1. Introduzione
1.1. Objectifs
Il PDF del documento è disponibile |QUI|.
Gli esempi del documento sono disponibili |QUI|.
In questa sede ci proponiamo di scoprire i concetti principali della persistenza dei dati con API JPA (Java Persistence API). Dopo aver letto questo documento e aver testato gli esempi, il lettore dovrebbe aver acquisito le basi necessarie per poter poi procedere in autonomia.
La API JPA è recente. È disponibile solo a partire dalla versione 1.5 della JDK. Il livello JPA trova la sua collocazione in un’architettura a più livelli. Consideriamo un’architettura di questo tipo piuttosto diffusa, quella a tre livelli:
 |
- il livello [1], qui denominato [ui] (User Interface), è il livello che interagisce con l’utente tramite un’interfaccia grafica Swing, un’interfaccia da console o un’interfaccia web. Il suo ruolo è quello di fornire i dati provenienti dall’utente al livello [2] oppure di presentare all’utente i dati forniti dal livello [2].
- Il livello [2], qui denominato [metier], è il livello che applica le cosiddette regole di business, c.a.d. la logica specifica dell’applicazione, senza preoccuparsi della provenienza dei dati che le vengono forniti né della destinazione dei risultati che produce.
- il livello [3], qui denominato [dao] (Data Access Object), è il livello che fornisce al livello [2] dati pre-registrati (file, database, ...) e che registra alcuni dei risultati forniti dal livello [2].
- Il livello [JDBC] è il livello standard utilizzato in Java per accedere ai database. È ciò che viene comunemente chiamato driver JDBC del SGBD.
Sono stati compiuti numerosi sforzi per facilitare la scrittura di questi diversi livelli da parte degli sviluppatori. Tra questi, JPA mira a facilitare la scrittura del livello [dao], quello che gestisce i cosiddetti dati persistenti, da cui il nome API (Java Persistence API). Una soluzione che negli ultimi anni si è affermata in questo ambito è quella di Hibernate:
 |
Il livello [Hibernate] si colloca tra il livello [dao] scritto dallo sviluppatore e il livello [Jdbc]. Hibernate è un ORM (Object Relational Mapping), uno strumento che fa da ponte tra il mondo relazionale dei database e quello degli oggetti gestiti da Java. Lo sviluppatore del livello [dao] non vede più né il livello [Jdbc] né le tabelle del database di cui intende sfruttare il contenuto. Vede solo l’immagine oggetto del database, fornita dal livello [Hibernate]. Il collegamento tra le tabelle del database e gli oggetti gestiti dal livello [dao] avviene principalmente in due modi:
- tramite file di configurazione di tipo XML
- tramite annotazioni Java nel codice, tecnica disponibile solo a partire dalla versione 1.5 di JDK
Il livello [Hibernate] è un livello di astrazione che mira a essere il più trasparente possibile. L'obiettivo ideale è che lo sviluppatore del livello [dao] possa ignorare completamente il fatto di lavorare con un database. Ciò è possibile se non è lui a scrivere la configurazione che funge da ponte tra il mondo relazionale e quello degli oggetti. La configurazione di questo ponte è piuttosto complessa e richiede una certa dimestichezza.
Il livello [4] degli oggetti, che rispecchia il BD, è denominato «contesto di persistenza». Un livello [dao] basato su Hibernate esegue operazioni di persistenza (CRUD: create - read - update - delete) sugli oggetti del contesto di persistenza; tali operazioni vengono tradotte da Hibernate in comandi SQL. Per le operazioni di interrogazione del database (il SQL Select), Hibernate fornisce allo sviluppatore un linguaggio HQL (Hibernate Query Language) per interrogare il contesto di persistenza [4] e non il BD stesso.
Hibernate è popolare ma complesso da padroneggiare. La curva di apprendimento, spesso descritta come facile, è in realtà piuttosto ripida. Non appena si ha a che fare con un database con tabelle che presentano relazioni uno-a-molti o molti-a-molti, la configurazione del ponte relazionale/oggetti non è alla portata del primo principiante che capita. Errori di configurazione possono quindi portare a applicazioni poco performanti.
