3. Introduzione al linguaggio SQL
In questa sezione del capitolo presentiamo i primi comandi SQL che consentono di creare e gestire una singola tabella. Ne forniamo in genere una versione semplificata. La loro sintassi completa è disponibile nelle guide di riferimento di Firebird (cfr. paragrafo 2.2).
Un database viene utilizzato da persone con competenze diverse:
- l’amministratore del database è in genere una persona che padroneggia il linguaggio SQL e i database. È lui a creare le tabelle, poiché questa operazione viene solitamente eseguita una sola volta. Nel corso del tempo, potrebbe essere necessario modificare la loro struttura. Un database è un insieme di tabelle collegate tra loro da relazioni. È l’amministratore del database a definire tali relazioni. È inoltre lui a concedere i diritti ai diversi utenti del database. In questo modo stabilirà che un determinato utente abbia il diritto di visualizzare il contenuto di una tabella ma non di modificarla.
- L’utente del database è colui che gestisce i dati. A seconda dei diritti concessi dall’amministratore del database, potrà aggiungere, modificare o eliminare dati nelle diverse tabelle del database. Potrà inoltre analizzarli per ricavarne informazioni utili al corretto funzionamento dell’azienda, dell’amministrazione, ecc.
Nel paragrafo 2.6 abbiamo presentato l’editor SQL dello strumento [IB-Expert]. È proprio questo strumento che utilizzeremo. Ricordiamo alcuni punti:
- L’editor SQL è accessibile tramite l’opzione di menu [Tools/SQL Editor] oppure tramite il tasto [F12]

Si aprirà quindi una finestra [SQL Editor] in cui è possibile digitare un comando SQL:
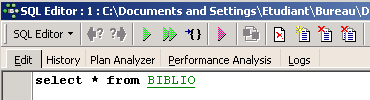
Lo screenshot qui sopra viene spesso rappresentato dal testo riportato di seguito:
3.1. I tipi di dati di Firebird
Quando si crea una tabella, è necessario specificare il tipo di dati che una colonna della tabella può contenere. Di seguito sono riportati i tipi di dati più comuni di Firebird. Si noti che questi tipi di dati possono variare da un SGBD all'altro.
numero intero nell'intervallo [-32768, 32767]: 4 | |
numero intero nel dominio [–2 147 483 648, 2 147 483 647]: -100 | |
numero reale di n cifre, di cui m dopo la virgola NUMERIC(5,2): -100,23, +027,30 | |
numero reale approssimato con 7 cifre significative: 10,4 | |
numero reale approssimato con 15 cifre significative: -100.89 | |
stringa di esattamente N caratteri. Se la stringa memorizzata ha meno di N caratteri, viene completata con spazi. CHAR(10): 'ANGERS ' (4 spazi finali) | |
stringa di al massimo N caratteri VARCHAR(10): 'ANGERS' | |
una data: '2006-01-09' (formato YYYY-MM-DD) | |
un'ora: '16:43:00' (formato HH:MM:SS) | |
data e ora insieme: '2006-01-09 16:43:00' (formato YYYY-MM-DD HH:MM:SS) |
La funzione CAST() consente di passare da un tipo all'altro quando necessario. Per convertire un valore V dichiarato come di tipo T1 in un tipo T2, si scrive: CAST(V,T2). È possibile effettuare le seguenti conversioni di tipo:
- da numero a stringa di caratteri. Questa conversione di tipo avviene implicitamente e non richiede l’uso della funzione CAST. Pertanto, l’operazione 1 + '3' non richiede la conversione del carattere '3'. Il suo risultato è il numero 4.
- Da DATE, TIME, TIMESTAMP a stringhe di caratteri e viceversa. Pertanto
- da TIMESTAMP a TIME o DATE e viceversa
In una tabella, una riga può contenere colonne prive di valore. Si dice che il valore della colonna sia la costante NULL. È possibile verificare la presenza di questo valore utilizzando gli operatori
IS NULL / IS NOT NULL
3.2. Creazione di una tabella
Per scoprire come creare una tabella, iniziamo creandone una in modalità [Design] con IBExpert. A tal fine seguiamo il metodo descritto al paragrafo 2.3. Creiamo così la seguente tabella:
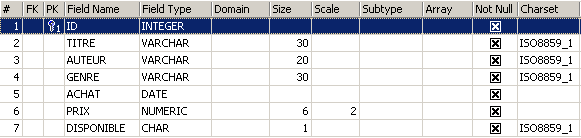
Questa tabella servirà a registrare i libri acquistati da una biblioteca. Il significato dei campi è il seguente:
Name | Tipo | Vincolo | Significato |
Questa tabella, creata utilizzando lo strumento IBEXPERT come procedura guidata, avrebbe potuto essere creata direttamente tramite i comandi SQL. Per conoscerli, è sufficiente consultare la scheda [DDL] della tabella:
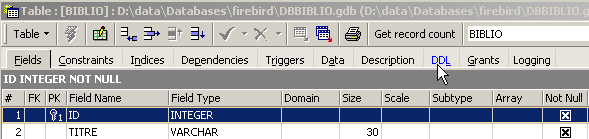
Il codice SQL che ha permesso di creare la tabella [BIBLIO] è il seguente:
- riga 1: proprietario Firebird - indica il livello del dialetto SQL utilizzato
- riga 2: proprietario Firebird - indica la famiglia di caratteri utilizzata
- righe 6 - 14: standard SQL: crea la tabella BIBLIO definendo il nome e il tipo di ciascuna delle sue colonne.
