4. e JPA: una panoramica
Il nostro obiettivo è quello di introdurre JPA (Java Persistence API) con alcuni esempi. JPA è trattato nel corso:
- Java 5 Persistence in Practice: [http://tahe.developpez.com/java/jpa] - fornisce gli strumenti per costruire il livello di accesso ai dati con JPA
4.1. Il ruolo di JPA in un'architettura a livelli
Si invitano i lettori a rileggere l'inizio di questo documento (paragrafo 2), che spiega il ruolo del livello JPA in un'architettura a livelli. Il livello JPA fa parte dei livelli di accesso ai dati:
 |
Il livello [DAO] interagisce con la specifica JPA. Indipendentemente dal prodotto che la implementa, l'interfaccia del livello JPA presentata al livello [DAO] rimane la stessa. Di seguito, presentiamo alcuni esempi tratti da [rif1] che ci aiuteranno a costruire il nostro livello JPA.
4.2. JPA - Esempi
4.2.1. Esempio 1 - Rappresentazione a oggetti di una singola tabella
4.2.1.1. La tabella [person]
Consideriamo un database con una singola tabella [person] il cui ruolo è quello di memorizzare alcune informazioni relative alle persone:
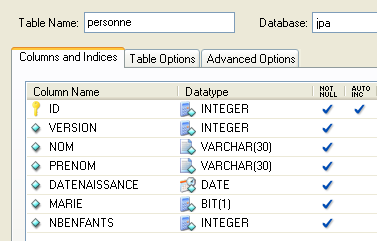 |
chiave primaria della tabella | |
versione della riga nella tabella. Ogni volta che la persona viene modificata, il numero di versione viene incrementato. | |
cognome della persona | |
nome | |
la loro data di nascita | |
numero intero 0 (non sposato) o 1 (sposato) | |
numero di figli |
4.2.1.2. L'entità [Persona]
Ci troviamo nel seguente ambiente di runtime:
 |
Il livello JPA [5] deve fungere da ponte tra il mondo relazionale del database [7] e il mondo degli oggetti [4] manipolati dai programmi Java [3]. Questo ponte viene stabilito tramite configurazione, e ci sono due modi per farlo:
- utilizzando file XML. Questo era praticamente l'unico modo per farlo fino all'avvento di JDK 1.5
- utilizzando le annotazioni Java a partire da JDK 1.5
In questo documento utilizzeremo esclusivamente il secondo metodo.
L'oggetto [Person] che rappresenta la tabella [person] presentata in precedenza potrebbe essere il seguente:
...
@SuppressWarnings("unused")
@Entity
@Table(name="Personne")
public class Personne implements Serializable{
@Id
@Column(name = "ID", nullable = false)
@GeneratedValue(strategy = GenerationType.AUTO)
private Integer id;
@Column(name = "VERSION", nullable = false)
@Version
private int version;
@Column(name = "NOM", length = 30, nullable = false, unique = true)
private String nom;
@Column(name = "PRENOM", length = 30, nullable = false)
private String prenom;
@Column(name = "DATENAISSANCE", nullable = false)
@Temporal(TemporalType.DATE)
private Date datenaissance;
@Column(name = "MARIE", nullable = false)
private boolean marie;
@Column(name = "NBENFANTS", nullable = false)
private int nbenfants;
// manufacturers
public Personne() {
}
public Personne(String nom, String prenom, Date datenaissance, boolean marie,
int nbenfants) {
setNom(nom);
setPrenom(prenom);
setDatenaissance(datenaissance);
setMarie(marie);
setNbenfants(nbenfants);
}
// toString
public String toString() {
...
}
// getters and setters
...
}
La configurazione viene eseguita utilizzando le annotazioni Java (@Annotation). Le annotazioni Java vengono elaborate dal compilatore o da strumenti specializzati in fase di esecuzione. A parte l'annotazione alla riga 3 destinata al compilatore, tutte le annotazioni qui presenti sono destinate all'implementazione JPA in uso, Hibernate o Toplink. Verranno quindi elaborate in fase di esecuzione. In assenza di strumenti in grado di interpretarle, queste annotazioni vengono ignorate. Pertanto, la classe [Person] sopra riportata potrebbe essere utilizzata in un contesto non JPA.
Esistono due casi distinti per l'utilizzo delle annotazioni JPA in una classe C associata a una tabella T:
- la tabella T esiste già: le annotazioni JPA devono quindi replicare la struttura esistente (nomi e definizioni delle colonne, vincoli di integrità, chiavi esterne, chiavi primarie, ecc.)
- la tabella T non esiste e verrà creata in base alle annotazioni presenti nella classe C.
Il caso 2 è il più semplice da gestire. Utilizzando le annotazioni JPA, specifichiamo la struttura della tabella T che desideriamo. Il caso 1 è spesso più complesso. La tabella T potrebbe essere stata creata molto tempo fa al di fuori di qualsiasi contesto JPA. La sua struttura potrebbe quindi non essere adatta al ponte relazionale-oggetto di JPA. Per semplificare le cose, ci concentreremo sul caso 2, in cui la tabella T associata alla classe C verrà creata in base alle annotazioni JPA nella classe C.
Esaminiamo le annotazioni JPA della classe [Person]:
- riga 4: l'annotazione @Entity è la prima annotazione essenziale. È posizionata prima della riga che dichiara la classe e indica che la classe in questione deve essere gestita dal livello di persistenza JPA. Senza questa annotazione, tutte le altre annotazioni JPA verrebbero ignorate.
- riga 5: l'annotazione @Table designa la tabella del database che la classe rappresenta. Il suo argomento principale è name, che specifica il nome della tabella. Senza questo argomento, la tabella prenderà il nome dalla classe, in questo caso [Person]. Nel nostro esempio, l'annotazione @Table è quindi superflua.
- Riga 8: l'annotazione @Id viene utilizzata per designare il campo nella classe che corrisponde alla chiave primaria della tabella. Questa annotazione è obbligatoria. Qui, indica che il campo id alla riga 11 corrisponde alla chiave primaria della tabella.
- Riga 9: L'annotazione @Column viene utilizzata per collegare un campo della classe alla colonna della tabella che il campo rappresenta. L'attributo name specifica il nome della colonna nella tabella. Se questo attributo viene omesso, alla colonna viene assegnato lo stesso nome del campo. Nel nostro esempio, l'argomento name era quindi facoltativo. L'argomento nullable=false specifica che la colonna associata al campo non può avere un valore NULL e che il campo deve quindi avere un valore.
- Riga 10: L'annotazione @GeneratedValue specifica come viene generata la chiave primaria quando questa viene generata automaticamente dal DBMS. Questo sarà il caso in tutti i nostri esempi. Non è obbligatoria. Pertanto, la nostra classe Person potrebbe avere un ID studente che funge da chiave primaria e che non viene generato dal DBMS, ma impostato dall'applicazione. In questo caso, l'annotazione @GeneratedValue verrebbe omessa. L'argomento strategy specifica come viene generata la chiave primaria quando generata dal DBMS. Non tutti i DBMS utilizzano la stessa tecnica per generare i valori delle chiavi primarie. Ad esempio:
utilizza un generatore di valori chiamato prima di ogni inserimento | |
il campo della chiave primaria è definito con il tipo Identity. Il risultato è simile al generatore di valori di Firebird, tranne per il fatto che il valore della chiave non è noto fino a quando la riga non viene inserita. | |
utilizza un oggetto chiamato SEQUENCE, che funge a sua volta da generatore di valori |
Il livello JPA deve generare diverse istruzioni SQL a seconda del DBMS per creare il generatore di valori. È configurato per specificare il tipo di DBMS che deve gestire. Di conseguenza, può determinare la strategia standard per la generazione dei valori delle chiavi primarie per quel DBMS. L'argomento strategy = GenerationType.*****AUTO* indica al livello JPA di utilizzare questa strategia standard. Questa tecnica ha funzionato in tutti gli esempi presenti in questo documento per i sette DBMS utilizzati.
- Riga 14: L'annotazione @Version designa il campo utilizzato per gestire l'accesso simultaneo alla stessa riga nella tabella.
Per comprendere la questione dell'accesso simultaneo alla stessa riga nella tabella [person], supponiamo che un'applicazione web consenta l'aggiornamento delle informazioni di una persona e consideriamo il seguente scenario:
Al momento T1, l'utente U1 inizia a modificare una persona P. In questo momento, il numero di figli è 0. Modifica questo numero in 1, ma prima di inviare le modifiche, l'utente U2 inizia a modificare la stessa persona P. Poiché U1 non ha ancora inviato le modifiche, U2 vede il numero di figli come 0 sul proprio schermo. U2 cambia il nome della persona P in maiuscolo. Quindi U1 e U2 salvano le loro modifiche in quell'ordine. La modifica di U2 avrà la precedenza: nel database, il nome sarà in maiuscolo e il numero di figli rimarrà a zero, anche se U1 crede di averlo cambiato in 1.
Il concetto di versione di una persona ci aiuta a risolvere questo problema. Rivediamo lo stesso caso d'uso:
Al momento T1, un utente U1 inizia a modificare una persona P. A questo punto, il numero di figli è 0 e la versione è V1. Modifica il numero di figli in 1, ma prima di confermare la modifica, un utente U2 inizia a modificare la stessa persona P. Poiché U1 non ha ancora confermato la modifica, U2 vede il numero di figli come 0 e la versione come V1. U2 cambia il nome della persona P in maiuscolo. Quindi U1 e U2 salvano le loro modifiche in quell'ordine. Prima di salvare una modifica, verifichiamo che l'utente che modifica la persona P abbia la stessa versione di quella attualmente salvata della persona P. Questo sarà il caso dell'utente U1. La sua modifica viene quindi accettata, e cambiamo quindi la versione della persona modificata da V1 a V2 per indicare che la persona ha subito una modifica. Nel convalidare la modifica di U2, noteremo che U2 ha la versione V1 della persona P, mentre la versione attuale è V2. Possiamo quindi informare l'utente U2 che qualcun altro ha agito prima di lui e che deve partire dalla nuova versione della persona P. Lo farà, recupererà una versione V2 della persona P che ora ha un figlio, scriverà il nome in maiuscolo e convaliderà. La sua modifica sarà accettata se la persona P registrata è ancora nella versione V2. In definitiva, le modifiche apportate da U1 e U2 saranno prese in considerazione, mentre nel caso d'uso senza versioni, una delle modifiche sarebbe andata persa.
Il livello [DAO] dell'applicazione client può gestire la versione della classe [Person] stessa. Ogni volta che un oggetto P viene modificato, la versione di quell'oggetto verrà incrementata di 1 nella tabella. L'annotazione @Version consente di trasferire questa gestione al livello JPA. Il campo in questione non deve necessariamente chiamarsi "version" come nell'esempio. Può avere qualsiasi nome.
