3. Estudo de caso com o SQL Server Express 2012
3.1. Introduction
Os exemplos encontrados na Internet para o Entity Framework são, na sua maioria, exemplos com o SQL Server. Isso é bastante normal. É provável que este seja o SGBD mais difundido no mundo das empresas .NET. Vamos seguir esta tendência. Os exemplos serão posteriormente alargados a todas as bases de dados mencionadas no parágrafo 1.2.
3.2. Instalação das ferramentas
Não iremos descrever a instalação das ferramentas. Com efeito, isso exigiria uma enorme quantidade de capturas de ecrã que se tornariam obsoletas rapidamente. Trata-se de uma tarefa (nem sempre fácil, é verdade) que deixamos a cargo do leitor.
É necessário instalar as seguintes ferramentas:
- o SGBD SQL Server Express 2012: [http://www.microsoft.com/fr-fr/download/details.aspx?id=29062]. Descarregue a versão «With Tools», que inclui, juntamente com o SGBD, uma ferramenta de administração:
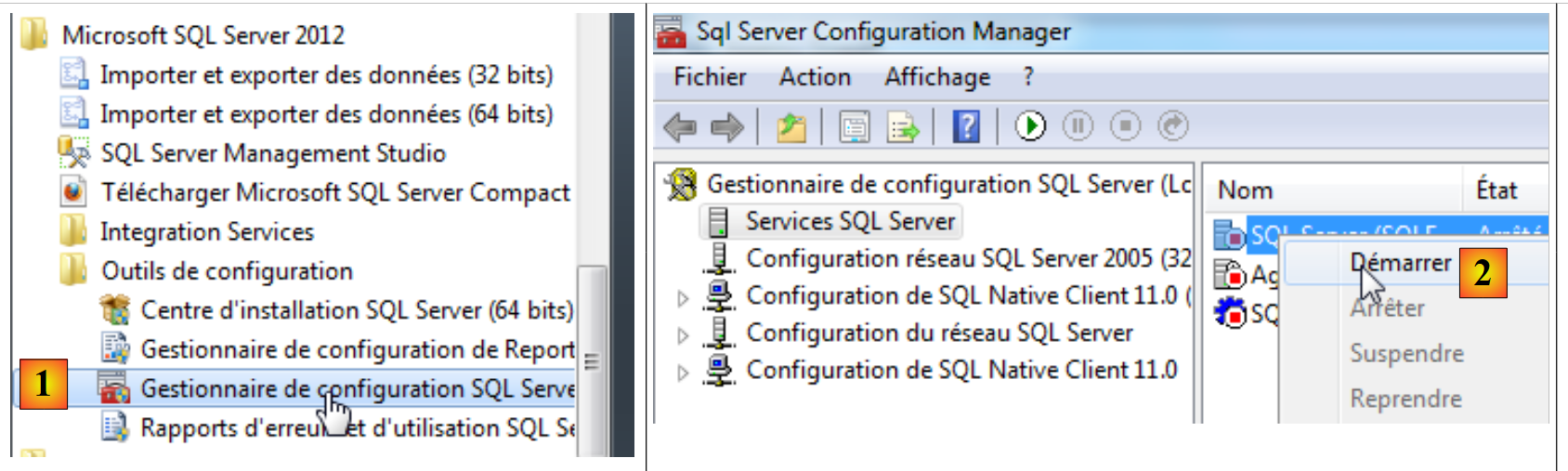
Depois de instalar o SGBD, executamo-lo:
 |
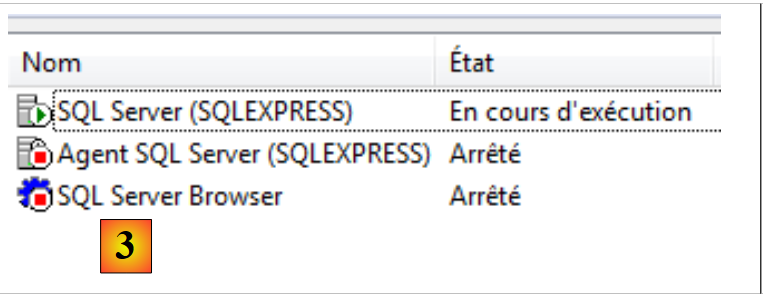 |
- [1]: no Menu Iniciar, inicie o «Gestor de configuração do servidor SQL»;
- [2]: neste gestor, inicie o servidor;
- [3]: o servidor está a funcionar.
Vamos agora iniciar a ferramenta de administração do SQL Server:
 |
- [1]: no Menu Iniciar, inicie o «SQL Server Management Studio»;
- [2]: a ferramenta de administração.
Vamos ligar-nos ao servidor:
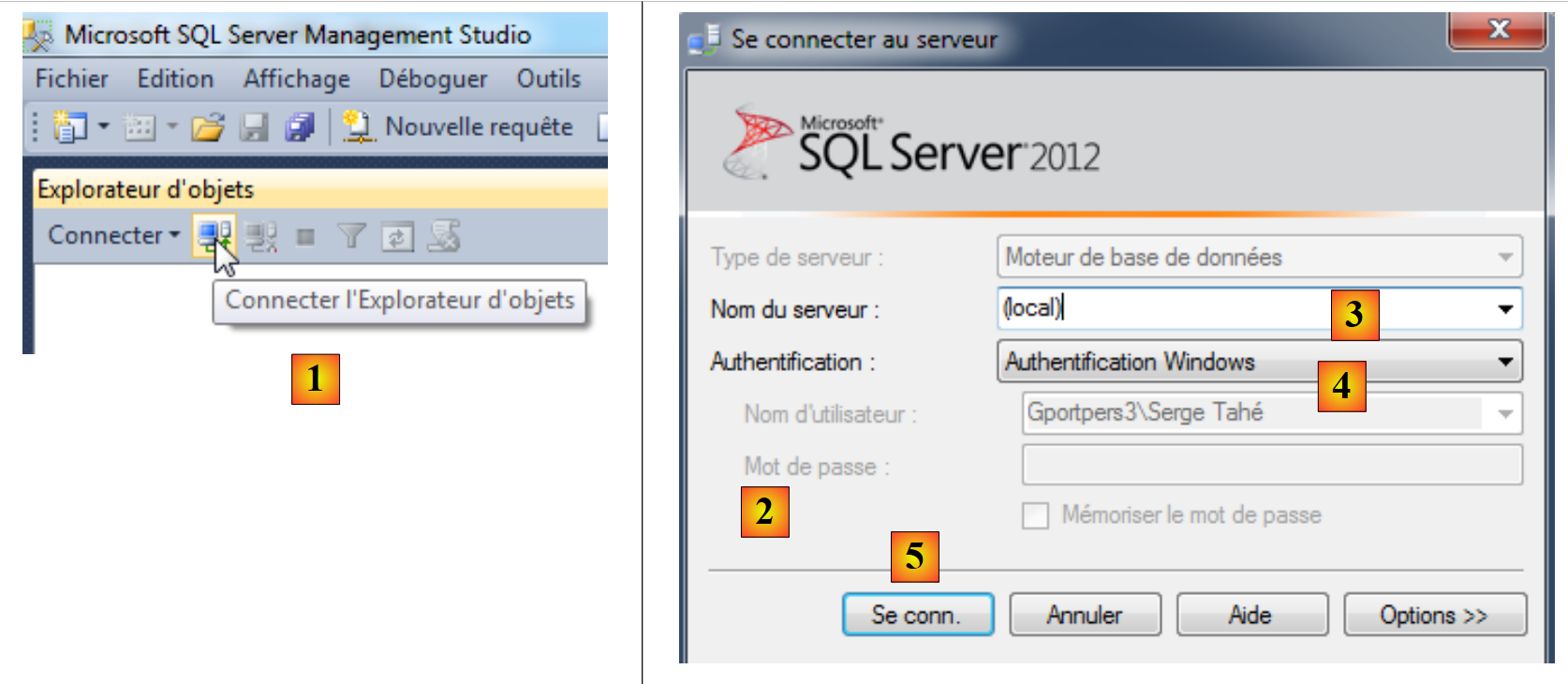 |
- em [1], abrimos o explorador de objetos;
- em [2], introduzimos os parâmetros de ligação:
- [3]: o servidor (local) (atenção aos parênteses necessários) refere-se ao servidor instalado no computador,
- [4]: escolhe-se a autenticação do Windows. É necessário ser administrador do próprio computador para que esta ligação seja bem-sucedida,
- [5]: efetua-se a ligação;
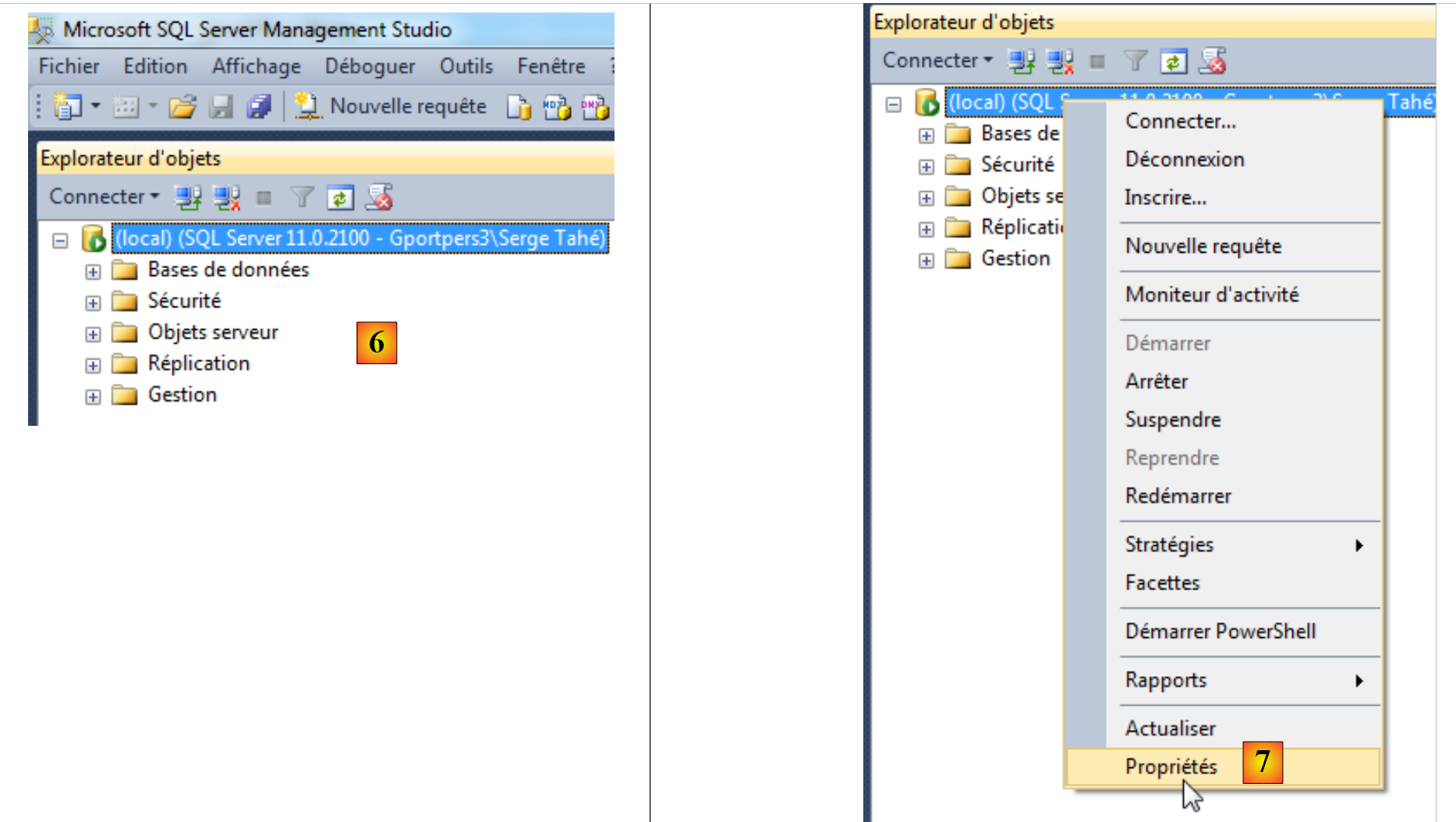 |
- [6]: a ligação foi estabelecida;
- [7]: pretende-se alterar algumas propriedades do servidor;
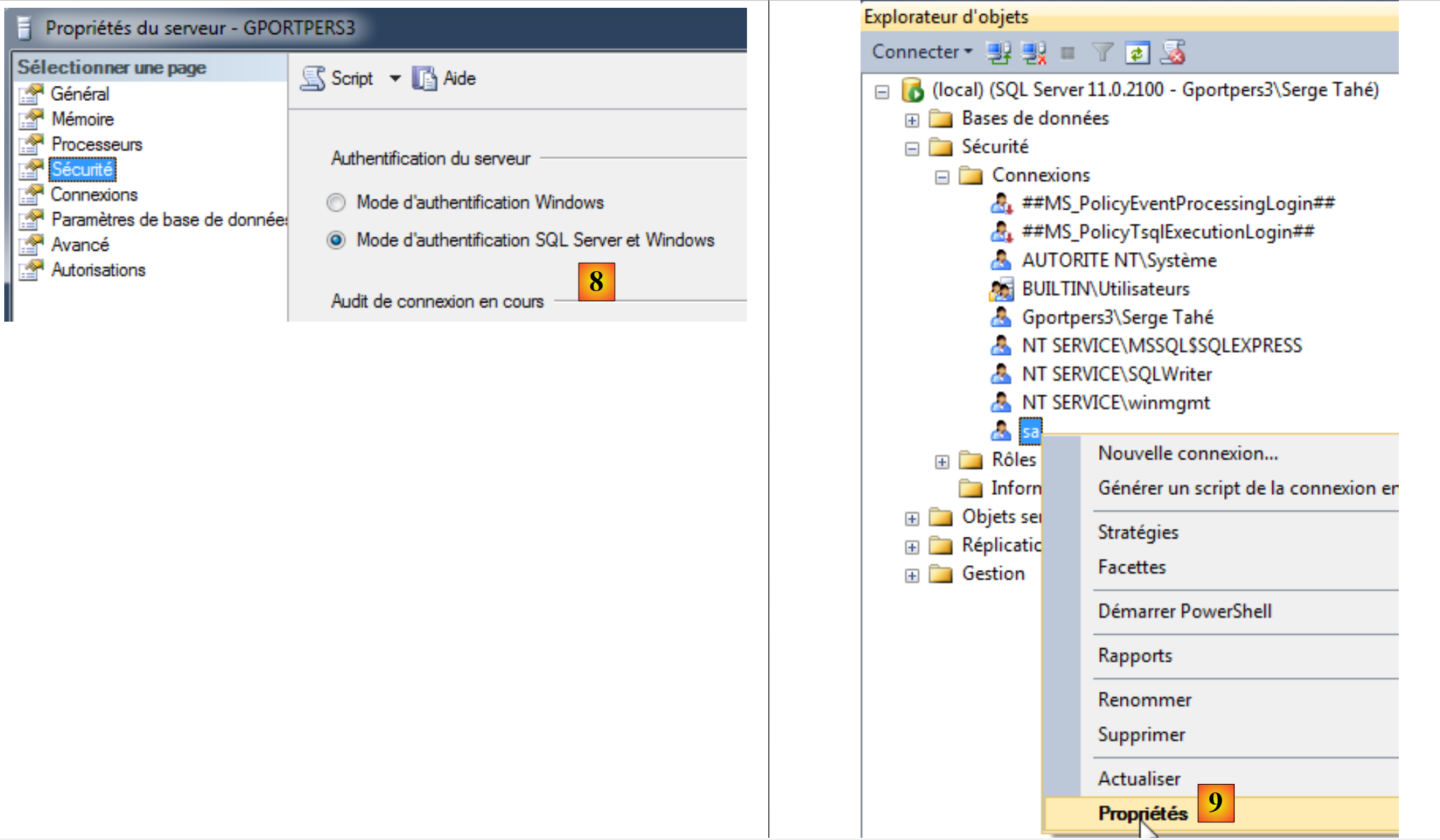 |
- [8]: solicita-se que existam dois modos de autenticação:
- autenticação do Windows, tal como acabou de ser utilizada. Um utilizador do Windows com os direitos adequados pode, assim, iniciar sessão,
- autenticação no servidor SQL. O utilizador deve fazer parte dos utilizadores registados no SGBD;
Feito isto, é possível validar as propriedades do servidor;
- [9]: editam-se as propriedades do utilizador «sa» (administrador do sistema);
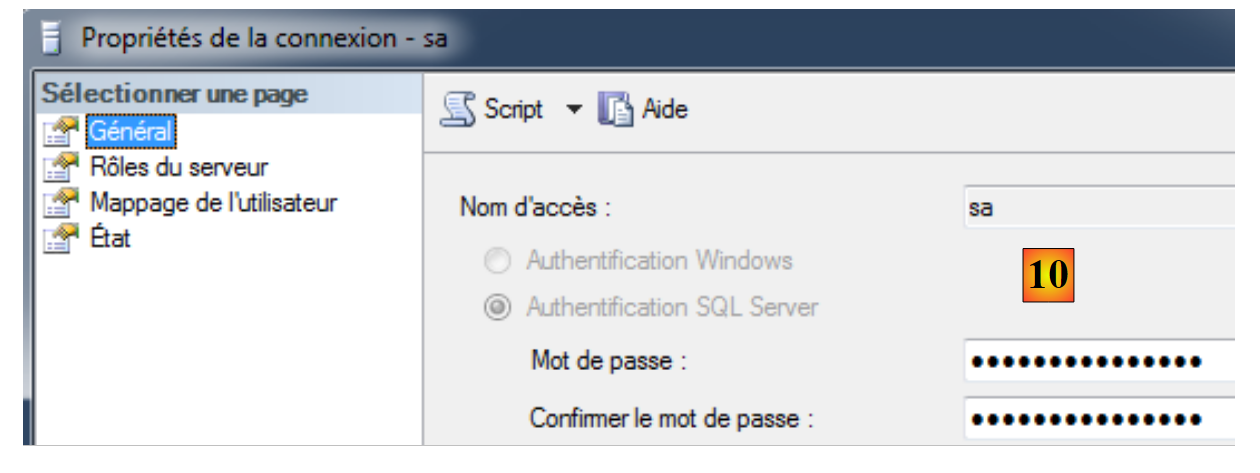 |
- no [10], define-se uma palavra-passe para ele. No restante deste documento, essa palavra-passe é «sqlserver2012»;
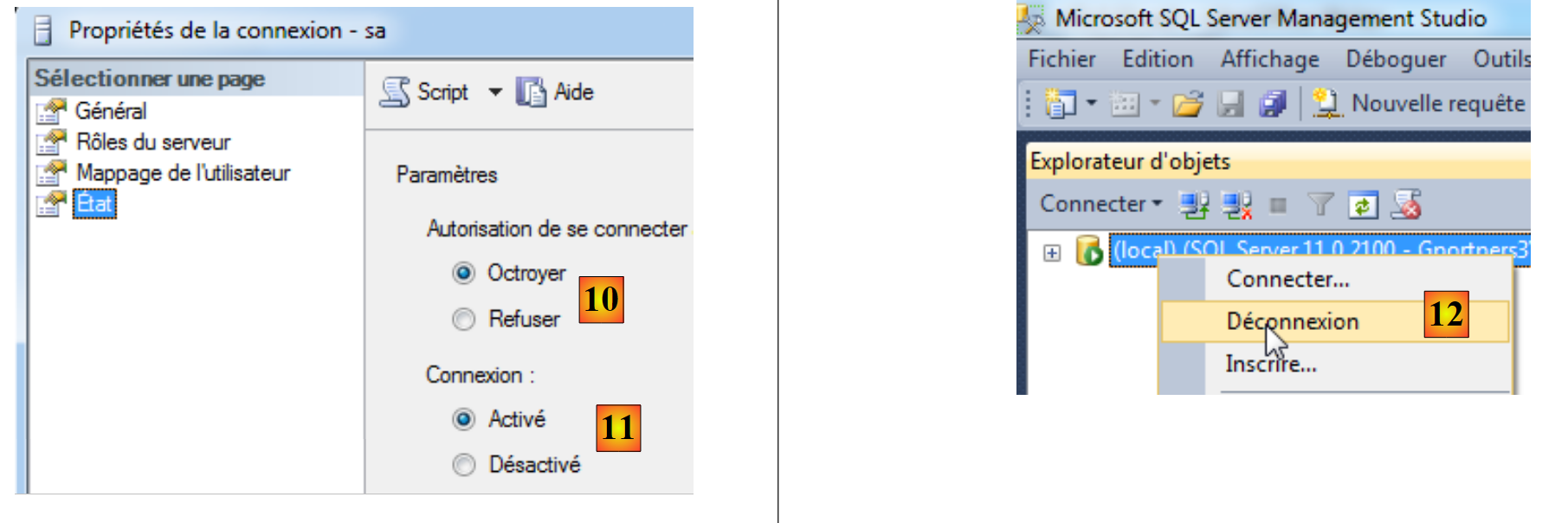 |
- em [10], concede-se-lhe autorização para se ligar;
- em [11], a ligação é ativada. Concluído isto, o assistente pode ser validado;
- em [12], desligamo-nos do servidor.
Agora, voltamos a ligar-nos com o login sa/sqlserver2012:
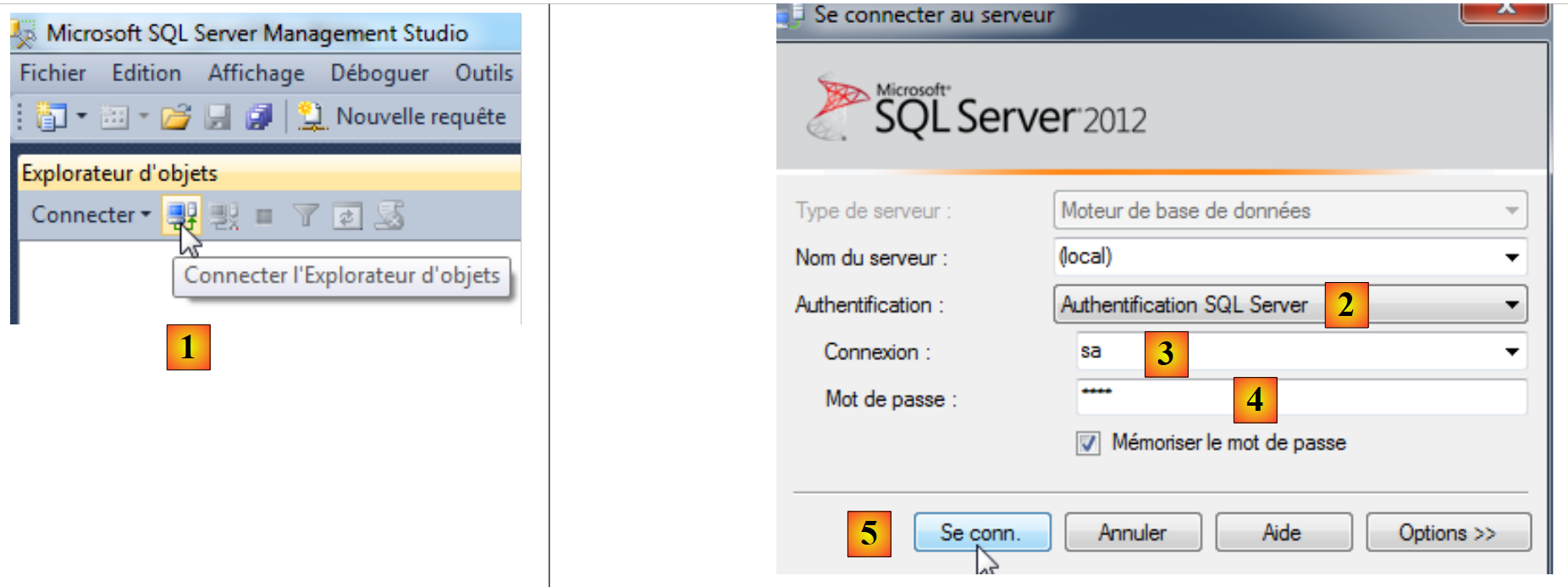 |
- em [1], voltamos a ligar-nos;
- em [2], na autenticação SQL Server;
- em [3], o utilizador é «sa»;
- em [4], a sua palavra-passe é sqlserver2012;
- em [5], efetua-se a ligação;
 |
- em [6], estamos ligados.
Vamos agora criar uma base de dados de demonstração:
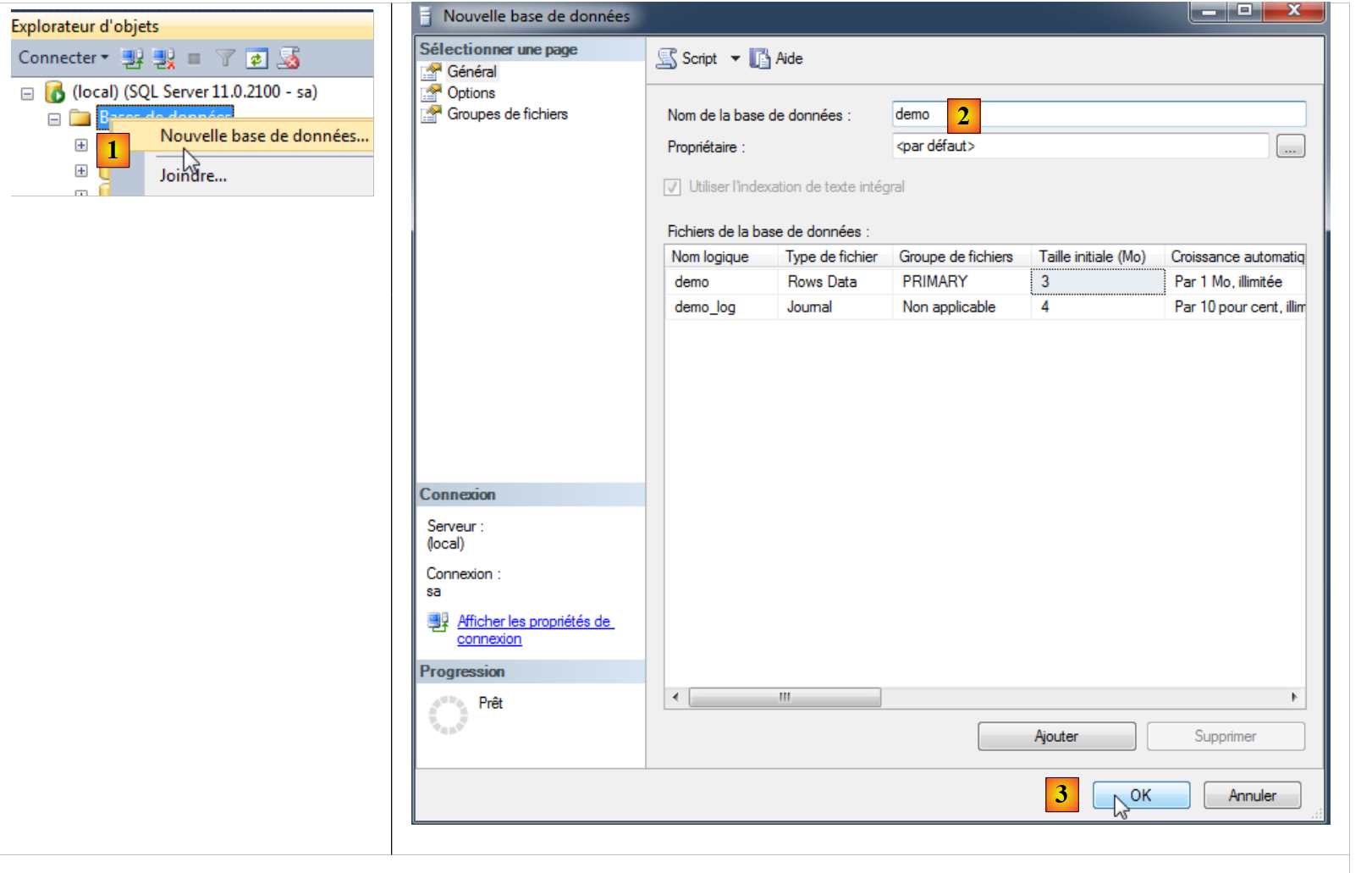 |
- em [1], criamos uma nova BD;
- em [2], que se chamará «demo»;
- em [3], confirmamos;
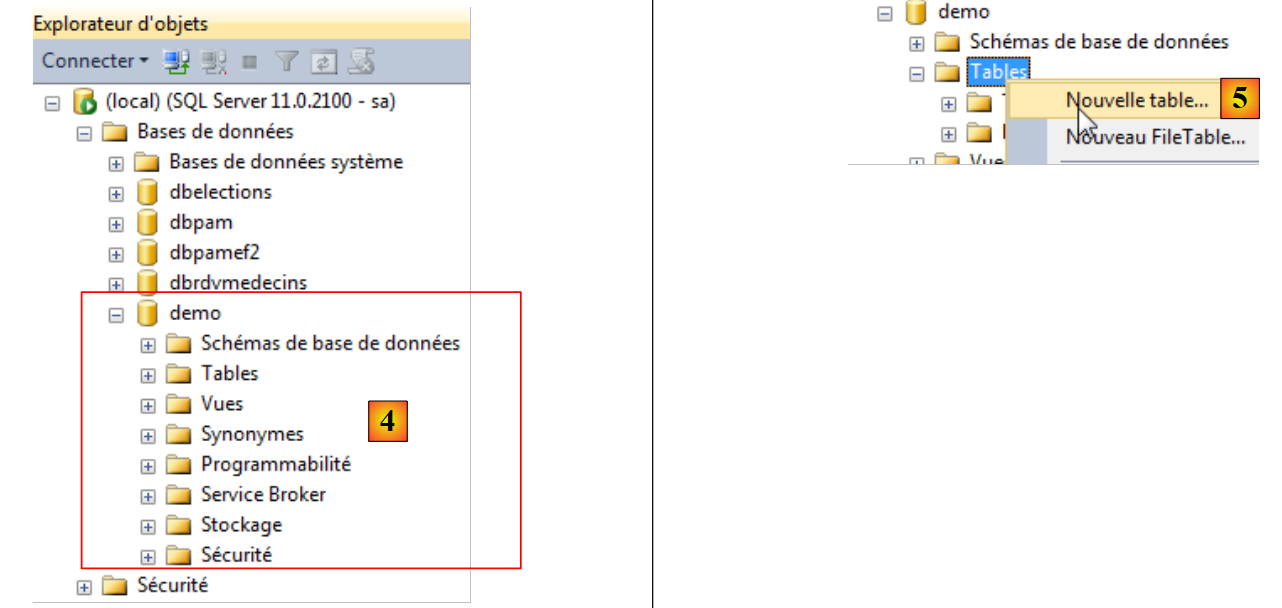 |
- no [4], a base de dados é criada;
- em [5], cria-se uma nova tabela na base de dados demo;
 |
 |
 |
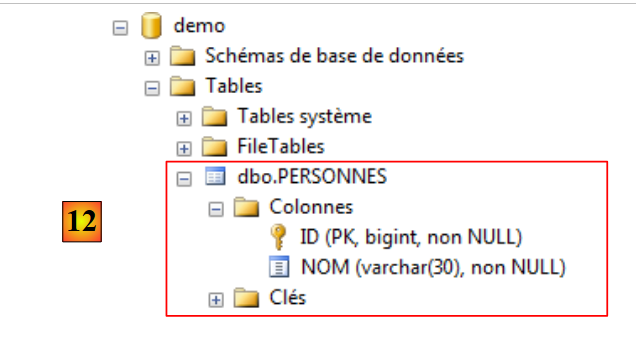 |
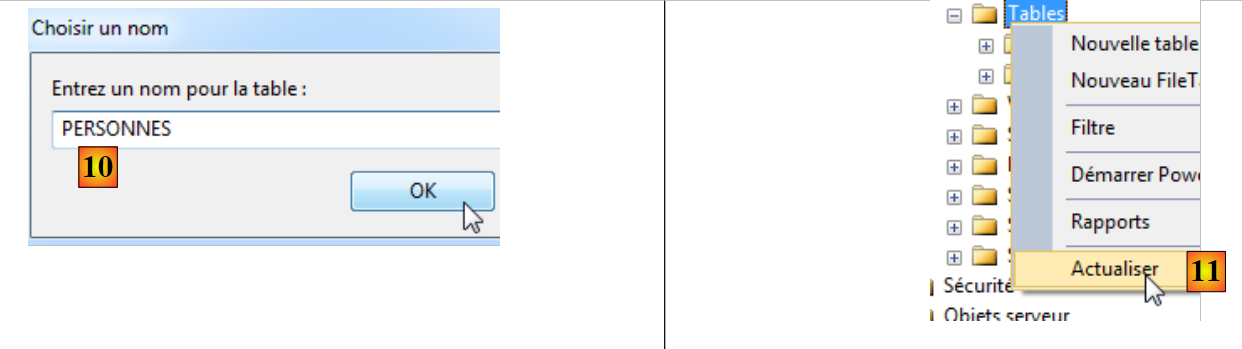
- na tabela [6], define-se uma tabela com duas colunas: ID e NOM;
- em [7], define-se a coluna [ID] como chave primária;
- em [8], a chave primária é representada por uma chave;
- em [9], guarda-se a tabela;
- em [10], atribui-se-lhe um nome;
- em [11], para que a tabela apareça na base de dados [demo], é necessário atualizar a base de dados;
- em [12], a tabela [PERSONNES] foi criada com sucesso.
Por agora, já sabemos o suficiente sobre a utilização da ferramenta de administração do SQL Server.
3.3. O servidor integrado (localdb)\v11.0
O VS Express 2012 inclui um servidor SQL integrado. Partimos do princípio de que o VS Express 2012 foi instalado no [http://www.microsoft.com/visualstudio/fra/downloads]. Iniciamos o VS 2012 no [1]:
 |
Inicia-se a ferramenta de administração do SQL Server 2012 [2] e efetua-se a ligação ao [3].
