5. Versione 1: Architettura Spring / JPA
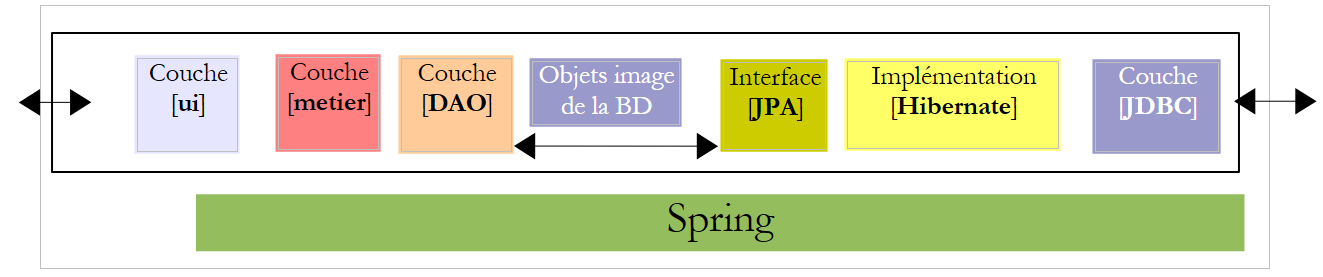
Si propone di scrivere un'applicazione da console e un'applicazione grafica che consentano di redigere la busta paga delle assistenti materne impiegate presso la "Maison de la petite enfance" di un comune. Tale applicazione avrà la seguente architettura:
 |
5.1. BD Il database
I dati statici necessari per la creazione della busta paga saranno inseriti in un database che d'ora in poi chiameremo dbpam. Questo database potrebbe contenere le seguenti tabelle:
Struttura:
chiave primaria | |
numero di versione – aumenta ad ogni modifica della riga | |
numero di previdenza sociale del dipendente – univoco | |
nome del dipendente | |
il suo nome | |
il suo indirizzo | |
la sua città | |
il suo codice postale | |
chiave esterna sul campo [ID] della tabella [INDEMNITES] |
Il contenuto potrebbe essere il seguente:

Struttura:
chiave primaria | |
numero di versione – aumenta ad ogni modifica della riga | |
percentuale: contributo sociale generalizzato + contributo al rimborso del debito sociale | |
percentuale: contributo sociale generalizzato deducibile | |
percentuale: previdenza sociale, vedovanza, vecchiaia | |
percentuale: pensione integrativa + assicurazione contro la disoccupazione |
Il contenuto potrebbe essere il seguente:
![]()
Le aliquote dei contributi sociali sono indipendenti dal dipendente. La tabella precedente contiene una sola riga.
chiave primaria | ||
numero di versione – aumenta ad ogni modifica della riga | ||
indice di elaborazione - univoco | ||
prezzo netto in euro per un'ora di guardia | ||
indennità di vitto e alloggio in euro per giorno di servizio | ||
indennità pasto in euro per giorno di assistenza | ||
indennità per ferie retribuite. Si tratta di una percentuale da applicare allo stipendio base. | ||
Il contenuto potrebbe essere il seguente:

Si noti che le indennità possono variare da un'assistente all'infanzia all'altra. Esse sono infatti associate a una specifica assistente all'infanzia tramite il suo indice di retribuzione. Pertanto, la signora Marie Jouveinal, che ha un indice retributivo pari a 2 (tabella EMPLOYES), ha una retribuzione oraria di 2,1 euro (tabella INDEMNITES).
5.2. Modalità di calcolo della retribuzione di un’assistente materna
Presentiamo ora il metodo di calcolo della retribuzione mensile di un'assistente materna. Non si tratta di quello effettivamente utilizzato nella realtà. Prendiamo ad esempio la retribuzione della signora Marie Jouveinal, che ha lavorato 150 ore in 20 giorni durante il mese di riferimento.
Vengono presi in considerazione i seguenti elementi: | | |
Lo stipendio base dell'assistente all'infanzia è dato dalla seguente formula: | ||
Una certa somma di contributi sociali devono essere trattenute da questo stipendio di base: | | |
Totale dei contributi sociali: | ||
Inoltre, l'assistente all'infanzia ha diritto, per ogni giorno lavorato, a un'indennità di mantenimento e a un'indennità di pasto. A tal titolo riceve le seguenti indennità: | | |
In definitiva, la retribuzione netta da corrispondere all’assistente materna è la seguente: |
5.3. Funzionamento dell'applicazione console
Ecco un esempio di esecuzione dell'applicazione da console in una finestra DOS:
Scriveremo un programma che riceverà le seguenti informazioni:
- numero di previdenza sociale della tata (254104940426058 nell'esempio - riga 1)
- numero totale di ore lavorate (150 nell'esempio - riga 1)
- numero totale di giorni lavorati (20 nell'esempio - riga 1)
Si nota che:
- righe 9-14: visualizzano le informazioni relative al dipendente di cui è stato fornito il numero di previdenza sociale
- righe 17-20: riportano le aliquote dei diversi contributi
- righe 23-26: riportano le indennità associate all’indice di retribuzione del dipendente (in questo caso l’indice 2)
- righe 29-33: visualizzano le componenti dello stipendio da corrispondere
L'applicazione segnala eventuali errori:
Chiamata senza parametri:
dos>java -jar pam-spring-ui-metier-dao-jpa-eclipselink.jar
Syntaxe : pg num_securite_sociale nb_heures_travaillées nb_jours_travaillés
Chiamata con dati errati:
dos>java -jar pam-spring-ui-metier-dao-jpa-eclipselink.jar 254104940426058 150x 20x
Le nombre d'heures travaillées [150x] est erroné
Le nombre de jours travaillés [20x] est erroné
Richiesta con numero di previdenza sociale errato:
dos>java -jar pam-spring-ui-metier-dao-jpa-eclipselink.jar xx 150 20
L'erreur suivante s'est produite : L'employé de n°[xx] est introuvable
5.4. Funzionamento dell'applicazione grafica
L'applicazione grafica consente il calcolo degli stipendi delle assistenti materne tramite un modulo Swing:
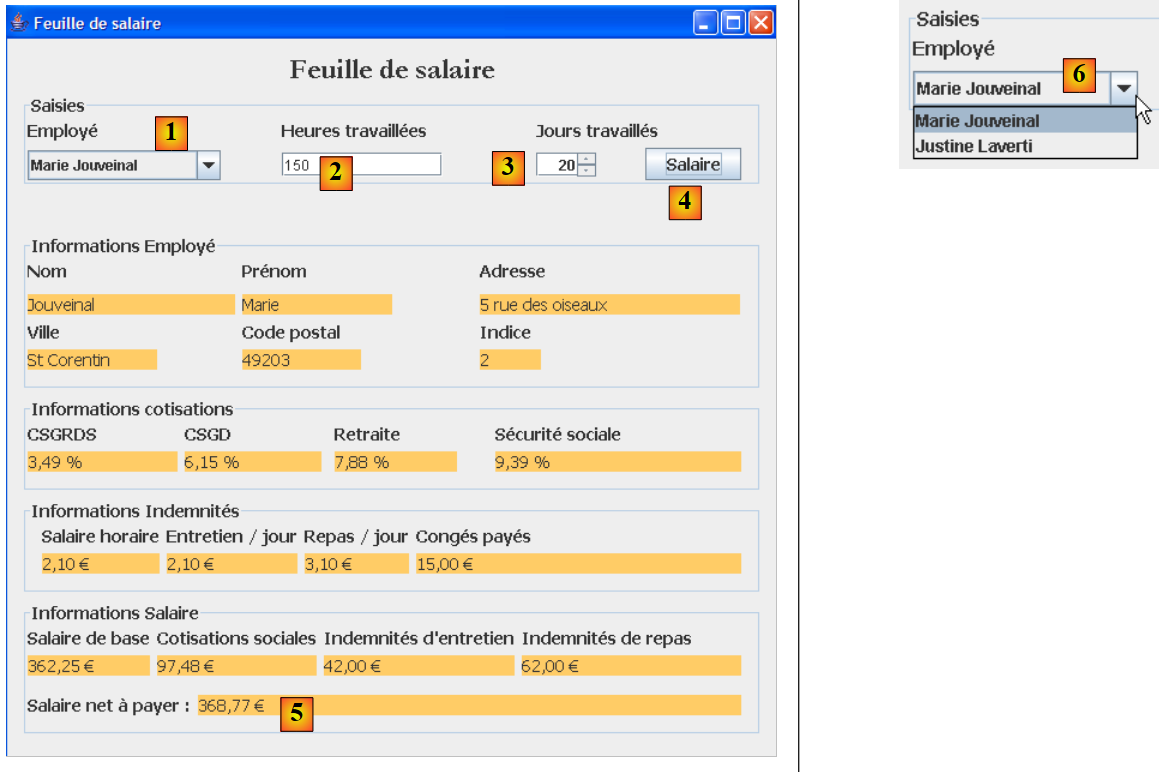 |
- le informazioni che prima venivano passate come parametri al programma da console, ora vengono inserite tramite i campi di immissione [1, 2, 3].
- Il pulsante [4] avvia il calcolo dello stipendio
- il modulo visualizza le diverse voci dello stipendio fino allo stipendio netto da corrispondere [5]
L'elenco a discesa [1, 6] non mostra i numeri SS dei dipendenti, ma i loro nomi e cognomi. Si ipotizza qui che non vi siano due dipendenti con lo stesso nome e cognome.
5.5. Creazione del database
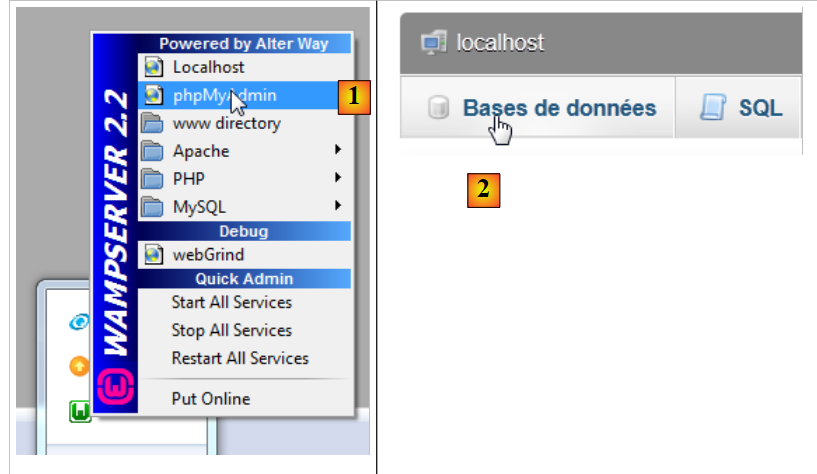
Avviamo WampServer e utilizziamo lo strumento PhpMyAdmin [1]:
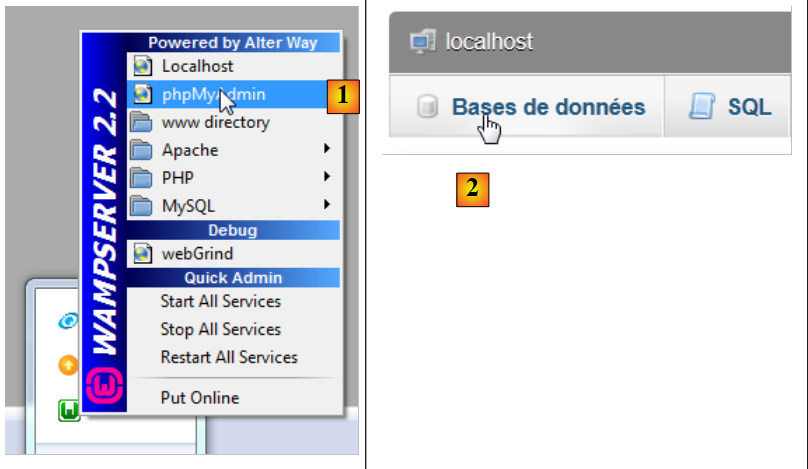 |
- in [2], si seleziona l’opzione [Bases de données],
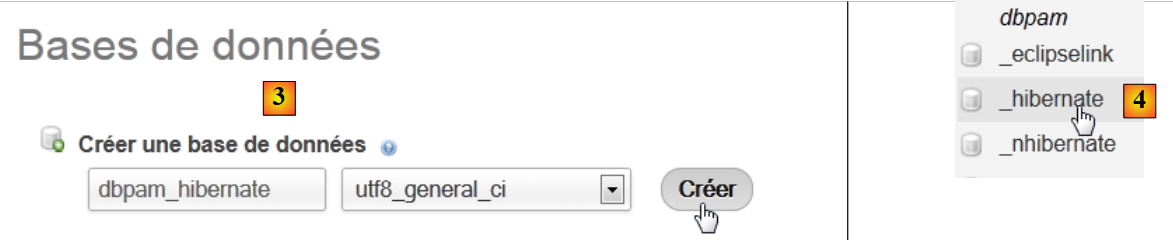 |
- in [3], si crea un database [dbpam_hibernate],
- in [4], il database creato. Lo si seleziona,
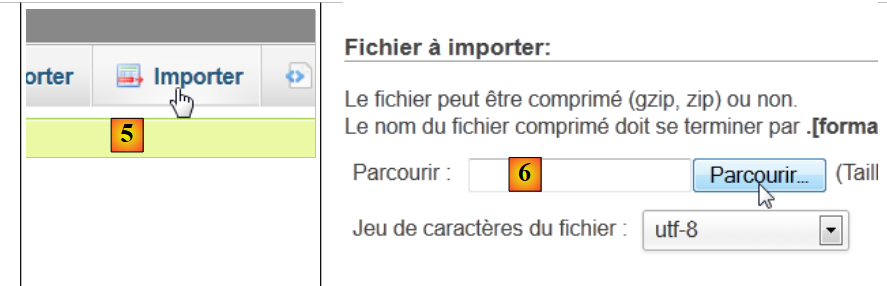 |
- in [5], si desidera importare uno script SQL,
- in [6], si utilizza il pulsante [Parcourir] per selezionare il file,
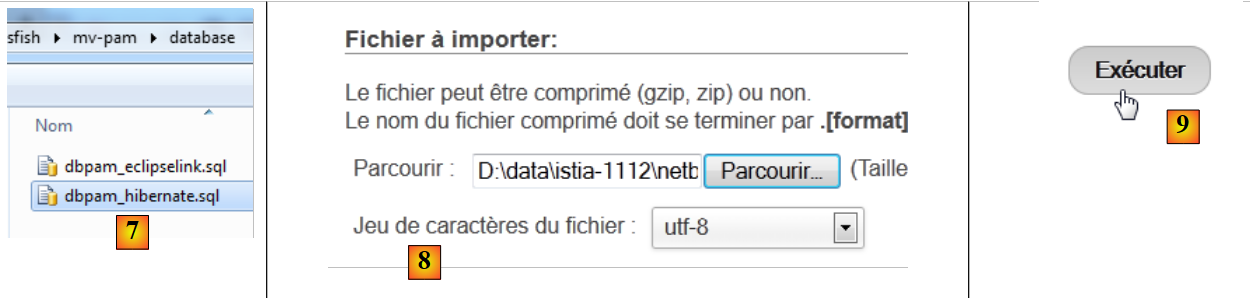 |
- in [7,8], si seleziona lo script SQL,
- in [9], lo si esegue,
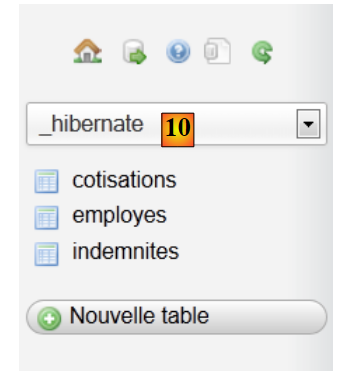 |
- in [10], le tabelle sono state create. Il loro contenuto è il seguente:
tabella EMPLOYES

tabella
tabella INDEMNITES

tabella
tabella COTISATIONS
![]()
5.6. Implementazione JPA
5.6.1. Layer JPA / Hibernate
Configureremo il livello JPA nel seguente ambiente:
 |
Un programma da console opererà con il database. A tal fine, è necessario:
- disporre di un database,
- disporre del driver JDBC per SGBD, in questo caso MySQL,
- implementare il livello JPA con Hibernate,
- scrivere il programma da console.
Creiamo il progetto Maven [mv-pam-jpa-hibernate] [1]:
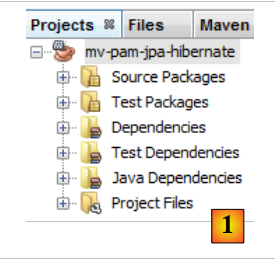 |
Nell'architettura della nostra applicazione sono necessari i seguenti elementi:
- il database,
- il driver JDBC di SGBD MySQL,
- il livello JPA / Hibernate (entità e configurazione),
- il programma di test da console.
5.6.1.1. Il database
Per prima cosa creiamo il database vuoto. Avviamo WampServer e utilizziamo lo strumento PhpMyAdmin [1]:
 |
- in [2], selezioniamo l’opzione [Bases de données],
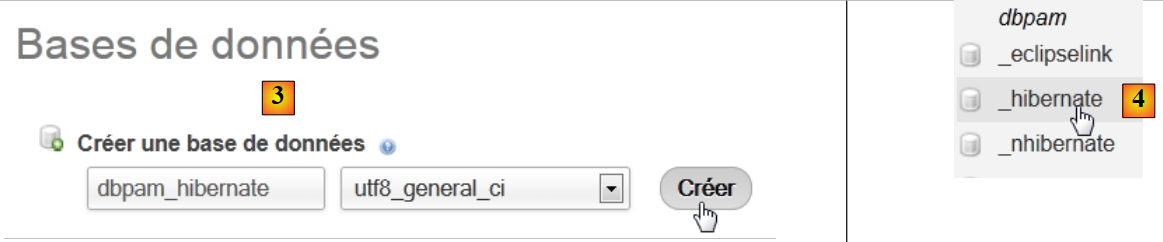 |
- in [3], si crea un database [dbpam_hibernate],
- in [4], il database creato.
