6. Arquiteturas de três camadas
6.1. Introduction
Voltemos à última versão da aplicação de cálculo de impostos:
using System;
namespace Chap3 {
class Program {
static void Main() {
// programa interativo de cálculo de impostos
// o utilizador introduz três dados através do teclado: casado nbEnfants salário
// o programa apresenta então o imposto a pagar
...
// criação de um objeto IImpot
IImpot impot = null;
try {
// criação de um objeto IImpot
impot = new FileImpot("DataImpotInvalide.txt");
} catch (FileImpotException e) {
// exibição de erro
...
// interrupção do programa
Environment.Exit(1);
}
// loop infinito
while (true) {
// são solicitados os parâmetros para o cálculo do imposto
Console.Write("Paramètres du calcul de l'Impot au format : Marié (o/n) NbEnfants Salaire ou rien pour arrêter :");
string paramètres = Console.ReadLine().Trim();
...
// os parâmetros estão corretos — calcula-se o imposto
Console.WriteLine("Impot=" + impot.calculer(marié == "o", nbEnfants, salaire) + " euros");
// próximo contribuinte
}//enquanto
}
}
}
A solução anterior inclui processos clássicos de programação:
- a recuperação de dados armazenados em ficheiros, bases de dados, etc. — linhas 12-21
- a interação com o utilizador, linhas 26 (introdução de dados) e 29 (exibição)
- a utilização de um algoritmo específico da área de negócio, linha 29
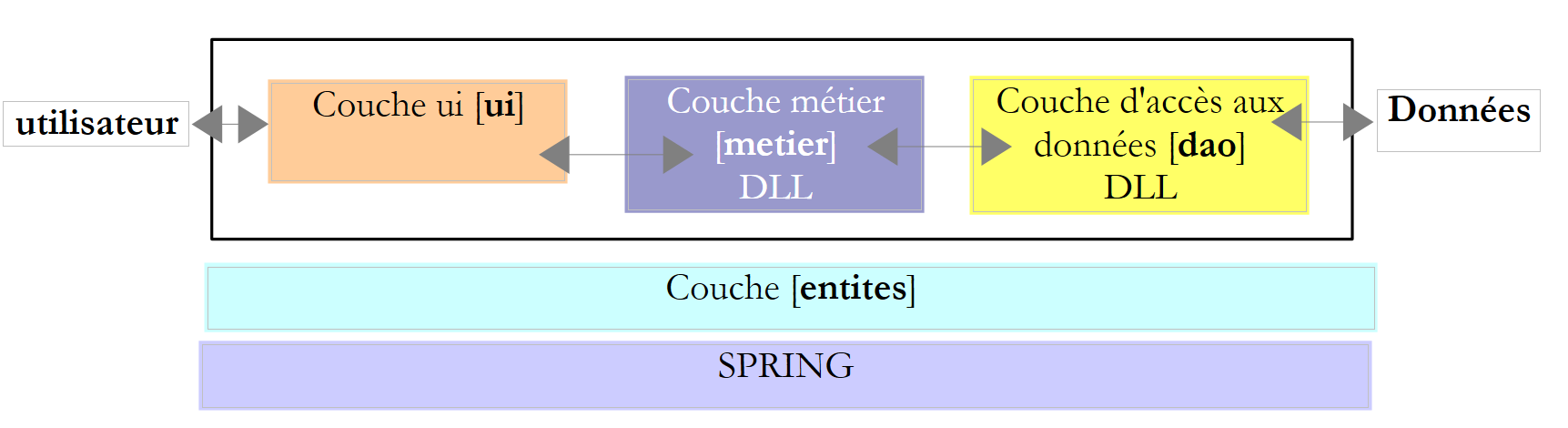
A prática demonstrou que isolar estes diferentes processos em classes separadas melhorava a facilidade de manutenção das aplicações. A arquitetura de uma aplicação assim estruturada é a seguinte:
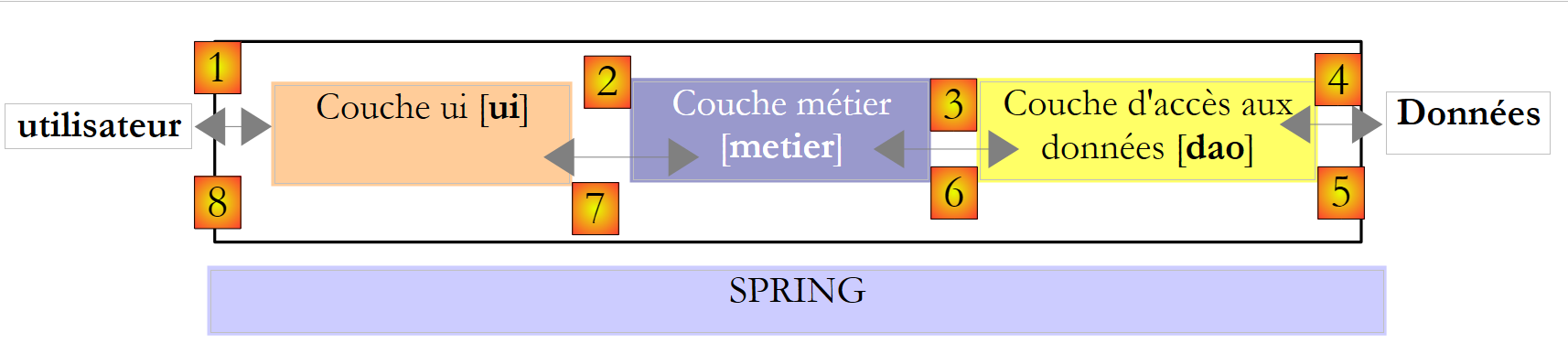 |
Esta arquitetura é designada por «arquitetura de três camadas», tradução do inglês «three-tier architecture». O termo «três camadas» refere-se normalmente a uma arquitetura em que cada camada se encontra numa máquina diferente. Quando as camadas se encontram na mesma máquina, a arquitetura passa a ser uma arquitetura de «três camadas».
- A camada [metier] é aquela que contém as regras de negócio da aplicação. No caso da nossa aplicação de cálculo de impostos, trata-se das regras que permitem calcular o imposto de um contribuinte. Esta camada necessita de dados para funcionar:
- as faixas de imposto, dados que mudam todos os anos
- o número de filhos, o estado civil e o salário anual do contribuinte
No esquema acima, os dados podem provir de dois locais:
- a camada de acesso aos dados ou [dao] (DAO = Data Access Object) para os dados já registados em ficheiros ou bases de dados. Este poderia ser o caso, aqui, das faixas de imposto, tal como foi feito na versão anterior da aplicação.
- a camada de interface com o utilizador ou [ui] (UI = Interface do Utilizador) para os dados introduzidos pelo utilizador ou apresentados ao utilizador. Este poderia ser o caso, aqui, do número de filhos, do estado civil e do salário anual do contribuinte
- De um modo geral, a camada [dao] encarrega-se do acesso a dados persistentes (ficheiros, bases de dados) ou não persistentes (rede, sensores, ...).
- A camada [ui], por sua vez, encarrega-se das interações com o utilizador, caso exista algum.
- As três camadas tornam-se independentes graças à utilização de interfaces.
Vamos retomar a aplicação [Impots], já estudada em várias ocasiões, para lhe conferir uma arquitetura de três camadas. Para tal, vamos analisar as camadas [ui, metier, dao] uma a uma, começando pela camada [dao], que se encarrega dos dados persistentes.
Antes disso, temos de definir as interfaces das diferentes camadas da aplicação [Impots].
6.2. As interfaces da aplicação [Impots]
Recorde-se que uma interface define um conjunto de assinaturas de métodos. As classes que implementam a interface dão conteúdo a esses métodos.
Voltemos à arquitetura de 3 camadas da nossa aplicação:
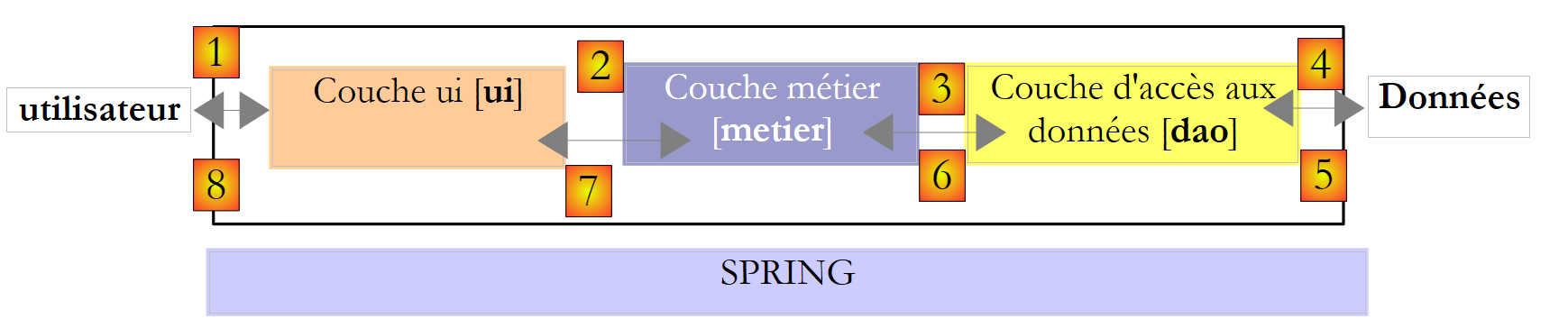 |
Neste tipo de arquitetura, é frequentemente o utilizador que toma a iniciativa. Este efetua um pedido em [1] e recebe uma resposta em [8]. A isto chama-se o ciclo pedido-resposta. Tomemos o exemplo do cálculo do imposto de um contribuinte. Este processo irá requerer várias etapas:
- a camada [ui] terá de solicitar ao utilizador o número de filhos, o estado civil e o salário anual. Trata-se da operação [1] acima referida.
- Feito isto, a camada [ui] solicitará à camada de negócio que efetue o cálculo do imposto. Para tal, transmitirá a esta os dados que recebeu do utilizador. Trata-se da operação [2].
- A camada [metier] necessita de determinadas informações para realizar o seu trabalho: as faixas de imposto. Solicitará essas informações à camada [dao] através do caminho [3, 4, 5, 6]. [3] é o pedido inicial e [6] é a resposta a esse pedido.
- Com todos os dados de que necessitava, a camada [metier] calcula o imposto.
- A camada [metier] pode agora responder à solicitação da camada [ui] efetuada em (b). Este é o caminho [7].
- A camada [ui] irá formatar estes resultados e, em seguida, apresentá-los ao utilizador. Este é o caminho [8].
- É possível imaginar que o utilizador faça simulações fiscais e queira guardá-las. Para tal, utilizará o caminho [1-8].
Vê-se nesta descrição que uma camada utiliza os recursos da camada que se encontra à sua direita, nunca da que se encontra à sua esquerda. Consideremos duas camadas contíguas:
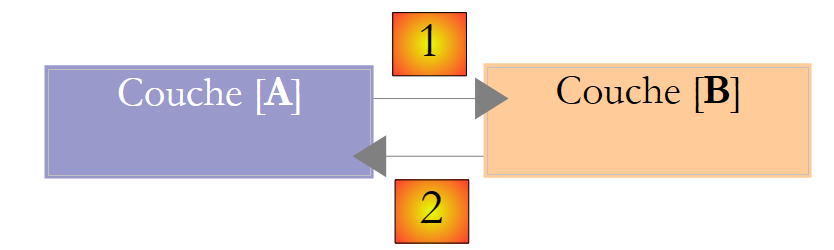 |
A camada [A] envia pedidos à camada [B]. Nos casos mais simples, uma camada é implementada por uma única classe. Uma aplicação evolui ao longo do tempo. Assim, a camada [B] pode ter diferentes classes de implementação, como a [B1, B2, ...]. Se a camada [B] for a camada [dao], esta pode ter uma primeira implementação, [B1], que obtém dados de um ficheiro. Alguns anos mais tarde, pode ser necessário colocar os dados numa base de dados. Nesse caso, será criada uma segunda classe de implementação, [B2]. Se, na aplicação inicial, a camada [A] trabalhasse diretamente com a classe [B1], seríamos obrigados a reescrever parcialmente o código da camada [A]. Suponhamos, por exemplo, que tenhamos escrito na camada [A] algo como o seguinte:
- linha 1: é criada uma instância da classe [B1]
- linha 3: são solicitados dados a essa instância
Se assumirmos que a nova classe de implementação [B2] utiliza métodos com a mesma assinatura que os da classe [B1], será necessário alterar todos os [B1] para [B2]. Este é o caso mais favorável e bastante improvável, caso não se tenha prestado atenção a estas assinaturas de métodos. Na prática, é frequente que as classes [B1] e [B2] não tenham as mesmas assinaturas de métodos e que, por isso, uma boa parte da camada [A] tenha de ser totalmente reescrita.
É possível melhorar a situação se se introduzir uma interface entre as camadas [A] e [B]. Isto significa que se fixam numa interface as assinaturas dos métodos apresentados pela camada [B] à camada [A]. O esquema anterior passa então a ser o seguinte:
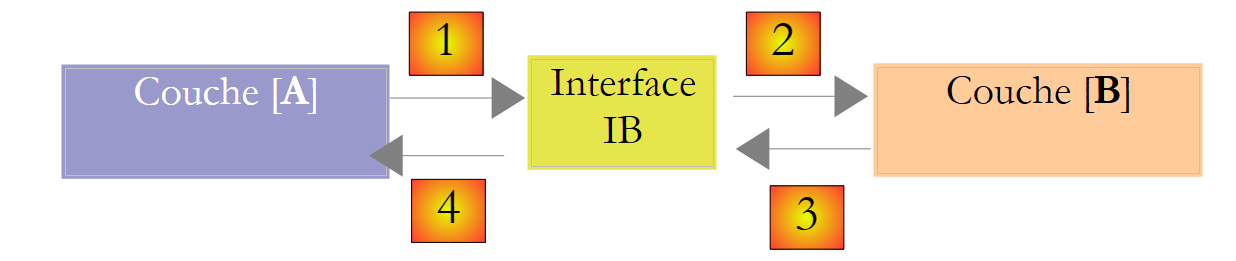 |
A camada [A] já não se dirige diretamente à camada [B], mas sim à sua interface [IB]. Assim, no código da camada [A], a classe de implementação [Bi] da camada [B] aparece apenas uma vez, no momento da implementação da interface [IB]. Assim, é a interface [IB] e não a sua classe de implementação que é utilizada no código. O código anterior passa a ser o seguinte:
- linha 1: é criada uma instância [ib] que implementa a interface [IB], através da instanciação da classe [B1]
- linha 3: são solicitados dados à instância [ib]
A partir de agora, se substituirmos a implementação [B1] da camada [B] por uma implementação [B2], e se ambas as implementações respeitarem a mesma interface [IB], então apenas a linha 1 da camada [A] deve ser alterada e nenhuma outra. Trata-se de uma grande vantagem que, por si só, justifica a utilização sistemática de interfaces entre duas camadas.
É possível ir ainda mais longe e tornar a camada [A] totalmente independente da camada [B]. No código acima, a linha 1 coloca um problema porque faz referência direta à classe [B1]. O ideal seria que a camada [A] pudesse dispor de uma implementação da interface [IB] sem ter de nomear uma classe. Isso seria coerente com o nosso esquema acima. Vemos que a camada [A] se dirige à interface [IB] e não se percebe por que razão precisaria de saber o nome da classe que implementa essa interface. Este detalhe não é útil para a camada [A].
O framework Spring (http://www.springframework.org) permite obter este resultado. A arquitetura anterior evolui da seguinte forma:
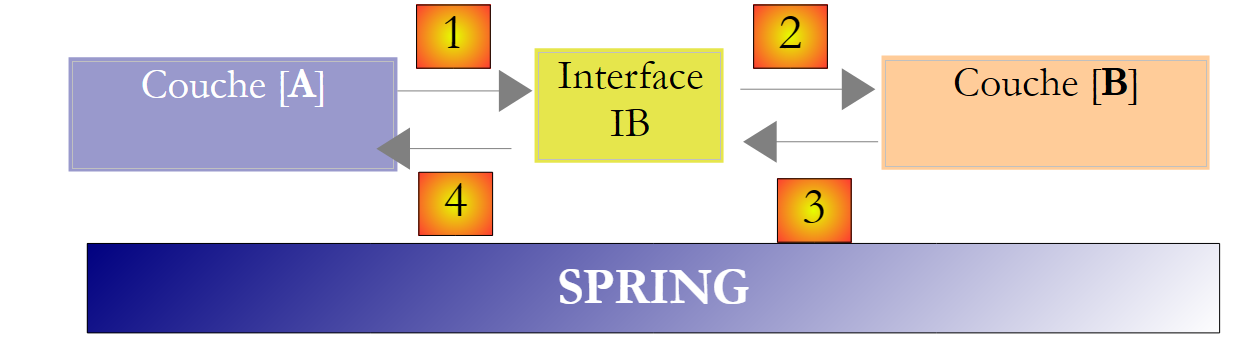 |
A camada transversal [Spring] permitirá que uma camada obtenha, por meio de configuração, uma referência à camada situada à sua direita, sem ter de saber o nome da classe de implementação dessa camada. Esse nome constará nos ficheiros de configuração e não no código C#. O código C# da camada [A] assume então a seguinte forma:
- linha 1: uma instância [ib] que implementa a interface [IB] da camada [B]. Esta instância é criada pelo Spring com base em informações encontradas num ficheiro de configuração. O Spring encarregar-se-á de criar:
- a instância [b] que implementa a camada [B]
- a instância [a] que implementa a camada [A]. Esta instância será inicializada. O campo [ib] acima receberá como valor a referência [b] do objeto que implementa a camada [B]
- linha 3: são solicitados dados à instância [ib]
Vemos agora que a classe de implementação [B1] da camada B não aparece em nenhuma parte do código da camada [A]. Quando a implementação [B1] for substituída por uma nova implementação [B2], nada mudará no código da classe [A]. Bastará alterar os ficheiros de configuração do Spring para instanciar [B2] em vez de [B1].
A combinação do Spring com as interfaces C# traz uma melhoria decisiva à manutenção das aplicações, tornando as suas camadas independentes umas das outras. É esta solução que iremos utilizar para uma nova versão da aplicação [Impots].
Voltemos à arquitetura de três camadas da nossa aplicação:
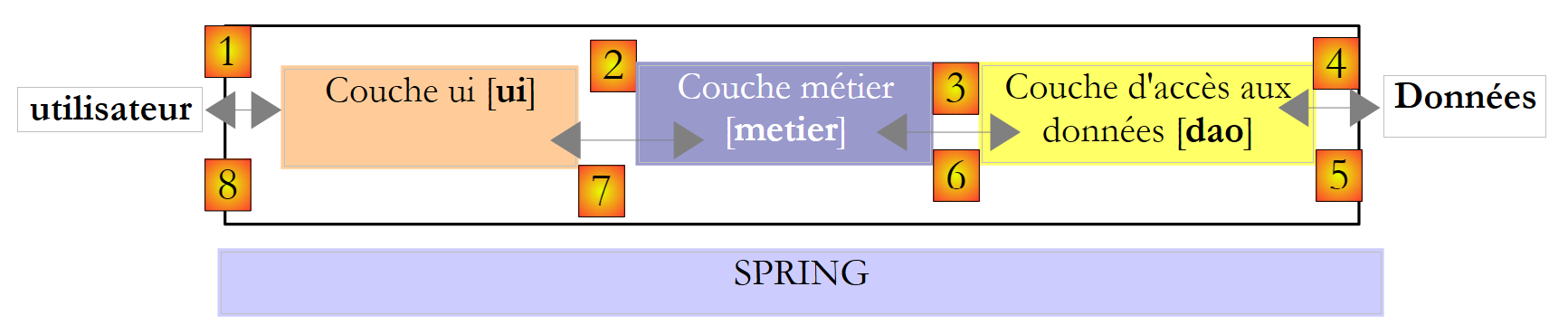 |
Em casos simples, podemos partir da camada [metier] para descobrir as interfaces da aplicação. Para funcionar, esta necessita de dados:
- já disponíveis em ficheiros, bases de dados ou através da rede. Estes são fornecidos pela camada [dao].
- ainda não disponíveis. Nesse caso, são fornecidos pela camada [ui], que os obtém junto do utilizador da aplicação.
Que interface deve a camada [dao] disponibilizar à camada [metier]? Quais são as interações possíveis entre estas duas camadas? A camada [dao] deve fornecer os seguintes dados à camada [metier]:
- as faixas de imposto
Na nossa aplicação, a camada [dao] utiliza dados existentes, mas não cria novos. Uma definição da interface da camada [dao] poderia ser a seguinte:
using Entites;
namespace Dao {
public interface IImpotDao {
// as faixas de imposto
TrancheImpot[] TranchesImpot{get;}
}
}
- linha 3: a camada [dao] será colocada no espaço de nomes [Dao]
- linha 6: a interface IImpotDao define a propriedade TranchesImpot, que fornecerá as faixas de imposto à camada [métier].