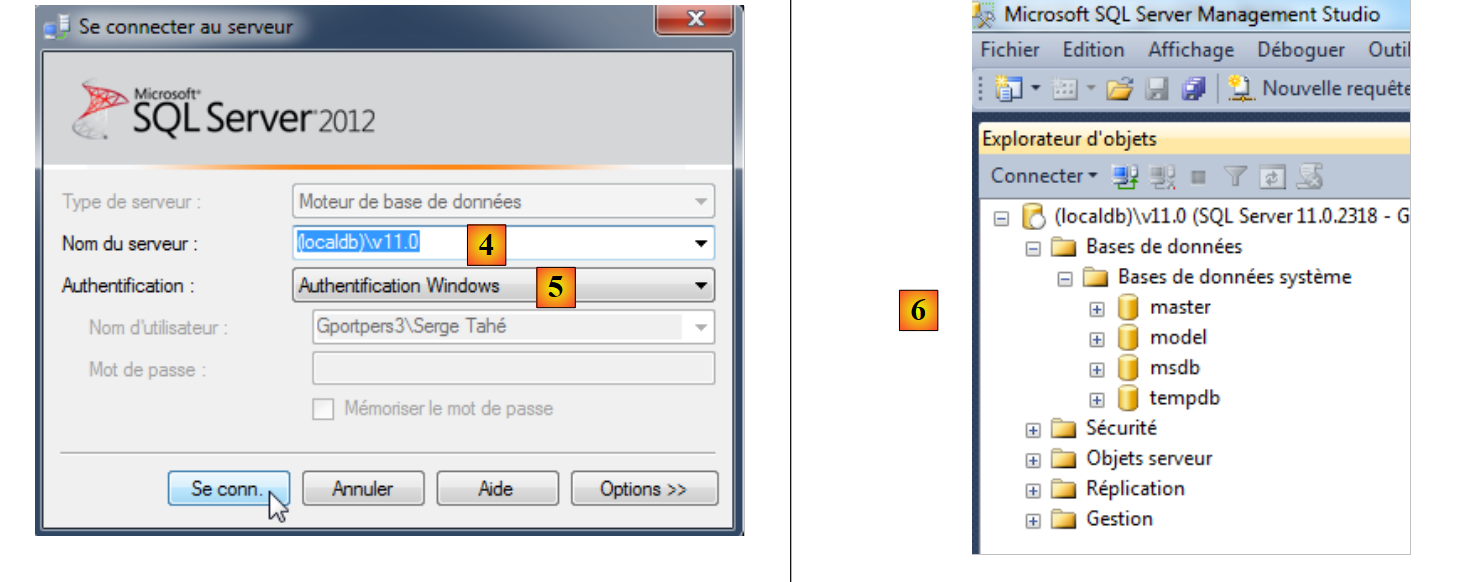 |
- no [4], ligamo-nos ao servidor (localdb)\v11.0;
- em [5], com autenticação do Windows;
- no [6], após a ligação bem-sucedida, são apresentadas as bases de dados do servidor. Tal como anteriormente, é possível criar uma nova base de dados.
Não iremos utilizar este servidor incorporado no VS 2012.
3.4. Criação da base de dados a partir das entidades
O Entity Framework 5 Code First permite criar uma base de dados a partir de entidades. É isso que vamos ver agora. Com o VS Express 2012, criamos um primeiro projeto de consola em C#:
 |
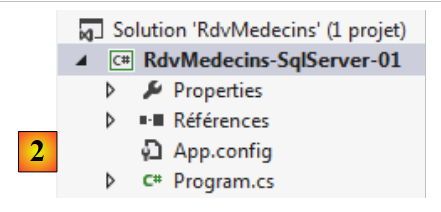 |
- em [1], a definição do projeto;
- em [2], o projeto criado.
Todos os nossos projetos vão precisar d , o DLL do Entity Framework 5. Adicionamo-lo:
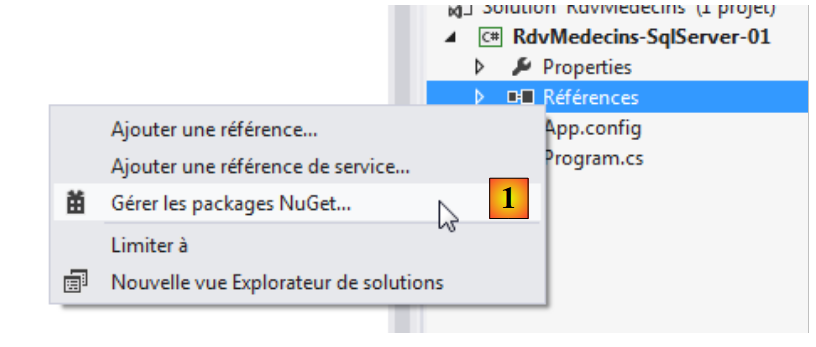 |
- em [1], a ferramenta NuGet permite descarregar dependências;
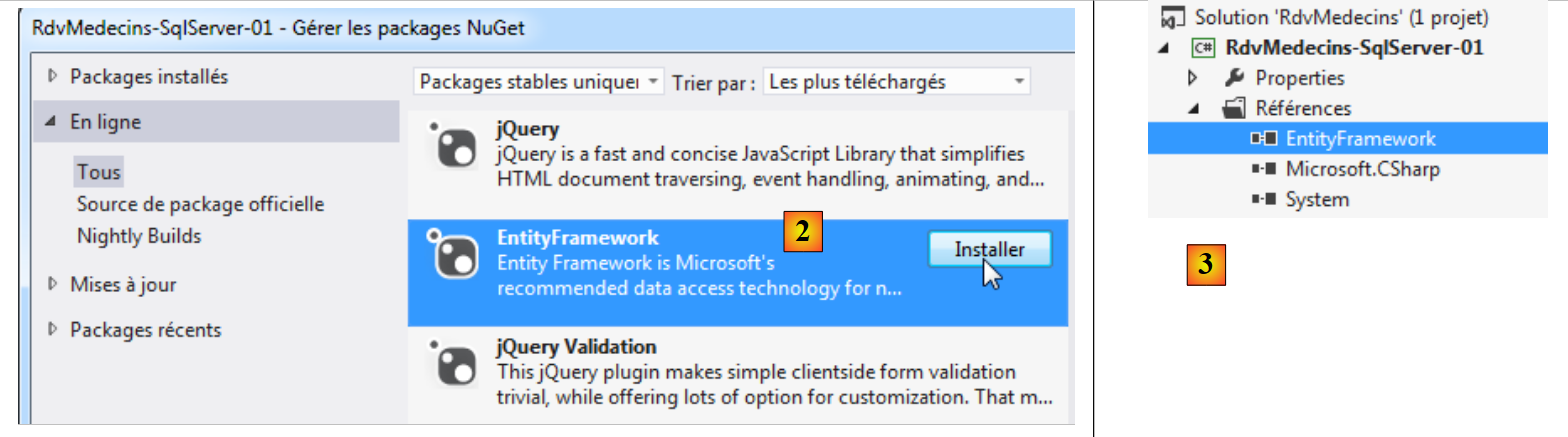 |
- em [2], descarregamos a dependência do Entity Framework;
- em [3], a referência foi adicionada ao projeto.
É possível obter mais informações consultando as propriedades da referência adicionada:
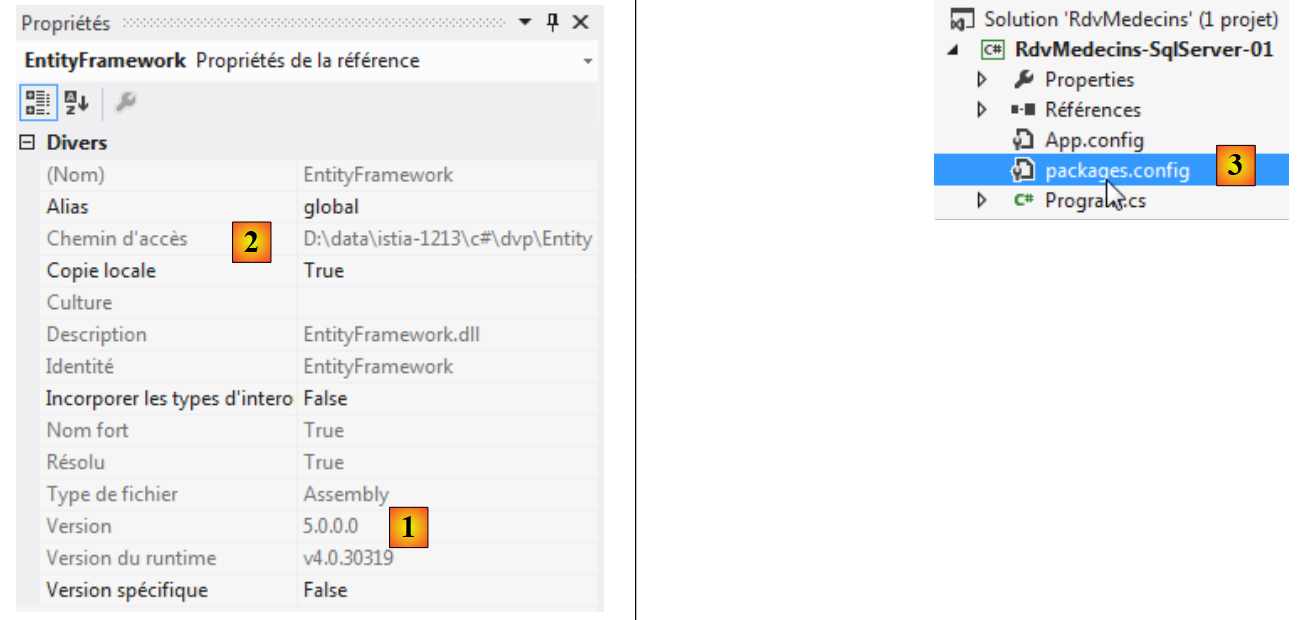 |
- em [1], a versão do DLL. É necessária a versão 5;
- em [2], a sua localização no sistema de ficheiros: <solução>\packages\EntityFramework.5.0.0\lib\net45\EntityFramework.dll, em que <solução> é a pasta da solução VS. Todos os pacotes adicionados pelo NuGet serão colocados na pasta <solução>/packages;
- no [3], foi criado um ficheiro [packages.config]. O seu conteúdo é o seguinte:
<?xml version="1.0" encoding="utf-8"?>
<packages>
<package id="EntityFramework" version="5.0.0" targetFramework="net45" />
</packages>
Este ficheiro lista os pacotes importados pelo NuGet.
Voltemos ao projeto VS e criemos uma pasta [Models] no projeto:
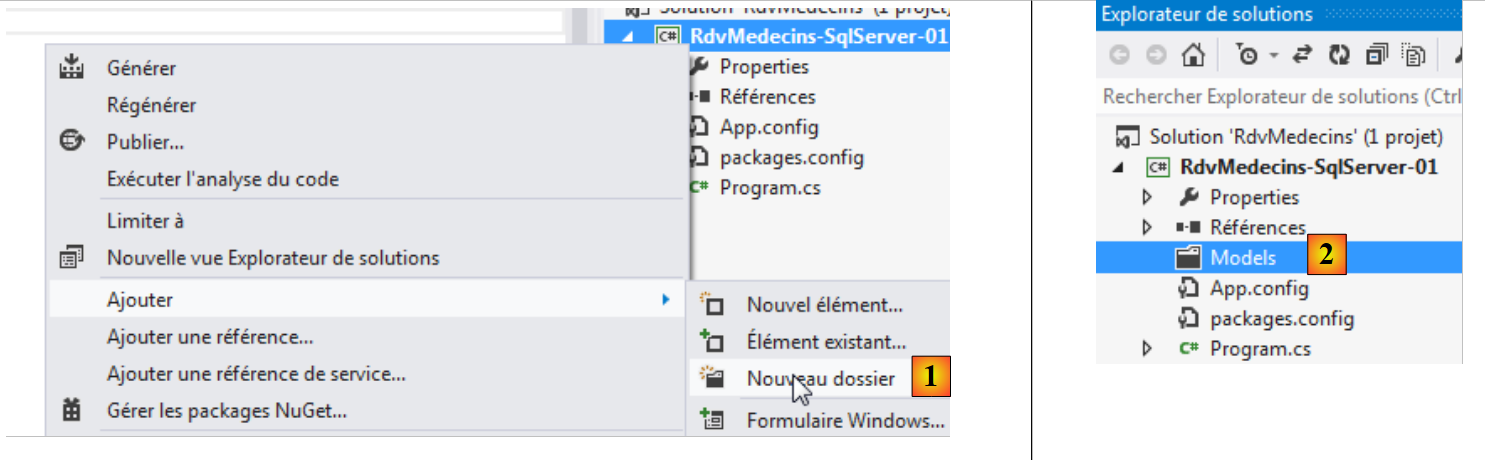 |
- em [1], adição de uma pasta ao projeto;
- em [2], que passará a chamar-se [Models].
Manteremos esta prática de, doravante, colocar a definição das nossas entidades na pasta [Models].
Para criar as nossas entidades, vamos recorrer à definição da base de dados MySQL 5 utilizada no projeto NHibernate. Recorde-se o papel das entidades EF:
 |
As entidades devem refletir as tabelas da base de dados. A camada de acesso aos dados utiliza estas entidades em vez de trabalhar diretamente com as tabelas. Comecemos pela tabela [MEDECINS]:
3.4.1. A entidade [Medecin]
Contém informações sobre os médicos geridos pela aplicação [RdvMedecins].
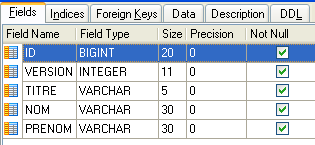 |  |
- ID: número que identifica o médico — chave primária da tabela
- VERSION: número que identifica a versão da linha na tabela. Este número é incrementado em 1 sempre que é feita uma alteração na linha.
- NOM: o nome do médico
- PRENOM: o seu nome próprio
- TITRE: o seu título (Menina, Sra., Sr.)
Poderíamos partir da seguinte classe [Medecin]:
using System;
[Table("MEDECINS", Schema = "dbo")]
namespace RdvMedecins.Entites
{
public class Medecin
{
// dados
public int Id { get; set; }
public string Titre { get; set; }
public string Nom { get; set; }
public string Prenom { get; set; }
}
- linha 3: a classe [Medecin] está associada à tabela [MEDECINS] da base de dados. Esta encontra-se num esquema denominado «dbo».
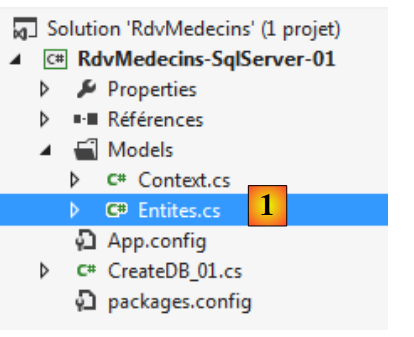
Colocamos esta classe num ficheiro [Entites.cs] [1]. É aí que iremos colocar todas as nossas entidades.
 |
Ainda na pasta [Models], criamos o seguinte ficheiro [Context.cs]:
using System.Data.Entity;
using RdvMedecins.Entites;
namespace RdvMedecins.Models
{
// o contexto
public class RdvMedecinsContext : DbContext
{
// os médicos
public DbSet<Medecin> Medecins { get; set; }
}
// inicialização da base de dados
public class RdvMedecinsInitializer : DropCreateDatabaseAlways<RdvMedecinsContext>
{
}
}
- linha 8: a classe [RdvMedecinsContext] irá representar o contexto de persistência, c.-à-d. o conjunto de entidades geridas pela ORM. Deve derivar da classe [System.Data.Entity.DbContext];
- linha 11: o campo [Medecins] representará as entidades do tipo [Medecin] do contexto de persistência. É do tipo DbSet<Medecin>. Normalmente, haverá tantos [DbSet] quantas as tabelas na base de dados, um por tabela;
- linha 15: define-se uma classe [RdvMedecinsInitializer] para inicializar a base de dados criada. Aqui, ela deriva da classe [DropCreateDataBaseAlways] que, tal como o próprio nome indica, elimina a base de dados se esta já existir e, em seguida, recria-a. Isto é útil na fase de desenvolvimento da BD. O parâmetro da classe [DropCreateDataBaseAlways] é o tipo de contexto de persistência associado à base de dados. É possível utilizar outras classes-pai além da [DropCreateDataBaseAlways] para a classe de inicialização:
- [DropCreateDatabaseIfModelChanges]: recria a base de dados se as entidades tiverem sido alteradas,
- [CreateDatabaseIfNotExists]: cria a base de dados se esta não existir;
Resta-nos criar um programa principal. Será o seguinte: [CreateDB_01.cs]:
using System;
using System.Data.Entity;
using RdvMedecins.Models;
namespace RdvMedecins_01
{
class CreateDB_01
{
static void Main(string[] args)
{
// criamos a base de dados
Database.SetInitializer(new RdvMedecinsInitializer());
using (var context = new RdvMedecinsContext())
{
context.Database.Initialize(false);
}
}
}
}
- linha 12: [System.Data.Entity.DataBase] é uma classe que oferece métodos estáticos para gerir a base de dados associada a um contexto de persistência. O método estático [SetInitializer] permite especificar a classe de inicialização da base de dados. Isto não inicia a inicialização;
- linha 13: para trabalhar com um contexto de persistência, é necessário instanciá-lo. É isso que se faz aqui. Utiliza-se uma cláusula «using» para que o contexto seja automaticamente fechado ao sair da cláusula. Assim, na linha 17, o contexto é fechado;
- linha 15: inicia-se explicitamente a geração da base de dados associada ao contexto de persistência [RdvMedecinsContext]. O parâmetro false indica que esta operação não deve ser realizada se já tiver sido efetuada para este contexto. Aqui, poderíamos igualmente ter utilizado true.
Quando se trabalha com uma base de dados, os parâmetros de ligação são geralmente registados no ficheiro [App.config]. Verifica-se que, por enquanto, não se encontram nesse ficheiro:
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<configSections>
<!-- Para mais informações sobre a configuração do Entity Framework, visite http://go.microsoft.com/fwlink/?LinkID=237468 -->
<section name="entityFramework" type="System.Data.Entity.Internal.ConfigFile.EntityFrameworkSection, EntityFramework, Version=5.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089" requirePermission="false" />
</configSections>
<startup>
<supportedRuntime version="v4.0" sku=".NETFramework,Version=v4.5" />
</startup>
<entityFramework>
<defaultConnectionFactory type="System.Data.Entity.Infrastructure.SqlConnectionFactory, EntityFramework" />
</entityFramework>
</configuration>
Os elementos acima foram gravados no ficheiro [App.config] quando adicionámos a dependência do Entity Framework às referências do projeto.
Vamos executar o projeto (Ctrl-F5) depois de ter iniciado o SQL Server Express (isto é importante):
 |  |
A execução deve terminar sem erros. Vamos agora abrir a ferramenta de administração do SQL Server e atualizar a visualização:
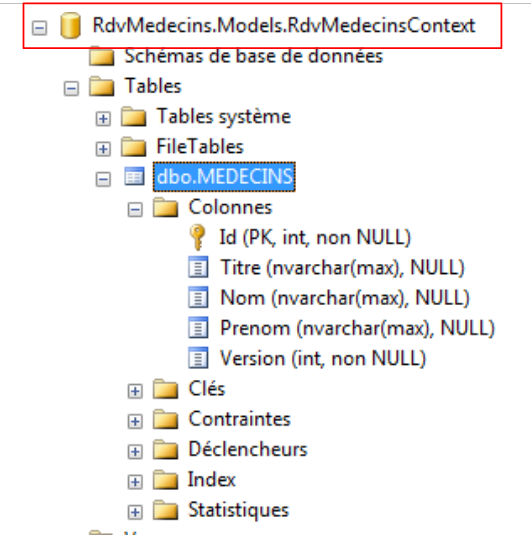 |
Verifica-se que foi criada uma base de dados com o nome completo da classe [RdvMedecinsContext] e que esta contém uma tabela [dbo.MEDECINS] (este é o nome que lhe foi atribuído) com colunas que correspondem aos nomes dos campos da entidade [Medecin]. Se o código tiver sido executado corretamente e a base de dados acima referida não aparecer, deve verificar-se o servidor incorporado (localdb)\v11.0 (ver página 19). Com o VS 2012 Pro, este servidor é utilizado se o servidor SQL não estiver ativo no momento da execução do código. Com o VS 2012 Express, não.
Analisemos a estrutura da tabela [MEDECINS]:
- ela retoma os nomes dos campos da entidade [Medecin];
- a coluna [Id] é a chave primária. Trata-se de uma convenção do EF: se a entidade E tiver um campo Id ou Eid (MedecinId), então essa coluna é a chave primária na tabela associada;
- os tipos das colunas da tabela são os dos campos da entidade;
- para as colunas Título, Apelido e Nome próprio, foi utilizado um tipo [nvarchar(max)]. Poderíamos ser mais precisos: 5 caracteres para o título, 30 para o apelido e o nome próprio;
- as colunas Título, Apelido e Nome próprio podem ter o valor NULL. Vamos alterar isso.
Vejamos as propriedades da chave primária [Id]:
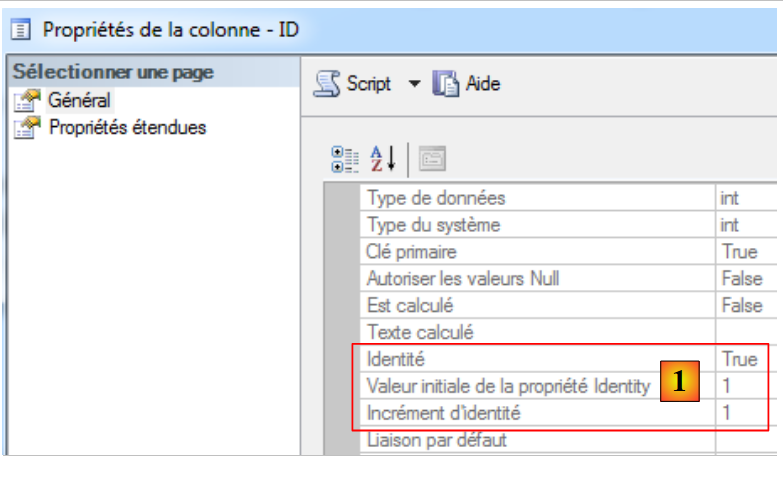 |
Em [1], vemos que a chave primária é do tipo [Identité], o que significa que o seu valor é gerado automaticamente pelo servidor SQL. Vamos adotar esta estratégia para todos os SGBD.
Vamos reduzir a dependência das convenções de EF através da utilização de anotações. O código da entidade em [Entites.cs] passa a ser o seguinte:
using System;
using System.ComponentModel.DataAnnotations;
using System.ComponentModel.DataAnnotations.Schema;
namespace RdvMedecins.Entites
{
[Table("MEDECINS", Schema = "dbo")]
public class Medecin
{
// dados
[Key]
[Column("ID")]
public int Id { get; set; }
[Required]
[MaxLength(5)]
[Column("TITRE")]
public string Titre { get; set; }
[Required]
[MaxLength(30)]
[Column("NOM")]
public string Nom { get; set; }
[Required]
[MaxLength(30)]
[Column("PRENOM")]
public string Prenom { get; set; }
[Required]
[Column("VERSION")]
public int Version { get; set; }
}
}
- linhas 2 e 3: as anotações encontram-se nos espaços de nomes [System.ComponentModel.DataAnnotations] (Key, Required, MaxLength) e [System.ComponentModel.DataAnnotations.Schema] (Column). Encontram-se outras anotações nos espaços de nomes URL e [http://msdn.microsoft.com/en-us/data/gg193958.aspx];
- linha 11: [Key] designa a chave primária;
- linha 12: [Column] define o nome da coluna correspondente ao campo;
- linha 14: [Required] indica que o campo é obrigatório (SQL, NOT, NULL);
- linha 15: [MaxLength] define o tamanho máximo da cadeia de caracteres, [MinLength] o seu tamanho mínimo;
Vamos executar o projeto com esta nova definição da entidade [Medecin]. A base de dados criada é então a seguinte:
 |
- as colunas têm o nome que lhes foi atribuído;
- a anotação [Required] foi convertida em SQL, NOT e NULL;
- a anotação [MaxLength(N)] foi convertida para o tipo SQL nvarchar(N).
Na aplicação NHibernate, a coluna [VERSION] existia para impedir acessos simultâneos à mesma linha de uma tabela. O princípio é o seguinte:
- um processo P1 lê uma linha L da tabela [MEDECINS] no momento T1. A linha tem a versão V1;
- um processo P2 lê a mesma linha L da tabela [MEDECINS] no momento T2. A linha tem a versão V1 porque o processo P1 ainda não validou a sua alteração;
- o processo P1 valida a sua alteração na linha L. A versão da linha L passa então para V2=V1+1;
- o processo P2 valida a sua alteração na linha L. O ORM lança então uma exceção, pois o processo P2 tem uma versão V1 da linha L diferente da versão V2 encontrada na base de dados.
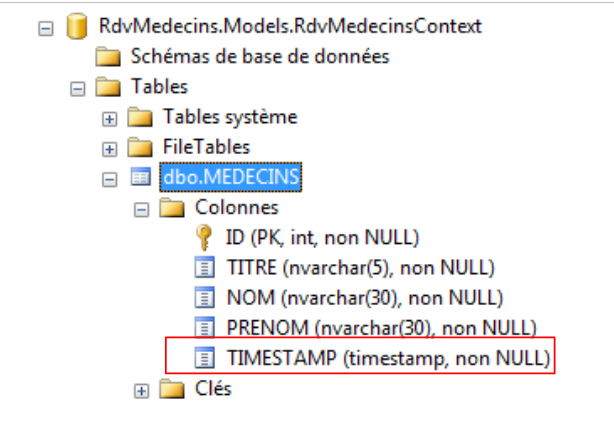
A isto chama-se gestão otimista de acessos concorrentes. Com o EF 5, um campo que desempenha esta função deve ter um dos dois atributos: [Timestamp] ou [ConcurrencyCheck]. O SQL Server tem um tipo [timestamp]. Numa coluna com este tipo, o valor é gerado automaticamente pelo SQL Server sempre que se insere ou altera uma linha. Essa coluna pode, então, servir para gerir a concorrência de acesso. Retomando o exemplo anterior, o processo P2 encontrará um timestamp diferente daquele que leu, pois, entretanto, a alteração efetuada pelo processo P1 terá modificado o mesmo.
A nossa entidade [Medecin] evolui da seguinte forma:
using System;
using System.ComponentModel.DataAnnotations;
using System.ComponentModel.DataAnnotations.Schema;
namespace RdvMedecins.Entites
{
[Table("MEDECINS", Schema = "dbo")]
public class Medecin
{
// dados
[Key]
[Column("ID")]
public int Id { get; set; }
[Required]
[MaxLength(5)]
[Column("TITRE")]
public string Titre { get; set; }
[Required]
[MaxLength(30)]
[Column("NOM")]
public string Nom { get; set; }
[Required]
[MaxLength(30)]
[Column("PRENOM")]
public string Prenom { get; set; }
[Column("TIMESTAMP")]
[Timestamp]
public byte[] Timestamp { get; set; }
}
}
- linhas 26-28: a nova coluna com o atributo [Timestamp] da linha 27. O tipo do campo deve ser byte[] (linha 28). O nome do campo pode ser qualquer um. Não se atribui o atributo [Required], pois não é a aplicação que fornecerá esse valor, mas sim o próprio SGBD.
Se executarmos o projeto com esta nova entidade, a base de dados evolui da seguinte forma:
 |
Resta-nos resolver um último ponto. O contexto de persistência «sabe» que uma entidade deve ser inserida na base de dados porque, nesse momento, a sua chave primária é igual a null. É a inserção na base de dados que irá atribuir um valor à chave primária. Neste caso, o tipo int atribuído à chave primária [Id] não é adequado, porque esse tipo não aceita o valor null. Assim, atribui-se-lhe o tipo «int?», que aceita os valores int e o ponteiro null. A entidade [Medecin] utilizada será, portanto, a seguinte:
public class Medecin
{
// dados
[Key]
[Column("ID")]
public int? Id { get; set; }
...
Resta-nos ver como representar numa entidade o conceito de chave estrangeira entre tabelas.
3.4.2. A entidade [Creneau]
A tabela [CRENEAUX] lista os intervalos horários em que os RV são possíveis:
 |
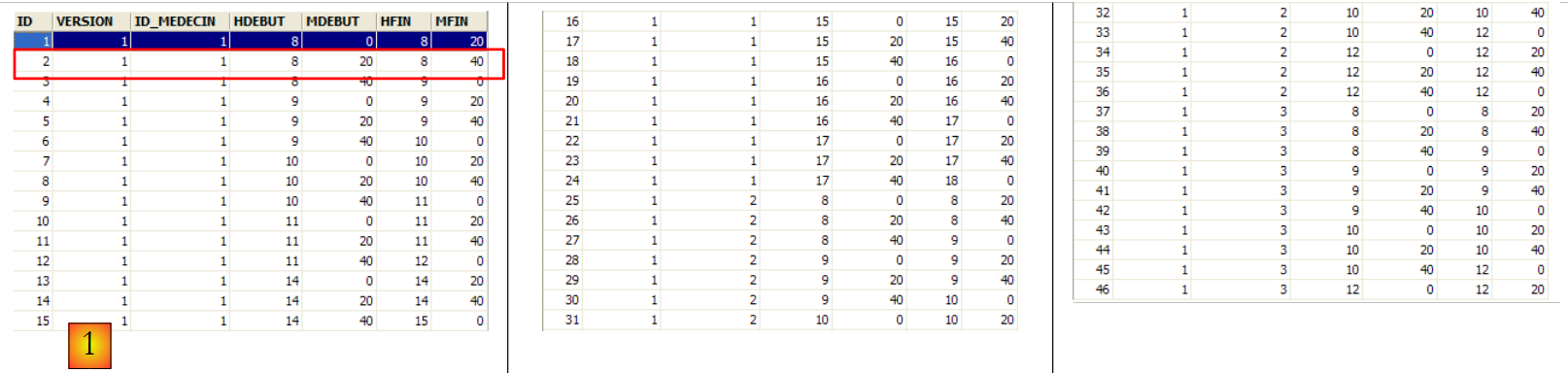 |
- ID: número que identifica o intervalo horário — chave primária da tabela
- VERSION: número que identifica a versão da linha na tabela. Este número é incrementado em 1 sempre que é feita uma alteração na linha.
- ID_MEDECIN: número que identifica o médico a quem pertence este intervalo horário – chave estrangeira na coluna MEDECINS (ID).
- HDEBUT: hora de início do intervalo
- MDEBUT: minutos de início do intervalo
- HFIN: hora de fim do intervalo
- MFIN: minutos de fim do intervalo
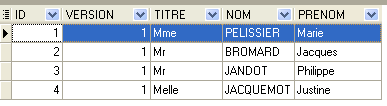
A segunda linha da tabela [CRENEAUX] (ver [1] acima) indica, por exemplo, que o intervalo n.º 2 começa às 8h20 e termina às 8h40 e pertence à médica n.º 1 (Sra. Marie PELISSIER).
Com base no que sabemos, podemos definir a entidade [Creneau] da seguinte forma na tabela [Entites.cs]:
[Table("CRENEAUX", Schema = "dbo")]
public class Creneau
{
// dados
[Key]
[Column("ID")]
public int? Id { get; set; }
[Required]
[Column("HDEBUT")]
public int Hdebut { get; set; }
[Required]
[Column("MDEBUT")]
public int Mdebut { get; set; }
[Required]
[Column("HFIN")]
public int Hfin { get; set; }
[Required]
[Column("MFIN")]
public int Mfin { get; set; }
[Required]
public virtual Medecin Medecin { get; set; }
[Column("TIMESTAMP")]
[Timestamp]
public byte[] Timestamp { get; set; }
}
A única novidade reside nas linhas 20-21. O facto de a tabela [CRENEAUX] ter uma chave estrangeira na tabela [MEDECINS] é refletido na entidade [Creneau] pela presença de uma referência à entidade [Medecin], linha 21. O nome do campo não tem importância; apenas o tipo é relevante. A propriedade deve ser declarada como virtual com a palavra-chave virtual. Com efeito, a EF tem de redefinir todas as propriedades ditas de navegação, ou seja, aquelas que correspondem a uma chave estrangeira e que permitem passar de uma tabela para outra.