Nel mondo commerciale esisteva un prodotto equivalente a Hibernate chiamato Toplink:
 |
Visto il successo dei prodotti ORM, Sun, il creatore di Java, ha deciso di standardizzare un livello ORM tramite una specifica denominata JPA, apparsa contemporaneamente a Java 5. La specifica JPA è stata implementata dai due prodotti Toplink e Hibernate. Toplink, che era un prodotto commerciale, è diventato nel frattempo un prodotto libero. Con JPA, l’architettura precedente diventa la seguente:
 |
Il livello [dao] interagisce ora con la specifica JPA, un insieme di interfacce. Lo sviluppatore ha guadagnato in termini di standardizzazione. In precedenza, se modificava il proprio livello ORM, doveva modificare anche il livello [dao], che era stato scritto per interagire con uno specifico ORM. Ora scriverà un livello [dao] che comunicherà con un livello JPA. Indipendentemente dal prodotto che lo implementa, l’interfaccia del livello JPA presentata al livello [dao] rimane la stessa.
Il presente documento illustrerà alcuni esempi relativi a JPA in diversi ambiti:
- innanzitutto, ci concentreremo sul ponte relazionale/oggettuale che il livello ORM costruisce. Questo verrà creato utilizzando le annotazioni Java 5 per database in cui sono presenti relazioni tra tabelle del tipo:
- uno a uno
- uno a molti
- molte a molte
Per illustrare questo ambito, creeremo le seguenti architetture di test:
 |
I nostri programmi di test saranno applicazioni da console che interagiranno direttamente con il livello JPA. In questa occasione scopriremo i principali metodi del livello JPA. Ci troveremo in un ambiente denominato «Java SE» (Standard Edition). JPA funziona sia in un ambiente Java SE che in uno Java EE5 (Enterprise Edition).
- Una volta acquisita padronanza sia della configurazione del ponte relazionale/oggetto sia dell’utilizzo dei metodi del livello JPA, torneremo a un’architettura multistrato più classica:
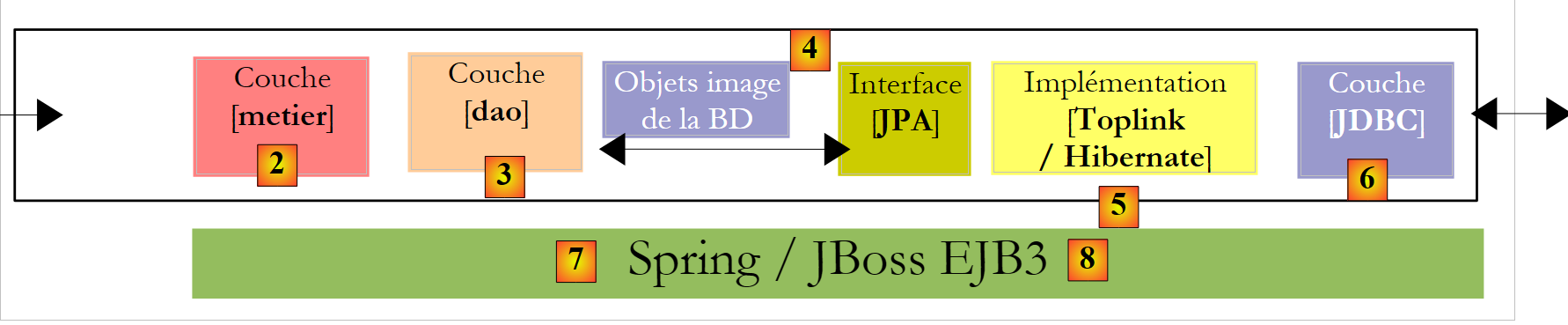 |
Si accederà al livello [JPA] tramite un'architettura a due livelli [metier] e [dao]. Il framework Spring [7], seguito dal contenitore EJB3 di JBoss, saranno utilizzati per collegare tra loro questi livelli.
Abbiamo detto in precedenza che JPA era disponibile negli ambienti SE e EE5. L'ambiente Java EE5 fornisce numerosi servizi nell'ambito dell'accesso ai dati persistenti, in particolare i pool di connessione, i gestori di transazioni, ecc. Per uno sviluppatore può essere interessante avvalersi di questi servizi. L’ambiente Java EE5 non è ancora molto diffuso (maggio 2007). Attualmente è disponibile sul server applicativo Sun Application Server 9.x (Glassfish). Un server applicativo è essenzialmente un server di applicazioni web. Se si sviluppa un’applicazione grafica autonoma di tipo Swing, non è possibile disporre dell’ambiente EE e dei servizi che esso offre. Questo rappresenta un problema. Si stanno iniziando a vedere ambienti EE “stand-alone”, c.a.d. utilizzabili al di fuori di un server di applicazioni. È il caso di JBos e EJB3, che useremo in questo documento.
