5. Relazioni tra tabelle
5.1. Chiavi esterne
Un database relazionale è un insieme di tabelle collegate tra loro da relazioni. Prendiamo un esempio ispirato alla precedente tabella [BIBLIO], la cui struttura era la seguente:
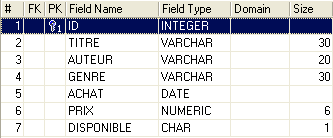
Un esempio di contenuto era il seguente:
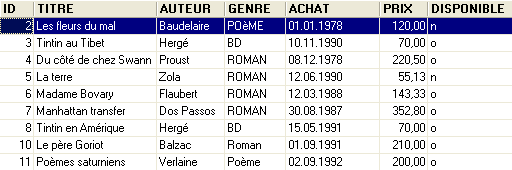
Potremmo voler ottenere informazioni sui diversi autori di queste opere, ad esempio nom e prénom, la loro data di nascita, nationalité. Creiamo una tabella di questo tipo. Facciamo clic con il tasto destro su [DBBIBLIO / Tables], quindi selezioniamo l’opzione [New Table]:
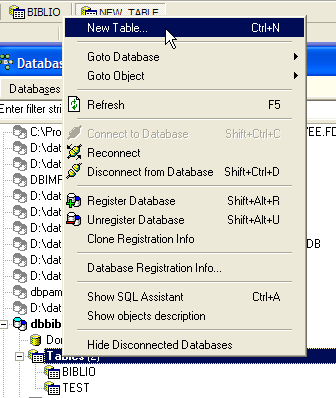
Ora creiamo la seguente tabella [AUTEURS]:
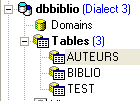 | 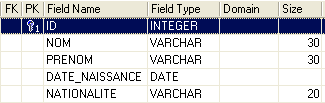 |
chiave primaria della tabella - serve a identificare in modo univoco una riga | |
nome dell'autore | |
nome dell'autore, se presente | |
la sua data di nascita | |
il suo paese di origine |
Il contenuto della tabella [AUTEURS] potrebbe essere il seguente:
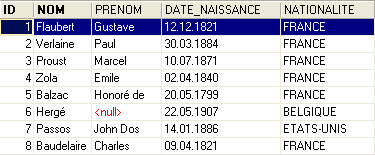
Torniamo alla tabella [BIBLIO] e al suo contenuto:
Nella riga [AUTEUR] della tabella, non è più necessario inserire il nome dell’autore. È invece preferibile inserire il numero (id) che gli è stato assegnato nella tabella [AUTEURS]. Creiamo quindi una nuova tabella denominata [LIVRES]. Per crearla, utilizzeremo lo script [biblio.sql] creato al paragrafo 3.14. Carichiamo questo script con lo strumento [Script Executive, Ctrl-F12]:
Modifichiamo lo script di creazione della tabella BIBLIO per adattarlo a quello della tabella LIVRES:
Commentiamo solo le modifiche:
- riga 4: la voce [AUTEUR] della tabella diventa un numero intero. Questo numero fa riferimento a uno degli autori della tabella [AUTEURS] creata in precedenza.
- righe 11-19: i nomi degli autori sono stati sostituiti dai rispettivi numeri di autore.
- riga 29: il nome del vincolo è stato modificato. In precedenza si chiamava [ UNQ1_BIBLIO ]. Ora si chiama [ UNQ1_LIVRES ]. Questo nome può essere qualsiasi cosa. È tuttavia preferibile che abbia un significato. In questo caso non è stato fatto questo sforzo. I vincoli sui diversi campi e sulle diverse tabelle di un database devono essere distinti da nomi diversi. Ricordiamo che il vincolo della riga 29 richiede che un titolo sia unico nella tabella.
- riga 36: modifica del nome del vincolo sulla chiave primaria ID.
