5. Appendici
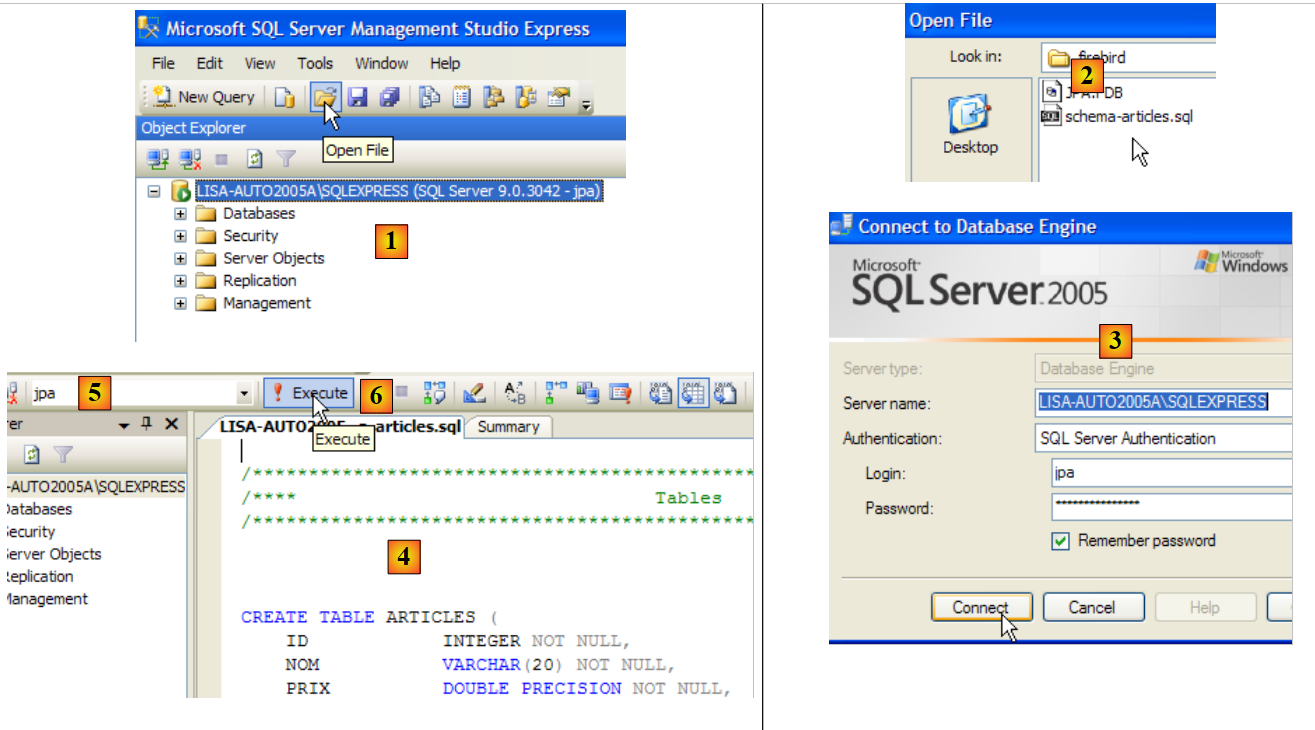
Qui descriviamo l'installazione e l'uso di base degli strumenti utilizzati nel documento "Java 5 Persistence in Practice". Le informazioni fornite di seguito sono aggiornate a maggio 2007. Diventeranno presto obsolete. Quando ciò accadrà, si consiglia al lettore di seguire procedure simili ma non identiche. Le installazioni sono state eseguite su un computer con Windows XP Professional.
5.1. Java
Utilizzeremo l'ultima versione di Java disponibile da Sun [http://www.sun.com]. I download sono accessibili tramite l'URL [http://java.sun.com/javase/downloads/index.jsp]:


Eseguire l'installazione del JDK dal file scaricato. Per impostazione predefinita, Java viene installato in [C:\Program Files\Java]:
5.2. Eclipse
5.2.1. Installazione di base
Eclipse è un IDE disponibile all'indirizzo [http://www.eclipse.org/] e può essere scaricato dall'indirizzo [http://www.eclipse.org/downloads/]. Di seguito, scarichiamo Eclipse 3.2.2:
![]()
Una volta scaricato il file ZIP, estrailo in una cartella sul tuo disco rigido:
Ci riferiremo alla cartella di installazione di Eclipse, mostrata sopra come [C:\devjava\eclipse 3.2.2\eclipse], come <eclipse>. [eclipse.exe] è il file eseguibile e [eclipse.ini] è il suo file di configurazione. Diamo un'occhiata al suo contenuto:
Questi argomenti vengono utilizzati al momento dell'avvio di Eclipse come segue:
In questo modo si ottiene lo stesso risultato dell'utilizzo del file .ini, creando un collegamento che avvia Eclipse con questi stessi argomenti. Vediamo di spiegarli:
- -vmargs: indica che gli argomenti seguenti sono destinati alla Java Virtual Machine che eseguirà Eclipse. Eclipse è un'applicazione Java.
- -Xms40m: ?
- -Xmx256m: imposta la dimensione della memoria in MB allocata alla Java Virtual Machine (JVM) che esegue Eclipse. Per impostazione predefinita, questa dimensione è di 256 MB, come mostrato qui. Se il sistema lo consente, è preferibile 512 MB.
Questi argomenti vengono passati alla JVM che eseguirà Eclipse. La JVM è rappresentata da un file [java.exe] o [javaw.exe]. Dove si trova questo file? In realtà, si trova in diversi modi:
- nel PATH del sistema operativo
- nella cartella <JAVA_HOME>/jre/bin, dove JAVA_HOME è una variabile di sistema che definisce la cartella principale di un JDK.
- in una posizione passata come argomento a Eclipse nella forma -vm <percorso>\javaw.exe
Quest'ultima soluzione è preferibile perché le altre due sono soggette ai capricci delle successive installazioni di applicazioni, che possono modificare il PATH del sistema operativo o la variabile JAVA_HOME.
Creiamo quindi il seguente collegamento:
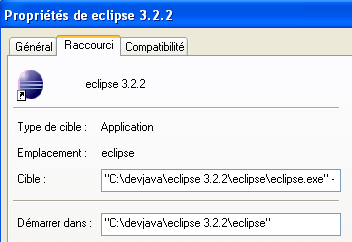
<eclipse>\eclipse.exe" -vm "C:\Program Files\Java\jre1.6.0_01\bin\javaw.exe" -vmargs -Xms40m -Xmx512m | |
cartella di installazione di Eclipse <eclipse> |
Una volta fatto ciò, avvia Eclipse utilizzando questo collegamento. Apparirà una finestra di dialogo:
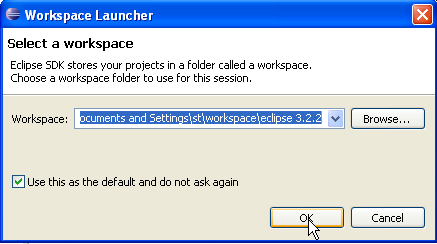
Un [workspace] è un'area di lavoro. Accettiamo i valori predefiniti forniti. Per impostazione predefinita, i progetti Eclipse verranno creati nella cartella <workspace> specificata in questa finestra di dialogo. Esiste un modo per sovrascrivere questo comportamento. Questo è ciò che faremo sistematicamente. Pertanto, la risposta fornita in questa finestra di dialogo non è importante.
Una volta completato questo passaggio, viene visualizzato l'ambiente di sviluppo Eclipse:
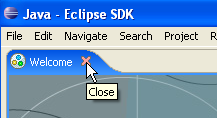
Chiudiamo la vista [Welcome] come suggerito sopra:
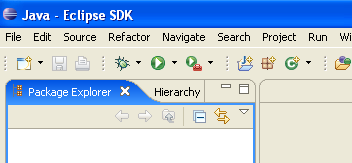
Prima di creare un progetto Java, configureremo Eclipse per specificare il JDK da utilizzare per la compilazione dei progetti Java. A tal fine, selezioniamo l'opzione [Window / Preferences / Java / Installed JREs]:
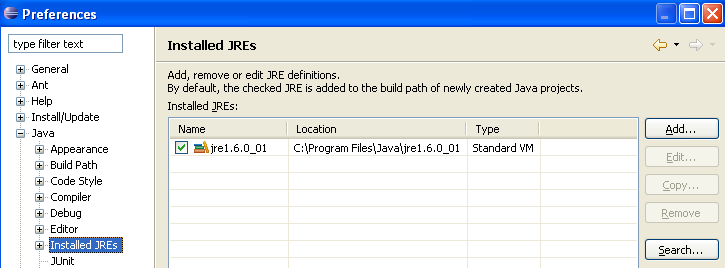
Normalmente, il JRE (Java Runtime Environment) utilizzato per avviare Eclipse stesso dovrebbe essere presente nell'elenco dei JRE. Di solito sarà l'unico. È possibile aggiungere JRE utilizzando il pulsante [Add]. È quindi necessario specificare la directory principale del JRE. Il pulsante [Cerca] avvierà una ricerca dei JRE sul disco. Questo è un buon modo per tenere traccia dei JRE che si installano e che poi ci si dimentica di disinstallare quando si esegue l'aggiornamento a una versione più recente. Sopra, il JRE selezionato è quello che verrà utilizzato per compilare ed eseguire i progetti Java. Questo è quello installato nella Sezione 5.1 e utilizzato anche per avviare Eclipse. Facendo doppio clic su di esso si aprono le sue proprietà:
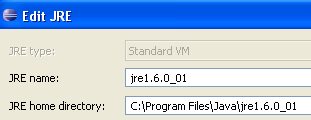
Ora, creiamo un progetto Java [File / Nuovo / Progetto]:
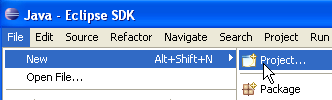 | 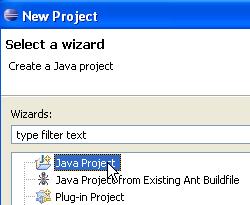 |
Selezionare [Progetto Java], quindi [Avanti] ->
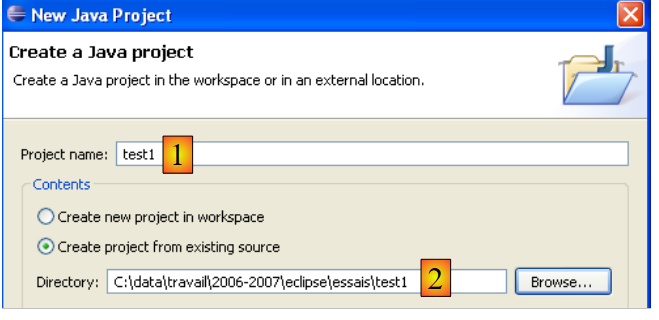
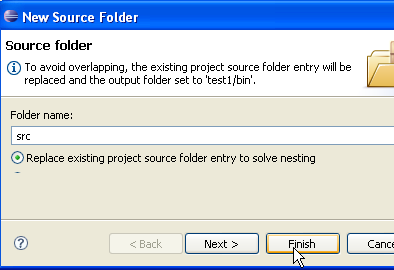
In [2], specifichiamo una cartella vuota in cui verrà installato il progetto Java. In [1], assegniamo un nome al progetto. Non è necessario che il nome corrisponda a quello della cartella, come potrebbe suggerire l'esempio sopra riportato. Una volta fatto ciò, utilizziamo il pulsante [Avanti] per passare alla pagina successiva della procedura guidata di creazione:
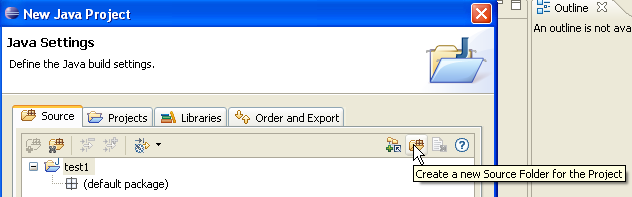
Qui sopra, creiamo una cartella speciale all'interno del progetto per archiviare i file sorgente (.java):
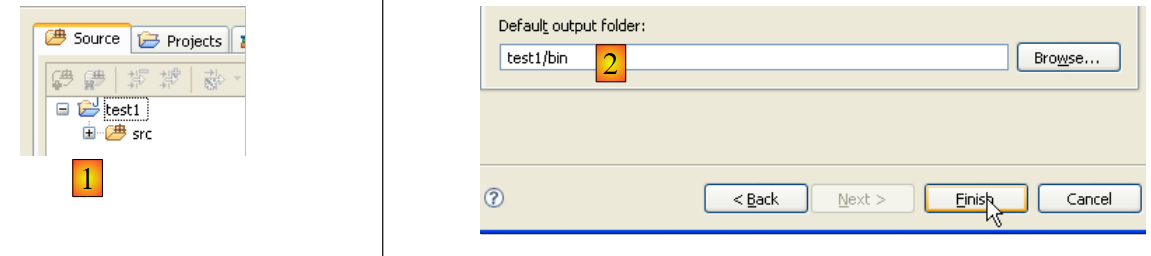 |
- In [1], vediamo la cartella [src], che conterrà i file sorgente .java
- In [2], vediamo la cartella [bin] dove verranno memorizzati i file .class compilati
Completiamo la procedura guidata cliccando su [Fine]. Ora disponiamo di uno scheletro di progetto Java:
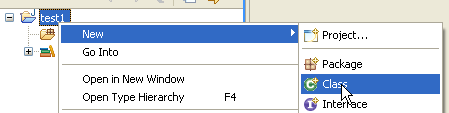
Fare clic con il tasto destro del mouse sul progetto [test1] per creare una classe Java:
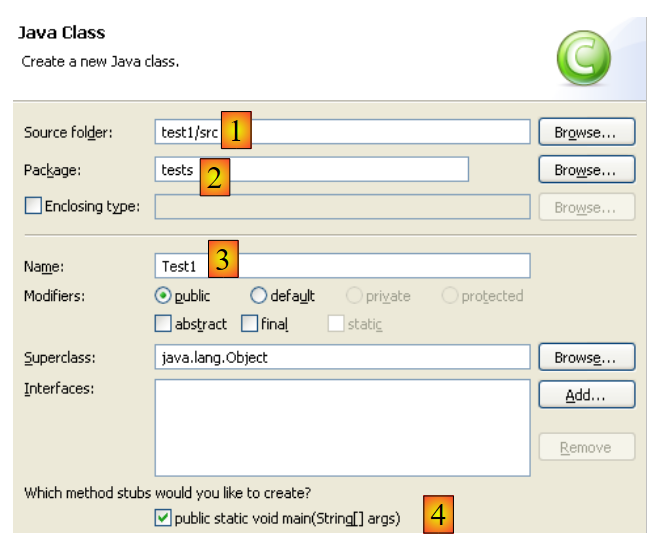 |
- In [1], la cartella in cui verrà creata la classe. Per impostazione predefinita, Eclipse suggerisce la cartella del progetto corrente.
- In [2], il pacchetto in cui verrà inserita la classe
- In [3], il nome della classe
- In [4], specifichiamo che il metodo statico [main] debba essere generato
Confermiamo la procedura guidata cliccando su [Fine]. Il progetto viene quindi arricchito con una classe:
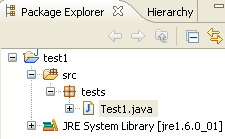
Eclipse ha generato lo scheletro della classe. È possibile accedervi facendo doppio clic su [Test1.java] qui sopra:
Modifichiamo il codice sopra riportato come segue:
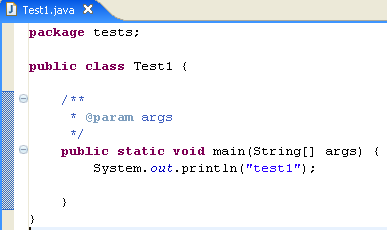
Eseguiamo il programma [Test1.java]: [clic destro su Test1.java -> Esegui come -> Applicazione Java]
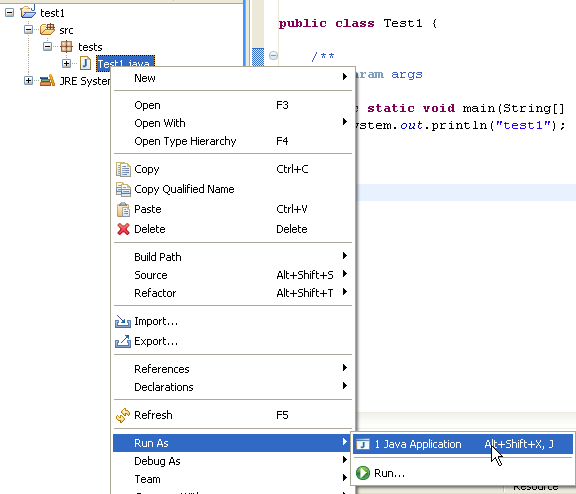
Il risultato dell'esecuzione viene visualizzato nella finestra [Console]:
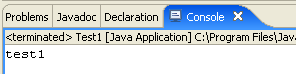
La finestra [Console] dovrebbe apparire per impostazione predefinita. Se così non fosse, è possibile visualizzarla tramite [Finestra/Mostra vista/Console]:
5.2.2. Scelta del compilatore
Eclipse consente di generare codice compatibile con Java 1.4, Java 1.5 e Java 1.6. Per impostazione predefinita, è configurato per generare codice compatibile con Java 1.4. L'API JPA richiede codice Java 1.5. Modifichiamo il tipo di codice generato tramite [Finestra / Preferenze / Java / Compilatore]:
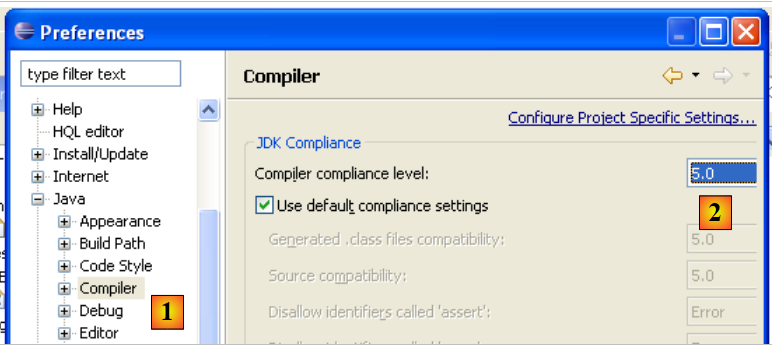 |
- in [1]: selezionando l'opzione [Java / Compilatore]
- in [2]: selezionare la compatibilità con Java 5.0
5.2.3. Installazione dell' e Callisto
La versione base installata sopra consente di creare applicazioni Java da console, ma non applicazioni Java di tipo web o Swing; in caso contrario, dovrete fare tutto da soli. Installeremo vari plugin:
Procedere come segue [Aiuto/Aggiornamenti software/Trova e installa]:
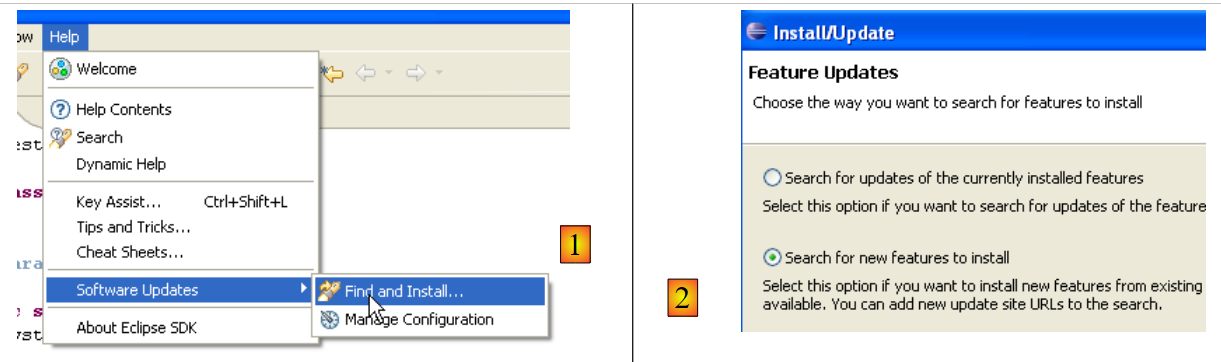 |
- In [2], specificare che si desidera installare nuovi plugin
 |
- In [3], specificare i siti in cui cercare i plugin
- In [4], selezionare i plugin desiderati
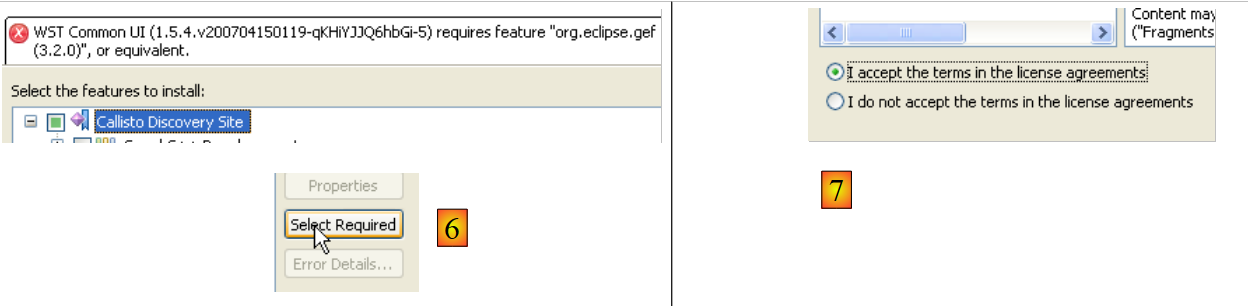 |
- In [5], Eclipse indica che è stato selezionato un plugin che dipende da altri plugin non selezionati
- In [6], utilizzare il pulsante [Seleziona richiesti] per selezionare automaticamente i plugin mancanti
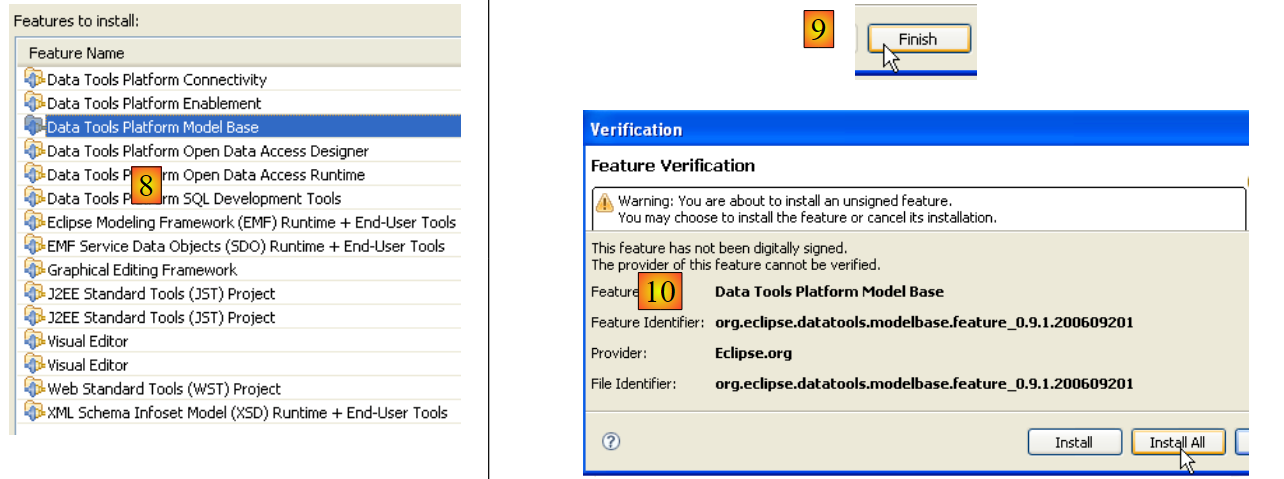
- In [7], accetta i termini di licenza per questi vari plugin
 |
- In [8], viene visualizzato un elenco di tutti i plugin che verranno installati
- In [9], avviare il download di questi plugin
- In [10], una volta scaricati, installali tutti senza verificarne le firme
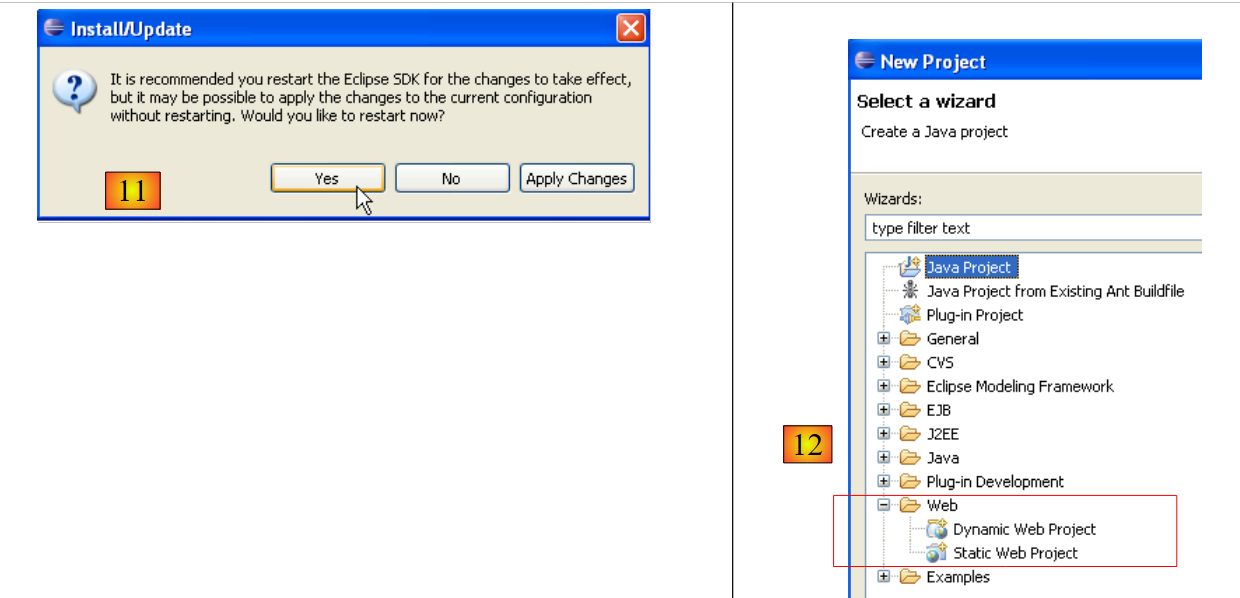 |
- In [11], una volta installati i plugin, riavviare Eclipse
- In [12], se vai su [File/Nuovo/Progetto], vedrai che ora puoi creare applicazioni web, cosa che inizialmente non era possibile.
5.2.4. Installazione del plugin [ TestNG]
TestNG (Test Next Generation) è uno strumento di test unitario simile nel concetto a JUnit. Tuttavia, offre miglioramenti che ci inducono a preferirlo a JUnit in questo caso. Procediamo come prima: [Aiuto/Aggiornamenti software/Trova e installa]:
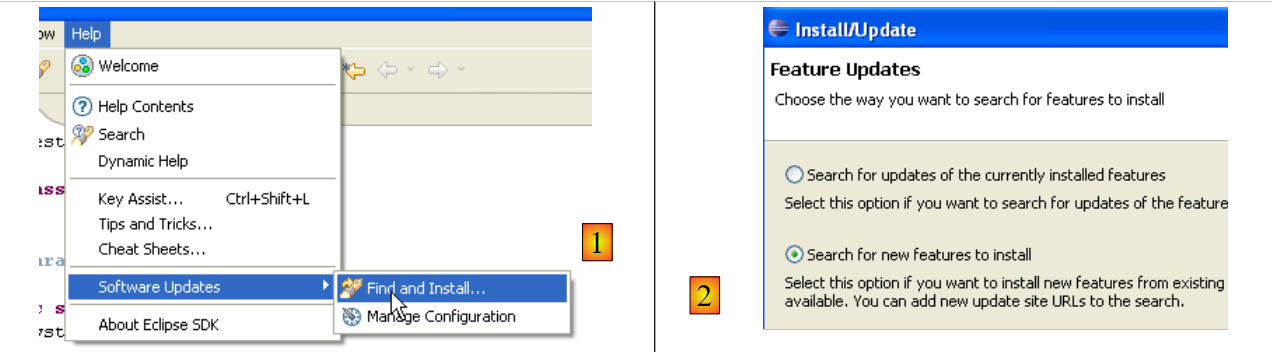 |
- In [2], indichiamo che vogliamo installare nuovi plugin
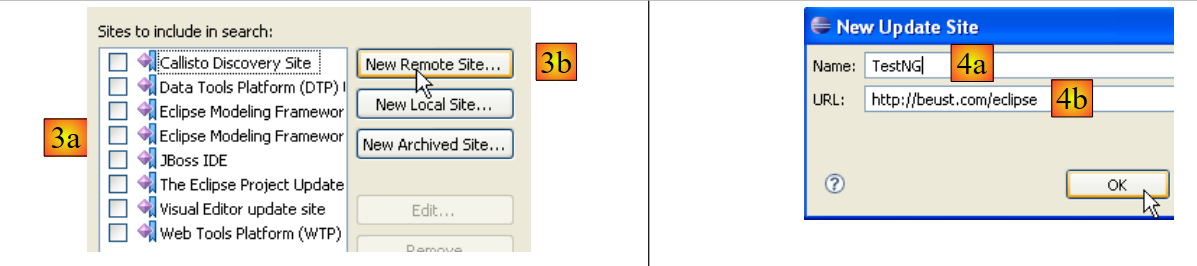 |
- in [3a], il sito di download di [TestNG] non è elencato. Lo aggiungiamo utilizzando [3b]
- In [4b]: il sito del plugin è [http://beust.com/eclipse]. In [4a], inserisci ciò che desideri.
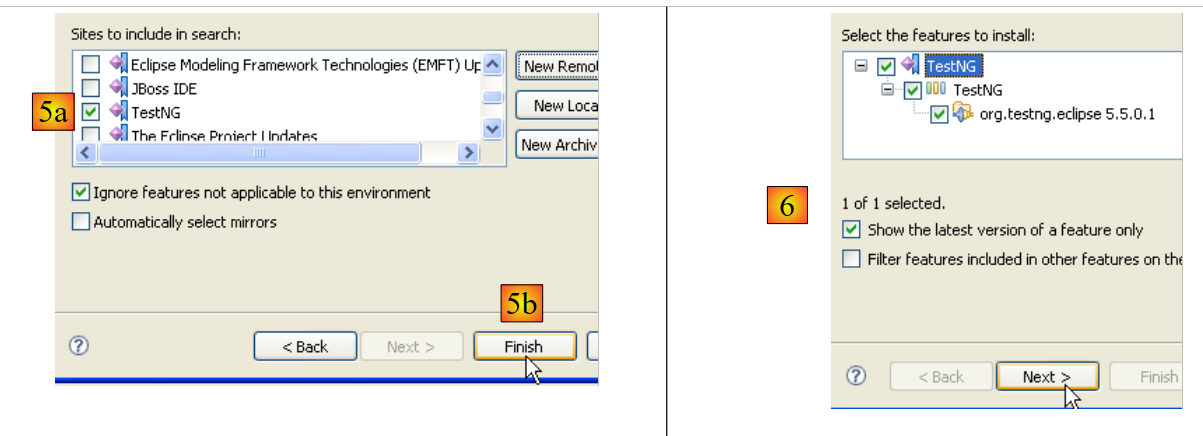 |
- In [5a], il plugin [TestNG] è selezionato per l'aggiornamento. In [5b], avviamo l'aggiornamento.
- In [6], è stata stabilita la connessione al sito web del plugin. Vengono mostrati tutti i plugin disponibili sul sito. Qui ce n'è solo uno, che selezioniamo prima di passare al passo successivo.
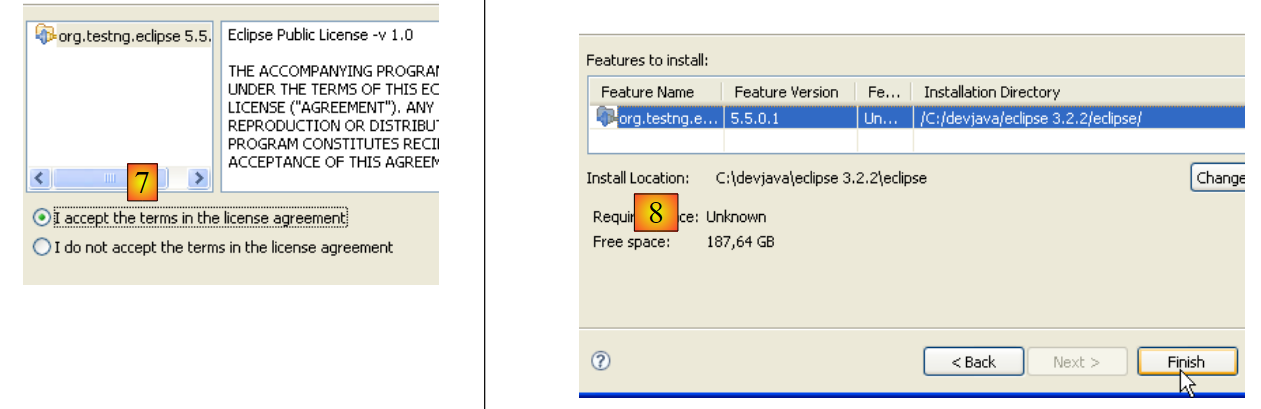 |
- In [7], accettiamo i termini della licenza del plugin
- In [8], vediamo un elenco di tutti i plugin che verranno installati: uno in questo caso. Avviamo il download. Quindi tutto procede come descritto sopra per i plugin Callisto.
Una volta riavviato Eclipse, possiamo verificare la presenza del nuovo plugin, ad esempio visualizzando le viste disponibili [Finestra / Mostra vista / Altro]:
 |
Come mostrato sopra, ora è presente una vista [TestNG] che prima non esisteva.
5.2.5. Installazione del plugin [ Hibernate Tools]
Hibernate è un provider JPA e il plugin [Hibernate Tools] per Eclipse è utile per la creazione di applicazioni JPA. A maggio 2007, solo la sua versione più recente (3.2.0beta9) supporta l'utilizzo di Hibernate/JPA e non è disponibile tramite il meccanismo appena descritto. Sono disponibili solo le versioni precedenti. Procederemo quindi in modo diverso.
Il plugin è disponibile sul sito web di Hibernate Tools: http://tools.hibernate.org/.
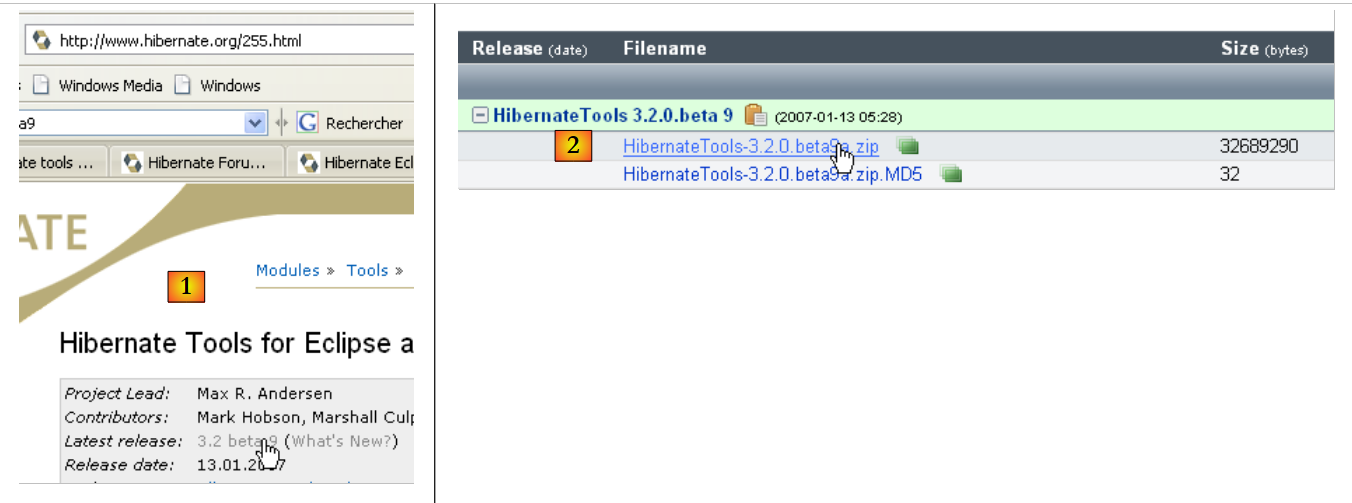 |
- In [1], selezionare l'ultima versione di Hibernate Tools
- In [2], scaricalo
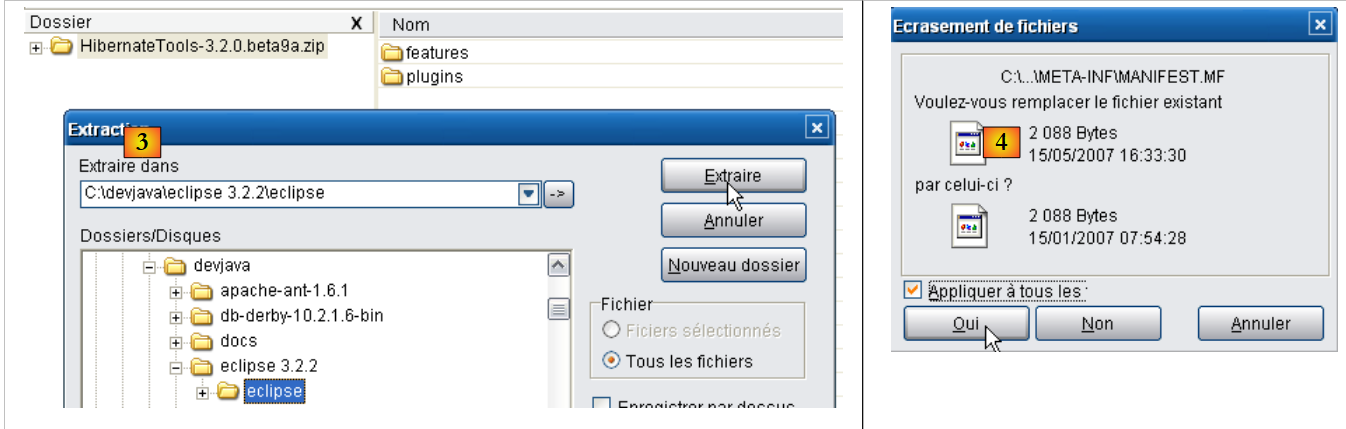 |
- In [3], usa uno strumento di decompressione per estrarre il file ZIP scaricato nella cartella <eclipse> (è meglio chiudere Eclipse)
- In [4], accettare che alcuni file vengano sovrascritti durante l'operazione
Riavviare Eclipse:
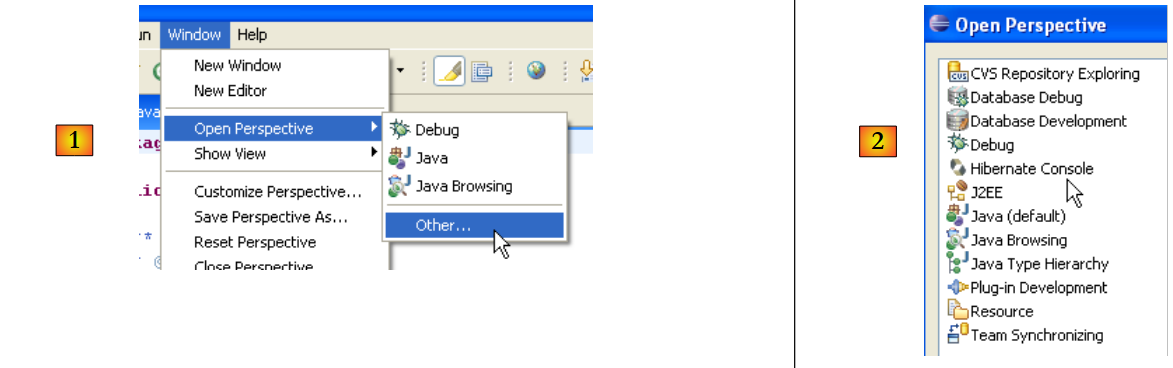 |
- in [1]: Apri una vista
- in [2]: ora è presente una prospettiva [Hibernate Console]
Non approfondiremo ulteriormente il plugin [Hibernate Tools] (Annulla in [2]). Il suo utilizzo è spiegato negli esempi del tutorial.
A volte Eclipse non rileva i nuovi plugin. È possibile forzare una nuova scansione di tutti i plugin utilizzando l'opzione -clean. Pertanto, l'eseguibile del collegamento di Eclipse verrebbe modificato come segue:
"<eclipse>\eclipse.exe" -clean -vm "C:\Program Files\Java\jre1.6.0_01\bin\javaw.exe" -vmargs -Xms40m -Xmx512m
Una volta che i nuovi plugin sono stati rilevati da Eclipse, rimuovere l'opzione -clean sopra indicata.
5.2.6. Installazione del plugin [ SQL Explorer]
Ora installeremo un plugin che ci consentirà di esplorare il contenuto di un database direttamente da Eclipse. I plugin disponibili per Eclipse sono reperibili sul sito web [http://eclipse-plugins.2y.net/eclipse/plugins.jsp]:
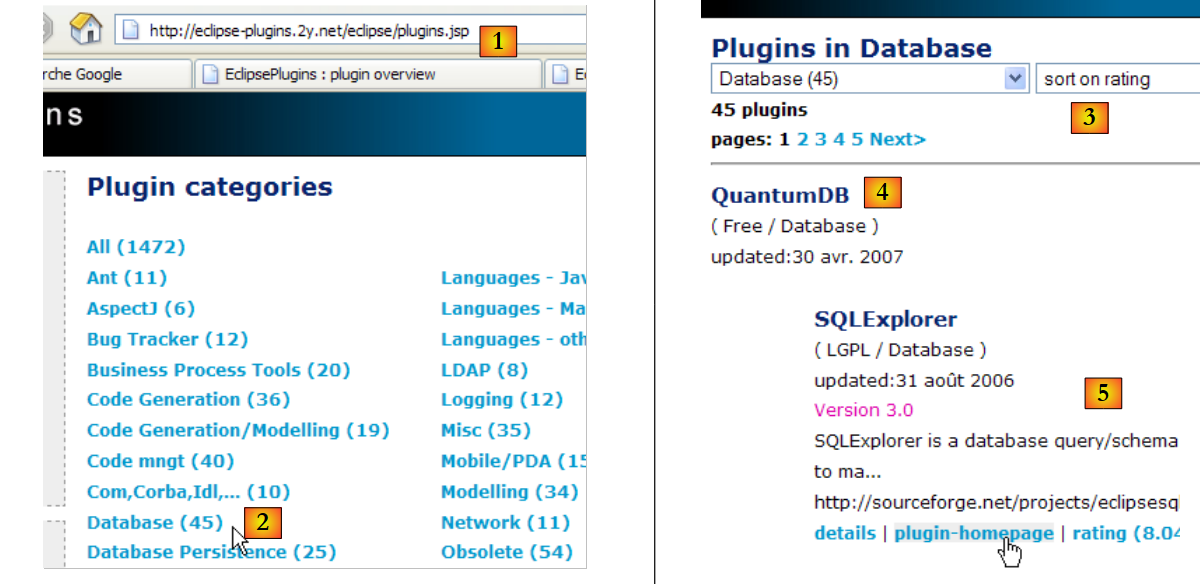 |
- al punto [1]: il sito web dei plugin di Eclipse
- al [2]: selezionare la categoria [Database]
- [3]: Nella categoria [Database], seleziona una visualizzazione ordinata per valutazione (non molto affidabile dato il numero esiguo di votanti)
- in [4]: QuantumDB è al primo posto
- in [5]: scegliamo SQLExplorer, che è più vecchio, ha un punteggio inferiore (3°) ma è comunque molto buono. Andiamo al sito web del plugin [plugin-homepage]
 |
- in [6] e [7]: scarichiamo il plugin.
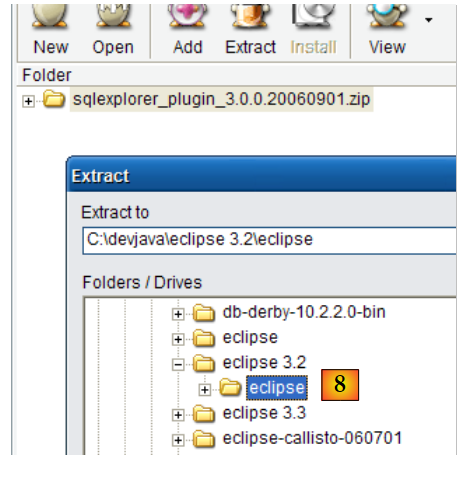 |
- in [8]: decomprimere il file zip del plugin nella cartella Eclipse.
Per verificare, riavvia Eclipse, eventualmente utilizzando l'opzione -clean:
 |
- in [1]: apri una nuova prospettiva
- in [2]: vediamo che è disponibile una prospettiva [SQL Explorer]. Ci torneremo più tardi.
5.3. Contenitore di servlet Tomcat 5.5
5.3.1. Installazione
Per eseguire i servlet, abbiamo bisogno di un contenitore di servlet. Qui ne presentiamo uno, Tomcat 5.5, disponibile all'indirizzo http://tomcat.apache.org/. Descriviamo la procedura (maggio 2007) per installarlo. Se è già installata una versione precedente di Tomcat, è meglio rimuoverla prima.

