2. Entità JPA
2.1. Esempio 1 - Rappresentazione a oggetti di una singola tabella
2.1.1. La tabella [person]
Consideriamo un database con una singola tabella [person] il cui scopo è quello di memorizzare alcune informazioni relative a individui:
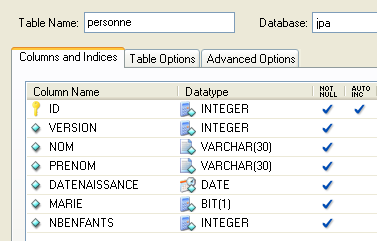 |
chiave primaria della tabella | |
versione della riga nella tabella. Ogni volta che viene modificata la persona, il numero di versione viene incrementato. | |
cognome | |
nome | |
la sua data di nascita | |
numero intero 0 (non sposata) o 1 (sposata) | |
numero di figli |
2.1.2. L'entità [Persona]
Ci troviamo nel seguente ambiente di runtime:
 |
Il livello JPA [5] deve fungere da ponte tra il mondo relazionale del database [7] e il mondo degli oggetti [4] manipolati dai programmi Java [3]. Questo ponte viene stabilito tramite configurazione, e ci sono due modi per farlo:
- utilizzando file XML. Questo era praticamente l'unico modo per farlo fino all'avvento di JDK 1.5
- utilizzando le annotazioni Java a partire da JDK 1.5
In questo documento utilizzeremo quasi esclusivamente il secondo metodo.
L'oggetto [Person] che rappresenta la tabella [person] presentata in precedenza potrebbe essere il seguente:
...
@SuppressWarnings("unused")
@Entity
@Table(name="Personne")
public class Personne implements Serializable{
@Id
@Column(name = "ID", nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Column(name = "VERSION", nullable = false)
@Version
private int version;
@Column(name = "NOM", length = 30, nullable = false, unique = true)
private String nom;
@Column(name = "PRENOM", length = 30, nullable = false)
private String prenom;
@Column(name = "DATENAISSANCE", nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(name = "MARIE", nullable = false)
private boolean marie;
@Column(name = "NBENFANTS", nullable = false)
private int nbenfants;
// manufacturers
public Personne() {
}
public Personne(String nom, String prenom, Date datenaissance, boolean marie,
int nbenfants) {
setNom(nom);
setPrenom(prenom);
setDatenaissance(datenaissance);
setMarie(marie);
setNbenfants(nbenfants);
}
// toString
public String toString() {
...
}
// getters and setters
...
}
La configurazione viene eseguita utilizzando le annotazioni Java (@Annotation). Le annotazioni Java vengono elaborate dal compilatore o da strumenti specializzati in fase di esecuzione. A parte l'annotazione alla riga 3 destinata al compilatore, tutte le annotazioni qui presenti sono destinate all'implementazione JPA in uso, Hibernate o Toplink. Verranno quindi elaborate in fase di esecuzione. In assenza di strumenti in grado di interpretarle, queste annotazioni vengono ignorate. Pertanto, la classe [Person] sopra riportata potrebbe essere utilizzata in un contesto non JPA.
Esistono due casi distinti per l'utilizzo delle annotazioni JPA in una classe C associata a una tabella T:
- la tabella T esiste già: le annotazioni JPA devono quindi replicare la struttura esistente (nomi e definizioni delle colonne, vincoli di integrità, chiavi esterne, chiavi primarie, ecc.)
- la tabella T non esiste e verrà creata in base alle annotazioni presenti nella classe C.
Il caso 2 è il più semplice da gestire. Utilizzando le annotazioni JPA, specifichiamo la struttura della tabella T che desideriamo. Il caso 1 è spesso più complesso. La tabella T potrebbe essere stata creata molto tempo fa al di fuori di qualsiasi contesto JPA. La sua struttura potrebbe quindi non essere adatta al ponte relazionale-oggetto di JPA. Per semplificare le cose, ci concentreremo sul caso 2, in cui la tabella T associata alla classe C verrà creata in base alle annotazioni JPA nella classe C.
Esaminiamo le annotazioni JPA della classe [Person]:
- riga 4: l'annotazione @Entity è la prima annotazione essenziale. È posizionata prima della riga che dichiara la classe e indica che la classe in questione deve essere gestita dal livello di persistenza JPA. Senza questa annotazione, tutte le altre annotazioni JPA verrebbero ignorate.
- riga 5: l'annotazione @Table designa la tabella del database che la classe rappresenta. Il suo argomento principale è name, che specifica il nome della tabella. Senza questo argomento, la tabella prenderà il nome dalla classe, in questo caso [Person]. Nel nostro esempio, l'annotazione @Table è quindi superflua.
- Riga 8: l'annotazione @Id viene utilizzata per designare il campo nella classe che rappresenta la chiave primaria della tabella. Questa annotazione è obbligatoria. In questo caso, indica che il campo id alla riga 11 rappresenta la chiave primaria della tabella.
- Riga 9: L'annotazione @Column viene utilizzata per collegare un campo della classe alla colonna della tabella che tale campo rappresenta. L'attributo name specifica il nome della colonna nella tabella. Se questo attributo viene omesso, la colonna assume lo stesso nome del campo. Nel nostro esempio, l'argomento name non era quindi necessario. L'argomento nullable=false indica che la colonna associata al campo non può assumere il valore NULL e che il campo deve quindi avere un valore.
- Riga 10: L'annotazione @GeneratedValue specifica come viene generata la chiave primaria quando viene generata automaticamente dal DBMS. Questo sarà il caso in tutti i nostri esempi. Non è obbligatoria. Pertanto, la nostra classe Person potrebbe avere un ID studente che funge da chiave primaria e non viene generato dal DBMS ma impostato dall'applicazione. In questo caso, l'annotazione @GeneratedValue verrebbe omessa. L'argomento strategy specifica come viene generata la chiave primaria quando generata dal DBMS. Non tutti i DBMS utilizzano la stessa tecnica per generare i valori delle chiavi primarie. Ad esempio:
utilizza un generatore di valori chiamato prima di ogni inserimento | |
il campo della chiave primaria è definito con il tipo Identity. Il risultato è simile al generatore di valori di Firebird, tranne per il fatto che il valore della chiave non è noto fino a quando la riga non viene inserita. | |
utilizza un oggetto chiamato SEQUENCE, che funge a sua volta da generatore di valori |
Il livello JPA deve generare diverse istruzioni SQL a seconda del DBMS per creare il generatore di valori. Specifichiamo il tipo di DBMS che deve gestire tramite la configurazione. Di conseguenza, può determinare la strategia standard per la generazione dei valori delle chiavi primarie per quel DBMS. L'argomento strategy = GenerationType.*****AUTO* indica al livello JPA di utilizzare questa strategia standard. Questa tecnica ha funzionato in tutti gli esempi presenti in questo documento per i sette DBMS utilizzati.
- Riga 14: L'annotazione @Version designa il campo utilizzato per gestire l'accesso simultaneo alla stessa riga nella tabella.
Per comprendere la questione dell'accesso concorrente alla stessa riga nella tabella [person], supponiamo che un'applicazione web consenta l'aggiornamento delle informazioni di una persona e consideriamo il seguente scenario:
Al momento T1, l'utente U1 inizia a modificare una persona P. In questo momento, il numero di figli è 0. Modifica questo numero in 1, ma prima di inviare le modifiche, l'utente U2 inizia a modificare la stessa persona P. Poiché U1 non ha ancora inviato le modifiche, U2 vede il numero di figli come 0 sul proprio schermo. U2 cambia il nome della persona P in maiuscolo. Quindi U1 e U2 salvano le loro modifiche in quell'ordine. La modifica di U2 avrà la precedenza: nel database, il nome sarà in maiuscolo e il numero di figli rimarrà a zero, anche se U1 crede di averlo cambiato in 1.
Il concetto di versione di una persona ci aiuta a risolvere questo problema. Rivediamo lo stesso caso d'uso:
Al momento T1, un utente U1 inizia a modificare una persona P. A questo punto, il numero di figli è 0 e la versione è V1. Modifica il numero di figli in 1, ma prima di confermare la modifica, un utente U2 inizia a modificare la stessa persona P. Poiché U1 non ha ancora confermato la modifica, U2 vede il numero di figli come 0 e la versione come V1. U2 cambia il nome della persona P in maiuscolo. Quindi U1 e U2 salvano le loro modifiche in quell'ordine. Prima di salvare una modifica, verifichiamo che l'utente che modifica la persona P abbia la stessa versione dell' e versione attualmente salvata della persona P. Questo sarà il caso dell'utente U1. La sua modifica viene quindi accettata, e noi cambiamo la versione della persona modificata da V1 a V2 per indicare che la persona ha subito una modifica. Nel convalidare la modifica di U2, noteremo che U2 possiede la versione V1 della persona P, mentre la versione attuale è V2. Possiamo quindi informare l'utente U2 che qualcun altro ha agito prima di lui e che deve partire dalla nuova versione della persona P. Lo farà, recupererà una versione V2 della persona P che ora ha un figlio, scriverà il nome con l'iniziale maiuscola e convaliderà. La sua modifica sarà accettata se la persona P registrata è ancora nella versione V2. In definitiva, le modifiche apportate da U1 e U2 saranno prese in considerazione, mentre nel caso d'uso senza versioni, una delle modifiche sarebbe andata persa.
Il livello [DAO] dell'applicazione client può gestire la versione della classe [Person] stessa. Ogni volta che un oggetto P viene modificato, la versione di quell'oggetto verrà incrementata di 1 nella tabella. L'annotazione @Version consente di trasferire questa gestione al livello JPA. Il campo in questione non deve necessariamente chiamarsi version come nell'esempio. Può avere qualsiasi nome.
I campi corrispondenti alle annotazioni @Id e @Version sono presenti a fini di persistenza. Non sarebbero necessari se la classe [Person] non dovesse essere persistita. Possiamo quindi vedere che un oggetto è rappresentato in modo diverso a seconda che debba o meno essere persistito.
- Riga 17: Ancora una volta, l'annotazione @Column fornisce informazioni sulla colonna della tabella [person] associata al campo name della classe Person. Qui troviamo due nuovi argomenti:
- unique=true indica che il nome di una persona deve essere univoco. Ciò comporterà l'aggiunta di un vincolo di unicità sulla colonna NAME della tabella [person] nel database.
- length=30 imposta il numero di caratteri nella colonna NAME a 30. Ciò significa che il tipo di questa colonna sarà VARCHAR(30).
- Riga 24: L'annotazione @Temporal viene utilizzata per specificare il tipo SQL per una colonna o un campo data/ora. Il tipo TemporalType.DATE indica una data senza un'ora associata. Gli altri tipi possibili sono TemporalType.TIME per la codifica di un'ora e TemporalType.TIMESTAMP per la codifica di una data e un'ora.
Commentiamo ora il resto del codice nella classe [Person]:
- Riga 6: La classe implementa l'interfaccia Serializable. La serializzazione di un oggetto consiste nel convertirlo in una sequenza di bit. La deserializzazione è l'operazione inversa. La serializzazione/deserializzazione è utilizzata in particolare nelle applicazioni client/server in cui gli oggetti vengono scambiati attraverso la rete. Le applicazioni client o server non sono a conoscenza di questa operazione, che viene eseguita in modo trasparente dalle JVM. Affinché ciò sia possibile, tuttavia, le classi degli oggetti scambiati devono essere "contrassegnate" con la parola chiave Serializable.
- Riga 37: un costruttore per la classe. Si noti che i campi id e version non sono inclusi tra i parametri. Questo perché questi due campi sono gestiti dal livello JPA e non dall'applicazione.
- Righe 51 e seguenti: i metodi get e set per ciascuno dei campi della classe. Si noti che le annotazioni JPA possono essere inserite sui metodi get dei campi anziché sui campi stessi. La posizione delle annotazioni indica la modalità che JPA deve utilizzare per accedere ai campi:
- se le annotazioni sono posizionate a livello di campo, JPA accederà direttamente ai campi per leggerli o scriverli
- se le annotazioni sono posizionate a livello di get, JPA accederà ai campi tramite i metodi get/set per leggerli o scriverli
La posizione dell'annotazione @Id determina la collocazione delle annotazioni JPA in una classe. Quando è collocata a livello di campo, indica l'accesso diretto ai campi; quando è collocata a livello di get, indica l'accesso ai campi tramite i metodi get e set. Le altre annotazioni devono quindi essere collocate allo stesso modo dell'annotazione @Id.
2.1.3. Il progetto di test Eclipse
Condurremo i nostri primi esperimenti con l'entità [Person] precedente. Li realizzeremo utilizzando la seguente architettura:
 |
- in [7]: il database che verrà generato sulla base delle annotazioni dell'entità [Person], nonché delle configurazioni aggiuntive specificate in un file denominato [persistence.xml]
- in [5, 6]: un livello JPA implementato da Hibernate
- in [4]: l'entità [Person]
- in [3]: un programma di test basato su console
Condurremo vari esperimenti:
- genereremo lo schema del database utilizzando uno script Ant e gli strumenti Hibernate
- genereremo il database e lo inizializzeremo con alcuni dati
- interagire con il database ed eseguire le quattro operazioni di base sulla tabella [person] (inserimento, aggiornamento, cancellazione, interrogazione)
Gli strumenti necessari sono i seguenti:
- Eclipse e i relativi plugin descritti nella Sezione 5.2.
- il progetto [hibernate-personnes-entites], che si trova nella cartella <examples>/hibernate/direct/personnes-entites
- i vari DBMS descritti nelle appendici (Sezione 5 e seguenti).
Il progetto Eclipse è il seguente:
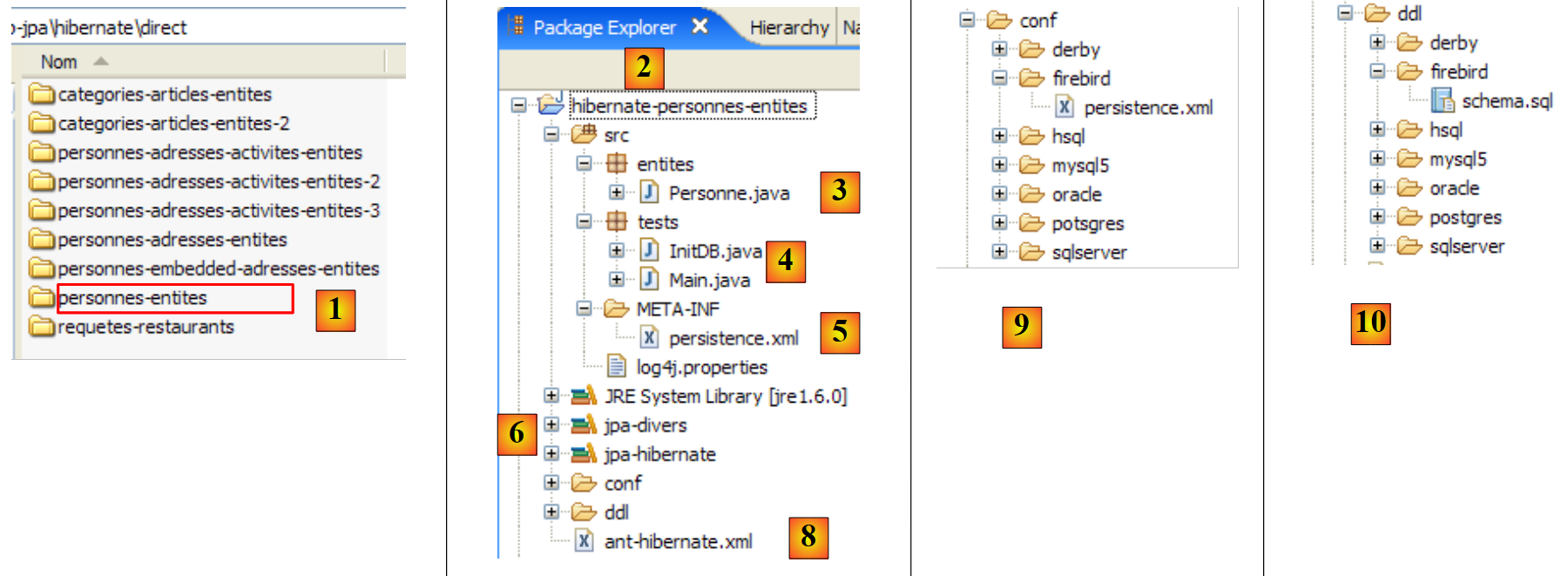 |
- in [1]: la cartella del progetto Eclipse
- in [2]: il progetto importato in Eclipse (File / Importa)
- in [3]: l'entità [Person] sottoposta a test
- in [4]: i programmi di test
- in [5]: [persistence.xml] è il file di configurazione per il livello JPA
- in [6]: le librerie utilizzate. Sono state descritte nella sezione 1.5.
- in [8]: uno script Ant che verrà utilizzato per generare la tabella associata all'entità [Person]
- in [9]: i file [persistence.xml] per ciascuno dei DBMS utilizzati
- in [10]: gli schemi del database generato per ciascuno dei DBMS utilizzati
Descriveremo questi elementi uno per uno.
2.1.4. L'entità [Person] (2)
Stiamo apportando una leggera modifica alla precedente descrizione dell'entità [Person], oltre ad aggiungere alcune informazioni aggiuntive:
package entites;
...
@SuppressWarnings({ "unused", "serial" })
@Entity
@Table(name="jpa01_personne")
public class Personne implements Serializable{
@Id
@Column(name = "ID", nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Column(name = "VERSION", nullable = false)
@Version
private int version;
@Column(name = "NOM", length = 30, nullable = false, unique = true)
private String nom;
@Column(name = "PRENOM", length = 30, nullable = false)
private String prenom;
@Column(name = "DATENAISSANCE", nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(name = "MARIE", nullable = false)
private boolean marie;
@Column(name = "NBENFANTS", nullable = false)
private int nbenfants;
// manufacturers
public Personne() {
}
public Personne(String nom, String prenom, Date datenaissance, boolean marie,
int nbenfants) {
....
}
// toString
public String toString() {
return String.format("[%d,%d,%s,%s,%s,%s,%d]", getId(), getVersion(),
getNom(), getPrenom(), new SimpleDateFormat("dd/MM/yyyy")
.format(getDatenaissance()), isMarie(), getNbenfants());
}
// getters and setters
...
}
- riga 7: chiamiamo la tabella associata all'entità [Person] [jpa01_personne]. In questo documento, verranno create varie tabelle in uno schema denominato sempre jpa. Alla fine di questo tutorial, lo schema jpa conterrà molte tabelle. Per aiutare il lettore a orientarsi, le tabelle correlate tra loro avranno lo stesso prefisso jpaxx_.
- riga 45: un metodo [toString] per visualizzare un oggetto [Person] sulla console.
2.1.5. Configurazione del livello di accesso ai dati
Nel progetto Eclipse sopra riportato, il livello JPA è configurato tramite il file [META-INF/persistence.xml]:
 |
In fase di esecuzione, il file [META-INF/persistence.xml] viene cercato nel classpath dell'applicazione. Nel nostro progetto Eclipse, tutto ciò che si trova nella cartella [/src] [1] viene copiato in una cartella [/bin] [2]. Questa cartella fa parte del classpath del progetto. Questo è il motivo per cui [META-INF/persistence.xml] verrà trovato quando il livello JPA si configurerà.
Per impostazione predefinita, Eclipse non colloca il codice sorgente nella cartella [/src] del progetto, ma direttamente nella cartella del progetto stesso. Tutti i nostri progetti Eclipse saranno configurati in modo che i sorgenti si trovino in [/src] e le classi compilate in [/bin], come mostrato nella Sezione 5.2.1.
Esaminiamo la configurazione del livello JPA nel file [persistence.xml] del nostro progetto:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Persistent classes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- logs SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
<property name="hibernate.connection.url" value="jdbc:mysql://localhost:3306/jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- automatic schematic creation -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
<!-- properties DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
Per comprendere questa configurazione, dobbiamo riesaminare l'architettura di accesso ai dati della nostra applicazione:
 |
- il file [persistence.xml] configura i livelli [4, 5, 6]
- [4]: implementazione JPA di Hibernate
- [5]: Hibernate accede al database tramite un pool di connessioni. Un pool di connessioni è un insieme di connessioni aperte al DBMS. Un DBMS è accessibile da più utenti, ma per motivi di prestazioni non può superare un limite N di connessioni aperte contemporaneamente. Un codice ben scritto apre una connessione al DBMS per il tempo minimo necessario: esegue i comandi SQL e chiude la connessione. Lo farà ripetutamente, ogni volta che dovrà lavorare con il database. Il costo dell’apertura e della chiusura di una connessione non è trascurabile, ed è qui che entra in gioco il pool di connessioni. All’avvio dell’applicazione, il pool di connessioni apre N1 connessioni al DBMS. L’applicazione richiede una connessione aperta dal pool ogni volta che ne ha bisogno. La connessione viene restituita al pool non appena l'applicazione non ne ha più bisogno, preferibilmente il più rapidamente possibile. La connessione non viene chiusa e rimane disponibile per l'utente successivo. Un pool di connessioni è quindi un sistema per la condivisione delle connessioni aperte.
- [6]: il driver JDBC per il DBMS in uso
Vediamo ora come il file [persistence.xml] configura i livelli [4, 5, 6] sopra indicati:
- riga 2: il tag radice del file XML è <persistence>.
- riga 3: <persistence-unit> viene utilizzato per definire un'unità di persistenza. Possono esserci più unità di persistenza. Ognuna ha un nome (attributo name) e un tipo di transazione (attributo transaction-type). L'applicazione accederà all'unità di persistenza tramite il suo nome, in questo caso jpa. Il tipo di transazione RESOURCE_LOCAL indica che l'applicazione gestisce le transazioni con il DBMS stesso. Questo sarà il caso qui. Quando l'applicazione viene eseguita in un contenitore EJB3, può utilizzare il servizio di transazione del contenitore. In tal caso, imposteremmo transaction-type=JTA (Java Transaction API). JTA è il valore predefinito quando l'attributo transaction-type viene omesso.
- Riga 5: Il tag <provider> viene utilizzato per definire una classe che implementa l'interfaccia [javax.persistence.spi.PersistenceProvider], che consente all'applicazione di inizializzare il livello di persistenza . Poiché stiamo utilizzando un'implementazione JPA/Hibernate, la classe utilizzata qui è una classe Hibernate.
- Riga 6: Il tag <properties> introduce proprietà specifiche del provider scelto. Pertanto, a seconda che abbiate scelto Hibernate, TopLink, Kodo, ecc., avrete proprietà diverse. Quelle che seguono sono specifiche di Hibernate.
- Riga 8: Indica a Hibernate di scansionare il classpath del progetto per trovare le classi annotate con @Entity in modo da poterle gestire. Le classi @Entity possono anche essere dichiarate utilizzando i tag <class>class_name</class>, direttamente sotto il tag <persistence-unit>. Questo è ciò che faremo con il provider JPA/Toplink.
- Le righe 10-12, qui commentate, configurano i log della console di Hibernate:
- Riga 10: per abilitare o disabilitare la visualizzazione delle istruzioni SQL inviate da Hibernate al DBMS. Ciò è molto utile durante la fase di apprendimento. Grazie al ponte relazionale/oggetto, l'applicazione opera su oggetti persistenti ai quali applica operazioni quali [persist, merge, remove]. È molto utile sapere quali istruzioni SQL vengono effettivamente inviate per queste operazioni. Studiandole, si impara gradualmente ad anticipare le istruzioni SQL che Hibernate genererà quando esegue tali operazioni sugli oggetti persistenti, e il ponte relazionale/oggetto comincia a prendere forma nella mente.
- Riga 11: Le istruzioni SQL visualizzate sulla console possono essere formattate in modo ordinato per renderle più facili da leggere
- Riga 12: Le istruzioni SQL visualizzate saranno anche annotate
- Le righe 15–19 definiscono il livello JDBC (livello [6] nell'architettura):
- riga 15: la classe del driver JDBC per il DBMS, in questo caso MySQL5
- riga 16: l'URL del database in uso
- Righe 17, 18: nome utente e password di connessione
- Qui utilizziamo elementi illustrati nelle appendici alla sezione 5.5. Si invita il lettore a consultare questa sezione su MySQL 5.
- riga 22: Hibernate deve sapere con quale DBMS sta lavorando. Questo perché tutti i DBMS hanno estensioni SQL proprietarie, come il proprio modo di gestire la generazione automatica dei valori delle chiavi primarie, ... il che significa che Hibernate deve conoscere il DBMS con cui sta lavorando per poter inviare comandi SQL che il DBMS sia in grado di comprendere. [MySQL5InnoDBDialect] si riferisce al DBMS MySQL5 con tabelle InnoDB che supportano le transazioni.
- Le righe 24–28 configurano il pool di connessioni c3p0 (livello [5] nell'architettura):
- Righe 24, 25: il numero minimo (predefinito 3) e massimo di connessioni (predefinito 15) nel pool. Il numero iniziale predefinito di connessioni è 3.
- Riga 26: tempo massimo di attesa in millisecondi per una richiesta di connessione da parte del client. Trascorso questo timeout, c3p0 genererà un'eccezione.
- Riga 27: per accedere al database, Hibernate utilizza istruzioni SQL preparate (PreparedStatement) che c3p0 può memorizzare nella cache. Ciò significa che se l'applicazione richiede una seconda volta un'istruzione SQL preparata che si trova già nella cache, non sarà necessario prepararla (la preparazione di un'istruzione SQL comporta un costo) e verrà utilizzata quella presente nella cache. Qui specifichiamo il numero massimo di istruzioni SQL preparate che la cache può contenere, su tutte le connessioni (un'istruzione SQL preparata appartiene a una singola connessione).
- Riga 28: Intervallo di controllo della validità della connessione in millisecondi. Una connessione nel pool può diventare non valida per vari motivi (il driver JDBC invalida la connessione perché è rimasta inattiva troppo a lungo, il driver JDBC presenta dei bug, ecc.).
- Riga 20: Qui specifichiamo che all'inizializzazione del livello di persistenza, lo schema del database per gli oggetti @Entity debba essere generato. Hibernate ora dispone di tutti gli strumenti per generare le istruzioni SQL per la creazione delle tabelle del database:
- la configurazione degli oggetti @Entity gli permette di sapere quali tabelle generare
- Le righe 15–18 e 24–28 gli consentono di stabilire una connessione con il DBMS
- la riga 22 indica quale dialetto SQL utilizzare per generare le tabelle
Pertanto, il file [persistence.xml] qui utilizzato ricrea un nuovo database ad ogni nuova esecuzione dell'applicazione. Le tabelle vengono ricreate (create table) dopo essere state eliminate (drop table) se esistevano. Si noti che questo ovviamente non è qualcosa da fare con un database di produzione...
I test hanno dimostrato che la fase di eliminazione/creazione delle tabelle può fallire. Ciò si è verificato in particolare quando, per lo stesso test, siamo passati da un livello JPA/Hibernate a un livello JPA/Toplink o viceversa. Partendo dagli stessi oggetti @Entity, le due implementazioni non generano esattamente le stesse tabelle, generatori, sequenze, ecc., e talvolta è accaduto che la fase di eliminazione/creazione fallisse, richiedendo la cancellazione manuale delle tabelle. La sezione "Appendici", a partire dal paragrafo 5, descrive gli strumenti disponibili per eseguire manualmente questa operazione. Va notato che l'implementazione JPA/Hibernate si è dimostrata la più efficiente durante questa fase iniziale di creazione del contenuto del database: i crash erano rari.
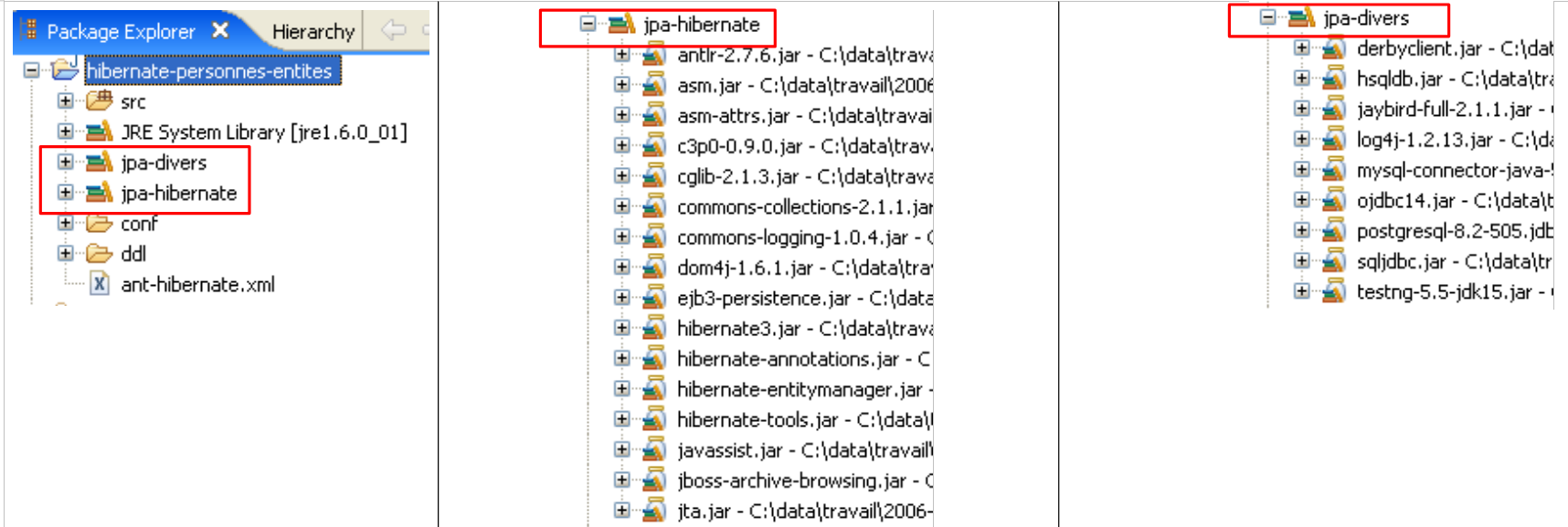
Gli strumenti utilizzati dal livello JPA/Hibernate si trovano nella libreria [jpa-hibernate], presentata nella sezione 1.5, pagina 8. I driver JDBC necessari per accedere al DBMS si trovano nella libreria [jpa-divers]. Queste due librerie sono state aggiunte al classpath del progetto qui studiato. Il loro contenuto è riassunto di seguito:
 |
2.1.6. Generazione del database con uno script Ant
Come abbiamo appena visto, Hibernate fornisce strumenti per generare lo schema del database per gli oggetti @Entity dell'applicazione. Hibernate può:
- generare il file di testo contenente le istruzioni SQL che creano il database. In questo caso viene utilizzato solo il dialetto specificato in [persistence.xml].
- creare le tabelle che rappresentano gli oggetti @Entity nel database di destinazione definito in [persistence.xml]. In questo caso, viene utilizzato l'intero file [persistence.xml].
Presenteremo uno script Ant in grado di generare lo schema del database per gli oggetti @Entity. Questo script non è mio: si basa su uno script simile tratto da [ref1]. Ant (Another Neat Tool) è uno strumento Java per l'esecuzione di attività batch. Gli script Ant non sono facili da comprendere per i principianti. Ne useremo solo uno, quello che stiamo commentando in questo momento:
 |
- in [1]: la struttura delle directory degli esempi in questo tutorial.
- in [2]: la cartella [people-entities] del progetto Eclipse attualmente in esame
- in [3]: la cartella <lib> contenente le cinque librerie JAR definite nella sezione 1.5.
- in [4]: l'archivio [hibernate-tools.jar] richiesto per una delle attività nello script [ant-hibernate.xml] che esamineremo.
 |
- in [5]: il progetto Eclipse e lo script [ant-hibernate.xml]
- in [6]: la cartella [src] del progetto
Lo script [ant-hibernate.xml] [5] utilizzerà i file JAR presenti nella cartella <lib> [3], in particolare il file [hibernate-tools.jar] [4] nella cartella [lib/hibernate]. Abbiamo riprodotto l'albero delle directory in modo che il lettore possa vedere che per trovare la cartella [lib] dalla cartella [people-entities] [2] nello script [ant-hibernate.xml], è necessario seguire il percorso: ../../../lib.
Esaminiamo lo script [ant-hibernate.xml]:
<project name="jpa-hibernate" default="compile" basedir=".">
<!-- nom du projet et version -->
<property name="proj.name" value="jpa-hibernate" />
<property name="proj.shortname" value="jpa-hibernate" />
<property name="version" value="1.0" />
<!-- Propriété globales -->
<property name="src.java.dir" value="src" />
<property name="lib.dir" value="../../../lib" />
<property name="build.dir" value="bin" />
<!-- le Classpath du projet -->
<path id="project.classpath">
<fileset dir="${lib.dir}">
<include name="**/*.jar" />
</fileset>
</path>
<!-- les fichiers de configuration qui doivent être dans le classpath-->
<patternset id="conf">
<include name="**/*.xml" />
<include name="**/*.properties" />
</patternset>
<!-- Nettoyage projet -->
<target name="clean" description="Nettoyer le projet">
<delete dir="${build.dir}" />
<mkdir dir="${build.dir}" />
</target>
<!-- Compilation projet -->
<target name="compile" depends="clean">
<javac srcdir="${src.java.dir}" destdir="${build.dir}" classpathref="project.classpath" />
</target>
<!-- Copier les fichiers de configuration dans le classpath -->
<target name="copyconf">
<mkdir dir="${build.dir}" />
<copy todir="${build.dir}">
<fileset dir="${src.java.dir}">
<patternset refid="conf" />
</fileset>
</copy>
</target>
<!-- Hibernate Tools -->
<taskdef name="hibernatetool" classname="org.hibernate.tool.ant.HibernateToolTask" classpathref="project.classpath" />
<!-- Générer la DDL de la base -->
<target name="DDL" depends="compile, copyconf" description="Génération DDL base">
<hibernatetool destdir="${basedir}">
<classpath path="${build.dir}" />
<!-- Utiliser META-INF/persistence.xml -->
<jpaconfiguration />
<!-- export -->
<hbm2ddl drop="true" create="true" export="false" outputfilename="ddl/schema.sql" delimiter=";" format="true" />
</hibernatetool>
</target>
<!-- Générer la base -->
<target name="BD" depends="compile, copyconf" description="Génération BD">
<hibernatetool destdir="${basedir}">
<classpath path="${build.dir}" />
<!-- Utiliser META-INF/persistence.xml -->
<jpaconfiguration />
<!-- export -->
<hbm2ddl drop="true" create="true" export="true" outputfilename="ddl/schema.sql" delimiter=";" format="true" />
</hibernatetool>
</target>
</project>
- Riga 1: Il progetto [ant] si chiama "jpa-hibernate". È costituito da un insieme di attività, una delle quali è l'attività predefinita: in questo caso, l'attività denominata "compile". Per eseguire un'attività T viene chiamato uno script Ant. Se non viene specificata alcuna attività, viene eseguita l'attività predefinita. basedir="." indica che, per tutti i percorsi relativi presenti nello script, il punto di partenza è la cartella contenente lo script Ant, in questo caso la cartella <examples>/hibernate/direct/people-entities.
- Righe 3–11: definiscono le variabili dello script utilizzando il tag <property name="variableName" value="variableValue"/>. La variabile può quindi essere utilizzata nello script con la notazione ${variableName}. I nomi possono essere qualsiasi cosa. Diamo un'occhiata più da vicino alle variabili definite alle righe 9–11:
- Riga 9: definisce una variabile denominata "src.java.dir" (il nome è arbitrario) che, più avanti nello script, farà riferimento alla cartella contenente il codice sorgente Java. Il suo valore è "src", un percorso relativo alla cartella designata dall'attributo basedir (riga 1). Si tratta quindi del percorso "./src", dove . si riferisce alla cartella <examples>/hibernate/direct/people-entities. Il codice sorgente Java si trova infatti nella cartella <people-entities>/src (vedi [6] sopra).
- Riga 10: definisce una variabile denominata "lib.dir" che, più avanti nello script, farà riferimento alla cartella contenente i file JAR richiesti dalle attività Java dello script. Il suo valore ../../../lib fa riferimento alla cartella <examples>/lib (vedi [3] sopra).
- Riga 11: definisce una variabile denominata "build.dir" che, più avanti nello script, farà riferimento alla cartella in cui devono essere collocati i file .class generati dalla compilazione dei sorgenti .java. Il suo valore "bin" fa riferimento alla cartella <personnes-entites>/bin. Abbiamo già spiegato che nel progetto Eclipse che abbiamo studiato, la cartella <bin> era quella in cui venivano generati i file .class. Ant farà lo stesso.
- Righe 14–18: Il tag <path> viene utilizzato per definire gli elementi del classpath che le attività Ant utilizzeranno. Qui, il percorso "project.classpath" (il nome è arbitrario) include tutti i file .jar nell'albero di directory <examples>/lib.
- Righe 21–24: Il tag <patternset> viene utilizzato per designare un insieme di file utilizzando modelli di denominazione. Qui, il patternset denominato conf si riferisce a tutti i file con estensione .xml o .properties. Questo patternset verrà utilizzato per fare riferimento ai file .xml e .properties nella cartella <src> (persistence.xml, log4j.properties) (vedi [6]), che sono file di configurazione dell'applicazione. Quando vengono eseguiti determinati task, questi file devono essere copiati nella cartella <bin> in modo che si trovino nel classpath del progetto. Utilizzeremo quindi il patternset conf per fare riferimento ad essi.
- Righe 27–30: Il tag <target> indica un'attività nello script. Questa è la prima che incontriamo. Tutto ciò che l'ha preceduta riguarda la configurazione dell'ambiente di esecuzione dello script Ant. L'attività si chiama clean. Si esegue in due fasi: la cartella <bin> viene eliminata (riga 28) e poi ricreata (riga 29).
- Righe 33–35: L'attività compile, che è l'attività predefinita dello script (riga 1). Dipende (attributo depends) dall'attività clean. Ciò significa che prima di eseguire l'attività compile, Ant deve eseguire l'attività clean, ovvero pulire la cartella <bin>. Lo scopo dell'attività compile in questo caso è compilare i file sorgente Java nella cartella <src>.
- Riga 34: Chiamata al compilatore Java con tre parametri:
- srcdir: la cartella contenente i file sorgente Java, in questo caso la cartella <src>
- destdir: la cartella in cui devono essere memorizzati i file .class generati, in questo caso la cartella <bin>
- classpathref: il classpath da utilizzare per la compilazione, in questo caso tutti i file JAR presenti nella struttura di directory <lib>
- (continua)
- righe 38–45: il task copyconf, il cui scopo è copiare tutti i file .xml e .properties dalla directory <src> nella directory <bin>.
- riga 48: definizione di un'attività utilizzando il tag <taskdef>. Tale attività è destinata ad essere riutilizzata in altre parti dello script. Si tratta di una comodità di codifica. Poiché l'attività viene utilizzata in vari punti dello script, viene definita una sola volta con il tag <taskdef> e poi riutilizzata tramite il suo nome quando necessario.
- Il task si chiama hibernatetool (attributo name).
- La sua classe è definita dall'attributo classname. In questo caso, la classe specificata si trova nell'archivio [hibernate-tools.jar] menzionato in precedenza.
- L'attributo classpathref indica ad Ant dove cercare la classe precedente
- (continua)
- Le righe 51–60 riguardano il task di nostro interesse: la generazione dello schema del database per gli oggetti @Entity nel nostro progetto Eclipse.
- Riga 51: L'attività si chiama DDL (abbreviazione di Data Definition Language, l'SQL utilizzato per creare oggetti del database). Dipende dalle attività compile e copyconf, in quest'ordine. L'attività DDL attiverà quindi, in ordine, l'esecuzione delle attività clean, compile e copyconf. Quando l'attività DDL ha inizio, la cartella <bin> contiene i file .class generati dai sorgenti .java, in particolare gli oggetti @Entity, nonché il file [META-INF/persistence.xml] che configura il livello JPA/Hibernate.
- Righe 53–59: Viene richiamata l'attività [hibernatetool] definita alla riga 48. Le vengono passati numerosi parametri, oltre a quelli già definiti alla riga 48:
- Riga 53: La directory di output per i risultati prodotti dal task sarà la directory corrente.
- Riga 54: il percorso di classe del task sarà la cartella <bin>.
- Riga 56: indica al task [hibernatetool] come determinare il proprio ambiente di runtime: il tag <jpaconfiguration/> indica che si trova in un ambiente JPA e che deve quindi utilizzare il file [META-INF/persistence.xml], che troverà qui nel proprio classpath.
- Riga 58: imposta le condizioni per la generazione del database: drop=true indica che le istruzioni SQL drop table devono essere eseguite prima della creazione delle tabelle; create=true indica che deve essere creato il file di testo contenente le istruzioni SQL per la creazione del database; outputfilename specifica il nome di questo file SQL — qui schema.sql nella cartella <ddl> del progetto Eclipse; export=false indica che le istruzioni SQL generate non devono essere eseguite in una connessione al DBMS. Questo punto è importante: significa che il DBMS di destinazione non deve essere in esecuzione per eseguire l'attività. delimiter imposta il carattere che separa due istruzioni SQL nello schema generato, mentre format=true richiede che al testo generato venga applicata una formattazione di base.
- Le righe 51–60 riguardano il task di nostro interesse: la generazione dello schema del database per gli oggetti @Entity nel nostro progetto Eclipse.
- (continua)
- Le righe 63–72 definiscono l'attività denominata BD. È identica alla precedente attività DDL, tranne per il fatto che questa volta genera il database (export="true" alla riga 70). L'attività apre una connessione al DBMS utilizzando le informazioni presenti in [persistence.xml], per eseguire lo schema SQL e generare il database. Per eseguire l'attività BD, il DBMS deve quindi essere in esecuzione.
2.1.7. Esecuzione del task DDL di Ant
Per eseguire lo script [ant-hibernate.xml], dobbiamo prima effettuare alcune configurazioni all'interno di Eclipse.
 |
- in [1]: selezionare [Strumenti esterni]
- in [2]: crea una nuova configurazione Ant
 |
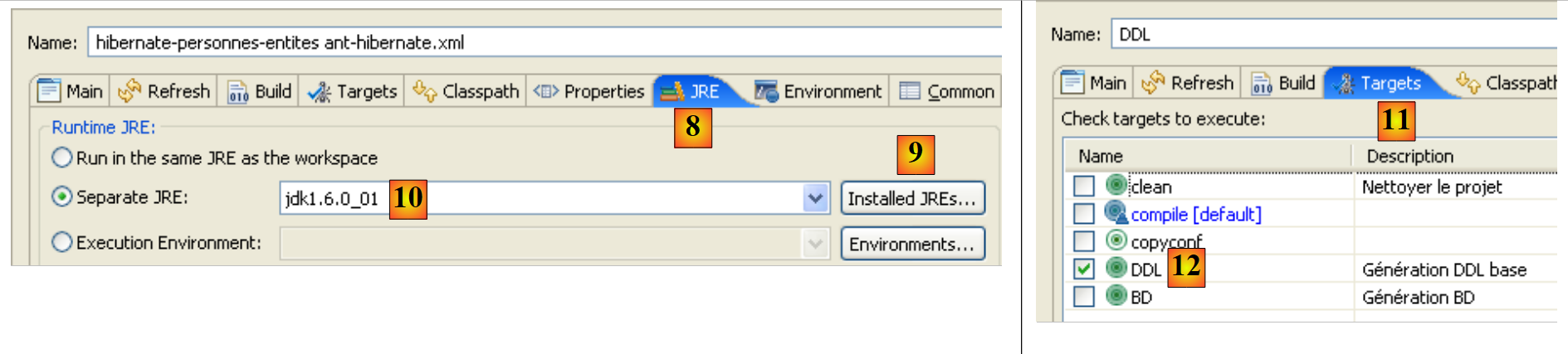
- in [3]: assegnare un nome alla configurazione Ant
- In [5]: specificare lo script Ant utilizzando il pulsante [4]
- Passaggio [6]: applicare le modifiche
- in [7]: la configurazione DDL di Ant è stata creata
 |
 |
- in [8]: nella scheda JRE, definire il JRE da utilizzare. Il campo [10] è solitamente precompilato con il JRE utilizzato da Eclipse. Pertanto, in genere non è necessario intervenire in questo pannello. Tuttavia, mi è capitato un caso in cui lo script Ant non riusciva a trovare il compilatore <javac>. Questo compilatore non si trova in un JRE (Java Runtime Environment) ma in un JDK (Java Development Kit). Lo strumento Ant di Eclipse individua questo compilatore tramite la variabile d'ambiente JAVA_HOME (Start / Pannello di controllo / Prestazioni e manutenzione / Sistema / scheda Avanzate / pulsante Variabili d'ambiente) [A]. Se questa variabile non è stata definita, è possibile consentire ad Ant di trovare il compilatore <javac> specificando un JDK invece di un JRE in [10]. Il JDK è disponibile nella stessa cartella del JRE [B]. Utilizzare il pulsante [9] per registrare il JDK tra i JRE disponibili [C] in modo da poterlo poi selezionare in [10].
- In [12]: Nella scheda [Targets], selezionare l'attività DDL. Pertanto, la configurazione Ant che abbiamo denominato DDL [7] corrisponderà all'esecuzione dell'attività denominata DDL [12], che, come sappiamo, genera lo schema DDL per il database che rappresenta gli oggetti @Entity dell'applicazione.
 |
- in [13]: convalida la configurazione
- In [14]: Eseguire
Nella vista [Console] vedrai i log relativi all'esecuzione del task DDL di Ant:
Buildfile: C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\ant-hibernate.xml
clean:
[delete] Deleting directory C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
[mkdir] Created dir: C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
compile:
[javac] Compiling 3 source files to C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
copyconf:
[copy] Copying 2 files to C:\data\2006-2007\eclipse\dvp-jpa\hibernate\direct\personnes-entites\bin
DDL:
[hibernatetool] Executing Hibernate Tool with a JPA Configuration
[hibernatetool] 1. task: hbm2ddl (Generates database schema)
[hibernatetool] drop table if exists jpa01_personne;
[hibernatetool] create table jpa01_personne (
[hibernatetool] ID integer not null auto_increment,
[hibernatetool] VERSION integer not null,
[hibernatetool] NOM varchar(30) not null unique,
[hibernatetool] PRENOM varchar(30) not null,
[hibernatetool] DATENAISSANCE date not null,
[hibernatetool] MARIE bit not null,
[hibernatetool] NBENFANTS integer not null,
[hibernatetool] primary key (ID)
[hibernatetool] ) ENGINE=InnoDB;
BUILD SUCCESSFUL
Total time: 5 seconds
- Ricordiamo che l'attività DDL è denominata [hibernatetool] (riga 10) e dipende dalle attività clean (riga 2), compile (riga 5) e copyconf (riga 7).
- Riga 10: l'attività [hibernatetool] utilizza il file [persistence.xml] da una configurazione JPA
- riga 11: il task [hbm2ddl] genererà lo schema DDL del database
- Righe 12–22: lo schema DDL del database
Ricordiamo che abbiamo indicato al task [hbm2ddl] di generare lo schema DDL in una posizione specifica:
<hbm2ddl drop="true" create="true" export="true" outputfilename="ddl/schema.sql" delimiter=";" format="true" />
- riga 74: lo schema deve essere generato nel file ddl/schema.sql. Verifichiamo:
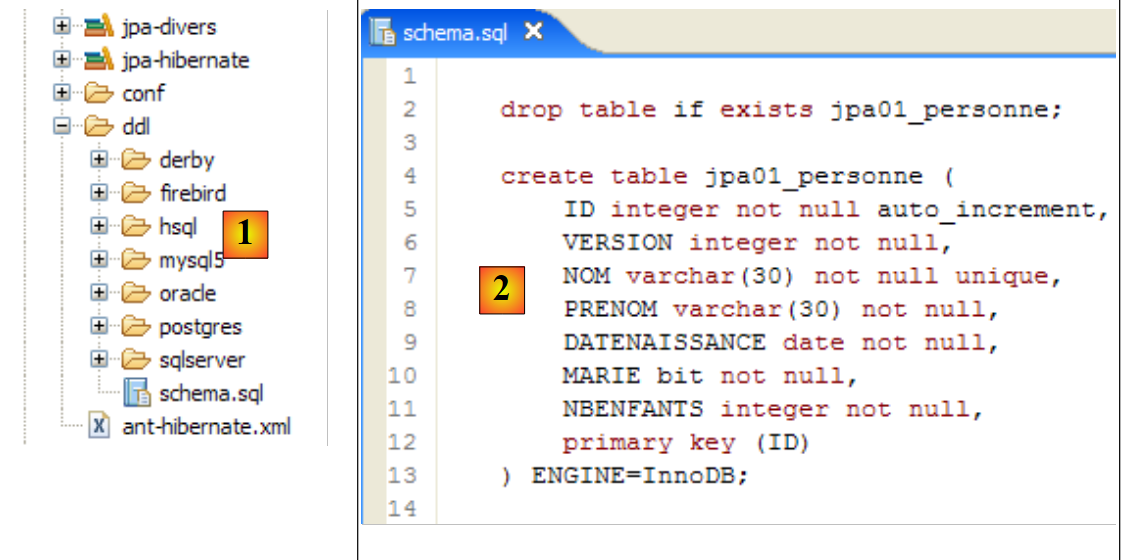 |
- in [1]: il file ddl/schema.sql è effettivamente presente (premere F5 per aggiornare l'albero delle directory)
- in [2]: il suo contenuto. Questo è lo schema per un database MySQL5. Il file di configurazione [persistence.xml] per il livello JPA specificava effettivamente un DBMS MySQL5 (riga 8 qui sotto):
<!-- connexion JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
...
