5. Classes .NET comumente utilizadas
Apresentamos aqui algumas classes frequentemente utilizadas da plataforma .NET. Antes disso, vamos mostrar-lhe como obter informações sobre as centenas de classes disponíveis. Esta ajuda é indispensável mesmo para o programador C# mais experiente. A qualidade da ajuda (fácil acesso, organização compreensível, relevância da informação, etc.) pode fazer a diferença num ambiente de desenvolvimento.
5.1. Encontre ajuda sobre as classes .NET
Apresentamos aqui algumas dicas sobre como encontrar ajuda no Visual Studio.NET
5.1.1. Ajuda/Índice
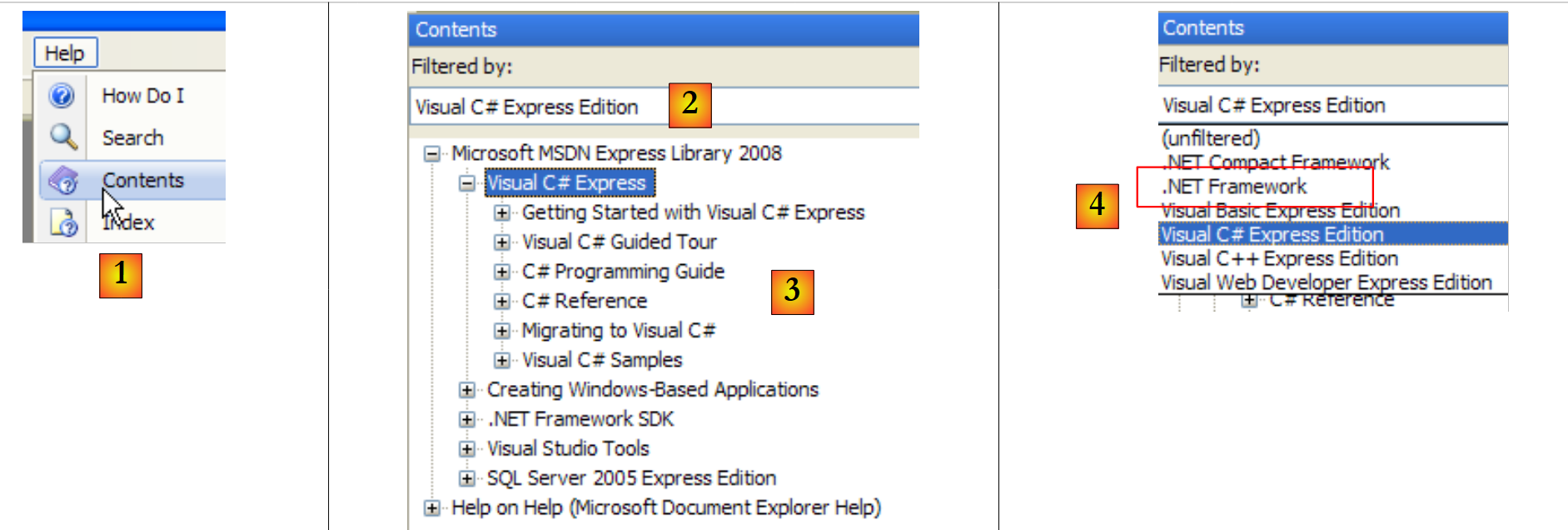 |
- em [1], selecione a opção do menu Ajuda/Índice.
- em [2], selecione a opção Visual C# Express Edition
- em [3], a árvore de ajuda do C#
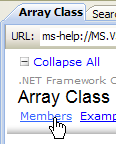
- em [4], outra opção útil é o .NET Framework, que dá acesso a todas as classes do .NET Framework.
Vamos dar uma vista de olhos aos títulos dos capítulos na Ajuda do C#:
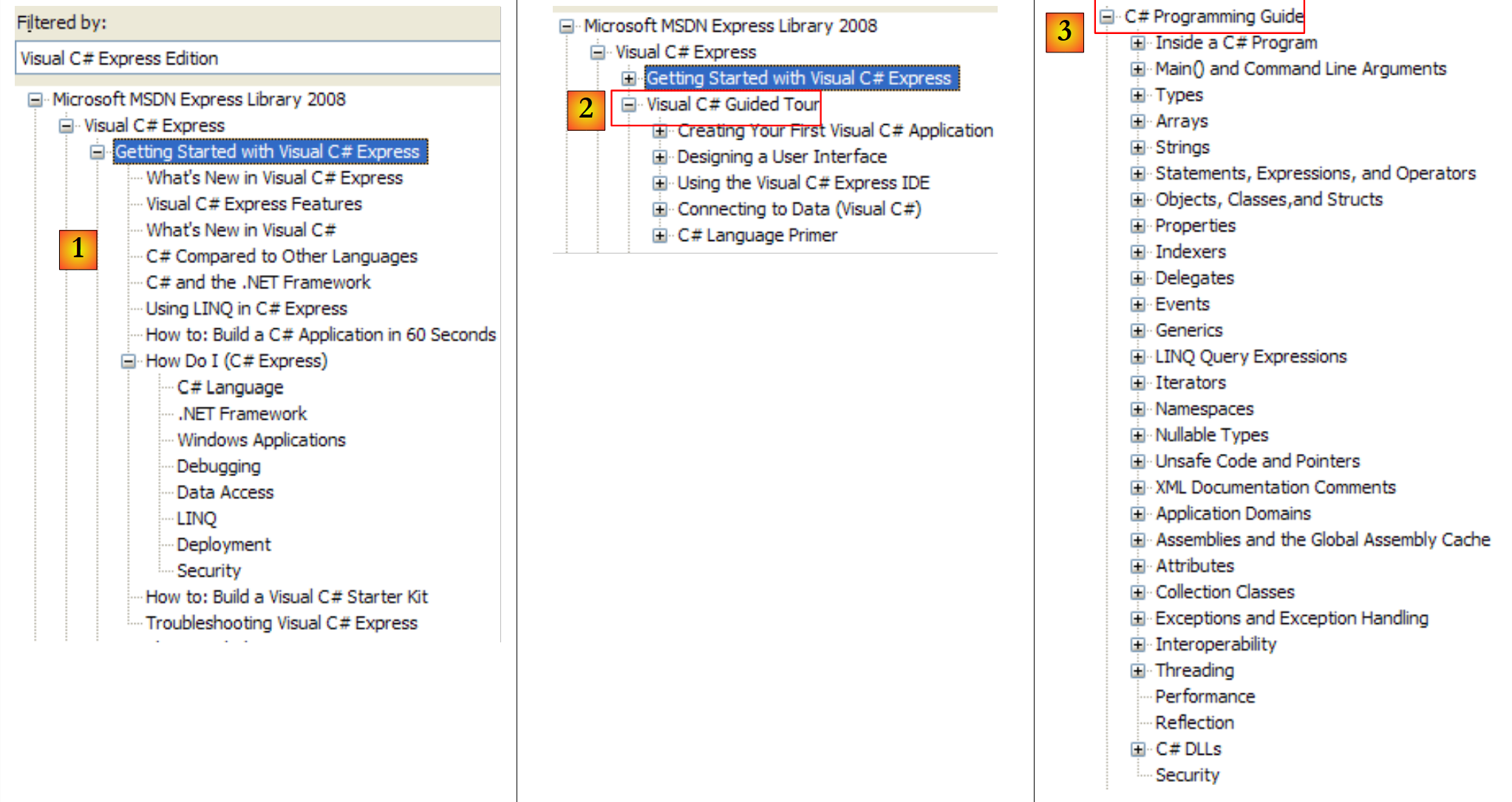 |
- [1]: uma visão geral do C#
- [2]: uma série de exemplos sobre determinados aspetos do C#
- [3]: um curso de C# — poderia substituir o presente documento..
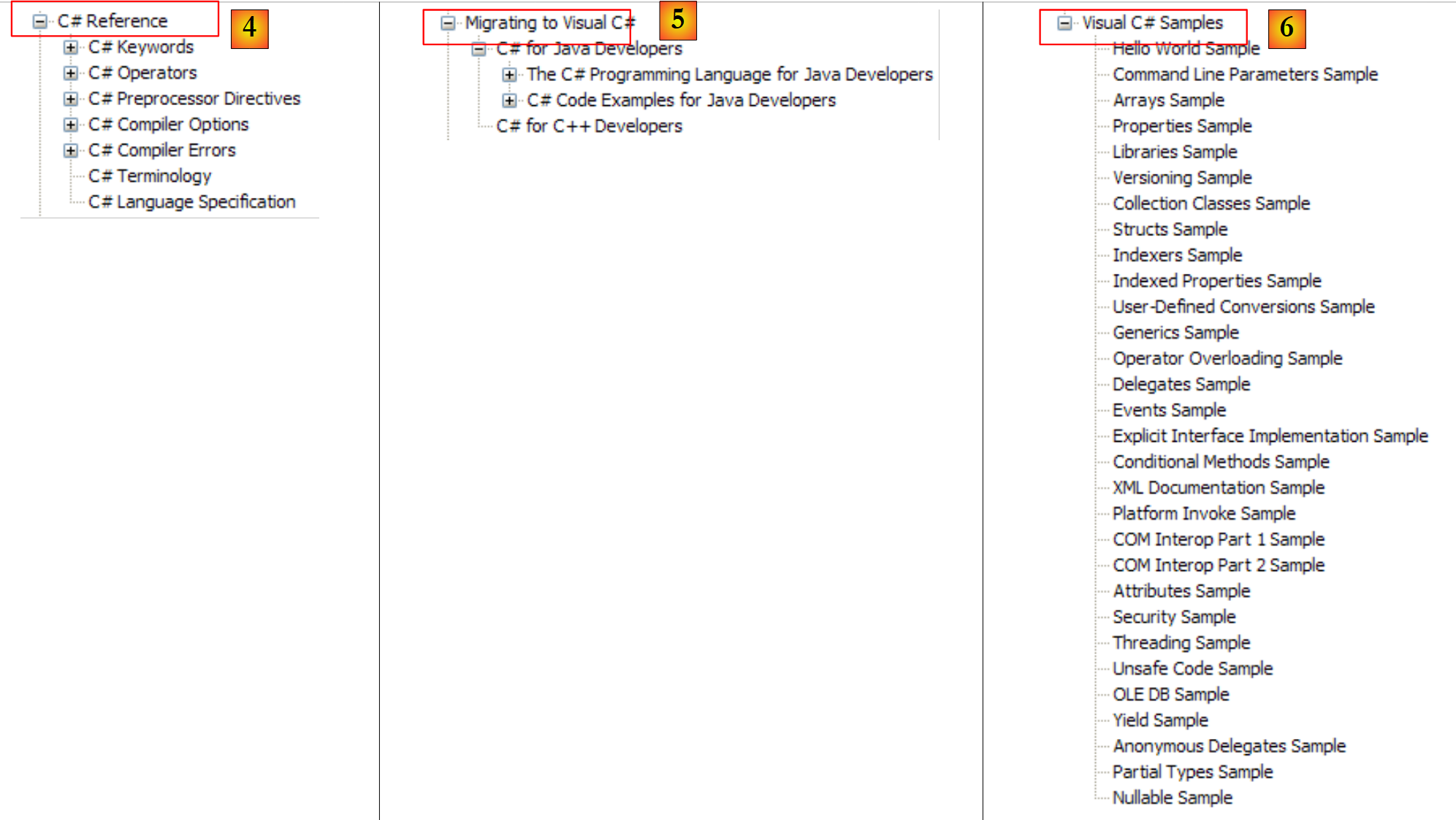 |
- [4]: para saber mais sobre C#
- [5]: útil para programadores de C++ ou Java. Ajuda a evitar algumas armadilhas.
- [6]: ao procurar exemplos, pode começar por aí.