Para testar a nova entidade, é necessário efetuar algumas alterações em [Context.cs]:
using System.Data.Entity;
using RdvMedecins.Entites;
namespace RdvMedecins.Models
{
// o contexto
public class RdvMedecinsContext : DbContext
{
// as entidades
public DbSet<Medecin> Medecins { get; set; }
public DbSet<Creneau> Creneaux { get; set; }
}
// inicialização da base
public class RdvMedecinsInitializer : DropCreateDatabaseIfModelChanges<RdvMedecinsContext>
{
}
}
A linha 12 reflete o facto de o contexto ter mais uma entidade para gerir. Quando executamos o projeto, obtemos a seguinte nova base de dados:
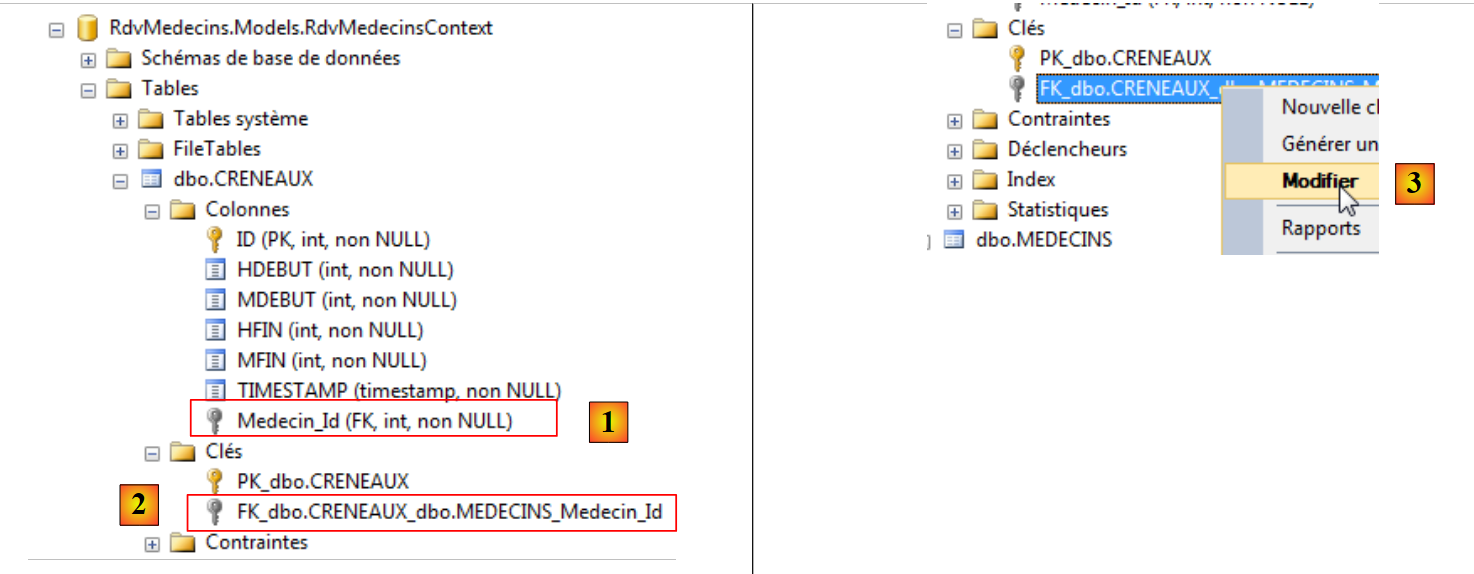 |
A tabela [CRENEAUX] foi efetivamente criada e a novidade é a presença de uma chave estrangeira [1] e [2]. O seu nome foi gerado a partir do nome do campo correspondente na entidade (Médico), com o sufixo «_Id». Para conhecer as propriedades desta chave estrangeira, tentamos alterá-la para [3].
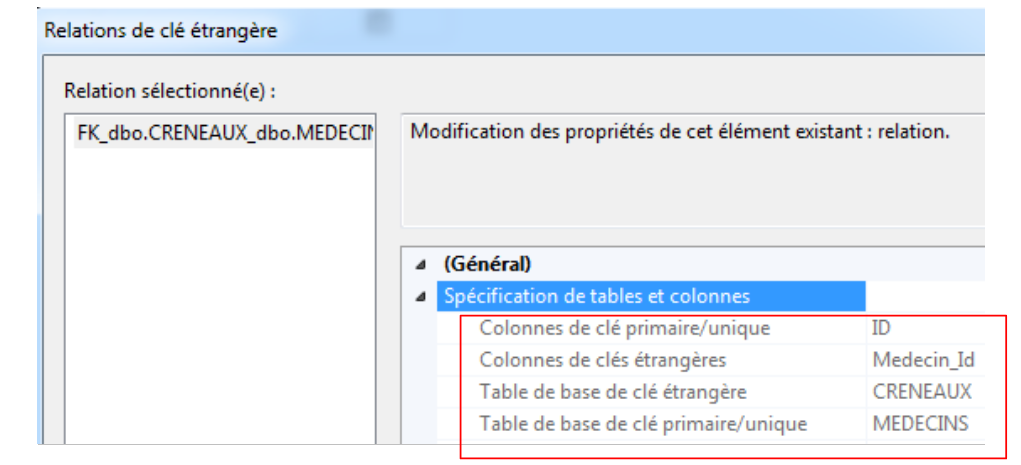 |
A captura de ecrã acima mostra que [Medecin_Id] é a chave estrangeira da tabela [CRENEAUX] e que faz referência à chave primária [ID] da tabela [MEDECINS].
Se criarmos as entidades para uma base de dados existente, a coluna da chave estrangeira não se chamará necessariamente [Medecin_Id]. No caso das outras colunas, vimos que a anotação [Column] resolvia este problema. Curiosamente, isto é mais complicado no caso de uma chave estrangeira. É necessário proceder da seguinte forma:
public class Creneau
{
// dados
...
[Required]
[Column("MEDECIN_ID")]
public int MedecinId { get; set; }
[Required]
[ForeignKey("MedecinId")]
public virtual Medecin Medecin { get; set; }
...
}
- linhas 5-7: cria-se um campo do tipo da chave estrangeira (int). Com o atributo [Column], especifica-se o nome da coluna que será a chave estrangeira na tabela associada à entidade;
- linha 9: adiciona-se a anotação [ForeignKey] ao campo do tipo [Medecin]. O argumento desta anotação é o nome do campo (não da coluna) que está associado à coluna-chave estrangeira da tabela.
A execução do projeto cria, desta vez, a seguinte tabela:
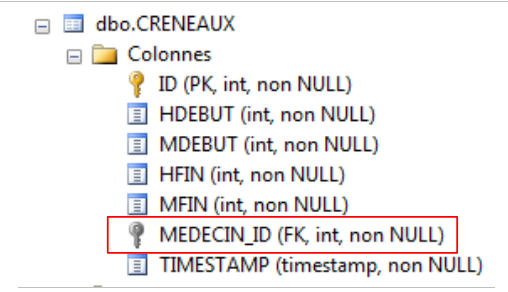 |
Na tabela acima, a coluna-chave estrangeira tem, de facto, o nome que lhe foi atribuído. É importante notar que os campos:
[Required]
[Column("MEDECIN_ID")]
public int MedecinId { get; set; }
[Required]
[ForeignKey("MedecinId")]
public virtual Medecin Medecin { get; set; }
deram origem a apenas uma coluna, a coluna [MEDECIN_ID]. No entanto, a presença do campo [MedecinId] é importante. Ao ler uma linha da tabela [CRENEAUX], esta receberá o valor da coluna [MEDECIN_ID], ou seja, o valor da chave estrangeira na tabela [MEDECINS]. Isto é frequentemente útil.
O campo [Medecin] acima reflete a relação «muitos para um» que liga a entidade [Creneau] à entidade [Medecin]. Vários objetos [Creneau] estão ligados a um mesmo [Medecin]. A relação inversa, em que um objeto [Medecin] está associado a vários objetos [Creneau], pode ser modelada através de um campo adicional na entidade [Medecin]:
public class Medecin
{
// dados
[Key]
[Column("ID")]
public int? Id { get; set; }
...
public ICollection<Creneau> Creneaux { get; set; }
[Column("TIMESTAMP")]
[Timestamp]
public byte[] Timestamp { get; set; }
Na linha 8, foi adicionado o campo [Creneaux], que é uma coleção de objetos [Creneau]. Este campo dar-nos-á acesso a todos os horários disponíveis do médico.
Ao executar novamente o projeto, verifica-se que a tabela [MEDECINS] não sofreu alterações:
 |
Não foi adicionada nenhuma coluna. A relação de chave estrangeira existente entre a tabela [CRENEAUX] e a tabela [MEDECINS] é suficiente para que a tabela EF consiga gerar os campos a ela associados:
public class Medecin
{
...
public ICollection<Creneau> Creneaux { get; set; }
...
}
public class Creneau
{
...
[Required]
[Column("MEDECIN_ID")]
public int MedecinId { get; set; }
[Required]
[ForeignKey("MedecinId")]
public virtual Medecin Medecin { get; set; }
...
}
Já sabemos o essencial. Podemos concluir com a criação das outras duas entidades.
3.4.3. As entidades [Client] e [Rv]
Com o que aprendemos, podemos criar as entidades [Client] e [Rv]. A entidade [Client] contém informações sobre os clientes geridos pela aplicação [RdvMedecins].
 | 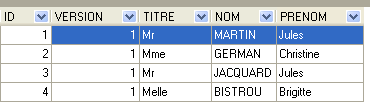 |
- ID: número que identifica o cliente — chave primária da tabela
- VERSION: número que identifica a versão da linha na tabela. Este número é incrementado em 1 sempre que é feita uma alteração na linha.
- NOM: o nome do cliente
- PRENOM: o seu nome próprio
- TITRE: o seu título (Menina, Sra., Sr.)
A entidade [Client] poderia ser a seguinte:
[Table("CLIENTS", Schema = "dbo")]
public class Client
{
// dados
[Key]
[Column("ID")]
public int? Id { get; set; }
[Required]
[MaxLength(5)]
[Column("TITRE")]
public string Titre { get; set; }
[Required]
[MaxLength(30)]
[Column("NOM")]
public string Nom { get; set; }
[Required]
[MaxLength(30)]
[Column("PRENOM")]
public string Prenom { get; set; }
// os Rvs do cliente
public ICollection<Rv> Rvs { get; set; }
[Column("TIMESTAMP")]
[Timestamp]
public byte[] Timestamp { get; set; }
}
A classe [Client] é praticamente idêntica à classe [Medecin]. Poderiam derivar de uma mesma classe pai. A novidade está na linha 21. Reflete o facto de um cliente poder ter vários compromissos e decorre da existência de uma chave estrangeira da tabela [RVS] para a tabela [CLIENTS].
A entidade [Rv] representa um compromisso:
 |
- ID: número que identifica o RV de forma única – chave primária
- JOUR: dia do RV
- ID_CRENEAU: intervalo horário do RV – chave estrangeira na coluna [ID] da tabela [CRENEAUX] – define simultaneamente o intervalo horário e o médico em questão.
- ID_CLIENT: número do cliente para quem é feita a reserva – chave estrangeira na coluna [ID] da tabela [CLIENTS]
A entidade [Rv] poderia ser a seguinte:
[Table("MEDECINS", Schema = "dbo")]
public class Rv
{
// dados
[Key]
[Column("ID")]
public int? Id { get; set; }
[Required]
[Column("JOUR")]
public DateTime Jour { get; set; }
[Column("CLIENT_ID")]
public int ClientId { get; set; }
[ForeignKey("ClientId")]
[Required]
public virtual Client Client { get; set; }
[Column("CRENEAU_ID")]
public int CreneauId { get; set; }
[ForeignKey("CreneauId")]
[Required]
public virtual Creneau Creneau { get; set; }
[Column("TIMESTAMP")]
[Timestamp]
public byte[] Timestamp { get; set; }
}
- linhas 5-7: chave primária;
- linhas 8-10: data da marcação;
- linhas 11-12: a chave estrangeira da tabela [RVS] para a tabela [CLIENTS];
- linhas 13-15: o cliente que tem a consulta;
- linhas 16-17: a chave estrangeira da tabela [RVS] para a tabela [CRENEAUX];
- linhas 18-20: o intervalo horário da marcação;
- linhas 21-23: o campo de gestão de acessos simultâneos.
Na linha 17, observa-se uma relação muitos-para-um: a um intervalo horário podem corresponder vários compromissos (não no mesmo dia). A relação inversa pode ser refletida na entidade [Creneau]:
public class Creneau
{
// as Rvs do intervalo
public ICollection<Rv> Rvs { get; set; }
...
}
Linha 4: o conjunto de compromissos marcados nesse intervalo horário.
Quando se executa o projeto, a base de dados gerada é a seguinte:
 |
As tabelas [MEDECINS] e [CRENEAUX] não sofreram alterações. As tabelas [CLIENTS] e [RVS] são as seguintes:
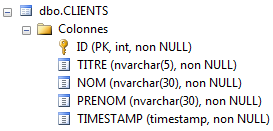 | 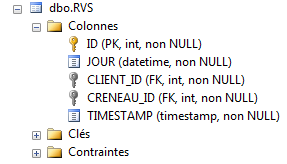 |
Era isto que se esperava. Faltam-nos ainda alguns pormenores para resolver:
- gerir o nome da base de dados. Neste caso, foi gerado pela tabela EF;
- preencher a base de dados com dados.
3.4.4. Definir o nome da base de dados
Para definir o nome da base de dados gerada pelo EF, utilizaremos uma cadeia de ligação definida no [App.config]. Este ficheiro de configuração passa a ter o seguinte aspeto:
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<configSections>
<!-- Para mais informações sobre a configuração do Entity Framework, visite http://go.microsoft.com/fwlink/?LinkID=237468 -->
<section name="entityFramework" type="System.Data.Entity.Internal.ConfigFile.EntityFrameworkSection, EntityFramework, Version=5.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089" requirePermission="false" />
</configSections>
<startup>
<supportedRuntime version="v4.0" sku=".NETFramework,Version=v4.5" />
</startup>
<entityFramework>
<defaultConnectionFactory type="System.Data.Entity.Infrastructure.SqlConnectionFactory, EntityFramework" />
</entityFramework>
<!-- cadeia de ligação à base de dados -->
<connectionStrings>
<add name="RdvMedecinsContext"
connectionString="Data Source=localhost;Initial Catalog=rdvmedecins-ef;User Id=sa;Password=sqlserver2012;"
providerName="System.Data.SqlClient" />
</connectionStrings>
<!-- o fornecedor de fábrica -->
<system.data>
<DbProviderFactories>
<add name="SqlClient Data Provider"
invariant="System.Data.SqlClient"
description=".Net Framework Data Provider for SqlServer"
type="System.Data.SqlClient.SqlClientFactory, System.Data,
Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089"
/>
</DbProviderFactories>
</system.data>
</configuration>
- linhas 15-19: a cadeia de ligação à base de dados;
- linha 16: o atributo [name] retoma o nome da classe [RdvMedecinsContext] utilizada para o contexto de persistência. É importante ter isto em conta. Esta restrição pode ser contornada no construtor do contexto:
// construtor
public RdvMedecinsContext()
: base("monContexte")
{
}
Neste caso, poderemos ter name= "monContexte". É isso que teremos no resto do documento.
- linha 17: a cadeia de ligação. [Data Source]: o nome do servidor onde se encontra o SGBD, [Initial Catalog]: o nome da base de dados, ou seja, neste caso, [rdvmedecins-ef]; [User Id]: o proprietário da ligação; [Password]: a sua palavra-passe. O leitor deverá adaptar esta cadeia ao seu ambiente;
- linhas 21-29: definem um [DbProviderFactory]. Não sei o que é isto. A julgar pelo nome, poderá ser uma classe que permite gerar a camada [ADO.NET] que separa EF de SGBD:
 |
Na verdade, estas linhas são desnecessárias para o SQL Server, mas tive de as adicionar para os outros SGBD. Por isso, coloco-as aqui apenas para memória. Não causam qualquer problema. O único ponto importante é a versão da linha 27. É a do DLL [System.Data] presente nas referências do projeto:
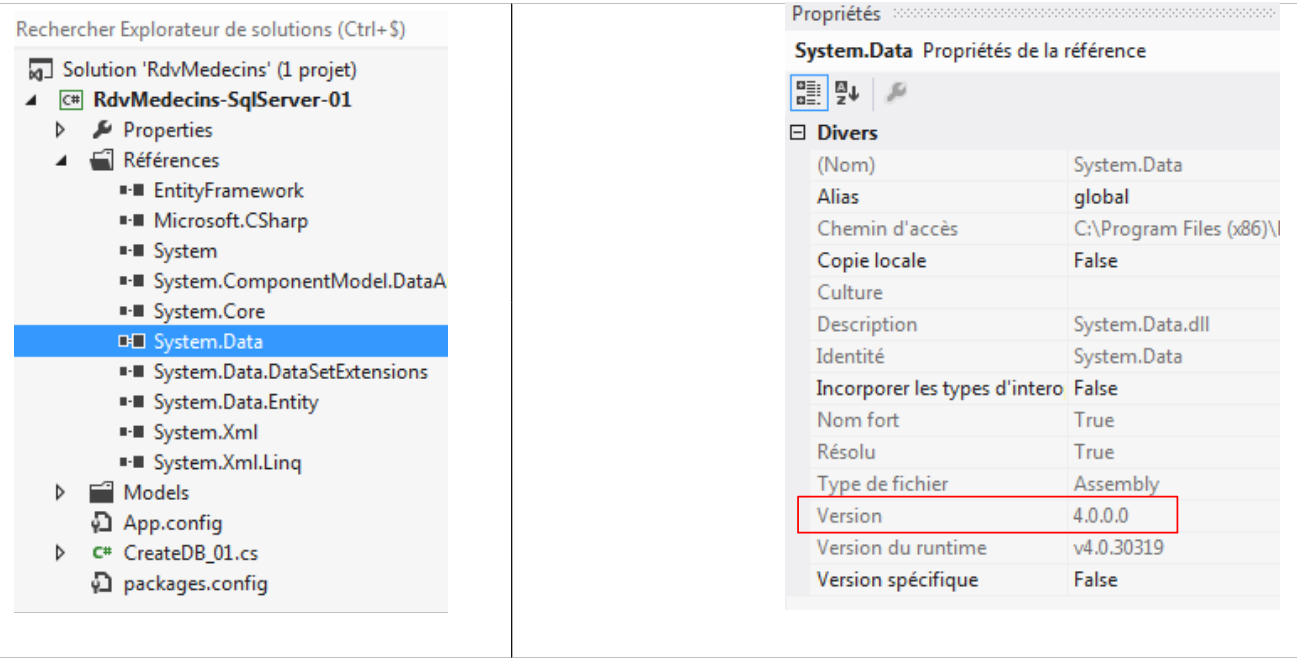 |
Pronto. Estamos prontos. Executamos o projeto e obtemos a base [rdvmedecins-ef] seguinte:
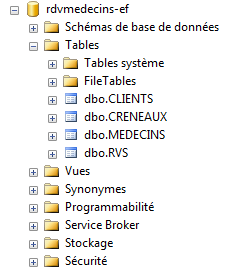 |
Esta será a nossa base definitiva. Resta-nos introduzir dados nela.
3.4.5. Preenchimento da base de dados
A classe de inicialização da base de dados pode ser utilizada para inserir dados na mesma:
public class RdvMedecinsInitializer : DropCreateDatabaseIfModelChanges<RdvMedecinsContext>
{
// inicialização da base de dados
public class RdvMedecinsInitializer : DropCreateDatabaseAlways<RdvMedecinsContext>
{
protected override void Seed(RdvMedecinsContext context)
{
base.Seed(context);
// inicialização da base de dados
// os clientes
Client[] clients ={
new Client { Titre = "Mr", Nom = "Martin", Prenom = "Jules" },
new Client { Titre = "Mme", Nom = "German", Prenom = "Christine" },
new Client { Titre = "Mr", Nom = "Jacquard", Prenom = "Jules" },
new Client { Titre = "Melle", Nom = "Bistrou", Prenom = "Brigitte" }
};
foreach (Client client in clients)
{
context.Clients.Add(client);
}
// os médicos
Medecin[] medecins ={
new Medecin { Titre = "Mme", Nom = "Pelissier", Prenom = "Marie" },
new Medecin { Titre = "Mr", Nom = "Bromard", Prenom = "Jacques" },
new Medecin { Titre = "Mr", Nom = "Jandot", Prenom = "Philippe" },
new Medecin { Titre = "Melle", Nom = "Jacquemot", Prenom = "Justine" }
};
foreach (Medecin medecin in medecins)
{
context.Medecins.Add(medecin);
}
// os horários disponíveis
Creneau[] creneaux ={
new Creneau{ Hdebut=8,Mdebut=0,Hfin=8,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=8,Mdebut=20,Hfin=8,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=8,Mdebut=40,Hfin=9,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=9,Mdebut=0,Hfin=9,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=9,Mdebut=20,Hfin=9,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=9,Mdebut=40,Hfin=10,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=10,Mdebut=0,Hfin=10,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=10,Mdebut=20,Hfin=10,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=10,Mdebut=40,Hfin=11,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=11,Mdebut=0,Hfin=11,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=11,Mdebut=20,Hfin=11,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=11,Mdebut=40,Hfin=12,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=14,Mdebut=0,Hfin=14,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=14,Mdebut=20,Hfin=14,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=14,Mdebut=40,Hfin=15,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=15,Mdebut=0,Hfin=15,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=15,Mdebut=20,Hfin=15,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=15,Mdebut=40,Hfin=16,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=16,Mdebut=0,Hfin=16,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=16,Mdebut=20,Hfin=16,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=16,Mdebut=40,Hfin=17,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=17,Mdebut=0,Hfin=17,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=17,Mdebut=20,Hfin=17,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=17,Mdebut=40,Hfin=18,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=8,Mdebut=0,Hfin=8,Mfin=20,Medecin=medecins[1]},
new Creneau{ Hdebut=8,Mdebut=20,Hfin=8,Mfin=40,Medecin=medecins[1]},
new Creneau{ Hdebut=8,Mdebut=40,Hfin=9,Mfin=0,Medecin=medecins[1]},
new Creneau{ Hdebut=9,Mdebut=0,Hfin=9,Mfin=20,Medecin=medecins[1]},
new Creneau{ Hdebut=9,Mdebut=20,Hfin=9,Mfin=40,Medecin=medecins[1]},
new Creneau{ Hdebut=9,Mdebut=40,Hfin=10,Mfin=0,Medecin=medecins[1]},
new Creneau{ Hdebut=10,Mdebut=0,Hfin=10,Mfin=20,Medecin=medecins[1]},
new Creneau{ Hdebut=10,Mdebut=20,Hfin=10,Mfin=40,Medecin=medecins[1]},
new Creneau{ Hdebut=10,Mdebut=40,Hfin=11,Mfin=0,Medecin=medecins[1]},
new Creneau{ Hdebut=11,Mdebut=0,Hfin=11,Mfin=20,Medecin=medecins[1]},
new Creneau{ Hdebut=11,Mdebut=20,Hfin=11,Mfin=40,Medecin=medecins[1]},
new Creneau{ Hdebut=11,Mdebut=40,Hfin=12,Mfin=0,Medecin=medecins[1]},
};
foreach (Creneau creneau in creneaux)
{
context.Creneaux.Add(creneau);
}
// as consultas
context.Rvs.Add(new Rv { Jour = new System.DateTime(2012, 10, 8), Client = clients[0], Creneau = creneaux[0] });
}
}
}
- linha 6: a inicialização ocorre no método [Seed]. Este existe na classe-pai. Aqui, é redefinido. O argumento é o contexto de persistência [RdvMedecinsContext] da aplicação;
- linha 8: o argumento é passado para a classe pai; é provável que esta abra o contexto de persistência que lhe foi passado, uma vez que essa abertura já não é necessária posteriormente;
- linhas 11-16: criação de 4 clientes;
- linhas 17-20: estes são adicionados ao contexto de persistência, mais precisamente aos médicos do mesmo. De salientar o método [Add] que permite isso. É importante recordar aqui a definição do contexto:
public class RdvMedecinsContext : DbContext
{
// as entidades
public DbSet<Medecin> Medecins { get; set; }
public DbSet<Creneau> Creneaux { get; set; }
public DbSet<Client> Clients { get; set; }
public DbSet<Rv> Rvs { get; set; }
...
Diz-se também que os clientes foram associados ao contexto, ou seja, que passaram a ser geridos pelo EF. Anteriormente, não estavam associados a ele. Existiam como objetos, mas não eram geridos pelo EF;
- linhas 21-27: criação de 4 médicos;
- linhas 28-31: colocam-se no contexto de persistência;
- linhas 33-70: criação de horários disponíveis. Linhas 34-57, para o médico medecins[0]; linhas 58-69, para o médico medecins[1]. Os restantes médicos não têm horários disponíveis;
- linhas 71-74: estes intervalos horários são colocados no contexto de persistência;
- linha 76: criação de uma consulta para o primeiro cliente com o primeiro horário disponível e a sua inserção no contexto de persistência.
Ao executar o projeto, obtém-se a seguinte base de dados:
 | 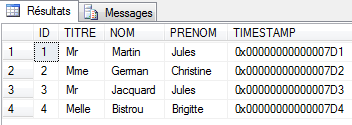 |
Acima, vemos a tabela [CLIENTS] preenchida.
3.4.6. Alteração das entidades
Atualmente, as classes [Medecin] e [Client] são praticamente idênticas. Na verdade, se retirarmos os campos adicionados para a gestão da persistência com EF 5, elas são idênticas. Vamos fazê-las derivar de uma classe [Personne]. Estas duas entidades passam então a ser as seguintes:
// uma pessoa
public abstract class Personne
{
// data
[Key]
[Column("ID")]
public int? Id { get; set; }
[Required]
[MaxLength(5)]
[Column("TITRE")]
public string Titre { get; set; }
[Required]
[MaxLength(30)]
[Column("NOM")]
public string Nom { get; set; }
[Required]
[MaxLength(30)]
[Column("PRENOM")]
public string Prenom { get; set; }
[Column("TIMESTAMP")]
[Timestamp]
public byte[] Timestamp { get; set; }
// assinatura
public override string ToString()
{
return String.Format("[{0},{1},{2},{3},{4}]", Id, Titre, Prenom, Nom, dump(Timestamp));
}
// assinatura curta
public string ShortIdentity()
{
...
}
// utilitário
private string dump(byte[] timestamp)
{
...
}
}
[Table("MEDECINS", Schema = "dbo")]
public class Medecin : Personne
{
// horários de atendimento do médico
public ICollection<Creneau> Creneaux { get; set; }
// assinatura
public override string ToString()
{
return String.Format("Medecin {0}", base.ToString());
}
}
[Table("CLIENTS", Schema = "dbo")]
public class Client : Personne
{
// as consultas do cliente
public ICollection<Rv> Rvs { get; set; }
// assinatura
public override string ToString()
{
return String.Format("Client {0}", base.ToString());
}
}
Ao executar o projeto, obtém-se a mesma base. O EF 5 mapeou as classes mais baixas da herança, cada uma para uma tabela. Na verdade, o EF 5 possui diferentes estratégias de geração de tabelas para representar a herança de entidades. Não as apresentaremos aqui. Pode-se consultar, por exemplo, « Entity Framework Code First Inheritance: Table Per Hierarchy and Table Per Type», em URL [http://www.codeproject.com/Articles/393228/Entity-Framework-Code-First-Inheritance-Table-Per].
A partir de agora, utilizaremos esta versão das entidades.
3.4.7. Adicionar restrições à base de dados
Resta-nos resolver um pormenor. A tabela [RVS] dos compromissos é a seguinte:
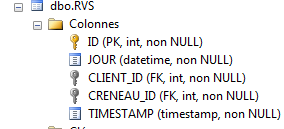 |
Esta tabela deve ter uma restrição de unicidade: para um determinado dia, um intervalo horário de um médico só pode ser reservado uma vez para uma consulta. Em termos de tabela, isto significa que o par (JOUR,CRENEAU_ID) deve ser único. Não sei se esta restrição pode ser expressa diretamente no código, seja nas entidades, seja no contexto. É provável que sim, mas ainda não verifiquei. Vamos adotar uma abordagem diferente. Vamos utilizar um cliente de administração do SQL Server para adicionar esta restrição.
Com o «SQL Server Management Studio», não encontrei nenhuma forma simples de adicionar esta restrição, a não ser executar o comando SQL que a cria:
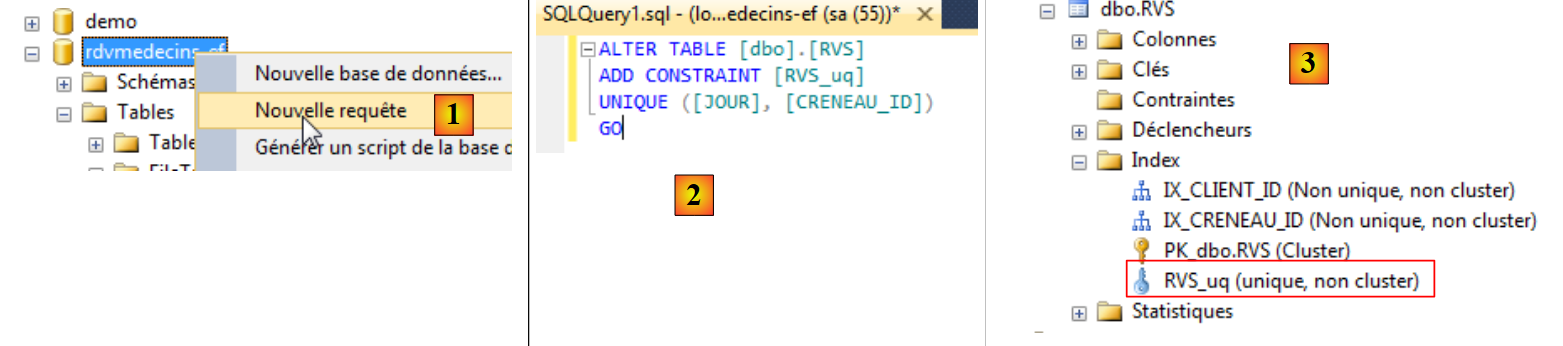 |
- no [1], cria-se uma consulta SQL para a base de dados [rdvmedecins-ef];
- em [2], a consulta SQL que cria a restrição de unicidade;
- em [3], a execução desta consulta criou um novo índice na tabela [RVS].
Existem outras ferramentas de administração do SQL Server. Vamos utilizar aqui a ferramenta EMS SQL Manager for SQL Server Freeware [http://www.sqlmanager.net/fr/products/mssql/manager/download]. Depois de instalada, iniciamo-la:
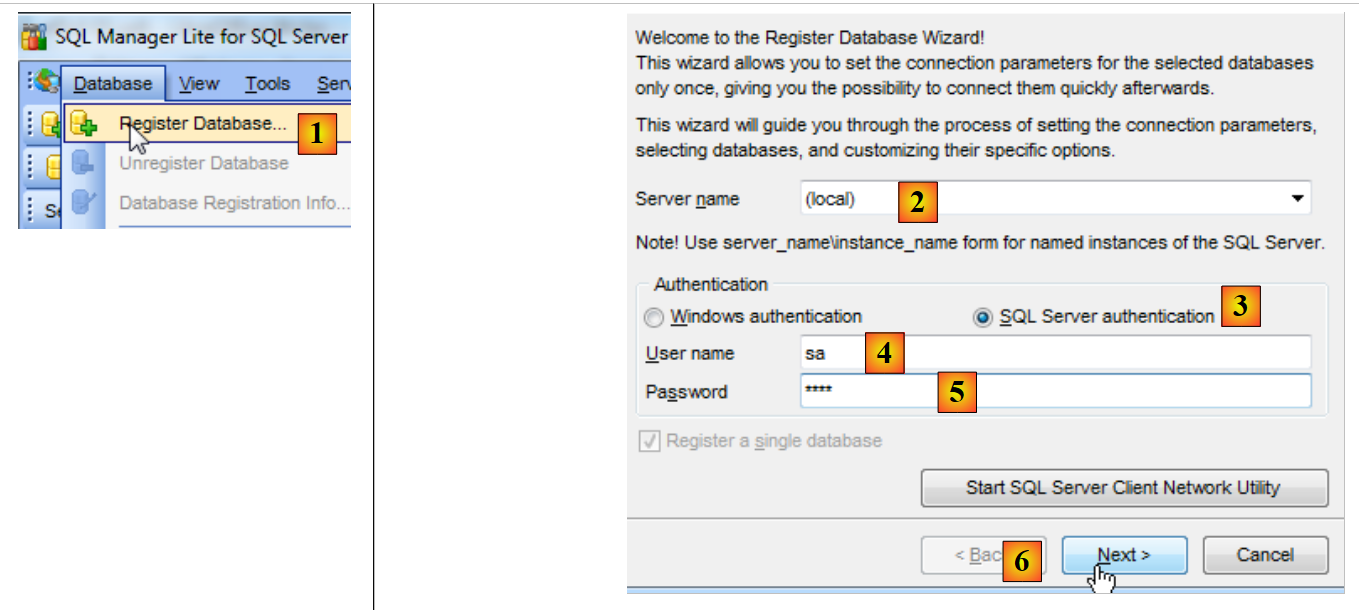 |
- no [1], guardamos uma base de dados;
- no [2], ligamo-nos ao servidor (local);
- em [3], com autenticação no servidor SQL;
- em [4], com a identidade «sa»;
- em [5], e a palavra-passe «sqlserver2012»;
- em [6], passa-se à etapa seguinte;
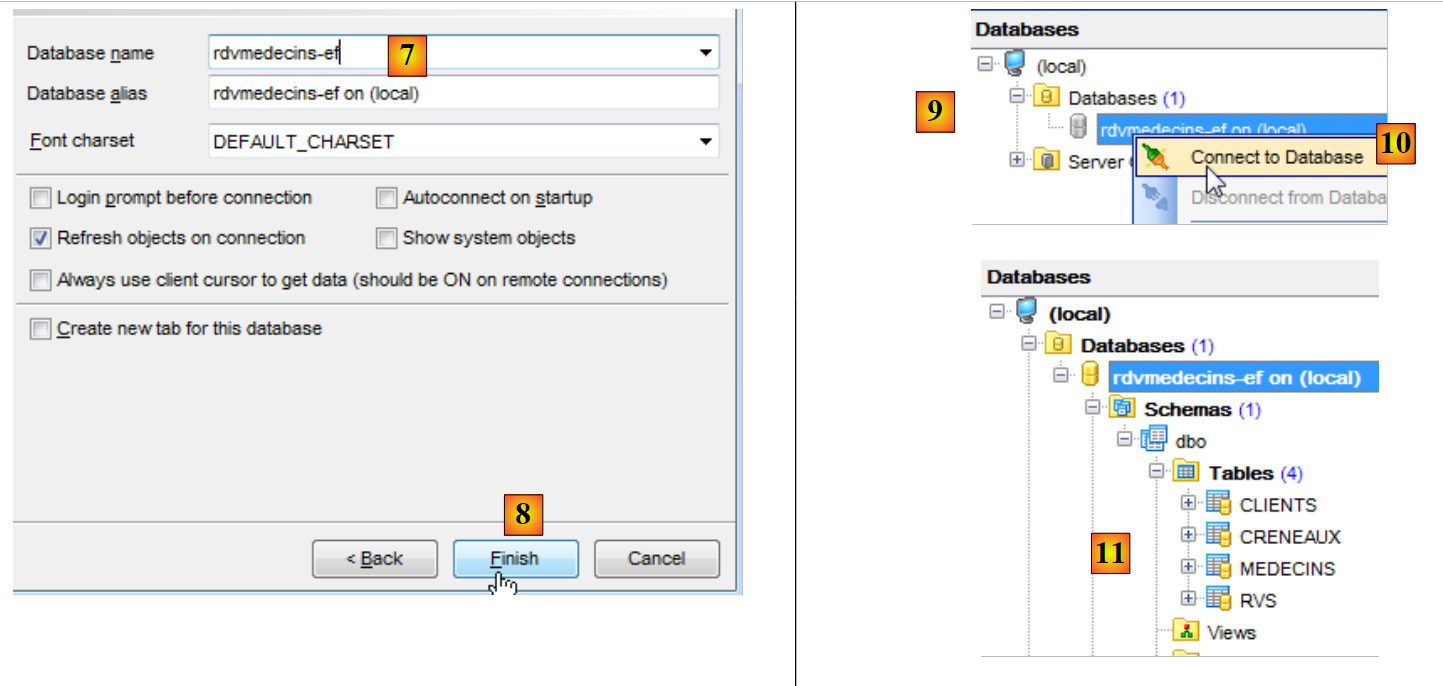 |
- em [7], seleciona-se a base de dados [rdvmedecins-ef];
- em [8], conclui-se o assistente;
- em [9], a base de dados aparece na árvore de bases de dados. Ligamo-nos a ela em [10];
- em [11], a ligação está estabelecida.