5.6.1.2. Configurazione del livello JPA
Il collegamento tra il livello JDBC e il database avviene nel file [persistence.xml], che configura il livello JPA. Questo file può essere creato con NetBeans:
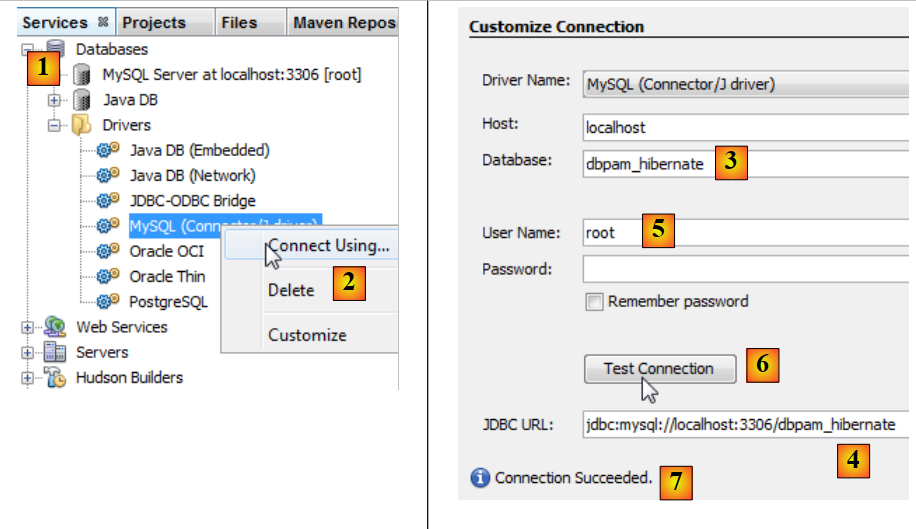 |
- nella scheda [services] [1], ci si connette al database con il driver JDBC di MySQL [2],
- in [3], il nome del database a cui ci si vuole connettere.
- in [4], il nome del database,
- in [5], ci si connette come root senza password,
- in [6], è possibile testare la connessione,
- in [7], la connessione è riuscita.
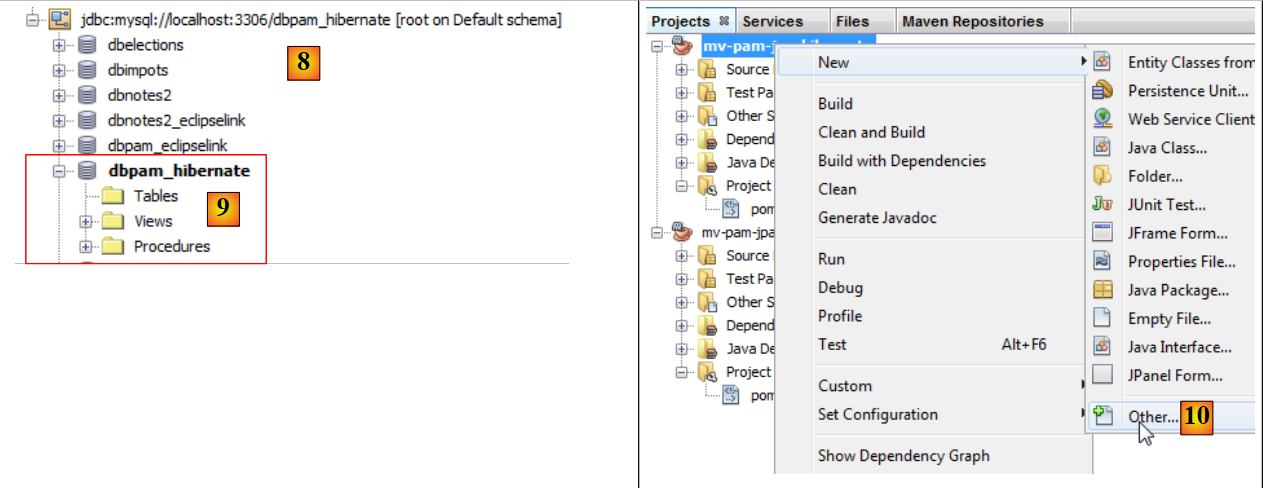 |
- la connessione appare in [8] e in [9],
- in [10], si aggiunge un nuovo elemento al progetto,
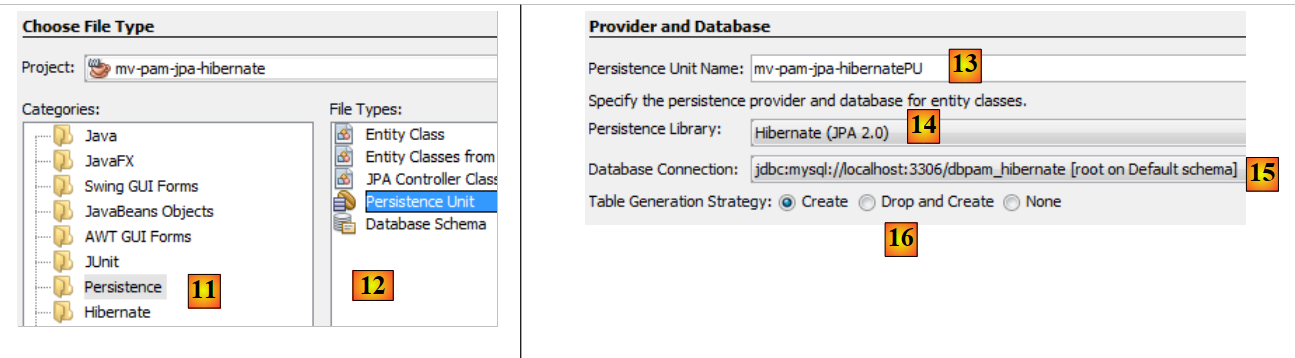 |
- in [11] si seleziona la categoria [Persistence] e in [12] l’elemento [Persistence Unit],
- in [13], si assegna un nome a questa unità di persistenza,
- in [14], si seleziona un'implementazione Hibernate,
- in [15], si indica la connessione appena creata al database MySQL,
- in [16], si specifica che all'istanziazione del livello JPA, questo debba creare (create) le tabelle corrispondenti alle entità JPA del progetto.
Al termine della procedura guidata viene generato il file [persistence.xml]:
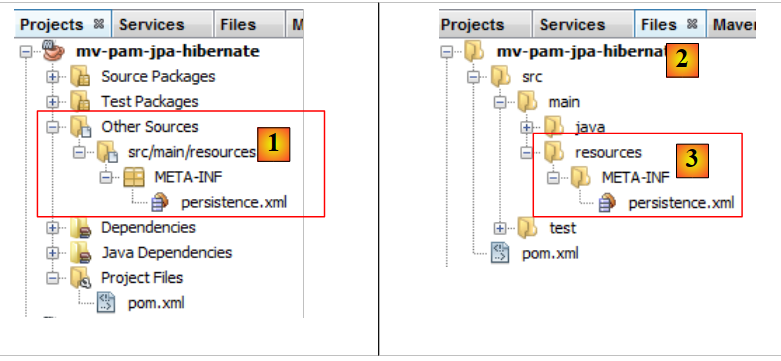 |
- il file compare in un nuovo ramo del progetto, nella cartella [META-INF] [1],
- che corrisponde alla cartella [src/main/resources] del progetto [2,3].
Il suo contenuto è il seguente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="mv-pam-jpa-hibernatePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbpam_hibernate"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="hibernate.cache.provider_class" value="org.hibernate.cache.NoCacheProvider"/>
<property name="hibernate.hbm2ddl.auto" value="create-drop"/>
</properties>
</persistence-unit>
</persistence>
- riga 3: il nome dell’unità di persistenza e il tipo di transazioni. RESOURCE_LOCAL indica che il progetto gestisce autonomamente le transazioni. In questo caso sarà il programma da console a doversene occupare,
- riga 4: l’implementazione JPA utilizzata è Hibernate,
- righe 6-9: le caratteristiche JDBC della connessione al database,
- riga 11: richiede la creazione delle tabelle corrispondenti alle entità JPA. In realtà, NetBeans genera qui una configurazione errata. La configurazione deve essere la seguente:
<property name="hibernate.hbm2ddl.auto" value="create"/>
Con l’opzione create, Hibernate, al momento dell’istanziazione del livello JPA, elimina e poi crea le tabelle corrispondenti alle entità JPA. L’opzione create-drop fa la stessa cosa, ma al termine del ciclo di vita del livello JPA elimina tutte le tabelle. Esiste un’altra opzione:
<property name="hibernate.hbm2ddl.auto" value="update"/>
Questa opzione crea le tabelle se non esistono, ma non le elimina se sono già presenti.
Aggiungeremo altre tre proprietà alla configurazione di Hibernate:
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
Queste proprietà richiedono a Hibernate di visualizzare i comandi SQL che invia al database. Il file completo è quindi il seguente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="mv-pam-jpa-hibernatePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<class>jpa.Cotisation</class>
<class>jpa.Employe</class>
<class>jpa.Indemnite</class>
<properties>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbpam_hibernate"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="hibernate.cache.provider_class" value="org.hibernate.cache.NoCacheProvider"/>
<property name="hibernate.hbm2ddl.auto" value="create"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
</properties>
</persistence-unit>
</persistence>
5.6.1.3. Le dipendenze
Torniamo all’architettura del progetto:
 |
Abbiamo configurato il livello JPA tramite il file [persistence.xml]. L’implementazione scelta è stata Hibernate. Ciò ha comportato alcune dipendenze nel progetto:
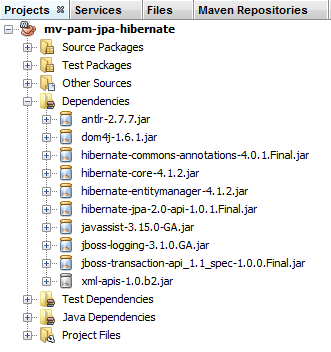 |
Queste dipendenze sono dovute all’inclusione di Hibernate nel progetto. Dobbiamo aggiungere un’altra dipendenza, quella del driver JDBC di MySQL che implementa il livello JDBC dell’architettura. Modifichiamo il file [pom.xml] nel modo seguente:
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>4.1.2</version>
</dependency>
...
<dependency>
<groupId>org.hibernate.common</groupId>
<artifactId>hibernate-commons-annotations</artifactId>
<version>4.0.1.Final</version>
</dependency>
</dependencies>
Le righe 8-12 aggiungono la dipendenza del driver JDBC da MySQL.
5.6.1.4. Le entità JPA
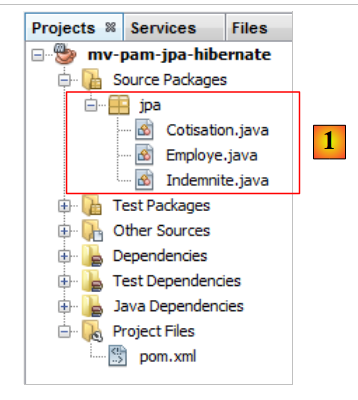 |
Domanda: Seguendo la procedura illustrata nell'esempio del paragrafo 4.4, generare le entità [Cotisation, Indemnite, Employe].
Note:
- le entità faranno parte di un pacchetto denominato [jpa],
- ogni entità avrà un numero di versione,
- se due entità sono collegate da una relazione, verrà creata solo la relazione principale @ManyToOne. La relazione inversa @OneToMany non verrà creata.
5.6.1.5. Il codice della classe principale
Includiamo nel progetto le entità JPA sviluppate in precedenza e [1]:
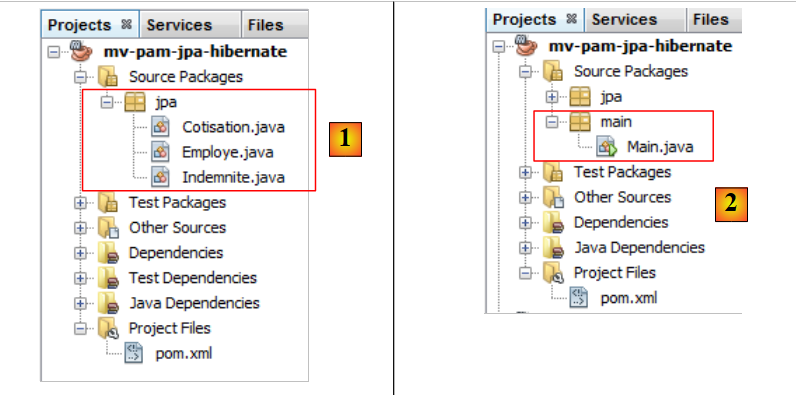 |
poi aggiungiamo [2], la seguente classe [main.Main]:
package main;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public class Main {
public static void main(String[] args) {
// È sufficiente creare l'Entity Manager per costruire il livello JPA
EntityManagerFactory emf = Persistence.createEntityManagerFactory("mv-pam-jpa-hibernatePU");
EntityManager em=emf.createEntityManager();
// liberazione delle risorse
em.close();
emf.close();
}
}
- riga 10: si crea l'unità di persistenza EntityManagerFactory denominata [mv-pam-jpa-hibernatePU]. Questo nome deriva dal file [persistence.xml]:
<persistence-unit name="mv-pam-jpa-hibernatePU" transaction-type="RESOURCE_LOCAL">
...
</persistence-unit>
- riga 12: si crea il file EntityManager. Questa operazione genera il livello JPA. Il file [persistence.xml] verrà elaborato e quindi verranno create le tabelle del database,
- righe 14-15: si liberano le risorse.
5.6.1.6. Tests
Torniamo all'architettura del nostro progetto:
 |
Tutti i livelli sono stati implementati. Eseguiamo il progetto [2].
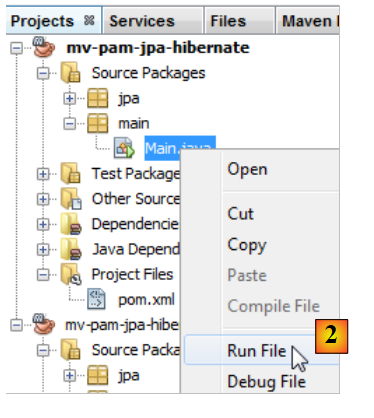 |
I risultati visualizzati in console sono i seguenti:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 | |
Nella console sono presenti solo i log di Hibernate, poiché il programma eseguito non fa altro che istanziare il livello JPA. Si notino i seguenti punti:
- riga 43: Hibernate tenta di eliminare la chiave esterna dalla tabella [EMPLOYES],
- righe 51-55: eliminazione delle tre tabelle,
- riga 57: creazione della tabella [COTISATIONS],
- riga 67: creazione della tabella [EMPLOYES],
- riga 80: creazione della tabella [INDEMNITES],
- riga 91: creazione della chiave esterna della tabella [EMPLOYES].
In NetBeans è possibile visualizzare le tabelle nella connessione creata in precedenza:
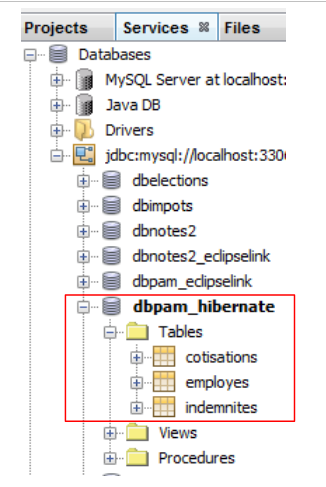 |
Le tabelle create dipendono sia dall’implementazione del livello JPA utilizzato sia da quella di SGBD. Pertanto, un’implementazione JPA / EclipseLink con lo stesso database può generare tabelle diverse. È proprio ciò che vedremo ora.
5.6.2. Layer JPA / EclipseLink
Creeremo un nuovo progetto Maven nel seguente ambiente:
 |
Seguiremo la procedura descritta nel paragrafo precedente:
- creare un database MySQL [dbpam_eclipselink]. Per generarlo useremo lo script [dbpam_eclipselink.sql],
- creare il file [persistence.xml] del progetto. Prendere l’implementazione JPA 2.0 EclipseLink,
- aggiungere nelle dipendenze generate la dipendenza del driver JDBC da MySQL,
- aggiungere le entità JPA e il programma da console,
- eseguire i test.
Il file [persistence.xml] sarà il seguente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="pam-jpa-eclipselinkPU" transaction-type="RESOURCE_LOCAL">
<provider>org.eclipse.persistence.jpa.PersistenceProvider</provider>
<class>jpa.Cotisation</class>
<class>jpa.Employe</class>
<class>jpa.Indemnite</class>
<properties>
<property name="eclipselink.target-database" value="MySQL"/>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbpam_eclipselink"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="eclipselink.logging.level" value="FINE"/>
<property name="eclipselink.ddl-generation" value="drop-and-create-tables"/>
</properties>
</persistence-unit>
</persistence>
- le proprietà da 9 a 13 sono state generate dall'assistente di NetBeans,
- riga 14: questa proprietà ci permette di impostare il livello di log di EclipseLink. Il livello di FINE ci permette di conoscere i comandi SQL che EclipseLink invierà al database,
- riga 15: all’istanziazione del livello JPA / EclipseLink, le tabelle delle entità JPA verranno eliminate e poi ricreate.
I risultati ottenuti in console sono i seguenti:
- righe 26-30: connessione al database MySQL,
- righe 31-34: conferma che la connessione è andata a buon fine,
- riga 36: eliminazione della chiave esterna dalla tabella [EMPLOYES],
- riga 37: eliminazione della tabella [COTISATIONS],
- riga 38: creazione della tabella [COTISATIONS]. È interessante notare che la chiave primaria ID non presenta l’attributo MySQL auto_increment. Ciò significa che non è MySQL a generare i valori della chiave primaria,
- riga 39: eliminazione della tabella [EMPLOYES],
- riga 40: creazione della tabella [EMPLOYES]. La sua chiave primaria ID non ha l'attributo MySQL auto_increment,
- riga 41: eliminazione della tabella [INDEMNITES],
- riga 42: creazione della tabella [INDEMNITES]. La sua chiave primaria ID non ha l'attributo MySQL auto_increment,
- riga 43: creazione della chiave esterna dalla tabella [EMPLOYES] alla tabella [INDEMNITES],
- riga 44: creazione di una tabella [SEQUENCE]. Verrà utilizzata per generare le chiavi primarie delle tre tabelle precedenti,
- riga 47: si verifica un'eccezione poiché questa tabella esisteva già,
- righe 51-53: inizializzazione della tabella [SEQUENCE].
L'esistenza delle tabelle generate può essere verificata in NetBeans [1]:
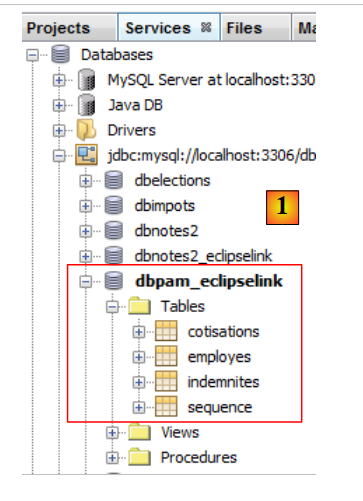 |
Pertanto, a partire dalle stesse entità JPA, le implementazioni JPA, Hibernate e EclipseLink non generano le stesse tabelle. Nel prosieguo del documento, quando l’implementazione JPA utilizzata è:
- Hibernate, si utilizzerà il database [dbpam_hibernate],
- EclipseLink, verrà utilizzato il database [dbpam_eclipselink].