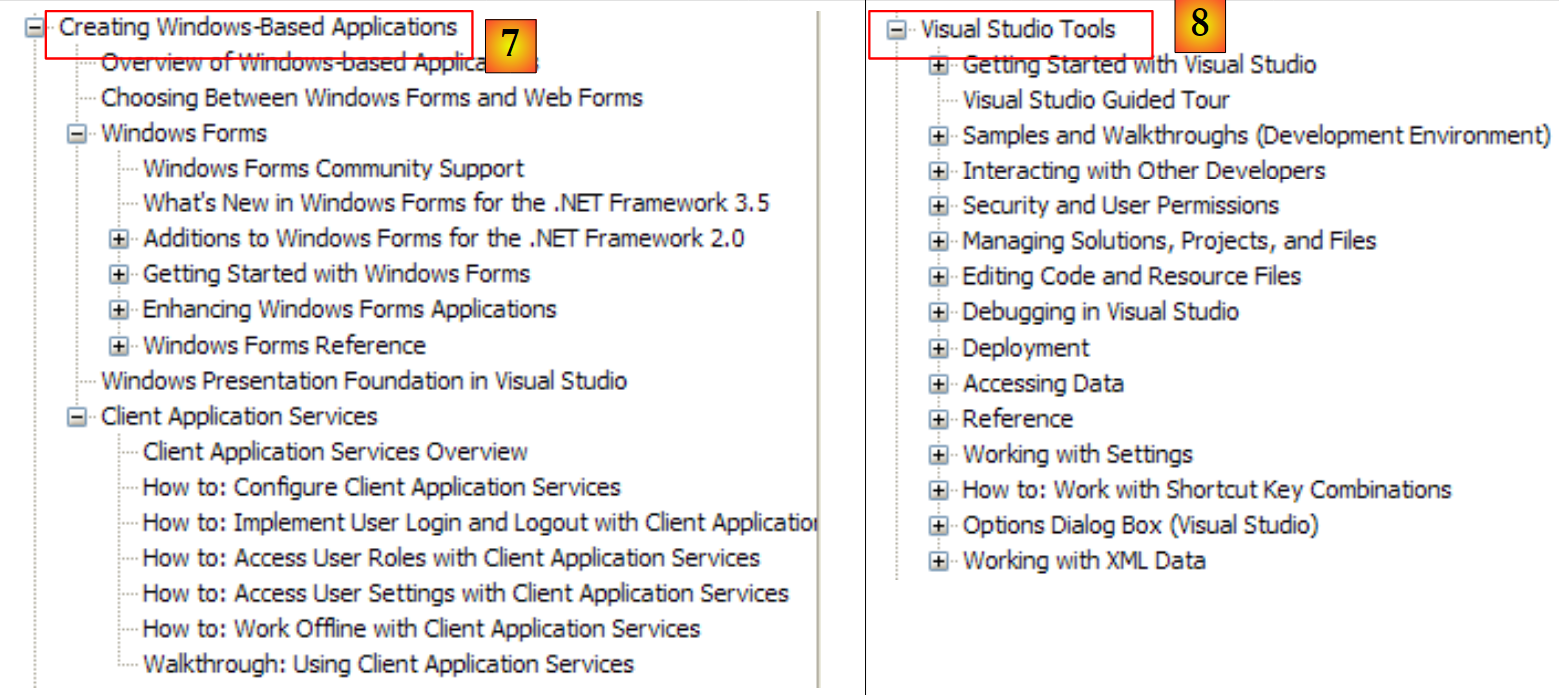 |
- [7]: o que precisa de saber para criar interfaces gráficas de utilizador
- [8]: para tirar o máximo partido do IDE Visual Studio Express
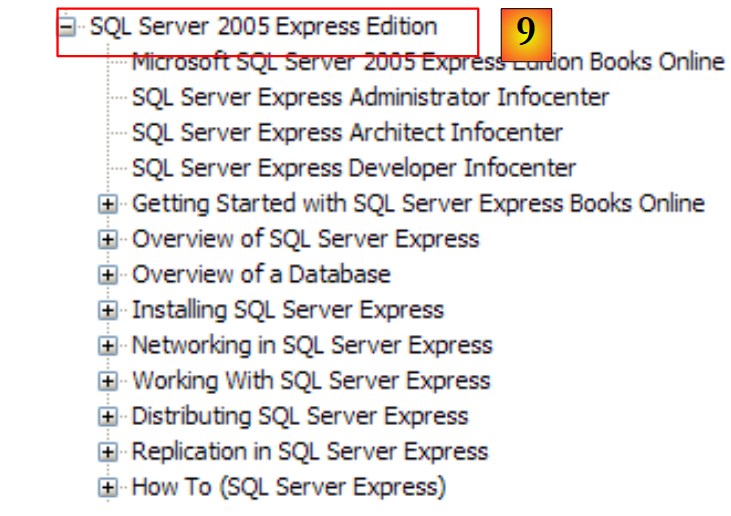 |
- [9]: O SQL Server Express 2005 é um SGBD de alta qualidade distribuído gratuitamente. Será utilizado neste curso.
A ajuda do C# é apenas uma parte do que o programador precisa. A outra parte é a ajuda com as centenas de classes do .NET Framework que facilitarão o seu trabalho.
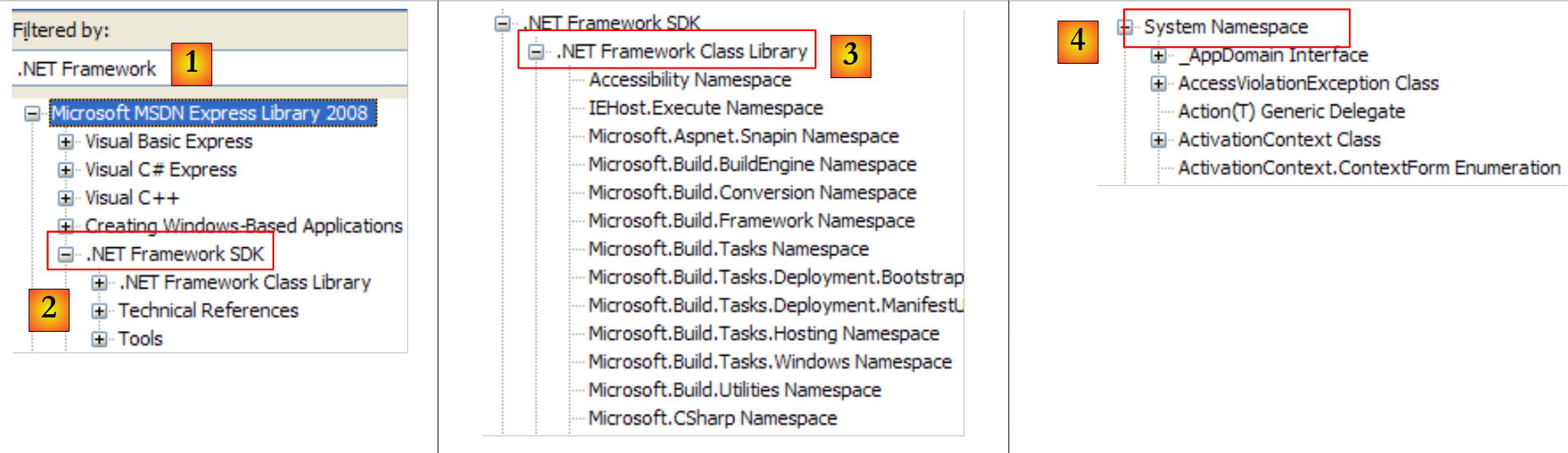 |
- [1]: selecione a ajuda sobre o .NET Framework
- [2]: a ajuda encontra-se no SDK do .NET Framework
- [3]: a ramificação «.NET Framework Class Library» apresenta todas as classes .NET de acordo com o namespace a que pertencem
- [4]: o namespace System, que foi o mais utilizado nos exemplos dos capítulos anteriores
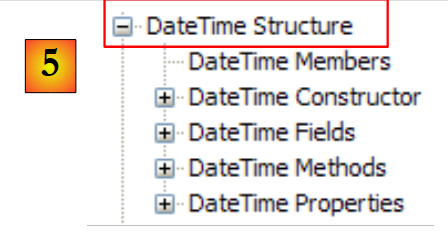 |
- [5]: no namespace System, um exemplo, neste caso a estrutura DateTime
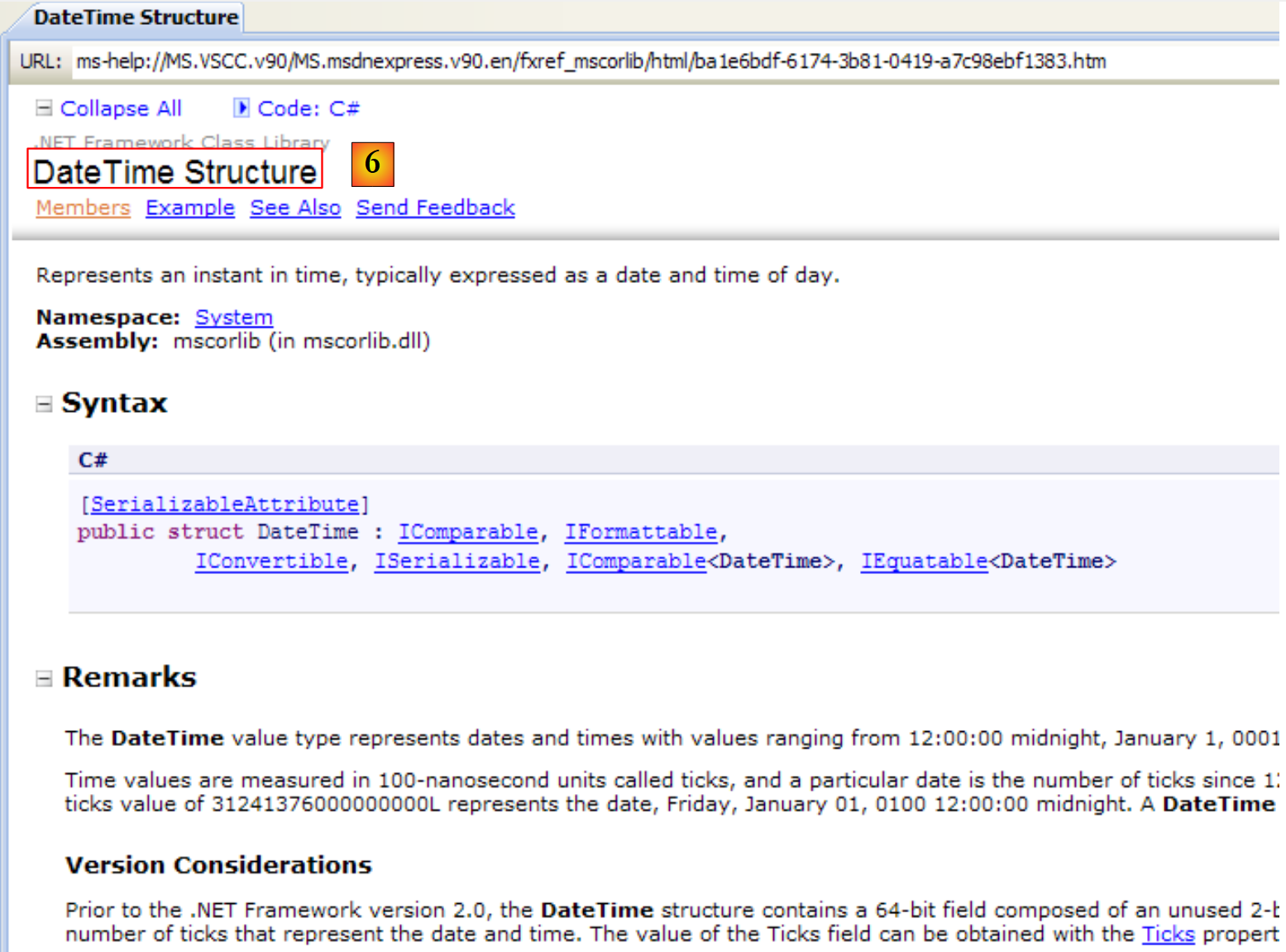 |
- [6]: ajuda sobre a estrutura DateTime
5.1.2. Ajuda/Índice/Pesquisa
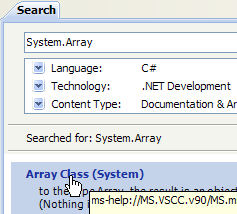
A ajuda fornecida pelo MSDN é imensa e pode não saber onde procurar. Pode então utilizar o índice de ajuda:
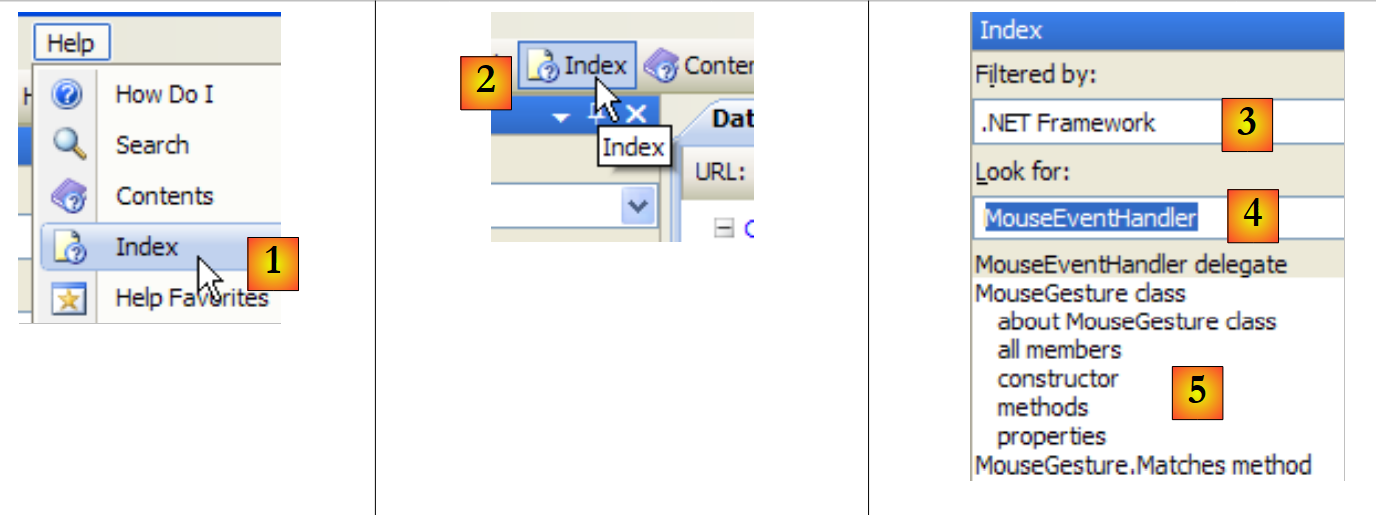 |
- em [1], utilize a opção [Ajuda/Índice] se a janela de ajuda ainda não estiver aberta; caso contrário, utilize [2] numa janela de ajuda já aberta.
