2. Architettura a livelli di un'applicazione Java
Un’applicazione Java è spesso suddivisa in livelli, ciascuno dei quali ha un ruolo ben definito. Consideriamo un’architettura comune, quella a tre livelli:
 |
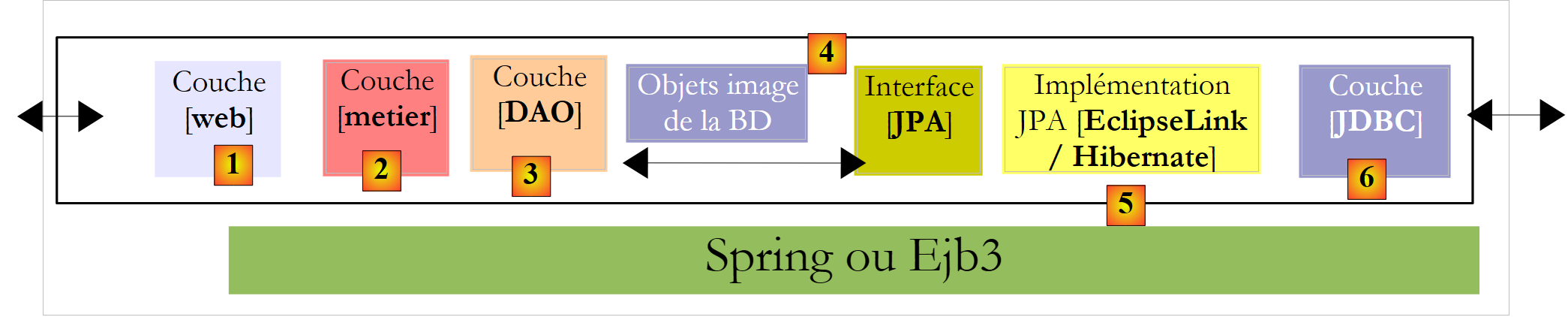
- il livello [1], qui denominato [ui] (User Interface), è il livello che interagisce con l’utente tramite un’interfaccia grafica Swing, un’interfaccia da console o un’interfaccia web. Il suo ruolo è quello di fornire i dati provenienti dall’utente al livello [2] oppure di presentare all’utente i dati forniti dal livello [2].
- Il livello [2], qui denominato [metier], è il livello che applica le cosiddette regole di business, c.a.d. la logica specifica dell’applicazione, senza preoccuparsi della provenienza dei dati che le vengono forniti né della destinazione dei risultati che produce.
- il livello [3], qui denominato [DAO] (Data Access Object), è il livello che fornisce al livello [2] dati pre-registrati (file, database, ...) e che registra alcuni dei risultati forniti dal livello [2].
Esistono diverse possibilità per implementare il livello [DAO]. Esaminiamone alcune:
 |
Il livello [JDBC] sopra indicato è il livello standard utilizzato in Java per accedere ai database. Esso isola il livello [DAO] dal livello SGBD che gestisce il database. In teoria è possibile cambiare il SGBD senza modificare il codice del livello [DAO]. Nonostante questo vantaggio, il API JDBC presenta alcuni svantaggi:
- tutte le operazioni sul SGBD possono generare l’eccezione controllata (checked) SQLException. Ciò obbliga il codice chiamante (in questo caso il livello [DAO]) a racchiuderle in blocchi try/catch, rendendo così il codice piuttosto pesante.
- il livello [DAO] non è completamente indipendente dal SGBD. Questi ultimi, ad esempio, dispongono di metodi proprietari per la generazione automatica dei valori delle chiavi primarie che il livello [DAO] non può ignorare. Pertanto, durante l’inserimento di un record:
- con Oracle, il livello [DAO] deve prima ottenere un valore per la chiave primaria del record e poi inserirlo.
- con SQL Server, il livello [DAO] inserisce il record, al quale viene assegnato automaticamente un valore di chiave primaria dal livello SGBD; tale valore viene poi restituito al livello [DAO].
Queste differenze possono essere eliminate tramite l’uso di procedure memorizzate. Nell’esempio precedente, il livello [DAO] richiamerà una procedura memorizzata in Oracle o in SQL Server che terrà conto delle particolarità del livello SGBD. Queste saranno nascoste al livello [DAO]. Tuttavia, sebbene la modifica di SGBD non comporti la riscrittura del livello [DAO], essa implica comunque la riscrittura delle procedure memorizzate. Ciò potrebbe non essere considerato un ostacolo insormontabile.