- riga 16: standard SQL: crea un vincolo che specifica che la colonna TITRE non ammette duplicati
- riga 17: standard SQL: indica che la colonna [ID] è la chiave primaria della tabella. Ciò significa che due righe della tabella non possono avere lo stesso valore per ID. In questo caso siamo vicini al vincolo [UNIQUE NOT NULL] della colonna [TITRE] e, di fatto, la colonna TITRE avrebbe potuto fungere da chiave primaria. La tendenza attuale è quella di utilizzare chiavi primarie prive di significato e generate dal SGBD.
La sintassi del comando [CREATE TABLE] è la seguente:
CREATE TABLE tabella (nom_colonne1 type_colonne1 contrainte_colonne1, nom_colonne2 type_colonne2 contrainte_colonne2, ..., nom_colonnen type_colonnen contrainte_colonnen, altri vincoli) | |||||||||
crea la tabella table con le colonne indicate
|
La tabella [BIBLIO] avrebbe potuto essere costruita anche con il seguente ordine SQL:
Vediamo come. Riprendiamo questa sequenza in un editor SQL (F12) per creare una tabella che chiameremo [BIBLIO2]:
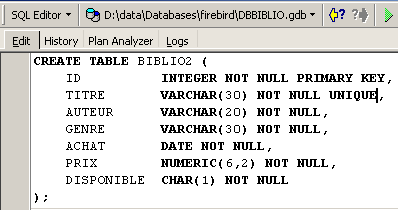
Dopo l’esecuzione, è necessario confermare la transazione per visualizzare il risultato nel database:
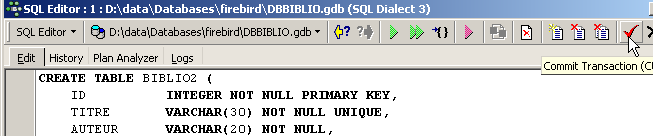
Una volta fatto ciò, la tabella appare nel database:
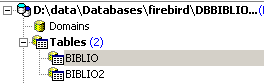
Facendo doppio clic sul suo nome, è possibile visualizzarne la struttura:
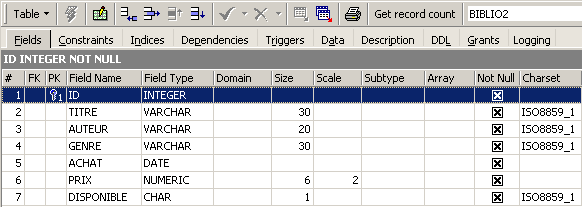
Si ritrova effettivamente la definizione che abbiamo creato per la tabella [BIBLIO2]
3.3. Eliminazione di una tabella
Il comando SQL per eliminare una tabella è il seguente:
DROP TABLE table | |
Supprime [table] |
Per eliminare la tabella [BIBLIO2] che abbiamo appena creato, ora eseguiamo il seguente comando SQL:
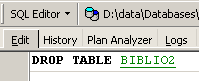
e lo confermiamo con [Commit]. La tabella [BIBLIO2] viene eliminata:
3.4. Inserimento di dati in una tabella
Inseriamo una riga nella tabella [BIBLIO] che abbiamo appena creato:
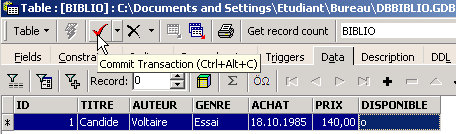
Confermiamo l’aggiunta della riga tramite [Commit], quindi facciamo clic con il tasto destro sulla riga aggiunta:
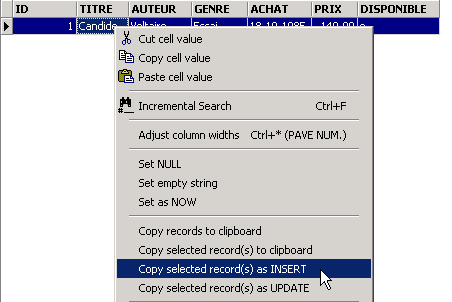
e richiediamo, come mostrato sopra, la copia della riga inserita negli appunti sotto forma di comando SQL INSERT. Apriamo quindi un qualsiasi editor di testo e incolliamo (Inserisci / Paste) ciò che abbiamo appena copiato. Otteniamo il seguente codice SQL:
INSERT INTO BIBLIO (ID,TITRE,AUTEUR,GENRE,ACHAT,PRIX,DISPONIBLE) VALUES (1,'Candide','Voltaire','Essai','18-OCT-1985',140,'o');
La sintassi di un comando di inserimento SQL è la seguente:
insert into table [(colonne1, colonne2, ..)] values (valore1, valore2, ....) | |
aggiunge una riga (valore1, valore2, ..) alla tabella table. Questi valori vengono assegnati alle colonne colonne1, colonne2, ... se presenti, altrimenti alle colonne della tabella nell'ordine in cui sono state definite. |
Per inserire nuove righe nella tabella [BIBLIO], si digiteranno i seguenti comandi INSERT nell’editor SQL. Si eseguiranno e si confermeranno [Commit] questi comandi uno per uno. Si utilizzerà il pulsante [New Query] per passare al comando INSERT successivo.