O «SQL Manager Lite for SQL Server» permite criar a restrição de unicidade na tabela [RVS].
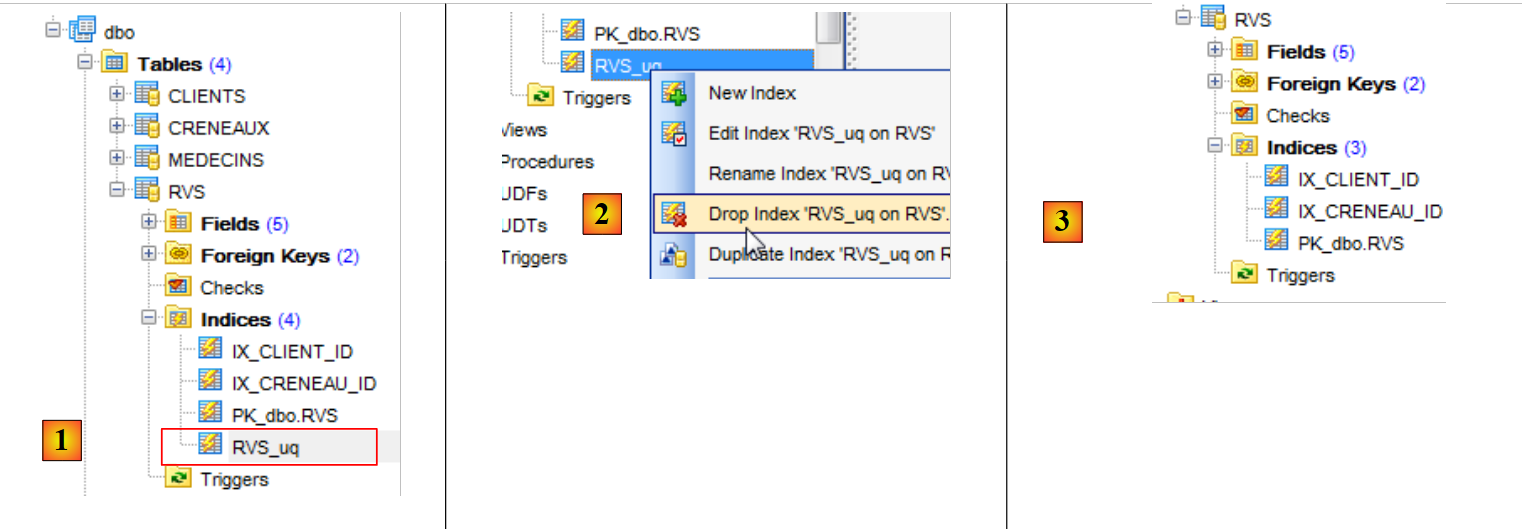 |
- no [1], vemos a restrição de unicidade que criámos anteriormente;
- em [2], eliminamo-la;
- em [3], o índice correspondente a esta restrição de unicidade desapareceu.
Recriamos a restrição eliminada:
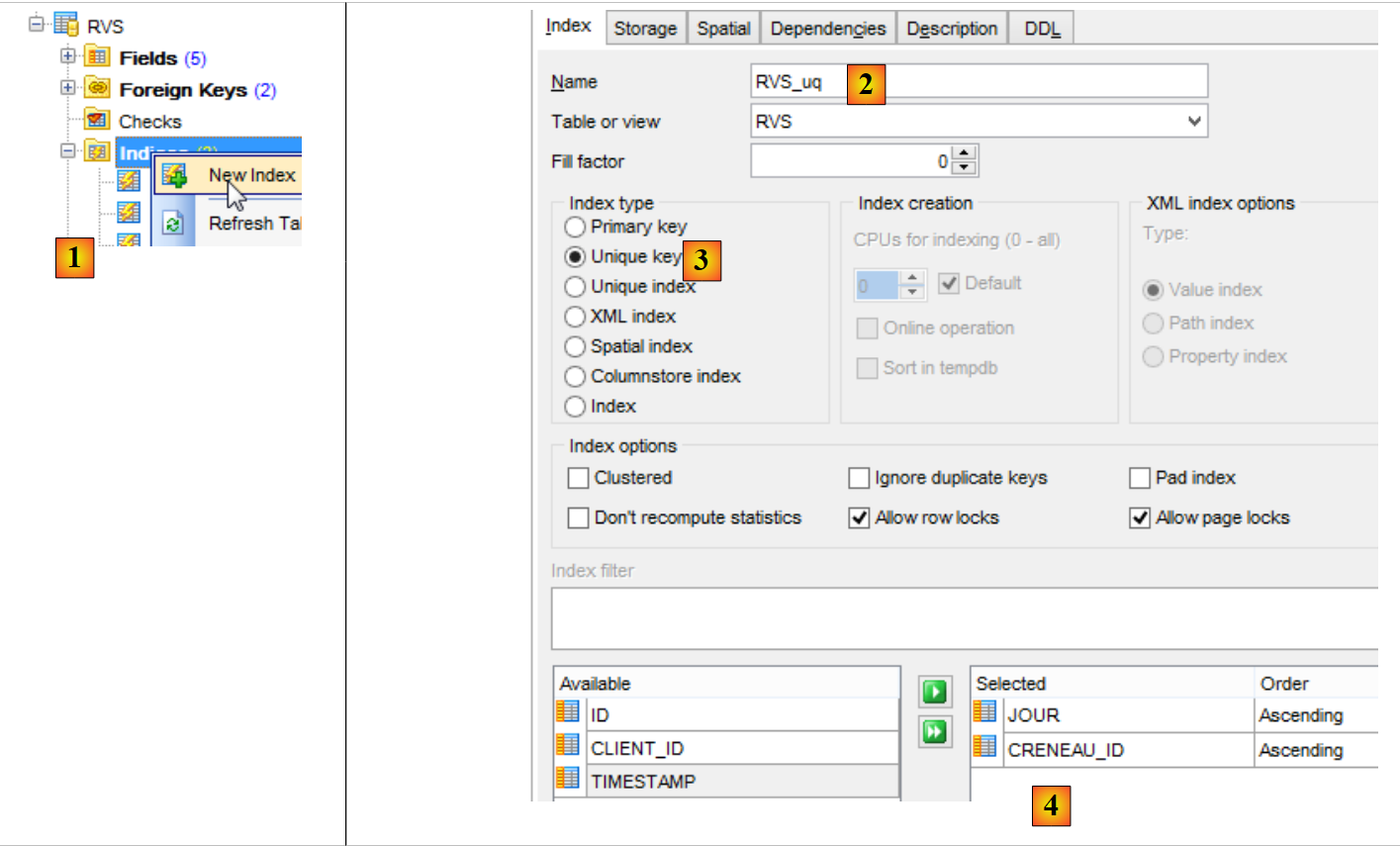 |
- em [1], criamos um novo índice para a tabela [RVS];
- em [2], atribui-se-lhe um nome;
- em [3], trata-se de uma restrição de unicidade;
- em [4], nas colunas JOUR e CRENEAU_ID;
O separador DDL fornece-nos o código SQL que vai ser executado:
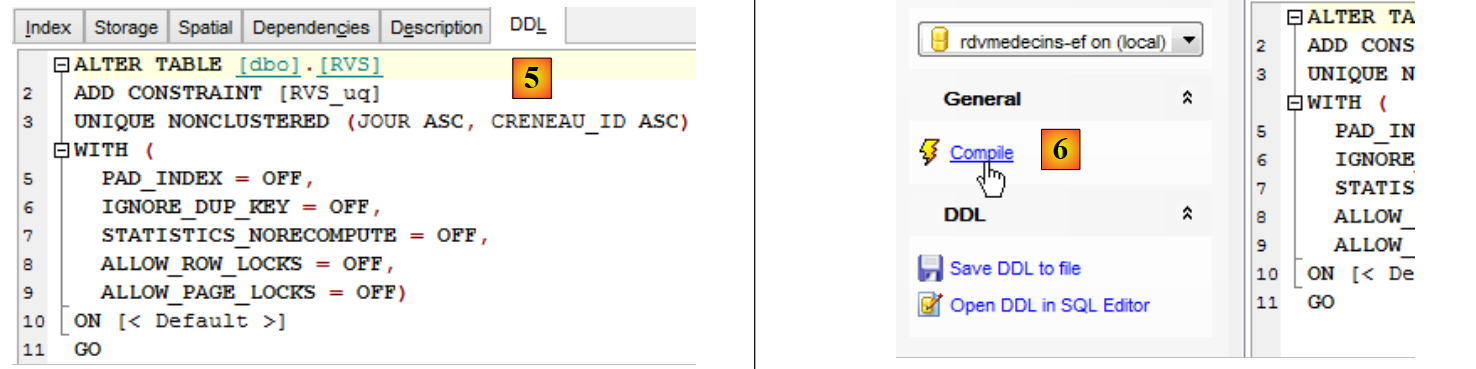 |
- em [6], compila-se a ordem SQL;
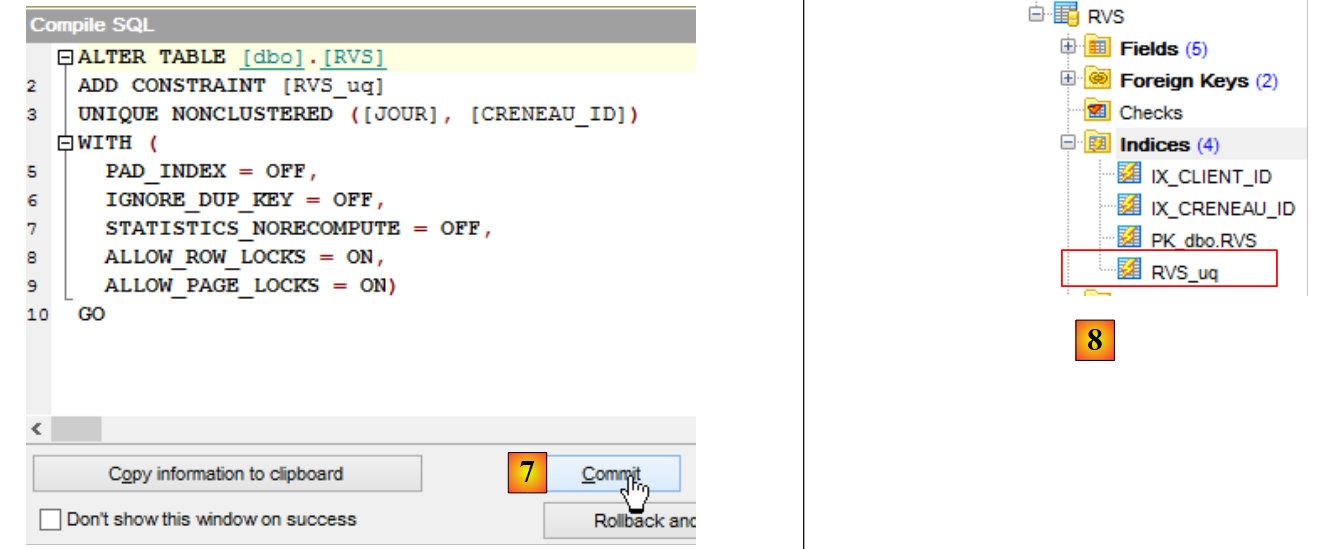 |
- em [7], confirma-se;
- em [8], o novo índice surgiu.
A interface disponibilizada pelo «SQL Manager Lite for SQL server» é semelhante à disponibilizada pelo «SQL Server Management Studio». É possível encontrar interfaces semelhantes para o SGBD Oracle, PostgreSQL, Firebird e MySQL. Assim, continuaremos a partir de agora com esta família de ferramentas de administração do SGBD.
Para aceder às informações de uma tabela, basta clicar duas vezes nela:
 |
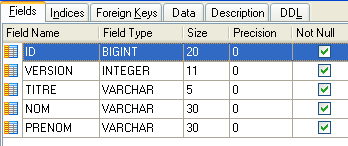
As informações sobre a tabela selecionada estão disponíveis em separadores. Acima, vemos o separador [Fields] da tabela [CLIENTS]. O separador [Data] apresenta o conteúdo da tabela:
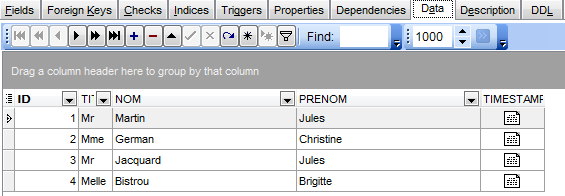
3.4.8. A base definitiva
Já temos a nossa base definitiva. Exportamos o seu script SQL para podermos regenerá-la, se necessário.
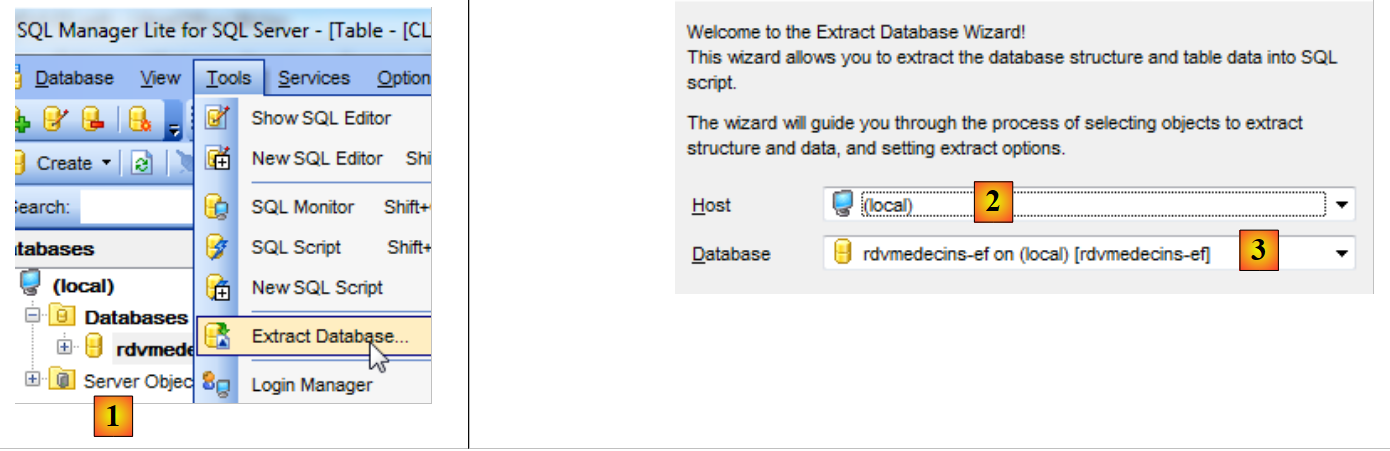 |
- em [1], início do assistente;
- para [2], o servidor;
- em [3], a base de dados que vai ser exportada;
 |
- em [4], especifique o nome do ficheiro onde será guardado o script SQL;
- em [5], especifique a sua codificação;
- em [6], especifique o que pretende extrair (tabelas, restrições, dados);
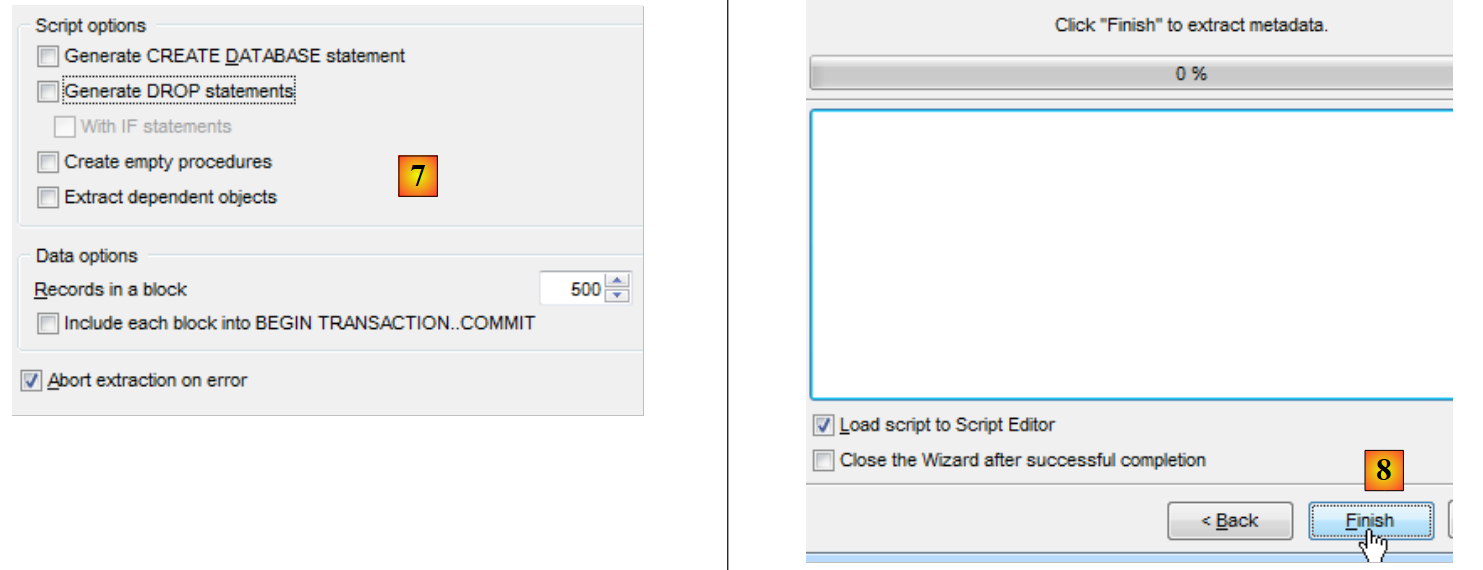 |
- no [7], pode ajustar o script que vai ser gerado;
- em [8], conclua o assistente.
O script foi gerado e carregado no editor de scripts. Pode consultar o código SQL gerado. Vamos reconstruir a base de dados a partir deste script.
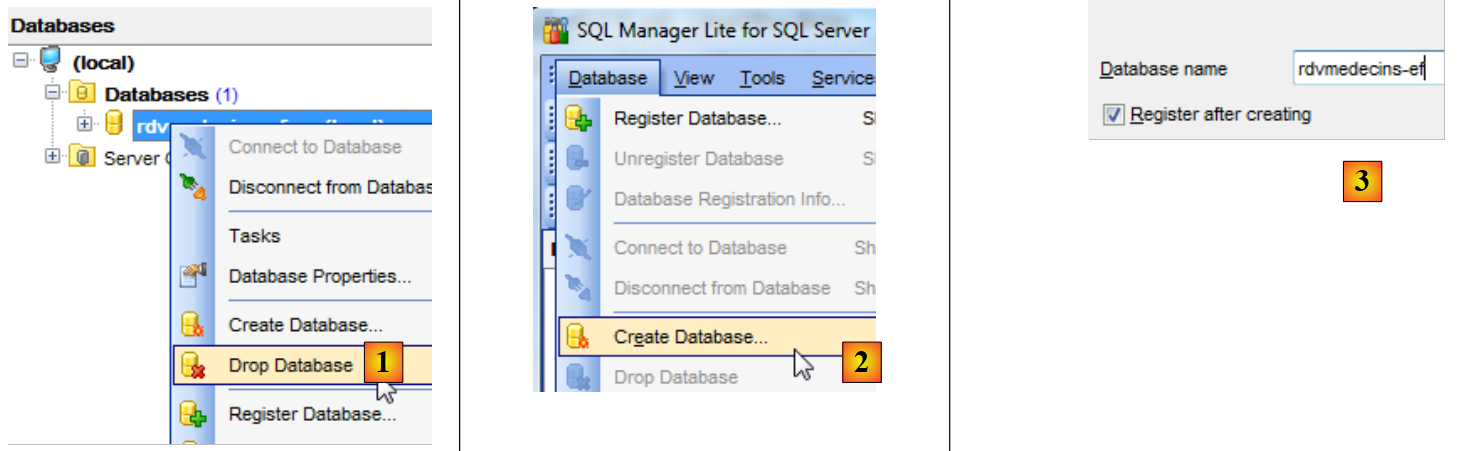 |
- em [1], elimina-se a base de dados;
- nos scripts [2] e [3], recriamos a base de dados;
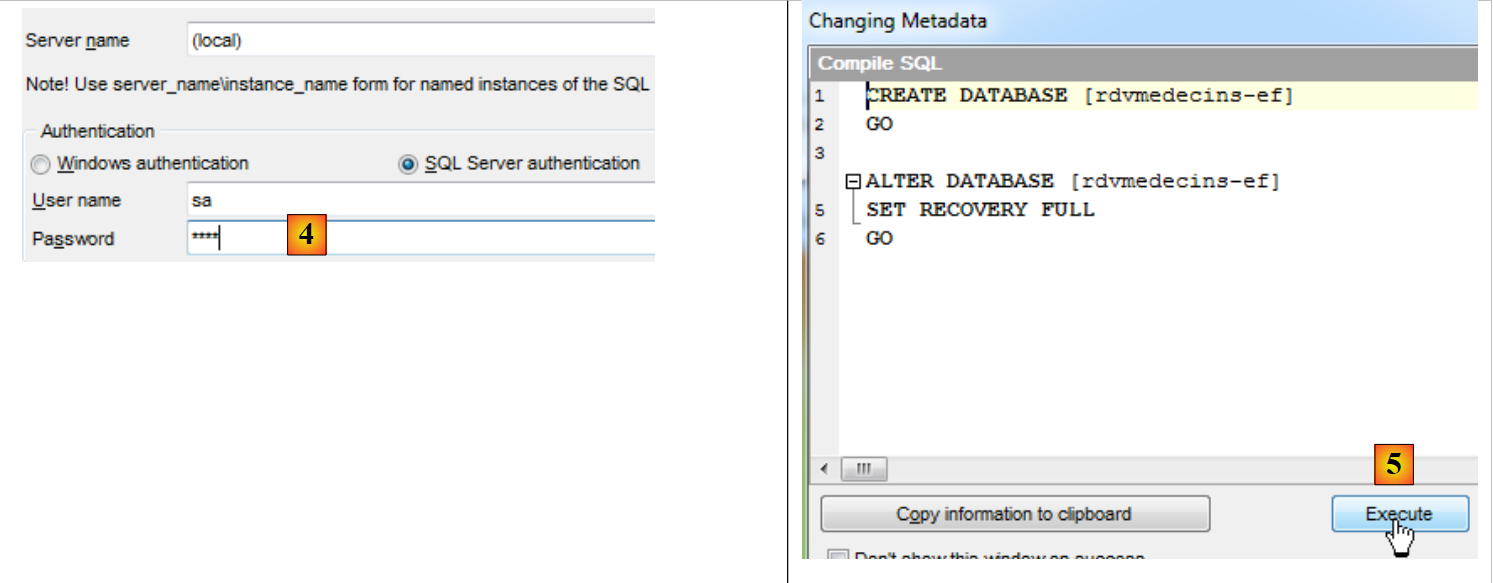 |
- em [4], efetua-se a autenticação;
- em [5], executa-se o script SQL para a criação da base de dados;
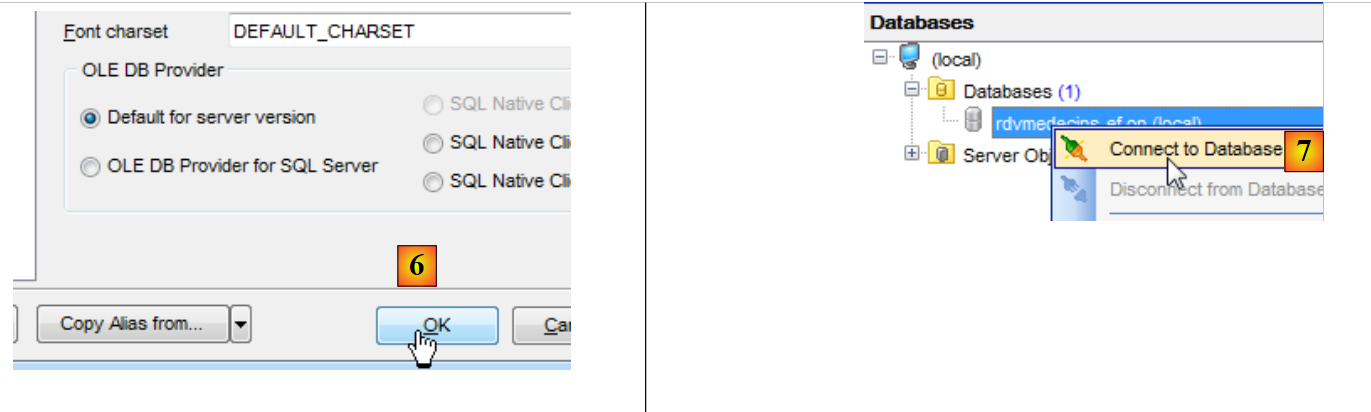 |
- no [6], guarda-se no «SQL Manager»;
- em [7], liga-se à base de dados que acabou de ser criada;
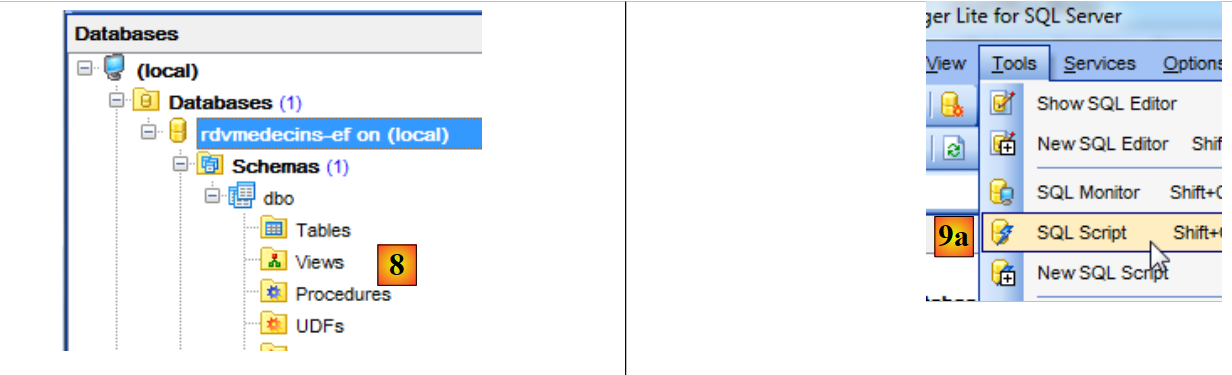 |
- em [8], a base de dados ainda não tem tabelas;
- em [9a], abre-se um editor de scripts SQL;
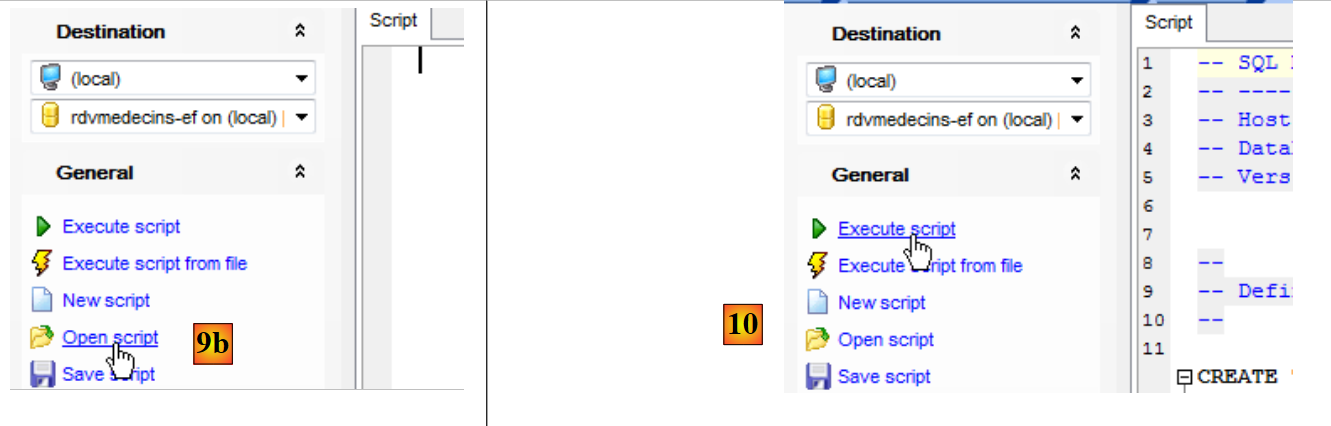 |
- em [9b], abre-se o script SQL criado anteriormente;
- em [10], executa-se o mesmo;
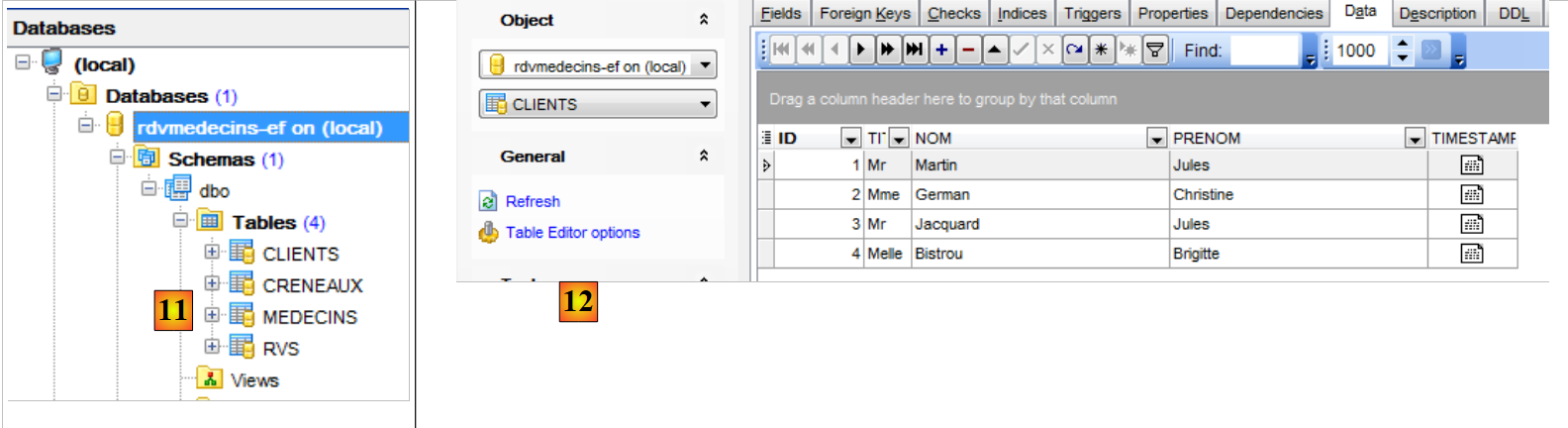 |
- em [11], as tabelas foram criadas;
- no [12], estas são preenchidas;
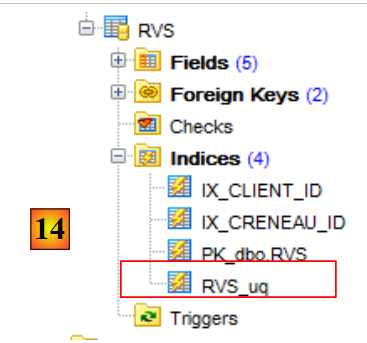 |
- em [14], encontramos a restrição de unicidade que tínhamos criado para a tabela [RVS].
Vamos agora trabalhar com esta base de dados existente. Se for destruída ou danificada, sabemos como regenerá-la.
3.5. Exploração da base de dados com o Entity Framework
Vamos:
- adicionar, eliminar e alterar elementos da base de dados;
- consultar a base de dados com LINQ to Entities;
- gerir os acessos simultâneos a um mesmo elemento da base de dados;
- compreender os conceitos de Lazy Loading / Eager Loading;
- descobrir que a atualização da base de dados pelo contexto de persistência é efetuada numa transação.
3.5.1. Eliminação de elementos do contexto de persistência
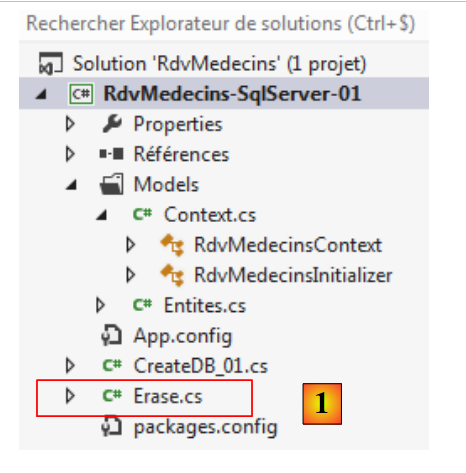
Temos uma base de dados preenchida. Vamos esvaziá-la. Criamos uma nova classe [Erase.cs] no projeto atual [1]:
 |
A classe [Erase] é a seguinte:
using RdvMedecins.Models;
namespace RdvMedecins_01
{
class Erase
{
static void Main(string[] args)
{
using (var context = new RdvMedecinsContext())
{
// limpar a base de dados atual
// os clientes
foreach (var client in context.Clients)
{
context.Clients.Remove(client);
}
// os médicos
foreach (var medecin in context.Medecins)
{
context.Medecins.Remove(medecin);
}
// guardar o contexto de persistência
context.SaveChanges();
}
}
}
}
- linha 9: as operações num contexto de persistência são sempre realizadas numa cláusula [using]. Isto garante que, ao sair do [using], o contexto tenha sido fechado;
- linha 13: percorre-se o contexto dos clientes [context.Clients]. Todos os clientes da base de dados serão colocados no contexto de persistência;
- linha 15: para cada um deles, executa-se a operação [Remove], que os remove do contexto. Na verdade, continuam no contexto, mas num estado «eliminado»;
- linhas 18-21: faz-se o mesmo para os médicos;
- linha 23: guarda-se o contexto de persistência na base de dados.