- em [3], especifique o campo no qual a pesquisa deve ser realizada
- em [4], especifique o que está à procura, neste caso uma classe
- em [5], a resposta
Outra forma de procurar ajuda é utilizar a ajuda de pesquisa:
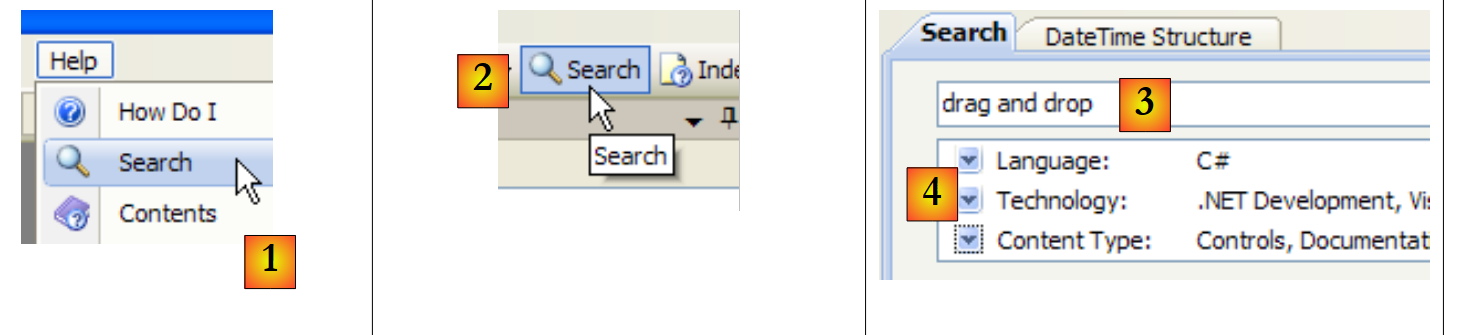 |
- em [1], utilize a opção [Ajuda/Pesquisar] se a janela de ajuda ainda não estiver aberta; caso contrário, utilize [2] numa janela de ajuda já aberta.
- em [3], especifique o que está a procurar
- em [4], filtre os campos de pesquisa
 |
- em [5], a resposta na forma de diferentes temas onde o texto pesquisado foi encontrado.
5.2. Sequências de caracteres
5.2.1. A classe System.String
 |  |  |
A classe System.String é idêntica ao tipo simples string. Possui muitas propriedades e métodos. Aqui estão apenas alguns deles:
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
| |
Um ponto importante a ter em conta: quando um método gera uma cadeia de caracteres, essa cadeia é uma cadeia diferente daquela à qual o método foi aplicado. Por exemplo, S1.Trim() gera uma cadeia de caracteres S2, e S1 e S2 são duas cadeias diferentes.
Uma string C pode ser considerada como uma matriz de caracteres. Assim,
- C[i] é o caractere i de C
- C.Length é o número de caracteres em C
Considere o seguinte exemplo:
using System;
namespace Chap3 {
class Program {
static void Main(string[] args) {
string uneChaine = "l'oiseau vole au-dessus des nuages";
affiche("uneChaine=" + uneChaine);
affiche("uneChaine.Length=" + uneChaine.Length);
affiche("chaine[10]=" + uneChaine[10]);
affiche("uneChaine.IndexOf(\"vole\")=" + uneChaine.IndexOf("vole"));
affiche("uneChaine.IndexOf(\"x\")=" + uneChaine.IndexOf("x"));
affiche("uneChaine.LastIndexOf('a')=" + uneChaine.LastIndexOf('a'));
affiche("uneChaine.LastIndexOf('x')=" + uneChaine.LastIndexOf('x'));
affiche("uneChaine.Substring(4,7)=" + uneChaine.Substring(4, 7));
affiche("uneChaine.ToUpper()=" + uneChaine.ToUpper());
affiche("uneChaine.ToLower()=" + uneChaine.ToLower());
affiche("uneChaine.Replace('a','A')=" + uneChaine.Replace('a', 'A'));
string[] champs = uneChaine.Split(null);
for (int i = 0; i < champs.Length; i++) {
affiche("champs[" + i + "]=[" + champs[i] + "]");
}//for
affiche("Join(\":\",champs)=" + System.String.Join(":", champs));
affiche("(\" abc \").Trim()=[" + " abc ".Trim() + "]");
}//Main
public static void affiche(string msg) {
// poster msg
Console.WriteLine(msg);
}//poster
}//class
}//namespace
A execução produz os seguintes resultados:
Vejamos um novo exemplo:
using System;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// the line to be analyzed
string ligne = "un:deux::trois:";
// field separators
char[] séparateurs = new char[] { ':' };
// split
string[] champs = ligne.Split(séparateurs);
for (int i = 0; i < champs.Length; i++) {
Console.WriteLine("Champs[" + i + "]=" + champs[i]);
}
// join
Console.WriteLine("join=[" + System.String.Join(":", champs) + "]");
}
}
}
e resultados de desempenho:
O método Split da classe String é utilizado para colocar elementos de uma cadeia de caracteres numa matriz. A definição do Split aqui utilizada é a seguinte:
public string[] Split(char[] separator);
matriz de caracteres. Estes caracteres representam os caracteres utilizados para separar os campos da cadeia de caracteres. Assim, se a cadeia de caracteres for "campo1, campo2, campo3", podemos utilizar separator=new char[] {','}. Se o separador for uma série de espaços, utilize separator=null. | |
matriz de cadeias de caracteres em que cada elemento da matriz é um campo de cadeia de caracteres. |
O método Join é um método estático da classe String :
public static string Join(string separator, string[] value);
matriz de strings | |
uma cadeia de caracteres a ser utilizada como separador de campos | |
uma cadeia de caracteres formada pela concatenação dos elementos da matriz valor, separados pelo separador de cadeia. |
5.2.2. A classe System.Text.StringBuilder
 |  |  |
Anteriormente, referimos que os métodos da classe String, quando aplicados a uma sequência de caracteres S1, criavam outra sequência S2. A classe System.Text.StringBuilder permite manipular S1 sem ter de criar uma sequência S2. Isto melhora o desempenho, evitando a multiplicação de sequências com uma vida útil muito limitada.
A classe admite vários construtores:
| |
|
Um objeto StringBuilder trabalha com blocos de capacidade de caracteres para armazenar a string subjacente. A configuração padrão da capacidade é 16. O terceiro construtor acima é usado para especificar a capacidade do bloco. O número de caracteres de capacidade necessários para armazenar uma string S é ajustado automaticamente pelo StringBuilder. Existem construtores para definir o número máximo de caracteres num objeto StringBuilder. Por padrão, essa capacidade máxima é 2.147.483.647.
Eis um exemplo para ilustrar o conceito de capacidade:
using System.Text;
using System;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// str
StringBuilder str = new StringBuilder("test");
Console.WriteLine("taille={0}, capacité={1}", str.Length, str.Capacity);
for (int i = 0; i < 10; i++) {
str.Append("test");
Console.WriteLine("taille={0}, capacité={1}", str.Length, str.Capacity);
}
// str2
StringBuilder str2 = new StringBuilder("test",10);
Console.WriteLine("taille={0}, capacité={1}", str2.Length, str2.Capacity);
for (int i = 0; i < 10; i++) {
str2.Append("test");
Console.WriteLine("taille={0}, capacité={1}", str2.Length, str2.Capacity);
}
}
}
}
- linha 7: criação do objeto StringBuilder com um tamanho de bloco de 16 caracteres
- linha 8: str.Length é o número atual de caracteres na string str. str.Capacity é o número de caracteres que podem ser armazenados na string str antes de reatribuir um novo bloco.
- linha 10: str.Append(String S) concatena a string S do tipo String na linha str do tipo StringBuilder.
- linha 14: criação do objeto StringBuilder com capacidade de bloco de 10 caracteres
Resultado da execução:
Estes resultados mostram que a classe segue o seu próprio algoritmo para alocar novos blocos quando a sua capacidade é insuficiente:
- linhas 4-5: aumento da capacidade para 16 caracteres
- linhas 8-9: capacidade aumentada de 16 para 32 caracteres.
Eis alguns dos métodos da classe:
| |
| |
| |
| |
|
Eis um exemplo:
using System.Text;
using System;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// str3
StringBuilder str3 = new StringBuilder("test");
Console.WriteLine(str3.Append("abCD").Insert(2, "xyZT").Remove(0, 2).Replace("xy", "XY"));
}
}
}
e os seus resultados:
5.3. Pinturas
As matrizes são derivadas da classe Array:
 |  | 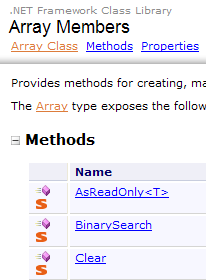 |
A classe Array possui vários métodos para ordenar uma matriz, procurar um elemento numa matriz, redimensionar uma matriz, etc. Apresentamos algumas das propriedades e métodos desta classe. Quase todos são sobrecarregados, c.a.d., e existem em diferentes variantes. Todas as matrizes os herdam.
Propriedades
Métodos
|
O programa seguinte ilustra a utilização de determinados métodos da classe Array:
using System;
namespace Chap3 {
class Program {
// search type
enum TypeRecherche { linéaire, dichotomique };
// main method
static void Main(string[] args) {
// reading table elements typed on the keyboard
double[] éléments;
Saisie(out éléments);
// unsorted table display
Affiche("Tableau non trié", éléments);
// Linear search in unsorted table
Recherche(éléments, TypeRecherche.linéaire);
// table sorting
Array.Sort(éléments);
// sorted table display
Affiche("Tableau trié", éléments);
// Dichotomous search in sorted table
Recherche(éléments, TypeRecherche.dichotomique);
}
// entering values for the elements table
// elements: reference on table created by the
static void Saisie(out double[] éléments) {
bool terminé = false;
string réponse;
bool erreur;
double élément = 0;
int i = 0;
// initially, the painting does not exist
éléments = null;
// table element input loop
while (!terminé) {
// question
Console.Write("Elément (réel) " + i + " du tableau (rien pour terminer) : ");
// reading the answer
réponse = Console.ReadLine().Trim();
// end of input if string empty
if (réponse.Equals(""))
break;
// input verification
try {
élément = Double.Parse(réponse);
erreur = false;
} catch {
Console.Error.WriteLine("Saisie incorrecte, recommencez");
erreur = true;
}//try-catch
// if no error
if (!erreur) {
// one more element in the table
i += 1;
// resize table to accommodate new element
Array.Resize(ref éléments, i);
// insert new element
éléments[i - 1] = élément;
}
}//while
}
// generic method for displaying a picture's elements
static void Affiche<T>(string texte, T[] éléments) {
Console.WriteLine(texte.PadRight(50, '-'));
foreach (T élément in éléments) {
Console.WriteLine(élément);
}
}
// recherche d'an element in the array
// elements: array of real
// TypeRecherche: dichotomous or linear
static void Recherche(double[] éléments, TypeRecherche type) {
// Search
bool terminé = false;
string réponse = null;
double élément = 0;
bool erreur = false;
int i = 0;
while (!terminé) {
// question
Console.WriteLine("Elément cherché (rien pour arrêter) : ");
// reading-checking response
réponse = Console.ReadLine().Trim();
// finished?
if (réponse.Equals(""))
break;
// check
try {
élément = Double.Parse(réponse);
erreur = false;
} catch {
Console.WriteLine("Erreur, recommencez...");
erreur = true;
}//try-catch
// if no error
if (!erreur) {
// on cherche l'element in the table
if (type == TypeRecherche.dichotomique)
// dichotomous search
i = Array.BinarySearch(éléments, élément);
else
// linear search
i = Array.IndexOf(éléments, élément);
// Display response
if (i >= 0)
Console.WriteLine("Trouvé en position " + i);
else
Console.WriteLine("Pas dans le tableau");
}//if
}//while
}
}
}
- linhas 27-62: o método Input captura os elementos de uma matriz digitados no teclado. Como não podemos dimensionar a matriz a priori (não sabemos o seu tamanho final), temos de redimensioná-la para cada novo elemento (linha 57). Um algoritmo mais eficiente teria sido alocar espaço para a matriz em grupos de N elementos. No entanto, uma matriz não foi concebida para ser redimensionada. Este caso é melhor tratado com uma lista (ArrayList, List<T>).