<!-- création automatique du schéma -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialecte -->
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
<!-- propriétés DataSource c3p0 -->
...
Esaminiamo la mappatura oggetto-relazionale implementata qui osservando la configurazione dell'oggetto @Entity Person e lo schema DDL generato:
 |
 |
Vale la pena sottolineare alcuni punti:
- A1-B1: Il nome della tabella specificato in A1 è effettivamente quello utilizzato in B1. Si noti l'istruzione `DROP` che precede `CREATE` in B1.
- A2-B2: mostrano come viene generata la chiave primaria. La modalità AUTO specificata in A2 ha generato l'attributo autoincremento specifico di MySQL 5. La modalità di generazione della chiave primaria è spesso specifica del DBMS.
- A3-B3: mostrano il tipo di bit SQL specifico di MySQL 5 utilizzato per rappresentare un tipo booleano Java.
Ripetiamo questo test con un altro DBMS:
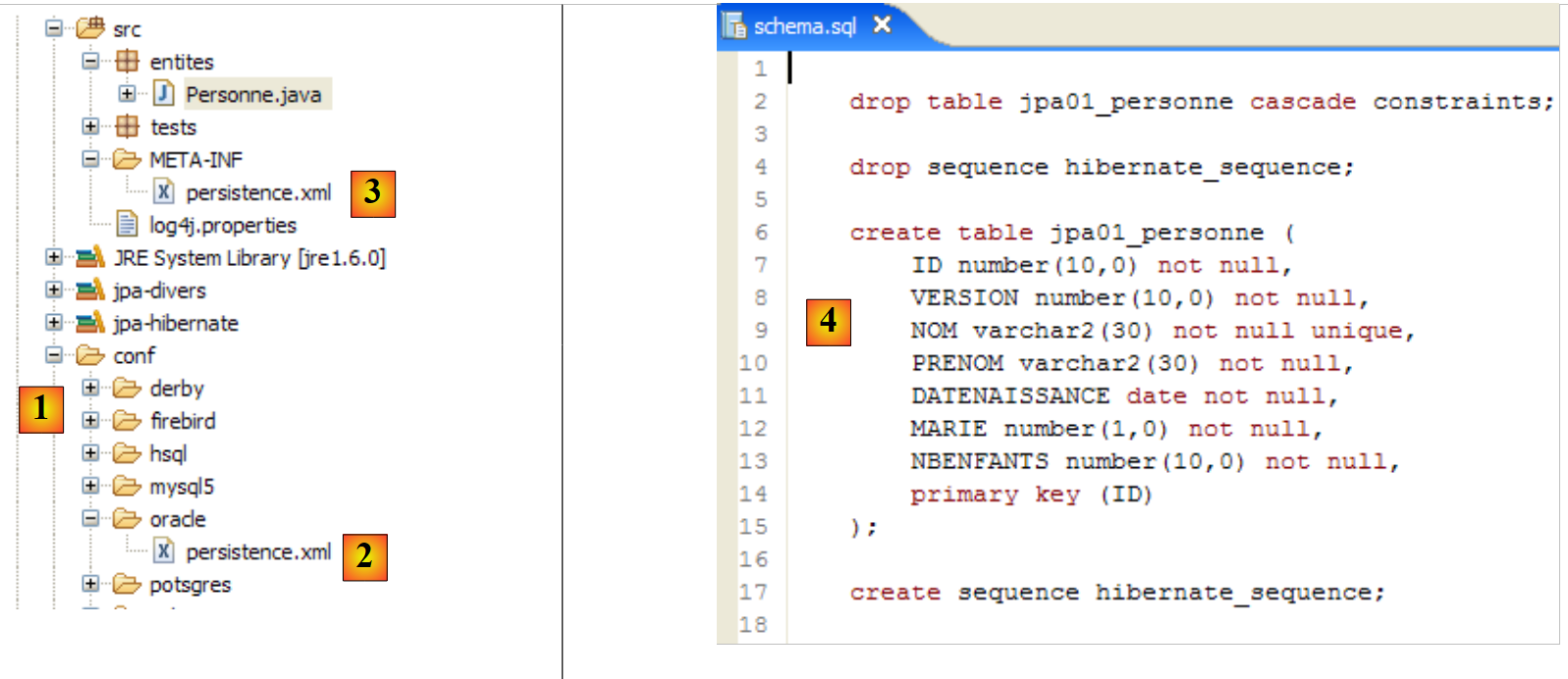 |
- La cartella [conf] [1] contiene i file [persistence.xml] per vari DBMS. Prendiamo ad esempio quello di Oracle [2] e inseriamolo nella cartella [META-INF] [3] al posto di quello precedente. Il suo contenuto è il seguente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Persistent classes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- logs SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="oracle.jdbc.OracleDriver" />
<property name="hibernate.connection.url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- automatic schematic creation -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.OracleDialect" />
<!-- properties DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
Si invita il lettore a consultare l'appendice, in particolare la sezione dedicata a Oracle (Sezione 5.7), soprattutto per comprendere la configurazione JDBC.
Qui è davvero importante solo la riga 25: stiamo dicendo a Hibernate che il DBMS ora è un DBMS Oracle. L'esecuzione del task DDL di Ant produce il risultato [4] mostrato sopra. Si noti che lo schema Oracle differisce dallo schema MySQL5. Questo è un punto di forza fondamentale di JPA: lo sviluppatore non deve preoccuparsi di questi dettagli, il che aumenta significativamente la portabilità delle proprie applicazioni.
2.1.8. Esecuzione del task Ant " "
Ricorderete che il task Ant denominato BD fa la stessa cosa del task *DDL*, ma genera anche il database. Il DBMS deve quindi essere in esecuzione. Useremo il DBMS MySQL5 e invitiamo il lettore a copiare il file [conf/mysql5/persistence.xml] nella cartella [src/META-INF]. Per verificare che il task funzioni, useremo il plugin SQL Explorer (vedi Sezione 5.2.6) per controllare lo stato del database JPA prima e dopo l'esecuzione del task Ant BD.
Per prima cosa, dobbiamo creare una nuova configurazione Ant per eseguire l'attività BD. Si invita il lettore a seguire la procedura descritta per la configurazione Ant DDL nella sezione 2.1.7. La nuova configurazione Ant sarà denominata BD:
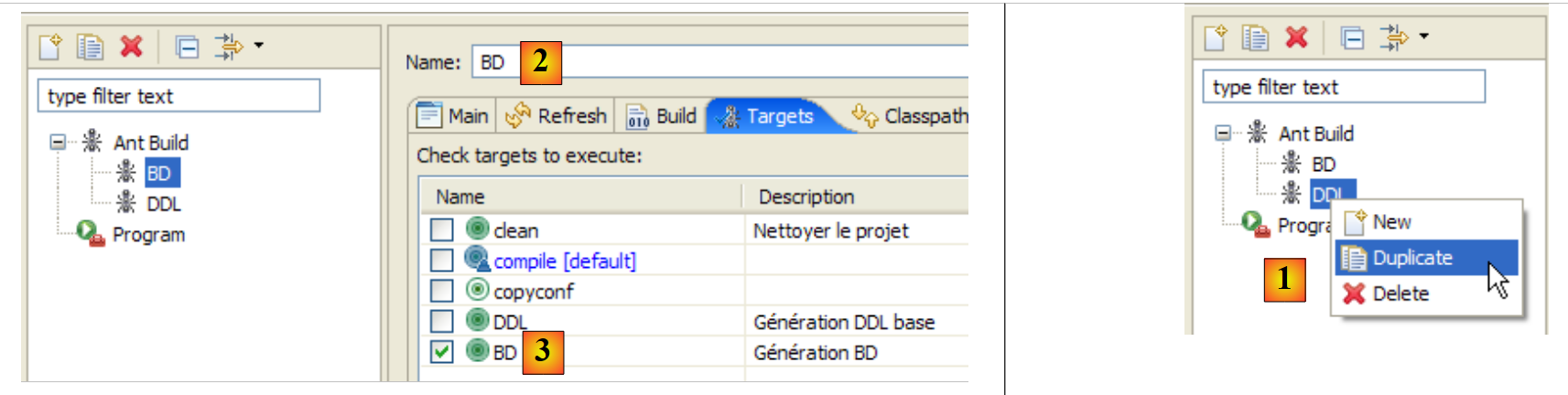 |
- in [1]: duplichiamo la configurazione precedente denominata DDL
- in [2]: assegniamo il nome BD alla nuova configurazione. Questa esegue il task ant BD [3], che genera fisicamente il database.
- Una volta fatto ciò, avviare il DBMS MySQL5 (Sezione 5.5).
Ora utilizziamo il plugin SQL Explorer per esplorare i database gestiti dal DBMS. Il lettore dovrebbe familiarizzare con questo plugin in anticipo, se necessario (vedere la sezione 5.2.6).
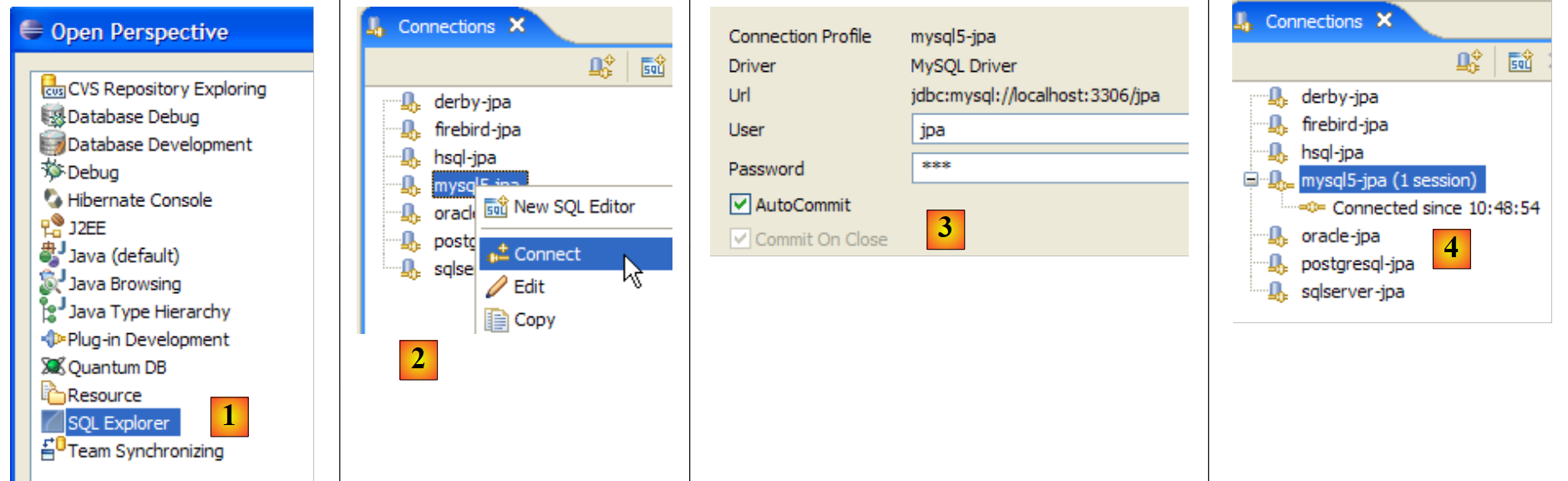 |
- [1]: Aprire la prospettiva SQL Explorer [Finestra / Apri prospettiva / Altro]
- [2]: Se necessario, creare una connessione [mysql5-jpa] (vedere la sezione 5.5.5, pagina 252) e aprirla
- [3]: Effettua l'accesso come jpa / jpa
- [4]: Ora sei connesso a MySQL5.
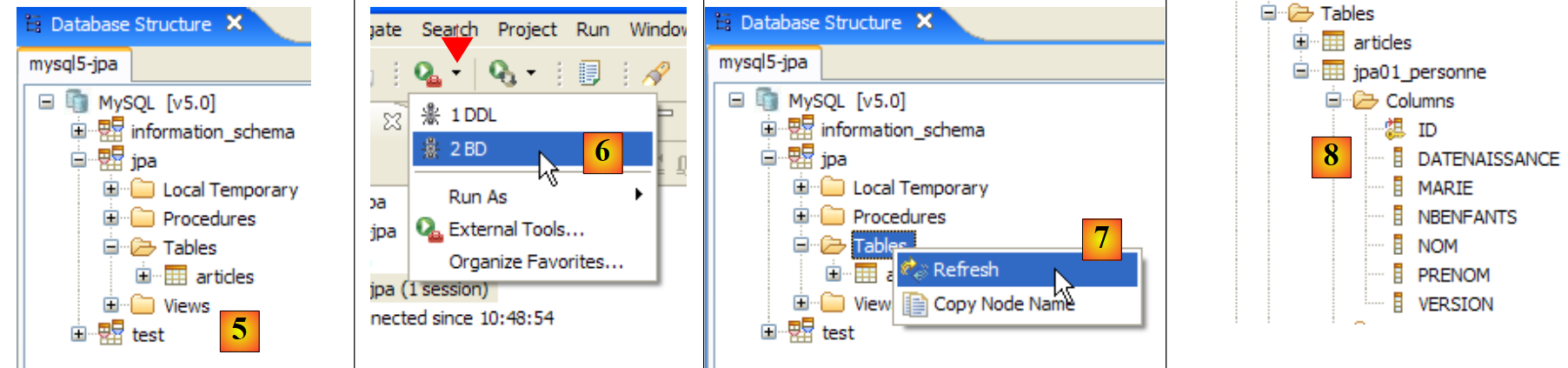 |
- In [5]: Il database jpa contiene una sola tabella: [articles]
- in [6]: Esegui il task Ant DB. Poiché ti trovi nella prospettiva [SQL Explorer], non puoi vedere la vista [Console], che mostra i log del task. Puoi visualizzare questa vista [Window / Show View / ...] oppure tornare alla prospettiva Java [Window / Open Perspective / ...].
- in [7]: una volta completata l'attività DB, tornare alla prospettiva [SQL Explorer] se necessario e aggiornare l'albero del database JPA.
- In [8]: È possibile vedere la tabella [jpa01_personne] che è stata creata.
Si invitano i lettori a ripetere questo processo di generazione del database con altri DBMS. La procedura è la seguente:
- Copiare il file [conf/<dbms>/persistence.xml] nella cartella [src/META-INF], dove <dbms> è il DBMS da testare
- avviare <dbms> seguendo le istruzioni riportate nell'appendice relativa a quel DBMS
- nella vista SQL Explorer, creare una connessione a <dbms>. Anche questo è spiegato nelle appendici relative a ciascun DBMS
- Ripetere i test precedenti
A questo punto, abbiamo acquisito una serie di approfondimenti:
- Abbiamo una migliore comprensione del concetto di ponte relazionale-oggetti. In questo caso, è stato implementato utilizzando Hibernate. In seguito useremo TopLink.
- Sappiamo che questo ponte oggetto-relazionale è configurato in due punti:
- negli oggetti @Entity, dove specifichiamo le relazioni tra i campi degli oggetti e le colonne delle tabelle del database
- in [META-INF/persistence.xml], dove forniamo all'implementazione JPA le informazioni sui due componenti del ponte oggetto-relazionale: gli oggetti @Entity (oggetto) e il database (relazionale).
- Abbiamo creato due attività Ant, denominate DDL e DB, che ci consentono di creare il database in base alla configurazione precedente, anche prima di scrivere qualsiasi codice Java.
Ora che il livello JPA della nostra applicazione è configurato correttamente, possiamo iniziare a esplorare l'API JPA con il codice Java.
2.1.9. Il contesto di persistenza di un'applicazione
Diamo un'occhiata più da vicino all'ambiente di runtime di un client JPA:
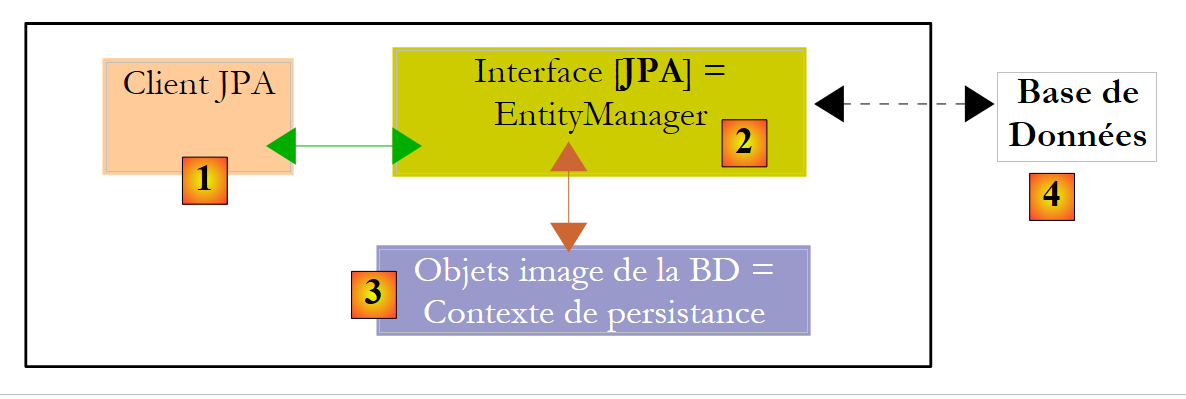 |
Sappiamo che il livello JPA [2] crea un ponte tra gli oggetti [3] e i dati relazionali [4]. Il "contesto di persistenza" si riferisce all'insieme di oggetti gestiti dal livello JPA all'interno di questo ponte oggetto-relazionale. Per accedere ai dati nel contesto di persistenza, un client JPA [1] deve passare attraverso il livello JPA [2]:
- può creare un oggetto e chiedere al livello JPA di renderlo persistente. L'oggetto diventa quindi parte del contesto di persistenza.
- può richiedere un riferimento a un oggetto persistente esistente dal livello [JPA].
- può modificare un oggetto persistente ottenuto dal livello JPA.
- può chiedere al livello JPA di rimuovere un oggetto dal contesto di persistenza.
Il livello JPA fornisce al client un'interfaccia chiamata [EntityManager] che, come suggerisce il nome, consente la gestione degli oggetti @Entity nel contesto di persistenza. Di seguito sono riportati i metodi principali di questa interfaccia:
Aggiunge l'entità al contesto di persistenza | |
rimuove l'entità dal contesto di persistenza | |
unisce un oggetto entità proveniente dal client che non è gestito dal contesto di persistenza con l'oggetto entità nel contesto di persistenza che ha la stessa chiave primaria. Il risultato restituito è l'oggetto entità proveniente dal contesto di persistenza. | |
inserisce un oggetto recuperato dal database tramite la sua chiave primaria. Il tipo T dell'oggetto permette al livello JPA di sapere quale tabella interrogare. L'oggetto persistente così creato viene restituito al client. | |
crea un oggetto Query da una query JPQL (Java Persistence Query Language). Una query JPQL è analoga a una query SQL, tranne per il fatto che interroga oggetti anziché tabelle. | |
Un metodo simile al precedente, tranne per il fatto che queryText è un'istruzione SQL anziché una query JPQL. | |
Un metodo identico a createQuery, tranne per il fatto che la query JPQL queryText è esternalizzata in un file di configurazione e associata a un nome. Questo nome è il parametro del metodo. |
Un oggetto EntityManager ha un ciclo di vita che non è necessariamente lo stesso di quello dell’applicazione. Ha un inizio e una fine. Pertanto, un client JPA può lavorare in successione con diversi oggetti EntityManager. Il contesto di persistenza dell' e associato a un EntityManager ha lo stesso ciclo di vita dell'EntityManager stesso. Sono inseparabili l'uno dall'altro. Quando un oggetto EntityManager viene chiuso, il suo contesto di persistenza viene sincronizzato con il database, se necessario, e poi cessa di esistere. Per ottenere un nuovo contesto di persistenza è necessario creare un nuovo EntityManager.
Il client JPA può creare un EntityManager e quindi un contesto di persistenza con la seguente istruzione:
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
- javax.persistence.Persistence è una classe statica utilizzata per ottenere una factory per gli oggetti EntityManager. Questa factory è associata a una specifica unità di persistenza. Ricordiamo che il file di configurazione [META-INF/persistence.xml] viene utilizzato per definire le unità di persistenza, ciascuna delle quali ha un nome:
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
Nell'esempio sopra riportato, l'unità di persistenza è denominata jpa. Essa è dotata di una propria configurazione specifica, che include il sistema di gestione del database (DBMS) con cui opera. L'istruzione [Persistence.createEntityManagerFactory("jpa")] crea un EntityManagerFactory in grado di fornire oggetti EntityManager progettati per gestire i contesti di persistenza associati all'unità di persistenza denominata jpa. Un oggetto EntityManager — e quindi un contesto di persistenza — viene ottenuto dall'oggetto EntityManagerFactory come segue:
I seguenti metodi dell'interfaccia [EntityManager] consentono di gestire il ciclo di vita del contesto di persistenza:
Il contesto di persistenza viene chiuso. Forza la sincronizzazione del contesto di persistenza con il database:
| |
Il contesto di persistenza viene svuotato di tutti i suoi oggetti ma non chiuso. | |
Il contesto di persistenza viene sincronizzato con il database come descritto per close() |
Il client JPA può forzare la sincronizzazione del contesto di persistenza con il database utilizzando il metodo [EntityManager].flush. La sincronizzazione può essere esplicita o implicita. Nel primo caso, spetta al client eseguire le operazioni di flush quando desidera sincronizzarsi; altrimenti, la sincronizzazione avviene in momenti specifici che specificheremo. La modalità di sincronizzazione è gestita dai seguenti metodi dell'interfaccia [EntityManager]:
Esistono due possibili valori per flushMode: FlushModeType.AUTO (impostazione predefinita): la sincronizzazione avviene prima di ogni query SELECT eseguita sul database. FlushModeType.COMMIT: la sincronizzazione avviene solo al termine delle transazioni del database. | |
restituisce la modalità di sincronizzazione corrente |
Riassumiamo. Nella modalità FlushModeType.AUTO, che è quella predefinita, il contesto di persistenza verrà sincronizzato con il database nei seguenti momenti:
- prima di ogni operazione SELECT sul database
- alla fine di una transazione sul database
- dopo un'operazione di flush o di chiusura sul contesto di persistenza
Nella modalità FlushModeType.COMMIT, vale lo stesso, tranne per l'operazione 1, che non si verifica. La modalità normale di interazione con il livello JPA è la modalità transazionale. Il client esegue varie operazioni sul contesto di persistenza all'interno di una transazione. In questo caso, i punti di sincronizzazione tra il contesto di persistenza e il database sono i casi 1 e 2 sopra indicati nella modalità AUTO, e solo il caso 2 nella modalità COMMIT.
Concludiamo con l'API dell'interfaccia Query, che consente di emettere comandi JPQL sul contesto di persistenza o comandi SQL direttamente sul database per recuperare i dati. L'interfaccia Query è la seguente:
 |
Utilizzeremo i metodi da 1 a 4 sopra indicati:
- 1 - Il metodo getResultList esegue una query SELECT che restituisce più oggetti. Questi vengono restituiti in un oggetto List. Questo oggetto è un'interfaccia. Fornisce un oggetto Iterator che consente di iterare attraverso gli elementi della lista L come segue:
Iterator iterator = L.iterator();
while (iterator.hasNext()) {
// exploiter l'objet iterator.next() qui représente l'élément courant de la liste
...
}
È possibile iterare sulla lista L anche utilizzando un ciclo for:
for (Object o : L) {
// exploiter objet o
}
- 2 - Il metodo `getSingleResult` esegue un'istruzione SELECT JPQL/SQL che restituisce un singolo oggetto.
- 3 - Il metodo `executeUpdate` esegue un'istruzione SQL UPDATE o DELETE e restituisce il numero di righe interessate dall'operazione.
- 4 - Il metodo setParameter(String, Object) consente di assegnare un valore a un parametro denominato in una query JPQL parametrizzata.
- 5 - Il metodo setParameter(int, Object) imposta il parametro, ma il parametro non è identificato dal suo nome bensì dalla sua posizione nella query JPQL.
2.1.10. Un primo client JPA
Torniamo alla prospettiva Java del progetto:
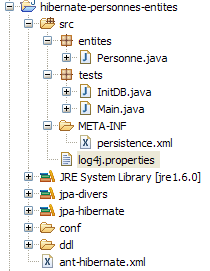 |
Ora sappiamo quasi tutto di questo progetto, tranne il contenuto della cartella [src/tests], che esamineremo in seguito. La cartella contiene due programmi di test per il livello JPA:
- [InitDB.java] è un programma che inserisce alcune righe nella tabella [jpa01_personne] del database. Il suo codice ci introdurrà ai primi elementi del livello JPA.
- [Main.java] è un programma che esegue operazioni CRUD sulla tabella [jpa01_personne]. Lo studio del suo codice ci consentirà di esplorare i concetti fondamentali del contesto di persistenza e del ciclo di vita degli oggetti all'interno di tale contesto.
2.1.10.1. Il codice
Il codice del programma [InitDB.java] è il seguente:
package tests;
import java.text.ParseException;
import java.text.SimpleDateFormat;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.EntityTransaction;
import javax.persistence.Persistence;
import entites.Personne;
public class InitDB {
// constant
private final static String TABLE_NAME = "jpa01_personne";
public static void main(String[] args) throws ParseException {
// Persistence unit
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
// retrieve a EntityManagerFactory from the persistence unit
EntityManager em = emf.createEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// delete items from the people table
em.createNativeQuery("delete from " + TABLE_NAME).executeUpdate();
// create two people
Personne p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// persistence of people
em.persist(p1);
em.persist(p2);
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// end transaction
tx.commit();
// end EntityManager
em.close();
// end EntityManagerFactory
emf.close();
// log
System.out.println("terminé ...");
}
}
Questo codice va letto alla luce di quanto spiegato nella sezione 2.1.9.
- Riga 19: viene richiesto un oggetto EntityManagerFactory (emf) per l'unità di persistenza JPA (definita in persistence.xml). Questa operazione viene normalmente eseguita una sola volta durante il ciclo di vita di un'applicazione.
- Riga 21: viene richiesto un oggetto EntityManager (em) per gestire un contesto di persistenza.
- Riga 23: viene richiesto un oggetto Transaction per gestire una transazione. Si noti che le operazioni sul contesto di persistenza devono essere eseguite all'interno di una transazione. Vedremo che ciò non è strettamente necessario, ma non farlo può causare problemi. Se l'applicazione viene eseguita in un contenitore EJB3, le operazioni sul contesto di persistenza vengono sempre eseguite all'interno di una transazione.
- Riga 24: La transazione ha inizio
- riga 26: esegue un'istruzione SQL di cancellazione sulla tabella "jpa01_personne" (nativeQuery). Lo facciamo per svuotare la tabella di tutti i contenuti e vedere così meglio il risultato dell'esecuzione dell'applicazione [InitDB]
- Righe 28–29: vengono creati due oggetti Person, p1 e p2. Si tratta di oggetti ordinari che, per il momento, non hanno nulla a che vedere con il contesto di persistenza. In relazione al contesto di persistenza, Hibernate definisce questi oggetti come in uno stato transitorio, in contrapposizione agli oggetti persistenti, che sono gestiti dal contesto di persistenza. Ci riferiremo invece a oggetti non persistenti (un termine non standard) per indicare che non sono ancora gestiti dal contesto di persistenza, e a oggetti persistenti per quelli che sono gestiti da esso. Incontreremo una terza categoria di oggetti: gli oggetti distaccati, ovvero oggetti che in precedenza erano persistenti ma il cui contesto di persistenza è stato chiuso. Il client può conservare riferimenti a tali oggetti, il che spiega perché non vengono necessariamente distrutti quando il contesto di persistenza viene chiuso. Si dice quindi che si trovino in uno stato distaccato. L'operazione [EntityManager].merge consente di riattaccarli a un contesto di persistenza appena creato.
- Righe 31–32: Le entità p1 e p2 vengono aggiunte al contesto di persistenza tramite l'operazione [EntityManager].persist. Diventano quindi oggetti persistenti.
- Righe 35–37: Viene eseguita una query JPQL “select p from Person p order by p.name asc”. Person non è la tabella (che si chiama jpa01_person) ma l’oggetto @Entity associato alla tabella. Qui abbiamo una query JPQL (Java Persistence Query Language) sul contesto di persistenza, non una query SQL sul database. Detto questo, a parte l’oggetto Person che ha sostituito la tabella jpa01_personne, le sintassi sono identiche. Un ciclo for itera attraverso l’elenco (di persone) risultante dal select per visualizzare ciascun elemento sulla console. Qui stiamo verificando che gli elementi inseriti nel contesto di persistenza alle righe 31–32 siano effettivamente presenti nella tabella. Si verificherà una sincronizzazione trasparente del contesto di persistenza con il database. Infatti, verrà emessa una query SELECT e abbiamo notato che questo è uno dei casi in cui avviene la sincronizzazione. È quindi in questo momento che, in background, JPA/Hibernate emetterà le due istruzioni SQL INSERT che inseriranno le due persone nella tabella jpa01_personne. L'operazione `persist` non ha fatto questo. Questa operazione aggiunge oggetti al contesto di persistenza senza influire sul database. Il lavoro effettivo avviene durante la sincronizzazione, in questo caso appena prima della query `SELECT` sul database.
- Riga 39: Terminiamo la transazione avviata alla riga 24. Si verificherà nuovamente una sincronizzazione. Qui non accadrà nulla poiché il contesto di persistenza non è cambiato dall'ultima sincronizzazione.
- Riga 41: Chiudiamo il contesto di persistenza.
- Riga 43: Chiudiamo la factory EntityManager.
2.1.10.2. L' : esecuzione del codice
- Avviare il DBMS MySQL5
- Se necessario, inserire conf/mysql5/persistence.xml in META-INF/persistence.xml
- Eseguire l'applicazione [InitDB]
Si ottengono i seguenti risultati:
 |
- in [1]: l'output della console nella prospettiva Java. Si ottengono i risultati attesi.
- in [2]: verifichiamo il contenuto della tabella [jpa01_personne] utilizzando la vista SQL Explorer, come spiegato nella sezione 2.1.8. Due punti meritano di essere sottolineati:
- l'ID della chiave primaria è stato generato automaticamente
- lo stesso vale per il numero di versione. Notiamo che la prima versione ha il numero 0..
Qui abbiamo i primi elementi del framework JPA. Abbiamo inserito con successo i dati in una tabella. Partiremo da queste basi per scrivere il secondo test, ma prima parliamo dei log.
2.1.11. Implementazione dei log di Hibernate
È possibile visualizzare le istruzioni SQL inviate al database dal livello JPA/Hibernate. È utile esaminarle per verificare se il livello JPA è efficiente quanto uno sviluppatore che avesse scritto le istruzioni SQL personalmente.
Con JPA/Hibernate, la registrazione SQL può essere configurata nel file [persistence.xml]:
<!-- Classes persistantes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- logs SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- connexion JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
- Righe 4–6: a questo punto i log SQL non erano abilitati. Li abilitiamo ora rimuovendo i tag di commento dalle righe 3 e 7.
Eseguiamo nuovamente l'applicazione [InitDB]. L'output della console diventa quindi il seguente:
- Righe 2-4: L'istruzione SQL DELETE risultante dal comando:
// supprimer les éléments de la table des personnes
em.createNativeQuery("delete from " + TABLE_NAME).executeUpdate();
- righe 5-18: le istruzioni SQL INSERT dalle istruzioni:
// persistance des personnes
em.persist(p1);
em.persist(p2);
- righe 21-32: l'istruzione SQL SELECT risultante dall'istruzione:
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList())
Se inseriamo delle stampe intermedie in console, noteremo che i log SQL relativi all'istruzione I nel codice Java vengono scritti al momento dell'esecuzione di tale istruzione. Ciò non significa che l'istruzione SQL visualizzata venga eseguita sul database in quel preciso istante. In realtà, essa viene memorizzata nella cache per essere eseguita durante la successiva sincronizzazione del contesto di persistenza con il database.
È possibile ottenere log aggiuntivi tramite il file [src/log4j.properties]:
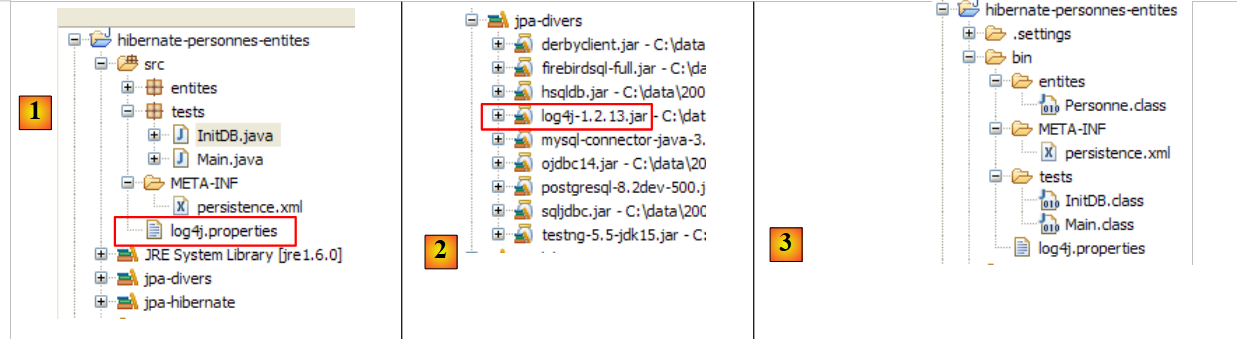 |
- In [1], il file [log4j.properties] viene utilizzato dall'archivio [log4j-1.2.13.jar] [2] dello strumento denominato LOG4j (Logs for Java), disponibile all'URL [http://logging.apache.org/log4j/docs/index.html]. Se collocato nella cartella [src] del progetto Eclipse, sappiamo che [log4j.properties] verrà automaticamente copiato nella cartella [bin] del progetto [3]. Una volta fatto ciò, si trova ora nel classpath del progetto, ed è lì che l’archivio [2] lo recupererà.
Il file [log4j.properties] ci permette di controllare alcuni log di Hibernate. Nelle esecuzioni precedenti, il suo contenuto era il seguente:
# Direct log messages to stdout
log4j.appender.stdout=org.apache.log4j.ConsoleAppender
log4j.appender.stdout.Target=System.out
log4j.appender.stdout.layout=org.apache.log4j.PatternLayout
log4j.appender.stdout.layout.ConversionPattern=%d{ABSOLUTE} %5p %c{1}:%L - %m%n
# Root logger option
log4j.rootLogger=ERROR, stdout
# Hibernate logging options (INFO only shows startup messages)
#log4j.logger.org.hibernate=INFO
# Log JDBC bind parameter runtime arguments
#log4j.logger.org.hibernate.type=DEBUG
Non mi dilungherò molto su questa configurazione poiché non ho mai avuto il tempo di approfondire seriamente LOG4j.
- Le righe da 1 a 8 si trovano in tutti i file log4j.properties che ho incontrato
- Le righe 10–14 sono presenti nei file log4j.properties degli esempi di Hibernate.
- Riga 11: controlla i log generali di Hibernate. Poiché la riga è commentata, questi log sono disabilitati in questo caso. Esistono diversi livelli di log: INFO (informazioni generali su ciò che sta facendo Hibernate), WARN (Hibernate ci avverte di un potenziale problema), DEBUG (log dettagliati). Il livello INFO è il meno dettagliato, mentre la modalità DEBUG è la più dettagliata. Abilitando la riga 11 è possibile vedere cosa sta facendo Hibernate, in particolare all'avvio dell'applicazione. Questo è spesso utile.
- La riga 12, se abilitata, consente di vedere gli argomenti effettivi utilizzati durante l'esecuzione di query SQL parametrizzate.
Iniziamo rimuovendo il commento dalla riga 14
# Log JDBC bind parameter runtime arguments
log4j.logger.org.hibernate.type=DEBUG
ed eseguire nuovamente [InitDB]. I nuovi log generati da questa modifica sono i seguenti (vista parziale):
- Le righe 8–10 sono nuovi log generati dall'abilitazione della riga 14 di [log4j.properties]. Indicano i 5 valori assegnati ai parametri formali ? della query parametrizzata nelle righe 2–7. Pertanto, vediamo che la colonna VERSION riceverà il valore 0 (riga 8).
Ora abilitiamo la riga 11 di [log4j.properties]:
e riesegui [InitDB]:
La lettura di questi log fornisce molte informazioni interessanti:
- riga 7: Hibernate indica il nome di una classe @Entity che ha trovato
- riga 8: indica che la classe [Person] verrà mappata alla tabella [jpa01_person]
- riga 9: indica il pool di connessioni C3P0 che verrà utilizzato, il nome del driver JDBC e l'URL del database da gestire
- riga 10: fornisce ulteriori dettagli sulla connessione JDBC: proprietario, tipo di commit, ecc.
- riga 14: il dialetto utilizzato per comunicare con il DBMS
- riga 15: il tipo di transazione utilizzato. JDBCTransactionFactory indica che l'applicazione gestisce le proprie transazioni. Non viene eseguita in un contenitore EJB3 che fornirebbe un proprio servizio di transazione.
- Le righe seguenti si riferiscono alle opzioni di configurazione di Hibernate che non abbiamo ancora incontrato. Si invitano i lettori interessati a consultare la documentazione di Hibernate.
- Riga 37: le istruzioni SQL verranno visualizzate sulla console. Ciò è stato richiesto in [persistence.xml]:
<property name="hibernate.show_sql" value="true" />
<property name="hibernate.format_sql" value="true" />
<property name="use_sql_comments" value="true" />
- Righe 43–45: Lo schema del database viene esportato nel DBMS, ovvero il database viene svuotato e poi ricreato. Questo meccanismo deriva dalla configurazione in [persistence.xml] (riga 4 di seguito):
...
<property name="hibernate.connection.password" value="jpa" />
<!-- création automatique du schéma -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialecte -->
...
Quando un'applicazione "si blocca" con un'eccezione Hibernate che non capisci, inizia abilitando i log di Hibernate in modalità DEBUG in [log4j.properties] per avere un quadro più chiaro:
# Root logger option
log4j.rootLogger=ERROR, stdout
# Hibernate logging options (INFO only shows startup messages)
log4j.logger.org.hibernate=DEBUG
Nel resto di questo documento, la registrazione è disabilitata per impostazione predefinita per garantire un output della console più leggibile.
2.1.12. Esplorazione del linguaggio di interrogazione JPQL/HQL con la console di Hibernate
Nota: questa sezione richiede il plugin Hibernate Tools (sezione 5.2.5).
Nel codice dell'applicazione [InitDB] abbiamo utilizzato una query JPQL. JPQL (Java Persistence Query Language) è un linguaggio per l'interrogazione del contesto di persistenza. La query utilizzata era la seguente:
Ha selezionato tutti i record dalla tabella associata a @Entity [Person] e li ha restituiti in ordine crescente per nome. Nella query sopra riportata, p.name è il campo nome di un'istanza p della classe [Person]. Una query JPQL opera quindi sugli oggetti @Entity nel contesto di persistenza e non direttamente sulle tabelle del database. Il livello JPA traduce questa query JPQL in una query SQL appropriata per il DBMS con cui sta lavorando. Pertanto, nel caso di un'implementazione JPA/Hibernate collegata a un DBMS MySQL5, la precedente query JPQL viene tradotta nella seguente query SQL:
select
personne0_.ID as ID0_,
personne0_.VERSION as VERSION0_,
personne0_.NOM as NOM0_,
personne0_.PRENOM as PRENOM0_,
personne0_.DATENAISSANCE as DATENAIS5_0_,
personne0_.MARIE as MARIE0_,
personne0_.NBENFANTS as NBENFANTS0_
from
jpa01_personne personne0_
order by
personne0_.NOM asc
Il livello JPA ha utilizzato la configurazione dell'oggetto @Entity [Person] per generare la query SQL corretta. Questo è un esempio dell'implementazione della mappatura oggetto-relazionale.
Il plugin [Hibernate Tools] (Sezione 5.2.5) offre uno strumento chiamato "Hibernate Console" che consente
- di eseguire query JPQL o HQL (Hibernate Query Language) sul contesto di persistenza
- per recuperare i risultati
- e di visualizzare l'equivalente SQL che è stato eseguito sul database
La Hibernate Console è uno strumento inestimabile per imparare il linguaggio JPQL e acquisire familiarità con il bridge JPQL/SQL. È risaputo che JPA ha attinto ampiamente da strumenti ORM come Hibernate o TopLink. JPQL è molto simile all’HQL di Hibernate, ma non ne include tutte le funzionalità. Nella console di Hibernate è possibile emettere comandi HQL che verranno eseguiti normalmente nella console ma che non fanno parte del linguaggio JPQL e quindi non possono essere utilizzati in un client JPA. In questi casi, lo segnaleremo.
Creiamo una console Hibernate per il nostro attuale progetto Eclipse:
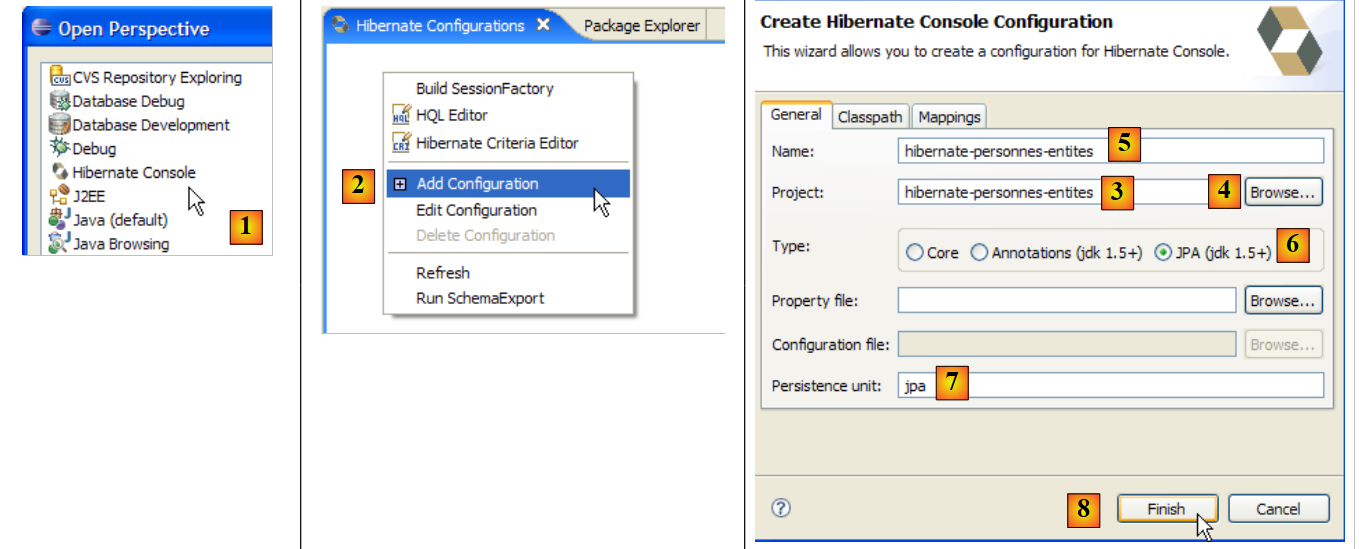 |
- [1]: Passare alla prospettiva [Hibernate Console] (Finestra / Apri prospettiva / Altro)
- [2]: Creiamo una nuova configurazione nella finestra [Configurazione Hibernate]
- utilizzando il pulsante [4], selezioniamo il progetto Java per il quale si sta creando la configurazione Hibernate. Il suo nome appare in [3].
- In [5], inseriamo il nome che vogliamo per questa configurazione. Qui, abbiamo usato [3].
- In [6], specifichiamo che stiamo utilizzando una configurazione JPA in modo che lo strumento sappia che deve utilizzare il file [META-INF/persistence.xml]
- In [7], specifichiamo che in questo file [META-INF/persistence.xml] deve essere utilizzata l'unità di persistenza denominata jpa.
- In [8], convalidiamo la configurazione.
Successivamente, è necessario avviare il DBMS. In questo caso, stiamo utilizzando MySQL 5.
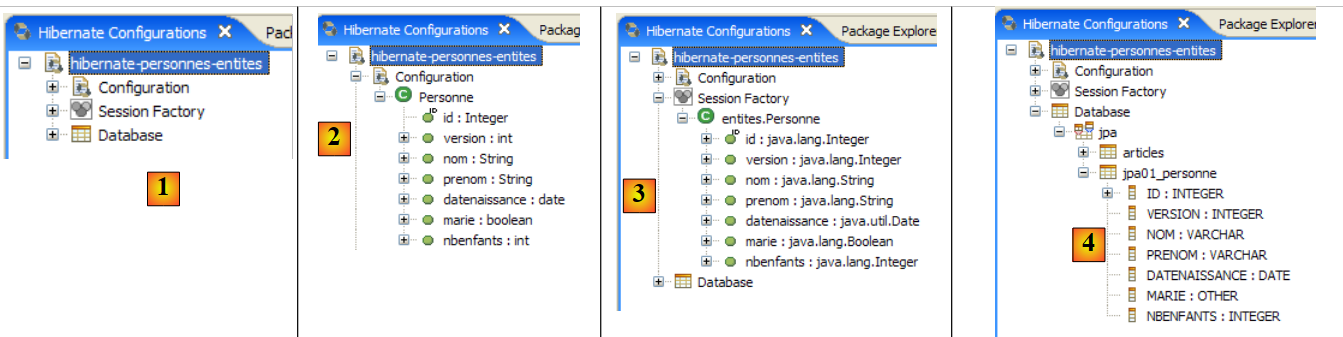 |
- In [1]: La configurazione creata mostra un albero a tre rami
- In [2]: Il ramo [Configuration] elenca gli oggetti utilizzati dalla console per configurarsi: in questo caso, l'@Entity Person.
- In [3]: La Session Factory è un concetto di Hibernate simile all’EntityManager di JPA. Colma il divario tra oggetti e relazionale utilizzando gli oggetti nel ramo [Configuration]. In [3] sono mostrati gli oggetti del contesto di persistenza; qui, ancora una volta, l’@Entity Person.
- in [4]: il database a cui si accede tramite la configurazione che si trova in [persistence.xml]. Lì si trova la tabella [jpa01_personne].
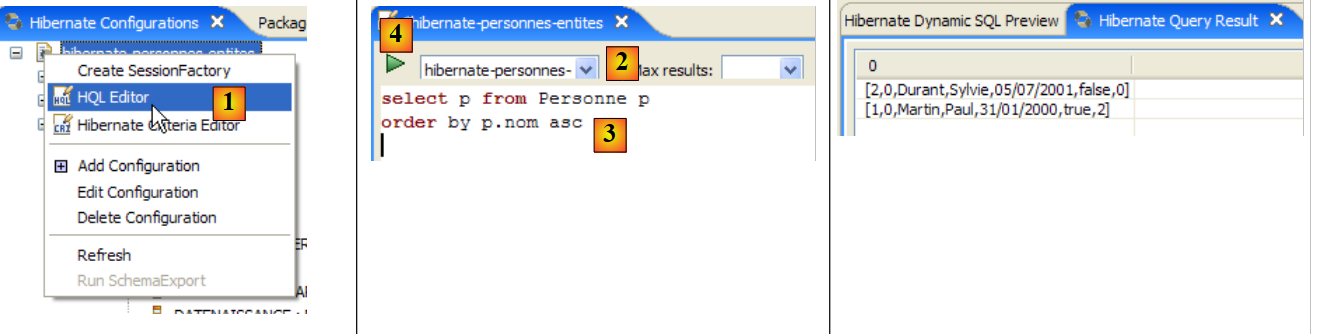 |
- In [1], creiamo un editor HQL
- nell'editor HQL,
- in [2], selezioniamo la configurazione di Hibernate da utilizzare se ce ne sono più
- in [3], digitiamo il comando JPQL che vogliamo eseguire
- in [4], lo si esegue
- In [5], si ottengono i risultati della query nella finestra [Hibernate Query Result]. Qui si potrebbero verificare due problemi:
- Non viene visualizzato nulla (nessuna riga). La console Hibernate ha utilizzato il contenuto di [persistence.xml] per stabilire una connessione con il DBMS. Tuttavia, questa configurazione presenta una proprietà che indica al database di essere svuotato:
<property name="hibernate.hbm2ddl.auto" value="create" />
È quindi necessario rieseguire l'applicazione [InitDB] prima di rieseguire il comando JPQL sopra riportato.