Ao guardar o contexto na base de dados, as entidades do contexto que:
- têm uma chave primária nula são alvo de uma operação SQL INSERT;
- se encontram no estado «eliminado» são alvo de uma operação SQL DELETE;
- estão no estado «modificado» são alvo de uma operação SQL UPDATE;
Como veremos mais adiante, estas operações SQL são realizadas no âmbito de uma transação. Se uma delas falhar, tudo o que foi feito anteriormente é revertido.
Vamos definir o programa [Erase] como o novo objeto de início do projeto [1] e, em seguida, executar o projeto.
 |
Vamos verificar a base de dados. Verificaremos que todas as tabelas estão vazias ([2]). Isto é surpreendente, pois solicitámos apenas a eliminação dos médicos e dos clientes. Foi devido ao funcionamento das chaves estrangeiras que as outras tabelas foram esvaziadas em cadeia.
A definição da chave estrangeira da tabela [CRENEAUX] para a tabela [MEDECINS] foi definida da seguinte forma pelo provedor de EF 5:
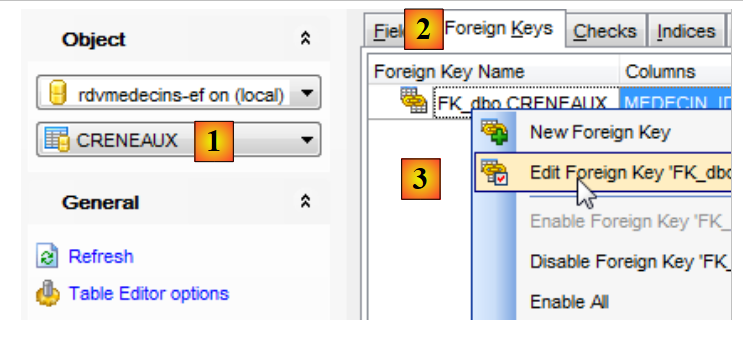 |
- na [1], seleciona-se a tabela [CRENEAUX];
- no [2], seleciona-se o separador das chaves estrangeiras;
- em [3], edita-se a única chave estrangeira;
 |
- em [4], no separador DDL, a definição SQL da restrição de chave estrangeira;
- Na tabela [5], a cláusula ON DELETE CASCADE faz com que a eliminação de um médico implique a eliminação dos horários que lhe estão associados.
As restrições de chave estrangeira da tabela [RVS] são definidas de forma análoga:
- linhas 1-6: a eliminação de um cliente eliminará também os horários que lhe estão associados;
- linhas 1-6: a eliminação de um intervalo de tempo eliminará também todos os compromissos que lhe estão associados.
3.5.2. Adicionar elementos ao contexto de persistência
Agora que esvaziamos a base de dados, vamos preenchê-la novamente. Adicionamos ao projeto o programa [Fill.cs] [1].
 |
O programa [Fill.cs] é o seguinte:
using RdvMedecins.Entites;
using RdvMedecins.Models;
namespace RdvMedecins_01
{
class Fill
{
static void Main(string[] args)
{
using (var context = new RdvMedecinsContext())
{
// esvazia-se a base de dados atual
foreach (var client in context.Clients)
{
context.Clients.Remove(client);
}
foreach (var medecin in context.Medecins)
{
context.Medecins.Remove(medecin);
}
// reinicializa-se
// os clientes
Client[] clients ={
new Client { Titre = "Mr", Nom = "Martin", Prenom = "Jules" },
new Client { Titre = "Mme", Nom = "German", Prenom = "Christine" },
new Client { Titre = "Mr", Nom = "Jacquard", Prenom = "Jules" },
new Client { Titre = "Melle", Nom = "Bistrou", Prenom = "Brigitte" }
};
foreach (Client client in clients)
{
context.Clients.Add(client);
}
// os médicos
Medecin[] medecins ={
new Medecin { Titre = "Mme", Nom = "Pelissier", Prenom = "Marie" },
new Medecin { Titre = "Mr", Nom = "Bromard", Prenom = "Jacques" },
new Medecin { Titre = "Mr", Nom = "Jandot", Prenom = "Philippe" },
new Medecin { Titre = "Melle", Nom = "Jacquemot", Prenom = "Justine" }
};
foreach (Medecin medecin in medecins)
{
context.Medecins.Add(medecin);
}
// os horários
Creneau[] creneaux ={
new Creneau{ Hdebut=8,Mdebut=0,Hfin=8,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=8,Mdebut=20,Hfin=8,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=8,Mdebut=40,Hfin=9,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=9,Mdebut=0,Hfin=9,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=9,Mdebut=20,Hfin=9,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=9,Mdebut=40,Hfin=10,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=10,Mdebut=0,Hfin=10,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=10,Mdebut=20,Hfin=10,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=10,Mdebut=40,Hfin=11,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=11,Mdebut=0,Hfin=11,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=11,Mdebut=20,Hfin=11,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=11,Mdebut=40,Hfin=12,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=14,Mdebut=0,Hfin=14,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=14,Mdebut=20,Hfin=14,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=14,Mdebut=40,Hfin=15,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=15,Mdebut=0,Hfin=15,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=15,Mdebut=20,Hfin=15,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=15,Mdebut=40,Hfin=16,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=16,Mdebut=0,Hfin=16,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=16,Mdebut=20,Hfin=16,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=16,Mdebut=40,Hfin=17,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=17,Mdebut=0,Hfin=17,Mfin=20,Medecin=medecins[0]},
new Creneau{ Hdebut=17,Mdebut=20,Hfin=17,Mfin=40,Medecin=medecins[0]},
new Creneau{ Hdebut=17,Mdebut=40,Hfin=18,Mfin=0,Medecin=medecins[0]},
new Creneau{ Hdebut=8,Mdebut=0,Hfin=8,Mfin=20,Medecin=medecins[1]},
new Creneau{ Hdebut=8,Mdebut=20,Hfin=8,Mfin=40,Medecin=medecins[1]},
new Creneau{ Hdebut=8,Mdebut=40,Hfin=9,Mfin=0,Medecin=medecins[1]},
new Creneau{ Hdebut=9,Mdebut=0,Hfin=9,Mfin=20,Medecin=medecins[1]},
new Creneau{ Hdebut=9,Mdebut=20,Hfin=9,Mfin=40,Medecin=medecins[1]},
new Creneau{ Hdebut=9,Mdebut=40,Hfin=10,Mfin=0,Medecin=medecins[1]},
new Creneau{ Hdebut=10,Mdebut=0,Hfin=10,Mfin=20,Medecin=medecins[1]},
new Creneau{ Hdebut=10,Mdebut=20,Hfin=10,Mfin=40,Medecin=medecins[1]},
new Creneau{ Hdebut=10,Mdebut=40,Hfin=11,Mfin=0,Medecin=medecins[1]},
new Creneau{ Hdebut=11,Mdebut=0,Hfin=11,Mfin=20,Medecin=medecins[1]},
new Creneau{ Hdebut=11,Mdebut=20,Hfin=11,Mfin=40,Medecin=medecins[1]},
new Creneau{ Hdebut=11,Mdebut=40,Hfin=12,Mfin=0,Medecin=medecins[1]},
};
foreach (Creneau creneau in creneaux)
{
context.Creneaux.Add(creneau);
}
// as consultas
context.Rvs.Add(new Rv { Jour = new System.DateTime(2012, 10, 8), Client = clients[0], Creneau = creneaux[0] });
// guardamos o contexto de persistência
context.SaveChanges();
}
}
}
}
- linha 10: abre-se o contexto de persistência;
- linhas 13-20: as linhas das tabelas [CLIENTS] e [MEDECINS] são inseridas no contexto e, em seguida, eliminadas do mesmo. Acabámos de ver que isto esvaziava totalmente a base de dados;
- linhas 22-88: são adicionados elementos ao contexto de persistência. Todos eles têm a chave primária definida como null. Serão, portanto, inseridos na base de dados;
- linha 90: as alterações efetuadas no contexto são sincronizadas com a base de dados. Esta será alvo de uma série de operações SQL DELETE, seguida de uma série de operações SQL INSERT;
Definimos o programa [Fill] como o novo objeto de início do projeto [1] e, em seguida, executamos este último.
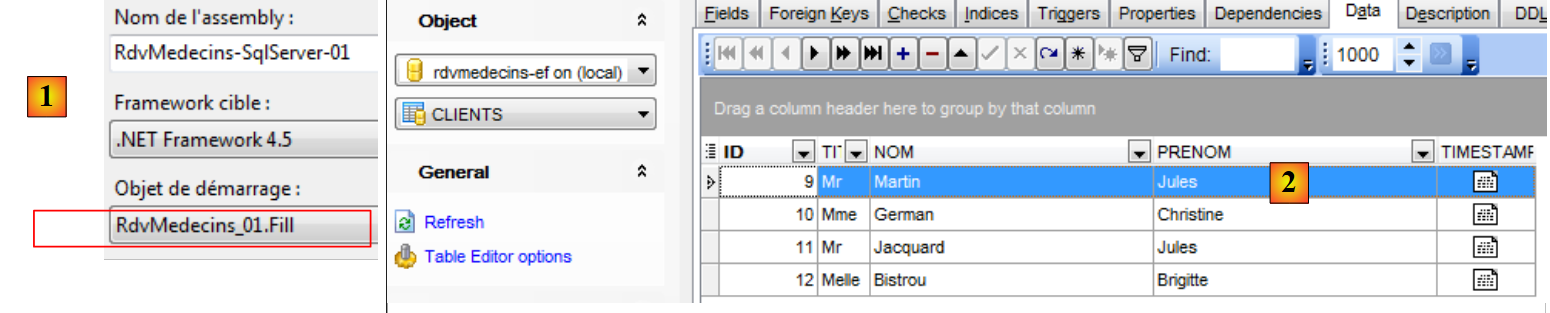 |
Verifica-se no [2] que as tabelas foram preenchidas.
3.5.3. Visualização do conteúdo da base de dados
Vamos agora visualizar o conteúdo da base de dados utilizando as consultas LINQ to Entity. O LINQ (Language INtegrated Query) surgiu com o framework .NET 3.5 em 2007. Apresenta-se como uma extensão das linguagens .NET e c.a.d, estando integrado na linguagem e a sua sintaxe é verificada pelo compilador. Permite consultar diferentes coleções com uma sintaxe que apresenta semelhanças com a linguagem SQL (Structured Query Language) de consulta de bases de dados. Existem diferentes versões do LINQ:
- LINQ to Object, para consultar coleções em memória;
- LINQ to XML, para consultar o XML;
- LINQ para Entity, para consultar bases de dados;
Para existir, o LINQ baseia-se em numerosas extensões feitas às linguagens .NET. Estas podem ser utilizadas fora do LINQ. Não iremos apresentá-las, mas limitar-nos-emos a indicar duas referências onde o leitor encontrará uma descrição aprofundada do LINQ:
- «LINQ in Action», de Fabrice Marguerie, Steve Eichert e Jim Wooley, publicado pela Manning;
- «LINQ pocket reference», de Joseph e Ben Albahari, publicado pela O'Reilly.
Li o primeiro e achei-o excelente. Não li o segundo, mas li, dos mesmos autores, «C# 3.0 in a nutshell», publicado na altura do lançamento do LINQ. Achei este livro muito acima da média dos livros que costumo ler. Parece que os outros livros destes dois autores têm o mesmo nível. Além disso, vamos utilizar o LINQPad, uma ferramenta de aprendizagem do LINQ escrita por Joseph Albahari.
Vamos apresentar as entidades presentes na base de dados. Para tal, adicionamos às respetivas classes dois métodos de apresentação. Comecemos pela entidade [Medecin]:
// um médico
public class Medecin
{
// dados
[Key]
[Column("ID")]
public int? Id { get; set; }
[Required]
[MaxLength(5)]
[Column("TITRE")]
public string Titre { get; set; }
[Required]
[MaxLength(30)]
[Column("NOM")]
public string Nom { get; set; }
[Required]
[MaxLength(30)]
[Column("PRENOM")]
public string Prenom { get; set; }
// os horários do médico
public ICollection<Creneau> Creneaux { get; set; }
[Column("TIMESTAMP")]
[Timestamp]
public byte[] Timestamp { get; set; }
// assinatura
public override string ToString()
{
return String.Format("Medecin[{0},{1},{2},{3},{4}]", Id, Titre, Prenom, Nom, dump(Timestamp));
}
// assinatura abreviada
public string ShortIdentity()
{
return ToString();
}
// utilitário
private string dump(byte[] timestamp){
string str = "";
foreach (byte b in timestamp)
{
str += b;
}
return str;
}
}
- linhas 27-30: o método ToString da classe. Note-se que este não exibe a coleção da linha 21;
- linhas 32-37: o método ShortIdentity, que faz o mesmo.
É necessário explicar aqui os conceitos de Lazy e Eager Loading para avaliar o impacto dos dois métodos anteriores. Vimos que uma entidade pode ter dependências em relação a outra entidade. Estas dependências são de dois tipos:
- de um para vários, como acima, em que um médico está ligado a vários horários;
- de vários para um, como na entidade [Creneau] abaixo, em que vários horários estão ligados ao mesmo médico;
public class Creneau
{
// dados
...
[Required]
[Column("MEDECIN_ID")]
public int MedecinId { get; set; }
[Required]
[ForeignKey("MedecinId")]
public virtual Medecin Medecin { get; set; }
...
}
Quando as dependências são carregadas ao mesmo tempo que as entidades às quais estão associadas, fala-se de «Eager Loading». Caso contrário, fala-se de Lazy Loading: as dependências só são carregadas quando são referenciadas pela primeira vez. Por predefinição, o EF 5 utiliza o Lazy Loading: as dependências não são carregadas em simultâneo com a entidade.
Vejamos o nosso método [ToString] acima:
// horários de atendimento do médico
public ICollection<Creneau> Creneaux { get; set; }
// assinatura
public override string ToString()
{
return String.Format("Medecin[{0},{1},{2},{3},{4}]", Id, Titre, Prenom, Nom, dump(Timestamp));
}
// assinatura abreviada
public string ShortIdentity()
{
return ToString();
}
O método [ToString] não exibe a dependência [Creneaux] da linha 2. Se o tivesse feito, teria forçado o carregamento de todos os horários do médico antes da sua execução. Foi para evitar este carregamento dispendioso que a dependência não foi incluída na assinatura da entidade. De um modo geral, iremos incluir duas assinaturas em cada entidade:
- um método ToString que exibirá a entidade e as suas eventuais dependências, uma a uma. Tal como acabou de ser explicado, isto provocará o carregamento da dependência;
- um método ShortIdentity que não fará referência a nenhuma dependência. Por conseguinte, não haverá qualquer carregamento de dependências;
Os métodos de visualização das outras entidades serão os seguintes:
A entidade [Client]:
public class Client
{
// dados
...
// as consultas do cliente
public ICollection<Rv> Rvs { get; set; }
// assinatura
public override string ToString()
{
return String.Format("Client[{0},{1},{2},{3},{4}]", Id, Titre, Prenom, Nom, dump(Timestamp));
}
// assinatura curta
public string ShortIdentity()
{
return ToString();
}
}
- linhas 9-12: o método [ToString] não apresenta a dependência da linha 6;
A entidade [Creneau]:
public class Creneau
{
...
[Required]
[Column("MEDECIN_ID")]
public int MedecinId { get; set; }
[Required]
[ForeignKey("MedecinId")]
public virtual Medecin Medecin { get; set; }
// as Rvs do intervalo
public ICollection<Rv> Rvs { get; set; }
// assinatura
public override string ToString()
{
return String.Format("Creneau[{0},{1},{2},{3},{4}, {5}]", Id, Hdebut, Mdebut, Hfin, Mfin, Medecin, dump(Timestamp));
}
// assinatura curta
public string ShortIdentity()
{
return String.Format("Creneau[{0},{1},{2},{3},{4}, {5}, {6}]", Id, Hdebut, Mdebut, Hfin, Mfin, Timestamp, MedecinId, dump(Timestamp));
}
}
- linha 16: o método [ToString] faz referência à dependência da linha 9. Isto irá forçar o seu carregamento;
- linha 11: a dependência [Rvs] não é referenciada. Não será carregada;
- linhas 21-22: o método [ShortIdentity] já não faz referência à referência [Medecin] da linha 9. Por conseguinte, esta não será carregada.
A entidade [Rv]:
public class Rv
{
// dados
...
[Column("CLIENT_ID")]
public int ClientId { get; set; }
[ForeignKey("ClientId")]
[Required]
public virtual Client Client { get; set; }
[Column("CRENEAU_ID")]
public int CreneauId { get; set; }
[ForeignKey("CreneauId")]
[Required]
public virtual Creneau Creneau { get; set; }
// assinatura
public override string ToString()
{
return String.Format("Rv[{0},{1},{2},{3},{4}]", Id, Jour, Client, Creneau, dump(Timestamp));
}
// assinatura curta
public string ShortIdentity()
{
return String.Format("Rv[{0},{1},{2},{3},{4}]", Id, Jour, ClientId, CreneauId, dump(Timestamp));
}
}
- linhas 17-20: o método [ToString] faz referência às dependências das linhas 9 e 14. Isto irá forçar o seu carregamento;
- linhas 17-20: o método [ShortIdentity] evita isso e, por conseguinte, as dependências não serão carregadas.
Em conclusão, devemos prestar atenção aos métodos [ToString] das entidades. Se não prestarmos atenção a isso, a exibição de uma tabela pode carregar metade da base de dados, caso a tabela tenha muitas dependências.
Dito isto, escrevemos o novo código [Dump.cs] a seguir:
using RdvMedecins.Entites;
using RdvMedecins.Models;
using System;
using System.Linq;
namespace RdvMedecins_01
{
class Dump
{
static void Main(string[] args)
{
// dump da base de dados
using (var context = new RdvMedecinsContext())
{
// os clientes
Console.WriteLine("Clients--------------------------------------");
var clients = from client in context.Clients select client;
foreach (Client client in clients)
{
Console.WriteLine(client);
}
// os médicos
Console.WriteLine("Médecins--------------------------------------");
var medecins = from medecin in context.Medecins select medecin;
foreach (Medecin medecin in medecins)
{
Console.WriteLine(medecin);
}
// os horários disponíveis
Console.WriteLine("Créneaux horaires--------------------------------------");
var creneaux = from creneau in context.Creneaux select creneau;
foreach (Creneau creneau in creneaux)
{
Console.WriteLine(creneau);
}
// as consultas
Console.WriteLine("Rendez-vous--------------------------------------");
var rvs = from rv in context.Rvs select rv;
foreach (Rv rv in rvs)
{
Console.WriteLine(rv);
}
}
}
}
}
Vamos explicar as linhas 17 a 21, que apresentam as entidades [Client]. A explicação fornecida aplica-se também às outras entidades.
// os clientes
Console.WriteLine("Clients--------------------------------------");
var clients = from client in context.Clients select client;
foreach (Client client in clients)
{
Console.WriteLine(client);
}
- linha 3: a palavra-chave var foi introduzida com o C# 3.0. Permite evitar indicar o tipo específico de uma variável. O compilador deduz então esse tipo a partir do tipo da expressão atribuída à variável;
- linha 3: a expressão atribuída à variável clients é uma consulta LINQ to Entity. Nela reconhecem-se palavras-chave da linguagem SQL incorporadas no LINQ. A sintaxe utilizada aqui é a seguinte:
from variable in DbSet select variable
Uma sintaxe mais geral de LINQ é
from variable in collection select variable
A coleção será percorrida e, para cada elemento da mesma, a variável será avaliada. Isto só acontece quando a variável [clients] da linha 3 for enumerada pelo for / each das linhas 4-7. Enquanto isso não acontecer, a variável [clients] é apenas uma consulta não avaliada;
- linha 4: a consulta [clients] é iterada. Isto forçará a avaliação da consulta. As linhas da tabela [CLIENTS] serão introduzidas, uma a uma, no contexto de persistência;
- linha 6: o método [ToString] da entidade [Client] é utilizado para a visualização. Não há carregamento de dependências;
Passemos às linhas seguintes do código:
- linhas 24-28: as linhas da tabela [MEDECINS] são introduzidas no contexto de persistência e apresentadas. Não há carregamento de dependências;
- linhas 31-35: as linhas da tabela [CRENEAUX] são introduzidas no contexto de persistência e apresentadas. Vimos que o método [ToString] desta entidade exibia a dependência [Medecin]. No entanto, esta já se encontra carregada. Por conseguinte, não haverá um novo carregamento;
- linhas 38-42: as linhas da tabela [RVS] são transferidas para o contexto de persistência e apresentadas. Vimos que o método [ToString] desta entidade exibia as dependências [Client] e [Creneau]. No entanto, estas já se encontram carregadas. Por conseguinte, não haverá novos carregamentos.
Note-se que a ordem de exibição não é neutra. Se se quisesse apresentar primeiro as entidades [Rv], o método [ToString] desta entidade teria provocado o carregamento das entidades [Client] e [Creneau] associadas a esses compromissos. As restantes não teriam sido carregadas. Teriam sido carregadas mais tarde, noutro ecrã. Isto tem impacto no desempenho. O código anterior necessita de quatro ordens SQL para apresentar todas as entidades. Suponhamos agora que se utilize primeiro a tabela [RVS] dos compromissos. É necessária uma primeira consulta SQL para a tabela [RVS]. Em seguida, o método [ToString] da entidade [Rv] irá provocar o eventual carregamento das entidades [Client] e [Creneau] associadas. É necessária uma consulta SQL para cada uma delas. Supondo que existam N2 clientes e N3 intervalos horários e que todas estas entidades estejam referenciadas na tabela [RVS], a sua visualização exigirá 1 + N2 + N3 consultas SQL. Por conseguinte, o desempenho é inferior ao da versão analisada. Para apresentar a tabela [RVS] com as suas dependências, seria necessária uma junção entre tabelas. É possível realizá-la com a tabela LINQ. Voltaremos a este assunto com um exemplo. Por enquanto, recordemos que devemos prestar atenção às consultas SQL subjacentes ao nosso código LINQ.
Configuramos o projeto para executar este novo código [1] e [2] e, em seguida, executamo-lo:
 |
A saída da consola é a seguinte:
3.5.4. Aprendizagem do LINQ com o LINQPad
Utilizámos acima as consultas LINQ to Entity para apresentar o conteúdo das tabelas da base de dados. Joseph Albahari escreveu um programa para aprender as diferentes formas de LINQ. Apresentamo-lo agora.
O LINQPad está disponível no seguinte URL [http://www.linqpad.net/]. Depois de instalado, executamo-lo [1]:
 |
O utilizador iniciante LINQ poderá familiarizar-se com os exemplos do separador [Samples] [2], que apresentam inúmeros exemplos. Selecionemos o exemplo [3], que é então apresentado numa outra janela [4]. O código completo do exemplo é o seguinte:
// Agora, uma expressão de consulta simples em LINQ-to-Objects (repare que não há ponto e vírgula):
from word in "The quick brown fox jumps over the lazy dog".Split()
orderby word.Length
select word
// Sinta-se à vontade para editar isto... (ninguém está a ver!) Ser-lhe-á solicitado que guarde quaisquer
// alterações num ficheiro separado.
//
// Dica: Pode executar parte de uma consulta selecionando-a e, em seguida, premindo F5.
As linhas 3-5 são um exemplo de consulta LINQ to Object. A consulta LINQ segue a sintaxe:
from variable in collection orderby élément1 select élément2
- A variável designa o elemento atual da coleção. No nosso exemplo, esta coleção é a lista de palavras resultantes da cadeia dividida;
- a coleção é ordenada de acordo com o parâmetro élément1 de
</span>**<span style="color: #000000">orderby**. No nosso exemplo, a coleção de palavras será ordenada de acordo com o seu comprimento; - a palavra-chave
selectindica o que se pretende extrair do elemento atual</span>*<span style="color: #000000">variable*da coleção. No nosso exemplo, será a palavra.
Vamos executar esta consulta LINQ:
 |
- em [1]: uma expressão LINQ é executada por [F5] ou através do botão de execução;
- em [2]: a visualização. As palavras são apresentadas por ordem de comprimento. Este exemplo simples demonstra o potencial de LINQ;
- no [3], é possível descarregar outros exemplos, nomeadamente os do livro «LINQ in action» [4];
 |
- em [5], escolhemos um exemplo do livro;
string[] words = { "hello", "wonderful", "linq", "beautiful", "world" };
// Agrupar palavras por comprimento
var groups =
from word in words
orderby word ascending
group word by word.Length into lengthGroups
orderby lengthGroups.Key descending
select new { Length = lengthGroups.Key, Words = lengthGroups };
// Imprimir cada grupo
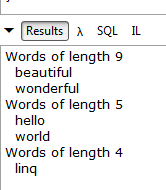
foreach (var group in groups)
{
Console.WriteLine("Words of length " + group.Length);
foreach (string word in group.Words)
Console.WriteLine(" " + word);
}
- linha 4: uma nova consulta LINQ com novas palavras-chave;
- linha 5: a coleção solicitada é a tabela de palavras da linha 1;
- linha 6: a coleção é ordenada por ordem alfabética das palavras;
- linha 7: a coleção é agrupada (palavra-chave «into») numa nova coleção lengthGroups. lengthGroups.Key representa o fator de agrupamento (palavra-chave «by»), neste caso, o comprimento das palavras. lengthGroups reúne as palavras com o mesmo fator de agrupamento, ou seja, o mesmo comprimento;
- linha 8: a coleção lengthGroups é ordenada por chave de agrupamento em ordem decrescente, ou seja, neste caso, por tamanho decrescente das palavras;
- linha 9: a partir desta coleção, são criados novos objetos (classes anónimas) com dois campos:
- Length: o comprimento das palavras,
- Words: as palavras com esse comprimento;
Aqui, verifica-se particularmente a utilidade da palavra-chave var da linha 4. Como se utilizou uma classe anónima na linha 9, não é possível especificar o tipo da variável groups. O compilador, por sua vez, atribuirá um nome interno à classe anónima e utilizará esse nome para tipar a variável groups. Posteriormente, será capaz de determinar se a variável groups está a ser utilizada corretamente
- linha 12: percurso da consulta da linha 4. Só neste momento é que esta é avaliada. Recorde-se que a sua execução irá produzir uma coleção de objetos, especificados na linha 9;
- linha 14: exibe-se a propriedade Length do elemento atual, ou seja, o comprimento das palavras;
- linhas 15-17: exibe-se cada elemento da coleção da propriedade Words, ou seja, o conjunto de palavras com o comprimento exibido anteriormente.
Quando executamos esta consulta, obtemos o seguinte resultado em LINQPad:
 |
Agora que vimos alguns exemplos de consultas [LINQ to Object], vamos ver consultas [LINQ to Entity] que nos permitirão consultar bases de dados. Primeiro, vamos ligar-nos à base de dados SQL Server que criámos e preenchemos:
 |
- em [1], adicionamos uma ligação a uma base de dados;
- em [2], definimos os meios de acesso à fonte de dados. Para aceder à base de dados SQL Server, utilizaremos [LINQPad Driver];
- no [3], também é possível recuperar um contexto de persistência [DbContext] definido num ficheiro .exe ou .dll assembly (opção 3). Infelizmente, até à data (8 de outubro de 2012), o Entity Framework 5 não é suportado;
- no [4], é possível descarregar controladores para outros SGBD que não o SQL Server;
- no [5], descarregue-se o controlador para os SGBD, MySQL e Oracle;
 |
- no [6], o controlador descarregado;
- em [7], ligamo-nos a uma base de dados SQL Server;
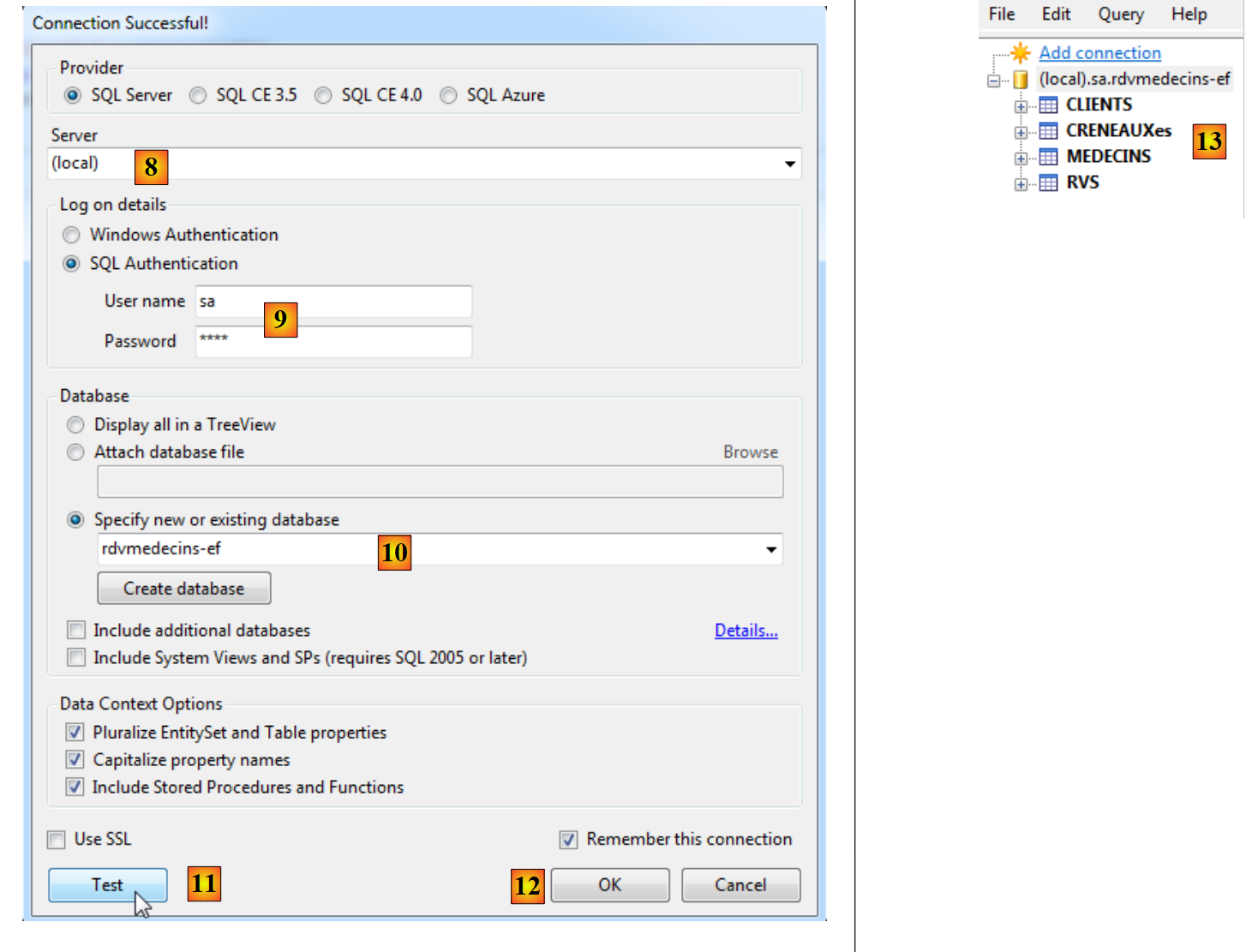 |
- em [8], a base de dados encontra-se no servidor de nomes (local);
- em [9], ligamo-nos com a autenticação sa / sqlserver2012;
- em [10], à base de dados [rdvmedecins-ef] que criámos;
- em [11], é possível testar a ligação;
- no [12], encerra-se o assistente;
- em [13], a ligação aparece em LINQPad.