- linha 1: importa o espaço de nomes no qual está definida a estrutura TrancheImpot:
namespace Entites {
// uma faixa de imposto
public struct TrancheImpot {
public decimal Limite { get; set; }
public decimal CoeffR { get; set; }
public decimal CoeffN { get; set; }
}
}
Voltemos à arquitetura de três camadas da nossa aplicação:
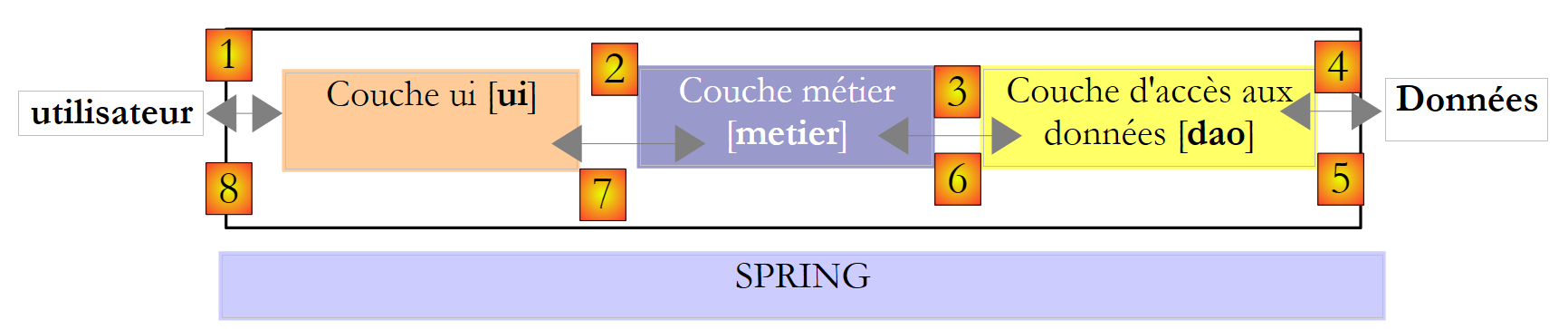 |
Que interface deve a camada [metier] apresentar à camada [ui]? Recorde-se as interações entre estas duas camadas:
- a camada [ui] solicita ao utilizador o número de filhos, o estado civil e o salário anual. Trata-se da operação [1] acima referida.
- Feito isto, a camada [ui] solicitará à camada de negócio que efetue o cálculo dos lugares. Para tal, transmitirá a esta os dados que recebeu do utilizador. Trata-se da operação [2].
Uma definição da interface da camada [metier] poderia ser a seguinte:
namespace Metier {
interface IImpotMetier {
int CalculerImpot(bool marié, int nbEnfants, int salaire);
}
}
- linha 1: colocaremos tudo o que diz respeito à camada [metier] no espaço de nomes [Metier].
- linha 2: a interface IImpotMetier define apenas um método: aquele que permite calcular o imposto de um contribuinte com base no seu estado civil, no número de filhos e no seu salário anual.
Estamos a estudar uma primeira implementação desta arquitetura em camadas.
6.3. Aplicação de exemplo - versão 4
6.3.1. O projeto do Visual Studio
O projeto do Visual Studio será o seguinte:
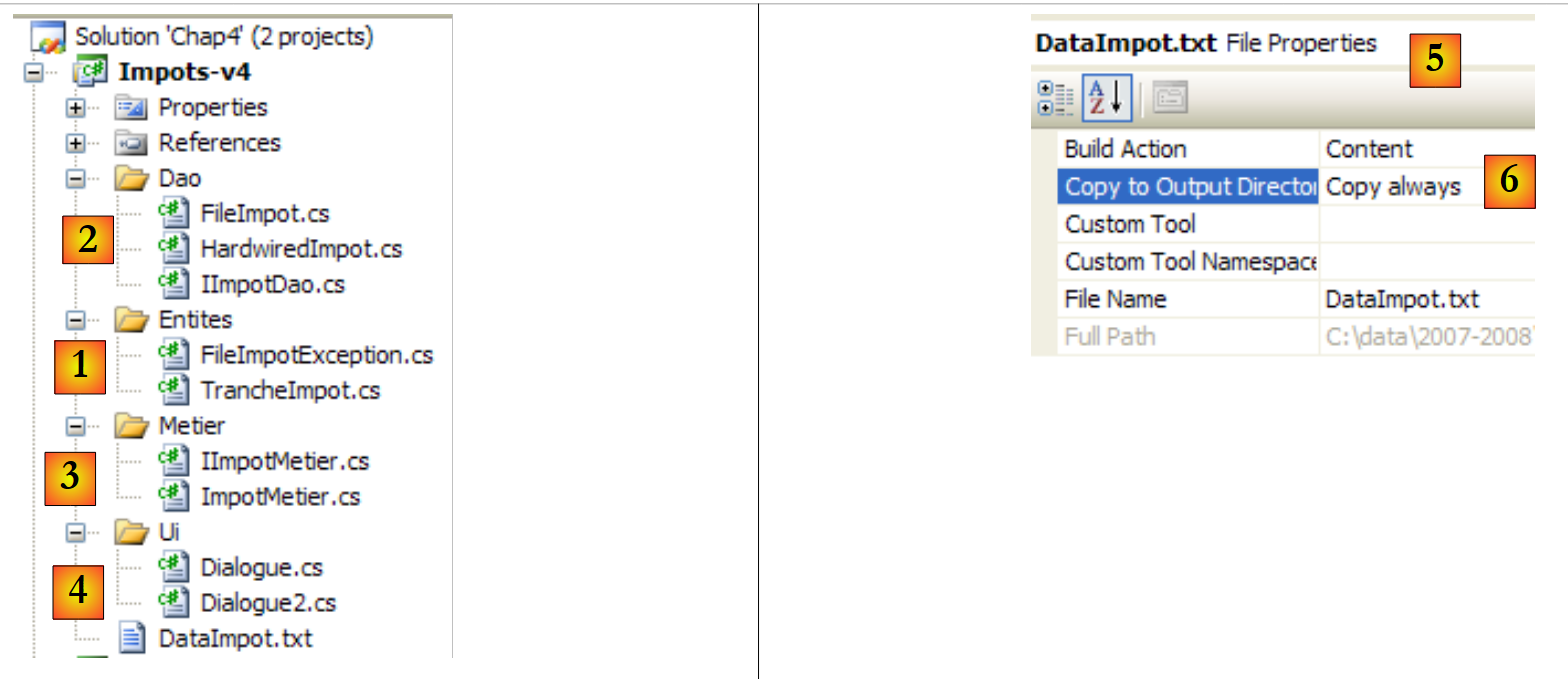 |
- [1]: a pasta [Entites] contém os objetos transversais às camadas [ui, metier, dao]: a estrutura TrancheImpot, a exceção FileImpotException.
- [2]: a pasta [Dao] contém as classes e interfaces da camada [dao]. Utilizaremos duas implementações da interface IImpotDao: a classe HardwiredImpot analisada no parágrafo 4.10 e a FileImpot analisada no parágrafo 5.8.
- [3]: a pasta [Metier] contém as classes e interfaces da camada [metier]
- [4]: a pasta [Ui] contém as classes da camada [ui]
- [5]: o ficheiro [DataImpot.txt] contém as faixas de imposto utilizadas pela implementação FileImpot da camada [dao]. O [6] está configurado para ser copiado automaticamente para a pasta de execução do projeto.
6.3.2. As entidades da aplicação
Voltemos à arquitetura de 3 camadas da nossa aplicação:
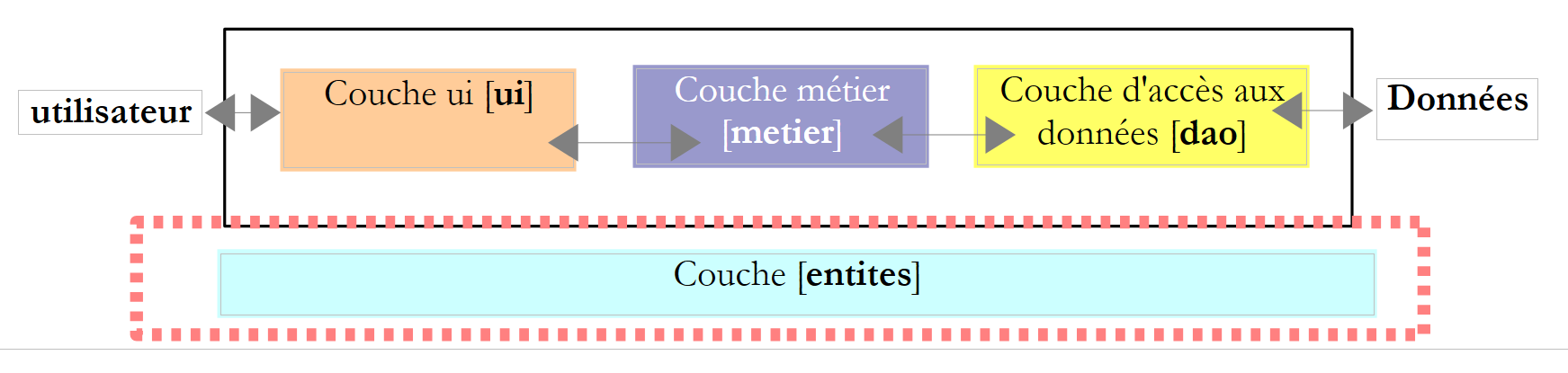 |
Denominamos entités as classes transversais às camadas. É o caso, em geral, das classes e estruturas que encapsulam dados da camada [dao]. Estas entidades remontam, geralmente, até à camada [ui].
As entidades da aplicação são as seguintes:
A estrutura TrancheImpot
namespace Entites {
// uma faixa de imposto
public struct TrancheImpot {
public decimal Limite { get; set; }
public decimal CoeffR { get; set; }
public decimal CoeffN { get; set; }
}
}
L'exceção FileImpotException
using System;
namespace Entites {
public class FileImpotException : Exception {
// códigos de erro
[Flags]
public enum CodeErreurs { Acces = 1, Ligne = 2, Champ1 = 4, Champ2 = 8, Champ3 = 16 };
// código de erro
public CodeErreurs Code { get; set; }
// fabricantes
public FileImpotException() {
}
public FileImpotException(string message)
: base(message) {
}
public FileImpotException(string message, Exception e)
: base(message, e) {
}
}
}
Nota: a classe FileImpotException só é útil se a camada [dao] for implementada pela classe FileImpot.
6.3.3. A camada [dao]
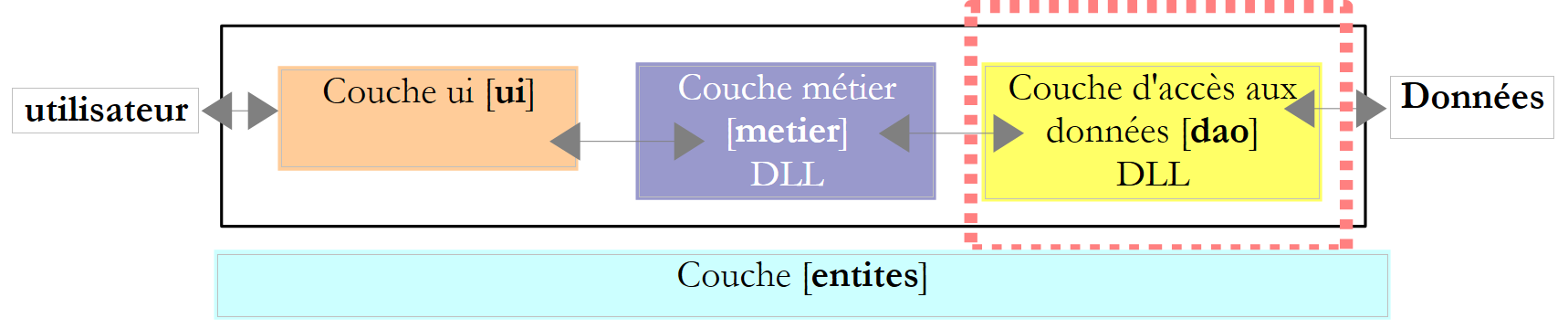 |
Recorde-se a interface da camada [dao]:
using Entites;
namespace Dao {
public interface IImpotDao {
// as faixas de imposto
TrancheImpot[] TranchesImpot{get;}
}
}
Iremos implementar esta interface de duas formas diferentes.
Em primeiro lugar, com a classe HardwiredImpot analisada no parágrafo 4.10:
using System;
using Entites;
namespace Dao {
public class HardwiredImpot : IImpotDao {
// tabelas de dados necessárias para o cálculo do imposto
decimal[] limites = { 4962M, 8382M, 14753M, 23888M, 38868M, 47932M, 0M };
decimal[] coeffR = { 0M, 0.068M, 0.191M, 0.283M, 0.374M, 0.426M, 0.481M };
decimal[] coeffN = { 0M, 291.09M, 1322.92M, 2668.39M, 4846.98M, 6883.66M, 9505.54M };
// faixas de imposto
public TrancheImpot[] TranchesImpot { get; private set; }
// construtor
public HardwiredImpot() {
// criação da tabela de escalões de imposto
TranchesImpot = new TrancheImpot[limites.Length];
// preenchimento
for (int i = 0; i < TranchesImpot.Length; i++) {
TranchesImpot[i] = new TrancheImpot { Limite = limites[i], CoeffR = coeffR[i], CoeffN = coeffN[i] };
}
}
}// classe
}// espaço de nomes
- linha 5: a classe HardwiredImpot implementa a interface IImpotDao
- linha 12: implementação da propriedade TranchesImpot da interface IImpotDao. Esta propriedade é automática. Implementa o método get da propriedade TranchesImpot da interface IImpotDao. Além disso, foi declarado um método set como privado, ou seja, interno à classe, para que o construtor das linhas 15-22 possa inicializar a matriz de escalões de imposto.
A interface IImpotDao será igualmente implementada pela classe FileImpot, analisada no parágrafo 5.8:
using System;
using System.Collections.Generic;
using System.IO;
using System.Text.RegularExpressions;
using Entites;
namespace Dao {
class FileImpot : IImpotDao {
// ficheiro de dados
public string FileName { get; set; }
// faixas de imposto
public TrancheImpot[] TranchesImpot { get; private set; }
// construtor
public FileImpot(string fileName) {
// guarda-se o nome do ficheiro
FileName = fileName;
// dados
List<TrancheImpot> listTranchesImpot = new List<TrancheImpot>();
int numLigne = 1;
// exceção
FileImpotException fe = null;
// leitura do conteúdo do ficheiro fileName, linha a linha
Regex pattern = new Regex(@"s*:\s*");
// inicialmente, sem erros
FileImpotException.CodeErreurs code = 0;
try {
using (StreamReader input = new StreamReader(FileName)) {
while (!input.EndOfStream && code == 0) {
// linha atual
string ligne = input.ReadLine().Trim();
// as linhas vazias são ignoradas
if (ligne == "")
continue;
// linha dividida em três campos separados por:
string[] champsLigne = pattern.Split(ligne);
// existem 3 campos?
if (champsLigne.Length != 3) {
code = FileImpotException.CodeErreurs.Ligne;
}
// conversões dos 3 campos
decimal limite = 0, coeffR = 0, coeffN = 0;
if (code == 0) {
if (!Decimal.TryParse(champsLigne[0], out limite))
code = FileImpotException.CodeErreurs.Champ1;
if (!Decimal.TryParse(champsLigne[1], out coeffR))
code |= FileImpotException.CodeErreurs.Champ2;
if (!Decimal.TryParse(champsLigne[2], out coeffN))
code |= FileImpotException.CodeErreurs.Champ3;
;
}
// erro?
if (code != 0) {
// regista-se o erro
fe = new FileImpotException(String.Format("Ligne n° {0} incorrecte", numLigne)) { Code = code };
} else {
// memoriza-se a nova faixa de imposto
listTranchesImpot.Add(new TrancheImpot() { Limite = limite, CoeffR = coeffR, CoeffN = coeffN });
// linha seguinte
numLigne++;
}
}
}
} catch (Exception e) {
// regista-se o erro
fe = new FileImpotException(String.Format("Erreur lors de la lecture du fichier {0}", FileName), e) { Code = FileImpotException.CodeErreurs.Acces };
}
// erro a comunicar?
if (fe != null) {
// lança-se a exceção
throw fe;
} else {
// a lista listImpot é inserida na tabela tranchesImpot
TranchesImpot = listTranchesImpot.ToArray();
}
}
}
}
- este código já foi analisado no parágrafo 5.8.
- linha 14: o método TranchesImpot da interface IImpotDao
- linha 76: inicialização dos escalões de imposto no construtor da classe, a partir do ficheiro cujo nome foi passado ao construtor na linha 17.
6.3.4. A fralda [metier]
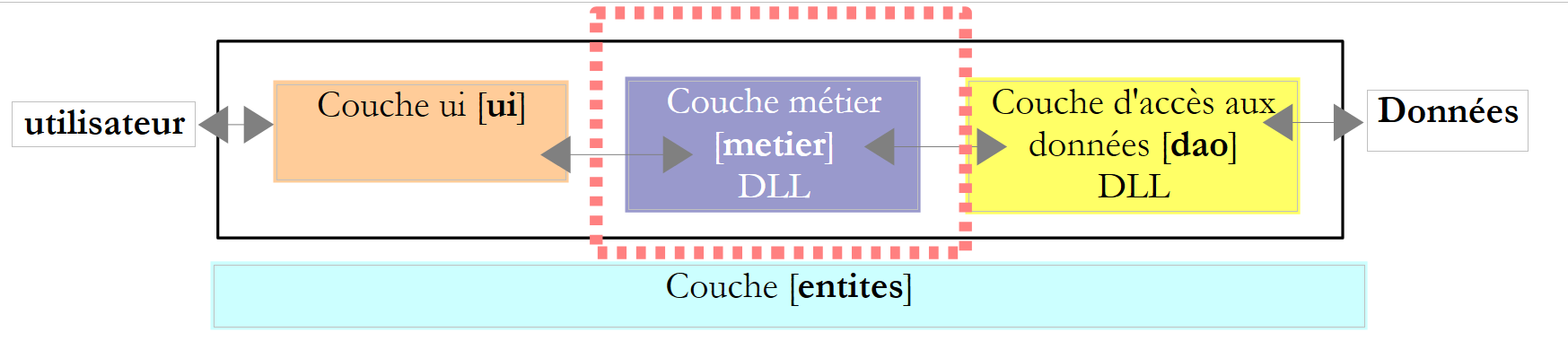 |
Recorde-se a interface desta camada:
namespace Metier {
public interface IImpotMetier {
int CalculerImpot(bool marié, int nbEnfants, int salaire);
}
}
A implementação ImpotMetier desta interface é a seguinte:
using Entites;
using Dao;
namespace Metier {
public class ImpotMetier : IImpotMetier {
// camada [dao]
private IImpotDao Dao { get; set; }
// faixas de imposto
private TrancheImpot[] tranchesImpot;
// construtor
public ImpotMetier(IImpotDao dao) {
// armazenamento
Dao = dao;
// faixas de imposto
tranchesImpot = dao.TranchesImpot;
}
// cálculo do imposto
public int CalculerImpot(bool marié, int nbEnfants, int salaire) {
// cálculo do número de quotas
decimal nbParts;
if (marié)
nbParts = (decimal)nbEnfants / 2 + 2;
else
nbParts = (decimal)nbEnfants / 2 + 1;
if (nbEnfants >= 3)
nbParts += 0.5M;
// cálculo do rendimento tributável e do quociente familiar
decimal revenu = 0.72M * salaire;
decimal QF = revenu / nbParts;
// cálculo do imposto
tranchesImpot[tranchesImpot.Length - 1].Limite = QF + 1;
int i = 0;
while (QF > tranchesImpot[i].Limite)
i++;
// retorno do resultado
return (int)(revenu * tranchesImpot[i].CoeffR - nbParts * tranchesImpot[i].CoeffN);
}//calcular
}//classe
}
- linha 5: a classe [Metier] implementa a interface [IImpotMetier].
- linhas 14-19: a camada [metier] deve colaborar com a camada [dao]. Por conseguinte, deve ter uma referência ao objeto que implementa a interface IImpotDao. É por isso que esta referência é passada como parâmetro ao construtor.
- linha 16: a referência à camada [dao] é armazenada no campo privado da linha 8
- linha 18: a partir desta referência, o construtor solicita a tabela de escalões de imposto e armazena uma referência à mesma na propriedade privada da linha 8.
- linhas 22-41: implementação do método CalculerImpot da interface IImpotMetier. Esta implementação utiliza a tabela de escalões de imposto inicializada pelo construtor.