- (continua)
- La finestra [Hibernate Query Result] non viene visualizzata. È possibile aprirla tramite [Window / Show View / ...]
La finestra [Hibernate Dynamic SQL preview] ([1] sotto) consente di visualizzare la query SQL che verrà eseguita per eseguire il comando JPQL che si sta scrivendo. Non appena la sintassi del comando JPQL è corretta, il comando SQL corrispondente appare in questa finestra:
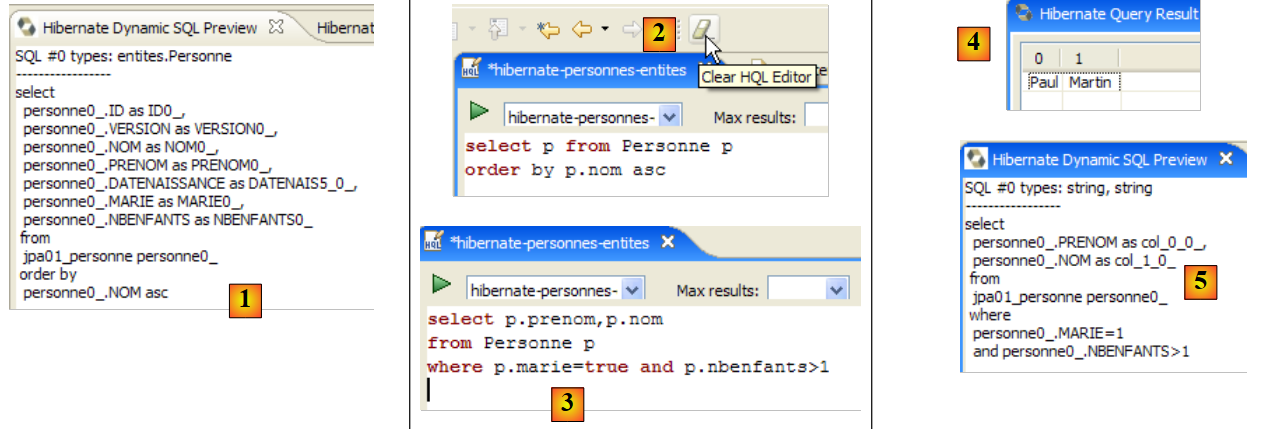 |
- In [2] è possibile cancellare il comando HQL precedente
- Al punto [3], se ne esegue uno nuovo
- in [4], il risultato
- in [5], il comando SQL che è stato eseguito sul database
L'editor HQL fornisce assistenza per la scrittura dei comandi HQL:
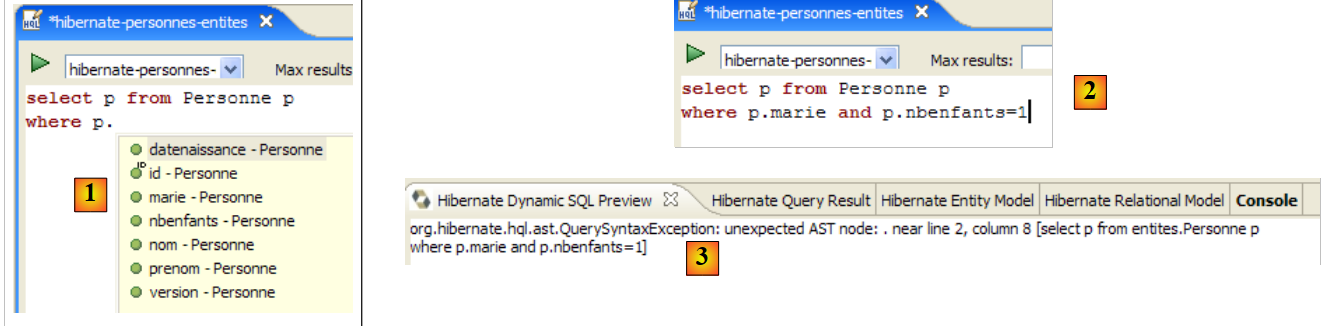 |
- in [1]: una volta che l'editor ha riconosciuto che p è un oggetto Person, può suggerire i campi di p durante la digitazione.
- in [2]: una query HQL errata. È necessario scrivere where p.marie=true.
- in [3]: l'errore viene segnalato nella finestra [Anteprima SQL]
Invitiamo il lettore a eseguire altri comandi HQL/JPQL sul database.
2.1.13. Un secondo client JPA
Torniamo alla prospettiva Java del progetto:
|
- [InitDB.java] è un programma che ha inserito alcune righe nella tabella [jpa01_personne] del database. Lo studio del suo codice ci ha permesso di comprendere le basi dell'API JPA.
- [Main.java] è un programma che esegue operazioni CRUD sulla tabella [jpa01_personne]. Esaminarne il codice ci consentirà di rivedere i concetti fondamentali del contesto di persistenza e del ciclo di vita degli oggetti all'interno di tale contesto.
2.1.13.1. La struttura del codice
[Main.java] eseguirà una serie di test, ciascuno progettato per dimostrare un aspetto specifico di JPA:
 |
Il metodo [main]
- chiama in successione i metodi da test1 a test11. Presenteremo il codice di ciascuno di questi metodi separatamente.
- Utilizza inoltre metodi di utilità privati: clean, dump, log, getEntityManager, getNewEntityManager.
Presentiamo il metodo main e i cosiddetti metodi di utilità:
package tests;
...
import entites.Personne;
@SuppressWarnings("unchecked")
public class Main {
// constant
private final static String TABLE_NAME = "jpa01_personne";
// Persistence context
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
private static EntityManager em = null;
// shared objects
private static Personne p1, p2, newp1;
public static void main(String[] args) throws Exception {
// base cleaning
log("clean");clean();
// dump table
dump();
// test1
log("test1");test1();
...
// test11
log("test11");test11();
// fine persistence context
if (em.isOpen())
em.close();
// closure EntityManagerFactory
emf.close();
}
// retrieve the current EntityManager
private static EntityManager getEntityManager() {
if (em == null || !em.isOpen()) {
em = emf.createEntityManager();
}
return em;
}
// pick up a new EntityManager
private static EntityManager getNewEntityManager() {
if (em != null && em.isOpen()) {
em.close();
}
em = emf.createEntityManager();
return em;
}
// table content display
private static void dump() {
// current persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// end transaction
tx.commit();
}
// raz BD
private static void clean() {
// persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// delete elements from the PERSONNES table
em.createNativeQuery("delete from " + TABLE_NAME).executeUpdate();
// end transaction
tx.commit();
}
// logs
private static void log(String message) {
System.out.println("main : ----------- " + message);
}
// object creation
public static void test1() throws ParseException {
...
}
// modify a context object
public static void test2() {
...
}
// request items
public static void test3() {
...
}
// delete an object belonging to the persistence context
public static void test4() {
....
}
// detach, reattach and modify
public static void test5() {
...
}
// delete an object not belonging to the persistence context
public static void test6() {
...
}
// modify an object not belonging to the persistence context
public static void test7() {
...
}
// reattach an object to the persistence context
public static void test8() {
...
}
// a select request causes synchronization
// with the persistence context
public static void test9() {
....
}
// version control (optimistic locking)
public static void test10() {
...
}
// transaction rollback
public static void test11() throws ParseException {
...
}
}
- Riga 13: L'oggetto EntityManagerFactory (emf) viene creato a partire dall'unità di persistenza JPA definita in [persistence.xml]. Ci consentirà di creare vari contesti di persistenza all'interno dell'applicazione.
- riga 14: un contesto di persistenza EntityManager che non è stato ancora inizializzato
- riga 17: tre oggetti [Person] condivisi dai test
- Riga 21: La tabella jpa01_personne viene svuotata e poi visualizzata alla riga 24 per assicurarci di partire da una tabella vuota.
- Righe 27–31: sequenza di test
- Righe 34–35: chiusura del contesto di persistenza se era aperto.
- Riga 38: l'oggetto EntityManagerFactory emf viene chiuso.
- Righe 42–47: il metodo [getEntityManager] restituisce l'EntityManager (o contesto di persistenza) corrente oppure ne crea uno nuovo se non esiste (righe 43–44).
- Righe 50-56: il metodo [getNewEntityManager] restituisce un nuovo contesto di persistenza. Se ne esisteva uno in precedenza, viene chiuso (righe 51-52)
- righe 59-72: il metodo [dump] visualizza il contenuto della tabella [jpa01_personne]. Questo codice è già stato visto in [InitDB].
- righe 75-85: il metodo [clean] svuota la tabella [jpa01_personne]. Questo codice è già stato visto in [InitDB].
- Righe 88–90: il metodo [log] visualizza sulla console il messaggio che gli è stato passato come parametro, in modo che venga notato.
Ora possiamo passare allo studio dei test.
2.1.13.2. Test 1
Il codice per il test 1 è il seguente:
// création d'objets
public static void test1() throws ParseException {
// contexte de persistance
EntityManager em = getEntityManager();
// création personnes
p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistance des personnes
em.persist(p1);
em.persist(p2);
// fin transaction
tx.commit();
// on affiche la table
dump();
}
Questo codice è già stato visto in [InitDB]: crea due persone e le inserisce nel contesto di persistenza.
- riga 4: recuperiamo il contesto di persistenza corrente
- righe 6-7: creiamo le due persone
- righe 9–15: le due persone vengono inserite nel contesto di persistenza all'interno di una transazione
- riga 15: poiché la transazione viene confermata, il contesto di persistenza viene sincronizzato con il database. Le due persone verranno aggiunte alla tabella [jpa01_personne].
- Riga 17: La tabella viene visualizzata
L'output della console per questo primo test è il seguente:
main : ----------- test1
[personnes]
[2,0,Durant,Sylvie,05/07/2001,false,0]
[1,0,Martin,Paul,31/01/2000,true,2]
2.1.13.3. Test 2
Il codice per il test 2 è il seguente:
// modifier un objet du contexte
public static void test2() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on incrémente le nbre d'enfants de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// on modifie son état marital
p1.setMarie(false);
// l'objet p1 est automatiquement sauvegardé (dirty checking)
// lors de la prochaine synchronisation (commit ou select)
// fin transaction
tx.commit();
// on affiche la nouvelle table
dump();
}
- Il Test 2 mira a modificare un oggetto nel contesto di persistenza e quindi a visualizzare il contenuto della tabella per verificare se la modifica è avvenuta
- Riga 4: Recupera il contesto di persistenza corrente
- Righe 6–7: Le operazioni saranno eseguite all'interno di una transazione
- Righe 9, 11: Il numero di figli della persona p1 viene modificato, così come il loro stato civile
- Riga 15: Fine della transazione, quindi il contesto di persistenza viene sincronizzato con il database
- Riga 17: visualizza tabella
L'output della console per il Test 2 è il seguente:
- riga 4: persona p1 prima della modifica
- riga 8: persona p1 dopo la modifica. Si noti che il numero di versione è cambiato in 1. Questo numero viene incrementato di 1 ogni volta che la riga viene aggiornata.
2.1.13.4. Test 3
Il codice per il Test 3 è il seguente:
// demander des objets
public static void test3() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on demande la personne p1
Personne p1b = em.find(Personne.class, p1.getId());
// parce que p1 est déjà dans le contexte de persistance, il n'y a pas eu d'accès à la base
// p1b et p1 sont les mêmes références
System.out.format("p1==p1b ? %s%n", p1 == p1b);
// demander un objet qui n'existe pas rend 1 pointeur null
Personne px = em.find(Personne.class, -4);
System.out.format("px==null ? %s%n", px == null);
// fin transaction
tx.commit();
}
- Il Test 3 si concentra sul metodo [EntityManager.find], che recupera un oggetto dal database e lo inserisce nel contesto di persistenza. Non spiegheremo più la transazione che avviene in tutti i test, a meno che non venga utilizzata in modo insolito.
- Riga 9: Chiediamo al contesto di persistenza la persona con la stessa chiave primaria della persona p1. Ci sono due casi:
- p1 è già nel contesto di persistenza. Questo è il caso in questione. Pertanto, non viene eseguito alcun accesso al database. Il metodo find restituisce semplicemente un riferimento all'oggetto persistito.
- p1 non è nel contesto di persistenza. In questo caso, viene eseguita una query sul database utilizzando la chiave primaria fornita. Il record recuperato viene aggiunto al contesto di persistenza e find restituisce un riferimento a questo nuovo oggetto persistito.
- Riga 12: Verifichiamo che `find` abbia restituito il riferimento all'oggetto `p1` già presente nel contesto
- Riga 14: Richiediamo un oggetto che non esiste né nel contesto di persistenza né nel database. Il metodo find restituisce quindi un puntatore nullo. Ciò viene verificato alla riga 15.
L'output della console per il Test 3 è il seguente:
2.1.13.5. Test 4
Il codice per il test 4 è il seguente:
// supprimer un objet appartenant au contexte de persistance
public static void test4() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on supprime l'objet persisté p2
em.remove(p2);
// fin transaction
tx.commit();
// on affiche la nouvelle table
dump();
}
- Il Test 4 si concentra sul metodo [EntityManager.remove], che consente di rimuovere un elemento dal contesto di persistenza e quindi dal database.
- riga 9: la persona p2 viene rimossa dal contesto di persistenza
- riga 11: sincronizzazione del contesto con il database
- Riga 13: visualizzazione della tabella. Normalmente, la persona p2 non dovrebbe più essere presente.
L'output della console per il Test 4 è il seguente:
- riga 3: persona p2 in test1
- righe 12-14: non esistono più dopo test4.
2.1.13.6. Test 5
Il codice per il test5 è il seguente:
// détacher, réattacher et modifier
public static void test5() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// p1 détaché
Personne oldp1=p1;
// on réattache p1 au nouveau contexte
p1 = em.find(Personne.class, p1.getId());
// vérification
System.out.format("p1==oldp1 ? %s%n", p1 == oldp1);
// fin transaction
tx.commit();
// on incrémente le nbre d'enfants de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// on affiche la nouvelle table
dump();
}
- Il Test 5 esamina il ciclo di vita degli oggetti persistiti attraverso diversi contesti di persistenza successivi. Finora, avevamo sempre utilizzato lo stesso contesto di persistenza nei vari test.
- Riga 4: viene richiesto un nuovo contesto di persistenza. Il metodo [getNewEntityManager] chiude quello precedente e ne apre uno nuovo. Di conseguenza, gli oggetti p1 e p2 detenuti dall'applicazione non sono più in uno stato persistente. Appartenevano a un contesto che è stato chiuso. Si dice che sono in uno stato distaccato. Non appartengono al nuovo contesto di persistenza.
- Righe 6–7: Inizio della transazione. Qui verrà utilizzata in modo insolito.
- Riga 9: prendiamo nota dell'indirizzo dell'oggetto p1, ora distaccato.
- Riga 11: Il contesto di persistenza viene interrogato per la persona p1 (utilizzando la chiave primaria di p1). Poiché il contesto è nuovo, la persona p1 non è presente al suo interno. Verrà quindi eseguita una query sul database. L'oggetto recuperato verrà inserito nel nuovo contesto.
- Riga 13: Verifichiamo che l'oggetto persistente p1 nel contesto sia diverso dall'oggetto oldp1, che era il vecchio oggetto distaccato p1.
- Riga 15: La transazione è completata
- Riga 17: Modifichiamo il nuovo oggetto persistito p1 al di fuori della transazione. Cosa succede in questo caso? Vogliamo saperlo.
- Riga 19: Richiediamo la visualizzazione della tabella. Si noti che, a causa dell'istruzione `SELECT` emessa dal metodo `dump`, il contesto di persistenza viene automaticamente sincronizzato con il database.
L'output della console per il Test 5 è il seguente:
- riga 5: il metodo find ha effettivamente effettuato l'accesso al database; altrimenti, i due puntatori sarebbero uguali
- Righe 7 e 3: il numero di figli di p1 è effettivamente aumentato di 1. La modifica, effettuata al di fuori di una transazione, è stata quindi presa in considerazione. Questo dipende in realtà dal DBMS utilizzato. In un DBMS, un'istruzione SQL viene sempre eseguita all'interno di una transazione. Se il client JPA non avvia esso stesso una transazione esplicita, il DBMS avvierà una transazione implicita. Esistono due casi comuni:
- 1 - Ogni singola istruzione SQL fa parte di una transazione, aperta prima dell'istruzione e chiusa dopo. Questa modalità è nota come modalità autocommit. Tutto si comporta quindi come se il client JPA stesse eseguendo transazioni per ogni istruzione SQL.
- 2 - Il DBMS non è in modalità autocommit e avvia una transazione implicita sulla prima istruzione SQL che il client JPA emette al di fuori di una transazione, lasciando al client il compito di chiuderla. Tutte le istruzioni SQL emesse dal client JPA fanno quindi parte della transazione implicita. Questa transazione può terminare a causa di vari eventi: il client chiude la connessione, avvia una nuova transazione, ecc.
Questa situazione dipende dalla configurazione del DBMS. Pertanto, il codice non è portabile. Mostreremo più avanti un esempio di codice senza transazioni e vedremo che non tutti i DBMS si comportano allo stesso modo con questo codice. Considereremo quindi il lavoro al di fuori delle transazioni come un errore di programmazione.
- Riga 7: Si noti che il numero di versione è stato aggiornato a 2.
2.1.13.7. Test 6
Il codice per il Test 6 è il seguente:
// supprimer un objet n'appartenant pas au contexte de persistance
public static void test6() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on supprime p1 qui n'appartient pas au nouveau contexte
try {
em.remove(p1);
// fin transaction
tx.commit();
} catch (RuntimeException e1) {
System.out.format("Erreur à la suppression de p1 : [%s,%s]%n", e1.getClass().getName(), e1.getMessage());
// on fait un rollback de la transaction
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s,%s]%n", e2.getClass().getName(), e2.getMessage());
}
}
// on affiche la nouvelle table
dump();
}
- Il test 6 tenta di eliminare un oggetto che non appartiene al contesto di persistenza.
- Riga 4: viene richiesto un nuovo contesto di persistenza. Quello precedente viene quindi chiuso e gli oggetti in esso contenuti vengono distaccati. Questo è il caso dell'oggetto p1 del precedente test 5.
- Righe 6–7: Inizio della transazione.
- Riga 10: l'oggetto distaccato p1 viene eliminato. Sappiamo che ciò causerà un'eccezione, quindi abbiamo racchiuso l'operazione in un blocco try/catch.
- Riga 12: il commit non avrà luogo.
- Righe 16–21: una transazione deve terminare con un commit (tutte le operazioni nella transazione vengono convalidate) o un rollback (tutte le operazioni nella transazione vengono annullate). Si è verificata un'eccezione, quindi eseguiamo il rollback della transazione. Non c'è nulla da annullare poiché l'unica operazione nella transazione ha fallito, ma il rollback termina la transazione. Questa è la prima volta che utilizziamo l'operazione [EntityTransaction].rollback. Avremmo dovuto farlo fin dai primissimi esempi. Non l'abbiamo fatto per mantenere il codice semplice. Il lettore dovrebbe comunque tenere presente che il caso di un rollback della transazione deve sempre essere preso in considerazione nel codice.
- Riga 24: Visualizziamo la tabella. Normalmente non dovrebbe essere cambiata.
L'output della console per il Test 6 è il seguente:
- riga 6: Eliminazione di p1 non riuscita. Il messaggio di eccezione spiega che è stato effettuato un tentativo di eliminare un oggetto distaccato, che non fa parte del contesto. Ciò non è possibile.
- Riga 8: La persona p1 è ancora presente.
2.1.13.8. Test 7
Il codice per il Test 7 è il seguente:
// modifier un objet n'appartenant pas au contexte de persistance
public static void test7() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on incrémente le nbre d'enfants de p1 qui n'appartient pas au nouveau contexte
p1.setNbenfants(p1.getNbenfants() + 1);
// fin transaction
tx.commit();
// on affiche la nouvelle table - elle n'a pas du changer
dump();
}
- Il test 7 tenta di modificare un oggetto che non appartiene al contesto di persistenza e osserva l'impatto che ciò ha sul database. Ci si potrebbe aspettare che non ce ne sia alcuno. Questo è ciò che mostrano i risultati del test.
- Riga 4: Viene richiesto un nuovo contesto di persistenza. Abbiamo quindi un nuovo contesto senza oggetti persistenti al suo interno.
- Righe 6–7: Inizio della transazione.
- Riga 9: L'oggetto distaccato p1 viene modificato. Si tratta di un'operazione che non coinvolge il contesto di persistenza em. Pertanto, non dovremmo aspettarci un'eccezione o qualcosa di simile. È un'operazione di base su un POJO.
- Riga 11: il commit sincronizza il contesto con il database. Questo contesto è vuoto. Pertanto, il database rimane invariato.
- Riga 24: La tabella viene visualizzata. Normalmente, non dovrebbe essere cambiata.
L'output della console per il test 7 è il seguente:
- riga 7: la persona p1 non è cambiata nel database. Per il prossimo test, tuttavia, terremo presente che in memoria il numero di figli è ora 5.
2.1.13.9. Test 8
Il codice per il test 8 è il seguente:
// réattacher un objet au contexte de persistance
public static void test8() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on réattache l'objet détaché p1 au nouveau contexte
newp1 = em.merge(p1);
// c'est newp1 qui fait désormais partie du contexte, pas p1
// fin transaction
tx.commit();
// on affiche la nouvelle table - le nbre d'enfants de p1 a du changer
dump();
}
- Il test 8 ricollega un oggetto distaccato al contesto di persistenza.
- Riga 4: viene richiesto un nuovo contesto di persistenza. Abbiamo quindi un nuovo contesto privo di oggetti persistenti.
- Righe 6-7: inizio della transazione.
- Riga 9: L'oggetto distaccato p1 viene ricollegato al contesto di persistenza. L'operazione di unione può comportare diversi scenari:
- Caso 1: nel contesto di persistenza è presente un oggetto persistente ps1 con la stessa chiave primaria dell'oggetto distaccato p1. Il contenuto di p1 viene copiato in ps1 e l'operazione di unione restituisce un riferimento a ps1.
- Caso 2: nel contesto di persistenza non esiste un oggetto persistente ps1 con la stessa chiave primaria dell'oggetto distaccato p1. Viene quindi interrogato il database per determinare se l'oggetto ricercato esiste nel database. In tal caso, questo oggetto viene inserito nel contesto di persistenza, diventa l'oggetto persistente ps1 e si ritorna al precedente Caso 1.
- Caso 3: non esiste alcun oggetto con la stessa chiave primaria dell'oggetto distaccato p1, né nel contesto di persistenza né nel database. Viene quindi creato un nuovo oggetto [Person] (new) e inserito nel contesto di persistenza. Si ritorna quindi al Caso 1.
- Alla fine: l'oggetto distaccato p1 rimane distaccato. L'operazione di unione restituisce un riferimento (qui newp1) all'oggetto persistente ps1 risultante dall'unione. L'applicazione client deve ora lavorare con l'oggetto persistente ps1 e non con l'oggetto distaccato p1.
- Si noti la differenza tra i casi 1 e 3 per quanto riguarda l'istruzione SQL utilizzata per l'unione: nei casi 1 e 2 si tratta di un'istruzione UPDATE, mentre nel caso 3 si tratta di un'istruzione INSERT.
- Riga 12: Il commit sincronizza il contesto con il database. Questo contesto non è più vuoto. Contiene l'oggetto newp1. Questo oggetto verrà salvato nel database.
- Riga 24: Visualizziamo la tabella per verificarla.
L'output della console per il Test 8 è il seguente:
- Il numero di figli per p1 era 4 nel test 6 (riga 4), poi è cambiato in 5 nel test 7 ma non è stato salvato nel database (riga 7). Dopo l'unione, newp1 è stato salvato nel database: riga 10, ora abbiamo 5 figli.
- Riga 10: Il numero di versione di newp1 è stato aggiornato a 3.
2.1.13.10. Test 9
Il codice per il Test 9 è il seguente:
// a select request causes synchronization
// with the persistence context
public static void test9() {
// persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// increment the number of children of newp1
newp1.setNbenfants(newp1.getNbenfants() + 1);
// people display - the number of children in newp1 must have changed
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// end transaction
tx.commit();
}
- Il Test 9 illustra il meccanismo di sincronizzazione del contesto che avviene automaticamente prima di un'istruzione SELECT.
- riga 5: il contesto di persistenza non viene modificato. newp1 si trova quindi al suo interno.
- Righe 7–8: Inizio della transazione.
- Riga 10: il numero di figli dell'oggetto persistente newp1 viene aumentato di 1 (da 5 a 6).
- Righe 12–15: la tabella viene visualizzata utilizzando un'istruzione SELECT. Il contesto verrà sincronizzato con il database prima dell'esecuzione dell'istruzione SELECT.
- Riga 17: Fine della transazione
Per visualizzare la sincronizzazione, abilitare l'output del log di Hibernate in modalità DEBUG (log4j.properties):
# Root logger option
log4j.rootLogger=ERROR, stdout
# Hibernate logging options (INFO only shows startup messages)
log4j.logger.org.hibernate=DEBUG
L'output della console per il test 9 è il seguente:
- Riga 1: Avvio del Test 9
- righe 2–6: inizia la transazione JDBC. La modalità autocommit del DBMS è disabilitata (riga 5)
- riga 7: visualizzazione attivata dalla riga 12 del codice Java. Le righe successive del codice Java attiveranno un SELECT e quindi sincronizzeranno il contesto di persistenza con il database.
- riga 8: la query JPQL che vogliamo eseguire è già stata eseguita. Hibernate la trova nella sua cache delle "query preparate".
- Riga 9: Hibernate annuncia che svuoterà il contesto di persistenza
- Righe 11–12: Hibernate (Hb) rileva che l'entità Person#1 (con chiave primaria 1) è stata modificata (dirty).
- Righe 12–13: Hb annuncia che sta aggiornando questo elemento e incrementa il suo numero di versione da 3 a 4.
- Riga 15: la sincronizzazione del contesto comporterà 0 inserimenti, 1 aggiornamento e 0 eliminazioni
- Righe 17-34: sincronizzazione del contesto (flush). Nota: l'incremento della versione (riga 19), l'istruzione SQL di aggiornamento preparata (riga 21) e i valori dei parametri per l'istruzione di aggiornamento (righe 24-31).
- Riga 35: Inizia l'istruzione SELECT
- riga 38: l'istruzione SQL da eseguire
- riga 40: la SELECT restituisce una sola riga
- riga 42: Hb scopre di avere già, nel proprio contesto di persistenza, l'entità Person#1 che il SELECT ha restituito dal database. Pertanto non copia la riga ottenuta dal database nel contesto, un'operazione che chiama "idratazione".
- riga 43: verifica se gli oggetti restituiti dal SELECT hanno dipendenze (di solito chiavi esterne) che dovrebbero essere caricate (collezioni non pigre). Qui non ce ne sono.
- Riga 44: Visualizzazione attivata dal codice Java
- Riga 45: Fine della transazione JDBC richiesta dal codice Java
- Riga 46: Inizia la sincronizzazione automatica del contesto, che avviene durante i commit.
- Riga 48: Hb rileva che il contesto non è cambiato dall'ultima sincronizzazione.
- Riga 50: Fine del commit.
Ancora una volta, i log di Hibernate in modalità DEBUG si rivelano molto utili per comprendere esattamente cosa sta facendo Hibernate.
2.1.13.11. Test 10
Il codice per il test 10 è il seguente:
// contrôle de version (optimistic locking)
public static void test10() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// incrémenter la version de newp1 directement dans la base (native query)
em.createNativeQuery(String.format("update %s set VERSION=VERSION+1 WHERE ID=%d", TABLE_NAME, newp1.getId())).executeUpdate();
// fin transaction
tx.commit();
// début nouvelle transaction
tx = em.getTransaction();
tx.begin();
// on incrémente le nbre d'enfants de newp1
newp1.setNbenfants(newp1.getNbenfants() + 1);
// fin transaction - elle doit échouer car newp1 n'a plus la bonne version
try {
tx.commit();
} catch (RuntimeException e1) {
System.out.format("Erreur lors de la mise à jour de newp1 [%s,%s,%s,%s]%n", e1.getClass().getName(), e1.getMessage(), e1.getCause().getClass().getName(), e1.getCause().getMessage());
// on fait un rollback de la transaction
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s,%s]%n", e2.getClass().getName(), e2.getMessage());
}
}
// on ferme le contexte qui n'est plus à jour
em.close();
// dump de la table - la version de p1 a du changer
dump();
}
- Il Test 10 illustra il meccanismo introdotto dal campo version dell'entità @Entity Person, che è annotata con l'annotazione JPA @Version. Abbiamo spiegato che questa annotazione fa sì che il valore della colonna associata all'annotazione @Version venga incrementato nel database ad ogni aggiornamento effettuato sulla riga a cui appartiene. Questo meccanismo, noto anche come blocco ottimistico, richiede che un client che desideri modificare un oggetto O nel database disponga dell'ultima versione di quell'oggetto. In caso contrario, significa che l'oggetto è stato modificato da quando il client lo ha ottenuto, e il client deve esserne informato.
- Riga 4: Non modifichiamo il contesto di persistenza. newp1 si trova quindi al suo interno.
- Righe 6–7: Inizio di una transazione.
- Riga 9: La versione dell'oggetto newp1 viene incrementata di 1 (da 4 a 5) direttamente nel database. Le query di tipo nativeQuery bypassano il contesto di persistenza e scrivono direttamente nel database. Il risultato è che l'oggetto persistente newp1 e la sua rappresentazione nel database non hanno più la stessa versione.
- Riga 10: fine della prima transazione
- Righe 13–14: Inizio di una seconda transazione
- Riga 16: il numero di figli dell’oggetto persistente newp1 viene aumentato di 1 (da 6 a 7).
- Riga 19: fine della transazione. Ha quindi luogo la sincronizzazione. Ciò innescherà un aggiornamento del numero di figli di newp1 nel database. L'operazione fallirà perché l'oggetto persistente newp1 ha la versione 4, mentre nel database l'oggetto da aggiornare ha la versione 5. Verrà generata un'eccezione, il che giustifica il blocco try/catch nel codice.
- Riga 21: Vengono visualizzati l'eccezione e la sua causa.
- Riga 25: Rollback della transazione
- Riga 33: Visualizzazione della tabella: dovremmo vedere che la versione di newp1 nel database è 5.
L'output della console per il test 10 è il seguente:
- Riga 5: Il commit genera effettivamente un'eccezione. È di tipo [javax.persistence.RollbackException]. Il messaggio associato è vago. Se esaminiamo la causa di questa eccezione (Exception.getCause), vediamo che si tratta di un'eccezione Hibernate dovuta al fatto che stiamo cercando di modificare una riga nel database senza disporre della versione corretta.
- Riga 7: Vediamo che la versione di newp1 nel database è stata effettivamente impostata a 5 dal nativeQuery.
2.1.13.12. Test 11
Il codice per il test 11 è il seguente:
// transaction rollback
public static void test11() throws ParseException {
// persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = null;
try {
tx = em.getTransaction();
tx.begin();
// reattach p1 to the context by fetching it from the base
p1 = em.find(Personne.class, p1.getId());
// increment the number of children in p1
p1.setNbenfants(p1.getNbenfants() + 1);
// display people - the number of children in p1 must have changed
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// creation of 2 persons with identical names, which is forbidden by the DDL
Personne p3 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p4 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
// persistence of people
em.persist(p3);
em.persist(p4);
// end transaction
tx.commit();
} catch (RuntimeException e1) {
// we had a problem
System.out.format("Erreur dans transaction [%s,%s,%s,%s,%s,%s]%n", e1.getClass().getName(), e1.getMessage(),
e1.getCause().getClass().getName(), e1.getCause().getMessage(), e1.getCause().getCause().getClass().getName(), e1.getCause().getCause()
.getMessage());
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s]%n", e2.getMessage());
}
// we abandon the current context
em.clear();
}
// dump - table must not have changed due to rollback
dump();
}
- Il test 11 si concentra sul meccanismo di rollback delle transazioni. Una transazione opera secondo il principio "tutto o niente": le operazioni SQL in essa contenute vengono eseguite con successo (commit) oppure vengono tutte annullate (rollback) se una di esse fallisce.
- riga 4: continuiamo con lo stesso contesto di persistenza. Il lettore ricorderà che il contesto era stato chiuso in seguito al crash nel test precedente. In questo caso, [getEntityManager] restituisce un contesto nuovo di zecca, e quindi vuoto.
- Righe 7–27: un singolo blocco try/catch per gestire eventuali problemi che potrebbero sorgere
- Righe 8–9: Inizio di una transazione che conterrà diverse operazioni SQL
- Riga 11: p1 viene recuperato dal database e inserito nel contesto
- Riga 13: Il numero di figli di p1 viene aumentato (da 6 a 7)
- Righe 15–18: Visualizziamo il contenuto del database, il che forzerà una sincronizzazione del contesto. Nel database, il numero di figli di p1 cambierà a 7, cosa che l'output della console dovrebbe confermare.
- Righe 20–21: Creazione di due persone, p3 e p4, con lo stesso nome. Tuttavia, il campo name dell'@Entity Person ha l'attributo unique=true, il che comporta un vincolo di unicità sulla colonna NAME della tabella [jpa01_personne].
- Righe 23–24: Le persone p3 e p4 vengono aggiunte al contesto di persistenza.
- Riga 26: La transazione viene confermata. Segue una seconda sincronizzazione del contesto, la prima essendo avvenuta durante l'istruzione SELECT. JPA emetterà due istruzioni SQL INSERT per le persone p3 e p4. p3 verrà inserita. Per p4, il DBMS genererà un'eccezione perché p4 ha lo stesso nome di p3. p4 non viene quindi inserita e il driver JDBC genera un'eccezione al client.
- Riga 27: Gestiamo l'eccezione
- Righe 29–31: Visualizziamo l'eccezione e le due cause precedenti nella catena di eccezioni che ci ha portato a questo punto.
- Riga 34: Eseguiamo il rollback della transazione attualmente attiva. Questa transazione è iniziata alla riga 9 del codice Java. Da allora, è stata eseguita un'operazione di aggiornamento per modificare il numero di figli di p1, seguita da un'operazione di inserimento per la persona p3. Tutto questo verrà annullato dal rollback.
- Riga 39: il contesto di persistenza viene cancellato
- Riga 42: Viene visualizzata la tabella [jpa01_personne]. Dobbiamo verificare che p1 abbia ancora 6 figli e che né p3 né p4 siano presenti nella tabella.
L'output della console per il test 11 è il seguente:
main : ----------- test11
[personnes]
[1,6,Martin,Paul,31/01/2000,false,7]
14:50:30,312 ERROR JDBCExceptionReporter:72 - Duplicate entry 'X' for key 2
Erreur dans transaction [javax.persistence.EntityExistsException,org.hibernate.exception.ConstraintViolationException: could not insert: [entites.Personne],org.hibernate.exception.ConstraintViolationException,could not insert: [entites.Personne],java.sql.SQLException,Duplicate entry 'X' for key 2]
[personnes]
[1,5,Martin,Paul,31/01/2000,false,6]
- riga 3: il numero di figli di p1 è cambiato da 6 a 7 nel database; la versione di p1 è stata aggiornata a 6.
- Riga 4: l'eccezione intercettata durante il commit della transazione. Se si legge attentamente, si può notare che la causa è una chiave duplicata X (il nome). È l'inserimento di p4 a causare questo errore, poiché anche p3, che è già stato inserito, ha il nome X.
- Riga 7: la tabella dopo il rollback. p1 è tornato alla versione 5 e ha di nuovo 6 figli; p3 e p4 non sono stati inseriti.
2.1.13.13. Test 12
Il codice per il test 12 è il seguente:
// we do the same thing again but without the transactions
// we obtain the same result as before with SGBD : FIREBIRD, ORACLE XE, POSTGRES, MYSQL5
// with SQLSERVER we have an empty table. The connection is left in a state that prevents reexecution
// of the program. The server must then be restarted.
// idem with SGBD Derby
// HSQL inserts 1st person - there is no rollback
public static void test12() throws ParseException {
// reconnect p1
p1 = em.find(Personne.class, p1.getId());
// increment the number of children in p1
p1.setNbenfants(p1.getNbenfants() + 1);
// display people - the number of children in p1 must have changed
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// creation of 2 persons with identical names, which is forbidden by the DDL
Personne p3 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p4 = new Personne("X", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
// persistence of people
em.persist(p3);
em.persist(p4);
// dump, which will sync the em context with the BD
try {
dump();
} catch (RuntimeException e3) {
System.out.format("Erreur dans dump [%s,%s,%s,%s]%n", e3.getClass().getName(), e3.getMessage(), e3.getCause().getClass().getName(), e3
.getCause().getMessage());
}
// we close the current context
em.close();
// dump
dump();
}
- Il Test 12 ripete lo stesso processo del Test 11, ma al di fuori di una transazione. Vogliamo vedere cosa succede in questo caso.
- Righe 1–6: mostrano i risultati del test con vari DBMS:
- con diversi DBMS (Firebird, Oracle, MySQL5, Postgres), otteniamo lo stesso risultato del test 11. Ciò suggerisce che questi DBMS abbiano avviato autonomamente una transazione che copre tutte le istruzioni SQL ricevute fino a quella che ha causato l'errore e che abbiano avviato essi stessi un rollback.
- Con altri DBMS (SQL Server, Apache Derby), l'applicazione e/o il DBMS va in crash.
- Con il DBMS HSQLDB, sembra che la transazione aperta dal DBMS sia in modalità autocommit: la modifica del numero di figli di p1 e l'inserimento di p3 vengono resi permanenti. Solo l'inserimento di p4 fallisce.
Abbiamo quindi un risultato che dipende dal DBMS, il che rende l'applicazione non portabile. Si noti che le operazioni sul contesto di persistenza devono sempre essere eseguite all'interno di una transazione.
2.1.14. Cambiare il DBMS
Rivediamo l'architettura di test del nostro progetto attuale:
 |
L'applicazione client [3] vede solo l'interfaccia JPA [5]. Non vede né la sua effettiva implementazione né il DBMS di destinazione. Dobbiamo quindi essere in grado di modificare questi due elementi della catena senza apportare modifiche al client [3]. Questo è ciò che cercheremo ora di dimostrare, iniziando con la modifica del DBMS. Finora abbiamo utilizzato MySQL5. Ne presentiamo altri sei descritti nelle appendici (sezione 5), sperando che tra questi vi sia il DBMS preferito dal lettore.
In ogni caso, la modifica da apportare al progetto Eclipse è semplice (vedi sotto): sostituire il file di configurazione persistence.xml [1] per il livello JPA con uno di quelli presenti nella cartella conf [2] del progetto. I driver JDBC per questi DBMS sono già presenti nelle librerie [jpa-divers] [3] e [4].
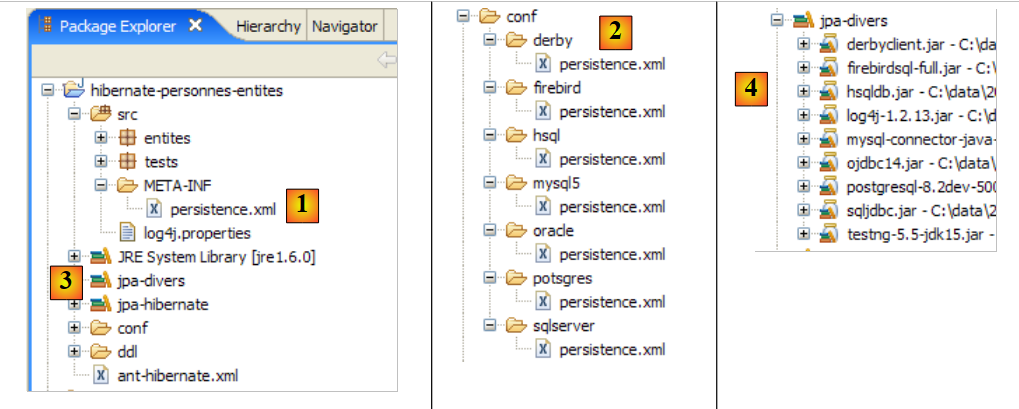 |
2.1.14.1. Oracle 10g Express
Oracle 10g Express è descritto nelle Appendici alla sezione 5.7. Il file persistence.xml di Oracle è il seguente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Persistent classes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- logs SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="oracle.jdbc.OracleDriver" />
<property name="hibernate.connection.url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- automatic schematic creation -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.OracleDialect" />
<!-- properties DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
Questa configurazione è identica a quella utilizzata per il DBMS MySQL5, con le seguenti piccole differenze:
- righe 15–18, che configurano la connessione JDBC al database
- riga 22: che imposta il dialetto SQL da utilizzare
Per gli esempi che seguiranno, specificheremo solo le righe che cambiano. Per una spiegazione della configurazione, fare riferimento all'appendice dedicata al DBMS in uso. In essa viene fornito ogni volta un esempio di utilizzo della connessione JDBC, nel contesto del plugin [SQL Explorer]. Con le informazioni dell'appendice, il lettore può ripetere il processo di verifica del risultato dell'applicazione [InitDB] eseguito nella sezione 2.1.10.2.
Si procede come indicato nella sezione sopra citata:
- avviare il DBMS Oracle
- inserire conf/oracle/persistence.xml in META-INF/persistence.xml
- eseguire l'applicazione [InitDB]
Sulla console compaiono i seguenti risultati:
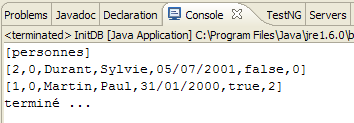 |
D'ora in poi non mostreremo più questa schermata, poiché rimane invariata. Più interessante è la vista SQL Explorer della connessione JDBC al DBMS. Seguiremo la procedura spiegata nella sezione 2.1.8.
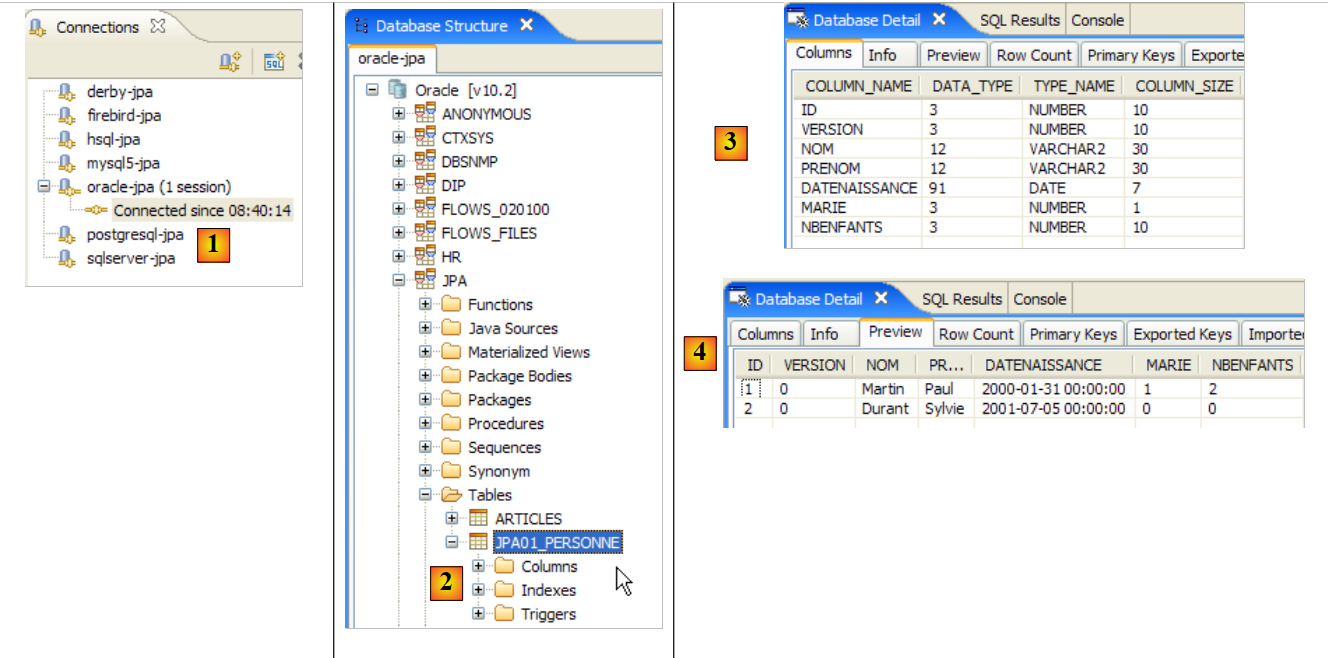 |
- in [1]: la connessione a Oracle
- in [2]: l'albero delle connessioni dopo l'esecuzione di [InitDB]
- in [3]: la struttura della tabella [jpa01_personne]
- in [4]: il suo contenuto.
Una volta fatto ciò, il lettore è invitato a eseguire l'applicazione [Main] e quindi a chiudere il DBMS.
2.1.14.2. PostgreSQL 8.2
PostgreSQL 8.2 è presentato nelle Appendici alla sezione 5.6. Il suo file persistence.xml è il seguente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="org.postgresql.Driver" />
<property name="hibernate.connection.url" value="jdbc:postgresql:jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
...
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.PostgreSQLDialect" />
...
</persistence-unit>
</persistence>
Per eseguire [InitDB]:
- Avviare il DBMS PostgreSQL
- inserire conf/postgres/persistence.xml in META-INF/persistence.xml
- eseguire l'applicazione [InitDB]
La vista SQL Explorer della connessione JDBC al DBMS è la seguente:
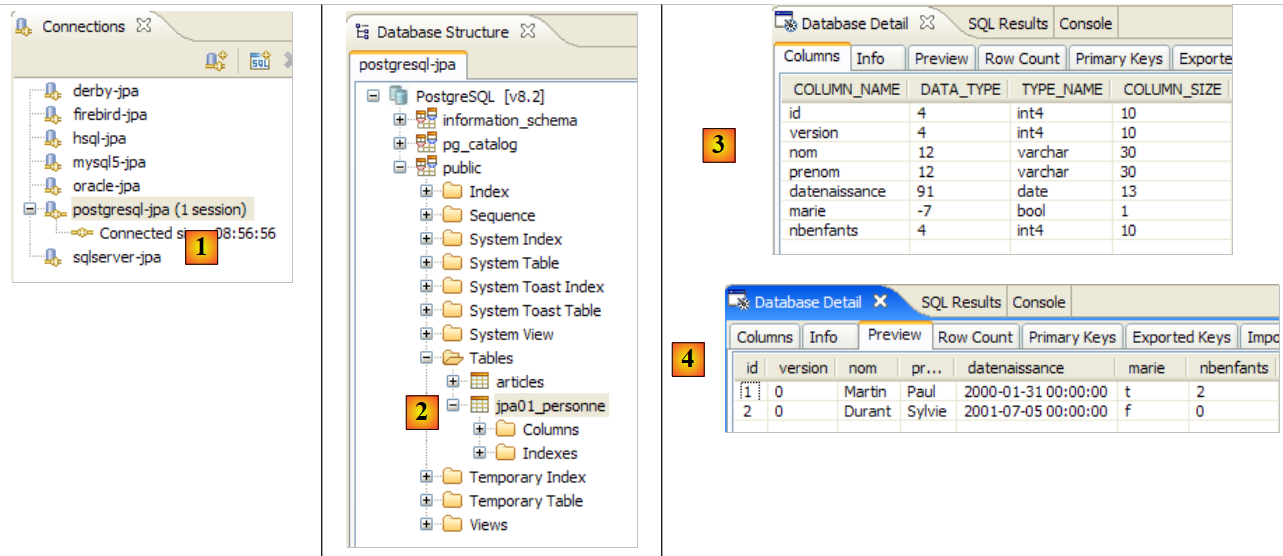 |
- in [1]: la connessione a PostgreSQL
- in [2]: l'albero delle connessioni dopo l'esecuzione di [InitDB]
- in [3]: la struttura della tabella [jpa01_personne]
- in [4]: il suo contenuto.