As entidades foram criadas a partir da tabela [rdvmedecins-ef]. São as seguintes:
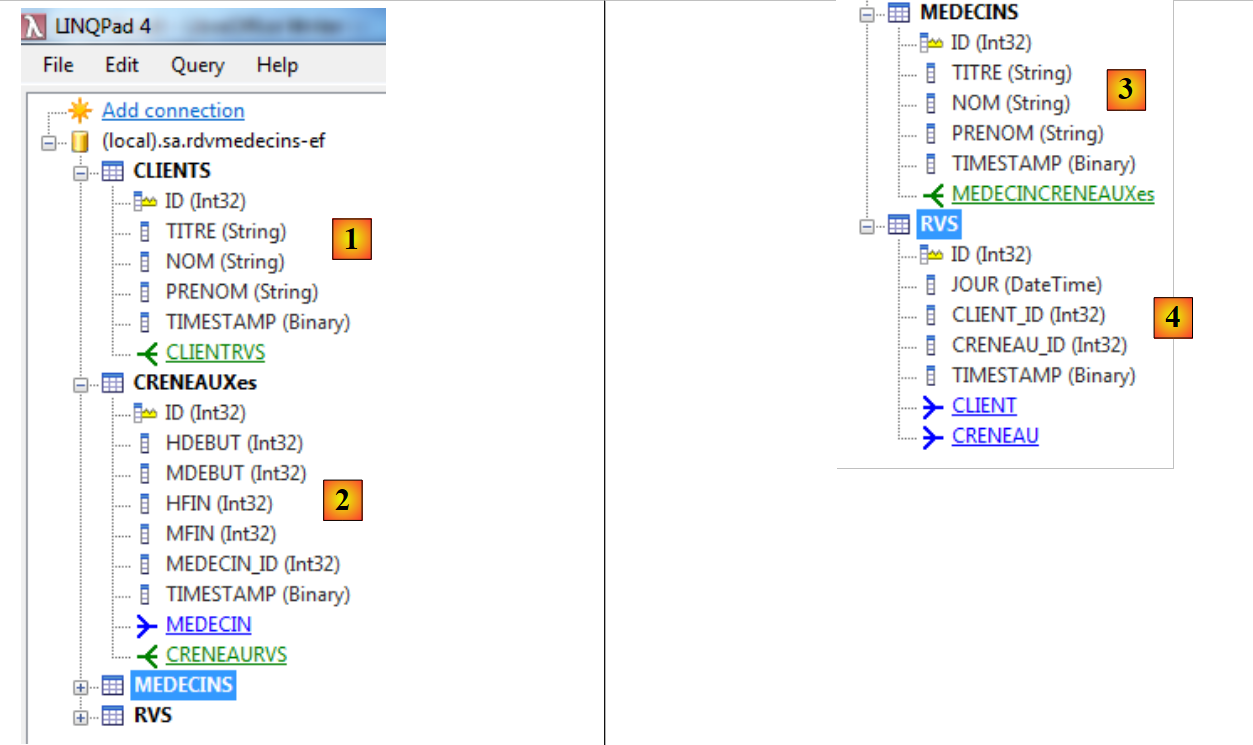 |
- em [1], [CLIENTS] representa o conjunto de entidades [Client]. Cada entidade tem:
- as propriedades (ID, TITRE, NOM, PRENOM, TIMESTAMP),
- uma relação de 1 para vários [CLIENTRVS];
- em que [2] e [CRENEAUXes] representam o conjunto de entidades [Creneau]. Cada entidade tem:
- as propriedades (ID, HDEBUT, MDEBUT, HFIN, MFIN, MEDECIN_ID, TIMESTAMP),
- uma relação «um para vários» [CRENEAURVS],
- uma relação de «muitos para 1» [MEDECIN];
- em [3], a entidade [MEDECINS] representa o conjunto das entidades [Medecin]. Cada entidade tem:
- as propriedades (ID, TITRE, NOM, PRENOM, TIMESTAMP),
- uma relação de 1 para vários [MEDECINCRENEAUXes];
- em [4], a entidade [RVS] representa o conjunto das entidades [Rv]. Cada entidade tem:
- as propriedades (ID, JOUR, CLIET_ID, CRENEAU_ID, TIMESTAMP),
- uma relação «muitos para um» com [CLIENT],
- uma relação muitos-para-um [CRENEAU].
Note-se que os nomes das propriedades acima são diferentes dos nomes que temos utilizado até agora. Isso não tem importância. Queremos apenas aprender os princípios básicos da consulta a bases de dados.
Vamos ver como podemos consultar esta base de entidades. Por exemplo, queremos a lista de médicos ordenada pelo seu TITRE e NOM:
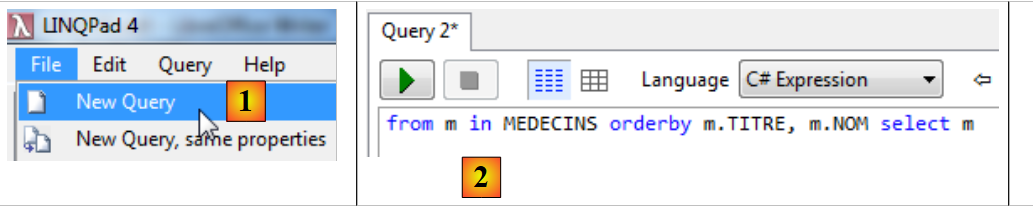 |
- em [1], criamos uma nova consulta;
- em [2], o texto da consulta;
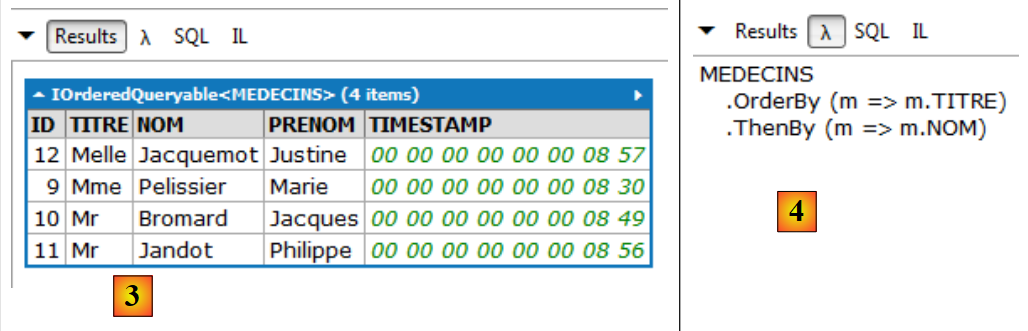 |
- em [3], o resultado da consulta;
- em [4], a mesma consulta com expressões lambda. Uma consulta com expressões lambda é menos legível do que uma consulta de texto e pode ser preferível evitá-las. No entanto, por vezes são indispensáveis, pois permitem fazer certas coisas que as consultas de texto não permitem. Uma expressão lambda designa uma função com um parâmetro de entrada a e um parâmetro de saída b, na forma a=>b. O método OrderBy acima aceita uma função lambda como único parâmetro. Esta fornece-lhe o parâmetro segundo o qual uma coleção deve ser ordenada. Assim, MEDECINS.OrderBy(m=>m.TITRE) é a lista de médicos ordenada pelos títulos. Esta instrução deve ser interpretada como um pipeline sobre uma coleção. A coleção de médicos é fornecida como entrada ao método OrderBy. Este irá processar as entidades [Medecin] uma a uma. Na expressão lambda m=>m.TITRE, m representa a entrada da função lambda. Pode ser nomeada como se quiser. Aqui, a entrada da função lambda será uma entidade [Medecin]. A função m=>m.TITRE pode ser interpretada da seguinte forma: se designar m como a minha entrada (uma entidade [Medecin]), então a minha saída é m.TITRE, ou seja, o nome do médico. MEDECINS.OrderBy(m=>m.TITRE) é, por sua vez, uma coleção, a coleção de médicos ordenada por títulos. Esta nova coleção pode alimentar outro método; no exemplo, o método ThenBy. Este funciona segundo o mesmo princípio. Serve para indicar parâmetros adicionais para a ordenação da coleção.
Ler o código lambda equivalente ao código de texto que costumamos escrever é uma boa forma de o aprender;
 |
- em [5], a ordem SQL emitida na base de dados. Mais uma vez, devemos ler atentamente este código. Permite avaliar o custo real de uma consulta LINQ.
A seguir, apresentamos alguns exemplos de consultas LINQ. Em cada caso, mostramos os resultados apresentados e os códigos lambda e SQL equivalentes. Para compreender estas consultas, é necessário recordar as relações «muitos para um» que ligam as entidades entre si. É através delas que se navega de uma entidade para outra. Chamam-se propriedades de navegação.
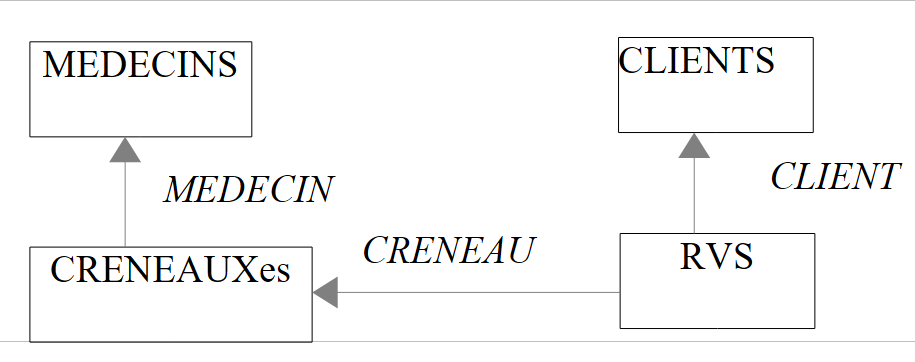 |
// os clientes cujo título é «Sr.» ordenados por ordem decrescente dos nomes
Resultados:
 |
LINQ | |
Lambda | |
SQL | |
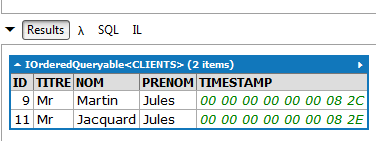
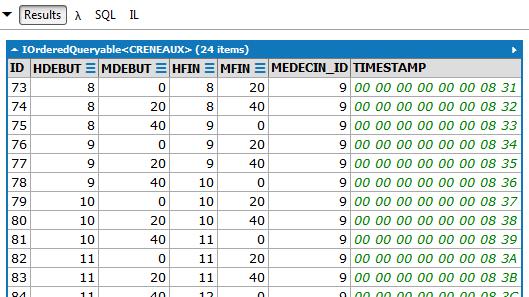
// todos os horários disponíveis com o médico associado
Resultados (parciais):
 |
LINQ | |
Lambda |  |
SQL | |
// todas as consultas com o cliente e o médico associados
Resultados:
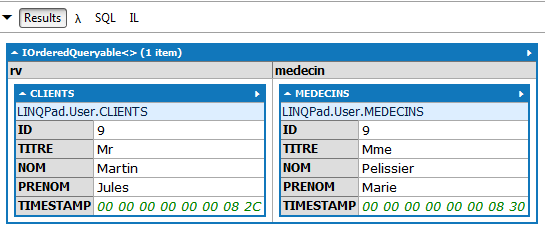 |
LINQ | |
Lambda | 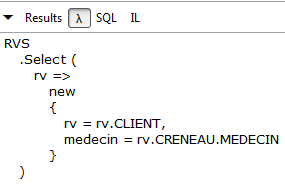 |
SQL | |
// médicos sem consultas marcadas
Resultados:
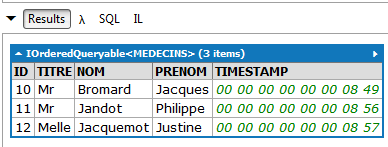 |
LINQ | |
Lambda | 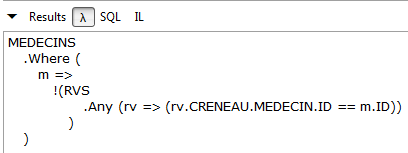 |
SQL | |
Não existe nenhuma consulta LINQ para este pedido. É necessário utilizar expressões lambda. Esta expressão lê-se da seguinte forma: pego na coleção de médicos (MEDECINS) e retenho (Where) apenas os médicos (m) para os quais não consigo encontrar, na coleção de consultas (RVS), uma consulta (rv) com esse médico (m).
// horários disponíveis da Sra. Pélissier
Resultados (parciais):
 |
LINQ | |
Lambda |  |
SQL | |
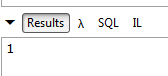
// número de consultas da Sra. Pélissier em 08/10/2012
Resultados:
 |
LINQ | |
Lambda | |
SQL | |
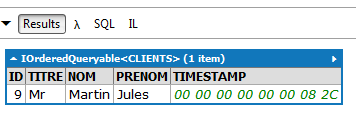
// lista de clientes que marcaram uma consulta com a Sra. Pélissier a 08/10/2012
Resultados:
 |
LINQ | |
Lambda | 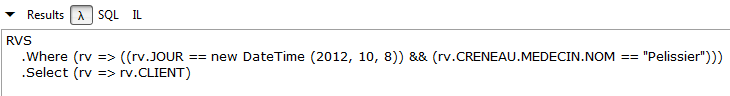 |
SQL | |
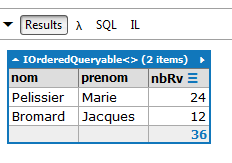
// número de horários por médico
Resultados:
 |
LINQ | |
Lambda | 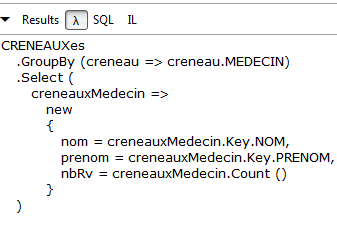 |
SQL | |
3.5.5. Alteração de uma entidade associada ao contexto de persistência
Vimos as seguintes operações no contexto de persistência:
- adicionar um elemento ao contexto ([dbContext].[DbSet].Add);
- remover um elemento do contexto ([dbContext].[DbSet].Remove);
- consultar um contexto com as consultas LINQ.
Quando se pretende sincronizar o contexto com a base de dados, escreve-se [dbContext].SaveChanges().
 |  |
O código [ModifyAttachedEntity] ilustra a modificação de uma entidade associada ao contexto:
using System;
using System.Data;
using System.Linq;
using RdvMedecins.Entites;
using RdvMedecins.Models;
namespace RdvMedecins_01
{
class ModifyAttachedEntity
{
static void Main(string[] args)
{
Client client1, client2, client3;
// 1.º contexto
using (var context = new RdvMedecinsContext())
{
// Esvaziar a base de dados atual
foreach (var client in context.Clients)
{
context.Clients.Remove(client);
}
foreach (var medecin in context.Medecins)
{
context.Medecins.Remove(medecin);
}
// Adicionar um cliente
client1 = new Client { Nom = "xx", Prenom = "xx", Titre = "xx" };
context.Clients.Add(client1);
// acompanhamento
Console.WriteLine("client1--avant");
Console.WriteLine(client1);
// guardar contexto
context.SaveChanges();
// acompanhamento
Console.WriteLine("client1--après");
Console.WriteLine(client1);
}
// 2.º contexto
using (var context = new RdvMedecinsContext())
{
// recuperar o cliente1 no cliente2
client2 = context.Clients.Find(client1.Id);
// acompanhamento
Console.WriteLine("client2");
Console.WriteLine(client2);
// altera-se o cliente2
client2.Nom = "yy";
// guardar contexto
context.SaveChanges();
}
// 3.º contexto
using (var context = new RdvMedecinsContext())
{
// recuperar o cliente2 no cliente3
client3 = context.Clients.Find(client2.Id);
// acompanhamento
Console.WriteLine("client3");
Console.WriteLine(client3);
}
}
}
}
- linha 15: abertura do contexto da aplicação;
- linhas 18-25: o contexto é esvaziado. Mais precisamente, todas as entidades são transferidas da base de dados para o contexto e passam para o estado «eliminado». Note-se que, nesta fase, a base de dados não sofreu alterações. Enquanto o contexto não estiver sincronizado com a base de dados, esta não sofre alterações. Recorde-se que basta eliminar as entidades [Medecin] e [Client] para esvaziar a base de dados através do mecanismo de eliminações em cascata;
- linhas 27-28: é adicionado um novo cliente à base de dados;
- linhas 30-31: este é apresentado antes de ser guardado na base de dados;
- linha 33: sincroniza-se o contexto com a base de dados. As entidades marcadas com o estado «eliminado» serão alvo de uma operação SQL DELETE, a entidade será adicionada a uma operação SQL INSERT;
- linhas 35-36: o cliente é apresentado após a sincronização com a base de dados;
O resultado obtido na consola é o seguinte:
É de salientar o seguinte:
- antes da sincronização com a base de dados, o cliente não tem nem chave primária, nem timestamp,
- após a sincronização, já as possui. Recorde-se aqui que a chave primária foi configurada para ser gerada pelo SQL Server. Da mesma forma, este SGBD gera automaticamente o timestamp;
- linha 37: o contexto de persistência é fechado. As entidades que ele continha tornam-se «desvinculadas». Existem como objetos, mas não como entidades vinculadas a um contexto de persistência;
- linha 39: inicia-se um novo contexto vazio;
- linha 42: recupera-se o cliente diretamente da base de dados através da sua chave primária. Este é então inserido no contexto. Se não for encontrado, o método Find devolve o ponteiro null;
- linhas 48-49: exibe-se o cliente;
Isto dá o seguinte resultado:
- linha 47: altera-se o valor;
- linha 49: sincroniza-se o contexto com a base de dados. EF irá detetar que alguns elementos do contexto foram alterados desde que foram introduzidos no mesmo. Para esses elementos, irá gerar ordens SQL e UPDATE na base de dados. Portanto, neste caso, a sincronização consistirá numa única ordem UPDATE;
- linha 50: o segundo contexto é fechado. A entidade client2, que estava associada ao contexto, fica agora desassociada deste;
- linha 52: abre-se um terceiro contexto vazio;
- linha 55: traz-se de novo o único cliente da base de dados. Pretende-se verificar se a alteração efetuada no cliente no contexto anterior foi refletida na base de dados;
- linhas 57-58: exibe-se o cliente. Isto dá o seguinte resultado:
O nome do cliente foi efetivamente alterado na base de dados. É interessante notar que o seu timestamp foi atualizado.
- linha 59: encerra-se o contexto. De passagem, note-se que, ao contrário das duas vezes anteriores, não foi necessário sincronizar previamente o contexto com a base de dados (SaveChanges), uma vez que o contexto não tinha sido alterado.
3.5.6. Gestão de entidades destacadas
Voltemos à arquitetura em camadas de uma aplicação como a do caso de estudo:
 |
A camada [DAO] utiliza a ORM e a EF5 para aceder aos dados. Temos os blocos de construção básicos desta camada. Cada método abrirá um contexto de persistência, realizará as operações necessárias (inserção, modificação, eliminação, consulta) e, em seguida, fechá-lo-á. As entidades geridas pela camada [DAO] serão encaminhadas até à camada web ASP.NET. Nesta camada, encontram-se fora do contexto de persistência, pelo que estão desligadas. Na camada web, um utilizador pode alterar estas entidades (adição, modificação, eliminação). Quando regressam à camada [DAO], continuam a estar desligadas. No entanto, a camada [DAO] terá de repercutir as alterações efetuadas pelo utilizador na base de dados. Por conseguinte, terá de trabalhar com entidades desligadas. Vejamos os três casos possíveis:
Adicionar uma entidade desligada
Este é o caso normal para uma adição. Basta adicionar (Add) a entidade destacada ao contexto, certificando-se de que esta tem uma chave primária igual a null.
Alterar uma entidade destacada
Pode utilizar-se o seguinte código:
- o método [DbContext].Entry(entidade-isolada) irá inserir a entidade no contexto;
- o estado dessa entidade é definido como «modificado», para que seja alvo de uma ordem SQL UPDATE.
Eliminar uma entidade destacada
Pode utilizar-se o seguinte código:
- linha 1: insere-se no contexto a entidade com a mesma chave primária que a entidade separada;
- linha 2: elimina-se a entidade:
Note-se que isto requer, como base, um SELECT seguido de um DELETE, quando normalmente basta apenas o DELETE. Também se pode seguir o exemplo da modificação de uma entidade separada e escrever:
Como não consegui implementar registos das operações SQL realizadas na base de dados, não sei se um método é mais recomendável do que o outro.
Eis um exemplo:
 |  |
O código do programa [ModifyDetachedEntities] é o seguinte:
using System;
using System.Data;
using RdvMedecins.Entites;
using RdvMedecins.Models;
namespace RdvMedecins_01
{
class ModifyDetachedEntities
{
static void Main(string[] args)
{
Client client1;
// esvazia-se a base de dados atual
Erase();
// adiciona-se um cliente
using (var context = new RdvMedecinsContext())
{
// criação de cliente
client1 = new Client { Titre = "x", Nom = "x", Prenom = "x" };
// adição do cliente ao contexto
context.Clients.Add(client1);
// guardar o contexto
context.SaveChanges();
}
// visualização da base de dados
Dump("1-----------------------------");
// O cliente1 não está no contexto — altera-se o contexto
client1.Nom = "y";
// novo contexto
using (var context = new RdvMedecinsContext())
{
// aqui, temos um contexto vazio
// colocamos o cliente1 no contexto num estado alterado
context.Entry(client1).State = EntityState.Modified;
// guardamos o contexto
context.SaveChanges();
}
// visualização básica
Dump("2-----------------------------");
// eliminação de entidade fora do contexto
using (var context = new RdvMedecinsContext())
{
// aqui, temos um novo contexto vazio
// coloca-se o cliente1 no contexto num estado eliminado
context.Entry(client1).State = EntityState.Deleted;
// guardamos o contexto
context.SaveChanges();
}
// visualização da base de dados
Dump("3-----------------------------");
}
static void Erase()
{
// esvazia a base de dados
using (var context = new RdvMedecinsContext())
{
foreach (var client in context.Clients)
{
context.Clients.Remove(client);
}
foreach (var medecin in context.Medecins)
{
context.Medecins.Remove(medecin);
}
// guarda-se o contexto
context.SaveChanges();
}
}
static void Dump(string str)
{
Console.WriteLine(str);
// exibe a base
using (var context = new RdvMedecinsContext())
{
foreach (var rv in context.Rvs)
{
Console.WriteLine(rv);
}
foreach (var creneau in context.Creneaux)
{
Console.WriteLine(creneau);
}
foreach (var client in context.Clients)
{
Console.WriteLine(client);
}
foreach (var medecin in context.Medecins)
{
Console.WriteLine(medecin);
}
}
}
}
}
- linha 15: a base de dados é apagada;
- linhas 17-25: é adicionado um cliente à base de dados;
- linha 27: apresenta o conteúdo da base de dados;
- após a linha 25, o contexto de persistência já não existe. Por conseguinte, já não há entidades associadas. A entidade client1 passou para o estado «desassociada»;
- linha 29: altera-se o nome da entidade desanexada;
- linha 31: abre-se um novo contexto vazio;
- linha 35: a entidade desanexada client1 é colocada no contexto no estado «modificado»;
- linha 37: o contexto é sincronizado com a base de dados;
- linha 38: é fechado;
- linha 40: a base de dados é apresentada;
O nome do cliente foi efetivamente alterado na base de dados. Note-se que o timestamp foi atualizado;
- linha 42: abertura de um novo contexto vazio;
- linha 46: a entidade destacada client1 é colocada no contexto com o estado «eliminado»;
- linha 48: o contexto é sincronizado com a base de dados;
- linha 49: é fechado;
- linha 51: a base de dados é apresentada;
A entidade foi efetivamente eliminada da base de dados.
Agora, vamos ver os dois modos de carregamento das dependências de uma entidade: Lazy e Eager Loading.
3.5.7. Carregamento Lazy e Eager
Voltemos ao esquema de dependências «muitos para um» de uma das nossas quatro entidades:
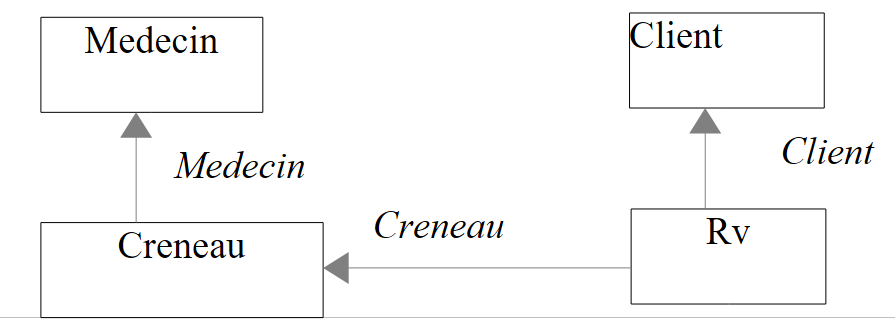 |
Acima, a entidade [Creneau] possui uma propriedade de navegação [Creneau.Medecin] para a entidade [Medecin]. A isto chama-se uma dependência. Vimos que também existem dependências de um para vários. O princípio que vai ser explicado aplica-se igualmente a estas.
Por predefinição, a entidade EF 5 está no modo «Lazy Loading»: quando traz uma entidade do banco de dados para o contexto de persistência, não traz as suas dependências. Estas serão carregadas quando forem utilizadas pela primeira vez. Trata-se de uma medida de bom senso. Se não fosse esse o caso, ao trazer os compromissos para o contexto, seriam também trazidas, de acordo com as dependências acima referidas:
- as entidades [Creneau] associadas aos compromissos;
- as entidades [Medecin] associadas a esses horários;
- as entidades [Clients] associadas aos compromissos.
Por vezes, no entanto, é necessária uma entidade e as suas dependências. Vamos ilustrar os dois modos de carregamento.
 |  |
O código de [LazyEagerLoading] é o seguinte:
using RdvMedecins.Entites;
using RdvMedecins.Models;
using System;
using System.Linq;
namespace RdvMedecins_01
{
class LazyEagerLoading
{
// as entidades
static Medecin[] medecins;
static Client[] clients;
static Creneau[] creneaux;
static void Main(string[] args)
{
// inicialização da base
InitBase();
Console.WriteLine("Initialisation terminée");
// carregamento antecipado
Creneau creneau;
int idCreneau = (int)creneaux[0].Id;
using (var context = new RdvMedecinsContext())
{
// intervalo n.º 0
creneau = context.Creneaux.Include("Medecin").Single<Creneau>(c => c.Id == idCreneau);
Console.WriteLine(creneau.ShortIdentity());
}
// exibição de dependências
try
{
Console.WriteLine("Médecin={0}", creneau.Medecin);
}
catch (Exception e)
{
Console.WriteLine("L'erreur 1 suivante s'est produite : {0}", e);
}
// carregamento diferido - modo predefinido
using (var context = new RdvMedecinsContext())
{
// intervalo n.º 0
creneau = context.Creneaux.Single<Creneau>(c => c.Id == idCreneau);
Console.WriteLine(creneau.ShortIdentity());
}
// exibição de dependências
try
{
Console.WriteLine("Médecin={0}", creneau.Medecin);
}
catch (Exception e)
{
Console.WriteLine("L'erreur 2 suivante s'est produite : {0}", e);
}
}
static void InitBase()
{
// inicialização da base de dados
using (var context = new RdvMedecinsContext())
{
// esvaziar a base de dados atual
...
// inicialização da base de dados
// os clientes
clients = new Client[] {
new Client { Titre = "Mr", Nom = "Martin", Prenom = "Jules" },
new Client { Titre = "Mme", Nom = "German", Prenom = "Christine" },
new Client { Titre = "Mr", Nom = "Jacquard", Prenom = "Jules" },
new Client { Titre = "Melle", Nom = "Bistrou", Prenom = "Brigitte" }
};
...
// as consultas
context.Rvs.Add(new Rv { Jour = new System.DateTime(2012, 10, 8), Client = clients[0], Creneau = creneaux[0] });
// guarda-se o contexto de persistência
context.SaveChanges();
}
}
}
}
- linha 18: parte-se de uma base conhecida, a que tem sido utilizada até agora. Após esta operação, as tabelas das linhas 11-13 são preenchidas com entidades isoladas;
- linhas 21-22: analisa-se o primeiro horário e o médico associado;
- linha 23: novo contexto;
- linha 26: insere-se o intervalo no contexto com a sua dependência (eager loading). Como este não é o modo predefinido, é necessário solicitar explicitamente essa dependência. É o método Include que permite isso. O seu parâmetro é o nome da dependência na entidade trazida para o contexto. A consulta que traz a entidade para o contexto utiliza expressões lambda. O método Single permite especificar uma condição que permite trazer uma única entidade. Aqui, procura-se na base de dados a entidade [Creneau], que tem a chave primária do intervalo n.º 0;
- linha 27: exibe-se a entidade recuperada. Recorde-se os dois métodos de gravação utilizados nas entidades:
// assinatura
public override string ToString()
{
return String.Format("Creneau[{0},{1},{2},{3},{4}, {5},{6}]", Id, Hdebut, Mdebut, Hfin, Mfin, Medecin, dump(Timestamp));
}
// assinatura curta
public string ShortIdentity()
{
return String.Format("Creneau[{0},{1},{2},{3},{4}, {5}, {6}]", Id, Hdebut, Mdebut, Hfin, Mfin, MedecinId, dump(Timestamp));
}
- linhas 2-5: o método [ToString] apresenta a dependência [Medecin]. Se esta ainda não estiver no contexto, será procurada na base de dados para ser inserida;
- linhas 8-11: o método [ShortIdentity] não apresenta a dependência [Medecin]. Por conseguinte, esta não será procurada na base de dados se não estiver no contexto;
Nesta fase, a saída da consola é a seguinte:
- linha 28: o contexto é fechado;
- linhas 30-37: tenta-se escrever a dependência [Medecin] da entidade. Recorde-se o funcionamento do Lazy Loading: uma dependência é carregada na sua primeira utilização, caso não esteja presente. Aqui, normalmente, está presente. A exibição é a seguinte:
- linhas 39-44: num novo contexto, o intervalo n.º 0 é novamente procurado na base de dados e importado para o contexto. Aqui, a dependência [Medecin] não é solicitada explicitamente. Por conseguinte, não será importada (Lazy Loading);
- linha 43: a exibição da identidade curta do intervalo é a seguinte:
Aqui, é importante utilizar ShortIdentity em vez de ToString para apresentar a entidade. Se se utilizar ToString, a dependência [Medecin] será apresentada e, para tal, será pesquisada na base de dados. No entanto, não é isso que pretendemos.
- linha 44: o contexto é fechado;
- linhas 46-53: tenta-se exibir a dependência da entidade. É importante fazer isto fora do contexto, caso contrário, ela será procurada na base de dados e encontrada. Aqui, estamos fora do contexto. A entidade [Creneau] está desanexada e a sua dependência [Medecin] está ausente (Lazy Loading). O que vai acontecer? A exibição no ecrã é a seguinte:
EF detetou que a dependência [Medecin] estava ausente. Tentou carregá-la, mas, como o contexto estava fechado, essa operação já não era possível. Vamos registar esta exceção [System.ObjectDisposedException], pois é característica do carregamento de uma dependência fora de um contexto aberto.
Vamos agora analisar a concorrência no acesso às entidades.
3.5.8. Concorrência no acesso às entidades
Voltemos à definição da entidade [Client]:
public class Client
{
// dados
[Key]
[Column("ID")]
public int? Id { get; set; }
[Required]
[MaxLength(5)]
[Column("TITRE")]
public string Titre { get; set; }
[Required]
[MaxLength(30)]
[Column("NOM")]
public string Nom { get; set; }
[Required]
[MaxLength(30)]
[Column("PRENOM")]
public string Prenom { get; set; }
// os Rvs do cliente
public ICollection<Rv> Rvs { get; set; }
[Column("TIMESTAMP")]
[Timestamp]
public byte[] Timestamp { get; set; }
// assinatura
...
}
Vamos centrar-nos no campo [Timestamp] da linha 23. Sabemos que o seu valor é gerado pelo SGBD. Referimos também que a anotação [Timestamp] da linha 22 fazia com que o EF 5 utilizasse o campo anotado para gerir a concorrência de acesso às entidades. Recorde-se o que é a gestão da concorrência de acesso:
- um processo P1 lê uma linha L da tabela [MEDECINS] no momento T1. A linha tem o timestamp TS1;
- um processo P2 lê a mesma linha L da tabela [MEDECINS] no momento T2. A linha tem os valores timestamp e TS1 porque o processo P1 ainda não validou a sua alteração;
- o processo P1 valida a sua alteração na linha L. O timestamp da linha L passa então para TS2;
- o processo P2 valida a sua alteração na linha L. OORM lança então uma exceção, pois o processo P2 tem um timestamp TS1 da linha L diferente do timestamp TS2 encontrado na base de dados.
A isto chama-se gestão otimista de acessos concorrentes. Com o EF 5, um campo que desempenha esta função deve ter um dos dois atributos: [Timestamp] ou [ConcurrencyCheck]. O servidor SQL tem um tipo [timestamp]. O valor de uma coluna com este tipo é gerado automaticamente pelo servidor SQL sempre que se insere ou altera uma linha. Uma coluna deste tipo pode, então, servir para gerir a concorrência de acesso.
Vamos ilustrar esta concorrência de acesso com dois threads que irão modificar, ao mesmo tempo, uma mesma entidade [Client] na base de dados. O projeto evolui da seguinte forma:
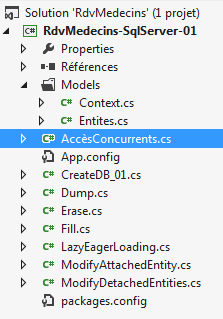 |  |
O código do programa [AccèsConcurrents] é o seguinte:
using System;
using System.Data;
using System.Linq;
using System.Threading;
using RdvMedecins.Entites;
using RdvMedecins.Models;
namespace RdvMedecins_01
{
// objeto trocado com os threads
class Data
{
public int Duree { get; set; }
public string Nom { get; set; }
public Client Client { get; set; }
}
// programa de teste
class AccèsConcurrents
{
static void Main(string[] args)
{
Client client1;
using (var context = new RdvMedecinsContext())
{
// thread principal
Thread.CurrentThread.Name = "main";
// esvazia-se a base de dados atual
foreach (var client in context.Clients)
{
context.Clients.Remove(client);
}
foreach (var medecin in context.Medecins)
{
context.Medecins.Remove(medecin);
}
// adiciona-se um cliente
client1 = new Client { Nom = "xx", Prenom = "xx", Titre = "xx" };
context.Clients.Add(client1);
// acompanhamento
Console.WriteLine("{0} client1--avant sauvegarde du contexte", Thread.CurrentThread.Name);
Console.WriteLine(client1.ShortIdentity());
// gravação
context.SaveChanges();
// acompanhamento
Console.WriteLine("{0} client1--après sauvegarde du contexte", Thread.CurrentThread.Name);
Console.WriteLine(client1.ShortIdentity());
}
// vamos modificar o cliente1 com duas threads
// thread t1
Thread t1 = new Thread(Modifie);
t1.Name = "t1";
t1.Start(new Data { Duree = 5000, Nom = "yy", Client = client1 });
// thread t2
Thread t2 = new Thread(Modifie);
t2.Name = "t2";
t2.Start(new Data { Duree = 5000, Nom = "zz", Client = client1 });
// aguardamos a conclusão das duas threads
Console.WriteLine("Thread {0} -- début attente fin des deux threads", Thread.CurrentThread.Name);
t1.Join();
t2.Join();
Console.WriteLine("Thread {0} -- fin attente fin des deux threads", Thread.CurrentThread.Name);
// exibimos a alteração — apenas uma deve ter sido bem-sucedida
using (var context = new RdvMedecinsContext())
{
// recuperamos o cliente1 no cliente2
Client client2 = context.Clients.Find(client1.Id);
Console.WriteLine("Thread {0} client2", Thread.CurrentThread.Name);
Console.WriteLine("Thread {0} {1}", Thread.CurrentThread.Name, client2.ShortIdentity());
}
}
// thread
static void Modifie(object infos)
{
...