I campi corrispondenti alle annotazioni @Id e @Version sono presenti a fini di persistenza. Non sarebbero necessari se la classe [Person] non dovesse essere persistita. Possiamo quindi vedere che un oggetto è rappresentato in modo diverso a seconda che debba o meno essere persistito.
- Riga 17: Ancora una volta, l'annotazione @Column fornisce informazioni sulla colonna nella tabella [person] associata al campo name della classe Person. Qui troviamo due nuovi argomenti:
- unique=true indica che il nome di una persona deve essere univoco. Ciò comporterà l'aggiunta di un vincolo di unicità sulla colonna NAME della tabella [person] nel database.
- length=30 imposta il numero di caratteri nella colonna NAME a 30. Ciò significa che il tipo di questa colonna sarà VARCHAR(30).
- Riga 24: L'annotazione @Temporal viene utilizzata per specificare il tipo SQL per una colonna o un campo data/ora. Il tipo TemporalType.DATE indica una data senza un'ora associata. Gli altri tipi possibili sono TemporalType.TIME per la codifica di un'ora e TemporalType.TIMESTAMP per la codifica di una data e un'ora.
Commentiamo ora il resto del codice nella classe [Person]:
- Riga 6: La classe implementa l'interfaccia Serializable. La serializzazione di un oggetto comporta la sua conversione in una sequenza di bit. La deserializzazione è l'operazione inversa. La serializzazione/deserializzazione è utilizzata in particolare nelle applicazioni client/server in cui gli oggetti vengono scambiati in rete. Le applicazioni client o server non sono a conoscenza di questa operazione, che viene eseguita in modo trasparente dalle JVM. Affinché ciò sia possibile, tuttavia, le classi degli oggetti scambiati devono essere "contrassegnate" con la parola chiave Serializable.
- Riga 37: un costruttore per la classe. Si noti che i campi id e version non sono inclusi tra i parametri. Questo perché questi due campi sono gestiti dal livello JPA e non dall'applicazione.
- Righe 51 e seguenti: i metodi get e set per ciascuno dei campi della classe. Si noti che le annotazioni JPA possono essere posizionate sui metodi get dei campi anziché sui campi stessi. La posizione delle annotazioni indica la modalità che JPA deve utilizzare per accedere ai campi:
- se le annotazioni sono posizionate a livello di campo, JPA accederà direttamente ai campi per leggerli o scriverli
- se le annotazioni sono posizionate a livello di get, JPA accederà ai campi tramite i metodi get/set per leggerli o scriverli
La posizione dell'annotazione @Id determina la collocazione delle annotazioni JPA in una classe. Quando è collocata a livello di campo, indica l'accesso diretto ai campi; quando è collocata a livello di get, indica l'accesso ai campi tramite i metodi get e set. Le altre annotazioni devono quindi essere collocate allo stesso modo dell'annotazione @Id.
4.2.2. Configurazione del livello JPA
I test del livello JPA possono essere eseguiti utilizzando la seguente architettura:
 |
- in [7]: il database che verrà generato dalle annotazioni dell'entità [Person] e dalle configurazioni aggiuntive effettuate in un file denominato [persistence.xml]
- in [5, 6]: un livello JPA implementato da Hibernate
- in [4]: l'entità [Person]
- in [3]: un programma di test basato su console
Il livello JPA è configurato tramite il file [META-INF/persistence.xml]:
 |
Durante l'esecuzione, il file [META-INF/persistence.xml] viene cercato nel classpath dell'applicazione.
Esaminiamo la configurazione del livello JPA nel file [persistence.xml] del nostro progetto:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="1.0" xmlns="http://java.sun.com/xml/ns/persistence">
<persistence-unit name="jpa" transaction-type="RESOURCE_LOCAL">
<!-- provider -->
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<!-- Persistent classes -->
<property name="hibernate.archive.autodetection" value="class, hbm" />
<!-- logs SQL
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
<property name="use_sql_comments" value="true"/>
-->
<!-- connection JDBC -->
<property name="hibernate.connection.driver_class" value="com.mysql.jdbc.Driver" />
<property name="hibernate.connection.url" value="jdbc:mysql://localhost:3306/jpa" />
<property name="hibernate.connection.username" value="jpa" />
<property name="hibernate.connection.password" value="jpa" />
<!-- automatic schematic creation -->
<property name="hibernate.hbm2ddl.auto" value="create" />
<!-- Dialect -->
<property name="hibernate.dialect" value="org.hibernate.dialect.MySQL5InnoDBDialect" />
<!-- properties DataSource c3p0 -->
<property name="hibernate.c3p0.min_size" value="5" />
<property name="hibernate.c3p0.max_size" value="20" />
<property name="hibernate.c3p0.timeout" value="300" />
<property name="hibernate.c3p0.max_statements" value="50" />
<property name="hibernate.c3p0.idle_test_period" value="3000" />
</properties>
</persistence-unit>
</persistence>
Per comprendere questa configurazione, dobbiamo riesaminare l'architettura di accesso ai dati della nostra applicazione:
 |
- il file [persistence.xml] configura i livelli [4, 5, 6]
- [4]: implementazione JPA di Hibernate
- [5]: Hibernate accede al database tramite un pool di connessioni. Un pool di connessioni è un insieme di connessioni aperte al DBMS. Un DBMS è accessibile da più utenti, ma per motivi di prestazioni non può superare un limite N di connessioni aperte contemporaneamente. Un codice ben scritto apre una connessione al DBMS per il tempo minimo necessario: esegue i comandi SQL e chiude la connessione. Lo farà ripetutamente, ogni volta che dovrà lavorare con il database. Il costo dell’apertura e della chiusura di una connessione non è trascurabile, ed è qui che entra in gioco il pool di connessioni. All’avvio dell’applicazione, il pool di connessioni apre N1 connessioni al DBMS. L’applicazione richiede una connessione aperta dal pool ogni volta che ne ha bisogno. La connessione viene restituita al pool non appena l'applicazione non ne ha più bisogno, preferibilmente il più rapidamente possibile. La connessione non viene chiusa e rimane disponibile per l'utente successivo. Un pool di connessioni è quindi un sistema per la condivisione delle connessioni aperte.
- [6]: il driver JDBC per il DBMS in uso
Vediamo ora come il file [persistence.xml] configura i livelli [4, 5, 6] sopra indicati:
- riga 2: il tag radice del file XML è <persistence>.
- riga 3: <persistence-unit> viene utilizzato per definire un'unità di persistenza. Possono esserci più unità di persistenza. Ognuna ha un nome (attributo name) e un tipo di transazione (attributo transaction-type). L'applicazione accederà all'unità di persistenza tramite il suo nome, in questo caso jpa. Il tipo di transazione RESOURCE_LOCAL indica che l'applicazione gestisce le transazioni con il DBMS stesso. Questo sarà il caso qui. Quando l'applicazione viene eseguita in un contenitore EJB3, può utilizzare il servizio di transazione del contenitore. In questo caso, imposteremo transaction-type=JTA (Java Transaction API). JTA è il valore predefinito quando l'attributo transaction-type viene omesso.
- Riga 5: Il tag <provider> viene utilizzato per definire una classe che implementa l'interfaccia [javax.persistence.spi.PersistenceProvider], che consente all'applicazione di inizializzare il livello di persistenza. Poiché stiamo utilizzando un'implementazione JPA/Hibernate, la classe utilizzata qui è una classe Hibernate.
- Riga 6: Il tag <properties> introduce proprietà specifiche del provider scelto. Pertanto, a seconda che abbiate scelto Hibernate, TopLink, Kodo, ecc., avrete proprietà diverse. Quelle che seguono sono specifiche di Hibernate.
- Riga 8: Indica a Hibernate di scansionare il classpath del progetto per trovare le classi annotate con @Entity in modo che possano essere gestite. Le classi @Entity possono anche essere dichiarate utilizzando i tag <class>class_name</class>, direttamente sotto il tag <persistence-unit>. Questo è ciò che faremo con il provider JPA/Toplink.
- Le righe 10-12, qui commentate, configurano i log della console di Hibernate:
- Riga 10: per abilitare o disabilitare la visualizzazione delle istruzioni SQL inviate da Hibernate al DBMS. Ciò è molto utile durante la fase di apprendimento. Grazie al ponte relazionale/oggetto, l'applicazione opera su oggetti persistenti ai quali applica operazioni quali [persist, merge, remove]. È molto utile sapere quali istruzioni SQL vengono effettivamente inviate per queste operazioni. Studiandole, si impara gradualmente ad anticipare le istruzioni SQL che Hibernate genererà quando esegue tali operazioni sugli oggetti persistenti, e il ponte relazionale/oggetto comincia a prendere forma nella mente.
- Riga 11: Le istruzioni SQL visualizzate sulla console possono essere formattate in modo ordinato per renderle più facili da leggere
- Riga 12: Le istruzioni SQL visualizzate saranno anche annotate
- Le righe 15–19 definiscono il livello JDBC (livello [6] nell'architettura):
- riga 15: la classe del driver JDBC per il DBMS, in questo caso MySQL5
- riga 16: l'URL del database in uso
- Righe 17, 18: nome utente e password di connessione
- riga 22: Hibernate deve sapere con quale DBMS sta lavorando. Questo perché tutti i DBMS hanno estensioni SQL proprietarie — come i propri metodi per generare automaticamente i valori delle chiavi primarie — il che significa che Hibernate deve identificare il DBMS specifico per inviare istruzioni SQL che possa comprendere. [MySQL5InnoDBDialect] si riferisce al DBMS MySQL5 con tabelle InnoDB che supportano le transazioni.
- Le righe 24-28 configurano il pool di connessioni c3p0 (livello [5] nell'architettura):
- Righe 24, 25: il numero minimo (predefinito 3) e massimo di connessioni (predefinito 15) nel pool. Il numero iniziale predefinito di connessioni è 3.
- Riga 26: tempo massimo di attesa in millisecondi per una richiesta di connessione da parte del client. Trascorso questo timeout, c3p0 restituirà un'eccezione.
- Riga 27: Per accedere al database, Hibernate utilizza istruzioni SQL preparate (PreparedStatement) che c3p0 può memorizzare nella cache. Ciò significa che se l'applicazione richiede una seconda volta un'istruzione SQL preparata già presente nella cache, non sarà necessario prepararla nuovamente (la preparazione di un'istruzione SQL comporta un costo) e verrà utilizzata quella presente nella cache. Qui specifichiamo il numero massimo di istruzioni SQL preparate che la cache può contenere, su tutte le connessioni (un'istruzione SQL preparata appartiene a una singola connessione).