Una volta fatto ciò, il lettore è invitato a eseguire l'applicazione [Main] e quindi a chiudere il DBMS
2.1.14.3. SQL Server Express 2005
SQL Server Express 2005 è presentato nelle Appendici alla sezione 5.8, pagina 270. Il suo file persistence.xml è il seguente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="com.microsoft.sqlserver.jdbc.SQLServerDriver" />
<property name="hibernate.connection.url" value="jdbc:sqlserver://localhost\\SQLEXPRESS:1433;databaseName=jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
...
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.SQLServerDialect" />
...
</persistence-unit>
</persistence>
Per eseguire [InitDB]:
- Avviare il DBMS SQL Server
- inserire conf/sqlserver/persistence.xml in META-INF/persistence.xml
- eseguire l'applicazione [InitDB]
La vista SQL Explorer della connessione JDBC al DBMS è la seguente:
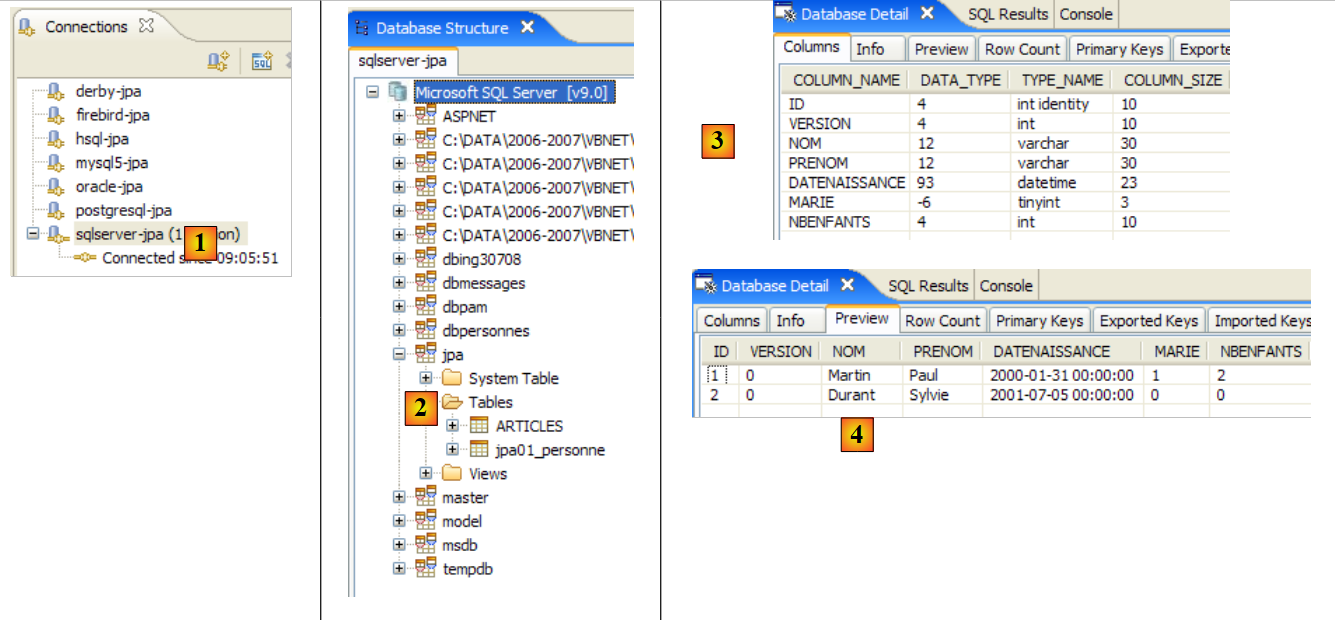 |
- in [1]: la connessione a SQL Server
- in [2]: l'albero delle connessioni dopo l'esecuzione di [InitDB]
- in [3]: la struttura della tabella [jpa01_personne]
- in [4]: il suo contenuto.
Una volta fatto ciò, il lettore è invitato a eseguire l'applicazione [Main] e quindi a chiudere il DBMS
2.1.14.4. Firebird 2.0
Firebird 2.0 è presentato nelle Appendici alla sezione 5.4. Il suo file persistence.xml è il seguente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="org.firebirdsql.jdbc.FBDriver" />
<property name="hibernate.connection.url" value="jdbc:firebirdsql:localhost/3050:C:\data\2006-2007\eclipse\dvp-jpa\annexes\firebird\jpa.fdb" />
<property name="hibernate.connection.username" value="sysdba" />
<property name="hibernate.connection.password" value="masterkey" />
...
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.FirebirdDialect" />
...
</persistence-unit>
</persistence>
Per eseguire [InitDB]:
- Avviare il DBMS Firebird
- inserire conf/firebird/persistence.xml in META-INF/persistence.xml
- eseguire l'applicazione [InitDB]
La vista SQL Explorer della connessione JDBC al DBMS è la seguente:
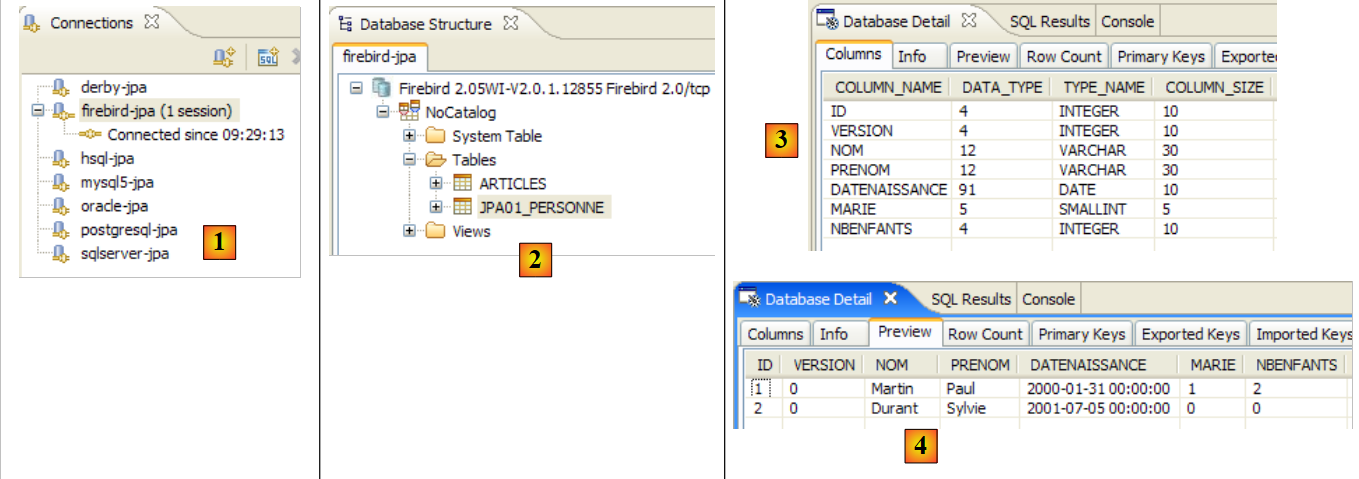 |
- in [1]: la connessione a Firebird
- in [2]: l'albero delle connessioni dopo l'esecuzione di [InitDB]
- in [3]: la struttura della tabella [jpa01_personne]
- in [4]: il suo contenuto.
Una volta fatto ciò, il lettore è invitato a eseguire l'applicazione [Main] e quindi a chiudere il DBMS.
2.1.14.5. Apache Derby
Apache Derby è presentato nelle Appendici alla Sezione 5.10. Il suo file persistence.xml è il seguente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="org.apache.derby.jdbc.ClientDriver" />
<property name="hibernate.connection.url" value="jdbc:derby://localhost:1527//data/2006-2007/eclipse/dvp-jpa/annexes/derby/jpa;create=true" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
...
<!-- Dialect -->
...
</persistence-unit>
</persistence>
Per eseguire [InitDB]:
- avviare il DBMS Apache Derby
- inserire conf/derby/persistence.xml in META-INF/persistence.xml
- eseguire l'applicazione [InitDB]
La vista SQL Explorer della connessione JDBC al DBMS è la seguente:
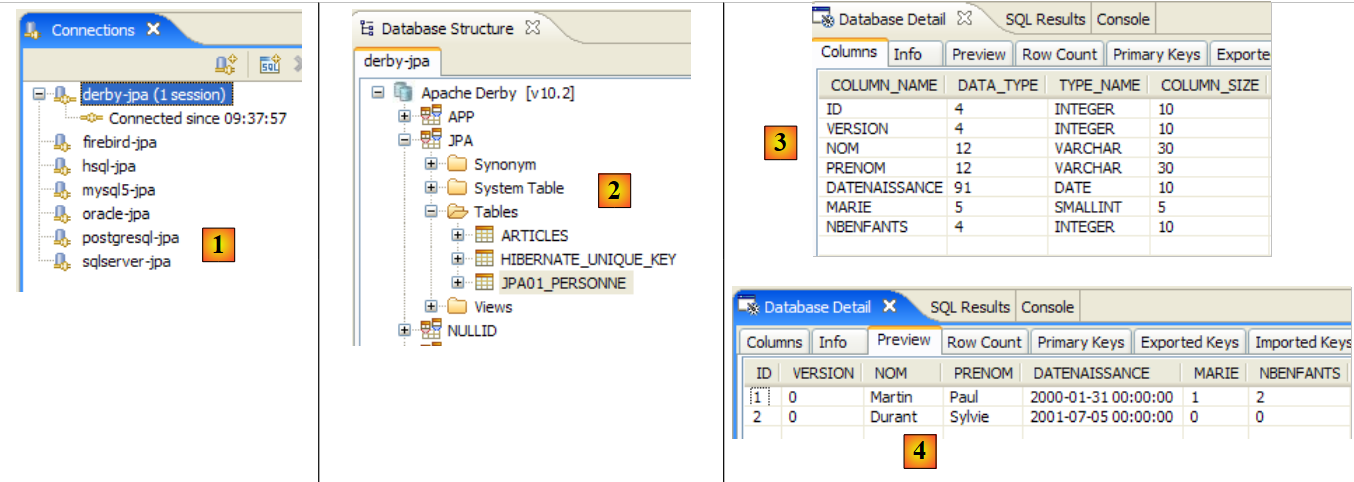 |
- in [1]: la connessione ad Apache Derby
- in [2]: l'albero delle connessioni dopo l'esecuzione di [InitDB]. Si noti la tabella [HIBERNATE_UNIQUE_KEY] creata da JPA/Hibernate per generare automaticamente valori successivi per l'ID della chiave primaria. Abbiamo già osservato che questo meccanismo è spesso proprietario. Ciò è chiaramente evidente in questo caso. Grazie a JPA, lo sviluppatore non deve addentrarsi in questi dettagli del DBMS.
- in [3]: la struttura della tabella [jpa01_personne]
- in [4]: il suo contenuto.
Una volta fatto ciò, il lettore è invitato a eseguire l'applicazione [Main] e quindi a chiudere il DBMS.
2.1.14.6. HSQLDB
HSQLDB è presentato nelle Appendici alla Sezione 5.9. Il suo file persistence.xml è il seguente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
...
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="org.hsqldb.jdbcDriver" />
<property name="hibernate.connection.url" value="jdbc:hsqldb:hsql://localhost" />
<property name="hibernate.connection.username" value="sa" />
<!--
<property name="hibernate.connection.password" value="" />
-->
...
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.HSQLDialect" />
...
</properties>
</persistence-unit>
</persistence>
Per eseguire [InitDB]:
- avviare il DBMS HSQL
- Inserire conf/hsql/persistence.xml in META-INF/persistence.xml
- eseguire l'applicazione [InitDB]
La vista SQL Explorer della connessione JDBC al DBMS è la seguente:
 |
- in [1]: la connessione a HSQL
- in [2]: l'albero delle connessioni dopo l'esecuzione di [InitDB].
- in [3]: la struttura della tabella [jpa01_personne]
- in [4]: il suo contenuto.
Una volta fatto ciò, il lettore è invitato a eseguire l'applicazione [Main] e poi a arrestare il DBMS.
2.1.15. Modifica dell'implementazione JPA
Rivediamo l'architettura di test del nostro progetto attuale:
 |
Lo studio precedente ha dimostrato che siamo stati in grado di cambiare il DBMS [7] senza modificare nulla nel codice client [3]. Ora cambieremo l'implementazione JPA [6] e dimostreremo ancora una volta che ciò può essere fatto in modo trasparente per il codice client [3]. Utilizzeremo un'implementazione TopLink [http://www.oracle.com/technology/products/ias/toplink/jpa/index.html]:
 |
2.1.15.1. Il progetto Eclipse
In concomitanza con la modifica nell'implementazione di JPA, stiamo creando un nuovo progetto Eclipse per non compromettere il progetto esistente. Infatti, il nuovo progetto utilizza librerie di persistenza che potrebbero entrare in conflitto con quelle di Hibernate:
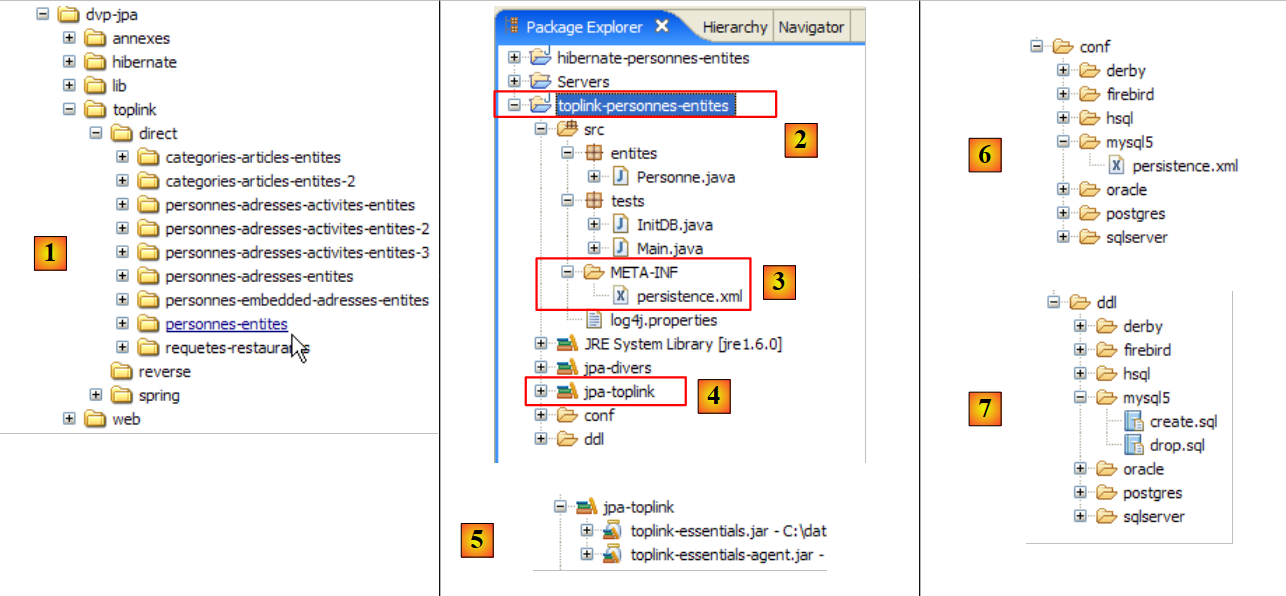 |
- in [1]: la cartella [<examples>/toplink/direct/people-entities] contiene il progetto Eclipse. Importalo.
- in [2]: il progetto [toplink-personnes-entites] importato. È identico (è stato copiato) al progetto [hibernate-personne-entites], con l'eccezione di due dettagli:
- il file [META-INF/persistence.xml] [3] ora configura un livello JPA/Toplink
- la libreria [jpa-hibernate] è stata sostituita dalla libreria [jpa-toplink] [4] e [5] (vedi paragrafo 1.5).
- in [6]: la cartella [conf] contiene una versione del file [persistence.xml] per ciascun DBMS.
- in [7]: la cartella [ddl], che conterrà gli script SQL per la generazione dello schema del database.
2.1.15.2. Configurazione dell' JPA / Toplink
Sappiamo che il livello JPA è configurato dal file [META-INF/persistence.xml]. Questo file ora configura un'implementazione JPA / Toplink. Il suo contenuto per un livello JPA che si interfaccia con il DBMS MySQL5 è il seguente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- persistent classes -->
<class>entites.Personne</class>
<!-- persistence unit properties -->
<properties>
<!-- connection JDBC -->
<property name="toplink.jdbc.driver" value="com.mysql.jdbc.Driver" />
<property name="toplink.jdbc.url" value="jdbc:mysql://localhost:3306/jpa" />
<property name="toplink.jdbc.user" value="jpa" />
<property name="toplink.jdbc.password" value="jpa" />
<property name="toplink.jdbc.read-connections.max" value="3" />
<property name="toplink.jdbc.read-connections.min" value="1" />
<property name="toplink.jdbc.write-connections.max" value="5" />
<property name="toplink.jdbc.write-connections.min" value="2" />
<!-- SGBD -->
<property name="toplink.target-database" value="MySQL4" />
<!-- application server -->
<property name="toplink.target-server" value="None" />
<!-- generation diagram -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
<property name="toplink.application-location" value="ddl/mysql5" />
<property name="toplink.create-ddl-jdbc-file-name" value="create.sql" />
<property name="toplink.drop-ddl-jdbc-file-name" value="drop.sql" />
<property name="toplink.ddl-generation.output-mode" value="both" />
<!-- logs -->
<property name="toplink.logging.level" value="OFF" />
</properties>
</persistence-unit>
</persistence>
- Riga 3: invariata
- riga 5: il provider ora è Toplink. La classe qui indicata si trova nella libreria [jpa-toplink] ([1] di seguito):
 |
- riga 7: il tag <class> viene utilizzato per elencare tutte le classi @Entity nel progetto; in questo caso, solo la classe Person. Hibernate disponeva di un'opzione di configurazione che ci permetteva di evitare di elencare queste classi. Avrebbe scansionato il classpath del progetto per trovare le classi @Entity.
- riga 9: il tag <properties> introduce proprietà specifiche dell'implementazione JPA in uso, in questo caso Toplink.
- Righe 11–14: Configurazione della connessione JDBC al DBMS MySQL5
- Righe 15–18: configurazione del pool di connessioni JDBC gestito in modo nativo da Toplink:
- Righe 15, 16: numero massimo e minimo di connessioni nel pool di connessioni di lettura. Impostazione predefinita (2,2)
- Righe 17, 18: numero massimo e minimo di connessioni nel pool di connessioni di scrittura. Impostazione predefinita (10,2)
- riga 20: il DBMS di destinazione. L'elenco dei DBMS supportati è disponibile nel pacchetto [oracle.toplink.essentials.platform.database] (vedi [2] sopra). Il DBMS MySQL5 non è incluso nell'elenco [2], quindi abbiamo scelto MySQL4. TopLink supporta un numero leggermente inferiore di DBMS rispetto a Hibernate. Pertanto, dei sette DBMS utilizzati nei nostri esempi, Firebird non è supportato. Anche Oracle non è presente nell'elenco. Si trova in realtà in un altro pacchetto ([3] sopra). Se, in questi due pacchetti, il DBMS di destinazione è designato dalla classe <Sgbd>Platform.class, il tag verrà scritto come:
<property name="toplink.target-database" value="<Sgbd>" />
- Riga 22: Imposta il server dell'applicazione se l'applicazione viene eseguita su un server di questo tipo. Valori attualmente possibili (None, OC4J_10_1_3, SunAS9). Impostazione predefinita (None).
- Righe 24–28: all'inizializzazione del livello JPA, viene richiesto di cancellare il database definito dalla connessione JDBC nelle righe 11–14. Ciò garantisce di iniziare con un database vuoto.
- Riga 24: TopLink riceve l'istruzione di eliminare e quindi creare le tabelle nello schema del database
- Riga 25: Indichiamo a TopLink di generare gli script SQL per le operazioni di eliminazione e creazione. application-location specifica la directory in cui verranno generati questi script. Impostazione predefinita: (directory corrente).
- Riga 26: Nome dello script SQL per le operazioni di creazione. Impostazione predefinita: createDDL.jdbc.
- Riga 27: Nome dello script SQL per le operazioni di eliminazione. Impostazione predefinita: dropDDL.jdbc.
- Riga 28: modalità di generazione dello schema (impostazione predefinita: both):
- both: script e database
- database: solo database
- sql-script: solo script
- Riga 30: la registrazione TopLink è disabilitata (OFF). I livelli di registrazione disponibili sono: OFF, SEVERE, WARNING, INFO, CONFIG, FINE, FINER, FINEST. Impostazione predefinita: INFO.
Consultare l'URL [http://www.oracle.com/technology/products/ias/toplink/JPA/essentials/toplink-jpa-extensions.html] per una definizione completa dei tag <property> utilizzabili con TopLink.
2.1.15.3. Test [InitDB]
Non c'è altro da fare. Siamo pronti per eseguire il primo test [InitDB]:
- Avviare il DBMS, in questo caso MySQL5
- eseguire [InitDB]
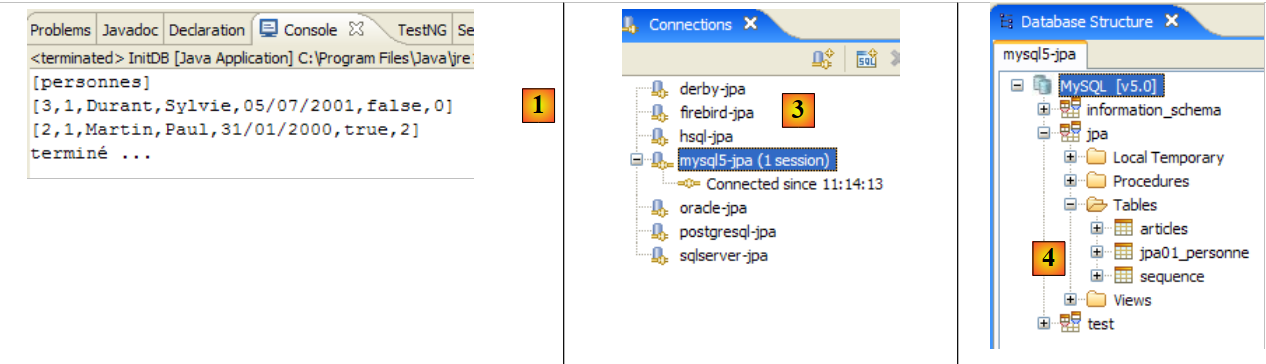 |
- in [1]: la visualizzazione della console. Vediamo i risultati già ottenuti con JPA / Hibernate.
- in [3]: aprire la prospettiva [SQL Explorer], quindi aprire la connessione [mysql5-jpa]
- in [4]: l'albero del database JPA. Si nota che l'esecuzione di [InitDB] ha creato due tabelle: [jpa01_personne], come previsto, e la tabella [sequence], che era meno prevedibile.
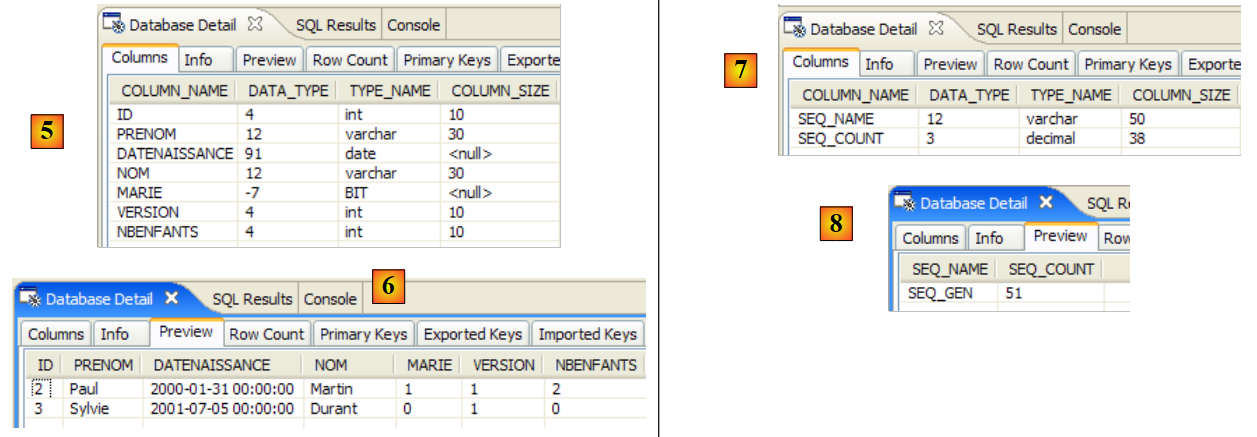 |
- in [5]: la struttura della tabella [jpa01_personne] e in [6] il suo contenuto
- In [7]: la struttura della tabella [sequence] e in [8] il suo contenuto.
Il file di configurazione [persistence.xml] ha richiesto la generazione di script DDL:
<!-- génération schéma -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
<property name="toplink.application-location" value="ddl/mysql5" />
<property name="toplink.create-ddl-jdbc-file-name" value="create.sql" />
<property name="toplink.drop-ddl-jdbc-file-name" value="drop.sql" />
<property name="toplink.ddl-generation.output-mode" value="both" />
Diamo un'occhiata a ciò che è stato generato nella cartella [ddl/mysql5]:
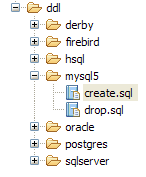 |
create.sql
CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, VERSION INTEGER NOT NULL, NBENFANTS INTEGER NOT NULL, PRIMARY KEY (ID))
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
- Riga 1: Il DDL per la tabella [jpa01_personne]. Si noti che Toplink non ha utilizzato l'attributo autoincrement per la chiave primaria ID. Di conseguenza, l'ID non viene incrementato automaticamente quando vengono inserite nuove righe.
- Riga 2: Il DDL per la tabella [sequence]. Il suo nome suggerisce che Toplink utilizzi questa tabella per generare valori per la chiave primaria ID.
- Riga 3: Inserimento di una singola riga in [SEQUENCE]
drop.sql
DROP TABLE jpa01_personne
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
- Riga 1: Eliminazione della tabella [jpa01_personne]
- Riga 2: Elimina una riga specifica dalla tabella [SEQUENCE]. La tabella stessa non viene eliminata, né vengono eliminate le altre righe che potrebbe contenere.
Per ulteriori informazioni sul ruolo della tabella [SEQUENCE], abilitare i log TopLink a livello FINE nel file [persistence.xml], un livello che tiene traccia delle istruzioni SQL emesse da TopLink:
<!-- logs -->
<property name="toplink.logging.level" value="FINE" />
Esegui nuovamente InitDB. Di seguito è riportata una vista parziale dell'output della console:
...
[TopLink Config]: 2007.05.28 12:07:52.796--ServerSession(12910198)--Connection(30708295)--Thread(Thread[main,5,main])--Connected: jdbc:mysql://localhost:3306/jpa
User: jpa@localhost
Database: MySQL Version: 5.0.37-community-nt
Driver: MySQL-AB JDBC Driver Version: mysql-connector-java-3.1.9 ( $Date: 2005/05/19 15:52:23 $, $Revision: 1.1.2.2 $ )
...
[TopLink Fine]: 2007.05.28 12:07:53.093--ServerSession(12910198)--Connection(19255406)--Thread(Thread[main,5,main])--DROP TABLE jpa01_personne
[TopLink Fine]: 2007.05.28 12:07:53.265--ServerSession(12910198)--Connection(30708295)--Thread(Thread[main,5,main])--CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, VERSION INTEGER NOT NULL, NBENFANTS INTEGER NOT NULL, PRIMARY KEY (ID))
[TopLink Fine]: 2007.05.28 12:07:53.468--ServerSession(12910198)--Connection(19255406)--Thread(Thread[main,5,main])--CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
[TopLink Warning]: 2007.05.28 12:07:53.468--ServerSession(12910198)--Thread(Thread[main,5,main])--Exception [TOPLINK-4002] (Oracle TopLink Essentials - 2.0 (Build b41-beta2 (03/30/2007)): oracle.toplink.essentials.exceptions.DatabaseException
Internal Exception: java.sql.SQLException: Table 'sequence' already exists
Error Code: 1050
Call: CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
Query: DataModifyQuery()
[TopLink Fine]: 2007.05.28 12:07:53.468--ServerSession(12910198)--Connection(30708295)--Thread(Thread[main,5,main])--DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
[TopLink Fine]: 2007.05.28 12:07:53.609--ServerSession(12910198)--Connection(19255406)--Thread(Thread[main,5,main])--SELECT * FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
[TopLink Fine]: 2007.05.28 12:07:53.609--ServerSession(12910198)--Connection(30708295)--Thread(Thread[main,5,main])--INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
[TopLink Fine]: 2007.05.28 12:07:53.734--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--delete from jpa01_personne
[TopLink Fine]: 2007.05.28 12:07:53.750--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--UPDATE SEQUENCE SET SEQ_COUNT = SEQ_COUNT + ? WHERE SEQ_NAME = ?
bind => [50, SEQ_GEN]
[TopLink Fine]: 2007.05.28 12:07:53.750--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--SELECT SEQ_COUNT FROM SEQUENCE WHERE SEQ_NAME = ?
bind => [SEQ_GEN]
[personnes]
[TopLink Fine]: 2007.05.28 12:07:53.906--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--INSERT INTO jpa01_personne (ID, PRENOM, DATENAISSANCE, NOM, MARIE, VERSION, NBENFANTS) VALUES (?, ?, ?, ?, ?, ?, ?)
bind => [3, Sylvie, 2001-07-05, Durant, false, 1, 0]
[TopLink Fine]: 2007.05.28 12:07:53.921--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--INSERT INTO jpa01_personne (ID, PRENOM, DATENAISSANCE, NOM, MARIE, VERSION, NBENFANTS) VALUES (?, ?, ?, ?, ?, ?, ?)
bind => [2, Paul, 2000-01-31, Martin, true, 1, 2]
[TopLink Fine]: 2007.05.28 12:07:53.937--ClientSession(15308417)--Connection(14069849)--Thread(Thread[main,5,main])--SELECT ID, PRENOM, DATENAISSANCE, NOM, MARIE, VERSION, NBENFANTS FROM jpa01_personne ORDER BY NOM ASC
[3,1,Durant,Sylvie,05/07/2001,false,0]
[2,1,Martin,Paul,31/01/2000,true,2]
[TopLink Config]: 2007.05.28 12:07:54.062--ServerSession(12910198)--Connection(30708295)--Thread(Thread[main,5,main])--disconnect
[TopLink Info]: 2007.05.28 12:07:54.062--ServerSession(12910198)--Thread(Thread[main,5,main])--file:/C:/data/2006-2007/eclipse/dvp-jpa/toplink/direct/personnes-entites/bin/-jpa logout successful
...
terminé ...
- Righe 2-5: una connessione al DBMS con i relativi parametri. In realtà, i log mostrano che Toplink crea effettivamente 3 connessioni al DBMS. Dobbiamo verificare se questo numero è correlato a uno dei valori di configurazione utilizzati per il pool di connessioni JDBC:
<property name="toplink.jdbc.read-connections.max" value="3" />
<property name="toplink.jdbc.read-connections.min" value="1" />
<property name="toplink.jdbc.write-connections.max" value="5" />
<property name="toplink.jdbc.write-connections.min" value="2" />
- Riga 7: eliminazione della tabella [jpa01_personne]. Ciò è normale, poiché il file [persistence.xml] richiede la pulizia del database JPA.
- riga 8: creazione della tabella [jpa01_personne]. Si noti che l'ID della chiave primaria non ha l'attributo autoincrement.
- riga 9: creazione della tabella [SEQUENCE], che esiste già, essendo stata creata durante l'esecuzione precedente.
- Righe 10–13: TopLink segnala un errore durante la creazione della tabella [SEQUENCE].
- Righe 15–18: TopLink cancella la tabella [SEQUENCE]. Dopo questa pulizia, la tabella [SEQUENCE] contiene una riga (SEQ_NAME, SEQ_COUNT) con i valori ('SEQ_GEN', 1).
- Riga 18: La tabella [jpa01_personne] viene svuotata.
- Righe 19–20: TopLink aggiorna l'unica riga in cui SEQ_NAME = 'SEQ_GEN' nella tabella [SEQUENCE], modificando il valore da ('SEQ_GEN', 1) a ('SEQ_GEN', 51).
- Riga 21: TopLink recupera il valore 51 dalla riga ('SEQ_GEN', 51) nella tabella [SEQUENCE].
- Righe 24–27: Toplink inserisce le due persone 'Martin' e 'Durant' nella tabella [jpa01_personne]. C'è un mistero qui: alle chiavi primarie di queste due righe vengono assegnati i valori 2 e 3, senza alcuna spiegazione su come siano stati ottenuti. Non è chiaro se il valore SEQ_COUNT (51) ottenuto alla riga 21 abbia avuto qualche utilità. Si noti che il valore della versione delle righe è 1, mentre Hibernate partiva da 0.
- Riga 28: TopLink esegue il SELECT per recuperare tutte le righe dalla tabella [jpa01_personne]
- Righe 29–30: Righe visualizzate dal client Java
- Righe 31-32: TopLink chiude una connessione. Ripeterà l'operazione per ciascuna delle connessioni inizialmente aperte.
In definitiva, non sappiamo esattamente a cosa serva la tabella [SEQUENCE], ma sembra comunque svolgere un ruolo nella generazione dei valori ID della chiave primaria. Impostando il livello di log al livello più dettagliato, FINEST, apprendiamo qualcosa in più sul ruolo della tabella [SEQUENCE].
<!-- logs -->
<property name="toplink.logging.level" value="FINEST" />
Di seguito abbiamo incluso solo i log relativi all'inserimento delle due persone nella tabella. È qui che vediamo il meccanismo di generazione dei valori della chiave primaria:
- riga 4: vediamo che il numero 51 recuperato dalla tabella [SEQUENCE] alla riga 2 viene utilizzato per delimitare un intervallo di valori per la chiave primaria: [2,51]
- riga 5: alla prima persona viene assegnato il valore 2 come chiave primaria
- riga 8: alla seconda persona viene assegnato il valore 3 come chiave primaria
- riga 12: mostra la gestione delle versioni per la prima persona
- riga 17: lo stesso vale per la seconda persona
Il livello di log [FINEST] mostra anche i confini delle transazioni emesse da Toplink. L'analisi di questi log rivela ciò che fa Toplink ed è un ottimo modo per comprendere il ponte relazionale-oggetti.
Punti chiave da quanto sopra:
- Implementazioni JPA diverse genereranno schemi di database diversi. In questo esempio, Hibernate e Toplink non hanno generato gli stessi schemi.
- I livelli di log FINE, FINER e FINEST di Toplink dovrebbero essere utilizzati ogni volta che si desidera chiarire esattamente cosa sta facendo Toplink.
2.1.15.4. Test [Main]
Ora eseguiamo il test [Main]:
 |
- in [1]: tutti i test sono stati superati tranne il test 11 [2]
- in [3]: riga 376, la riga di codice in cui si è verificata l'eccezione
Il codice che genera l'eccezione è il seguente:
} catch (RuntimeException e1) {
// on a eu un pb
System.out.format("Erreur dans transaction [%s,%s,%s,%s,%s,%s]%n", e1.getClass().getName(), e1.getMessage(),
e1.getCause().getClass().getName(), e1.getCause().getMessage(), e1.getCause().getCause().getClass().getName(), e1.getCause().getCause()
.getMessage());
try {
...
- riga [3]: la riga dell'eccezione. Abbiamo una NullPointerException, il che suggerisce che uno dei metodi getCause alle righe 4 e 5 abbia restituito un puntatore nullo. Un'espressione come [e1.getCause().getCause()] presuppone che la catena di eccezioni abbia 3 elementi [e1.getCause().getCause(), e1.getCause(), e1]. Se ne ha solo due, la prima espressione causerà un'eccezione.
Modifichiamo il codice precedente in modo che visualizzi solo le ultime due eccezioni nella catena di eccezioni:
} catch (RuntimeException e1) {
// on a eu un pb
System.out.format("Erreur dans transaction [%s,%s,%s,%s,]%n", e1.getClass().getName(), e1.getMessage(),
e1.getCause().getClass().getName(), e1.getCause().getMessage());
try {
...
Una volta eseguito, otteniamo il seguente risultato:
...
[personnes]
[2,5,Martin,Paul,31/01/2000,false,6]
main : ----------- test11
[personnes]
Erreur dans transaction [javax.persistence.OptimisticLockException,Exception [TOPLINK-5006] (Oracle TopLink Essentials - 2.0 (Build b41-beta2 (03/30/2007))): oracle.toplink.essentials.exceptions.OptimisticLockException
Exception Description: The object [[2,6,Martin,Paul,31/01/2000,false,7]] cannot be updated because it has changed or been deleted since it was last read.
Class> entites.Personne Primary Key> [2],oracle.toplink.essentials.exceptions.OptimisticLockException,
Exception Description: The object [[2,6,Martin,Paul,31/01/2000,false,7]] cannot be updated because it has changed or been deleted since it was last read.
Class> entites.Personne Primary Key> [2],]
[personnes]
[2,5,Martin,Paul,31/01/2000,false,6]
Questa volta, il Test 11 viene superato. I log delle eccezioni (righe 6–10) sono stati generati dal codice Java (riga 3 del codice sopra riportato). Ricordiamo che il Test 11 ha concatenato, all'interno di una singola transazione, diverse operazioni SQL, una delle quali ha dato esito negativo e avrebbe dovuto causare il rollback della transazione. Gli stati della tabella [jpa01_personne] prima (riga 3) e dopo il test (riga 12) sono identici, a dimostrazione del fatto che il rollback è avvenuto.
È importante notare qui che le implementazioni JPA/Hibernate e JPA/Toplink non sono intercambiabili al 100%. In questo esempio, dobbiamo modificare il codice client JPA per evitare una NullPointerException. Incontreremo nuovamente questo problema più avanti, questa volta nel contesto di un'eccezione.
2.1.16. Modifica del DBMS nell'implementazione JPA/Toplink
Rivediamo l'architettura di test del nostro progetto attuale:
 |
In precedenza, il DBMS utilizzato in [7] era MySQL 5. Mostreremo come passare a Oracle. In ogni caso, la modifica richiesta nel progetto Eclipse è semplice (vedi sotto): sostituire il file di configurazione persistence.xml [1] per il livello JPA con uno di quelli presenti nella cartella conf del progetto ([2] e [3]).
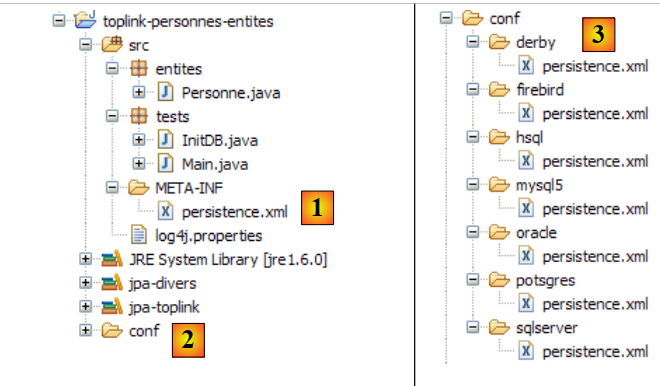 |
2.1.16.1. Oracle 10g Express
Oracle 10g Express è descritto nelle Appendici alla sezione 5.7. Il file persistence.xml di Oracle per Toplink è il seguente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- persistent classes -->
<class>entites.Personne</class>
<!-- persistence unit properties -->
<properties>
<!-- connection JDBC -->
<property name="toplink.jdbc.driver" value="oracle.jdbc.OracleDriver" />
<property name="toplink.jdbc.url" value="jdbc:oracle:thin:@localhost:1521:xe" />
<property name="toplink.jdbc.user" value="jpa" />
<property name="toplink.jdbc.password" value="jpa" />
<property name="toplink.jdbc.read-connections.max" value="3" />
<property name="toplink.jdbc.read-connections.min" value="1" />
<property name="toplink.jdbc.write-connections.max" value="5" />
<property name="toplink.jdbc.write-connections.min" value="2" />
<!-- SGBD -->
<property name="toplink.target-database" value="Oracle" />
<!-- application server -->
<property name="toplink.target-server" value="None" />
<!-- generation diagram -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
<property name="toplink.application-location" value="ddl/oracle" />
<property name="toplink.create-ddl-jdbc-file-name" value="create.sql" />
<property name="toplink.drop-ddl-jdbc-file-name" value="drop.sql" />
<property name="toplink.ddl-generation.output-mode" value="both" />
<!-- logs -->
<property name="toplink.logging.level" value="OFF" />
</properties>
</persistence-unit>
</persistence>
Questa configurazione è identica a quella utilizzata per il DBMS MySQL5, con le seguenti piccole differenze:
- righe 11–14, che configurano la connessione JDBC al database
- riga 20: che specifica il DBMS di destinazione
- riga 25: che specifica la directory per la generazione degli script SQL DDL
Per eseguire il test [InitDB]:
- avviare il DBMS Oracle
- Inserire conf/oracle/persistence.xml in META-INF/persistence.xml
- Eseguire l'applicazione [InitDB]
I seguenti risultati vengono visualizzati sulla console e nella vista [SQL Explorer]:
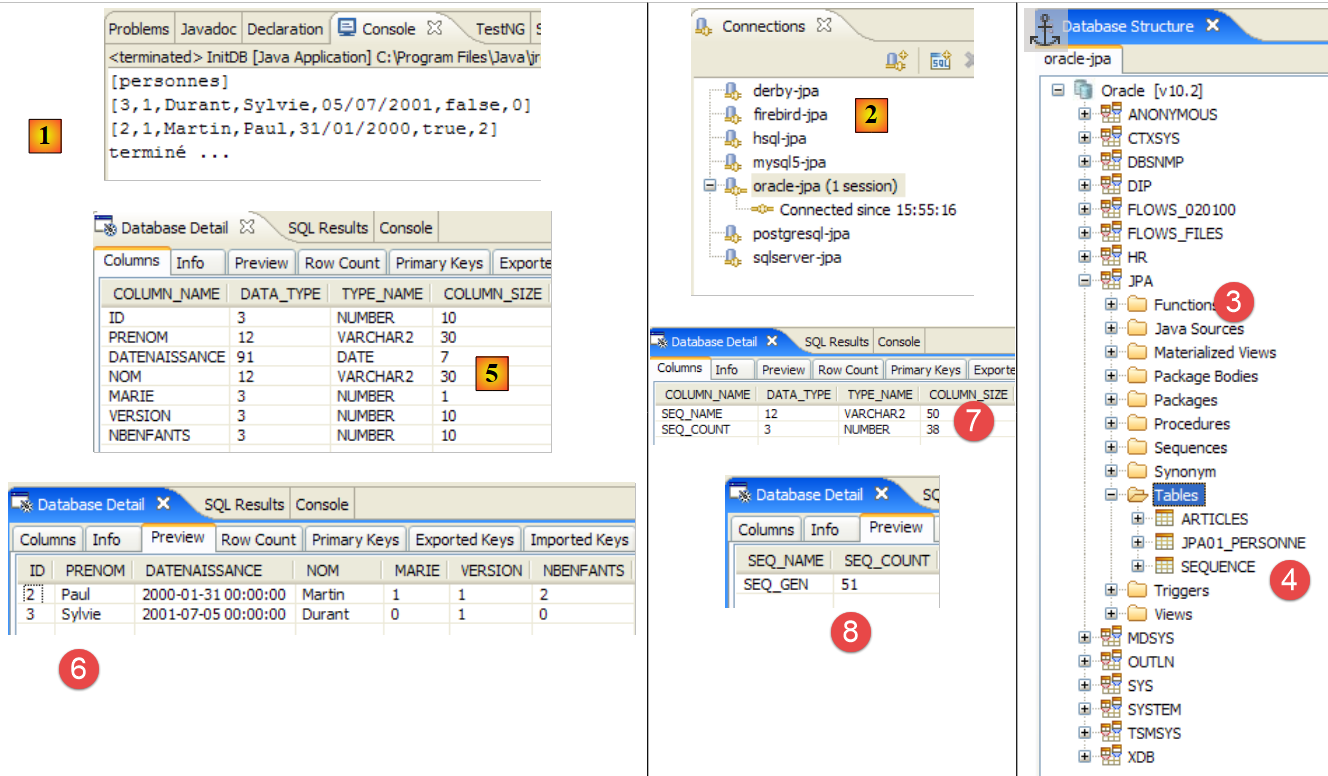 |
- [1]: la visualizzazione della console
- [2]: la connessione [oracle-jpa] in SQL Explorer
- [3]: il database JPA
- [4]: InitDB ha creato due tabelle: JPA01_PERSONNE e SEQUENCE, come con MySQL5. A volte in [4] compaiono tabelle [BIN*]. Queste corrispondono a tabelle eliminate. Per osservare questo fenomeno, è sufficiente rieseguire [InitDB]. La fase di inizializzazione del livello JPA include una pulizia del database JPA durante la quale la tabella [JPA01_PERSONNE] viene eliminata:
 |
In [A] compare una tabella [BIN]. Oracle non elimina definitivamente una tabella che è stata rimossa, ma la colloca in un [Cestino]. Questo Cestino è visibile [B] utilizzando lo strumento SQL Developer descritto nella sezione 5.7.4. In [B], possiamo eliminare definitivamente la tabella [JPA01_PERSONNE] dal Cestino. Questo svuota il Cestino [C]. Se aggiorniamo le tabelle in SQL Explorer (clic destro / Aggiorna), vediamo che la tabella BIN non è più presente [D].
- [5, 6]: struttura e contenuti della tabella [JPA01_PERSONNE]
- [7, 8]: la struttura e il contenuto della tabella [SEQUENCE]
Ecco fatto! Il lettore è ora invitato a eseguire l'applicazione [Main] su Oracle.
2.1.16.2. Altri DBMS
Non tratteremo altri DBMS in dettaglio. È sufficiente seguire la stessa procedura utilizzata per Oracle. Si notino i seguenti punti:
- Indipendentemente dal DBMS, Toplink utilizza sempre la stessa tecnica per generare i valori ID della chiave primaria per la tabella [JPA01_PERSONNE]: utilizza la tabella [SEQUENCE] descritta sopra.
- TopLink non supporta il DBMS Firebird. Per questi casi è disponibile un'impostazione generica del database:
Con questo database generico denominato [Auto], i test con Firebird falliscono a causa di errori di sintassi SQL. Toplink utilizza il tipo SQL Number(10) per l'ID della chiave primaria, che Firebird non riconosce. È quindi necessario scegliere un DBMS con gli stessi tipi SQL di Firebird (per questo esempio). Questo è il caso di Apache Derby:
<!-- connexion JDBC -->
<property name="toplink.jdbc.driver" value="org.firebirdsql.jdbc.FBDriver" />
...
<!-- SGBD -->
<!--
TopLink ne reconnaît pas Firebird pour l'instant (05/07). Derby convient pour remplacer.
-->
<property name="toplink.target-database" value="Derby" />
...
- TopLink non è in grado di generare lo schema originale del database per il DBMS HSQLDB. Cioè, la direttiva:
<!-- génération schéma -->
<property name="toplink.ddl-generation" value="drop-and-create-tables" />
non funziona con HSQLDB. La causa è un errore di sintassi durante la creazione della tabella [jpa01_personne]:
[TopLink Fine]: 2007.05.29 09:44:18.515--ServerSession(12910198)--Connection(29775659)--Thread(Thread[main,5,main])--DROP TABLE jpa01_personne
[TopLink Fine]: 2007.05.29 09:44:18.531--ServerSession(12910198)--Connection(29775659)--Thread(Thread[main,5,main])--CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, MARIE TINYINT NOT NULL, VERSION INTEGER NOT NULL, NBENFANTS INTEGER NOT NULL, PRIMARY KEY (ID))
[TopLink Warning]: 2007.05.29 09:44:18.531--ServerSession(12910198)--Thread(Thread[main,5,main])--Exception [TOPLINK-4002] (Oracle TopLink Essentials - 2.0 (Build b41-beta2 (03/30/2007)): oracle.toplink.essentials.exceptions.DatabaseException
Internal Exception: java.sql.SQLException: Unexpected token: UNIQUE in statement [CREATE TABLE jpa01_personne (ID INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, NOM VARCHAR(30) UNIQUE]
Riga 4: la sintassi LAST_NAME VARCHAR(30) UNIQUE NOT NULL non è accettata da HSQL. Hibernate ha utilizzato la sintassi: LAST_NAME VARCHAR(30) NOT NULL, UNIQUE(LAST_NAME).