}
- linha 26: inicia-se um contexto vazio;
- linha 29: atribui-se um nome ao thread atual para o diferenciar dos dois threads que serão criados posteriormente;
- linhas 31-38: as entidades [Medecin] e [Client] são colocadas no estado «eliminado»;
- linhas 40-41: insere-se um cliente no contexto;
- linhas 43-44: exibe-se o cliente antes da sincronização do contexto;
- linha 46: sincronização do contexto com a base de dados: as entidades no estado «eliminado» serão eliminadas da base de dados. A entidade [Client] colocada no contexto será inserida na base de dados. Será o único elemento da base de dados;
- linhas 47-49: o cliente é apresentado após a sincronização do contexto. Nesta fase, as visualizações no ecrã são as seguintes:
Note-se que, após a sincronização do contexto, o cliente tem uma chave primária e um timestamp;
- linha 50: o contexto é fechado;
- linha 53: um thread t1 é associado ao método [Modifie] da linha 84. Isto significa que, quando for iniciado, executará o método [Modifie];
- linha 54: atribui-se um nome ao thread t1;
- linha 55: o thread t1 é iniciado. São-lhe passados parâmetros sob a forma de uma estrutura [Data] definida nas linhas 12-17:
- Duração: o thread irá parar Durée segundos antes de concluir a sua execução,
- Cliente: uma referência ao cliente a atualizar na base de dados,
- Nome: nome a atribuir a este cliente;
- linhas 57-59: o mesmo com um segundo thread. No final, dois threads vão tentar alterar, na base de dados, o nome do mesmo cliente;
- linhas 60-63: depois de iniciar os dois threads, o thread principal aguarda o fim da sua execução;
- linha 62: espera pelo fim do thread t1;
- linha 63: espera pela conclusão do thread t2;
- linha 64: não se sabe em que ordem as duas threads vão terminar. O que é certo é que, na linha 64, elas já terminaram;
- linhas 66-72: num novo contexto, vai-se buscar o cliente na base de dados para verificar em que estado se encontra.
Vejamos agora o que fazem os dois threads t1 e t2. Executam o seguinte método [Modifie]:
static void Modifie(object infos)
{
// recuperamos o parâmetro
Data data = (Data)infos;
try
{
using (var context = new RdvMedecinsContext())
{
Console.WriteLine("Début Thread {0}", Thread.CurrentThread.Name);
// recupera o cliente1 no cliente2
Client client2 = context.Clients.Find(data.Client.Id);
Console.WriteLine("Thread {0} client2", Thread.CurrentThread.Name);
Console.WriteLine("Thread {0} {1}", Thread.CurrentThread.Name, client2.ShortIdentity());
// altera-se o cliente2
client2.Nom = data.Nom;
// aguarda-se um pouco
Thread.Sleep(data.Duree);
// guardamos as alterações
context.SaveChanges();
}
}
catch (Exception e)
{
// exceção
Console.WriteLine("Thread {0} {1}", Thread.CurrentThread.Name, e);
}
// fim do thread
Console.WriteLine("Fin Thread {0}", Thread.CurrentThread.Name);
}
- linha 4: recuperam-se os parâmetros do thread (Duração, Nome, Cliente);
- linha 7: novo contexto;
- linha 11: o cliente é inserido no contexto;
- linhas 12-13: acompanhamento para verificar o estado do cliente;
- linha 15: altera-se o nome do cliente;
- linha 17: o thread pára durante Duree milissegundos. Isto tem um efeito interessante. O thread liberta o processador que o estava a executar, dando lugar a outro thread. No nosso exemplo, temos três threads: main, t1 e t2. O thread main está parado, à espera que os threads t1 e t2 terminem. Supondo que a thread t1 tenha o processador em primeiro lugar, passa-o agora à thread t2. Isto terá como efeito que a thread t2 irá ler exatamente o mesmo que a thread t1, o mesmo cliente com o mesmo timestamp;
- linha 19: o contexto está sincronizado com a base de dados. Suponhamos novamente que o thread t1 retome a execução primeiro. Ele irá guardar o cliente com o nome «yy». Poderá fazê-lo porque tem o mesmo timestamp que na base de dados. Devido a esta atualização, o SGBD irá alterar o timestamp. Quando a thread t2 acordar por sua vez, terá um cliente com um timestamp diferente daquele que se encontra agora na base de dados. A sua atualização será recusada.
As mensagens apresentadas no ecrã são as seguintes:
- linha 4: o cliente na base de dados;
- linha 9: o cliente tal como é lido pela thread t2;
- linha 11: o cliente tal como é lido pelo thread t1. Os dois threads leram, portanto, a mesma informação;
- linha 12: o thread t2 termina primeiro. Conseguiu, portanto, efetuar a sua atualização. O nome deve ter passado para «zz»;
- linha 13: o thread t1 lança uma exceção do tipo [System.Data.OptimisticConcurrencyException]. O EF detetou que não tinha o timestamp correto;
- linha 21: o thread t1 termina, por sua vez;
- linha 22: o thread principal terminou a sua espera;
- linha 24: o thread principal apresenta o cliente na base de dados. Foi mesmo o thread t2 que venceu. O nome é «zz». Note-se que o timestamp mudou.
Agora, vamos analisar outro aspeto: a transação que enquadra a sincronização do contexto de persistência com a base de dados.
3.5.9. Sincronização numa transação
A tabela [CRENEAUX] tem uma restrição de unicidade que adicionámos manualmente (ver parágrafo 2.2.4, página 12):
Vamos proceder da seguinte forma: vamos adicionar, ao mesmo tempo, duas consultas para o mesmo médico, no mesmo dia e no mesmo intervalo horário. Vamos ver o que acontece.
O projeto evolui da seguinte forma:
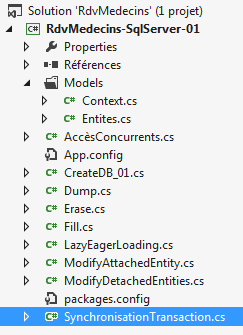 |  |
O código do programa [SynchronisationTransaction] é o seguinte:
using System;
using System.Linq;
using RdvMedecins.Entites;
using RdvMedecins.Models;
namespace RdvMedecins_01
{
// programa de teste
class SynchronisationTransaction
{
static void Main(string[] args)
{
using (var context = new RdvMedecinsContext())
{
// esvazia-se a base de dados atual
foreach (var client in context.Clients)
{
context.Clients.Remove(client);
}
foreach (var medecin in context.Medecins)
{
context.Medecins.Remove(medecin);
}
context.SaveChanges();
}
// cria-se um cliente
Client client1 = new Client { Nom = "xx", Prenom = "xx", Titre = "xx" };
// criação de um médico
Medecin medecin1 = new Medecin { Nom = "xx", Prenom = "xx", Titre = "xx" };
// cria-se um horário para este médico
Creneau creneau1 = new Creneau { Hdebut = 8, Mdebut = 20, Hfin = 8, Mfin = 40, Medecin = medecin1 };
// criam-se duas consultas para este médico e este cliente, no mesmo dia, no mesmo horário
Rv rv1 = new Rv { Client = client1, Creneau = creneau1, Jour = new DateTime(2012, 10, 18) };
Rv rv2 = new Rv { Client = client1, Creneau = creneau1, Jour = new DateTime(2012, 10, 18) };
try
{
// coloca-se tudo isto no contexto de persistência
using (var context = new RdvMedecinsContext())
{
context.Clients.Add(client1);
context.Creneaux.Add(creneau1);
context.Medecins.Add(medecin1);
context.Rvs.Add(rv1);
context.Rvs.Add(rv2);
// guarda-se o contexto — deve ocorrer uma exceção
// porque a tabela subjacente BD tem uma restrição de unicidade que impede
// que existam dois RDV no mesmo dia, no mesmo intervalo
context.SaveChanges();
}
}
catch (Exception e)
{
Console.WriteLine("Erreur : {0}", e);
}
// se o armazenamento ocorrer numa transação, então nada deve ter sido inserido na base de dados
// devido à exceção anterior — verifica-se
using (var context = new RdvMedecinsContext())
{
// os clientes
Console.WriteLine("Clients--------------------------------------");
var clients = from client in context.Clients select client;
foreach (Client client in clients)
{
Console.WriteLine(client);
}
// os médicos
Console.WriteLine("Médecins--------------------------------------");
var medecins = from medecin in context.Medecins select medecin;
foreach (Medecin medecin in medecins)
{
Console.WriteLine(medecin);
}
// os horários
Console.WriteLine("Créneaux horaires--------------------------------------");
var creneaux = from creneau in context.Creneaux select creneau;
foreach (Creneau creneau in creneaux)
{
Console.WriteLine(creneau);
}
// as consultas
Console.WriteLine("Rendez-vous--------------------------------------");
var rvs = from rv in context.Rvs select rv;
foreach (Rv rv in rvs)
{
Console.WriteLine(rv);
}
}
}
}
}
- linhas 15-27: utiliza-se um contexto de persistência para esvaziar a base de dados;
- linha 30: criação de um objeto [Client];
- linha 32: criação de um objeto [Medecin];
- linha 34: criação de um objeto [Creneau];
- linha 36: criação de um objeto [Rv];
- linha 37: criação de um segundo objeto [Rv] idêntico ao anterior;
- linha 41: abertura de um novo contexto;
- linhas 43-47: os objetos criados anteriormente são associados ao novo contexto. Note-se aqui que, tendo em conta as dependências, poderíamos ter minimizado o número de operações Add. Mas a EF irá otimizar as ordens SQL e INSERT a emitir para a base de dados;
- linha 51: o contexto está sincronizado com a base de dados. Tal como indicado no comentário, a inserção de um dos dois compromissos deve falhar devido à restrição de unicidade na tabela [RVS]. Mas, além disso, se a sincronização ocorrer numa transação, tudo deve ser revertido. Portanto, nenhuma inserção deve ocorrer. A base de dados deve permanecer vazia;
- linha 53: o contexto é encerrado;
- linhas 61-90: exibição do conteúdo da base de dados. Esta deve estar vazia.
A exibição no ecrã é a seguinte:
- linha 1: exceção devido à violação da restrição de unicidade na tabela [RVS];
- linhas 9-12: a base de dados está, de facto, vazia. A sincronização do contexto com a base de dados ocorreu, portanto, numa transação.
Haveria, sem dúvida, outros aspetos a explorar na tabela EF 5. Mas sabemos o suficiente para regressarmos ao nosso estudo de uma arquitetura multicamadas. O leitor encontrará no início deste documento referências a artigos e livros que lhe permitirão aprofundar os seus conhecimentos sobre a tabela EF 5.
3.6. Estudo de uma arquitetura multicamadas baseada em EF 5
Voltamos ao nosso estudo de caso descrito no parágrafo 2. Trata-se de uma aplicação web ASP.NET estruturada da seguinte forma:
 |
Vamos começar por construir a camada [DAO] de acesso aos dados. Esta camada basear-se-á em EF5.
3.6.1. O novo projeto
Criamos um novo projeto de consola VS 2012 [RdvMedecins-SqlServer-02] na solução atual [1]:
 |
Acrescentamos quatro pastas [2], nas quais iremos distribuir os nossos códigos. A pasta [Entites] é uma cópia da pasta [Entites] do projeto anterior. Após esta cópia, surgem erros devido ao facto de não termos as referências corretas. Temos de adicionar uma referência ao Entity Framework 5. Para tal, seguiremos o método explicado no parágrafo 3.4, página 21. A lista de referências passa a ser a seguinte: [3]:
 |
Nesta fase, o projeto já não deve apresentar erros de compilação. Do projeto anterior, copiamos também o ficheiro [App.config], que configura a ligação à base de dados:
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<configSections>
<!-- Para mais informações sobre a configuração do Entity Framework, visite http://go.microsoft.com/fwlink/?LinkID=237468 -->
<section name="entityFramework" type="System.Data.Entity.Internal.ConfigFile.EntityFrameworkSection, EntityFramework, Version=5.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089" requirePermission="false" />
</configSections>
<startup>
<supportedRuntime version="v4.0" sku=".NETFramework,Version=v4.5" />
</startup>
<entityFramework>
<defaultConnectionFactory type="System.Data.Entity.Infrastructure.SqlConnectionFactory, EntityFramework" />
</entityFramework>
<!-- cadeia de ligação à base de dados -->
<connectionStrings>
<add name="monContexte"
connectionString="Data Source=localhost;Initial Catalog=rdvmedecins-ef;User Id=sa;Password=sqlserver2012;"
providerName="System.Data.SqlClient" />
</connectionStrings>
<!-- o fornecedor de fábrica -->
<system.data>
<DbProviderFactories>
<add name="SqlClient Data Provider"
invariant="System.Data.SqlClient"
description=".Net Framework Data Provider for SqlServer"
type="System.Data.SqlClient.SqlClientFactory, System.Data,
Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089"
/>
</DbProviderFactories>
</system.data>
</configuration>
3.6.2. A classe Exception
Vamos utilizar uma classe de exceção específica do projeto. É esta que será gerada pela camada [DAO]:
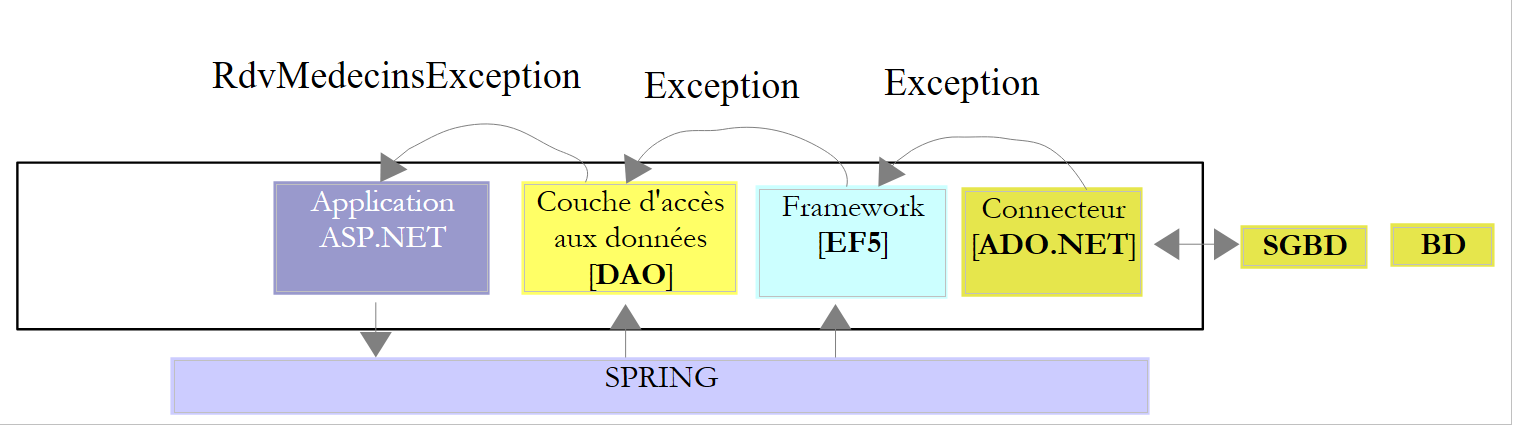 |
A camada [DAO] irá interceptar todas as exceções que forem encaminhadas até ela e encapsulá-las numa exceção do tipo [RdvMedecinsException]. Esta exceção será a seguinte:
using System;
namespace RdvMedecins.Exceptions
{
public class RdvMedecinsException : Exception
{
// propriedades
public int Code { get; set; }
// construtores
public RdvMedecinsException()
: base()
{
}
public RdvMedecinsException(string message)
: base(message)
{
}
public RdvMedecinsException(int code, string message)
: base(message)
{
Code = code;
}
public RdvMedecinsException(int code, string message, Exception ex)
: base(message, ex)
{
Code = code;
}
// identidade
public override string ToString()
{
if (InnerException == null)
{
return string.Format("RdvMedecinsException[{0},{1}]", Code, base.Message);
}
else
{
return string.Format("RdvMedecinsException[{0},{1},{2}]", Code, base.Message, base.InnerException.Message);
}
}
}
}
- linha 5: a classe deriva da classe [Exception];
- linha 9: adiciona um código de erro à sua classe base;
- linhas 12-32: os diferentes construtores integram a presença do campo [Code].
O projeto evolui da seguinte forma:
 |
3.6.3. A camada [DAO]
 |
A camada [DAO] fornece uma interface para a camada [ASP.NET]. Para identificar esta última, é necessário consultar as páginas web da aplicação:
 |
- em [1], acima, a lista suspensa foi preenchida com a lista de médicos. A camada [DAO] fornecerá essa lista;
- em [2], a camada [DAO] fornecerá;
- a lista de consultas de um médico para um determinado dia,
- a lista de horários disponíveis de um médico,
- informações adicionais sobre o médico selecionado;
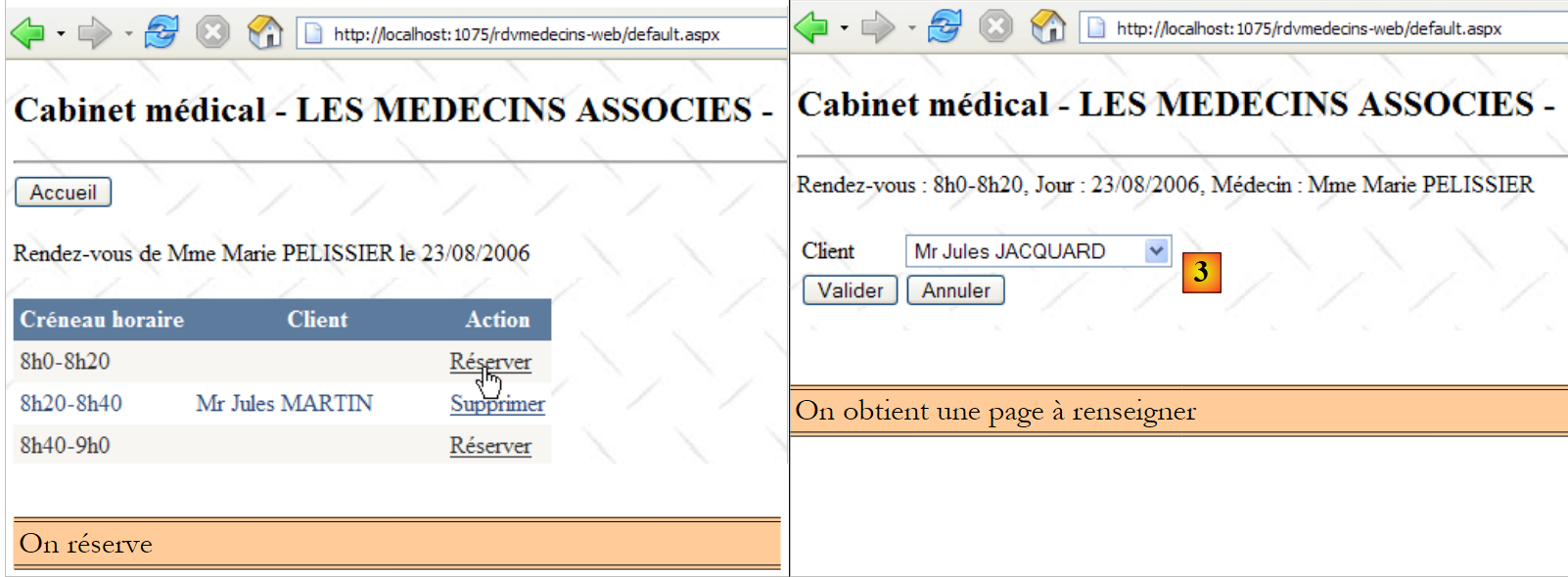 |
- em [3], a lista suspensa de clientes será fornecida pela camada [DAO];
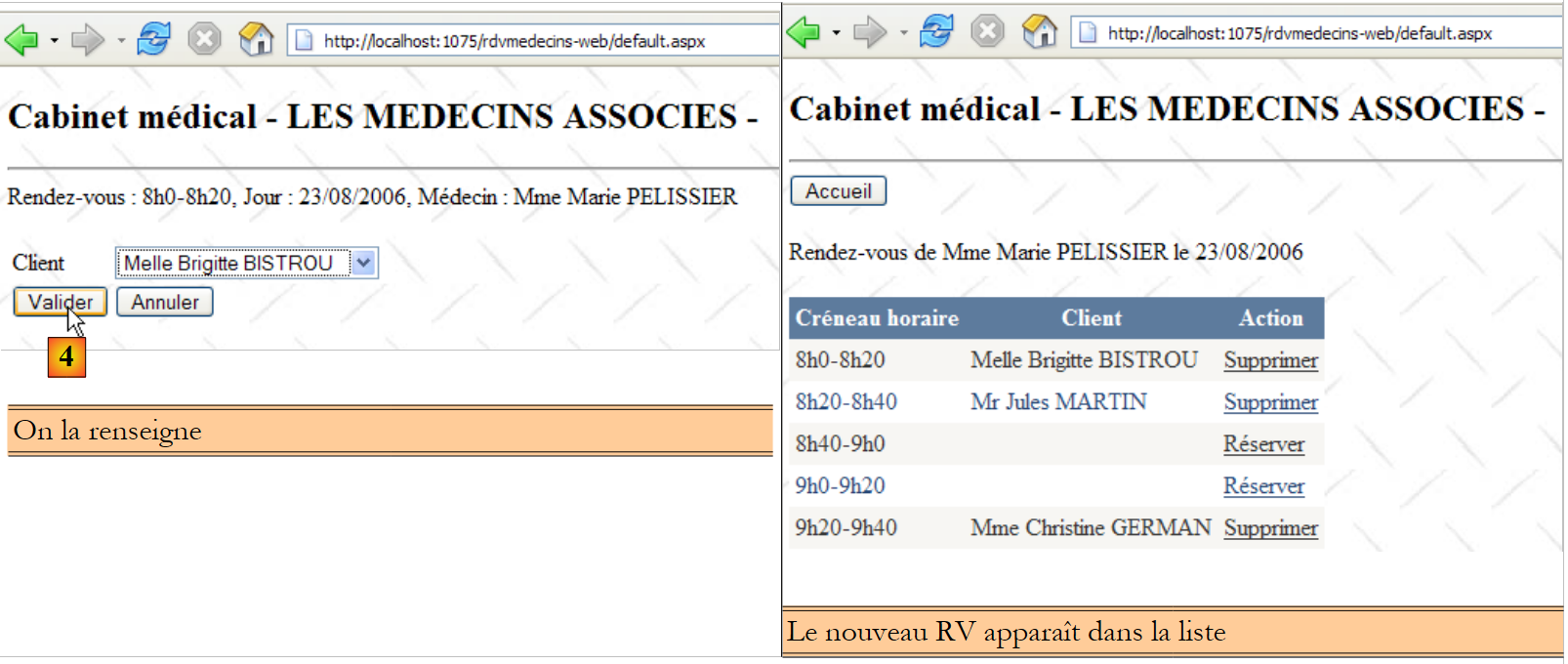 |
- em [4], o utilizador confirma uma consulta. A camada [DAO] deve poder adicioná-la à base de dados. Deve também poder fornecer informações adicionais sobre o cliente selecionado;
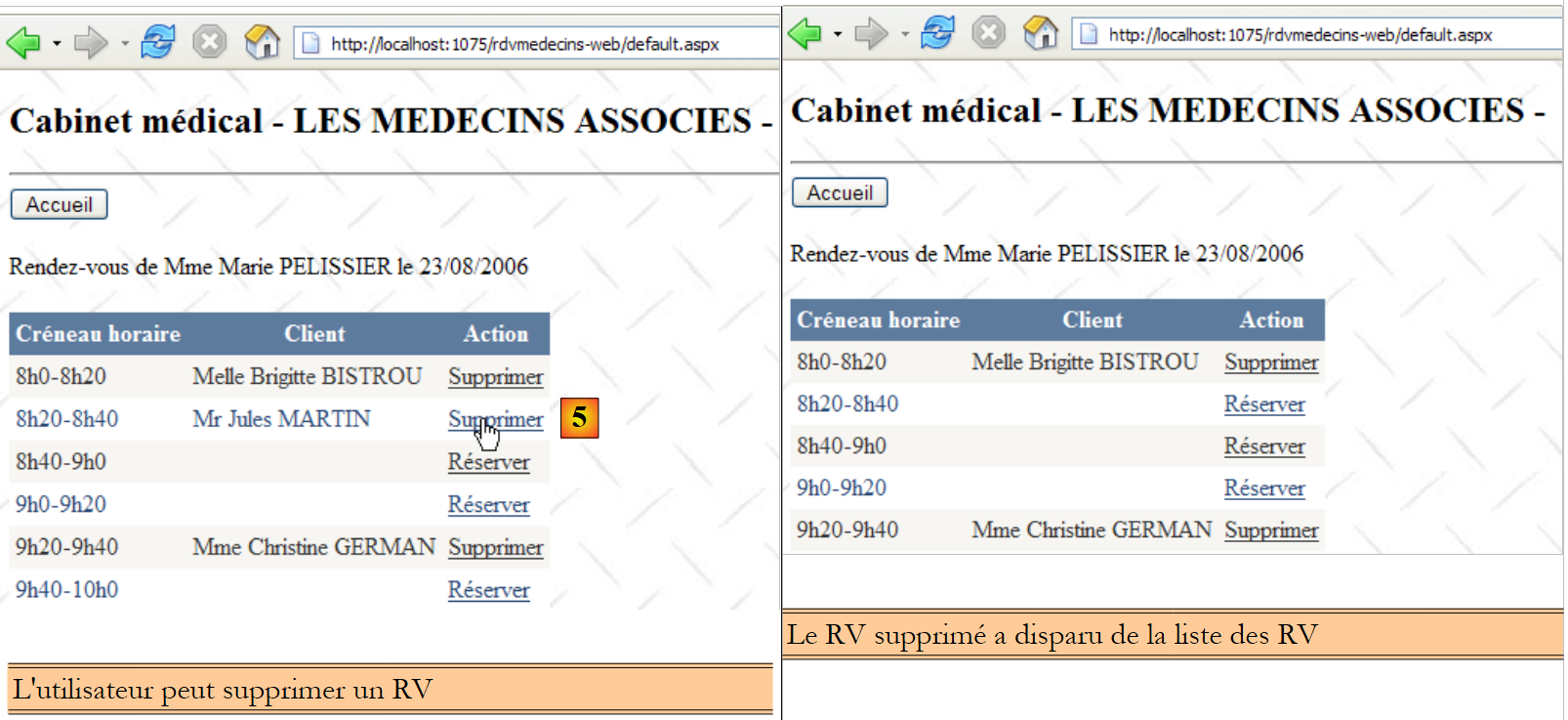 |
- em [5], o utilizador elimina um compromisso. A camada [DAO] deve permitir essa ação.
Com estas informações, a interface [IDao] da camada [DAO] poderia ser a seguinte:
using System;
using System.Collections.Generic;
using RdvMedecins.Entites;
namespace RdvMedecins.Dao
{
public interface IDao
{
// lista de clientes
List<Client> GetAllClients();
// lista de médicos
List<Medecin> GetAllMedecins();
// lista de horários disponíveis de um médico
List<Creneau> GetCreneauxMedecin(int idMedecin);
// lista dos RV de um determinado médico, num determinado dia
List<Rv> GetRvMedecinJour(int idMedecin, DateTime jour);
// adicionar um RV
int AjouterRv(DateTime jour, int idCreneau, int idClient);
// eliminar um RV
void SupprimerRv(int idRv);
// encontrar uma entidade T através da sua chave primária
T Find<T>(int id) where T : class;
}
}
Os métodos das linhas 10 a 20 decorrem da análise que acabou de ser feita. O método da linha 22 existe para contornar o facto de se trabalhar com Lazy Loading. Se, na camada [ASP.NET], for necessária uma dependência de uma entidade, esta será obtida da base de dados através deste método.
A implementação [Dao] desta interface será a seguinte:
using System;
using System.Collections.Generic;
using System.Linq;
using RdvMedecins.Entites;
using RdvMedecins.Exceptions;
using RdvMedecins.Models;
namespace RdvMedecins.Dao
{
public class Dao : IDao
{
//lista de clientes
public List<Client> GetAllClients()
{
// lista de clientes
List<Client> clients = null;
try
{
// abrir contexto de persistência
using (var context = new RdvMedecinsContext())
{
// lista de clientes
clients = context.Clients.ToList();
}
}
catch (Exception ex)
{
throw new RdvMedecinsException(1, "GetAllClients", ex);
}
// retornar o resultado
return clients;
}
// lista de médicos
public List<Medecin> GetAllMedecins()
{
// lista de médicos
List<Medecin> medecins = null;
try
{
// abertura do contexto de persistência
using (var context = new RdvMedecinsContext())
{
// lista de médicos
medecins = context.Medecins.ToList();
}
}
catch (Exception ex)
{
throw new RdvMedecinsException(2, "GetAllMedecins", ex);
}
// retorna o resultado
return medecins;
}
// lista dos horários disponíveis de um determinado médico
public List<Creneau> GetCreneauxMedecin(int idMedecin)
{
...
}
// lista dos RV de um médico para um determinado dia
public List<Rv> GetRvMedecinJour(int idMedecin, DateTime jour)
{
...
}
// adicionar um RV
public int AjouterRv(DateTime jour, int idCreneau, int idClient)
{
...
}
// eliminar um RV
public void SupprimerRv(int idRv)
{
...
}
// encontrar um cliente
public Client FindClient(int id)
{
...
}
// encontrar um horário disponível
public Creneau FindCreneau(int id)
{
...
}
// encontrar um médico
public Medecin FindMedecin(int id)
{
....
}
// encontrar uma consulta
public Rv FindRv(int id){
...
}
}
}
Vamos explicar o método [GetAllClients], que deve devolver a lista de todos os clientes:
- linhas 18-31: a pesquisa de clientes é efetuada num try/catch. O mesmo se aplica a todos os métodos seguintes;
- linha 21: abertura de um novo contexto;
- linha 24: as entidades [Client] são carregadas no contexto e colocadas numa lista.
O método [GetAllMedecins], que deve devolver a lista de todos os médicos, é análogo (linhas 37-57).
O método [GetCreneauxMedecin] é o seguinte:
// lista dos horários disponíveis de um determinado médico
public List<Creneau> GetCreneauxMedecin(int idMedecin)
{
// lista de horários
try
{
// abrir contexto de persistência
using (var context = new RdvMedecinsContext())
{
// recupera-se o médico com os seus horários disponíveis
Medecin medecin = context.Medecins.Include("Creneaux").Single(m => m.Id == idMedecin);
// lista dos horários do médico
return medecin.Creneaux.ToList<Creneau>();
}
}
catch (Exception ex)
{
throw new RdvMedecinsException(3, "GetCreneauxMedecin", ex);
}
}
- linha 9: abertura de um novo contexto de persistência;
- linha 11: procura-se o médico cuja chave primária se conhece. Solicita-se a inclusão da dependência [Creneaux], que é uma coleção dos horários disponíveis do médico. Se o médico não existir, o método Single lança uma exceção;
- linha 13: devolve-se a lista de horários.
O método [GetRvMedecinJour] deve devolver a lista de consultas de um médico para um determinado dia. O seu código poderia ser o seguinte:
// lista dos RV de um médico para um determinado dia
public List<Rv> GetRvMedecinJour(int idMedecin, DateTime jour)
{
// lista de consultas
List<Rv> rvs = null;
try
{
// abertura do contexto de persistência
using (var context = new RdvMedecinsContext())
{
// recuperação do médico
Medecin medecin = context.Medecins.Find(idMedecin);
if (medecin == null)
{
throw new RdvMedecinsException(10, string.Format("Médecin [{0}] inexistant", idMedecin));
}
// lista das consultas
rvs = context.Rvs.Where(r => r.Creneau.Medecin.Id == idMedecin && r.Jour == jour).ToList();
}
}
catch (Exception ex)
{
throw new RdvMedecinsException(4, "GetRvMedecinJour", ex);
}
// retornar o resultado
return rvs;
}
- linha 13: insere-se no contexto o médico cuja chave primária se possui;
- linhas 14-17: se não existir, lança-se uma exceção;
- linha 19: a consulta LINQ para recuperar as consultas desse médico;
O método [AjouterRv] deve adicionar uma consulta à base de dados e deve devolver a chave primária do elemento inserido. O seu código poderia ser o seguinte:
// adicionar um RV
public int AjouterRv(DateTime jour, int idCreneau, int idClient)
{
// n.º da consulta adicionada
int idRv;
try
{
// abertura do contexto de persistência
using (var context = new RdvMedecinsContext())
{
// recuperar o intervalo de tempo
Creneau creneau = context.Creneaux.Find(idCreneau);
if (creneau == null)
{
throw new RdvMedecinsException(5, string.Format("Créneau [{0}] inexistant", idCreneau));
}
// recuperação do cliente
Client client = context.Clients.Find(idClient);
if (client == null)
{
throw new RdvMedecinsException(6, string.Format("Client [{0}] inexistant", idCreneau));
}
// criação do horário
Rv rv = new Rv { Jour = jour, Client = client, Creneau = creneau };
// adição ao contexto
context.Rvs.Add(rv);
// gravação do contexto
context.SaveChanges();
// recuperar a chave primária do compromisso adicionado
idRv = (int)rv.Id;
}
}
catch (Exception ex)
{
throw new RdvMedecinsException(7, "AjouterRv", ex);
}
// resultado
return idRv;
}
- linha 12: procura-se o intervalo de tempo da consulta na base de dados;
- linhas 13-16: se não for encontrado, é lançada uma exceção;
- linha 18: procura-se o cliente do compromisso na base de dados;
- linhas 19-22: se não o encontrarmos, lançamos uma exceção;
- linha 24: cria-se um objeto [Rv] com as informações necessárias;
- linha 26: adiciona-se ao contexto de persistência;
- linha 28: sincroniza-se o contexto de persistência com a base de dados. O compromisso será então inserido na base de dados;
- linha 30: sabemos que, após a sincronização da base de dados, as chaves primárias dos elementos inseridos estão disponíveis. Recuperamos a chave primária do compromisso adicionado;
- linha 31: fecha-se o contexto de persistência.