Per scaricare il prodotto, seguire il link [Tomcat 5.x] sopra:

È possibile scaricare il file .exe per la piattaforma Windows. Una volta scaricato, avviare l'installazione di Tomcat facendo doppio clic sul file:
Accetta i termini della licenza ->
Fare clic su [Avanti] ->
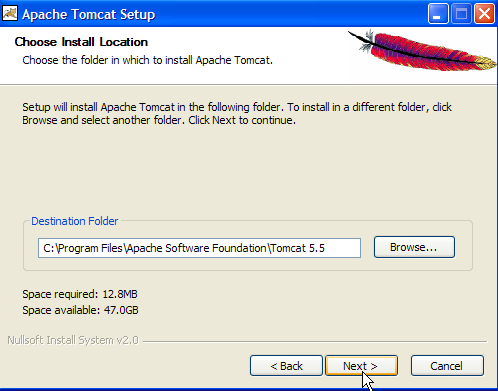
Accetta la cartella di installazione suggerita oppure modificala utilizzando [Sfoglia] ->
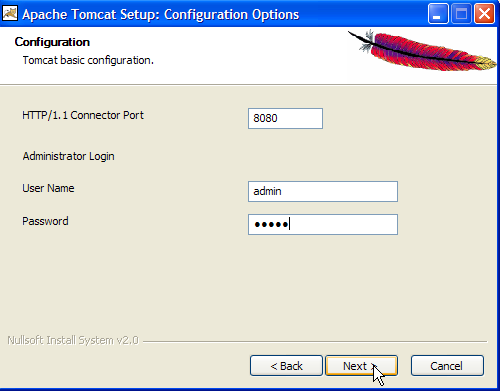
Imposta il nome utente e la password per l'amministratore del server Tomcat. Qui abbiamo utilizzato [admin / admin] ->
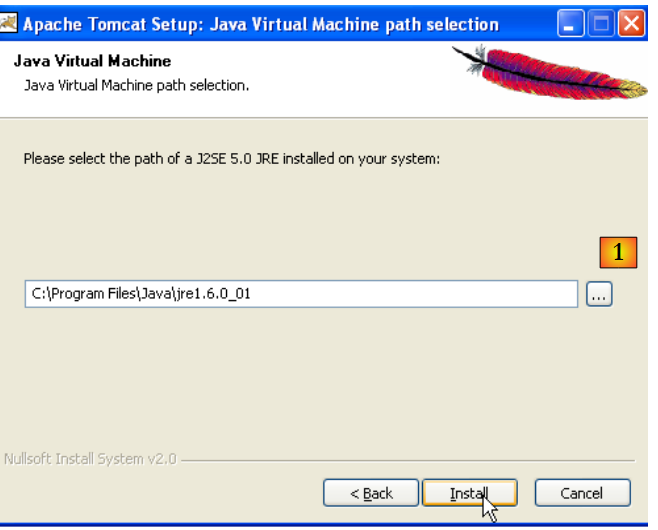 |
Tomcat 5.x richiede JRE 1.5. Normalmente dovrebbe rilevare quello installato sul tuo computer. Sopra, il percorso specificato è quello del JRE 1.6 scaricato nella sezione 5.1. Se non viene trovato alcun JRE, specifica la sua directory principale utilizzando il pulsante [1]. Una volta fatto ciò, utilizza il pulsante [Install] per installare Tomcat 5.x ->
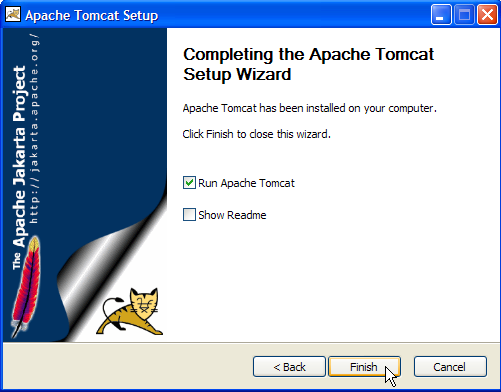
Il pulsante [Finish] completa l'installazione. La presenza di Tomcat è indicata da un'icona sul lato destro della barra delle applicazioni di Windows:
Facendo clic con il tasto destro su questa icona si accede ai comandi Avvia e Arresta del server:
Utilizziamo l'opzione [Interrompi servizio] per arrestare il server web:
Si noti il cambiamento di stato dell'icona. L'icona può essere rimossa dalla barra delle applicazioni:
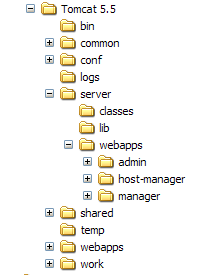
Tomcat è stato installato nella cartella scelta dall'utente, che d'ora in poi chiameremo <tomcat>. La struttura delle directory per la versione scaricata di Tomcat 5.5.23 è la seguente:
L'installazione di Tomcat ha aggiunto una serie di collegamenti al menu [Start]. Utilizziamo il collegamento [Monitor] qui sotto per avviare lo strumento di avvio/arresto di Tomcat:
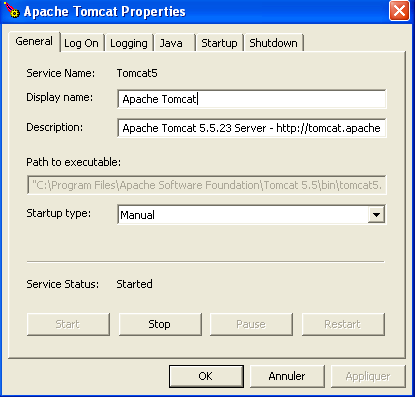
Viene quindi visualizzata l'icona mostrata in precedenza:
Il monitor di Tomcat può essere avviato facendo doppio clic su questa icona:
I pulsanti [Start - Stop - Pause] - Restart ci consentono di avviare, arrestare e riavviare il server. Avviamo il server facendo clic su [Start], quindi, utilizzando un browser, inseriamo l'URL http://localhost:8080. Dovremmo visualizzare una pagina simile alla seguente:
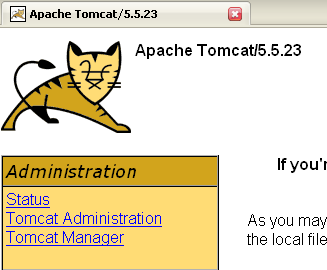
È possibile seguire i link riportati di seguito per verificare che Tomcat sia stato installato correttamente:

Vale la pena esplorare tutti i link presenti nella pagina [http://localhost:8080], e invitiamo il lettore a farlo. Avremo modo di tornare sui link che consentono di gestire le applicazioni web distribuite sul server:

5.3.2. Distribuzione di un'applicazione web sul server Tomcat
5.3.3. Distribuzione
Un'applicazione web deve seguire determinate regole per essere distribuita all'interno di un contenitore di servlet. Supponiamo che <webapp> sia la directory di un'applicazione web. Un'applicazione web è costituita da:
nella cartella <webapp>\WEB-INF\classes | |
nella cartella <webapp>\WEB-INF\lib | |
nella cartella <webapp> o nelle sottocartelle |
L'applicazione web è configurata da un file XML: <webapp>\WEB-INF\web.xml. Questo file non è necessario in casi semplici, in particolare quando l'applicazione web contiene solo file statici. Creiamo il seguente file HTML:
<html>
<head>
<title>Application exemple</title>
</head>
<body>
Application exemple active ....
</body>
</html>
e salviamolo in una cartella:
Se carichiamo questo file in un browser, otteniamo la seguente pagina:

L'URL visualizzato dal browser mostra che la pagina non è stata fornita da un server web, ma caricata direttamente dal browser. Ora vogliamo che sia disponibile tramite il server web Tomcat.
Torniamo alla struttura di directory <tomcat>:
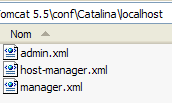
Le applicazioni web distribuite sul server Tomcat vengono configurate utilizzando file XML situati nella cartella [<tomcat>\conf\Catalina\localhost]:
 |  |
Questi file XML possono essere creati manualmente poiché la loro struttura è semplice. Anziché adottare questo approccio, utilizzeremo gli strumenti web forniti da Tomcat.
5.3.4. Amministrazione di Tomcat
Nella pagina di accesso http://localhost:8080, il server fornisce dei link per l'amministrazione:

Il link [Amministrazione di Tomcat] ci permette di configurare le risorse che Tomcat mette a disposizione delle applicazioni web distribuite al suo interno, come ad esempio un pool di connessioni al database. Seguiamo il link:

La pagina che appare indica che l'amministrazione di Tomcat 5.x richiede un pacchetto specifico chiamato "admin". Torniamo al sito web di Tomcat [http://tomcat.apache.org/download-55.cgi]:
Scarichiamo il file zip denominato [Web Application Administration] e poi decomprimiamolo. Il suo contenuto è il seguente:
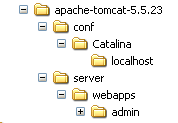
La cartella [admin] deve essere copiata in [<tomcat>\server\webapps], dove <tomcat> è la cartella in cui è stato installato Tomcat 5.x:
La cartella [localhost] contiene un file [admin.xml] che deve essere copiato in [<tomcat>\conf\Catalina\localhost]:
Se Tomcat era in esecuzione, arrestarlo e quindi riavviarlo. Quindi, utilizzando un browser, richiedere nuovamente la pagina di accesso del server web:

Fare clic sul collegamento [Tomcat Administration]. Verrà visualizzata una pagina di accesso (potrebbe essere necessario ricaricare o aggiornare la pagina per visualizzarla):
 |  |
Qui devi reinserire le credenziali fornite durante l'installazione di Tomcat. Nel nostro caso, inseriamo "admin" come nome utente e password. Cliccando sul pulsante [Login] si accede alla pagina seguente:
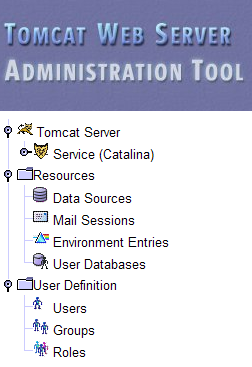
Questa pagina consente all'amministratore di Tomcat di definire
- le origini dati,
- le informazioni necessarie per l'invio di e-mail (Sessioni di posta),
- i dati di ambiente accessibili a tutte le applicazioni (Voci di Ambiente),
- gestire gli utenti e gli amministratori di Tomcat (Utenti),
- gestione dei gruppi di utenti (Gruppi),
- definizione dei ruoli (ovvero, ciò che un utente può e non può fare),
- definire le caratteristiche delle applicazioni web distribuite dal server (Catalina Service)
Seguiamo il link [Ruoli] qui sopra:
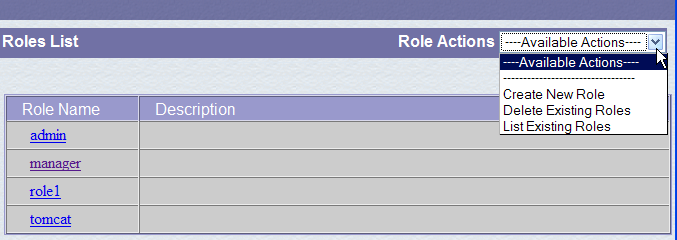
Un ruolo consente di definire ciò che un utente o un gruppo di utenti può o non può fare. A un ruolo sono associati determinati diritti. Ogni utente è associato a uno o più ruoli e dispone dei diritti ad essi associati. Il ruolo [manager] riportato di seguito concede il diritto di gestire le applicazioni web distribuite in Tomcat (distribuzione, avvio, arresto, scaricamento). Creeremo un utente [manager] e lo assoceremo al ruolo [manager] per consentirgli di gestire le applicazioni Tomcat. Per farlo, seguiamo il link [Users] nella pagina di amministrazione:
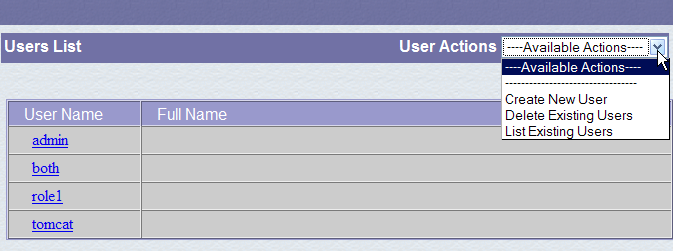
Notiamo che esistono già diversi utenti. Utilizziamo l'opzione [Crea nuovo utente] per creare un nuovo utente:
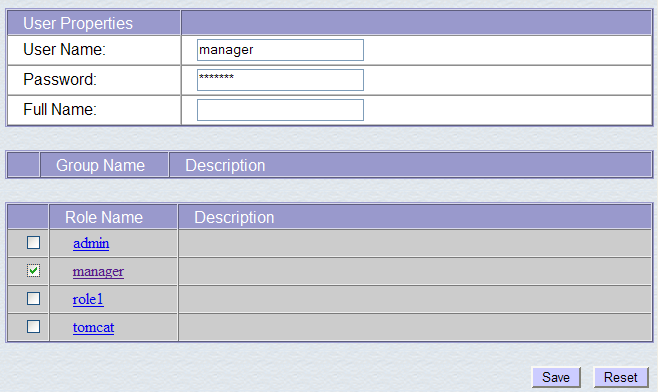
Assegniamo all'utente manager la password manager e gli attribuiamo il ruolo manager. Utilizziamo il pulsante [Salva] per confermare questa aggiunta. Il nuovo utente appare nell'elenco degli utenti:
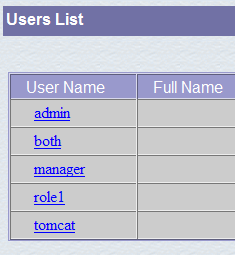
Questo nuovo utente verrà aggiunto al file [<tomcat>\conf\tomcat-users.xml]:
il cui contenuto è il seguente:
<?xml version='1.0' encoding='utf-8'?>
<tomcat-users>
<role rolename="tomcat"/>
<role rolename="role1"/>
<role rolename="manager"/>
<role rolename="admin"/>
<user username="tomcat" password="tomcat" roles="tomcat"/>
<user username="role1" password="tomcat" roles="role1"/>
<user username="both" password="tomcat" roles="tomcat,role1"/>
<user username="manager" password="manager" fullName="" roles="manager"/>
<user username="admin" password="admin" roles="admin,manager"/>
</tomcat-users>
- Riga 10: l'utente [manager] che è stato creato
Un altro modo per aggiungere utenti è modificare direttamente questo file. Questa è la procedura da seguire se, ad esempio, avete dimenticato la password per l'account admin o manager.
5.3.5. Gestione delle applicazioni web distribuite
Ora torniamo alla pagina di accesso [http://localhost:8080] e seguiamo il link [Tomcat Manager]:

Si aprirà una pagina di autenticazione. Effettuiamo l'accesso come manager / manager, ovvero l'utente con il ruolo [manager] che abbiamo appena creato. Infatti, solo un utente con questo ruolo può utilizzare questo link. Alla riga 11 di [tomcat-users.xml], vediamo che anche l'utente [admin] ha il ruolo [manager]. Potremmo quindi utilizzare anche le credenziali [admin / admin].
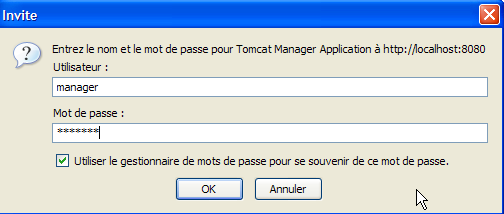
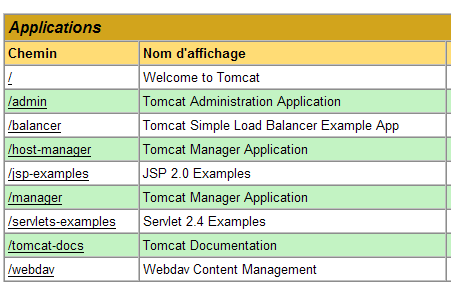
Verrà visualizzata una pagina che elenca le applicazioni attualmente distribuite in Tomcat:
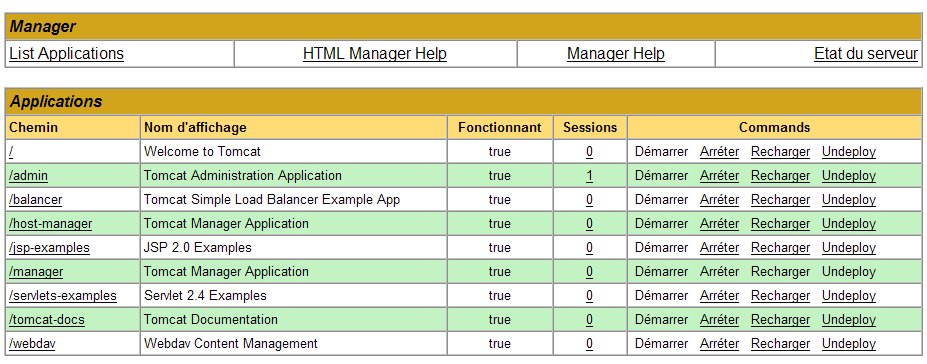
Possiamo aggiungere una nuova applicazione utilizzando i moduli nella parte inferiore della pagina:
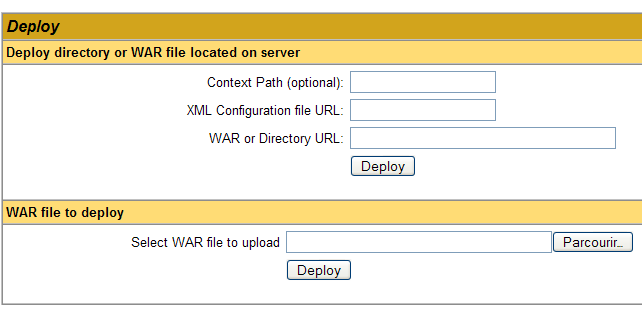
In questo caso, vogliamo distribuire l'applicazione di esempio che abbiamo creato in precedenza all'interno di Tomcat. Procediamo come segue:
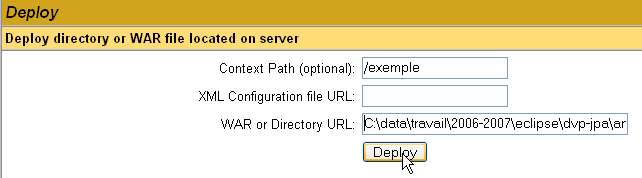
/example | il nome utilizzato per identificare l'applicazione web da distribuire | |
C:\data\work\2006-2007\eclipse\dvp-jpa\annexes\tomcat\example | la cartella dell'applicazione web |
Per recuperare il file [C:\data\work\2006-2007\eclipse\dvp-jpa\annexes\tomcat\example\example.html], richiederemo l'URL [http://localhost:8080/exemple/exemple.html] a Tomcat. Il contesto viene utilizzato per denominare la radice dell'albero di directory dell'applicazione web distribuita. Utilizziamo il pulsante [Deploy] per distribuire l'applicazione. Se tutto va bene, otteniamo la seguente pagina di risposta:

e la nuova applicazione appare nell'elenco delle applicazioni distribuite:
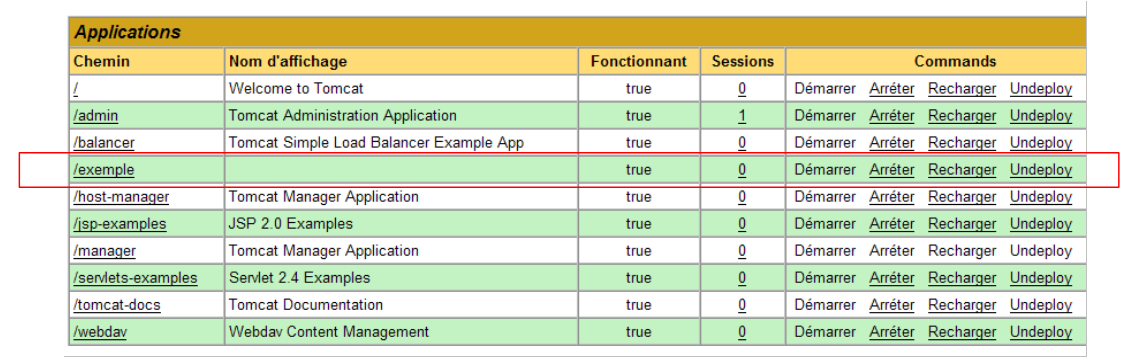 |
Commentiamo la riga relativa al contesto /example sopra riportata:
link a http://localhost:8080/exemple | |
consente di avviare l'applicazione | |
consente di arrestare l'applicazione | |
ricarica l'applicazione. Ciò è necessario, ad esempio, quando si sono aggiunte, modificato o eliminato determinate classi dall'applicazione. | |
Rimuove il contesto [/example]. L'applicazione scompare dall'elenco delle applicazioni disponibili. |
Ora che la nostra applicazione /example è stata distribuita, possiamo eseguire alcuni test. Richiediamo la pagina [example.html] tramite l'URL [http://localhost:8080/exemple/vues/exemple.html]:
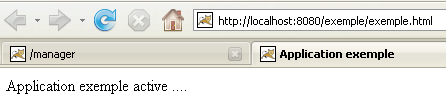
Un altro modo per distribuire un'applicazione web sul server Tomcat consiste nel fornire le informazioni inserite tramite l'interfaccia web in un file [context].xml situato nella cartella [<tomcat>\conf\Catalina\localhost], dove [context] è il nome dell'applicazione web.
Torniamo all'interfaccia di amministrazione di Tomcat:

Rimuoviamo l'applicazione [/example] utilizzando il link [Undeploy]:
L'applicazione [/example] non fa più parte dell'elenco delle applicazioni attive. Ora definiamo il seguente file [example.xml]:
Il file XML è costituito da un unico tag <Context> il cui attributo docBase definisce la cartella contenente l'applicazione web da distribuire. Inseriamo questo file in <tomcat>\conf\Catalina\localhost:
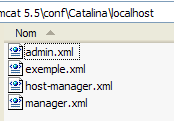
Se necessario, arrestare e riavviare Tomcat, quindi visualizzare l'elenco delle applicazioni attive utilizzando l'amministratore di Tomcat:
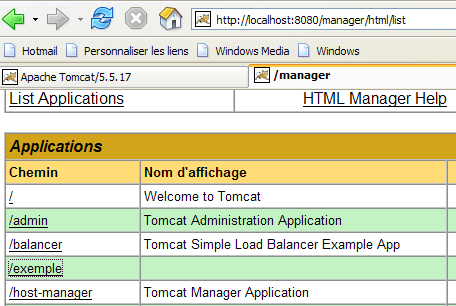
L'applicazione [/example] è effettivamente presente. Richiediamo l'URL in un browser:
[http://localhost:8080/exemple/exemple.html]:
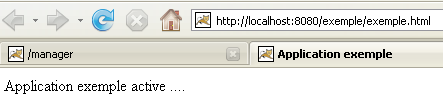
Un'applicazione web distribuita in questo modo può essere rimossa dall'elenco delle applicazioni distribuite, allo stesso modo di prima, utilizzando il link [Undeploy]:
In questo caso, il file [example.xml] viene automaticamente rimosso dalla cartella [<tomcat>\conf\Catalina\localhost].
Infine, per distribuire un'applicazione web all'interno di Tomcat, è anche possibile definirne il contesto nel file [<tomcat>\conf\server.xml]. Non tratteremo questo argomento in questa sede.
5.3.6. Applicazione web con una home page
Quando richiediamo l'URL [http://localhost:8080/exemple/], otteniamo la seguente risposta:
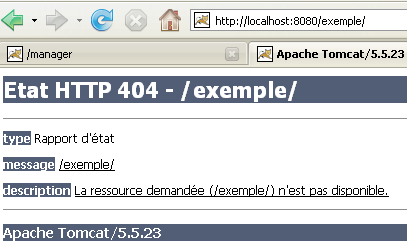
Con alcune versioni precedenti di Tomcat, avremmo ricevuto il contenuto della directory fisica dell'applicazione [/example].
Possiamo configurare il sistema in modo che, quando viene richiesto il contesto, venga visualizzata una cosiddetta home page. Per farlo, creiamo un file [web.xml] e lo collochiamo nella cartella <example>\WEB-INF, dove <example> è la cartella fisica dell'applicazione web [/example]. Il file è il seguente:
- Righe 2–5: Il tag radice <web-app> con attributi copiati e incollati dal file [web.xml] dell'applicazione Tomcat [/admin] (<tomcat>/server/webapps/admin/WEB-INF/web.xml).
- Riga 7: il nome visualizzato dell'applicazione web. Si tratta di un nome scelto liberamente con meno vincoli rispetto al nome del contesto dell'applicazione. Ad esempio, può contenere spazi, cosa impossibile con il nome del contesto. Questo nome viene visualizzato, ad esempio, dall'amministratore di Tomcat:

- Riga 8: Descrizione dell'applicazione web. Questo testo può poi essere recuperato a livello di programmazione.
- Righe 9–11: L'elenco dei file di benvenuto. Il tag <welcome-file-list> viene utilizzato per definire l'elenco delle viste da visualizzare quando un client richiede il contesto dell'applicazione. Possono esserci più viste. Al client viene presentata la prima vista trovata. In questo caso ne abbiamo solo una: [/example.html]. Pertanto, quando un client richiede l'URL [/example], gli verrà effettivamente servito l'URL [/example/example.html].
Salviamo questo file [web.xml] in <example>\WEB-INF:
Se Tomcat è ancora in esecuzione, è possibile forzare il ricaricamento dell'applicazione web [/example] utilizzando il link [Reload]:

Durante questa operazione di "ricaricamento", Tomcat rilegge il file [web.xml] contenuto in [<example>\WEB-INF] se esiste. In questo caso è così. Se Tomcat è stato arrestato, riavviarlo.
Utilizzando un browser, richiedere l'URL [http://localhost:8080/exemple/]:
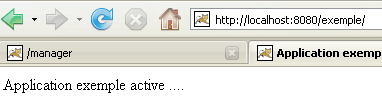
Il meccanismo del file host ha funzionato.
5.3.7. Integrazione di Tomcat in Eclipse
Ora integreremo Tomcat in Eclipse. Questa integrazione consente di:
- avviare/arrestare Tomcat dall'interno di Eclipse
- sviluppare applicazioni web Java ed eseguirle su Tomcat. L'integrazione Eclipse/Tomcat consente di tracciare (debug) l'esecuzione dell'applicazione, compresa l'esecuzione delle classi Java (servlet) gestite da Tomcat.
Avviamo Eclipse, quindi apriamo la vista [Servers]:
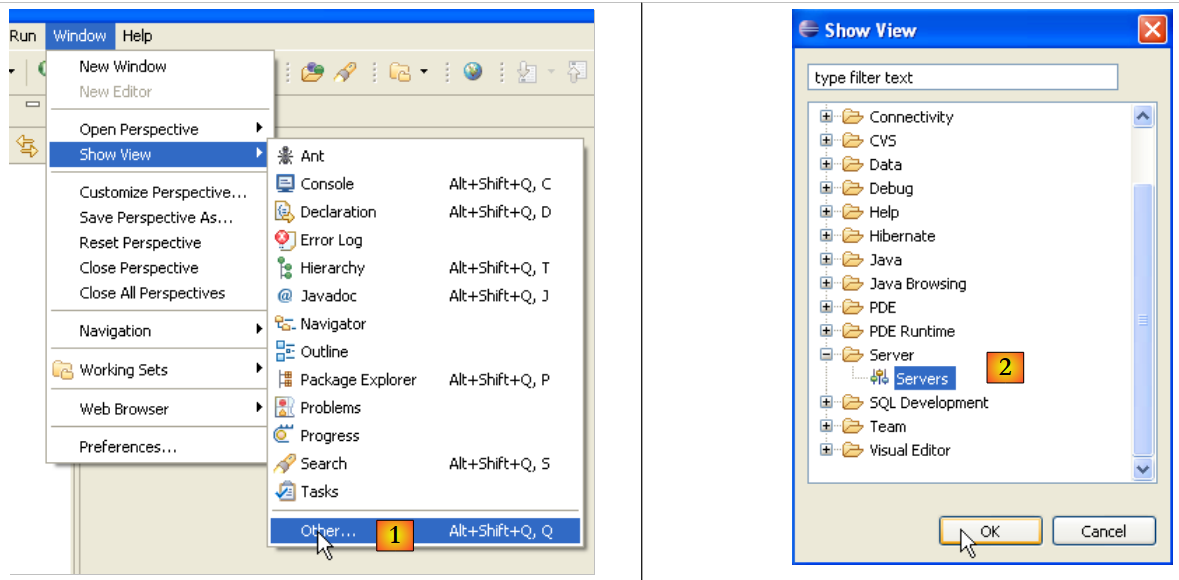 |
- in [1]: Finestra/Mostra vista/Altro
- in [2]: selezionare la vista [Server] e fare clic su [OK]
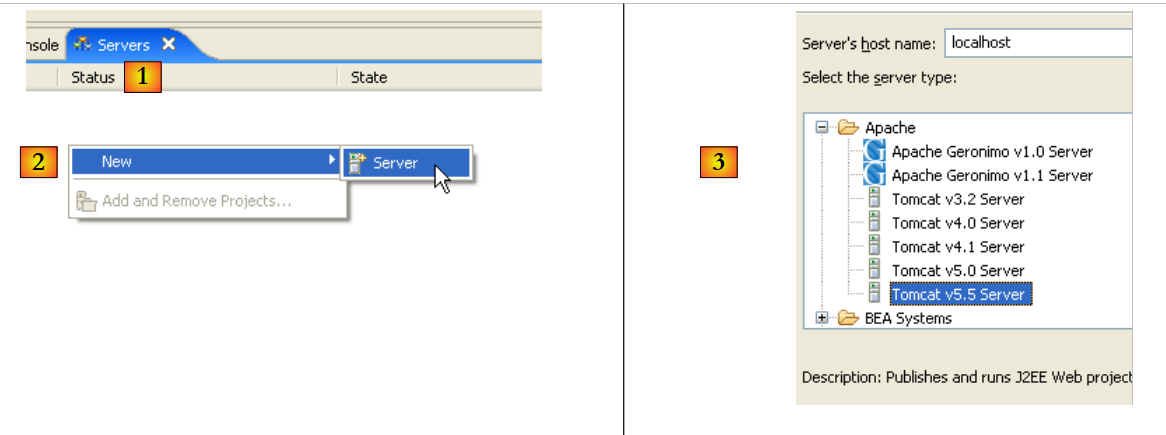 |
- in [1], ora abbiamo una nuova vista [Server]
- In [2], fare clic con il tasto destro sulla vista e selezionare [Nuovo/Server]
- in [3], selezionare il server [Tomcat 5.5], quindi fare clic su [Avanti]
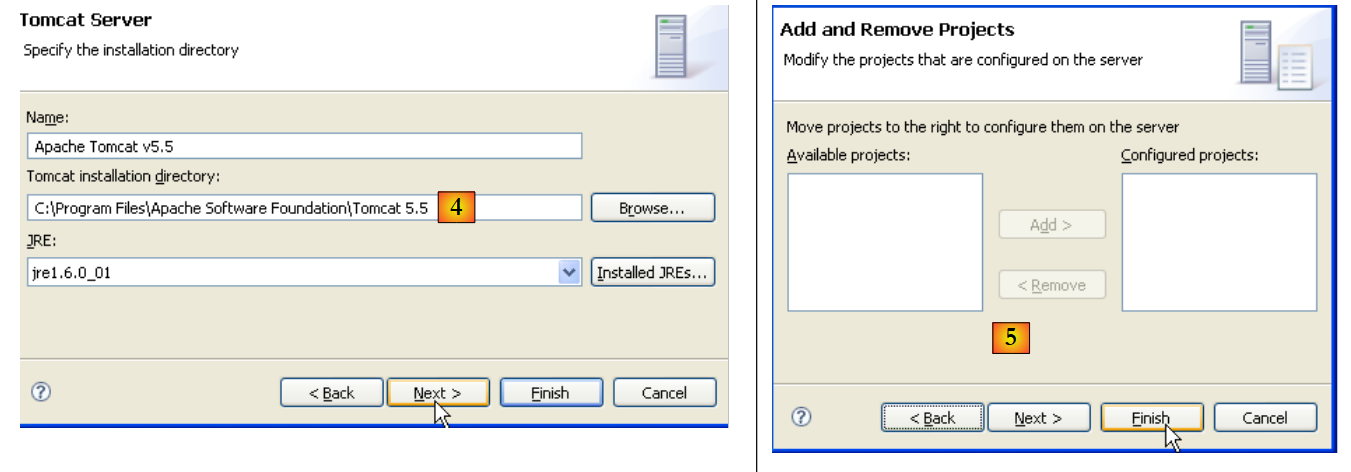 |
- In [4], specificare la directory di installazione di Tomcat 5.5
- In [5], indicare che al momento non ci sono progetti Eclipse/Tomcat. Fare clic su [Fine]
L'aggiunta del server comporta la comparsa di una cartella nell'Eclipse Project Explorer [6] e di un server nella vista [Servers] [7]:
 |
La vista [Servers] mostra tutti i server registrati; in questo caso, solo il server Tomcat 5.5 appena aggiunto. Facendo clic con il tasto destro del mouse su di esso si accede ai comandi per avviare, arrestare o riavviare il server:
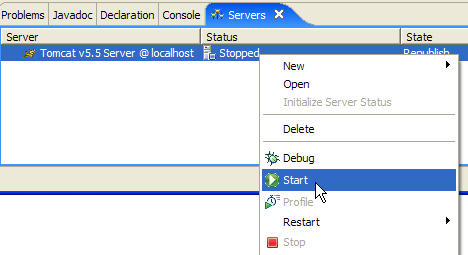
Sopra, stiamo avviando il server. All'avvio, nella vista [Console] vengono registrati diversi log:
Ci vuole un po' di tempo per abituarsi a interpretare questi log. Per ora non ci soffermeremo su di essi. Tuttavia, è importante verificare che non indichino errori di caricamento del contesto. Infatti, all'avvio, il server Tomcat/Eclipse tenta di caricare il contesto delle applicazioni che gestisce. Il caricamento del contesto di un'applicazione comporta l'elaborazione del suo file [web.xml] e il caricamento di una o più classi che lo inizializzano. Possono verificarsi diversi tipi di errori:
- il file [web.xml] presenta un errore di sintassi. Questo è l'errore più comune. Si consiglia di utilizzare uno strumento in grado di convalidare un documento XML durante la sua creazione.
- alcune classi da caricare non sono state trovate. Vengono cercate in [WEB-INF/classes] e [WEB-INF/lib]. In generale, è necessario verificare la presenza delle classi necessarie e l'ortografia di quelle dichiarate nel file [web.xml].
Il server avviato da Eclipse non ha la stessa configurazione di quello installato nella Sezione 5.3. Per verificarlo, accedere all'URL [http://localhost:8080] utilizzando un browser:
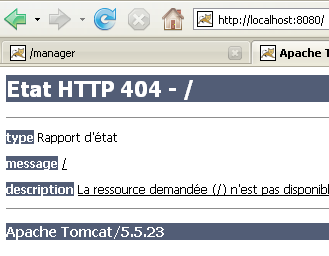
Questa risposta non indica che il server non funziona, ma piuttosto che la risorsa richiesta non è disponibile. Con il server Tomcat integrato in Eclipse, queste risorse saranno progetti web. Lo vedremo più avanti. Per ora, fermiamo Tomcat:
La modalità operativa precedente può essere modificata. Torniamo alla vista [Servers] e facciamo doppio clic sul server Tomcat per accedere alle sue proprietà:
 | 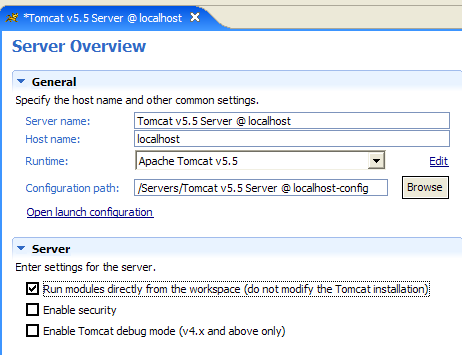 |
La casella di controllo [1] è responsabile del comportamento descritto in precedenza. Se selezionata, le applicazioni web sviluppate in Eclipse non vengono dichiarate nei file di configurazione del server Tomcat associato, ma in file di configurazione separati. Di conseguenza, le applicazioni predefinite del server Tomcat — [admin] e [manager], che sono due applicazioni utili — non sono disponibili. Quindi, deselezioniamo [1] e riavviamo Tomcat:
 |  |
Ora che abbiamo fatto questo, proviamo a richiedere l'URL [http://localhost:8080] in un browser:
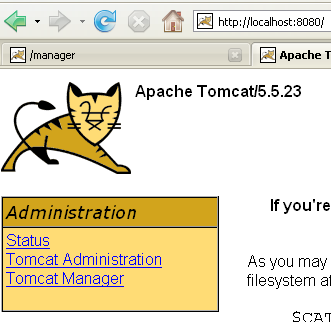
Si osserva il comportamento descritto nella Sezione 5.3.4.
Negli esempi precedenti abbiamo utilizzato un browser esterno a Eclipse. Possiamo anche utilizzare un browser integrato in Eclipse:
Sopra, selezioniamo il browser interno. Per avviarlo da Eclipse, è possibile utilizzare la seguente icona:
Il browser che verrà effettivamente avviato sarà quello selezionato tramite l'opzione [Finestra -> Browser Web]. In questo caso, si aprirà il browser interno:

Se necessario, avviare Tomcat da Eclipse e inserire l'URL [http://localhost:8080] in [1]:
Seguire il link [Tomcat Manager]:
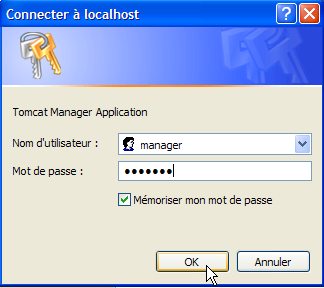
Ti verrà richiesto di inserire [nome utente/password] necessari per accedere all'applicazione [manager]. In base alla configurazione di Tomcat che abbiamo impostato in precedenza, puoi inserire [admin/admin] o [manager/manager]. Verrà quindi visualizzato l'elenco delle applicazioni distribuite:
5.4. DBMS Firebird
5.4.1. DBMS Firebird
Il DBMS Firebird è disponibile all'indirizzo [http://www.firebirdsql.org/]:
 |
- in [1]: utilizzare l'opzione [Download.Firebird Relational Database]
- in [2]: selezionare la versione desiderata di Firebird
- in [3]: scaricare il file binario di installazione
Una volta scaricato il file [3], fare doppio clic su di esso per installare il DBMS Firebird. Il DBMS viene installato in una cartella con contenuti simili ai seguenti:
I file binari si trovano nella cartella [bin]:
consente di avviare/arrestare il DBMS | |
client a riga di comando per la gestione dei database |
Si noti che, per impostazione predefinita, l'amministratore del DBMS si chiama [SYSDBA] e la password è [masterkey]. Sono stati aggiunti dei menu a [Start]:
L'opzione [Firebird Guardian] consente di avviare/arrestare il DBMS. Dopo l'avvio, l'icona del DBMS rimane nella barra delle applicazioni di Windows:
 |
Per creare e gestire i database Firebird utilizzando il client da riga di comando [isql.exe], è necessario consultare la documentazione inclusa con il prodotto, accessibile tramite i collegamenti Firebird in [Start/Programmi/Firebird 2.0].
Un modo rapido per lavorare con Firebird e imparare l’SQL è utilizzare un client grafico. Uno di questi client è IB-Expert, descritto nella sezione seguente.
5.4.2. Lavorare con il DBMS Firebird utilizzando IB- Expert
Il sito web principale di IB-Expert è [http://www.ibexpert.com/].
 |
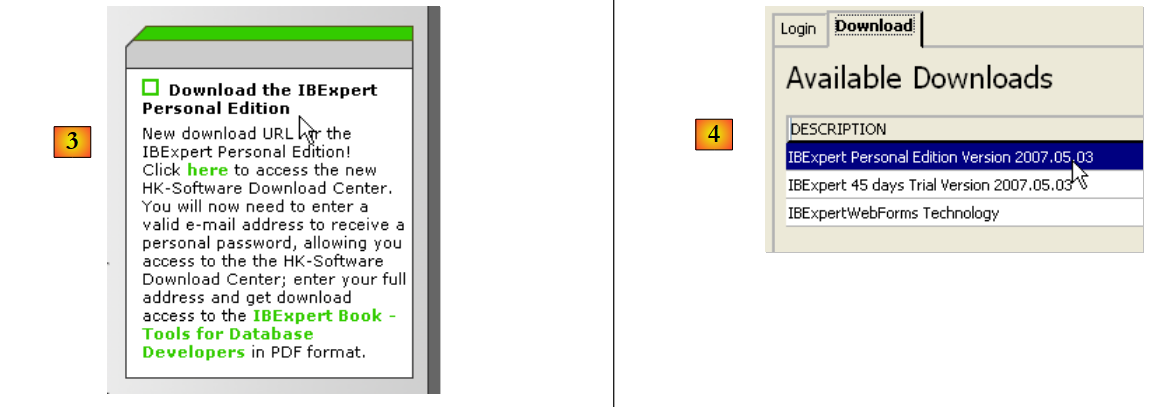 |
- In [1], selezionare IBExpert
- In [2], seleziona il download dopo aver scelto la lingua preferita, se necessario
- In [3], seleziona la versione "Personal", poiché è gratuita. Devi, tuttavia, registrarti sul sito.
- In [4], scarica IBExpert
IBExpert viene installato in una cartella simile alla seguente:
Il file eseguibile è [ibexpert.exe]. Normalmente è disponibile un collegamento nel menu [Start]:

Una volta avviato, IBExpert visualizza la seguente finestra:
Per creare un database, utilizzare l'opzione [ Database/Crea database]:
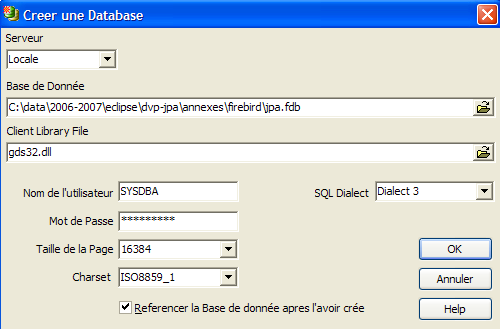
può essere [local] o [remote]. In questo caso, il nostro server si trova sulla stessa macchina di [IBExpert]. Scegliamo [locale] | |
Utilizza il pulsante [cartella] nel menu a tendina per selezionare il file del database. Firebird memorizza l'intero database in un unico file. Questo è uno dei suoi vantaggi. È possibile trasferire il database da un computer all'altro semplicemente copiando il file. Il suffisso [.fdb] viene aggiunto automaticamente. | |
SYSDBA è l'amministratore predefinito per le attuali distribuzioni di Firebird | |
masterkey è la password dell'amministratore SYSDBA nelle attuali distribuzioni di Firebird | |
il dialetto SQL da utilizzare | |
Se questa casella è selezionata, IBExpert visualizzerà un collegamento al database dopo che è stato creato |
Se, quando si fa clic sul pulsante [OK] per creare il database, viene visualizzato il seguente avviso:
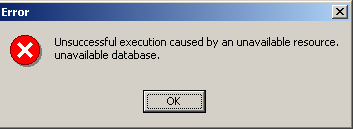
significa che non hai avviato Firebird. Avvialo. Apparirà una nuova finestra:
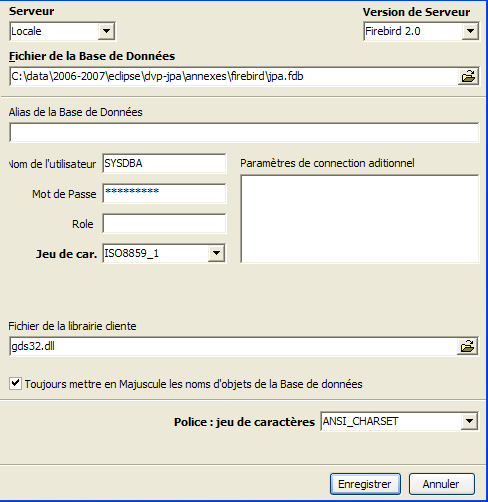
Il set di caratteri da utilizzare. Si consiglia di selezionare [ISO-8859-1] dall'elenco a discesa, che consente l'uso di caratteri latini accentati. |
[IBExpert] è in grado di gestire vari DBMS derivati da Interbase. Seleziona la versione di Firebird che hai installato. |
Una volta confermata questa nuova finestra cliccando su [Registra], vedrai il risultato [1] nella finestra [Database Explorer]. Questa finestra potrebbe chiudersi accidentalmente. Per riaprirla, procedi come segue [2]:
 |
Per accedere al database creato, è sufficiente fare doppio clic sul relativo collegamento. IBExpert visualizzerà quindi una struttura ad albero che consente di accedere alle proprietà del database:
5.4.3. Creazione di una tabella dati
Creiamo una tabella. Fare clic con il tasto destro del mouse su [Tabelle] (vedere la finestra sopra) e selezionare l'opzione [Nuova tabella]. Si aprirà la finestra per la definizione delle proprietà della tabella:
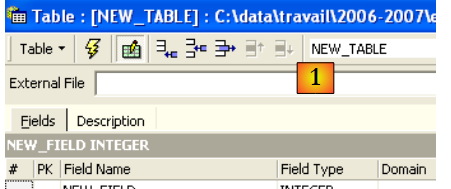 |
Iniziamo assegnando alla tabella il nome [ARTICLES] utilizzando il campo di immissione [1]:
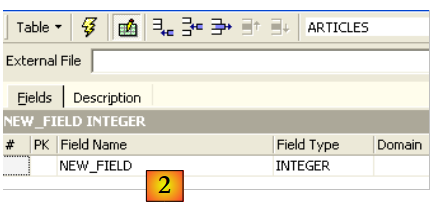
Utilizza il campo di immissione [2] per definire una chiave primaria [ID]:
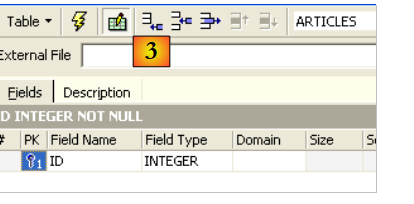
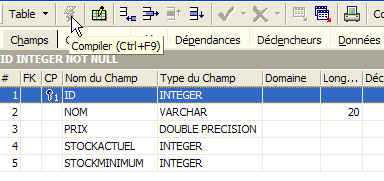
Un campo viene impostato come chiave primaria facendo doppio clic sul campo [PK] (Chiave primaria). Aggiungiamo dei campi utilizzando il pulsante in alto [3]:
Finché non abbiamo "compilato" la nostra definizione, la tabella non viene creata. Utilizza il pulsante [Compila] in alto per finalizzare la definizione della tabella. IBExpert prepara le query SQL per generare la tabella e chiede conferma:
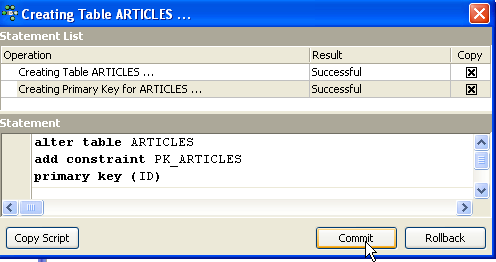
È interessante notare che IBExpert visualizza le query SQL che ha eseguito. Ciò consente di apprendere sia il linguaggio SQL che qualsiasi dialetto SQL proprietario che possa essere utilizzato. Il pulsante [Commit] convalida la transazione corrente, mentre [Rollback] la annulla. In questo caso, la accettiamo cliccando su [Commit]. Una volta fatto ciò, IBExpert aggiunge la tabella creata alla nostra struttura ad albero del database:
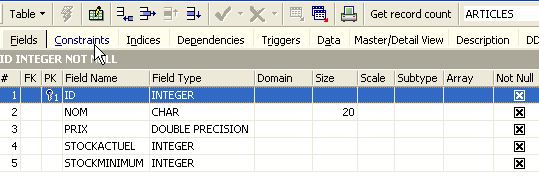
Facendo doppio clic sulla tabella, possiamo accedere alle sue proprietà:
Il pannello [Vincoli] ci permette di aggiungere nuovi vincoli di integrità alla tabella. Apriamolo:
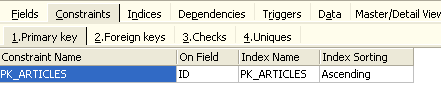
Vediamo il vincolo di chiave primaria che abbiamo creato. Possiamo aggiungere altri vincoli:
- chiavi esterne [Foreign Keys]
- vincoli di integrità dei campi [Controlli]
- vincoli di unicità dei campi [Uniques]
Specifichiamo che:
- i campi [ID, PRICE, CURRENTSTOCK, MINIMUMSTOCK] devono essere >0
- il campo [NAME] deve essere non vuoto e univoco
Apri il pannello [Controlli] e fai clic con il tasto destro del mouse nell'area di definizione dei vincoli per aggiungere un nuovo vincolo:
Definiamo i vincoli desiderati:
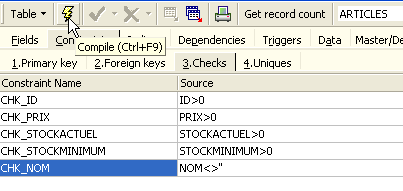
Si noti che il vincolo [NAME<>''] utilizza due virgolette singole, non doppie. Compilare questi vincoli utilizzando il pulsante [Compila] in alto:
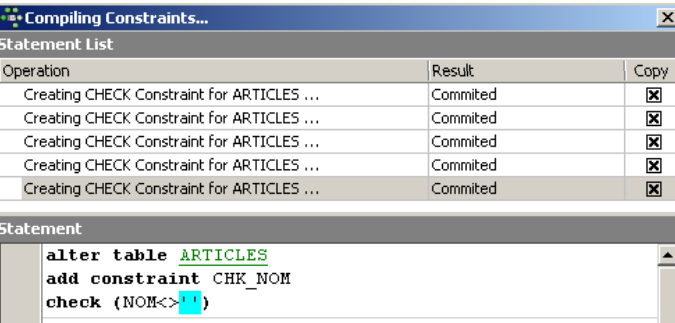
Ancora una volta, IBExpert dimostra la sua facilità d'uso visualizzando le query SQL che ha eseguito. Passiamo ora al pannello [Constraints/Unique] per specificare che il nome deve essere univoco. Ciò significa che lo stesso nome non può apparire due volte nella tabella.
Definiamo il vincolo:
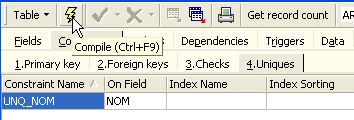
Quindi compiliamolo. Una volta fatto ciò, apriamo il pannello [DDL] (Data Definition Language) per la tabella [ARTICLES]:

Questo pannello mostra il codice SQL per generare la tabella con tutti i suoi vincoli. Puoi salvare questo codice in uno script per eseguirlo in un secondo momento:
SET SQL DIALECT 3;
SET NAMES ISO8859_1;
CREATE TABLE ARTICLES (
ID INTEGER NOT NULL,
NOM VARCHAR(20) NOT NULL,
PRIX DOUBLE PRECISION NOT NULL,
STOCKACTUEL INTEGER NOT NULL,
STOCKMINIMUM INTEGER NOT NULL
);
ALTER TABLE ARTICLES ADD CONSTRAINT CHK_ID check (ID>0);
ALTER TABLE ARTICLES ADD CONSTRAINT CHK_PRIX check (PRIX>0);
ALTER TABLE ARTICLES ADD CONSTRAINT CHK_STOCKACTUEL check (STOCKACTUEL>0);
ALTER TABLE ARTICLES ADD CONSTRAINT CHK_STOCKMINIMUM check (STOCKMINIMUM>0);
ALTER TABLE ARTICLES ADD CONSTRAINT CHK_NOM check (NOM<>'');
ALTER TABLE ARTICLES ADD CONSTRAINT UNQ_NOM UNIQUE (NOM);
ALTER TABLE ARTICLES ADD CONSTRAINT PK_ARTICLES PRIMARY KEY (ID);
5.4.4. Inserimento di dati in una tabella
È ora il momento di inserire i dati nella tabella [ARTICLES]. Per farlo, utilizzare il pannello [Dati]:
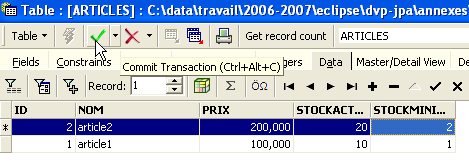
I dati vengono inseriti facendo doppio clic sui campi di immissione di ciascuna riga della tabella. Una nuova riga viene aggiunta utilizzando il pulsante [+], mentre una riga viene eliminata utilizzando il pulsante [-]. Queste operazioni vengono eseguite all'interno di una transazione che viene confermata utilizzando il pulsante [Conferma transazione] (vedi sopra). Senza questa conferma, i dati andranno persi.
5.4.5. L'editor SQL [IB-Expert]
Il linguaggio SQL (Structured Query Language) consente all'utente di:
- creare tabelle specificando il tipo di dati che conterranno e i vincoli che i dati devono soddisfare
- inserire dati al loro interno
- modificare determinati dati
- eliminare altri dati
- utilizzare i dati per recuperare informazioni
- ...
IBExpert consente agli utenti di eseguire graficamente i passaggi da 1 a 4. Lo abbiamo appena visto. Quando un database contiene molte tabelle, ciascuna con centinaia di righe, sono necessarie informazioni difficili da ottenere visivamente. Supponiamo, ad esempio, che un negozio online abbia migliaia di clienti al mese. Tutti gli acquisti vengono registrati in un database. Dopo sei mesi, si scopre che il prodotto "X" è difettoso. L'azienda vuole contattare tutti coloro che lo hanno acquistato in modo che possano restituire il prodotto per una sostituzione gratuita. Come si possono trovare gli indirizzi di questi acquirenti?
- Si potrebbero esaminare manualmente tutte le tabelle e cercare questi acquirenti. Ciò richiederebbe alcune ore.
- Possiamo eseguire una query SQL che restituirà un elenco di queste persone in pochi secondi
SQL è utile ogni volta che
- la quantità di dati nelle tabelle è elevata
- ci sono molte tabelle collegate tra loro
- le informazioni da recuperare sono distribuite su più tabelle
- ...
Ora presenteremo l'Editor SQL di IBExpert. È possibile accedervi tramite l'opzione [Strumenti/Editor SQL] o premendo [F12]:
Questo vi dà accesso a un editor avanzato di query SQL dove potete eseguire le query. Digitiamo una query:
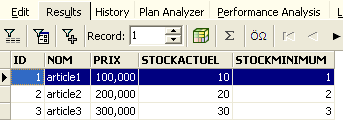
Esegui la query SQL utilizzando il pulsante [Esegui] in alto. Otterrai il seguente risultato:
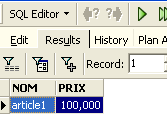
Nella scheda [Risultati] sopra riportata viene visualizzata la tabella dei risultati del comando SQL [Seleziona]. Per eseguire un nuovo comando SQL, è sufficiente tornare alla scheda [Modifica]. Verrà quindi visualizzato il comando SQL che è stato eseguito.

Diversi pulsanti sulla barra degli strumenti sono utili:
- Il pulsante [Nuova query] consente di passare a una nuova query SQL:

Verrà quindi visualizzata una pagina di modifica vuota:
A questo punto è possibile inserire una nuova query SQL:
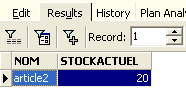
ed eseguirla:
Torniamo alla scheda [Modifica]. Le varie istruzioni SQL eseguite vengono memorizzate da [IBExpert]. Il pulsante [Query precedente] consente di tornare a un'istruzione SQL eseguita in precedenza:

Si torna quindi alla query precedente:
Il pulsante [Next Query] consente di passare all'istruzione SQL successiva:
Verrà quindi visualizzata l'istruzione SQL successiva nell'elenco delle istruzioni SQL memorizzate:
Il pulsante [Elimina query] consente di eliminare un'istruzione SQL dall'elenco delle istruzioni memorizzate:
Il pulsante [Cancella query corrente] cancella il contenuto dell'editor relativo all'istruzione SQL visualizzata:
Il pulsante [Conferma] consente di salvare in modo permanente le modifiche apportate al database:

Il pulsante [RollBack] consente di annullare le modifiche apportate al database dall'ultimo [Commit]. Se non è stato eseguito alcun [Commit] dal momento della connessione al database, vengono annullate le modifiche apportate a partire da quella connessione.
Vediamo un esempio. Inseriamo una nuova riga nella tabella:

L'istruzione SQL viene eseguita ma non viene visualizzato nulla. Non sappiamo se l'inserimento sia avvenuto. Per scoprirlo, eseguiamo la seguente istruzione SQL [New Query]:
Otteniamo il seguente risultato:
La riga è stata effettivamente inserita. Esaminiamo ora il contenuto della tabella in un altro modo. Facciamo doppio clic sulla tabella [ARTICLES] nell'esploratore del database:
Otteniamo la seguente tabella:
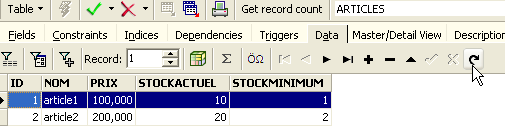
Il pulsante con la freccia in alto consente di aggiornare la tabella. Dopo l'aggiornamento, la tabella sopra non cambia. Sembra che la nuova riga non sia stata inserita. Torniamo all'editor SQL (F12) e confermiamo l'istruzione SQL utilizzando il pulsante [Commit]:
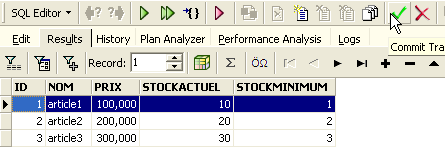
Una volta fatto ciò, torniamo alla tabella [ARTICLES]. Possiamo vedere che nulla è cambiato, anche utilizzando il pulsante [Refresh]:
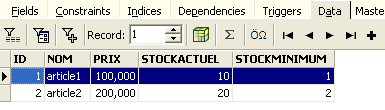
In alto, apri la scheda [Fields], quindi torna alla scheda [Data]. Questa volta, la riga inserita appare correttamente:
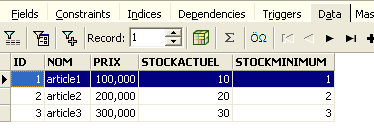
Quando inizia l'esecuzione delle varie istruzioni SQL, l'editor apre quella che viene chiamata una transazione sul database. Le modifiche apportate da queste istruzioni SQL nell'editor SQL saranno visibili solo finché rimani nello stesso editor SQL (puoi aprirne più di uno). È come se l'editor SQL non lavorasse sul database vero e proprio, ma su una sua copia. In realtà, non è esattamente così che funziona, ma questa analogia può aiutarci a comprendere il concetto di transazione. Tutte le modifiche apportate alla copia durante una transazione saranno visibili nel database vero e proprio solo dopo che saranno state confermate tramite [Commit Transaction]. La transazione corrente viene quindi terminata e ne inizia una nuova.
Le modifiche apportate durante una transazione possono essere annullate tramite un'operazione chiamata [Rollback]. Proviamo il seguente esperimento. Avviamo una nuova transazione (semplicemente [Commit] la transazione corrente) con la seguente istruzione SQL:
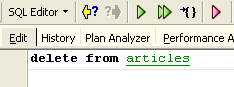
Eseguiamo questo comando, che elimina tutte le righe dalla tabella [ARTICLES], quindi eseguiamo [New Query] con il seguente nuovo comando SQL:
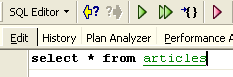
Otteniamo il seguente risultato:
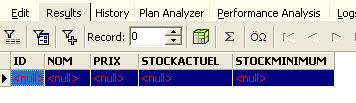
Tutte le righe sono state eliminate. Ricordiamo che questa operazione è stata eseguita su una copia della tabella [ARTICLES]. Per verificarlo, facciamo doppio clic sulla tabella [ARTICLES] qui sotto:
e visualizza la scheda [Dati]:
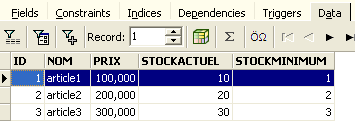
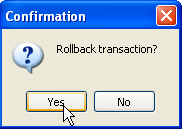
Anche se utilizziamo il pulsante [Aggiorna] o passiamo alla scheda [Campi] e poi torniamo alla scheda [Dati], il contenuto sopra rimane invariato. Questo è stato spiegato. Ci troviamo in un'altra transazione che sta lavorando sulla propria copia. Ora torniamo all'editor SQL (F12) e utilizziamo il pulsante [RollBack] per annullare le eliminazioni delle righe che sono state effettuate:

Ci viene richiesta una conferma:
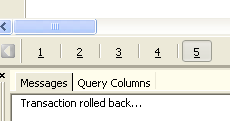
Verifichiamo. L'editor SQL conferma che le modifiche sono state annullate:
Eseguiamo nuovamente la query SQL sopra riportata per verificare. Le righe che erano state eliminate sono ora tornate:
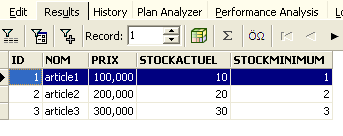
L'operazione [Rollback] ha ripristinato la copia su cui sta lavorando l'editor SQL allo stato in cui si trovava all'inizio della transazione.
5.4.6. Esportazione di un database Firebird in uno script SQL
Quando si lavora con diversi DBMS, come nel caso del tutorial "Java 5 Persistence in Practice", è utile poter esportare un database dal DBMS 1 in uno script SQL e poi importare tale script nel DBMS 2. Ciò evita una serie di operazioni manuali. Tuttavia, ciò non è sempre possibile, poiché i DBMS spesso presentano estensioni SQL proprietarie.
Vediamo come esportare il precedente database [dbarticles] in uno script SQL:
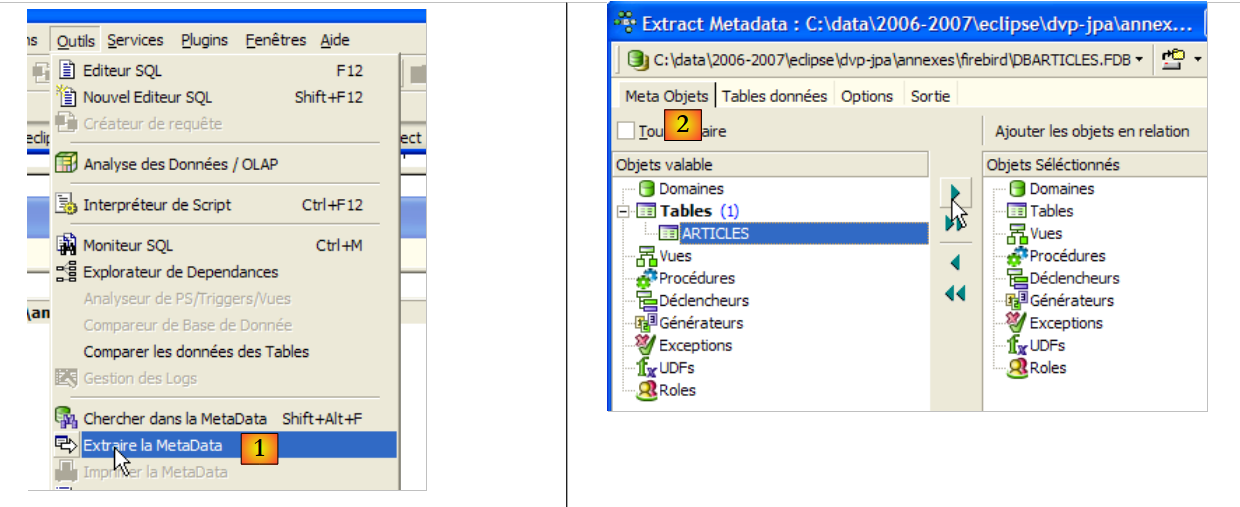 |
- in [1]: Strumenti / Estrai metadati, per estrarre i metadati
- in [2]: scheda Meta Objects
- in [3]: selezionare la tabella [Articoli] di cui si desidera estrarre la struttura (metadati)
- in [4]: per spostare l'oggetto selezionato a sinistra verso destra
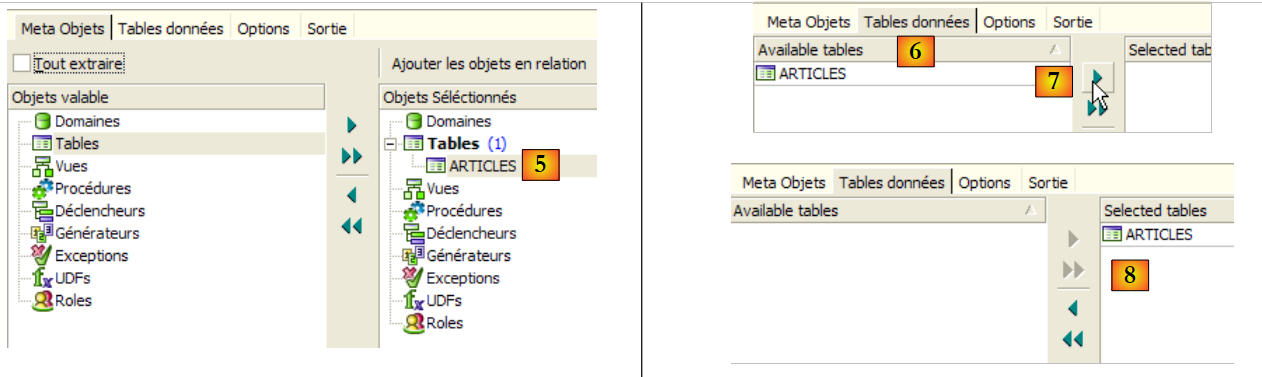 |
- in [5]: la tabella [ARTICLES] verrà inclusa nei metadati estratti
- in [6]: la scheda [Tabella dati] serve a selezionare le tabelle da cui si desidera estrarre il contenuto (nel passaggio precedente è stata esportata la struttura della tabella)
- in [7]: per spostare l'oggetto selezionato a sinistra verso destra
- in [8]: il risultato ottenuto
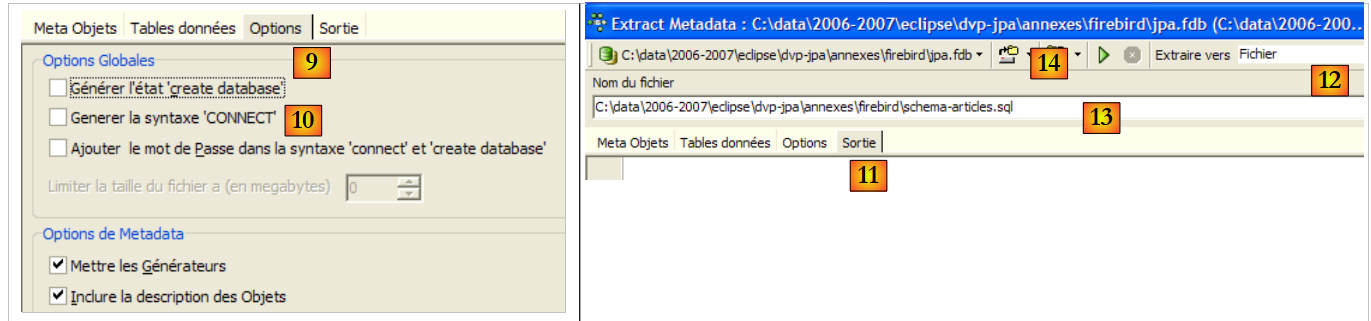 |
- in [9]: la scheda [Opzioni] consente di configurare alcune impostazioni di estrazione
- in [10]: deselezionare le opzioni relative alla generazione di istruzioni SQL per la connessione al database. Queste sono specifiche di Firebird e quindi non rilevanti per noi.
- in [11]: la scheda [Output] consente di specificare dove verrà generato lo script SQL
- in [12]: specificare che lo script deve essere generato in un file
- in [13]: Specificare la posizione di questo file
- in [14]: Avvia la generazione dello script SQL
Lo script generato, con i commenti rimossi, è il seguente:
Nota: le righe 1-2 sono specifiche di Firebird. Devono essere rimosse dallo script generato per ottenere un codice SQL generico.
5.4.7. Driver JDBC Firebird
Un programma Java accede ai dati di un database tramite un driver JDBC specifico per il DBMS in uso:
 |
In un'architettura multilivello come quella sopra descritta, il driver JDBC [1] viene utilizzato dal livello [DAO] (Data Access Object) per accedere ai dati di un database.
Il driver JDBC di Firebird è disponibile all'URL da cui è stato scaricato Firebird:
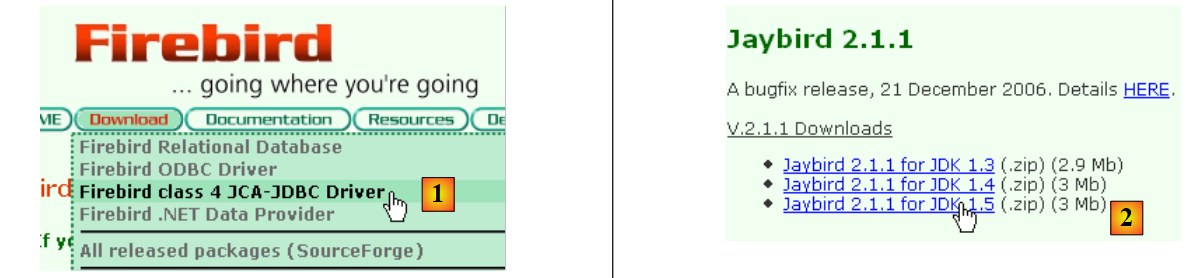 |
 |
- in [1]: scegliere di scaricare il driver JDBC
- in [2]: selezionare un driver JDBC compatibile con JDK 1.5
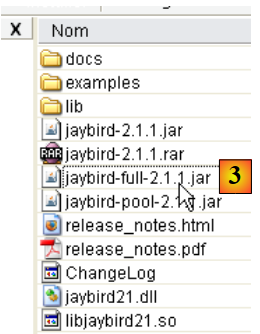
- in [3]: l'archivio contenente il driver JDBC è [jaybird-full-2.1.1.jar]. Estrai questo file. Verrà utilizzato per tutti gli esempi JPA con Firebird.
Lo collochiamo in una cartella che chiameremo <jdbc>:
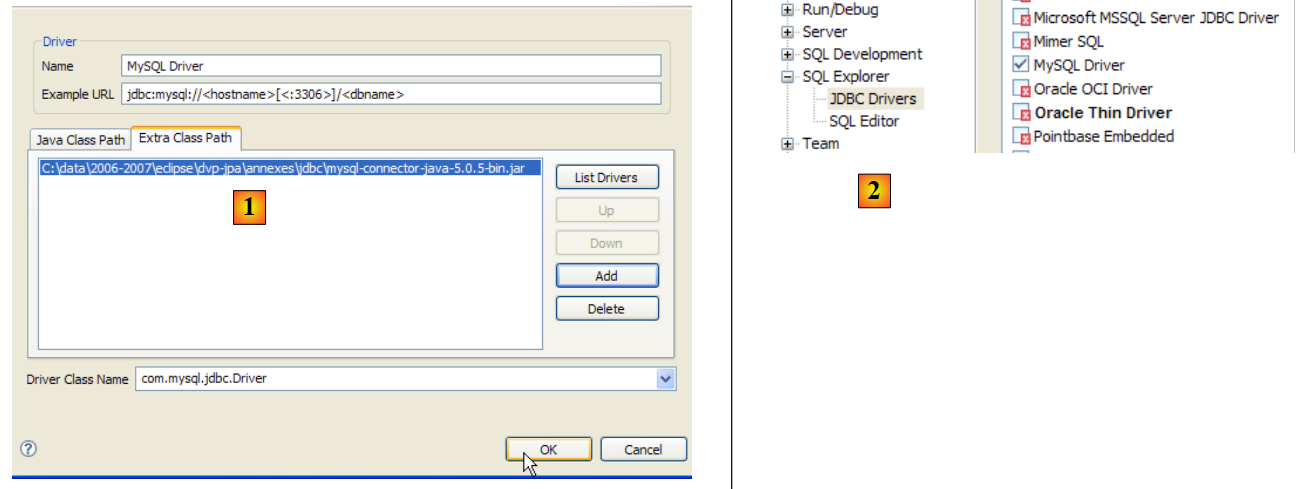
Per verificare questo driver JDBC, useremo Eclipse e il plugin SQL Explorer (Sezione 5.2.6). Iniziamo dichiarando il driver JDBC di Firebird:
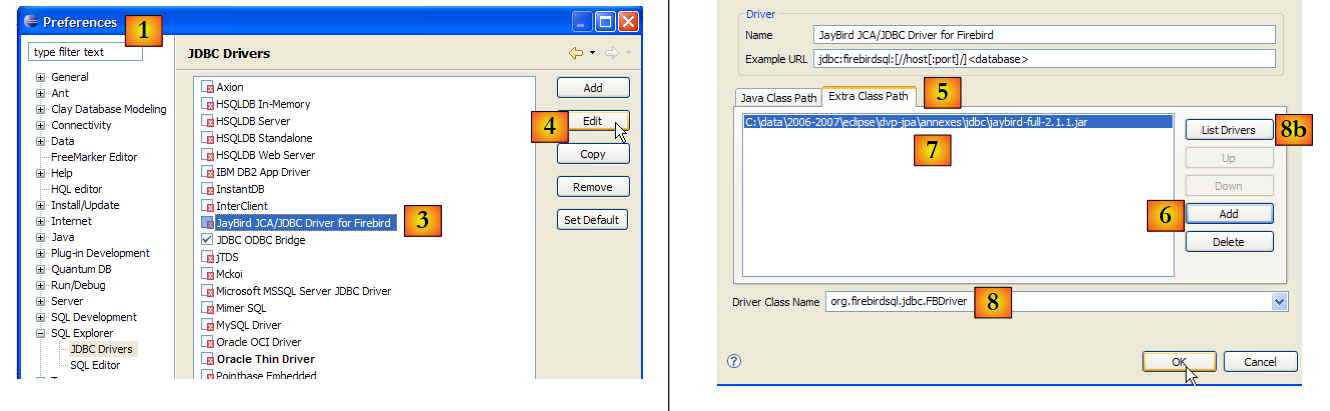 |
- in [1]: andare su Window / Preferences
- in [2]: selezionare l'opzione SQL Explorer / JDBC Drivers
- in [3]: selezionare il driver JDBC per Firebird
- in [4]: passare alla fase di configurazione
- in [5]: vai alla scheda [Percorso classe aggiuntivo]
- In [6], seleziona il file del driver JDBC. Una volta selezionato, apparirà in [7]. Qui, seleziona il driver precedentemente inserito nella cartella <jdbc>
- in [8]: il nome della classe Java del driver JDBC. È possibile ottenerlo cliccando sul pulsante [8b].
- Fare clic su [OK] per confermare la configurazione
 |
- in [9]: il driver JDBC di Firebird è ora configurato. È possibile procedere al suo utilizzo.
 |
- In [1]: Aprire una nuova prospettiva
- in [2]: selezionare la prospettiva [SQL Explorer]
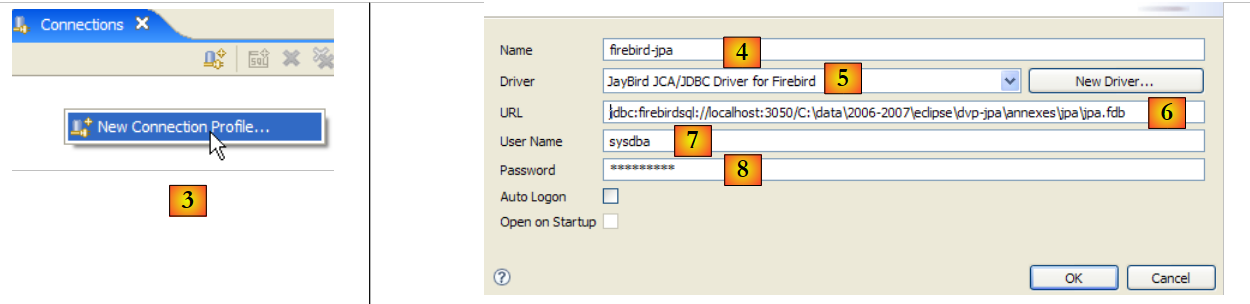 |
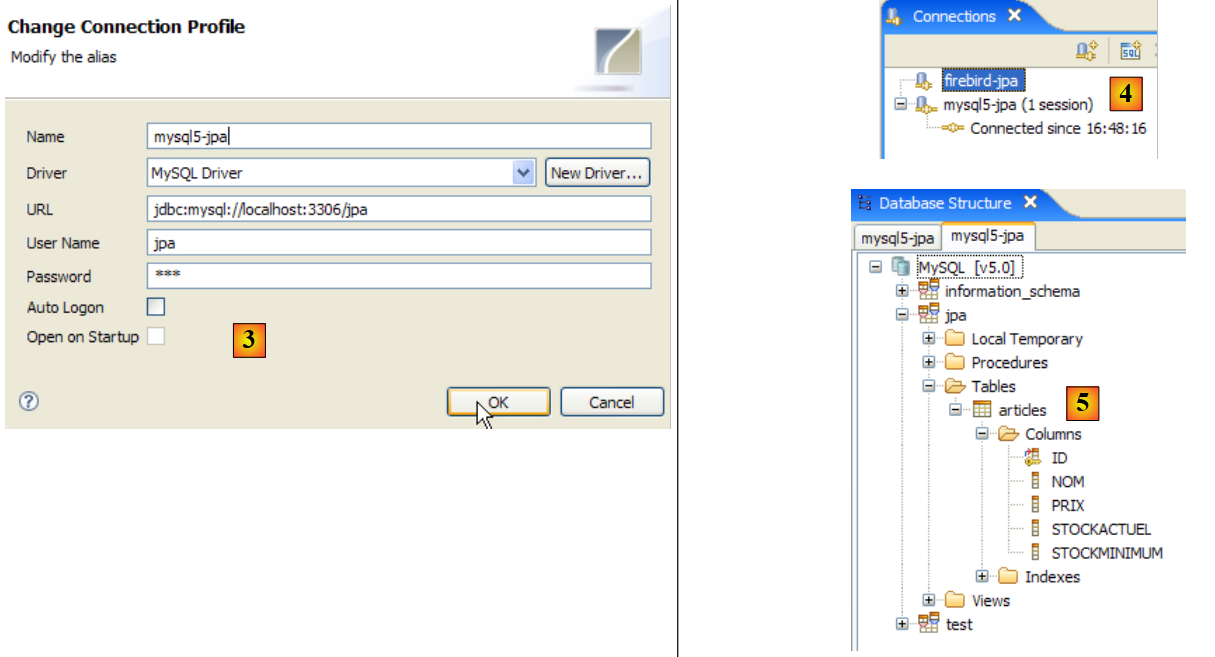
- in [3]: creare una nuova connessione
- Passaggio [4]: assegnare un nome
- in [5]: selezionare il driver JDBC di Firebird dall'elenco a discesa
- in [6]: specificare l'URL del database a cui ci si vuole connettere, in questo caso: [jdbc:firebirdsql:localhost/3050:C:\data\2006-2007\eclipse\dvp-jpa\annexes\jpa\jpa.fdb]. [jpa.fdb] è il database creato in precedenza con IBExpert.
- in [7]: il nome utente per la connessione, in questo caso [sysdba], l'amministratore di Firebird
- in [8]: la relativa password [masterkey]
- Confermare le impostazioni di connessione facendo clic su [OK]
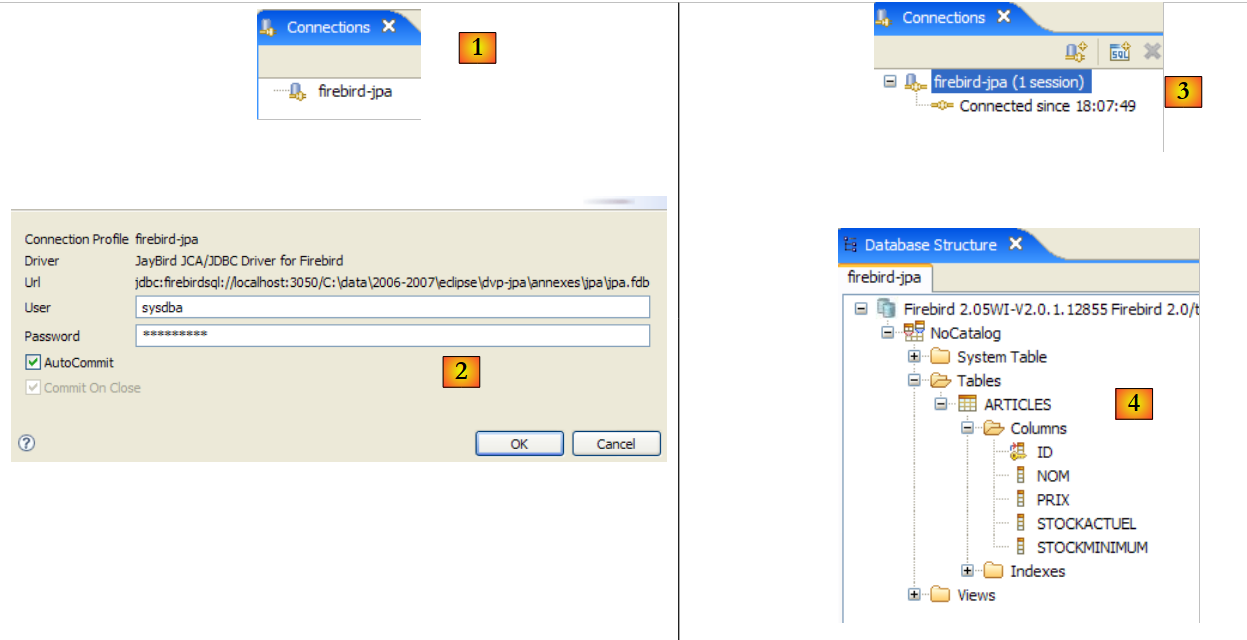 |
- in [1]: fare doppio clic sul nome della connessione che si desidera aprire
- in [2]: effettuare il login (sysdba, masterkey)
- in [3]: la connessione è aperta
- in [4]: viene visualizzata la struttura del database. È visibile la tabella [ARTICLES]. Selezionarla.
 |
- In [5]: nella finestra [Dettagli database] sono visibili i dettagli dell'oggetto selezionato in [4], in questo caso la tabella [ARTICLES]
- in [6]: la scheda [Columns] mostra la struttura della tabella
- in [7]: la scheda [Anteprima] mostra la struttura della tabella
È possibile eseguire query SQL nella finestra [Editor SQL]:
 |
- in [1]: selezionare una connessione aperta
- in [2]: digitare l'istruzione SQL da eseguire
- in [3]: eseguila
- in [4]: rivedere l'istruzione eseguita
- in [5]: il suo risultato
5.5. Il DBMS s MySQL5
5.5.1. Installazione
Il DBMS MySQL5 è disponibile all'URL [http://dev.mysql.com/downloads/]:
 |
- in [1]: selezionare la versione desiderata
- in [2]: scegliere una versione per Windows
 |
- in [3]: selezionare la versione di Windows desiderata
- in [4]: il file ZIP scaricato contiene un eseguibile [Setup.exe] [4b] che devi estrarre ed eseguire per installare MySQL5
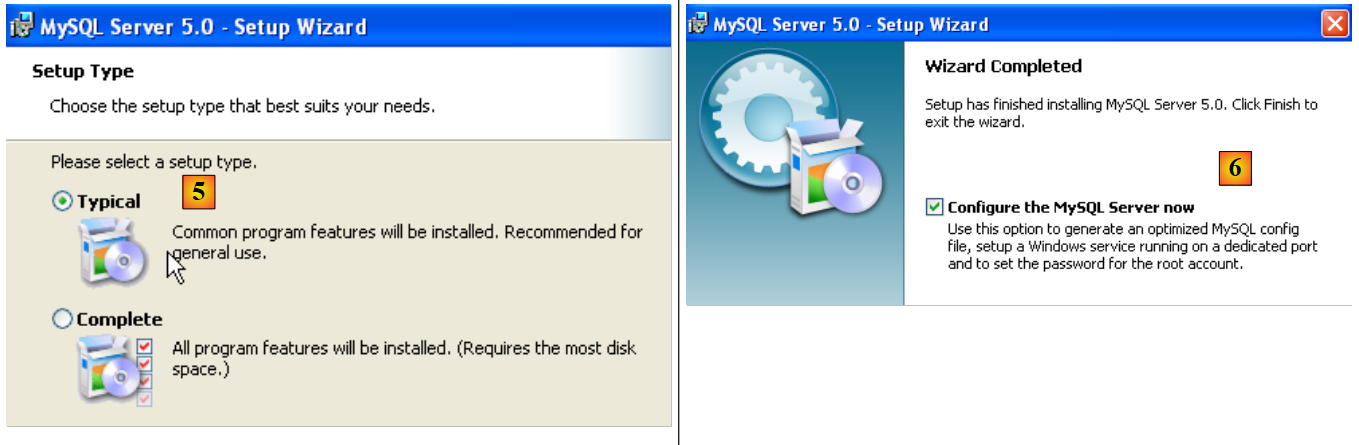 |
- in [5]: selezionare un'installazione tipica
- in [6]: una volta completata l'installazione, è possibile configurare il server MySQL5
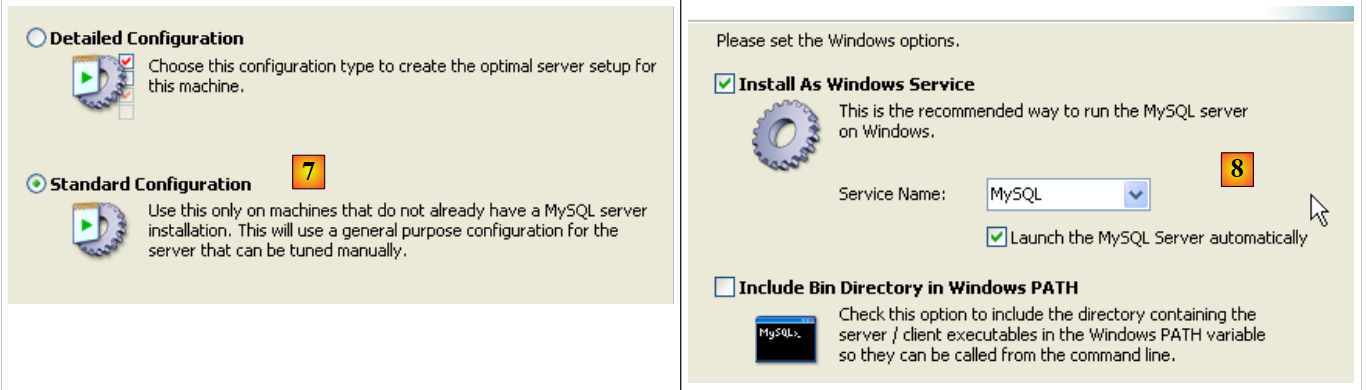 |
- in [7]: scegli una configurazione standard, quella che richiede meno domande
- in [8]: il server MySQL5 sarà un servizio di Windows
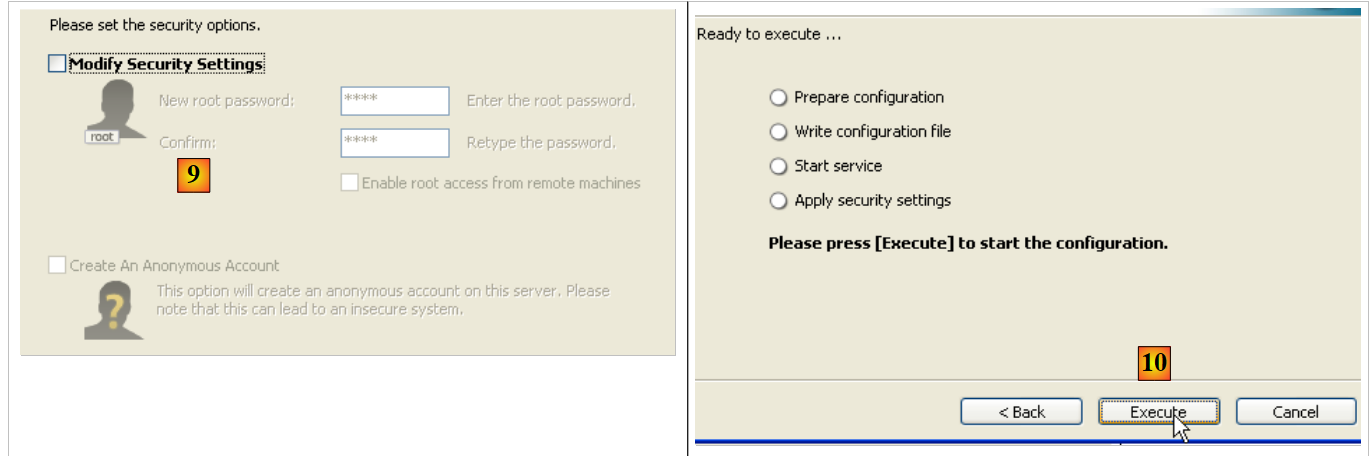 |
- in [9]: Per impostazione predefinita, l'amministratore del server è root senza password. È possibile mantenere questa configurazione o impostare una nuova password per root. Se l'installazione di MySQL5 segue la disinstallazione di una versione precedente, questo passaggio potrebbe fallire. Non c'è modo di annullarlo.
- in [10]: viene richiesto di configurare il server
L'installazione di MySQL5 crea una cartella in [Start / Programmi]:

È possibile utilizzare la [Procedura guidata di configurazione dell'istanza del server MySQL] per riconfigurare il server:
 |
 |
 |
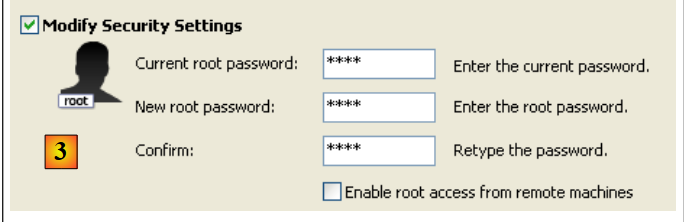
- in [3]: modifichiamo la password di root (qui root/root)
5.5.2. Avvia / Arresta MySQL5
Il server MySQL5 è stato installato come servizio di Windows che si avvia automaticamente, ovvero si avvia all'avvio di Windows. Questa modalità di funzionamento non è pratica. La modificheremo:
[Start / Pannello di controllo / Prestazioni e manutenzione / Strumenti di amministrazione / Servizi]:
 |
- in [1]: facciamo doppio clic su [Servizi]
- in [2]: vediamo che è presente un servizio denominato [MySQL], che è in esecuzione [3] e che si avvia automaticamente [4].
Per modificare questa impostazione, fare doppio clic sul servizio [MySQL]:
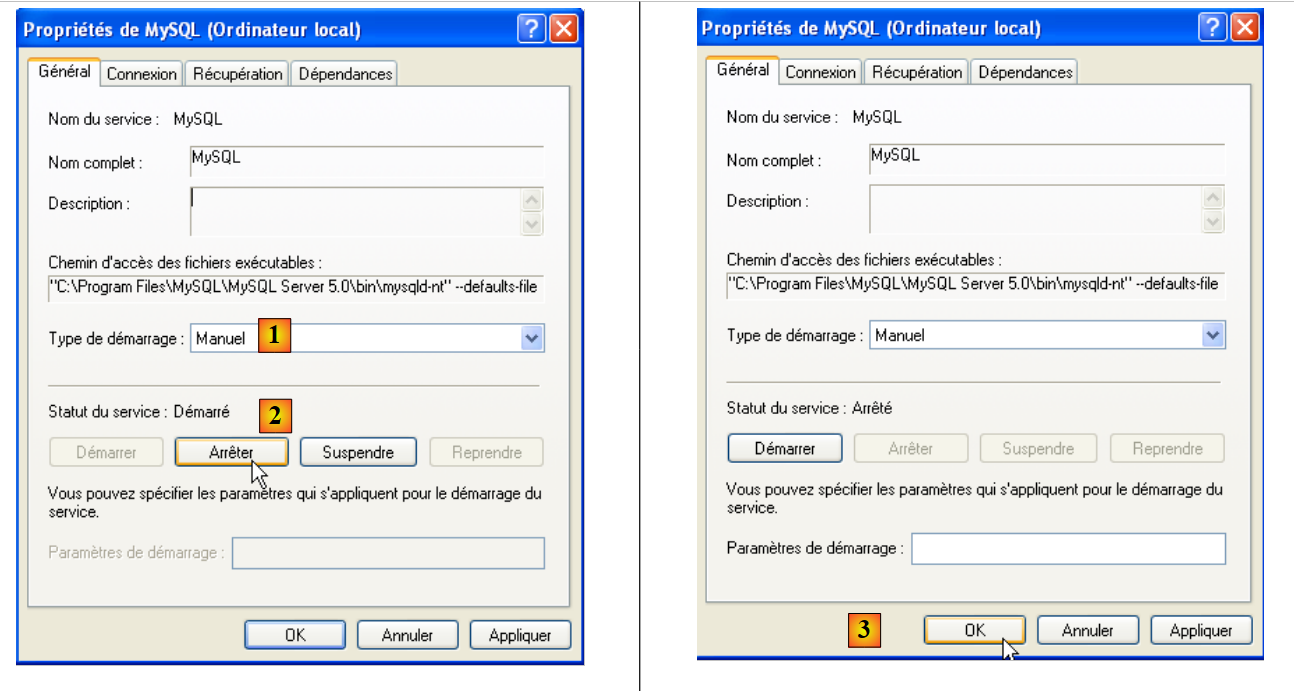 |
- in [1]: imposta l'avvio del servizio su manuale
- in [2]: arrestarlo
- in [3]: confermiamo la nuova configurazione del servizio
Per avviare e arrestare manualmente il servizio MySQL, possiamo creare due collegamenti:
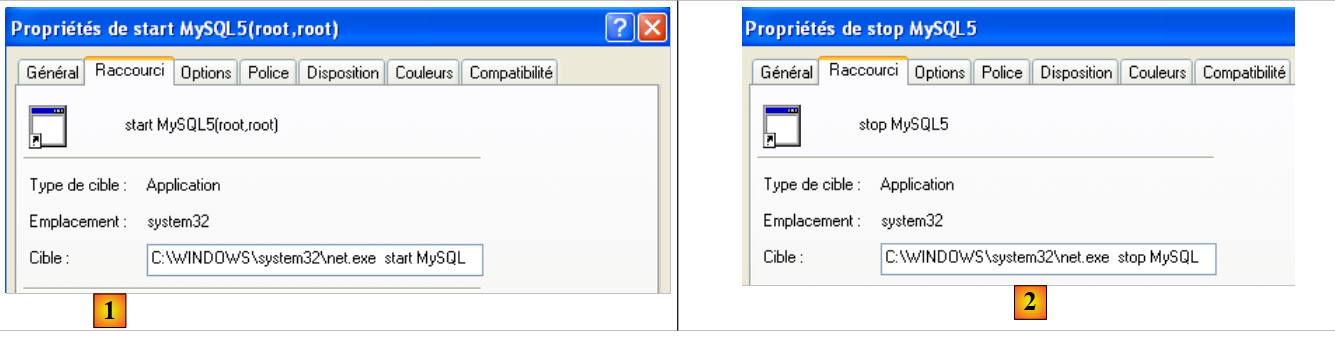 |
- in [1]: il collegamento per avviare MySQL5
- in [2]: il collegamento per arrestarlo
5.5.3. Client di amministrazione MySQL
Sul sito web di MySQL è possibile trovare i client di amministrazione del DBMS:
 |
- [1]: Selezionare [MySQL GUI Tools], che include vari client grafici sia per l'amministrazione del DBMS che per il suo utilizzo
- in [2]: selezionare la versione Windows appropriata
 |
- in [3]: scaricare un file .msi da eseguire
- in [4]: una volta completata l'installazione, appariranno nuovi collegamenti nella cartella [Menu Start / Programmi / MySQL].
Avvia MySQL (utilizzando i collegamenti creati), quindi avvia [MySQL Administrator] dal menu in alto:
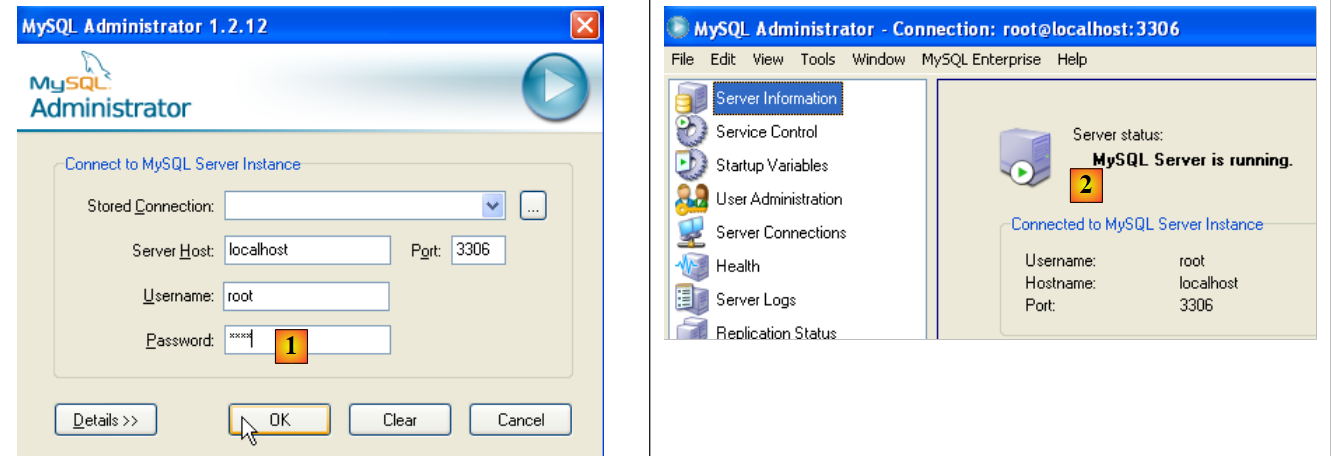 |
- in [1]: inserisci la password dell'utente root (in questo caso root)
- in [2]: hai effettuato l'accesso e puoi vedere che MySQL è attivo
5.5.4. Creazione di un utente jpa e di un database jpa
Questo tutorial utilizza MySQL 5 con un database denominato jpa e un utente con lo stesso nome. Ora li creeremo. Innanzitutto, l'utente:
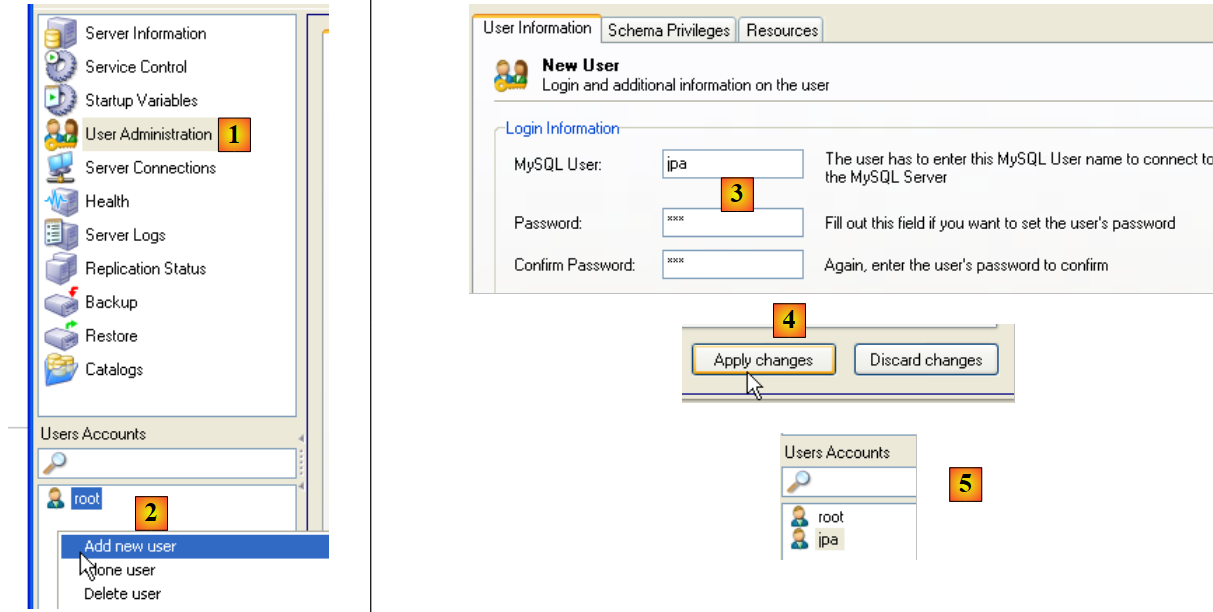 |
- in [1]: selezionare [Amministrazione utenti]
- in [2]: clicca con il tasto destro nella sezione [Account utente] per creare un nuovo utente
- in [3]: l'utente si chiama jpa e la sua password è jpa
- in [4]: confermare la creazione
- in [5]: l'utente [jpa] compare nella finestra [Account utente]
Ora il database:
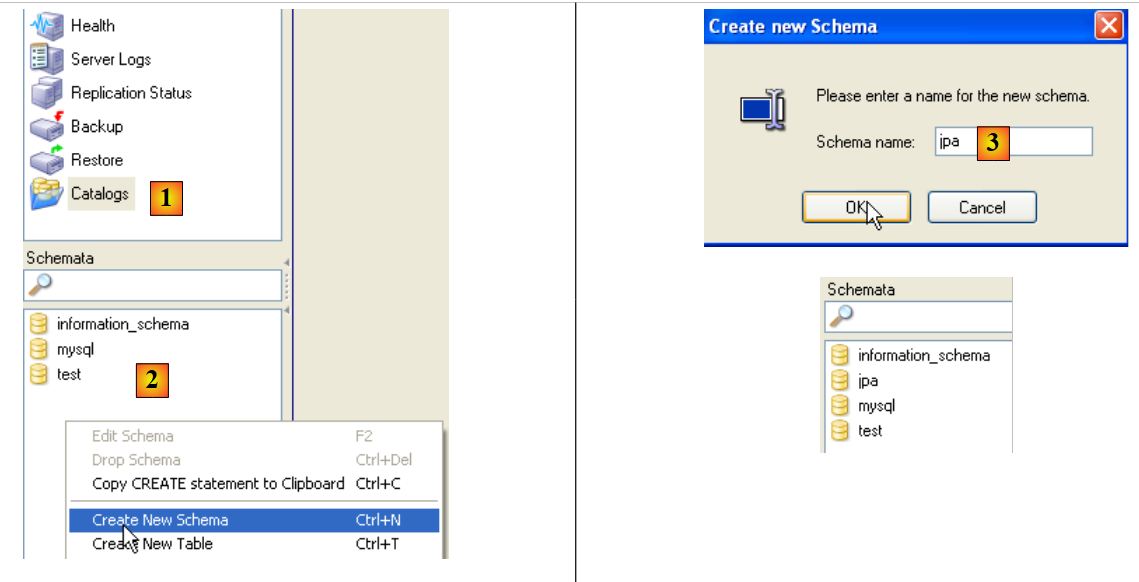 |
- in [1]: selezionare l'opzione [Cataloghi]
- in [2]: clicca con il tasto destro sulla finestra [Schemi] per creare un nuovo schema (che definisce un database)
- in [3]: assegnare un nome al nuovo schema
- in [4]: compare nella finestra [Schemi]
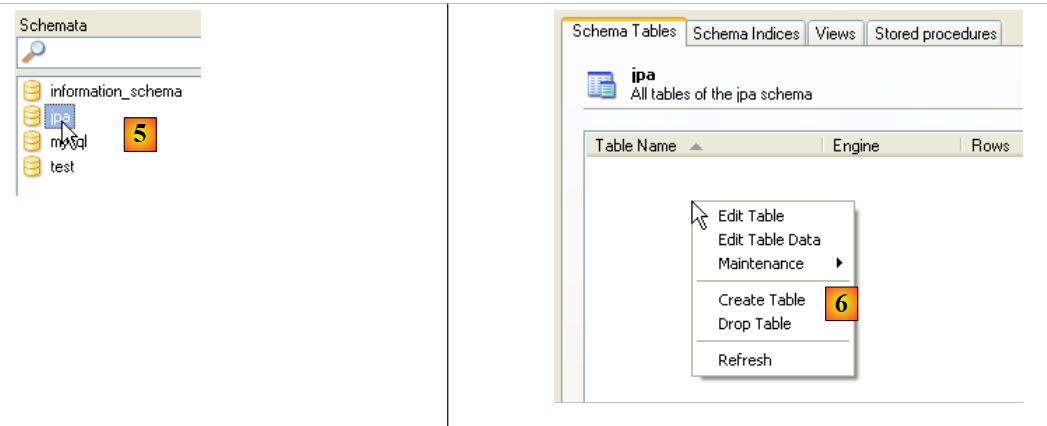 |
- in [5]: selezionare lo schema [jpa]
- in [6]: compaiono gli oggetti dello schema [jpa], comprese le tabelle. Non ce ne sono ancora. Facendo clic con il tasto destro del mouse è possibile crearle. Lasciamo che sia il lettore a farlo.
Torniamo all'utente [jpa] per concedergli i permessi completi sullo schema [jpa]:
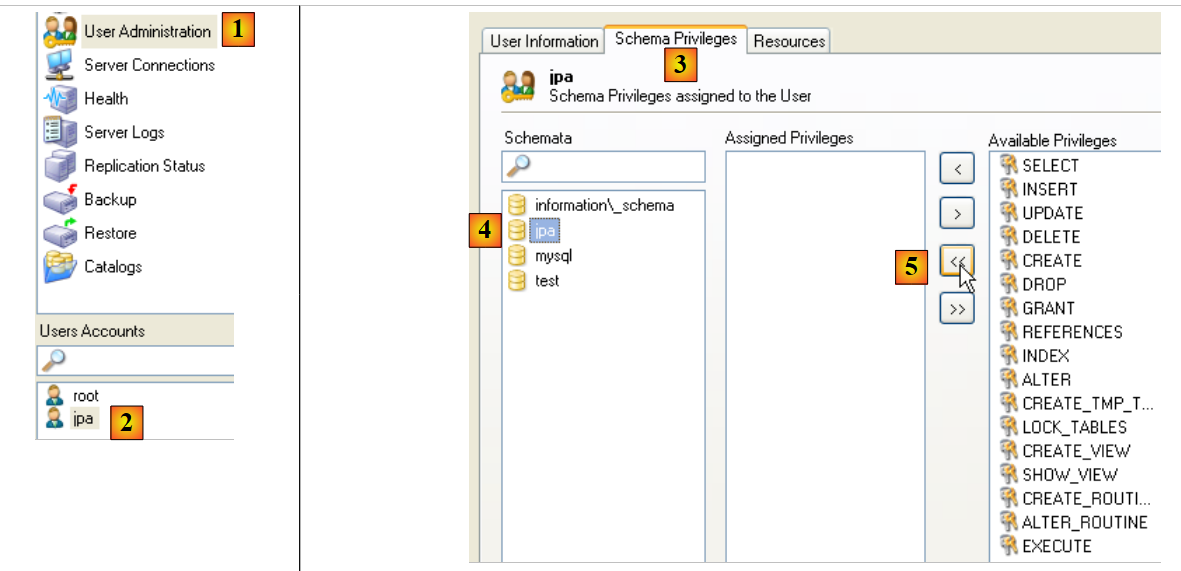 |
- in [1], poi [2]: selezionare l'utente [jpa]
- in [3]: selezionare la scheda [Privilegi dello schema]
- in [4]: selezionare lo schema [jpa]
- in [5]: concedere all'utente [jpa] tutti i privilegi sullo schema [jpa]
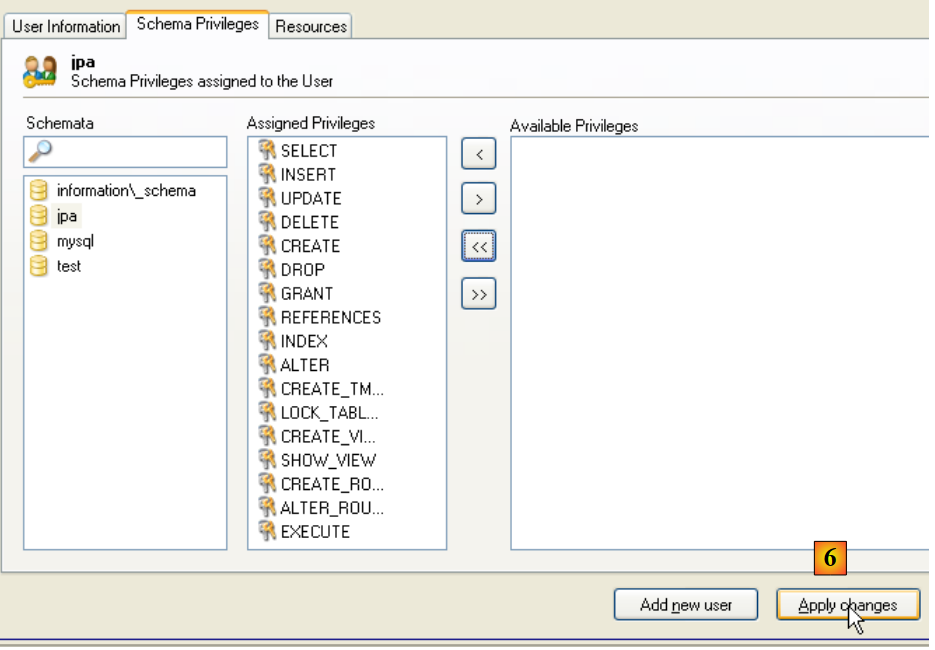 |
- in [6]: confermare le modifiche
Per verificare che l'utente [jpa] possa operare con lo schema [jpa], chiudere l'amministratore di MySQL. Riavviarlo e questa volta effettuare l'accesso come [jpa/jpa]:
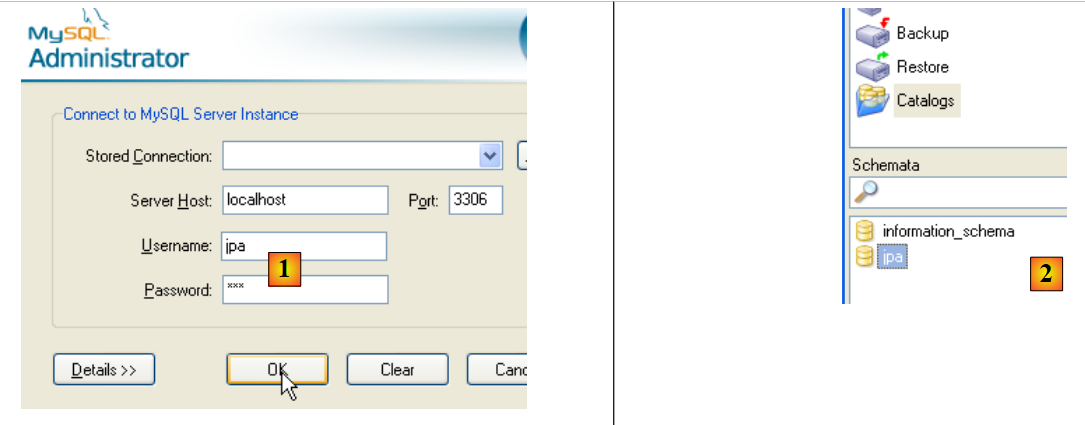 |
- in [1]: accedi (jpa/jpa)
- in [2]: la connessione è andata a buon fine e in [Schemi] vediamo gli schemi per i quali abbiamo i permessi. Vediamo lo schema [jpa].
Ora creeremo la stessa tabella [ARTICLES] utilizzata con il DBMS Firebird utilizzando lo script SQL [schema-articles.sql] generato nella sezione 5.4.6.
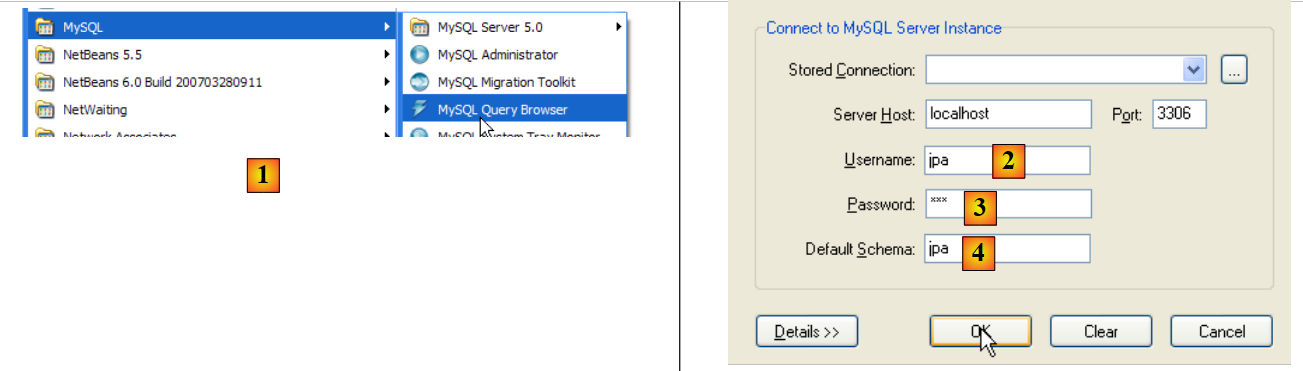 |
- in [1]: utilizzare l'applicazione [MySQL Query Browser]
- in [2], [3], [4]: effettuare il login (jpa / jpa / jpa)
 |
- in [5]: aprire uno script SQL per eseguirlo
- in [6]: selezionare lo script [schema-articles.sql] creato nella sezione 5.4.6.
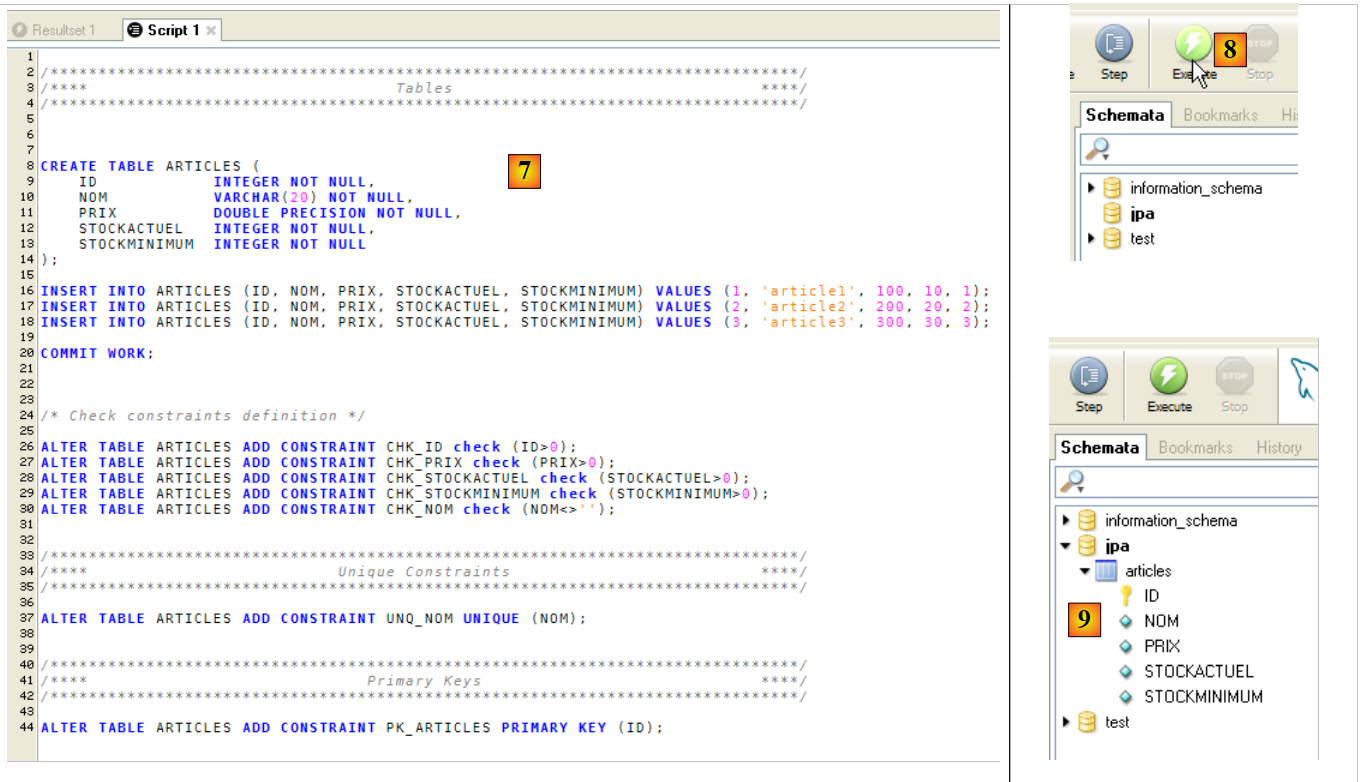 |
- in [7]: lo script è stato caricato
- in [8]: eseguirlo
- in [9]: la tabella [ARTICLES] è stata creata
5.5.5. Driver JDBC per MySQL 5
Il driver JDBC di MySQL può essere scaricato dalla stessa posizione del DBMS:
 |
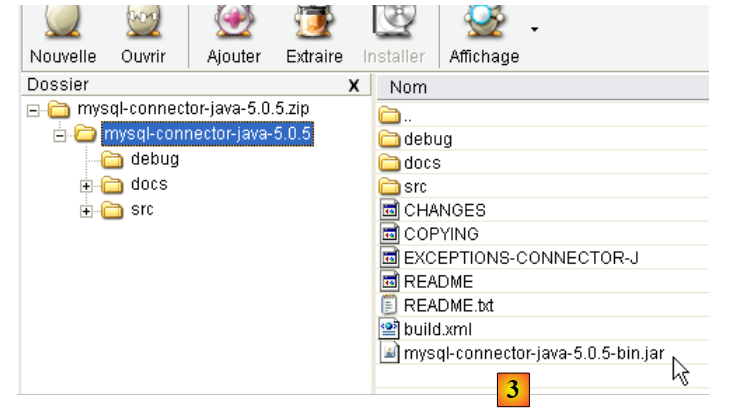 |
- in [1]: selezionare il driver JDBC appropriato
- in [2]: selezionare la versione di Windows appropriata
- in [3]: nel file ZIP scaricato, l'archivio Java contenente il driver JDBC è [mysql-connector-java-5.0.5-bin.jar]. Lo estrarremo per utilizzarlo negli esempi del tutorial JPA.
Lo collochiamo come in precedenza (sezione 5.4.7) nella cartella <jdbc>:
 |
Per testare questo driver JDBC, useremo Eclipse e il plugin SQL Explorer. Invitiamo il lettore a seguire la procedura spiegata nella sezione 5.4.7. Ecco alcune schermate significative:
 |
- in [1]: abbiamo selezionato l'archivio del driver JDBC MySQL5
- in [2]: è disponibile il driver JDBC per MySQL 5
 |
- in [3]: definizione della connessione (utente, password)=(jpa, jpa)
- in [4]: la connessione è attiva
- in [5]: il database è connesso
5.6. Il DBMS PostgreSQL
5.6.1. Installazione
Il DBMS PostgreSQL è disponibile all'URL [http://www.postgresql.org/download/]:
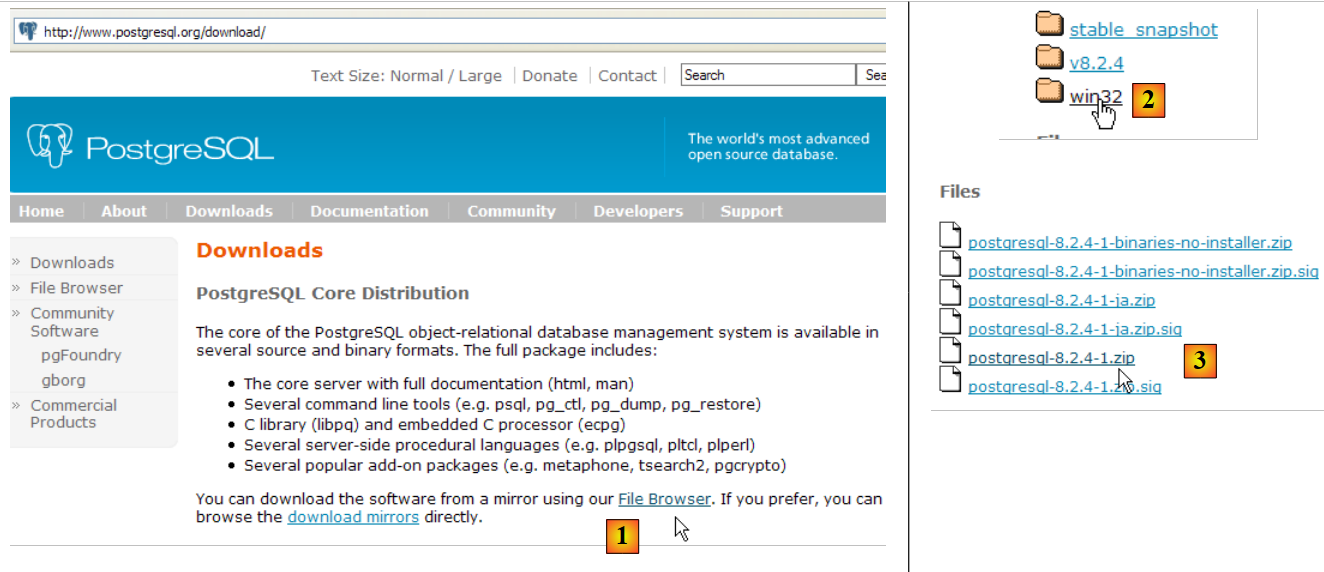 |
- all'indirizzo [1]: siti di download di PostgreSQL
- in [2]: scegli una versione per Windows
- in [3]: scegli una versione con programma di installazione
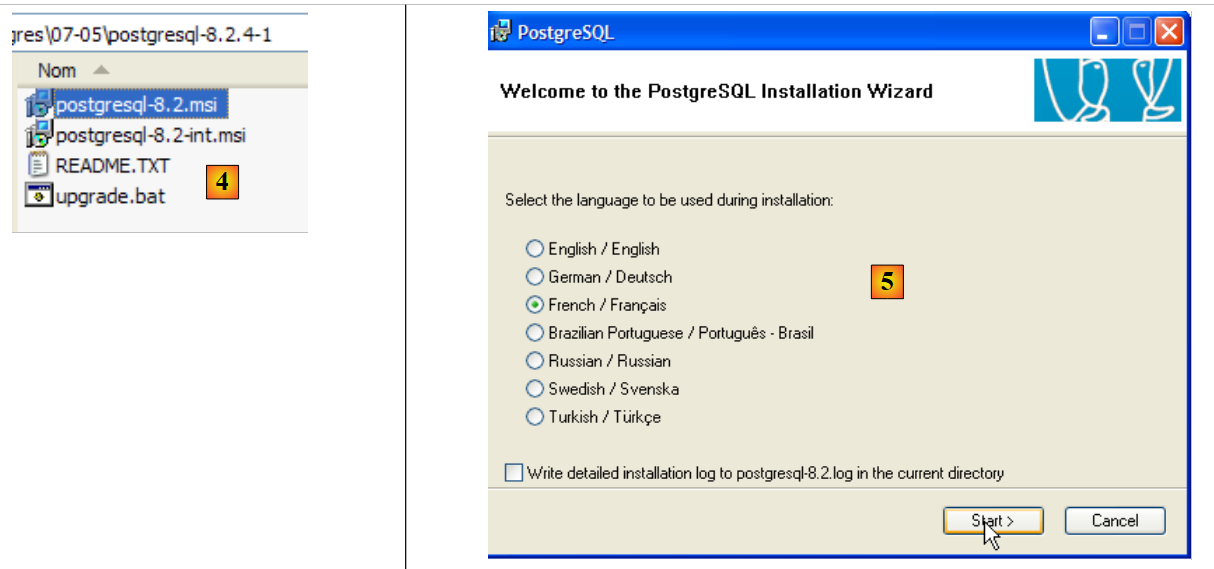 |
- [4]: il contenuto del file ZIP scaricato. Fare doppio clic sul file [postgresql-8.2.msi]
- in [5]: la prima pagina della procedura guidata di installazione
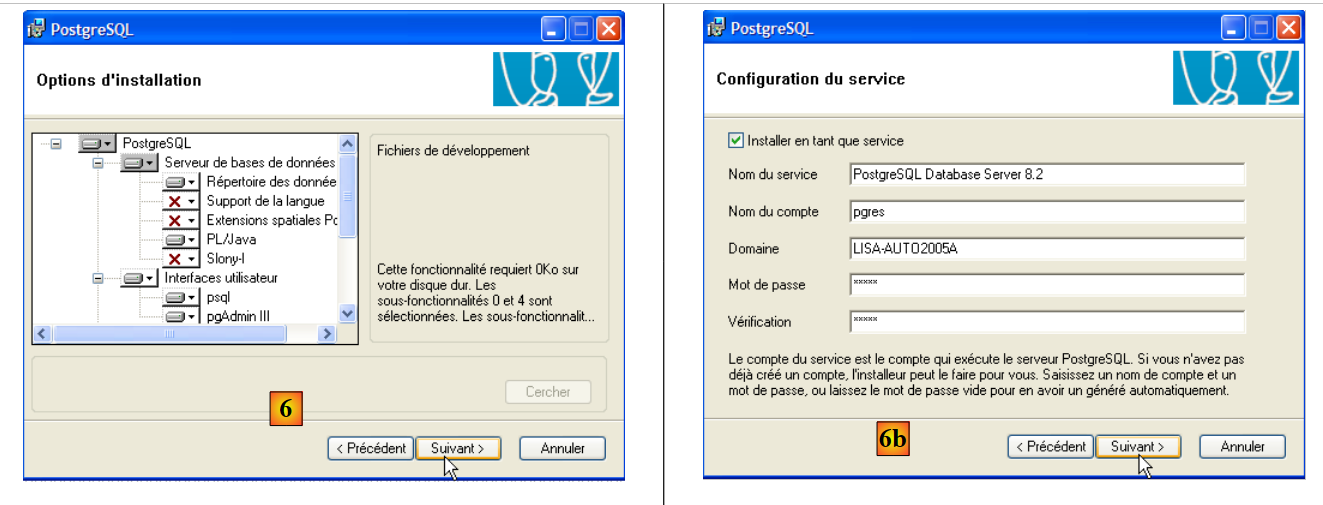 |
- in [6]: scegli un'installazione tipica accettando i valori predefiniti
- in [6b]: creare l'account Windows che eseguirà il servizio PostgreSQL; in questo caso, l'account è pgres con la password pgres.
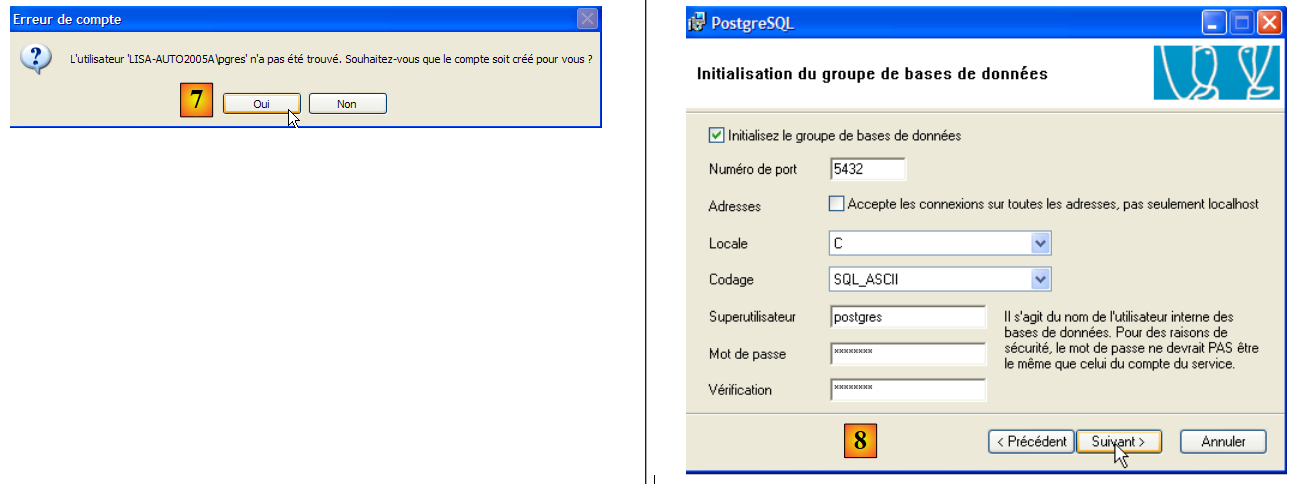 |
- in [7]: lasciare che PostgreSQL crei l'account [pgres] se non esiste già
- in [8]: definire l'account amministratore del DBMS, in questo caso postgres con la password postgres
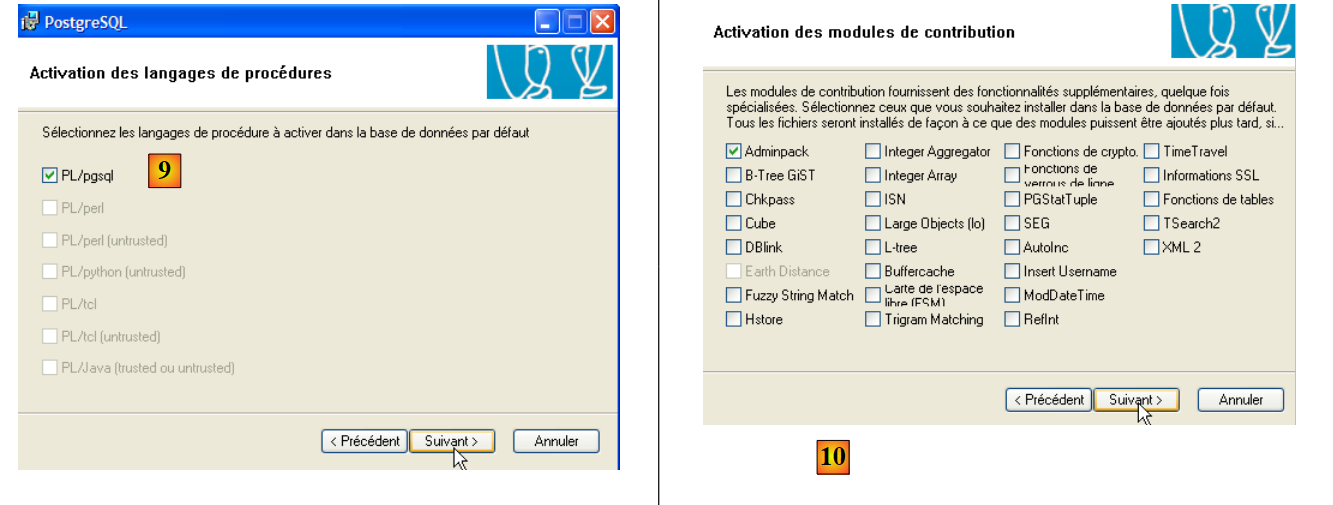 |
- in [9] e [10]: accettare i valori predefiniti fino alla fine della procedura guidata. PostgreSQL verrà installato.
L'installazione di PostgreSQL crea una cartella in [Start / Programmi]:
5.6.2. Avvia / Arresta PostgreSQL
Il server PostgreSQL è stato installato come servizio di Windows che si avvia automaticamente, ovvero si avvia non appena si avvia Windows. Questa configurazione non è molto pratica. La modificheremo:
[Start / Pannello di controllo / Prestazioni e manutenzione / Strumenti di amministrazione / Servizi]:
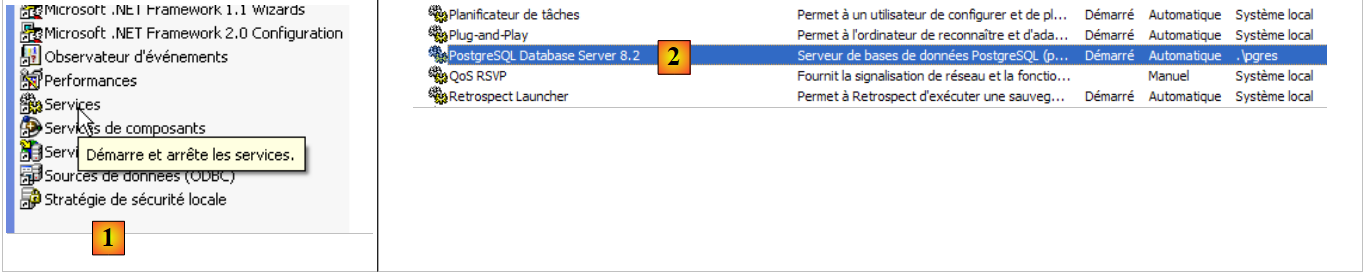 |
- In [1]: fare doppio clic su [Servizi]
- in [2]: vediamo che è presente un servizio denominato [PostgreSQL], che è in esecuzione [3] e che si avvia automaticamente [4].
Per modificare questa impostazione, fare doppio clic sul servizio [PostgreSQL]:
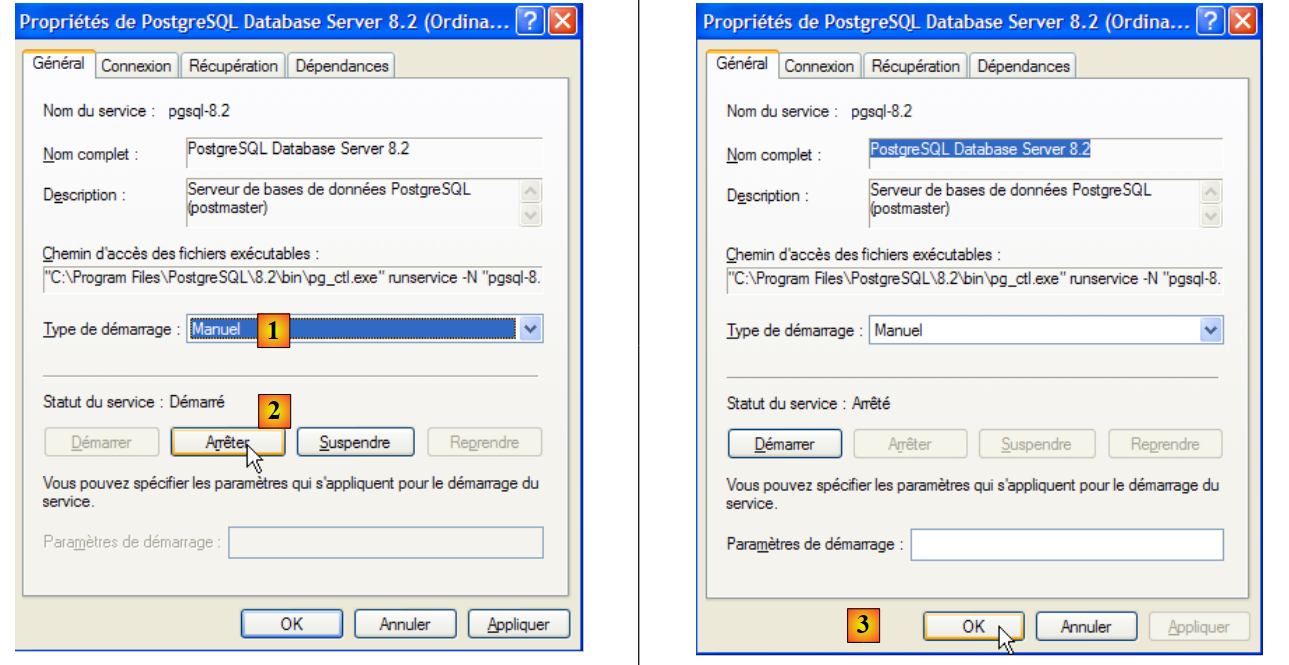 |
- in [1]: imposta l'avvio del servizio su manuale
- in [2]: arrestarlo
- in [3]: confermiamo la nuova configurazione del servizio
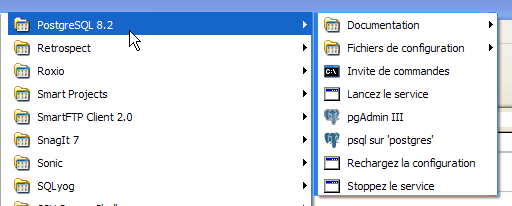
Per avviare e arrestare manualmente il servizio PostgreSQL, è possibile utilizzare i collegamenti presenti nella cartella [PostgreSQL]:
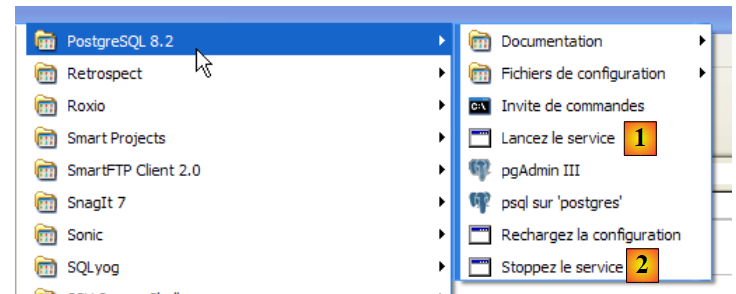 |
- in [1]: il collegamento per avviare PostgreSQL
- in [2]: il collegamento per arrestarlo
5.6.3. Amministrazione di PostgreSQL
Nello screenshot qui sopra, l'applicazione [pgAdmin III] (3) consente di amministrare il DBMS PostgreSQL. Avviamo il DBMS, quindi lanciamo [pgAdmin III] tramite il menu in alto:
 |
- in [1]: fare doppio clic sul server PostgreSQL per connettersi