Dopo aver confermato i vari comandi SQL, si ottiene la tabella seguente:
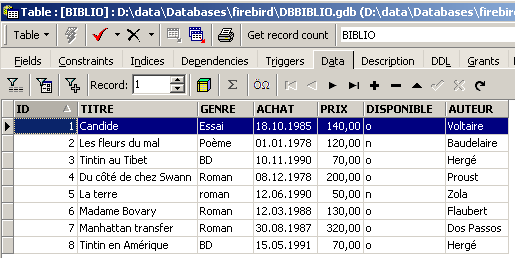 |
3.5. Consultazione di una tabella
3.5.1. Introduzione
Nell’editor SQL, digitiamo il seguente comando:
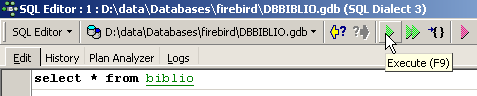
ed eseguiamolo. Otteniamo il seguente risultato:
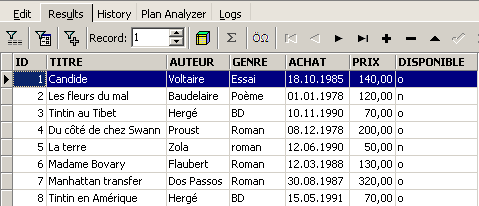
Il comando SELECT consente di visualizzare il contenuto delle tabelle del database. Questo comando presenta una sintassi molto articolata. Qui presentiamo solo quella che consente di interrogare una singola tabella. Tratteremo in seguito l’interrogazione simultanea di più tabelle. La sintassi del comando SQL [SELECT] è la seguente:
SELECT [ALL|DISTINCT] [*|expression1 alias1, expression2 alias2, ...] FROM table | |
visualizza i valori di expressioni per tutte le righe della tabella. expressioni può essere una colonna o un'espressione più complessa. Il simbolo * indica l'insieme delle colonne. Per impostazione predefinita, vengono visualizzate tutte le righe della tabella (ALL). Se è presente DISTINCT, le righe identiche selezionate vengono visualizzate una sola volta. I valori di expressioni vengono visualizzati in una colonna con titolo expressioni o aliasi, se quest’ultimo è stato utilizzato. |
Esempi:
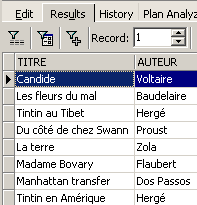
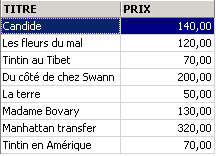
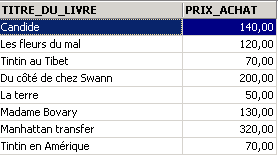
Sopra abbiamo associato degli alias (TITRE_DU_LIVRE, PRIX_ACHAT) alle colonne richieste.
3.5.2. Visualizzazione delle righe che soddisfano una condizione
SELECT .... WHERE condition | |
vengono visualizzate solo le righe che soddisfano la condizione condition |
Esempi
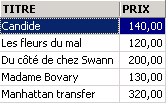

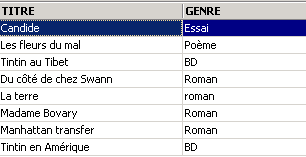
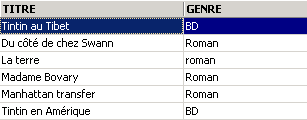
Uno dei libri ha il genere "romanzo" e non "Romanzo". Utilizziamo la funzione upper che converte una stringa di caratteri in maiuscolo per ottenere tutti i romanzi.
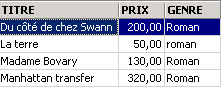
Possiamo combinare le condizioni tramite gli operatori logici
ET logique | |
OU logique | |
Negazione logica |
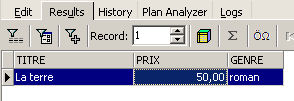
![]()
 |
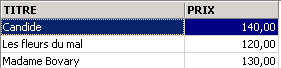
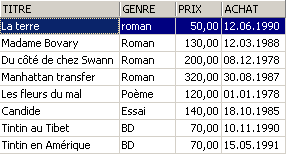
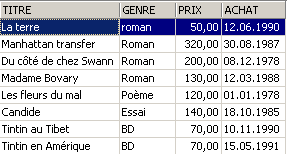
3.5.3. Visualizzazione delle righe secondo un ordine prestabilito
Alle sintassi precedenti è possibile aggiungere una clausola ORDER BY che indica l'ordine di visualizzazione desiderato:
SELECT .... ORDER BY expression1 [asc|desc], expression2 [asc|dec], ... | |
Le righe risultanti dalla selezione vengono visualizzate nell’ordine di 1: ordine crescente (asc / ascending, che è il valore predefinito) o decrescente (desc / descending) di expression1 2: in caso di parità di expression1, la visualizzazione avviene in base ai valori di expression2 ecc. |
Esempi:
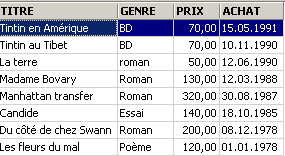
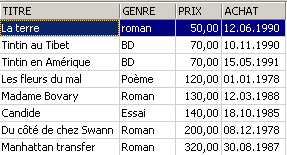
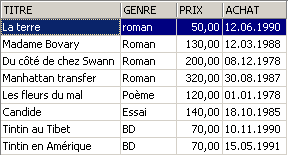
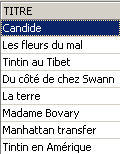
3.6. Eliminazione di righe in una tabella
DELETE FROM table [WHERE condition] | |
elimina le righe di table verificando condition. Se quest'ultima è assente, tutte le righe vengono eliminate. |
Esempi:
I due comandi riportati di seguito vengono eseguiti uno dopo l'altro:
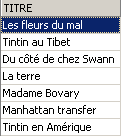
3.7. Modifica del contenuto di una tabella
update table set colonna1 = espressione1, colonna2 = espressione2, ... [where condition] | |
Per le righe di table che verificano condition (tutte le righe se non vi è alcuna condizione), colonnei riceve il valore expressioni. |
Esempi:
Si scrivono tutti i generi in maiuscolo:
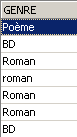
Si verifica:
![]()
Si visualizzano i prezzi:

Il prezzo dei romanzi aumenta del 5%:
Si verifica:

3.8. Aggiornamento definitivo di una tabella
Quando si apportano modifiche a una tabella, Firebird le genera di fatto su una copia della tabella. Possono quindi essere rese definitive oppure annullate tramite i comandi COMMIT e ROLLBACK.