In un ambiente EE5, i livelli sono implementati da oggetti denominati EJB (Enterprise Java Bean). Nelle versioni precedenti di EE, i EJB (EJB 2.x) sono considerati difficili da implementare, da testare e talvolta poco performanti. Si distinguono i EJB2.x "entity" e i EJB2.x "session". In breve, un EJB2.x "entity" rappresenta una riga di una tabella di database, mentre un EJB2.x "session" è un oggetto utilizzato per implementare i livelli [metier], [dao] di un’architettura multistrato. Una delle principali critiche mosse ai livelli implementati con EJB è che sono utilizzabili solo all’interno di contenitori EJB, un servizio fornito dall’ambiente EE. Ciò rende problematici i test unitari. Pertanto, nello schema sopra riportato, i test unitari dei livelli [metier] e [dao], costruiti con EJB, richiederebbero l’installazione di un server applicativo, un’operazione piuttosto onerosa che non incoraggia particolarmente lo sviluppatore a eseguire test con frequenza.
Il framework Spring è nato in risposta alla complessità dei EJB2. Spring fornisce, in un ambiente SE, un numero significativo dei servizi solitamente forniti dagli ambienti EE. Pertanto, nell’ambito della “persistenza dei dati” che ci interessa in questa sede, Spring fornisce i pool di connessione e i gestori di transazioni necessari alle applicazioni. L’emergere di Spring ha favorito la diffusione dei test unitari, che sono diventati improvvisamente molto più facili da implementare. Spring consente l’implementazione dei livelli di un’applicazione tramite oggetti Java classici (POJO, Plain Old/Ordinary Java Object), permettendo il loro riutilizzo in un altro contesto. Infine, integra numerosi strumenti di terze parti in modo abbastanza trasparente, in particolare strumenti di persistenza come Hibernate, Ibatis, ...
Java EE5 è stato progettato per colmare le lacune della precedente specifica EE. I EJB e 2.x sono diventati EJB3. Questi sono POJOs contrassegnati da annotazioni che li rendono oggetti particolari quando si trovano all’interno di un contenitore EJB3. All’interno di quest’ultimo, l’EJB3 potrà usufruire dei servizi del contenitore (pool di connessioni, gestore delle transazioni, ecc.). Al di fuori del contenitore EJB3, l’oggetto EJB3 diventa un normale oggetto Java. Le sue annotazioni EJB vengono ignorate.
Quanto sopra illustra Spring e JBoss EJB3 come possibile infrastruttura (framework) della nostra architettura multistrato. È questa infrastruttura che fornirà i servizi di cui abbiamo bisogno: un pool di connessioni e un gestore di transazioni.
- Con Spring, i livelli saranno implementati tramite POJOs. Questi avranno accesso ai servizi di Spring (pool di connessioni, gestore delle transazioni) tramite l’iniezione di dipendenze in tali POJOs: durante la loro creazione, Spring inietta in essi i riferimenti ai servizi di cui avranno bisogno.
-
JBoss EJB3 è un contenitore EJB in grado di funzionare al di fuori di un server applicativo. Il suo principio di funzionamento (per lo sviluppatore) è analogo a quello descritto per Spring. Troveremo poche differenze.
-
Concluderemo il documento con un esempio di applicazione web a tre livelli, semplice ma comunque rappresentativo:
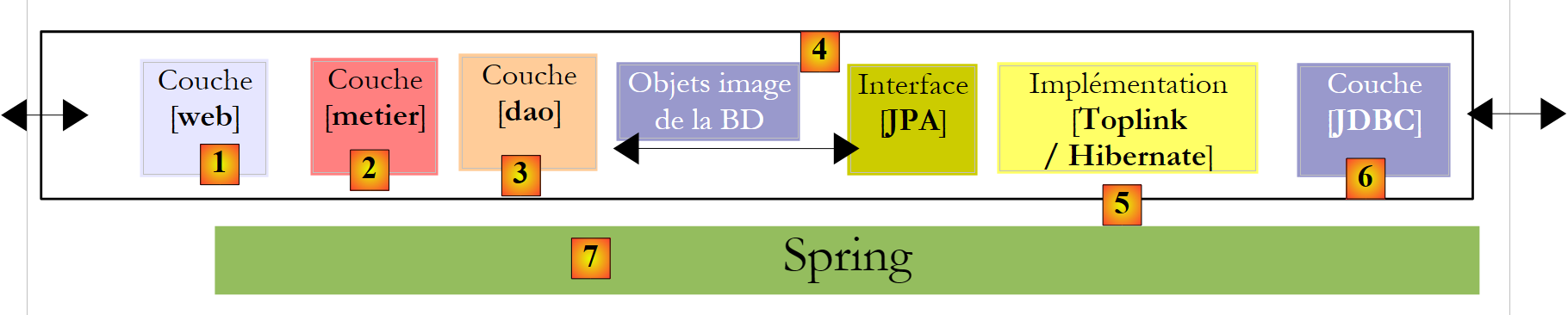 |
1.2. Références
[ref1]: Java Persistence with Hibernate, di Christian Bauer e Gavin King, edito da Manning.