Eseguiamo questo script. Se va a buon fine, otteniamo la seguente nuova tabella [LIVRES]:
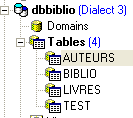 | 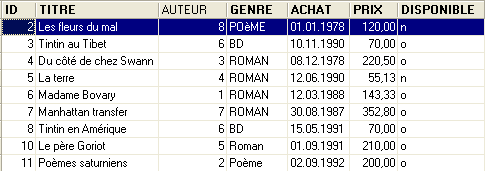 |
Ci si potrebbe chiedere se, alla fine, ne sia valsa la pena. Infatti, la tabella [LIVRES] riporta i numeri degli autori al posto dei loro nomi. Dato che ci sono migliaia di autori, sembra difficile stabilire il collegamento tra un libro e il suo autore. Fortunatamente il linguaggio SQL è lì per aiutarci. Ci permette di interrogare più tabelle contemporaneamente. A titolo di esempio, presentiamo la query SQL che ci permette di ottenere i titoli dei libri della biblioteca, associati alle informazioni sui loro autori. Utilizziamo l’editor SQL (F12) per inviare il comando SQL seguente:
SQL> select LIVRES.titre, AUTEURS.nom, AUTEURS.prenom,AUTEURS.date_naissance
FROM LIVRES inner join AUTEURS on LIVRES.AUTEUR=AUTEURS.ID
ORDER BY AUTEURS.nom asc
È troppo presto per spiegare questo ordine SQL. Ne riparleremo prossimamente. Il risultato di questa richiesta è il seguente:
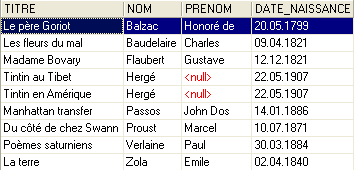
Ogni libro è stato correttamente associato al proprio autore e alle informazioni ad esso relative.
Riassumiamo ciò che abbiamo appena fatto:
- abbiamo due tabelle che raccolgono informazioni di natura diversa:
- la tabella AUTEURS raccoglie informazioni sugli autori
- la tabella LIVRES raccoglie informazioni sui libri acquistati dalla biblioteca
- queste tabelle sono collegate tra loro. Un libro ha necessariamente un autore. Può anche averne più di uno. Questo caso non è stato preso in considerazione qui. La colonna [AUTEUR] della tabella [LIVRES] fa riferimento a una riga della tabella [AUTEURS]. Questo fenomeno viene definito «relazione».
La relazione che collega la tabella [LIVRES] alla tabella [AUTEURS] è in realtà una forma di vincolo: una riga della tabella [LIVRES] deve sempre avere un numero d’autore presente nella tabella [AUTEURS]. Se una riga della tabella [LIVRES] avesse un numero d’autore che non esiste nella tabella [AUTEURS], ci troveremmo in una situazione anomala in cui non saremmo in grado di individuare l’autore di un libro.
La tabella SGBD è in grado di verificare che questo vincolo sia sempre rispettato. A tal fine, aggiungeremo un vincolo alla tabella [LIVRES]:
 | 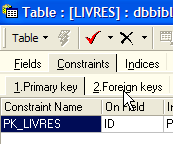 | 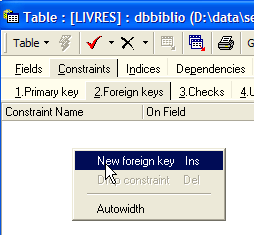 |
Il collegamento che unisce la voce [AUTEUR] della tabella [LIVRES] al campo [ID] della tabella [AUTEURS] è denominato "collegamento con chiave esterna". Il campo [AUTEUR] della tabella [LIVRES] è denominato «chiave esterna» o «foreign key» nella procedura guidata sopra riportata. Definire una chiave esterna significa stabilire che il valore di una colonna [c1] di una tabella [T1] deve essere presente nella colonna [c2] della tabella [T2]. La colonna [c1] è detta "chiave esterna" della tabella T1 rispetto alla colonna [c2] della tabella [T2]. La colonna [c2] è spesso la chiave primaria della tabella [T2], ma non è obbligatorio.