- Riga 28: Frequenza in millisecondi per il controllo della validità delle connessioni. Una connessione nel pool può diventare non valida per vari motivi (il driver JDBC invalida la connessione perché è rimasta aperta troppo a lungo, il driver JDBC presenta dei "bug", ecc.).
- Riga 20: Qui specifichiamo che, all'inizializzazione del livello di persistenza, deve essere generato lo schema del database per gli oggetti @Entity. Hibernate dispone ora di tutti gli strumenti per generare le istruzioni SQL per la creazione delle tabelle del database:
- la configurazione degli oggetti @Entity gli consente di determinare quali tabelle generare
- Le righe 15–18 e 24–28 gli consentono di stabilire una connessione con il DBMS
- la riga 22 indica quale dialetto SQL utilizzare per generare le tabelle
Pertanto, il file [persistence.xml] qui utilizzato ricrea un nuovo database ogni volta che l'applicazione viene eseguita. Le tabelle vengono ricreate (create table) dopo essere state eliminate (drop table), se esistevano. Si noti che questo ovviamente non è qualcosa da fare con un database di produzione...
4.2.3. Esempio 2: Relazione uno-a-molti
4.2.3.1. Il file dello schema del database [
1 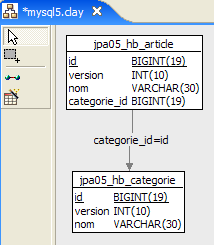 | 2 |
- in [1], il database, e in [2], il suo DDL (MySQL5)
Un articolo A(id, versione, nome) appartiene esattamente a una categoria C(id, versione, nome). Una categoria C può contenere 0, 1 o più articoli. Abbiamo una relazione uno-a-molti (Categoria -> Articolo) e la relazione inversa molti-a-uno (Articolo -> Categoria). Questa relazione è rappresentata dalla chiave esterna che la tabella [articolo] possiede sulla tabella [categoria] (righe 24–28 del DDL).
4.2.3.2. Gli oggetti @Entity che rappresentano il database
Un articolo è rappresentato dal seguente @Entity [Article]:
package entites;
...
@Entity
@Table(name="jpa05_hb_article")
public class Article implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// main relationship Article (many) -> Category (one)
// implemented by a foreign key (categorie_id) in Article
// 1 Article must have 1 Category (nullable=false)
@ManyToOne(fetch=FetchType.LAZY)
@JoinColumn(name = "categorie_id", nullable = false)
private Categorie categorie;
// manufacturers
public Article() {
}
// getters and setters
...
// toString
public String toString() {
return String.format("Article[%d,%d,%s,%d]", id, version, nom, categorie.getId());
}
}
- righe 9-11: chiave primaria dell'@Entity
- righe 13-15: il suo numero di versione
- righe 17-18: nome dell'articolo
- righe 20-25: relazione molti-a-uno che collega l'@Entity Article all'@Entity Category:
- riga 23: l'annotazione ManyToOne. Il Many si riferisce all'@Entity Article in cui ci troviamo, mentre il One si riferisce all'@Entity Category (riga 25). Una categoria (One) può avere più articoli (Many).
- riga 24: l'annotazione ManyToOne definisce la colonna della chiave esterna nella tabella [article]. Si chiamerà (name) categorie_id e ogni riga dovrà avere un valore in questa colonna (nullable=false).
- Riga 25: la categoria a cui appartiene l'articolo. Quando un articolo viene aggiunto al contesto di persistenza, richiediamo che la sua categoria non venga aggiunta immediatamente (fetch=FetchType.LAZY, riga 23). Non sappiamo se questa richiesta abbia senso. Vedremo.
Una categoria è rappresentata dalla seguente @Entity [Category]:
package entites;
...
@Entity
@Table(name="jpa05_hb_categorie")
public class Categorie implements Serializable {
// fields
@Id
@GeneratedValue(strategy = GenerationType.AUTO)
private Long id;
@SuppressWarnings("unused")
@Version
private int version;
@Column(length = 30)
private String nom;
// inverse relationship Category (one) -> Article (many) from relationship Article (many) -> Category (one)
// cascade insertion Category -> insertion Articles
// cascade maj Category -> maj Articles
// cascade delete Category -> delete Articles
@OneToMany(mappedBy = "categorie", cascade = { CascadeType.ALL })
private Set<Article> articles = new HashSet<Article>();
// manufacturers
public Categorie() {
}
// getters and setters
...
// toString
public String toString() {
return String.format("Categorie[%d,%d,%s]", id, version, nom);
}
// bidirectional association Category <--> Article
public void addArticle(Article article) {
// the item is added to the collection of items in the category
articles.add(article);
// article changes category
article.setCategorie(this);
}
}
- righe 8-11: la chiave primaria dell'@Entity
- righe 12-14: la sua versione
- righe 16-17: il nome della categoria
- righe 19-24: l'insieme degli articoli nella categoria
- riga 23: l'annotazione @OneToMany denota una relazione uno-a-molti. Il "One" si riferisce all'@Entity [Category] in cui ci troviamo, mentre il "Many" si riferisce al tipo [Article] alla riga 24: una (One) categoria ha molti (Many) articoli.
- riga 23: l'annotazione è l'inverso (mappedBy) dell'annotazione ManyToOne posta sul campo category dell'@Entity Article: mappedBy=category. La relazione ManyToOne posta sul campo category dell'@Entity Article è la relazione primaria. È essenziale. Implementa la relazione di chiave esterna che collega l'@Entity Article all'@Entity Category. La relazione OneToMany inserita nel campo articles dell'@Entity Category è la relazione inversa. Non è essenziale. È una comodità per recuperare gli articoli di una categoria. Senza questa comodità, questi articoli verrebbero recuperati tramite una query JPQL.
- Riga 23: cascadeType.ALL garantisce che le operazioni (persist, merge, remove) eseguite su un @Entity Category siano propagate ai suoi articoli.
- Riga 24: Gli articoli di una categoria saranno inseriti in un oggetto di tipo `Set<Article>`. Il tipo `Set` non ammette duplicati. Pertanto, lo stesso articolo non può essere aggiunto due volte all'oggetto `Set<Article>`. Cosa si intende per "lo stesso articolo"? Per indicare che l'articolo `a` è uguale all'articolo `b`, Java utilizza l'espressione `a.equals(b)`. Nella classe Object, la classe padre di tutte le classi, a.equals(b) è vero se a==b, ovvero se gli oggetti a e b hanno la stessa posizione in memoria. Si potrebbe voler dire che gli elementi a e b sono uguali se hanno lo stesso nome. In questo caso, lo sviluppatore deve ridefinire due metodi nella classe [Item]:
- equals: che deve restituire true se i due elementi hanno lo stesso nome
- hashCode: deve restituire lo stesso valore intero per due oggetti [Articolo] che il metodo equals considera uguali. Qui, il valore sarà quindi costruito a partire dal nome dell'articolo. Il valore restituito da hashCode può essere un numero intero qualsiasi. Viene utilizzato in vari contenitori di oggetti, in particolare nei dizionari (Hashtable).
La relazione OneToMany può utilizzare tipi diversi da Set per memorizzare il Many, come gli oggetti List. Non tratteremo questi casi in questo documento. Il lettore può trovarli in [ref1].
- Riga 38: Il metodo [addArticle] ci permette di aggiungere un articolo a una categoria. Il metodo garantisce che entrambe le estremità della relazione OneToMany che collega [Category] ad [Article] vengano aggiornate.
4.3. L'API del livello JPA
Chiariamo l'ambiente di runtime di un client JPA:
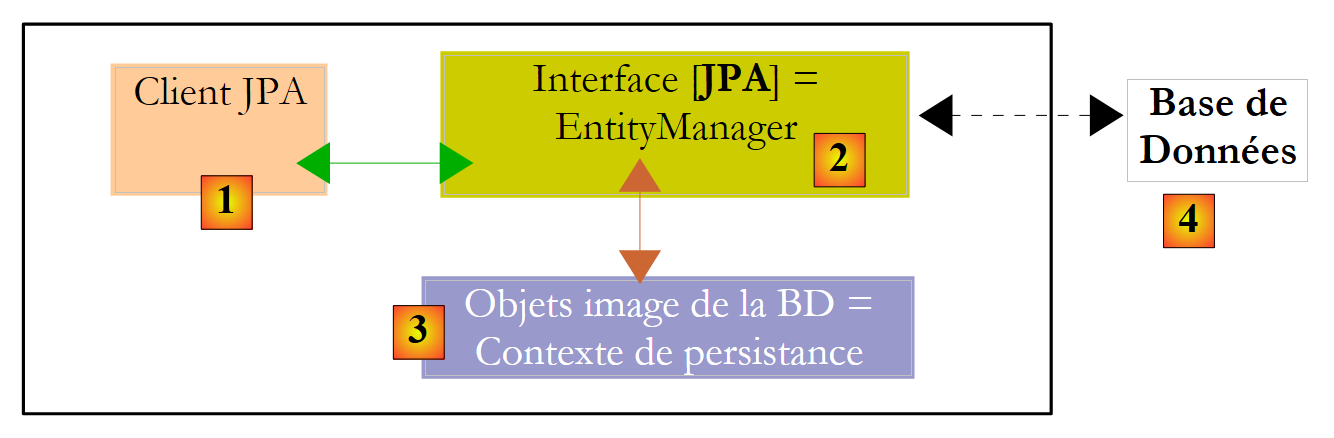 |
Sappiamo che il livello JPA [2] crea un ponte tra il dominio degli oggetti [3] e quello relazionale [4]. L'insieme di oggetti gestiti dal livello JPA all'interno di questo ponte oggetto/relazionale è chiamato "contesto di persistenza". Per accedere ai dati nel contesto di persistenza, un client JPA [1] deve passare attraverso il livello JPA [2]:
- può creare un oggetto e chiedere al livello JPA di renderlo persistente. L'oggetto diventa quindi parte del contesto di persistenza.
- può richiedere un riferimento a un oggetto persistente esistente dal livello [JPA].
- può modificare un oggetto persistente ottenuto dal livello JPA.
- può chiedere al livello JPA di rimuovere un oggetto dal contesto di persistenza.