[ref1] è il documento che è servito da base per quanto segue. Si tratta di un libro esaustivo di oltre 800 pagine sull’utilizzo di Hibernate in due contesti diversi: con o senza JPA. L’utilizzo di Hibernate senza JPA è infatti ancora attuale per gli sviluppatori che utilizzano JDK 1.4 o versioni precedenti, poiché JPA è apparso solo con JDK 1.5.
Dopo aver letto più di tre quarti del libro e aver dato un'occhiata al resto, mi è sembrato che tutto fosse utile in questo documento. L'utente esperto di Hibernate dovrebbe conoscere la quasi totalità delle informazioni fornite nelle 800 pagine. Christian Bauer e Gavin King sono stati esaustivi, ma raramente per descrivere situazioni che non si incontreranno mai. Vale la pena leggere tutto. Il libro è scritto in modo didattico: c’è una reale volontà di non lasciare nulla nell’oscurità. Il fatto che sia stato scritto per l’utilizzo di Hibernate sia con che senza JPA rappresenta una difficoltà per chi è interessato solo a una delle due tecnologie. Ad esempio, gli autori descrivono, attraverso numerosi esempi, il ponte relazionale/oggetto in entrambi i contesti. I concetti utilizzati sono molto simili, poiché JPA si è fortemente ispirato a Hibernate. Tuttavia, presentano alcune differenze. Di conseguenza, ciò che vale per Hibernate potrebbe non valere più per JPA, e questo finisce per creare confusione nel lettore.
Gli autori mostrano esempi di applicazioni a tre livelli nel contesto di un contenitore EJB3. Non parlano di Spring. Vedremo, con un esempio, che Spring è tuttavia più semplice da utilizzare e ha una portata più ampia rispetto al contenitore JBoss EJB3 utilizzato in [ref1]. Ciononostante, «Java Persistence with Hibernate» è un ottimo libro che consiglio per tutte le nozioni fondamentali che vi si apprendono sui ORM.
L’utilizzo di un ORM è complesso per un principiante.
- Ci sono concetti da comprendere per configurare il ponte relazionale/oggetto.
- C’è il concetto di contesto di persistenza con le relative nozioni di oggetti in stato “persistente”, “distaccato” e “nuovo”
- ci sono i meccanismi relativi alla persistenza (transazioni, pool di connessioni), generalmente servizi forniti da un container
- ci sono le impostazioni da configurare per le prestazioni (cache di secondo livello)
- ...
Introdurremo questi concetti attraverso degli esempi. Non ci soffermeremo molto sugli aspetti teorici. Il nostro obiettivo è semplicemente, ogni volta, consentire al lettore di comprendere l’esempio e di farne proprio il contenuto, fino a essere in grado di apportarvi modifiche autonomamente o di riproporlo in un altro contesto.
1.3. Strumenti utilizzati
Gli esempi contenuti nel presente documento utilizzano i seguenti strumenti. Alcuni di essi sono descritti negli allegati (download, installazione, configurazione, utilizzo). In tal caso, vengono indicati il numero del paragrafo e la pagina.