COMMIT | |
rende definitivi gli aggiornamenti apportati alle tabelle dall'ultima esecuzione di COMMIT. |
ROLLBACK | |
annulla tutte le modifiche apportate alle tabelle dall'ultimo COMMIT. |
Un COMMIT viene eseguito implicitamente nei seguenti momenti: a) Alla disconnessione da Firebird b) Dopo ogni comando che modifica la struttura delle tabelle: CREATE, ALTER, DROP. |
Esempi
Nell’editor SQL, si riporta il database a uno stato noto convalidando tutte le operazioni effettuate dall’ultimo COMMIT o ROLLBACK:
Si richiede l’elenco dei titoli:
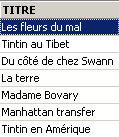
Eliminazione di un titolo:
Verifica:
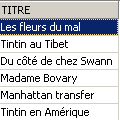
Il titolo è stato eliminato correttamente. Ora invalidiamo tutte le modifiche apportate dall'ultimo COMMIT / ROLLBACK:
Verifica:
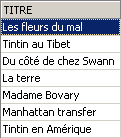
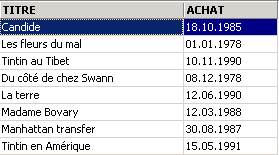
Il titolo eliminato è stato ripristinato. Richiediamo ora l’elenco dei prezzi:
![]()
Supponiamo che tutti i prezzi siano azzerati.
Verifichiamo i prezzi:
![]()
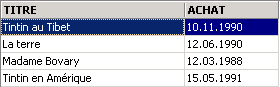
Eliminiamo le modifiche apportate alla base:
e ricontrolliamo i prezzi:
![]()
Abbiamo recuperato i prezzi originali.
3.9. Aggiunta di righe in una tabella provenienti da un’altra tabella
È possibile aggiungere righe da una tabella a un'altra quando le loro strutture sono compatibili. Per dimostrarlo, iniziamo creando una tabella [BIBLIO2] con la stessa struttura di [BIBLIO].
Nell’esploratore di database di IBExpert, facciamo doppio clic sulla tabella [BIBLIO] per accedere alla scheda [DDL]:
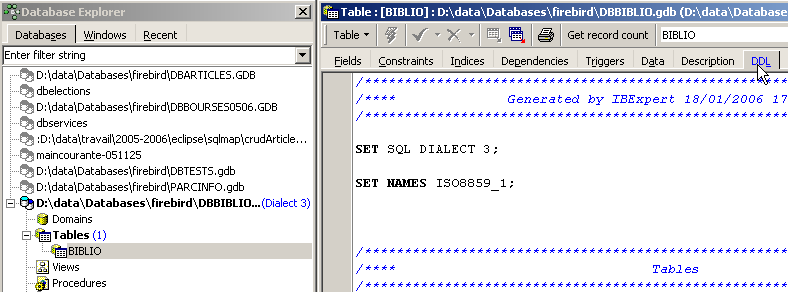
In questa scheda è presente l’elenco dei comandi SQL che consentono di generare la tabella [BIBLIO]. Copiamo l'intero codice negli appunti (CTRL-A, CTRL-C). Quindi avviamo uno strumento denominato [Script Executive] che consente di eseguire un elenco di comandi SQL:
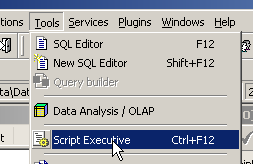
Si apre un editor di testo, nel quale possiamo incollare (CTRL-V) il testo precedentemente copiato negli appunti:
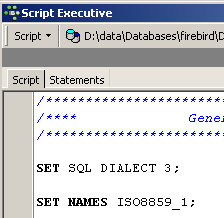
Spesso si definisce script SQL un elenco di comandi SQL. [Script Executive] ci consentirà di eseguire uno script di questo tipo, mentre l’editor SQL permetteva l’esecuzione di un solo comando alla volta. L'attuale script SQL consente di creare la tabella [BIBLIO]. Facciamo in modo che crei una tabella denominata [BIBLIO2]. A tal fine è sufficiente sostituire [BIBLIO] con [BIBLIO2]:
Eseguiamo questo script utilizzando il pulsante [Run Script] qui sotto:

Lo script viene eseguito:
e si può vedere la nuova tabella nell'esploratore dei database:
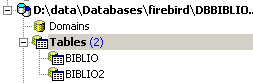
Se si fa doppio clic su [BIBLIO2] per verificarne il contenuto, si scopre che è vuota, il che è normale:
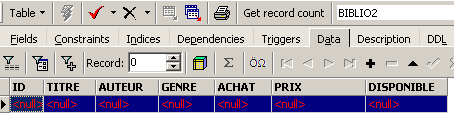
