em [4]: a ligação está ativa
- em [5]: base de dados ligada
- em [6]: o conteúdo da tabela [ARTICLES]
5.7. O SGBD a Oracle 10g Express
5.7.1. Instalação
O SGBD Oracle 10g Express está disponível no URL [http://www.oracle.com/technology/software/products/database/xe/index.html]:
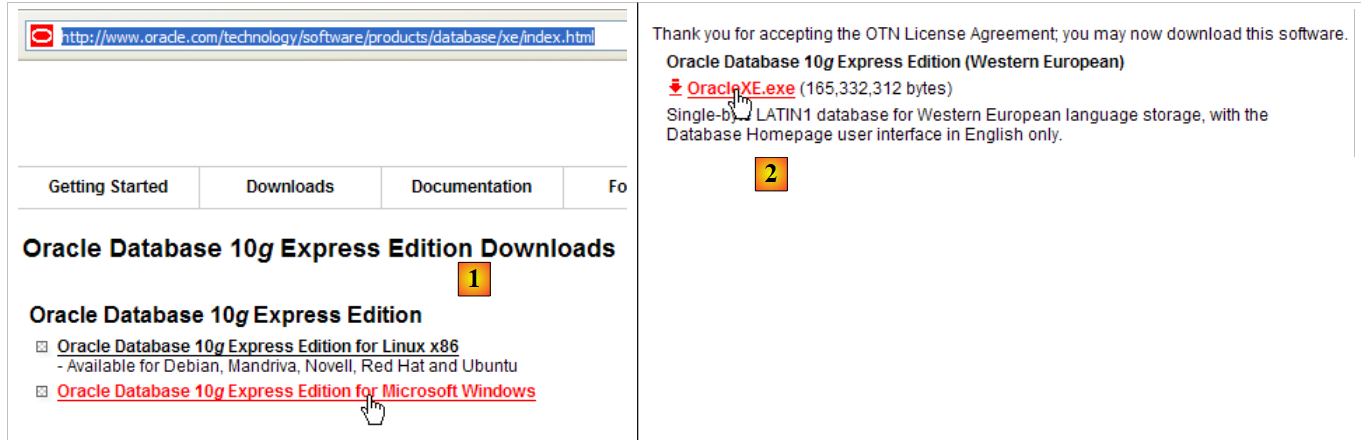 |
- em [1]: o site de transferência do Oracle 10g Express
- em [2]: escolher uma versão para Windows. Depois de descarregar o ficheiro, execute-o:
 |
- em [1]: clicar duas vezes no ficheiro [OracleXE.exe]
- em [2]: a primeira página do assistente de instalação
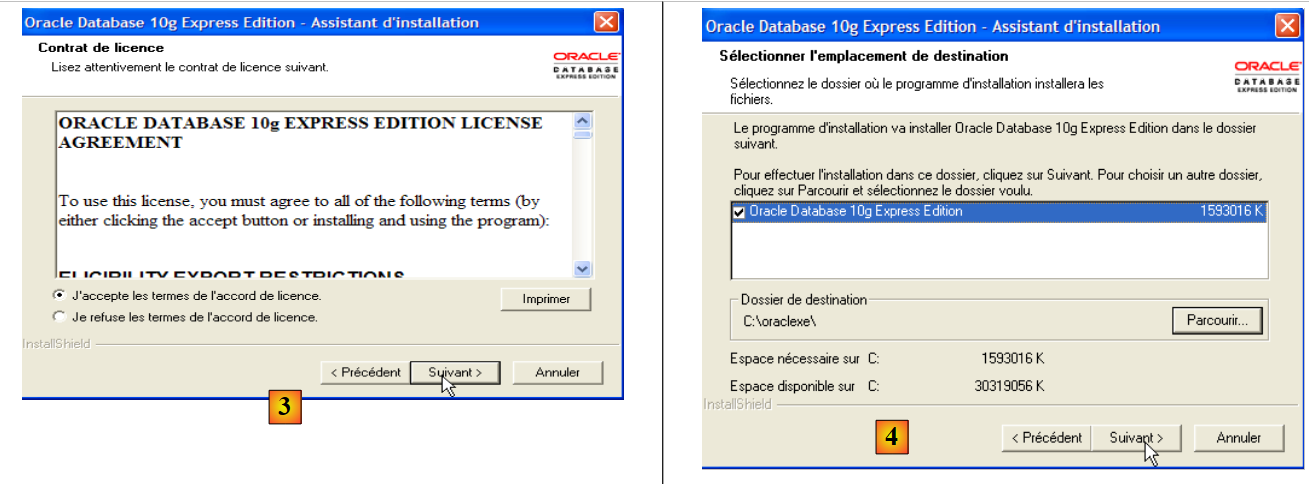 |
- em [3]: aceitar a licença
- em [4]: aceite os valores predefinidos.
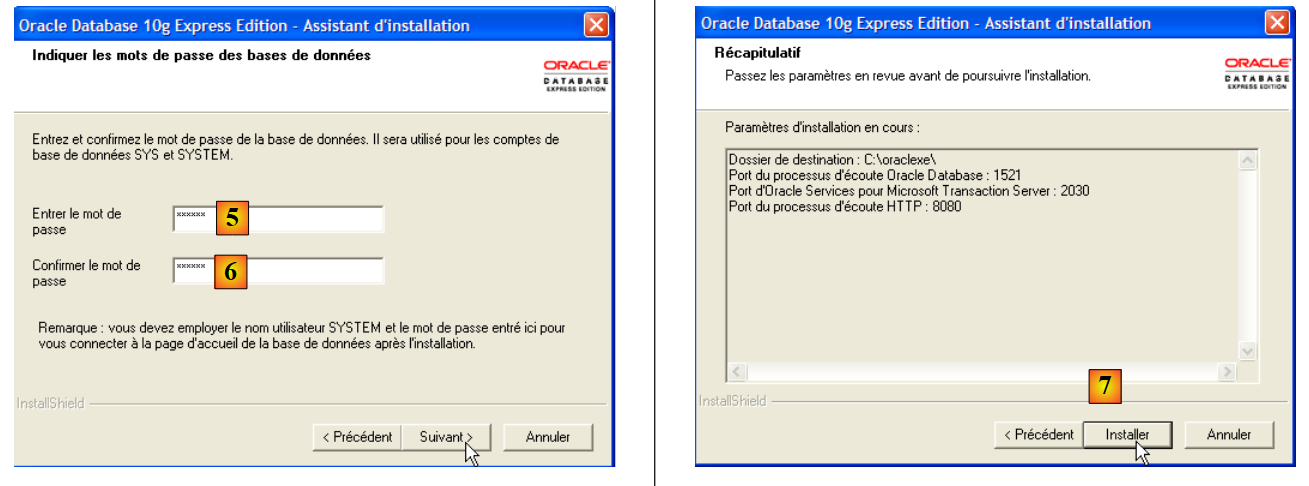 |
- em [5,6]: o utilizador SYSTEM terá a palavra-passe «system».
- em [7]: inicia-se a instalação
A instalação do Oracle 10g Express cria uma pasta em [Démarrer / Programmes ]:
5.7.2. Iniciar/Parar o Oracle 10g
Tal como nos SGBD anteriores, o Oracle 10g foi instalado como um serviço do Windows com arranque automático. Vamos alterar esta configuração:
[Démarrer / Panneau de configuration / Performances et maintenance / Outils d'administration / Services ]:
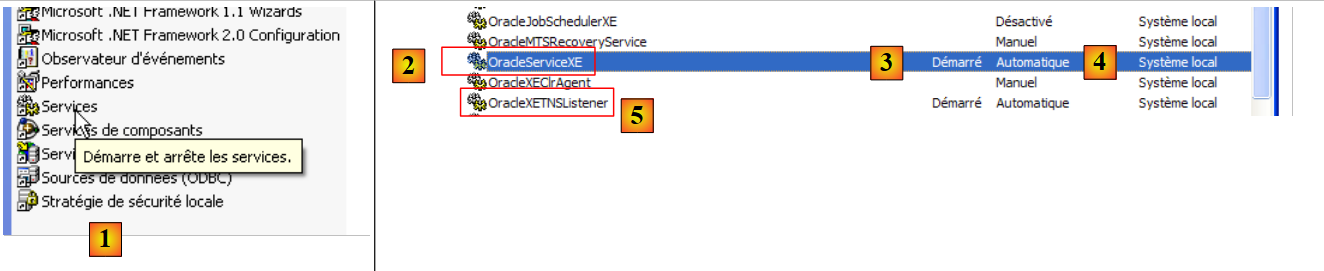 |
- para [1]: clicamos duas vezes em [Services]
- em [2]: verificamos que existe um serviço denominado [OracleServiceXE], que está em execução ([3]) e que o seu arranque é automático ([4]).
- em [5]: outro serviço da Oracle, denominado «Listener», também está ativo e com arranque automático.
Para alterar este comportamento, clicamos duas vezes no serviço [OracleServiceXE]:
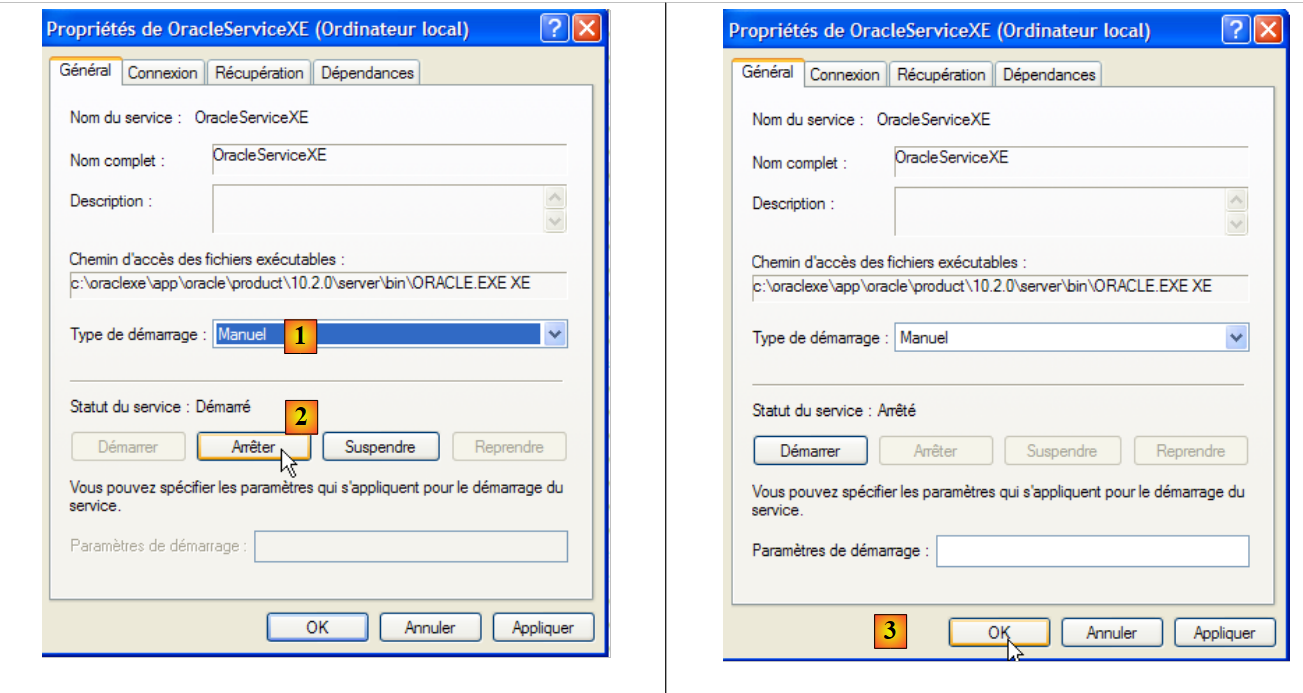 |
- em [1]: definimos o serviço para arranque manual
- em [2]: paramos o serviço
- em [3]: confirmamos a nova configuração do serviço
Proceder-se-á da mesma forma com o serviço [OracleXETNSListener] (ver [5] acima). Para iniciar e parar manualmente o serviço OracleServiceXE, poderá utilizar-se os atalhos da pasta [Oracle]:
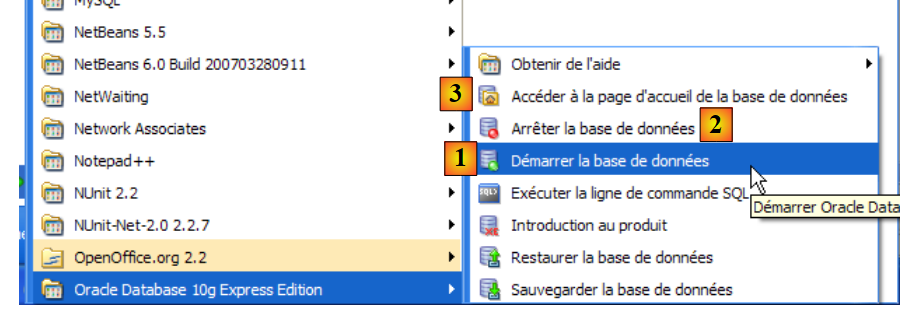 |
- em [1]: para iniciar o SGBD
- em [2]: para o parar
- em [3]: para o administrar (o que o inicia, caso ainda não esteja em execução)
5.7.3. Criação de um utilizador jpa e de uma base de dados jpa
Na captura de ecrã acima, a aplicação [3] permite administrar o SGBD Oracle 10g Express. Vamos iniciar o SGBD [1] e, em seguida, a aplicação de administração [3] através do menu acima:
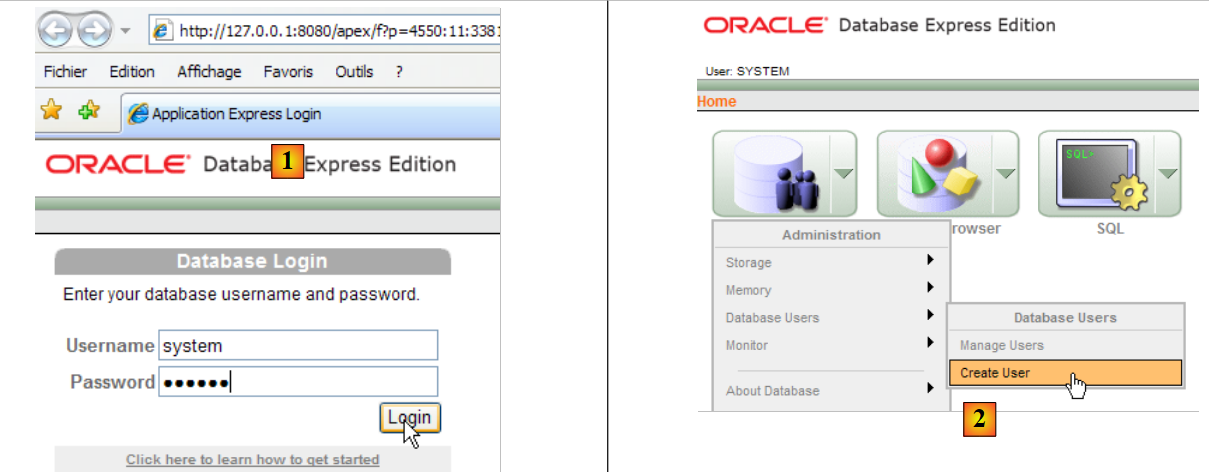 |
- no [1]: identifique-se como administrador do SGBD, neste caso (system / system)
- no [2]: cria-se um novo utilizador
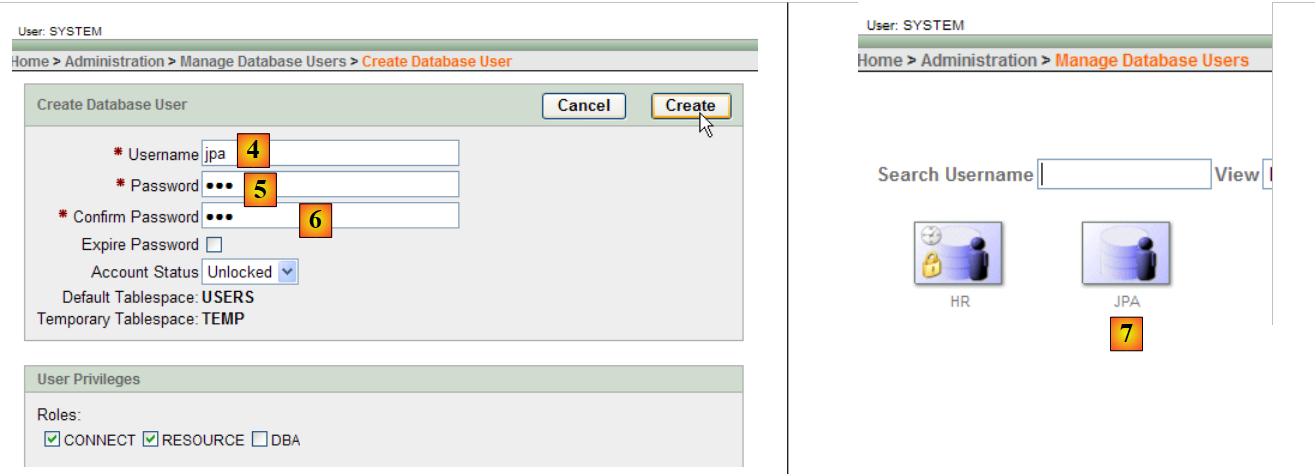 |
- em [4]: nome de utilizador
- em [5, 6]: a sua palavra-passe, neste caso «jpa»
- em [7]: o utilizador jpa foi criado
No Oracle, um utilizador é automaticamente associado a uma base de dados com o mesmo nome. A base de dados jpa existe, portanto, ao mesmo tempo que o utilizador jpa.
5.7.4. Criação da tabela [ARTICLES] da base de dados jpa
O OracleXE foi instalado com um cliente SQL que funciona em modo de linha de comandos. É possível trabalhar de forma mais confortável com o SQL Developer, também fornecido pela Oracle. Pode ser encontrado no site:
[http://www.oracle.com/technology/products/database/sql_developer/index.html]
 |
- em [1]: o site de download
- em [2]: escolha uma versão para Windows sem o JRE, caso este já esteja instalado (como é o caso aqui), uma vez que o [SQL Developer] é uma aplicação Java.
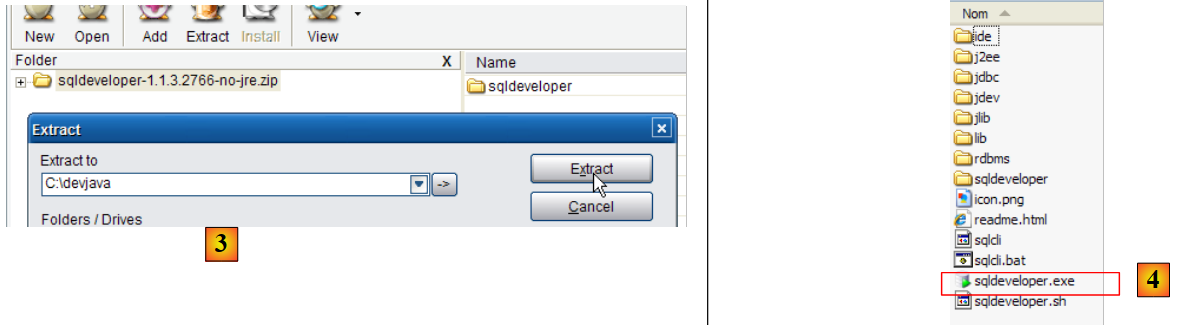 |
- em [3]: descompactar o ficheiro ZIP descarregado
- em [4]: executar o ficheiro executável [sqldeveloper.exe]
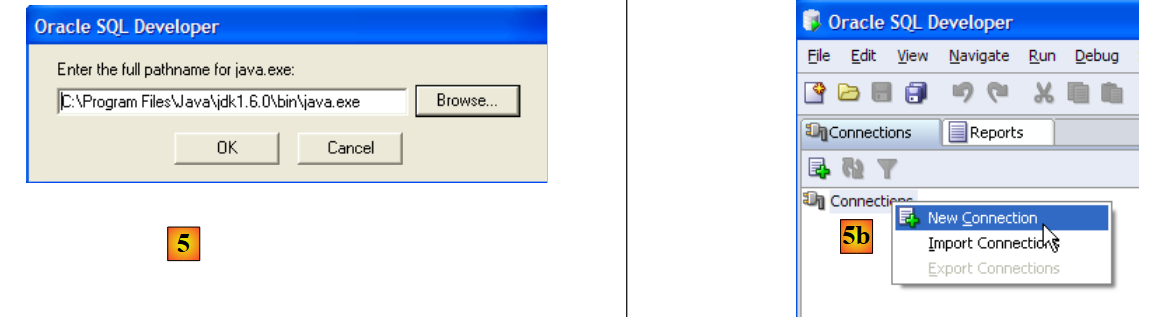 |
- em [5]: na primeira execução do [SQL Developer], indicar o caminho do JRE instalado no computador
- em [5b]: criar uma nova ligação
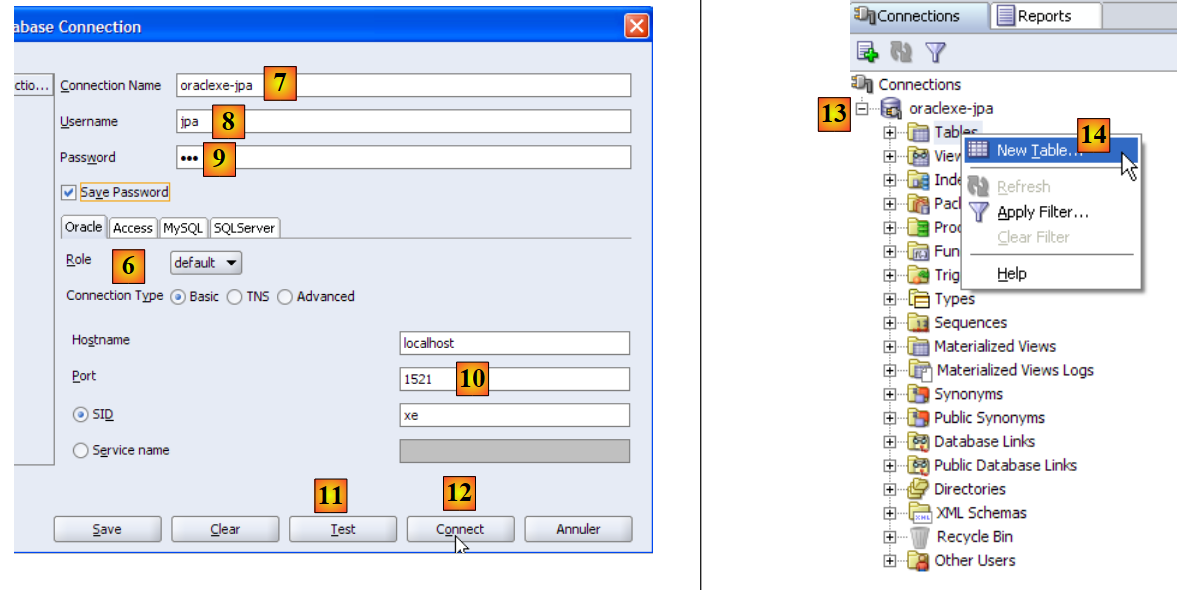 |
- em [6]: o SQL Developer permite ligar-se a vários SGBD. Selecione Oracle.
- em [7]: nome atribuído à ligação que está a ser criada
- em [8]: proprietário da ligação
- em [9]: a sua palavra-passe (jpa)
- em [10]: manter os valores predefinidos
- em [11]: para testar a ligação (o Oracle deve estar em execução)
- em [12]: para concluir a configuração da ligação
- em [13]: os objetos da base de dados jpa
- em [14]: é possível criar tabelas. Tal como nos casos anteriores, vamos criar a tabela [ARTICLES] a partir do script criado no parágrafo 5.4.6.
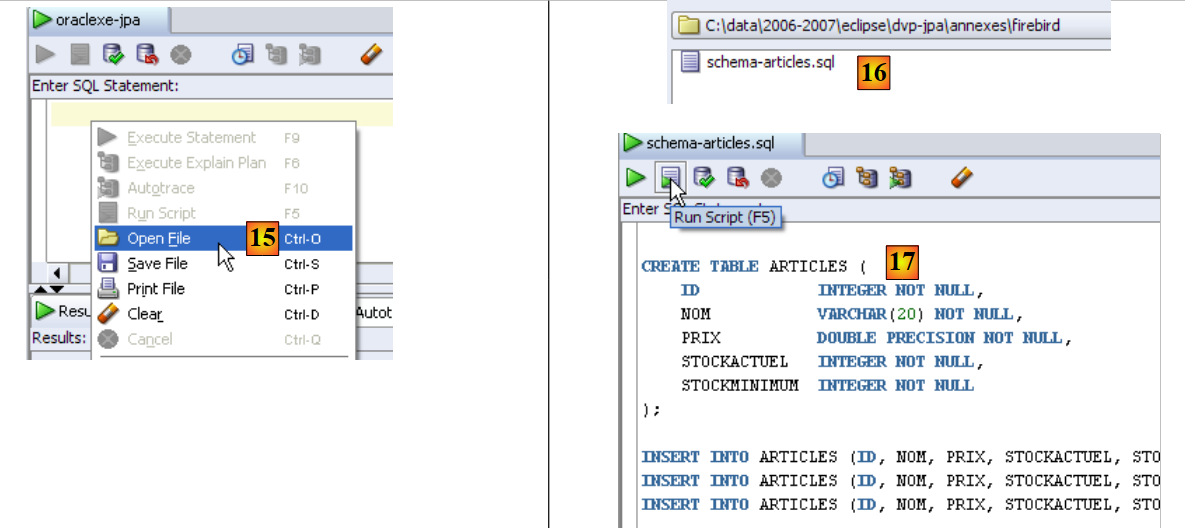 |
- em [15]: abre-se um script SQL
- em [16]: indicamos o script SQL criado no parágrafo 5.4.6.
- em [17]: o script que vai ser executado
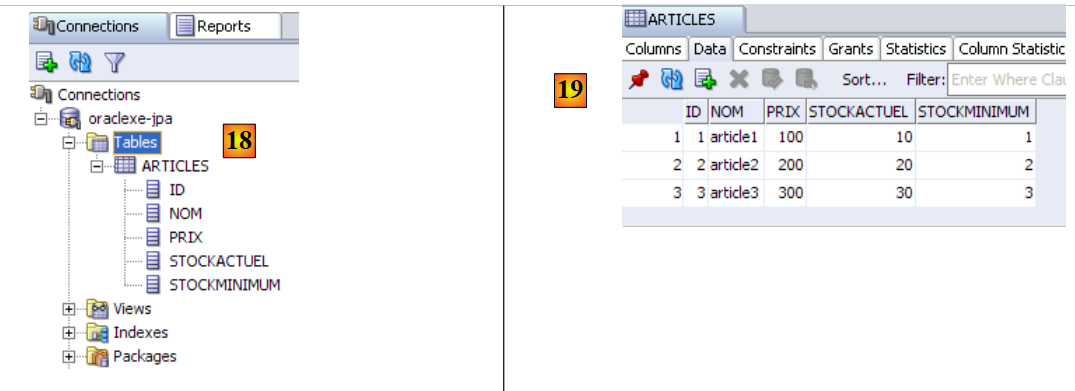 |
- em [18]: o resultado da execução: a tabela [ARTICLES] foi criada. Clica-se duas vezes nela para aceder às suas propriedades.