Il livello JPA fornisce al client un'interfaccia chiamata [EntityManager] che, come suggerisce il nome, consente la gestione degli oggetti @Entity nel contesto di persistenza. Di seguito sono riportati i metodi principali di questa interfaccia:
Aggiunge l'entità al contesto di persistenza | |
Rimuove l'entità dal contesto di persistenza | |
unisce un oggetto entità proveniente dal client che non è gestito dal contesto di persistenza con l'oggetto entità nel contesto di persistenza che ha la stessa chiave primaria. Il risultato restituito è l'oggetto entità proveniente dal contesto di persistenza. | |
inserisce un oggetto recuperato dal database nel contesto di persistenza tramite la sua chiave primaria. Il tipo T dell'oggetto permette al livello JPA di sapere quale tabella interrogare. L'oggetto persistente così creato viene restituito al client. | |
crea un oggetto Query da una query JPQL (Java Persistence Query Language). Una query JPQL è analoga a una query SQL, tranne per il fatto che interroga gli oggetti anziché le tabelle. | |
Un metodo simile al precedente, tranne per il fatto che queryText è un Una query SQL anziché una query JPQL. | |
Un metodo identico a createQuery, tranne per il fatto che la query JPQL queryText è esternalizzata in un file di configurazione e associata a un nome. Questo nome è il parametro del metodo. |
Un oggetto EntityManager ha un ciclo di vita che non è necessariamente lo stesso di quello dell'applicazione. Ha un inizio e una fine. Pertanto, un client JPA può lavorare in successione con diversi oggetti EntityManager. Il contesto di persistenza associato a un EntityManager ha lo stesso ciclo di vita dell'EntityManager stesso. Sono inseparabili l'uno dall'altro. Quando un oggetto EntityManager viene chiuso, il suo contesto di persistenza viene, se necessario, sincronizzato con il database e quindi cessa di esistere. Per ottenere un nuovo contesto di persistenza è necessario creare un nuovo EntityManager.
Il client JPA può creare un EntityManager e quindi un contesto di persistenza con la seguente istruzione:
EntityManagerFactory emf = Persistence.createEntityManagerFactory("nom d'une unité de persistance");
- javax.persistence.Persistence è una classe statica utilizzata per ottenere una factory per gli oggetti EntityManager. Questa factory è associata a una specifica unità di persistenza. Ricordiamo che il file di configurazione [META-INF/persistence.xml] viene utilizzato per definire le unità di persistenza e che queste unità hanno un nome:
<persistence-unit name="elections-dao-jpa-mysql-01PU" transaction-type="RESOURCE_LOCAL">
Nell'esempio sopra riportato, l'unità di persistenza è denominata elections-dao-jpa-mysql-01PU. Essa è dotata di una propria configurazione specifica, che include il DBMS con cui opera. L'istruzione [Persistence.createEntityManagerFactory("elections-dao-jpa-mysql-01PU")] crea un EntityManagerFactory in grado di fornire oggetti EntityManager destinati a gestire i contesti di persistenza associati all'unità di persistenza denominata elections-dao-jpa-mysql-01PU. Un oggetto EntityManager — e quindi un contesto di persistenza — viene ottenuto dall'oggetto EntityManagerFactory come segue:
I seguenti metodi dell'interfaccia [EntityManager] consentono di gestire il ciclo di vita del contesto di persistenza:
Il contesto di persistenza viene chiuso. Forza la sincronizzazione del contesto di persistenza con il database:
| |
Il contesto di persistenza viene svuotato di tutti i suoi oggetti ma non chiuso. | |
Il contesto di persistenza viene sincronizzato con il database come descritto per close() |
Il client JPA può forzare la sincronizzazione del contesto di persistenza con il database utilizzando il metodo [EntityManager].flush. La sincronizzazione può essere esplicita o implicita. Nel primo caso, spetta al client eseguire le operazioni di flush quando desidera sincronizzarsi; altrimenti, la sincronizzazione avviene in momenti specifici che specificheremo. La modalità di sincronizzazione è gestita dai seguenti metodi dell'interfaccia [EntityManager]:
Esistono due possibili valori per flushMode: FlushModeType.AUTO (impostazione predefinita): la sincronizzazione avviene prima di ogni query SELECT eseguita sul database. FlushModeType.COMMIT: la sincronizzazione avviene solo alla fine delle transazioni sul database. | |
restituisce la modalità di sincronizzazione corrente |
Riassumendo: nella modalità FlushModeType.AUTO, che è quella predefinita, il contesto di persistenza verrà sincronizzato con il database nei seguenti momenti:
- prima di ogni operazione SELECT sul database
- alla fine di una transazione sul database
- dopo un'operazione di flush o di chiusura sul contesto di persistenza
Nella modalità FlushModeType.COMMIT, vale lo stesso, tranne per l'operazione 1, che non si verifica. La modalità normale di interazione con il livello JPA è la modalità transazionale. Il client esegue varie operazioni sul contesto di persistenza all'interno di una transazione. In questo caso, i punti di sincronizzazione tra il contesto di persistenza e il database sono i casi 1 e 2 sopra indicati nella modalità AUTO, e solo il caso 2 nella modalità COMMIT.
Concludiamo con l'API dell'interfaccia Query, che consente di emettere comandi JPQL sul contesto di persistenza o comandi SQL direttamente sul database per recuperare i dati. L'interfaccia Query è la seguente:
 |
- 1 - Il metodo getResultList esegue una query SELECT che restituisce più oggetti. Questi vengono restituiti in un oggetto List. Questo oggetto è un'interfaccia. Fornisce un oggetto Iterator che consente di iterare attraverso gli elementi della lista L come segue:
Iterator iterator = L.iterator();
while (iterator.hasNext()) {
// exploiter l'objet iterator.next() qui représente l'élément courant de la liste
...
}
È possibile iterare sulla lista L anche utilizzando un ciclo for:
for (Object o : L) {
// exploiter objet o
}
- 2 - Il metodo getSingleResult esegue un'istruzione JPQL/SQL SELECT che restituisce un singolo oggetto.
- 3 - Il metodo executeUpdate esegue un'istruzione SQL UPDATE o DELETE e restituisce il numero di righe interessate dall'operazione.
- 4 - Il metodo setParameter(String, Object) consente di assegnare un valore a un parametro denominato di una query JPQL parametrizzata
- 5 - Il metodo setParameter(int, Object) imposta il parametro, ma il parametro non è identificato dal suo nome bensì dalla sua posizione nella query JPQL.
4.4. s (JPQL)
JPQL (Java Persistence Query Language) è il linguaggio di query del livello JPA. Il linguaggio JPQL è simile al linguaggio SQL utilizzato nei database. Mentre SQL opera con le tabelle, JPQL opera con gli oggetti che rappresentano tali tabelle. Esamineremo un esempio all'interno della seguente architettura:
 |
Il database, che chiameremo [ dbrdvmedecins2], è un database MySQL5 con quattro tabelle:
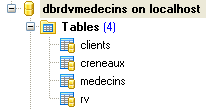 |
Raccoglie le informazioni necessarie per gestire gli appuntamenti di un gruppo di medici.
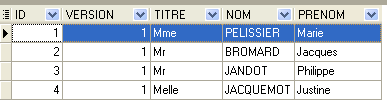
4.4.1. La tabella [MEDECINS]
Contiene informazioni sui medici.
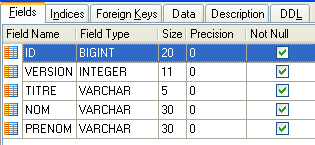 |  |
- ID: il numero identificativo del medico — la chiave primaria della tabella
- VERSION: un numero che identifica la versione della riga nella tabella. Questo numero viene incrementato di 1 ogni volta che viene apportata una modifica alla riga.
- LAST_NAME: il cognome del medico
- FIRST NAME: il nome del medico
- TITOLO: il titolo (Sig.ra, Sig.ra, Sig.)
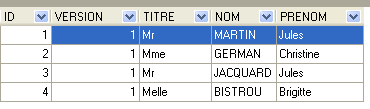
4.4.2. La tabella [CLIENTI]
I clienti dei vari medici sono memorizzati nella tabella [CLIENTS]:
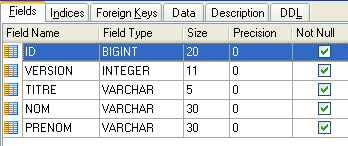 |  |
- ID: numero identificativo del cliente - chiave primaria della tabella
- VERSION: numero che identifica la versione della riga nella tabella. Questo numero viene incrementato di 1 ogni volta che viene apportata una modifica alla riga.
- COGNOME: il cognome del cliente
- NOME: il nome del cliente
- TITOLO: il titolo (Sig.ra, Sig.ra, Sig.)
4.4.3. La tabella [SLOTS]
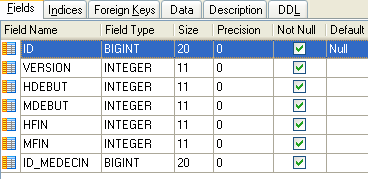
Elenca le fasce orarie in cui sono disponibili gli appuntamenti:
 |
 |
- ID: numero identificativo della fascia oraria - chiave primaria della tabella (riga 8)
- VERSION: numero che identifica la versione della riga nella tabella. Questo numero viene incrementato di 1 ogni volta che viene apportata una modifica alla riga.
- DOCTOR_ID: numero ID che identifica il medico a cui appartiene questa fascia oraria – chiave esterna sulla colonna DOCTORS(ID).
- START_TIME: ora di inizio della fascia oraria
- MSTART: minuti di inizio della fascia oraria
- HFIN: ora di fine della fascia oraria
- MFIN: minuti di fine della fascia oraria
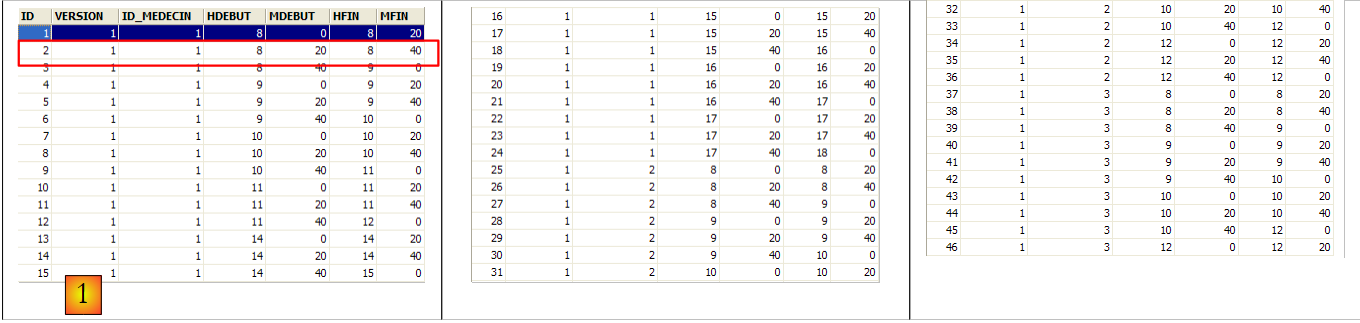
La seconda riga della tabella [SLOTS] (vedi [1] sopra) indica, ad esempio, che la fascia oraria n. 2 inizia alle 8:20 e termina alle 8:40 e appartiene al medico n. 1 (dott.ssa Marie PELISSIER).