Sono stati compiuti numerosi sforzi per isolare il livello [DAO] dagli aspetti proprietari di SGBD. Una soluzione che ha riscosso un vero successo in questo ambito negli ultimi anni è quella di Hibernate:
 |
Il livello [Hibernate] si colloca tra il livello [DAO] scritto dallo sviluppatore e il livello [JDBC]. Hibernate è un ORM (Object Relational Mapper), uno strumento che fa da ponte tra il mondo relazionale dei database e quello degli oggetti gestiti da Java. Lo sviluppatore del livello [DAO] non vede più né il livello [JDBC] né le tabelle del database di cui intende sfruttare il contenuto. Vede solo l’immagine oggetto del database, fornita dal livello [Hibernate]. Il collegamento tra le tabelle del database e gli oggetti gestiti dal livello [DAO] avviene principalmente in due modi:
- tramite file di configurazione di tipo XML
- tramite annotazioni Java nel codice, tecnica disponibile solo a partire dalla versione 1.5 di JDK
Il livello [Hibernate] è un livello di astrazione che mira a essere il più trasparente possibile. L'obiettivo ideale è che lo sviluppatore del livello [DAO] possa ignorare completamente il fatto di lavorare con un database. Ciò è possibile se non è lui a scrivere la configurazione che funge da ponte tra il mondo relazionale e quello degli oggetti. La configurazione di questo ponte è piuttosto complessa e richiede una certa dimestichezza.
Il livello [4] degli oggetti, che rispecchia il BD, è denominato «contesto di persistenza». Un livello [DAO] basato su Hibernate esegue operazioni di persistenza (CRUD: create - read - update - delete) sugli oggetti del contesto di persistenza, azioni tradotte da Hibernate in comandi SQL eseguiti dal livello JDBC. Per le operazioni di interrogazione del database (il SQL Select), Hibernate mette a disposizione dello sviluppatore un linguaggio HQL (Hibernate Query Language) per interrogare il contesto di persistenza [4] e non la BD stessa.
Hibernate è molto diffuso ma complesso da padroneggiare. La curva di apprendimento, spesso descritta come facile, è in realtà piuttosto ripida. Non appena si ha a che fare con un database contenente tabelle con relazioni uno-a-molti o molti-a-molti, la configurazione del ponte relazionale/oggetti non è alla portata del primo principiante che capita. Errori di configurazione possono portare a applicazioni poco performanti.
Visto il successo dei prodotti ORM, Sun, il creatore di Java, ha deciso di standardizzare un livello ORM tramite una specifica denominata JPA (Java Persistence API), apparsa contemporaneamente a Java 5. La specifica JPA è stata implementata da diversi prodotti: Hibernate, Toplink, EclipseLink, OpenJpa, .... Con JPA, l’architettura precedente diventa la seguente:
 |
Il livello [DAO] interagisce ora con la specifica JPA, un insieme di interfacce. Lo sviluppatore ha ottenuto un vantaggio in termini di standardizzazione. In precedenza, se modificava il proprio livello ORM, doveva modificare anche il livello [DAO], che era stato scritto per interagire con uno specifico ORM. Ora scriverà un livello [DAO] che comunicherà con un livello JPA. Indipendentemente dal prodotto che lo implementa, l’interfaccia del livello JPA presentata al livello [DAO] rimane la stessa.
In questo documento utilizzeremo un livello [DAO] basato su un livello JPA/Hibernate o JPA/EclipseLink. Inoltre, utilizzeremo il framework Spring 2.8 per collegare tra loro questi livelli.
 |
Il grande vantaggio di Spring è che consente di collegare i livelli tramite configurazione e non nel codice. Pertanto, se l’implementazione JPA / Hibernate deve essere sostituita da un'implementazione Hibernate senza JPA, perché, ad esempio, l'applicazione viene eseguita in un ambiente JDK 1.4 che non supporta JPA, questo cambiamento nell’implementazione del livello [DAO] non ha alcun impatto sul codice del livello [métier]. Deve essere modificato solo il file di configurazione Spring che collega i livelli tra loro.