- em [19]: o conteúdo da tabela.
5.7.5. Driver JDBC de OracleXE
O controlador JDBC de OracleXE está disponível na pasta [jdbc/lib] da pasta de instalação de OracleXE [1]:
 |
Colocamos o arquivo Jdbc [ojdbc14.jar], tal como os anteriores (parágrafo 5.4.7), na pasta <jdbc> [2]:
Para testar este controlador JDBC, vamos utilizar o Eclipse e o plugin SQL Explorer. O leitor é convidado a seguir os passos explicados no parágrafo 5.4.7. Apresentamos algumas capturas de ecrã significativas:
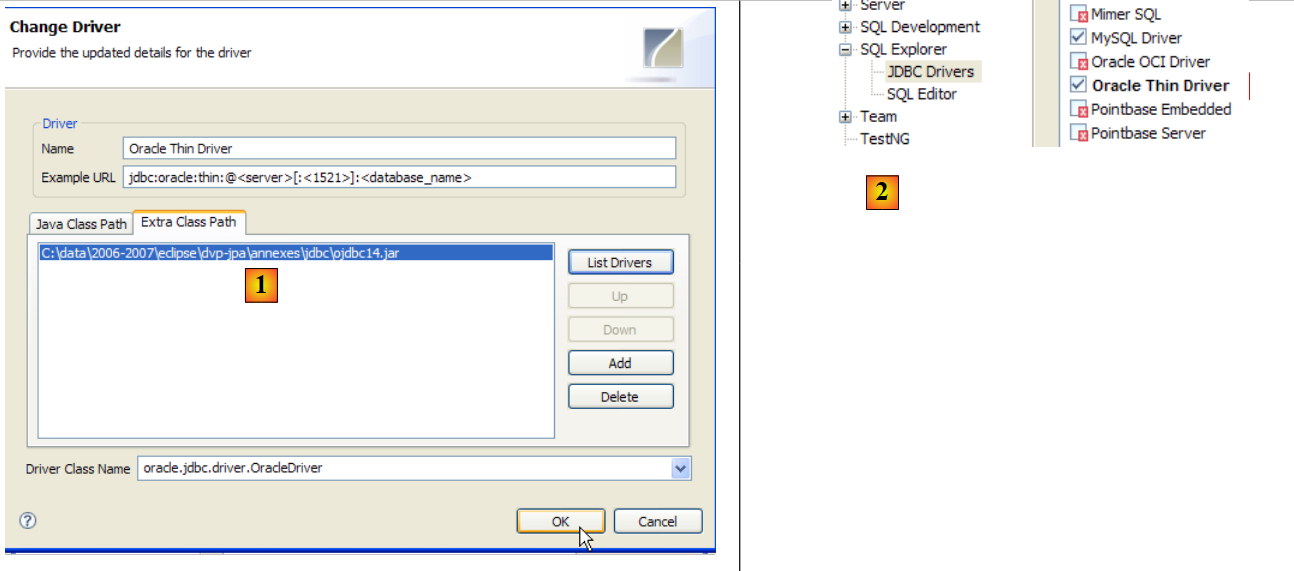 |
- no [1]: foi especificado o arquivo do controlador JDBC de OracleXE
- em [2]: o controlador JDBC, proveniente de OracleXE, está disponível
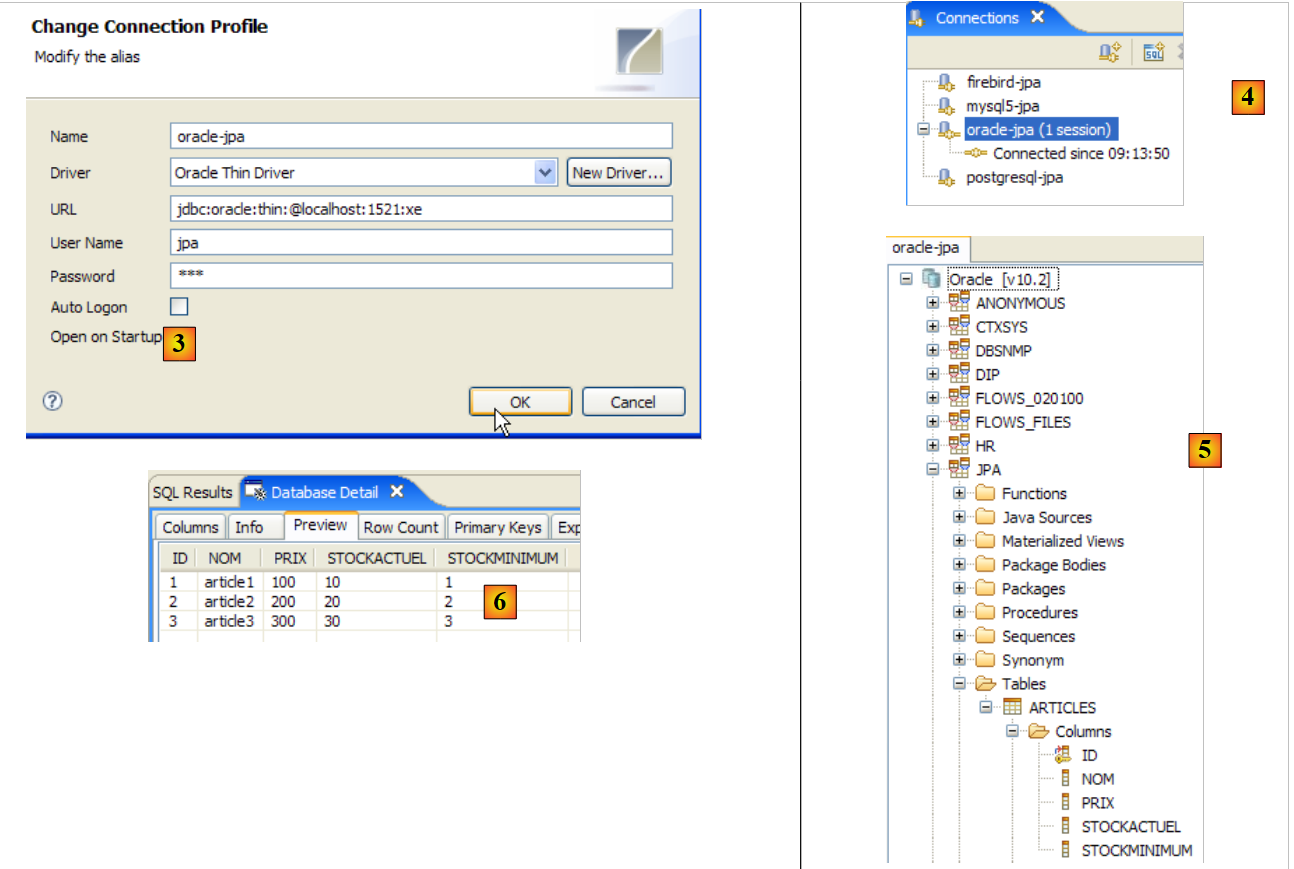 |
- para [3]: definição da ligação (utilizador, palavra-passe)=(jpa, jpa)
- em [4]: a ligação está ativa
- em [5]: base de dados ligada
- em [6]: o conteúdo da tabela [ARTICLES]
5.8. O SGBD e o SQL Server Express 2005
5.8.1. Instalação
O SGBD SQL Server Express 2005 está disponível no URL [http://msdn.microsoft.com/vstudio/express/sql/download/]:
 |
- em [1]: primeiro, descarregue e instale a plataforma .NET 2.0
- em [2]: em seguida, instale e descarregue o SQL Server Express 2005
- em [3]: em seguida, instale e descarregue o SQL Server Management Studio Express, que permite administrar o SQL Server
A instalação do SQL Server Express cria uma pasta no [Démarrer / Programmes ]:
 |
- no [1]: a aplicação de configuração do SQL Server. Permite também iniciar/parar o servidor
- em [2]: a aplicação de administração do servidor
5.8.2. Iniciar/Parar o servidor SQL
Tal como nos casos anteriores do SGBD, o servidor SQL Express foi instalado como um serviço do Windows com arranque automático. Vamos alterar esta configuração:
[Démarrer / Panneau de configuration / Performances et maintenance / Outils d'administration / Services ]:
 |
- para [1]: clicamos duas vezes em [Services]
- em [2]: verifica-se que existe um serviço denominado [SQL Server], que está em execução ([3]) e que o seu arranque é automático ([4]).
- em [5]: outro serviço relacionado com o SQL Server, denominado «SQL Server Browser», também está ativo e tem arranque automático.
Para alterar este comportamento, clicamos duas vezes no serviço [SQL Server]:
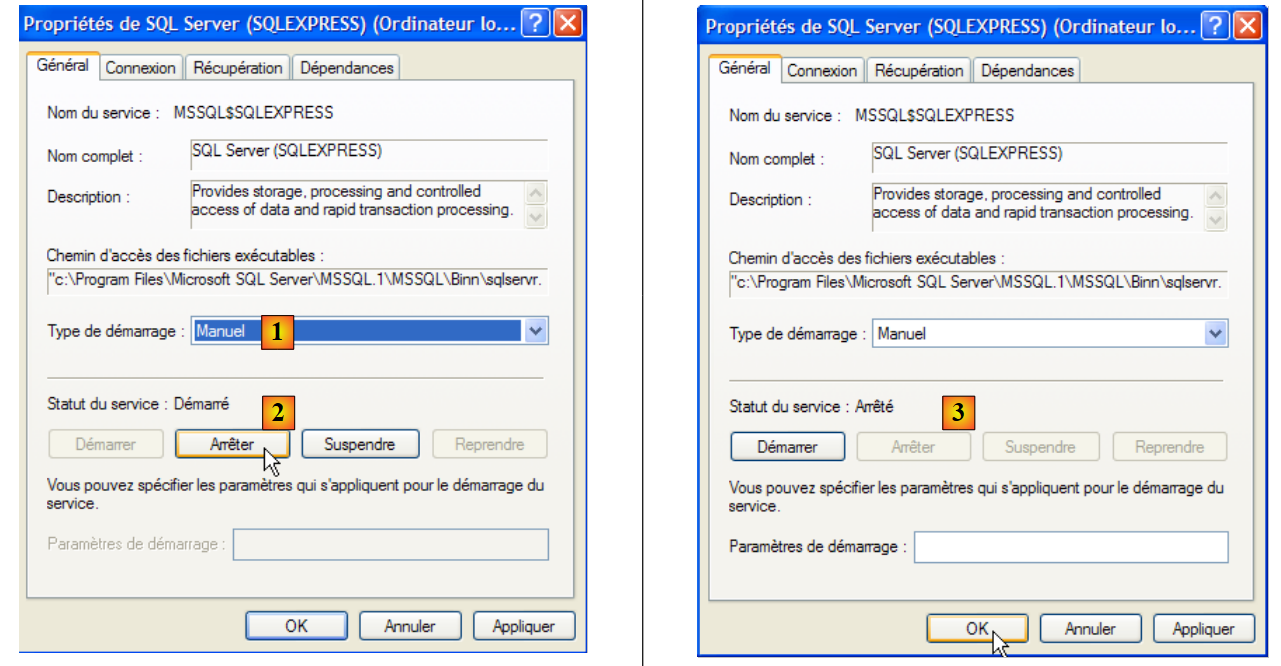 |
- em [1]: definimos o serviço para arranque manual
- em [2]: paramos o serviço
- em [3]: confirmamos a nova configuração do serviço
Proceder-se-á da mesma forma com o serviço [SQL Server Browser] (ver [5] acima). Para iniciar e parar manualmente o serviço SQL, pode utilizar-se a aplicação [1] da pasta [SQL server]:
 |
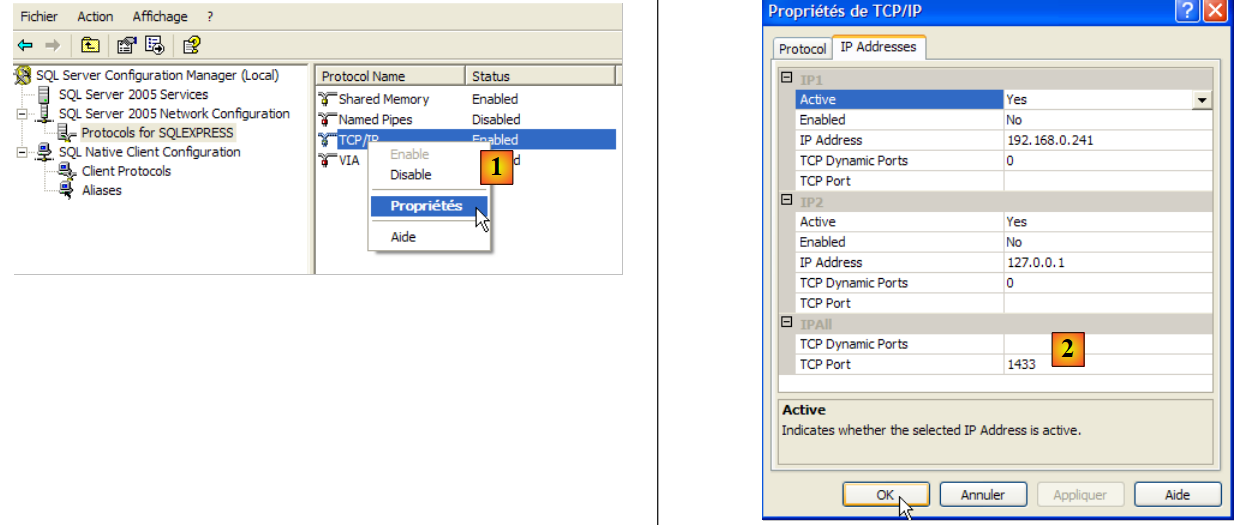 |
- em [1]: certifique-se de que o protocolo TCP/IP está ativo (enabled) e, em seguida, aceda às propriedades do protocolo.