4.4.4. La tabella [RV]
Elenca gli appuntamenti fissati per ciascun medico:
 |
- ID: identificatore univoco dell'appuntamento – chiave primaria
- GIORNO: giorno dell'appuntamento
- SLOT_ID: fascia oraria dell'appuntamento – chiave esterna sul campo [ID] della tabella [SLOTS] – determina sia la fascia oraria che il medico coinvolto.
- CLIENT_ID: ID del cliente per il quale è stata effettuata la prenotazione – chiave esterna sul campo [ID] della tabella [CLIENTS]
Questa tabella ha un vincolo di unicità sui valori delle colonne unite (GIORNO, SLOT_ID):
Se una riga nella tabella [RV] ha il valore (DAY1, SLOT_ID1) per le colonne (DAY, SLOT_ID), questo valore non può comparire in nessun altro punto. In caso contrario, ciò significherebbe che sono stati prenotati due appuntamenti contemporaneamente per lo stesso medico. Dal punto di vista della programmazione Java, il driver JDBC del database genera un'eccezione SQLException quando ciò si verifica.
La riga con ID pari a 3 (vedi [1] sopra) indica che è stato prenotato un appuntamento per lo slot n. 20 e il cliente n. 4 il 23/08/2006. La tabella [SLOTS] ci dice che lo slot n. 20 corrisponde alla fascia oraria 16:20 – 16:40 e appartiene al medico n. 1 (Sig.ra Marie PELISSIER). La tabella [CLIENTS] ci dice che il cliente n. 4 è la sig.ra Brigitte BISTROU.
4.4.5. Generazione del database
Per creare le tabelle e popolarle, è possibile utilizzare lo script [dbrdvmedecins2.sql]. Con [WampServer], è possibile procedere come segue:
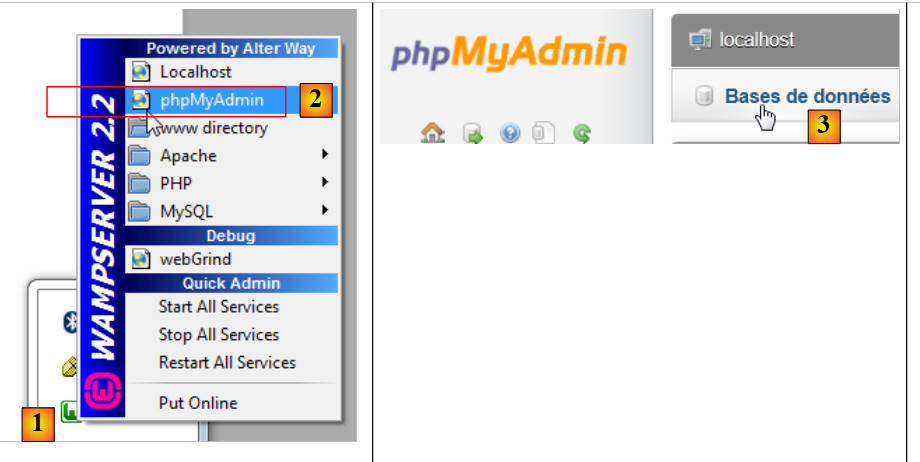 |
- In [1], fare clic sull'icona [WampServer] e selezionare l'opzione [PhpMyAdmin] [2],
- In [3], nella finestra che si apre, selezionare il link [Databases],
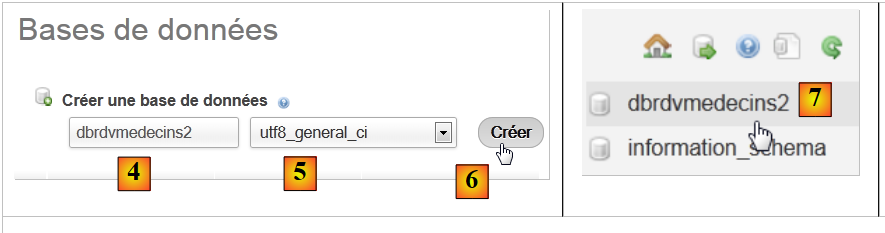 |
- In [2], crea un database con il nome [4] e la codifica [5],
- In [7], il database è stato creato. Clicca sul suo link,
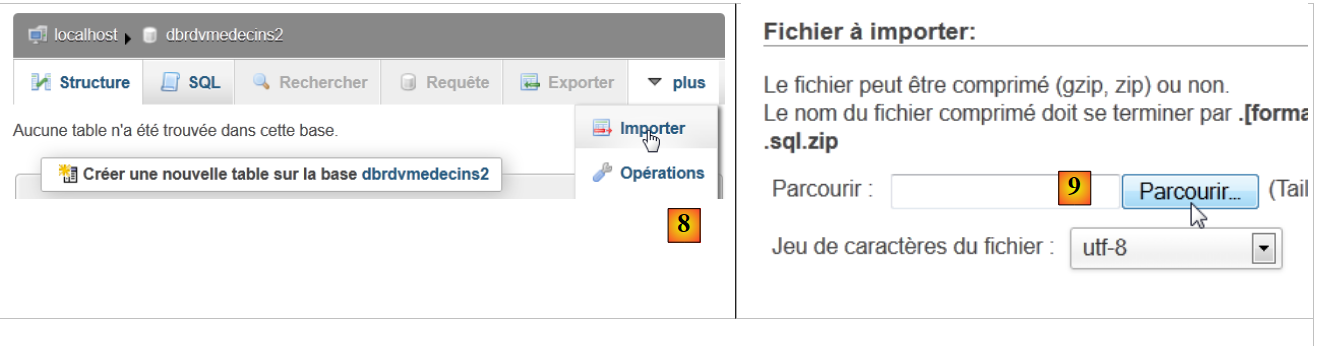 |
- in [8], importare un file SQL,
- che si seleziona dal file system utilizzando il pulsante [9],
 |
- in [11], selezionare lo script SQL e in [12] eseguirlo,
- in [13], le quattro tabelle nel database sono state create. Segui uno dei link,
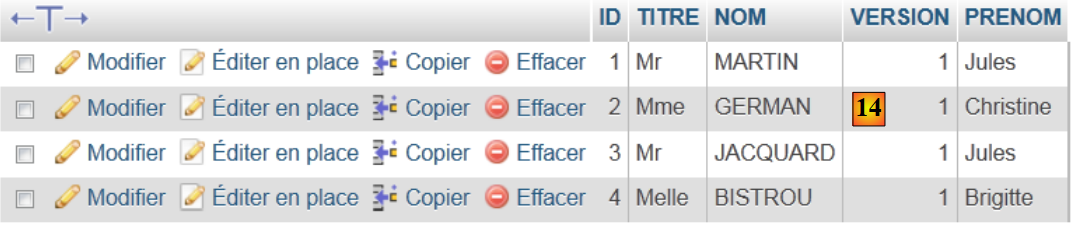 |
- in [14], il contenuto della tabella.
Non torneremo più su questo database. Tuttavia, invitiamo il lettore a seguirne l'evoluzione nel corso dei programmi, specialmente quando le cose non funzionano.
4.4.6. Il livello [JPA]
Torniamo all'architettura dell'esempio:
 |
Stiamo ora compilando il progetto Maven per il livello [JPA].
4.4.7. Il progetto NetBeans
Ecco come si presenta:
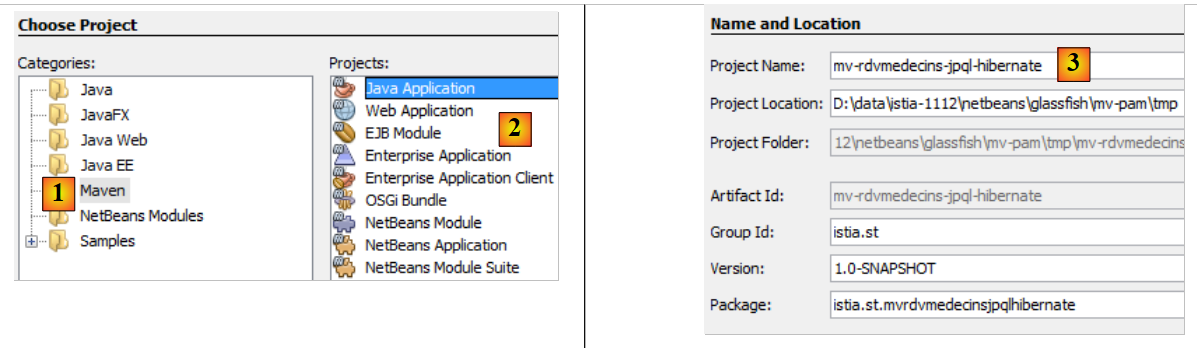 |
- In [1], creiamo un progetto Maven di tipo [Applicazione Java] [2],
- in [3], diamo un nome al progetto,
 |
- in [4], il progetto generato.
4.4.8. Generazione del livello [JPA]
Torniamo all'architettura che dobbiamo costruire:
 |
Con NetBeans è possibile generare automaticamente il livello [JPA]. È utile acquisire familiarità con questi metodi di generazione automatica perché il codice generato fornisce preziose indicazioni su come scrivere entità JPA.