6.3.5. A camada [ui]
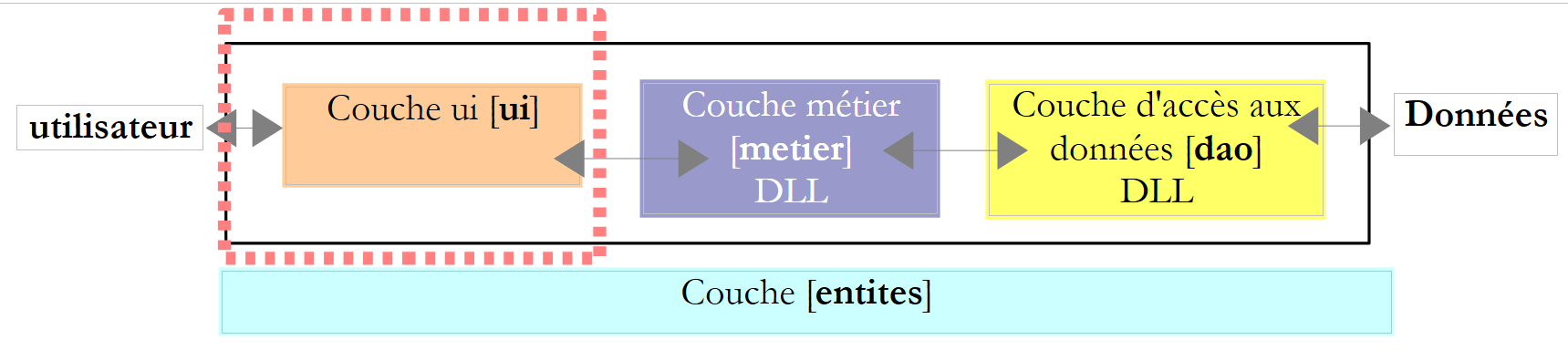 |
As classes de diálogo com o utilizador das versões 2 e 3 eram muito semelhantes. A da versão 2 era a seguinte:
using System;
namespace Chap2 {
public class Program {
static void Main() {
...
// criação de um objeto IImpot
IImpot impot = new HardwiredImpot();
// loop infinito
while (true) {
...
}//while
}
}
}
e a da versão 3:
using System;
namespace Chap3 {
public class Program {
static void Main() {
...
// criação de um objeto IImpot
IImpot impot = null;
try {
// criação de um objeto IImpot
impot = new FileImpot("DataImpotInvalide.txt");
} catch (FileImpotException e) {
// exibição de erro
string msg = e.InnerException == null ? null : String.Format(", Exception d'origine : {0}", e.InnerException.Message);
Console.WriteLine("L'erreur suivante s'est produite : [Code={0},Message={1}{2}]", e.Code, e.Message, msg == null ? "" : msg);
// interrupção do programa
Environment.Exit(1);
}
// loop infinito
while (true) {
...
}//while
}
}
}
A única diferença reside na forma de instanciar o objeto do tipo IImpot, que permite o cálculo do imposto. Este objeto corresponde, neste caso, à nossa camada [métier].
Para uma implementação [dao] com a classe HardwiredImpot, a classe de diálogo é a seguinte:
using System;
using Metier;
using Dao;
using Entites;
namespace Ui {
public class Dialogue2 {
static void Main() {
...
// Criação das camadas [metier et dao]
IImpotMetier metier = new ImpotMetier(new HardwiredImpot());
// loop infinito
while (true) {
...
// os parâmetros estão corretos - calcula-se o imposto
Console.WriteLine("Impot=" + metier.CalculerImpot(marié == "o", nbEnfants, salaire) + " euros");
// próximo contribuinte
}//enquanto
}
}
}
- linha 12: instanciação das camadas [dao] e [metier]. Recorde-se que a camada [metier] necessita da camada [dao].
- linha 18: utilização da camada [metier] para calcular o imposto
Para uma implementação [dao] com a classe FileImpot, a classe de diálogo é a seguinte:
using System;
using Metier;
using Dao;
using Entites;
namespace Ui {
public class Dialogue {
static void Main() {
...
// criam-se as camadas [metier et dao]
IImpotMetier metier = null;
try {
// criação da camada [metier]
metier = new ImpotMetier(new FileImpot("DataImpot.txt"));
} catch (FileImpotException e) {
// exibição de erro
string msg = e.InnerException == null ? null : String.Format(", Exception d'origine : {0}", e.InnerException.Message);
Console.WriteLine("L'erreur suivante s'est produite : [Code={0},Message={1}{2}]", e.Code, e.Message, msg == null ? "" : msg);
// paragem do programa
Environment.Exit(1);
}
// loop infinito
while (true) {
...
// os parâmetros estão corretos - está a ser calculado o imposto
Console.WriteLine("Impot=" + metier.CalculerImpot(marié == "o", nbEnfants, salaire) + " euros");
// próximo contribuinte
}//while
}
}
}
- linhas 11-21: instanciação das camadas [dao] e [metier]. Uma vez que a instanciação da camada [dao] pode lançar uma exceção, esta é tratada
- linha 26: utilização da camada [metier] para calcular o imposto, tal como na versão anterior
6.3.6. Conclusão
A arquitetura em camadas e a utilização de interfaces conferiram uma certa flexibilidade à nossa aplicação. Esta flexibilidade é particularmente evidente na forma como a camada [ui] instancia as camadas [dao] e [métier]:
// criam-se as camadas [metier et dao]
IImpotMetier metier = new ImpotMetier(new HardwiredImpot());
num caso e:
// criam-se as camadas [metier et dao]
IImpotMetier metier = null;
try {
// criação da camada [metier]
metier = new ImpotMetier(new FileImpot("DataImpot.txt"));
} catch (FileImpotException e) {
// exibição de erro
string msg = e.InnerException == null ? null : String.Format(", Exception d'origine : {0}", e.InnerException.Message);
Console.WriteLine("L'erreur suivante s'est produite : [Code={0},Message={1}{2}]", e.Code, e.Message, msg == null ? "" : msg);
// paragem do programa
Environment.Exit(1);
}
no outro. Excluindo o tratamento da exceção no caso 2, a instanciação das camadas [dao] e [metier] é semelhante nas duas aplicações. Uma vez instanciadas as camadas [dao] e [metier], o código da camada [ui] é idêntico em ambos os casos. Isto deve-se ao facto de a camada [métier] ser manipulada através da sua interface IImpotMetier e não através da classe de implementação desta. Alterar a camada [metier] ou a camada [dao] da aplicação sem alterar as respetivas interfaces equivalerá sempre a alterar apenas as linhas anteriores na camada [ui].
Outro exemplo da flexibilidade proporcionada por esta arquitetura é a implementação da camada [métier]:
using Entites;
using Dao;
namespace Metier {
public class ImpotMetier : IImpotMetier {
// camada [dao]
private IImpotDao Dao { get; set; }
// faixas de imposto
private TrancheImpot[] tranchesImpot;
// construtor
public ImpotMetier(IImpotDao dao) {
// armazenamento
Dao = dao;
// faixas de imposto
tranchesImpot = dao.TranchesImpot;
}
// cálculo do imposto
public int CalculerImpot(bool marié, int nbEnfants, int salaire) {
...
}//calcular
}//classe
}
Na linha 14, verifica-se que a camada [métier] é construída a partir de uma referência à interface da camada [dao]. Alterar a implementação desta última não tem, portanto, qualquer impacto na camada [métier]. É por isso que a nossa única implementação da camada [métier] conseguiu funcionar sem alterações com duas implementações diferentes da camada [dao].
6.4. Aplicação de exemplo — versão 5
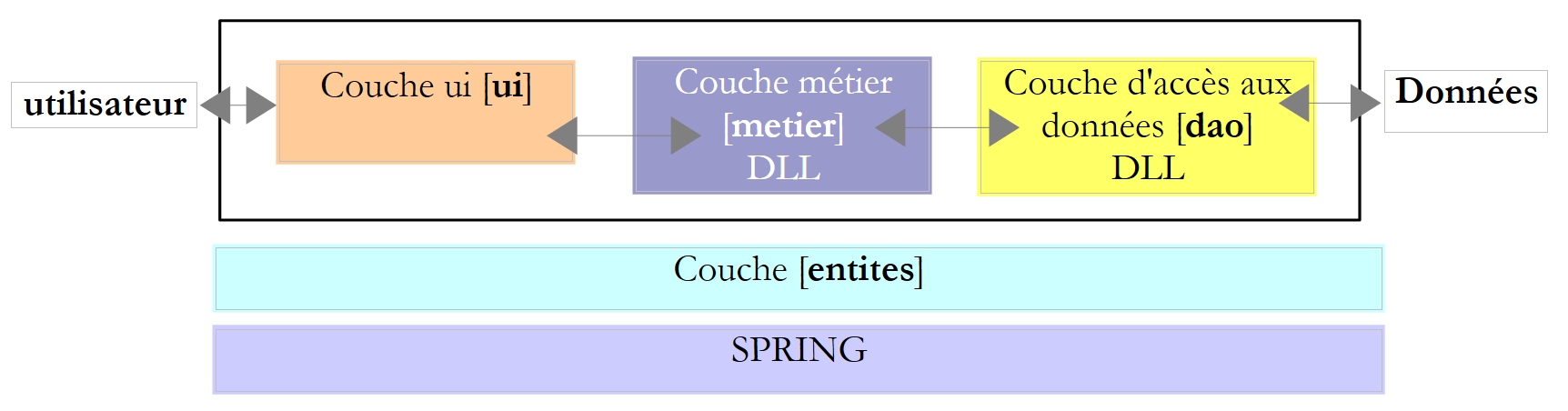 |
Esta nova versão retoma a anterior, introduzindo as seguintes alterações:
- as camadas [métier] e [dao] estão, cada uma, encapsuladas numa DLL e testadas com o framework de testes unitários NUnit.
- A integração das camadas é assegurada pelo framework Spring
Em projetos de grande dimensão, vários programadores trabalham no mesmo projeto. As arquiteturas em camadas facilitam este modo de trabalho: como as camadas comunicam entre si através de interfaces bem definidas, um programador que trabalha numa camada não precisa de se preocupar com o trabalho dos outros programadores nas restantes camadas. Basta que todos respeitem as interfaces.
No exemplo acima, o programador da camada [métier] precisará, na altura dos testes da sua camada, de uma implementação da camada [dao]. Enquanto esta não estiver concluída, pode utilizar uma implementação fictícia da camada [dao], desde que esta respeite a interface IImpotDao. Esta é também uma vantagem da arquitetura em camadas: um atraso na camada [dao] não impede os testes da camada [métier]. A implementação fictícia da camada [dao] tem também a vantagem de ser, muitas vezes, mais fácil de implementar do que a camada real [dao], que pode exigir o arranque de um SGBD, ligações de rede, etc.
Quando a camada [dao] estiver concluída e testada, será fornecida aos programadores da camada [métier] sob a forma de um DLL, em vez de código-fonte. No final, a aplicação é frequentemente entregue sob a forma de um executável .exe (o da camada [ui]) e de bibliotecas de classes .dll (as outras camadas).
6.4.1. NUnit
Os testes realizados até agora para as nossas diversas aplicações baseavam-se numa verificação visual. Verificava-se se o que aparecia no ecrã correspondia ao esperado. Este método é impraticável quando há muitos testes a realizar. O ser humano está, de facto, sujeito à fadiga e a sua capacidade de verificar testes diminui ao longo do dia. Os testes devem, portanto, ser automatizados e ter como objetivo não necessitar de qualquer intervenção humana.
Uma aplicação evolui ao longo do tempo. A cada evolução, é necessário verificar se a aplicação não sofre «regressão», c.a.d, e se continua a passar nos testes de bom funcionamento que foram realizados durante a sua criação inicial. Estes testes são designados por testes de «não regressão». Uma aplicação de alguma envergadura pode exigir centenas de testes. De facto, testa-se cada método de cada classe da aplicação. A isto chama-se testes unitários. Estes podem mobilizar muitos programadores se não tiverem sido automatizados.
Foram desenvolvidas ferramentas para automatizar os testes. Uma delas chama-se NUnit. Está disponível no site [http://www.nunit.org]:
 |  |
Foi utilizada a versão 2.4.6 acima referida para este documento (março de 2008). A instalação coloca um ícone [1] no ambiente de trabalho:
 |
Um duplo-clique no ícone [1] inicia a interface gráfica do NUnit [2]. Esta interface não contribui de forma alguma para a automatização dos testes, uma vez que, mais uma vez, somos obrigados a recorrer a uma verificação visual: o testador verifica os resultados dos testes apresentados na interface gráfica. No entanto, os testes também podem ser executados por ferramentas em lote e os seus resultados guardados em ficheiros XML. É este método que é utilizado pelas equipas de desenvolvimento: os testes são lançados durante a noite e os programadores têm o resultado na manhã seguinte.
Vamos analisar, com um exemplo, o princípio dos testes NUnit. Em primeiro lugar, vamos criar um novo projeto C# do tipo Console Application:
 |
No [1], vemos as referências do projeto. Estas referências são références que contêm classes e interfaces utilizadas pelo projeto. As apresentadas em [1] são incluídas por predefinição em cada novo projeto C#. Para podermos utilizar as classes e interfaces do framework NUnit, temos de adicionar [2] uma nova referência ao projeto.
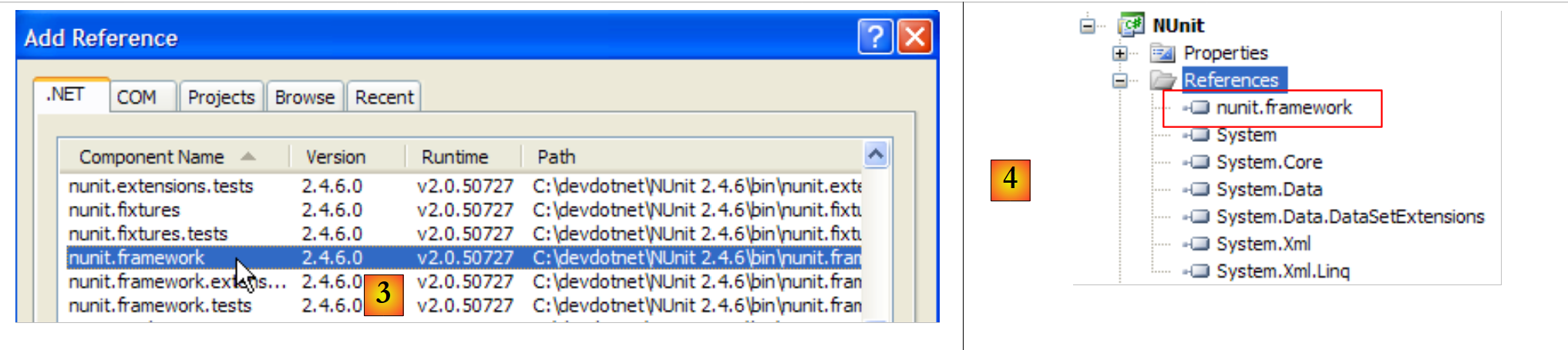 |
No separador .NET acima, selecionamos o componente [nunit.framework]. Os componentes [nunit.*] acima não estão presentes por predefinição no ambiente .NET. Foram introduzidos através da instalação anterior do framework NUnit. Assim que a adição da referência for validada, esta aparece como [4] na lista de referências do projeto.
Antes da geração da aplicação, a pasta [bin/Release] do projeto está vazia. Após a geração (F6), verifica-se que a pasta [bin/Release] já não está vazia:
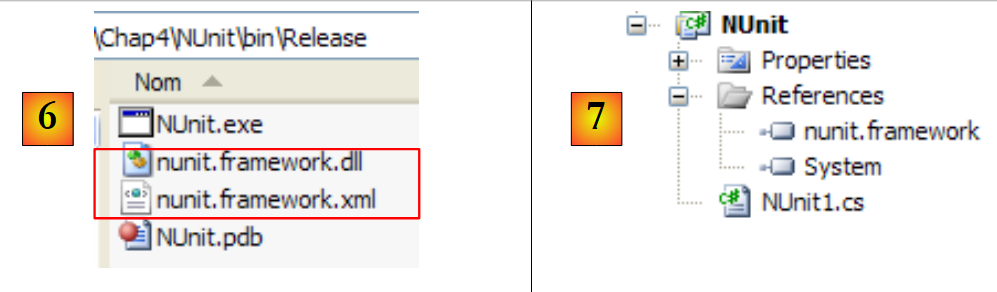 |
Em [6], verifica-se a presença de DLL e [nunit.framework.dll]. Foi a adição da referência [nunit.framework] que provocou a cópia deste DLL para a pasta de execução. Esta é, de facto, uma das pastas que serão exploradas pelo CLR (Common Language Runtime) .NET para encontrar as classes e interfaces referenciadas pelo projeto.
Vamos criar uma primeira classe de teste, NUnit. Para tal, eliminamos a classe [Program.cs] gerada por predefinição e, em seguida, adicionamos uma nova classe, [Nunit1.cs], ao projeto. Eliminamos também as referências desnecessárias [7].
A classe de teste NUnit1 ficará da seguinte forma:
using System;
using NUnit.Framework;
namespace NUnit {
[TestFixture]
public class NUnit1 {
public NUnit1() {
Console.WriteLine("constructeur");
}
[SetUp]
public void avant() {
Console.WriteLine("Setup");
}
[TearDown]
public void après() {
Console.WriteLine("TearDown");
}
[Test]
public void t1() {
Console.WriteLine("test1");
Assert.AreEqual(1, 1);
}
[Test]
public void t2() {
Console.WriteLine("test2");
Assert.AreEqual(1, 2, "1 n'est pas égal à 2");
}
}
}
- linha 6: a classe NUnit1 deve ser pública. A palavra-chave «public» não é gerada por predefinição pelo Visual Studio. É necessário adicioná-la.
- linha 5: o atributo [TestFixture] é um atributo NUnit. Indica que a classe é uma classe de teste.
- linhas 7-9: o construtor. Aqui, é utilizado apenas para exibir uma mensagem no ecrã. Pretendemos verificar quando é executado.
- linha 10: o atributo [SetUp] define um método executado antes de cada teste unitário.
- linha 14: o atributo [TearDown] define um método executado após cada teste unitário.
- linha 18: o atributo [Test] define um método de teste. Para cada método anotado com o atributo [Test], o método anotado [SetUp] será executado antes do teste e o método anotado [TearDown] será executado após o teste.
- linha 21: um dos métodos [Assert.*] definidos pelo framework NUnit. Encontram-se os seguintes métodos [Assert]:
- [Assert.AreEqual(expression1, expression2)]: verifica se os valores das duas expressões são iguais. São aceites vários tipos de expressão (int, string, float, double, decimal, ...). Se as duas expressões não forem iguais, é lançada uma exceção.
- [Assert.AreEqual(réel1, réel2, delta)]: verifica se dois números reais são iguais com uma tolerância de delta, c.a.d abs(real1-real2)<=delta. Por exemplo, pode escrever-se [Assert.AreEqual(réel1, réel2, 1E-6)] para verificar se dois valores são iguais com uma tolerância de 10⁻⁶.
- [Assert.AreEqual(expression1, expression2, message)] e [Assert.AreEqual(réel1, réel2, delta, message)] são variantes que permitem especificar a mensagem de erro a associar à exceção lançada quando o método [Assert.AreEqual] falha.
- [Assert.IsNotNull(object)] e [Assert.IsNotNull(object, message)]: verifica se object não é igual a null.
- [Assert.IsNull(object)] e [Assert.IsNull(object, message)]: verificam se o objeto é igual a null.
- [Assert.IsTrue(expression)] e [Assert.IsTrue(expression, message)]: verifica se a expressão é igual a «true».
- [Assert.IsFalse(expression)] e [Assert.IsFalse(expression, message)]: verifica se a expressão é igual a «false».
- [Assert.AreSame(object1, object2)] e [Assert.AreSame(object1, object2, message)]: verifica se as referências object1 e object2 apontam para o mesmo objeto.
- [Assert.AreNotSame(object1, object2)] e [Assert.AreNotSame(object1, object2, message)]: verifica se as referências object1 e object2 não apontam para o mesmo objeto.