In generale, Hibernate si è dimostrato più efficace di Toplink nel riconoscere i DBMS utilizzati nei test descritti in questo documento.
2.1.17. Conclusione
Lo studio dell'@Entity [Person] termina qui. Da un punto di vista concettuale, non è stato fatto molto: abbiamo esaminato il ponte oggetto-relazionale nella sua forma più semplice: un oggetto @Entity <--> una tabella. Tuttavia, questa analisi ci ha permesso di introdurre gli strumenti che useremo in tutto il documento. Questo ci consentirà di procedere un po' più rapidamente d'ora in poi mentre esaminiamo gli altri casi del ponte oggetto-relazionale:
- all'@Entity [Person] precedente, aggiungeremo un campo indirizzo modellato da una classe [Address]. Dal punto di vista del database, esamineremo due possibili implementazioni. Gli oggetti [Person] e [Address] danno origine a
- una singola tabella [Persona] che include l'indirizzo
- due tabelle [persona] e [indirizzo] collegate da una relazione uno-a-uno tramite chiave esterna.
- un esempio di relazione uno-a-molti in cui una tabella [articolo] è collegata a una tabella [categoria] tramite una chiave esterna
- un esempio di relazione molti-a-molti in cui due tabelle [Persona] e [Attività] sono collegate da una tabella di join [Persona_Attività].
2.2. Esempio 2: Relazione uno-a-uno tramite inclusione
2.2.1. Lo schema del database
1  | 2 |
- in [1]: il database (plugin Azurri Clay)
- in [2]: il DDL generato da Hibernate per MySQL5
La tabella [jpa02_personne] è la tabella [jpa01_personne] discussa in precedenza, alla quale è stato aggiunto un indirizzo (righe 12–18 del DDL).
2.2.2. Gli oggetti @Entity che rappresentano il database
L'indirizzo di una persona sarà rappresentato dalla seguente classe [Address]:
package entites;
...
@SuppressWarnings("serial")
@Embeddable
public class Adresse implements Serializable {
// fields
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
// manufacturers
public Adresse() {
}
public Adresse(String adr1, String adr2, String adr3, String codePostal, String ville, String cedex, String pays) {
...
}
// getters and setters
...
// toString
public String toString() {
return String.format("A[%s,%s,%s,%s,%s,%s,%s]", getAdr1(), getAdr2(), getAdr3(), getCodePostal(), getVille(), getCedex(), getPays());
}
}
- L'innovazione principale risiede nell'annotazione @Embeddable alla riga 5. La classe [Address] non è destinata a creare una tabella, quindi non presenta l'annotazione @Entity. L'annotazione @Embeddable indica che la classe è destinata a essere incorporata all'interno di un oggetto @Entity e quindi all'interno della tabella ad esso associata. Questo è il motivo per cui, nello schema del database, la classe [Address] non appare come una tabella separata, ma come parte della tabella associata all'@Entity [Person].
La classe @Entity [Person] è cambiata poco rispetto alla versione precedente: è stato semplicemente aggiunto un campo address:
package entites;
...
@Entity
@Table(name = "jpa02_hb_personne")
public class Personne implements Serializable{
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
@Embedded
private Adresse adresse;
// manufacturers
public Personne() {
}
...
}
- La modifica riguarda le righe 33–34. L'oggetto [Person] ora presenta un campo address di tipo Address. Questo vale per il POJO. L'annotazione @Embedded è destinata al ponte oggetto-relazionale. Indica che il campo [Address address] deve essere incapsulato nella stessa tabella dell'oggetto [Person].
2.2.3. L'ambiente di test
Eseguiremo test molto simili a quelli studiati in precedenza. Saranno condotti nel seguente contesto:
 |
L'implementazione utilizzata è JPA/Hibernate [6]. Il progetto di test Eclipse è il seguente:
 |
Il progetto Eclipse [1] differisce da quello precedente solo per il codice Java [2]. L'ambiente (librerie – persistence.xml – DBMS – cartelle conf e DDL – script Ant) è quello già discusso in precedenza, in particolare nella Sezione 2.1.5. Questo continuerà ad essere il caso per i futuri progetti Hibernate e, salvo eccezioni, non torneremo su questo ambiente. In particolare, i file persistence.xml che configurano il livello JPA/Hibernate per diversi DBMS sono quelli già esaminati e si trovano nella cartella <conf>.
Se il lettore ha dei dubbi sulle procedure da seguire, è invitato a rivedere quelle trattate nello studio precedente.
Il progetto Eclipse è disponibile [3] nella cartella examples [4]. Lo importeremo.
2.2.4. Generazione del DDL del database
Seguendo le istruzioni della Sezione 2.1.7, il DDL generato per il DBMS MySQL 5 è il seguente:
drop table if exists jpa02_hb_personne;
create table jpa02_hb_personne (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
prenom varchar(30) not null,
datenaissance date not null,
marie bit not null,
nbenfants integer not null,
adr1 varchar(30) not null,
adr2 varchar(30),
adr3 varchar(30),
codePostal varchar(5) not null,
ville varchar(20) not null,
cedex varchar(3),
pays varchar(20) not null,
primary key (id)
) ENGINE=InnoDB;
Hibernate ha correttamente riconosciuto che l'indirizzo della persona doveva essere incluso nella tabella associata all'@Entity Person (righe 11–17).
2.2.5. InitDB
Il codice per [InitDB] è il seguente:
package tests;
...
public class InitDB {
// constant
private final static String TABLE_NAME = "jpa02_hb_personne";
public static void main(String[] args) throws ParseException {
// Persistence context
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// a EntityManager is retrieved from the previous EntityManagerFactory
em = emf.createEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// request
Query sql1;
// delete elements from the PERSONNE table
sql1 = em.createNativeQuery("delete from " + TABLE_NAME);
sql1.executeUpdate();
// creating people
Personne p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// address creation
Adresse a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
Adresse a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
// associations person <--> address
p1.setAdresse(a1);
p2.setAdresse(a2);
// persistence of people
em.persist(p1);
em.persist(p2);
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// end transaction
tx.commit();
// end EntityManager
em.close();
// end EntityManagerFactory
emf.close();
// log
System.out.println("terminé...");
}
}
Non c'è nulla di nuovo in questo codice. Tutto è già stato trattato in precedenza. L'esecuzione di [InitDB] con MySQL5 produce i seguenti risultati:
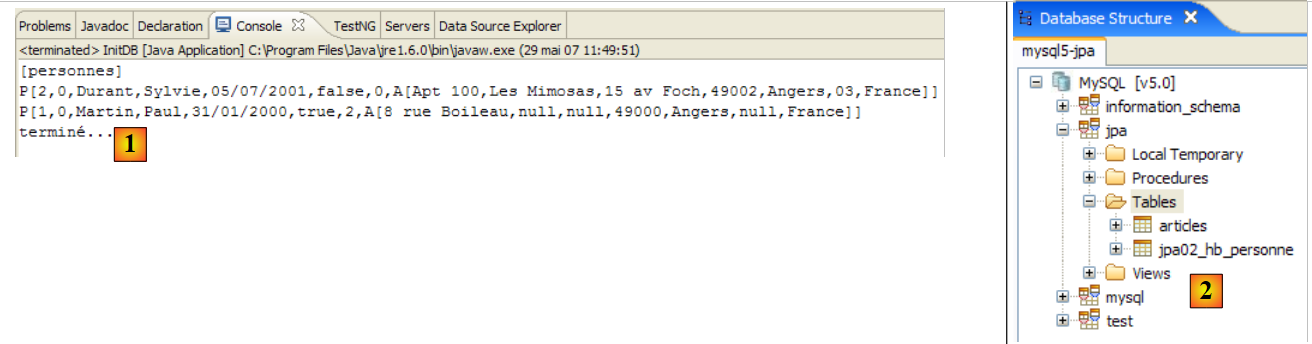 |
 |
- [1]: l'output della console
- [2]: la tabella [jpa02_hb_personne] nella vista SQL Explorer
- [3] e [4]: la sua struttura e il suo contenuto.
2.2.6. Main
La classe [Main] è la seguente:
package tests;
...
import entites.Adresse;
import entites.Personne;
@SuppressWarnings( { "unused", "unchecked" })
public class Main {
// constant
private final static String TABLE_NAME = "jpa02_hb_personne";
// Persistence context
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
private static EntityManager em = null;
// shared objects
private static Personne p1, p2, newp1;
private static Adresse a1, a2, a3, a4, newa1, newa4;
public static void main(String[] args) throws Exception {
// we retrieve a EntityManager from the EntityManagerFactory
em = emf.createEntityManager();
// base cleaning
log("clean");clean();
// dump table
dumpPersonne();
// test1
log("test1"); test1();
// test2
log("test2"); test2();
// test3
log("test3"); test3();
// test4
log("test4"); test4();
// test5
log("test5");test5();
// fine persistence context
if (em != null && em.isOpen())
em.close();
// closure EntityManagerFactory
emf.close();
}
// retrieve the current EntityManager
private static EntityManager getEntityManager() {
...
}
// pick up a new EntityManager
private static EntityManager getNewEntityManager() {
...
}
// display table content Person
private static void dumpPersonne() {
...
}
// raz BD
private static void clean() {
...
}
// logs
private static void log(String message) {
...
}
// object creation
public static void test1() throws ParseException {
// persistence context
EntityManager em = getEntityManager();
// creating people
p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// address creation
a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
// associations person <--> address
p1.setAdresse(a1);
p2.setAdresse(a2);
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistence of people
em.persist(p1);
em.persist(p2);
// end transaction
tx.commit();
// dump
dumpPersonne();
}
// modify a context object
public static void test2() {
// persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// increment the number of children in p1
p1.setNbenfants(p1.getNbenfants() + 1);
// change your marital status
p1.setMarie(false);
// object p1 is automatically saved (dirty checking)
// at next synchronization (commit or select)
// end transaction
tx.commit();
// the new table is displayed
dumpPersonne();
}
// delete an object belonging to the persistence context
public static void test4() {
// persistence context
EntityManager em = getEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// delete attached object p2
em.remove(p2);
// end transaction
tx.commit();
// the new table is displayed
dumpPersonne();
}
// detach, reattach and modify
public static void test5() {
// new persistence context
EntityManager em = getNewEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// reattach p1 to the new context
p1 = em.find(Personne.class, p1.getId());
// end transaction
tx.commit();
// change p1's address
p1.getAdresse().setVille("Paris");
// the new table is displayed
dumpPersonne();
}
}
Ancora una volta, nulla che non abbiamo già visto. L'output della console è il seguente:
Il lettore è invitato a stabilire il collegamento tra i risultati e il codice.
2.2.7. Implementazione JPA / Toplink
Ora stiamo utilizzando un'implementazione JPA / Toplink:
 |
Il nuovo progetto di test Eclipse è il seguente:
 |
Il codice Java è identico a quello del precedente progetto Hibernate. L'ambiente (librerie – persistence.xml – DBMS – cartelle conf e ddl – script Ant) è quello già descritto nella sezione 2.1.15.2. Questo continuerà a valere per i futuri progetti Toplink e, salvo eccezioni, non torneremo su questo ambiente. In particolare, i file persistence.xml che configurano il livello JPA/Toplink per diversi DBMS sono quelli già discussi e si trovano nella cartella <conf>.
Se il lettore ha dei dubbi sulle procedure da seguire, è invitato a rivedere quelle trattate nello studio precedente.
Il progetto Eclipse è disponibile [3] nella cartella examples [4]. Lo importeremo.
L'esecuzione di [InitDB] con il DBMS MySQL5 produce i seguenti risultati:
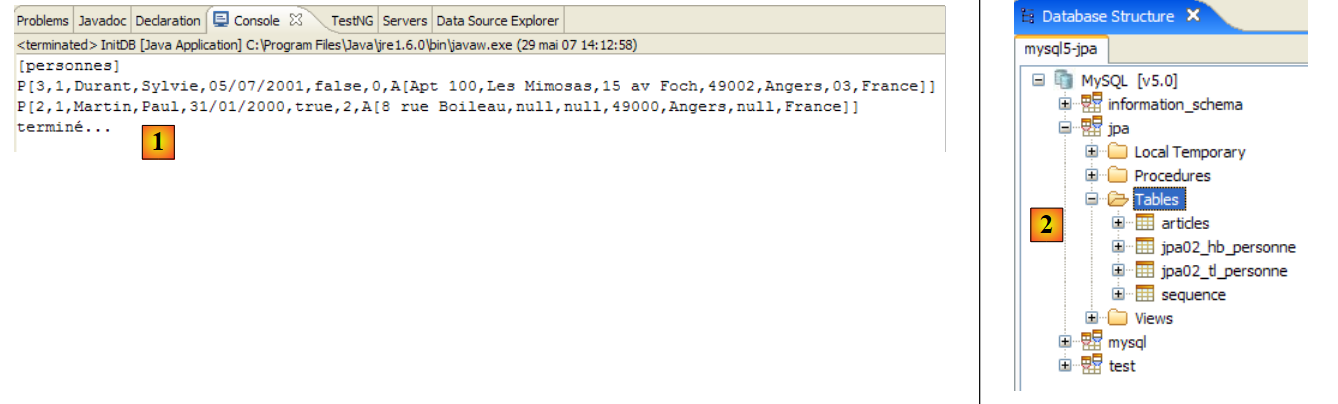 |
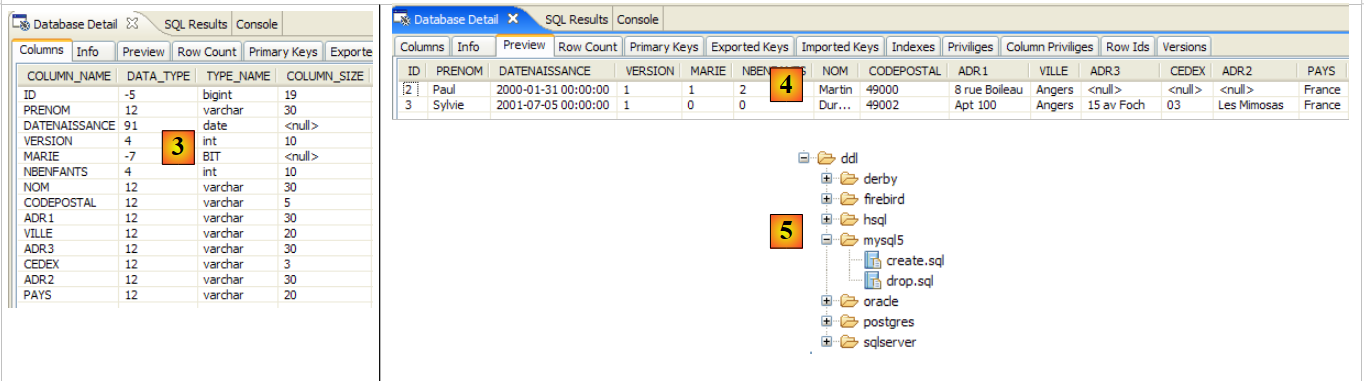 |
- [1]: l'output della console
- [2]: le tabelle [jpa02_tl_personne] e [SEQENCE] nella vista SQL Explorer
- [3] e [4]: la struttura e il contenuto di [jpa02_tl_personne].
Gli script SQL generati in ddl/mysql5 [5] sono i seguenti:
create.sql
CREATE TABLE jpa02_tl_personne (ID BIGINT NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, VERSION INTEGER NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NBENFANTS INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, CODEPOSTAL VARCHAR(5) NOT NULL, ADR1 VARCHAR(30) NOT NULL, VILLE VARCHAR(20) NOT NULL, ADR3 VARCHAR(30), CEDEX VARCHAR(3), ADR2 VARCHAR(30), PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
drop.sql
DROP TABLE jpa02_tl_personne
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
2.3. Esempio 3: Relazione uno-a-uno tramite chiave esterna
2.3.1. : Schema del database
1 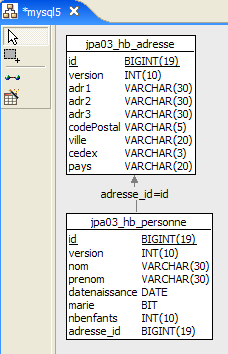 | 2 |
- in [1]: il database. In questo caso, l'indirizzo della persona è memorizzato in una tabella separata [adresse]. La tabella [personne] è collegata a questa tabella tramite una chiave esterna.
- in [2]: il DDL generato da Hibernate per MySQL5:
- righe 9–20: la tabella [address] che sarà collegata alla classe [Address], che è diventata un oggetto @Entity.
- riga 10: la chiave primaria della tabella [address]
- riga 30: invece di un indirizzo completo, la tabella [person] ora contiene l'identificatore [address_id] per quell'indirizzo.
- righe 34–38: `person(address_id)` è una chiave esterna su `address(id)`.
2.3.2. Gli oggetti @Entity che rappresentano il database
Una persona con un indirizzo è ora rappresentata dalla seguente classe [Person]:
package entites;
...
@Entity
@Table(name = "jpa03_hb_personne")
public class Personne implements Serializable{
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
@OneToOne(cascade = CascadeType.ALL, fetch=FetchType.LAZY)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
...
}
- righe 32–34: l'indirizzo della persona
- riga 32: l'annotazione @OneToOne indica una relazione uno-a-uno: una persona ha almeno un indirizzo e al massimo un indirizzo. L'attributo cascade = CascadeType.ALL significa che qualsiasi operazione (persist, merge, remove) sull'@Entity [Person] deve essere propagata all'@Entity [Address]. Dal punto di vista del contesto di persistenza em, ciò significa quanto segue. Se p è una persona e ha un indirizzo:
- un'operazione esplicita em.persist(p) attiverà un'operazione implicita em.persist(a)
- un'operazione esplicita em.merge(p) innescherà un'operazione implicita em.merge(a)
- un'operazione esplicita em.remove(p) innescherà un'operazione implicita em.remove(a)
- riga 32: l'annotazione @OneToOne indica una relazione uno-a-uno: una persona ha almeno un indirizzo e al massimo un indirizzo. L'attributo cascade = CascadeType.ALL significa che qualsiasi operazione (persist, merge, remove) sull'@Entity [Person] deve essere propagata all'@Entity [Address]. Dal punto di vista del contesto di persistenza em, ciò significa quanto segue. Se p è una persona e ha un indirizzo:
L'esperienza dimostra che queste cascate implicite non sono una panacea. Gli sviluppatori finiscono per dimenticare cosa fanno. Potrebbero essere preferibili operazioni esplicite nel codice. Esistono diversi tipi di cascate. L'annotazione @OneToOne avrebbe potuto essere scritta come segue:
//@OneToOne(cascade = CascadeType.ALL, fetch=FetchType.LAZY)
@OneToOne(cascade = {CascadeType.MERGE, CascadeType.PERSIST, CascadeType.REFRESH, CascadeType.REMOVE}, fetch=FetchType.LAZY)
L'attributo cascade accetta come valore un array di costanti che specificano i tipi di cascata desiderati.
L'attributo fetch=FetchType.LAZY indica a Hibernate di caricare la dipendenza all'ultimo momento possibile. Quando si aggiunge un elenco di persone al contesto di persistenza, potrebbe non essere necessario includere i loro indirizzi. Ad esempio, si potrebbe volere quell'indirizzo solo per una persona specifica selezionata da un utente tramite un'interfaccia web. L'attributo fetch=FetchType.EAGER, d'altra parte, richiede che le dipendenze vengano caricate immediatamente.
- (continua)
- riga 33: l'annotazione @JoinColumn definisce la chiave esterna che la tabella @Entity [Person] ha sulla tabella @Entity [Address]. L'attributo name definisce il nome della colonna che funge da chiave esterna. L'attributo unique=true impone una relazione uno a uno: lo stesso valore non può apparire due volte nella colonna [address_id]. L'attributo nullable=false impone che una persona debba avere un indirizzo.
L'indirizzo di una persona è ora rappresentato dalla seguente entità @Entity [Address]:
package entites;
...
@Entity
@Table(name = "jpa03_hb_adresse")
public class Adresse implements Serializable {
// fields
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
@OneToOne(mappedBy = "adresse", fetch=FetchType.LAZY)
private Personne personne;
// manufacturers
public Adresse() {
}
...
}
- riga 4: la classe [Address] diventa un oggetto @Entity. Sarà quindi oggetto di una tabella nel database.
- righe 9–12: Come ogni oggetto @Entity, [Address] possiede una chiave primaria. È stata denominata Id e presenta le stesse annotazioni (standard) della chiave primaria Id dell'@Entity [Person].
- righe 39–40: la relazione uno-a-uno con l'@Entity [Person]. Ci sono diverse sottigliezze qui:
- Innanzitutto, il campo `person` non è obbligatorio. Ci permette di utilizzare un indirizzo per identificare la singola persona associata a quell'indirizzo. Se non volessimo questa funzionalità, il campo `person` non esisterebbe e tutto funzionerebbe comunque.
- La relazione uno-a-uno che collega le due entità [Person] e [Address] è già stata configurata in @Entity [Person]:
@OneToOne(cascade = CascadeType.ALL, fetch=FetchType.LAZY)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
Per evitare che le due configurazioni uno-a-uno entrino in conflitto tra loro, una viene considerata primaria e l'altra inversa. È la relazione primaria che viene gestita dal ponte relazionale-oggettuale. L'altra relazione, nota come relazione inversa, non viene gestita direttamente: viene gestita indirettamente attraverso la relazione primaria. In @Entity [Address]:
@OneToOne(mappedBy = "adresse", fetch=FetchType.LAZY)
private Personne personne;
è l'attributo mappedBy che rende la relazione uno-a-uno sopra riportata la relazione inversa della relazione uno-a-uno primaria definita dal campo address di @Entity [Person].
2.3.3. Il progetto Eclipse / Hibernate 1
L'implementazione JPA utilizzata qui è Hibernate. Il progetto di test Eclipse è il seguente:
 |
Il progetto si trova [3] nella cartella degli esempi [4]. Lo importeremo.
2.3.4. Generazione del DDL del database
Seguendo le istruzioni della Sezione 2.1.7, il DDL ottenuto per il DBMS MySQL 5 è quello mostrato all'inizio di questa sezione.
2.3.5. InitDB
Il codice per [InitDB] è il seguente:
package tests;
...
import entites.Adresse;
import entites.Personne;
public class InitDB {
// constant
private final static String TABLE_PERSONNE = "jpa03_hb_personne";
private final static String TABLE_ADRESSE = "jpa03_hb_adresse";
public static void main(String[] args) throws ParseException {
// Persistence context
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// a EntityManager is retrieved from the previous EntityManagerFactory
em = emf.createEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// request
Query sql1;
// delete elements from the PERSONNE table
sql1 = em.createNativeQuery("delete from " + TABLE_PERSONNE);
sql1.executeUpdate();
// delete elements from the ADRESSE table
sql1 = em.createNativeQuery("delete from " + TABLE_ADRESSE);
sql1.executeUpdate();
// creating people
Personne p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// address creation
Adresse a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
Adresse a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
Adresse a3 = new Adresse("x", "x", "x", "x", "x", "x", "x");
Adresse a4 = new Adresse("y", "y", "y", "y", "y", "y", "y");
// associations person <--> address
p1.setAdresse(a1);
a1.setPersonne(p1);
p2.setAdresse(a2);
a2.setPersonne(p2);
// persistence of persons and cascading of their addresses
em.persist(p1);
em.persist(p2);
// and a3 and a4 addresses not linked to persons
em.persist(a3);
em.persist(a4);
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// address display
System.out.println("[adresses]");
for (Object a : em.createQuery("select a from Adresse a").getResultList()) {
System.out.println(a);
}
// end transaction
tx.commit();
// end EntityManager
em.close();
// end EntityManagerFactory
emf.close();
// log
System.out.println("terminé...");
}
}
Ci limiteremo a commentare le novità rispetto a quanto già trattato:
- righe 31–32: creiamo due persone
- righe 34–37: creiamo quattro indirizzi
- righe 39-42: associamo le persone (p1, p2) agli indirizzi (a1, a2). Gli indirizzi (a3, a4) rimangono orfani. Nessuna persona li fa riferimento. Il DDL lo consente. Mentre una persona deve avere un indirizzo, il contrario non è vero.
- righe 44-45: salviamo le persone (p1, p2). Poiché abbiamo impostato l'attributo cascade su CascadeType.ALL nella relazione uno-a-uno che collega una persona al proprio indirizzo, anche gli indirizzi (a1, a2) di queste due persone dovrebbero essere salvati. Questo è ciò che vogliamo verificare. Per gli indirizzi orfani (a3, a4), dobbiamo farlo in modo esplicito (righe 47–48).
- righe 51–53: visualizzazione della tabella delle persone
- Righe 56–57: visualizzazione della tabella degli indirizzi
L'esecuzione di [InitDB] con MySQL5 produce i seguenti risultati:
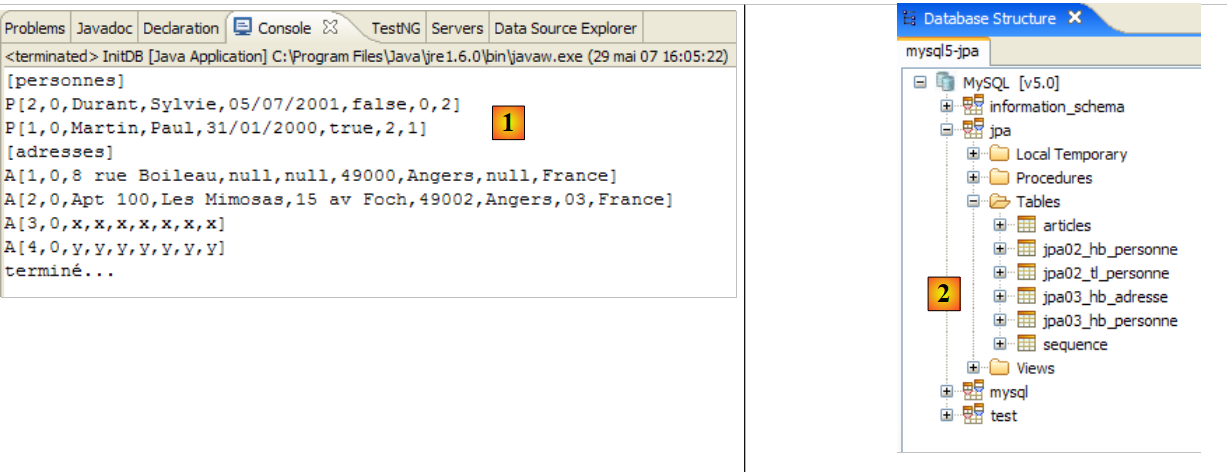 |
 |
- [1]: l'output della console
- [2]: le tabelle [jpa03_hb_*] nella vista SQL Explorer
- [3]: la tabella people
- [4]: la tabella degli indirizzi. Sono tutte presenti. Si noti inoltre la relazione tra la colonna [adresse_id] in [3] e la colonna [id] in [4] (chiave esterna).
2.3.6. Main
La classe [Main] esegue sei test, che esamineremo.
2.3.6.1. Test1
Questo test è il seguente:
// création d'objets
public static void test1() throws ParseException {
// contexte de persistance
EntityManager em = getEntityManager();
// création personnes
p1 = new Personne("Martin", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
p2 = new Personne("Durant", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// création adresses
a1 = new Adresse("8 rue Boileau", null, null, "49000", "Angers", null, "France");
a2 = new Adresse("Apt 100", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
a3 = new Adresse("x", "x", "x", "x", "x", "x", "x");
a4 = new Adresse("y", "y", "y", "y", "y", "y", "y");
// associations personne <--> adresse
p1.setAdresse(a1);
a1.setPersonne(p1);
p2.setAdresse(a2);
a2.setPersonne(p2);
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistance des personnes
em.persist(p1);
em.persist(p2);
// et des adresses a3 et a4 non liées à des personnes
em.persist(a3);
em.persist(a4);
// fin transaction
tx.commit();
// on affiche les tables
dumpPersonne();
dumpAdresse();
}
Questo codice è tratto da [InitDB]. Il risultato è il seguente:
Entrambe le tabelle sono state compilate.
2.3.6.2. Test2
Questo test è il seguente:
// modifier un objet du contexte
public static void test2() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on incrémente le nbre d'enfants de p1
p1.setNbenfants(p1.getNbenfants() + 1);
// on modifie son état marital
p1.setMarie(false);
// l'objet p1 est automatiquement sauvegardé (dirty checking)
// lors de la prochaine synchronisation (commit ou select)
// fin transaction
tx.commit();
// on affiche la nouvelle table
dumpPersonne();
}
Il risultato è il seguente:
- riga 4: la persona p1 ha visto aumentare di 1 il numero dei propri figli e cambiare la propria versione da 0 a 1
2.3.6.3. Test 4
Questo test è il seguente:
// supprimer un objet appartenant au contexte de persistance
public static void test4() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on supprime l'objet attaché p2
em.remove(p2);
// fin transaction
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpAdresse();
}
- Riga 9: Rimuoviamo la persona p2. Questa persona ha una relazione a cascata con l'indirizzo a2. Pertanto, anche l'indirizzo a2 dovrebbe essere rimosso.
Il risultato del test 4 è il seguente:
- La persona p2 che compare alla riga 3 del test 1 non è più presente nel test 4
- Lo stesso vale per il suo indirizzo a2, che compare nella riga 7 del test 1 ma è assente dal test 4.
2.3.6.4. Test 5
Questo test è il seguente:
// détacher, réattacher et modifier
public static void test5() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on réattache p1 au nouveau contexte
p1 = em.find(Personne.class, p1.getId());
// on change l'adresse de p1
p1.getAdresse().setVille("Paris");
// fin transaction
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpAdresse();
}
- Riga 4: Abbiamo un nuovo contesto di persistenza, quindi è vuoto.
- Riga 9: aggiungiamo la persona p1. p1 viene recuperata dal database perché non è nel contesto. Gli elementi dipendenti da p1 (il suo indirizzo) non vengono recuperati dal database perché abbiamo scritto:
@OneToOne(..., fetch=FetchType.LAZY)
Questo è il concetto di "caricamento pigro": le dipendenze di un oggetto persistente vengono caricate in memoria solo quando sono necessarie.
- Riga 11: modifichiamo il campo città dell'indirizzo di p1. A causa della chiamata getAddress, e se l'indirizzo di p1 non era già nel contesto di persistenza, verrà recuperato dal database.
- Riga 13: Eseguiamo il commit della transazione, che sincronizzerà il contesto di persistenza con il database. Il database rileverà che l'indirizzo della persona p1 è stato modificato e lo salverà.
L'esecuzione di test5 produce i seguenti risultati:
- La persona p1 (riga 3 del test4, riga 10 del test5) ha osservato correttamente il cambiamento della propria città da Angers (riga 5 del test4) a Parigi (riga 12 del test5).
2.3.6.5. Test6
Questo test è il seguente:
// delete an Address object
public static void test6() {
EntityTransaction tx = null;
// new persistence context
EntityManager em = getNewEntityManager();
// start of transaction
tx = em.getTransaction();
tx.begin();
// reattach address a3 to new context
a3 = em.find(Adresse.class, a3.getId());
System.out.println(a3);
// we delete it
em.remove(a3);
// end transaction
tx.commit();
// dump table Address
dumpAdresse();
}
- Riga 5: Ci troviamo in un nuovo contesto di persistenza, quindi è vuoto.
- Riga 10: inseriamo l'indirizzo a3 nel contesto di persistenza
- riga 13: lo eliminiamo. Era un indirizzo orfano (non collegato a una persona). L'eliminazione è quindi possibile.
Il risultato dell'esecuzione è il seguente:
- L'indirizzo a3 del test 5 (riga 6) è scomparso dagli indirizzi del test 6 (righe 11-12)
2.3.6.6. Test 7
Questo test è il seguente:
// rollback
public static void test7() {
EntityTransaction tx = null;
try {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
tx = em.getTransaction();
tx.begin();
// on réattache l'adresse a1 au nouveau contexte
newa1 = em.find(Adresse.class, a1.getId());
// on réattache l'adresse a4 au nouveau contexte
newa4 = em.find(Adresse.class, a4.getId());
// on essaie de les supprimer - devrait lancer une exception car on ne peut supprimer une adresse liée à une personne, ce qui est le cas de newa1
em.remove(newa4);
em.remove(newa1);
// fin transaction
tx.commit();
} catch (RuntimeException e1) {
// on a eu un pb
System.out.format("Erreur dans transaction [%s%n%s%n%s%n%s]%n", e1.getClass().getName(), e1.getMessage(), e1.getCause(), e1.getCause()
.getCause());
try {
if (tx.isActive())
tx.rollback();
} catch (RuntimeException e2) {
System.out.format("Erreur au rollback [%s]%n", e2.getMessage());
}
// on abandonne le contexte courant
em.clear();
}
// dump - la table Adresse n'a pas du changer à cause du rollback
dumpAdresse();
}
- test7: verifica del rollback di una transazione
- riga 6: ci troviamo in un nuovo contesto di persistenza, quindi è vuoto.
- riga 11: inseriamo l'indirizzo a1 nel contesto di persistenza, sotto il riferimento newa1
- riga 13: inseriamo l'indirizzo a4 nel contesto di persistenza, sotto il riferimento newa4
- righe 15-16: eliminiamo i due indirizzi newa1 e newa4. newa1 è l'indirizzo della persona p1 ed è quindi referenziato da p1 nel database tramite una chiave esterna. L'eliminazione di newa1 fallirà quindi e genererà un'eccezione quando il contesto di persistenza verrà sincronizzato al momento del commit della transazione (riga 18). La transazione verrà annullata (riga 25) e quindi entrambe le operazioni nella transazione verranno cancellate. Dovremmo quindi osservare che l'indirizzo newa4, che avrebbe potuto essere legalmente eliminato, non è stato eliminato.
L'esecuzione produce il seguente risultato:
main : ----------- test6
A[3,0,x,x,x,x,x,x,x]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
main : ----------- test7
Erreur dans transaction [javax.persistence.RollbackException
Error while commiting the transaction
org.hibernate.ObjectDeletedException: deleted entity passed to persist: [entites.Adresse#<null>]
null]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
- La tabella degli indirizzi nel Test 7 (righe 12–13) è identica a quella del Test 6 (righe 4–5). Sembra che il rollback sia avvenuto. Detto questo, il messaggio di errore alla riga 9 è un mistero e merita un'ulteriore indagine. Sembra che l'eccezione verificatasi non sia quella prevista. Dobbiamo impostare i log di Hibernate in modalità DEBUG in log4j.properties per avere un quadro più chiaro:
# Root logger option
log4j.rootLogger=ERROR, stdout
# Hibernate logging options (INFO only shows startup messages)
log4j.logger.org.hibernate=DEBUG
Possiamo quindi notare che quando l'indirizzo a1 è stato inserito nel contesto di persistenza, Hibernate vi ha inserito anche la persona p1, probabilmente a causa della relazione uno-a-uno di @Entity [Address]:
@OneToOne(mappedBy = "adresse", fetch=FetchType.LAZY)
private Personne personne;
Sebbene qui sia stato richiesto il "LazyLoading", la dipendenza [Person] viene comunque caricata immediatamente. Ciò significa probabilmente che l'attributo fetch=FetchType.LAZY non ha alcun effetto in questo caso. Si osserva quindi che, al momento del commit della transazione, Hibernate ha preparato l'eliminazione degli indirizzi a1 e a4, nonché il salvataggio della persona p1. Ed è qui che si verifica l'eccezione: poiché la persona p1 ha una cascata sul proprio indirizzo, Hibernate vuole anche mantenere l'indirizzo a1, anche se è stato appena eliminato. È Hibernate a generare l'eccezione, non il driver JDBC. Da qui il messaggio alla riga 9 sopra. Inoltre, possiamo vedere che il rollback alla riga 25 non viene mai eseguito perché la transazione è diventata inattiva. Il test alla riga 24 impedisce quindi il rollback.
Non abbiamo quindi raggiunto l'obiettivo desiderato: dimostrare un rollback. Infatti, non è mai stata emessa alcuna istruzione SQL al database. Ricapitoliamo alcuni punti chiave:
- l'importanza di abilitare la registrazione dettagliata per comprendere cosa sta facendo l'ORM
- se da un lato un ORM può semplificare la vita di uno sviluppatore, dall'altro può anche complicarla nascondendo comportamenti che lo sviluppatore deve conoscere. In questo caso, il modo in cui vengono caricate le dipendenze di un @Entity.
2.3.7. Progetto Eclipse / Hibernate 2
Copiamo e incolliamo il progetto Eclipse/Hibernate per apportare alcune piccole modifiche alla configurazione degli oggetti @Entity:
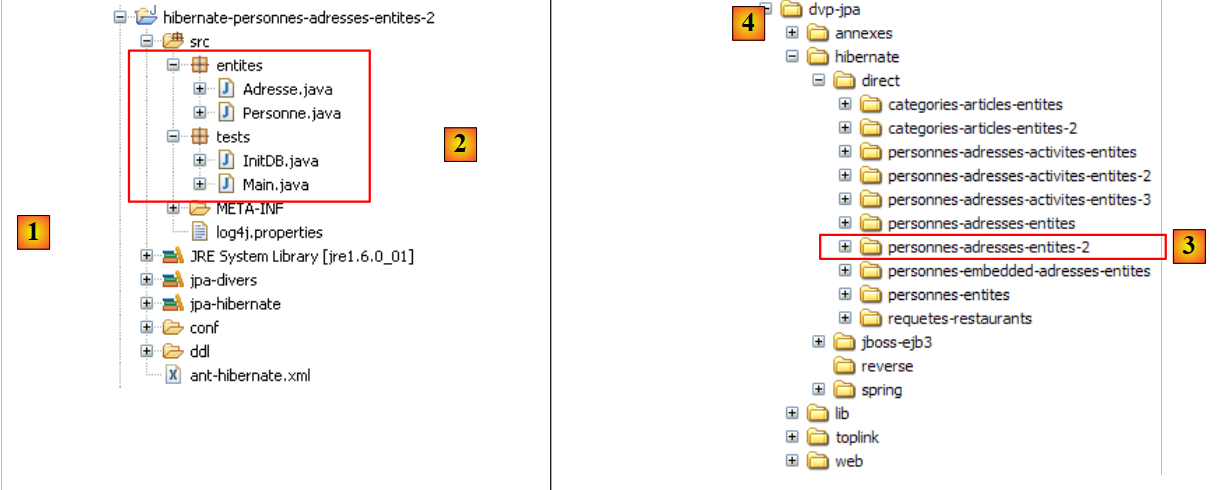 |
Il progetto si trova [3] nella cartella degli esempi [4]. Lo importeremo.
Modifichiamo solo l'@Entity [Address] in modo che non abbia più una relazione inversa uno-a-uno con l'@Entity [Person]:
package entites;
...
@Entity
@Table(name = "jpa04_hb_adresse")
public class Adresse implements Serializable {
// fields
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
...
@Column(length = 20, nullable = false)
private String pays;
// @OneToOne(mappedBy = "address", fetch=FetchType.LAZY)
// private Person person;
// manufacturers
public Adresse() {
}
- righe 25-26: la relazione inversa @OneToOne viene rimossa. È importante comprendere che una relazione inversa non è mai essenziale. Lo è solo la relazione primaria. La relazione inversa può essere utilizzata per comodità. In questo caso, ha fornito un modo semplice per recuperare il proprietario di un indirizzo. Una relazione inversa può sempre essere sostituita da una query JPQL. Questo è ciò che dimostreremo nell'esempio seguente.
I programmi di test sono identici. Quello che ci interessa è solo il Test 7, quello in cui abbiamo visto la relazione inversa uno-a-uno in azione. Aggiungiamo anche il Test 8 per mostrare come, senza la relazione inversa Indirizzo -> Persona, possiamo comunque recuperare la persona con un dato indirizzo.
Il Test 7 rimane invariato. Eseguendolo ora si ottengono i seguenti risultati (log disabilitati):
main : ----------- test6
A[3,0,x,x,x,x,x,x,x]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
main : ----------- test7
Erreur dans transaction [javax.persistence.RollbackException
Error while commiting the transaction
org.hibernate.exception.ConstraintViolationException: could not delete: [entites.Adresse#1]
java.sql.SQLException: Cannot delete or update a parent row: a foreign key constraint fails (`jpa/jpa04_hb_personne`, CONSTRAINT `FKEA3F04515FE379D0` FOREIGN KEY (`adresse_id`) REFERENCES `jpa04_hb_adresse` (`id`))]
[adresses]
A[1,1,8 rue Boileau,null,null,49000,Paris,null,France]
A[4,0,y,y,y,y,y,y,y]
- Questa volta otteniamo l'eccezione prevista: quella generata dal driver JDBC perché abbiamo tentato di eliminare una riga nella tabella [address] a cui fa riferimento una chiave esterna da una riga nella tabella [person]. La riga [10] spiega chiaramente la causa dell'errore.
- Il rollback ha effettivamente avuto luogo: alla fine del test 7, la tabella [address] (righe 12–13) è la stessa di quella alla fine del test 6 (righe 4–5).
Qual è la differenza rispetto al Test 7 del precedente progetto Eclipse? Perché qui si verifica un'eccezione Jdbc che non si era verificata nel test precedente? Perché l'entità @Entity [Address] non ha più una relazione inversa uno-a-uno con l'entità @Entity [Person]; essa viene gestita in modo indipendente da Hibernate. Quando l'indirizzo newa1 è stato inserito nel contesto di persistenza, Hibernate non ha inserito in quel contesto anche la persona p1 associata a quell'indirizzo. L'eliminazione degli indirizzi newa1 e newa4 è quindi avvenuta senza alcuna entità Person nel contesto.
Ora, come potremmo utilizzare l'indirizzo newa1 per trovare la persona p1 con quell'indirizzo? È una domanda legittima. Il seguente Test 8 risponde a questa domanda:
// relation inverse un-à-un
// réalisée par une requête JPQL
public static void test8() {
EntityTransaction tx = null;
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
tx = em.getTransaction();
tx.begin();
// on réattache l'adresse a1 au nouveau contexte
newa1 = em.find(Adresse.class, a1.getId());
// on récupère la personne propriétaire de cette adresse
Personne p1 = (Personne) em.createQuery("select p from Personne p join p.adresse a where a.id=:adresseId").setParameter("adresseId", newa1.getId())
.getSingleResult();
// on les affiche
System.out.println("adresse=" + newa1);
System.out.println("personne=" + p1);
// fin transaction
tx.commit();
}
- riga 6: nuovo contesto di persistenza vuoto
- righe 8-9: avvia transazione
- riga 11: l'indirizzo a1 viene inserito nel contesto di persistenza e referenziato da newa1.
- riga 13: la persona p1 con indirizzo newa1 viene recuperata tramite una query JPQL. Sappiamo che [Person] e [Address] sono collegati da una relazione di chiave esterna. Nella classe [Person], è il campo [address] ad avere l'annotazione @OneToOne, che definisce questa relazione. L'istruzione JPQL "select p from Person p join p.address a" esegue un join tra le tabelle [Person] e [Address]. L'SQL equivalente generato in una console Hibernate (vedere gli esempi nella sezione 2.1.12) è il seguente:
Il join tra le due tabelle è chiaramente visibile. Ogni persona è ora collegata al proprio indirizzo. Resta da specificare che ci interessa solo l'indirizzo newa1. La query diventa "select p from Person p join p.address a where a.id=:addressId". Si noti l'uso degli alias p e a. Le query JPQL fanno ampio uso di alias. Pertanto, l'espressione "from Person p join p.address a" significa che una persona è rappresentata dall'alias p e il suo indirizzo (p.address) dall'alias a. L'operazione di restrizione "where a.id=:adresseId" limita le righe richieste solo a quelle persone p il cui indirizzo a ha il valore :adresseId come identificatore. :adresseId è chiamato parametro e la query JPQL è una query JPQL parametrizzata. In fase di esecuzione, a questo parametro deve essere assegnato un valore. Ciò avviene utilizzando il metodo
che consente di assegnare un valore a un parametro identificato dal suo nome. Si noti che setParameter restituisce un oggetto Query, proprio come il metodo createQuery. Ciò significa che è possibile concatenare le chiamate ai metodi [ad es. createQuery(...).setParameter(...).getSingleResult(...)], poiché i metodi [setParameter, getSingleResult] sono metodi dell'interfaccia Query. Il metodo [getSingleResult] viene utilizzato per le query Select che restituiscono un solo risultato. È il caso in questione.
- Righe 16–17: Visualizziamo l'indirizzo newa1 e la persona p1 associata a quell'indirizzo, a scopo di verifica.
Il risultato ottenuto è il seguente:
È corretto. Da questo esempio possiamo concludere che la relazione inversa uno-a-uno dall'@entità [Indirizzo] all'@entità [Persona] non era essenziale. L'esperienza ha dimostrato in questo caso che la sua rimozione ha portato a un comportamento del codice più prevedibile. Questo accade spesso.
2.3.8. Console Hibernate
Il precedente Test 8 utilizzava un comando JPQL per eseguire un join tra le entità Person e Address. Sebbene simili all'SQL, il JPQL di JPA e l'HQL di Hibernate richiedono un apprendimento, e la console di Hibernate è eccellente a questo scopo. L'abbiamo già utilizzata nella Sezione 2.1.12 per interrogare una singola tabella. Lo faremo di nuovo qui per interrogare due tabelle collegate da una relazione di chiave esterna.
Creiamo una console Hibernate per il nostro attuale progetto Eclipse:
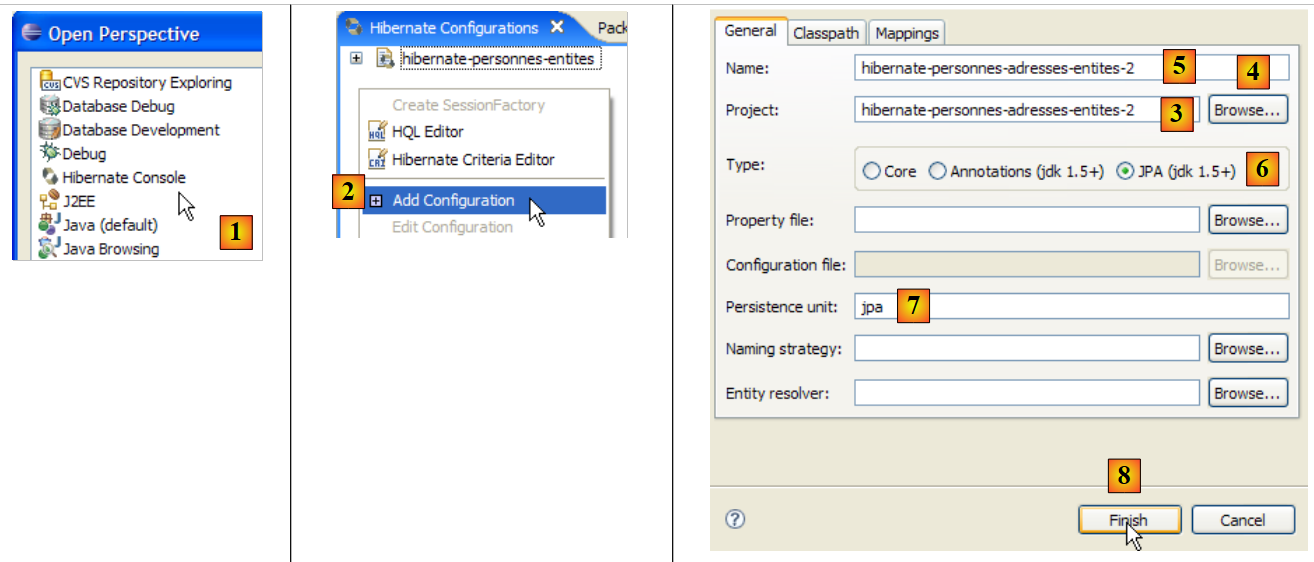 |
- [1]: Passare alla prospettiva [Hibernate Console] (Finestra / Apri prospettiva / Altro)
- [2]: Creiamo una nuova configurazione
- utilizzando il pulsante [4], selezioniamo il progetto Java per il quale si sta creando la configurazione Hibernate. Il suo nome appare in [3].
- In [5], inseriamo il nome che vogliamo per questa configurazione. Qui abbiamo utilizzato il nome del progetto Java.