Con Java EE 5, esiste un’altra soluzione: implementare i livelli [metier] e [DAO] utilizzando EJB3 (Enterprise Java Bean versione 3):
 |
Vedremo che questa soluzione non è molto diversa da quella che utilizza Spring. L'ambiente Java EE5 è disponibile all'interno dei cosiddetti server applicativi, quali Sun Application Server 9.x (Glassfish), Jboss Application Server, Oracle Container for Java (OC4J), ... Un server di applicazioni è essenzialmente un server di applicazioni web. Esistono anche ambienti EE 5 detti “stand-alone”, c.a.d. che possono essere utilizzati al di fuori di un server applicativo. È il caso di JBoss, EJB3 o OpenEJB.
In un ambiente EE5, i livelli sono implementati da oggetti denominati EJB (Enterprise Java Bean). Nelle versioni precedenti di EE, i EJB (EJB 2.x) erano considerati difficili da implementare, da testare e talvolta poco performanti. Si distinguono i EJB2.x "entity" e i EJB2.x "session". In breve, un EJB2.x "entity" rappresenta una riga di una tabella di database, mentre un EJB2.x "session" è un oggetto utilizzato per implementare i livelli [metier], [DAO] di un’architettura multistrato. Una delle principali critiche mosse ai livelli implementati con EJB è che sono utilizzabili solo all’interno di contenitori EJB, un servizio fornito dall’ambiente EE. Questo ambiente, più complesso da implementare rispetto a un ambiente SE (Standard Edition), può scoraggiare lo sviluppatore dall’effettuare test frequenti. Tuttavia, esistono ambienti di sviluppo Java che facilitano l’utilizzo di un server applicativo automatizzando la distribuzione dei EJB sul server: Eclipse, NetBeans, JDeveloper, IntelliJ e IDEA. In questa sede utilizzeremo NetBeans 6.8 e il server applicativo GlassFish v3.
Il framework Spring è nato in risposta alla complessità dei EJB2. Spring fornisce, in un ambiente SE, un numero significativo dei servizi solitamente forniti dagli ambienti EE. Pertanto, nella sezione “Persistenza dei dati”, Spring fornisce i pool di connessione e i gestori di transazioni necessari alle applicazioni. L’emergere di Spring ha favorito la diffusione dei test unitari, diventati più facili da implementare nel contesto SE rispetto a quello EE. Spring consente l’implementazione dei livelli di un’applicazione tramite oggetti Java classici (POJO, Plain Old/Ordinary Java Object), permettendo il loro riutilizzo in un altro contesto. Infine, integra numerosi strumenti di terze parti in modo abbastanza trasparente, in particolare strumenti di persistenza come Hibernate, EclipseLink, Ibatis, ...
Java EE5 è stato progettato per colmare le lacune della specifica EJB2. I EJB 2.x sono diventati i EJB3. Questi sono POJOs contrassegnati da annotazioni che li rendono oggetti particolari quando si trovano all’interno di un contenitore EJB3. All’interno di quest’ultimo, l’EJB3 potrà usufruire dei servizi del contenitore (pool di connessioni, gestore delle transazioni, ecc.). Al di fuori del contenitore EJB3, l’oggetto EJB3 diventa un normale oggetto Java. Le sue annotazioni EJB vengono ignorate.
Quanto sopra illustra Spring e un contenitore EJB3 come possibile infrastruttura (framework) della nostra architettura multistrato. È questa infrastruttura che fornirà i servizi di cui abbiamo bisogno: un pool di connessioni e un gestore di transazioni.
- Con Spring, i livelli saranno implementati con POJOs. Questi avranno accesso ai servizi di Spring (pool di connessioni, gestore delle transazioni) tramite l’iniezione di dipendenze in questi POJOs: durante la loro creazione, Spring inietta in essi i riferimenti ai servizi di cui avranno bisogno.
- Con il contenitore EJB3, i livelli saranno implementati con EJB. Un’architettura a livelli implementata con EJB3 è poco diversa da quella implementata con POJO istanziati da Spring. Troveremo molte somiglianze.
- Per concludere, presenteremo un esempio di applicazione web multistrato:
 |