- linha 21: a asserção deve ser bem-sucedida
- linha 26: a asserção deve falhar
Vamos configurar o projeto para que a sua geração produza um DLL em vez de um executável .exe:
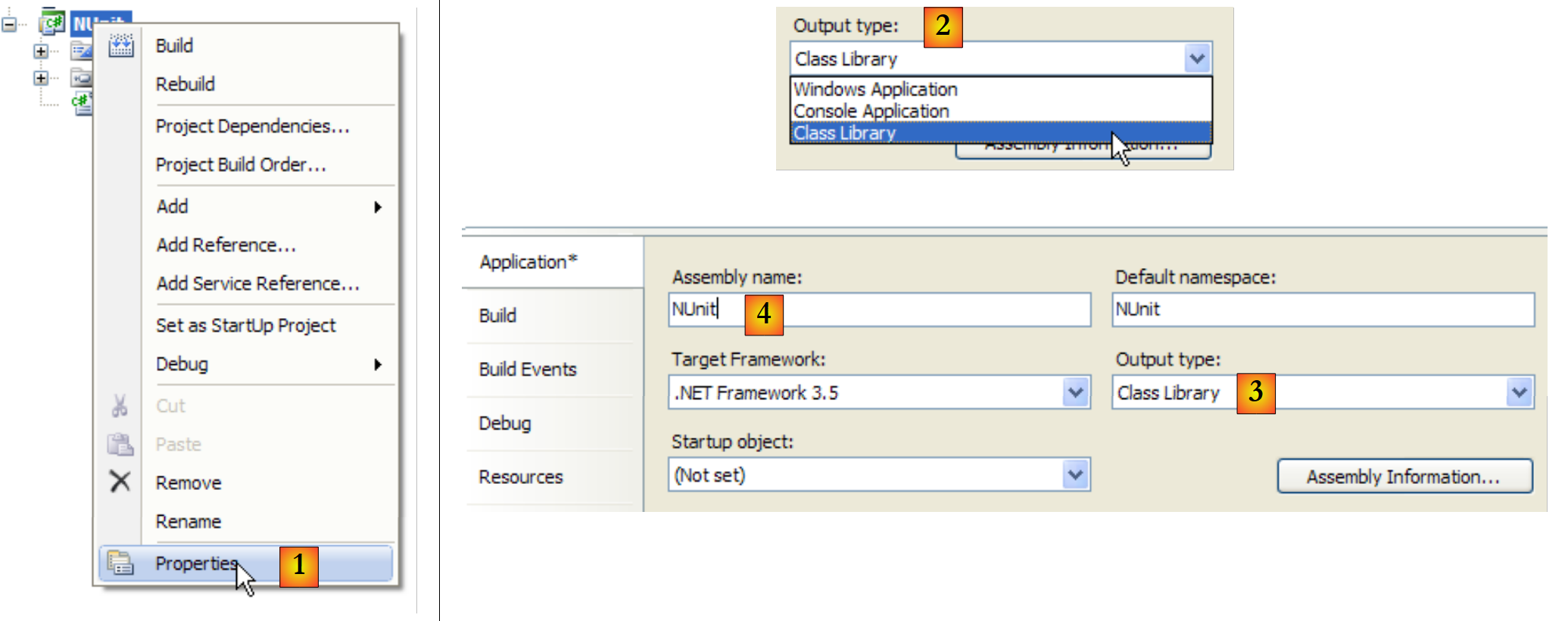 |
- em [1]: propriedades do projeto
- em [2, 3]: como tipo de projeto, escolhe-se [Class Library] (Biblioteca de classes)
- em [4]: a geração do projeto irá produzir um DLL (assembly) denominado [Nunit.dll]
Vamos agora utilizar o NUnit para executar a classe de teste:
 |
- em [1]: abertura de um projeto NUnit
- em [2, 3]: carregamos o ficheiro DLL bin/Release/Nunit.dll produzido pela geração do projeto C#
- em [4]: o DLL foi carregado
- em [5]: a árvore de testes
- em [6]: estão a ser executados
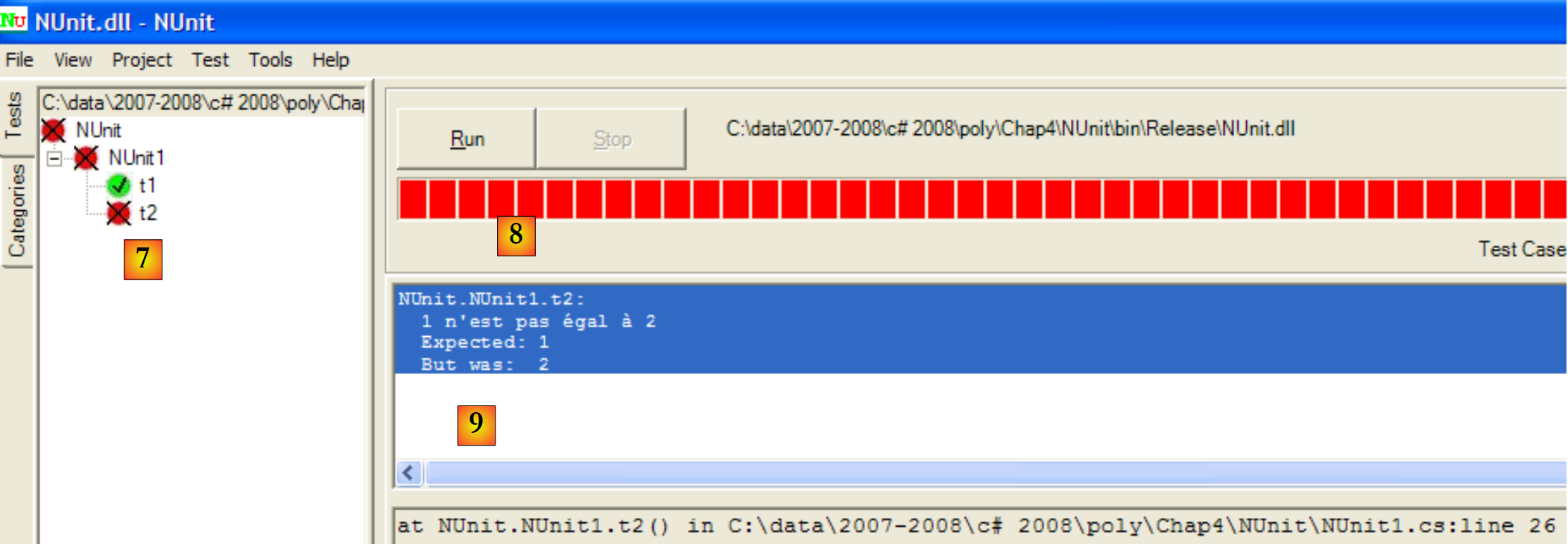 |
- em [7]: os resultados: t1 foi bem-sucedido, t2 falhou
- em [8]: uma barra vermelha indica a falha global da classe de testes
- em [9]: a mensagem de erro relacionada com o teste falhado
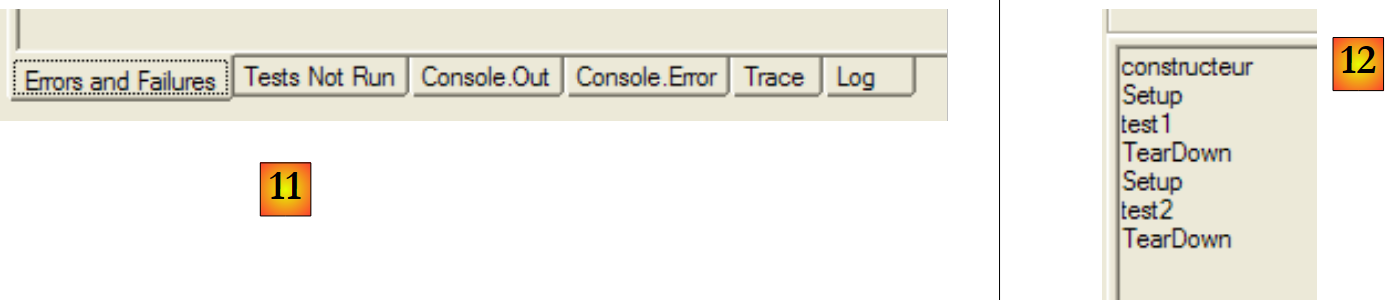 |
- em [11]: os diferentes separadores da janela de resultados
- em [12]: o separador [Console.Out]. Nele pode ver-se que:
- o construtor foi executado apenas uma vez
- o método [SetUp] foi executado antes de cada um dos dois testes
- o método [TearDown] foi executado após cada um dos dois testes
É possível especificar os métodos a testar:
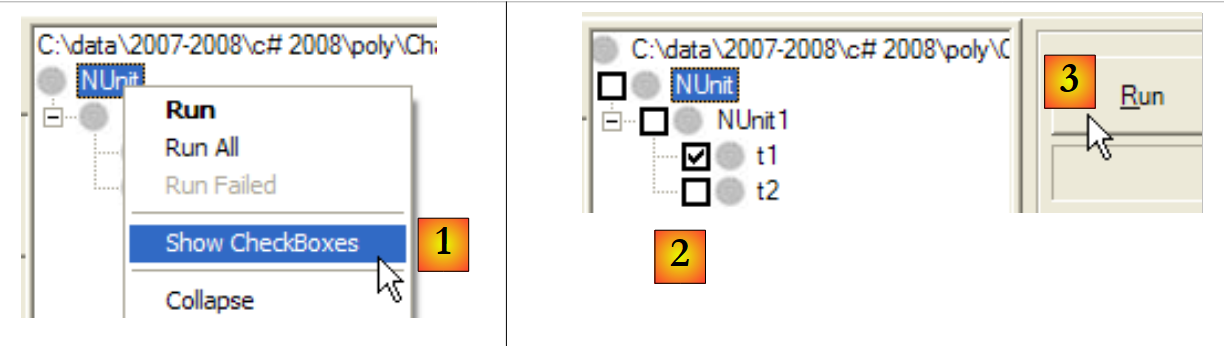 |
- no [1]: solicita-se a exibição de uma caixa de seleção ao lado de cada teste
- no [2]: marcam-se os testes a executar
- em [3]: executam-se os testes
Para corrigir os erros, basta corrigir o projeto C# e regenerá-lo. O NUnit deteta que o DLL que está a testar foi alterado e carrega automaticamente a nova versão. Basta, então, reiniciar os testes.
Consideremos a seguinte nova classe de teste:
using System;
using NUnit.Framework;
namespace NUnit {
[TestFixture]
public class NUnit2 : AssertionHelper {
public NUnit2() {
Console.WriteLine("constructeur");
}
[SetUp]
public void avant() {
Console.WriteLine("Setup");
}
[TearDown]
public void après() {
Console.WriteLine("TearDown");
}
[Test]
public void t1() {
Console.WriteLine("test1");
Expect(1, EqualTo(1));
}
[Test]
public void t2() {
Console.WriteLine("test2");
Expect(1, EqualTo(2), "1 n'est pas égal à 2");
}
}
}
A partir da versão 2.4 do NUnit, ficou disponível uma nova sintaxe, a das linhas 21 e 26. Para tal, a classe de teste deve derivar da classe AssertionHelper (linha 6).
A correspondência (não exaustiva) entre a sintaxe antiga e a nova é a seguinte:
Vamos adicionar o seguinte teste à classe NUnit2:
[Test]
public void t3() {
bool vrai = true, faux = false;
Expect(vrai, True);
Expect(faux, False);
Object obj1 = new Object(), obj2 = null, obj3=obj1;
Expect(obj1, Not.Null);
Expect(obj2, Null);
Expect(obj3, SameAs(obj1));
double d1 = 4.1, d2 = 6.4, d3 = d1;
Expect(d1, EqualTo(d3).Within(1e-6));
Expect(d1, Not.EqualTo(d2));
}
Se gerarmos (F6) o novo DLL do projeto C#, o projeto NUnit passa a ter o seguinte aspeto:
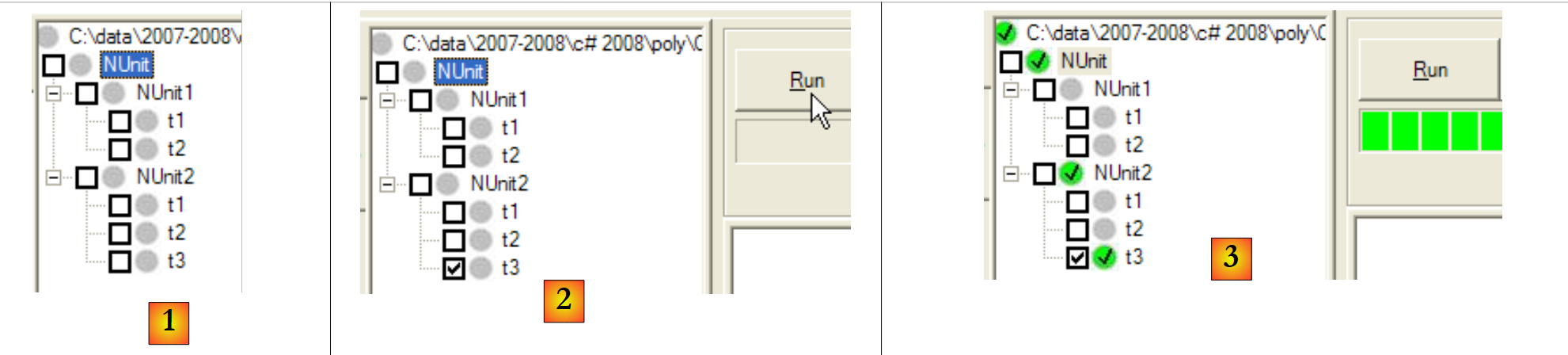 |
- em [1]: a nova classe de teste [NUnit2] foi detetada automaticamente
- em [2]: está a ser executado o teste t3 de NUnit2
- em [3]: o teste t3 foi bem-sucedido
Para saber mais sobre o NUnit, consulte a ajuda do NUnit:
 |  |
6.4.2. A solução do Visual Studio
 |
Vamos construir, passo a passo, a seguinte solução do Visual Studio:
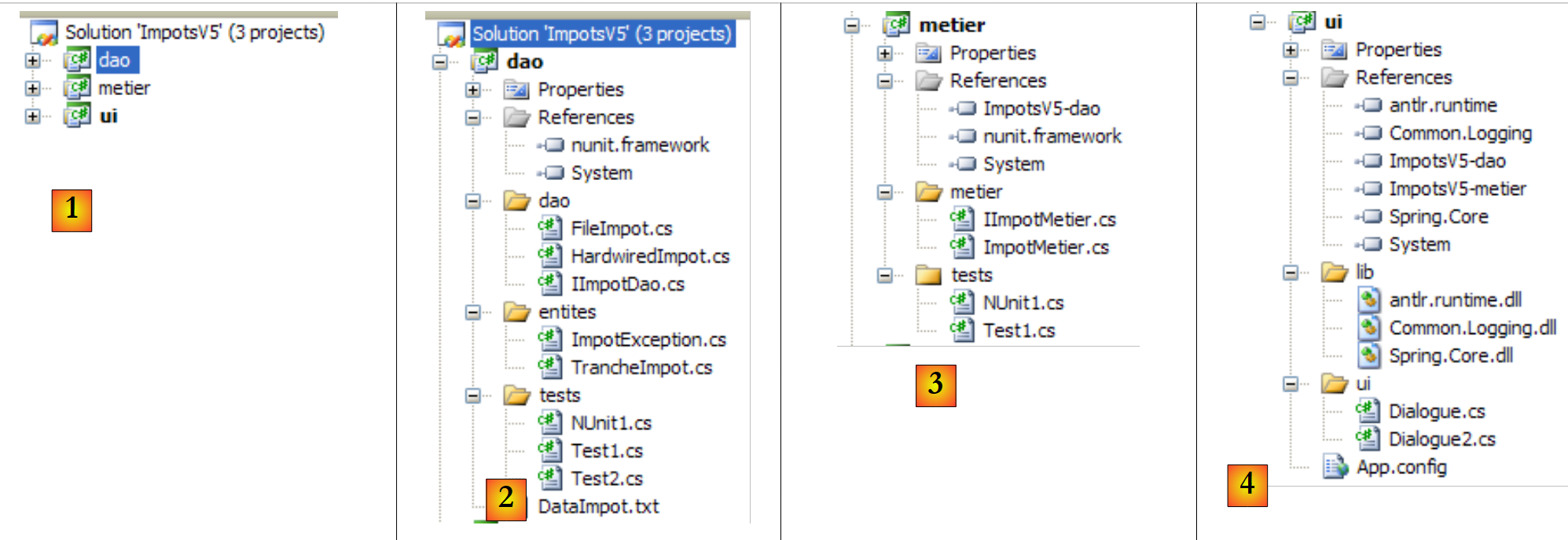 |
- em [1]: a solução ImpotsV5 é composta por três projetos, um para cada uma das três camadas da aplicação
- em [2]: o projeto [dao] da camada [dao]
- em [3]: o projeto [metier] da camada [metier]
- em [4]: o projeto [ui] da camada [ui]
A solução ImpotsV5 pode ser construída da seguinte forma:
1  | 234 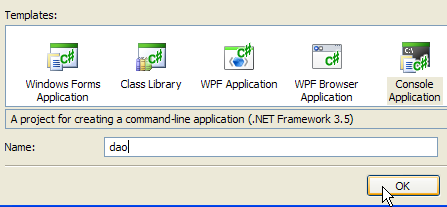 | 5 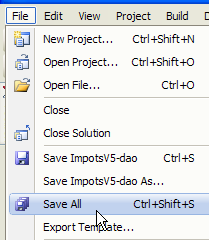 |
- em [1]: criar um novo projeto
- em [2]: selecionar uma aplicação de consola
- em [3]: aceder ao projeto [dao]
- em [4]: criar o projeto
- em [5]: depois de criado o projeto, guardá-lo
 |
- em [6]: manter o nome [dao] para o projeto
- em [7]: especificar uma pasta para guardar o projeto e a sua solução
- em [8]: atribuir um nome à solução
- em [9]: indicar que a solução deve ter a sua própria pasta
- em [10]: guardar o projeto e a sua solução
- em [11]: o projeto [dao] na sua solução ImpotsV5
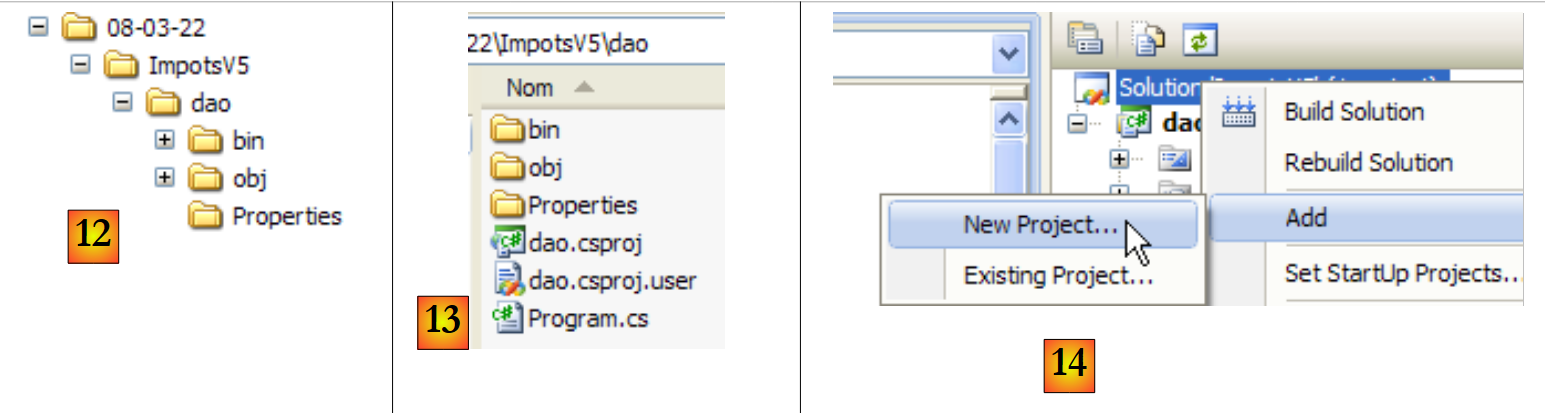 |
- em [12]: a pasta da solução ImpotsV5. Contém a pasta [dao] da pasta [dao].