- em [2]: no separador [IP Addresses], opção [IPAll]:
- o campo [TCP Dynamic ports] é deixado em branco
- a porta de escuta do servidor está definida para 1433 em [TCP Port]
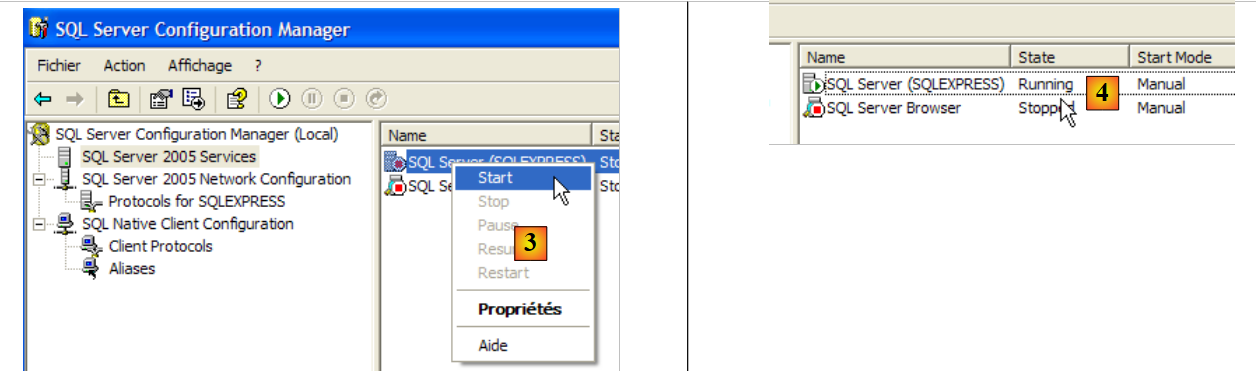 |
- em [3]: um clique com o botão direito do rato no serviço [SQL Server] dá acesso às opções de arranque/paragem do servidor. Aqui, iniciamos o servidor.
- em [4]: o servidor SQL está a ser iniciado
5.8.3. Criação de um utilizador jpa e de uma base de dados jpa
Iniciemos o SGBD conforme indicado acima e, em seguida, a aplicação de administração [1] através do menu abaixo:
 |
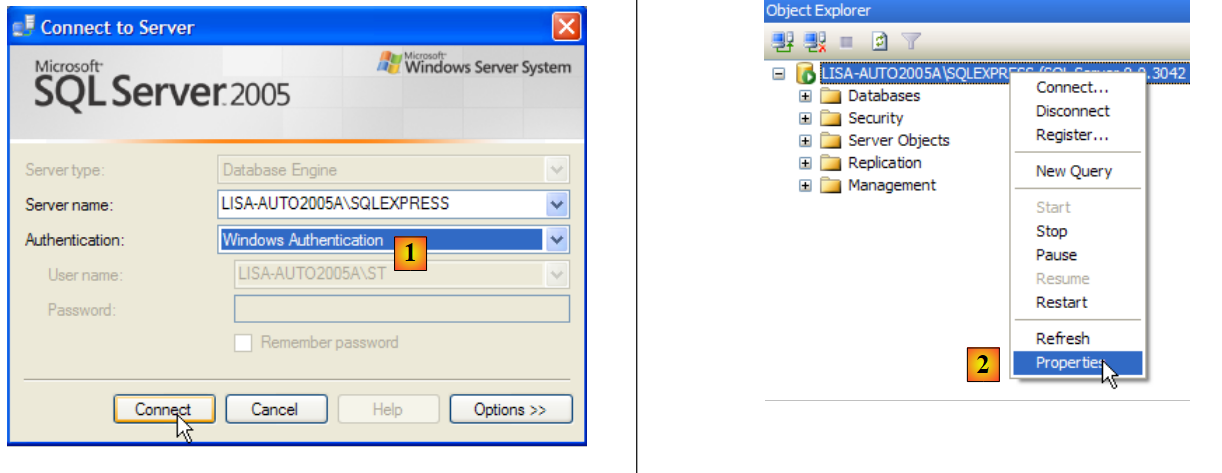 |
- no [1]: ligamo-nos ao servidor SQL como administrador do Windows
- em [2]: configure as propriedades da ligação
 |
- em [3]: autoriza-se um modo misto de ligação ao servidor: quer com um login do Windows (um utilizador do Windows), quer com um login do servidor SQL (conta definida no servidor SQL, independente de qualquer conta do Windows).
- em [3b]: cria-se um utilizador do servidor SQL
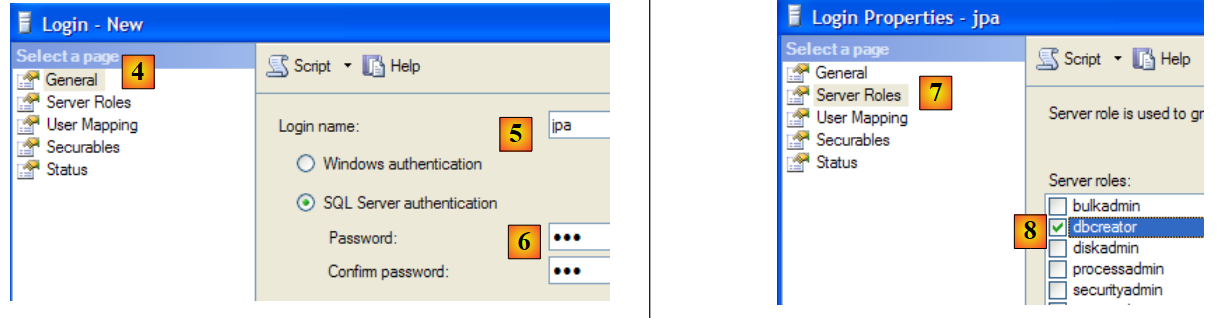 |
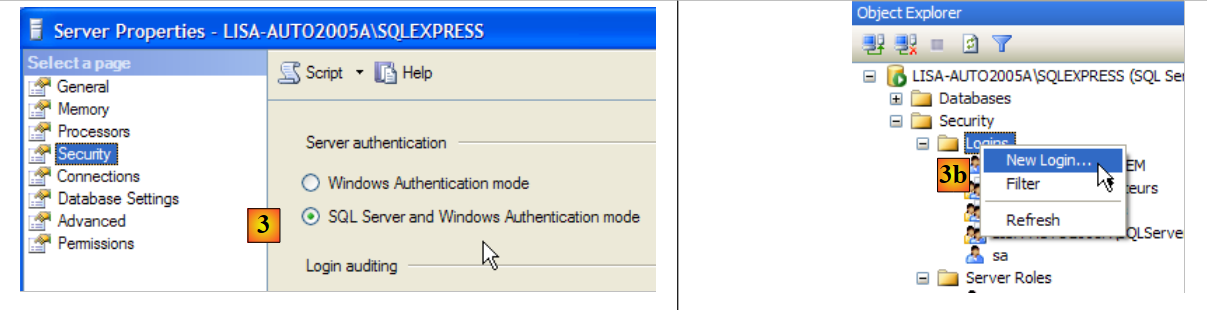
- no [4]: opção [General]
- em [5]: o nome de utilizador
- em [6]: a palavra-passe (jpa aqui)
- em [7]: opção [Server Roles]
- em [8]: o utilizador jpa terá permissão para criar bases de dados
Validamos esta configuração:
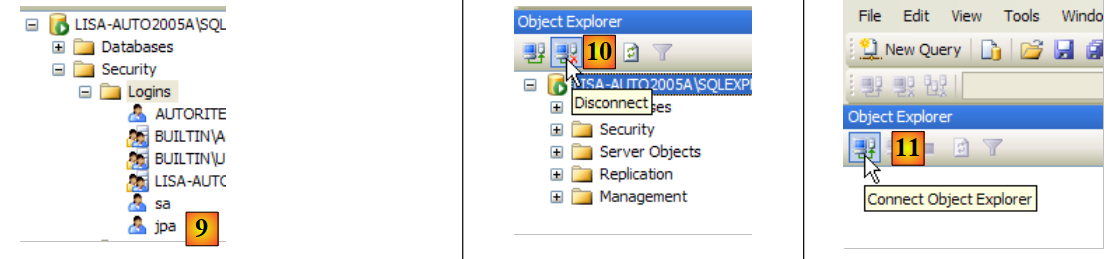 |
- em [9]: o utilizador jpa foi criado
- em [10]: desligamo-nos
- em [11]: volta-se a iniciar sessão
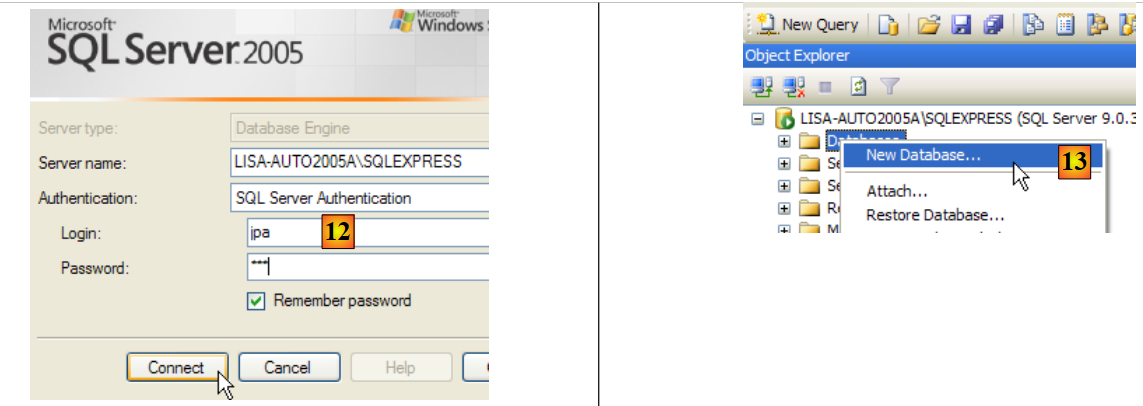 |
- em [12]: está a iniciar sessão como utilizador jpa/jpa
- em [13]: uma vez ligado, o utilizador jpa cria uma base de dados
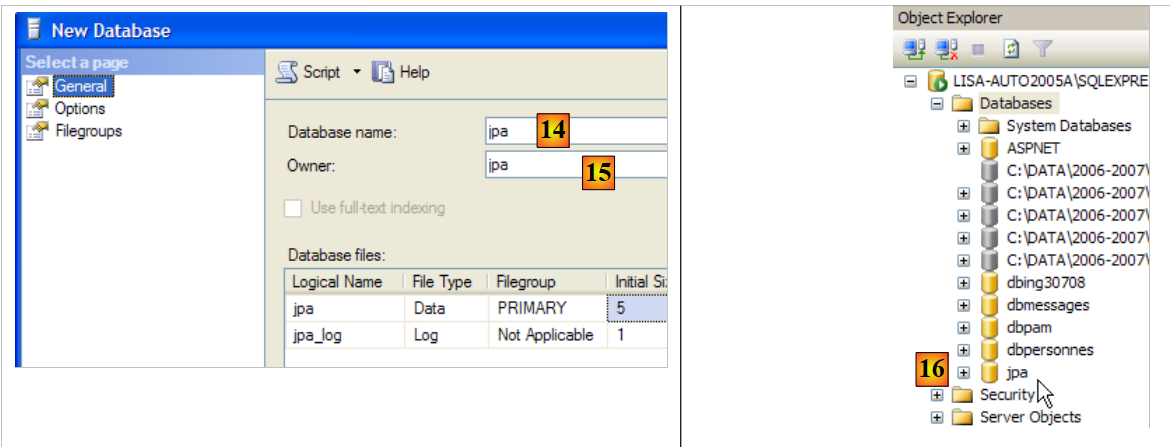 |
- em [14]: a base de dados terá o nome jpa
- em [15]: e pertencerá ao utilizador jpa
- em [16]: a base de dados jpa foi criada
5.8.4. Criação da tabela [ARTICLES] da base de dados jpa
Tal como nos exemplos anteriores, vamos criar a tabela [ARTICLES] a partir do script criado no parágrafo 5.4.6.