- In [6], specifichiamo che stiamo utilizzando una configurazione JPA in modo che lo strumento sappia che deve utilizzare il file [META-INF/persistence.xml]
- In [7], specifichiamo nel file [META-INF/persistence.xml] che deve essere utilizzata l'unità di persistenza denominata jpa.
- In [8], convalidiamo la configurazione.
Successivamente, è necessario avviare il DBMS. In questo caso, si tratta di MySQL 5.
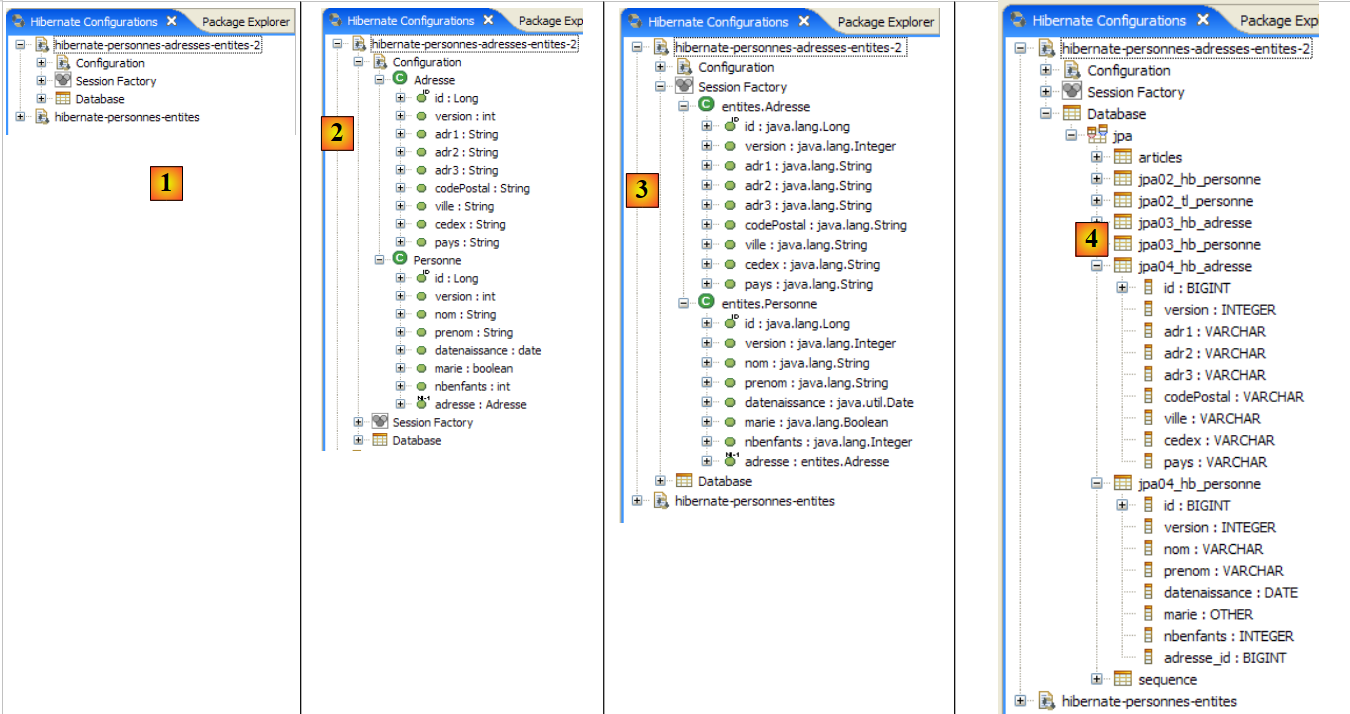 |
- In [1]: La configurazione creata ha una struttura ad albero a tre rami
- in [2]: il ramo [Configuration] elenca gli oggetti utilizzati dalla console per configurarsi: in questo caso, @Entity Person e Address.
- In [3]: La Session Factory è un concetto di Hibernate simile all’EntityManager di JPA. Colma il divario tra oggetti e relazionale utilizzando oggetti dal ramo [Configuration]. [3] presenta gli oggetti del contesto di persistenza, in questo caso le entità @Entity Person e Address.
- in [4]: il database a cui si accede tramite la configurazione presente in [persistence.xml]. Qui troviamo le tabelle [jpa04_hb_*] generate dal nostro attuale progetto Eclipse.
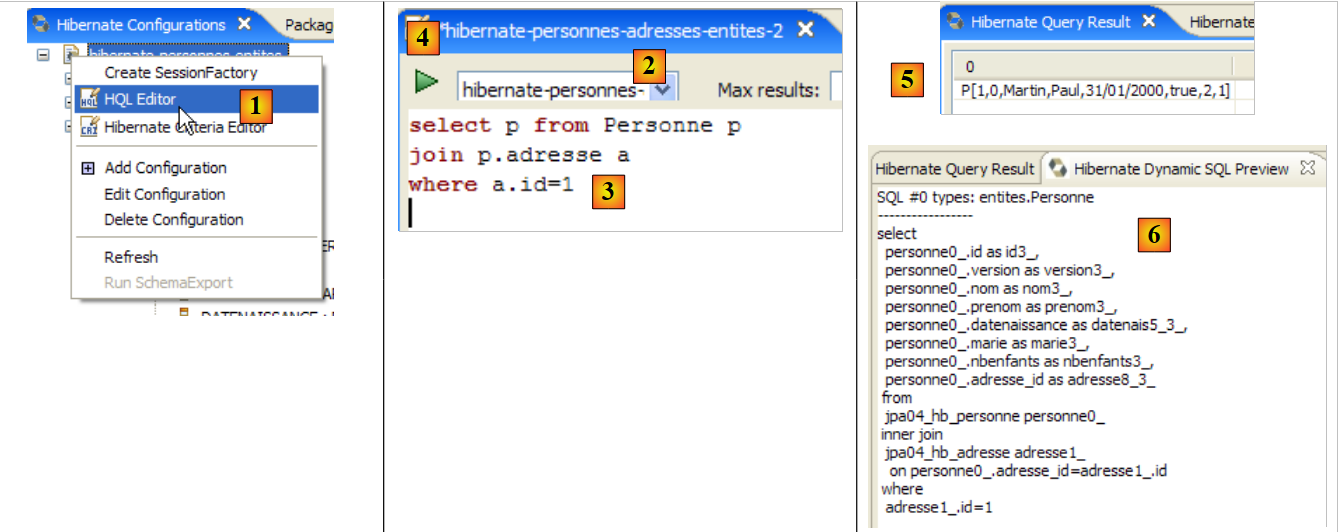 |
- In [1], creiamo un editor HQL
- nell'editor HQL,
- in [2], selezioniamo la configurazione Hibernate da utilizzare se ce ne sono più di una (come in questo caso)
- in [3], digitare il comando JPQL che si desidera eseguire; in questo caso, il comando JPQL del Test 8
- in [4], lo eseguiamo
- In [5], si ottengono i risultati della query nella finestra [Hibernate Query Result].
- In [6], la finestra [Hibernate Dynamic SQL preview] consente di visualizzare la query SQL che è stata eseguita.
Un altro modo per ottenere lo stesso risultato:
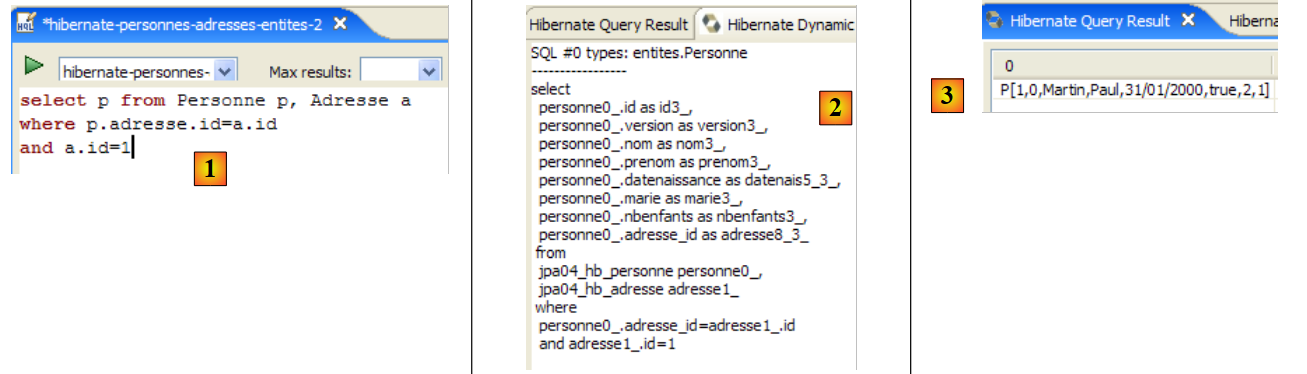 |
- In [1]: il comando JPQL che esegue il join tra le entità Person e Address. [ref1] definisce questa forma come "theta join".
- in [2]: l'equivalente SQL
- In [3]: il risultato
Una terza forma accettata solo da Hibernate (HQL):
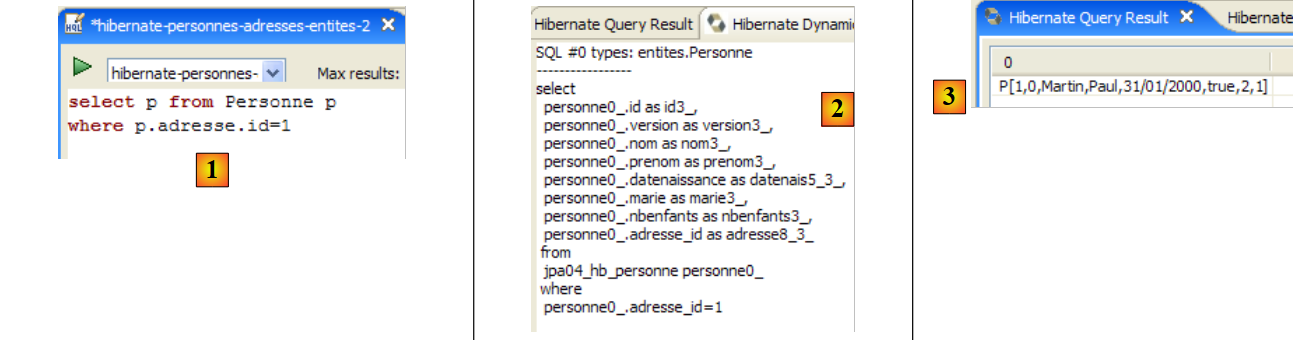 |
- in [1]: la query HQL. JPQL non accetta la notazione p.address.id. Accetta solo un livello di indirezione.
- in [2]: l'equivalente SQL. Si noti che evita il join tra tabelle.
- in [3]: il risultato
Ecco alcuni altri esempi:
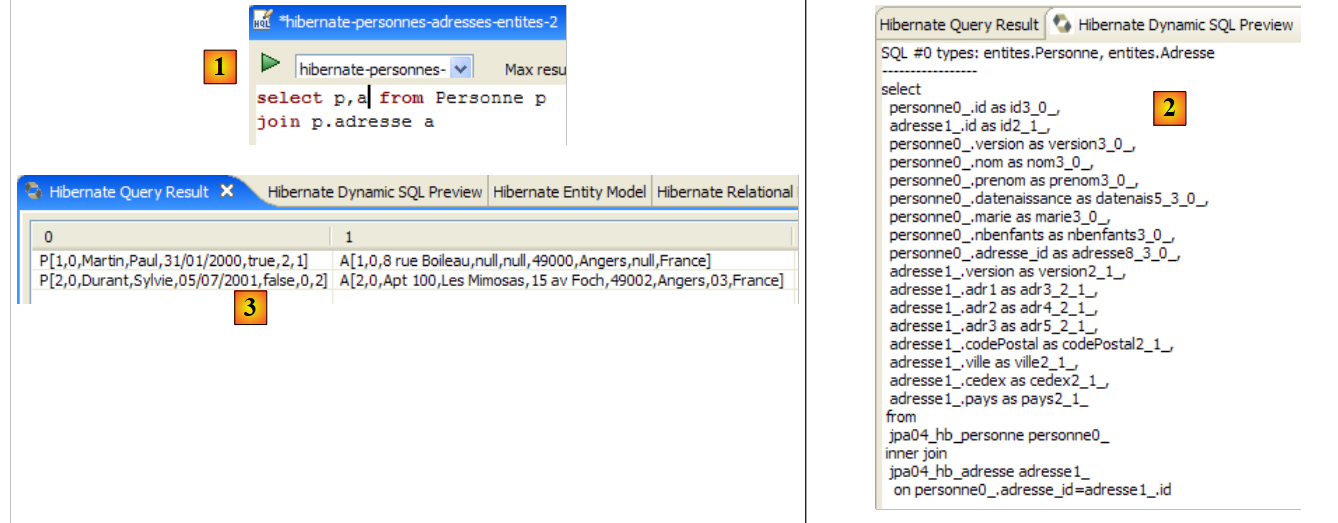 |
- in [1]: l'elenco delle persone con i relativi indirizzi
- in [2]: l'equivalente SQL.
- in [3]: il risultato
 |
- in [1]: l'elenco degli indirizzi con il relativo proprietario, se presente, oppure nessuno in caso contrario (join esterno a destra: l'entità Address, che fornirà le righe non correlate a Person, si trova a destra della parola chiave join).
- in [2]: l'equivalente SQL.
- in [3]: il risultato
Si noti che solo l'entità Person ha una relazione con l'entità Address. Il contrario non è più vero poiché abbiamo rimosso la relazione inversa uno-a-uno denominata Person nell'entità Address. Se questa relazione inversa fosse esistita, avremmo potuto scrivere:
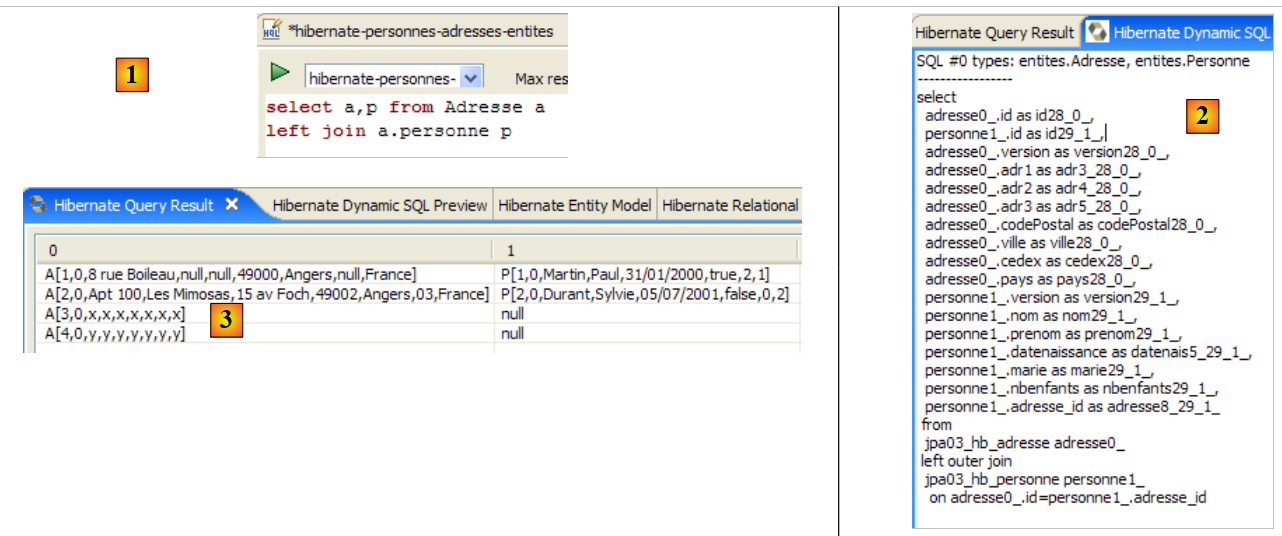 |
- in [1]: l'elenco degli indirizzi con il relativo proprietario, se presente, oppure nessuno in caso contrario (join esterno a sinistra: l'entità Address, che restituirà righe senza alcuna relazione con Person, si trova sul lato sinistro della parola chiave join).
- in [2]: l'equivalente SQL.
- in [3]: il risultato
Consigliamo vivamente al lettore di esercitarsi con il linguaggio JPQL utilizzando la console di Hibernate.
2.3.9. Implementazione JPA / Toplink
Ora stiamo utilizzando un'implementazione JPA / Toplink:
 |
Il nuovo progetto di test Eclipse è il seguente:
 |
Il codice Java è identico a quello del precedente progetto Hibernate. L'ambiente (librerie – persistence.xml – DBMS – cartelle conf e ddl – script Ant) è quello descritto nella sezione 2.1.15.2. Il progetto Eclipse è disponibile [3] nella cartella degli esempi [4]. Lo importeremo.
Il file <persistence.xml> è stato modificato in un punto, in particolare nelle entità dichiarate:
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- classes persistantes -->
<class>entites.Personne</class>
<class>entites.Adresse</class>
<!-- propriétés de l'unité de persistance -->
...
- righe 5 e 6: le due entità gestite
L'esecuzione di [InitDB] con il DBMS MySQL5 produce i seguenti risultati:
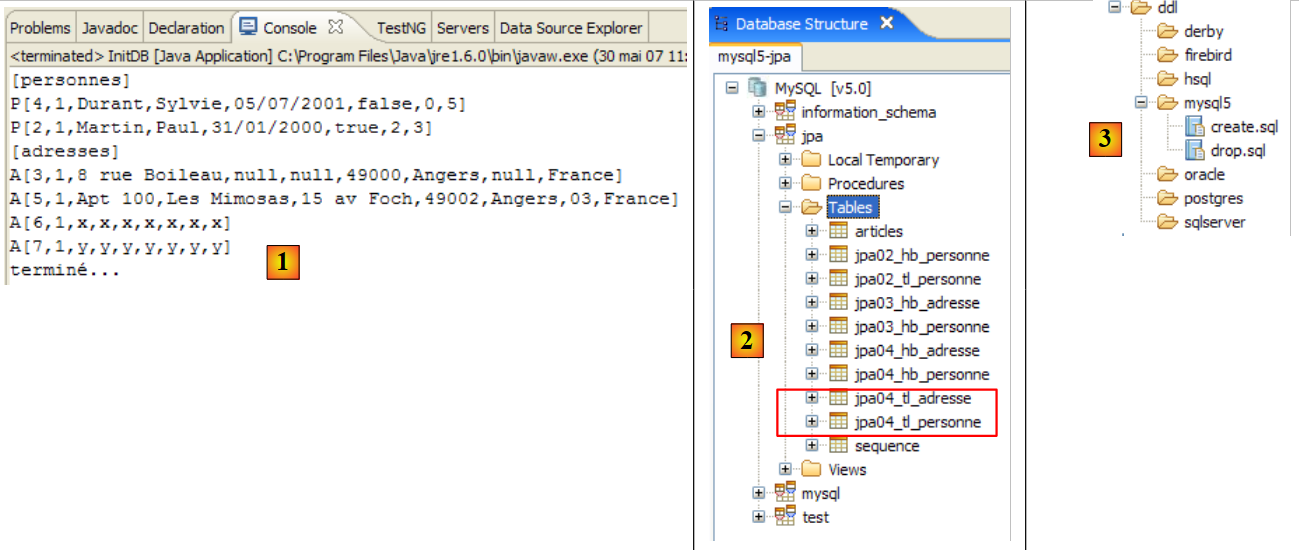 |
In [1], l'output della console; in [2], le due tabelle [jpa04_tl] generate; in [3], gli script SQL generati. Il loro contenuto è il seguente:
create.sql
CREATE TABLE jpa04_tl_personne (ID BIGINT NOT NULL, PRENOM VARCHAR(30) NOT NULL, DATENAISSANCE DATE NOT NULL, VERSION INTEGER NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NBENFANTS INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, adresse_id BIGINT UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa04_tl_adresse (ID BIGINT NOT NULL, ADR3 VARCHAR(30), CODEPOSTAL VARCHAR(5) NOT NULL, ADR1 VARCHAR(30) NOT NULL, VILLE VARCHAR(20) NOT NULL, VERSION INTEGER NOT NULL, CEDEX VARCHAR(3), ADR2 VARCHAR(30), PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa04_tl_personne ADD CONSTRAINT FK_jpa04_tl_personne_adresse_id FOREIGN KEY (adresse_id) REFERENCES jpa04_tl_adresse (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
drop.sql
ALTER TABLE jpa04_tl_personne DROP FOREIGN KEY FK_jpa04_tl_personne_adresse_id
DROP TABLE jpa04_tl_personne
DROP TABLE jpa04_tl_adresse
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
2.4. Esempio 4: Relazione uno-a-molti
2.4.1. Lo schema del database
1  | 2 |
- in [1], il database, e in [2], il suo DDL (MySQL5)
Un articolo A(id, versione, nome) appartiene esattamente a una categoria C(id, versione, nome). Una categoria C può contenere 0, 1 o più articoli. Abbiamo una relazione uno-a-molti (Categoria -> Articolo) e la relazione inversa molti-a-uno (Articolo -> Categoria). Questa relazione è rappresentata dalla chiave esterna che la tabella [articolo] possiede sulla tabella [categoria] (righe 24–28 del DDL).
2.4.2. Gli oggetti @Entity che rappresentano il database
Un articolo è rappresentato dal seguente @Entity [Article]:
package entites;
...
@Entity
@Table(name="jpa05_hb_article")
public class Article implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// main relationship Article (many) -> Category (one)
// implemented by a foreign key (categorie_id) in Article
// 1 Article must have 1 Category (nullable=false)
@ManyToOne(fetch=FetchType.LAZY)
@JoinColumn(name = "categorie_id", nullable = false)
private Categorie categorie;
// manufacturers
public Article() {
}
// getters and setters
...
// toString
public String toString() {
return String.format("Article[%d,%d,%s,%d]", id, version, nom, categorie.getId());
}
}
- righe 9-11: chiave primaria dell'@Entity
- righe 13-15: il suo numero di versione
- righe 17-18: nome dell'articolo
- righe 20-25: relazione molti-a-uno che collega l'@Entity Article all'@Entity Category:
- riga 23: l'annotazione ManyToOne. Il Many si riferisce all'@Entity Article in cui ci troviamo, e il One si riferisce all'@Entity Category (riga 25). Una categoria (One) può avere più articoli (Many).
- riga 24: l'annotazione ManyToOne definisce la colonna della chiave esterna nella tabella [article]. Si chiamerà (name) categorie_id e ogni riga dovrà avere un valore in questa colonna (nullable=false).
- Riga 25: la categoria a cui appartiene l'articolo. Quando un articolo viene aggiunto al contesto di persistenza, richiediamo che la sua categoria non venga aggiunta immediatamente (fetch=FetchType.LAZY, riga 23). Non sappiamo se questa richiesta abbia senso. Vedremo.
Una categoria è rappresentata dalla seguente @Entity [Category]:
package entites;
...
@Entity
@Table(name="jpa05_hb_categorie")
public class Categorie implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// inverse relationship Category (one) -> Article (many) from relationship Article (many) -> Category (one)
// cascade insertion Category -> insertion Articles
// cascade maj Category -> maj Articles
// cascade delete Category -> delete Articles
@OneToMany(mappedBy = "categorie", cascade = { CascadeType.ALL })
private Set<Article> articles = new HashSet<Article>();
// manufacturers
public Categorie() {
}
// getters and setters
...
// toString
public String toString() {
return String.format("Categorie[%d,%d,%s]", id, version, nom);
}
// bidirectional association Category <--> Article
public void addArticle(Article article) {
// the item is added to the collection of items in the category
articles.add(article);
// article changes category
article.setCategorie(this);
}
}
- righe 8-11: la chiave primaria dell'@Entity
- righe 12-14: la sua versione
- righe 16-17: il nome della categoria
- righe 19-24: l'insieme degli elementi nella categoria
- Riga 23: l'annotazione @OneToMany denota una relazione uno-a-molti. "One" si riferisce all'@Entity [Category] in cui ci troviamo attualmente, mentre "Many" si riferisce al tipo [Article] alla riga 24: una (One) categoria ha molti (Many) articoli.
- Riga 23: L'annotazione è l'inverso (mappedBy) dell'annotazione ManyToOne posta sul campo category dell'@Entity Article: mappedBy=category. La relazione ManyToOne posta sul campo category dell'@Entity Article è la relazione primaria. È essenziale. Implementa la relazione di chiave esterna che collega l'@Entity Article all'@Entity Category. La relazione OneToMany inserita nel campo articles dell'@Entity Category è la relazione inversa. Non è essenziale. È una comodità per recuperare gli articoli di una categoria. Senza questa comodità, questi articoli verrebbero recuperati tramite una query JPQL.
- Riga 23: `cascadeType.ALL` specifica che le operazioni (persist, merge, remove) eseguite su un `@Entity Category` devono propagarsi ai suoi articoli.
- Riga 24: Gli articoli di una categoria saranno inseriti in un oggetto di tipo `Set<Article>`. Il tipo `Set` non ammette duplicati. Pertanto, lo stesso articolo non può essere aggiunto due volte all'oggetto `Set<Article>`. Cosa si intende per «lo stesso articolo»? Per indicare che l'articolo `a` è uguale all'articolo `b`, Java utilizza l'espressione `a.equals(b)`. Nella classe Object, la classe padre di tutte le classi, a.equals(b) è vero se a==b, ovvero se gli oggetti a e b hanno la stessa posizione in memoria. Si potrebbe voler dire che gli elementi a e b sono uguali se hanno lo stesso nome. In questo caso, lo sviluppatore deve ridefinire due metodi nella classe [Item]:
- equals: che deve restituire true se i due elementi hanno lo stesso nome
- hashCode: deve restituire un valore intero identico per due oggetti [Article] che il metodo equals considera uguali. In questo caso, il valore sarà quindi costruito a partire dal nome dell'articolo. Il valore restituito da hashCode può essere un numero intero qualsiasi. Viene utilizzato in vari contenitori di oggetti, in particolare nei dizionari (Hashtable).
La relazione OneToMany può utilizzare tipi diversi da Set per memorizzare il Many, come gli oggetti List. Non tratteremo questi casi in questo documento. Il lettore può trovarli in [ref1].
- Riga 38: Il metodo [addArticle] ci permette di aggiungere un articolo a una categoria. Il metodo garantisce che entrambe le estremità della relazione OneToMany che collega [Category] ad [Article] vengano aggiornate.
2.4.3. Il progetto Eclipse / Hibernate 1
L'implementazione JPA utilizzata in questo caso è Hibernate. Il progetto di test Eclipse è il seguente:
 |
Il progetto si trova [3] nella cartella degli esempi [4]. Lo importeremo.
2.4.4. Generazione del DDL del database
Seguendo le istruzioni della Sezione 2.1.7, il DDL generato per il DBMS MySQL 5 è quello mostrato all'inizio di questo esempio, nella Sezione 2.4.1.
2.4.5. InitDB
Il codice per [InitDB] è il seguente:
package tests;
...
public class InitDB {
// constant
private final static String TABLE_ARTICLE = "jpa05_hb_article";
private final static String TABLE_CATEGORIE = "jpa05_hb_categorie";
public static void main(String[] args) {
// Persistence context
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// a EntityManager is retrieved from the previous EntityManagerFactory
em = emf.createEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// request
Query sql1;
// delete elements from the ARTICLE table
sql1 = em.createNativeQuery("delete from " + TABLE_ARTICLE);
sql1.executeUpdate();
// delete elements from the CATEGORIE table
sql1 = em.createNativeQuery("delete from " + TABLE_CATEGORIE);
sql1.executeUpdate();
// create three categories
Categorie categorieA = new Categorie();
categorieA.setNom("A");
Categorie categorieB = new Categorie();
categorieB.setNom("B");
Categorie categorieC = new Categorie();
categorieC.setNom("C");
// create 3 items
Article articleA1 = new Article();
articleA1.setNom("A1");
Article articleA2 = new Article();
articleA2.setNom("A2");
Article articleB1 = new Article();
articleB1.setNom("B1");
// link them to their category
categorieA.addArticle(articleA1);
categorieA.addArticle(articleA2);
categorieB.addArticle(articleB1);
// persist categories and cascade (insert) articles
em.persist(categorieA);
em.persist(categorieB);
em.persist(categorieC);
// category display
System.out.println("[categories]");
for (Object p : em.createQuery("select c from Categorie c order by c.nom asc").getResultList()) {
System.out.println(p);
}
// item display
System.out.println("[articles]");
for (Object p : em.createQuery("select a from Article a order by a.nom asc").getResultList()) {
System.out.println(p);
}
// end transaction
tx.commit();
// end EntityManager
em.close();
// end EntityMangerFactory
emf.close();
// log
System.out.println("terminé...");
}
}
- righe 22-27: le tabelle [article] e [category] vengono svuotate. Si noti che dobbiamo iniziare dalla tabella contenente la chiave esterna. Se iniziassimo dalla tabella [category], elimineremmo le categorie a cui fanno riferimento le righe della tabella [article] e il DBMS rifiuterebbe questa operazione.
- righe 29-34: creiamo tre categorie A, B, C
- Righe 36–41: creiamo tre articoli: A1, A2 e B1 (la lettera indica la categoria)
- Righe 43–45: i tre articoli vengono inseriti nelle rispettive categorie
- Righe 47–49: le tre categorie vengono inserite nel contesto di persistenza. A causa della cascata Categoria → Articolo, anche gli articoli associati verranno inseriti lì. Pertanto, tutti gli oggetti creati si trovano ora nel contesto di persistenza.
- Righe 50-59: Il contesto di persistenza viene interrogato per ottenere l'elenco delle categorie e degli elementi. Sappiamo che ciò innescherà una sincronizzazione del contesto con il database. È a questo punto che le categorie e gli elementi verranno salvati nelle rispettive tabelle.
L'esecuzione di [InitDB] con MySQL5 produce i seguenti risultati:
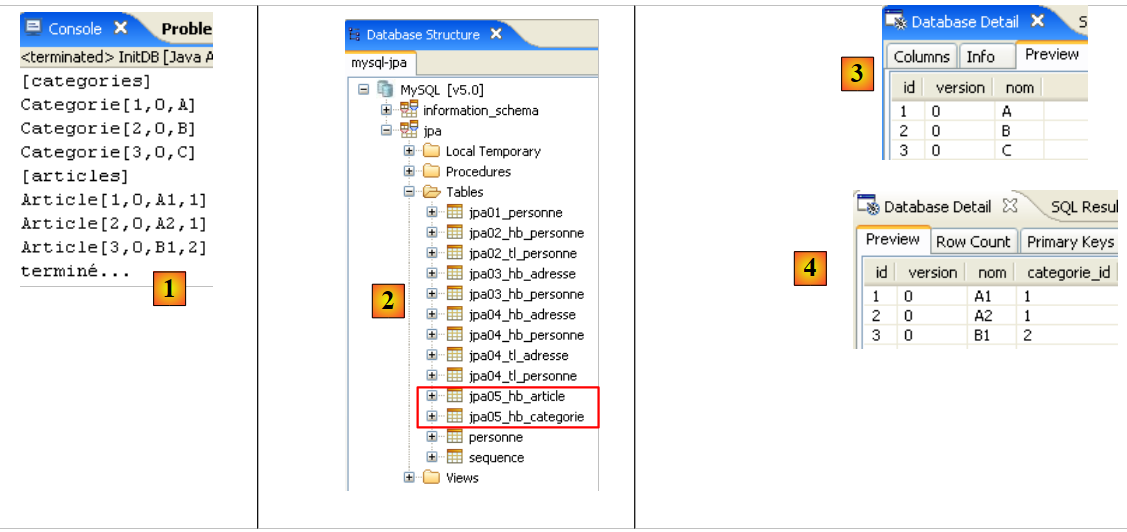 |
- [1]: l'output della console
- [2]: le tabelle [jpa05_hb_*] nella vista SQL Explorer
- [3]: la tabella delle categorie
- [4]: la tabella degli articoli. Si noti la relazione tra [categorie_id] in [4] e [id] in [3] (chiave esterna).
2.4.6. Main
La classe [Main] esegue una serie di test che esamineremo, ad eccezione dei test 1 e 2, che utilizzano il codice di [InitDB] per inizializzare il database.
2.4.6.1. Test3
Questo test è il seguente:
// search for a particular item
public static void test3() {
// new persistence context
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// loading category
Categorie categorie = em.find(Categorie.class, categorieA.getId());
// category display and related articles
System.out.format("Articles de la catégorie %s :%n", categorie);
for (Article a : categorie.getArticles()) {
System.out.println(a);
}
// end transaction
tx.commit();
}
- riga 4: abbiamo un nuovo contesto di persistenza, quindi è vuoto
- righe 6-7: avvio della transazione
- riga 9: la categoria A viene recuperata dal database nel contesto di persistenza
- riga 11: visualizziamo la categoria A
- righe 12–14: visualizziamo gli elementi della categoria A. Questo dimostra il vantaggio della relazione inversa OneToMany per l'@Entity Category. La sua presenza ci evita di dover eseguire una query JPQL per recuperare gli elementi della categoria A. Per ottenerli, utilizziamo il metodo get del campo items.
I risultati sono i seguenti:
- riga 20: categoria A
- Righe 21-22: i due articoli della categoria A
2.4.6.2. Test4
Questo test è il seguente:
// supprimer un article
@SuppressWarnings("unchecked")
public static void test4() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// chargement article A1
Article newarticle1 = em.find(Article.class, articleA1.getId());
// suppression article A1 (aucune catégorie n'est actuellement chargée)
em.remove(newarticle1);
// toplink : l'article doit être enlevé de sa catégorie sinon le test6 plante
// hibernate : ce n'est pas nécessaire
newarticle1.getCategorie().getArticles().remove(newarticle1);
// fin transaction
tx.commit();
// dump des articles
dumpArticles();
}
- Il test 4 elimina l'elemento A1
- riga 5: si parte da un nuovo contesto vuoto
- riga 10: l'articolo A1 viene aggiunto al contesto di persistenza. Lì sarà referenziato da newarticle1.
- riga 12: viene rimosso dal contesto
- riga 15: le categorie A, B e C, e gli elementi A1, A2 e B1, se non sono più persistenti, sono comunque ancora in memoria. Sono semplicemente distaccati dal contesto di persistenza. L'articolo A1, , che fa parte degli articoli della categoria A, viene rimosso da essa. Ciò consentirà in seguito di ricollegare la categoria A al contesto di persistenza. Se ciò non viene fatto, la categoria A verrà ricollegata con un insieme di articoli, uno dei quali è stato eliminato. Ciò non sembra creare problemi a Hibernate, ma causa il crash di TopLink.
- Riga 19: Visualizziamo tutti gli elementi per verificare che A1 sia stato rimosso.
I risultati sono i seguenti:
L'elemento A1 è effettivamente scomparso.
2.4.6.3. Test5
Questo test è il seguente:
// modification d'1 article
public static void test5() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// modification articleA2
articleA2.setNom(articleA2.getNom() + "-");
// articleA2 est remis dans le contexte de persistance
em.merge(articleA2);
// fin transaction
tx.commit();
// dump des articles
dumpArticles();
}
- Il test 5 modifica il nome dell'elemento A2
- Riga 4: iniziamo con un nuovo contesto vuoto
- riga 9: cambiamo il nome dell'elemento distaccato A2, che diventa "A2-".
- riga 11: l'elemento distaccato A2 viene ricollegato al contesto di persistenza. Si noti che A2 rimane un oggetto distaccato. È l'oggetto em.merge(itemA2) che ora fa parte del contesto di persistenza. Questo oggetto non è stato memorizzato in una variabile, come di consueto. È quindi inaccessibile.
- Riga 13: sincronizzazione del contesto di persistenza con il database. L'articolo A2 verrà modificato nel database e il suo numero di versione passerà da N a N+1. La versione in memoria distaccata articleA2 non è più valida. Lo stesso vale per l'oggetto distaccato che rappresenta la categoria A, poiché contiene articleA2 tra i suoi articoli.
- Riga 15: Visualizziamo tutti gli articoli per verificare il cambio di nome dell'articolo A2
I risultati sono i seguenti:
Il nome dell'elemento A2 è effettivamente cambiato.
2.4.6.4. Test6
Questo test è il seguente:
// modification d'1 catégorie et de ses articles
public static void test6() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// chargement catégorie
categorieA = em.find(Categorie.class, categorieA.getId());
// liste des articles de la catégorie A
for (Article a : categorieA.getArticles()) {
a.setNom(a.getNom() + "-");
}
// modification nom catégorie
categorieA.setNom(categorieA.getNom() + "-");
// fin transaction
tx.commit();
// dump des catégories et des articles
dumpCategories();
dumpArticles();
}
- Il test 6 modifica il nome della categoria A e di tutti i suoi articoli
- riga 4: iniziamo con un nuovo contesto vuoto
- riga 9: recuperiamo la categoria A dal database. Non uniamo l'oggetto categoryA distaccato perché sappiamo che ha un riferimento all'articolo A2, che è diventato obsoleto. Partiamo quindi da zero.
- Righe 11–12: Modifichiamo il nome di tutti gli articoli nella categoria A. Anche in questo caso, utilizziamo la relazione OneToMany inversa tramite il metodo getArticles.
- Riga 15: viene modificato anche il nome della categoria
- Riga 17: Fine della transazione. Il contesto viene sincronizzato con il database. Tutti gli oggetti nel contesto che sono stati modificati verranno aggiornati nel database.
- Righe 21–22: Gli articoli e le categorie vengono visualizzati per la verifica
I risultati sono i seguenti:
L'articolo A2 ha cambiato nuovamente nome, così come la categoria A.
2.4.6.5. Test7
Questo test è il seguente:
// category deletion
public static void test7() {
// new persistence context
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// persistence catégorieB and cascade (merge) associated items
Categorie mergedcategorieB = em.merge(categorieB);
// category deletion and cascading (delete) of associated items
em.remove(mergedcategorieB);
// end transaction
tx.commit();
// dump categories and articles
dumpCategories();
dumpArticles();
}
- Il test 7 elimina la categoria B e, di conseguenza, i suoi articoli
- riga 4: iniziamo con un nuovo contesto vuoto
- riga 9: la categoria B esiste in memoria come oggetto distaccato dal contesto di persistenza. La ricongiungiamo al contesto di persistenza. Di conseguenza, anche i suoi articoli (articolo B1) verranno ricongiunti e quindi reintegrati nel contesto di persistenza.
- riga 11: ora che la categoria B è nel contesto, possiamo rimuoverla. Per effetto a cascata, anche i suoi elementi verranno rimossi. Questa operazione è possibile perché l'operazione di unione alla riga 9 li ha reintegrati nel contesto di persistenza.
- Riga 13: Fine della transazione. Il contesto verrà sincronizzato. Gli oggetti nel contesto che sono stati rimossi verranno eliminati dal database.
- Righe 15–16: visualizziamo gli articoli e le categorie per la verifica
I risultati sono i seguenti:
La categoria B e l'articolo B1 sono effettivamente scomparsi.
2.4.6.6. Test8
Questo test è il seguente:
// requêtes
@SuppressWarnings("unchecked")
public static void test8() {
// nouveau contexte de persistance
EntityManager em = getNewEntityManager();
// transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// liste des articles de la catégorie A
List articles = em
.createQuery(
"select a from Categorie c join c.articles a where c.nom like 'A%' order by a.nom asc")
.getResultList();
// affichages articles
System.out.println("Articles de la catégorie A");
for (Object a : articles) {
System.out.println(a);
}
// fin transaction
tx.commit();
}
- Il Test 7 mostra come recuperare gli elementi da una categoria senza utilizzare la relazione inversa. Ciò dimostra che la relazione inversa non è essenziale.
- riga 4: iniziamo con un nuovo contesto vuoto
- riga 10: una query JPQL che recupera tutti gli articoli di una categoria il cui nome inizia con A
- Righe 15–17: visualizzazione dei risultati della query.
I risultati sono i seguenti:
2.4.7. Progetto Eclipse / Hibernate 2
Copiamo e incolliamo il progetto Eclipse / Hibernate per chiarire un punto relativo al concetto di relazione primaria / relazione inversa che abbiamo stabilito intorno all'annotazione @ManyToOne (primaria) dell'@Entity [Articolo] e alla relazione inversa @OneToMany (inversa) dell'@Entity [Categoria]. Vogliamo dimostrare che se quest'ultima relazione non viene dichiarata come inversa dell'altra, lo schema generato per il database risulta completamente diverso da quello generato in precedenza.
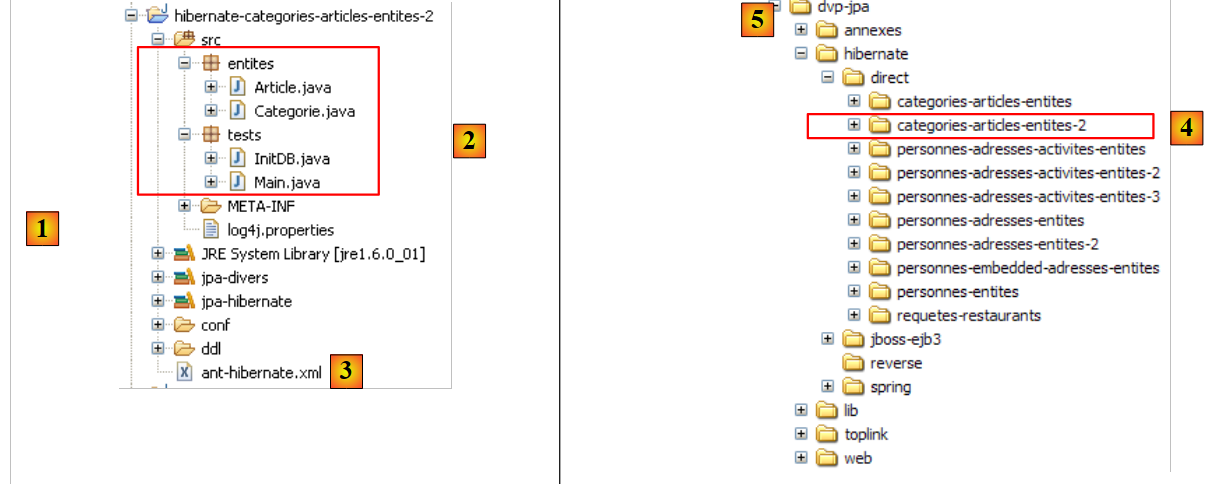 |
In [1] si trova il nuovo progetto Eclipse. In [2] si trova il codice Java, mentre in [3] si trova lo script Ant che genererà lo schema SQL del database. Il progetto si trova [4] nella cartella degli esempi [5]. Lo importeremo.
Modifichiamo solo l'@Entity [Category] in modo che la sua relazione @OneToMany con l'@Entity [Article] non sia più dichiarata come l'inverso della relazione @ManyToOne che l'@Entity [Article] ha con l'@Entity [Category]:
...
@Entity
@Table(name="jpa05_hb_categorie")
public class Categorie implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// relationship OneToMany not inverse (no mappedby) Category (one) -> Article (many)
// implemented by a Categorie_Article join table, so that, starting from a category
// you can reach the items in this category
@OneToMany(cascade=CascadeType.ALL, fetch=FetchType.LAZY)
private Set<Article> articles = new HashSet<Article>();
// manufacturers
...
- righe 18–22: vogliamo comunque mantenere la possibilità di trovare articoli in una determinata categoria utilizzando la relazione @OneToMany alla riga 21. Tuttavia, vogliamo comprendere l'effetto dell'attributo mappedBy, che trasforma una relazione nell'inverso di una relazione primaria definita altrove in un altro @Entity. Qui, il mappedBy è stato rimosso.
Eseguiamo il task ant-DLL (vedi sezione 2.1.7) con il DBMS MySQL5. Lo schema risultante è il seguente:
 |
Si notino i seguenti punti:
- È stata creata una nuova tabella [categorie_articolo] [1]. In precedenza non esisteva.
- Si tratta di una tabella di join tra le tabelle [categorie] [2] e [articolo] [3]. Se gli oggetti Articolo a1 e a2 appartengono alla categoria c1, la tabella di join conterrà le seguenti righe:
dove c1, a1 e a2 sono le chiavi primarie degli oggetti corrispondenti.
- La tabella di join [category_article] [1] è stata creata da Hibernate in modo che, partendo da un oggetto Category c, sia possibile recuperare gli oggetti Article a appartenenti a c. È la relazione @OneToMany che ha reso necessaria la creazione di questa tabella. Poiché non l'abbiamo dichiarata come inversa della relazione primaria @ManyToOne dell'@Entity Article, Hibernate non sapeva di poter utilizzare questa relazione primaria per recuperare gli articoli di una categoria c. Ha quindi trovato un altro modo.
- Questo esempio aiuta a chiarire i concetti di relazioni primarie e inverse. Una (quella inversa) utilizza le proprietà dell'altra (quella primaria).
Lo schema SQL per questo database in MySQL 5 è il seguente:
alter table jpa05_hb_categorie_jpa06_hb_article
drop
foreign key FK79D4BA1D26D17756;
alter table jpa05_hb_categorie_jpa06_hb_article
drop
foreign key FK79D4BA1D424C61C9;
alter table jpa06_hb_article
drop
foreign key FK4547168FECCE8750;
drop table if exists jpa05_hb_categorie;
drop table if exists jpa05_hb_categorie_jpa06_hb_article;
drop table if exists jpa06_hb_article;
create table jpa05_hb_categorie (
id bigint not null auto_increment,
version integer not null,
nom varchar(30),
primary key (id)
) ENGINE=InnoDB;
create table jpa05_hb_categorie_jpa06_hb_article (
jpa05_hb_categorie_id bigint not null,
articles_id bigint not null,
primary key (jpa05_hb_categorie_id, articles_id),
unique (articles_id)
) ENGINE=InnoDB;
create table jpa06_hb_article (
id bigint not null auto_increment,
version integer not null,
nom varchar(30),
categorie_id bigint not null,
primary key (id)
) ENGINE=InnoDB;
alter table jpa05_hb_categorie_jpa06_hb_article
add index FK79D4BA1D26D17756 (jpa05_hb_categorie_id),
add constraint FK79D4BA1D26D17756
foreign key (jpa05_hb_categorie_id)
references jpa05_hb_categorie (id);
alter table jpa05_hb_categorie_jpa06_hb_article
add index FK79D4BA1D424C61C9 (articles_id),
add constraint FK79D4BA1D424C61C9
foreign key (articles_id)
references jpa06_hb_article (id);
alter table jpa06_hb_article
add index FK4547168FECCE8750 (categorie_id),
add constraint FK4547168FECCE8750
foreign key (categorie_id)
references jpa05_hb_categorie (id);
- Righe 19–24: creazione della tabella [categorie] e righe 33–39: creazione della tabella [articolo]. Si noti che sono identiche a quelle dell'esempio precedente.
- Righe 26–31: creazione della tabella di join [categorie_article] a causa della presenza della relazione @OneToMany non inversa dell'entità @Entity Categorie. Le righe di questa tabella sono di tipo [c,a], dove c è la chiave primaria di una categoria c e a è la chiave primaria di un articolo a appartenente alla categoria c. La chiave primaria di questa tabella di join è costituita dalle due chiavi primarie [c,a] concatenate (riga 29).
- righe 41-45: il vincolo di chiave esterna dalla tabella [categorie_article] alla tabella [categorie]
- righe 47–51: il vincolo di chiave esterna dalla tabella [categorie_article] alla tabella [article]
- Righe 53–57: il vincolo di chiave esterna dalla tabella [article] alla tabella [categorie]
Il lettore è invitato a eseguire i test [InitDB] e [Main]. Essi producono gli stessi risultati di prima. Tuttavia, lo schema del database è ridondante e le prestazioni risulteranno inferiori rispetto alla versione precedente. Probabilmente dovremmo approfondire la questione delle relazioni inverse/primarie per verificare se la nuova configurazione introduca anche conflitti dovuti al fatto che abbiamo due relazioni indipendenti che rappresentano la stessa cosa: la relazione molti-a-uno tra la tabella [article] e la tabella [category].
2.4.8. Implementazione JPA / Toplink - 1
Ora stiamo utilizzando un'implementazione JPA / Toplink:
 |
Il progetto Eclipse con Toplink è una copia del progetto Eclipse con Hibernate, versione 1:
 |
Il codice Java è identico a quello del precedente progetto Hibernate — versione 1. L'ambiente (librerie – persistence.xml – DBMS – cartelle conf e ddl – script Ant) è quello descritto nella sezione 2.1.15.2. Il progetto Eclipse è disponibile [3] nella cartella degli esempi [4]. Lo importeremo.
Il file <persistence.xml> [2] è stato modificato in un punto, ovvero le entità dichiarate:
...