- em [13]: o conteúdo da pasta [dao]
- em [14]: adiciona-se um novo projeto à solução ImpotsV5
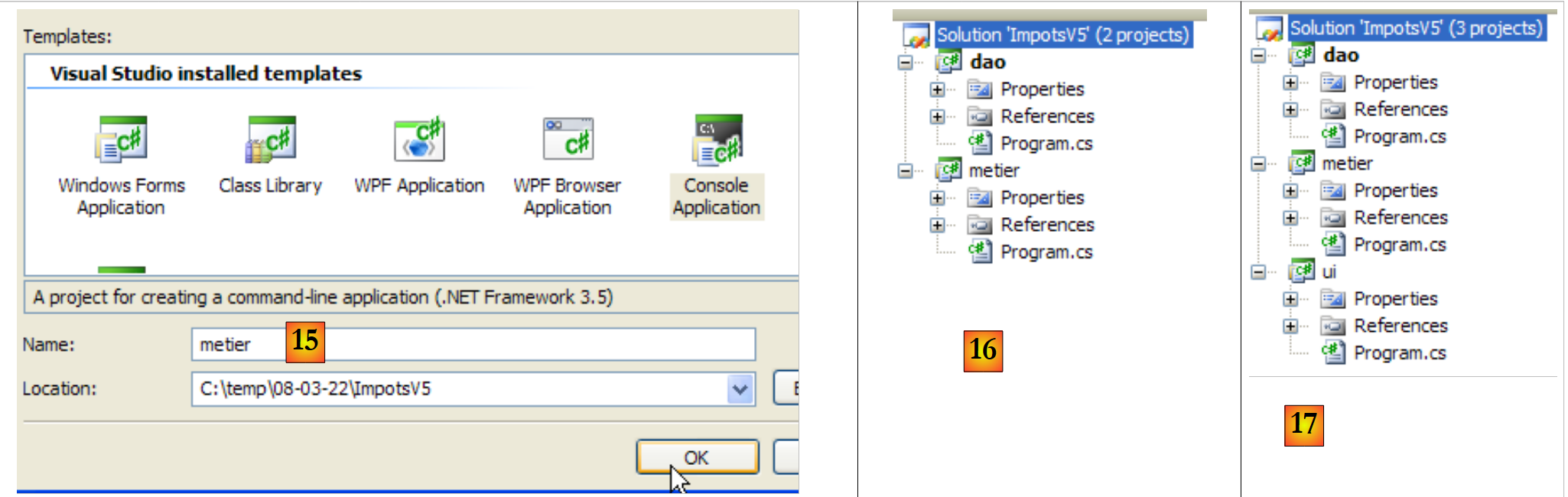 |
- em [15]: o novo projeto chama-se [metier]
- em [16]: a solução com os seus dois projetos
- em [17]: a solução, depois de ter sido adicionado o terceiro projeto [ui]
 |
- em [18]: a pasta da solução e as pastas dos três projetos
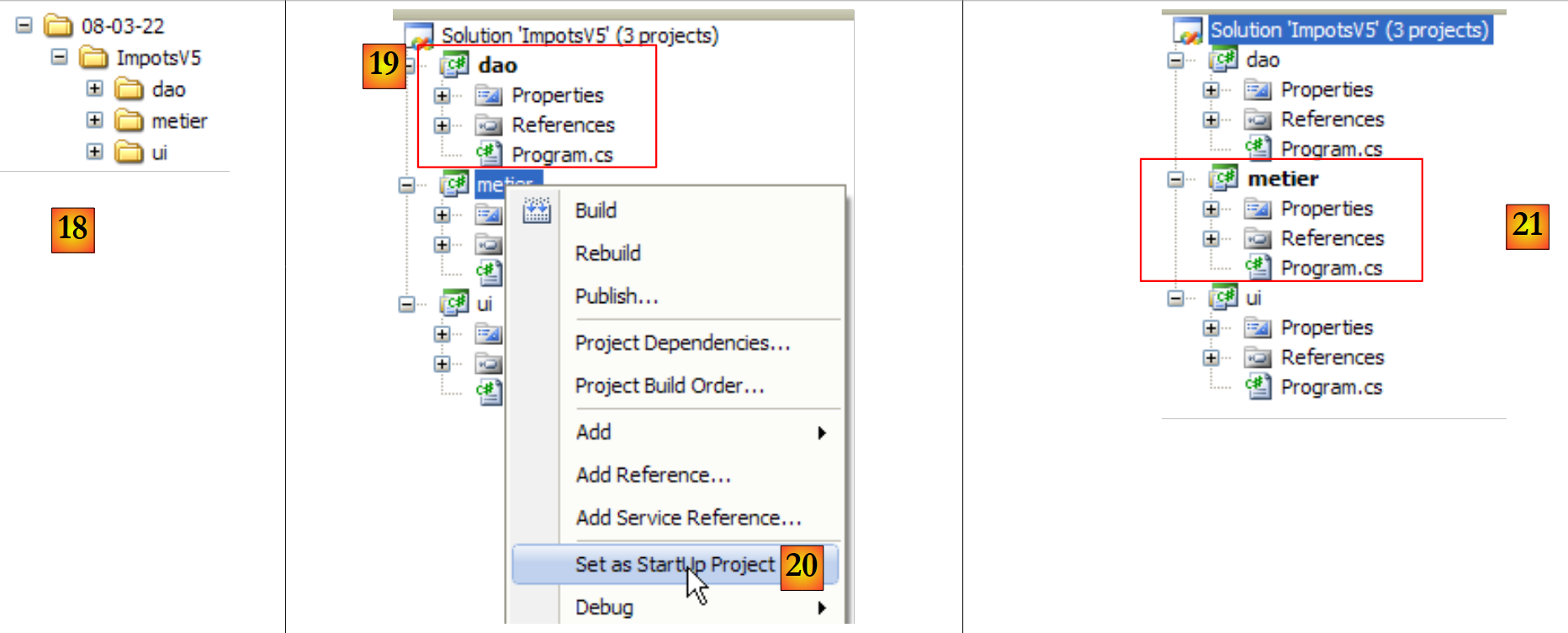
- quando se executa uma solução através de (Ctrl+F5), é o projeto ativo que é executado. O mesmo se aplica quando se gera (F6) a solução. O nome do projeto ativo aparece a negrito [19] na solução.
- em [20]: para alterar o projeto ativo da solução
- em [21]: o projeto [metier] é agora o projeto ativo da solução
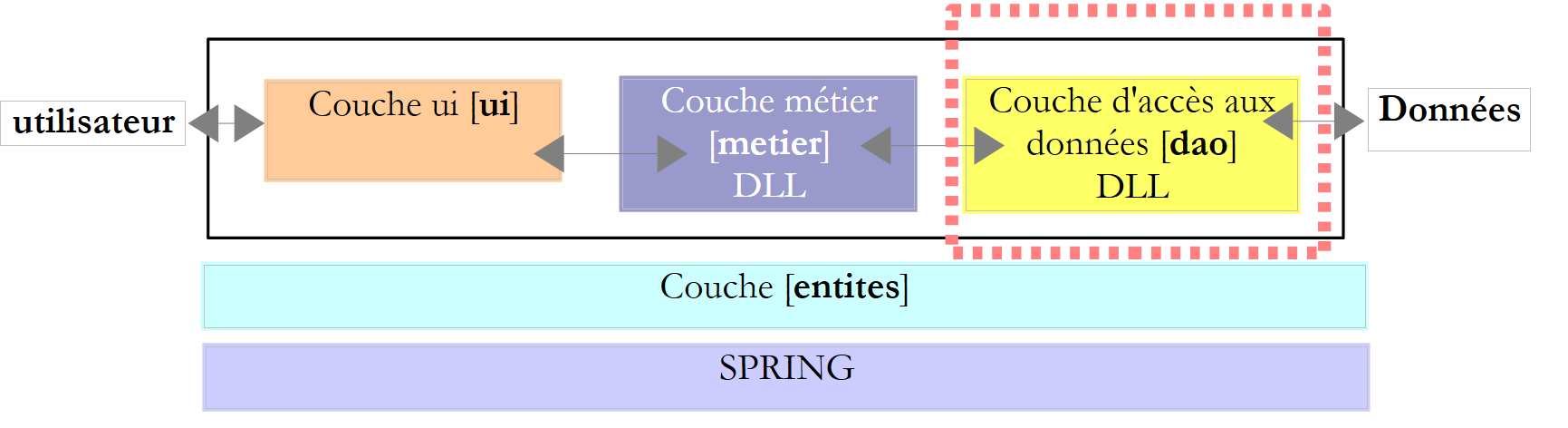
6.4.3. A camada [dao]
 |
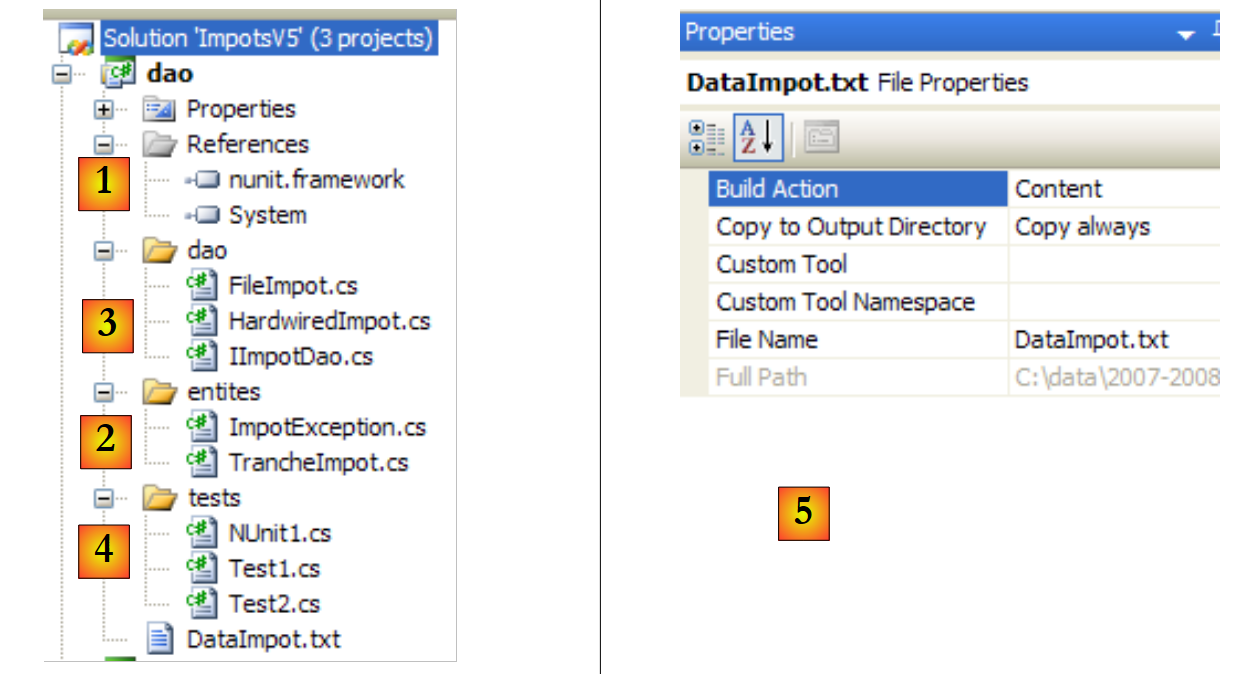 |
As referências do projeto (ver [1] no projeto)
Adiciona-se a referência [nunit.framework] necessária para os testes [NUnit]
As entidades (ver [2] no projeto)
A classe [TrancheImpot] é a das versões anteriores. A classe [FileImpotException] da versão anterior é renomeada para [ImpotException], para a tornar mais genérica e não a associar a uma camada [dao] específica:
using System;
namespace Entites {
public class ImpotException : Exception {
// código de erro
public int Code { get; set; }
// fabricantes
public ImpotException() {
}
public ImpotException(string message)
: base(message) {
}
public ImpotException(string message, Exception e)
: base(message, e) {
}
}
}
A camada [dao] (ver [3] no projeto)
A interface [IImpotDao] é a da versão anterior. O mesmo se aplica à classe [HardwiredImpot]. A classe [FileImpot] é atualizada para ter em conta a alteração da exceção [FileImpotException] para [ImpotException]:
...
namespace Dao {
public class FileImpot : IImpotDao {
// códigos de erro
[Flags]
public enum CodeErreurs { Acces = 1, Ligne = 2, Champ1 = 4, Champ2 = 8, Champ3 = 16 };
...
// fabricante
public FileImpot(string fileName) {
// o nome do ficheiro é guardado
FileName = fileName;
...
// inicialmente, sem erros
CodeErreurs code = 0;
try {
using (StreamReader input = new StreamReader(FileName)) {
while (!input.EndOfStream && code == 0) {
...
// erro?
if (code != 0) {
// regista-se o erro
fe = new ImpotException(String.Format("Ligne n° {0} incorrecte", numLigne)) { Code = (int)code };
} else {
...
}
}
}
} catch (Exception e) {
// regista-se o erro
fe = new ImpotException(String.Format("Erreur lors de la lecture du fichier {0}", FileName), e) { Code = (int)CodeErreurs.Acces };
}
// erro a assinalar?
...
}
}
}
- linha 8: os códigos de erro que anteriormente se encontravam na classe [FileImpotException] foram transferidos para a classe [FileImpot]. Trata-se, de facto, de códigos de erro específicos desta implementação da interface [IImpotDao].
- linhas 26 e 34: para encapsular um erro, utiliza-se agora a classe [ImpotException] e não mais a classe [FileImpotException].
O teste [Test1] (ver [4] no projeto)
A classe [Test1] limita-se a apresentar as faixas de imposto no ecrã:
using System;
using Dao;
using Entites;
namespace Tests {
class Test1 {
static void Main() {
// cria-se a camada [dao]
IImpotDao dao = null;
try {
// criação da camada [dao]
dao = new FileImpot("DataImpot.txt");
} catch (ImpotException e) {
// exibição de erro
string msg = e.InnerException == null ? null : String.Format(", Exception d'origine : {0}", e.InnerException.Message);
Console.WriteLine("L'erreur suivante s'est produite : [Code={0},Message={1}{2}]", e.Code, e.Message, msg == null ? "" : msg);
// encerramento do programa
Environment.Exit(1);
}
// são apresentadas as faixas de imposto
TrancheImpot[] tranchesImpot = dao.TranchesImpot;
foreach (TrancheImpot t in tranchesImpot) {
Console.WriteLine("{0}:{1}:{2}", t.Limite, t.CoeffR, t.CoeffN);
}
}
}
}
- linha 13: a camada [dao] é implementada pela classe [FileImpot]
- linha 14: trata-se da exceção do tipo [ImpotException] que pode ocorrer.
O ficheiro [DataImpot.txt], necessário para os testes, é copiado automaticamente para a pasta de execução do projeto (ver [5] no projeto). O projeto [dao] terá várias classes que contêm um método [Main]. É necessário, portanto, indicar explicitamente a classe a executar quando o utilizador solicitar a execução do projeto através de Ctrl-F5:
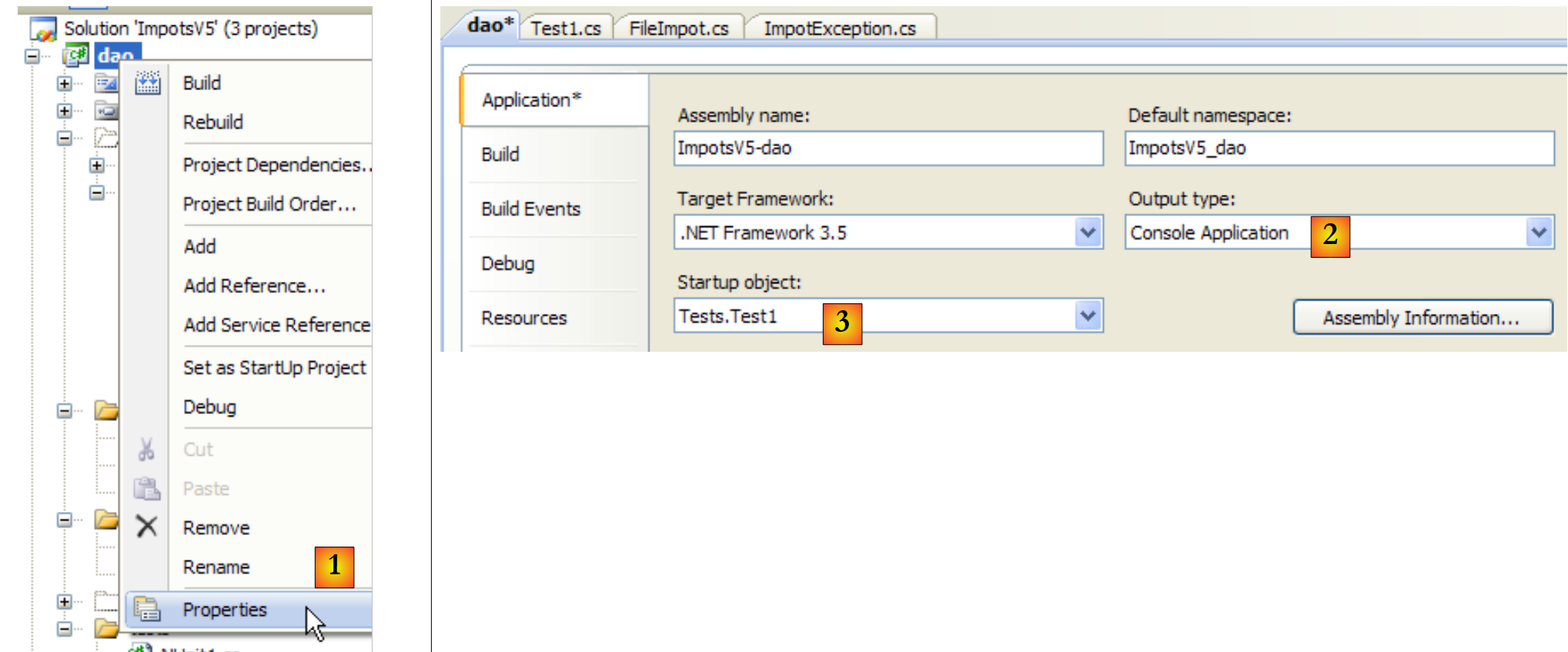 |
- em [1]: aceder às propriedades do projeto
- em [2]: especificar que se trata de uma aplicação de consola
- em [3]: especificar a classe a executar
A execução da classe anterior [Test1] produz os seguintes resultados:
4962:0:0
8382:0,068:291,09
14753:0,191:1322,92
23888:0,283:2668,39
38868:0,374:4846,98
47932:0,426:6883,66
0:0,481:9505,54
O teste [Test2] (ver [4] no projeto)
A classe [Test2] faz o mesmo que a classe [Test1], implementando a camada [dao] com a classe [HardwiredImpot]. A linha 13 de [Test1] é substituída pela seguinte:
dao = new HardwiredImpot();
O projeto é alterado para passar a executar a classe [Test2]:
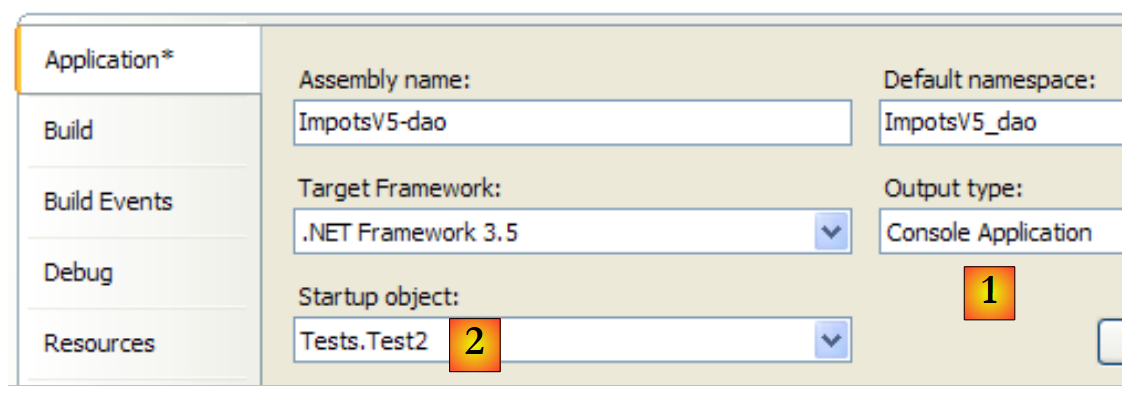 |
Os resultados no ecrã são os mesmos que anteriormente.
O teste NUnit [NUnit1] (ver [4] no projeto)
O teste unitário [NUnit1] é o seguinte:
using System;
using Dao;
using Entites;
using NUnit.Framework;
namespace Tests {
[TestFixture]
public class NUnit1 : AssertionHelper{
// camada [dao] a testar
private IImpotDao dao;
// fabricante
public NUnit1() {
// inicialização da camada [dao]
dao = new FileImpot("DataImpot.txt");
}
// teste
[Test]
public void ShowTranchesImpot(){
// são apresentadas as faixas de imposto
TrancheImpot[] tranchesImpot = dao.TranchesImpot;
foreach (TrancheImpot t in tranchesImpot) {
Console.WriteLine("{0}:{1}:{2}", t.Limite, t.CoeffR, t.CoeffN);
}
// alguns testes
Expect(tranchesImpot.Length,EqualTo(7));
Expect(tranchesImpot[2].Limite,EqualTo(14753));
Expect(tranchesImpot[2].CoeffR, EqualTo(0.191));
Expect(tranchesImpot[2].CoeffN, EqualTo(1322.92));
}
}
}
- a classe de teste deriva da classe [AssertionHelper], o que permite a utilização do método estático Expect (linhas 27-30).
- linha 10: uma referência à camada [dao]
- linhas 13-16: o construtor instancia a camada [dao] com a classe [FileImpot]
- linhas 19-20: o método de teste
- linha 22: recupera-se a tabela de escalões de imposto da camada [dao]
- linhas 23-25: exibem-se como anteriormente. Esta exibição não teria razão de ser num teste unitário real. Aqui, esta exibição tem um objetivo pedagógico.
- linha 27: verifica-se se existem efetivamente 7 escalões de imposto
- linhas 28-30: verifica-se os valores da faixa de imposto n.º 2
Para executar este teste unitário, o projeto deve ser do tipo [Class Library]:
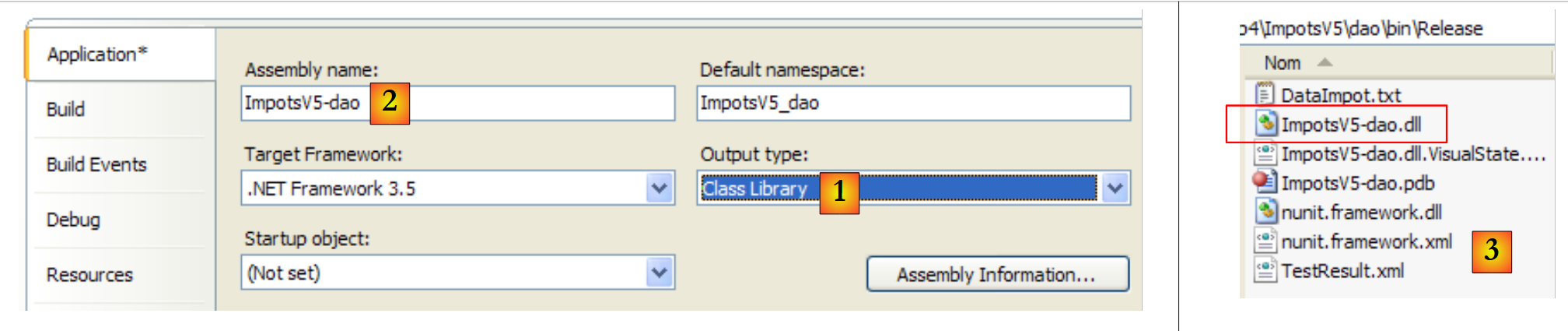 |
- em [1]: a natureza do projeto foi alterada
- para [2]: o DLL gerado passará a chamar-se [ImpotsV5-dao.dll]
- em [3]: após a geração (F6) do projeto, a pasta [dao/bin/Release] contém o DLL e o [ImpotsV5-dao.dll]
A DLL [ImpotsV5-dao.dll] é, em seguida, carregada no framework NUnit e executada:
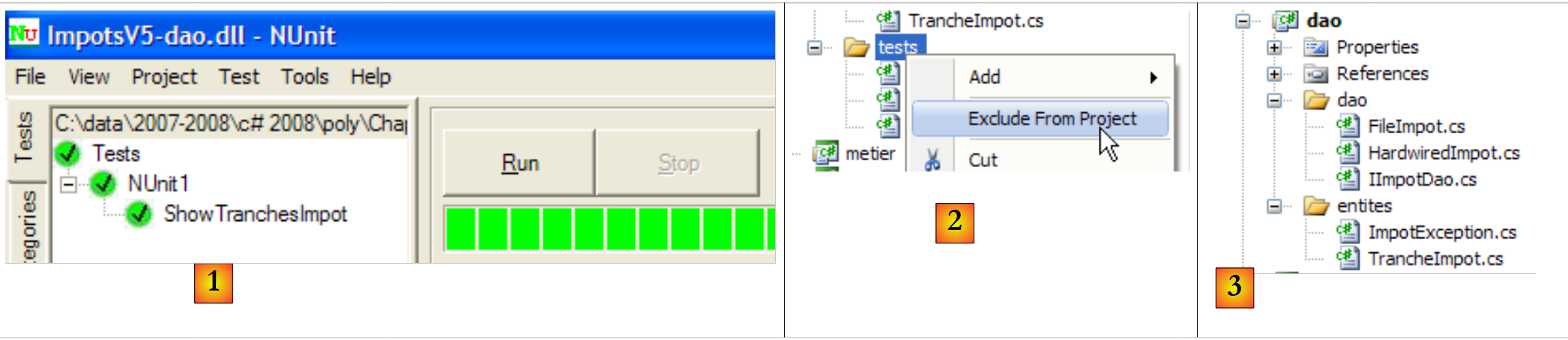 |
- no [1]: os testes foram bem-sucedidos. Consideramos agora a camada [dao] operacional. O seu DLL contém todas as classes do projeto, incluindo as classes de teste. Estas últimas são desnecessárias. Estamos a reconstruir a DLL para excluir as classes de teste.