- linhas 75-113: o método Search para pesquisar na tabela um elemento digitado no teclado. O modo de pesquisa difere consoante a tabela esteja ordenada ou não. Para uma matriz não ordenada, é realizada uma pesquisa linear utilizando o IndexOf da linha 106. Para uma tabela ordenada, é realizada uma pesquisa dicotómica utilizando o BinarySearch na linha 103.
- linha 18: a tabela é ordenada por elementos. Utilizamos o Ici, uma variante do Spell que tem apenas um parâmetro: a matriz a ser ordenada. A relação de ordem utilizada para comparar os elementos da matriz é, então, a implícita desses elementos. No caso do Ici, os elementos são numéricos. É utilizada a ordem natural dos números.
Os resultados no ecrã são os seguintes:
5.4. Coleções genéricas
Para além das matrizes, existem várias classes para armazenar coleções de elementos. Existem versões genéricas no espaço de nomes System.Collections.Generic e versões não genéricas em System.Collections. Apresentamos duas coleções genéricas frequentemente utilizadas: a lista e o dicionário.
A lista de coleções genéricas é a seguinte:
5.4.1. A classe genérica List<T>
A classe System.Collections.Generic.List<T> permite implementar coleções de objetos do tipo T cujo tamanho varia durante a execução do programa. Um objeto do tipo List<T> pode ser manipulado quase como uma matriz. Assim, o elemento i de uma lista l é denotado por l[i].
Existe também um tipo de lista não genérico: ArrayList, capaz de armazenar referências a qualquer objeto. ArrayList é funcionalmente equivalente a List<Object>. Um objeto ArrayList tem o seguinte aspeto:
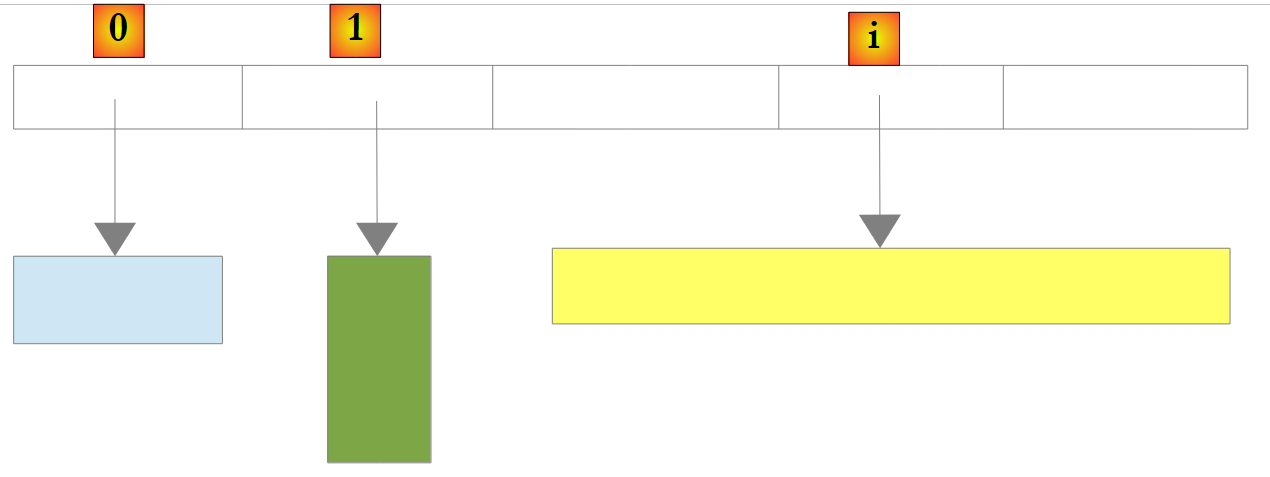 |
Acima, os elementos 0, 1 e i na lista apontam para objetos de tipos diferentes. Um objeto deve ser criado antes de adicionar a sua referência à lista ArrayList. Embora um ArrayList armazene referências a objetos, é possível armazenar números. Isto é feito através de um mecanismo chamado Boxing: o número é encapsulado num objeto O do tipo Object e a referência O é armazenada na lista. Este mecanismo é transparente para o programador. Pode escrever:
Isto produzirá o seguinte resultado:
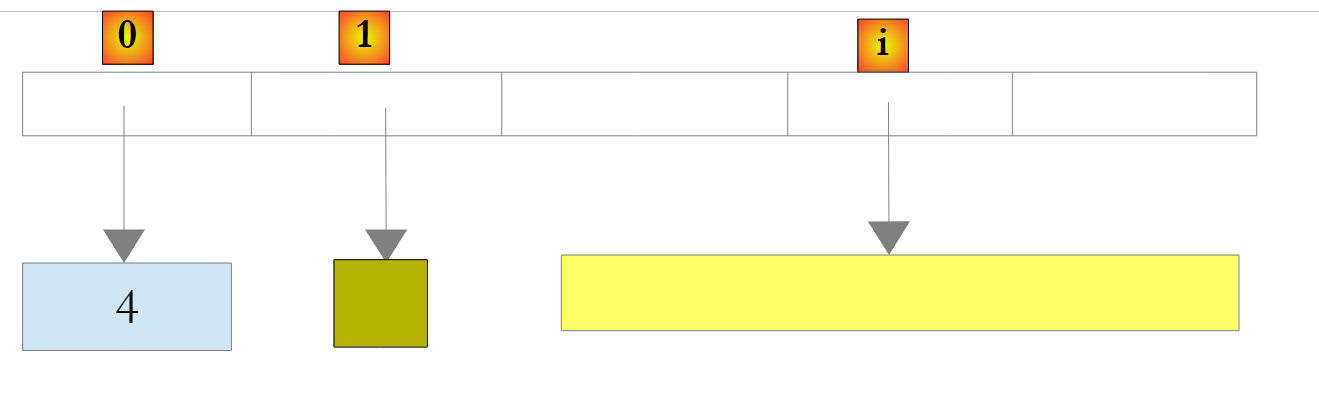 |
Acima, o número 4 foi encapsulado num objeto O e a referência a O foi armazenada na lista. Para o recuperar, escreva:
int i = (int)liste[0];
A operação Object -> int é chamada de Unboxing. Se uma lista for composta inteiramente por int, declará-la como List<int> melhora o desempenho. Na verdade, os números do tipo int são então armazenados na própria lista e não em um objeto fora da lista. As operações de Boxing / Unboxing deixam de ocorrer.
Para um objeto List<T> ou T for uma classe, a lista armazena novamente referências a objetos do tipo T:
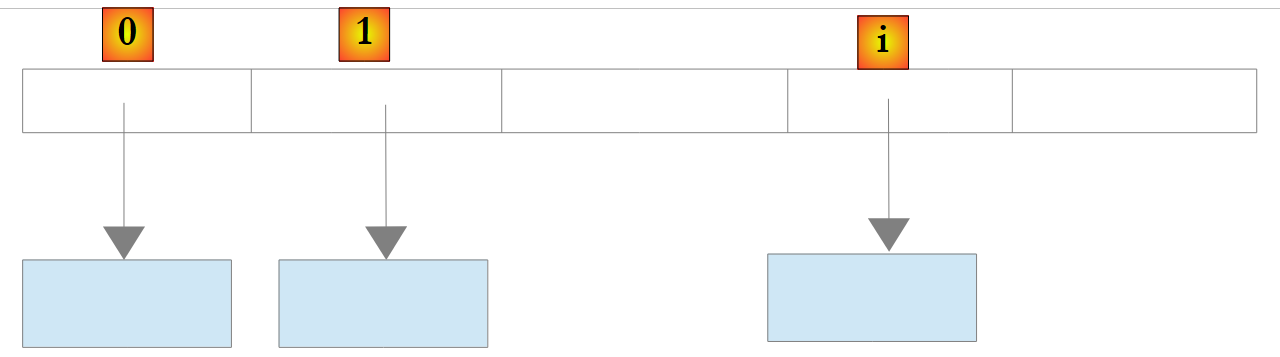 |
Aqui estão algumas das propriedades e métodos das listas genéricas:
Propriedades
|
Métodos
| |
| |
Voltemos ao exemplo anterior com um objeto do tipo Array e tratemos-no agora com um objeto do tipo List<T>. Como a lista é um objeto semelhante à matriz, o código muda muito pouco. Apresentamos apenas as alterações mais notáveis:
using System;
using System.Collections.Generic;
namespace Chap3 {
class Program {
// search type
enum TypeRecherche { linéaire, dichotomique };
// main method
static void Main(string[] args) {
// play list items typed on keyboard
List<double> éléments;
Saisie(out éléments);
// number of elements
Console.WriteLine("La liste a {0} éléments et une capacité de {1} éléments", éléments.Count, éléments.Capacity);
// display unsorted list
Affiche("Liste non triée", éléments);
// Linear search in unsorted list
Recherche(éléments, TypeRecherche.linéaire);
// list sorting
éléments.Sort();
// sorted list display
Affiche("Liste triée", éléments);
// Dichotomous search in sorted list
Recherche(éléments, TypeRecherche.dichotomique);
}
// enter values for the items list
// elements: reference to the list created by the
static void Saisie(out List<double> éléments) {
...
// initially, the list is empty
éléments = new List<double>();
// list item entry loop
while (!terminé) {
...
// if no error
if (!erreur) {
// one more item in the list
éléments.Add(élément);
}
}//while
}
// generic method for displaying the elements of an enumerable object
static void Affiche<T>(string texte, IEnumerable<T> éléments) {
Console.WriteLine(texte.PadRight(50, '-'));
foreach (T élément in éléments) {
Console.WriteLine(élément);
}
}
// search for an item in a list
// elements: list of real numbers
// TypeRecherche: dichotomous or linear
static void Recherche(List<double> éléments, TypeRecherche type) {
...
while (!terminé) {
...
// if no error
if (!erreur) {
// search for the element in the list
if (type == TypeRecherche.dichotomique)
// dichotomous search
i = éléments.BinarySearch(élément);
else
// linear search
i = éléments.IndexOf(élément);
// Display response
...
}//if
}//while
}
}
}
- linhas 46-51: o método genérico Poster<T> tem dois parâmetros:
- o primeiro parâmetro é um texto a ser escrito
- o segundo parâmetro é um objeto que implementa a interface genérica IEnumerable<T>:
A estrutura foreach( T element in elements), na linha 48, é válida para quaisquer objetos elements que implementem a interface IEnumerable. As tabelas (Array*) e as listas (List<T>*) implementam a interface IEnumerable<T>*. O Poster* é igualmente adequado para apresentar tabelas e listas.
Os resultados da execução do programa são os mesmos do exemplo que utiliza o Array.
5.4.2. A classe Dictionary<TKey,TValue>
A classe System.Collections.Generic.Dictionary<TKey,TValue> é utilizada para implementar um dicionário. Um dicionário pode ser considerado como uma matriz com duas colunas:
chave | valor |
chave1 | valor1 |
chave2 | valor2 |
.. | ... |
Na sala de aula, as chaves do Dicionário<TKey,TValue> são do tipo TKey e os valores do tipo TValue. As chaves são únicas, ou seja, não podem existir duas chaves idênticas. Um dicionário deste tipo poderia ter o seguinte aspeto se os tipos TKey e TValue designassem classes:
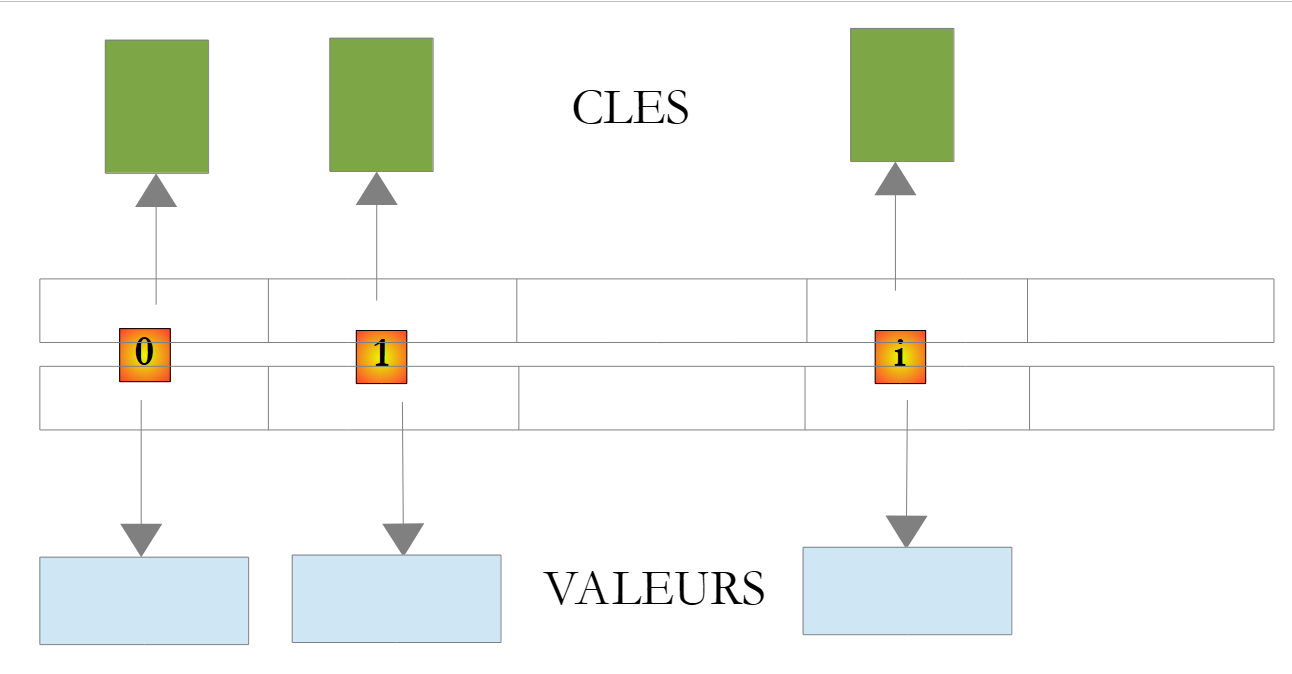 |
O valor associado à chave C de um dicionário D é dado pela notação D[C]. Este valor é legível e gravável. Assim, podemos escrever:
Se a chave c não existir no dicionário D, a operação D[c] lança uma exceção.