5.6.3. Compito da svolgere
Seguendo la stessa procedura descritta in precedenza,
- creare e testare un progetto [mv-pam-jpa-hibernate-oracle] utilizzando un'implementazione JPA di Hibernate e un'implementazione SGBD di Oracle,
- creare e testare un progetto [mv-pam-jpa-hibernate-mssql] utilizzando un'implementazione JPA con Hibernate e un server SGBD SQL,
- creare e testare un progetto [mv-pam-jpa-eclipselink-oracle] utilizzando un'implementazione JPA EclipseLink e un server Oracle SGBD,
- creare e testare un progetto [mv-pam-jpa-eclipselink-mssql] utilizzando un'implementazione JPA EclipseLink e un server SGBD SQL,
5.6.4. Lazy o Eager?
Torniamo a una possibile definizione dell’entità [Employe]:
package jpa;
...
@Entity
@Table(name="EMPLOYES")
public class Employe implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Version
@Column(name="VERSION",nullable=false)
private int version;
@Column(name="SS", nullable=false, unique=true, length=15)
private String SS;
@Column(name="NOM", nullable=false, length=30)
private String nom;
@Column(name="PRENOM", nullable=false, length=20)
private String prenom;
@Column(name="ADRESSE", nullable=false, length=50)
private String adresse;
@Column(name="VILLE", nullable=false, length=30)
private String ville;
@Column(name="CP", nullable=false, length=5)
private String codePostal;
@ManyToOne(fetch= FetchType.LAZY)
@JoinColumn(name="INDEMNITE_ID",nullable=false)
private Indemnite indemnite;
...
}
Le righe 27-29 definiscono la chiave esterna dalla tabella [EMPLOYES] alla tabella [INDEMNITES]. L'attributo fetch della riga 27 definisce la strategia di ricerca del campo indemnite della riga 29. Esistono due modalità:
- FetchType.LAZY: quando si cerca un dipendente, l’indennità a lui corrispondente non viene recuperata. Verrà recuperata quando il campo [Employe].indemnite verrà richiamato per la prima volta.
- FetchType.EAGER: quando si cerca un dipendente, viene visualizzata l’indennità a lui corrispondente. È la modalità predefinita quando non viene specificata alcuna modalità.
Per comprendere l’utilità dell’opzione FetchType.LAZY, si può prendere il seguente esempio. In una pagina web viene presentato un elenco di dipendenti senza le indennità tramite un link [Details]. Cliccando su questo link vengono quindi visualizzate le indennità del dipendente selezionato. Si nota che:
- per visualizzare la prima pagina non sono necessari i dipendenti con le relative indennità. La modalità FetchType.LAZY è quindi adeguata;
- per visualizzare la seconda pagina con i dettagli, è necessario effettuare una query aggiuntiva al database per ottenere le indennità del dipendente selezionato.
La modalità FetchType.LAZY evita di recuperare troppi dati di cui l’applicazione non ha bisogno nell’immediato. Vediamo un esempio.
Il progetto [mv-pam-jpa-hibernate] viene duplicato:
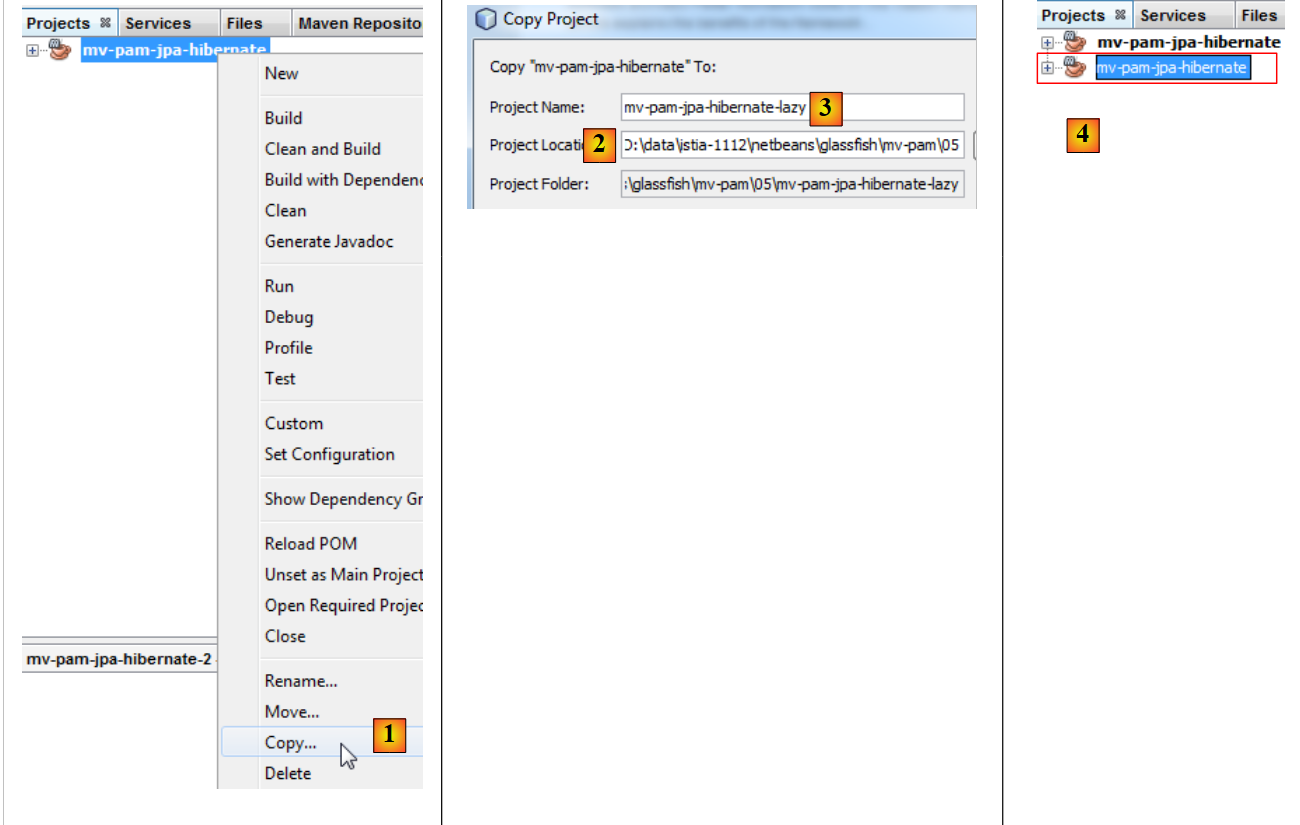 |
- in [1] si copia il progetto,
- in [2] si indica la cartella di destinazione della copia e in [3] il suo nome,
- in [4], il nuovo progetto ha lo stesso nome di quello precedente. Modifichiamo questo aspetto:
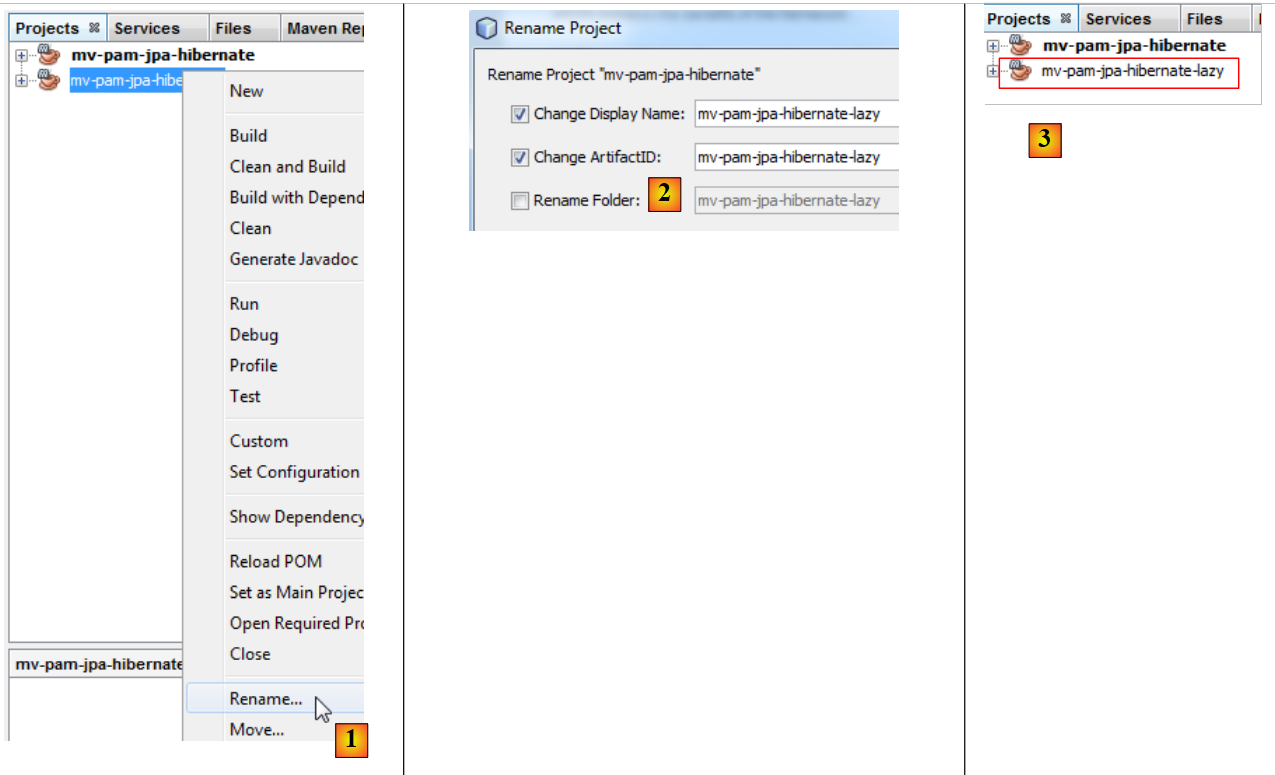 |
- in [1], rinominiamo il progetto,
- in [2], rinominiamo il progetto e il suo artifactId,
- in [3], il nuovo progetto.
Modifichiamo il programma [Main.java] nel modo seguente:
package main;
import java.util.List;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
import jpa.Employe;
public class Main {
// la richiesta JPQL riportata di seguito restituisce un dipendente
// la chiave esterna [Employe].indemnite si trova in FetchType.LAZY
public static void main(String[] args) {
// è sufficiente creare l’Entity Manager per costruire il livello JPA
EntityManagerFactory emf = Persistence.createEntityManagerFactory("pam-jpa-hibernatePU");
// primo tentativo
EntityManager em = emf.createEntityManager();
Employe employe = (Employe) em.createQuery("select e from Employe e where e.nom=:nom").setParameter("nom", "Jouveinal").getSingleResult();
em.close();
// viene visualizzato il dipendente
try {
System.out.println(employe);
} catch (Exception ex) {
System.out.println(ex);
}
// secondo tentativo
em = emf.createEntityManager();
employe = (Employe) em.createQuery("select e from Employe e left join fetch e.indemnite where e.nom=:nom").setParameter("nom", "Jouveinal").getSingleResult();
// liberare le risorse
em.close();
// visualizzazione del dipendente
try {
System.out.println(employe);
} catch (Exception ex) {
System.out.println(ex);
}
// liberazione delle risorse
emf.close();
}
}
- riga 15: si crea il file EntityManagerFactory dal livello JPA,
- riga 17: si ottiene il programma EntityManager che ci permette di interagire con il livello JPA,
- riga 18: si richiede il dipendente denominato Jouveinal,
- riga 19: si chiude EntityManager. Ciò comporta la chiusura del contesto di persistenza.
- riga 22: si visualizza il dipendente ricevuto.
La classe [Employe] è la seguente:
package jpa;
...
@Entity
@Table(name="EMPLOYES")
public class Employe implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@Version
@Column(name="VERSION",nullable=false)
private int version;
@Column(name="SS", nullable=false, unique=true, length=15)
private String SS;
@Column(name="NOM", nullable=false, length=30)
private String nom;
@Column(name="PRENOM", nullable=false, length=20)
private String prenom;
@Column(name="ADRESSE", nullable=false, length=50)
private String adresse;
@Column(name="VILLE", nullable=false, length=30)
private String ville;
@Column(name="CP", nullable=false, length=5)
private String codePostal;
@ManyToOne(fetch= FetchType.LAZY)
@JoinColumn(name="INDEMNITE_ID",nullable=false)
private Indemnite indemnite;
/**
* Returns a string representation of the object. This implementation constructs
* that representation based on the id fields.
* @return a string representation of the object.
*/
@Override
public String toString() {
return "jpa.Employe[id=" + getId()
+ ",version="+getVersion()
+",SS="+getSS()
+ ",nom="+getNom()
+ ",prenom="+getPrenom()
+ ",adresse="+getAdresse()
+",ville="+getVille()
+",code postal="+getCodePostal()
+",indice="+getIndemnite().getIndice()
+"]";
}
...
}
- riga 27: il campo indemnite viene riportato alla modalità LAZY,
- riga 47: utilizza il campo indemnite. Se il metodo toString viene chiamato mentre il campo indemnite non è stato ancora ripristinato, verrà ripristinato in quel momento. A meno che il contesto di persistenza non sia stato chiuso, come nell’esempio.
Torniamo al codice di [Main]:
- righe 21-25: dovrebbe verificarsi un'eccezione. Infatti, verrà chiamato il metodo toString, che utilizzerà il campo indemnite. Quest'ultimo verrà cercato. Poiché il contesto di persistenza è stato chiuso, l’entità [Employe] recuperata non esiste più, da qui l’eccezione.
- riga 27: si crea un nuovo EntityManager,
- riga 28: si richiede il dipendente Jouveinal specificando esplicitamente nella query JPQL l’indennità corrispondente. Questa richiesta esplicita è necessaria perché la modalità di ricerca di tale indennità è LAZY,
- riga 30: si chiude la EntityManager,
- righe 32-36: si visualizza nuovamente il dipendente. Non dovrebbero verificarsi eccezioni.
Per eseguire il progetto, è necessario disporre di un database compilato. Lo creeremo seguendo la procedura descritta nel paragrafo 5.5. Inoltre, il file [persistence.xml] deve essere modificato:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="mv-pam-jpa-hibernatePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<class>jpa.Cotisation</class>
<class>jpa.Employe</class>
<class>jpa.Indemnite</class>
<properties>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbpam_hibernate"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="hibernate.cache.provider_class" value="org.hibernate.cache.NoCacheProvider"/>
</properties>
</persistence-unit>
</persistence>
- è stata rimossa l’opzione che creava le tabelle. Il database in questo caso esiste già ed è popolato,
- sono state rimosse le opzioni che facevano sì che Hibernate registrasse i comandi SQL che inviava al database.
L'esecuzione del progetto produce i seguenti due messaggi nella console:
- riga 1: l’eccezione verificatasi quando si è dovuto cercare l’indennità mancante mentre la sessione era chiusa. Si nota che l’indennità non era stata recuperata a causa della modalità LAZY,
- riga 2: il dipendente con la sua indennità ottenuta tramite una query che ha aggirato la modalità LAZY.
5.6.5. Compito da svolgere
Seguendo una procedura analoga a quella appena descritta, creare un progetto [mv-pam-pa-eclipselink-lazy] che mostri il comportamento di EclipseLink rispetto alla modalità LAZY.
Si ottengono i seguenti risultati:
Nella modalità LAZY, entrambe le query hanno restituito l’indennità associata al dipendente. Cercando informazioni su Internet riguardo a questa anomalia, si scopre che l’annotazione [FetchType.LAZY] (riga 1):
@ManyToOne(fetch= FetchType.LAZY)
@JoinColumn(name="INDEMNITE_ID",nullable=false)
private Indemnite indemnite;
non è un comando ma una richiesta. L’implementatore JPA non è obbligato a seguirla. Si vede quindi che il codice a volte dipende dall’implementazione JPA utilizzata. È possibile impostare tramite configurazione a EclipseLink il comportamento previsto per la modalità LAZY.
5.6.6. Per il seguito
L’architettura dell’applicazione da realizzare è la seguente:
 |
Per il prosieguo del documento, si duplicherà il progetto Maven [mv-pam-jpa-hibernate] nel progetto [mv-pam-spring-hibernate] [1, 2, 3]:
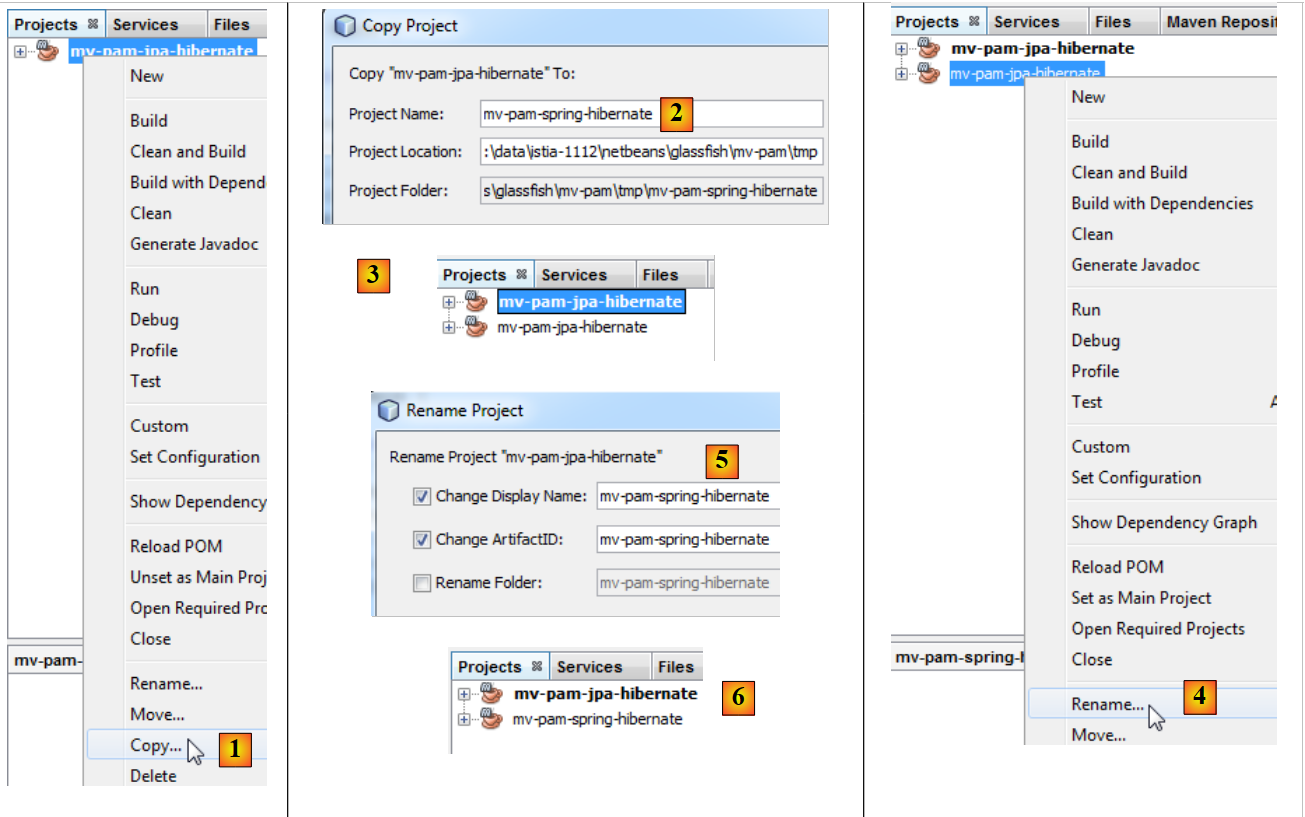 |
- quindi rinomineremo il nuovo progetto [4, 5, 6].
