9. Uso del conversor DOCX → HTML
El comando para convertir un documento DOCX de Word es muy similar al de la conversión de un documento ODT de LibreOffice. Vamos a modificar el estilo del título del documento en [config.py]:
STYLES = {
"style_names": [
"Título"
]
}
- línea 3: escribe «Título». Este es el estilo del documento DOCX que vas a convertir. Lo veremos en las líneas de depuración del conversor.
Siempre en el terminal de PyCharm, escribe el siguiente comando:
PS C:\Data\st-2025\GitHub Pages\word-odt-vers-html\v2> python .\convert_docx_v18.py .\word-odt-vers-html-janv-2026.docx .\config.py
C:\Data\st-2025\GitHub Pages\word-odt-vers-html\v2\convert_docx_v18.py:976: SyntaxWarning: secuencia de escape no válida '\h'
- Marcador REF \h
--- DOCX to MkDocs Converter V16 ---
Copiado: google5179c0eaff293e02.html
Copiado: robots.txt
Copiado: word-odt-a-html-ene-2026.pdf
Copiado: word-odt-a-html-ene-2026.zip
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] estilo=Estándar encabezado=Ninguno rebase=0 numId=Ninguno ilvl=Ninguno lista=Ninguno:0/Ninguno txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=StandardWW heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=StandardWW heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Título heading=Ninguno rebase=0 numId=Ninguno ilvl=Ninguno list=Ninguno:0/Ninguno txt='<span>Convertir un documento Word u ODT a un sitio HTML estático compatible con Mk...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Estándar heading=Ninguno rebase=0 numId=Ninguno ilvl=Ninguno list=Ninguno:0/Ninguno txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='<b>Serge Tahé</b><span>, enero de 2026</span>...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=Standard heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=StandardWW heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=StandardWW heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=StandardWW heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='...'
[DEBUG PRE-H1] style=StandardWW heading=None rebase=0 numId=None ilvl=None list=None:0/None txt='<b>Este sitio ha sido creado con el conversor [Word u ODT - > HTML] cr...'
[DEBUG PRE-H1] style=Título1 heading=1 rebase=0 numId=1 ilvl=0 list=numPr:1/ordered txt='<span>Introducción</span>...'
Finalizado. (audit.json, audit.txt, report.txt generados)
- línea 1: el comando es el siguiente: [python .\convert_docx_v18.py .\word-odt-vers-html-janv-2026.docx .\config.py] (Adapta el número de versión (aquí 18) a la versión que hayas descargado):
- el primer parámetro [.\convert_docx_v18.py] es el conversor de DOCX a HTML
- el segundo parámetro [.\word-odt-vers-html-janv-2026.docx] es el nombre del documento DOCX que se va a convertir;
- el tercer parámetro [.\config.py] es el archivo de configuración;
- línea 33: el conversor indica que se han generado tres archivos:
 |
El archivo [audit.txt] es el siguiente:
Versión: V16
Párrafos: 2029
Tablas: 97
Imágenes (blips): 2
Encabezados detectados (sin procesar): 53
Nivel mínimo de encabezado detectado (sin procesar): 1
Desplazamiento de rebase aplicado: 0
Estilos de párrafo principales:
- SourceCodenumrot: 1054
- StandardWW: 594
- Estándar: 146
- Parágrafo de la lista: 113
- SourceCodenumrotrsultados: 33
- código nuevo: 28
- Título 2: 25
- Título 1: 14
- Título 3: 14
- EstándarWWWW: 6
- Texto sin formato: 1
- Título: 1
Lista de párrafos:
- con numeración: 1329
- por estilo de reserva: 49
- no reconocidos: 0
- línea 2: el número de párrafos del documento de Word;
- línea 3: el número de tablas;
- líneas 9-21: los estilos encontrados en el documento;
- líneas 10, 14, 15: el estilo de los bloques de código. Probablemente habría bastado con un solo estilo;
- líneas 11-12, 19: el estilo de los párrafos estándar. Probablemente habría bastado con un solo estilo;
- líneas 16-18, 21: los estilos de los títulos del documento. En la línea 21, vemos que solo un párrafo tiene el estilo «Título». Se trata del título del documento que precede al primer «Título 1»;
Esta revisión del documento de Word es una buena forma de evaluar la calidad del documento. Aquí veo que he utilizado demasiados estilos diferentes para lo mismo en mi documento de Word.
El archivo [audit.json] es idéntico al archivo [audit.txt], pero en formato JSON:
{
"version": "V16",
"file": "word-odt-vers-html-janv-2026.docx",
"counts": {
"paragraphs": 2029,
"tables": 97,
"image_blips": 2,
"headings_raw": 53
},
"listas": {
"with_numpr": 1329,
"by_style": 49,
"unrecognized": 0
},
"heading": {
"min_level_raw": 1,
"rebase_offset": 0
},
"top_styles": [
[
"SourceCodenumrot",
1054
],
[
"StandardWW",
594
],
[
«Standard»,
146
],
[
«Párrafo de la lista»,
113
],
[
"Número de resultados del código fuente",
33
],
[
"codenouveau",
28
],
[
"Título2",
25
],
[
"Título1",
14
],
[
"Título 3",
14
],
[
"EstándarWWWW",
6
],
[
"Texto sin formato",
1
],
[
"Título",
1
]
]
}
El archivo [report.txt] es este:
[RESUMEN] Listas detectadas mediante el método de reserva «por estilo» (agregado)
- Paragraphedeliste -> level=1 type=unordered: 49
[RESUMEN] Bloques de Word ignorados (agregado)
- <w:sectPr>: 1
No lo he entendido…
Es posible solicitar solo la auditoría del documento de Word para evaluar su calidad con el parámetro [--audit]:
python .\convert_docx_v18.py .\word-odt-vers-html-janv-2026.docx .\config.py --audit
En este caso, solo se realiza la auditoría del documento. No se genera el sitio MkDocs.