Os principais métodos e propriedades do Dictionary<TKey,TValue> são os seguintes:
Fabricantes
Propriedades
Métodos
Considere o seguinte programa de exemplo:
using System;
using System.Collections.Generic;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// creation of a <string,int> dictionary
string[] liste = { "jean:20", "paul:18", "mélanie:10", "violette:15" };
string[] champs = null;
char[] séparateurs = new char[] { ':' };
Dictionary<string,int> dico = new Dictionary<string,int>();
for (int i = 0; i <liste.Length; i++) {
champs = liste[i].Split(séparateurs);
dico[champs[0]]= int.Parse(champs[1]);
}//for
// number of elements in the dictionary
Console.WriteLine("Le dictionnaire a " + dico.Count + " éléments");
// kEY LIST
Affiche("[Liste des clés]",dico.Keys);
// list of values
Affiche("[Liste des valeurs]", dico.Values);
// list of keys & values
Console.WriteLine("[Liste des clés & valeurs]");
foreach (string clé in dico.Keys) {
Console.WriteLine("clé=" + clé + " valeur=" + dico[clé]);
}
// delete the "paul" key
Console.WriteLine("[Suppression d'une clé]");
dico.Remove("paul");
// list of keys & values
Console.WriteLine("[Liste des clés & valeurs]");
foreach (string clé in dico.Keys) {
Console.WriteLine("clé=" + clé + " valeur=" + dico[clé]);
}
// dictionary search
String nomCherché = null;
Console.Write("Nom recherché (rien pour arrêter) : ");
nomCherché = Console.ReadLine().Trim();
int value;
while (!nomCherché.Equals("")) {
dico.TryGetValue(nomCherché, out value);
if (value!=0) {
Console.WriteLine(nomCherché + "," + value);
} else {
Console.WriteLine("Nom " + nomCherché + " inconnu");
}
// next search
Console.Out.Write("Nom recherché (rien pour arrêter) : ");
nomCherché = Console.ReadLine().Trim();
}//while
}
// generic method for displaying elements of an enumerable type
static void Affiche<T>(string texte, IEnumerable<T> éléments) {
Console.WriteLine(texte.PadRight(50, '-'));
foreach (T élément in éléments) {
Console.WriteLine(élément);
}
}
}
}
- linha 8: uma tabela de strings que será usada para inicializar o dicionário <string,int>
- linha 11: o dicionário <string,int>
- linhas 12-15: a sua inicialização a partir da string na linha 8
- linha 17: número de entradas do dicionário
- linha 19: chaves do dicionário
- linha 21: valores do dicionário
- linha 29: elimina uma entrada do dicionário
- linha 41: pesquisa de uma chave no dicionário. Se não existir, o TryGetValue definirá 0 como valor, porque o valor é numérico. Esta técnica só pode ser utilizada aqui porque sabemos que o valor 0 não está no dicionário.
Os resultados são os seguintes:
5.5. Ficheiros de texto
5.5.1. A classe StreamReader
A classe System.IO.StreamReader permite ler o conteúdo de um ficheiro de texto. Na verdade, pode operar em fluxos que não sejam ficheiros. Aqui estão algumas das suas propriedades e métodos:
Fabricantes
Propriedades
Métodos
Eis um exemplo:
using System;
using System.IO;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// execution directory
Console.WriteLine("Répertoire d'exécution : "+Environment.CurrentDirectory);
string ligne = null;
StreamReader fluxInfos = null;
// read contents of infos.txt file
try {
// reading 1
Console.WriteLine("Lecture 1----------------");
using (fluxInfos = new StreamReader("infos.txt")) {
ligne = fluxInfos.ReadLine();
while (ligne != null) {
Console.WriteLine(ligne);
ligne = fluxInfos.ReadLine();
}
}
// reading 2
Console.WriteLine("Lecture 2----------------");
using (fluxInfos = new StreamReader("infos.txt")) {
Console.WriteLine(fluxInfos.ReadToEnd());
}
} catch (Exception e) {
Console.WriteLine("L'erreur suivante s'est produite : " + e.Message);
}
}
}
}
- linha 8: exibe o nome do diretório de execução
- linhas 12, 27: um try / catch para lidar com uma possível exceção.
- linha 15: a estrutura using flux=new StreamReader(...) é um recurso para evitar ter de fechar explicitamente o fluxo após a sua utilização. Isto é feito automaticamente assim que sair do âmbito do using.
- linha 15: o ficheiro lido chama-se infos.txt. Como se trata de um nome relativo, será procurado no diretório de execução exibido pela linha 8. Se não estiver lá, será lançada uma exceção e tratada pelo try / catch.
- linhas 16-20: o ficheiro é lido em linhas sucessivas
- linha 25: o ficheiro é lido de uma só vez
O ficheiro infos.txt tem o seguinte conteúdo:
e colocado na seguinte pasta do projeto C#:
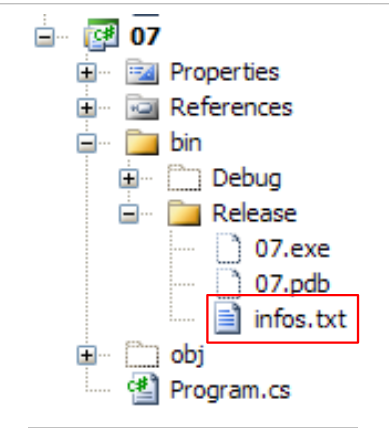 |
Estamos prestes a descobrir que «bin/Release» é a pasta de execução quando o projeto é executado com Ctrl-F5.
A execução produz os seguintes resultados:
Se, na linha 15, colocarmos o nome do ficheiro xx.txt, obtemos os seguintes resultados:
5.5.2. A classe StreamWriter
A classe System.IO.StreamReader permite-lhe escrever num ficheiro de texto. Tal como o StreamReader, é, na verdade, capaz de explorar fluxos que não são ficheiros. Aqui estão algumas das suas propriedades e métodos:
Fabricantes
Propriedades
Métodos
Considere o seguinte exemplo:
using System;
using System.IO;
namespace Chap3 {
class Program2 {
static void Main(string[] args) {
// execution directory
Console.WriteLine("Répertoire d'exécution : " + Environment.CurrentDirectory);
string ligne = nu ll; // one line of text
StreamWriter fluxInfos = nu ll; // the text file
try {
// text file creation
using (fluxInfos = new StreamWriter("infos2.txt")) {
Console.WriteLine("Mode AutoFlush : {0}", fluxInfos.AutoFlush);
// read line typed on keyboard
Console.Write("ligne (rien pour arrêter) : ");
ligne = Console.ReadLine().Trim();
// loop as long as the line entered is not empty
while (ligne != "") {
// write line to text file
fluxInfos.WriteLine(ligne);
// read new line on keyboard
Console.Write("ligne (rien pour arrêter) : ");
ligne = Console.ReadLine().Trim();
}//while
}
} catch (Exception e) {
Console.WriteLine("L'erreur suivante s'est produite : " + e.Message);
}
}
}
}
- linha 13: mais uma vez, usamos a sintaxe using(stream) para evitar ter de fechar explicitamente o fluxo com um Close. Isto é feito automaticamente quando o using.
- porquê um try / catch, linhas 11 e 27? na linha 13, poderíamos indicar um nome de ficheiro na forma /rep1/rep2/ .../ficheiro com um caminho /rep1/rep2/... que não existe, tornando impossível criar um ficheiro. Seria então lançada uma exceção. Existem outras exceções possíveis (disco cheio, direitos insuficientes, etc.)
Os resultados são os seguintes:
O ficheiro infos2.txt foi criado na pasta bin/Release do projeto:
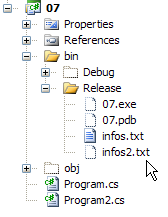 |  |
5.6. Ficheiros binários
As classes System.IO.BinaryReader e System.IO.BinaryWriter são utilizadas para ler e escrever ficheiros binários.
Considere a seguinte aplicação:
// syntaxe pg texte bin logs
// on lit un fichier texte (texte) et on range son contenu dans un fichier binaire (bin
// le fichier texte a des lignes de la forme nom : age qu'on rangera dans une structure string, int
// (logs) est un fichier texte de logs
O ficheiro de texto tem o seguinte conteúdo:
O programa é o seguinte:
using System;
using System.IO;
// syntax pg text bin logs
// read a text file (text) and store its contents in a binary file (bin)
// the text file has lines of the form name: age, which will be stored in a structure string, int
// (logs) is a text log file
namespace Chap3 {
class Program {
static void Main(string[] arguments) {
// you need 3 arguments
if (arguments.Length != 3) {
Console.WriteLine("syntaxe : pg texte binaire log");
Environment.Exit(1);
}//if
// variables
string ligne=null;
string nom=null;
int age=0;
int numLigne = 0;
char[] séparateurs = new char[] { ':' };
string[] champs=null;
StreamReader input = null;
BinaryWriter output = null;
StreamWriter logs = null;
bool erreur = false;
// read text file - write binary file
try {
// open text file in read mode
input = new StreamReader(arguments[0]);
// open binary file for writing
output = new BinaryWriter(new FileStream(arguments[1], FileMode.Create, FileAccess.Write));
// open write log file
logs = new StreamWriter(arguments[2]);
// text file processing
while ((ligne = input.ReadLine()) != null) {
// one more line
numLigne++;
// empty line?