O método [SupprimerRv] deve eliminar um compromisso cuja chave primária lhe é passada.
// eliminar um RV
public void SupprimerRv(int idRv)
{
try
{
// abertura do contexto de persistência
using (var context = new RdvMedecinsContext())
{
// recuperar o Rv
Rv rv = context.Rvs.Find(idRv);
if (rv == null)
{
throw new RdvMedecinsException(5, string.Format("Rv [{0}] inexistant", idRv));
}
// eliminação do Rv
context.Rvs.Remove(rv);
// guardar o contexto
context.SaveChanges();
}
}
catch (Exception ex)
{
throw new RdvMedecinsException(8, "SupprimerRv", ex);
}
}
- linha 7: novo contexto de persistência;
- linha 10: insere-se no contexto o compromisso a eliminar;
- linhas 11-15: se não existir, lança-se uma exceção;
- linha 16: elimina-se do contexto;
- linha 18: sincroniza-se o contexto com a base de dados;
- linha 19: fecha-se o contexto.
O método [Find<T>] permite pesquisar na base de dados uma entidade do tipo T, através da sua chave primária. O seu código poderia ser o seguinte:
public T Find<T>(int id) where T : class
{
try
{
// abertura do contexto de persistência
using (var context = new RdvMedecinsContext())
{
return context.Set<T>().Find(id);
}
}
catch (Exception ex)
{
throw new RdvMedecinsException(20, "Find<T>", ex);
}
}
- linha 8: o método Set<T> permite recuperar um DbSet<T> ao qual se podem aplicar os métodos habituais.
O projeto evolui da seguinte forma:
 |
3.6.4. Teste da camada [DAO]
Vamos criar um programa de teste da camada [DAO]. A arquitetura do teste será a seguinte:
 |
Um programa de consola solicita ao [Spring.net] que instancie a camada [DAO]. Feito isso, testa as diferentes funcionalidades da interface da camada [DAO]. Em vez de um programa de consola, teria sido preferível escrever um programa de teste do tipo NUnit. Um programa de teste da camada [DAO] poderia ser o seguinte:
using System;
using System.Collections.Generic;
using RdvMedecins.Dao;
using RdvMedecins.Entites;
using RdvMedecins.Exceptions;
using Spring.Context.Support;
namespace RdvMedecins.Tests
{
class Program
{
public static void Main()
{
IDao dao = null;
try
{
// instanciação da camada [DAO] através do Spring
dao = ContextRegistry.GetContext().GetObject("rdvmedecinsDao") as IDao;
// exibição de clientes
List<Client> clients = dao.GetAllClients();
DisplayClients("Liste des clients :", clients);
// exibição de médicos
List<Medecin> medecins = dao.GetAllMedecins();
DisplayMedecins("Liste des médecins :", medecins);
// lista de horários disponíveis do médico n.º 0
List<Creneau> creneaux = dao.GetCreneauxMedecin((int)medecins[0].Id);
DisplayCreneaux(string.Format("Liste des créneaux horaires du médecin {0}", medecins[0]), creneaux);
// lista de consultas de um médico para um determinado dia
DisplayRvs(string.Format("Liste des RV du médecin {0}, le 23/11/2013 :", medecins[0]), dao.GetRvMedecinJour((int)medecins[0].Id, new DateTime(2013, 11, 23)));
// adicionar um RV ao médico n.º 1 no horário n.º 0
Console.WriteLine(string.Format("Ajout d'un RV au médecin {0} avec client {1} le 23/11/2013", medecins[0], clients[0]));
int idRv1 = dao.AjouterRv(new DateTime(2013, 11, 23), (int)creneaux[0].Id, (int)clients[0].Id);
Console.WriteLine("Rdv ajouté");
DisplayRvs(string.Format("Liste des RV du médecin {0}, le 23/11/2013 :", medecins[0]), dao.GetRvMedecinJour((int)medecins[0].Id, new DateTime(2013, 11, 23)));
// adicionar uma consulta num horário já ocupado — deve provocar uma exceção
int idRv2;
Console.WriteLine("Ajout d'un RV dans un créneau déjà occupé");
try
{
idRv2 = dao.AjouterRv(new DateTime(2013, 11, 23), (int)creneaux[0].Id, (int)clients[0].Id);
Console.WriteLine("Rdv ajouté");
DisplayRvs(string.Format("Liste des RV du médecin {0}, le 23/11/2013 :", medecins[0]), dao.GetRvMedecinJour((int)medecins[0].Id, new DateTime(2013, 11, 23)));
}
catch (RdvMedecinsException ex)
{
Console.WriteLine(string.Format("L'erreur suivante s'est produite : {0}", ex));
}
// eliminar uma consulta
Console.WriteLine(string.Format("Suppression du RV n° {0}", idRv1));
dao.SupprimerRv(idRv1);
DisplayRvs(string.Format("Liste des RV du médecin {0}, le 23/11/2013 :", medecins[0]), dao.GetRvMedecinJour((int)medecins[0].Id, new DateTime(2013, 11, 23)));
}
catch (Exception ex)
{
Console.WriteLine(string.Format("L'erreur suivante s'est produite : {0}", ex));
}
//pausa
Console.ReadLine();
}
// métodos utilitários - apresenta listas
public static void DisplayClients(string Message, List<Client> clients)
{
Console.WriteLine(Message);
foreach (Client c in clients)
{
Console.WriteLine(c.ShortIdentity());
}
}
public static void DisplayMedecins(string Message, List<Medecin> medecins)
{
...
}
public static void DisplayCreneaux(string Message, List<Creneau> creneaux)
{
...
}
public static void DisplayRvs(string Message, List<Rv> rvs)
{
...
}
}
}
- linha 14: a referência à camada [DAO]. Para tornar o teste independente da implementação real desta, esta referência é do tipo da interface [IDao] e não do tipo da classe [Dao];
- linha 18: a camada [DAO] é instanciada pelo Spring. Voltaremos à configuração necessária para que isso seja possível. Fazemos o cast da referência de objeto devolvida pelo Spring para uma referência do tipo da interface [IDao];
- linhas 21-22: apresentam os clientes;
- linhas 25-26: apresentam os médicos;
- linhas 29-30: apresentam a lista de horários do médico n.º 0;
- linha 33: apresenta as consultas do médico n.º 0 na data de 23/11/2013. Não deve haver nenhuma;
- linha 37: adiciona uma consulta ao médico n.º 0 para 23/11/2013;
- linha 39: apresenta as consultas do médico n.º 0 na data de 23/11/2013. Deve haver uma;
- linha 46: adiciona pela segunda vez a mesma consulta. Deve ocorrer uma exceção;
- linha 57: elimina-se a única consulta adicionada;
- linha 58: apresenta as consultas do médico n.º 0 na data de 23/11/2013. Não deve haver nenhuma.
3.6.5. Configuração do Spring.net
No programa de teste acima, passámos rapidamente pela instrução que instancia a camada [DAO]:
dao = ContextRegistry.GetContext().GetObject("rdvmedecinsDao") as IDao;
A classe [ContextRegistry] é uma classe do Spring no espaço de nomes [Spring.Context.Support]. Para podermos utilizar o Spring, temos de adicionar o seu DLL às referências do projeto. Procedemos da seguinte forma:
 |
- em [1], procuramos pacotes com a ferramenta [NuGet];
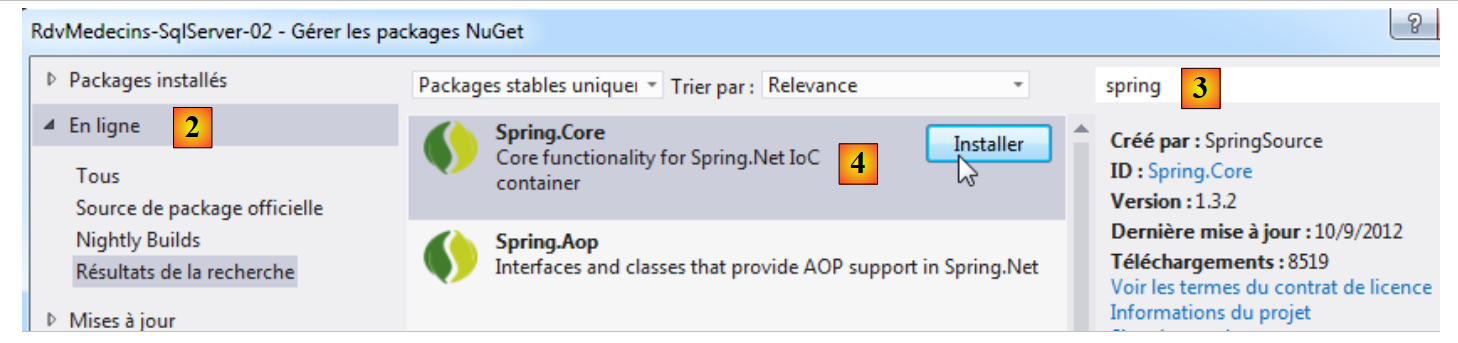 |
- em [2], procuramos pacotes online;
- em [3], insere-se a palavra-chave spring na área de pesquisa;
- em [4], são apresentados os pacotes cuja descrição contém essa palavra-chave. Neste caso, é o [Spring.Core] que nos interessa. Instalamo-lo.
As referências do projeto evoluem da seguinte forma:
 |
O pacote [Spring.Core] tinha uma dependência do pacote [Common.Logging]. Este último também foi carregado. Nesta fase, o projeto já não deve apresentar erros.
Mas isso não significa que vá funcionar. Primeiro, temos de configurar o Spring no ficheiro [App.config]. Esta é a parte mais delicada do projeto. O novo ficheiro [App.config] é o seguinte:
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<configSections>
<!-- Para mais informações sobre a configuração do Entity Framework, visite http://go.microsoft.com/fwlink/?LinkID=237468 -->
<section name="entityFramework" type="System.Data.Entity.Internal.ConfigFile.EntityFrameworkSection, EntityFramework, Version=5.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089" requirePermission="false" />
<!-- Spring -->
<sectionGroup name="spring">
<section name="context" type="Spring.Context.Support.ContextHandler, Spring.Core" />
<section name="objects" type="Spring.Context.Support.DefaultSectionHandler, Spring.Core" />
</sectionGroup>
<!-- registo comum-->
<section name="logging" type="Common.Logging.ConfigurationSectionHandler, Common.Logging" />
</configSections>
<startup>
<supportedRuntime version="v4.0" sku=".NETFramework,Version=v4.5" />
</startup>
<!-- Entity Framework -->
<entityFramework>
<defaultConnectionFactory type="System.Data.Entity.Infrastructure.LocalDbConnectionFactory, EntityFramework">
<parameters>
<parameter value="v11.0" />
</parameters>
</defaultConnectionFactory>
</entityFramework>
<!-- Cadeias de ligação -->
<connectionStrings>
<add name="monContexte" connectionString="Data Source=localhost;Initial Catalog=rdvmedecins-ef;User Id=sa;Password=sqlserver2012;" providerName="System.Data.SqlClient" />
</connectionStrings>
<system.data>
<DbProviderFactories>
<add name="SqlClient Data Provider" invariant="System.Data.SqlClient" description=".Net Framework Data Provider for SqlServer" type="System.Data.SqlClient.SqlClientFactory, System.Data, Version=4.0.0.0, Culture=neutral, PublicKeyToken=b77a5c561934e089" />
</DbProviderFactories>
</system.data>
<!-- configuração do Spring -->
<spring>
<context>
<resource uri="config://spring/objects" />
</context>
<objects xmlns="http://www.springframework.net">
<object id="rdvmedecinsDao" type="RdvMedecins.Dao.Dao,RdvMedecins-SqlServer-02" />
</objects>
</spring>
<!-- configuração common.logging -->
<logging>
<factoryAdapter type="Common.Logging.Simple.ConsoleOutLoggerFactoryAdapter, Common.Logging">
<arg key="showLogName" value="true" />
<arg key="showDataTime" value="true" />
<arg key="level" value="DEBUG" />
<arg key="dateTimeFormat" value="yyyy/MM/dd HH:mm:ss:fff" />
</factoryAdapter>
</logging>
</configuration>
Comecemos por remover tudo o que já é conhecido: Entity Framework, cadeias de ligação, ProviderFactory. O ficheiro fica assim:
<?xml version="1.0" encoding="utf-8"?>
<configuration>
<configSections>
<!-- Para mais informações sobre a configuração do Entity Framework, visite http://go.microsoft.com/fwlink/?LinkID=237468 -->
<section name="entityFramework" ... />
<!-- spring -->
<sectionGroup name="spring">
<section name="context" type="Spring.Context.Support.ContextHandler, Spring.Core" />
<section name="objects" type="Spring.Context.Support.DefaultSectionHandler, Spring.Core" />
</sectionGroup>
<!-- registo comum-->
<sectionGroup name="common">
<section name="logging" type="Common.Logging.ConfigurationSectionHandler, Common.Logging" />
</sectionGroup>
</configSections>
...
<!-- configuração do Spring -->
<spring>
<context>
<resource uri="config://spring/objects" />
</context>
<objects xmlns="http://www.springframework.net">
<object id="rdvmedecinsDao" type="RdvMedecins.Dao.Dao,RdvMedecins-SqlServer-02" />
</objects>
</spring>
<!-- configuração common.logging -->
<common>
<logging>
<factoryAdapter type="Common.Logging.Simple.ConsoleOutLoggerFactoryAdapter, Common.Logging">
<arg key="showLogName" value="true" />
<arg key="showDataTime" value="true" />
<arg key="level" value="DEBUG" />
<arg key="dateTimeFormat" value="yyyy/MM/dd HH:mm:ss:fff" />
</factoryAdapter>
</logging>
</common>
</configuration>
- linhas 3-15: definem secções de configuração;
- linha 8: define a classe que irá gerir a secção <spring><context> do ficheiro XML (linhas 19-21);
- linha 9: define a classe que irá gerir a secção <spring><objects> do ficheiro XML (linhas 22-24);
- linha 13: define a classe que irá gerir a secção <common><logging> do ficheiro XML (linhas 27-36);
- linhas 7-14: são fixas. Não precisam de ser alteradas noutro projeto;
- linhas 18-25: configuração do Spring. É estável, exceto nas linhas 22-24, que definem os objetos que o Spring irá instanciar;
- linha 23: definição de um objeto. O atributo id é livre. É o identificador do objeto. O atributo type indica a classe a instanciar na forma «nome completo da classe, Assembly que contém a classe». A classe aqui é aquela que implementa a camada [DAO]: [RdvMedecins.Dao.Dao]. Para saber o seu assembly, é necessário consultar as propriedades do projeto:
 |
Em [1], o nome do assembly a fornecer;
- linhas 27-36: a configuração de «Common Logging» é estável. Pode ser necessário alterar o nível de informação, na linha 32. Após a fase de depuração, pode-se alterar o nível para INFO.
No final, embora pareça complexo à primeira vista, o ficheiro de configuração do Spring revela-se simples. Basta alterar:
- as linhas 22-24, que definem os objetos a instanciar;
- a linha 32: o nível de registo.
No programa de teste, a instrução que instancia a camada [DAO] é a seguinte:
dao = ContextRegistry.GetContext().GetObject("rdvmedecinsDao") as IDao;
[ContextRegistry] é uma classe do Spring que utiliza a configuração do Spring definida num ficheiro [Web.config] ou [App.config]. Neste caso, irá utilizar a seguinte secção do ficheiro [App.config]:
<spring>
<context>
<resource uri="config://spring/objects" />
</context>
<objects xmlns="http://www.springframework.net">
<object id="rdvmedecinsDao" type="RdvMedecins.Dao.Dao,RdvMedecins-SqlServer-02" />
</objects>
</spring>
- ContextRegistry.GetContext() utiliza o contexto das linhas 2 a 4. A linha 3 significa que os objetos Spring estão definidos na secção [spring/objects] do ficheiro de configuração. Esta secção corresponde às linhas 5 a 7;
- ContextRegistry.GetContext().GetObject("rdvmedecinsDao") utiliza a secção das linhas 5 a 7. Devolve uma referência ao objeto que tem o atributo id= "rdvmedecinsDao". Trata-se do objeto definido na linha 6. O Spring irá então instanciar a classe definida pelo atributo type, utilizando o seu construtor sem parâmetros. Este deve, portanto, existir. Feito isto, a referência do objeto criado é devolvida ao código chamador. Se o objeto for solicitado uma segunda vez no código, o Spring limita-se a devolver uma referência ao primeiro objeto criado. Trata-se do padrão de conceção (Design Pattern) denominado singleton.
A criação do objeto pode ser mais complexa. É possível utilizar um construtor com parâmetros ou especificar a inicialização de determinados campos do objeto após a sua criação. Para mais informações sobre este assunto, pode-se consultar o artigo «Tutorial Spring IOC para .NET», no URL [http://tahe.developpez.com/dotnet/springioc/].
Feito isto, podemos executar a aplicação. Os resultados no ecrã são os seguintes:
Os resultados estão de acordo com o esperado. Passaremos agora a considerar que a nossa camada [DAO] é válida. O tutorial poderia terminar aqui. Até agora, demonstrámos:
- os conceitos básicos do Entity Framework 5 ORM;
- uma camada [DAO] que utiliza este ORM.
Recordemos o nosso caso de estudo descrito no início deste documento. Partimos de uma aplicação existente com a seguinte arquitetura:
 |
que pretendemos transformar nesta:
 |
onde o EF5 substituiu o NHibernate. Acabámos de construir a camada [DAO2]. Na verdade, esta não apresenta a mesma interface que a camada [DAO1], cuja interface era mais reduzida:
public interface IDao
{
// lista de clientes
List<Client> GetAllClients();
// lista de médicos
List<Medecin> GetAllMedecins();
// lista de horários disponíveis de um médico
List<Creneau> GetCreneauxMedecin(int idMedecin);
// lista dos RV de um determinado médico, num determinado dia
List<Rv> GetRvMedecinJour(int idMedecin, DateTime jour);
// adicionar um RV
int AjouterRv(DateTime jour, int idCreneau, int idClient);
// eliminar um RV
void SupprimerRv(int idRv);
}
A camada [DAO2] adicionou a esta interface o método:
// encontrar uma entidade T através da sua chave primária
T Find<T>(int id) where T : class;
A adição deste método deve-se ao facto de a camada ORM EF 5 funcionar, por predefinição, no modo Lazy Loading. As entidades chegam à camada [ASP.NET] sem as suas dependências. O método acima permite-nos recuperá-las caso seja necessário, o que, em certos casos, acontece. O NHibernate também funciona, por predefinição, no modo «Lazy Loading», mas eu tinha-o utilizado no modo «Eager Loading». As entidades chegavam à camada [ASP.NET] com as suas dependências.
Vamos concluir a migração da aplicação ASP.NET / NHibernate para a aplicação ASP.NET / EF 5. No entanto, como isto já não diz respeito ao EF5, não iremos comentar o código web. Explicaremos simplesmente como configurar a aplicação web e testá-la. Esta está disponível no site deste tutorial.
3.6.6. Geração do DLL a partir da camada [DAO]
Na seguinte arquitetura:
 |
a camada [ASP.NET] terá à sua disposição as camadas à sua direita sob a forma de DLL. Assim, criamos a DLL a partir da camada [DAO].
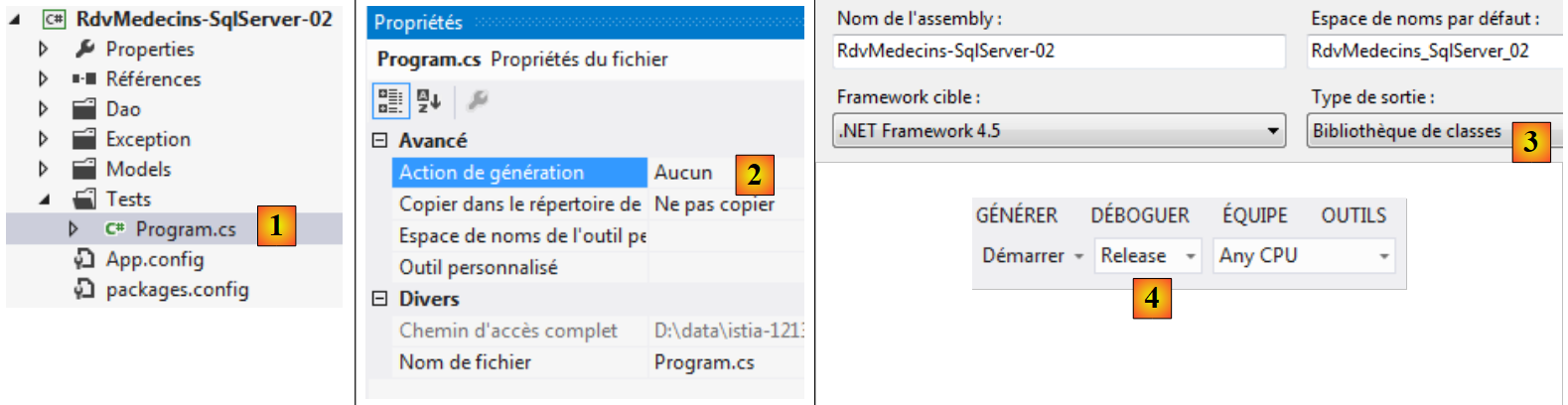 |
- em [1], seleciona-se o programa de teste e, em [2], não o inclui na DLL que vai ser gerada;
- no [3], nas propriedades do projeto, indica-se que o assembly a criar é um DLL;
- no [4], no menu do VS, indica-se que se vai gerar um assembly do tipo [Release], que contém menos informações do que um assembly do tipo [Debug];
 |
- no [5], regenera-se o assembly do projeto. Será gerado o DLL;
- em [6], exibem-se todos os ficheiros do projeto;
 |
- em [7], o DLL do projeto da camada [DAO]. É este que o projeto web ASP.NET irá utilizar;
- em [8], atualizamos a visualização do projeto;
 |
- no [9], os ficheiros DLL da pasta [Release] são reunidos numa pasta externa [lib], [10]. É aí que o projeto web irá buscar as suas referências.
3.6.7. A camada [ASP.NET]
Vamos explicar aqui a migração da aplicação [ASP.NET / NHibernate] para a aplicação [ASP.NET / EF 5]. Vamos trabalhar com o Visual Studio Express 2012 para a Web, disponível gratuitamente no URL [http://www.microsoft.com/visualstudio/fra/downloads].
Vamos partir do projeto web existente criado com o VS 2010.
 |
- no [1], abrimos o projeto existente:
- no [2], o projeto carregado tem as seguintes referências [3]:
- [NHibernate] é o DLL do framework NHibernate,
- [Spring.Core] é o DLL do framework Spring.net,
- [log4net] é o DLL do framework de registos log4net. Este framework é utilizado pelo Spring.net,
- o [MySql.Data] é o controlador ADO.NET do SGBD MySQL,
- o [rdvmedecins] é o DLL da camada [DAO] construída com o NHibernate;
- em [4], alteramos o nome do projeto e, em [5], eliminamos as referências anteriores;
 |
- no [6], adicionamos referências ao projeto;
- em [7], no assistente, utilizamos a opção [Parcourir];
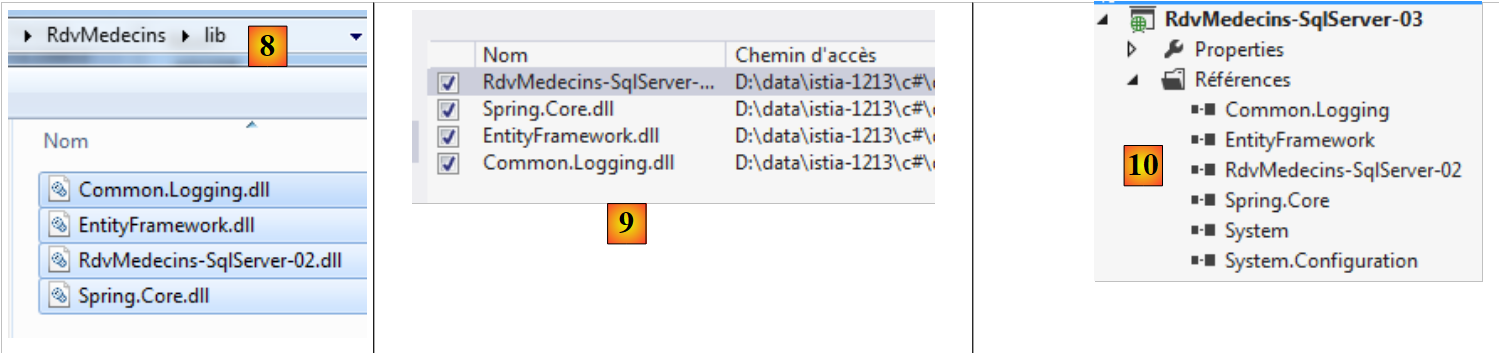 |
- em [8], selecionamos todos os DLL do projeto n.º 2 anteriormente colocados na pasta [lib];
- em [9], um resumo que validamos;
- em [10], o projeto web com as suas novas referências.
Feito isto, o projeto apresenta-se da seguinte forma:
 |
- em [1], o código de gestão das páginas web está distribuído pelos dois ficheiros [Global.asax] e [Default.aspx]. O código utilitário foi colocado na pasta [Entites]. Por fim, a aplicação é configurada pelo ficheiro [Web.config];
- no ficheiro [2], geramos a compilação do projeto;
- no ficheiro [3], surgem erros.
Vamos analisar os erros, por exemplo, o seguinte:
![]()
e a sua explicação:
![]()
O tipo de [medecin.Id] é int?, enquanto o método [GetCreneauxMedecin] é do tipo int. Por isso, é necessário um cast. Este erro é recorrente em todo o código, uma vez que as entidades do projeto ASP.NET / NHibernate tinham chaves primárias do tipo int, enquanto as do projeto ASP.NET / EF 5 são do tipo int?. Corrigimos todos os erros deste tipo e regeneramos o projeto. Deixam então de existir.
Resta-nos um pormenor a resolver antes de executar o projeto: a instanciação da camada [DAO] pelo framework Spring. Esta é feita em [Global.asax]:
protected void Application_Start(object sender, EventArgs e)
{
// armazenamos em cache determinados dados da base de dados
try
{
// instanciação da camada [dao]
Dao = ContextRegistry.GetContext().GetObject("rdvmedecinsDao") as IDao;
...
}
catch (Exception ex)
{...
}
}
No programa de teste da camada [DAO], esta instanciava a camada [DAO] da seguinte forma:
dao = ContextRegistry.GetContext().GetObject("rdvmedecinsDao") as IDao;
Os dois métodos são idênticos. Recorde-se que esta instanciação da camada [DAO] se baseava numa configuração efetuada em [App.config]. Substituímos então o conteúdo atual [Web.config] do projeto web pelo conteúdo de [App.config] do projeto da camada [DAO], de modo a obter a mesma configuração.
Estamos prontos para uma primeira execução. A página inicial é apresentada como [1]:
 |
- em [2], introduzimos uma data de compromisso e confirmamos;
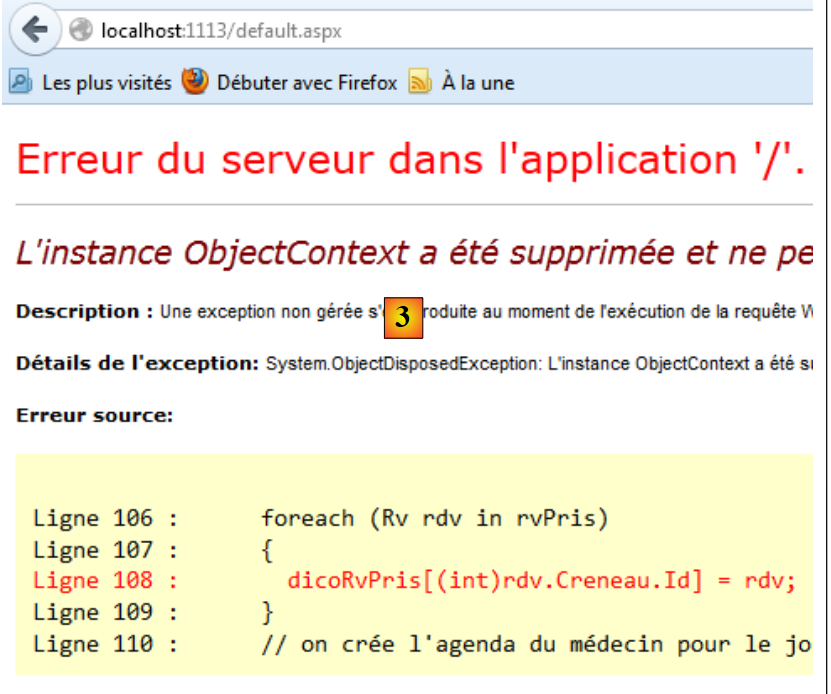 |
- em [3], ocorre um erro.
Ao analisar o texto de erro apresentado pela página, verifica-se que a exceção sinalizada é a do Lazy Loading: tentou-se carregar uma dependência de um objeto quando o contexto de persistência que o gere já tinha sido encerrado. O objeto encontra-se agora num estado «desvinculado». Este erro deve-se ao facto de o NHibernate ter sido utilizado no modo Eager Loading, enquanto o EF funciona, por predefinição, em Lazy Loading. Na linha a vermelho acima:
- rdv representa um objeto [Rv] que foi carregado sem as suas dependências;
- para avaliar rdv.Creneau.Id, a aplicação tenta carregar a dependência rdv.Creneau. Mas, como já não estamos no contexto, isso não é possível, daí a exceção.
Aqui, a solução é simples. Na linha 108, cria-se uma entrada num dicionário com a chave primária do intervalo de tempo de um compromisso como chave. Ora, acontece que a entidade [Rv] encapsula a chave primária do intervalo de tempo associado. Escreve-se, portanto:
dicoRvPris[(int)rdv.CreneauId] = rdv;
Tentamos novamente a execução. Desta vez, o erro é o seguinte:
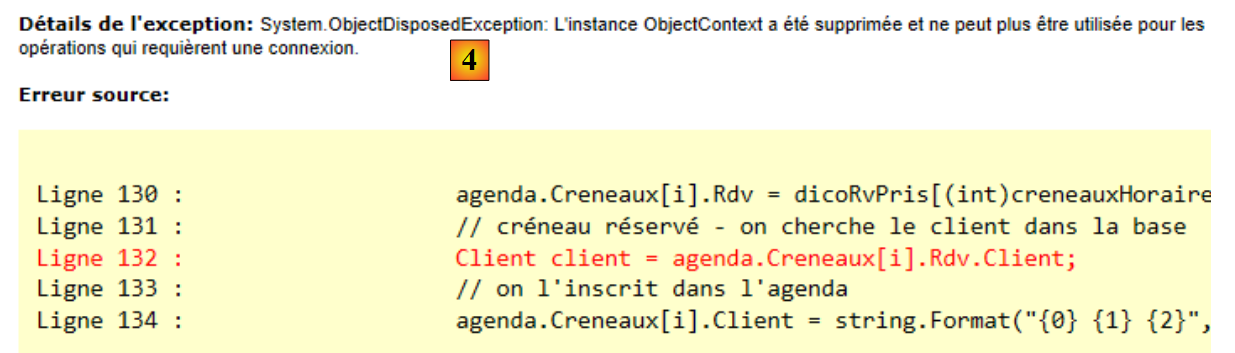 |
O erro é semelhante. Na linha 132, tenta-se carregar a dependência [Client] de um objeto [Rv] na camada ASP.NET, ou seja, fora do contexto. É necessário ir buscar o objeto [Client] à base de dados. Foi para resolver este problema que a interface [IDao] foi enriquecida com o seguinte método:
// encontrar uma entidade T através da sua chave primária
T Find<T>(int id) where T : class;
Isto permitirá recuperar as dependências. Assim, a linha incorreta acima será reescrita da seguinte forma:
Client client = Global.Dao.Find<Client>(agenda.Creneaux[i].Rdv.ClientId);
Mais uma vez, salienta-se a importância de as entidades incluírem as suas chaves estrangeiras. Neste caso, a entidade [Rv] dá-nos acesso à chave estrangeira da dependência [Creneau] associada. Após estas duas correções, a aplicação funciona. Convidamos o leitor a testar a aplicação [RdvMedecins-SqlServer-03], disponível nas transferências de exemplos do site deste artigo.
3.7. Conclusion
Concluímos com sucesso a adaptação de uma aplicação ASP.NET / NHibernate:
 |
para uma aplicação ASP.NET / EF 5:
 |
Embora esta arquitetura nos devesse ter permitido manter intacta a camada [ASP.NET], tivemos de a modificar por duas razões:
- as entidades não eram exatamente as mesmas. O tipo das chaves primárias das entidades NHibernate era «int», enquanto o das entidades EF 5 era «int?». Isso levou-nos a introduzir cast no código web;
- o modo de carregamento das entidades não era o mesmo para as duas: Eager Loading para NHibernate e Lazy Loading para EF 5. Isso levou-nos a enriquecer a interface da camada [DAO] com um método genérico que permite recuperar uma entidade através da sua chave primária.
No entanto, a migração revelou-se bastante simples, justificando mais uma vez, se é que era necessário, a arquitetura em camadas e a injeção de dependências com o Spring ou outro framework de injeção de dependências.
Vamos agora avaliar o impacto de uma alteração no SGBD na arquitetura anterior. Vamos portar todos os projetos anteriores para outros quatro SGBD:
- Oracle Database Express Edition 11g Versão 2;
- MySQL 5.5.28;
- PostgreSQL 9.2.1;
- Firebird 2.1.
Os códigos já não vão mudar. Apenas os seguintes elementos vão mudar:
- a definição, nas entidades, do campo utilizado para controlar a concorrência de acesso a uma entidade;
- os ficheiros de configuração [App.config] ou [Web.config];
Iremos comentar apenas os elementos que se alteram.