Una variante del comando SQL INSERT consente di inserire in una tabella righe provenienti da un’altra tabella:
INSERT INTO table1 [(colonne1, colonne2, ...)] SELECT colonna, colonna, ... FROM table2 WHERE condition | |
Le righe di table2 che verificano condition vengono aggiunte a table1. Le colonne colonnea, colonneb, ... di table2 vengono assegnate nell'ordine a colonna1, colonna2, ... di table1 e devono quindi essere di tipo compatibile. |
Torniamo all'editor SQL:
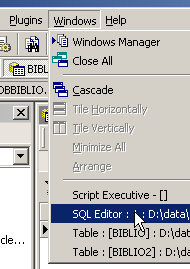
e inviamo il comando SQL seguente:
che inserisce in [BIBLIO2] tutte le righe di [BIBLIO] corrispondenti a un romanzo. Dopo l’esecuzione del comando SQL, confermiamolo con un [Commit]:
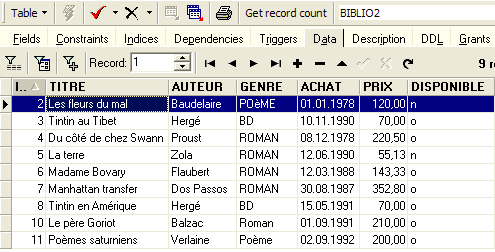
Fatto ciò, consultiamo i dati della tabella [BIBLIO2]:

3.10. Eliminazione di una tabella
DROP TABLE table | |
supprime table |
Esempio: si elimina la tabella BIBLIO2
Si conferma la modifica:
Nel gestore delle tabelle, si aggiorna la visualizzazione delle tabelle:
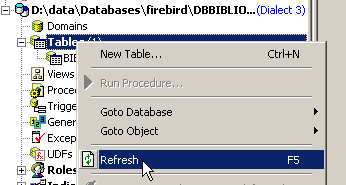
Si nota che la tabella [BIBLIO2] è stata eliminata:
3.11. Modifica della struttura di una tabella
ALTER TABLE table [ ADD nom_colonne1 type_colonne1 contrainte_colonne1] [ALTER nom_colonne2 TYPE type_colonne2] [DROP nom_colonne3] [ADD contrainte] [DROP CONSTRAINT nom_contrainte] | |
consente di aggiungere (ADD), modificare (ALTER) ed eliminare (DROP) colonne di una tabella. La sintassi nom_colonnei type_colonnei contrainte_colonnei è quella di CREATE TABLE. È inoltre possibile aggiungere o eliminare i vincoli della tabella. |
Esempio: eseguiamo in successione i due comandi SQL seguenti nell’editor SQL
Nell’esploratore dei database, verifichiamo la struttura della tabella [BIBLIO]:
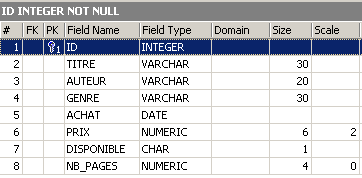
Le modifiche sono state applicate. Vediamo come è cambiato il contenuto della tabella:
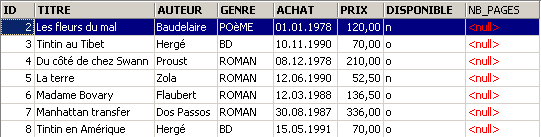
È stata creata la nuova colonna [NB_PAGES], ma non contiene alcun valore. Eliminiamo questa colonna:
Verifichiamo la nuova struttura della tabella [BIBLIO]:
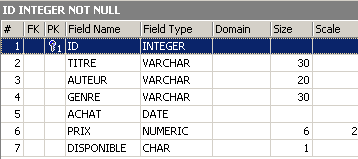
La colonna [NB_PAGES] è stata effettivamente rimossa.
3.12. Le viste
È possibile avere una vista parziale di una tabella o di più tabelle. Una vista si comporta come una tabella ma non contiene dati. I suoi dati vengono estratti da altre tabelle o viste. Una vista presenta diversi vantaggi:
- Un utente potrebbe essere interessato solo ad alcune colonne e righe di una determinata tabella. La vista gli consente di visualizzare esclusivamente tali righe e colonne.
- Il proprietario di una tabella potrebbe voler concedere solo un accesso limitato ad altri utenti. La vista gli permette di farlo. Gli utenti da lui autorizzati avranno accesso solo alla vista da lui definita.