<!-- classes persistantes -->
<class>entites.Categorie</class>
<class>entites.Article</class>
...
- Righe 3 e 4: le due entità gestite
L'esecuzione di [InitDB] con il DBMS MySQL5 produce i seguenti risultati:
 |
In [1], l'output della console; in [2], le due tabelle [jpa05_tl] generate; in [3], gli script SQL generati. Il loro contenuto è il seguente:
create.sql
CREATE TABLE jpa05_tl_article (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), categorie_id BIGINT NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa05_tl_categorie (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), PRIMARY KEY (ID))
ALTER TABLE jpa05_tl_article ADD CONSTRAINT FK_jpa05_tl_article_categorie_id FOREIGN KEY (categorie_id) REFERENCES jpa05_tl_categorie (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
drop.sql
ALTER TABLE jpa05_tl_article DROP FOREIGN KEY FK_jpa05_tl_article_categorie_id
DROP TABLE jpa05_tl_article
DROP TABLE jpa05_tl_categorie
DELETE FROM SEQUENCE WHERE SEQ_NAME = 'SEQ_GEN'
L'esecuzione di [Main] si conclude senza errori.
2.4.9. Implementazione JPA / Toplink - 2
Questo progetto Eclipse è stato creato clonando quello precedente. Poiché è stato realizzato con Hibernate, rimuoviamo l'attributo mappedBy dalla relazione @OneToMany dell'entità @Entity Category.
@Entity
@Table(name = "jpa06_tl_categorie")
public class Categorie implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Version
private int version;
@Column(length = 30)
private String nom;
// relation OneToMany not inverse (no mappedby) Category (one) ->
// Article (many)
// implemented by a Categorie_Article join table, so that from
// category
// several items can be reached
@OneToMany(cascade = CascadeType.ALL, fetch = FetchType.LAZY)
private Set<Article> articles = new HashSet<Article>();
Lo schema SQL generato per MySQL5 è quindi il seguente:
create.sql
CREATE TABLE jpa06_tl_categorie (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), PRIMARY KEY (ID))
CREATE TABLE jpa06_tl_categorie_jpa06_tl_article (Categorie_ID BIGINT NOT NULL, articles_ID BIGINT NOT NULL, PRIMARY KEY (Categorie_ID, articles_ID))
CREATE TABLE jpa06_tl_article (ID BIGINT NOT NULL, VERSION INTEGER, NOM VARCHAR(30), categorie_id BIGINT NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa06_tl_categorie_jpa06_tl_article ADD CONSTRAINT FK_jpa06_tl_categorie_jpa06_tl_article_articles_ID FOREIGN KEY (articles_ID) REFERENCES jpa06_tl_article (ID)
ALTER TABLE jpa06_tl_categorie_jpa06_tl_article ADD CONSTRAINT jpa06_tl_categorie_jpa06_tl_article_Categorie_ID FOREIGN KEY (Categorie_ID) REFERENCES jpa06_tl_categorie (ID)
ALTER TABLE jpa06_tl_article ADD CONSTRAINT FK_jpa06_tl_article_categorie_id FOREIGN KEY (categorie_id) REFERENCES jpa06_tl_categorie (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
- Riga 2: la tabella di join che implementa la precedente relazione @OneToMany non invertita.
L'esecuzione di [InitDB] si completa senza errori, ma l'esecuzione di [Main] va in crash al test 7 con i seguenti log (FINEST):
- Riga 3: l'unione sulla categoria B
- riga 4: l'articolo dipendente B1 viene inserito nel contesto
- riga 5: lo stesso per la categoria B stessa
- riga 6: la rimozione sulla categoria B
- riga 7: rimozione sull'elemento B1 (a cascata)
- Riga 8: il codice Java richiede un commit della transazione
- riga 9: inizia una transazione, quindi apparentemente non era ancora iniziata.
- riga 10: l'elemento B1 sta per essere eliminato da un'operazione DELETE sulla tabella [item]. È qui che sta il problema. La tabella di join [category_item] ha un riferimento alla riga B1 nella tabella [item]. L'eliminazione di B1 da [item] violerà un vincolo di chiave esterna.
- Righe 13 e seguenti: si verifica l'eccezione
Cosa possiamo concludere?
- Ancora una volta, abbiamo un problema di portabilità tra Hibernate e Toplink: Hibernate ha superato questo test
- TopLink ha difficoltà a gestire situazioni in cui due relazioni sono effettivamente inverse l'una rispetto all'altra, con una non dichiarata come relazione primaria e l'altra come inversa. Ciò è accettabile perché questo scenario rappresenta in realtà un errore di configurazione. Nel nostro esempio, la tabella [article] non ha alcuna relazione con la tabella di join [categorie_article]. Sembra quindi naturale che durante un'operazione sulla tabella [article], Toplink non tenti di lavorare con la tabella [categorie_article].
2.5. Esempio 5: Relazione molti-a-molti con una tabella di join esplicita
2.5.1. Lo schema del database
|
- in [1], il database MySQL5
Abbiamo già familiarità con le tabelle [person] [2] e [address] [3]. Ne abbiamo parlato nella Sezione 2.3.1. Stiamo utilizzando la versione in cui l'indirizzo della persona è memorizzato in una tabella separata [address] [3]. Nella tabella [person], la relazione che collega una persona al proprio indirizzo è implementata tramite un vincolo di chiave esterna.
Una persona svolge delle attività. Queste attività sono memorizzate nella tabella [activity] [4]. Una persona può svolgere più attività e un'attività può essere svolta da più persone. Una relazione molti-a-molti collega quindi le tabelle [person] e [activity]. Questa relazione è rappresentata dalla tabella di join [person_activity] [5].
2.5.2. Gli oggetti @Entity che rappresentano il database
Le tabelle di cui sopra saranno rappresentate dalle seguenti @Entities:
- l'@Entity Person rappresenterà la tabella [person]
- l'@Entity Address rappresenterà la tabella [address]
- l'@Entity Activity rappresenterà la tabella [activity]
- l'@Entity PersonneActivite rappresenterà la tabella [personne_activite]
Le relazioni tra queste entità sono le seguenti:
- Una relazione uno-a-uno collega l'entità Person all'entità Address: una persona p ha un indirizzo a. L'entità Person che contiene la chiave esterna sarà l'entità primaria, mentre l'entità Address sarà l'entità inversa.
- Una relazione molti-a-molti collega le entità Person e Activity: una persona ha più attività e un'attività è praticata da più persone. Questa relazione potrebbe essere implementata direttamente utilizzando un'annotazione @ManyToMany in ciascuna delle due entità, con una dichiarata come inversa dell'altra. Questa soluzione verrà esaminata in seguito. Qui, implementiamo la relazione molti-a-molti utilizzando due relazioni uno-a-molti:
- una relazione uno-a-molti che collega l'entità Person all'entità PersonActivity: una singola riga (One) nella tabella [person] è referenziata da più (Many) righe nella tabella [person_activity]. La tabella [person_activity] , che contiene la chiave esterna, avrà la relazione primaria @ManyToOne, mentre l'entità Person avrà la relazione inversa @OneToMany.
- una relazione uno-a-molti che collega l'entità Activity all'entità PersonActivity: una (One) riga nella tabella [activity] è referenziata da molte (Many) righe nella tabella [person_activity]. La tabella [person_activity], che contiene la chiave esterna, avrà la relazione primaria @ManyToOne, mentre l'entità Activity avrà la relazione inversa @OneToMany.
L'entità @Entity Person è la seguente:
@Entity
@Table(name = "jpa07_hb_personne")
public class Personne implements Serializable {
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
// main relationship Person (one) -> Address (one)
// implemented by the foreign key Person(adresse_id) -> Address
// cascade insert Person -> insert Address
// cascade shift Person -> shift Address
// cascade deletion Person -> deletion Address
// a Person must have 1 Address (nullable=false)
// 1 Address belongs to 1 person only (unique=true)
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
// relation Person (one) -> PersonneActivite (many)
// inverse of existing relationship PersonneActivite (many) -> Personne (one)
// cascade deletion Person -> supression PersonneActivite
@OneToMany(mappedBy = "personne", cascade = { CascadeType.REMOVE })
private Set<PersonneActivite> activites = new HashSet<PersonneActivite>();
// manufacturers
Questo @Entity è ben noto. Ci limiteremo a commentare le relazioni che intrattiene con altre entità:
- righe 30–39: una relazione uno-a-uno @OneToOne con l'@Entity Address, implementata tramite una chiave esterna [address_id] (riga 38) che la tabella [Person] avrà sulla tabella [Address].
- Righe 41–45: una relazione uno-a-molti (@OneToMany) con l'@Entity PersonneActivite. Una persona (One) è referenziata da più (Many) righe nella tabella di join [personne_activite] rappresentata dall'@Entity PersonneActivite. Questi oggetti PersonneActivite saranno inseriti in un tipo Set<PersonneActivite>, dove PersonneActivite è un tipo che definiremo tra poco.
- Riga 44: la relazione uno-a-molti definita qui è l'inverso di una relazione primaria definita sul campo person dell'@Entity PersonneActivite (parola chiave mappedBy). Abbiamo una cascata Person -> Activity in caso di eliminazioni: l'eliminazione di una persona p comporterà l'eliminazione degli elementi persistenti di tipo PersonneActivite presenti nella collezione p.activites.
L'@Entity Address è la seguente:
@Entity
@Table(name = "jpa07_hb_adresse")
public class Adresse implements Serializable {
// fields
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
@OneToOne(mappedBy = "adresse")
private Personne personne;
- Righe 28-29: la relazione @OneToOne che è l'inverso della relazione @OneToOne address dell'entità @Entity Person (righe 37-38 di Person).
L'@Entity Activity è la seguente
@Entity
@Table(name = "jpa07_hb_activite")
public class Activite implements Serializable {
// fields
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
// relation Activite (one) -> PersonneActivite (many)
// inverse of existing relationship PersonneActivite (many) -> Activite (one)
// cascade suppression Activite -> supression PersonneActivite
@OneToMany(mappedBy = "activite", cascade = { CascadeType.REMOVE })
private Set<PersonneActivite> personnes = new HashSet<PersonneActivite>();
- righe 6-9: la chiave primaria dell'attività
- righe 11-13: il numero di versione dell'attività
- righe 15-16: il nome dell'attività
- righe 18-22: la relazione uno-a-molti che collega l'@Entity Activity all'@Entity PersonActivity: un'attività (One) è referenziata da più (Many) righe nella tabella di join [person_activity] rappresentata dall'@Entity PersonActivity. Questi oggetti PersonneActivite saranno inseriti in un tipo Set<PersonneActivite>.
- Riga 22: la relazione uno-a-molti definita qui è l'inverso di una relazione primaria definita sul campo `activity` in `@Entity PersonneActivite` (utilizzando la parola chiave `mappedBy`). Abbiamo una cascata Activity -> PersonActivity in caso di eliminazione: l'eliminazione di un'attività dalla tabella [activity] innescherà l'eliminazione delle entità PersonActivity persistenti presenti nella collezione a.people della tabella di join [person_activity].
L'@Entity PersonneActivite è la seguente:
@Entity
// join table
@Table(name = "jpa07_hb_personne_activite")
public class PersonneActivite {
@Embeddable
public static class Id implements Serializable {
// composite key components
// points to a Person
@Column(name = "PERSONNE_ID")
private Long personneId;
// on an Activity
@Column(name = "ACTIVITE_ID")
private Long activiteId;
// manufacturers
...
// getters and setters
...
// toString
public String toString() {
return String.format("[%d,%d]", getPersonneId(), getActiviteId());
}
}
// fields of the Personne_Activite class
// composite key
@EmbeddedId
private Id id = new Id();
// main relationship PersonneActivite (many) -> Nobody (one)
// implemented by the foreign key: personneId (PersonneActivite (many) -> Personne (one)
// personneId is also part of the composite primary key
// JPA does not need to manage this foreign key (insertable = false, updatable = false), as this is done by the application itself in its constructor
@ManyToOne
@JoinColumn(name = "PERSONNE_ID", insertable = false, updatable = false)
private Personne personne;
// main relationship PersonneActivite -> Activity
// implemented by the foreign key: activiteId (PersonneActivite (many) -> Activite (one)
// activiteId is also part of the composite primary key
// JPA does not need to manage this foreign key (insertable = false, updatable = false), as this is done by the application itself in its constructor
@ManyToOne()
@JoinColumn(name = "ACTIVITE_ID", insertable = false, updatable = false)
private Activite activite;
// manufacturers
public PersonneActivite() {
}
public PersonneActivite(Personne p, Activite a) {
// foreign keys are set by the application
getId().setPersonneId(p.getId());
getId().setActiviteId(a.getId());
// two-way associations
this.setPersonne(p);
this.setActivite(a);
p.getActivites().add(this);
a.getPersonnes().add(this);
}
// getters and setters
...
// toString
public String toString() {
return String.format("[%s,%s,%s]", getId(), getPersonne().getNom(), getActivite().getNom());
}
}
Questa classe è più complessa delle precedenti.
- La tabella [person_activity] contiene righe della forma [p,a], dove p è la chiave primaria di una persona e a è la chiave primaria di un'attività. Ogni tabella deve avere una chiave primaria e [person_activity] non fa eccezione. Finora avevamo definito chiavi primarie generate dinamicamente dal DBMS. Potremmo fare lo stesso anche qui. Useremo però un'altra tecnica, in cui è l'applicazione stessa a definire i valori della chiave primaria di una tabella. Qui, una riga [p1,a1] indica che una persona p1 partecipa all'attività a1. Questa stessa riga non può comparire una seconda volta nella tabella. Pertanto, la coppia (p,a) è un'ottima candidata per una chiave primaria. Questa è chiamata chiave primaria composita.
- Righe 30–31: la chiave primaria composita. L'annotazione @EmbeddedId (precedentemente @Id) è analoga alla notazione @Embedded applicata al campo Address di una persona. In quel caso, significava che il campo Address era un'istanza di una classe esterna ma doveva essere inserito nella stessa tabella della persona. Qui, il significato è lo stesso, tranne che per indicare che si tratta della chiave primaria, l'annotazione diventa @EmbeddedId.
- Riga 31: un oggetto vuoto che rappresenta la chiave primaria `id` viene creato quando viene istanziato l'oggetto `PersonneActivite`. La classe che rappresenta la chiave primaria è definita alle righe 7–26 come una classe statica pubblica interna alla classe `PersonneActivite`. Il fatto che sia pubblica e statica è richiesto da Hibernate. Se sostituiamo public static con private, si verifica un'eccezione e il messaggio di errore associato indica che Hibernate ha tentato di eseguire l'istruzione new PersonneActivite$Id. Pertanto, la classe Id deve essere sia statica che pubblica.
- Riga 6: La classe Id della chiave primaria è dichiarata @Embeddable. Ricordiamo che l'id della chiave primaria alla riga 31 era stato dichiarato @EmbeddedId. La classe corrispondente deve quindi avere l'annotazione @Embeddable.
- Abbiamo affermato che la chiave primaria della tabella [person_activity] è costituita dalla coppia (p, a), dove p è la chiave primaria di una persona e a è la chiave primaria di un'attività. Troviamo i due elementi (p, a) della chiave composita [ ] alla riga 11 (personId) e alla riga 15 (activityId). Le colonne associate a questi due campi sono denominate: PERSON_ID per la persona, ACTIVITY_ID per l'attività.
- Riga 31: La chiave primaria è stata definita con le sue due colonne (PERSON_ID, ACTIVITY_ID). Non ci sono altre colonne nella tabella [person_activity]. Non resta che definire le relazioni tra l'@Entity PersonneActivite che stiamo descrivendo e le altre @Entities nello schema relazionale. Queste relazioni riflettono i vincoli di chiave esterna che la tabella [personne_activite] ha con le altre tabelle.
- Righe 33–39: definiscono la chiave esterna dalla tabella [person_activity] alla tabella [person]
- Riga 37: la relazione è di tipo @ManyToOne: una (One) riga nella tabella [person] è referenziata da molte (Many) righe nella tabella [person_activity].
- Riga 38: Assegniamo un nome alla colonna della chiave esterna. Utilizziamo lo stesso nome assegnato alla componente "person" della chiave esterna (riga 10). Gli attributi insertable=false, updatable=false servono a impedire a Hibernate di gestire la chiave esterna. Questa chiave è, infatti, una componente di una chiave primaria calcolata dall'applicazione, e Hibernate non deve intervenire.
- Righe 41–47: Definiamo la chiave esterna dalla tabella [person_activity] alla tabella [activity]. Le spiegazioni sono le stesse fornite in precedenza.
- Righe 54–63: Costruttore per un oggetto PersonActivity basato su una persona p e un'attività a. Ricordiamo che durante la creazione di un oggetto PersonActivity, l'id della chiave primaria alla riga 31 puntava a un oggetto Id vuoto. Le righe 56-57 assegnano un valore a ciascuno dei campi (personId, activityId) dell'oggetto Id. Questi valori sono, rispettivamente, le chiavi primarie della persona p e dell'attività a passate come parametri al costruttore. La chiave primaria id (riga 31) ha quindi ora un valore.
- Riga 59: Al campo "persona" della riga 39 viene assegnato il valore "p"
- Riga 60: Al campo "activite" nella riga 47 viene assegnato il valore "a"
- È stato creato e inizializzato un oggetto [PersonActivity]. Aggiorniamo le relazioni inverse tra l'@Entity Person (riga 61) e l'@Entity Activity (riga 62) con l'@Entity PersonActivity appena creata.
Abbiamo completato la descrizione delle entità del database. Ci troviamo in una situazione complessa ma purtroppo comune. Vedremo che esiste un'altra possibile configurazione del livello JPA che nasconde parte di questa complessità: la tabella di join diventa implicita, costruita e gestita dal livello JPA. Qui abbiamo scelto la soluzione più complessa, ma che permette allo schema relazionale di evolversi. Ciò consente di aggiungere colonne alla tabella di join, cosa che non è possibile nella configurazione in cui la tabella di join non è un @Entity esplicito. [ref1] raccomanda la soluzione che stiamo attualmente esaminando. Le informazioni che hanno permesso lo sviluppo di questa soluzione sono state trovate in [ref1].
2.5.3. Il progetto Eclipse / Hibernate
L'implementazione JPA qui utilizzata è Hibernate. Il progetto Eclipse per i test è il seguente:
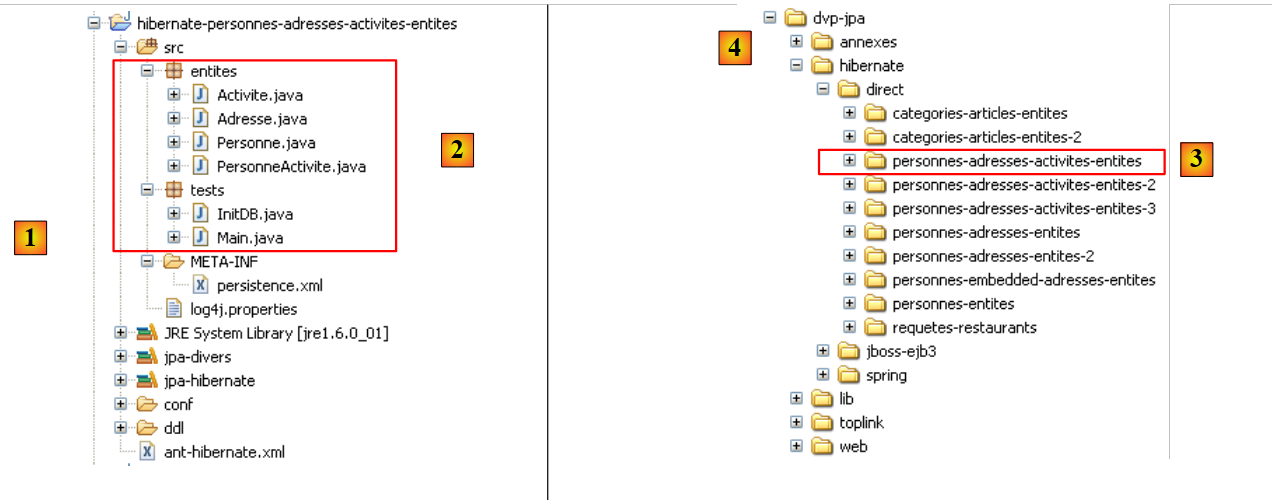
In [1], il progetto Eclipse; in [2], il codice Java. Il progetto si trova in [3] all'interno della cartella degli esempi [4]. Lo importeremo.
2.5.4. Generazione del DDL del database
Seguendo le istruzioni della sezione 2.1.7, il DDL generato per il DBMS MySQL 5 è il seguente:
alter table jpa07_hb_personne
drop
foreign key FKB5C817D45FE379D0;
alter table jpa07_hb_personne_activite
drop
foreign key FKD3E49B06CD852024;
alter table jpa07_hb_personne_activite
drop
foreign key FKD3E49B0668C7A284;
drop table if exists jpa07_hb_activite;
drop table if exists jpa07_hb_adresse;
drop table if exists jpa07_hb_personne;
drop table if exists jpa07_hb_personne_activite;
create table jpa07_hb_activite (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa07_hb_adresse (
id bigint not null auto_increment,
version integer not null,
adr1 varchar(30) not null,
adr2 varchar(30),
adr3 varchar(30),
codePostal varchar(5) not null,
ville varchar(20) not null,
cedex varchar(3),
pays varchar(20) not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa07_hb_personne (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
prenom varchar(30) not null,
datenaissance date not null,
marie bit not null,
nbenfants integer not null,
adresse_id bigint not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa07_hb_personne_activite (
PERSONNE_ID bigint not null,
ACTIVITE_ID bigint not null,
primary key (PERSONNE_ID, ACTIVITE_ID)
) ENGINE=InnoDB;
alter table jpa07_hb_personne
add index FKB5C817D45FE379D0 (adresse_id),
add constraint FKB5C817D45FE379D0
foreign key (adresse_id)
references jpa07_hb_adresse (id);
alter table jpa07_hb_personne_activite
add index FKD3E49B06CD852024 (ACTIVITE_ID),
add constraint FKD3E49B06CD852024
foreign key (ACTIVITE_ID)
references jpa07_hb_activite (id);
alter table jpa07_hb_personne_activite
add index FKD3E49B0668C7A284 (PERSONNE_ID),
add constraint FKD3E49B0668C7A284
foreign key (PERSONNE_ID)
references jpa07_hb_personne (id);
- righe 21-26: la tabella [activity]
- righe 28-39: la tabella [address]
- righe 41-51: la tabella [person]
- righe 53-57: la tabella di join [person_activity]. Notare la chiave composta (riga 56)
- righe 59-63: la chiave esterna dalla tabella [persona] alla tabella [indirizzo]
- righe 65-69: la chiave esterna dalla tabella [person_attività] alla tabella [attività]
- righe 71-75: la chiave esterna dalla tabella [person_activity] alla tabella [person]
2.5.5. InitDB
Il codice per [InitDB] è il seguente:
package tests;
...
public class InitDB {
// constant
private final static String TABLE_PERSONNE_ACTIVITE = "jpa07_hb_personne_activite";
private final static String TABLE_PERSONNE = "jpa07_hb_personne";
private final static String TABLE_ACTIVITE = "jpa07_hb_activite";
private final static String TABLE_ADRESSE = "jpa07_hb_adresse";
public static void main(String[] args) throws ParseException {
// Persistence context
EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
EntityManager em = null;
// we retrieve a EntityManager from the EntityManagerFactory
// previous
em = emf.createEntityManager();
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// request
Query sql1;
// delete elements from the PERSONNE_ACTIVITE table
sql1 = em.createNativeQuery("delete from " + TABLE_PERSONNE_ACTIVITE);
sql1.executeUpdate();
// delete elements from the PERSONNE table
sql1 = em.createNativeQuery("delete from " + TABLE_PERSONNE);
sql1.executeUpdate();
// delete elements from the ACTIVITE table
sql1 = em.createNativeQuery("delete from " + TABLE_ACTIVITE);
sql1.executeUpdate();
// delete elements from the ADRESSE table
sql1 = em.createNativeQuery("delete from " + TABLE_ADRESSE);
sql1.executeUpdate();
// creation activities
Activite act1 = new Activite();
act1.setNom("act1");
Activite act2 = new Activite();
act2.setNom("act2");
Activite act3 = new Activite();
act3.setNom("act3");
// persistence activities
em.persist(act1);
em.persist(act2);
em.persist(act3);
// creating people
Personne p1 = new Personne("p1", "Paul", new SimpleDateFormat("dd/MM/yy").parse("31/01/2000"), true, 2);
Personne p2 = new Personne("p2", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
Personne p3 = new Personne("p3", "Sylvie", new SimpleDateFormat("dd/MM/yy").parse("05/07/2001"), false, 0);
// address creation
Adresse adr1 = new Adresse("adr1", null, null, "49000", "Angers", null, "France");
Adresse adr2 = new Adresse("adr2", "Les Mimosas", "15 av Foch", "49002", "Angers", "03", "France");
Adresse adr3 = new Adresse("adr3", "x", "x", "x", "x", "x", "x");
Adresse adr4 = new Adresse("adr4", "y", "y", "y", "y", "y", "y");
// associations person <--> address
p1.setAdresse(adr1);
adr1.setPersonne(p1);
p2.setAdresse(adr2);
adr2.setPersonne(p2);
p3.setAdresse(adr3);
adr3.setPersonne(p3);
// persistence of persons and therefore of associated addresses
em.persist(p1);
em.persist(p2);
em.persist(p3);
// persistence of a4 address not linked to a person
em.persist(adr4);
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// address display
System.out.println("[adresses]");
for (Object a : em.createQuery("select a from Adresse a").getResultList()) {
System.out.println(a);
}
System.out.println("[activites]");
for (Object a : em.createQuery("select a from Activite a").getResultList()) {
System.out.println(a);
}
// associations person <-->activity
PersonneActivite p1act1 = new PersonneActivite(p1, act1);
PersonneActivite p1act2 = new PersonneActivite(p1, act2);
PersonneActivite p2act1 = new PersonneActivite(p2, act1);
PersonneActivite p2act3 = new PersonneActivite(p2, act3);
// persistence of person <--> activity associations
em.persist(p1act1);
em.persist(p1act2);
em.persist(p2act1);
em.persist(p2act3);
// people display
System.out.println("[personnes]");
for (Object p : em.createQuery("select p from Personne p order by p.nom asc").getResultList()) {
System.out.println(p);
}
// address display
System.out.println("[adresses]");
for (Object a : em.createQuery("select a from Adresse a").getResultList()) {
System.out.println(a);
}
System.out.println("[activites]");
for (Object a : em.createQuery("select a from Activite a").getResultList()) {
System.out.println(a);
}
System.out.println("[personnes/activites]");
for (Object pa : em.createQuery("select pa from PersonneActivite pa").getResultList()) {
System.out.println(pa);
}
// end transaction
tx.commit();
// end EntityManager
em.close();
// end EntityManagerFactory
emf.close();
// log
System.out.println("terminé...");
}
}
- righe 27-38: le tabelle [person_activity], [person], [address] e [activity] vengono svuotate. Si noti che dobbiamo iniziare dalle tabelle che contengono chiavi esterne.
- righe 40-45: creiamo tre attività: act1, act2 e act3
- righe 47–49: vengono inserite nel contesto di persistenza.
- righe 51-53: vengono create tre persone, p1, p2 e p3.
- Righe 55–58: vengono creati quattro indirizzi (da adr1 a adr4).
- Righe 60–65: gli indirizzi adr1–adr4 vengono associati alle persone p1–p3. Ci sono due operazioni da eseguire ogni volta perché la relazione Persona <-> Indirizzo è bidirezionale.
- righe 67–69: le persone da p1 a p3 vengono inserite nel contesto di persistenza. A causa della cascata Persona -> Indirizzo, questo vale anche per gli indirizzi da adr1 a adr3.
- Riga 71: Il quarto indirizzo, adr4, che non è associato a una persona, viene inserito esplicitamente nel contesto di persistenza.
- Righe 73–85: il contesto di persistenza viene interrogato per recuperare gli elenchi di entità di tipo [Persona], [Indirizzo] e [Attività]. Sappiamo che queste query attiveranno la sincronizzazione del contesto con il database: le entità create verranno inserite nel database e verrà loro assegnata una chiave primaria. È importante comprenderlo per quanto segue.
- Righe 87–90: creiamo quattro associazioni Persona <-> Attività. I loro nomi indicano quale persona è collegata a quale attività. Ricorderete che la chiave primaria di un'entità PersonaAttività è una chiave composita costituita dalle chiavi primarie di una Persona e di un'Attività. Questa operazione è possibile perché le entità Persona e Attività hanno ottenuto le loro chiavi primarie durante una sincronizzazione precedente.
- Righe 92–95: Queste 4 associazioni vengono aggiunte al contesto di persistenza.
- Righe 87–86: Il contesto di persistenza viene interrogato per recuperare gli elenchi di entità di tipo [Persona], [Indirizzo], [Attività] e [PersonaAttività]. Sappiamo che queste query attiveranno la sincronizzazione del contesto con il database: le entità PersonaAttività create verranno inserite nel database.
L'esecuzione di [InitDB] con MySQL5 produce il seguente output della console:
Potrebbe sorprendere vedere che nelle righe 15–16 i numeri di versione per le persone p1 e p2 sono 1, e che lo stesso vale nelle righe 24–26 per le tre attività. Cerchiamo di capire.
Nelle righe 2–4, i numeri di versione per le persone sono 0, e nelle righe 11–13, i numeri di versione per le attività sono 0. Queste visualizzazioni avvengono prima che vengano create le relazioni Persona <-> Attività. Le righe 87-90 del codice Java creano relazioni tra le persone p1 e p2 e le attività act1, act2 e act3. Queste vengono create utilizzando il costruttore @Entity PersonneActivite (vedere la Sezione 2.5.2). Leggendo il codice di questo costruttore si nota che quando una persona p è collegata a un'attività a:
- l'attività a viene aggiunta all'insieme p.activities
- la persona p viene aggiunta all'insieme a.personnes
Pertanto, quando scriviamo new PersonneActivite(p, a)*, la persona p e l'attività a subiscono una modifica in memoria. Quando vengono eseguite le righe 97–113 di [InitDB], il contesto di persistenza viene sincronizzato con il database e JPA/Hibernate rileva che le entità persistenti p1, p2, act1, act2 e act3* sono state modificate. Queste modifiche devono essere apportate nel database. Esse vengono effettivamente scritte nella tabella di join [person_activity], ma JPA/Hibernate incrementa comunque il numero di versione di ciascuna entità persistente modificata.
Nella vista SQL Explorer, i risultati sono i seguenti:
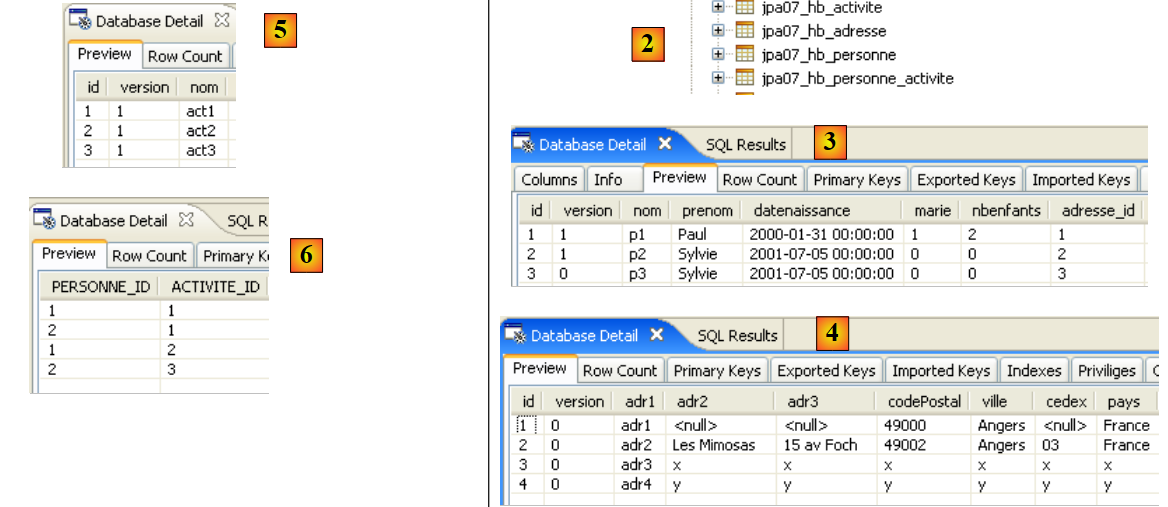 |
- [2]: la tabella [jpa07_hb_*]
- [3]: la tabella people
- [4]: la tabella degli indirizzi.
- [5]: la tabella delle attività
- [6]: la tabella di join persona <-> attività
2.5.6. Main
La classe [Main] esegue una serie di test che analizzeremo, ad eccezione del test 1, che utilizza il codice di [InitDB] per inizializzare il database.
2.5.6.1. Test2
Questo test è il seguente:
// suppression Personne p1
public static void test2() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// suppression dépendances sur p1 : pas nécessaire à hibernate mais
// indispensable à toplink
act1.getPersonnes().remove(p1act1);
act2.getPersonnes().remove(p1act2);
// suppression personne p1
em.remove(p1);
// fin transaction
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpActivite();
dumpAdresse();
dumpPersonne_Activite();
}
- Riga 4: Utilizziamo il contesto di persistenza di test1, dove la persona p1 è un oggetto nel contesto.
- riga 13: eliminazione della persona p1. A causa dell'attributo:
- cascadeType.ALL su Address, l'indirizzo associato alla persona p1 verrà eliminato
- cascadeType.REMOVE su PersonActivity, le attività della persona p1 verranno eliminate.
- Righe 10–11: Rimuoviamo le dipendenze che altre entità hanno sulla persona p1, che verrà eliminata alla riga 13. Le attività act1 e act2 sono eseguite dalla persona p1. I collegamenti sono stati creati dal costruttore dell'entità PersonActivity, il cui codice è il seguente:
public PersonneActivite(Personne p, Activite a) {
// les clés étrangères sont fixées par l'application
getId().setPersonneId(p.getId());
getId().setActiviteId(a.getId());
// associations bidirectionnelles
setPersonne(p);
setActivite(a);
p.getActivites().add(this);
a.getPersonnes().add(this);
}
Alla riga 9, l'attività a riceve un elemento aggiuntivo di tipo PersonActivity nella sua collezione persons. Questo elemento è di tipo (p,a) per indicare che la persona p partecipa all'attività a. Nel test1 all'interno di [Main], sono stati creati in questo modo due collegamenti (p1,act1) e (p1,act2) . Le righe 10 e 11 di test2 rimuovono queste dipendenze. Si noti che Hibernate funziona senza rimuovere queste dipendenze sulla persona p1, mentre Toplink no.
- Righe 17–20: vengono visualizzate tutte le tabelle
I risultati sono i seguenti:
- La persona p1, presente in test1 (riga 3), non è più presente alla fine di test2 (righe 22–23)
- L'indirizzo adr1 della persona p1, presente in test1 (riga 11), non è più presente dopo test2 (righe 29–31)
- le attività (p1,act1) (riga 16) e (p1,act2) (riga 18) della persona p1, presenti in test1, non sono più presenti alla fine di test2 (righe 33-34)
2.5.6.2. Test3
Questo test è il seguente:
// suppression activite act1
public static void test3() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// suppression dépendances sur act1 : pas nécessaire à hibernate mais
// indispensable à toplink
p2.getActivites().remove(p2act1);
// suppression activité act1
em.remove(act1);
// fin transaction
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpActivite();
dumpAdresse();
dumpPersonne_Activite();
}
- Riga 4: utilizziamo il contesto di persistenza di test2
- riga 12: eliminazione dell'attività act1. A causa dell'attributo:
- cascadeType.REMOVE su PersonneActivite, le righe (p, act1) nella tabella [personne_activite] verranno eliminate.
- Riga 10: Prima di rimuovere act1 dal contesto di persistenza, eliminiamo eventuali dipendenze che altre entità potrebbero avere su questo oggetto persistente. Dopo aver eliminato la persona p1 nel test precedente, solo la persona p2 esegue l'attività act1.
- Righe 13–16: vengono visualizzate tutte le tabelle
I risultati sono i seguenti:
- Nel test2, l'attività act1 esiste (riga 6). Nel test3, non esiste più (righe 21-22)
- Nel test2, il collegamento (p2,act1) esiste (riga 14). Nel test3, non esiste più (riga 28)
2.5.6.3. Test4
Questo test è il seguente:
// récupération activités d'une personne
public static void test4() {
// contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on récupère la personne p2
p2 = em.find(Personne.class, p2.getId());
System.out.format("1 - Activités de la personne p2 (JPQL) :%n");
// on scanne ses activités
for (Object pa : em.createQuery("select a.nom from Activite a join a.personnes pa where pa.personne.nom='p2'").getResultList()) {
System.out.println(pa);
}
// on passe par la relation inverse de p2
p2 = em.find(Personne.class, p2.getId());
System.out.format("2 - Activités de la personne p2 (relation inverse) :%n");
// on scanne ses activités
for (PersonneActivite pa : p2.getActivites()) {
System.out.println(pa.getActivite().getNom());
}
// fin transaction
tx.commit();
}
- Il Test 4 mostra le attività della persona p2.
- riga 4: iniziamo con un nuovo contesto vuoto
- righe 12–14: visualizziamo i nomi delle attività svolte dalla persona p2 utilizzando una query JPQL.
- Viene eseguito un join tra Activity (a) e PersonActivity (pa) (join a.people)
- Nelle righe di questo join (a, pa), visualizziamo il nome dell'attività (a.name) per la persona p2 (pa.person.name='p2').
- Righe 16–21: facciamo lo stesso di prima, ma utilizzando la relazione OneToMany p2.activites della persona p2. La query JPQL sarà generata da JPA. Qui vediamo il vantaggio della relazione OneToMany inversa: evita una query JPQL.
I risultati sono i seguenti:
2.5.6.4. Test5
Questo test è il seguente:
// récupération personnes faisant une activité donnée
public static void test5() {
// contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
System.out.format("1 - Personnes pratiquant l'activité act3 (JPQL) :%n");
// on demande les activités de p2
for (Object pa : em.createQuery("select p.nom from Personne p join p.activites pa where pa.activite.nom='act3'").getResultList()) {
System.out.println(pa);
}
// on passe par la relation inverse de act3
System.out.format("2 - Personnes pratiquant l'activité act3 (relation inverse) :%n");
act3 = em.find(Activite.class, act3.getId());
for (PersonneActivite pa : act3.getPersonnes()) {
System.out.println(pa.getPersonne().getNom());
}
// fin transaction
tx.commit();
}
- Il Test 6 mostra le persone che eseguono l'attività act3. L'approccio è simile a quello del Test 6. Lasciamo al lettore il compito di individuare la connessione tra i due frammenti di codice.
I risultati sono i seguenti:
I test 4 e 5 avevano lo scopo di dimostrare ancora una volta che una relazione inversa non è mai essenziale e può sempre essere sostituita da una query JPQL.
2.5.7. Implementazione JPA / Toplink
Ora stiamo utilizzando un'implementazione JPA / Toplink:
 |
Il progetto Eclipse con Toplink è una copia del progetto Eclipse con Hibernate:
 |
Il codice Java è identico a quello del precedente progetto Hibernate, con alcune piccole differenze di cui parleremo. L'ambiente (librerie – persistence.xml – DBMS – cartelle conf e ddl – script Ant) è quello descritto nella sezione 2.1.15.2. Il progetto Eclipse è disponibile [3] nella cartella degli esempi [4]. Lo importeremo.
Il file <persistence.xml> [2] è stato modificato in un punto: le entità dichiarate:
<!-- classes persistantes -->
<class>entites.Activite</class>
<class>entites.Adresse</class>
<class>entites.Personne</class>
<class>entites.PersonneActivite</class>
- Righe 2–5: le quattro entità gestite
L'esecuzione di [InitDB] con il DBMS MySQL5 produce i seguenti risultati:
 |
In [1], l'output della console; in [2], le tabelle [jpa07_tl] generate; in [3], gli script SQL generati. Il loro contenuto è il seguente:
create.sql
CREATE TABLE jpa07_tl_activite (ID BIGINT NOT NULL, VERSION INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa07_tl_adresse (ID BIGINT NOT NULL, ADR3 VARCHAR(30), CODEPOSTAL VARCHAR(5) NOT NULL, VERSION INTEGER NOT NULL, VILLE VARCHAR(20) NOT NULL, ADR2 VARCHAR(30), CEDEX VARCHAR(3), ADR1 VARCHAR(30) NOT NULL, PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa07_tl_personne_activite (PERSONNE_ID BIGINT NOT NULL, ACTIVITE_ID BIGINT NOT NULL, PRIMARY KEY (PERSONNE_ID, ACTIVITE_ID))
CREATE TABLE jpa07_tl_personne (ID BIGINT NOT NULL, DATENAISSANCE DATE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, NBENFANTS INTEGER NOT NULL, VERSION INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, adresse_id BIGINT UNIQUE NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa07_tl_personne_activite ADD CONSTRAINT FK_jpa07_tl_personne_activite_ACTIVITE_ID FOREIGN KEY (ACTIVITE_ID) REFERENCES jpa07_tl_activite (ID)
ALTER TABLE jpa07_tl_personne_activite ADD CONSTRAINT FK_jpa07_tl_personne_activite_PERSONNE_ID FOREIGN KEY (PERSONNE_ID) REFERENCES jpa07_tl_personne (ID)
ALTER TABLE jpa07_tl_personne ADD CONSTRAINT FK_jpa07_tl_personne_adresse_id FOREIGN KEY (adresse_id) REFERENCES jpa07_tl_adresse (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
L'esecuzione di [InitDB] e [Main] si conclude senza errori.
2.6. Esempio 6: Relazione molti-a-molti con una tabella di join implicita
Torniamo all'Esempio 4, ma ora lo gestiamo con una tabella di join implicita generata dal livello JPA stesso.
2.6.1. Lo schema del database
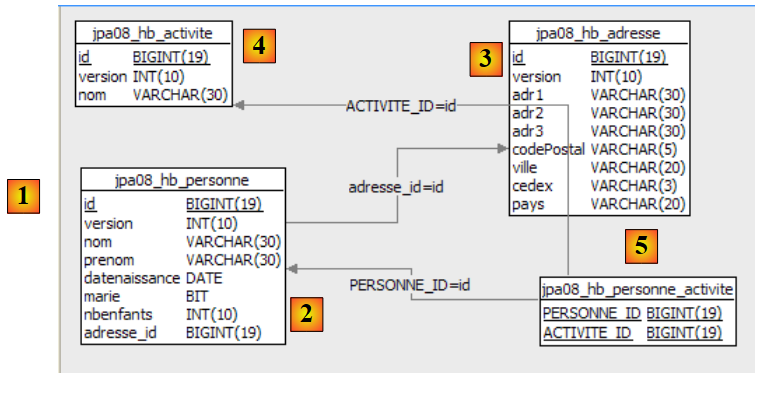 |
- in [1], il database MySQL5 – in [2]: la tabella [person] – in [3]: la tabella associata [address] – in [4]: la tabella [activity] per le attività – in [5]: la tabella di join [person_activity] che collega persone e attività.
2.6.2. Gli oggetti @Entity che rappresentano il database
Le tabelle sopra indicate saranno rappresentate dalle seguenti annotazioni @Entity:
- L'@Entity Person rappresenterà la tabella [person]
- l'@Entity Address rappresenterà la tabella [address]
- l'@Entity Activity rappresenterà la tabella [activity]
- La tabella [person_activity] non è più rappresentata da un @Entity
Le relazioni tra queste entità sono le seguenti:
- Una relazione uno-a-uno collega l'entità Person all'entità Address: una persona p ha un indirizzo a. L'entità Person che contiene la chiave esterna sarà l'entità primaria, mentre l'entità Address sarà l'entità inversa.
- Una relazione molti-a-molti collega le entità Person e Activity: una persona ha più attività e un'attività è praticata da più persone. Questa relazione sarà implementata utilizzando un'annotazione @ManyToMany in ciascuna delle due entità, con una dichiarata come inversa dell'altra.
L'entità @Entity Person è la seguente:
@Entity
@Table(name = "jpa08_hb_personne")
public class Personne implements Serializable {
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
// toplink sqlserver :@GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
@Column(length = 30, nullable = false)
private String prenom;
@Column(nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(nullable = false)
private boolean marie;
@Column(nullable = false)
private int nbenfants;
// main relationship Person (one) -> Address (one)
// implemented by the foreign key Person(adresse_id) -> Address
// cascade insert Person -> insert Address
// cascade shift Person -> shift Address
// cascade deletion Person -> deletion Address
// a Person must have 1 Address (nullable=false)
// 1 Address belongs to 1 person only (unique=true)
@OneToOne(cascade = CascadeType.ALL)
@JoinColumn(name = "adresse_id", unique = true, nullable = false)
private Adresse adresse;
// relationship Person (many) -> Activity (many) via a personne_activite join table
// personne_activite(PERSONNE_ID) is a foreign key on Person(id)
// personne_activite(ACTIVITE_ID) is a foreign key on Activite(id)
// cascade=CascadeType.PERSIST: persistence of 1 person leads to persistence of their activities
@ManyToMany(cascade={CascadeType.PERSIST})
@JoinTable(name="jpa08_hb_personne_activite",joinColumns = @JoinColumn(name = "PERSONNE_ID"), inverseJoinColumns = @JoinColumn(name = "ACTIVITE_ID"))
private Set<Activite> activites = new HashSet<Activite>();
// manufacturers
public Personne() {
}
Ci limiteremo a commentare la relazione @ManyToMany alle righe 46–48, che collega l'@Entity Person all'@Entity Activity:
- riga 48: una persona ha delle attività. Il campo activities le rappresenterà. Nella versione precedente, il tipo degli elementi nel set activities era PersonActivity. Qui è Activity. Accediamo quindi direttamente alle attività di una persona, mentre nella versione precedente dovevamo passare attraverso l’entità intermedia PersonActivity.
- Riga 46: la relazione che collega l'@Entity Person che stiamo esaminando all'@Entity Activity nell'insieme delle attività alla riga 48 è di tipo molti-a-molti (ManyToMany):
- una persona (One) ha più attività (Many)
- un'attività (One) è praticata da diverse persone (Many)
- In definitiva, le @Entity Person e Activity sono collegate da una relazione ManyToMany. Come per la relazione OneToOne, le entità in questa relazione sono simmetriche. Possiamo scegliere liberamente quale @Entity avrà la relazione primaria e quale avrà la relazione inversa. Qui, decidiamo che l’@Entity Person avrà la relazione primaria.
- Come abbiamo visto nell'esempio precedente, la relazione @ManyToMany richiede una tabella di join. Mentre in precedenza l'avevamo definita utilizzando un'@Entity, qui la tabella di join è definita utilizzando l'annotazione @JoinTable alla riga 47.
- L'attributo name assegna un nome alla tabella.
- La tabella di join è costituita dalle chiavi esterne delle tabelle che unisce. In questo caso, ci sono due chiavi esterne: una dalla tabella [person], l'altra dalla tabella [activity]. Queste colonne di chiave esterna sono definite dagli attributi joinColumns e inverseJoinColumns.
- L'annotazione @JoinColumn sull'attributo joinColumns definisce la chiave esterna sulla tabella dell'@Entity che detiene la relazione primaria @ManyToMany, in questo caso la tabella [person]. Questa colonna di chiave esterna sarà denominata PERSON_ID.
- L'annotazione @JoinColumn dell'attributo inverseJoinColumns definisce la chiave esterna nella tabella dell'@Entity che contiene la relazione @ManyToMany inversa, in questo caso la tabella [activity]. Questa colonna di chiave esterna sarà denominata ACTIVITY_ID.
L'@Entity Address è la seguente:
@Entity
@Table(name = "jpa07_hb_adresse")
public class Adresse implements Serializable {
// fields
@Id
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false)
private String adr1;
@Column(length = 30)
private String adr2;
@Column(length = 30)
private String adr3;
@Column(length = 5, nullable = false)
private String codePostal;
@Column(length = 20, nullable = false)
private String ville;
@Column(length = 3)
private String cedex;
@Column(length = 20, nullable = false)
private String pays;
@OneToOne(mappedBy = "adresse")
private Personne personne;
- Righe 28-29: la relazione @OneToOne che è l'inverso della relazione @OneToOne address dell'entità @Entity Person (righe 37-38 di Person).