Modificheremo le dipendenze del nuovo progetto. Il file [pom.xml] diventa il seguente:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>istia.st</groupId>
<artifactId>mv-pam-spring-hibernate</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>mv-pam-spring-hibernate</name>
<url>http://maven.apache.org</url>
<repositories>
<repository>
<url>http://repo1.maven.org/maven2/</url>
<id>swing-layout</id>
<layout>default</layout>
<name>Repository for library Library[swing-layout]</name>
</repository>
</repositories>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
<type>jar</type>
</dependency>
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.2.2</version>
</dependency>
<dependency>
<groupId>commons-pool</groupId>
<artifactId>commons-pool</artifactId>
<version>1.6</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>4.1.2</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>org.swinglabs</groupId>
<artifactId>swing-layout</artifactId>
<version>1.0.3</version>
</dependency>
</dependencies>
</project>
- righe 25-31: la dipendenza per i test JUnit,
- righe 32-41: le dipendenze per il pool di connessioni Apache DBCP,
- righe 42-65: le dipendenze per il framework Spring,
- righe 67-71: le dipendenze per l'implementazione JPA / Hibernate,
- righe 72-76: la dipendenza dal driver JDBC di MySQL,
- righe 77-81: la dipendenza dall'interfaccia Swing. Questa viene aggiunta automaticamente da NetBeans quando si aggiunge un'interfaccia Swing al progetto.
Inoltre, verranno generati i due database MySQL:
- [dbpam_hibernate] dallo script [dbpam_hibernate.sql],
- [dbpam_eclipselink] dallo script [dbpam_eclipselink.sql],
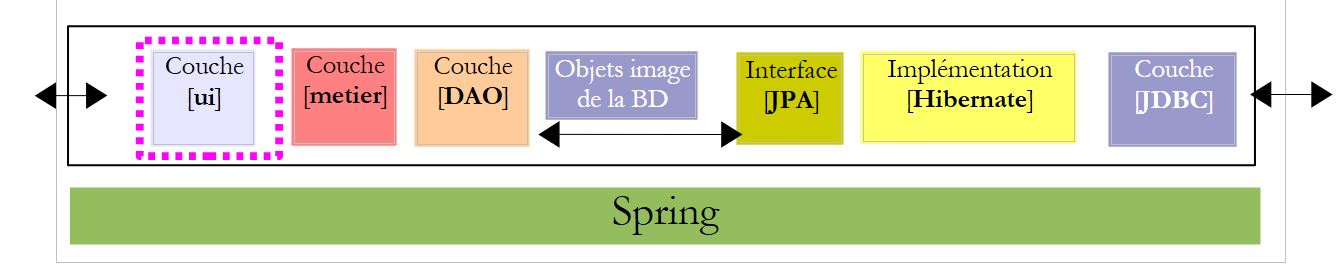
5.7. e interfacce dei livelli [metier] e [DAO]
Torniamo all’architettura dell’applicazione:
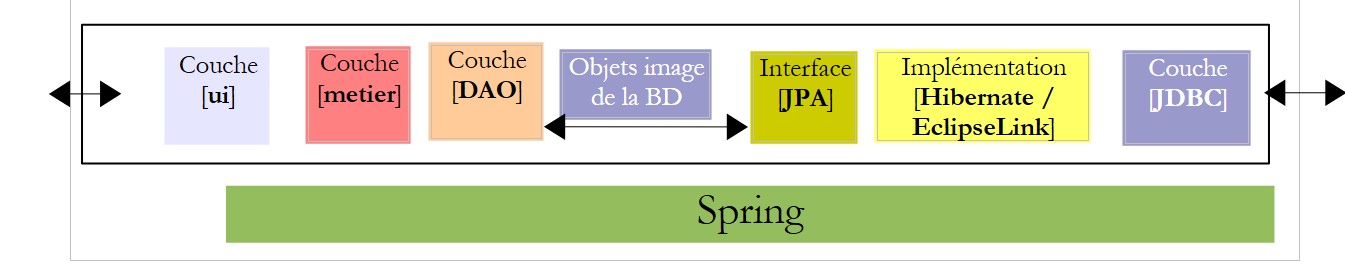 |
Nell’architettura sopra riportata, quale interfaccia deve fornire il livello [DAO] al livello [metier] e quale interfaccia deve fornire il livello [metier] al livello [ui]? Un primo approccio per definire le interfacce dei diversi livelli consiste nell’esaminare i diversi casi d’uso (use case) dell’applicazione. In questo caso ne abbiamo due, a seconda dell’interfaccia utente scelta: console o modulo grafico.
Esaminiamo le modalità di utilizzo dell’applicazione da console:
L’applicazione riceve tre informazioni dall’utente (cfr. riga 1 sopra)
- il numero di previdenza sociale della tata
- il numero di ore lavorate nel mese
- il numero di giorni lavorati nel mese
Sulla base di queste informazioni e di altre registrate nei file di configurazione, l'applicazione visualizza le seguenti informazioni:
- righe 4-6: i valori inseriti
- righe 8-10: le informazioni relative al dipendente di cui è stato fornito il numero di previdenza sociale
- righe 12-14: le aliquote dei diversi contributi sociali
- righe 16-17: le diverse indennità versate alla tata
- righe 19-24: gli elementi della busta paga dell’assistente materna
Il livello [metier] deve fornire una serie di informazioni al livello [ui]:
- le informazioni relative a un'assistente materna identificata dal proprio numero di previdenza sociale. Queste informazioni si trovano nella tabella [EMPLOYES]. Ciò consente di visualizzare le righe 6-8.
- gli importi delle varie aliquote contributive da prelevare dalla retribuzione lorda. Queste informazioni si trovano nella tabella [COTISATIONS]. Ciò consente di visualizzare le righe 10-12.
- gli importi delle varie indennità relative alla funzione di assistente materna. Queste informazioni si trovano nella tabella [INDEMNITES]. Ciò consente di visualizzare le righe 14-15.
- gli elementi costitutivi dello stipendio visualizzati nelle righe 18-22.
Da ciò, si potrebbe decidere di effettuare una prima scrittura dall’interfaccia [IMetier], presentata dal livello [metier], al livello [ui]:
- riga 1: gli elementi del livello [metier] vengono inseriti nel pacchetto [metier]
- riga 5: il metodo [ calculerFeuilleSalaire ] accetta come parametri le tre informazioni acquisite dal livello [ui] e restituisce un oggetto di tipo [FeuilleSalaire] contenente le informazioni che il livello [ui] visualizzerà sulla console. La classe [FeuilleSalaire] potrebbe essere la seguente:
- riga 9: il dipendente interessato dalla busta paga - informazione n. 1 visualizzata dal livello [ui]
- riga 10: le diverse aliquote contributive - informazione n. 2 visualizzata dal livello [ui]
- riga 11: le diverse indennità legate all’indice del dipendente – informazione n. 3 visualizzata dal livello [ui]
- riga 12: le componenti della sua retribuzione - informazione n. 4 visualizzata dal livello [ui]
Un secondo caso d’uso del livello [métier] si presenta con l’interfaccia grafica:
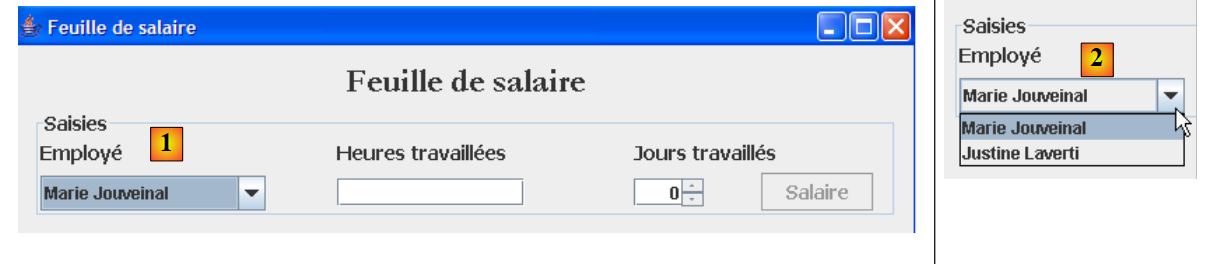 |
Come si vede sopra, l’elenco a discesa [1, 2] presenta tutti i dipendenti. Questo elenco deve essere richiesto al livello [métier]. L’interf ace di quest’ultimo si evolve quindi nel modo seguente:
- riga [10]: il metodo che consentirà al livello [ui] di richiedere l’elenco di tutti i dipendenti al livello [métier].
Il livello [metier] può inizializzare i campi [Employe, Cotisation, Indemnite] dell'oggetto [FeuilleSalaire] sopra indicato solo interrogando il livello [DAO], poiché tali informazioni si trovano nelle tabelle del database. Lo stesso vale per ottenere l’elenco di tutti i dipendenti. È possibile creare un’unica interfaccia [DAO] che gestisca l’accesso alle tre entità [Employe, Cotisation, Indemnite]. In questo caso, tuttavia, abbiamo deciso di creare un’interfaccia [DAO] per ciascuna entità.
L’interfaccia [DAO] per l’accesso alle entità [Cotisation] della tabella [COTISATIONS] sarà la seguente:
- alla riga 6, l'interfaccia [ICotisationDao] gestisce l'accesso all'entità [Cotisation] e quindi alla tabella [COTISATIONS] del database. La nostra applicazione necessita solo del metodo [findAll] della riga 16, che consente di recuperare l’intero contenuto della tabella [COTISATIONS]. In questo caso abbiamo voluto considerare un caso più generale in cui tutte le operazioni CRUD (Create, Read, Update, Delete) vengono eseguite sull’entità.
- riga 8: il metodo [create] crea una nuova entità [Cotisation]
- riga 10: il metodo [edit] modifica un'entità [Cotisation] esistente
- riga 12: il metodo [destroy] elimina un'entità [Cotisation] esistente
- riga 14: il metodo [find] consente di recuperare un'entità [Cotisation] esistente tramite il suo identificatore id
- riga 16: il metodo [findAll] restituisce in un elenco tutte le entità [Cotisation] esistenti
Soffermiamoci sulla firma del metodo [create]:
Il metodo create ha un parametro cotisation di tipo Cotisation. Il parametro cotisation deve essere salvato, c.a.d. qui inserito nella tabella [COTISATIONS]. Prima di questa persistenza, il parametro cotisation ha un identificatore id senza valore. Dopo la persistenza, il campo id ha un valore che corrisponde alla chiave primaria del record aggiunto alla tabella [COTISATIONS]. Il parametro cotisation è quindi un parametro di ingresso/uscita del metodo create. Non sembra necessario che il metodo create restituisca inoltre il parametro cotisation come risultato. Poiché il metodo chiamante detiene un riferimento all’oggetto [Cotisation cotisation], se quest’ultimo viene modificato, il metodo chiamante ha accesso all’oggetto modificato in quanto ne possiede un riferimento. Può quindi conoscere il valore che il metodo create ha assegnato al campo id dell’oggetto [Cotisation cotisation]. La firma del metodo potrebbe quindi essere più semplice:
Quando si scrive un'interfaccia, è bene ricordare che può essere utilizzata in due contesti diversi: local e distant. Nel contesto local, il metodo chiamante e il metodo chiamato vengono eseguiti nello stesso JVM:
 |
Se il livello [metier] chiama il metodo create del livello [DAO], ha effettivamente un riferimento al parametro [Cotisation cotisation] che passa al metodo.
Nel contesto distant, il metodo chiamante e il metodo chiamato vengono eseguiti in JVM diversi:
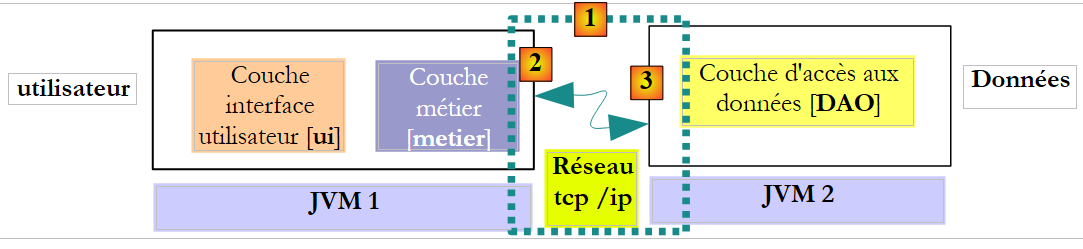 |
Nell’esempio sopra riportato, il livello [metier] viene eseguito nel JVM 1 e il livello [DAO] nel JVM 2 su due macchine diverse. I due livelli non comunicano direttamente. Tra di essi si interpone un livello che chiameremo livello di comunicazione [1]. Questo è composto da un livello di trasmissione [2] e da un livello di ricezione [3]. In genere, lo sviluppatore non deve scrivere questi livelli di comunicazione. Essi vengono generati automaticamente da strumenti software. Il livello [metier] è scritto come se venisse eseguito nello stesso JVM del livello [DAO]. Non è quindi necessaria alcuna modifica al codice.
Il meccanismo di comunicazione tra il livello [metier] e il livello [DAO] è il seguente:
- il livello [metier] chiama il metodo create del livello [DAO] passando il parametro [Cotisation cotisation1]
- questo parametro viene di fatto passato al livello di trasmissione [2]. Quest’ultimo trasmetterà sulla rete il valore del parametro cotisation1 e non il suo riferimento. La forma esatta di questo valore dipende dal protocollo di comunicazione utilizzato.
- Il livello di ricezione [3] recupererà questo valore e ricostruirà, a partire da esso, un oggetto [Cotisation cotisation2] che rispecchia il parametro iniziale inviato dal livello [metier]. Ora abbiamo due oggetti identici (in termini di contenuto) in due JVM diverse: cotisation1 e cotisation2.
- Il livello di ricezione passerà l'oggetto cotisation2 al metodo create del livello [DAO], che lo salverà nel database. Dopo questa operazione, il campo id dell'oggetto cotisation2 è stato inizializzato con la chiave primaria del record aggiunto alla tabella [COTISATIONS]. Questo non è il caso dell’oggetto cotisation1, a cui il livello [metier] fa riferimento. Se si desidera che il livello [metier] abbia un riferimento all’oggetto cotisation2, è necessario inviarglielo. Pertanto, è necessario modificare la firma del metodo create del livello [DAO]:
- Con questa nuova firma, il metodo create restituirà come risultato l’oggetto persistito cotisation2. Questo risultato viene restituito al livello di ricezione [3] che aveva chiamato il livello [DAO]. Quest’ultimo restituirà il valore (e non il riferimento) di cotisation2 al livello di trasmissione [2].
- Il livello di emissione [2] recupererà questo valore e ricostruirà, a partire da esso, un oggetto [Cotisation cotisation3] che rappresenta il risultato restituito dal metodo create del livello [DAO].
- L’oggetto [Cotisation cotisation3] viene restituito al metodo del livello [metier], la cui chiamata al metodo create del livello [DAO] aveva avviato l’intero meccanismo. Il livello [metier] può quindi conoscere il valore della chiave primaria assegnato all’oggetto [Cotisation cotisation1] di cui aveva richiesto la persistenza: si tratta del valore del campo id di cotisation3.
L’architettura precedente non è quella più comune. È più frequente trovare i livelli [metier] e [DAO] all’interno dello stesso JVM:
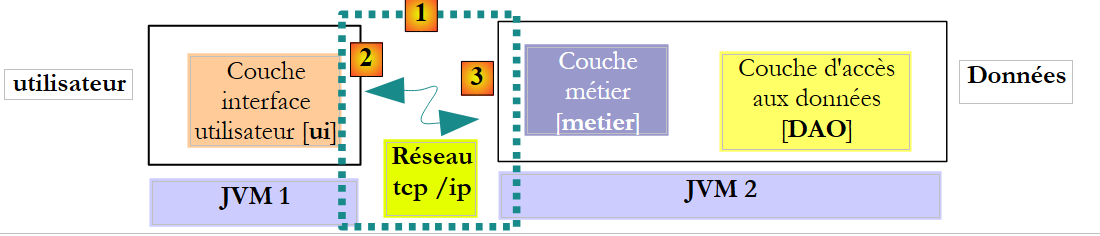 |
In questa architettura, sono i metodi del livello [metier] che devono restituire i risultati e non quelli del livello [DAO]. Tuttavia, la seguente firma del metodo create del livello [DAO]:
ci permette di non formulare ipotesi sull’architettura effettivamente implementata. L’utilizzo di firme che funzionino indipendentemente dall’architettura scelta, locale o remota, implica che, nel caso in cui un metodo chiamato modifichi alcuni dei propri parametri:
- questi debbano far parte anche del risultato del metodo chiamato
- il metodo chiamante deve utilizzare il risultato del metodo chiamato e non i riferimenti ai parametri modificati che ha trasmesso al metodo chiamato.
Ci si lascia così la possibilità di passare da un livello di un’architettura locale a un’architettura distante senza modificare il codice. Riesaminiamo, alla luce di ciò, l’interfaccia [ICotisationDao]:
- riga 8: è stato trattato il caso del metodo create
- riga 10: il metodo edit utilizza il proprio parametro [Cotisation cotisation1] per aggiornare il record della tabella [COTISATIONS] avente la stessa chiave primaria dell’oggetto cotisation. Come risultato restituisce l’oggetto cotisation2, che rappresenta l’immagine del record modificato. Il parametro cotisation1 non viene invece modificato. Il metodo deve restituire cotisation2 come risultato, sia nell’ambito di un’architettura distante che locale.
- riga 12: il metodo destroy elimina il record della tabella [COTISATIONS] avente la stessa chiave primaria dell’oggetto cotisation passato come parametro. Quest’ultimo non viene modificato. Non deve quindi essere restituito.
- riga 14: il parametro id del metodo find non viene modificato dal metodo. Non deve quindi far parte del risultato.
- riga 16: il metodo findAll non ha parametri. Non è quindi necessario esaminarlo.
In definitiva, solo la firma del metodo create deve essere adattata per poter essere utilizzata nell’ambito di un’architettura distante. Le considerazioni precedenti valgono anche per le altre interfacce [DAO]. Non le ripeteremo e utilizzeremo direttamente le firme utilizzabili sia nell’ambito di un’architettura distante che locale.