3.12.1. Creazione di una vista
CREATE VIEW nom_vue AS SELECT colonna1, colonna2, ... FROM table WHERE condition [ WITH CHECK OPTION ] | |
crea la vista nom_vue. Si tratta di una tabella con la struttura colonna1, colonna2, ... di table e, come righe, le righe di table che soddisfano la condizione di condition (tutte le righe se non vi è alcuna condizione) | |
Questa clausola opzionale indica che gli inserimenti e gli aggiornamenti sulla vista non devono creare righe che la vista non potrebbe selezionare. |
Nota La sintassi di CREATE VIEW è in realtà più complessa di quella illustrata sopra e consente, in particolare, di creare una vista a partire da più tabelle. A tal fine è sufficiente che la query SELECT riguardi più tabelle (cfr. capitolo seguente).
Esempi
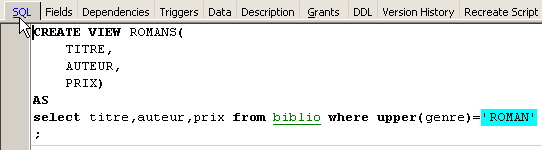
Si crea, a partire dalla tabella biblio, una vista che includa solo i romanzi (selezione di righe) e solo le colonne titolo, autore, prezzo (selezione di colonne):
Nel Database Explorer, aggiorniamo la vista (F5). Viene visualizzata una vista:
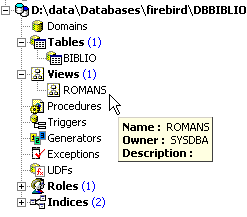
È possibile conoscere l’ordine SQL associato alla vista. A tal fine, facciamo doppio clic sulla vista [ROMANS]:
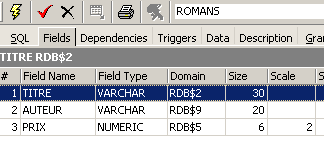
Una vista è simile a una tabella. Ha una struttura:
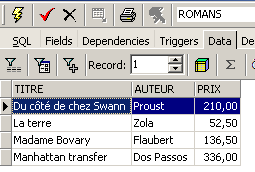
e un contenuto:
Una vista si utilizza come una tabella. È possibile eseguire query SQL su di essa. Ecco alcuni esempi da provare nell'editor SQL:
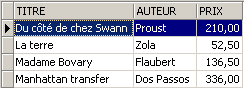
Il nuovo romanzo è visibile nella vista [ROMANS]?
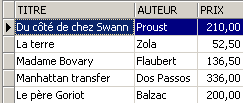
Aggiungiamo qualcosa di diverso da un romanzo alla tabella [BIBLIO]:
SQL> insert into biblio(id,titre,auteur,genre,achat,prix,disponible) values (11,'Poèmes saturniens','Verlaine','Poème','02-sep-92',200,'o');
Controlliamo la tabella [BIBLIO]:
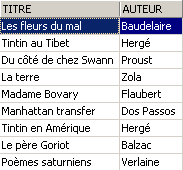
Controlliamo la vista [ROMANS]:
Il libro aggiunto non è presente nella vista [ROMANS] perché non aveva upper(genre)='ROMAN'.
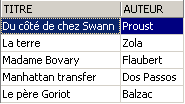
3.12.2. Aggiornamento di una vista
È possibile aggiornare una vista proprio come si fa con una tabella. Tutte le tabelle da cui vengono estratti i dati della vista sono interessate da questo aggiornamento. Ecco alcuni esempi:
SQL> insert into biblio(id,titre,auteur,genre,achat,prix,disponible) values (13,'Le Rouge et le Noir','Stendhal','Roman','03-oct-92',110,'o')
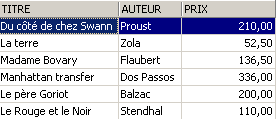
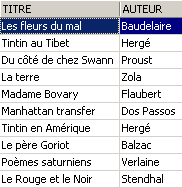
Si elimina una riga dalla vista [ROMANS]:
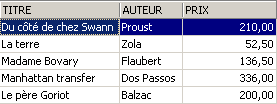
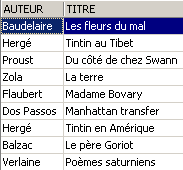
La riga eliminata dalla vista [ROMANS] è stata eliminata anche nella tabella [BIBLIO]. Ora si aumenta il prezzo dei libri della vista [ROMANS]:
Si verifica in [ROMANS]:
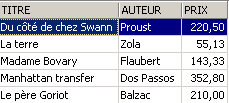
Qual è stato l’impatto sulla tabella [BIBLIO]?
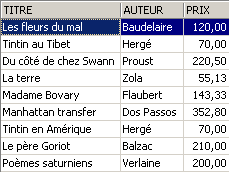
Anche nella tabella [BIBLIO] i romanzi sono stati aumentati del 5%.
3.12.3. Eliminare una vista
DROP VIEW nom_vue | |
elimina la vista denominata |
Esempio
Nel Database Explorer è possibile aggiornare la vista (F5) per verificare che la vista [ROMANS] sia scomparsa:
3.13. Utilizzo delle funzioni di gruppo
Esistono funzioni che, invece di operare su ogni riga di una tabella, operano su gruppi di righe. Si tratta essenzialmente di funzioni statistiche che consentono di calcolare la media, la deviazione standard, ecc. dei dati di una colonna.