- em [2]: a pasta [tests] é excluída do projeto
- em [3]: o novo projeto. Este é regenerado pelo F6 para gerar um novo DLL.
6.4.4. A camada [metier]
 |
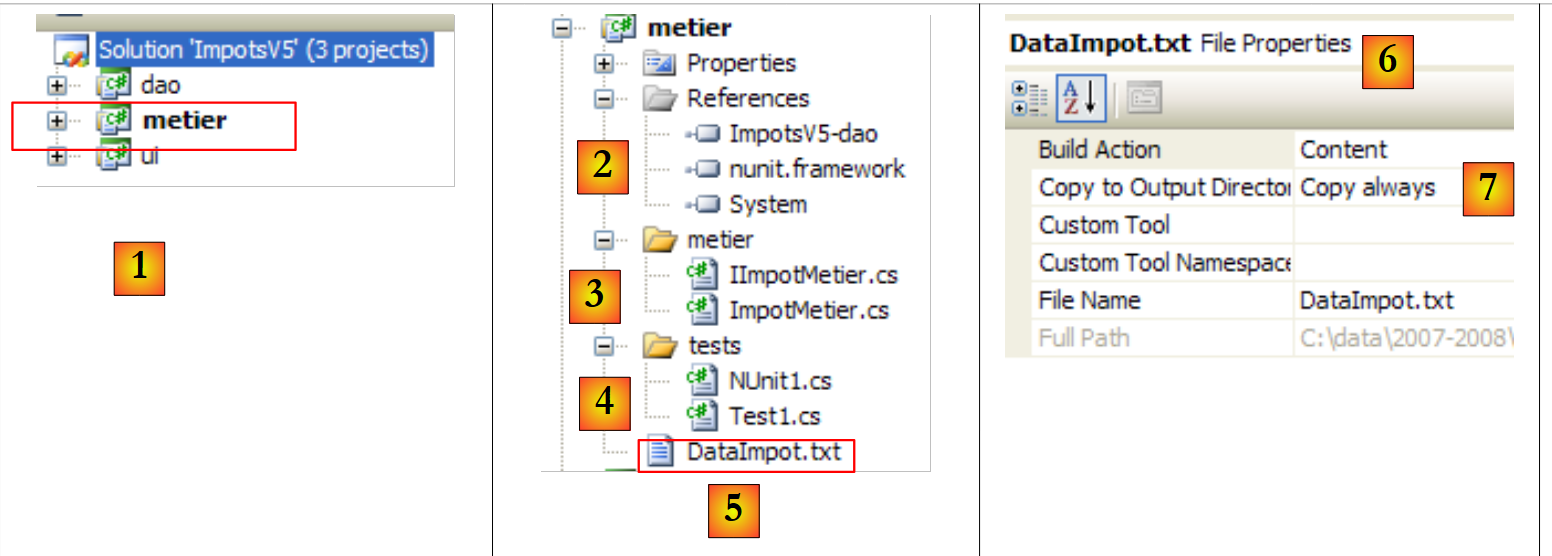 |
- em [1], o projeto [metier] tornou-se o projeto ativo da solução
- em [2]: as referências do projeto
- em [3]: a camada [metier]
- em [4]: as classes de teste
- em [5]: o ficheiro [DataImpot.txt] das faixas de imposto, configurado em [6] para ser copiado automaticamente para a pasta de execução do projeto [7]
As referências do projeto (ver [2] no projeto)
Tal como no projeto [dao], adiciona-se a referência [nunit.framework] necessária para os testes [NUnit]. A camada [metier] necessita da camada [dao]. Por isso, necessita de uma referência à camada DLL. Proceda da seguinte forma:
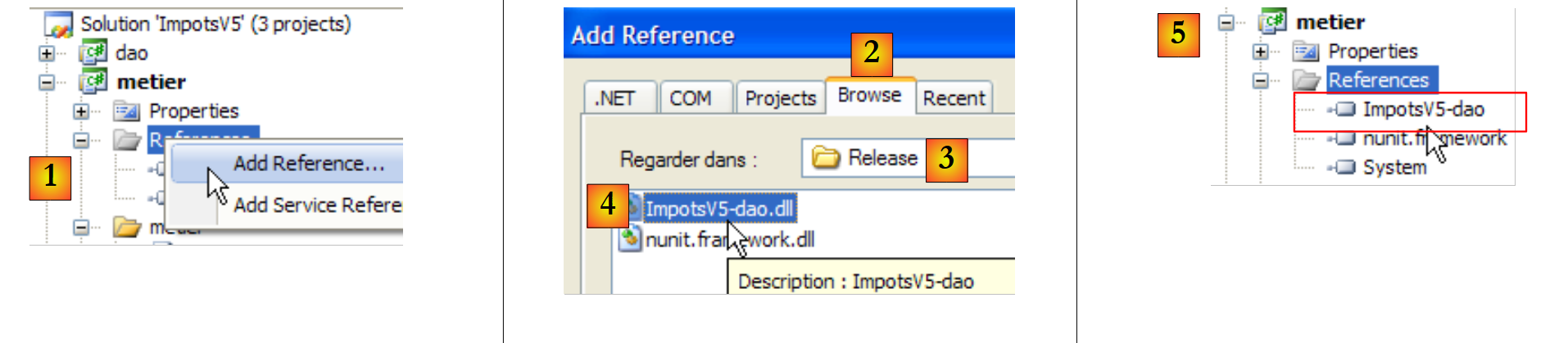 |
- em [1]: adiciona-se uma nova referência às referências do projeto [metier]
- em [2]: seleciona-se o separador [Browse]
- em [3]: seleciona-se a pasta [dao/bin/Release]
- em [4]: seleciona-se o DLL [ImpotsV5-dao.dll] gerado no projeto [dao]
- em [5]: a nova referência
A camada [metier] (ver [3] no projeto)
A interface [IImpotMetier] é a da versão anterior. O mesmo se aplica à classe [ImpotMetier].
O teste [Test1] (ver [4] no projeto)
A classe [Test1] limita-se a efetuar alguns cálculos salariais:
using System;
using Dao;
using Entites;
using Metier;
namespace Tests {
class Test1 {
static void Main() {
// é criada a camada [metier]
IImpotMetier metier = null;
try {
// criação da camada [metier]
metier = new ImpotMetier(new FileImpot("DataImpot.txt"));
} catch (ImpotException e) {
// exibição de erro
string msg = e.InnerException == null ? null : String.Format(", Exception d'origine : {0}", e.InnerException.Message);
Console.WriteLine("L'erreur suivante s'est produite : [Code={0},Message={1}{2}]", e.Code, e.Message, msg == null ? "" : msg);
// interrupção do programa
Environment.Exit(1);
}
// cálculo de alguns impostos
Console.WriteLine(String.Format("Impot(true,2,60000)={0} euros", metier.CalculerImpot(true, 2, 60000)));
Console.WriteLine(String.Format("Impot(false,3,60000)={0} euros", metier.CalculerImpot(false, 3, 60000)));
Console.WriteLine(String.Format("Impot(false,3,60000)={0} euros", metier.CalculerImpot(false, 3, 6000)));
Console.WriteLine(String.Format("Impot(false,3,60000)={0} euros", metier.CalculerImpot(false, 3, 600000)));
}
}
}
- linha 14: criação das camadas [metier] e [dao]. A camada [dao] é implementada com a classe [FileImpot]
- linhas 12-21: gestão de uma eventual exceção do tipo [ImpotException]
- linhas 23-26: chamadas repetidas do único método CalculerImpot da interface [IImpotMetier].
O projeto [metier] está configurado da seguinte forma:
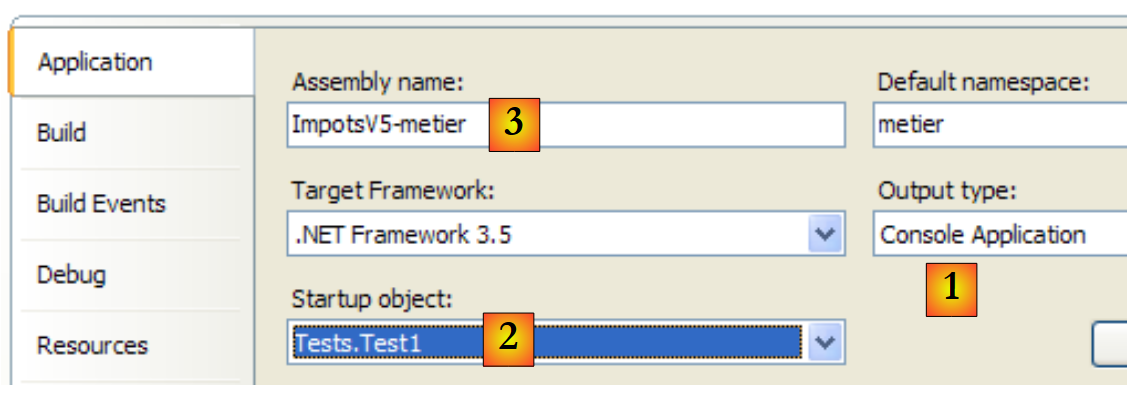 |
- [1]: o projeto é do tipo aplicação de consola
- [2]: a classe executada é a classe [Test1]
- [3]: a compilação do projeto irá produzir o executável [ImpotsV5-metier.exe]
A execução do projeto produz os seguintes resultados:
O teste [NUnit1] (ver [4] no projeto)
A classe de testes unitários [NUnit1] retoma os quatro cálculos anteriores e verifica os respetivos resultados:
using Dao;
using Metier;
using NUnit.Framework;
namespace Tests {
[TestFixture]
public class NUnit1:AssertionHelper {
// camada [metier] a testar
private IImpotMetier metier;
// fabricante
public NUnit1() {
// inicialização da camada [metier]
metier = new ImpotMetier(new FileImpot("DataImpot.txt"));
}
// teste
[Test]
public void CalculsImpot(){
// exibem-se as faixas de imposto
Expect(metier.CalculerImpot(true, 2, 60000), EqualTo(4282));
Expect(metier.CalculerImpot(false, 3, 60000), EqualTo(4282));
Expect(metier.CalculerImpot(false, 3, 6000), EqualTo(0));
Expect(metier.CalculerImpot(false, 3, 600000), EqualTo(179275));
}
}
}
- linha 14: criação das camadas [metier] e [dao]. A camada [dao] é implementada com a classe [FileImpot]
- linhas 21-24: chamadas repetidas do único método CalculerImpot da interface [IImpotMetier] com verificação dos resultados.
O projeto [metier] está agora configurado da seguinte forma:
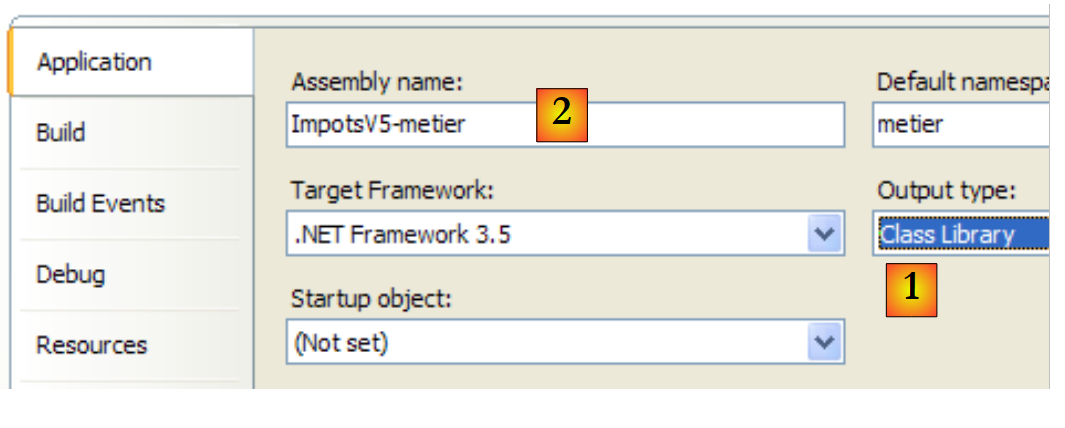 |
- [1]: o projeto é do tipo «biblioteca de classes»
- [2]: a geração do projeto irá produzir o DLL [ImpotsV5-metier.dll]
O projeto é gerado (F6). Em seguida, o DLL, [ImpotsV5-metier.dll] e gerados são carregados no NUnit e testados:
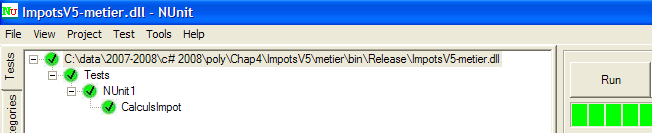 |
Acima, os testes foram bem-sucedidos. Consideramos agora a camada [metier] operacional. A sua DLL contém todas as classes do projeto, incluindo as classes de teste. Estas últimas são desnecessárias. Estamos a reconstruir a DLL para excluir as classes de teste.
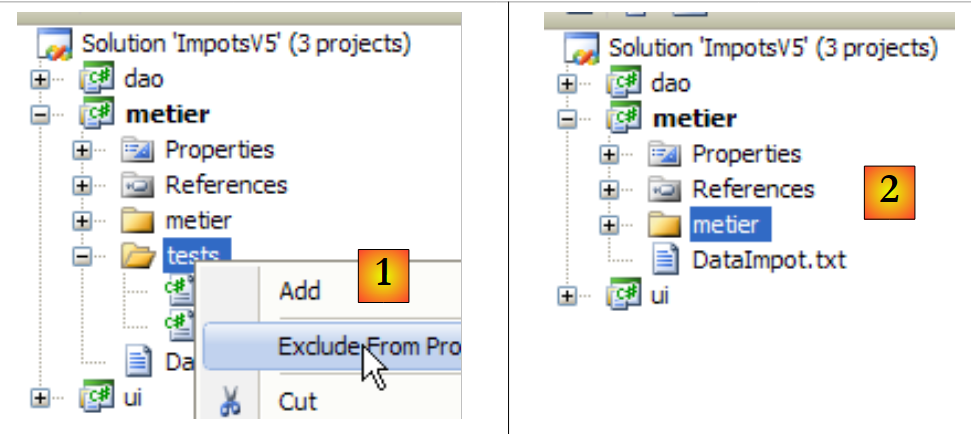 |
- em [1]: a pasta [tests] é excluída do projeto
- em [2]: o novo projeto. Este é regenerado pelo F6 para gerar um novo DLL.
6.4.5. A camada [ui]
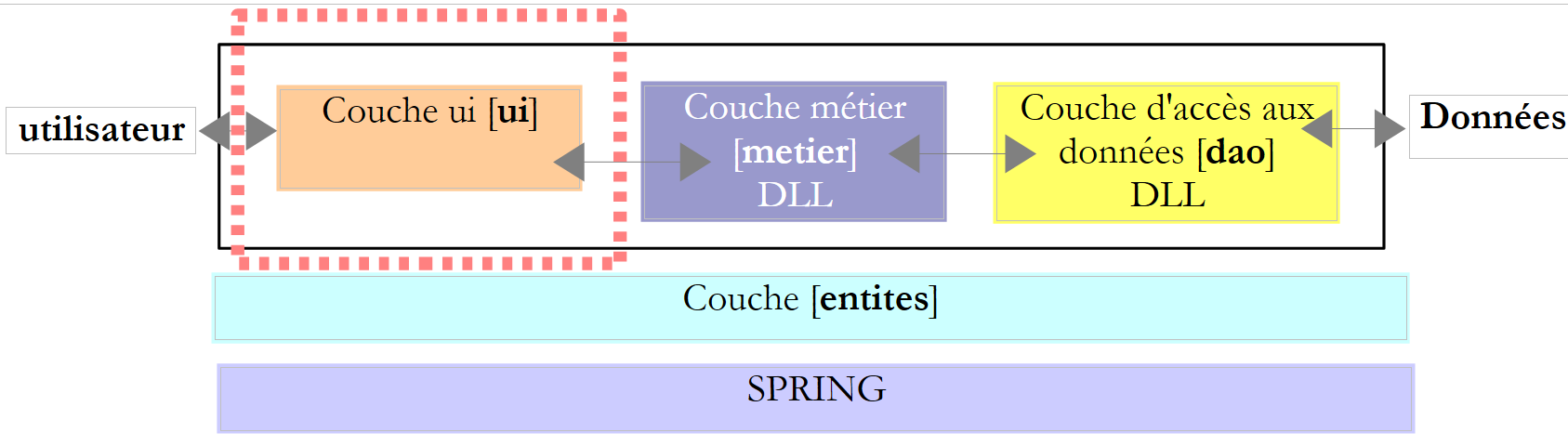 |
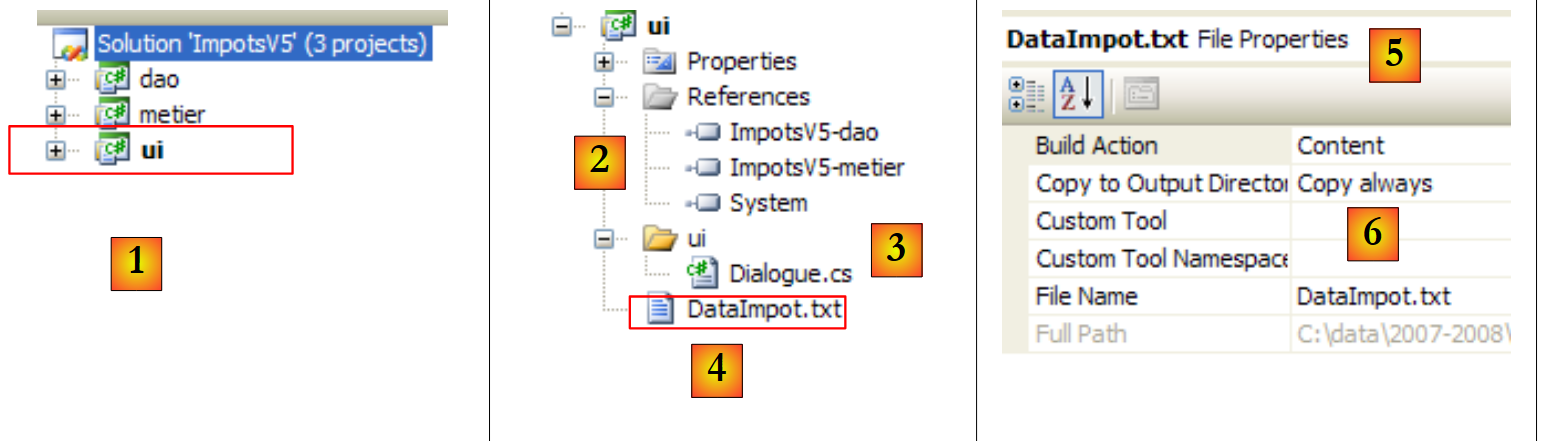 |
- em [1], o projeto [ui] tornou-se o projeto ativo da solução
- em [2]: as referências do projeto
- em [3]: a camada [ui]
- em [4]: o ficheiro [DataImpot.txt] das faixas de imposto, configurado em [5] para ser copiado automaticamente para a pasta de execução do projeto [6]
As referências do projeto (ver [2] no projeto)
A camada [ui] necessita das camadas [metier] e [dao] para realizar os seus cálculos de impostos. Por isso, necessita de uma referência às camadas DLL destas duas camadas. Proceda-se tal como foi demonstrado para a camada [metier]
A classe principal [Dialogue.cs] (ver [3] no projeto)
A classe [Dialogue.cs] corresponde à versão anterior.