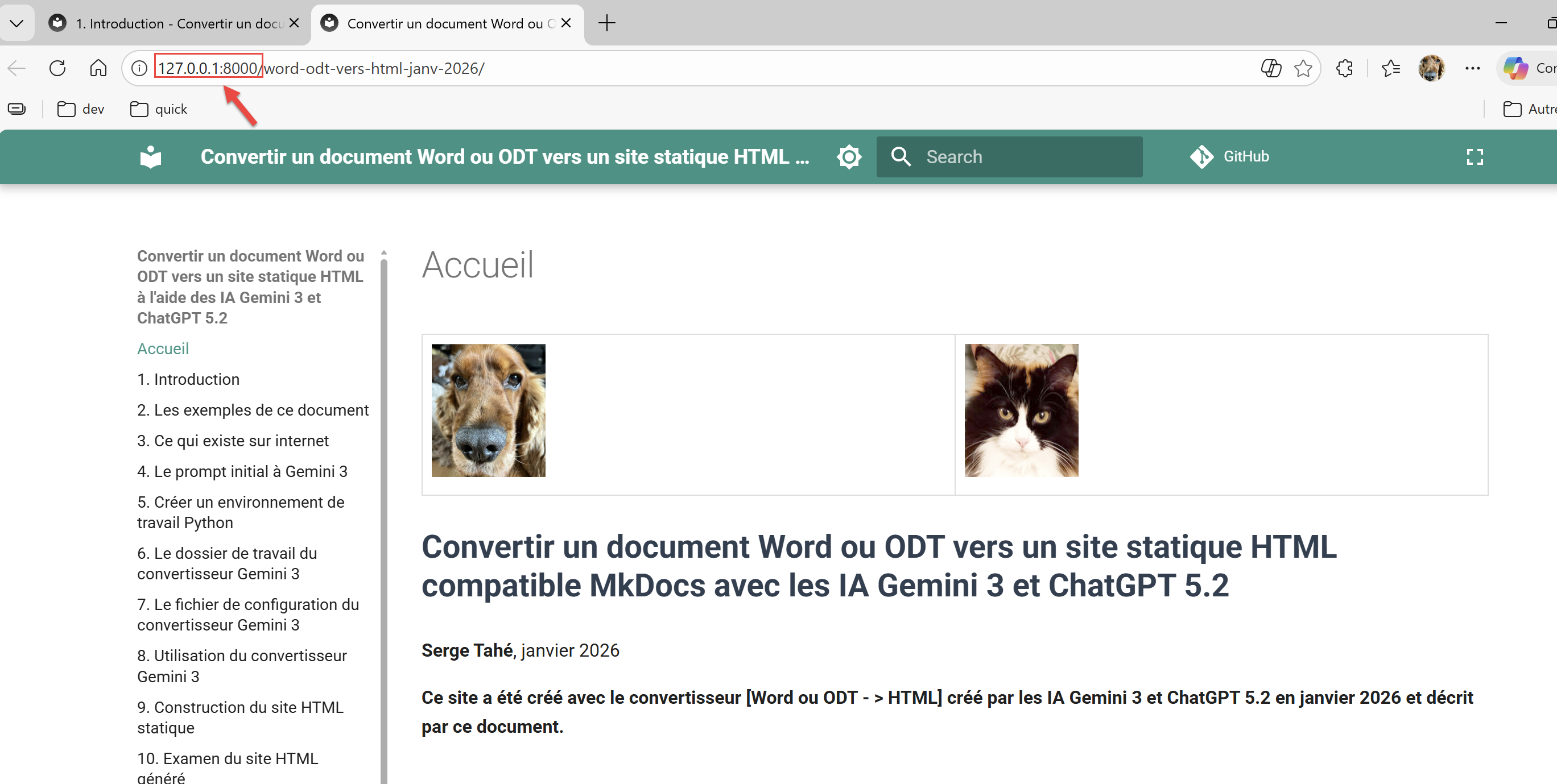
Como se ha mostrado anteriormente, puede visualizar el sitio MkDocs generado por el conversor:
PS C:\Data\st-2025\GitHub Pages\word-odt-vers-html\v2> python -m mkdocs serve
INFO - Compilando la documentación...
INFO - Limpiando el directorio del sitio
INFO - Documentación generada en 0,59 segundos
INFO - [06:05:48] Servido en http://127.0.0.1:8000/word-odt-vers-html-janv-2026/
Ctrl-Haga clic en la URL de la línea 5:
 |