if (ligne.Trim() == "") {
// on ignore
continue;
}
// one line name: age
champs = ligne.Split(séparateurs);
// we need 2 fields
if (champs.Length != 2) {
// on logue l'erreur
logs.WriteLine("La ligne n° [{0}] du fichier [{1}] a un nombre de champs incorrect", numLigne, arguments[0]);
// next line
continue;
}//if
// 1st field must be non-empty
erreur = false;
nom = champs[0].Trim();
if (nom == "") {
// on logue l'erreur
logs.WriteLine("La ligne n° [{0}] du fichier [{1}] a un nom vide", numLigne, arguments[0]);
erreur = true;
}
// the second field must be an integer >=0
if (!int.TryParse(champs[1],out age) || age<0) {
// on logue l'erreur
logs.WriteLine("La ligne n° [{0}] du fichier [{1}] a un âge [{2}] incorrect", numLigne, arguments[0], champs[1].Trim());
erreur = true;
}//if
// if no error, write data to binary file
if (!erreur) {
output.Write(nom);
output.Write(age);
}
// next line
}//while
}catch(Exception e){
Console.WriteLine("L'erreur suivante s'est produite : {0}", e.Message);
} finally {
// closing files
if(input!=null) input.Close();
if(output!=null) output.Close();
if(logs!=null) logs.Close();
}
}
}
}
Vamos concentrar-nos nas operações relacionadas com o BinaryWriter:
- linha 34: o objeto BinaryWriter é aberto pelo
output=new BinaryWriter(new FileStream(arguments[1],FileMode.Create,FileAccess.Write));
O argumento do construtor deve ser um fluxo. Aqui, trata-se de um fluxo criado a partir de um ficheiro (FileStream) fornecido:
- (continuação)
- o nome
- a operação a ser realizada, aqui FileMode.Create para criar o
- tipo de acesso, aqui FileAccess.Write para acesso de escrita ao ficheiro
- linhas 70-73: operações de escrita
A classe BinaryWriter dispõe de vários métodos Write sobrecarregados para escrever os vários tipos de dados simples
- linha 81: operação de encerramento do fluxo
Os três argumentos do método Main são fornecidos ao projeto (através das suas propriedades) [1] e o ficheiro de texto a utilizar é colocado na pasta bin/Release [2] :
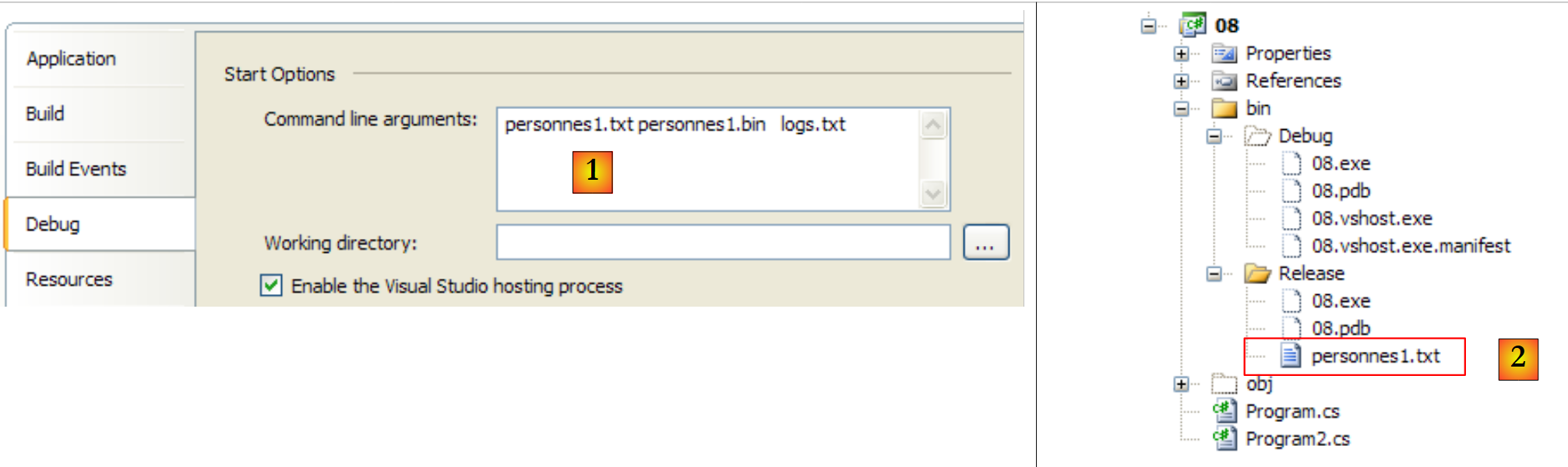 |
Com o seguinte ficheiro [personnes1.txt]:
os resultados são os seguintes:
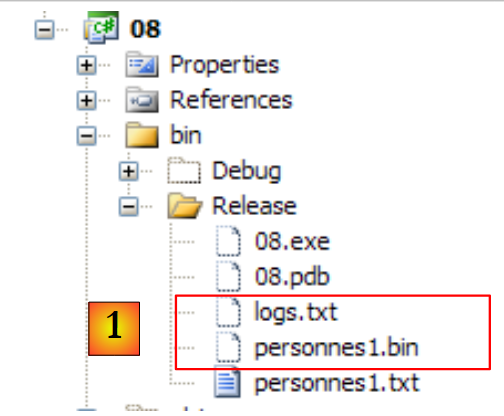 |
- em [1], o ficheiro binário criado [personnes1.bin] e o ficheiro de registo [logs.txt]. Este último tem o seguinte conteúdo:
O conteúdo do ficheiro binário [personnes1.bin] será fornecido pelo seguinte programa. Este também aceita três argumentos:
// syntaxe pg bin texte logs
// on lit un fichier binaire bin et on range son contenu dans un fichier texte (texte)
// le fichier binaire a une structure string, int
// le fichier texte a des lignes de la forme nom : age
// logs est un fichier texte de logs
Por isso, realizamos a operação inversa. Lemos um ficheiro binário para criar um ficheiro de texto. Se o ficheiro de texto produzido for idêntico ao ficheiro original, saberemos que a conversão texto --> binário --> texto foi bem-sucedida. O código é o seguinte:
using System;
using System.IO;
// syntax pg bin text logs
// read a binary bin file and store its contents in a text file (text)
// the binary file has a structure string, int
// the text file has lines of the form name: age
// logs is a text log file
namespace Chap3 {
class Program2 {
static void Main(string[] arguments) {
// you need 3 arguments
if (arguments.Length != 3) {
Console.WriteLine("syntaxe : pg binaire texte log");
Environment.Exit(1);
}//if
// variables
string nom = null;
int age = 0;
int numPersonne = 1;
BinaryReader input = null;
StreamWriter output = null;
StreamWriter logs = null;
bool fini;
// read binary file - write text file
try {
// open binary file for reading
input = new BinaryReader(new FileStream(arguments[0], FileMode.Open, FileAccess.Read));
// open text file for writing
output = new StreamWriter(arguments[1]);
// open write log file
logs = new StreamWriter(arguments[2]);
// binary file processing
fini = false;
while (!fini) {
try {
// read name
nom = input.ReadString().Trim();
// age reading
age = input.ReadInt32();
// writing to text file
output.WriteLine(nom + ":" + age);
// next person
numPersonne++;
} catch (EndOfStreamException) {
fini = true;
} catch (Exception e) {
logs.WriteLine("L'erreur suivante s'est produite à la lecture de la personne n° {0} : {1}", numPersonne, e.Message);
}
}//while
} catch (Exception e) {
Console.WriteLine("L'erreur suivante s'est produite : {0}", e.Message);
} finally {
// closing files
if (input != null)
input.Close();
if (output != null)
output.Close();
if (logs != null)
logs.Close();
}
}
}
}
Vamos concentrar-nos nas operações relacionadas com o BinaryReader:
- linha 30: o objeto BinaryReader é aberto pelo
input=new BinaryReader(new FileStream(arguments[0],FileMode.Open,FileAccess.Read));
O argumento do construtor deve ser um fluxo. Aqui, trata-se de um fluxo criado a partir de um ficheiro (FileStream) fornecido:
- (continuação)
- o nome
- a operação a ser realizada, aqui FileMode.Open para abrir um ficheiro existente
- tipo de acesso, aqui FileAccess.Read para acesso de leitura ao ficheiro
- linhas 40, 42: operações de leitura
A classe BinaryReader dispõe de um conjunto de métodos ReadXX para ler diferentes tipos de dados simples
- linha 60: operação de encerramento do fluxo
Se executarmos os dois programas em sequência, transformando o ficheiro «personnes1.txt» no ficheiro «personnes1.bin» e, em seguida, o ficheiro «personnes1.bin» no ficheiro «personnes2.txt2», obtemos os seguintes resultados:
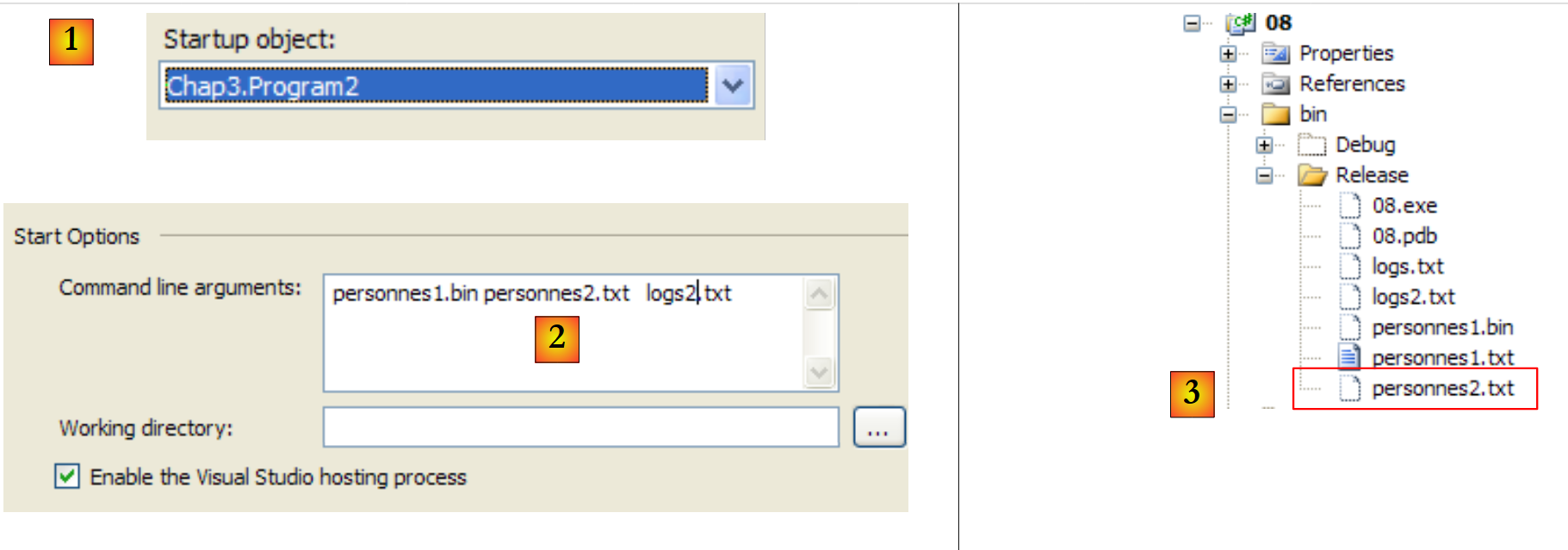 |
- em [1], o projeto está configurado para executar a segunda aplicação
- em [2], os argumentos passados para Main
- em [3], os ficheiros produzidos pela execução da aplicação.