4.4.9. Creazione di una connessione NetBeans al database
- Avviare il DBMS MySQL 5 in modo che il database sia disponibile,
- creare una connessione NetBeans al database [dbrdvmedecins2],
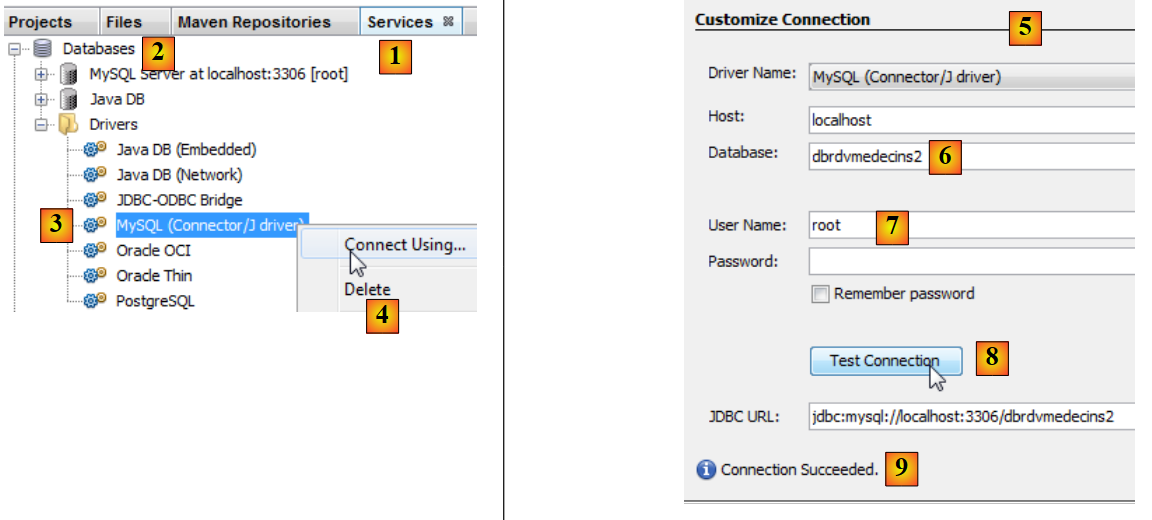 |
- nella scheda [Servizi] [1], nella sezione [Database] [2], selezionare il driver JDBC di MySQL [3],
- quindi selezionare l'opzione [4] "Connetti utilizzando" per creare una connessione a un database MySQL,
- in [5], inserisci le informazioni richieste. In [6], il nome del database; in [7], l'utente e la password del database;
- in [8], è possibile verificare le informazioni fornite,
- in [9], il messaggio che dovrebbe apparire se le informazioni sono corrette,
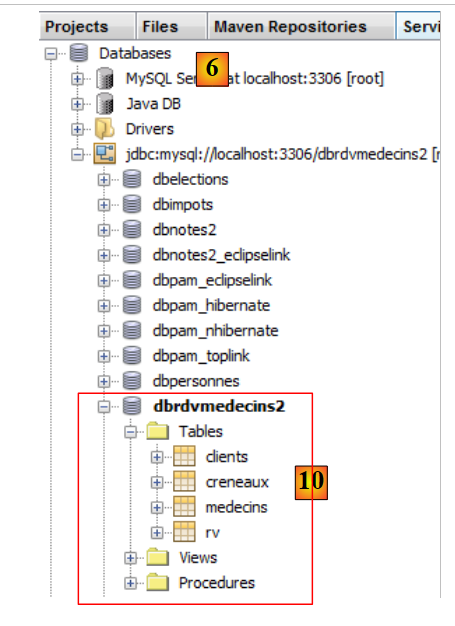 |
- in [10], la connessione è stata stabilita. È possibile visualizzare le quattro tabelle nel database collegato.
4.4.10. Creazione di un'unità di persistenza
Torniamo all'architettura che stiamo realizzando:
 |
Attualmente stiamo realizzando il livello [JPA]. La sua configurazione avviene in un file [persistence.xml] in cui sono definite le unità di persistenza. Ciascuna di esse richiede le seguenti informazioni:
- i dettagli della connessione JDBC (URL, nome utente, password),
- le classi che rappresenteranno le tabelle del database,
- l'implementazione JPA utilizzata. Infatti, JPA è una specifica implementata da vari prodotti. In questo caso, useremo Hibernate.
NetBeans può generare questo file di persistenza utilizzando una procedura guidata.
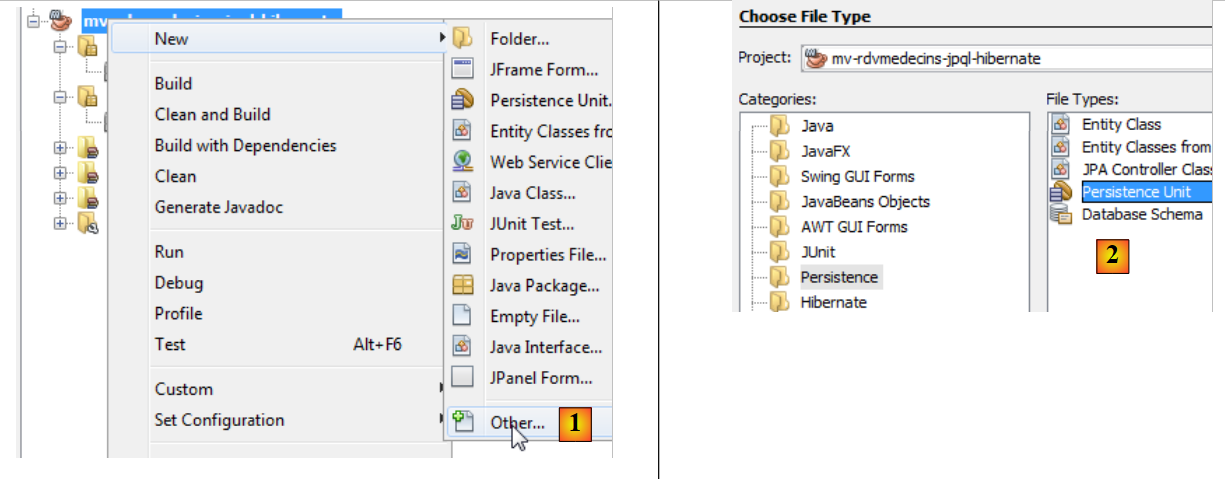 |
- Fare clic con il tasto destro del mouse sul progetto e selezionare "Crea unità di persistenza" [1],
- in [2], creare un'unità di persistenza,
|
- in [3], assegnare un nome all'unità di persistenza che si sta creando,
- in [4], selezionare l'implementazione JPA di Hibernate (JPA 2.0),
- in [5], indicare che le tabelle del database esistono già e quindi non devono essere create. Confermare la procedura guidata,
- in [6], il nuovo progetto,
- in [7], il file [persistence.xml] è stato generato nella cartella [META-INF],
- in [8], sono state aggiunte nuove dipendenze al progetto Maven.
Il file [META-INF/persistence.xml] generato è il seguente:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="mv-rdvmedecins-jpql-hibernatePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbrdvmedecins2"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="hibernate.cache.provider_class" value="org.hibernate.cache.NoCacheProvider"/>
</properties>
</persistence-unit>
</persistence>
Include le informazioni fornite nella procedura guidata:
- riga 3: il nome dell'unità di persistenza,
- riga 3: il tipo di transazioni del database. Qui, RESOURCE_LOCAL indica che l'applicazione gestirà le proprie transazioni,
- righe 6–9: le proprietà JDBC dell'origine dati.
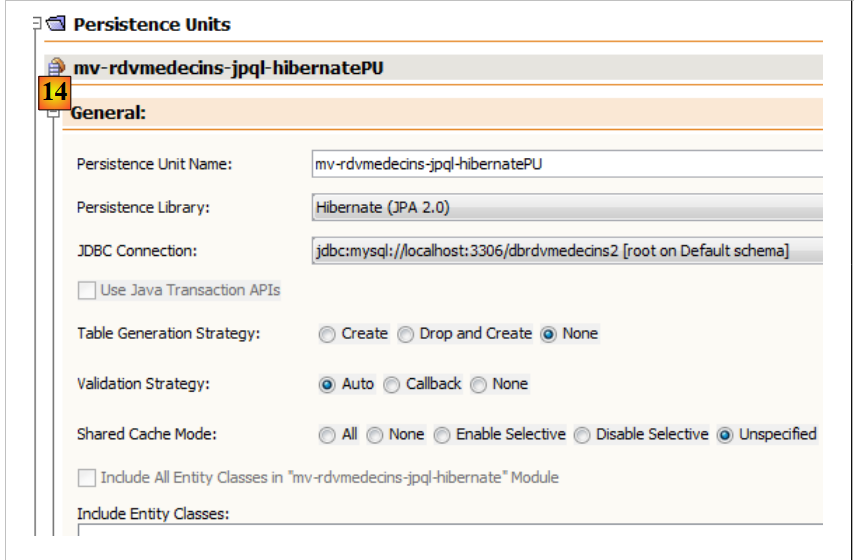
Nella scheda [Design], è possibile visualizzare una panoramica del file [persistence.xml]:
 |
Per abilitare la registrazione di Hibernate, completiamo il file [persistence.xml] come segue:
<?xml version="1.0" encoding="UTF-8"?>
<persistence version="2.0" xmlns="http://java.sun.com/xml/ns/persistence" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance" xsi:schemaLocation="http://java.sun.com/xml/ns/persistence http://java.sun.com/xml/ns/persistence/persistence_2_0.xsd">
<persistence-unit name="mv-rdvmedecins-jpql-hibernatePU" transaction-type="RESOURCE_LOCAL">
<provider>org.hibernate.ejb.HibernatePersistence</provider>
<properties>
<property name="javax.persistence.jdbc.url" value="jdbc:mysql://localhost:3306/dbrdvmedecins2"/>
<property name="javax.persistence.jdbc.password" value=""/>
<property name="javax.persistence.jdbc.driver" value="com.mysql.jdbc.Driver"/>
<property name="javax.persistence.jdbc.user" value="root"/>
<property name="hibernate.cache.provider_class" value="org.hibernate.cache.NoCacheProvider"/>
<property name="hibernate.show_sql" value="true"/>
<property name="hibernate.format_sql" value="true"/>
</properties>
</persistence-unit>
</persistence>
- Riga 11: richiediamo di visualizzare le istruzioni SQL emesse da Hibernate,
- riga 12: questa proprietà consente una visualizzazione formattata di tali istruzioni.