Definiamo la chiave esterna [AUTEUR] della tabella [LIVRES] sul campo [ID] della tabella [AUTEURS] nel modo seguente:
 |
- nome del vincolo: libero
- colonna "chiave esterna", in questo caso la colonna [AUTEUR] della tabella [LIVRES]
- tabella a cui fa riferimento la chiave esterna. In questo caso, la colonna [AUTEUR] della tabella [LIVRES] deve avere un valore nella colonna [ID] della tabella [AUTEURS]. È quindi la tabella [AUTEURS] a essere referenziata.
- colonna a cui fa riferimento la chiave esterna. In questo caso, la colonna [ID] della tabella [AUTEURS].
Convalidiamo questo vincolo:
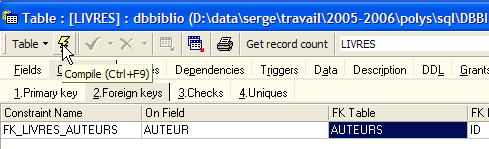
Se tutto va bene, viene accettato:
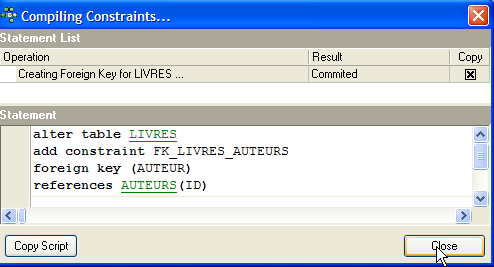
Qual è la conseguenza di questo nuovo vincolo di chiave esterna? Con l’editor SQL (F12), proviamo a inserire una riga nella tabella LIVRES con un numero di autore inesistente:
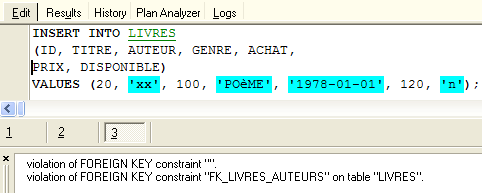
L’operazione [INSERT] sopra riportata ha tentato di inserire un libro con un numero d’autore (100) inesistente. L’esecuzione della query non è andata a buon fine. Il messaggio di errore associato indica che si è verificata una violazione del vincolo di chiave esterna "FK_LIVRES_AUTEURS". Si tratta di quello che abbiamo appena definito.
5.2. Operazioni di join tra due tabelle
Sempre nel database [DBBIBLIO] (o in qualsiasi altro database), creiamo due tabelle di prova denominate TA e TB e definite come segue:
Tabella TA
- ID: chiave primaria della tabella TA - DATA: un dato qualsiasi | 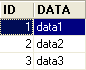 |
Tabella TB
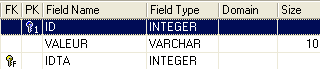 - ID: chiave primaria della tabella TB - IDTA: chiave esterna della tabella TB che fa riferimento alla colonna ID della tabella TA. Pertanto, un valore della colonna IDTA della tabella TA deve essere presente nella colonna ID della tabella TA - VALEUR: un dato qualsiasi | 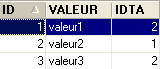 |
Nell’editor SQL (F12), emetteremo comandi SQL che utilizzano contemporaneamente le due tabelle TA e TB.