L'interfaccia [DAO] per l'accesso alle entità [Indemnite] della tabella [INDEMNITES] sarà la seguente:
- alla riga 6, l'interfaccia [IIndemniteDao] gestisce gli accessi all'entità [Indemnite] e quindi alla tabella [INDEMNITES] del database. La nostra applicazione necessita solo del metodo [findAll] della riga 16, che consente di recuperare l'intero contenuto della tabella [INDEMNITES]. In questo caso abbiamo voluto considerare un caso più generale in cui tutte le operazioni CRUD (Create, Read, Update, Delete) vengono eseguite sull’entità.
- riga 8: il metodo [create] crea una nuova entità [Indemnite]
- riga 10: il metodo [edit] modifica un'entità [Indemnite] esistente
- riga 12: il metodo [destroy] elimina un'entità [Indemnite] esistente
- riga 14: il metodo [find] consente di recuperare un'entità [Indemnite] esistente tramite il suo identificativo id
- riga 16: il metodo [findAll] restituisce in un elenco tutte le entità [Indemnite] esistenti
L'interfaccia [DAO] per l'accesso alle entità [Employe] della tabella [EMPLOYES] sarà la seguente:
- alla riga 6, l'interfaccia [IEmployeDao] gestisce l'accesso all'entità [Employe] e quindi alla tabella [EMPLOYES] del database. La nostra applicazione necessita solo del metodo [findAll] della riga 16, che consente di recuperare l'intero contenuto della tabella [EMPLOYES]. In questo caso abbiamo voluto considerare un caso più generale in cui tutte le operazioni CRUD (Create, Read, Update, Delete) vengono eseguite sull’entità.
- riga 8: il metodo [create] crea una nuova entità [Employe]
- riga 10: il metodo [edit] modifica un'entità [Employe] esistente
- riga 12: il metodo [destroy] elimina un'entità [Employe] esistente
- riga 14: il metodo [find] consente di recuperare un'entità [Employe] esistente tramite il suo identificativo id
- riga 16: il metodo [find(String SS)] consente di recuperare un'entità [Employe] esistente tramite il suo numero SS. Abbiamo visto che questo metodo era necessario per l'applicazione console.
- riga 18: il metodo [findAll] restituisce in un elenco tutte le entità [Employe] esistenti. Abbiamo visto che questo metodo era necessario per l’applicazione grafica.
5.8. La classe [PamException]
Il livello [DAO] opererà con il API JDBC di Java. Questo API genera eccezioni controllate di tipo [SQLException] che presentano due svantaggi:
- appesantiscono il codice, che deve necessariamente gestire queste eccezioni con blocchi try/catch;
- devono essere dichiarate nella firma dei metodi dell’interfaccia [IDao] tramite un "throws SQLException". Ciò impedisce l’implementazione di questa interfaccia da parte di classi che genererebbero un’eccezione controllata di tipo diverso da [SQLException].
Per risolvere questo problema, il livello [DAO] «trasmetterà» solo le eccezioni non controllate di tipo [PamException].
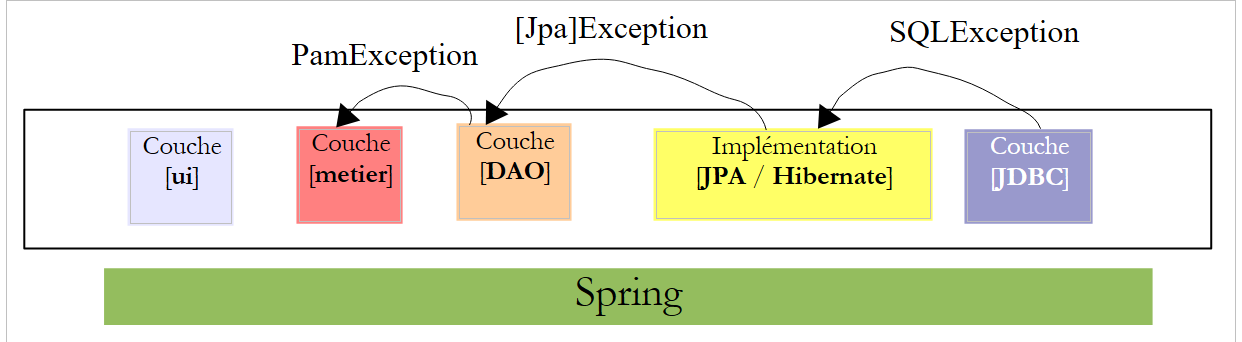 |
- il livello [JDBC] genera eccezioni di tipo [SQLException]
- il livello [JPA] genera eccezioni specifiche dell’implementazione JPA utilizzata
- il livello [DAO] genera eccezioni di tipo [PamException] non controllate
Ciò comporta due conseguenze:
- il livello [metier] non sarà tenuto a gestire le eccezioni del livello [DAO] con istruzioni try/catch. Potrà semplicemente lasciarle risalire fino al livello [ui].
- i metodi dell’interfaccia [IDao] non devono specificare nella loro firma la natura dell’eccezione [PamException], il che lascia la possibilità di implementare tale interfaccia con classi che genererebbero un altro tipo di eccezione non controllata.
La classe [PamException] verrà inserita nel pacchetto [exception] del progetto NetBeans:
 |
Il suo codice è il seguente:
- riga 4: [PamException] deriva da [RuntimeException]. Si tratta quindi di un tipo di eccezione che il compilatore non ci obbliga a gestire tramite un try/catch né a inserire nella firma dei metodi. È per questo motivo che [PamException] non è presente nella firma dei metodi dell’interfaccia [IDao]. Ciò consente a questa interfaccia di essere implementata da una classe che genera un altro tipo di eccezioni, a condizione che anche questa derivi da [RuntimeException].
- Per distinguere gli errori che possono verificarsi, si utilizza il codice di errore della riga 7. I tre costruttori delle righe 14, 19 e 24 sono quelli della classe padre [RuntimeException], ai quali è stato aggiunto un parametro: quello del codice di errore che si desidera assegnare all’eccezione.
Il funzionamento dell’applicazione, dal punto di vista delle eccezioni, sarà il seguente:
- il livello [DAO] incapsulerà qualsiasi eccezione riscontrata in un'eccezione di tipo [PamException] e la rilancerà al livello [métier].
- Il livello [métier] consentirà il passaggio delle eccezioni lanciate dal livello [DAO]. Incapsulerà ogni eccezione che si verifica nel livello [métier] in un'eccezione di tipo [PamException] e la rilancerà al livello [ui].
- Il livello [ui] intercetta tutte le eccezioni che risalgono dai livelli [métier] e [DAO]. Si limiterà a visualizzare l’eccezione sulla console o sull’interfaccia grafica.
Esaminiamo ora in successione l’implementazione dei livelli [DAO] e [metier].
5.9. Il livello [DAO] dell’applicazione [PAM]
Ci collochiamo nel contesto della seguente architettura:
 |
5.9.1. Implementazione
Letture consigliate: paragrafo 3.1.3 di [ref1]
Domanda: Utilizzando l’integrazione Spring / JPA, scrivere le classi [CotisationDao, IndemniteDao, EmployeDao] per l’implementazione delle interfacce [ICotisationDao, IIndemniteDao, IEmployeDao]. Ogni metodo di classe intercetterà un'eventuale eccezione e la incapsulerà in un'eccezione di tipo [PamException] con un codice di errore specifico per l'eccezione intercettata.
Le classi di implementazione faranno parte del pacchetto [dao]:
 |
5.9.2. Configurazione
Letture consigliate: paragrafo 3.1.5 di [ref1]
L'integrazione DAO / JPA è configurata dal file Spring [spring-config-dao.xml] e dai file JPA e [persistence.xml]:
 |
Domanda: scrivere il contenuto di questi due file. Si suppone che il database utilizzato sia il database MySQL5 [dbpam_hibernate] generato dallo script SQL [dbpam_hibernate.sql]. Il file Spring definirà i seguenti tre bean: employeDao di tipo EmployeDao, indemniteDao di tipo IndemniteDao, cotisationDao di tipo CotisationDao. Inoltre, l’implementazione JPA utilizzata sarà Hibernate.
5.9.3. Test
Letture consigliate: paragrafi 3.1.6 e 3.1.7 di [ref1]
Ora che il livello [DAO] è stato scritto e configurato, possiamo testarlo. L’architettura dei test sarà la seguente:
 |
5.9.4. InitDB
Creeremo due programmi di test per il livello [DAO]. Questi saranno inseriti nel pacchetto [dao] [2] del ramo [Test Packages] [1] del progetto NetBeans. Questo ramo non è incluso nel progetto generato dall’opzione [Build project], il che ci garantisce che i programmi di test che vi inseriamo non saranno inclusi nel file .jar finale del progetto.
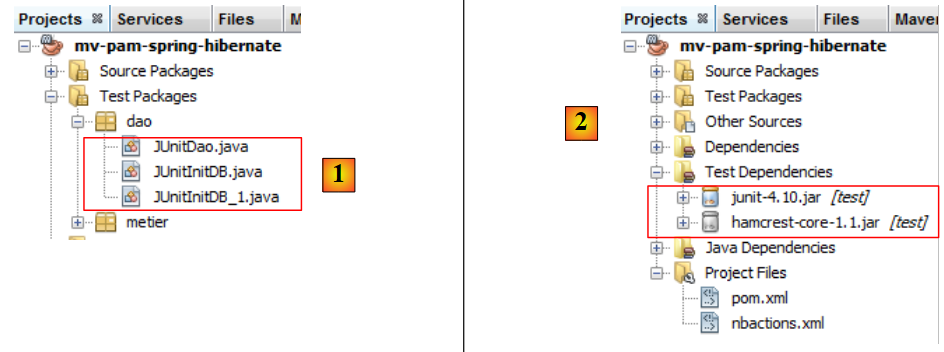 |
Le classi inserite nel ramo [Test Packages] hanno accesso alle classi presenti nel ramo [Source Packages] e alle librerie di classi del progetto. Se i test necessitano di librerie diverse da quelle del progetto, queste devono essere dichiarate nel ramo [Test Libraries] [2].
Le classi di test utilizzano lo strumento di test unitari JUnit:
- [JUnitInitDB] non esegue alcun test. Popola il database con alcuni record e li visualizza successivamente sulla console.
- [JUnitDao] esegue una serie di test e ne verifica il risultato.
Lo scheletro della classe [JUnitInitDB] è il seguente:
- il metodo [init] viene eseguito prima dell’inizio della serie di test (annotazione @BeforeClass). Esso istanzia il livello [DAO].
- Il metodo [clean] viene eseguito prima di ogni test (annotazione @Before). Svuota il database.
- Il metodo [initDB] è un test (annotazione @Test). È l'unico. Un test deve contenere istruzioni di asserzione Assert.assertCondition. In questo caso non ce ne saranno. Il metodo è quindi un falso test. Ha il compito di popolare il database con alcune righe e poi di visualizzarne il contenuto sulla console. Qui vengono utilizzati i metodi create e findAll dei livelli [DAO].
Domanda: completare il codice della classe [JUnitInitDB]. Ci si baserà sull’esempio del paragrafo 3.1.6 di [ref1]. Il codice genererà il contenuto presentato al paragrafo 5.1.
5.9.5. Implementaz e dei test
Ora siamo pronti per eseguire [InitDB]. Descriviamo la procedura utilizzando SGBD e MySQL5:
 |
- le classi [1], i file di configurazione [2] e le classi di test del livello [DAO] [3] sono stati implementati,
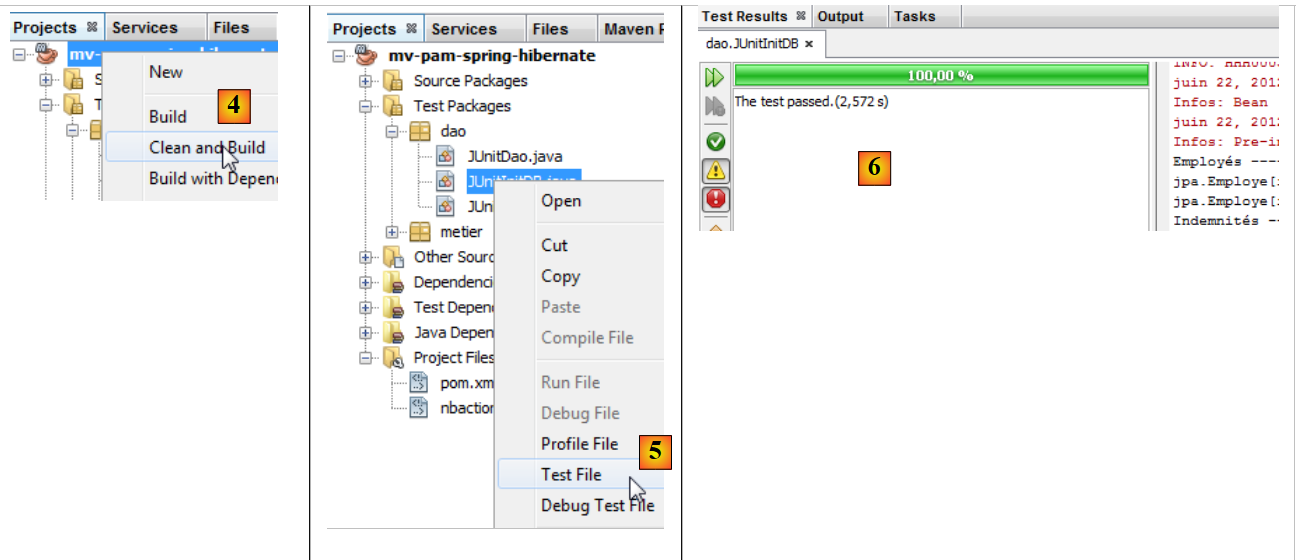 |
- il progetto viene compilato [4]
- viene eseguita la classe [JUnitInitDB] [5]. SGBD MySQL5 viene avviato con una base esistente [dbpam_hibernate],
- la finestra [Test Results] e [6] indica che i test sono stati superati. Questo messaggio non è rilevante in questo contesto, poiché il programma [JUnitInitDB] non contiene alcuna istruzione di asserzione Assert.assertCondition che potrebbe causare il fallimento del test. Tuttavia, ciò dimostra che non si sono verificate eccezioni durante l’esecuzione del test.
La finestra [Output] contiene i log dell'esecuzione, quelli di Spring e quelli del test stesso. I messaggi visualizzati dalla classe [JUnitInitDB] sono i seguenti:
Le tabelle [EMPLOYES, INDEMNITES, COTISATIONS] sono state popolate. È possibile verificarlo tramite una connessione NetBeans al database [dbpam_hibernate].
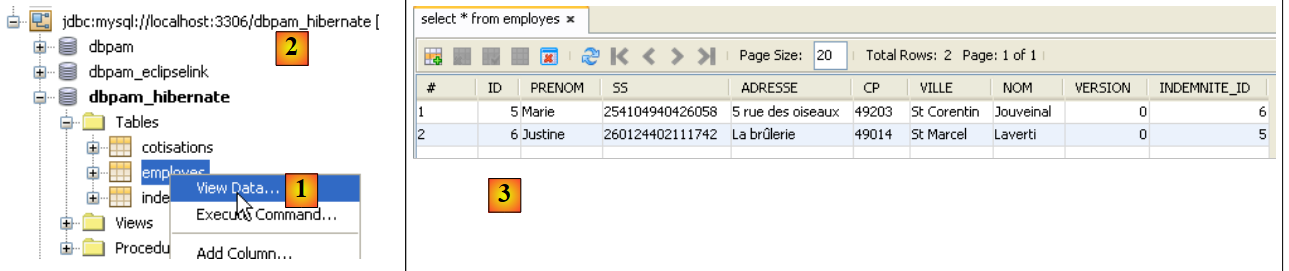 |
- in [1], nella scheda [services], si visualizzano i dati della tabella [employes] della connessione [dbpam_hibernate] [2],
- in [3] il risultato.
5.9.6. JUnitDao
Passiamo ora a una seconda classe di test [JUnitDao]:
 |
La struttura della classe sarà la seguente:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 138 139 140 141 142 143 144 145 146 147 148 149 150 151 152 153 154 155 156 157 158 159 160 161 162 163 164 165 166 167 168 169 170 171 172 173 174 175 176 177 178 179 180 181 182 183 184 185 186 187 | |
Nella classe di test precedente, la base viene svuotata prima di ogni test.
Domanda: scrivere i seguenti metodi:
1 - test02: ci si ispirerà a test01
2 - test03: un dipendente ha un campo di tipo Indemnite. È quindi necessario creare un'entità Indemnite e un'entità Employe
3 - test04.
Procedendo allo stesso modo della classe di test [JUnitInitDB], si ottengono i seguenti risultati:
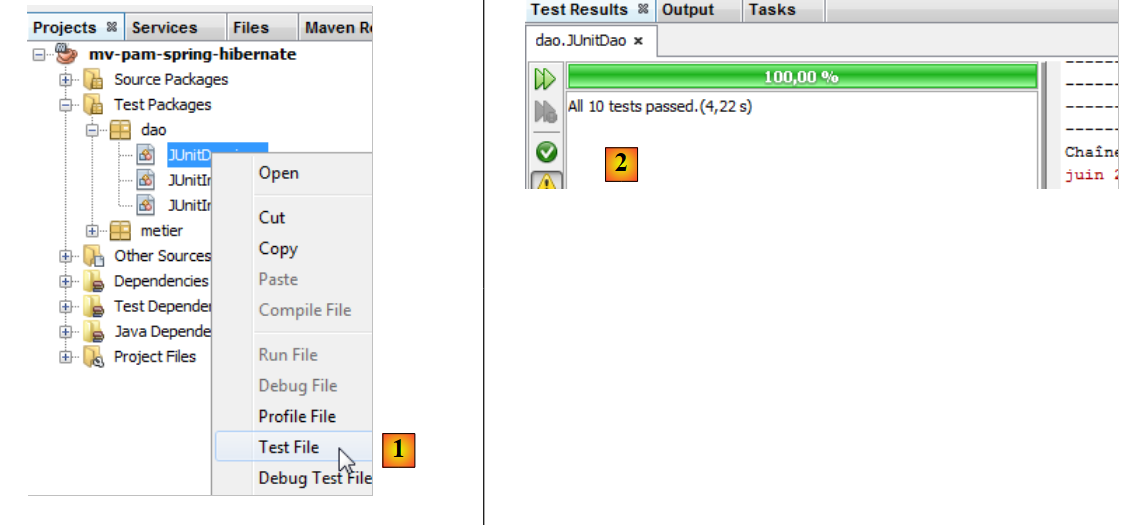 |
- in [1], si esegue la classe di test
- in [2], i risultati dei test nella finestra [Test Results]
Proviamo a generare un errore per vedere come viene segnalato nella pagina dei risultati:
Riga 13: l’asserzione causerà un errore, poiché il valore di Csgrds è 3,49 (riga 8). L’esecuzione della classe di test fornisce i seguenti risultati:
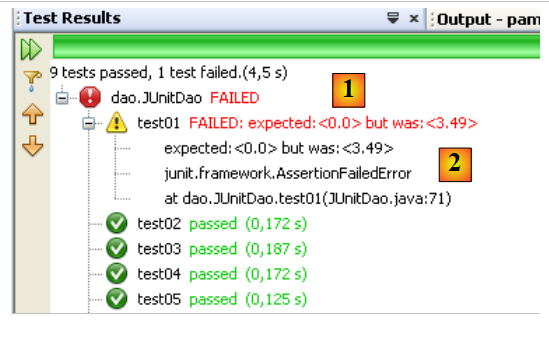 |
- la pagina dei risultati [1] mostra ora che alcuni test non sono stati superati.