Le dipendenze sono state aggiunte al progetto. Il file [pom.xml] è il seguente:
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>istia.st</groupId>
<artifactId>mv-rdvmedecins-jpql-hibernate</artifactId>
<version>1.0-SNAPSHOT</version>
<packaging>jar</packaging>
<name>mv-rdvmedecins-jpql-hibernate</name>
<url>http://maven.apache.org</url>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
</properties>
<dependencies>
<dependency>
<groupId>junit</groupId>
<artifactId>junit</artifactId>
<version>3.8.1</version>
<scope>test</scope>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-entitymanager</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>org.jboss.logging</groupId>
<artifactId>jboss-logging</artifactId>
<version>3.1.0.GA</version>
</dependency>
<dependency>
<groupId>org.jboss.spec.javax.transaction</groupId>
<artifactId>jboss-transaction-api_1.1_spec</artifactId>
<version>1.0.0.Final</version>
</dependency>
<dependency>
<groupId>org.hibernate</groupId>
<artifactId>hibernate-core</artifactId>
<version>4.1.2</version>
</dependency>
<dependency>
<groupId>antlr</groupId>
<artifactId>antlr</artifactId>
<version>2.7.7</version>
</dependency>
<dependency>
<groupId>dom4j</groupId>
<artifactId>dom4j</artifactId>
<version>1.6.1</version>
</dependency>
<dependency>
<groupId>org.hibernate.javax.persistence</groupId>
<artifactId>hibernate-jpa-2.0-api</artifactId>
<version>1.0.1.Final</version>
</dependency>
<dependency>
<groupId>org.javassist</groupId>
<artifactId>javassist</artifactId>
<version>3.15.0-GA</version>
</dependency>
<dependency>
<groupId>org.hibernate.common</groupId>
<artifactId>hibernate-commons-annotations</artifactId>
<version>4.0.1.Final</version>
</dependency>
</dependencies>
</project>
Le dipendenze aggiunte sono tutte relative all'ORM Hibernate. Aggiungeremo la dipendenza del driver JDBC di MySQL:
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>5.1.6</version>
</dependency>
4.4.11. Generazione di entità JPA
Le entità JPA possono essere generate utilizzando una procedura guidata di NetBeans:
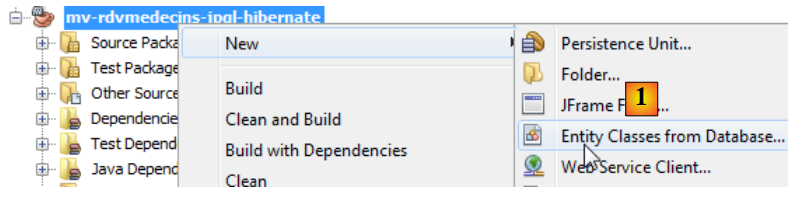 |
- In [1], creare entità JPA da un database,
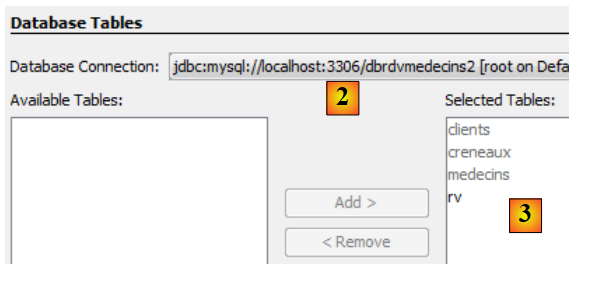 |
- in [2], selezionare la connessione creata in precedenza [dbrdvmedecins2],
- in [3], selezionare tutte le tabelle dal database associato,
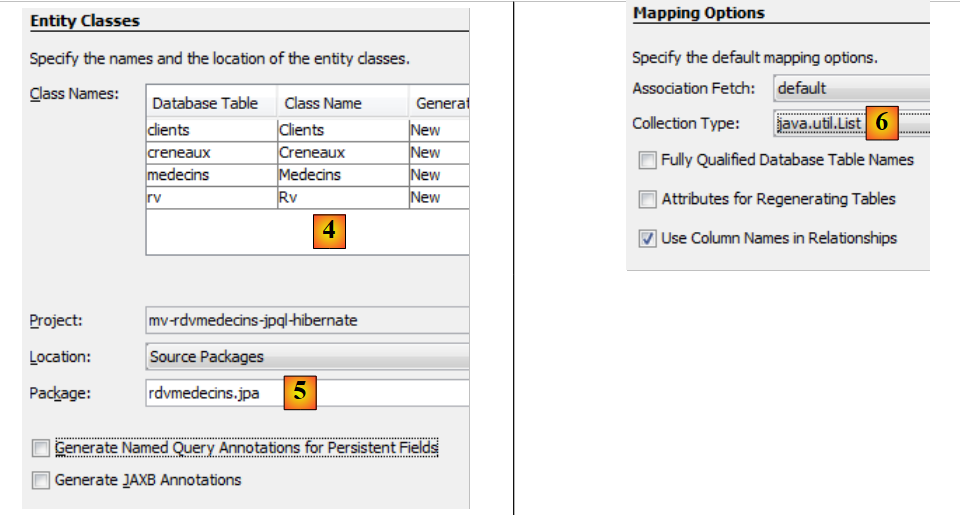 |
- in [4], assegnare un nome alle classi Java associate alle quattro tabelle,
- nonché un nome del pacchetto [5],
- in [6], JPA raggruppa le righe delle tabelle del database in collezioni. Scegliamo una lista come collezione,
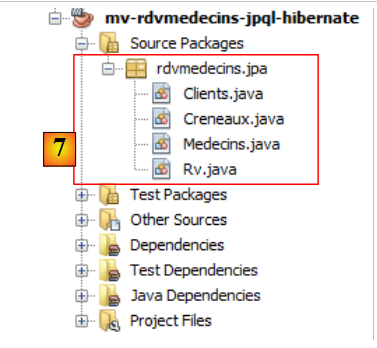 |
- in [7], le classi Java create dalla procedura guidata.
4.4.12. Le entità JPA generate
L'entità [Medecin] rispecchia la tabella [medecins]. La classe Java è disseminata di annotazioni che rendono il codice di difficile lettura a prima vista. Se manteniamo solo ciò che è essenziale per comprendere il ruolo dell'entità, otteniamo il seguente codice:
package rdvmedecins.jpa;
...
@Entity
@Table(name = "medecins")
public class Medecin implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "TITRE")
private String titre;
@Column(name = "NOM")
private String nom;
@Column(name = "VERSION")
private int version;
@Column(name = "PRENOM")
private String prenom;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "idMedecin")
private List<Creneau> creneauList;
// manufacturers
....
// getters and setters
....
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
...
}
}
- Riga 4: L'annotazione @Entity rende la classe [Medecin] un'entità JPA, ovvero una classe collegata a una tabella del database tramite l'API JPA.
- riga 5: il nome della tabella del database associata all'entità JPA. Ogni campo della tabella corrisponde a un campo della classe Java,
- riga 6: la classe implementa l'interfaccia Serializable. Ciò è necessario nelle applicazioni client/server, dove le entità vengono serializzate tra il client e il server.
- righe 10–11: il campo id della classe [Doctor] corrisponde al campo [ID] (riga 10) della tabella [doctors],
- righe 13–14: il campo title della classe [Doctor] corrisponde al campo [TITLE] (riga 13) della tabella [doctors],
- righe 16–17: il campo `nom` della classe [Medecin] corrisponde al campo `[NOM]` (riga 16) della tabella [medecins],
- righe 19-20: il campo "version" della classe [Medecin] corrisponde al campo [VERSION] (riga 19) della tabella [doctors]. In questo caso, la procedura guidata non riconosce che la colonna è in realtà una colonna di versione che deve essere incrementata ogni volta che viene modificata la riga a cui appartiene. Per assegnarle questo ruolo, è necessario aggiungere l'annotazione @Version. Lo faremo in un passaggio successivo,
- righe 22–23: il campo first_name della classe [Doctor] corrisponde al campo [FIRST_NAME] della tabella [doctors],
- righe 10–11: il campo id corrisponde alla chiave primaria [ID] della tabella. Le annotazioni alle righe 8–9 chiariscono questo punto,
- riga 8: l'annotazione @Id indica che il campo annotato è associato alla chiave primaria della tabella,
- riga 9: il livello [JPA] genererà la chiave primaria per le righe che inserisce nella tabella [Doctors]. Esistono diverse strategie possibili. In questo caso, la strategia GenerationType.IDENTITY indica che il livello JPA utilizzerà la modalità auto_increment della tabella MySQL,
- righe 25–26: la tabella [slots] ha una chiave esterna sulla tabella [doctors]. Uno slot appartiene a un medico. Al contrario, un medico ha diversi slot associati. Abbiamo quindi una relazione uno-a-molti (un medico a molti slot), una relazione qualificata dall'annotazione @OneToMany in JPA (riga 25). Il campo alla riga 26 conterrà tutti gli slot del medico. Ciò si ottiene senza alcuna programmazione. Per comprendere appieno la riga 25, dobbiamo introdurre la classe [Creneau].
Essa è la seguente:
package rdvmedecins.jpa;
import java.io.Serializable;
import java.util.List;
import javax.persistence.*;
import javax.validation.constraints.NotNull;
@Entity
@Table(name = "creneaux")
public class Creneau implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "MDEBUT")
private int mdebut;
@Column(name = "HFIN")
private int hfin;
@Column(name = "HDEBUT")
private int hdebut;
@Column(name = "MFIN")
private int mfin;
@Column(name = "VERSION")
private int version;
@JoinColumn(name = "ID_MEDECIN", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Medecin idMedecin;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "idCreneau")
private List<Rv> rvList;
// manufacturers
...
// getters and setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
...
}
}
Ci limitiamo a commentare le nuove annotazioni:
- abbiamo specificato che la tabella [slots] ha una chiave esterna verso la tabella [doctors]: uno slot è associato a un medico. Più slot possono essere associati allo stesso medico. Abbiamo una relazione dalla tabella [slots] alla tabella [doctors] definita come molti-a-uno (slot verso medico). L'annotazione @ManyToOne alla riga 32 viene utilizzata per definire la chiave esterna,
- la riga 31, con l'annotazione @JoinColumn, specifica la relazione di chiave esterna: la colonna [ID_MEDECIN] nella tabella [slots] è una chiave esterna sulla colonna [ID] nella tabella [doctors],
- Riga 33: un riferimento al medico a cui appartiene lo slot. Anche in questo caso ciò si ottiene senza alcuna codifica.
La relazione di chiave esterna tra l'entità [Creneau] e l'entità [Medecin] è quindi implementata da due annotazioni:
- nell'entità [Creneau]:
@JoinColumn(name = "ID_MEDECIN", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Medecin idMedecin;
- nell'entità [Doctor]:
@OneToMany(cascade = CascadeType.ALL, mappedBy = "idMedecin")
private List<Creneau> creneauList;
Entrambe le annotazioni riflettono la stessa relazione: quella della chiave esterna dalla tabella [appointments] alla tabella [doctors]. Si dice che siano inverse l'una rispetto all'altra. Solo la relazione @ManyToOne è essenziale. Essa definisce in modo univoco la relazione di chiave esterna. La relazione @OneToMany è facoltativa. Se presente, fa semplicemente riferimento alla relazione @ManyToOne a cui è associata. Questo è il significato dell'attributo mappedBy alla riga 1 dell'entità [Medecin]. Il valore di questo attributo è il nome del campo nell'entità [Creneau] che ha l'annotazione @ManyToOne che specifica la chiave esterna. Sempre alla riga 1 dell'entità [Medecin], l'attributo cascade=CascadeType.ALL definisce il comportamento dell'entità [Medecin] rispetto all'entità [Creneau]:
- se una nuova entità [Doctor] viene inserita nel database, allora devono essere inserite anche le entità [TimeSlot] nel campo alla riga 2,
- se un'entità [Doctor] viene modificata nel database, allora anche le entità [Slot] nel campo alla riga 2 devono essere modificate,
- se un'entità [Doctor] viene eliminata dal database, allora anche le entità [Slot] nel campo alla riga 2 devono essere eliminate.