Testes
O projeto [ui] está configurado da seguinte forma:
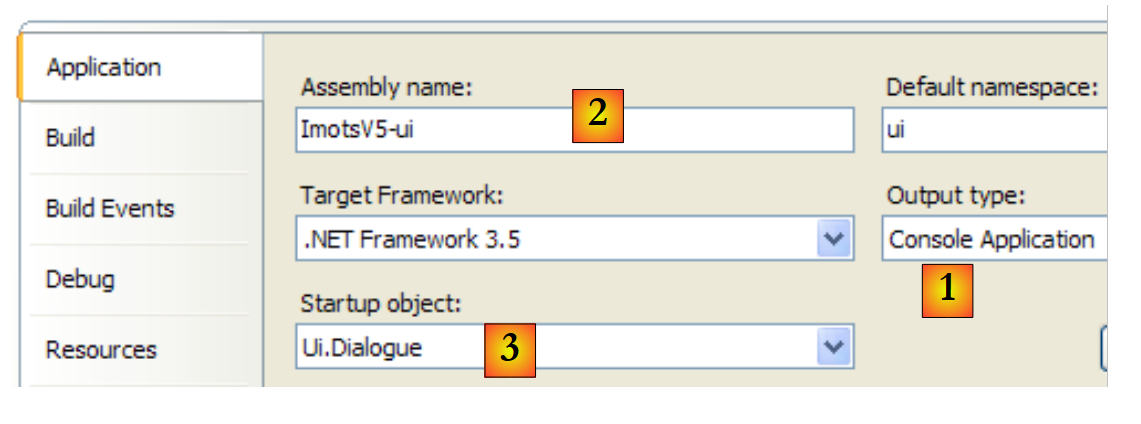 |
- [1]: o projeto é do tipo «aplicação de consola»
- [2]: a compilação do projeto irá produzir o executável [ImpotsV5-ui.exe]
- [3]: a classe que será executada
Um exemplo de execução (Ctrl+F5) é o seguinte:
Paramètres du calcul de l'Impot au format : Marié (o/n) NbEnfants Salaire ou rien pour arrêter :o 2 60000
Impot=4282 euros
6.4.6. A camada [Spring]
Voltemos ao código em [Dialogue.cs], que cria as camadas [dao] e [metier]:
// criam-se as camadas [metier et dao]
IImpotMetier metier = null;
try {
// criação da camada [metier]
metier = new ImpotMetier(new FileImpot("DataImpot.txt"));
} catch (ImpotException e) {
// exibição de erro
...
// paragem do programa
Environment.Exit(1);
}
A linha 5 cria as camadas [dao] e [metier], nomeando explicitamente as classes de implementação das duas camadas: FileImpot para a camada [dao], ImpotMetier para a camada [metier]. Se a implementação de uma das camadas for feita com uma nova classe, a linha 5 será alterada. Por exemplo:
metier = new ImpotMetier(new HardwiredImpot());
Para além desta alteração, nada mudará na aplicação, uma vez que cada camada comunica com a seguinte através de uma interface. Desde que esta última não mude, a comunicação entre camadas também não muda. O framework Spring permite-nos ir um pouco mais longe na independência das camadas, permitindo-nos externalizar num ficheiro de configuração o nome das classes que implementam as diferentes camadas. Alterar a implementação de uma camada equivale, assim, a alterar um ficheiro de configuração. Não há qualquer impacto no código da aplicação.
 |
No exemplo acima, a camada [ui] irá solicitar ao Spring queinstanciar as camadas [dao], [1], [metier] e [2] com base nas informações contidas num ficheiro de configuração. A camada [ui] solicitará então ao Spring [3] uma referência à camada [metier]:
// criam-se as camadas [metier et dao]
IImpotMetier metier = null;
try {
// contexto Spring
IApplicationContext ctx = ContextRegistry.GetContext();
// solicita-se uma referência na camada [metier]
metier = (IImpotMetier)ctx.GetObject("metier");
} catch (Exception e1) {
...
}
- linha 5: instanciação das camadas [dao] e [metier] pelo Spring
- linha 7: obtém-se uma referência à camada [metier]. Note-se que a camada [ui] obteve esta referência sem indicar o nome da classe que implementa a camada [metier].
O framework Spring existe em duas versões: Java e .NET. A versão .NET está disponível no URL (março de 2008) [http://www.springframework.net/]:
 |
- em [1]: o site de [Spring.net]
- em [2]: a página de downloads
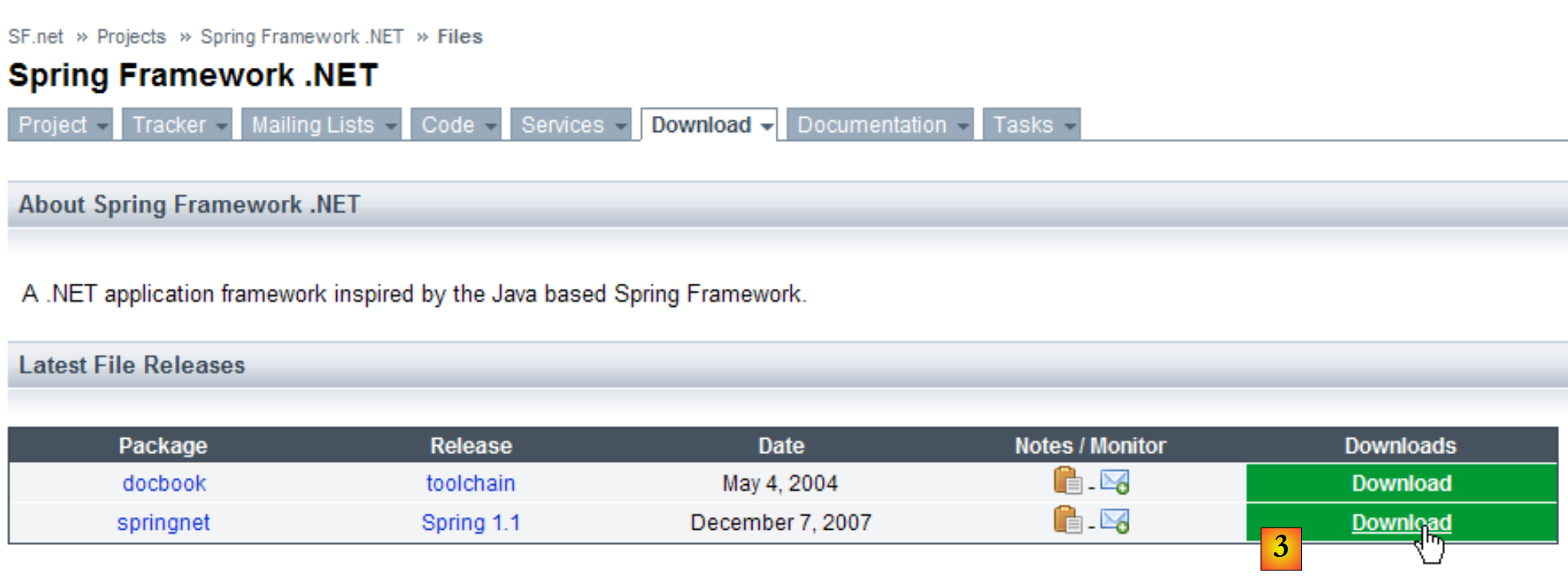 |
- em [3]: descarregar o Spring 1.1 (março de 2008)
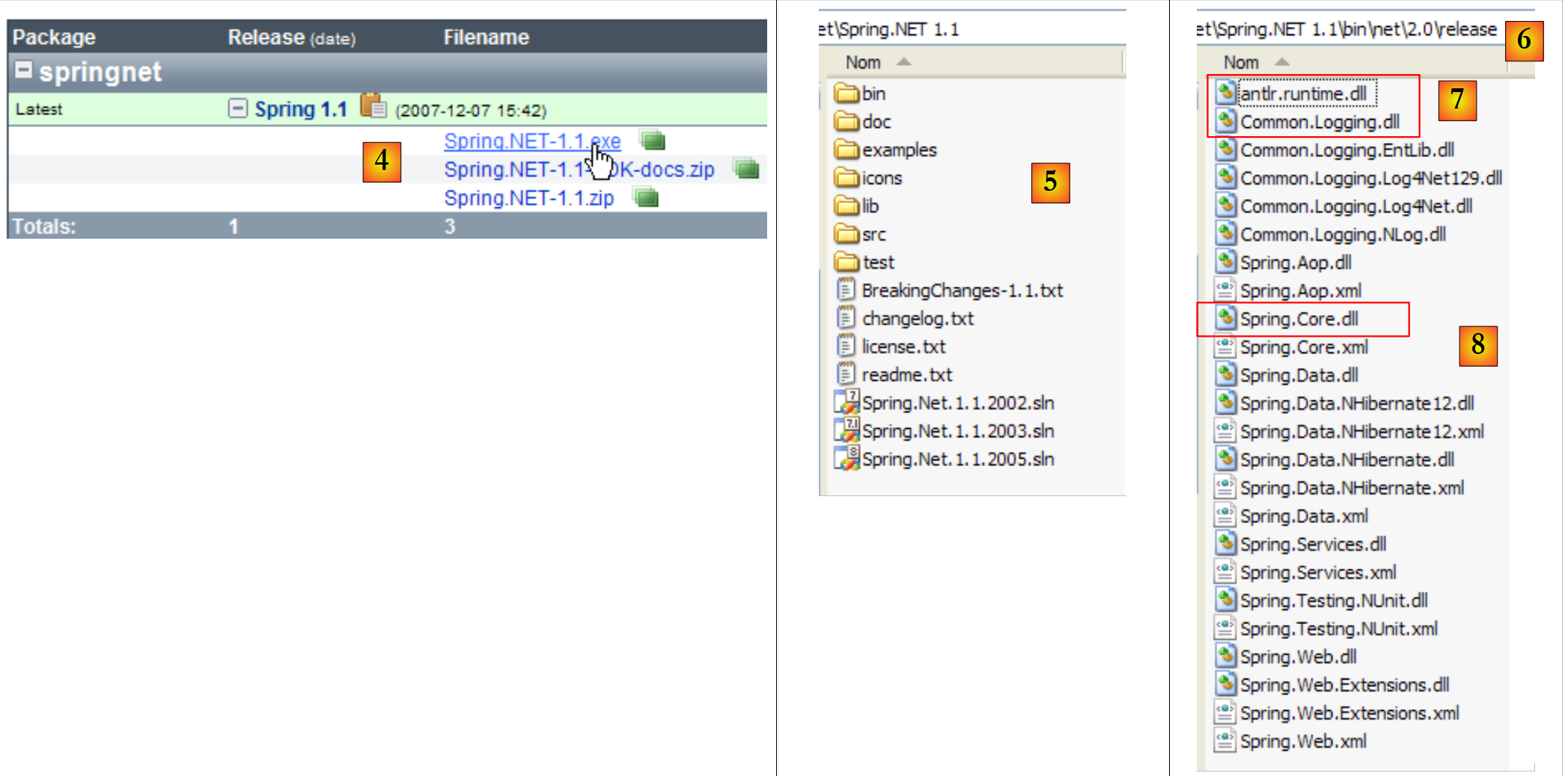 |
- em [4]: descarregar a versão .exe e, em seguida, instalá-la
- em [5]: a pasta gerada pela instalação
- em [6]: a pasta [bin/net/2.0/release] contém os ficheiros DLL do Spring para projetos do Visual Studio .NET 2.0 ou superior. O Spring é um framework abrangente. O aspeto do Spring que iremos utilizar aqui para gerir a integração das camadas numa aplicação chama-se IoC: Inversão de Controlo ou ainda DI: Injeção de Dependências. O Spring fornece bibliotecas para o acesso a bases de dados com NHibernate, a geração e a exploração de serviços web, de aplicações web, ...
- os DLL necessários para gerir a integração das camadas numa aplicação são os DLL, [7] e [8].
Armazenamos estes três DLL numa pasta [lib] do nosso projeto:
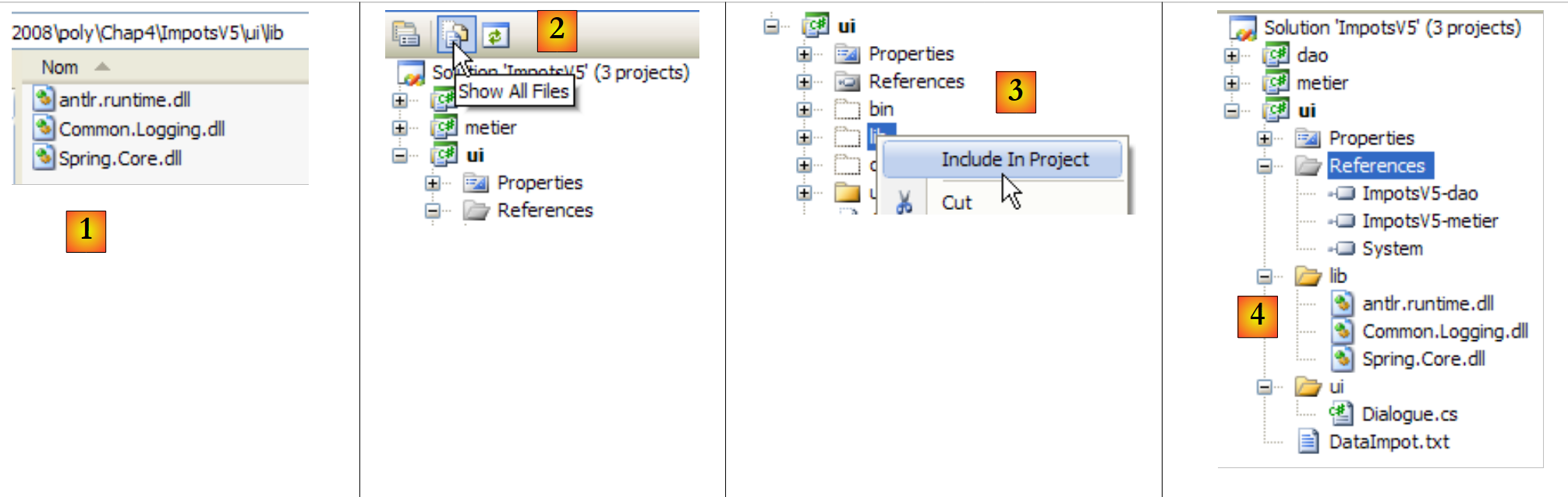 |
- [1]: os três ficheiros DLL são colocados na pasta [lib] utilizando o Explorador do Windows
- [2]: no projeto [ui], exibimos todos os ficheiros
- [3]: a pasta [ui/lib] está agora visível. Inclui-se no projeto
- [4]: a pasta [ui/lib] faz parte do projeto
A criação da pasta [lib] não é de forma alguma indispensável. As referências podiam ser criadas diretamente nas três pastas DLL da pasta [bin/net/2.0/release] de [Spring.net]. No entanto, a criação da pasta [lib] permite desenvolver a aplicação num computador que não disponha do [Spring.net], tornando-a assim menos dependente do ambiente de desenvolvimento disponível.
Adicionamos ao projeto [ui] referências às três novas pastas DLL:
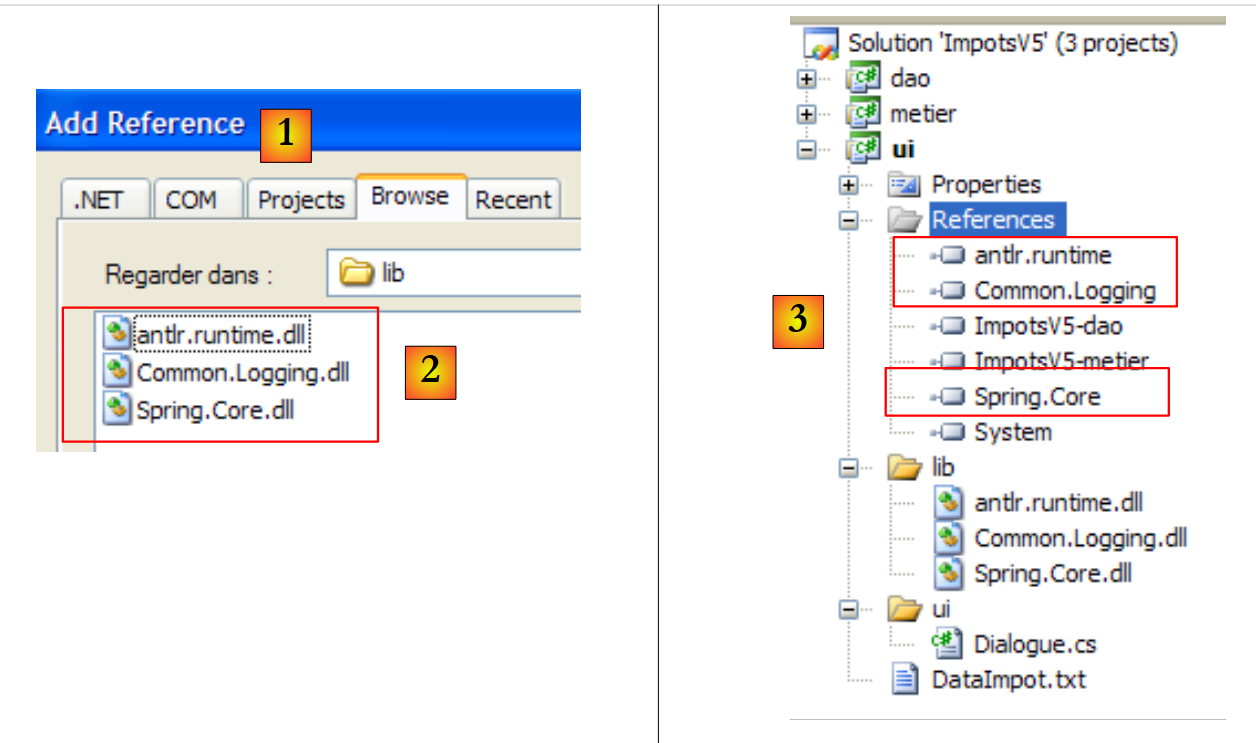 |
- [1]: criamos referências às três DLL da pasta [lib] [2]
- [3]: os três DLL fazem parte das referências do projeto
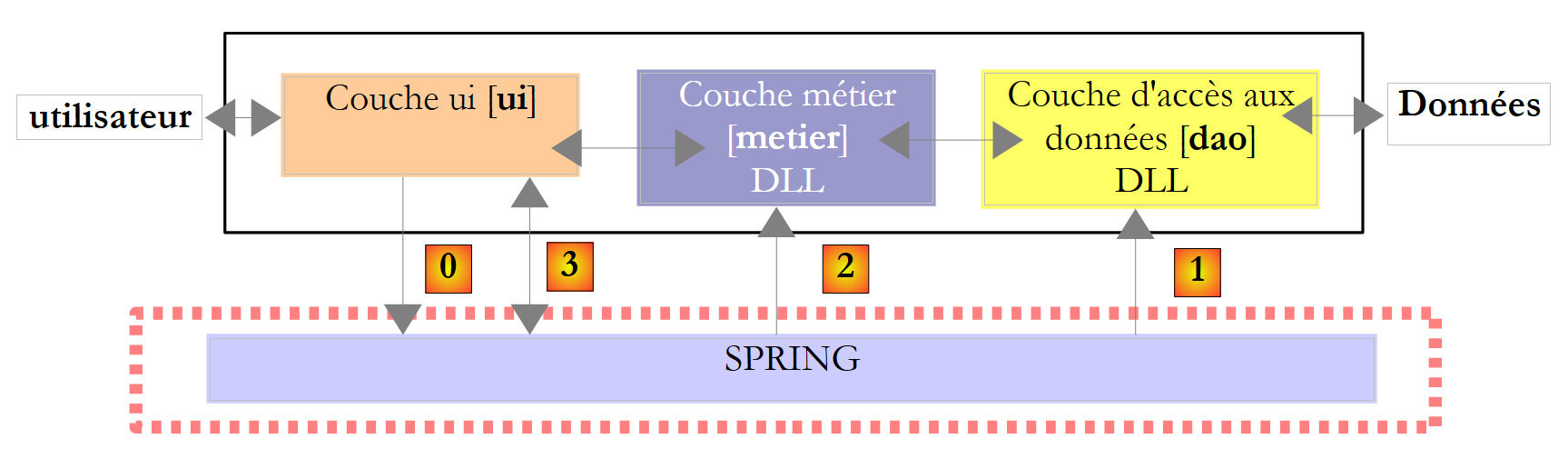
Voltemos a uma visão geral da arquitetura da aplicação:
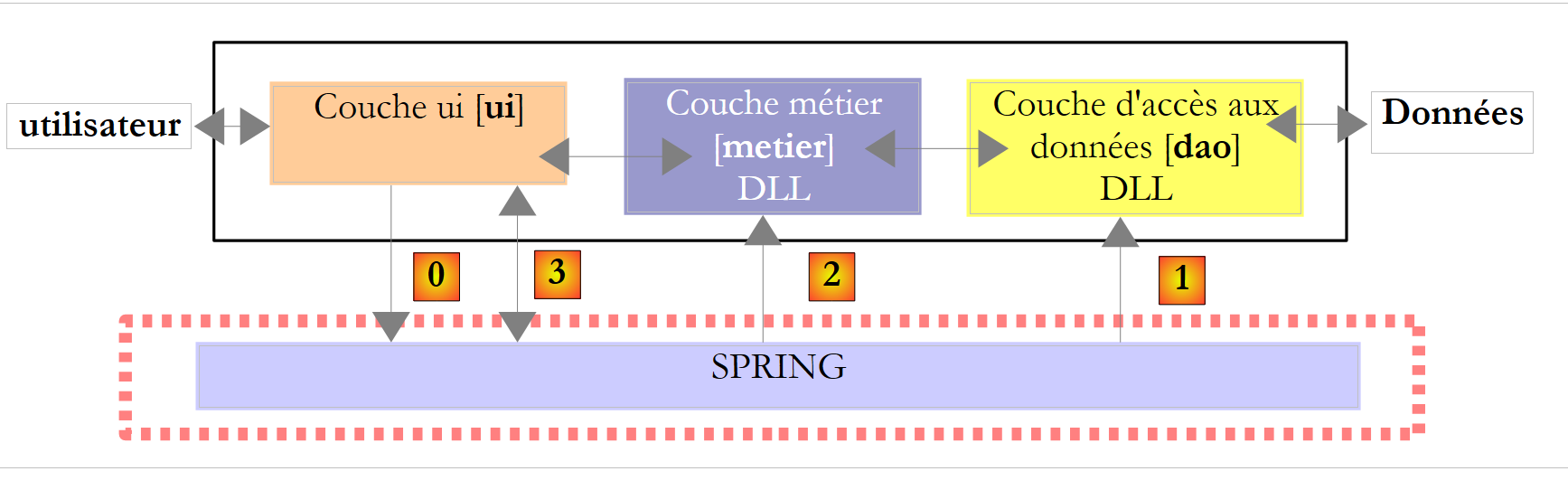 |
Acima, a camada [ui] irá solicitar ao Spring que instancie a camada [0]instanciar as camadas [dao], [1], [metier] e [2] com base nas informações contidas num ficheiro de configuração. A camada [ui] solicitará, em seguida, ao Spring [3] uma referência à camada [metier]. Isto traduzir-se-á na camada [ui] pelo seguinte código:
// criam-se as camadas [metier et dao]
IImpotMetier metier = null;
try {
// contexto Spring
IApplicationContext ctx = ContextRegistry.GetContext();
// é solicitada uma referência à camada [metier]
metier = (IImpotMetier)ctx.GetObject("metier");
} catch (Exception e1) {
...