- In [2] è riportato un riepilogo dell’eccezione che ha causato il fallimento del test. Qui è indicato il numero della riga del codice Java in cui si è verificata l’eccezione.
5.10. Il livello [metier] dell'applicazione [PAM]
Ora che il livello [DAO] è stato scritto, passiamo all’analisi del livello business [2]:
 |
5.10.1. L'interfaccia Java [IMetier]
Questa è stata descritta al paragrafo 5.7. La riportiamo di seguito:
L'implementazione del livello [metier] avverrà in un pacchetto [metier]:
 |
Il pacchetto [metier] comprenderà, oltre all’interfaccia [IMetier] e alla sua implementazione [Metier], altre due classi: [FeuilleSalaire] e [ElementsSalaire]. La classe [FeuilleSalaire] è stata brevemente presentata nel paragrafo 5.7. Torniamo ora su di essa.
5.10.2. La classe [FeuilleSalaire]
Il metodo [calculerFeuilleSalaire] dell’interfaccia [IMetier] restituisce un oggetto di tipo [FeuilleSalaire] che rappresenta i diversi elementi di una busta paga. La sua definizione è la seguente:
- riga 7: la classe implementa l'interfaccia Serializable poiché le sue istanze possono essere scambiate in rete.
- riga 9: il dipendente a cui si riferisce la busta paga
- riga 10: le diverse aliquote contributive
- riga 11: le diverse indennità legate all’indice del dipendente
- riga 12: le componenti della sua retribuzione
- righe 14-22: i due costruttori della classe
- righe 25-27: metodo [toString] che identifica un oggetto specifico [FeuilleSalaire]
- righe 29 e successive: gli accessori pubblici ai campi privati della classe
La classe [ElementsSalaire], a cui si fa riferimento alla riga 11 della classe [FeuilleSalaire] sopra riportata, raggruppa gli elementi che costituiscono una busta paga. La sua definizione è la seguente:
- riga 3: la classe implementa l’interfaccia Serializable poiché è un componente della classe FeuilleSalaire che deve essere serializzabile.
- riga 6: lo stipendio base
- riga 7: i contributi sociali versati su questo stipendio base
- riga 8: le indennità giornaliere per il mantenimento del figlio
- riga 9: le indennità giornaliere per i pasti del bambino
- riga 10: lo stipendio netto da corrispondere alla tata
- righe 12-24: i costruttori della classe
- righe 27-31: metodo [toString] che identifica un oggetto specifico [ElementsSalaire]
- righe 34 e successive: gli accessori pubblici ai campi privati della classe
5.10.3. La classe di implementazione [Metier] del livello [metier]
La classe di implementazione [Metier] del livello [metier] potrebbe essere la seguente:
- riga 5: l'annotazione Spring @Transactional fa sì che ogni metodo della classe venga eseguito all'interno di una transazione.
- righe 9-10: i riferimenti ai livelli [DAO] delle entità [Cotisation, Employe, Indemnite]
- righe 14-17: il metodo [calculerFeuilleSalaire]
- righe 20-22: il metodo [findAllEmployes]
- riga 24 e seguenti: gli accessori pubblici dei campi privati della classe
Domanda: scrivere il codice del metodo [findAllEmployes].
Domanda: scrivere il codice del metodo [calculerFeuilleSalaire].
Si notino i seguenti punti:
- il metodo di calcolo dello stipendio è stato spiegato al paragrafo 5.2.
- se il parametro [SS] non corrisponde a nessun dipendente (il livello [DAO] ha restituito un puntatore null), il metodo genererà un'eccezione di tipo [PamException] con un codice di errore appropriato.
5.10.4. Test del livello [metier]
Creiamo due programmi di test:
 |
Le classi di test [3] vengono create in un pacchetto [metier] [2] del ramo [Test Packages] [1] del progetto.
La classe [JUnitMetier_1] potrebbe essere la seguente:
Nella classe non è presente alcuna asserzione Assert.assertCondition. Si sta semplicemente cercando di calcolare alcuni stipendi per poi verificarli manualmente. L'output ottenuto dall'esecuzione della classe precedente è il seguente:
- riga 4: la busta paga di Justine Laverti
- riga 5: la busta paga di Marie Jouveinal
- riga 6: l'eccezione dovuta al fatto che il dipendente con n. SS 'xx' non esiste.
Domanda: la riga 17 di [JUnitMetier_1] utilizza il bean Spring denominato metier. Fornire la definizione di questo bean nel file [spring-config-metier-dao.xml].
La classe [JUnitMetier_2] potrebbe essere la seguente:
La classe [JUnitMetier_2] è una copia della classe [JUnitMetier_1], ma in questo caso sono state inserite delle asserzioni nel metodo test01.
Domanda: scrivere il metodo test01.
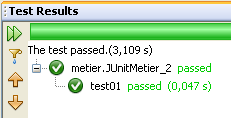
Durante l'esecuzione della classe [JUnitMetier_2], se tutto va bene si ottengono i seguenti risultati:
5.11. Il livello [ui] dell’applicazione [PAM] – versione console
Ora che il livello [metier] è stato scritto, resta da scrivere il livello [ui] [1]:
 |
Creeremo due diverse implementazioni del livello [ui]: una versione console e una versione grafica swing:
 |
5.11.1. La classe [ui.console.Main]
Ci concentriamo innanzitutto sull’applicazione da console implementata dalla classe [ui.console.Main] sopra citata. Il suo funzionamento è stato descritto nel paragrafo 5.3. Lo scheletro della classe [Main] potrebbe essere il seguente:
Domanda: completare il codice sopra riportato.
5.11.2. Esecuzione
Per eseguire la classe [ui.console.Main], procedere come segue:
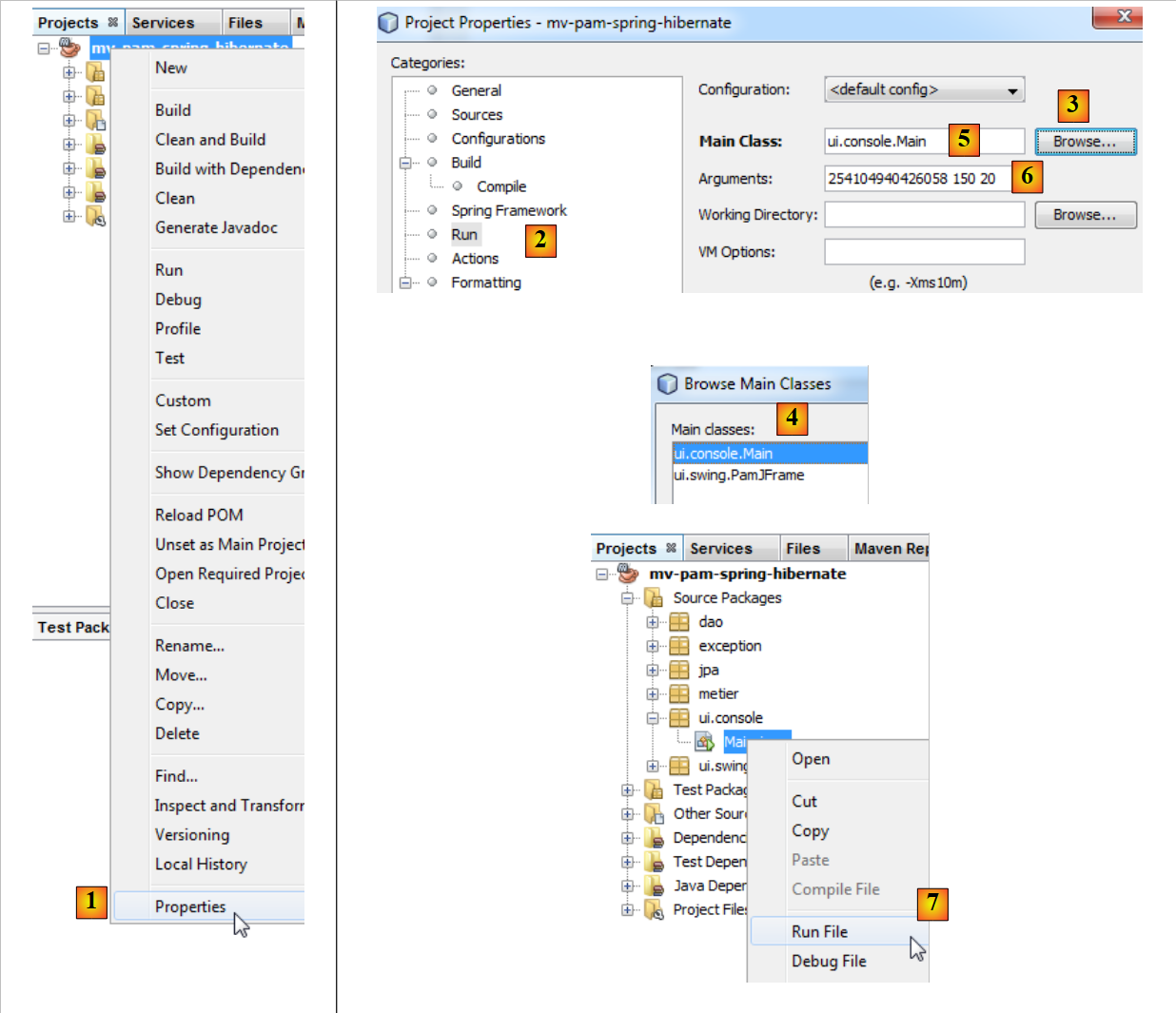 |
- in [1], selezionare le proprietà del progetto,
- in [2], selezionare la proprietà [Run] del progetto,
- utilizzare il pulsante [3] per indicare la classe (detta classe principale) da eseguire,
- selezionare la classe [4],
- la classe appare in [5]. Questa richiede tre argomenti per essere eseguita (n. SS, numero di ore lavorate, numero di giorni lavorati). Questi argomenti vengono inseriti in [6],
- fatto ciò, è possibile eseguire il progetto [7]. La configurazione precedente fa sì che venga eseguita la classe [ui.console.Main].
I risultati dell’esecuzione sono visualizzati nella finestra [output]:
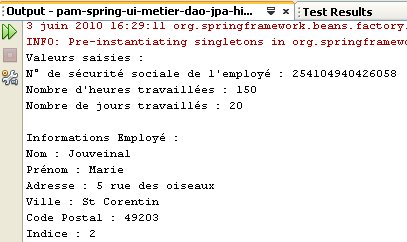 | 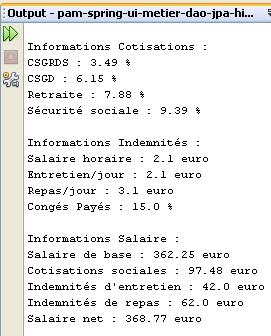 |
5.12. Il livello [ui] dell'applicazione [PAM] – versione grafica
Ora implementiamo il livello [ui] con un'interfaccia grafica:
 |
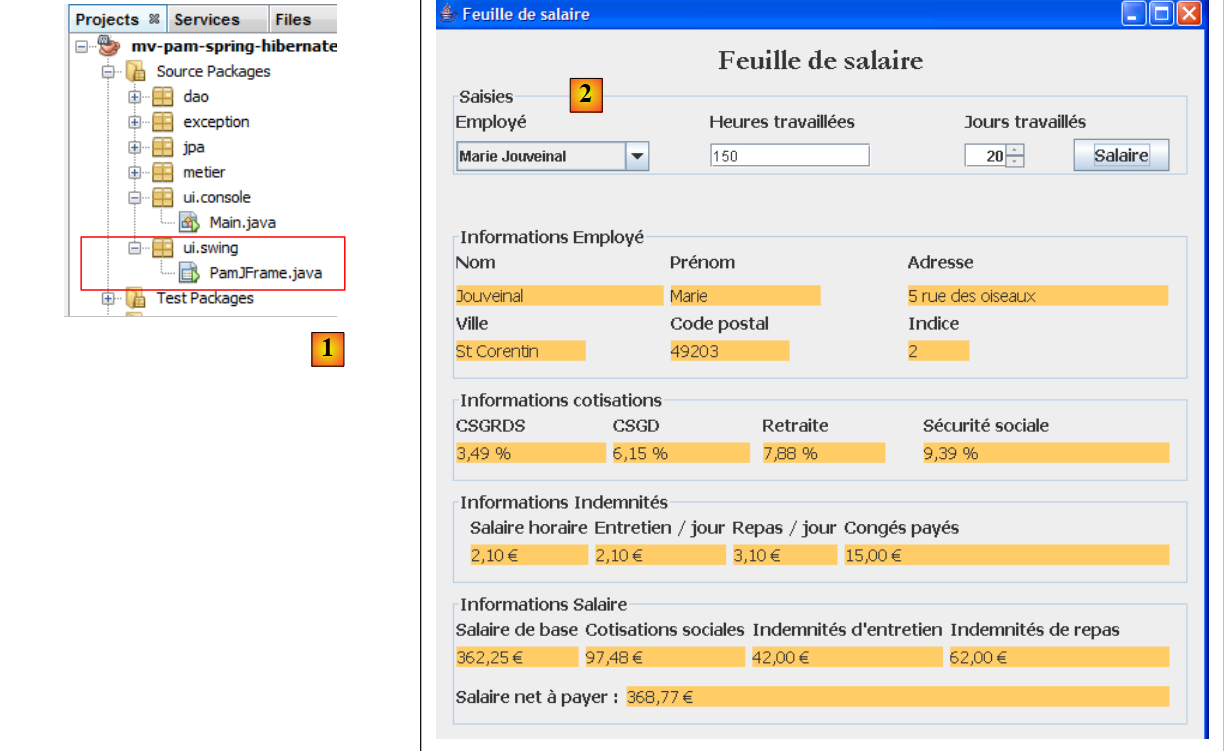 |
- in [1], la classe [PamJFrame] dell'interfaccia grafica
- in [2]: l’interfaccia grafica
5.12.1. Un breve tutorial
Per creare l'interfaccia grafica, si può procedere nel modo seguente:
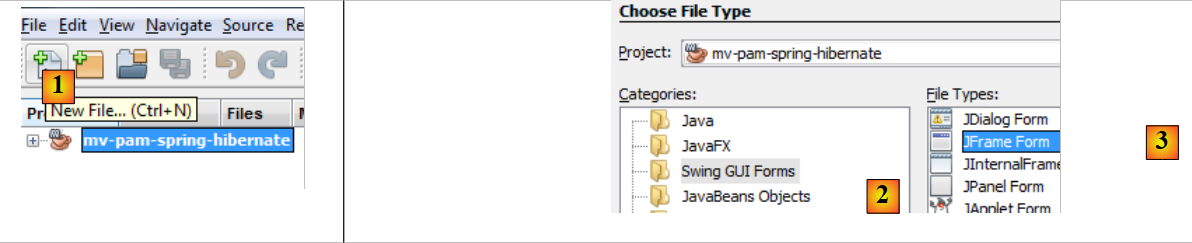 |
- [1]: si crea un nuovo file con il pulsante [1] [New File...]
- [2]: si seleziona la categoria del file [Swing GUI Forms], c.a.d. Moduli grafici
- [3]: si seleziona il tipo [JFrame Form], un tipo di modulo vuoto
 |
- [5]: si assegna un nome al modulo, che fungerà anche da classe
- [6]: si inserisce il modulo in un pacchetto
- [8]: il modulo viene aggiunto alla struttura ad albero del progetto
- [9]: il modulo è accessibile da due prospettive: [Design] e [9], che consentono di disegnare i vari componenti del modulo, e [Source] e [10 ci-dessous], che danno accesso al codice Java del modulo. In definitiva, un modulo è una classe Java come un’altra. La prospettiva [Design] è uno strumento che facilita la progettazione del modulo. Ogni volta che si aggiunge un componente in modalità [Design], nella prospettiva [Source] viene aggiunto del codice Java per tenerne conto.
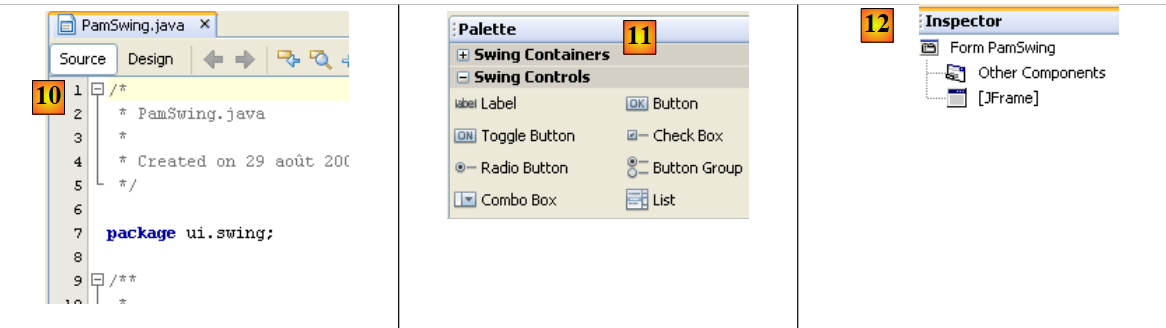 |
- [11]: l’elenco dei componenti Swing disponibili per un modulo si trova nella finestra [Palette].
- [12]: la finestra [Inspector] mostra la struttura ad albero dei componenti del modulo. I componenti con una rappresentazione visiva si trovano nel ramo [JFrame], gli altri nel ramo [Other Components].
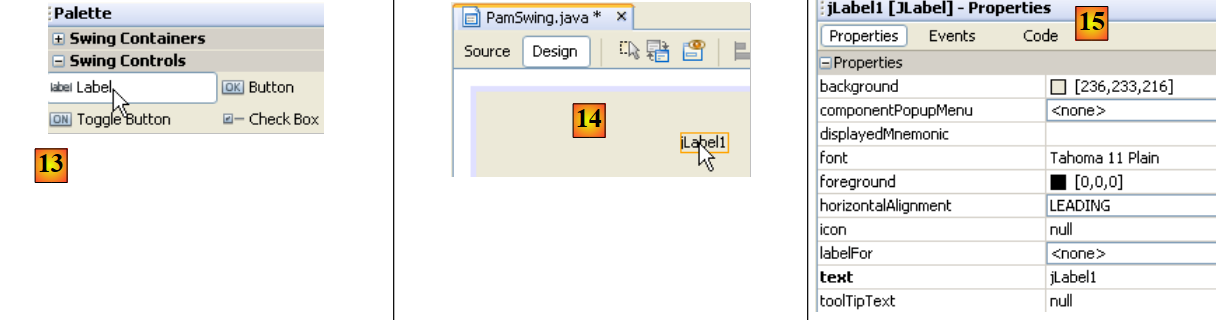 |
- in [13], selezioniamo un componente [JLabel] con un semplice clic
- in [14], lo trasciniamo sul modulo in modalità [Design]
- in [15], definiamo le proprietà di JLabel (testo, carattere).
 |
- in [16], il risultato ottenuto.