- un JDK 1.6 (paragrafo 5.1)
- IDE per lo sviluppo Java in Eclipse 3.2.2 (paragrafo 5.2)
- plugin Eclipse WTP (Web Tools Package) (paragrafo 5.2.3)
- plugin Eclipse SQL Explorer (paragrafo 5.2.6)
- plugin Eclipse Hibernate Tools (paragrafo 5.2.5)
- plugin Eclipse TestNG (paragrafo 5.2.4)
- contenitore di servlet Tomcat 5.5.23 (paragrafo 5.3)
- SGBD Firebird 2.1 (paragrafo 5.4)
- SGBD MySQL5 (paragrafo 5.5)
- SGBD PosgreSQL (paragrafo 5.6)
- SGBD Oracle 10g Express (paragrafo 5.7)
- SGBD SQL Server 2005 Express (paragrafo 5.8)
- SGBD HSQLDB (paragrafo 5.9)
- SGBD Apache Derby (paragrafo 5.10)
- Spring 2.1 (paragrafo 5.11)
- contenitore EJB3 di JBoss (paragrafo 5.12)
1.4. Download degli esempi di
Sul sito di questo documento, gli esempi trattati sono scaricabili sotto forma di file zip che, una volta decompresso, genera la seguente cartella:
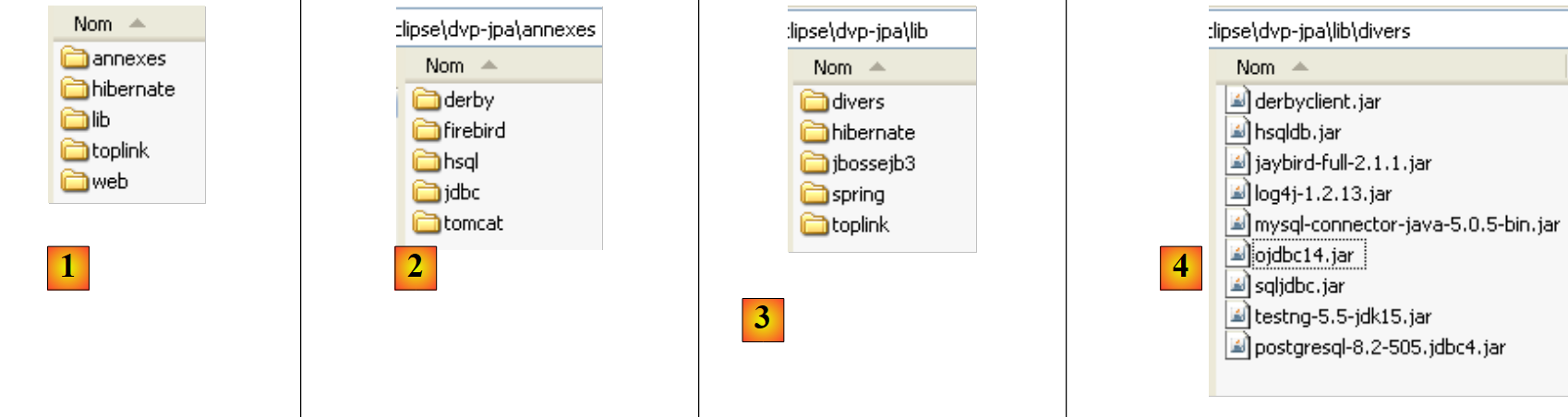 |
- in [1]: la struttura degli esempi