}
- linha 5: instanciação das camadas [dao] e [metier] pelo Spring
- linha 7: obtém-se uma referência à camada [metier].
A linha [5] acima utiliza o ficheiro de configuração [App.config] do projeto do Visual Studio. Num projeto C#, este ficheiro serve para configurar a aplicação. [App.config] não é, portanto, um conceito do Spring, mas sim um conceito do Visual Studio que o Spring utiliza. O Spring sabe utilizar outros ficheiros de configuração além do [App.config]. A solução aqui apresentada não é, portanto, a única disponível.
Vamos criar o ficheiro [App.config] com o assistente do Visual Studio:
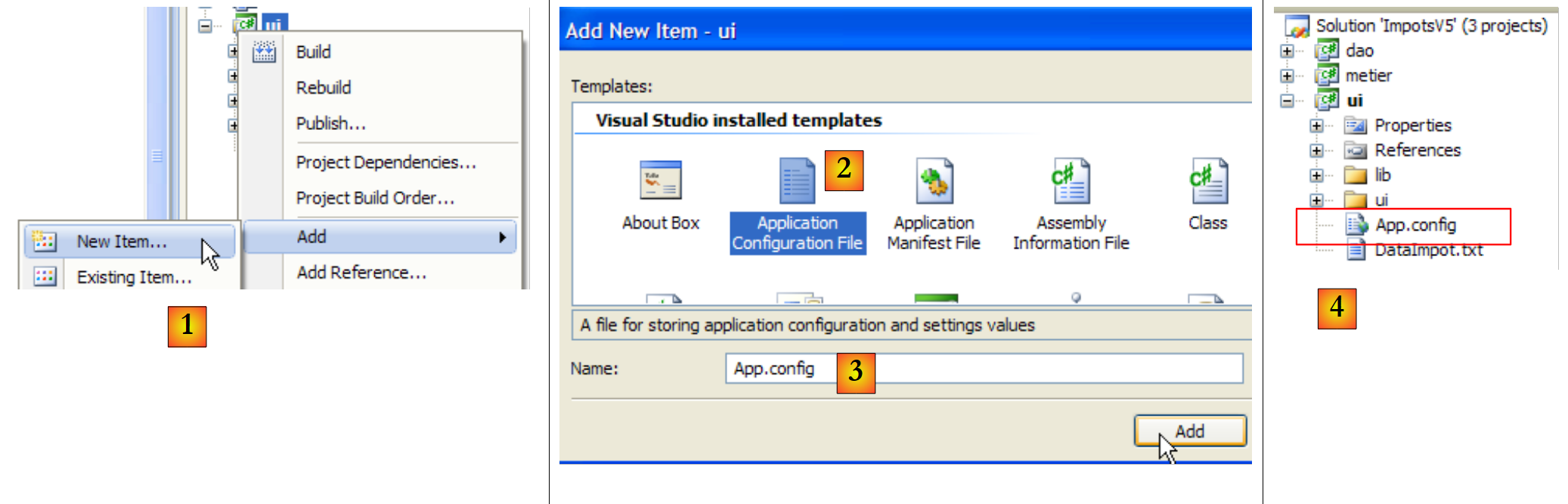 |
- em [1]: adição de um novo elemento ao projeto
- em [2]: selecionar «Application Configuration File»
- em [3]: [App.config] é o nome predefinido deste ficheiro de configuração
- em [4]: o ficheiro [App.config] foi adicionado ao projeto
O conteúdo do ficheiro [App.config] é o seguinte:
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
</configuration>
[App.config] é um ficheiro XML. A configuração do projeto é definida entre as balizas <configuration>. A configuração necessária para o Spring é a seguinte:
<?xml version="1.0" encoding="utf-8" ?>
<configuration>
<configSections>
<sectionGroup name="spring">
<section name="context" type="Spring.Context.Support.ContextHandler, Spring.Core" />
<section name="objects" type="Spring.Context.Support.DefaultSectionHandler, Spring.Core" />
</sectionGroup>
</configSections>
<spring>
<context>
<resource uri="config://spring/objects" />
</context>
<objects xmlns="http://www.springframework.net">
<object name="dao" type="Dao.FileImpot, ImpotsV5-dao">
<constructor-arg index="0" value="DataImpot.txt"/>
</object>
<object name="metier" type="Metier.ImpotMetier, ImpotsV5-metier">
<constructor-arg index="0" ref="dao"/>
</object>
</objects>
</spring>
</configuration>
- linhas 11-23: a secção delimitada pela baliza <spring> é designada por grupo de secções <spring>. É possível criar quantos grupos de secções se desejar no [App.config].
- Um grupo de secções contém secções: é o que acontece aqui:
- linhas 12-14: a secção <spring/context>
- linhas 15-22: a secção <spring/objects>
- linhas 4-9: a região <configSections> define a lista de gestores (handlers) dos grupos de secções presentes em [App.config].
- linhas 5-8: definem a lista de gestores das secções do grupo <spring> (name="spring").
- linha 6: o gestor da secção <context> do grupo <spring>:
- name: nome da secção gerida
- type: nome da classe que gere a secção no formato NomClasse, NomDLL.
- a secção <context> do grupo <spring> é gerida pela classe [Spring.Context.Support.ContextHandler], que se encontra em DLL [Spring.Core.dll]
- linha 7: o gestor da secção <objects> do grupo <spring>
As linhas 4-9 são padrão num ficheiro [App.config] com o Spring. Basta copiá-las de um projeto para outro.
- linhas 12-14: definem a secção <spring/context>.
- linha 13: a baliza <resource> tem como objetivo indicar onde se encontra o ficheiro que define as classes que o Spring deve instanciar. Estas podem estar no ficheiro [App.config], como aqui, mas também podem estar noutro ficheiro de configuração. A localização destas classes é indicada no atributo uri da baliza <resource>:
- <resource uri="config://spring/objects> indica que a lista de classes a instanciar se encontra no ficheiro [App.config] (config:), na secção //spring/objects, c.a.d, dentro da baliza <objects> da baliza <spring>.
- <resource uri="file://spring-config.xml"> indicaria que a lista de classes a instanciar se encontra no ficheiro [spring-config.xml]. Este ficheiro deve ser colocado nas pastas de execução (bin/Release ou bin/Debug) do projeto. O mais simples é colocá-lo, tal como foi feito com o ficheiro [DataImpot.txt], na raiz do projeto com a propriedade [Copy to output directory=always].
As linhas 12-14 são padrão num ficheiro [App.config] com o Spring. Basta copiá-las de um projeto para outro.
- linhas 15-22: definem as classes a instanciar. É nesta parte que se realiza a configuração específica de uma aplicação. A baliza <objects> delimita a secção de definição das classes a instanciar.
- linhas 16-18: definem a classe a instanciar para a camada [dao]
- linha 16: cada objeto instanciado pelo Spring é objeto de uma baliza <object>. Esta possui um atributo name que corresponde ao nome do objeto instanciado. É através deste que a aplicação solicita uma referência ao Spring: «dá-me uma referência ao objeto chamado dao». O atributo type define a classe a instanciar na forma NomClasse, NomDLL. Assim, a linha 16 define um objeto chamado «dao», instância da classe «Dao.FileImpot», que se encontra no «DLL» «ImpotsV5-dao.dll». Note-se que se indica o nome completo da classe (incluindo o espaço de nomes) e que o sufixo .dll não é especificado no nome da DLL.
Uma classe pode ser instanciada de duas formas com o Spring:
- através de um construtor específico ao qual se passam parâmetros: é o que se faz nas linhas 16-18.
- através do construtor por defeito, sem parâmetros. O objeto é então inicializado através das suas propriedades públicas: a baliza <object> contém, nesse caso, subbalizas <property> para inicializar essas diferentes propriedades. Não temos aqui nenhum exemplo deste caso.
- (continuação)
- linha 16: a classe instanciada é a classe FileImpot. Esta possui o seguinte construtor:
public FileImpot(string fileName);
Os parâmetros do construtor são definidos através das tags <constructor-arg>.
- linha 17: define o primeiro e único parâmetro do construtor. O atributo index é o número do parâmetro do construtor, o atributo value é o seu valor: <constructor-arg index="i" value="valuei"/>
- linhas 19-21: definem a classe a instanciar para a camada [metier]: a classe [Metier.ImpotMetier], que se encontra na DLL [ImpotsV5-metier.dll].
- linha 19: a classe instanciada é a classe ImpotMetier. Esta possui o seguinte construtor:
public ImpotMetier(IImpotDao dao);
- (continuação)
- linha 20: define o primeiro e único parâmetro do construtor. Acima, o parâmetro dao do construtor é uma referência a um objeto. Neste caso, na baliza <constructor-arg>, utiliza-se o atributo ref em vez do atributo value que foi utilizado para a camada [dao]: <constructor-arg index="i" ref="refi"/>. No construtor acima, o parâmetro dao representa uma instância na camada [dao]. Esta instância foi definida pelas linhas 16 a 18 do ficheiro de configuração. Assim, na linha 20:
<constructor-arg index="0" ref="dao"/>
ref="dao" representa o objeto Spring «dao» definido nas linhas 16 a 18.
Em resumo, o ficheiro [App.config]:
- instancia a camada [dao] com a classe FileImpot, que recebe como parâmetro DataImpot.txt (linhas 16 a 18). O objeto resultante é denominado «dao»
- instancia a camada [metier] com a classe ImpotMetier, que recebe como parâmetro o objeto «dao» anterior (linhas 19-21).
Resta-nos apenas utilizar este ficheiro de configuração do Spring na camada [ui]. Para tal, duplicamos a classe [Dialogue.cs] para [Dialogue2.cs] e tornamos esta última a classe principal do projeto [ui]:
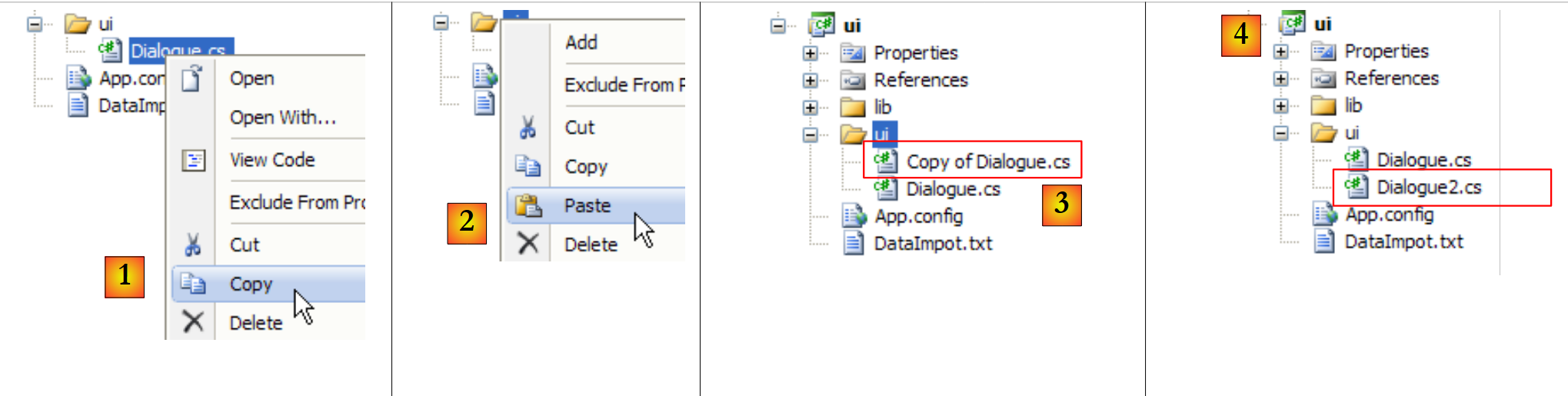 |
- em [1]: cópia de [Dialogue.cs]
- para [2]: fusão
- em [3]: a cópia de [Dialogue.cs]
- em [4]: renomeado para [Dialogue2.cs]
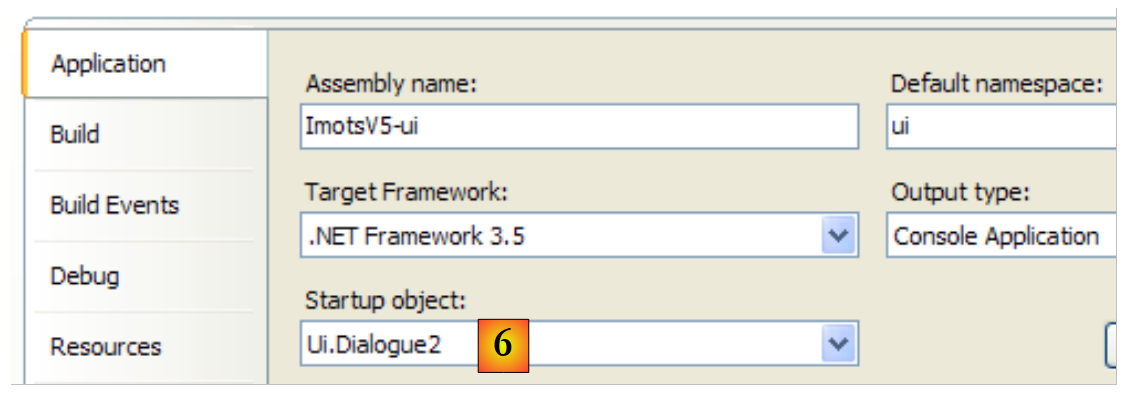 |
- em [6]: define-se [Dialogue2.cs] como a classe principal do projeto [ui].
O código seguinte de [Dialogue.cs]:
// criam-se as camadas [metier et dao]
IImpotMetier metier = null;
try {
// criação da camada [metier]
metier = new ImpotMetier(new FileImpot("DataImpot.txt"));
} catch (ImpotException e) {
// exibição de erro
string msg = e.InnerException == null ? null : String.Format(", Exception d'origine : {0}", e.InnerException.Message);
Console.WriteLine("L'erreur suivante s'est produite : [Code={0},Message={1}{2}]", e.Code, e.Message, msg == null ? "" : msg);
// paragem do programa
Environment.Exit(1);
}
// loop infinito
while (true) {
...
passa a ser o seguinte em [Dialogue2.cs]:
// Criação das camadas [metier et dao]
IApplicationContext ctx = null;
try {
// contexto Spring
ctx = ContextRegistry.GetContext();
} catch (Exception e1) {
// exibição de erro
Console.WriteLine("Chaîne des exceptions : \n{0}", "".PadLeft(40, '-'));
Exception e = e1;
while (e != null) {
Console.WriteLine("{0}: {1}", e.GetType().FullName, e.Message);
Console.WriteLine("".PadLeft(40, '-'));
e = e.InnerException;
}
// encerramento do programa
Environment.Exit(1);
}
// solicita-se uma referência na camada [metier]
IImpotMetier metier = (IImpotMetier)ctx.GetObject("metier");
// loop infinito
while (true) {
....................................
- linha 2: IApplicationContext dá acesso a todos os objetos instanciados pelo Spring. A este objeto chama-se o contexto Spring da aplicação ou, mais simplesmente, o contexto da aplicação. Por enquanto, este contexto ainda não foi inicializado. É o bloco try/catch que se segue que o faz.
- linha 5: a configuração do Spring em [App.config] é lida e processada. Após esta operação, se não tiver ocorrido nenhuma exceção, todos os objetos da secção <objects> foram instanciados:
- o objeto Spring «dao» é uma instância na camada [dao]
- o objeto Spring «metier» é uma instância na camada [metier]
- linha 19: a classe [Dialogue2.cs] necessita de uma referência na camada [metier]. Esta é solicitada ao contexto da aplicação. O objeto IApplicationContext dá acesso aos objetos Spring através do seu nome (atributo «name» da tag <object> da configuração Spring). A referência devolvida é uma referência ao tipo genérico Object. É necessário converter a referência devolvida para o tipo correto, neste caso, o tipo da interface da camada [metier]: IImpotMetier.
Se tudo correu bem, após a linha 19, [Dialogue2.cs] tem uma referência à camada [metier]. O código das linhas 21 e seguintes é o da classe [Dialogue.cs] já analisada.
- linhas 6-17: gestão da exceção que ocorre quando a execução do ficheiro de configuração do Spring não pode ser concluída. Podem existir várias razões para isso: sintaxe incorreta do próprio ficheiro de configuração ou impossibilidade de instanciar um dos objetos configurados. No nosso exemplo, este último caso ocorreria se o ficheiro DataImpot.txt da linha 17 do [App.config] não fosse encontrado na pasta de execução do projeto.
A exceção que é propagada na linha 6 faz parte de uma cadeia de exceções, em que cada exceção tem duas propriedades:
- Mensagem: a mensagem de erro associada à exceção
- InnerException: a exceção anterior na cadeia de exceções
O ciclo das linhas 10-14 exibe todas as exceções da cadeia na forma: classe da exceção e mensagem associada.
Quando se executa o projeto [ui] com um ficheiro de configuração válido, obtêm-se os resultados habituais:
Paramètres du calcul de l'Impot au format : Marié (o/n) NbEnfants Salaire ou rien pour arrêter :o 2 60000
Impot=4282 euros
Quando se executa o projeto [ui] com um ficheiro [DataImpotInexistant.txt] inexistente,
<object name="dao" type="Dao.FileImpot, ImpotsV5-dao">
<constructor-arg index="0" value="DataImpotInexistant.txt"/>
</object>
obtêm-se os seguintes resultados:
- linha 17: a exceção original do tipo [FileNotFoundException]
- linha 15: a camada [dao] encapsula esta exceção num tipo [Entites.ImpotException]
- linha 9: a exceção lançada pelo Spring porque não conseguiu instanciar o objeto denominado «dao». No processo de criação deste objeto, ocorreram anteriormente duas outras exceções: as das linhas 11 e 13.
- Como o objeto «dao» não pôde ser criado, o contexto da aplicação não pôde ser criado. É este o significado da exceção da linha 5. Anteriormente, tinha ocorrido outra exceção, a da linha 7.
- Linha 3: a exceção de nível mais elevado, a última da cadeia: é sinalizado um erro de configuração.
De tudo isto, fica a retê-se que é a exceção mais profunda, neste caso a da linha 17, que é frequentemente a mais significativa. Note-se, no entanto, que o Spring conservou a mensagem de erro da linha 17 para a transmitir à exceção de nível superior, na linha 3, de modo a identificar a causa original do erro ao nível mais elevado.
O Spring merece, por si só, um livro. Aqui, apenas abordámos superficialmente o assunto. É possível aprofundá-lo com o documento [spring-net-reference.pdf], que se encontra na pasta de instalação do Spring:
 |
Pode-se também consultar o [http://tahe.developpez.com/dotnet/springioc], um tutorial sobre o Spring apresentado num contexto VB.NET.