O conteúdo de [personnes2.txt] é o seguinte:
5.7. Expressões regulares
A classe System.Text.RegularExpressions.Regex permite a utilização de expressões regulares. Estas permitem-lhe verificar o formato de uma cadeia de caracteres. Por exemplo, podemos verificar se uma cadeia que representa uma data está no formato dd/mm/aa. Para tal, utilizamos um modelo e comparamos a cadeia com esse modelo. Neste exemplo, d, m e a devem ser números. O modelo para um formato de data válido é, então, "\d\d/\d\d/\d\d", em que o símbolo \d designa um número. Os seguintes símbolos podem ser utilizados num modelo:
Descrição | |
Marca o caractere seguinte como especial ou literal. Por exemplo, "n" corresponde ao caractere "n". "\n" corresponde a um caractere de nova linha. A sequência "\" corresponde a "\", enquanto "\(" corresponde a "(". | |
Corresponde ao início da entrada. | |
Corresponde ao fim da entrada. | |
Corresponde ao caractere anterior zero ou mais vezes. Por exemplo, «zo*» corresponde a «z» ou «zoo». | |
Corresponde ao caractere anterior uma ou mais vezes. Por exemplo, «zo+» corresponde a «zoo», mas não a «z». | |
Corresponde ao caractere anterior zero ou uma vez. Por exemplo, "a?ve?" corresponde a "ve" em "lever". | |
Corresponde a qualquer caractere único, exceto ao caractere de nova linha. | |
Pesquisa o modelo e memoriza a correspondência. A subcadeia correspondente pode ser extraída das correspondências utilizando Item [0]...[n]. Para encontrar correspondências com caracteres entre parênteses ( ), utilize "\(" ou "\)". | |
Corresponde a x ou a y. Por exemplo, "z|foot" corresponde a "z" ou "foot". "(z|f)oo" corresponde a "zoo" ou "foo". | |
n é um número inteiro não negativo. Corresponde exatamente a n vezes o caractere. Por exemplo, "o{2}" não corresponde a "o" em "Bob", mas aos dois primeiros "o"s em "fooooot". | |
n é um número inteiro não negativo. Corresponde a pelo menos n vezes o carácter. Por exemplo, "o{2,}" não corresponde a "o" em "Bob", mas a todos os "o"s em "fooooot". "o{1,}" é igual a "o+" e "o{0,}" é igual a "o*". | |
m e n são números inteiros não negativos. Corresponde a pelo menos n e, no máximo, m ocorrências do caractere. Por exemplo, "o{1,3}" corresponde aos primeiros três "o" em "foooooot" e "o{0,1}" é equivalente a "o?". | |
Conjunto de caracteres. Corresponde a um dos caracteres indicados. Por exemplo, "[abc]" corresponde a "a" em "plat". | |
Conjunto de caracteres negativo. Corresponde a qualquer caractere não especificado. Por exemplo, "[^abc]" corresponde a "p" em "plat". | |
Intervalo de caracteres. Corresponde a qualquer caractere no intervalo especificado. Por exemplo, "[a-z]" corresponde a qualquer caractere alfabético minúsculo entre "a" e "z". | |
Intervalo de caracteres negativo. Corresponde a qualquer caractere que não esteja no intervalo especificado. Por exemplo, "[^m-z]" corresponde a qualquer caractere que não esteja entre "m" e "z". | |
Corresponde a um limite que representa uma palavra, ou seja, a posição entre uma palavra e um espaço. Por exemplo, "er\b" corresponde a "er" em "lever", mas não a "er" em "verb". | |
Corresponde a um limite que não representa uma palavra. "en*t\B" corresponde a "ent" em "bien entendu". | |
Corresponde a um caractere que representa um dígito. Equivalente a [0-9]. | |
Corresponde a um caractere que não representa um dígito. Equivalente a [^0-9]. | |
Corresponde a um caractere de quebra de página. | |
Corresponde a um caractere de nova linha. | |
Corresponde a um caractere de retorno de carro. | |
Corresponde a qualquer espaço em branco, incluindo espaço, tabulação, quebra de página, etc. Equivalente a "[ \f\r\t\v]". | |
Corresponde a qualquer caractere que não seja um espaço em branco. Equivalente a "[^ \f\n\r\t\v]". | |
Corresponde a um caractere de tabulação. | |
Corresponde a um caractere de tabulação vertical. | |
Corresponde a qualquer caractere que represente uma palavra, incluindo o sublinhado. Equivalente a "[A-Za-z0-9_]". | |
Corresponde a qualquer caractere que não represente uma palavra. Equivalente a "[^A-Za-z0-9_]". | |
Corresponde a num, onde num é um número inteiro positivo. Refere-se a correspondências armazenadas. Por exemplo, "(.)\1" corresponde a dois caracteres idênticos consecutivos. | |
Corresponde a n, onde n é um valor de escape octal. Os valores de escape octais devem conter 1, 2 ou 3 dígitos. Por exemplo, "\11" e "\011" correspondem ambos a um caractere de tabulação. "\0011" é equivalente a "\001" e "1". Os valores de escape octais não devem exceder 256. Se tal fosse o caso, apenas os dois primeiros dígitos seriam tidos em conta na expressão. Permite que os códigos ASCII sejam utilizados em expressões regulares. | |
Corresponde a n, onde n é um valor de escape hexadecimal. Os valores de escape hexadecimais devem conter dois dígitos. Por exemplo, "\x41" corresponde a "A". "\x041" é equivalente a "\x04" e "1". Permite que códigos ASCII sejam utilizados em expressões regulares. |
Um elemento num modelo pode estar presente em 1 ou mais cópias. Vejamos alguns exemplos envolvendo o símbolo \d, que representa 1 dígito:
modelo | significado |
\d | um número |
\d? | 0 ou 1 dígito |
\d* | 0 ou mais dígitos |
\d+ | 1 ou mais dígitos |
\d{2} | 2 algarismos |
\d{3,} | pelo menos 3 dígitos |
\d{5,7} | entre 5 e 7 dígitos |
Agora, imaginemos um modelo capaz de descrever o formato esperado para uma cadeia de caracteres:
string de pesquisa | modelo |
uma data no formato dd/mm/aa | \d{2}/\d{2}/\d{2} |
uma hora no formato hh:mm:ss | \d{2}:\d{2}:\d{2} |
um inteiro sem sinal | \d+ |
uma sequência de espaços, possivelmente vazia | \s* |
um inteiro sem sinal que pode ser precedido ou seguido por espaços | \s*\d+\s* |
um inteiro que pode ser assinado e precedido ou seguido por espaços | \s*[+|-]?\s*\d+\s* |
um número real sem sinal que pode ser precedido ou seguido por espaços | \s*\d+(.\d*)?\s* |
um número real que pode ser assinado e precedido ou seguido por espaços | \s*[+|]?\s*\d+(.\d*)?\s* |
uma cadeia de caracteres contendo a palavra just | \bjust\b |
Pode especificar em que parte da cadeia procurar o modelo:
modelo | significado |
^modelo | o modelo inicia a cadeia |
modelo$ | o modelo termina a cadeia |
^modelo$ | o modelo inicia e termina a cadeia |
modelo | o modelo é procurado em toda a cadeia, começando pelo início. |
cadeia de pesquisa | modelo |
uma cadeia que termina com um ponto de exclamação | !$ |
uma cadeia que termina com um ponto | \.$ |
uma cadeia que começa com a sequência // | ^// |
uma cadeia que contém apenas uma palavra, possivelmente seguida ou precedida por espaços | ^\s*\w+\s*$ |
uma cadeia que contenha apenas duas palavras, possivelmente seguida ou precedida por espaços | ^\s*\w+\s*\w+\s*$ |
uma cadeia que contém a palavra secret | \bsecret\b |
Os subconjuntos de um modelo podem ser «recuperados». Desta forma, não só podemos verificar se uma cadeia corresponde a um modelo específico, como também podemos recuperar dessa cadeia os elementos correspondentes aos subconjuntos do modelo que foram colocados entre parênteses. Assim, se estivermos a analisar uma cadeia que contenha uma data dd/mm/aa e também quisermos recuperar os elementos dd, mm, aa dessa data, utilizaremos o modelo (dd)/(dd)/(dd).
5.7.1. Verificar se uma cadeia corresponde a um determinado modelo
Um objeto do tipo Regex é construído da seguinte forma:
Depois de construída a expressão regular do modelo, esta pode ser comparada com cadeias de caracteres utilizando o IsMatch :
Eis um exemplo:
using System;
using System.Text.RegularExpressions;
namespace Chap3 {
class Program {
static void Main(string[] args) {
// a regular expression template
string modèle1 = @"^\s*\d+\s*$";
Regex regex1 = new Regex(modèle1);
// compare a copy with the model
string exemplaire1 = " 123 ";
if (regex1.IsMatch(exemplaire1)) {
Console.WriteLine("[{0}] correspond au modèle [{1}]", exemplaire1, modèle1);
} else {
Console.WriteLine("[{0}] ne correspond pas au modèle [{1}]", exemplaire1, modèle1);
}//if
string exemplaire2 = " 123a ";
if (regex1.IsMatch(exemplaire2)) {
Console.WriteLine("[{0}] correspond au modèle [{1}]", exemplaire2, modèle1);
} else {
Console.WriteLine("[{0}] ne correspond pas au modèle [{1}]", exemplaire2, modèle1);
}//if
}
}
}
e resultados de desempenho:
5.7.2. Encontrar todas as ocorrências de um padrão numa cadeia
O método Matches recupera os elementos de uma cadeia que correspondem a um :
A classe MatchCollection possui uma propriedade Count, que é o número de elementos na coleção. Se results for um objeto MatchCollection, results[i] é o elemento i desta coleção e é do tipo Match. A classe Match possui várias propriedades, incluindo as seguintes:
- Value : objeto Match, um elemento correspondente ao
- Index: a posição onde o elemento foi encontrado na cadeia explorada
Considere o seguinte exemplo:
using System;
using System.Text.RegularExpressions;
namespace Chap3 {
class Program2 {
static void Main(string[] args) {
// several occurrences of the model in the copy
string modèle2 = @"\d+";
Regex regex2 = new Regex(modèle2);
string exemplaire3 = " 123 456 789 ";
MatchCollection résultats = regex2.Matches(exemplaire3);
Console.WriteLine("Modèle=[{0}],exemplaire=[{1}]", modèle2, exemplaire3);
Console.WriteLine("Il y a {0} occurrences du modèle dans l'exemplaire ", résultats.Count);
for (int i = 0; i < résultats.Count; i++) {
Console.WriteLine("[{0}] trouvé en position {1}", résultats[i].Value, résultats[i].Index);
}//for
}
}
}
- linha 8: o padrão procurado é uma sequência de números
- linha 10: a cadeia de caracteres na qual procurar este padrão
- linha 11: todos os elementos da cópia3 que verificam o padrão model2
- linhas 14-16: são exibidos
Os resultados do programa são os seguintes:
5.7.3. Recuperar partes de um modelo
Os subconjuntos de um modelo podem ser «recuperados». Desta forma, não só podemos verificar se uma cadeia corresponde a um modelo específico, como também podemos recuperar dessa cadeia os elementos correspondentes aos subconjuntos do modelo que foram colocados entre parênteses. Assim, se estivermos a analisar uma cadeia de caracteres que contenha uma data dd/mm/aa e também quisermos recuperar os elementos dd, mm, aa dessa data, utilizaremos o modelo (dd)/(dd)/(dd).
Considere o seguinte exemplo:
using System;
using System.Text.RegularExpressions;
namespace Chap3 {
class Program3 {
static void Main(string[] args) {
// capture elements in the model
string modèle3 = @"(\d\d):(\d\d):(\d\d)";
Regex regex3 = new Regex(modèle3);
string exemplaire4 = "Il est 18:05:49";
// model checking
Match résultat = regex3.Match(exemplaire4);
if (résultat.Success) {
// the copy corresponds to the model
Console.WriteLine("L'exemplaire [{0}] correspond au modèle [{1}]",exemplaire4,modèle3);
// display groups of parentheses
for (int i = 0; i < résultat.Groups.Count; i++) {
Console.WriteLine("groupes[{0}]=[{1}] trouvé en position {2}",i, résultat.Groups[i].Value,résultat.Groups[i].Index);
}//for
} else {
// the copy does not correspond to the model
Console.WriteLine("L'exemplaire[{0}] ne correspond pas au modèle [{1}]", exemplaire4, modèle3);
}
}
}
}
A execução deste programa produz os seguintes resultados:
A novidade está nas linhas 12-19:
- linha 12: a cadeia exemplary4 é comparada com a regex3 através do Match. Isto cria um objeto Match já apresentado. Utilizamos aqui duas novas propriedades desta classe:
- Success (linha 13): indica se houve uma correspondência
- Groups (linhas 17, 18): coleção onde
- Groups[0] é a parte da string correspondente ao modelo
- Groups[i] (i>=1) corresponde ao grupo de parênteses n.º i
Se o tipo de resultado for Match, o tipo de results.Groups é GroupCollection e o tipo de results.Groups[i] é Group. A classe Group tem duas propriedades que usamos aqui:
- Valor (linha 18): valor do objeto «Group», que é o elemento correspondente ao conteúdo de um parêntese
- Índice (linha 18): a posição em que o elemento foi encontrado na cadeia explorada
5.7.4. Um programa de aprendizagem
Encontrar a expressão regular para verificar se uma cadeia corresponde a um determinado padrão pode ser um verdadeiro desafio. O programa seguinte dá-lhe a oportunidade de praticar. Pede um padrão e uma cadeia, e indica se a cadeia corresponde ou não ao padrão.
using System;
using System.Text.RegularExpressions;
namespace Chap3 {
class Program4 {
static void Main(string[] args) {
// data
string modèle, chaine;
Regex regex = null;
MatchCollection résultats;
// the user is asked for models and samples to compare with this one
while (true) {
// the model is requested
Console.Write("Tapez le modèle à tester ou rien pour arrêter :");
modèle = Console.In.ReadLine();
// finished?
if (modèle.Trim() == "")
break;
// we create the regular expression
try {
regex = new Regex(modèle);
} catch (Exception ex) {
Console.WriteLine("Erreur : " + ex.Message);
continue;
}
// the user is asked for the specimens to be compared with the model
while (true) {
Console.Write("Tapez la chaîne à comparer au modèle [{0}] ou rien pour arrêter :", modèle);
chaine = Console.ReadLine();
// finished?
if (chaine.Trim() == "")
break;
// we make the comparison
résultats = regex.Matches(chaine);
// success?
if (résultats.Count == 0) {
Console.WriteLine("Je n'ai pas trouvé de correspondances");
continue;
}//if
// the elements corresponding to the model are displayed
for (int i = 0; i < résultats.Count; i++) {
Console.WriteLine("J'ai trouvé la correspondance [{0}] en position [{1}]", résultats[i].Value, résultats[i].Index);
// sub-elements
if (résultats[i].Groups.Count != 1) {
for (int j = 1; j < résultats[i].Groups.Count; j++) {
Console.WriteLine("\tsous-élément [{0}] en position [{1}]", résultats[i].Groups[j].Value, résultats[i].Groups[j].Index);
}
}
}
}
}
}
}
}
Eis um exemplo:
5.7.5. O método Split
Já nos deparámos com este método na String :
|
O método Split da classe Regex permite-nos expressar o separador em termos de um :
|
Por exemplo, suponhamos que temos linhas num ficheiro de texto com o formato campo1, campo2, …, campo n. Os campos estão separados por vírgulas, que podem ser precedidas ou seguidas por espaços. A classe String da Split não é adequada. A RegEx fornece a solução. Se linha for a linha lida, os campos podem ser obtidos através de
conforme mostrado no exemplo a seguir:
using System;
using System.Text.RegularExpressions;
namespace Chap3 {
class Program5 {
static void Main(string[] args) {
// a line
string ligne = "abc , def , ghi";
// a model
Regex modèle = new Regex(@"\s*,\s*");
// decomposition of line into fields
string[] champs = modèle.Split(ligne);
// display
for (int i = 0; i < champs.Length; i++) {
Console.WriteLine("champs[{0}]=[{1}]", i, champs[i]);
}
}
}
}
Resultados de desempenho:
5.8. Aplicação de exemplo - V3
Voltamos à aplicação estudada nos parágrafos 3.6 (versão 1) e 4.10 (versão 2).