- in [2]: la cartella <annexes> contiene gli elementi presentati nella sezione ANNEXES, paragrafo 5. In particolare, la cartella <jdbc> contiene i driver JDBC di SGBD utilizzati per gli esempi del tutorial.
- in [3]: la cartella <lib> raggruppa in 5 cartelle i diversi file .jar utilizzati dal tutorial
- in [4]: la cartella <lib/divers> raggruppa i file: - i driver JDBC di SGBD - dello strumento di test unitario [testNG] - dello strumento di log [log4j]
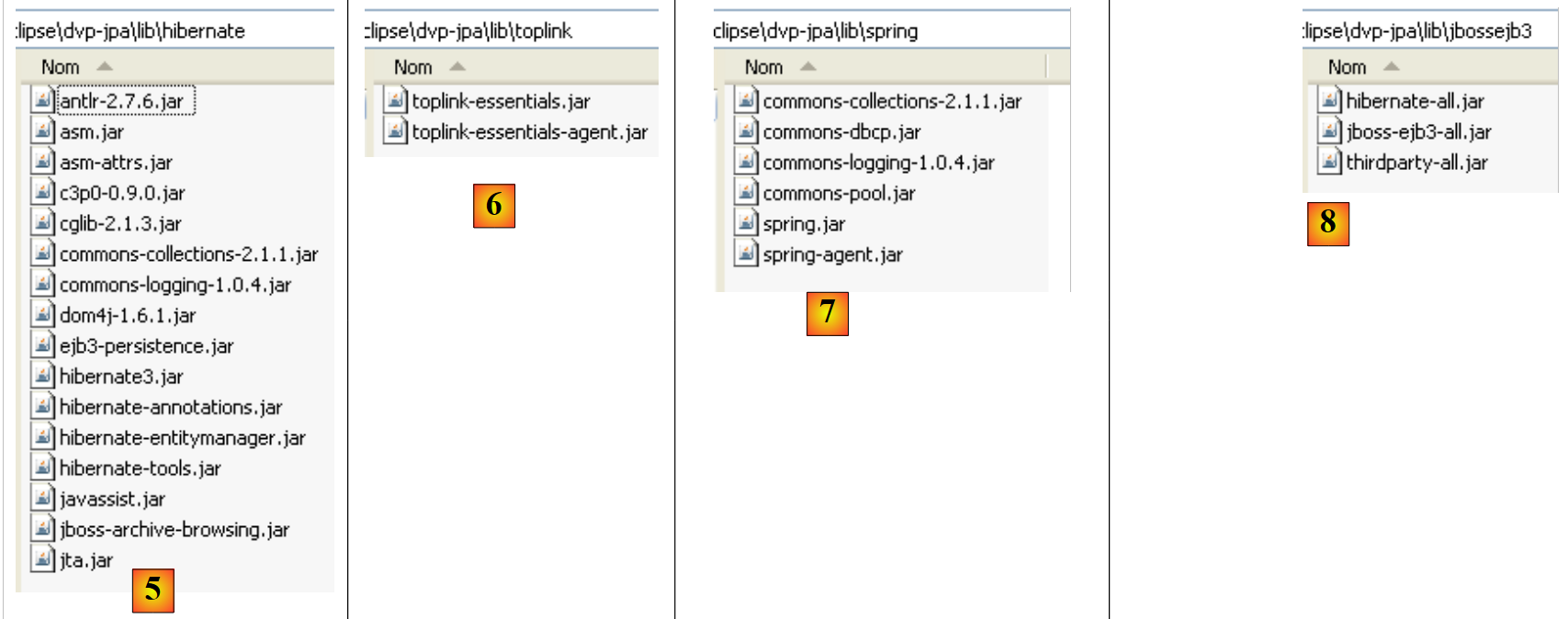 |
- in [5]: gli archivi dell'implementazione JPA/Hibernate e degli strumenti di terze parti necessari per Hibernate
- in [6]: gli archivi dell'implementazione JPA/Toplink
- in [7]: gli archivi di Spring 2.x e degli strumenti di terze parti necessari per Spring
- in [8]: gli archivi del contenitore EJB3 di JBoss
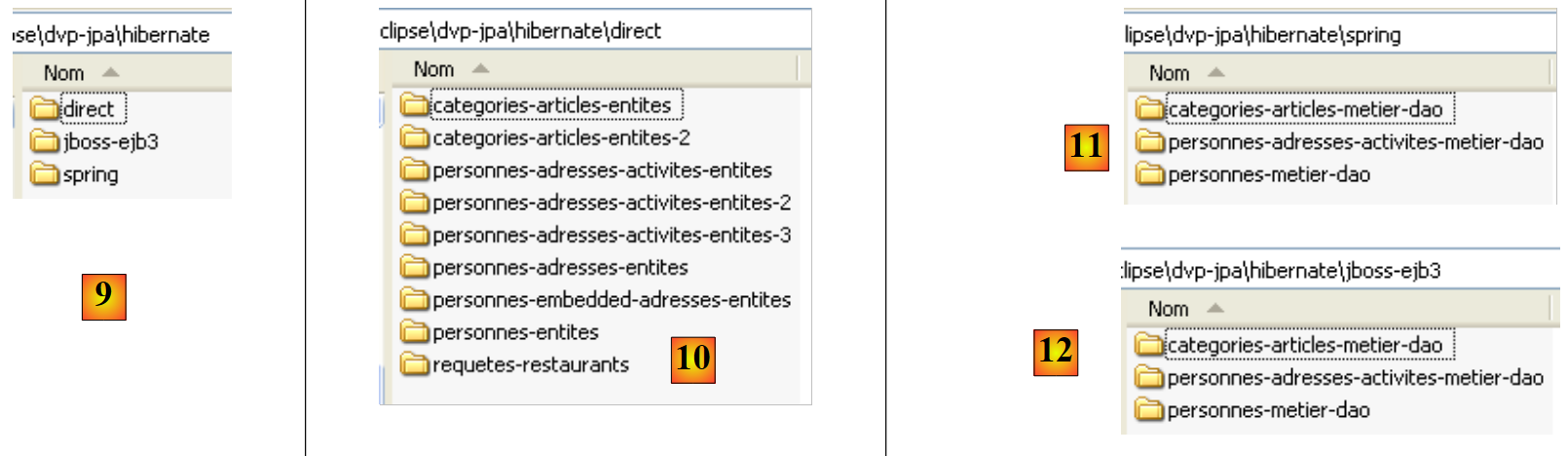 |
- in [9]: la cartella <hibernate> raggruppa gli esempi trattati con il livello di persistenza JPA/Hibernate
- in [10]: la cartella <hibernate/direct> raggruppa gli esempi in cui il livello JPA viene utilizzato direttamente con un programma di tipo [Main].