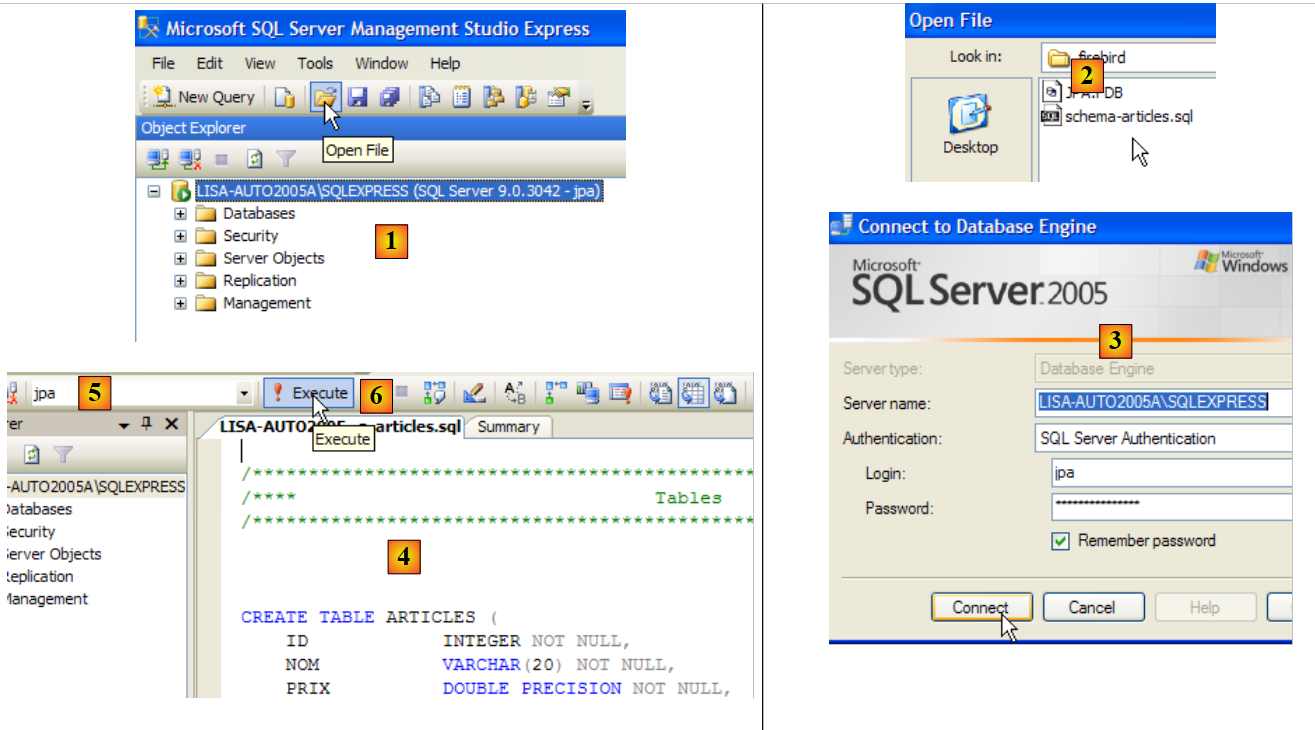 |
- em [1]: abre-se um script SQL
- em [2]: indicamos o script SQL criado no parágrafo 5.4.6, página 240.
- em [3]: é necessário identificar-se novamente (jpa/jpa)
- em [4]: o script que vai ser executado
- em [5]: selecionar a base de dados na qual o script será executado
- em [6]: executá-lo
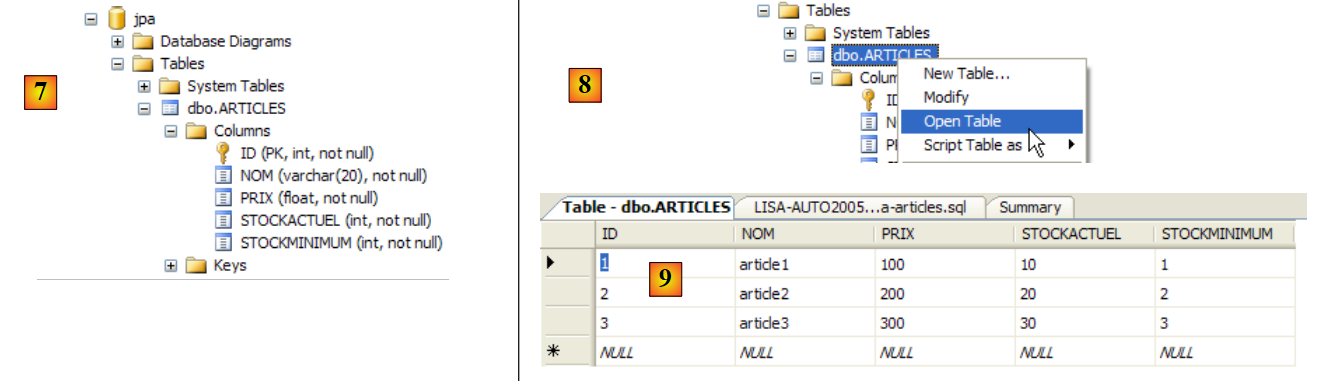 |
- em [7]: o resultado da execução: a tabela [ARTICLES] foi criada.
- em [8]: solicita-se a visualização do seu conteúdo
- em [9]: o conteúdo da tabela.
5.8.5. Driver JDBC do SQL Server Express
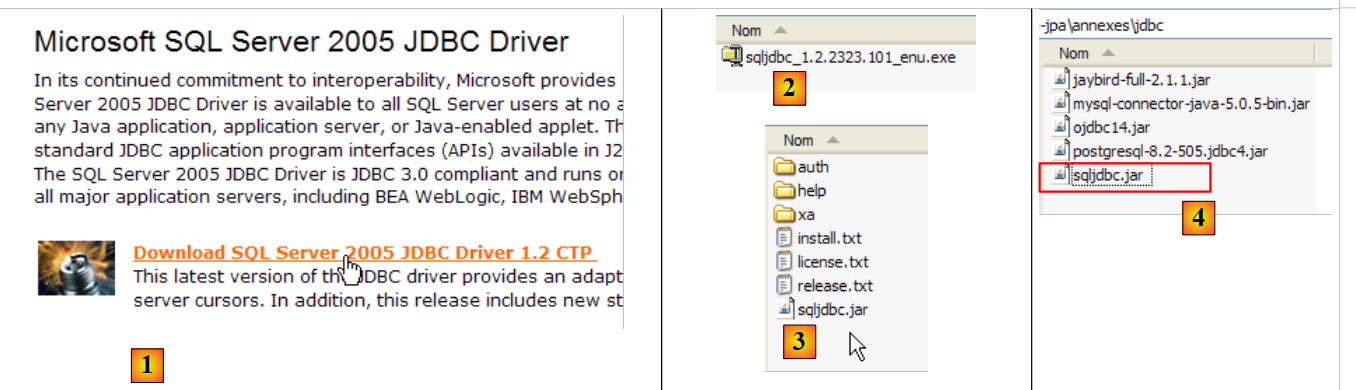 |
- em [1]: uma pesquisa no Google com o texto [Microsoft SQL Server 2005 JDBC Driver] leva-nos à página de download do controlador JDBC. Selecionamos a versão mais recente
- em [2]: o ficheiro descarregado. Fazemos duplo clique nele. O ficheiro é descompactado, criando uma pasta na qual se encontra o controlador Jdbc [3]
- em [4]: colocamos o arquivo Jdbc [sqljdbc.jar], tal como os anteriores (parágrafo 5.4.7), na pasta <jdbc>
Para testar este controlador JDBC, vamos utilizar o Eclipse e o plugin SQL Explorer. O leitor é convidado a seguir os passos explicados no parágrafo 5.4.7. Apresentamos algumas capturas de ecrã significativas:
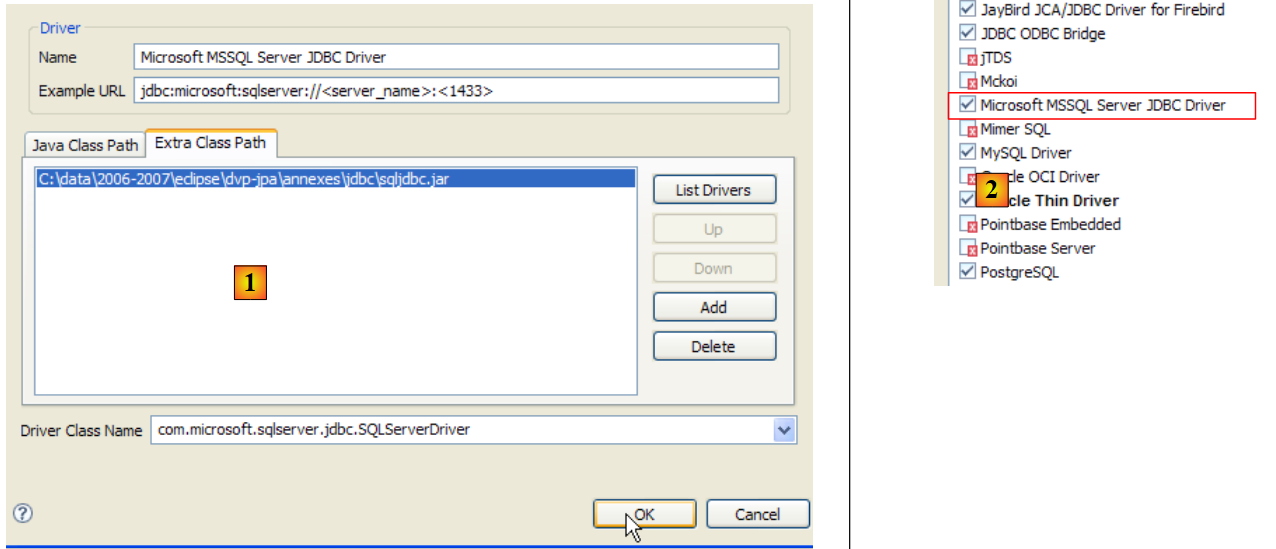 |
- no [1]: foi especificado o arquivo do controlador JDBC do servidor SQL
- em [2]: o controlador JDBC do servidor SQL está disponível
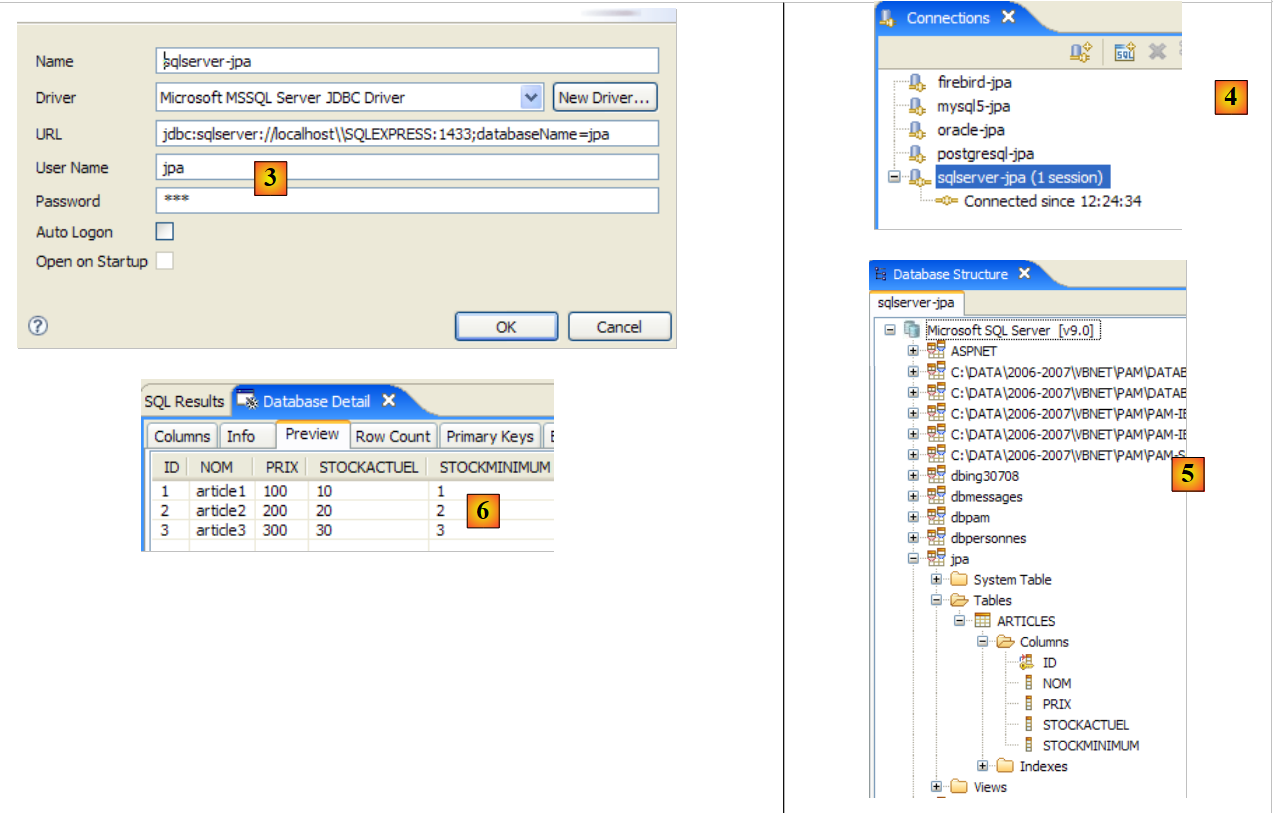 |
- em [3]: definição da ligação (utilizador, palavra-passe)=(jpa, jpa)
- em [4]: a ligação está ativa
- em [5]: base de dados ligada
- em [6]: o conteúdo da tabela [ARTICLES]
5.9. O SGBD e ao HSQLDB
5.9.1. Instalação
O SGBD HSQLDB está disponível no URL [http://sourceforge.net/projects/hsqldb]. Trata-se de um SGBD escrito em Java, muito leve em termos de memória, que gere bases de dados na memória e não no disco. O resultado é uma enorme rapidez na execução das consultas. Esta é a sua principal vantagem. As bases de dados assim criadas na memória podem ser recuperadas quando o servidor é desligado e, posteriormente, reiniciado. Com efeito, os comandos SQL emitidos para criar as bases de dados são guardados num ficheiro de registo para serem reproduzidos no próximo arranque do servidor. Desta forma, obtém-se uma persistência das bases de dados ao longo do tempo.