SELECT f1, f2, .., fn FROM table [ WHERE condition ] | |
calcola le funzioni statistiche fi su tutte le righe della tabella, verificando l'eventuale presenza di condition. |
SELECT f1, f2, .., fn FROM table [ WHERE condition ] [ GROUP BY expr1, expr2, ..] | |
La parola chiave GROUP BY ha l'effetto di suddividere le righe della tabella in gruppi. Ogni gruppo contiene le righe per le quali le espressioni expr1, expr2, ... hanno lo stesso valore. Esempio: GROUP BY genere raggruppa i libri dello stesso genere. La clausola GROUP BY autore,genere raggrupperebbe nello stesso gruppo i libri con lo stesso autore e lo stesso genere. La clausola WHERE condizione elimina innanzitutto dalla tabella le righe che non soddisfano la condizione. Successivamente, i gruppi vengono formati dalla clausola GROUP BY. Le funzioni fi vengono quindi calcolate per ciascun gruppo di righe. |
SELECT f1, f2, .., fn FROM table [ WHERE condition ] [ GROUP BY expression] [ HAVING condition_de_groupe] | |
La clausola HAVING filtra i gruppi formati dalla clausola GROUP BY. È quindi sempre legata alla presenza di questa clausola GROUP BY. Esempio: GROUP BY genere HAVING genere!='ROMAN' |
Le funzioni statistiche fi disponibili sono le seguenti:
media dell'espressione | |
numero di righe in cui l’espressione ha un valore | |
numero totale di righe nella tabella | |
valore massimo dell'espressione | |
minimo dell'espressione | |
somma dell'espressione |
Esempi
![]()
Prezzo medio? Prezzo massimo? Prezzo minimo?
![]()
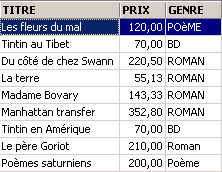
Prezzo medio di un romanzo? Prezzo massimo?
![]()
Quanti BD?
![]()
Quanti romanzi costano meno di 100 F?
![]()

Numero di libri e prezzo medio per i libri dello stesso genere?
SQL> select upper(genre) GENRE,avg(prix) PRIX_MOYEN,count(*) NOMBRE from biblio group by upper(genre)
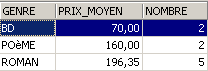
Stessa domanda, ma solo per i libri che non sono romanzi:
SQL>
select upper(genre) GENRE,avg(prix) PRIX_MOYEN,count(*) NOMBRE
from biblio
group by upper(genre)
having upper(GENRE)!='ROMAN'
![]()
Stessa domanda, ma solo per i libri che costano meno di 150 F:
SQL>
select upper(genre) GENRE,avg(prix) PRIX_MOYEN,count(*) NOMBRE
from biblio
where prix<150
group by upper(genre)
having upper(GENRE)!='ROMAN'
![]()
Stessa domanda, ma si mantengono solo i gruppi con un prezzo medio per libro >100 F
SQL>
select upper(genre) GENRE, avg(prix) PRIX_MOYEN,count(*) NOMBRE
from biblio
group by upper(genre)
having avg(prix)>100
![]()
3.14. Creare lo script SQL " " da una tabella
Il linguaggio SQL è un linguaggio standard utilizzabile con numerosi SGBD. Per poter passare da un SGBD a un altro, è utile esportare un database o semplicemente alcuni suoi elementi sotto forma di script SQL che, una volta eseguito in un altro SGBD, sarà in grado di ricreare gli elementi esportati nello script.