- in [17], si richiede l’anteprima del modulo
- in [18], il risultato
- in [19], l'etichetta [JLabel1] è stata aggiunta all'albero dei componenti nella finestra [Inspector]
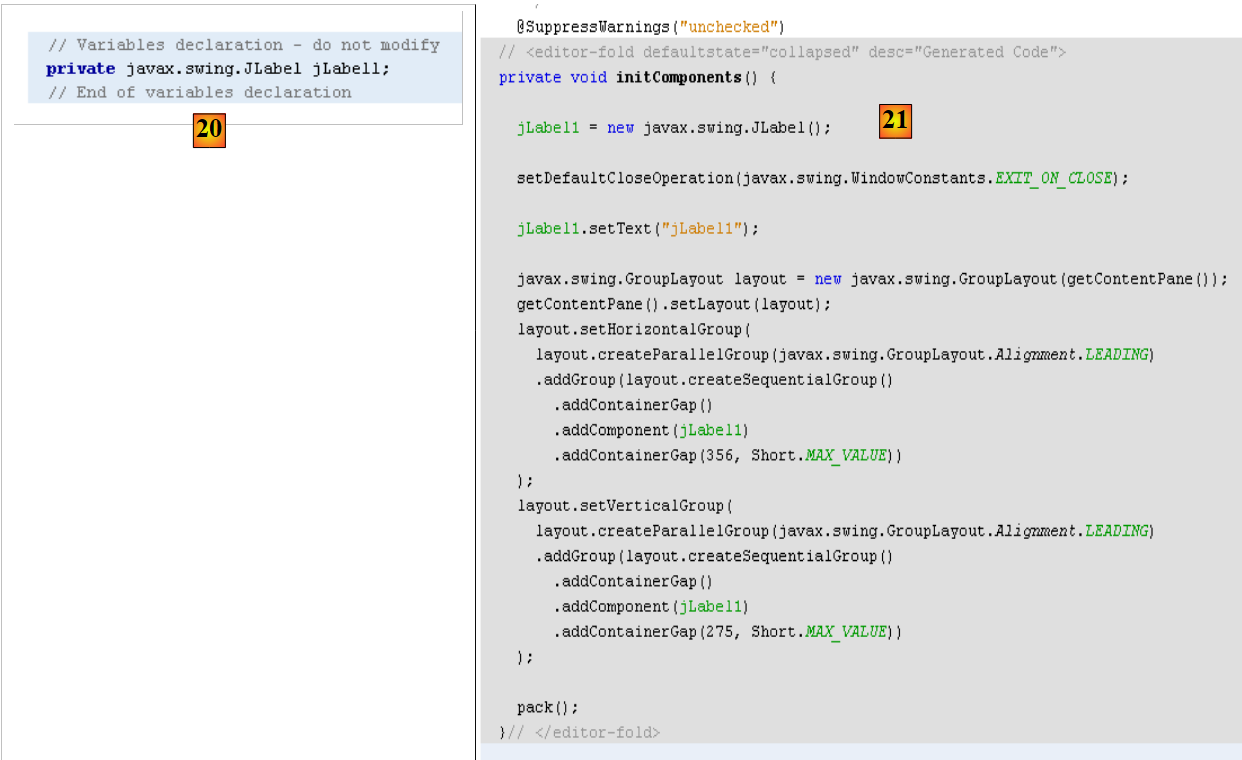 |
- in [20] e [21]: nella prospettiva [Source] del modulo è stato aggiunto del codice Java per gestire il JLabel aggiunto.
All'indirizzo [http://www.netbeans.org/kb/trails/matisse.html] è disponibile un tutorial sulla creazione di moduli con NetBeans.
5.12.2. L'interfaccia grafica [PamJFrame]
Si realizzerà la seguente interfaccia grafica:
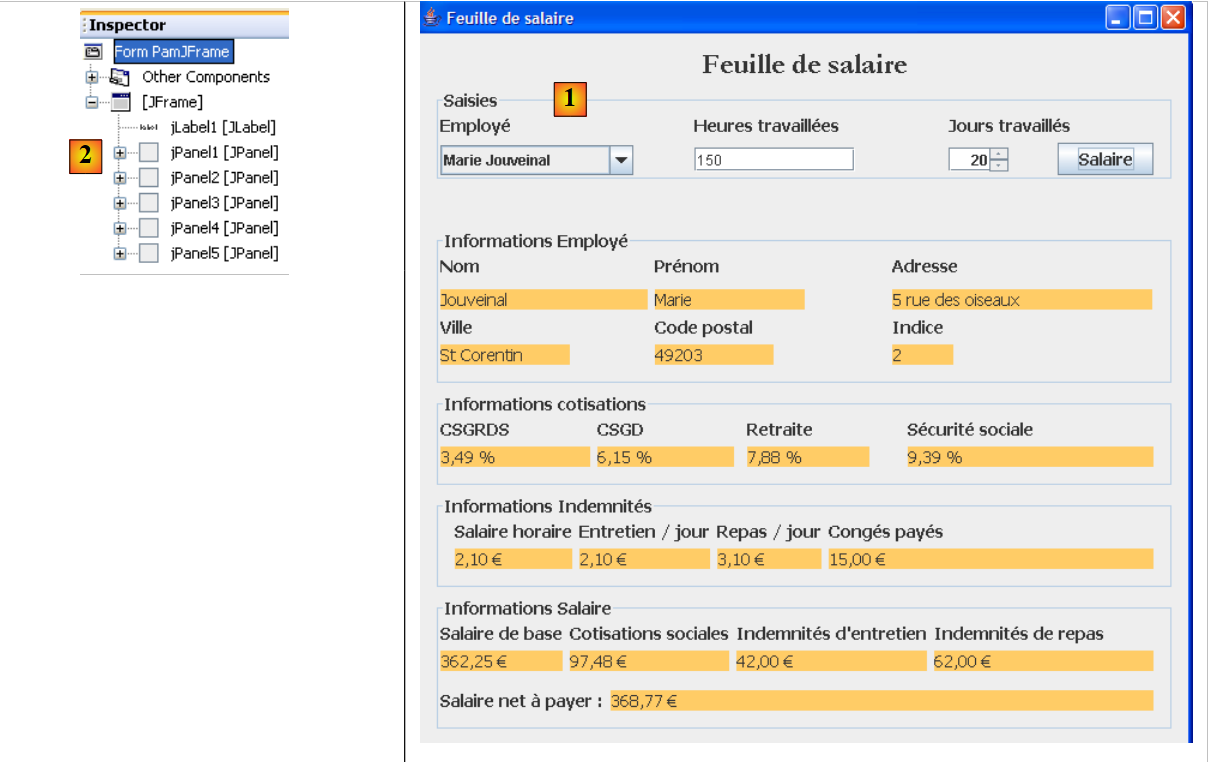 |
- in [1], l’interfaccia grafica
- in [2], l’albero dei suoi componenti: un JLabel e sei contenitori JPanel
JLabel1
 |
JPanel1
 | 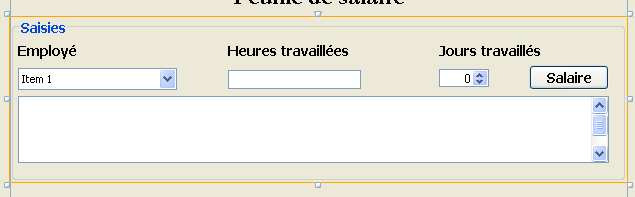 |
JPanel2
 |  |
JPanel3
 |  |
JPanel4
 |  |
JPanel5
 |  |
Esercitazione pratica: realizzare l'interfaccia grafica precedente seguendo il tutorial [http://www.netbeans.org/kb/trails/matisse.html].
5.12.3. Gli eventi dell'interfaccia grafica
Letture consigliate: capitolo [Interfaces graphiques] di [ref2].
Gestiremo il clic sul pulsante [jButtonSalaire]. Per creare il metodo di gestione di questo evento, si potrà procedere come segue:
 |
Viene generato il gestore del clic sul pulsante [JButtonSalaire]:
Viene generato anche il codice Java che associa il metodo precedente al clic sul pulsante [JButtonSalaire]:
Sono le righe 2-5 a indicare che il clic (evt di tipo ActionPerformed) sul pulsante [jButtonSalaire] (riga 2) deve essere gestito dal metodo [jButtonSalaireActionPerformed] (riga 4).
Gestiremo inoltre l’evento [caretUpdate] (spostamento del cursore di immissione) sul campo di immissione [jTextFieldHT]. Per creare il gestore di questo evento, procediamo come in precedenza:
 |
Viene generato il gestore dell’evento [caretUpdate] sul campo di immissione [jTextFieldHT]:
Viene generato anche il codice Java che associa il metodo precedente all'evento [caretUpdate] nel campo di immissione [jTextFieldHT]:
Le righe 1-4 indicano che l'evento [caretUpdate] (riga 2) sul pulsante [jTextFieldHT] (riga 1) deve essere gestito dal metodo [ jTextFieldHTCaretUpdate] (riga 3).
5.12.4. Inizializzazione dell'interfaccia grafica
Torniamo all’architettura della nostra applicazione:
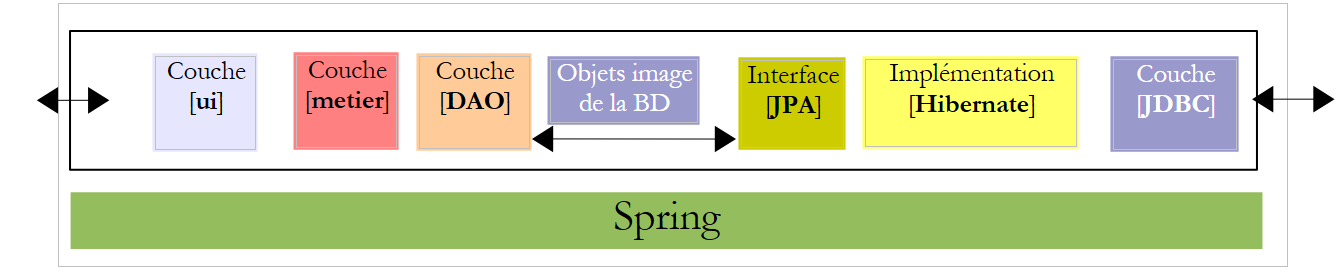 |
Il livello [ui] necessita di un riferimento al livello [metier]. Ricordiamo come tale riferimento era stato ottenuto nell’applicazione console:
Il metodo è lo stesso nell’applicazione grafica. È necessario che, al momento dell’inizializzazione di quest’ultima, venga inizializzato anche il riferimento [IMetier metier] della riga 3 sopra riportata. Il codice generato per l’interfaccia grafica è per ora il seguente:
- righe 29-35: il metodo statico [main] che avvia l'applicazione
- riga 32: viene creata e resa visibile un'istanza dell'interfaccia grafica [PamJFrame].
- righe 7-9: il costruttore dell’interfaccia grafica.
- riga 8: chiamata al metodo [initComponents] definito alla riga 17. Questo metodo è generato automaticamente in base al lavoro svolto in modalità [Design]. Non deve essere modificato.
- riga 21: il metodo che gestirà lo spostamento del cursore di immissione nel campo [jTextFieldHT]
- riga 25: il metodo che gestirà il clic sul pulsante [jButtonSalaire]
Per aggiungere al codice precedente le nostre inizializzazioni, possiamo procedere come segue:
- riga 4: viene chiamato un metodo proprietario per eseguire le nostre inizializzazioni. Queste sono definite dal codice delle righe 10-42
Domanda: avvalendosi dei commenti, completare il codice della procedura [doMyInit].
5.12.5. Gestori di eventi
Domanda: scrivere il metodo [jTextFieldHTCaretUpdate]. Questo metodo deve garantire che, se il dato presente nel campo [jTextFieldHT] non è un numero reale >=0, il pulsante [jButtonSalaire] risulti inattivo.
Domanda: scrivere il metodo [jButtonSalaireActionPerformed] che deve visualizzare la busta paga del dipendente selezionato in [jComboBoxEmployes].
5.12.6. Esecuzione dell'interfaccia grafica
Per eseguire l’interfaccia grafica, si modificherà la configurazione [Run] del progetto:
 |
- in [1], inserire la classe dell’interfaccia grafica
Il progetto deve essere completo con i relativi file di configurazione (persistence.xml, spring-config-metier-dao.xml) e la classe dell'interfaccia grafica. Avviare il target SGBD prima di eseguire il progetto.
5.13. Implementazione del livello JPA con EclipseLink
Ci interessa la seguente architettura in cui il livello JPA è ora implementato da EclipseLink:
 |
5.13.1. Il progetto NetBeans
Il nuovo progetto NetBeans si ottiene copiando il progetto precedente:
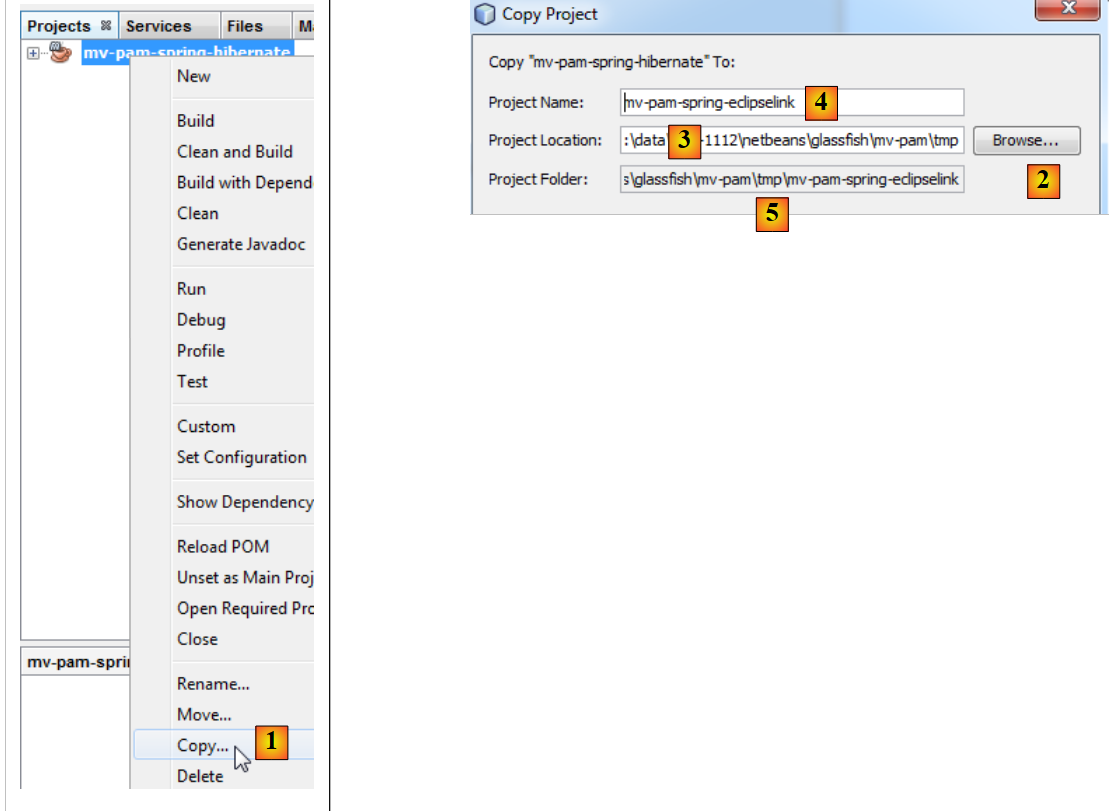 |
- in [1]: dopo aver cliccato con il tasto destro del mouse sul progetto Hibernate, selezionare Copy
- utilizzando il pulsante [2], selezionare la cartella principale del nuovo progetto. Il nome della cartella appare in [3].
- in [4], assegnare un nome al nuovo progetto
- in [5], il nome della cartella del progetto
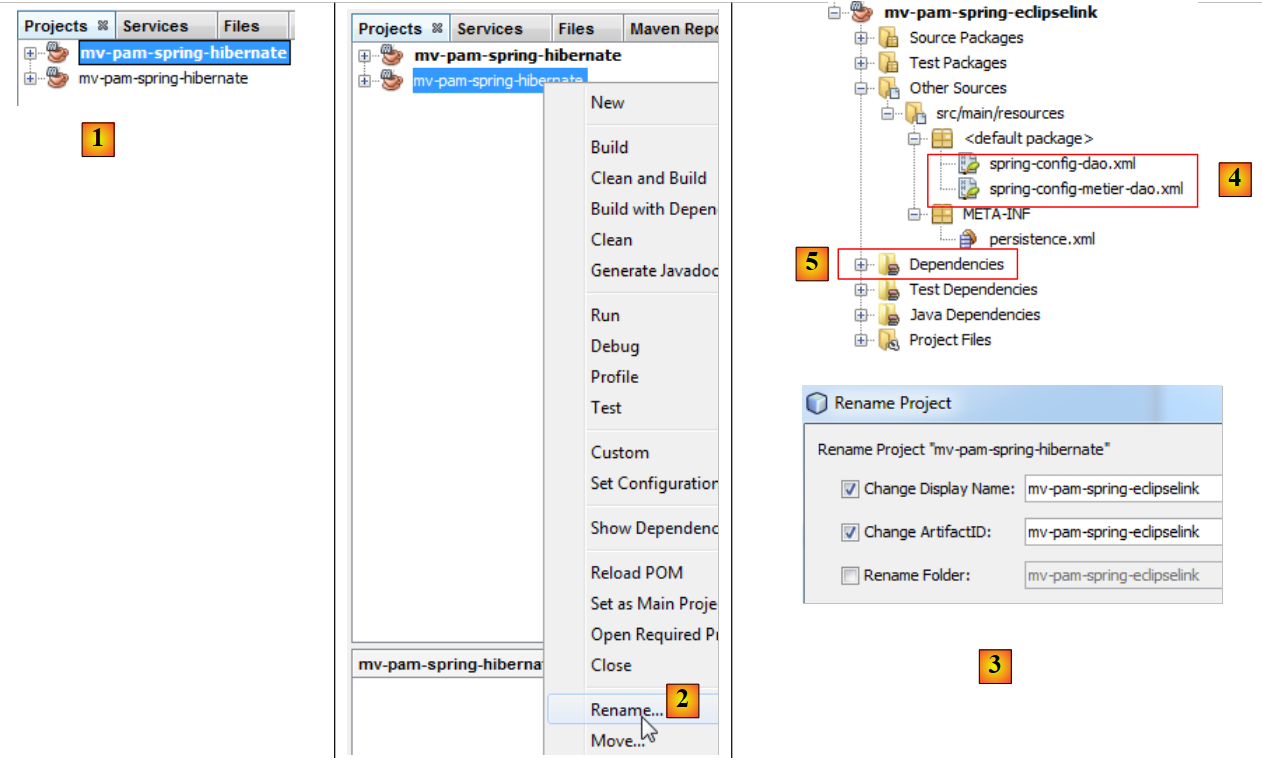 |
- in [1], il nuovo progetto è stato creato. Ha lo stesso nome dell'originale,
- in [2] e [3], lo rinominiamo [mv-pam-spring-eclipselink].