Este método tem as suas limitações e o HSQLDB não é um SGBD destinado a fins comerciais. O seu principal interesse reside em testes ou aplicações de demonstração. Por exemplo, o facto de o HSQLDB estar escrito em Java permite incluí-lo em tarefas do Ant (Another Neat Tool), uma ferramenta Java de automatização de tarefas. Assim, os testes diários de códigos em desenvolvimento, automatizados pelo Ant, poderão integrar testes de bases de dados geridas pelo SGBD e pelo HSQLDB. O servidor será iniciado, encerrado e gerido por tarefas Java.
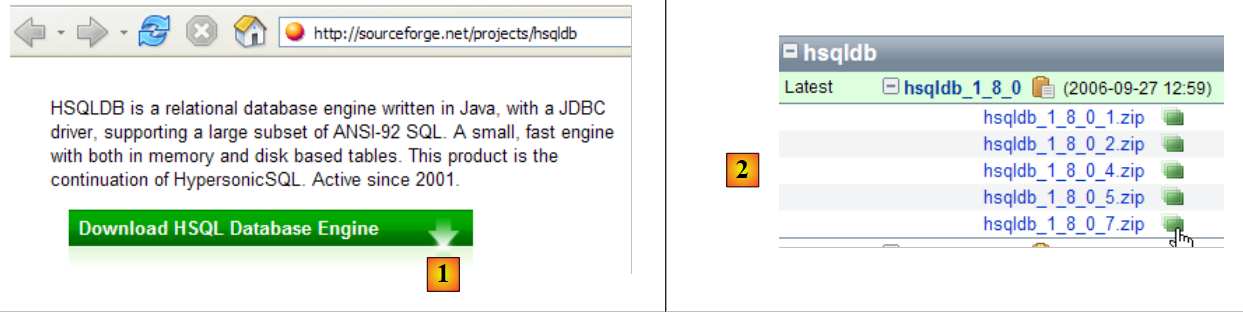 |
- em [1]: o site de downloads
- em [2]: obter a versão mais recente
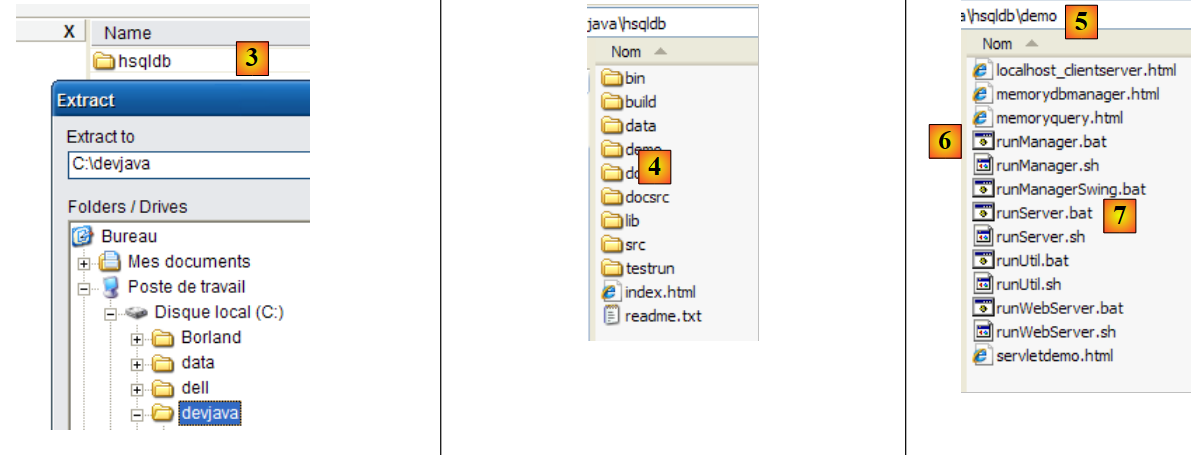 |
- em [3]: descompactar o ficheiro zip descarregado
- em [4]: a pasta [hsqldb] resultante da descompactação
- em [5]: a pasta [demo], que contém o script que permite iniciar o servidor [hsql] e [6], e, em [7], o que permite iniciar uma ferramenta simples de administração do servidor.
5.9.2. Iniciar/Parar o HSQLDB
Para iniciar o servidor HSQLDB, clique duas vezes na aplicação [runManager.bat] [6] acima:
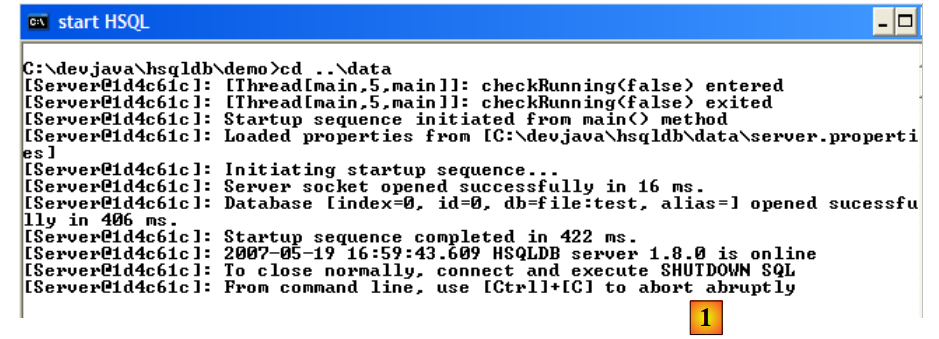 |
- no [1]: verifica-se que, para parar o servidor, basta premir Ctrl-C na janela.
5.9.3. A base de dados [test]
A base de dados gerida por predefinição encontra-se na pasta [data]:
 |
- em [1]: ao iniciar, o SGBD HSQL executa o script denominado [test.script]
- linha 1: é criado um esquema [public]
- linha 2: é criado um utilizador [sa] com uma palavra-passe vazia
- linha 3: o utilizador [sa] recebe direitos de administração
No final, foi criado um utilizador com direitos de administração. É este utilizador que iremos utilizar daqui em diante.
5.9.4. Driver JDBC de HSQL
O controlador JDBC de SGBD HSQL encontra-se na pasta [lib]:
 |
- em [1]: o arquivo [hsqldb.jar] contém o controlador JDBC do SGBD HSQL
- em [2]: colocamos este arquivo, tal como os anteriores (parágrafo 5.4.7), na pasta <jdbc>
Para verificar este controlador JDBC, vamos utilizar o Eclipse e o plugin SQL Explorer. O leitor é convidado a seguir os passos explicados no parágrafo 5.4.7. Apresentamos algumas capturas de ecrã significativas:
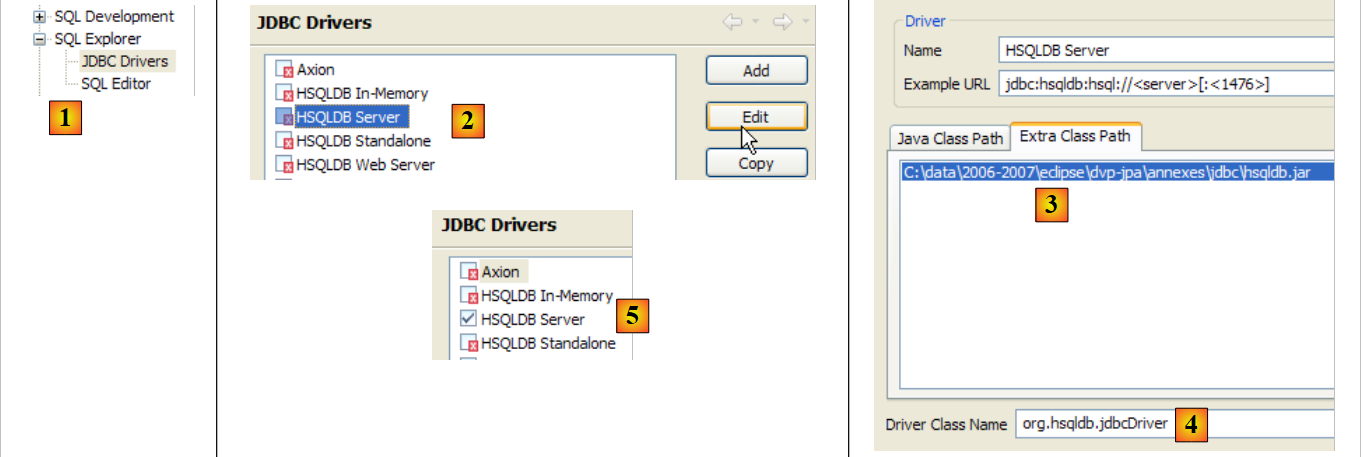 |
- no [1]: [window / preferences / SQL Explorer / JDBC Drivers]
- em [2]: configura-se o servidor [HSQLDB]
- em [3]: indica-se o arquivo [hsqldb.jar] que contém o controlador JDBC
- em [4]: o nome da classe Java do controlador JDBC
- em [5]: o controlador JDBC está configurado
Feito isto, estabelece-se ligação ao servidor HSQL. Este deve ser iniciado previamente.
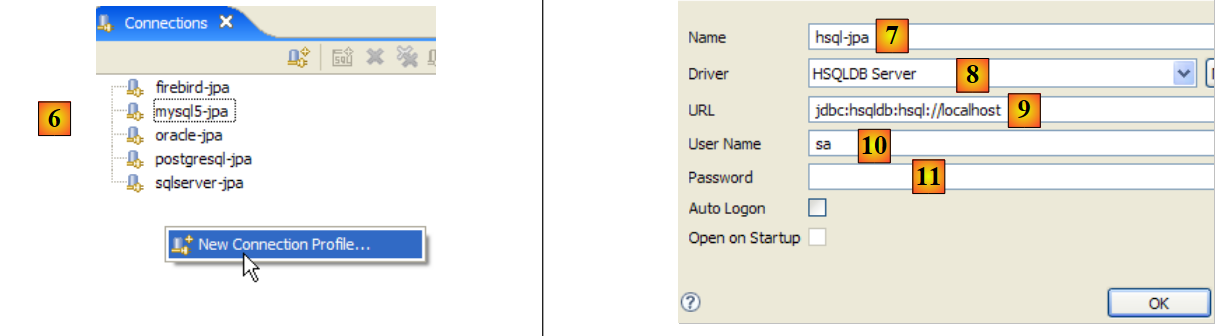 |
- em [6]: cria-se uma nova ligação
- em [7]: atribui-se-lhe um nome
- em [8]: pretendemos ligar-nos ao servidor HSQLDB
- em [9]: a URL da base de dados à qual se pretende ligar. Será a base [test] vista anteriormente.
- em [10]: ligamo-nos como utilizador [sa]. Vimos que este era administrador do SGBD.
- em [11]: o utilizador [sa] não tem palavra-passe.
Validamos a configuração da ligação.
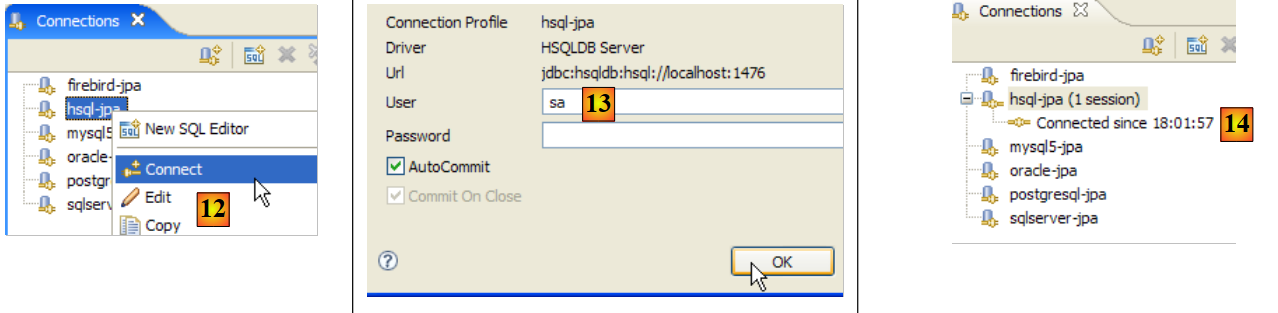 |
- no [12]: efetuamos a ligação
- em [13]: a identificação é efetuada
- em [14]: está-se ligado
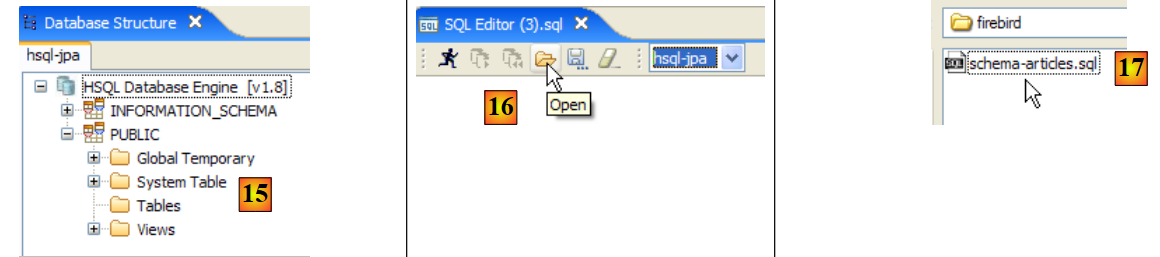 |
- em [15]: o esquema [PUBLIC] ainda não tem nenhuma tabela
- em [16]: vamos criar a tabela [ARTICLES] a partir do script [schema-articles.sql] criado no parágrafo 5.4.6.