In questo caso esporteremo la tabella [BIBLIO]. Scegliamo l’opzione [Extract Metadata]:
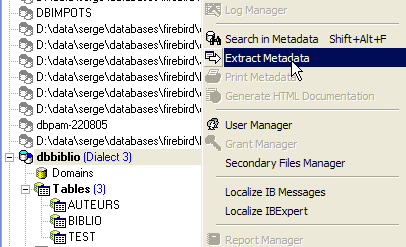
Si noti che, come illustrato sopra, è necessario selezionare il database dal quale si desidera esportare gli elementi. L’opzione avvia una procedura guidata:
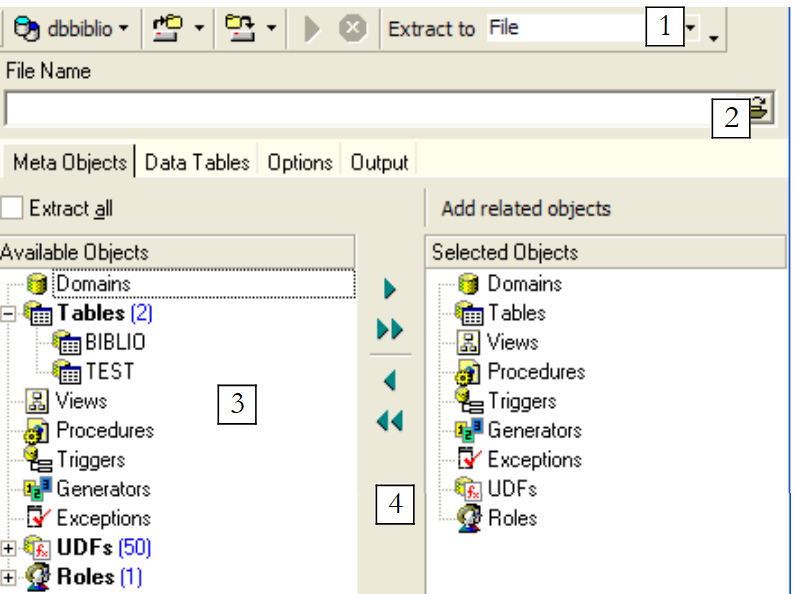 |
dove generare lo script SQL:
| |
nome del file se si seleziona l'opzione [File] | |
Cosa esportare | |
pulsanti per selezionare (->) o deselezionare (<-) gli oggetti da esportare |
Se volessimo esportare l'intero database, spunteremmo l'opzione [Extract All] sopra indicata. Vogliamo semplicemente esportare la tabella BIBLIO. Per farlo, con [4] selezioniamo la tabella [BIBLIO] e con [2] indichiamo un file:
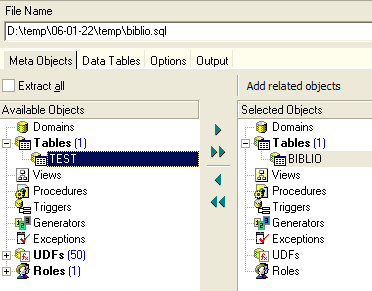
Se ci fermiamo qui, verrà esportata solo la struttura della tabella [BIBLIO]. Per esportarne il contenuto, dobbiamo utilizzare la scheda [Data Tables]:
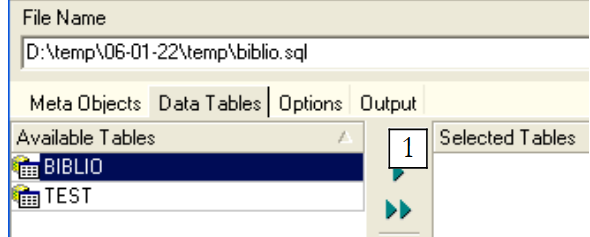 |
Utilizziamo [1] per selezionare la tabella [BIBLIO]:
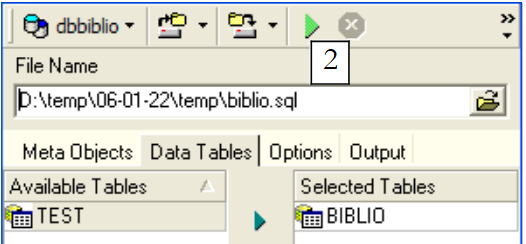 |
Utilizziamo [2] per generare lo script SQL:
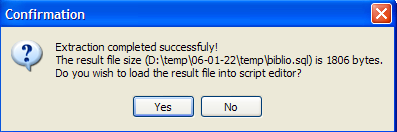
Accettiamo l’offerta. Questo ci permette di visualizzare lo script generato nel file [biblio.sql]:
- le righe da 1 a 3 sono commenti
- le righe da 5 a 12 sono in SQL proprietario di Firebird
- le altre righe sono del formato standard SQL e dovrebbero poter essere rieseguite in un file SGBD che contenga i tipi di dati dichiarati nella tabella BIBLIO.
Rieseguiamo questo script all’interno di Firebird per creare una tabella BIBLIO2 che sarà un clone della tabella BIBLIO. A tal fine utilizziamo [Script Executive] (Ctrl-F12):
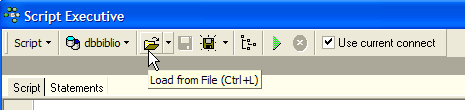
Carichiamo lo script [biblio.sql] che abbiamo appena generato:
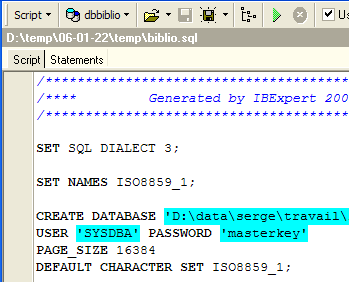
Modifichiamolo in modo da mantenere solo la parte relativa alla creazione della tabella e all’inserimento delle righe. La tabella viene rinominata [BIBLIO2]:
CREATE TABLE BIBLIO2 (
ID INTEGER NOT NULL,
TITRE VARCHAR(30) NOT NULL,
AUTEUR VARCHAR(20) NOT NULL,
GENRE VARCHAR(30) NOT NULL,
ACHAT DATE NOT NULL,
PRIX NUMERIC(6,2) DEFAULT 10 NOT NULL,
DISPONIBLE CHAR(1) NOT NULL
);
INSERT INTO BIBLIO2 (ID, TITRE, AUTEUR, GENRE, ACHAT, PRIX, DISPONIBLE) VALUES (2, 'Les fleurs du mal', 'Baudelaire', 'POèME', '1978-01-01', 120, 'n');
...
COMMIT WORK;
Eseguiamo questo script:
 |  |
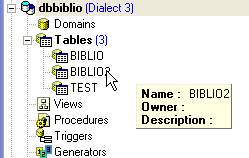
Possiamo verificare nel Database Explorer che la tabella [BIBLIO2] sia stata effettivamente creata e che presenti la struttura e il contenuto previsti:
 |  |