- in [11] e [12]: esempi in cui il livello JPA viene utilizzato tramite i livelli [metier] e [dao] in un'architettura multilivello, che rappresenta il caso d'uso standard. I servizi (pool di connessioni, gestore delle transazioni) utilizzati dai livelli [metier] e [dao] sono forniti da Spring [11] oppure da JBoss EJB3 [12].
 |
- in [13]: la cartella <toplink> riprende gli esempi della cartella <hibernate> [9], ma questa volta con un livello di persistenza JPA/Toplink invece di JPA/Hibernate. Non[13] non contiene la cartella <jbossejb3> poiché non è stato possibile far funzionare un esempio in cui il livello di persistenza fosse gestito da Toplink e i servizi dal contenitore EJB3 di JBoss.
- In [14]: una cartella <web> raggruppa tre esempi di applicazioni web con un livello di persistenza JPA:
- [15]: un esempio con Spring / JPA / Hibernate
- [16]: lo stesso esempio con Spring / JPA / Toplink
- [17]: lo stesso esempio con JBoss EJB3 / JPA / Hibernate. Questo esempio non funziona, probabilmente a causa di un problema di configurazione non chiarito. È stato comunque lasciato in modo che il lettore possa esaminarlo ed eventualmente trovare una soluzione al problema.