- em [17]: seleciona-se o script
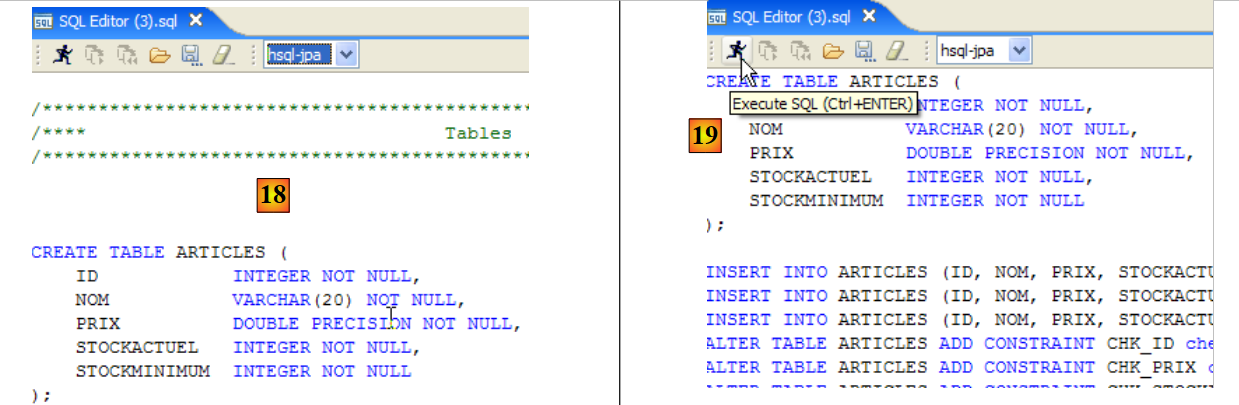 |
- em [18]: o script a executar
- No [19]: executa-se depois de remover todos os comentários, pois o HSQLB não os aceita.
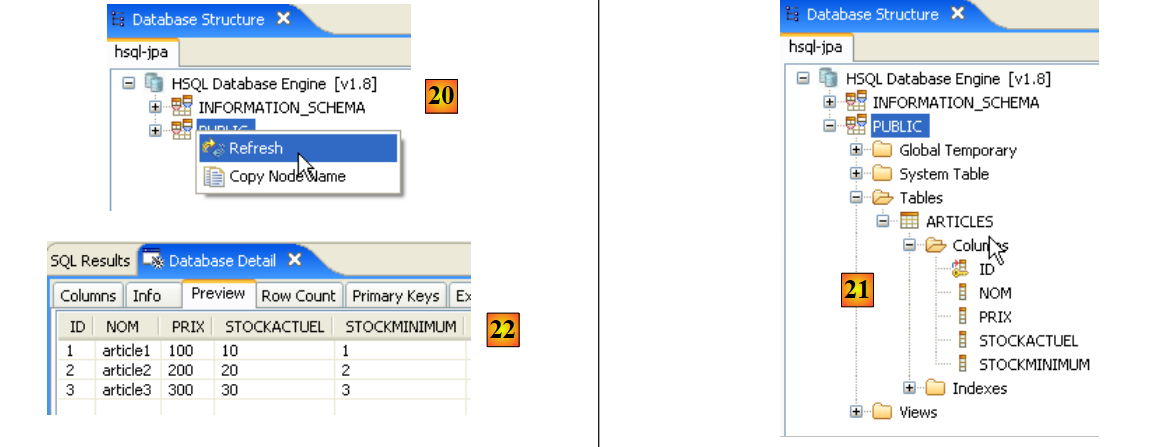 |
- assim que o script for executado, atualiza-se a visualização da base de dados em [20]
- em [21]: a tabela [ARTICLES] está lá
- em [22]: o seu conteúdo
Vamos parar e, em seguida, reiniciar o servidor HSQLDB. Feito isto, vamos examinar o ficheiro [test.script]:
Vemos que o SGBD memorizou os diferentes comandos SQL executados na sessão anterior e que os executa novamente no início da nova sessão. Além disso, verifica-se (linha 2) que a tabela [ARTICLES] é criada na memória (MEMORY). Em cada sessão, os comandos SQL emitidos são memorizados em [test.log] para serem copiados no início da sessão seguinte para [test.script] e executados novamente no início da sessão.
5.10. O SGBD e do Apache Derby
5.10.1. Instalação
O SGBD Apache Derby está disponível no URL [http://db.apache.org/derby/]. Trata-se de um SGBD, também escrito em Java e igualmente muito leve em termos de memória. Apresenta vantagens semelhantes às do HSQLDB. Também pode ser incorporado em aplicações Java, c.a.d, tornando-se parte integrante da aplicação e funcionando na mesma JVM.
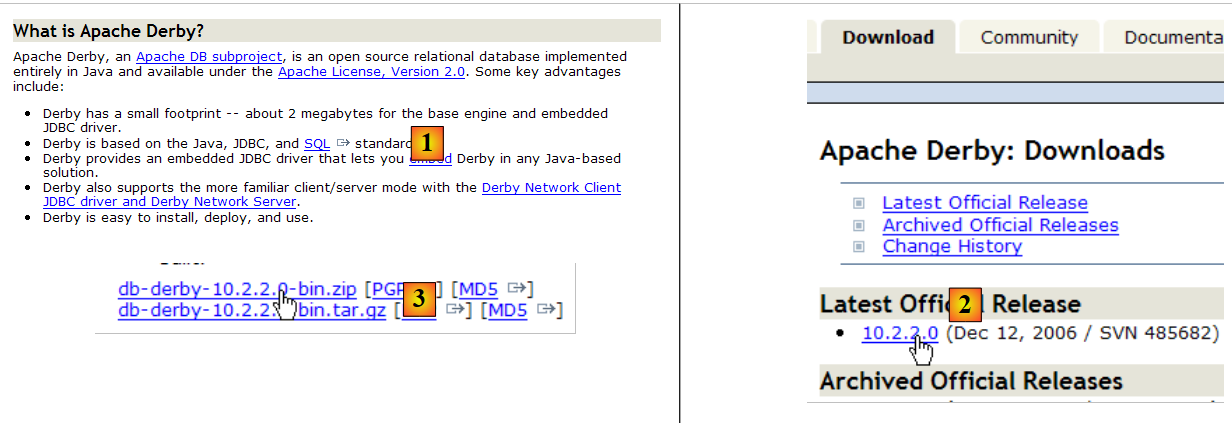 |
- em [1]: o site de download
- em [2,3]: descarregue a versão mais recente
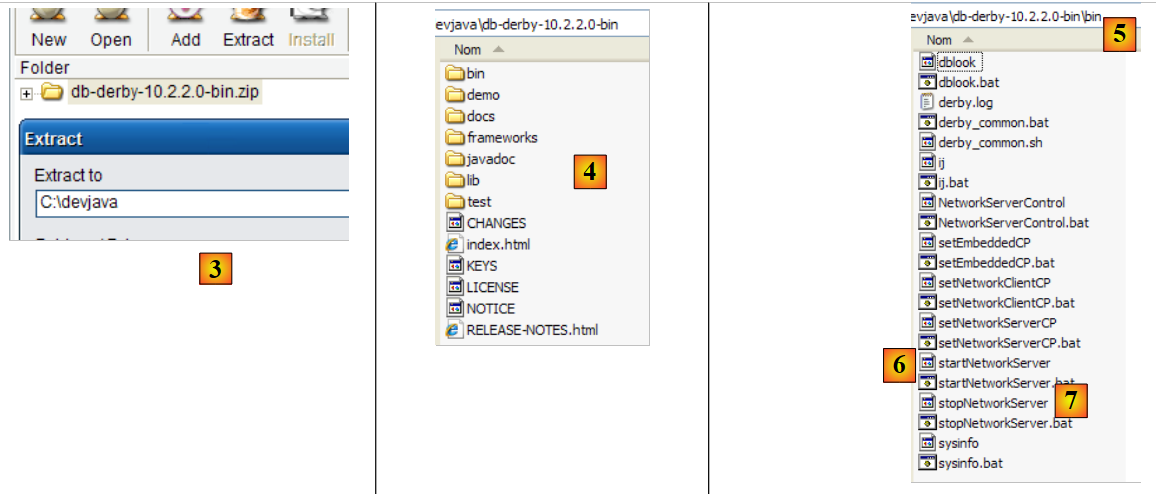 |
- em [3]: descompactar o ficheiro zip descarregado
- em [4]: a pasta [db-derby-*-bin] resultante da descompactação
- em [5]: a pasta [bin], que contém o script para iniciar o servidor [db derby] [6] e, em [7], o script para o parar.
5.10.2. Iniciar/Parar o Apache Derby (Db Derby)
Para iniciar o servidor Db Derby, clique duas vezes na aplicação [startNetworkServer] [6] acima:
 |
- em [1]: o servidor está iniciado. Irá pará-lo com a aplicação [stopNetworkServer] [7] acima.
5.10.3. Driver JDBC do Db Derby
O controlador JDBC do SGBD Db Derby encontra-se na pasta [lib] da pasta de instalação:
 |
- em [1]: o arquivo [derbyclient.jar] contém o controlador JDBC do SGBD Db Derby
- em [2]: colocamos este arquivo, tal como os anteriores (parágrafo 5.4.7), na pasta <jdbc>
Para testar este controlador JDBC, vamos utilizar o Eclipse e o plugin SQL Explorer. O leitor é convidado a seguir os passos explicados no parágrafo 5.4.7. Apresentamos algumas capturas de ecrã significativas:
 |
- em [1]: [window / preferences / SQL Explorer / JDBC Drivers]
- em [2]: o controlador JDBC do Apache Derby não consta da lista. Adiciona-se o mesmo.
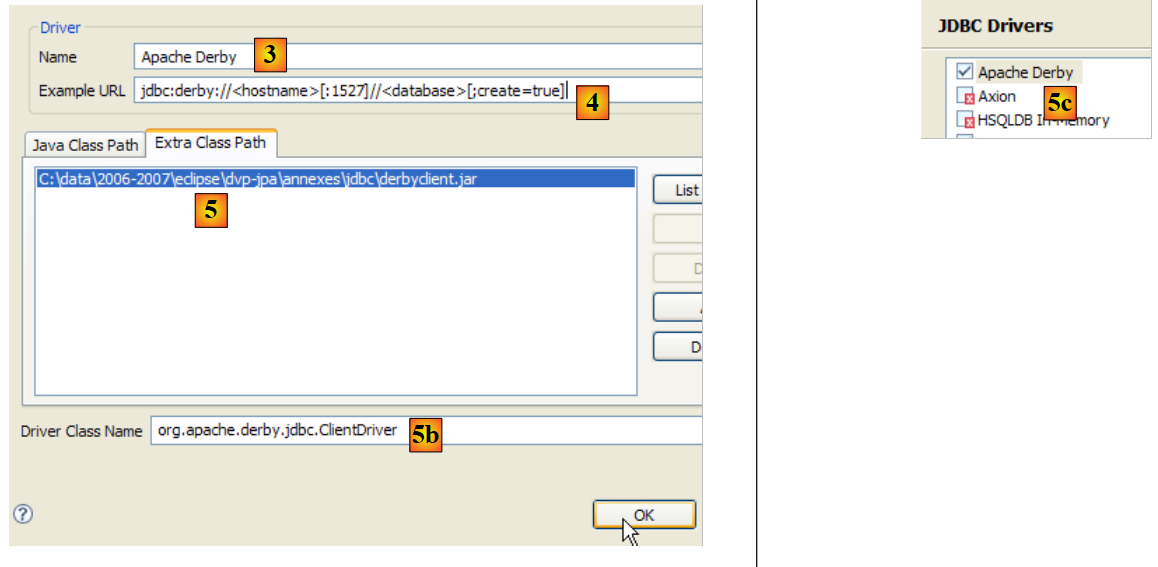 |
- em [3]: atribui-se um nome ao novo controlador
- em [4]: especifica-se o formato das URLs geridas pelo controlador JDBC
- em [5]: indicamos o ficheiro .jar do controlador JDBC
- em [5b]: o nome da classe Java do controlador JDBC
- em [5c]: o controlador JDBC está configurado
Feito isto, ligamo-nos ao servidor Apache Derby. Este deve ser iniciado previamente.
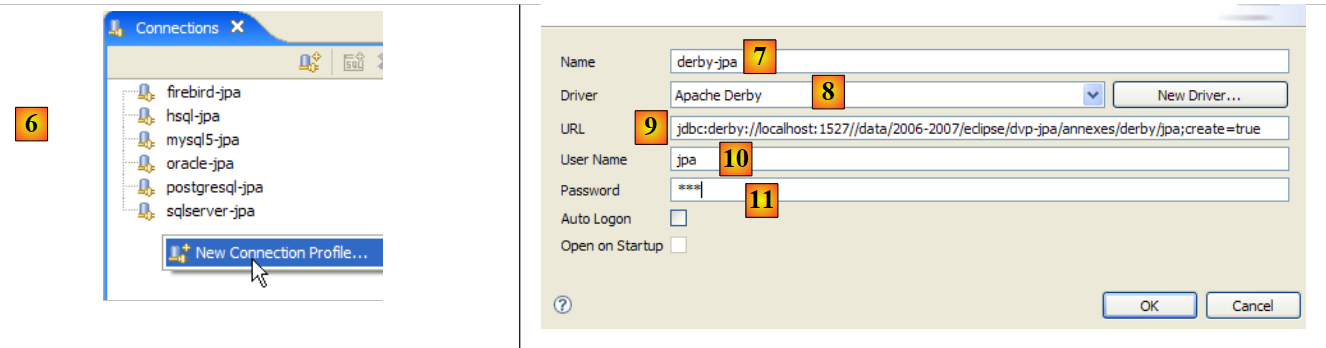 |
- em [6]: cria-se uma nova ligação
- em [7]: atribui-se-lhe um nome
- em [8]: pretende-se ligar-se ao servidor Apache Derby
- em [9]: a URL da base de dados à qual se pretende ligar. Após o início padrão [jdbc:derby://localhost:1527], deve indicar-se o caminho para uma pasta no disco que contenha uma base de dados Derby. A opção [create=true] permite criar essa pasta caso ainda não exista.