- in [2,3]: effettuare l'accesso come amministratore del DBMS, in questo caso (postgres / postgres)
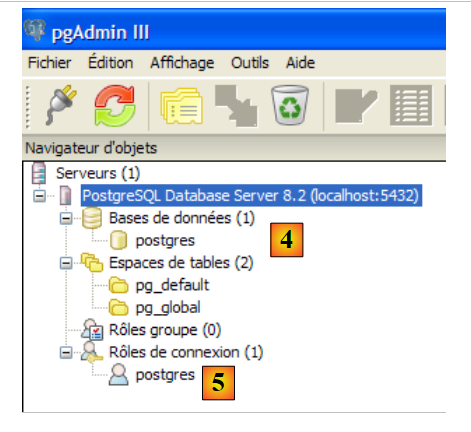 |
- in [4]: l'unico database esistente
- in [5]: l'unico utente esistente
5.6.4. Creazione di un utente JPA e di un database JPA
Il tutorial utilizza PostgreSQL con un database denominato jpa e un utente con lo stesso nome. Ora li creeremo. Innanzitutto, l'utente:
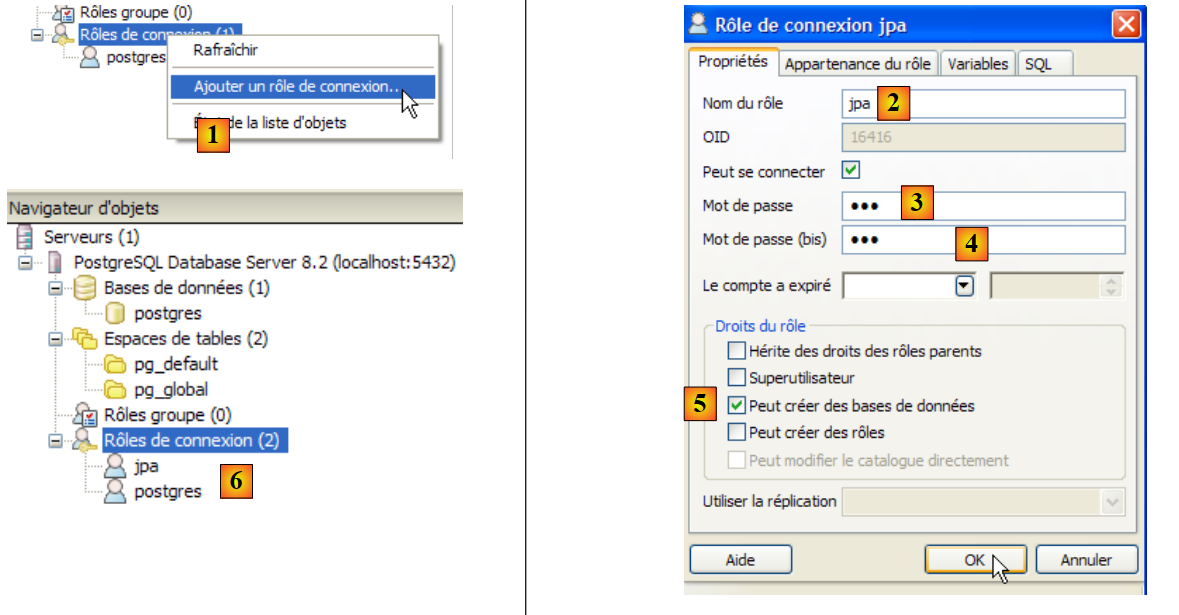 |
- in [1]: creare un nuovo ruolo (~utente)
- in [2]: creazione dell'utente jpa
- in [3]: la loro password è jpa
- in [4]: ripetiamo la password
- in [5]: concediamo all'utente il permesso di creare database
- in [6]: l'utente [jpa] compare tra i ruoli di accesso
Ora passiamo al database:
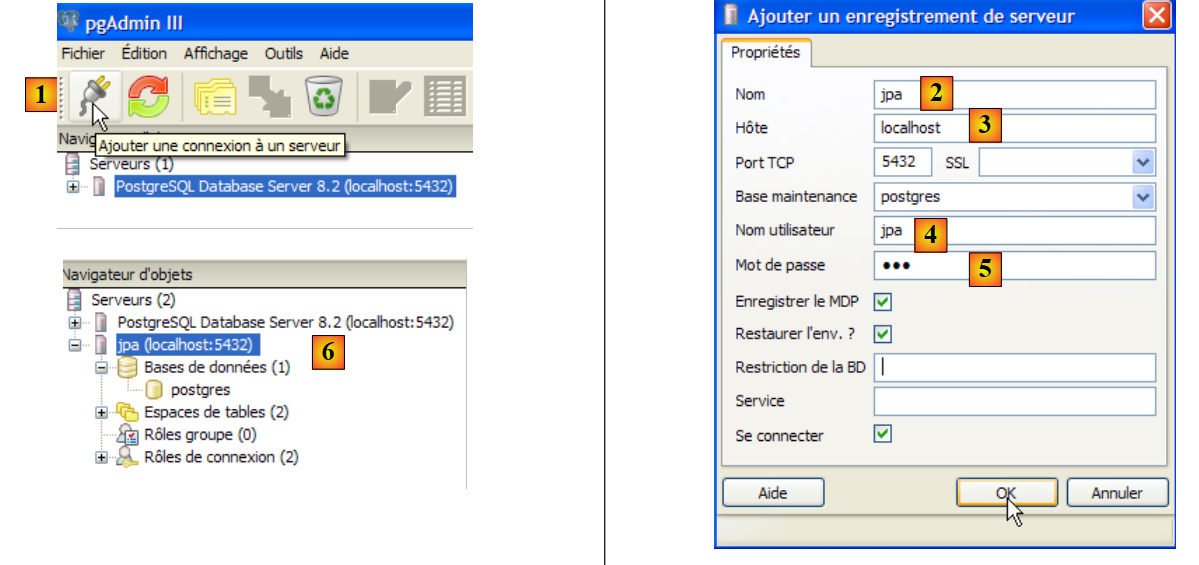 |
- in [1]: creare una nuova connessione al server
- in [2]: verrà denominata jpa
- in [3]: il computer a cui vogliamo collegarci
- in [4]: l'utente che effettua l'accesso
- in [5]: la sua password. Confermiamo le impostazioni di connessione cliccando su [OK]
- in [6]: la nuova connessione è stata creata. Appartiene all'utente jpa. Questo utente creerà ora un nuovo database:
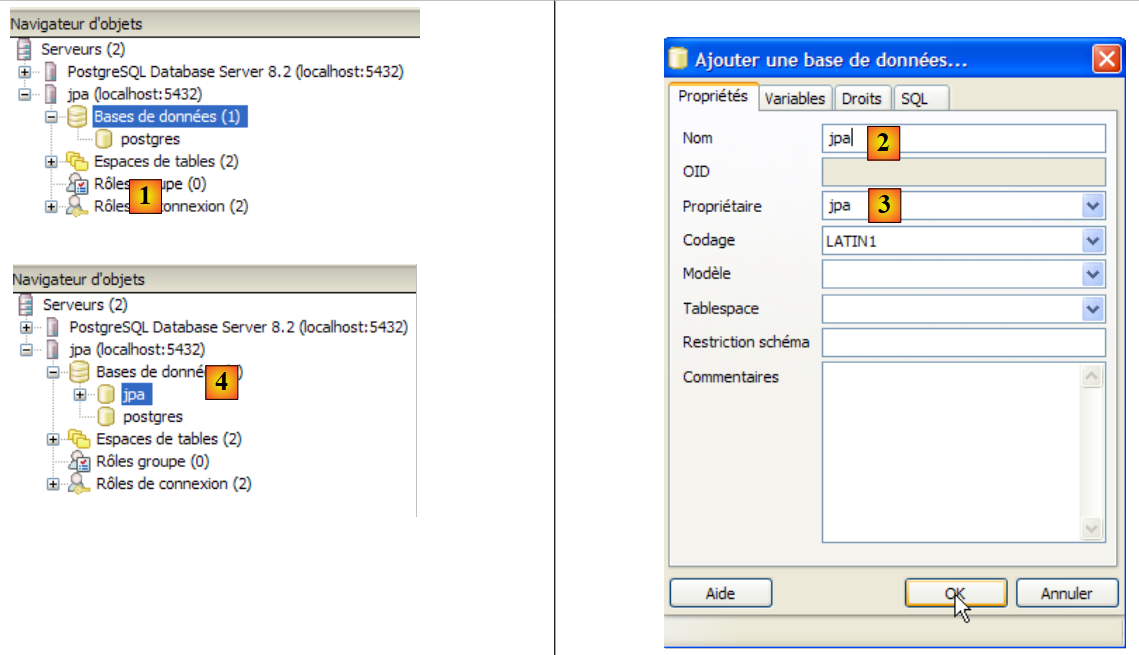 |
- n [1]: aggiungi un nuovo database
- in [2]: il suo nome è jpa
- in [3]: il proprietario è l'utente jpa creato in precedenza. Fare clic su [OK] per confermare
- in [4]: il database jpa è stato creato. Un semplice clic su di esso ci connette ad esso e ne rivela la struttura:
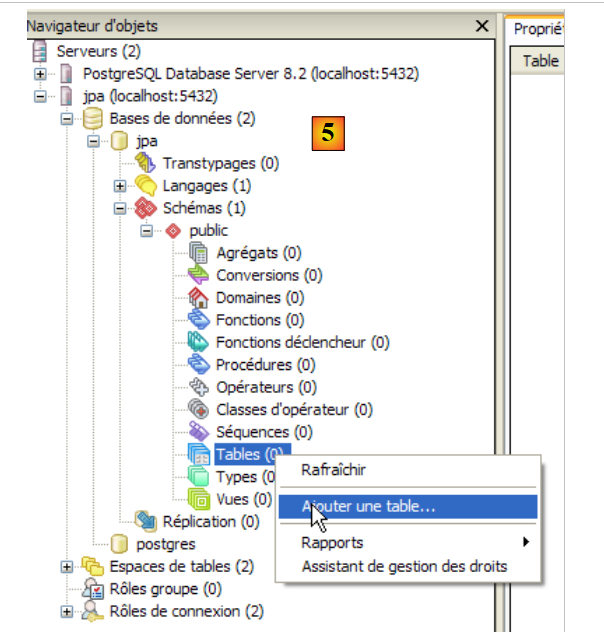 |
- in [5]: compaiono gli oggetti dello schema [jpa], in particolare le tabelle. Non ce ne sono ancora. Un clic con il tasto destro del mouse ci consentirebbe di crearle. Lasceremo questo compito al lettore.
Ora creeremo la stessa tabella [ARTICLES] utilizzata con i DBMS precedenti utilizzando lo script SQL [schema-articles.sql] generato nella sezione 5.4.6.
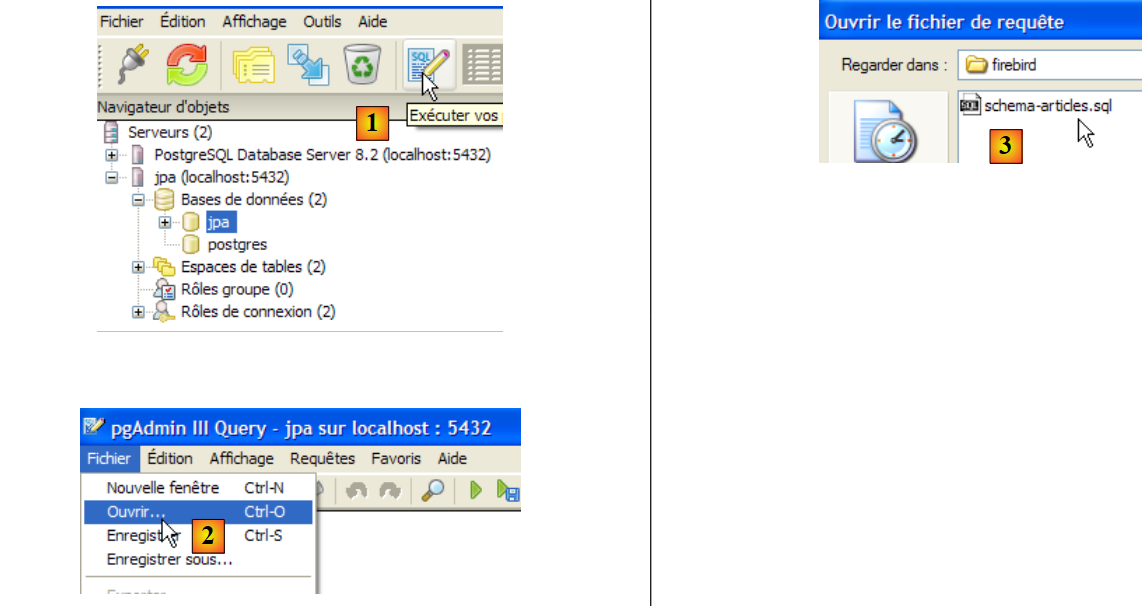 |
- in [1]: aprire l'editor SQL
- in [2]: aprire uno script SQL
- in [3]: selezionare lo script [schema-articles.sql] creato nella sezione 5.4.6
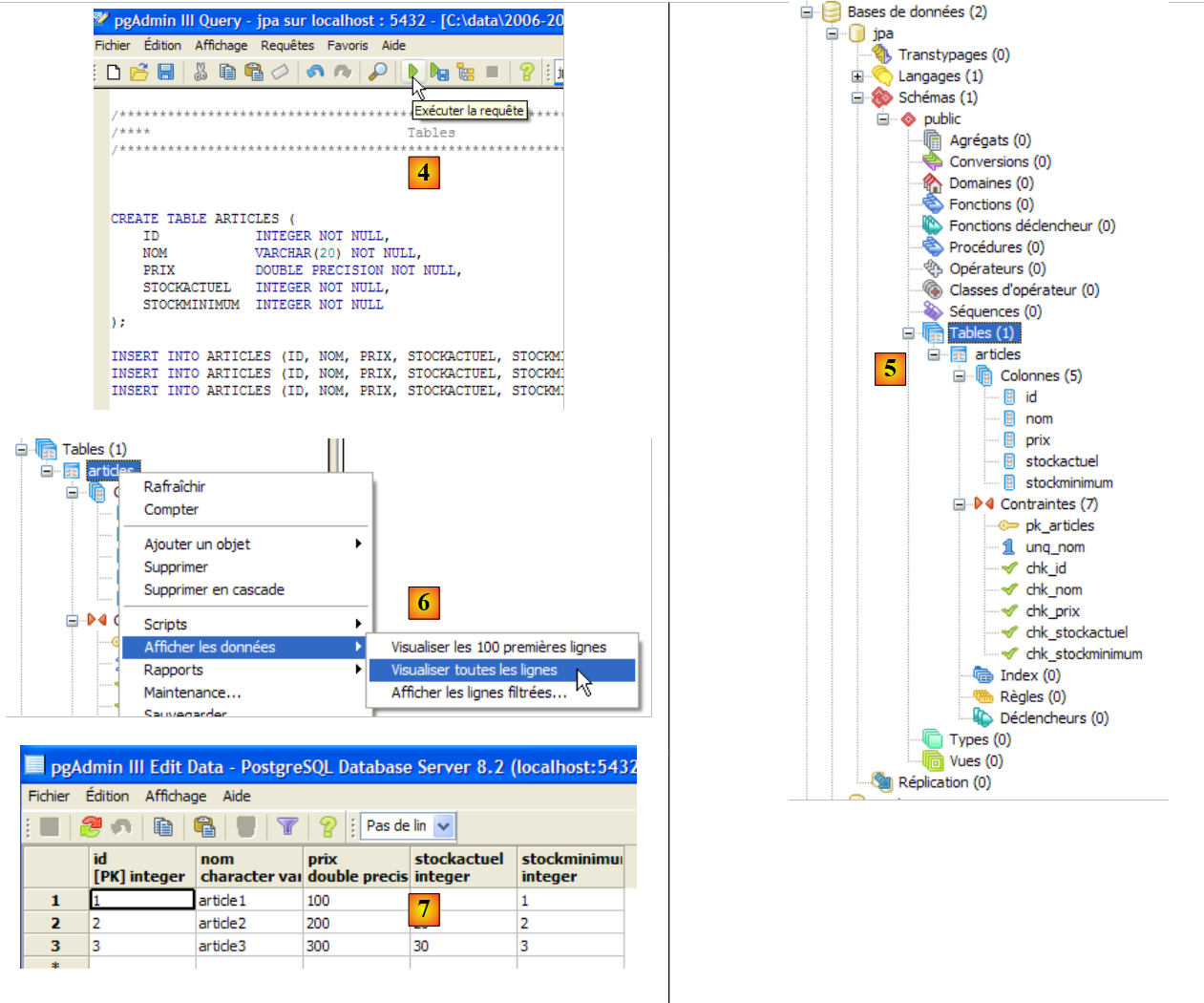 |
- in [4]: lo script è stato caricato. Lo eseguiamo.
- in [5]: la tabella [ARTICLES] è stata creata.
- in [6, 7]: il suo contenuto
5.6.5. Driver JDBC di PostgreSQL
Il driver JDBC di PostgreSQL è disponibile nella cartella [jdbc] all'interno della directory di installazione di PostgreSQL:
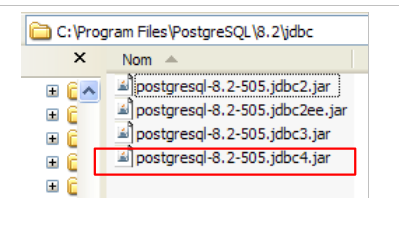 |
Collochiamo l'archivio JDBC, come per i precedenti (sezione 5.4.7), nella cartella <jdbc>:
 |
Per testare questo driver JDBC, utilizzeremo Eclipse e il plugin SQL Explorer. Invitiamo il lettore a seguire la procedura illustrata nella sezione 5.4.7. Di seguito presentiamo alcune schermate significative:
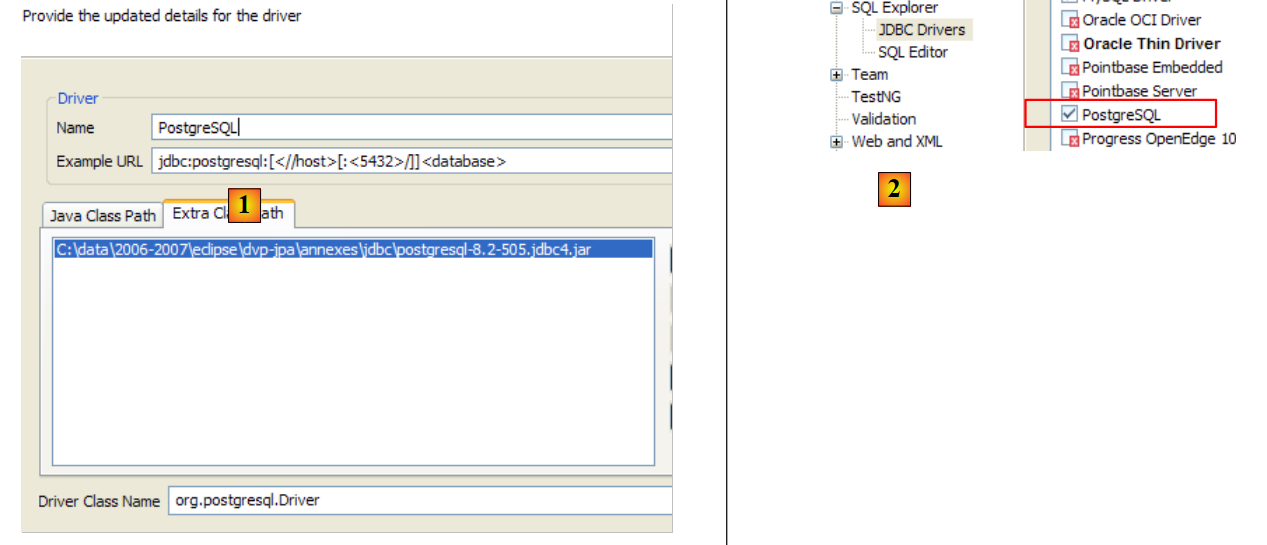 |
- in [1]: abbiamo selezionato l'archivio del driver JDBC PostgreSQL
- in [2]: il driver JDBC di PostgreSQL è disponibile
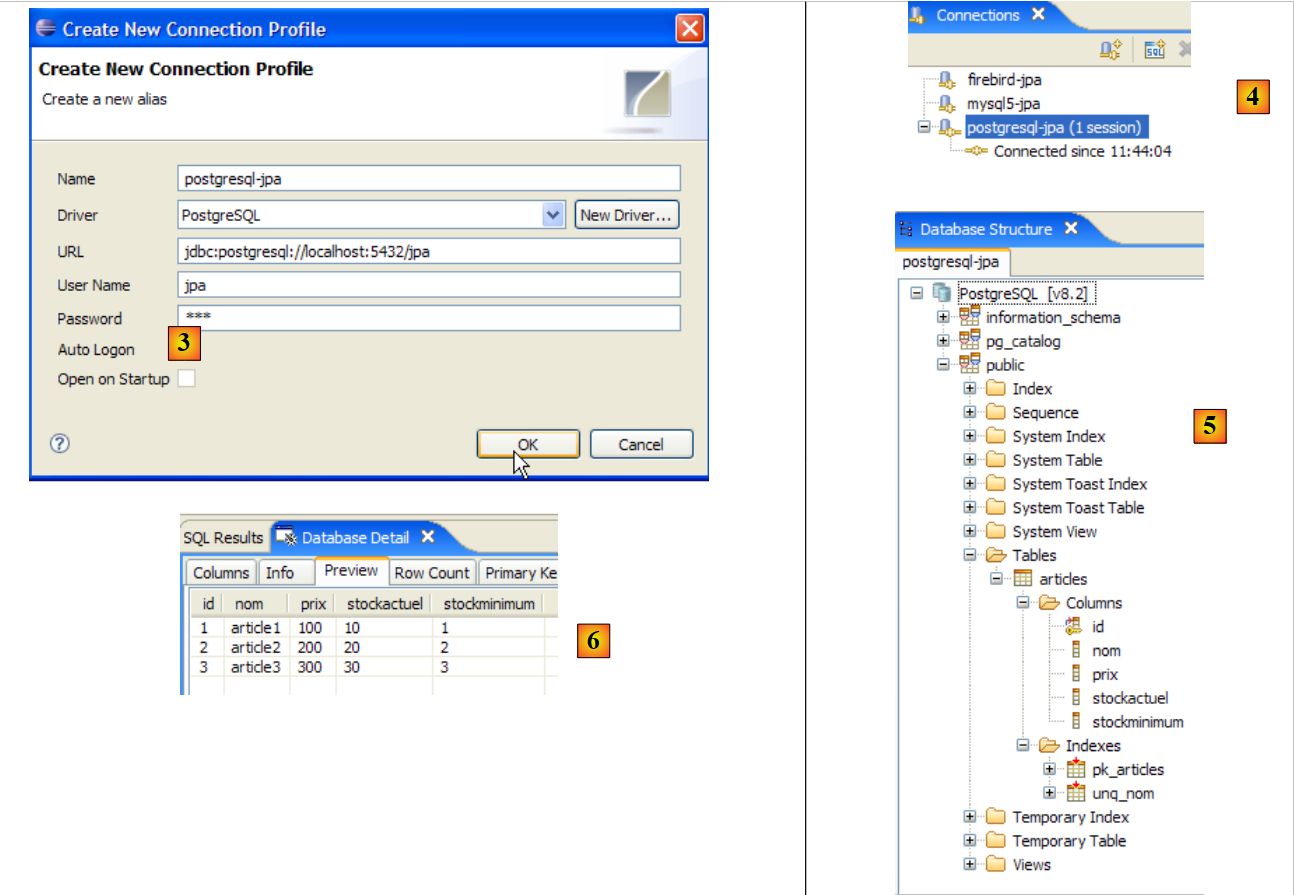 |
- in [3]: definizione della connessione (utente, password)=(jpa, jpa)
- in [4]: la connessione è attiva
- in [5]: il database connesso
- in [6]: il contenuto della tabella [ARTICLES]
5.7. Il DBMS Oracle 10g Express
5.7.1. Installazione
Il DBMS Oracle 10g Express è disponibile all'indirizzo [http://www.oracle.com/technology/software/products/database/xe/index.html]:
 |
- all'indirizzo [1]: il sito di download di Oracle 10g Express
- all'indirizzo [2]: selezionare una versione per Windows. Una volta scaricato il file, eseguirlo:
 |
- in [1]: fare doppio clic sul file [OracleXE.exe]
- in [2]: la prima pagina della procedura guidata di installazione
 |
- in [3]: accetta la licenza
- in [4]: Accetta le impostazioni predefinite.
 |
- in [5,6]: l'utente SYSTEM avrà la password "system".
- in [7]: Avvia l'installazione
L'installazione di Oracle 10g Express crea una cartella in [Start / Programmi]:
5.7.2. Avvia / Arresta Oracle 10g
Come per i DBMS precedenti, Oracle 10g è stato installato come servizio di Windows che si avvia automaticamente. Modificheremo questa configurazione:
[Start / Pannello di controllo / Prestazioni e manutenzione / Strumenti di amministrazione / Servizi]:
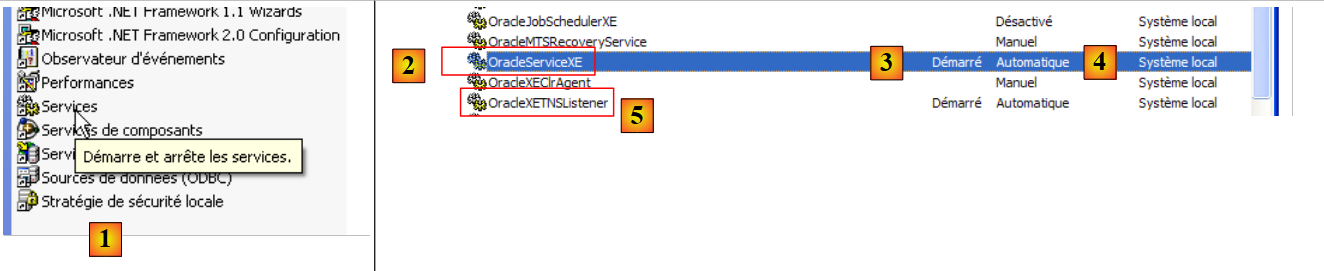 |
- in [1]: facciamo doppio clic su [Servizi]
- in [2]: vediamo che è presente un servizio chiamato [OracleServiceXE], che è in esecuzione [3] e che si avvia automaticamente [4].
- in [5]: è attivo anche un altro servizio Oracle, chiamato "Listener", impostato per l'avvio automatico.
Per modificare questo comportamento, fare doppio clic sul servizio [OracleServiceXE]:
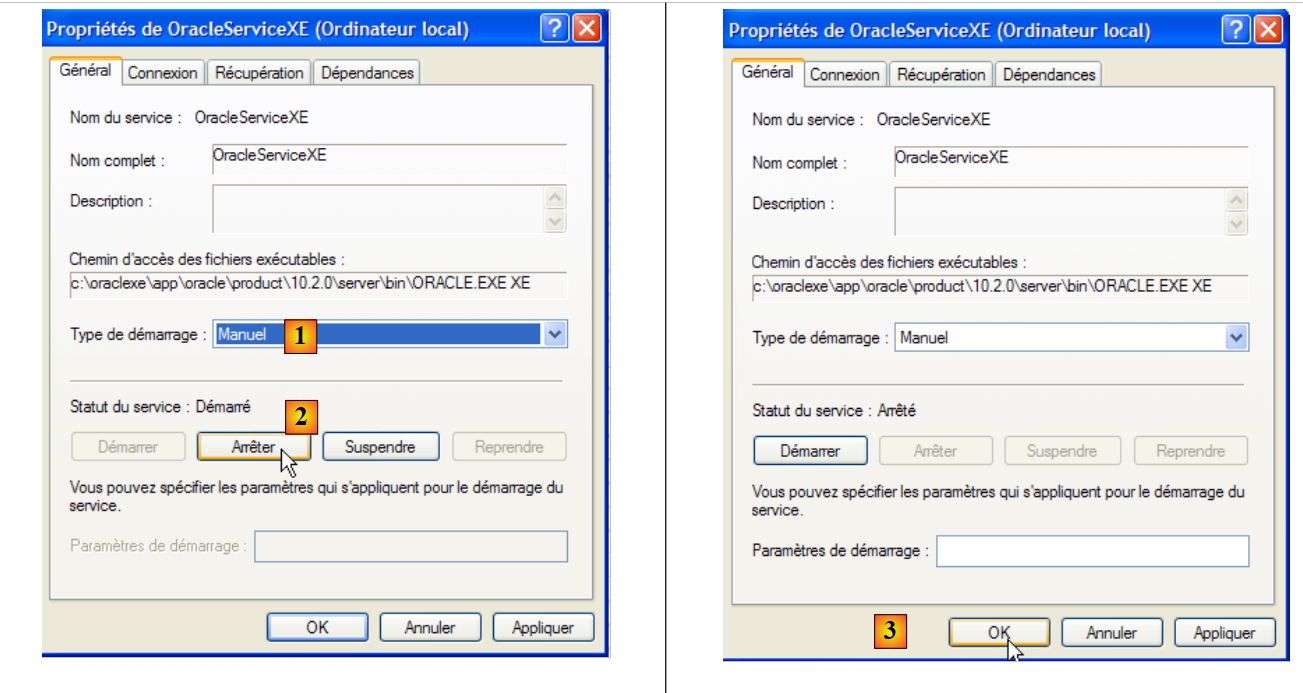 |
- in [1]: impostare l'avvio del servizio su manuale
- in [2]: lo arrestiamo
- in [3]: confermiamo la nuova configurazione del servizio
Faremo lo stesso con il servizio [OracleXETNSListener] (vedi [5] sopra). Per avviare e arrestare manualmente il servizio OracleServiceXE, possiamo utilizzare i collegamenti presenti nella cartella [Oracle]:
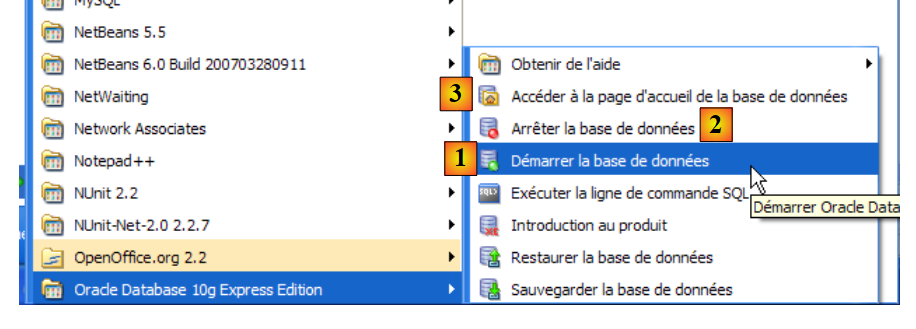 |
- in [1]: per avviare il DBMS
- in [2]: per arrestarlo
- in [3]: per gestirlo (il che lo avvia se non è già in esecuzione)
5.7.3. Creazione di un utente JPA e di un database JPA
Nello screenshot sopra, l'applicazione [3] consente di amministrare il DBMS Oracle 10g Express. Avviamo il DBMS [1], quindi l'applicazione di amministrazione [3] tramite il menu in alto:
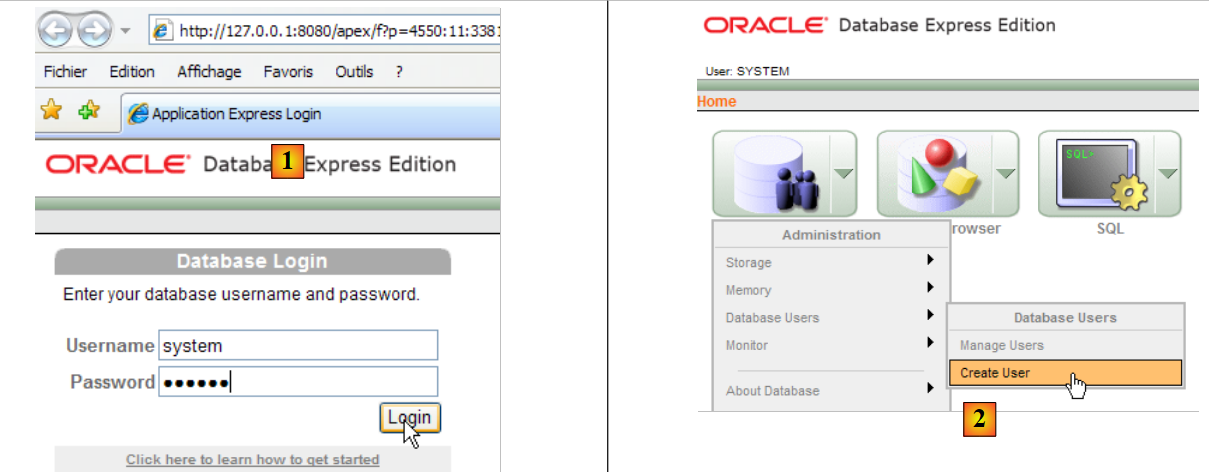 |
- in [1]: effettuare l'accesso come amministratore del DBMS, in questo caso (system/system)
- in [2]: creare un nuovo utente
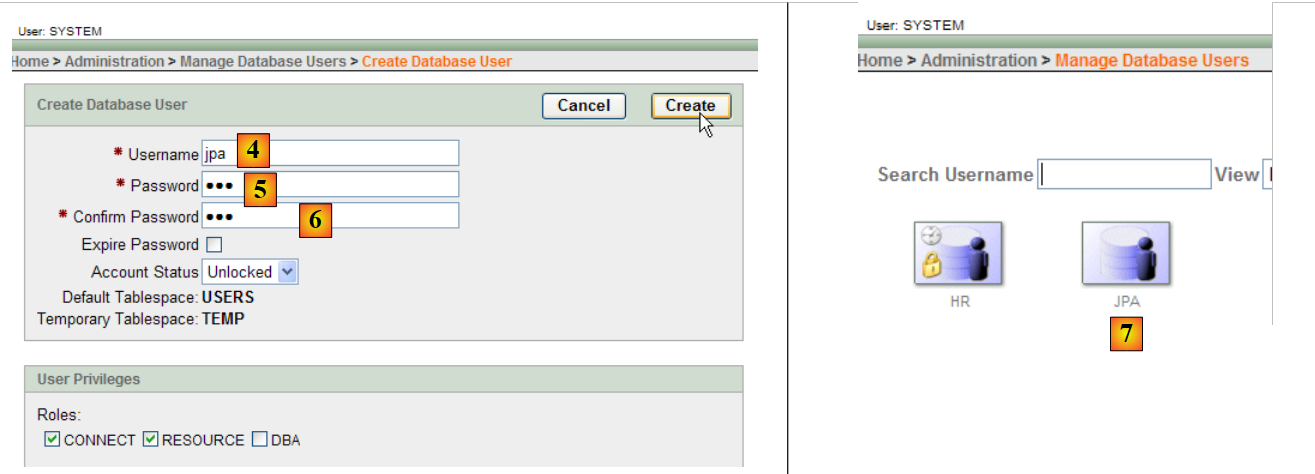 |
- in [4]: nome utente
- in [5, 6]: la sua password, qui jpa
- in [7]: l'utente jpa è stato creato
In Oracle, un utente viene automaticamente associato a un database con lo stesso nome. Il database jpa esiste quindi contemporaneamente all'utente jpa.
5.7.4. Creazione della tabella [ARTICLES] nel database jpa
OracleXE è stato installato con un client SQL in esecuzione in modalità riga di comando. È possibile lavorare in modo più comodo con l' e SQL Developer, anch'esso fornito da Oracle. È disponibile all'indirizzo:
[http://www.oracle.com/technology/products/database/sql_developer/index.html]
 |
- in [1]: il sito di download
- al punto [2]: scegli una versione di Windows senza JRE se è già installato (come in questo caso), poiché [SQL Developer] è un'applicazione Java.
 |
- [3]: decomprimere il file scaricato
- in [4]: esegui il file eseguibile [sqldeveloper.exe]
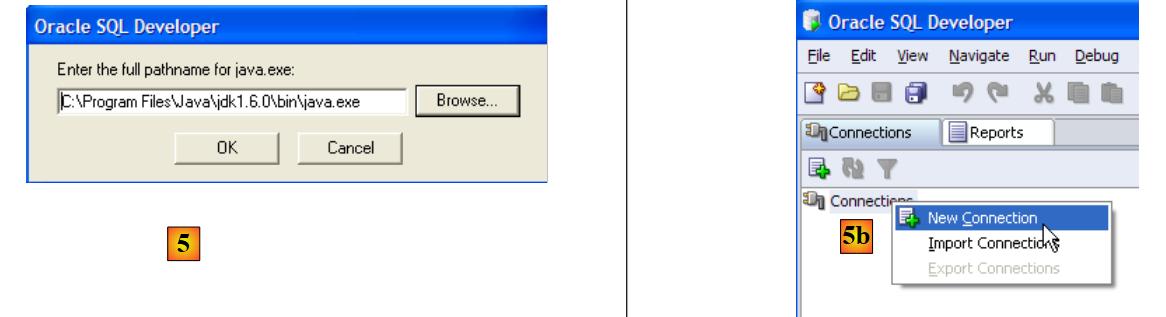 |
- in [5]: Al primo avvio di [SQL Developer], specificare il percorso del JRE installato sul computer
- in [5b]: creare una nuova connessione
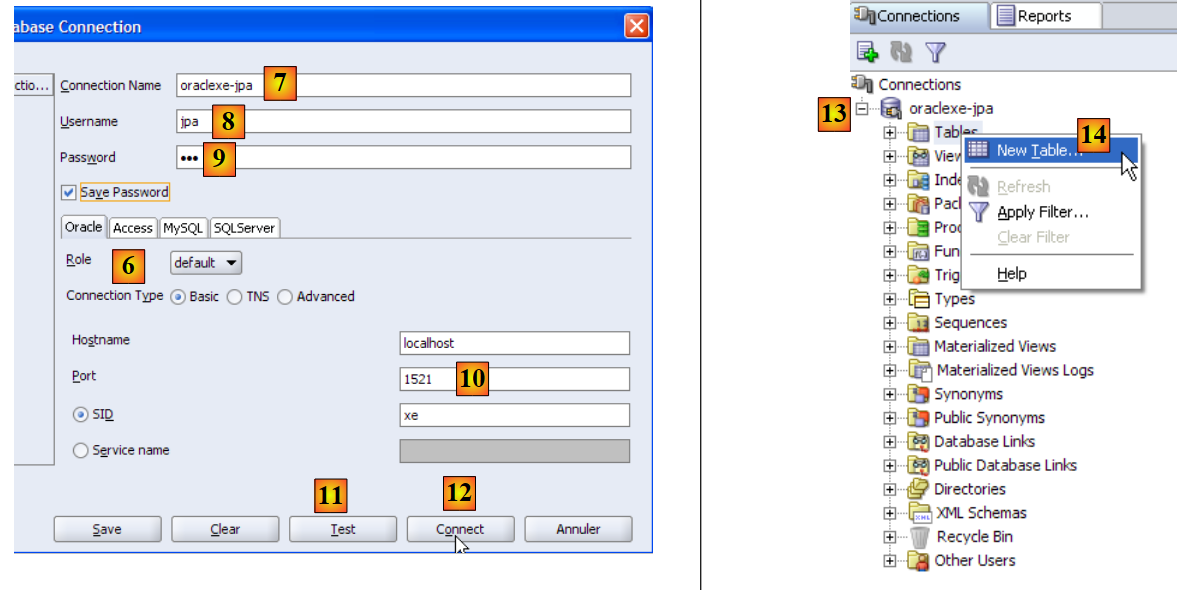 |
- in [6]: SQL Developer consente di connettersi a vari DBMS. Selezionare Oracle.
- in [7]: nome assegnato alla connessione che si sta creando
- in [8]: proprietario della connessione
- in [9]: la relativa password (jpa)
- in [10]: mantenere i valori predefiniti
- in [11]: per testare la connessione (Oracle deve essere in esecuzione)
- in [12]: per completare la configurazione della connessione
- in [13]: gli oggetti nel database jpa
- in [14]: è possibile creare tabelle. Come nei casi precedenti, creeremo la tabella [ARTICLES] utilizzando lo script creato nella sezione 5.4.6.
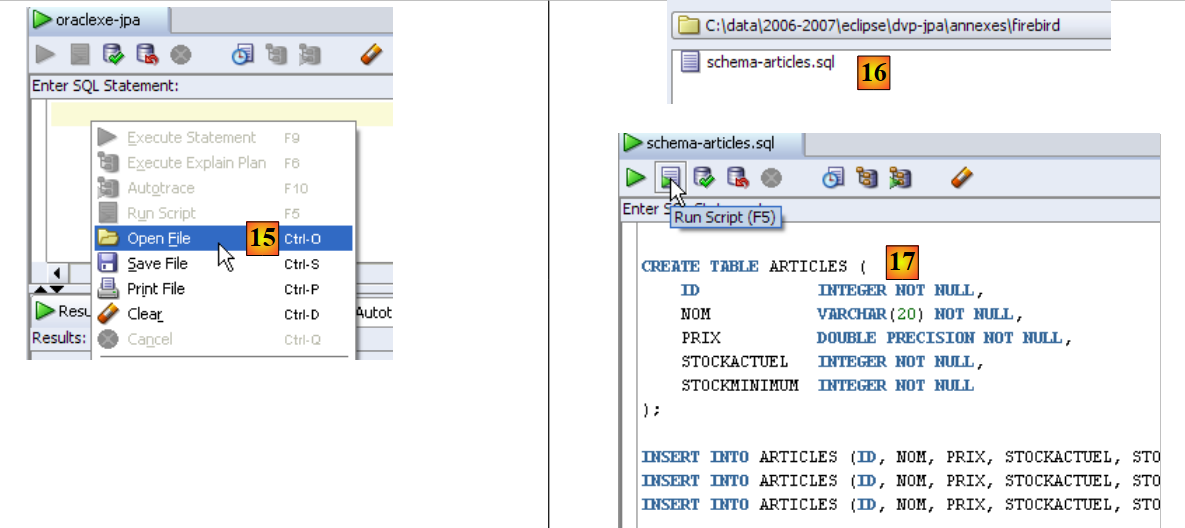 |
- in [15]: aprire uno script SQL
- in [16]: selezionare lo script SQL creato nella sezione 5.4.6
- in [17]: lo script da eseguire
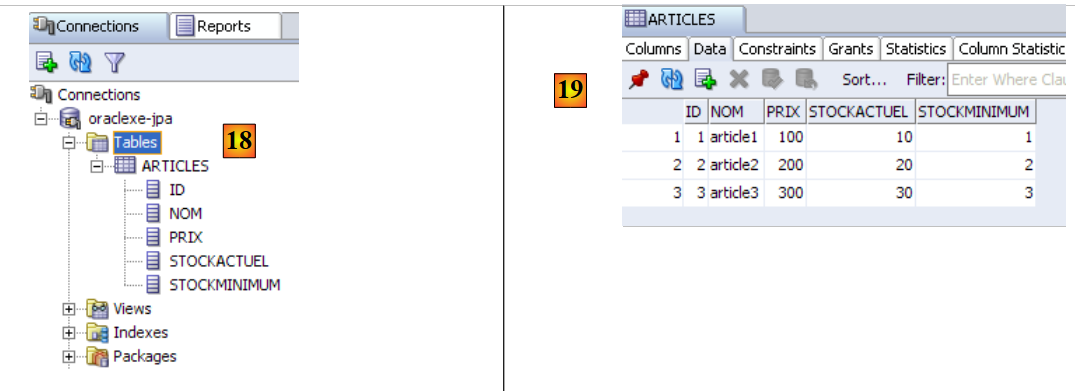 |
- in [18]: il risultato dell'esecuzione: la tabella [ARTICLES] è stata creata. Fare doppio clic su di essa per accedere alle sue proprietà.
- in [19]: il contenuto della tabella.
5.7.5. Driver JDBC OracleXE
Il driver JDBC OracleXE è disponibile nella cartella [jdbc/lib] all'interno della directory di installazione di OracleXE [1]:
 |
Inseriamo l'archivio JDBC [ojdbc14.jar] nella cartella <jdbc> [2], proprio come abbiamo fatto in precedenza (sezione 5.4.7):
Per testare questo driver JDBC, utilizzeremo Eclipse e il plugin SQL Explorer. Invitiamo il lettore a seguire la procedura illustrata nella sezione 5.4.7. Presentiamo alcuni screenshot significativi:
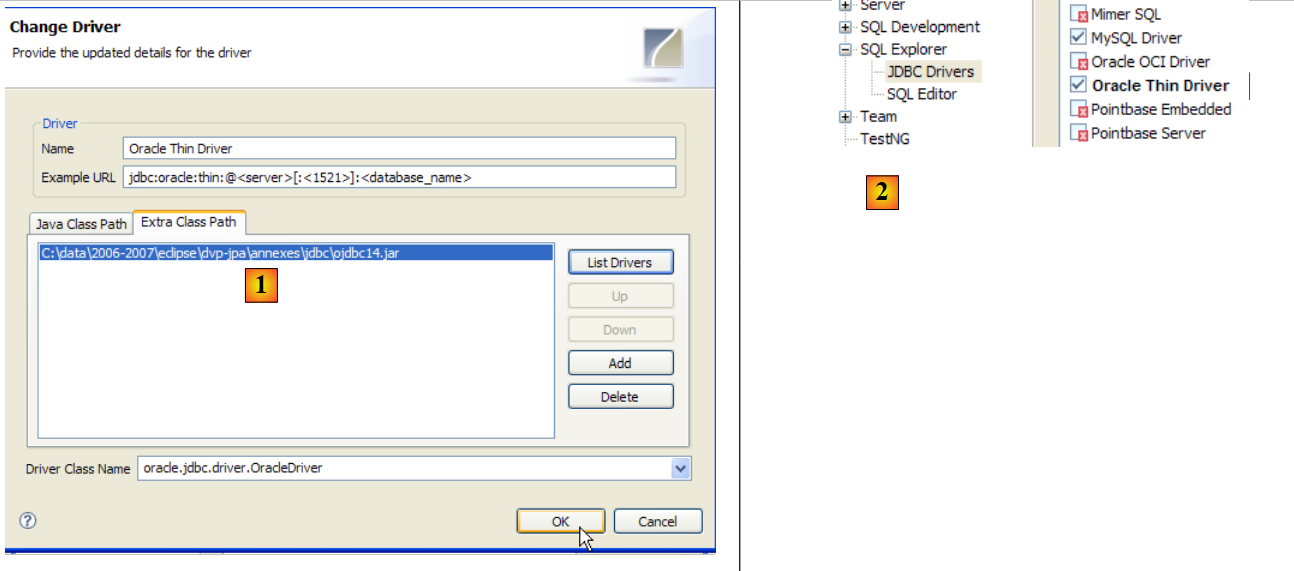 |
- in [1]: abbiamo specificato l'archivio del driver JDBC OracleXE
- in [2]: il driver JDBC di OracleXE è disponibile
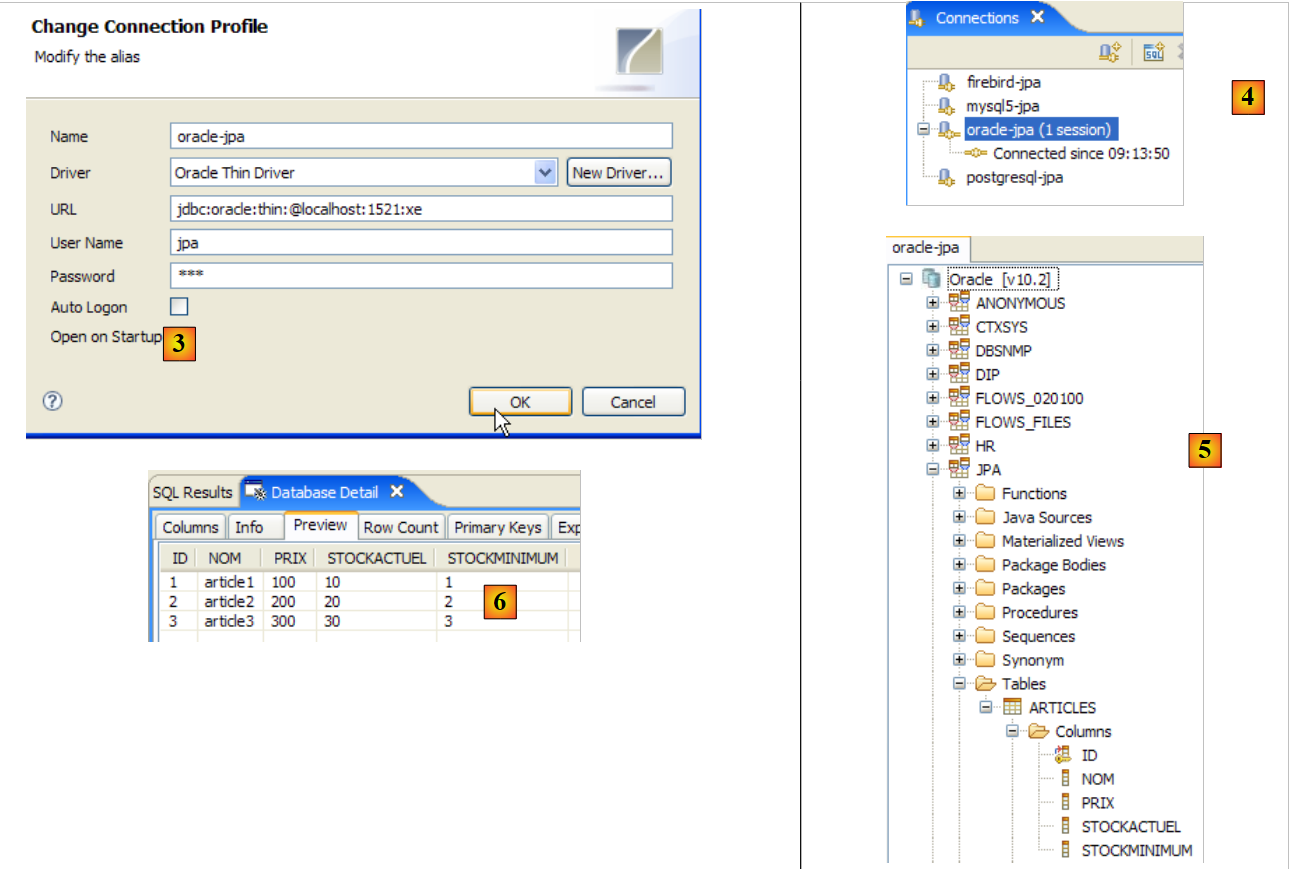 |
- in [3]: definizione della connessione (utente, password)=(jpa, jpa)
- in [4]: la connessione è attiva
- in [5]: il database connesso
- in [6]: il contenuto della tabella [ARTICLES]
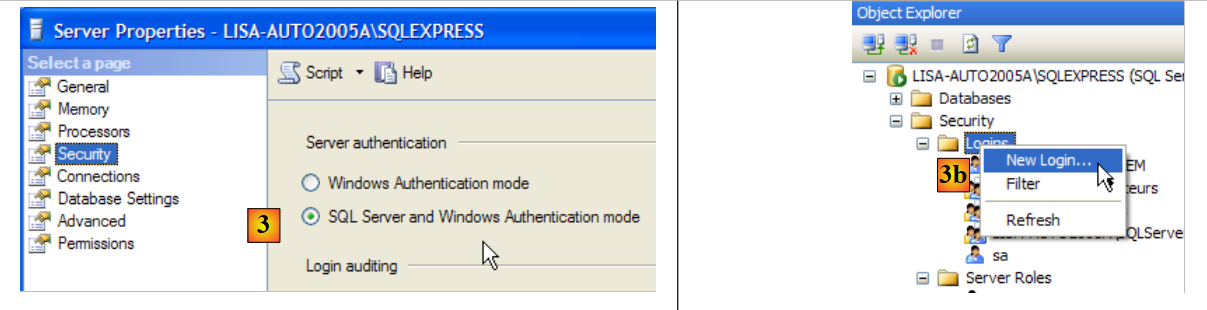
5.8. Il DBMS a SQL Server Express 2005
5.8.1. Installazione
SQL Server Express 2005 è disponibile all'indirizzo [http://msdn.microsoft.com/vstudio/express/sql/download/]:
 |
- in [1]: prima scarica e installa la piattaforma .NET 2.0
- in [2]: quindi installare e scaricare SQL Server Express 2005
- Passo [3]: Successivamente, installare e scaricare SQL Server Management Studio Express, che consente di amministrare SQL Server
L'installazione di SQL Server Express crea una cartella in [Start / Programmi]:
 |
- in [1]: l'applicazione di configurazione di SQL Server. Consente inoltre di avviare/arrestare il server
- in [2]: l'applicazione di amministrazione del server
5.8.2. Avvia / Arresta SQL Server
Come nei DBMS precedenti, SQL Server Express è stato installato come servizio di Windows che si avvia automaticamente. Modificheremo questa configurazione:
[Start / Pannello di controllo / Prestazioni e manutenzione / Strumenti di amministrazione / Servizi]:
 |
- in [1]: facciamo doppio clic su [Servizi]
- in [2]: vediamo che è presente un servizio chiamato [SQL Server], che è in esecuzione [3] e che si avvia automaticamente [4].
- in [5]: è attivo anche un altro servizio relativo a SQL Server, chiamato "SQL Server Browser", impostato per l'avvio automatico.
Per modificare questo comportamento, fare doppio clic sul servizio [SQL Server]:
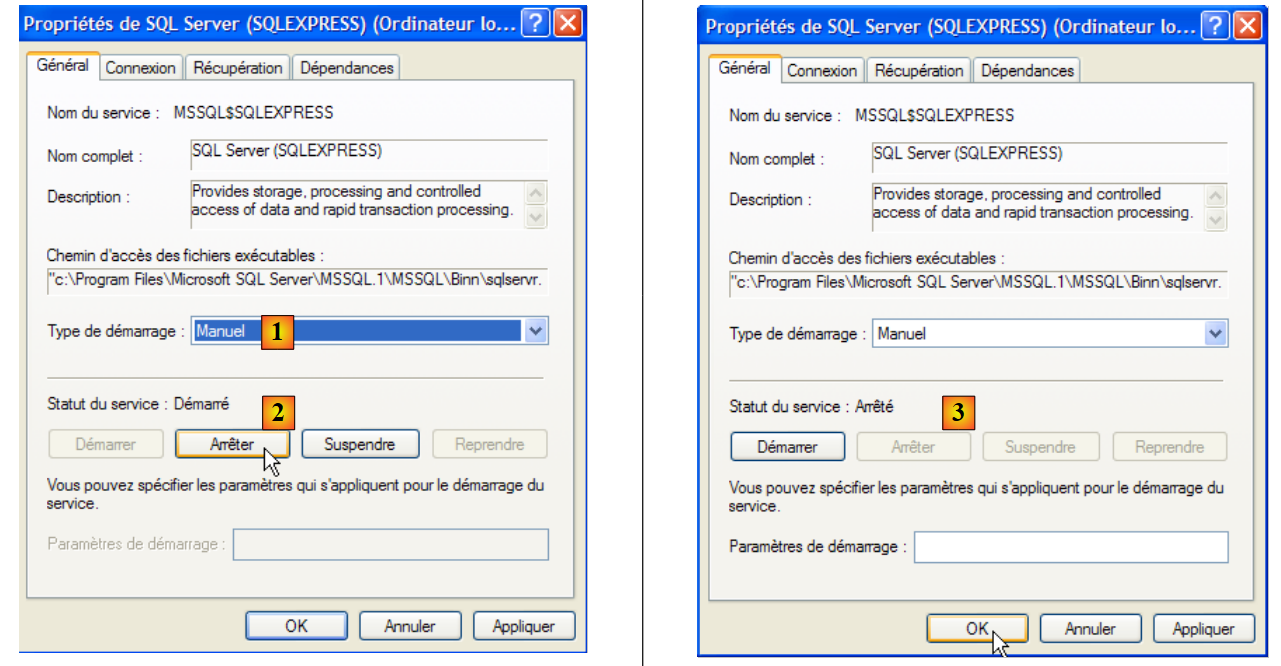 |
- in [1]: impostare l'avvio del servizio su manuale
- in [2]: lo arrestiamo
- in [3]: confermiamo la nuova configurazione del servizio
Faremo lo stesso con il servizio [SQL Server Browser] (vedi [5] sopra). Per avviare e arrestare manualmente il servizio SQL Server, possiamo utilizzare l'applicazione [1] nella cartella [SQL Server]:
 |
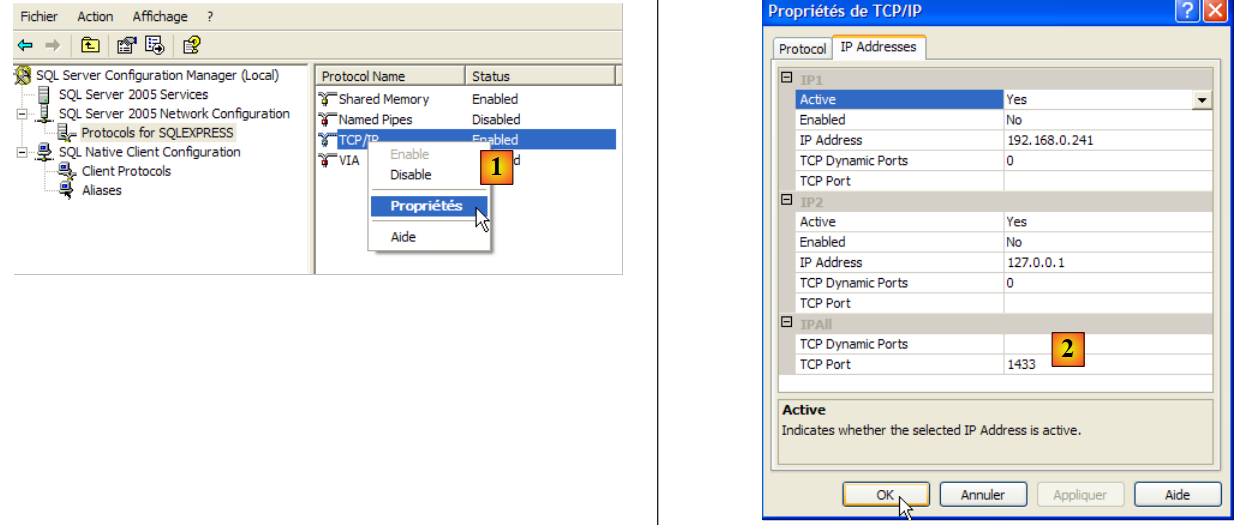 |
- in [1]: assicurarsi che il protocollo TCP/IP sia abilitato, quindi accedere alle proprietà del protocollo.
- in [2]: nella scheda [Indirizzi IP], opzione [IPAll]:
- il campo [Porte TCP dinamiche] è lasciato vuoto
- la porta di ascolto del server è impostata su 1433 in [Porta TCP]
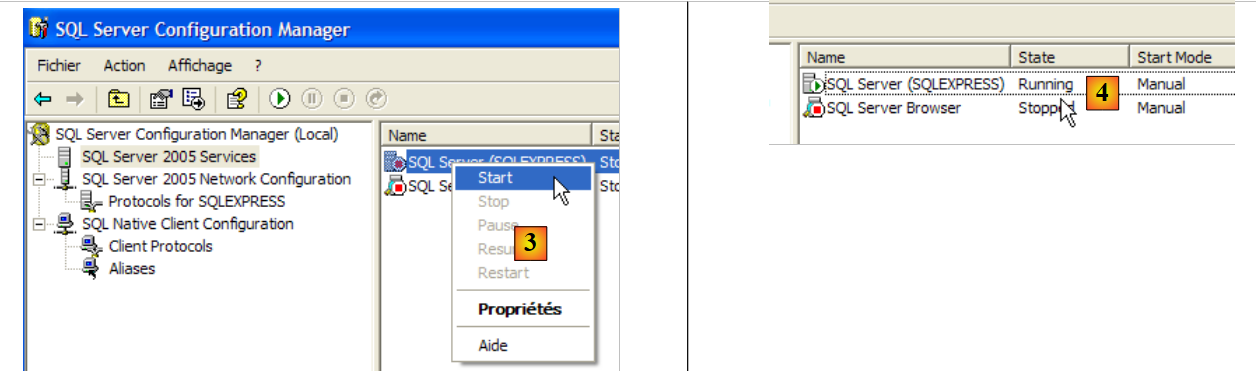 |
- In [3]: facendo clic con il tasto destro del mouse sul servizio [SQL Server] si accede alle opzioni di avvio/arresto del server. Qui lo avviamo.
- in [4]: SQL Server viene avviato
5.8.3. Creazione di un utente JPA e di un database JPA
Avviare il DBMS come descritto sopra, quindi l'applicazione di amministrazione [1] tramite il menu sottostante:
 |
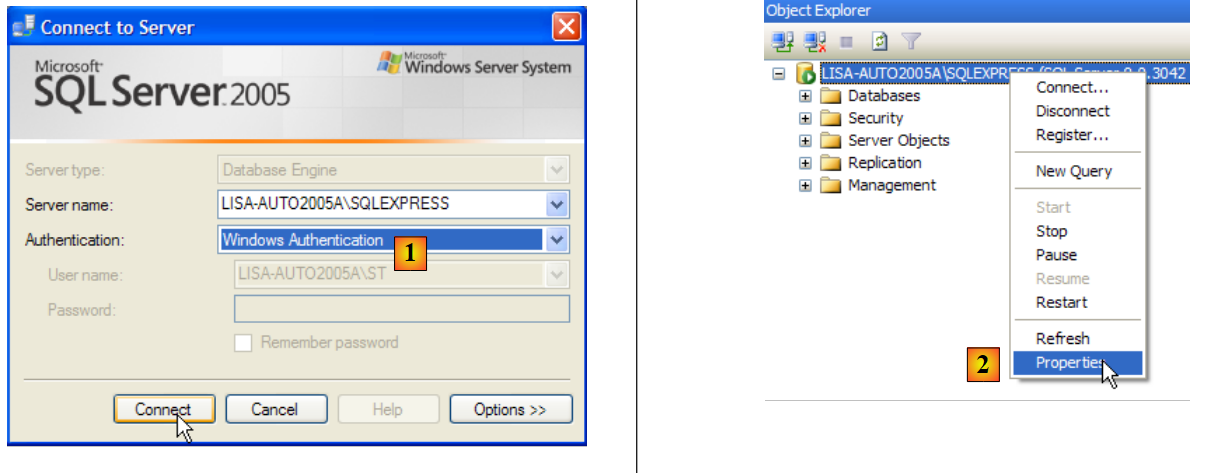 |
- in [1]: accedere a SQL Server come amministratore di Windows
- in [2]: configurare le proprietà di connessione
 |
- in [3]: abilitiamo la modalità mista per la connessione al server: sia con un login Windows (un utente Windows) sia con un login SQL Server (un account definito all'interno di SQL Server, indipendente da qualsiasi account Windows).
- in [3b]: creare un utente SQL Server
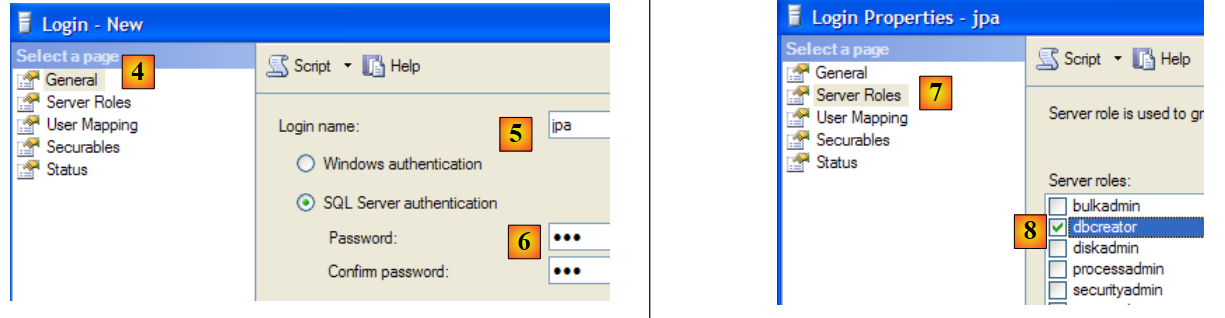 |
- in [4]: scheda [Generale]
- in [5]: il nome utente
- in [6]: la password (jpa in questo caso)
- in [7]: opzione [Ruoli server]
- in [8]: l'utente jpa avrà il diritto di creare database
Conferma questa configurazione:
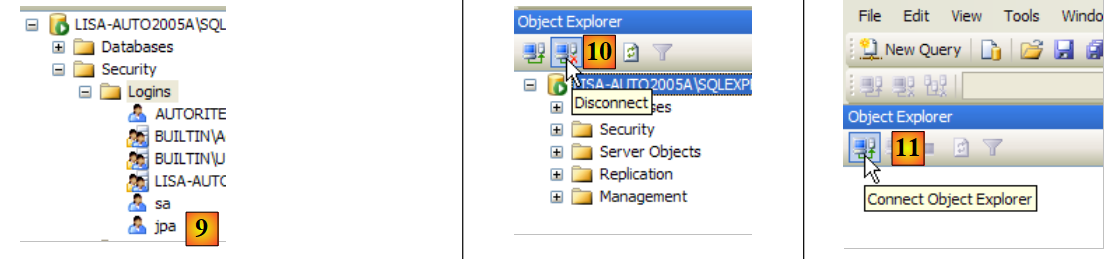 |
- in [9]: l'utente jpa è stato creato
- in [10]: esci
- in [11]: effettuare nuovamente l'accesso
 |
- in [12]: accedi come utente jpa/jpa
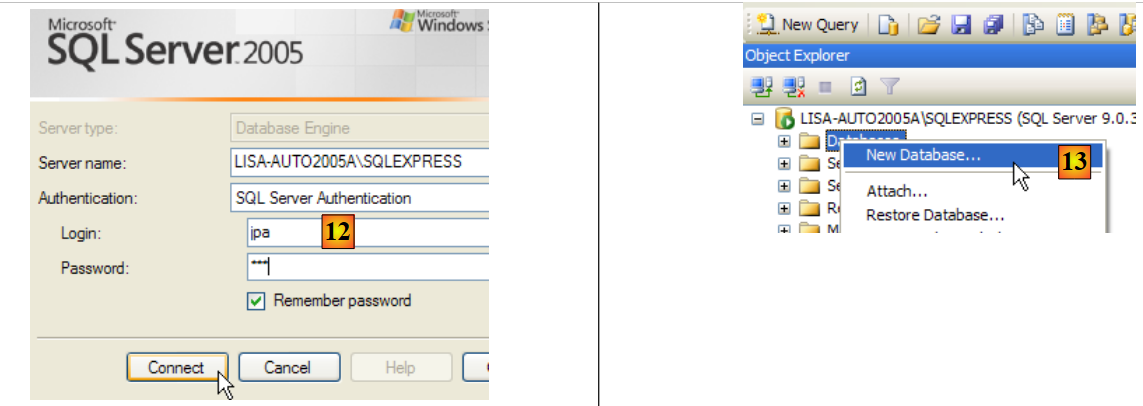
- in [13]: una volta effettuato l'accesso, l'utente jpa crea un database
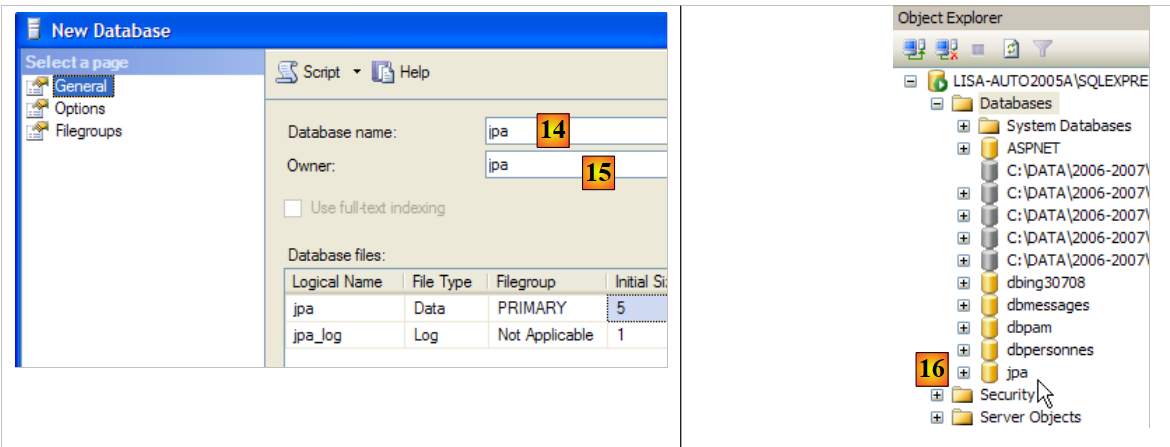 |
- in [14]: il database si chiamerà jpa
- in [15]: e apparterrà all'utente jpa
- in [16]: Il database jpa è stato creato
5.8.4. Creazione della tabella [ARTICLES] nel database jpa
Come negli esempi precedenti, creeremo la tabella [ARTICLES] utilizzando lo script creato nella sezione 5.4.6.
 |
- in [1]: apriamo uno script SQL
- in [2]: selezionare lo script SQL creato nella sezione 5.4.6, pagina 240.
- in [3]: effettuare nuovamente l'accesso (jpa/jpa)
- in [4]: lo script da eseguire
- in [5]: selezionare il database in cui verrà eseguito lo script
- in [6]: eseguirlo
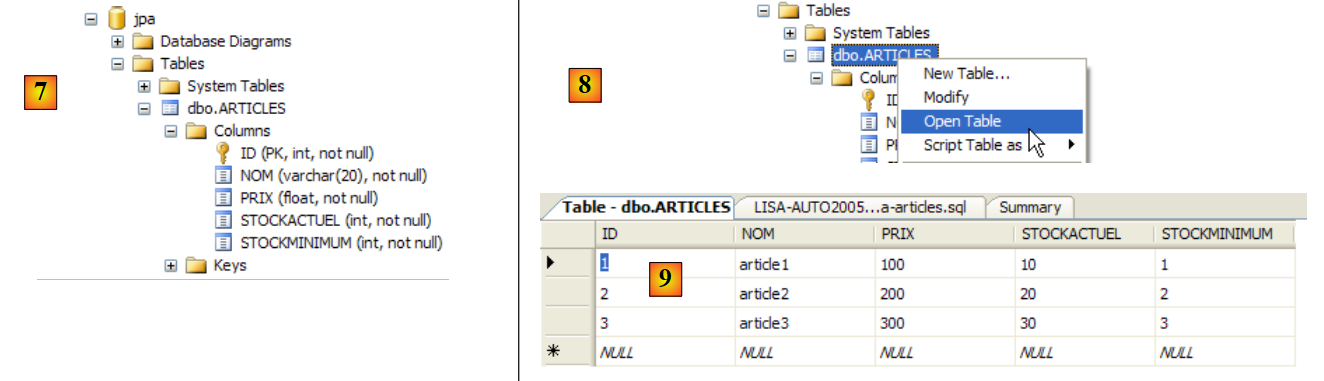 |
- in [7]: il risultato dell'esecuzione: la tabella [ARTICLES] è stata creata.
- in [8]: richiediamo di visualizzarne il contenuto
- in [9]: il contenuto della tabella.
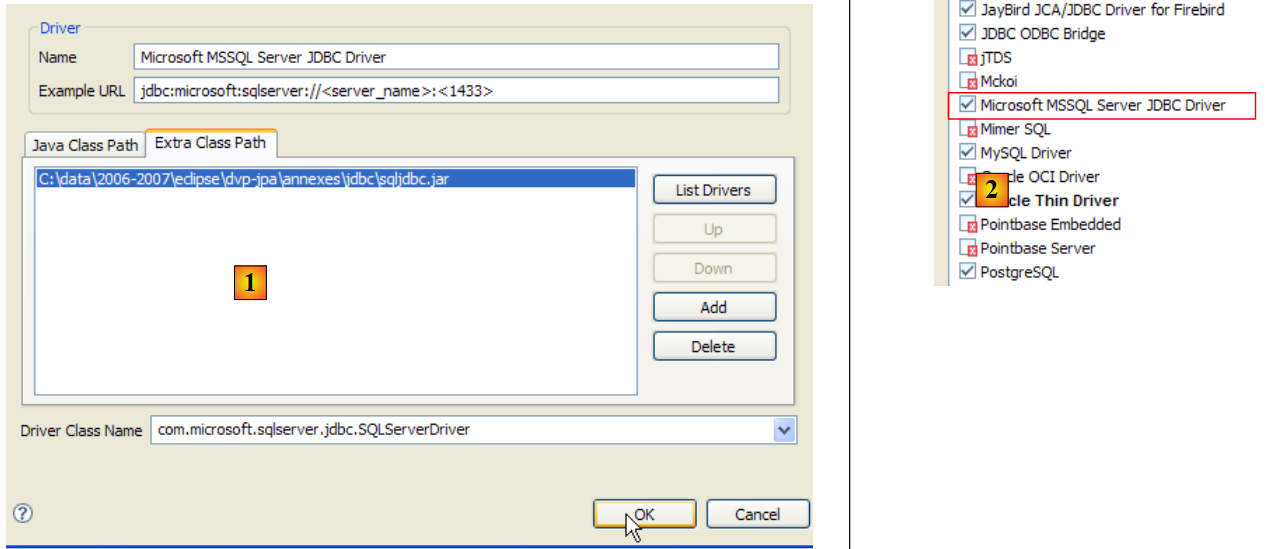
5.8.5. Driver JDBC di SQL Server Express
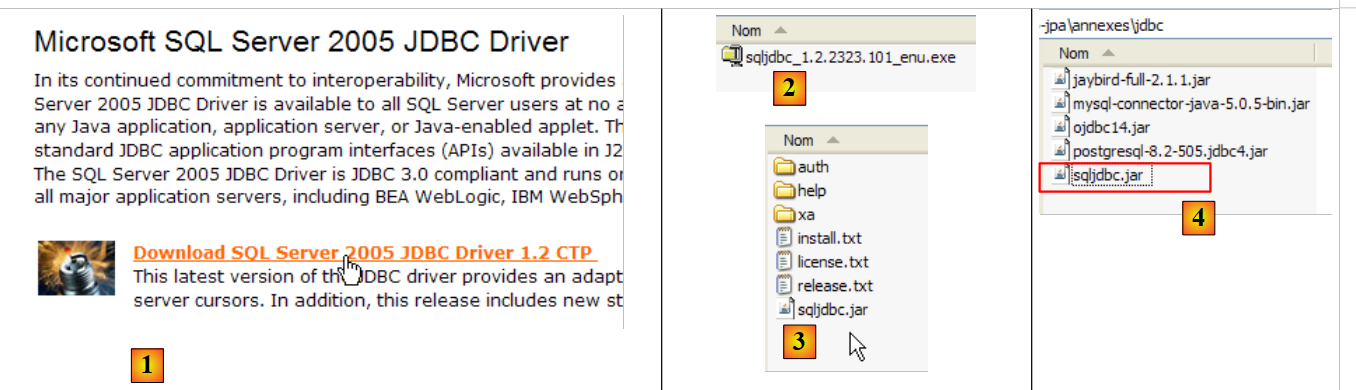 |
- in [1]: Una ricerca su Google per [Microsoft SQL Server 2005 JDBC Driver] ci porta alla pagina di download del driver JDBC. Selezioniamo la versione più recente
- in [2]: il file scaricato. Facciamo doppio clic su di esso. Il file viene estratto, creando una cartella contenente il driver JDBC [3]
- in [4]: inseriamo l'archivio JDBC [sqljdbc.jar] nella cartella <jdbc>, proprio come abbiamo fatto in precedenza (sezione 5.4.7)
Per testare questo driver JDBC, useremo Eclipse e il plugin SQL Explorer. Invitiamo il lettore a seguire la procedura spiegata nella sezione 5.4.7. Presentiamo alcuni screenshot rilevanti:
 |
- in [1]: abbiamo specificato l'archivio del driver JDBC di SQL Server
- in [2]: il driver JDBC di SQL Server è disponibile
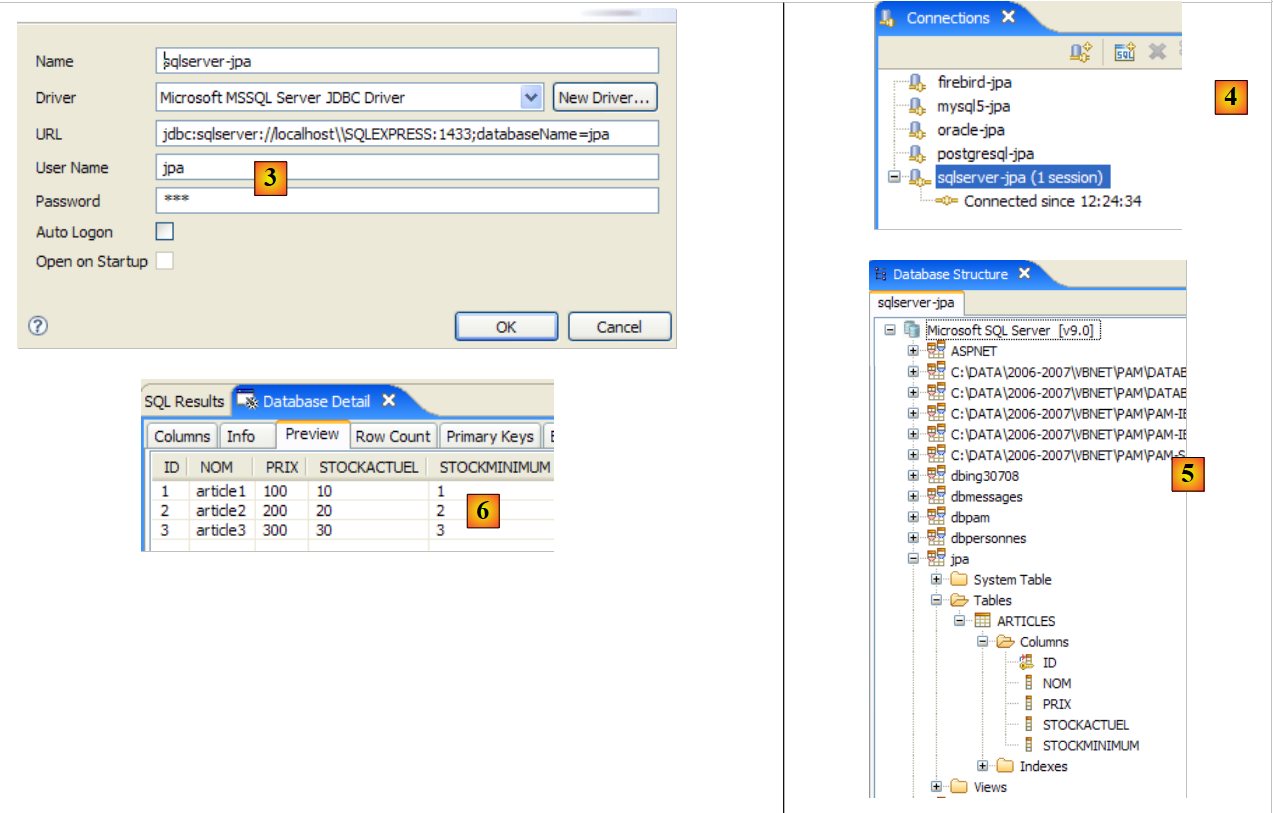 |
- in [3]: definizione della connessione (utente, password)=(jpa, jpa)
- in [4]: la connessione è attiva
- in [5]: il database connesso
- in [6]: il contenuto della tabella [ARTICLES]
5.9. Il DBMS HSQLDB
5.9.1. Installazione
Il DBMS HSQLDB è disponibile all'URL [http://sourceforge.net/projects/hsqldb]. Si tratta di un DBMS scritto in Java, molto leggero in termini di memoria, che gestisce i database in memoria anziché su disco. Il risultato è un'esecuzione delle query estremamente veloce. Questo è il suo principale vantaggio. I database creati in memoria in questo modo possono essere recuperati quando il server viene spento e poi riavviato. Questo perché i comandi SQL emessi per creare i database vengono memorizzati in un file di log per essere riprodotti al successivo avvio del server. Ciò garantisce la persistenza dei database nel tempo.
Il metodo ha i suoi limiti e HSQLDB non è un DBMS di livello commerciale. Il suo valore principale risiede nelle applicazioni di test o dimostrative. Ad esempio, il fatto che HSQLDB sia scritto in Java permette di includerlo nelle attività di Ant (Another Neat Tool), uno strumento di automazione delle attività Java. Pertanto, i test quotidiani del codice per il software in fase di sviluppo, automatizzati da Ant, possono incorporare test del database gestiti dal DBMS HSQLDB. Il server verrà avviato, arrestato e gestito dalle attività Java.
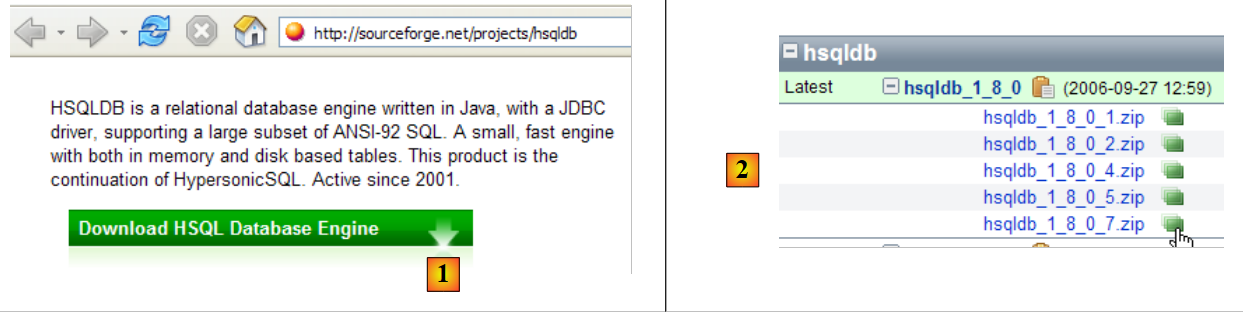 |
- in [1]: il sito di download
- in [2]: scarica l'ultima versione
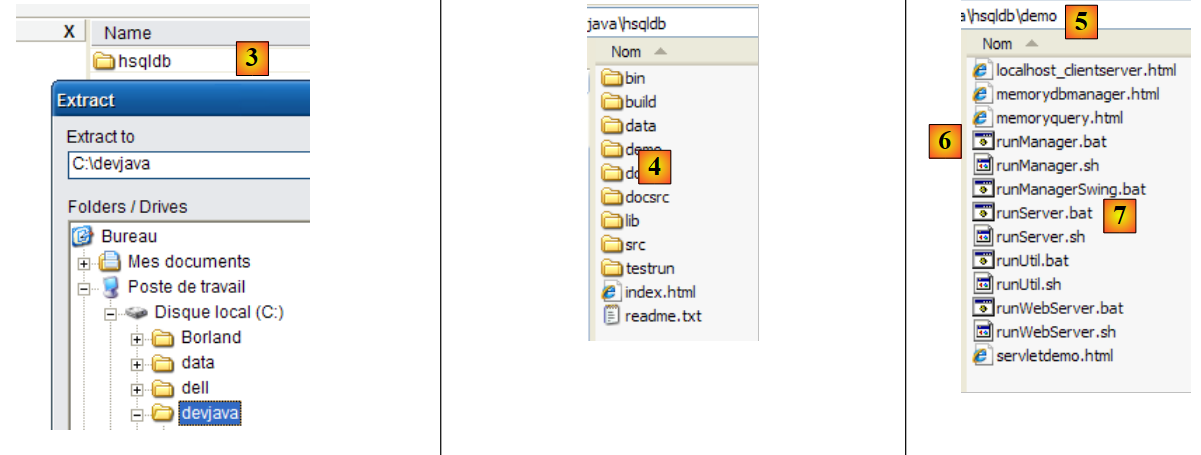 |
- in [3]: decomprimere il file scaricato
- in [4]: la cartella [hsqldb] risultante dall'estrazione
- in [5]: la cartella [demo] contenente lo script per avviare il server [hsql] [6] e in [7], quello per avviare uno strumento di amministrazione di base del server.
5.9.2. Avvia / Arresta HSQLDB
Per avviare il server HSQLDB, fare doppio clic sull'applicazione [runManager.bat] [6] sopra indicata:
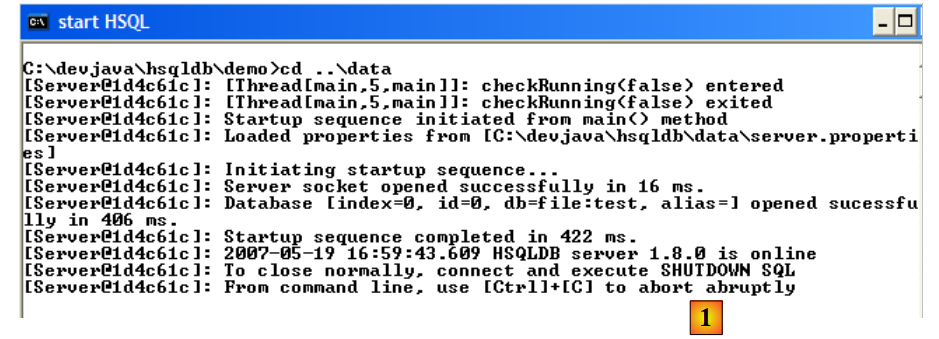 |
- in [1]: come puoi vedere, per arrestare il server è sufficiente premere Ctrl-C nella finestra.
5.9.3. Il database [test]
Il database predefinito si trova nella cartella [data]:
 |
- in [1]: all'avvio, il DBMS HSQL esegue lo script denominato [test.script]
- Riga 1: viene creato uno schema [public]
- Riga 2: viene creato un utente [sa] con password vuota
- Riga 3: All'utente [sa] vengono concessi i privilegi di amministratore
Alla fine, è stato creato un utente con privilegi amministrativi. Questo è l'utente che useremo d'ora in poi.