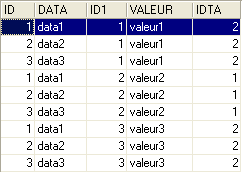
L'ordine SQL coinvolge, dopo la parola chiave FROM, le due tabelle TA e TB. L'operazione FROM TA, TB provocherà la creazione temporanea di una nuova tabella in cui ogni riga della tabella TA sarà associata a ciascuna delle righe della tabella TB. Pertanto, se la tabella TA ha NA righe e la tabella TB ha NB righe, la tabella risultante avrà NA × NB righe. È quanto mostra la schermata qui sopra. Inoltre, ogni riga contiene le colonne di entrambe le tabelle. Le colonne coli specificate nell'ordine [SELECT col1, col2, ... FROM ...] indicano quelle da mantenere. In questo caso, la parola chiave * indica che vengono richieste tutte le colonne della tabella risultante. A volte si dice che la tabella risultante dall’ordine precedente SQL sia il prodotto cartesiano delle tabelle TA e TB.
Nell’esempio sopra riportato, ogni riga della tabella TA è stata associata a ogni riga della tabella TB. In generale, si desidera associare a una riga della tabella TA le righe della tabella TB che hanno una relazione con essa. Tale relazione assume spesso la forma di un vincolo di chiave esterna. È proprio questo il caso. A una riga della tabella TA è possibile associare le righe della tabella TB che soddisfano la relazione TB.IDTA=TA.ID. Esistono diversi modi per eseguire questa operazione:
L'ordine SQL è analogo al precedente, con due differenze:
- le righe risultanti dal prodotto cartesiano TA x TB vengono filtrate da una clausola WHERE che associa a una riga della tabella TA, le sole righe della tabella TB che soddisfano la relazione TB.IDTA=TA.ID
- si richiedono solo alcune colonne con la sintassi [T.col], dove T è il nome di una tabella e col il nome di una colonna di tale tabella. Questa sintassi consente di eliminare l'ambiguità che potrebbe sorgere se due tabelle avessero colonne con lo stesso nome. Quando tale ambiguità non sussiste, è possibile utilizzare la sintassi [col] senza specificare la tabella a cui appartiene la colonna.
Il risultato ottenuto è il seguente:
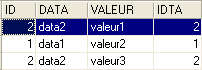
Lo stesso risultato può essere ottenuto con il seguente comando SQL:
Dal termine [inner join] deriva il nome di «join interno» attribuito a questo tipo di operazioni tra due tabelle. Vedremo che esiste anche un «join esterno». In un join interno, l’ordine delle tabelle nella query non ha alcuna influenza sul risultato: FROM TA inner join TB è equivalente a FROM TB inner join TA.
L'ordine precedente SQL inserisce nella tabella risultante solo le righe della tabella TA a cui fa riferimento almeno una riga della tabella TB. Pertanto, la riga di TA [3, data3] non compare nel risultato poiché non è referenziata da una riga di TB. Si potrebbe voler selezionare tutte le righe di TA, indipendentemente dal fatto che siano o meno referenziate da una riga di TB. In tal caso si utilizza un join esterno tra le due tabelle:
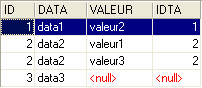
Qui abbiamo un "left outer join". Per comprendere il termine "FROM TA left outer join TB", bisogna immaginare un join con la tabella TA a sinistra e la tabella TB a destra. Tutte le righe della tabella di sinistra compaiono nel risultato di un join esterno sinistro, anche quelle per le quali la relazione di join non è verificata. Questa relazione di join non è necessariamente un vincolo di chiave esterna, anche se si tratta comunque del caso più comune.
Nel seguente ordine:
è la tabella TB a trovarsi «a sinistra» nel join esterno. Nel risultato si ritroveranno quindi tutte le righe di TB:
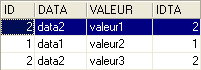
A differenza del join interno, l’ordine delle tabelle è quindi importante. Esistono anche join esterni a destra:
- FROM TA left outer join TB è equivalente a FROM TB right outer join TA: la tabella TA è a sinistra
- FROM TB con left outer join su TA è equivalente a FROM TA con right outer join su TB: la tabella TB si trova a sinistra
Ora che conosciamo le basi dell’utilizzo simultaneo di più tabelle, possiamo affrontare operazioni di interrogazione più complesse sui database.