Il tutorial fa spesso riferimento a questa struttura di directory, in particolare durante i test degli esempi trattati. Il lettore è invitato a scaricare questi esempi e a installarli. D'ora in poi, chiameremo <esempi> la struttura di directory degli esempi sopra descritta.
1.5. Configurazione dei progetti Eclipse degli esempi
Gli esempi utilizzano librerie "utente". Si tratta di archivi .jar raggruppati sotto un unico nome. Quando si include una libreria di questo tipo nel classpath di un progetto Java, tutti gli archivi in essa contenuti vengono inclusi in tale classpath. Vediamo come procedere in Eclipse:
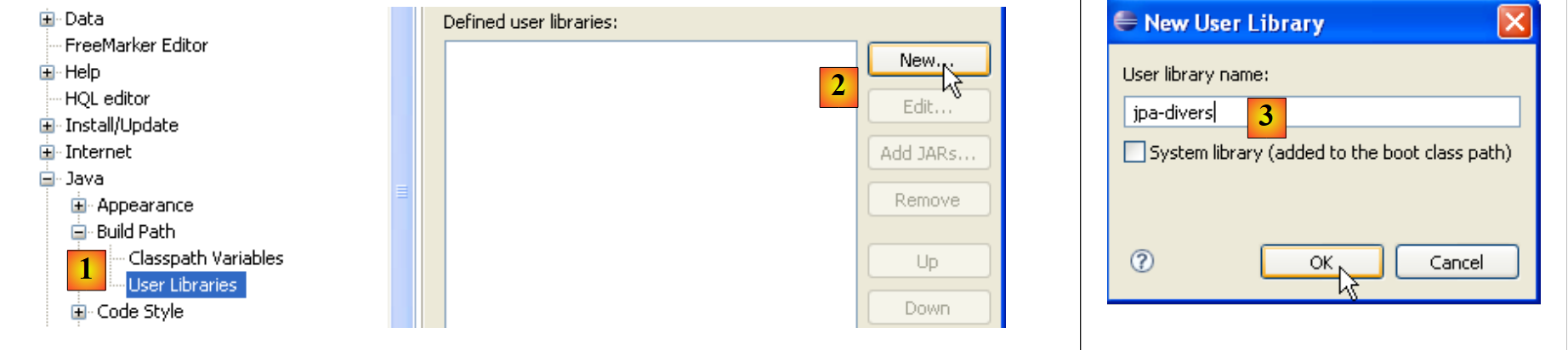 |
- in [1]: [Window / Preferences / Java / Buld Path / User Libraries]
- in [2]: si crea una nuova libreria
- in [3]: le si assegna un nome e si conferma
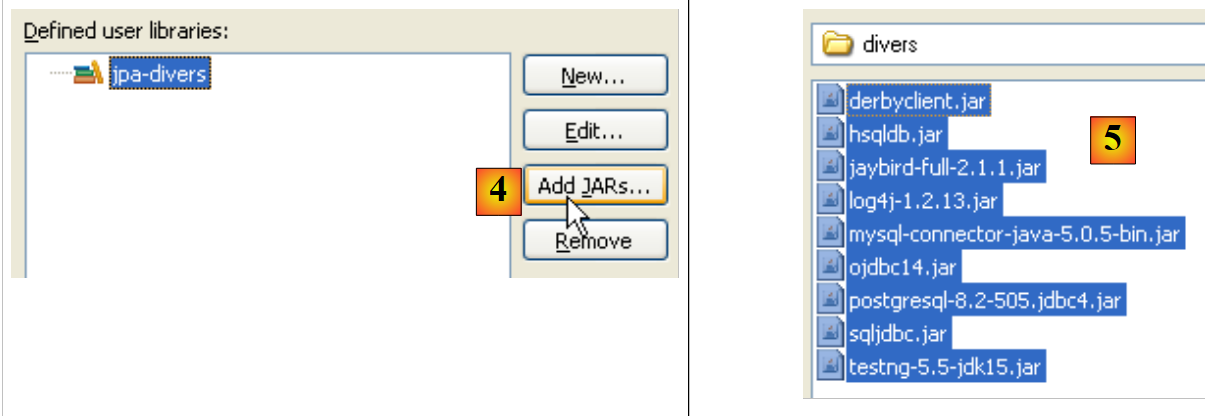 |
- in [4]: si selezionano i file JAR che faranno parte della libreria [jpa-divers]
- in [5]: si selezionano tutti i file JAR presenti nella cartella <esempi>/lib/vari
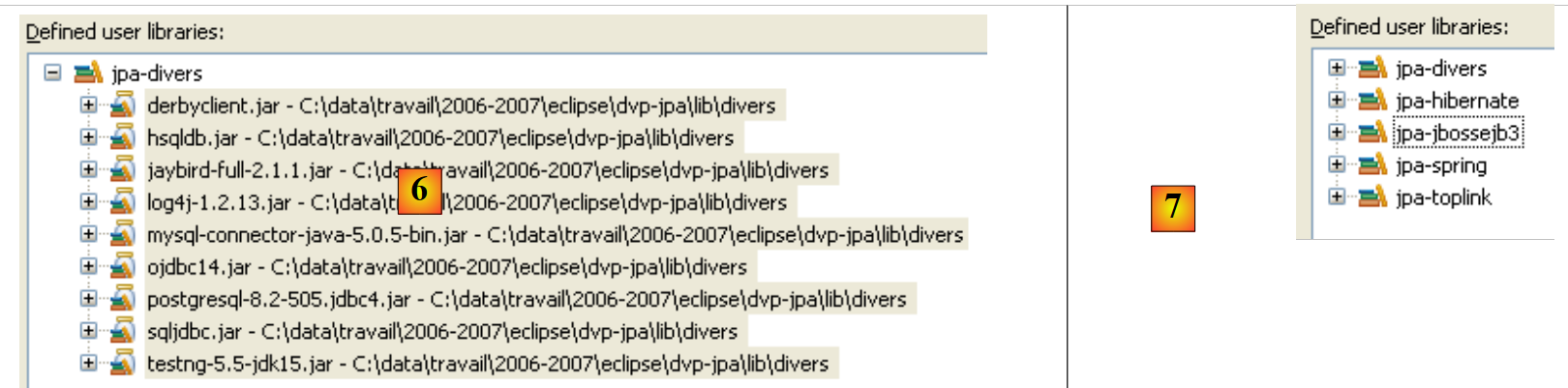 |
- in [6]: è stata definita la libreria utente [jpa-divers]
- in [7]: si ripete la stessa procedura per creare altre 4 librerie:
Libreria | Cartella dei file JAR della libreria |
<esempi>/lib/hibernate | |
<esempi>/lib/toplink | |
<esempi>/lib/spring | |
<esempi>/lib/jbossejb3 |