5.9.4. Driver JDBC HSQL
Il driver JDBC per il DBMS HSQL si trova nella cartella [lib]:
 |
- in [1]: l'archivio [hsqldb.jar] contiene il driver JDBC del DBMS HSQL
- in [2]: inseriamo questo archivio, come i precedenti (sezione 5.4.7), nella cartella <jdbc>
Per verificare questo driver JDBC, useremo Eclipse e il plugin SQL Explorer. Invitiamo il lettore a seguire la procedura spiegata nella sezione 5.4.7. Presentiamo alcuni screenshot rilevanti:
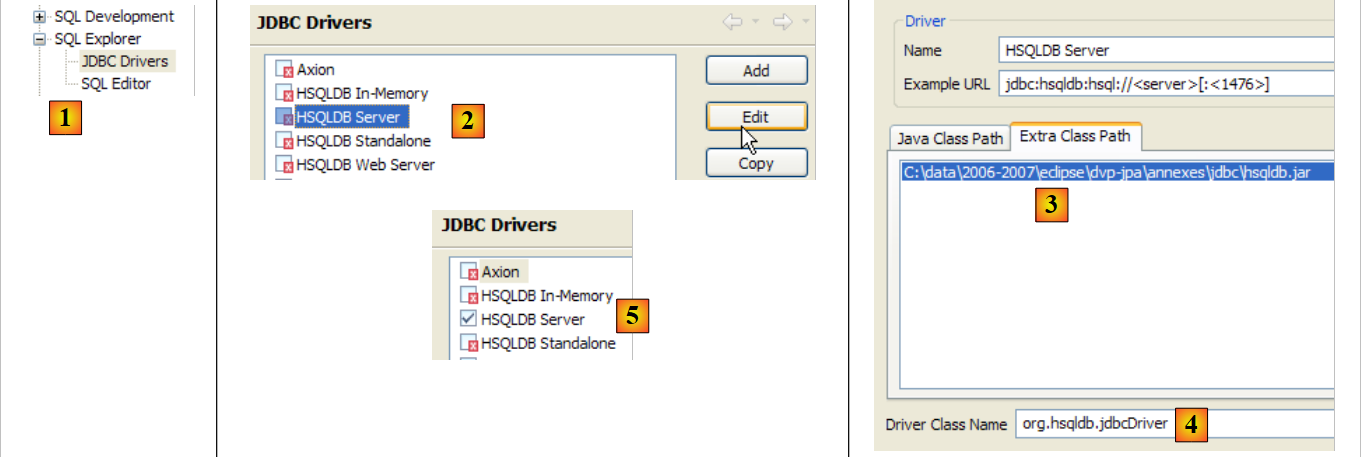 |
- in [1]: [Finestra / Preferenze / SQL Explorer / Driver JDBC]
- in [2]: configurare il server [HSQLDB]
- in [3]: specificare l'archivio [hsqldb.jar] contenente il driver JDBC
- in [4]: il nome della classe Java del driver JDBC
- in [5]: il driver JDBC è configurato
Una volta fatto ciò, ci connettiamo al server HSQL. Per prima cosa avviamo il server.
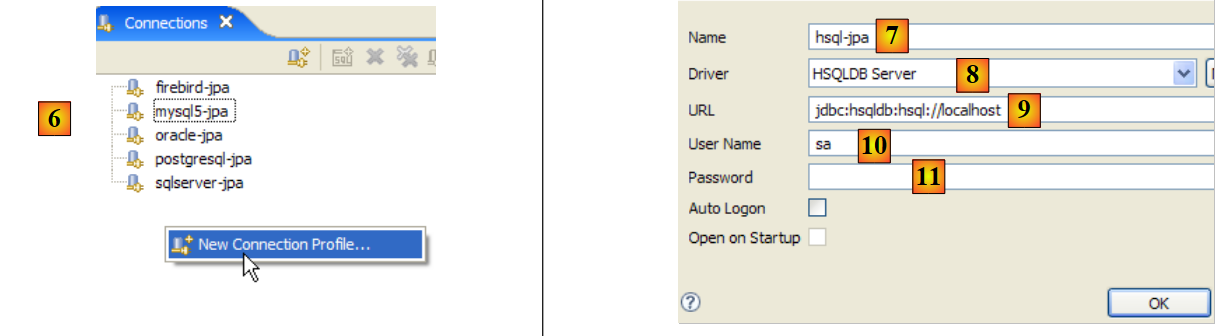 |
- in [6]: creare una nuova connessione
- in [7]: assegnagli un nome
- in [8]: vogliamo collegarci al server HSQLDB
- in [9]: l'URL del database a cui ci si vuole connettere. Questo sarà il database [test] visto in precedenza.
- in [10]: effettuare il login come utente [sa]. Abbiamo visto che è l'amministratore del DBMS.
- in [11]: l'utente [sa] non ha una password.
Convalidiamo la configurazione della connessione.
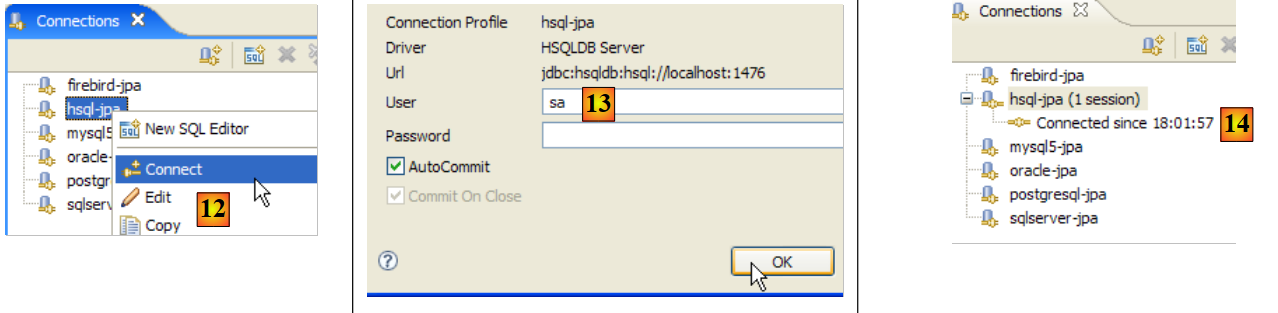 |
- in [12]: ci colleghiamo
- in [13]: effettuiamo l'accesso
- in [14]: hai effettuato l'accesso
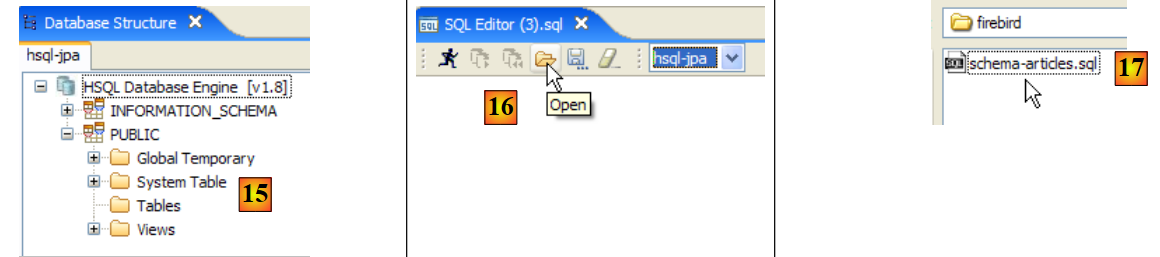 |
- in [15]: lo schema [PUBLIC] non ha ancora una tabella
- in [16]: creeremo la tabella [ARTICLES] utilizzando lo script [schema-articles.sql] creato nella sezione 5.4.6.
- in [17]: selezionare lo script
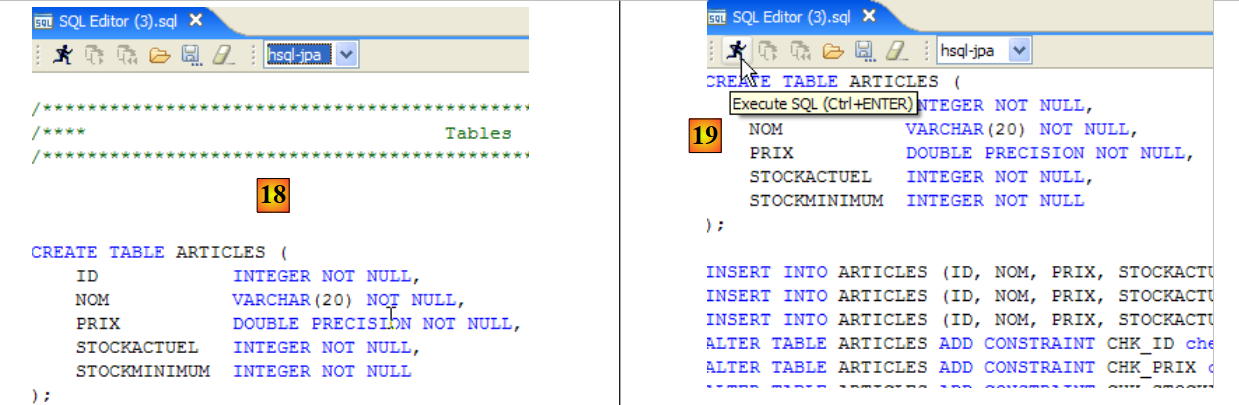 |
- in [18]: lo script da eseguire
- in [19]: lo eseguiamo dopo aver rimosso tutti i commenti, poiché HSQLB non li accetta.
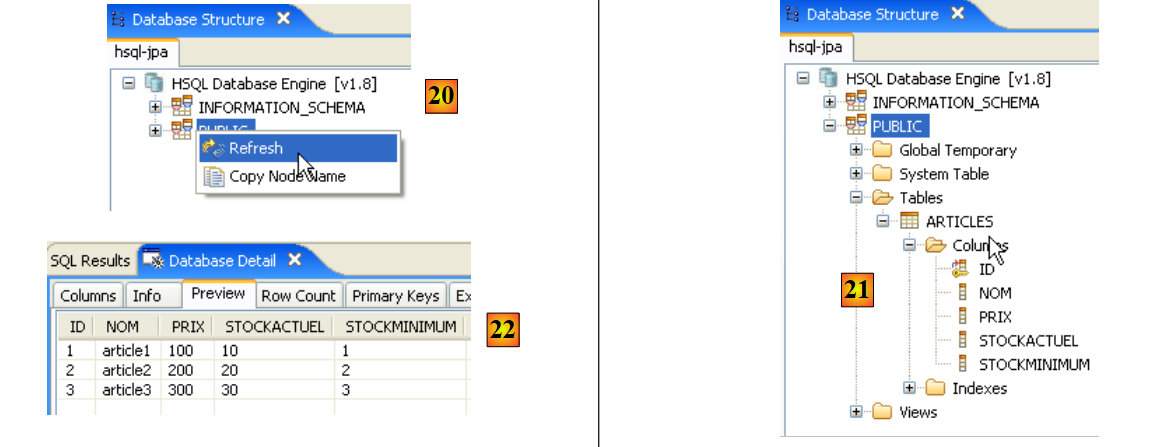 |
- Una volta eseguito lo script, aggiorna la vista del database in [20]
- in [21]: la tabella [ARTICLES] è presente
- in [22]: il suo contenuto
Fermiamo e poi riavviamo il server HSQLDB. Una volta fatto ciò, esaminiamo il file [test.script]:
Possiamo notare che il DBMS ha memorizzato le varie istruzioni SQL eseguite durante la sessione precedente e le riesegue all'avvio della nuova sessione. Possiamo anche notare (riga 2) che la tabella [ARTICLES] viene creata in memoria (MEMORY). All'inizio di ogni sessione, le istruzioni SQL emesse vengono memorizzate in [test.log] per essere copiate all'inizio della sessione successiva in [test.script] e riprodotte all'inizio della sessione.
5.10. Il DBMS Apache Derby
5.10.1. Installazione
Il DBMS Apache Derby è disponibile all'URL [http://db.apache.org/derby/]. Si tratta di un DBMS scritto anch'esso in Java e, analogamente, molto leggero in termini di memoria. Offre vantaggi simili a quelli di HSQLDB. Anch'esso può essere incorporato nelle applicazioni Java, ovvero essere parte integrante dell'applicazione ed essere eseguito all'interno della stessa JVM.
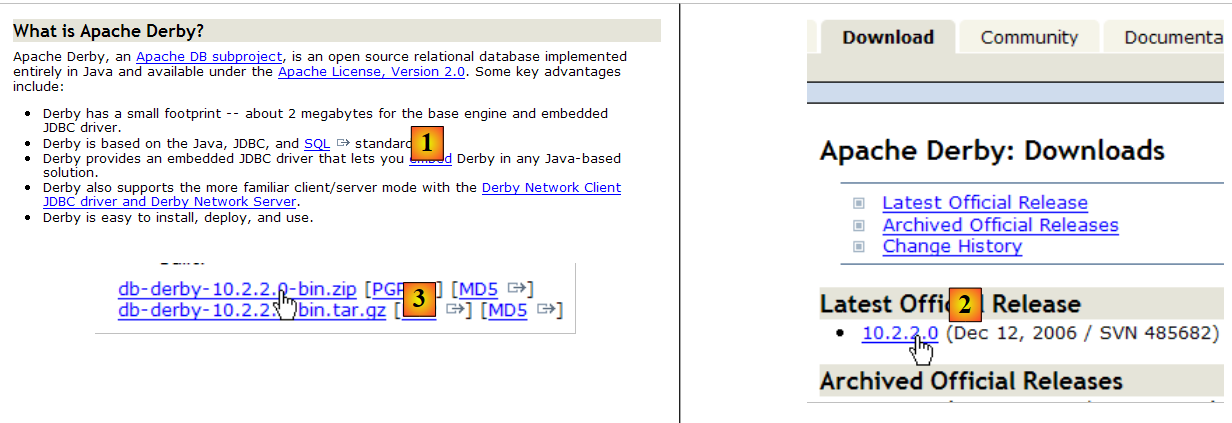 |
- in [1]: il sito di download
- in [2,3]: scarica l'ultima versione
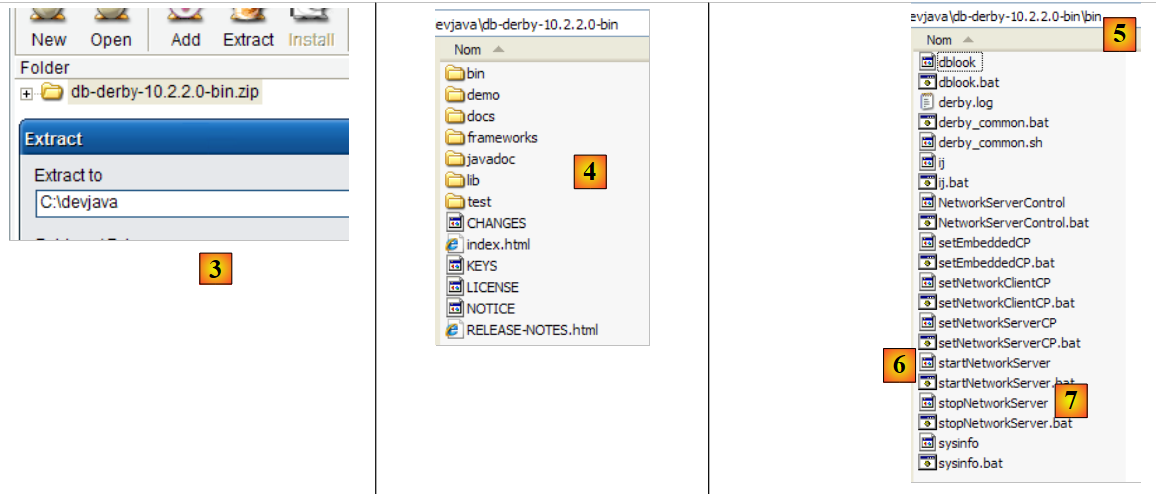 |
- in [3]: decomprimere il file scaricato
- in [4]: la cartella [db-derby-*-bin] risultante dall'estrazione
- in [5]: la cartella [bin] contenente lo script per avviare il server [db derby] [6] e in [7], quello per arrestarlo.
5.10.2. Avvio / Arresto di Apache Derby (DB Derby)
Per avviare il server Db Derby, fare doppio clic sull'applicazione [startNetworkServer] [6] sopra:
 |
- in [1]: il server è avviato. Verrà arrestato utilizzando l'applicazione [stopNetworkServer] [7] sopra.
5.10.3. Driver JDBC per Derby
Il driver JDBC per il DBMS Db Derby si trova nella cartella [lib] della directory di installazione:
 |
- in [1]: l'archivio [derbyclient.jar] contiene il driver JDBC per il DBMS Db Derby
- in [2]: collochiamo questo archivio, come i precedenti (sezione 5.4.7), nella cartella <jdbc>
Per testare questo driver JDBC, useremo Eclipse e il plugin SQL Explorer. Invitiamo il lettore a seguire la procedura spiegata nella sezione 5.4.7. Presentiamo alcuni screenshot rilevanti:
 |
- in [1]: [Finestra / Preferenze / SQL Explorer / Driver JDBC]
- in [2]: il driver JDBC di Apache Derby non è presente nell'elenco. Lo aggiungiamo.
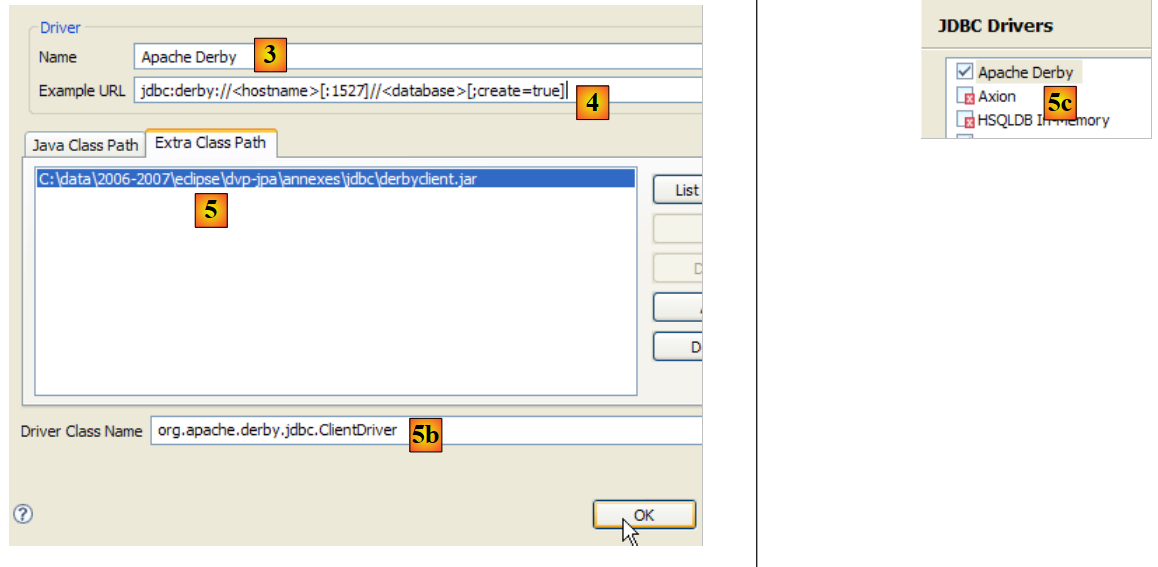 |
- in [3]: assegniamo un nome al nuovo driver
- in [4]: specifichiamo il formato degli URL supportati dal driver JDBC
- in [5]: specifichiamo il file .jar per il driver JDBC
- in [5b]: il nome della classe Java del driver JDBC
- in [5c]: il driver JDBC è configurato
Una volta fatto questo, connettiti al server Apache Derby. Avvia il server in anticipo.
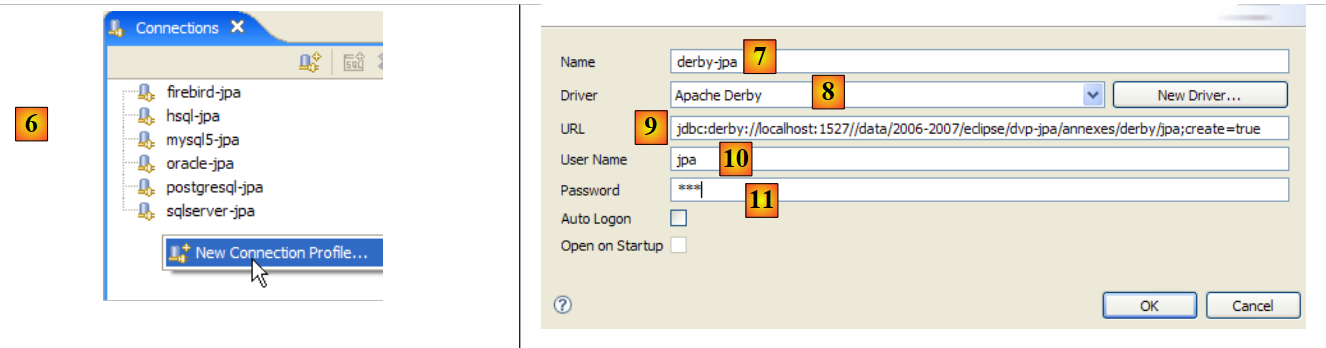 |
- in [6]: creare una nuova connessione
- in [7]: gli diamo un nome
- in [8]: vogliamo collegarci al server Apache Derby
- in [9]: l'URL del database a cui vogliamo collegarci. Dopo il prefisso standard [jdbc:derby://localhost:1527], specificheremo il percorso di una directory sul disco contenente un database Derby. L'opzione [create=true] ci permette di creare questa directory se non esiste ancora.
- in [10,11]: ci connettiamo come utente [jpa/jpa]. Non ho approfondito la questione, ma sembra che si possano utilizzare qualsiasi nome utente e password si desideri. Qui specifichiamo il proprietario del database se create=true.
Convalidiamo la configurazione della connessione.
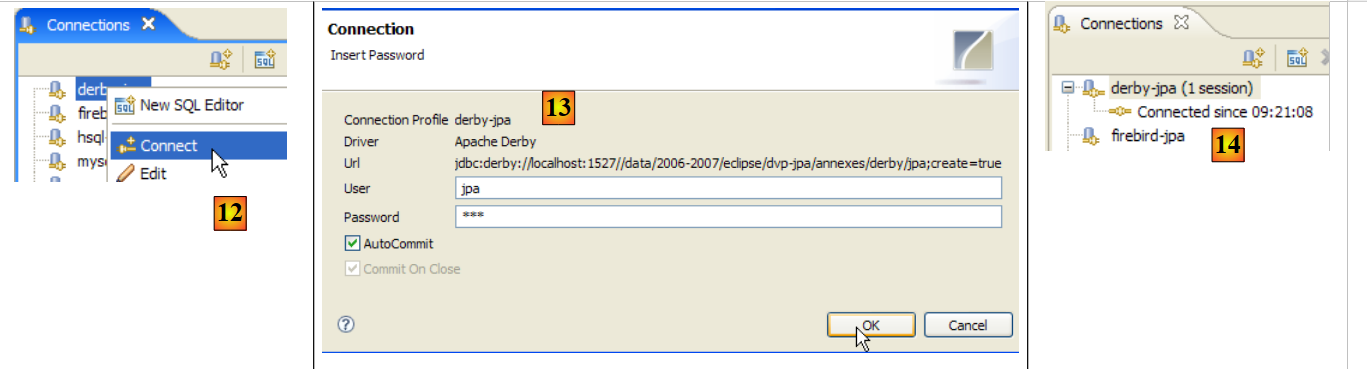 |
- in [12]: accedi
- in [13]: accedi (jpa/jpa)
- in [14]: hai effettuato l'accesso
 |
- in [15]: lo schema [jpa] non è ancora visibile.
- in [16]: creeremo la tabella [ARTICLES] dallo script [schema-articles.sql] creato nella sezione 5.4.6.
- in [17]: selezionare lo script
 |
- in [18]: lo script da eseguire
- in [19]: lo eseguiamo dopo aver rimosso tutti i commenti, poiché Apache Derby, come HSQLB, non li accetta.
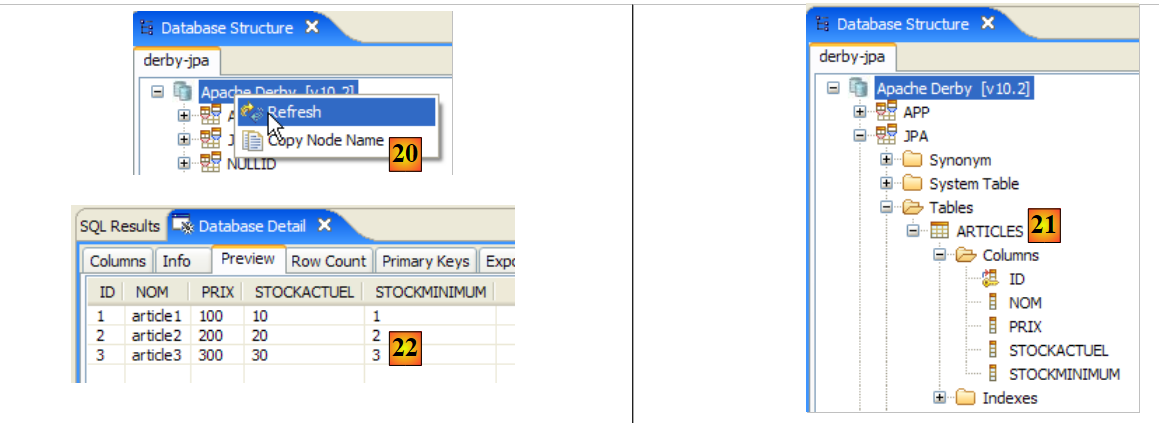 |
- Una volta eseguito lo script, aggiorna la vista del database in [20]
- in [21]: lo schema [jpa] e la tabella [ARTICLES] sono presenti
- in [22]: il contenuto della tabella [ARTICLES]
 |
- in [23]: il contenuto della cartella [derby\jpa] in cui è stato creato il database.
5.11. Il framework Spring 2
Il framework Spring 2 è disponibile all'URL [http://www.springframework.org/download]:
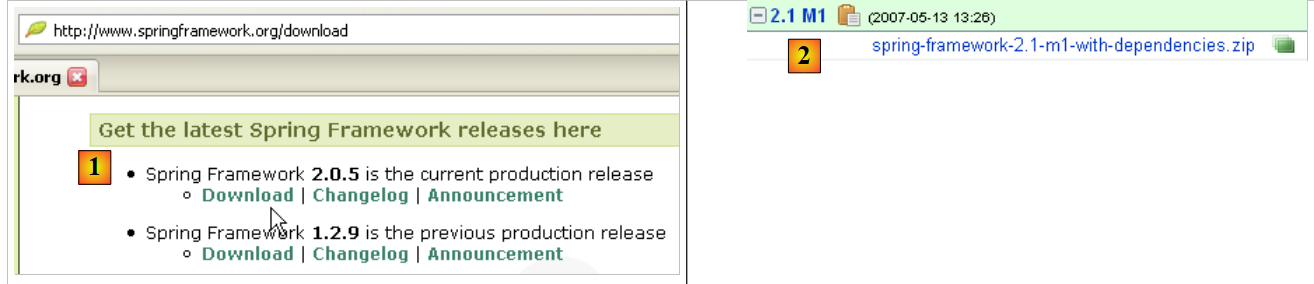 |
- all'indirizzo [1]: scaricare l'ultima versione
- in [2]: scarica la versione contrassegnata come "con dipendenze" perché contiene i file .jar per gli strumenti di terze parti che Spring integra e di cui hai sempre bisogno.
 |
- in [3]: decomprimere l'archivio scaricato
- in [4]: la cartella di installazione di Spring 2.1
 |
- in [5]: nella cartella <dist> troverete gli archivi Spring. L'archivio [spring.jar] contiene tutte le classi del framework Spring. Queste sono disponibili anche per modulo nella cartella <modules> in [6]. Se sapete di quali moduli avete bisogno, potete trovarli qui. In questo modo eviterete di includere nell'applicazione archivi di cui non ha bisogno.
 |
- in [7]: la cartella <lib> contiene gli archivi degli strumenti di terze parti utilizzati da Spring
- in [8]: alcuni archivi del progetto [jakarta-commons]
Quando il tutorial utilizza gli archivi Spring, è necessario recuperarli dalla cartella <dist> o dalla cartella <lib> all'interno della directory di installazione di Spring.
5.12. Il contenitore JBoss EJB3
Il contenitore JBoss EJB3 è disponibile all'URL [http://labs.jboss.com/jbossejb3/downloads/embeddableEJB3]:
 |
- in [1]: Scarica JBoss EJB3. Si noti la data del prodotto (settembre 2006), anche se il download viene effettuato nel maggio 2007. Ci si potrebbe chiedere se questo prodotto sia ancora in fase di sviluppo.
- in [2]: il file scaricato
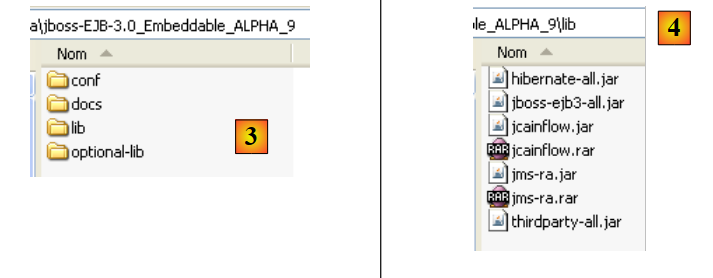 |
- in [3]: il file ZIP decompresso
- in [4]: gli archivi [hibernate-all.jar, jboss-ejb3-all.jar, thirdparty-all.jar] costituiscono il contenitore JBoss EJB3. Devono essere inseriti nel classpath dell'applicazione che utilizza questo contenitore.