- em [10,11]: liga-se como utilizador [jpa/jpa]. Não aprofundei a questão, mas parece que se pode definir o que se quiser como nome de utilizador/palavra-passe. Aqui declara-se o proprietário da base de dados, se create=true.
Valida-se a configuração da ligação.
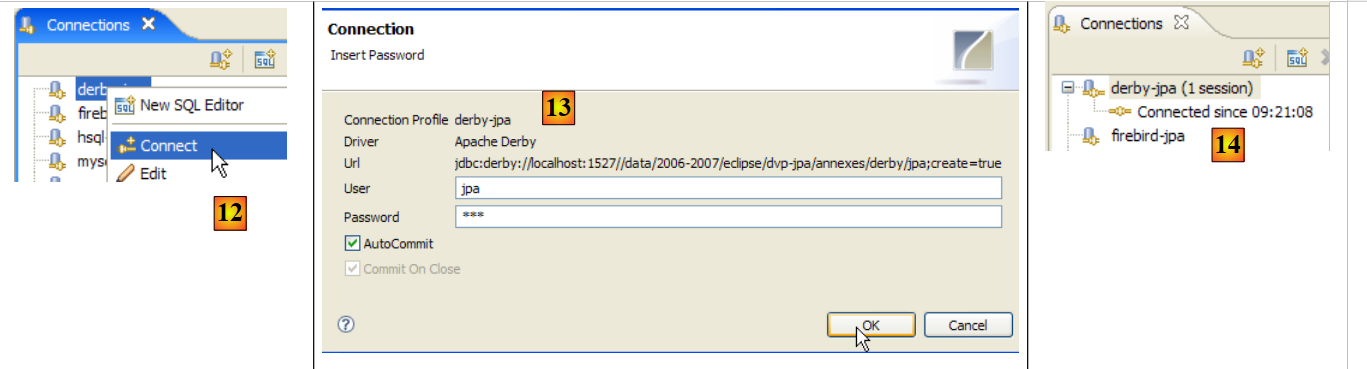 |
- em [12]: faz-se a ligação
- em [13]: identificamo-nos (jpa/jpa)
- em [14]: estamos ligados
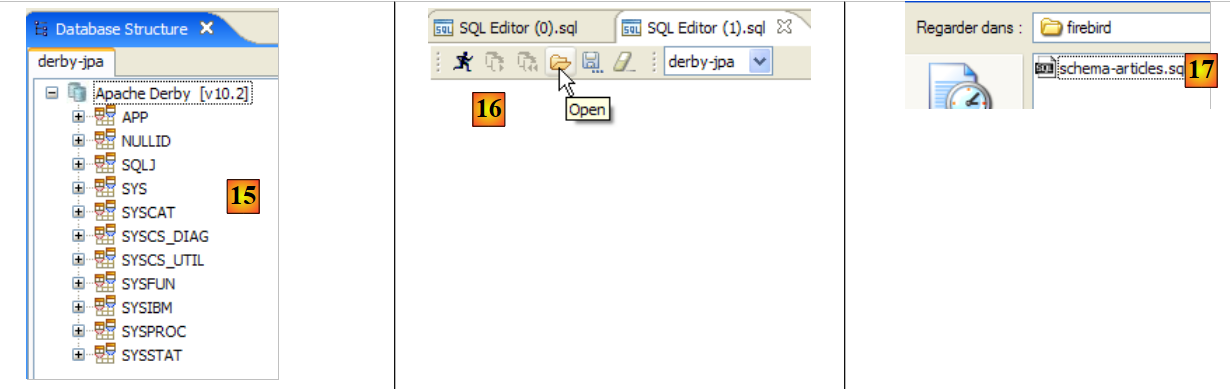 |
- em [15]: o esquema [jpa] ainda não aparece.
- em [16]: vamos criar a tabela [ARTICLES] a partir do script [schema-articles.sql] criado no parágrafo 5.4.6.
- em [17]: seleciona-se o script
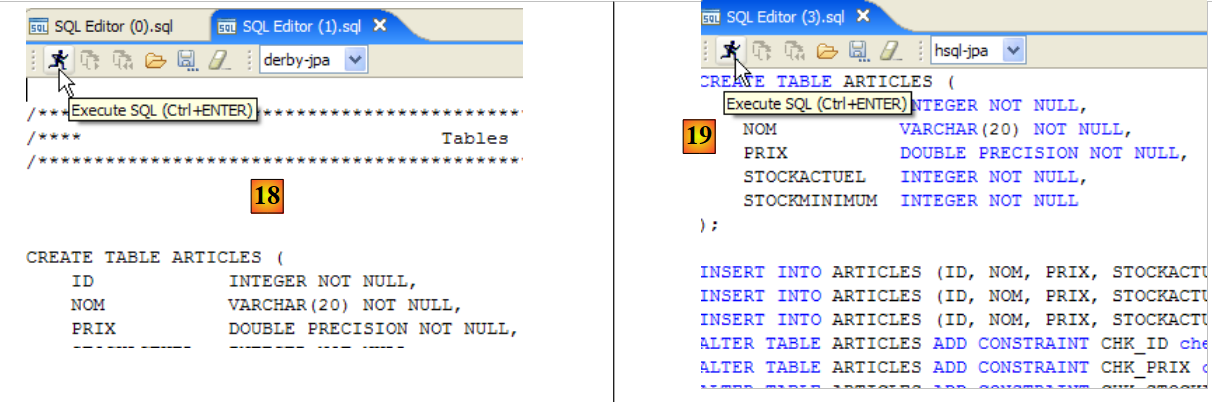 |
- em [18]: o script a executar
- em [19]: executa-se o script após remover todos os comentários, uma vez que o Apache Derby, tal como o HSQLB, não os aceita.
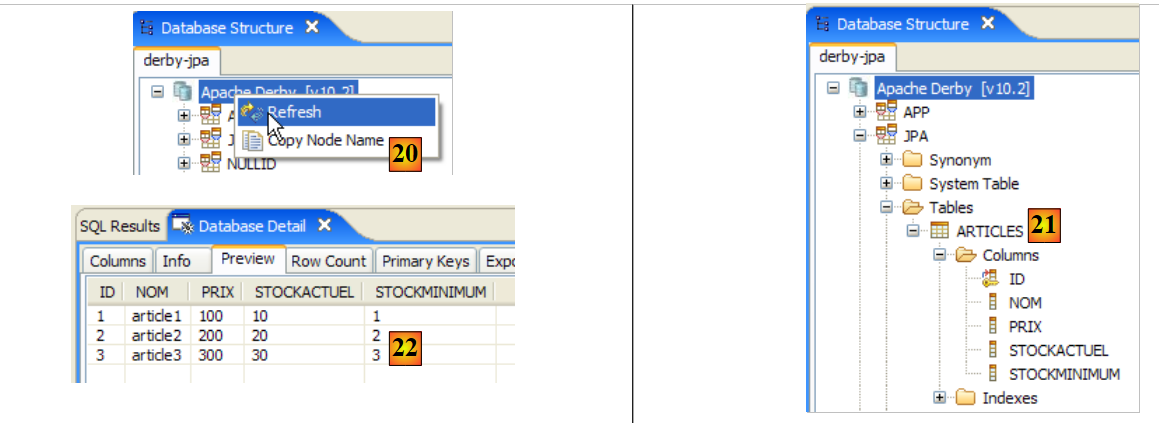 |
- assim que o script estiver executado, atualiza-se em [20] a visualização da base de dados
- em [21]: o esquema [jpa] e a tabela [ARTICLES] estão lá
- em [22]: o conteúdo da tabela [ARTICLES]
 |
- em [23]: o conteúdo da pasta [derby\jpa] na qual foi criada a base de dados.
5.11. O framework Spring 2 da
O framework Spring 2 está disponível no URL [http://www.springframework.org/download]:
 |
- em [1]: descarregue a versão mais recente
- No [2]: descarrega-se a versão denominada «com dependências», pois contém os ficheiros .jar das ferramentas de terceiros que o Spring integra e das quais se necessita constantemente.
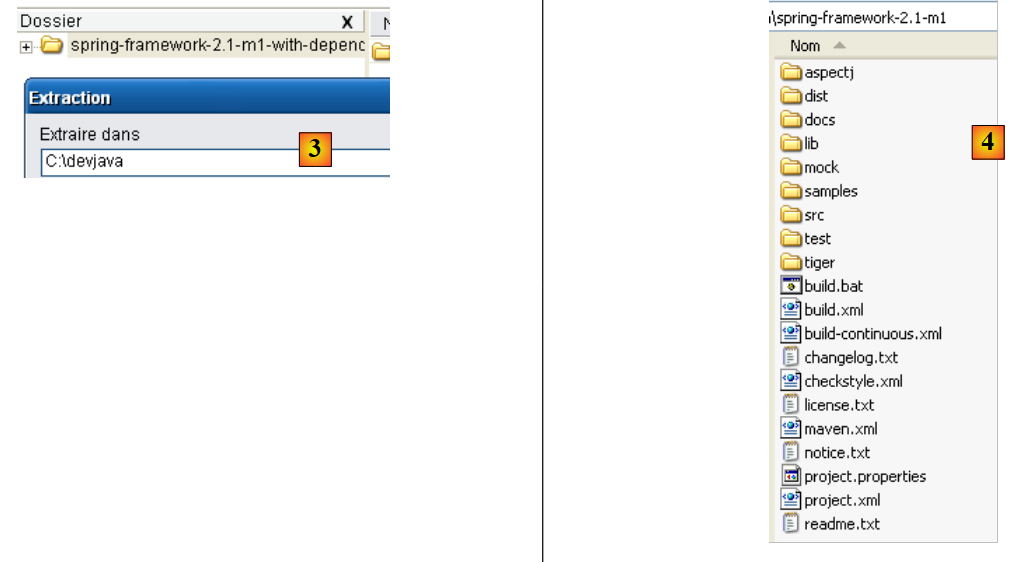 |
- em [3]: descompactamos o arquivo descarregado
- em [4]: a pasta de instalação do Spring 2.1
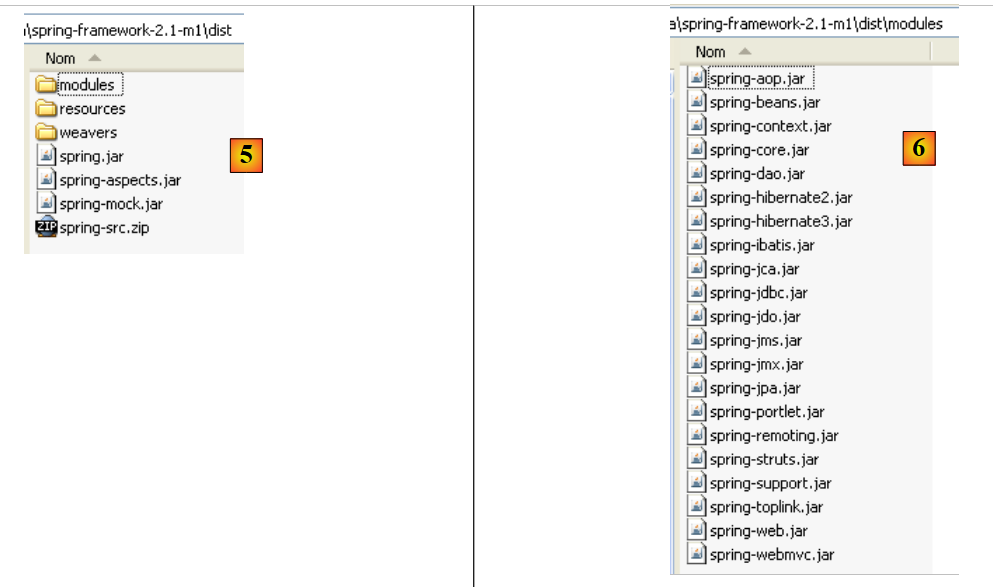 |
- em [5]: na pasta <dist>, encontram-se os arquivos do Spring. O arquivo [spring.jar] reúne todas as classes do framework Spring. Estas também estão disponíveis por módulos na pasta <modules> em [6]. Se soubermos quais os módulos de que precisamos, podemos encontrá-los aqui. Desta forma, evitamos incluir na aplicação arquivos de que ela não necessita.
 |
- em [7]: a pasta <lib> contém os arquivos das ferramentas de terceiros utilizadas pelo Spring
- em [8]: alguns arquivos do projeto [jakarta-commons]
Quando o tutorial utiliza arquivos do Spring, é necessário procurá-los na pasta <dist> ou na pasta <lib> da pasta de instalação do Spring.
5.12. O contentor EJB3 de JBoss
O contentor EJB3 de JBoss está disponível no URL [http://labs.jboss.com/jbossejb3/downloads/embeddableEJB3]:
 |
- em [1]: descarrega-se JBoss e EJB3. É possível observar a data do produto (setembro de 2006), embora o descarregamento tenha ocorrido em maio de 2007. É de questionar se este produto continua a ser atualizado.
- em [2]: o ficheiro descarregado
 |
- em [3]: o ficheiro ZIP descompactado
- em [4]: os arquivos [hibernate-all.jar, jboss-ejb3-all.jar, thirdparty-all.jar] formam o contêiner EJB3 de JBoss. É necessário colocá-los no classpath da aplicação que utiliza este contêiner.