Il progetto deve essere modificato in due punti per adattarlo al nuovo livello JPA / EclipseLink:
- in [4], i file di configurazione di Spring devono essere modificati. In essi è infatti presente la configurazione del livello JPA.
- in [5], le librerie del progetto devono essere modificate: quelle di Hibernate devono essere sostituite con quelle di EclipseLink.
Cominciamo da quest’ultimo punto. Il file [pom.xml] per il nuovo progetto sarà il seguente:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>istia.st</groupId>
<artifactId>mv-pam-spring-eclipselink</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>mv-pam-spring-eclipselink</name>
<url>http://maven.apache.org</url>
<repositories>
<repository>
<url>http://repo1.maven.org/maven2/</url>
<id>swing-layout</id>
<layout>default</layout>
<name>Repository for library Library[swing-layout]</name>
</repository>
<repository>
<url>http://download.eclipse.org/rt/eclipselink/maven.repo/</url>
<id>eclipselink</id>
<layout>default</layout>
<name>Repository for library Library[eclipselink]</name>
</repository>
</repositories>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>4.10</version>
<scope>test</scope>
<type>jar</type>
</dependency>
<dependency>
<groupId>commons-dbcp</groupId>
<artifactId>commons-dbcp</artifactId>
<version>1.2.2</version>
</dependency>
<dependency>
<groupId>commons-pool</groupId>
<artifactId>commons-pool</artifactId>
<version>1.6</version>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-tx</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-beans</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-context</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.springframework</groupId>
<artifactId>spring-orm</artifactId>
<version>3.1.1.RELEASE</version>
<type>jar</type>
</dependency>
<dependency>
<groupId>org.eclipse.persistence</groupId>
<artifactId>eclipselink</artifactId>
<version>2.3.0</version>
</dependency>
<dependency>
<groupId>org.eclipse.persistence</groupId>
<artifactId>javax.persistence</artifactId>
<version>2.0.3</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
<dependency>
<groupId>org.swinglabs</groupId>
<artifactId>swing-layout</artifactId>
<version>1.0.3</version>
</dependency>
</dependencies>
</project>
- righe 73-82: le dipendenze per l’implementazione JPA EclipseLink,
- righe 19-24: il repository Maven per EclipseLink.
I file di configurazione di Spring devono essere modificati per indicare che l'implementazione JPA è cambiata. In entrambi i file, cambia solo la sezione che configura il livello JPA. Ad esempio, in [spring-config-metier-dao.xml] si ha:
Le righe 19-36 configurano il livello JPA. L’implementazione JPA utilizzata è Hibernate (riga 22). Inoltre, il database di destinazione è [dbpam_hibernate] (riga 41).
Per passare a un'implementazione JPA / EclipseLink, le righe 19-35 sopra riportate vengono sostituite dalle righe seguenti:
- riga 5: l’implementazione JPA utilizzata è EclipseLink
- riga 9: la proprietà databasePlatform imposta il SGBD di destinazione, in questo caso MySQL
- riga 11: per generare le tabelle del database quando viene istanziato il livello JPA. In questo caso, la proprietà è commentata.
- riga 7: per visualizzare sulla console i comandi SQL emessi dal livello JPA. In questo caso, la proprietà è commentata.
Inoltre, il database di destinazione diventa [dbpam_eclipselink] (riga 4 qui sotto):
5.13.2. Esecuzione dei test
Prima di testare l’intera applicazione, è opportuno verificare se i test JUnit superano la nuova implementazione JPA. Prima di procedere, si inizierà eliminando le tabelle dal database. A tal fine, nella scheda [Runtime] di NetBeans, se necessario, si creerà una connessione al database dbpam_eclipselink / MySQL5. Una volta connessi al database dbpam_eclipselink / MySQL5, sarà possibile procedere all’eliminazione delle tabelle come illustrato di seguito:
- [1]: prima dell’eliminazione
- [2]: dopo l’eliminazione
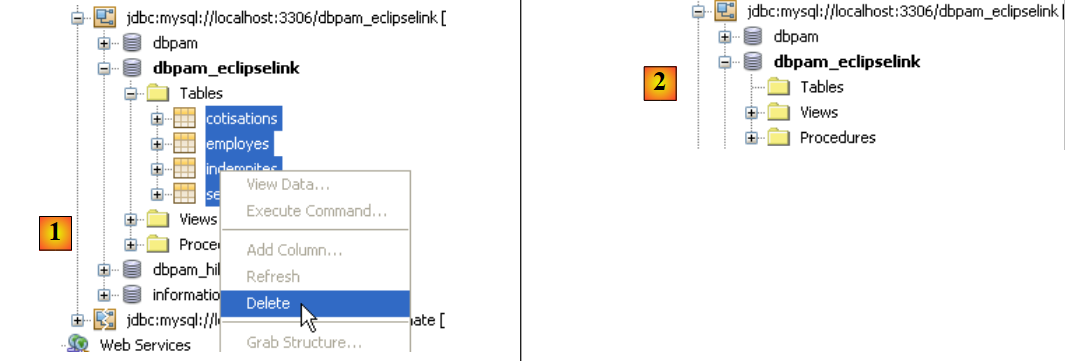 |
Fatto ciò, è possibile eseguire il primo test sul livello [DAO]: InitDB che popola il database. Affinché le tabelle precedentemente eliminate vengano ricreate dall’applicazione, è necessario assicurarsi che nella configurazione JPA / EclipseLink di Spring sia presente la riga:
sia presente e non sia commentata.
Compiliamo il progetto (Build) e poi eseguiamo il test [JUnitInitDB] :
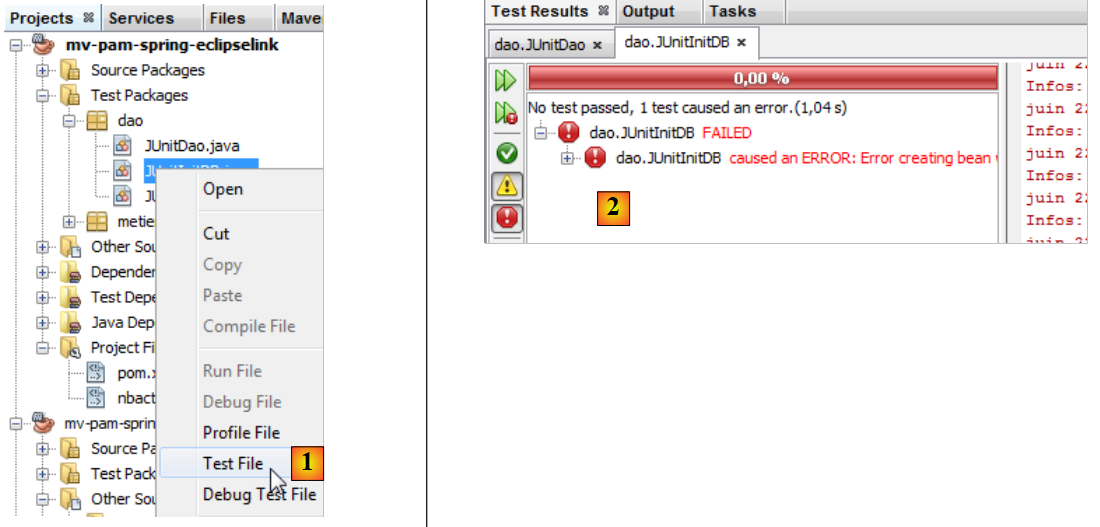 |
- in [1], viene eseguito il test InitDB.
- In [2], il test fallisce. L’eccezione viene generata da Spring e non da un test che avrebbe fallito.
Causa: org.springframework.beans.factory.BeanCreationException: Errore durante la creazione del bean con nome 'entityManagerFactory' definito nella risorsa del percorso di classe [spring-config-DAO.xml]: Chiamata del metodo init non riuscita; l'eccezione annidata è java.lang.IllegalStateException: Per utilizzare InstrumentationLoadTimeWeaver è necessario avviare l'agente Java. Consultare la documentazione di Spring.
Spring segnala un problema di configurazione. Il messaggio non è chiaro. Il motivo dell'eccezione è stato spiegato al paragrafo 3.1.9 di [ref1]. Affinché la configurazione Spring / EclipseLink funzioni, JVM, che esegue l’applicazione, deve essere avviato con un parametro specifico, ovvero un agente Java. Il formato di questo parametro è il seguente:
[spring-agent.jar] è l'agente Java necessario a JVM per gestire la configurazione Spring / EclipseLink.
Quando si esegue un progetto, è possibile passare argomenti a JVM:
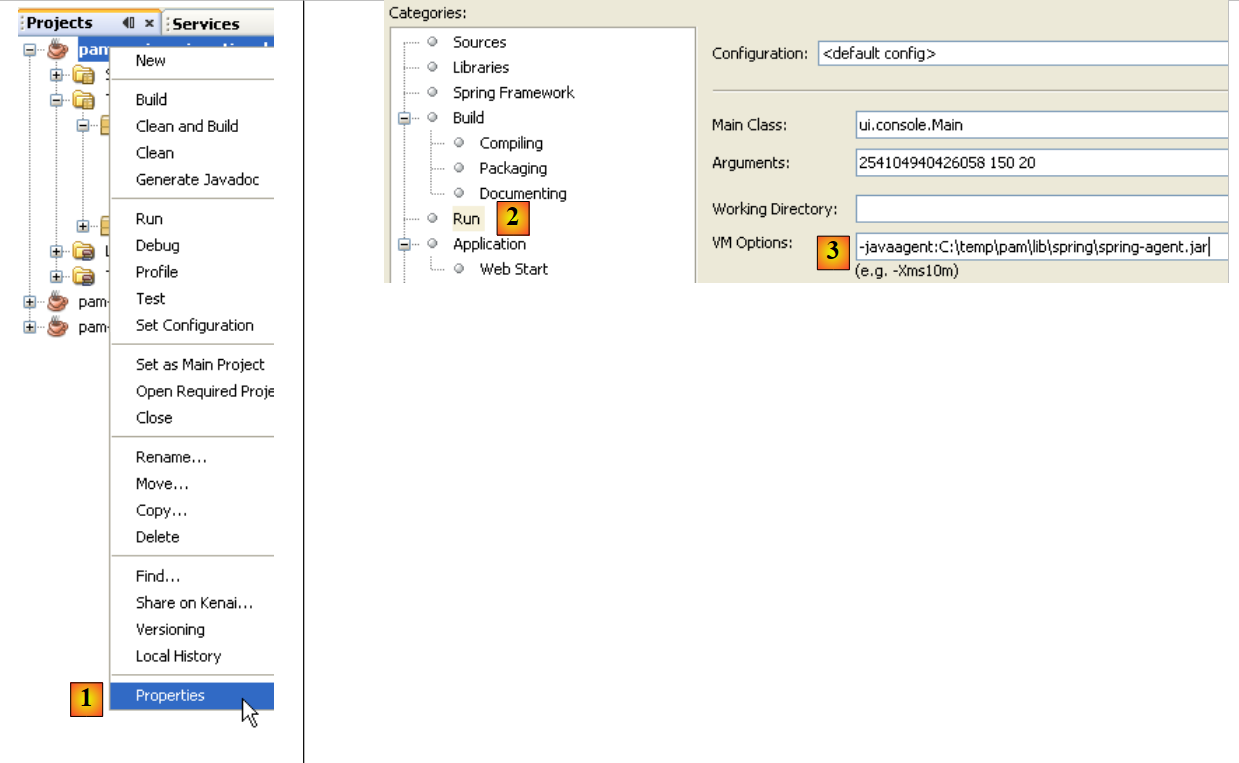 |
- in [1], si accede alle proprietà del progetto
- con [2] si visualizzano le proprietà di Run
- in [3], si passa il parametro -javaagent a JVM
5.13.3. InitDB
Ora siamo pronti per testare nuovamente [InitDB]. Questa volta i risultati ottenuti sono i seguenti:
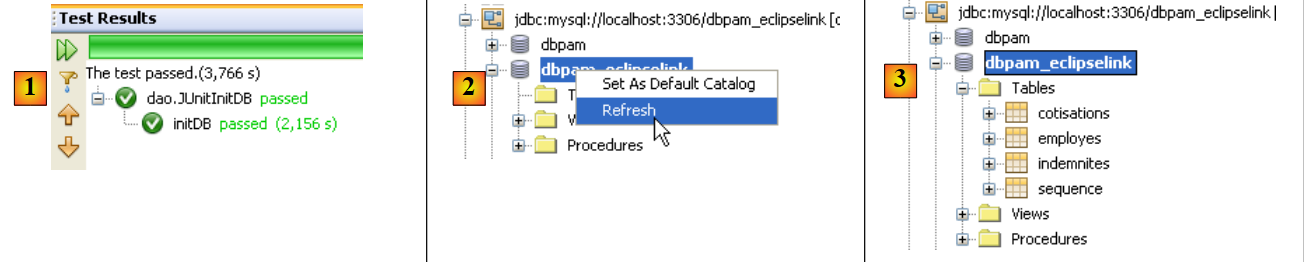 |
- in [1], il test è andato a buon fine
- in [2], nella scheda [Services], si aggiorna la connessione di NetBeans al database [dbpam_eclipselink]
- in [3], sono state create quattro tabelle
 |
- in [5], si visualizza il contenuto della tabella [employes]
- in [6], il risultato.
5.13.4. JUnitDao
L'esecuzione della classe di test [JUnitDao] potrebbe fallire, anche se con l'implementazione JPA / Hibernate aveva avuto esito positivo. Per capire il motivo, analizziamo un esempio.
Il metodo sottoposto a test è il seguente: IndemniteDao.create:
- righe 15-22: il metodo testato
Il metodo di test è il seguente:
package dao;
...
public class JUnitDao {
// livelli DAO
static private IEmployeDao employeDao;
static private IIndemniteDao indemniteDao;
static private ICotisationDao cotisationDao;
@BeforeClass
public static void init() {
// log
log("init");
// configurazione dell'applicazione
ApplicationContext ctx = new ClassPathXmlApplicationContext("spring-config-DAO.xml");
// livelli DAO
employeDao = (IEmployeDao) ctx.getBean("employeDao");
indemniteDao = (IIndemniteDao) ctx.getBean("indemniteDao");
cotisationDao = (ICotisationDao) ctx.getBean("cotisationDao");
}
@Before()
public void clean() {
// svuotamento del database
for (Employe employe : employeDao.findAll()) {
employeDao.destroy(employe);
}
for (Cotisation cotisation : cotisationDao.findAll()) {
cotisationDao.destroy(cotisation);
}
for (Indemnite indemnite : indemniteDao.findAll()) {
indemniteDao.destroy(indemnite);
}
}
// log
private static void log(String message) {
System.out.println("----------- " + message);
}
// test
….
@Test
public void test05() {
log("test05");
// si creano due indennità con lo stesso indice
// violazione del vincolo di unicità dell'indice
boolean erreur = true;
Indemnite indemnite1 = null;
Indemnite indemnite2 = null;
Throwable th = null;
try {
indemnite1 = indemniteDao.create(new Indemnite(1, 1.93, 2, 3, 12));
indemnite2 = indemniteDao.create(new Indemnite(1, 1.93, 2, 3, 12));
erreur = false;
} catch (PamException ex) {
th = ex;
// verifiche
Assert.assertEquals(31, ex.getCode());
} catch (Throwable th1) {
th = th1;
}
// verifiche
Assert.assertTrue(erreur);
// sequenza di eccezioni
System.out.println("Chaîne des exceptions --------------------------------------");
System.out.println(th.getClass().getName());
while (th.getCause() != null) {
th = th.getCause();
System.out.println(th.getClass().getName());
}
// il primo indennizzo doveva essere stato salvato
Indemnite indemnite = indemniteDao.find(indemnite1.getId());
// verifica
Assert.assertNotNull(indemnite);
Assert.assertEquals(1, indemnite.getIndice());
Assert.assertEquals(1.93, indemnite.getBaseHeure(), 1e-6);
Assert.assertEquals(2, indemnite.getEntretienJour(), 1e-6);
Assert.assertEquals(3, indemnite.getRepasJour(), 1e-6);
Assert.assertEquals(12, indemnite.getIndemnitesCP(), 1e-6);
// la seconda indennità non doveva essere salvata
List<Indemnite> indemnites = indemniteDao.findAll();
int nbIndemnites = indemnites.size();
Assert.assertEquals(nbIndemnites, 1);
}
...
}
Domanda: spiegare cosa fa il test test05 e indicare i risultati attesi.
I risultati ottenuti con uno strato JPA / Hibernate sono i seguenti:
Il test viene superato, c.a.d. Le asserzioni sono state verificate e non vi sono eccezioni che escono dal metodo di test.
Domanda: spiegare cosa è successo.
I risultati ottenuti con uno strato JPA / EclipseLink sono i seguenti:
Come in precedenza con Hibernate, il test viene superato, c.a.d. Le asserzioni sono state verificate e non si è verificata alcuna eccezione nel metodo di test.
Domanda: spiegare cosa è successo.
Domanda: da questi due esempi, cosa si può concludere riguardo all’intercambiabilità delle implementazioni JPA? È totale in questo caso?
5.13.5. Gli altri test
Una volta testato e ritenuto corretto il livello [DAO], si potrà passare ai test del livello [metier] e a quelli del progetto stesso nella sua versione da console o grafica. Il cambiamento di implementazione JPA non influisce in alcun modo sui livelli [metier] e [ui] e quindi, se questi livelli funzionavano con Hibernate, funzioneranno con EclipseLink, salvo alcune eccezioni: l’esempio precedente mostra infatti che le eccezioni generate dai livelli [DAO] possono differire. Pertanto, nel caso del test, Spring / JPA / Hibernate genera un'eccezione di tipo [PamException], un'eccezione specifica dell'applicazione [pam], mentre Spring / JPA / EclipseLink genera invece un'eccezione di tipo [TransactionSystemException], un'eccezione del framework Spring. Se, nel caso d’uso del test, il livello [ui] si aspetta un’eccezione di tipo [PamException] perché è stato realizzato con Hibernate, non funzionerà più quando si passerà a EclipseLink.
5.13.6. Compito da svolgere
Esercitazione pratica: ripetere i test delle applicazioni console e swing con diversi SGBD: MySQL5, Oracle XE, SQL Server.