L'@Entity Activity è la seguente
@Entity
@Table(name = "jpa08_hb_activite")
public class Activite implements Serializable {
// fields
@Id()
@Column(nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
// toplink sqlserver : @GeneratedValue(strategy = GenerationType.IDENTITY)
private Long id;
@Column(nullable = false)
@Version
private int version;
@Column(length = 30, nullable = false, unique = true)
private String nom;
// inverse relationship Activity -> Person
@ManyToMany(mappedBy = "activites")
private Set<Personne> personnes = new HashSet<Personne>();
...
- Righe 20–21: La relazione molti-a-molti che collega l'@Entity Activity all'@Entity Person. Questa relazione è già stata definita nell'@Entity Person. Qui, specifichiamo semplicemente che la relazione è l'inversa (mappedBy) della relazione @ManyToMany esistente sul campo activites (mappedBy="activites") dell'@Entity Person.
- Ricordiamo che una relazione inversa è sempre facoltativa. Qui la utilizziamo per recuperare le persone che partecipano all'attività corrente. Per recuperarle verrà utilizzata la collezione Set<Person> people. La modalità di caricamento per le dipendenze Person dell'@Entity Activity non è specificata. Non l'abbiamo specificata nemmeno nell'esempio precedente. Per impostazione predefinita, questa modalità è fetch=FetchType.LAZY.
Abbiamo terminato la descrizione delle entità del database. È stato più semplice rispetto al caso in cui la tabella di join [person_activity] è una tabella esplicita. Questa soluzione più semplice può presentare degli svantaggi nel tempo: non consente di aggiungere colonne alla tabella di join. Ciò potrebbe tuttavia rivelarsi necessario per soddisfare nuovi requisiti, come l'aggiunta di una colonna alla tabella [person_activity] che indichi la data in cui la persona si è registrata all'attività.
2.6.3. Il progetto Eclipse / Hibernate
L'implementazione JPA utilizzata in questo caso è Hibernate. Il progetto Eclipse per i test è il seguente:
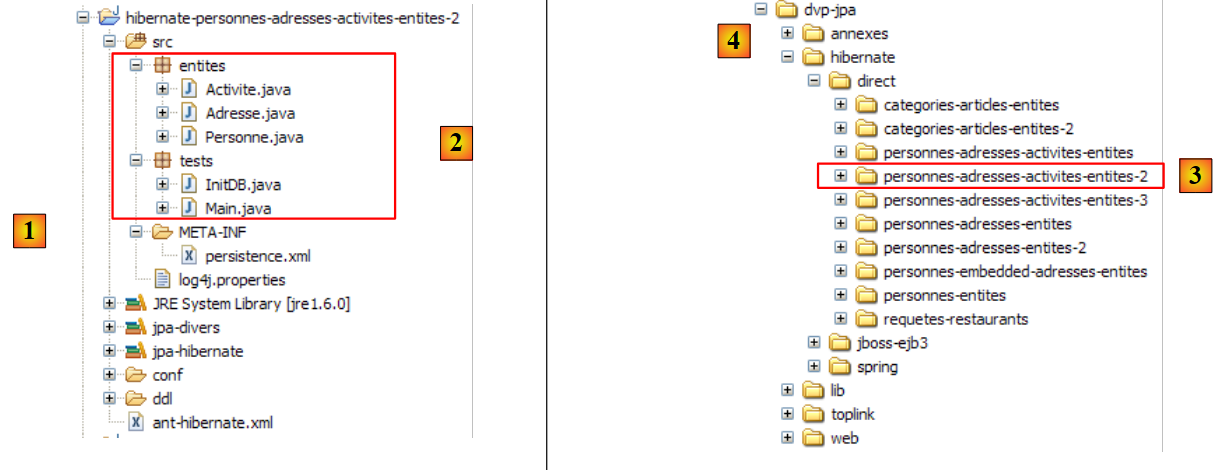 |
In [1], il progetto Eclipse; in [2], il codice Java. Il progetto si trova in [3] all'interno della cartella degli esempi [4]. Lo importeremo.
2.6.4. Generazione del DDL del database
Seguendo le istruzioni della sezione 2.1.7, il DDL generato per il DBMS MySQL 5 è il seguente:
alter table jpa08_hb_personne
drop
foreign key FKA44B1E555FE379D0;
alter table jpa08_hb_personne_activite
drop
foreign key FK5A6A55A5CD852024;
alter table jpa08_hb_personne_activite
drop
foreign key FK5A6A55A568C7A284;
drop table if exists jpa08_hb_activite;
drop table if exists jpa08_hb_adresse;
drop table if exists jpa08_hb_personne;
drop table if exists jpa08_hb_personne_activite;
create table jpa08_hb_activite (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa08_hb_adresse (
id bigint not null auto_increment,
version integer not null,
adr1 varchar(30) not null,
adr2 varchar(30),
adr3 varchar(30),
codePostal varchar(5) not null,
ville varchar(20) not null,
cedex varchar(3),
pays varchar(20) not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa08_hb_personne (
id bigint not null auto_increment,
version integer not null,
nom varchar(30) not null unique,
prenom varchar(30) not null,
datenaissance date not null,
marie bit not null,
nbenfants integer not null,
adresse_id bigint not null unique,
primary key (id)
) ENGINE=InnoDB;
create table jpa08_hb_personne_activite (
PERSONNE_ID bigint not null,
ACTIVITE_ID bigint not null,
primary key (PERSONNE_ID, ACTIVITE_ID)
) ENGINE=InnoDB;
alter table jpa08_hb_personne
add index FKA44B1E555FE379D0 (adresse_id),
add constraint FKA44B1E555FE379D0
foreign key (adresse_id)
references jpa08_hb_adresse (id);
alter table jpa08_hb_personne_activite
add index FK5A6A55A5CD852024 (ACTIVITE_ID),
add constraint FK5A6A55A5CD852024
foreign key (ACTIVITE_ID)
references jpa08_hb_activite (id);
alter table jpa08_hb_personne_activite
add index FK5A6A55A568C7A284 (PERSONNE_ID),
add constraint FK5A6A55A568C7A284
foreign key (PERSONNE_ID)
references jpa08_hb_personne (id);
Questo DDL è analogo a quello ottenuto con la tabella di join esplicita e corrisponde allo schema già presentato:
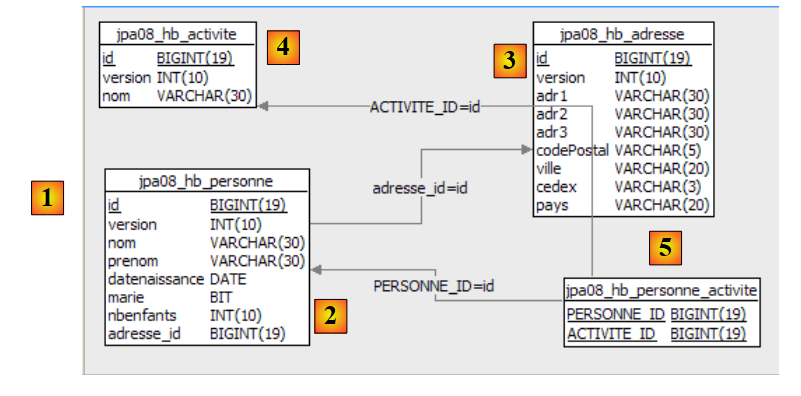 |
2.6.5. InitDB
Non ci soffermeremo molto sulla classe [InitDB], che è identica alla versione precedente e produce gli stessi risultati. Concentriamoci invece sul codice seguente, che mostra il join Persona <-> Attività:
// people/activities display
System.out.println("[personnes/activites]");
Iterator iterator = em.createQuery("select p.id,a.id from Personne p join p.activites a").getResultList().iterator();
while (iterator.hasNext()) {
Object[] row = (Object[]) iterator.next();
System.out.format("[%d,%d]%n", (Long) row[0], (Long) row[1]);
}
- Riga 3: La query JPQL che esegue il join. Il risultato dell'istruzione SELECT restituisce gli ID delle entità Person e Activity collegate dalla tabella di join. L'elenco restituito dall'istruzione SELECT è costituito da righe contenenti due oggetti Long. Per iterare su questo elenco, la riga 3 richiede un oggetto Iterator per l'elenco.
- Righe 4–7: utilizzando l'oggetto Iterator della riga precedente, viene attraversato l'elenco.
- Riga 5: ogni elemento dell'elenco è un array contenente una riga del risultato SELECT
- Riga 6: Gli elementi della riga corrente risultante dall'istruzione SELECT vengono recuperati effettuando le opportune conversioni di tipo.
Il risultato di [InitDB] è il seguente:
2.6.6. Main
La classe [Main] esegue una serie di test, alcuni dei quali esamineremo.
2.6.6.1. Test3
Questo test è il seguente:
// suppression activite act1
public static void test3() {
// contexte de persistance
EntityManager em = getEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// suppression activité act1 de p2
p2.getActivites().remove(act1);
// on retire act1 du contexte de persistance
em.remove(act1);
// fin transactions
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpActivite();
dumpAdresse();
dumpPersonne_Activite();
}
- Riga 11: L'attività act1 viene rimossa dal contesto di persistenza
- Riga 9: L'attività act1 è una delle attività dell'unica persona rimasta nel contesto, la persona p2. La riga 9 rimuove l'attività act1 dalle attività della persona p2. Lo facciamo per mantenere la coerenza del contesto di persistenza, poiché lo useremo in seguito.
I risultati sono i seguenti:
- L'attività act1 alla riga 26 in test2 è scomparsa dalle attività in test3 (righe 40-41)
- La persona p2 aveva l'attività act1 in test2 (riga 33). Alla fine di test3, non ce l'ha più (riga 47)
2.6.6.2. Test6
Questo test è il seguente:
// modification des activités d'une personne
public static void test6() {
// contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// on récupère la personne p2
p2 = em.find(Personne.class, p2.getId());
// on récupère l'activité act2
act2 = em.find(Activite.class, act2.getId());
// p2 ne pratique plus que l'activité act2
p2.getActivites().clear();
p2.getActivites().add(act2);
// fin transaction
tx.commit();
// on affiche les nouvelles tables
dumpPersonne();
dumpActivite();
dumpPersonne_Activite();
}
- Riga 4: viene utilizzato un nuovo contesto di persistenza vuoto
- riga 9: la persona p2 viene recuperata dal database nel contesto di persistenza
- riga 11: l'attività act2 viene recuperata dal database nel contesto di persistenza
- riga 13: le attività della persona p2 (act3) vengono recuperate dal database nel contesto (fetchType.LAZY). La chiamata [getActivites] innesca questo caricamento. Rimuoviamo le attività di p2. Non si tratta di una rimozione effettiva delle attività (remove), ma di una modifica dello stato della persona p2. Non è più impegnata in alcuna attività.
- Riga 14: l'attività act2 viene aggiunta alla persona p2. In definitiva, l'insieme delle nuove attività per la persona p2 è l'insieme {act2}.
- Riga 16: Fine della transazione. La sincronizzazione esaminerà gli oggetti nel contesto (p2, act2, act3) e rileverà che lo stato di p2 è cambiato. Verranno eseguite le istruzioni SQL che riflettono questa modifica nel database.
- Righe 18–20: Vengono visualizzate tutte le tabelle
I risultati sono i seguenti:
- Alla fine del test 4, la persona p2 stava svolgendo l'attività act3 (riga 3).
- Alla fine del test 6 (riga 19), la persona p2 non sta più svolgendo l'attività act3 (riga 3) e sta svolgendo l'attività act2.
2.6.7. Implementazione JPA / Toplink
Ora stiamo utilizzando un'implementazione JPA / Toplink:
 |
Il progetto Eclipse con Toplink è una copia del progetto Eclipse con Hibernate:
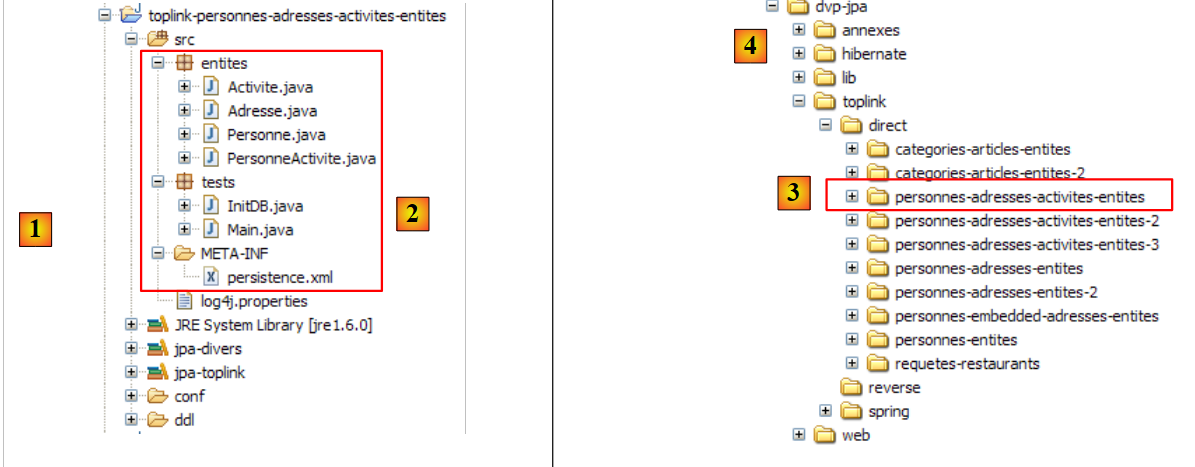 |
Il file <persistence.xml> [2] è stato modificato in un punto, in particolare per quanto riguarda le entità dichiarate:
<!-- provider -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- classes persistantes -->
<class>entites.Activite</class>
<class>entites.Adresse</class>
<class>entites.Personne</class>
...
- righe 4-6: le entità gestite
L'esecuzione di [InitDB] con il DBMS MySQL5 produce i seguenti risultati:
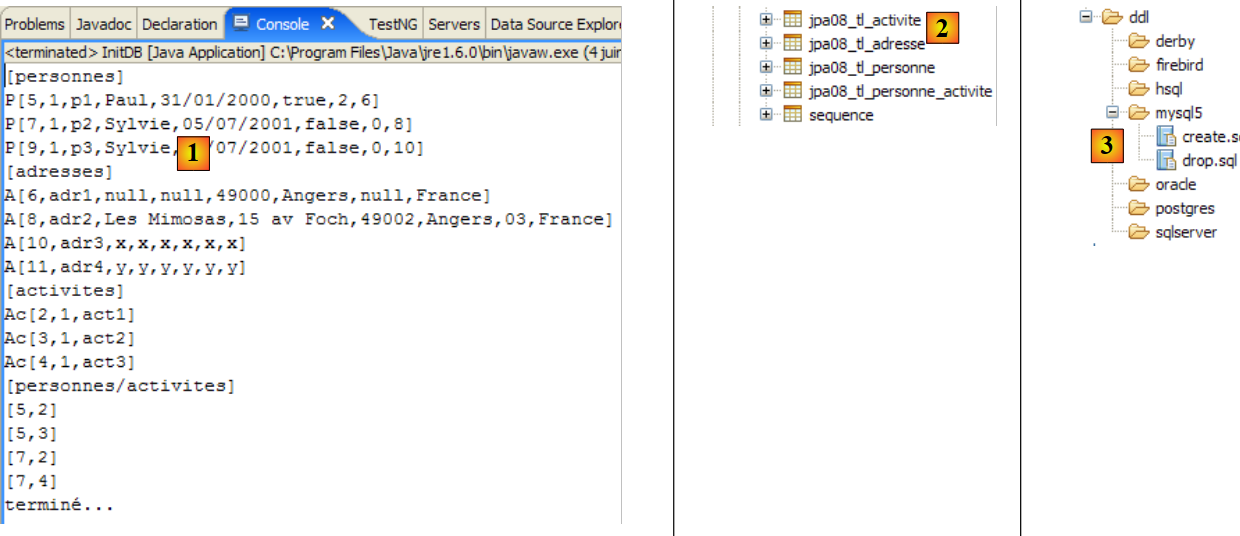 |
In [1], l'output della console; in [2], le tabelle [jpa07_tl] generate; in [3], gli script SQL generati. Il loro contenuto è il seguente:
create.sql
CREATE TABLE jpa08_tl_personne_activite (PERSONNE_ID BIGINT NOT NULL, ACTIVITE_ID BIGINT NOT NULL, PRIMARY KEY (PERSONNE_ID, ACTIVITE_ID))
CREATE TABLE jpa08_tl_activite (ID BIGINT NOT NULL, VERSION INTEGER NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa08_tl_personne (ID BIGINT NOT NULL, DATENAISSANCE DATE NOT NULL, MARIE TINYINT(1) default 0 NOT NULL, NOM VARCHAR(30) UNIQUE NOT NULL, NBENFANTS INTEGER NOT NULL, VERSION INTEGER NOT NULL, PRENOM VARCHAR(30) NOT NULL, adresse_id BIGINT UNIQUE NOT NULL, PRIMARY KEY (ID))
CREATE TABLE jpa08_tl_adresse (ID BIGINT NOT NULL, ADR3 VARCHAR(30), CODEPOSTAL VARCHAR(5) NOT NULL, VERSION INTEGER NOT NULL, VILLE VARCHAR(20) NOT NULL, ADR2 VARCHAR(30), CEDEX VARCHAR(3), ADR1 VARCHAR(30) NOT NULL, PAYS VARCHAR(20) NOT NULL, PRIMARY KEY (ID))
ALTER TABLE jpa08_tl_personne_activite ADD CONSTRAINT FK_jpa08_tl_personne_activite_ACTIVITE_ID FOREIGN KEY (ACTIVITE_ID) REFERENCES jpa08_tl_activite (ID)
ALTER TABLE jpa08_tl_personne_activite ADD CONSTRAINT FK_jpa08_tl_personne_activite_PERSONNE_ID FOREIGN KEY (PERSONNE_ID) REFERENCES jpa08_tl_personne (ID)
ALTER TABLE jpa08_tl_personne ADD CONSTRAINT FK_jpa08_tl_personne_adresse_id FOREIGN KEY (adresse_id) REFERENCES jpa08_tl_adresse (ID)
CREATE TABLE SEQUENCE (SEQ_NAME VARCHAR(50) NOT NULL, SEQ_COUNT DECIMAL(38), PRIMARY KEY (SEQ_NAME))
INSERT INTO SEQUENCE(SEQ_NAME, SEQ_COUNT) values ('SEQ_GEN', 1)
L'esecuzione di [InitDB] e [Main] si conclude senza errori.
2.6.8. Il progetto Eclipse / Hibernate 2
Creiamo un progetto Eclipse basato su quello precedente copiandolo:
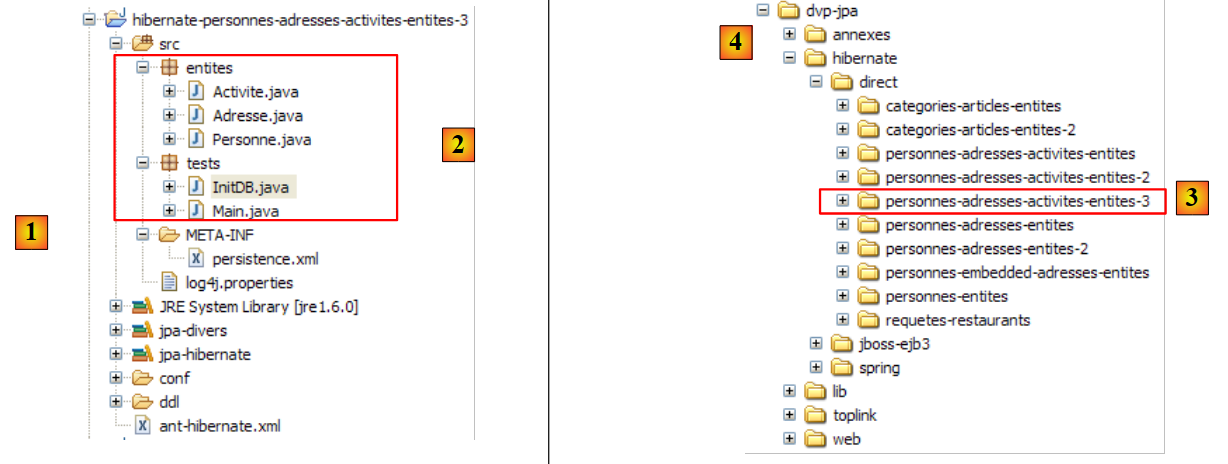 |
In [1], il progetto Eclipse; in [2], il codice Java. Il progetto si trova in [3] all'interno della cartella degli esempi [4]. Lo importeremo.
Modifichiamo la relazione che collega Person ad Activity come segue:
Person
// relation Personne (many) -> Activite (many) via une table de jointure personne_activite
// personne_activite(PERSONNE_ID) est clé étangère sur Personne(id)
// personne_activite(ACTIVITE_ID) est clé étangère sur Activite(id)
// plus de cascade sur les activités
// @ManyToMany(cascade={CascadeType.PERSIST})
@ManyToMany()
@JoinTable(name = "jpa09_hb_personne_activite", joinColumns = @JoinColumn(name = "PERSONNE_ID"), inverseJoinColumns = @JoinColumn(name = "ACTIVITE_ID"))
private Set<Activite> activites = new HashSet<Activite>();
- Riga 6: La relazione primaria @ManyToMany non ha più una cascata di persistenza da Persona a Attività (vedi versione precedente, riga 5)
Attività
// plus de relation inverse avec Personne
// @ManyToMany(mappedBy = "activites")
// private Set<Personne> personnes = new HashSet<Personne>();
- Righe 2-3: La relazione inversa @ManyToMany Attività -> Persona è stata rimossa
Il nostro obiettivo è dimostrare che gli attributi rimossi (cascata e relazione inversa) non sono essenziali. La prima modifica introdotta da questa nuova configurazione si trova in [InitDB]:
// associations personnes <--> activites
p1.getActivites().add(act1);
p1.getActivites().add(act2);
p2.getActivites().add(act1);
p2.getActivites().add(act3);
// persistance des activites
em.persist(act1);
em.persist(act2);
em.persist(act3);
// persistance des personnes
em.persist(p1);
em.persist(p2);
em.persist(p3);
// et de l'adresse a4 non liée à une personne
em.persist(adr4);
- righe 7–9: siamo tenuti a inserire esplicitamente le attività da act1 a act3 nel contesto di persistenza. Quando esisteva la cascata di persistenza Persona -> Attività, le righe 11–13 mantenevano sia le persone da p1 a p3 sia le attività di quelle persone da act1 a act3.
Una seconda modifica è visibile in [Main]:
// récupération personnes faisant une activité donnée
public static void test5() {
// contexte de persistance
EntityManager em = getNewEntityManager();
// début transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
System.out.format("1 - Personnes pratiquant l'activité act3 (JPQL) :%n");
// on demande les activités de p2
for (Object pa : em.createQuery("select p.nom from Personne p join p.activites a where a.nom='act3'").getResultList()) {
System.out.println(pa);
}
// fin transaction
tx.commit();
}
- righe 9-12: la query JPQL che recupera le persone che partecipano all'attività act3
- Nella versione precedente, lo stesso risultato veniva ottenuto anche tramite la relazione inversa Activity -> Person, che ora è stata rimossa:
// we use the inverse relationship of act3
System.out.format("2 - Personnes pratiquant l'activité act3 (relation inverse) :%n");
act3 = em.find(Activite.class, act3.getId());
for (Personne p : act3.getPersonnes()) {
System.out.println(p.getNom());
}
2.6.9. Il progetto Eclipse / Toplink 2
Stiamo creando un progetto Eclipse basato sul precedente progetto Eclipse / Toplink copiandolo:
 |
In [1], il progetto Eclipse; in [2], il codice Java. Il progetto si trova in [3] nella cartella degli esempi [4]. Lo importeremo.
Il codice Java è identico a quello della versione Hibernate.
2.7. Esempio 7: Utilizzo delle query con nome
Concludiamo questa lunga panoramica sulle entità JPA, iniziata al paragrafo 2, con un ultimo esempio che illustra l'uso delle query JPQL esternalizzate in un file di configurazione. Questo esempio è tratto dalla seguente fonte:
[ref2]: "Getting Started With JPA in Spring 2.0" di Mark Fisher all'URL
[http://blog.springframework.com/markf/archives/2006/05/30/getting-started-with-jpa-in-spring-20/].
2.7.1. Il database di esempio
Il database è il seguente:
 |
- in [1]: un elenco di ristoranti con i relativi nomi e indirizzi
- in [2]: la tabella degli indirizzi dei ristoranti, limitata al numero civico e al nome della via. Esiste una relazione uno-a-uno tra le tabelle dei ristoranti e degli indirizzi: un ristorante ha un solo e unico indirizzo.
- in [3]: una tabella dei piatti con i loro nomi e un flag vero/falso che indica se il piatto è vegetariano o meno
- in [4]: la tabella di join ristorante/piatto: un ristorante serve più piatti e lo stesso piatto può essere servito da più ristoranti. Esiste una relazione molti-a-molti tra le tabelle dei ristoranti e dei piatti.
2.7.2. Gli oggetti @Entity che rappresentano il database
Le tabelle sopra riportate saranno rappresentate dalle seguenti @Entities:
- l'@Entity Restaurant rappresenterà la tabella [restaurant]
- l'@Entity Address rappresenterà la tabella [address]
- l'@Entity Dish rappresenterà la tabella [dish]
Le relazioni tra queste entità sono le seguenti:
- Una relazione uno-a-uno collega l'entità Restaurant all'entità Address: un ristorante r ha un indirizzo a. L'entità Restaurant, che contiene la chiave esterna, sarà l'entità primaria. L'entità Address non avrà una relazione inversa.
- Una relazione molti-a-molti collega le entità Ristorante e Piatto: un ristorante serve più piatti e lo stesso piatto può essere servito da più ristoranti. Questa relazione verrà implementata utilizzando l'annotazione @ManyToMany nell'entità Ristorante. L'entità Piatto non avrà una relazione inversa.
L'entità @Entity Ristorante è la seguente:
package entites;
...
@Entity
@Table(name = "jpa10_hb_restaurant")
public class Restaurant implements java.io.Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(unique = true, length = 30, nullable = false)
private String nom;
@OneToOne(cascade = CascadeType.ALL)
private Adresse adresse;
@ManyToMany(cascade = { CascadeType.PERSIST, CascadeType.MERGE })
@JoinTable(name = "jpa10_hb_restaurant_plat", inverseJoinColumns = @JoinColumn(name = "plat_id"))
private Set<Plat> plats = new HashSet<Plat>();
// manufacturers
public Restaurant() {
}
public Restaurant(String name, Adresse address, Set<Plat> entrees) {
...
}
// getters and setters
...
// toString
public String toString() {
String signature = "R[" + getNom() + "," + getAdresse();
for (Plat e : getPlats()) {
signature += "," + e;
}
return signature + "]";
}
}
- Riga 17: La relazione uno-a-uno tra l'entità Restaurant e l'entità Address. Tutte le operazioni di persistenza su un ristorante vengono propagate al suo indirizzo.
- Riga 20: la relazione che collega l'@Entity Ristorante all'@Entity Piatto nella collezione dei piatti alla riga 22 è di tipo molti-a-molti (ManyToMany):
- un ristorante (Uno) ha più piatti (Molti)
- un piatto (Uno) può essere servito da più ristoranti (Molti)
- In definitiva, @Entity Restaurant e @Entity Dish sono collegati da una relazione ManyToMany. Decidiamo che @Entity Restaurant sarà la relazione primaria e che @Entity Dish non avrà una relazione inversa.
- La relazione @ManyToMany richiede una tabella di join. Questa viene definita utilizzando l'annotazione @JoinTable alla riga 47.
- L'attributo name assegna un nome alla tabella.
- La tabella di join è costituita dalle chiavi esterne delle tabelle che unisce. In questo caso, ci sono due chiavi esterne: una dalla tabella [restaurant] e l'altra dalla tabella [dish]. Queste colonne di chiave esterna sono definite dagli attributi joinColumns e inverseJoinColumns.
- L'attributo joinColumns definisce la chiave esterna sulla tabella dell'@Entity che contiene la relazione @ManyToMany primaria, in questo caso la tabella [restaurant]. L'attributo joinColumns qui manca. JPA ha un valore predefinito in questo caso: [table]_[table_primary_key], qui [jpa10_hb_restaurant_id].
- L'annotazione @JoinColumn per l'attributo inverseJoinColumns definisce la chiave esterna nella tabella dell'@Entity che contiene la relazione @ManyToMany inversa, in questo caso la tabella [dish]. Questa colonna della chiave esterna sarà denominata dish_id.
L'@Entity Address è la seguente:
package entites;
...
@Entity
@Table(name="jpa10_hb_adresse")
public class Adresse implements java.io.Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(name = "NUMERO_RUE")
private int numeroRue;
@Column(name = "NOM_RUE", length=30, nullable=false)
private String nomRue;
// getters and setters
...
// manufacturers
public Adresse(int streetNumber, String streetName){
...
}
public Adresse(){
}
// toString
public String toString(){
return "A["+getNumeroRue()+","+getNomRue()+"]";
}
}
- L'entità @Entity Address è un'entità senza relazioni dirette con altre entità. Può essere salvata solo tramite un'entità Restaurant.
- Un indirizzo è definito da un nome di via (riga 16) e da un numero civico (riga 13).
L'entità @Entity Dish è la seguente
package entites;
...
@Entity
@Table(name="jpa10_hb_plat")
public class Plat implements java.io.Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private long id;
@Column(unique=true, length=50, nullable=false)
private String nom;
private boolean vegetarien;
// manufacturers
public Plat() {
}
public Plat(String name, boolean vegetarian) {
...
}
// getters and setters
...
// toString
public String toString() {
return "E[" + getNom() + "," + isVegetarien() + "]";
}
}
- L'entità @Entity Dish è un'entità senza relazioni dirette con altre entità. Può essere salvata solo tramite un'entità Restaurant.
- Un piatto è definito da un nome (riga 12) e dal fatto che sia vegetariano o meno (riga 14).
2.7.3. Il progetto Eclipse / Hibernate
L'implementazione JPA utilizzata in questo caso è Hibernate. Il progetto di test Eclipse è il seguente:
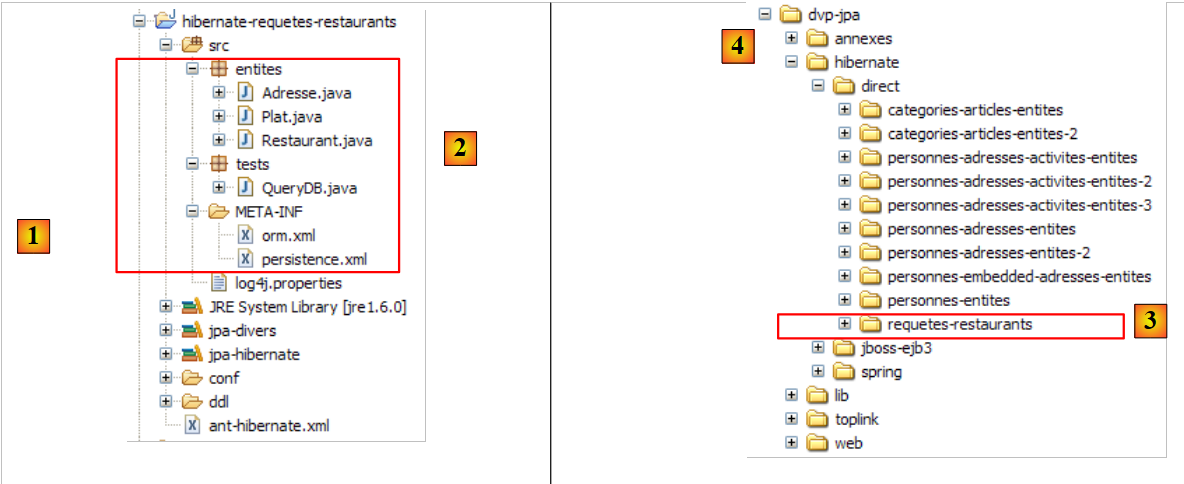 |
In [1], il progetto Eclipse; in [2], il codice Java e la configurazione del livello JPA. Si noti la presenza di un file [orm.xml], che non abbiamo incontrato prima. Il progetto si trova in [3] all'interno della cartella degli esempi [4]. Lo importeremo.
2.7.4. Generazione del DDL del database
Seguendo le istruzioni della sezione 2.1.7, il DDL risultante per il DBMS MySQL 5 è il seguente:
alter table jpa10_hb_restaurant
drop
foreign key FK3E8E4F5D5FE379D0;
alter table jpa10_hb_restaurant_plat
drop
foreign key FK1D2D06D11F0F78A4;
alter table jpa10_hb_restaurant_plat
drop
foreign key FK1D2D06D1AFAC3E44;
drop table if exists jpa10_hb_adresse;
drop table if exists jpa10_hb_plat;
drop table if exists jpa10_hb_restaurant;
drop table if exists jpa10_hb_restaurant_plat;
create table jpa10_hb_adresse (
id bigint not null auto_increment,
NUMERO_RUE integer,
NOM_RUE varchar(30) not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa10_hb_plat (
id bigint not null auto_increment,
nom varchar(50) not null unique,
vegetarien bit not null,
primary key (id)
) ENGINE=InnoDB;
create table jpa10_hb_restaurant (
id bigint not null auto_increment,
nom varchar(30) not null unique,
adresse_id bigint,
primary key (id)
) ENGINE=InnoDB;
create table jpa10_hb_restaurant_plat (
jpa10_hb_restaurant_id bigint not null,
plat_id bigint not null,
primary key (jpa10_hb_restaurant_id, plat_id)
) ENGINE=InnoDB;
alter table jpa10_hb_restaurant
add index FK3E8E4F5D5FE379D0 (adresse_id),
add constraint FK3E8E4F5D5FE379D0
foreign key (adresse_id)
references jpa10_hb_adresse (id);
alter table jpa10_hb_restaurant_plat
add index FK1D2D06D11F0F78A4 (plat_id),
add constraint FK1D2D06D11F0F78A4
foreign key (plat_id)
references jpa10_hb_plat (id);
alter table jpa10_hb_restaurant_plat
add index FK1D2D06D1AFAC3E44 (jpa10_hb_restaurant_id),
add constraint FK1D2D06D1AFAC3E44
foreign key (jpa10_hb_restaurant_id)
references jpa10_hb_restaurant (id);
- righe 21-26: la tabella [address]
- righe 28-33: la tabella [dish]
- righe 35-40: la tabella [restaurant]
- righe 42-46: la tabella di join [restaurant_dish]. Notare la chiave composta (riga 45)
- righe 48-52: la chiave esterna dalla tabella [restaurant] alla tabella [address]
- righe 54–58: la chiave esterna dalla tabella [restaurant_dish] alla tabella [dish]
- Righe 60–64: la chiave esterna dalla tabella [restaurant_dish] alla tabella [restaurant]
Questo DDL corrisponde allo schema già presentato:
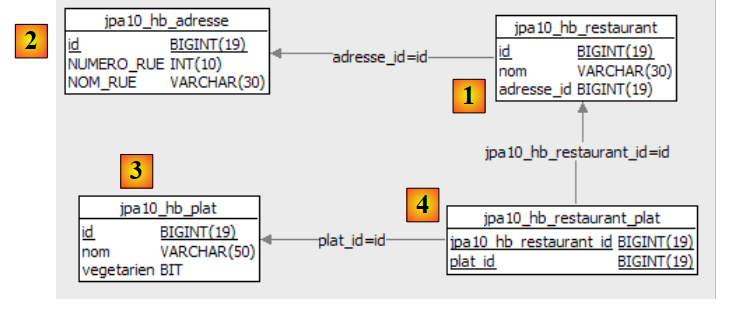 |
Nella vista SQL Explorer, il database appare come segue:
 |
- in [1]: le 4 tabelle del database
- in [2]: gli indirizzi
- in [3]: i piatti
- in [4]: i ristoranti. [address_id] fa riferimento agli indirizzi di [2].
- in [5]: la tabella di join [restaurant,dish]. [jpa10_hb_restaurant_id] fa riferimento ai ristoranti in [4] e [dish_id] fa riferimento ai piatti in [3]. Pertanto, [1,1] significa che il ristorante "Burger Barn" serve il piatto "CheeseBurger".
Per recuperare i dati sopra indicati, è stato eseguito il programma [QueryDB] del progetto Eclipse.
2.7.5. Query JPQL con una console Hibernate
Creiamo una console Hibernate collegata al precedente progetto Eclipse. Seguiremo la procedura già descritta due volte, in particolare nella sezione 2.1.12.
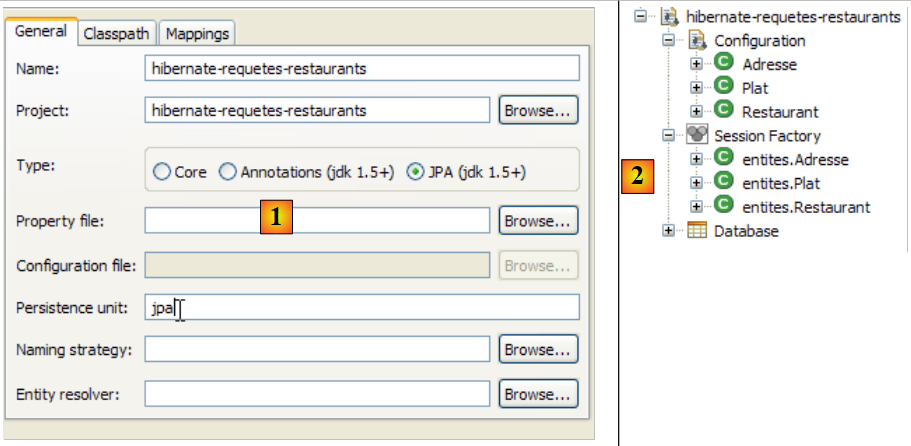 |
- In [1] e [2]: la configurazione della console Hibernate
 |
- in [3]: una query JPQL e in [4] il risultato.
- in [5]: l'istruzione SQL equivalente
Presenteremo ora una serie di query JPQL. Invitiamo il lettore a eseguirle e a scoprire l'istruzione SQL generata da Hibernate per eseguirle.
Recupera tutti i ristoranti con i relativi piatti:
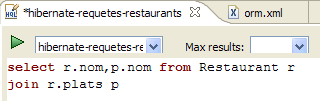 | 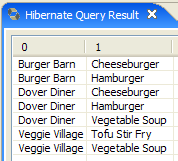 |
Ottieni i ristoranti che servono almeno un piatto vegetariano:
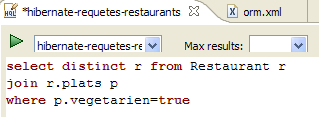 |  |
Trova i nomi dei ristoranti che servono solo piatti vegetariani:
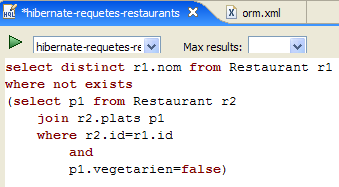 | 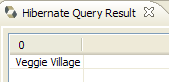 |
Scopri i ristoranti che servono hamburger:
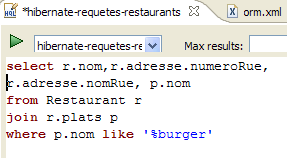 | 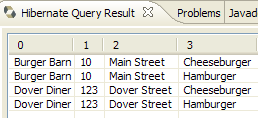 |
2.7.6. QueryDB
Ora esamineremo il programma [QueryDB] del progetto Eclipse, che:
- popolerà il database
- ed esegue una serie di query JPQL su di esso. Queste sono memorizzate nel file [META-INF/orm.xml] del progetto Eclipse:
 |
Il file [orm.xml] può essere utilizzato per configurare il livello JPA al posto delle annotazioni Java. Ciò offre flessibilità nella configurazione del livello JPA. Può essere modificato senza ricompilare il codice Java o il file [ . La configurazione JPA viene prima impostata utilizzando le annotazioni Java e poi utilizzando il file [orm.xml]. Pertanto, se si desidera modificare una configurazione definita da un'annotazione Java senza ricompilare, è sufficiente inserire tale configurazione in [orm.xml]. Avrà la precedenza.
Nel nostro esempio, il file [orm.xml] viene utilizzato per memorizzare i testi delle query JPQL. Il suo contenuto è il seguente:
<?xml version="1.0" encoding="UTF-8" ?>
<entity-mappings xmlns="http://java.sun.com/xml/ns/persistence/orm" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://java.sun.com/xml/ns/persistence/orm http://java.sun.com/xml/ns/persistence/orm_1_0.xsd" version="1.0">
<description>Restaurants</description>
<named-query name="supprimer le contenu de la table restaurant">
<query>delete from Restaurant</query>
</named-query>
<named-query name="supprimer le contenu de la table plat">
<query>delete from Plat</query>
</named-query>
<named-query name="obtenir tous les restaurants">
<query>select r from Restaurant r order by r.nom asc</query>
</named-query>
<named-query name="obtenir toutes les adresses">
<query>select a from Adresse a order by a.nomRue asc</query>
</named-query>
<named-query name="obtenir tous les plats">
<query>select p from Plat p order by p.nom asc</query>
</named-query>
<named-query name="obtenir tous les restaurants avec leurs plats">
<query>select r.nom,p.nom from Restaurant r join r.plats p</query>
</named-query>
<named-query name="obtenir les restaurants ayant au moins un plat vegetarien">
<query>select distinct r from Restaurant r join r.plats p where p.vegetarien=true</query>
</named-query>
<named-query name="obtenir les restaurants avec uniquement des plats vegetariens">
<query>
select distinct r1.nom from Restaurant r1 where not exists (select p1 from Restaurant r2 join r2.plats p1 where r2.id=r1.id and
p1.vegetarien=false)
</query>
</named-query>
<named-query name="obtenir les restaurants d'une certaine rue">
<query>select r from Restaurant r where r.adresse.nomRue=:nomRue</query>
</named-query>
<named-query name="obtenir les restaurants qui servent des burgers">
<query>select r.nom,r.adresse.numeroRue, r.adresse.nomRue, p.nom from Restaurant r join r.plats p where p.nom like '%burger'</query>
</named-query>
<named-query name="obtenir les plats du restaurant untel">
<query>select p.nom from Restaurant r join r.plats p where r.nom=:nomRestaurant</query>
</named-query>
</entity-mappings>
- La radice del file [orm.xml] è <entity-mappings> (riga 2).
- Righe 5–7: le query JPQL con nome sono racchiuse nei tag <named-query name="...">testo</named-query>.
- L'attributo name del tag è il nome della query.
- Il contenuto testuale del tag è il testo della query.
QueryDB eseguirà le query precedenti. Il codice è il seguente:
package tests;
...
public class QueryDB {
// Persistence context
private static EntityManagerFactory emf = Persistence.createEntityManagerFactory("jpa");
private static EntityManager em = emf.createEntityManager();
public static void main(String[] args) {
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// delete [restaurant] table items
em.createNamedQuery("supprimer le contenu de la table restaurant").executeUpdate();
// delete table items [flat]
em.createNamedQuery("supprimer le contenu de la table plat").executeUpdate();
// creation of Address objects
Adresse adr1 = new Adresse(10, "Main Street");
Adresse adr2 = new Adresse(20, "Main Street");
Adresse adr3 = new Adresse(123, "Dover Street");
// creation of Entree objects
Plat ent1 = new Plat("Hamburger", false);
Plat ent2 = new Plat("Cheeseburger", false);
Plat ent3 = new Plat("Tofu Stir Fry", true);
Plat ent4 = new Plat("Vegetable Soup", true);
// creation of Restaurant objects
Restaurant restaurant1 = new Restaurant();
restaurant1.setNom("Burger Barn");
restaurant1.setAdresse(adr1);
restaurant1.getPlats().add(ent1);
restaurant1.getPlats().add(ent2);
Restaurant restaurant2 = new Restaurant();
restaurant2.setNom("Veggie Village");
restaurant2.setAdresse(adr2);
restaurant2.getPlats().add(ent3);
restaurant2.getPlats().add(ent4);
Restaurant restaurant3 = new Restaurant();
restaurant3.setNom("Dover Diner");
restaurant3.setAdresse(adr3);
restaurant3.getPlats().add(ent1);
restaurant3.getPlats().add(ent2);
restaurant3.getPlats().add(ent4);
// persistence of Restaurant objects (and other objects through cascading)
em.persist(restaurant1);
em.persist(restaurant2);
em.persist(restaurant3);
// end transaction
tx.commit();
// dump base
dumpDataBase();
// end EntityManager
em.close();
// end EntityManagerFactory
emf.close();
}
// database content display
@SuppressWarnings("unchecked")
private static void dumpDataBase() {
// test2
log("données de la base");
// start of transaction
EntityTransaction tx = em.getTransaction();
tx.begin();
// restaurant displays
log("[restaurants]");
for (Object restaurant : em.createNamedQuery("obtenir tous les restaurants").getResultList()) {
System.out.println(restaurant);
}
// address display
log("[adresses]");
for (Object adresse : em.createNamedQuery("obtenir toutes les adresses").getResultList()) {
System.out.println(adresse);
}
// flat displays
log("[plats]");
for (Object plat : em.createNamedQuery("obtenir tous les plats").getResultList()) {
System.out.println(plat);
}
// displays links restaurants <--> dishes
log("[restaurants/plats]");
Iterator record = em.createNamedQuery("obtenir tous les restaurants avec leurs plats").getResultList().iterator();
while (record.hasNext()) {
Object[] currentRecord = (Object[]) record.next();
System.out.format("[%s,%s]%n", currentRecord[0], currentRecord[1]);
}
log("[Liste des restaurants avec au moins un plat végétarien]");
for (Object r : em.createNamedQuery("obtenir les restaurants ayant au moins un plat vegetarien").getResultList()) {
System.out.println(r);
}
// query
log("[Liste des restaurants avec seulement des plats végétariens]");
for (Object r : em.createNamedQuery("obtenir les restaurants avec uniquement des plats vegetariens").getResultList()) {
System.out.println(r);
}
// query
log("[Liste des restaurants dans Dover Street]");
for (Object r : em.createNamedQuery("obtenir les restaurants d'une certaine rue").setParameter("nomRue", "Dover Street").getResultList()) {
System.out.println(r);
}
// query
log("[Liste des restaurants ayant un plat de type burger]");
record = em.createNamedQuery("obtenir les restaurants qui servent des burgers").getResultList().iterator();
while (record.hasNext()) {
Object[] currentRecord = (Object[]) record.next();
System.out.format("[%s,%d,%s,%s]%n", currentRecord[0], currentRecord[1], currentRecord[2], currentRecord[3]);
}
// query
log("[Plats de Veggie Village]");
for (Object r : em.createNamedQuery("obtenir les plats du restaurant untel").setParameter("nomRestaurant", "Veggie Village").getResultList()) {
System.out.println(r);
}
// end transaction
tx.commit();
}
// logs
private static void log(String message) {
System.out.println(" -----------" + message);
}
}
Il risultato dell'esecuzione di [QueryDB] è il seguente:
Lasciamo al lettore il compito di stabilire la corrispondenza tra il codice e i risultati. A tal fine, consigliamo di eseguire le query JPQL nella console di Hibernate ed esaminare il codice SQL corrispondente.
2.7.7. Il progetto Eclipse / Toplink
I lettori interessati troveranno il progetto precedente implementato con Toplink negli esempi disponibili per il download con questo tutorial:
 |
Il progetto Eclipse con Toplink è una copia del progetto Eclipse con Hibernate:
 |
Il file <persistence.xml> [2] dichiara le entità gestite:
<!-- provider -->
<provider>oracle.toplink.essentials.PersistenceProvider</provider>
<!-- classes persistantes -->
<class>entites.Restaurant</class>
<class>entites.Adresse</class>
<class>entites.Plat</class>
...
- righe 4-6: entità gestite
Le query JPQL memorizzate in [orm.xml] vengono eseguite correttamente da TopLink. Per garantire ciò, nel progetto precedente abbiamo fatto attenzione a non utilizzare query HQL (Hibernate Query Language), che sono di fatto un superset di JPQL e la cui sintassi non è pienamente supportata da JPQL.
2.8. Conclusione
Questo conclude la nostra panoramica sulle entità JPA. È stato un processo lungo, ma alcuni argomenti importanti (per gli sviluppatori esperti) non sono stati trattati. Ancora una volta, consigliamo di leggere un libro di riferimento come quello utilizzato per questo tutorial:
[ref1]: Java Persistence with Hibernate, di Christian Bauer e Gavin King, pubblicato da Manning.