Na última versão estudada, o cálculo do imposto foi realizado na classe abstrata AbstractImpot :
namespace Chap2 {
abstract class AbstractImpot : IImpot {
// tax brackets required to calculate tax
// come from an external source
protected TrancheImpot[] tranchesImpot;
// tAX CALCULATION
public int calculer(bool marié, int nbEnfants, int salaire) {
// calculating the number of shares
decimal nbParts;
if (marié) nbParts = (decimal)nbEnfants / 2 + 2;
else nbParts = (decimal)nbEnfants / 2 + 1;
if (nbEnfants >= 3) nbParts += 0.5M;
// calculation of taxable income & family quota
decimal revenu = 0.72M * salaire;
decimal QF = revenu / nbParts;
// tAX CALCULATION
tranchesImpot[tranchesImpot.Length - 1].Limite = QF + 1;
int i = 0;
while (QF > tranchesImpot[i].Limite) i++;
// return result
return (int)(revenu * tranchesImpot[i].CoeffR - nbParts * tranchesImpot[i].CoeffN);
}//calculate
}//class
}
O método calculate na linha 38 utiliza o tranchesImpot da linha 35, uma matriz não inicializada pelo AbstractImpot. É por isso que é abstrato e deve ser derivado para ser útil. Esta inicialização foi realizada pela classe derivada HardwiredImpot :
using System;
namespace Chap2 {
class HardwiredImpot : AbstractImpot {
// data tables required to calculate the
decimal[] limites = { 4962M, 8382M, 14753M, 23888M, 38868M, 47932M, 0M };
decimal[] coeffR = { 0M, 0.068M, 0.191M, 0.283M, 0.374M, 0.426M, 0.481M };
decimal[] coeffN = { 0M, 291.09M, 1322.92M, 2668.39M, 4846.98M, 6883.66M, 9505.54M };
public HardwiredImpot() {
// creation of a table of
tranchesImpot = new TrancheImpot[limites.Length];
// filling
for (int i = 0; i < tranchesImpot.Length; i++) {
tranchesImpot[i] = new TrancheImpot { Limite = limites[i], CoeffR = coeffR[i], CoeffN = coeffN[i] };
}
}
}// class
}// namespace
Acima, os dados necessários para calcular o imposto foram codificados diretamente no código da classe. A nova versão do exemplo coloca-os num ficheiro de texto:
4962:0:0
8382:0,068:291,09
14753:0,191:1322,92
23888:0,283:2668,39
38868:0,374:4846,98
47932:0,426:6883,66
0:0,481:9505,54
Como a execução deste ficheiro pode gerar exceções, criamos uma classe especial para as tratar:
using System;
namespace Chap3 {
class FileImpotException : Exception {
// error codes
[Flags]
public enum CodeErreurs { Acces = 1, Ligne = 2, Champ1 = 4, Champ2 = 8, Champ3 = 16 };
// error code
public CodeErreurs Code { get; set; }
// manufacturers
public FileImpotException() {
}
public FileImpotException(string message)
: base(message) {
}
public FileImpotException(string message, Exception e)
: base(message,e) {
}
}
}
- linha 4: a classe FileImportException deriva da classe Exception. Será utilizada para registar quaisquer erros que possam ocorrer durante o processamento do ficheiro de texto de dados.
- linha 7: uma enumeração que representa códigos de erro:
- Access: erro ao aceder ao ficheiro de dados de texto
- Line : linha sem os três campos esperados
- Field1: o campo n.º 1 está incorreto
- Champ2: o campo n.º 2 está incorreto
- Campo3: o campo n.º 3 está incorreto
Alguns destes erros podem ser combinados (Campo1, Campo2, Campo3). Por isso, a enumeração CodeErreurs foi anotada com o atributo [Flags], o que implica que os vários valores da enumeração devem ser potências de 2. Um erro nos campos 1 e 2 resultará, então, no código de erro Campo1 | Campo2.
- linha 10: o código de propriedade automática armazenará o código de erro.
- linhas 15: um construtor para criar um objeto FileImportException com uma mensagem de erro como parâmetro.
- linhas 18: um construtor para criar um objeto FileImportException, passando uma mensagem de erro e a exceção que causou o erro como parâmetros.
A classe que inicializa a classe tranchesImpot, AbstractImpot, é agora a seguinte:
using System;
using System.Collections.Generic;
using System.IO;
using System.Text.RegularExpressions;
namespace Chap3 {
class FileImpot : AbstractImpot {
public FileImpot(string fileName) {
// data
List<TrancheImpot> listTranchesImpot = new List<TrancheImpot>();
int numLigne = 1;
// exception
FileImpotException fe = null;
// read the contents of the fileName file, line by line
Regex pattern = new Regex(@"s*:\s*");
// initially no error
FileImpotException.CodeErreurs code = 0;
try {
using (StreamReader input = new StreamReader(fileName)) {
while (!input.EndOfStream && code == 0) {
// current line
string ligne = input.ReadLine().Trim();
// ignore empty lines
if (ligne == "") continue;
// line broken down into three fields separated by :
string[] champsLigne = pattern.Split(ligne);
// do we have 3 fields?
if (champsLigne.Length != 3) {
code = FileImpotException.CodeErreurs.Ligne;
}
// 3-field conversions
decimal limite = 0, coeffR = 0, coeffN = 0;
if (code == 0) {
if (!Decimal.TryParse(champsLigne[0], out limite)) code = FileImpotException.CodeErreurs.Champ1;
if (!Decimal.TryParse(champsLigne[1], out coeffR)) code |= FileImpotException.CodeErreurs.Champ2;
if (!Decimal.TryParse(champsLigne[2], out coeffN)) code |= FileImpotException.CodeErreurs.Champ3; ;
}
// mistake?
if (code != 0) {
// on note l'erreur
fe = new FileImpotException(String.Format("Ligne n° {0} incorrecte", numLigne)) { Code = code };
} else {
// the new tax bracket is memorized
listTranchesImpot.Add(new TrancheImpot() { Limite = limite, CoeffR = coeffR, CoeffN = coeffN });
// next line
numLigne++;
}
}
}
// transfer the listImpot list to the tranchesImpot array
if (code == 0) {
// transfer the listImpot list to the tranchesImpot array
tranchesImpot = listTranchesImpot.ToArray();
}
} catch (Exception e) {
// on note l'erreur
fe= new FileImpotException(String.Format("Erreur lors de la lecture du fichier {0}", fileName), e) { Code = FileImpotException.CodeErreurs.Acces };
}
// error to report?
if (fe != null) throw fe;
}
}
}
- linha 7: a classe FileImpot deriva da classe AbstractImpot como HardwiredImpot.
- linha 9: o construtor da classe FileImpot é utilizado para inicializar o campo tranchesImpot da sua classe base AbstractImpot. O seu parâmetro é o nome do ficheiro de texto que contém os dados.
- linha 11: o campo tranchesImpot da classe base AbstractImpot é uma matriz a ser preenchida com dados do ficheiro passado como parâmetro. A leitura de um ficheiro de texto é sequencial. O número de linhas não é conhecido até que todo o ficheiro tenha sido lido. Como resultado, o tranchesImpot. On armazenará temporariamente os dados na lista genérica listTranchesImpot.
Lembre-se de que o TrancheImpot é um :
namespace Chap3 {
// a tax bracket
struct TrancheImpot {
public decimal Limite { get; set; }
public decimal CoeffR { get; set; }
public decimal CoeffN { get; set; }
}
}
- linha 14: o tipo fe FileImportException é utilizado para encapsular um possível erro de operação no ficheiro de texto.
- linha 16: expressão regular para o separador de campos numa linha field1:field2:field3 do ficheiro de texto. Os campos são separados pelo caractere :, precedido e seguido por qualquer número de espaços.
- linha 18: código de erro em caso de erro
- linha 20: processamento do ficheiro de texto com um StreamReader
- linha 21: repete enquanto ainda houver uma linha para ler e não tiver ocorrido nenhum erro
- linha 27: a linha lida é dividida em campos utilizando a expressão regular da linha 16
- linhas 29-31: verifique se a linha tem três campos - registe quaisquer erros
- linhas 33-38: converter as três cadeias de caracteres em três números decimais - registar quaisquer erros
- linhas 40-43: se tiver ocorrido um erro, é criada uma exceção do tipo FileImportException.
- linhas 44-47: se não tiver sido detetado nenhum erro, a linha seguinte do ficheiro de texto é lida, após guardar os dados da linha atual.
- linhas 52-55: na saída do while, os dados da lista genérica listTranchesImpot são copiados para a tabela tranchesImpot da classe base AbstractImpot. Este era o objetivo do fabricante.
- linhas 56-59: tratamento de exceções. Isto é encapsulado num objeto do tipo FileImpotException.
- linha 61: se a exceção fe da linha 18 tiver sido inicializada, então é lançada.
O projeto C# completo é o seguinte:
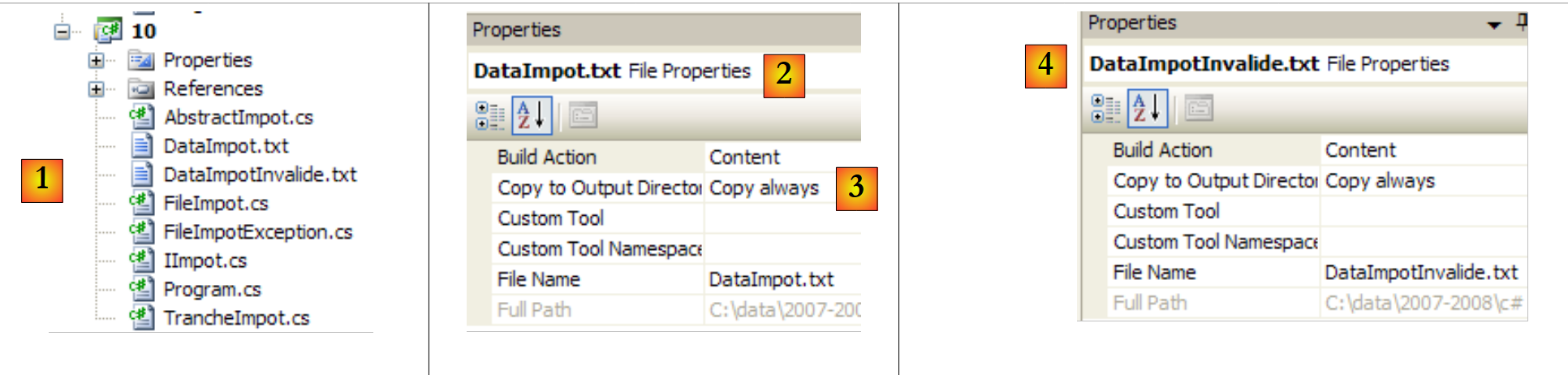 |
- em [1]: o projeto completo
- em [2,3]: propriedades do ficheiro [DataImpot.txt] [2]. A propriedade [Copiar para o diretório de saída] [3] está definida como sempre. Isto faz com que o ficheiro [DataImpot.txt] seja copiado para a pasta bin/Release (modo Release) ou bin/Debug (modo Debug) em cada execução. É aqui que o executável o procura.
- em [4]: faça o mesmo com o ficheiro [DataImpotInvalide.txt].
O conteúdo do [DataImpot.txt] é o seguinte:
4962:0:0
8382:0,068:291,09
14753:0,191:1322,92
23888:0,283:2668,39
38868:0,374:4846,98
47932:0,426:6883,66
0:0,481:9505,54
O conteúdo do ficheiro [DataImpotInvalide.txt] é o seguinte:
O programa de teste [Program.cs] não sofreu alterações: é o mesmo que na versão 2, parágrafo 4.10, com a seguinte diferença:
using System;
namespace Chap3 {
class Program {
static void Main() {
...
// creation of a IImpot object
IImpot impot = null;
try {
// creation of a IImpot object
impot = new FileImpot("DataImpot.txt");
} catch (FileImpotException e) {
// error display
string msg = e.InnerException == null ? null : String.Format(", Exception d'origine : {0}", e.InnerException.Message);
Console.WriteLine("L'erreur suivante s'est produite : [Code={0},Message={1}{2}]", e.Code, e.Message, msg == null ? "" : msg);
// program stop
Environment.Exit(1);
}
// infinite loop
while (true) {
...
}//while
}
}
}
- linha 8: interface de objeto do tipo IImpot
- linha 11: instância do objeto tax com um objeto do tipo FileImpot. Isto pode gerar uma exceção, que é tratada pelo try / catch nas linhas 9 / 12 / 18.
Aqui estão alguns exemplos:
Com o [DataImpot.txt]
Com um [xx] nenhum
Com o [DataImportInvalid.txt]