Forniamo il codice per le altre due entità senza commenti specifici poiché non introducono alcuna nuova notazione.
L'entità [Client]
package rdvmedecins.jpa;
...
@Entity
@Table(name = "clients")
public class Client implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "TITRE")
private String titre;
@Column(name = "NOM")
private String nom;
@Column(name = "VERSION")
private int version;
@Column(name = "PRENOM")
private String prenom;
@OneToMany(cascade = CascadeType.ALL, mappedBy = "idClient")
private List<Rv> rvList;
// manufacturers
...
// getters and setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
...
}
}
- Le righe 24–25 riflettono la relazione di chiave esterna tra la tabella [rv] e la tabella [clients].
L'entità [Rv]:
package rdvmedecins.jpa;
...
@Entity
@Table(name = "rv")
public class Rv implements Serializable {
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Column(name = "JOUR")
@Temporal(TemporalType.DATE)
private Date jour;
@JoinColumn(name = "ID_CRENEAU", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Creneau idCreneau;
@JoinColumn(name = "ID_CLIENT", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Client idClient;
// manufacturers
...
// getters and setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
...
}
}
- La riga 13 definisce il campo `jour` come un tipo Java Date. Specifica che nella tabella [rv], la colonna [JOUR] (riga 12) è di tipo data (senza ora),
- Righe 16–18: definiscono la relazione di chiave esterna dalla tabella [rv] alla tabella [slots],
- Righe 20–22: definiscono la relazione di chiave esterna dalla tabella [rv] alla tabella [clients].
La generazione automatica delle entità JPA ci fornisce una base di lavoro. A volte questo è sufficiente, a volte no. È il caso qui:
- dobbiamo aggiungere l'annotazione @Version ai vari campi di versione delle entità,
- dobbiamo scrivere metodi toString più espliciti di quelli generati,
- le entità [Medecin] e [Client] sono analoghe. Le faremo derivare da una classe [Person],
- rimuoveremo le relazioni inverse @OneToMany dalle relazioni @ManyToOne. Non sono essenziali e introducono complicazioni di programmazione,
- rimuoviamo la validazione @NotNull sulle chiavi primarie. Quando si persiste un'entità JPA con MySQL, l'entità inizialmente ha una chiave primaria nulla. È solo dopo la persistenza nel database che la chiave primaria dell'entità persistita ha un valore.
Con queste specifiche, le varie classi diventano le seguenti:
La classe Person viene utilizzata per rappresentare medici e clienti:
package rdvmedecins.jpa;
import java.io.Serializable;
import javax.persistence.*;
@MappedSuperclass
public class Personne implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Column(name = "ID")
private Long id;
@Basic(optional = false)
@Column(name = "TITRE")
private String titre;
@Basic(optional = false)
@Column(name = "NOM")
private String nom;
@Basic(optional = false)
@Column(name = "VERSION")
@Version
private int version;
@Basic(optional = false)
@Column(name = "PRENOM")
private String prenom;
// manufacturers
...
// getters and setters
...
@Override
public String toString() {
return String.format("[%s,%s,%s,%s,%s]", id, version, titre, prenom, nom);
}
}
- Riga 6: Si noti che la classe [Person] non è di per sé un'entità (@Entity). Fungerà da classe padre per le entità. L'annotazione @MappedSuperClass lo indica.
L'entità [Client] incapsula le righe della tabella [clients]. Deriva dalla precedente classe [Person]:
package rdvmedecins.jpa;
import java.io.Serializable;
import javax.persistence.*;
@Entity
@Table(name = "clients")
public class Client extends Personne implements Serializable {
private static final long serialVersionUID = 1L;
// manufacturers
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
return String.format("Client[%s,%s,%s,%s]", getId(), getTitre(), getPrenom(), getNom());
}
}
- Riga 6: la classe [Client] è un'entità JPA,
- riga 7: è associata alla tabella [clients],
- riga 8: deriva dalla classe [Person].
L'entità [Doctor], che incapsula le righe della tabella [doctors], segue lo stesso schema:
package rdvmedecins.jpa;
import java.io.Serializable;
import javax.persistence.*;
@Entity
@Table(name = "medecins")
public class Medecin extends Personne implements Serializable {
private static final long serialVersionUID = 1L;
// manufacturers
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
return String.format("Médecin[%s,%s,%s,%s]", getId(), getTitre(), getPrenom(), getNom());
}
}
L'entità [Creneau] incapsula le righe della tabella [creneaux]:
package rdvmedecins.jpa;
import java.io.Serializable;
import java.util.List;
import javax.persistence.*;
@Entity
@Table(name = "creneaux")
public class Creneau implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Basic(optional = false)
@Column(name = "ID")
private Long id;
@Basic(optional = false)
@Column(name = "MDEBUT")
private int mdebut;
@Basic(optional = false)
@Column(name = "HFIN")
private int hfin;
@Basic(optional = false)
@NotNull
@Column(name = "HDEBUT")
private int hdebut;
@Basic(optional = false)
@Column(name = "MFIN")
private int mfin;
@Basic(optional = false)
@Column(name = "VERSION")
@Version
private int version;
@JoinColumn(name = "ID_MEDECIN", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Medecin medecin;
// manufacturers
...
// getters and setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
// TODO: Warning - this method won't work in the case the id fields are not set
...
}
@Override
public String toString() {
return String.format("Creneau [%s, %s, %s:%s, %s:%s,%s]", id, version, hdebut, mdebut, hfin, mfin, medecin);
}
}
- Le righe 40–42 modellano la relazione "molti-a-uno" tra la tabella [slots] e la tabella [doctors] nel database: un medico ha più slot e uno slot appartiene a un singolo medico.
L'entità [Rv] incapsula le righe della tabella [rv]:
package rdvmedecins.jpa;
import java.io.Serializable;
import java.util.Date;
import javax.persistence.*;
@Entity
@Table(name = "rv")
public class Rv implements Serializable {
private static final long serialVersionUID = 1L;
@Id
@GeneratedValue(strategy = GenerationType.IDENTITY)
@Basic(optional = false)
@Column(name = "ID")
private Long id;
@Basic(optional = false)
@Column(name = "JOUR")
@Temporal(TemporalType.DATE)
private Date jour;
@JoinColumn(name = "ID_CRENEAU", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Creneau creneau;
@JoinColumn(name = "ID_CLIENT", referencedColumnName = "ID")
@ManyToOne(optional = false)
private Client client;
// manufacturers
...
// getters and setters
...
@Override
public int hashCode() {
...
}
@Override
public boolean equals(Object object) {
...
}
@Override
public String toString() {
return String.format("Rv[%s, %s, %s]", id, creneau, client);
}
}
- Le righe 27–29 modellano la relazione "molti-a-uno" tra la tabella [rv] e la tabella [clients] (un cliente può comparire in più voci Rv) nel database, mentre le righe 23–25 modellano la relazione "molti-a-uno" tra la tabella [rv] e la tabella [slots] (uno slot può comparire in più voci Rv).
4.4.13. Il codice di accesso ai dati
Aggiungeremo ora al progetto il codice per l'accesso ai dati tramite il livello JPA:
 |
 |
La classe [MainJpql] è la seguente:
package rdvmedecins.console;
import java.util.Scanner;
import javax.persistence.EntityManager;
import javax.persistence.EntityManagerFactory;
import javax.persistence.Persistence;
public class MainJpql {
public static void main(String[] args) {
// EntityManagerFactory
EntityManagerFactory emf = Persistence.createEntityManagerFactory("mv-rdvmedecins-jpql-hibernatePU");
// entityManager
EntityManager em = emf.createEntityManager();
// keyboard scanner
Scanner clavier = new Scanner(System.in);
// query entry loop JPQL
System.out.println("Requete JPQL sur la base dbrdvmedecins2 (* pour arrêter) :");
String requete = clavier.nextLine();
while (!requete.trim().equals("*")) {
try {
// display query result
for (Object o : em.createQuery(requete).getResultList()) {
System.out.println(o);
}
} catch (Exception e) {
System.out.println("L'exception suivante s'est produite : " + e);
}
// clear the persistence context
em.clear();
// new request
System.out.println("---------------------------------------------");
System.out.println("Requete JPQL sur la base dbrdvmedecins2 (* pour arrêter) :");
requete = clavier.nextLine();
}
// resource closure
em.close();
emf.close();
}
}
- Riga 12: Creazione dell'EntityManagerFactory associata all'unità di persistenza creata in precedenza. Il parametro del metodo `createEntityManagerFactory` è il nome di questa unità di persistenza:
<persistence-unit name="mv-rdvmedecins-jpql-hibernatePU" transaction-type="RESOURCE_LOCAL">
...
</persistence-unit>
- riga 14: creazione dell'EntityManager che gestisce il livello di persistenza,
- Riga 19: inserimento di una query JPQL SELECT,
- righe 23–28: visualizzazione del risultato della query,
- riga 20: l'immissione dei dati si interrompe quando l'utente digita *.
Domanda: Fornire le query JPQL per recuperare le seguenti informazioni:
- elenco dei medici in ordine decrescente per cognome
- elenco dei medici il cui titolo è 'Mr'
- elenco degli slot di appuntamento della sig.ra Pelissier
- elenco degli appuntamenti in ordine crescente per data
- elenco dei clienti (cognome) che hanno fissato un appuntamento con la sig.ra Pelissier il 24/08/2006
- Numero di clienti della sig.ra Pelissier il 24/08/2006
- clienti che non hanno fissato un appuntamento
- Medici che non hanno appuntamenti
Prenderemo spunto dall'esempio riportato nella sezione 2.7 di [rif. 1]. Ecco un esempio di esecuzione:
- riga 2: la query JPQL,
- righe 3–11: la query SQL corrispondente,
- righe 12–15: il risultato della query JPQL.
4.5. Collegamenti tra contesto di persistenza e DBMS
4.5.1. La classe Person
4.5.2. Il programma di test
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 73 74 75 76 77 78 79 80 81 82 83 84 85 86 87 88 89 90 91 92 93 94 95 96 97 98 99 100 101 102 103 104 105 106 107 108 109 110 111 112 113 114 115 116 117 118 119 120 121 122 123 124 125 126 127 128 129 130 131 132 133 134 135 136 137 | |
4.5.3. Configurazione di Hibernate
4.5.4. La configurazione di log4j.properties
4.5.5. Risultati
Domanda: Spiega la relazione tra il codice Java e i risultati visualizzati.